
Abstract
Purpose:
This preliminary study explored patterns of English past tense production, in 10 Spanish-L1-English-L2 dual language learners (DLLs), predicted by Bybee’s usage-based Network Model (NM).
Methodology:
DLLs completed the Test of Early Grammatical Impairment and the semantic and morphosyntax subtests from the Bilingual English-Spanish Assessment (BESA). The Paradis corpus was employed, as a representative corpus, to index English language input among DLLs. Using these data, we examined the relationship between language input (i.e., word and lemma frequencies for verbs) and phonological properties (i.e., stem-final endings corresponding to regular past tense allomorphs) found to relate to past tense production during English second language (L2) acquisition. Connections between English lexical and semantic knowledge and the use of the past tense were also investigated, as research has linked lexical, semantic, and broad grammatical skills during children’s L2 language acquisition.
Data and analysis:
A Friedman test and Kendall’s tau-b correlations were conducted to compare production accuracy between the allomorphs and to determine relationships between language input, phonological properties, lexical-semantic knowledge and English past tense production.
Conclusions:
DLLs produced past tense allomorphs with comparable rates of accuracy. In addition, DLLs’ use of allomorph /d/ positively correlated with their semantic knowledge in English. Relationships between past tense production accuracy, language input, and lexical knowledge were not observed.
Originality:
This study uniquely contributes to our understanding of the potential link between language input, phonological properties, lexical-semantic knowledge and English pasttense marking in dual language learners.
Significance:
These findings extend our understanding of English past tense production during childhood L2 acquisition.
Keywords
Introduction
Extant research suggests that language input (e.g., word and lemma frequencies for verbs; henceforth input) and phonological properties (i.e., stem-final endings corresponding to regular past tense allomorphs) relate to past tense use during English second language (L2) acquisition (Blom & Paradis, 2013). Research also indicates a positive within-language association between lexical, semantic, and broad grammatical skills during L2 acquisition (e.g., Kohnert et al., 2010; Simon-Cereijido & Méndez, 2018). However, the connection between Spanish L1 and English L2 dual language learners’ (DLLs) developing L2 lexical and semantic knowledge and English past tense marking, a fundamental aspect of verb morphology, is less understood. To better understand patterns of language use and factors critical for English past tense production among DLLs, we examined past tense learning predictions purported by Bybee’s usage-based Network Model (NM; Bybee, 2008). By examining past tense use in the context of the NM model, this preliminary investigation serves as an initial step in exploring potential connections between input, phonological properties, lexical-semantic knowledge, and past tense production in a small sample of Spanish-speaking children learning English as a L2.
Bybee’s NM and the Relationship Between English L2 Input and Past Tense Marking
According to the NM, regular (e.g., lifted) and irregular (e.g., wrote) past tense verb acquisition depend on the lexical strength of a word (Blom et al., 2012). Lexical strength can be considered a measure of the “processing load” associated with a word (Blom et al., 2012). For verbs, each exposure to a verb provides an imprint in the lexicon and increases the verb’s lexical strength. Regularly encountered verbs become more deeply rooted in the lexicon and, in turn, have greater lexical strength. The NM also indicates that lexical representations, distinct forms of words, are stored as unique, mono- or multimorphemic entities in the lexicon. For instance, the lexical representations “lift,” “lifted,” and “lifting” would each be considered distinctive phonological-semantic entries in the lexicon. Given that “lifted” and “lifting” each consist of more than one morpheme, the presence of these entities in the lexicon would be exemplars of multimorphemic storage (Blom et al., 2012).
In the NM, token- and type-based learning have an important role in establishing and bolstering the productive and accurate use of morphological forms (Blom & Paradis, 2013). These aspects of learning are commonly indexed by the input properties of token and type frequency. Token frequency is a raw count of the total number of times that a linguistic form (e.g., a verb’s frequency of use) occurs in the input, whereas type frequency, another frequency count, denotes the total unique occurrences of a particular linguistic form or pattern (Berg, 2014; Blom et al., 2012; Jacobson & Yu, 2018). For example, this could include the number of distinct past tense forms; that is, the “number of verbs with –ed endings” (Jacobson & Yu, 2018).
Because of multimorphemic storage and an individual’s proposed sensitivity to frequency, it is expected that a word present in the input more frequently, with a greater token or word frequency, would be produced more accurately by those acquiring the language. In contrast, a word with low token or word frequency would be more inclined to errors (Blom et al., 2012). In line with the NM and in the case of the past tense –ed, the number of distinct word roots or lexemes (e.g., paint, brush, kick, clean) with which the –ed inflection is used denotes the type frequency for this grammatical form (Blom & Paradis, 2013). For example, painted, brushed, kicked, and cleaned depict four unique types for the past tense –ed.
Bybee (2001) characterized the emergence of morphological structure such as the past tense as schematization. A schema concerns the manner in which linguistic components are stored (Bybee 2001). Blom and Paradis (2013) suggested that a schema for a morphological structure with several different word stems in the input would have a high type frequency, which is also associated with productivity (i.e., a function of the similarity among the words in a schema) and the likelihood that a schema will apply to novel words. In the case of regular past tense allomorphs (i.e., /ɪd/, /t/ and /d/), because allomorphs /t/ and /d/ occur more frequently as representations of the past tense compared to allomorph /ɪd/ in English, the former allomorphs are considered to have higher type frequency (Blom & Paradis, 2013). Together, these patterns suggest that word and type frequencies would affect DLLs’ accurate use of regular and irregular past tense forms (Blom & Paradis, 2013).
Blom and Paradis (2013) investigated predictors of the accurate use of regular and irregular past tense forms in the context of L2 acquisition according to the NM (Bybee, 2007). Participants included 5- and 6-year-old DLLs, with varying language-learning ability (i.e., developmental language disorder 1 and typical language development) and L1 backgrounds, who were learning English as a L2. DLLs completed the past tense probe from the Test of Early Grammatical Impairment (Rice & Wexler, 2001). Along with word frequency, lemma frequency also predicted DLLs’ production accuracy for irregular past tense forms. Blom and Paradis suggested these outcomes aligned with predictions that follow from the NM. Collectively, these findings highlight word and lemma frequencies as being among the factors that are important for L2 past tense production.
Phonological Properties and English L2 Past Tense
For regular verbs, past tense marking is realized by distinct phonological forms referred to as allomorphs. The allomorphs of past tense –ed include /t/, /d/, and /ɪd/ and are distributed in English according to the context in which they occur (Carstairs-McCarthy, 2002). When a verb ends in an alveolar stop (/t/ or /d/), the allomorph /ɪd/ is utilized. The allomorph /t/ occurs with verbs that end in a voiceless consonant. Allomorph /d/ appears most frequently in the language and is used to mark the past tense on all other verbs, particularly those ending in a vowel or a voiced consonant. Table 1 depicts the phonological contexts in which allomorphs occur in English.
Examples of the Phonological Contexts of the English Past Tense Allomorphs.

Blom and Paradis also found that allomorph type correlated with and contributed to the variation in the accurate use of (regular) past tense forms. Moreover, the investigators applied the NM to determine whether the phonological properties of verb stems, corresponding to the regular past tense allomorphs, affected past tense production during L2 English learning and suggested that each allomorph type had a distinct schema with its own strength, based on word frequency, type frequency, and variability of the schema. In contrast, English irregular past tense acquisition was suggested to largely rely on word frequency (Blom & Paradis, 2013).
Though unique characteristics of each allomorph were discussed, Blom and Paradis (2013) suggested that these forms were interrelated given their mutual past tense meaning. Study results indicated a phonological effect for regular and irregular past tense production. Namely, regular past tense marking was omitted after alveolar stops more regularly, resulting in the omission of the allomorph /ɪd/ more often relative to allomorphs /t/ or /d/. Furthermore, DLLs used allomorph /d/ most accurately and irregular verbs with /t/ or /d/ stem-final endings were overregularized less frequently compared to other irregular verbs.
Overall, the differential production accuracy of allomorphs was taken to suggest that DLLs’ regular past tense schemas were in the process of developing, and that the omission of allomorph /ɪd/ occurred most frequently because their schemas identified verbs ending in /t/ or /d/ as permissible past tense forms. In addition, the use of this type of schema was suggested as being substantiated by DLLs’ use of overregularizations less often when irregular verbs had /t/ or /d/ endings (Blom & Paradis, 2013). The researchers also proposed that the observed patterns of allomorph use may be explained by type frequency. Specifically, the production accuracy for allomorph /d/ may have been related to its high type frequency in the input and used by DLLs to link verbs requiring allomorph /d/ and, in turn, create a schema (Blom & Paradis, 2013). Jointly, these findings reveal the importance of examining the phonological properties of verbs when investigating factors related to past tense production during English L2 acquisition.
