
Abstract
The proliferation of artificially generated images has introduced a new class of visual propaganda referred to as deepfakes, which can deceptively mimic reality and manipulate perception on a massive scale. Although propaganda is hardly a new social problem, the emergence of deepfakes necessitates an interdisciplinary response from the social sciences as well as cyber/computer sciences. In this study, the research team revisited long recognized propaganda categories to determine which types were most impactful across X.com with a focus on the 2024 U.S. Presidential Election. Working from a data set of 202 politically charged deepfakes, images were classified across 17 classic propaganda techniques (e.g., bandwagon, fear, transfer) and a propaganda impact score was introduced to quantify impact, which was a composite metric integrating reach, sentiment, and toxicity. The results of this study show that the propaganda categories of preemptive framing, deification, and bandwagon disproportionately shaped engagement and emotional response. Put differently, the results of this study showed that the most virally effective images are not necessarily the most toxic, but rather those that strategically pair emotional resonance with algorithmically optimized reach. Thus, a key takeaway from this study for cybersecurity and security professionals who are charged with combating disinformation in various spaces is that particular types of propaganda are more effective and dangerous to eliciting emotional responses relative to others.
The 2024 U.S. Presidential Election highlighted the dangers of deepfakes generated using artificial intelligence (AI), namely, fabricated images, audio, and video indistinguishable from authentic media, as tools of political manipulation (Dobber et al., 2021; Dan, 2025). Documented incidents during the election cycle ranged from AI-generated imagery misrepresenting candidates to an AI voice-cloned robocall impersonating President Biden, which was deployed to suppress votes in the New Hampshire primary (NPR, 2024). The need to study AI propaganda is especially urgent during high-stakes events like national elections when public opinion can be swayed and democratic processes undermined (Dan, 2025; Dobber et al., 2021). Furthermore, recent reports show that deepfake personas have already been deployed in covert influence campaigns aimed at manipulating US election discourse (Festus, 2025; Jowett & O'Donnell, 2019). Thus, deepfakes threaten a society not only at an individual level, but also on a larger scale by undermining trust in civic institutions (Fallis, 2021).
Considering the aforementioned risks at a national level, the Department of Homeland Security has stated that “…deepfakes and the misuse of synthetic content pose a clear, present, and evolving threat to the public across national security, law enforcement, financial, and societal domains” (Brooks et al., 2020: 16; Vaccari & Chadwick, 2020). The threat referenced in the prior statement, more specifically, is the ability of deepfake creators to tap into and spur emotional reactions in their targets, which inherently subverts critical thinking skills. Given the prior statements, the extent of the dangers posed by already emotionally charged environments like social media sites is easily understood—particularly during polarizing events like US presidential elections—where deepfakes can rapidly spread across many users who are unable to recognize them as false (DiResta & Goldstein, 2024; Muller et al., 2021; Ruffin et al., 2024). Compounding this problem, algorithms can unintentionally magnify deceptive content, which only increases their attractiveness as tools for adversaries (Gamage et al., 2021; Weikmann et al., 2025). Before addressing how this study was designed to help security professionals respond to incidents it is prudent to discuss what deepfakes (within this context) are at the basest level: propaganda.
The evolution of propaganda with technology
Propaganda scholars have produced considerable work over decades, and one of the earliest contributors was Lasswell (1927, p. 627) who defined the manipulative content as “…the management of collective attitudes by the manipulation of significant symbols.” Later definitions, like Jowett and O’Donnell's (2019, p. 7), define propaganda as “the deliberate, systematic attempt to shape perceptions, manipulate cognitions, and direct behavior to achieve a response that furthers the desired intent of the propagandist.” In shaping perceptions, there is no one approach or propaganda type. For example, Leonard (n.d.) identifies many types of propaganda within an adversary's toolbox through an expansive list, such as bandwagon appeal (“everyone is doing it”) or glittering generalities (associating positive wording, such as “justice,” with a target).
Although scholarly work has focused on the use of propaganda to elicit negative emotions (like anger, rage) in its targets, it is important to reiterate that this form of manipulative content is not identified as eliciting one emotion or the other, nor by whether it is truthful or not, but rather by the propagandist's intent and content's function. Indeed, as researchers of social engineering have pointed out within that related scholarly space, psychological manipulations with kernels of truth (such as in a spear-phishing) can be more effective than broadly designed content (Ferreira & Lenzini, 2015). Aside from the content itself, Sproule (2005) notes effective propaganda also utilizes repetition, emotional appeal, timing, and audience segmentation. These features, developed in the context of 20th-century mass media, were incorporated within this study. Before outlining how our study incorporated the prior features into our methodology, we briefly discuss prior work on the recognition and impact of deepfake content.
