
Abstract
This study examines the efficacy of tort reforms instituted throughout the country during the last decade, improving upon existing semiparametric density ratio estimation (DRE) methodologies in the process. DRE is a well-known semiparametric modelling technique that has been used for well over two decades. Although the approach has been demonstrated to be extremely useful in statistical modelling, it has suffered from one main limitation—the methodology has thus far not been capable of modelling individual-level heterogeneity. We address this issue by presenting a novel adaptation of DRE to model individual level heterogeneity. We do so by marginalizing the associated empirical likelihood function involving density ratios to provide an overall distribution of the entire population despite having extremely limited initial information about each individual in the dataset. We apply this approach to medical malpractice loss data from the previous decade to quantify the probability of changes in tort losses. Our results demonstrate the success of a number of recently implemented malpractice reforms. Comparisons to existing DRE methods, as well as standard regression methods, illustrate the efficacy of our approach.
Keywords
Introduction
Tort reform
From fields ranging from obstetrics to surgery to opthomology, medical doctors all across the United States face the risk of being unnecessarily sued. These risks often raise health care costs by forcing doctors to engage in defensive medicine (Crain et al., 2009; Kessler and McClellan, 1996; Studdert et al., 2005). These concerns have made reforming the civil justice system as it applies to doctors a top priority among many policy-makers both on the left and right side of the aisle (Jones, 2010, March 5).
Such reforms to the civil justice system are known as medical malpractice reforms. Belonging to a larger class of reforms known as tort reform, medical malpractice reform seeks to fundamentally transform important aspects of the civil justice system to preserve its integrity. Some approaches to tort reform include imposition of monetary caps, which limit the amount of money that a jury may award a plaintiff. These caps may apply to punitive damages, monetary damage awards, non-economic damages or appeal bonds. Other approaches have been to reform certain aspects of the civil justice system such as statutes of limitations and class action lawsuits among others.
In this study, we estimate the impact of malpractice reforms over the course of the last decade by computing probabilities regarding tort losses. This question is important to look at because policy-makers often wonder about the efficacy of reforms that have been implemented. Estimation of the associated probabilities, however, is not elementary as public policy research has clearly illustrated that different states exhibit different degrees of litigiousness (American Tort Reform Association, 2014; McQuillan and Abramyan, 2008a, McQuillan and Abramyan, 2010). Texas and Alaska have been demonstrated, for instance, to be substantially less litigious than other states such as California and New York (McQuillan and Abramyan, 2010). Additionally, different areas within states (such as New York City versus western upstate New York) may also exhibit a certain degree of heterogeneity. For example, the American Tort Reform Association has recently published a study titled ‘Judicial Hellholes 2014–2015’ discussing localities ‘where judges in civil cases systematically apply laws and court procedures in an unfair and unbalanced manner’. They argue that although ‘entire states are occasionally cited as Hellholes, specific counties or courts in a given state more typically warrant such citations’, (American Tort Reform Association, 2014). Although one study quantitatively looks at the impact of tort reforms via linear regression methods (Crain et al., 2009), it ignores this heterogeneity. We improve semiparametric density ratio estimation (DRE) methodologies to model this heterogeneity and compare this new approach to existing semiparametric density ratio methods as well as to standard regression methods.
Bayesian parametric methods
Given the dramatic improvements in statistical computing power over the course of the last few decades, incorporating heterogeneity in parametric models has become increasingly common in statistical modelling. Statisticians can now choose from a variety of methodologies ranging from Bayesian methods to finite mixture methods to combinations of the two (Kamakura and Russell, 1989; Kyung et al., 2011; Lenk and DeSarbo, 2000; Rossi and Allenby, 2003).
Modelling individual-level heterogeneity is important in understanding real-world phenomena as there is often no a priori reason to believe that all individuals (or observations) in a dataset behave in the same manner. However, with data sets often possessing limited information about each individual, it is often impossible to estimate models incorporating heterogeneity from a frequentist perspective. The Bayesian approach enables the researcher to assume that individual-level parameters follow a lower dimensional probability distribution from which statistical inferences can be made (Gelfand, 1996; Morris, 1983).
In this study, we apply an empirical Bayesian approach to a semiparametric methodology used thus far only for frequentist statistical modelling. Our approach allows these models to accommodate individual-level heterogeneity, thus enabling the researcher to make direct statistical inference about the overall population. We discuss this semiparametric methodology in the following section.
Density ratio estimation
DRE methods have been around for decades. In 1997, following Prentice and Pyke (1979) and others, Qin and Zhang (1997) proposed the idea of making assumptions about the ratios of probability densities (referred to as tilts) based on subsamples within the data sets. Such density ratios have been looked at extensively in machine learning research. Some approaches have utilized kernel-based methods among other methods to estimate the actual ratio, known as the importance, between the two densities. These methods are useful in covariate shift adaptation as well as outlier detection (Kanamori et al., 2009; Sugiyama et al., 2008).
DRE itself has had myriads of applications in statistical research (Owen, 1988; Prentice and Pyke, 1979; Qin and Zhang, 1997). In 1999, Gilbert et al. improved on DRE's methodologies and applied these improvements to understand the efficacy of human immunodeficiency virus (HIV) vaccine trials. In 2005, Qin and Zhang posited that the tilt functions have an exponential functional form (Qin and Zhang, 2005). Three years later, Kedem et al. (2008) applied the methodology to time series analysis (Gilbert et al., 1999; Kedem et al., 2008). A variety of studies in recent research have used DRE to understand the distributional properties of data. For example, in 2009, Kedem et al. utilized DRE to understand risk factors regarding cancer. They compared case and control groups to estimate the probabilities of particular risk factors influencing the incidence of cancer. Voulgaraki et al. (2012) extended this research to understand the distributional properties of height, weight and age on cancer patients. They utilized these distributions to estimate conditional expectations of weight, given height and age of patients. Subsequently, in 2014, Kedem et al. utilized DRE to understand food contamination. Having data about food contamination, the authors examined the probabilities of these contaminants exceeding critical thresholds to determine the risk of contracting particular illnesses. In addition to these studies, there have been many other studies that have utilized the semiparametric benefits of the DRE approach (Fokianos, 2004; Fokianos et al., 2001; Kedem et al., 2009; Phue et al., 2007; Prentice and Pyke, 1979).
