
Abstract
Aims and objectives:
This paper attempts to develop a predictive computational model of Cantonese–English code-switching (CS) in Hong Kong, informed by language-internal and “language-external” (e.g., social) factors. I analyze this bilingual practice with respect to these factors and evaluate how accurately a model informed by this analysis can forecast Cantonese–English lexical choice in the context of digital platform WhatsApp.
Approach:
A quantitative “bag-of-words” approach was used to analyze bilingual variability/choice. The paper will focus on analyzing the frequency distribution of English and Cantonese choice at the word level without considering information in peripheral constituents (i.e., part-of-speech of the preceding and succeeding word, collocations).
Data and analysis:
A 329,087-word sociolinguistic corpus of WhatsApp messages from 24 Hong Kong residents was used. The data were analyzed using principal components analysis, sentiment analysis, and Bayesian multivariate regression.
Findings:
Part-of-speech, style, proficiency in English and Cantonese as well as attitudes toward switching to Cantonese interact with matrix language to condition CS. Switches from Cantonese to English signal “interpersonality” whereas the maintenance of English in English-matrix clauses index “informationality.” Individual factors have less of an impact than other factors, suggesting uniformity within the community. Attitudes toward mixing and preference for frequent mixing do not correlate with rates of CS.
Originality:
Unlike prior work, this paper analyzes original, manually collected WhatsApp data, typically underexplored due to access and privacy limitations, leveraging understudied variables such as style, sentiment (affect/emotion), attitudes, and linguistic factors and their interactions under a single model of digital CS. Furthermore, this paper considers the effect of individual/stylistic and dialectal/social factors on CS.
Significance and implications:
This paper advances research on Cantonese-English code-switching in Hong Kong and East Asia, enriching our understanding of bilingualism’s social, linguistic, and affective dimensions while informing multilingual AI models. By prioritizing a simple ‘bag-of-words’ approach to modeling, it also offers a computationally efficient method accessible to researchers with limited resources, broadening the methodological toolkit for sociolinguistic analysis.
Keywords
Introduction
Artificial intelligence or AI prediction tools have garnered increasing attention for their potential to model and predict patterns of language use (MacKenzie, 2020; Szmrecsanyi et al., 2019). Among these tools, generative pretrained transformers (GPT) represent a significant advancement, capable of processing and generating text with naturalistic fluency. These systems rely on statistical models trained on extensive datasets to identify and replicate language and stylistic patterns, producing outputs that are linguistically coherent. Similarly, regression-based models of language use are frequently employed to identify correlations between linguistic behavior and specific variables, enabling predictions based on new input values.
Despite their potential, the development of AI-driven language models has largely been confined to a dominant majority of languages, particularly English. While there are exceptions—such as predictive models for Australian Kriol and Lánnang-uè (Dickson & Durantin, 2019; Gonzales, 2022)—most language models focus predominantly on linguistic variables, such as phonotactics, phonology, and word classes. For instance, lexical models have been used to identify borrowings across languages (Miller et al., 2020), and frameworks like “Variation-Based Distance and Similarity” (VADIS) quantify variation between dialects or varieties based on how speakers encode the same concept using different expressions (Szmrecsanyi et al., 2019). However, even cutting-edge models like GPT operate primarily with linguistic input, often neglecting sociolinguistic factors and broader contextual influences on language use (M. Zhang & Li, 2021). This linguistic bias limits their capacity to account for sociolinguistic phenomena, particularly in minoritized and underdocumented languages (Calude et al., 2020). As such, the development of predictive models for these varieties remains a significant challenge, as they often lack the sociolinguistic grounding necessary for both accuracy and nuance.
In response to these limitations, this paper proposes the development of a supervised predictive model that integrates both linguistic and social factors to better understand underexplored multilingual practices. Recognizing that hybrid language practices are often deeply rooted in social dynamics (Thomason, 2007, 2010), this study seeks to identify the most robust predictors of language choice, particularly within digital contexts. By bridging linguistic and sociolinguistic dimensions, the model aims to provide a more comprehensive and contextually informed approach to language prediction.
The focus will be on Cantonese–English code-switching (CS) in Hong Kong, where I attempt to examine to what extent linguistic and social factors jointly condition and can be used to predict the choice of language (English vs. Cantonese use). I specifically investigate the contemporary practice of Cantonese–English code-mixing in computer-mediated communication (CMC), with specific emphasis on the WhatsApp instant messaging service. The platform was chosen because it is widely used in Hong Kong and enables easier data collection. Examining this platform could also potentially lead to a more holistic understanding of the Cantonese–English code-mixing phenomenon beyond conventional contexts, such as speech and writing. I build on one of the more recent works on Cantonese–English code-mixing in WhatsApp—Gonzales and Tsang’s (2023) work—by re-examining their sociolinguistic corpus of WhatsApp messages. I employ natural language processing (NLP) and other computational and statistical techniques to re-analyze the occurrences of code-mixing in this largely unexplored communication medium and to investigate how these patterns are impacted by intra- and extra-linguistic 1 factors. In Gonzales and Tsang’s work, variables such as part-of-speech, sex, medium of instruction in basic education, and educational major in college were investigated (Gonzales & Tsang, 2023). This study will incorporate the mentioned variables and also include novel computationally-derived variables in a unified analysis of CS patterns. It will also delve deeper by examining some interactions between these variables and identifying variables that strongly condition the variability. Using these findings, I then assess to what extent a model informed by what I have analyzed can accurately predict Cantonese–English use (henceforth, C-E choice) in the context of digital CS.
The section “Variation and the digital world” provides an overview of the sociolinguistic landscape of Hong Kong, situating the study within the broader context of Cantonese–English CS practices in the region and highlighting key research on sociolinguistic variation and digital communication, particularly on WhatsApp. The “Methodology” section details the data source and methodological framework, including the types of analyses undertaken. The “Results and discussion” section presents and critically examines the main findings, offering insights into the interplay of linguistic and social factors in CS. Finally, the “Conclusion” section concludes by summarizing the study’s key contributions, addressing its limitations, and proposing directions for future research in this area.
Variation and the digital world
The Hong Kong context
Hong Kong is a cosmopolitan city renowned for its ethnolinguistic diversity; it is a prime example of a society in which multiple languages are extensively in contact. Its dynamic linguistic ecology comprises dominant languages such as Cantonese, Mandarin (known as Putonghua in this region), and English, as well as minority languages like Bahasa Indonesia, Tagalog, Urdu, and Nepali (Bolton et al., 2020). Most Hong Kong residents are multilingual and often employ linguistic resources from their multilingual repertoire in a variety of communicative practices such as CS, code-mixing, style-shifting, and translanguaging (K. L. R. Chan, 2019; Chen, 2005), such as in the trilingual practice of Cantonese–English–Putonghua/Mandarin CS (K. L. R. Chan, 2019). Arguably, the most well-known and extensively studied mixing practice is the alternation between Cantonese and English among many Chinese-heritage Hong Kong residents, also known colloquially as “Cantonese-English code-switching” or code-mixing (B. H.-S. Chan, 2015, p. 17), or even as a translanguaging practice (B. H.-S. Chan, 2022). This phenomenon has been the focus of many sociolinguistic and psycholinguistic studies (Hui et al., 2022) and its usage is generally associated with a range of social and contextual factors (Yim & Clément, 2019) across various mediums of communication (e.g., Cantopop television drama) (Ng, 2021).
Factors that influence Cantonese–English mixing
Scholars have identified some sociolinguistic factors that influence patterns of Cantonese–English CS. Chen (2005), drawing on recorded speech, identified style and overseas exposure as conditioning variables of CS. They observed that speakers tend to use more Cantonese than English (i.e., occasional inserting of English into Cantonese) when using a “mainstream style” or a local style of CS that is predominantly used in Hong Kong. This style has been noted to be often used by locals without much exposure to overseas education in English-speaking countries. Chen (2005) also found that some of their speakers have distinct language-mixing patterns that constitute a “non-mainstream style.” These speakers—often individuals who are educated overseas—tend to use more English lexicon, as manifested in Cantonese insertion into English, English insertion into Cantonese, as well as frequent clausal/constituent alternation between Cantonese and English. Style and linguistic exposure, in Chen’s study, are important predictors of English and Cantonese lexicon use. This is echoed by other recent studies, which have also found the existence of stylistic differences in Cantonese–English mixing (Weston, 2016).
In D. C. S. Li’s (2000, p. 309) systematic review of CS literature in Hong Kong, age, ethnic orientation, or degree of affiliation with a particular ethnic group, and “expedient” or convenient switching appear to be some predictors of CS patterns (Luke, 1998). Young speakers, those with a more “Western” outlook, and those needing to fill a lexical or stylistic gap in Cantonese tend to use more English lexicon. However, D. C. S. Li (2000) also noted English also tends to be used more when the speaker wants to euphemize the Cantonese word, that is, to allude “to the same referent without making explicit mention of that potentially embarrassing” concepts (e.g., use of the English word bra instead of Cantonese words like naai5 zaau3 “breast cover” and hung1 zaau3 “chest cover”) (D. C. S. Li, 2000, p. 312). They also note that English tends to be preferred when the speaker needs hypernyms that are not conceivable in Cantonese. For example, speakers would use English fan instead of Cantonese mai4 because mai4 is unacceptable without a premodifier in Cantonese (e.g., go1 mai4 “song fan” and jing3 mai4 “film fan”) (D. C. S. Li, 2000, p. 313). Deliberate and creative use of linguistic resources such as bilingual puns (e.g., use of English fun to mean “fun” and Cantonese “share”), as well as shorter, more efficient ways of relaying information (see 1 and 2, where 2 is a shorter variant of 1), have also been identified to increase the likelihood of English in Cantonese–English mixing.
(1) Nei5 baan6lei5 -zo2 jap6zyu6 sau2zuk6 mei6 aa3? 2.SG arrange -PFV stay procedure NEG SFP “Have you checked in (to your room) already?” (D. C. S. Li, 2000, p. 317) (2) Nei5
2.SG check in -PFV NEG SFP “Have you checked in already?” (D. C. S. Li, 2000, p. 317)
Scholars have also identified language-internal conditions for English lexicon use. B. H.-S. Chan (1998) drew on a corpus of transcribed spontaneous Cantonese–English utterances and focused on structural conditions. They found that speakers tend to use English in certain parts of speech categories, such as nouns (3), verbs (4), adjectives, prepositions, and conjunctions. They did not find English modal verbs, auxiliary verbs, pronouns, possessives, and quantifiers in their study. They identified morphosyntactic constraints of this mixing practice using Myers-Scotton’s (1993) matrix language framework.
(3) aa3
AFF Paul send -PFV CLF postcard give 1.SG “Paul sent a postcard to me.” (B. H.-S. Chan, 1998, p. 193) (4) keoi5-dei6
3.SG.PL plan -PFV DEM -CLF summer.vacation heoi3 au1zau1 leoi5hang4 go Europe travel “They have planned to go travelling to Europe this summer vacation” (B. H.-S. Chan, 1998, p. 194)
Although there are additional variables mentioned in the literature that have been proven to increase the chances of using English lexicon, they are not identified here due to space limitations. Nonetheless, it is evident from the information presented thus far that both factors external to language and those internal to language can influence the patterns of English–Cantonese mixing in Hong Kong.
Sociolinguistic studies using WhatsApp
The surge in sociolinguistic studies on WhatsApp reflects a growing interest in how this digital platform influences linguistic practices and code-mixing. Research has expanded to include various linguistic features and sociocultural contexts, with studies such as those by Pérez-Sabater and Montero-Fleta (2015) in Spain and Alazzawie (2022) in Canada exploring bilingual texters’ usage of English, Spanish, and linguistic styles in text messaging. Investigations into code-mixing practices, like those by Haryati and Prayuana (2020) in Indonesia, highlight how individual bilingualism, situational context, and social factors like prestige and interlocutor relationships shape linguistic variations. Furthermore, corpus-based studies in Singapore (Leimgruber et al., 2021) have delved into gender and ethnicity’s impact on discourse particles and innovative constructions (Gonzales et al., 2022), indicating nuanced linguistic preferences among different demographic groups (Hiramoto et al., 2022).
Sociolinguistic research on WhatsApp in Hong Kong is likewise beginning to flourish. However, current studies reveal a notable gap: a holistic understanding of CS that integrates linguistic, cognitive, and social factors remains underexplored. Existing scholarship often isolates these dimensions, offering valuable yet fragmented insights. For instance, Har (2021) examined Cantonese–English code-mixing among government sector colleagues in Hong Kong, focusing on social factors. This study demonstrated that code-mixing is frequent and found that individuals with postgraduate education were more likely to switch to English. Gonzales and Tsang (2023), in an exploratory mixed-methods study, broadened the scope by identifying cognitive (e.g., conceptual gap-filling), linguistic (e.g., part-of-speech), and social factors (e.g., sex, medium of instruction, identity construction) influencing CS. Their findings indicated that common nouns, proper nouns, verbs, and adjectives were the most frequently switched word types. In addition, their data revealed that women, non-English majors, and those educated primarily in Cantonese at the primary and secondary levels were more inclined to engage in intra-clausal Cantonese–English CS. This study also identified deliberate motivations for CS, such as identity construction and negotiation, aligning with prior findings (K. L. R. Chan, 2018).
While these studies contribute to the growing literature, their methodological approaches analyzed factors independently, leaving critical questions unanswered. To what extent do these factors interact to shape CS practices under a holistic framework? Moreover, could the influence of certain previously identified factors diminish when considered alongside more robust predictors? Addressing these questions is essential for advancing our understanding of the dynamic interplay of sociolinguistic, cognitive, and linguistic dimensions in multilingual digital communication.
Computational models of CS around the world
The evolution of computational models for CS has been extensive and significant, with researchers developing a variety of models to delve deeper into the complexities and subtleties of bilingual speech. Starting with the works of Chan et al. (2009) and Cao (2011), both focusing on recognition models, we see an early emphasis on developing large-vocabulary code-mixing speech recognition systems. Chan et al. introduced a model based on a two-pass decoding algorithm with cross-lingual acoustic models, highlighting the importance of language boundary detection for improving decoding accuracy. Similarly, Cao employed a cross-linguistic, multilingual approach to tackle the challenges of Cantonese–English code-mixing speech recognition, emphasizing the need for a comprehensive understanding of linguistic properties and the development of a relevant bilingual pronunciation dictionary for enhanced recognition performance.
Subsequent studies introduced different perspectives and methodologies to the field. For instance, Filippi et al. (2014) shifted focus to a processing model, exploring the time costs associated with Italian–English bilingual CS and providing insights into the control processes involved in bilingual language production. Meanwhile, Weston (2016) did not develop a computational model but underscored the significance of incorporating stylistic factors into any computational model of CS, reflecting on the diverse CS practices and perceptions among Cantonese–English bilinguals from different social backgrounds. Goldrick et al. (2016) and Goral et al. (2019) both contributed production models, with the former introducing a Gradient Symbolic Computation-based model focusing on doubling constructions and the latter examining code-mixing among multilingual people with aphasia, suggesting that language mixing might serve as a communicative strategy to bypass word-retrieval difficulties.
More recent contributions like those from Tsoukala et al. (2021) and Bustin et al. (2022) highlight the advancements in computational cognitive modeling and predictive modeling, respectively. Tsoukala introduced a simulation-based neural network model for Spanish–English bilingual CS, providing a novel method for studying the phenomenon and comparing simulated production with human bilinguals. Bustin et al. developed a predictive model of CS accuracy, focusing on various factors such as switch direction and language dominance, and testing the grammaticality predictions of different linguistic models. Finally, K. K. Li et al. (2023) modeled the phonological effects of CS between tonal and non-tonal languages, revealing language-dependent tonal effects and emphasizing the complex interplay of prosodic features and social variables in CS.
The development of a predictive computational model of Cantonese–English CS in this study was inspired by the aforementioned works and builds on the foundation laid by these diverse computational models, aiming to incorporate both language-internal and language-external factors, including social dynamics, into understanding bilingual lexical choices on the digital platform WhatsApp. Unlike previous models that focused either on speech recognition, processing costs, or sociolinguistic factors in isolation, this work proposes a comprehensive production model. This model intends to encapsulate a range of identified influences—including stylistic preferences, social backgrounds, language proficiency, and syntactic considerations—within a unified framework for predicting bilingual lexical choices in Hong Kong’s Cantonese–English CS context. By examining how the choice of language at the lexical level correlates and interacts with these diverse factors, this study introduces an innovative approach to analyzing bilingual behavior and enhancing our understanding of bilingualism, particularly through the lens of Cantonese–English mixing.
Methodology
Data source
Because free and publicly accessible Cantonese–English CS corpora in Hong Kong are almost impossible to find, I used a self-compiled corpus of WhatsApp messages: Gonzales and Tsang’s (2023) sociolinguistic corpus of WhatsApp messages in Hong Kong, compiled between Fall 2022 and Winter 2023. WhatsApp was selected due to its status as the predominant instant messaging application in Hong Kong, boasting an 85.5% penetration rate as of January 2022 (DataReportal, 2022). Recent statistics indicate that Hong Kong residents favor WhatsApp (65%) over other platforms such as Instagram (14%) and WeChat (9%) (DataReportal, 2022) for interpersonal communication, making it the most prevalent social media platform for daily discourse. Its widespread usage locally renders it an ideal choice for data collection, streamlining the sampling process.
The compilation of the corpus commenced with having our research protocol vetted by the university ethics review board and the establishment of a collection matrix. At the time, Tsang and I (Gonzales & Tsang, 2023) were interested in examining the potential main and interaction effects of gender, educational background, and college major (specialization/field of study). Therefore, a 2 × 2 × 2 data collection matrix was devised, ensuring an equally distributed number of participants across gender, educational background, and college major (specialization/field of study).
Tsang, a Hong Kong local, leveraged her social network to gather the majority of the data. In total, 24 individuals were identified who expressed willingness to share their WhatsApp conversations verbally. Although we told the participants that the data would eventually be disconnected from their names and identities, as a precaution, they were invited to remove content or utterances that they were not comfortable sharing with the public. After submitting their curated WhatsApp data in raw text format, participants were also requested to complete a sociolinguistic survey questionnaire via Google Forms (Gonzales & Tsang, 2023). The survey encompassed fixed-response questions, 5-point Likert-type scale inquiries, and open-ended prompts, covering topics such as personal background, CS practices, and attitudes toward these practices. The questionnaire structure and content were influenced by prior research on CS (Lo, 1999). Sociolinguistic information was collected since sociolinguistic factors have been found to shape language behavior in Hong Kong (Gonzales, 2023b, 2024c; Hansen Edwards, 2018) and could also influence CS behavior and explain possible differences in CS patterns. Participants submitted the demographic and social information anonymously.
Upon data collection, the raw WhatsApp text files underwent preprocessing, involving the conversion of each text file into a spreadsheet format where each row represents an utterance (i.e., a message bubble on WhatsApp). The resultant preprocessed dataset comprises approximately 329,087 words from roughly 55,000 utterances from 24 Hong Kong residents (see section “Sociolinguistic profile of participants”). This corpus has been designed so that every utterance from the participants is connected to the social metadata from a sociolinguistic survey that they filled out. This data includes information such as age, gender, educational background, and the self-reported proficiency in Cantonese and English. The availability of social metadata makes it possible to analyze and comment on possible sociolinguistic patterns. On the other hand, the systematically organized linguistic data allows for the derivation or approximation of variables that could condition CS (e.g., style) in addition to the metadata already present in the corpus. Overall, the corpus in this study is a valuable resource, as statistical models can be created from the social and linguistic data it contains to predict C-E choice based on both internal and external language parameters.
In consideration of privacy concerns raised by certain participants, all identifying information (e.g., phone numbers, names, etc.) was diligently removed from the utterances to the best of my abilities using a combination of manual and computational techniques (Malmgren, 2021).
Sociolinguistic profile of participants
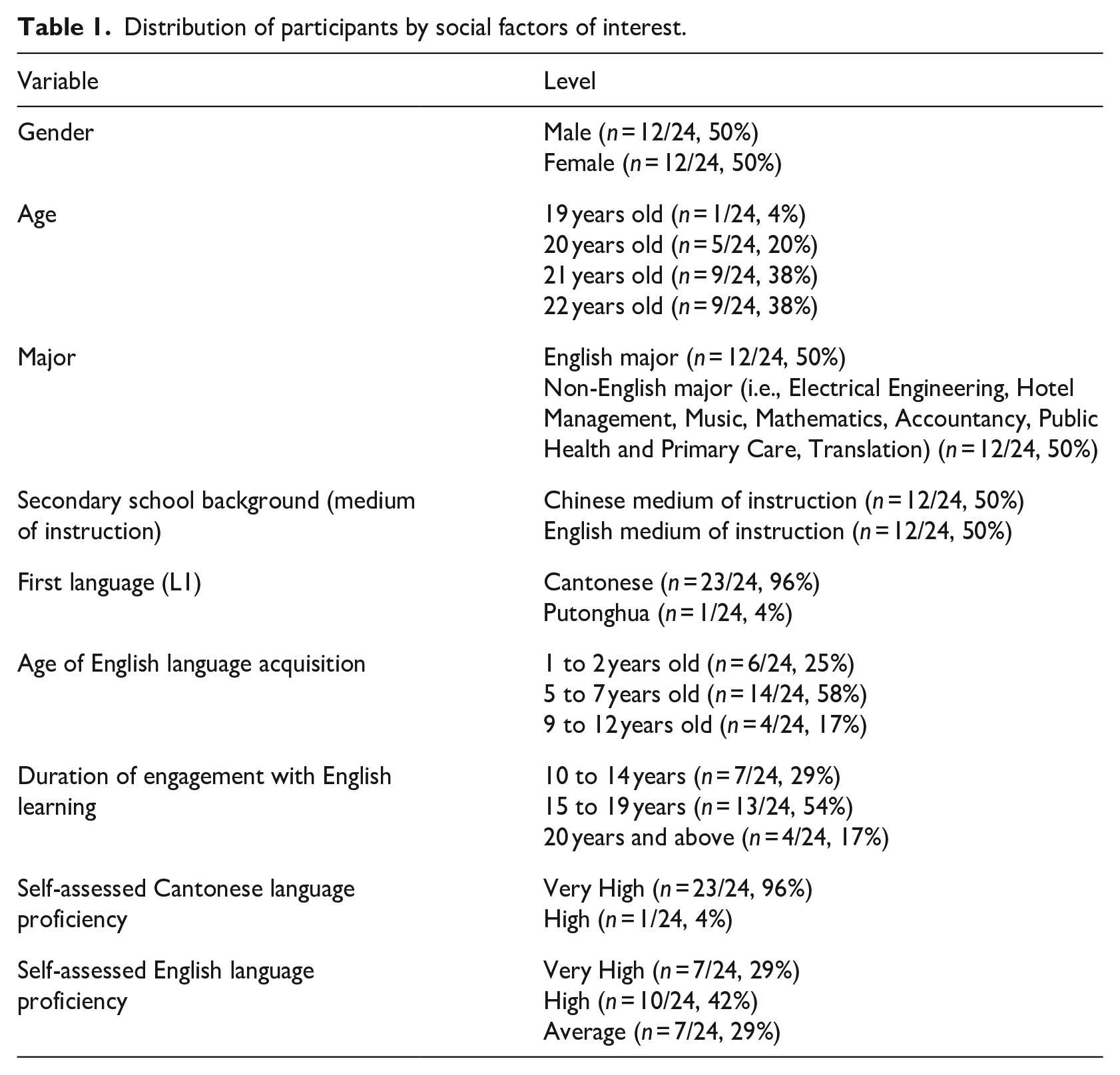
The corpus data is sourced from a cohort of 24 young residents of Hong Kong, all currently enrolled as undergraduate students in public universities within the region. To facilitate comprehensive analysis while considering potential influences stemming from gender, academic discipline at university, and secondary school background (i.e., dominant language used as a medium of instruction), the participants were meticulously stratified across these variables. The group comprises an equal split of 12 individuals identifying as male and 12 as female, with an average age of 21 years (SD = 0.86). Within each gender category, six participants specialize in English studies, while the remaining six pursue non-English majors. In addition, the participants are evenly distributed based on their secondary school backgrounds, with half originating from English medium of instruction (EMI) schools and the remainder from Chinese medium of instruction (CMI) schools.
All participants except one share Cantonese as their first or native language (L1). The majority reported commencing their English language acquisition between the ages of 1 and 2, while others began later, at ages 9 to 12. On average, participants have engaged in English learning for 15.6 years (SD = 3.3). Regarding self-assessed language proficiency, nearly all participants expressed high levels of proficiency in Cantonese (M = 4.96, SD = 0.2). However, self-reported English proficiency demonstrates slightly lower scores and greater variability, as indicated by mean and standard deviation values (M = 4, SD = 0.76).
The distribution of participants across the aforementioned variables is summarized in Table 1.
Distribution of participants by social factors of interest.
Factors of interest and approach
One of the main goals of this study is to attempt to account for and predict English lexicon use over Cantonese lexicon use based on the intra- and extra-linguistic factors listed below. Some of these factors (e.g., part-of-speech, sex) have been identified as robust predictors of Cantonese–English CS choice in prior work (Gonzales & Tsang, 2023). The rest are hypothesized to also be robust predictors based on variationist sociolinguistic research in neighboring languages (Gonzales, 2023a, 2024a; Noels et al., 2014; Starr & Balasubramaniam, 2019).
Intra-linguistic factors
Part-of-speech (e.g., noun, verb, adjective)
Matrix language (English vs. Cantonese)
Extra-linguistic factors
Individual factors (i.e., user ID)
Sex (male vs. female)
Major (English vs. Other)
Medium of instruction (English vs. Chinese)
Year of utterance
Style ○ informal–formal ○ interpersonal–informational
Sentiment/affect ○ negative–positive ○ neutral–nonneutral
Self-reported proficiency ○ Cantonese ○ English
Preference for frequent code-switching
Attitudes toward code-switching ○ fluency aid ○ enrichment tool ○ bilingual identity marker ○ Hong Kong identity marker ○ trendy
Attitudes ○ English code-switching ○ Cantonese code-switching
Because of its focus on C-E choice at the lexical level, this study will primarily adopt a “bag-of-words” approach to investigate the phenomenon (Goldberg, 2017, p. 69; Y. Zhang et al., 2010). That is, it will focus on linguistic choice at the word level without considering information in peripheral constituents (e.g., part-of-speech of the preceding and succeeding word, collocations). However, I do integrate syntactic information as captured in the computational derivation of each word’s part-of-speech category. This approach not only aligns with the study’s lexical focus but also ensures computational efficiency, making the analysis more accessible to researchers with limited resources.
Data preprocessing
While the dataset proves useful for preliminary research, conducting detailed sociolinguistic studies and statistical analysis is difficult with the data in its original form. Therefore, I undertook six preprocessing steps to render my data suitable for analysis.
Step 1: Deriving style variables
I adopted Grafmiller et al.’s (2018) method and utilized principal components analysis (PCA) to derive two stylistic variables (i.e., stylistic formality and stylistic informationality) using linguistic variables (Baayen, 2008; Lê et al., 2008). Essentially, what PCA does for this study is distill, combine, and cluster-related linguistics variables, in this case, linguistic variables that relate to formality or informationality (e.g., preposition stranding) (Tables 2 and 3), and transform them into new variables that capture the essential main patterns and relationships—interpreted to be stylistic variables of formality or informationality. Unlike averaging variable values, PCA uniquely enables the identification of the most effective weighted combination of these (stylistic) variables, minimizing the loss of information or data. The linguistic variables used to derive the stylistic variables, not only included those identified in Grafmiller’s work but also H. Li et al.’s (2016) study, added further linguistic indicators of formality in Chinese, such as narrativity, cohesion, and embodiment (Tables 2 and 3; see discussion and derivation of variables in Li et al.).
Strongest associations of original variables with dimension 2 of PCA, interpreted as the level of stylistic informationality (as opposed to interpersonal-ness).
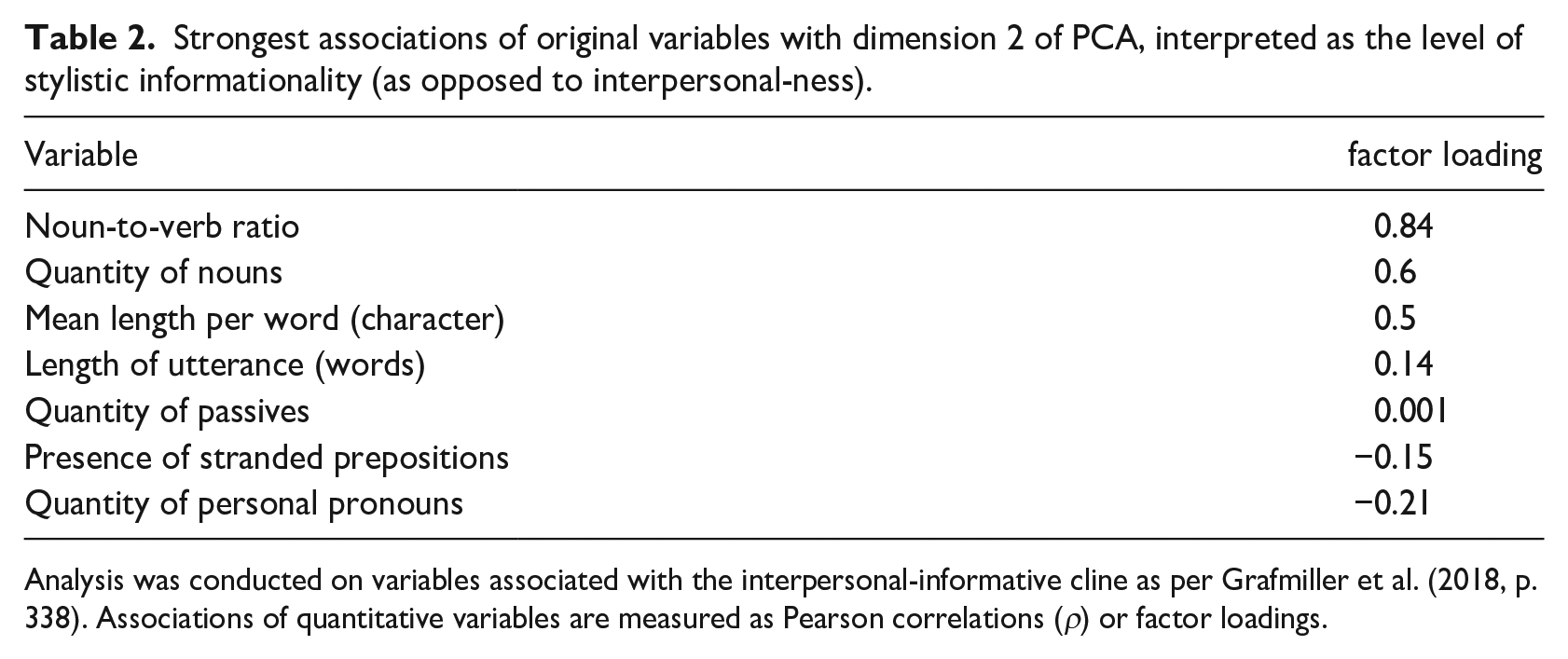
Analysis was conducted on variables associated with the interpersonal-informative cline as per Grafmiller et al. (2018, p. 338). Associations of quantitative variables are measured as Pearson correlations (ρ) or factor loadings.
Strongest associations of original variables with dimension 2 of PCA, interpreted as the level of stylistic formality. Analysis conducted on variables associated with the informal–formal cline as per Grafmiller et al. (2018, p. 338) and H. Li et al. (2016).

Associations of quantitative variables are measured as Pearson correlations (ρ) or factor loadings.
Step 2: Deriving affect/sentiment variables
To derive affect (i.e., level of affective neutrality and degree of polarity), I conducted sentiment analyses on each utterance. For English linguistic elements, I used the sentimentR package in the R environment (R Core Team, 2015; Rinker, 2022). The package takes in a string of text (i.e., the English parts of each WhatsApp utterance or text bubble) and outputs a positive, zero, or negative value that corresponds to the degree of polarity, that is, how much positive or negative affect is associated with the word/utterance based on an English sentiment model (i.e., learned affect–word associations based on large-scale curated affect–text data) based on “valence shifters” such as negators, amplifiers (intensifiers), de-amplifiers (downtoners), and adversative conjunctions (Rinker, 2022). For English, multiple models exist, but for Cantonese, there do not seem to be similar models of packages like sentimentR that are publicly available. For this reason, I opted for a dictionary- or term-based approach to approximate sentiment for Cantonese linguistic elements. I first compiled a list of positive and negative words or expressions, with the help of a dictionary and two Cantonese-as-first-language (L1) speaker consultants. Then, I derive a polarity/sentiment index for Cantonese linguistic elements by assigning a value of −0.5 2 if the word can be found in the list of negative terms, a value of 0.5 if the word can be found in the list of positive terms, and zero (neutral) otherwise. After getting the value for each Cantonese word, I averaged the values of all Cantonese words to get the polarity/sentiment index for Cantonese linguistic elements.
I opted to utilize two different approaches to measure affect for each language (i.e., comprehensive sentiment model prediction for English using sentimentR and purely lexicon-based affect approximation for Cantonese) to optimize the accuracy of affect approximation. Utilizing a purely lexicon-based approach to measuring affect in English will not be able to provide more accurate affect approximations than an approach that also takes into consideration valence shifters (i.e., sentimentR), so using two approaches will get us closer to the “real” affect value compared to using one approach (i.e., lexicon-based approach) that performs averagely. As mentioned earlier, using sentimentR-like models for both English and Cantonese elements is not possible due to the lack of availability of or access to such models.
To get the overall sentiment or affect of the utterance, that is, English and Cantonese elements combined, I weighted the affective values or polarity/sentiment indices for Cantonese and English elements based on the proportion of English and Cantonese words in the utterance. So, if an utterance has two English words and three Cantonese words, the affective score/index for English elements will be multiplied by 0.4 (2/5), and the index of Cantonese elements will be multiplied by 0.6 (3/5). These scores will then be added to form the weighted affect.
Step 3: Linking language data to survey-related metadata
After deriving the affective and stylistic variables, I linked survey responses from Gonzales and Tsang’s (2023) study to each utterance. These include (1) categorical variables, such as sex, major, and medium of instruction, (2) Likert-type-scale responses on proficiency, preference, and attitudes toward CS, and (3) computationally-derived numerical attitudes approximating the affective value of open-ended responses of participants toward Cantonese and English code-switches, respectively.
Step 4: Matrix language coding
When all of this was done, I tagged each utterance for matrix language. It should be acknowledged that the notion of “matrix language” (Myers-Scotton, 1993, p. 75) is a controversial concept in linguistics. Scholars studying CS in bilingual communication frequently posit or assume that one language acts as the foundational “matrix” or “base,” incorporating elements from the other language (e.g., Hokkien–Tagalog–English CS) (Deuchar, 2006; Gonzales, 2016; Myers-Scotton, 1993). However, the standards for identifying a matrix language in a sentence are heavily debated (Auer & Muhamedova, 2005; Sharath, 2018; Wang, 2016; Wasserscheidt, 2020), particularly due to instances worldwide where a clear distinction between matrix and embedded languages is lacking (e.g., some cases of Russian–Kazakh, Dutch–Turkish, Mandarin–Southern Min) (Auer & Muhamedova, 2005, p. 42; Wang, 2016, p. 369). Determining the matrix language is influenced by various factors, such as the overall frequency of words from one language, the predominance of closed class or grammatical morphemes, or the language identified through left-to-right syntactic analysis, often leading to inconsistent conclusions. For instance, in the sentence “Being bilingüe is más sexy,” the matrix language could be construed as either Spanish or English depending on the linguistic classification of “sexy” (Sharath, 2018); however, it would unequivocally be deemed English when considering the gerund structure, the presence of the copula, or its initial position in the sentence (Sharath, 2018).
Despite criticisms of the “matrix language” concept, it was employed in this case study due to its ability to account for the structural patterns in both Cantonese- and English-dominant code-switched utterances in the current dataset. In my pilot study involving a subset of the data, I found that the “Matrix Language Framework” (Myers-Scotton & Jake, 2017) effectively identified consistent syntactic and morphological constraints, particularly the dominance of Cantonese as the structural frame in most utterances, while English insertions followed predictable patterns within this framework. Qualitative findings confirmed that language dominance was not arbitrary but followed consistent structural principles, aligning with prior studies on bilingual communities documenting alternating language dominance based on context (Deuchar, 2006; Gonzales, 2016).
The matrix language concept proved analytically valuable as it systematically identifies the dominant language and explains how its morphosyntactic rules integrate lexical items from the other language. Alternative frameworks, such as translanguaging, which focus on fluid integration without addressing structural dominance, or interlanguage, suited for analyzing learner grammars, were less appropriate for this study of stable, bilingual CS.
Moreover, conversations with the data collector revealed that participants themselves could readily distinguish “Cantonese” and “English” clauses. Nevertheless, it was anticipated that determining the matrix language might not always be straightforward, prompting the application of specific criteria. To be classified as “Cantonese,” an utterance must comprise over 50% Cantonese elements/words and must be recognized as “Cantonese” by a local speaker (i.e., the data collector) intimately familiar with the sociolinguistic dynamics of Cantonese–English CS. The same criteria apply to English. For instance, the phrase “你話我同唔同 supervisor 講好?” “You told me whether I already discussed this with my supervisor.” is identified as having a Cantonese matrix language, as 8 out of 9 (89%) words in the phrase are Cantonese, and the coder also categorized it as a Cantonese utterance. However, there are instances like “Roll 走 ” “roll away” that should be classified as English based on the first criterion (not more than 50%) but pose ambiguity for the native user coder. These instances account for approximately 5% of the original dataset comprising 7,048 utterances and were excluded from the current analysis.
The coder employed in this study was my 22-year-old simultaneous bilingual research assistant, who has lived exclusively in Hong Kong. Fluent in both Cantonese and English as primary languages and Putonghua (Mandarin) as a secondary language, the coder is an undergraduate student (at the time of data collection) who now teaches at a Hong Kong secondary school. Their daily linguistic practices include active use and absorption of Cantonese–English CS, making them well-suited for the task. Nonetheless, the reliance on a single coder constitutes a limitation of this study, as cross-validation by additional coders could have strengthened the reliability of the classifications.
This limitation arose due to ethical constraints specified in the participants’ consent forms, which explicitly restricted access to the data to the researcher (myself) and the designated research assistant or coder. As I am neither a local nor a “native” Cantonese–English code-switcher, only the research assistant or data coder was available to perform this task. While this ensured adherence to the participants’ preferences regarding data confidentiality, it also precluded the involvement of additional coders.
Step 5: Part-of-speech tagging
Part-of-speech tagging was done next. Because there are currently no bilingual part-of-speech taggers for Cantonese–English code-mixed utterances, I ran two different taggers: one for the English data, and another for the Cantonese data, similar to the strategies adopted in previous CS work on Vietnamese–English (Nguyen & Bryant, 2020), Hindi–English (K. K. Li et al., 2023), and even Cantonese–Mandarin–English CS (K. L. R. Chan, 2018). I tokenized each utterance by language, and tagged English utterances using sPacy in the Python environment (Bird et al., 2009), utilizing the publicly available en_core_web_sm model to classify English words based on their part-of-speech (Honnibal et al., 2020). I decided to use the pyCantonese package for Cantonese strings in the same environment (Lee et al., 2022). sPacy’s Chinese model was an option, but initial testing showed that it was better suited for written Chinese and Putonghua, which did not fit the Cantonese WhatsApp data due to its more verbal nature.
Step 6: Word tokenization
After each utterance had been tagged for part-of-speech, I tokenized each utterance by word, using the word-level segmenter in PyCantonese 3 and sPacy. Some of the “word” tokens consist of punctuations, numbers, and blank spaces. There were also words that were not identified as English or Cantonese/Chinese by a Python-based language identifier (Lui & Baldwin, 2012). After removing all these tokens, only 243,316 tokens remain. Because it is difficult to ascertain whether the English and Cantonese utterances are truly products of inter-clausal CS, I removed all utterances that are not tagged as “intra-clausal” CS in Gonzales and Tsang’s (2023) study. The remaining dataset consisting of English and Cantonese word tokens in an intra-clausal CS context has 51,700 tokens.
Preparations to test for model performance
The filtered dataset was randomly divided into two sections to assess the model’s performance: the “training” and “testing” sets. The “training” set contains 41,360 utterances (80%), which will be used to analyze the patterns of language choice in Cantonese–English code-switched utterances and create a statistical model. The “testing” set (n = 10,340 utterances, 20%) will not be used in analysis or description. Instead, it will be used to measure the model’s accuracy with unseen data.
Data analysis
My research on C-E choice is guided by the principles of Labovian theory, which considers both linguistic and external (e.g., social) influences on variation (Labov, 1972). To analyze the binary dependent variables (e.g., Cantonese vs. English), I used mixed-effects logistic regression models with the Bayesian Markov chain Monte Carlo (MCMC) algorithm (Franke & Roettger, 2019; Makowski et al., 2019; McElreath, 2020) implemented in the brms package within the R environment (Bürkner, 2017; R Core Team, 2015). In addition to the factors mentioned in the section “Sociolinguistic profile of participants,” the model includes interaction factors involving both social and linguistic factors. It also considers the possibility of individual variation through the inclusion of random intercepts for each of the 24 participants.
Bayesian techniques were employed to identify sociolinguistic factors that can affect C-E choice, even though such methods can be computationally intensive (~12 hours for the current model). Compared to frequentist models (models with p-values), Bayesian methods have a similar output but offer a more intuitive interpretation in terms of probability and the capacity to comment on the absence of an effect (McElreath, 2020; Vasishth & Nicenboim, 2016).
The results of the Bayesian models can be understood through posterior draws (Bürkner, 2017). To determine which predictors are notable, I will use three statistical measures: probability of direction (pd), region of practical equivalence (ROPE), and Bayesian factor (BF). A predictor is said to affect the dependent variable if the median value is far from zero or if the credibility intervals do not include zero (MacKenzie, 2020; Makowski et al., 2019). pd will be used to evaluate the certainty of an effect. A higher pd (close to 1) indicates a higher confidence that a non-zero effect exists, while a lower pd suggests that the effect may not exist (Makowski et al., 2019). I will not only evaluate the existence of an effect but also assess its significance by referring to the percentage within the ROPE, as outlined by Kruschke and Liddell (2018). A value close to one indicates a minimal effect, while a value close to zero suggests a substantial effect. Furthermore, I will assess the BF of each predictor to evaluate the presence and significance of the effect. According to Makowski et al. (2019), a high BF (above 1) is evidence of a significant effect and a low BF (below 1) suggests an insignificant effect. In conclusion, I will use pd, ROPE, and BF to analyze the potential impact of internal and external language factors on language choice in a CS context.
Results and discussion
Evidence of variability
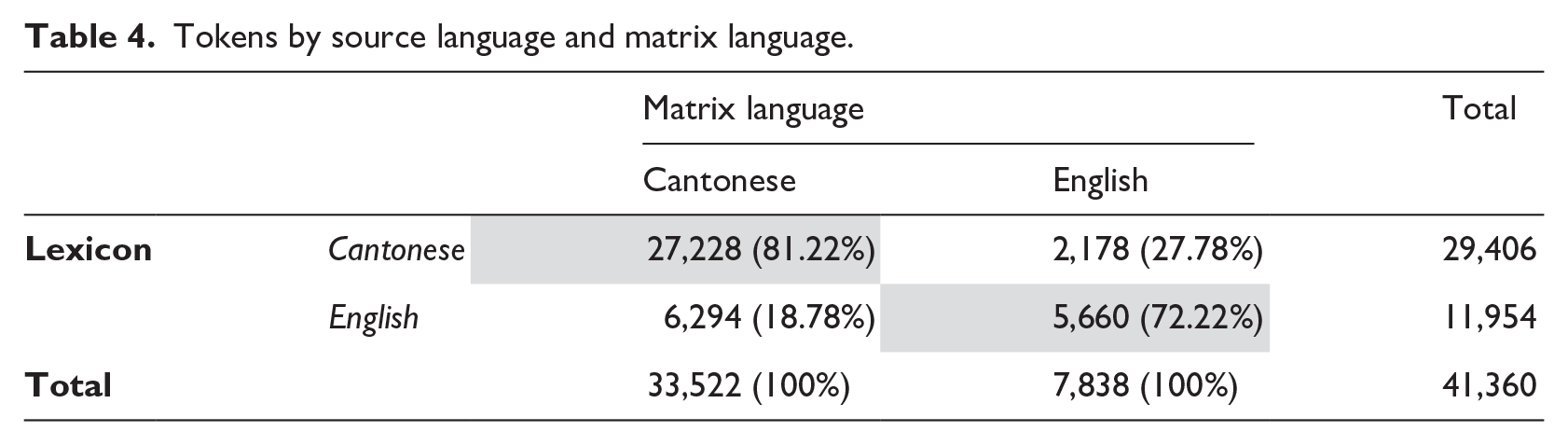
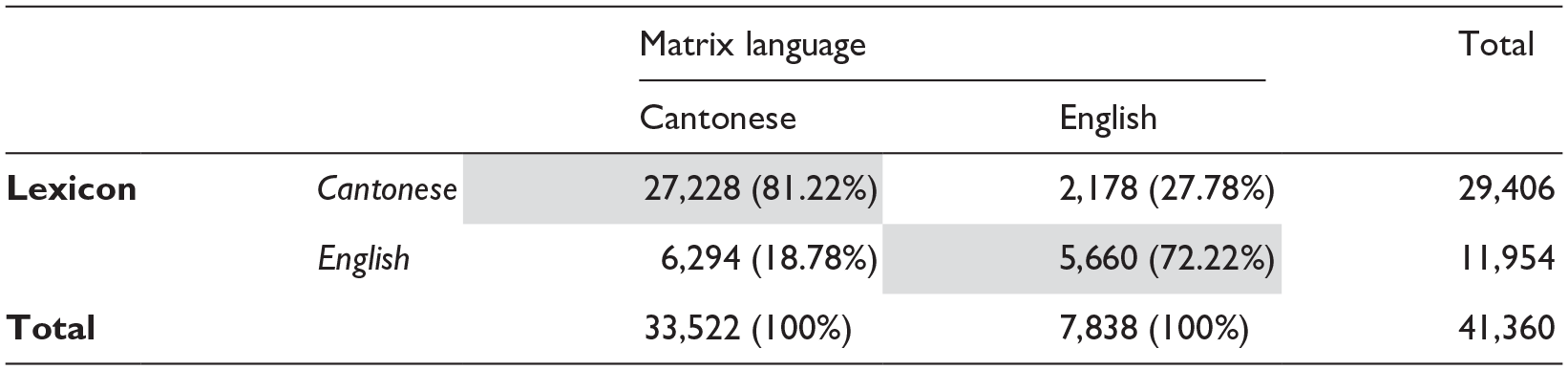
To perform regression analyses and create language models, it is crucial to have evidence of linguistic variability. By examining the breakdown of the tokens based on their source language and the language they are incorporated in (i.e., the matrix language), sufficient levels of variability can be observed in the data (Table 4). The majority of tokens in Cantonese utterances are in Cantonese, with some in English, whereas most of the tokens in English utterances are in English, with some in Cantonese.
Tokens by source language and matrix language.
Bayesian model
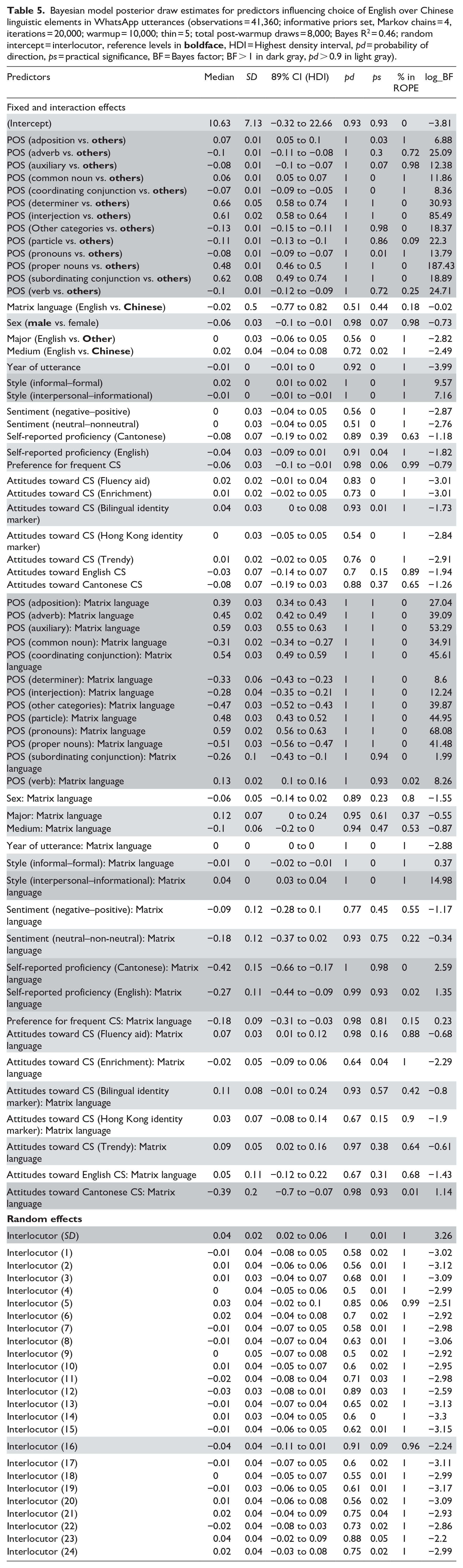
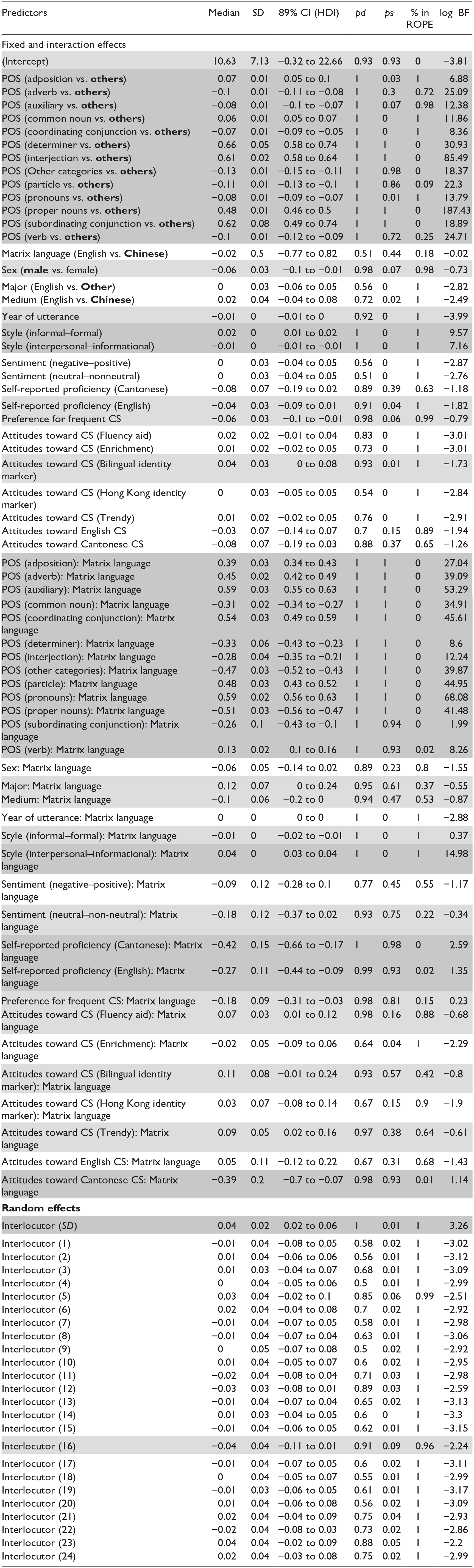
The Bayesian model employed to analyze the choice of English over Chinese linguistic elements provides valuable insights into the factors that influence such a choice. The findings are succinctly presented in Table 5. According to the model, nearly all the language-internal and language-external predictors that were incorporated into the analysis (45 out of 63 fixed and interaction effect factors, or 71% of all variables) contribute to one’s propensity to use English instead of Cantonese in intra-clausal Cantonese–English CS. The factors that are likely to positively/negatively influence C-E choice (highlighted in gray) have a very high likelihood of doing so (above 90%), and 32 of these language-internal and language-external factors are highly likely to significantly condition C-E choice (highlighted in dark gray).
Bayesian model posterior draw estimates for predictors influencing choice of English over Chinese linguistic elements in WhatsApp utterances (observations = 41,360; informative priors set, Markov chains = 4, iterations = 20,000; warmup = 10,000; thin = 5; total post-warmup draws = 8,000; Bayes R2 = 0.46; random intercept = interlocutor, reference levels in
Language-internal and external constraints on lexicon choice (general)
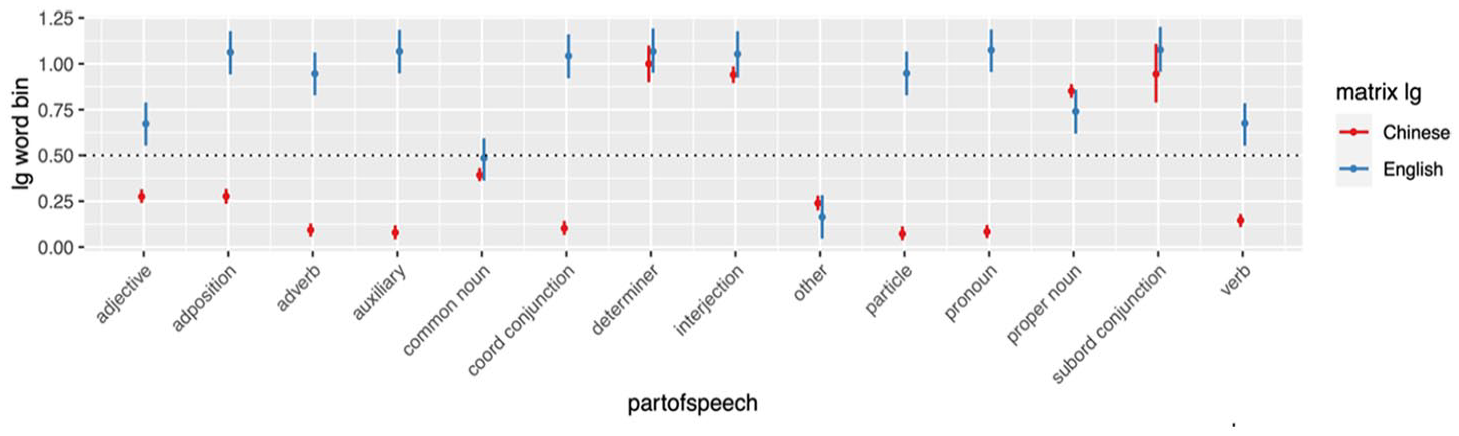
Several factors have been identified to affect C-E choice irrespective of the matrix language. One such set of factors is related to part-of-speech. All the parts-of-speech variables examined in the model appear to have a significant impact on Cantonese–English choice. English is clearly favored for subordinating conjunctions, proper nouns, interjections, determiners, and adpositions (Figure 1, Table 6). On the other hand, Cantonese tends to be used more for words with other parts of speech, such as adjectives, adverbs, common nouns, and verbs. For example, in (5), we see that English is favored for conjunctions like but, while 醬 jeung “sauce,” a common noun is expressed in Cantonese.
(5) but not enough 醬 “but not enough sauce” (CS002-367, Female, English major, EMI)
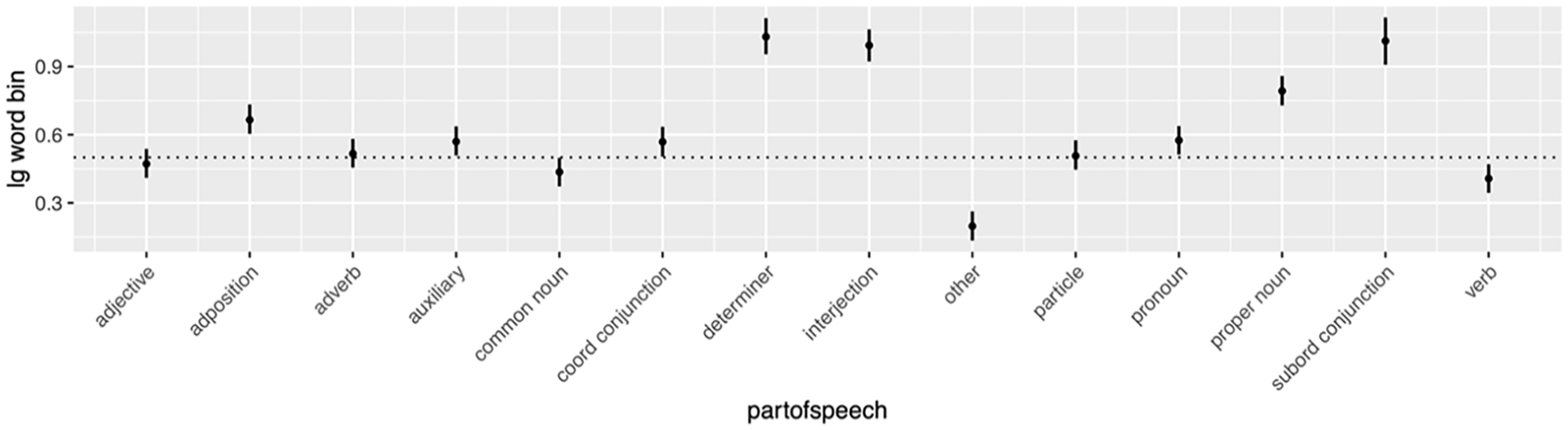
Marginal effects of part-of-speech on likelihood to use English lexicon over Chinese/Cantonese lexicon.
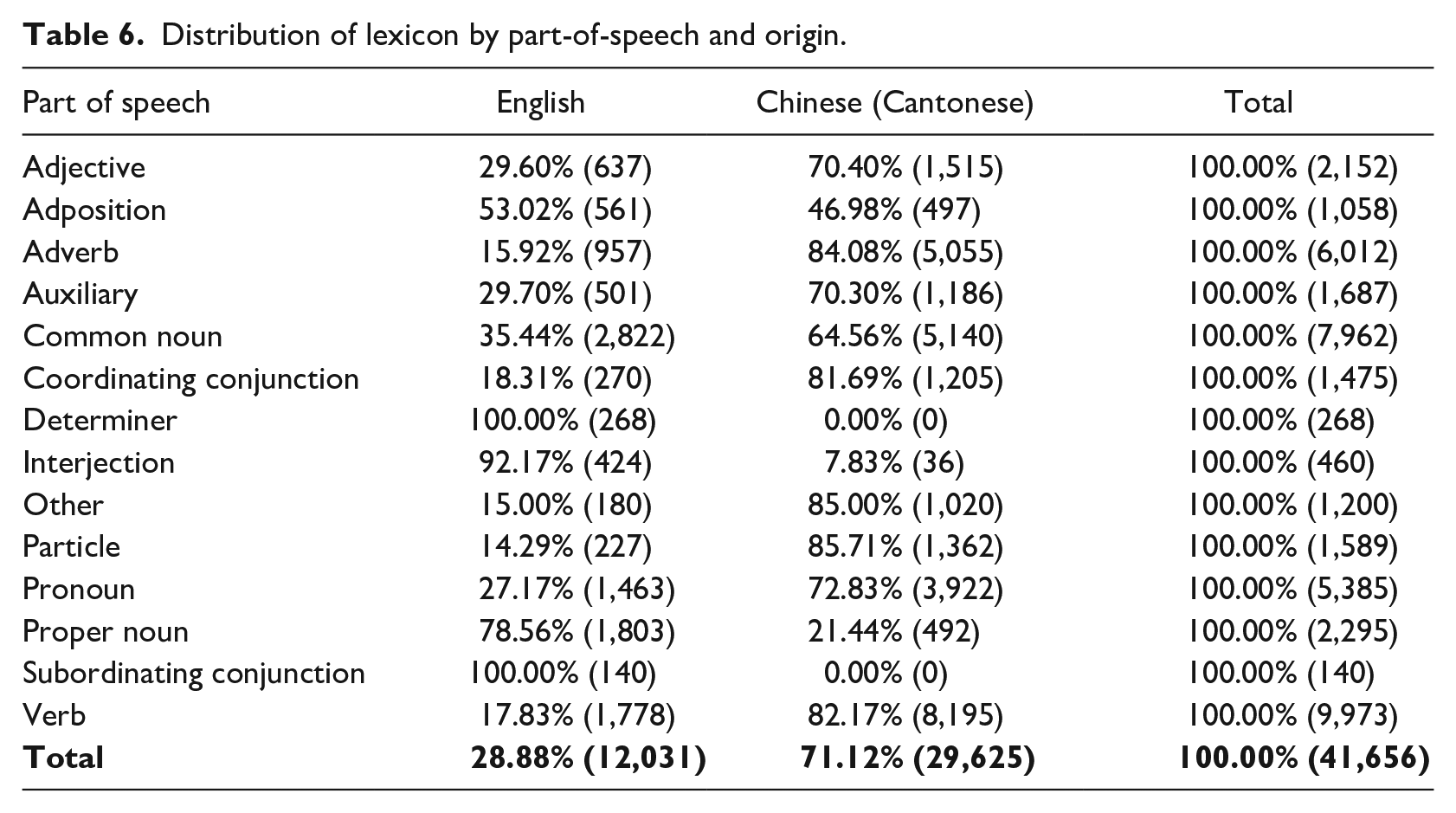
Distribution of lexicon by part-of-speech and origin.
Regardless of the matrix language, sex or gender appears to have some conditioning effect on C-E choice, in line with sociolinguistic theories of gender (Eckert, 1989). Those who identified as women tend to be more likely to incorporate the Cantonese lexicon into their utterances of intra-clausal CS compared to the English lexicon (Figure 2(a)). That is, in both Cantonese- and English-frame utterances, women tend to use more Cantonese than English. This finding appears to contradict the results of Gonzales and Tsang (2023) on Cantonese–English CS as well as Farida et al.’s (2018) study on Sindhi–English CS, where women were found to be more likely to use English lexicon than men. However, the focus of this study was specifically on intra-clausal CS, while the other two studies mentioned above looked at both intra- and inter-clausal types of CS. Because both studies draw from the same pool of data, we can conclude that female participants employ more Cantonese lexicon in intra-clausal CS but use less Cantonese in inter-clausal CS (i.e., they tend to use more English-exclusive utterances than Cantonese-exclusive utterances).
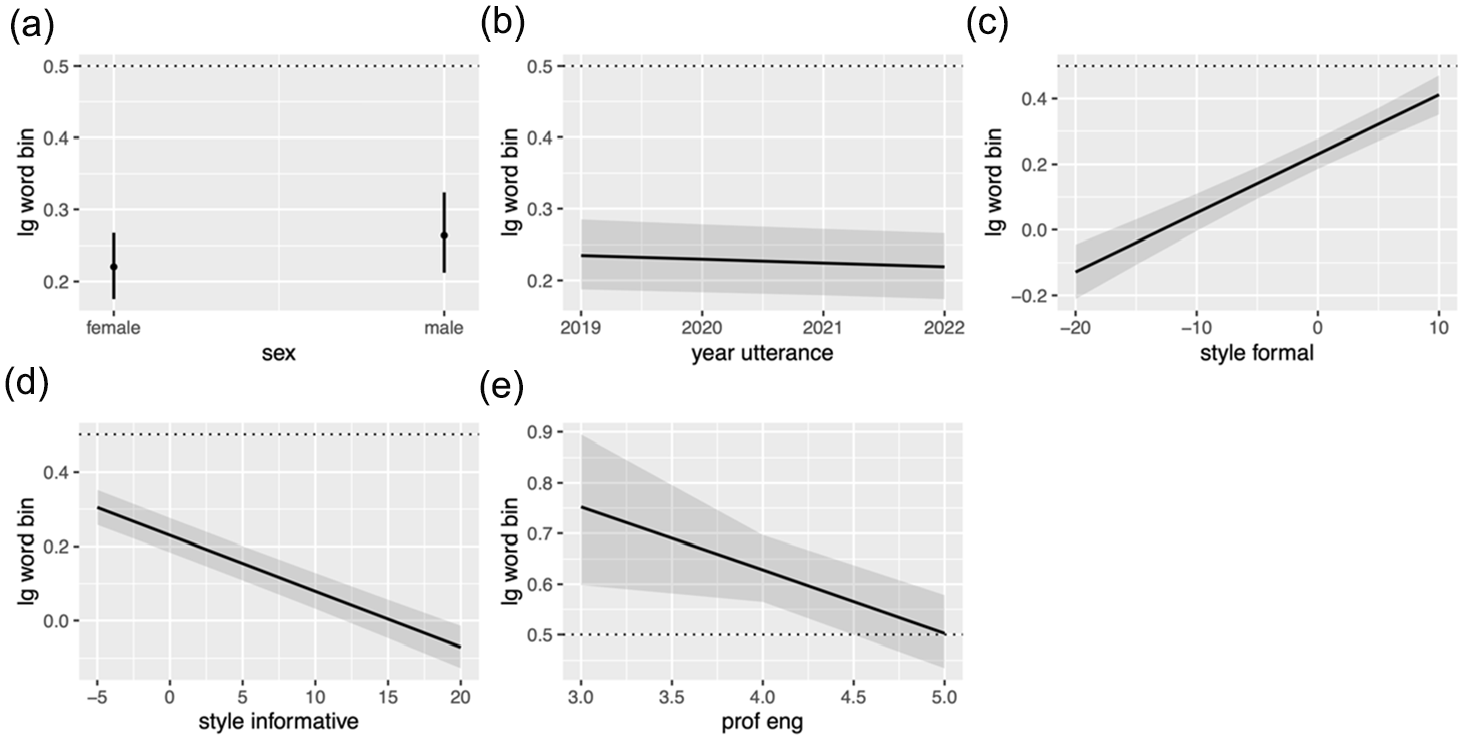
Marginal effects of language-external factors not involving attitude/sentiment on likelihood to use English lexicon over Chinese/Cantonese lexicon y-axis: 0 = more likely to use Cantonese lexicon, 1 = more likely to use English lexicon, x-axis: (a) sex, (b) year of utterance, (c) stylistic formality, (d) stylistic informationality (as opposed to interpersonal-ness and (e) self-reported proficiency in English.
In addition to sex, C-E choice is also conditioned by the year of utterance. From 2019 to 2022, there has been a slight but statistically significant decrease in the use of English words in Cantonese–English intra-clausal CS (Figure 2(b)). This suggests that a shift toward a Cantonese-dominated multilingual practice is currently underway.
Stylistic context and self-reported English proficiency have also been observed to have a strong influence on general CS patterns. Speakers tend to use more English for utterances stylized as formal and interpersonal, and more Cantonese for utterances stylized as informal and informational, regardless of the matrix language (Figure 2(c) and (d)).
Those who reported to be proficient in English were found to use fewer English elements for intra-clausal CS (Figure 2(e)). This outcome was surprising, as one would have expected increased English use in intra-clausal CS among these speakers. One possible reason for this pattern can be gleaned from the ethnographic work of Gonzales and Tsang (2023) on WhatsApp Cantonese–English CS, who found that proficiency in English tends to manifest as inter-clausal CS to English, rather than as intra-clausal English elements. This phenomenon could be understood through the social constructionist view, where my speakers tend not to use English words and phrases to demonstrate their English proficiency, but rather full English sentences (Gonzales & Tsang, 2023). Notably, this finding diverges from observations in other linguistic contexts, such as among English-proficient Turkish speakers in New York, who show a higher tendency for intra-clausal switching to English (Koban, 2013). Various factors, including the different social connotations or meanings associated with CS either between or within clauses, may account for this discrepancy. For instance, in New York, switching between clauses may signal or index a lower proficiency in English, while the opposite interpretation applies in the Hong Kong context. Overall, the findings suggest that proficiency-related social meanings attached to English resources at the word and phrasal level are different from those associated with English resources at the utterance level.
Language attitudes can act as a powerful driving force behind language choice and change. Among the fixed-effects factors that influence attitudes and sentiment toward CS, only attitudes toward CS as a marker of bilingual identity seem to have an impact on the likelihood of using English over Cantonese. People who utilize Cantonese–English CS as a way to demonstrate their bilingual identity tend to use English more frequently (and more consistently) than Cantonese (Figure 3). That is, those who consider CS as a tool to construct their bilingual identity appear to be utilizing more English resources than those who do not. Supplementary evidence from my ethnographic work in 2022 suggests that these participants use more English to “accentuate” their English repertoire and proficiency in English in a Cantonese-dominant society (Bolton et al., 2020).
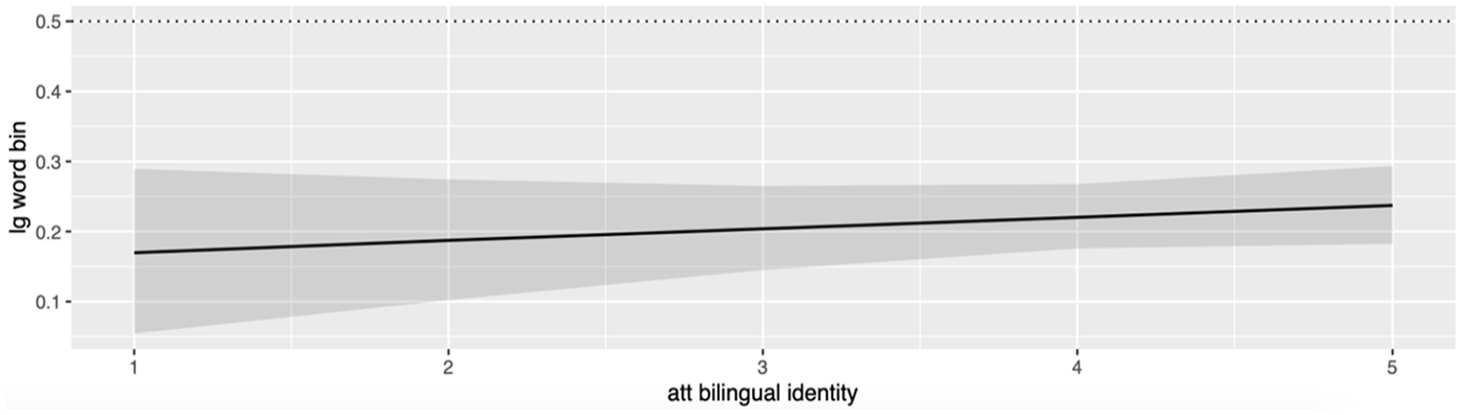
Marginal effects of attitudes toward Cantonese–English code-switching as bilingual identity marker on likelihood to use English lexicon over Chinese/Cantonese lexicon (0 = Cantonese, 1 = English).
Language-internal and external constraints on lexicon choice (by matrix language)
Up to this point, I have emphasized how sociolinguistic factors influence the use of English versus Cantonese, regardless of the dominant language. In this section, I will explore the significance of the matrix language by examining how it interacts with other factors in the model.
In the previous section, the part-of-speech of a word was found to be a strong predictor of whether English or Cantonese would be used. However, upon closer examination, it becomes clear that the effects of part-of-speech on the choice of language vary depending on the matrix language (Figure 4).
Marginal effects of part of speech on likelihood to use English lexicon over Chinese/Cantonese lexicon (by matrix language) (0 = Cantonese, 1 = English).
In cases where English is the matrix language, switches to Cantonese are more likely to involve proper nouns, common nouns (e.g., 機 gei “machine” in (6)), verbs (開 hoi “open” in (6)), and adjectives (舒服 syufuk “comfortable” in (7)). Among these, switches involving common nouns tend to be the most frequent in code-switches in utterances with an English matrix language frame.
(6) how can I how can 1.SG open machine “How can I turn on the machine?” (CS002-388, Female, English major, EMI) (7) so 唔
very NEG comfortable “I am very uncomfortable.” (CS002-417, Female, English major, EMI)
When Cantonese is the matrix language, switches to English are more likely to occur if the switch involves a determiner, an interjection (ahhhhhh in (8) and lolol in (9)), a proper noun (Blackboard in (10)), a subordinating conjunction, or a common noun. Words with other functions tend to be expressed in Cantonese (e.g., 好hou “very”).
(8) ahhhhhhh very struggle ahhhhhh ‘Ahhh. . . it’s such a struggle. Ahhh!’ (CS008-5376, Female, Non-English major, EMI) (9) 點解 可以 甘 basic 既 野 都 唔 知
why can such basic MOD thing also NEG know lolol “Why is such a basic thing also incomprehensible to me?” (CS014-5505, Female, English major, CMI) (10) 全部 都 係 經
all also COP pass Blackboard submit “Everything needs to be submitted through Blackboard.” (CS019-6791, Female, Non-English major, CMI)
The observed distribution supports Chan’s (1998, p. 193) findings regarding more frequent use of English in nouns and certain conjunctions in Cantonese-frame utterances, but not their finding of frequent English-sourced verbs and adjectives in Cantonese-dominant utterances. If the datasets are indeed comparable, the differences in patterns over time could indicate actual diachronic changes, with the part-of-speech domains that were previously dominated by English in Cantonese–English CS in the late 1990s now gradually being taken over by Cantonese in the early 2020s. It may also be the case that the differences in patterning between the datasets are reflective of stylistic differences between WhatsApp-style messaging and non-WhatsApp-style messaging.
The findings altogether indicate that the choice of matrix language plays an important role in Cantonese–English CS. While the part-of-speech of a word is a robust predictor of language choice, its effect is mediated by the matrix language. This underscores the importance of examining CS at a more fine-grained level to gain insights into the complexities of localized multilingual practices. The reasons why the distribution of English and Cantonese elements in CS varies based on the matrix language remain unclear in this study due to methodological limitations. However, there could be several factors that influence this variability, such as the need to fill lexical, semantic, or functional gaps in the matrix language or the conscious intention to enhance its grammar.
Apart from part-of-speech, there are additional factors whose effects on English–Cantonese lexicon choice depend on the matrix language. They include college major, secondary school’s medium of instruction, stylistic context, and language proficiency. For instance, the effect of college major on lexical choice is much more salient in English matrix clauses (blue, Figure 5(a)) compared to Cantonese matrix languages (red, Figure 5(a)). Those who report being English majors, use more English (less Cantonese) than non-English majors when they converse using English-dominant utterances. However, when conversing in Cantonese-dominant utterances, their use of English patterns is similar to that of non-English majors.
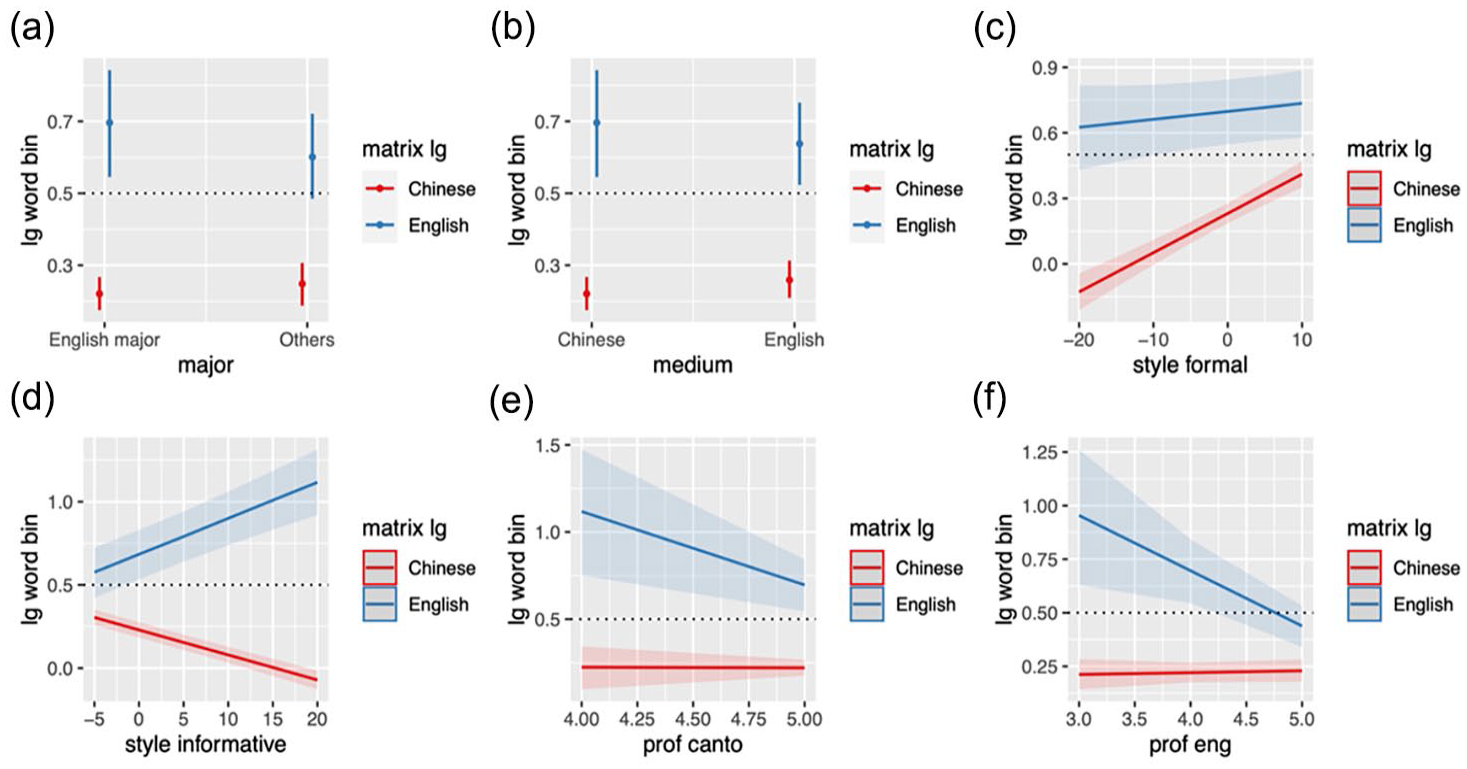
Marginal effects of language-external factors not involving attitude/sentiment on likelihood to use English lexicon over Chinese/Cantonese lexicon (by matrix language) y-axis: 0 = more likely to use Cantonese lexicon, 1 = more likely to use English lexicon, x-axis: (a) user major of study, (b) user’s school’s medium of instruction, (c) stylistic formality, (d) stylistic informationality (as opposed to interpersonal-ness, (e) self-reported proficiency in Cantonese and (f) self-reported proficiency in English.
Another interesting finding was that the impact of stylistic formality on C-E choice (i.e., increased formality, increased use of English) is more salient in Cantonese-matrix utterances than in English-matrix utterances (Figure 5(c)). My results showcase an interesting situation where the “formality” meaning attached to English use has higher levels of activation in particular situations (e.g., use of Cantonese-dominant utterances) compared to others.
My analysis also reveals that while stylistic informationality typically reduces the likelihood of CS to English (as explained in the “Language-internal and external constraints on lexicon choice (by matrix language)” section), people tend to incorporate more English in English-matrix utterances when these are styled as “informational,” but use less English in Cantonese-matrix utterances with similar styles (Figure 5(d)). This suggests that when code-switching, the use of English words can convey different social meanings depending on the dominant language. For example, in utterances with a Chinese base, English is associated with the “interpersonal” meaning (i.e., the “interpersonal” meaning is highly activated), while in those with an English base, English is linked to the “informational” meaning (i.e., the “informational” meaning is highly activated).
The findings related to style, particularly situation-dependent social meanings, provide some support for Eckert’s (2008, p. 453) notion of the indexical field, where in a constellation of possible social meanings of a variable, any meaning can be “activated in the situated use of the variable.”
My findings also indicate that an individual’s self-reported proficiency in Cantonese and English influences their tendency to use English instead of Cantonese, but this only applies to utterances where English serves as the matrix language (Figure 5(e) and (f)). Those who report higher levels of proficiency in both Cantonese and English are less likely to use English in English-matrix utterances (i.e., they are more likely to code-switch to Cantonese). However, the proportion of English and Cantonese elements in Cantonese-matrix utterances does not appear to be conditioned by linguistic proficiency in Cantonese and English.
Factors related to sentiment or affect condition C-E choice differently depending on the matrix language (Figure 6(a)). In English-dominant utterances, speakers whose utterances have a stronger affect (i.e., positive or negative) tend to use less English and more Cantonese. Under constructivist lenses, speakers seem to be switching from English to Cantonese to increase the intensity of their utterances. The same effect cannot be observed in Cantonese-dominant utterances. Although the use of English slightly increases in situations that require stronger affect, the effect is not as large as the one found in English-dominant clauses. Regardless, the fact that there are effects in both types of utterances nonetheless shows that, in the Cantonese-English mixing practice, the use of more than one language in a single utterance functions as a resource for speakers to convey their intended meaning with greater nuance and emotional depth.
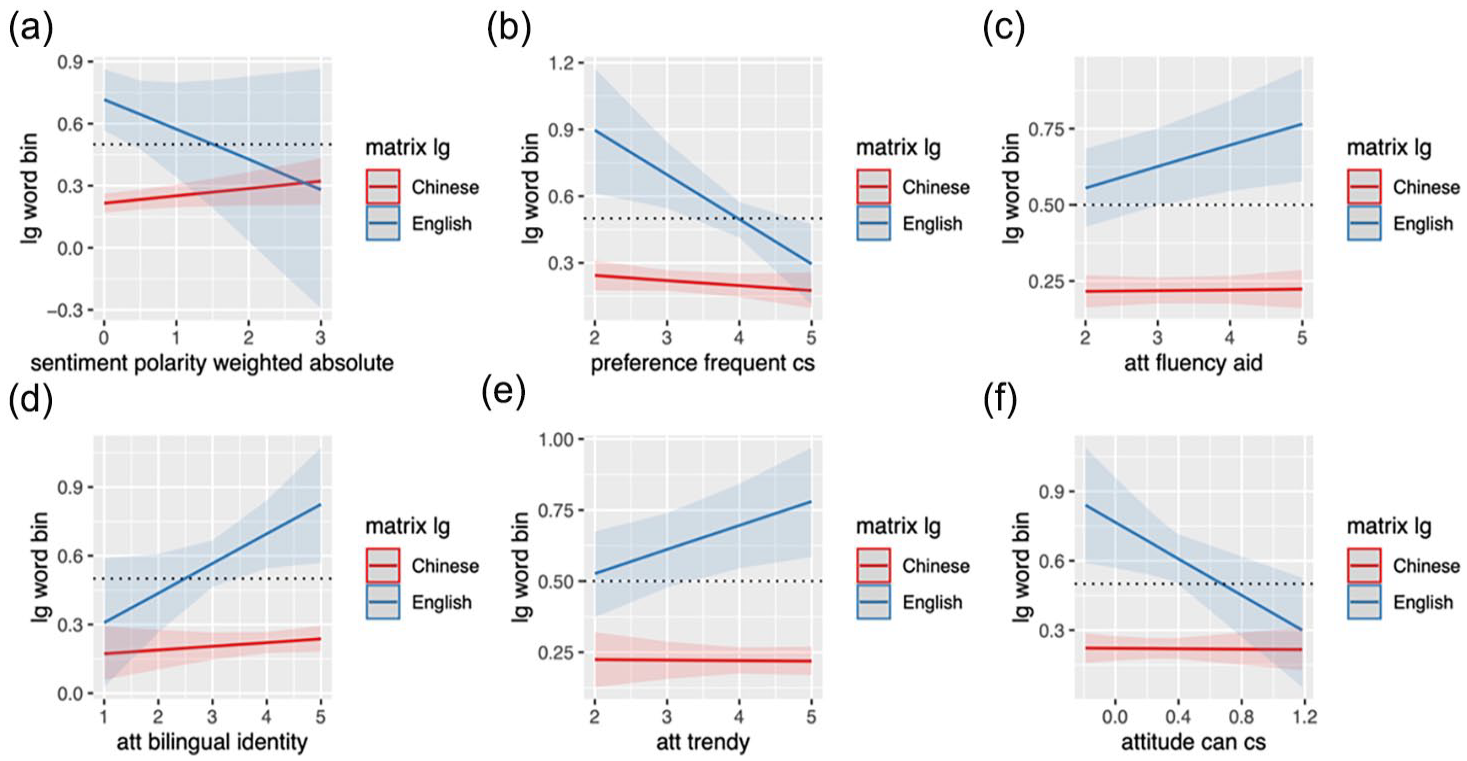
Marginal effects of language-external factors involving attitude/sentiment on likelihood to use English lexicon over Chinese/Cantonese lexicon by matrix language) (y-axis: 0 = more likely to use Cantonese lexicon, 1 = more likely to use English lexicon, x-axis: (a) weighted absolute sentiment polarity, (b) self-reported preference for frequent code-switching, (c) attitudes: CS aids fluency, (d) attitudes: CS indexes bilingual identity, (e) attitudes: CS is trendy and (f) attitudes: code-switching to Cantonese from English.
Attitudes toward CS also condition language mixing patterns, but the effects only seem to be salient in English-matrix utterances. For example, those who have positive attitudes toward Cantonese tend to use less English and more Cantonese in English-matrix clauses (Figure 6(f)). However, positive attitudes toward mixing do not necessarily always lead to actual mixing. Contradictory to my expectations, speakers who possess positive attitudes toward CS (i.e., CS as a tool to aid fluency, to project bilingual identity, to sound “trendy”) tend to use less Cantonese and more English in English-dominant clauses, and those who have negative attitudes use more Cantonese lexicon in English-matrix utterances (Figure 6(c) to (e)). While unexpected, the patterns are not unprecedented, as similar mismatches have been observed in other linguistic phenomena. For example, many speakers of a mixed language called Lánnang-uè in the Philippines tend to think of Lánnang-uè as broken and unsystematic but still use it in a systematic manner (Gonzales, 2018, 2024b; Gonzales et al., 2022). The same goes for many users of “Hong Kong English” or Cantonese-influenced English, who have been found to exhibit a similar behavior of “linguistic schizophrenia,” where they would criticize the use of their English but use it robustly in communication (Groves, 2011, p. 33).
Individual-related constraints on lexicon choice
Individual factors also constrain the choice between English and Cantonese lexicons though not as much as the other factors mentioned. As Figure 7 shows, some speakers use more English than Cantonese, while others have more preference for Cantonese over English. Nevertheless, the individual distinctions are generally insignificant, apart from CS012, who appears to have a strong inclination for the Cantonese lexicon more than the other participants. Apart from this speaker, the patterns of each participant are nearly identical, indicating some evidence for the stability of the linguistic mixing practice in this group, at least on WhatsApp.
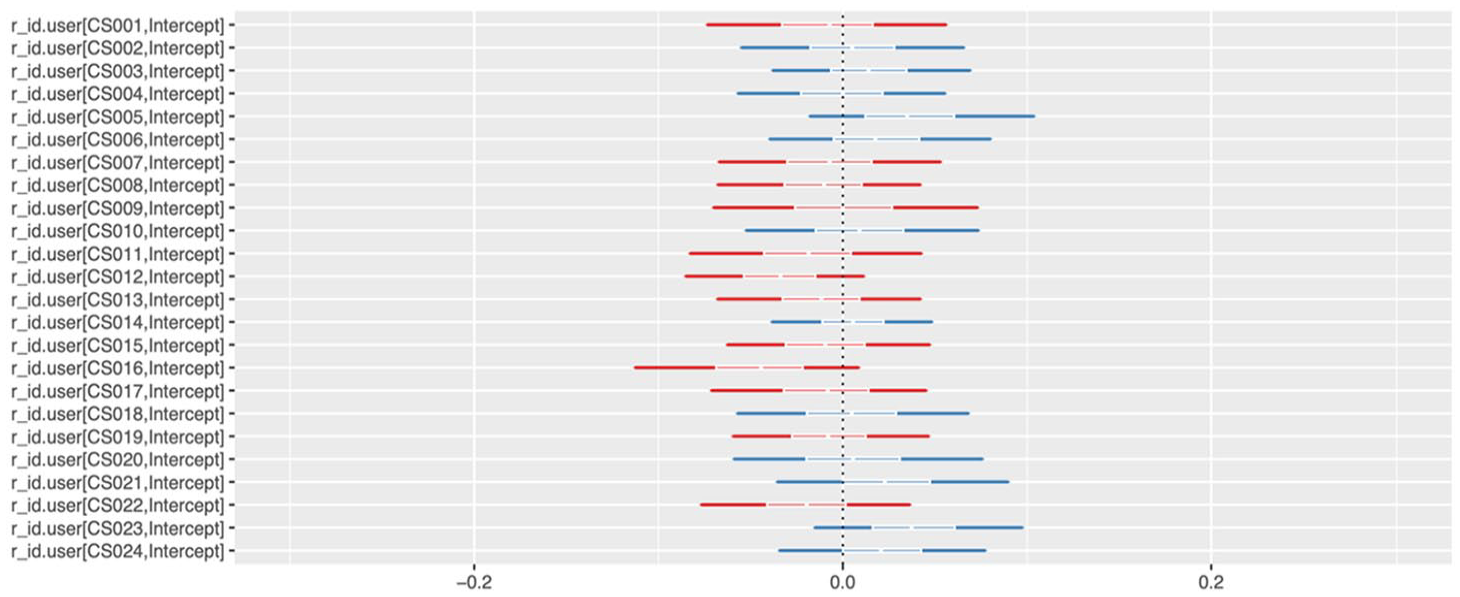
Random intercepts by interlocutor (red = more Chinese/Cantonese lexicon, blue = more English lexicon) (0 = Cantonese, 1 = English).
Model predictions and accuracy
A model is only as good as the predictions it makes. I used my model of C-E choice discussed earlier to predict Cantonese–English lexical choice using the “test” dataset set aside earlier—a dataset that my model has not “seen.” The model was able to accurately predict the outcome (i.e., English, Cantonese lexicon) roughly 85% of the time (Table 7), with a confidence interval of 84.02% to 85.42%. This is a significant improvement from the chance baseline of 50%. The accuracy was also significantly higher than the no information rate (NIR) of 71.5% (p < .0001), which is the accuracy of a model without any of the factors discussed included. The performance of our model and the baseline model is not equal (McNemar’s test p < .0001). The correlation between actual responses and predicted responses is significant (ρ
Cantonese–English lexicon use model accuracy—confusion matrix (n = 10,340 unobserved tokens).
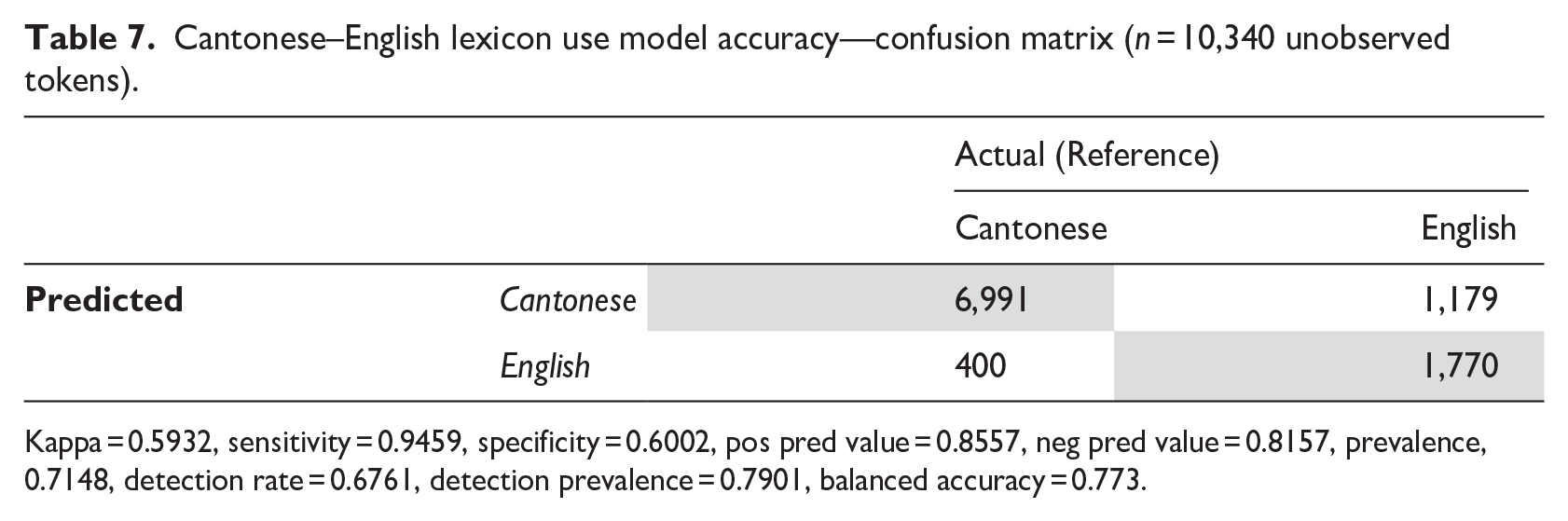

Kappa = 0.5932, sensitivity = 0.9459, specificity = 0.6002, pos pred value = 0.8557, neg pred value = 0.8157, prevalence, 0.7148, detection rate = 0.6761, detection prevalence = 0.7901, balanced accuracy = 0.773.
Upon scrutinizing the errors using the confusion matrix (Table 7), it becomes evident that the model exhibits a greater inclination to misclassify English tokens as Cantonese tokens rather than misclassifying Cantonese tokens as English. This may stem from the fact that the training data disproportionately represents certain linguistic patterns or contexts more prevalent in Cantonese usage, leading the model to be more sensitive to features characteristic of Cantonese. In addition, structural similarities between Cantonese and English may contribute to the model’s tendency to more readily classify English tokens as Cantonese.
There were some obvious factors that should have been included in the model, such as deliberate choice, function, word lexeme, and linguistic context. However, these were not included in the interest of focus and the inability to automatically derive these variables for all 51,700 utterances. Although these factors could not be incorporated into the present model, the analysis nonetheless achieved relatively high accuracy, suggesting the potential for a computationally efficient approach that remains accessible to researchers with limited resources. This highlights the broader implications for developing models that balance computational efficiency with predictive power. Future research may explore strategies for integrating these additional variables, allowing for further refinement of accuracy while considering the trade-offs between parsimony and computational accessibility.
Conclusion
This paper seeks to create a supervised predictive model of Hong Kong Cantonese–English CS based upon both social and linguistic factors, taking into account that such hybrid practices are often rooted in social motivations (Thomason, 2007, 2010). The objectives of the study are two-fold. First, I intend to conduct a comprehensive examination of CS patterns using variables that have been studied in Gonzales and Tsang’s (2023) paper (e.g., sex, major) and variables that have not been explored before, some of which can be acquired computationally (e.g., style, sentiment). Furthermore, I hope to identify which of these factors can be used to reliably predict C-E choice, especially in an online environment. Then, utilizing these results, I evaluate how accurately a model informed by this analysis can forecast C-E choice in the context of digital CS. My analysis of Gonzales and Tsang’s (2023) dataset revealed some noteworthy findings:
Part-of-speech and stylistic context (i.e., interpersonal–informational, informal–formal) strongly condition C-E choice regardless of the matrix language. Other factors such as sex, year, self-reported proficiency in English, and attitudes toward CS as a marker of bilingual identity have been found to also condition this choice, but to a noticeably lower extent.
Matrix language interacts with many sociolinguistic factors to condition C-E choice. The effect of part-of-speech, style, self-reported proficiency in English and Cantonese as well as attitudes toward switching to Cantonese (among other factors) are strongly dependent on the matrix language.
Multilingual lexicon and resources can have dynamic meaning and functions, depending on their situated use. For example, switches from Cantonese to English signal “interpersonality,” whereas the maintenance of English in English-matrix clauses index “informationality.” Switches to Cantonese from English allow speakers to convey their intended meaning with greater nuance and emotional depth.
Individual factors or constraints have less of an impact than intra-linguistic or extra-linguistic factors (such as part-of-speech or style) when it comes to Cantonese–English mixing, suggesting a level of uniformity within the speech community.
Positive attitudes toward mixing and reported preference for frequent mixing do not necessarily correlate to (or perhaps, lead to) higher rates of mixing. Like the case of Lánnang-uè (Gonzales, 2022), language attitudes and verbal preferences do not have to align with actual practice.
While there is a significant amount of research on Cantonese–English code-mixing, there remains a considerable gap in understanding the specific patterns of language mixing in the area and the comprehensive set of sociolinguistic conventions that dictate these patterns. A notable shortfall of the current model is its disregard for the word lexeme; it does not control for or address the propensity for Cantonese or English to be used for specific words/lexemes. Future research could aim to integrate lexeme information into the model to explore if it enhances the model’s effectiveness. The extensive body of sociolinguistic research, especially on lexical variation, supports the likelihood of such an enhancement (Eisenstein et al., 2010; Grieve et al., 2019).
Despite these challenges, this study hopes to contribute to our understanding of bilingualism by an innovative, relatively parsimonious, and computationally accessible approach that enables a detailed exploration of the factors influencing this particular code-mixing behavior in Hong Kong. This research places a focus on variables previously underexplored in the literature. This paper stands out from other studies due to its utilization of a novel CMC dataset and its investigation of sociolinguistic variables (e.g., part-of-speech, style, sentiment) that have not been explicitly reported by participants but are instead computationally inferred from the linguistic context. Furthermore, in contrast to much of the existing research, I have considered the effect of individual differences on top of dialectal or sociolectal disparities. Finally, this paper has the advantage of employing Bayesian statistical and computational techniques to expand our understanding of sociolinguistic variability in the region, which has the benefit of providing more robust probabilistic inferences, accommodating uncertainty, and allowing for the integration of prior knowledge in modeling linguistic variation. My ultimate goal is to highlight a new facet of Cantonese–English CS or translanguaging, while simultaneously strengthening the current body of research on code-mixing in Hong Kong and the broader East Asian region.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: I am grateful for the support provided for this sub-project by the Chinese University of Hong Kong as part of the larger funded project “Examining the socio-indexical meaning of written language among individuals with neurodivergence” (Project code: #4051270), which was also supported by the University.