
Abstract
Purpose:
This paper presents event-related potential (ERP) findings from a study investigating mismatch negativity (MMN) and late discriminative negativity (LDN) response asymmetries in trilingual listeners. The research aimed to explore phonetic representation in multilingual individuals. While theories predicting privative feature specification suggest stronger MMN and (potentially) LDN effects when the standard auditory stimuli have a feature that is specified in the lexical representation, while the deviant lacks it, models like the Perceptual Magnet Model, and the Natural Referent Vowel framework offer competing predictions based on vowel peripherality or prototypicality.
Methodology:
We employed the Oddball paradigm with a ‘flip-flop’ design to compare neural responses evoked by vowel pairs processed by L1 Polish – L2 English – L3/Ln Norwegian listeners.
Data and Analysis:
EEG data were recorded from 22 trilingual participants using 64 active scalp electrodes. Two linear mixed-effects models were fitted, with the amplitude difference (deviant minus standard, in μV) as the dependent variable.
Findings:
The results indicated that language status influenced the (a)symmetry of the MMN and LDN effects, with L3/Ln Norwegian being the only language where asymmetry was observed for both MMN and LDN, while L1 Polish triggered asymmetry for LDN. These findings are partly consistent with the Featurally Underspecified Lexicon model, the Perceptual Magnet Model, and the Natural Referent Vowel framework.
Originality:
The study used the ‘flip-flop’ paradigm to investigate MMN and LDN (a)symmetries in the processing of non-native sounds, focusing specifically on multilingual listeners rather than bilinguals.
Introduction
The ability to discriminate and identify non-native sounds is crucial for the successful acquisition of second language (L2) pronunciation. However, numerous questions concerning the access to phonological representations in L2 when compared with L1 still remain largely unanswered. For instance, it is often postulated that native phonological representations are reduced to a small subset of features sufficient for effective production and perception (Chomsky & Halle, 1968); however, it is not yet clear to what extent this assumption applies to L2. Even less is known about the differences between the second (L2) and third/additional (L3/Ln) foreign language.
The event-related potential (ERP) component, which has been identified as an index of the listener’s sensitivity to speech sounds drawn from phonemic contrasts, is the mismatch negativity (MMN) response. Since it was first observed (Näätänen et al., 1997), the component has been typically elicited in the so-called Oddball tasks, where a series of frequently occurring auditory stimuli (typically referred to as ‘standards’) is occasionally interrupted by infrequent stimuli (typically referred to as ‘deviants’). In such designs, the deviant sounds evoke larger MMN amplitudes than standard ones. The MMN effect, that is, the difference in amplitude between the standard and deviant sounds observed frontally around 100–150 ms after the sound onset, has been investigated in numerous studies, involving native (e.g., Kujala & Näätänen, 2003; Näätänen et al., 1997; Näätänen et al., 2007) and non-native languages (e.g., Liang & Chen, 2022; Winkler et al., 1999; Wottawa et al., 2022). Given that the MMN is believed to reflect the level of the perceived acoustic and phonological difference between two sounds, various (oftentimes opposing) predictions could be made concerning the directions conducive to a stronger or weaker MMN.
In general, the speech recognition theories which predict equipollent feature specification (i.e., traditional generative phonology, e.g., Chomsky & Halle, 1968; Kenstowicz & Kisseberth, 1979) also anticipate symmetrical MMNs from sound A to B and vice versa, especially in one’s native language. Contrastingly, the theories that assume privative feature specification in one of the investigated sounds predict asymmetrical MMNs. This idea is posited, for example, by the Featurally Underspecified Lexicon model (FUL) (Eulitz et al., 1995; Harris & Lindsey, 1995; Lahiri & Reetz, 2010). Thus, if a standard stimulus is specified for a property which the deviant stimulus lacks (e.g., [HIGH], [DORSAL]), the listener is easily susceptible to this mismatch detection, which results in a strong MMN effect (i.e., a large MMN amplitude difference between standard and deviant stimuli). When the standard sound is underspecified for the feature, the comparison of the deviant with the standard is hindered, which results in a weak MMN effect (see Lahiri & Reetz, 2010 for a discussion). Such asymmetries have indeed been reported in numerous oddball studies (e.g., de Jonge & Boersma, 2015; Eulitz & Lahiri, 2004; Hestvik & Durvasula, 2016; Yu & Shafer, 2021).
Several phonetic theories also predict asymmetries in phoneme perception. According to the Natural Referent Vowel (NRV) framework (Polka & Bohn, 2003, 2011), while acquiring a language, we exhibit a perceptual preference for vowels that are located on the periphery of the F1/F2 vowel space. The discrimination process is facilitated if the standard vowel is more centralized in the F1/F2 space when compared to the deviant. Crucially, this bias has been shown to apply to infants (Polka & Werker, 1994). In behavioral studies, the asymmetries have not been attested for adult native listeners (Polka et al., 2005), but they seem to reappear in adults learning a second language (Nishi et al., 2008), although not in the case of simultaneous bilinguals (Molnar et al., 2013). Along somewhat similar lines, the observed MMN asymmetries could also be explained in terms of a better/worse exemplars distinction postulated by Kuhl’s perceptual magnet model (PMM, Kuhl et al., 1992). According to their findings, the discrimination is facilitated if the worst exemplar (i.e., a less prototypical sound) serves as the standard.
The mismatch negativity (MMN) is often succeeded by the late discriminative negativity (LDN), a negative waveform typically observed at fronto-central electrode sites approximately 350–600 ms after the onset of a deviant stimulus. While the precise functional role of the LDN remains unclear (see Jakoby et al., 2011 for an in-depth discussion), it is generally linked to the pre-attentive cognitive evaluation of stimuli (Liang & Chen, 2022) or the successful establishment of memory traces related to specific phonemic representations (Barry et al., 2009; Jakoby et al., 2011). Research on non-native phoneme processing has reported a reduced LDN response for non-native languages compared to L1 (Jakoby et al., 2011; Liang & Chen, 2022; Song & Iverson, 2018). In addition, some studies examining LDN have observed that the effect tends to be more pronounced in highly proficient or more successful L2 learners when compared with less proficient ones (Jakoby et al., 2011; Liang & Chen, 2022). Although Kędzierska et al. (2023) found no significant difference in LDN amplitude between L2 English and L3/Ln Norwegian (elicited in response to vowels), both languages showed reduced effects compared to L1 Polish.
Most research addressing MMN asymmetries has largely overlooked potential LDN asymmetries, with some notable exceptions. For instance, Yu and Shafer (2021) examined English vowels and identified parallel patterns of asymmetry for both MMN and LDN. Similarly, Hestvik and Durvasula (2016) – in their experiments involving multiple tokens (i.e., Experiments 1–2) – found that both MMN and LDN exhibited the same asymmetric pattern for the English voicing contrast: larger responses when a specified voiceless /t/ standard was followed by a voiced /d/ deviant, and smaller responses in the reverse order. This alignment of MMN and LDN effects supports the view that long-term phonological representations may be specified or are underspecified in ways that influence multiple stages of auditory processing. Importantly, Experiment 3 in Hestvik and Durvasula (2016), which employed a single-token design, showed symmetric MMN but asymmetric LDN effects, with the asymmetry reflecting differences in specification (i.e., underspecified segments elicited reduced LDN effects compared to specified ones).
Current Study
As a testing ground for the current study, we chose three languages (i.e., L1 Polish, L2 English, and L3/Ln Norwegian) with notable distinctions, including variations in vowel inventory density. Polish is an example of a modest vowel system, featuring only six monophthongs (Jassem, 2003), whereas English and Norwegian exhibit more extensive vocalic inventories with 12 and 18 monophthongs, respectively (Hawkins & Midgely, 2005; Kristoffersen, 2000). The selected stimuli featured Polish /ɛ/, which is a mid-front vowel, while /a/ is a low and central vowel. In comparison to the chosen Polish /a/ stimulus, British English /æ/ is slightly higher and fronted, whereas /ɑː/ is more retracted. Among other aspects, the languages under investigation differ with respect to lip-rounding and backness. All three languages exhibit front unrounded vowels and back rounded vowels; however, English /uː/ and /ʊ/ and Norwegian /ʉ(ː)/ are high or mid-high central rounded vowels. In addition, only Norwegian incorporates high front rounded vowels /y/ and /ʏ/ and mid central rounded vowels /øː/ and /œ/, which are considered less frequent among languages of the world (Maddieson, 2013).
The study examined vowel contrasts drawn from three languages, each differing along well-established phonological dimensions. In Polish, the contrast /ɛ/–/a/ primarily involves vowel height and, to a lesser extent, backness distinction: /ɛ/ is a mid-front unrounded vowel, whereas /a/ is a low central unrounded vowel. In English, the contrast /æ/–/ɑ/ also involves backness distinction and, to a lesser extent, height, with /æ/ realized as a checked low front unrounded vowel and /ɑ/ as a free low back unrounded vowel. Finally, in Norwegian, the contrast /ø/–/u/ involves differences in backness and height distinction in rounded vowels: /ø/ is a mid-front rounded vowel, while /u/ is a high back rounded vowel. These contrasts, therefore, differ in the number and type of featural dimensions involved, allowing us to test the robustness of the observed effects across three languages and their vowel systems. The order in which the participants in the present study learned languages would then imply a progressive broadening of their phonemic, especially vowel, repertoire.
The current study aimed at investigating phoneme processing differences in three languages in the same group of speakers. We use the term language status to refer to the position of a language in a speaker’s linguistic repertoire (operationalized as L1, L2, or L3/Ln). Language status often correlates with factors such as proficiency and order of acquisition, but in our participant group, these variables were fully aligned: L1 Polish was the earliest-acquired and most proficient language, L2 English was acquired later and with lower proficiency compared to the native language, and L3/Ln Norwegian was acquired last and was the least proficient. Previous neurolinguistic research has demonstrated that language status influences phoneme discrimination: reduced MMN amplitudes were observed in non-native languages when compared with L1 (Jakoby et al., 2011; Liang & Chen, 2022; Song & Iverson, 2018) as well as in L3/Ln when compared with L2 (Kędzierska et al., 2023). Several studies have shown that the strength of the effect in the non-native language was additionally influenced by the listener’s proficiency level (Jakoby et al., 2011; Liang & Chen, 2022) and the age of acquisition (Kędzierska et al., 2023). While previous ERP research has primarily examined the effects of language status effects on MMN amplitude, largely ignoring potential asymmetries, the current study investigates whether language status is associated with asymmetries in the MMN and LDN effects.
