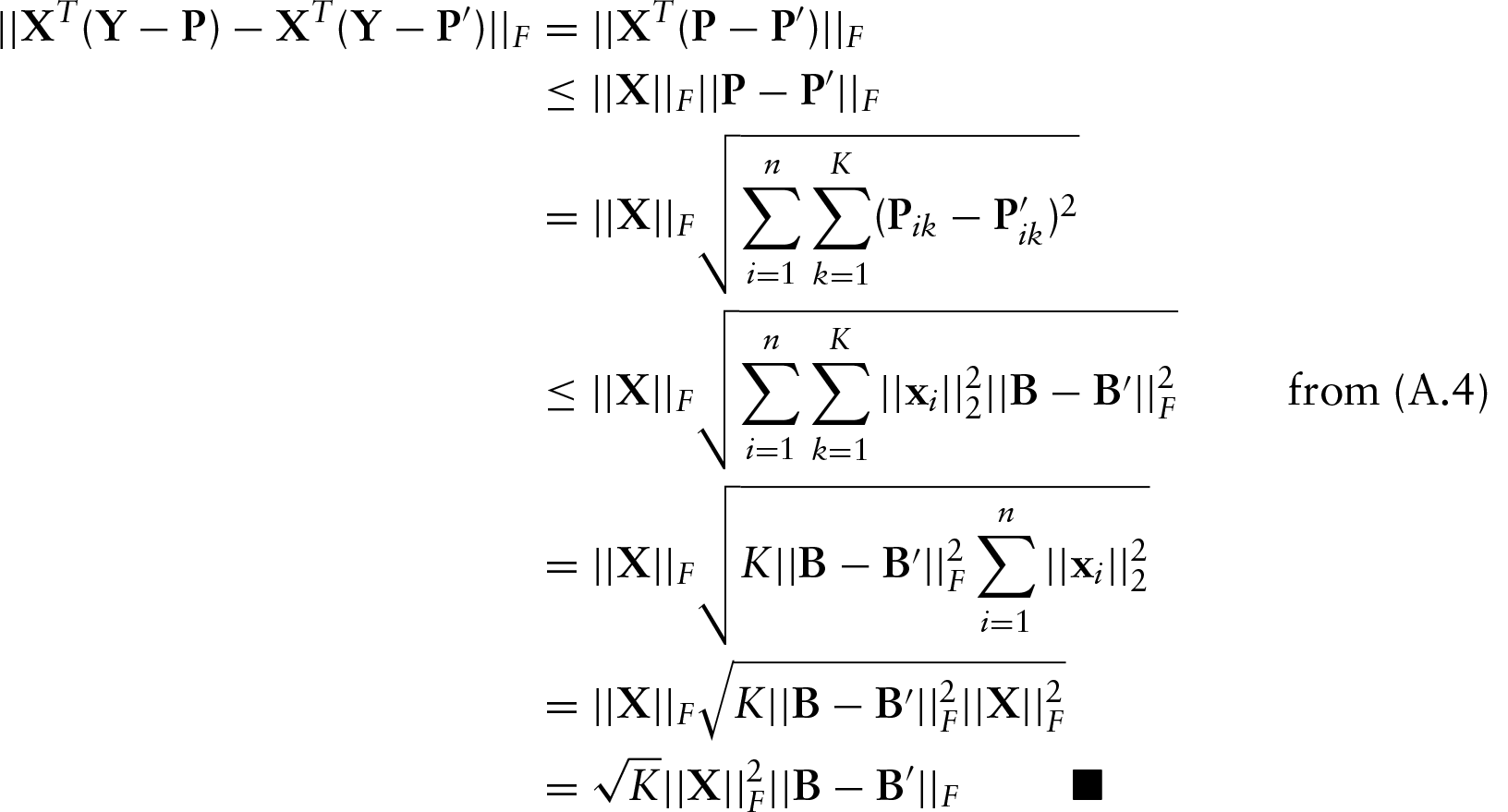Abstract
We propose the nuclear norm penalty as an alternative to the ridge penalty for regularized multinomial regression. This convex relaxation of reduced-rank multinomial regression has the advantage of leveraging underlying structure among the response categories to make better predictions. We apply our method, nuclear penalized multinomial regression (NPMR), to Major League Baseball play-by-play data to predict outcome probabilities based on batter–pitcher matchups. The interpretation of the results meshes well with subject-area expertise and also suggests a novel understanding of what differentiates players.
Introduction
A baseball game comprises a sequence of matchups between one batter and one pitcher. Each matchup, or plate appearance (PA), results in one of several outcomes. Disregarding some obscure possibilities, we consider nine categories for PA outcomes: flyout (F), groundout (G), strikeout (K), base on balls (BB), hit by pitch (HBP), single (1B), double (2B), triple (3B) and home run (HR).
A problem which has received a prodigious amount of attention in sabermetric (the study of baseball statistics) literature is determining the value of each of the above outcomes, as it leads to scoring runs and winning games. But that is only half the battle. Much less work in this field focuses on an equally important problem: optimally estimating the probabilities with which each batter and pitcher will produce each PA outcome. Even for ‘advanced metrics’, this second task is usually done by taking simple empirical proportions, perhaps shrinking them towards a population mean using a Bayesian prior.
In statistics literature, on the other hand, many have developed shrinkage estimators for a set of probabilities with application to batting averages, starting with Stein's estimator (Efron and Morris, 1975). Since then, Bayesian approaches to this problem have been popular. Morris (1983) and Brown (2008) used empirical Bayes for estimating batting averages, which are binomial probabilities. We are interested in estimating multinomial probabilities, such as the nested Dirichlet model of Null (2009) and the hierarchical Bayesian model of Albert (2016). What all of the earlier works have in common is that they do not account for the ‘strength of schedule’ faced by each player: How skilled were his opponents?
The state-of-the-art approach, Deserved Run Average (Judge and BP Stats Team, 2015; DRA) is similar to the adjusted plus–minus model from basketball and the Rasch model used in psychometrics. The latter models the probability (on the logistic scale) that a student correctly answers an exam question as the difference between the student's skill and the difficulty of the question. DRA models players’ skills as random effects and also includes fixed effects like the identity of the ballpark where the PA took place. Each category of the response has its own binomial regression model. Taking HR as an example, each batter
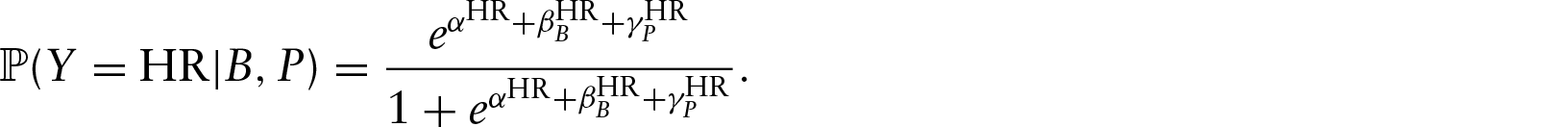
One bothersome aspect of DRA is that the probability estimates do not sum to one; a natural solution is to use a single multinomial regression model instead of several independent binomial regression models. Making this adjustment would result in a model very similar to ridge multinomial regression (described in Section 3.3), and we will compare the results of our model with the results of ridge regression as a proxy for DRA. Ridge multinomial regression applied to this problem has about 8 000 parameters to estimate (one for each outcome for each player) on the basis of about 160 000 PAs in a season, bound together only by the restriction that probability estimates sum to one. One may seek to exploit the structure of the problem to obtain better estimates, as in ordinal regression. The categories have an ordering, from least to most valuable to the batting team:
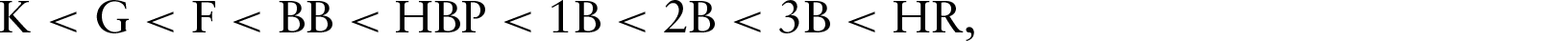
with the ordering of the first three categories depending on the game situation. But the proportional odds model used for ordinal regression assumes that when one outcome is more likely to occur, the outcomes close to it in the ordering are also more likely to occur. That assumption is woefully off base in this setting because as we show in the following, players who hit a lot of home runs tend to strike out often, and they tend not to hit many triples. The proportional odds model is better suited for response variables on the Likert scale (Likert, 1932), for example.
