
Abstract
Around the world, museums dedicate enormous resources to developing exhibitions with the aim of making their collections and knowledge accessible to broad public audiences. Interpretive texts, both spoken and written, play an important role in this endeavour, underpinned by the belief that they will add ‘something more’ to the experience gained by looking alone. But is this belief justified? This article draws on recent theoretical developments in systemic functional linguistics (SFL) and multimodal semiotics to explore the complexity of meanings and relations involved in the interaction between (verbal) text, displayed artefact and visitor in an art exhibition and a history exhibition. Focusing on two key dimensions, vergence and presence, it shows how the texts work in very different ways to shape visitor experience, both in terms of scaffolding the interaction and in adding meaning to the encounter. It proposes the idea of ‘verbal vectors’ that are gradable in strength as a feature that explicitly ‘motivates’ visitors to look at the displayed artefacts and the idea of ‘shell’ vectors as a particular feature of texts in art exhibitions.
Keywords
Museums are important cultural resources, and they invest heavily in developing exhibitions with the aim of making their collections and knowledge accessible to broad public audiences. The exhibitions they produce are complex, multimodal experiences (McMurtrie, 2013; Ravelli and Stenglin, 2008), unfolding across time and three-dimensional space through a cacophony of modes and media: artefact, still and moving image, written and spoken text, built form, gesture and movement, audio, video, even virtual and augmented reality. Yet in most exhibitions the core experience remains the interaction that occurs between a visitor and a displayed artefact: an object or artwork experienced visually, with, in most instances, a spoken or written text offered to help visitors look at it more closely or deeply.
This idea that the verbal texts that accompany a displayed artefact are there to add ‘something more’ to the experience gained by looking alone has become deeply entrenched in contemporary museum practice (e.g. Schaffner, 2006; Serrell, 2015). It underpins a huge commitment in terms of time, effort, materials and budget in developing and producing museum texts, and a huge literature on how and how not to write them (e.g. Bitgood, 1989; Blais, 1995; Ravelli, 2006; Serrell, 2015). Yet, despite this abundance of advice and guidelines, the literature says remarkably little about how object and verbiage act together to make meaning; the semantic relations construed between a displayed object and its related verbiage remain largely unexamined. As a result, we have little evidence to show what exactly all the words bring to the experience of looking.
This article draws on recent theoretical developments in systemic functional linguistics (SFL) and multimodal semiotics to tease apart the dynamic interplay of looking and reading, listening, talking, experiencing and meaning-making that occurs around a displayed artefact. More particularly, it draws on the approach used by Painter et al. (2013) to examine visual–verbal relations in picture books and Martin’s notion of ‘presence’ (Martin and Matruglio, 2013) to bring this complexity of relations into view. Also influential has been Liu and O’Halloran’s (2009) notion of intersemiotic texture, in which ‘specific kinds of relationships’ act to ‘motivate’ semantic interaction across modalities, and in doing so ‘orchestrate’ semantic expansion (pp. 367–369). From this starting point, this article proposes an analytical framework and applies it to show how the label texts in an art exhibition and a history exhibition work in very different ways to shape the visitor experience of a displayed artefact.
Finding a Vantage Point
Over recent decades, the social semiotic framework has provided a principled and powerful model for multimodal research; in Bateman’s (2014: 45) words, due to its strength theoretically and analytically, it represents ‘the most widespread general approach to multimodal description worldwide’. Building on Halliday’s pioneering conception of language (see, for example, Halliday, 1978; Halliday and Matthiessen, 2004), this approach understands meaning as systemic and functional: systemic in that it conceptualizes meaning as a system of choices (or rather, an integrated network of systems of choices) and functional in that it sees meaning as simultaneously enacting three functions, or metafunctions: representing experience (ideational), enacting relationships and values (interpersonal), and forming coherent ‘texts’ from smaller units of meaning (textual). Different meaning-making resources – for example, language, image, gesture, three-dimensional space – share this common architecture of meaning organized metafunctionally into systems of choices. 1 Importantly, however, the systems themselves are different for each modality, with their own distinct range and configuration of options (Painter et al., 2013: 133). Thus, while this creates complementarities within and between modalities, because each semiotic system has its own affordances, the complementarity between modes is ‘not always tidy’ (p. 136). As a result, work on intermodal relationships, that is, on how modalities work together to co-construct meaning, has been theoretically challenging (Martin, 2011). In terms of visual–verbal relations, many accounts to date framed within the social semiotic perspective have drawn on the principle of extending taxonomies of relations based on language across modalities, with such approaches falling into two main groups: those using relations anchored at the level of lexicogrammar (e.g. Kong, 2006; Martinec and Salway, 2005; Unsworth and Chan, 2009), and those anchored at the level of discourse semantics (e.g. Jones, 2006; Liu and O’Halloran, 2009; Nascimento, 2012; Royce, 2007). These approaches have contributed greatly to developing detailed and comprehensive accounts of visual–verbal relations. However, the principle of extending various text-forming resources from within systems of language to explain intermodal relations remains problematic and restrictive in that it does not allow the theoretical space to model the full embrace of synchronicities, complementarities and relative weightings of the different meaning potentials across the metafunctions as they interact to make meaning. In effect, by treating the visual mode as another clause and thus interpreting visual–verbal combinations as they would clause complexes, these approaches reduce multimodal texts to monomodal ones (Martin, 2015).
Accordingly, this analysis takes as a starting point more recent approaches which argue that intermodal relations are different in kind from intramodal relations and have stepped ‘back’ from both lexicogrammar and discourse semantics to the common architecture of semiosis in an attempt to better capture these differences (Painter et al., 2013; also De Souza, 2013; Hood, 2011; Tian, 2010). Rather than applying ‘a limited taxonomy of possible image–verbiage relations’, the approach in these studies has been ‘to map out’ the meanings instantiated in the various systems in each contributing modality across the three metafunctions and then compare their relative contribution to overall meaning (Painter et al., 2013: 156).
From this vantage point, Painter et al. (2013) work with two basic intermodal relations: converging relations, where there is a commonality or co-commitment of meaning across modalities, and diverging relations, where meanings differ. 2 These relations play out across the metafunctions to create patterns they term concurrence (ideational), resonance (interpersonal) and synchronicity (textual). For example, from their analysis of the picture book Not Now Bernard (David McKee, 2017[1980]), a strong pattern of intermodal concurrence is built up during the first part of the book as each character depicted visually is also identified in the accompanying verbiage: there is a converging or co-patterning of ideational meaning. In contrast, in the second half of the book there is a divergent coupling, where the verbal identity ‘Bernard’ now co-patterns with an image of a monster. In this story, this shift in concurrence plays a key role in creating humour and in invoking negative judgment on Bernard’s parents (who are so inattentive they fail to notice the change). The example also shows how a dual reading of the coupling, as both diverging and converging, enables a further metaphorical reading of the monster as a transformed version of Bernard (Painter et al., 2013: 145). From this same text, an example of intermodal resonance would be the lack of eye contact between the depicted characters and the reader, and the use of a third person narrator in the verbiage; i.e. there is a co-patterning, or convergence, of visual and verbal focalization, and thus interpersonal resonance (p. 145; see also Tian, 2010, for an exploration of resonance in picture books in terms of converging and diverging interpersonal meanings). An example of intermodal synchronicity is where the verbal News 3 are picked up in the main focus group of the image, creating a synchronicity in prominence between the visual and verbal phasing of the story (p. 146).
In the context of the questions at issue in this article, meanings in the verbiage can converge with those instantiated visually in the displayed artefact or artwork or they can diverge. Where they converge, that is, where there is a co-patterning of meaning, we can argue that the verbiage is working to connect the two modalities (Liu and O’Halloran, 2009). Conversely, where they diverge, that is, where meanings in the text are not also instantiated visually in the displayed artefact or artwork, we can justifiably claim that the verbiage is bringing new meanings to the encounter. In short, these relations give us a useful starting point for interrogating the idea that verbal texts ‘add to the looking’ and for describing the specific kinds of contributions they make.
