
Abstract
Uncertainty in machine learning models is a timely and vast field of research. In supervised learning, uncertainty can already occur in the first stage of the training process, the annotation phase. This scenario is particularly evident when some instances cannot be definitively classified. In other words, there is inevitable ambiguity in the annotation step and hence, not necessarily a single ‘ground truth’ associated with each instance. This work approaches the problem from a statistical modelling perspective. The main idea is to drop the assumption of a ground truth label and instead embed the annotations into a multidimensional space. This embedding is derived from the empirical distribution of annotations within a Bayesian setup, modelled using a Dirichlet-Multinomial framework. We estimate the model parameters and posteriors using a stochastic Expectation Maximizsation algorithm with Markov Chain Monte Carlo (MCMC) steps. The methods developed in this article readily extend to various situations in which multiple annotators independently label instances. To showcase the generality of the proposed approach, we apply our approach to three benchmark datasets for image classification and natural language inference (NLI), in which multiple annotations per instance are available. Besides the embeddings, we can investigate the resulting correlation matrices, which reflect the semantic similarities of the original classes for all three exemplary datasets.
Keywords
Introduction
Machine Learning models are increasingly used for a growing number of applications, one of which is supervised classification, for example in the form of images or texts. While such models have achieved impressive standards in recent years in terms of accuracy, the assessment of uncertainty remains an active field of open problems and research challenges. Recent survey articles discussing the field include Gawlikowski et al. (2023) or Hüllermeier and Waegeman (2021). Uncertainty thereby has numerous and intertwined sources as discussed in Gruber et al. (2023) or Baan et al. (2023) and is heavily impacted at multiple stages of the common machine learning pipeline. Gruber et al. (2023) also explicitly emphasize the role of the data itself for appropriately assessing uncertainty entirely.
In the field of deep learning, multiple major streams of research related to the quantification of uncertainty exist. Besides ensemble methods and Bayesian approaches, evidential neural networks have been gained attention as a deterministic method for uncertainty quantification (Sensoy et al., 2018). Specifically, these methods conceptualize learning as the acquisition of evidence, where each new training example adds support to a learned evidential distribution. A recent survey by Ulmer et al. (2023) provides an extensive overview of evidential deep learning and discusses its strengths and weaknesses in depth. However, some lines of work also advise caution when employing evidential networks for uncertainty quantification. Jürgens et al. (2024) state that generally, epistemic uncertainty is not reliably represented by those methods and Meinert et al. (2023) showcase the issue of overparameterization for evidential regression.
However, while some parts of the overall uncertainty are already heavily studied in research, less attention has been paid to one of the major prerequisites for training classification models, namely the (un)availability of reliable ground truth labels for the training data and their uncertainty. In fact, uncertainty already starts in the labelling process for supervised machine learning, where human annotators label images or texts. Any supervised model will rely on these ‘ground truth’ labels, inherently incorporating their associated uncertainty. We refer to this type of uncertainty as ‘label uncertainty’. Commonly, such gold labels are acquired with human labelling effort, leading to multiple annotations per instance. Depending on the complexity of the problem at hand, it might suffice to aggregate the annotations into a single ground truth label, for example, by majority voting. However, in many realistic application areas, such as the classification of complex images or the assessment of language and speech, this assumption does not hold true.
Of course, humans are naturally prone to errors, leading to unreliable annotations or mistakes and therewith, label noise or label errors. The problem was already tackled and discussed early in the statistical literature; see for example, Dawid and Skene (1979). In recent years, more and more methods have been developed for handling data despite human errors, for example in the context of neural networks (Dgani et al., 2018). Peterson et al. (2019) argue that incorporating human ambiguity can improve classification models in terms of robustness. However, training supervised machine learning models based on noisy or deficient labels can lead to poor performance and highuncertainties; see, for example, Frénay et al. (2014) or more recently Frénay and Verleysen (2014) for an overview. Also, the labels might introduce some bias, as shown by Jiang and Nachum (2020), that needs to be identified and corrected if possible. Different algorithms have been introduced to tackle the problem of noisy labels, see Algan and Ulusoy (2021) for an extensive survey on various methods.
