
Abstract
Non-Gaussian outcomes are frequently modelled using members of the exponential family. In particular, the Bernoulli model for binary data and the Poisson model for count data are well-known. Two reasons for extending this family are (1) the occurrence of overdispersion, implying that the variability in the data is not adequately described by the models, and (2) the incorporation of hierarchical structure in the data. These issues are routinely addressed separately, the first one through overdispersion models, the second one, for example, by means of random effects within the generalized linear mixed models framework. Molenberghs et al. (2007, 2010) introduced a so-called ‘combined model’ that simultaneously addresses both. In these and subsequent papers, a lot of attention was given to binary outcomes, counts, and time-to-event responses. While common in practice, ordinal data have not been studied from this angle. In this article, a model for ordinal repeated measures, subject to overdispersion, is formulated. It can be fitted without difficulty using standard statistical software. The model is exemplified using data from an epidemiological study in diabetic patients and using data from a clinical trial in psychiatric patients.
Keywords
Introduction
Next to continuous and binary outcomes, count data features are extensively covered in the modelling literature and play a prominent role in applied statistical work. It is common to place such models in a generalized linear modelling (GLM) framework (Nelder and Wedderburn, 1972; McCullagh and Nelder, 1989; Agresti, 2002). It allows one to specify either the first and second moments only or the full distribution. In the latter case, the exponential family (McCullagh and Nelder, 1989) has been of particular interest, given that it provides an elegant and encompassing mathematical framework with the normal, Bernoulli/binomial, and Poisson models as prominent members.
The elegance of the GLM framework draws from certain linearity properties of the log-likelihood function, leading to mathematically convenient score equations and ultimately to a straightforward use of inferential instruments, both in terms of estimation and inference. A key feature of the GLM model and the exponential family is the ‘mean-variance relationship’, a term used to indicate that the variance v is a deterministic function of the mean
The above explains why most early work was on formulating models that explicitly allow for a dispersion not following the base models. It is often referred to as overdispersion, but underdispersion can occur as well. Hinde and Demétrio (1998a, 1998b) provide broad overviews of approaches for dealing with overdispersion, considering moment-based as well as full-distribution avenues. For purely binary data, the mean-variance link can only be violated in case of hierarchical data, e.g., in case of longitudinal data, where an outcome is recorded repeatedly over time for a number of study subjects. Apart from overdispersion, hierarchies in the data imply associations between measurements on the same unit as well. Thus, a flexible parametric model ought to properly capture the mean function, the variance function, and the association function. The so-called generalized linear mixed model (GLMM; Breslow and Clayton, 1993; Wolfinger and O’Connell, 1993; Engel and Keen, 1994; Molenberghs and Verbeke, 2005) has become the dominant tool for hierarchical non-Gaussian data.
Molenberghs, Verbeke and Demétrio (2007; henceforth MVD) and Molenberghs, Verbeke, Demétrio and Vieira (2010; henceforth MVDV) and Molenberghs, Verbeke, Iddi and Demétrio (2012; henceforth MVID) showed that accommodating either overdispersion or hierarchically-induced association may fall short when properly modelling the data. MVD focused on counts, MVDV laid out a general framework, whereas MVID tackles binary and binomial outcomes. The topic of the current article is the modelling of repeated, overdispersed ordinal data.
The article is structured out as follows. In Section 2, two motivating case studies are introduced; they are analyzed in Section 6. It will be shown that the first one shows strong overdispersion and correlation, while the second study will enable to study the model’s behaviour when in fact overdispersion is absent. Section 3 briefly summarizes relevant modelling background; the proposed model for repeated, overdispersed ordinal outcomes is presented in Section 4. Parameter estimation is considered in Section 5.
Motivating case studies
Fluvoxamine trial
This study is concerned with psychiatric symptoms allegedly resulting from a dysregulation of serotonine in the brain. A multicentre study was undertaken, enrolling 315 patients that were treated by fluvoxamine. The data are discussed in several places, including Molenberghs and Verbeke (2005), Molenberghs and Lesaffre (1994), Kenward, Lesaffre, and Molenberghs (1994), Molenberghs, Kenward, and Lesaffre (1997), and Michiels and Molenberghs (1997). Once recruited, patients were assessed at four visits. The therapeutic effect and the extent of side effects were scored at each visit on an ordinal scale. The side effect response is coded as (1) none; (2) not interfering with functionality; (3) interfering significantly with functionality; (4) side effects surpasses the therapeutic effect. Similarly, the effect of therapy is recorded on a four-point ordinal scale: (1) no improvement or worsening; (2) minimal improvement; (3) moderate improvement and (4) important improvement. Thus, a side effect occurs if new symptoms occur while there is therapeutic effect if old symptoms disappear. A total of 299 patients have at least one measurement, including 242 completers. There is also baseline covariate information on each subject, including gender, age, presence of psychiatric antecedents, initial severity of the disease, duration of the actual mental illness. A summary is given in Table 1.
