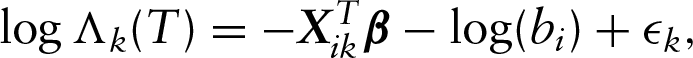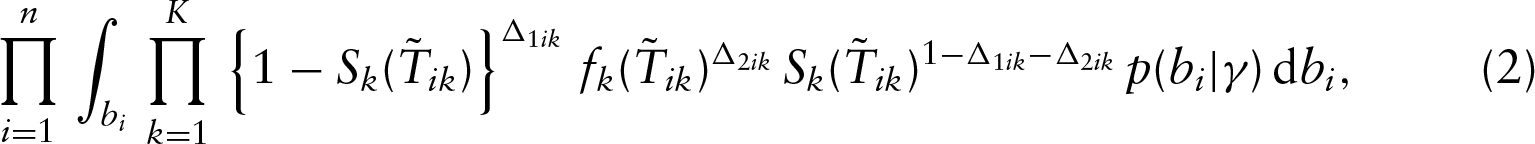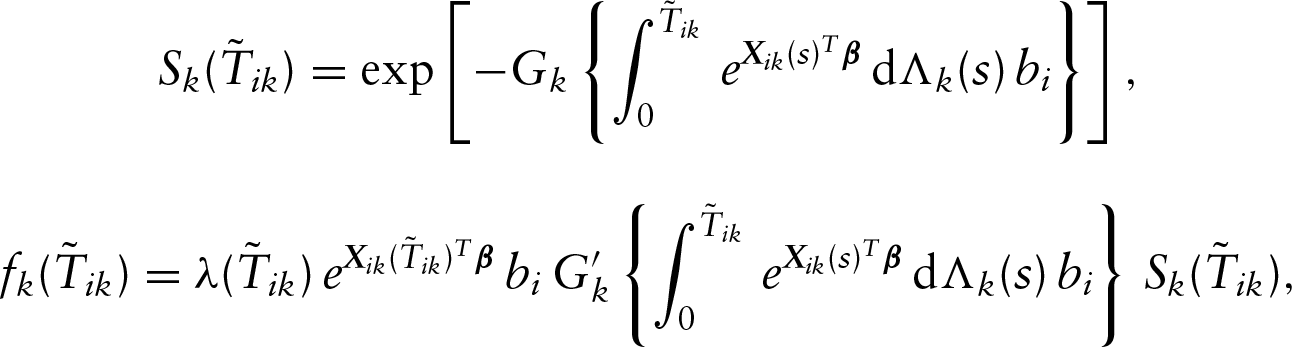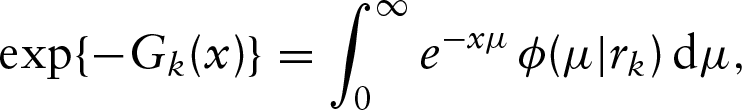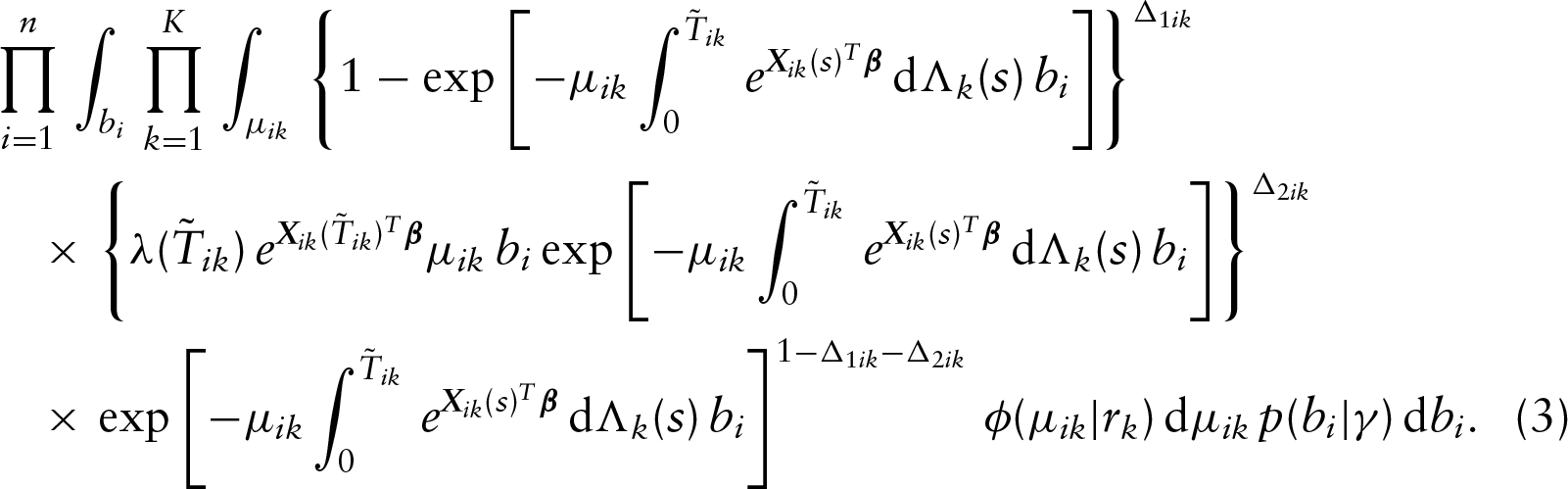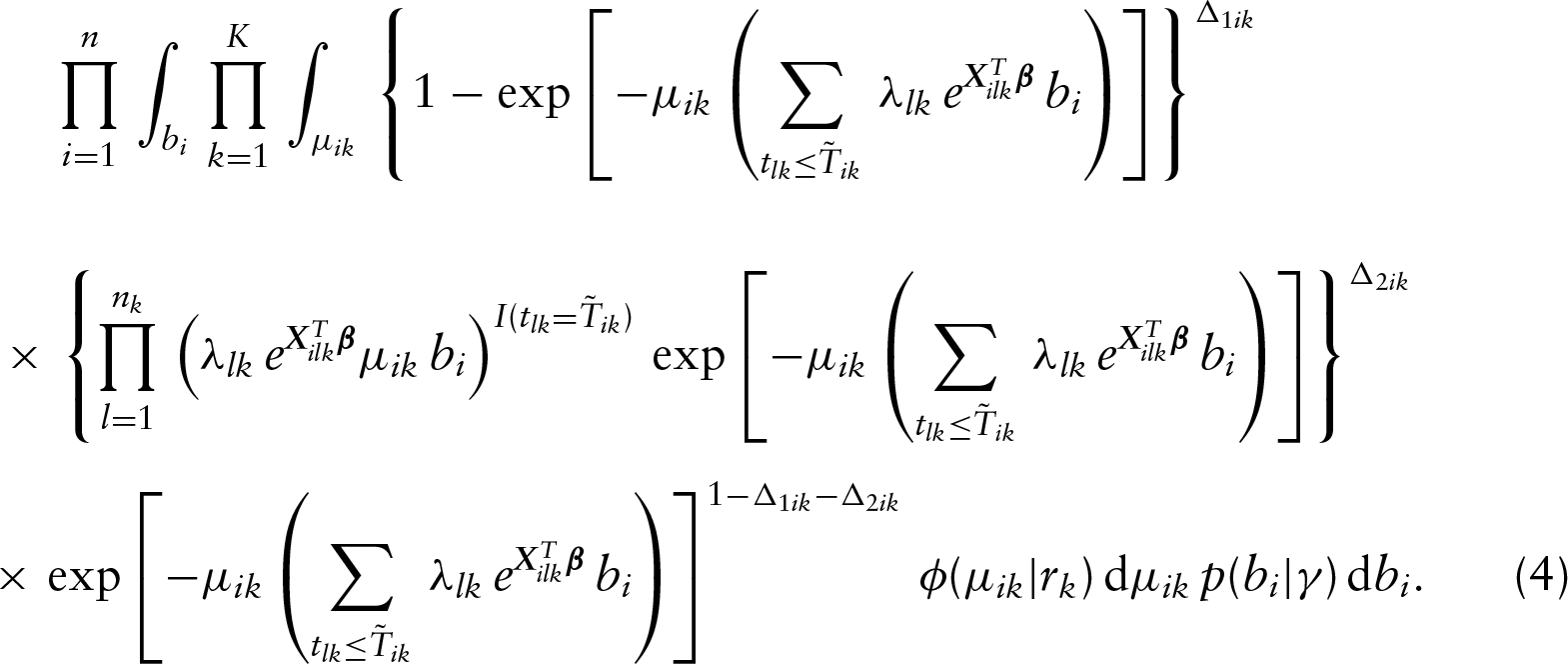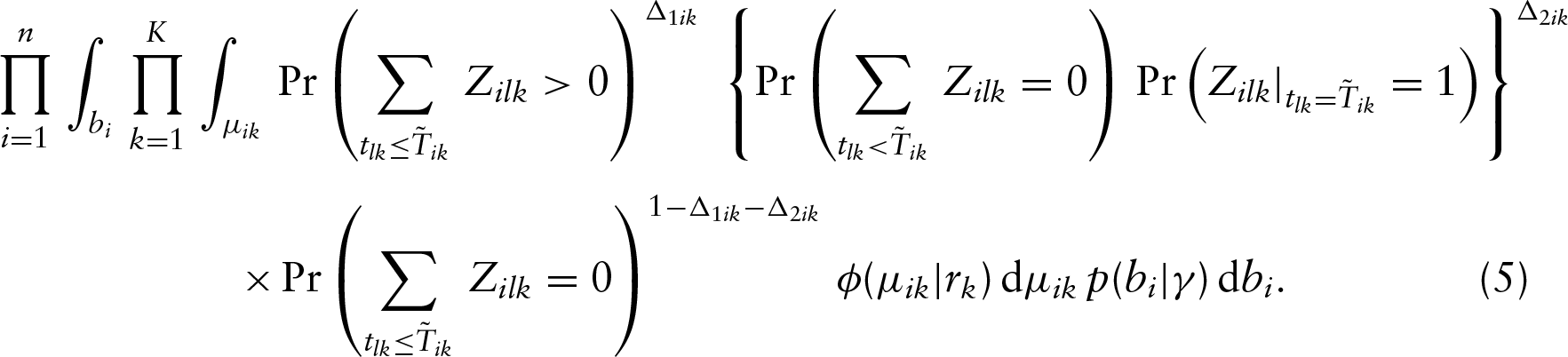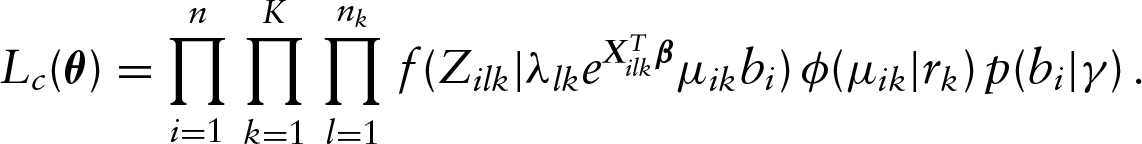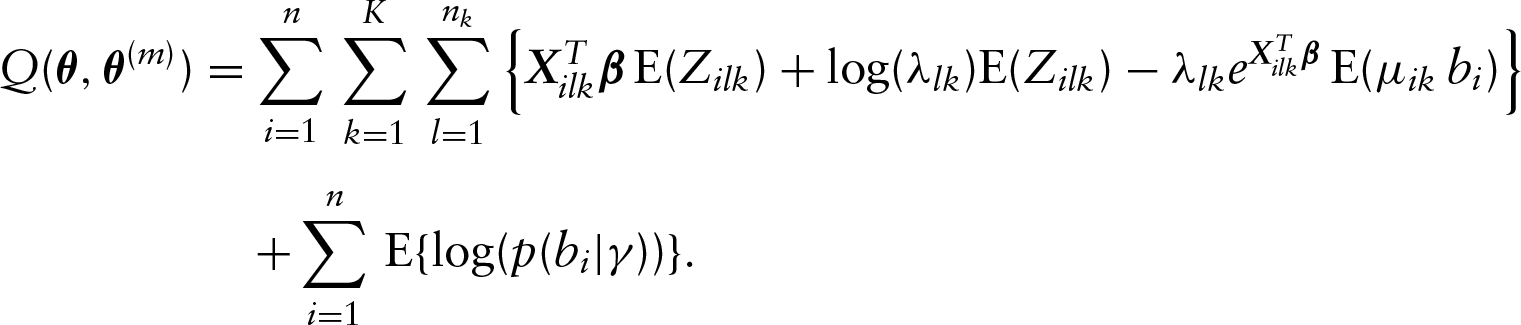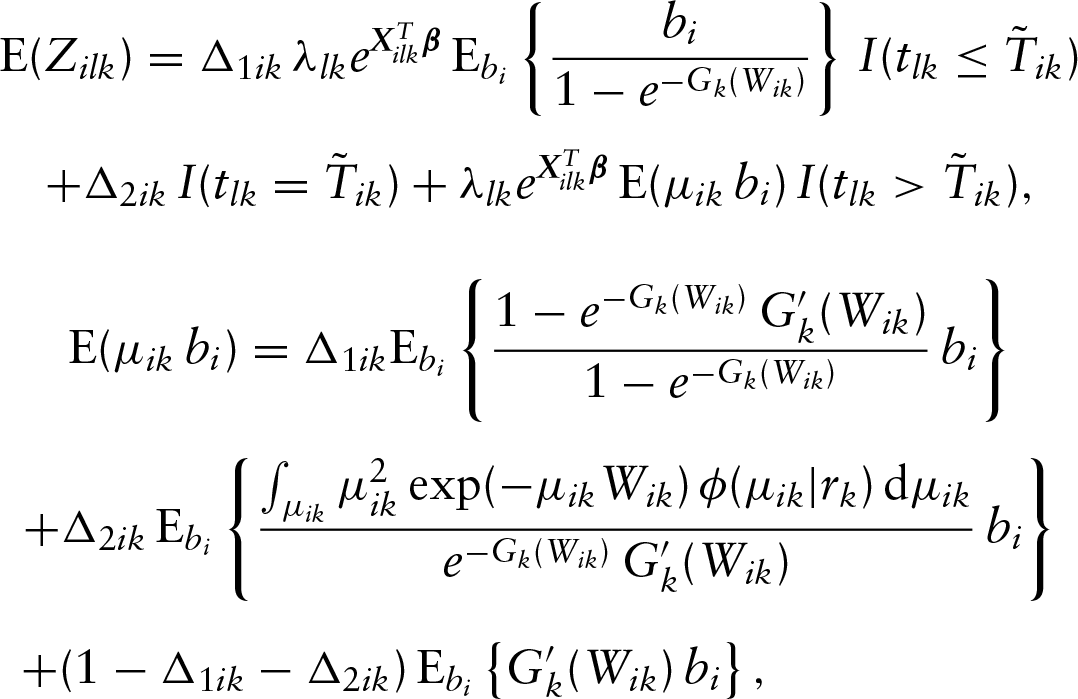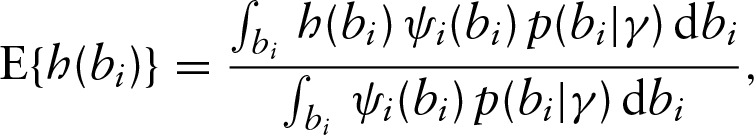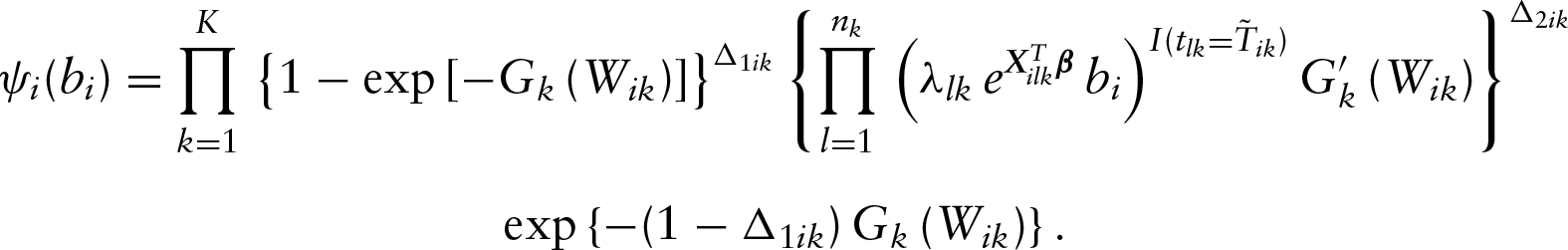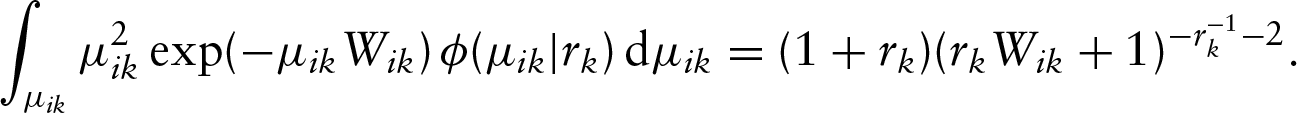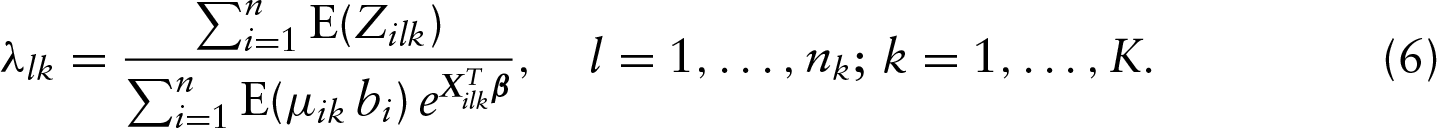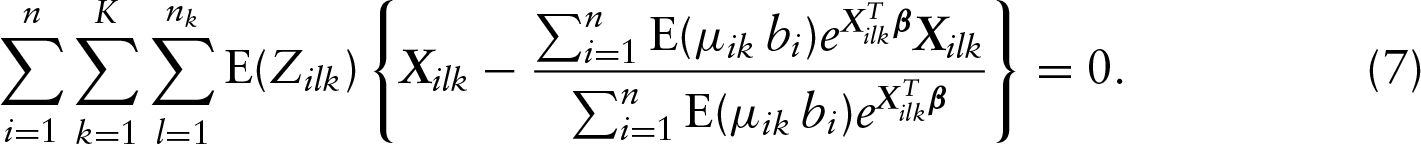