
Abstract
Aims and Objectives:
It remains debated whether second language learners whose native language lacks agreement morphology are sensitive to number agreement attraction. This study investigates whether highly proficient Chinese–English bilinguals are susceptible to number agreement attraction in L2 sentence processing and how subject modifier structures and verb types modulate this effect.
Methodology:
Participants completed an acceptability judgment task and a self-paced reading task to assess reading times and accuracy rates for sentences containing potential number agreement attractors.
Data and Analysis:
Data from 38 proficient Chinese–English bilinguals were analyzed using linear mixed-effects models (LMMs) to examine sensitivity to number agreement attraction across the different syntactic and verb conditions.
Findings:
Results revealed that proficient Chinese–English bilinguals were sensitive to number agreement attraction and displayed grammatical asymmetry, indicating reliance on cue-based memory retrieval mechanisms. Unlike native speakers, they exhibited inhibitory rather than facilitatory interference for number-matching attractors, reflecting L1–L2 processing constraints.
Originality:
This study distinguishes itself by isolating the specific effects of subject modifier structures and verb types on agreement attraction in L2 learners whose L1 lacks morphological agreement markers.
Implications:
Findings enhance understanding of L2 subject–verb agreement processing and demonstrate how cross-linguistic differences shape attraction interference patterns.
Keywords
Introduction
In the field of second language acquisition, whether second language (L2) learners can ultimately attain native-like language processing has long been considered a central goal of L2 learning (Hernandez et al., 2021; Hulstijn, 2001; Segalowitz, 2003). One phenomenon that has been particularly informative for addressing this issue is subject–verb number agreement attraction, a systematic processing illusion that occurs even in native speakers (Lago and Felser, 2018; Lee and Phillips, 2023).
Number agreement attraction arises when a verb incorrectly agrees in number with a local noun rather than the head noun of a complex subject (Alonso et al., 2021; Bhatia & Dillon, 2022; Bock & Miller, 1991). For instance, in the sentence “The key to the doors *are lost,” the plural local noun doors interferes with agreement computation, increasing the likelihood of an erroneous plural verb. This phenomenon provides a valuable testing ground for examining whether L2 learners compute agreement in a native-like manner.
Although number agreement attraction has been extensively documented in native speakers, it remains debated whether L2 learners exhibit similar sensitivity, particularly when their first language lacks subject–verb agreement morphology (Bhatia & Dillon, 2022; Lee & Phillips, 2023). Previous studies have yielded mixed findings, with some showing attraction effects in L2 sentence processing and others reporting little or no such effects (Jegerski, 2016; Jiang, 2004; Lago & Felser, 2018; Lee & Phillips, 2023). Resolving this inconsistency is crucial for understanding whether L2 sentence processing relies on mechanisms comparable to those of native speakers.
Studies investigating L2 learners whose first language encodes subject–verb agreement have generally found that proficient learners are susceptible to agreement attraction and may rely on memory retrieval mechanisms similar to those proposed for native speakers (Jegerski, 2016; Lago & Felser, 2018; Lago et al., 2015). However, these findings may be facilitated by cross-linguistic similarity between the learners’ L1 and L2, especially when both languages share agreement morphology (Bhatia & Dillon, 2022; Lee & Phillips, 2023).
The issue becomes more complex when considering L2 learners whose native language lacks subject–verb agreement morphology, such as Chinese learners of English. Empirical findings on agreement attraction in Chinese–English learners remain inconsistent (Bian & Zhang, 2023; Chen et al., 2007; Jiang, 2004; Ma, 2022; Schlueter, 2017). Some studies report limited or absent sensitivity to subject–verb agreement violations (Jiang, 2004; Ma, 2022), whereas others provide evidence that proficient learners do exhibit attraction effects and grammatical asymmetry during processing (Bian & Zhang, 2023; Zhang et al., 2011). These mixed results suggest that the mechanisms underlying agreement processing in this population are not yet well understood and warrant further investigation.
In addition to cross-linguistic differences, sentence-internal factors may further modulate agreement attraction in L2 processing (Bock & Cutting, 1992; Franck et al., 2002; Lago & Felser, 2018; Lee & Phillips, 2023). Previous research suggests that the structure of the subject modifier, such as prepositional phrases (PPs) and relative clauses (RCs), can influence the magnitude of attraction effects, although theoretical accounts make different predictions regarding the direction of this influence (Bock & Cutting, 1992; Franck et al., 2002; Lee & Phillips, 2023).
Verb type has also been proposed as a potential factor in subject–verb agreement processing. While studies on native speakers often report minimal effects of verb type (Hammerly et al., 2019; Lago et al., 2015), research on L2 learners—particularly those whose L1 lacks agreement morphology—suggests that verb type, i.e., auxiliary and lexical verbs, may differ in their susceptibility to agreement errors (Chang & Ma, 2006; Chen & Zhang, 2017; Hawkins & Casillas, 2008). These findings point to the possibility that L2 learners rely on different cues during agreement computation.
Given the unresolved debate regarding agreement attraction in Chinese learners of English, this study investigates whether proficient Chinese–English learners exhibit number agreement attraction during L2 sentence processing and whether their processing patterns resemble those reported for native speakers. Specifically, the study examines the effects of subject modifier structure (PPs vs. RCs) and verb type (copular vs. lexical verbs) using acceptability judgment and self-paced reading tasks. By examining attraction effects in learners whose native language lacks subject–verb agreement morphology, the study aims to clarify whether sensitivity to agreement attraction can emerge in L2 processing despite substantial cross-linguistic differences. Evidence of attraction effects would suggest that L2 learners may rely on agreement computation mechanisms in a manner partially similar to native speakers, whereas divergent patterns would indicate continued influence of L1-specific grammatical properties on L2 sentence processing.
Literature Review
Number Agreement Attraction in Native Sentence Processing
Number agreement attraction effect was first identified in studies of sentence production in native English speakers and later extended to sentence comprehension (Bock & Miller, 1991; Dillon et al., 2017; Laurinavichyute & von der Malsburg, 2022; Tanner et al., 2014; Wagers et al., 2009). Native speakers have been shown to be susceptible to interference from local nouns embedded within complex subjects, particularly when the head noun and the local noun mismatch in number. In such cases, speakers and comprehenders may incorrectly treat the local noun as the controller of subject–verb agreement (e.g., Bock & Cutting, 1992; Eberhard, 1997; Sturt & Kwon, 2023; Veenstra et al., 2014). Behavioral evidence further indicates that native speakers tend to show higher acceptability rates and shorter reading/listening times when ungrammatical sentences contain attractors that match the verb in number, suggesting facilitation effects under certain conditions (Tanner et al., 2014; Wagers et al., 2009). These robust attraction effects have motivated extensive investigation into the cognitive mechanisms underlying subject–verb agreement processing (Alonso et al., 2021; Hammerly et al., 2019; Jäger et al., 2017; Wagers et al., 2009).
Theoretical Accounts of Number Agreement Attraction
To date, two main accounts have been proposed to explain the cognitive mechanisms underlying number agreement attraction effects, i.e., representational-based accounts and retrieval-based accounts (Alonso et al., 2021; Bhatia & Dillon, 2022; Eberhard et al., 2005; Hammerly et al., 2019; Paspali & Marinis, 2020; Wagers et al., 2009). One class of explanations attributes agreement attraction to faulty or ambiguous representations of the subject’s morphosyntactic features, commonly referred to as representational accounts (e.g., Eberhard et al., 2005; Franck et al., 2002; Santesteban et al., 2017). Within this framework, attraction errors arise because the number features of the subject are not correctly specified during grammatical encoding. A prominent group of representational models are feature percolation models, which propose that the number feature of a local noun may percolate upward within the syntactic structure and contaminate the representation of the subject as a whole (Franck et al., 2002; Nicol et al., 1997; Vigliocco et al., 1995). Early formulations include the linear distance hypothesis, which emphasizes proximity between the local noun and the verb (Quirk et al., 1972), and the syntactic distance hypothesis, which highlights the hierarchical position of the local noun within the syntactic tree (Bock & Cutting, 1992; Franck et al., 2002). Under these models, attraction effects are expected to vary depending on the structural configuration of the subject. Another influential representational model is the Marking and Morphing model, positing that agreement computation reflects the conceptual number of the subject, with plural conceptual representations increasing the likelihood of attraction errors (Bock & Middleton, 2011; Eberhard et al., 2005). Importantly, representational accounts generally predict grammatical symmetry, such that both grammatical and ungrammatical sentences are similarly affected by attraction.
