
Abstract
Abstract
A functional linear discriminant analysis approach to classify a set of kinematic data (human movement curves of individuals performing different physical activities) is performed. Kinematic data, usually collected in linear acceleration or angular rotation format, can be identified with functions in a continuous domain (time, percentage of gait cycle, etc.). Since kinematic curves are measured in the same sample of individuals performing different activities, they are a clear example of functional data with repeated measures. On the other hand, the sample curves are observed with noise. Then, a roughness penalty might be necessary in order to provide a smooth estimation of the discriminant functions, which would make them more interpretable. Moreover, because of the infinite dimension of functional data, a reduction dimension technique should be considered. To solve these problems, we propose a multi-class approach for penalized functional partial least squares (FPLS) regression. Then linear discriminant analysis (LDA) will be performed on the estimated FPLS components. This methodology is motivated by two case studies. The first study considers the linear acceleration recorded every two seconds in 30 subjects, related to three different activities (walking, climbing stairs and down stairs). The second study works with the triaxial angular rotation, for each joint, in 51 children when they completed a cycle walking under three conditions (walking, carrying a backpack and pulling a trolley). A simulation study is also developed for comparing the performance of the proposed functional LDA with respect to the corresponding multivariate and non-penalized approaches.
Keywords
Introduction
Biomechanical gait data are commonly used to differentiate between several gait pathologies or different physical activities. Different statistical methodologies for classification of gait data have been developed in the literature with this aim. Gait data are usually collected at different points in a continuous scale, such as time, so that they are generated from an underlying time-varying function. In the applications that motivate this research, acceleration curves are measured at real time every two seconds, and rotation curves are measured in terms of the percentage of gait cycle. In spite of the continuous nature of kinematics curves, in many of the biomechanical studies the statistical analysis is made from a sample of summary measures for each curve such as minima, maxima, area under the curve, angles at heel strike, range of motion or the timing of specific events (Sadeghi et al., 1997; Sadeghi, 2003; Schmidt and Docherty, 2010; Orantes-González et al., 2015).
Currently, data science tools are being developed to build accurate classification and prediction models for gait research by using all the available information. One of them is functional data analysis (FDA) that begins by reconstructing the true functional form of each sample curve from discrete sampling points that could be different for different subjects. This way all the available information about the sample curves is exploited to explain the movement in the statistical analysis. A detailed description of the most common FDA methodologies, and interesting FDA applications with R and Matlab, are described in the pioneer books by Ramsay and Silverman (1997), Ramsay and Silverman (2002) and Ramsay et al.(2009). A complete study of nonparametric FDA techniques can be seen in Ferraty and Vieu (2006). Statistical inference for functional data has been studied in Horvath and Kokoszka (2012). A more recent book is by Kokoszka and Reimherr (2017), where new methods for FDA are collected (functional time series, spatial functional data, between others).
Biomechanical data are usually obtained over a number of discrete time points (snapshots) and assumed to be generated by some underlying smooth function. Because of this, the steps typically used when FDA is applied to the analysis of biomechanical data are: basis expansion representation, curve registration (time normalization or landmark registration) and functional principal component analysis (FPCA) (dimension reduction and variability explanation in terms of uncorrelated scalar variables). The first step consists of obtaining smooth representations of the sample curves in terms of a basis of functions (Fourier, B-splines, wavelets, etc.). In the second step, registration is used to reduce phase variability between curves while preserving the individual curve's shape and amplitude. The effect of different registration methods on cyclical kinematic data is analysed in Crane et al. (2010). In the third step, FPCA is successfully applied to explain the ways of variation in biomechanics of sports injuries and coordination in race-walking, jumping and running (Ryan et al., 2006; Harrison et al., 2007; Donoghue et al., 2008; Donà et al., 2009). On the other hand, multivariate principal component analysis (PCA) on the raw discrete-time observations of the biomechanics curves has also been applied to provide biomechanics interpretation of the principal component scores and to discriminate between healthy and sick subjects (Deluzio et al., 1997; Daffertshofer et al., 2004; Milovanovic and Popovic, 2012).
This work is motivated by two different sets of biomechanical data: the human activity data and the gait data. The first dataset is based on the human activity recognition collected by Anguita et al. (2013). The original experiments were carried out with a group of 30 volunteers within an age bracket of 19–48 years. Each person performed three different activities wearing a smartphone on the waist (walking, walking upstairs and walking downstairs). Using its embedded accelerometer and gyroscope, they captured 3-axial linear acceleration and 3-axial angular velocity at a constant rate of 50Hz every two seconds. The aim is to classify the curves of acceleration according to the categorical variable given by the three mentioned physical activities. The gait dataset comes from a wide experimental study developed in the biomechanics laboratories of the Sport and Health Institute of the University of Granada (iMUDS). In order to collect the data, 26 reflective markers were placed on the skin of a total of 51 children between 8 and 11 years old. The data were recorded by a 3D motion capture system meanwhile each subject completed a cycle walking over the platform in three conditions (walking, carrying a backpack that weighs 20% of the subject's weight and pulling a trolley that weighs 20% of the subject's weight). For each subject, the 3-axial angular rotation were registered for each join (ankle, foot progress, hip, knee, pelvis, thorax), and all conditions, in 101 equidistant points of the complete gait cycle. Now, the aim is to classify the rotation curves according to the three different load types.
Both case studies considered in this article are clear examples of functional data with repeated measures because the functional variables of interest (angular rotation and linear acceleration) are measured repeatedly on the same sample individuals under different experimental conditions. Therefore, the aim of this article is to classify a set of functional data with repeated measures (kinematic curves) according to a categorical variable with more than two categories (measurement conditions). In this article, an extension of linear discriminant analysis (LDA) to the case of functional data with repeated measurements will be considered. Alternative classification approaches based on logit regression were developed and successfully applied in different areas as environment, medicine, marketing and so on (James, 2002; Escabias et al., 2004, 2005, 2007; Delaigle and Hall, 2012a; Aguilera-Morillo and Aguilera, 2013; Escabias et al., 2014). An extension to functional data of nonparametric Bayes classifiers based on simple density ratios was proposed in (Dai et al., 2017) for the case of binary classification.
LDA is a popular and consolidate methodology for classification and dimension reduction (Fisher, 1936). So, LDA provides a sequence of linear combinations of the original predictor variables (linear discriminants) that maximize the between-class variance relative to the within-class variance. An important problem is that LDA overfits the data when we have a large number of highly correlated predictor variables because the within-class covariance matrix is difficult to estimate. This is the case of FDA that works with a large number of discrete-time observations for each sample curve. A way to solve this problem is to introduce some kind of regularization in the estimation of the covariance matrix (Friedman, 1989; Frank and Friedman, 1989; Hastie et al., 1995). A general review of regularized techniques in discriminant analysis was developed in Mkhadri et al. (1997). A Bayesian approach for Fisher's discriminant analysis of stochastic process was introduced in Shin, (2008). An alternative solution, for the case of irregularly sampled curves, is based on using as predictors a spline basis expansion of the discrete-time observations and assuming Gaussian distribution of the vector of basis coefficients with common covariance matrix for all classes, by analogy with LDA (James and Hastie, 2001). This functional LDA approach was used to assessment of embryonic growth (Bottomley et al., 2009). Other way of solution consists of projecting the predictor vectors (multivariate analysis) or curves (FDA) onto a finite dimensional basis so that LDA, or any other discrimination procedures, can then be used taking the resulting basis coefficients as predictors. A common approach is based on the representation of the original predictors by a small set of orthogonal scalar variables given by PCA or partial least squares (PLS) regression. Both approaches are commonly used in chemometrics to discriminate between essential properties of substances from discrete measurements of the near-infrared (NIR) spectra. PCA was applied in Sato (1994) to classify NIR spectral data of vegetable oils. PLS regression was performed in Li et al. (2000) to discriminate edible fats and oils by Fourier transform NIR spectroscopy. Multivariate classification techniques such as LDA, quadratic discriminant analysis (QDA) and logit regression were applied in Indahl et al. (1999). In the functional data context, reduction dimension techniques and regularization can be jointly used to get good classification rates and accurate interpretation of the results. The functional LDA approach presented in this article is inspired in this research line.
Functional PCA and functional PLS regression were introduced as natural extensions of their multivariate counterparts to solve the problems of high dimension and multicollinearity associated with the scalar-on-function linear model (Deville, 1974; Dauxois et al., 1982; Ocaña et al., 1999; 2007; Preda and Saporta, 2005; Aguilera et al., 2016). Both methodologies were compared on different simulated datasets concluding that they have similar forecasting performance, but the estimated parameter function provided by functional PLS regression is more accurate and needs fewer components (Reiss and Ogden, 2007; Aguilera et al., 2010; Delaigle and Hall, 2012b; Delaigle and Hall, 2012c). In addition, the performance of PCA for discrimination may not be optimal, because PCA only identifies gross variability, and then it is not capable to distinguish the between-groups and within-groups variability. In that sense, several authors proposed to use PLS regression for dimension reduction, as for example Barker and Rayens (2003), Pérez-Enciso and Tenenhaus (2003) in the multivariate context and Preda et al. (2007) in the functional context.
