The Bradley–Terry–Luce (BTL) model for paired comparison data is able to obtain a ranking of the objects that are compared pairwise by subjects. The task of each subject is to make preference decisions in favour of one of the objects. This decision is binary when subjects prefer either the first object or the second object, but can also be ordinal when subjects make their decisions on more than two preference categories. Since subject-specific covariates, which reflect characteristics of the subject, may affect the preference decision, it is essential to incorporate subject-specific covariates into the model. However, the inclusion of subject-specific covariates yields a model that contains many parameters and thus estimation becomes challenging. To overcome this problem, we propose a procedure that is able to select and estimate only relevant variables.
In paired comparisons, several objects are compared pairwise to obtain an overall preference ranking of the objects. In many application fields, such as, marketing research or psychometric experiments, objects are presented in a pairwise manner to judges, or, as they are called here, subjects. Their task for each comparison is to make a preference decision in favour of one of the presented objects according to specific subjective criteria, for example, the fragrance of perfumes when two perfumes are the objects being compared. Subjects can typically choose to prefer either the first or the second object, so that the response is represented by a binary variable. Alternatively, the subjects can make their preference decisions on more than two preference categories, such as, preferring the first object strongly or weakly, preferring neither of the objects, or preferring the second object strongly or weakly. This procedure yields an ordinal response that allows for a more precise preference ranking of the objects because it uses additional information about how strongly an object is preferred.
One of the most widely used models for paired comparisons with a binary response is the model suggested by Bradley and Terry (1952). It is closely related to the choice axiom of Luce (1959) with the restriction of choices to between two objects. Thus, the model is also known as Bradley–Terry–Luce (BTL) model. Several extensions have been proposed in the literature to allow for responses with more than two preference categories. The former approaches allowed only a third category and were proposed by Rao and Kupper (1967) and Davidson (1970). Later, ordinal BTL models that allow for any number of ordered response categories were considered by Tutz (1986), Agresti (1992), Dittrich et. al. (2004)) and Dittrich et. al.(2007). Ordinal regression models, in particular the cumulative logit model and the adjacent categories logit model, are in common use when an ordinal response is present. The models presented in this paper assume independence among all observations, so that pairwise ratings from the same subject are modelled as independent. However, in some applications, including a dependence structure is more realistic. In this context, Böckenholt (2001) introduced dependencies among observations by including subject- and object-specific random components.
The main objective of this article is to develop a method that allows for variable selection in a model that also contains subject-specific covariates. These covariates are characteristics of the subject and are assumed to affect the decision of a subject. Selection of relevant subject-specific covariates is very important because subject-specific BTL models typically contain a large number of parameters, and the estimation of all these parameters becomes challenging. Therefore, we focus on detecting important characteristics that determine the preference of objects.
Paired comparison models
The binary BTL model
Let be the number of objects that are being compared and let the pair refer to the comparison of object and object . The response connected to this comparison is denoted by , where
indicat indicates the preference for object r and
indicates the preference for object s. Let with k = 1, 2 and denote the probability of whether object r (for k = 1) or object s (for k = 2) is preferred. The binary BTL model can then be written as a logistic model
where the components of the vector are defined as
Given the pair , the vector has a on the th position and a on the th position. The vector contains all object parameters that are to be estimated, where each parameter reflects the worth of object . For model identifiability, we use the restriction , that is, object is considered as reference object. The ranking of objects is based on estimated object parameters, where estimation is carried out by maximum likelihood estimation for ordinary logistic models (Turner and Firth, 2012).
Ordinal BTL models
In the binary BTL model, the subjects can prefer the first object or the second object of a comparison. In more general settings, the subjects can make their preference decisions on more than two preference categories. In this case, the binary response is extended to a symmetric ordinal response , where denotes an arbitrary number of response categories. In our notation, lower response categories indicate the preference for object . Thus, is the most favourable response category for object and is the most favourable response category for object , or, equivalently, the least favourable response category for object . To ensure that the comparison of the pair yields the same result as the comparison of the pair , the ordinal response is assumed to be symmetric, that is, and therefore (Agresti 1992).
The cumulative model
The cumulative BTL model for ordinal responses uses the cumulative probabilities and , with . The model can be formulated as a cumulative logit model (McCullagh, 1980) with the link function , where
links the considered probabilities to the linear predictor , so that
for all and with the threshold parameters . Because of the symmetric response, the thresholds need to be restricted as follows (see Tutz, 1986):
(1) If is odd
(2) If is even
It can be seen that only threshold parameters need to be estimated; the other ones are determined by the symmetry constraints (2.3) and (2.4).
The adjacent categories model
Another model that also allows for ordinal responses is the adjacent categories BTL model. It is based on the adjacent categories logit model using the link function , with
The model is then defined by
Here, the same restrictions (2.3) and (2.4) are valid and allow for symmetric thresholds see Agresti, (1992). The adjacent categories BTL model can also be represented as a log-linear model, which has been extensively discussed in the literature (see Agresti 1992; Dittrich et. al., 1998, 2004, 2007). When the response consists of categories, the binary BTL model (2.1) is a special case of the cumulative BTL model (2.2) and the adjacent categories BTL model (2.5). In this case, the cumulative BTL model and the adjacent categories BTL model are equivalent.
It should be noted that the cumulative model and the adjacent categories model for ordinal responses use the same set of linear predictors
Therefore, the inclusion of subject-specific covariates for both models is obtained by modifying the same linear predictors.
Including subject-specific covariates
A very restrictive assumption for the models considered in Section 2.2 is that the worth of an object is the same for all subjects. Therefore, the ranking of the objects is the same for all subjects. However, in most applications it is to be expected that the preference for an object and thus the ranking of all objects depends on characteristics of the subject that makes the preference decision (Dittrich et. al., 1998; Francis et. al., 2002). To explicitly model this heterogeneity, we introduce subject-specific covariates , which can be both categorical or continuous characteristics of the subject. In this case, reflects the number of characteristics and refers to a single subject. The object parameters are now assumed to be determined by these characteristics, such that the object parameters vary across subjects. The resulting object parameter for subject is then specified by
where is a parameter for object that is independent of the characteristics of the subject, and is a modifying effect for object depending on the th subject-specific covariate. This means that is a subject–object interaction parameter. To ensure model identifiability, we constraint the subject–object interaction parameters by setting , for all (Francis et. al., 2002). Assuming that there are subjects, the linear predictor from equation (2.6) can be replaced by a more flexible linear predictor that also considers subject-specific covariates and has the form
Here, the vector contains all subject–object interactions that belong to the th subject-specific covariate and is the corresponding vector of subject–object (interaction) parameters, such that refers to the th object and the th subject-specific covariate.
