
Abstract
Aims and Objectives:
The objective of this paper is to explore how learners organize and access their mental lexicon in the L1 and L2 and to look for similarities and differences in these processes. We wanted to explore the impact of L1 linguistic and cultural background on semantic categorization.
Methodology:
The method used includes data gathering, graph analyses and computing. Specifically, graphs were calculated from experimental data and, then, distances among the graphs were computed.
Data and Analyses:
Data were obtained from 430 English as a foreign language (EFL) learners from a Spanish background aged 15–16. Analyses compared English and Spanish semantic categorization data. Several analyses using different methodologies were conducted (based on vectorization of networks, computing distances by means of metrics and spectral vectorizations) and found similar conclusions.
Findings:
Our results suggest that the thematic axis outweighs the language axis for Spanish learners of English in semantic categorization. Furthermore, the direction of links and their weights seems irrelevant: this might point to a high homogeneity in semantic categorization.
Originality:
To our knowledge, this is the first time these methods are used on a large sample of experimental linguistic data.
Significance:
Our results provide further evidence of a semantic categorization process which is shared by speakers and learners of different languages, showing that semantic similarity is an overriding factor over language in categorization, either because of a shared conceptual space or as a result of a translation process from L1 into L2/EFL.
Introduction
Semantic categorization is a mental process pertaining to how humans organize and make sense of the world around them, of reality (cf., Coni et al., 2019; Sass et al., 2009). Semantic categories are stored in semantic memory, but how exactly these categories are organized still remains an open question. In general, it is believed that we organize and group information based on similarity, mainly semantic, but also formal (orthographic or phonological), syntactical (e.g., collocations), functional or pragmatic and experiential (Aitchinson, 1994), and hence, semantic categories are formed. Examples of semantic categories are Animals, Colours, Occupations, Food and drink and so on. This organization of similar or related concepts facilitates cognition and word retrieval for communication (e.g., Bower et al., 1969). Generally, there are some exemplars in the category which are believed to be the best examples, most representative or typical members, also known as prototypes (cf., Rosch, 1978). These ideal members are most easily accessed. Membership in the category is decided upon the number of shared properties or features of one category member and the others.
The way in which categories are formed changes based on several variables. For instance, the type of category is paramount in determining the nature of the relations among the members of the said category. Hence, we distinguish among taxonomic, ad hoc and experiential or thematic categories (see, e.g., Benn et al., 2023), also known as schema categories (e.g., Mandler, 1984). Taxonomic categories are similarity-based, generally found in nature, and can be named by superordinate terms, for example, Animals, Food and drink (e.g., Hernández-Muñoz et al., 2025; Kleiber, 1995), whereas thematic or experiential are co-occurrence-based and refer to events or scenarios like things you find in the Countryside or things that you Love (Benn et al., 2023). Ad hoc categories tend to be more novel or spontaneous groupings, Things that are yellow (Barsalou, 1983; Barsalou, 2010; Hernández-Muñoz et al., 2025), which base their belonging on a shared objective or idea. Some previous studies revealed that language is more relevant in ad hoc categorization or when the members of the category share fewer properties (e.g., Lupyan & Mirman, 2013). Accordingly, the smaller the linguistic resources, that is, the vocabulary in the L2, for example, the more difficult it will be for learners to respond to these categories. Also, category types such as experiential, like Sports and Hobbies, or schema-based, like Countryside, have an internal structure that is less robust and stable and highly influenced by cultural, emotional and linguistic experiences (cf. Hernández-Muñoz et al., 2025). Accordingly, taxonomic categories such as Animals might be less influenced by the linguistic knowledge of the learners, and therefore, L1 and L2 categorization might be closer. However, more experiential categories based on ad hoc decisions or dependent on cultural scenarios might appear more distant in L1 and L2 renderings.
Apart from the internal characteristics of the category, other factors, such as age, or language and culture of origin might impact the structure of the category. Thus, children tend to organize their semantic information according to their experience of the world in a slot-filler way. As age increases, and vocabulary knowledge does as well, conceptual similarity takes over and organization becomes more taxonomic, that is, according to the natural organization of the world (cf. Shivabasappa et al., 2017).
Although categorization is a typically human activity that spreads across languages, there are some slight variations as to how speakers of disparate languages and cultures organize the members in the category. The internal structure of the categories is not only cognitive, but also culture-dependent (cf. Kövecses, 2006; Lakoff, 1986). Cultural availability or familiarity with the exemplars of the categories is a crucial element that determines the structure of a semantic category (Lin et al., 1990; Shivabasappa et al., 2017). For instance, pie might be a good example of the category Food and drink for the British speaker, but not necessarily for the French, German or Spanish native, who might rather refer to quiche, sausage or omelette, respectively, instead, as prototypical or first responses. In addition, different languages map concepts onto lexical words differently. Several studies (e.g., Ameel et al., 2005; Malt et al., 1999; Wierzbicka, 1992) have noticed that speakers of different languages map conceptual meanings into words in disparate ways so that word-to-word mappings among the different languages are not always identical. These differences may affect the structure of the semantic categories in the different languages. Mirroring these previous studies, in the present research, we distinguish between lexical items, which are the observable responses produced by participants, and conceptual organization, which refers to the semantic relations underlying those responses.
