
Abstract
Aims and Objectives:
Given the substantial amount of work indicating how acquiring tonal information is harder than segmental information when L2 Chinese learners were tested in tasks requiring speech perception and/or production, this study investigates whether this differential activation between segmental and tonal information extends to L2 reading.
Methodology:
Native speakers and highly proficient L2 learners of Chinese were tested in a phonological Stroop task. The participants named the ink color of the Chinese characters that were visually presented to them. The Chinese character and the ink color were manipulated such that they overlapped in both segmental and tonal information (S+T+); either segmental or tonal information (S+T– or S–T+); or no overlap at all (S–T–).
Data and Analysis:
Reaction times and accuracy data from native speakers and L2 Chinese learners were first manually marked using CheckVocal, and then they were analyzed using linear mixed-effects models.
Findings:
Although native Chinese speakers showed facilitation naming the ink color when the ink color and these visually presented characters shared any phonological information (i.e., segmental and/or tonal), L2 Chinese learners showed facilitation only when segmental information was shared between the ink color and the characters, suggesting that they were not able to activate tonal information of visually presented words even though they were capable of activating segmental information.
Originality:
This is one of the first studies that uses an implicit task to test the automatic processing of segmental and tonal information during visual word recognition in highly proficient L2 Chinese learners.
Implications:
This study shows that tonal information is not automatically activated during visual word recognition even in highly proficient L2 Chinese learners. Further research is necessary to find out if suprasegmental information develops later than segmental information.
Keywords
Learning a new language involves learning a new set of phonology, words, and grammar. Within phonology, it is important to learn not just segmental information, or phonetic information, such as vowels and consonants, but also suprasegmental information, as in phonological information beyond phones (Wang & Arciuli, 2015). In Chinese, a tonal language, it is especially important to learn lexical tones (suprasegmental information) because they behave as cues that disambiguate words that have otherwise the same segmental information. For example, the segmental syllable (Li et al., 2018) “ma” can become different words with different meanings depending on its lexical tone: (1) “mother” 妈, mā, with tone 1; (2) “hemp” 麻, má, with tone 2; (3) “horse” 马, mǎ, with tone 3; and (4) “to scold” 骂, mà, with tone 4. Note that the Roman alphabet following the Chinese characters is Pinyin, which represents segmental information in Chinese, and the diacritics on Pinyin represent the tones. This is in contrast to suprasegmental information in English, in which lexical stress may not be as critical. For example, if a second language (L2) speaker pronounces computer with a stress on the first syllable, most native speakers would still understand that they are referring to computers. Without the lexical tones in Chinese, however, it becomes difficult to identify which word was uttered. Yet, tones in Chinese are generally considered to be difficult for learners who are learning this language as a second language (L2; see, for example, Hao, 2012; Wang et al., 2006). Therefore, it is important to know whether this difficulty in learning L2 tones is limited to listening (see, for example, Hao, 2012; Malins & Joanisse, 2010; Pelzl et al., 2018; Tong et al., 2008) and speaking (see, for example, Hao, 2012; Wang et al., 2015), or whether this extends to reading in Chinese. Thus, this study examines whether L2 Chinese learners at later stages of L2 acquisition who use Chinese daily are able to activate tonal information when they are reading in L2 Chinese. More specifically, this study tests whether tonal information is more difficult to activate than segmental information during visual word recognition.
In contrast to L2 Chinese learners, there is plenty of evidence indicating that native speakers of tonal languages are capable of automatically activating phonological information in general (e.g., Perfetti & Zhang, 1991; Tan et al., 1995; Tan & Perfetti, 1998, 1999) and tonal information in particular (Li et al., 2013; Spinks et al., 2000; Wang et al., 2015; Winskel & Perea, 2014) during visual word recognition. Interestingly, it also seems like tonal information can be activated independently of segmental information in native speakers of Chinese (Li et al., 2013). This is not surprising given that the Chinese writing system, Hanzi, is morpho-syllabic (Mattingly, 1987; Perfetti et al., 2005; Sze et al., 2015), with each character mapping onto a morpheme and a syllable. In other words, Hanzi does not visually mark phonological information such that it allows for phonological assembly when reading out loud (Perfetti et al., 2005). This is in contrast to other languages, such as English, Vietnamese and Thai. That is, in languages such as English, Vietnamese, and Thai, it is possible to generate the phonological code including tones through the lexical route and the spelling-to-sound conversion rules, whereas in Chinese, the phonological code must come directly from memory (Perfetti et al., 2005; Yu & Reichle, 2017). Even if a character has a phonetic component that may suggest its segmental information, the phonological reading of the character is not very consistent (see Yin & Rohsenow, 1994). According to Zhou (2003), out of the 8,075 characters that appear in Xinhua Dictionary ( Xīnhuá zìdiǎn, 1971) dictionary, 1,348 characters are the bases for the phonetic components (or phonophores, according to the translation provided in Zhou, 2003), and 6,542 of them carry one of these characters as their phonetic component. Thus, it would seem that as long as one knows how to read the 1,348 characters, they can read other characters correctly as well. Unfortunately, Zhou (2003) pointed out that this does not seem to be the case because—roughly 35% of these characters with phonetic components have the same segmental information, but different tonal information; 48% may be read the same as the phonetic component character, but there are other characters with the same phonetic component and yet have a different pronunciation; and 17% have different readings from the phonetic component. For instance, 花 has a phonetic component 化, and even though the segmental information is the same hua, 花 is pronounced with tone 1, and 化 with tone 4 (Yu & Reichle, 2017). Thus, given the unreliability of predicting the correct pronunciation of each character based on the phonetic component (Yin & Rohsenow, 1994), when a language learner is presented with a new Chinese character or Hanzi, it is necessary for the learner to learn both the segmental and tonal information simultaneously to acquire the pronunciation of a Chinese character.
