
Abstract
This article maps the
Introduction
Based in Los Angeles (LA), San Francisco, and New York City, the Anti-Eviction Mapping Project (AEMP) uses mapping, data visualization, and oral histories to investigate housing precarity (Maharawal and McElroy, 2018). Speaking about their work with tenants, AEMP (2018) writes, “The more that we produced maps [and data], the more we became concerned with the dangers of reducing complex social and political worlds to simple dots
Despite critiques, cities across the globe reify dominant narratives about data. When Los Angeles Mayor Garcetti announced his Open Data Initiative, he invoked common themes within these value-laden imaginaries. Garcetti writes that data “empowers,” “promotes innovation,” and “fosters creative new thinking about solving our most intractable challenges” (Office of Los Angeles Mayor Eric Garcetti, 2013). Within this narrative, data are almost inherently beneficial for building “better” communities because it fosters participation, innovation, and creativity. Yet, organizations like AEMP encounter obstacles to fostering meaningful data-driven impacts. Their work illustrates the significant barriers that limit communities’ actualization of benefits while also underscoring the inequalities embedded within extant infrastructures.
This article examines how activists in LA reimagine data practices for racial justice amid the “contentious politics of data” (Beraldo and Milan, 2019). Methodologically, I take a broad view of “data” and “data-driven analysis,” which includes nontraditional sources such as interviews, oral histories, zines, and digital archives; and qualitative, mixed-methods, and participatory action approaches to analyzing data. I also use a “bottom-up” approach to explore opportunities for more viable, community-based versions of data-driven racial justice, an underexamined area of inquiry. In this article, first, I survey the extant literature to develop my novel typology of data activism: data use, reuse, refusal, and production. Second, I provide an overview of the study’s methods and context, and I then detail organizations’ implementation of strategies, individually and in tandem. Third, I discuss and critically reflect on the implications of these strategies. In all, I illustrate the methodological and theoretical utility of attending to community organizations’ multiple, concurrent data engagements and disengagements. I also develop the term
Background literature
The existing literature shows how dominant data narratives uphold the status quo of inequality while justifying datafication’s expansion. Data’s influence resides in its imagined ability to “speak for themselves,” even when predictions are proven wrong (Dourish and Gómez Cruz, 2018). This perception disguises how data disparately harms minoritized individuals and groups (Benjamin, 2019; Noble, 2018). Quantitatively driven views normalize racial sorting and surveillance under the guise of value-free neutrality (Gandy, 1993; Hoffmann, 2019), amplifying inequity within everyday life.
Data activism and/as interventions
I use the term “imaginaries” to refer to narratives connecting the present with varying data futures; these narratives are shaped by different actors, views, and ideologies. To illustrate their contested nature, I focus on both dominant and alternative imaginaries, highlighting how data activism typically seeks to subvert dominant data imaginaries. My conceptualization draws upon both Mager and Katzenbach’s (2021) demonstration of technology companies’ heavy influence on dominant imaginaries, and Kazansky and Milan’s (2021) analysis of the different tactics groups employed to contest the harms and risks of these corporate-driven imaginaries.
As such, data activism centers “bottom-up” approaches to reimagining responsible and just data futures (Milan and Van der Velden, 2016). Notably, Beraldo and Milan (2019) develop the notion of the “contentious politics of data” to foreground the power relations underlying the ownership, accrual, and use of data within state- and corporate-driven projects. That is, data activism problematizes the beneficiaries of dominant imaginaries, highlighting how grassroot campaigns connect data-related issues to economic and social injustice (Dencik et al., 2016; Gangadharan and Niklas, 2019; Taylor, 2017).
In this piece, I contribute a framework for studying data activism that draws from the fields of communication and information studies, and the sociology of social movements (see Table 1 for key concepts). First, I draw upon Ruppert et al.’s (2017) analysis that while data act as an object of knowledge and power, data subjects can (and should) assert agency in shaping their data rights. As such, my framework assumes that data activism is both proactive and reactive. Here, I integrate Milan and Van der Velden’s (2016) analysis that data activism entails using data as a strategic tool as well as responding to (and decrying) data’s harms. I also draw upon Beraldo and Milan (2019) who argue that data can be treated as repertoires, or a political tool for data-enabled activism. For example, my research shows that the Million Dollar Hoods (MDH) project uses data visualizations of Los Angeles Police Department (LAPD) data to highlight racial disparities in neighborhood policing. At the same time, my framework assumes that data can also operate and constitute the stakes, or central issues, for data-oriented activism. For example, Stop LAPD Spying continually challenges and protests the continued use of data-driven tools for police surveillance. Put another way, whereas data as repertoires entail the use (and analysis) of data for research and advocacy, data as stakes entail protesting data harms.