However, ambiguity in annotations cannot always be attributed to the fallibility of human annotators. Instead, label variation is also likely to arise if the assumption of a singular ground truth label for each instance is questionable. In the context of language, Plank (2022) discusses the sources of label variation. Particularly, the authors argue that the absence of a singular ground truth is often reasonable and should not be considered erroneous by default. In this line, the survey by Uma et al. (2021) discusses the disagreement of annotators. The authors conclude that suitable evaluation methods are required if a single gold label cannot be assigned. Various works in multiple domains show that disregarding label variation and leaving it untreated can indeed lead to quality issues and uncertainty. The common approach to simply summarize the annotations into a single label does not only discard valuable information, it is also an inappropriate representation of the truth and introduces remarkable amounts of uncertainty, in particular in the ‘gold’ label (Uma et al., 2021 or Aroyo and Welty, 2013; Davani et al., 2022).
This problem is prevalent across various classification domains, specifically for application areas characterized by inherent ambiguity. To showcase this, let us first consider the domain of natural language processing (NLP) or more specifically NLI, where ambiguity is ubiquitous due to the subjective interpretation of language and speech. This issue has been already extensively discussed, see, for example, Plank (2022). NLI corresponds to the task of discerning the logical relationship between two sentences, typically whether one entails the other, contradicts it or is unrelated to it. Naturally, the perception of language differs for the human annotators causing high rates of disagreement (Pavlick and Kwiatkowski, 2019; Nie et al., 2020). Table 1 shows example cases of such ambiguities. Each sentence (left column, called ‘context’) is accompanied by a second sentence (middle column, called ‘statement’). A group of 100 human labellers are asked to classify the sentence pair into either C = contradiction, N = neutral or E = entailment. Contradiction means, that the ‘statement’ contradicts the ‘context’, entailment means that the two sentences mean the same just with different wording and neutral means that the contents of the two sentences are unrelated. The ambiguity in the labelling process is clearly reflected. Gruber et al. (2024) provide a statistical approach for modelling the data-generating process in order to gain a better understanding of the label uncertainty. However, their modelling approach assumes a latent ground truth label associated with each sentence pair. While this is only a modelling assumption, numerous works claim that the assumption of a single ground truth is not appropriate for NLI tasks and instead, a more realistic representation of the labels should be used, see, for example, Aroyo and Welty (2015), Uma et al. (2021) or Plank (2022).
The table shows 4 examples of sentence pairs from ChaosSNLI, along with the annotations, see Gruber et al. (2024). Each pair of context and statement is classified by 100 human annotators with the categories ‘contradiction’ (C), ‘neutral’ (N) and ‘entailment’ (E).
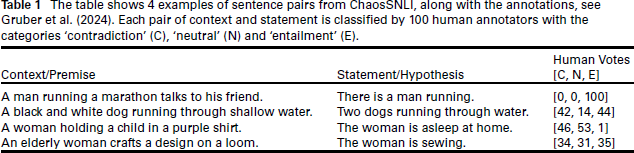
The table shows 4 examples of sentence pairs from ChaosSNLI, along with the annotations, see Gruber et al. (2024). Each pair of context and statement is classified by 100 human annotators with the categories ‘contradiction’ (C), ‘neutral’ (N) and ‘entailment’ (E).
Similar problems arise in the domain of image classification if either the categories or the images themselves are ambiguous. Depending on the nature of the problem, assigning a singular ground truth label is often simply impossible. We consider two examples here. First, we utilize a benchmark dataset on image classification; secondly, we extend our previous work on remote sensing image classification (Hechinger et al., 2024). For the interest of space, details on the latter example are found in the supplementary material. Focussing on image classification, there are situations without a distinct ground truth, as shown in Figure 1. The exemplary images are part of the benchmark dataset Cifar-10H, introduced by Peterson et al. (2019). The dataset is designed such that each instance is assigned to a single unambiguous class, at least in theory. Still, some images defy easy classification due to ambiguities caused by the size or quality of the picture, leading to high disagreement rates within the annotations. Consequently, relying solely on majority voting to assign a singular label in such cases does not accurately reflect the underlying truth. A similar problem occurs in the classification of satellite images, which is discussed in detail in the supplementary material. Finally, we want to emphasize that the three datasets are constructed in that the observations are not random samples from some ‘super-population’. This raises the question of whether any trained model can be deployed to novel data. We do not discuss this question in this article, since our focus is on modelling uncertainty and not on the deployment to new data, if the training data are biased.