Fluvoxamine Trial. Number of observations with therapeutic effect categories for each of the four follow-up time points
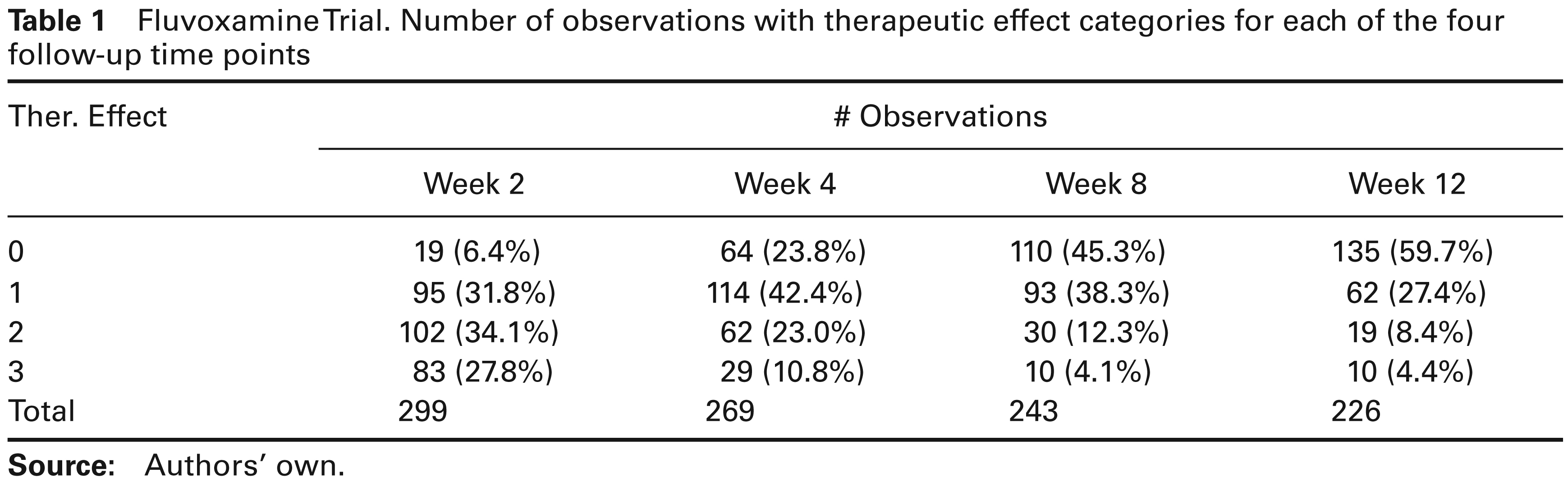
Fluvoxamine Trial. Number of observations with therapeutic effect categories for each of the four follow-up time points
In Belgium, the diabetes project was conducted from January 2005 until December 2006, with the aim to study the effect of implementing a structured model for chronic diabetes care on the patients’ clinical outcomes. General practitioners (GPs) were offered assistance and could redirect patients to the diabetes care team, consisting of a nurse educator, a dietician, an ophthalmologist, and an internal medicine doctor. For the project, two programmes were implemented and GPs were randomized to one of two groups: UQIP: Usual Quality Improvement Programme and AQIP: Advanced Quality Improvement Programme. A total of 120 GPs took part in the study, 53 in the UQIP group and 67 in the AQIP group, including 918 and 1577 patients, respectively.
Diabetes Data. Number of observations with the corresponding clinical targets reached at every time point, for both treatment groups separately
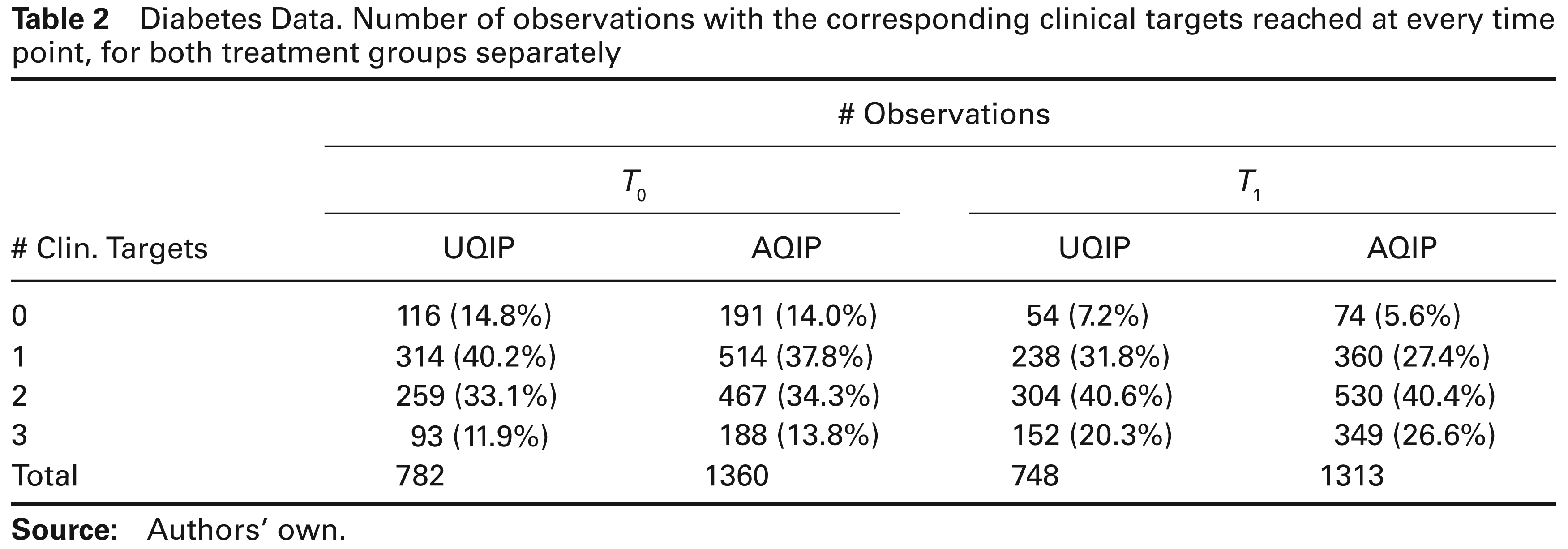
Diabetes Data. Number of observations with the corresponding clinical targets reached at every time point, for both treatment groups separately
During the project, several outcomes useful to evaluate how well diabetes is controlled were measured, at the moment the programme was initiated (time T0) and one year later (T1). The most important outcomes were HbA1c (glycosylated hemoglobin), LDL-cholesterol (low-density lipoprotein cholesterol) and SBD (systolic blood pressure). Furthermore, experts specified cut off values defining so-called ‘a clinical target’ for each outcome: HBA1C < 7%, LDL-cholesterol < 100 mg/dl and SBD # 130 mmHg. As a result, for a particular time point, every patient could reach minimum 0–maximum 3 clinical targets. This number was reflected in the variable ‘number of clinical targets’. If at least one measurement per patient was missing, the value for the number of clinical targets was set to missing as well. The data are discussed in Borgermans et al. (2009). A summary is given in Table 2.
