
Abstract
Lossy compression often results in artifacts due to block-based encoding and decoding. A common strategy to mitigate these artifacts is the adaptive loop filter (ALF) method, which calculates the optimal filter for each image frame. However, achieving global adaptive filtering increases bitrate during code transmission. To address this challenge, this paper introduces the global adaptive loop filter and machine learning-based model (GALFMLM), an algorithm that effectively eliminates artifacts and enhances the quality of reconstructed images. It employs a more rational pixel classification method, incorporates inherent sharpening and contrast enhancement effects, and trains global filter coefficients using a substantial amount of training data. Simultaneously, a rate-distortion optimization technique is used to determine whether adaptive or global filter coefficients should be employed during the encoding process. Notably, this approach leverages machine learning methods, offering computational speed advantages over deep learning-based techniques. Experimental results demonstrate significant improvements in image compression performance compared to the JPEG standard, highlighting the efficacy and robustness of the proposed algorithm.
Introduction
Image compression has gained attention in image processing and computer vision due to its applications in visual systems. 1 Convolutional neural networks are used in image compression systems. Lossy compression methods reduce image precision and discard redundant info, but introduce artifacts like distorted colors, blurred edges, or jagged artifacts. These artifacts cause a decline in image quality and impact user experience. Balancing compression ratio and image quality while minimizing artifacts is essential. Therefore, there are many methods available for removing artifacts such as blocking in JPEG images.2–5 These methods can be broadly classified into two categories: adaptive loop filtering methods and deep learning-based image filtering methods. Adaptive loop filtering methods typically rely on statistical features of the image and human visual perception models. They employ techniques such as filtering, interpolation, and local adjustments to improve the visual quality of the image.6–9 These methods effectively enhance the visual appearance of the image and can be incorporated into existing compression platforms by further restoring the decoded image to eliminate artifacts. The main advantage of these methods is their relatively low computational complexity, but they may have limited effectiveness in severe blocky artifacts.
On the other hand, deep learning-based image filtering methods aim to restore artifact-free images from compressed ones.10,11 They model the image and estimate/reconstruct the original signal using deep learning techniques. These methods demonstrate good performance in eliminating blocky artifacts and can adapt to various complex scenarios.
Image compression faces challenges balancing compression ratio and image quality, especially with diverse image types. Machine learning techniques can help enabling compression algorithms to automatically identify important info, adapt to different image types, and optimize compression rates in real-time. Advanced signal processing techniques can also improve compression algorithms’ efficiency, similar to super-resolution techniques that enhance low-res images to high-res. This approach offers superior quality and speed compared to traditional methods. While the aforementioned super-resolution methods excel in image restoration, these methods can be computationally expensive due to the utilization of large mapping dictionaries and may introduce distortions when reconstructing the image. To overcome this issue, an improvement is made by employing RAISR (Rapid and Accurate Image Super-Resolution), 12 which utilizing machine learning methods for global image filter parameter learning to restore high-definition images. Based on the characteristics of JPEG decoded images, the main concept involves enhancing the image through the utilization of global image filters. By employing a hashing mechanism to select image blocks and applying a collection of pre-learned filters, the reconstructed image quality is enhanced. The filters are obtained by pairing image blocks from the reconstructed and source high-definition images, while hashing is accomplished by estimating local gradient statistics.
With a sufficient amount of training data, global filters can be learned to enhance PSNR and generate higher-resolution images without extra cost for unseen images. However, global methods may be less effective due to encoding parameter variations. In such cases, computational adaptive filters can be used instead. ALF in video coding uses a Wiener-based approach to minimize the mean square error between original and reconstructed samples, significantly improving compression performance. Due to the limited subjective improvement and performance of ALF, the Geometry Transformation-Based Adaptive Loop Filter (GALF) 13 has been developed, which offers improved classification capabilities. A fixed set of filters is tested for each pixel category and used as predictors for calculating Wiener filter coefficients, thus reducing the encoding cost of transmitting these coefficients. These techniques allow for more coding gains. Accurate pixel classification is crucial for improving subjective visual quality. However, the number of pixel classifications is limited, with only 25 different categories, and the pixel classification filters for subjective visual quality improvement are not very reasonable, such as sharpening and contrast enhancement. In this paper, both global filters and computational adaptive filter coefficients (from public ALF) are used simultaneously via rate-distortion optimization. Our proposed method, feature-based classification, is inspired by Google’s super-resolution paper RAISR, 12 which utilizes gradients (angle, intensity, and coherence) to compute a filter hash table. Additionally, we specifically train a large number of global filters for image loss.
The key contributions of this paper are summarized as follows: (1) Faster machine learning methods have been adopted as a replacement for traditional deep learning techniques to enhance the quality of reconstructed images. (2) The introduction of gradient statistics methods, computing gradients (angle, intensity, and coherence) for corresponding pixels, and selecting different filtering methods, enabling the system to adapt to different types of images. (3) Training multiple sets of image filtering methods based on different spatial positions and using rate-distortion optimization to select the best image filtering parameters or disable filtering methods, achieving optimal performance.
