
Abstract
Purpose:
Drawing on the notions of ‘interface’ and ‘cross-linguistic influence’ in second language acquisition (L2A), the present study addresses the possible role of French as a third language (L3) in the L2A of English number agreement with two major concerns: (1) the degree to which third language acquisition (L3A) will bring about any positive or negative influence on L2A, and (2) the way in which an L3 interacts with L2 and/or even L1 on narrow syntax or an internal interface as identified in L2A.
Design:
To address the research concerns, a comparison was made between 48 L1 Cantonese–L2 English–L3 French (CEF) participants and 46 L1 Cantonese–L2 English (CE) participants. Twenty English native controls were also recruited. All participants completed two timed tasks: a grammaticality judgement-correction task and a free writing task. After the experiment proper, the grammatical component of the Oxford placement test, consisting of 60 items, was administered to the two groups of L1 Cantonese speakers.
Data and analysis:
The following tests were run: the Wilcoxon signed ranks test, the Mann–Whitney U test, the Kruskal–Wallis one-way analysis of variance, the non-parametric x2-test and the two-sample Kolmogorov–Smirnov test.
Findings/conclusions:
While the placement test indicated comparable English levels between the two L1 Cantonese groups, the free writing task revealed certain distinctive patterns, suggesting possible influence from L3 French to L2 English among the CEF participants. In particular, the advanced L3 French participants were different from their L3 French peers and the CE participants in their free production of grammatical nominal plurals.
Originality:
The study highlights the potential of reverse cross-linguistic influence from L3 to L2 among L1 Cantonese speakers.
Significance/implications:
Possible traces of L3 French–L2 English effect were noted in affecting the CEF learners’ use of English plural morphology by ‘neutralising’ their production of missing or redundant plural ‘-s’. Typological similarities between French and English and L3 proficiency were found to play a role in such transfers.
Keywords
Introduction
Among the various differences between English and Chinese (both Mandarin Chinese and Cantonese Chinese – Cantonese hereafter), nominal number agreement constitutes one key difference that has drawn much attention among researchers in second language acquisition (L2A). This is closely related to how number agreement is represented via distinctive means in the two languages. The language-specific representations of number agreement have resulted in differences in the judgement on and production of the abstract feature among L1 Chinese–L2 English speakers.
Various specific hypotheses in the generative L2A tradition have been proposed to discuss the L2A of English morphology, which expresses different meanings such as number, gender and tense (e.g. Hawkin’s (2003) representational deficit theories, and Prevost and White’s (2000) missing surface inflection hypothesis). A recent theory is the interface hypothesis (IH), which categorises language structures broadly in terms of ‘internal’ and ‘external’ interfaces and explains the acquisitional implications associated with the two interfaces (e.g. being easy or difficult for advanced or near-native learners). Number agreement belongs to one of the internal interfaces, and the internal interfaces (as well as narrow syntax) are considered to be less challenging than the external interfaces.
Drawing on the notions of ‘interface’ and ‘cross-linguistic influence’ in L2A, the present study addresses the possible role of French as a third language (L3) in the L2A of English number agreement with two major concerns: (1) the degree to which third language acquisition (L3A) will bring about any positive or negative influence on L2A, and (2) the way in which an L3 interacts with L2 and/or even L1 on narrow syntax/an internal interface as identified in L2A.
This paper starts with a brief comparison of nominal number agreement among the three languages concerned, namely English, Cantonese and French. The connection between nominal number agreement and L2A is then elucidated, with a review of (a) different L2A theories/hypotheses about specific English number agreement and (b) the key L2A studies on English number agreement by Chinese native speakers. The notion of reverse transfer is also explained. Finally, the acquisition of English number agreement by L1 Cantonese–L2 English–L3 French (CEF) learners is discussed in detail, with particular attention to the difference between this group of learners and two other groups of English speakers (L1 Cantonese–L2 English and L1 English).
Number agreement in English, Cantonese and French
Nominal number agreement, as the term denotes, refers to the marking of number in nouns in a language. Such marking can be realised by different means. In some languages, for example Chinese and Japanese, number agreement is expressed by the presence of numerals (e.g. Cantonese: Matthews & Yip, 2011, pp. 444–460; Mandarin Chinese: Li & Thompson, 1981, pp. 11–12; Japanese: Kaiser, Ichikawa, Kobayashi, & Yamamoto, 2013, pp. 9–12). In some other languages, for example English and French, the presence of numerals is accompanied by some inflectional marking on the nouns to indicate plurality (e.g. English: Green, Yang, & Li, 2009, p.1; Parrott, 2010, p. 10; French: Hawkins & Towell, 2010, p. 19; Price, 2008, pp. 86–89).
As far as the present study is concerned, a comparison of English, Cantonese and French, in terms of number agreement, is deemed necessary:
1. He has one apple.
2. He has two apple
3. J’ai une
I’ve one apple
‘I’ve one apple.’
4. J’ai trois pomme
I’ve three apples I’ve three apple
‘I have three apples (*apple).’
5. 我有一個
ngo5 jau5 jat1go3 ping4gwo2
I have one CL apple (CL = classifier)
‘I have one apple.’
6. 我有三個
ngo5 jau5 saam1go3 ping4gwo2
I have three CL apple (CL = classifier)
‘I have three apples.’
Number agreement in English is principally marked by the presence of the inflectional suffix ‘-s’ and its allomorphs (e.g. ‘-es’). In example (1), the noun ‘apple’ is preceded by the numeral ‘one’. With the change of the numeral ‘one’ to ‘two’ in example (2), the addition of the plural suffix ‘-s’ to the noun ‘apple’ is warranted, resulting in ‘apple
Similar to English, French makes use of morphological marking to indicate number agreement, as shown by the French rendition of the English examples, i.e. (3) and (4). The regular plural marking is in the form of ‘-s’, while a number of irregular plural forms are also present (e.g. travaux ‘roadworks’ for travail ‘work’, mois ‘months’ for mois ‘month’). However, unlike English with its regular plural ‘-s’ being audible in its spoken form, the French regular counterpart is hardly audible in spoken speech; it is only compulsory in written French, as indicated by the ungrammatical example (Lang & Perez, 2004, p. 28). What is more, French adjectives, definite articles and possessive adjectives are also inflected for plural nouns (e.g. les and rouges in
Unlike English and French, Cantonese does not have any morphological marking for plural nouns, as shown in the Cantonese renditions of the English examples (i.e. (5) and (6)). The noun in both (5) and (6), 蘋果 ping4gwo2 ‘apple’, remains the same and plurality is expressed only by the numeral (i.e. 三 saam1 ‘three’).
The above brief description of English, French and Cantonese shows that the first two languages share some similarities in plural marking (the use of both numerals and morphological marking) but Cantonese differs from both of them (the use of numerals only) (see Table 1).
Number agreement in English, French and Cantonese.

In considering the language-specific features of number agreement among the three languages in terms of the notion of transfer in L2A, it is noted that English and French are hypothesised to cause positive transfer (i.e. a facilitating role) to each other but Cantonese is assumed to cause negative transfer (i.e. a debilitating role) to English or French.
Number agreement and L2A
In the generative L2A tradition, English inflectional marking has received much attention and led to the development of a number of theoretical hypotheses which are specific to it (e.g. Hawkins’ representational deficit theories (Hawkins, 2003; Hawkins & Chan, 1997), Prévost and White’s (2000) missing surface inflection hypothesis, and Lardiere’s (2008, 2009) feature (re-)assembly hypothesis). All these hypotheses or theories have been based on and supported by research on verbal inflectional marking (i.e. ‘-s’ and ‘-ed’), and only Lardiere (2009) includes number agreement as one of the structures in explaining her feature (re-)assembly hypothesis. Given that the focus of this paper is on English number agreement, Lardiere’s (2009) hypothesis is to be discussed here. After reviewing Lardiere’s hypothesis, the connection between English nominal number agreement and Sorace’s interface hypothesis (2011, 2012) is then elucidated. Following the L2A theories is a review of the most recent L2A studies on number agreement.
Lardiere’s feature (re-)assembly hypothesis (2008, 2009)
Following Chomsky’s minimalist programme and echoing Travis’ (2008) comment on the development of L2A, Lardiere argues for the challenge in reconfiguring or reassembling functional features already fixed in L1 to fit in with an L2. To illustrate how such reconfiguration/re-assembly takes place in L2A and constitutes potential difficulties for L2 learners, Lardiere refers to three of her L2A studies: one on the L2A of English plural marking (Lardiere, 2007b, 2008), and two on the L2A of Korean variable expressions (Choi & Lardiere, 2006a, 2006b). Lardiere (2007b, 2008), as will be reviewed later in this section, highlights the undersuppliance of the English plural ‘-s’ of a native Chinese speaker, Patty. Similar reconfigurational difficulty was noted in two studies conducted by Choi and Lardiere (2006a, 2006b), where two groups of L1 English–L2 Korean participants (intermediate and advanced L2 Korean) were involved. In the first study, the intermediate group was found to have correctly interpreted Korean variable expressions in the [+Q] context (which is similar to their L1 English) but not those in the [–Q] context. 1 In a follow-up study, only a very small proportion of the L2 Korean advanced participants (17%, four out of 24) correctly interpreted variable expressions in both [+Q] and [–Q] contexts. The results of both studies, according to Lardiere, suggest transfer of L1 English reconfigurational features to L2 Korean. Lardiere further conducts a focused comparison between English, Chinese and Korean plural marking, highlighting the complexity of the number system of the Korean language.
