
Abstract
This 8-week randomized controlled experiment tested the different effects of adaptive artificial intelligence-based feedback versus static rule-based feedback on learner engagement and the acquisition of second language writing in 216 undergraduate students of English as a foreign language. The respondents were randomly divided into a control group that used standard automated feedback and an artificial intelligence-adaptive feedback group in which the responses were customized according to individual proficiency levels and error patterns. Validated analytical rubrics (intraclass correlation coefficient = 0.89) were used to evaluate the writing quality, and the involvement was assessed through self-reports and system logs weekly. The multilevel analysis of the growth curve revealed that there were high treatment effects, in that the artificial intelligence-adaptive group was more responsive to writing improvements (b = 0.42, p < .001), and maintained a high level of engagement in the study. The connection between the type of feedback and writing gains was partially mediated by cognitive and behavioral engagement, with 34% of the overall effect. The strength of the findings was ensured by using propensity score matching after removing baseline differences. The results indicate that more dynamic adaptive artificial intelligence feedback systems that dynamically adjust to the requirements of the learner are more interesting and bring deeper development in writing than non-adaptive automated systems do. The technological implications of language teaching and the future of intelligent tutoring systems for language teaching writing in languages other than English are discussed in this paper.
Keywords
1. Introduction
Although the incorporation of artificial intelligence (AI) in second language (L2) writing teaching has revolutionized conventional feedback practices, many questions remain unanswered regarding the comparative effectiveness of adaptive and non-adaptive automated systems (Crosthwaite & Sun, 2026; S. Li, 2025; Yuen & Schlote, 2024). Although automated writing evaluation (AWE) solutions have become a widespread part of the language classroom environment, their impact on the growth of writing skills varies greatly based on the structure of the system and its utilization (Sari & Han, 2024; Evans et al., 2025). The emergence of new trends in generative AI has opened the possibility of other higher-level feedback systems that are sensitive to the specifics of the student. However, there is no empirical data on such systems in terms of their effectiveness in teaching.
Most traditional AWE systems follow rule-based algorithms that do not provide different feedback based on skill levels, error rates, or individual learning processes (Z. V. Zhang, 2020). This blanket approach conflicts with long-established principles of differentiated instruction and the zone of proximal development (ZPD)—the gap between what a learner can do on his or her own and what he or she can achieve with help (Vygotsky, 1978)—which might adversely affect the performance of the system with learners of diverse backgrounds. Conversely, adaptive AI systems use machine learning to tailor feedback to continue to assess student performance and, in principle, offer more focused and developmentally relevant help (Godwin-Jones, 2024; Cole, 2024).
Although learner engagement is one of the main mediators of technology-enhanced language teaching, its role in AI feedback environments has remained unexplored. Behavioral and affective variables can significantly influence learning outcomes, whereas cognitive interest in feedback content influences the uptake and revision quality (Hiver et al., 2024; J. Li & Yuan, 2024). Systematic research is justified by the need to establish how feedback adaptivity is related to the patterns of engagement, particularly considering the evidence suggesting that the engagement of learners via static automated feedback may not be sufficient to maintain their motivation over a long time (Yan & Zhang, 2024). See Figure 1.
Conceptual framework: Adaptive AI feedback effects on L2 writing development.
This study addresses three gaps in research that exist in the existing literature. First, although there is growing interest in AI-based feedback, the number of experimental studies that have examined the disparities between adaptive and fixed systems in detail through a well-constructed quasi-experimental design with adequate statistical power is limited. Second, few studies have examined the influence of feedback type on writing development, and engagement is not a major concern. Third, previous studies have methodological weaknesses, including small sample sizes, brief intervention periods, and a lack of control over confounding factors, which restrict the applicability of the data (Karatay & Karatay, 2024; Lai & Sundqvist, 2026).
With 216 participants over an 8-week period, we employed a randomized controlled experiment to test the following hypotheses.
1. Adaptive AI-driven feedback enhances writing development more than rule-based feedback.
2. The type of feedback changes its impact on various dimensions of cognitive, behavioral, and affective engagement. and
3. The correlation between feedback type and writing improvement is mediated by engagement.
The methodology used in our analysis was propensity score matching, mediation estimation, and multilevel growth curve modeling because such approaches enabled us to make a strong causal inference.
1.1. Literature Review
1.1.1. L2 Writing Automated Feedback Systems
AWE systems have developed significantly since their inception, shifting from grammar checkers to more advanced systems that can assess various writing quality dimensions, such as task achievement, coherence, lexical range, and grammatical accuracy (Barrot, 2023). A systematic review conducted by Barrot concluded that AWE is capable of providing credible and fast feedback that lessens the workload of instructors, but there is a limited amount of what these tools can validly measure. Higher-order writing, including the quality of argumentation, rhetorical structure, and content elaboration, remains a challenge for algorithms, and most commercial systems remain focused on superficial capabilities, such as grammar, mechanics, and vocabulary (Liu, 2024). The extensive overview of AWE feedback validity provided by Liu also confirmed that the depth of engagement with the feedback is not always deep and task-independent, which further directly inspired the current research interest in the depth of engagement design in the system. Hybrid methods that incorporate automated and human feedback have been suggested to overcome these drawbacks, but their use is quite disparate in different contexts (Z. Zhang et al., 2025), and no agreement has been reached on how to optimally balance automated and instructor-generated feedback.
There is evidence of the effectiveness of AWE, which is mixed and context-dependent. A Bayesian meta-analysis by Brown et al. (2026) found that written corrective feedback interventions, such as AWE, result in small but significant increases in linguistic accuracy, especially at lower-level accuracy features, such as morphology and punctuation. Nevertheless, they warned that the effects on the quality of holistic writing were less predictable, which is also supported by Kao and Reynolds (2024), who showed that the effect of AWE on the performance of students in timed writing varies widely depending on their perception of the feedback provided by a credible source. These inconsistencies among studies can probably be explained by differences in the design of the system, the quality of its implementation, the demographics of the learners, and the outcome measures. Importantly, the difference between adaptive and static feedback systems has not been studied empirically. With static systems, the same error detection and feedback templates are applied to all learners, which can run the risk of offering developmentally inappropriate feedback that is too challenging to struggling writers or not challenging enough to competent writers (Al-Inbari & Al-Wasy, 2023; Zhan & Xu, 2025). In contrast, adaptive systems maintain dynamic learner models that follow individual error patterns, proficiency development, and revision behavior, and adapt feedback complexity and focus on these aspects (Curran et al., 2010; Ghorbandordinejad & Kenshinbay, 2024). This individualization is consistent with sociocultural views, placing effective learning support in the ZPD of individual learners (Lantolf et al., 2020; Storch, 2018), and is the main theoretical difference that drives this study.
1.1.2. Automated Feedback and Learner Interaction
Engagement is a complex construct that involves cognitive, behavioral, and affective dimensions, each of which plays a unique role in influencing learning outcomes (Fredricks et al., 2004). In a systematic review of 20 years of literature, Hiver et al. (2024) found these 3 dimensions to be the most frequently operationalized in language learning situations, with considerable variability in how they are operationalized and theorized across studies. Cognitive engagement in L2 writing refers to the depth of mental processing in the interaction of feedback, metacognitive monitoring, strategic revision planning, and effortful interpretation of feedback content. Behavioral engagement involves observable interactions with feedback systems, including time on tasks, feedback consultation frequency, and persistence through revision cycles. Affective engagement is the emotional aspect of learning, such as interest, enjoyment, the ability to endure frustration, and the perceived worth of feedback. These dimensions are conceptually connected and empirically different: a learner can behaviorally respond to feedback (doing revisions) without any cognitive (thinking deeply about the feedback) or affective (finding it motivating) processing. Insights into the activation of these dimensions by feedback design are critical for explaining the differences in writing results.