Assessing recognition and impact of deepfakes
Given the nascency of this social problem and typical discipline segmentation within academia, the interdisciplinary approach presented here is the first of its kind (to the best of our knowledge). However, scholarly work is increasingly emerging from across disciplines that focuses on the social or technical factors associated with these occurrences. For example, in a study involving 417 participants who were asked to read tweets from three separate sources (bot profiles, deepfake profiles, and organization profiles), the results showed people struggled to recognize deepfake profiles and, by contrast, assessed the deepfake profile's tweets to be more genuine than the other groups included in the study (Ruffin et al., 2024). Not only does research suggest individuals struggle with identifying deepfakes, but there are various risks informing whether individuals act on the content. Indeed, in Ahmed's (2021) study, greater deepfake exposure increased the odds of inadvertently sharing malicious content, but greater cognitive ability mitigated that sharing. The inadvertent sharing of deepfaked content is especially problematic if it comes from a prominent account that can shape collective understanding, which was the focus of a study by Pérez Dasilva and colleagues in 2021. In that study, using data on X (Pérez Dasilva et al., 2021), journalists and politicians significantly shaped conversations about deepfakes especially given the interconnectedness of that online space. Taking into account that the noted interconnectedness can be weaponized to spread harmful content, Pérez Dasilva et al. (2021) discuss that prominent accounts must be vigilant in examining potentially problematic content.
In addition to whether individuals can recognize manipulative content overall, notable work has emerged from the computational social sciences that focuses on assessing toxicity and sentiment levels deepfakes spur in their audiences. For instance, Bidirectional Encoder Representations from Transformers (BERT) and its derivatives have shown accuracy in identifying toxic behavior, particularly when fine-tuned on domain-specific corpora; however, as large transformer models, they typically require substantial training resources (Google, n.d.; Oskouie et al., 2024). Transformer-based models also support the extraction of contextual toxicity across multilingual and informal texts, a crucial feature for real-time monitoring of disinformation campaigns (Mosleh et al., 2024). In terms of assessing sentiment, lexicon-based models like the Valence Aware Dictionary and Sentiment Reasoner (VADER) remain widely used because of their interpretability and computational efficiency (Ali et al., 2022; Hutto & Gilbert, 2014). Although deep learning models such as RoBERTa or XLNet have achieved high benchmark scores on sentiment tasks, they often require substantial resources and lack transparency, making them less ideal for high-throughput or exploratory analyses (Areshey & Mathkour, 2024). Studies continue to validate VADER's effectiveness on short-form, social media content where intensity modifiers and emotive punctuation significantly alter sentiment polarity (Ali et al., 2022; Areshey & Mathkour, 2024).
Putting it together
The rapid advancement of technology has produced considerable social benefits in terms of greater access to information and abilities to form/maintain meaningful human connections; however, this same progression has also widened the propagandist's toolbox too. Now, compared with decades past, propagandists can create deepfake content that is difficult to distinguish within an information-saturated landscape, release it to massive audiences, and participate in its amplification/spread. Prior research has found that individuals have trouble distinguishing between authentic and deepfaked content (Ruffin et al., 2024) and that certain background factors impact risk of acting upon fictitious content (Ahmed, 2021). Moreover, given the interconnectedness of social platforms themselves, certain accounts can disproportionately impact the spread and understanding of content (Pérez Dasilva et al., 2021). However, the results of these studies also provide glimmers of opportunity that underscore the need for the current study. One area of opportunity is seen in Ahmed's (2021) work, which shows that cognitive ability can mitigate acting upon deepfaked content. A second area of opportunity is the concern around deepfakes that already exist within political discussion spheres (Pérez Dasilva et al., 2021). Taking the prior statements together and relating them to the current study, which is exploratory and the first of its kind, this research was constructed to identify the most virally effective deepfakes, so that public awareness programs could be constructed to raise the cognitive abilities of receivers—both those with prominence in interconnected networks and among lay users.
To carry out that overall objective of identifying what types of deepfakes are most virally effective, we used two systemic approaches. First, we built upon existing propaganda categories and slightly revised them to encompass the specific capabilities and manifestations of AI-generated visual content captured in this analysis (see the section Types of AI-Generated Image-Based Propaganda). Second, we created a “propaganda impact score,” which is a quantitative measurement system that evaluated a deepfake's audience reach (via quotes, retweets), sentiment (positive/negative), and toxicity (multiple categories). Our two broad research questions guiding this exploratory study were: (a) what propaganda category was the most impactful overall (assessed via the propaganda impact score) within our sample of deepfakes found on X during the period of the 2024 U.S. Presidential Election under consideration here; and (b) what propaganda category (or categories) was more impactful in terms of reach, sentiment, and toxicity within that same noted sample as above?
Research methods
Data collection and content classification
This case study uses data collected manually from X.com over a three-month period—October through December 2024—because our focus is the 2024 U.S. Presidential Election. We collected 202 posts from X.com where each post had deceptive and malicious content, prominently featuring deepfakes, explicitly targeting political figures or parties involved in the 2024 US election. Posts were found through a systematic manual search of X.com using politically relevant keywords and hashtags (e.g., #Election2024, #Trump2024, #Harris2024, #MAGA) combined with monitoring of various popular political communities on X.com during the election window. A post was included in the data set if it met three criteria: (a) it featured an image that was identified as AI-generated or synthetically manipulated; (b) it explicitly referenced or depicted a political figure or party involved in the 2024 US Presidential Election; and (c) the post was published no more than six months prior to the election to ensure the data reflected a relevant time frame. Posts were excluded if the synthetic origin of the image could not be assessed or if the political targeting was ambiguous.