Applying the feature (re-)assembly hypothesis to the present study, it can be conjectured that L1 Cantonese would influence both the CEF and CE participants in their acquisition and use of the English number system. Both groups of participants would find it difficult to ‘reconfigure’ or ‘reassemble’ their L1 Cantonese nominal plural features to accommodate their L2 English.
Sorace’s interface hypothesis (2011, 2012)
The interface hypothesis (IH) was first advanced by Sorace and Filiaci (2006) in their study on a group of near-native L2 Italian speakers whose L1 is English. The syntactic structures concern Italian pronominal subjects in complex sentences and are considered to be at the interface between one linguistic domain and one cognitive domain: syntax and discourse. Through a picture verification task, the L1 English–L2 Italian speakers were observed to show asymmetry in their interpretations of null and overt subjects. Sorace and Filiaci therefore argue that the syntax–discourse interface is more vulnerable or difficult, even among near-native learners, where ‘residual first language (L1) effects, indeterminacy or optionality’ (p. 340) can be found.
The IH centres on the concept of ‘interface’. As pointed out by Sorace in her keynote article (2011, p. 6), the term ‘interface’ can be defined as ‘syntactic structures that are sensitive to conditions … [which] have to be satisfied … for the structure to be grammatical and/or felicitous’. The definition implies that an interface involves a syntactic structure and the conditions relevant to the structure. Should the conditions be related to morphology (e.g. number agreement in English), the interface concerned is the syntax–morphology interface. Should the conditions concern discourse (e.g. null arguments in Greek), the interface is the syntax–discourse interface. Interfaces broadly fall into two groups: internal and external. Internal interfaces cover the interaction between syntax and other language-internal domains (e.g. semantics), while external interfaces relate to the interaction between syntax and language-external domains such as the cognitive domain and world knowledge (e.g. pragmatics). It is assumed that the internal interfaces (e.g. syntax–morphology and syntax–semantics) are not problematic among advanced or near-native learners, but the external interfaces (e.g. syntax–discourse) are (Sorace, 2012).
Given that the advanced or near-native learners only experience difficulty on the external interfaces, unlike the earlier generative perspective, inflectional morphology is not the prime concern of the early version of the IH. This probably has to do with the nature of inflectional morphology and one assumption of the IH. In the literature, inflectional morphology has been categorised as one either at the syntax–semantics interface (as in Lardiere, 2009) or at the syntax–morphology interface (Montrul, 2011; White, 2010, 2011), suggesting that inflectional morphology belongs to the internal interface(s).
In a later article, however, Sorace (2012) revisits the notion of narrow syntax/internal interfaces, where she acknowledges the potential complexity of narrow syntax and internal interfaces: ‘narrow syntactic properties and internal interfaces can be computationally complex and resource consuming too, as Gurel observes’ (p. 210). This in turn encourages the investigation of the acquisition of structures/features in narrow syntax or the internal interfaces, one of which is the English morphological number system, the structure under examination in the present study.
Should the IH, Lardiere’s hypothesis about the difficulty in learning the English number system, and different empirically based studies within the generative framework be taken into consideration, English number agreement would present a vulnerable or difficult structure for L1 Chinese speakers, who would be more likely to omit the English plural morphological marking.
L2 acquisition of English number agreement by Chinese learners of English
Thanks to Brown’s (1973) pioneering study, much research has been conducted on the L1 acquisition of English number agreement from various perspectives (e.g. Kouider, Halberda, Wood, & Carey, 2006; Mervis & Johnson, 1991; Nicolaci-Da-Costa & Harris, 1984; Zapf, 2007, to name just a few). However, not very much (and not very recent) research has focused on the L2A of English number agreement by adult L1 Chinese speakers (as pointed out by Jia (2003) and Law (2012)). One early empirical study on L1 Cantonese–L2 English children was conducted by Dulay and Burt (1974) (as cited in Hawkins, 2001). Among those recent empirical studies on the L2 acquisition of English number agreement by L1 Chinese speakers, Lardiere (2007a, 2007b, 2008), Jia (2003), and Setter, Wong and Chan (2010) are likely to be the most recent. 2
As reviewed in Hawkins (2001), Dulay and Burt (1974) examine the oral production of two groups of child L2 English speakers – L1 Spanish and L1 Cantonese – for any evidence of L1 influence on L2A. Using the bilingual syntax measure, Dulay and Burt analyse the use of 11 English grammatical morphemes in obligatory contexts (e.g. ‘-ed’ for regular past verbs) among the two groups of L1 Spanish/Cantonese–L2 English speakers. The performance of the two groups of children revealed a similar group accuracy profile of the 11 English morphemes. However, the L1 Spanish children were found to attain a higher accuracy score than their L1 Cantonese counterpart, suggesting possible influence of L1 on L2A. As far as number agreement among L1 Cantonese speakers, plural ‘-s’ ranked the fifth in terms of the group accuracy scores and the group score of the L1 Cantonese children was about 50 (out of a total of 100).
Similar to Dulay and Burt (1974) (as cited in Hawkins, 2001), who focus on L2 Chinese children, Jia (2003) also looks into the use of English nominal plural forms among 10 native Chinese children in the United States. The data, collected via a picture elicitation task and spontaneous conversations in a five-year study, were analysed, supplemented by data from a parental questionnaire, child and parent interviews and researcher’s observations. Special attention was paid to the production of the plural forms, as well as individual and age differences. The overall results showed that the L1 Chinese–L2 English children had omitted the required plural marker the most (over 80% of all ungrammatical forms). They also exhibited inconsistent plural marking or omission (i.e. a high degree of variation or fluctuation) during the five years of data collection. Younger participants, who were in a richer English environment, were found to be more able to master the plural forms than older participants, who might still be under the influence of their L1 Chinese. Jia attributes the observed patterns to the amount of input the children had been exposed to: the richer the English environment, the more English being encountered and used.
Instead of working with L2 Chinese children, Lardiere’s (2007a, 2007b, 2008) discussion of L2A of English plural marking centres on her longitudinal study of an adult US immigrant, called Patty, who is a native speaker of Mandarin and Hokkien Chinese, and had been residing in the States for around 10 years at the time of the study. Various structures were examined in the written and spoken data collected from Patty, one of which was number agreement. Table 2 (reproduced from Lardiere, 2007a, p. 241) shows the percentage of missing morphological marking for plurality in Patty’s English.
Plural marking in obligatory quantified expressions (Lardiere 2004, 2006, as cited in 2007a).

As the percentages indicate, Patty frequently omitted the morphological marker when required by the context in the first recording, with improvement shown in the two later recordings. However, the suppliance rates across the three recordings were rather low, with approximately half of the plural markers missing in the second and third recordings. Lardiere explains such omission of plural ‘-s’ by following Aoun and Li’s (2003) analysis of Chinese and stating that the [+plural] feature in Chinese and that in English are realised differently. She also highlights the need to account for morphological variability among L2 learners in terms of any phonological/formal/semantic features involved and puts forward the feature re-assembly hypotheses (as reviewed in the previous section).
The most recent study by Setter, Wong, and Chan (2010) discusses different features of Hong Kong English by collecting oral data from five native speakers of Cantonese in the UK.
3
The five participants were asked to recount a happy event in their lives and complete a map task (guiding the interviewer to a particular place on a map), and their speech was examined in terms of different linguistic levels such as phonology, morphosyntax and lexis. At the morphosyntactic level, various kinds of omission (e.g. three
As shown in the above review, Lardiere’s (2007a, 2007b, 2008) research examines an adult Chinese speaker, while Setter et al. (2010) look into L1 Chinese children/adolescents. The four studies adopt different theoretical stands in examining L2 English plural marking: error analysis (Dulay & Burt, 1974, as cited in Hawkins, 2001), sociolinguistics (Jia, 2003), holistic/sociolinguistics (Setter et al., 2010), and generative (Lardiere, 2007a, 2007b, 2008). No matter which age group or which L2A perspective, English number agreement has been and is probably still considered to be challenging for L1 Chinese speakers. This in turn stimulates more research in the acquisition of English number agreement by L1 Chinese speakers, especially adult L1 Chinese speakers, who have been relatively less studied in the literature.