From a methodological point of view, the originality of our work lies, on the one hand, in proposing a penalized spline estimation of the PLS components to solve the problem of lack of smoothness, and on the other hand, in considering a multi-class approach for PLS regression based on the split-up variation to solve the problem of repeated measures. Then, classic LDA is carried out on the estimated PLS components. To the best of our knowledge, it is the first approach in the literature for functional linear discriminant analysis (FLDA) with repeated measures based on functional PLS. Then, in order to classify gait curves according to the kind of activity and take into account both, the lack of smoothness in the data and the correlation between repeated measurements, a new multi-class FLDA based on penalized functional PLS regression for repeated measures is proposed in Section 2. The classification results of the considered multi-class functional LDA-PLS approach on simulated data and both biomechanical datasets are presented and discussed in Sections 3 and 4. Conclusions are finally included in Section 5.
Multi-class classification of functional data
Let us consider a categorical response variable
The aim of FLDA is to find linear combinations
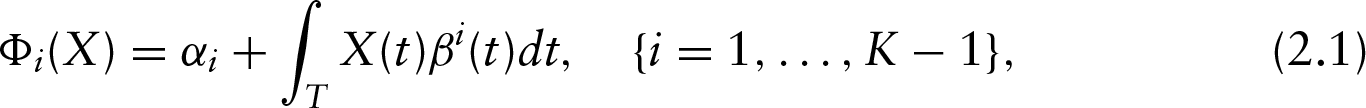
so that the between-class variance is maximized with respect to the total variance
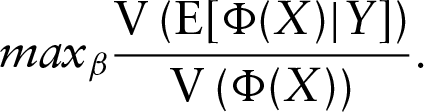
Due to the high dimension of Step 1. Dimension reduction by penalized and non-penalized multi-class functional PLS regression (for repeated measures) of the random vector Step 2. Functional LDA of Y on a reduced set of functional PLS components estimated in the above step.
In order to reduce the dimension, PLS regression of the vector
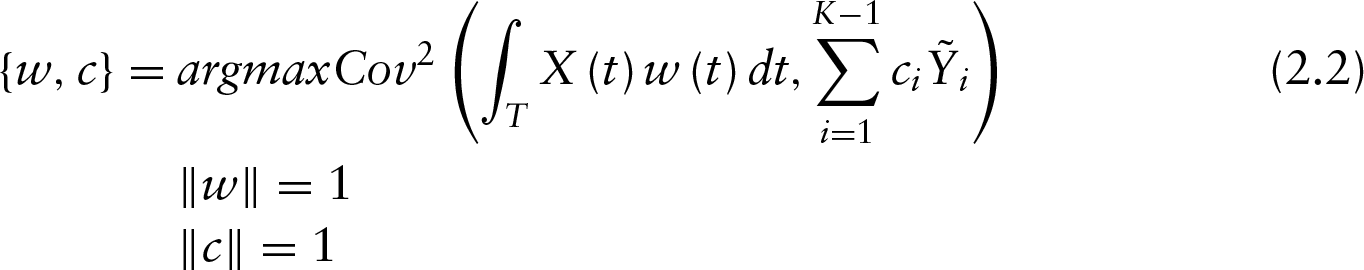
with
From Proposition 1 in Preda and Saporta (2005), it can be seen that the solution to this maximization problem is reached for
Then, the first PLS component,
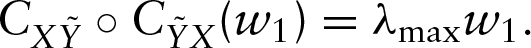
PLS regression is an iterative algorithm and the first PLS step is completed by ordinary linear regression of
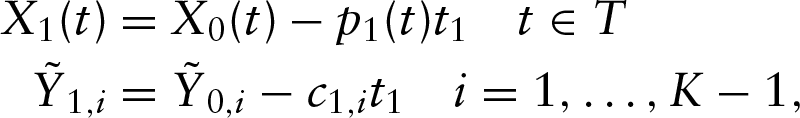
where
In general, let us consider the hth PLS component,
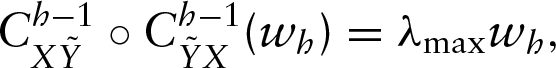
where
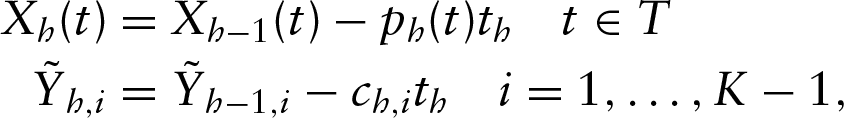
where
A basis representation approach
Let us consider now the basis representation of the functional predictor and the weight function, that is,
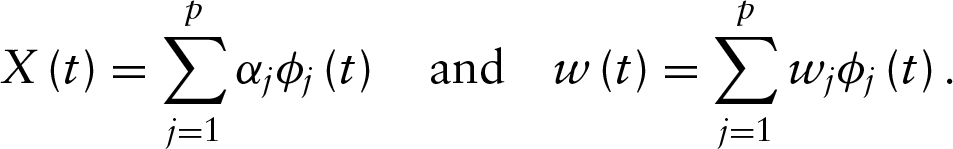
As a consequence, the maximization problem in Equation (2.2) can be written as follows:
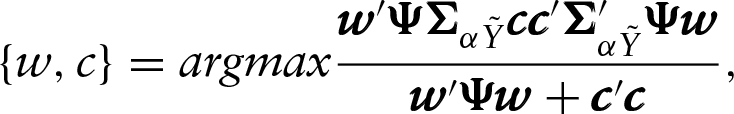
with
The cross-covariance operators expressed in terms of the basis expansion of the functional predictor
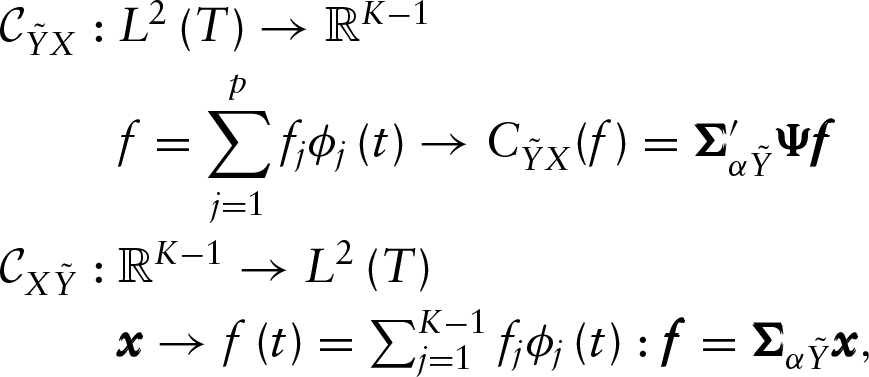
where
Then, at the first PLS step, the weight function

and the weight vector
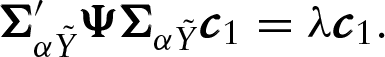
Let us consider now the decomposition
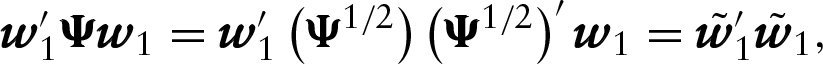
with
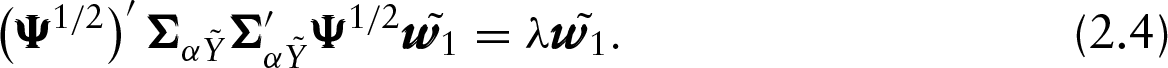
At the hth PLS step, the hth PLS component is estimated in terms of the associated weight function by solving to the following problem
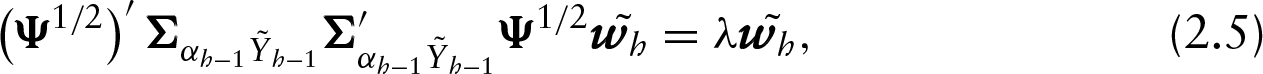
where
In general, by considering Equations (2.4) and (2.5) and taking into account that
As the biomechanical data analysed in this article are not smooth enough, a penalized approach for multi-class functional partial least squares (FPLS) regression is proposed.