The alternative account is the cue-based memory retrieval account, which attributes agreement attraction to erroneous retrieval of the agreement controller from memory (Brehm et al., 2020; Dempsey et al., 2022; Dillon et al., 2013; Franck & Wagers, 2020; Wagers et al., 2009). According to this view, sentence constituents are encoded in memory, and verbs trigger a retrieval process to locate the appropriate subject using morphosyntactic cues such as number. When the number features of the verb and the subject head noun mismatch, the retrieval process may erroneously identify a plural local noun as the agreement controller, resulting in attraction effects. Crucially, this account predicts grammatical asymmetry: attraction effects should primarily arise in ungrammatical sentences, while grammatical sentences should show little or no interference (Brehm et al., 2020; Lago et al., 2015; Wagers et al., 2009). Empirical studies of native sentence comprehension largely support this prediction, reporting facilitatory interference in ungrammatical sentences with number-matching attractors (Jäger et al., 2017). Although some researchers have suggested the possibility of inhibitory interference in grammatical sentences, such effects are generally small and difficult to detect (Lewis & Vasishth, 2005; Nicenboim et al., 2018).
Number Agreement Attraction in L2 Sentence Processing
Developing from native speaker research, several studies have examined whether L2 learners whose first language encodes subject–verb agreement exhibit attraction effects during L2 processing. Findings from English–Spanish and Turkish–German bilinguals suggest that highly proficient learners are susceptible to agreement attraction and may rely on cue-based memory retrieval mechanisms similar to those of native speakers (Jegerski, 2016; Lago et al., 2019; Tanner, 2011). These results have been taken as evidence that native-like agreement processing can emerge in L2 learners, particularly when the L1 and L2 share comparable morphosyntactic features. However, the extent to which such findings generalize to learners whose L1 lacks subject–verb agreement remains contested. Chinese learners of English constitute a particularly informative population, as Chinese does not encode agreement morphology on verbs (Jiang, 2004; Schlueter, 2017). Empirical findings in this population are mixed. Some studies report that Chinese learners show limited sensitivity to subject–verb agreement violations, even at relatively high levels of proficiency (Jiang, 2004; Ma, 2022). In contrast, other studies provide evidence that proficient learners do exhibit agreement attraction effects and grammatical asymmetry, suggesting sensitivity to agreement relations during online processing (Bian & Zhang, 2023; Zhang et al., 2011). The observed discrepancies necessitate a re-evaluation of how Chinese learners parse number agreement, highlighting the potential impact of confounding linguistic variables.
Structural and Lexical Factors in Agreement Attraction
Subject modifier structure has been proposed as an important factor modulating agreement attraction (Bock & Cutting, 1992; Franck et al., 2002; Lago & Felser, 2018; Lee & Phillips, 2023). From a representational perspective, attraction effects are expected to be weaker when the local noun occupies a structurally distant position, such as within an RC, compared with a PP (Bock & Cutting, 1992; Franck et al., 2002). In contrast, studies adopting a retrieval-based perspective have reported stronger attraction effects in RC structures for some groups of L2 learners, suggesting that retrieval difficulty may vary across syntactic configurations (Lee & Phillips, 2023; Tanner, 2011). These findings highlight the importance of examining modifier structure when investigating agreement processing in L2s.
Verb type has also been examined as a potential modulator of agreement attraction. While studies on native speakers often report no significant differences between auxiliary and lexical verbs (Hammerly et al., 2019; Lago et al., 2015), research on L2 learners suggests that verb type may play a more prominent role when learners’ L1 lacks agreement morphology (Chang & Ma, 2006; Chen & Zhang, 2017; Hawkins & Casillas, 2008). Notably, studies reporting minimal verb-type effects have largely focused on native speakers, whereas studies demonstrating verb-type sensitivity have primarily involved L2 learners. This contrast suggests that verb type may differentially influence agreement processing in native and non-native populations.
The Present Study
Existing research demonstrates that agreement attraction is a robust phenomenon in native sentence processing, with strong support for cue-based memory retrieval accounts. However, findings in L2 processing—particularly among learners whose L1 lacks agreement morphology—remain mixed. Structural factors such as subject modifier type and lexical factors such as verb type may further modulate attraction effects, underscoring the need for systematic investigation in populations like Chinese learners of English.
Therefore, this study examines subject–verb number agreement computation in highly proficient Chinese–English bilinguals whose first language lacks overt agreement morphology. Given ongoing debates about the extent to which L2 learners exhibit native-like sensitivity to agreement relations, the study aims to clarify the presence, nature, and modulation of number agreement attraction effects in L2 sentence comprehension. Accordingly, the study addresses the following research questions:
Method
Participants
G*Power 3.1.9.7 (Faul et al., 2007) was used to calculate the estimated sample sized required in this study. To reach a 95% statistic power level for detecting a medium effect (f = 0.25) at a significance criterion of α = .05, a total sample size N = 15 was needed. Data from 40 participants were collected, with two being ruled out due to computer breakdown problem. Thus, 38 participants were included in the final analysis. They were all senior and graduate students majoring in English with Chinese as their native language. There were 33 females and 5 males among all the participants. The average age was 22.29 years (SD of age: 0.5), and ages ranged between 22 and 24 years. All participants were right-handed, and had normal or corrected-to-normal vision. All participants had passed the Test for English Majors Band 8 (TEM-8), a national standardized proficiency examination administered by the Chinese Ministry of Education. TEM-8 is designed to assess advanced English proficiency in English majors at the completion of their undergraduate training and is widely regarded as an indicator of high-level L2 proficiency, covering listening, reading, writing, translation, and grammatical competence. Previous research has treated TEM-8 certification as evidence of advanced or highly proficient English ability in Chinese L2 learners (e.g., Chang et al., 2023; Liao et al., 2025a, 2025b; Zhou et al., 2017). On this basis, the participants in this study are operationally defined as highly proficient Chinese–English bilinguals. The participants received some gifts for their contributions to the research.
Materials
The materials used in this experiment were arranged in a 2*2*2*2 within-subjects design, with factors for attractor number (singular or plural), structure of the subject modifier (PP or RC), verb type (copular verb or lexical verb), and grammaticality (grammatical sentence or ungrammatical sentence). The experimental sentences were exampled in Table 1. Adapted from the experimental items used by Lee and Phillips (2023) and Tanner (2011), 48 items were created in this study, where careful measures were taken to balance the words across modifier structures. As such, the stimuli all contained nine words, among which half of the predicate verbs in the stimuli were copular verbs (is/are) and the other half were lexical verbs. Half of the stimuli included PP modifiers, while the other half included RCs, and for each condition, half were grammatical and the other half were ungrammatical, each with or without attractors matching in number.
Example Sentences in Each Condition of the Experiment.