To distinguish AI-generated deepfakes from conventionally edited content, the research team applied a multi-step verification protocol. First, images were visually inspected by at least two members of the research team for hallmarks of generative AI synthesis, including unnatural facial geometry, gibberish text, lighting inconsistencies, irregular background artifacts, and implausible contextual details commonly associated with diffusion-model or Generative Adversarial Network (GAN)-based generation (Mirsky & Lee, 2020). Second, where visual inspection was ambiguous, images were sent to publicly available AI-detection tools, such as Hive Moderation, as a secondary check. Finally, if there was disagreement, the image was sent to TinEye and Google Reverse Image Search to assess whether it corresponded to a widely circulated deepfake. Popular deepfakes typically have associated articles or original sources naming the image as AI-generated before they are misused elsewhere. Images were kept in the data set only when both the manual review and the secondary check converged on an AI-generated classification. Cases in which the two methods disagreed were reviewed collectively by the full research team, after a reverse image search was done to get more background and were excluded if consensus could not be reached. The collected data included post IDs, URLs, image files, captions, posting dates, usernames, display names, follower counts, and engagement metrics (i.e., likes, retweets, comments, views, posting frequency). In addition, comments associated with each post were collected separately to facilitate a comprehensive analysis. After collecting these data, we categorized the content into propaganda types.
Traditional propaganda analysis relies on categorization systems developed for text-based and conventional visual media; however, the fast-paced emergence of AI-generated content has introduced new capabilities for manipulation that transcend the boundaries of classical propaganda techniques. Generative AI systems can easily alter facial expressions, manipulate contextual settings, generate entirely synthetic scenarios, and combine elements from multiple sources with unprecedented realism (Mirsky & Lee, 2020). These technological capabilities require a fundamental reconceptualization of how propaganda works in the digital age. Thus, after collecting data for this study, we redefined classical propaganda categories to accommodate the AI-generated visual content within our data. Our redefinition relied on the propaganda categories outlined by Leonard (n.d.) as a starting point (column A in Table 1) that we then built upon with revised labeling (column B in Table 1) of how the content often appeared in deepfake or synthetic media.
Types of AI-generated image-based propaganda.

After collecting these data and establishing a coding scheme based on classic propaganda categories, we implemented a consensus-driven manual sorting process to categorize each image into one or more propaganda type. This process began by everyone on the research team (N = 3) sorting all images on their own based on their own understanding. After individual sorting, the research team met to discuss content where there was disagreement on categorization to share feedback as a group. Through these group discussions, consensus was reached or the content was excluded entirely (N = 0). This multi-stage, consensus-driven decision-making approach not only addressed interrater reliability, but ensured these data were valid in terms of construct validity.
The coding process also allowed for the identification and correction of biases or inconsistencies that automated models might overlook, particularly in the context of nuanced propaganda strategies. At the conclusion of the sorting stage, the team moved on to creating algorithms that generated three separate composite scores across all content, which connected back to our research questions: (a) the deepfake's reach (i.e., how widely it spread via sharing mechanisms by the user, such as retweeting); (b) the deepfake's sentiment (i.e., positive, negative, or neutral); and (c) the deepfake's toxicity level (i.e., type of harmful content, such as obscene). By using the previously mentioned three scores, this analysis addressed the impact of propaganda from a holistic vantage point that included the depth of engagement, the affective tone of content and audience reactions as captured through sentiment analysis, and the degree of hostile or harmful language present in audience responses as captured through toxicity analysis.
Deepfake content assessment score 1: Reach analysis
The reach score reflects how widely a given deepfake spread across X.com and the depth of engagement among content consumers. To create the reach score, we selected engagement metrics that best represented content visibility (as captured via “poster's follower count” and “views”), amplification (as captured via “comments” and “retweets”), and user interaction (as captured via “likes”). In terms of gauging the depth of deepfake engagement, we weighed our data to distinguish among active engagement, passive engagement, and simple viewing across audiences. In other words, “commenting” or “retweeting” was weighted as the highest (.30) form of engagement within the data set given it indicated active participation with deepfaked content, which is in contrast to “likes” (weight = .20) given it was considered akin to a simple acknowledgment or agreement, which further contrasted with simple visibility (weight = .10) as captured by “poster's follower count” or “views.”
The tiered weighting scheme was grounded in prior literature related to platform engagement. Active engagement behaviors such as “commenting” and “retweeting” require deliberate user action and signal deeper cognitive investment in content, a distinction supported by research on dual-process models of social media engagement, which differentiates between effortful, active participation and passive consumption (Mosleh et al., 2024). “Likes” occupy a middle tier in weight assignment because they require a single intentional action but carry no amplification effect as the content does not propagate further as a direct result. “Views” and “follower count,” by contrast, represent potential or incidental exposure rather than confirmed engagement, and were therefore assigned the lowest weight.
Taking the aforementioned into account, the formula used to capture “reach” was: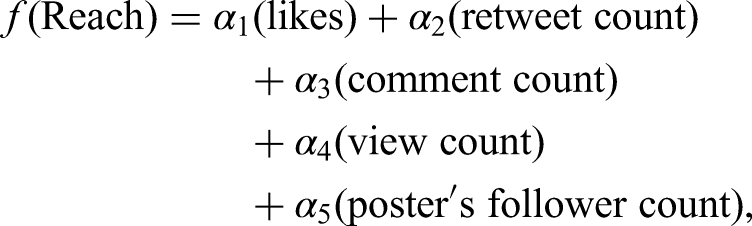
This formula considers both view count and follower count because they capture distinct dimensions of exposure. While views represent the count of users who actually encountered the content, the follower count represents the structural reach capacity of the posting account, reflecting the propagandist's platform footprint independent of any single post's performance. To mitigate the risk of artificial inflation, both variables were assigned the lowest weight (.10), limiting their combined contribution to 20% of the total reach score.