Illustration of the hierarchical structure among the PA outcome categories, adapted from Baumer and Zimbalist (2014). Dark terminal nodes correspond to the nine outcome categories in the data. Light internal nodes have the following meaning: TTO, three true outcomes; BIP, balls in play; W, walks; H, hits; O, outs. Outcomes close to each other (in terms of number of edges separating them) tend to occur in similar circumstances
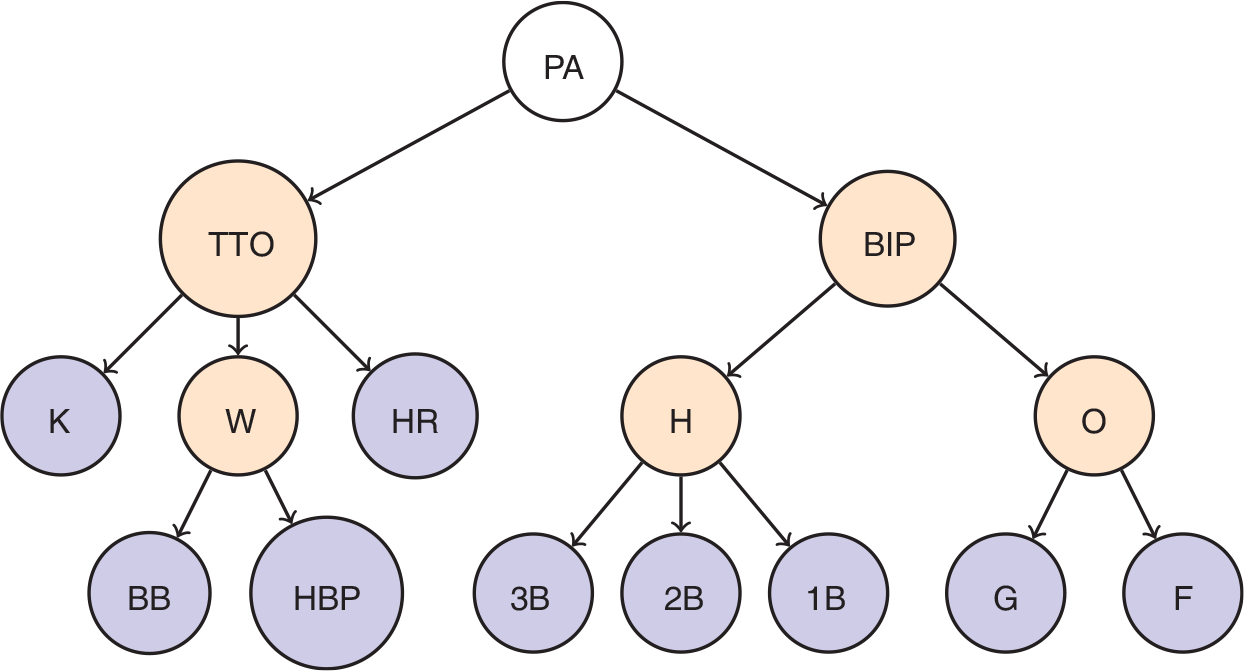
Illustration of the hierarchical structure among the PA outcome categories, adapted from Baumer and Zimbalist (2014). Dark terminal nodes correspond to the nine outcome categories in the data. Light internal nodes have the following meaning: TTO, three true outcomes; BIP, balls in play; W, walks; H, hits; O, outs. Outcomes close to each other (in terms of number of edges separating them) tend to occur in similar circumstances
The actual relationships among the outcome categories are more similar to the hierarchical structure illustrated by Figure 1. The outcomes fall into two categories: balls in play (BIP) and the ‘three true outcomes’ (TTO). The TTO, as they have become traditionally known in sabermetric literature, include home runs, strikeouts and walks (which itself includes BB and HBP). The distinction between BIP and TTO is important because the former category involves all eight position players in the field on defence, whereas the latter category involves only the batter and the pitcher. Figure 1 has been designed (roughly) by baseball experts so that terminal nodes close to each other (by the number of edges separating them) are likely to co-occur. Players who hit a lot of home runs tend to strike out a lot, and the outcomes K and HR are only two edges away from each other. Hence, the graph reveals something of the underlying structure in the outcome categories.
Biplots of the principal component analyses of player outcome matrices, separate for batters and pitchers. The dots represent players and the arrows (corresponding to the top and right axes) show the loadings for the first two principal components on each of the outcomes. We exclude outcomes for which the loadings of both of the first two principal components are sufficiently small
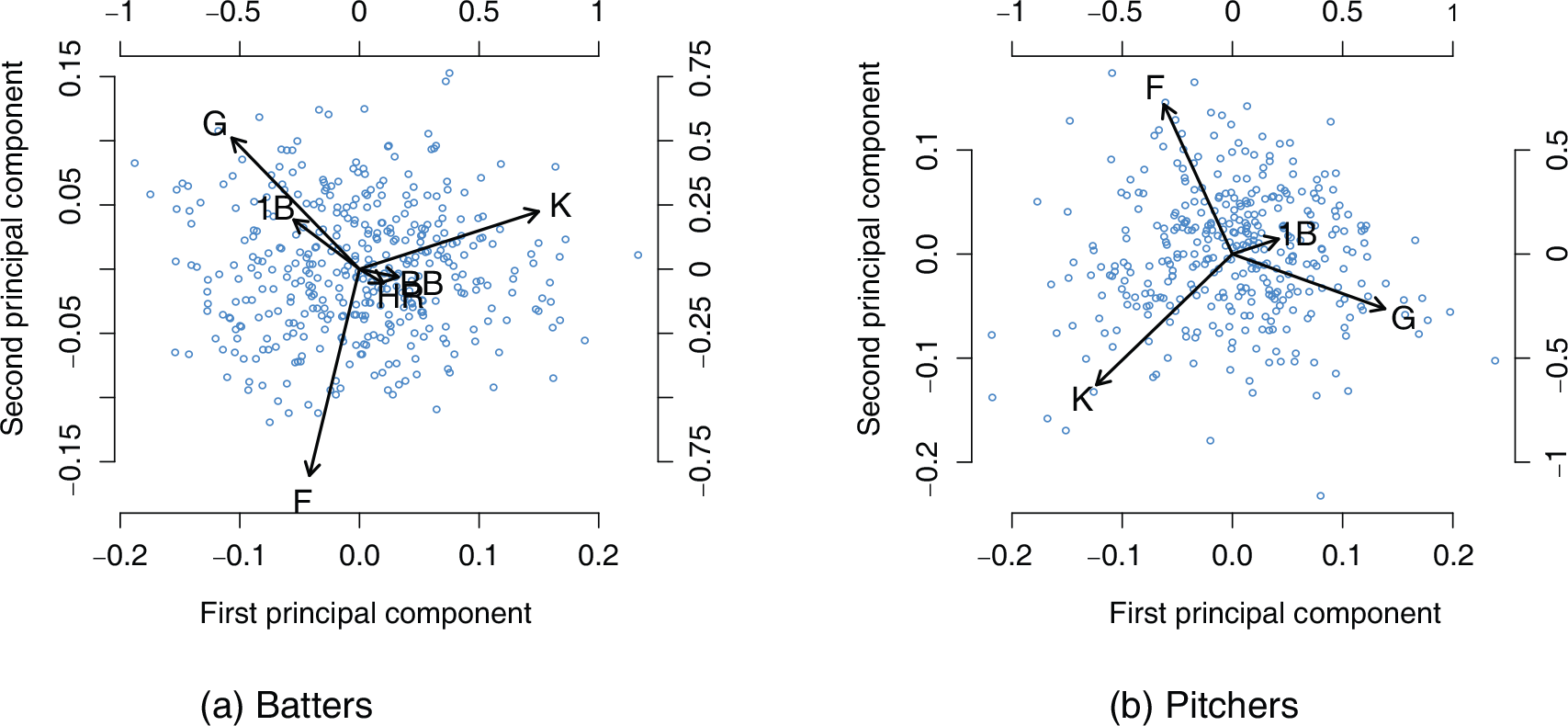
This structure is further evidenced by principal component (PC) analysis of the player–outcome matrix, illustrated in Figure 2 and Table 1. The player–outcome matrix has a row for each player giving the proportion of PAs which have resulted in each of the nine outcomes in the dataset. For batters, the PC which describes most of the variance in observed outcome probabilities has negative loadings on all of the BIP outcomes and positive loadings on all of the TTO outcomes. For both batters and pitchers, the percentage of variance explained after two PCs drops off precipitously.