Experimental work investigating the involvement of automated feedback demonstrates worrying trends in long-term attrition. A longitudinal study by Z. V. Zhang and Hyland (2018) reported that early enthusiasm for AWE feedback generally faded away as learners started to feel that it was redundant, unresponsive, or not in line with their emerging levels of proficiency. Ziqi et al. (2024) also revealed that this disengagement is especially acute in cases when the content of feedback does not correspond to the current skill level of the learner, when it is either too simplistic for more advanced writers or too complicated and full of jargon for novices. These findings imply that the very fact that the traditional version of AWE, which is not dynamic and is a one-size-fits-all solution, might be a structural obstacle to long-term engagement, and not necessarily a motivational or individual difference factor.
An emerging body of research places engagement as a result of feedback design and as a mediator between feedback input and writing development. In a study of Chinese learners of English as a foreign language (EFL), J. Li and Yuan (2024) showed that the affective and behavioral dimensions of engagement were highly predictive of writing performance gains and that grit mediated the strength of the relationships between engagement and writing performance gains, indicating that engagement does not have the same effect on writing performance gains across learners with different persistence characteristics. In a mixed-method multiple case study, Yan and Zhang (2024) discovered that the degree of cognitive involvement in the process of ChatGPT-mediated revision was directly correlated with subsequent improvements in writing quality, whereas superficial behavioral adherence (completing revisions without in-depth consideration) was not. These findings suggest that not every type of engagement is as productive; it is the quality, depth, and consistency of engagement that makes feedback exposure quantifiable in terms of learning and not participation. This insight provides the conceptual justification for the present study to examine engagement as a mediator between the type of feedback and writing performance and disaggregate engagement into cognitive, behavioral, and affective elements in measurement and analysis.
2. Theoretical Framework: Sociocultural Perspectives
The most important theoretical approach to the current study is sociocultural theory (SCT), which can be used to position cognitive development within the framework of social interaction and the use of cultural tools (Vygotsky, 1978). In this context, feedback can be seen as a way of mediation, as a means by which learners can obtain insights and skills that they could not acquire on their own (Aljaafreh & Lantolf, 1994). Aljaafreh and Lantolf showed that successful corrective feedback in writing is implicit and not explicit as learners progress through the process of competence acquisition, with scaffolding being withdrawn gradually as competence is attained—a process that adaptive AI systems are uniquely poised to simulate on a computational level. The quality and suitability of this mediation are not peripheral but core: feedback that is not well matched to the current stage of development of the learner can cripple growth despite its technical complexity, no matter how sophisticated it is.
The concept of the ZPD is especially educative when it comes to comprehending how the limitations of static and adaptive feedback systems compare to each other. Since the support given by static feedback is the same as that of the learner at any given stage of development, it is structurally unable to stay in the changing learner’s ZPD as they continue to develop. As students advance, the aspects of feedback that used to challenge them are no longer necessary, and the areas where students have persistent problems might not be given enough attention. Theoretically, by continuously adjusting feedback to the showcased performance, adaptive systems can maintain optimal levels of challenge, ensuring that feedback remains within the ZPD of the learner at every successive developmental stage (D. Li & Wang, 2024; Torres & Saribas, 2024). The implication of such recalibration for self-regulated learning is that with proper calibration of feedback, learners are more likely to participate in the metacognitive monitoring and strategic revision behaviors of deeper learning (Deci & Ryan, 2012; Ryan & Deci, 2020). Autonomy-supportive feedback, where explanations are meaningful (and not error indications), has been associated with increased intrinsic motivation and increased investment in revision, the two core components of the self-regulatory processes through which self-regulated writing is developed over the long term.
Modern uses of SCT in technology-enhanced language learning have increasingly anticipated the concept of distributed agency—the idea that cognitive and developmental work is not owned by individual learners but exists in the distribution among learners, tools, and social contexts (Godwin-Jones, 2024; He et al., 2025). In feedback situations mediated by AI, the AI system serves as a developmental partner by co-creating learning opportunities through reciprocal responses. More importantly, this distributed agency model does not replace human pedagogical judgment with AI but rather augments it, allowing the reach of individualized support that cannot be offered by a single teacher to a heterogeneous group to an even greater extent. To make this collaboration work, the AI element should be responsive to the present condition of the learner and modify its contribution. Therefore, the question underlying the current research is not whether AI feedback works, but whether adaptive AI feedback, feedback that implements the distributed agency principle by using real-time learner modeling, has significantly better developmental results than non-adaptive alternatives, and how these results are mediated by cognitive and behavioral mechanisms.
3. Written Corrective Feedback Research
Although most studies on the effectiveness of written corrective feedback (WCF) in L2 writing have focused on human-generated feedback instead of automated feedback (Mao et al., 2024), meta-analyses support the fact that specific corrective feedback to address particular types of errors results in measurable improvements in accuracy when combined with revision opportunities (Ellis, 2010; Kayapinar, 2014). However, the outcomes are related to the quality of feedback, the preparation of the learner, and the quality of their involvement.
Yet the application of these concepts in automated feedback situations is not fully understood. Although AWE systems can provide quick and stable feedback with minimal workload increase for the instructor, there is a risk of misunderstanding the feedback and its practicality (Asadi et al., 2025; Hox & Stoel, 2005). Some statistics state that students are not able to comprehend automated feedback, particularly when the explanations are expressed in technical language or when they do not have contextualized illustrations (McCoach & Kaniskan, 2010; Fathi & Rahimi, 2026). This problem of understanding can make the feedback less effective, which is why it is important to implement adaptive systems that can alter the complexity of the explanations and adapt them to the skill level of the learner.
4. Method
4.1. Participants and Setting
The respondents of this research were 216 undergraduate students (134 females, 82 males; mean age 20.3, standard deviation 1.8) who had taken the necessary academic writing courses at one of the large mainland Chinese institutions. All participants, who were native Chinese speakers learning English as an L2, had IELTS-equivalent scores ranging from 5.0 to 6.5, indicating an intermediate level of English proficiency. To minimize cross-group contamination, individual-level random selection of participants was performed in six intact courses taught by three different teachers. The study was approved by the Institutional Review Board, and all participants provided informed consent.
The exclusion criteria were as follows: (a) pre-intervention participation in advanced writing programs; (b) long residence in an English-speaking country (over 6 months); (c) current participation in other writing interventions; and (d) self-reported writing impairing learning. The attrition analysis showed that completers and non-completers (n = 12) did not have significant differences in terms of their demographics or baseline writing measures.
4.2. Research Approach
To ensure group equivalence, we randomly assigned participants to a randomized controlled two-arm experiment with two parallel conditions: an AI-adaptive feedback experimental group (n = 108) and a fixed-rule-based feedback control group (n = 108). Random assignment was stratified by computer-generated sequences using class and baseline writing competence. The participants wrote 6 timed argumentation essays (300–400 words each) over 2 weeks during the 8-week intervention. At α = 0.05, this design was sufficiently powerful in terms of statistics (1-β = 0.85) to find medium effect sizes (Cohen’s d = 0.50) (see Table 1).