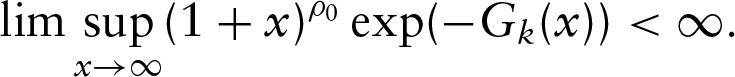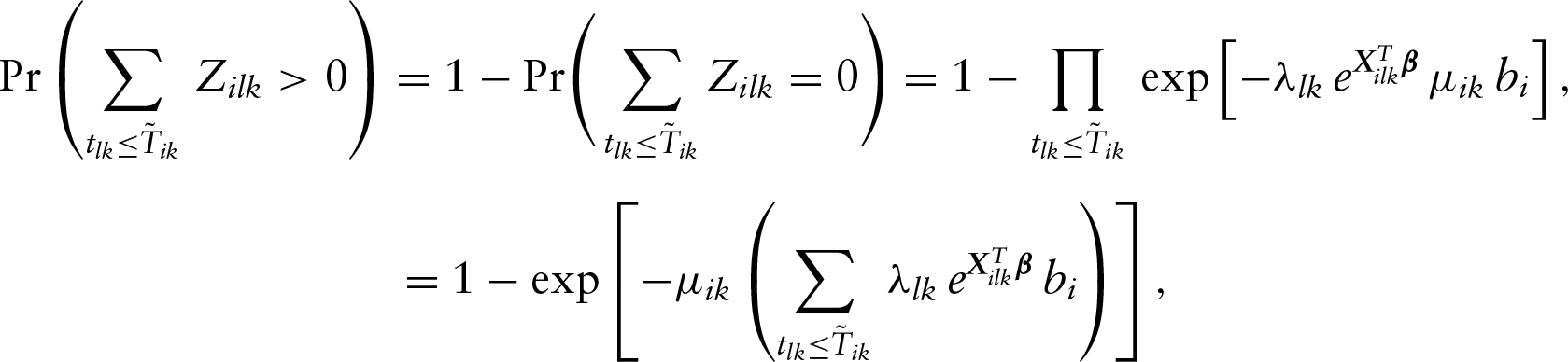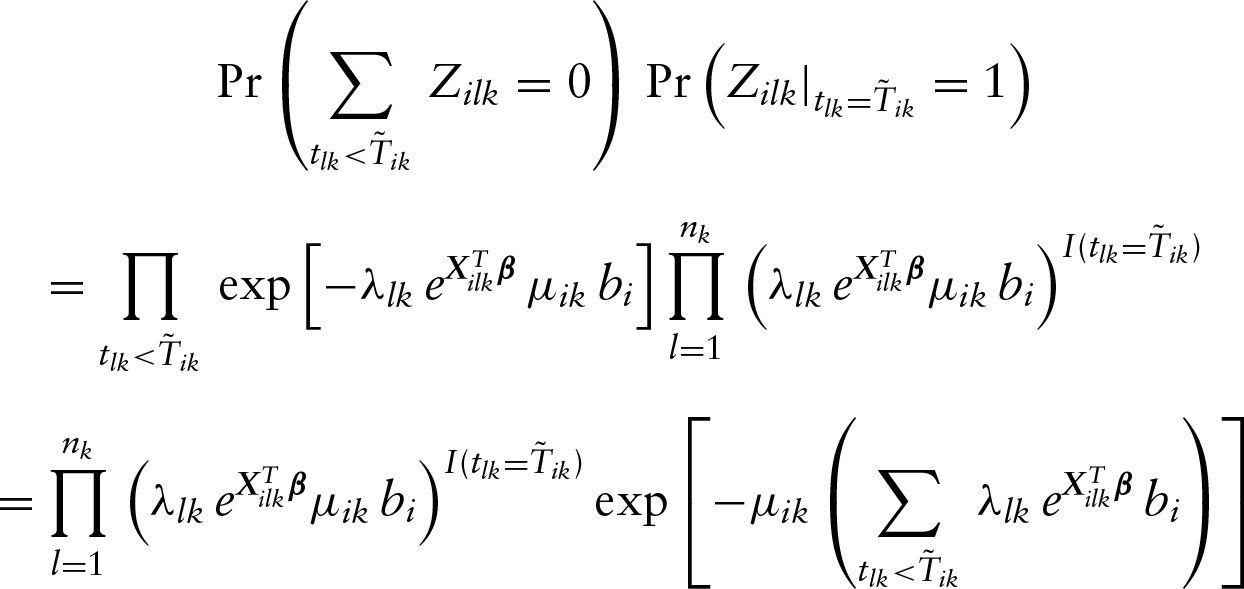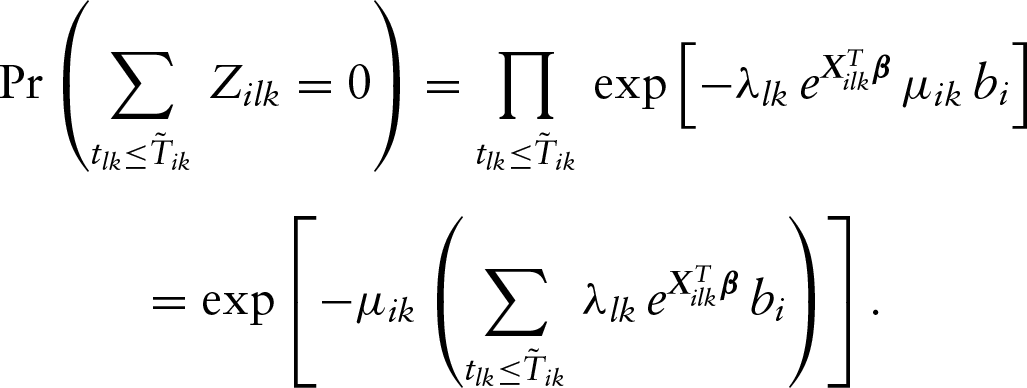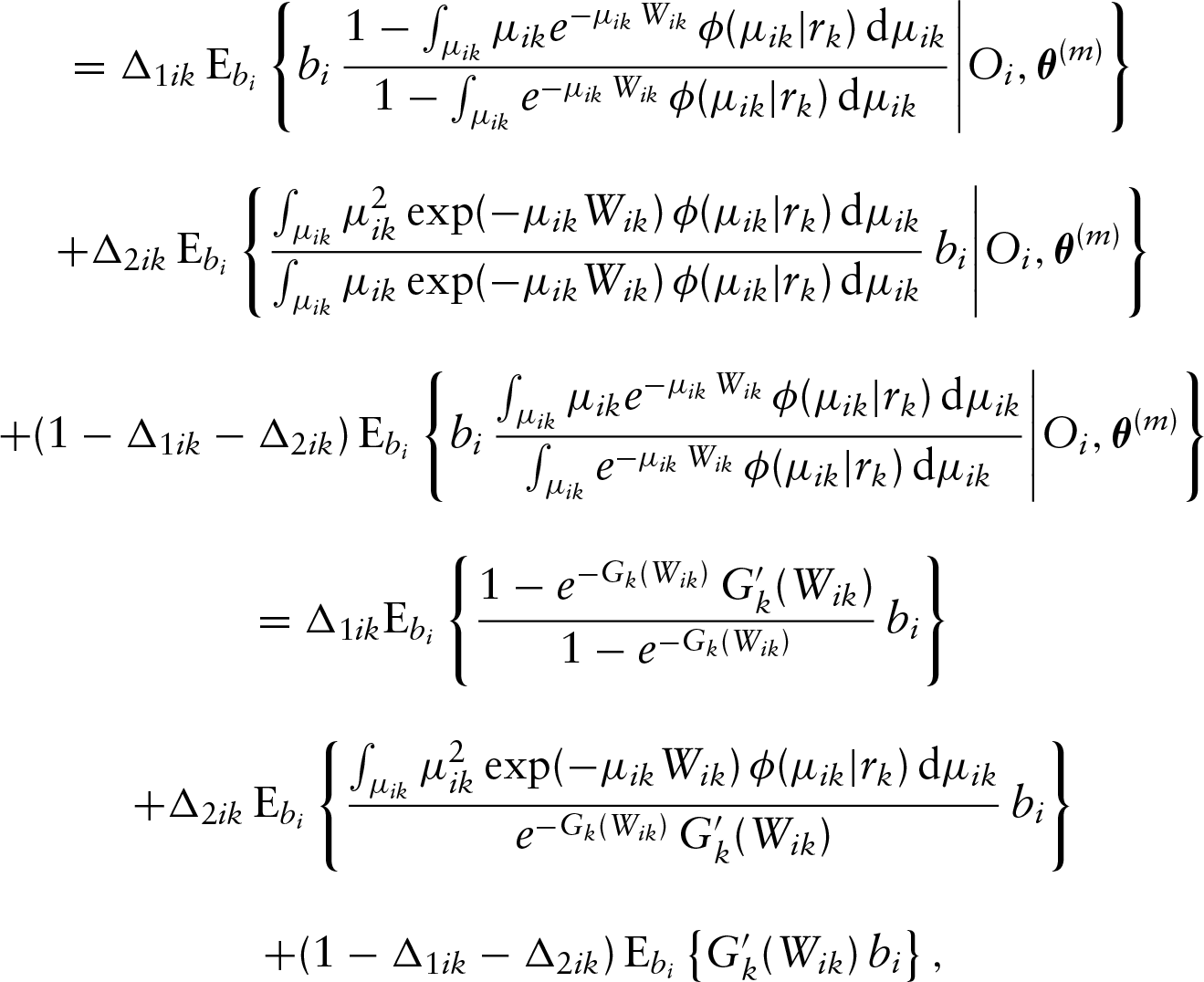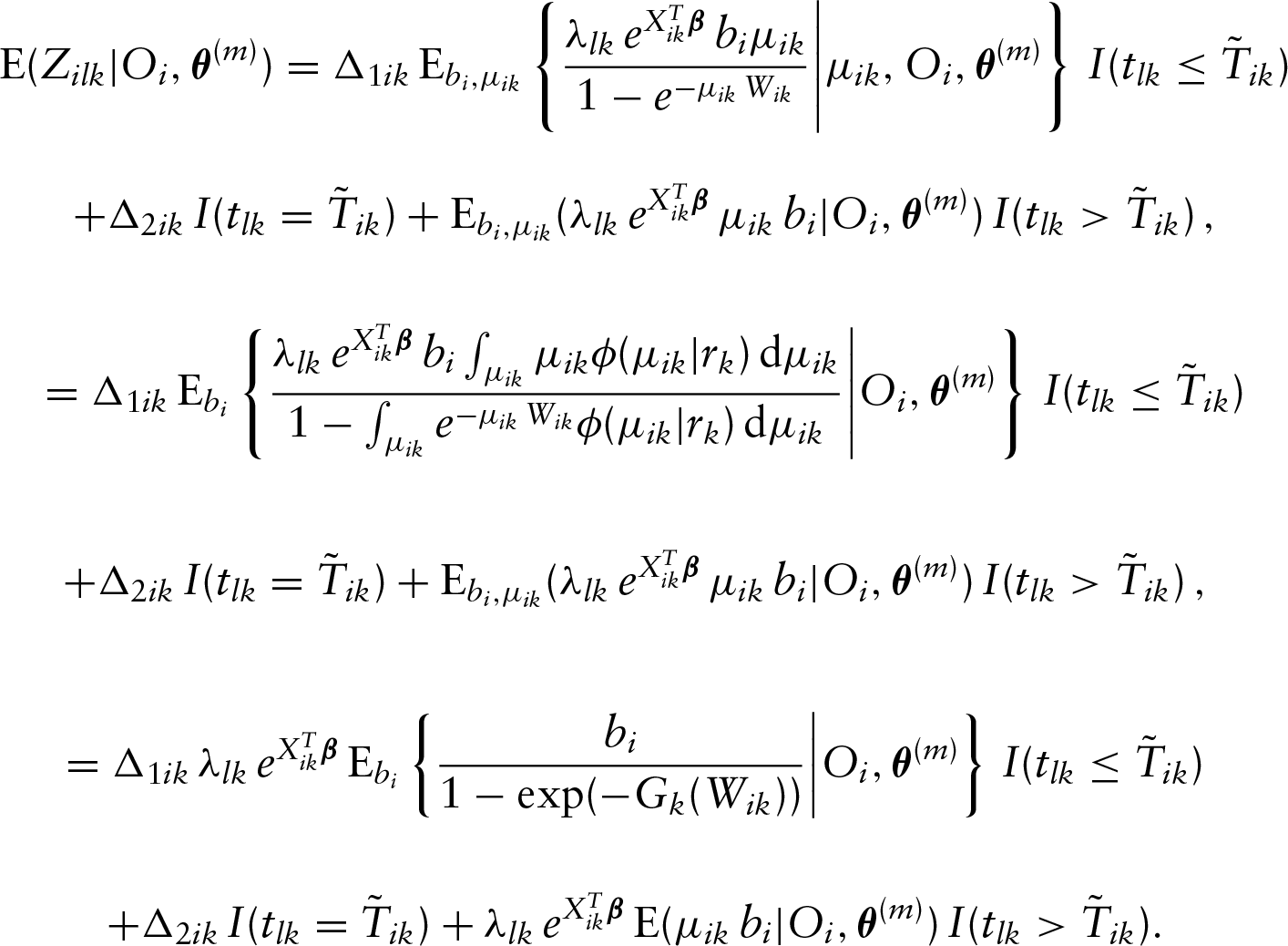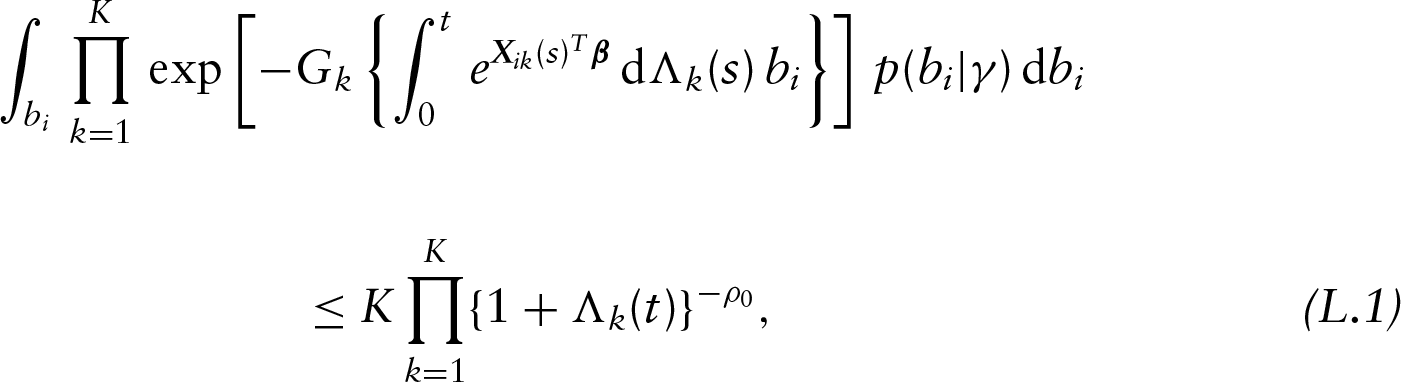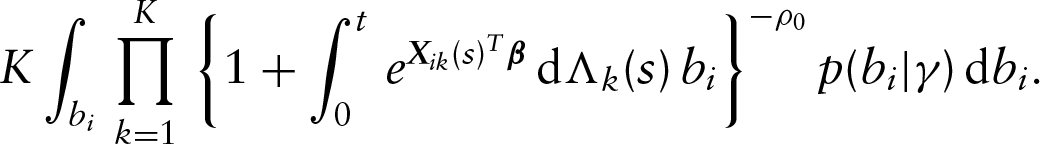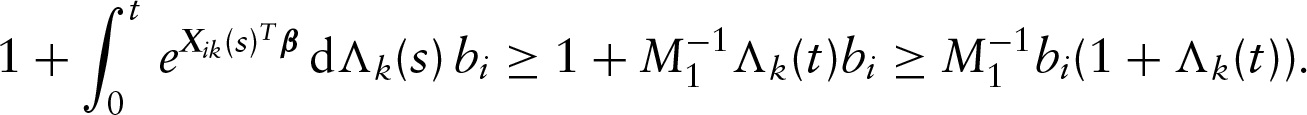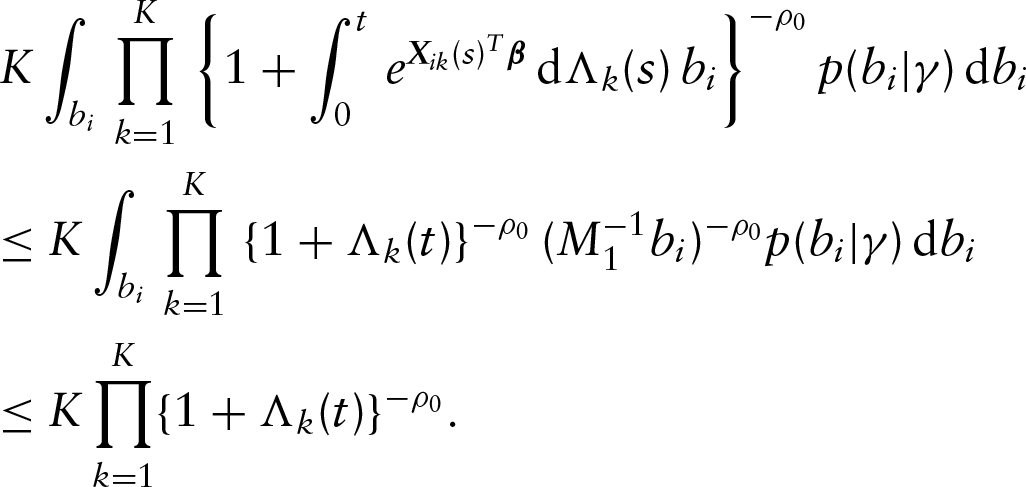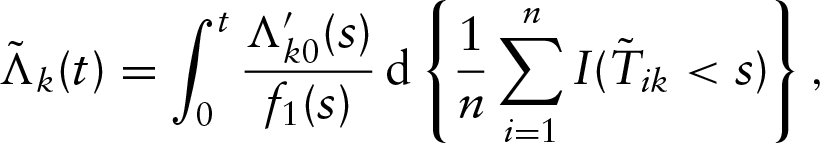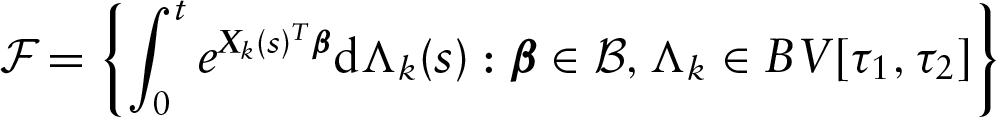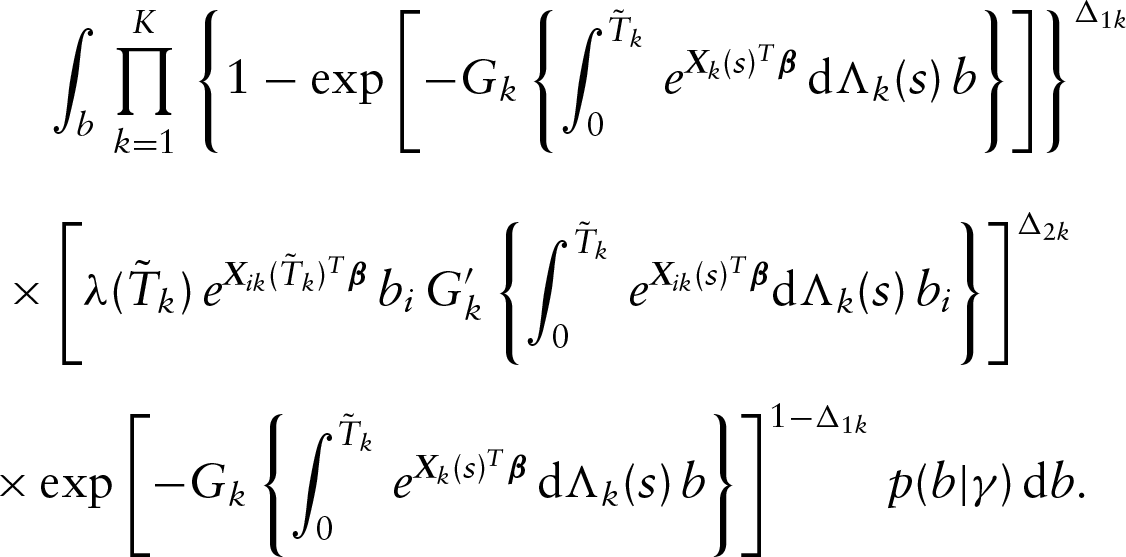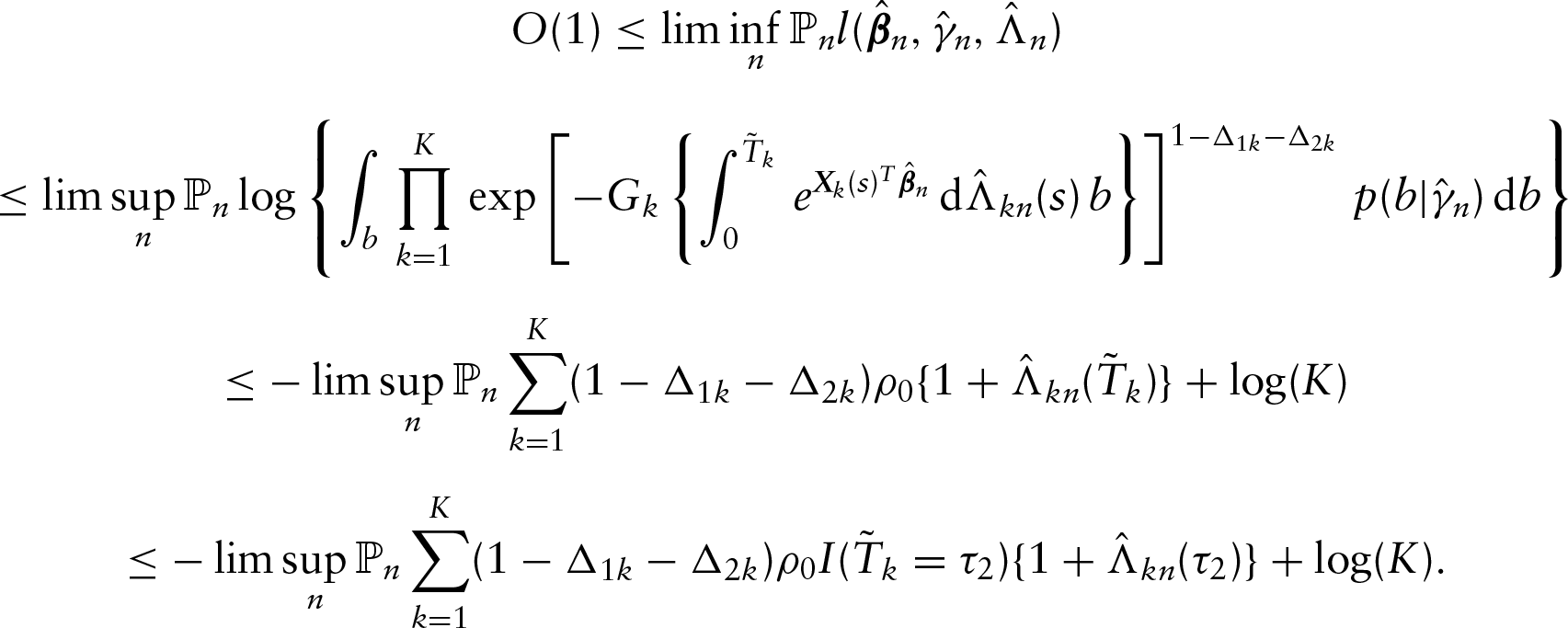