Visualization of principal component analysis of player–outcome matrices, separate for batters and for pitchers. The visualization shows the loadings for each PC, along with a highlighted bar plot corresponding to the percentage of variance explained by each PC, which is also printed in the row below the matrix of PC loadings
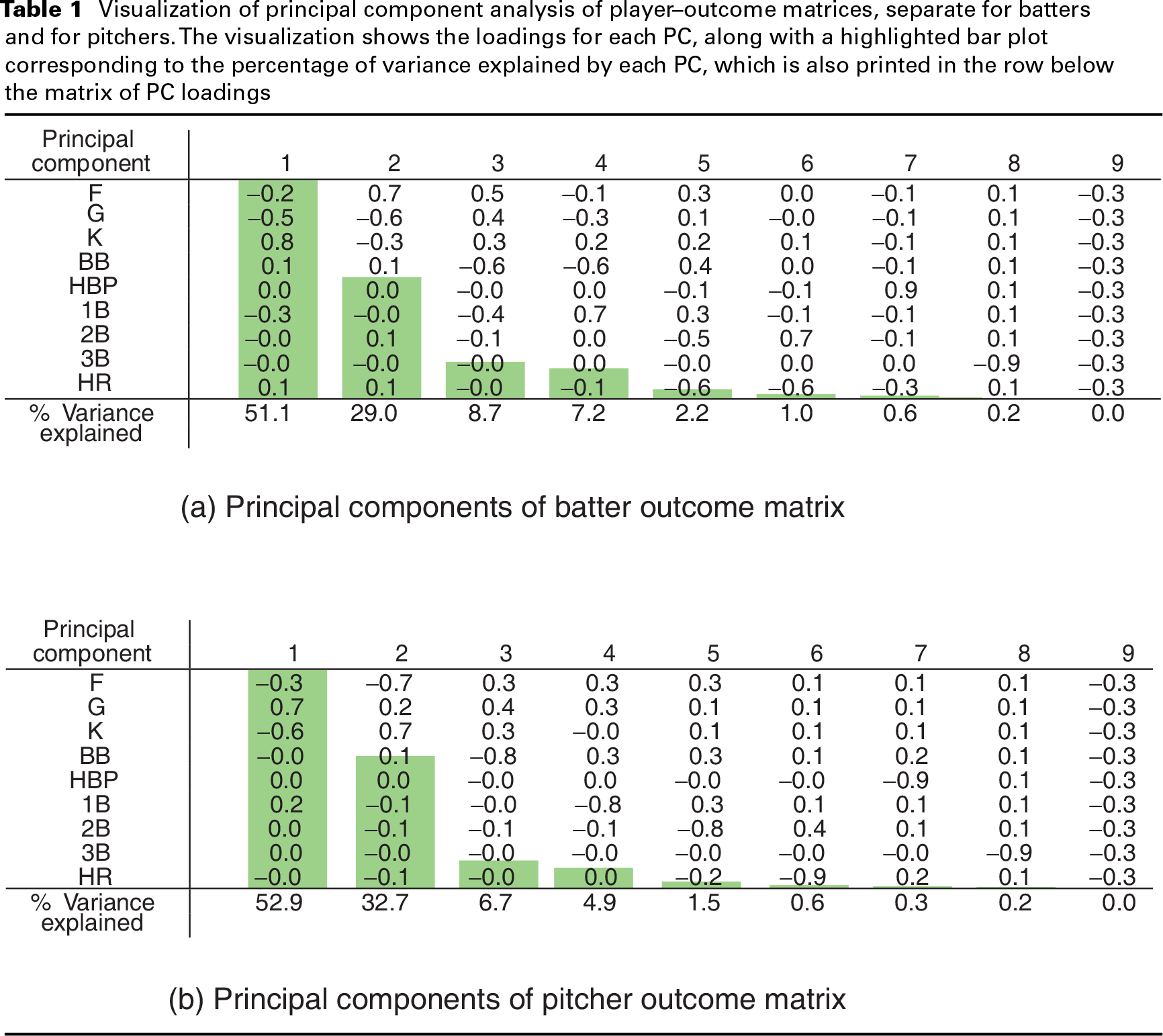
PC analysis is useful for illustrating the relationships between the outcome categories. For example, Table 1(a) suggests that batters who tend to hit singles (1B) more than average also tend to ground out (G) more than average. So an estimator of a batter's groundout rate could benefit from taking into account the batter's single rate, and vice versa. This is an example of the type of structure in outcome categories that motivates our proposal, which aims to leverage this structure to obtain better regression coefficient estimates in multinomial regression.
In Section 2, we review reduced-rank multinomial regression, a first attempt at leveraging this structure. We improve on this in Section 3 by proposing nuclear penalized multinomial regression (NPMR), a convex relaxation of the reduced-rank problem. We compare our method with ridge regression in a simulation study in Section 4. In Section 5, we apply our method and interpret the results on the baseball data, as well as another application. The manuscript concludes with a discussion in Section 6.
Suppose that we observe data

In contrast with logistic regression, multinomial regression involves estimating not a vector but a matrix of regression coefficients: one for each independent variable, for each class. We denote this matrix by
Yee and Hastie (2003) generalized the model to reduced-rank vector generalized linear models. In detail, the reduced-rank multinomial logistic model (RR-MLM) fits (2.1) by solving, for some
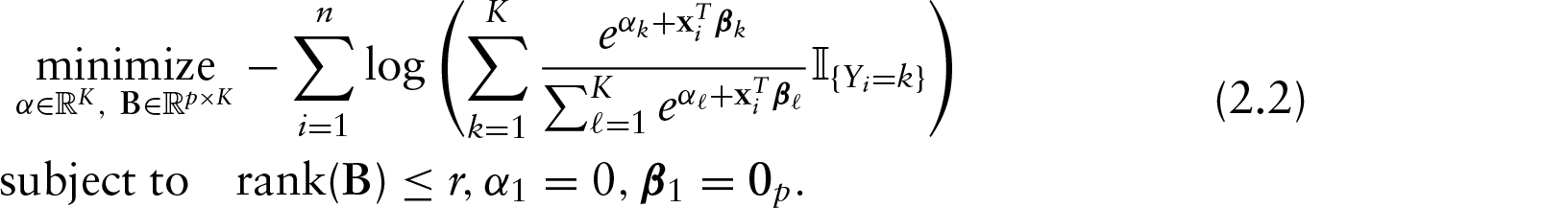
The optimization problem (2.2) is not convex because rank
Because of the computational difficulty of solving (2.2), we propose replacing the rank restriction with a restriction on the nuclear norm
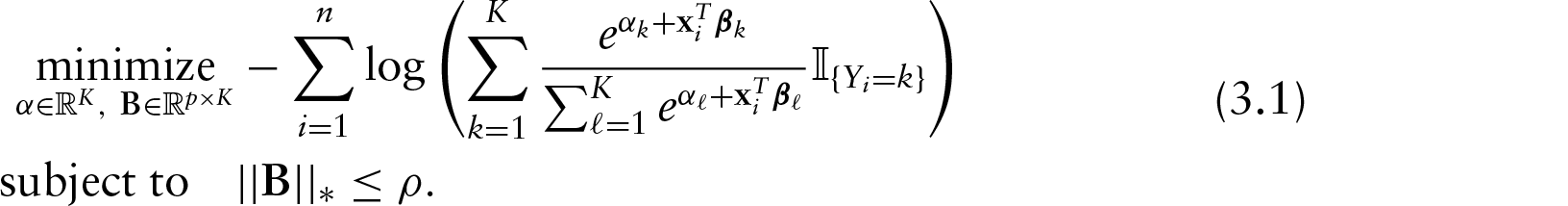
We prefer to frame the problem in its equivalent Lagrangian form: For some
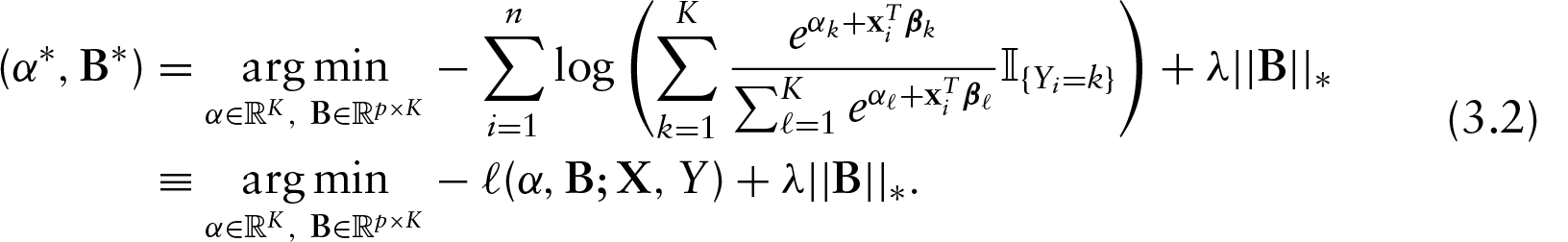

Consider the singular value decomposition
NPMR relies on solving (3.2). The objective is convex but non-differentiable where any singular values of

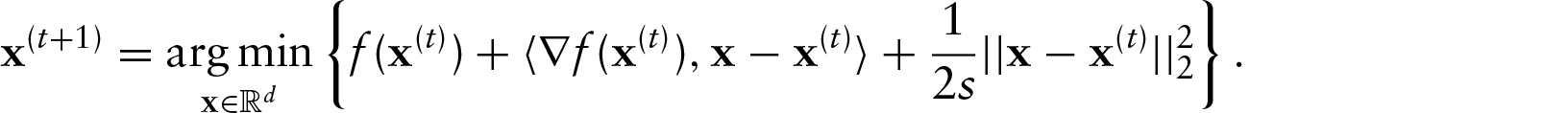
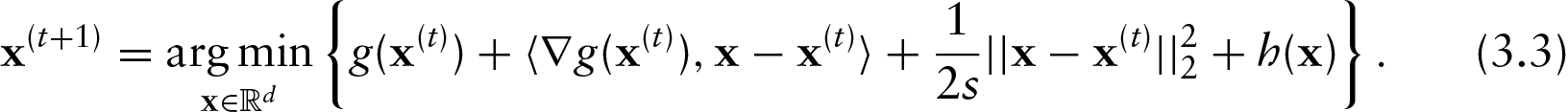
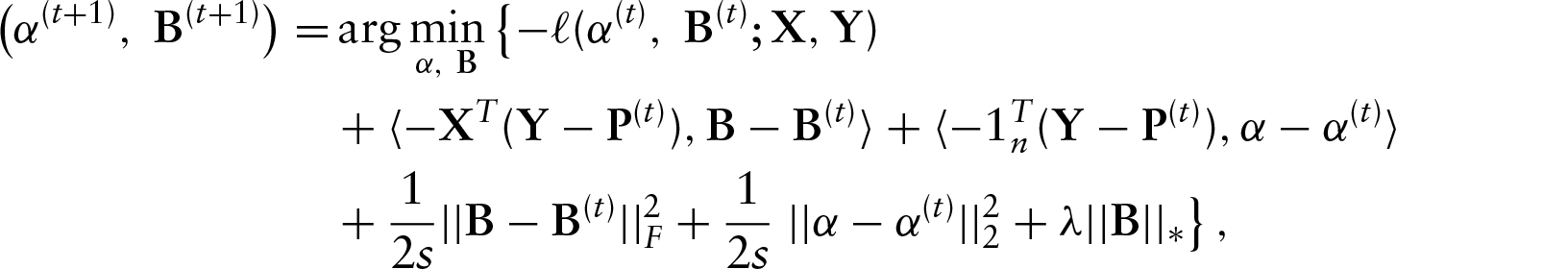
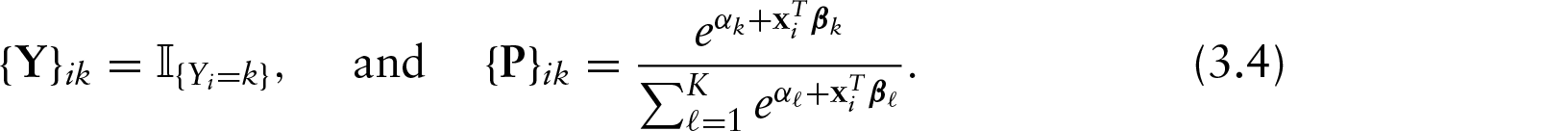
The problem is separable in
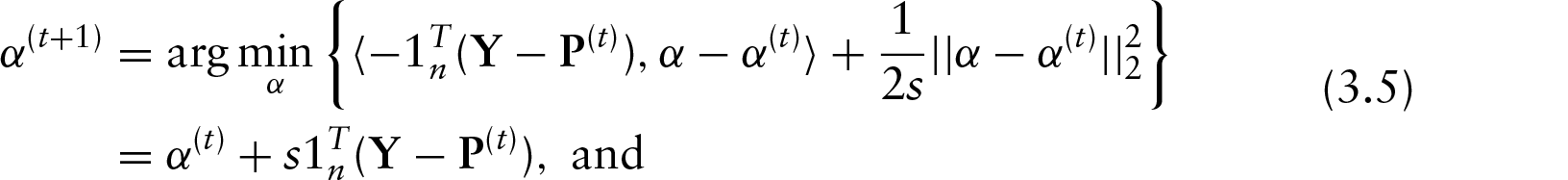
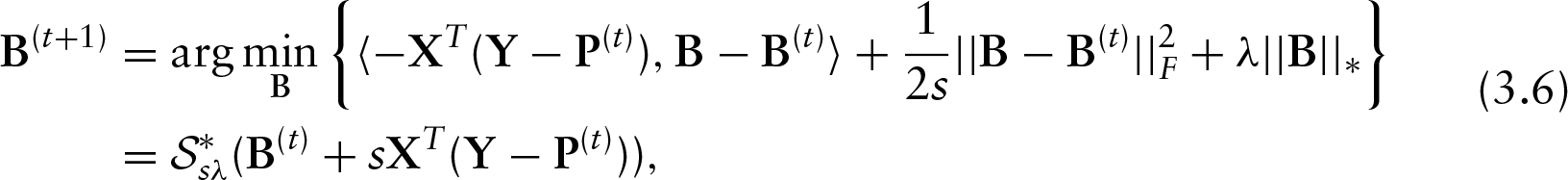
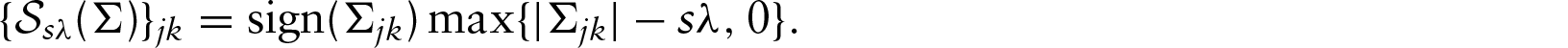
So to solve (3.2), initialize
In practice, we find that it helps to speed things up considerably to use an accelerated PGD method, also due to Nesterov (2007). Specifically, we iteratively apply the following updates:
The function
Related work
Tutz and Gertheiss (2016) provide a systematic review of regularized regression for categorical data. NPMR is a novel method in this category and would fit well in their section on categorical response variables. The authors describe penalties for variable selection multinomial logistic regression and in ordinal regression. None of these methods induces low rank in the solution, as NPMR does. The idea of using a nuclear norm penalty as a convex relaxation to reduced-rank regression has previously been proposed in the Gaussian regression setting (Chen et al., 2013), but we are not aware of any attempt to do so in the multinomial setting.