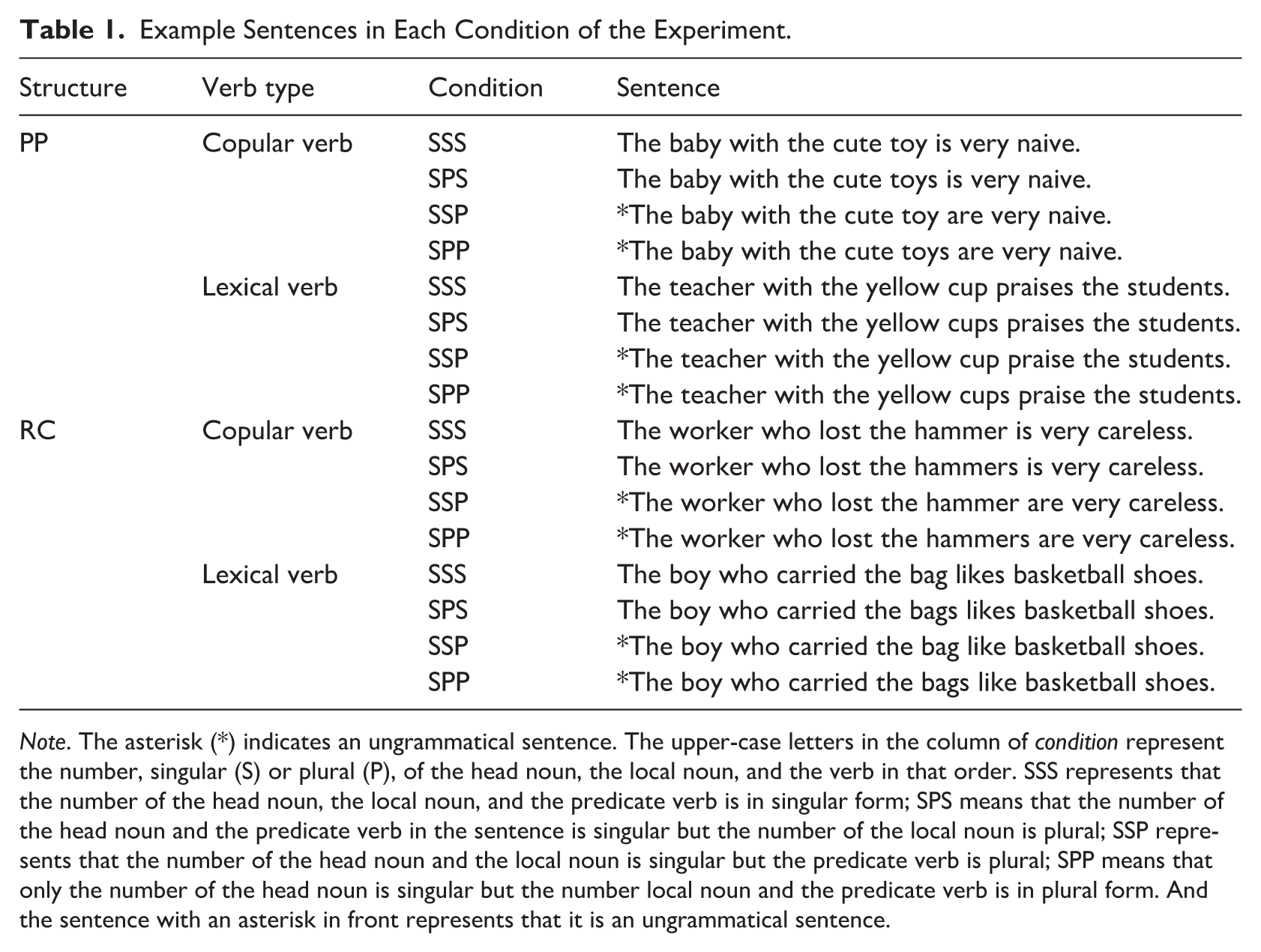
Note. The asterisk (*) indicates an ungrammatical sentence. The upper-case letters in the column of condition represent the number, singular (S) or plural (P), of the head noun, the local noun, and the verb in that order. SSS represents that the number of the head noun, the local noun, and the predicate verb is in singular form; SPS means that the number of the head noun and the predicate verb in the sentence is singular but the number of the local noun is plural; SSP represents that the number of the head noun and the local noun is singular but the predicate verb is plural; SPP means that only the number of the head noun is singular but the number local noun and the predicate verb is in plural form. And the sentence with an asterisk in front represents that it is an ungrammatical sentence.
Each experimental item contained a complex subject with a singular head noun. This design choice was motivated by the markedness effect reported in previous agreement-attraction studies, according to which singular-head configurations are more likely to elicit robust attraction effects than plural-head configurations (Wagers et al., 2009). The modifier of each head noun was the referential determiner “the” for the purpose of avoiding the impact of quantificational determiners on number attraction (Eberhard et al., 2005; Li et al., 2023). The embedded verbs used in RC modifiers were in past tense and the predicate verb were in present tense. All sentences with copular verbs (is/are) were constructed in SVP and sentences with lexical verbs were constructed in SVO.
Forty-eight sentence sets in the experiment were distributed across four lists in a Latin Square design. Another 48 filler sentences were designed in the items with half grammatical and half ungrammatical with errors of gender, tense, third person-s and so on. In addition, four practice sentences were designed to help participants familiarize with the experiment; therefore, each participant read 100 sentences in total during the whole experiment.
Procedure
Participants were seated in a quiet classroom in front of whom presented a computer screen and keyboard. The stimuli were presented by E-prime 3.0 and displayed word by word in a self-paced moving window paradigm at the center of a 17-inch computer screen with 1024 × 768-pixel resolution. At the beginning of each trial, the sentence was masked by a row of dashes after a fixation for 1,000 ms. Participants revealed each word by pressing the space bar with only one word visible each time. After finishing one sentence, an acceptability judgment task appeared and the participants were asked to respond with “F” for “no” and “J” for “yes.” The participants were asked to finish the four practice sentences before the formal experiment. The practice trial was set to ensure that all participants are sufficiently familiar with the task. The formal experiment will only begin after the participants have successfully completed the practice trial.
To evaluate whether the participants were concentrated on the experiment, a comprehension question was presented on the screen every four sentences and the participants needed to respond in the same pattern of an acceptability judgment task. Feedback was provided in practice sentences in both acceptability judgment task and comprehension task. But in the formal experiment, no feedback for acceptability judgment task and feedback was provided in comprehension task only when the participants made a false response. The participants were instructed to read at a natural speed and were allowed to have a rest in the middle of the experiment. The experiment lasted for 20 to 30 min.
Data Analysis
Data were analyzed in R (R core team, 2021, version 3.7.2). Two participants’ data were ruled out from data analysis due to technical problems. Thirty-eight participants were included for the final analysis. The accuracy rate for the comprehension questions was 94.4%. Acceptance rates and response times (RT) were served as the dependent variable. Just et al. (1982) found the existence of spillover effect in the cumulative tasks, in which the effect of word N would influence the following words after it. Some previous studies also observed the spillover region when they applied self-paced reading task (Jegerski, 2016; Lago et al., 2015). Thus, in the light of the spillover effect of self-paced reading task, one more word immediately after the verb was also analyzed. The response time of sentence acceptability was analyzed after deleting data outside of M ± 3SD, accounting for 1.75% of the total data. 2.14% of data were deleted outside of M ± 3SD for the response time of the verb. And 2.41% of the data outside of M ± 3SD in the response time was deleted for the spillover word.
The analysis of acceptance rates and RTs were using the linear mixed effects models (LMM) in R by the packages lme4 (Douglas Bates et al., 2015). Attractor number (singular/plural), grammaticality (grammatical/ungrammatical), verb type (copular/lexical verb) and modifier structure (PP/RC) were performed as fixed effects. The structure of random effects involved by-subject random intercepts. This model reported t-values using the lme4 packages. To compute more precise p-values in the models and run post hoc tests in the emmeans command (Lenth, 2021), the lmerTest packages (Kuznetsova et al., 2017) were used. For all the analysis, the final best-fitting model were chosen (Barr et al., 2013).