Another valuable concept, also recently reworked from a broader, metafunctional perspective, is ‘presence’, which develops the linguistic notion of context dependency (e.g. Cloran, 1999; Halliday and Hasan, 1976; Martin, 1992). Motivated by recent collaborations with Legitimation Code Theory and its concept of semantic gravity (Maton, 2014), Martin and Matruglio (2013) proposed ‘presence’ as a package of linguistic resources which act together to anchor or release meaning from its immediate context. Interpreted metafunctionally, presence comprises the variables of iconicity, negotiability and implicitness. In language, iconicity is the key variable in terms of ideational meaning; it denotes the extent to which meaning is realized congruently (i.e. in ways that map more directly to lived experience). This plays out in a number of ways, including the degree to which events unfold in a text in the sequence in which they occur in the material world (field time) or the extent to which they are reconfigured, notably through grammatical metaphor, into discourse that is more abstract and self-organizes to suit its rhetorical needs (text time). Negotiability is the key variable of interpersonal meaning; it references the extent to which a proposition is arguable and the nature of attitude involved. For example, a first or second person reference in the ‘nub’ (subject) of a proposition strengthens presence by directly implicating a given reader/listener and thus anchoring modal responsibility in that context/moment. Similarly, affect, as the direct expression of feeling, is argued to have greater presence than appreciation or judgment, which can be interpreted as an institutionalized expression of feelings (Martin and White, 2005). Implicitness is the key variable textually; it reflects the extent to which meaning is ‘recoverable’ from the text itself or from the immediate context, for example through exophoric reference, ellipsis, substitution (Martin and Matruglio, 2013). Thus, relative to the questions at stake here, presence specifies the linguistic resources that act to anchor or free the verbal texts from the immediate context of the display. If we focus our view of this context on the displayed work itself, then presence can provide a further perspective on the nature of the relationship between verbiage and artefact. In effect, it reprises Barthes’ (1977) notion of ‘anchorage’ (see also Bateman, 2014; Martinec and Salway, 2005) but with a more developed set of analytical tools for exploring that relationship.
In summary, then, this analysis begins with two sets of relations, both enacted metafunctionally: vergence, where meanings instantiated in each modality can co-pattern (converge) or differ (diverge); and presence, where meanings can be tied to the present context (i.e. the displayed work) or independent of it (see Table 1). In the discussion that follows, however, the focus will remain largely on ideational and textual meanings – not because there is little to say about interpersonal meanings but in fact the reverse, and thus more fitting for a separate article. The discussion will also focus on the relationship between a displayed artefact or artwork and its related ‘object’ text. While acknowledging these texts form part of a larger hierarchy of texts within the exhibitions (including room/section themes and subthemes), 4 the aim is to offer a detailed account of the meaning potentials and interactions in this key moment of the exhibition experience. In this way, while this article concerns museum exhibitions, the approach and findings have relevance more broadly to work in multiliteracies and other contexts where a verbal text is intended to add or elaborate a visual stimulus, such as a captioned image or diagram, or a spoken commentary accompanying slides in a talk or lecture.
Metafunctional organization of vergence and presence (after Painter et al., 2013; Martin and Matruglio, 2013).

Connecting Modalities: Converging Relations
The data in this study comes from two exhibitions: an exhibition on Renaissance art held at a national art museum, and an exhibition on the history of a now-demolished entertainment venue, held at a city history museum. Beginning with relations of convergence across the metafunctions, two highly complementary patterns quickly come into view, pointing to a marked difference in the nature of the meaning-making work being done by the verbal texts in the two exhibitions.
Ideational concurrence
As noted above, ‘concurrence’ occurs when similar ideational meanings are instantiated in both visual and verbal modes. Looking firstly at the object labels in the Renaissance exhibition, there were multiple points where the object labels instantiated meanings that were also instantiated visually in the related displayed work. In other words, the exhibition was rich with instances of ideational concurrence across the visual and verbal modes, creating multiple points of convergence between the label text and the displayed artwork. For example, in the label text reproduced in (Table 2), there are 17 instances of concurrence (in bold), where ideational meanings instantiated in the verbiage (participants, processes, circumstances) are also instantiated in the work.
Concurrence in a Renaissance label text (Portrait of an elderly man seated by Giovan Battista Moroni, 1575–79. Accademia Carrara Bergamo 58AC00084).

Looking more closely at these points of concurrence, we see that what is said in the verbiage relates to the displayed work or object in three ways. The first is through a relationship of meronymy, where the text references an aspect or part of the displayed object (e.g. ‘the silvery-grey background’). The second is through a relation of correspondence, where the text references the displayed object as a whole (e.g. ‘this painting’). 5 The third is through a relation of hyponymy, where the text references a larger class or category to which the displayed item belongs (e.g. ‘portraiture’).
Additional examples of these relations are summarized in Table 3: correspondence, when the text makes a specific reference to the displayed artefact as a whole; meronymy, where the text explicitly references some part or feature of the displayed object, for example an element of subject matter or physical structure; and hyponymy, where the text references a larger class of things of which the displayed object is a member or example.
Summary of types of ideational concurrence from the case study exhibitions.
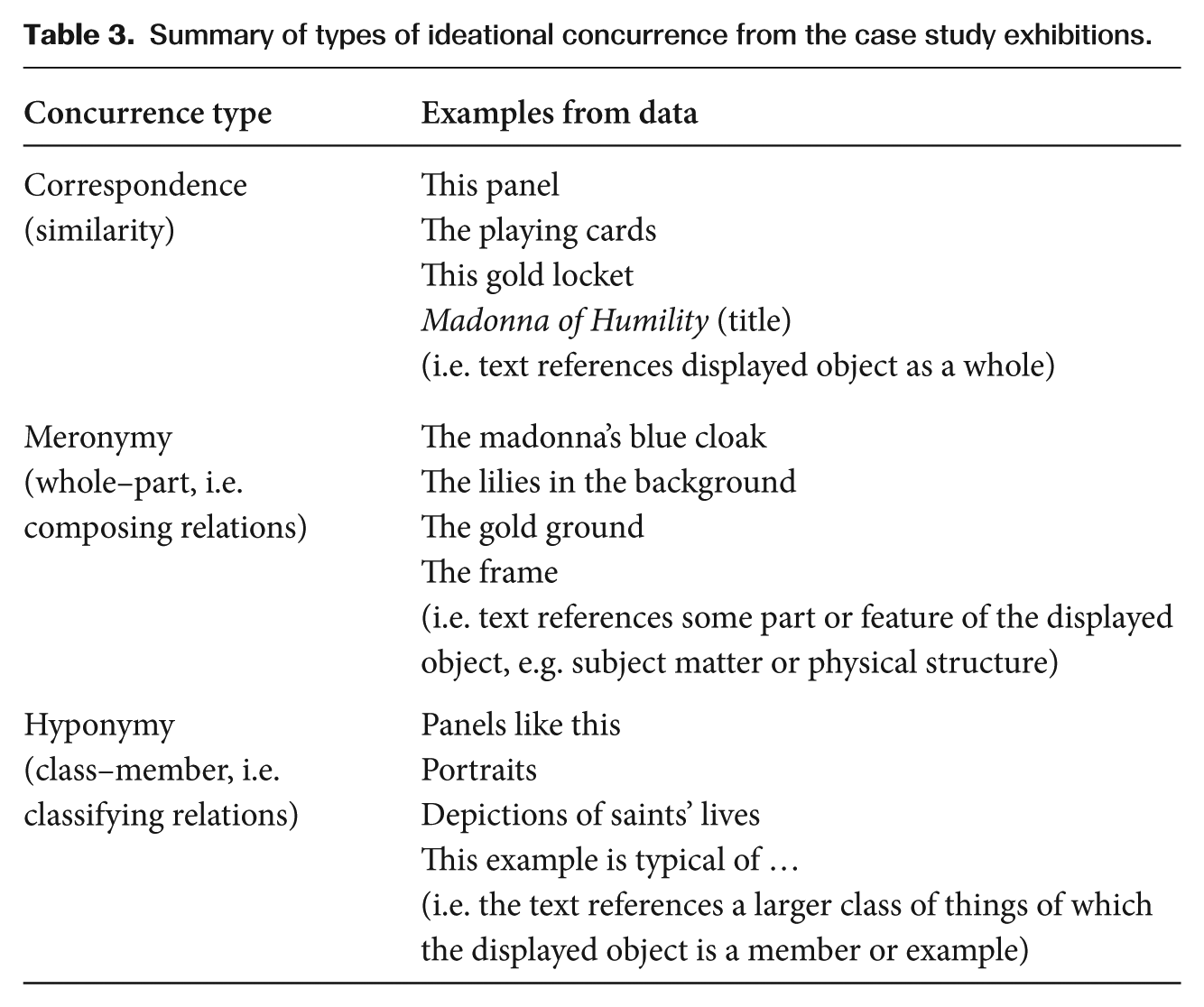
As reflected in the Moroni example Table 2, in the Renaissance labels there was a mix of these three types of concurrence, with each type doing a different kind of linguistic work. Relations of hyponymy act to explicitly connect the displayed item to broader classes of phenomena, committing meanings that move beyond the present context and thus explicitly scaffold transferrable, cumulative knowledge. Relations of correspondence reference the displayed item as a whole, so while they may modify or moderate a visual reading of the item by virtue of the different affordances language brings, they do not explicitly prompt the reader/viewer to consider any particular element or attribute of the item. Relations of meronymy, on the other hand, do exactly this. They burrow down to a finer level of detail to concern the elements or parts that comprise particular objects. At the very least, they give salience to the feature they reference, by selecting that feature out of an infinite number of possible features that could have been referenced. But they can also act to explicitly link the referenced feature to non-visible meanings and thus interpret that feature in some way. In the Renaissance object labels, the marked dominance of relations of meronymy (nearly 90% of instances of concurrence) point to the work of these texts in interpreting specific aspects of the displayed object rather than the item as a whole. In sum, for the Renaissance exhibition we can say that the high overall level of ideational concurrence between label text and displayed object (a total of 339 instances in 245 clauses, or an average rate of 14 in every 10 clauses) shows that the labels were strongly connected to works they referenced. The relative proportion of the different concurrence types demonstrates that while they were working to some extent to interpret the works as entities in their own right (via correspondence) and as examples of larger histories, practices and ideas (via hyponymy), in large part, their main work was focused on interpreting elements specific to the individual displayed artwork (via meronymy).