The nearest competitor to NPMR that can feasibly be applied to the baseball matchup dataset is multinomial ridge regression, which penalizes the squared Frobenius norm (the sum of the squares of the entries) of the coefficient matrix, instead of the nuclear norm. In detail, ridge regression estimates the regression coefficients by solving the optimization problem
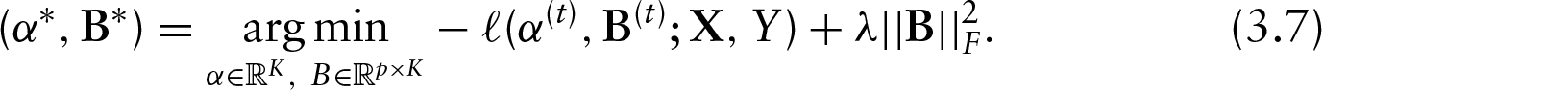
In this section, we present the results of two different simulations, one using a full-rank coefficient matrix and the other using a low-rank coefficient matrix. In both settings, we vary the training sample size



Simulation results. We plot the percentage of deviance explained in a test set against training sample size. The oracle prediction is based on the known class probabilities from which the test class was drawn. In (a), the full-rank setting, ridge regression outperforms NPMR by a slim margin. In (b), the low-rank setting, NPMR wins, especially for smaller sample sizes
In the low-rank setting, we first simulate two intermediary matrices
In these simulations and throughout this manuscript, we evaluate the methods using percentage of deviance explained in the test set. Multinomial deviance is twice the negative log of the probability predicted for the class observed. The null deviance corresponds to using the overall frequency of each class in the training set as the predicted probability for that class. The percentage of deviance explained is the difference between the null deviance and the deviance of the method's predictions, divided by the null deviance.
In the full-rank setting, we expect ridge regression to out perform NPMR because ridge regression shrinks all coefficient estimates towards zero, which is the mean of the generating distribution for the coefficients in the simulation. If this were a Gaussian regression problem instead of a multinomial regression problem, then the ridge regression coefficient estimates would correspond (Hastie et al., 2009) to the posterior mean estimate under a Bayesian prior of (4.1). In fact, ridge regression does beat NPMR in this simulation (for all training sample sizes
The low-rank setting is one in which NPMR should have better test performance than does ridge regression. NPMR bets on sparsity in the singular values of the coefficient matrix, and in this setting the bet pays off. The simulation results verify that this intuition is correct. NPMR beats ridge regression for all training sample sizes
In summary, this simulation demonstrates that each of NPMR and ridge regression is superior in a simulation tailored to its strengths, confirming our intuition. Furthermore, in a simulation constructed in favour of ridge regression, NPMR performs nearly as well. Meanwhile, NPMR leads to more significant gains over ridge regression in the low-rank setting. In this simulation and in the applications to follow, the number of response categories is more than just a few. This is intentional; for a small number of classes, for example,
