
Abstract
Hodges and Lehmann proposed using rank test statistics evaluated at inversely transformed data to construct estimating equations. This paper reframes the resulting estimates in terms of a rank likelihood. In the context of a model of the form Y = h(e; z, β), where Y is a response, z a vector of predictors and e is a random error, this approach corresponds to computing the inverse e = g(Y, z; β) by solving Y = h(e; z, β) for e and using the distribution of the ranks of independent e’s as a likelihood. The properties of the resulting estimators have been developed in many important contexts. This paper will review and extend asymptotic optimality properties of Hodges Lehmann estimators in semiparametric models. In particular, the paper will establish semiparametric optimality of the estimate obtained from a Gaussian linear model. Moreover, it will be shown that the Hodges-Lehmann estimate obtained from the exponential likelihood is asymptotically minimax for the semiparametric accelerated failure time model with increasing hazard rates, and it will be shown that a uniform (Wilcoxon) score estimate applied to log Yi, 1 ≤ i ≤ n, is asymptotically minimax for an accelerated failure time model with increasing logit rate. References to recently developed software in R is provided.
1 Introduction
One of the goals of statistical research is to develop methods that make efficient use of available data. One very efficient method is the normal scores inverse rank (NSIR) estimator which is based on the ideas in a paper by Hodges and Lehmann (1963). In a regression framework based on a linear model with general error distribution, this method is asymptotically uniformly more efficient