Heuristic grouping of data activism strategies.

Of note, I deploy the term “imaginary” in multiple ways, to distinguish between the ways data activists concurrently navigate multiple kinds of data narratives and futures. For one, Lehtiniemi and Ruckenstein (2019) document how: (1) technological imaginaries center novel data infrastructures and practices as sites for intervention and (2) socio-critical imaginaries question the efficacy of these technical fixes. While they argue for bridging these imaginaries as an intervention, I contend that data activists are already navigating multiple—dominant and alternative, socio-critical and technological—imaginaries at the same time. By disentangling the continuities and divergences between community organizations’ varied responses to racial inequality, I take seriously Benjamin’s (2019) call to explore the multiple versions and visions of racial justice that can overcome the “default settings of white supremacy.”
My framework thus relies upon these related concepts to conceptualize the multiple levels of intervention that can be deployed through data activism, whether it is at the level of infrastructure, practices, or imaginaries. It also helps make explicit the vitality of data for the purpose of social movement work across multiple angles. In this sense, I aim to contribute a distinct framework that calls attention to the fluidity, co-occurrence, and complementarity of different constellations of data engagements and disengagements.
In addition, my novel framework emphasizes and disentangles the tensions of data activism. I draw upon the idea that datafication is so influential that activism emphasizes the necessity of its integration within organizing, thus encouraging the use of social media and other online data sources. I thus contend that
Data activism for racial justice
Although data activists contest dominant data narratives, racial justice often remains underexamined. Among the exceptions, existing work shows how “top-down” solutions can inflict harm, generating greater benefits for institutions (i.e. non-governmental organizations (NGOs) and state actors) rather than for impacted—and target—communities (Chenou and Cepeda-Másmela, 2019; Heeks and Shekhar, 2019). Consequently, data activism for racial justice entails broadening narratives about data’s impacts, decentering technology, and connecting technological issues to racial discrimination and inequality (Gangadharan and Niklas, 2019). Relatedly, Crooks and Currie (2021)’s work on agonistic data practices highlights how data can be a powerfully persuasive storytelling tool, especially for mobilizing minoritized Black and Latinx communities to collective action. Drawing from these works, I seek to center “the margins” and address knowledge gaps about how racially minoritized groups respond to mainstream data regimes (Milan and Treré, 2021). I probe not only at the data activism strategies employed by organizations, but also their surrounding narratives and visions: the how and why they connect data to broader community concerns (e.g. racial surveillance), and the tensions and divergences encompassed within different campaigns.
To further inform my analysis, I locate the genealogy of data activism for racial justice within histories of Black struggle, such as the work of Ida B. Wells-Barnett. That is, Wells-Barnett (2012) illustrated the impacts of structural racism (e.g. the Atlantic slave trade and institutionalized racism) through one of the first tabulations of lynchings of African Americans. These analyses contested the Moynihan Report’s key claims (Office of Policy Planning and Research, 1965), wherein data were wielded to justify institutionalized racism (and sexism). Indeed, I draw upon her work because it highlights, rather than diminishes, persistent concerns about race and power. It inspires me to not only describe data activism but to analyze and seriously heed the narratives and rationales for—and the nuances and tensions of—using and/or refusing data within social movement work.
Research questions
Considering this, I probe a wide range of community-based responses for documenting and navigating the contentious racial politics of data:
RQ1. In what ways do organizations use/reuse or refuse data for racial justice?
RQ2. How does their data activism connect with contesting racial inequality and articulating novel data practices for racial justice?
In all, I ground my exploration within the tensions of the “double bind” of data activism (Crooks and Currie, 2021): that is, how data simultaneously operates as both the repertoires for data-enabled activism as well as the stakes for data-oriented organizing (Beraldo and Milan, 2019). I heed calls for alternative approaches “from the margins”: first, by moving beyond the asocial, ahistorical, and decontextualized tendencies of data universalism; and second, by foregrounding critical, “bottom-up” engagements with data.