Implementation details
The 2015 MLB play-by-play dataset from Retrosheet includes an entry for every PA during the six-month regular season. For the purposes of fitting NPMR to predict the outcomes of PAs, the following relevant variables are recorded for the
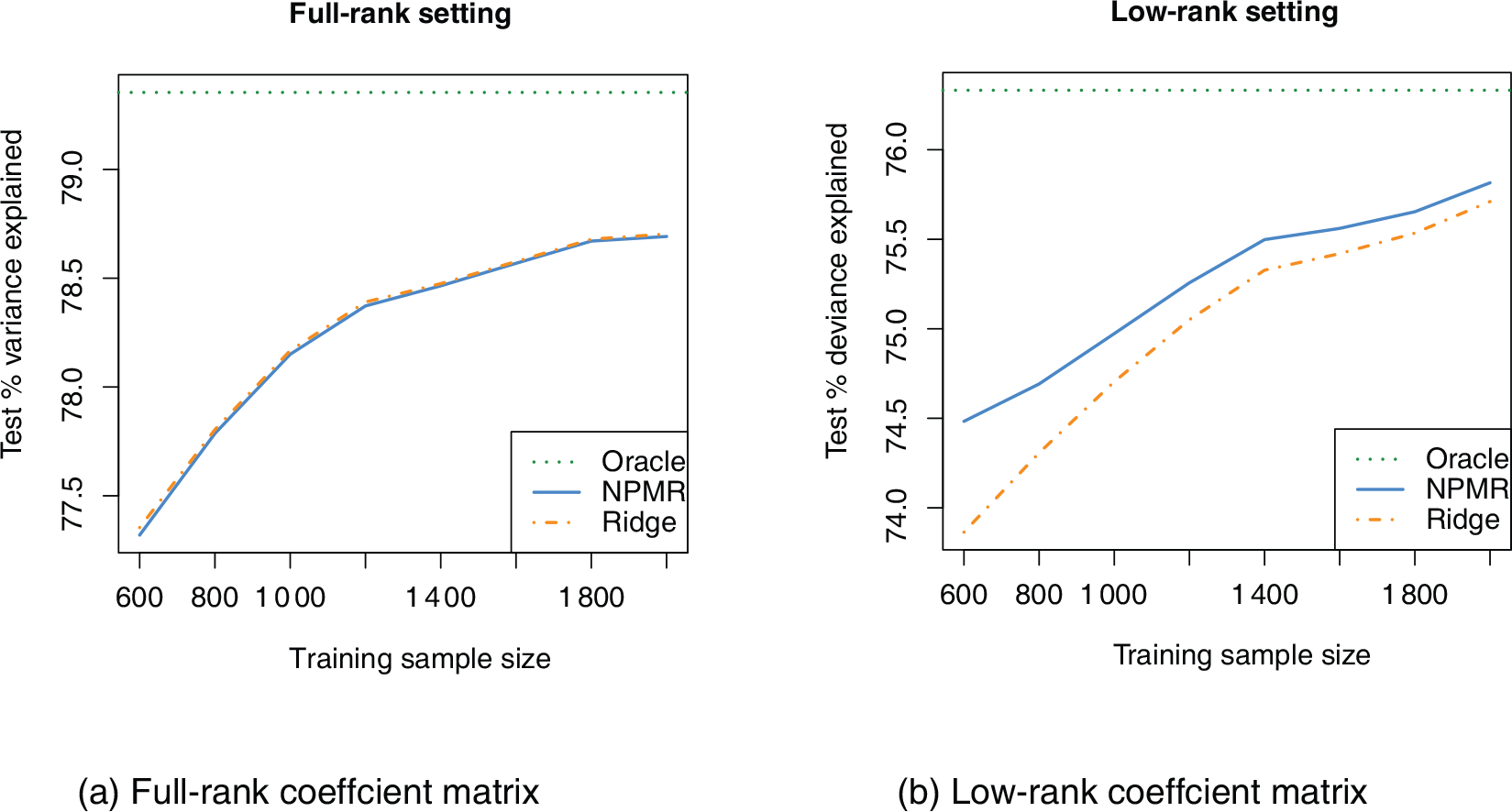
For each outcome
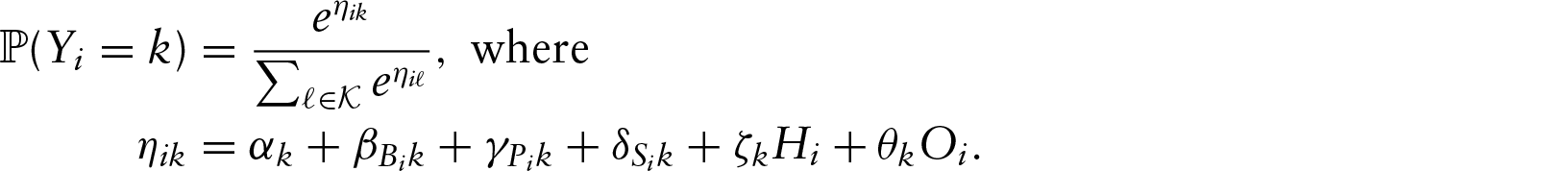
NPMR and ridge regression fit the same multinomial regression model and differ only in the regularizations used in their objective functions, yielding different results. See Section 3 for details. However, there is a minor tweak to NPMR for application to these data. Instead of adding to the objective a penalty on the nuclear norm of the whole coefficient matrix, we add penalties on the nuclear norms of the three coefficient sub-matrices corresponding to batters, pitchers and stadiums. The coefficients for home-field advantage and opposite handedness remain unpenalized. The result is that NPMR learns different latent variables for batters than it does for pitchers, instead of learning one set of latent variables for both groups.
We process the PA data before applying NPMR and ridge regression. First, we define a minimum PA threshold separately for batters and pitchers. For batters, the threshold is the
Validation
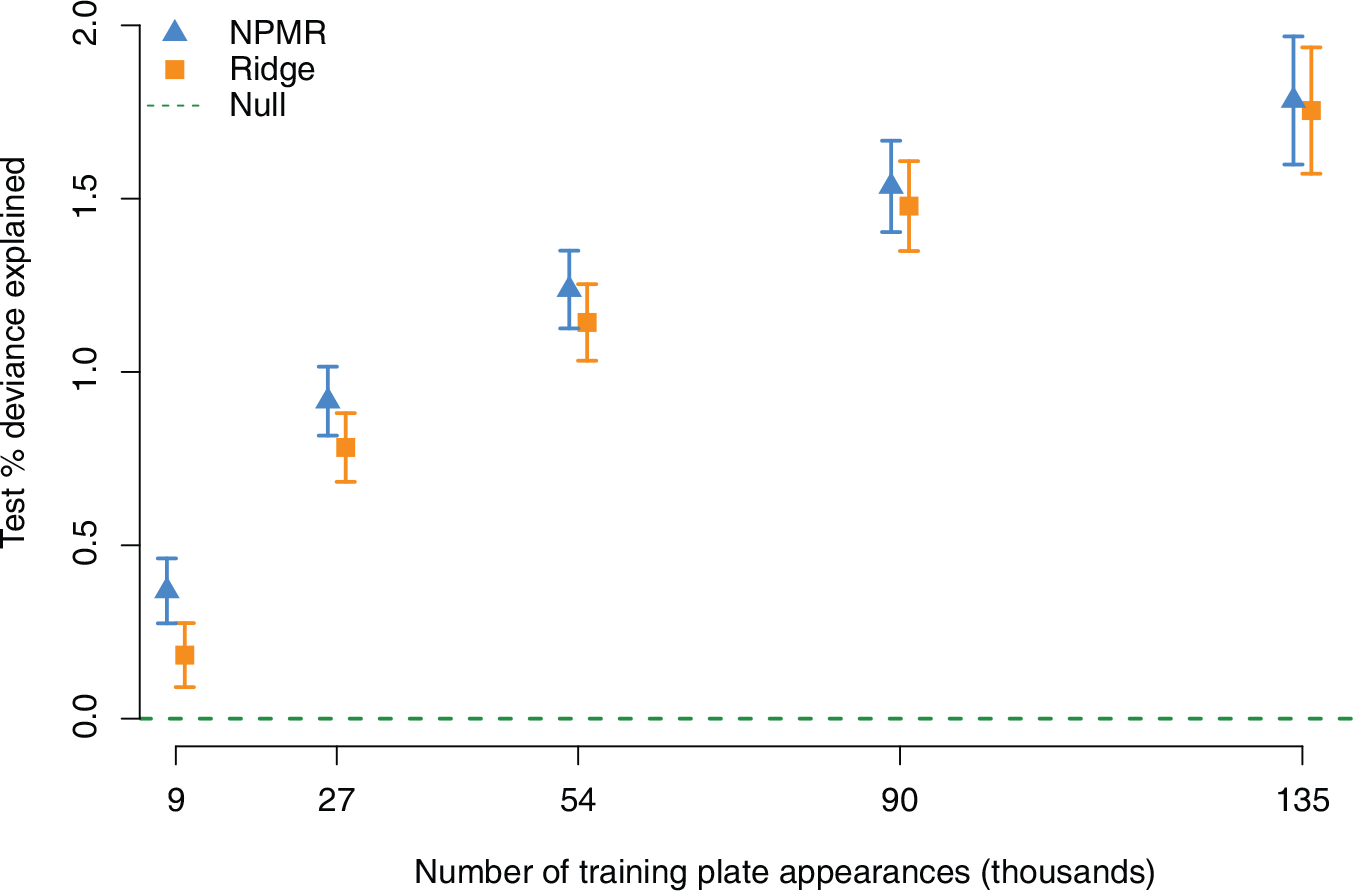
We fit NPMR and ridge regression to the baseball data, using a training sample that varied from 5% (roughly 9 000 PAs) to 75% (roughly 135 000 PAs) of the data. We used the remaining data to test the models, reporting the percentage of deviance explained in the test set, as described in Section 4. Figure 4 gives the results.
Out-of-sample test performance of NPMR, ridge and null estimators on baseball plate appearance result prediction. Each estimator was trained on a fraction of the 2015 regular season data (varying from 5% to 75%) and tested on the remaining data. The error bars correspond to one standard error. The standard error of the mean test deviance is its standard deviation across test samples, divided by the square root of the number of test samples
Out-of-sample test performance of NPMR, ridge and null estimators on baseball plate appearance result prediction. Each estimator was trained on a fraction of the 2015 regular season data (varying from 5% to 75%) and tested on the remaining data. The error bars correspond to one standard error. The standard error of the mean test deviance is its standard deviation across test samples, divided by the square root of the number of test samples
For each training sample size, NPMR outperforms ridge regression though the difference is not statistically significant. Note that the standard errors reflect random variation in the test set, for a single training set. At the smallest sample size, NPMR, unlike ridge regression, explains significantly more test deviance than does the null estimator. There is value in improved estimation of players’ skills in small sample sizes because this can inform early-season decision-making. For all other sample sizes, both NPMR and ridge regression achieves performances which are statistically significantly better than the null. The primary benefit of NPMR relative to ridge regression is the interpretation, as described in the next section.