In the absence of subject-specific covariates, that is, , for all , one obtains an ordinal BTL model as described previously. The model that considers subject-specific covariates is more flexible and accounts for heterogeneity between subjects but suffers from the large number of parameters. This is because one has to estimate subject–object parameters, namely, , for each additional subject-specific covariate (that is, when increases by ). To overcome this problem, we present a component-wise boosting algorithm that implicitly selects the influential variables.
Boosting
Basic concept of boosting
Before introducing the boosting algorithm for ordinal BTL models, we will first illustrate the concept of boosting on a linear regression model and then proceed to boosting for ordinal BTL models.
Assume the linear regression model with covariates and observations. In matrix representation, the model can be described as
with the vectors , , and the design matrix that contains the components for . The structure of a generalized linear model (GLM) is determined by , where is a known response function and is the link function that links the conditional expectation to the linear predictor . Using the vectors and , we can also write and . The linear model above can be incorporated within the framework of GLMs by using the identity function as the link function, that is, . For a large number of covariates , it is of interest to estimate the model using only influential variables. There are several methods that perform well in such high-dimensional settings while offering a sparse model; one of these methods is boosting (see Bühlmann, 2006). Boosting has its origin in the machine learning community (see Schapire 1990; Freund 1995, 1997) and can be formulated within the framework of statistical modelling as iteratively fitting parts of the model using the residuals of the previous iteration as the response of the current iteration (Friedman et. al., 2000; Friedman 2001). The basic concept of boosting is to use a set of so-called base learners and combine them to gain a strong learner. A base learner can be a function of a set of covariates or even a single covariate. In this article, we will consider only linear base learners that are able to express a linear effect of the considered covariate(s). In the linear model, a single linear base learner for the th component is, for example,
Tutz and Binder (2006) introduced likelihood-based boosting for GLMs. Instead of the iteratively refitting of residuals, they used the linear predictor of the previous iteration as an offset that adds up to the linear predictor of the current iteration . We describe a component-wise boosting algorithm, where component-wise means that in each iteration only a single component is considered at a time.
Component-wise Boosting
Step 1: Initialization
Fit the intercept model with by maximizing the likelihood to obtain the estimated intercept . Initialize
Step 2: For each boosting iteration
(a) Estimation: Fit the models
for all components by one-step Fisher scoring, where is used as an offset. This yields the one-step Fisher scoring estimates for the corresponding th component. In general, the Fisher scoring algorithm is an iterative estimation procedure and uses the Fisher-matrix and the score function (for more details, see Tutz and Binder 2006).
(b) Selection: From the models fitted in (a), choose the component that yields the best fit with respect to some criteria (e.g., the model with the lowest deviance, Akaike information criterion (AIC) or Bayesian information criterion (BIC)) and set
(c) Update:
, with
Boosting ordinal BTL models
Boosting ordinal BTL models The boosting algorithm described in this section is a component-wise boosting procedure based on the pomBoost algorithm (Zahid and Tutz, 2013), which has been developed for the cumulative logit model. It allows for ordinal responses and can be extended to the adjacent categories logit model by modifying the link function to obtain the adjacent categories logit model (see Section 2.2). We will use a specific feature of the pomBoost algorithm, which allows to split the parameters into two groups to distinguish between obligatory parameters that have to be included in the model and optional parameters that might be of relevance and where a variable selection is applied. In our context, the object parameters are considered as obligatory and the subject-specific parameters , for all are considered as optional. To be more flexible, one can divide the optional subject-specific covariates into two disjoint sets and , with . This will allow selection of two different types of covariates, namely,
: subject-specific covariates, for which all the associated subject–object interactions should be selected simultaneously and
: subject-specific covariates, for which all associated subject–object interactions should be selected separately.
The reason for distinguishing these two groups is that for some subject-specific covariates, it might be interesting for the practitioner to have the possibility to select the respective subject–object interactions simultaneously or separately (we refer to the application section for an illustrating example). The subject–object interaction parameters that are associated with the th subject-specific covariate are given by the set of parameters . If the subject-specific covariate is considered as being from , the parameters are included as a set or left out, which yields variable selection in terms of the subject-specific covariates. However, if the subject-specific covariate is considered as being from , only single parameters from the set are included or left out, which yields selection of subject–object interactions.
The boosting algorithm below uses the design matrix for paired comparisons , where contains the components for the thresholds, contains the components for the objects and contain the components for the subject-specific covariates (for more details on the multivariate structure, see Appendix A). Specifically, all matrices , with , have columns, where each column is denoted by and reflects a single subject–object interaction between the th subject-specific covariate and object . Thus, these matrices have the form . The algorithm proposed is the following:
BTLboost
Step 1: Initialization
Fit the intercept model by maximizing the likelihood in order to obtain estimates for the threshold parameters . Initialize
Step 2: For each boosting iteration
Step 2.1: Update of threshold and object parameters
Estimation: Fit the model by one-step Fisher scoring, where is used as an offset. One obtains the estimates , and defines
Update:
Step 2.2: Update of parameters for the optional covariates
(a) Estimation: For each subject-specific covariate , fit the models
where is used as offset. The estimated parameters and are obtained by one-step Fisher scoring.
(b) Selection: From the models fitted in (a), choose the model that maximally improves the fit with respect to some criteria (e.g., deviance, AIC or BIC) and set if the -th subject–object interaction yields the best fit or if the set of subject–object interactions associated with the -th subject-specific covariate yields the best fit. This yields the estimated parameter vector
(c) Update:
Within each boosting iteration, the algorithm switches between two stages. The first stage (Step ) considers only the object parameters along with the threshold parameters for an update, so that these parameters will always be part of the paired comparison model. In the second stage (Step ), we consider the subject-specific covariates that might enter into the paired comparison model. If the associated subject–object interactions are to be selected simultaneously (), the full subject-specific parameter vector is updated. If they are to be selected separately (), only a single subject–object interaction parameter from the full subject-specific parameter is updated within each boosting iteration. This procedure is repeated until a predefined number of boosting iterations is reached. In the next section, we discuss how the optimal number of boosting iterations can be obtained.