The figure shows exemplary images from Cifar-10H along with their original labels, where a high disagreement rate between the annotators could be observed hinting at the ambiguity of the images.

In this work, we propose to move away from the premise of a sole ground truth. The three examples demonstrated in this world underpin that the assumption of a ground truth is not always appropriate. Therefore, we explicitly allow for ambiguity for each instance. In this article, we aim to statistically model such situations in a distributional framework. Namely, we employ a Dirichlet-Multinomial Model, as discussed in Minka (2000) or Mosimann (1962). Variants of this model class have, for example, been used for clustering of text documents (Yin and Wang, 2014) and genomics data (Holmes et al., 2012 or Harrison et al., 2020). Avetisyan and Fox (2012) deploy a Dirichlet-Multinomial Mixture Model to estimate survey response rates. Eswaran et al. (2017) also connected this model class to uncertainty quantification and modeled beliefs as Dirichlet distributions to capture uncertainty. In this work, we propose a Dirichlet-Multinomial Model to estimate
The article is structured as follows. Section 2 describes the distributional framework and the algorithm used for estimation. The results on two different datasets are reported in Section 3, the third example (remote sensing) is found in the supplementary material. We consider some possible further steps and applications in Section 4. Section 5 concludes the article with a detailed discussion. The code and the data are available via github; see the Appendix for details.
Notations
Each image i, with
Binary case: K = 2
For a more straightforward presentation and interpretation of our modelling strategy, we start with the binary case K = 2. We assume a binary label representation, which is embedded into the two-dimensional space. That is, each instance (image or text) is allocated as following:
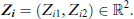
The vector
The embedding steers ambiguity as well as the uncertainty of the labelling process. This is achieved by relating Z to the coefficients of a Beta distribution. To be specific we define 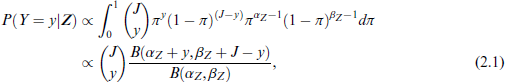
where B(.) denotes the univariate Beta function.
Within this model setup, we can derive a couple of interpretations. Interpreting 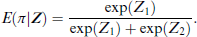
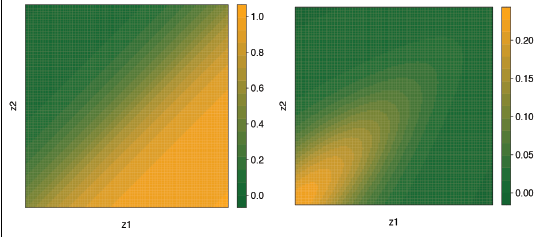
Additionally, we can also quantify uncertainty by calculating the variance, which results as following:
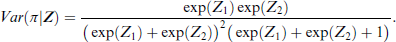
Figure 2 The figure shows the mean (left) and log-variance (right) of the Beta-Binomial distribution for different values of
The figure shows the mean (left) and log-variance (right) of the Beta-Binomial distribution for different values of Z, expressed through colour.
For different values of Z, we plot the mean and the (log)-variance of the Beta-Binomial distribution in Figure 2. The variance expresses the uncertainty, which is how likely an image or text is misclassified given the data at hand. The larger
The quantity Z is latent, but we aim to draw information about Z given the votes Y. The two variables are connected via the Beta-Binomial model (2.1) and we can estimate the distribution of Z for given votes Y by drawing MCMC samples. To do so, we sample from the posterior as follows:
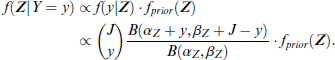
As prior distribution for Z, we use a bivariate normal with mean μ and variance matrix
With
Estimating the embeddings.