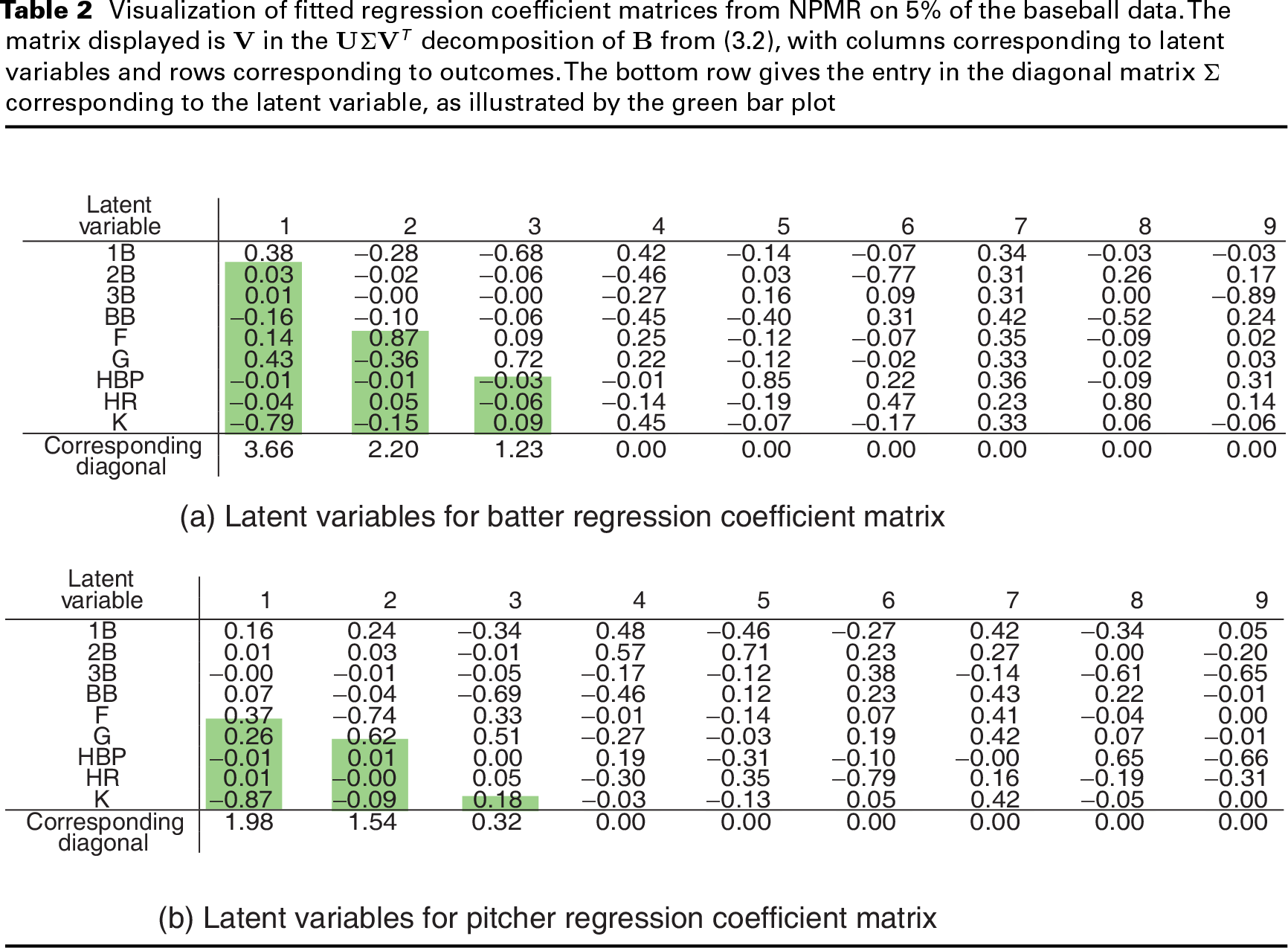
We focus on the results of fitting NPMR on 5% of the training data because there the difference between NPMR and ridge regression is the greatest (Figure 4). As the sample size increases, the need for a low-rank regression coefficient matrix is reduced, and the NPMR solution becomes more similar to the ridge solution. Table 2 visualizes the singular value decomposition of the fitted-regression coefficient submatrices corresponding to batters and pitchers. Unlike in Table 1, the diagonal entries shown in the bottom row are shrunk towards zero and cannot be interpreted in the context of percent variance explained. Note that for both batters and pitchers, six of the nine diagonal entries are exactly zero, illustrating the ability of NPMR to perform selection on the latent skills.
We observe that for both batters and pitchers, NPMR identifies three latent variables which differentiate players from one another. By construction, these latent variables are measuring separate aspects of players’ skills; across players, expression in each latent skill is uncorrelated with expression in each other latent skill. In that sense, we have identified three separate skills which characterize hitters and three separate skills which characterize pitchers. In baseball scouting parlance, these skills are called ‘tools’, but unlike the five traditional baseball tools (hitting for power, hitting for contact, running, fielding and throwing), the tools we identify are uncorrelated with one another.
Visualization of fitted regression coefficient matrices from NPMR on 5% of the baseball data. The matrix displayed is
in the
decomposition of B from (3.2), with columns corresponding to latent variables and rows corresponding to outcomes. The bottom row gives the entry in the diagonal matrix
corresponding to the latent variable, as illustrated by the green bar plot
Visualization of fitted regression coefficient matrices from NPMR on 5% of the baseball data. The matrix displayed is
in the
decomposition of B from (3.2), with columns corresponding to latent variables and rows corresponding to outcomes. The bottom row gives the entry in the diagonal matrix
corresponding to the latent variable, as illustrated by the green bar plot
The interpretation of Table 2 is very attractive in the context of domain knowledge. In reading the columns of Skill 1: Patience. The loadings of the first latent variable discriminate perfectly between the TTO outcomes and the BIP outcomes described in Section 1. We label this skill as ‘patience’ because when a batter swings at fewer pitches, he is less likely to hit the ball in play. Skill 2: Trajectory. The second latent variable distinguishes primarily between F and G, corresponding to the vertical angle of the ball off the bat. Skill 3: Speed. The third latent variable distinguishes primarily between 1B and G. Examining the players with strong positive expression of this skill, we find fast players who are more difficult to throw out at first base on a ground ball.
From this interpretation, we learn that the primary skill which distinguishes betwen batters is how often they hit the ball into the field of play. One outcome over which batters have relatively large control is how often they swing at pitches. Among balls that are put into play, batters have less but still subtantial control over whether those are ground balls or fly balls. It is the vertical angle of the batter's swing plane, along with whether he tends to contact the top half or the bottom half of the ball, that determines his trajectory tendency. Finally, given the trajectory of the ball off the bat, the batter has relatively little control over the outcome of the PA. But to the extent that he can influence this outcome, fast runners tend to hit more singles and fewer groundouts.
Based on Table 2, we interpret the pitchers’ skills as follows:
Skill 1: Power. The first latent variable distinguishes primarily between K and F (and G), thus identifying how the pitcher gets outs. Pitchers who tend to get their outs via the strikeout are known in baseball as ‘power pitchers’. Skill 2: Trajectory. As with batters, the second latent variable distinguishes primarily between F and G, corresponding to the batted ball's angle. Skill 3: Command. The third latent variable distinguishes primarily between positive outcomes for the pitcher (F, G and K) and negative outcomes for the pitcher (BB and 1B), reflecting how well he is able to control his pitches.
The interpretation of the first two skills for pitchers is very similar to the interpretation of the first two skills for batters. Primarily, pitchers can influence how often balls are hit into play against them, but they exhibit less control over this than batters do. Secondarily, as with hitters, pitchers exhibit some control over the vertical launch angle of the ball off the bat. This is based on the location and movement of their pitches. The third skill, distinguishing between positive and negative outcomes, has a relatively small magnitude.