than the least squares (LS) estimator, and the LS estimator in turn is best linear unbiased by the Gauss-Markov Theorem. Moreover, Monte Carlo simulations have shown that the superiority of the NSIR estimator also holds for finite sample sizes. Nevertheless, the NSIR estimator is hardly main stream in the statistical literature. One reason this may be is that it does not appear to have the prestige that comes with being based on a likelihood. Moreover, there is a lack of asymptotic semiparametric optimality results. Another reason may be that computational software has not been readily available until now.
This paper frames Hodges-Lehmann inverse rank estimators as likelihood based, reviews some of the properties and develops asymptotic minimax properties of inverse rank estimates based on normal, exponential and uniform scores.
In this paper → will denote convergence in distribution. The asymptotic distribution results used in this paper are from Adichie (1967), Jurečková (1971), Koul (1971) Jaeckel (1972), Kraft and van Eeden (1972), among others. Books that include Hodges-Lehmann estimates are by Lehmann (1975), Bickel and Doksum (1977), Hettmansperger (1984) and Hettmansperger and McKean (2011). Software in R for inverse rank estimates incuding the NSIR estimator has been developed by Kloke and McKean (2012). See the Appendix.
2 Rank and inverse rank likelihoods
Let X = (Y, Z), Y ∈ R, Z ∈ Rd, denote data with probability distribution P, and let p(x; θ) denote a parametric density for P with θ = (β, Λ), where β ∈ Rpand Λ is a function or a vector of functions. The profile likelihood is
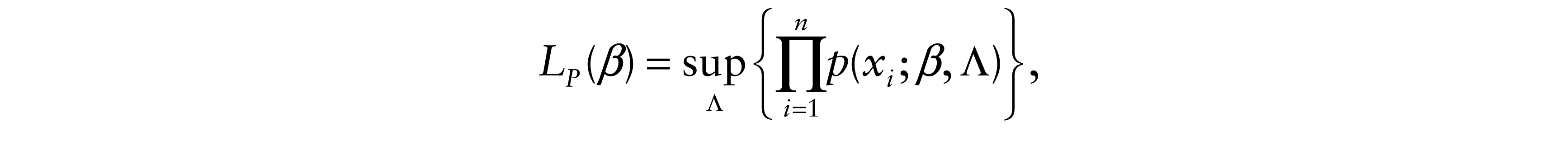