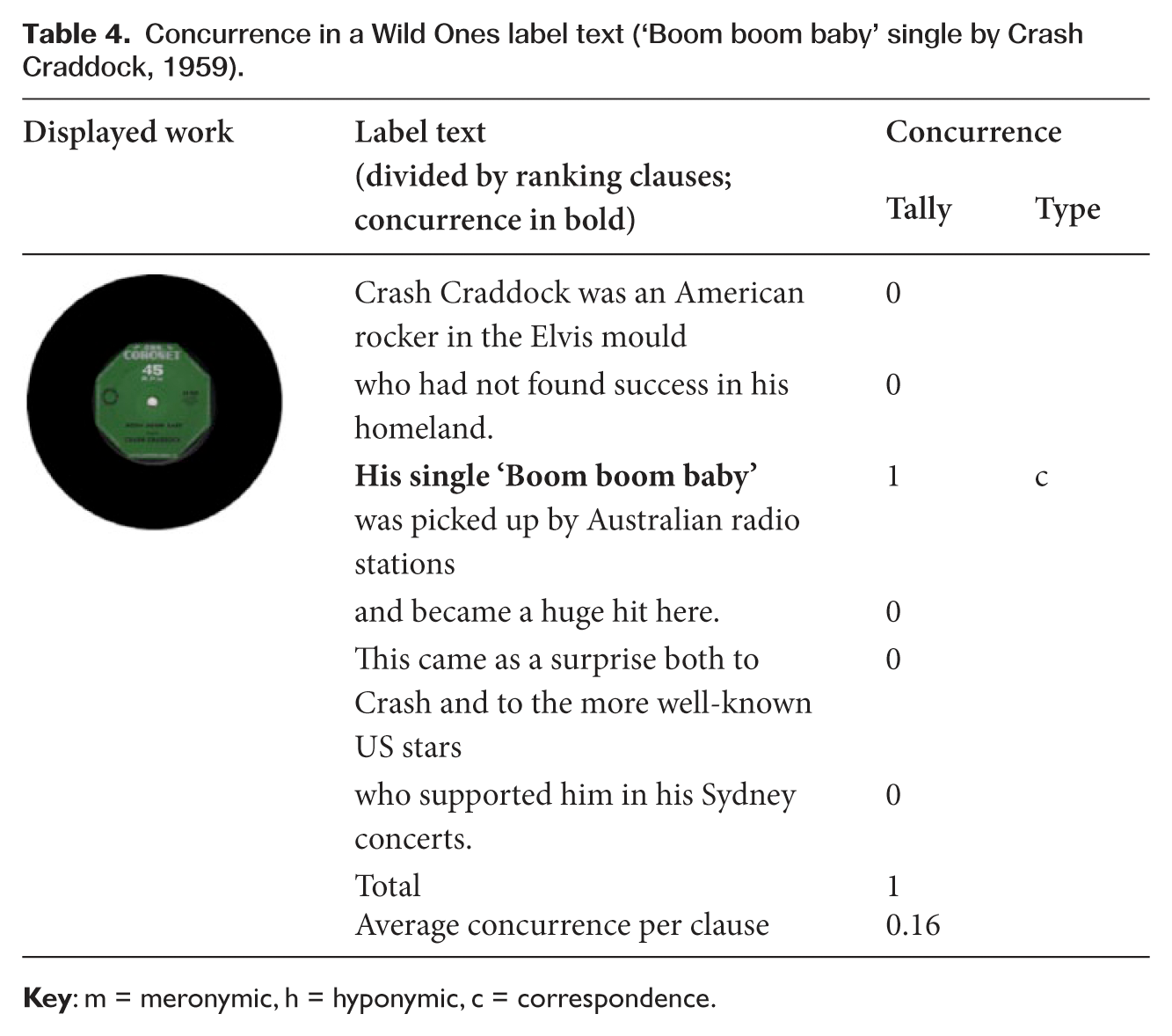
In contrast, the object texts in the history exhibition, titled The Wild Ones, contained relatively few instances of ideational concurrence, where participants, processes and circumstances in the label texts were also instantiated visually in the displayed artefact (a total of 96 instances in 202 clauses, or an average rate of about 4 in 10 clauses). As a result, there were relatively few direct points of convergence. In the label text shown in Table 4, there is only one such moment of concurrence, and this pattern was typical of the exhibition. In other words, the label texts made relatively few direct references to the displayed objects. The label text, in effect, functioned more as a parallel discourse; object and verbiage co-existed in space and time but the text was not working to explicitly link them, either in terms of connecting the individual object to broader ideas, histories or contexts, or of interpreting its particular details or aspects. Instead, this work was being left to the reader/viewer to initiate and follow through.
Concurrence in a
Interpersonal resonance
Shifting briefly to look at these texts from the perspective of interpersonal meaning, there was also a certain convergence of meanings across the two modes. Most noticeable is the co-patterning of tenor: the Renaissance labels are more formal and less personal. For example, in the Moroni text, the word choices are more rarified (‘establishes’ rather than ‘sets’); there is a generous use of nominalization which removes the sense of agency (development, pose); and the artist himself is present as an attribute rather than as a person (Moroni’s late period, Moroni’s portraits, his career) or as a generic category rather than individual (‘the artist’). There is thus a synergy between the tenor of the label text and the formality of the display, with the portrait set within an extravagant gold frame, remote in time and place from the viewer’s everyday world. The reference to ‘old men’ creates a singular more personal moment within an otherwise restrained and remote text, where ‘things’ are appreciated rather than feelings directly expressed. This juxtaposition mirrors the painting itself, with the old man’s face and his direct gaze creating a personal and powerful contrast within the otherwise cool, remote and muted ground.
The Crash Craddock text, on the other hand, is personal and informal in tenor. It deliberately adopts a more spoken style, with vernacular word choices (‘rocker’, ‘picked up’, ‘huge’) creating a synergy with the popular culture context from which the displayed object came and thus with the object itself. Unlike Moroni, Craddock himself is present (‘Crash Craddock’, ‘Crash’, ‘him’) and directly evaluated in the text through inscribed judgment and affect – ‘a rocker in the Elvis mould’ (+ social esteem: capacity); ‘not a success’ (– social esteem: capacity); ‘surprise’ (+ happiness). The effect is to create a person-to-person bond, reducing the social distance between the history being told and the viewer/reader.