L2 learners develop semantic categorizations that are influenced by both their L1 and L2, indicating the importance of language in shaping these categories (e.g., Ameel & Storms, 2006). The impact of language on categorization varies across different semantic categories. Taxonomic categories, whose members are close in conceptual space, might be less prone to be influenced by language or cultural experience. On the contrary, those involving conceptually more distant items or exemplars might be more affected (e.g., Imai & Gentner, 1997). In addition, larger semantic categories facilitate learning of prototypes in L2, suggesting an inherent influence of the semantic category itself (e.g., Malt et al., 1999).
Aitchinson (1994), who investigated the categorization of items and the prototype effects in vocabulary learning, reached the conclusion that the differences in the responses of adult learners of English as a foreign language (EFL) with different native languages who participated in her study were due to their native language and culture. Cross-linguistic differences reveal that bilingual speakers show different categorization patterns depending on the language they are using, suggesting a strong influence of language-specific features (e.g., Pavlenko, 2009; Viñas-Guasch et al., 2017).
In conclusion, while both language and semantic category are important factors in semantic categorization, their relative importance appears to vary depending on the specific context, type of categorization task and the nature of the semantic categories involved. The interaction between these factors suggests that neither can be considered universally more important than the other across all situations.
Semantic Categorization in L1 versus L2
Previous studies have also dealt with semantic processing in the L1 and the L2 via semantic processing tasks. Please note that we refer to semantic processing for discussions of access and activation in the mental lexicon, whereas semantic categorization refers mainly to the task and the resulting organization of responses. There seems to be a general consensus that there is a partial overlap of core conceptual systems, with disparate boundaries, radial or external members and even different categorization strategies, depending on linguistic structure, cultural, emotional and experiential context (cf., e.g., Francis, 1999; Teixeira-Moláns, 2024). Specifically, L2 learners develop semantic categorization in their second language through a complex process that involves both L1 influence (e.g., Wolter & Yamashita, 2018) and the formation of new L2-specific categories (Saji et al., 2024). The evidence suggests a combination of both strategies, rather than a simple reliance on L1 categorization or complete native-like L2 categorization. Generally, L1 and L2 categorization processes converge with increased bilingual experience (cf. Ameel & Storms, 2006).
Recently, the application of complex network analysis has allowed for some insights into how semantic categories are organized and structured. Hernández-Muñoz et al. (2025) use complex network analysis to examine empirical language data, specifically, how actual speakers respond to active categorization tasks. They conclude that network metrics such as betweenness centrality or extint, the strength of the association within and outside the communities, serve to describe the categories and discriminate among the members. Furthermore, they believe that categories are small-world structures, characterized by short path lengths and high clustering, which facilitates navigation and efficient word retrieval and that modularity of the network, that is, the way in which word clusters are established and the strength of their links, helps distinguish among categories. Hence, taxonomic categories display fewer communities with more numerous clusters of members, whereas experiential or schema categories exhibit a more dispersed structure and ad hoc categories lie in between. The creation of lexical-semantic networks as complex graphs with experimental linguistic data is a metaphorical approximation to the mental lexicon and the relations among the words (e.g., Collins & Loftus, 1975; Dubossarsky et al., 2017; Hernández-Muñoz et al., 2025; Steyvers & Tenenbaum, 2005). Both L1 and L2 lexical-semantic networks display small-world and scale-free network properties, featuring short paths connecting words and strong clustering (Feng & Liu, 2023), which in linguistic terms means that speakers have readily available vocabulary and that communication does indeed proceed successfully (Steyvers & Tenenbaum, 2005). However, L2 lexical-semantic networks are less densely connected and less well-organized compared to L1 networks (e.g., Borodkin et al., 2016); they evolve with time and L2 proficiency, gradually departing from L1 patterns and becoming more similar to those of native speakers of the L2 (Feng & Liu, 2023; Quintanilla & Kloss, 2024). Besides, as measured by processing time studies, L2 response times to semantic processing tasks and semantic fluency tasks are generally slower (cf. Fitzpatrick & Izura, 2011) and show stronger frequency effects than L1 processing, suggesting more lexical involvement in L2 processing (Plat et al., 2018). This slowness is generally interpreted as a reflection of the L2 lexical-semantic system being less automatized and less densely connected (as discussed with the network analysis). Accessing or searching through the L2 mental lexicon requires more cognitive effort and time because the links between concepts and words are not as strong, or well-practised as they are in the L1. In the L1, semantic access is thought to be highly efficient, possibly allowing for a more direct conceptual route where word meaning is rapidly retrieved, regardless of frequency. In the L2, the learner may rely more heavily on the lexical (word form) route and the strength of the lexical-conceptual link. High-frequency words have stronger connections in the L2 network, making them easier and faster to activate. For low-frequency words, the weaker connections require a more effortful search or activation process, causing the stronger frequency effect to surface. This indicates that the L2 system is less robustly connected and still relies more on the strength of repeated exposure (frequency) to facilitate semantic access. Furthermore, Kroll and Tokowicz (2001) suggest that during L2 processing, learners automatically activate L1 translations, which can influence semantic judgements and word retrieval. In this sense, typological closeness, that is, formal and semantic similarity among the L1 and L2, might play a role in L2 lexical-semantic organization, with L1 structures influencing and facilitating L2 word retrieval, even at advanced levels of proficiency (e.g., Dijkstra & van Heuven, 2002; Wolter & Yamashita, 2018).