Stopping criteria
The number of boosting iterations is the main tuning parameter in boosting. Typically, a sufficiently high number of iterations is chosen; the optimal number of iterations is then determined afterwards. Common choices for determining are either information criteria, such as, the AIC or BIC, or cross-validation. In this paper, we consider only the two information criteria mentioned earlier, which are known measures for the trade-off between goodness-of-fit and model complexity. The computation of both criteria is based on the deviance and the degrees of freedom after boosting iterations.
The AIC and BIC after iterations are given by
and
where is the number of observations, or, in our case, the number of comparisons that are made by all subjects, namely, . The penalty term, which is for the AIC and for the BIC, controls the model complexity, so that, in general, higher values for the penalty term result in sparser models.
Since the boosting algorithm is an iterative procedure, the true degrees of freedom after boosting iterations are unknown and need to be approximated. In the literature, it is often suggested to use the trace of the hat matrix after boosting iterations as an approximation for the degrees of freedom (Tutz and Binder, 2006; Bühlmann and Hothorn, 2007a). Thus, a possible approximation of the degrees of freedom is given by
where is the approximate hat matrix after iterations. A detailed derivation of the formula for this hat matrix can be found in Zahid and Tutz (2013).
An alternative, computationally simpler method proposed by Bühlmann and Hothorn (2007b) uses the size of the active set, which corresponds to the number of non-zero parameters in the th boosting iteration, in order to approximate the degrees of freedom . In this case, the number of non-zero coefficients until the th boosting iteration is given by
where is the number of threshold parameters, is the number of object parameters, are all non-zero subject–object parameters of the th iteration, and is the indicator function, such that if the expression is true, else . To limit the computational burden, we use this more convenient method to approximate the degrees of freedom in the simulation and application section.
The optimal stopping iteration is chosen from among the iterations as the one yielding the best (=lowest) or , respectively. Thus, one has to compute the AIC or BIC for all iterations. The optimal stopping iteration is then determined afterwards using
when the AIC is chosen as stopping criterion or
when the BIC is chosen as stopping criterion, respectively.
Simulation
Simulation set-up
We investigate the performance of the boosting algorithm for different simulation settings with simulations for each setting. For the simulated data, we generate subject-specific covariates denoted by from the following distributions and and use objects that have to be compared by subjects. We use response categories, so that each simulated subject has the possibility to prefer the first object, neither of the objects or the second object. In all settings, the ordinal response is computed by assuming an underlying cumulative BTL model with the linear predictor
using the threshold parameters and the object parameters . The settings are organized as follows.
Setting 1: Only the subject-specific covariates are influential (parameter values can be obtained from Table 1), while all other subject-specific covariates are non-influential. For each subject-specific covariate, the associated subject–object interactions are selected simultaneously, that is, and .
Setting 2: Only the subject-specific covariates are influential (parameter values can be obtained from Table 1). For each subject-specific covariate, the associated subject–object interactions are selected separately, that is, and .
Setting 3: In this setting, we consider a miss-specified model. That is, after computing the ordinal response using the influential subject-specific covariates with the associated parameter values from Table 1, some influential subject-specific covariates were removed from the simulated data set:
(a) The covariates were removed and the boosting algorithm was applied as in Setting 1, that is, the subject–object interactions for each subject-specific covariate were selected simultaneously, so that all considered covariates are from .
(b) The covariates were removed and the boosting algorithm was applied as in Setting 2, that is, the subject–object interactions for each subject-specific covariate were selected separately, so that all considered covariates are from .
Setting 4: Same as Setting 1, except that only one subject-specific covariate, , is considered as influential.
Setting 5: Same as Setting 2, except that only one subject-specific covariate, , is considered as influential.
As variable selection criterion in each boosting iteration, we use the deviance, which often yields the fully saturated model when the stopping iteration is sufficiently high, i.e., (see Bühlmann and Yu, 2003). Therefore, there is a need for determining the optimal number of iterations using a stopping criterion that chooses the best model among all iterations. In the next section, we compare the results when the AIC and BIC are used as stopping criteria. The degrees of freedoms for the computation of the AIC and BIC are approximated as in equation (4.1).
Results
Results To investigate the performance of the algorithm, we compute the hit rate
which represents the percentage of correctly identified influential subject–object interactions, and the false alarm rate
which represents the percentage of non-influential subject–object interactions that are mistakenly identified as influential subject–object interactions. The closer the hit rate to 1 and the closer the false alarm rate to 0, the better, because then the model contains many influential subject–object interactions and few non-influential subject–object interactions at the same time.
