
Abstract
Aim and objective:
This paper investigates the language independence and speaker-specificity of the nasal consonants /m/ and /n/ in multilingual speakers. The research aims to determine how these nasal sounds manifest across different languages and whether their spectral properties − specifically the centre of gravity (COG) and standard deviation (SD) − remain consistent within individual speakers regardless of the language spoken.
Methodology:
Data were collected through studio recordings of read speech from nine young, balanced bilingual speakers with Catalan and Spanish as their first languages and a proficient level of English as an additional language.
Data and analysis:
Statistical analyses were conducted to compare the COG and SD values across languages and speakers, with the aim of measuring both within-speaker and between-speaker variability and within-speaker and between-language variability.
Findings:
The findings support the hypothesis that the spectral properties of /m/ and /n/ remain stable across the three languages, demonstrating low within-speaker variability. Moreover, the results confirm the speaker-specificity of these traits, as they exhibit greater variability between different speakers than within the same speaker. Consequently, these results suggest that nasal consonants are speaker-specific across multiple languages.
Originality:
This study provides further evidence supporting the speaker-specificity of nasal consonants in multilingual speakers. Although research areas such as forensic linguistics have examined within- and between-speaker variability in various sounds, including nasals, research remains scarce involving multilingual speakers.
Implications:
The research advances the fields of phonetics and multilingualism by enhancing our understanding of how linguistic and indexical information interconnect across different languages.
Keywords
Introduction
Whenever a speaker speaks, their message conveys two main types of information. On the one hand, linguistic information refers to what is said regarding its meaning and linguistic characteristics (grammar, syntax, pragmatics, etc.). At the same time, a speaker’s utterance also conveys indexical information, which relates to characteristics of the speaker, such as their origin, gender, or even transitory states like being ill or being nervous (Bradlow et al., 2018; Dellwo et al., 2007; Hughes et al., 2023). Such speaker-specific information, which makes it possible for listeners to recognise individuals with whom they are familiar, is sometimes complex to define since it is not usually the result of a single category but a series of acoustic, anatomical, and linguistic traits that intertwine with each other (Dellwo et al., 2007). Traditionally, phoneticians have divided such speaker-specific characteristics into two categories: organic, which are related to the speaker’s physical and anatomical characteristics and constraints, and learned, which are related to the acquired patterns that depend on the speaker’s linguistic environment (e.g., Garvin & Ladefoged, 1963; Wolf, 1972). However, this dichotomy fails to account for the complexity behind individuality in language, in that these two sources are not ‘discretely different dimensions of variation in the speech signal’ (Nolan, 1997, p. 748). Thus, speakers can vary in several dimensions simultaneously, and some of these dimensions depend on one another. For example, speaker-specificity can be encoded in vowel formants, which rely on sociolinguistic factors such as place of origin, gender, or age, but, at the same time, the acoustic properties of vowel formants also depend on the physiological characteristics of the speaker’s larynx and vocal tract (Dellwo et al., 2007).
Moreover, indexicality is not only present in static acoustic properties such as vowel formants or fricative spectra but also in dynamic traits derived from coarticulation and overlapping of phonetic gestures, what Nolan (1997) calls the phonetic implementation of the physical and linguistic mechanisms. Consequently, speakers vary between each other in many different segmental and suprasegmental properties such as vowels, consonants, fundamental frequency, voice quality, intonation, rhythm, pauses, and other disfluencies, to name a few (see Hughes et al., 2023, for a summary of the main speaker-specific traits that can vary between speakers). At the same time, it is also undeniable that speakers may also show differences in the different linguistic productions they generate – that is, intra-speaker variability − that may be subject to various factors, such as style-shifting (e.g., Labov, 1972), change over time (e.g., Bowie, 2010; Harrington, 2007), or even temporary states such as being stressed, anxious, angry, or scared (e.g., Boss, 1996; Braun, 1995; Nolan, 2005).
Most existing literature on speaker-specific traits has been carried out in monolingual speakers. Not much is known about how indexical information intertwines in the different languages a speaker may speak (Mok et al., 2015). As Bradlow et al. (2018) explain, in the case of monolingual speakers, both linguistic and indexical information are linked to the different acoustic dimensions of the speech signal. Still, in bilingual and multilingual speakers, where different linguistic systems interact and are actively controlled, such a relationship becomes very complex. More research is needed on the relationship between indexical information in the different languages spoken by an individual and whether speaker-specific traits can be independent of the languages spoken by a single speaker.
Specificity in multilingual speakers
Some recent studies with bilingual speakers suggest that certain phonetic behaviours in the first language (L1) can successfully predict the behaviour of the same speakers in their second language (L2). For example, Bradlow et al. (2017) explored the speaking rate of individuals with diverse language backgrounds conversing in both their L1 and L2. They identified a notable positive correlation between the speaking rates in both languages, a relationship not attributable to proficiency differences, as this aspect was controlled for in their study. Similarly, findings from Derwing et al. (2009) and de Jong and Mora (2019) also suggest a link between fluency in L1 and L2 within the same speakers, especially when it comes to the duration of pauses. Furthermore, Bradlow et al. (2018) reported a positive connection between intelligibility in L1 and L2 among Mandarin-English and Korean-English bilinguals. The authors in this last study posited that an idiosyncratic element exists in speech extending beyond the linguistic diversity a speaker may exhibit, indicating that speaker-specificity may not be solely determined by language. According to their view, speaker-specific traits in bilingual contexts may interact with language-related or proficiency-related factors, rather than being solely determined by them (Bradlow et al., 2018, p. 17).
In defining speaker-specific traits, the field of forensic phonetics – focused on identifying phonetic and linguistic features that distinguish individuals – can offer valuable insights for other areas of linguistics, such as sociophonetics, speech technology, second language acquisition, and clinical phonetics. Yet, finding phonetic traits that go beyond the particular phonological inventories and phonetic implementations specific to each language is undoubtedly challenging. Moreover, the ethical code of the leading forensic phoneticians association warns experts of conducting forensic speech work with samples involving different languages (International Association for Forensic Phonetics and Acoustics, 2020, section 3.10). Still, forensic contexts involving multilingual or multidialectal situations are increasingly common (Rose, 2003, p. 103), and in many countries, such as Germany or the United Kingdom, speaker-recognition cases may often involve speech material in more than one language (Künzel, 2013; Lo, 2021). Therefore, even with these drawbacks, a section of forensic phonetic research has recently focused on finding speaker-specific traits in cross-linguistic comparisons and has successfully found indexical traits − both segmental and suprasegmental − that seem to be language-independent. Research shows that parameters related to voice variability, such as voice spectra, long-term formants (LTF), and long-term average speech spectra, can be speaker-specific in cross-language situations (Cho & Munro, 2017; Heeren et al., 2014; Johnson et al., 2020). On the other hand, fundamental frequency (F0) seems to be a complex feature that depends on the group of speakers analysed since even if some studies point to speaker-specificity that is language-independent (e.g., Marquina, 2012, 2016; Roseano et al., 2015), the majority of studies suggest that speakers show variations in F0 depending on the language (Altenberg & Ferrand, 2006; Bruyninckx et al., 1994; Cheng, 2020; Harmegnies et al., 1991; Lee & Van Lancker Sidtis, 2017; Mennen et al., 2012; Nevo et al., 2015; Ng et al., 2012; Schwab & Goldman, 2016). Other features related to suprasegmental characteristics that have been studied from a multilingual perspective are rhythmic measures (Dellwo & Schmid, 2016) and hesitation behaviour (de Boer & Heeren, 2020; Kolly et al., 2015; Lo, 2020; Tomić, 2017; Wong & Papp, 2017). Most of the results point to a certain degree of stability that can be seen in many (though often not all) research subjects.
Research on segmental features, the type of feature explored in this study, is still quite inconsistent. Marquina (2016) investigated various vocalic and consonantal parameters in bilingual speakers of Catalan and Spanish, concluding that the formants of lateral /l/, the voice onset time (VOT) of /k/, the vowel formants of /a/, and the spectral characteristics of /s/, including its peak of maximum intensity, exhibit idiosyncrasies irrespective of the language spoken. Johnson (2021) found that Cantonese–English bilinguals show speaker-specific patterns in voice onset time (VOT), although these patterns do not consistently transfer across languages, indicating that VOT is shaped both by individual habits and language-specific phonetic norms. In the case of /s/, several studies likewise suggest that its spectral properties may not be as stable across different populations (de Boer & Heeren, 2025; Kitikanan et al., 2015; Lo, 2021; Quené et al., 2017). Yet, nasal consonants have yielded more consistent results in studies involving bilingual speakers, as explained in the following section.
Nasal consonants
Nasal consonants have proved to be speaker-specific in monolingual speakers, as they show relatively high between-speaker variability and low within-speaker variability (Amino & Arai, 2009; Amino et al., 2006; Kavanagh, 2012, 2013; Schindler & Draxler, 2013; Tabain et al., 2016). On the one hand, the relatively rigid nasal cavity – compared to the oral cavity – results in low within-speaker variability (Nolan, 1997; Rose, 2003). On the other hand, between-speaker variability derives from different anatomical features in the nasal cavities of various speakers and differences in the timing of opening and closing the velopharyngeal port (Rose, 2003; Stevens, 1998). Moreover, Su et al. (1974) and, more recently, Smorenburg and Heeren (2021) suggest that there is speaker-specificity in the coarticulation of nasal sounds with the following vowel. Such variability is particularly evident for the bilabial nasal /m/ in comparison with the alveolar /n/ because, at the time of the bilabial closure for /m/, the tongue does not have a clear target in the oral cavity. This leaves more room for acoustic differences derived from the tongue’s position in the oral cavity, which may depend on the following sound and the speaker’s preferences. In contrast, an alveolar nasal articulation involves a clear alveolar target for the tongue, so the tongue cannot anticipate the following sound or adopt different positions. However, this articulatory difference interacts with syllable position, as Smorenburg and Heeren (2021) found in their study with L1 Dutch speakers. Results from that study showed that, generally, /m/ was more speaker-specific than /n/ in onset position, whereas /n/ outperformed /m/ in coda position. The authors argue that the better performance of /m/ in onset position can be explained by the freer position of the tongue, as described above, whereas the better performance of /n/ in coda position is in line with previous studies that show that weaker parts of speech, such as codas, can be prone to more between-speaker variability (cf. He et al., 2019).
To the authors’ knowledge, the only study that has looked at nasal consonants in bilingual speakers is by de Boer and Heeren (2023), who analysed the first four formants and their bandwidths of /m/ in 53 L1 Dutch-L2 English female speakers. They found that, even if some speakers showed more within-speaker variability than others, in such cases, such variability fell ‘within the range that is expected for that speaker even within one language’ (de Boer & Heeren, 2023, p. 2174). Therefore, the sound /m/ seems to remain stable in L1 Dutch–L2 English speakers, although it might be affected by the preceding and following phonetic context, confirming previous research that states that /m/ is particularly prone to coarticulation (Su et al., 1974) and especially affected by surrounding back segments (Smorenburg & Heeren, 2021). Yet, the effect of back segments on /m/ is still unclear, since Smorenburg and Heeren (2021) report a lowering effect on nasal formants and bandwidths, while de Boer and Heeren (2023) found a heightening effect. The authors hypothesise that such a discrepancy may be related to different methodological designs − the first study was conducted with telephone filtering, whereas the second one had studio recordings − and differences in the task. Moreover, they also suggest that there might be other confounding variables that affect nasals which were not controlled, for example, lip rounding, and the fact that silent pauses were included in the non-back category, but may have impacted the nasal sound differently than actual non-back segments. Finally, the authors claim that given that /m/ occurs in similar positions in both languages studied (Dutch and English), it is not possible to generalise these findings to other language combinations, which could involve more different surrounding contexts.
Objectives and hypotheses
As shown in the previous section, the current literature suggests that nasal consonants seem to be speaker-specific not only in monolingual contexts but also in bilingual contexts, although more research on bilingual/multilingual speakers is needed. This study is an exploration of the language-dependency and the speaker-specificity of the acoustic traits − the first two spectral moments, centre of gravity (COG), and standard deviation (SD), as explained below − of the two nasal consonants /n/ and /m/ in multilingual speakers of Spanish and Catalan as L1 (they are balanced bilinguals) who speak English as an additional language (AL) 1 with a proficient level. These two sounds are assumed to show a high degree of articulatory similarity in the three languages involved in this study − Spanish, Catalan, and English − as /m/ is produced as a bilabial sound, and /n/ is produced as an apical alveolar sound in the three languages (Dart, 1998; Martínez Celdrán, 1996; Recasens, 2010). Given this articulatory similarity, and consistent with cross-linguistic evidence on L1 transfer in segmental production (e.g., Best & Tyler, 2007; Flege, 1995), speakers are expected to produce /m/ and /n/ in their AL in much the same way as in their L1s, with little or no adaptation. Two main hypotheses are formulated:
H1. The spectral properties of the sounds /m/ and /n/ will remain stable across the three languages spoken by the speakers in the corpus. This hypothesis is based on the low within-speaker variability of nasal consonants in the first language (L1) and the unlikelihood of speakers significantly altering these sounds in their additional languages (AL). Consequently, the factor Language should not reveal statistically significant differences when samples are compared within the same speaker.
H2. The spectral properties of the sounds /m/ and /n/ will show greater variability between samples produced by different speakers than between samples produced by the same speaker. This expectation is based on the high variability of nasal consonants in the first language (L1) and the improbability of significant alterations to these sounds in their AL. Consequently, the factor Speaker should exhibit statistically significant differences when comparing samples across different speakers.
Method
Corpus of study
The corpus of study comprises read speech data from nine female students (ages 21–27, mean age 22.6) at Universitat Autònoma de Barcelona (UAB), all in their final or penultimate year of their English Studies degree, who were selected for their advanced oral English proficiency. Initially, ten speakers were recorded, but data from one speaker were excluded due to technical problems during the recording. All participants had completed an obligatory English course, with the final exam equivalent to a C2 level on the Common European Framework of Reference for Languages. The recordings were conducted at the phonetics laboratory at UAB (Servei de Tractament de la Parla i el So) in a soundproof room using an Alesis Multimix 8 mixer with a sampling frequency of 44.1 kHz.
All participants were balanced bilingual in Catalan and Spanish. To assess their degree of bilingualism, they completed the bilingual language profile (BLP) Catalan–Spanish questionnaire (Birdsong et al., 2012), which measures language dominance based on self-reported data and provides a dominance score. Scores range from +218 to −218, with a score near 0 indicating balanced bilingualism. A positive score suggests dominance in Catalan, while a negative score indicates dominance in Spanish. The BLP results showed that two participants were balanced bilinguals with scores close to 0; six participants were slightly dominant in Catalan with scores of 15, 48, 57, 66, 70, and 81; and two participants were slightly dominant in Spanish with scores of −6 and −73.
The same newspaper article, approximately 400 words in length in each language, was presented in Catalan, Spanish, and English. Each speaker read the English version twice, followed by the Spanish version twice, and finally the Catalan version twice, resulting in two recordings per language per speaker. In total, 54 speech samples were analysed. The reading order was kept constant across participants to ensure consistency and comparability. By placing English first, we aimed to minimise potential cross-linguistic priming effects from the participants’ L1s, which might have been activated if their L1s had been activated earlier in the session. While a fixed order may introduce some risk of order effects (such as task familiarity or fatigue), the length of the reading passages was kept short, with brief pauses between readings, to minimise such effects. The inclusion of two repetitions per language facilitated the analysis of intra-speaker variability within each language, and the use of the same text across all three languages supported controlled comparisons across speakers.
Variables
The variables under study are the first two spectral moments of the nasal sounds /m/ and /n/, that is, COG and SD. Spectral moments have been used to describe nasal consonants alongside formants and bandwidths (Amino & Arai, 2009; Amino et al., 2006; Kavanagh, 2012, 2013; Schindler & Draxler, 2013; Smorenburg & Heeren, 2021; Tabain et al., 2016). Spectral moments measure the output spectrum of sounds, providing information about the source and the various filters applied. In the case of nasal consonants, they are determined by the nasal, oral, and pharyngeal resonances and anti-resonances (Tabain et al., 2016). Of all the spectral moments of nasal consonants, the ones that appear to be most relevant and speaker-specific are COG and SD, as they capture characteristics of the spectrum derived from individual differences in the nasal and oral cavities (Kavanagh, 2012; Tabain et al., 2016). COG is a measure of the mean concentration of energy determined by the size of the vocal tract. A lower COG may indicate energy concentrated at lower frequencies due to a longer vocal tract (Reetz & Jongman, 2009, cited in Kavanagh, 2012). SD measures the dispersion of the spectral frequencies around the COG, and in the case of nasal consonants, SD may be affected by individual differences in the nasal and oral cavities (Stevens, 1998, cited in Kavanagh, 2013; Tabain et al., 2016). The between-speaker variability of SD is related to individual differences in the surface area that result from the coupling of the nasal and oral cavities, which affects the bandwidth of poles and zeros (Stevens, 1998, cited in Kavanagh, 2012). Thus, a high SD value may indicate higher frequency dispersion around the COG due to a larger surface area, whereas a low SD value results from a dense concentration of energy around the COG (Kavanagh, 2012).
The selection of words was based on three main factors: immediate phonetic environment, syllable position, and stress. First, only nasal consonants in intervocalic positions were chosen for the phonetic environment. The height and frontness of surrounding vowels were not controlled for, as this would have significantly reduced the sample size. Research indicates that back segments may impact nasal consonants, although the nature of this impact remains unclear (de Boer & Heeren, 2023; Smorenburg & Heeren, 2021). Nonetheless, in this corpus, most words were followed by front vowels. Second, the intervocalic position typically meant that the target consonants served as the onset of the following syllable, thus considering syllable position. Target nasals in final positions that could be syllabified with the following vowel (e.g., the /n/ in ‘reduction of’) were included, except when a pause was produced after the nasal, in which case it was discarded. The position in the syllable was considered, given evidence that it may influence the production and speaker-specificity of nasal consonants (de Boer & Heeren, 2023; Smorenburg & Heeren, 2021). Finally, stress was also accounted for by selecting only nasal consonants followed by an unstressed vowel. Unstressed realisations were chosen primarily because they were more abundant, and controlling for stress was necessary, as a reduced environment may affect the spectral characteristics of these consonants (van Son & Pols, 1999). The number of potential instances of /m/ to be analysed was 20 in Spanish, 16 in Catalan, and 17 in English. The number of /n/ instances was 30, 27, and 22, respectively.
A total of 1,032 realisations of /m/ and 1,361 realisations of /n/ were analysed within the same phonetic context across the three languages. The final number of realisations varied slightly by language due to differences in the number of words containing nasals within the selected phonetic context and by speaker due to exclusions based on initial criteria or variations in repetitions. After excluding outliers, the mean number of realisations per speaker was 31.9 (SD = 2.9) for /m/ in Catalan, 44 (SD = 2.1) in Spanish, and 38.8 (SD = 1.6) in English. For /n/, the mean number of realisations per speaker was 53.2 (SD = 7.3) in Catalan, 51.1 (SD = 9.3) in Spanish, and 46.9 (SD = 5.8) in English.
Procedure
The delimitation of the sounds was carried out through version 6.3.03 of Praat (Boersma & Weenink, 2019), and every sound was manually segmented and labelled by means of auditory and acoustic cues with an interval tier from the beginning to the end of the nasal consonant. A script was run, which generated a fast Fourier transform (FFT) spectrum of the central part of the nasal (excluding 20% of its duration at the beginning of the sound, and another 20% at the end). The first two spectral moments (COG and SD) were extracted from the files.
The data were analysed using SPSS v. 29. Each consonant (/m/ and /n/) was examined separately. Outliers were identified by calculating z-scores for each consonant within each speaker-by-consonant cluster. To assess the significance of intra-speaker variability across languages, two-way analysis of variances (ANOVAs) were performed with Language and the interaction between Language and Repetition as fixed factors. R-squared values were calculated to determine the proportion of variance in the dependent variables explained by the independent variables (Pardo & Ruiz, 2002, p. 288). For example, an R-squared value of 0.008 means that the model explains only 0.8% of the variance. In addition, univariate ANOVAs with fixed (Language) and random (Speaker) factors were conducted to evaluate the effect of Speaker on variability. Partial Eta-squared (ηp²) statistics were used to quantify the amount of variance explained by the independent variables in all tests.
Results and discussion
Results for COG
Figure 1 presents boxplots illustrating the distribution of COG values for /m/ and /n/ across the nine analysed speakers, with separate bars representing each language: Catalan, Spanish, and English. The plots indicate considerable inter-speaker variability, as evidenced by the differing distributions of spectral measures among speakers. Despite this variability, the COG values for the same speaker tend to fall within a similar range across the three languages, although slight differences in tendencies can be observed for some speakers depending on the language.
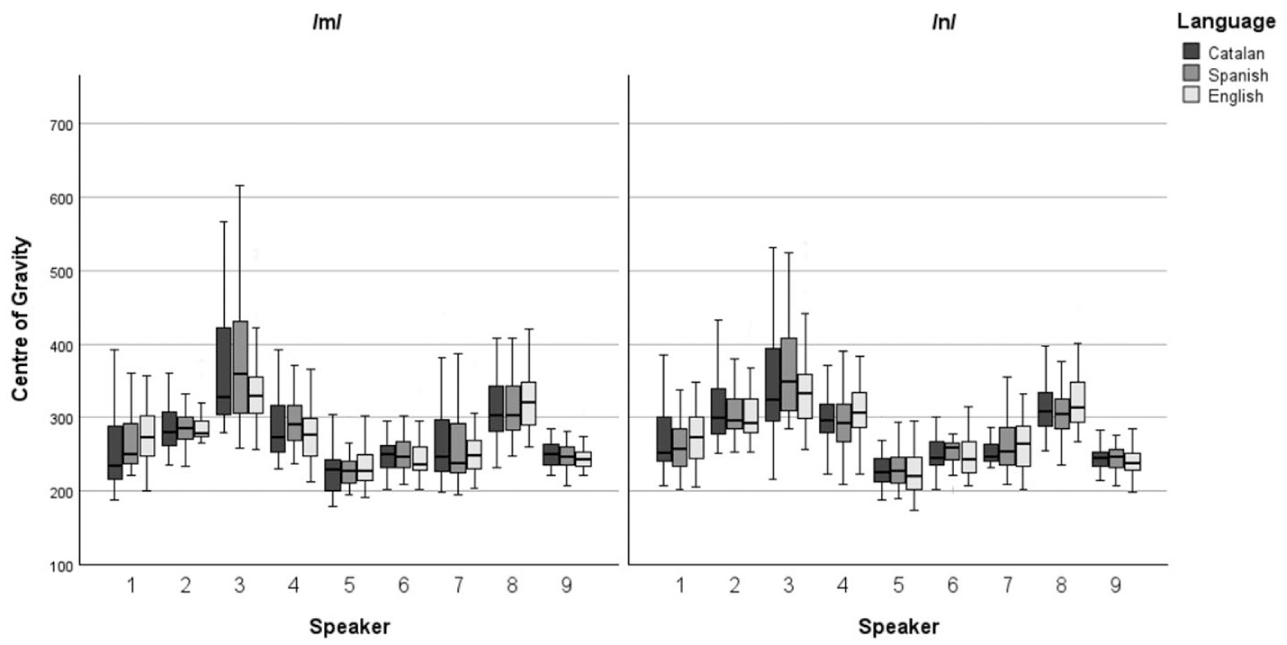
Clustered boxplot of COG by speaker by language of /m/ and /n/.
A series of two-way ANOVAs for each speaker independently (with Language as a fixed factor and the interaction between Language and Repetition) has been used to explore intra-speaker variability. Tables 1 and 2 show the results of the two-way ANOVA for each speaker for /m/ and /n/, respectively. For both /m/ and /n/ p-values, the results for the Language × Repetition factor show no statistical differences between the two readings of the same text in each language by any of the speakers, indicating low intra-speaker variability within the same language.
Results of the univariate ANOVA tests for each individual speaker for /m/.
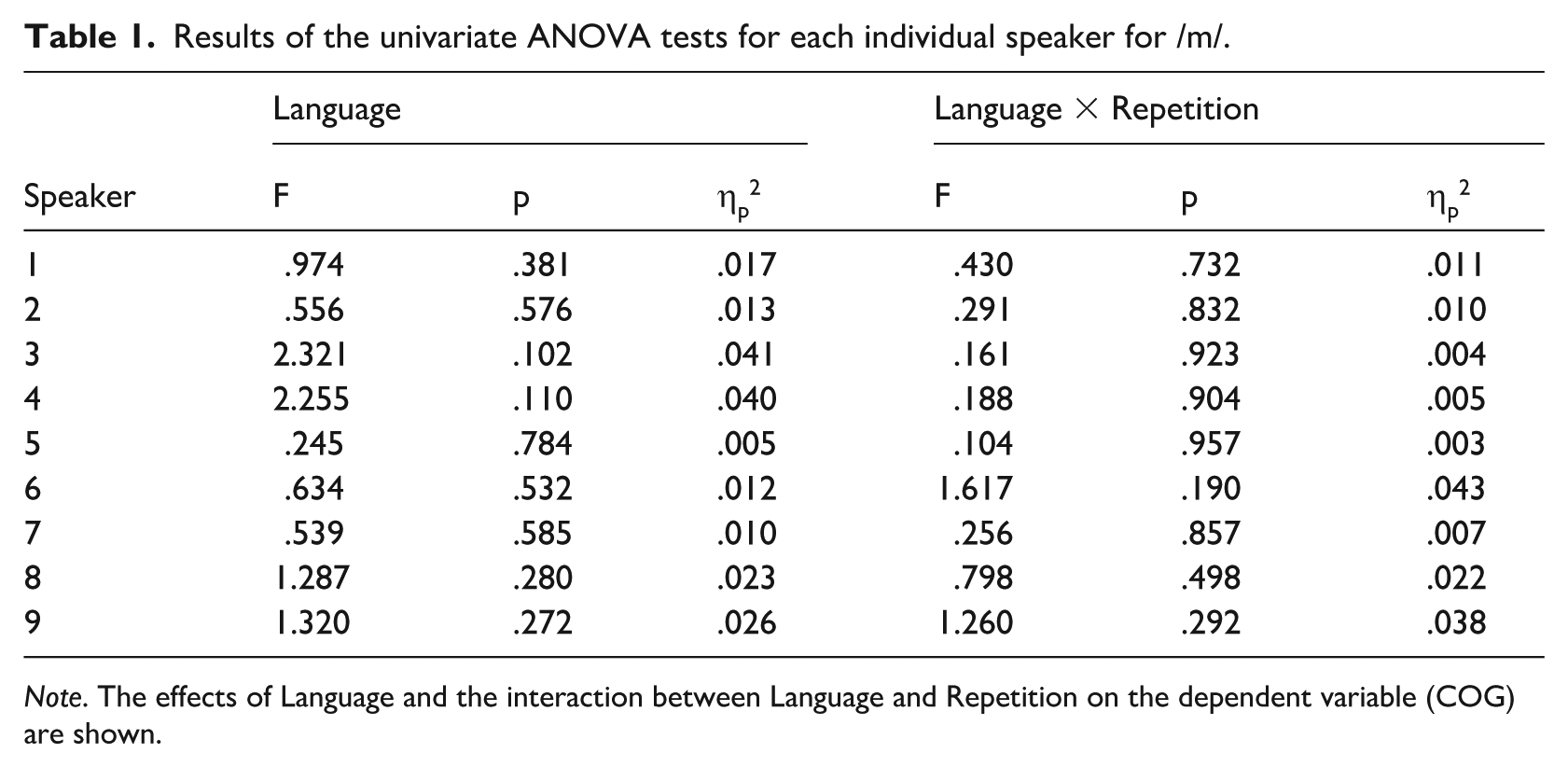
Note. The effects of Language and the interaction between Language and Repetition on the dependent variable (COG) are shown.
Results of the univariate ANOVA tests for each individual speaker for /n/.
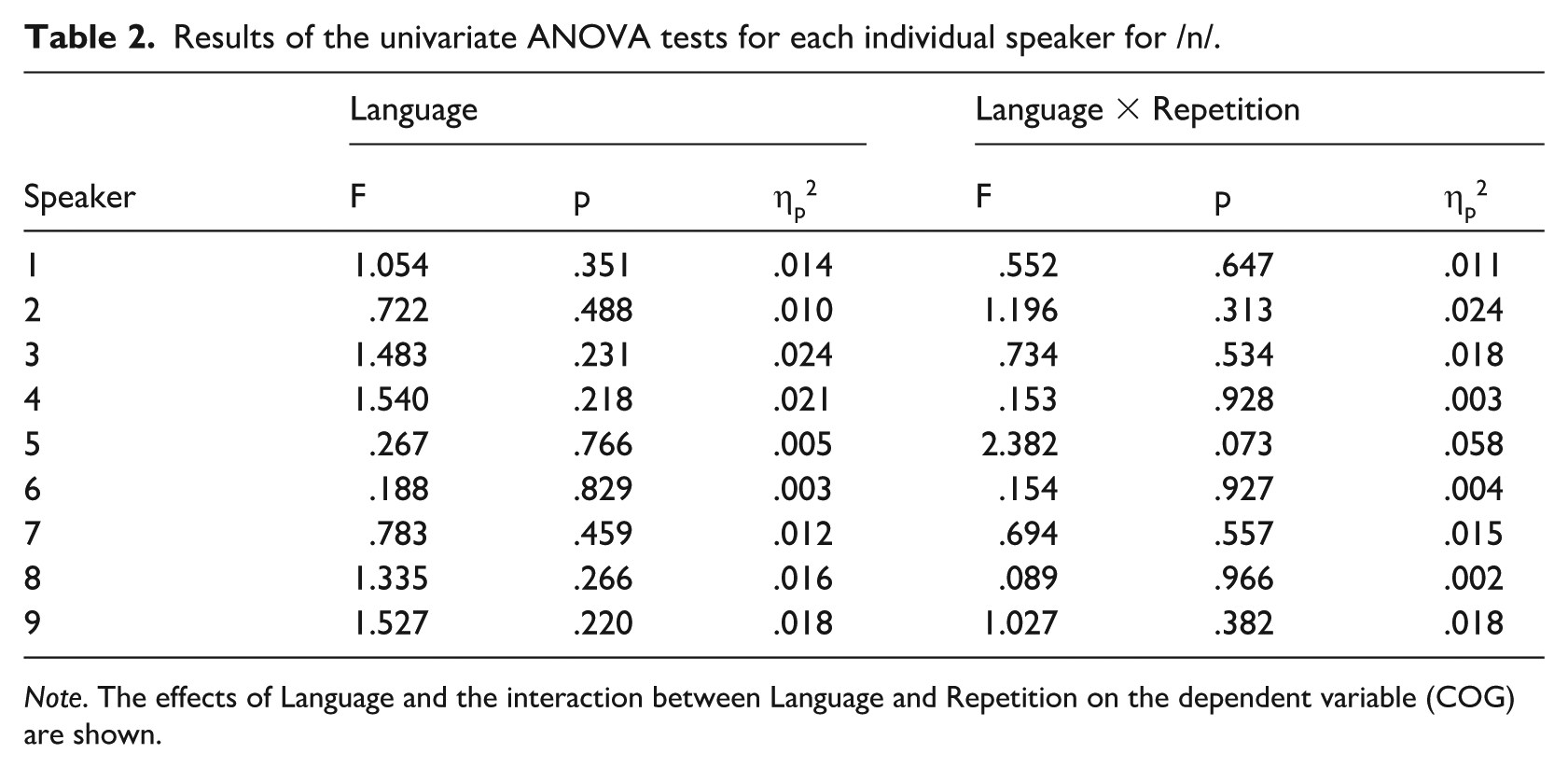
Note. The effects of Language and the interaction between Language and Repetition on the dependent variable (COG) are shown.
Moreover, this model accounts for a very small proportion of the variability, with R-squared values ranging from .008 to .062 for /m/ and from .007 to .066 for /n/. These low values indicate that almost none of the observed variability can be attributed to the factors under investigation – Language and Repetition. In addition, partial Eta-squared values further confirm that the intra-speaker variability attributable to these variables is minimal.
On the other hand, to test the hypothesis that COG measures are speaker-specific in this multilingual context, that is, the intra-speaker variability is lower than inter-speaker variability across the three languages and two repetitions of each reading, two univariate ANOVAs (with Language as a fixed factor and Speaker as a random effect) were conducted separately for /m/ and /n/.
The results for both consonants (see Table 3) indicate that the factor Speaker is statistically significant for both /m/ and /n/. This finding supports the hypothesis that inter-speaker variability is substantially greater than intra-speaker variability. Notably, the partial Eta-squared value for this factor is quite high (.383), suggesting that Speaker accounts for a significant proportion of the variability observed in the data. Conversely, the factor Language does not reach statistical significance in any of the analyses, with an exceptionally low partial Eta-squared value (.003). This suggests that the COG values for these nasal consonants are largely independent of the language spoken. Therefore, the variability attributable to the factor Speaker is markedly higher than that associated with the factor Language.
Results of the univariate ANOVA tests for /m/ and /n/.


Note. The effects of Language and Speaker on the dependent variable (COG) are shown.
Bold values indicate statistically significant results (p < .001).
In sum, results related to COG indicate that the variability found within samples produced by the same speaker is low, even when comparing samples produced in different languages. At the same time, partial Eta-squared values show that most of the variability can be attributed to the factor Speaker, whereas the proportion of variability explained by Language is minimal. Differences between samples produced by the same speaker are not significant, regardless of the language. Consequently, hypothesis 2 seems to be validated since COG values for both nasal consonants are quite stable within the same speaker, regardless of the language used, while speakers differ from each other in their COG values for both nasal consonants.
Results for SD
Figure 2 presents boxplots illustrating the distribution of SD values for /m/ and /n/ across the nine speakers in the corpus. Similar to COG, these plots reveal substantial inter-speaker variability, indicating varying spectral measures among speakers. Furthermore, values in the three languages coincide in general for the same speaker. This similarity is confirmed by the univariate ANOVA tests conducted on /m/ and /n/ for each speaker (shown in Tables 4 and 5) since no significant differences are observed across any of the speakers.
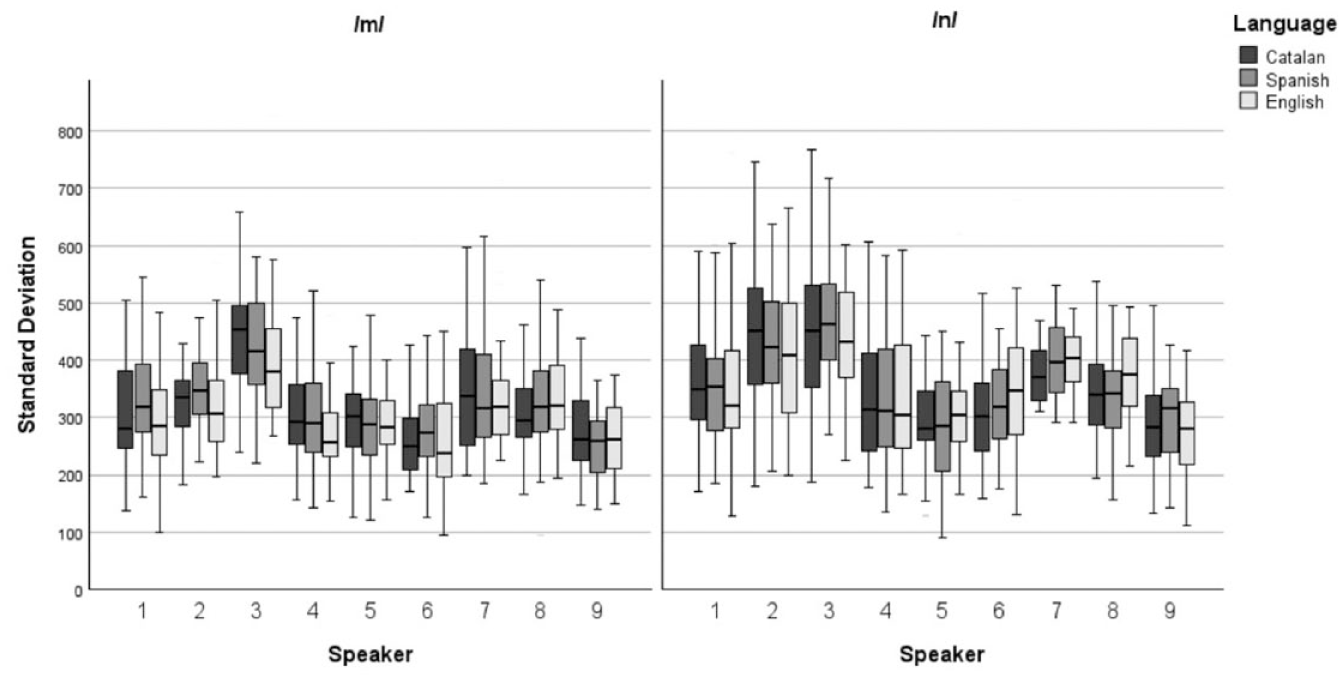
Clustered boxplot of SD by speaker by language.
Results of the univariate ANOVA tests for each individual speaker of /m/ consonant.
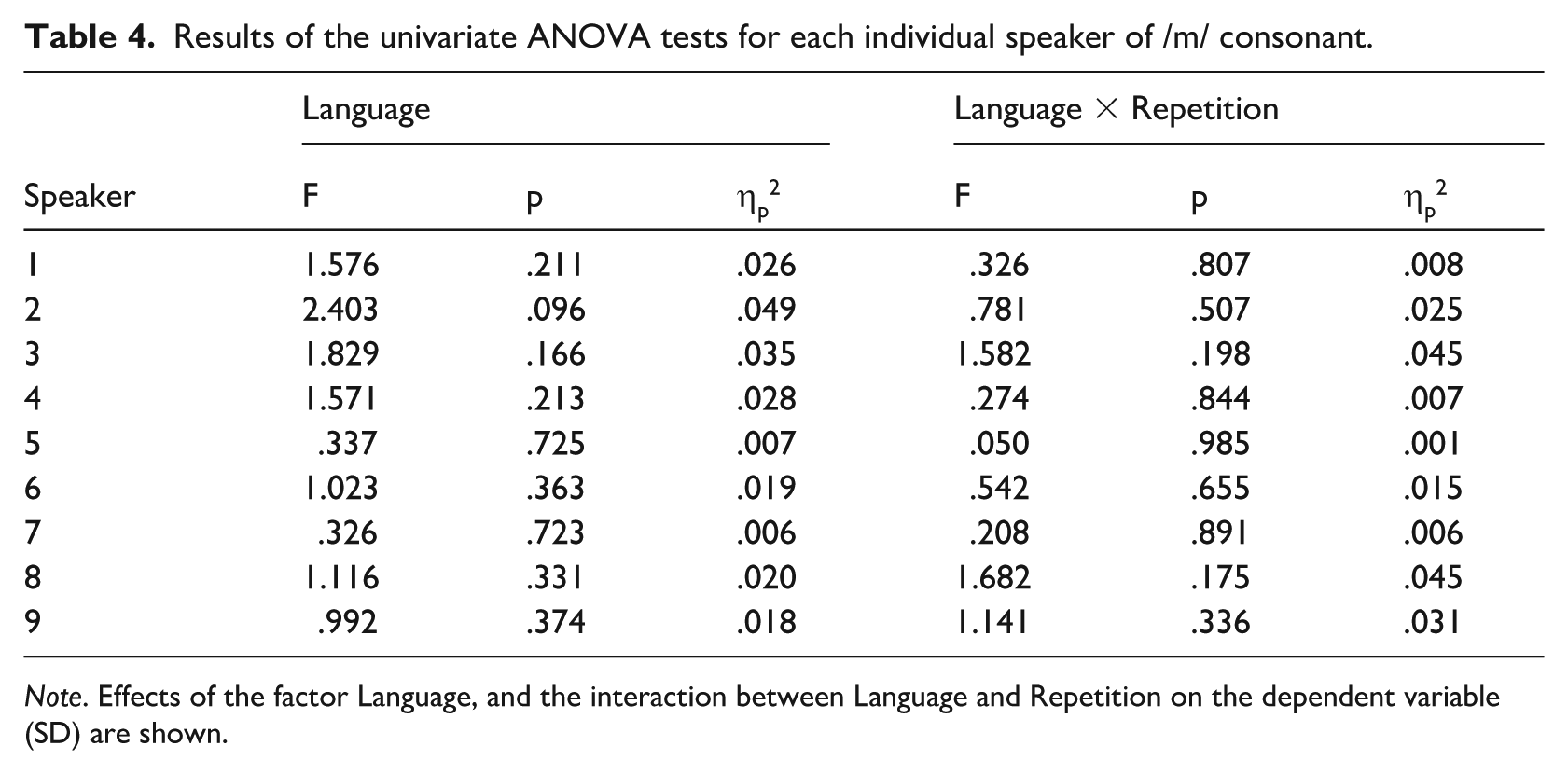
Note. Effects of the factor Language, and the interaction between Language and Repetition on the dependent variable (SD) are shown.
Results of the univariate ANOVA tests for each individual speaker of /n/ consonant.
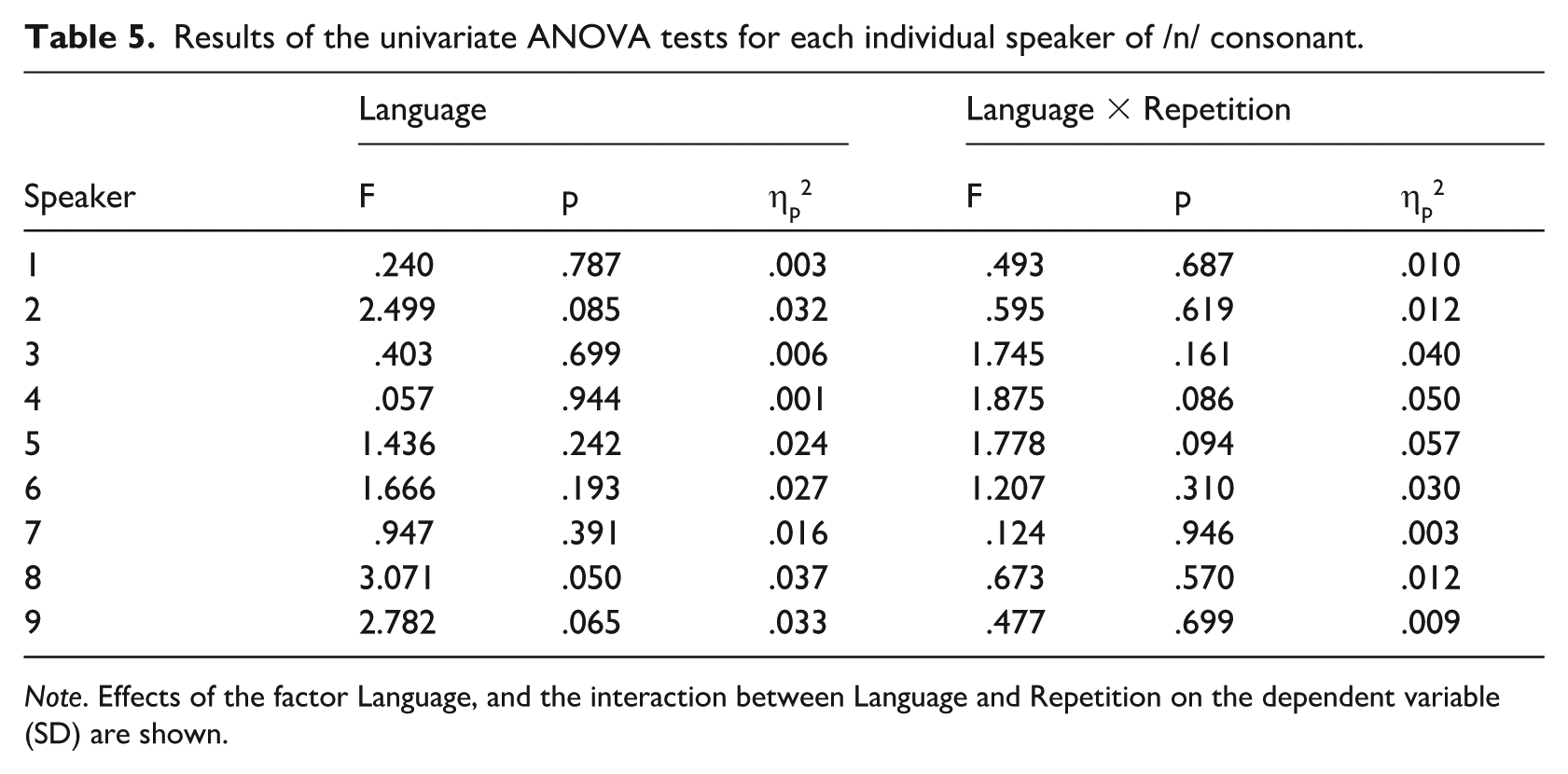
Note. Effects of the factor Language, and the interaction between Language and Repetition on the dependent variable (SD) are shown.
The R-squared values for /m/ range from .008 to .078, suggesting that intra-speaker variability is not significantly influenced by repetition or language. Similarly, R-squared values for /n/ range from .012 to .084. Furthermore, partial Eta-squared values for both consonants indicate that the intra-speaker variability attributable to the variables under study is minimal.
Moreover, to test the hypothesis that SD values exhibit less intra-speaker than inter-speaker variation, separate univariate ANOVAs were conducted for each nasal sound, treating Language as a fixed factor and Speaker as a random effect. Table 6 presents the results of these analyses. Similarly to COG results, Speaker proves significant for both /m/ and /n/, with partial Eta-squared values indicating that a substantial portion of the variability in the data can be attributed to this factor (.204 for /m/ and .221 for /n/).
Results of the univariate ANOVA tests of /m/ consonant.


Note. The effects of the factors Language and Speaker, on the dependent variable (SD) are shown.
Bold values indicate statistically significant results (p < .001).
However, while the Language factor does not reach significance for consonant /n/, it does for /m/ (p = .020). Nevertheless, the partial Eta-squared value suggests that the variability explained by Language is minimal (.008) compared to the variability explained by Speaker (.204). Post-hoc tests reveal that Language differences are not significant when comparing SD values between Catalan and Spanish, whereas significant differences emerge when comparing English with Catalan and English with Spanish.
In sum, the SD results suggest that, although there is some language-related variability in the production of /m/, particularly when English is involved, the overall magnitude of this variability remains low. In other words, while the Language factor reaches significance for /m/, its effect size is minimal, and the dominant source of variability is still the Speaker. Finally, differences among samples from the same speaker are not statistically significant, irrespective of language. These results confirm hypothesis 2, revealing stable SD values for both nasal consonants within individual speakers across languages, while highlighting significant variability in SD values between different speakers. The observed differences involving English will be explored in more detail in the next section, as they may be related to differences in the immediate phonetic environment.
Discussion
Discussion of the results
The main objective of this paper was to explore the speaker specificity and language independence of the nasal consonants /m/ and /n/ in nine speakers of Catalan and Spanish as L1 with proficient English as an AL. The first two spectral moments, COG and SD, were analysed. The results show that variability was relatively low when comparing samples from the same speaker, as neither the factor Language nor the interaction between Language and Repetition yielded statistical significance. These results support Hypothesis 1, indicating that /m/ and /n/ seem to be produced with a high degree of intra-speaker consistency while demonstrating language independence in the particular corpus analysed.
By contrast, the factor Speaker showed a significant effect when comparing samples from different speakers, explaining a much higher proportion of variability in the data than any other factor, as indicated by the higher partial Eta-squared values. This finding supports Hypothesis 2, demonstrating that inter-speaker variability is substantially higher than intra-speaker variability. These results suggest that the spectral characteristics of /m/ and /n/ could not only be consistent within individual speakers but also carry speaker-specific information that may remain stable across languages.
One exception emerged in the SD values of /m/, where the factor Language reached statistical significance in comparisons involving Catalan and Spanish versus English (p = .020). While this small but notable effect could suggest that certain features of /m/ vary across languages, we consider the immediate phonetic environment a more likely explanation. Although efforts were made to control for phonetic context by analysing target sounds in intervocalic, coda, and unstressed positions, the intervocalic category might have been too broad, potentially allowing for coarticulatory variation across languages. Previous studies have shown that the spectral properties of nasal sounds, particularly the bilabial /m/, are highly sensitive to the characteristics of adjacent segments (de Boer & Heeren, 2023; Smorenburg & Heeren, 2021). This is especially true for /m/, since, during its production, the tongue lacks a specific target during the closure phase and may assume various positions (Smorenburg & Heeren, 2021; Su et al., 1974). While we cannot completely rule out the possibility of language-related effects, the small effect size and known sensitivity of /m/ to phonetic context make coarticulation the more plausible explanation in this case.