Textual synchronicity
In language, one of the key resources of the textual metafunction is periodicity, which acts to manage the flow of meaning. Waves of periodicity at different levels in a text give prominence to certain meanings, predicting forwards to prepare the reader/listener for meanings to come, and consolidating back to reinforce and synthesize meanings already instantiated. Martin and Rose (2007: 187–189) describe periodicity in terms of a hierarchy, built up through the interaction of ‘little waves’ at the clause level, ‘bigger waves’ at the paragraph level or phase level, and ‘tidal waves’ working to organize larger segments and whole texts:
The term ‘wave’ is used to capture the sense in which moments of framing represent a peak of textual prominence, followed by a trough of lesser prominence. So discourse creates expectations by flagging forward and consolidates them by summarizing back. These expectations are presented as crests of information, and the meanings fulfilling these expectations can be seen as relative diminuendos, from the point of view of information flow. (p. 189)
In terms of the analysis here, it is the little waves that are of particular interest. At the clause level, a peak of prominence occurs at the beginning of each clause. Referred to as Theme, this peak identifies the point of departure of the message to come; it signals what the message will be about. For example, ‘the white lilies symbolise purity and the Annunciation’ is a message about the white lilies: ‘the white lilies’ is the Theme, with the remainder of the clause, the information to come, referred to as New.
Based on this SFL conception of Theme, meanings located in Theme position thus carry a particular kind of affording prominence. So, for example, if a relation of ideational concurrence in the verbal text is located in Theme position, it has a certain predictive prominence in that it takes on the role of framing the message to come in relation to something also seen in the related object. In effect, it anchors the point of departure of the message in the object.
Shifting to consider these texts from the perspective of presence, it also becomes clear that the resources of presence act to strengthen moments of convergence. In other words, while vergence creates synergies between the two modes, presence acts to explicitly ‘motivate’, to reprise Liu and O’Halloran’s (2009: 368) term, interaction between the different modalities. So when ideational concurrence couples with presence in the verbal text, the relationship strengthens to form, in effect, a kind of ‘verbal vector’ that pushes the viewer’s gaze from text to displayed artefact.
For example, looking at the sentence below (Figure 1), ideational concurrence is coupled with presence, created textually through exophoric reference (‘the’) and ideationally through the congruent and specific wording ‘white lilies’. This combination acts to direct the viewer’s gaze to the lilies in the painting in order to retrieve the referenced meanings.

Concurrence and presence in Theme position (Madonna and child with angels by Benozzo Gozzoli, 1449–50. Accademia Carrara Bergamo 81LC00202).