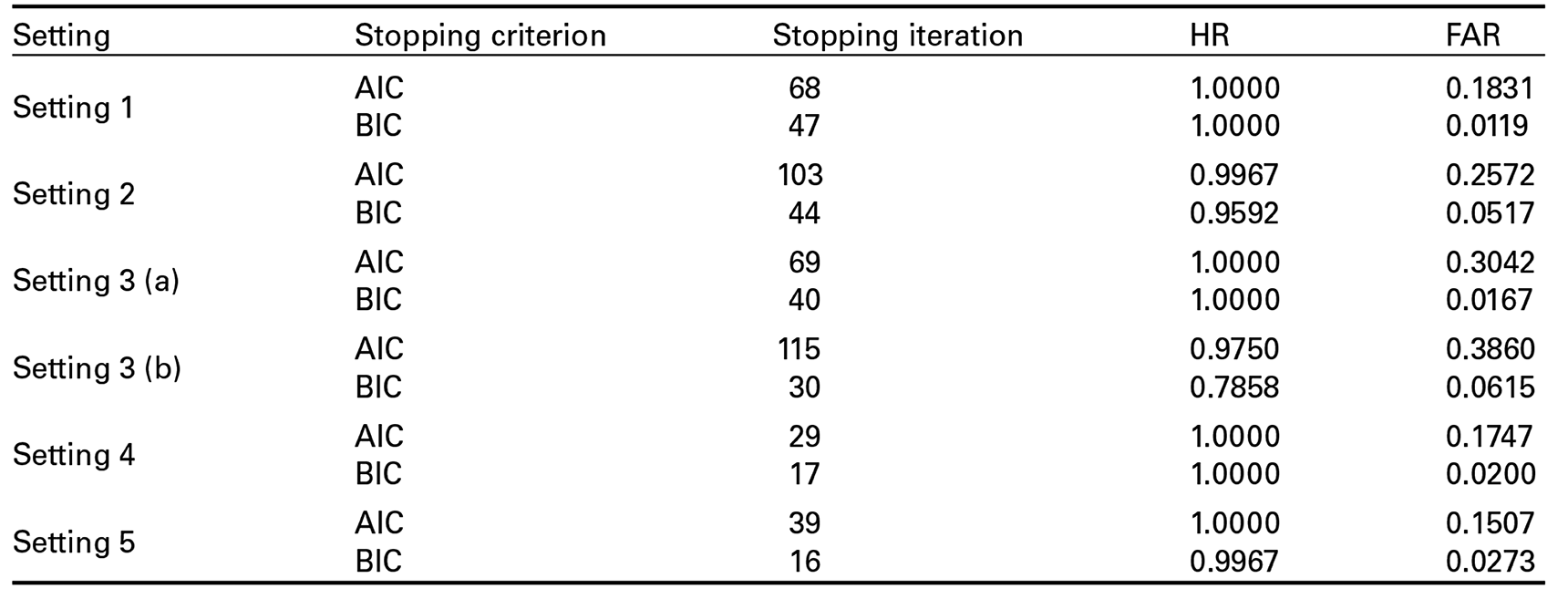
Table 2 shows the averaged number of boosting iterations, as well as the averaged hit rates and false alarm rates over all simulations in each setting. As the model complexity is supposed to be penalized stronger by the BIC, one sees an earlier stopping of the boosting algorithm when using the BIC instead of the AIC. Except for Setting 2 and Setting 3 (b), the hit rates for the AIC and BIC are very similar and close to 1, that is, the boosting algorithm was always able to identify all (or almost all when using the BIC in Setting 5) influential covariates for Settings 1, 3 (a), 4 and 5. However, at the same time, using the BIC yields a much lower false alarm rate suggesting that using the BIC is more appropriate. In Setting 2, we have a slightly higher hit rate when the AIC is used (the difference in the hit rates is ). However, the false alarm rate is almost five times higher when the AIC is used instead of the BIC ( compared to ). Using the AIC in Setting 3 (a) yields a higher hit rate, where the difference in the hit rates is . At the same time, the false alarm rate is much worse ( for the AIC and for the BIC). Thus, the question of whether the AIC or BIC should be used depends on whether one is interested in identifying most of the influential subject–object interactions (then the AIC might be more appropriate) or in identifying many influential subject–object interactions and few non-influential subject–object interactions at the same time (then the BIC might be more appropriate). In all settings, the false alarm rate is much higher when the AIC is used instead of the BIC. This suggests that more non-influential subject–object interactions are included in the final model determined by the AIC.
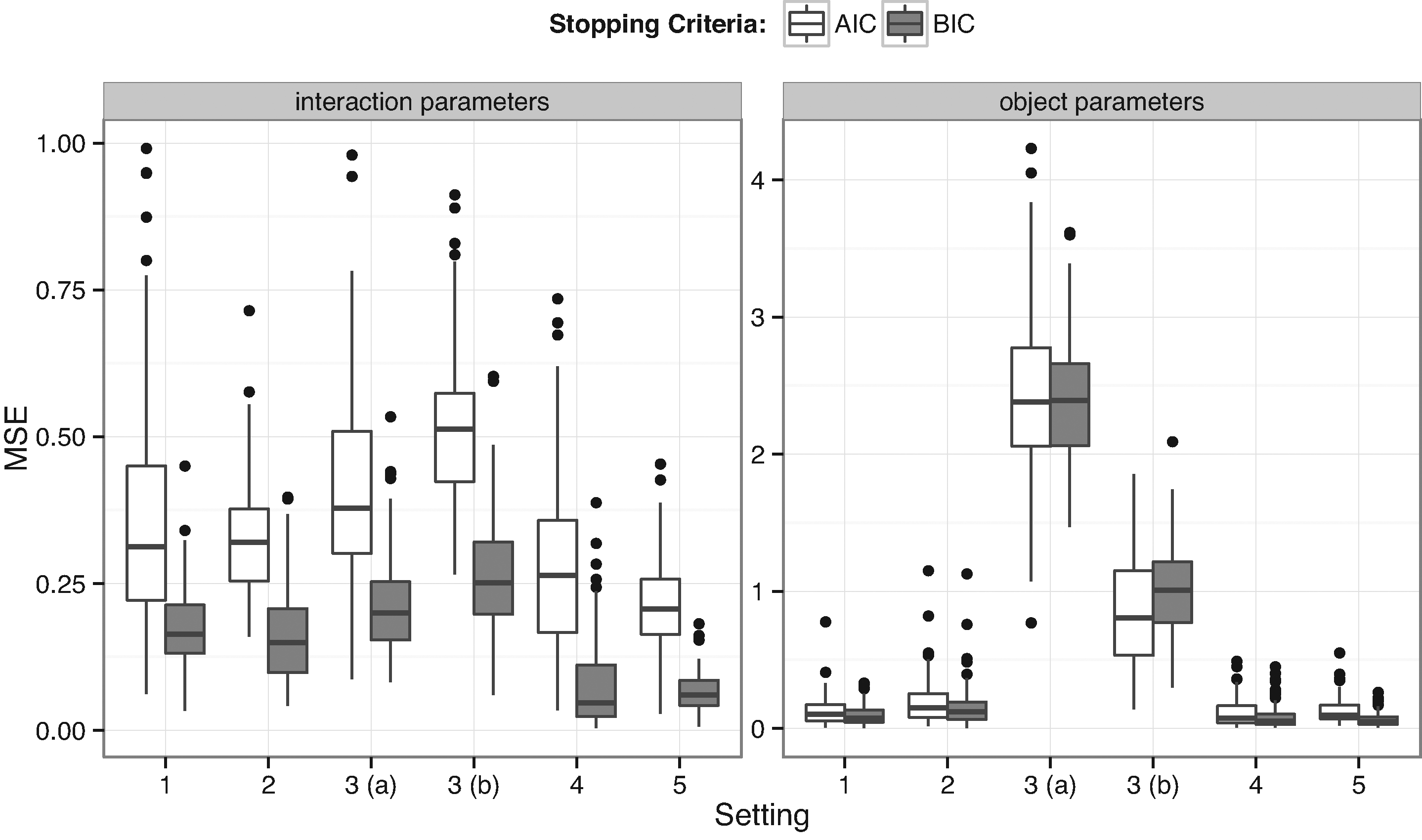
To measure the discrepancy of the parameter estimates with the true parameter values, we use the Mean squared error (MSE). Before computing the MSE for the final model, a final refitting step using the selected subject–object interaction parameters is done. Figure 1 displays the MSE for all simulations and suggests that for the selected subject–object interaction parameters the BIC performs better than the AIC because of smaller MSEs in all settings. It can also be seen that in Setting 3, where a miss-specified model is considered, the MSEs are much larger for the object parameters than for the selected subject–object interaction parameters as compared to the other settings.