A fundamental tool, in general and for us here, is the exponential family (Jørgensen, 1987; McCullagh and Nelder, 1989). The generic density for a random variable Y is then:
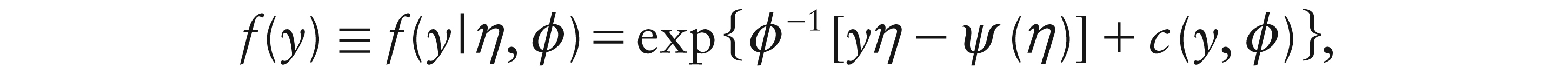
where 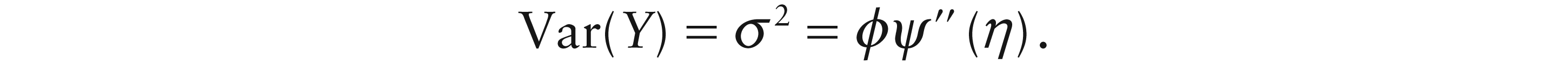
The model naturally leads to a so-called mean–variance relationship:
The mean
The mean–variance relation can be restrictive. The phenomenon where the empirical variance does not obey the prescribed mean–variance relationship is termed overdispersion. Hinde and Demétrio (1998a, 1998b) offer reviews as to how the GLM can be modified to accommodate overdispersion. One route is via the overdispersion parameter 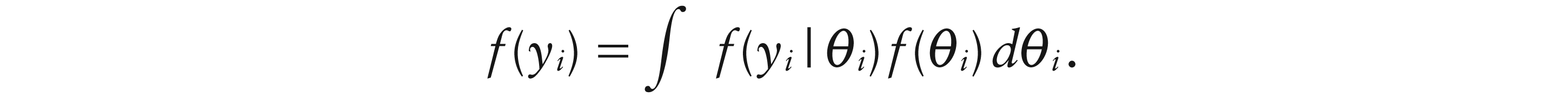
Two natural ways to introduce random effects into the GLM framework are either by the use of a so-called conjugate distribution (in the sense of Cox and Hinkley, 1974, p. 370, and Lee, Nelder and Pawitan, 2006, p. 178) for the parameter or by including normal random effects into the linear predictor. Mathematically,
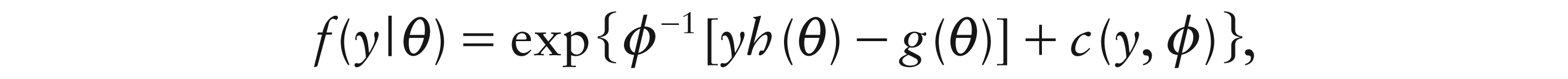
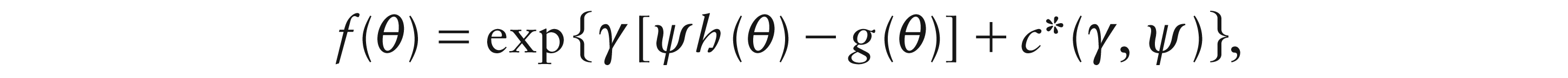
where 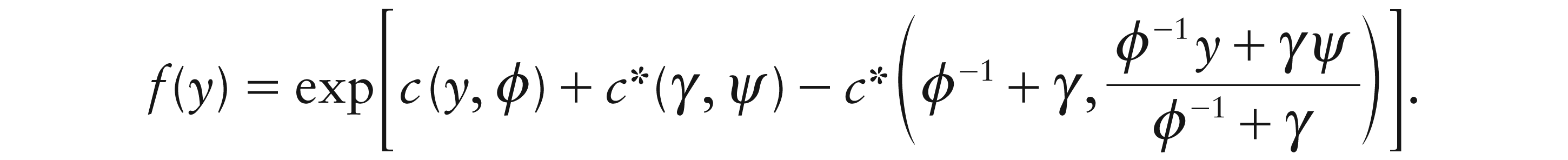
When Yi would be Bernoulli, then conjugacy leads to the beta distribution for
For longitudinal or otherwise hierarchical data, the GLMM (Breslow and Clayton, 1993; Wolfinger and O’Connell, 1993; Engel and Keen, 1994) is popular. Let now Yij be outcome j = 1, …, ni for subject i = 1, …, N, and let 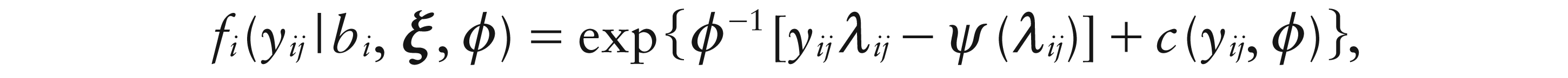
where
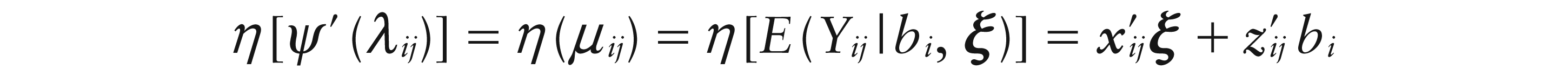
for a given link function
Assume the ordinal outcome Yij can take values r = 1, …, R. We replace it by a set of R dummies:
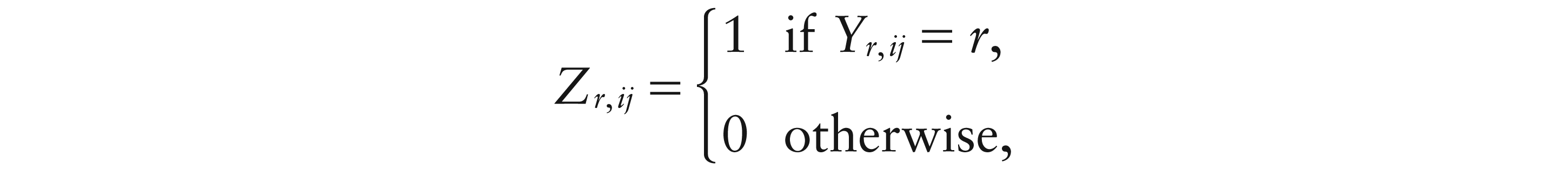
for r = 1, …, R. Evidently, there are redundant dummies, but any subset of R – 1 components is not. Group the dummies into vectors 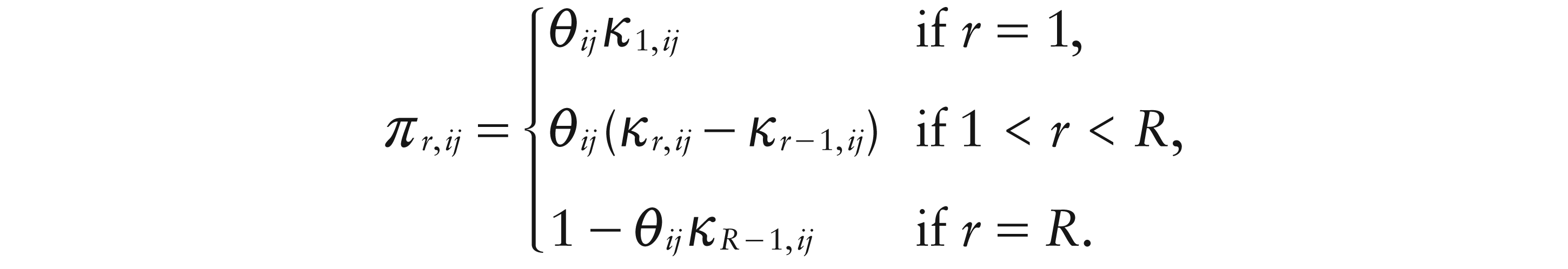
where
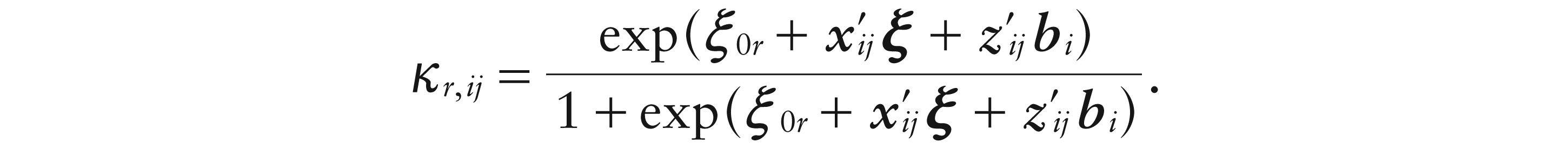
Here,
As argued in MVDV and MVID, closed-form expressions for marginal means, variances, covariances, and even the entire marginal distribution, i.e., integrated over both sets of random effects, cannot be derived in the binary case with logit link and normal random effects (regardless of the overdispersion random effects). Evidently, the same will be true for the ordinal case. If necessary, numerical integration or other Monte Carlo methods can be used to derive such marginal quantities.
MVID mentioned several possible estimation strategies, then focused on maximum likelihood. Because likelihood inference is based on the marginal density of the outcomes, one needs to integrate over the normal and beta random effects. MVID proceeded by analytically integrating over the beta random effects, leading to a so-called partially marginalized density. In our case, this takes the form:
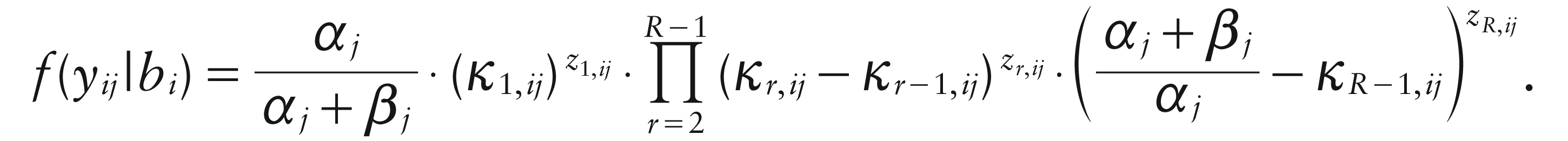
Then, a generic maximum likelihood routine that allows for integration over normal random effects can be used. We follow this route and use the SAS procedure NLMIXED to this effect. The following choices were made for conducting integration: adaptive Gaussian quadrature, which is more accurate than ordinary Gaussian quadrature (Molenberghs and Verbeke, 2005); the number Q of quadrature points is preferably user-defined than selected in an automated way and, once converged, a numerical sensitivity analysis to check whether Q was chosen sufficiently large is advisable.
Data analysis
Fluvoxamine trial
The fluvoxamine trial encompasses four time points. The response studied here is the therapeutic effect, rated on a four-point ordinal scale, as explained in Section 2.1. Two versions are analyzed. First, we use the measurements from the first and the last clinical visits only (week 2 and week 12). Second, all four measurements (weeks 2, 4, 8, and 12) are used. Juxtaposing both can be seen as an informal sensitivity analysis, investigating numerical stability, identifiability, etc. Also, the two-time-point case is similar to the diabetes data set, analyzed in the previous section. The results are presented in Tables 3 and 4. Covariate effects were retained by way of backward selection. Covariates considered are psychiatric antecedents (X2i), age (X3i), duration of the illness (X4i), and initial severity (X5i). In the analysis of all four repeated measurements, time was allowed to have a differential effect at the various time points.
Let Yij be the score of the therapeutic effect for patient i at time point j. We consider the same set of four models as for the diabetes study. The combined proportional odds logistic model for the two-time-point case equals:
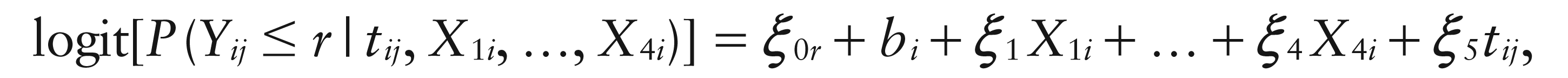
(r = 0, …, 3). For the four-times case the model takes the form:
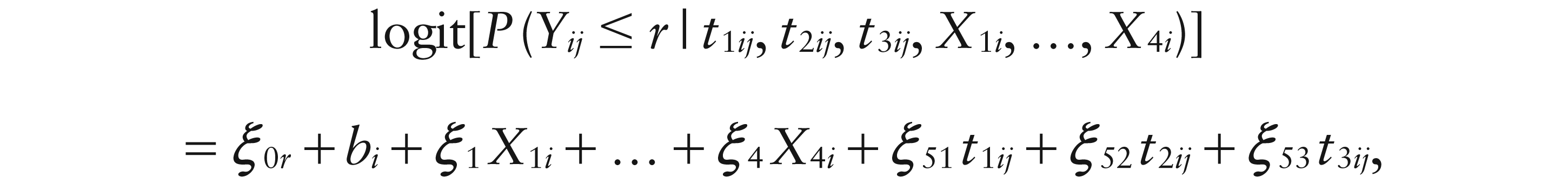
where t1ij, t2ij and t3ij are dummies corresponding to weeks 4, 8, and 12.
The results obtained here differ qualitatively from the ones reached for the diabetes study. There clearly is an improvement in terms of the likelihood when moving to the overdispersion models, already for the case of only two time points. We will study these model comparisons more formally, realizing that there are some subtle issues.
Fluvoxamine Trial. Two time points. Parameter estimates and standard errors from the regression coefficients in (1) the ordinary proportional odds model, (2) the proportional odds model with beta overdispersion effect, (3) the proportional odds model with random normal effect, together with (4) the combined model. Estimation was done by using maximum likelihood with numerical integration over the normal random effect, if present
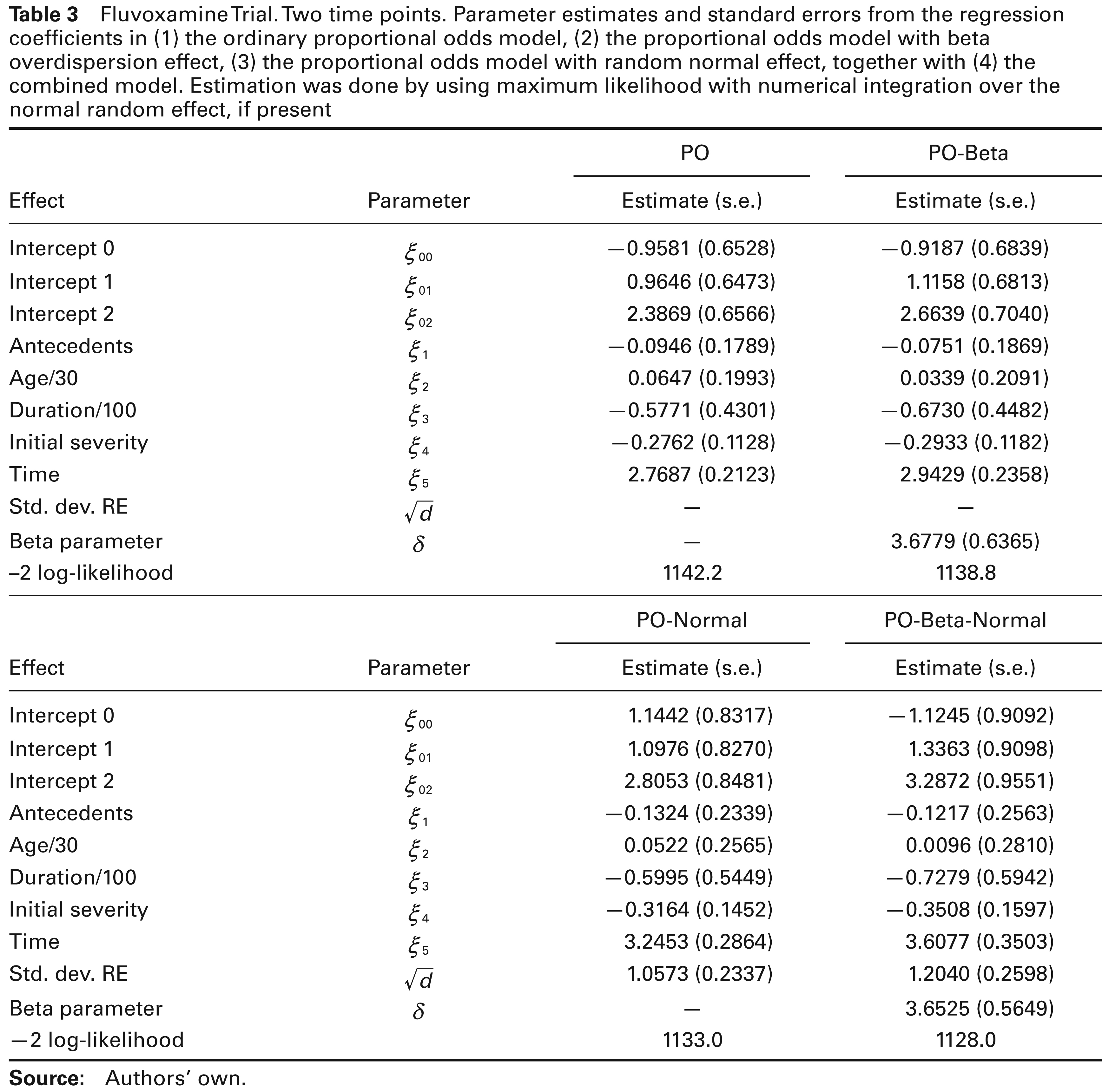
Fluvoxamine Trial. Two time points. Parameter estimates and standard errors from the regression coefficients in (1) the ordinary proportional odds model, (2) the proportional odds model with beta overdispersion effect, (3) the proportional odds model with random normal effect, together with (4) the combined model. Estimation was done by using maximum likelihood with numerical integration over the normal random effect, if present
To compare the PO and PO-Beta models for the case of two time points, the likelihood ratio test can be used. The difference in deviance is 3.4. However, care has to be taken when comparing such models, because of the special status of variance components. As explained in Verbeke and Molenberghs (2000), and further expanded upon in Verbeke and Molenberghs (2003) and Molenberghs and Verbeke (2007), two views can be taken. In a hierarchical view, the variance components are formally considered to describe random effects, and hence have the meaning of a variance (like d) or a variance parameter (like
Likewise, when comparing the PO-Normal and PO-Beta-Normal models, the same null distributions apply. The likelihood ratio test statistic now takes the value 5. The hierarchical p-value, again from a
Finally, we can compare PO and PO-Beta-Normal directly. This situation is different from all previous ones, because we now test for two variance components at the same time. Both lie on the boundary of the parameter space, and there is no covariance term between them. This ‘variance-component’ situation was discussed also by Verbeke and Molenberghs (2003). The likelihood ratio test statistic in the two-time-points case is 14.2, with hierarchical
From this analysis, we also deduce that there is weak or no evidence for the need of a beta random effect when comparing PO and PO-Beta with two time points. However, the corresponding assessment based on comparing the PO-Normal model and the PO-Beta-Normal model provides much stronger evidence for the need for such beta random effects. In other words, while there seems little evidence for overdispersion based on the model without normal random effects, the need for overdispersion becomes evident when the random effects in the data are accounted for. This strongly suggests that the incorporation of one of the sources of variability may not tell the entire story. We therefore recommend starting model building from the most general model, the PO-Beta-Normal in this case, and then examining whether simplification is possible.
Which model is chosen also has an impact on resulting inference. Consider the time effect based on the model with two time points. The corresponding z-ratio takes values 13.04, 12.48, 11.33, and 10.30 for the PO, PO-Beta, PO-Normal and PO-Beta-Normal models, respectively. Even though not spectacular, the impact is noticeable. Equally, the impact on resulting confidence intervals should not be discarded.
We will analyze the diabetes data, introduced in Section 2.2. The rationale for this case study is to contrast it with the previous study. Indeed, the fluvoxamine study exhibits strong correlation and overdispersion, whereas there will be little or no overdispersion here. Because in such a case the beta parameter is expected to grow large, the model could be relatively unstable to fit and therefore empirical evidence needs to be built as to the model’s performance. The issue is known in particular for the combined model in the binary case (Molenberghs et al., 2012), reinforcing the fact that it needs to be scrutinized here too.
Let 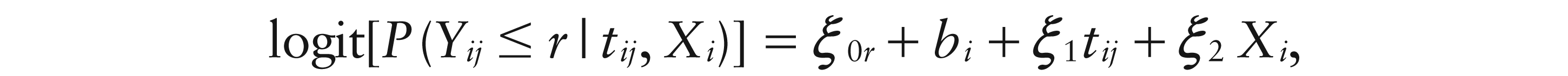
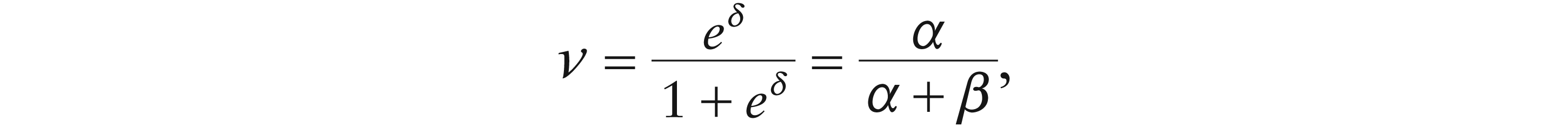
thus simultaneously avoiding identifiability and range violation issues. The parameter
Fluvoxamine trial. Four time points. Parameter estimates and standard errors from the regression coefficients in (1) the ordinary proportional odds model, (2) the proportional odds model with beta overdispersion effect, (3) the proportional odds model with random normal effect, together with (4) the combined model. Estimation was done by maximum likelihood using numerical integration over the normal random effect, if present
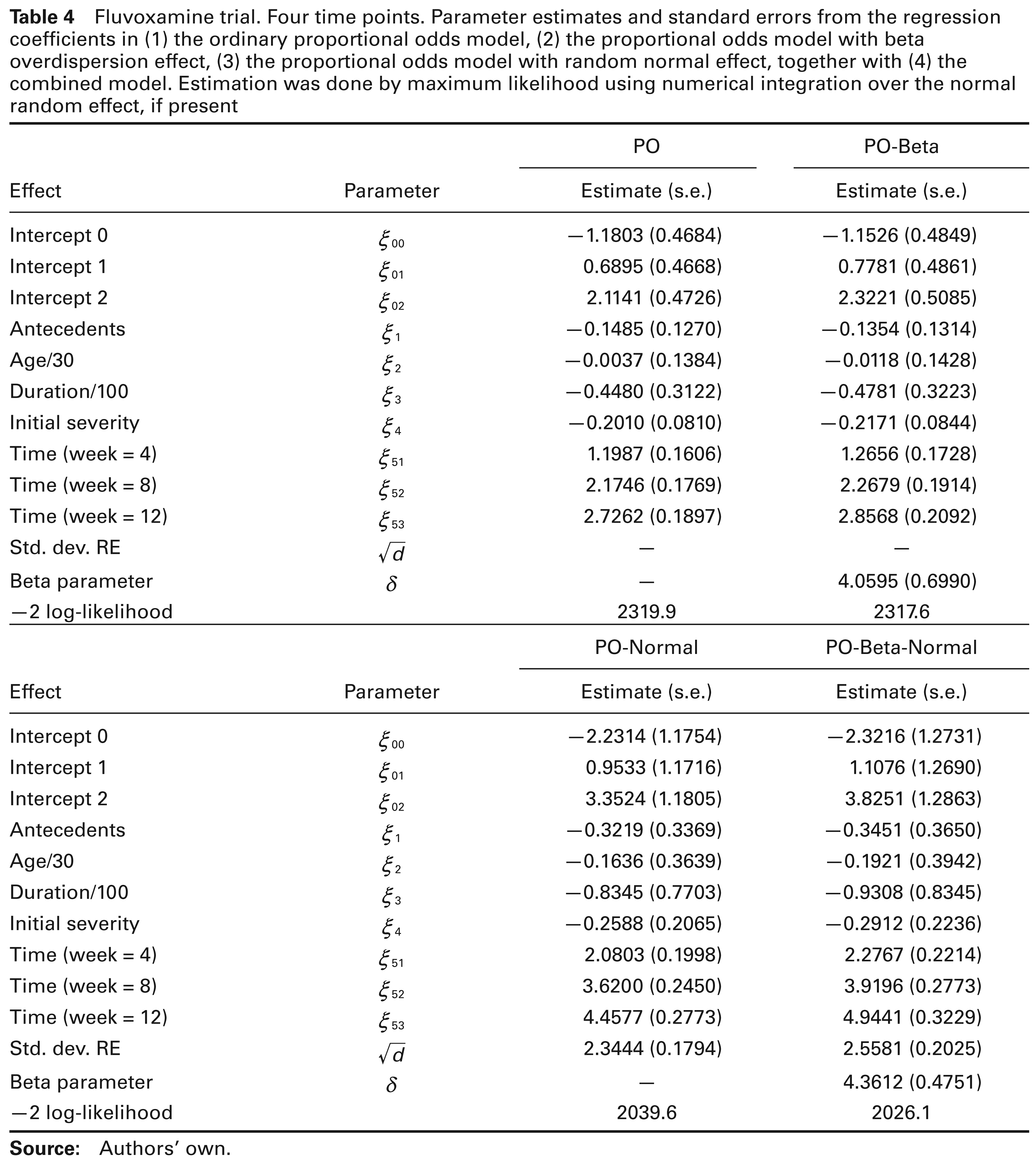
Fluvoxamine trial. Four time points. Parameter estimates and standard errors from the regression coefficients in (1) the ordinary proportional odds model, (2) the proportional odds model with beta overdispersion effect, (3) the proportional odds model with random normal effect, together with (4) the combined model. Estimation was done by maximum likelihood using numerical integration over the normal random effect, if present
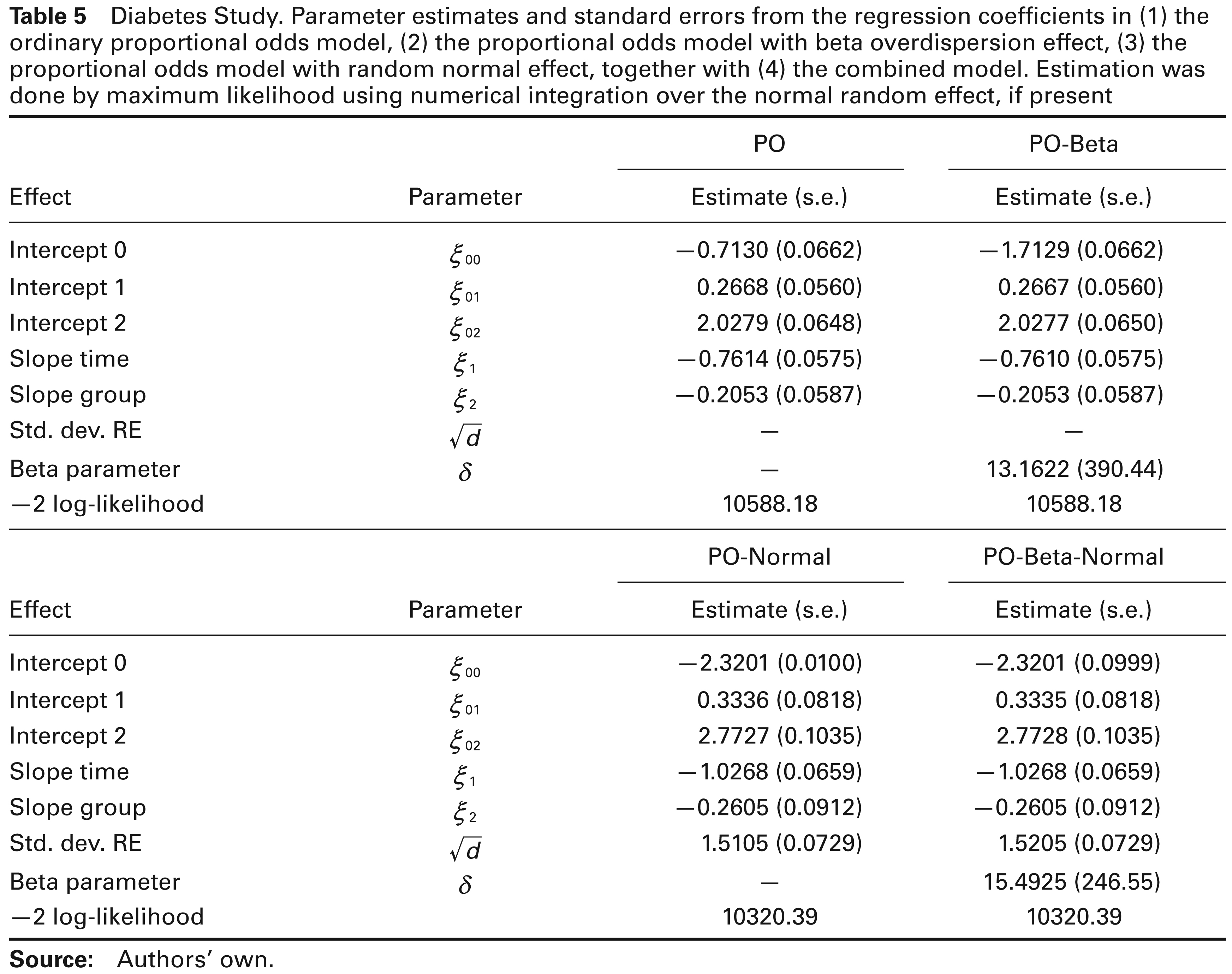
Diabetes Study. Parameter estimates and standard errors from the regression coefficients in (1) the ordinary proportional odds model, (2) the proportional odds model with beta overdispersion effect, (3) the proportional odds model with random normal effect, together with (4) the combined model. Estimation was done by maximum likelihood using numerical integration over the normal random effect, if present
In this article, we have proposed a model for overdispersed, repeated ordinal data. The model combines the proportional odds assumption to handle the ordinal nature of the outcome, with normal random effects in the linear predictor to deal with correlation across repeated measures, and beta random effects to account for overdispersion. Similar models had been proposed by MVD, MVDV, and MVID, for count data, binary and binomial data, and time-to-event outcomes. Ordinal outcomes seem a logical extension, but the ordinal nature of the outcome is generally handled by replacing it with a set of non-redundant indicator variables. This adds a layer of complexity to the modelling process that had not been studied earlier.
The model is easy to formulate and can be fitted in almost a routine fashion using, for example, the SAS procedure NLMIXED. Example code is provided and briefly discussed in the Appendix.