Fokianos and Qin (2008) applied importance sampling in conjunction with DRE, which necessitated the generation of artificial data (Fokianos and Qin, 2008). Prior to the Fokianos and Qin study, however, all research utilizing DRE was based on within-sample data. With data divided into smaller subsets, comparisons would be made between these sets. A number of recent studies proposed an innovative adaptation of DRE known as ‘out of sample fusion’. Using the idea of having a single primary dataset as a reference, and an additional artificial (possibly simulated) dataset, the studies have shown that more accurate inferences can be made regarding the primary dataset by applying DRE to both the samples (Katzoff et al., 2014; Kedem et al., 2014; Zhou, 2012). Dayaratna (2014) found that this methodology can be particularly useful for analyzing Bayesian posterior samples (Dayaratna, 2014).
Multi task learning is another related field of density ratio modelling. The primary idea behind multi-task learning is to understand multiple tasks collectively with the goal to improve classification accuracy or to improve performance of an existing task. Bickel et al. (2008), for example, used multi task learning to forecast the outcome of therapy attempts for HIV patients with certain genetic properties.
Although a few studies have utilized Bayesian methods to look at these types of problems, no research, to our knowledge, has done so merging the semiparametric DRE method with Bayesian methods for modelling individual-level heterogeneity to understand overall distributional properties about the population (Lazar, 2003; Mengersen et al., 2013; Schennach, 2005; Yang et al., 2012). We ameliorate this limitation in this study. Specifically, we adapt a Bayesian approach to the semiparametric DRE method to model individual-level heterogeneity. We apply this methodology to a dataset used in a tort reform study performed by the Pacific Research Institute to understand changes in per capita tort losses throughout the country (Crain et al., 2009). Our focus is, therefore, on understanding the overall distributional properties of per capita tort losses, rather than making individual level predictions as done in Bickel et al. (2008). As a result, we harness our attention away from developing techniques to estimate the actual density ratio (as described in many papers—see, for example, (Sugiyama et al., 2008) and instead towards understanding overall distributional properties. We compare our approach to existing density ratio methods that ignore heterogeneity as well as standard regression methods.
Problem formulation
Suppose that we are given a dataset consisting of
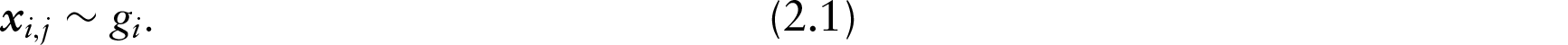

For example, one potential choice for
We assume the above parameterization for α i (with a constant variance) to ensure statistical identifiability of the model after marginalization.
We make this assumption so that our two samples are identical in size, although it is not necessarily a requirement that they be equal. If they are not equal, then the estimation becomes more dependent on the sample of greater size.
Let

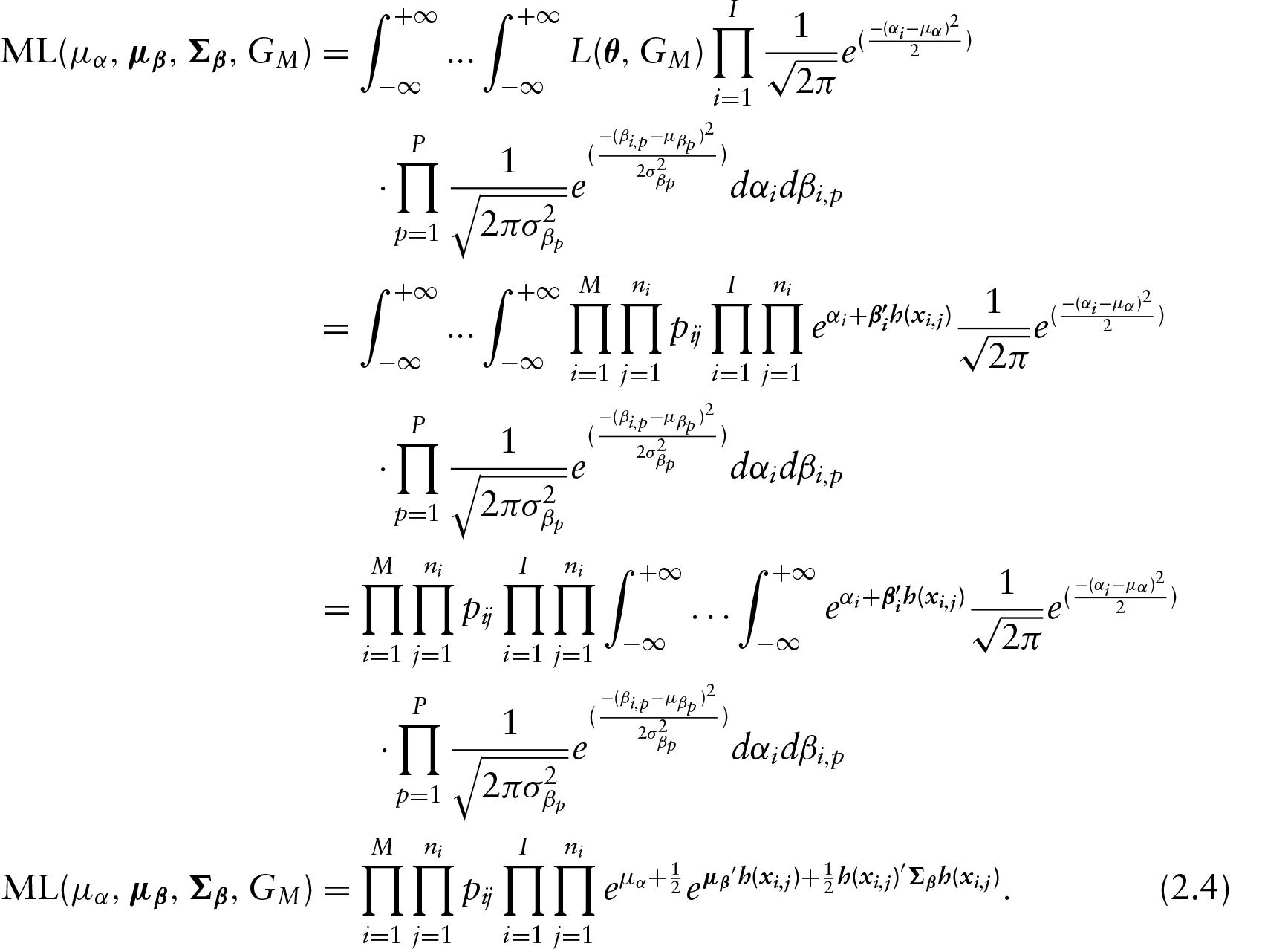
This result provides us with the following result:
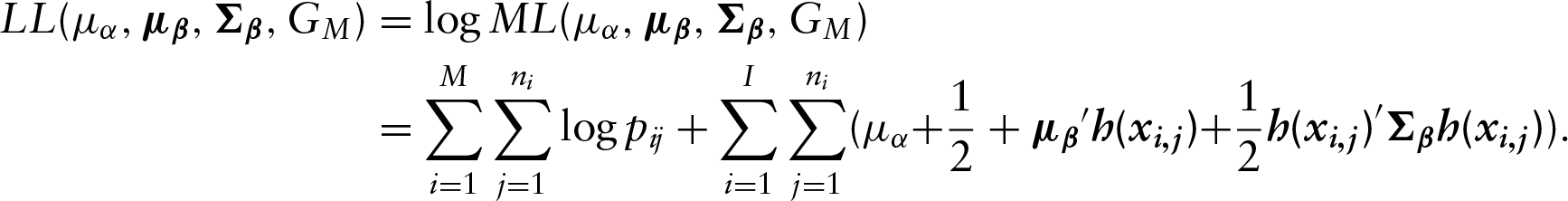
This result is simply due to taking the logarithm of Equation (2.4).
We can maximize the above marginalized likelihood subject to constraints analogous to those used in Voulgaraki et al. (2012):
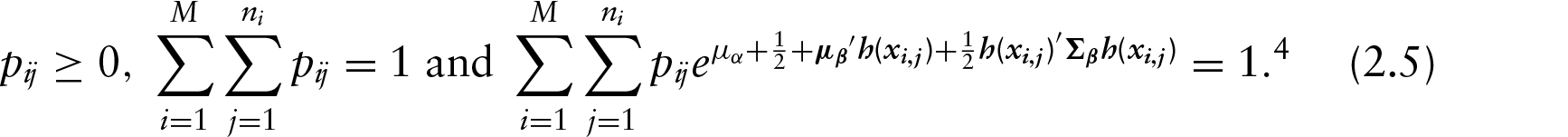
This constraint is easy to see after integration of both sides of the constraint imposed in Voulgaraki et al (2012):
The marginalization presented above has a few important purposes. In data sets having small
Derivation of distributions
Our optimization of the empirical likelihood can be used to derive the empirical distributions. Defining
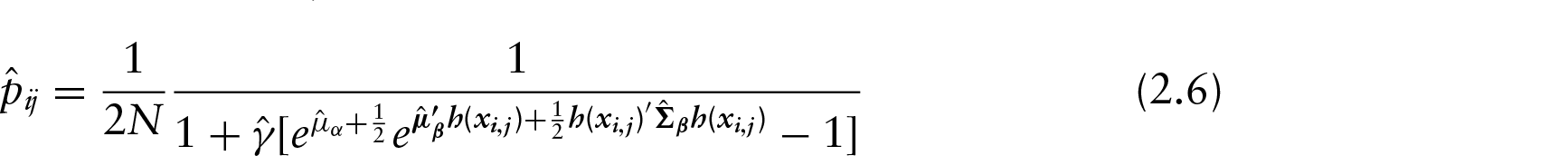
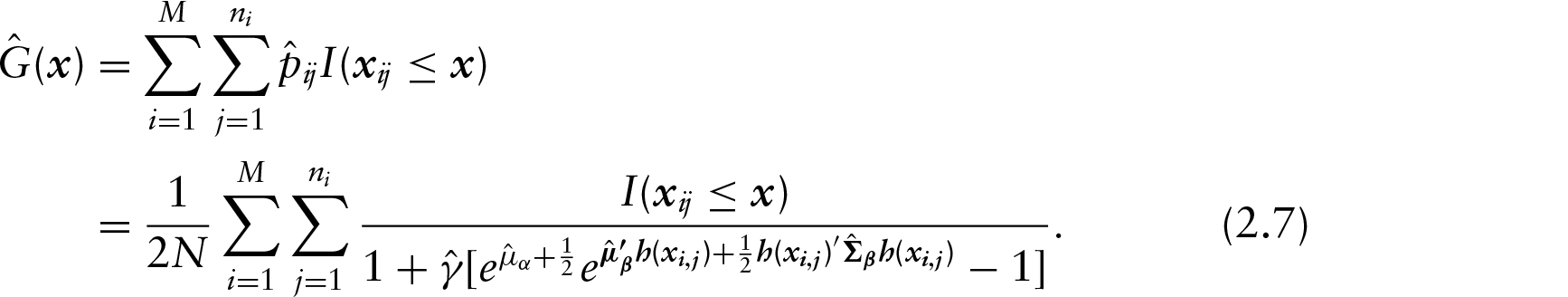
Furthermore, as our ‘marginalized distribution’, which we will hereafter refer to as
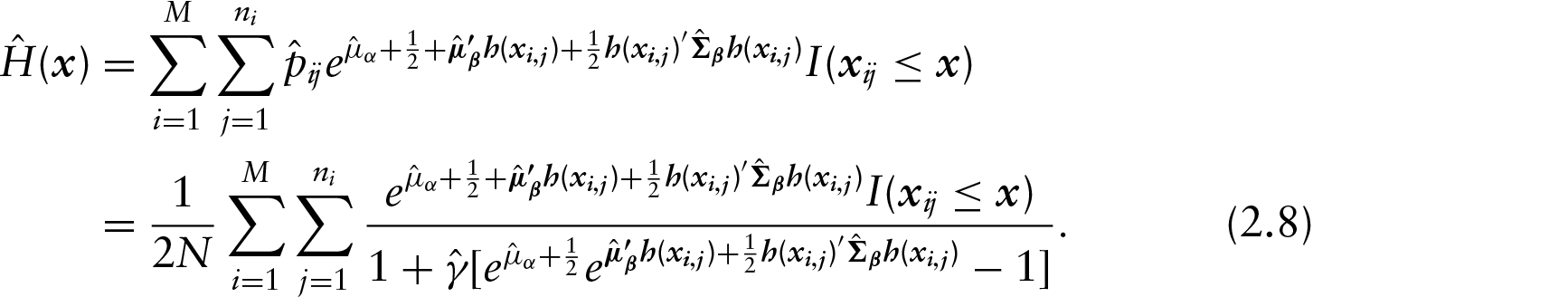
Despite the fact that each of the first
A series of numerical simulations illustrating the efficacy of this approach is discussed in detail in Dayaratna, (2014). For researchers interested in estimating the probability density function of the sample, kernel density estimators can be found. Optimal bandwidth selection for kernel density estimation is discussed in detail in Voulgaraki et al., 2012.
In this section, we analyze tort loss data from the 50 states belonging to the United States of America. We utilize the Bayesian DRE approach presented in this study to quantify the probability of the difference in tort losses between 2004 and 2006 being below a particular amount (Crain et al., 2009). These probabilities provide information regarding the efficacy of recently instituted tort reforms. After computing these probabilities, we compare this approach to existing DRE methods as well as standard regression methods.
Data
Our dataset was identical to that used in the Crain et al. (2009) study and was provided to us by two of the paper's authors. We examined per capita tort losses defined by Crain et al. (2009) to be the ‘payments by defendants (or their insurance companies) for judgements, settlements, attorney fees, and administrative expenses in tort lawsuits...’, in thousands of (real 2006) dollars per capita, of each of the 50 US states in 2004 and 2006 (Crain et al., 2009). For this analysis, we specifically examined medical malpractice tort losses, although analysis of other aspects of the civil justice system are useful ideas for future research.
Summary table of data of per capita tort losses

Summary table of data of per capita tort losses
There have been many medical malpractice reforms instituted in the early 2000s. For example, Arkansas, Colorado, Florida, Idaho, Mississippi, Missouri, Ohio, Oklahoma, South Carolina, West Virginia and Wisconsin instituted laws placing caps on damage awards in medical malpractice lawsuits. Arizona, Georgia, Montana, North Dakota, South Carolina and Virginia placed laws regarding the conditions on the use of expert witnesses in medical malpractice lawsuits. Nevada and Washington placed laws regarding the use of statues of limitations in medical malpractice lawsuits. Florida and Nevada passed laws regarding limiting attorney fees. New Hampshire, South Carolina, Washington and Wyoming instituted laws regarding pre-trial screening and arbitration for medical malpractice cases (McQuillan and Abramyan, 2008b). We used 2004 and 2006 data in our analysis because as the above reforms were implemented during the first half of the last decade, the distributional differences in per capita tort losses between the two years would serve as reasonable indicator of their efficacy at reducing the probability of extreme tort losses. In doing so, as discussed earlier, since different states may differ in how litigious they are it is of utmost importance to incorporate this heterogeneity in our modelling. Our semiparametric Bayesian approach thus enables us to reduce the dimensionality of the problem and generate an overall marginalized distribution of differences in per capita tort losses all across the country.
It is informative to understand the distributions of the difference in per capita tort losses between 2004 and 2006 as these distributions will shed light on the efficacy of tort reforms that had been recently instituted around that time period (Crain et al., 2009). Treating each state-based observation within each year as an independent single-unit sample with its own unique parametrization, we examined the difference in losses between the two years. We did so by utilizing the following model specification:

where
We also utilized a bootstrap approach to estimate confidence intervals around these point estimates. In particular, we resampled our dataset (with replacement) 1000 times and re-estimated our probabilities for each sample and used the resulting set to determine our interval estimates. The results are depicted in Tables 2 and 3.
Coefficient estimates, using Bayesian DRE approach

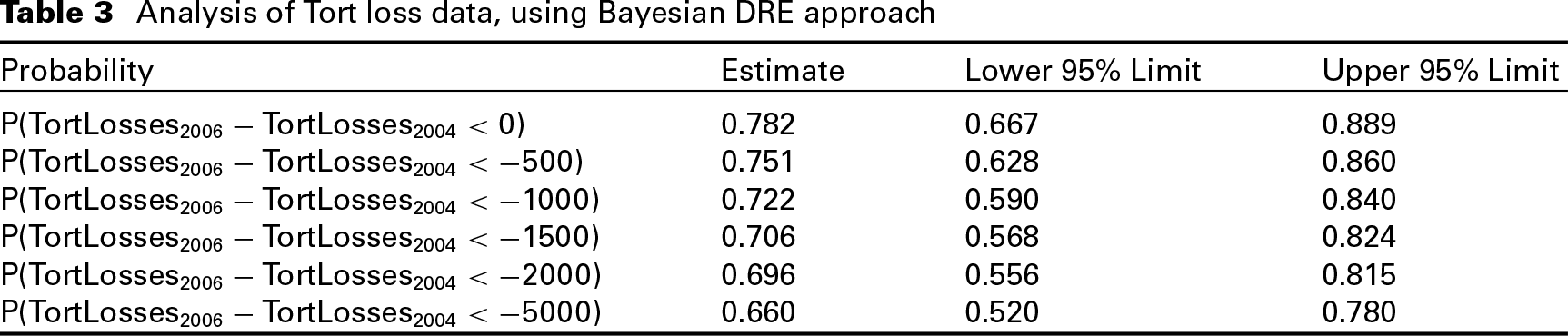
Analysis of Tort loss data, using Bayesian DRE approach
Additionally, to understand the model's (which we hereafter refer to as Bayesian DRE approach) goodness of fit compared to existing DRE methods (standard DRE approach) that ignore heterogeneity, we used an approach suggested in Voulgaraki et al., (2012):

In (3.2),
Goodness of fit diagnostics

Plot of
vs.
‐ DRE, Difference in Per Capita Tort Loss Data between 2006 and 2004
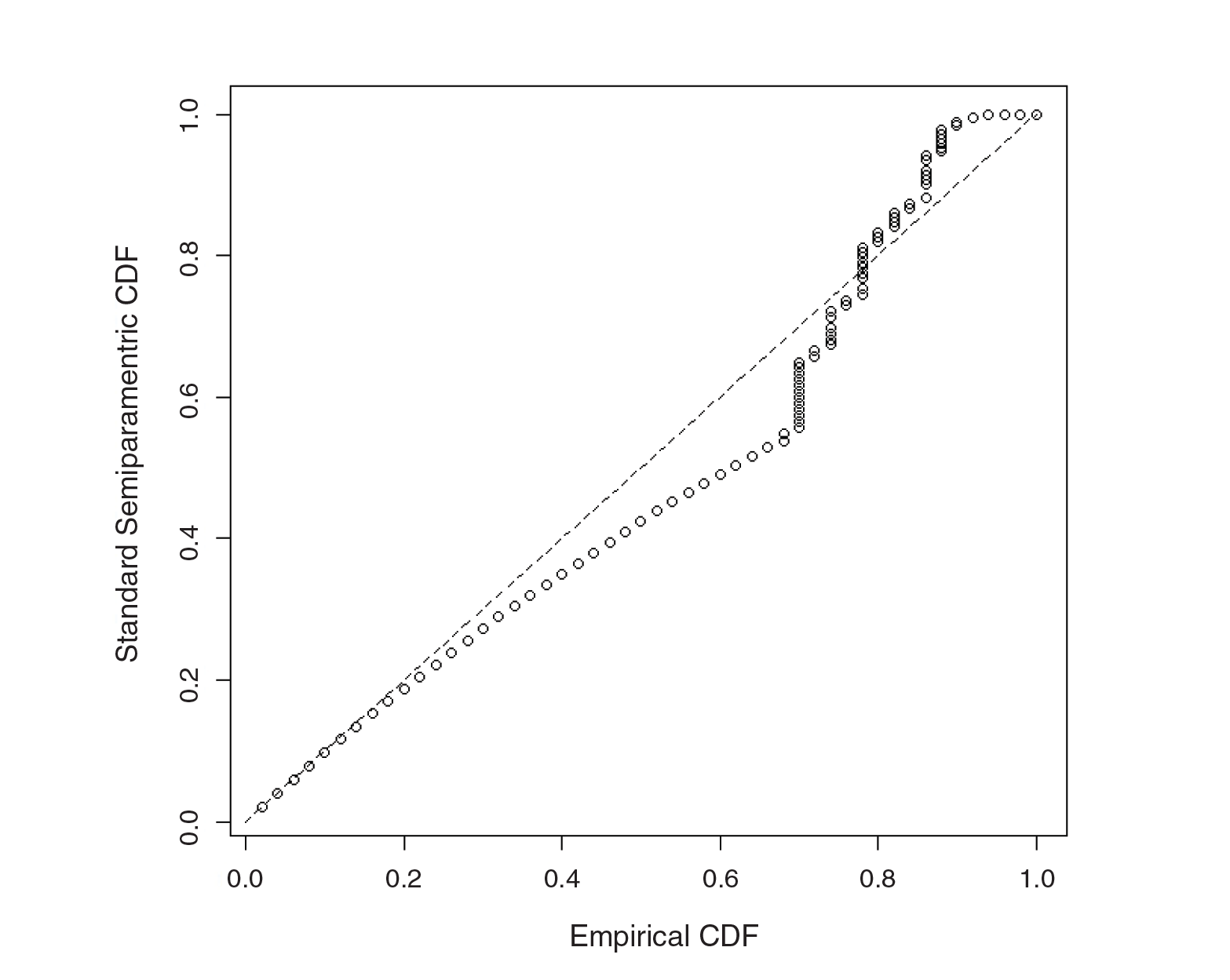
Plot of
vs.
‐ Bayesian DRE, Difference in Per Capita Tort Loss Data between 2006 and 2004
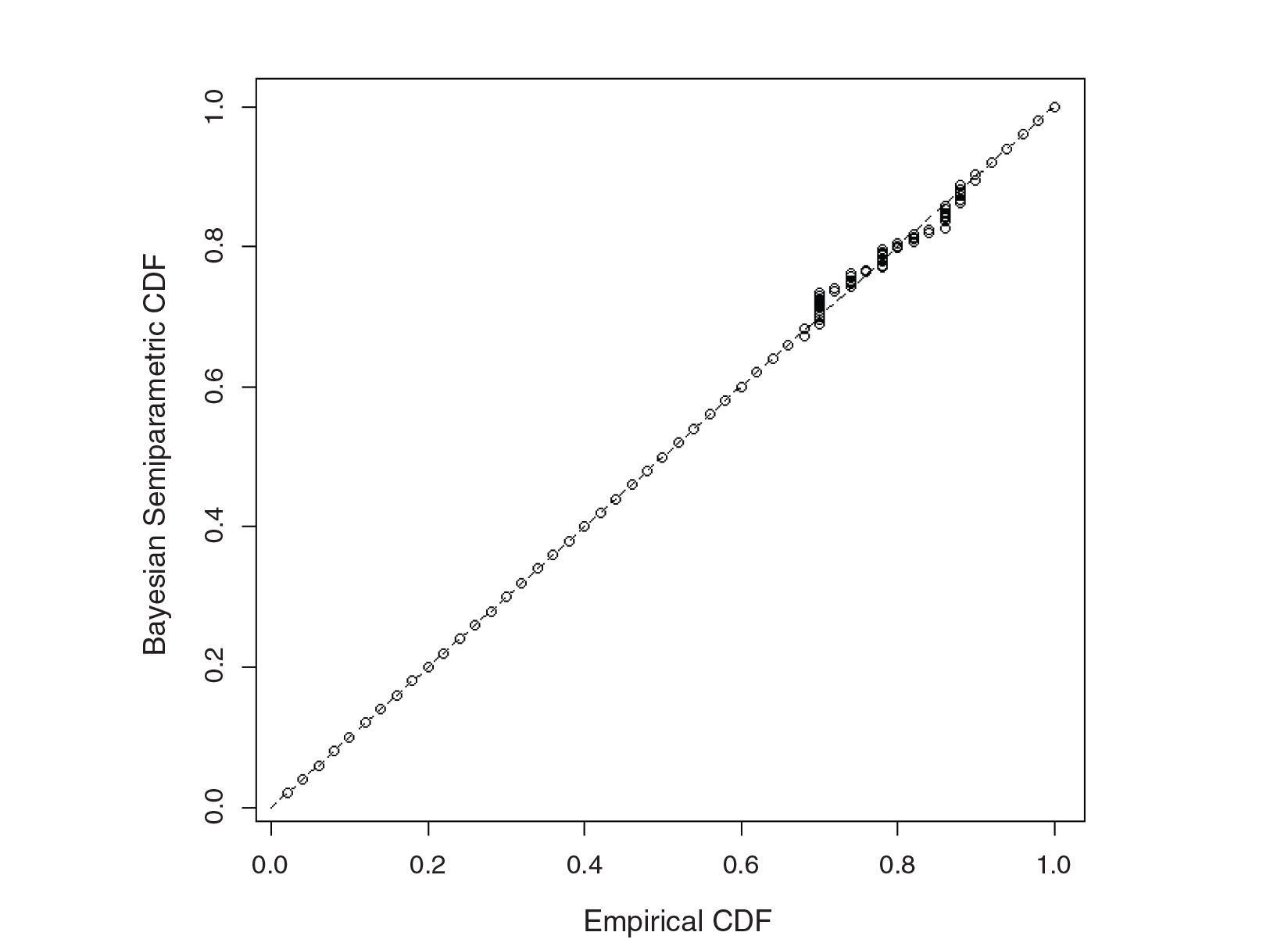
Our analysis illustrates that the Bayesian DRE approach substantially improved model fit indicating the presence of unobserved heterogeneity across the country during that year that the standard DRE approach was unable to properly model. Furthermore, our results illustrate a substantial reduction in per capita tort losses. For example, Table 3 suggests a 0.66 probability of a reduction greater than 5000 dollars per capita with the interval estimates for these probabilities being well above zero. These results alongside the results from Crain et al. (2009) demonstrate the success of state-based medical malpractice reforms, many of which had been instituted around this time period (Crain et al., 2009). These reforms included imposition of strict statute of limitations for filing lawsuits, standards regarding expert witnesses, economic damage caps, attorney fee limitations, and requirements for pre-trial screening. In addition, existing tort laws, not necessarily recently instituted, may have become more stringently enforced during this time period.
We also compared our modeling approach to that of a standard analysis of variance approach modeling per capita tort losses as a function of location. In particular, we specified the model:

Probability of per capita Tort losses being below 0, ANOVA approach

The ANOVA model has a coefficient of determination of 0.77 compared to goodness of fit diagnostics of virtually 1 from our Bayesian DRE approach. Additionally, the results Table 5 suggest the same phenomenon as suggested by Table 3 from our Bayesian DRE analysis ’ The success of recently instituted tort reforms in reducing tort losses. These results thus further substantiate our findings and also illustrate that our Bayesian DRE approach significantly fits our application better than existing methods.
The Congressional Budget Office has found that state-based tort reform reduced the number of lawsuits, reduced the quantity of damage awards, and brought down insurance claims (Congressional Budget Office, 2004). Our analysis also demonstrates that the risks associated with the civil justice system declined between 2004 and 2006. These reductions were the result of state-based tort reforms implemented throughout the country, including economic caps as well as standards regarding expert witnesses among others (Crain et al., 2009). Although these results illustrate the efficacy of certain malpractice reforms instituted around this time period, considerably more can be done (McQuillan, 2007; Crain et al., 2009). In fact, recent research has discussed the benefits of malpractice reform, noting that such reforms have the capacity to improve the practicing environment for physicians, which can tremendously benefit patients (Cornyn and Meese, 2010; Rubin and Shepherd, 2007; Levy, 2005; Rivlin, 2012; Kessler et al., 2005; Kessler and McClellan, 1996; Studdert et al., 2005).
Coefficient estimates
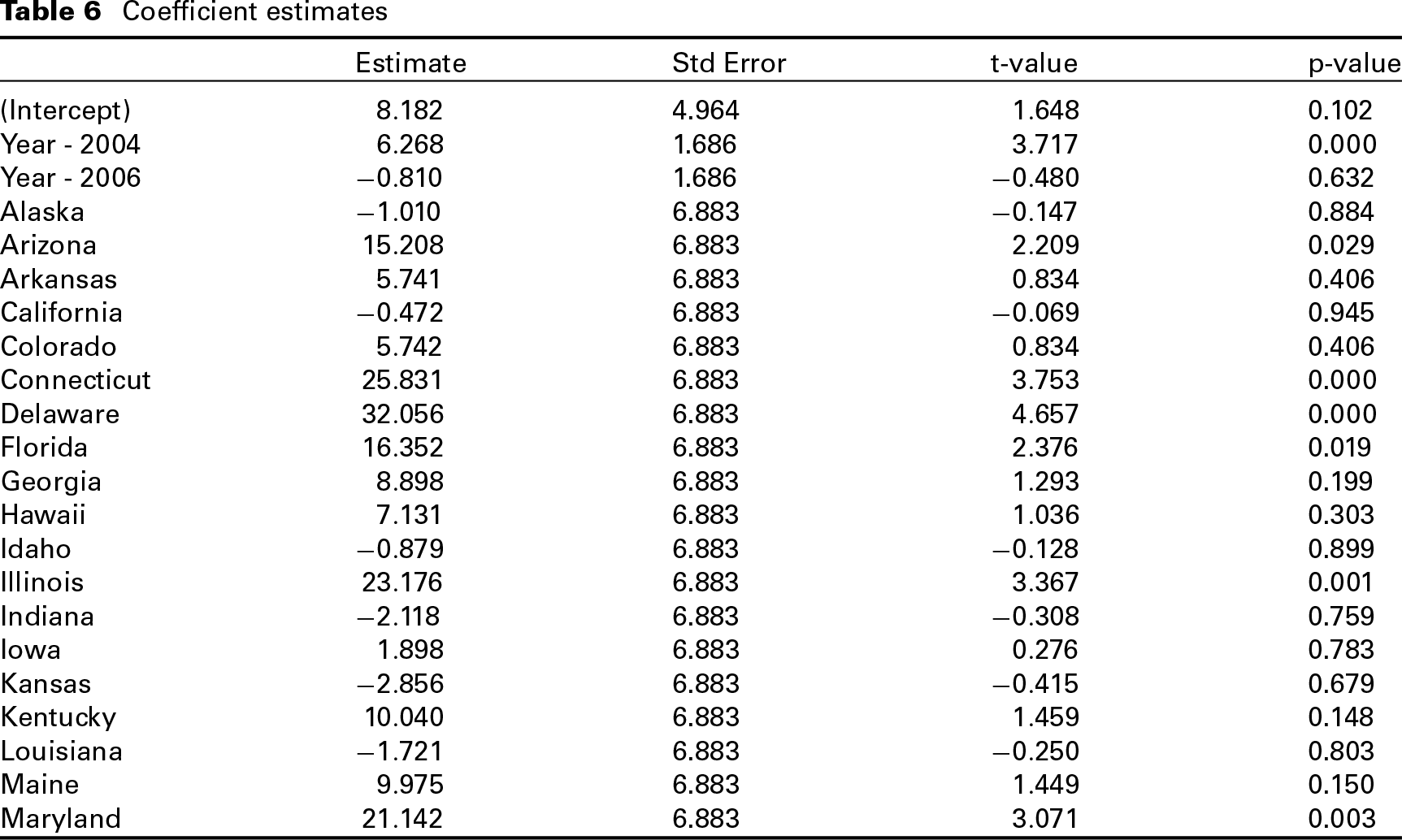
Coefficient estimates
Coefficient estimates
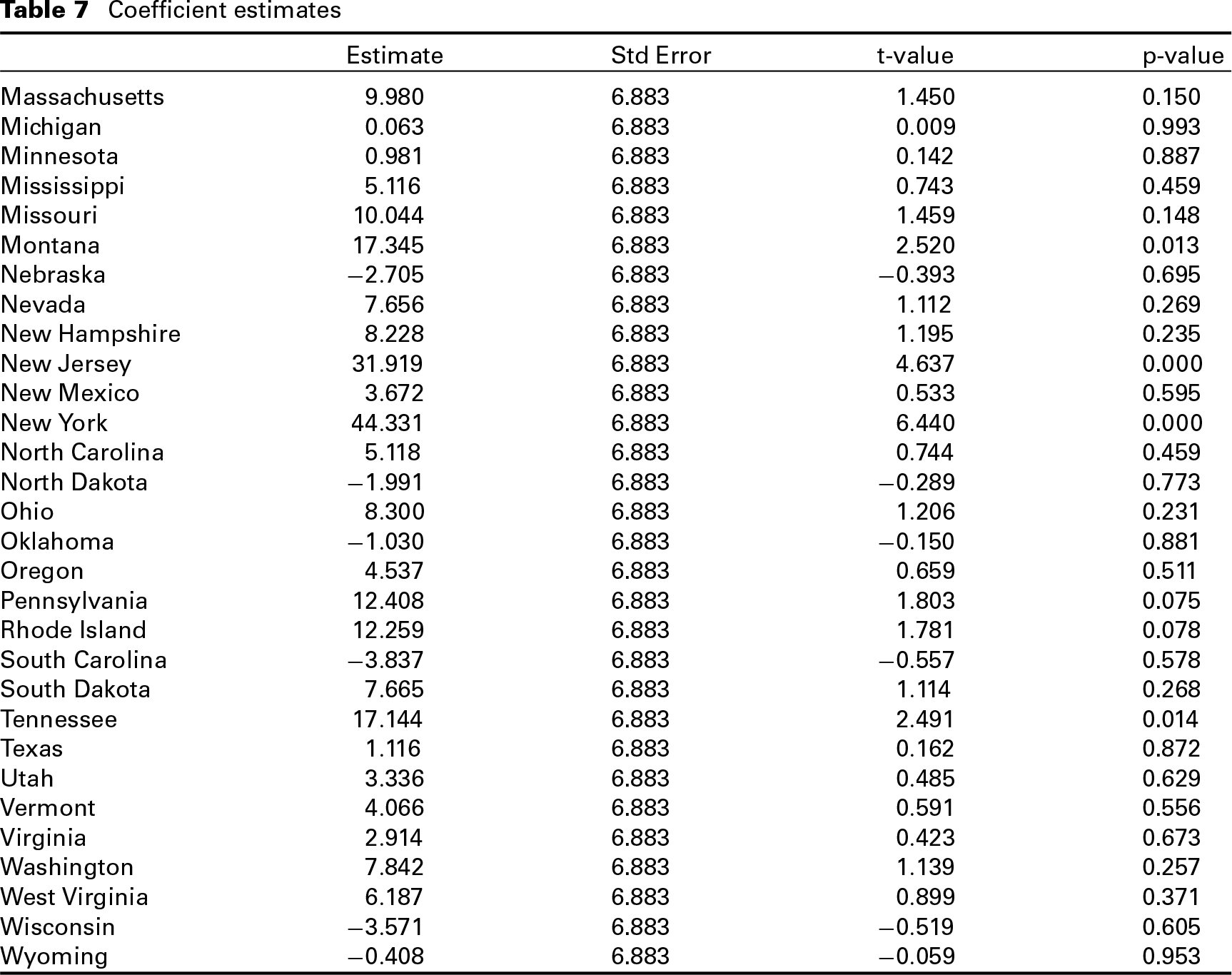
This study demonstrates the success of medical malpractice reform in reducing the probabilities of extreme tort losses. Medical malpractice reform, in addition to other reforms, such as instilling competition in the health care markets can be important in reducing the costs and improving the quality of care (Dayaratna, 2012; Dayaratna, 2013; Capretta and Dayaratna, 2013; Parente et al., 2011). From a methodological perspective, this study applies empirical Bayesian methods to semiparametric density ratio modeling, allowing statisticians to incorporate individual-level heterogeneity in such models. Our marginalization provides a closed-form empirical likelihood, allowing us to make direct inferences regarding the population sans the computationally intensive approaches typically associated with Bayesian methods (Gelfand and Smith, 1990).