Average of the HR, the FAR and the number of boosting iterations.
Setting
Stopping criterion
Stopping iteration
HR
FAR
Setting 1
AIC
68
1.0000
0.1831
BIC
47
1.0000
0.0119
Setting 2
AIC
103
0.9967
0.2572
BIC
44
0.9592
0.0517
Setting 3 (a)
AIC
69
1.0000
0.3042
BIC
40
1.0000
0.0167
Setting 3 (b)
AIC
115
0.9750
0.3860
BIC
30
0.7858
0.0615
Setting 4
AIC
29
1.0000
0.1747
BIC
17
1.0000
0.0200
Setting 5
AIC
39
1.0000
0.1507
BIC
16
0.9967
0.0273
Source: Authors' computation.
Source: Authors' computation.
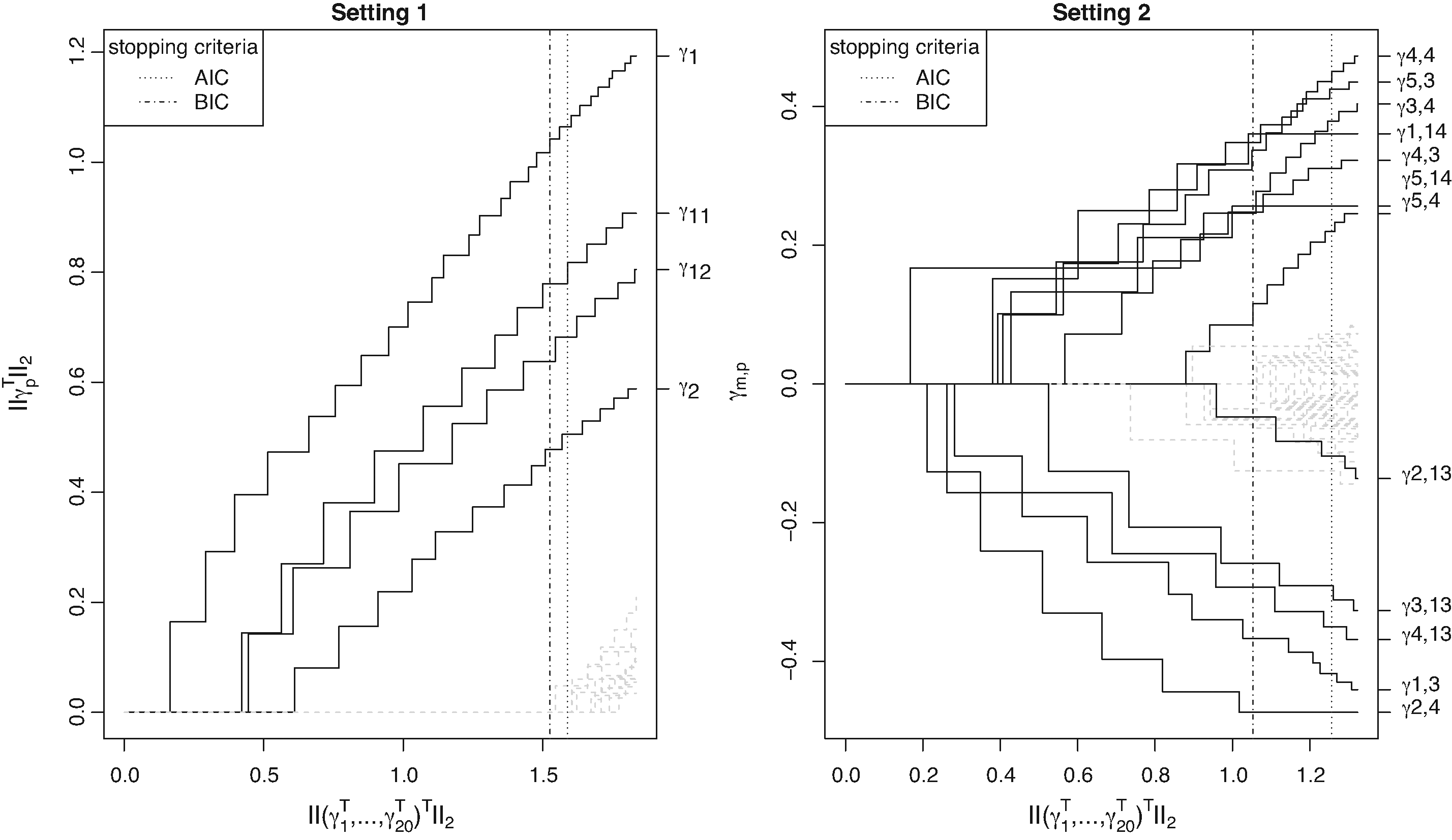
Figure 2 illustrates an exemplary coefficient build-up of the estimated parameters for one out of the simulations of Setting 1 and Setting 2. Within each boosting iteration of Setting 1 (left figure), the set of subject–object interaction parameters associated with a single subject-specific covariate are updated. Therefore, the norm of a single subject-specific parameter vector for each of the covariates is plotted against the norm of the parameter vector containing all subject–object parameters . Conversely, in Setting 2 (right figure) only the parameter of a single subject–object interaction is updated within each boosting iteration. Therefore, the estimates for a single subject–object interaction parameter are plotted against the norm of the parameter vector containing all subject–object parameters . The coefficient paths show that the non-influential subject–object interaction parameters (dashed gray lines) enter the model in higher boosting iterations and their parameter estimates are small because they are either selected and updated in higher boosting iterations, or they are updated only a few number of times. Since the AIC determines a higher optimal boosting iteration than the BIC, the figure confirms that the final model based on the AIC criterion contains more non-influential subject–object interactions than the final model based on the BIC criterion.