In addition, a closer examination of the target words in the corpus reveals differences in vowel context that may explain the observed variability. Three of the Spanish tokens (15%) and three of the Catalan tokens (19%) involved a following back vowel, whereas none of the English tokens did. While these differences may seem minor, the nature of the target words in Catalan and Spanish might be more similar to each other than to the target words in English. Notably, the three words where /m/ is followed by a back vowel are the same in both Catalan and Spanish: simulación, como, comunicado in Spanish, and simulació, com una, comunicat in Catalan. Given the evident linguistic closeness of Catalan and Spanish, the analysed words were practically the same in these two languages, whereas the words found in English were more different. For example, the words comisión (Spanish) and comissió (Catalan) were analysed, whereas the cognate Commission in English was not because the /m/ appeared before a stressed vowel, so it did not meet the established criteria. Therefore, even if many cognates were present in the three languages, the final list of words was inevitably more similar in Catalan and Spanish than in English, which may have resulted in lower variability of the immediate phonetic context when comparing Catalan and Spanish and higher variability when comparing these languages to English.
In addition to phonetic factors, the broader linguistic context may also play a role. Catalan and Spanish are both L1s for the speakers and are used daily in an official bilingual context in the area where the speakers live (Greater Barcelona). In contrast, English, although spoken proficiently, is used less frequently and in more limited domains. This difference in language status may have contributed to slightly greater variability in the nasal consonants produced in English compared to those produced in Catalan and Spanish, possibly due to more careful or hyper-articulated speech or due to differences in fluency between the L1s and the AL (de Jong & Mora, 2019; Derwing et al., 2009). Even so, the variability explained by the factor Language was still much lower than that explained by Speaker, as indicated by the partial Eta-squared values, reaffirming that individual speaker characteristics were the strongest source of variability.
Taken together, the findings suggest that /m/ and /n/ exhibit consistent, speaker-specific acoustic characteristics across languages, including in multilingual settings. This extends prior work on the speaker-specificity of nasals in monolingual contexts (e.g., Amino & Arai, 2009; Amino et al., 2006; Kavanagh, 2012, 2013; Schindler & Draxler, 2013; Tabain et al., 2016) by showing that such patterns also hold across languages spoken by the same individual. It aligns with de Boer and Heeren’s (2023) findings, which identified similar realisations of the bilabial consonant /m/ in Dutch and English. However, as these authors note, this hypothesis should be tested in more diverse language pairings (p. 2175). In this study, Catalan and Spanish are typologically and phonotactically similar and in constant contact. Therefore, results in these two languages could be expected to show low variability within the same speakers. The inclusion of English, a more phonologically distinct AL, did not significantly alter the spectral properties of /m/ and /n/, even though /m/ showed slightly higher variability in SD values. Despite English’s differences from Catalan and Spanish, both /m/ and /n/ have similar articulatory gestures in the three languages (Dart, 1998; Martínez Celdrán, 1996; Recasens, 2010). Therefore, while this study provides additional evidence of the language independence of /m/ and /n/, the question posed by de Boer and Heeren (2023) remains partly unanswered, as other language pairings might yield different results. For instance, Dart (1998) reports that /n/ is primarily apicolamino-dental in French but apico-alveolar in English, a difference that could hypothetically lead to greater language-dependency (and lower intra-speaker consistency) of /n/ in bilingual speakers of English and French. Further research involving less related language pairs may help refine our understanding of how nasal acoustics vary across multilingual speakers.
Limitations and future directions
The results of this study are preliminary and represent an initial exploration of the speaker consistency and language independence of nasal consonants /m/ and /n/. The most significant limitation is the small speaker sample, consisting of only nine speakers. Although six samples from each speaker were analysed (totalling 54 samples and 2,393 target sounds), this number is insufficient for drawing broad conclusions about inter-speaker or cross-linguistic variability in the general population. The goal of this study is not to produce definitive results but to establish the feasibility and relevance of spectral measures of nasals for future, larger-scale research. Future studies with larger and more diverse speaker samples, including male participants, should aim to replicate and extend these findings and examine whether gender-related variation plays a role in the production of these consonants.
In addition, the number of lexical items per language and per sound category is limited. Once the influence of contextual factors is taken into account (such as surrounding segments, position in the utterance, and prosodic structure), the number of observations for individual conditions becomes relatively small. This raises the possibility that item-specific characteristics may influence the results, particularly in cases such as the /m/ variability patterns discussed in the analysis. Expanding the recording materials in future work would help control for variation associated with specific lexical items and provide a more comprehensive picture of the phenomena under study.
Finally, another limitation is the exclusive use of read speech. While this approach offers a consistent and controlled environment in which to examine the target sounds, it may not fully reflect how these sounds behave in more spontaneous or conversational settings. Previous research has shown that read and spontaneous speech may differ in their patterns of variability, although the direction and source of such differences are not always straightforward. Baese-Berk and Morrill (2015) found higher variability in both non-native and native English speech during a reading task. However, a follow-up study by Morrill et al. (2016), using the same speakers in spontaneous tasks, observed that native English speech exhibited more variability than non-native speech. The researchers concluded that variability should not be linked to reading proficiency differences. Instead, they attributed it to the complex coordination required for reading at various linguistic levels (phoneme, syllable, and phrase), suggesting that disruptions at any of these levels could lead to inconsistent speaking rates (Baese-Berk and Morrill, 2015, p. El227). By contrast, spontaneous tasks, which do not require meticulous planning, tend to exhibit lower variability. Future studies should use complementary data from more naturalistic tasks to further assess the generalisability of the current findings.
To sum up, while limited in scope, this study offers new evidence supporting the language independence of /m/ and /n/, contributing to an area of phonetic research that remains underexplored in multilingual contexts. These findings are particularly relevant to two domains of phonetics. First, in the field of second and additional language acquisition, the results suggest that speakers tend to maintain their L1 articulatory patterns when producing /m/ and /n/ in both their L1s (Catalan, Spanish) and their AL (English). Second, in forensic phonetics, the consistency of these sounds across languages highlights their potential usefulness as speaker-specific markers in multilingual contexts, whether comparing samples across different languages or samples in non-native speech. Overall, this study provides a starting point for future research on the phonetic stability of nasals across speakers and languages, particularly using larger, more diverse, and more naturalistic speech data.
Conclusion
The relationship between indexical information and the various languages spoken by an individual remains underexplored, particularly regarding whether speaker-specific traits persist across different languages. This study investigates the speaker specificity and language independence of the nasal consonants /m/ and /n/ in multilingual speakers with Catalan and Spanish as their first languages and English as an additional language. Analyses of the COG and SD reveal that variability within the same speaker, even across different languages, is minimal, while variability between different speakers is significantly higher, as evidenced by the statistically significant effects of the factor Speaker for both COG and SD. Thus, the spectral characteristics of these nasal consonants appear to be speaker-specific across the languages spoken by the participants. Although preliminary, this study contributes valuable insights to the limited research on speaker-dependent traits that are language-independent.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.