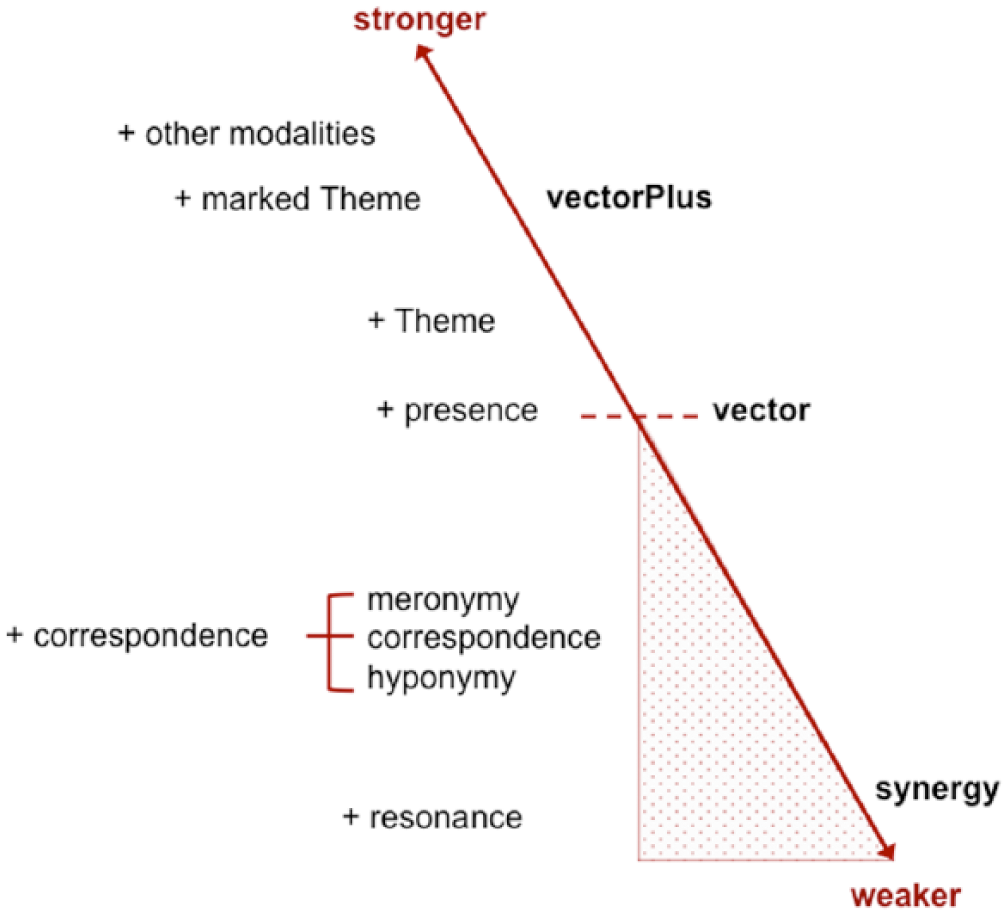
In the label texts in this study, these verbal vectors were found to be present in a number of recurring configurations, which, depending on their patterning of couplings, can be thought of as gradable in strength. For example, as noted above, the coupling of Theme and presence with a concurrence relation of correspondence, meronymy or hyponymy anchors the verbal text’s ‘point of departure’ in the displayed object as a whole or a specific visible feature of it. This coupling creates an additional salience or weight (Martin, 2010) and thus a strong verbal vector. It arguably acts as a metaphorical realization of an imperative:
reads as
Furthermore, when such a ‘Thematic vector’ is directly linked to meanings that are not visible (to the non-specialist viewer) in the displayed object, this can be justly claimed to ‘add something more’ to the looking (see Table 5 for more examples).
‘Adding to the looking’.

A second pattern occurred when a coupling of correspondence, meronymy or hyponymy and presence was realized in non-Theme position. This also creates a verbal vector to the displayed object as a whole or a specific visible feature of it. But here it does not have the same semantic prominence or congruent ordering of the experiential as occurs in the Thematic vector. As a result, the ‘push’ to look feels weaker. For example, compare the following pair; the push feels stronger, or more direct, in the second version:
The Old Testament story of Adam and Eve’s two sons and their tragic fraternal rivalry is depicted
and
A third scenario occurred when verbal vectors existed but were semiotically ‘empty’. This occurred when a vector did not explicitly link to divergent meanings. For example, a coupling of concurrence and presence in the Theme (red) may be paired with a second coupling of concurrence and presence in the non-Theme position (blue), with no further elaboration:
Or a vector may link to divergent information, but the significance or meaning is ambiguous or not explicitly stated; instead it assumes existing, often specialized, knowledge of the field:
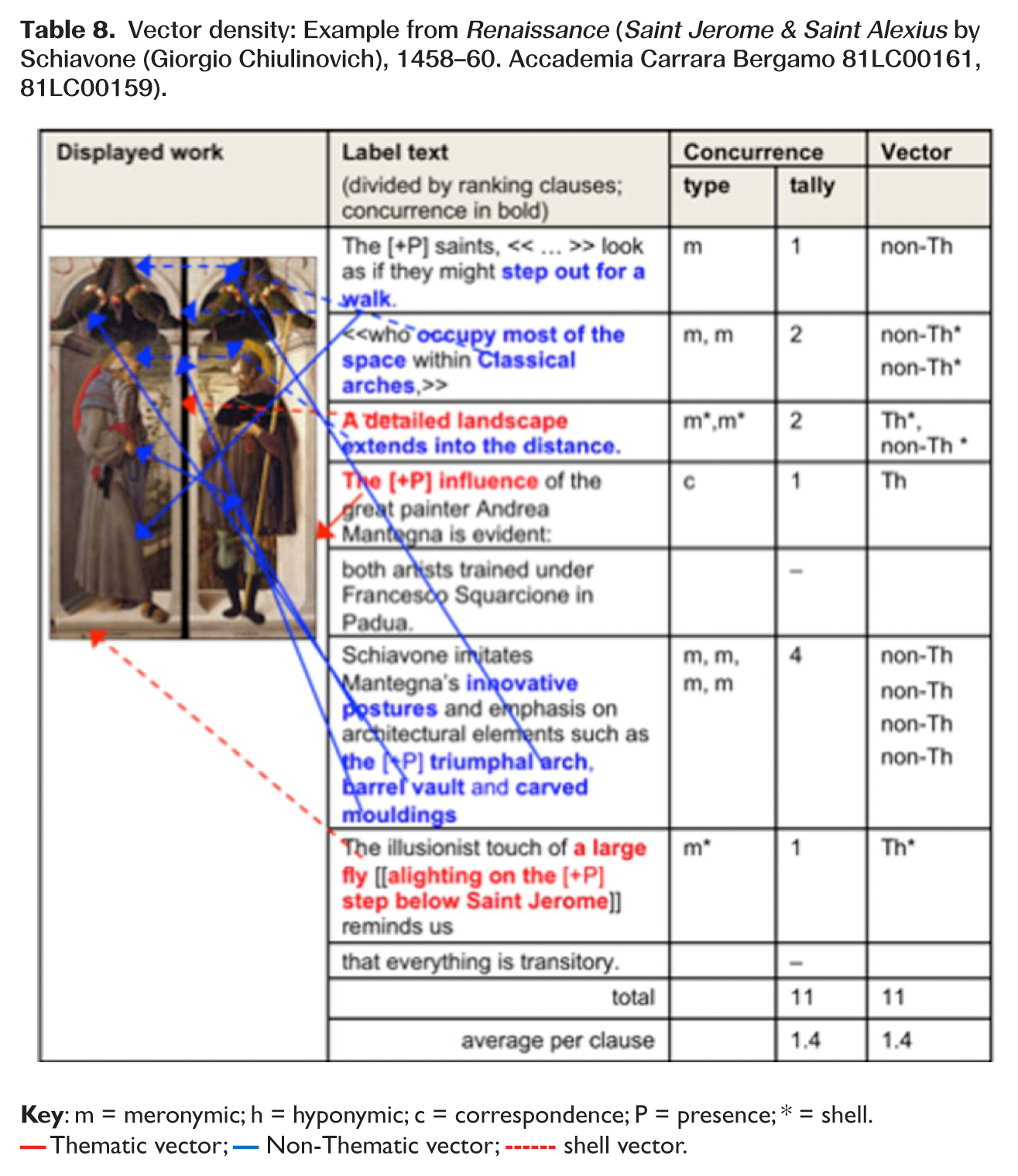
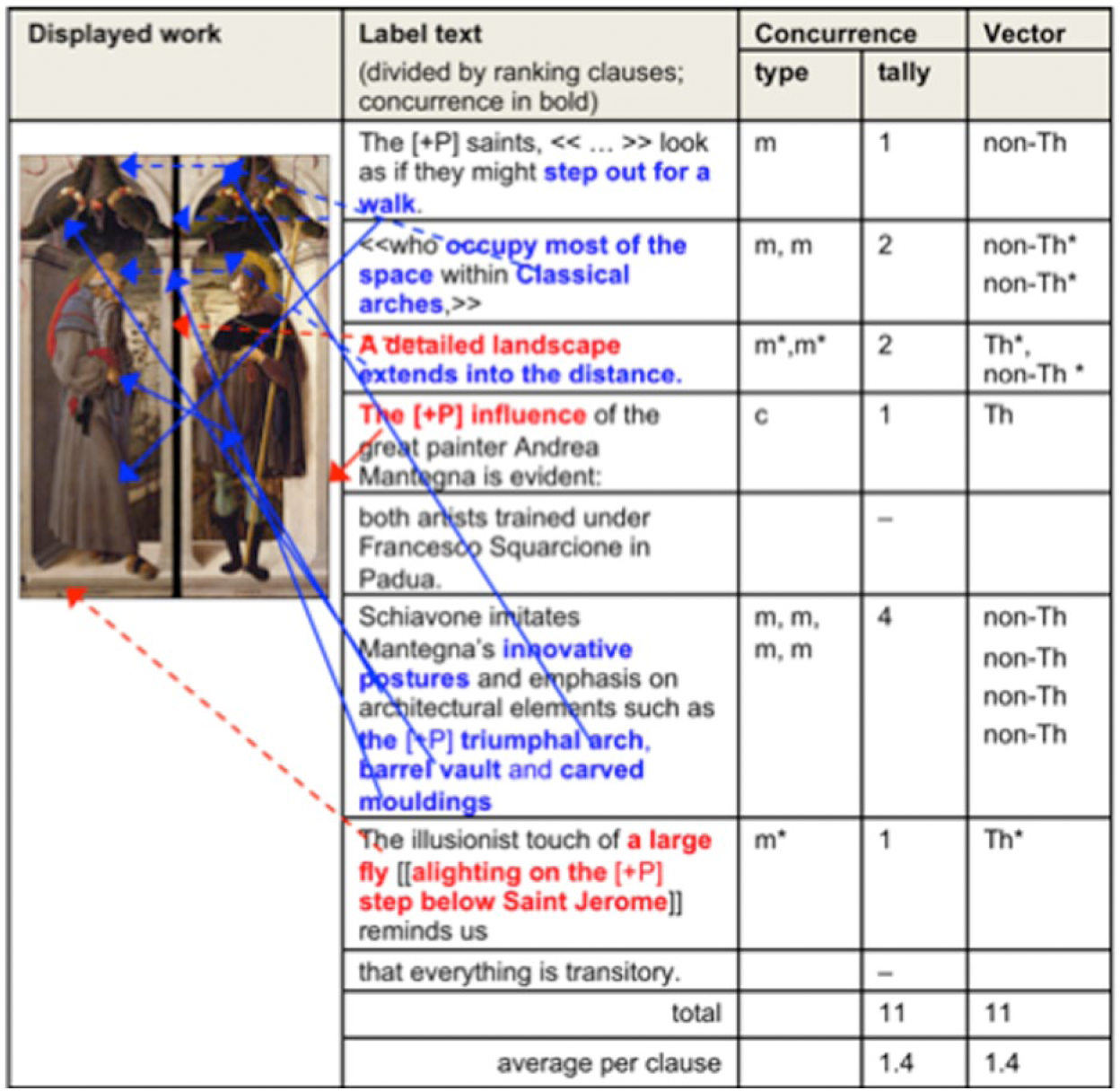
The effect is to create verbal vectors, which prompt or ‘motivate’ the viewer to look at a particular feature or features of the artefact and set up an expectation of something new to follow. But this is not delivered; the viewer is left thinking, ‘So what?’ In other words, the vector gives a focus or salience to the feature it points to, but beyond this is semiotically ‘empty’. It is ‘a shell’, to reprise Schmid’s description of ‘shell nouns’ as a class of general or ‘low-content’ abstract nouns (e.g. ‘thing’, ‘reason’, ‘way’) which function as ‘conceptual shells’ or ‘containers’ for meanings expressed elsewhere in the discourse (Schmid, 2000: 6; see Figure 2).
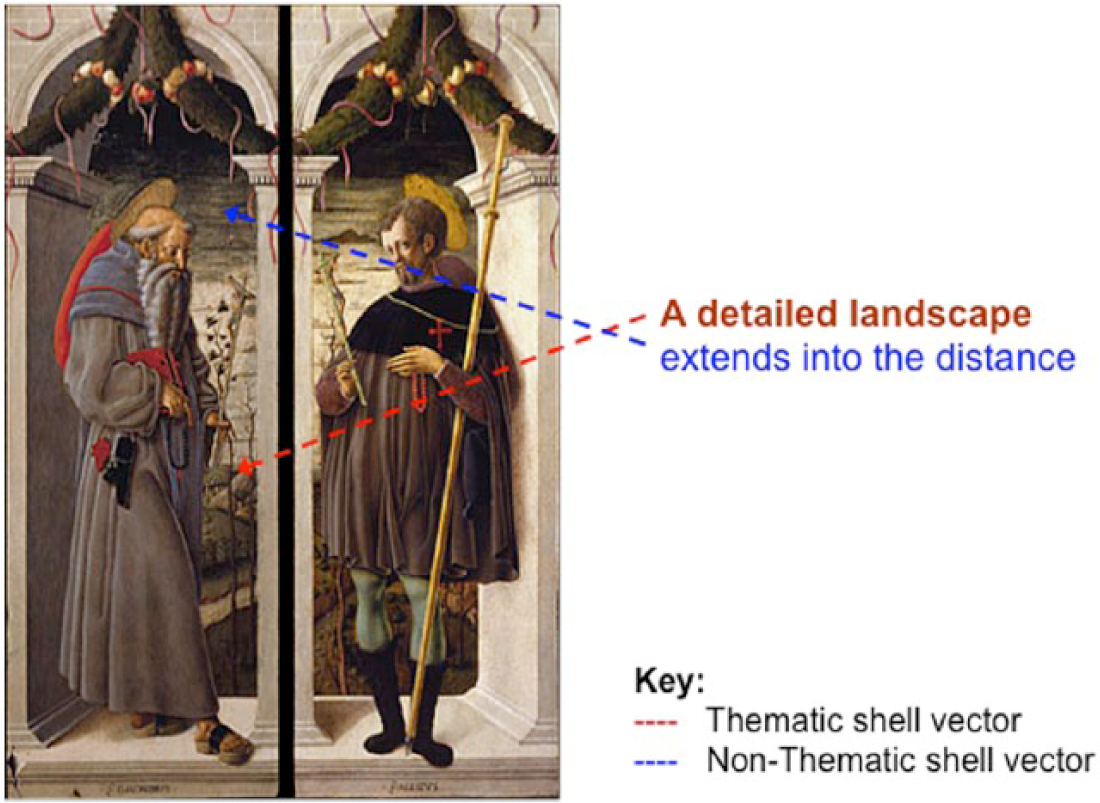
Example of shell vector (Saint Jerome & Saint Alexius by Schiavone (Giorgio Chiulinovich), 1458–60. Accademia Carrara Bergamo 81LC00161, 81LC00159).