In addition, prior to inclusion in the reach function, each engagement metric was normalized using min–max scaling to standardize across variable audience sizes and post types. Here min–max scaling was used because it preserves the relative distances between observations in a bounded [0,1] range, which is necessary to ensure the weighted summation in the reach formula remains interpretable and comparably scaled across all five input variables. By combining these carefully weighted sub-components, the reach score (
The composite reach score
Deepfake assessment score 2: Sentiment analysis
After assessing how widely deepfakes spread across X and the depth of engagement across content consumers, we shifted our attention to generating a measure by which to assess the general sentiment (i.e., emotion) of deepfaked content. To create this composite score, we conducted a sentiment analysis on both image captions and the associated user comments using the VADER sentiment analyzer (Hutto & Gilbert, 2014). VADER was selected for the sentiment analysis because it incorporates lexical valence, intensity modifiers, punctuation cues, and emoji signals commonly found in social media text, such as within the X platform.
Upon utilization, VADER returns the following polarity scores that were weighted within our data set as indicated: “positive” or indicating explicitly supportive emotional language (weight = .20); “neutral” or capturing emotionally neutral or objective language (weight = .20); “negative” or indicating hostile or critical reactions (weight = .20); and “compound” or a measure indicating overall emotional intensity and direction (weight = .40). These scores were then combined through a weighted scheme, with weights β₁–β₄ summing to 1.
The same weight for positive and negative was also used for neutral for two reasons. First, within the context of propaganda analysis, emotionally neutral or objective framing is not analytically inert, it can function as a deliberate rhetorical strategy. Propagandists sometimes deploy neutral or factual-appearing language precisely to lend credibility to manipulative content, a phenomenon consistent with research on ‘astroturfing’ and pseudo-journalistic disinformation formats (Jowett & O'Donnell, 2019). Discounting neutral sentiment would therefore risk underweighting a potentially meaningful propaganda signal. Second, VADER's neutral score captures residual sentiment mass not absorbed by the positive or negative categories—it is a structural component of the compound score calculation rather than simply an absence of sentiment. However, these weights can be updated based on the nature of the analysis being conducted. Ultimately, the resulting formula to calculate sentiment was: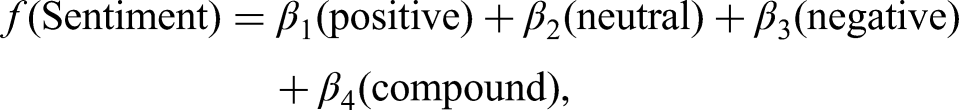
The composite sentiment score
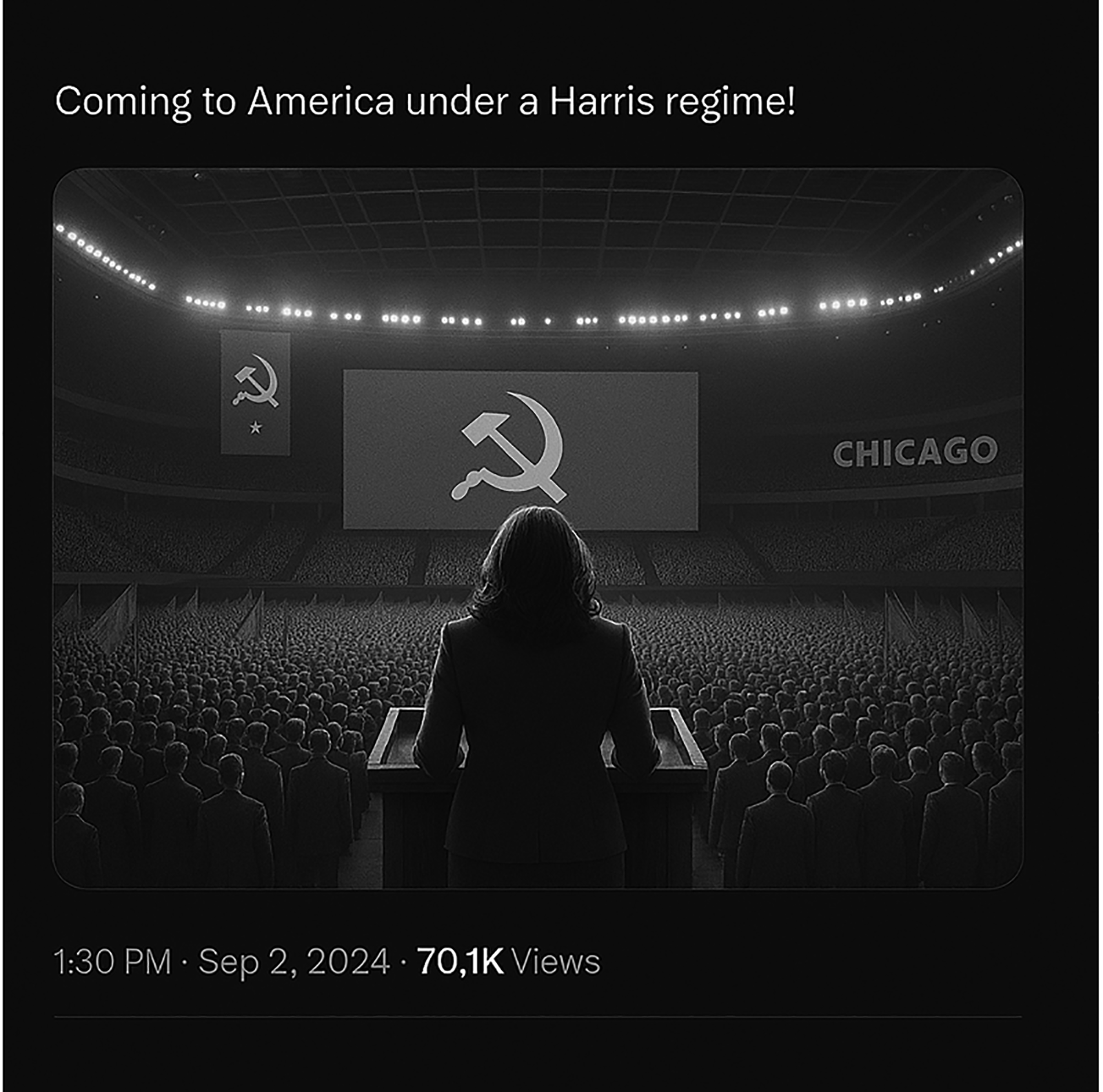
Example of image labeled as negative sentiment.
Deepfake assessment score 3: Toxicity analysis
To assess a deepfake's toxicity level, or the presence of hostile or harmful language associated with an image, a custom BERT model (Bert-base-uncased) was fine-tuned using publicly available Google's Jigsaw Toxicity Prediction data sets. To train our BERT model, we curated a subset of ∼300,000 examples, each weighted with six toxicity categories. The original data set showed extreme class imbalance, with toxic comments rarely represented and some categories even rarer (toxic comments account for 9.5% of the data set, whereas categories such as threat appear in only 0.2% of samples). This