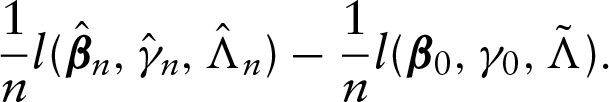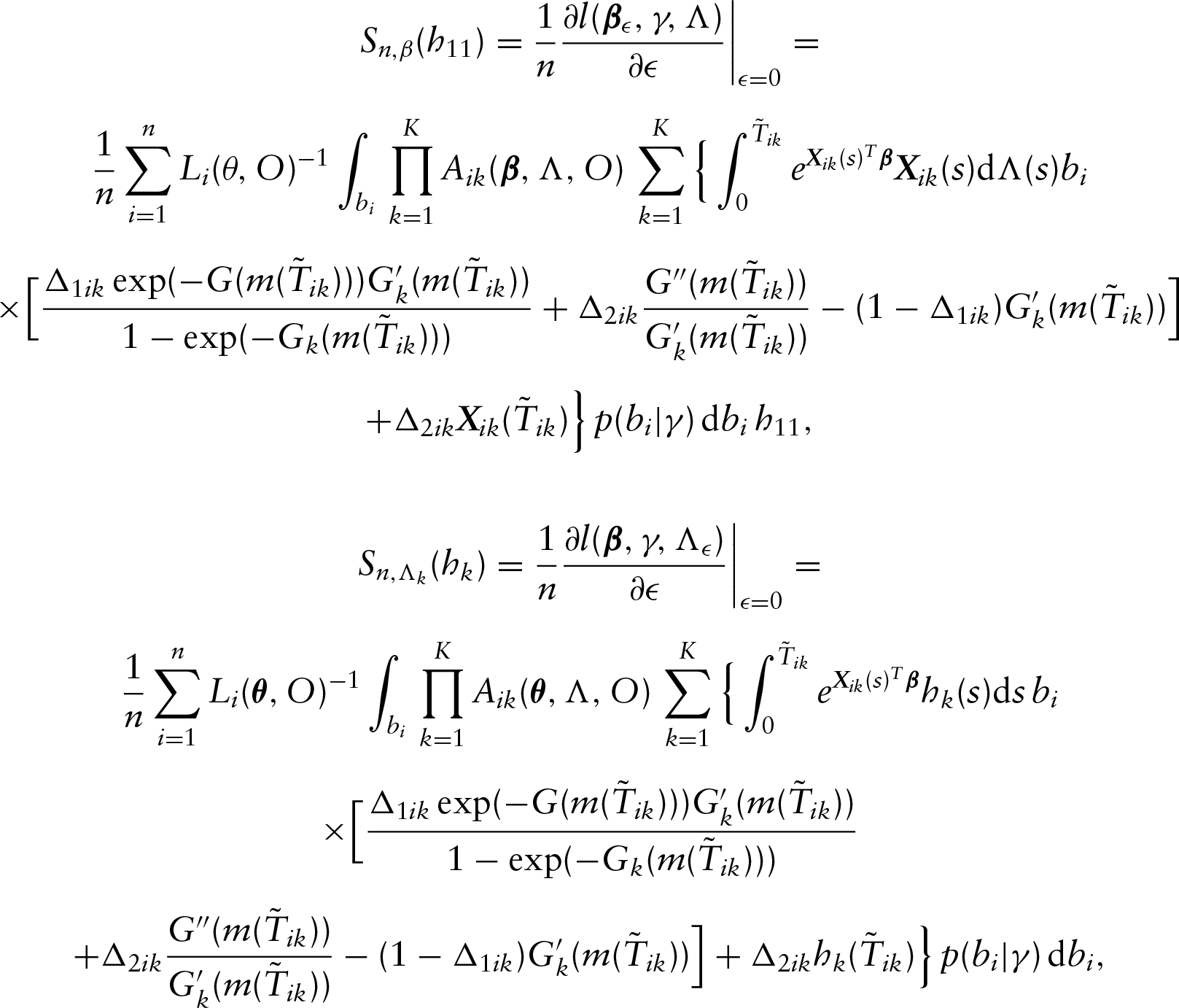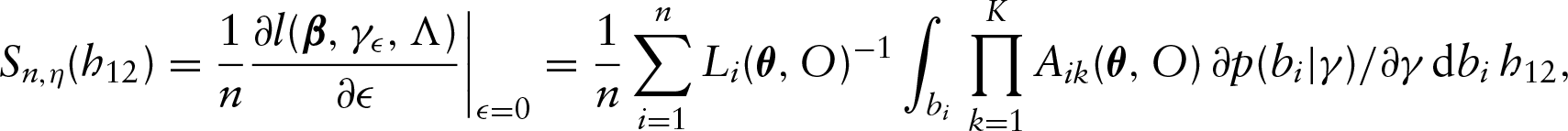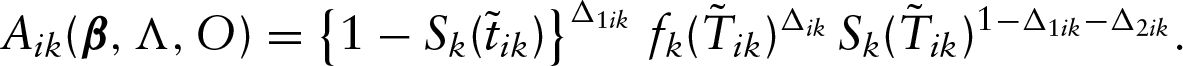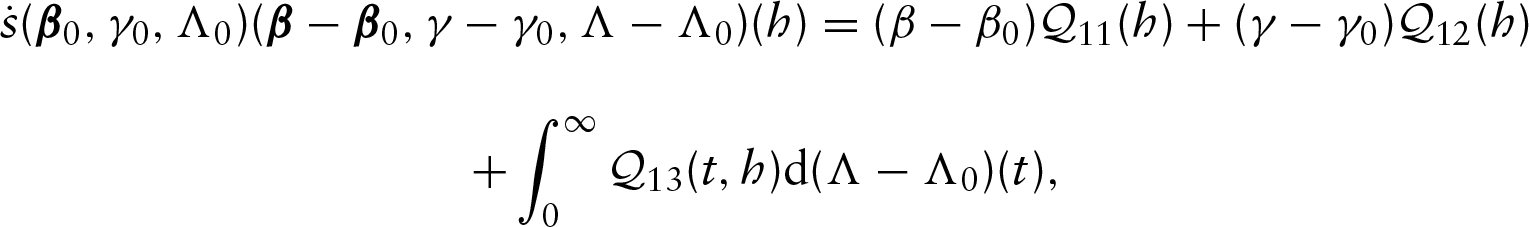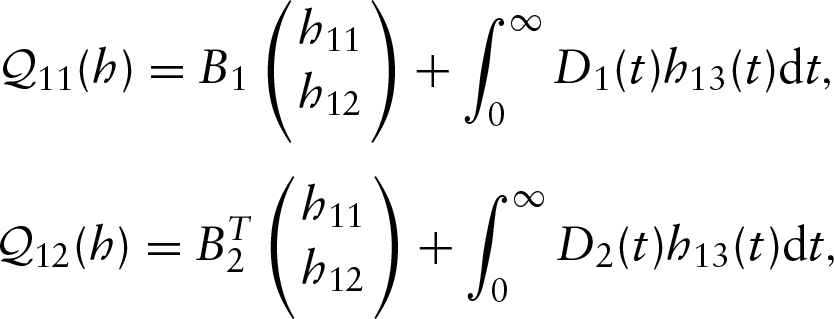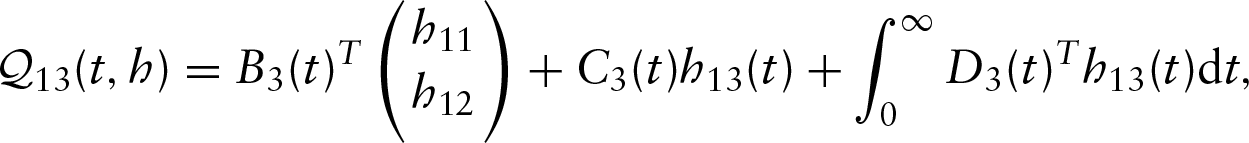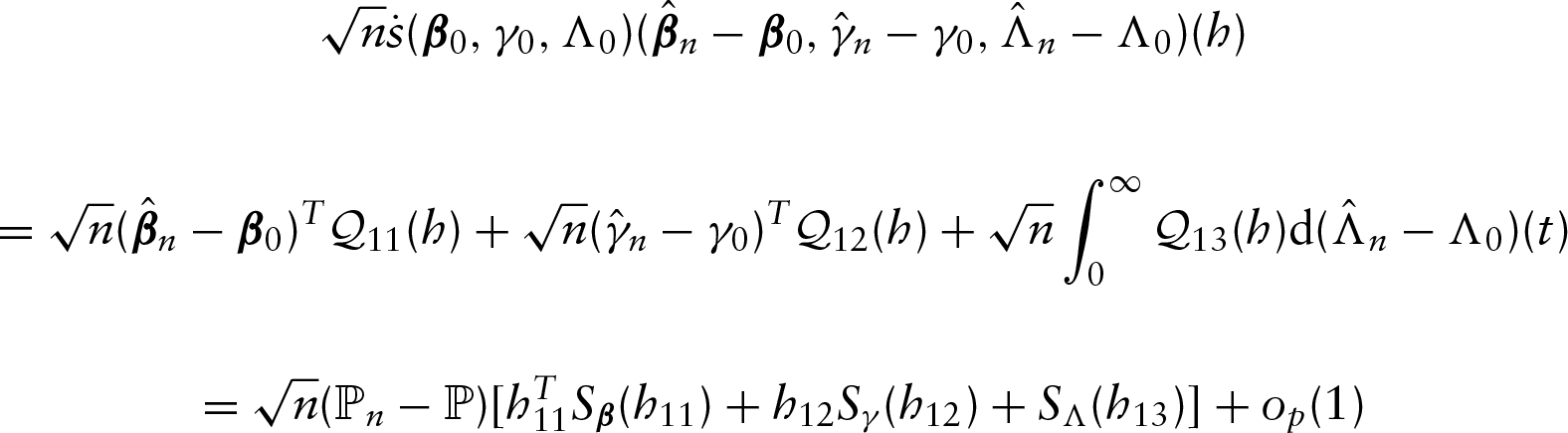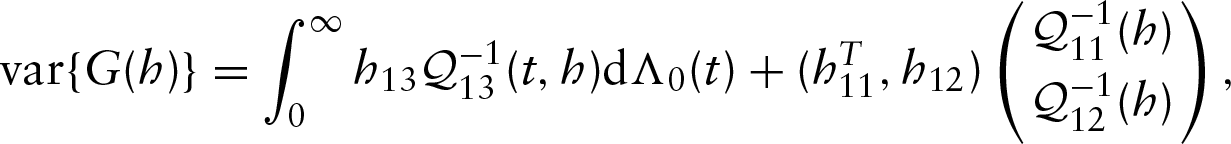This article discusses regression analysis of multivariate doubly censored data with a wide class of flexible semiparametric transformation frailty models. The proposed models include many commonly used regression models as special cases such as the proportional hazards and proportional odds frailty models. For inference, we propose a nonparametric maximum likelihood estimation method and develop a new expectation–maximization algorithm for its implementation. The proposed estimators of the finite-dimensional parameters are shown to be consistent, asymptotically normal and semiparametrically efficient. We also conduct a simulation study to assess the finite sample performance of the developed estimation method, and the proposed methodology is applied to a set of real data arising from an AIDS study.