Let us consider now the roughness penalty function
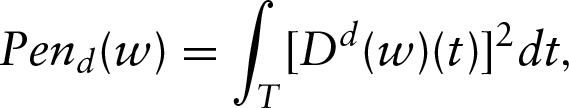
with
In this section the PLS components are estimated by solving the following problem
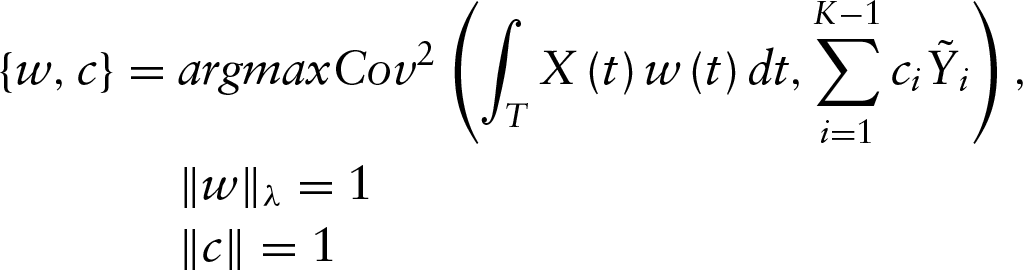
with
Then, the hth PLS component (
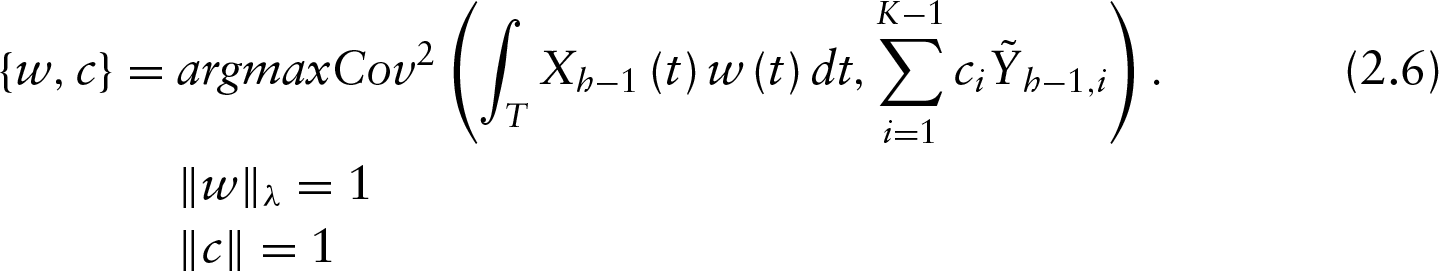
By assuming the basis representation of the functional predictor and the weight function, the problem in (2.6) can be written as follows
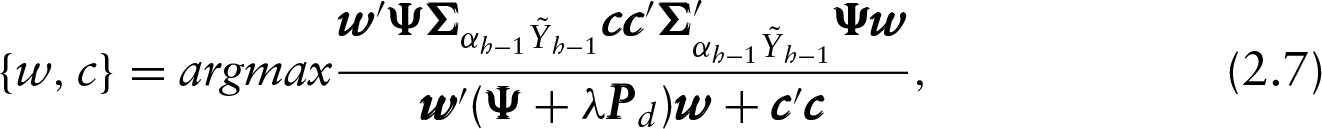
with
Assuming the decomposition
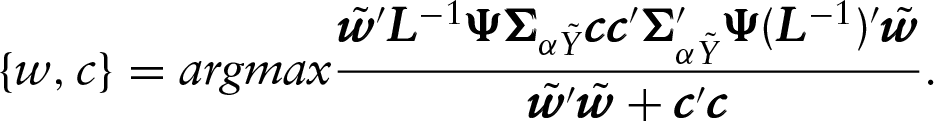
By analogy with the non-penalized approach, the associated eigenproblem is
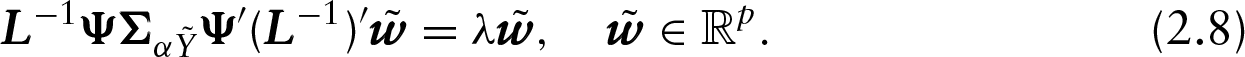
In general, the hth PLS component,
Finally, taking into account that
In previous sections, penalized and non-penalized approaches for the multi-class FPLS regression have been proposed. However, these approaches are based on ordinary PLS, and then the between-subject and the within-subject variations are not studied by separate.
As solution to the problem of repeated measures, in this section a multi-class approach for penalized and non-penalized FPLS regression based on the split-up variation is proposed. In the same spirit as in de Nord and Theobald (2005), Westerhuis et al. (2010) and Liquet et al. (2012), this approach first decomposes the variability in the data matrix and then applies the multi-class PLS regression on the within-subject variation matrix.
For a more detailed explanation of the multi-class approach, let us consider
Then, the sample estimation of the multi-class FPLS described in sections 2.1 (non-penalized) and 2.2 (penalized) is as follows:
Non-penalized multi-class FPLS: multi-class PLS of Penalized multi-class FPLS: multi-class PLS of
with
In practice, functional data are observed in a finite set of points. Because of this, matrix
Split-up variation
In general, let us consider a data matrix
Following the mixed-effect models philosophy, matrix
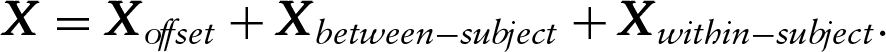
But mixed models rely on assumptions such as Gaussian distribution of random effects. As an alternative, a split-up variation approach, which does not require the above-mentioned assumptions, is considered in this article. Exactly, the offset, between-subject and within-subject variation matrices (
Multi-class approach for FPLS
Once the split-up variation has been carried out, penalized and non-penalized multi-class FPLS regression is performed on the within-subject variation matrix. In that sense, the penalized and non-penalized multi-class approaches for FPLS regression are given by
Non-penalized multi-class FPLS: multi-class PLS of Penalized multi-class FPLS: multi-class PLS of
where
Functional LDA on a reduced set of functional PLS components
Let Non-penalized multi-class FPLS: Penalized multi-class FPLS:
with
Once the PLS components have been estimated, LDA of the original sample values of
But the aim is to estimate the discriminant functions
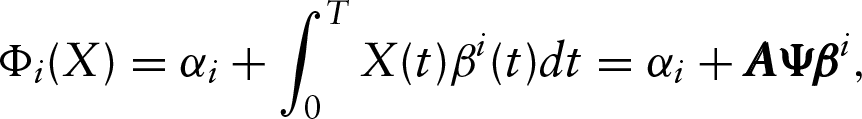
with
Finally, taking into account the sample estimation of Non-penalized multi-class FPLS: Penalized multi-class FPLS:
Once the random vector of discriminant functions
Then given a new sample observation
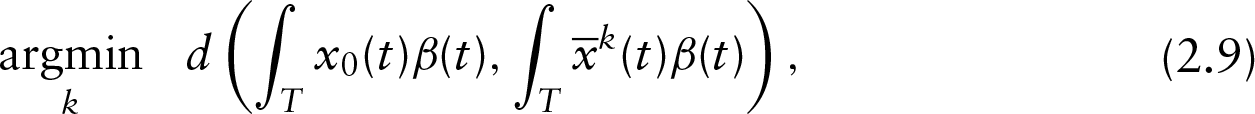
where
By assuming the basis representations of
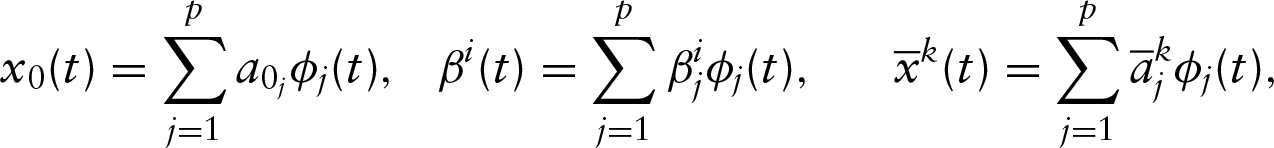
problem (2.9) can be rewritten as follows
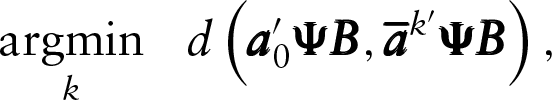
with
The smoothing parameter
All the analysis in Sections 3 and 4 were carried out in a computer with an Intel Core i5 processor at 3 GHz with 8Gb of RAM, running R-project version 3.5.1 (R Development Core Team, 2008). The two multi-class functional PLS approaches were reduced to multi-class PLS regression (in the multivariate context), and then they were implemented in R using the function spls available in the mixOmics R package developed by Rohart et al. (2017).
Authors are preparing an R package that, among other things, includes the code used in the manuscript. For readers wishing to use the software, it will be available as soon as possible at the R repository website. However, you can contact the corresponding author if you need more information regarding the code.
In order to test the performance of the proposed methods, a simulation study has been carried out. Inspired by Cuevas et al.(2004), let us consider
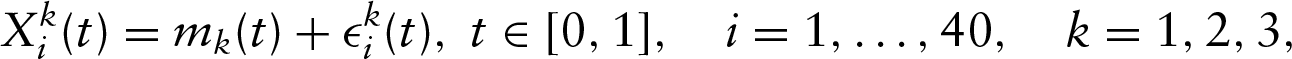
where
But our work is focused on the presence of repeated measurements in the
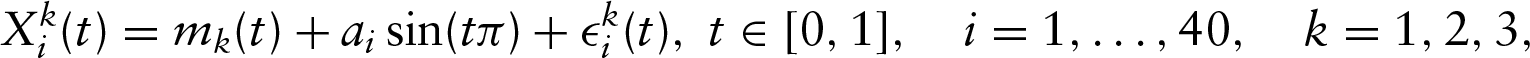
with
The sample curves from two different subjects, and for each of the three classes, are shown in Figure 1. As we can see, there is a clear dependency structure between the three observations of the same subject, and the between-subjects variation is not only given by a magnitude effect, but also by a shape variation. This is a realistic simulation of the performance of kinematic data since it makes no sense to assume that the curves of the different subjects are parallel.