Source: Authors' computation.
CEMS data
6CEMS data To illustrate how the variable selection method works, we use the Community of European management schools (CEMS) data from Dittrich et. al. (1998), which was collected in a survey of students of the Vienna University of Economics. The aim of the study was to investigate the preferences of students for studying at least one semester abroad in one of six different universities (London, Paris, Barcelona, St.Gall, Milan and Stockholm) and to establish an overall ranking of these universities. For each of the comparisons of universities, the students could either prefer the first university, none of both universities or the second university. Additionally, the data contains subject-specific different characteristics of the students (subject-specific covariates). An overview is given in Table 3.
Description of subject-specific covariates.
Covariate
Description
Coding
STUD
Main discipline of study
0 = other, 1 = commerce
ENG
Knowledge of English
0 = good, 1 = poor
FRA
Knowledge of French
0 = good, 1 = poor
SPA
Knowledge of Spanish
0 = good, 1 = poor
ITA
Knowledge of Italian
0 = good, 1 = poor
WOR
Full-time employment while studying
0 = no, 1 = yes
DEG
Intention to take an international degree
0 = no, 1 = yes
SEX
Gender
0 = female, 1 = male
Source: Authors' computation.
A model that includes all these subject-specific covariates has a total number of subject–object interaction parameters. To identify only influential subject-specific covariates, we apply the BTLboost algorithm with two different settings.
In the first setting, we use and . Therefore, subject-specific covariates containing information about the knowledge of a specific language are included in the set and are selected interaction-wise, so that the final model does not necessarily contain all subject–object interactions that are associated to a specific language. In contrast to this, the set contains subject-specific covariates that are selected along with all associated subject–object interactions. This distinction was chosen because language-specific covariates may interact stronger with one university. For example, students with poor knowledge of Italian may have a lower tendency to prefer the university of Milan.
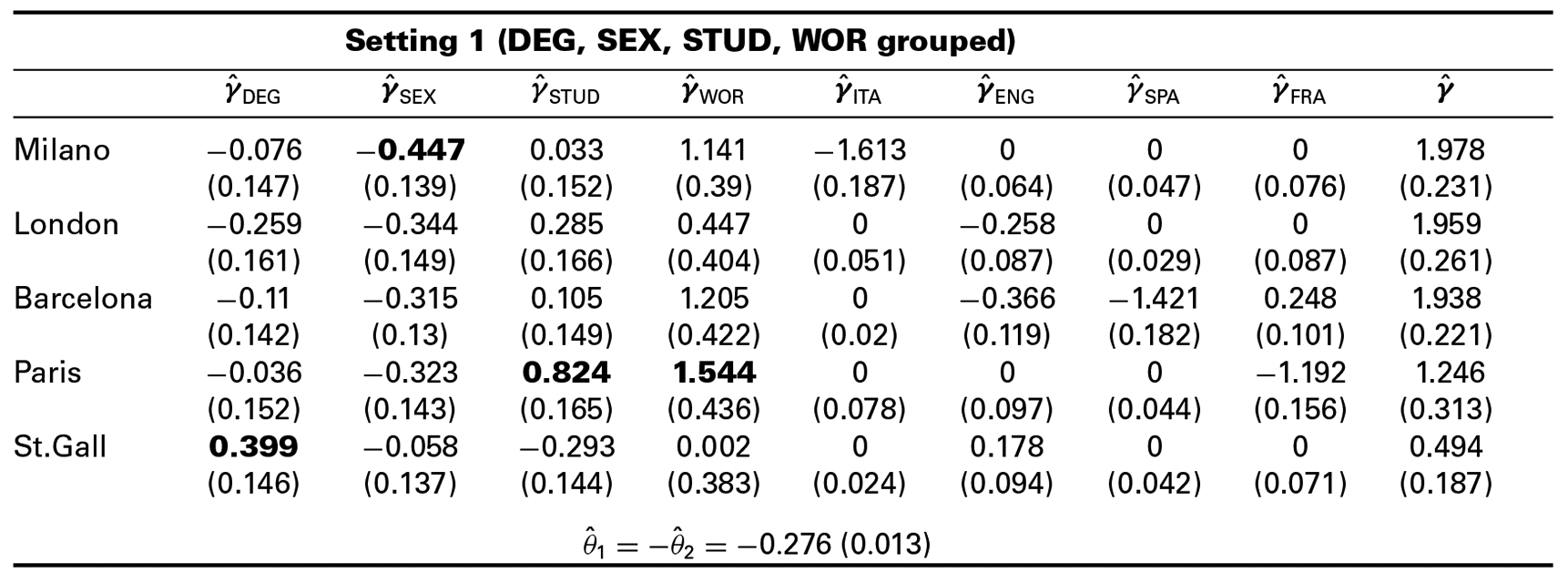
In the second setting, we use and . Thus, for each subject-specific covariate only the associated subject–object interactions are considered. For both settings, we apply the BTLboost algorithm to the cumulative BTL model using the AIC and BIC as stopping criteria. The estimated parameters after a final refitting step with bootstrapped standard errors can be found in Table 4 and Table 5. Because the BIC performed better in the simulation study, both tables show only the estimated parameters when using the BIC as stopping criterion. The optimal number of iterations when using the BIC was 34 in the first setting and 30 in the second setting.
Estimates for selected subject–object interaction and object parameters after a final refitting step for Setting 1. The figures in brackets reflect standard error estimates based on bootstrapped samples.
Setting 1 (DEG, SEX, STUD, WOR grouped)
Milano
0.076
0.447
0.033
1.141
1.613
0
0
0
1.978
(0.147)
(0.139)
(0.152)
(0.39)
(0.187)
(0.064)
(0.047)
(0.076)
(0.231)
London
0.259
0.344
0.285
0.447
0
0.258
0
0
1.959
(0.161)
(0.149)
(0.166)
(0.404)
(0.051)
(0.087)
(0.029)
(0.087)
(0.261)
Barcelona
0.11
0.315
0.105
1.205
0
0.366
1.421
0.248
1.938
(0.142)
(0.13)
(0.149)
(0.422)
(0.02)
(0.119)
(0.182)
(0.101)
(0.221)
Paris
0.036
0.323
0.824
1.544
0
0
0
1.192
1.246
(0.152)
(0.143)
(0.165)
(0.436)
(0.078)
(0.097)
(0.044)
(0.156)
(0.313)
St.Gall
0.399
0.058
0.293
0.002
0
0.178
0
0
0.494
(0.146)
(0.137)
(0.144)
(0.383)
(0.024)
(0.094)
(0.042)
(0.071)
(0.187)
Source: Authors' computation.