Again, this is in contrast to another tonal language, Thai, for example, which has an alphabetic writing system. In Thai, both segmental and tonal information are generally clearly marked in their writing, with the tone marker over the consonant character (e.g., “ั” in ห้อง, /hᴐ:ŋ2/, “room”; example from Winskel & Perea, 2014). This means that the Thai writing system allows for phonological assembly both at the segmental and the tonal level. In such a language, tonal information seems to be secondary to segmental information even in native Thai speakers (Winskel & Perea, 2014). Given that Chinese writing does not explicitly mark segmental or tonal information, and thus has to be learnt together when learning to read a new character, the question arises as to whether L2 Chinese learners in general would show difficulty in processing tonal information relative to segmental information during reading. In other words, the study examines whether tonal information gets activated along with segmental information during the L2 reading of Chinese, or whether there are differential effects for segments and tones.
There has only been one study so far (to the best of our knowledge) that specifically investigated whether tonal information is activated during visual word recognition in L2 learners (Li et al., 2018). Li et al. (2018) conducted a homophone judgment task, in which participants were asked to decide whether the two stimuli presented on the computer screen share the same segmental and tonal information. The stimuli were either two Hanzi characters (市 时), or a Pinyin and a Hanzi character (shì 时). Each target word (市, shì, “city”) was paired with one of the four phonological variations of the target character, which involved: (1) a full homophone with exactly the same segmental and tonal information (S+T+, 事, shì, “problem / issue”); (2) a character sharing only segmental information (S+T–, 时, shí, “time”); (3) a character sharing only tonal information (S–T+, 掉, dìao, “drop”); or (4) a control character with different segmental and tonal information (S–T–, 本, běn, “source”). Critical analyses were based on “NO” responses since any activation of segmental and/or tonal information should lead to interference effects as observed in their slower response times. They found that both native speaker and L2 learner participants (with a variety of L1 backgrounds, all of which were non-tonal) showed difficulties when the two stimuli had segmental overlap. This suggests that, like native speakers, L2 learners can activate the segmental information. However, the interference effect from the S–T+ condition, which tested the independent role of tones, was only found in native speakers but not for L2 learners, suggesting that, unlike native speakers, L2 learners seemed not to be able to activate the tonal information without the segmental information. Based on these findings, Li et al. (2018) concluded that L2 learners do not represent and activate tones in a comparable manner with the native speakers even during reading.
It is important to note, however, that the homophone judgment task used in Li et al. (2018) might have been insufficient to reveal whether phonological information is accessible to L2 Chinese learners during online reading. First, this particular task requires the use of metalinguistic awareness of what homophones are. Participants might have been unaware that homophones must share both segmental and tonal information, and not just segmental information. In fact, Taft and Chen (1992) have reported anecdotal evidence suggesting that even native Chinese speakers rely only on segmental information when deciding what makes two words homophones. Thus, it would not be surprising if L2 learners might make such decisions similarly when they were asked to complete such a metalinguistic task. Indeed, Li et al. (2018) reported that both their L1 native speaker and L2 learner participants needed to be instructed and trained that tonal information should be considered when making homophone judgments before they proceeded to the formal experiment. Such a task is not ideal because even if the L2 learners were able to activate both segmental and tonal information, because the task asked for the use of metalinguistic strategies, it might have only revealed the use of segmental information when participants were making decisions. Second, this task forces participants to process the phonological information of the visually presented characters in order for them to distinguish the phonological difference between the two stimuli (i.e., to provide NO response). This makes it harder to know whether L2 learners activate phonological information, segmental or tonal, automatically, or whether this particular task requires them to activate phonological information. As such, a different task is necessary to explore the question of whether L2 learners can automatically activate tones during reading in a similar manner to native speakers.
The present study employed a phonological Stroop task to explore whether phonological information is activated during reading in L2 Chinese learners. In particular, the study examines whether segmental and tonal information are activated and used in a similar or in a different manner during reading. In a Stroop task, participants are asked to name the ink color of the visually presented stimulus. This stimulus is usually a word that might have some linguistic information shared with the ink color. In this study, each participant would be presented with the character 瓶 (píng, “bottle”) in red, for example. The participant is asked to then say 红 (hóng, “red”) because that is the color in which the character was written. The visual stimulus, 瓶, shares tonal information but not the segmental information with the ink color, 红. We predicted that when the color name and the character overlapped segmentally, there would be facilitation in naming the ink color. We were interested in investigating whether there being a tonal overlap between the color name and the character would facilitate naming of the ink color similarly or not—as in this example. If participants are faster naming the ink color under this condition when compared with being visually presented with 爸 (bà, “father”) which does not have tonal or segmental information in common with the color red, this would indicate that the tonal information had been accessed and hence facilitated the naming of the ink color.
This phonological Stroop task was used for several reasons. First, the Stroop task can test the automatic processing of visual stimuli (Stroop, 1935). In this task, participants are simply asked to name the ink color of the stimuli that are presented visually. Thus, participants do not need to process the lexical information of the visually presented stimulus to perform the task. If participants do not process lexical information, then there will be little influence from the stimulus. On the other hand, if participants indeed process such information, then there will be some influence from the stimulus. Hence, this Stroop task makes it possible to test whether the segmental and/or suprasegmental information was automatically activated. In other words, this phonological Stroop task allows us to explore what type of information may be automatically accessible to the participants. Second, the phonological Stroop task has been frequently employed to test phonological processing in visual word recognition (see, for example, Coltheart et al., 1999; Han & Verdonschot, 2019; Verdonschot & Kinoshita, 2018). Third, this modified Stroop task has been used to test automatic phonological activation in Chinese (e.g., Li et al., 2013; Spinks et al., 2000), and therefore it would make the findings of this study more comparable with other studies in the literature. In fact, this task has been used in a study that has found that native Chinese speakers can automatically activate phonological information, including tonal information, during visual word recognition (Li et al., 2013; see also Spinks et al., 2000).