Research methodology
The bulk of my analysis explores the connections between data activism strategies and campaigns for racial justice. I conducted a qualitative content analysis of 11 organizations’ public posts (n = 74) about their data engagements and disengagements, employing qualitative techniques and human coding methods to examine organizations’ messaging about their use, collection, and analysis of data. Although I closely observed, interviewed, and engaged with most of these groups as a credentialed researcher within the context of a larger 3-year study, this article focuses on a content analysis study conducted over the span of 6 months, wherein my coding partner and I examined organizations’ public documents and records. Given the public nature of the social media posts and meetings observed, I did not alter organizations’ names, to acknowledge their expertise. I also did not overly expose individual strategies and only published posts that address the public. 1
Sampling strategy
I employed a purposive sampling strategy (Lacy et al., 2015) to explore how meso-level actors (i.e. grassroots and community-based organizations) redirect data practices with a racial justice goal. First, I included organizations based in LA with a stated mission of addressing technology and data justice, especially with a “racial” justice lens. I identified these organizations through LA-based listservs (e.g. LA Tech4Good) and community events (e.g. townhalls and rallies) touching on technology issues. I excluded organizations that did not mention technological notions of data justice even if they emphasized community-based research. The resultant list included three groups for observation, noted as “LA-based organizations” in Table 2.
Summary table of posts analyzed.
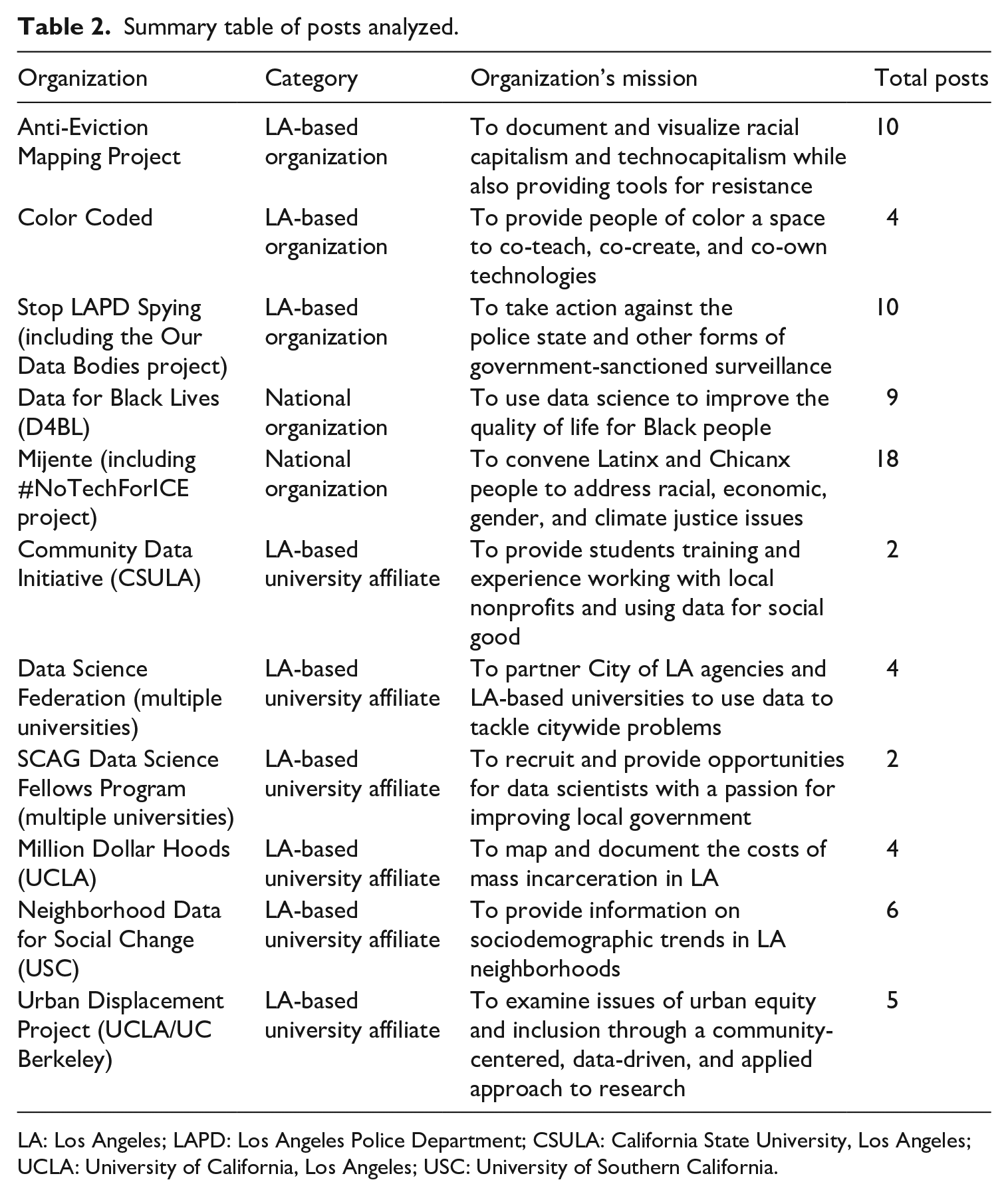
LA: Los Angeles; LAPD: Los Angeles Police Department; CSULA: California State University, Los Angeles; UCLA: University of California, Los Angeles; USC: University of Southern California.