In a recent study, Kędzierska et al. (2023) examined how sensitive the MMN effect is to phoneme contrasts in L1 Polish, L2 English and L3/Ln Norwegian naturalistic (‘immersive’) learners – a group of Polish migrants living in Norway. They found out that language status had an impact on the MMN effect, which was smaller for L3/Ln Norwegian when compared with L2 English and with L1 Polish. However, the experiment by Kędzierska et al. (2023) did not employ the so-called ‘flip-flop’ design, which ensures that each member of the phoneme pair serves as a deviant/standard an equal number of times: in one block, phoneme A is presented frequently as the standard and phoneme B infrequently as the deviant, and in the other block, the roles are reversed. This design controls for acoustic and contextual differences associated with stimulus roles and has been shown to reveal robust directional effects in speech processing (e.g., de Jonge & Boersma, 2015; Eulitz & Lahiri, 2004; Yu & Shafer, 2021). Since Kędzierska et al. (2023) used a single-direction oddball design, questions about potential phoneme perception asymmetries could not be addressed in their study.
To compensate for this limitation, we designed an ERP Oddball study with trilingual L1 Polish – L2 English – L3/Ln Norwegian learners, who were presented with three vowel pairs (i.e., [ɛ]–[a] in Polish, 1 [æ]–[ɑ] in English and [ø]–[u] in Norwegian) in six counterbalanced language blocks. Every pair member served as a standard in one block and as a deviant in another block. Such a design enabled us to address the following research question:
Two conflicting hypotheses were formulated based on models of phonetic representations discussed in the ‘Introduction’ section.
In line with the FUL principle, we predicted that the feature specification would trigger the following ERP responses:
A standard containing a feature specified in the lexicon → deviant with an incompatible feature in the phonetic representation, may be underspecified in the lexicon = mismatch leading to a more robust MMN effect.
A standard containing a feature that is not specified in the lexicon → deviant with an incompatible feature in the phonetic representation, may be specified or underspecified in the lexicon = no mismatch in features leading to a reduced or absent MMN effect.
Vowel Pairs Descriptions and FUL Model Predictions.

Note. ⇑, stronger MMN/LDN effect (with the vowel in the adjacent line serving as the standard).
H1 is based on the assumption that [DORSAL] or [LOW] is a specified vowel feature encoded in the lexicon, which would lead to a stronger MMN and (potentially) LDN effect when the standard sound has a specified feature and the deviant contains an incompatible feature, leading to a feature mismatch scenario. Consequently, we could predict to observe a stronger MMN in the blocks allowing for a ‘leftwards’ change direction: from [ɑ] as the standard to [æ] as the deviant in English and from [u] as the standard to [ø] as the deviant in Norwegian (see Table 1). Despite differences in phonetic realization across English and Norwegian, MMN asymmetries will follow a uniform featural logic: standards involving height or place specifications encoded in the lexicon, and deviants with incompatible features will yield asymmetry patterns.
Vowel Pairs Descriptions and PMM and NRV Model Predictions.

Note. ⇓, weaker MMN/LDN effect (with the vowel in the adjacent line serving as the standard).
With reference to the perceptual magnet model (Kuhl et al., 1992), it is hard to predict which sounds serve as better exemplars for the participants in the current study, but we may assume that both Polish sounds (i.e., [ɛ] and [a]) will serve as equally good exemplars of their categories. We may also tentatively predict that native Polish learners might consider the Norwegian sound [ø] as a worse exemplar of /u/ when compared with [u] and the English sound [æ] as a worse exemplar of /a/ when compared with [ɑ] (based on the results of an assimilation test; see the Materials section). According to the NRV, peripherality matters in discrimination. A more peripheral vowel is the one that falls closer to the periphery of the F1/F2 vowel space (Polka & Bohn, 2011). In a non-native language, a vowel change from a more central to a more peripheral vowel is easier to discriminate than the same contrast presented in the reverse direction. Moreover, no asymmetry is to be expected in Polish, since this is the native language of the listeners (otherwise, a change from [ɛ] to [a] should be easier to discriminate, as [ɛ] is more central). In English, the vowel [ɑ] is more peripheral when compared with [æ] and is then expected to act as a referent. What is more, [ø] is less peripheral than [u]. We then predicted to observe a stronger MMN effect with [æ] as the standard and [ɑ] as the deviant in L2 English, and with [ø] as the standard and [u] as the deviant in L3/Ln Norwegian.
Based on prior studies focusing on LDN (e.g., Yu & Shafer, 2021 and Hestvik & Durvasula, 2016), we aimed to test whether the MMN and LDN effects would show comparable asymmetry patterns.
Method
Participants
Twenty-four participants were recruited to participate in the study. Data obtained from two participants were excluded from subsequent analyses: one due to technical issues during recording and one due to an excessive number of EEG artifacts. Thus, data obtained from 22 participants (mean age = 22.27, SD = 4.27; 16 women, 5 men and 1 non-binary person) were included in the final analyses. All the participants were right-handed as determined by the Edinburgh Handedness Inventory (adapted from Oldfield, 1971; LQ = 83.64%, SD = 13.82%) and had normal or corrected-to-normal vision. None of the participants reported any neurological impairments, psychiatric disorders, or hearing problems.
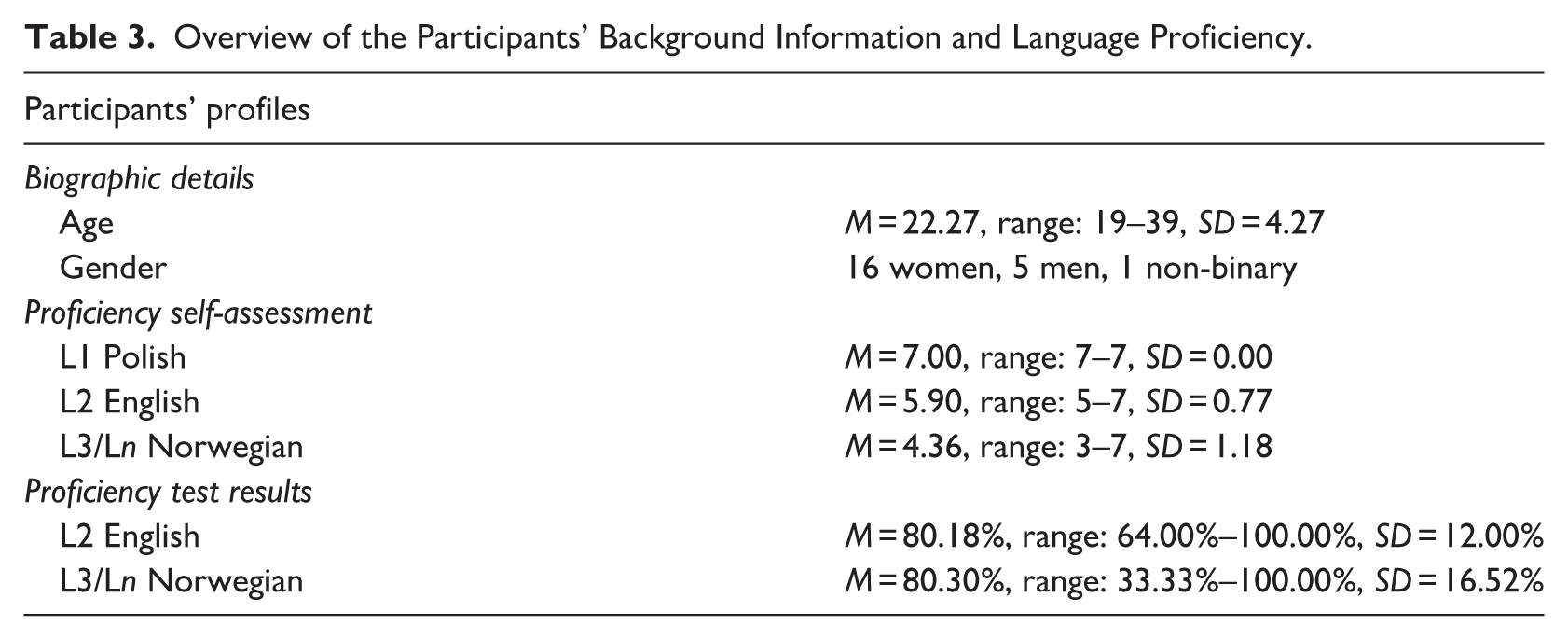
At the time of the experiment, nineteen participants were BA students of Scandinavian Studies (i.e., Norwegian philology) at Adam Mickiewicz University. One participant had graduated from this program a year earlier, and two learned Norwegian at a private language school. The participants reported their age of onset of acquisition as 7.5 years (range: 4–13, SD = 2.61) for L2 English and as 19.45 years (range: 17–35, SD = 4.62) for L3/Ln Norwegian. A more detailed summary of the participants’ biographic data and foreign language proficiency is included in Table 3.
Overview of the Participants’ Background Information and Language Proficiency.