Reverse transfer among L1 Chinese speakers
Most of the studies on L2A (including the ones reviewed above) have been in the realm of forward transfer, i.e. an earlier acquired language affecting a later acquired one. However, the opposite path, i.e. reverse transfer from a later acquired language back to an earlier acquired one, is not impossible. Reverse transfer is closely related to the notion of multi-competence as advocated in Cook (1991, 2003). By definition, multi-competence refers to ‘the compound state of a mind with two grammars’ (Cook, 1991, p. 112) as a result of the ‘knowledge of two or more languages in one mind’ (Cook, 2003, p. 2). In relation to multi-competence is Cook’s (2002) Integration continuum, which is a composition of three models: separation, integration and interconnection (see Figure 1).
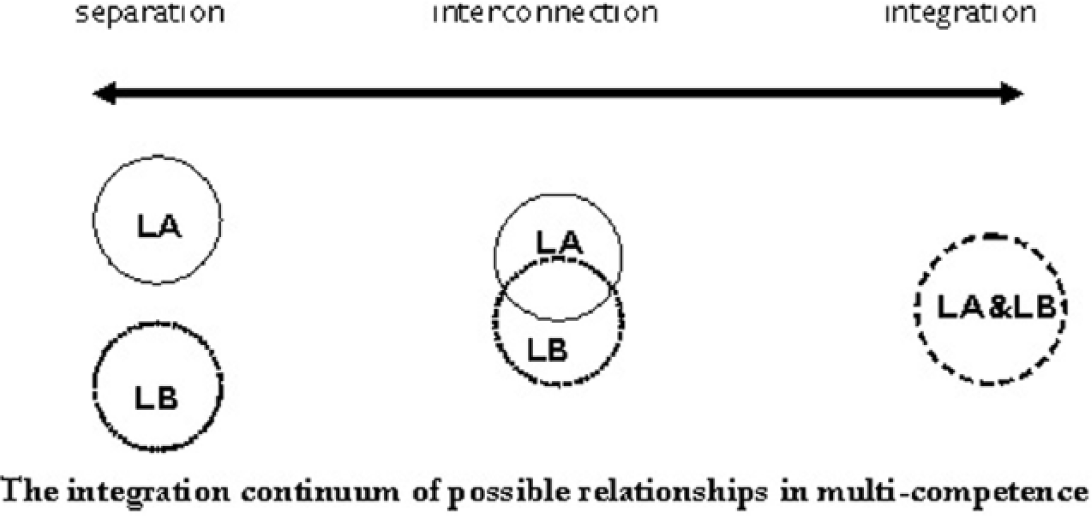
Cook’s integration continuum.
The separation model on the left of Figure 1 states that basically there is no interaction between the two languages (LA and LB). The languages are in ‘watertight compartments’ and cross-linguistic influence is not feasible. However, this model seems less tenable because there has been evidence of possible interaction between L1 and L2. On the far right is the integration model, which suggests the presence of a single system. This in turn denotes no distinction between LA and LB, which again is not tenable in that learners can always tell the languages apart. Last, the interconnection model, which is in the middle, shows partial interaction between LA and LB as a result of shared or overlapping language aspects. It is in this model that interaction between languages can possibly trigger both forward transfer and reverse transfer.
The notion of reverse transfer has been investigated in a number of L2A studies, such as the ones in Cook’s (2003) volume. Various methods and techniques deployed to demonstrate reverse transfer in a foreign language environment (i.e. language learning mostly in a classroom context) are also discussed in Kecskes and Papp’s (2000) as well as their later work in the Cook’s (2003) volume (Kecskes & Papp, 2003). They suggest that reverse transfer can be observed in tasks which focus on content rather than language structures, for example the picture-writing task, free writing task and summary writing task. Special attention needs to be paid to three aspects: structural well-formedness (the complexity and nature of clauses), lexical quality (the variation and sophistication of the words), and cognitive functioning (the use of modality and metaphorical expressions).
Comparatively speaking, research on reverse transfer in L3A with L1 Chinese learners is still in its infancy, with two recent empirical studies involving L1 Cantonese speakers in the L3A context. Hui (2010) investigates the use of English relative clauses among a group of L1 Cantonese–L2 English–L3 French speakers. Through a written picture elicitation task, the L3 French participants, when compared with a group of L1 Cantonese–L2 English speakers, were found to have used more full subject-extracted relative clauses (e.g. the boy
The other study was done by Cheung, Matthews, and Tsang (2011) on the judgement on and production of English past simple tense among a group of L1 Cantonese–L2 English–L3 German speakers. In light of two possible renditions of the German past form (past simple or present perfect), it was hypothesised that L3 German might affect the learners’ L2 English past simple tense. Through a free writing task and an acceptability judgement task, differences were found between the L3 German group and the L2 English control group. The L3 group produced non-target present perfect instances in the English writing task while the control L1 Cantonese–L2 English group did not produce any present perfect instances. The L3 groups also displayed a higher acceptance rate of non-target English present perfect sentences in the judgement task. The performance of the L3 group in both tasks thus indicated possible traces of negative transfer from L3 German to L2 English.
Hence, it could be seen that both forward and reverse transfer is possible, which corresponds to Pavlenko and Jarvis’ (2002) remark on ‘bidirectional language transfer’ in their L1 Russian–L2 English study. Similarly, Cenoz (2001, p. 2) highlights such possibility in L3A: ‘…bi-directional relationships can take place in third language acquisition: the L3 can influence the L1 and be influenced by the L1
Should reverse transfer hold in L3A, it would be interesting to examine if a later learnt L3 (e.g. French) could affect the learners in their acquisition and use of an early learnt L2, especially when their L2 is similar to L3 but different from L1. One starting point of such an investigation could be the acquisition and use of an L2 morphological structure (e.g. English) by the speakers of a morphologically richer L3 (e.g. French) but a less morphologically richer L1 (e.g. Chinese).
The present study
Drawing on the notions of ‘interface’ and ‘reverse transfer’ in L2A, the present study, which is part of a larger project on reverse transfer in L3A, addresses the possible role of L3 French in the L2A of English number agreement with two major concerns: (1) the degree to which L3A will bring about a positive or negative transfer effect on L2A, and (2) the way in which an L3 interacts with L2 and/or even L1 on an internal interface as identified in L2A.
These two research concerns served as the underpinnings of the main research question of the study:
Does the acquisition of a later acquired language (i.e. French) have any effect on the judgement on and production of number agreement of an earlier acquired language (i.e. English)?
In light of the language background of the two groups of learner participants, the literature of L2A of English number agreement by L1 Chinese speakers, the IH and the notion of ‘reverse transfer’, the following hypotheses were made in response to the above research question:
Hypothesis 1: Reverse transfer effect took place among the CEF participants (relating to research concern 1 and the possibility of reverse transfer involving an L3).
Under the influence of their L3 French, the CEF participants would (a) judge English number agreement more accurately and (b) produce fewer non-target English number agreement forms than their CE peers.
Under the influence of L1 Cantonese, the CEF participants, just like their CE peers, would still (a) judge English number agreement less accurately and (b) produce more English plural markers than the control native participants.
To address the research question and validate the above hypotheses, a comparison was made between the CEF group and a group of L1 Cantonese–L2 English (CE) participants. The CE participants did not have knowledge of any languages which are typologically similar or closer to English. This made them different from the CEF group, who have knowledge of French, a language being structurally closer to English.
Participants
Three groups of participants were involved, one of which was the experimental group and two of which were the control groups:
Experimental group: L1 Cantonese–L2 English–L3 French (CEF) (n=48)
(CEF-high (CEF-H), n=10; CEF-medium (CEF-M), n=21;
CEF-low (CEF-L), n=17)
Control groups: L1 Cantonese–L2 English (CE) (n=46)
L1 English (E) (n=20)
The CEF group consisted of L1 Cantonese–L2 English speakers who were also students of French at a local English-medium university in Hong Kong and did not have any knowledge of another Romance or Germanic language (e.g. Italian or German). 4 The CE group was L1 Cantonese–L2 English speakers who were also students of the same university but did not have knowledge of a Romance or Germanic language. The background questionnaire showed that they did have knowledge of languages other than Cantonese and English, meaning that they were L3 learners of languages other than Cantonese, English, and French (and other typologically related or similar ones). The E group, being composed of L1 English speakers, was made up of exchange students at the same English-medium university.
Design of the study
With the aim of revealing the possible cross-linguistic influence via triangulation, the study consisted of two timed experimental components: a grammaticality judgement-correction task and a free writing task. All participants were asked to finish the writing task first so that their free production would not be affected by the input from the other experimental task. After working on the two tasks, the CEF and CE participants completed an English placement test. The CEF group further finished a French placement test about a week later.
Timed grammaticality judgement-correction task
A timed grammaticality judgement-correction task, which consisted of 50 pairs of sentences, was used to retrieve learners’ judgement on five English structures. Ten of the 50 pairs of sentences in the task covered English number agreement, five of which were grammatical sentences and five ungrammatical. The remaining 40 pairs of sentences covered other test structures (as well as distracters) examined in the project. In each pair of sentences, the first one introduced a context and the second one was the ‘real’ test sentence with the target structure. Two examples are shown below:
7. I need to make a cake this weekend. Can you buy some small chestnuts on the way home?
8. * It’s Halloween this coming Monday. Would you like to buy a few pumpkin for the kids?