In the case of bilingual and multilingual lexical representations, it is crucial to determine whether L1 and L2 forms share a conceptual node. Different theories have accounted for shared and separate conceptual representations, see the Revised Hierarchical Model (RHM) in Kroll and Stewart (1994), the Bilingual Interactive Activation (BIA) model in Kroll and de Groot (2005) and Kroll and Tokowicz (2005) for a review. The former proposes that the L1 lexicon is strongly connected to the conceptual store, while the L2 lexicon has a weaker and indirect connection to concepts, relying primarily on a strong link to the L1 lexicon. The L1 word serves as the main access route to meaning, especially for novice learners. The latter model posits that the lexical items of both the L1 and L2 are stored in a single, integrated system and are simultaneously activated whenever a bilingual encounters language input, regardless of the intended language. This model is characterized by non-selective access and interactive activation at the word form level, where activation flows between orthographic (spelling/form), phonological (sound) and semantic levels across both languages. However, empirical evidence pointing to one or the other is scarce and contentious. In this sense, most empirical evidence conducted via word association tests, semantic fluency tasks and translation priming highlight that there is a word effect pointing to cognate word, words that are concrete or with universal referents to share conceptual representation, whereas more abstract, emotional or culturally-loaded words might be stored separately with separate or partially separate conceptual nodes (cf. Chaouch-Orozco et al., 2024; Kolers, 1963).
Borodkin et al. (2016) examined L2 lexical-semantic networks with participants with a highly structured L1 lexicon already in place. They found out that L2 networks, although thematically organized, were more dispersed and thematic clusters were fuzzier than in the L1 networks. On their part, Feng and Liu (2024) state that “L2 learners are assumed to apply their L1 lexical-semantic knowledge to build their L2 lexical semantic networks.” Accordingly, their L2 networks might resemble or imitate their L1, both in terms of word responses and in terms of their connections and the nature of these connections.
Here, we intend to explore this issue by applying network theory analysis to experimental linguistic data. Hence, we propose a methodology to analyse empirical linguistic data derived from fluency tests, and which allows for between-groups comparisons. Banking on previous findings with L1 and L2 lexico-semantic networks, the present study asks whether the organization of lexical responses in L2 semantic categorization resembles that observed in L1, and whether this similarity varies according to category type (taxonomic vs. experiential/schema-based). Data will be approached in an aggregated fashion and distances will be computed using different methods, as explained below in detail.
Methodology
We calculated distances between graph metrics in L1 and L2 for both semantic categories to find out how close or far they were. Specifically, we used two methods for distance calculation to check generalizability capacity.
Participants
Our study has been carried out with a group of Spanish students of EFL L2 to compare their semantic categorization in Spanish L1 and EFL. Specifically, a group of 430 Spanish EFL learners participated in the study. All of them completed a semantic fluency task, first in English, the FL, and then in Spanish, their L1. This order of administration was followed to avoid any priming effect deriving from the L1. They were in the final year of their secondary education, grade 10. They were aged 15–16. All students were learners of EFL and were at the low-to-high intermediate level of proficiency in English (A2–B2) as per the Oxford Placement Test (UCLES, 2001), which they completed prior to the semantic fluency task.
Instruments
A semantic fluency task called Lexical Availability task (LAT), which is a multi-response fluency task type, was used to elicit production of vocabulary data from informants. The LAT presents informants with a stimulus or cue word and asks them to generate responses related to the stimulus category. In particular, learners had to write, in 2 minutes, as many words as came to their mind. Specifically, we had participants respond to the categories (Animals and Love), the former a taxonomic category and the latter a more experiential one (e.g., Hernández-Muñoz, 2014; Jiménez-Catalán, 2014) in relation to the prompts: Animals and Love. These two prompts were selected on three grounds: they feature (a) different productivity, (b) different response diversity or response spread and (c) different cohesion index. Animals is an inclusive or closed category which gives rise to many but very homogeneous responses. Love is a less productive prompt, but where a broader amount of types are to be found, it is more open and gives rise to more heterogeneous responses (e.g., Hernández-Muñoz, 2014; Tomé-Cornejo, 2015). Participants were instructed in Spanish L1 and each prompt and the corresponding responses occupied an independent sheet. Participants had to respond in Spanish L1 and EFL. The LAT collects multiple responses from learners (cf. Jiménez-Catalán, 2014; Schmitt, 1998) and gives thus a more complete picture of learners’ lexicons (Precosky, 2011; Sheng et al., 2006). Multiple-response association tests tend to prompt chain responses that associate one another rather than with the stimulus word (cf. De-Deyne & Storms, 2008; Precosky, 2011), that is, the word produced will facilitate or prime recall at two levels simultaneously, that of other related concepts or word forms; this is called a priming effect.