Simulation study. Sample paths related to classes 1, 2 and 3 (solid, dashed and dotted line, respectively) for two subjects A and B, black and grey lines, respectively
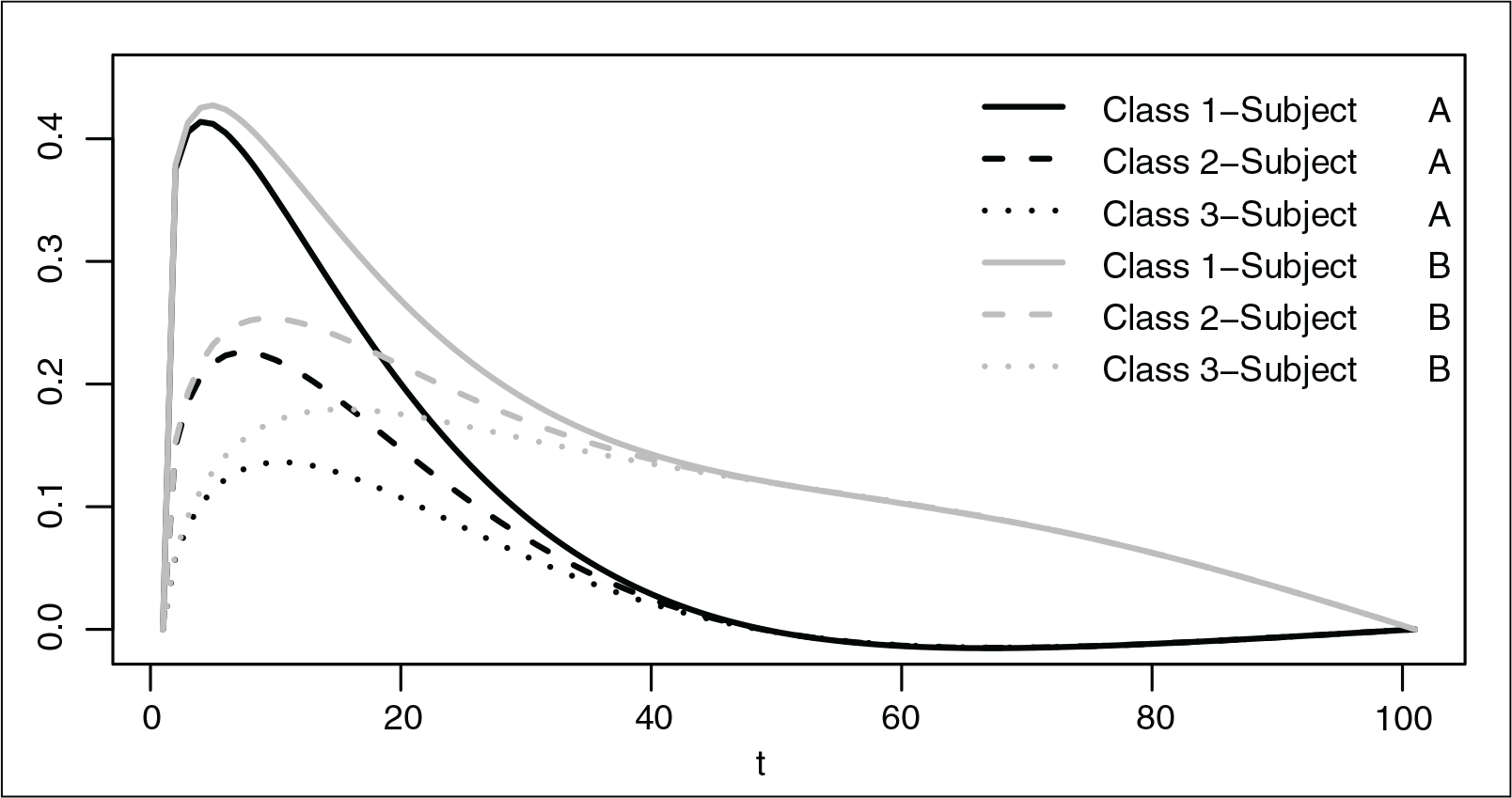
Simulation study. Sample paths related to classes 1, 2 and 3 (solid, dashed and dotted line, respectively) for two subjects A and B, black and grey lines, respectively
In Figure 2, all the sample curves, with and without noise, are displayed highlighting the three classes by different line types. In order to fit the regression splines, a cubic B-spline basis defined on 15 basis knots has been considered.
Simulation study. Smooth and noisy sample paths (left and right panel, respectively) related to classes 1, 2 and 3 (solid line, dashed line and dotted line, respectively) for 30 subjects
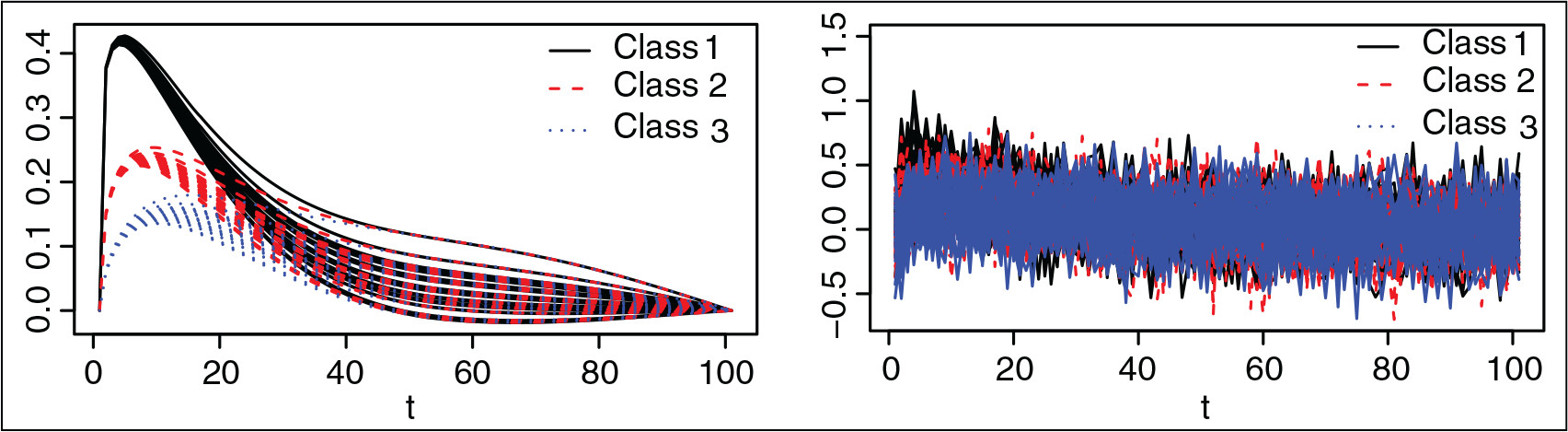
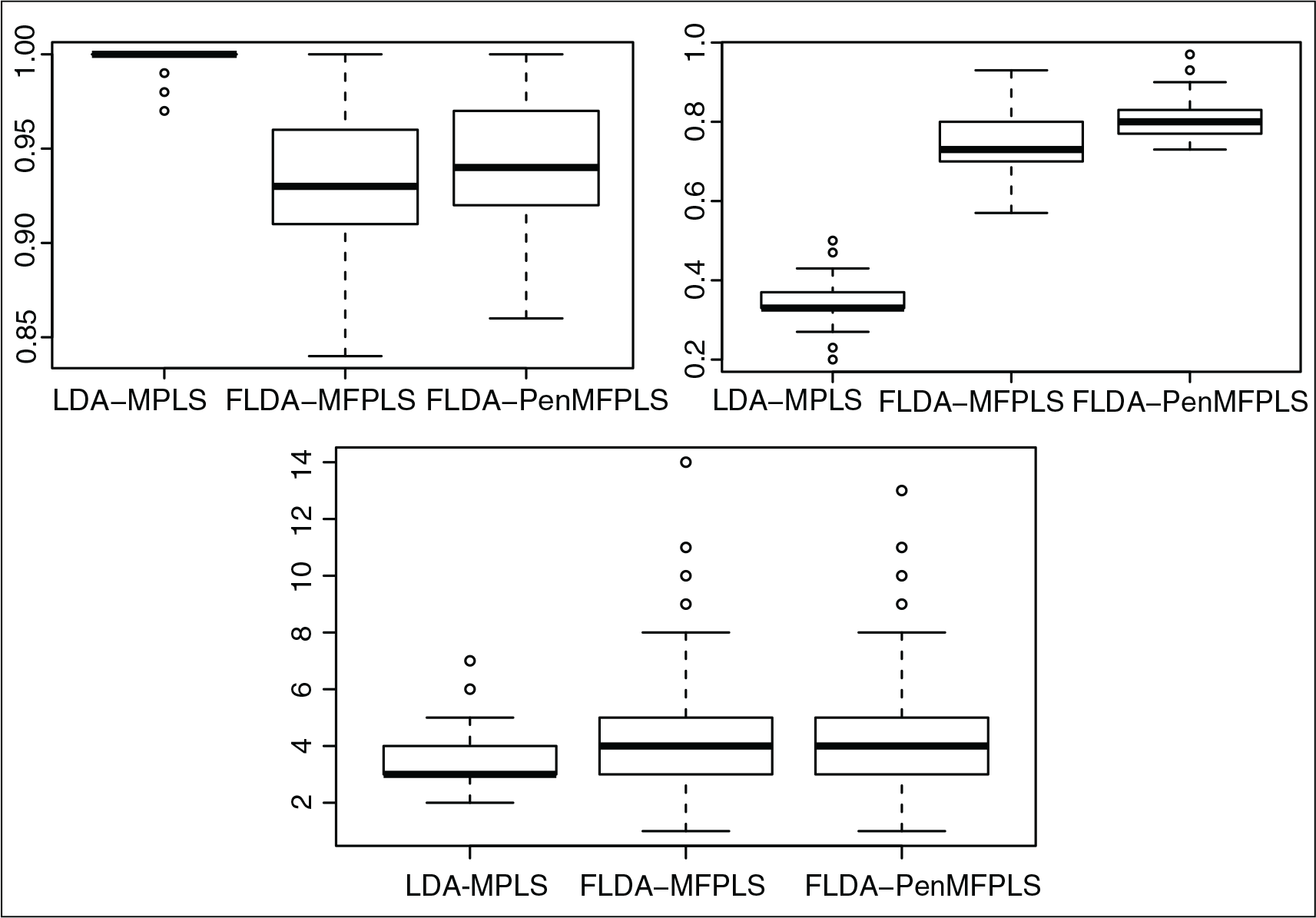
The simulation scheme was run 500 times and the main results are summarized in Figure 3. As we can see, the two functional approaches tend to select a larger number of PLS components than the multivariate version, as covariates in the LDA. But there is not a great difference between them. Regarding the correct classification rates (CCR), there is a clear overfitting in the multivariate approach, which provides CCR close to 1 in the cross-validation. Between the two proposed functional approaches, the one based on penalized multi-class functional PLS regression provides the best performance, with the highest CCR and the minimum variability.