In each of the above two pairs, the first sentence presents a context for the second sentence. The context in the first sentence or the presence of a plural quantifier in the second sentence requires the use of the plural marker ‘-s’ in the head noun. Since the noun ‘pumpkin’ in (8) is in its singular form and does not agree with the plural quantifier ‘a few’, the pair in (7) is grammatical whereas the one in (8) is not.
Two versions with different orderings of the sentences were devised to minimise the ordering effect on the participants’ judgement or correction. The sentences in the task were copyedited by experienced English teachers who are also native English speakers. To test the suitability of the sentences and work out the time needed for the completion of the task, the two versions were piloted among one group of L1 English speakers and one group of L1 Cantonese–L2 English speakers.
During the task, the participants were told that they were going to read 50 pairs of sentences presented in natural contexts and decide whether the sentences were grammatical by circling one of the numbers on a Likert scale from ‘1’ to ‘4’ (see Figure 2). They also knew that the number chosen represented the degree of grammaticality of the sentence (‘1’ and ‘2’ under the category of ‘ungrammatical’ and ‘3’ and ‘4’ under ‘grammatical’). If they gave a particular sentence a rating of ‘1’ or ‘2’, they were required to make any amendments to justify their rating. This could tap into why they rejected the sentence and facilitate the subsequent analysis of the rating (to be explained in the next paragraph). 5

Timed grammaticality judgement-correction task
In the analysis of the ratings, the overall mean ratings of the test sentences were examined. To ensure that the ratings reflect the judgement of the participants to the greatest degree possible, only those sentences with both the target ratings (i.e. ‘1’ and ‘2’ for ungrammatical sentences and ‘3’ and ‘4’ for grammatical sentences), and target amendments for ungrammatical sentences (i.e. target amendments for those sentences scoring ‘1’ and ’2’) were counted. Any target rating plus non-target amendment (or non-target rating plus target amendment) were excluded from the analysis. Following Yuan and Dugarova (2011), and in light of the distinction made in Sheskin (2011), non-parametric tests were used to statistically analyse the data in the present study. The Wilcoxon signed ranks test was run to discern any statistical significance in the mean ratings of the sentences with each participant group. The Mann–Whitney U test and the Kruskal–Wallis one-way analysis of variance were run to compare the means of the three participant groups statistically.
Timed free writing task
A timed writing task was designed to investigate the participants’ production of the target structure in a ‘free’ context, focusing on the learners’ ability to produce patterns with English number agreement in their free writing. In the writing task, a topic relating to a past experience – A memorable trip – was given and the participants were asked to write about 150 to 200 words. The prose collected aided the understanding of how the test language property was realised in the learners’ free use of the language.
Since the focus of the task was on the production of number agreement in obligatory contexts, following Jia (2003), a composite percentage score was calculated. The composite score was made up of two components: number of target/non-target tokens vs. number of obligatory contexts, and the score for nominal plural forms is displayed below:
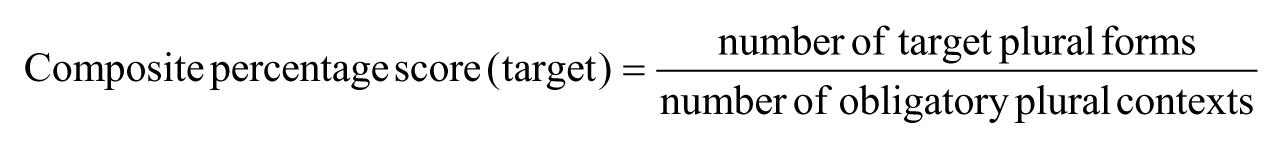
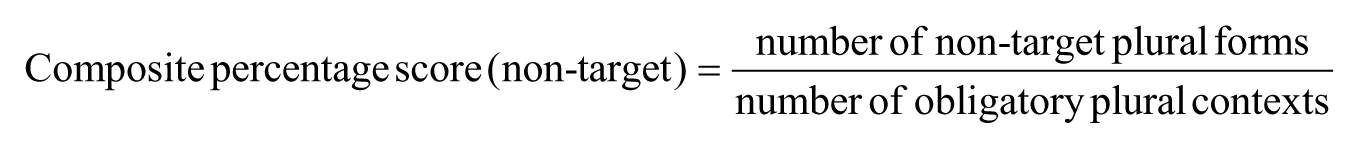
In identifying the target/non-target tokens, both structural clues and contextual clues were followed. Structural clues referred to those signalled by words or phrases such as plural numerals/quantifiers (e.g. ‘two’, ‘a few’). Contextual clues were those indicated by the contexts in which the tokens appeared (e.g. in (7), making a cake would be a natural context where more than one chestnut is needed, resulting in the use of ‘chestnuts’ in the second sentence). Ambiguous tokens were discarded in order not to over-count the number of target or non-target items.
The non-parametric x2-test was used to examine if there were any differences in the composite percentage scores attained by the participants.
Placement tests and background questionnaire
After the experiment proper, the grammatical component of the Oxford placement test (UCLES, 2001), consisting of 60 items, was administered to the two groups of L1 Cantonese speakers. The English proficiency test aimed at discerning the L1 Cantonese speakers’ standard of English in order to examine how comparable their English proficiency was. Table 3 displays the performance of the learner participants (CEF and CE) in the placement test.
Placement test scores.

A two-sample Kolmogorov–Smirnov test found that the scores of the two L2 English groups were not statistically different, suggesting that their English levels were comparable. A comparison of the average scores of the CEF sub-groups (out of 60) in the English placement test did not reveal any statistical difference either.
A French proficiency test with 60 items, namely the Test de Connaissance du Français (TCF), was also completed by the CEF group so that they were put into three proficiency groups: beginner, intermediate, and advanced. Such sub-grouping of the L3 French group helped investigate whether and to what extent their French proficiency interacted with their use of English in the assigned English tasks. The placement test could also ensure that the L3 French participants had enough knowledge of the French language to complete the French tasks.
After all the language tasks, the three groups of participants filled in a questionnaire that elicited information about their acquisition of English (and French) (e.g. length of studying English and French, use of English and French, perception of the similarities and differences among English, Cantonese and French). Their responses in the questionnaire helped understand how different aspects of language understanding and learning may be relevant to their performance in the two experimental tasks (See Tsang, 2014, for a detailed description and analysis of the questionnaire data).
L2 acquisition of English number agreement by L1 Cantonese–L2 English–L3 French speakers
Two sources of data were collected in the present study to examine the acquisition of English number agreement by L1 Cantonese–L2 English–L3 French (CEF) speakers: grammaticality judgement-correction and free writing. These two types of data are to be discussed in the following sub-sections in order.
English number agreement in the grammaticality judgement-correction task
In the timed grammaticality judgement-correction task, the overall mean ratings of the test sentences were calculated, involving only the target ratings, i.e. ‘3’ and ‘4’ for grammatical sentences and ‘1’ and ‘2’ (plus target amendments) for ungrammatical sentences. In what follows, overall comparisons of the grammatical and ungrammatical instances of the three groups – CEF, CE, and E – will first be presented. Then, the judgement of the three CEF sub-groups will be compared among themselves and with that of the other two groups.
Overall mean rating: overall comparison
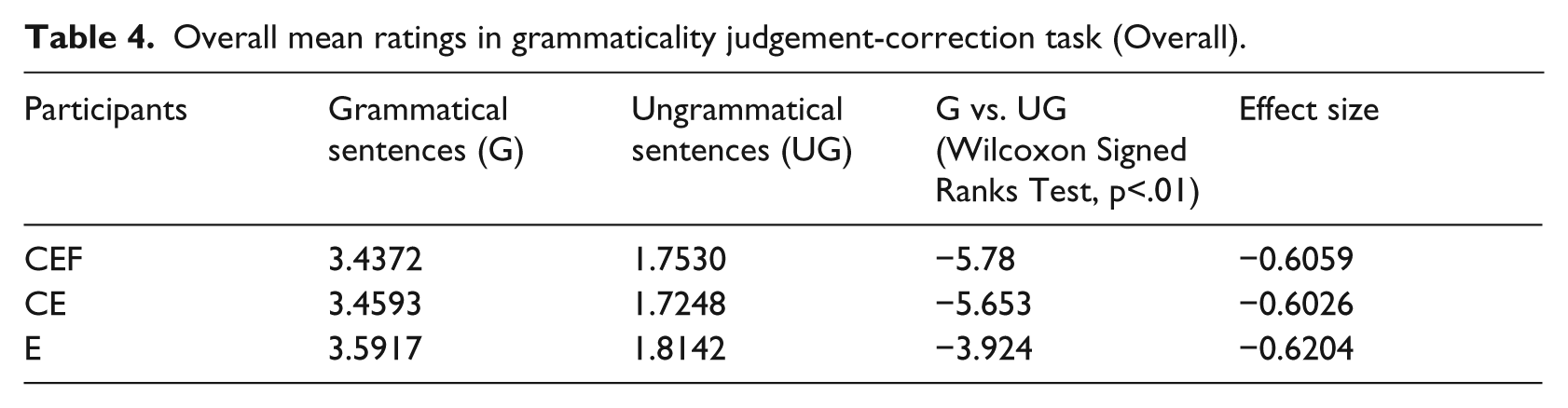
Table 4 displays the overall mean ratings for grammatical and ungrammatical instances of English number agreement in the grammaticality judgement-correction task. All the ratings for the grammatical sentences were in the range of 3.4 to 3.5, while those for the ungrammatical tokens were in the range of 1.7 to 1.8. The ratings for the grammatical sentences given by all three groups of participants were significantly higher than those for ungrammatical sentences. Meanwhile, no statistical significance was noted in comparing the ratings across the three groups.
Overall mean ratings in grammaticality judgement-correction task (Overall).
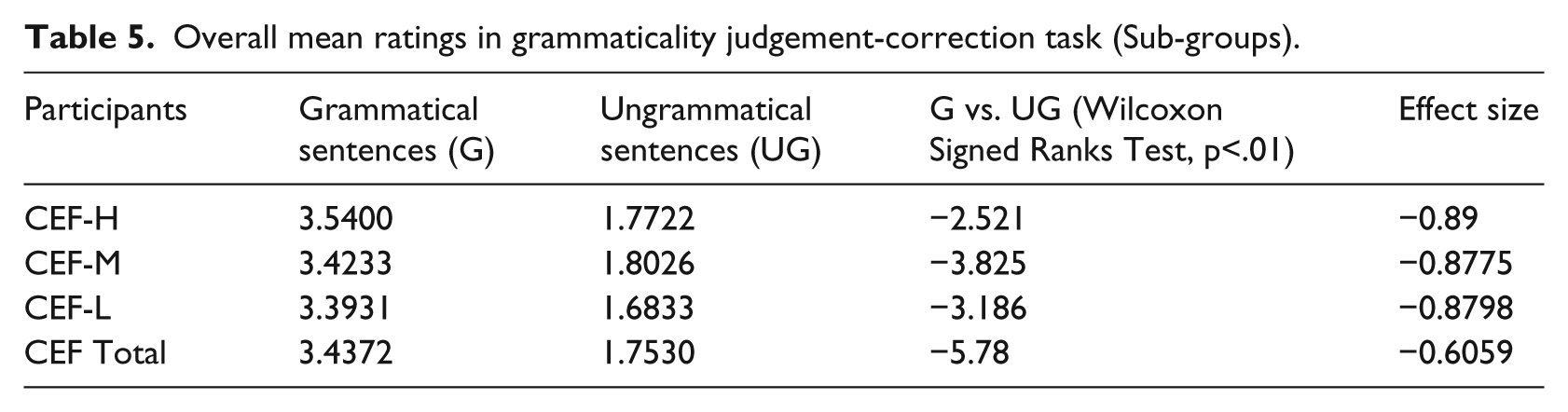
Overall mean rating: CEF sub-group comparison
Within the CEF group, all three sub-groups gave significantly higher ratings to grammatical sentences than to ungrammatical sentences. No significant differences were noted among the three sub-groups. Further comparison between the CEF sub-groups and the CE/E groups did not reveal any significant group differences either (see Table 5).
Overall mean ratings in grammaticality judgement-correction task (Sub-groups).
Summary. The following points summarise the observations from the grammaticality judgement-correction task:
All three participant groups, including the three CEF sub-groups, attained significant differences between the ratings for the grammatical sentences and those for the ungrammatical sentences (Tables 4 and 5).
There was no significant difference among all participant groups (as well as the three CEF sub-groups) in terms of the ratings for the grammatical/ungrammatical sentences (Tables 4 and 5).
English number agreement in free writing
Recall that the free writing task asked the participants to write about one of their unforgettable trips. Such description of a trip involved the mention of multifarious people, objects and events, and such mention in turn required the use of nominal phrases in singular and plural forms.
In what follows, overall comparisons of the grammatical and ungrammatical instances of the three groups – CEF, CE, and E – will first be presented. Then, the performance of the three CEF sub-groups will be compared with the other two groups.
Overall comparison
Table 6 shows the grammatical and ungrammatical instances of English number agreement collected from the free writing task.
Grammatical and ungrammatical instances in free writing (Overall).
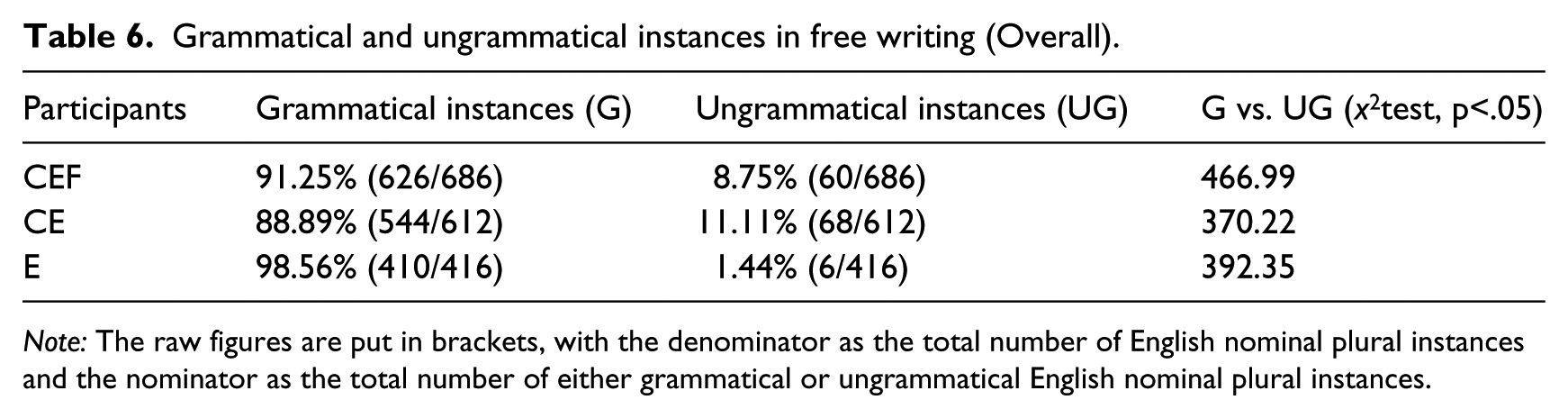
Note: The raw figures are put in brackets, with the denominator as the total number of English nominal plural instances and the nominator as the total number of either grammatical or ungrammatical English nominal plural instances.
As the table shows, within each group, significantly more grammatical instances of English number agreement were produced than ungrammatical instances. Cross-group comparisons indicated that the two learner groups produced significantly fewer grammatical nominal plural instances (and more ungrammatical ones) than the native group (CEF vs. E: x2=24.5371, CE vs. E: x2=34.658, p<.05), possibly suggesting the different proficiency levels between the learner groups and the native group. Meanwhile, the two learner groups did not differ significantly in terms of the number of grammatical and ungrammatical instances of number agreement.
Further analysis of the ungrammatical instances of number agreement was conducted to look for any potential differences between the learner groups. Three types of ungrammatical English number agreement instances, with authentic examples listed below, were found in the participants’ free writing, and the proportion of each of the three types is displayed in Table 7:
1. missing the plural morphological marker (missing ‘-s’)
e.g. * One of my unforgettable
* We took a lot of
* My most unforgettable trip is my journey to other
* In the next two
2. redundant plural morphological marker (redundant ‘-s’)
e.g. * When we visited different cities, it was not difficult to find
* I hugged every
* The trip wasn’t a very fun one, as we were mainly carrying out some applications for our
3. wrong plural morpheme
e.g. * I have travelled to many different
* The
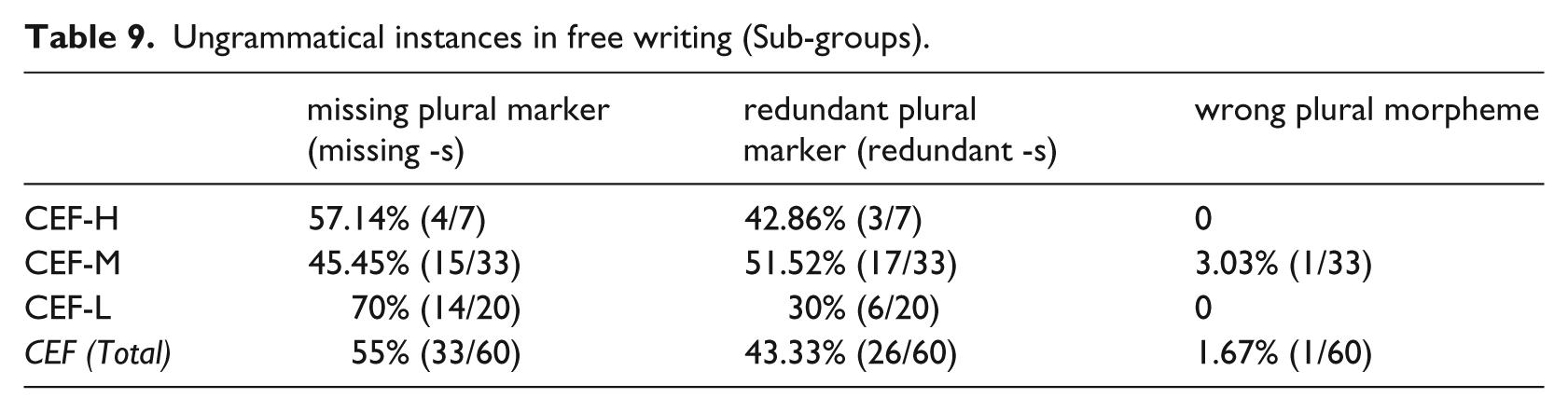
Ungrammatical instances in free writing (Overall).