where the sup is over step functions Λ that jump at the ordered y’s. (e.g., Murphy and van der Vaart, 2000). If λ(y; β|z) is the conditional hazard rate, then the Cox partial likelihood is
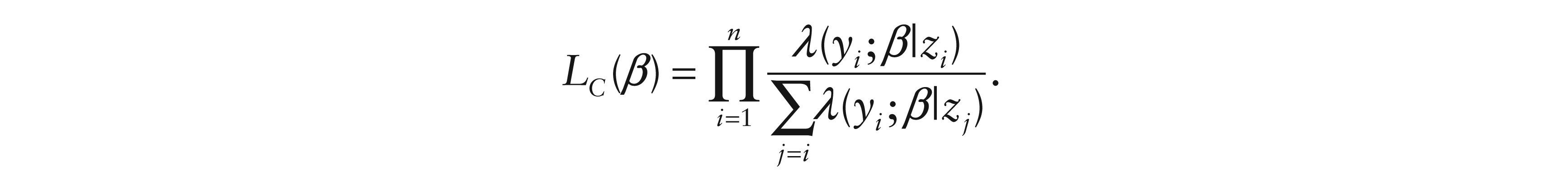
Let Ri = Rank(Yi), R = (R1, …, Rn), let θ0 denote a H0 (nullhypothesis) parameter value and let V(1) < … < V(n) denote p(υ; θ0|z) order statistics, then the Hoeffding likelihood is
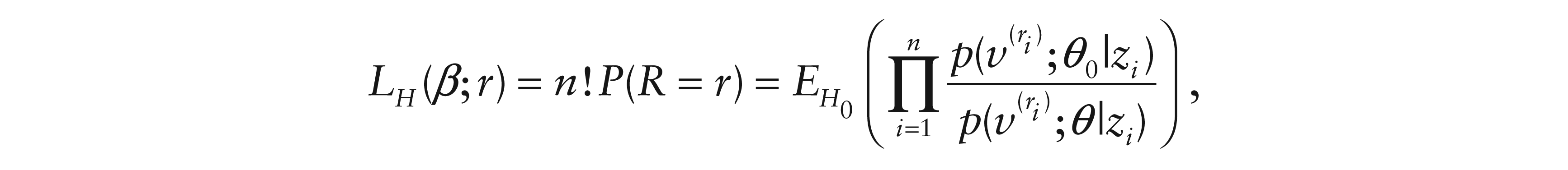
where r1, …, rn denote the observed ranks and r = (r1, …, rn).
The estimate
For example, consider the linear model
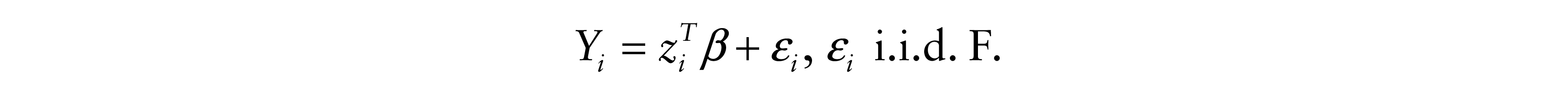
The KP approach has H0 : β = 0 and
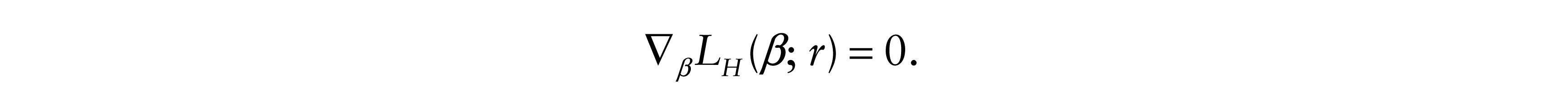
In contrast, in this linear model, the Hodges-Lehmann estimate is the solution for β*of
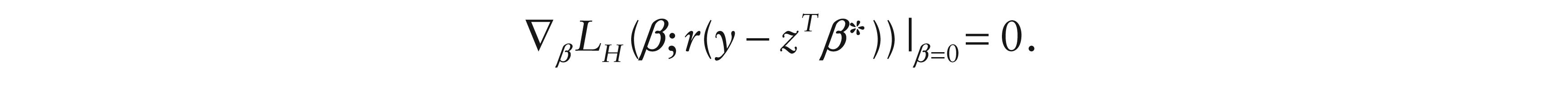
Thus the Hodges-Lehmann estimate is likelihood based, but rather than ranking Yi, it ranks
For a familiar example, consider the logistic two-sample shift model F2(x) = F1 (x – β). In this case, ∇βΛΗ|β=0 is proportional to the Wilcoxon statistic and
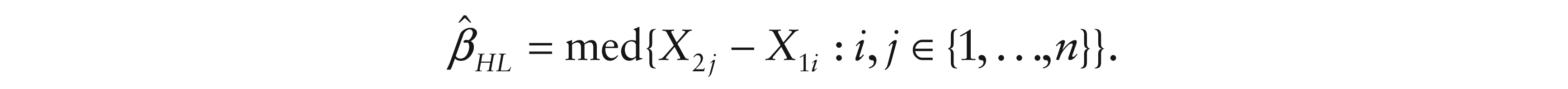
In general, the Hodges-Lehmann inverse rank estimate can be defined as follows: consider a model where for some function h
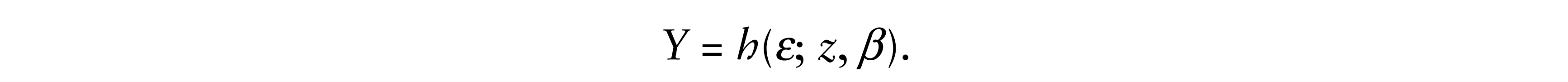
Let ε*(y; z, b) be the solution (inverse) for ε of h(ε; z, β) = y, then 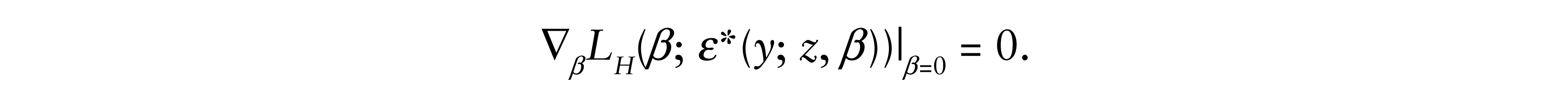
3 Basic properties of the Hodges-Lehmann inverse rank estimate
Consider again the linear model
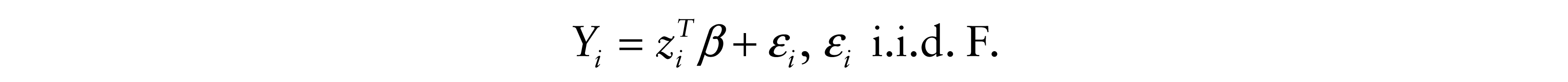
We use LH with H0 : β = β0 = 0. In this case,
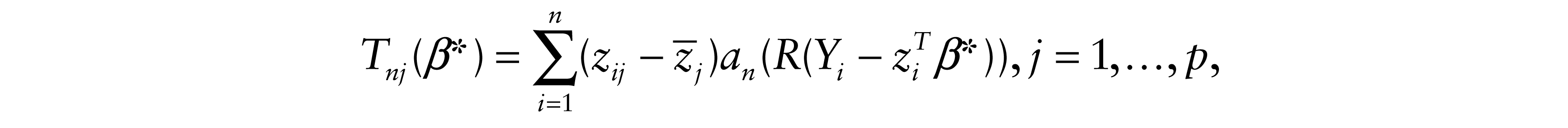
where R denotes rank and
If an(1) < … < an(n) and S(β) is a nonnegative, continuous and convex function of β. If (zij)n×p is of full rank, S(β) reaches its minimum.
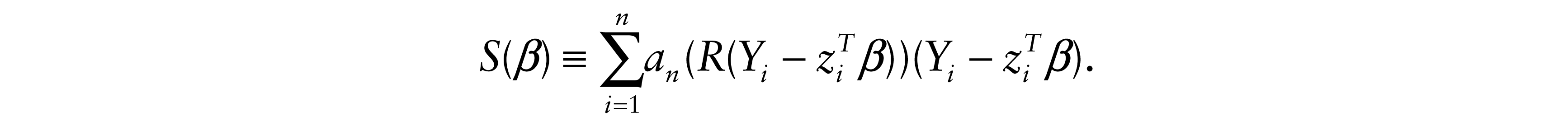
In model (2.1), let
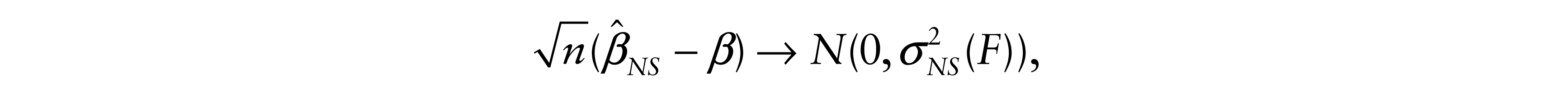
where
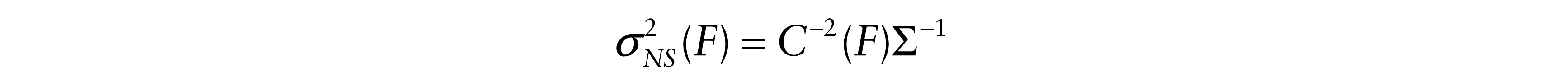
and
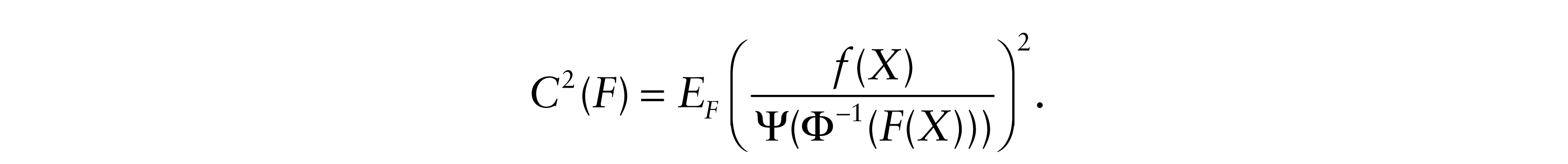
The corresponding result for the LS estimate when ∑–1 and σ2(F) = var(ε) exist is
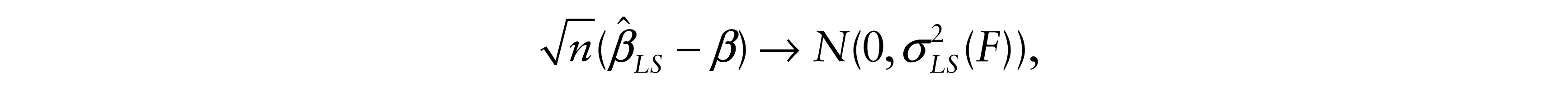
where
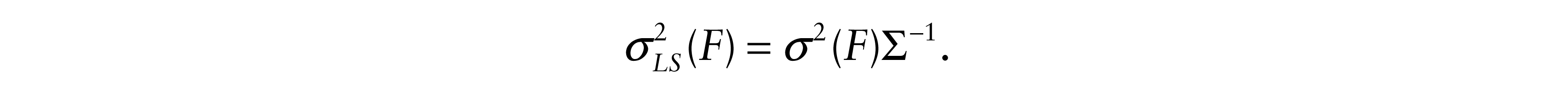
It follows that
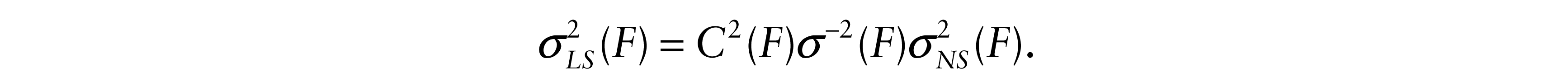
Chernoff and Savage (1958) showed that σ2(F)C2(F) ≥ 1 with equality iff F is Gaussian. A simple proof based on the Jensen and Cauchy-Schwarz inequalities was given by Gastwirth and Wolff (1968). It follows that.
4 Naive asymptotic semiparametric minimax theory
There was a time when most mathematics students and faculty read the book ‘Naive Set Theory’ by PR Halmos (1960). It presented the main concepts and results of set theory without detailed justifications. With apologies to Halmos, the naive asymptotic semiparametric minimax approach amounts to finding a decision rule δ0 and a function Λ0 such that δ0 has maximum asymptotic risk at Λ0, and δ0 has smaller asymptotic risk than other δ at Λ0. Then, if R(δ, Λ , β) is the asymptotic risk,
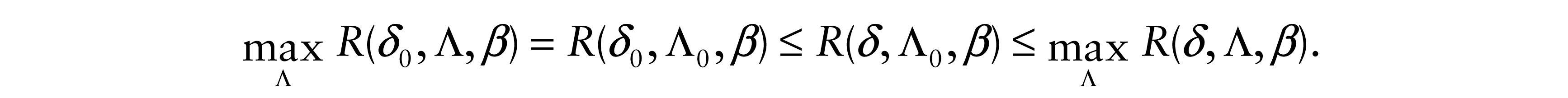
That is, (δ0, Λ0) is a saddle point and δ0 is a minimax for R.
For example, in the proportion hazard rate model, where the hazard rate satisfies λ(y; β|z) = λ(y)exp(zTβ) for some baseline hazard λ(⋅), the Cox partial likelihood estimate
This naive approach makes it straightforward to show semiparametric asymptotic optimality of Hodges-Lehmann inverse rank estimators.
Next consider the accelerated failure time model, where Y1, …, Yn are independent with Y|z distribution defined by
For this model,
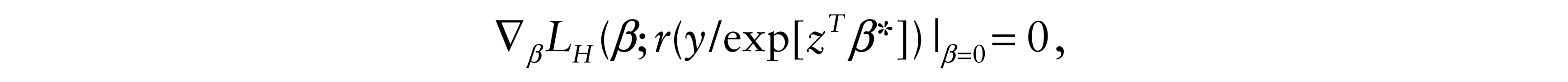
which is equivalent to solving
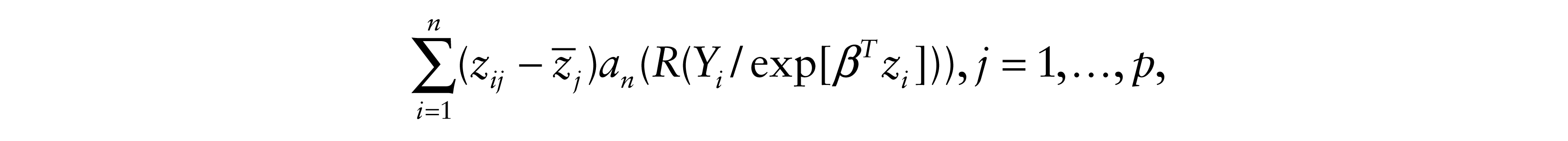
where an(i) = EK(V(i)) –1 with K(t) = 1 – exp(–t). Here an(i) is often approximated with
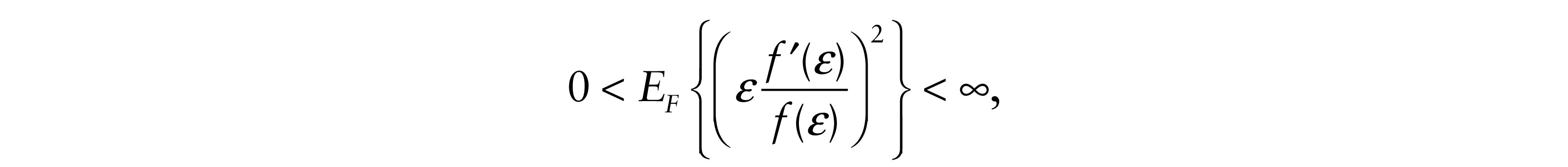
then
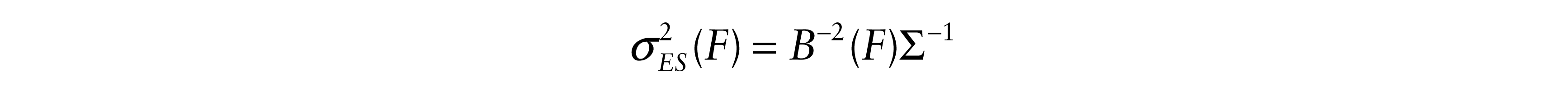
with
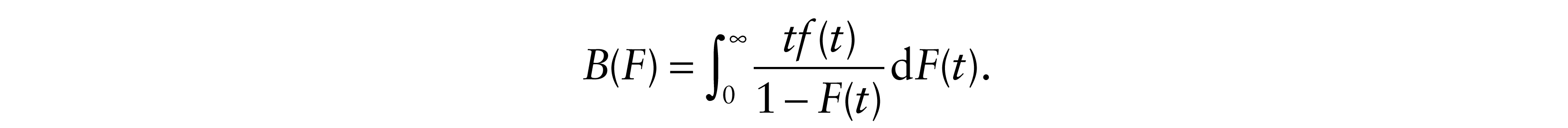
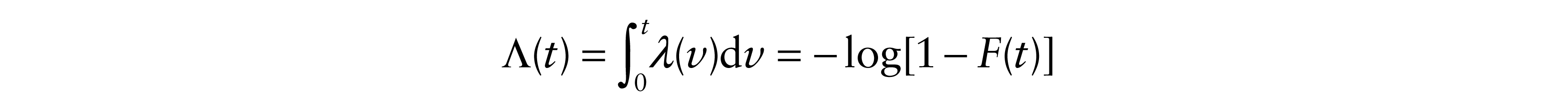
is convex, which implies that t–1Λ(t) is nondecreasing. Thus
which implies
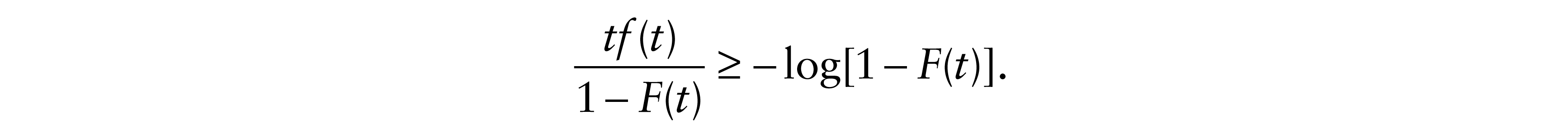
Thus
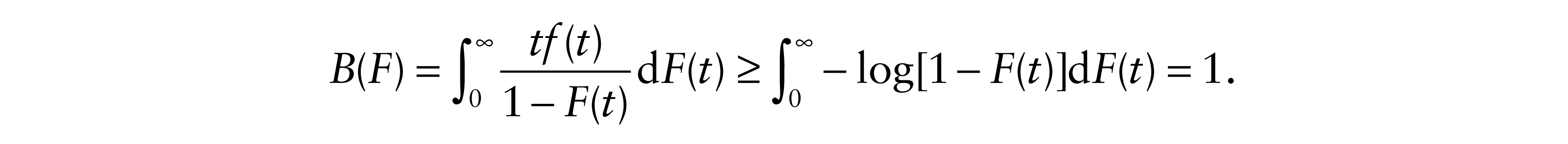
Here equality holds iff F is exponential. Thus
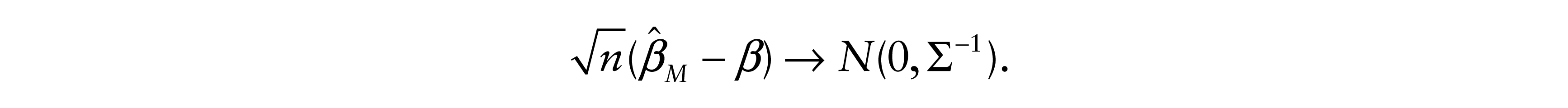
Thus
This result is for uncensored data. Tsiatis (1990) has extended inverse rank estimates to censored data. It is conjectured that Theorem 4.3 holds for censored data.
A logit survival model
Doksum and Gasko (1990) and others have examined the correspondence between models in binary regression analysis and survival analysis. Thus the Cox proportional hazard model corresponds to the complimentary log–log link function in the binary regression model. Here we next consider a survival model related to the logit binary regression model.