level of imbalance can negatively impact machine learning models, because classifiers may develop a strong bias toward the majority non-toxic class and fail to capture patterns among toxic examples with so few instances to train on. Although the majority of real-world cases may be non-toxic, the classifier still needs to identify rare classes effectively when they occur. To mitigate this, we adjusted the sample distribution to oversample high values from the six categories in the training set, improving the model's performance when used to assess our political comments. After additional tuning and testing, our BERT model achieved an overall accuracy of 96.46% across all categories.
As in the case of prior measures, toxicity categories were weighted to reflect the potential reach and engagement with the content. However, within this analysis area, generalized attacks were assigned greater weight relative to more extreme content. The prior decision was made based on the premise that egregious displays of hate and toxicity would repel potential audiences who deemed it as going “too far,” which could also be why these categories of content were much less represented within the overall data set relative to generalized attacks. Thus, toxicity included content tagged as: “generally toxic” or general harmful or offensive language that is not directly targeted (weight = .20); “severely toxic” or extremely hostile or damaging language (weight = .10); “obscene” or vulgar or sexually offensive expressions (weight = .10); “threatening” or direct or implied threats of harm (weight = .10); “insulting” or derogatory or mocking statements directed at individuals or groups (weight = .20); “identity attacks” or language targeting race, gender, religion, or other identity attributes (weight = .20); or “sexually explicit” or inflammatory or inappropriate sexual content (weight = .10). Ultimately, each of these variables contributes to a weighted toxicity function, with associated weights γ₁–γ₇ summing to 1.00 that is calculated according to the following formula: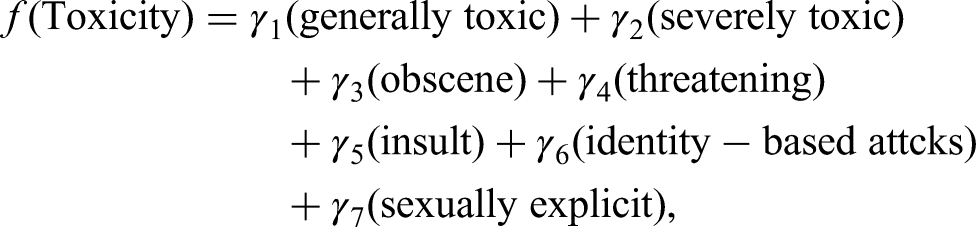
The weighting scheme for toxicity categories was designed to reflect not the moral severity of content in the abstract, but its empirically observed capacity for broad audience engagement within this specific data set and platform context. Categories assigned higher weights (“generally toxic” (.20), “insult” (.20), and “identity attack” (.20)) were weighted more heavily because they represent the forms of hostile content most commonly encountered and shared by general audiences on X.com, and therefore most likely to drive the widescale engagement that characterizes effective propaganda. More extreme categories ('severely toxic” (.10), “threatening” (.10), “obscene” (.10), and “sexually explicit” (.10)) were assigned lower weights based on two converging observations: first, these categories were substantially underrepresented in the data set relative to generalized attacks, consistent with prior research suggesting that overtly extreme content triggers platform moderation and audience aversion rather than amplification (Gamage et al., 2021); and second, content flagged in these categories is more likely to be removed or suppressed by X.com's content moderation systems before achieving significant reach, limiting its relevance to a reach-weighted propaganda impact score. These weights were held constant in our current work and represent a heuristic that future work could refine through user-study validation.