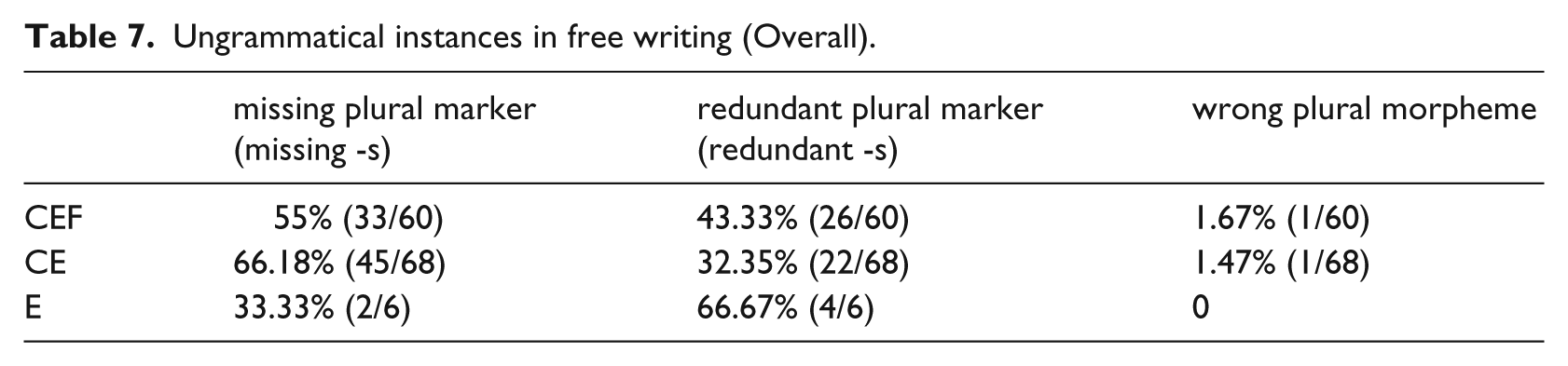
All learner participants showed a slightly higher percentage of missing plural marking than redundant plural marking in their writing. On the contrary, the native group was found to have a slightly higher percentage of redundant plural marking. Between the learner groups, one probable distinction between the CE group and the CEF group was noted. While no statistical significance was found in comparing the learner groups in terms of their respective missing/redundant instances, unlike their CEF peers, the CE group showed a significant difference between the number of ungrammatical missing plural instances (66.18%) and that of ungrammatical redundant plural instances (32.35%) (x2=7.896, p<.05). In other words, the CE participants missed the plural marker more often than adding a plural marker redundantly in their free writing. Significantly more missing instances in turn might suggest that they were less sensitive to the use of a morphological marker in indicating plurality and therefore missed the plural markers in their writing. Their lower sensitivity in turn draws our attention to one potential difference between the CE group and the CEF group, a point to be explored in the Discussion section.
CEF sub-group comparison
Table 8 displays the performance of the three CEF sub-groups in free writing.
Grammatical/Ungrammatical instances in free writing (Sub-groups).
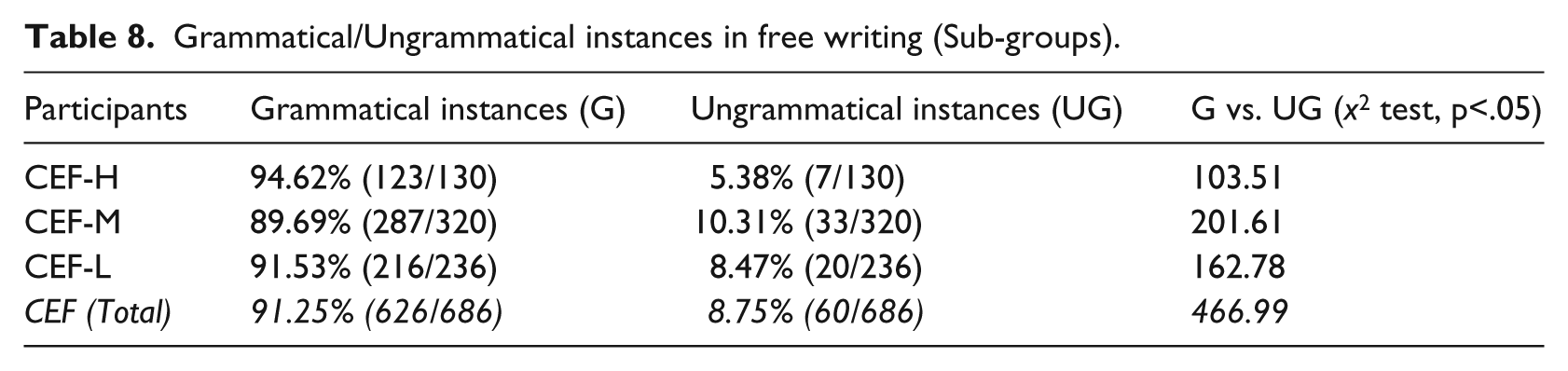
All three CEF sub-groups produced significantly more grammatical instances of number agreement than ungrammatical instances (Table 8). No significant differences were noted in comparing these three CEF sub-groups. Further comparison was made between these sub-groups and the other two groups (CE and E), and two instances of significant differences were noted: (1) all three sub-groups produced significantly fewer grammatical nominal plural instances than the E group (CEF-H: x2=6.6231; CEF-M: x2=28.3589; CEF-L: x2=19.4489, p<.05); (2) the CEF-H group produced significantly more grammatical nominal plural phrases than the CE group (x2=3.8698, p<.05).
No statistical significance was recorded in the number of each type of ungrammatical instances across the three sub-groups (i.e. cross-group comparisons). While both the CEF-M and CEF-H groups produced similar numbers of ungrammatical missing ‘-s’ and redundant ‘-s’ nominal forms, a significant percentage of the ungrammatical nominal plural phrases were produced by the CEF-L group. Although no statistical significance was found between the two percentages (70% vs. 30%, x2=3.20, p=.074), the seeming difference of the CEF-L group (Table 9) is similar to that of the CE counterpart (Table 7). In light of the two similar patterns, as well as the difference between the CEF-H and the other two sub-groups, the question of whether L3 French proficiency might have contributed to such difference among the sub-groups is raised.
Ungrammatical instances in free writing (Sub-groups).
Summary. To sum up the results from the free writing task, the following three main observations deserve our further attention:
The two learner groups produced significantly more ungrammatical nominal plural instances than the native group (Table 6);
Significant difference between the ungrammatical missing and redundant instances was noted among the CE participants, indicating one potential difference between the CE group and the CEF group (Table 7);
The CEF-H group produced significantly more grammatical nominal plural phrases than the CE group, suggesting one possible difference between the CEF-H group and the other two sub-groups (CEF-M and CEF-L) (Tables 6 and 8).
Discussion: L3 French–L2 English number agreement
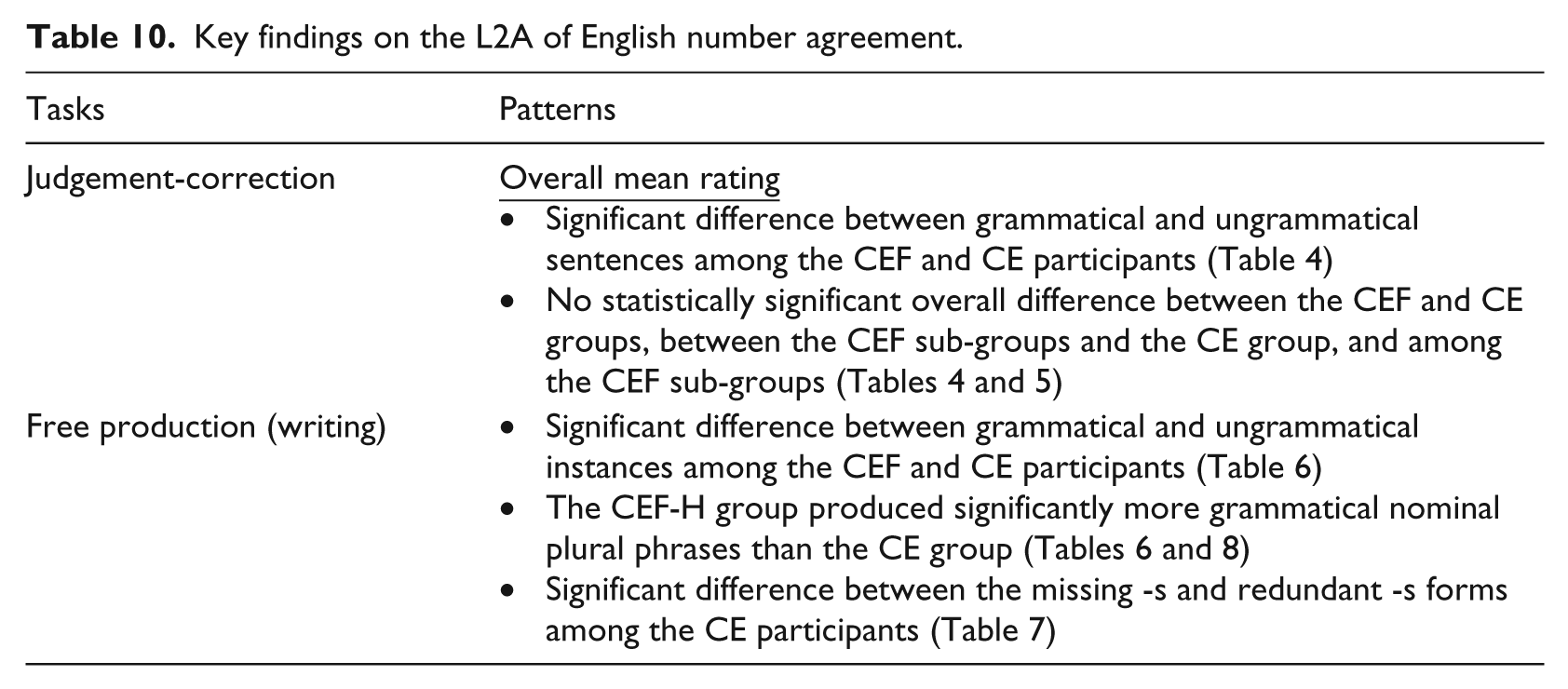
The previous section presents the performance of three groups of participants (CEF, CE, and E) in the two experimental tasks, namely the grammaticality judgement-correction task and free writing task. Table 10 summarises the key patterns involving the CEF participants.
Key findings on the L2A of English number agreement.
The above patterns, which revealed the judgement on and production of English number agreement, are to be discussed in this section in terms of the research question and hypotheses recapitulated below:
Does the acquisition of a later acquired language (i.e. French) have any effect on the judgement on and production of number agreement of an earlier acquired language (i.e. English)?
(1) Reverse transfer effect would take place: Under the influence of their L3 French, the CEF participants would (a) judge English number agreement more accurately and (b) produce fewer non-target English number agreement forms than their CE peers.
(2) English number agreement would be problematic in some way: Under the influence of L1 Cantonese, the CEF participants, just like their CE peers, would still (a) judge English number agreement less accurately and (b) produce more English plural markers than the control native participants.
The research question and hypotheses, as explained above, are based on two research concerns: (1) positive or negative transfer effect of L3 onto L2 (i.e. interaction between L3 French and L2 English (and possibly L1 Cantonese)) and (2) the vulnerability of different interfaces. Given that the focus of the paper is on English number agreement, the syntax–morphology interface, which is one of the internal interfaces, is likely to be involved. Both cross-group and within-group comparisons are to be discussed below.
Research concern 1: positive or negative transfer effect of L3 on L2
The above result sections present that all cross-group comparisons between the CEF group and the CE group in terms of their judgement-correction and free production did not bear any statistical difference. The lack of cross-group statistical difference could be taken as an indication that the data collected did not reveal any effect of L3 French on L2 English among the CEF participants and Hypothesis 1 was not supported. However, in considering within-group comparisons or cross-group comparisons among the CEF sub-groups and the other participant groups from the judgement-correction task and free production task, some possible indication of transfer effect of L3 French on L2 English among the CEF participants can be identified from the free writing task:
Unlike the CEF group, the CE group produced significantly more ungrammatical missing ‘-s’ forms than ungrammatical redundant ‘-s’ forms (Table 7).
The CEF-H group produced significantly more grammatical nominal plural phrases than the CE group (Tables 6 and 8).
These significant differences do help reflect how L3 French may have influenced the CEF group’s L2 English in the surface manifestation of plural nominal forms in a certain way.
L3 transfer effect and surface manifestation of plural nominal forms
While the judgement-correction task helped show the somehow psychological aspect of L3 French–L2 English transfer effect, the free writing task, with the presence of two ungrammatical forms, i.e. missing ‘-s’ and ungrammatical redundant ‘-s’ forms, revealed the L3 French–L2 English learners’ non-target use (and probable misunderstanding) of morphological marking in English.
As explained above, missing ‘-s’ forms refer to the noun phrases which are not morphologically marked by the plural ‘-s’ when warranted. An example of the missing ‘-s’ forms is ‘three apple’, where the numeral in the noun phrase ‘three’ requires the presence of the plural ‘-s’ in the head noun to convey the plural meaning but the noun is bare (i.e. no ‘-s’). Should a learner miss an ‘-s’ in a plural noun, such omission can be caused by a variety of factors, possibly depending on the theoretical stance being held. For example, the learner may not be aware of the need to use the morphological ‘-s’ in English, suggesting the absence of the marker and therefore some kind of problem in his/her underlying representation in his/her mind (cf. Hawkins, 2003; Hawkins & Chan, 1997; Lardiere, 2007b, 2008). The learner may, on the other hand, know of the need to use the morphological ‘-s’ in the language (i.e. no underlying problem), but may experience difficulty at the point of producing the forms (cf. Prevost & White, 2000). These two possibilities and many others have been discussed in the literature on inflectional marking. Contrary to the missing ‘-s’ forms, redundant ‘-s’ forms appear when the presence of the plural ‘-s’ is not needed, for example, ‘-s’ in the noun phrase ‘every destinations’. This implies that the learner is aware of the presence of the morphological ‘-s’ in English, but seems to encounter difficulty when using the marker concerned. In other words, morphological ‘-s’ is likely to be present in the learner’s mind, but the understanding and use of the marker has not reached the target level, resulting in the ungrammatical redundant ‘-s’ forms. Table 11 summarises the difference between the two ungrammatical forms.
Missing -s forms vs. Redundant -s forms.

Albeit both being ungrammatical, the missing ‘-s’ forms appear to be more problematic than the redundant ‘-s’ forms in that the missing ‘-s’ forms, but not the redundant ones, are associated with the absence of the surface manifestation of the ‘-s’ form and could even relate to the possible absence of morphological ‘-s’ in the learner’s mind (i.e. no underlying representation of ‘-s’).
Should the above differences between the two ungrammatical forms be interpreted in our understanding of possible L3-to-L2 transfer effect, three points about the role of L3 French in L2 English can be made here.
First, as noted above, the CE group, unlike their CEF counterpart, displayed significant differences in the production of the two ungrammatical forms. The CE participants were found to produce more instances of missing ‘-s’ than redundant ‘-s’. Given that missing ‘-s’ forms seem more problematic than redundant ‘-s’ (Table 11), the CE group appeared to be more likely to encounter difficulty in marking plural nominal forms than the CEF group. On the other hand, the CEF participants, thanks to French as their L3, seem to have ‘neutralised’ the difference between the two non-target plural forms because their attention to the use of morphological marking in languages such as French and English was enhanced (a point to be elaborated in the coming paragraphs). They may therefore be more ready to use the plural marker to indicate number agreement. However, without any statistical difference noted between the CEF and CE groups in terms of their non-target missing or redundant ‘-s’ forms, rigorous tests would be needed to find out more about the production of the target and non-target nominal plural forms among the two types of participants and gain more significant support for the conjectures about the two groups of participants.
Another point to explore concerns the connection between the L3 transfer effect and the nature of the representation of the nominal ‘-s’ among the two groups of participants. Given that the CE group produced significantly more missing ‘-s’ forms, they may have two possible representations of nominal ‘-s’ (cf. the distinction between the two structures as shown in Table 11): (1) no underlying and surface representation of nominal ‘-s’ or (2) underlying (but maybe non-target) representation of nominal ‘-s’ but no surface representation of the ‘-s’ form. Since both the CEF and CE participants in the study attained high scores in the grammaticality judgement-correction task, they are very likely to be ‘productively aware’ (Hawkins & Liszka, 2003, p. 32) of the need to use the morphological marker in indicating English nominal plurality. Therefore, instead of opting for the first possibility and expecting that the learners did not have any representation of the plural -s form, it is speculated that the CE participants did have the plural ‘-s’ registered in their minds but had difficulty in the surface production of the form. Their CEF peers, on the other hand, tended to experience less difficulty in the surface manifestation of the ‘-s’ form, probably thanks to their knowledge of French. Their L3 French might have positively affected the surface representation of their L2 English plural nominal forms: their sensitivity to the morphological plural marker, via their exposure to French, which also requires some form of morphological marking for plurality, could have enhanced their production of the ‘-s’ form in indicating English nominal plurality, thus enabling them not to miss the plural ‘-s’ form so often.
Finally, the analysis of the CEF sub-group data further revealed the possible role of L3 proficiency, again in the L3 French–L2 English transfer effect on the surface manifestation of the plural ‘-s’ marker. The CE group was found to have missed the plural morphological marker significantly more than overused the marker (i.e. redundant ‘-s’) in their writing, and the CEF-L also shared the same pattern in the production of missing ‘-s’ and redundant ‘-s’ forms, almost reaching statistical significance (Table 8). Meanwhile, the CEF-H and CEF-M sub-groups shared the other pattern (i.e. no statistical difference between missing ‘-s’ forms and redundant ‘-s’ forms). This in turn suggests that L3 proficiency may be involved in the L3 French–L2 English transfer effect, if there exists such an effect: the transfer effect from L3 French to L2 English could only take place when a learner’s L3 has reached a more advanced proficiency level. 6
Summary
To conclude, despite the lack of overall significant difference between the CEF and CE groups in both the judgement-correction and free writing tasks, some possible traces of positive transfer effect from L3 French might have been manifested via the number of missing ‘-s’ plural forms and redundant ‘-s’ forms in the free production task. The possible L3 French–L2 English effect might be related to the typological distance between French and English. A comparison of the three languages that the CEF group knows would strongly suggest that English and French share more structural similarities than Cantonese and are thus typologically closer to each other. Both English and French, for example, have a comparatively richer morphological system than Cantonese. As reviewed in Tsang (2014), typologically closer languages are more likely to cause such an effect. What is more, with the possibility of cross-linguistic interaction among learners as highlighted by Cook (1991, 2003, 2007) and Herdina and Jessner (2002), L3 French could have been activated among the CEF participants when they were asked to use the other two languages they know. Meanwhile, the L3 French–L2 English transfer effect may be subject to the learner’s L3 proficiency level, as implied by the differences among the CEF sub-groups and also between the CEF sub-groups and the other two participant groups.
Research concern 2: vulnerability of the internal interface
After examining the possible L3 French–L2 English effect on the L2A of English number agreement in the previous section, this section focuses on Hypothesis 2, which concerned the vulnerability of English number agreement. The question being addressed is: Was the L2A of English number agreement problematic for the CEF participants in the present study?
Recall that the above question was raised in light of one early claim of the interface hypothesis (IH): narrow syntax and the internal interfaces (such as syntax–morphology) are not problematic among advanced or near-native learners of English. In a later version, however, the IH states that internal interfaces may present some difficulty for the learners. Such difficulty seems to hinge largely on the languages involved. By intuition, L1 speakers with a morphologically impoverished language are more likely to encounter difficulty in acquiring another language with more robust morphological marking, thus making the syntax–morphology interface problematic for them. Given that Cantonese is not as morphologically rich as English and French, it is worth investigating to what extent (and how) English number agreement was challenging for the CEF participants, whose L1 Cantonese does not possess a strong morphological system.
One direct manifestation of the difficulty of a language structure for learners is probably the degree of accuracy in using the structure. In the present study, such accuracy was measured by two sources: (1) overall mean rating in the judgement-correction task and (2) number of target and non-target instances in free writing. Among the two tasks, the performance of the CEF group in the free writing task tends to suggest that English number agreement could still constitute some form of difficulty for the participants. Despite their high mean scores for the judgement-correction task, the CEF group, just like the CE group, produced significantly fewer grammatical nominal plural tokens than the native group in their writing (Table 6). While about 90% of the nominal plural instances were grammatical, the presence of significantly more ungrammatical nominal plural items in the learners’ writing implies that their knowledge of the language structure at the time of the study was likely not to be at the native level, even though they were advanced or near-native English speakers. This, interpreted from the perspective of the IH, would support the claim that the internal interface, in the form of English number agreement, was still problematic for the advanced or near-native English group in the study.
It is also interesting to note that the difficulty of English number agreement was only shown in the free writing task but not the judgement-correction task. This might be related to the nature of the tasks, which could be argued to correspond to different kinds of usage of the target language on one interface. The judgement-correction task in the study presented some language input for the participants, who were required to make use of their English knowledge in a more controlled manner: to rate the given sentences. They were asked to focus their attention on the language per se. On the contrary, the free writing task corresponded to a more ‘natural’ use of the English language, where the participants were asked to write whatever they preferred within the given topic. The only ‘controlled’ element was the topic, and the learners could decide what to write about. The focus was thus on the content rather than the language. What is more, the difference between the writing task and the judgement-correction tasks, though sharing the same language structure (i.e. English number agreement), needed at least two different kinds of language use: writing and judgement (whether and which one was grammatical). All these differences in the usage of one structure pattern in turn lead to a speculation in relation to the IH: the difficulty of a structure on an interface may be subject to the nature of use of the structure (e.g. judgement vs. free writing). Should the advanced or near-native learners be asked to judge a structure on the internal interface, their performance might not differ much from that of the native speakers. However, the learners would experience more difficulty than the native speakers in the free production of the target structure. In other words, even within an interface, different use of the same language structure would generate various degrees of difficulty for the learners.
Meanwhile, the difficulty of English nominal plural morphology as experienced by L1 Chinese speakers (e.g. the CEF and CE participants in the present study) has been much discussed in the literature. Besides Lardiere’s generative series of discussions, as reviewed above, some other recent descriptive studies, such as Chan (2004a) and Liu, Tindall and Nisbet (2006), reiterate that number agreement in English is the main problem among Chinese learners. Chan’s contrastive analysis, supported by authentic examples produced by 387 L1 Chinese–L2 English speakers in another study of hers, explains that number is ‘one fundamental difference between English and Chinese’ (Chan, 2004a, p. 35, with emphasis added). Liu et al. (2006) also explain how ‘distinctly different’ (p. 134) Chinese and English are in marking number agreement, and describe the structural features as ‘fundamental differences’ (p. 135). They also list a number of difficult areas the learners face, among which are omission and redundancy of the English plural marker. Thus, the problems that L1 Chinese speakers encounter, which largely relate to the morphological differences between Chinese (including Cantonese) and English, are still emphasised in recent descriptive and generative accounts, and that Chinese does not possess a morphological system in representing number agreement causes negative transfer from L1 Chinese to L2 English. Without a native knowledge of the connection between morphology and number agreement in their L1, as well as under the influence of their L1, the CEF participants were more likely to encounter problems in using morphological marking in English. Hence, they would still produce non-target nominal plural instances on narrow syntax or one of the internal interfaces: the syntax–morphology interface.
Conclusions and implications for future research
Through a judgement-correction task and a free writing task, the present study has drawn our attention to the following aspects of the L2A of English number agreement by a group of L1 Cantonese–L2 English–L3 French (CEF) speakers:
No traces of L3 French–L2 English effect were observed in the grammaticality judgement-correction task, where the judgement of the sentences on nominal agreement among the CEF and CE participants did not differ significantly.
Possible traces of L3 French–L2 English effect were noted in affecting the CEF learners’ use of English plural morphology by ‘neutralising’ their production of missing or redundant plural ‘-s’.
Proficiency of L3 French was found to play a role in causing a possible L3 French–L2 English effect in the free production task.
English nominal agreement still presented a challenge to the CEF participants, who were advanced or near-native speakers of English at the time of the study.
The above findings have possibly indicated potential reverse cross-linguistic influence from a later acquired language (L3 French) to an earlier one (L2 English) at the level of free production of nominal agreement. Awareness of such potential reverse cross-linguistic influence is of prime importance to learners and language teachers. For learners, understanding the possible interaction among the languages they know would probably enhance their ability to compare and contrast those languages and facilitate their acquisition and use of the language being acquired. For language teachers, the familiarity of the possible interaction among the languages the learners know would help design more focused activities for learners to overcome any potential negative cross-linguistic influence, thereby assisting the learners in the acquisitional process.
Meanwhile, one important caveat is that possible reverse transfer was noted only in the free writing task, where fewer instances of missing or redundant plural ‘-s’ were found among the CEF participants. More rigorous tests are required to discern all aspects of the possible reverse transfer effect, especially at the level of accuracy of using the target structure. A much higher number of advanced L3 French learners need to be recruited in order to investigate further the role of L3 proficiency in bringing out reverse cross-linguistic influence.
Footnotes
Acknowledgements
Sincere thanks go to the anonymous reviewers for their constructive comments and suggestions. All errors or oversights remain solely my responsibility.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Research Grants Council of the Government of the Hong Kong Special Administrative Region [RCC-GRF-Grant HKU 755111].