Vector gradability
As proposed above, the coupling of concurrence and presence with periodic structure creates ‘verbal vectors’ from text to displayed artefact, with vectors emanating from Theme position having a greater prominence or weighting. These can be further strengthened in a number of ways, notably by adding further meaning into the Theme, and/or by pairing the vector with resources from other modalities.
For example, when a coupling of concurrence and presence is realized in the Theme position, with a marked Theme that further specifies some detail (for example, location) of the artefact,
6
this can be said to ‘commit’ more meaning to the Theme and thus the vector, creating a vector that has a stronger semantic density or weight: a ‘vector plus’. For example:
This pattern has the potential to be further reinforced through other modes. For example, when a verbal text is being delivered in person by a guide, a verbal vector may be accompanied by pointing (gesture), eye contact, increased stress or volume etc., giving further emphasis to the vector; in a written text, added emphasis could be achieved typographically (e.g. by bolding all converging references) or through other design elements.
It follows then that in a given instance of verbiage and displayed artefact, a greater strength of vectors and/or higher number of vectors can be claimed to afford a greater interdependency of verbiage and object. And, when these vectors are explicitly linked to meanings that are not accessible (for the non-specialist) by looking alone, the verbal texts can justly claim to be ‘adding’ more meaning to the looking.
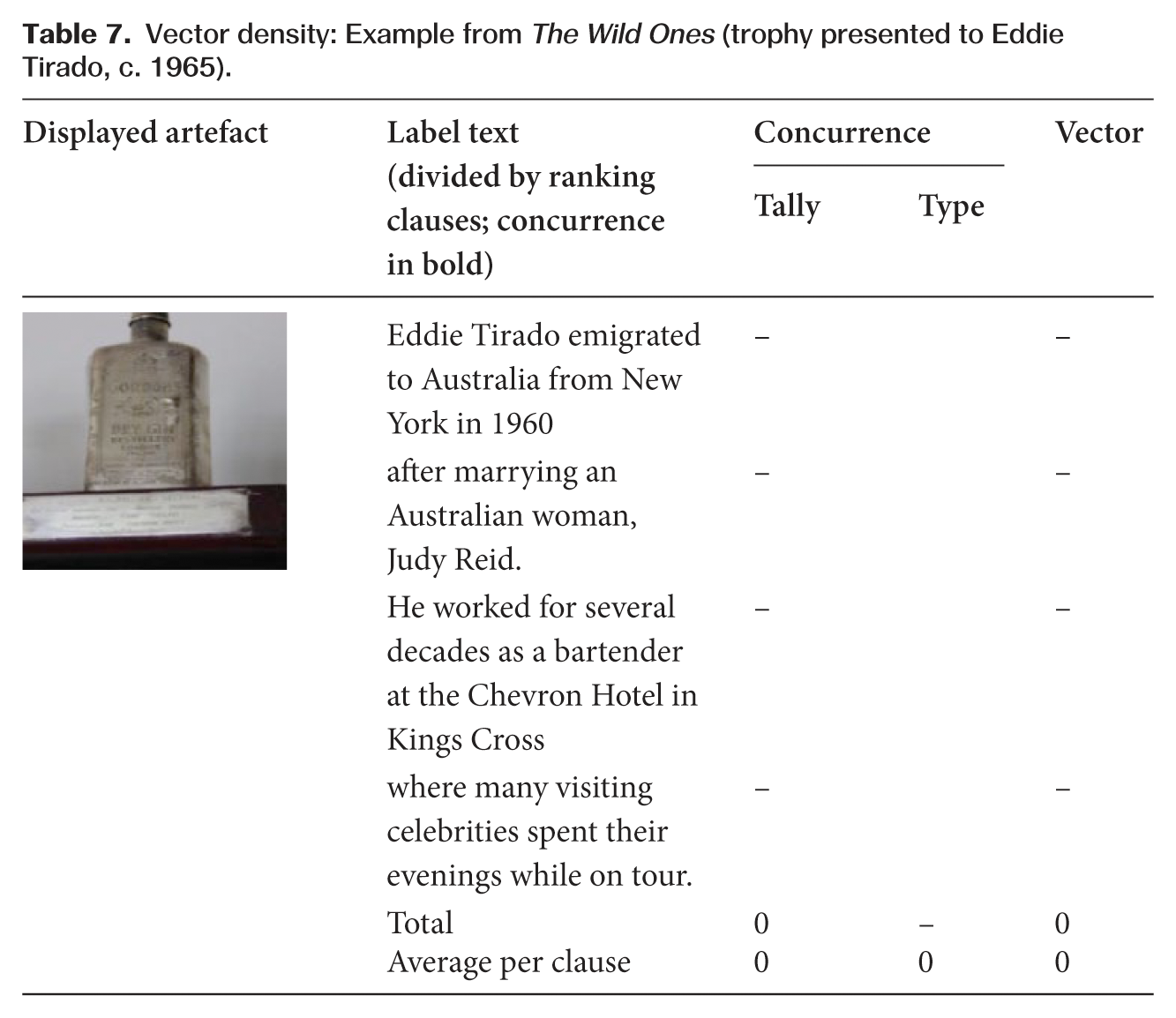
Conversely, when such vectors are not present or are very few, it can be argued that the verbiage is doing less to motivate intersemiotic interaction; the verbiage may be interesting and meaningful, but rather than explicitly ‘motivating’ the viewer to look at the displayed objects, it functions as a parallel discourse. For example, the following label text from The Wild Ones exhibition (Table 7) makes no direct reference to the displayed object it accompanies. While the text brings a series of meanings that are not instantiated visually in the object (a trophy), the verbiage does not explicitly ‘motivate’ the viewer to look to the object.
This was very much the pattern in The Wild Ones exhibition as a whole. There were few vectors overall, and of those present, most targeted the object as a whole (e.g. ‘This locket’, ‘The photo’). Thus, while the label texts brought new meanings to the context of display, they did not explicitly work to motivate the reader/viewer to look at the displayed objects (through a relation of correspondence) or particular parts of them (through a relation of meronymy), nor did they work to explicitly build transferrable knowledge (through a relation of hyponymy).
In contrast, the Renaissance object labels were relatively dense with vectors, providing multiple prompts to visitors to look at particular elements of the displayed works. The mix of concurrence types and vector types worked to direct viewers to ‘focus in’ on specific details and, although to a lesser degree, to relate the individual displayed work to larger categories of phenomena and more generalized knowledge claims. However, the pushes to look were not always paired with new or meaningful information; due to further concurrence, technicality or ambiguity, ‘looking closely’ was not always rewarded. The label text in Table 8 exemplifies this pattern: the short text contains 11 vectors, most pointing to specific details of the work. However, of these, five could be classified as shell vectors in that they act to link two visible features of the work without explicitly adding new information, or they point to a feature of the work but the significance relies on existing specialized knowledge.
In summary, the discussion so far has explored converging relations between object label text and displayed object from a number of perspectives in order to show the nature of the meaning-making ‘work’ being done. The analysis has shown that relations of convergence work to create synergies of meaning between text and object, which work to interpret the displayed object in different ways. Relations of correspondence work to interpret the object as a whole. Relations of meronymy work to explicitly scaffold detailed reading of objects by focusing attention on or interpreting particular elements or details. Relations of hyponymy link an individual object to a larger class or idea, explicitly scaffolding transferable, cumulative knowledge.