This measure, as noted in previous passages, allows us to assess the language dynamics associated with deepfaked content in a systematic manner, capturing the degree to which audiences respond to deepfakes with abusive, threatening, or identity-targeting language. The composite toxicity score
Overall deepfake assessment: Propaganda impact score computation
Lastly, to quantify the influence of deepfake images overall, we created an image-level propaganda impact score that integrated the three previous categories while also accounting for their importance in assessing the spread and reception of deepfake content: reach (weighted as 50%), sentiment (weighted as 20%), and toxicity (weighted as 30%) together. The impact score is calculated using the following formula: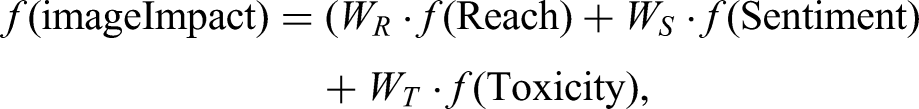
The propaganda impact score is grounded in a multi-pathway model of propaganda effectiveness drawn from communication and influence literature. Effective propaganda does not operate through a single mechanism, instead it achieves influence by simultaneously maximizing audience exposure (reach), triggering affective responses that lower critical resistance (sentiment), and generating hostile social environments that reinforce in-group solidarity and out-group rejection (toxicity). These three pathways correspond respectively to the distributional, affective, and antagonistic dimensions of propaganda effectiveness identified in Jowett and O'Donnell's (2019) framework, and to Sproule's (2005) observation that effective propaganda combines repetition and scale with emotional appeal and audience segmentation.
In addition, reach was weighted most heavily (50%) because distributional success is the necessary precondition for any downstream psychological effect. In other words, content that does not reach audiences cannot influence them regardless of its affective or toxic properties. Sentiment was weighted at 20% to reflect its role as a moderating signal: positive sentiment indicates content designed to inspire affiliation and loyalty, whereas negative sentiment indicates content designed to provoke fear or hostility, both of which are recognized propaganda mechanisms. Toxicity was weighted at 30% because hostile and harmful language in audience responses represents a measurable downstream behavioral outcome of propaganda exposure, indicating that content has successfully activated antagonistic responses in its audience. The composite score is best understood as an overall index of propaganda footprint by capturing how widely a deepfake traveled, how emotionally charged its reception was, and how much hostile discourse it generated, rather than as a direct measure of persuasion or behavioral change.
An additional benefit of creating this overall image-level propaganda impact score was it enabled us to also compute the impact score for each of the 17 propaganda categories as well by using the following formula: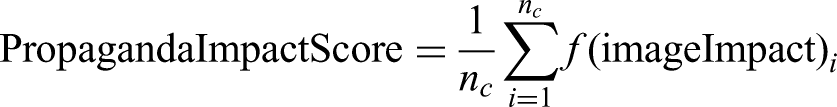
Results
Descriptive statistics
To begin addressing the second research question, we calculated descriptive statistics to assess reach, sentiment, and toxicity of deepfaked content. Descriptive statistics (not shown in Table) about deepfake reach showed that deceptive content that was critical of candidates represented the vast majority of user engagement and reach—both in terms of active and deep interaction via commenting (75%) and retweeting (83%) as well as passive interaction via likes (72%). The pattern of critical content having a wider reach was also obvious when looking at total views by users (83%) and total posts (72%) where engagement with negative material far outpaced positively framed content.
When reviewing average scores (not shown in Table ) associated with sentiment, they were emotionally congruent. In other words, deepfakes that were associated with the positive framing of candidates had a higher average positive VADER score (0.17) relative to content that was critical of candidates (0.09). Likewise, deepfakes associated with negative framing of candidates had a higher average negative sentiment (0.06) relative to content that was positive of candidates (0.04). Interestingly, and somewhat in contrast to the descriptive statistics about reach, deepfake content that positively framed candidates had a higher compound score (0.25), which indicated a stronger emotional reaction.
Finally, in terms of toxicity, descriptive statistics (not given in Table ) showed an average toxicity score across all image-caption pairs of 0.11 (SD = 0.21), with values ranging from 0.00 to 0.91. “Insulting” followed as the second-highest toxicity category with a mean of 0.08 (SD = 0.18, range = 0.00 to 0.83). Other toxicity categories had lower average scores, with values ranging from 0.01 (e.g., “severely toxicity,” “threatening,” and “sexually explicit”) to 0.03 (“obscene”). Notably, although the mean values for categories like “identity attack” and “obscene” were low, some individual posts reached high toxicity extremes, such as 0.85 and 0.57 respectively. Overall, this modeling approach enabled a comprehensive assessment of the toxic language dynamics in deepfakes, capturing both subtle and overt forms of verbal harm that are often missed by surface-level text classifiers.
Image-level propaganda impact scores
To address the first research question that focused on determining which propaganda categories were most impactful within the collected sample, we calculated the image-level propaganda impact scores across all images within the sample. The propaganda type, total number of images, and mean component scores for reach, sentiment, and toxicity are shown in Table 2. In addition, the resulting composite score for each propaganda category is also shown.
Impact score by propaganda category under a reach priority.
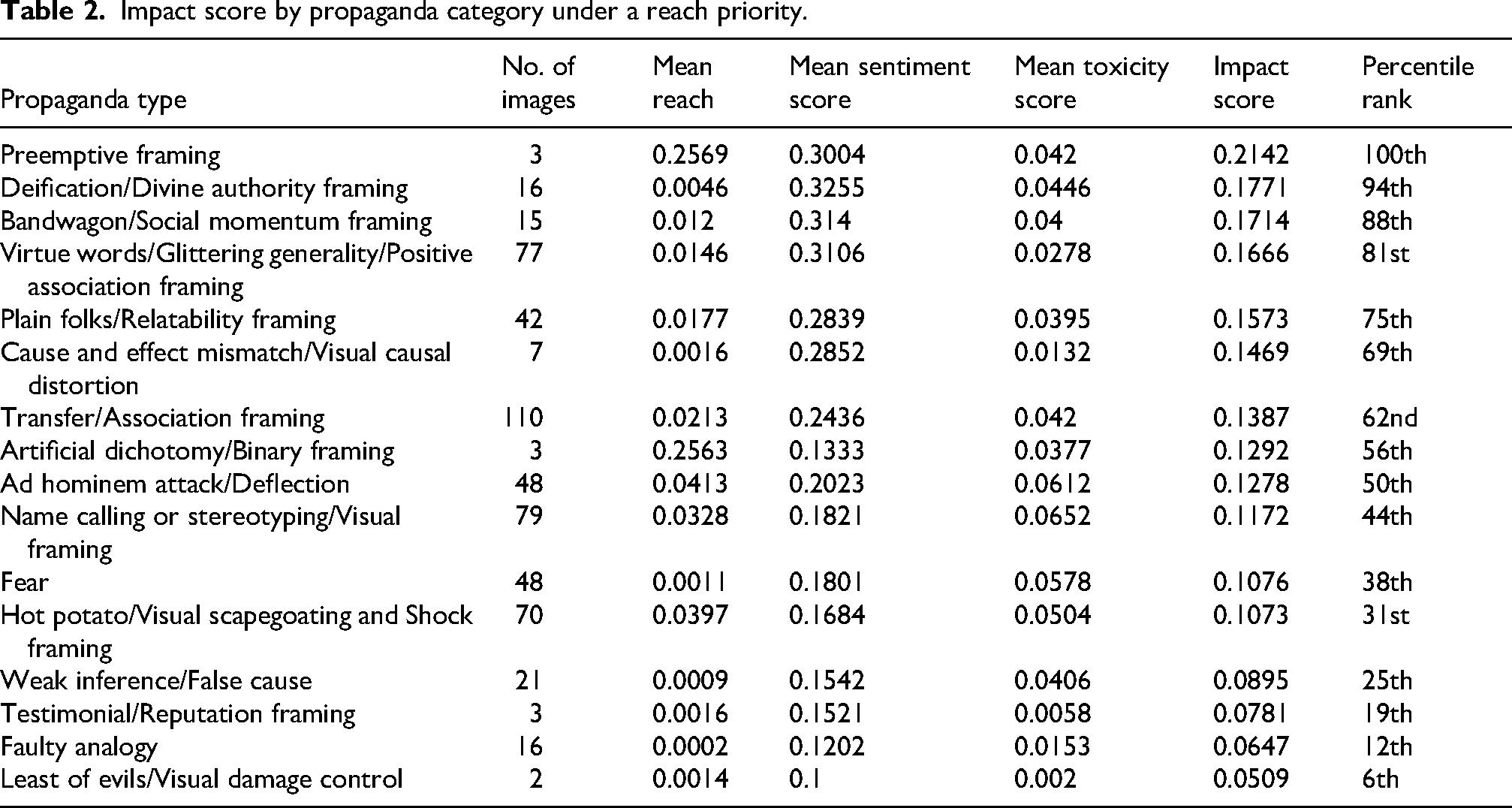
The propaganda impact score for any given category represents the mean of all image-level impact scores within that category, and therefore inherits the bounded [0,1] range of the image-level score. Across the full sample of 202 images, the mean image-level propaganda impact score was 0.137 (SD = 0.089), with scores ranging from approximately 0.04 to 0.51. Within this distribution, a category-level score below 0.10 indicates below-average impact relative to the full sample, a score between 0.10 and 0.17 indicates average to moderate impact, and a score above 0.17 indicates above-average impact.
“Preemptive framing,” or shaping the context of an anticipated news/story to control public reaction, recorded the highest overall impact (0.2142, 100th percentile within sample), followed by deification (0.1771, 94th percentile within sample) or associating the content with faith authorities or themes, which was then followed by “bandwagon” (0.1714, 88th percentile within sample) or grounding the content in an opportunity one needs to “jump on” before it passes by given its popularity. The propaganda category of “virtue words/glittering generality,” which refers to content in which positive labels and imagery are associated with a target to spur positive feelings, also garnered a high impact score (0.1666, 81st percentile within sample). These categories appear particularly well-optimized for visibility and engagement, suggesting that emotionally resonant or polarizing content is often rewarded with wide dissemination. By contrast, categories such as “testimonial” (0.0781, 19th percentile within sample) or the inclusion of a notable person's opinion (such as a celebrity) to assess the message, “faulty analogy” (0.0647, 12th percentile within sample) or improperly comparing two issues/people/things, and “least of evils” (0.0509, 6th percentile within sample) or presenting a forced binary choice where both options are undesirable to the audience, scored significantly lower given the limited reach of the content.
Discussion
This study was designed around two research questions broadly centered on identifying virally effective propaganda. The first research question, which leveraged a composite measure (i.e., propaganda impact score) we created to assess the overall footprint of various deepfake propaganda, showed that preemptive framing, deification, and bandwagon were the most effective types of malicious content within the sample and period under investigation here. Relatedly, the second research question focused on identifying what deepfake propaganda was most likely to resonate and spread across audiences in terms of reach, sentiment, and toxicity, specifically. The data within our sample for the period under investigation here indicate that deepfake propaganda that was critical of candidates, which was characterized as generally toxic or insulting, was most frequently spread and typically spurred emotionally congruent responses in their audiences.
These data can spur multiple proactive and reactive actions among security personnel. First, as prior research shows, individuals with increased cognitive abilities are less likely to act on deceptive content (Ahmed, 2021). Given that, incorporating messaging within platforms that educates users on how to identify deceptive content or prompting pop-ups that ask for reflection before sharing content are relatively simple steps to increase the cognitive abilities of a general audience. In addition, engaging key stakeholders and individuals with high follower accounts can help reinforce cybersecurity messaging and foster a more vigilant online community, given research that identified online spaces like X can be extremely interconnected within political arenas (Pérez Dasilva et al., 2021). These efforts are not limited to the cybersecurity professionals involved in the day-to-day social media platform management, but can also be conducted by law enforcement engaging in community policing via public awareness campaigns and workshops hosted for the public, particularly around periods when emotionally charged events are occurring (like elections). Even though disinformation propaganda is an online social problem, it is mistake to believe the impacts of these activities stay isolated within cyberspace. Thus, public awareness and educational campaigns to help a general audience recognize disinformation can act to combat occurrences, akin to community policing discussed or implemented to varying degrees that focus on preventing specific cybercrimes like cyberfraud (Zulyadi & Frensh, 2025) or on various offenses within that broad category (Abdullahi et al., 2026).
Although this study contributes to the existing literature by introducing a novel way to assess the effectiveness of deepfake propaganda, it is not without its limitations that should be kept in mind when assessing these results. First, although we have proposed an effective methodology by which to assess the overall impact of a type of deepfake/propaganda category, it is important to remember that the propaganda impact score reported in this study is a metric built from weighted combinations of reach, sentiment, and toxicity metrics. As such, the values it produces reflect the modeling decisions embedded in its design, including the choice of input variables, normalization method, and weight assignments, rather than a direct empirical observation of real-world influence or persuasion. Thus, the impact score is best understood as a structured approximation of propaganda footprint: a systematic, reproducible way of ranking deepfake content along dimensions theoretically associated with propaganda effectiveness. Readers should interpret differences between category scores as reflecting relative standing within this modeling framework rather than as precise measurements of actual impact on audiences. For example, an examination of descriptive statistics indicated that content critical of candidates garnered the most frequent and deepest levels of engagement across users.
A second limitation of this study is the sample collected here from one platform during a small window of time. Thus, these findings cannot be generalized to other periods (such as election off years) or other platforms (such as TikTok). Social media sites are akin to separate virtual environments with their own subcultures and norms. Considering that shift in spaces, it is entirely possible that one category of propaganda may resonate more strongly across a platform or one type versus the other. A third limitation of this study is that the reliance on algorithms to generate quantitative scores introduces the possibility of missing context, which would shift the interpretation if human eyes were upon that content. As previously mentioned, although this project involved multiple individuals who were cross-checking the accuracy of algorithms and scoring strategies, both against the raw outputs and against each other, it is possible key context was missed despite our implemented safeguards. However, we believe the chances of misclassification are slim given the amount of people involved in this study.
Conclusion
This study utilized an interdisciplinary lens to study deepfake propaganda by assessing how widely it spread across X, the toxicity of the content itself, and the sentiment it spurred in audiences. Within the manually collected sample gathered for this study, the results showed that deepfake propaganda aligning with preemptive framing, deification, and bandwagon carried the largest overall footprint. When assuming a nuanced look, content that was critical or generally toxic was more frequently spread and typically caused emotionally congruent responses in content viewers.
These results represent opportunities for security professionals. For this particular study, the most direct implication is that these findings can spur proactive steps to help users quickly identify and pro-socially respond to problematic content, such as providing users with messaging or pop-ups that prompt education and reflection. Likewise, these data points can inform community policing and outreach given cyberspace is too vast for law enforcement to effectively manage on its own. Social problems necessitate social solutions. Indeed, the goal of these data are to identify characteristics of the most virally effective deepfake propaganda for mitigation by both offline and online guardians of all sorts.

Example image scoring low across all toxicity categories.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.