Simulation study. Box plots showing to the number of PLS components used in the LDA (bottom panel), the correct classification rates from the cross-validation on the training sample and from the classification of the test sample (top-left and top-right panels, respectively). Experiments run 500 times
In this section, the results from the analysis of two real kinematic datasets are summarized. In general, kinematic data from inertial sensors placed on human body is usually collected in the format of linear acceleration or angular rotation. Linear acceleration or angular rotation represent the trajectory of the human movement, which can be identified with a function in time and frequency domain. In that sense, data from kinematic studies can be considered as a functional dataset, and then functional data techniques can be applied to analyse this type of data. In addition, it is important to remark the presence of repeated measures in kinematic studies. So, both the between-subject and within-subject variations must be taken into account.
Human activity data
The human activity dataset is part of a wider experiment, focused on the human activity recognition, carried out by Anguita et al. (2013). In this article, let us consider the linear acceleration (metre per second squared), measured on axis X and recorded in 128 equidistant knots at the interval
Human activity data. Raw data. Sample paths displayed separately by stimulus: walking, walking upstairs and walking downstairs, from left to right, respectively
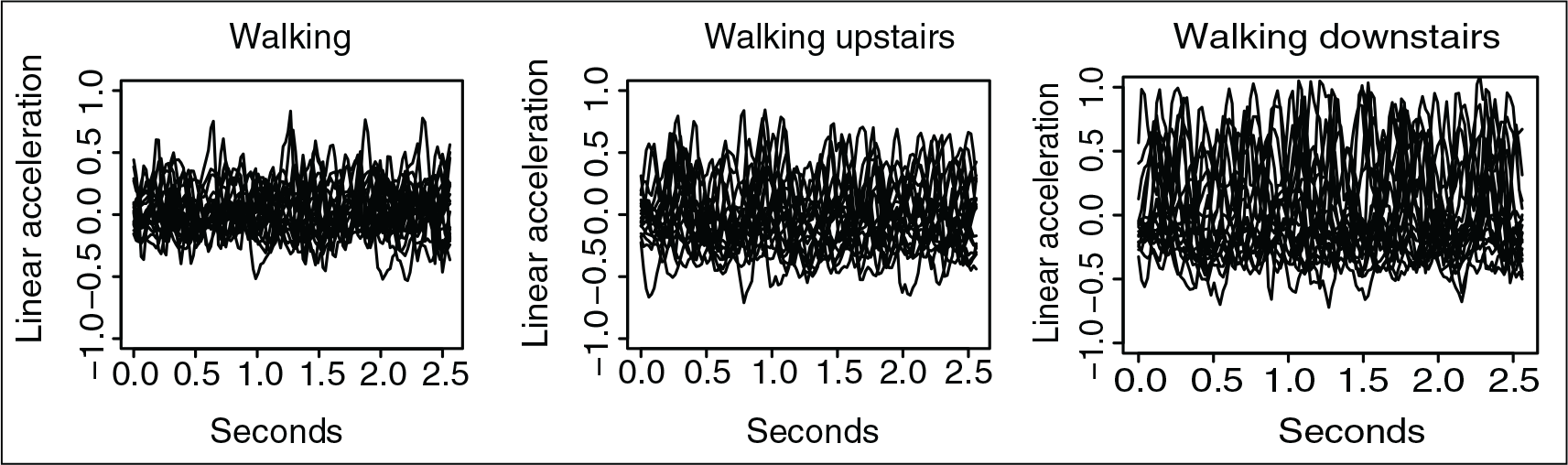
Human activity data. Raw data. Sample paths displayed separately by stimulus: walking, walking upstairs and walking downstairs, from left to right, respectively
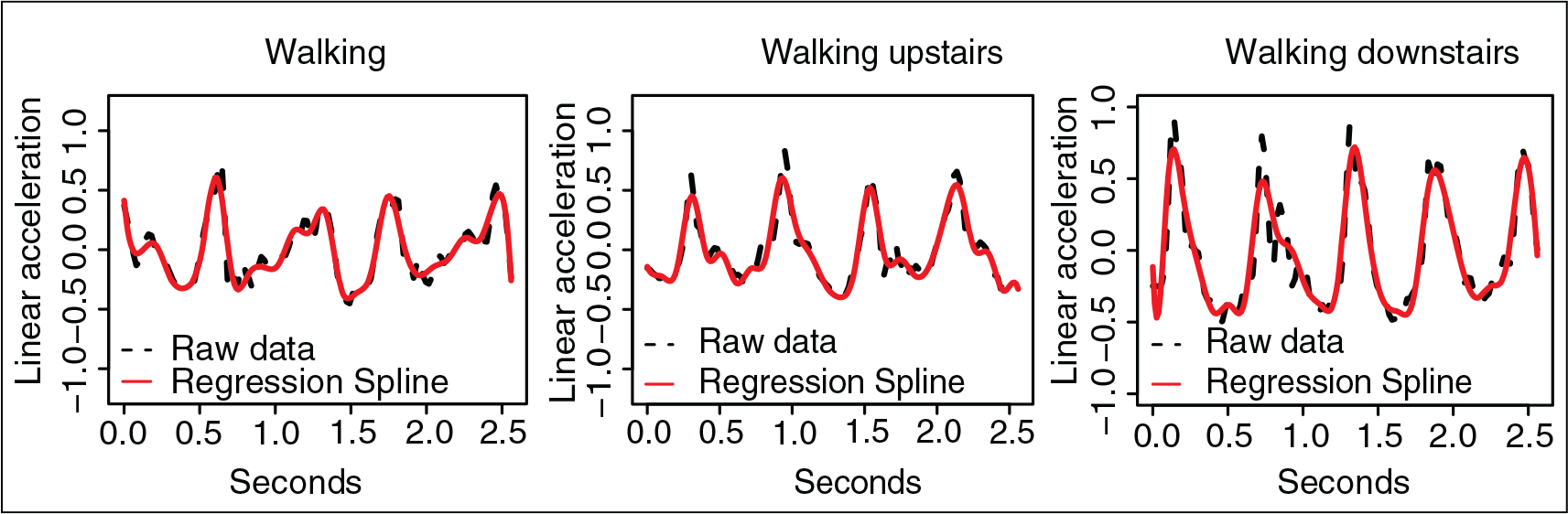
The first step in the analysis was to approximate the sample curves by mean of a basis representation and using a cubic B-spline basis defined on 25 equidistant knots. In Figure 6 the raw data together with the regression spline can be seen. Once the sample curves have been approximated, the aim is the human activity pattern recognition. To this end FLDA based on a multi-class approach for functional PLS regression (FLDA-MFPLS) was carried out to classify the sample curves according to the stimulus which produced them. It could be assumed that the raw data, which were collected by a smartphone on the waist of the subjects, are affected by some error or noise. In that sense, and aiming to avoid a possible lack of smoothness in the estimation of the discriminant functions, the penalized version of FLDA-MFPLS (FLDA-PenMFPLS), proposed in section 2.3, was also considered.
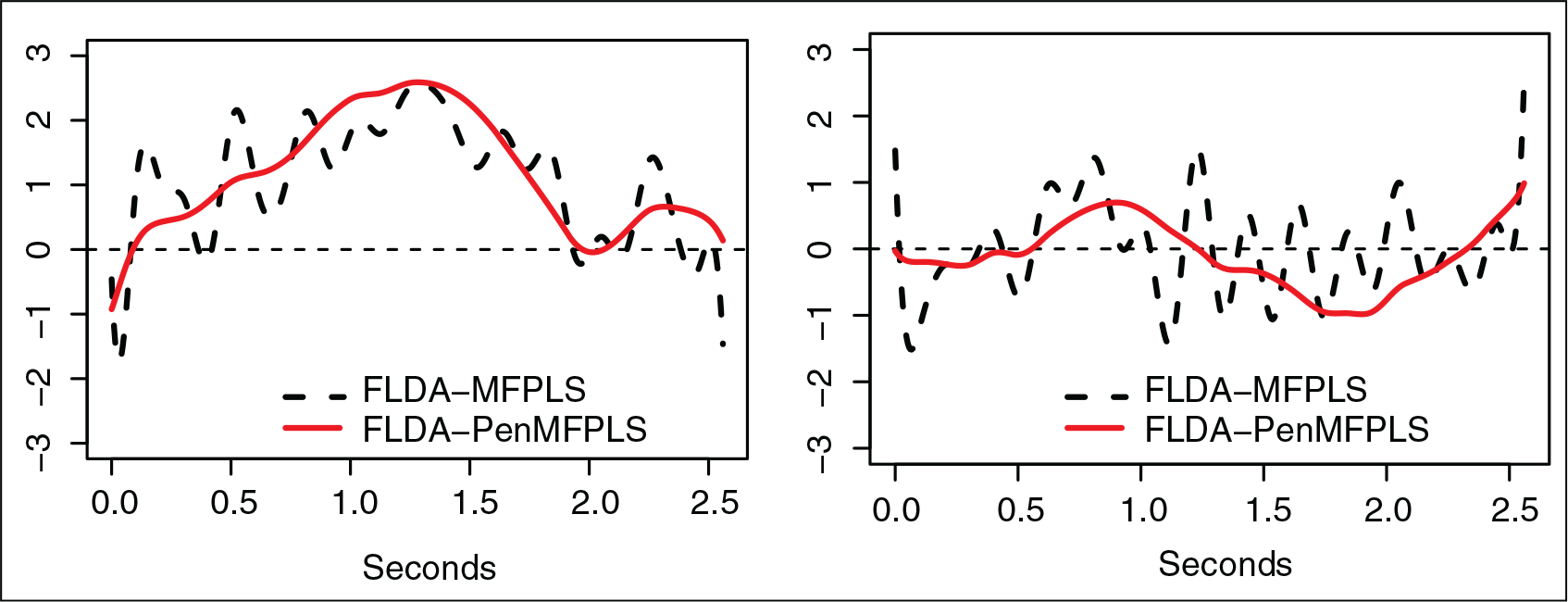
The discriminant functions estimated from penalized and non-penalized functional LDA can be seen in Figure 7. The necessity of smoothing in the estimation of the discriminant functions is obvious, with penalized functional LDA providing the smoothest and the most interpretable functions.