The binary model can now be easily extended to more than two classes by employing the Dirichlet distribution. Now, 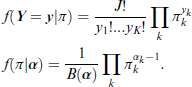
In this case, the function B(.) denotes the multivariate version of the Beta function. The vector π remains unobserved and we can calculate the probability of Y given Z by marginalizing over π as follows:
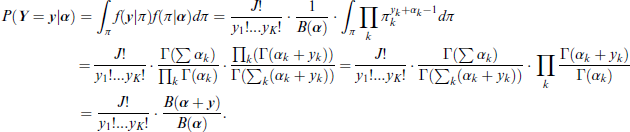
Again, the embedded ground truth values
We obtain a Dirichlet-Multinomial Model by assuming a K-dimensional embedded ground truth
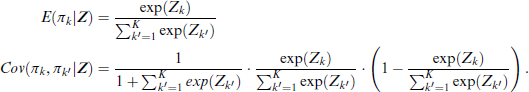
Each entry of
Following the estimation procedure described in Section 2.2 adapted to the multiclass case leads to values
Results
To showcase the generality and versatility of the proposed approach in various applications, the proposed model is applied to the three datasets described in the introduction. The datasets are typical examples in the field of multiple annotations and annotator disagreement and hence provide ground for analyzing the uncertainty associated with the labels. Table 2 contains general information about the three datasets discussed in this section.
Overview of the datasets.

Overview of the datasets.
First, we explore the advantages of the proposed methodology in the context of the classification of language, that is, the domain of NLI, as shortly introduced in Section 1. The multi-annotator dataset ChaosSNLI1 is based on the development set of the Standford Natural Language Inference (SNLI) dataset (Bowman et al., 2015) and was introduced in the context of label ambiguity by Nie et al. (2020). It contains multiple annotations for sentence pairs, that is, pairs of premise and hypothesis. For each premise, three hypotheses are originally generated by an annotator, as an entailing, neutral and contradicting description of the premise. The resulting sentence pairs of premise and hypothesis can therefore be classified as entailment, neutral or contradiction. Note that a subjective ground truth, namely the original intention of the first annotator, is available for this specific dataset. However, it cannot be recovered by the annotators in many cases and the dataset ChaosSNLI especially showcases this problem as it contains sentence pairs exhibiting a high rate of disagreement. Particularly, N = 1514 sentence pairs are re-assessed by a large number of annotators, that is, J = 100 and assigned to one of the three classes, as shown in Table 1. Due to the ambiguous nature of language and the individual perception, the disagreement rate in the annotations is high and the original true label cannot be recovered reliably. For the classification of language, the existence of a single ‘gold’ label is especially doubtful and hence, the need for alternative and more appropriate representations of labels persists. Applying the methodology proposed in Section 2 allows us to estimate embedded ground truth vectors for the observations based on the provided annotations, which will be analyzed in this subsection. First, let us return to the
The plots show the estimated embedded ground truth vectors for exemplary sentence pairs from the dataset ChaosSNLI. The actual estimated vector is shown as orange line, the green lines represent the MCMC samples and the actual annotations are shown as grey bars.
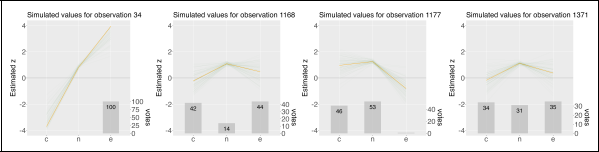
The plots show the estimated embedded ground truth vectors for exemplary sentence pairs from the dataset ChaosSNLI. The actual estimated vector is shown as orange line, the green lines represent the MCMC samples and the actual annotations are shown as grey bars.
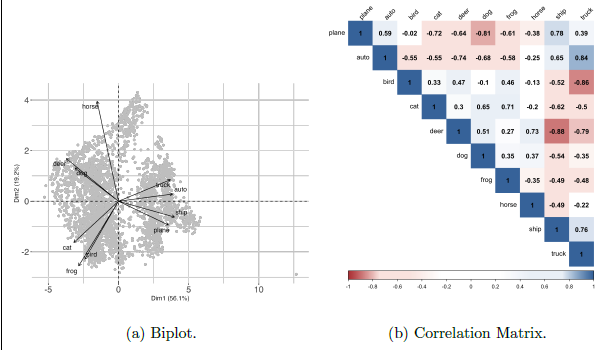
For this particular application, the classes themselves are by definition uncorrelated or negatively correlated. This property is also expressed by the resulting estimated embeddings. To visually inspect the results, we employ dimensionality reduction techniques for easier exploration. We specifically utilize principal component analysis (PCA) to extract the principal components from the estimated embeddings. PCA is a widely used technique for linear dimensionality reduction, commonly employed for exploratory analysis and visualization of high-dimensional data. For detailed information on the methodology, refer to, for example, Jolliffe (2002). Here, we especially focus on the visualization benefits of the technique. Namely, it is possible to plot the observations in a so-called two-dimensional

The second dataset is a version of Cifar-10, a popular benchmark dataset for image classification, as introduced by Krizhevsky et al. (2009). The subset Cifar-10H2 as introduced by Peterson et al. (2019) contains multiple annotations for images in the test set, reflecting the uncertainty stemming from differences in human perception. Here, the natural images are categorized into unambiguous classes, see Table 2. The original dataset has been extended with soft labels, that is, multiple annotations, to achieve better generalization for classification models, specifically on out-of-sample datasets, see Peterson et al. (2019) and Battleday et al. (2020). Therefore, N = 10000 images of K = 10 classes from the test set of Cifar-10 were annotated by 2571 Amazon Mechanical Turk workers. After an initial training phase, each worker annotated 200 images, 20 per category. To identify and remove low-performance annotators, attention checks were introduced after every 20 trials.
The biplot shows the estimated embeddings for ChaosSNLI, projected into two dimensions. The scatterpoints represent the instances, coloured by majority vote. The original dimensions are represented as arrows.
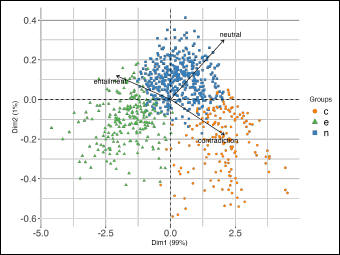
The biplot shows the estimated embeddings for ChaosSNLI, projected into two dimensions. The scatterpoints represent the instances, coloured by majority vote. The original dimensions are represented as arrows.
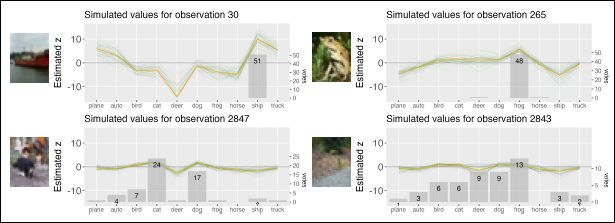
The current setting differs from the previously discussed dataset. Most images belong to one of the unambiguous categories and can be reliably classified by untrained annotators. Nevertheless, it is helpful to additionally inspect label embeddings reflecting the individual human perception, which can still be ambiguous. Due to the small size of the images, the pictured class is also not always identifiable, as shown in Figure 1. The dataset contains a high degree of human consensus due to its nature but also enough images where the annotation is still uncertain. This is also visible in the majority votes. While each class originally contains 1000 images, the number of images classified into the categories according to the majority vote varies slightly between 981 and 1015. Additionally, the images can be easily assessed and evaluated against the annotations, in contrast to the dataset presented previously. By applying the proposed model we generate embeddings of the images in the appropriate label space, which contain a notion of uncertainty and reflect the original annotations, without the loss of information by taking the majority voting.
Returning to the
The plots show the estimated embeddings (orange) for exemplary images of the dataset Cifar-10H, along with the votes (bars) and the MCMC samples (green).
Next, we repeat the analyses for the previous datasets, that is, plotting the estimates of the embeddings on a two-dimensional
The subfigures show additional results for the dataset Cifar-10H via the biplot and the correlation matrix of the estimated embeddings.
Final, for the results on the remote sensing example we refer to the supplementary material.