Let Y0 be a baseline survival time, let F0 denote its distribution function and define
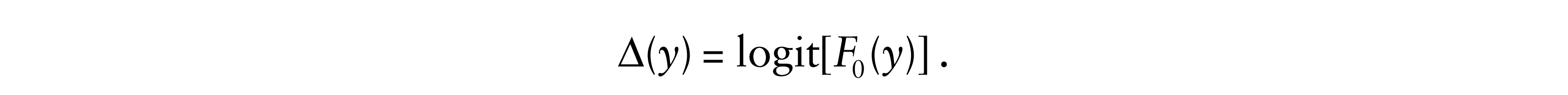
Our model is the accelerated failure time model where Y1, …, Yn are independent with Y|z distributed as
Previously we assumed that the baseline integrated hazard rate Λ(y) = –log(1 – F0(y)) was convex, that is, the rate λ(y) is nondecreasing. Now we assume that the
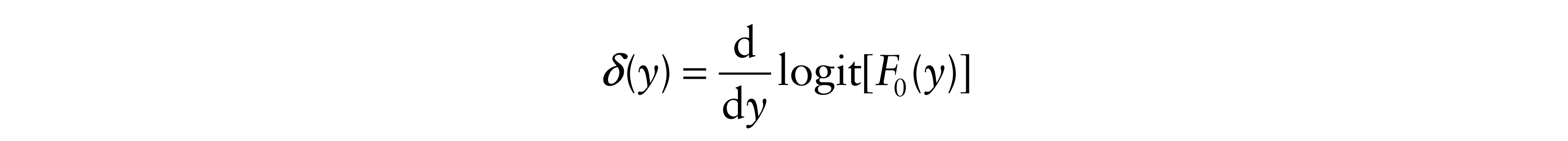
is nondecreasing. We write that F0 has an increasing logit rate (ILR). Intuitively, objects that wear over time will have ILR failure time distributions.
To show a minimax result for the ILR model, we need to ‘guess’ the minimax rule. To this end we introduce the inverse rank estimate
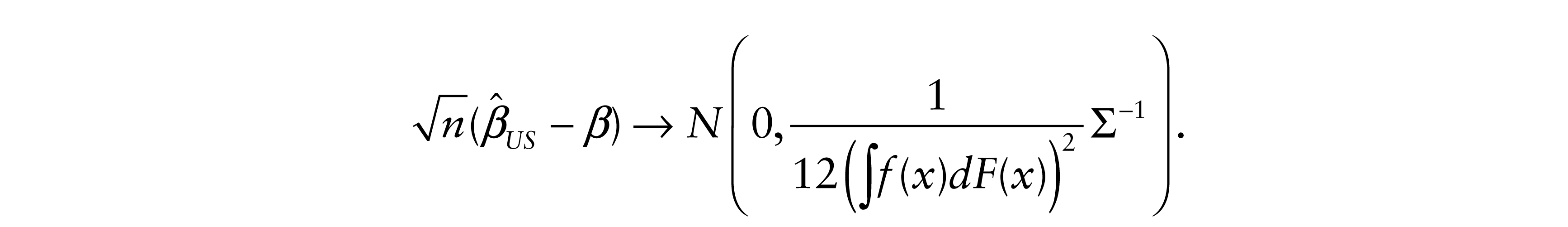
It turns out that the asymptotically minimax estimate for the accelerated failure time model with increasing logit rate can be obtained from Theorem 4.4.