In this study, we did not group L2 learners depending on whether their L1s were from another tonal language or not. Some studies seem to suggest that whether the learner has a tonal L1 or not affected the discrimination of L2 tones that were presented auditorily (e.g., Lee et al., 1996; Wayland & Guion, 2004; Yu et al., 2019). Other studies indicate that whether the learner’s L1 was tonal or not did not affect their performance on the perception and production of L2 tones (e.g., Francis et al., 2008; Hao, 2012; So, 2006; So & Best, 2010; Tsukada & Kondo, 2018; Wang, 2006). In contrast to these previous studies, the main focus of this study was whether tonal information is activated during L2 Chinese reading (as opposed to auditory tasks, such as discrimination of L2 tones, and/or perception and production of L2 tones). Thus, it is important to consider the unique writing system of Chinese. As mentioned earlier, Chinese is unique in that it is written in Hanzi, a morpho-syllabic system that does not mark segmental or tonal information. Even though there are other languages that use the Hanzi-based writing system, it is not the case that these languages are tonal. For instance, Japanese uses Kanji, which is based on Hanzi, but Japanese is not a tonal language. There are other languages, such as Thai, that are tonal, but use an alphabetic writing system. Thus, all of our L2 speakers were similar with each other in that none of them had an L1 that is written morpho-syllabically and is a tonal language. It is also important to consider that because different languages have different numbers and types of tones (Burnham & Mattock, 2007), it remains unclear how tones in one’s L1 affect the learning of tones in L2 especially when the tones in these languages are not the same. This is especially the case when tonal languages may use different phonological features to distinguish the tones in their language, such as F0, duration, and voice register (Yip, 2002), and it is yet to be studied how such differences in distinguishing tones in L1 might affect the tonal processing during L2 reading. For example, even though both Chinese and Thai are contour tone languages (i.e., using pitch contours to distinguish different tones), they differ in terms of (1) the number of tones, with Chinese having four pitch contours and Thai having five; (2) the types of tones, with Chinese having high flat, rising, falling-rising, and falling and Thai having mid, low, high, rising, and falling; and (3) pitch heights. Given these reasons, it is more important to establish a baseline of whether tonal information can be accessed in L2 Chinese reading before we dive into further exploration on how L1 tonal status might influence such processing. As such, we decided that we should consider all the L2 speaker participants as one group for this study.
This study, therefore, reports findings from an experiment with native speakers and L2 learners of Chinese using the phonological Stroop task to examine whether L2 Chinese learners can automatically activate phonological information during reading in a similar manner compared with native speakers. Participants had to name four ink colors—red, yellow, blue, and green—under six different conditions—congruent, S+T+, S+T–, S–T+, S–T–, and incongruent. In congruent and incongruent conditions, participants were presented with a color character that was either congruent or incongruent with the ink color. In S+T+, S+T–, and S–T+ conditions, in which S stands for segmental information and T for tonal, if the character shares such information with the ink color, then it is denoted by a positive (+) mark, and if the information is not shared, it is denoted with a negative (–) mark. The S–T– condition was used as the baseline condition. Based on previous literature (Li et al., 2013), it was predicted that native speakers would show facilitatory effects for all S+T+, S+T–, and S–T+ conditions when compared with the S–T– condition. L2 learners of Chinese, on the other hand, were expected to show facilitatory effects for S+T+ and S+T– conditions. Critically, we wanted to see whether they show facilitatory effects in the S–T+ condition.
Method
Participants
Two groups of participants voluntarily took part in the experiment. The first group consisted of 28 native Chinese speakers, who served as the control group. Out of the 28 speakers, 20 speakers were tested in mainland China, and eight speakers in the USA. It is important to note that all of them identified Chinese as their L1. The second group of participants were 34 L2 Chinese learners, who were all residing in mainland China using and studying Chinese daily at the time of testing. Seven participants were eliminated due to a high error rate of 20% or higher; thus, the remaining 27 participants were included in the analysis. These L2 learners came from various L1 backgrounds—French (N = 1), Kazakh (N = 1), Kyrgyz (N = 1), Laos (N = 1), Uzbek (N = 1), Indonesia (N = 2), Korean (N = 3), Urdu (N = 7), and Thai (N = 10). They all passed the Level V of the Hanyu Shuiping Kaoshi (HSK) test or above, except for one participant who passed their Level IV test but with a high score (i.e., 273 out of 300). Thus, this participant was included in the analysis. The HSK test, a standardized Chinese language proficiency measure administered by an agency of the central Chinese government, has six levels (Levels I–VI), with Levels V and VI considered as advanced (as of 2020). All participants reported having normal vision with no deficiency in color identification, and normal hearing, and had no known language or learning disabilities. The language learning backgrounds of the 27 L2 Chinese learner participants that were included in the analysis are presented in Table 1.
Language learning information of L2 Chinese learners.
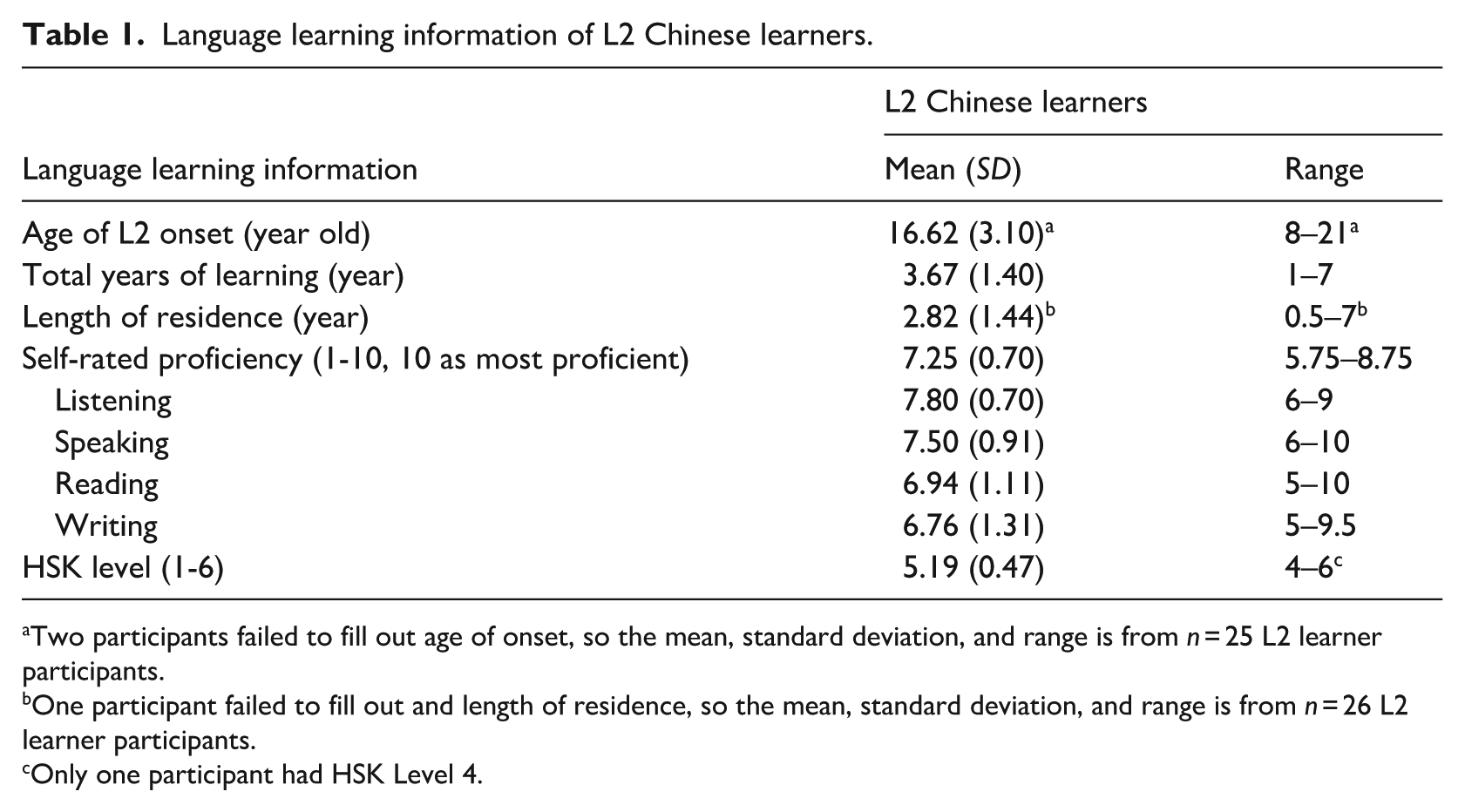
Two participants failed to fill out age of onset, so the mean, standard deviation, and range is from n = 25 L2 learner participants.
One participant failed to fill out and length of residence, so the mean, standard deviation, and range is from n = 26 L2 learner participants.
Only one participant had HSK Level 4.
The sample size of participants in each group was determined based on previous studies testing phonological activation of Chinese characters, using the same phonological Stroop task. The number of native speaker participants in previous studies ranged from 17 (Guo et al., 2005) to 25 (Spinks et al., 2000). Based on this, we made sure that the number of participants in each group in this study had more than 25 participants.
Materials and design
The experimental items consisted of 20 Hanzi characters, as in Table 2. Half of the experimental characters were taken from Li et al. (2013), while the other half were replaced with different characters to accommodate the L2 learners. All the ink colors and their characters remained the same as in Li et al. (2013). The replaced items were selected based on the following process. First, all the characters were pre-selected from a textbook for beginner learners of L2 Chinese in the US, “Integrated Chinese Level I. Part 1 (3rd Ed.)” (Liu et al., 2008). Second, the first author, who is a highly proficient Chinese–English bilingual, consulted with an experienced Chinese instructor at a US university and together confirmed that L2 Chinese learners should have explicit phonological knowledge of the stimuli as long as they have taken two semesters of Chinese since all the characters commonly appear in textbooks for beginner learners. Third, to serve as a more objective criterion, the newly selected Chinese characters were approximately matched in terms of frequency and number of strokes to the color characters. Frequency was initially manipulated based on the Modern Chinese Character Frequency List (Da, 2004) because this was the corpus used to control for frequency in Li et al. (2013). However, this corpus provides cumulative frequencies instead of occurrences per million. Thus, frequencies of the stimulus characters were checked using SUBTLEX-CH (Cai & Brysbaert, 2010). According to the SUBTLEX-CH, the mean frequency of color characters was 91 occurrences per million (opm), the mean frequency of stimuli in the S+T+ condition was 87 opm, 85 opm in the S+T– condition, 373 opm in the S–T+ condition, and 489 opm in the S–T– condition. The mean number of strokes for stimuli in the S+T+ condition was 8.75, 10 in the S+T– condition, 9.25 in the S–T+ condition, and 10.25 in the S–T– condition. Finally, we made sure that all the stimuli words had only one way of reading with a set of segmental and tonal information, and did not have multiple ways of reading. This way, we could see whether tonal information was computed or not, and that participants did not have to select among various tones.
Stimuli used in the experiment.
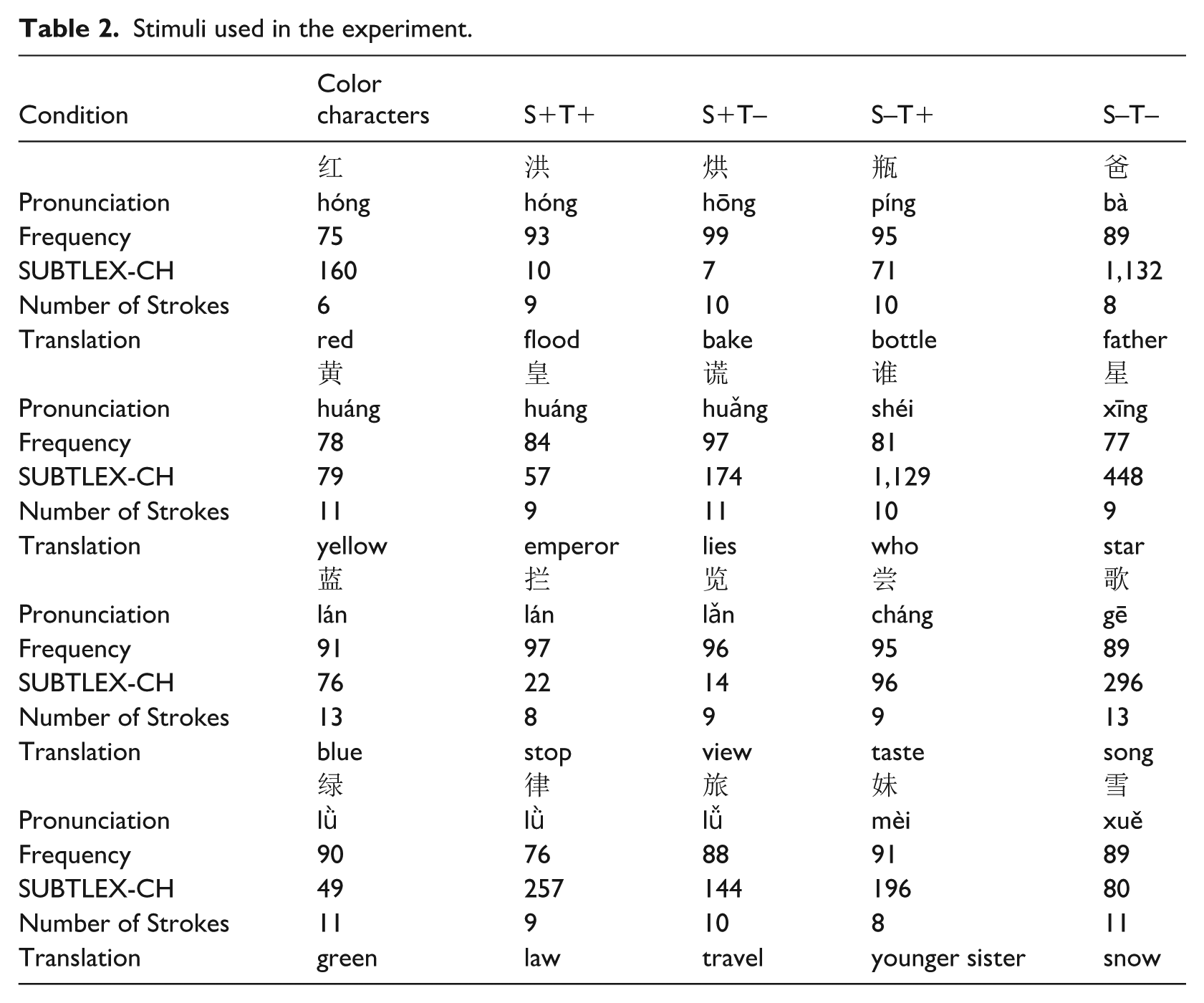
The design of the experiment roughly follows Li et al. (2013) with one minor change—that is, this study did not include filler characters. This was to make sure that the L2 learners were familiar with all the characters used in this study. (Note that Li et al., 2013, only tested native speakers.) In sum, the 20 critical items were used to create six types of stimuli: (1) congruent color characters (CCC; 红, hóng, “red” in red ink); (2) incongruent color characters (ICC; 红, hóng, “red” in blue ink); (3) homophones of the color characters (S+T+; 洪, hóng, “flood” in red ink); (4) different-tone homophones of color characters (S+T–; 烘, hōng, “bake” in red ink); (5) characters that shared the same tone but differed in segments with the color characters (S–T+; 瓶, píng, “bottle” in red ink); and (6) neutral characters (S–T–; 牵, qiān1, “leading through” in red ink). All participants were tested on the same list.
Procedure
The experiment was conducted using DMDX (Forster & Forster, 2003). The participants were asked to fill out a language background questionnaire before proceeding to the formal experiment. Additional questions related to experience learning Chinese were included for L2 learners. In the experiment, the participants were asked to name the ink color of each character as quickly and as accurately as possible. For each trial, a fixation mark “+” appeared in the center of the screen for 500 ms, followed by the target character appearing for 1,000 ms. The target was replaced by the following trial after a naming response was made or after 3,000 ms with no response. There was a 1,000 ms interval between trials. The trials were pseudorandomized such that participants did not see the same color or character consecutively. All experimental stimuli were presented three times. The stimuli in the ICC condition, however, were presented in a different color each time. Eight practice trials preceded the formal experiment. All stimuli were coded in bold Simsun 48-point font on black background such that the ink colors of the experimental characters popped out. Instructions were presented in white. Both the questionnaire and the experiment were in Chinese.
Results
The beginnings of vocal responses were first manually marked using CheckVocal (Protopapas, 2007). Responses, in which the participant did not name either the segmental or tonal information of the ink color correctly, or responses without a clear beginning, were marked as incorrect responses and were not included in the naming latencies/reaction time (RT) analysis. As mentioned earlier, seven participants from the L2 group were excluded from the analysis because their accuracy rate for naming ink colors was lower than 80%. Thus, data from 28 native speakers and 27 L2 learners were included in statistical analyses. (Data and the codes for analysis are available on
Estimated marginal means and standard errors (in parentheses) for the log-transformed RTs in each condition (based on the linear mixed-effects model reported for each region).
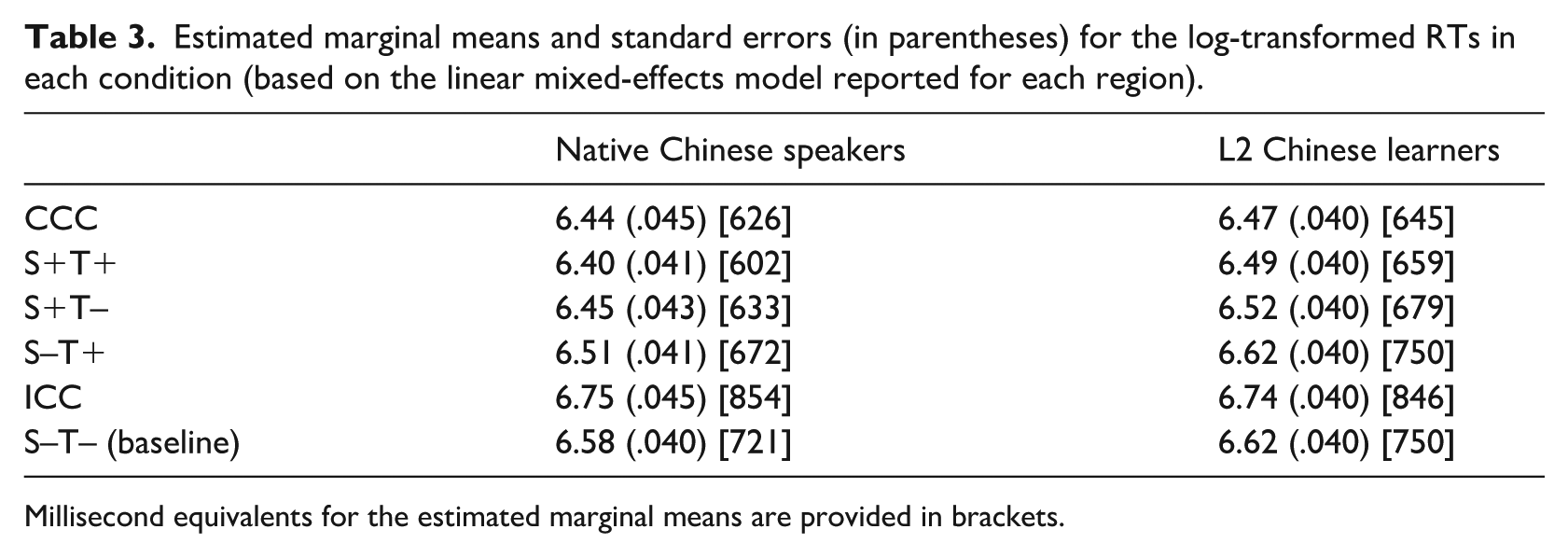
Millisecond equivalents for the estimated marginal means are provided in brackets.
Data for RTs and accuracy rates were analyzed using mixed-effects regression models with the lme4 package (Bates et al., 2015) in R (version 4.2.2; R Core Team, 2022). In the linear mixed-effects for both participant groups, stimuli condition (CCC, ICC, S+T+, S+T–, S–T+, S–T–) was a fixed effect predictor. This factor was treatment coded, with the S–T– condition as the reference level, since this condition served as the baseline condition. The models also included random slopes and intercepts for participants and color whenever possible. When this maximal model (Barr et al., 2013) failed to converge, the random effects structure was simplified until it converged. This was done by eliminating either the by-subjects or by-color random slope, whichever random slope that had the smallest variance. The p-values for these analyses were estimated using Satterthwaite approximation implemented in the lmerTest package (Kuznetsova et al., 2017). Raw RTs were log-transformed prior to analysis to meet the distributional assumptions of the statistical models. The statistical analyses of RTs and accuracy are reported separately for native speakers and L2 learners below. Estimated marginal means and standard errors for these log-transformed RTs were calculated based on the linear mixed-effects model reported for each condition (see Table 3) using the emmeans package (Lenth, 2023).
Native speaker results
The maximal model for the RT data analysis for native speakers failed to converge. As such, the random effect structure was simplified by dropping Condition from the by-color random slope since this random slope had the smaller variance. Significant facilitation was found for four of the five conditions when compared with the baseline S–T– condition in the RT data—specifically, the congruent color characters (CCC) condition (β = –0.14, SE = 0.02, t = –7.73, p < .001); the S+T+ condition (β = –0.18, SE = 0.02, t = –11.89, p < .001); the S+T– condition (β = –0.13, SE = 0.01, t = –8.87, p < .001); and the S–T+ condition (β = –0.07, SE = 0.01, t = –5.60, p < .001). As expected, a significant inhibition was found for the characters in the ICC condition (β = 0.17, SE = 0.02, t = 9.48, p < .001), compared with the S–T– condition. The emmeans further yielded interesting differences between each of the experimental conditions. These comparisons revealed that the S+T+ and S+T– conditions showed a significant difference (β = –0.05, SE = 0.01, t = –4.05, p = .0014). Similarly, the S+T+ condition showed larger facilitation than the S–T+ condition (β = –0.11, SE = 0.01, t = –8.17, p < .001). This indicates that segmental and tonal information independently contribute to the facilitation of S+T+ condition given that this condition showed larger facilitation than S+T– or S–T+ conditions. Interestingly, S+T– condition showed larger facilitation than the S–T+ condition (β = –0.06, SE = 0.01, t = –4.62, p = .0003). These results combined suggest that even in these native speakers, segmental information seems to be more helpful relative to tonal information.
The maximal model for the accuracy data converged. The accuracy analyses did not show interesting differences, except that the ICC condition was responded to less accurately than the reference level, S–T– condition (β = –1.93, SE = 0.83, z = –2.33, p = .0199).
L2 learner results
The maximal model for the RT data analysis for L2 learners failed to converge. Following the same model simplification procedure as above, the random effect structure was simplified by dropping Condition from the by-color random slope since this random slope had the smaller variance. This model also failed to converge, and thus Condition from the by-participant random slope was dropped as well. Results from this model are reported below. Similar to the native speakers’ results, when compared with the baseline condition, the S–T– condition, significant facilitation was found in the CCC condition (β = –0.15, SE = 0.01, t = –9.79, p < .001); the S+T+ condition (β = –0.13, SE = 0.01, t = –8.41, p < .001); and the S+T– condition (β = -0.10, SE = 0.01, t = –6.79, p < .001). Interestingly, the S–T+ condition did not yield any difference relative to its baseline (p = .66). The ICC condition did show significant interference (β = 0.13, SE = 0.02, t = 7.97, p < .001). The emmeans showed that the S+T+ and S+T– conditions showed no difference (p = .56). The S+T+ condition was responded to faster than the S–T+ condition (β = –0.13, SE = 0.01, t = –8.86, p < .001). The S+T– and S–T+ conditions were also responded to in a different way (β = –0.11, SE = 0.01, t = –7.24, p < .001). Unlike native Chinese speakers who computed tonal information even though its impact was smaller than the segmental information, L2 Chinese learners did not show any indication of activating tonal information.
The maximal model for the accuracy data for the L2 learners converged. Similar to the native speaker accuracy data, only the ICC condition showed less accuracy compared with the reference level (β = –1.65, SE = 0.65, z = –2.53, p = .0113).
Discussion
As anticipated, the native Chinese speakers activated both segmental and tonal information automatically. Furthermore, segmental information did not seem to be activated prior to the activation of tonal information with both S+T– and S–T+ conditions showing significant effects. However, segmental information seems to be used primarily over tonal information in native speakers since there was also a difference in facilitation between S+T– and S–T+ conditions. L2 Chinese learners, on the other hand, could only activate segmental information automatically. This confirms Li et al. (2018) findings, that tonal information does not seem to be accessed in L2 learners, and this was the case even when a task that taps into automatic processing was used.
One factor, however, that might have prevented us from reaching the conclusion that L2 learners can activate tonal information sufficiently to observe an effect is that we treated all L2 learners as a homogeneous group. L1 tonal status could have potentially influenced the results. We should note, however, that some studies have divided their L2 learner participants into tonal and non-tonal L1s, and they have failed to find a reliable difference in the performance of L2 tones even in auditory tasks (see, for example, Hao, 2012). As previously mentioned, given that this study examined how segmental and tonal information is processed during visual word recognition of Hanzi, we deemed it unnecessary to divide the L2 group based on the tonal status of these participants’ L1s. This is because none of these participants had L1 that used a morpho-syllabic writing system and was a tonal language. Because the Chinese writing system does not mark segmental or tonal information in each of their characters, it was not clear how the tonal status of L1 could affect the processing of tone during reading. However, based on a suggestion from a reviewer, we decided to conduct a follow-up analysis with the 10 L1 Thai speakers to see if they show any indication of tonal activation, given that Thai is a tonal language as well. The main RT analysis showed no reliable difference, presumably due to the fact that there were only a small number of participants. Interestingly though, emmeans showed a significant difference between the S+T– and S–T+ conditions (β = –0.12, SE = 0.03, t = –4.38, p = .017), suggesting that even for learners of L2 Chinese who come from a tonal L1 have difficulty activating tonal information during the reading of L2 Chinese. However, we believe that this should be taken with a grain of salt. If it were the case that segmental information is primarily activated over tonal information, then we should also find a difference between the S+T+ and S–T+ conditions, but we do not find any difference between these two conditions (p = .21). This makes it difficult to conclude from these speakers.
Another factor that could have influenced our findings is the frequency of the stimuli. There is some variance in the mean frequency of the stimuli in each condition (as mentioned in the Materials section, the mean frequency of stimuli in the S+T+ condition was 87 opm, in the S+T– condition, it was 85 opm, in the S–T+ condition 373 opm, and in the S–T– condition 489 opm). Although S–T+ and S–T– conditions had the highest mean frequency counts, interestingly, these two conditions had the slowest response times in both native and L2 Chinese speakers. We expected that words with higher frequency would yield faster response times, but this was simply not the case. Thus, we can safely assume that the facilitation observed in S+T+ and S+T– conditions (relative to S–T– condition) in native and L2 Chinese speakers and the facilitation obtained in S–T+ condition in native speakers must be due to the shared phonological information, and not because of the frequency variation among the stimuli in each condition. Crucially, the differences in the mean frequency of the stimuli could not be a critical factor that prevented us from observing facilitation in the S–T+ condition in L2 learners.
The last factor that might have prevented us from demonstrating that L2 users could automatically activate tonal information during reading is that we did not independently check whether the L2 learners in our study had at least explicit phonological knowledge of the experimental characters. It is possible that L2 learners did not show evidence of activating L2 tones automatically because they did not know how to pronounce the stimuli presented in this study. This, however, seems to be unlikely for the following reasons. First, as mentioned earlier, when readers learn a new Chinese character, they need to learn both segmental and tonal information. It is difficult to conceive of cases in which they learn only the segmental information, but not the tonal information. In fact, at least in terms of naming ink colors, our participants were capable of using both the segmental and tonal information correctly, such that they were able to perform the task well. If they mispronounced either the segmental and tonal information incorrectly in ink naming, then their responses would have been marked as incorrect. Thus, it is unlikely that the L2 Chinese speakers in our study just did not explicitly know the tones of the characters used in this study, but when it was not necessary to perform the task, they just did not activate such information. Second, several criteria were used for item selection to make sure that our participants know the pronunciation of our stimuli. Given that the L2 learners in our study named the ink colors correctly for the most part both in terms of segments and tones, it is safe to assume that our participants have been able to name the non-color stimuli as well because the frequency of these items were comparable with the color characters. Third, 17 out of 20 stimuli appear in the vocabulary lists for Levels I to V of the HSK test. For the other three stimuli, two characters (洪, hóng, “flood,” an item in the S+T+ condition; 烘, hōng, “bake,” an item in the S+T– condition) appear in the vocabulary of Level VI of the HSK test, and one stimulus (瓶, píng, “bottle,” an item in the S–T+ condition) did not appear in any of the HSK vocabulary list. Given that all but one of our participants have successfully passed Level V of the HSK test, and that they all have lived in China, it seems unlikely that our participants were not aware of the pronunciation of the experimental stimuli. Even if we assume that the L2 learner participants did not explicitly know some of the characters, it is still interesting to see that there was facilitation from the two S + conditions (S+T+ and S+T–), but was not assisted by the S–T+ condition. This further supports the difficulty L2 Chinese learners face when learning to process L2 tones in Chinese.
It might be worth considering here, however, what is meant by “explicit” knowledge of tonal information. As previously mentioned, it seems like L2 learners of Chinese find that perception and production of these tonal information to be generally difficult (see, for example, Hao, 2012; Malins & Joanisse, 2010; Pelzl et al., 2018; Tong et al., 2008; Wang et al., 2015). It is not clear from these studies what the correlation between having explicit knowledge and being able to accurately perceive and produce tones is. Even if one had explicit knowledge of tones, phonological activation during reading might rely more on implicit knowledge, and if so, it is not surprising that we failed to find evidence for the automatic activation of tonal information during reading when these learners have not developed implicit knowledge of such information. Future studies should examine whether automatic activation of tonal information during reading is limited to learners who are able to perceive and produce various tones.
If we assume that our L2 learners had explicit phonological knowledge of the Hanzi stimuli, it is then important to consider why they could not activate tonal information in the same manner as native speakers. It is possible that the L2 proficiency level of these learners was just not high enough. Recall, however, that the learners in this study were all highly proficient in L2 Chinese, because all but one of our participants have passed Level V of the HSK test, which was the same proficiency level as those in Li et al. (2018). What is interesting is that neither Li et al. (2018) participants in their explicit task or our participants in the implicit task were able to access tones when presented with the Hanzi characters. This seems to suggest that there is a disparity in how segmental and tonal information is acquired—both in terms of explicit knowledge and automatic activation during reading even when the L2 proficiency is relatively high. As maintained by Saito (2018), suprasegmental information, specifically tonal information in our study, seems to require more practice in order for learners to be able to process such information.
It is important to consider why using tonal information is difficult even for these highly proficient L2 Chinese learners. According to Taft and Chen (1992), native Chinese speakers have separate implicit representations for segmental and tonal information (for a similar argument, see also Li et al., 2013). Taft and Chen (1992) further maintain that segmental and tonal information only gets integrated when there is vocalization, otherwise these pieces of information remain separate. If this is the case, and segmental and tonal information are indeed separate representations in native speakers, the native speaker findings of this study would also support such an argument. Namely, the native speakers in our study not only were able to access both segmental and tonal information automatically, they also seem to be able to activate these pieces of information independently of one another. That is, both the S+T– and S–T+ conditions showed facilitation. Such findings were obtained probably because the modified Stroop task used in this study does not require the vocalization of the visual stimulus. As such, it was possible for both segmental and tonal information to facilitate the naming of ink colors separately. L2 learners in our study, on the other hand, may not have separate representations for segmental and tonal information. Indeed, facilitation was found in S+T– condition, but not in the S–T+ condition. This might suggest that L2 learners have not fully developed representations for tonal information independently of segmental information in their L2 Chinese. How segmental and tonal information are represented in native speakers and L2 Chinese learners certainly requires further investigation.
For highly proficient L2 Chinese learners, it is also possible that they could have deficits in both the way tonal information is represented, and/or how this information is accessed. (For similar representation/processing contrast in morphological processing, see Jiang, 2004.) Although it seems like these L2 Chinese learners have developed a rich representational system for segmental information, this does not seem to be the case for tonal information. Indeed, Li et al. (2018) argued that tonal information is more poorly represented in non-native Chinese speakers compared with native speakers. Furthermore, it is also possible that these L2 learners have not developed a processing system that allows for tonal information to be activated and used automatically. Indeed, it seems like these L2 learners are selectively relying on segmental information, such that both S+T+ and S+T– conditions yield similar facilitation. This study cannot distinguish whether the locus of the deficit of tonal activation in L2 learners originate at the representational or at the processing level, but it is clear that these learners have developed such a system for computing segmental information. Such dissociation seems to confirm the hypothesis of separate systems in native speakers, as maintained by Taft and Chen (1992). That is, segmental and tonal information seem to develop in a separate manner in L2 learners.
The question remains as to why these L2 learners do not activate tonal information during visual word recognition. It might be more economical to only partially activate phonological information for an L2 in a bilingual. Recall that our participants needed to name the ink color correctly both segmentally and tonally to complete the experimental task. This would suggest that they might have developed some representations for tones in their L2. Despite this, we still did not observe facilitation in the S–T+ condition. Unlike native speakers, who presumably acquired the spoken form of the word prior to the visual form, L2 learners most likely learned both the visual and spoken word forms simultaneously. Somehow, during that learning process, they might have acquired the Chinese language such that they do not activate the entirety of the phonological information during visual word recognition. Given that Hanzi characters do not mark any phonological information, the more efficient way of processing visually presented Chinese words for many L2 learners is to not activate all phonological information, but directly access their meanings. In other words, it might be more economical to only partially activate phonological information during visual word recognition. All in all, it is important to further test why L2 learners do not activate tonal information automatically in reading.
Of course, more studies need to be carried out to test whether such highly proficient L2 learners of Chinese really have explicit tonal knowledge, and just cannot activate such knowledge in an implicit task. This would give us a clearer idea of how tonal information might be represented in these learners, which would also allow us to determine whether the seemingly lack of activation of tonal information is a representational issue or a processing issue.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported in part by the CoLA Dean’s Award for Research, University of Texas at Arlington, USA, awarded to first author, Rongchao Tang.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.