
Abstract
Textbooks play a pivotal role in fostering English as a foreign language (EFL) learners’ language proficiency. Among the various skills addressed in English language teaching (ELT) materials, reading comprehension is widely regarded as an essential component for improving learners’ linguistic knowledge. Typically, reading passages are followed by a series of activities designed both to assess students’ understanding and to enhance their ability to interpret, analyze, and engage more deeply with the text. Although a substantial body of literature has examined the cognitive demands of EFL instructional content, relatively little attention has been devoted to analyzing second language reading comprehension questions and task types. To fill this lacuna, this study examined the representation of post-reading comprehension questions and tasks using Freeman’s taxonomy across nine Iranian high school English language textbooks from three successive generations in the history of ELT in Iran. The post-reading comprehension questions and tasks in each textbook were analyzed and categorized using a descriptive content analysis approach. The findings indicated that the Content category was the most prevalent across all three generations, followed by the Language and Affect categories. In addition, Generation 2 textbooks contained the highest overall frequency of post-reading comprehension question types, except for the Form question type, which occurred most frequently in Generation 1 textbooks. Across all nine textbooks analyzed, the Explicit question type emerged as the most commonly used, whereas the Evaluation question type was the least represented. The results of the chi-square tests also revealed significant differences among the three generations in terms of the frequency of different question types. The findings have several practical implications for policy makers, material writers, and English teachers.
Keywords
I Introduction
Textbooks have long played a fundamental and indispensable role in language learning and teaching, functioning both as structured repositories of pedagogical content and as the primary medium through which educational objectives are operationalized (Richards, 2014; Tomlinson, 2012). Textbooks provide a structured roadmap for both teachers and learners, facilitating sequential knowledge acquisition. Within English as a foreign language (EFL) programs, particularly those delivered in state education systems such as Iran’s, textbooks are often described as “the visible heart of any English language teaching (ELT) program” (Sheldon, 1988, p. 237) because of their ability to standardize instruction, align with national curricula, and streamline lesson planning for teachers (McDonough et al., 2013). Despite significant advancements in language teaching methodologies, the reliance on textbooks remains a defining feature of EFL instruction.
Among the components embedded in EFL textbooks, reading comprehension has consistently occupied a privileged position because of its essential role in broadening learners’ knowledge and enriching their educational experience (Willis, 2008). Reading as a receptive skill facilitates language acquisition by enabling learners to engage with diverse textual inputs, thus fostering the development of both linguistic and cognitive competencies. Reading comprehension questions, which typically follow reading passages, function not only to evaluate learners’ understanding but also to actively promote it (Mckee, 2012). These questions are widely recognized as recurring and well-established activities that not only stimulate learner engagement but also facilitate deeper interaction with textual material (Atai, 2002; Willis, 2008). The critical importance of reading comprehension questions has prompted numerous researchers to propose and apply taxonomies for their analysis. Early taxonomies, such as Bloom’s (1956) cognitive hierarchy and Nuttall’s (1996) reading skills framework, classified questions according to their cognitive demand and textual orientation. More recently, Freeman (2014) proposed a comprehensive, integrative taxonomy that addresses previous limitations by categorizing comprehension questions into three distinct domains: Content, Language, and Affect. This taxonomy has received wide acclaim for its versatility and depth and is widely regarded as a valuable framework for reading comprehension questions (Baleghizadeh & Zakervafaei, 2020).
While many studies have relied primarily on Bloom’s taxonomy and its adaptations to evaluate textbook-based activities (Adli & Mahmoudi, 2017; Razmjoo & Kazempourfard, 2012; Roohani et al., 2014), relatively few investigations have applied Freeman’s framework (e.g., Baleghizadeh & Zakervafaei, 2020). Nevertheless, despite the valuable insights these investigations offer, the literature still lacks a historically grounded comparative analysis of reading comprehension questions and tasks in Iranian high school English language textbooks. Most prior research has adopted a synchronic approach, focusing on evaluating textbooks in their entirety, often without attending to the specific treatment of individual skills such as reading. Furthermore, the chronological dimension of textbook development, specifically how different types of questions and tasks have evolved across different curricular revisions, remains largely unexplored. To address these gaps, the present study aims to conduct a historical comparative analysis of post-reading comprehension questions and tasks across different generations of Iranian high school English language textbooks, drawing on Freeman’s (2014) taxonomy as the analytical framework. This research aims to contribute to the growing body of empirical work on reading comprehension questions, aligning with Freeman’s (2014) call for more systematic investigation in this area and providing practical insights for educators, policymakers, and materials developers engaged in the ongoing improvement of EFL instructional resources, particularly in Iran.
II Literature review
1 Curriculum shifts in Iran’s English language education
The evolution of Iran’s high school English curriculum has proceeded through three sequential policy-oriented shifts that gradually redefined syllabus objectives and teacher and learner roles. The first major shift (1982–1990) produced a curriculum rooted in the grammar translation method (GTM), in which short, decontextualized reading passages, isolated grammar points, and controlled practice formed the core of instruction. This period corresponded predominantly to a structural-reading syllabus designed to prepare learners for text-based examinations rather than for communicative use. Teachers occupied a highly authoritative role and were expected to transmit textual knowledge, explain grammar deductively, and manage translation activities. Learners, in turn, assumed a passive, receptive role, engaging mainly in comprehension, vocabulary memorization, and discrete-point written practice (Ajideh & Panahi, 2016; Mehri et al., 2020).
The second shift (1991–2015) largely preserved a reading-focused syllabus but incorporated longer passages, expanded vocabulary lists, and situational or functional elements. Despite these additions, classroom tasks remained mainly multiple-choice, cloze, and fill-in-the-blank, perpetuating the marginalization of oral and written production and creating a hybrid structural–situational syllabus that formally broadened content but, in practice, retained many multiple-choice and fill-in-the-blank assessment formats. Teachers in this phase were encouraged to diversify techniques and introduce situational practice, but were still largely constrained in delivering content and prioritizing high-stakes reading-based assessment, whereas students experienced a modest expansion of productive opportunities without full agency (Ajideh & Panahi, 2016).
The third and most recent shift (2016–present) represents a stronger alignment with communicative language teaching (CLT) and an eclectic, unit-based syllabus. Content is organized thematically, integrating listening, speaking, reading, and writing through communicative tasks, project work, and pair/group interaction. This transition reflects an explicit movement from form-focused, text-driven instruction toward a task- and meaning-oriented curriculum designed to develop learners’ holistic communicative competence. The CLT-influenced series, however, reimagines the teacher as a mediator, guide, and task designer who scaffolds interaction, promotes the negotiation of meaning, and supports collaborative language use. Similarly, learners are repositioned as active participants who coconstruct meaning through peer work, discussions, roleplaying, and integrated skills tasks. However, the success of these expanded roles is moderated by external constraints, particularly the dominance of high-stakes examinations that still emphasize reading comprehension and grammar accuracy (Barzan & Sayyadi, 2023). As a result, even within a communicative curriculum framework, teachers may struggle to balance examination preparation with student-centered pedagogy, thereby creating a persistent gap between the intended and enacted curricula.
2 Reading comprehension questions in ELT contexts: existing taxonomies
Reading comprehension plays a central role in both first-language and second-language (L2) pedagogies, where it functions as both an outcome and instrument for reinforcing learners’ linguistic resources, genre knowledge, and disciplinary discourse practices (Duke et al., 2021; Freeman, 2014; Mckee, 2012). The capacity to construct coherent meaning from written discourse necessitates the orchestration of decoding skills and higher-order inferential processing (Gu, 2003; Hoover & Gough, 1990). In the classroom context, reading comprehension questions have emerged not only as assessment devices but also as pedagogical scaffolds that shape learners’ engagement with texts, direct attention to critical linguistic and semantic features, and promote the cognitive and metacognitive operations essential for academic literacy which ultimately enhance the internalization of domain-specific vocabulary and genre-appropriate discourse structures (Ertugruloglu et al., 2023; Grabe, 2009; Mežek et al., 2022).
The scholarly discourse surrounding comprehension questions and tasks has historically interrogated their role in fostering authentic interpretive engagement versus encouraging superficial textual retrieval. Nation (1979), drawing on the seminal work of Davies and Widdowson (1974), argued that many traditional comprehension exercises fail to promote transferable reading strategies, instead confining learners to text-bound information matching. He proposed that effective reading tasks should redirect attention to ubiquitous textual phenomena, such as cohesive devices, inferencing mechanisms, and thematic structuring, that extend beyond the confines of a specific passage. This proposition was later echoed and refined by Cunningsworth (1995), who articulated a typology of comprehension tasks based on their cognitive depth: literal comprehension (requiring surface-level recognition), inferential comprehension (demanding integration across textual elements), and evaluative comprehension (inviting judgment and critical reflection). This hierarchical model emphasized a fundamental pedagogical principle: comprehension tasks must not merely assess retention but rather cultivate the reader’s interpretive agency and metacognitive awareness.
Similarly, Bloom’s (1956) six-level taxonomy of educational objectives, namely, knowledge, comprehension, application, analysis, synthesis, and evaluation, remained foundational for classifying the cognitive demands of reading comprehension tasks. Initially developed as an interdisciplinary framework to facilitate the exchange of assessment materials, its hierarchical structure progressed from basic recall to increasingly sophisticated operations such as problem-solving, inferential reasoning, and critical judgment. In the following years, Sanders (1966) translated Bloom’s hierarchical taxonomy into classroom practice by aligning distinct question formats with each cognitive level. This alignment provided educators with a concrete framework for constructing assessment items that systematically elicit both lower- and higher-order thinking processes. Both Sanders’ and Bloom’s taxonomies provided the foundation for Barrett’s reading comprehension framework. Referenced by Clymer (1968) and later detailed in Smith and Barrett (1974), this taxonomy was developed in direct response to Guszak’s (1967) critique that reading instruction places excessive emphasis on the retrieval of trivial factual details. Instead, his taxonomy redirected focus toward higher-order cognitive operations, which included five graded comprehension levels: literal recognition and recall, literal comprehension, inferential comprehension, critical reading, and appreciation.
To address the unique challenges of L2 readers, Nuttall (1996) refined Barrett’s taxonomy for L2 contexts and introduced two domain-specific types of questions: personal response, which fosters affective engagement through learner reflection, and how writers say what they mean, which promotes metacognitive awareness of text-attack and word-attack strategies. Despite the considerable breadth of these frameworks, none fully encompasses the triadic demands of contemporary L2 reading materials, including content comprehension, language-focused processing, and affective response. This gap necessitated a synthetic approach that draws upon the hierarchical precision of Bloom, the pedagogical pragmatism of Sanders, the text-specific elaboration of Barrett, and the L2-centered orientation of Nuttall. Consequently, Freeman (2014) introduced a reading-specific taxonomy that offered a more text-sensitive alternative to the aforementioned models by foregrounding the multifaceted functions that comprehension questions can serve. His taxonomy encompasses three types of questions: Content questions (explicit, implicit, and inferential comprehension), which assess textual understanding at various depths; Language questions (lexical, reorganization, and form), which focus on the linguistic aspects of the text; and Affect questions (personal response and evaluation), which aim to engage learners affectively and critically.
Freeman’s taxonomy has multifaceted value. First, it promotes teachers’ awareness of diverse question types and their respective cognitive demands, which serve distinct instructional purposes. Second, it can be embedded within textbook-evaluation checklists (either as a central analytic category or as an independent tool) to support evidence-based decisions regarding material selection, adaptation, and adoption, and to ensure that reading tasks are meaningful, cognitively appropriate, and aligned with pedagogical objectives (Freeman, 2014; Harwood, 2021). Third, it provides a concrete basis for teacher education and professional development by encouraging teachers to deepen their pedagogical content knowledge and to engage in reflective practice on question design and text suitability (Tomlinson, 2012). Finally, perhaps the taxonomy’s greatest contribution lies in supporting teachers’ development of their own instructional materials. Research indicates that not all teachers possess the skills necessary to design effective materials, despite the increased availability of authentic reading texts (Mishan, 2015). Given the time-intensive nature of materials writing and the persistent neglect of materials design in some teacher-training programs, integrating the taxonomy into such programs can provide essential guidance. It not only supports teachers in developing high-quality, locally relevant, task-based materials (an important affordance, given teachers’ central role as adaptors and creators of classroom resources) but also encourages decision-making about how authentic texts are selected and used in the classroom (Moore et al., 2021; Rathert & Cabaroğlu, 2024).
3 Empirical trends in reading comprehension research
In an attempt to systematize the cognitive demands of comprehension questions and tasks, many researchers have turned to Bloom’s (1956) taxonomy as an analytical framework. For example, Roohani et al. (2014) found that lower-order tasks (knowledge, comprehension, and application) predominate in popular series such as Four Corners 2 and 3, whereas Razmjoo and Kazempourfard (2012) reported that the Interchange series incorporates more analysis, synthesis, and evaluation-level activities. These findings parallel those of Adli and Mahmoudi (2017), who criticized the overreliance on factual recall and advocated for the incorporation of analysis- and synthesis-driven questioning to facilitate deeper textual engagement.
Applied to a range of contemporary ELT series, such as Headway, Inside Out, American File, and Cutting Edge, Freeman’s (2014) taxonomy revealed an overwhelming preponderance of Content questions, particularly of the explicit and reorganization types. Baleghizadeh and Zakervafaei (2020), employing a similar categorization, further authenticated these patterns in the Four Corners series, where language awareness and affective response questions were marginal or absent. The findings suggest a pedagogical imbalance that favors text-bound comprehension at the expense of linguistic analysis and personal interpretation, both of which are essential for developing advanced literacy competencies.
The implications of these taxonomic analyses become particularly salient with the widespread unfamiliarity among EFL instructors with Bloom’s or Freeman’s frameworks (Nurmatova & Altun, 2023). This deficiency contributes to a reliance on lower-order questioning strategies, even when the educational context would profit from deeper, critical engagement. Empirical analyses of locally produced textbooks, such as the Vision series in Iran, similarly reflect these concerns. Studies by Khodabandeh and Mombini (2018) and Gheitasi et al. (2020) have demonstrated that, despite the incorporation of authentic and culturally pertinent texts into contemporary ELT materials, the accompanying comprehension tasks continue to favor literal interpretations and factual analysis. Masoumi Sooreh and Ahour (2020) also observed that, even when higher-order questions are present, they are inconsistently distributed and fail to align with the overarching learning outcomes. Consequently, learners are seldom challenged to synthesize information, critique textual perspectives, or articulate reasoned arguments that are foundational to academic literacy.
A review of the literature reveals a conspicuous gap in a systematic, chronological analysis of the evolution and construction of comprehension questions and tasks in Iran’s educational language textbooks. To address this deficiency, the present study seeks to conduct a historical-comparative analysis of different types of questions and tasks in Iranian high school English language textbooks to identify diachronic patterns in question formulation and evaluate whether contemporary revisions align with progressive pedagogical practices. These findings are expected to assist educators and policymakers in developing instructional materials that not only facilitate but also enrich meaningful language learning experiences in EFL contexts. In light of the aforementioned considerations, this study adopts a descriptive content analysis approach, which is designed to transform qualitative, verbal material into measurable, quantitative data (Cohen et al., 2017). As a result, in line with its aims, this study explored the following research questions:
RQ1. To what extent have the question types, as classified by Freeman’s taxonomy, evolved and been reflected in the content of three sequential generations of English language textbooks?
RQ2. Is there a significant difference among the frequencies of reading comprehension questions across the three generations?
III Methodology
1 Corpus
The corpus of the study comprised the latest editions of English textbooks for the final 3 years of high school, spanning Iran’s major pedagogical shifts across three periods. During the first curriculum shift, the English series (1982–1990) was used, which adhered to a grammar–translation tradition characterized by brief, decontextualized reading passages, isolated grammar drills, and bilingual glossaries with little systematic skill progression or authentic discourse. During the second curriculum shift, the English Books series (1991–2015) was presented, which retained a reading-method focus, expanding passage length and vocabulary lists but relying predominantly on multiple-choice and fill-in-the-blank exercises that continued to marginalize oral and written communicative practice. During the third curriculum shift, the Vision series (2016–present) was introduced, which foregrounds CLT principles and embraces an eclectic, student-centered approach, organizing content into thematic units that integrate listening, speaking, reading, and writing tasks to foster holistic language competence.
For ease of readability, each textbook series corresponding to a distinct curricular period is represented by a single label throughout the study: Generation 1 refers to the first-period textbooks (1982–1990), Generation 2 refers to the second-period textbooks (1991–2015), and Generation 3 refers to the third-period textbooks (2016–present). In addition, the term “q-type” will henceforth be used as an umbrella designation encompassing different types of activities, tasks, exercises, and questions that are presented subsequent to reading passages, regardless of their format or function.
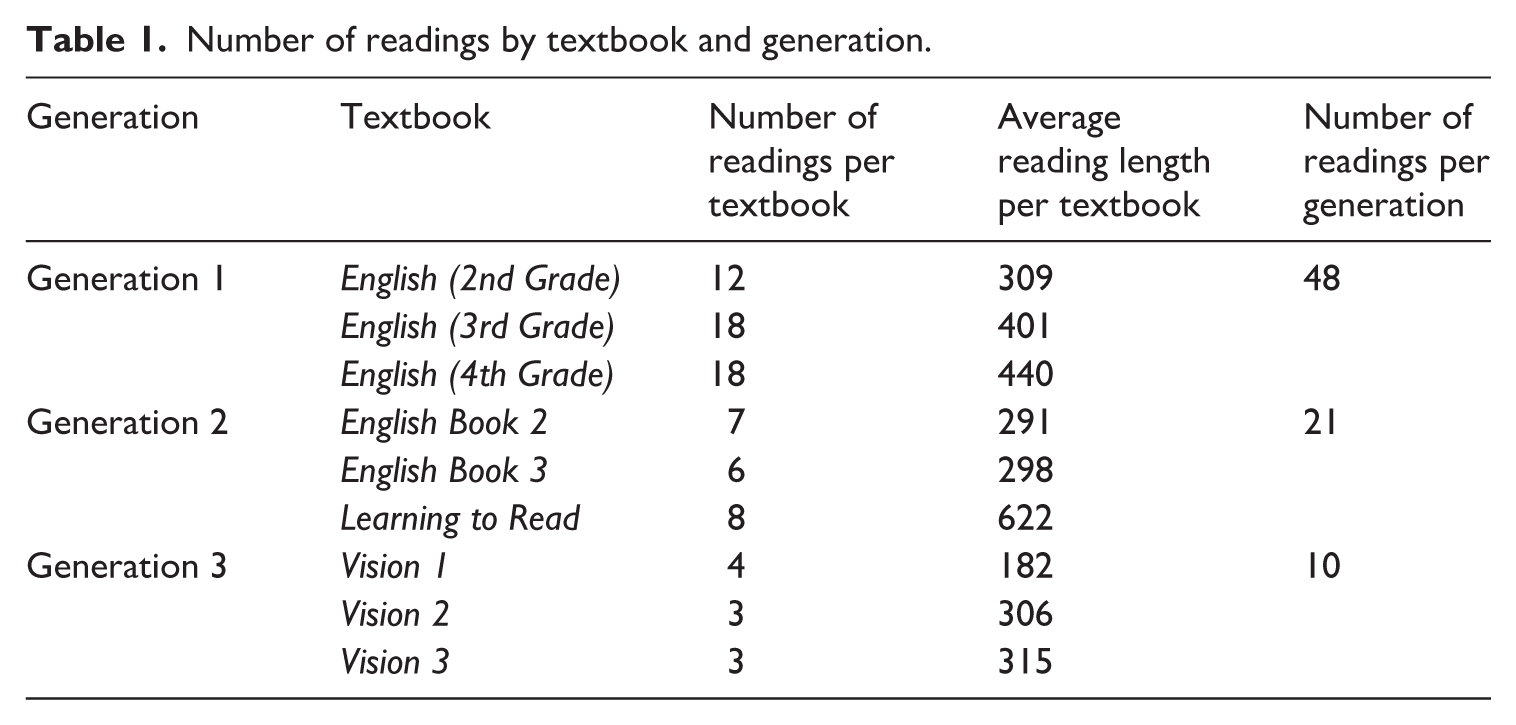
Table 1 presents the distribution of reading texts per textbook and generation. There are a total of 79 readings across all the English textbooks. In the first generation, encompassing English (2nd Grade), English (3rd Grade), and English (4th Grade), a total of 48 readings were included, with the highest contributions from the 3rd- and 4th-grade textbooks (18 readings each). The second generation, represented by English Book 2, English Book 3, and Learning to Read, contained a total of 21 readings, indicating a reduction in the quantity of reading materials. In contrast, the third generation, consisting of Vision 1, Vision 2, and Vision 3, featured only 10 readings, reflecting a further decline.
Number of readings by textbook and generation.
Across the three first-generation textbooks, the readings revolve mainly around four broad themes, including science and technology (e.g., Electricity; Radar; Digestion), nature and environment (e.g., Air Pollution; Ecology; Life in Deserts 1), morality and human relationships (e.g., Friend or Enemy; A Guest from India; A Typical Day in Ali’s Life), and education, language, and art (e.g., Using a Dictionary; Some Uses of Art; Reading). Similarly, in the second-generation textbooks, the readings cluster around three main themes, namely, science, technology and the environment (e.g., Global Warming, Global Concern; Earthquakes and How to Survive Them; IT and Its Services), social problems and ethics (e.g., Child Labor: A Global Issue; Mother Teresa), and communication and language (e.g., Every Word Is a Puzzle; How to Give a Good Speech). Likewise, in the third-generation textbooks, the themes of the readings mainly overlap with those of the previous two generations. They represent ethics and perseverance (e.g., Respect Your Parents; No Pain No Gain), language and learning (e.g., How to Use a Dictionary; Languages of the World ), the environment (e.g., Earth for Our Children; Endangered Animals), and art, culture, and national identity (e.g., Art, Culture and Society; Iran: A True Paradise).
Across all three generations of Iranian English textbooks, the readings share a stable core of themes. They all use texts about science and technology (from electricity and astronomy to computers, health science, and energy) and nature and the environment (deserts, ecology, global warming, earthquakes, endangered animals) to build knowledge while teaching language. They consistently emphasize morality, responsibility, and human relationships, showing sacrifice, compassion, respect for family, social justice, and responsible behavior. Each generation also promotes communication, education, and language through lessons on reading, writing, using dictionaries, and sometimes public speaking. Thus, what is common is not specific stories but a fixed framework through which each generation uses readings about science, technology, nature, morality, ethics, and study skills to teach English and shape students’ knowledge, values, and everyday behavior. Later generations update only the topics while keeping the same underlying themes.
2 Underlying framework
This study employed Freeman’s (2014) taxonomy of comprehension q-types as an evaluative and analytical tool to examine the pedagogical value of the questions used in English reading lessons. The Freeman’s taxonomy of comprehension q-types is organized into three overarching categories: Content, which includes three q-types ranging from lower- to higher-order thinking; Language, which consists of three nonhierarchically arranged q-types; and Affect, which comprises two q-types, one representing lower-order thinking and the other higher-order thinking. Each of the eight q-types is situated within its corresponding category and is accompanied by explanatory notes in Table 2.
Freeman’s taxonomy of post-reading comprehension q-types (adapted from Freeman (2014)).
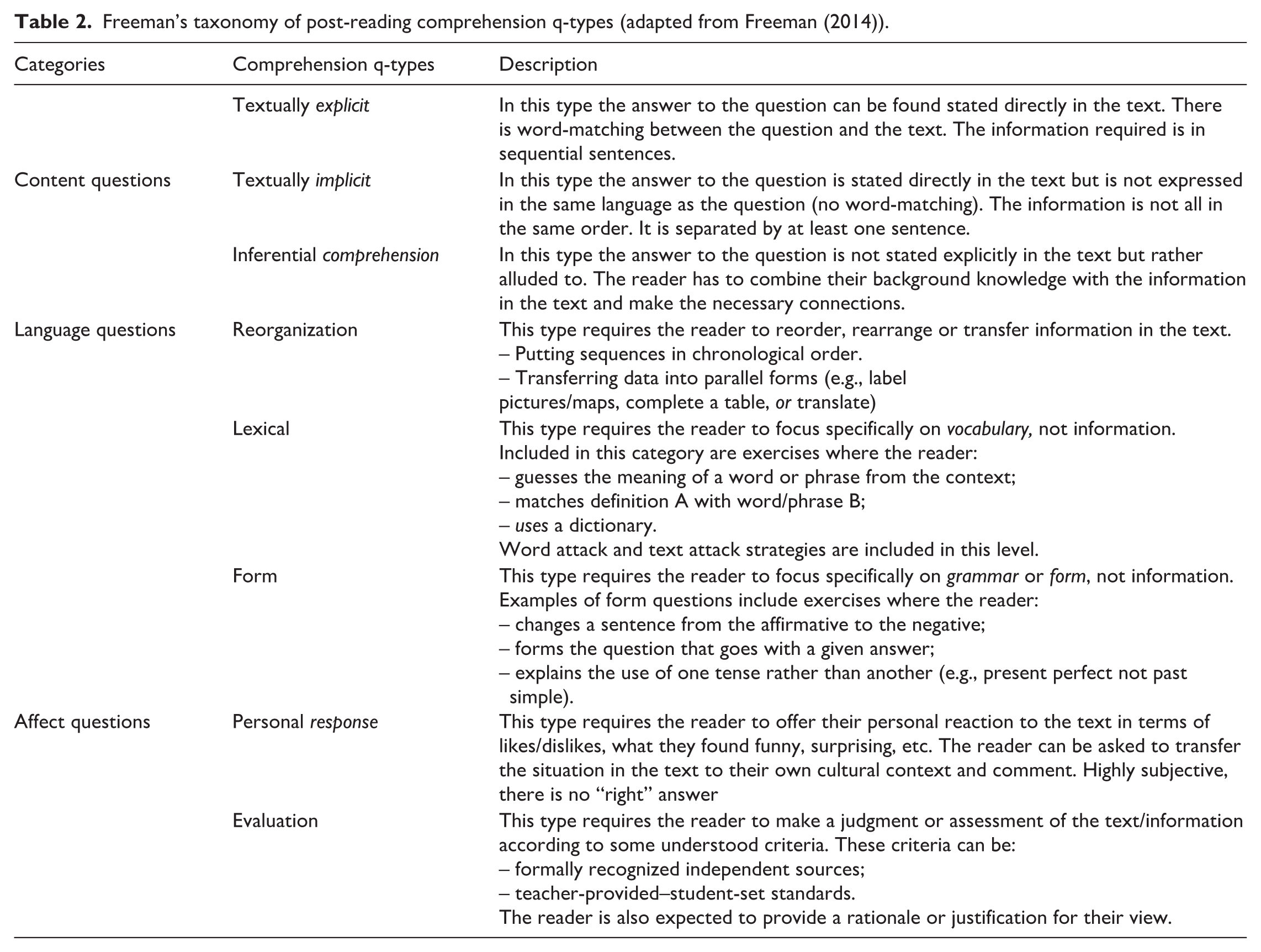
Freeman’s taxonomy provides several advantages for the present study. First, it is specifically tailored to classify comprehension questions in textbooks and therefore aligns directly with the study’s central purpose. Second, unlike broader cognitive taxonomies that focus exclusively on the cognitive dimension (e.g., Bloom, 1956) or frameworks that emphasize task complexity without isolating the question function (e.g., Webb, 2002), Freeman’s model integrates three distinct but mutually interrelated dimensions, which enable a more holistic evaluation. Third, its eight discrete q-types provide sufficient detail to distinguish the differences among reading questions and are concrete enough to support reliable coding and inter-rater agreement. The combination of hierarchical (Content) and nonhierarchical (Language and Affect) elements also reflects textbook structures more faithfully than do purely hierarchical schemes; not all pedagogically important question features fall along a single developmental scale.
3 Analysis
The present study examined post-reading comprehension questions drawn from three distinct generations of English language textbook series corresponding to sequential curricular paradigms: (1) the 1982–1990 curriculum, (2) the 1991–2015 curriculum, and (3) the 2016–present curriculum. In the English series of the 1980s (English (2nd Grade), English (3rd Grade), and English (4th Grade)), the textbook units did not distinguish among the four language skills; consequently, only the main lesson post-reading and reading comprehension sections, as well as the review lesson reading comprehension exercises, were selected for analysis. Ancillary sections lacking explicit comprehension objectives were excluded. In contrast, the English Books (English Book 2, English Book 3, and Learning to Read) and Vision series (Vision 1, Vision 2, and Vision 3) textbooks are organized into discrete, skill-based modules (e.g., Reading, Speak Out, Language Functions, Pronunciation Practice, and Vocabulary).
To ensure consistency across English textbooks, this study confined its analysis to the textbooks used at the final three grade levels. This deliberate allocation reduced curricular variation, yielded a uniform corpus, and, more importantly, enabled a precise, systematic cross-sectional analysis of the evolution of pedagogical tasks and question design throughout the series. Furthermore, consistent with the scope of this study, extraction was confined to post-reading comprehension exercises that appeared solely within the reading modules. To establish clear and objective boundaries, any textual passage accompanied by comprehension exercises in the primary reading sections was classified as a “reading” text. Short, context-driven passages in ancillary sections (e.g., “Grammar” in Vision 3) that primarily aim to teach vocabulary or grammar were excluded from the dataset. Similarly, exercises functioning solely as model responses with answers provided to students were omitted from both categorization and quantitative counts.
The fundamental unit of analysis was the individual comprehension question. When a single exercise comprised multiple interrogatives, each question was disaggregated and treated as an independent data point. For instance, in Learning to Read (p. 37, Exercise 3: “Are earthquakes always frightening? Why?”), two distinct items were identified, both of which were classified as Personal Response questions. Furthermore, exercises subdivided into multiple parts were parsed so that each subsection corresponded to a separate question. Each was subsequently categorized according to its cognitive or response type and included in the overall frequency tally. For example, an exercise in Learning to Read (p. 58) comprised fourteen discrete items: seven prompting identifications of “who” and “what” and the remaining seven requiring students to locate and relate specific events referenced in the reading passage (Figure 1).
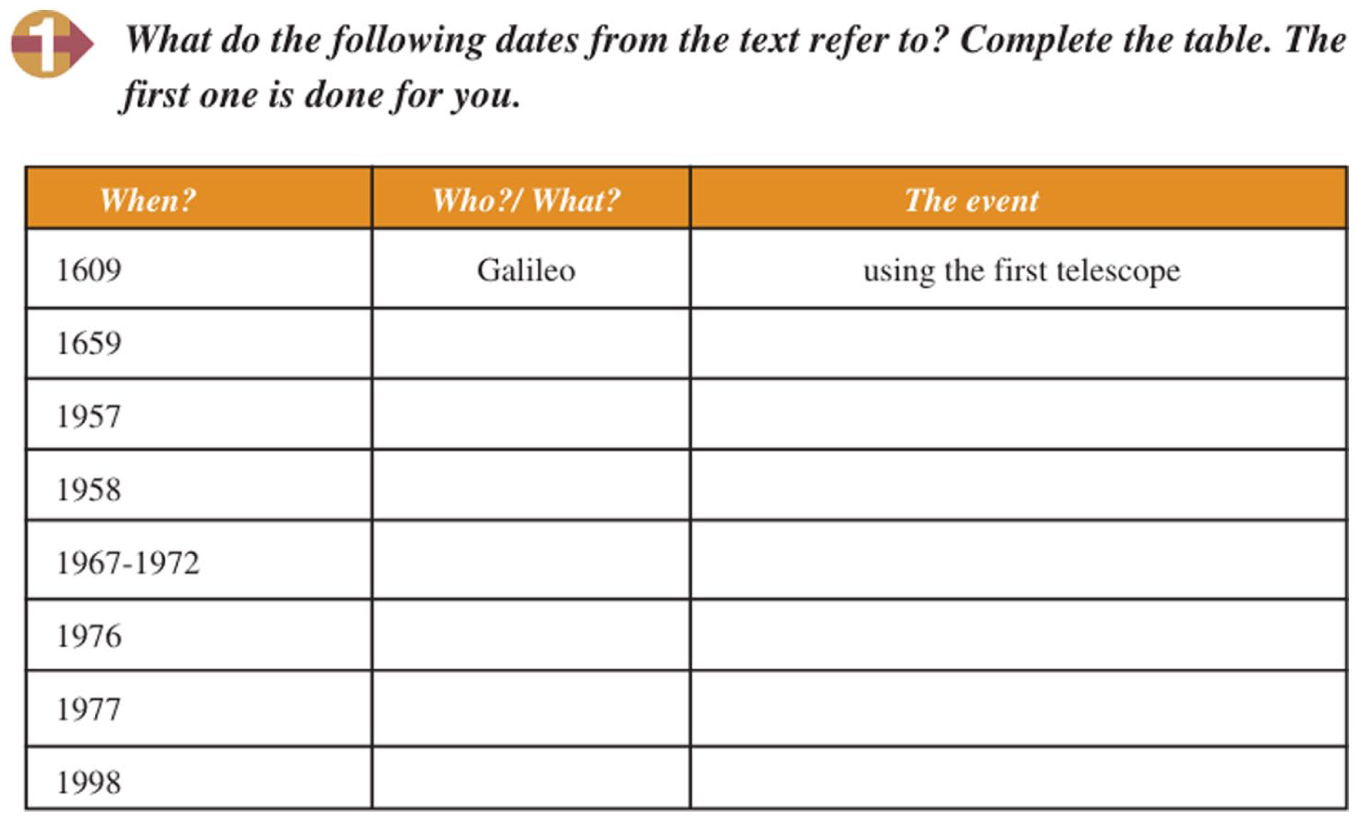
An example of a reading comprehension question in the Learning to Read textbook.
Moreover, exercises accompanied by pre-provided model answers designed to illustrate expected responses were not systematically incorporated into both the quantitative tallies and the subsequent categorical analyses.
Initially, the second author analyzed, coded, and classified the entire dataset. To ensure the consistency of the analyses, a second rater (the third author) also independently coded and categorized the entire dataset. The resulting inter-rater agreement for this study was .89. However, this relatively high level of reliability may be attributed to the multiple categorization and discussion sessions conducted both prior to and during the analysis phase, alongside concurrent engagement with similar datasets, particularly when the categorization proved challenging. To resolve outstanding issues, the first author, who possesses subject-matter expertise, joined the deliberations, resulting in a considerable reduction in unresolved discrepancies. For instance, when a single comprehension question could plausibly be classified as both Implicit and Inferential Comprehension, and clear differentiation was unfeasible, during the discussion sessions, the most salient type was ultimately selected. Likewise, each post-reading comprehension question was classified exclusively into a single category (Content, Language, or Affect); no single question was assigned to more than one category. Finally, to determine statistical significance when comparing a specific q-type or category across generations, a series of chi-square tests was employed.
IV Results
The findings are presented by first providing a comprehensive overview of all textbooks across the three generations for each q-type. The frequency of q-types is subsequently compared across the three categories (Affect, Language, and Content) over the generations. Following this, the frequency of q-types within each category is examined across the three time periods. Finally, the frequency of each q-type is examined in the textbooks of each generation separately to determine the trend across the final 3 years of high school study. To determine statistical significance when comparing a specific q-type across different generations (e.g., the Reorganization q-type in Generation 1 versus Generation 2) or a particular category across generations (e.g., the Content category in Generation 1 compared with Generation 2), a series of chi-square tests was employed.
1 General trend overview: all question types, all textbooks
Figure 2 displays how the eight comprehension q-types are distributed in terms of frequency across the nine textbooks examined in this study. In each graph, the first three columns represent the Content category, the next three the Language category, and the final two the Affect category.
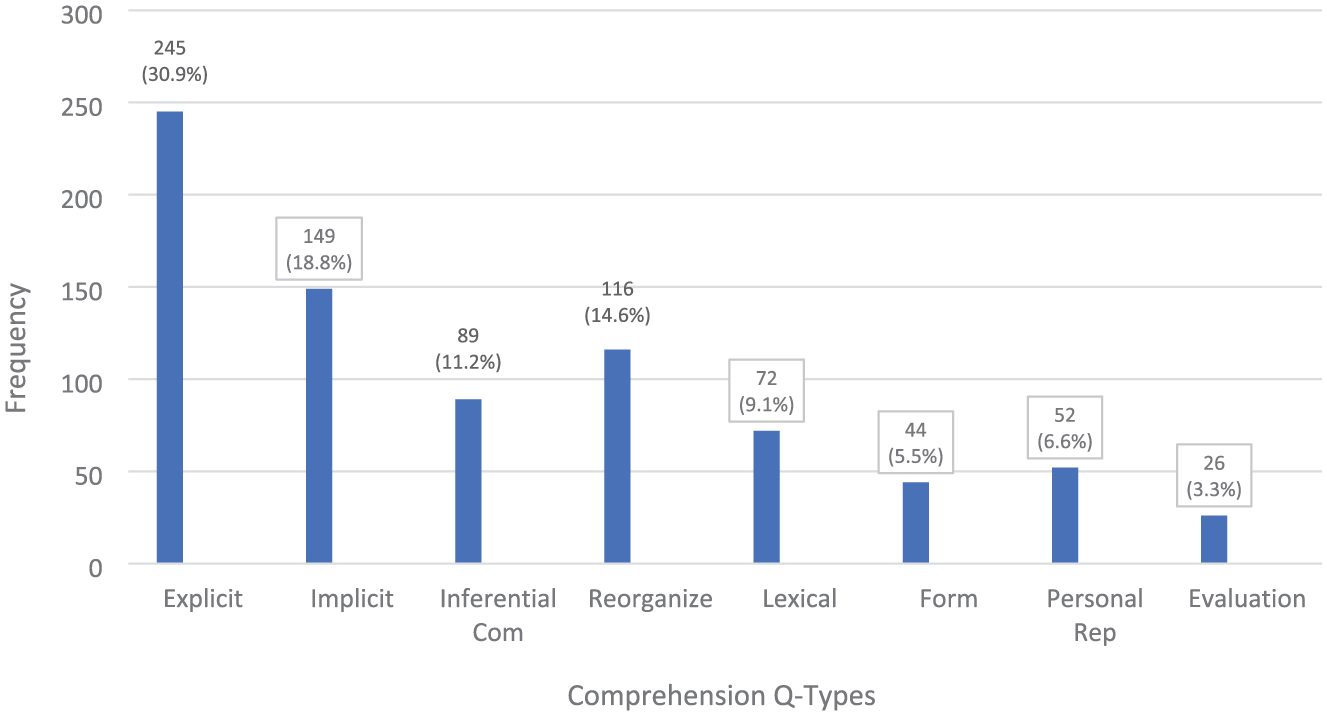
Frequencies of comprehension q-types: all textbooks of all generations.
The graph presents the overall frequency for each comprehension q-type, indicating how frequently each type appears across all reading texts in the textbooks. The numerical values displayed on the bars denote both the absolute frequencies of each q-type and their relative proportions within the overall set of comprehension questions. As depicted in Figure 2, the Content category emerges as the most prevalent in terms of frequency. A single question type stands out in each of the Language and Affect categories: Reorganization is most prevalent in the former and Personal Response dominates the latter.
2 Comparative overview: Content, Language, and Affect across generations
This section examines whether the textbooks within each generation demonstrate a discernible preference for particular comprehension q-types. Figure 3 presents the proportional distribution of q-types by generation, aggregating data across all textbooks in each generation.
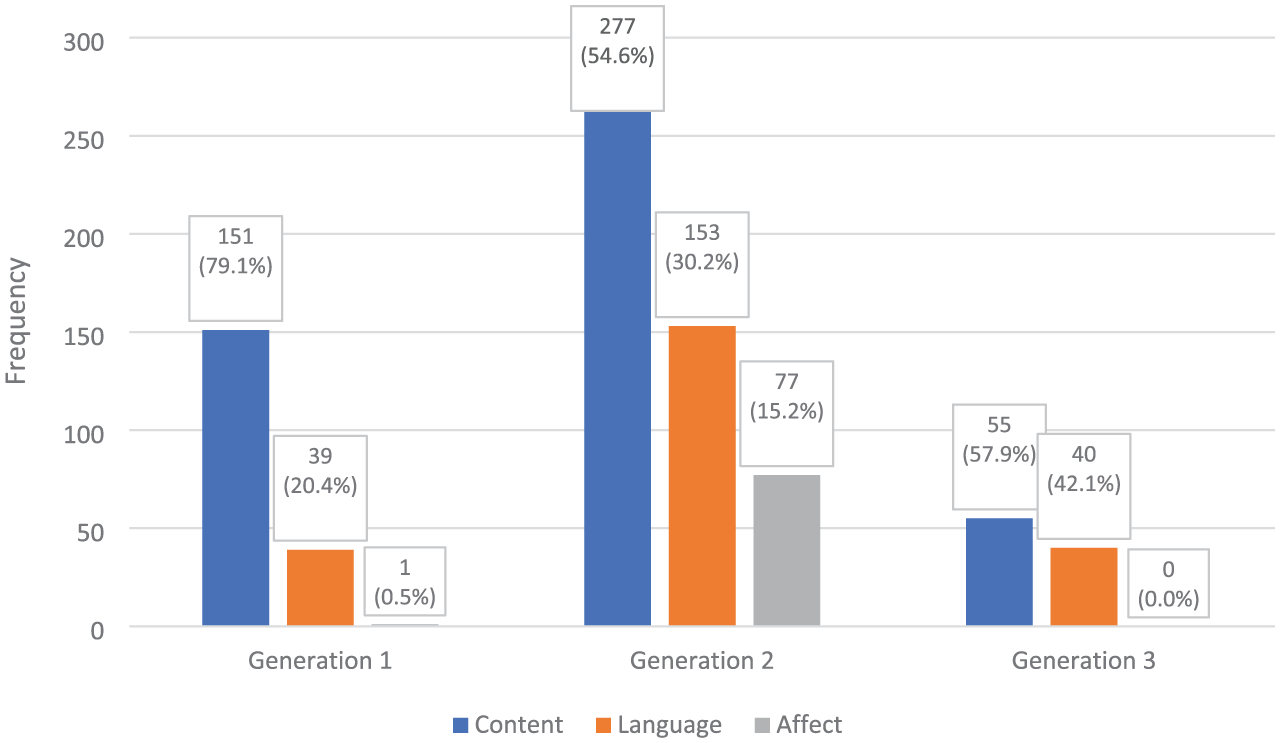
Frequencies of comprehension q-types: generation comparison.
Echoing the overall trends observed in Figure 2, Figure 3 indicates that, in every generation under investigation, a greater number of comprehension questions fall within the Content category (comprising Explicit, Implicit, and Inferential Comprehension) than within either the Affect or Language categories. When the generations are compared, clear patterns of preference emerge. Generation 2 has a significantly greater frequency of Content questions than both Generations 1 and 3 (both p < .001), whereas Generation 1 also significantly outperforms Generation 3 (p < .001). In addition, the distribution of Language questions varies notably across generations. Statistically significant differences are observed between Generations 2 and 3 (p < .001) and between Generations 1 and 2 (p < .001), with Generation 2 containing a markedly greater number of Language questions than the other two. Conversely, the comparison between Generations 1 and 3 yields no significant difference (p = .91), suggesting similar frequencies of Language questions in those periods. Finally, the Affect q-type was effectively exclusive to Generation 2, with a complete or near-complete absence in the other periods. Generation 2 includes significantly more Affect questions than either Generation 1 or Generation 3 (both p < .001). However, a statistical comparison between Generations 1 and 3 was not feasible because both generations had zero or near-zero instances. This absence of data violates the chi-square test assumptions due to extremely low expected frequencies and lack of variance, thereby precluding any inferential statistical conclusions between these two generations.
As the data show, Generation 2 has significantly more comprehension questions from all three categories (i.e., Content, Language, and Affect) than Generations 1 and 3. From Generation 1 to Generation 2, the reading section moves from brief, basic checks within a grammar–translation approach to a range of questions that tightly control what happens after reading. Generation 1 contains many reading passages but relatively few post-reading q-types per text; most items ask for literal information or simple inference. Language q-type exists to a small extent since it is mostly outside the reading section, and Affect q-type is essentially absent. In Generation 2, however, each passage is followed by a larger set of items that break the text into small steps and combine meaning checks (Content) with attention to form (Language). Affect q-type appears mainly as short, final prompts asking for an opinion. The unusually heavy load of questions in Learning to Read is the main driver of this increase.
From Generation 2 to Generation 3, the Vision series adopts CLT and shifts more activity to other parts of the unit rather than adding questions after reading. There are fewer readings and fewer immediate q-types; Content questions remain, but are reduced in number. Language questions are not expanded in the post-reading slot and are instead built into later grammar and writing tasks. Affect is again minimal in the coded post-reading section.
3 Generation comparison: Individual categories
Building on the analysis of category-level totals, the subsequent graphs depict the distribution of individual q-types within each category.
a Content (Explicit–Implicit–Inferential Comprehension)
Figure 4 provides a detailed examination of the Content category, illustrating the prevalence of each of the three Content q-types across the generations.
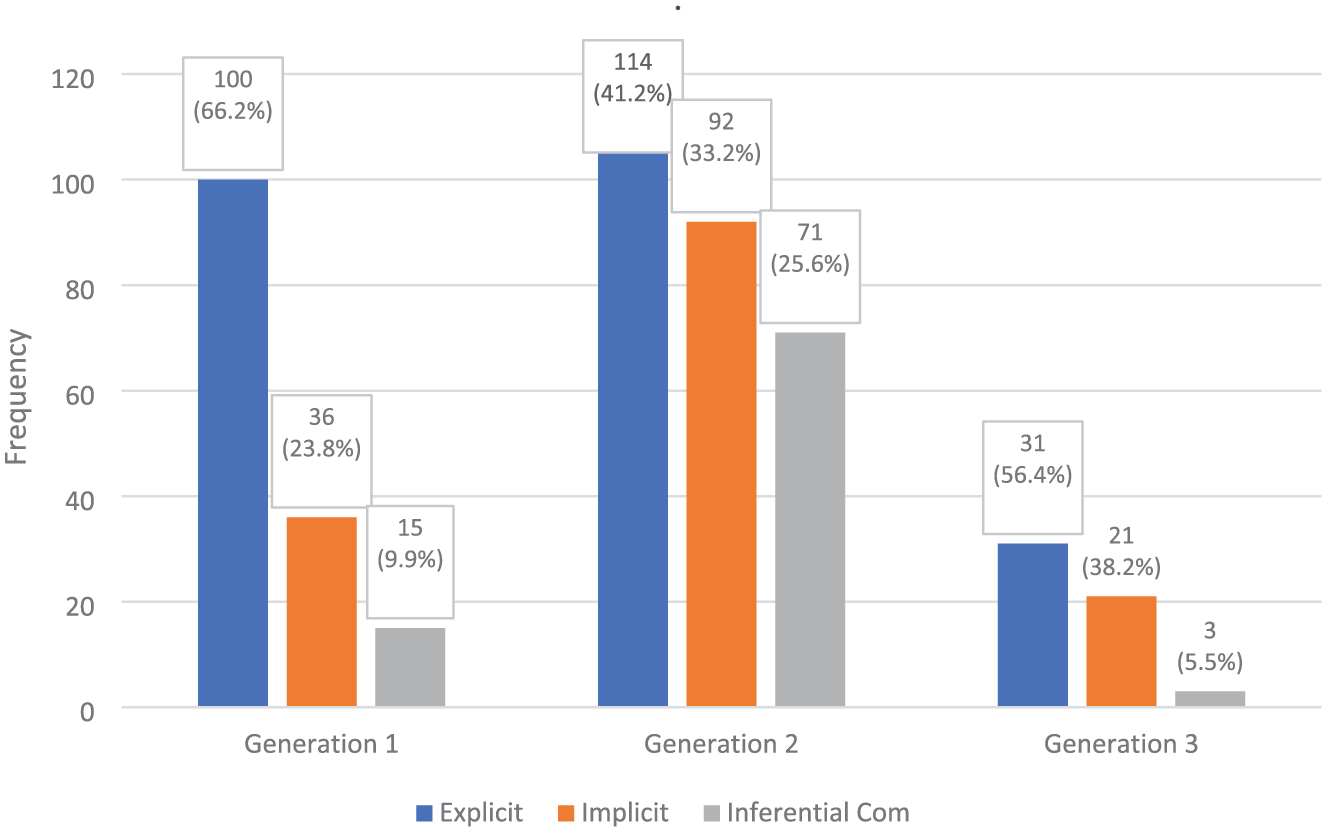
Frequencies of content q-types.
Notably, the Explicit q-type dominates across all generations. Generation 2 has significantly more Explicit questions than Generation 3 (p < .001). In addition, the differences between Generations 1 and 3, as well as between Generations 2 and 3, are highly significant (both p < .001), demonstrating a significant decrease in the preference for the Explicit q-type in Generation 3.
With respect to the Implicit q-type, Generation 2 is the most prominently represented. The chi-square test results revealed that there was a significant difference between Generations 1 and 2 (p < .001), indicating that the frequency of the Implicit q-type was higher in the latter. The difference between Generations 1 and 3 was also significant (p = .032); however, this does not satisfy the Bonferroni-adjusted alpha threshold of p = .0167 and is therefore not considered statistically significant. The comparison of Generation 2 with Generation 3 yielded highly significant differences (p < .001), indicating a marked decrease in the number of Implicit questions in Generation 3.
Like Explicit and Implicit q-types, Generation 2 includes the highest number of Inferential Comprehension questions in terms of frequency. Statistical comparisons revealed that the contrasts between Generations 2 and 3 (p < .001) and between Generations 1 and 2 (p < .001) are highly significant. These results indicate a substantial increase in the number of Inferential Comprehension questions in Generation 2 and a substantial decrease in Generation 3. In contrast, the comparison between Generations 1 and 3 (p = .44) is not statistically significant, suggesting similarly low frequencies in those two generations.
Across all three generations, Content q-type remains the core of post-reading work, but its density and depth change. Generation 1 relies on short, mostly explicit checks with occasional simple inference, matching its grammar–translation orientation. Generation 2 intensifies the reading page, where Explicit questions multiply and are joined by many Implicit and Inferential Comprehension questions that break the text into multiple questions (especially driven by Learning to Read). Generation 3 reduces all Content questions (Explicit and Implicit alike) because meaning-making is increasingly carried out in later, integrated tasks. As a result, the reading section shows a clear drop in explicitness and fewer higher-level inferences than in Generation 2.
b Language (Reorganization–Lexical–Form)
The Language category consists of three q-types: Reorganization, Lexical, and Form. An analysis of these q-types, as shown in the frequency graph in Figure 5, indicates that Reorganization is the most commonly used Language q-type. Generation 2 contains substantially more instances of this q-type than Generations 1 and 3 (both p < .001), whereas Generation 1 provides no instance of the Reorganization q-type.
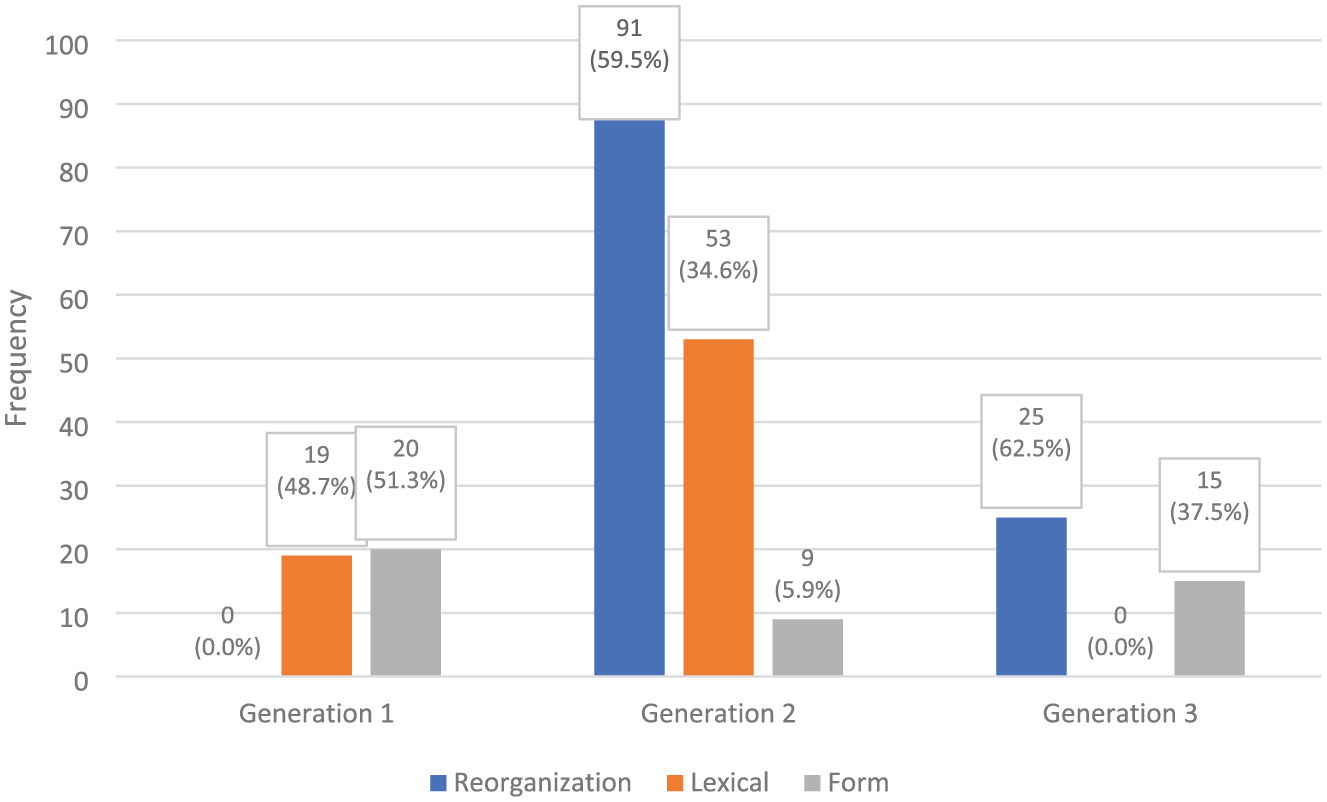
Frequencies of language q-types.
Regarding the Lexical q-type, Figure 5 indicates that their frequency is highest in Generation 2, with a total of 72 instances. Statistical analyses revealed that Generation 2 contained significantly more Lexical questions than did Generations 1 and 3 (both p < .001). The difference between Generations 1 and 3 is also significant (p < .001), emphasizing the absence of the Lexical q-type in Generation 3.
Unlike Reorganization and Lexical q-types, the Form q-type appears in all three generations. However, this q-type is the least frequent overall, with only 44 instances recorded. Although Generation 1 includes more Form questions than subsequent generations, the observed decreases are not statistically significant (p > .13).
Language q-types shift from peripheral to prominent and back again. Generation 1 includes some Form items but offers no Reorganization and little Lexical work, since form practice largely sits outside the reading page. Generation 2 brings Language to the forefront. Reorganization becomes the dominant subtype (e.g., ordering, summarizing, and mapping ideas), and Lexical items surge (word meaning, collocations), creating a text-proximal space for metalinguistic noticing alongside comprehension checks. In Generation 3, language work is recentered into communicative tasks elsewhere. Reorganization and especially Lexical questions retreat from the post-reading slot, whereas Form appears in all periods but remains the least-frequent overall, with Generation 1 being only modestly higher than later series.
c Affect (Personal Response–Evaluation)
Figure 6 provides a detailed examination of the Affect category. As depicted in Figure 6, only Generation 2 textbooks contain both Personal Response and Evaluation q-types, except for one Evaluation q-type in Generation 1. The presence of Personal Response q-type in Generation 2 differed significantly from their complete absence in the other two generations (Generations 1 and 3, both p < .001). However, no statistical comparison could be made between Generations 1 and 3 since no cases were observed in either generation. A similar pattern emerges with the Evaluation q-type, which, like the Personal Response q-type, is heavily concentrated in Generation 2 and virtually absent in the remaining generations.