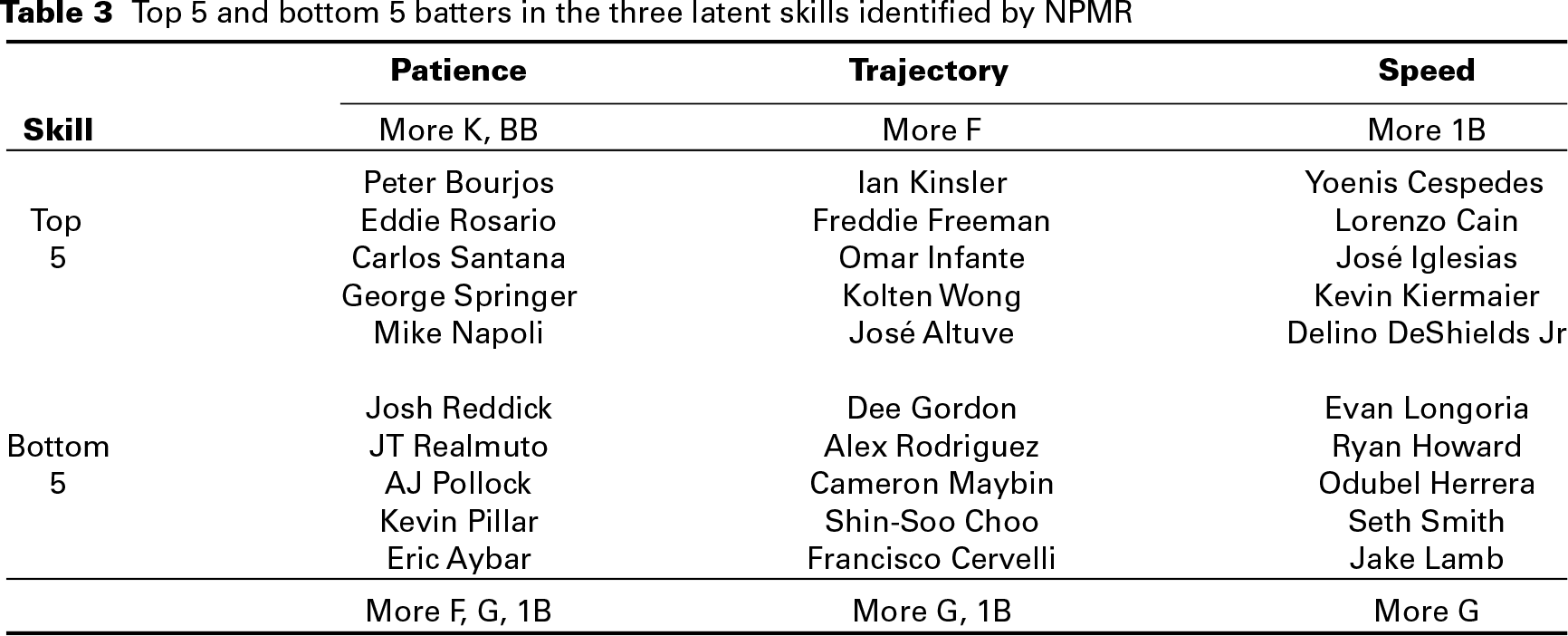
Table 3 lists the top five and bottom five players in each of the three latent batting skills learned by NPMR. These results largely match intuition for the players listed, and to the extent that they do not, it is worth a reminder that they are based on 5% of the full season's data. That is roughly equivalent to nine days’ worth of data from the six-month season. The median number of PAs per batter in the training set is 21.
Top 5 and bottom 5 batters in the three latent skills identified by NPMR
Top 5 and bottom 5 pitchers in the three latent skills identified by NPMR
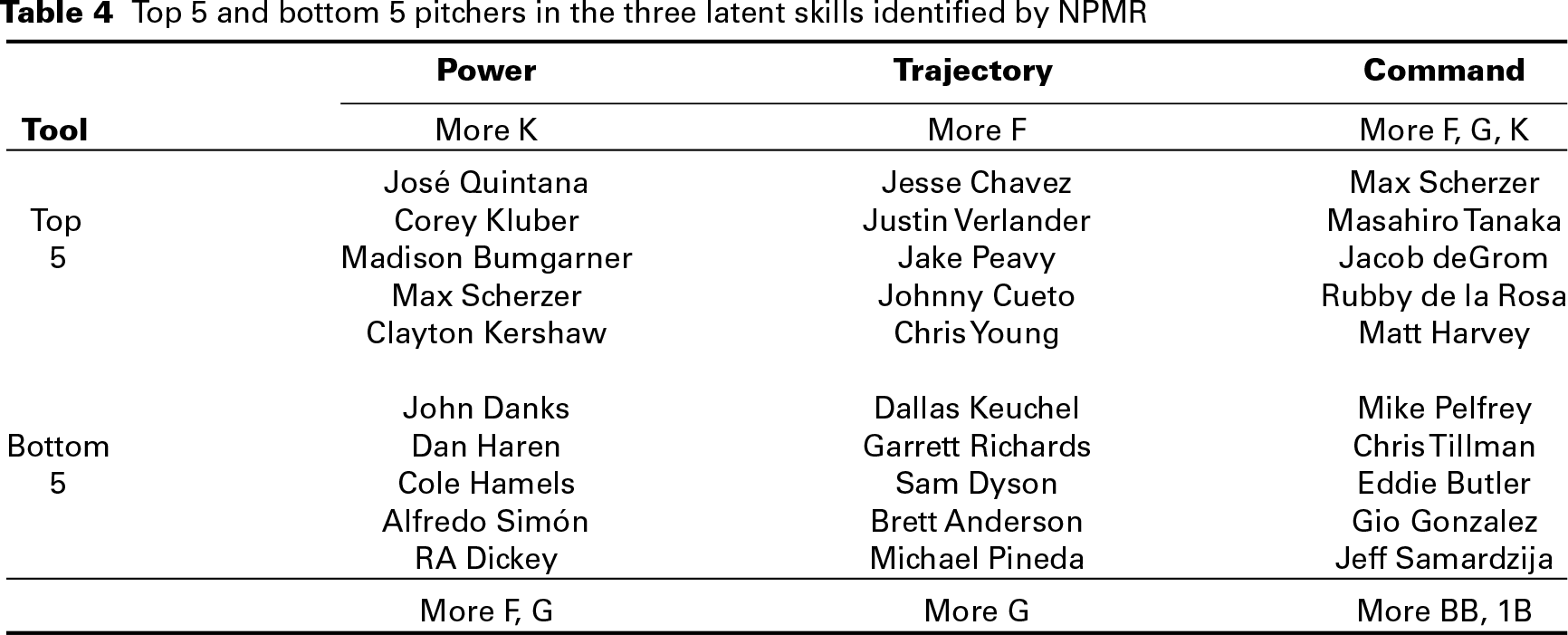
The results in Table 4, listing the top and bottom players in each of the three latent pitching skills, are more interesting. The top five power pitchers are all among the top starting pitchers in the game. All the way on the other side of the spectrum is knuckleball pitcher RA Dickey. The knuckleball is a unique pitch in baseball thrown relatively softly with as little spin as possible to create unpredictable movement. Its goal is not to overpower the opposing batter but to induce weak contact. Another interesting pitcher low on power is Cole Hamels. Two of the leading sabermetric websites, Baseball Prospectus and FanGraphs, disagree greatly on Hamels’ value. The discrepancy stems from Baseball Prospectus giving full weight to BIP outcomes, while FanGraphs ignores them. Because Hamels tends to get outs via fly balls and ground balls rather than strikeouts, FanGraphs estimates a much lower value for Hamels than Baseball Prospectus does.
In a dataset collected by Deterding (1990) and popularized in part by Robinson (1989), the author recorded samples of 11 vowels spoken by 15 unique speakers. Each audio clip is split into 6 frames during a duration of steady audio, yielding 6 pseudo-replicates. Hence, the dataset consists of
Vowels and corresponding words from Deterding (1990). Each word is provided to illustrate the vowel sound represented by the corresponding symbol

Vowels and corresponding words from Deterding (1990). Each word is provided to illustrate the vowel sound represented by the corresponding symbol
We fit NPMR and ridge regression to the training data over a wide range of regularization parameters, with the results reported in Figure 5. As the regularization parameter decreases for each method, the training performance improves. The test performance initially improves and then worsens as the model overfits to the training data. We observe that over the whole solution path, for the same training deviance, NPMR consistently explains more of the test deviance than ridge regression.