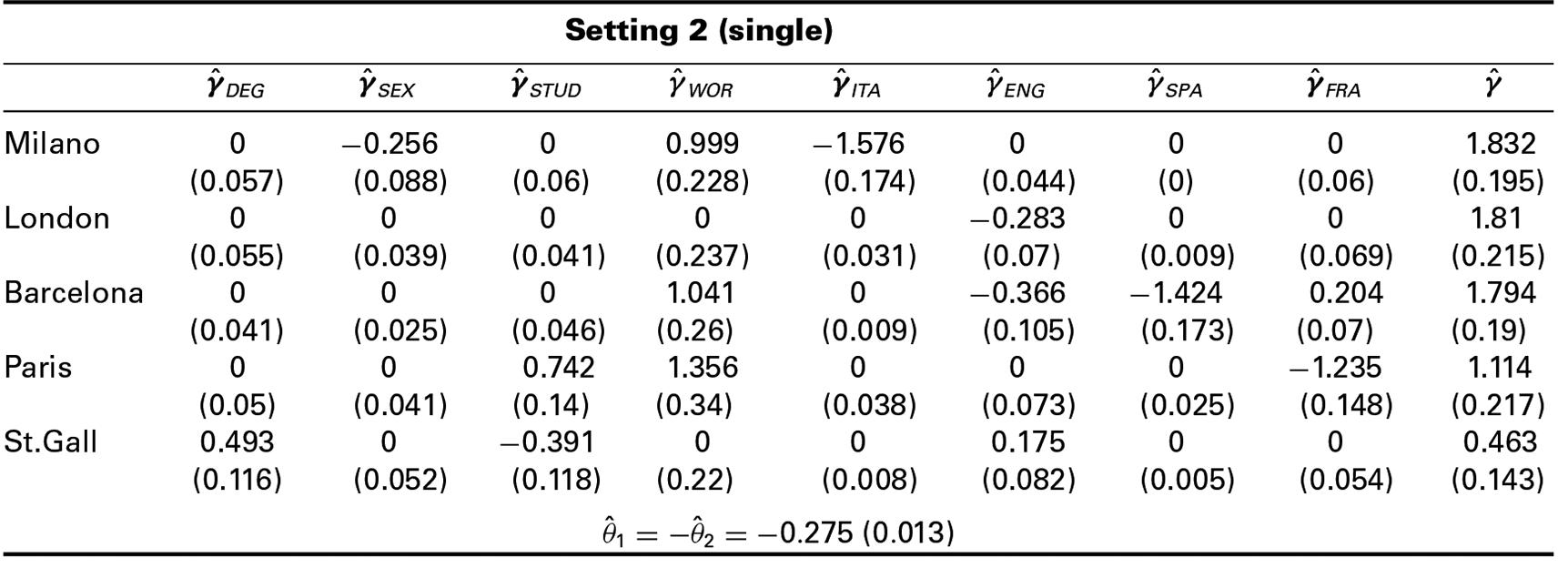
Estimates for selected subject–object interactions and object parameters after a final refitting step for Setting 2. The figures in brackets reflect standard error estimates based on bootstrapped samples.
Setting 2 (single)
Milano
0
0.256
0
0.999
1.576
0
0
0
\hskip 3.6pt1.832
(0.057)
(0.088)
(0.06)
(0.228)
(0.174)
(0.044)
(0)
(0.06)
(0.195)
London
0
0
0
0
0
0.283
0
0
\hskip 3.6pt1.81
(0.055)
(0.039)
(0.041)
(0.237)
(0.031)
(0.07)
(0.009)
(0.069)
(0.215)
Barcelona
0
0
0
1.041
0
0.366
1.424
0.204
\hskip 3.6pt1.794
(0.041)
(0.025)
(0.046)
(0.26)
(0.009)
(0.105)
(0.173)
(0.07)
(0.19)
Paris
0
0
0.742
1.356
0
0
0
1.235
\hskip 2.8pt1.114
(0.05)
(0.041)
(0.14)
(0.34)
(0.038)
(0.073)
(0.025)
(0.148)
(0.217)
St.Gall
0.493
0
0.391
0
0
0.175
0
0
\hskip 3.4pt0.463
(0.116)
(0.052)
(0.118)
(0.22)
(0.008)
(0.082)
(0.005)
(0.054)
(0.143)
Source: Authors' computation.
The results show that the ranking of objects (here universities), which is based on ordering the estimates for , is the same for both settings. Milan has the greatest estimate (e.g., from Table 4) and thus the most preferred university is Milan, followed by London, Barcelona, Paris, St.Gall and the reference university Stockholm, for which . However, the ranking changes for different values of the subject-specific covariates. For example, if we consider students who are employed full-time while studying (), the ranking is based on yielding a different university ranking for those students. The estimates and are all negative valued, and therefore they indicate that students with poor knowledge of English, French, Italian and Spanish have a lower tendency to prefer the universities in London, Paris, Milan and Barcelona, respectively. The main difference between Setting 1 and Setting 2 is that the subject–object interactions associated with the subject-specific covariates STUD, WOR, DEG and SEX were selected simultaneously in Setting 1 and separately in Setting 2. Nevertheless, all subject–object interactions that are highlighted in boldface in Table 4 were also identified in Setting 2. These subject–object interactions are the ones with the largest absolute value within the associated subject-specific parameter. Thus, the model from Setting 2 was able to identify the subject–object interactions from Setting 1 with the strongest effect.
Concluding remarks
Boosting is a technique that addresses the estimation problems in high-dimensional settings and provides variable selection when using component-wise boosting. In this article, we proposed a new estimation procedure for ordinal BTL models based on this technique. The simulation results showed that the method performs well concerning the identification of influential covariates. In the application section, the selected subject–object interactions are similar to those from the final model of Dittrich et. al. (1998), although they used a different model and a variable selection approach based on forward selection and backward elimination. In the algorithm proposed here, the variable selection is carried out during the fitting process. Thus, it can also be applied in cases where the maximum likelihood estimate does not exist, for example, when the data contains more subject-specific covariates than observations.