But while these relations of convergence create different kinds of synergies between a verbal text and the accompanying displayed artefact, they do not take on the work of specifically ‘motivating’ intermodal interaction. For this to occur, presence is proposed as a critical element in that it acts to transform such synergies into ‘verbal vectors’ that direct the reader/viewer’s attention to the artefact or a particular element of it. Based on the two exhibitions studied, a series of recurring vector types were identified, with periodic structure playing a key role in grading their relative strength. In short, the analysis has brought into view how (con)vergence acts to create synergies of meaning between text and object, how presence acts to convert such synergies into verbal vectors, and how Thematic structure acts with presence to grade the strength of these vectors. These vector types are summarized in Table 6 and represented diagrammatically in Figure 3.
Summary of verbal vector types.

Diagrammatic representation of converging relations.
Vector density: Example from The Wild Ones (trophy presented to Eddie Tirado, c. 1965).
Vector density: Example from Renaissance (Saint Jerome & Saint Alexius by Schiavone (Giorgio Chiulinovich), 1458–60. Accademia Carrara Bergamo 81LC00161, 81LC00159).
 Thematic vector;
Thematic vector;  Non-Thematic vector;
Non-Thematic vector;  shell vector.
shell vector.
Categorizing entities: Renaissance and Wild Ones label texts (after Dreyfus and Jones, 2011; Hao, 2015; Kress and Van Leeuwen, 2006; Martin and Rose, 2007).
Example of field as construed in diverging relations (The mystic marriage of Saint Catherine of Alexandria, with the donor Niccolò Bonghi by Lorenzo Lotto, 1523. Accademia Carrara Bergamo 81LC00185).

Example of field as construed in diverging relations (‘Boom boom baby’ single by Crash Craddock, 1959).

Finally, the analysis has shown that when such vectors are linked with meanings that are not also instantiated visually in the displayed artefact, then the verbal text can justifiably claim to be ‘adding something more’ to the looking. It is to consider these diverging meanings that the discussion now turns.
Diverging Relations: Enabling Semantic Expansion
Again, taking a metafunctional approach, these diverging meanings can be considered from three perspectives. From the perspective of ideational meaning, we might ask what fields are being construed in these diverging meanings; in what ways do the diverging meanings relate to the displayed item (are they identifying, attributing, locating in time and place, explaining or simply adding to what can be seen?); what is their degree of generality, that is, do these meanings reference only the present item and situation or are they transportable to others? From the perspective of interpersonal meaning, we might ask what values are being attached to the displayed artefact, whose voices are included, or how is the viewer positioned in the communicative interaction. Finally, from the perspective of textual meaning, we could examine how these divergent meanings are being positioned in the flow of meaning as the communicative event unfolds through time.
In the remaining space of this article, however, the discussion will focus on ideational meaning.
Ideation: mapping field
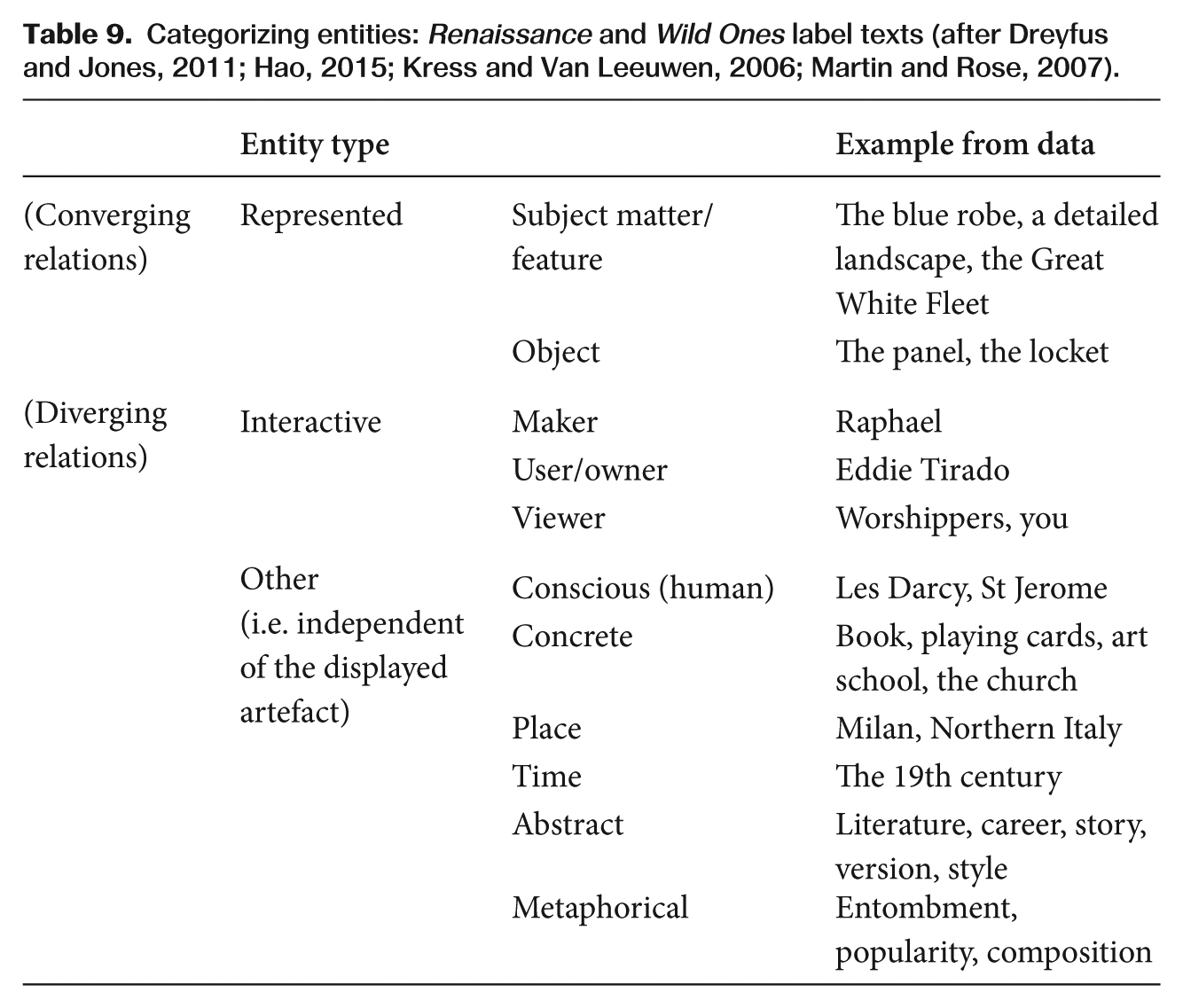
SFL emphasizes two aspects of discourse as being especially productive in describing and differentiating fields. These are the patterning of entities and activity sequences (see, for example, Hao, 2015; Martin and Rose, 2007). Looking first at entities, Table 9 summarizes the entity types that were identified in the Renaissance and Wild Ones label texts.
The first group of entity types, ‘represented’, relate directly to what can be seen (Kress and Van Leeuwen, 2006). As such, they indicate converging relations and so, by leaving them aside, we are left with a view of the fields being represented in the diverging, or ‘additional’, meanings. Here again, the two exhibitions show a very different pattern. For example, there was a substantial difference in the overall proportion of ‘diverging’ entities (over 80% in The Wild Ones, and less than 60% in Renaissance). In other words, the Renaissance texts are spending relatively less time referencing what can’t be seen and thus less on bringing new information to the encounter. Of these diverging entities, the greater proportion were abstract and metaphorical entities, suggesting a text typical of a specialized rather than everyday field of experience.
The following label text (Table 10) is a typical example in this regard. The label makes multiple references to entities depicted in the painting (9), a mix of human, concrete and metaphorical. As proposed above, the combination of ideational concurrence, presence and Thematic structure creates a series of vectors that motivate the viewer to look at specific features of the work, while the diverging meanings bring new meaning to the interaction. These also comprise a mix of entity types, but they are mostly metaphorical (6). The text is contained to the fields of art history and Catholicism; no other fields are referenced.
Looking at the activity sequences, there is a dominance of relational processes. This indicates that the text is primarily acting to construe relationships between entities, for example, relations that identify, attribute, classify or compose, rather than to construe them as participants in some unfolding sequence of actions in the material world.