Materials
To verify the pre-selected stimuli, we conducted 3 norming tests on independent groups of 25 native speakers of Polish, 20 native speakers of English, 2 and 30 native speakers of Norwegian. The listeners who took part in the norming task did not participate in the main ERP experiment. All pre-tests were conducted online (via Qualtrics) with the participants being recruited via Prolific or personal networking. They were instructed that they would listen to and evaluate short recordings of vowels presented in isolation 3 and that the task would last approximately 10–15 minutes. Each pre-test experimental set included a larger sample of vowels (17 for Polish, 26 for English, and 14 for Norwegian), prepared for the purpose of the main experiment, with the aim of selecting the best vowel exemplars in each language. In the first question, the participants had to choose one out of several multiple-choice options to identify the vowel. Then they evaluated the stimulus as a good/bad example of a particular vowel (on a scale from 1 – a very bad example to 9 – a very good example). Vowel stimuli that received the highest ratings in terms of accuracy and goodness-of-fit were selected to be included in the main EEG task. The frequencies of vowel formants of the selected stimuli are displayed in Table 4, and the results of the assimilation tests are presented in Table 5.
The Frequencies of Vowel Formants Used for Stimuli Synthesis (in Hz) and Euclidean Distances Between Generated Vowels (in Hz and Bark).
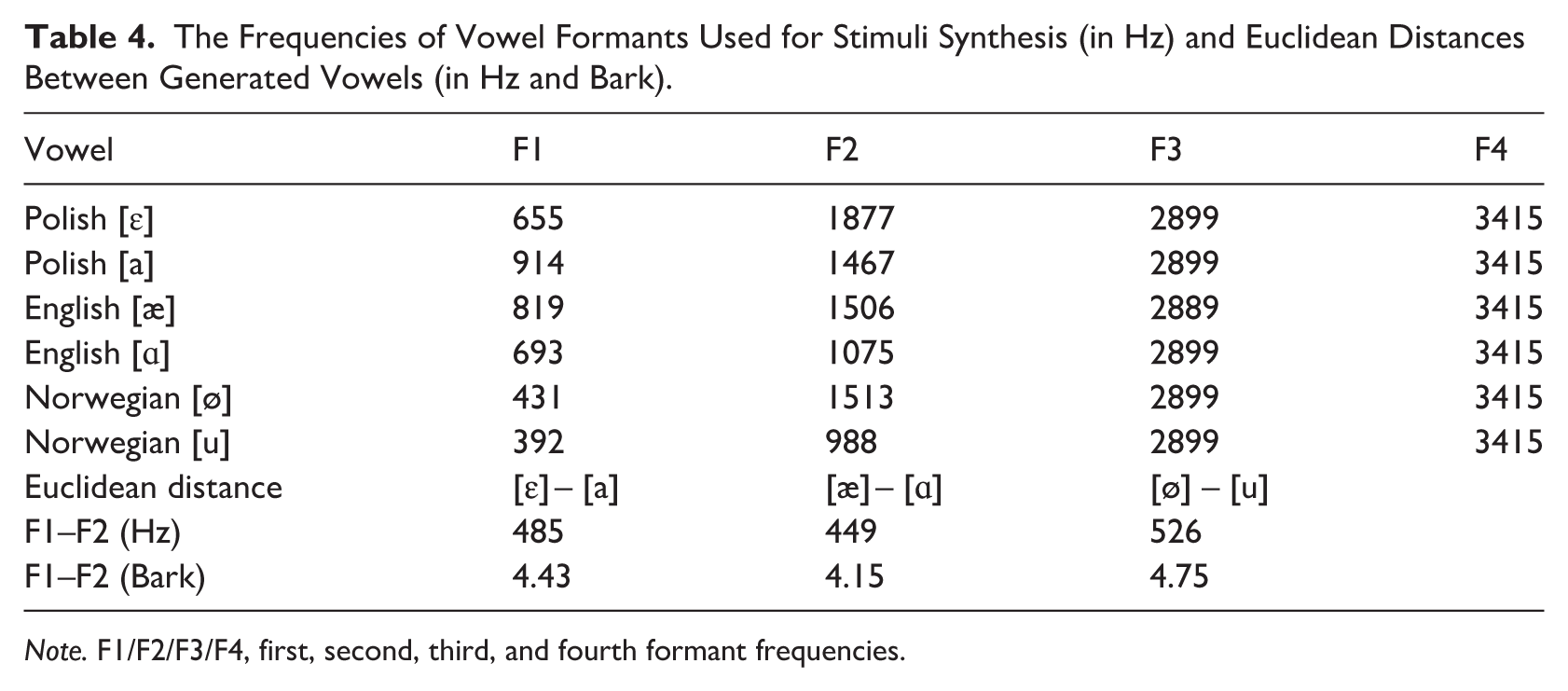
Note. F1/F2/F3/F4, first, second, third, and fourth formant frequencies.
The Results of Assimilation Tests (A Pre-Test and a Post Hoc Test).
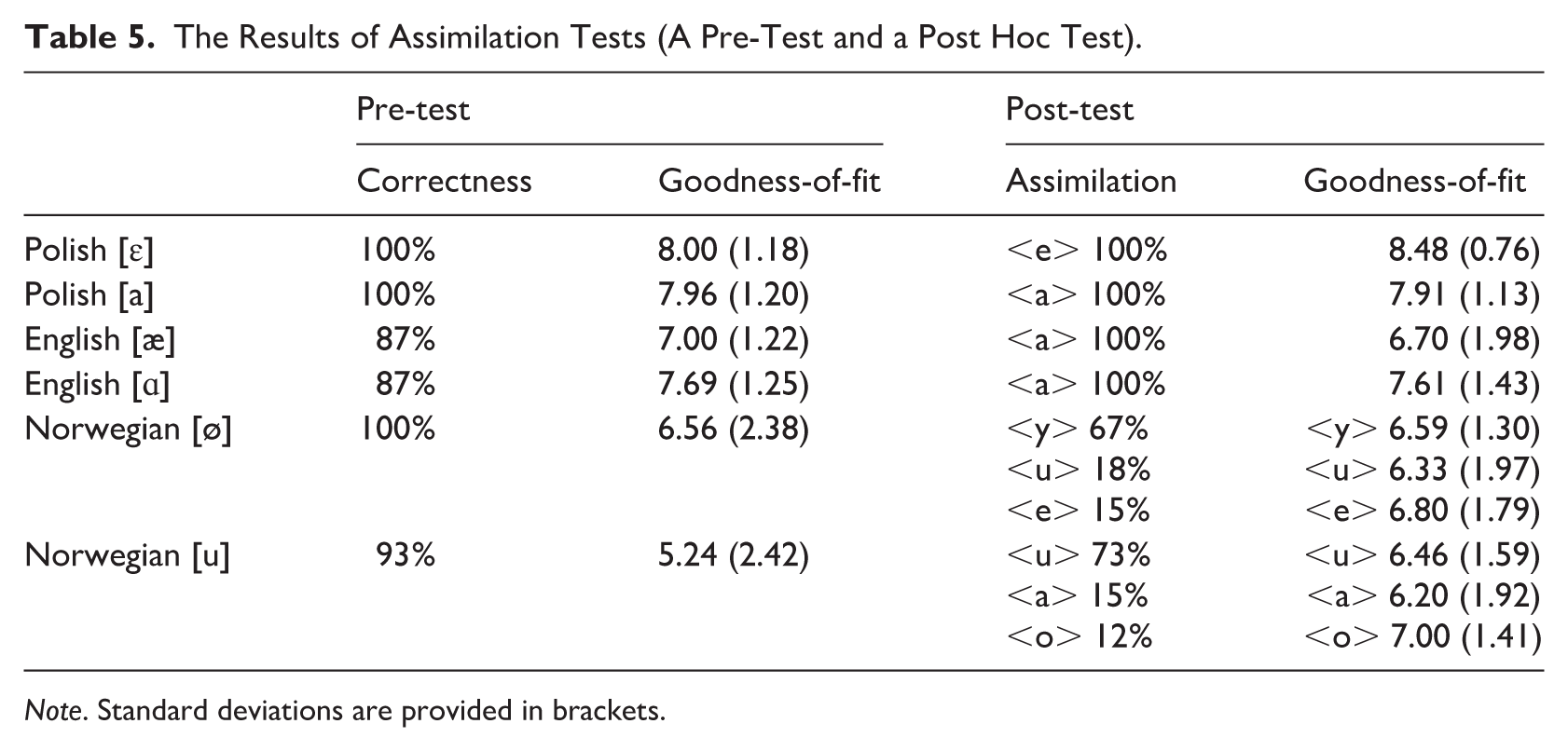
Note. Standard deviations are provided in brackets.
A similar norming task was also distributed to the participants of the main experiment after the EEG session (also via Qualtrics) to elucidate the ERP findings obtained for the specific group of Polish–English–Norwegian trilinguals. Eleven participants agreed to take part in this post hoc task. They were asked to identify the six vowels presented during the EEG task as Polish <a> – /a/, <e> – /ɛ/, <i> – /i/, <y> – /ɨ/, <o> – /ɔ/, or <u> – /u/. Orthographic labels were used in the experiment, as Polish vowel orthography is transparent. In addition, we asked the participants to evaluate the stimulus as good/bad vowel examples (on a scale from 1 to 9). The results suggest that while Polish [ɛ] and [a] were both unanimously recognized as respectively <e> and <a>, the two English vowels (i.e., [æ] and [ɑ]) were both classified as belonging the category <a>, and the Norwegian vowels elicited more ambiguous responses, with [ø] mostly classified as <y> and [u] typically perceived as <u> (see Table 5).
Following most of the classic EEG perception research (e.g., Kujala & Näätänen, 2003; Näätänen et al., 1997; Näätänen et al., 2007; Winkler et al., 1999), we used a single-token design to control acoustic variability and isolate systematic asymmetries in processing. Also, the work by Polka and Bohn (2011) showed that vowels with greater formant frequency convergence, which are perceptually more salient, could lead to MMN asymmetries at the phonetic level, without targeting phonological processing and the effects of underspecification. Recent EEG studies in bilingual discrimination increasingly adopt multiple-token designs (e.g., Gilbert et al., 2025) involving minimal acoustic differences between tokens, but this is not yet a universal approach in EEG non-native speech perception research.