Procedures and Analyses
Data were collected via an online application specifically designed for the purposes of a larger project, within which this study is framed. Participants completed the LAT in class in the presence of the teacher and the researchers conducting the study. Responses were obtained in computer-readable form for each of the prompts. The data were carefully edited, adopting the following criteria:
No repetitions per informant were allowed.
Spelling errors were corrected.
Multiple-word responses were hyphenated in order for them to be counted as a single word (e.g., fresh-air).
Once the editing process was complete, the data were typed into text files. Data were processed by means of the Gephi software package (Cherven, 2015) (see also Borodkin et al., 2016; Christensen & Kenett, 2021; Zemla & Austerweil, 2022 for alternative ways to construct graphs). Gephi allows one to construct graphs from association data and obtain different key statistical measures, such as, for instance, average degree, clustering coefficient, diameter, eigenvector centrality or closeness, to mention but a few.
Comparing Linguistic Graphs
While there is a panoply of methods for comparing networks (see, for instance, Tantardini et al., 2019), only some of them are useful when comparing linguistic graphs as the ones obtained through Lexical Availability tasks. The methods for network comparison can be divided into two different types. The first type focuses on the study of the relative complexity of a pair of networks with the same nodes or, equivalently, of two networks with natural bijection between their sets of nodes. This is not applicable in the present case, where the number of nodes depends on the learners’ responses, which can be, and actually are, different with respect to each stimulus. Furthermore, even if we were to discretionally impose a fixed number of nodes, as will be done for methodological reasons in the next section, establishing a natural bijection between the set of nodes remains impossible. For instance, the 50 most frequent words observed for Animals in the L2 network do not correspond to the translation of the 50 most frequent words with respect to Animales in L1.
Given these constraints, the analyses of our data necessitated the selection of methods of the second type, specifically those designed to compare networks with different number of nodes (Tantardini et al., 2019). From this anthology of options, we chose approaches rooted in graph vectorization. In this technique, a network is represented by means of a numerical vector, and then differences between two graphs are measured through the distances between the corresponding vectors. In this paper, we focus on the Euclidean distance:
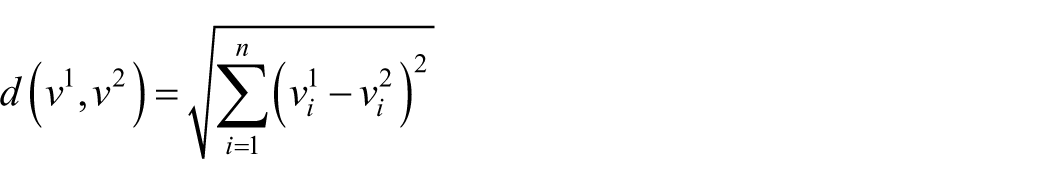
where
Considering that we should compare three graphs denoted by
In our first approach, a vectorization by global statistics (Tantardini et al., 2019) or features was selected. We compute, for each graph, the values of 11 features calculated by default in Gephi:
Number of nodes.
Number of edges.
Average degree. The degree of a node is the number of nodes adjacent (i.e., to say: linked with at least one edge) to it. The average degree is the arithmetic mean of the degrees of all nodes.
Average weighted degree. As the precedent one, but counting the number of edges linking each pair of nodes.
Diameter. A path between two nodes
Density. Graph density is the ratio of the actual number of edges to the maximum possible number of edges in a graph (which depends on the number of nodes).
Number of connected components.
Modularity. Modularity is a measure of the strength of a graph’s division into communities (see details in Blondel et al., 2008).
Statistical inference number. This number measures assortative communities in networks based on a nonparametric Bayesian formulation (see the formal definitions in Zhang & Peixoto, 2020).
Clustering coefficient. The clustering coefficient is a measure of the degree to which nodes in a graph tend to cluster together (see Barrat et al., 2004 for details).
Average path length. The average path length of a graph is the average of the shortest path lengths between all possible pairs of nodes in the graph.
Being aware that feature vectorization could have certain drawbacks in some circumstances (see Tantardini et al., 2019), we thought about using other ways of vectorization to confirm our insights. We moved to spectral vectorization. This method is not free of deficiencies either, see again (Tantardini et al., 2019), but we hope that mixing two very different approaches to computing distances between graphs could offset the potential drawbacks of each method in isolation. The spectral method consists of representing each network by means of the eigenvalues of its adjacency matrix, sorted in decreasing order. To be able to sort the eigenvalues, it is required that they are real numbers (and not complex numbers, which is the case in general), and then that the adjacency matrices are symmetric. Our initial graphs are weighted and directed, so their adjacency matrices do not satisfy the required properties. It is so mandatory to transform our graphs to obtain their simple and undirected counterparts. As a byproduct, as we will explain in the next section, this will allow us to stress that some of our outcomes are not dependent on the orientation and weight of edges.
Results
Once our graphs have been built, we got four networks denoted by the name of the stimulus which produced each one of them; namely,
Gephi capture of the Animales graph is displayed by means of the Fruchterman-Reingold distribution.
Gephi capture. The Animals graph.
Gephi capture of the Love graph.

Gephi capture of the Amor graph.