Next, I reviewed university-affiliated projects engaged with racial and data justice in LA, focusing on the California State University, Los Angeles (CSULA); University of California, Los Angeles (UCLA), and University of Southern California (USC). While not community organizations per se, university partnerships often enhance community organizations’ research capacities, especially overburdened organizations (Friedland and Rotkin, 2003). I selected university projects (n = 6) if they were more recognized partnerships, as evidenced by larger grants; but also, to represent a broad range of disciplines. Finally, I included national groups working with communities of color—Data for Black Lives (D4BL) and Mijente—due to their leading role in data activism for racial justice. This sample was purposive, driven by a concern with how racial justice goals might redirect data activism in novel ways. While I did not aim to produce a representative sample or exhaustive list, I aimed to capture a robust sampling of non-profit, university-based, and national organizations at the vanguard of racial and data justice between 2018 and 2020.
Data collection
To construct a corpus for content analysis (Riffe et al., 2014), I collected organizations’ public posts (i.e. press releases, public blogs, and opinion pieces) published between January 2014 and May 2020. The process consisted of visiting organizations’ websites and social media. When I found a post, I recorded the organization’s name, article author, publication date, and URL. Social media posts shorter than two sentences and without hyperlinks to a webpage were not recorded because they were assumed to be sporadic updates rather than strategic, mission-driven messaging.
All publications on a website were included, except in the case of AEMP. AEMP posts were sampled randomly using a web-based generator because the website had a larger number of posts. This process ensured AEMP posts were not oversampled, compared to other groups. During the coding stage, these articles were excluded: articles that did not mention a given organization; podcasted, non-text-based interviews; and pay-walled articles. Table 2 summarizes the resultant total number of posts (n = 74) by organization and category.
Data analysis
To analyze the corpus, I employed an iterative process (Srivastava and Hopwood, 2009), in which human coders examined the posts from Table 2 (Zamith and Lewis, 2015). This iterative, qualitative approach (Huberman and Miles, 2002) emphasized researcher reflexivity, and captured emerging patterns. I devised a preliminary framework akin to Table 1’s heuristic groupings: that is, data use vis-à-vis data refusal. I added the category of data reuse to reflect work that has captured a range of community-based responses to rhetoric about data’s promise for addressing social ills, particularly through reappropriating data for purposes beyond their intended use (Hemphill et al., 2021; see also AEMP, 2018; Mijente, 2018). I then worked with a colleague to code these themes within each post.
Based on early reflections, we added the category of “production” to denote the co-production and dissemination of datasets and other outputs for public use and education: this is like what Benjamin (2019) discusses as “bringing to life” novel data applications that reimagine technology outside of its “default settings” of white supremacy. As previously noted, such efforts to create, and maintain, community resources often go unrewarded. We annotated the corpus according to the revised framework and discussed subthemes in detail. Using Krippendorff’s (2004) alpha, intercoder reliability was calculated (α = 0.92) based on a subsample (n = 25). Its value exceeds the threshold for best practices (Lacy et al., 2015).
Coding framework and definitions
The coding framework established a typology of the varying kinds of data engagements for racial justice: data use, reuse, production, and refusal. Due to an absence in the literature regarding racial justice issues specifically, I drew from “general” data activism concepts to formulate the framework. Table 3 summarizes the definitions and keywords of each strategy that was a part of the coding framework and data activism typology. While we treated the three former categories as discrete categories and thus distinct from one another, upon subsequent coding discussions, we nested data use, reuse, and production within the same grouping: that is, they were grouped and defined as similar and, at times, not discrete—thus, the aggregation of use, reuse, and production within one column of Table 1. Again, my framework of data activism seeks to disentangle the tensions of data activism and thus it emphasizes the simultaneous co-existence and co-occurrence of strategies from both columns of Table 1. That is, within the results and discussion, I unpack how and why organizations employ both groupings in tandem, and over time, as part of their data repertoires.
Data activism coding framework.

Results
Data activists’ novel models for racially conscious data practices made it evident that their repertoires of multiple, co-occurring strategies were varied and intentional. That is, data use, reuse, production, and/or refusal strategies were simultaneously employed to broaden narratives about how data issues connect with racial and social issues; and relatedly, how these strategies connected with the envisioning of racially equitable data infrastructures, practices, and futures. Yet, organizational motives resulted in divergent strategies and repertoires. Whether through use, reuse, and production for a racially conscious approach to data analysis and resource sharing, or through a politically active refusal campaign, community organizations demonstrated the myriad ways that data can be engaged—and disengaged—for racial justice.
To describe and analyze how data activists connect issues of racial and data justice in novel ways, I develop my analysis in two parts: Part 1 provides an overview of each individual strategy, and its underlying goals (RQ1). Part 2 highlights how organizations connect the use of concurrent strategies with contesting the
Part 1: data activism strategies for racial justice
Community organizations employed multiple data activism strategies, for a variety of goals. The goals of each strategy show the wide range of actors and systems they strive to resist and hold accountable (e.g. Big Tech, carceral actors, data capitalism, and the carceral state) as well as the diverse and intersecting racial issues impacted by data (e.g. surveillance, policing, public health, unjust evictions, and the Atlantic slave trade’s continued impacts). These goals also highlight how the histories and contexts of target communities were guideposts for repertoires (i.e. collections) of strategies: for one, D4BL connects the Atlantic slave trade to the loss of life during Covid-19 in 2020 as well as general health disparities within vulnerable Black communities—and resultantly, the need for data use and reuse to fill data gaps. The goals of each strategy of my data activism typology—of use, reuse, production, and refusal—are briefly summarized in Table 4 and then discussed in detail below.
Summary of data activism goals (by strategy).

Data use
When engaging in data use, organizations strove to evince the oft-hidden ways in which data has masked racial inequalities, while reclaiming data to contest the reproduction of racially exploitative systems. Organizational practices of use and reuse were largely responses and counterweights to the depoliticization of data, striving to connect data collection and analysis to the continued subjugation of communities of color, reproduction of the carceral state, and perpetuation of surveillant systems. Data use was generally driven
Indeed, data use in these and related examples was an opportunity to uplift the voices and lived experiences of impacted community members, largely in response to persistent gaps. Relatedly, use was a means
Data reuse
Like use, organizations described data reuse as a strategy The NDSC Criminal Justice Data Initiative will provide users with a detailed and nuanced understanding of key indicators to track criminal justice trends within specific Los Angeles neighborhoods. (USC Price Center for Social Innovation, n.d.)
In a similar project, the MDH team describes how they filed Public Records Act requests, to access police arrest data (Bryan et al., 2017). These instances of reuse pushed for a race-conscious approach of compiling, analyzing, and repurposing retrievable data.
Unlike data use, reuse (i.e. the repurposing of data) was often distinct in its attempts to
Data production
All observed projects employed data production, often with the aim of engaging broad publics. Considering the collaborative values of production, the high presence of co-produced materials is unsurprising. That is, many data production outputs (i.e. research reports, zines, and shareable datasets) emphasized the importance of a collaborative, process-driven, and externally-engaged approach to community partnerships. Whereas researchers could use and reuse data for consultative purposes, production was a novel response requiring a greater degree of participation—that is, co-production—on the part of communities. Posts describing production emphasized the results of these processes alongside the process itself (and its values), and how production contested mainstream data practices. They noted the immense resources required to create and maintain partnerships while highlighting the lack of (academic and public) incentives for this work (see Hemphill et al., 2021, e.g.). Despite this, organizations employed production
To foster and demonstrate public engagement, both the Data Science Federation and NDSC displayed projects that resulted from co-production workshops: for example, studies touching on issues of homelessness and education. The NDSC also collaborated with local radio to share data-driven stories. Color Coded’s mission asserts that “tech is not neutral” and thus the public—especially marginalized communities—must be engaged in co-producing datasets and technologies. The organization regularly acted as a hub for convening participatory events, to explore alternative models and modes of technological engagement.
In addition to engaging publics, data production was employed to counternarrate the negative impacts of datafication: to produce stories that contest the notion that “big” data projects are superior to other forms of evidence. Tied to calls for involving impacted communities, such productions—that is, data visualizations, reports, and websites—explicated how racialized communities bore a disparate proportion of harms. Organizations “reclaimed” data by showcasing the merits of mixed-methods, qualitative, and participatory approaches, guided by novel methodologies and politically informed analyses.
To a lesser degree, organizations used their production to articulate new codes of ethics. They aimed to foster novel approaches for data-driven work. Color Coded and D4BL proffered divergent strategies in co-production, a contrast discussed in Part 2.
Data refusal
Whereas the first three approaches used or reused data, data refusal connected organizations’ political analysis of data with their disengagements. Data refusal articulated distinct political agendas and developments of public education campaigns against the pernicious uses of data (see, e.g. Cifor et al., 2019). Like what Milan and Van der Velden (2016) term as “reactive” activism and Beraldo and Milan (2019) describe as the stakes for “data-oriented” activism, I documented how data refusal was employed to: (1)
On the one hand, refusal frequently manifested in the form of documenting individual and civil rights that had been infringed upon, such as privacy or anti-discrimination. Groups that “refused” data worked with communities to spotlight harms and concretely capture negative impacts. Beyond this, organizations contextualized harms and risks for public awareness and education. That is, data refusal often articulated how present data-driven infringements upon rights were tied to longer histories of inequality. When writing about how exploitative databases connected to the Atlantic slave trade, for example, D4BL founder Milner (2019) wrote: “There is nothing more powerful than technology to veil, disguise, transform, deceive and deny violent conditions of existence, to deny people of their sanity, their agency, their personhood.” In turn, Milner calls for the refusal of technologies that perpetuate this devaluation of Black life, such as facial recognition and credit scoring.
Of note, not all institutions refuse data. Universities often exemplify this dynamic whereby refusing data was not widely adopted. The Community Data Initiative, Data Science Federation, Southern California Association of Government’s (SCAG) Data Science Fellows program, and NDSC commonly refrained from emphasizing data’s political relations. They did not prominently feature policy stances but instead encouraged visitors to engage with data to form opinions, conveying an apolitical, agnostic stance and approach.
Part 2: contesting the contentious racial politics of data
My proposed approach of analyzing multiple, co-occurring data activism strategies (vs a binary understanding) provides more vivid cases for how the racialization of data concretely manifests within everyday life, disparately impacting minoritized communities within uneven infrastructures. This is particularly important to consider within data activism, as contentions for racial justice (and related claims to power and rights) within local communities are increasingly facilitated or forestalled through data. Moreover, rather than drawing focus to one way over the other, what I call a “co-occurrence analysis” illustrates how data activists must employ multi-pronged, adaptive, and creative strategies to contest the uneven power relations embedded within data practices and processes.
Varied strategies for racial justice
One of the clearest examples of using, reusing, and producing data to illuminate racial disparities in infrastructures became evident within D4BL’s repertoires. For instance, during the early stages of the Covid-19 pandemic in 2020, Yeshimabeit Milner (2020) of D4BL articulated the need for government agencies to collect original data as a means of ensuring accountability:
We demand accurate, comprehensive and transparent collection and public reporting of COVID-19 data, which should be used for advancing structural racism interventions . . .
Later, Milner (2020) explained why such data was important, especially for organizations such as D4BL:
We organize in this moment because we believe the tremendous loss of life we have experienced cannot be in vain . . . COVID-19 data can help point us in the right direction.
In short, D4BL viewed extant resources—which lacked racial data—as ill-suited to stem the “tremendous loss of life” in the Covid-19 crisis, particularly to advocate for vulnerable Black communities. D4BL responded to gaps by collecting (and using) their data, while also pressing public health agencies for more accurate, comprehensive, and transparent data for their (and others’) reuse.
Put another way, D4BL connected data issues with the livelihood—and deaths—of the Black community as well as broader, historic struggles for power and recognition, as part of a long-standing trend of discriminating against Black communities. Their Covid-19 data campaign complements D4BL’s and Milner’s (2018) open letter to Facebook in response to the Cambridge Analytica scandal, 2 where they list in detail how Facebook can remediate harms. They also invite the company to co-create products tied to, and driven by, an alternative code of ethics.
In contrast, in speaking about production, Color Coded pushes to move beyond “ethical” technologies. Mainly, they assert the need for “Respectful Technologies for Our Collective Liberation” and hosted co-design workshops to explore possibilities for “co-produced and co-owned” technologies. This orientation is largely informed by goals of dismantling “harmful world design” and combatting “colonial” uses and tools. Color Coded’s events and projects are largely outside the purview of dominant corporate and state actors within the technology space, and this stark contrast alludes to the contentious, distrustful relationship between technology and minoritized communities. Not all community organizations trust technology corporations and governmental agencies to engage data in communities’ best interests: thus, groups like Color Coded call for alternative practices and ownership models outside of their involvement whereas D4BL was seemingly more open to collaboration, at least initially.
Highlighting unequal relations within data infrastructures
To call attention to the power relations within data infrastructures, data use, reuse, and production were often geared toward gathering community input for local issues. The previous examples illustrate how data activism is largely propelled by pushes to show the negative impacts upon communities—and their far reaches; and how data activism is driven by goals of illustrating the racial underpinnings of data-driven work. As we noted earlier about Our Data Bodies and the Urban Displacement Project, this goal often motivated data use: that is, collecting oral histories from community members, to capture insights and lived experiences obfuscated within extant resources.
Along these lines, Stop LAPD Spying Coalition (2014a) co-produced artwork with communities to illustrate the infrastructures of what they term “the police state.” The visuals—and the report in which they are included—argue that data-driven technologies should be understood in relation to the sociopolitical processes in which they are embedded: mainly, the police state. They argue that data-driven tools have amplified, and will only continue to amplify, racially discriminatory policing and surveillance. Thus, while the report can be viewed as a form of production, its political analysis illustrates their active use of data productions for refusal campaigns. Among other goals, Stop LAPD Spying employs data production and refusal as strategies for both public engagement and political consciousness raising.
Reimagining the boundaries of data and racial justice
Moving beyond documenting harms, Mijente sought to refuse the harmful practices of the technology industry more generally. Mijente reused public comments from the Chicago Police Department (CPD) website as evidence of the public’s concern regarding data-driven surveillance. Mijente’s reuse also underscored how data and power act in tandem: how powerful actors (such as the CPD) hide data and high-quality data, to limit audits and obscure unethical processes.
Meanwhile, Mijente’s #NoTechForICE campaign was oriented toward broadening the narrative about data harms, capturing how companies were implicated in political controversies, such as the Trump Administration’s attempts to expand immigrant detention and deportation efforts. Mijente (n.d.) produced data visualizations and reports, such as No Tech for ICE, to question the efficacy of corporate- and carceral-sponsored technology ethics workshops, as juxtaposed to the far reaches of technological tools (e.g. Palantir data dashboards and software) for immigrant surveillance. Indeed, Mijente organizer Jacinta Gonzalez called attention to this duplicity of the tech industry: They [tech companies] all say they care about immigrants, they all point to their history caring for immigrants . . . and then when it comes time to actually stop collaborating with a regime engaged in a wholesale war against immigrants, they waffle and say it’s better to have a seat at the table. (as cited in Ghaffary, 2019)
Similarly, AEMP leveraged public data to document the influence of real estate corporations, uncovering how they hid wealth, ownership, and records of unjust evictions through multiple limited liability corporations, therein evading audits of such questionable tactics, which primarily targeted working-class communities of color. AEMP describes an adaptive approach to data reuse: consulting many sources to capture the presence and impact of serial evictors. Triangulating sources overcame the limits of each singular dataset, leading to the documentation of a trend of hidden yet predatory practices. Meanwhile, Color Coded organized and co-organized workshops, such as “A People’s History to Science,” to bolster public education surrounding these issues, especially as they pertained to sociohistorical legacies of racial inequality.