Lexical and Semantic Knowledge and L2 Grammatical Skills in DLLs
Research indicates a cross-domain relationship between L2 semantic and grammatical skills among DLLs (e.g., Simon-Cereijido & Méndez, 2018). For instance, Simon-Cereijido and Méndez (2018) investigated the connection between lexical (language-specific and conceptual [bilingual] vocabulary) and grammatical skills of young Latino DLLs at the start of preschool with typical language development. DLLs in the study ranged in age from 47 to 58 months (Mage = 4 years; 5 months) and spoke Spanish, as an L1, and no or limited English per parent interview, teacher report, and conversational sample. Language proficiency in Spanish and English was determined by information gathered from parent and teacher questionnaires and classroom observations. Parents and teachers rated English proficiency lower than Spanish proficiency using Gutiérrez-Clellen and Kreiter’s (2003) Likert-type scale that ranged from 1 (minimal ability) to 5 (native ability). Parents’ mean ratings of DLLs’ English receptive and expressive skills were 3.14 (SD = .98) and 2.61 (SD = .70), respectively. Similarly, teachers rated English proficiency as 2.17 (SD = 1.09) on average based on DLLs’ classroom interactions with teachers, assistants, and peers.
To index receptive and expressive semantic knowledge, DLLs completed the Spanish semantic subtest of the Bilingual English-Spanish Assessment (BESA; Peña et al., 2014). The researchers discussed the subtest as a bilingual measure that permitted semantically appropriate responses in Spanish and English. Simon-Cereijido and Méndez suggested that assessment measures such as the BESA that involve making comparisons between objects and categorizing items, among other semantic tasks, allow responses in Spanish and English and tap into the depth of children’s bilingual semantic knowledge. Using a series of hierarchical linear regressions, the researchers found that Spanish lexical variables explained 16% of the variance in DLLs’ strong language, Spanish. However, semantic (bilingual) skill was also a significant predictor and explained an additional 8% of the variance in DLLs’ grammatical performance in Spanish, which was indexed with a sentence repetition task. In addition, English vocabulary was revealed as the strongest predictor of grammatical skill in English.
Based on the semantic-grammatical association observed in Spanish, the investigators posited that semantic skill has a greater effect on grammatical performance as levels of proficiency increase. Moreover, this relationship suggests that, along with lexical skill (i.e., language-specific and conceptual vocabulary), semantic knowledge may also relate to DLLs’ grammatical skill in English as their English semantic skills increase. It also highlights the need to examine the relationship between semantic and grammatical knowledge further among DLLs, specifically those who are at later points in their L2 learning and may have greater language proficiency in their L2, English. In addition, these findings also raise questions about the precise nature of the semantic-grammatical link, such as whether this connection can be attributed to task-specific properties or more generally results from the interconnectedness of these domains of language.
To refine our understanding of the development of these linguistic domains as factors relevant for past tense production during English L2 acquisition, we explored the relationship between DLLs’ semantic knowledge, as assessed by the English semantic subtest of the BESA, and their English past tense use in early elementary grades. Thus, this study extends our understanding of factors that may relate to regular and irregular past tense learning according to Bybee’s NM, and explores potential connections between input, phonological properties, lexical-semantic knowledge, and past tense production in a small sample of Spanish-English DLLs learning English as a L2.
This work was guided by two research questions:
We postulated that DLLs would produce allomorph /d/ with greater accuracy than allomorph /t/ followed by allomorph /ɪd/. This prediction aligns with child L2 research showing a phonological effect on regular and irregular past tense production, with allomorphs /t/ and /d/ produced more accurately compared to /ɪd/ and overregularized less often as stem-final endings than other irregular past tense forms (Blom & Paradis, 2013).
Method
Participants
Ten Spanish-English DLLs in kindergarten and first grade (seven females; three males) who ranged in age from 62 to 82 months (M = 71.40 months, SD = 6.00 months) were recruited from community organizations and elementary schools in central Indiana and North Carolina. DLLs began acquiring English after the age of 3 in their educational settings (i.e., preschool or elementary school). 2 At the time of the study, on average, children had been exposed to formal English instruction for 2 years and eight out of ten of them were receiving English as a second language (L2) services. In addition, children came from families with varied Spanish-speaking countries of origin (i.e., Dominican Republic, Guatemala, Honduras, Mexico, and El Salvador) and resided in homes in which one or both parents were born in Spanish-speaking countries and immigrated to the United States as adults.
Inclusionary Criteria
The first author, a speech-language pathologist with experience assessing young Spanish-English DLLs, screened participants’ general cognitive skills and identified their language-learning ability. The author learned Spanish as a second language and used Spanish in the home environment with Spanish first language learners for about 25% of a typical week for more than 6 years before the study. DLLs in the investigation presented without a known diagnosis of intellectual or learning disability, and/or a disorder affecting language comprehension.
Participants’ language-learning ability was identified with converging evidence from the Spanish and English semantic and morphosyntax subtests and the home survey of the Instrument to Assess Language Knowledge (ITALK) from the BESA. DLLs’ standard scores on the BESA subtests were interpreted using the age- and subtest-specific cutoff scores and the 95% confidence intervals provided in the BESA manual. The confidence intervals of DLLs’ standard scores on the Spanish and/or English semantic and morphosyntax subtests fell above the cutoff scores for each respective subtest, except for one participant. 3
The ITALK, a home language questionnaire from the BESA, was employed to further assess DLLs’ language proficiency and skills. Using the ITALK, the first author interviewed parents about DLLs’ relative vocabulary, phonology, sentence production, grammar, and comprehension skills, in Spanish and English, and concerns about DLLs’ language and/or speech development. Participants’ parents reported no concerns about their children’s expressive and receptive language skills. The subtests of the BESA and the ITALK were scored following the procedures in the BESA manual. DLLs also exhibited no elevated risk of cognitive impairment as determined by a screening with the Matrix subtest of the Kaufman Basic Intelligence Scale (KBIT-2; Kaufman & Kaufman, 2004). Moreover, all DLLs passed a pure-tone hearing screening bilaterally at 20 dB at 500 Hz, 1,000 Hz, 2,000 Hz, and 4,000 Hz, completed prior to the start of testing, earlier during the academic year at the children’s schools, or by their primary care providers. In addition, all DLLs exhibited the ability to produce the phonological structures required to produce English past tense morphemes. The DLLs in this study participated in Jenkins and Anderson (2021), which examined different research questions.
Language Exposure
The first author used the Bilingual Input-Output Survey (BIOS-Home) from the BESA to interview parents about DLLs’ language history. Parents provided information regarding when (i.e., from birth to participants’ age at the time of testing) and in what environments (i.e., home and school) DLLs had used Spanish and English on a yearly basis. At the outset of the study, DLLs had 1–3 years of exposure to English through formal instruction in preschool, kindergarten, and/or first grade. Moreover, the Home Language Profile/Familial Routine from the BIOS-Home was used to gather information about DLLs’ language input and output during a typical school and weekend day on an hourly basis. Per parent report, on average, DLLs were exposed to English for 2 years and at school through formal instruction at the onset of the study. Table 2 provides a descriptive overview of DLLs’ months of English exposure, current language input and language output in the home at study outset, and English semantic subtest scores.
Characteristics of the DLLs.

Note. Exposure to English = exposure to English in months, Spanish input and output = mean percentage of Spanish input and output in the home at testing, English input and output = mean percentage of English input and output in the home at testing.
Measures
In this study, relationships between past tense marking, including regular past tense allomorphs and irregular forms, lexical and semantic knowledge, and input properties were analyzed in English. The dependent variables employed in this investigation included (a) allomorph accuracy scores and irregular past tense accuracy scores across participants and (b) mean percentage of correct use scores across regular and irregular verbs. The independent variables included DLLs’ standard scores on the English semantic subtest, number of different verbs (NDV) used in narrative retell language samples, and word and lemma frequency metrics for target verbs.
English Past Tense Marking
Test of Early Grammatical Impairment
The dependent variables were derived from participants’ use of regular and irregular past tense forms and elicited with the past tense probe of the Test of Early Grammatical Impairment (TEGI; Rice & Wexler, 2001). This probe has been utilized in previous studies examining the production of finite verb morphology in children learning English as an L2 and was found to be an effective task for eliciting the use of English past tense forms (e.g., Paradis, 2005, 2016). The researchers administered the past tense probe following the procedures outlined in the TEGI manual. DLLs’ responses to probe items were scored as correct, incorrect, or unscorable according to the guidelines provided in the manual. Table 3 provides a description of the past tense probe and examples of probe items.
TEGI Past Tense Probe.