Looking further at the relationship between the diverging meanings and what can be seen (i.e. the displayed artefact and converging verbal meanings), the data revealed five main roles. These are:
identifying: who/what is represented (Id)
attributing: qualities to what is represented (Att)
locating: what is represented in time and or place (Loc: T/P)
explaining: how or why something is represented (Ex)
adding: meanings about entities that are not represented (Add)
Each of these could be construed as applying only to the specific instance, or as being generalizable to other contexts. For example, ‘The red flower is a carnation’ identifies the type of flower in a particular painting; ‘The red flower is a carnation, representing the emotion of love’ explicitly adds meaning that the viewer can apply in other contexts. This quality of generality is especially salient given the assumptions and aspirations of many museums that a visitor’s experiences and learnings will have some cumulative or transferrable value (Blunden, 2016: 230; Maton, 2013: 8).
Applying these criteria to the text in Table 10 shows that in this label, the text is bringing meanings that function to identify who and what is represented (clause 1), attribute qualities (clauses 3 and 6.2), explain the meanings of what is represented (2.4, 4, 5.1, 5.2 and 6), and tell us something about the artist (2.1). It includes a mix of meanings that are specific to this particular work and those that are transportable to other contexts. Across the exhibition overall, the primary roles played by diverging relations were to identify, attribute, locate and add to what could be seen; there were relatively few that served to explain.
The Wild Ones object label texts were quite different. There was a greater proportion of diverging entities, that is, those not instantiated visually in the displayed object. Overall, there was a far greater proportion of human and concrete participants. For example, looking again at the Crash Craddock label text (Table 11), the majority of entities are human (5). Together, the participant and activity chains construe a sequence of events unfolding in the material world in the past. These relate to the displayed item principally by adding and attributing meanings about the item and interactive participants. This is typical of the object label texts as a whole in this exhibition, which for the most part served to add, identify and locate in time and place. Again, relatively few served to explain.
Tallying the ideational meanings brought to the experience of the displayed work in the object label texts (i.e. the diverging meanings), in the Renaissance exhibition these showed a dominance of two fields: the field of art and the field of religion, specifically Catholicism. In other words, the label texts were concerned with the displayed items as works of art and with the subject matter being represented, with little contextualizing within the field of history more generally and very few references to everyday life. In short, the labels brought a layer of interpretation that constructed a view of art as separate from daily life, both historically and in relation to the everyday world of exhibition visitors. In The Wild Ones exhibition, the object label texts were strongly located in the field of popular culture and the everyday; compared with Renaissance, the focus on the two primary fields was even more pronounced, with only the occasional reference to other fields, such as art. Thus, in this exhibition, the labels can be said to have constructed a view of history (the past) that makes everyday life central, but marginalizes specialized fields of practice.
Summary and Conclusions
This article has looked to recent research in intermodality to propose a ‘toolkit’ of principles that can be used to probe the dynamic relationship between visual and verbal modes that occurs at and around a displayed artefact. These include two sets of relations: vergence and presence. Vergence comprises converging relations, where similar meanings are committed in each modality, and diverging relations, where meanings committed in one modality are not committed in the other. The analysis showed how converging relations act to connect modalities by linking, integrating and amplifying meaning. In particular, it showed how the coupling of (ideational) concurrence with presence and verbal Thematic structure acts to create vectors which explicitly ‘motivate’ or push the viewer to look at the displayed artefact and/or attend to particular features of it. The analysis identified three key types of vectors, termed Thematic vectors, non-Thematic vectors and Shell vectors, and showed how these vectors can be thought of as gradable in strength. Diverging relations, on the other hand, were shown to expand meaning by bringing new meanings to the interaction. Finally, the article has demonstrated how, when converging meanings are explicitly linked to diverging meanings (i.e. meanings that are additional to those that can be gained by a ‘just looking’ reading of the artefact), the verbal text can justly claim to be ‘adding to the looking’.
In applying this methodology to two exhibitions, an art exhibition and a social history exhibition, a very different picture emerged in terms of the meanings that were brought to the interaction by the object label texts. The Wild Ones (object) label texts overall were characterized by their relative independence of the displayed artefacts, with few direct moments of convergence across the modalities. In terms of ideational meaning, there were relatively few instances of ideational concurrence, and even fewer coupled with presence to create vectors. As a result, there were few moments in the text that explicitly pushed visitors to look at the displayed artefact. Of instances where ideational concurrence occurred, most were in a relation of ‘correspondence’, where they referenced the whole item (e.g. ‘the locket’) rather than a particular feature of it, or a larger class to which the item belonged. In this way, the texts acted neither to scaffold ‘close looking’ by motivating viewers to attend to particular details of the item, nor build transportable knowledge by explicitly linking the displayed item to a larger class or concept. In terms of diverging relations, the analysis showed how the texts brought meanings that acted principally to identify and locate (in time and place) the people and events associated with the displayed items. In doing so, the texts merged the fields of history and everyday life, while, through a range of interpersonal choices, they framed a familiar and personal relationship with the viewer/visitor. In short, the label texts were shown to tell a ‘parallel story’, where the displayed objects were ideationally incidental but interpersonally resonant. In other words, they acted to integrate fields but not modalities; they ‘worked’ to make ‘our story your story’ but not to expressly motivate visitors to look at the displayed items closely, or even at all.
In contrast, the Renaissance object label texts were characterized by their high level of integration across modalities. Multiple couplings of ideational concurrence and presence created numerous vectors that explicitly pushed viewers to look at the displayed work, and mostly, through a relation of meronymy, to a particular element or feature of the work. In this way, the label texts can justly be said to be scaffolding ‘close looking’. Further analysis, however, showed this was not necessarily ‘deep looking’. This was due to two main factors. The first relates to the kind of meanings linked to the vector. Often these were meanings that identified or attributed qualities to what could be seen, rather than explaining how or why something was seen. The second relates to the common pattern of pairing two converging relations, that is, of pairing ‘something that can be seen’ with ‘something that can be seen’ to form a ‘shell’ vector, that is, a vector that does not explicitly link to new meaning. The analysis further suggested that such shell vectors set up an expectation that some new meaning would be given but fail to fulfil that expectation. In this way, they may be one reason why visitors often describe the texts in art museums as strangely empty, alienating and unfulfilling (Beckett, 2013; Ravelli, 1998). Shell vectors were only present in the Renaissance data set, and thus may be a particular feature of art museum texts. Further research in this regard would be of great value.
The analysis also showed that while the Renaissance label texts integrated modalities, they did not integrate fields. While the diverging meanings, that is, the new meanings being brought to the interaction by the label texts, referenced both the fields of art and Catholicism, these two fields were construed linguistically in very different ways. The field of art, for example, was predominantly one of relationships between abstractions and material form, with interpersonal choices that distanced author from reader/viewer. The field of Catholicism was more one of doings and happenings in the material (and spiritual) world. In short, the object labels in the Renaissance exhibition acted to integrate modalities but not fields; they ‘worked’ to motivate visitors to look closely at the works, but not necessarily deeply, and they constructed art as ‘a world apart’.
For the purposes of this article, the discussion has focused on ideational and textual meanings in the object label texts, touching only very briefly on the interpersonal. Using this framework, however, a more detailed consideration of interpersonal meanings, and of the other verbal texts, both spoken and written, that were offered as part of these two exhibitions, would further extend our understanding of how these texts worked to scaffold the visitor’s interaction with the displayed artefacts and the kinds of meanings they brought to the experience of these two exhibitions. More broadly, this article has proposed a sensitive and principled framework for bringing to view the complexity of meanings and relations that are central to the work and experience of museums, and to our understanding of multimodal texts and literacies. In looking closely at the idea of ‘close looking’, it hopes to invite further ‘close looking’ at this important area.
Footnotes
Acknowledgements and Funding
This research was made possible through the support of an Australian Government Research Training Program Scholarship. Text examples and images courtesy Sydney Living Museums and the National Gallery of Australia, with Renaissance works from the collection of the Fondazione Accademia Carrara, Bergamo, and reproduced with their permission. There is no conflict of interest.
Notes
Biographical Note
JENNIFER BLUNDEN works as a writer, producer and language advisor in the museum and cultural heritage sectors. She currently works in the exhibitions department of the State Library of New South Wales and has recently completed a doctorate at the University of Technology Sydney in the area of language, accessibility and learning in museums. In 2014, Jennifer was awarded the inaugural Sylvan C Coleman and Pamela Coleman Memorial Fellowship in Museum Education and Public Practice at the Metropolitan Museum of Art in New York.
Address: School of Education Faculty of Arts & Social Sciences, University of Technology Sydney, PO Box 123, Broadway, Sydney, NSW 2007, Australia. [email: