
Abstract
As AI increasingly influences content production in news, and at a time when media organizations aim to restore credibility through higher transparency, public perceptions of AI play a role in shaping evaluations of the message and the source. This between-subject experiment (n = 415) examined how the label used to describe AI involvement (“influenced,” “assisted,” “generated”), the media format (blog vs news agency), and individual differences in perceptions of AI’s editorial value and AI literacy influence credibility. Results indicated that message credibility varied significantly by label, with AI-generated content perceived as least credible and AI-influenced content as most credible. This pattern may reflect audiences’ preference for human judgment in content creation and greater skepticism toward messages produced entirely by AI. In contrast, source credibility was unaffected by the label but was higher for a news agency than for blogs, likely due to trust in perceived professional standards associated with institutional journalism. Perceived AI editorial value emerged as a strong predictor of source credibility, whereas AI literacy did not moderate these effects. Findings suggest that while audiences negatively respond to full AI authorship in evaluating message credibility, trust in the source depends more on editorial value than AI labeling.
Introduction
During the 2024 summer months, several local and national U.S. newsrooms encompassing agencies, newspapers, radios, and TV stations (e.g., Associated Press, The Texas Tribune, Iowa Public Radio, and KXAN in Austin) participated in an initiative aimed at understanding audience perceptions of artificial intelligence (AI) use in the news industry (Walsh, 2024). Data from interviews and surveys indicate that 93.8% of respondents want journalists to disclose their use of AI (Walsh, 2024).
Such overwhelming public demand for transparency would usually be considered music to publishers’ ears if it did not come with the caveat that some audiences perceive news organizations that disclose their use of AI as less trustworthy (Toff and Simon, 2025). As Toff and Simon (2025) stated, this constitutes a true dilemma, particularly at a time when news organizations seek to restore their credibility (Peacock et al., 2020), and government entities such as the U.S. Congress and the European Union have issued regulations regarding AI disclosures.
So, confronted with this dynamic, what should news content providers do? To date, the scholarship has indicated how the public perceives AI-generated content more negatively than human-authored texts (Altay and Gilardi, 2024; Chen et al., 2025; Graefe and Bohlken, 2020; Palmer and Spirling, 2023; Toff and Simon, 2025). Yet, data has also revealed that labeling content as AI does not lead the public to assign significantly lower ratings than those attributed to human-authored texts (Gallegos et al., 2025; Gilardi et al., 2024; Henestrosa et al., 2023).
Today, as Simon (2024) explained, several outlets have already adopted AI labeling to inform their audiences, and although reports have revealed that a transparent disclosure of AI could be a double-edged sword, scant research has documented whether specific labels are more effective than others as it relates to the perception of trust and credibility of the content (Simon, 2024). Furthermore, no research known to date has compared specific wording of AI disclosures and their respective effects on public perceptions of news content.
It is in light of such a conundrum and in an effort to contribute to existing scholarship that the present study, conducted in April-May 2025, examined whether the wording used to describe AI usage, along with audience perceptions of AI’s editorial value and literacy, influences credibility perceptions. This approach sought to advance understanding of how subtle differences in labeling modulate audience perceptions of AI-generated content. More specifically, this study asked the following question: Do source and message credibility vary as a result of the disclosure label (AI-generated, AI-assisted, or AI-influenced) assigned to a story?
Literature review
As AI increasingly participates in news content creation, questions about transparency, authorship, and audience trust have become central to media credibility research (Wang and Huang, 2024). System transparency, or the extent to which audiences understand how AI contributes to journalistic work, has been shown to guide how people process machine authorship cues (Sundar, 2020). Transparent disclosures can initiate cognitive heuristics that shape credibility perception: when audiences perceive automation as efficient and objective, transparency through an AI label may elicit positive evaluations, but when it exposes machine fallibility, it can amplify doubts (Banas et al., 2022). Recent controversies illustrate these risks, such as Sports Illustrated publishing articles in 2023 under AI-generated profiles (Bauder, 2023). The content was removed and a vendor contract was terminated amidst concerns of undisclosed AI involvement and authorship. In this context, credibility concerns surrounding AI-generated content must consider public trust in not only the way that content is produced, but also the credibility of the sources delivering it.
Mixed effects of AI labels
Several studies have investigated the effect of labeling messages as AI-generated and how the public perceives such AI-generated content (e.g., Altay and Gilardi, 2024; Chen et al., 2025; Toff and Simon, 2025). Scholarship on AI disclosures reveals inconsistent effects on perceptions of credibility, ranging from diminished trust to perceptions of equivalence or even enhanced evaluations relative to human-authored content. Predominant findings indicate that labels connoting full automation elicit adverse responses. For instance, Toff and Simon (2025) demonstrated that AI-disclosed news was perceived as less trustworthy, particularly among audiences with greater knowledge about journalism, while Altay and Gilardi (2024), Chen et al. (2025), and Palmer and Spirling (2023) documented reduced sharing intentions and attributions of authenticity. Corroborating these results, Graefe and Bohlken’s (2020) meta-analysis established that human authorship disclosures elevate credibility and readability assessments. A countervailing body of evidence reports null or affirmative outcomes. Gallegos et al. (2025) and Gilardi et al. (2024) observed no differences across terms. For example, Gilardi et al. (2024) found no differential impacts on persuasion, accuracy, or engagement across AI-generated, AI-assisted, and human conditions. These labels may also index qualitatively different editorial practices, ranging from AI as a minor influence on human-authored content to being the primary content producer. This study, therefore, examines not only how disclosure wording shapes perceptions of credibility but also how audiences evaluate different modes of AI integration, with labels communicating distinctions.
Critically, the labels under examination here (i.e., AI-influenced/assisted/AI-generated) do not represent arbitrary terminological variation as each one may describe a qualitatively different relationship between human editorial judgment and machine production. To label content as AI-influenced, for example, may assert that a human author remained in substantive control, while “generated” may signal that a human was not the primary author. Audience responses to these labels may therefore reflect not simply reactions to words, but considered evaluations of distinct editorial realities. The present study uses labels as a means of communication that indicate AI disclosure to bridge newsroom practices and public perceptions.
These divergent outcomes necessitate distinguishing message credibility (perceived quality, accuracy, and thoroughness of content) from source credibility (perceived expertise and trustworthiness of the communicator), as AI labels may affect these constructs differentially (Hovland et al., 1953; Kiousis, 2001; Sundar, 2008). Studies consistently demonstrate that AI labels most strongly undermine message credibility by activating heuristics of detachment and fallibility (Graefe and Bohlken, 2020; Toff and Simon, 2025), whereas source credibility is more resistant due to enduring institutional trust (Johnson and Kaye, 2000; Metzger and Flanagin, 2013).
One theoretical framework particularly useful for understanding how AI disclosure labels shape these credibility judgments is Sundar’s (2008, 2020) MAIN model which proposes that technological features of media serve as heuristic cues that trigger cognitive shortcuts in how audiences evaluate content. Of particular relevance is the agency heuristic, which refers to the degree to which audiences perceive a human or machine as the source of content. When audiences detect machine agency, the heuristic may activate associations about accountability and the absence of human judgment, thereby reducing credibility. Conversely, labels that preserve some perception of human oversight, such as AI-influenced, may mitigate these associations by signaling that editorial control remained with a human author. Importantly, however, it remains unclear whether audiences respond to these labels through heuristic processing or through more deliberate evaluation of what each label implies about actual editorial practice.
Based on this body of evidence, label effects are expected to be stronger for message credibility than for source credibility. While the literature suggests that source credibility is more resistant to label effects due to enduring institutional trust, this resistance does not preclude a directional effect, and labels connoting greater automation may still elicit some reduction in source credibility evaluations relative to labels signaling human oversight. The following hypothesis is therefore posed for both outcomes, with the expectation that effects will be more pronounced for message credibility:
H1a-b: The label used to describe AI involvement (influenced, assisted, generated) will significantly affect perceptions of (a) source credibility and (b) message credibility, with “generated” predicted to yield lower credibility ratings than “influenced” or “assisted.”
Source credibility across media ecologies
Amid eroding confidence in legacy media (Murphy and Auter, 2012; Peacock et al., 2020), source credibility, conceptualized as perceived expertise and trustworthiness (Hovland et al., 1953; Kiousis, 2001), differentiates institutional outlets from alternative platforms. Blogs, as a distinctive form of online journalism, often present partisan viewpoints and develop communities of like-minded readers, which can exacerbate selective exposure and confirmation biases (Stroud, 2007). They simultaneously function as platforms for citizen journalism, at times challenging mainstream media narratives and influencing public discourse through agenda-setting power (Drezner and Farrell, 2004; Murphy and Auter, 2012). News agencies surpass blogs in perceived credibility, owing to imputed editorial rigor, despite blogs’ agenda-setting efficacy and participatory appeal (Drezner and Farrell, 2004; Johnson and Kaye, 2000, 2007, 2010; Metzger and Flanagin, 2013). This subsequent erosion of trust in mainstream media positions blogs in opposition to established news agencies, which traditionally represent broader journalistic standards. To address what emerged from the literature, the present study proposes the following hypothesis and research questions:
H2a-b: The source of the content (blog vs news agency article) will significantly affect perceptions of (a) source credibility and (b) message credibility, with news agency content generating greater perceptions of credibility than blog content.
RQ1a-b: Is there an interaction between format and labels on (a) source credibility or (b) message credibility?
Perceptions of AI editorial value and AI literacy
Audience appraisals of AI’s editorial utility and technological literacy further delineate credibility perceptions, with elevated AI trust correlating positively with acceptance (Shin, 2022; Wang et al., 2025). AI facilitates production phases from ideation to dissemination (Cools and Diakopoulos, 2024; Nishal and Diakopoulos, 2024). In a recent study, Shin (2022) found that participants who demonstrated a higher level of literacy and trust in AI ultimately attributed a higher message credibility to AI-mediated content, suggesting that individual differences in AI perceptions may shape credibility judgments beyond the experimental manipulation of labels alone. It is clear that the integration of AI tools in journalism has created significant implications for how audiences perceive and evaluate news content. While journalists themselves navigate AI adoption through what research terms a “value-motivated use” perspective, where professional principles of truthfulness, accuracy, transparency, balance, and journalistic integrity guide their technology use (Wu, 2024), the broader public’s understanding of AI’s role in news production may be more complicated (Deuze, 2005; Shoemaker and Reese, 1996). Research examining newsroom AI implementation reveals that these tools now assist across various production stages, from news gathering and writing to editing and promotion, raising questions about how public awareness of such practices influences perceptions of news credibility (Cools and Diakopoulos, 2024; Nishal and Diakopoulos, 2024).
Public perceptions of AI’s editorial value emerge as a potential moderator of credibility judgments (Shin, 2022; Wang et al., 2025). Among AI disclosures, “generated” is predicted to elicit particularly pronounced negative reactions because it connotes full automation and complete displacement of human judgment, eliminating perceptions of editorial oversight that influenced or assisted labels may preserve (Altay and Gilardi, 2024; Toff and Simon, 2025). This presents an opportunity to assess how pre-existing beliefs about AI’s editorial worth may significantly influence credibility assessments, with those who view AI as enhancing rather than compromising journalistic quality being more likely to maintain trust in news sources that employ such technology. RQ2: Is the relationship between labels and source credibility moderated by perceptions of AI’s editorial value, such that the negative effect of the “generated” label on credibility is stronger for participants with low perceptions of AI’s editorial value?
H3: Participants’ perceptions of the editorial value of AI (high vs low) will significantly predict source credibility, with those perceiving higher editorial value reporting higher credibility ratings.
Additionally, recent research revealed that participants who reported having a higher knowledge of AI explained that they were somewhat skeptical of the technology. They thought it could inherently contain biases associated with its human-generated creation as well as corporate interests (Yeste-Piquer et al., 2025). In other words, a higher level of familiarity with AI led to greater skepticism about AI neutrality. Yet, the research did not disclose nuances related to news formats nor sources, so as more evidence is garnered, the following questions are proposed: RQ3: To what extent do AI literacy, content format, and labels predict source credibility? RQ4: Does AI literacy moderate label effects?
Method
A 2 (format: news agency article vs blog) x 3 (disclosure label: AI-generated, AI-assisted, AI-influenced) between-subjects factorial design was developed to examine the effects of content format and AI disclosure labeling on perceptions of source and message credibility. The study, approved by the Institutional Review Board of a large public Southeastern research institution, was administered via Qualtrics, where participants were randomly exposed to one of six conditions before completing measures on dependent variables, AI editorial value perceptions, AI literacy, and demographics. In addition to manipulated factors, individual-level variables were incorporated to address the proposed hypotheses and research questions. Participants’ perceptions of the editorial value of AI were measured and dichotomized using a median split, producing high versus low perception groups. This allowed us to assess whether individuals who view AI as adding greater editorial value rate the message and the source as more credible compared to those with lower evaluations. In particular, the analysis examined whether the negative effect of the “generated” label on credibility was amplified among participants with low perceptions of AI’s editorial value. To address the final research question, a multiple linear regression analysis was conducted to evaluate the extent to which AI literacy, content format, and labeling terminology predicted perceptions of source credibility. Interaction terms between AI literacy and terminology were incorporated to test for potential moderation effects to assess whether individual differences in AI literacy influence credibility evaluations.
Stimuli
Participants were randomly assigned to view a mock news or blog article created in Adobe Photoshop by a member of the research team, which mimicked real articles. The agency news article was 120 words in length, while the blog post contained a total of 121 words, and all featured a soft news story related to a new clothing trend presented at an international fashion show. Reuters was selected as a news source as it is traditionally identified as an unbiased news agency (Lin et al., 2023). The selected blog was from an existing company, Big Valley Marketing, whose generic name was deemed by researchers to reduce bias. The AI disclosure manipulation comprised two complementary elements: (a) headline-adjacent disclosure labels varying by condition (AI-generated, AI-influenced, or AI-assisted); and (b) a consistent footnote articulating the involvement, adapted from Reuters’ existing guidelines with condition-specific one-line clarifications for each label
1
(see Figure 1). This dual-component design reflects real-world journalistic practice, in which AI disclosures typically combine terminology with explanatory context. While the footnote remained constant across conditions, the experimental manipulation tests how varying terminology on the label, signaling the degree of AI involvement, shapes perceptions of credibility. AI-influenced news article.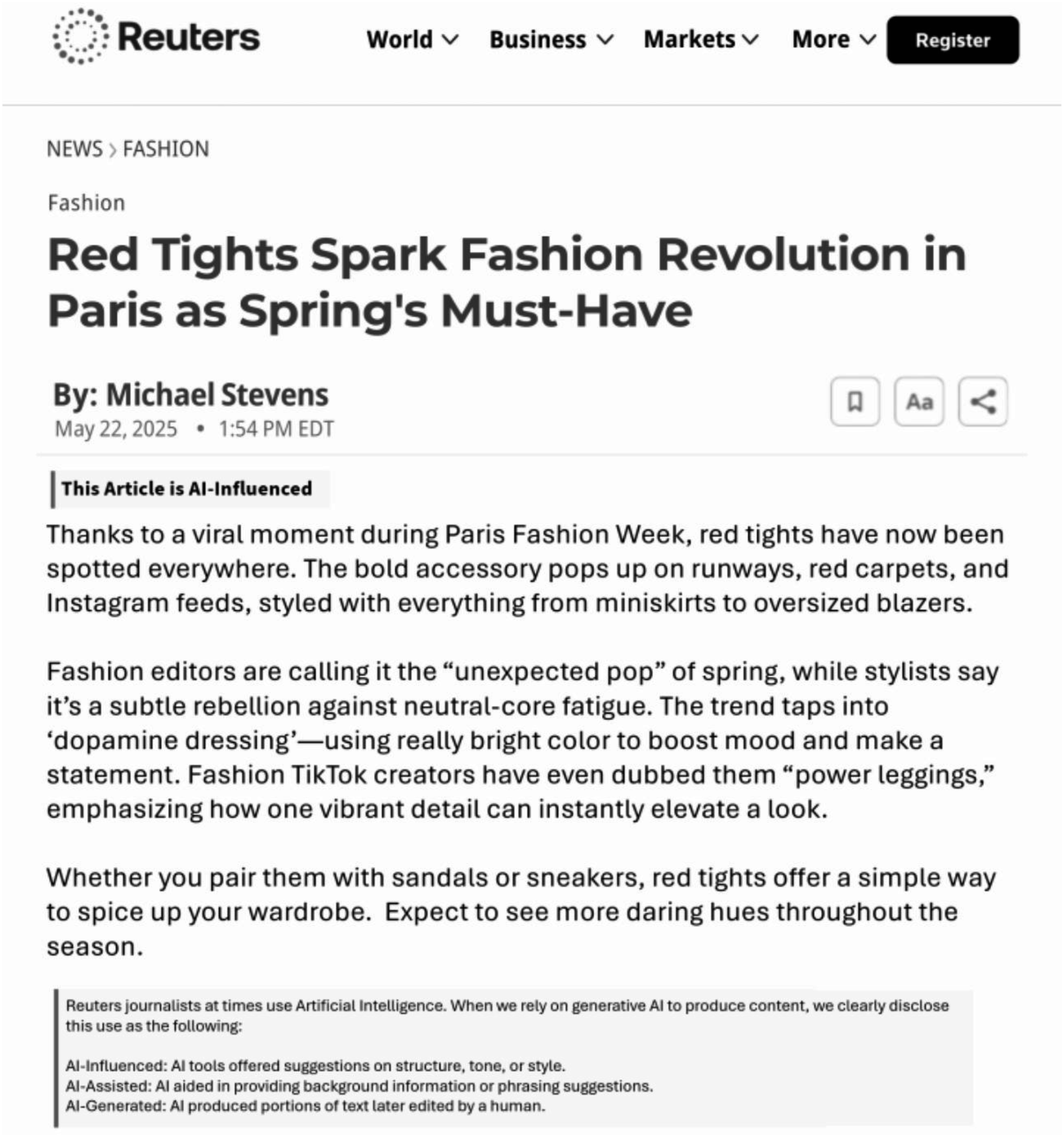
The stimuli and story layout were developed with support from Claude AI, ChatGPT, and Adobe Express. Both Claude AI and ChatGPT contributed to creating graphic elements, including logos, banners, and other design components. AI-generated designs were then integrated into Adobe Express to ensure authenticity and alignment with real-world examples.
Measures
Participants were asked to evaluate source credibility using a 10-item semantic differential scale adapted from Ohanian (1990), rated 1–7 across polar opposites: dependable-undependable, honest-dishonest, reliable-unreliable, sincere-insincere, trustworthy-untrustworthy, expert-not an expert, experienced-inexperienced, knowledgeable-unknowledgeable, qualified-unqualified, skilled-unskilled (M = 4.91, SD = 1.71, Cronbach’s α = .96). Message credibility was adapted from Appelman and Sundar (2016) and was measured using three items on a 7-point Likert scale (1 = strongly disagree, 7 = strongly agree), assessing believability, accuracy, and authenticity of the message (M = 4.43, SD = 1.56, Cronbach’s alpha = 0.92).
Perceptions of the editorial value of AI were measured on a 7-point Likert scale that adapted three items from Sun et al.’s (2022) measure of AI advantages, including “AI is more advantageous than traditional methods for news writing,” “AI is more advantageous than traditional methods for editing,” and “AI is more advantageous than traditional methods for fact checking” (M = 5.16, SD = 1.14, Cronbach’s alpha = 0.90). The median score of this variable was calculated to classify participants into two groups 2 . Participants with scores at or below the median were categorized as the “low” group, and those with scores above the median as the “high” group. This grouping was created using an if-else condition in R. Subsequently, the sample sizes for each group in the main experiment included 181 participants in the high group and 234 in the low group.
Using six items from Carolus et al.’s (2023) META AI literacy scale. AI literacy was assessed through measuring participants’ ability to apply AI in daily life, including items such as, “I can integrate artificial intelligence into my work processes and everyday life,” “I can correctly interpret information from artificial intelligence applications,” and “I can deal responsibly with the results of artificial intelligence,” on a 7-point Likert scale (M = 5.05, SD = 0.99, Cronbach’s alpha = 0.90). Balance checks using one-way ANOVAs confirmed no significant differences in AI editorial value perceptions (p = .41) or AI literacy (p = .10) across conditions, and no significant pairwise differences (Tukey HSD; all p > .37).
For controls, participants’ preexisting attitudes toward the two source formats, Big Valley Marketing and Reuters, were measured as control variables prior to stimulus exposure on a 0 (very negative) to 100 (very positive) scale, with 50 representing a neutral midpoint (Reuters: M = 61.96, SD = 23.32; Big Valley Marketing: M = 64.12, SD = 25.60). Another control variable assessed participants’ AI use, measured by how often participants reported using AI in a typical week, with 27.47% using AI several times a day, 12.53% once a day, 33.73% a few times a week, 20.48% less than once a week, and 5.78% never.
Participants
Power analyses using G*Power, assuming a medium effect size (f 2 = 0.25), an alpha level of .05, and 95% power for this study indicated a minimum required sample size of 400 participants. An additional 100 participants were recruited to account for the complexity of the manipulation. Although only one AI involvement label appeared at the top of each article, all three terms were also included in a footnote to reflect realistic disclosure practices, making the manipulation check potentially more difficult to pass. As such, for the main experiment, a representative U.S. census-ratio sample of 500 participants was recruited from CloudResearch in October 2025. CloudResearch was selected as the online platform for this research as it provides the highest data quality in online human-subject research (Douglas et al., 2023). Of the 500 participants, 85 were excluded from analyses due to failure to pass the manipulation checks following stimulus exposure: (1) AI disclosure recall asked participants to identify the extent of AI involvement disclosed: AI-generated, AI-assisted, AI-influenced (53 did not pass), and (2) format identification asked participants to classify the content as a blog post or news agency article (33 did not pass). Participants who failed either check were excluded from analyses (85/500 excluded; 83% overall passing rate). Exclusion rates, as assessed by chi-square, did not differ across experimental conditions (p = .83).
The final sample consisted of 415 participants distributed across six conditions: blog/influenced (n = 70), blog/assisted (n = 68), blog/generated (n = 67), agency/influenced (n = 70), agency/assisted (n = 70), and agency/generated (n = 70). Participants were additionally categorized by perceptions of the editorial value of AI, with 181 classified as having high perceptions and 234 as having low perceptions.
Of the 415 participants, 50.36% (n = 209) identified as male and 49.64% (n = 206) identified as female with an average age of 46.11 years (range 18-83). The majority of participants identified as white (69.40%, n = 288), followed by Black or African American (14.22%, n = 59), Hispanic or Latino (10.36%, n = 43), Asian (4.34%, n = 18), Native Hawaiian or Pacific Islander (0.96%, n = 4), and other or mixed race (0.72%, n = 3), which included responses such as Chicano/white, Mexican American, Mahli and Puerto Rican, and mixed identities. In terms of education, participants most commonly reported holding a bachelor’s degree (41.20%, n = 171), followed by some college but no degree (21.20%, n = 88), a master’s degree (14.46%, n = 60), a high school diploma or GED (11.33%, n = 47), an associate degree (8.67%, n = 36), a doctoral or professional degree (2.89%, n = 12), and other (0.24%, n = 1). Most participants reported being employed (67.95%, n = 282), followed by unemployed (13.73%, n = 57), retired or other (13.25%, n = 55), students (4.10%, n = 17), and homemakers (0.96%, n = 4). “Other” responses included business owners, homemakers, individuals with disabilities, self-employed professionals, and retirees, several of whom indicated part-time or hybrid employment arrangements.
Results
To test the hypotheses and answer the research questions, a combination of statistical tests was employed, including two-way ANCOVAs to examine the main and interaction effects of AI involvement label and format on outcomes and multiple regression analyses, with all models incorporating covariate adjustments to isolate unique effects and control for confounding variables. Where ANCOVA effects were significant, pairwise comparisons were conducted using Tukey HSD to examine differences between conditions. Two separate regression models were specified to address distinct theoretical questions: the first examined AI editorial value as a predictor of source credibility and tested its interaction with labels, while the second examined AI literacy as a predictor and moderator. The models met all necessary assumptions, including linearity, normality, homoscedasticity, independence of residuals, and homogeneity. An exploratory factor analysis confirmed source and message credibility as distinct factors, accounting for 70.3% of variance: Factor 1 (source credibility loadings > .83, α = .96) and Factor 2 (message credibility loadings > .41, α = .92). The factors exhibited moderate correlation, r (413) = .57, p < .001, 95% CI [.50, .63], consistent with theoretical distinction between the two.
A two-way ANCOVA was conducted to examine the effects of AI involvement label (influenced, assisted, generated) and format (blog, news agency) on source credibility, controlling for preexisting attitudes and AI use. For source credibility, there was no significant main effect of label, F (2, 406) = 1.64, p = .20, partial η2 = .008, but the format significantly affected source credibility, F (1, 406) = 15.01, p < .001, partial η2 = .04, with blog rated lower in credibility (M = 4.61, SE = 0.11, 95% CI = [4.41, 4.82]) than the news agency (M = 5.21, SE = 0.11, 95% CI = [4.99, 5.43]; see Figure 2). The interaction between label and format was not significant (p = .45, partial η2 = .004). Thus, H1a was not supported. However, H2a was supported, with higher credibility perceptions for the news agency. RQ1a found no evidence of an interaction between label and format on source credibility. Estimated marginal means for source credibility by content source.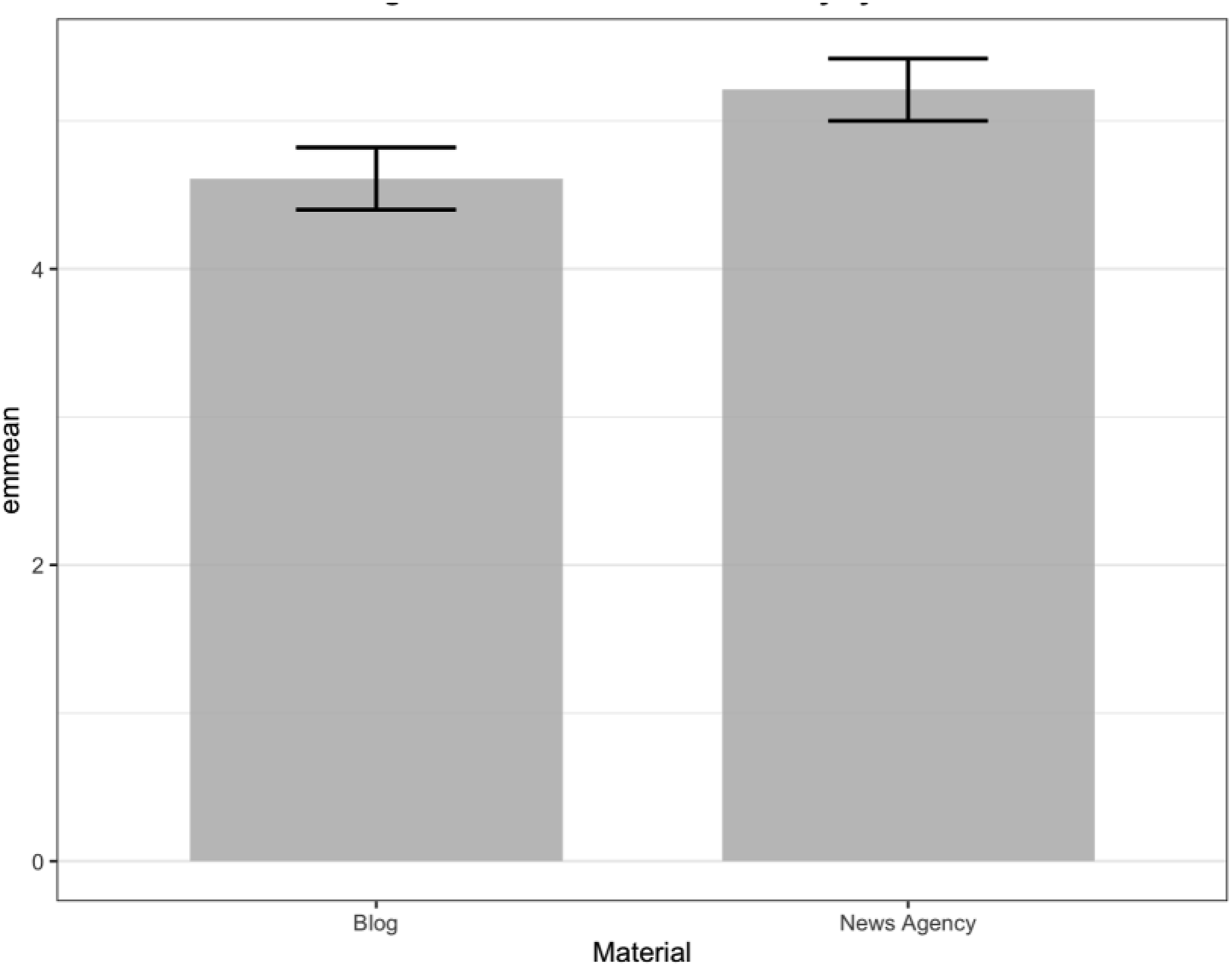
For message credibility, ANCOVA results showed a significant main effect of the label, F (2, 406) = 25.78, p < .001, partial η
2
= 0.11, supporting H1b. Content labeled “influenced” (M = 5.03, SE = 0.12, 95% CI = [4.79, 5.27]), perceived as having greater message credibility than “assisted” (M = 4.41, SE = 0.12, 95% CI = [4.17,4.65]) and “generated” (M = 3.85, SE = 0.12, 95% CI = [3.62, 4.09]; see Figure 3). Estimated marginal means for message credibility by AI involvement label.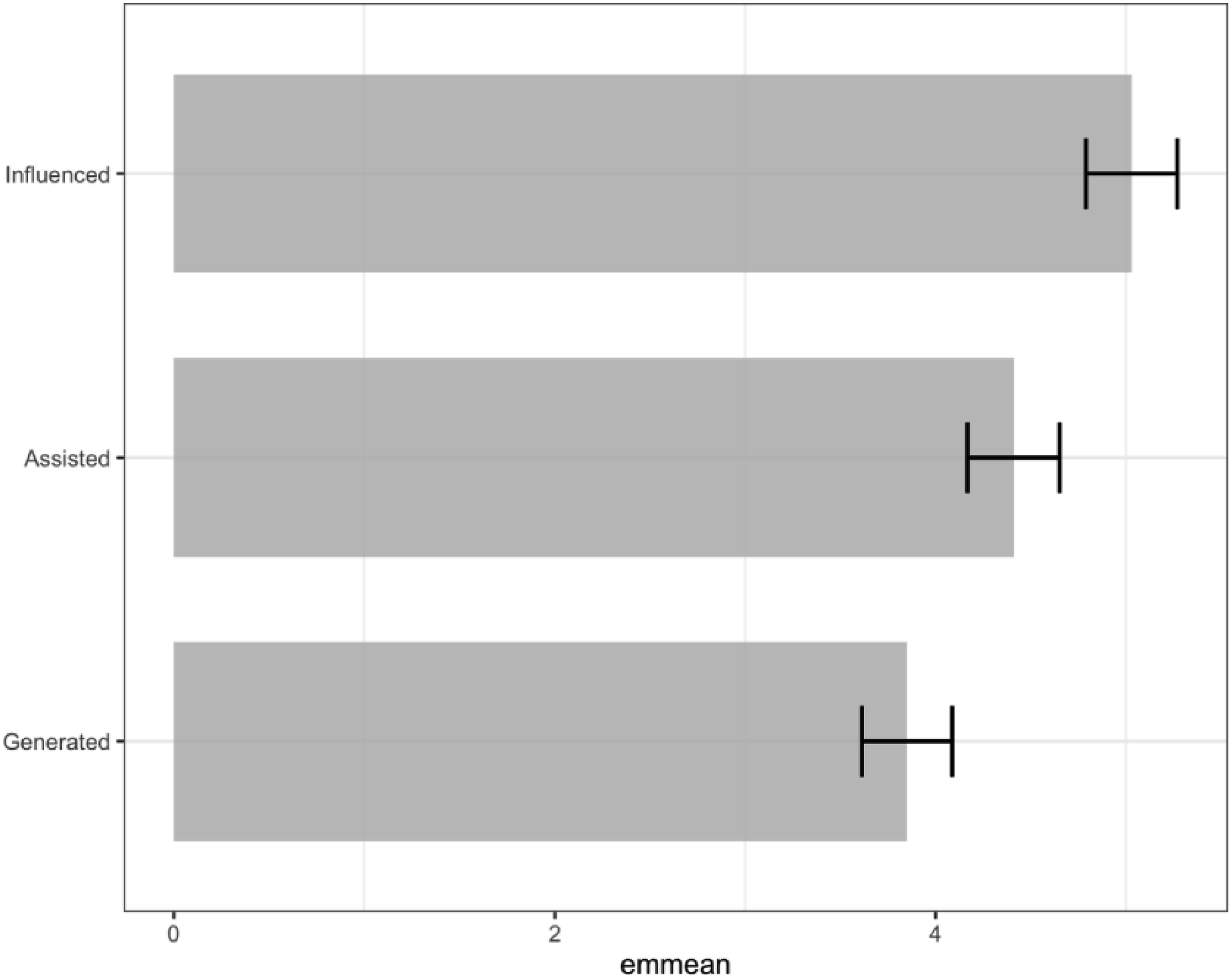
While the main effect of the format was nonsignificant, F (1, 406) = 0.47, p = .49, simple comparisons showed higher credibility for news-generated content. There was a significant label and format interaction, as illustrated in Figure 4, F (2, 406) = 3.50, p = .03, partial η2 = .02, informing RQ1b. Refer to Table 1 in the supplementary materials for a report of estimated marginal means and pairwise comparisons for message credibility by format and label. Estimated marginal means of message credibility by label and format.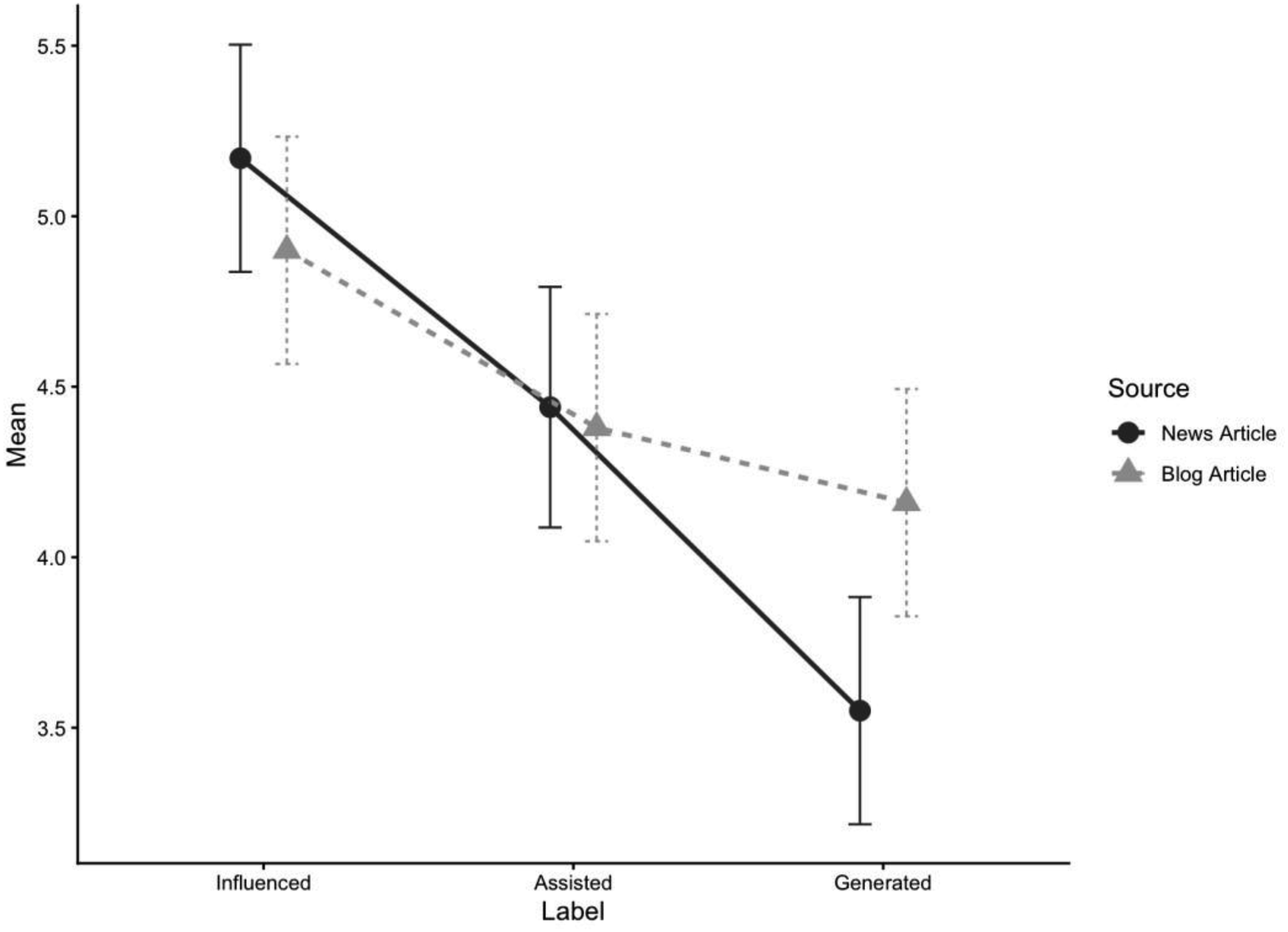
Because the ANCOVA results established a robust label effect on message credibility, the regression analyses were focused on source credibility, where individual differences in editorial value and literacy offered the most explanatory value for variance not accounted for by the manipulations. Regarding H3 and RQ2, multiple regression models predicting source credibility included the label, format, perceptions of AI’s editorial value, and their interactions, controlling for attitudes and AI frequency. The model was significant, F (9, 405) = 23.81, p < .001, explaining 30% of variance. AI’s editorial value had a significant effect, b = 0.55, p < .001, partial η 2 = .07, confirming H3: participants who viewed AI as having higher editorial value rated both the message and source format as more credible. The format remained a significant predictor (b = −0.63, p < .001, partial η 2 = .05), but label and its interaction with editorial value were not significant (p > .32), providing no support for RQ2.
For AI literacy prediction and moderation (RQ3 and RQ4), regression results revealed a significant model, F (9, 405) = 13.47, p < .001, explaining 23% of variance, but AI literacy and its interaction with the label were not significant predictors (p > .10). These results suggest that AI literacy did not moderate labeling effects on source credibility. Full regression results are available in Supplemental Materials, Table 2.
Discussion
The rapid integration of AI into journalism signals a paradigm shift that is reshaping traditional news production, editorial workflows, and professional norms (Simon, 2024; Sun et al., 2022; Toff and Simon, 2025). The present findings align with broader scholarship portraying AI as both a transformative and disruptive force, enhancing efficiency and scale while raising ethical and epistemological concerns (Calvo-Rubio and Rojas-Torrijos, 2024; Sonni et al., 2025). As prior research suggests, the incorporation of AI into journalism is not merely technical but involves a fundamental reconfiguration of journalistic identity and credibility (Pavlik, 2023; Sonni et al., 2025). Despite AI’s growing sophistication, including its ability to produce text indistinguishable from human writing, its use in news production remains bounded by human editorial oversight and accountability (Pavlik, 2023). Thus, AI is better characterized as an augmenting tool than a replacement, offering efficiency in reporting while introducing challenges surrounding transparency, fairness, and trust.
This study examined how terminology describing AI involvement (i.e., “influenced,” “assisted,” “generated”) and format (i.e., blog vs news agency) shape audience perceptions of credibility, along with the roles of AI editorial value and AI literacy. The labels under examination here each describe a qualitatively different relationship between human editorial judgment and machine production. For example, to label content as AI-influenced asserts that a human author remained in substantive control but “generated” signals that AI had more primary authorship (but there was still some human editing in this study’s operationalized approach to “generated”). Audience responses to these labels may therefore reflect not only reactions to words but evaluations of editorial realities.
Results indicate that message credibility was significantly shaped by AI labeling, whereas source credibility remained stable across labels, influenced instead by content origin and perceptions of editorial value. Specifically, messages labeled as “AI-generated” received the lowest perceptions of message credibility, while those labeled “AI-influenced” were evaluated most positively. This suggests that audiences respond negatively when a label signals full automation but view partial or supportive AI involvement more favorably, which is a pattern consistent with previous research showing that explicit AI authorship cues can elicit skepticism or reduce perceived authenticity (Altay and Gilardi, 2024; Chen et al., 2025; Graefe and Bohlken, 2020; Palmer and Spirling, 2023; Sun et al., 2022).
In contrast, source credibility depended primarily on the content origin and participants’ perceptions of AI’s editorial value. News agency articles were viewed as more credible than blogs, reinforcing the enduring weight of institutional trust. Reuters’ established reputation as a recognized and credible news agency likely accounts for higher source credibility ratings relative to the blog, an effect attributable to prior attitudes toward the outlet rather than to AI disclosure itself.
Participants who valued AI’s editorial potential tended to rate sources as more credible overall, illustrating that acceptance of AI-mediated journalism is closely tied to underlying attitudes about AI’s professional utility. The absence of significant moderation by AI literacy suggests that familiarity alone may not drive trust; rather, perceptions of editorial value exert a stronger influence on credibility judgments. This distinction may reflect the difference between knowing about AI and holding opinions about its editorial worth. Audiences who view AI as prone to inaccuracy or bias may discount its editorial value regardless of their familiarity with the technology, whereas those who perceive AI as enhancing rather than compromising journalistic quality may be more willing to maintain trust in AI-mediated content (Yeste-Piquer et al., 2025). The finding that editorial value predicted source credibility while literacy did not suggest that what audiences believe AI can do for journalism matters more than how much they know about AI itself.
While the pattern of results may be consistent with dual-process accounts in which AI labels function as heuristic cues (Chaiken, 1980; Sundar, 2008), another interpretation deserves consideration. That is, participants may have been making deliberate evaluations of distinct editorial practices rather than relying on cognitive shortcuts. The three terms (i.e., generated, assisted, influenced) describe fundamentally different levels of human oversight and AI involvement, and the footnote clarifications in the stimuli gave participants concrete information to reason from (systematically). The non-significant effect of AI labeling on source credibility further suggests that audiences distinguish between evaluating what is said and who is saying it, possibly interpreting disclosure through perceived editorial control and journalistic legitimacy rather than responding uniformly to the presence of an AI label. Future research incorporating process measures could disentangle whether credibility differences reflect heuristic activation, considered judgment about editorial practice, or both.
Theoretical implications
The results contribute to theories of media credibility and AI transparency in several ways. First, by demonstrating that disclosure framing influences message evaluations more strongly than source assessments. Participants in this study appeared willing to trust a source even when the source disclosed AI involvement, while applying more scrutiny to the content itself as labels signaled higher degrees of machine involvement. This distinction has implications for how news organizations weigh the costs and benefits of AI use, as transparently communicated via AI involvement labels. This may be understood through Sundar’s (2020) framework which suggests that transparency statements about AI use not inherently build trust but instead activate cognitive associations tied to the degree of machine autonomy implied by the disclosure. Moreover, the predictive role of AI editorial value emphasizes that credibility judgments depend not only on source and message features but also on users’ interpretive schemas rooted in perceived technological competence and control (Shin, 2022; Toff and Simon, 2025). This extends source credibility theory to AI-mediated journalism by foregrounding how technological mediation intersects with institutional credibility and audience inferences about editorial agency.
Recent scholarship underscores that credibility responses to AI disclosure are influenced by how specifically and accurately the disclosures characterize the role of AI in the process. Leuppert et al. (2025) found that the negative credibility effects of AI-author labels may stem not only from automation cues but also from vague or underspecified wording (e.g., “comment written by artificial intelligence”), which obscures AI’s actual role in the production process. They argue that transparency should extend beyond simple disclosures to include details, such as the software, training data, and algorithmic methods, as richer explanations of AI’s editorial role have been shown to increase perceived credibility (Lermann-Henestrosa and Kimmerle, 2025; Metzger et al., 2024; Montal and Reich, 2017). The present findings are broadly consistent with this account: labels that more precisely characterize the nature of AI involvement produce different perceptions of credibility. It can also be noted that the footnotes provided to participants described each label, it may provide further description that Leuppert et al. (2025) advocate for, such as including the software company or developer and methodology within its algorithm. Whether this degree of specificity might further modulate perceptions of credibility or contribute to cognitive overload remains a question. More broadly, these findings align with growing research demonstrating that audiences may not just be passive recipients of these disclosures but actively interpret cues to infer the degree of human involvement in what they consume (Altay and Gilardi, 2024; Chen et al., 2025).
Drawing on Sundar’s (2008, 2020) MAIN model, the pattern of findings is consistent with the view that AI disclosure labels may activate cognitive associations connected to the degree of machine autonomy they signal. When content is labeled as “AI-generated,” audiences may interpret greater automation with reduced human accountability and editorial judgment, which are particularly consequential in evaluative contexts where judgment and interpretation are important. In contrast, “AI-influenced” may preserve some perception of human oversight while still allowing audiences to attribute AI involvement. This hybrid framing, which might signal collaboration rather than displacement, could explain why “influenced” was evaluated more favorably. Participants in this study appear sensitive to gradations of AI involvement, differentiating meaningfully between labels that connote more automation versus partial or limited AI use. This sensitivity informs how audiences may construct meaning from signals about the distribution of agency between human and machine in the editorial process. It is important to note that the present design does not inform whether these responses reflect heuristic or systematic processing (or some combination of both), which is a distinction that future research incorporating processing and need for cognition measures might clarify. More broadly, this framing connects disclosure research to questions in human-AI interaction related to how people assess trust when agency is shared, distributed, or ambiguous, raising implications well beyond journalism for any domain in which decision-making related to AI use must be communicated to a public audience.
Practical implications
For practitioners, the findings highlight that not all AI disclosures are equally effective, thus underlining the double-edge of such a transparent action as previously discussed by Toff and Simon (2025). News organizations seeking transparency should carefully frame AI involvement in ways that emphasize collaboration rather than automation, but, most importantly, the word used to label the information should accurately reflect the action taken. The label “AI-influenced” appears best suited to maintain message credibility without undermining audience trust. Additionally, fostering public understanding of AI’s supportive editorial functions could mitigate skepticism, particularly among audiences less confident in AI’s value for journalism. Findings may suggest that people hold a greater concern for editorial practices perceived as being more automated than human-driven and editorially overseen by reporters. As such, journalism practices described as AI-influenced would be viewed as more favorable than AI-generated. The perception of a higher editorial control would lead to higher trust and credibility in the content produced.
These insights guide transparency strategies for media organizations, balancing ethical disclosure with credibility preservation.
Limitations and future research
While this study offers important insights into AI disclosure effects as of late-October 2025, the results should be interpreted in light of rapid technological evolution and shifting audience familiarity. As generative AI becomes more pervasive, audience perceptions of credibility and transparency may evolve, warranting longitudinal research to capture shifts over time. Second, the AI literacy measure captured perceived rather than objective AI knowledge, relying on self-reported familiarity rather than a validated quiz assessing actual technical understanding. This distinction is critical, as divergence between perceived and actual knowledge may confound interpretations of literacy effects.
Attention should also be given to label salience. Although the majority of participants passed the manipulation check, approximately 11% failed to correctly identify the AI disclosure label they were exposed to. This is consistent with Tewksbury et al. (2011), who suggest that disclosure cues may not always attract conscious attention. Future research incorporating eye-tracking could clarify whether and when audiences notice AI labels before forming credibility judgments, and whether increased label salience would strengthen or alter the effects observed here.
The footnote describing the AI-generated label in the stimuli also warrants attention. As noted in the stimuli description, this label was operationalized to include human editing of AI-produced text, a choice that reflects a real hybrid practice but may have attenuated the credibility differences between conditions. Understanding the public perception of the use of AI in journalism may be richer if a future design included a condition that indicated complete AI generation with no human involvement, and a control condition or a disclosure reading “AI was not used.”
Further work could also explore linguistic framing and visual disclosure designs to determine which transparency practices to prioritize trust in journalism. Finally, a future study could explore whether other topics, especially hard news, yield similar findings, and whether different news outlets and a more familiar blogger also influence the public perceptions similarly.
Conclusion
This study sheds light on how audiences interpret disclosures of AI usage in journalism. Beyond the question of labeling per se, this study underscores that audience responses may reflect judgments about actual differences in how AI is or might be used by newsrooms, with generated, assisted, and influenced denoting meaningfully distinct editorial practices that carry different implications for human oversight, accuracy, and accountability. Transparency strategies should therefore be grounded in an honest representation of AI’s actual role in content production, not merely in choosing language that is strategically favorable. Messages described as AI-generated were viewed as less credible than those labeled as AI-influenced or AI-assisted, suggesting continued caution toward full automation in news production. At the same time, perceptions of editorial value and trust in institutional sources meaningfully shaped credibility evaluations, underscoring that technological transparency alone does not ensure trust. Instead, audience interpretations are guided by beliefs about human oversight and AI’s journalistic value. As AI becomes increasingly embedded in newsroom practices, news organizations should consider how disclosure language and audience education can reinforce credibility, framing AI as a tool that supports, rather than replaces, human editorial judgment.
Supplemental material
Supplemental Material - Are all uses of AI created equal? An experimental review of AI disclosure types on credibility
Supplemental material for Are all uses of AI created equal? An experimental review of AI disclosure types on credibility by Patrick F Merle, Erika J Schneider, Mitch Krueger in Journalism
Footnotes
Ethical considerations
This study received ethical approval from the FSU IRB (approval #STUDY00006100).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data is available upon request to the corresponding author.
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.