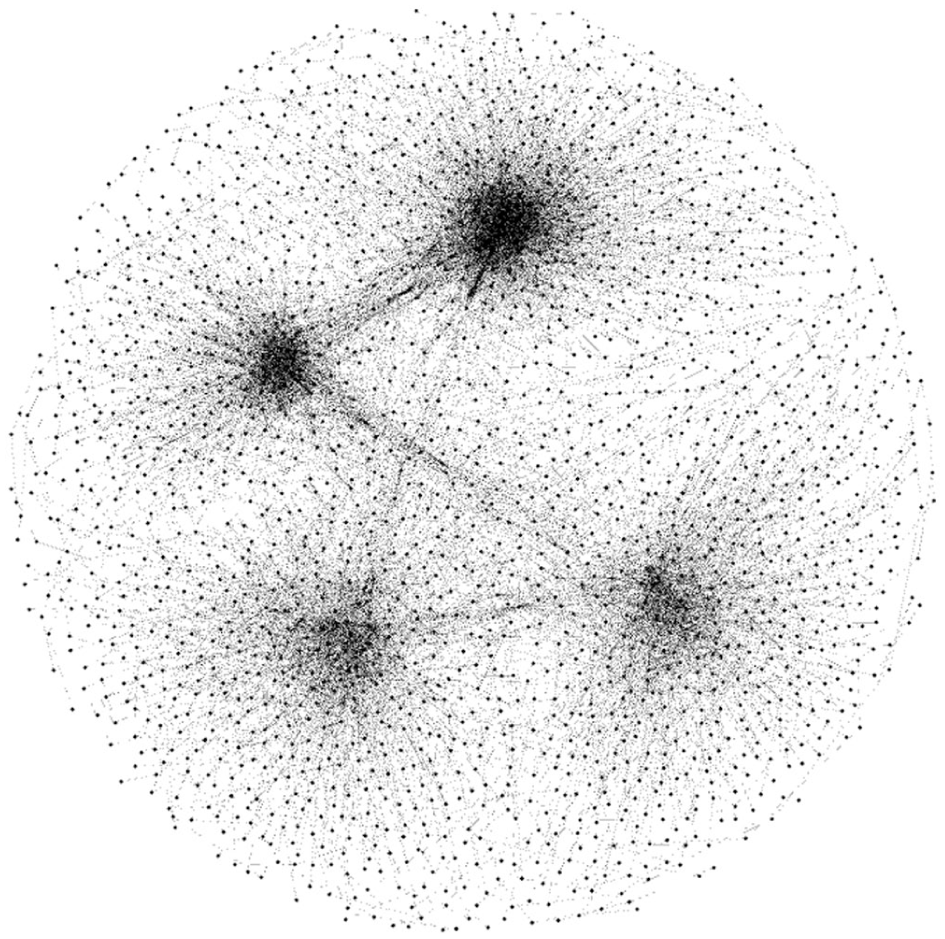
Gephi capture of the four stimuli put together.
Nevertheless, when trying to reflect this property in a quantitative way, we found the problem that the noisy nature of this kind of lexical availability graphs (with many vertices with very small degree) perturbed a clean comparison. Hence, we pruned the graphs, keeping only the 50 most central [highest degree] or generation-frequent words for each stimulus (as it was done in the paper Agustín-Llach & Rubio, 2024), obtaining four new graphs, called

Gephi capture of the Animales graph pruned up to the 50 most frequent nodes.

Gephi capture of the Animals graph pruned up to the 50 most frequent nodes.
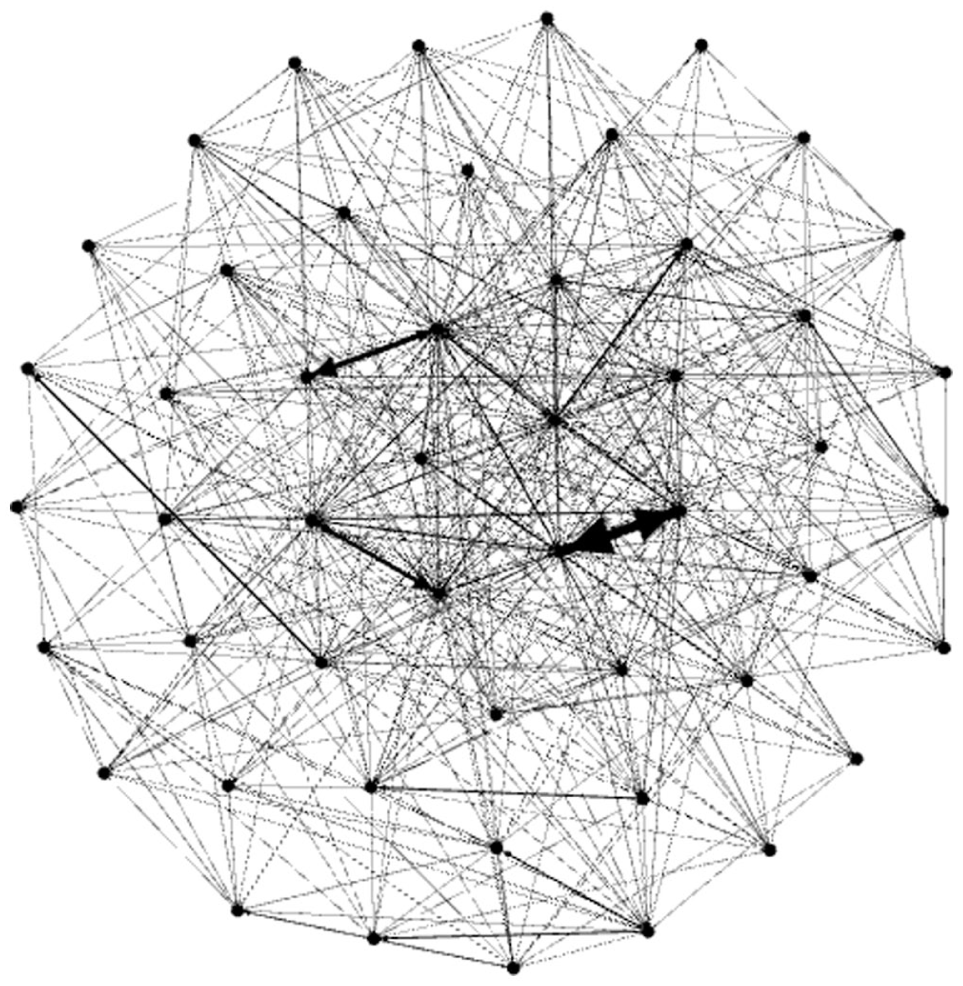
Gephi capture of the Love graph pruned up to the 50 most frequent nodes.