Results
Acceptance Rates
The linear mixed effect model was conducted with attractors (singular/plural), grammaticality (grammatical/ungrammatical), verb type (copular/lexical verb) and structure (PP/RC) as fixed effects with interactions, and subjects as the random intercept. The model was presented in Table 2. A significant main effect was yielded, respectively, for structure (F = 25.88, p < .001) and verb type (F = 4.65, p < .05). The acceptance rates were higher for sentences with the PP structure (M = 0.89, SD = 0.32) than those with the RC structure (M = 0.80, SD = 0.40). And the acceptance rates were higher for sentences with lexical verbs (M = 0.86, SD = 0.34) than those with copular verbs (M = 0.83, SD = 0.38). There was an Attractor × Structure interaction (p < .001). Post hoc Test revealed that only on the condition that the attractor was singular (i.e., number-matching attractor), the acceptance rates of sentences with PP structure were significantly higher than those with RC structure (p < .0001). When the attractor was plural, the acceptance rates between PP structure and RC structure were not significantly different (p = .297). It also showed that whether in PP structure or in RC structure, the acceptance rates between sentences with singular and plural attractors had significant differences (both p < .05). However, in PP structure, sentences with singular attractors had significant higher acceptance rates than those with plural attractors (p < .05); in RC structure, sentences with plural attractors had significant higher acceptance rates than those with singular attractors (p < .01). There was also a significant three-way interaction between Attractor, Grammaticality, and Verb type (p < .05). Post hoc Test showed that when the attractor was singular and the verb was copular verb, the acceptance rates of grammatical sentences were significantly higher than those of ungrammatical sentences (p < .05). When the attractor was singular and the verb was lexical verb, the acceptance rates of ungrammatical sentences were significantly higher than those of grammatical sentences (p < .05). Meanwhile, when the attractor was singular in ungrammatical sentences, the acceptance rates of sentences with lexical verbs were significantly higher than those with copular verbs (p < .001). The mean acceptance rates are shown in Figure 1. In addition, there was a significant four-way interaction between Attractor, Grammaticality, Structure, and Verb (p < .01). Post hoc Test indicated that in the sentences with singular attractors and RC structure, when the verb was copular verb, the acceptance rates of grammatical sentences were significantly higher than those of ungrammatical sentences (p < .05). In the sentences with singular attractors and RC structure, when the verb was lexical verb, the acceptance rates of ungrammatical sentences were significantly higher than those of grammatical sentences (p < .001).
Results of the Linear Mixed Effect Model on Acceptance Rates.
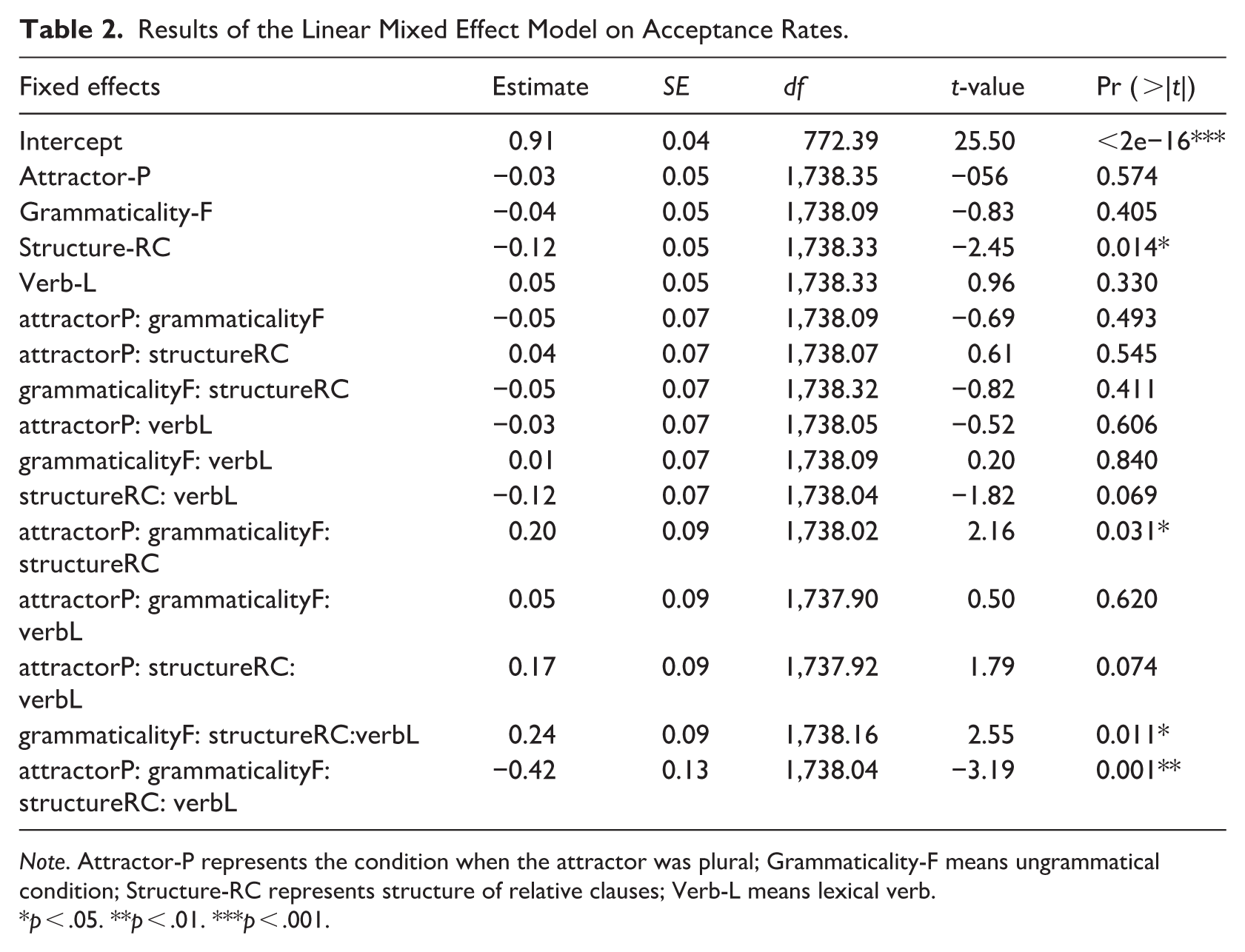
Note. Attractor-P represents the condition when the attractor was plural; Grammaticality-F means ungrammatical condition; Structure-RC represents structure of relative clauses; Verb-L means lexical verb.
p < .05. **p < .01. ***p < .001.
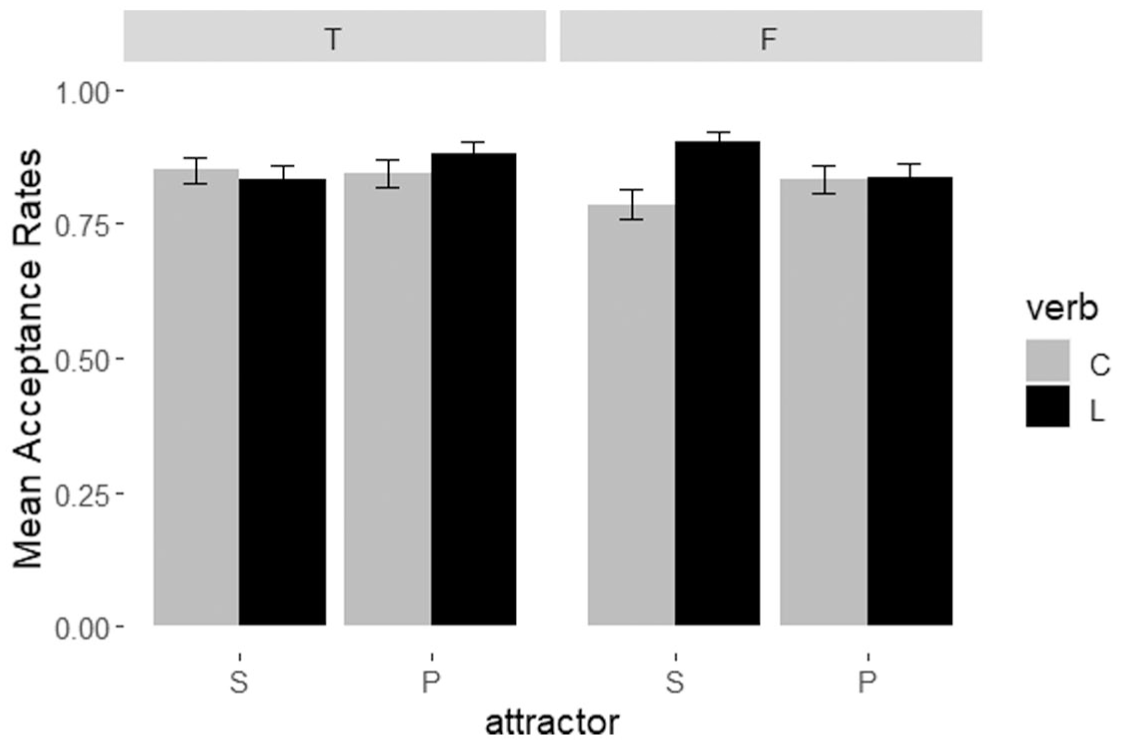
Mean acceptance rates of sentences under the three-way interaction between attractor, grammaticality, and verb.
Response Times of the Critical Verb Region
The linear mixed effect model was conducted with attractors (singular/plural), grammaticality (grammatical/ungrammatical), verb type (copular/lexical verb) and structure (PP/RC) as fixed effects with interactions, and subjects as the random intercept. The model was presented in Table 3. A significant main effect was revealed for attractor (F = 4.46, p < .05), in which the RTs of verbs following plural attractors (M = 1,107.84, SD = 602.32) were longer than those with singular attractors (M = 1,054.66, SD = 581.23). There was also a significant main effect of grammaticality (F = 35.48, p < .001), where the RTs of verbs in ungrammatical sentences (M = 1,157.68, SD = 621.58) were significantly longer than RTs of verbs in grammatical sentences (M = 1,004.81 SD = 551.35). Significant main effects were also showed, respectively, for structure (F = 8.40, p < .01) and verb type (F = 10.70, p < .01). The RTs of verbs in sentences with RC structure (M = 1,118.29, SD = 643.00) were longer than PP structure (M = 1,044.98, SD = 536.05) and the RTs of lexical verbs (M = 1,124.00, SD = 575.11) were longer than copular verb (M = 1,038.07, SD = 606.38). An Attractor × Grammaticality interaction was revealed (p < .001). Post hoc Test indicated that only when the attractor was plural, the RTs of verbs in grammatical sentences were significantly shorter than those in ungrammatical sentences (p < .0001). And only in ungrammatical sentences, RTs of verbs in sentences with plural attractors were significantly longer than RTs of verbs in sentences with singular attractors (p < .0001). There was also a Grammaticality × verb type interaction (p < .01). Post hoc Test revealed that whether the verb was lexical verb or copular verb, the RTs of verbs in grammatical sentences were always shorter than those in ungrammatical sentences (both p < .05). But only in the grammatical sentences, the RTs of copular verbs were significantly shorter than those of lexical verbs (p < .0001). Meanwhile, there was a three-way interaction of Attractor × Grammaticality × Verb type (p < .01). Post hoc Test showed that when the attractor was plural, verbs in grammatical sentences always had significant shorter RTs than in ungrammatical sentences no matter what kind of verb it was (all p < .0001). When the attractor was singular, only the RTs of copular verbs in grammatical sentences were significantly shorter than those in ungrammatical sentences (p < .001). When the attractor was singular, the RTs of lexical verbs in grammatical sentences were longer than those in ungrammatical sentence without significance (p = .11). When the attractor was plural, the RTs of copular verbs were always significantly shorter than those of lexical verbs both in grammatical and ungrammatical sentences (both p < .05). When the attractor was singular, the RTs of copular verbs were significantly shorter than those of lexical verbs in grammatical sentences (p < .01). But in ungrammatical sentences, when the attractor was singular, the RTs of copular verbs were longer than those of lexical verbs without significant differences (p = .13). The mean response times are presented in Figure 2.
Results of the Linear Mixed Effect Model on Response Times of the Verb Region.
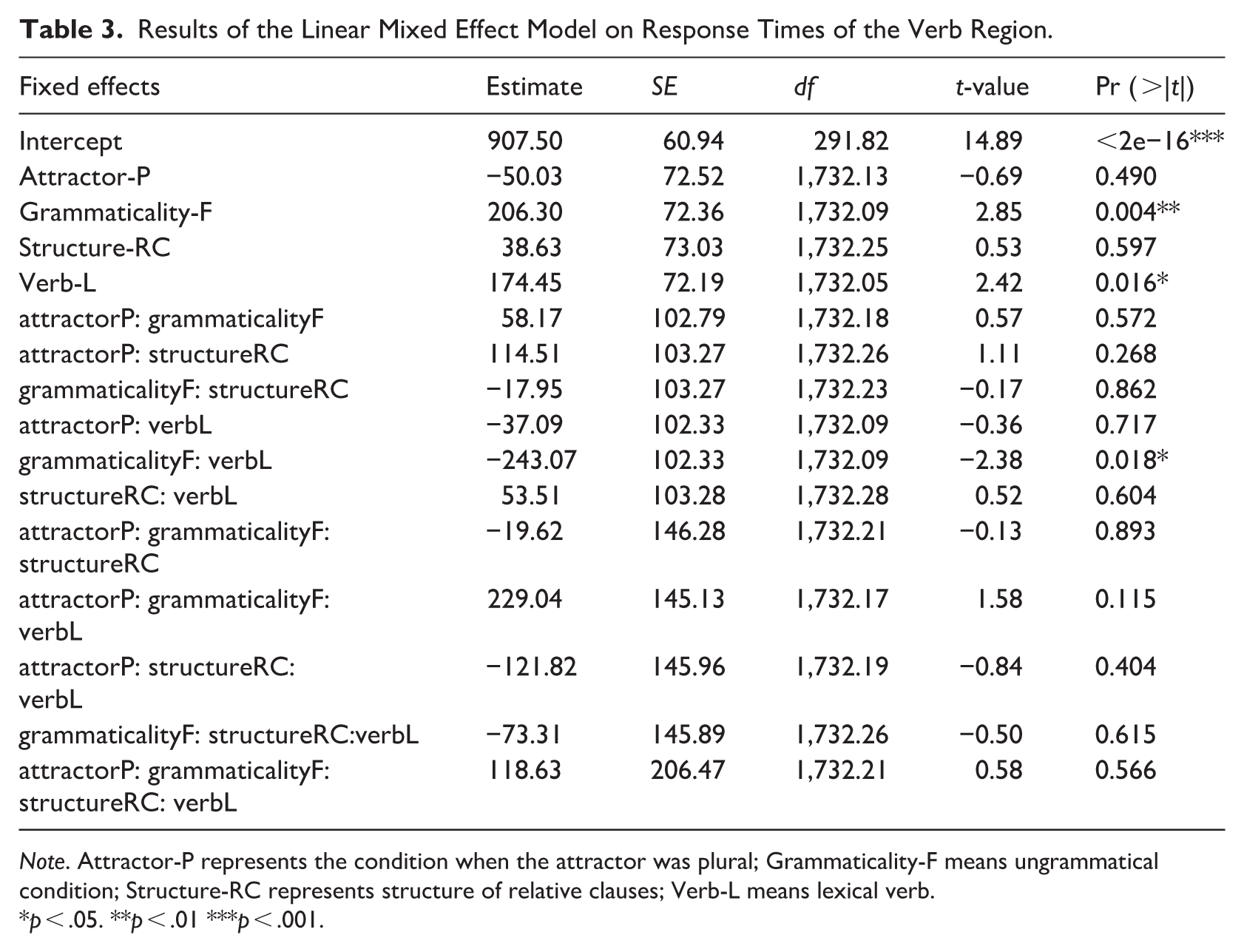
Note. Attractor-P represents the condition when the attractor was plural; Grammaticality-F means ungrammatical condition; Structure-RC represents structure of relative clauses; Verb-L means lexical verb.
p < .05. **p < .01 ***p < .001.
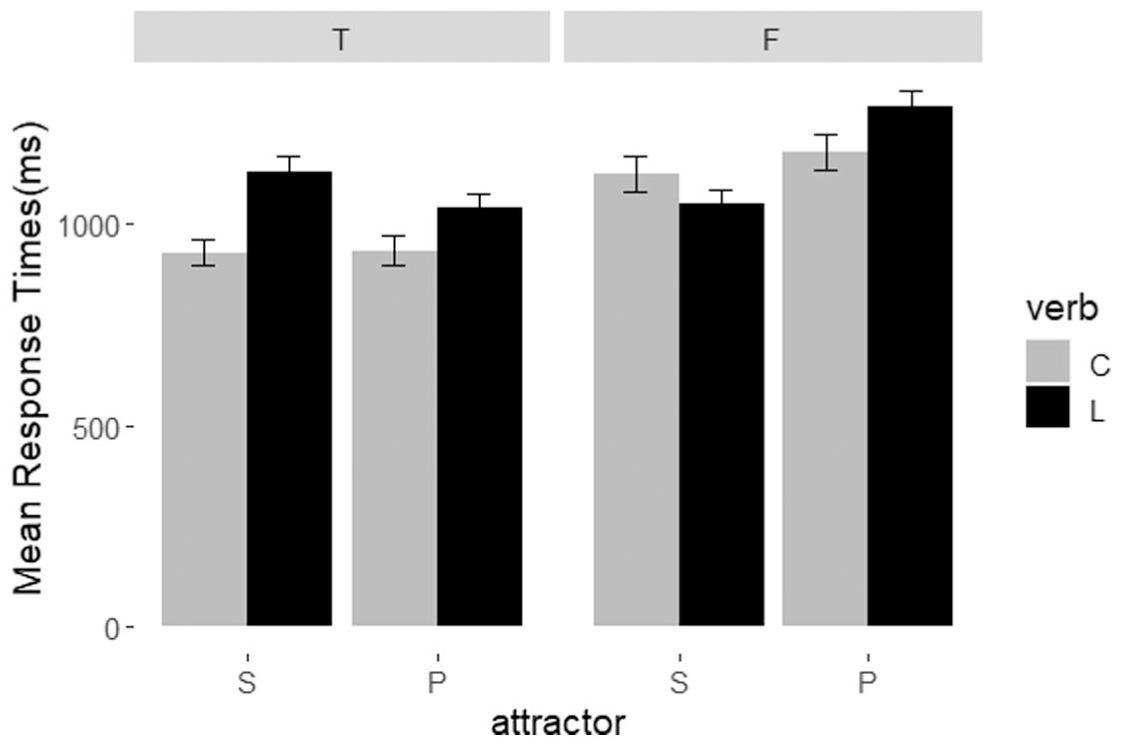
Mean response times of the critical verb region under the three-way interaction between attractor, grammaticality, and verb.
Response Times of Spillover Region (Verb + 1)
The linear mixed effect model was conducted with attractors (singular/plural), grammaticality (grammatical/ungrammatical), verb type (copular/lexical verb) and structure (PP/RC) as fixed effects with interactions, and subjects as the random intercept. The model was presented in Table 4. There was a significant main effect of structure (F = 9.47, p < .01) and Structure × Verb type interaction (p < .05). The RTs of the spillover word in sentences with RC structure (M = 685.69, SD = 374.71) were significantly longer than those with PP structure (M = 637.09, SD = 318.37). Post hoc test revealed that when the verb was lexical verb, the spillover word in sentences with RC structure had significantly longer RTs than those with PP structure (p < .001). The mean response times are presented in Figure 3.
Results of the Linear Mixed Effect Model on Response Times of the Spillover Region (verb + 1).
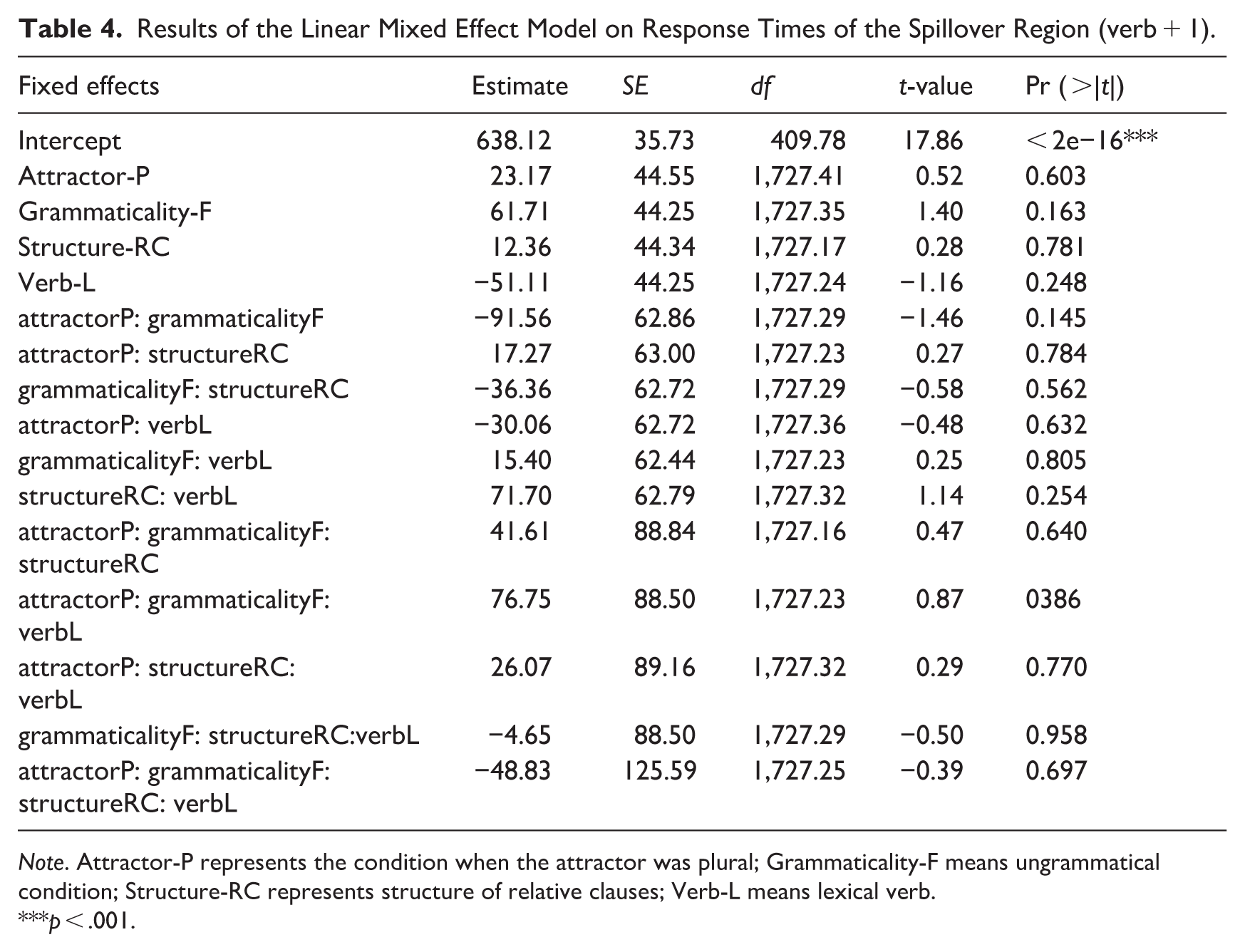
Note. Attractor-P represents the condition when the attractor was plural; Grammaticality-F means ungrammatical condition; Structure-RC represents structure of relative clauses; Verb-L means lexical verb.
p < .001.
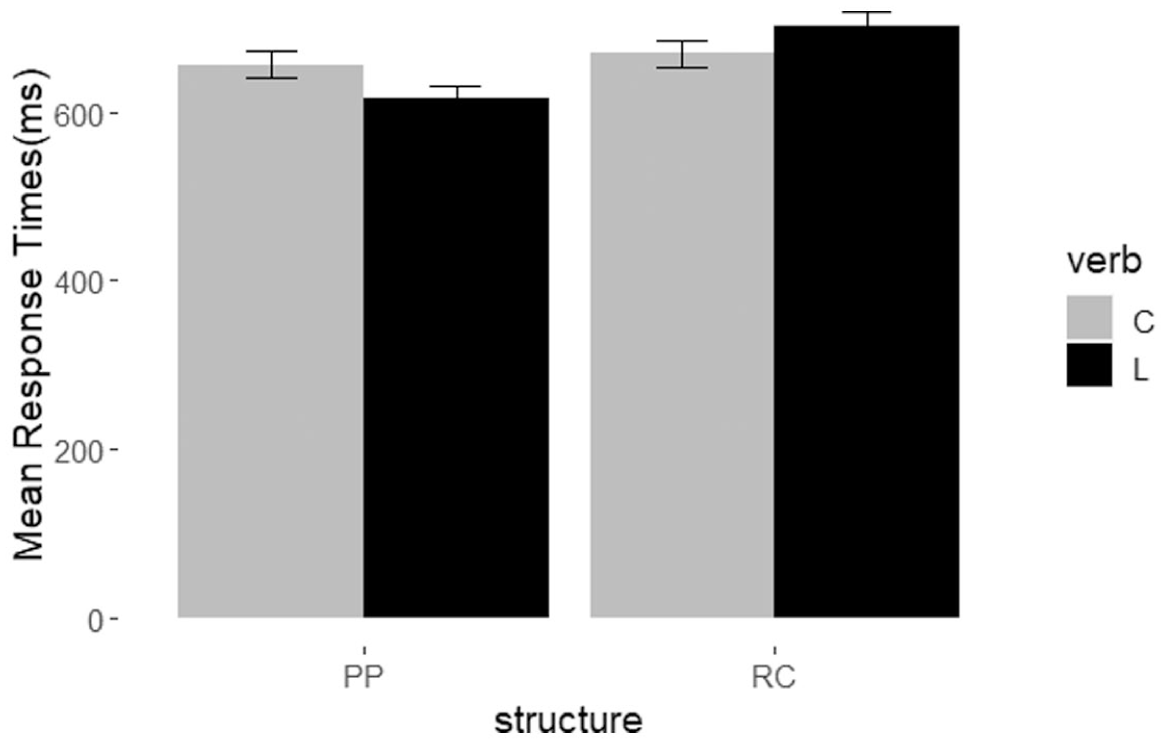
Mean response times of the spillover region under the interaction between structure and verb.
Discussion
This study found that highly proficient Chinese–English bilinguals were sensitive to number agreement attraction during L2 sentence comprehension, but the pattern of number attraction interference was different from that of English native speakers, manifested as inhibitory interference rather than facilitatory interference. Furthermore, this sensitivity to number agreement attraction was affected by the structure of the subject and the verb type in the sentence. This was evidenced by the finding that plural attractors only improved the acceptance rates of sentences with RC subject modifiers, and that the reading times of lexical verbs were significantly longer than those of copular verbs only in grammatical sentences. Meanwhile, the number agreement attraction of highly proficient Chinese–English bilinguals displayed grammatical asymmetry, where the number agreement attraction effect only affected ungrammatical sentences and did not affect grammatical sentences, a pattern that is consistent with memory retrieval accounts. Importantly, although participants demonstrated robust sensitivity to subject–verb agreement, their processing patterns did not fully converge with those reported for native speakers, suggesting that high proficiency does not necessarily entail native-like interference patterns in L2 agreement computation.
The main effect of attractor number on RTs of the verb region revealed that highly proficient Chinese–English bilinguals took longer to read the verbs after plural attractors than after singular attractors. Specifically, the reading times in SPS and SPP sentences were significantly longer than those in SSS and SSP sentences. This result is consistent with the findings of some previous studies (Bhatia & Dillon, 2022; Jegerski, 2016; Tanner et al., 2014; Tucker et al., 2021), illustrating that highly proficient Chinese–English bilinguals were more prone to interference from plural (mismatched) attractors, regardless of modifier structure or verb type. One explanation for the differences in reading times between verbs following plural local nouns and following singular local nouns could be attributed to the mismatch between the number of head nouns and the number of attractors (local nouns). Specifically, the ambiguous number representations of the complex subject (with plural local nouns) can lead to uncertainty in the correct verb form, resulting in longer response times, as also suggested by Staub (2009). On the other hand, the mispairing in number between head nouns and local nouns might increase the processing difficulty in memory retrieval (Veenstra et al., 2014, 2018). When speakers see the sentence verb, they retrospectively search for and retrieve an appropriate target word as the agreement controller from their memory. During this process, other target word candidates (such as local nouns) in the memory representation may also be activated, thereby interfering with sentence comprehension. When the number feature of the local noun is not consistent with that of the head noun, it is more likely for participants to take longer to read the verb.
Moreover, the highly proficient Chinese–English bilinguals showed a reliable grammaticality effect. They took significantly longer to read ungrammatical sentences involving subject–verb number agreement than grammatical sentences. This is not surprising given the disagreement effect (Pearlmutter et al., 1999). This result indicated that the proficient Chinese–English bilinguals were sensitive to number agreement and disagreement. The interaction between attractor number and grammaticality is particularly noteworthy, showing that only in ungrammatical sentences did the reading time of verbs following plural attractors exceed that of verbs following singular attractors. By contrast, there was no significant difference in reading times of verbs in grammatical sentences. This pattern manifests grammatical asymmetry predicted by the cue-based memory retrieval model (Wagers et al., 2009) and poses challenges to misrepresentational accounts including feature percolation models and the Marking and Morphing model. For one thing, the asymmetrical pattern in grammaticality is consistent with most previous studies (Brehm et al., 2020; Dillon et al., 2013; Lago et al., 2015, 2021; Yadav et al., 2023). Taken together, these results suggest that highly proficient bilinguals whose L1 lacks number agreement rely on retrieval-based mechanisms for agreement computation, although the efficiency and outcomes of these mechanisms may differ from those of native speakers.
More critically, the interference pattern revealed in this study is different from that typically reported for native speakers in grammatical asymmetry. Prior studies have found that native speakers are likely to display shorter reading times of ungrammatical sentences with attractors that match the sentence verbs in number than those with mismatching attractors, leading to facilitatory interference (Jäger et al., 2017; Lee & Phillips, 2023; Tanner et al., 2014; Wagers et al., 2009). However, this study found that reading times for verbs preceded by plural attractors were longer than those preceded by singular attractors in ungrammatical sentences. Given that this study only used the singular form of head nouns, this indicates that proficient Chinese–English bilinguals processed verbs in ungrammatical sentences with number-matching attractors more slowly than those without number-matching attractors, exhibiting inhibitory interference. This finding can be interpreted in light of the proposals of Cunnings (2017), who argues that although highly proficient L2 learners may construct sentence processing patterns broadly similar to those of native speakers, systematic differences between L1 and L2 processing remain. These differences are manifested in two main aspects. One is that proficient bilinguals are more prone to interference during their memory retrieval processes, compared with native speakers. The other is that bilinguals and native speakers weight cues that initiate memory retrieval differently. The highly proficient bilinguals tend to use lexical or semantic cues in the retrieval process of L2 sentence processing, while the native speakers tend to use syntactic cues during the process.
The result that highly proficient Chinese–English bilinguals took longer to read the verbs following plural attractors in ungrammatical sentences is consistent with the view that the syntactic parser in L2 processing is more strongly affected by interference from competing representations during memory retrieval. On the other hand, due to the lack of overt morphological agreement markers in Chinese, semantic or discourse-related cues may be overweighted relative to syntactic cues during English subject–verb number agreement processing, leading to increased processing difficulty when plural attractors are present. More importantly, Wagers (2017) put forward that differences in interference effects between bilinguals and native speakers may also be related to differences in how information is activated and allocated within the focus of attention. Unlike native speakers, who may retrieve relevant linguistic information directly from the focus of attention, bilinguals may need to retrieve such information from their working memory and then activate it in their focus of attention. That is to say, as soon as the Chinese–English bilinguals see the predicate verb, the nouns in the sentence subject will be retrieved from their working memory to their focus of attention, and subject–verb number agreement can then be processed. Therefore, highly proficient Chinese–English bilinguals may require greater cognitive resources, such as attention and working memory, for subject–verb agreement processing, thereby amplifying interference effects associated with plural local nouns.
The main effect of modifier structure on both acceptance rates and RTs demonstrated that number agreement attraction was modulated by the structure of subject modifiers. Participants showed higher acceptance rates for sentences with PP modifiers than for those with RC modifiers, and verbs following PP modifiers were processed faster than those following RC modifiers. These findings showed that the number attraction effect induced by RC modifiers was stronger than that induced by PP modifiers. Specifically, the interaction between attractor number and modifier structure indicated a structural asymmetry in subject–verb agreement processing. It was found that in RC modifiers, participants showed higher acceptance rates for sentences with plural attractors than for those with singular attractors, whereas in PP modifiers, sentences with plural attractors were less acceptable than those with singular attractors. In other words, attraction effects emerged in sentences with RC modifiers but not in those with PP modifiers. These results echoed the research findings of Lee and Phillips (2023), Schlueter (2017), Lim and Christianson (2015), Tanner (2011), among others. For instance, Lee and Phillips (2023) also found that advanced Korean-English bilinguals showed a number attraction effect in sentences with RC structures but not in sentences with PP structures. Although previous studies have reported mixed findings regarding the role of modifier structure (e.g., Bian & Zhang, 2023; Parker & An, 2018), the present results suggest that structural complexity increases retrieval difficulty for highly proficient bilinguals, lending further support to retrieval-based accounts over syntactic distance hypotheses (Franck et al., 2002).
Finally, this study also revealed significant effects of verb type on both acceptance rates and RTs. Participants accepted sentences with lexical verbs more readily than those with copular verbs, yet they read lexical verbs more slowly than copular verbs. This pattern differs from findings reported in studies of native speakers and speakers of morphologically rich languages, which have often found no processing differences between copular and lexical verbs (Hammerly et al., 2019; Lago et al., 2015; Tanner et al., 2014). One possible explanation for this discrepancy lies in cross-linguistic differences in morphological systems. Because Chinese lacks rich inflectional morphology, Chinese–English bilinguals may experience greater difficulty processing English verbal morphology. This interpretation is supported by previous studies on Chinese–English bilinguals (e.g., Chen & Zhang, 2017). It also suggests that cross-linguistic variation has an impact on how bilinguals process language and compute number agreement. The retrieval mechanism of highly proficient bilinguals may vary depending on the features of different languages. In addition, the interaction between grammaticality and verb type indicated that differences between lexical and copular verbs emerged only in grammatical sentences. This excludes the possibility that the observed differences were due solely to the verbs themselves. Instead, it revealed that the verb type in the sentence had an impact on the subject–verb number agreement processing. Only when an agreement relation is successfully established, namely when the verb matches the true controller (the head noun), does the influence of verb type emerge. At this stage, the lexico-semantic differences between copular and lexical verbs might result in different levels of processing difficulties. On the other hand, this difference is also consistent with the order of second language morpheme acquisition (Zobl & Liceras, 1994), in which the acquisition of L2 learners for the third person singular form of the lexical verb (suffix -s) is later than the acquisition of the third person singular of the copular verb. In this regard, we believe that a possible explanation is that from the perspective of input processing, the third person singular -s is a bound morpheme with low visual salience and short pronunciation. But the copular verb be is a free morpheme with high visual prominence and a complete phonetic form, making it more likely that the latter will be noticed and internalized. Chinese–English bilinguals should therefore read copular verbs as predicates faster than lexical verbs. Another possible reason could be due to the inflated word length effect, in which longer words may take more time to read (Frederikson & Kroll, 1976; Lee & Cochran, 2000). The word length of lexical verbs is normally longer than that of copular verbs. Such kind of one-letter difference may have no impact on English native speakers, but affect the Chinese–English bilinguals in an inflated way, resulting in a significant difference in processing time (Jiang, 2004).
Despite these findings, several limitations of this study should be acknowledged. First, the study did not include a native English control group. Although the current findings provide important evidence regarding subject–verb number agreement attraction in highly proficient Chinese–English bilinguals, direct comparisons between L1 and L2 processing were beyond the scope of this study. Future research incorporating native English speakers may help clarify the extent to which the observed retrieval patterns overlap with or diverge from native sentence processing mechanisms. Second, this study only examined configurations with singular head nouns. This design choice was intentional, as previous agreement-attraction research has shown that singular-head configurations are more likely to elicit robust attraction effects due to the markedness effect (Wagers et al., 2009). Nevertheless, future studies may further examine whether comparable patterns emerge in plural-head configurations, thereby providing a more comprehensive understanding of agreement computation in L2 sentence processing. Finally, this study focused exclusively on highly proficient Chinese–English bilinguals. Consequently, the developmental trajectory of agreement attraction across different proficiency levels remains unclear. Future research involving learners with varying levels of L2 proficiency may further illuminate how retrieval-based agreement processing develops during second language acquisition.
Conclusion
Highly proficient Chinese–English bilinguals are susceptible to subject–verb number agreement attraction during L2 processing, and this effect exhibits grammatical asymmetry, supporting their use of a cue-based memory retrieval mechanism. However, unlike the facilitatory interference typically observed in native speakers for ungrammatical sentences, Chinese–English bilinguals demonstrate inhibitory interference. Subject modifier structure (RCs vs. PPs) and verb type are important modulating factors: attraction effects are observed only in sentences with relative clause modifiers, and verb-related differences emerge only in grammatical sentences. These results further indicate that sensitivity to number agreement attraction may be attenuated under certain structural and lexical conditions. This study thus contributes to a more nuanced understanding of L2 agreement processing and offers pedagogical implications by highlighting the role of cross-linguistic differences in shaping grammatical computation.
Footnotes
Ethical Considerations
This study was approved by the local ethics committee of Tongji University (No. tjsflrec202304) and was conducted in accordance with the Declaration of Helsinki (2013).
Consent to participate
Informed consent was obtained from all participants involved in the study.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.