Doubly censored data arise frequently in many scientific areas including clinical trials, demographical investigations, epidemiology studies and tumorigenicity experiments (Gehan (1965); Chang and Yang (1987); Chang (1990); Mykland and Ren (1996); Zhang and Jamshidian 2004). For such data, the outcome variable of interest can only be observed accurately within a certain interval, and outside this interval, the outcome variable is either left censored or right censored rather than observed exactly. An example of such data is given by an AIDS clinical trial involving the measurement of the plasma HIV-1 RNA level, which is usually done by the use of the NucliSens assay that is highly unreliable if the RNA level is below 400 or above 750 000 per millilitre of plasma. In other words, one can obtain the exact plasma HIV-1 RNA level if it is between 400 and 750 000, and otherwise, the plasma HIV-1 RNA level is either left censored by 400 or right censored by 750 000. That is, we only have doubly censored data on RNA level or value. If the outcome variable is a failure time such as the chronic Hepatitis B virus (HBV) infection time, then the left censoring occurs when a subject has already been infected with the HBV before the entry of the study and the right censoring occurs when the subject has not yet experienced the HBV infection by the end of the study. Multivariate doubly censored data mean that there exist several correlated outcomes of interest and only doubly censored data are available for each outcome variables.
It is worth noting that in the literature, the terminology doubly censored data may sometimes be used to denote another type of censored data in which the outcome variable of interest is defined as the elapsed or gap time from an initial event to a subsequent event, and the occurrences of both events may suffer interval censoring (Sun (1995); Sun (2006); Komárek and Lesaffre 2006). A typical example of such data occurs in an AIDS cohort study in which the interest lies in investigating the effect of covariates on the AIDS incubation time defined as the elapsed time from the infection of human immunodeficiency virus (initial event) to the onset of AIDS (subsequent event). Note that the data structures of such data and the data discussed above are quite different and they also require different statistical techniques for their analyses. In the following, we will focus on the first type of doubly censored data.
Many methods have been proposed for the analysis of univariate doubly censored data, especially for their regression analysis (Zhang and Li (1996); Cai and Cheng (2004); Kim et al. (2010); Kim et al. (2013); Li et al. 2018). For example, Cai and Cheng (2004), Kim et al. (2013) and (Li et al. 2018) studied the fitting of the linear transformation model, the proportional hazards model and a class of semiparametric transformation models to such data, respectively. In general, regression analysis of doubly censored data is much more challenging than that of right-censored data due to the presence of left-censorship. Under this situation, the classical partial likelihood approach for the proportional hazards model with right-censored data is no longer applicable and one has to deal with or estimate both infinite-dimensional nuisance parameter and finite-dimensional regression parameters together.
For the analysis of multivariate censored data, one of the main challenges is how to deal with the correlation of different outcome variables. For this, one of the most commonly used approaches is the marginal model-based approach, which relies on the working independence assumption and can give consistent estimates if the marginal models are correctly specified (Goggins and Finkelstein (2000); Wei et al. 2015). Another commonly used approach is the joint modelling approach which characterizes the relationship of the correlated outcome variables by using either the copula or the frailty model (Wang and Ding (2000); Sun et al. (2006); Wang et al. (2015); Wen and Chen (2015); Su and Wang (2016); Hu et al. 2017). The former models the joint cumulative distribution or survival function of the correlated outcome variables with some copula function, while the latter uses some latent variables or frailties to link the marginal hazard functions of different failure times together. With the latter approach, for estimation, the expectation–maximization (EM) algorithm is commonly employed by treating the latent variables as observable.
In the following, we will employ the latter approach and present a wide class of semiparametric transformation frailty models, which is quite flexible and includes many commonly used models such as proportional hazards and proportional odds frailty models as special cases. For inference, we consider the nonparametric maximum likelihood method and develop a novel EM algorithm with the use of some Poisson variables. In particular, in the E-step of the algorithm, we propose to jointly employ probability integral transformation and Gaussian–Hermite quadrature techniques to calculate the conditional expectations with respect to the frailties, which is reliable and can apply to the general situation as discussed below.
The rest of this article is organized as follows. In Section 2, we introduce the data structure and the models, and present the corresponding likelihood function. Section 3 discusses the proposed nonparametric maximum likelihood estimation procedure and the development of a novel EM algorithm. The asymptotic properties of the proposed estimators are established in Section 4. In Section 5, we conduct a simulation study to evaluate the finite sample performance of the proposed method. In Section 6, we illustrate the usefulness of the proposed method with an AIDS dataset, and Section 7 includes some discussion and concluding remarks.
Data, models and the likelihood function
Consider a study that involves independent subjects and each subject can experience different, correlated events. Let denote the outcome variable of the th event for the th subject, , . As mentioned above, such multivariate data occur commonly in many fields, and one example is given by the AIDS Clinical Trials Group study (Goggins and Finkelstein (2000); Zhou et al. 2017), which investigated whether the baseline CD4 cell count is predictive of the cytomegalovirus (CMV) shedding in both blood and urine. In the following, suppose that only the doubly censored data are available on the ’s. That is, for each and , can only be observed exactly within the window , where , and the observed information for each subject is given by . Here, , , , denotes the indicator function, and is a -dimensional vector of possibly time-dependent covariates. It is easy to see that if is right censored.
In the following, we will consider the frailty model-based approach and assume that there exists a latent variable for each subject and the ’s follow the density function , which has mean one and is known up to the unknown parameter . Also assume that given the covariate process and , the cumulative hazard function of has the form
In the above, denotes an unknown increasing baseline cumulative hazard function, is a -dimensional vector of regression parameters and is a prespecified function that is also increasing. Furthermore, it will be assumed that given , are independent, a commonly used assumption under the framework of frailty models (Zeng et al. (2008); Zhou et al. 2017).
The class of models (1) is quite flexible and encompasses many commonly used models as special cases. For example, we can obtain the proportional hazards frailty model by letting and it gives the proportional odds frailty model when . If the covariates are time-invariant, then it reduces to the linear transformation model
where is a random term with a known distribution function . Note that among others, Zeng et al. (2008) and Zeng et al. (2009) used the similar transformation frailty models as above for the analysis of multivariate right-censored data.
Let and denote the density and survival functions of the th outcome variable, respectively. Then under the conditional independence assumption between and given and , the observed data likelihood function takes the form
where
and . Note that the conditional independence assumption described above can be relaxed to the noninformative censoring assumption, meaning that the joint distribution of the ’s and ’s does not involve any unknown parameters in the class of models (1) for (Scharfstein and Robins (2002); Siannis et al. 2005; Gómez et al. 2009).
For the estimation, it is obvious that a natural way is the direct maximization of the likelihood function (2). On the other hand, one can see that this would be very challenging and can be unstable due to the complex data structure and the existence of the nonparametric functions ’s. Thus, in the following, we will develop an EM algorithm with the use of Poisson variables. A key advantage of the described data augmentation is that one only needs to maximize an objective function with a much simpler form in the M-step of the algorithm, which can also be easily implemented as seen below.
Maximum likelihood estimation and the EM algorithm
In this section, we will discuss the development of an EM algorithm for the maximization of the likelihood function given in (2). For this, first note that the transformation function can be derived as follows
where is the density function of the frailty with the known parameter . For example, we can obtain , the logarithmic transformation function, if is the density function of a gamma random variable with mean one and variance . This suggests that one can convert the class of transformation frailty models (2) into the proportional hazards model with two sets of frailties Kosorok et al. (2004).
To develop the proposed EM algorithm, we will first describe the needed data augmentation. Let the ’s be the replicates of above. Then the likelihood function given in (2) can be equivalently expressed as
For the infinite-dimensional function , we propose to approximate it with a step function with non-negative jumps at all distinct uncensored observations and an additional set of left-censored observations of the th event, a subset of with or . The aim of including left-censored observations in the support of is to ensure the existence of the nonparametric maximum likelihood estimator, and for more details on this, one can refer to the Lemma 2.1 given in Su and Wang (2016) and the Corollary 5 given in Mykland and Ren (1996). We denote those distinct time points in ascending order by with corresponding jump sizes for . For notational simplicity, in the following, we denote and for . Then the likelihood function becomes
Next, for the th event of the th subject, we introduce a set of independent latent variables , where follows the Poisson distribution with mean . Then we find that the likelihood function can be rewritten as
That is, we have re-expressed the likelihood function (4) with some Poisson variables, which is crucial and useful for the development of the following complete data likelihood function with a much simpler form.
Let be the density function of with the parameter and be the vector containing all parameters to be estimated. Then if we assume all latent variables ’s and ’s were observable, the complete data likelihood function can be given as
In the above, we require that if , and if and if . Note that one can retrieve the likelihood function by integrating ’s and ’s out of the complete data likelihood function .
Note that many authors have recently considered the use of Poisson variables to construct EM algorithms under various situations, but the details behind these methods are different according to the models and data structure considered (McMahan et al. (2013); Wang et al. (2015); Zeng et al. (2016); Li et al. 2018). Here, we extend the proposed method of Li et al. (2018) for univariate doubly censored data analysis to multivariate doubly censored data setting, which poses more difficulty due to the presence of multivariate cumulative baseline hazard functions and the unobserved latent variables or frailties. Also the determination of the conditional expectations of the latent variables are much more complicated than those given in Li et al. (2018) as discussed below.
Now we are ready to present the E-step of the proposed algorithm. In this step, we need to determine the conditional expectations of all latent variables in the log-likelihood function , which yields
Note that here, for notational simplicity, we have ignored the conditional arguments in all conditional expectations. In the above,
and
where , and
The details for deriving the above conditional expectations are given in Appendix A. Note that if is the density function of the gamma variable, one can calculate the following integration with respect to explicitly
Otherwise, we propose to employ Gauss–Laguerre quadrature technique to calculate the integrations with respect to that have no closed form.
For calculating , in particular, we suggest to employ the probability integral transformation technique to transform into a standard normal variable and then adopt Gaussian–Hermite quadrature method to calculate this expectation. To illustrate this, let be a standard normal random variable. Then we know that the distribution function of , , follows the uniform distribution over . Also note that follows a parametric distribution, and therefore, the cumulative distribution function of denoted by has specific form and also follows uniform distribution over . This suggests that one can connect with a standard normal distributed variable by setting . Nelson et al. (2006) gave a detailed discussion about the probability integral transformation when the random effects or frailties follow a non-normal distribution. The numerical study below suggests that the joint use of the probability integral transformation and Gaussian–Hermite quadrature techniques provides a satisfactory performance in practice.
In the M-step of the EM algorithm, by setting , we can update each as follows
Note that, for each , we have closed-form estimators for the ’s and this avoids the inversion of the possibly high-dimensional and ill-conditioned matrix in the optimization procedure. This is a desirable feature of the proposed method as it can be easily implemented. By plugging the estimators above into , we have the estimation equation for the regression vector given as
Finally, the estimator of can be obtained by solving .
In summary, by combining all steps described above, the proposed EM algorithm is as follows.
Step 0: Choose an initial estimator .
Step 1: At the th iteration, first calculate the conditional expectations , and at .
Step 2: Update by solving the estimation equation with one-step Newton–Raphson method.
Step 3: can be determined explicitly by , in which is inserted.
Step 4: Calculate by solving .
Step 5: Repeat Steps 1–4 until the convergence is achieved.
Asymptotic properties
Now we establish the asymptotic properties of the proposed estimators. Let with and being the true values of and , respectively. Also let denote the maximum likelihood estimator of defined above. To establish the asymptotic properties of , we need the following regularity conditions.
(A1) belongs to a known compact set in . For each , is continuously differentiable with positive derivatives in , where is the support of with and is a large positive constant.
(A2) For each , the vector is uniformly bounded with finite total variation over and its left limit exists for any
(A3) If for all with probability one, then for all and
(A4) is twice continuously differentiable on with and In addition, there exists a positive constant such that
(A5) For any smooth function , for , where denotes the th derivative of with respect to .
Conditions (A1) and (A2) are standard conditions in survival analysis (Zeng et al. 2016). Condition (A3) holds if the matrix is nonsingular for all . Condition (A4) holds for many transformation function families such as the logarithmic family (Zeng et al. 2008). Condition (A5) is a commonly used assumption on the random-effect distribution for modelling the multivariate or clustered data with frailty models (Zeng et al. 2008).
Theorem 1.Under regularity conditions (A1)–(A5) described above, , and almost surely, where is the Euclidean norm.
Theorem 2.Under regularity conditions (A1)–(A5) described above, the random element converges weakly to a zero-mean Gaussian process in the metric space where , is a normed space consisting of all the bounded functions and the norm is defined as the supremum norm on Furthermore, and are asymptotically efficient.
The proofs of the two theorems above are deferred to the Appendix B. For inference about the parameters of interest, it is apparent that one needs to estimate the asymptotic covariance matrix of . For this, it would be very difficult to derive the consistent estimator as discussed below and thus instead, we propose to employ the nonparametric bootstrap procedure (Su and Wang 2016). To be specific, we first repeatedly draw new datasets of sample size with replacement from the original observed data for times, where is a prespecified positive integer. The newly resampled datasets are denoted by for . Let denote the resulting estimator of based on . Then one can estimate the covariance matrix of by the empirical covariance matrix of .
A simulation study
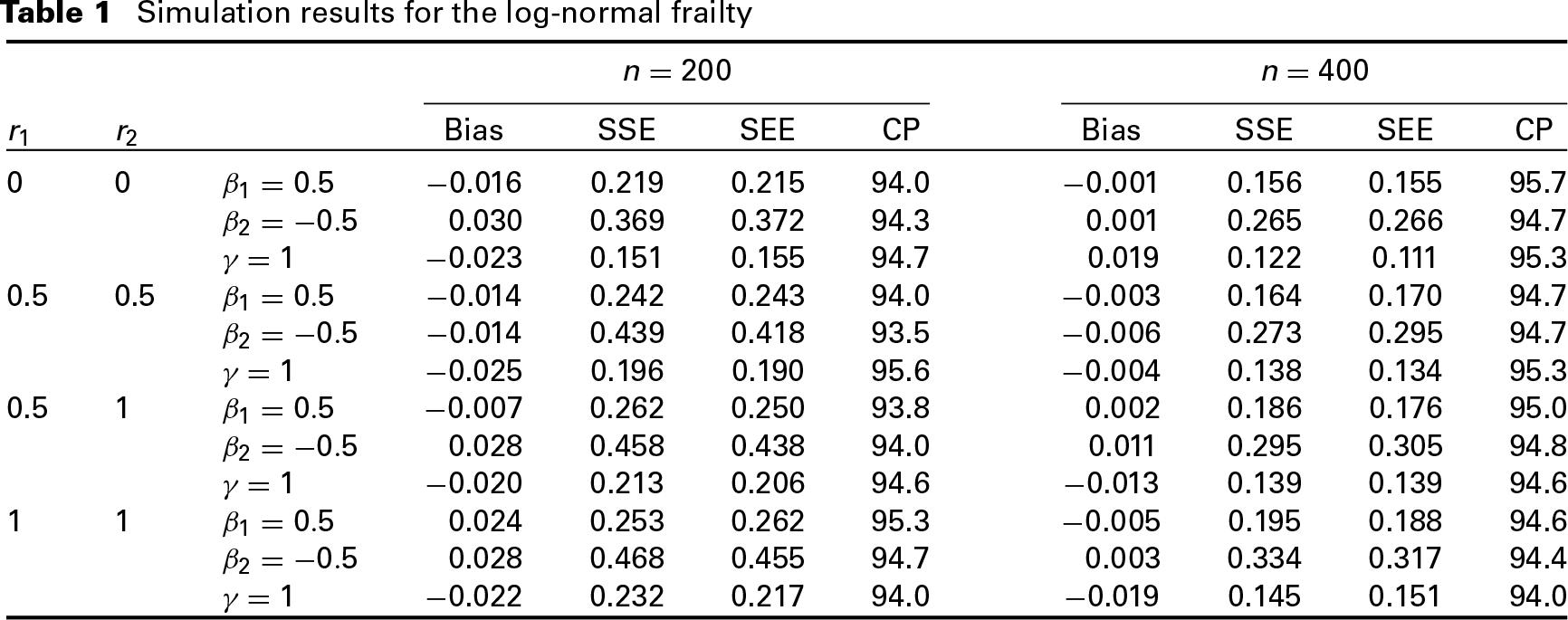
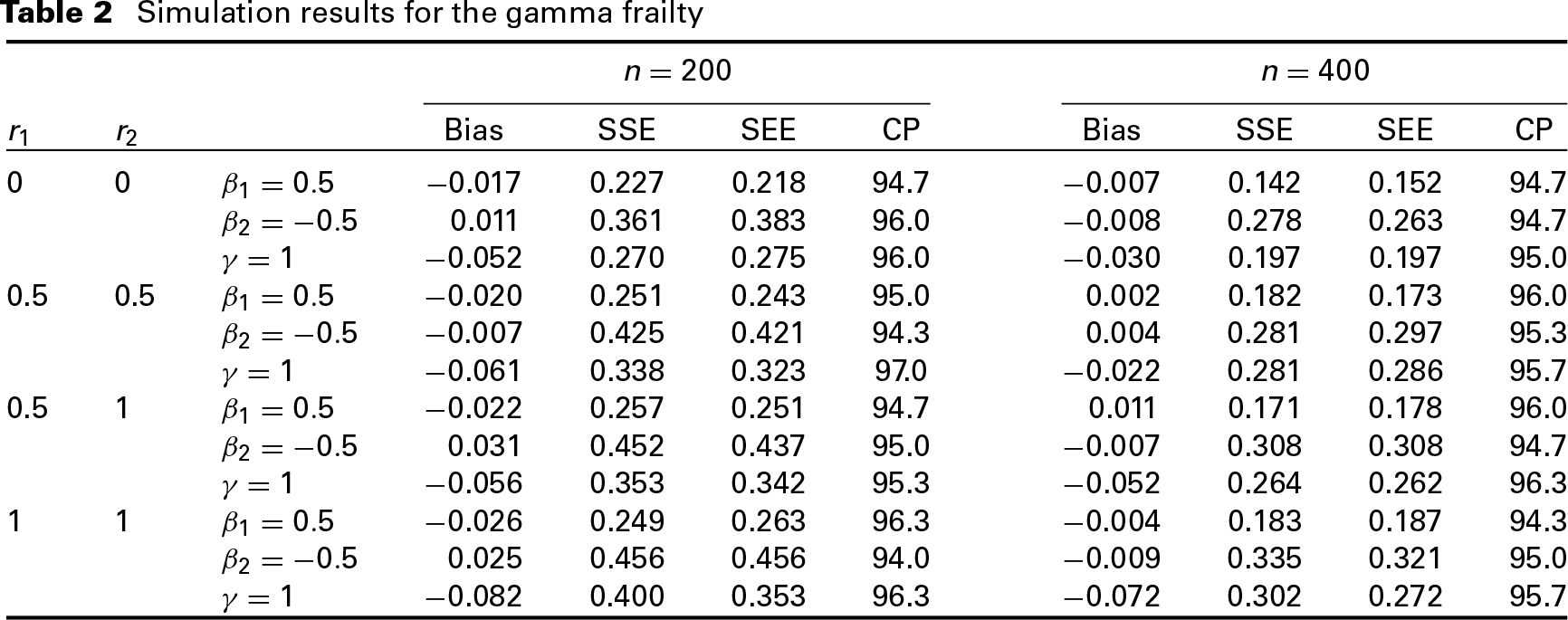
A simulation study was conducted to assess the numerical performance of the proposed methodology in finite samples. In the study, the ’s were generated from the class of transformation models (1) with and for . Here, we took each be 0, 0.5 or 1 and considered the combinations of different values of and . More details are given in the first two columns of the tables below. Note that the choices of and correspond to the proportional hazards and proportional odds frailty models, respectively. Here, we considered two frailty distributions: the log-normal frailty with mean one and variance and the gamma frailty with mean one and variance . For subject , we randomly generated the left-censored variable and the right-censored variable according to the uniform distributions and respectively. For the generation of covariates, we considered the two-dimensional coavariate setting with ’s following the Bernoulli distribution with the success probability of 0.5 and ’s being generated from The true values of denoted by were set to be . The results below are based on 500 replications, and or .
Simulation results for the log-normal frailty
Bias
SSE
SEE
CP
Bias
SSE
SEE
CP
0
0
0.016
0.219
0.215
94.0
0.001
0.156
0.155
95.7
0.030
0.369
0.372
94.3
0.001
0.265
0.266
94.7
0.023
0.151
0.155
94.7
0.019
0.122
0.111
95.3
0.5
0.5
0.014
0.242
0.243
94.0
0.003
0.164
0.170
94.7
0.014
0.439
0.418
93.5
0.006
0.273
0.295
94.7
0.025
0.196
0.190
95.6
0.004
0.138
0.134
95.3
0.5
1
0.007
0.262
0.250
93.8
0.002
0.186
0.176
95.0
0.028
0.458
0.438
94.0
0.011
0.295
0.305
94.8
0.020
0.213
0.206
94.6
0.013
0.139
0.139
94.6
1
1
0.024
0.253
0.262
95.3
0.005
0.195
0.188
94.6
0.028
0.468
0.455
94.7
0.003
0.334
0.317
94.4
0.022
0.232
0.217
94.0
0.019
0.145
0.151
94.0
Simulation results for the gamma frailty
Bias
SSE
SEE
CP
Bias
SSE
SEE
CP
0
0
0.017
0.227
0.218
94.7
0.007
0.142
0.152
94.7
0.011
0.361
0.383
96.0
0.008
0.278
0.263
94.7
0.052
0.270
0.275
96.0
0.030
0.197
0.197
95.0
0.5
0.5
0.020
0.251
0.243
95.0
0.002
0.182
0.173
96.0
0.007
0.425
0.421
94.3
0.004
0.281
0.297
95.3
0.061
0.338
0.323
97.0
0.022
0.281
0.286
95.7
0.5
1
0.022
0.257
0.251
94.7
0.011
0.171
0.178
96.0
0.031
0.452
0.437
95.0
0.007
0.308
0.308
94.7
0.056
0.353
0.342
95.3
0.052
0.264
0.262
96.3
1
1
0.026
0.249
0.263
96.3
0.004
0.183
0.187
94.3
0.025
0.456
0.456
94.0
0.009
0.335
0.321
95.0
0.082
0.400
0.353
96.3
0.072
0.302
0.272
95.7
The results under the log-normal and gamma frailties are given in Tables 1 and 2, respectively. We mainly focused on the estimated bias (Bias) given by the average of the estimates minus the true value, the sample standard error (SSE) of the obtained estimates, the average of the standard error estimates (SEE), and the 95% empirical coverage probability (CP). One can see from both tables that the proposed nonparametric maximum likelihood estimates have little biases and the SEE based on nonparametric bootstrap method are in well agreement with the simulated SSE. Also, all empirical CPs are quite close to the nominal value, indicating that the normal distribution provides a reasonable approximation to the distribution of the proposed estimator.
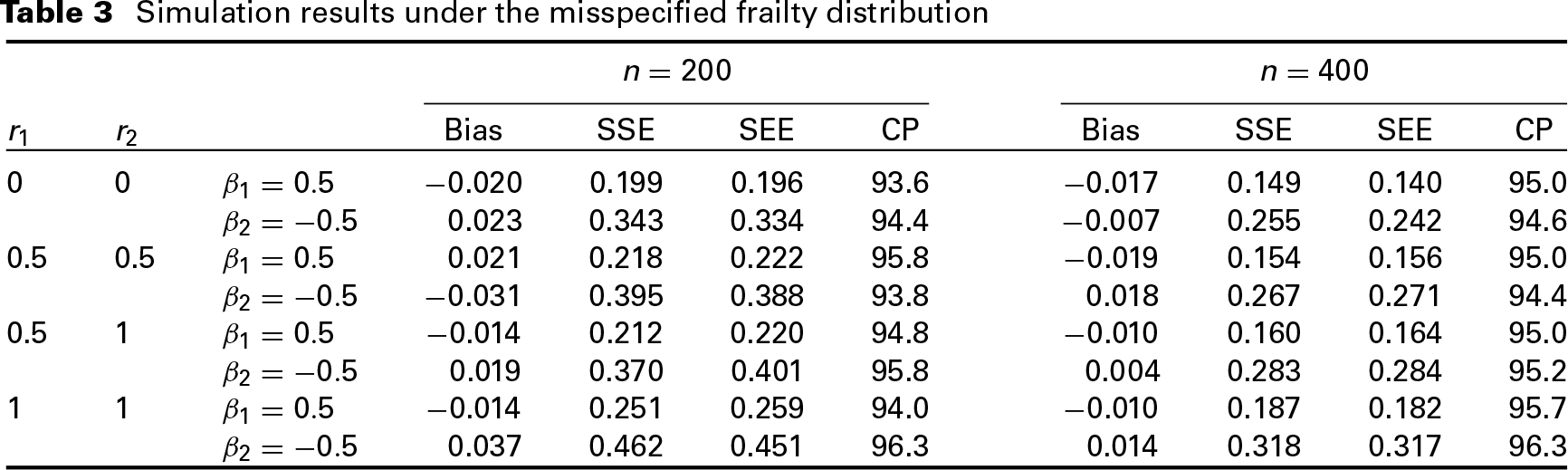
Note that in the proposed method, we have assumed that the distribution for the ’s is known and thus it is of interest to investigate how sensitive the proposed method is to the misspecification of the frailty distribution. For this, we generated the latent variables ’s from the gamma distribution with mean one and variance one, but fitted the simulated data with the transformation models with the log-normal frailty, and kept the other model specifications being the same as above. The results given in Table 3 indicate that the proposed method seems to work well for the situations considered here.
Simulation results under the misspecified frailty distribution
Bias
SSE
SEE
CP
Bias
SSE
SEE
CP
0
0
0.020
0.199
0.196
93.6
0.017
0.149
0.140
95.0
0.023
0.343
0.334
94.4
0.007
0.255
0.242
94.6
0.5
0.5
0.021
0.218
0.222
95.8
0.019
0.154
0.156
95.0
0.031
0.395
0.388
93.8
0.018
0.267
0.271
94.4
0.5
1
0.014
0.212
0.220
94.8
0.010
0.160
0.164
95.0
0.019
0.370
0.401
95.8
0.004
0.283
0.284
95.2
1
1
0.014
0.251
0.259
94.0
0.010
0.187
0.182
95.7
0.037
0.462
0.451
96.3
0.014
0.318
0.317
96.3
An application
In this section, we apply the proposed methodology to a set of real doubly censored data arising form the AIDS Clinical Trials Group Protocol 320 (ACTG 320) study conducted between 29 January 1996 and 27 January 1997 (Hammer et al. (1997); Cai et al. 2014). The aim of this study was to compare the treatment effects of the 2-drug combination of zidovudine (ZDV) and lamivudine (3TC) and the 3-drug combination of ZDV, 3TC and indinavir (RTV) for the type-I HIV infected patients. In AIDS studies, two indicators are commonly used for assessing the good curative effect of a treatment. One is the increment of the cluster of differentiation 4 (CD4) count and the other is the decrement of the plasma HIV-1 RNA level. The measurement of the RNA level is usually done by the NucliSens assay, which is known to be highly unreliable if the RNA level is below 400 or above 750 000 per millilitre of plasma. In other words, the RNA level suffers left censoring at 400 and right censoring at 750 000. Therefore, we can only have doubly censored data on the plasma HIV-1 RNA level under this situation.
For the analysis here, we will consider the 838 patients who were followed up to 24 weeks with the focus on the changes in CD4 count and RNA level between their values at week 0 and week 24. For this, define to be the CD4 value at week 24 minus its value at week 0 and the RNA level at week 0 denoted by minus its level at week 24. Note that here we used different definitions for the two indicators because of their nature and relationship with the AIDS progress. For this set of data, the measurements of the RNA at week 0 for all subjects are within the limit of quantification, and therefore, can be either left censored by or right censored by . The percentages of the left-censored and right-censored observation for the RNA level are 1.67% and 29.12%, respectively. Also note that here we do not have any censoring on , which corresponds to the situation where and for and . In the following, we define the covariate be if the patient was in the 3-drug combination group and 0 otherwise.
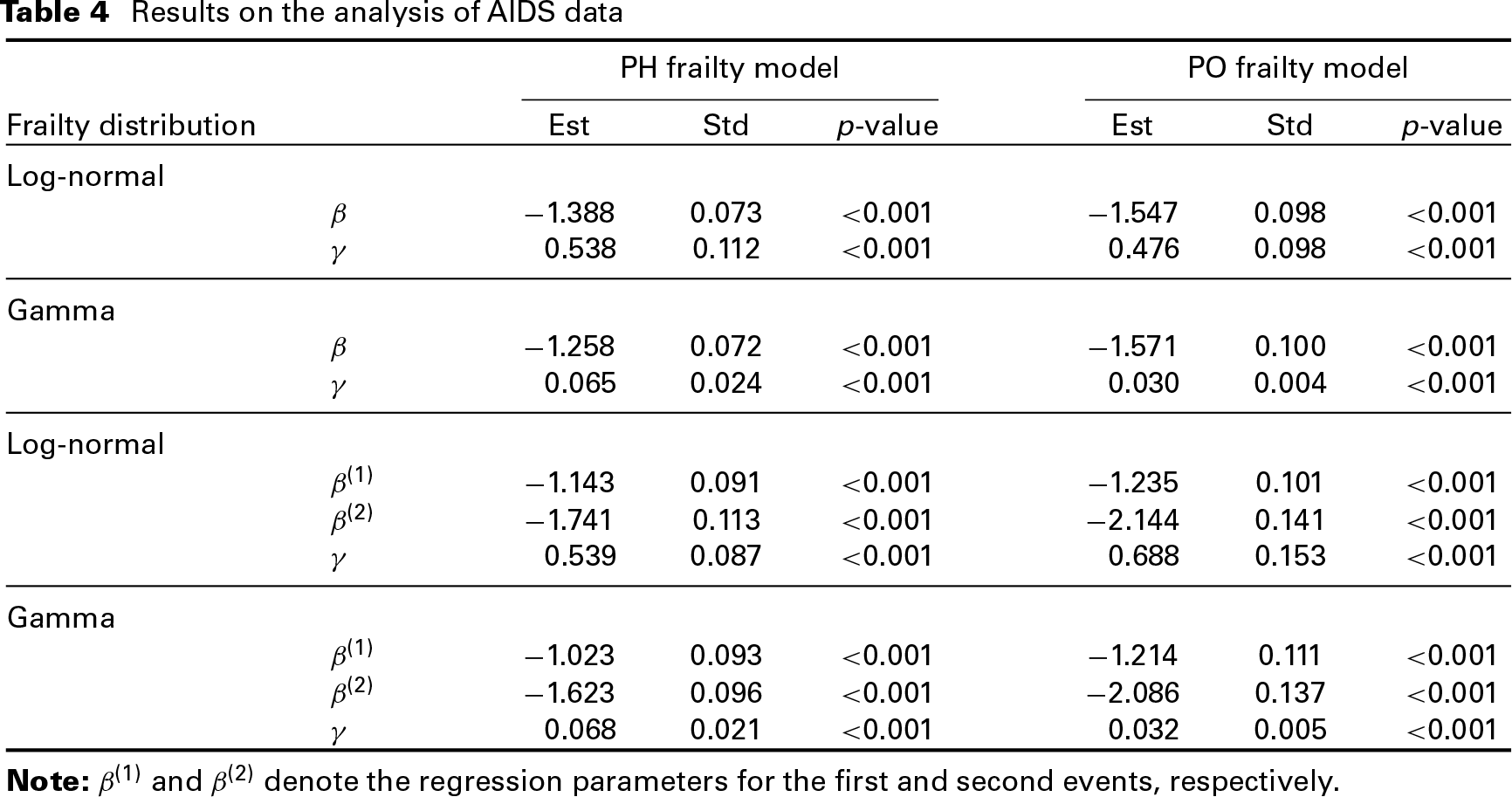
To fit the class of the models (1), as in the simulation study, we considered both the log-normal and gamma frailties and set , the logarithmic transformation function. We first assumed that the covariate had the same effect on the two events, and then performed the analysis by assuming that the effects may be different, which can be easily achieved by redefining a larger covariate vector in the proposed models. Here, we considered each ranging from 0 to 3 with an increment of 0.1 and performed grid search for the optimal and by considering all different combinations. Through the analysis, it turned out that the optimal model was given by proportional hazards model (PH frailty model) with gamma frailty and different covariate effects, which yields the largest log-likelihood value.
The results are summarized in Tables 4 and 5, and we also report the results obtained from the commonly used proportional odds frailty model (PO frailty model) for comparison. One can see from the two tables above that all results consistently indicate that the treatment effect was significant. Note that the negative estimate of the regression parameter corresponds to a lower hazard value or higher survival value. This indicates that the plasma HIV-1 RNA level decreased more and the CD4 count increased more compared to the baseline values, respectively. In other words, the 3-drug combination was significantly more effective in reducing the plasma HIV-1 RNA level and increasing the CD4 count than the 2-drug combination. This also suggests the beneficial effect of the addition of RTV for treating the AIDS infected patients. Additionally, the frailty variance is significant under 0.05 level, which indicates that there exists the positive correlation between the two outcomes.
Discussion and concluding remarks
In this article, we discussed regression analysis of multivariate doubly censored data with a wide class of semiparametric transformation frailty models. For inference, a novel and computationally stable EM algorithm was developed with the use of some Poisson variables to determine the proposed nonparametric maximum likelihood estimators. The resulting estimators of the finite-dimensional parameters were shown to be consistent, asymptotically normal and semiparametrically efficient. Also the numerical results obtained by a simulation study indicated that the proposed method works well in finite samples.
The presence of the left-censorship in doubly censored data poses great computational challenges in deriving the nonparametric maximum likelihood estimators for the semiparametric regression models. This is mainly due to the complex form of the observed data likelihood function and the lack of the closed-form solutions for the high-dimensional parameters involved in the cumulative hazard function. However, the proposed usage of some Poisson variables in the data augmentation part allows us to calculate the high-dimensional parameters ’s with closed forms and the finite-dimensional parameters and can be updated with one-step Newton–Raphson approach separately. This avoids the inversion of the possibly high-dimensional and ill-conditioned matrix, and thus makes the estimating procedure easily implemented. Furthermore, the joint usage of the probability integral transformation technique and Gauss–Hermite quadrature method can calculate the conditional expectations in the E-step under various frailty distributions. Thus, the proposed method can apply to more general situations in practice.
Results on the analysis of AIDS data
PH frailty model
PO frailty model
Frailty distribution
-value
-value
Log-normal
1.388
0.073
0.001
1.547
0.098
0.001
0.538
0.112
0.001
0.476
0.098
0.001
Gamma
1.258
0.072
0.001
1.571
0.100
0.001
0.065
0.024
0.001
0.030
0.004
0.001
Log-normal
1.143
0.091
0.001
1.235
0.101
0.001
1.741
0.113
0.001
2.144
0.141
0.001
0.539
0.087
0.001
0.688
0.153
0.001
Gamma
1.023
0.093
0.001
1.214
0.111
0.001
1.623
0.096
0.001
2.086
0.137
0.001
0.068
0.021
0.001
0.032
0.005
0.001
Note: and denote the regression parameters for the first and second events, respectively.
Note that in the preceding sections, we showed that the proposed method can deal with the type of data in which the outcome variable may not a typical failure time. For such outcomes, a natural or straightforward approach may be linear model-based procedures if there is no censoring. However, in the presence of double censoring, the development of some estimation procedures may not be an easy task, and instead, the hazard-based method can provide a good alternative. Among others, Cai and Cheng (2004) and Li et al. (2018) discussed such approaches for the analysis of doubly censored data.
In many scientific studies, one often assumes that all subjects under study will eventually experience the event of interest if the follow-up is sufficient long. However, in practice, there may exist a non-susceptible subpopulation, which is usually referred to as cured fraction and in this situation, some cure models may provide a better fit. Hence, it may be helpful to extend the proposed method to this cured situation. It is also necessary to allow for informative censoring in the analysis where the outcome variable of interest and the censoring variables are not independent as often happen in many medical research fields (Li et al. 2017). Another direction for future research is to develop the estimation procedure for other commonly used semiparamteric regression models such as the additive hazards model (Lin and Ying 1994).
Appendix
Appendix A: More details about the proposed EM algorithm
Note that we have re-expressed likelihood function (4) with the equivalent form (5) by using some Poisson variables, and to see this derivation, we note that if ,
if , we have
and if , we have
In the following, we will discuss the derivation of the conditional expectations and in the E-step. Here, we denote the observed data for subject by and current estimates of parameters by in all conditional expectations. Also the following derivations of the following conditional expectations are based on the constraints in the complete likelihood function, if , and if and if . Let , by using the law of iterated expectations and Bayes’ theorem, we know that
and
Appendix B: Proofs of Theorems 1 and 2
For the proofs, we will mainly use some results about empirical processes given in (van der Vaart and Wellner 1996). In the following, for a function and a random variable with the distribution , define and . Let denote the Euclidean norm and denote the usual norm.
Lemma 1.Under conditions (A4) and (A5), with probability one, we have
where represents a generic constant that may vary from place to place and is independent of and .
Proof. Under condition (A4), we have . Therefore, the left-hand side of equation (L.1) is bounded by
Let be a large positive constant such that . We can show that
Therefore,
Since are bounded and satisfies condition (A5), Lemma 1 holds for some constant .
Proof of Theorem 1.
We will first prove that is bounded almost surely as for . That is, can be regarded as a bounded measure. By Helly's selection theorem and the compactness of the parameter space, for any subsequence of converges to , converges to , and converges weekly to some on . The proof will be completed if we can show that . To establish the consistency of the estimators, we first define
where denotes the Radon–Nikodym derivative of . We conclude that converges uniformly to with probability one for in that uniformly in with probability one as . Let denote the functions whose total variation in are bounded by a given constant, and the class of functions
be a Donsker class due to the fact that is a convex hull of functions . By conditions (A4) and (A5), we know that
is bounded away from zero. Therefore, belongs to some Donsker class due to the preservation property of the Donsker class under the Lipschitz–continuous transformations. Then we can conclude that converges almost surely to as . Since we denote as the maximum likelihood estimator, we have . Additionally, we know that converges to , which is finite. Therefore, we can conclude that . By following the conclusion of the Lemma 1, we know that
Hence, , which implies with probability one. By Helly's selection theorem and the compactness of the parameter space, for any subsequence of converges to , converges to , and converges weekly to some on . Next, we consider the following difference of log-likelihood
By Lebesgue's theorem, we know that the left-hand side of the equation above converges to almost surely. Since the limit is the Kullback–Leibler divergence which is non-positive, we have with probability one. Specially, for each , by choosing and using condition (A3), we can show the identifiability of the model parameters. Therefore, we can conclude that and , which completes the proof.
Proof of Theorem 2.
For the proof of this theorem, we propose to verify the four conditions stated in Theorem 2 of Murphy (1995) as has been done in Li et al. (2018). However, the techniques behind it are more complicated than those given in Li et al. (2018) due to the presence of frailty distribution in multivariate doubly censored data. Define . Consider parametric submodels , , and , where . Let Therefore, the score functions along these submodels are given by
and
where and
Denote , where . Furthermore, we define the limit map as , where the linear functionals , and are obtained by replacing the empirical sum by the expectation and . Clearly, and . The desired asymptotic normality will be established if we can verify the four conditions stated in Theorem 2 of Murphy (1995). The first condition that converges weakly to a tight Gaussian process on holds since belongs to a Donsker class and , and are bounded Lipschitz functionals with respect to By Proposition 1 in the Appendix of Bickel et al. (1993), we can show that is Frchet differentiable. The approximation condition can be proved using Lemma 3.3.5 in van der Vaart and Wellner (1996). Let denote the corresponding Frchet derivative of at . After some algebra, we can have
where
and
where is a matrix, and are -dimensional vectors, , and are scalar functions and is a -dimensional vector function.
Therefore, the invertibility of is equivalent to the invertibility of the continuous linear operator for any . It suffices to prove that is a one-to-one map (Rudin 1973). Note that if then for any in the neighbourhood of We choose , and By the definition of Thus, almost surely. After some algebra, we can obtain and by condition (A3).
Since it has already been shown that is invertible, the asymptotic property stated in Theorem 2 now follows from Theorem 2 of Murphy (1995). Furthermore,
uniformly in Therefore, converges in distribution to a tight Gaussian process , whose variance is given by
where is the inverse of . Note that is an asymptotically linear estimator for , and its influence function belongs to the space spanned by the score functions, which indicates is semiparametrically efficient (Bickel et al. 1993).
Footnotes
Acknowledgments
This work was partly supported by the National Nature Science Foundation of China grant nos. 11671274, 11731011 and 11671168, the Support Project of High-level Teachers in Beijing Municipal Universities in the Period of 13th Five-year Plan grant CIT & TCD 201804078, the Capacity Building for Sci-Tech Innovation-Fundamental Scientific Research Funds grant 025185305000/204, the Youth Innovative Research Team of Capital Normal University, and the Science and Technology Developing Plan of Jilin Province grant 20170101061 J.C.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This work was partly supported by the National Nature Science Foundation of China grant nos. 11671274, 11731011 and 11671168, the Support Project of High-level Teachers in Beijing Municipal Universities in the Period of 13th Five-year Plan grant CIT & TCD 201804078, the Capacity Building for Sci-Tech Innovation-Fundamental Scientific Research Funds grant 025185305000/204, the Youth Innovative Research Team of Capital Normal University, and the Science and Technology Developing Plan of Jilin Province grant 20170101061 J.C.
References
1.
BickelPJ, KlaassenCAJ, RitovYWellnerJA (1993) Efficient and Adaptive Estimation for Semiparametric Models. Baltimore, MD: Johns Hopkins University Press.
ChangMN (1990) Weak convergence of a self-consistent estimator of the survival function with doubly censored data. The Annals of Statistics, 18, 391–404.
5.
ChangMNYangGL (1987) Strong consistency of a nonparametric estimator of the survival function with doubly censored data. The Annals of Statistics, 15, 1536–47.
6.
GehanEA (1965) A generalized two-sample Wilcoxon test for doubly censored data. Biometrika, 52, 650–53.
7.
GogginsWBFinkelsteinDM (2000) A pro- portional hazards model for multivariate interval-censored failure time data. Biometrics, 56, 940–43.
8.
GómezG, CalleML, OllerRLangohrK (2009) Tutorial on methods for interval- censored data and their implementation in R. Statistical Modelling, 9, 259–97.
9.
GuoGRodriguezG (1992) Estimating a multivariate proportional hazards model for clustered data using the EM algorithm, with an application to child survival in Guatemala. Journal of the American Statistical Association, 87, 969–76.
10.
HammerS, SquiresK, HughesM, GrimesJ, DemeterL, CurrierJ, EronJ, FeinbergJ, BalfourH, DeytonL, ChodakewitzJFischlM (1997) A controlled trial of two nucleoside analogues plus indinavir in persons with human immunodeficiency virus infection and CD4 cell counts of 200 per cubic millimeter or less. New England Journal of Medicine, 337, 725–33.
11.
KimY, KimBJangW (2010) Asymptotic properties of the maximum likelihood estimator for the proportional hazards model with doubly censored data. Journal of Multivariate Analysis, 101, 1339–51.
12.
KimY, KimJJangW (2013) An EM algorithm for the proportional hazards model with doubly censored data. Computational Statistics and Data Analysis, 57, 41–51.
13.
KomarekALesaffreE (2006) Bayesian semi-parametric accelerated failure time model for paired doubly-interval-censored data. Statistical Modelling, 6, 3–22.
14.
KosorokMRLeeBLFineJP (2004) Robust inference for univariate proportional hazards frailty regression models. The Annals of Statistics, 32, 1448–91.
15.
HuTZhouQSunJ (2017) Regression analysis of bivariate current status data under the proportional hazards model. The Canadian Journal of Statistics, 45, 410–24.
16.
LiSHuTWangPSunJ (2017) Regression analysis of current status data in the presence of dependent censoring with applications to tumorigenicity. Computational Statistics and Data Analysis, 110, 75–86.
17.
LiSHuTWangPSunJ. (2018) A class of semiparametric transformation models for doubly censored failure time data. Scandinavian Journal of Statistics. doi: 10.1111/sjos.12319.
18.
LinDYYingZ (1994) Semiparametric analysis of the additive risk model. Biometrika, 81, 61–71.
19.
McMahanCS, WangLTebbsJM (2013) Regression analysis for current status data using the EM algorithm. Statistics in Medicine, 32, 4452–66.
20.
MurphySA (1995) Asymptotic theory for the frailty model. The Annals of Statistics, 23, 182–98.
21.
MyklandPARenJJ (1996) Algorithms for computing self-consistent and maximum likelihood estimators with doubly censored data. The Annals of Statistics, 24, 1740–64.
22.
NelsonKPLipsitzSRFitzmauriceGMIbrahimJParzenMStrawdermanR (2006) Use of the probability integral transformation to fit nonlinear mixed-effects models with nonnormal random effects. Journal of Computational and Graphical Statistics, 15, 39–57.
23.
Rudin W (1973) Functional Analysis. New York, NY: McGraw-Hill.
24.
ScharfsteinDORobinsJM (2002) Estimation of the failure time distribution in the presence of informative censoring. Biometrika, 89, 617–34.
25.
SiannisFCopasJLuG (2005) Sensitivity analysis for informative censoring in parametric survival models. Biostatistics, 6, 77–91.
26.
SuYRWangJL (2016) Semiparametric efficient estimation for shared-frailty models with doubly censored clustered data. The Annals of Statistics, 44, 1298–1331.
27.
SunJ (1995) Empirical estimation of a distribution function with truncated and doubly interval-censored data and its application to AIDS studies. Biometrics, 51, 1096–1104.
28.
SunJ (2006) The Statistical Analysis of Interval-censored Failure Time Data. New York, NY: Springer.
29.
SunLWangLSunJ (2016) Estimation of the association for bivariate interval-censored failure time data. Scandinavian Journal of Statistics, 33, 637–49.
30.
van der VaartAWWellnerJA (1996) Weak Convergence and Empirical Processes. New York, NY: Springer.
31.
WangNWangLMcMahanCS (2015) Regression analysis of bivariate current status data under the gamma-frailty proportional hazards model using the EM algorithm. Computational Statistics and Data Analysis, 83, 140–50.
32.
WangWDingAA (2000) On assessing the association for bivariate current status data. Biometrika, 87, 879–93.
33.
WeiLJLinDYWeissfeldL (1989) Regression analysis of multivariate incomplete failure time data by modelling marginal distributions. Journal of the American Statistical Association, 84, 1065–73.
34.
WenCCChenYH (2011) Nonparametric maximum likelihood analysis of clustered current status data with the gamma-frailty Cox model. Computational Statistics and Data Analysis, 55, 1053–60.
ZengDLinDYLinXH (2008) Semiparametric transformation models with random effects for clustered failure time data. Statistica Sinica, 18, 355–77.
37.
ZengDMaoLLinDY (2016) Maximum likelihood estimation for semiparametric transformation models with interval-censored data. Biometrika, 103, 253–71.
38.
ZhangCHLiX (1996) Linear regression with doubly censored data. The Annals of Statistics, 24, 2720–43.
39.
ZhangYJamshidianM (2004) On algorithms for the nonparametric maximum likelihood estimator of the failure function with censored data. Journal of Computational and Graphical Statistics, 13, 123–40.
40.
ZhouQHuTSunJ (2017) A sieve semiparametric maximum likelihood approach for regression analysis of bivariate interval-censored failure time data. Journal of the American Statistical Association, 112, 664–72.