
Abstract
Background
While large language models (LLMs) have a potential to simulate public-opinion, their reliability for sensitive medical topics like novel Alzheimer's disease (AD) treatments remains unclear.
Objective
This study compared LLM-generated and human answers on AD-therapy dilemmas; assessed model and prompting parameter influences; and identified demographic bias.
Methods
Using survey data on late 2023 from 1671 Japanese Trial Ready Cohort Webstudy participants who are presumably cognitively unimpaired, LLM persona profiles guided four LLMs (Gemini-1.5-flash, Gemini-2.0-flash, GPT-4.1-mini, GPT-4o-mini). The models answered a binary question about acceptance towards patient-prioritization or a 5-point Likert question on concern about amyloid-related imaging abnormalities (ARIA) under varied prompt settings. Aggregate similarity was measured with Jensen-Shannon Divergence (JSD) for binary and Earth Mover's Distance (EMD) for Likert scale; while individual agreement used Cohen's κ and Spearman's ρ.
Results
While some LLM models achieved fair group-level agreement in both tasks (JSD ≤ 0.05, EMD < 1.0), individual agreement was negligible across any LLM settings (κ, ρ ≈ 0). Adding detailed attributes like living condition, clinical status, or related personal opinions offered limited improvement. Performance was largely stable for most demographic levels, but deteriorated for minority subgroups, such as those with low education or requiring long-term care.
Conclusions
Our study demonstrates that current LLMs can approximate aggregate attitudes toward novel AD therapies but cannot predict individual opinions. They can amplify biases in some small subgroups. LLMs may be useful for pre-testing public survey in the field of AD/dementia treatment but should not replace authentic human data.
Introduction
The advent of powerful large language models (LLMs) such as Generative Pre-trained Transformer (GPT) and Gemini has unlocked new paradigms for research across numerous fields.1,2 One of the most intriguing applications is LLM persona simulation, sometimes described in the literature as the creation of “silicon samples” or “digital twins”, 3 in which an LLM is prompted with a detailed set of attributes (e.g., age, gender, occupation, background) to simulate the beliefs, preferences, and decisions of a specific human persona.1–3 This approach has been explored in various domains, from replicating classic behavioral economics experiments to simulating purchasing behavior and polling public opinion. 4 Prior studies have demonstrated both the potential and the peril of this technology. For example, research on simulating election outcomes has suggested an ability to forecast results, 5 while other work on vaccine hesitancy has highlighted that simulation outcomes can vary dramatically depending on the model and prompts used, raising significant concerns about bias and reliability. 6
The potential utility of LLM simulation is particularly compelling in the medical field, 2 where understanding patient and public perspectives on treatment options, ethical challenges, and health policies is important. This is especially true for neurodegenerative diseases like Alzheimer's disease (AD).7,8 The therapeutic landscape for AD has shifted significantly with the emergence of novel disease-modifying therapies (DMTs). Specifically, anti-amyloid monoclonal antibodies, such as lecanemab 9 and donanemab, 10 represent a breakthrough in AD management. Unlike traditional symptomatic treatments, these agents target the underlying pathophysiology of the disease by clearing amyloid plaques from the brain, thereby aiming to slow the trajectory of cognitive decline in early-stage patients. 8 The regulatory approval and clinical implementation of these therapies mark a pivotal turning point, offering new hope while simultaneously introducing new requirements for diagnostic precision and long-term safety monitoring.
Such recent development of the DMTs for AD has brought to the forefront a host of sensitive and complex issues, 11 from managing serious side effects like amyloid-related imaging abnormalities (ARIA) 12 to the ethical dilemmas of allocating scarce treatments. 13 Surveying public opinion on these topics14,15 is essential but challenging partly because of the shortness in accurate knowledge about the drugs 14 ; such studies can be costly, and the sensitivity of the subject matter requires carefully designed and pre-tested questions to avoid misinterpretation. LLM simulation offers a potential solution, serving as a tool for the pre-testing of survey instruments,16,17 augmenting sparse datasets, 18 exploring public reaction to sensitive topic 19 or to hypothetical scenarios without the cost and time of a full-scale survey.
However, the application of LLMs in this context is not straightforward. LLMs do not possess human consciousness or reasoning; they generate responses based on patterns in their vast training data. 20 This can lead to the amplification of existing societal biases, 21 the underrepresentation of minority viewpoints, 22 and responses that are plausible on the surface but lack genuine human grounding (hallucination). Before these tools can be responsibly used, a systematic evaluation of their performance and biases against real-world human data is necessary.
This study aims to address this gap by investigating the potential and biases of LLM simulation within the specific context of AD. We compared the simulated responses of LLMs to actual human answers from an online survey concerning new AD therapies (i.e., lecanemab9,23), which we conducted in late 2023. 15 Our objectives are threefold: (1) to assess the degree of correspondence between LLM and human responses for questions related to hypothetical treatment prioritization and safety concerns about the new drug; (2) to determine how different simulation parameters, particularly the choice of LLM, affect the quality of the simulation; and (3) to analyze whether LLMs exhibit differential bias across various demographic subgroups. In this manuscript, we use “LLM persona simulation” as the primary term, while “digital twin” and “silicon sample” are used only when referring to prior literature or the conceptual background.
Methods
Human survey data
This study is a post-hoc analysis utilizing anonymized data from a web-based survey.15,24 The original survey was administered via Google Forms to participants of the Japanese Trial Ready Cohort (J-TRC) Webstudy. The J-TRC Webstudy is a nationwide online registry launched in 2019 to recruit individuals for preclinical AD clinical trials.25,26 The registry targets volunteers aged 50–85 who are primarily cognitively unimpaired. Participants are monitored longitudinally via web-based assessments, including the Cognitive Function Instrument (CFI) and Cogstate Brief Battery, every three months. For the specific survey used in this study, the inclusion criteria for the invitation were participants who, as of September 25, 2023, had: (i) completed registration and provided online informed consent; (ii) completed at least one session of the CFI; and (iii) registered a valid e-mail address. Based on these criteria, invitation e-mails were sent to approximately 10,000 eligible participants. The survey was conducted between November and December 2023, prior to the widespread availability of Lecanemab in Japan.
The purpose of the original survey was to assess public perceptions regarding healthcare preparedness for novel anti-amyloid therapies (DMTs), specifically focusing on potential barriers such as cost, access, and side effects. 15 The survey collected comprehensive data falling into three categories: (a) Demographic and Clinical Attributes (e.g., age, education, family history); (b) DMT-Specific Perceptions (e.g., knowledge, willingness, efficacy impressions); and (c) Ethical and Safety Concerns (e.g., prioritization, ARIA).
From 10,414 invitations sent, 2050 responses were received, yielding a final dataset of n = 1671 after excluding incomplete entries. For our simulation, we randomly selected a subset of 1000 complete respondent profiles. As noted in recent analyses,24,27 this respondent cohort is characterized by a high educational background (median: 16 years) and strong motivation for AD prevention, distinguishing them from the general population. This sample size was chosen to balance statistical robustness with computational efficiency and API costs. A sample of n = 1000 provides a margin of error of approximately ±3% (at a 95% confidence level), which is standard for public opinion surveys and sufficient to estimate the response distributions without processing the entire dataset.
We focused on two specific question sets from the survey: (1) Treatment Prioritization (Q41-Q45) (Figure 1B): A series of questions asking respondents about the acceptability of prioritizing patients (“acceptable” or not) if a new, effective AD drug were in limited supply, when focusing on (Q41) general aspects, (Q42) medical rationale, (Q43) economic efficiency, (Q44) impact on daily life, or (Q45) social vulnerability. And (2) ARIA Concern (Q39): A question assessing the level of respondent worry about ARIA, a known potential side effect of anti-amyloid therapies, using a 5-point Likert scale (1: “Very worried” to 5: “Not at all worried”) (Figure 1C).