Outlook
Naturally, the question arises of how to use the information gained from embedding the ambiguous labels into a multidimensional space. The two main goals are to improve the supervised model assigned with the corresponding classification task and to possibly refine its uncertainty estimates. In many applications, training the classification model based on averaged labels or labels obtained via majority voting is still common practice. In the case of high annotator disagreement due to ambiguities, this can lead to major problems related to the associated uncertainties (Davani et al., 2022; Plank, 2022; Baan et al., 2023). Koller et al. (2024) propose to instead integrate the annotation uncertainty via the empirical distribution of the annotations. Their work shows that incorporating this uncertainty leads to better generalization and calibration of the classification model. However, the benefit of the empirical distribution of course strongly depends on the number of annotations and is limited to the observed disagreement for one single instance only. The idea of estimating label embeddings via a distributional approach presented in this work offers a possibility to overcome said limitations. In particular, it is possible to train a classification model directly on the estimated embeddings
Discussion
For classification models, the dependence on labelled training data is a common practice, that is, each instance is linked to an established ground truth label or ‘gold’ label. Generating these ground truth labels requires substantial human effort and is prone to errors causing uncertainty. However, unreliable labels cannot always be attributed to human failure. In many applications, assigning a single label is unrealistic or even impossible due to the ambiguity of the instances themselves. A single ground truth label often cannot account for the complexity of, for example, images or sentences. This is often expressed through a high rate of disagreement in the annotations received from human labellers. Hence, the single-label approach results in a substantial loss of information and introduces additional uncertainty into the classification process. Therefore, moving beyond this limiting assumption is necessary in certain applications. This can be done by considering more flexible and adaptive strategies.
This article focuses on classifying text or images addressing the specific case where we cannot assume that every observation can be uniquely classified into one class. Based on multiple annotations per observation, we propose to embed the images into a K-dimensional space instead of restricting them to a single label.
The proposed estimation procedure leads to interesting results, as reported in Section 3. We estimate label embeddings for three different datasets, emphasizing the generality of our approach and its usefulness in diverse settings. First, we apply the method to the dataset ChaosSNLI from the domain of language classification. The dataset contains especially ambiguous sentence pairs and a high number of annotations per instance. The assumption of a singular gold label is especially doubtful for the classification of language, due to its inherent ambiguity and subjectivity. Instead, multi-dimensional embeddings can serve as a more appropriate representation of the underlying truth. Moreover, we move away from expert labels and inspect the performance of our model on a crowd-sourced dataset, namely the multiply annotated dataset Cifar-10H. The results show that even the classification of images into well-separated and naturally distinguishable categories could benefit from using label embeddings instead of hard-coded labels. Third, we apply the proposed method to the earth observation dataset So2Sat LCZ42, as provided in the supplementary material. Here, the satellite images themselves exhibit a high degree of ambiguity but also the categories are similar in terms of their composition, complicating the assignment of a singular label even more.
The proposed model and the estimation framework are very flexible and hence, the presented work can be easily adapted to any classification problem with multiple annotations.
These insights can be valuable in multiple regards and pave the way for future research in various directions. While the presented results already deliver interesting insights into the annotation tasks, they of course rather serve as a preprocessing step for further work. The long-term goal is to use label embeddings within a complete machine-learning framework. In particular, we are interested in training classification models on multi-dimensional embeddings instead of single labels, that is, incorporating information about label uncertainty directly into the model. This work can also serve as a basis for analyzing different design choices for label generation for image classification problems. The trade-off between the number of instances and the number of annotators is a well-known problem, related to experimental design. For problems with a high degree of ambiguity, determined by the proposed model, acquiring more annotations instead of more instances is beneficial. Vice versa, if classification is ‘easy’, that is, the embeddings reflect clear class affiliations, a smaller number of annotations might be sufficient and one should concentrate on generating more labelled instances instead. This boils down to the question ‘more labels or more cases’ with some first ideas in the field of NLP discussed in Gruber et al. (2024). We believe that our modelling framework could be of great benefit for future steps towards better handling label uncertainty for machine learning models.
Footnotes
Acknowledgements
The present contribution is supported by the Helmholtz Association under the joint research school ‘HIDSS-006 - Munich School for Data Science@Helmholtz, TUM and LMU’. The last author also acknowledges the Munich Center for Machine Learning (MCML).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.
Notes
Supplementary material
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.