Procedure
Each participant was tested individually in a quiet room. At the start of the experimental session, they completed a language history questionnaire (LHQ) (adapted from Li et al., 2020) and the Edinburgh Handedness Inventory (based on Oldfield, 1971). During the experiment, the participants were instructed in their L1 Polish to focus on the content of a silent cartoon and to ignore the sounds which were presented to them binaurally the earphones. Each experimental trial involved the presentation of a phonetic sound for 150 ms, followed by an interstimulus interval of 700–1,000 ms. The experimental session included six experimental blocks: two involving Polish sounds ([ɛ] as the standard vs. [a] as the standard), two with English sounds ([æ] as the standard vs. [ɑ] as the standard), and two with Norwegian sounds ([ø] as the standard vs. [u] as the standard). The order of blocks was pseudorandomized across participants, so that the blocks including sounds in one language were always separated by two blocks presenting sounds in the remaining two languages. Each block involved 600 standard sounds and 60 deviant sounds, presented at an intensity of 75 dB. Every deviant stimulus was preceded by at least three standard stimuli.
At the end of the session, the participants were requested to complete two language proficiency tests (the Cambridge General English Assessment Test and the UiT Norwegian Placement Test) as well as a short test containing ten multiple-choice questions about the content of the cartoon. Each proficiency test consisted of 25 multiple-choice questions, primarily targeting grammar and vocabulary. All procedures were accepted by the Ethics Committee for Research with Human Participants at Adam Mickiewicz University. The participants were offered gift cards in compensation for their time.
EEG Acquisition and Signal Processing
The EEG signal was acquired using Brain Products actiCHamp system device at a sampling rate of 1000 Hz, with signals captured from 64 active electrodes positioned based on the extended 10–20 convention. The ground was placed at AFz, and the reference electrode (used both as the online and offline reference) was placed on the tip of the nose. Electrodes to monitor the eye movements were placed bilaterally at the outer canthus of each eye and above and below the right eye, with impedance levels maintained below 10 kΩ. EEG data processing was conducted using Brain Vision Analyzer 2 software from Brain Products, Gilching.
The data underwent offline filtering using a 0.1–30 Hz band-pass filter. Subsequently, we applied a semi-automatic ICA ocular correction. Epochs of 800 ms duration (ranging from –200 to 600 ms) time-locked to the target stimuli were extracted and baseline-corrected (from –200 to 0 ms). To ensure signal-to-noise ratio comparability across conditions, only standard stimuli immediately preceding a deviant stimulus were included in the analysis. Epochs containing ocular or muscular artifacts were rejected from the analysis based on predefined criteria (e.g., maximal allowed voltage step: 50 μV/ms, maximal allowed difference of values in intervals: 200 μV, minimal allowed amplitude: −100 μV, maximal allowed amplitude: 100 μV). The average percentage of rejected epochs was 5.8%.
For each participant, we first computed the averaged waveforms for the standard and the deviant conditions followed by the difference (i.e., deviant minus standard) waveforms. We defined the time windows of interest based on the ‘collapsed localizers’ approach (Luck & Gaspelin, 2017), i.e., averaged standard and deviant waveforms, without taking the effects of language and direction into account. We observed an increased negativity in the 100–200 ms and in the 350–600 ms time windows. Notably, these time windows have already been applied in the literature, including studies of the MMN (e.g., Kujala & Näätänen, 2003) and the LDN (e.g., Di Dona et al., 2022). Moreover, the same MMN time window and a comparable LDN time window (350–800 ms) were utilized in the studies by Kędzierska et al. (2023, 2025), whose results we directly compare with our findings (see the replication analysis in Appendix A). Electrodes from the frontal-central brain area (i.e., F1, F2, F3, F4, Fz, FC1, FC2, FC3, FC4, FCz, C1, C2, C3, C4, Cz), in which both the MMN and the LDN are commonly observed (Kujala & Näätänen, 2003), were included in the analysis.
Statistical Analysis
The statistical analysis was performed with the aid of R software version 4.3.2 (R Core Team, 2023). We employed the lme4 package (Bates et al., 2012) to conduct a linear mixed-effects analysis exploring the relationship between the studied languages (i.e., Polish, English and Norwegian) and directions (i.e., ‘rightwards’: [ɛ] to [a] in Polish, [æ] to [ɑ] in English, and [ø] to [u] in Norwegian, and ‘leftwards’: [a] to [ɛ] in Polish, [ɑ] to [æ] in English, and [u] to [ø] in Norwegian). The dependent variables in each model included mean amplitude differences, i.e., deviant minus standard (in μV). The models were fitted independently in the two time windows in question (i.e., 100–200 ms and 350–600 ms). For each analysis, we initially specified a model including fixed effects of language, direction, and their interaction, with random intercepts for participants and electrodes. Models were fit using maximum likelihood. For the MMN time window, the initial model resulted in a singular fit, indicating that the variance associated with the electrode random intercept was estimated at or near zero. Therefore, the electrode random intercept was removed, yielding a non-singular and well-converging model. For the LDN time window, the initial model converged without singularity and was retained. No random slopes were included, and no fixed effects were removed in either analysis. Full model outputs, including fixed and random effect estimates and model fit statistics, are provided in Appendix B (Tables B1 and B2). The models were applied to data averaged across 360 trials (60 for each condition, i.e., 3 language conditions × 2 direction conditions). Only standard stimuli that immediately preceded a deviant stimulus were included in the analysis.
Visual examination of the residual plots did not reveal any evident deviations from homoscedasticity or normality across all analyzed data sets. P-values were obtained using likelihood ratio tests 4 comparing the full model with the two-way interaction effect of language and direction against models with respective simple main effects. Post hoc pairwise comparisons were computed with the emmeans package (Lenth, 2024), with Tukey correction.
To find out whether we would be able to replicate previous findings concerning the pre-attentional phoneme processing in multilinguals (Kędzierska et al., 2023; Kędzierska et al., 2025), we conducted an additional analysis including language (i.e., L1 Polish, L2 English, and L3/Ln Norwegian) and sound (i.e., standard and deviant) as fixed effects, hence ignoring the two direction conditions (i.e., ‘leftwards’ and ‘rightwards’) (see Appendix A). The replication analysis revealed that the differences between standard and deviant sounds were statistically significant for all three language pairs (all ps < .001) and in both time windows (MMN and LDN). However, contrary to what was previously observed by Kędzierska et al. (2023, 2025), the current analyses revealed the largest differences between L2 English and L3/Ln Norwegian.
The raw data and codes utilized in this study are accessible in the first author’s OSF repository: https://osf.io/2ys9n/?view_only=eca222d28afe4a439d6164f7863d203e.
Results
Comprehension Questions
On average, the participants answered correctly 9.05 out of 10 multiple-choice questions about the video, which was displayed to them (range: 7–10, SD = 1.13). This confirms that during the experimental session, the participants tended to focus on the content of the cartoon rather than on the auditory stimuli, which enabled a pre-attentive sound processing.
ERP Results
In accordance with our predictions, the deviant sounds elicited the MMN-LDN effect in all three investigated languages. The grand average ERPs and mean voltage difference maps are displayed below in Figure 1 (for L1 Polish), Figure 2 (for L2 English) and Figure 3 (for L3/Ln Norwegian). Descriptive statistics for the analyzed conditions in the selected time windows are presented in Table 6 (for the MMN effect) and in Table 7 (for the LDN effect).
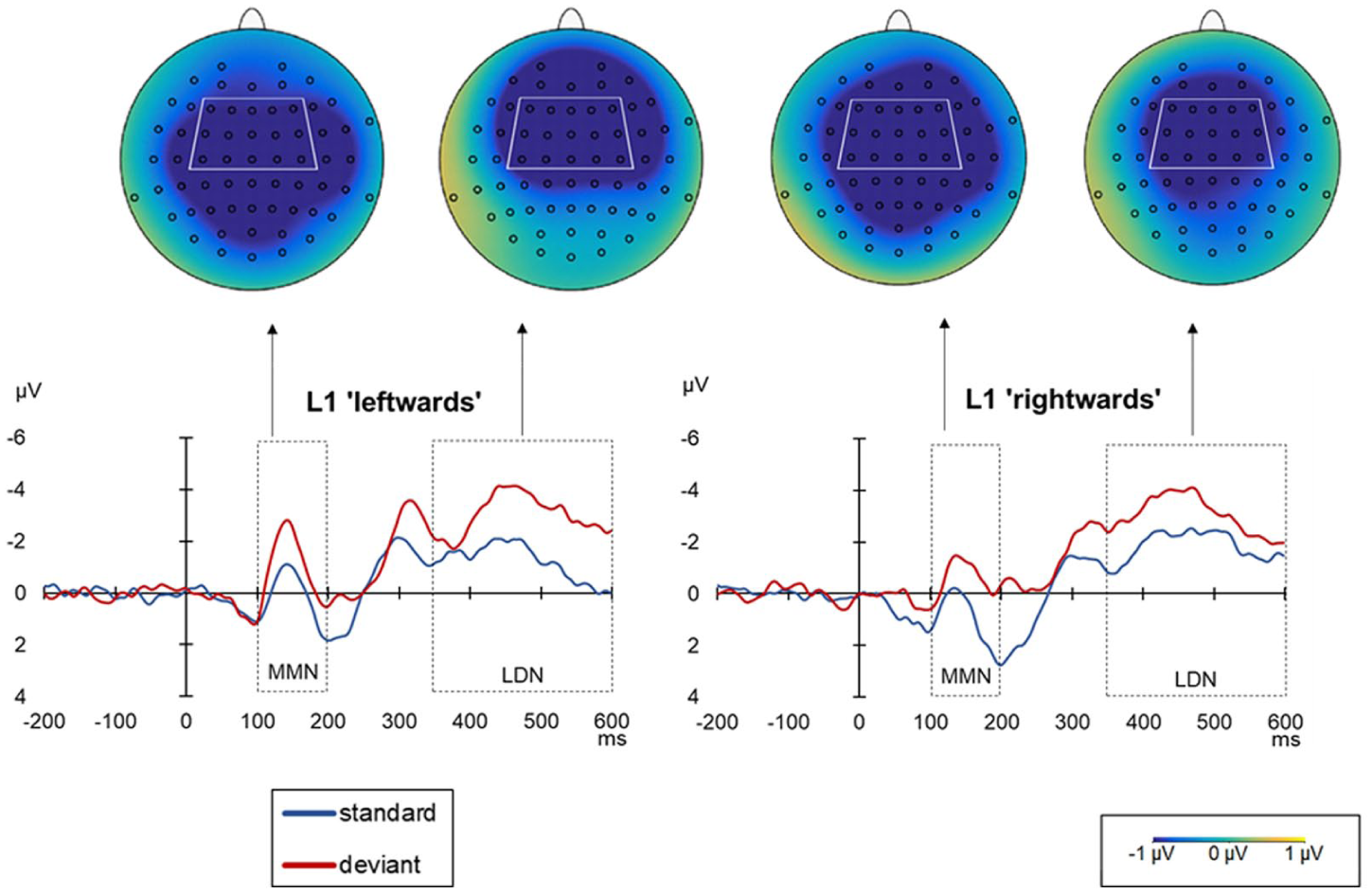
The grand average ERPs and mean voltage difference maps (deviant minus standard) for L1 Polish in the ‘leftwards’ ([a] to [ɛ]) and ‘rightwards’ ([ɛ] to [a]) conditions.
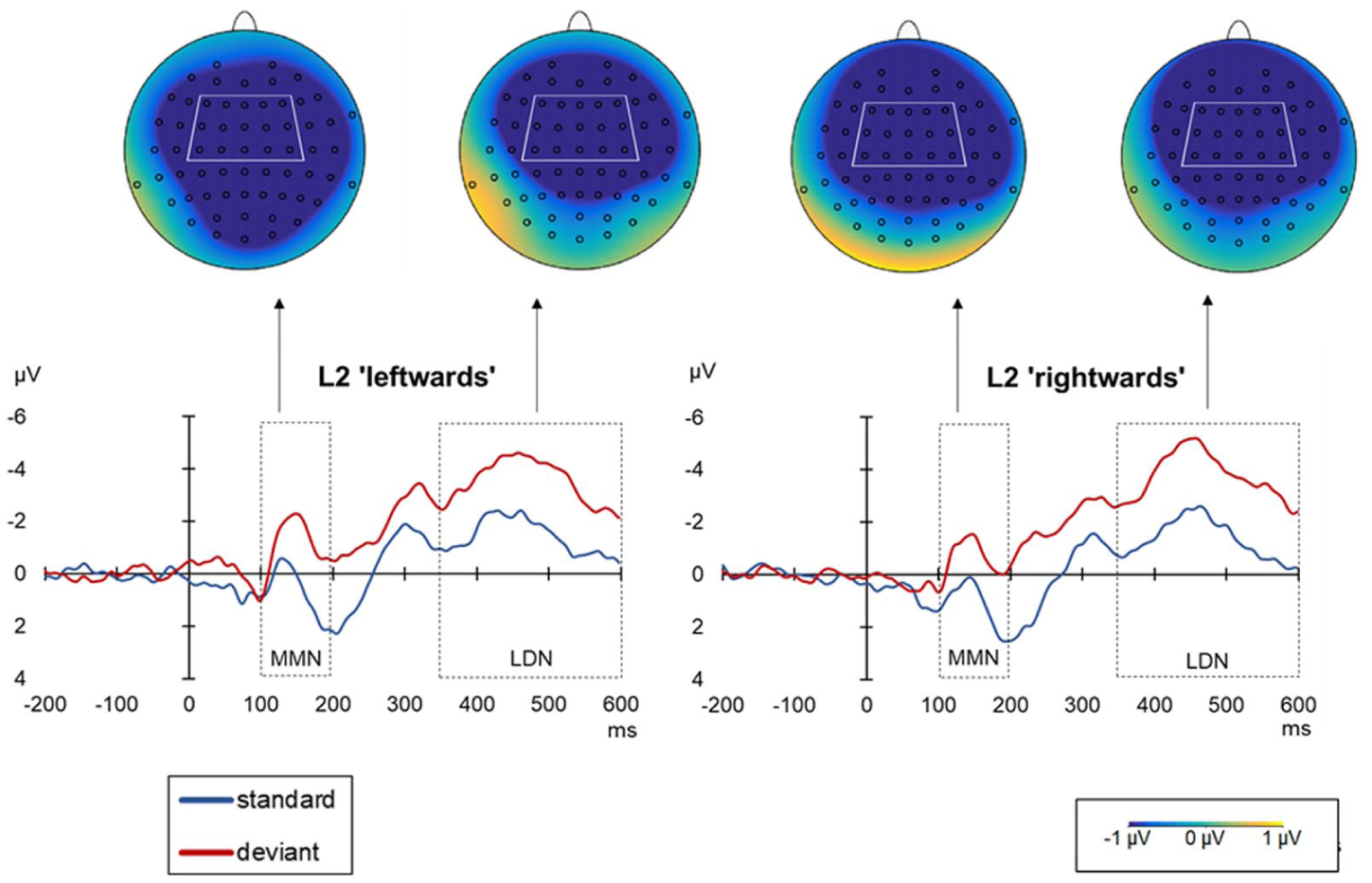
The grand average ERPs and mean voltage difference maps (deviant minus standard) for L2 English in the ‘leftwards’ ([ɑ] to [æ]) and ‘rightwards’ ([æ] to [ɑ]) conditions.
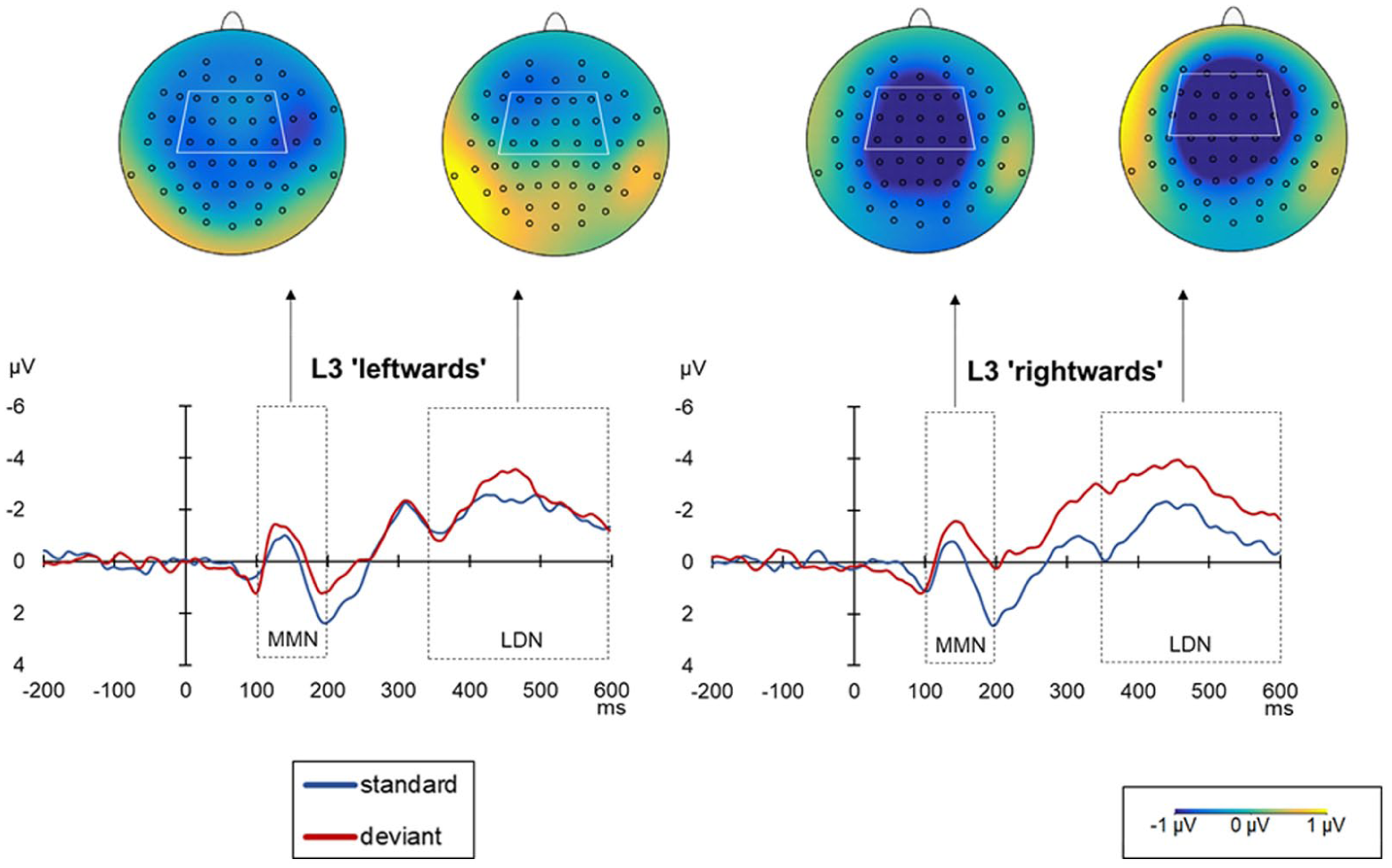
The grand average ERPs and mean voltage difference maps (deviant minus standard) for L3/Ln Norwegian in the ‘leftwards’ ([u] to [ø]) and ‘rightwards’ ([ø] to [u]) conditions.
Descriptive Statistics for Experimental Conditions in the MMN (100–200 ms) Time Window.
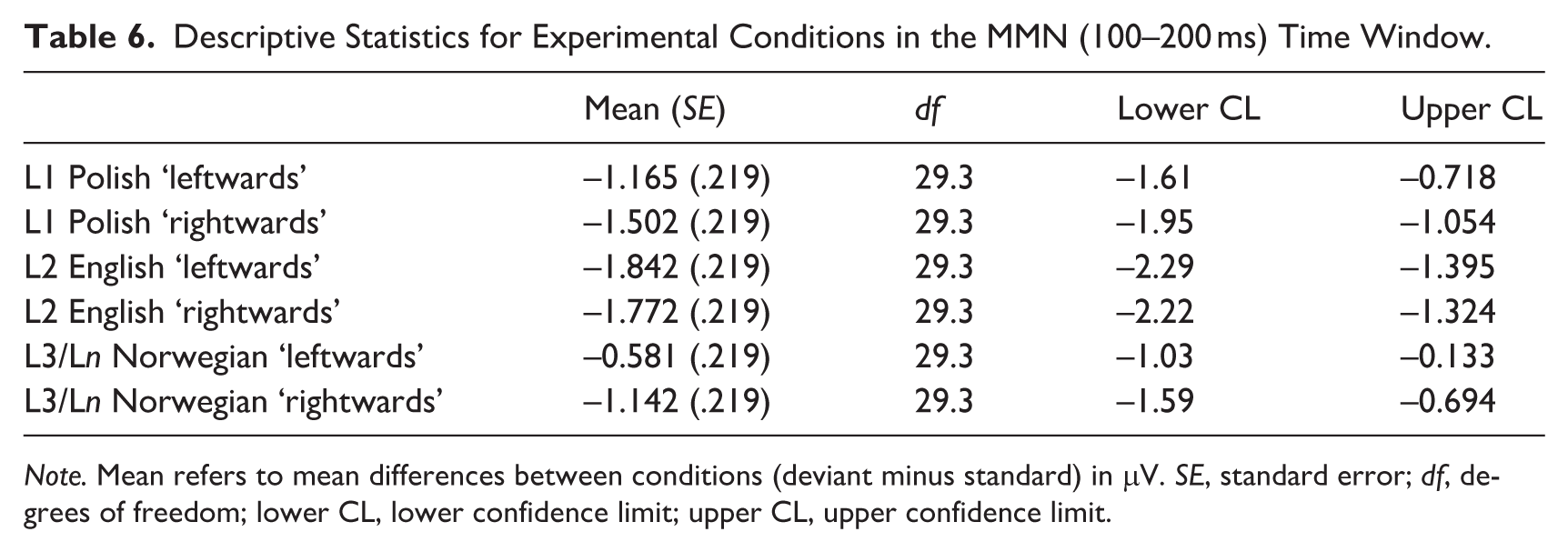
Note. Mean refers to mean differences between conditions (deviant minus standard) in μV. SE, standard error; df, degrees of freedom; lower CL, lower confidence limit; upper CL, upper confidence limit.
Descriptive Statistics for Experimental Conditions in the LDN (350–600 ms) Time Window.
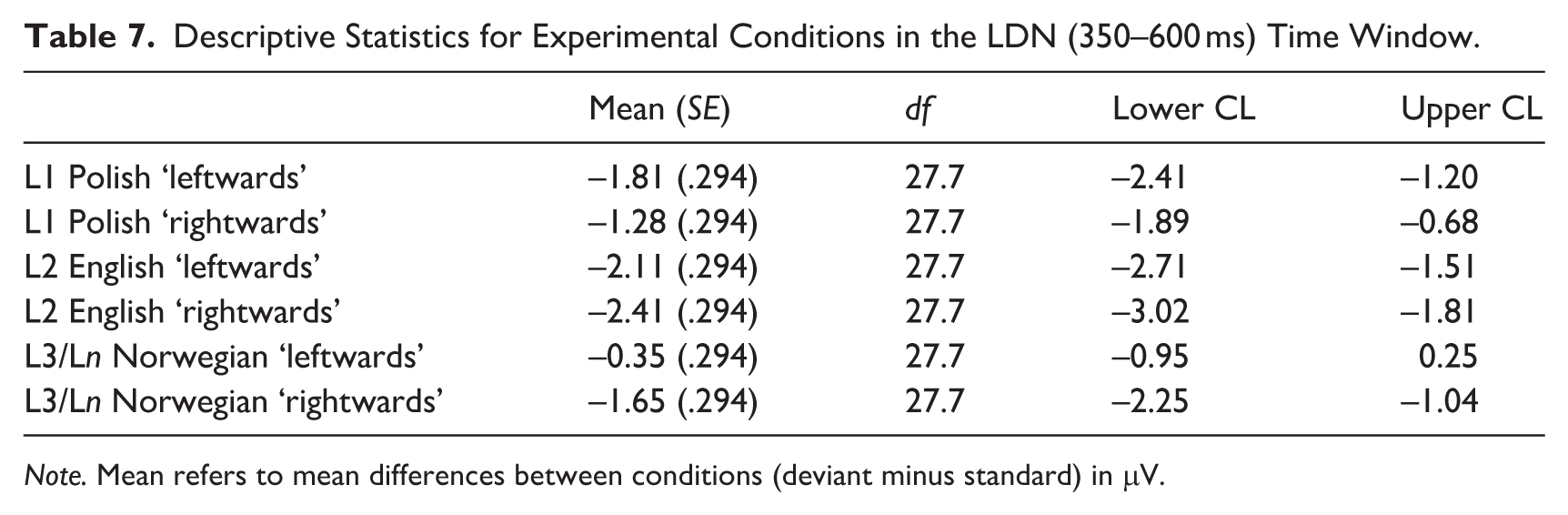
Note. Mean refers to mean differences between conditions (deviant minus standard) in μV.
MMN
In the MMN (i.e., 100–200 ms) time window, model comparison revealed a statistically significant two-way language × direction interaction, χ2(2) = 11.596; p < .01. The results of Tukey-based pairwise comparisons for language and direction contrasts are presented in Table 8. They revealed statistically significant differences between ‘rightwards’ and ‘leftwards’ conditions in L3/Ln Norwegian (p < .001) (see Figure 4), but not in L1 Polish (p = .1146) or L2 English (p = .995) (see Figure 5).
Pairwise Comparisons for the MMN Effect in the Language and Direction Conditions.
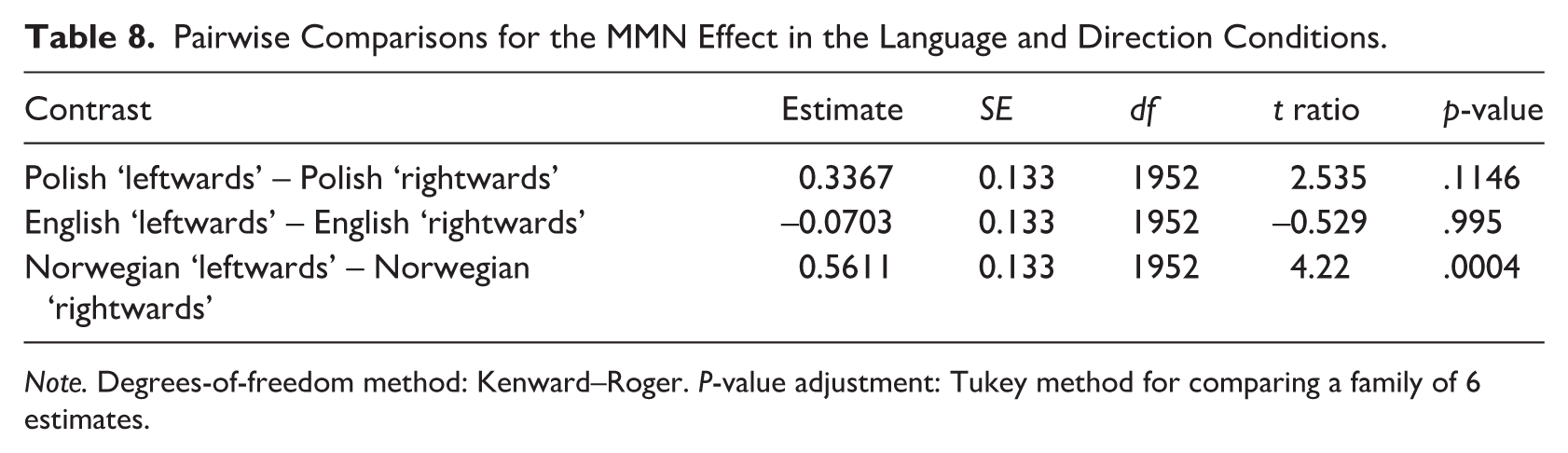
Note. Degrees-of-freedom method: Kenward–Roger. P-value adjustment: Tukey method for comparing a family of 6 estimates.
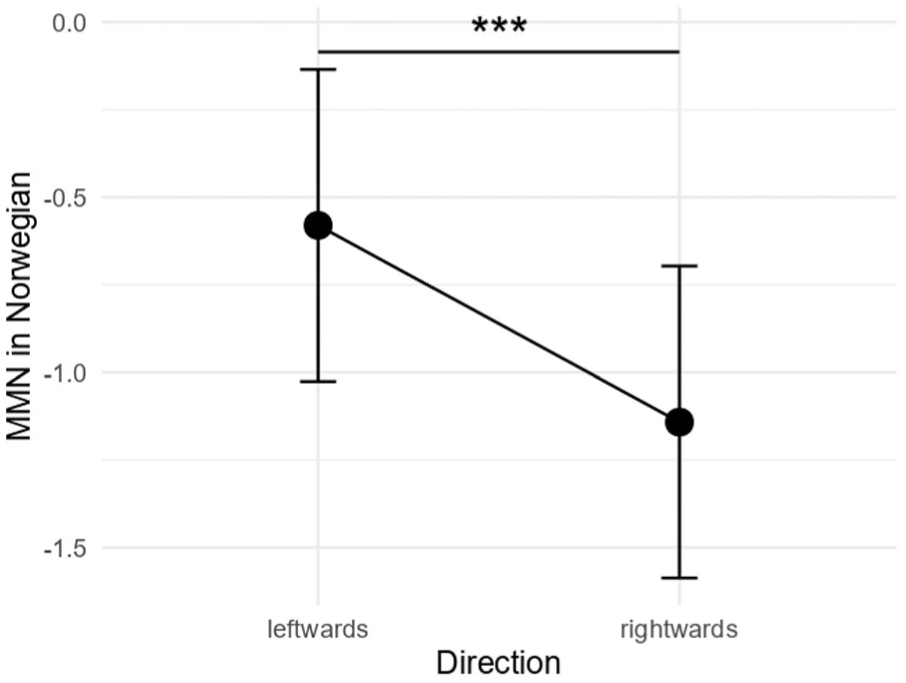
Directional asymmetry of the MMN effect in L3/Ln Norwegian in the 100–200 ms time window.
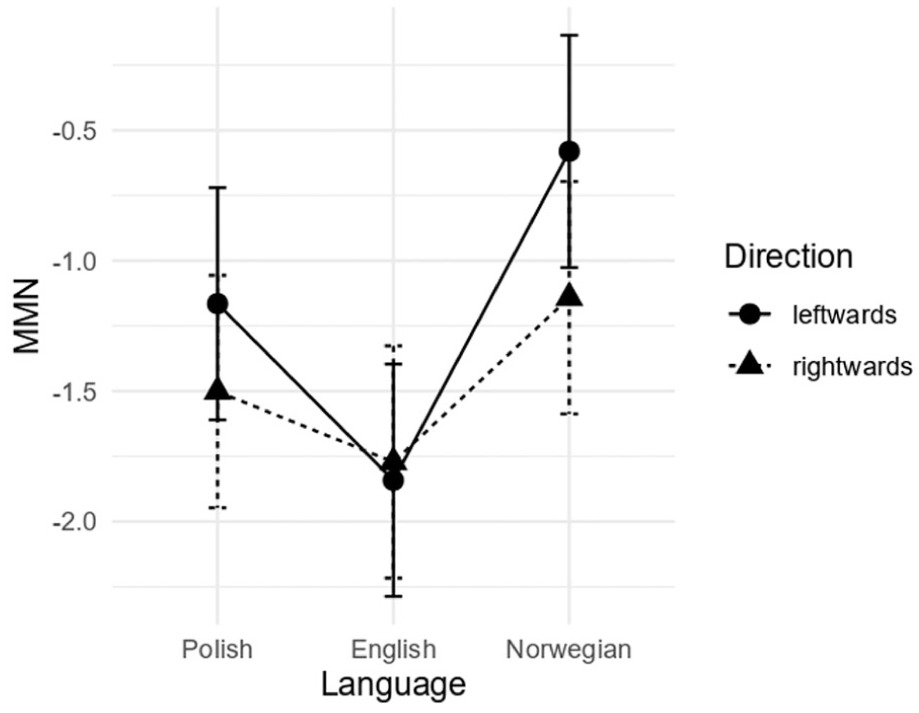
Mean amplitude differences (deviant minus standard) in μV for the analyzed languages and directions in the 100–200 ms time window.
LDN
In the LDN (i.e., 350–600 ms) time window, model comparison revealed a statistically significant two-way language × direction interaction, χ2(2) = 61.171; p < .001. The results of Tukey-based pairwise comparisons for language and direction contrasts are presented in Table 9. They revealed statistically significant differences between ‘rightwards’ and ‘leftwards’ conditions in the case of L3/Ln Norwegian (p < .001) and L1 Polish (p < .05), but not L2 English (p = .44) (see Figure 6).
Pairwise Comparisons for the LDN Effect in the Language and Direction Conditions.
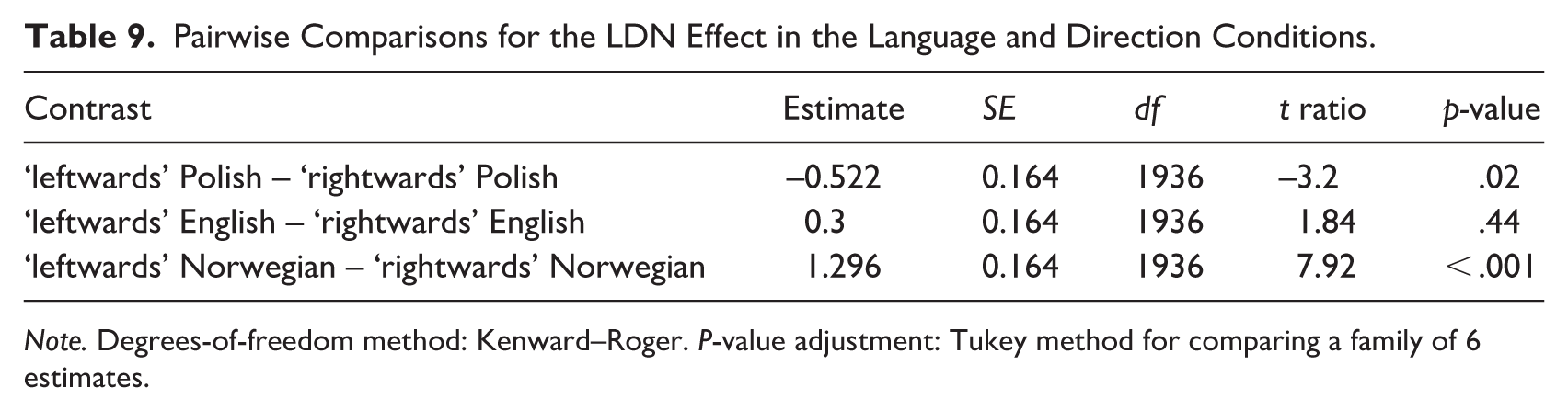
Note. Degrees-of-freedom method: Kenward–Roger. P-value adjustment: Tukey method for comparing a family of 6 estimates.
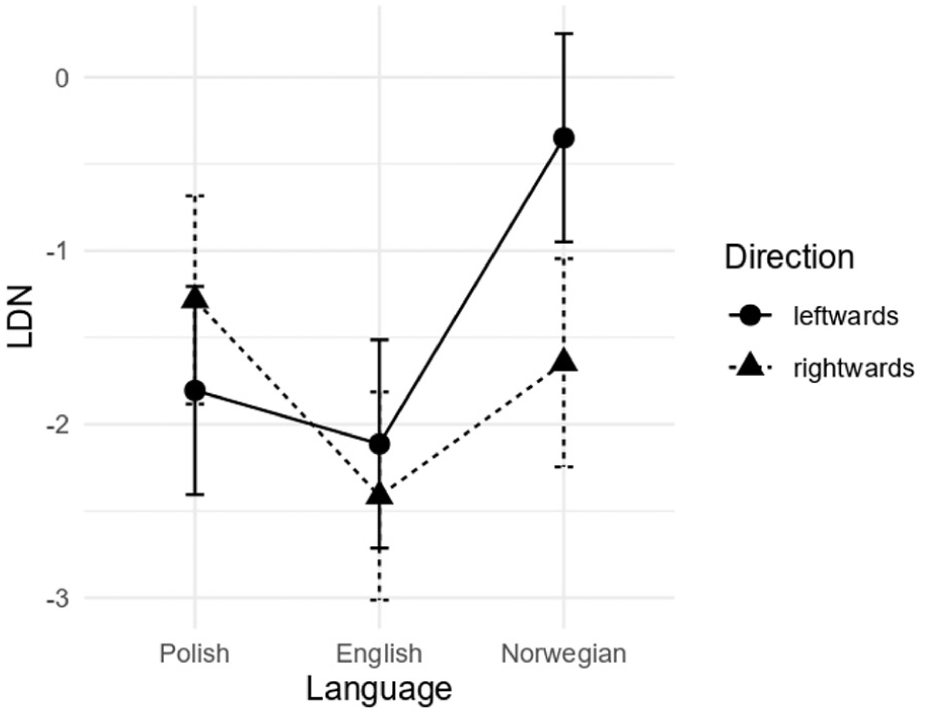
Mean amplitude differences (deviant minus standard) for the analyzed languages and directions in the 350–600 ms time window.
Discussion
Asymmetric MMN responses have been observed in numerous Oddball studies and are accounted for by several speech recognition theories (e.g., de Jonge & Boersma, 2015; Eulitz & Lahiri, 2004; Yu & Shafer, 2021). The main objective of the current paper was to shed more light on the issue of (a)symmetrical MMN and LDN responses in multilingual speakers and, in this way, to contribute to an ongoing scientific debate concerning phonological representations in native and non-native languages (e.g., Díaz et al., 2016; Jakoby et al., 2011; Kędzierska et al., 2023; Liang & Chen, 2022; Wottawa et al., 2022). Specifically, we were interested whether language status (i.e., L1 Polish, L2 English or L3/Ln Norwegian) would affect the (a)symmetry of the MMN and LDN response in a group of trilingual listeners. We believe that the novelty of the study lies not only in the use of the so-called ‘flip-flop’ paradigm, which enabled us to elucidate the issue of MMN and LDN (a)symmetries, but also in the selection of multilingual listeners instead of bilingual listeners—a choice rarely made in the electrophysiological literature thus far.
Two conflicting predictions were made with respect to the study’s outcome (see Table 10). Based on the FUL model (Eulitz et al., 1995; Eulitz & Lahiri, 2004; Harris & Lindsey, 1995; Lahiri & Reetz, 2010), we predicted that the MMN effect should be stronger if vowels with specified features serve as the standard, i.e., in the ‘leftwards’ direction condition. More precisely, [ø] is specified as [CORONAL][LABIAL], and in post hoc behavioral assimilation tests, 67% of the time it was assimilated to [ɨ] which is [CORONAL] and 18% of the time it was assimilated to /u/ ([HIGH][DORSAL][LABIAL]). In the case of no assimilation, that is, faithful perception, the ‘leftwards’ condition, from [u], which is [HIGH][DORSAL][LABIAL] to [ø] would lead to one feature mismatch (between [CORONAL] and [DORSAL]) and one feature missing from the deviant ([HIGH]), while the ‘rightwards’ condition, from [ø] to [u], would lead to one feature mismatch only (between [CORONAL] and [DORSAL]). We would then expect a stronger asymmetry in the ‘leftwards’ direction. In the case of assimilation to [ɨ], there would be a difference in rounding. Finally, in the case of assimilation to /u/, it is no longer a case of discrimination between two phonemes, but within-category differences, therefore MMN would not be driven by differences in feature specification, and the FUL models would predict a feature match, so no asymmetry.