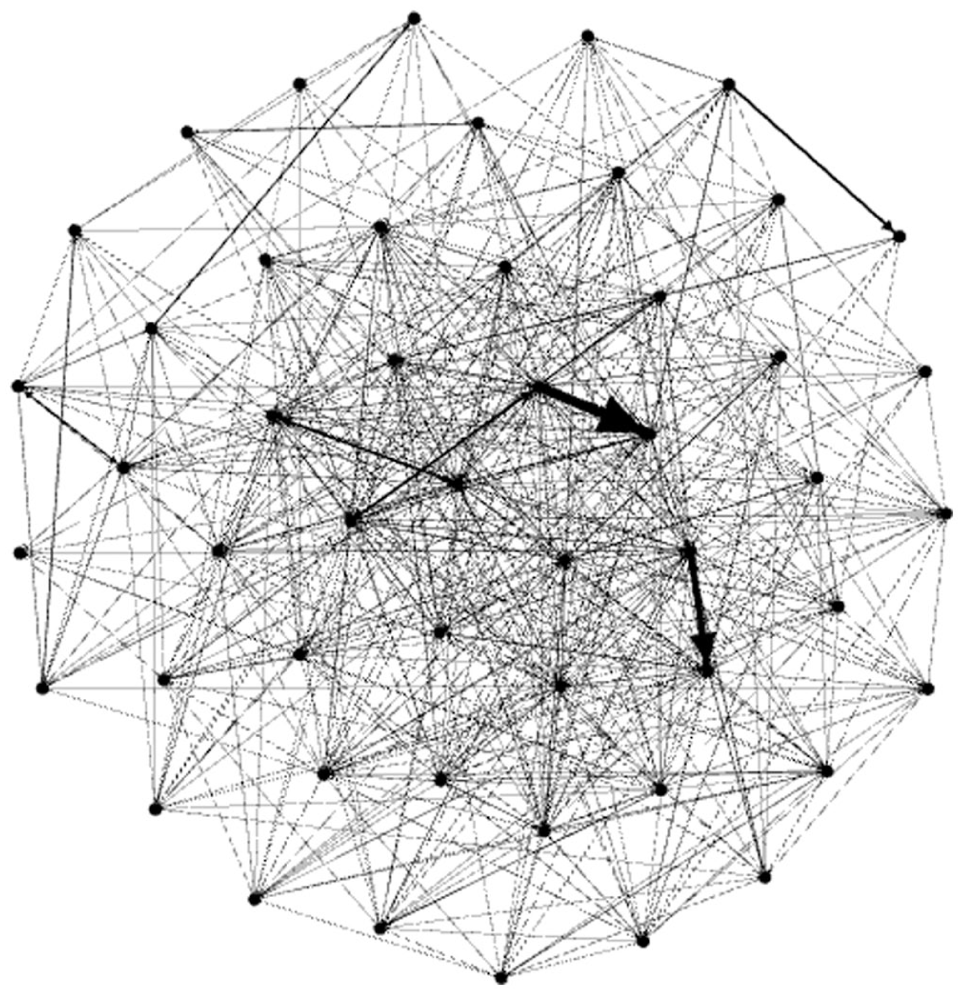
Gephi capture of the Amor graph pruned up to the 50 most frequent nodes.
As explained in the previous section, we proceed to vectorize our graph by means of the 11-statistics offered by default in Gephi. But, before comparing these vectors, it is necessary to normalize their values. The reason is that each statistic is on a very different scale. For instance, modularity is a number between 0 and 1, while the statistical inference number runs over tens of thousands. Then, comparing distances of vectors would be distorted, and the statistical inference number would hide the differences related to modularity and other metrics. Therefore, we proceed to normalize each component in the vector in such a way that all of them are numbers between 0 and 1. Even after this normalization process, when replacing each graph
Distances for Graphs Pruned to 50 Nodes, Vectorized With All 11 Gephi Features.