Although our marginalization is useful, we looked at tort losses on a per-capita basis. Future research could potentially look tort losses with respect to the number of overall claims and perhaps use the approach presented in this study while comparing it to existing difference in difference methods. Furthermore, future research could also look at the different definitions of treatment and control groups; for example, states that instituted caps on damages only as well as states with historically above-average payments before 2004. Additionally, although our focus in this study is on medical malpractice reform, this approach can be extended to many other settings where modeling individual-level heterogeneity is important. From biostatistics to economics to professional sports the Bayesian approach presented here is a useful addition to the applied statistician's toolbox (Voulgaraki et al., 2012; Greenspan, 2013; Miller, 2007; Dayaratna and Miller, 2013).
Appendix
As discussed in Section 3.3, we compared our model to a standard analysis of variance approach that modeled per capita tort losses as a function of location. Specifically, we modeled:

where
As discussed earlier, this model had an
Footnotes
Acknowledgments
The authors would like to thank Mark Crain and Hovannes Abramyan for providing the data used in this project. This article is based on a component of the author's doctoral dissertation (Dayaratna, 2014). We would like to thank Sashi Dayaratna, Hovannes Abramyan, Sandra Dayaratna, colleagues in The Heritage Foundation's Center for Data Analysis, John Malcolm, and conference participants at the 30th International Workshop on Statistical Modelling in Linz, Austria for constructive comments. An abridged version of this manuscript was published as part of the Proceedings of the 30th International Workshop on Statistical Modelling in Linz, Austria (Dayaratna and Kedem, 2015). Please note that nothing written here is to be construed as necessarily reflecting the views of The Heritage Foundation or as an attempt to aid or hinder the passage of any bill before Congress.