Results of fitting NPMR and ridge regression on vowel data. Test deviance explained is plotted against training deviance explained. Training performance serves as a surrogate for degrees of freedom in the model fit. The null prediction assigns equal probability to all categories. Error bars represent one standard error in estimation of the test deviance explained
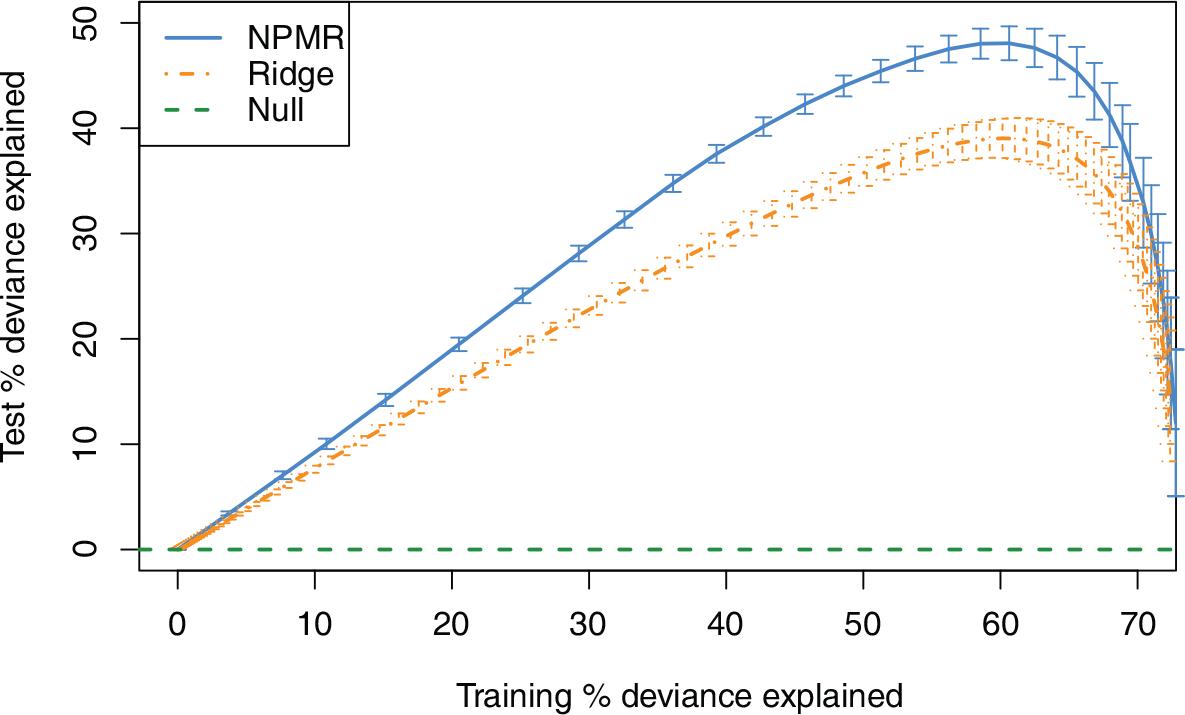
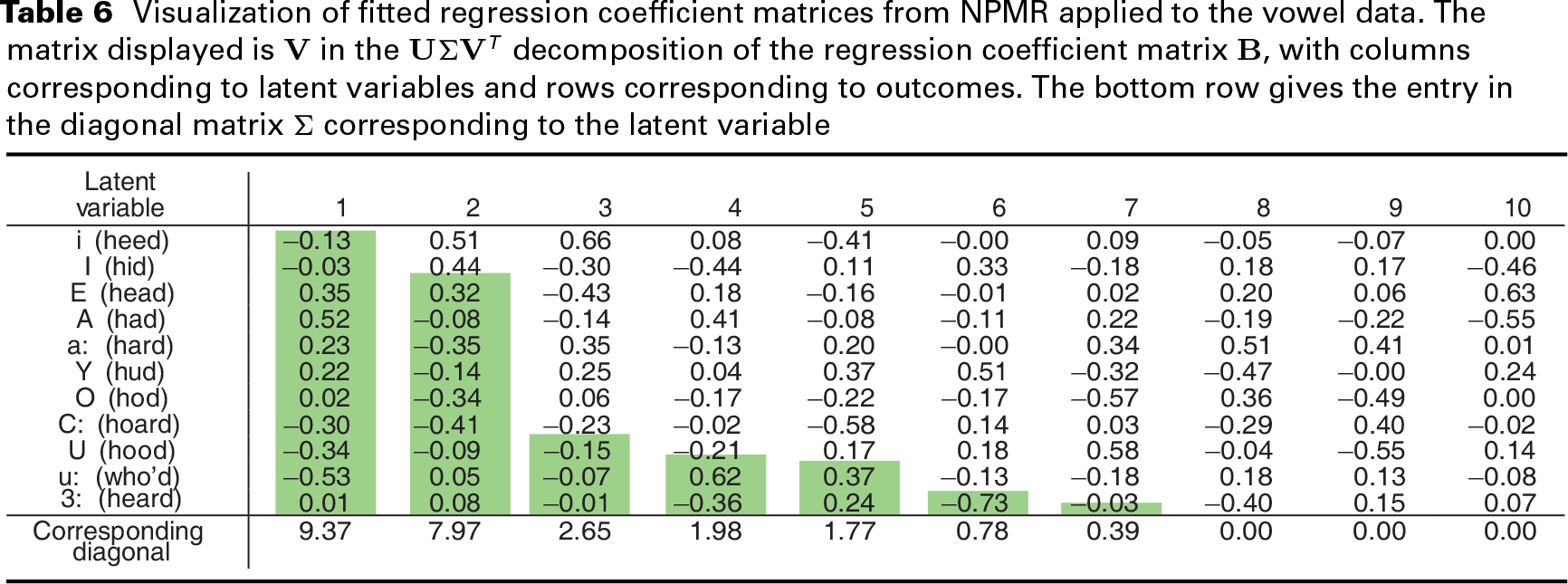
Table 6 reveals a possible explanation why NPMR outperforms ridge regression on the vowel data. For example, the results show that when the vowel i is a likely label, the vowel I is also a likely label. The first two latent variables explain a significant portion of the variance in the regression coefficients for the vowels. The first latent variable distinguishes between two groups of vowels, with C:, U and u: having the most negative values and E, A, a: and Y having the most positive values. NPMR beats ridge regression here by leveraging a hidden structure among response classes.
Visualization of fitted regression coefficient matrices from NPMR applied to the vowel data. The matrix displayed is V in the U ΣV
T
decomposition of the regression coefficient matrix B , with columns corresponding to latent variables and rows corresponding to outcomes. The bottom row gives the entry in the diagonal matrix Σ corresponding to the latent variable
The potential for reduced-rank multinomial regression to leverage the underlying structure among response categories has been recognized in the past. But the computational cost for the state-of-the-art algorithm for fitting such a model is so great as to make it infeasible to apply to a dataset as large as the baseball play-by-play data in the present work. Using a convex relaxation of the problem, by penalizing the nuclear norm of the coefficient matrix instead of its rank, leads to better results.
The interpretation of the results on the baseball data is promising in how it coalesces with modern baseball understanding. Specifically, the NPMR model has quantitative implications on leveraging the structure in PA outcomes to better jointly estimate outcome probabilities. Additional application to vowel recognition in speech shows improved out-of-sample predictive performance, relative to ridge regression. This matches the intuition that NPMR is well suited to multinomial regression in the presence of a generic structure among the response categories. We recommend the use of NPMR for any multinomial regression problem for which there is some non-ordinal structure among the outcome categories.
Acknowledgements
The authors would like to thank Hristo Paskov, Reza Takapoui and Lucas Janson for helpful discussions, as well as Balasubramanian Narasimhan for computational assistance.We are grateful to Andreas Groll and an anonymous reviewer for a careful review and comments that led to improvements to this work.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Appendix
Identifiability of multinomial logistic regression model
We observe in Section 2 that the model (2.1) is not identifiable: For any 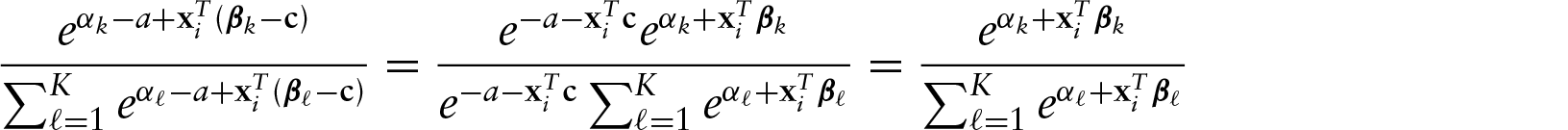

Similarly, the NPMR solution must satisfy

Note that 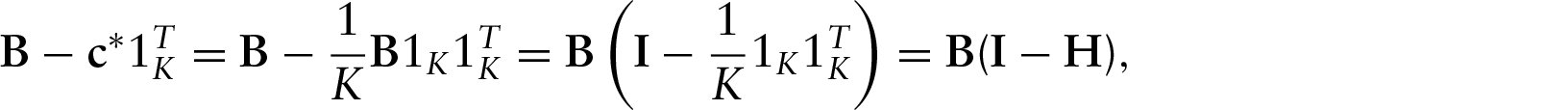
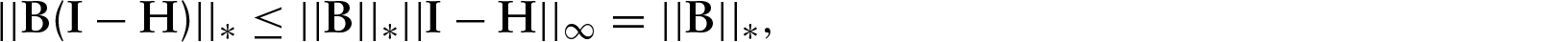

The problem with a lack of identifiability in the multimonial regression model comes in the interpretation of the regression coefficients. When comparing coefficients across variables for the same outcome class, it is concerning that an arbitrary increase in either coefficient can correspond to the same fitted probabilities (if that same increase applies to all other coefficients for the same variable). This does not apply to any of the interpretation in Section 5.3, but in the absence of certainty that there is a unique solution to (A.2), we take the NPMR solution to be the one for which the mean of
Proof of Lipschitz condition for multinomial log likelihood
We prove that the multinomial log-likelihood 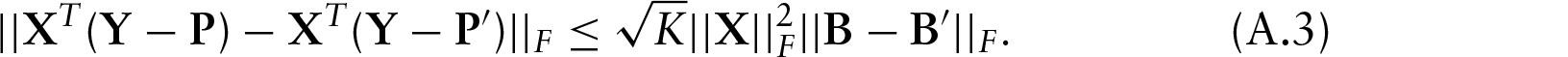
Consider a single entry 
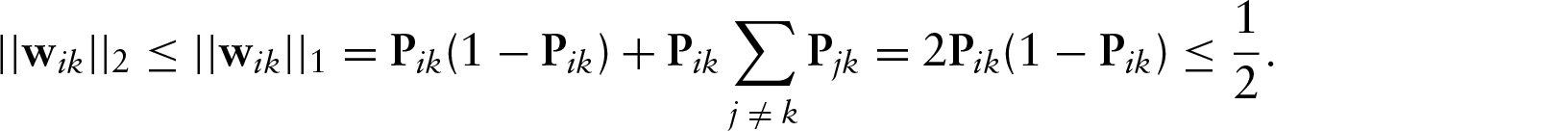

Now we are ready to prove (A.3).