In Table 1 we read, for instance, that d(vNLove50, vNAmor50) = 0.652 and d(vNAmor50, vNAnimals50) = 2.661, showing that
But we wondered why consider all the Gephi features offered by default to encode our graphs as vectors. There is no special reason, and then, it could occur that the previous distances could be produced by some random characteristics. Let us note, in particular, that the number of nodes cannot have any discrimination capacity, since the four graphs have been forced to have 50 nodes. In addition, we know that several of these statistics are strongly correlated (for instance, the density of a graph is determined by the number of nodes and the number of edges). Then, to clear up this doubt, we undertake a systematic study considering all the possible combinations (in number of
Interestingly enough, if we exclude the combinations with one or two features (that, evidently, have less discrimination power), in all the failure cases, except one, the metric modularity is included among the features involved. In fact, the closest pair with respect to modularity is
Coming back to the non-failure cases, the most frequent ones, after carefully examining the different combinations of features, we conclude that three statistics are enough to explain the differences among the four graphs
Distances for Graphs Pruned to 50 Nodes, Vectorized With the Features Average Degree, Density and Average Path Length.

As announced in the previous section, to ensure that the differences found by using the feature vectors do not depend on this specific method of vectorization, the so-called spectral vectorization was employed, too. To this aim, we transform our graphs to obtain their simple (S) and undirected (U) counterparts. We called these new graphs
Spectral Distances for Graphs Pruned to 50 Nodes and Made Simple and Undirected.

One more time, Table 3 describes a crisp separation between the pairs
Distances for Graphs Pruned to 50 Nodes, and Made Simple and Undirected, With All the 11 Gephi Features.

Not only does Table 4 repeat the same pattern: when performing the same systematic study like before, from the
Comparing Words and Links
To illustrate the above result, we checked among the 50 most central [highest degree] words in each category and looked for overlaps. Centrality measured as degree is chosen as a proxy of lexicon organization because central nodes are believed to serve as anchors for community navigation since they are more readily accessible (Agustín-Llach & Rubio, 2024) and also as anchors for new words so that lexicon growth is based on these central words (cf. Feng & Liu, 2024; Steyvers & Tenenbaum, 2005).
Accordingly, the overlap between Animals and Animales amounts to 86% (43 out of 50), that is, the responses to the category Animals in EFL reproduce the answers given to the category Animales in L1, and this is true both for cognate words and also for non-cognate translation equivalents. For Love and Amor a large, but smaller, overlap is also found with 78% (39 out of 50). The different nature of the categories: taxonomic and concrete versus more experiential and abstract, is to be made accountable for the differences.
Discussion
The results of our analyses lead us to believe that L2 semantic categorization is inspired by L1 categorization and that category type is an overriding factor in categorization over task language. Accordingly, we assume that not only are L1 responses translated or transposed into the L2, but also the associations they established. And this is true not only when cognates are at play, but also with other translation equivalents.
Our results support the idea that the notion of semantic category is crucial in the structure of the mental lexicon and that the nature of the categories at stake (taxonomic, ad hoc, schema or experiential, for instance) plays an outstanding role in shaping the lexical-semantic network and determining network metrics (cf. Hernández-Muñoz et al., 2025; Sánchez-Saus & Alvarez-Torres, 2024).
Differences in L1L2 category overlap between the categories Animals and Love can be explained by word concreteness. Concrete words align highly with their translation equivalents, think of perro-dog, león-lion, whereas more abstract words might share a smaller number of semantic features such as novia-girlfriend or confianza-trust, but also faith, familiarity, confidence (see Chaouch-Orozco et al., 2024). The conceptual scenario changes slightly in Spanish and English. Chaouch-Orozco et al. (2024) believe that whereas concrete words have a common or holistic conceptual node, abstract words might have conceptual nodes which are similar or have some shared aspects, but not strictly identical in L1 and L2. In this sense, they concur with van Hell and de Grot (1998) in that abstract words are more context and language-specific, instantiating similar, but not necessarily identical, conceptual scenarios. The responses prompted by the stimulus amor/love are more of an abstract nature than those given in response to animales/animals, which are not only concrete, but which have universal referents in the extra-linguistic reality: cat, dog, elephant, mammal and so on. Also, taxonomic categories include members which are conceptually universal or very close in different languages and cultures. Conceptual similarity over linguistic differences might also account for our results, then. Cultural background may shape the internal organization of schema-based categories; however, because the present sample is limited to Spanish L1 learners, this study cannot directly test cross-L1 cultural variation.
This result could be interpreted in two ways. First, the L1 categorization process (lexical-semantic and conceptual organization of words in the mental lexicon) is reproduced in the L2. The fact that not only words, but also associations are reproduced in the L2 responses serves as evidence for this interpretation, learners use their L1 networks to build their L2 networks. In addition, and in line with Pavlenko’s (2017) observation, one could think that the fact that learners’ L2 experience is mainly confined to formal learning in the classroom and deprived of real-life experiences accounts for learners resorting to their L1 categorization frames as their main, and probably only, reference of categorization of the world. The low proficiency of the learners, together with their limited exposure to natural language use, might be made accountable for the similarity in their L1 and L2 categorization systems. Our results tie in with the idea of conceptual transfer where learners rely on their well-established and reliable L1 conceptual scenarios to categorize and conceptualize reality (cf. Cadierno, 2017; Jarvis & Pavlenko, 2008), also in the L2, since their L2 patterns are probably less developed and automatized. The limited and often decontextualized nature of classroom input means L2 lexical-semantic terms lack the strong, multimodal and sensorimotor connections that are vital for robust acquisition and conceptual grounding, as per an embodied cognition perspective (Lu & Yang, 2025). Consequently, the L1 categorization system remains the default and most accessible conceptual framework, as evidenced by the observed structural similarity between L1 and L2 categorization systems in our data. Further evidence in favour of the translation/transposing scenario is the fact that, as ascertained by Feng and Liu (2024), most central words in L1 are also most frequent in L1 corpus terms, but not in L2, which might again point to learners’ using the translation equivalents of their L1 responses. Second, our results could indicate that while responding in the L2, learners also activate their L1, supporting the parallel activation paradigm of bilingual processing (see Chaouch-Orozco et al., 2024; Dijkstra & van Heuven, 2002; Kroll & Stewart, 1994; also see Collins & Loftus, 1975 for their spreading activation model). Zhao and Li (2022) believe that learners develop parasitic representations of L2 words based on L1 information. In this sense, L2 representations are fuzzier and less strong. Still, another explanation might refer to the shared conceptual system in English and Spanish. Both languages are semantically and lexically very close. Further research could include comparisons with typologically more distant languages such as Arabic, Russian or Chinese.
Accordingly, our results support previous evidence that L1 lexical-semantic networks show thematic structure (De-Deyne & Storms, 2008); that is, words are grouped according to semantic and/or thematic similarity, and go beyond that to prove that this thematic structure replicates in L2 networks. The semantic category students are responding to is more important than language in terms of network organization.
In this sense, our results agree with Feng and Liu (2024) in identifying a large proportion of shared words between L1 and L2 lexical-semantic systems, especially among the most central words. When there is a lack of overlap, lexical gaps in L2 can be identified, and this can serve to inform vocabulary instruction in the classroom, for example.
Conclusion
The present study wanted to look into semantic categorization in Spanish as an L1 and EFL. For that purpose, we design and propose a methodology of analysis that we believe can throw interesting results and be useful for the study of semantic categorization distances. Two different categories were selected, a taxonomic one, Animals, and an experiential or scheme-organized one, Love. Taxonomic categories reflect nature since they contain expressions that show an existential belonging to the category; in this sense, their members are close in conceptual space, and are little influenced by contextual factors such as linguistic or cultural background. Our results support this idea, showing the very close proximity of Animals and Animales. Our results also show high similarity in categorization and organization for Love and Amor, revealing that learners also use their L1 conceptual and lexical-semantic information as a scaffold to delineate semantic categories in the L2. This reliance on L1 conceptual knowledge is particularly pronounced when dealing with schema-organized categories. In addition, we also could show that semantic categorization within a language across categories, be it Spanish L1 or EFL, also yields short distances, but longer than within categories across languages, pointing to the outstanding role of semantic category over language in the categorization process. Two main interpretations can be brandished to account for the similarity found across categories. First, we might think that because of cultural and linguistic proximity, most conceptual space is shared between Animales and Animals and Amor and Love. Second, learners might be translating L1 lexical-semantic items into the L2 and thus L2 semantic categorization mirrors L1. This L1-mediated categorization has frequent support in the literature (see, e.g., Chaouch-Orozco et al., 2024). Although previous studies (cf. Matsuki et al., 2021) could point to cultural immersion as an overriding predictor of semantic categorization over L2 proficiency, the participants in the present study lack cultural immersive experience and have limited L2 exposure in natural context, but also a limited L2 proficiency, both presumably affecting their categorization process. Further research should focus on examining categorization in more distant languages, as well as the categorization process of monolinguals and bilinguals in their shared language. The cultural dimension deserves particular attention in schema-organized categories, mainly. Unlike taxonomic categories, which are often more stable and closer to universal conceptual structure, experiential categories are more dependent on personal experience and sociocultural knowledge. Because the present study focuses on Spanish L1 learners of English, it has not directly tested cross-cultural or cross-linguistic variation. Future research should therefore compare participants with different L1s and cultural backgrounds to determine whether the patterns observed here reflect general tendencies in L2 semantic categorization.
Footnotes
Ethical Considerations
The study was approved by the Ethics Committee of the University of La Rioja and the Ethics Committee of the University Extremadura and complies with all the ethical requirements concerning participant information and consent.
Consent to Participate
Participant consent was given in written form via the online application.
Author Contributions
MariaPilar Agustín-Llach: conceptualization, literature review, data gathering and study design, and paper writing and conclusions.
Julio Rubio: conceptualization, mathematical calculations and analyses and study design, paper writing and conclusions.
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was partially supported by Grants PID2022-137337NB-C21, PID2024-155834NB-I00 and PID2024-157733NB-I00, by MICIU/AEI/10.13039/501100011033 and by ERDF/EU and AFIANZA 2024/03 (funded by La Rioja Government).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.