We applied the method to two sets of data, with quite different results. In the diabetes study, there clearly is no need for an overdispersion random effect, so that the conventional generalized linear mixed model, the PO-Normal model in this instance, suffices. For the fluvoxamine trial the situation is different and presents a peculiarity. First comparing the univariate PO model with the PO-Beta model for overdispersion seems to suggest that there no overdispersion is present in the data. However, comparing the PO model with the PO-Normal model suggests that there is a need for normal random effects, which is not surprising given the longitudinal design. Once accounting for the normal random effects, strong evidence is found in favour of overdispersion, when comparing the PO-Normal to the PO-Beta-Normal model. The conclusion is that a forward selection on these sources of variability is not the best route. Instead, a backward selection procedure is advisable, where the more complex model, i.e., the PO-Beta-Normal model, is fitted first. The consequence is that one better starts with the model correcting for overdispersion in addition to correcting for correlation. In other words, a combined model such as the PO-Beta-Normal model would have to be considered more, and more routinely, than is currently the case.
Footnotes
Acknowledgements
Financial support from the IAP research network #P7/06 of the Belgian Government (Belgian Science Policy) is gratefully acknowledged.
SAS implementation
By way of example code, we will illustrate the procedures for the case of four time points per subject. These procedures can simply be reformulated by the user to the case of different numbers of time points, and different numbers of categories per ordinal outcome.
We use the following instance of the NLMIXED procedure in SAS, for the proportional odds model with normal random effect. In line with Molenberghs and Verbeke (2005, Ch. 18) the programme makes use of so-called general-likelihood feature, i.e., a user-defined likelihood that can be applied with the ‘general()’ option in the MODEL statement:
Similar logic in programming the model was followed by Booth et al. (2003). For a given data analysis, it is best to let the number of quadrature points (‘qpoint=’ option) be decided using a numerical sensitivity analysis. This is easily done by progressively letting the number of quadrature points increase, until parameter estimates and all related quantities (including standard errors, log-likelihood at maximum, etc.) stabilize.
The special case of the proportional odds model, without random effects, simply is obtained by removing the RANDOM statement, and by excluding the random intercept:
The general likelihood feature is also ideally suited to implement the combined models. The following SAS code is an example of this for a proportional combined odds model:
The combined model is relatively easy to implement and certainly of the same order of programming complexity as the classical proportional odds model with random effect.