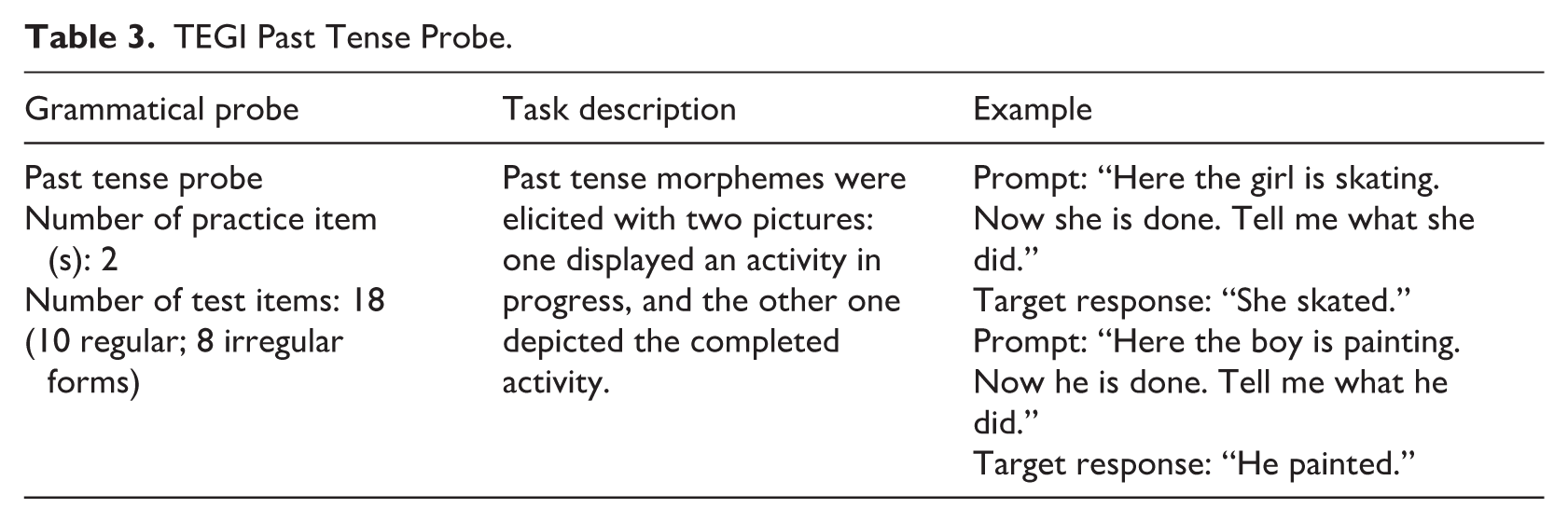
Occasionally, DLLs used other verbs (i.e., finished and scooted) than those targeted by the TEGI. Such verbs were scored as described above and included in later analyses. Altogether, the DLLs used 12 regular and 8 irregular unique verbs, which are provided in Appendix 1. In line with the TEGI guidelines, scorable responses included target like (e.g., brushed, blew), zero-marked (e.g., kick, jump), and overregularizations (e.g., digged, writed); other responses were considered unscorable (e.g., jumps for jumped; was lifting for lifted). DLLs produced 136 scorable responses and 30 unscorable responses on the past tense probe. The use of regular and irregular past tense forms was indexed by allomorph and irregular past tense accuracy scores, respectively. These scores reflected the correct use of target regular and irregular past tense verbs from the TEGI and other accurately produced past tense verb forms. We computed accuracy scores by dividing the total number of correct uses of target past tense forms by the total number of correct and incorrect uses.
Language Input Properties: Word Frequency and Lemma Frequency
The Paradis corpus served as a reference corpus in the current investigation because it included data from L2 learners who were in the early process of acquiring English formally in their educational settings. The word and lemma frequency measures employed to index lexical properties of English input in our study were derived from the Paradis corpus data. Specifically, these measures were calculated from conversation language samples, which included samples obtained from 25 children learning English as an L2, for five rounds of data collection for 19 of the 25 children, at 6-month intervals, over the course of 2 years (Paradis, 2005). Six children included in the corpus were Spanish first language (L1) learners and enrolled in kindergarten and first grade at study onset.
Description of Paradis Corpus
Children included in the corpus started learning English as an L2 after their L1 had been largely established. At the study outset, they lived in Edmonton, Canada, an English-majority city, and were 5 years and 6 months of age on average. Children spoke a variety of L1s, and those children born in Canada were almost exclusively exposed to their home language, with 9.5 months of exposure to English in preschool or elementary school. Per parent report, children did not receive constant exposure to English until they began preschool or elementary school (for a complete description of study procedures, see Paradis, 2005).
English-speaking research assistants obtained language samples from children during conversation using a list of interview questions. Conversations between children and research assistants were approximately 45 minutes in duration and were videotaped and subsequently transcribed. Research assistants morphologically tagged transcriptions in the Codes for the Human Analysis of Transcripts (CHAT) coding system using the Computerized Language Analyses (CLAN) software (MacWhinney, 2008b). In total, 105 language samples were available in the corpus. Participant characteristics are depicted in Table 4.
Paradis Corpus Characteristics for All Participants and the Subgroup of Spanish L1 Learners.
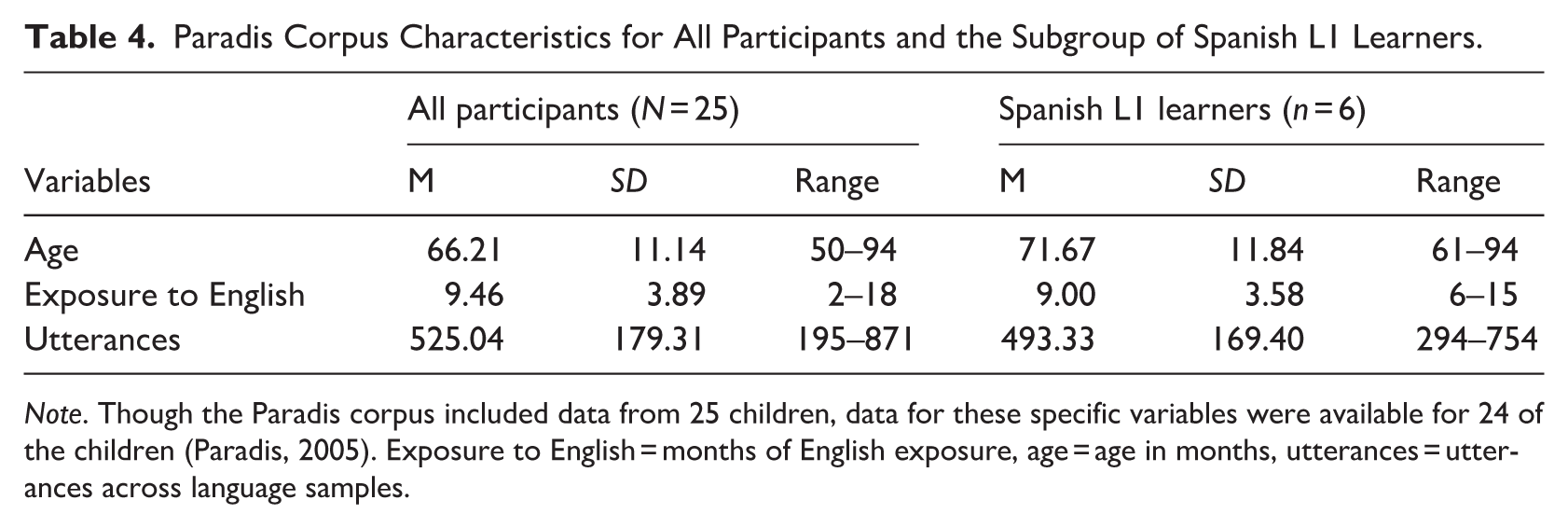
Note. Though the Paradis corpus included data from 25 children, data for these specific variables were available for 24 of the children (Paradis, 2005). Exposure to English = months of English exposure, age = age in months, utterances = utterances across language samples.
Our Analysis of the Paradis Corpus Language Samples
Using the conversation language samples from all five rounds of data collection included in the Paradis corpus, we conducted a morphosyntactic analysis in CLAN to later compute word and lemma frequencies similar to the procedures followed by Blom and Paradis (2013) to calculate word frequency and lemma frequency metrics. The morphological tagging procedure used in the analysis did not generate tags for nontarget forms and therefore overregularized and double-marked past tense forms, and were not included in the frequency counts. Subsequently, we recorded word frequency and computed lemma frequency counts for each verb produced in the language samples to generate frequency lists. Word frequency was the total number of past tense forms of a given verb (range = 0–528) in the Paradis corpus. Lemma frequency (range = 1–3,254) was the sum of all the inflected forms of a verb in the corpus, including bare stems (e.g., “jump”), inflected –ed (e.g., “jumped”) and –s forms (e.g., “jumps”), past participles (e.g., “jumped”), and progressive participles (e.g., “jumping”). The transcriptions analyzed in the current study consisted of 732,617 words.
Phonological Properties of Past Tense Marking: Regular Past Tense Allomorphs
DLLs’ correct use of regular past tense forms on the TEGI past tense probe were coded and analyzed for the correct use of the three stem-final endings corresponding to the English regular past tense allomorphs: /ɪd/ for verbs ending in an alveolar stop (i.e., paint, lift, plant), /t/ for verbs ending in a voiceless consonant (i.e., brush, kick, jump, pick), and /d/ for all other regular verbs (i.e., clean, climb, tie). Accuracy scores for allomorphs /ɪd/, /t/, and /d/ were calculated by dividing the total number of correct uses of each allomorph by the total number of correct and incorrect uses. The variation in past tense production among allomorphs relates to the first research question addressed in this investigation.
English Lexical and Semantic Knowledge and the L2 Past Tense
Narrative Retell Language Samples
In the current investigation, an analysis of the narrative retell language samples collected in Jenkins and Anderson (2021) was examined with different research questions to obtain information about DLLs’ English lexical knowledge, which is important for our second research question. Specifically, the NDV was used as a gross measure of participants’ verb knowledge, as verb vocabulary has been associated with English tense production (Blom et al., 2012). Though the language samples were elicited in English, English and Spanish verbs were included in the NDV metric, given that DLLs in the study were acquiring their languages in a bilingual context in the United States.