The model estimation for ordinal BTL models is computed with the ordBTL package (Casalicchio, 2013), which is implemented in the statistical software R (R Core Team, 2013). The package is able to fit models with any number of response categories and implements the BTLboost algorithm. The data used in Section 6 is also available in the package. Other packages for model estimation, which can handle responses up to 3 categories but have no built-in variable selection procedure, are prefmod (Hatzinger and Dittrich, 2012) and BradleyTerry2 (Turner and Firth, 2012).
Appendix A: Matrix representation
The representation used here is that of a multivariate generalized linear model, which has, in terms of paired comparisons, the following basic form
where is a -dimensional link function, is the vector of coefficients, is the vector of response probabilities, is the subject-specific linear predictor, and is the design matrix for the pair and subject . If the design matrix and the link function is specified, the Fisher scoring algorithm for multivariate maximum likelihood estimation can be used to obtain the parameter estimates (see Fahrmeir and Tutz, 2001; Tutz, 2012).
Before describing the design matrix in more detail, we first let , with , denote a vector containing all threshold parameters that have to be estimated and denote a vector containing all threshold parameters in the model, including those that are restricted by the symmetry constraints from equations (2.3) and (2.4). For each pair and each subject , we define the matrix of dimension , such that
satisfies the symmetry constraints and ensures that the thresholds will be symmetric. Thus, the matrix can be seen as a so-called constraint matrix (for more details, see Yee, 2010).
To obtain the general structure of , we use the null vector of length and the matrices
The matrix satisfying equation (A.2) is a block matrix that has the same form for each pair and each subject , namely,
The subject-specific design matrix used in equation (A.1) is given by
where the vector has the length . In a complete paired comparison experiment, we have comparisons for each subject, where denotes the binomial coefficient representing the number of all distinct pairs when comparing different objects, namely,
The complete design matrix contains information about all possible comparisons made by any subject and has therefore rows. It can be written as a block matrix of the form
where is the matrix for the thresholds , is the matrix for the object parameters and are matrices for the subject-specific parameters .
The linear predictor contains all comparisons made by any subject and has the form with the vector containing all parameters that have to be estimated, that is, all threshold parameters, all object parameters and all subject–object interaction parameters for each of the subject-specific covariates.
Footnotes
Acknowledgments
Financial support from LMUexcellent is gratefully acknowledged.
References
1.
AgrestiA (1992) Analysis of ordinal paired comparison data. Journal of the Royal Statistical Society. Series C (Applied Statistics), 41, 287–97.
BradleyRATerryME (1952) Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika, 39, 324–45.
4.
BühlmannP (2006) Boosting for high-dimensional linear models. The Annals of Statistics, 34, 559–83.
5.
BühlmannPHothornT (2007a) Boosting algorithms: Regularization, prediction and model fitting. Statistical Science, 22, 477–505.
6.
BühlmannPHothornT (2007b) Rejoinder: Boosting algorithms: Regularization, prediction and model fitting. Statistical Science, 22, 516–22.
7.
BühlmannPYuB (2003) Boosting with the L2-loss: Regression and classification. Journal of the American Statistical Association, 98, 324–39.
8.
CasalicchioG (2013) ordBTL: Modelling comparison data with ordinal response. R package version 0.8.
9.
DavidsonRR (1970) On extending the Bradley-Terry model to accommodate ties in paired comparison experiments. Journal of the American Statistical Association, 65, 317–28.
10.
DittrichRHatzingerRKatzenbeisserW (1998) Modelling the effect of subject-specific covariates in paired comparison studies with an application to university rankings. Journal of the Royal Statistical Society: Series C (Applied Statistics), 47, 511–25.
11.
DittrichRHatzingerRKatzenbeisserW (2004) A log-linear approach for modelling ordinal paired comparison data on motives to start a PhD programme. Statistical Modelling, 4, 181–93.
12.
DittrichRFrancisBHatzingerRKatzenbeisserW (2007) A paired comparison approach for the analysis of sets of Likert-scale responses. Statistical Modelling, 7, 3–28.
13.
FahrmeirLTutzG (2001) Multivariate statistical modelling based on generalized linear models. New York: Springer.
14.
FrancisBDittrichRHatzingerRPennR (2002) Analysing partial ranks by using smoothed paired comparison methods: An investigation of value orientation in Europe. Journal of the Royal Statistical Society: Series C (Applied Statistics), 51, 319–36.
15.
FreundY (1995) Boosting a weak learning algorithm by majority. Information and Computation, 121, 256–85.
16.
FreundY (1997) A decision-theoretic generalization of on-line learning and an application to boosting?Journal of Computer and System Sciences, 55, 119–39.
17.
FriedmanJHastieTTibshiraniR (2000) Special invited paper. Additive ogistic regression: A statistical view of boosting. The Annals of Statistics, 28, 337–74.
18.
FriedmaJH (2001) Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29, 1189–232.
19.
HatzingerRDittrichR (2012) prefmod: An R package for modeling preferences based on paired comparisons, rankings, or ratings. Journal of Statistical Software, 48, 1–31.
20.
LuceRD (1959) Individual choice behavior a theoretical analysis. New York: Wiley.
21.
McCullaghP (1980) Regression models for ordinal data. Journal of the Royal Statistical Society. Series B (Methodological), 42, 109–42.
22.
R Core Team (2013) R: A language and environment for statistical computing. R Foundation for Statistical ComputingVienna, Austria.
23.
RaoPVKupperLL (1967) Ties in paired-comparison experiments: A generalization of the Bradley-Terry model. Journal of the American Statistical Association, 62, 194–204.
24.
SchapireRE (1990) The strength of weak learnability. Machine Learning, 5, 197–227.
25.
TurnerHFirthD (2012) Bradley-Terry models in R: The BradleyTerry2 package. Journal of Statistical Software, 48.
26.
TutzG (1986) Bradley-Terry-Luce models with an ordered response. Journal of Mathematical Psychology, 30, 306–16.
27.
TutzG (2012) Regression for categorical data. Cambridge University Press.
28.
TutzGBinderH (2006) Generalized additive modeling with implicit variable selection by likelihood-based boosting. Biometrics, 62, 961–71.
29.
YeeTW (2010) The VGAM package for categorical data analysis. Journal of Statistical Software, 32, 1–34.
30.
ZahidFMTutzG (2013) Proportional odds models with high-dimensional data structure. International Statistical Review, 81, 388–406.