Intervention Design and Assessment Schedule.
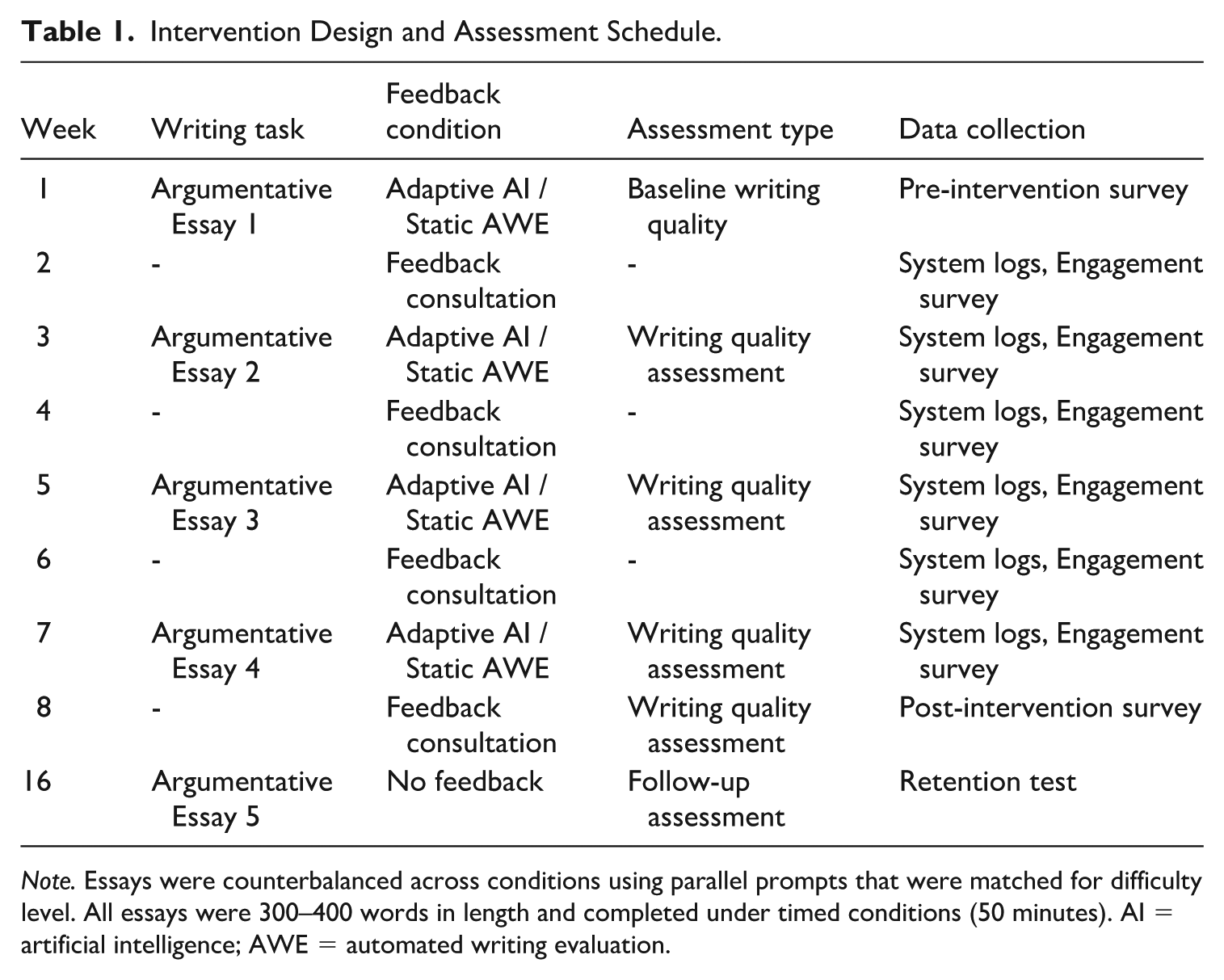
Note. Essays were counterbalanced across conditions using parallel prompts that were matched for difficulty level. All essays were 300–400 words in length and completed under timed conditions (50 minutes). AI = artificial intelligence; AWE = automated writing evaluation.
4.3. Intervention Conditions
4.3.1. AI-Adaptive Feedback Group
To customize the feedback, a special-purpose platform that utilized machine learning methods was used. The system learner model tracked the error rate, tendency to make corrections, and skill development. The feedback was manipulated in three dimensions.
1. The priority of the errors was to concentrate on the most significant ones and was adjusted to the current skill level of an individual.
2. The level of the complexity of the explanations was also varied.
3. The level of the scaffolding was given with a gradual decrease as a person became more skilled.
The system combined generative AI to generate contextualized explanations and natural language processing to identify mistakes.
4.3.2. Semi-static Rule-Based Feedback Group
Grammarly Premium is a commercial AWE that offers regular feedback based on predetermined algorithms and was used by the control group. This system identifies grammatical, mechanical, and stylistic problems, with a rule-based detection system providing unidimensional explanations regardless of the learner’s profile. Despite some context-sensitive features of Grammarly Premium, it does not model learners and personalize feedback according to proficiency or error patterns, which is why it was considered a static system for the purposes of this study. This difference may limit the present study. This was the case with a typical example of AWE use in schools, which guarantees ecological validity. The two groups were free to interact with the systems during the interventions and were provided with equal feedback. Teachers were oriented to ensure that the implementation was similar across courses, using fidelity that was tracked through weekly logs and analytics on platforms.
4.4. Measures
Table 2 defines and describes the three dimensions of learner engagement operationalized in this study: cognitive, behavioral, and affective. The choice and design of all engagement measures in this study were based on these operational definitions.
Dimensions of Learner Engagement: Operational Definitions and Measurement Approaches.
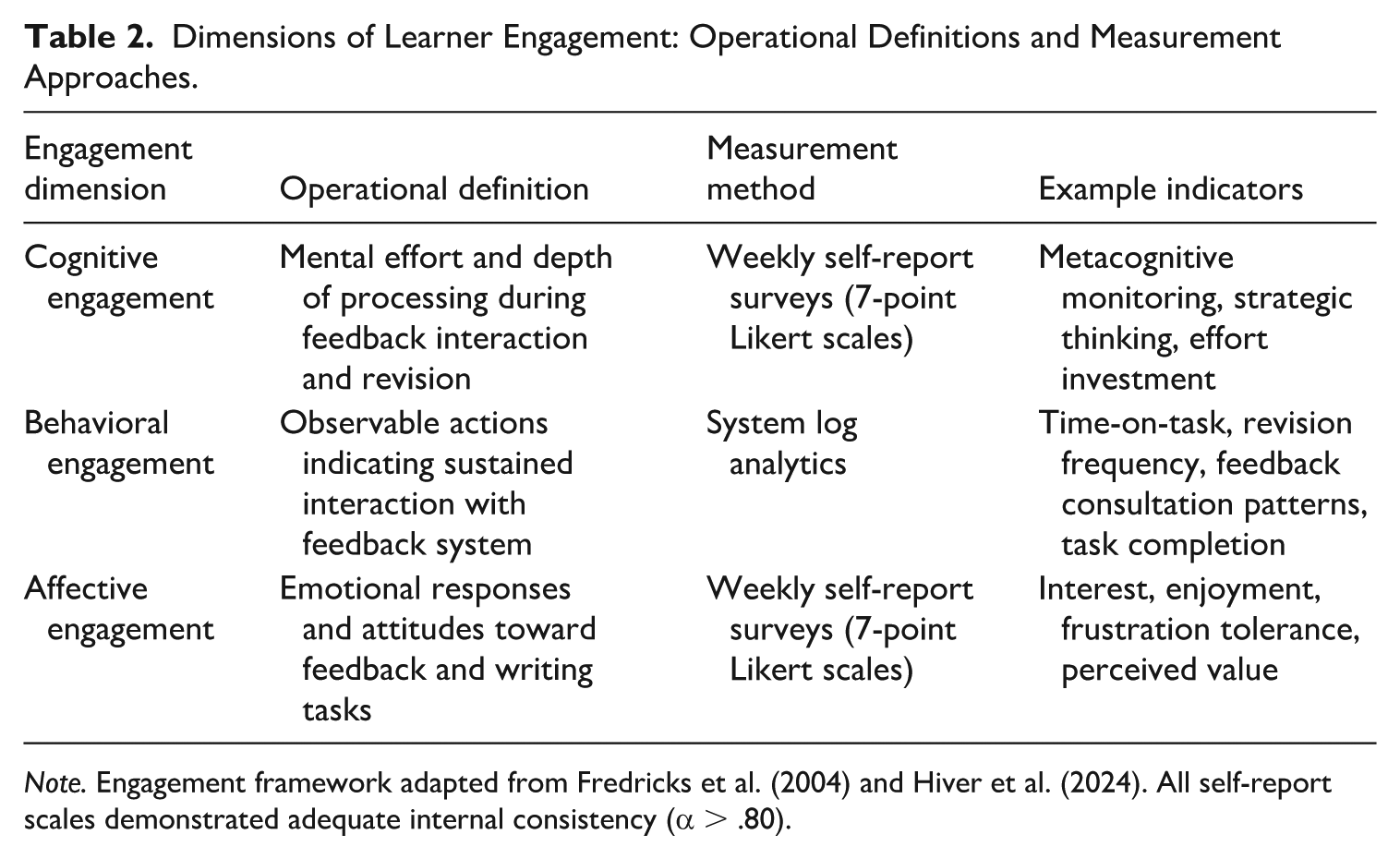
Note. Engagement framework adapted from Fredricks et al. (2004) and Hiver et al. (2024). All self-report scales demonstrated adequate internal consistency (α > .80).
4.4.1. Assessment of Writing Quality
Six trained raters evaluated essays based on an analytical rubric inspired by the IELTS Writing Task 2 rubric in four categories: task completion, coherence and cohesion, vocabulary resources, and grammatical range and accuracy (Hyland & Hyland, 2019; Weigle, 2013). The scores range from 0 to 36, with each dimension having a score ranging from 0 to 9. Inter-rater reliability was used to determine the scoring consistency, and the coefficients were calculated as two-way random intraclass correlation coefficient (ICC) and were found to be higher than the acceptable levels (ICC = 0.89, 95% confidence interval (CI) [0.85–0.92]) (Hallgren, 2012; Koo & Li, 2016). The order of the essays and allocation of treatment remained unknown to the raters.
4.4.2. Learner Engagement
Following Fredricks et al. (2004), engagement was operationalized using several indicators. Self-report surveys, which were conducted weekly using validated scales, assessed mental effort, metacognitive monitoring, and strategic thinking during revision. Behavioral engagement measurements were taken based on system log data and comprised time on the task, frequency of revision, pattern of feedback consultation, and completion rates. Affective engagement indicators were measured through self-reported interest, enjoyment, and frustration tolerance, measured on a 7-point Likert scale weekly (Cronbach’s α = 0.84).
4.4.3. Control Variables
The potential covariates included writing competence at baseline, years of learning an L2, self-belief in their competence, and anxiety about writing. These variables were added to the propensity score models and sensitivity analyses to enhance the causal inferences.
4.5. Data Analysis
Multilevel growth curve modeling with the help of the lme4 package in R was applied to the pattern of writing development through the six points of evaluation (Raudenbush, 2002; Singer & Willett, 2003). The level-1 model was used, which defined writing scores as a time-based (centered around the midpoint of the intervention) function, whereas the level-2 models examined the between-person variation in intercepts and slopes as functions of treatment condition and covariates. Before adding predictors, baseline variance partitioning was determined using unconditional models, and the model fit was evaluated based on the information criteria (Akaike information criterion (AIC) and Bayesian information criterion (BIC)) and likelihood ratio tests (Gwet, 2014; Zhou et al., 2023).
The mediation analysis of the effect of treatment on writing improvement using structural equation modeling determined whether the engagement dimensions mediated the effects. In accordance with existing longitudinal mediation procedures (Jia & Hui, 2025), we estimated the indirect effects using engagement growth paths. The confidence intervals of the indirect effects were created using bootstrap procedures (5,000 iterations), with the significance of the results assessed based on the CI that did not necessarily include zero.
Propensity score matching was used to statistically match groups based on the observed covariates and enhance causal inferences (Austin, 2011; Fan & Nowell, 2011). Propensity scores were estimated using logistic regression, which predicted treatment allocation based on the baseline characteristics. Nearest-neighbor matching (caliper = 0.2 SD) was used to establish balanced comparison groups. Matched samples were re-estimated to assess the strength of treatment effects (Powell et al., 2020; West et al., 2014). Covariate balance was measured using standardized mean differences (SMDs) and the ratio of variance, with balance considered adequate as SMD below 0.10 (Brookhart et al., 2006; Culham, 2003).
Sensitivity analysis was performed on Rosenbaum bounds to determine the likelihood of unmeasured confounding and the degree to which unmeasured bias would have to cancel out the results. Subsequent analyses examined the heterogeneity of treatment effects by level of proficiency and evaluated whether the effects of interventions were still present at 2 months’ follow-up.
5. Results
5.1. Initial Evaluations
Descriptive statistics showed that randomization was effective, as there were no significant differences in baseline writing ability between the groups (t(214) = 0.87, p = .38), and learning experience (t(214) = 1.13, p = .26), or measures of participation (all ps >.20). There was no significant difference in the attrition rates 5.6% vs. 5.5%, χ²(1) = 0.001, p = .97, suggesting that the factors leading to missing data were not treatment-related.
Unconditional growth models revealed significant variation among individuals in their initial status (τ₀₀ = 18.76) and growth rates (τ11 = 2.91), and significant inter-individual differences in their writing scores across time points (σ² = 12.43). Sixty percent of the total variance between individuals, which was established by intraclass correlation, justified the use of multilevel modeling.
5.2. Producing Paths for Writing Development
Table 3 lists the results of the multilevel growth model. In the unconditional model (Model 1), time had a linear relationship with the writing scores (= 0.58, p < .001), although the developmental trajectories were variable among individuals. In Model 2, which used treatment condition as an independent variable, the slope of improvement in participants in adaptive feedback was significantly steeper than that in the controls ( = 0.42, p < .001). This is a medium-large effect size (Cohen d = 0.67) suggests real-world relevance.
Multilevel Growth Curve Models Predicting Writing Quality Development.
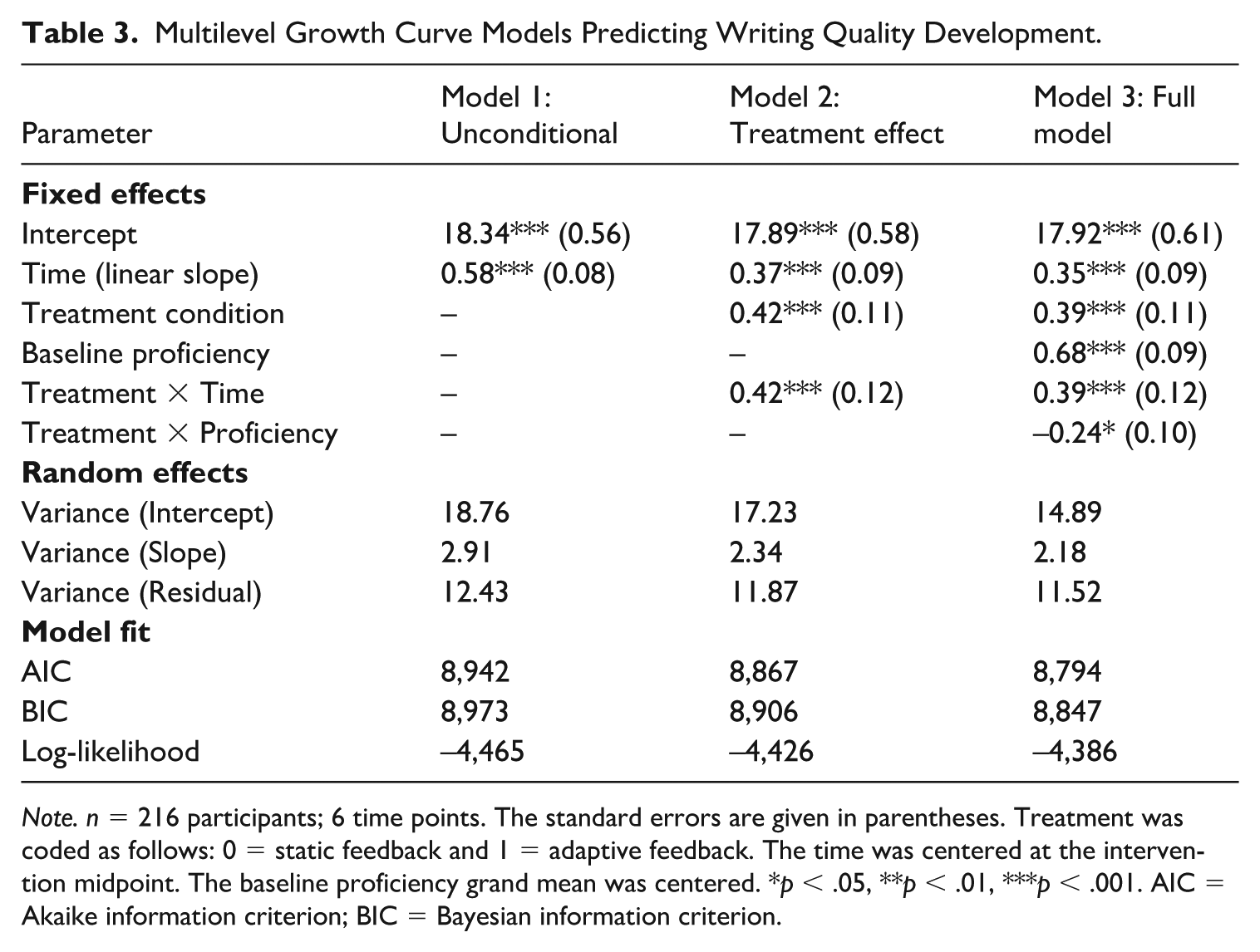
Note. n = 216 participants; 6 time points. The standard errors are given in parentheses. Treatment was coded as follows: 0 = static feedback and 1 = adaptive feedback. The time was centered at the intervention midpoint. The baseline proficiency grand mean was centered. *p < .05, **p < .01, ***p < .001. AIC = Akaike information criterion; BIC = Bayesian information criterion.
The treatment effects in Model 3 were also robust when adjusted for baseline covariates, initial proficiency, learning experience, and psychological factors ( = 0.39, p < .001). There was evidence of cross-level interactions, indicating that the treatment effects were strongest among lower-proficient learners (.24, p = .02), which means that adaptive feedback was particularly beneficial for students who required more intensive feedback.
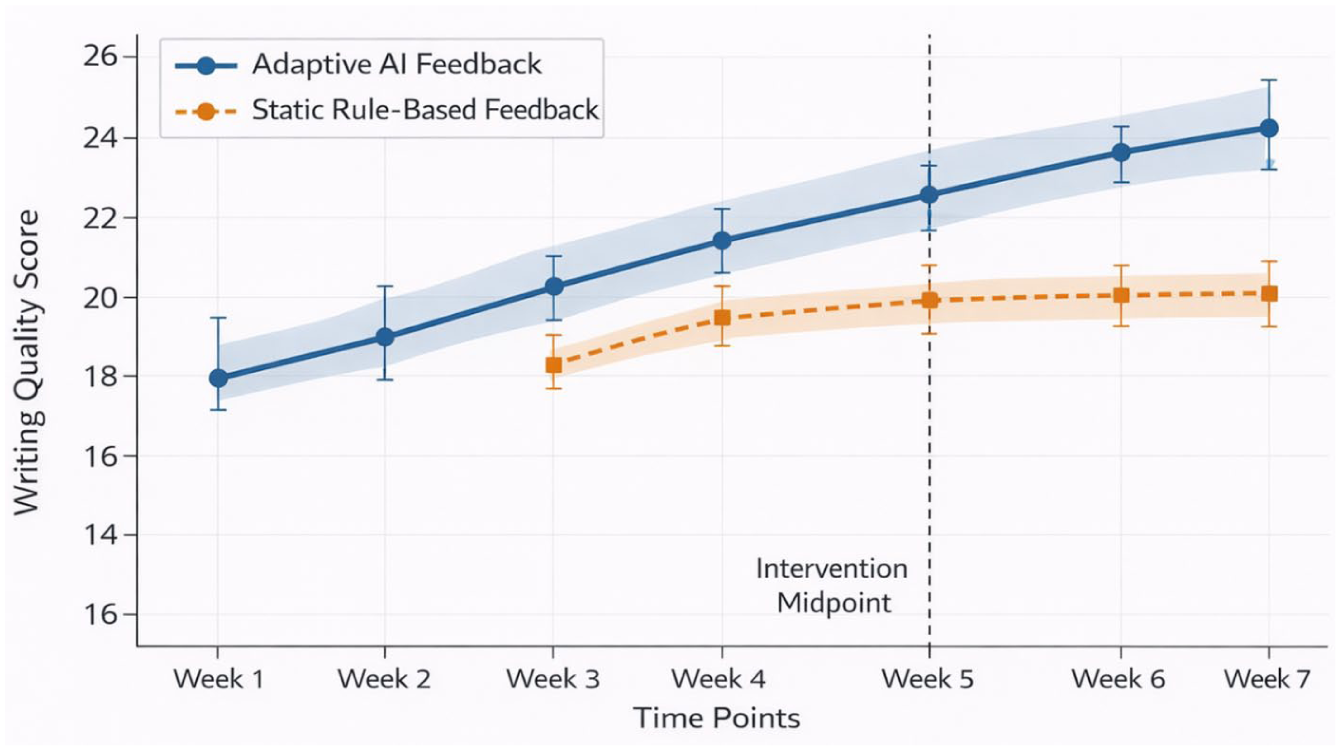
The growth patterns of the treatments observed visually showed that there were clear differences in the growth patterns of the treatments. At weeks 1–4, both groups started recording improvement, but the improvement in the control group slowed at weeks 5–8 and the adaptive group improved in a linear manner during the intervention. Based on this pattern, adaptive systems were able to retain developmental benefits by continually personalizing themselves, and the use of any given feedback became less efficient as students exhausted their capabilities.