DLLs provided the narrative retells during a story-retell task based on the wordless picture book Frog Goes to Dinner (Mayer, 1974). During the task, they viewed the book while they listened to a pre-recorded English narration of the story (Miller & Iglesias, 2017). Subsequently, participants retold the story while they viewed the book. The first author provided DLLs with neutral verbal prompts, such as Mmhmm, What else happened, Tell me more), as required, to support adequate sampling of their language.
Research assistants and the first author transcribed and coded the retells with the Systematic Analysis of Language Transcripts (SALT 18) software (Miller & Iglesias, 2017). We employed the transcription conventions provided in the SALT reference book (Miller et al., 2015). Participants produced a mean of 33 complete and intelligible utterances across the narrative retells, with a range of 24–40 utterances. In the current study, we used SALT 20 to determine the NDV that DLLs produced in their utterances that were complete and intelligible.
Bilingual English-Spanish Assessment
DLLs’ standard scores from the English semantic subtest were used as a gross index of the depth of their semantic knowledge in English. Using the English semantic subtest, participants’ expressive and receptive semantic abilities were evaluated across a variety of knowledge criteria: (i) linguistic concepts (color, number, shape), (ii) similarities/differences (making comparisons among objects), (iii) categorization (naming or identifying items by category), (iv) characteristic properties (describing objects), (v) functioning word associations (naming or identifying how pictured items are used), (vi) analogies (explaining or pointing to the relationship between objects, and short passages), and (vii) responding to “wh” questions about objects or actions of characters. The English semantic subtest scores were derived from the sum of correct items and scored according to the BESA manual.
Data Collection Procedures
The study was reviewed and approved by the Institutional Review Board at Indiana University Bloomington. The first author gathered data over the course of four testing sessions. During the initial sessions, participants completed a hearing screening and the measures from the BESA and KBIT-2. In the sessions that followed, participants completed the past tense probe from the TEGI. All testing was conducted in a quiet room in DLLs’ schools or homes and audio recorded for later reliability checks.
Inter- and Intra-Rater Reliability
To establish the inter- and intra-rater reliability of scoring and coding accuracy, 20% of the English semantic subtests and past tense probes were randomly selected and independently scored and/or coded by a research assistant as a second rater or judge. If differences in scoring and/or coding occurred, they were resolved through discussion prior to further analysis. Two-way mixed effects, consistency single score models of the intra-class correlation coefficient (ICC) were employed to compute estimates of reliability. The inter- and intra-reliability ICC agreement values for all the variables of interest ranged from .833 to 1.00. Thus, all the inter- and intra-reliability ICC agreement values fell within the scope of excellent reliability (between .75 and 1.00; Cicchetti, 1994).
Data Analyses
Prior to performing our statistical analyses, we screened the data for normality and linearity.
Visual inspection of the data indicated linear relationships between the variables of interest. Kurtosis was observed in the data, which indicated a slight deviation from normality. Nonparametric statistical tests were used in the analyses that followed to estimate the properties of the sampling distribution from the data. Specifically, we conducted a Friedman test and Kendall’s tau-b correlations.
Results
Descriptive and Inferential Statistics
A Friedman test was performed to compare production accuracy between the allomorphs. Subsequently, Kendall’s tau-b correlations were performed to determine relationships between DLLs’ (i) chronological age, (ii) English exposure, (iii) lexical measure (number of different verbs), (iv) semantic measure (English semantic score), (v) irregular past tense accuracy scores, and (vi) allomorph accuracy scores across participants. To examine the relationship between English input measures and production accuracy across verbs, we also conducted Kendall’s tau-b correlations between the mean percentage of correct use scores for regular and irregular verbs and word and lemma frequencies across verbs. Descriptive statistics for the lexical, semantic, and irregular and regular past tense measures are displayed in Table 5.
Descriptive Statistics for the Number of Different Verbs, English Semantic Scores, Irregular Past Tense Accuracy Scores, and Allomorph Accuracy Scores Across Participants.
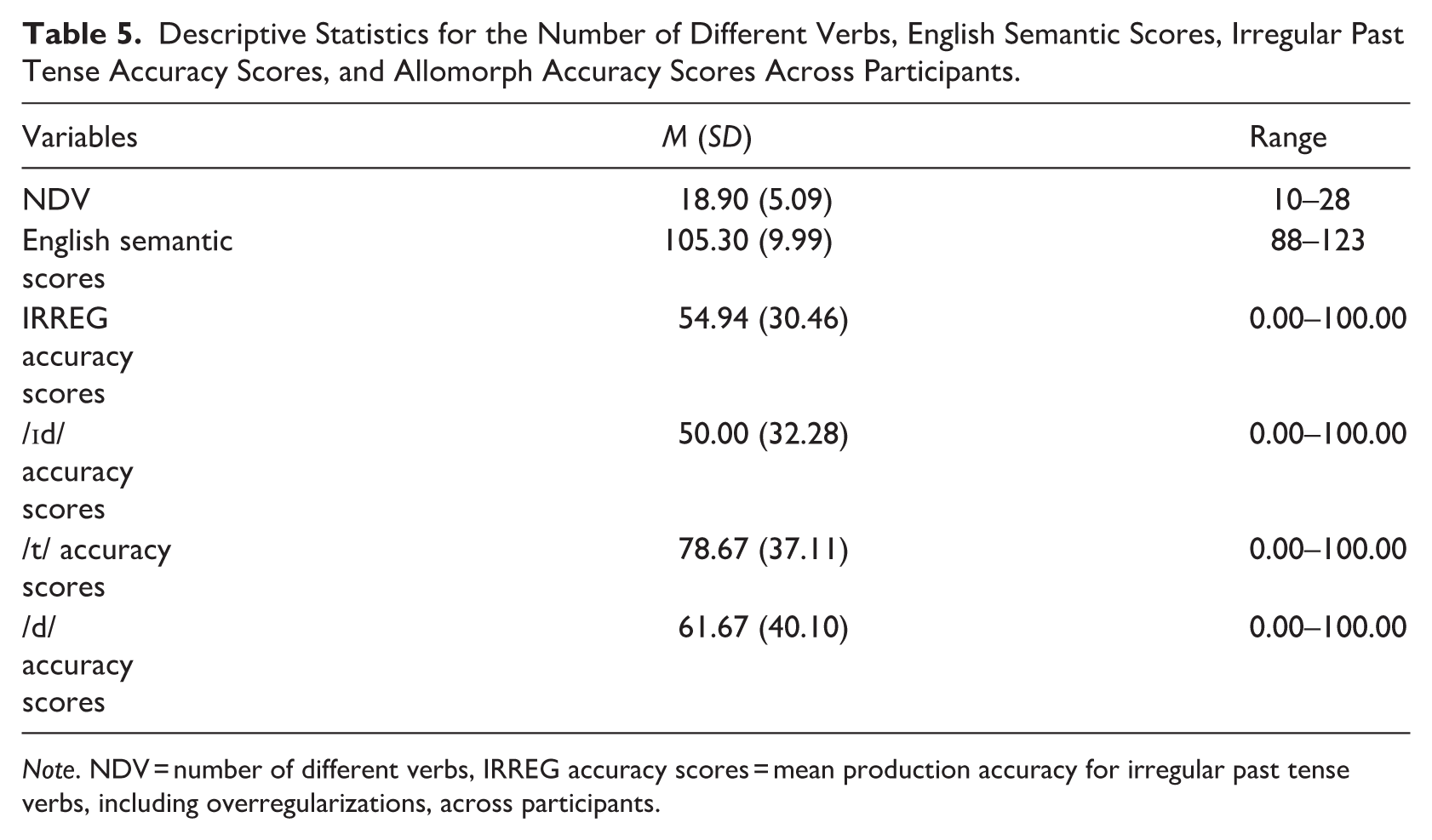
Note. NDV = number of different verbs, IRREG accuracy scores = mean production accuracy for irregular past tense verbs, including overregularizations, across participants.
The descriptive statistics for the mean percentage of correct use scores for verbs and input measures are presented in Table 6.
Descriptive Statistics for Mean Percentage of Correct Use Scores and Word and Lemma Frequencies for Regular and Irregular Past Tense Verbs.