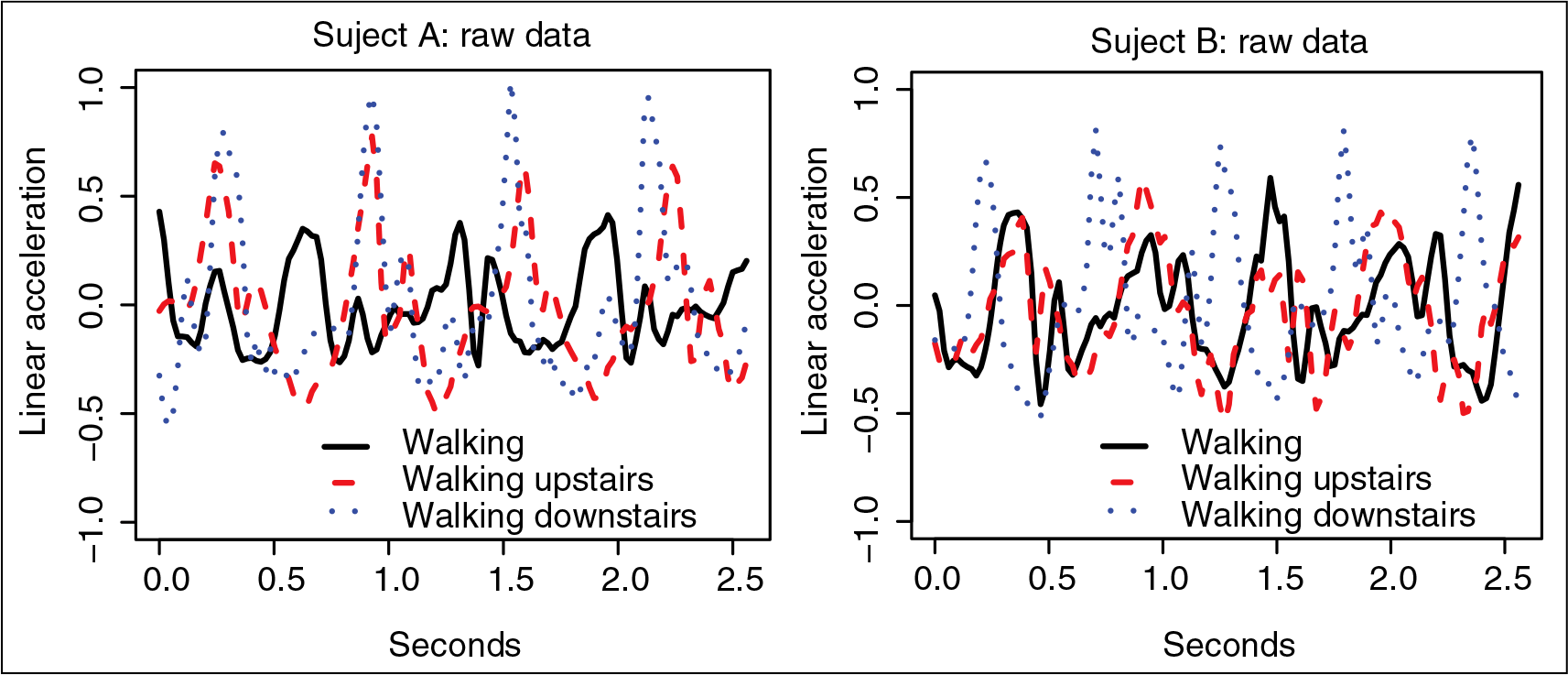
Human activity data. Raw data. Sample paths related to walking (solid line), walking upstairs (dashed line) and walking downstairs (dotted line) for two subjects A and B, left and right panel, respectively
Human activity data. A sample path for each stimulus (dashed line) together with the regression spline (solid line) estimated with a cubic B-splines basis defined on 25 equidistant knots
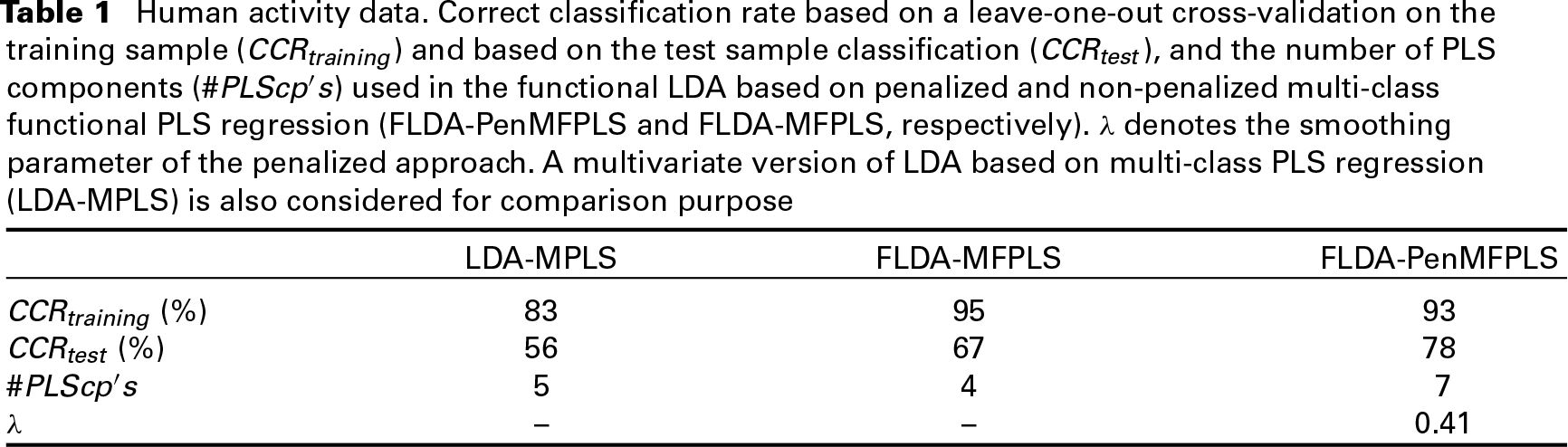
In order to evaluate the ability of penalized and non-penalized approaches for human activity pattern recognition, Table 1 summarizes information related to the CCR based on a leave-one-out cross-validation on the training sample (
It can be seen that functional LDA performs better than the multivariate approach. Besides, between the two functional approaches (penalized and non-penalized), the one based on penalized multi-class functional PLS (FLDA-PenMFPLS) achieves the highest CCR in both, training and test samples. A considerable difference between the CCR in training and test samples highlights a possible overfitting mainly in the multivariate and in the non-penalized functional approaches. In the penalized approach this fact is not so remarkable, providing then the best classification rate.
Human activity data. Discriminant functions estimated by functional LDA based on non-penalized (dashed line) and penalized (solid line) multi-class functional PLS regression, using 4 and 7 PLS components, respectively
Human activity data. Correct classification rate based on a leave-one-out cross-validation on the training sample (
) and based on the test sample classification (
), and the number of PLS components (
) used in the functional LDA based on penalized and non-penalized multi-class functional PLS regression (FLDA-PenMFPLS and FLDA-MFPLS, respectively).
denotes the smoothing parameter of the penalized approach. A multivariate version of LDA based on multi-class PLS regression (LDA-MPLS) is also considered for comparison purpose
The gait dataset comes from a wide experimental study developed in the biomechanics laboratories of the iMUDS. A total of 51 participants (25 boys and 28 girls) between 8 and 11 years old were involved in this study. In order to collect the data, 26 reflective markers were placed on the children's skin. The kinematics data was recorded by a 3D motion capture system (Qualisys AB, Göteborg, Sweden). Each subject completed a cycle walking over the platform in three conditions (walking, carrying a backpack that weighs 20% of the subject's weight and pulling a trolley that weighs 20% of the subject's weight). For each subject, the 3-axial angular rotation were registered for each join (ankle, foot progress, hip, knee, pelvis, thorax) in all conditions. Finally, the angular rotation curve represents the observation for the subject's gait cycle for each join, axis direction and experimental condition. Interested readers could request access to the data from Jose M. Heredia-Jiménez and Eva Orantes-González from iMUDS.
In this section, only a part of the above-described experimental dataset has been considered. Exactly, we are interested on the thorax angular position (radians) measured on axis Z. This is a clear example of functional data with repeated measures in the sense that three curves, concerning the three experimental conditions, are available for each subject. In addition, each sample curve was recorded in 101 equidistant points of the gait cycle. So, the interval
Subject 10 was removed from the sample for being an outlier. The remaining sample observations were distributed into training and test samples, with observations (repeated measures) related to 39 and 11 subjects, respectively. The raw data (displayed by experimental conditions) are shown in Figure 8.
Gait data. Raw data. Sample paths displayed separately by type of activity: walking, carrying a backpack and pulling a trolley, both weighing 20% of the children's weight, from left to right, respectively
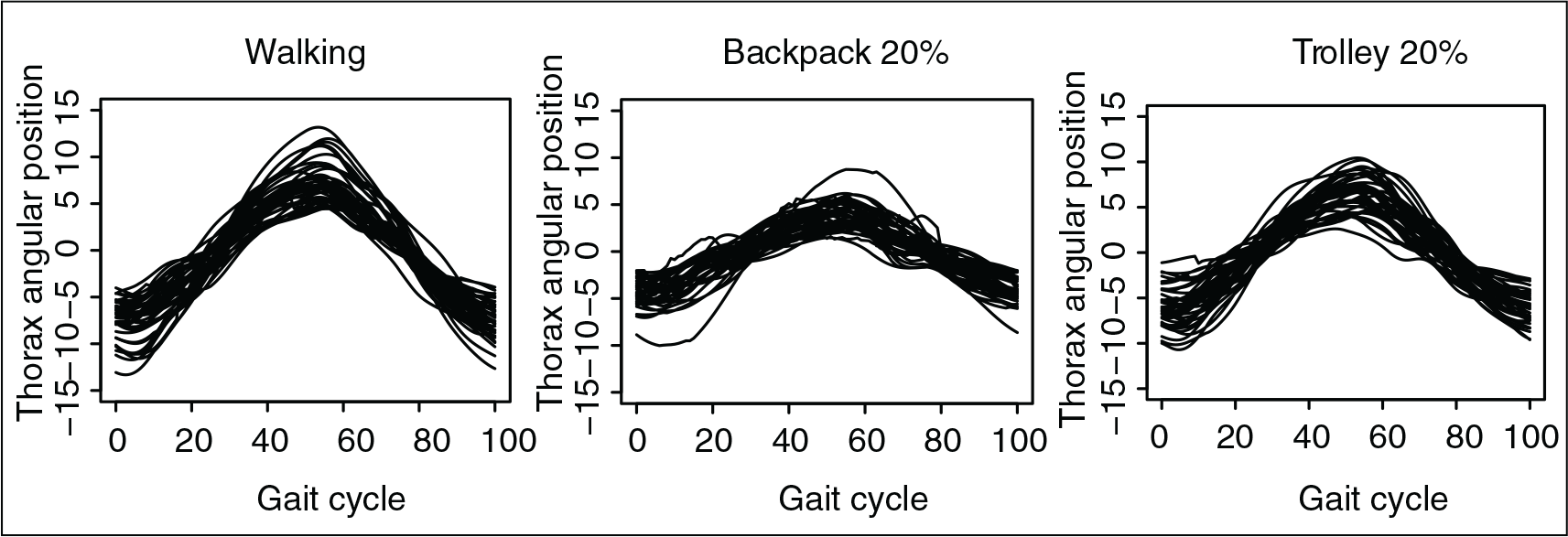
Gait data. Raw data. Sample paths displayed separately by type of activity: walking, carrying a backpack and pulling a trolley, both weighing 20% of the children's weight, from left to right, respectively
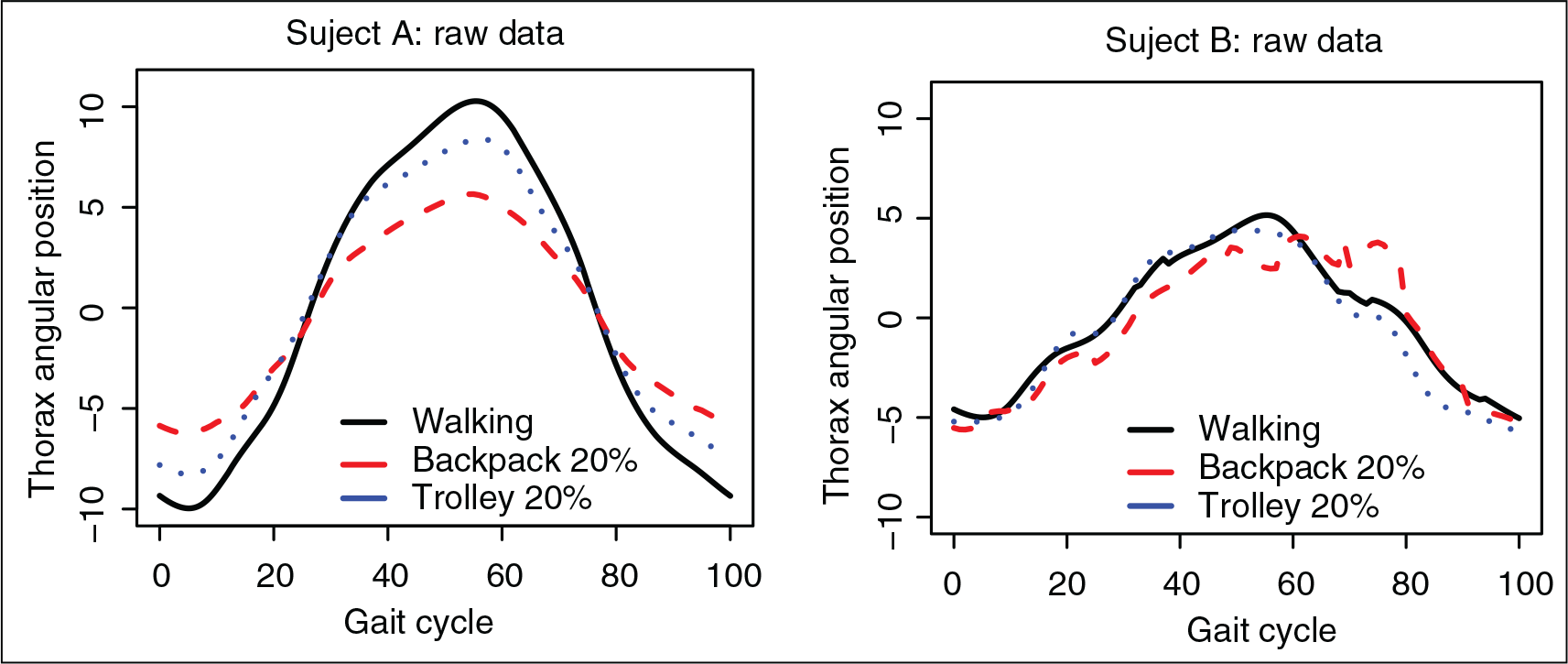
In order to visualize the within subjects and the between subjects variability, in Figure 9 the spectra related to the three gait events have been overlapped for two subjects A and B, left and right panel, respectively. It can be seen that walking and walking with a trolley provide sample paths with a more similar shape than walking with a backpack. Also it is interesting to highlight the between subjects variability (differences in scale and shape).
Gait data. Raw data. Sample paths related to walking (solid line), carrying a backpack (dashed line) and pulling a trolley (dotted line), both weighing 20% of the children's weight and walking downstairs from two sample individuals A and B, left and right panel, respectively
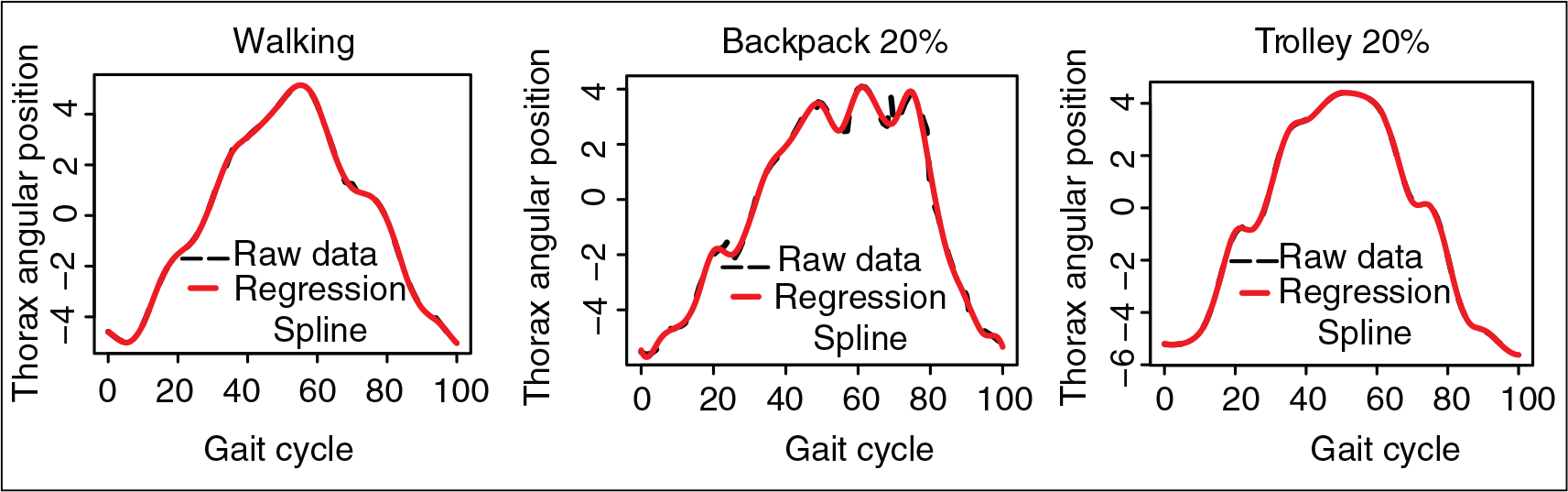
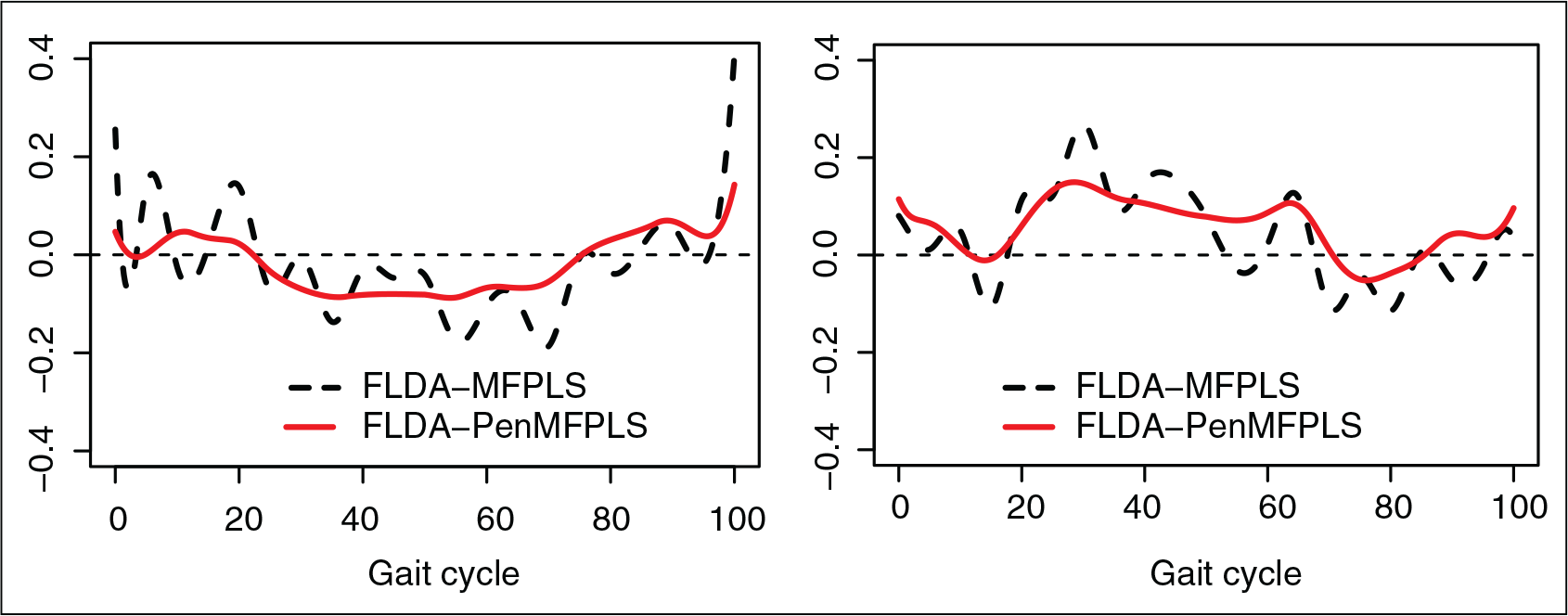
The sample curves have been approximated by mean of a basis representation using a cubic B-spline basis defined on 20 equidistant knots. In Figure 10 the raw data and the regression splines have been displayed. Once the sample curves have been approximated, the aim is the classification of the thorax angular rotation curves. In that sense, the discriminant functions estimated by penalized and non-penalized functional LDA can be seen in Figure 11. Once again the penalized approach provides the smoothest functions, providing an intuitive interpretation in relation with detecting periods in which the function is positive or negative.
Gait data. A sample path for each stimulus (dashed line) together with the regression spline (solid line) estimated with a cubic B-splines basis defined on 20 equidistant knots
Gait data. Discriminant functions estimated by functional LDA based on non-penalized (dashed line) and penalized (solid line) multi-class functional PLS regression, using 5 and 3 PLS components, respectively
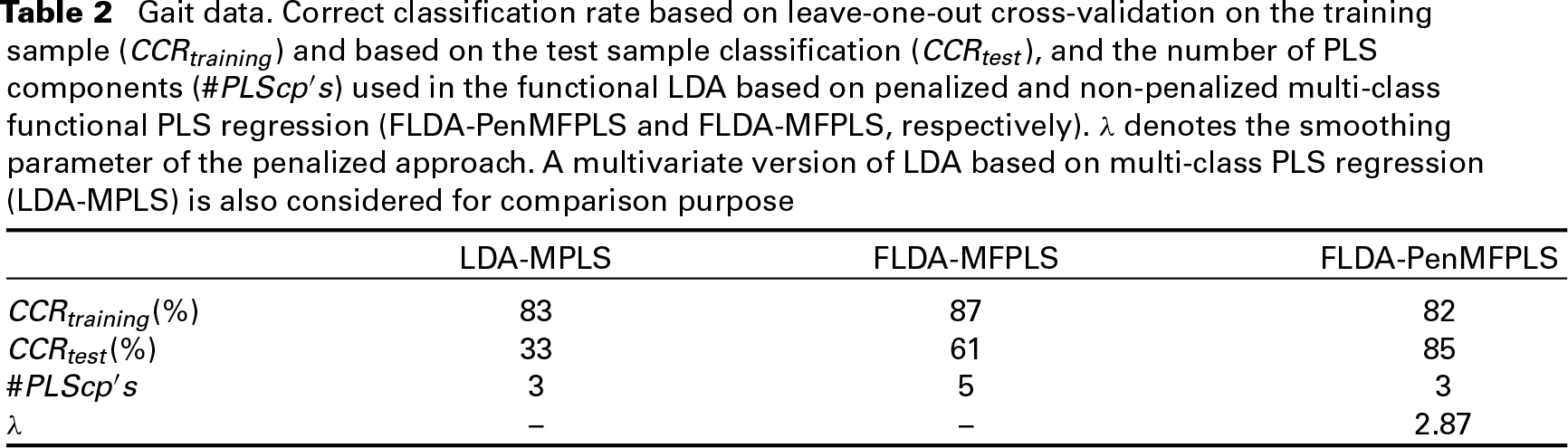
The classification performance of the penalized and non-penalized approaches is shown in Table 2. It obvious that functional LDA performs better than the multivariate approach. Between the two functional approaches, the one based on penalized multi-class functional PLS (FLDA-PenMFPLS) achieves the best classification performance (the highest CCR on the test sample).
Gait data. Correct classification rate based on leave-one-out cross-validation on the training sample (
) and based on the test sample classification (
), and the number of PLS components (
) used in the functional LDA based on penalized and non-penalized multi-class functional PLS regression (FLDA-PenMFPLS and FLDA-MFPLS, respectively).
denotes the smoothing parameter of the penalized approach. A multivariate version of LDA based on multi-class PLS regression (LDA-MPLS) is also considered for comparison purpose
In this work, a methodological solution to the problem of multi-class classification of functional data with repeated measures has been proposed. FLDA has been considered as a classifier, by solving the problem of infinite dimension of the functional data by means of a novel approach of functional PLS regression for repeated measures described in Section 2. This work has been motivated by two real problems related to kinematic data. In both cases, data is affected by some noise, and then some type of penalization must be considered in the estimation of the discriminant functions. To solve this problem in the case of functional data with repeated measures, a multi-class approach for penalized functional PLS, that introduces a P-spline penalty in the definition of the inner product in the PLS algorithm, is proposed in Sections 2.2 and 2.3.
In Sections 3 and 4, the performance of the two functional approaches (penalized and non-penalized, FLDA-PenMFPLS and FLDA-MFPLS, respectively) are compared with a multivariate version of LDA based on multi-class PLS regression (LDA-MPLS). As we can see in Figure 3 and Tables 1 and 2, from a classification point of view, functional approaches perform better than the multivariate version, increasing the CCR on a test sample in a very significant way. Regarding the two functional approaches, the one based on penalized multi-class functional PLS achieves the best classification ability, with a difference in the CCR of more than 10% in both case studies.
The discriminant functions estimated from penalized and non-penalized functional LDA are shown in Figures 7 and 11. It can be seen that the penalized version (FLDA-PenMFPLS) provides smoother functions, which are more interpretable in the sense of detecting periods in which the function is positive or negative.
Finally, it can be concluded that LDA based on a multi-class approach for penalized functional PLS is the most competitive method from both classification and estimation point of view.
Footnotes
Acknowledgments
This research has been supported by the research projects MTM2017-88708-P, Spanish Ministry of Economy and Competitiveness (also supported by the FEDER program) and IJCI-2017-34038, Agencia Estatal de Investigacin, Ministerio de Ciencia, Innovacin y Universidades.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This research has been supported by the research projects MTM2017-88708-P, Spanish Ministry of Economy and Competitiveness (also supported by the FEDER program) and IJCI-2017-34038, Agencia Estatal de Investigacin, Ministerio de Ciencia, Innovacin y Universidades.