Results Predicted by the Hypotheses Versus the Results Obtained in the Study.

Contrastingly, based on the perceptual magnet model (Kuhl et al., 1992) and the Natural Referent Vowel framework (Bohn & Polka, 2001), we hypothesized that the MMN would decrease if the worse exemplar vowels (according to the perceptual magnet model) or less peripheral vowels (according to the NRV framework) served as the standards. Since we observed asymmetrical MMN only in the case of L3/Ln Norwegian, it might be argued that the current results are mostly compatible with the latter hypothesis: native Polish learners of Norwegian are generally more likely to consider the Norwegian sound [ø] as a worse exemplar of /u/ when compared with [u] (see Balas et al., 2023). When the worse exemplar [ø] vowel served as the standard, the discrimination of a good exemplar [u] vowel was facilitated. This resulted in an enhanced MMN, when compared to a scenario in which the good exemplar [u] served as the standard. The asymmetrical MMN in the case of L3/Ln Norwegian can also be accounted for by the Natural Referent Vowel framework (Bohn & Polka, 2001). The Norwegian rounded [u] is more peripheral than [ø], and hence it acts as a referent vowel. If the less peripheral [ø] is used as a standard, it facilitates the perception of the [u] deviant.
It should be noted that using a single auditory token design may enhance sensitivity to acoustic differences and therefore does not allow for a strict test of abstract phonological representations alone. In light of this, our results should be interpreted with caution with respect to claims about the Featurally Underspecified Lexicon (FUL) model, which relies on phonological representations. Also, since all languages tested have a different status in the participants’ language repertoires, we can speculate that the less proficient Norwegian L3/Ln learners may not have such stable abstract representations for Norwegian vowels as they have for their highly proficient L2 English or native Polish.
According to the NRV, in the case of adults, perceptual asymmetries were not expected for the native contrast. Following this line of reasoning, it should come as no surprise that we observed no difference between the ‘rightwards’ and ‘leftwards’ direction conditions in the case of L1 Polish. Both [a] and [ɛ] could be considered as well-established phonemes in the vowel repertoire of the native Polish participants, as indicated by both by a pre-test on an independent group of Polish native speakers and by a post hoc test involving the study participants’ pool. In both these tests, the vowels were beyond the slightest doubts classified as [a] or [ɛ] accordingly and were judged as very good exemplars of their categories (recall Table 5). In accordance with some previous research (Molnar et al., 2013), we did not observe any differences between the ‘rightwards’ and ‘leftwards’ direction conditions in L2 English, which could have been driven by the listener’s high L2 proficiency. In the case of a relatively proficient L2 (cf. Molnar et al., 2013), we could expect no asymmetries, as L2 English vowels are processed in a more native-like manner than the newly acquired L3/Ln Norwegian vowels.
The most surprising result of the study is the strongest MMN response observed for L2 English (see Appendix A), which is difficult to reconcile with previous findings. Most studies show a stronger MMN for native languages (Liang & Chen, 2022; Winkler et al., 1999; Wottawa et al., 2022). Two recent Oddball studies on Polish–English–Norwegian speakers (Kędzierska et al., 2023; Kędzierska et al., 2025) showed the strongest MMN for L1 Polish [ɨ]–[ɛ], a smaller or comparable MMN for L2 English [ɪ]–[ʊ], and the weakest for L3 Norwegian [i]–[ʏ]. One speculative explanation of the current finding involves the English stimuli (i.e., [æ] and [ɑ]) being often emphasized in classrooms, so the current result might perhaps be viewed as an effect of training.
In all investigated languages, the MMN effect was followed by the LDN, whose overall amplitude aligned with the pattern of the earlier effect. That is, it was the largest in L2 English, smaller in L1 Polish, and the smallest in L3/Ln Norwegian. While the LDN is generally believed to indicate whether memory traces associated with a specific phonemic representation have been formed successfully (Barry et al., 2009; Jakoby et al., 2011; Kędzierska et al., 2023), to the best of our knowledge, no previous studies have investigated the (a)symmetry of LDN in the context of multilingual listeners. While no LDN asymmetry was observed for L2 English, for L3/Ln Norwegian, the effect was stronger in the ‘rightwards’ direction, similar to the MMN, and hence can be accounted for by the perceptual magnet model (Kuhl et al., 1992) and the Natural Referent Vowel framework (Bohn & Polka, 2001). Importantly, Experiment 3 in Hestvik and Durvasula (2016) also showed asymmetric LDN, with the asymmetry reflecting differences in specification (underspecified segments elicited reduced LDN compared to the specified ones). This pattern is consistent with our LDN results, where [ø] (underspecified) showed a non-significant LDN compared to [u] (specified), which elicited a robust negative LDN. In L1 Polish, where no MMN asymmetry was observed, the LDN effect was significantly stronger in the ‘leftwards’ direction. Notably, the difference between the two direction conditions was weaker in L1 Polish (the estimate for ‘leftwards’ Polish – ‘rightwards’ Polish: –0.522) than in L3/Ln Norwegian (the estimate for ‘leftwards’ Norwegian – ‘rightwards’ Norwegian: 1.296).
While there is no single theory which could encompass the results for both the native language and non-native languages, the current results have important implications for phonological representations in multilingual listeners. The MMN results tentatively suggest that while the NRV and the perceptual magnet model make correct predictions about non-native phoneme processing, the assumptions of the FUL model seem to more adequately apply to L1 processing, as the symmetry for L1 Polish, predicted by the perceptual magnet model (Kuhl et al., 1992), Natural Referent Vowel framework (Bohn & Polka, 2001) and the FUL model (Eulitz & Lahiri, 2004), was confirmed by the MMN effect. In addition, since in the present study the ‘leftwards’ asymmetry for the LDN is found only in the L1, a tentative conclusion could be that the privative features are represented differently or have a different effect or status in native and non-native languages. However, we need to bear in mind that the theories discussed here were proposed for the L2, whereas multilingual representations are even more complex.
Undoubtedly, the current study also faced several limitations, which, apart from a small sample size, also involve a focus on specific language acquisition order, that is, L1 Polish, L2 English, and L3/Ln Norwegian. As in the case of any multilingual research, it would be ideal to test different language combinations in future studies and hence disentangle the issue of language status and the characteristics of the presented auditory stimuli as two factors independently influencing pre-attentional phoneme processing. Given the use of single-token standards and deviants, we acknowledge that this may be seen as a limitation with respect to fully isolating abstract phonological representations. Therefore, the present findings should be interpreted as reflecting perceptual sensitivity to systematic contrasts that may have both acoustic and phonological sources. Future research using multiple auditory token variability would further clarify the contributions of acoustic versus phonological factors.
Another limitation of the present study concerns participants’ language mode during the task. Although English and Norwegian vowels were intended as non-Polish categories, participants may have perceived them as Polish throughout the experiment. As all interactions were conducted in Polish, participants were likely to be operating in a Polish language mode, which is known to influence bilingual speech perception (Antoniou et al., 2012). In the absence of strong contextual cues, categorization may have relied primarily on acoustic properties (García-Sierra et al., 2021; Wig & Garcia-Sierra, 2021), potentially leading to the assimilation of non-Polish vowels to Polish categories, which should be taken into account when interpreting the results.
Conclusion
The main aim of our study was to elucidate the issue of phonemic contrast processing in three languages in the same group of speakers. By employing the so-called ‘flip-flop’ design, we wished to extend previous research on multilingual phoneme processing and investigate the issue of MMN (a)symmetry in multilingual listeners. The findings indicate that language status (operationalized as L1, L2, or L3/Ln) affected the (a)symmetry of the MMN and LDN responses. The only language for which we observed asymmetrical MMN was L3/Ln Norwegian (with the effect stronger in the ‘rightwards’ direction), but not L1 Polish or L2 English. Some of the obtained results were correctly predicted by the perceptual magnet model (Kuhl et al., 1992) as well as with the Natural Referent Vowel framework (Bohn & Polka, 2001) and Featurally Underspecified Lexicon (Eulitz & Lahiri, 2004). What is surprising is the lack of MMN asymmetry in L2 English, which could, however, be accounted for, given that English was a relatively proficient and early-acquired foreign language for the current participants. As far as we know, the study was a first attempt to investigate the MMN and LDN asymmetry in multilingual learners, and provided clear evidence for the processing differences in L3/Ln as opposed to L2. Nevertheless, further in-depth research is needed to solidify the current findings.
Supplemental Material
sj-docx-1-ijb-10.1177_13670069261455629 – Supplemental material for MMN and LDN asymmetries in Polish–English–Norwegian trilingual listeners
Supplemental material, sj-docx-1-ijb-10.1177_13670069261455629 for MMN and LDN asymmetries in Polish–English–Norwegian trilingual listeners by Hanna Kędzierska, Karolina Rataj, Anna Balas and Magdalena Wrembel in International Journal of Bilingualism
Supplemental Material
sj-docx-2-ijb-10.1177_13670069261455629 – Supplemental material for MMN and LDN asymmetries in Polish–English–Norwegian trilingual listeners
Supplemental material, sj-docx-2-ijb-10.1177_13670069261455629 for MMN and LDN asymmetries in Polish–English–Norwegian trilingual listeners by Hanna Kędzierska, Karolina Rataj, Anna Balas and Magdalena Wrembel in International Journal of Bilingualism
Footnotes
Appendix A
Appendix B
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: *The research leading to these results has received funding from the Norwegian Financial Mechanism 2014–2021 project number 2019/34/H/HS2/00495. The authors thank Zuzanna Cal, Justyna Gruszecka, and Iryna Kravchuk for their assistance with the EEG recordings.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.