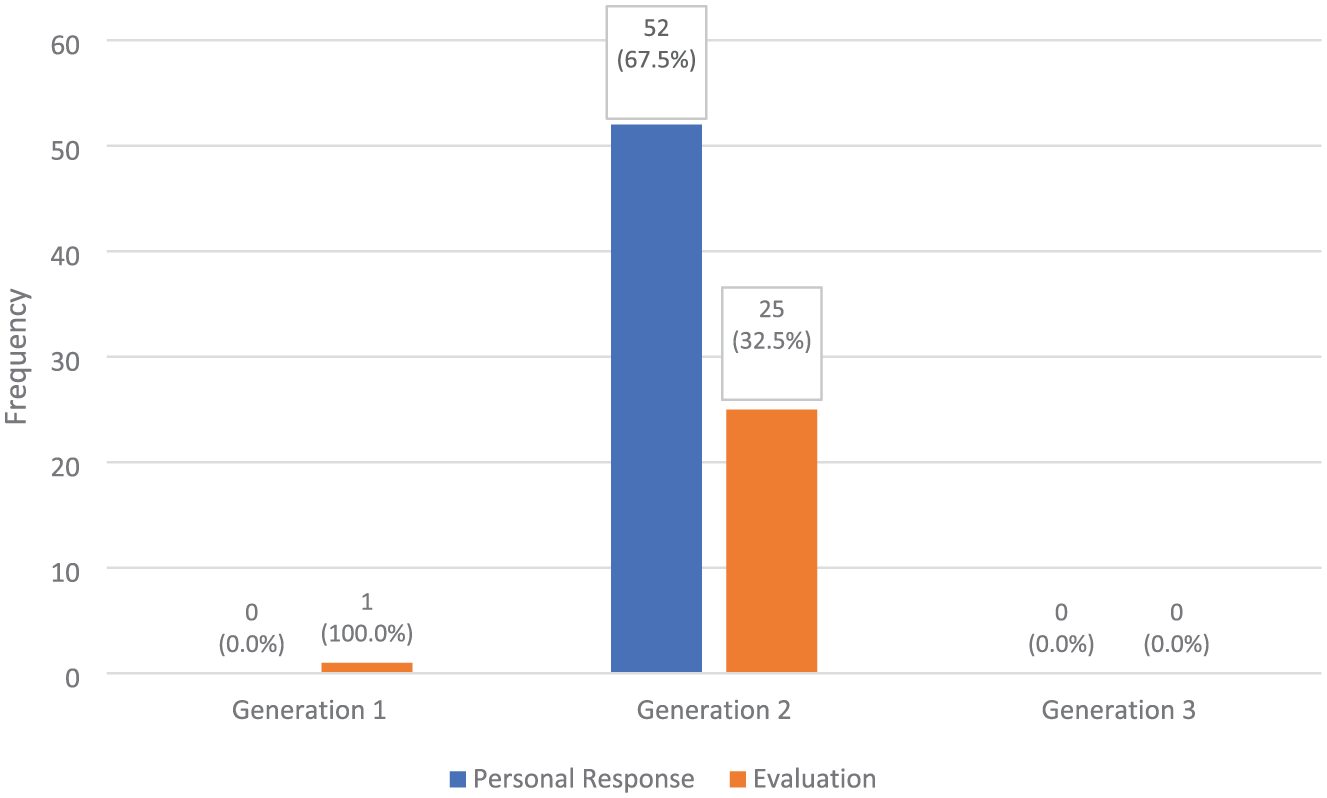
Frequencies of affect q-types.
The Affect q-type shows a punctuated pattern. Generation 1 is virtually Affect-free, reflecting a view of reading as a vehicle for checking uptake rather than inviting a stance. Generation 2 introduces both Personal Response and Evaluation, asking learners to give their opinions or personal views regarding the topic of each passage. In Generation 3, Affect q-type is again scarce in the coded post-reading space. Under CLT, Personal Response and Evaluation are more often embedded in subsequent pair-work, project, and speaking tasks, which fall outside the study’s q-type frame.
4 Textbooks comparison: individual generations
Figure 7 illustrates the frequency of the different comprehension q-types across nine English language textbooks divided into three chronological cohorts: Generation 1 (English (2nd Grade), English (3rd Grade), and English (4th Grade)), Generation 2 (English Book 2, English Book 3, and Learning to Read), and Generation 3 (Vision 1, Vision 2, and Vision 3). The comparison suggests significant changes in pedagogical focus over time regarding q-types and cognitive demand.
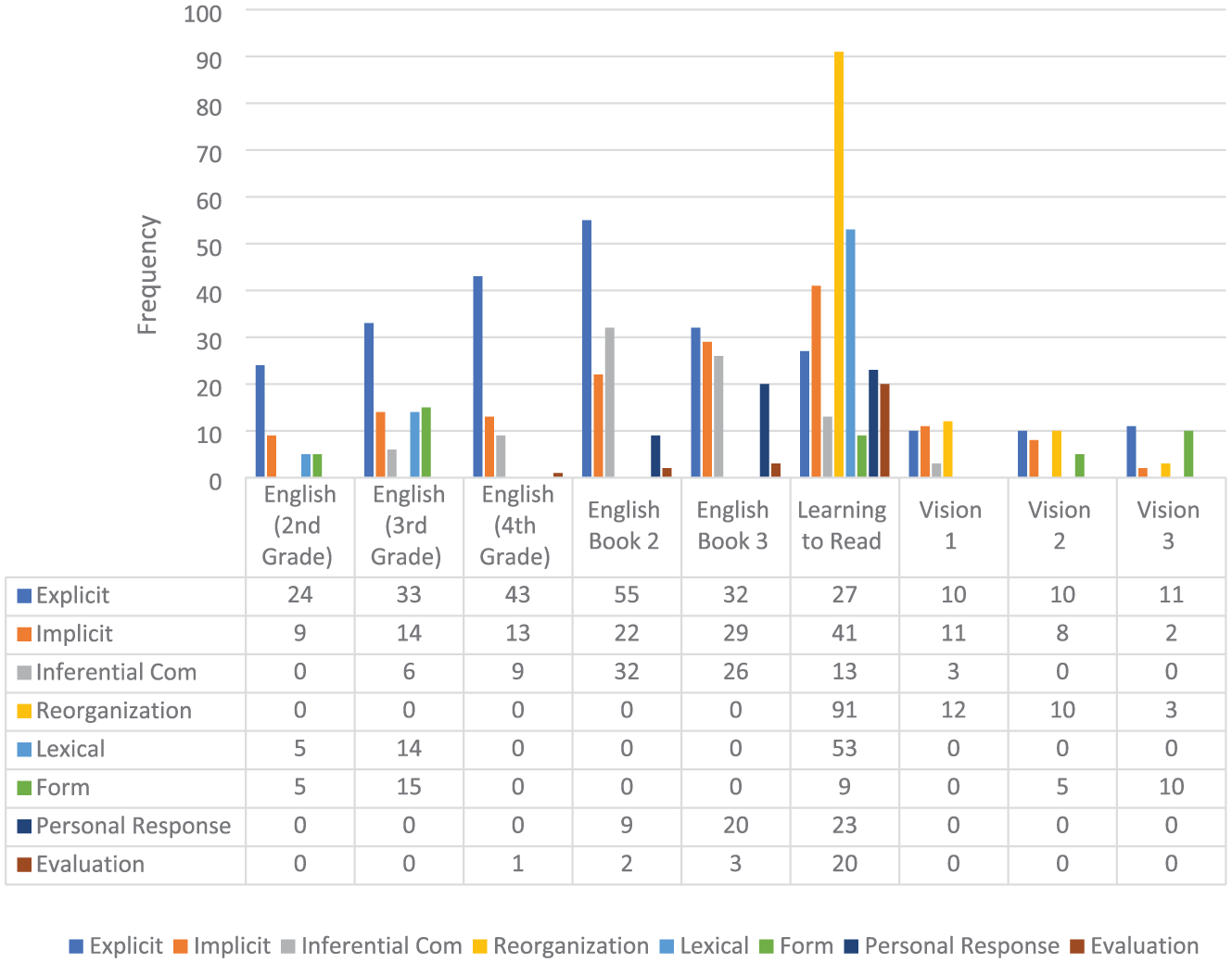
Frequencies of comprehension q-types across three generations of Iranian high school English language textbooks.
In Generation 1, the comprehension q-type framework is dominated primarily by the Explicit q-type, which progressively increases from 24 to 43 instances across the three textbooks. Other q-types, such as Implicit, Inferential Comprehension, Lexical, and Form, are presented but are relatively infrequent. Notably, no Reorganization, Personal Response, or Evaluation questions are observed during this period (with the exception of one instance of an Evaluation question in English (4th Grade)).
Generation 2, however, marks a significant pedagogical departure characterized by a substantial increase in both the diversity and frequency of higher-order comprehension q-types. The Explicit q-type continues to feature prominently, peaking at 55 instances in English Book 2 before tapering off in subsequent volumes. Simultaneously, Implicit and Inferential Comprehension q-types show a marked increase and decrease, respectively, in subsequent textbooks, most notably with Implicit peaking at 41 instances in Learning to Read and Inferential Comprehension declining to 13 instances in English Book 2. The emergence and exceptional frequency of Reorganization questions in Learning to Read (91 instances) is particularly striking, highlighting an instructional emphasis on text restructuring and synthesis. In addition, Lexical and Form q-types reach their zenith in Learning to Read, with 53 and 9 instances, respectively, whereas Personal Response and Evaluation q-types (nearly absent in the previous generation) make their first strong appearance, starting from 9 and 2 instances in English Book 2 to 23 and 20 in Learning to Read, respectively. Finally, among all textbooks across all generations, Learning to Read is the only textbook that includes all the different comprehension q-types, with the highest number of comprehension questions (N = 277).
In contrast, Generation 3 (Vision series) reflects a notable regression in both the quantity and complexity of comprehension questions. Explicit questions decline dramatically to a uniform range of 10–11 instances across all three textbooks. More cognitive-oriented q-types, such as Implicit, Inferential Comprehension, and Reorganization, also diminish significantly, with some disappearing entirely. The Form q-type persists but at a minimal level, and the Lexical, Personal Response, and Evaluation categories are absent.