In summary, these organizations employed data refusal alongside various data use, reuse, and production campaigns to resist specific technologies and frameworks (and imaginaries) that propagated—and justified—data harms and risks (e.g. racism and xenophobia). These campaigns spoke against the use of data, historicized and contextualized data use and reuse, and increased public awareness. Data use and reuse were used in tandem at times, but not always.
Through the simultaneous use of multiple strategies, organizations reconfigure and reclaim data for communities of color: they contest dominant, idealized claims of data’s utility and instead articulate alternative, critical engagements and disengagements—which center impacted communities and contest the legacies of oppression they contend with. These strategies are not predicated on the expansion of datafication but rather view data as something that can be disengaged. In short, my findings show that data is a strategic tool—and only one tool in a vast repertoire—for racial and data justice. Overall, these collections of strategies—what I call
Discussion
Data activism strategies employed for racial justice goals, in different ways and to different degrees, call attention to what racial justice advocates articulate as the non-neutrality of data infrastructures, or what I term the
As my analysis argues, data can be a tool of both racial oppression and liberation; data can be something to resist as well as something to use and reuse within resistance efforts. In addition, although these strategies were like those used within more “general” social justice campaigns, the importance of racial justice goals in orienting them became apparent through organizations’ narratives about their collective repertoires. Past research often alludes to the importance of racial lines (e.g. Milan and Treré, 2019 & 2021), but my work concretely documents and describes how racial justice informs data activism. It also examines the divergent responses to the tensions of such work and acute awareness of the connections between data and racial injustice. For example, D4BL connects use, reuse, and production to the continued impacts of the Atlantic slave trade. Meanwhile, Mijente captures the repeated weaponization of data for criminalizing immigrants and Latinx communities through their use, reuse, and refusal. In all, analyzing organizations’ racial justice data repertoires illustrates how their data activism strategies were often guided by a longer history and understanding of data and racial (in)justice, and an exploration of an alternative data future. Organizations leveraged individual strategies in tandem, to illustrate the contentious racial politics of data: the exclusionary and uneven nature of data infrastructures, wherein marginalized communities have minimal visibility—and resources—to become active and vital stakeholders in data-driven governance.
Certainly, it is important to note the range of political stances within the observed body of organizations, which were not fully explored. Different motivating factors and agendas guided repertoires. On the one hand, although they engaged in production, Stop LAPD Spying did not emphasize use, reuse, or production as much as refusal. They mainly focused on the need to resist infrastructures for policing. In contrast, AEMP, D4BL, and the university-based projects typically engaged in use and reuse as key strategies. These divergent repertoires illuminate the different visions of justice within organizations: namely, while AEMP, D4BL, and university-based projects saw use and reuse as potentially appropriate tools for effecting racial justice, Stop LAPD Spying, founded as an abolitionist anti-policing organization, was more skeptical. Such divergences illuminate the ambiguities, complexities, and pressures of data activism—compounded by structural inequalities tied to access, resources, and investments in data infrastructures—requiring minoritized groups to straddle tensions in varied and nuanced ways. In developing racial justice data repertoires, individuals and organizations orient themselves divergently.
Moving beyond bifurcated understandings of data activism, my typology and its related concepts push scholars to consider how to develop frameworks that attend to the multiplicative, co-occurring nature of data activism within social movements. In doing so, we can further develop data practices that are accountable to communities while maintaining a focus on how data is intertwined with the persistence of racial inequalities. In fact, I suggest future works explore the nuances and divergences of racial justice data repertoires from a transnational or global lens, to probe at globally shaping forces and move beyond the US-based limits of my work. Consider, for example, the repeated expansion of data collection efforts around Arab and Muslim Americans and undocumented migrants. Moreover, I suggest further investigating how organizations’ distinct racial justice data repertoires provide short- and long-term gains for communities, and within different communities and types of racial landscapes.
Footnotes
Acknowledgements
The author would like to thank Tawanna Dillahunt, Rachel Kuo, and Anna Lauren Hoffmann for substantive feedback on earlier versions of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.