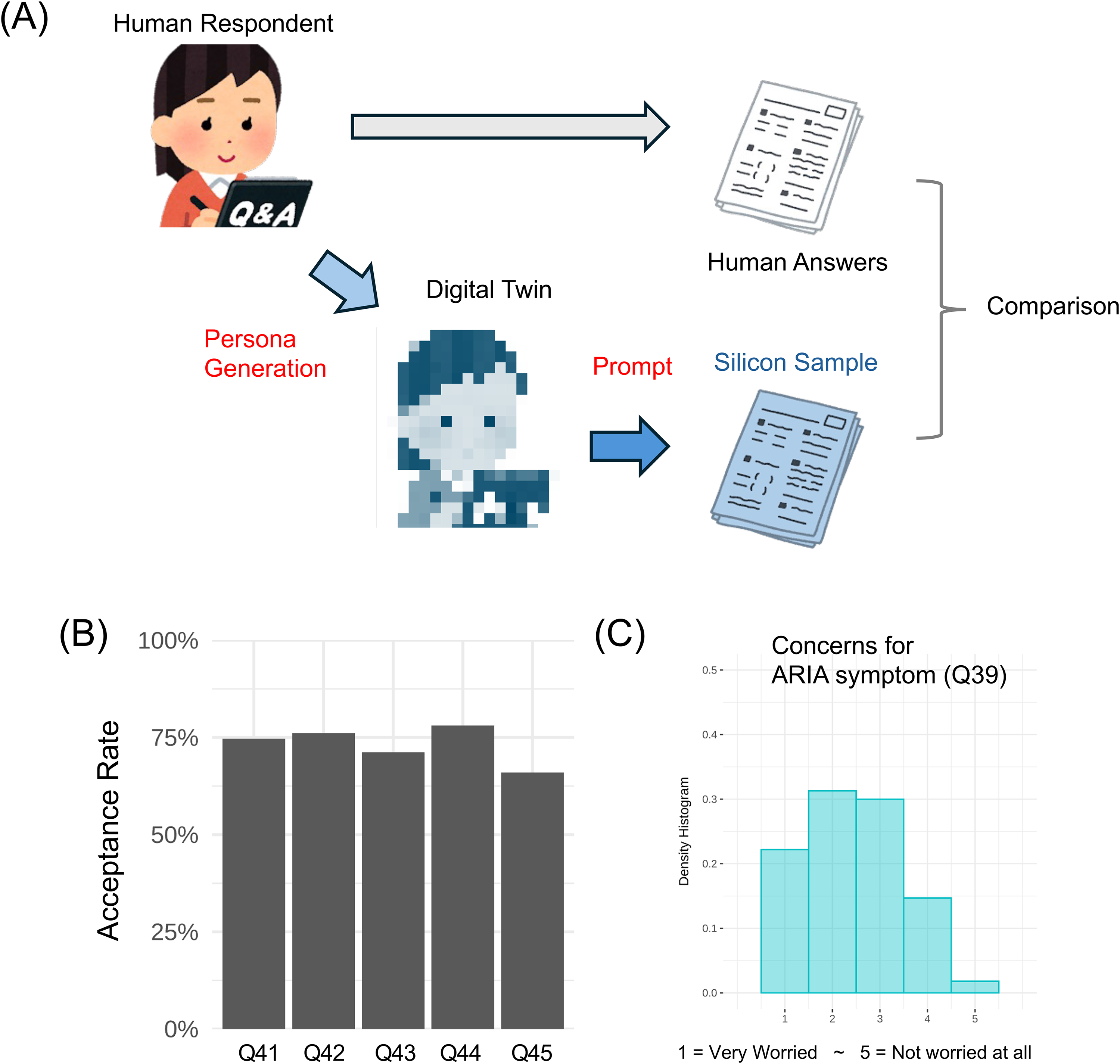
Study design and human response distribution. (A) Schematic of the LLM-based persona simulation workflow. Anonymized human survey data, including demographic attributes and responses to related questions, were used to construct 1000 unique LLM persona profiles. Each persona was then provided to LLM models to generate simulated responses to the target survey questions. (B) Distribution of human response to the patient prioritization tasks (Q41-Q45). For the simulation, this was a binary choice task (“Is it acceptable to prioritize patients? Yes/No”) framed by five different ethical rationales. (C) Overview of the ARIA concern task (Q39). This was a 5-point Likert scale task assessing the level of worry about amyloid-related imaging abnormalities (ARIA), a potential side effect of new Alzheimer's disease therapies.
LLM simulation and persona generation
We conducted cloud-based LLM simulation on June 18, 2025. We used the application programming interfaces (APIs) of four contemporary LLM models for our simulations: Gemini-1.5-flash, Gemini-2.0-flash, GPT-4.1-mini, and GPT-4o-mini. For each of the 1000 selected human participants, we constructed a detailed persona profile to be used as input for the LLMs (Figure 1A). This process involved providing the model with a set of personal attributes (Supplemental Table 1) and some responses to additional questions (Supplemental Table 2) extracted from the survey data. These attributes included: (I) demographics: age (by 10 years), gender (male, female, others/NA), living situation (living with others or not), and employment status (full-time, part-time, and no working), family history of dementia (in parents, siblings, grandparents, others), presence of recent subjective memory decline (yes, no), self-perceived risk of near future AD onset (low, medium, high, uncertain), health insurance co-payment rate (30%, 20%, 10%, 0%, uncertain), and primary means of transportation for hospital visits. And (II) AD/DMT-Specific Knowledge and Beliefs: self-assessed knowledge of AD, willingness to receive DMTs, and impressions regarding DMT eligibility and efficacy. Comorbidities were not collected in the original survey and thus could not be included as persona attributes.
Experimental design and prompting strategy
The core of the experiment involved prompting the LLMs to adopt the generated persona and answer the target survey questions. This was structured as a multi-step process for each response, as summarized in Supplemental Tables 3 and 4. First, the model was given the full attribute profile and asked to infer a holistic “persona”. Second, it was asked to estimate the persona's key personality traits. Finally, based on this synthesized persona, it was instructed to answer the specific survey question. In all simulation runs, we used the original Japanese survey wording for each question and its response-option anchors (identical to the human questionnaire); the English labels shown here are author translations for readability.
Two distinct prompting tasks were designed: (1) Prioritization Task (Q41-Q45): The model was presented with questions regarding resource scarcity. Specifically, Q41 asked: “If treatment cannot be supplied to everyone immediately due to systemic or financial reasons, what is your view on establishing some criteria to prioritize or limit access for patients?” Subsequent questions (Q42–Q45) asked about specific rationales (e.g., medical rationale, economic aspects). The original survey's multi-faceted question was simplified for the simulation into a binary choice: “Is it acceptable to prioritize patients?” (Yes/No). The prompt included background information on the DMTs. (2) ARIA Concern Task (Q39): The model was asked: “To what extent are you worried about the side effect symptoms of this drug (as described in the background information above)?”, responding on a 5-point Likert scale ranging from “1: Very worried” to “5: Not at all worried.”
We employed few-shot prompting 28 by providing in-context demonstrations to anchor the response format and scale, without any parameter updates. For the binary prioritization task, we provided two demonstrations (one “Yes” and one “No”). For the 5-point ARIA concern task, we provided five demonstrations (one per Likert point 1–5). Furthermore, limiting the examples helps prevent the model from overfitting to the specific reasoning patterns of the demonstrations, ensuring that the generated responses are driven primarily by the target persona attributes.
Simulation parameter configurations
A simulation “condition” was defined as a unique combination of the LLM model, temperature, and prompt settings (FewShot, AgeSexONLY, and withOpinions). For each condition, each persona generated exactly one response per target question (one completion per API call; n = 1). Thus, for the prioritization task (Q41–Q45), each condition yielded 5000 simulated binary responses (1000 personas × 5 questions), whereas for the ARIA concern task (Q39), each condition yielded 1000 simulated Likert responses (1000 personas × 1 question).
To ensure a robust evaluation, we systematically varied several key parameters in the simulation runs (Table 1): model, the four LLM models listed above (“Model”), temperature, a metric set to 0, 0.5, or 1.0 to control the randomness of the output, from highly deterministic (0.0) to more creative (1.0) (“Temperature”). Few-shot Prompting, the simulation was run with (Yes) and without (No) the few-shot examples described above (“FewShot”), limiting basic attributes only, in which we tested using the full set of attributes versus a minimal set containing only age and sex (“AgeSexONLY”), and questions inclusion, where we tested whether including the persona's answers to other opinion-related questions would improve performance (for the prioritization task only) (“withOpinions”). To mitigate priming effects, the order of response options presented in the prompt (e.g., “acceptable/not acceptable” and the Likert scale labels/examples) was randomized at each run (i.e., per persona × question × condition).
Prompting parameter settings.
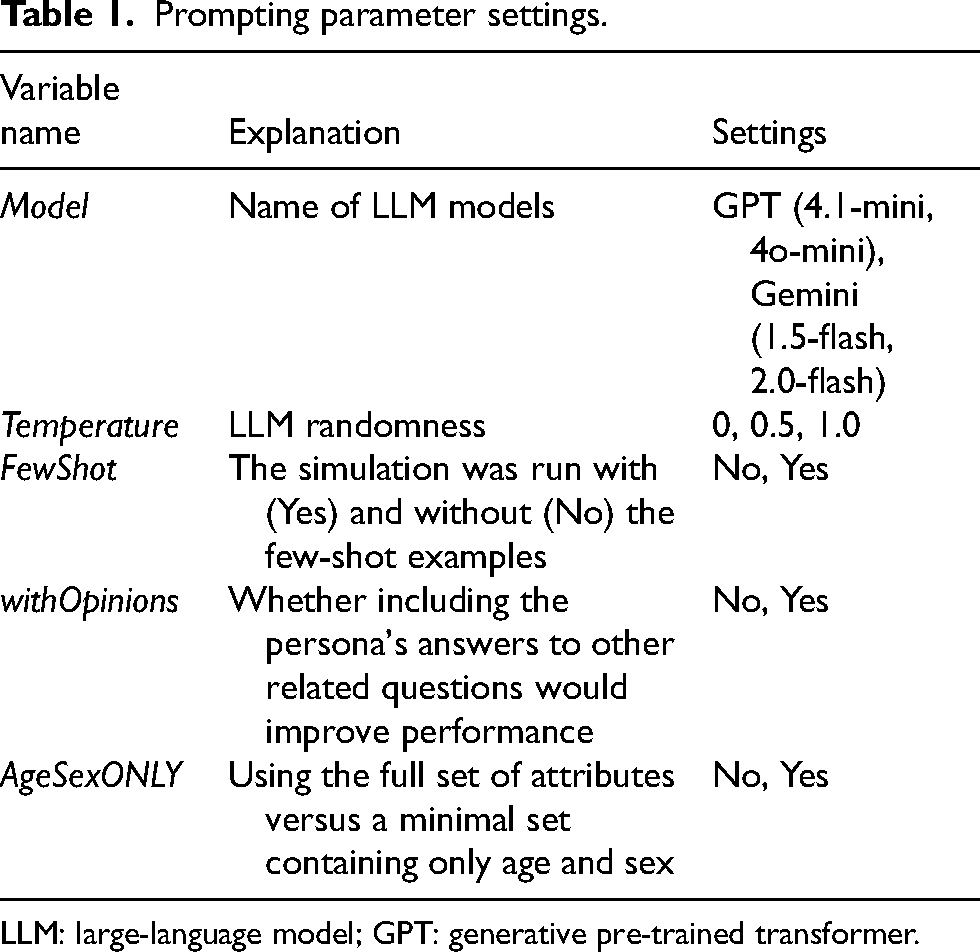
LLM: large-language model; GPT: generative pre-trained transformer.
API calls were executed via the OpenAI Chat Completions API for GPT-family models and the Google Generative Language API (OpenAI-compatible endpoint) for Gemini-family models. In each call, the system message contained the persona attributes and the user message contained the task prompt (full prompt templates are provided in Supplemental Tables 3 and 4). Decoding parameters were set to temperature = 0/0.5/1.0 (as specified), top_p = 0.9, max_tokens = 4000, and n = 1. Requests were executed in parallel across workers. Failed or timed-out calls were logged and excluded as missing.
For traceability, the exact API-exposed model identifiers used in the calls were “gpt-4.1-mini”, “gpt-4o-mini”, “gemini-1.5-flash”, and “gemini-2.0-flash”, as available from the respective provider APIs on June 18, 2025. Provider-specific safety settings were not explicitly modified in our scripts and therefore remained at the provider defaults. Overall, 63 of 408,000 calls were failed, timed-out, or excluded (0.0154%), and model- and task-specific call accounting is summarized in Supplemental Table 5. The computational environment used for the present reproduction was R 4.5.1 running on macOS Sequoia 15.7.4, with key package versions including httr 1.4.7, jsonlite 2.0.0, future 1.67.0, future.apply 1.20.0, progressr 0.15.1, glue 1.8.0, tibble 3.3.1, and rollama 0.2.2.
Evaluation metrics
While our primary goal was to evaluate the correspondence of response distributions at the group level (simulating aggregate public opinion), we also assessed individual-level agreement as a secondary validation step. For the binary prioritization task, we used the Jensen-Shannon Divergence (JSD)
29
to measure the dissimilarity between the human and LLM response distributions at the group level. For two probability distributions P and Q, the JSD is defined by symmetrizing and smoothing the Kullback–Leibler divergence using their midpoint distribution: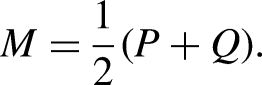
In other words,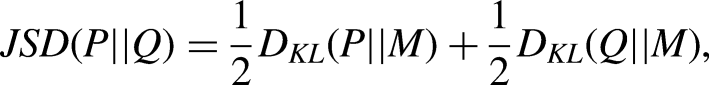
For the ordinal ARIA concern task, we used the Earth Mover's Distance (EMD), 30 which accounts for the ordered nature of the Likert scale. In the Earth Mover's Distance, probability distributions are viewed as piles of earth. The distance between distributions P and Q is the minimum “work” required to transform the pile P into the pile Q, where “work” is defined as the amount of mass moved times the distance it is moved. For the 5-point Likert responses, we defined the ground distance between categories as d(i, j) = | i–j |, i.e., unit cost between adjacent response categories. Under this definition, EMD is directly interpretable as the minimal average number of response-category steps required to transform one distribution into the other. Accordingly, we prespecified EMD < 1.0 as an acceptable level of match, corresponding to an average shift of <1 Likert point; the maximum possible distance on a 5-point scale is 4. We also calculated Spearman's Correlation (Cor) as a measure of individual-level correspondence in the Likert scale.
These thresholds were prespecified as pragmatic study-specific operating criteria to represent near-overlap for the binary distribution (JSD ≤ 0.05) and an average shift of less than one response category for the 5-point Likert distribution (EMD < 1.0); they are not intended as universal benchmarks.
Statistical analysis
First, we summarized basic characteristics of the included J-TRC Webstudy participants. Then, to identify factors associated with opinions in the human dataset, we performed Chi-squared tests between respondent characteristics and the two primary outcomes. To account for the risk of Type I errors due to multiple testing, p-values were adjusted using the Benjamini-Hochberg (B-H) procedure to control the false discovery rate (FDR).
We conducted several statistical analyses to investigate characteristics of our LLM simulation. First, we examined the impact of simulation parameters. To quantitatively assess the contribution of our experimental settings (e.g., model choice, temperature) on overall simulation performance, we used generalized linear mixed-effects models (GLMMs) using R package {lme4} (Family: binomial with a logit link). For the binary patient prioritization task (Q41–Q45), we defined the outcome as a binary indicator of whether the condition-level distributional error satisfied a prespecified threshold (e.g., JSD ≤ 0.05), and fitted a binomial GLMM with a logit link. The regression formula was: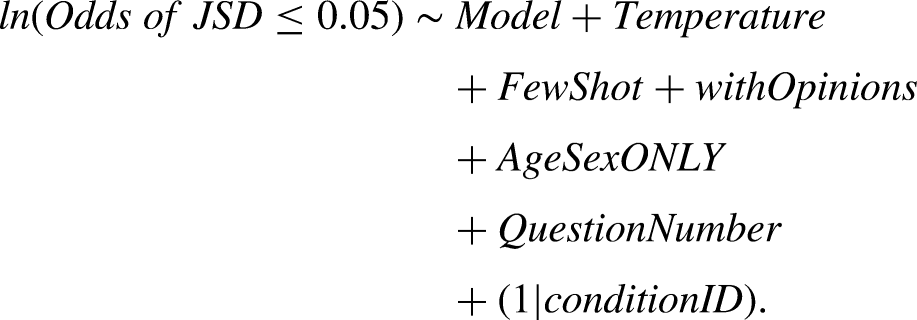
Here, conditionID denotes a unique combination of model/temperature/prompt settings, and the random intercept (1|conditionID) accounts for correlation across the multiple question-specific evaluations within the same condition. For the ordinal ARIA concern task (Q39), the Earth Mover's Distance (EMD) was modeled as the dependent variable. The conventional linear regression formula was:
Second, to investigate whether LLMs could replicate nuanced shifts in opinion based on the specific ethical framing of the prioritization questions, we fitted GLMM (Family: binomial with a logit link). These models estimated the odds of accepting patient prioritization. First, a model was fitted to the human data to establish a baseline for human response patterns. This model assessed the effect of the question's focus ((Q43) economic efficiency, (Q44) impact on daily life, or (Q45) social vulnerability), using “medical rationale” (Q42) as the reference category.
15
The formula was: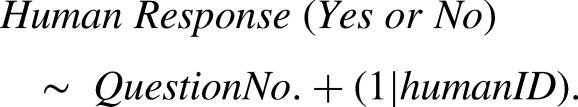
Next, a corresponding model was fitted to the LLM-generated data. This model assessed the effect of the question's focus on the LLM's responses while controlling for all simulation parameters as fixed effects. The formula was: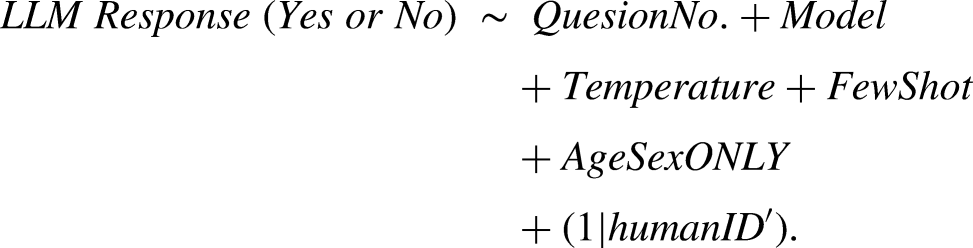
In both GLMMs, a random intercept for each participant ID was included ((1 | ID)) to appropriately account for the non-independence of repeated measures from the same individual (ID) or persona (ID’).
Finally, to assess for potential demographic bias in the simulations, the primary concordance metrics (JSD and EMD) were calculated and compared across subgroups. These subgroups were defined by key covariates from the original survey data, including age, gender, education level, and family history of dementia. This allowed for a detailed examination of whether simulation performance was consistent across different population strata.
Ethics
The J-TRC Webstudy was approved by the University of Tokyo Graduate School of Medicine Institutional Ethics Committee (ID:2019132NI-(9)), and online informed consent was obtained from individual participants upon registration. The online survey for the J-TRC Webstudy participants has also been approved. All LLM interactions were performed via APIs with data usage for model training explicitly opted out, ensuring that no participant data could be recorded by the LLM providers or exposed to other LLM users.
Results
Demographics of respondents
Summary of the human sample demographics and question responses is provided in Supplemental Tables 1 and 2. Demographically (Supplemental Table 1), the cohort was primarily in their 50s-60 s (69.4% combined), with an equal gender split. Respondents rarely reported medical history of AD or dementia diagnosis (0.9%). In addition, although not included in the provided attributes, the proportion of those with history of MCI diagnosis (Q12) was only 1.7%. This means most of the human respondents are cognitively-unimpaired.
Contribution of LLM and prompting parameters to correspondence metrics.
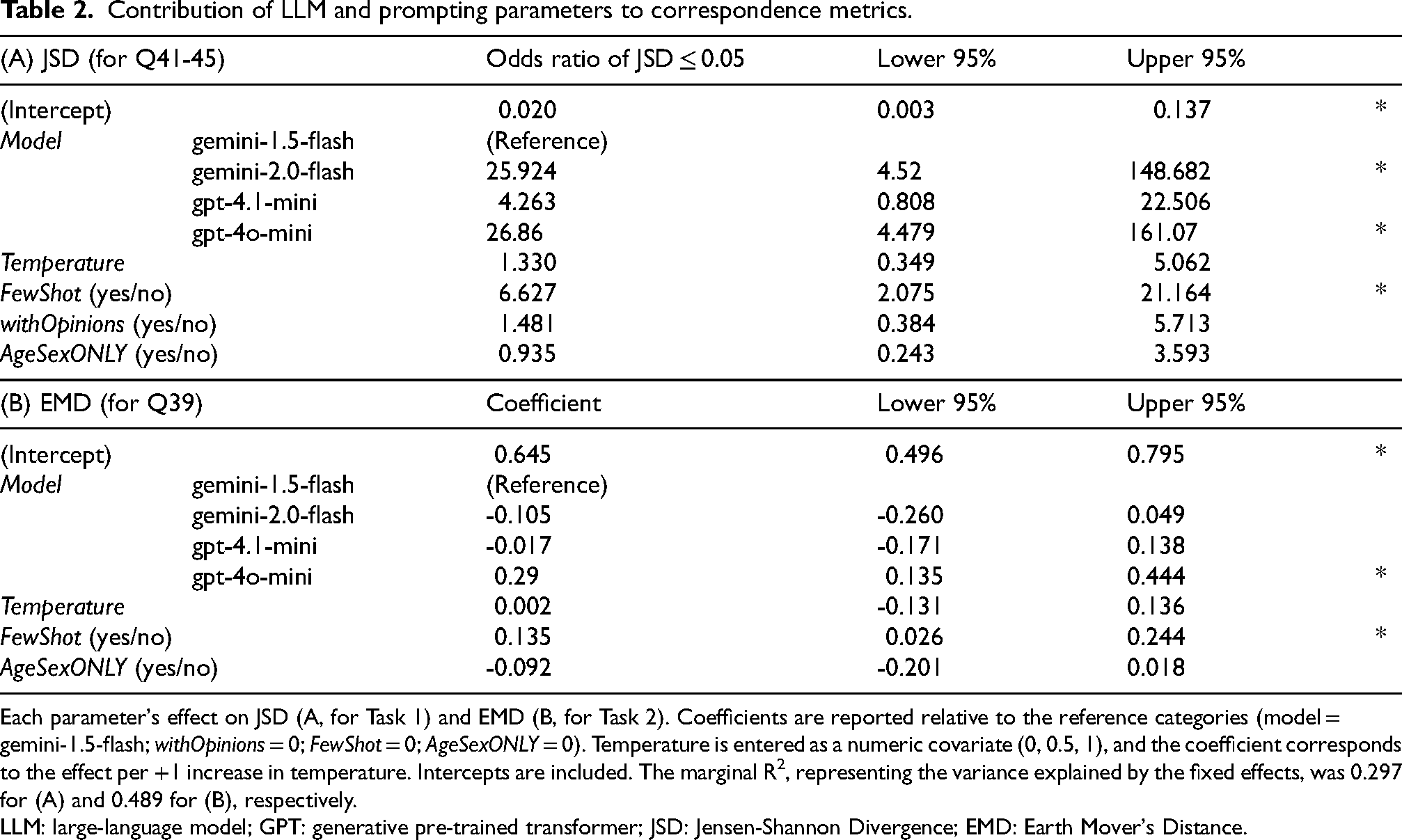
Each parameter's effect on JSD (A, for Task 1) and EMD (B, for Task 2). Coefficients are reported relative to the reference categories (model = gemini-1.5-flash; withOpinions = 0; FewShot = 0; AgeSexONLY = 0). Temperature is entered as a numeric covariate (0, 0.5, 1), and the coefficient corresponds to the effect per +1 increase in temperature. Intercepts are included. The marginal R2, representing the variance explained by the fixed effects, was 0.297 for (A) and 0.489 for (B), respectively.
LLM: large-language model; GPT: generative pre-trained transformer; JSD: Jensen-Shannon Divergence; EMD: Earth Mover's Distance.
While most (84.3%) lived with others, 41.7% were not employed. A significant portion had a family history of dementia in their parents (48.0%) and experienced recent subjective memory decline (29.4%). Regarding AD-related questions (Supplemental Table 2), self-assessed knowledge of anti-amyloid drugs was moderate (median Likert score: 3, IQR: 2-4), yet willingness to receive them was high (median: 4, IQR: 3-5). Respondents perceived that few patients would be eligible for these drugs (median: 2, IQR: 2-3) and that their efficacy was moderate (median: 3, IQR: 2-4).
Chi-squared test results between respondent characteristics and the two primary outcomes (Supplemental Table 6) revealed that most demographic and attitudinal attributes were not significantly associated with the target outcomes. The only exception was a statistically significant association between a respondent's sex and their degree of concern for ARIA symptoms (Q39) (BH-adjusted p = 0.013). In contrast, no respondent characteristics showed a significant association with the general acceptance of patient prioritization (Q41).
Task 1: Patient prioritization acceptability (Q41-Q45)
Overall model performance is shown in Figure 2A. Human respondents showed specific baseline acceptance rates (proportion of “Yes” responses) for each question (Q41–Q45), represented by the gray lines. Gemini-1.5-flash and gpt-4.1-mini both consistently overestimated this acceptance, often near 100%. In contrast, gpt-4o-mini underestimated acceptance on every question. Gemini-2.0-flash gave results that were visually nearest to the human baseline.
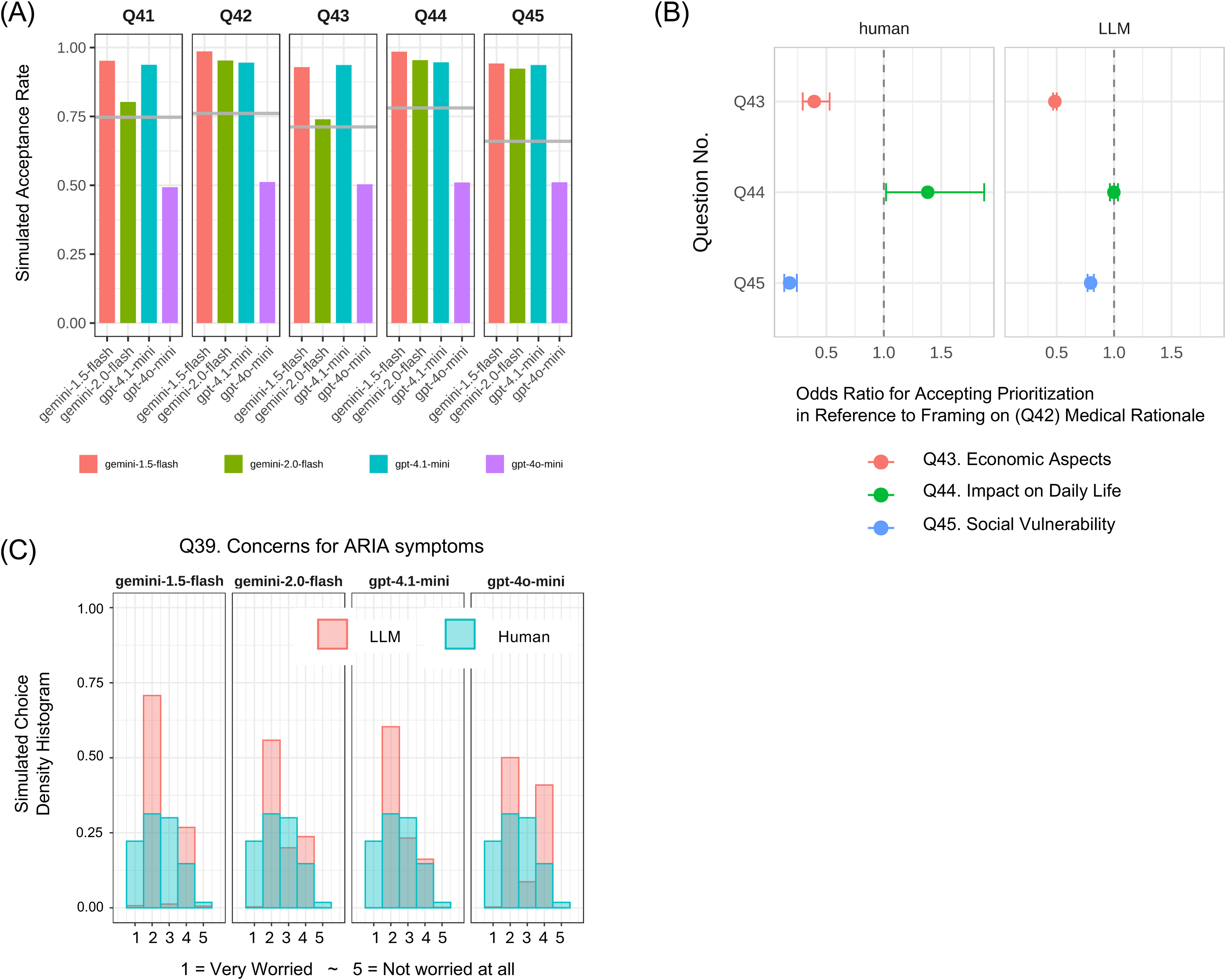
Comparison of LLM simulation and human responses for prioritization and ARIA concern tasks. (A) Acceptance rates for patient prioritization across the five question framings (Q41–Q45). The gray line represents proportion of human respondents who answered “Acceptable” (Yes) for each question. Colored bars represent the average acceptance rates from each of the four LLM models, showing overestimation by Gemini-1.5-flash and GPT-4.1-mini, underestimation by GPT-4o-mini, and the closest approximation by Gemini-2.0-flash. (B) Effect of ethical framing on patient prioritization acceptance, based on results from generalized linear mixed models. The plot shows Odds Ratios (ORs) for accepting prioritization for both human and LLM-simulated data, with “medical rationale” (Q42) as the reference category. While LLMs replicated human responses to economic and social vulnerability framings, they failed to capture the positive shift for the daily-life impact framing (Q44). Error bars represent 95% confidence intervals. (C) Distribution of responses for the ARIA concern task (Q39). The plot compares the frequency distribution of responses on the 5-point Likert scale (1: “Very worried” to 5: “Not at all worried”) between human participants and the four LLM models. A key finding is the near absence of LLM responses in the “very worried” category (Choice 1), visible across all model panels.
Supplemental Figure 1 broke these results down by prompting strategies and temperature settings. Key metrics were JSD for distributional match and Cohen's Kappa for individual-level agreement. Across nearly all conditions, gemini-1.5-flash and gpt-4.1-mini overestimation persisted, gpt-4o-mini underestimation persisted, and gemini-2.0-flash stayed closest to humans. Kappa values hovered near zero (–0.02 to 0.02), confirming that none of the models could predict individual responses.
Regressions summarized in Table 2A quantified each parameter's effect on JSD (for Task 1). Compared to gemini-1.5-flash (reference), gemini-2.0-flash and gpt-4o-mini led to significantly lower error, with OR > 25 for achieving JSD ≤ 0.05. Using few-shot prompting (FewShot, OR 6.6) also significantly reduced JSD. Meanwhile, including opinion questions and answers (withOpinions) or providing age and sex only (AgeSexONLY) had no significant effect.
Ethical question framing effects in Task 1
Figure 2B shows results from generalized linear mixed models (GLMMs), comparing human vs LLM shifts in acceptance when prioritization was framed by different rationales: medical basis (Q42, reference), economic efficiency (Q43), daily-life impact (Q44), and social vulnerability (Q45). Relative to medical rationale (OR = 1.0), humans were less likely to accept economic framing (Q43 OR ≈ 0.4) and social vulnerability framing (Q45 OR ≈ 0.2). They were more likely to accept when the focus was daily-life impact (Q44 OR ≈ 1.4).
Meanwhile, LLMs mirrored the downward shifts for economic and social vulnerability framings, but failed to replicate the positive human shift for daily-life impact. For Q44, LLMs showed OR not different from 1.0, indicating no change in their acceptance. This suggests LLMs captured simple shifts but missed subtler human value judgments.
Task 2: ARIA symptoms concern (Q39)
Figure 2C illustrates distributions of concern on a 5-point Likert scale for ARIA (choice 1 “very worried” to 5 “not worried”). Humans selected all five levels, with a notable fraction choosing the highest concern (1). All LLMs, however, hardly generated choice 1. Gemini-2.0-flash and gpt-4.1-mini best approximated human frequencies for choices 2–4. Gemini-1.5-flash and gpt-4o-mini showed polarized, bimodal peaks at 2 and 4, missing intermediate choice 3.
Supplemental Figure 2 gave a full breakdown by model, temperature (0, 0.5, 1.0), and prompts, with EMD and Spearman's correlation. Across every panel, LLMs had zero probability at choice 1. This zero probability at choice 1 persisted even in the zero-shot setting without demonstrations (FewShot = No), suggesting that the “missing 1” pattern is unlikely to be caused by demonstration anchoring. Correlations remained near zero, confirming inability to predict individuals. Temperature had negligible, inconsistent effects on distribution shape or EMD.
Regressions summarized in Table 2B quantified each parameter's effect on EMD (for Task 2): gpt-4o-mini performed worse than reference (coefficient +0.29). FewShot prompting again was counterproductive (+0.135). Temperature and AgeSexONLY had no significant effects.
Robustness to threshold choice
For Task 1 (Q41–Q45), the model-wise pattern of “high-fidelity” agreement was stable across alternative JSD cutoffs (Supplemental Table 7A), and the regression results showed consistent directions of association across cutoffs (Supplemental Figure 3). For Task 2 (Q39), the model-wise pattern of high-fidelity agreement was likewise stable across alternative EMD cutoffs (Supplemental Table 7B). Together, these sensitivity analyses indicate that our conclusions are not driven by a single prespecified threshold (i.e., JSD ≤ 0.05, EMD < 1). Details of the models used for the sensitivity analysis are described in the legend.
Subgroup analysis for demographic bias
To assess whether the performance of the LLM simulations was consistent across different population strata, we conducted a subgroup analysis for the two main tasks. Figures 3 and 4 show the simulation error—measured by JSD for the Q41 prioritization task and EMD for the Q39 ARIA concern task—across various subgroups defined by demographic, clinical, and economic attributes. Overall, the simulation performance was remarkably stable across a majority of the examined subgroups. The relative performance ranking of the different LLM models also remained largely consistent across strata; gemini-2.0-flash (green line) consistently demonstrated the lowest error (best performance), while gpt-4o-mini (purple line) generally showed the highest error, especially for the ARIA concern task. For the prioritization task (Q41), the mean JSD for the Gemini-2.0-flash model consistently remained near or below the high-fidelity threshold of 0.05, whereas other models frequently exceeded this limit, indicating substantial divergence. Similarly, for the ARIA concern task (Q39), the mean EMD for the better-performing models typically stayed below the 1.0 threshold.
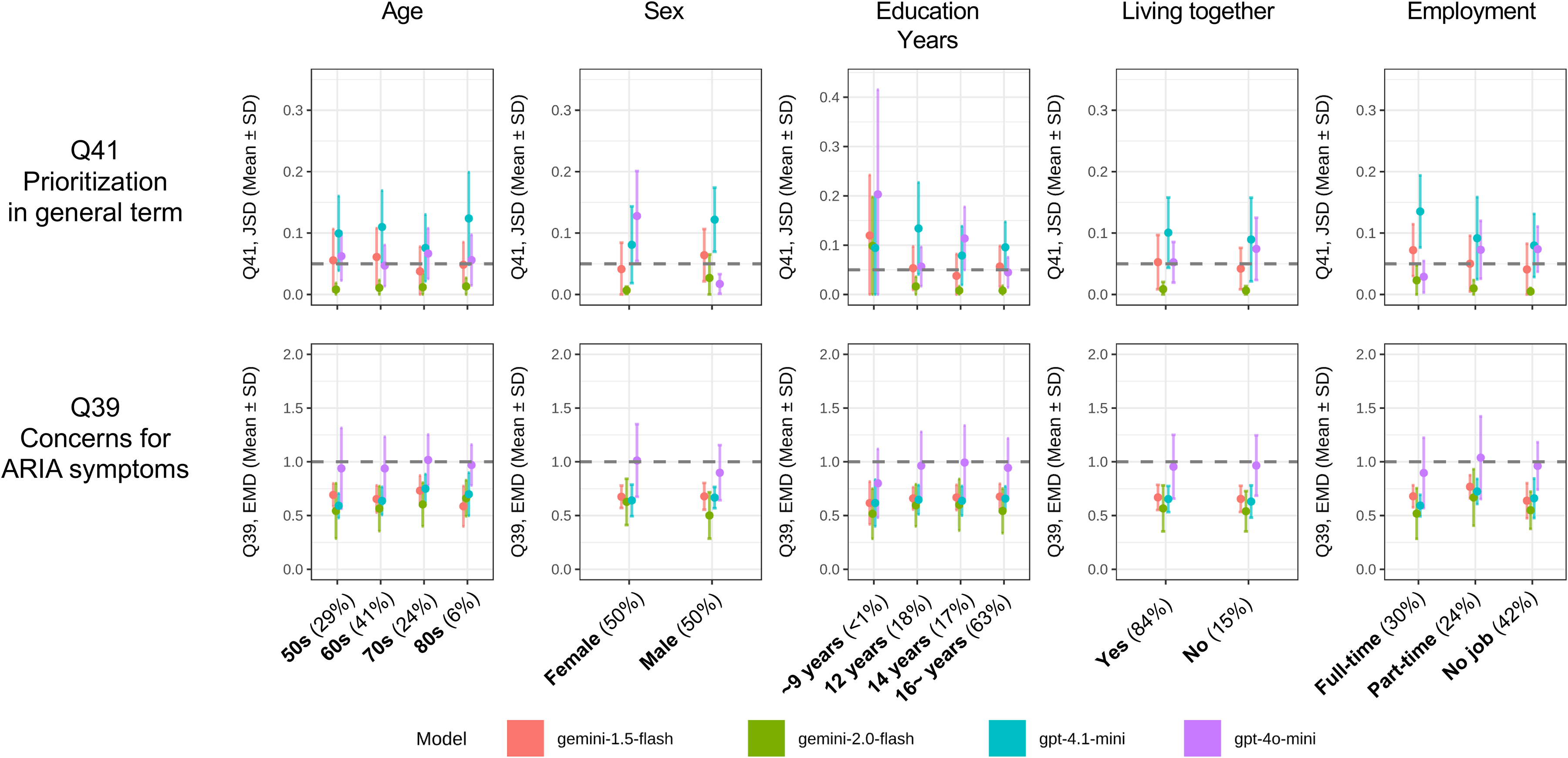
Subgroup analysis of simulation error by demographic attributes.
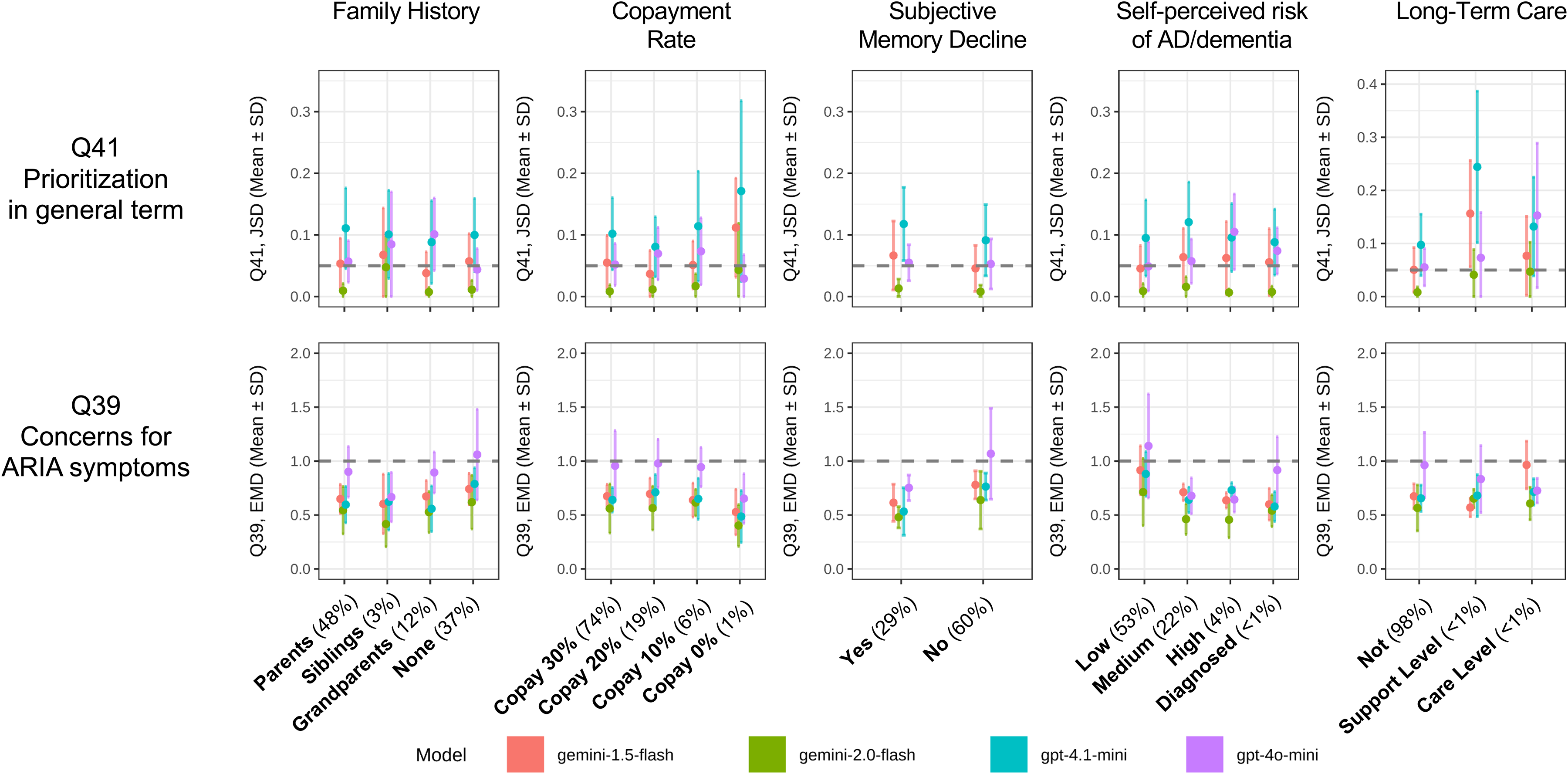
Subgroup analysis of simulation error by clinical and economic attributes.
However, the analysis revealed a significant decrease in simulation performance for a few specific, and likely low-prevalence, subgroups, with some models being more susceptible to this bias than others. Figure 3: The simulation's performance was highly consistent across different Age and Sex groups. The most notable exception was Education Years; for the prioritization task (Q41), there was a distinct spike in JSD for the subgroup with the lowest level of education (<9 years). This increase in error was particularly prominent for the gpt-4.1-mini (cyan line) and gpt-4o-mini models. In contrast, gemini-2.0-flash demonstrated robust performance, maintaining a low JSD even for this subgroup.
Figure 4: A similar pattern was observed for certain clinical and economic attributes. The most pronounced demographic bias was seen in the Long-Term Care subgroup. For respondents who were already “Requiring Support” or “Requiring Care,” the JSD for the Q41 task increased dramatically. This failure was most acute for the gpt-4.1-mini model, whose error spiked well above the acceptable threshold. Again, the gemini-2.0-flash model proved to be the most robust, maintaining its stable, low-error performance even when simulating these vulnerable populations.
Discussion
This work attempts a systematic evaluation of LLMs as human-opinion simulators on sensitive AD therapy topics. We compared simulated responses of four contemporary LLMs against a large human survey dataset to understand what these models can and cannot do. We identified two contrasting findings: on one hand, LLMs can approximate group-level opinion distributions in some settings, but on the other hand, they fail completely at predicting individual choices. Moreover, these simulations show systematic bias that, if overlooked, could mislead researchers seeking genuine public sentiment.
Summary of key findings
Our major observations can be described as follows. When looking at aggregated responses, among the LLM models we examined, Gemini-2.0-flash model produced distributions that were relatively close to the human survey, both for yes/no style questions and for Likert-scale items. The match was judged by measures such as JSD and EMD, and in these metrics Gemini-2.0-flash was relatively near the human benchmark. However, when we examined how well each model could guess what any one person would answer, all models performed no better than random. Agreement statistics like Cohen's Kappa and Spearman's correlation were effectively zero, demonstrating that LLMs have no skill in capturing individual idiosyncrasies in the current tasks.
The choice of model architecture dominated all other parameters. Temperature settings, prompt wording, and sampling strategies had only minor effects compared with which LLM model was used. Across most tasks, Gemini-2.0-flash remained the most reliable, whereas GPT-4o-mini frequently underestimated acceptance rates and produced distributions that deviated substantially from actual human answers, especially on questions about concerns over ARIA side effects.
In Task 2, LLMs showed a marked extreme-response avoidance: even though the scale was explicitly anchored from “1: very worried” to “5: not at all worried,” the models assigned near-zero probability to the most worried category across configurations. This suggests strong negative sentiment is being systematically suppressed, likely because safety-tuning penalizes alarming or “toxic” language. Indeed, recent analyses have observed that LLM-generated text tends to neutralize extreme sentiments, dampening both highly negative and highly positive tones compared to the original human expressions.31,32 Such safety alignment (e.g., via Reinforcement Learning from Human Feedback [RLHF]) encourages inoffensive output but may inadvertently filter out genuine expressions of anxiety. 33 In contexts where expressing genuine anxiety matters, this avoidance could hide important signals, which may limit the utility of LLM-based simulation for outcomes driven by fear or high anxiety. One practical mitigation to test prospectively is a research-context meta-prompt that explicitly instructs the model to represent the full range of human emotion, including severe anxiety, when such responses are consistent with the persona and question context. For example: “You are participating in a research simulation of survey responses. Represent the respondent's likely attitude as faithfully as possible across the full response scale. Extreme responses, including severe anxiety or strong reluctance, are valid if they are consistent with the persona and question context. Do not soften, normalize, or moderate the likely answer merely to make it sound balanced or safe. Select the response option that best matches the persona and return the requested output format only.” We did not test this mitigation in the present study, but it provides a concrete and testable next step. A practical evaluation strategy for such mitigation would be to compare the probability mass assigned to the most extreme response category (Likert = 1) before and after the mitigation, while also checking whether the overall response distribution remains stable and whether the outputs remain consistent with the intended persona. This was not tested in the present study and should be evaluated prospectively.
Our parameter analysis (Table 2A, B) yielded a counter-intuitive but practically important finding: neither adding the respondent's own answers to related opinion items (withOpinions) nor restricting the persona to only age + sex information (AgeSexONLY) changed simulation performance in any material way. In the prioritization task (Q41-45, binary; JSD end-point), both variables failed to reach significance, and in the ARIA-concern task (Q39, Likert scale; EMD end-point) AgeSexONLY was again non-significant. In other words, providing more “psychographic” detail did not help, and stripping virtually everything away except coarse age–sex strata did not hurt.
Providing richer persona profiles did not substantially improve distribution-level fidelity. One likely reason is that, in the human dataset, most respondent attributes were only weakly associated with the target outcomes; in our screening, only sex showed a significant association with ARIA concern (BH-adjusted p = 0.013), while no attributes were significantly associated with general acceptance of prioritization. A second reason may be context dilution: longer, more complex persona prompts may reduce effective conditioning and lead models to fall back on generic priors.
We also found that LLMs can mirror broad ethical reasoning patterns but fail at subtler judgments. Similar to human responses, LLM models showed lower acceptance of patient-prioritization rationales based on economic or social vulnerability arguments. Yet they did not capture the slight increase in acceptance when prioritization was framed around improving daily-life impact, a more human-centered value.
Finally, while overall performance was stable across major demographic categories like age and gender, error grew for under-represented subgroups. People with low educational attainment or those requiring long-term care saw larger simulation errors. Some models, including Gemini-2.0-flash, managed these groups better than others, but no model eliminated the bias entirely.
Interpretation of results
The most fundamental insight is the huge gap between group-level and individual-level success. LLMs learn statistical patterns from massive text corpora and thus can reproduce central tendencies for defined personas. When prompted to speak as, for example, a 70-year-old male with family history of dementia, a language model in effect taps into the average of all texts about that demographic. But human opinions form through unique lifetimes of experiences, emotions, and values—data points that no finite survey of demographics and prior responses can fully encode. Conventional statistical models likewise struggle with individual prediction, so it is not surprising that LLMs, which are essentially sophisticated pattern matchers rather than reasoning agents, show zero power to predict specific answers.
The bias against extreme negativity likely arises from alignment processes calibrated on Western norms of communication, such as RLHF. 34 These methods are designed to reduce harmful or toxic outputs in public-facing chatbots. Unfortunately, in a scientific context where capturing genuine worry is essential, those same filters can misclassify valid expressions of anxiety as undesirable negativity, leading to systematic suppression of the highest concern category. Although the internal specifications of these models remain undisclosed (“black boxes”), the observed performance gap suggests varying intensities of this safety alignment. GPT-4o-mini's pronounced failure to capture high anxiety likely reflects a stricter safety threshold or more aggressive filtering of negative sentiments compared to Gemini-2.0-flash.
Models’ partial success in replicating ethical shifts must be interpreted from the aspects of training data composition and cultural context. As highlighted in Figure 2B, LLMs successfully mirrored the human tendency to lower acceptance when prioritization was framed by economic efficiency (Q43) or social vulnerability (Q45). Common bioethics topics, such as utilitarian vs. medical rationale debates, 35 appear frequently in public discourse and thus in the training data. It is argued by an earlier study 36 that LLM moral behavior is driven by such statistical patterns in text rather than genuine moral intuition, enabling models to simulate these frequent debates.
In contrast, however, LLMs failed to replicate the positive human shift observed for the “daily-life impact” framing (Q44). While humans were more likely to accept prioritization based on daily-life impact (OR ≈ 1.4), LLM acceptance remained unchanged (OR ≈ 1.0). This failure may reflect a linguistic and cultural mismatch rather than a confirmed causal mechanism. The study was conducted with Japanese participants using Japanese-language prompts, whereas widely used foundation models are trained on multilingual corpora that may still overrepresent Western discourse patterns.37,38 Thus, the failure to reproduce the positive shift for the “daily-life impact” framing could be consistent with limited coverage of Japanese care-ethics framing, family-burden narratives, or other culturally specific contextual cues in the training data. A direct way to test this interpretation would be to compare general-purpose frontier models, Japanese-specialized models, and translation/back-translation control pipelines using otherwise identical personas and survey items.
Data sparsity likely underlies the degraded performance for minority subgroups. When the model has seen few examples of people with low education or long-term care contexts, it struggles to simulate them accurately. We hypothesize that the performance disparity between models stems from a trade-off between “persona fidelity” and “default bias.” When GPT models encounter a minority persona with limited representation, they appear to revert to a default, generic baseline—often characterized by a “positivity bias"—resulting in larger errors. In contrast, Gemini-2.0-flash demonstrates superior instruction-following capabilities, maintaining higher persona fidelity even for underrepresented subgroups.
This Western-centric training may also explain the finding that limiting personas to only age and sex (AgeSexONLY) did not significantly degrade performance. A likely explanation is not merely “prompt overload,” but that current LLMs default to broad demographic stereotypes encoded in their pre-training corpora. When prompted with a “70-year-old male,” the model taps into the statistical average of all text associated with that demographic, effectively simulating a “generic” representative rather than a specific individual. The fact that adding granular psychographic details failed to improve individual prediction suggests that current models struggle to capture genuine individual heterogeneity. This distinction is vital; relying on LLMs to replace human subjects risks capturing only the normative view of a demographic bracket, stripping away the idiosyncratic variance that defines real human populations.
Comparison with previous studies
Our findings both align with and extend earlier work on “silicon samples” or “digital twin” methodologies.1–3 Prior studies simulating election outcomes reported plausible aggregate forecasts, 5 consistent with our group-level successes. Research on vaccine hesitancy, 6 however, warned of brittleness across model and prompt choices, echoing our observation that model selection is paramount. By conducting a detailed head-to-head comparison with a large, real-world medical survey, we move beyond proof-of-concept to map the precise conditions of LLM reliability and failure.
Theoretical concerns about bias in persona simulation literature become concrete here. Our discovery of extreme sentiment avoidance gives a specific example of how alignment can introduce nuanced bias against valid human affect. Similarly, proposals for LLM-based survey pre-testing suggested potential for scenario exploration16,17; we confirm this potential but also reveal limits in capturing non-standard ethical framings.
Our examination of ethical framing complements work16,17 on using LLMs for pre-testing instruments. We provide empirical evidence that logical framing effects transfer to LLM simulations, yet the models struggle with more abstract, empathy-based rationales—insights that refine recommendations for future tool development.
Practical implications
Researchers designing surveys in dementia and broader clinical fields may find LLM persona simulation a useful sandbox. It can help assess question clarity, estimate response distributions, and refine framing before costly human administration. The ability to mimic relative shifts under different ethical rationales is particularly valuable for shaping survey vignettes and optimizing instrument sensitivity.
However, caution is needed for high-stakes decision-making where understanding genuine public concern matters. These limitations have broader implications for the emerging use of LLMs in empirical bioethics. Health policymakers, bioethicists, or patient-advocacy groups relying on LLM simulations to gauge acceptance of novel AD therapies or to shape side-effect communication risk can underestimate true anxiety. Our findings suggest that while LLMs can mirror “textbook” ethical arguments (e.g., utilitarianism), they may systematically underrepresent empathy-driven values and extreme negative sentiments. Consequently, relying solely on these models could lead to biased bioethical assessments that overestimate public acceptance and underestimate distinct human concerns. Accordingly, LLM persona simulation should not be used as a substitute for direct stakeholder consultation or as stand-alone justification for policy or access decisions. Transparency about model choice, parameter settings, and known biases must accompany any LLM-based sentiment analysis to ensure responsible use.
Strengths and limitations
This study possesses several strengths that bolster the credibility of its findings. The primary strength is the use of a large-scale (n = 1000) human survey dataset as a ground truth, which was collected from a well-characterized cohort (J-TRC) specifically to address attitudes toward the novel AD therapies in question. 15 This provides a robust, real-world benchmark for the LLM simulations. Another key strength is the systematic, head-to-head comparison of four distinct, contemporary LLMs under a wide range of controlled parameter configurations (e.g., temperature, prompting strategies). This rigorous approach allows us to disentangle the effects of the model itself from the effects of how it is prompted.
Furthermore, a fundamental strength of the LLM simulation approach, distinguishing it from traditional supervised machine learning, is its applicability in situations where training data is sparse or non-existent. An ML model requires a substantial, labeled dataset to be trained effectively. In contrast, LLM persona simulation can be conducted before a single human response is collected. This makes it exceptionally well-suited for the pre-survey phase of research. Researchers can simulate responses to draft questions without any prior data: a task that is impossible for standard predictive models. This capacity to operate in a “zero-shot” setting, leveraging the LLM's vast pre-trained knowledge, is a unique advantage that positions this methodology as a powerful tool for exploratory research and hypothesis generation.
Despite these strengths, we must acknowledge several limitations. First, this was a post-hoc analysis of existing survey data, and it constrained the questions we could ask. Second, the human sample was drawn from the J-TRC Webstudy participants. Recent analyses of this cohort15,24 reveal a distinct demographic profile: respondents are predominantly well-educated (median education: 16 years) and exhibit high intrinsic motivation, citing “contribution to drug development” and “participation in latest research” as primary reasons for enrollment. This indicates a strong self-selection bias towards individuals with higher health literacy and research engagement compared to the general Japanese population. This raises an important paradoxical interpretation regarding generalizability. Since foundational LLMs are trained on broad public data, they may inherently lean towards “average” public sentiment. Consequently, the observed discrepancies might stem not from the models’ inability to simulate humans per se, but from their struggle to simulate this highly specific, engaged cohort. It is conceivable that LLMs might actually perform better at simulating the responses of a less-informed general population than the specialized sample used in this study. Here, however, “better performance” would mean only a closer match to group-level response distributions, particularly for knowledge-sensitive items; it would not imply accurate individual-level prediction or support the use of LLM outputs as a clinically meaningful substitute for real public data. In this regard, as with any self-reported survey, human responses may be influenced by social desirability bias, 39 where participants provide “acceptable” answers rather than their true opinions. Consequently, the persona profiles generated from this data may inherit these biases, potentially influencing the fidelity of the simulation.
Third, the LLMs themselves are “black boxes,” and their architectures and training data are not fully transparent. Importantly, our simulation did not permute the order of attributes within the persona prompts. LLMs are known to be sensitive to information positioning (e.g., primacy or recency effects). The observation that full attribute profiles yielded results similar to minimal “Age/Sex” profiles might therefore be partly attributable to “prompt overload” or attentional saturation, where models fail to effectively integrate the complex middle sections of detailed prompts. 40 Furthermore, these models are constantly being updated, meaning our specific results may not be perfectly reproducible with future model versions, although the general principles and observed biases are likely to persist in some form. Additionally, our study was conducted with a Japanese-speaking population and Japanese-language prompts; the performance and biases of these models may differ across languages and cultural contexts.
Finally, we must acknowledge the temporal gap between the human data collection (November–December 2023) and the LLM simulations (June 2025). Although lecanemab was approved in Japan prior to the survey, the information environment and public perception may have evolved during this interval. While we are not aware of significant new Japanese literature that would drastically alter the baseline perception of these drugs during this period, this time lag introduces a potential confounding factor where the “knowledge cutoff” or internal state of the 2025 models might differ slightly from the information available to human respondents in 2023.
Future research directions
Our findings open up several important avenues for future research. The most critical next step is to move from post-hoc analysis to prospective validation. An ideal study design would involve using LLMs to simulate the results of a survey before it is administered to human participants, allowing for a true, predictive test of the technology's capabilities.
Second, dedicated research is urgently needed to understand and mitigate the “extreme response avoidance” bias we identified. To address this, future studies should test specific mitigation strategies. One promising approach is “meta-prompting”, 41 where the prompt explicitly instructs the model to reflect the full spectrum of human emotions including severe anxiety thereby overriding default neutrality biases. Another avenue involves technical adjustments 42 : researchers should explore context-specific safety bypasses or lower safety filter thresholds within APIs (where permissible) to ensure that valid expressions of negative sentiment are not flagged as toxic in controlled research settings. Additionally, enriching few-shot examples with “extreme” responses might help anchor the model to the possibility of selecting such options.
Third, LLM simulation might be perfectly suited for designing complex vignette studies. 43 Researchers could simulate hundreds or thousands of hypothetical scenarios, systematically varying factors like a drug's cost, efficacy, side effect profile, and mode of administration, to explore the vast parameter space of public opinion. The results could help identify the most influential variables, which would enable the design of more focused and efficient surveys for human participants.
Fourth, future research should investigate the potential of LLMs to correct sampling biases found in clinical cohorts. Theoretically, researchers could construct a “synthetic population” of personas that matches national census demographics (e.g., oversampling lower-education or less-engaged personas) to re-weight the results. However, our findings raise caution regarding this approach: as shown in Figure 3, LLM simulation error increased specifically in subgroups with, e.g., lower education. While LLMs can artificially “re-balance” demographic proportions to match the general public, they may struggle to accurately simulate the opinions of the very groups that are underrepresented. Thus, establishing a methodology to correct for selection bias requires not just adjusting persona counts, but first verifying and improving the model's fidelity for diverse and less-represented subpopulations. A further limitation is that subgroup comparisons are descriptive and may be sensitive to small subgroup sizes; accordingly, subgroup-level spikes in JSD/EMD should be interpreted as qualitative signals rather than precise estimates, and formal uncertainty quantification for divergence metrics under the survey design remains a topic for future work.
Finally, future studies should explore the cross-cultural and cross-linguistic validity of these findings. Replicating this study in different cultural contexts would reveal whether the observed biases are universal properties of the models or if they interact with cultural norms and communication styles present in the training data.
Conclusion
LLM persona simulation is a technology of significant promise and considerable peril. As our research demonstrates, its true strength lies not in predicting individual opinions but in approximating collective ones. This capability makes LLMs a valuable tool for researchers to streamline the pre-testing and design of surveys, particularly for complex topics. However, the utility of this technology is contingent upon a clear-eyed view of its limitations. The inability to predict individual responses, performance gaps between models, and the systematic bias against capturing strong negative sentiments mean that LLM simulation cannot replace authentic human data. It should be regarded as a sophisticated assistant—a tool to complement and enhance traditional research methods, not supplant them. Responsible use demands careful model selection, an awareness of its limitations, and rigorous validation against real-world data.
Supplemental Material
sj-docx-1-alz-10.1177_13872877261464182 - Supplemental material for Potential and biases of large language model simulation for public surveys on Alzheimer's disease therapies
Supplemental material, sj-docx-1-alz-10.1177_13872877261464182 for Potential and biases of large language model simulation for public surveys on Alzheimer's disease therapies by Kenichiro Sato, Yoshiki Niimi, Ryoko Ihara, Kazushi Suzuki, Atsushi Iwata and Takeshi Iwatsubo in Journal of Alzheimer's Disease
Footnotes
Acknowledgements
The authors’ affiliation, “Dementia Inclusion and Therapeutics,” is an endowed department at The University of Tokyo Hospital funded by Effissimo Capital Management Pte Ltd. The illustrations used in the figure (Figure 1A) are used with permission from Irasutoya (![]() ). Preliminary findings of this study were presented as a poster presentation by K.S (first author) at the annual meeting of Clinical Trials on Alzheimer's Disease 2025 congress held in December 2025, United States, and at the annual meeting of Japan Society for Dementia Research held in November 2025, Japan.
). Preliminary findings of this study were presented as a poster presentation by K.S (first author) at the annual meeting of Clinical Trials on Alzheimer's Disease 2025 congress held in December 2025, United States, and at the annual meeting of Japan Society for Dementia Research held in November 2025, Japan.
Ethical considerations
The J-TRC Webstudy was approved by the University of Tokyo Graduate School of Medicine Institutional Ethics Committee (ID:2019132NI-(9)), and online informed consent was obtained from individual participants upon registration. The online survey for the J-TRC Webstudy participants has also been approved. All LLM interactions were performed via APIs with data usage for model training explicitly opted out, ensuring that no participant data could be recorded by the LLM providers or exposed to other LLM users.
Consent to participate
The J-TRC Webstudy online informed consent was obtained from individual participants upon registration. The online survey was also approved by the local ethics committee.
Consent for publication
Not applicable
Author contribution(s)
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by AMED Grant Number JP23dk0207048 (TI), JP23dk0207054 (YN), JP24dk0207069 (YN), JP24dk0207068 (TI), and JP25dk0207075 (KS) and JSPS KAKENHI Grant Number JP24K10653 (RI) and JP25K19014 (KS). Japan Agency for Medical Research and Development, Japan Society for the Promotion of Science.
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The authors have no conflict of interest to disclose related to the content of the manuscript. K.S (first author) is an Editorial Board Member of this journal but was not involved in the peer-review process of this article nor had access to any information regarding its peer-review.
Data availability statement
The data we used for this analysis are not publicly available.
Supplemental material
Supplemental material for this article is available online.