V Discussion
The diachronic analysis conducted in this study identified three principal transformations in the conformation of post-reading questions within Iranian high school English language textbooks. First, in every textbook examined, questions targeting content comprehension (e.g., Explicit, Implicit, and Inferential Comprehension) consistently constituted the majority of the exercises. This predominant focus on surface-level understanding corroborated earlier content analyses by Adli and Mahmoudi (2017) and Roohani et al. (2014), both of which documented a continued reliance on lower-order cognitive activities in EFL reading materials. In contrast to synchronic analyses, the chronological investigation demonstrated that the textbooks in Generation 2 temporarily broadened their repertoire to feature a markedly higher proportion of Implicit and Inferential Comprehension questions, which required learners not only to locate information but also to draw conclusions from unstated premises, integrate prior knowledge with textual cues, and construct meaning beyond the literal wording of the passage. This approach directly reflects Cunningsworth’s (1995) schema-and-inference framework and Grabe’s (2009) emphasis on activating background knowledge to support deeper comprehension. However, this enriched questioning strategy largely disappeared in the subsequent Vision series (Generation 3), where the emphasis reverted to the surface-level, text-bound items designed for straightforward information retrieval rather than for promoting analytic or interpretive engagement.
Second, an analysis of the q-type distribution revealed that in Generation 2, there was a significant increase in language-focused questions, specifically those encompassing Reorganization, Lexical, and Forms, with Reorganization exercises driving much of this growth. This pattern not only reflected Freeman’s (2014) argument for deliberately fostering metalinguistic awareness but also corroborated Baleghizadeh and Zakervafaei’s (2020) identification of a distinctive, if fleeting, pedagogical moment in which text-restructuring tasks assumed a central role. Moreover, none of the post-reading comprehension questions in the textbooks from Generation 3 directly targeted vocabulary. Given that language-teaching materials often reflect the authors’ underlying theories of language acquisition (Richards, 2006), this absence may indicate that post-reading questions should prioritize reading comprehension over vocabulary instruction. Notably, all the textbooks from this generation (Vision series) include a separate section, “New Words and Expressions,” prior to the main reading text, specifically designed to pre-teach vocabulary that appears in the subsequent reading passage. This approach also appears to align with Masuhara’s (2013) suggestion to differentiate between “teaching reading and teaching language using texts” (p. 170).
Third, questions designed to examine learners’ affect (e.g., emotion, interest, and attitude), namely, Personal Response and Evaluation, are almost entirely confined to the middle-period cohort. This concentration validated the assertions of Batini et al. (2021) regarding the pedagogical value of fostering emotional investment in reading comprehension. Tomlinson and Masuhara (2013) further reinforce this finding by advocating for the design of tasks that connect language learning to learners’ personal experiences. However, these Affect-oriented q-types vanish from the Vision series, despite its stated emphasis on learner-centered pedagogy.
Notably, the quantitative analysis of reading text inclusion across the three generations revealed a clear, downward trajectory of the number of reading texts (48 in Generation 1, 21 in Generation 2, and only 10 in Generation 3), which authenticated a systematic process of curricular refinement. In Generation 1, pedagogical practice was firmly rooted in the grammar–translation paradigm, with a special focus on decontextualized texts, isolated grammar drills, and minimal attention to progressive skill development. The revision in Generation 2 emphasized a reading-method orientation, lengthened reading texts, and expanded vocabulary listings; nevertheless, it continued to anchor multiple-choice and fill-in-the-blank formats. A marked pedagogical shift occurred in Generation 3, with the adoption of CLT tenets: content is now organized into thematic units that explicitly integrate listening, speaking, reading, and writing activities to promote authentic communicative proficiency. This evolution of reading passage selection and task design is mirrored in the distribution of reading comprehension q-types (191 in Generation 1, 507 in Generation 2, and 95 in Generation 3), with the peak in Generation 2 (despite fewer reading texts than in Generation 1), which reflects the Ministry of Education’s reading-oriented emphasis at that stage.
One insight from the quantitative analysis was the identification of a clear outlier among the selected textbooks within the three generations. The volume Learning to Read (also published under the title English for Pre-University Students) distinguished itself by integrating eight discrete reading texts accompanied by a total of 277 reading comprehension questions. Unlike its contemporaries, this book incorporated the full taxonomy of question typologies (Explicit, Implicit, Inferential Comprehension, Lexical, Reorganization, Form, Personal Response, and Evaluation). This breadth of content design was intentionally adopted to align with the demands of the national university entrance examination and to equip learners with the diverse analytical reading skills they would require in their subsequent English for Specific Purposes (ESP) courses and authentic academic texts at the tertiary level.
These evolving patterns of q-type enrichment reflect underlying transformations in educational priorities and assessment philosophy, and they carry far-reaching implications for both pedagogical practice and education policy. Although the second generation’s curricular reforms briefly introduced tasks that reinforced higher-order thinking and affective engagement, these innovations dissipated without the scaffolding of systemic support. To address this structural misalignment and ensure that textbook content not only aligns with national educational priorities but also systematically fosters the development of advanced academic literacy, it is essential to implement a triad of mutually reinforcing strategies sustainably.
First, Freeman’s (2014) taxonomy of comprehension q-types should be systematically embedded within national and institutional syllabus frameworks. This integration should be accompanied by explicit policy directives specifying the inclusion of each category (e.g., Content, Language, and Affect), with clearly defined frequency benchmarks that ensure curricular coherence and cognitive progression (Porter et al., 2009). Such codification would provide curriculum developers and textbook publishers with a taxonomy-based evaluative framework that standardizes expectations and ensures consistent cognitive breadth across instructional materials. Thus, the findings of this diachronic analysis have significant implications not only for the Iranian EFL context but also for broader ELT settings characterized by centralized curriculum control and policy-driven textbook production, such as in Turkey and Arab countries, where similar tensions between mandated materials and classroom needs have been widely documented (e.g., Rathert & Cabaroğlu, 2022; Şahin, 2022; Somaili & Alhamami, 2023). The observed reduction in higher-order, language-focused, and Affect-oriented question types in the most recent generation of textbooks underscores a wider regional pattern in which curricular reforms shift toward communicative pedagogy but fail to address the cognitive and affective demands necessary for deep reading engagement. For textbook developers in Iran and similar educational systems, these findings highlight the need to revise existing resources and to include a wider variety of reading-comprehension item types in new editions. In particular, materials development teams should broaden the mix of question formats across content, linguistic, and affective dimensions to achieve more balanced cognitive demands and to facilitate the use of diverse reading strategies.
Second, to operationalize these curricular standards at the classroom level, a structured, sustained professional development continuum must be incorporated. This should consist of iterative, empirically grounded training modules that strengthen the theoretical knowledge and practical competencies of both pre-service and in-service teachers to design, adapt, and implement cognitively rich and affectively relevant questions (Darling-Hammond et al., 2017; Johnson & Golombek, 2020; Ramdani et al., 2023). These workshops should be scaffolded through exemplar-based instruction, collaborative task design, and reflective pedagogical inquiry to foster a deeper understanding of the cognitive processes underpinning question construction. Following these workshops, teachers can audit existing item banks using a multidimensional framework that explicitly interrogates content validity, linguistic focus, and affective engagement prior to their adoption and produce supplementary, sequenced task packs that extend reading practice through scaffolded activities and higher-order prompts to foster deeper comprehension and metacognitive strategy use. Furthermore, for Iranian ELT scholars, this study provides a research-based foundation for investigating how teachers adapt to or compensate for question-type imbalances in policy-mandated materials, which contributes to regional debates on curriculum implementation and teacher agency.
Third, the blueprint for high-stakes national assessments must be strategically restructured to place greater emphasis on items that evaluate learners’ capacity for critical analysis, argument construction, and metacognitive engagement (Shepard et al., 2018). By realigning examination criteria to privilege depth over recall, such reform would not only reinforce classroom-level pedagogical shifts but also encourage textbook producers to embed a wider array of question types in their materials. Consequently, this approach helps close the feedback loop between the curriculum, instruction, and assessment and moves the system decisively beyond surface-level learning objectives (Andrade, 2019; Gan & Lam, 2025; Huang & Zeng, 2025).
VI Conclusion
This study investigated the representation of post-reading comprehension q-types in nine Iranian high school English textbooks, applying Freeman’s (2014) taxonomy. These textbooks were produced across three distinct periods in the history of ELT in Iran. The analysis revealed an uneven representation of comprehension questions and task types across the generations, with Generation 2 containing the highest number of post-reading comprehension questions (N = 507) and Generation 3 the lowest (N = 95). In addition, the findings indicated that the Content category was the most prevalent across all three periods, with the Explicit subcategory emerging as the most frequently employed comprehension q-type. The results from the chi-square tests further confirmed statistically significant differences among the three generations regarding the frequency distributions of the various q-types.
Although this research provides a useful historical discussion on the evolution of comprehension q-types in Iranian high school English textbooks, it has some limitations. First, the study focuses solely on textbook content and ignores how materials are implemented, supplemented, or adapted in the classroom. Future inquiries may include semi-structured interviews with teachers and classroom observations to delve into implementation, supplementation, or adaptation in real classroom practices. The second constraint of the research pertains to the fact that the study was confined to a single, centrally controlled national curriculum in Iran, which may limit the generalizability of the findings to decentralized or private-sector learning environments. To enhance generalizability, future research can investigate English textbooks of various educational systems to identify cross-cultural patterns and divergences. Finally, the analysis was confined to textbooks used in the final three grade levels of upper-secondary high school, which may limit the generalizability of the findings to earlier stages of English instruction. Future research could extend the present analysis to textbooks used at earlier grade levels (e.g., lower secondary), to trace how reading comprehension questions develop across the entire schooling trajectory.