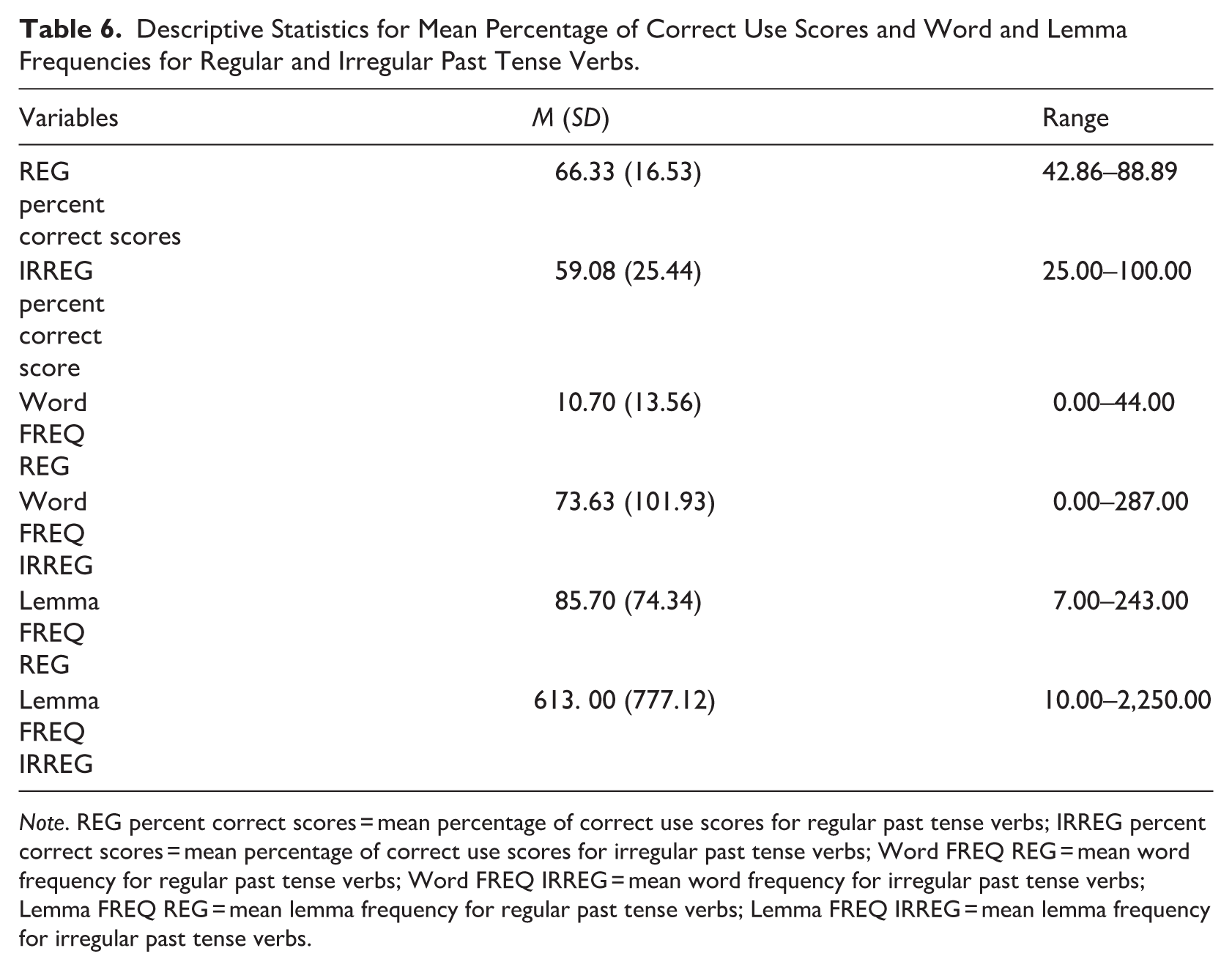
Note. REG percent correct scores = mean percentage of correct use scores for regular past tense verbs; IRREG percent correct scores = mean percentage of correct use scores for irregular past tense verbs; Word FREQ REG = mean word frequency for regular past tense verbs; Word FREQ IRREG = mean word frequency for irregular past tense verbs; Lemma FREQ REG = mean lemma frequency for regular past tense verbs; Lemma FREQ IRREG = mean lemma frequency for irregular past tense verbs.
Allomorph Production Accuracy
Friedman Test
The Friedman test compared the production accuracy between the regular past tense allomorphs. No statistically significant differences were found between the accuracy scores for the /ɪd/ (Mdn = 50.00), /t/ (Mdn = 100.00), or /d/ (Mdn = 66.67) allomorphs, z = 2.70, p = .26, suggesting that this group of DLLs produced all regular past tense allomorphs with similar rates of accuracy.
Relationships Between Lexical and Semantic Knowledge, Irregular Past Tense Marking, and Regular Past Tense Allomorphs
Zero-Order Correlations
We performed Kendall’s tau-b correlation analyses to explore associations between DLLs’ English lexical and semantic knowledge and production of irregular past forms and regular past tense allomorphs, along with their age and English language exposure. The following variables were included in our first correlation analysis: (i) age (in months), (ii) English exposure (in months), (iii) NDV, (iv) English semantic scores, (v) irregular past tense accuracy scores, (vi) /ɪd/ accuracy scores, (vii) /t/ accuracy scores, and (viii) /d/ accuracy scores. A scatterplot matrix displaying these relationships is depicted in Figure 1.
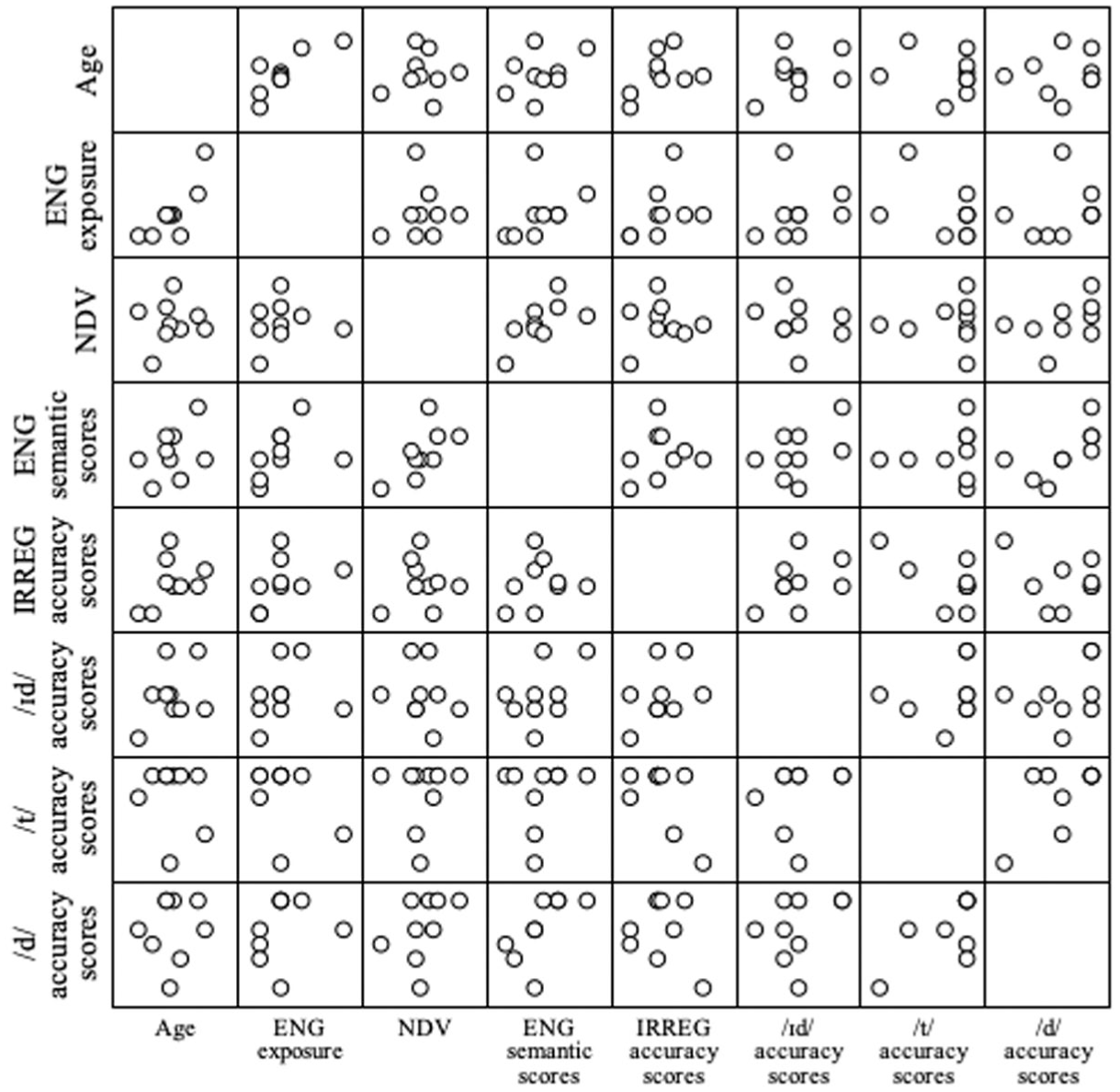
Relationships between age, English exposure, number of different verbs, semantic scores, irregular past tense accuracy scores, and regular past tense allomorph accuracy scores.
Statistically significant positive correlations were revealed between (i) English exposure and English semantic scores, (ii) number of different verbs and English semantic scores, and (iii) English semantic scores and /d/ accuracy scores. The moderate, positive relationships that surfaced in these analyses suggested that greater English exposure was associated with greater semantic knowledge, as would be expected. In addition, greater use of different verbs related to greater English semantic scores and greater English semantic scores correlated with more accurate production of allomorph /d/.
No statistically significant correlations were found between (i) number of different verbs, (ii) irregular past tense accuracy scores, (iii) /ɪd/ accuracy scores, and (iv) /t/ accuracy scores. In addition, no statistically significant correlations were found between (i) English semantic scores, (ii) irregular past tense accuracy scores, (iii) /ɪd/ accuracy scores, (iv) /t/ accuracy scores or (v) between the variables of interest and the background variables. Kendall’s τ correlation coefficients for the associations between these variables are presented in Table 7.
Zero-Order Correlation Between English Semantic Knowledge, Irregular Past Tense Marking, and Regular Past Tense Allomorph Scores for the DLLs (N = 10).
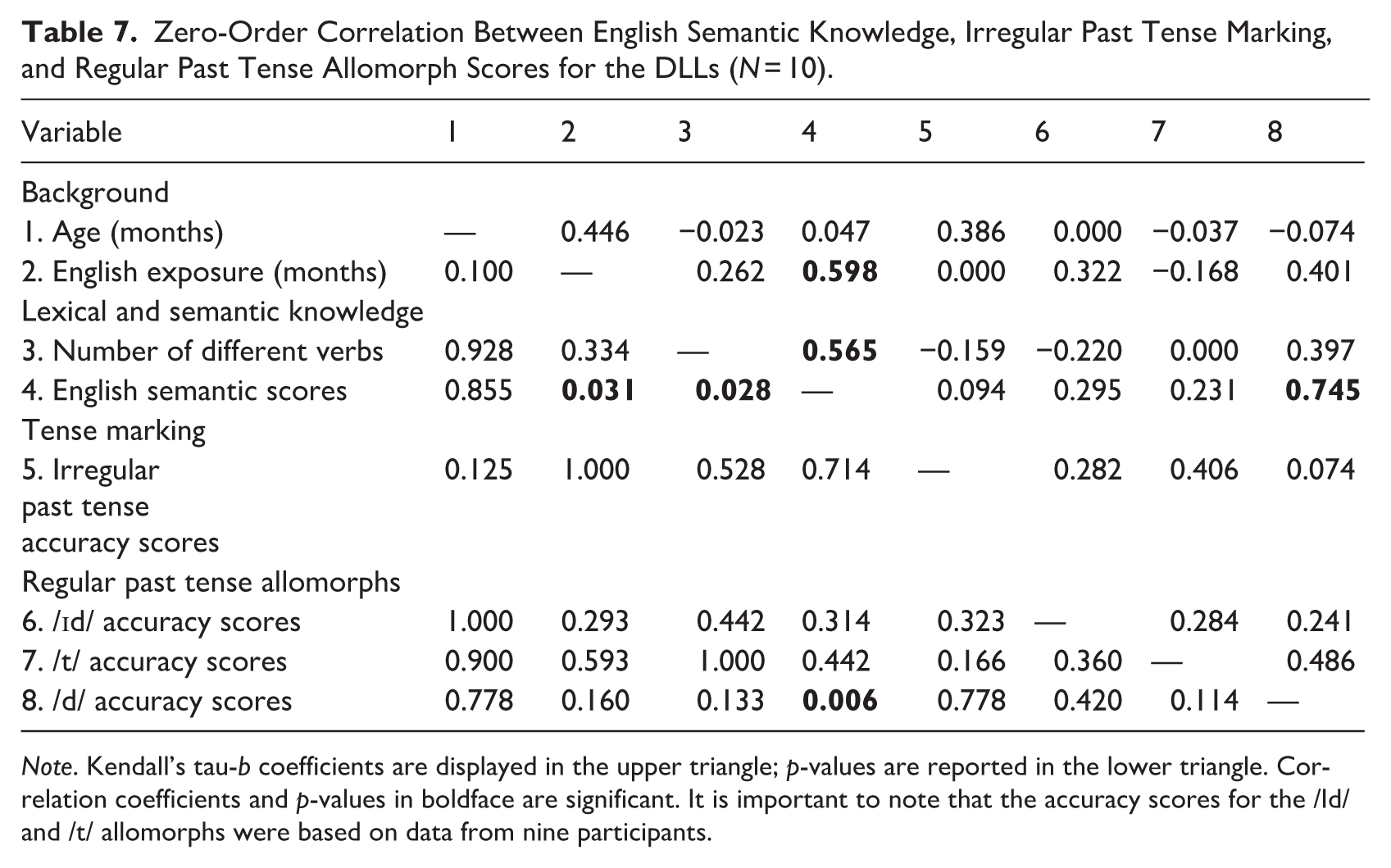
Note. Kendall’s tau-b coefficients are displayed in the upper triangle; p-values are reported in the lower triangle. Correlation coefficients and p-values in boldface are significant. It is important to note that the accuracy scores for the /Id/ and /t/ allomorphs were based on data from nine participants.
Partial Correlations
Kendall’s tau-b, two-tailed, partial correlations were performed to determine whether the observed positive correlation between English semantic scores and /d/ accuracy scores persisted when DLLs’ chronological age, English exposure, and NDV were controlled. After controlling for age, a statistically significant positive correlation persisted between the English semantic scores and the /d/ accuracy scores, τb = .75, p = .02. In addition, a statistically significant, positive correlation remained between the English semantic scores and /d/ accuracy scores when adjusted for English exposure, τb = .688, p = .04 and subsequently for NDV, τb = .687, p = .04.
Word and Lemma Frequencies and Past Tense Marking
Our second correlation analysis examined relationships between the (i) mean percentage of correct use scores for regular past tense verbs, (ii) mean percentage of correct use scores for irregular past tense verbs, (iii) word frequency for regular verbs, (iv) word frequency for irregular verbs, (v) lemma frequency for regular verbs, and (vi) lemma frequency for irregular verbs. Scatterplots displaying these relationships are depicted in Figures 2 and 3.
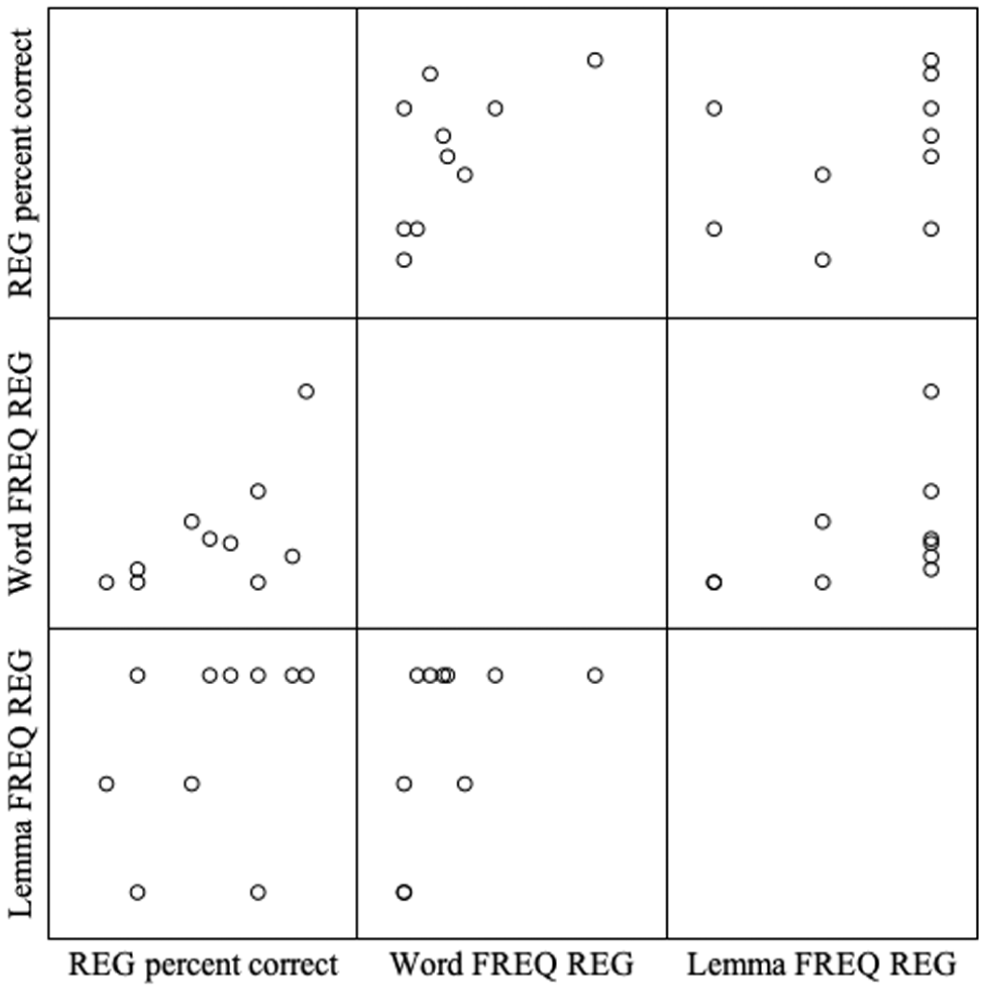
Correlations among mean percentage of correct use scores for regular past tense verbs and mean word and lemma frequencies across regular verbs.
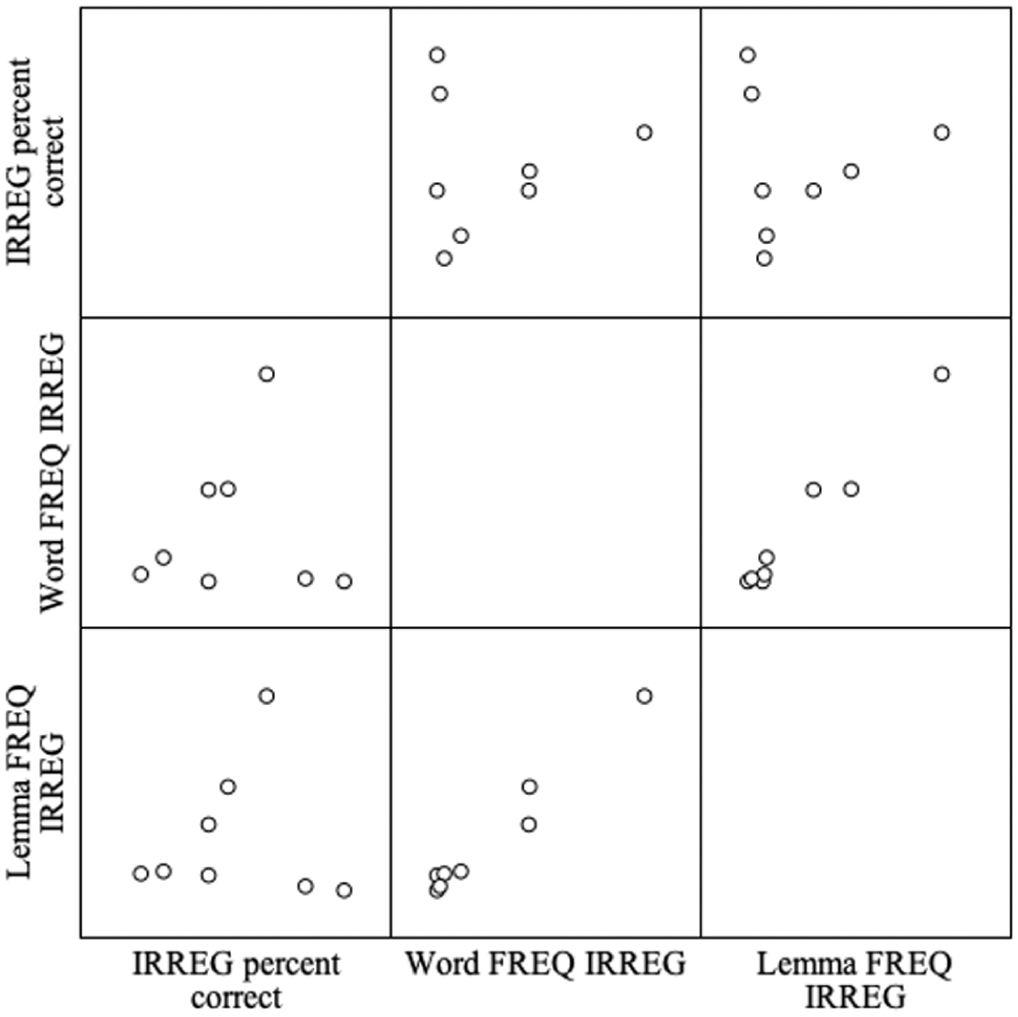
Correlations among mean percentage of correct use scores for irregular past tense verbs and mean word and lemma frequencies across irregular verbs.
Kendall’s τ correlation coefficients for associations between past tense verbs and word and lemma frequency variables are presented in Tables 8 and 9. Positive, moderate associations were found between the word and lemma frequencies for regular and irregular past tense verbs. No statistically significant correlations were found between the mean percentage of correct use and word or lemma frequencies for the regular past tense verbs and the percentage of correct use and the word or lemma frequencies for irregular past tense verbs.
Zero-Order Correlation Between Mean Percentage of Correct Use Scores for Regular Verbs, Mean Word Frequency Across Regular Past Tense Verbs, and Mean Lemma Frequency Across Regular Past Tense Verbs.
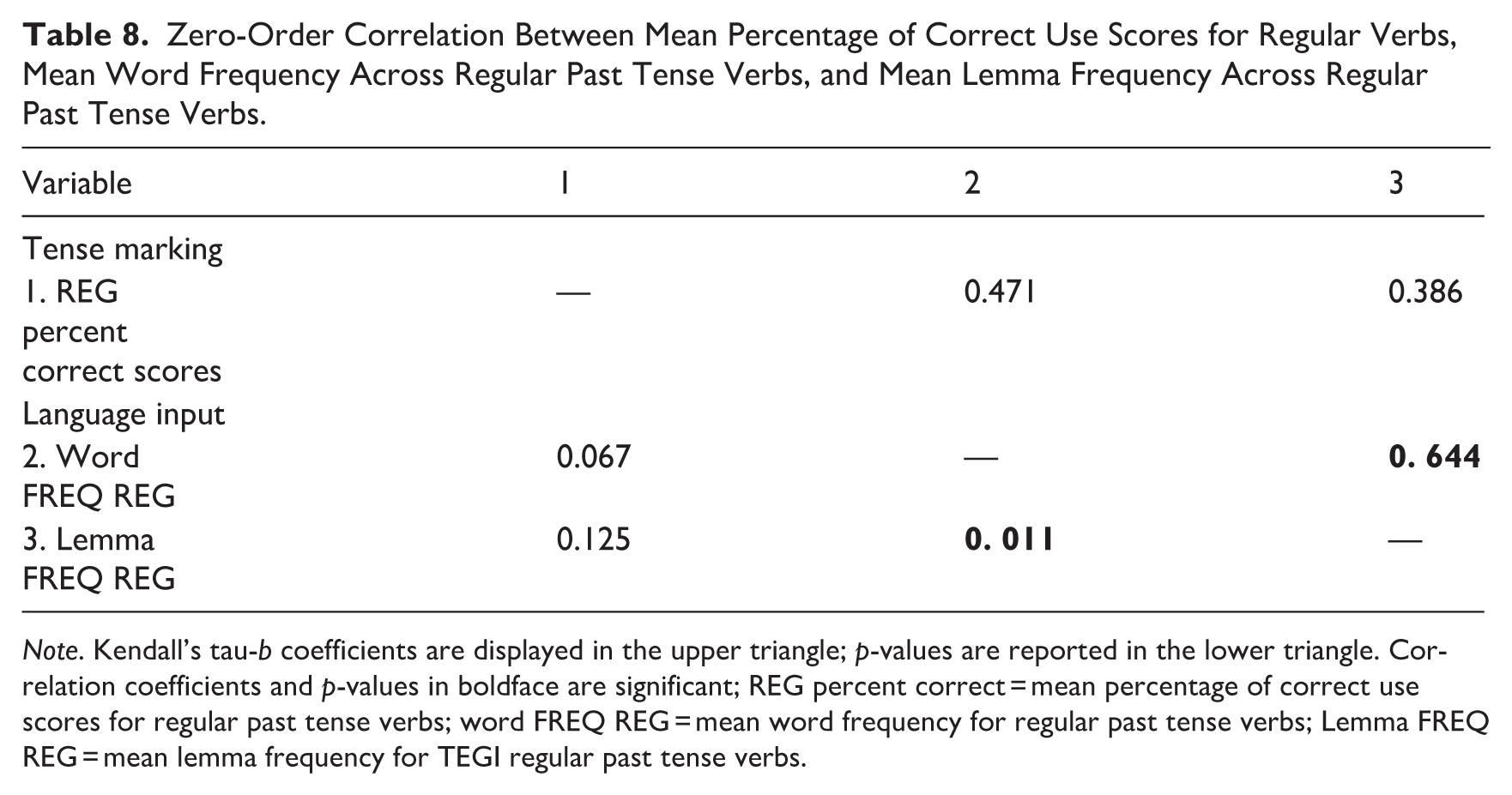
Note. Kendall’s tau-b coefficients are displayed in the upper triangle; p-values are reported in the lower triangle. Correlation coefficients and p-values in boldface are significant; REG percent correct = mean percentage of correct use scores for regular past tense verbs; word FREQ REG = mean word frequency for regular past tense verbs; Lemma FREQ REG = mean lemma frequency for TEGI regular past tense verbs.
Zero-Order Correlation Between Mean Percentage of Correct Use Scores for Irregular Verbs, Mean Word Frequency Across Irregular Past Tense Verbs, and Mean Lemma Frequency Across Irregular Past Tense Verbs.

Note. Kendall’s tau-b coefficients are displayed in the upper triangle; p-values are reported in the lower triangle. Correlation coefficients and p-values in boldface are significant, IRREG percent correct = mean percentage of correct use scores for irregular verbs, word FREQ IRREG = word frequency for irregular past tense verbs, Lemma FREQ REG = mean lemma frequency for irregular past tense verbs.
Discussion
This study examined English past tense production among DLLs with a specific focus on irregular and regular forms, specifically allomorphs. In so doing, we explored the relationship between language input and lexical-semantic factors associated with past tense production.
Findings related to regular and irregular past tense use will be discussed, followed by connections between the variables of interest and the predictions from the NM.
Phonological Properties and English L2 Past Tense
Our first research question compared DLLs’ production accuracy across regular past tense allomorphs. Recall that Blom and Paradis reported a phonological effect for regular and irregular past tense production. Namely, the DLLs in their study used allomorph /d/ most accurately followed by allomorphs /t/ and /ɪd/ and produced fewer overregularizations for irregular past tense verbs ending in /t/ and /d/. The researchers posited that DLLs’ differential production accuracy across allomorphs indicated that their past tense schemas were still developing, and verbs with /t/ and /d/ endings were considered acceptable past tense forms. Moreover, Blom and Paradis proposed that this type of past tense schema specification was also supported by the less frequent overregularization of verbs with /t/ and /d/ endings noted previously and the fact that allomorph /d/’s high type frequency may have contributed to its production accuracy and association with the past tense schema.
Unlike Blom and Paradis, we found that DLLs in our study produced all allomorphs with comparable rates of accuracy, indicating that an observable phonological effect for DLLs’ use of the regular past tense may not have been present. Given the size of our sample, we did not perform further analyses to determine whether overregularizations differed by allomorph type.
Differences in the relationship between verbs’ phonological properties and accuracy between the two studies may have resulted from distinctions among the participants.
In both studies, DLLs had a similar duration of English exposure, approximately 24 months, in educational settings in which English was the primary language of instruction. On average, the children in the present study were older than those in Blom and Paradis, which may have affected the nature of the input they received. Namely, given that the DLLs in our study were older, explicit instruction focused on past tense learning may have been provided in their general education and English as a L2 curricula. If so, DLLs’ past tense schemas could have been at a point in development in which all allomorphs were specified as permissible past tense forms. There were indications of a differential association between allomorph production accuracy and semantic knowledge, which we will discuss in the subsequent section.
Lexical and Semantic Knowledge, English Input, and L2 Past Tense Marking
Our second research question explored potential connections between (a) input properties, (b) lexical-semantic knowledge, (c) phonological properties, and (d) the English past tense. We predicted a positive association between DLLs’ English lexical and semantic knowledge and past tense marking, and our hypothesis was partially supported. Similarly, we predicted that DLLs’ past tense use would positively correlate with English input factors, a relationship which we did not observe. First, we will discuss the relationship between past tense production and lexical-semantic knowledge, followed by a discussion of Bybee’s NM and English input.
Lexical and Semantic Knowledge and L2 Past Tense Marking
Prior research indicates within-language connections between Spanish-English DLLs’ lexical, semantic, and grammatical skills (e.g., Simon-Cereijido & Méndez, 2018). Recall that Simon-Cereijido and Méndez (2018) found that conceptual (bilingual) and English vocabulary skills related to and accounted for the variation in DLLs’ English grammatical performance and conceptual (bilingual) vocabulary. Spanish semantic skills were associated with and uniquely contributed to explaining the variance in DLLs’ Spanish grammatical performance during a sentence repetition task, along with Spanish vocabulary.
Our findings differed from those of Simon-Cereijido and Méndez. Specifically, we did not observe a connection between DLLs’ English lexical and grammatical abilities. These divergent findings may relate to distinctions in DLLs’ linguistic skills in each of these domains and their English language proficiency. Namely, the DLLs in the current investigation had been exposed to English for a mean of 2 years, at the time of testing, and spoke English 36% of the time, on average, in the home environment, with English input and output ranging from 27% to 50% across DLLs. Though cumulative English exposure was not discussed explicitly in Simon-Cereijido and Méndez, the researchers reported that DLLs in their investigation spoke no or limited English, suggesting that they were earlier in the process of English learning than the DLLs in our study.
A differential connection has been found between children’s lexical and grammatical abilities at different points in development (e.g., Moyle et al., 2007). Moyle et al. (2007) investigated language development longitudinally in typically developing and late-talking monolingual English-speaking children. Using cross-lagged correlations, the investigators examined associations between measures of vocabulary and grammar from the MacArthur-Bates Communicative Development Inventories (Fenson et al., 1993) at five timepoints to determine the nature of the relationship between these domains when children were between 2 and 5 years of age. For the typically developing children, there was a significant positive relation between words and grammar at younger ages; however, the connections among these domains did not persist beyond the age of 3.
Moyle et al. suggested that the absence of the lexical-grammatical association later in development aligned with the view that connections between these linguistic domains are most pertinent at the initial process of language acquisition. However, with more advanced language and or cognition, lexical and grammatical skills become independent. Similarly, perhaps the DLLs in this study were at a point in their development at which a correlation between these domains had declined and was no longer observable.
Regarding semantic and grammatical skills, we found a robust cross-domain link in English, indicating that DLLs with greater semantic knowledge produced allomorph /d/ more accurately. Remember that Simon-Cereijido and Méndez posited that growth in language proficiency may increase the effect of their semantic knowledge on their grammatical skill. Thus, it appears that the DLLs in our study had gained enough traction in their English proficiency that a within-language semantic and grammatical relationship could be observed. One question that follows is why allomorph /d/ was correlated with semantic skill. Though it’s possible that all allomorphs were allowable past tense forms, as we discussed previously, perhaps the connection between allomorph /d/ and semantic knowledge reflects the greater representation of allomorph /d/ in English compared to the other allomorphs.
The connection that surfaced between English semantic skill and past tense marking in our investigation and Spanish semantic knowledge and grammatical skill more broadly in Simon-Cereijido and Méndez suggests that this link persists across different types of tasks and reflects the interrelation of these domains of language.
Bybee’s NM, English Input and L2 Past Tense Marking
We also investigated relationships between English words and lemma frequencies and past tense marking. As aforementioned, Blom and Pardis found that verbs’ word frequency correlated and predicted past tense marking and that lemma frequency also explained the variation in the production accuracy of these grammatical forms, which guided our prediction that these aspects would be linked. However, we did not observe associations between these input properties and DLLs’ use of past tense forms as predicted.
Connections between the regular and irregular past tense and input properties may have been more granular than what we measured. For example, Blom et al. (2012) deconstructed their lemma frequency metric into its component word frequencies: frequency of third-person singular –3s, bare verbs, past tense verbs, past participles, and progressive participles. The researchers computed individual frequencies for each of these forms to examine the hypothesis that specific forms account for the effect of lemma frequency and found that the more often a verb occurred in its bare form, the more likely it was that participants with isolating L1s deleted the –3s inflection.
Although the DLLs in our study had an inflecting L1, Spanish, perhaps given the size of our sample, a similar metric that separated the frequency of individual lexemes was needed to examine the connection between lemma frequency and past –ed production more precisely. A similar, more fine-grained distinction may have been required to better capture the relationship between past –ed production and word frequency, as greater production accuracy has been reported with irregular past tense verbs with higher frequency than mid-to-low frequency (Blom et al., 2012).
Even though no relationship was observed between word and lemma frequencies and production accuracy for regular and irregular past tense forms, there were indications of a potential input effect based on DLLs’ use of overregularizations. Jacobson and Yu (2018) followed typically developing Spanish-English DLLs who were acquiring English tense marking and reported DLLs’ continual use of overregularized forms or the alternation between irregular and overregularized past tense forms over time. The researchers suggested that this pattern of production aligns with input-based explanations for past tense learning and mirrors patterns observed during typical monolingual acquisition at earlier ages. Perhaps the DLLs in our study experienced a similar input-based effect, given that they commonly used irregular and overregularized forms. We realize that this line of reasoning is speculative at best because we did not follow DLLs’ past tense production longitudinally and additional investigation is needed to fully explore this explanation.
This study has limitations that may be addressed by future research. We conducted several statistical analyses to address our research questions. A larger sample of DLLs would permit the use of fewer analyses and reduce the potential for statistical error while also increasing statistical power for our analyses. Including additional participants in our sample would allow for more fine-grained analyses of production patterns for regular and irregular past tense forms and further exploration as to how these patterns may relate to DLLs’ lexical, semantic, and phonological skills. In addition, our findings revealed that DLLs’ English semantic skills were correlated with their production of regular past tense forms, specifically allomorph /d/; however, we only observed DLLs’ use of past tense forms in one context, an elicitation task.
In the current study, we used data elicited with the TEGI to compare production accuracy for each allomorph type. Similar comparisons were unable to be made using the DLLs’ narrative retell language samples. Given the child-led nature of the narrative retell task, DLLs selected vocabulary to include in their narratives with minimal prompting as described in the “Method” section. Therefore, there was a limited number of obligatory contexts for each type of allomorph in some of the samples. Further investigation including additional types of language sample tasks (e.g., picture description and semi-structured conversation about a past event) would allow for more contexts to observe production accuracy between the allomorphs and help refine our understanding of the relationship between past tense use and important related factors during English L2 learning.
Conclusion
This study explored the use of past tense forms in Spanish-English DLLs who were acquiring English as L2. As such, we examined DLLs’ use of regular past tense allomorphs and found similar rates of production accuracy in this group of DLLs. Next, we explored the relationship between input properties, phonological properties, lexical-semantic knowledge, and the production accuracy of past tense forms in English and past tense learning predictions aligned with the NM. A semantic and grammatical connection surfaced in the data, substantiating within-language cross-domain links during L2 language acquisition and distinctively contributing to our understanding of the nature of those relationships.
To increase our understanding of production patterns and these associations during English L2 past tense learning, future studies could explore this grammatical aspect longitudinally and in a variety of language tasks. Such studies could examine initial English exposure, so as to test theories of child L2 acquisition while enhancing our understanding of characteristics of Spanish-English DLLs’ emerging and developing past tense marking paradigm. Moreover, these studies could develop experimental tasks to examine relationships between past tense marking skill, syntactic complexity, and semantic-lexical knowledge more comprehensively. Finally, subsequent work could employ a heteroglossic approach to understanding Spanish-English DLLs’ linguistic repertoire with particular focus on the concurrent development of Spanish and English language skills.
Footnotes
Appendix 1
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.