5.3. Effects of Mediation and Engagement Patterns
The analysis of engagement showed several trends in the conditions. Self-reporting indicated that the level of cognitive engagement in the adaptive group (M ranging from 5.2 to 5.6 on a 7-point scale) did not change significantly during the course of the study, whereas it declined in the control group (from 5.1 to 4.2, β = −0.15 per week, p < .001). The same outcomes were observed with the indicators of behavioral engagement: participants in the adaptive group used feedback more often (M = 8.3 vs. 5.7 consultations per essay, p < .001) and spent more time revising based on feedback (M = 47.2 vs. 32.6 minutes, p < .001). Adaptive condition also showed higher affective engagement, with participants reporting greater interest (d = 0.54) and lower frustration (d = −0.48).
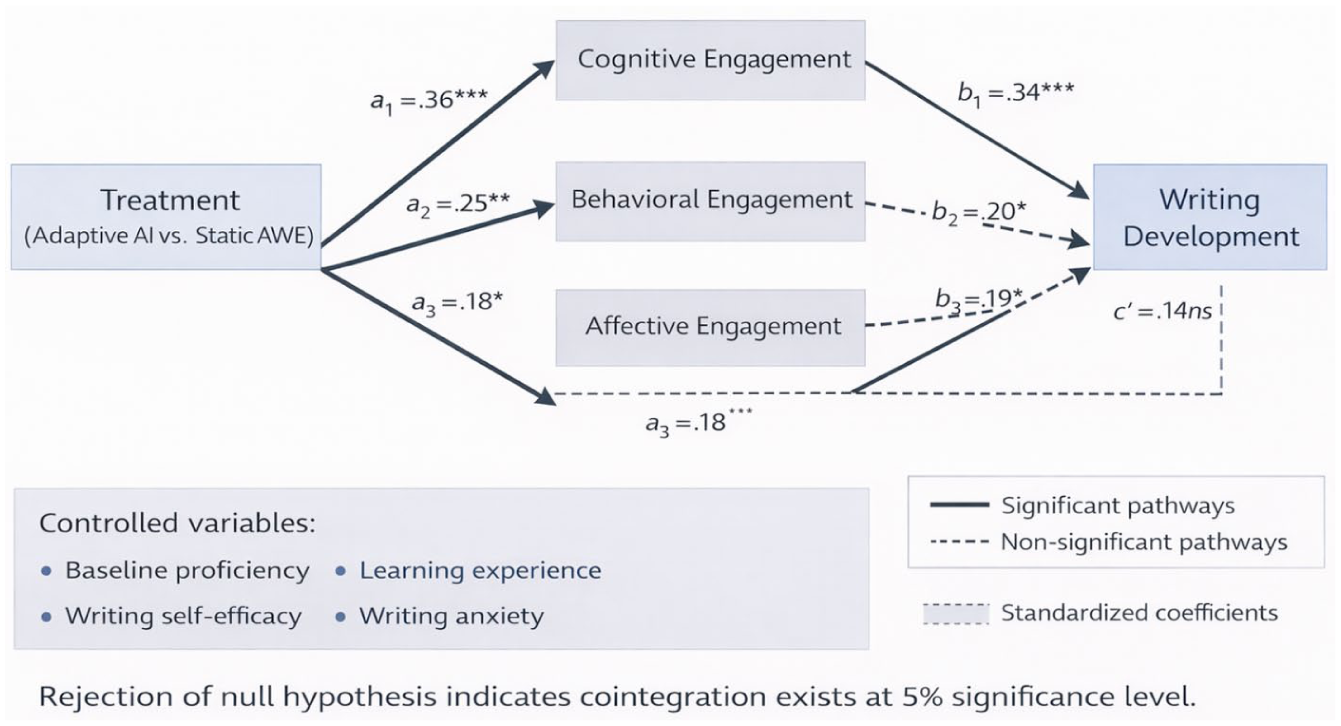
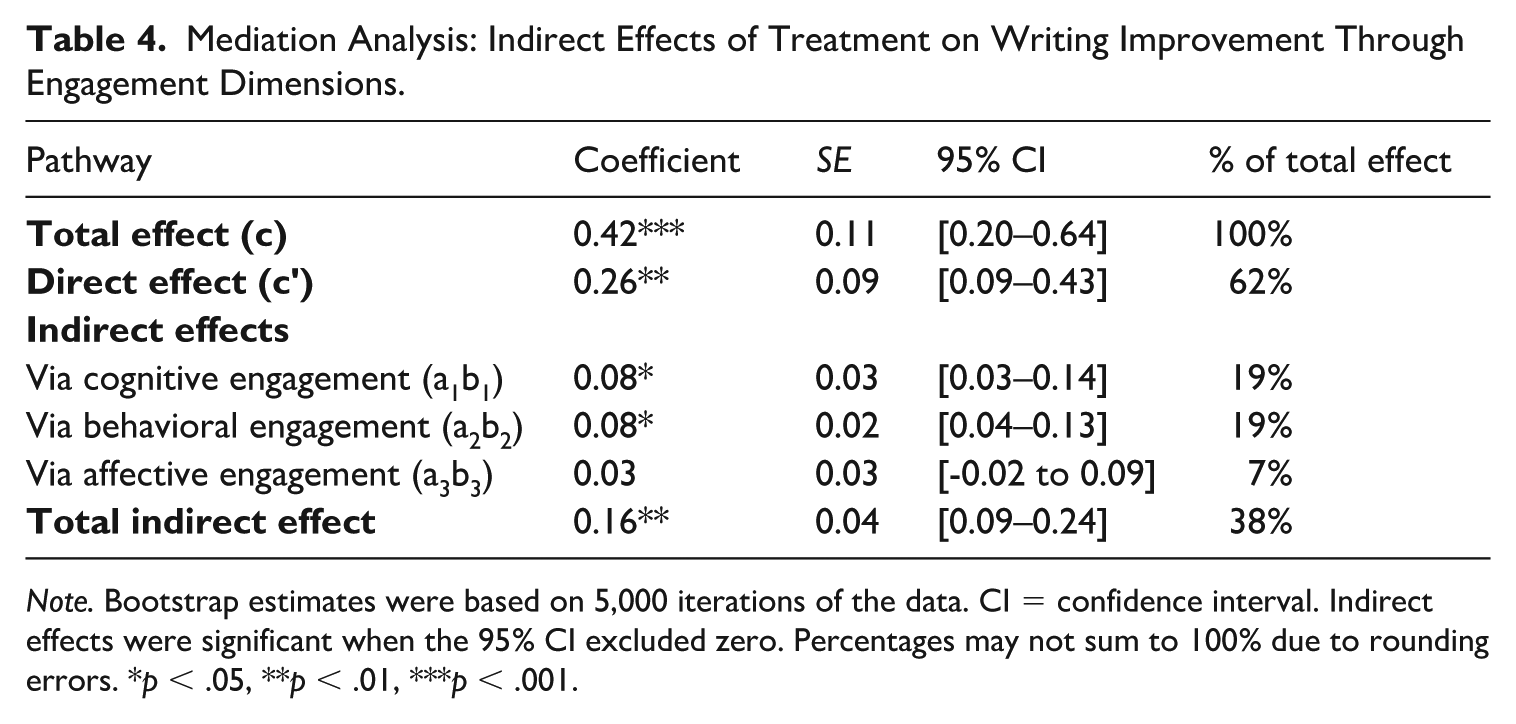
The improvement in writing treatment was analyzed through mediation analyses, with engagement dimensions as explanatory factors. Figure 2 illustrates the mediation model, in which the path coefficients indicate the relationship between treatment, engagement, and writing outcomes. The results also showed evidence of mediation: Although engagement was taken into account, the direct effect of the treatment on writing improvement remained significant (β = 0.26, p = .003). The indirect effects of cognitive engagement (β = 0.08, 95% CI [0.03–0.14]) and behavioral involvement (β = 0.08, 95% CI [0.04–0.13]) were also statistically significant. Engagement is a crucial factor contributing to writing development, as evidenced by the fact that 34% of the total effect of therapy is due to the combined indirect effects. See Table 4.
Longitudinal writing quality trajectories by feedback condition.
Mediation Analysis: Indirect Effects of Treatment on Writing Improvement Through Engagement Dimensions.
Note. Bootstrap estimates were based on 5,000 iterations of the data. CI = confidence interval. Indirect effects were significant when the 95% CI excluded zero. Percentages may not sum to 100% due to rounding errors. *p < .05, **p < .01, ***p < .001.
Surprisingly, the effect of treatment did not significantly mediate affective engagement (0.03; 95% CI: –0.02 to 0.09). This result indicates that, although affective responses varied across conditions, there was no direct correlation between affective responses and writing improvement, which is likely due to the fact that cognitive engagement and behavioral engagement have more proximal effects on the quality of revision and learning.
5.4. Robustness Checks
Using propensity score matching, we created balanced comparison groups (n = 95 per condition) with SMDs of less than 0.10 for all covariates. The estimates of the treatment effects of the matched sample ( = 0.38, p < .001) were close to the complete sample, indicating resistance to potential selection bias. Sensitivity analyses based on Rosenbaum bounds indicated that unmeasured confounders would need to increase the odds of treatment assignment by 2.3-fold to nullify the observed effect, which means that the conclusions are fairly insensitive to the latent bias.
Subgroup analyses revealed significant heterogeneity patterns. Students with lower proficiency had greater treatment benefits ( = 0.54 p < .001) compared to more advanced ones (β = 0.28, p = .02), and the effect of the interaction was also significant (p = .03). This means that adaptive feedback is most effective when students face serious developmental challenges that require specific assistance.
Post-intervention follow-up tests at 8 weeks indicated sustained improvement in the adaptive group. Unlike the controls, the adaptive group had better ratings at the end of the intervention than at baseline (retained gains: 62% vs. 41%, p = .02), which suggest more sustained learning effects, even though there was some degradation in both groups in terms of their writing performance.
6. Discussion
This experimental study, which is a randomized controlled experiment, offers strong empirical evidence for the hypothesis that adaptive AI-based feedback generates better writing development in L2 than rule-based systems, and that cognitive and behavioral engagement acts as a partial mediating variable. The results are timely and substantive to the emerging literature on AI-enhanced language pedagogy at a time when generative AI is rapidly changing the feedback landscape (Crosthwaite & Sun, 2026; S. Li, 2025). This research contributes to previous research in three mutually reinforcing ways, including providing causal estimates of the adaptive-versus-static comparison using random assignment and propensity score testing and verifying the causation by breaking the mediation pathway of engagement into its cognitive, behavioral, and affective components and quantifying the persistence of the effects of adaptive feedback at 2-month follow-up. The following sections discuss each contribution.
The size of the treatment effect (Cohen’s d = 0.67) is significantly larger than the small-to-moderate size of pooled effects of written corrective feedback interventions in a Bayesian meta-analysis of written corrective feedback interventions by Brown et al. (2026) and in a synthesis of AWE studies in L2 classrooms by Karatay and Karatay (2024), which reported that this increase is not likely to be induced by sampling artifact, considering it was a well-randomized study, with propensity score checks and sensitivity analysis with a Rosenbaum bound of Γ = 2.3. Instead, we explain the overall effect as representing the unique developmental process that adaptive systems initiate: the adaptive system maintained a fruitful challenge over the 8 weeks of the intervention by continuously recalibrating feedback to stay in the evolving ZPD of each learner. The growth trajectory data can be directly interpreted in this manner. As may be seen, the plateau of improvement in the control group occurred between weeks 5 and 8. In the adaptive group, the improvement continued in a linear fashion, indicating that adaptive feedback does not lose its developmental leverage in the same place where the developmental leverage of static feedback is lost. This result is consistent with the fact observed by Liu (2024) that interaction with AWE feedback is often shallow and task-specific and indicates that the key to solving the problem is not to improve the content of static feedback but to fundamentally redesign the feedback relationship to make it responsive and dynamic.
The proficiency-by-treatment interaction in the subgroup analyses offers valuable theoretical nuance in line with sociocultural explanations of scaffolded learning (Lantolf et al., 2020; Vygotsky, 1978). Adaptive feedback had the most significant effect on lower-proficiency learners ( = 0.54) and a less significant yet significant effect on higher-proficiency learners ( = 0.28). This pattern of differential response is consistent with the ZPD model: learners with more developmental difficulty have a broader zone of possible development to be catalyzed with focused scaffolding, whereas more competent learners potentially have enough self-regulatory resources to glean developmental advantage even from less-fine-tuned feedback. This explanation is in line with the seminal observation of Aljaafreh and Lantolf (1994) that the regulatory role of feedback changes as learners progress—explicit and corrective support giving place to implicit prompting—and indicates that adaptive systems may be specifically designed to carry out this gradual scaffolding fading away. The practical consequence is high: in heterogeneous classrooms with a significant level of proficiency, adaptive AI systems can support struggling learners with intensive assistance simultaneously and more challenging and meaning-oriented engagement to advanced learners, a level of differentiation that is structurally infeasible with a single, fixed system.