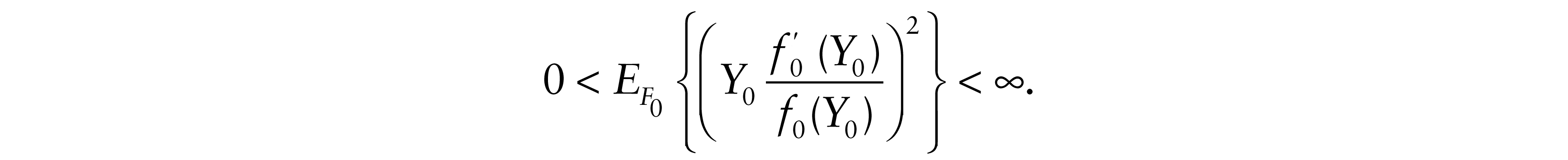
Then
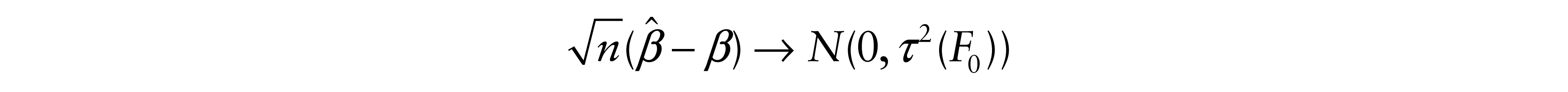
for some τ2(F0), then
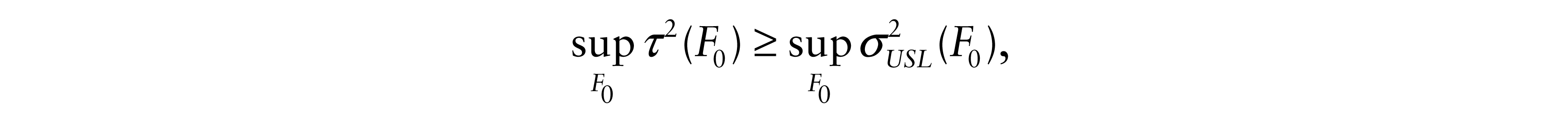
where the sup is over F0 ILR.
where ε = log Y0. Let F(t) = P(ε ≤ t) = F0(et). Then logit[F(t)] = logit[F0(et)] is convex. It follows that logit[F(t)] – t is nondecreasing. Thus
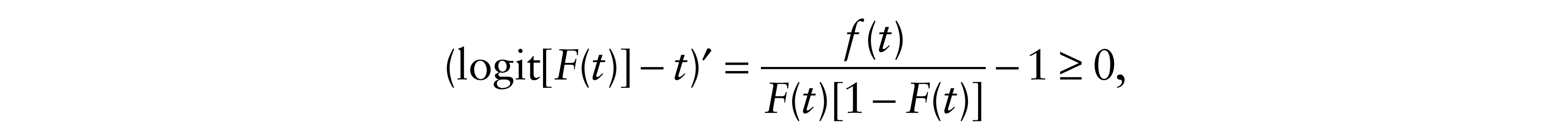
which implies
and
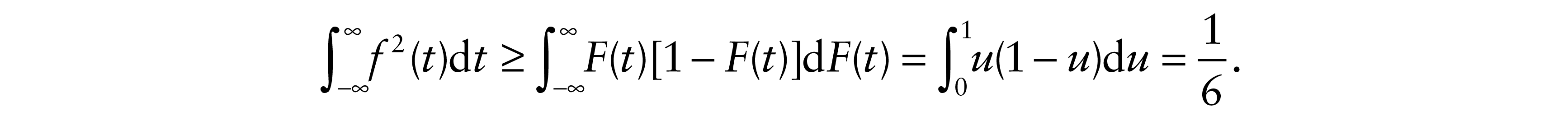
This and Theorem 4.4 show that
It is clear from this proof that the result holds if we widen the class of ILR distributions to the class of models where logit[F0(ex)] is convex.
Appendix: Rfit code
To indicate how easy it is now to compute inverse rank estimators, we add the few lines of appropriate Rfit code. Assuming that the vector y and the matrix x contain the responses and the design matrix, respectively, then the Rfit commands to obtain the Wilcoxon, normal scores, and log-rank fits are
fitw < – rfit(y ∼ x) fitns < – rfit(y ∼ x, scores = nscores) lrs < – new (“scores”, phi = function(u){–1 –log(1 – u)}, Dphi = function(u){1/(1 – u)} fitlr < – rfit(y ∼ x, scores = lrs)
The uniform Wilcoxon scores are default in Rfit, the normal scores are in Rfit, but the log-rank scores need to be defined.