
Abstract
Previous research has demonstrated that retrieval practice and contextual inference are equally effective in learning and retention of first language words from reading, but their effectiveness for contextual learning of second language words has yet to be established. This study extends this line of inquiry, investigating the comparative effects of retrieval and contextual inference on contextual learning and retention of second language multi-word expressions. Eighty-five Iranian learners of English as a foreign language were randomly assigned to retrieval and contextual inference groups. The retrieval group read 28 neutral texts and were required to retrieve and write the target items while the contextual inference group read the informative texts which triggered contextual inference. Learning was measured by immediate and delayed form and meaning recall post-tests. Results of the mixed-effects regression analysis showed that contextual inference was significantly more effective than retrieval in both post-tests, suggesting potential boundary conditions of retrieval-enhanced learning from reading.
1. Introduction
Multi-word expressions (MWEs) are linguistic units consisting of more than one word (Siyanova-Chanturia & Pellicer-Sánchez, 2019). MWEs make up approximately half of language use (Erman & Warren, 2000), emphasizing their crucial role in attaining language proficiency as knowledge of these lexical items enhances reading and listening comprehension as well as second language (L2) fluency (e.g., Tavakoli & Uchihara, 2019; Yeldham, 2018). There are various types of MWEs, with the current study focusing on phrasal verbs. Phrasal verbs pose a significant learning challenge for L2 learners, largely due to their distinct properties, despite being commonly used in language (Omidian et al., 2019). For example, the majority of phrasal verbs are polysemous (e.g., come out meaning to leave a place, to become known after being kept secret, or to become available to the public). Additionally, they vary greatly in terms of semantic transparency. Although some are highly transparent (e.g., climb up), others are figurative (e.g., give up). Previous studies have shown that transparency affects phrasal verb learning. For example, Dagut and Laufer (1985) and Hulstijn and Marchena (1989) found that L2 learners avoided using non-transparent phrasal verbs. Sonbul et al. (2020) further indicated that opaqueness is an important determining factor in learning figurative phrasal verbs.
Intentional interventions that engage learners in deliberate learning of phrasal verbs have resulted in noticeable learning gains (e.g., Herra, 2013; Yasuda, 2010). However, the large number of MWEs makes it impractical to teach them all explicitly within class time. Consequently, researchers have suggested alternative approaches, such as contextual learning, which involves acquiring new vocabulary through reading or natural encounters (Elgort et al., 2018). However, this approach also poses significant challenges for L2 learners, who struggle to learn new words in context. For example, previous research has shown that L2 learners struggle to learn MWEs from reading without additional support or explicit instruction (Szudarski, 2012; Szudarski & Carter, 2014). Research has also shown that contextual word learning in a first language (L1) may be less susceptible to forgetting (Hulme & Rodd, 2021, L1 contextual word learning).
To improve contextual vocabulary gains, engaging learners in retrieval practice has been suggested (see Barcroft, 2015, for contextual learning of L2 vocabulary; van den Broek et al., 2022, for contextual vocabulary learning in an L1 context). Importantly, although the term retrieval practice is often used broadly, research in cognitive psychology emphasizes that retrieval practice typically involves multiple retrieval attempts, often spaced over time, and that this temporal structure is central to the testing effect. In second language acquisition (SLA) research, however, retrieval-based interventions may differ in how retrieval is operationalized, particularly regarding repetition, timing, and classroom versus laboratory implementation. To avoid conceptual ambiguity, it is therefore essential to distinguish between retrieval (a single retrieval opportunity) and retrieval practice (repeated retrieval under controlled timing). This distinction is especially relevant for classroom-based studies, where strict control over time intervals is rarely feasible. The present study investigates whether engaging learners in single retrieval opportunities embedded within contextual encounters can support the learning of phrasal verbs under ecologically valid classroom conditions. Although this procedure does not constitute full retrieval practice due to the absence of repeated retrievals, immediate feedback has been shown to reinforce memory in ways that partially mirror the benefits of repeated retrieval. Research demonstrates that retrieval accompanied by corrective feedback enhances learning by confirming correct responses, supporting error correction, and reducing forgetting or interference (e.g., Aljabri, 2024; Stenlund et al., 2016). By situating the intervention within these authentic instructional parameters, the present study offers a transparent account of how single retrieval with immediate feedback (rather than repeated retrieval practice) supports contextual learning of phrasal verbs in L2 settings.
2. Literature Review
2.1. Retrieval Practice and Contextual Vocabulary Learning
The advantages of retrieval practice, the process of accessing and recalling previously acquired knowledge from memory (van den Broek et al., 2022), has been well established across various fields, enhancing learning and retention in memory studies, (e.g., Baddeley & Wilson, 1994), educational psychology (e.g., Healy et al., 2017), and language learning studies focusing on L1 vocabulary (Goossens et al., 2014), L2 grammar (e.g., Bird, 2010), and L2 vocabulary learning (e.g., Nakata, 2015; Serrano & Huang, 2018; Strong & Boers, 2019). However, the potential benefits of retrieval practice to enhance vocabulary learning and retention during reading has received little attention. Few studies have examined the impacts of retrieval practice on contextual vocabulary learning. These studies have focused on the learning of vocabulary either in the learners’ L1 (van den Broek et al., 2018, 2022) or the learning of single words in an L2 context (e.g., Barcroft, 2015). For example, Barcroft (2015) investigated the impacts of retrieval practice on contextual L2 vocabulary learning and retention. The target words were embedded in a story three times, with the experimental group seeing the word and its translation only once, then attempting to recall the word when given the translation in subsequent encounters. In contrast, the control group saw the word and translation all three times without attempting retrieval. The results showed a significant advantage for the retrieval practice group, outperforming the control group.
Research findings have further shown that the effectiveness of learning vocabulary from context depends on the level of support provided by the surrounding text (Boers, 2020; Mondria & Wit-de Boer, 1991; Webb, 2008). Contexts with more supportive clues enable readers to infer the meanings of unfamiliar words more easily, whereas contexts with fewer clues make it more challenging for learners to understand new vocabulary. Mondria and Wit-de Boer (1991) found that Dutch high school students better inferred L2 vocabulary meanings when encountering words in supportive sentence contexts. However, this initial learning advantage was associated with poorer retention.
Providing more contextual clues may facilitate easier inferencing, but potentially hinders retention, whereas fewer clues may challenge learners to retrieve target words, promoting deeper learning. The complex relationship between contextual clues and retention in L2 vocabulary learning, as evidenced by previous research findings (e.g., Mondria & Wit-de Boer, 1991; Webb, 2008), highlights the importance of investigating the effects of context and retrieval practice on contextual vocabulary learning to determine the optimal balance between these factors and inform effective instructional strategies.
2.2. Contextual Inferences, Retrieval Practice, and Contextual Vocabulary Learning
Despite the critical role of contextual inferences and retrieval practice on contextual vocabulary learning, few studies have investigated their effects in tandem. Van den Broek et al. (2018) compared the efficacy of contextual inferences and retrieval practice on learning words from single sentence contexts. There was a pre-training stage in which the meanings of the target items pre-encoded. Participants then practiced the critical items under supportive and neutral contexts. In the supportive context, an additional sentence provided a clue from which the meaning could be inferred, whereas in the retrieval contexts such clues were absent, requiring students to retrieve the meanings from memory. They found that the retrieval condition led to superior long-term retention compared to the sentence inference condition, provided that retrieval trials were successful or feedback on unsuccessful retrieval was given.
Taking these findings into account, van den Broek et al. (2022) conducted another study that more closely resembles a contextual vocabulary learning condition. This study aimed to test the efficacy of retrieval practice in contextualized word learning situations. Twenty-four Lithuanian words were pre-encoded through Lithuanian-Dutch word lists. The target words were embedded into two Dutch stories with the same content, differing in the amount of information provided to infer the meaning of those words. In the retrieval condition, no contextual clues were available for the readers to guess the meanings of the critical items, whereas in the inference condition there were enough cues for the readers to guess the meanings of the target words. Participants were not required to overtly provide the meaning of the words. In contrast to van den Broek et al. (2018), inference condition led to superior word retention compared to the retrieval condition. They provided some explanations for the results. First, the effects of retrieval practice might be subordinate to the impacts of contextual clues in the contextual vocabulary learning conditions. Second, the stories they used provided various contextual details that helped participants retrieve the word meanings and were therefore more effective than the retrieval condition. Another explanation was that in van den Broek et al. (2018), the participants received feedback on their retrieval trials, and this allowed learners to re-encode the words’ meanings. Also, the pre-training stage was short which could lead to more failed retrievals. Therefore, they extended the pre-training stage and provided feedback on the retrieval condition in another experiment. By these changes, they predicted that the retrieval condition would lead to superior outcomes compared to the inference condition. However, the results showed that even with the presence of feedback and extended pre-encoding stage, the two conditions were equal in terms of enhancing retention. They concluded that there might be boundary conditions of retrieval-enhanced learning.
In van den Broek et al. (2022), the participants were not required to write an overt response in the retrieval condition. It was assumed that the learners would retrieve the meanings from the pre-training stage when they encounter them in neutral contexts. Therefore, it is not clear whether learners were actually involved in the retrieval attempts. Overall, the results obtained from van den Broek et al. (2022) showed further studies were needed to shed light on the efficacy of retrieval practice and contextual inference during contextual word learning. This would provide the necessary background for comparing the effects of contextual support with retrieval practice which would, in turn, reveal whether there are boundary conditions of retrieval-enhanced learning during contextual word learning.
To find out this and extend it to the contextual learning of L2 vocabulary, Tadayonifar and Strong (2024) tested the effects of retrieval practice and contextual inference during contextual learning of L2 MWEs. Three hundred Iranian learners of English as a foreign language (EFL) were randomly assigned to two experimental groups (overt retrieval and contextual inference) and one control group after an initial encoding stage. The experimental groups read 20 short texts containing the target MWEs repeated 3 times. They then retrieved these MWEs either overtly (by writing the retrieved words) or covertly (by inferring meanings through contextual clues), whereas the control group received no such treatment. The results showed that retrieval practice significantly improved contextual learning and retention of the target MWEs in the immediate and delayed tests measuring knowledge of form and meaning of the target items. In contrast to van den Broek et al. (2022), they found that the retrieval group was significantly more effective than the contextual inference in both tests. The way the retrieval and contextual inference were operationalized, however, was different from van den Broek et al. (2022). In Tadayonifar and Strong (2024), the participants were required to produce an overt response in the retrieval condition. Also, despite encountering the target items three times in the texts, contextual clues were only provided after the first encounter, leaving it uncertain whether retrieval actually occurred after the clues were given. Future research should focus on developing methodologies to operationalize contextual inference that ensure retrieval occurs concurrently with the inferencing process, while students are actively engaged in making meaning from context (Tadayonifar & Strong, 2024). One possibility is to provide contextual clues after each contextual encounter in the text to ensure accurate inferencing has occurred in the contextual inference condition. This might make the retrieval and contextual inference conditions more comparable and equal in terms of learning opportunities, thereby allowing for a clearer determination of which strategy is more effective in enhancing contextual L2 vocabulary learning from reading. Therefore, the present study was conducted to compare the impacts of retrieval and contextual inferencing conditions on contextual learning and retention of L2 MWEs.
3. Research Questions
4. Methodology
4.1. Participants
Eighty-five Iranian male and female English learners aged between 10 and 18 years old (M = 15) participated in this study. They were studying English at pre-intermediate (A2) level based on the results of the reading section of the Preliminary English Test (PET) for schools (M = 17.49, SD = 4.4). They were taking the language institute’s courses (twice a week for 75 minutes). Their native language was Persian. Information about the general aims of the study was presented to the participants before starting the data collection and they agreed to participate.
5. Materials
5.1. Target Phrasal Verbs
This study explored the use of figurative phrasal verbs (e.g., chip in meaning contribute) in short reading texts. Twenty-eight phrasal verbs were selected taking into account a set of criteria. The initial selection of phrasal verbs was based on corpus-based lists (Gardner & Davies, 2007; Garnier & Schmitt, 2015), and textbooks (e.g., McCarthy & O’Dell, 2004) with a Mutual Information (MI) score of 3 and above to ensure the selected phrasal verbs had strong co-occurrence relationships.
Multiple norming procedures followed this step.
The first norming study recruited 10 native English speakers to evaluate the figurative nature of selected phrasal verbs on a 7-point Likert scale (1 being fully literal and 7 being completely figurative), based on their intuitive judgments. The study included 90 sentences: 60 phrasal verb items and 30 literal fillers, designed to use the verbs in their intended figurative senses. Items with a mean score above 4 were selected. To ensure the figurative meaning was predominant, the first 50 concordance lines from the Corpus of Contemporary American English (COCA; Davies, 2008) were additionally rated on a binary scale (figurative or literal). Items meeting this criterion were then included in a subsequent norming study with language learners.
A group of students, matching the actual participants in proficiency, age, and language background, were asked to define the selected phrasal verbs. The survey consisted of 72 sentences, using simple vocabulary (from the first 2,000 headwords) appropriate for the participants’ pre-intermediate level. Students were asked to provide definitions for each individual word and the entire phrase. The ideal items were those where at least 80% of the students failed to provide the correct overall meaning, despite being familiar with the individual words.
The final norming study consulted teachers to determine whether their students would likely know the meanings of the selected items. Four teachers participated, and items were selected if at least 75% of them rated the items as unknown to their students. Consistent with Vilkaitė and Schmitt’s (2019) findings on the different processing of adjacent and non-adjacent MWEs by non-native speakers, only adjacent forms were included. All relevant data and materials are accessible via this anonymized Open Science Framework (OSF) link: https://osf.io/fvz7h/?view_only=ac9be28c951849ab9502e1ac9c960a32.
5.2. The Texts
This study explored the impact of overt and covert retrieval on learning and retaining L2 MWEs in context. To achieve this, 28 texts were developed in 2 types: neutral and supportive. The neutral texts, used for overt retrieval, were 79–92 words long, while the supportive texts were 89–111 words long. The texts were carefully constructed based on a range of linguistic and pedagogical considerations, including word frequency, readability indices, text length, the proximity of the verb and particle, repetition, the form of the target items, and expert judgments from L1 speakers regarding the texts’ informativeness. When developing the texts, the most frequent 2,000 words of the British National Corpus, as well as proper nouns and transparent compounds were used to create more natural texts. The AntWordProfiler tool (Antony, 2022) was used to ensure that 100% of the words in the texts, excluding the target phrasal verbs, fell within this criterion, promoting optimal vocabulary learning conditions.
The Flesch-Kincaid grade level (Kincaid et al., 1975) was used to calculate the readability scores using an online instrument (https://charactercalculator.com/flesch-reading-ease/, 2023). It shows the number of years of education required to understand a text. The mean readability scores of the neutral texts (M = 5.39, SD = 1.14) as well as supportive texts (M = 6.52, SD = 0.72) indicated that the passages were appropriate for 5th to 7th graders.
Research indicates that at least three exposures to L2 vocabulary through reading are necessary to trigger initial understanding (Boutorwick et al., 2019). Therefore, the target phrasal verbs were intentionally repeated three times in the texts to facilitate vocabulary acquisition.
To ensure the texts were neutral, a norming study was conducted with eight L1 English speakers, who were asked to identify words that could easily reveal the meanings of the target items. Based on their feedback, the texts were revised, and the revealing words were either deleted or replaced with alternative words.
For the contextual inference group, another version of the texts was developed using the same content and criteria described above. However, to trigger covert retrieval, some contextual clues in the form of short definitions were added consistently after the last repetition. To ensure the added clues were informative enough, the last sentence and the related clues were given to 10 L1 English speakers in a cloze completion task. The cloze completion task has been used extensively as an effective tool to determine the constraint of contexts (e.g., Chen et al., 2017; Frishkoff et al., 2010; Staub et al., 2015). In this task, the last sentences in each text, which contained the contextual clues as well as the critical items, were used. For example: “Sometimes you have no other choice but to _________ an invitation. One way to politely reject or refuse to consider an invitation is to keep it short and to the point.”
The blank could be completed by the phrase “turn down.” Ten L1 English-speaking participants were asked to come up with the missing phrase or word. Then, the guesses obtained from the cloze task were included in a 5-point rating study. Two L1 English speakers were asked to rate how close the guesses obtained from previous norming were to the actual phrasal verbs. More than 97.4% of guesses were rated as very close in meaning (they obtained mean scores of 4 and 5). This indicated that the clues were effective in assisting the learners in retrieving the target items’ meaning during reading. However, to increase inference accuracy, some contextual clues were also added after each contextual encounter. As each item was repeated three times, contextual clues were added consistently three times across each text either before or after each repetition. This is important as retrieval after each encounter was required.
6. Measures
6.1. Pre-Tests
6.1.1.Translation Pre-Test
Two weeks prior to the main study, a sentence translation pre-test was administered to ensure that the selected phrasal verbs were unfamiliar to the participants. The results indicated that the items were indeed unknown, with over 94.5% of responses being either incorrect or providing a meaning that was not the focus of the study (e.g., translating chip in as interrupt, which, although not entirely wrong, was not the intended meaning). This confirmed that the participants lacked prior knowledge of the target phrasal verbs, making them suitable for the study
6.1.2. The PET
To select participants with similar English proficiency, the PET was used. The PET, offered by Cambridge Assessment English, is an intermediate-level exam that assesses learners’ mastery of English fundamentals. The test consists of four sections: reading, writing, listening, and speaking. In this study, only the reading section was utilized, which comprises 6 parts and 32 questions, taking approximately 45 minutes to complete. According to the Cambridge scoring system, PET scores correspond to the following levels: Elementary (A1, scores 1–12), Pre-intermediate (A2, scores 13–22), Intermediate (B1, scores 23–28), and Upper-intermediate (B2, scores 29–32).
6.2. Post-Tests
6.2.1. Gap-Fill Test
A recall test, identical to the validated test in Garnier and Schmitt (2015), was employed to measure learners’ explicit knowledge of the critical items’ form. The gap-fill test, a pencil-and-paper form recall measurement, presented target items in supportive sentences with two gaps corresponding to the verb and particle of the phrasal verb. The initial letter of each word was provided as a clue, and the meanings of the target items were given in bold font and italics to facilitate recognition. For example: “When your blood sugar suddenly drops, you may feel like you are going to b. . .. o. . .. soon. (
A binary scoring system was employed, where responses were scored 1 if they matched the target phrase or had minor spelling errors that did not affect the response as ambiguous. Ambiguous responses were scored 0, as were responses with no particle, unrecognizable responses, or those lacking a verb. The primary researcher scored the post-tests, and a second experienced researcher independently scored 25% of the data. Inter-coder reliability was calculated at 90% based on overall agreement. Any discrepancies were resolved through consensus-driven discussions.
6.2.2. Meaning Generation Test
To assess learners’ explicit knowledge of meaning, a meaning generation post-test was administered, mirroring the type of knowledge required during reading comprehension (Elgort et al., 2020). This test has been previously employed in research to measure knowledge of meaning (e.g., Elgort et al., 2020; Frishkoff et al., 2010). In the meaning generation test, target items were presented in neutral sentences, and participants were required to provide written explanations of their meanings. Responses in either L1 or L2, including synonyms or close approximations, were considered correct. Two experienced researchers independently scored the test, yielding a high inter-rater reliability of over 95%, ensuring the accuracy of the results.
A binary scoring system was employed to score the test, where participants could provide either a Persian translation or an English definition for target words. Responses in Persian were compared to dictionary translations and definitions from bilingual and monolingual sources, focusing on core meaning. Scores were assigned as follows: 1 if the response matched or closely approximated a dictionary entry (e.g., to rob people’s money for rip off), and 0 if it did not (e.g., to move backwards and forwards for shake off). The primary researcher scored the post-tests, and a second experienced researcher independently scored 25% of the data. Inter-coder reliability was calculated at 93% based on overall agreement. Any discrepancies were resolved through consensus-driven discussions.
6.3. Procedure
The current study used a between-participant design with two practice conditions, namely retrieval condition (pre-encoding, reading neutral texts, retrieving words) and contextual inference condition (pre-encoding, reading supportive texts). The participants were selected based on the PET proficiency test. The majority of them were pre-intermediate learners based on their PET scores. Then, they were randomly assigned to the retrieval and contextual inference groups. Group 1 consisted of 18 students, Group 2 included 17 students, and Groups 3 and 4 each comprised 25 students. Data were collected from four groups. In each group, the items were divided into four sets. Each set comprised seven different items. These sets were counterbalanced across all four groups (Table 1).
Counterbalancing of Experimental Treatments.
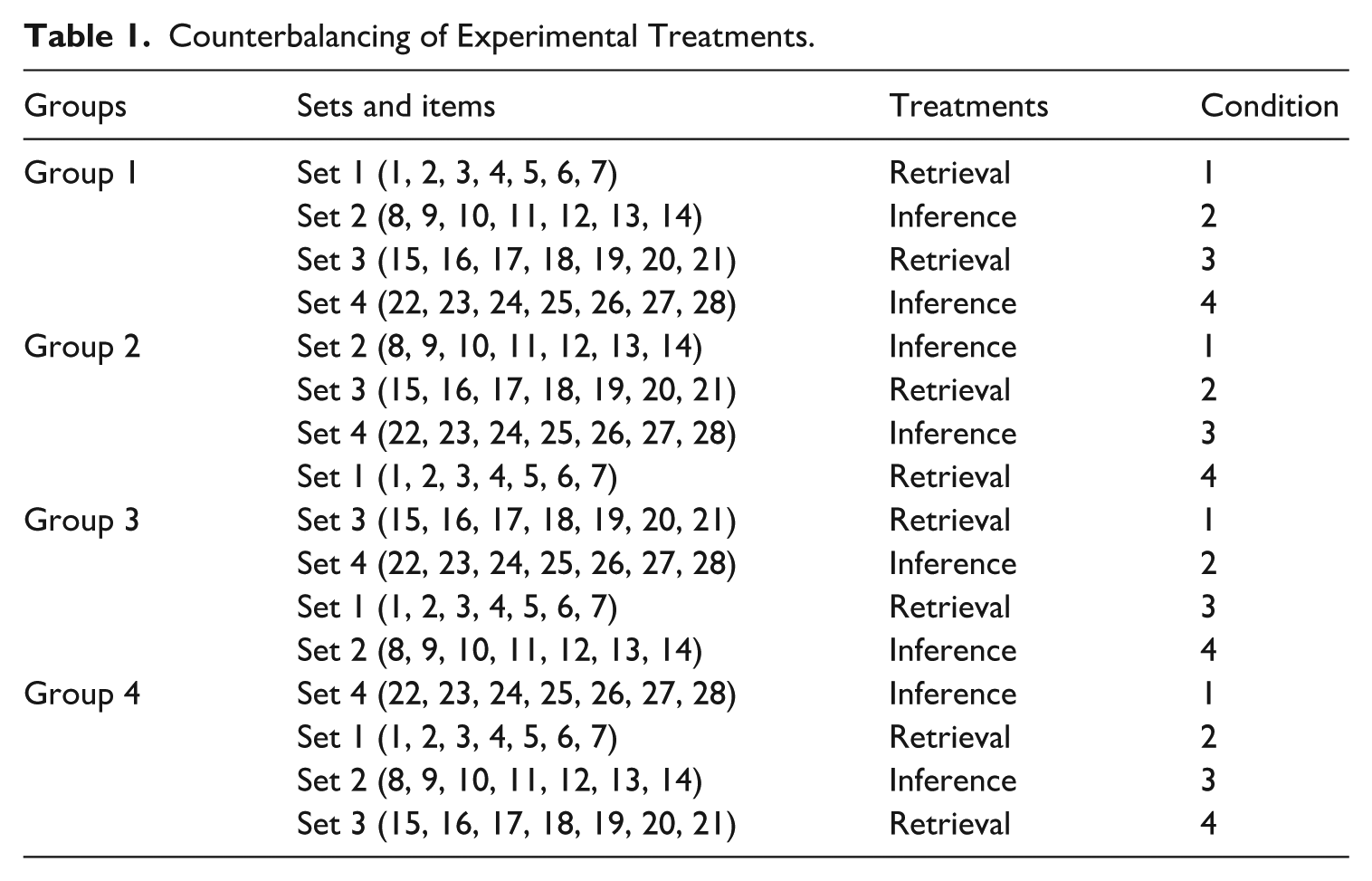
Group 1 started with set 1 and finished with set 4. Group 2 started with set 2 and ended with set 1. To create new groups, the same procedure, to move up the second set in each group and put it at the beginning of the following group and to move down the first set and put it as the last set in the new group, was used until all the sets were counterbalanced across the groups. This allowed contextual inference and overt retrieval to be counterbalanced between the sets in each group.
The retrieval group was involved in reading the neutral texts while the contextual inference group read the supportive texts after an initial encoding phase for both groups. In the encoding phase, the participants were instructed to carefully study the target items and their translations until they felt confident that they remembered the meanings. Then, they read the assigned texts in 2 sessions (14 texts per session). Each session lasted approximately 90 minutes: 20 minutes were allocated to the pre-training phase, 60 minutes to reading the target texts, and the remaining time for students to rest. Figure 1 illustrates the experimental procedure.
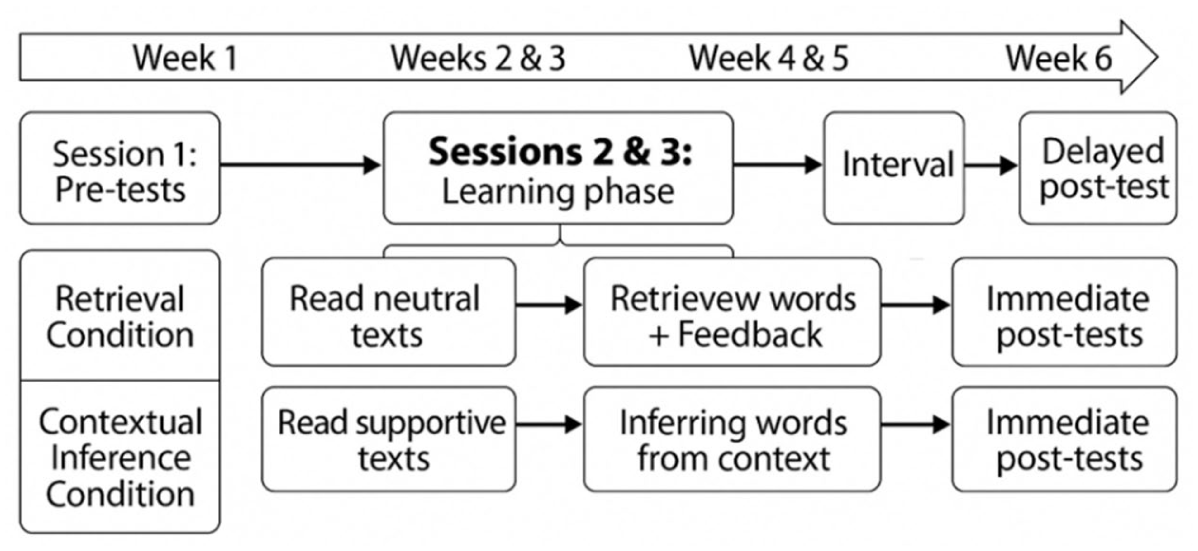
Overview of the experimental procedure.
In weeks 4 and 5, no experimental procedures were implemented. During this period, students engaged in their regular classroom activities, which primarily consisted of grammar exercises and sentence writing. In the present study, although the learning materials varied across weeks 2 and 3, the retrieval task (i.e., the core intervention) was implemented only during the main retrieval activity. Earlier exposure to the materials served solely as pre-training or familiarization, rather than as part of the intervention. Thus, there were the following phases: a pre-training/exposure phase where students were introduced to the materials but did not engage in structured retrieval or receive feedback; a retrieval phase (main intervention) where the participants attempted to retrieve the target items, with immediate feedback provided for incorrect or missing responses in the retrieval group; and a post-test phase when participants’ recall and comprehension of the target items were assessed.
After reading the texts, the retrieval group were required to write the recalled words and their translations in their L1, Persian, immediately after reading the texts. During this phase, participants recorded their responses on a structured worksheet containing numbered spaces corresponding to each set of target items. Following the presentation of each set of seven items, participants were instructed to attempt retrieval by recalling and writing down as many target words as they could remember from the previous set. No additional cues or prompts were provided. After completing each set, participants in the retrieval group received written feedback.
The feedback provided to the retrieval group was written and consisted of the correct translation of the target items. As participants read the texts in sets of seven, feedback was given after each set rather than item by item. During this stage, those who could not retrieve the words or provided an incorrect response had the chance to have a successful retrieval. Having the chance to successfully retrieve the items at least once before the post-test was important as retrieval success has been shown to affect later performance (e.g., Smith et al., 2013). The participants then took the immediate post-tests of form and meaning of the target phrasal verbs.
In this study, students followed task instructions within normal classroom conditions, rather than under experimentally timed intervals. After reading the texts, the retrieval group were instructed to immediately write down the words they recalled along with their L1 (Persian) translations. The contextual inference group, by contrast, were not required to produce any output and therefore did not receive feedback; instead, they simply had access to contextual cues each time they encountered the target items. Because these procedures occurred during regular class time, it was not feasible to control the exact timing of each step. Classroom instruction naturally varies in pace due to interactions, questions, and lesson flow. Moreover, imposing strict, laboratory-style temporal control in a classroom study would reduce the generalizability of the findings, as it would no longer reflect how retrieval practice naturally operates in real educational contexts. In the present study, participants completed a brief pre-training stage, but during the main task each target item was retrieved only once. However, learners received immediate feedback following each retrieval attempt. This ensured that students who initially failed to recall an item, or recalled it incorrectly, were able to achieve a correct retrieval before taking the post-test. Although this procedure does not involve repeated retrieval and therefore does not constitute full retrieval practice, immediate feedback can reinforce memory in ways that partially mirror the benefits of repeated retrieval. Previous studies demonstrated that retrieval is more effective when accompanied by corrective feedback (e.g., Aljabri, 2024; Stenlund et al., 2014). Feedback enhances the retrieval process by confirming correct responses and helping learners correct misunderstandings, thereby boosting the overall learning value of retrieval. Conversely, in the absence of feedback, correct information is more prone to forgetting or interference, and learners may inadvertently consolidate errors.
7. Data Analysis
The presented study tested the effects of retrieval practice and contextual inference on contextual learning and retention of L2 phrasal verbs controlling for the effects of item-related characteristics (including phrasal verb frequency and figurativeness) as well as learner-related characteristics (including English reading proficiency).
Statistical analyses were conducted to investigate the impacts of retrieval and contextual inference on explicit knowledge of form and meaning of 28 phrasal verbs measured by immediate and delayed post-tests that measured knowledge of form (gap-fill) and meaning (meaning generation) of the critical phrasal verbs. Mixed-effects models were fitted to the data, using the glmer function in the lme4 package in R (version 4.3.0; Bates et al., 2015). Separate models were fitted to the two binary outcome variables: gap-fill (correct = 1, incorrect = 0) and meaning generation (correct = 1, incorrect = 0). The primary interest predictor was the learning treatment with two levels (retrieval and contextual inference. Although only phrasal verbs with a mean figurative score of above 4 were included in the study (M = 5.24, SD = 0.77), there was variation in the level of figurativeness of the target items from a minimum of 4.1 to a maximum of 6.5. According to PET, participants were generally pre-intermediate English learners (M = 17.49, SD = 4.4). However, there were variations between them, ranging from 10 to 27 (out of 32). There were also considerable variations among the phrasal verbs ranging from 741 to 71711. These variations had the potential to influence outcome variables and therefore were accounted for in the model by including them as covariates. All continuous data were log-transformed and centered to avoid multicollinearity (Frost, 2014). All categorical data were contrast coded.
The initial statistical models included fixed effects for the main predictor and covariates, as well as random intercepts for items and participants. Then, a backward stepwise variable selection procedure was applied to simplify the models and retain only the significant predictors. The likelihood ratio test was used to compare and validate the models, following the approach described by Baayen et al. (2008). In the gap-fill model, it was found that phrasal verb frequency and figurativeness as well as English proficiency did not improve the model fit (χ2 = 0.02, p = .88, χ2 = 1.46, p = .23, χ2 = 0.00, p = .96, respectively). Then, the random slopes were tested one at a time. In the gap-fill model, it was found that fitting treatments by participants and items did not improve model fit (χ2 = 0, p = 1, χ2 = 0.93, p = .63, respectively). However, the model containing random effects of participants led to singular fit warning. Thus, it was decided to first run the model with the participant as random effect and then remove it to avoid a singular fit and see how the obtained outputs differed. The results were similar indicating that the random effect of participant did not significantly impact the model's estimates. Therefore, the model without the participant as a random effect (the simpler model) was selected as the final model. The final model for the gap-fill outcome variable is provided: Outcome variable (Gap-Fill) ~ Treatments + (1|Items).
In the meaning generation model it was found that it was found that phrasal verb frequency and English reading proficiency did not improve the model fit (χ2 = 1.42, p = .23, χ2 = 0.04, p = .85, respectively) and were dropped from the model. However, dropping phrasal verb figurativeness affected model negatively (χ2 = 9.20, p < .001). So, figurative scores were included in the meaning generation model. Then, the random slopes were tested one at a time. In the meaning generation model, it was found that fitting treatments by participants and items did not improve model fit (χ2 = 0, p = 1, χ2 = 1.75, p = .42, respectively). Also, fitting phrasal verb figurativeness by participants and items did not improve model fit (χ2 = 0.08, p = .96, χ2 = 2.86, p = .24, respectively). However, the model containing random effects of participants led to singular fit warning. The same approach as in the gap-fill model was used to account for this warning. The final model for the meaning generation outcome variable is provided: (Meaning Generation) ~ Treatments + Phrasal Verb Figurativeness + (1|Items). Effect sizes were interpreted following Brysbaert and Stevens (2018) suggesting that a typical effect size in similar psychology studies is between d = 0.3 and d = 0.4.
8. Results
8.1. Gap-Fill Test
Table 2 displays descriptive results of the proportion of correct responses on the immediate and delayed gap-fill post-tests.
Means and 95% Confidence Intervals of the Immediate and Delayed Gap-Fill Post-Test.
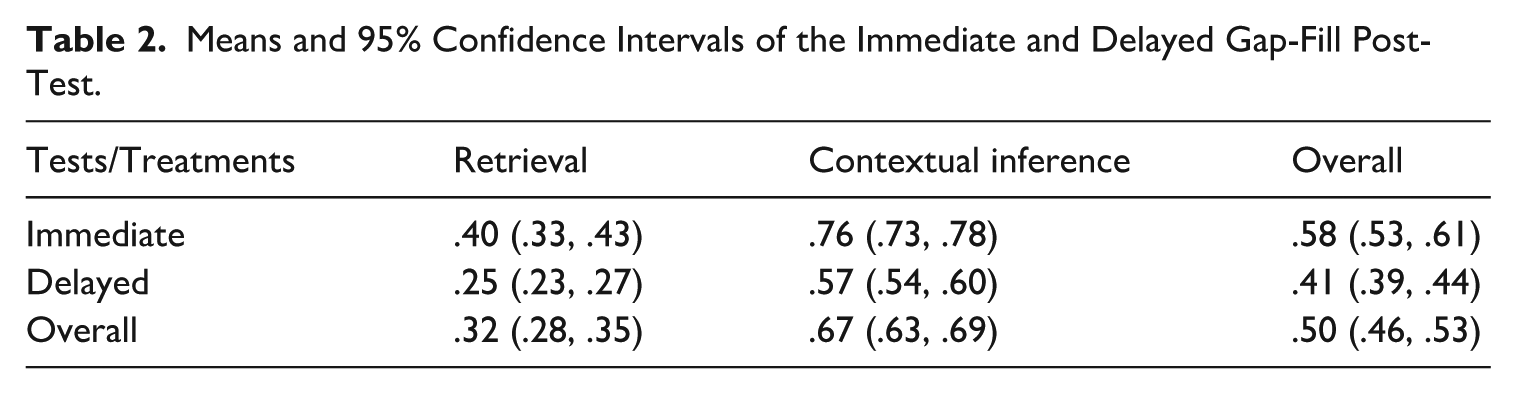
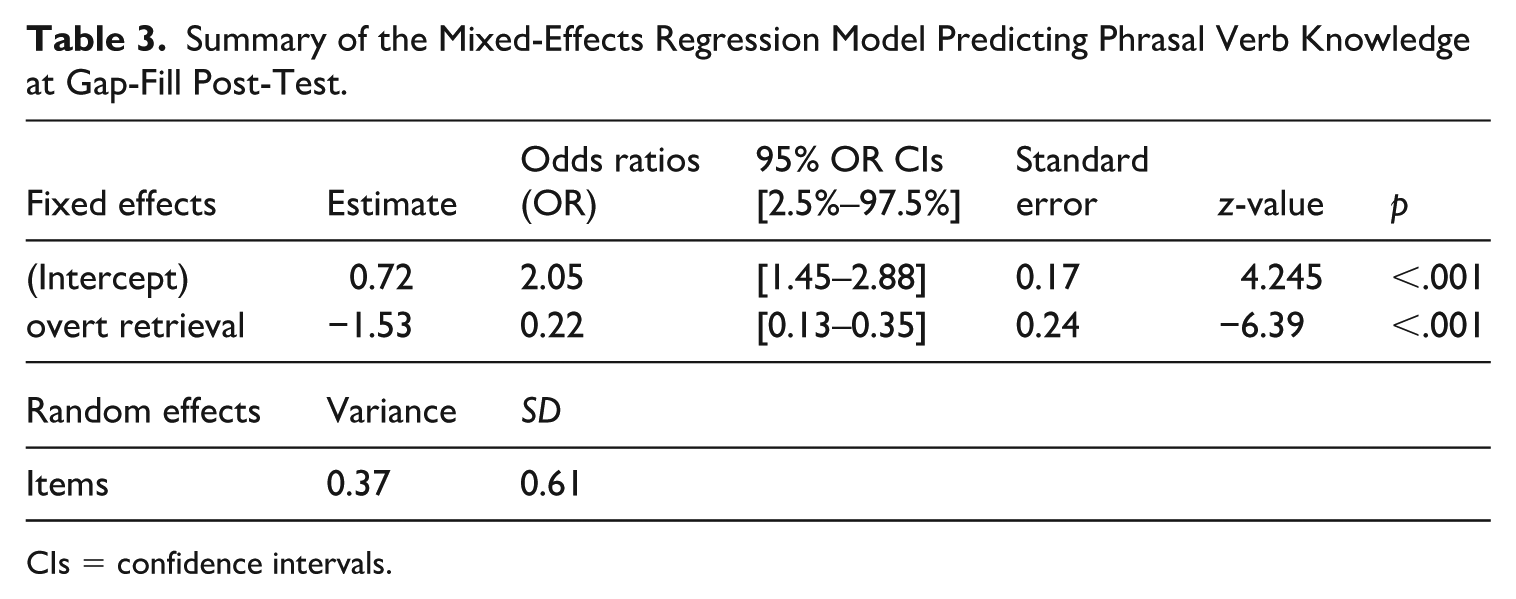
On average, participants were able to achieve 58% and 41% form recall accuracy on the immediate and delayed post-tests, respectively. Although the retrieval achieved 32% response accuracy in the immediate and delayed gap-fill post-tests, the contextual inference group achieved 67% response accuracy. To check the significance of this difference and consider items and participants’ characteristics, a generalized linear mixed model was conducted to examine the effect of treatments on gap-fill post-test. The results are listed in Table 3. The results showed that the contextual inference group demonstrated significantly higher phrasal verb knowledge at gap-fill post-test (b = 0.72, SE = 0.17, z = 4.245, p < .001) compared to the retrieval group (b = -1.53, SE = 0.24, z = -6.39, p < .001). Specifically, the contextual inference group exhibited a significant positive effect (b = 0.72), whereas the retrieval group showed a significant negative effect (b = -1.53).
Summary of the Mixed-Effects Regression Model Predicting Phrasal Verb Knowledge at Gap-Fill Post-Test.
CIs = confidence intervals.
The odds ratios (OR) for the contextual inference group were also significantly higher in the contextual inference condition (OR = 2.05 (95% CI [1.45–2.88]) compared to the retrieval group (OR = 0.22 (95% CI [0.13–0.35].
8.2. Meaning Generation Test
Table 4 displays descriptive results of the proportion of correct responses on the immediate and delayed MG post-tests.
Means and 95% Confidence Intervals of the Immediate and Delayed Meaning Generation Post-Test.
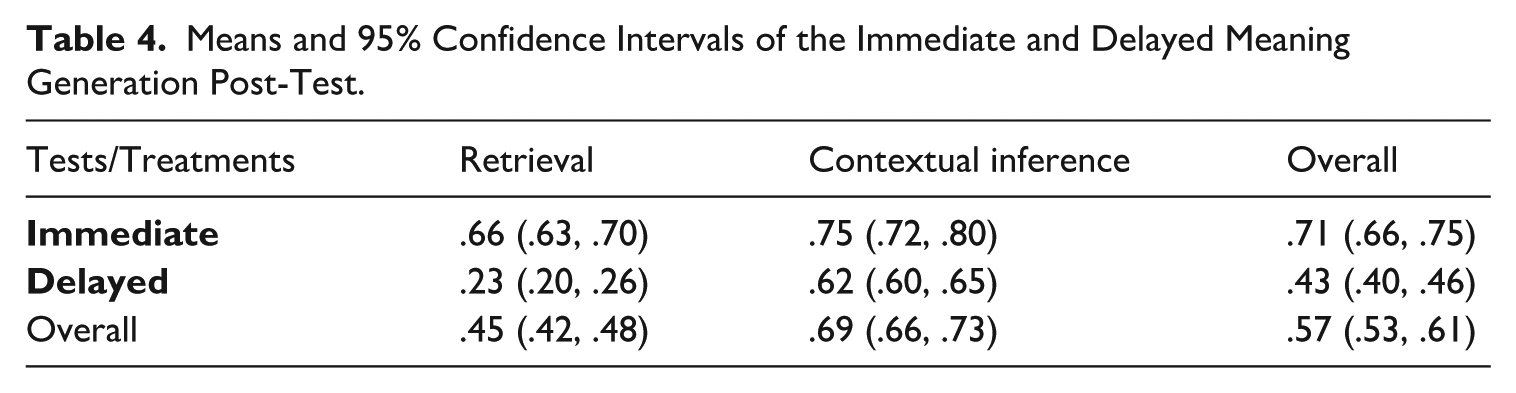
On average, participants were able to achieve 71% and 43% meaning recall accuracy on the immediate and delayed post-tests, respectively. Although the retrieval achieved 45% response accuracy in the immediate and delayed meaning generation post-tests, the contextual inference group achieved 69% response accuracy. To check the significance of this difference and consider items and participants’ characteristics, a generalized linear mixed model was conducted to examine the effect of treatments on meaning generation post-tests. The results are shown in Table 5.
Summary of the Mixed-Effects Regression Model Predicting Phrasal Verb Knowledge at Meaning Generation Post-Test.
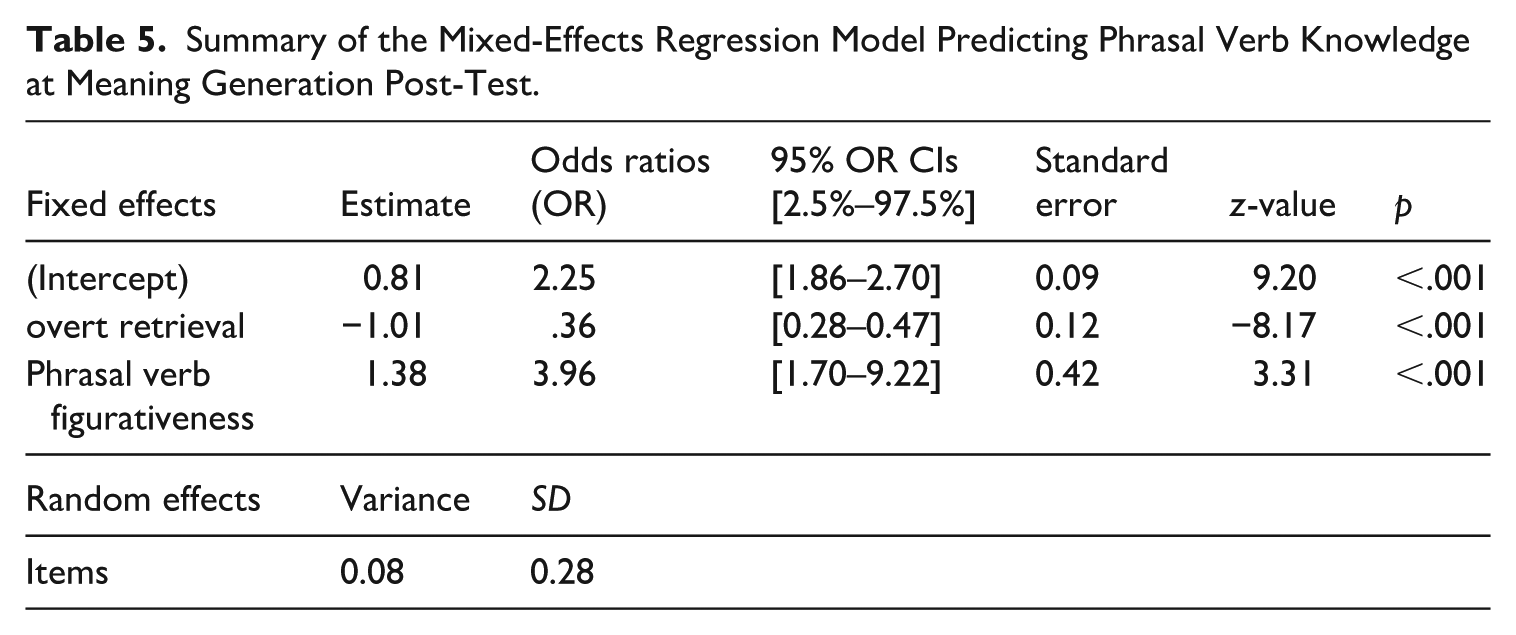
The results showed that the contextual inference group demonstrated significantly higher phrasal verb knowledge at meaning generation post-test (b = 0.81, SE = 0.09, z = 9.20, p < .001) compared to the retrieval group (b = -1.01, SE = 0.12, z = -8.17, p < .001). Specifically, the contextual inference group exhibited a significant positive effect (b = 0.81), whereas the retrieval group showed a significant negative effect (b = -1.01). The ORs for the contextual inference group were also significantly higher in the contextual inference condition (OR = 2.25 (95% CI [1.86–2.70]) compared to the retrieval group (OR = 0.36 (95% CI [0.28–0.47]. Further, the Wald chi-square test showed that phrasal verb figurativeness, included in the model as a fixed effects covariate, had a significant effect on contextual learning and retention of the target phrasal verb (χ2 = 10.99, p < .001).
9. Discussion
The study compared the effects of retrieval practice with contextual inference condition on contextual learning and retention of L2 MWEs. The retrieval group read the neutral texts and were then required to write the retrieved words while the contextual inference group read the informative texts which encouraged word inference. Participants demonstrated steady learning and recall of target phrasal verbs, with 50% form recall and 57% meaning recall in the post-tests. These findings are notable when compared to the limited learning gains reported in previous studies on contextual L2 vocabulary learning without support (e.g., Pavia et al., 2019; Peters & Webb, 2018; Webb et al., 2023). The findings of the present study align with the growing body of evidence emphasizing the benefits of supportive learning environments in promoting successful learning of MWEs from reading (Tadayonifar & Strong, 2024).
The results further revealed that the contextual inference group outperformed the retrieval group in both immediate and delayed measurements of form and meaning recall for the target phrasal verbs. Notably, this finding contrasts with Mondria and Wit-de Boer’s (1991) study, which showed that neutral texts led to higher word retention. In the present study, the group that read neutral texts actually retrieved fewer items, suggesting that the benefits of contextual inference may outweigh the effects of retrieval in promoting word learning. One explanation for this difference is that the target words in this study were MWEs whereas the critical items in Mondria and Wit-de Boer (1991) were single words. Unlike single words, MWEs are likely more complex entities that require repeated contextual exposure and multiple encounters to be effectively learned and retrieved. This inherent complexity explains why the group that read informative texts outperformed the group that read neutral texts, as the former received more contextual support and repetition, facilitating better learning and retention.
The results are in contrast with van den Broek et al. (2018) who found that the retrieval condition led to superior long-term retention compared to the sentence inference condition. However, when methodological differences between the two studies are taken into account, this discrepancy can be explained. First, the target items were single words whereas the target items used in the present research were MWEs. Research has shown that the learning trajectory of MWEs is different from that of single words (e.g., Bahns & Eldaw, 1993; Siyanova-Chanturia & Martinez, 2015). Second, they conducted their study in an L1 learning environment whereas the present study looked into learning L2 words. The difference in learning environments between L1 and L2 may have played a significant role in the contrasting findings between the two studies. In L1 learning, learners are familiar with the language’s grammar, syntax, and phonology, and words are automatized, making processing easier and faster (Wray, 2002). In contrast, L2 learning involves unfamiliarity, controlled processing, and the development of new semantic networks, requiring more extensive exposure, practice, and contextualization to achieve lasting retention (Nation, 2013; Webb et al., 2012). As a result, L2 learners need repeated exposure to L2 vocabulary to achieve long-term retention (Webb et al., 2012).
The third reason for the contrasting results between the present study and van den Broek et al. (2018) is that it was not a true contextual vocabulary learning study as the target items were embedded in short single sentences, which resembles intentional vocabulary learning conditions. MWEs require repeated exposure and contextual support to be learned contextually. Consequently, learners need more extensive exposure to these expressions in diverse contexts to solidify their understanding and achieve lasting retention (Siyanova-Chanturia & Martinez, 2015; Webb et al., 2012; Wray, 2002).
The contextual inference group was presented with informative texts that contained embedded contextual clues, which provided additional support for retrieving the target items from the pre-training stage. In contrast, the overt retrieval group lacked these clues, requiring participants to rely solely on their prior exposure during the pre-training stage, making it a more challenging condition. The absence of contextual clues in the retrieval group made it more difficult for participants to retrieve the target items, whereas the contextual inference group benefited from the extra support provided by the clues. According to the desirable difficulty hypothesis, it was expected that the retrieval group would outperform the contextual inference group, as the former’s more challenging retrieval conditions would foster deeper processing and improved retention. Furthermore, the production effect hypothesis (MacLeod et al., 2010) suggests that actively producing an overt response would enhance memory and promote long-term retention, providing an additional advantage to the overt retrieval group. In line with these predictions but in contrast with the results of the present study, Tadayonifar and Strong (2024) found that the retrieval condition involved in reading neutral texts (and then overtly retrieving items) was significantly more effective than the contextual inference condition involved in reading texts with added contextual clues (and inferring items’ meanings) after only the first encounter with the items. The two conditions in Tadayonifar and Strong (2024), however, differ in their potential for contextual vocabulary learning. The retrieval group was required to provide an overt response and received feedback on their attempt, ensuring that retrieval (correct or incorrect) took place. In contrast, the contextual inference group was not required to produce an overt response and had only one opportunity for covert retrieval of target items, making it unclear whether retrieval actually occurred. Additionally, this group did not receive feedback. Considering these methodological differences helps explain why the two studies yielded conflicting results
Based upon the results of the current study, it seems that there are possible boundary conditions of retrieval-enhanced learning. Given that participants had sufficient time to study the words during the pre-encoding stage and only proceeded to read the texts once they felt confident in their knowledge of the target items’ form and meaning, it was expected that the retrieval group reading neutral texts would outperform the contextual inference group, consistent with the desirable difficulty hypothesis. However, the results surprisingly revealed the opposite trend. This suggests that, in the context of vocabulary learning, the benefits of retrieval are outweighed by the powerful support provided by contextual clues, which facilitated more effective learning in the contextual inference group.
In line with the findings of the present study, van den Broek et al. (2022) found that inference condition led to superior word retention. Their discussion of the results provides valuable insights that are relevant to the current study. First, the effects of retrieval practice might be subordinate to the impacts of contextual clues in the contextual vocabulary learning conditions. Second, the stories they used provided various contextual details that helped participants retrieve the word meanings and were therefore more effective than the retrieval condition. Even after they prolonged the pre-encoding stage to increase retrieval success and included feedback, the contextual inference and retrieval conditions were equal in terms of enhancing retention. They concluded that there might be boundary conditions of retrieval-enhanced learning.
One concern was that as the format of the retrieval did not require participants to write an overt response in the retrieval condition, it might have influenced the obtained results in favor of the inference condition. However, as it was shown in the current study, even with the presence of pre-training stage, feedback, and overt retrieval, the contextual inference condition led to superior results confirming the boundary conditions hypothesis, proposed by van den Broek et al. (2022), for retrieval enhanced learning. It seems that the benefits of retrieval practice are less prominent during contextualized vocabulary learning compared to intentional practice (van den Broek et al., 2022).
The results also shed some light on the controversial issues over the efficacy of contextual support in vocabulary learning from reading. Initial evidence regarding the superior role of informative contexts over neutral texts in learning vocabulary from learning was reported in van Parreren (1992). Later evidence, however, questioned this belief. For example, Zahar et al. (2001) showed that contextual support is subordinate to the frequency of occurrence. Similarly, Reynolds (2020) revealed that the contextual clues surrounding target items influenced vocabulary learning from reading to a lesser degree than the frequency of exposure. However, Webb (2008) found that contextual support positively influenced contextual vocabulary learning as participants who were reading informative texts performed significantly better in the recall and recognition of word meanings whereas there were no differences in the recall and recognition of word forms. Webb (2008) predicted that contextual clues might affect different aspects of vocabulary knowledge in different ways. Contrary to this prediction, the results of the current study showed that contextual clues were effective in enhancing learning and retention of word forms and meanings in a similar way.
The present study’s findings on the significant impact of phrasal verb figurativeness on contextual learning and retention align with previous research highlighting the importance of item-related characteristics in language learning (Mulder et al., 2019; Sonbul et al., 2020). Specifically, Sonbul et al. (2020) identified phrasal verb opaqueness as a crucial factor influencing receptive and productive knowledge of phrasal verbs. However, they also noted that phrasal verb figurativeness can pose challenges for learners, leading to avoidance strategies when encountering figurative phrasal verbs (Hulstijn & Marchena, 1989; Liao & Fukuya, 2004; Saari, 2017). In contrast, the current study suggests that contextualizing phrasal verbs and providing supportive techniques like contextual clues and retrieval practice can facilitate learning of figurative phrasal verbs. This is consistent with research emphasizing the benefits of contextualized learning (Webb, 2008) and the effectiveness of retrieval practice in promoting long-term retention (Butler & Roediger, 2008). Moreover, the findings of this study contribute to the growing body of research on the role of semantic processing in language learning (García-Gámez & Macizo, 2022). By highlighting the importance of phrasal verb figurativeness in contextual learning, this study underscores the need for learners to engage with the semantic properties of language to achieve effective learning outcomes.
In addition to the cognitive mechanisms typically invoked to explain retrieval‑enhanced learning, it is also plausible that affective factors such as learners’ enjoyment, interest, and engagement contributed to the performance differences observed between the retrieval and contextual‑inference groups. Recent SLA research indicates that these affective variables can shape learners’ depth of processing and sustained involvement in learning tasks. For instance, research shows that interest (rather than joy) predicts vocabulary learning outcomes among advanced L2 learners (Driver, 2025). Likewise, classroom climate, growth mindset, and achievement goals positively predicted EFL learners’ engagement, implying that more engaged learners may allocate attention more strategically and persist longer with demanding activities (Ma et al., 2024). Taken together, these findings suggest that affective factors may have amplified the benefits of retrieval practice by enhancing learners’ attentional focus, willingness to persevere, and overall task engagement (Driver, 2025; Ma et al., 2024). The informative texts used in the contextual‑inference condition may have been more engaging or enjoyable than the repeated retrieval task, potentially leading to deeper processing and stronger retention of target words. Although the present study did not directly measure these affective variables, it is plausible that they acted as moderating factors, influencing the extent to which each learning condition supported contextual learning and retention. Future studies should incorporate validated measures of affect (e.g., enjoyment, interest, task engagement) to more precisely trace how emotional and motivational states interact with retrieval and inference processes in L2 vocabulary learning.
10. Conclusion, Limitations, and Future Research
The current study tested the efficacy of retrieval and contextual inference on contextual learning and retention of figurative phrasal verbs during reading. The results showed that contextual inference facilitated phrasal verb learning and retention from reading more than retrieval conditions. This study offers valuable insights into the effects of retrieval practice and contextual inferencing, but it also has some limitations. One potential issue is that the order of the post-tests may have affected the results. Specifically, completing the gap-fill post-test before the meaning generation post-test may have helped participants recall the meanings of the items, even though the exact phrasal verb forms were not shown. This could have improved their performance on the meaning generation post-test, but it is unclear whether they actually linked the meanings to their corresponding phrasal verb forms. The current study investigated the impact of item-related (figurativeness and frequency) and learner-related (proficiency) characteristics on learning outcomes. However, there are additional item-related and learner-related features to consider, such as working memory capacity. Working memory, in particular, plays a crucial role in the context of this study, as participants were required to study and remember word definitions (translations) during the pre-training stage. Individual differences in working memory capacity may significantly influence learning outcomes.
During the overt retrieval task, the number of correctly recalled words and the accuracy of L1 translations was not systematically recorded. Collecting such data could provide valuable insight into participants’ retrieval success and its relation to subsequent learning outcomes. Future studies should incorporate measures of retrieval performance to better understand how retrieval accuracy and feedback contribute to learning, and to allow for more precise comparisons between retrieval and retrieval-practice conditions.
Furthermore, this study advanced a primarily cognitive account of retrieval‑enhanced learning and did not operationalize or control affective variables (e.g., enjoyment, interest, engagement) that may affect the learning outcomes. Given recent SLA evidence regarding the effects of such factors (Driver, 2025; Ma et al., 2024), such affective variance could have differentially influenced attentional allocation, persistence, and depth of processing across conditions. As such, future studies would benefit from incorporating affective measures to more fully account for the interplay between cognitive and affective contributors to retrieval‑enhanced learning.
Supplemental Material
sj-docx-1-ltr-10.1177_13621688261452314 – Supplemental material for Boundary Conditions of Retrieval-Enhanced Learning: Evidence from Contextual Learning and Retention of Second Language Multi-Word Expressions
Supplemental material, sj-docx-1-ltr-10.1177_13621688261452314 for Boundary Conditions of Retrieval-Enhanced Learning: Evidence from Contextual Learning and Retention of Second Language Multi-Word Expressions by Mojtaba Tadayonifar and Mahnaz Entezari in Language Teaching Research
Footnotes
Acknowledgements
We would like to express our sincere gratitude to Professor Irina Elgort and Professor Anna Siyanova for their invaluable support throughout this study. Their guidance, insightful feedback, and encouragement have been instrumental in shaping the direction and quality of this research.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.