The mediation results shed light on the psychological processes by which adaptive feedback can be converted into writing gains and pose theoretically significant questions regarding the contributions of various aspects of engagement. The partial mediation pattern, where cognitive and behavioral engagement explained nearly equal amounts (18.6% and 19.4%, respectively) of the overall treatment effect, and affective engagement did not become significant, is both in line with the larger engagement literature and questions some common beliefs about technology-enhanced learning research. J. Li and Yuan (2024) showed that affective engagement was a predictor of writing performance in Chinese EFL students, but our data indicate that positive affect, although differing across conditions, did not have an independent effect on writing outcomes when cognitive and behavioral engagement were controlled for. One way to think of this difference is that affective engagement is not a mechanism but an enabling condition; it might represent a duration that allows cognitive and behavioral engagement to take place but does not affect the quality of revision processing. This is consistent with self-determination theory (Deci & Ryan, 2012), which identifies autonomous motivation (intrinsic interest) and self-regulated behavior (actual effortful engagement with task demands), the latter being more proximate to performance outcomes. Future studies should focus on whether affective involvement mediates long-term retention and transfer outcomes, in which motivational procedures can have a longer-term impact than the intervention period.
The dissimilar patterns of engagement under different conditions are also worth paying special attention to, as they reveal a structural constraint of the existing static AWE that has been outlined qualitatively in the previous literature but has rarely been demonstrated longitudinally with objective behavioral measures. In line with the results of Z. V. Zhang and Hyland (2018), involvement in the control group reduced significantly after the middle of the intervention, cognitive engagement decreased to an average of 4.2 on a 7-point scale, and the frequency of feedback consultation decreased similarly. The trend indicates that learners within the system in the static condition had already begun to harness the existing developmental value of the system by the halfway point of the intervention, beyond which further interaction provided fewer cognitive benefits. The adaptive group, in turn, did not change cognitive engagement (mean range 5.256), which is in accordance with the hypothesis that ongoing personalization does not affect the newness and developmental significance of feedback. Pedagogically, the implication of this finding is that the effectiveness of any AWE system must be measured not only at the endpoint but also along the path of an intervention: a system that yields high initial gains and falls short of continued engagement might eventually yield less-sustained learning than one that continues to challenge development.
The post-intervention follow-up data collected 8 weeks later arguably provided the most practically relevant evidence in this study. The adaptive group maintained 62% of their writing improvements compared to the baseline, compared to 41% in the control group, with statistical and practical significance. This retention benefit indicates that adaptive feedback facilitates the internalization of writing strategies and not occasional performance improvement, which is temporary and depends on continued feedback. This interpretation is consistent with the model of effective feedback suggested by Hattie and Timperley (2007), which differentiates between feedback that focuses on task performance and feedback that helps establish the learner’s ability to self-monitor and self-regulate. The higher retention in the adaptive condition suggests that learners acquired more transferable metacognitive resources—the capacity to recognize and remedy their own writing shortcomings—that were maintained without feedback when it was discontinued. From a technology investment perspective, this retention benefit goes a long way in supporting adaptive systems: when the fixed AWE provides similar short-term benefits at a lower cost but poorer long-term retention, the perceived benefit of cost might be neutralized by the necessity of making the intervention again. Combined, effect size, engagement trajectory, mediation pathways, and retention data convergent evidence suggest a consistent explanation of adaptive AI feedback effectiveness: adaptive AI feedback keeps developmental challenge within learner ZPDs, sustains cognitive and behavioral engagement in the long term, and transfers self-regulatory skills to the learning process.
6.1. Restrictions and Future Projections
This study had several limitations. Our sample was picked from one school, and only students of Chinese as a foreign language were utilized, which could restrict its application to other linguistic and cultural settings. Replication in other populations is needed to determine external validity of the results. Second, long-term treatments may be characterized by different patterns in the sense of whether they are still divergent or stable with time, but 8 weeks may have been sufficient to take developmental courses.
The exact adaptive algorithms applied are also a factor. In our system, specific design choices regarding the priority of errors, complexity of explanations, and scaffolding reduction rates were made. Other implementations may have different outcomes; thus, a systematic study is required to identify which adaptive characteristics have the most significant effects on outcomes. In our study, we compared adaptive AI feedback to fixed AWE but did not compare it to human feedback or hybrid approaches that combine AI and instructor input. Future research should examine these alternative designs to gain better insights into the role of AI in full feedback ecosystems (Xu, 2022; Asadi et al., 2025; Z. Zhang et al., 2025).
Despite being multidimensional, our engagement measures relied on self-reports to some extent, which are susceptible to social desirability biases. System log data provide objective behavioral data, but more sophisticated measurement methods, such as keystroke logs, think-aloud records, and eye tracking, may provide a more detailed view of the cognitive processes involved in revision. Despite being informative, mediation studies have resorted to the use of correlational designs, which do not allow for firm causal statements on the role of engagement. Experiments can be enhanced by controlling the level of engagement to infer causality.
Finally, our study focused on the theme of composing argumentative essays at universities. Whether the findings can be generalized to other genres (descriptive, narrative), modalities (workplace communication, creative writing), or skill sets (reading, speaking) remains unclear. Research on adaptive feedback in diverse learning settings can provide deeper insights into the scope and constraints of this concept.
6.2. Real-World Implications
When considering the choice of technology platform in educational practice, it has been demonstrated that it matters that the institution adopts adaptive as opposed to fixed AWE systems, especially in courses where the student body is not homogeneous. The fact that adaptive systems have high benefits for lower-level learners implies that achievement gaps can be closed with the help of adaptive systems, where struggling learners can receive personalized support that would not be possible with larger classes through one-on-one teacher support. When implementing AI feedback systems, instructors should be concerned with the dynamics of engagement as one of the possible early signs of diminishing efficiency. This decline in engagement observed in our control group is indicative of the fact that in situations where students extract the value of fixed systems, they may lose interest. Periodic alternation of feedback techniques or the addition of human factors can decrease this trend. Our research also aids in the development of AI systems. The developers ought to add learner modeling capability to monitor student performance and the error patterns of each student to allow the development of true adaptivity and not a simple veneer of personalization. The identified cognitive and behavioral engagement mechanisms that prove to be effective demand that efficient systems must not only be able to detect errors but they must be able to support long-term mental attention and efficient revision processes. Both presuppose a certain focus on interface design and feedback delivery (Godwin-Jones, 2024; Kern, 2024).
7. Conclusion
With some of its treatment effects partly explained by a greater degree of cognitive and behavioral engagement, the given randomized controlled experiment provides effective evidence that adaptive AI-driven feedback generates far more effective L2 writing development than rule-only systems. According to the results, the main factor that makes the difference between an efficient automated feedback system and an inefficient one is adaptivity, which is defined as the capacity of the system to dynamically adjust to the specifics of a certain student and their development. The consciousness of the conditions where AI technologies enable learning becomes increasingly important when the latter becomes more popular in the field of language teaching. We propose that technological advancement alone will not suffice; systems must show real adaptability that meets the changing needs of learners, keep the system alive through continuous developmental challenges, and encourage deep thinking rather than merely correcting errors. The course topic must focus on creating and applying adaptive systems to simplify learning without compromising the basic aspects of human pedagogy, rather than whether or not to employ AI in teaching writing. Further studies should address the long-term impact of adaptive feedback, explore the best algorithm to use with various learner types and settings, and explore how it can be integrated to constitute whole feedback ecologies that include AI, peer, and instructor feedback. One can argue that the distinction between adaptive and static systems is changing as AI abilities advance, and the findings of this study can be more actively and easily implemented in evidence-based decision-making processes in educational technology.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was supported by the 2025 Teacher Teaching Competence Improvement Project of Henan Polytechnic University (No. 2025NLTS23): Eco-literacy-oriented Implementation Pathways of Humanistic Value Cultivation in College English Teaching.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.