Related work
Lossy image compression is a common method of compressing images by sacrificing image quality to reduce data size and achieve file compression. The main idea behind lossy image compression is to reduce data size by discarding redundant information, reducing image accuracy, and compressing image encoding. During image decoding, certain reconstruction algorithms are employed to preserve the original image features as much as possible. The key focus of image compression is to find efficient compression schemes that minimize the distortion of compressed data while ensuring compression efficiency. However, this process inevitably introduces some unavoidable distortions, such as distorted colors, blurred edges, or jagged shapes, known as artifacts. The presence of these artifacts can degrade the quality of compressed images and potentially impact user experience. For example, when watching videos, one may experience stuttering, blurriness, or noise, while browsing through images may lead to the appearance of mosaic patterns. Therefore, when performing lossy image compression, it is necessary to consider how to balance compression ratio and image quality, minimizing the generation of artifacts and improving user experience.
JPEG is a lossy image compression method. It divides the image into blocks, applies DCT to each block, selects higher-energy coefficients, and performs compression through quantization and entropy coding. During the JPEG compression process, artifacts are mainly caused by two factors: The DCT transformation and quantization play crucial roles in image compression. They involve converting the image from the spatial to the frequency domain. However, this transformation inherently leads to the loss of certain frequency information, consequently causing the appearance of high-frequency artifacts. At the same time, the quantization process introduces errors because the quantization matrix has limited representation capability compared to the original image information. This results in low-frequency artifacts due to the discrepancy. Additionally, the JPEG format has a limitation in handling jagged edges in non-smooth regions, which may result in aliasing artifacts in the compressed image.
All these complex artifacts not only degrade the visual perceptual quality but also have adverse effects on various low-level image processing routines based on compressed images. Therefore, there are many methods available to remove artifacts such as JPEG blocking effects. Two common approaches are adaptive loop filtering and deep learning-based image filtering methods.
Traditional methods for removing JPEG artifacts generally employ adaptive filtering techniques, which select filters based on the content of the image. These methods analyze the local characteristics of the image and choose different filter parameters for different regions, resulting in better handling of complex structures and details to improve artifact removal. These methods are widely preferred for their simplicity, ease of implementation, and low computational requirements. However, these linear methods do not adaptively select interpolation kernels (up sampling filters) based on the content of the image, thus having certain limitations. These methods have limited effectiveness in reconstructing complex structures and often generate noticeable ringing artifacts and excessively smoothed regions.
Currently, there have been numerous deep learning-based methods proposed for removing JPEG artifacts. These methods mainly fall into two categories: those based on convolutional neural networks (CNNs) and those based on generative adversarial networks (GANs). CNN-based methods typically partition the image into small blocks and perform denoising and artifact removal on these blocks, followed by reassembling them to form the complete image. On the other hand, GAN-based methods improve the performance of the artifact removal network through the adversarial interplay between a generator and a discriminator. Additionally, there are several novel deep learning methods proposed, such as attention-based methods, joint-training methods, deep decoding network-based methods, and super-resolution-based methods. Each of these methods has its own advantages and limitations, but they all demonstrate the powerful capability of deep learning in removing JPEG artifacts, and hold promise for further advancement in this field.
Additionally, a wide range of machine learning methods have been developed for image compression and artifact removal.14,15 These methods are becoming increasingly popular in the field of image processing, as they can achieve high-quality results while being efficient in terms of computation and storage. The machine learning methods for image compression typically rely on analyzing the statistical properties of images to develop models that can effectively compress and decompress the image data.
This model does not adopt explicit dictionary learning for image block modeling. Instead, it relies on implicit learning through convolutional layers. Specifically, one method utilizes a convolutional neural network (CNN) for JPEG artifact removal, where the hidden convolutional layers automatically learn the features of image blocks and construct appropriate models to capture these features without explicitly defining and constructing a dictionary. Deep learning-based image artifact removal methods can achieve a certain level of image restoration performance.
Google proposed the RAISR method with the objective of enhancing the perceptual clarity of blurred images by improving the fine details in the low-frequency range. This method also includes an extremely efficient way of training 4243*3 filters based on pixel classification, which generates a significantly sharper image than the input blurry image. The RAISR method is interpretable and has fast computational speed. Inspired by the super-resolution capability of RAISR, we propose the global adaptive loop filter using machine learning methods, which can effectively improve image compression efficiency. After lossy reconstruction of the reconstructed image by video codecs, the concept involves acquiring a set of mapping filters through the learning process from a sufficient amount of training data consisting of paired data between the decoded reconstructed images and the source high-resolution images.
Methods
We propose a machine learning-based global filtering method that effectively removes artifacts introduced during the image compression process. This method employs adaptive loop filtering, introducing gradient statistics to compute corresponding angles, intensities, and coherences. Different filtering methods are selected to enable the system to adapt to different types of images. Multiple sets of image filtering methods are trained based on different spatial positions. Rate-distortion optimization is employed to choose the optimal image filtering parameters or disable the filtering method to achieve the best performance.
Network architecture
Inspired by the RAISR model proposed by Google, this paper presents a global adaptive loop filter and machine learning-based model (GALFMLM) that effectively removes artifacts introduced during the image codec process and improves the quality of reconstructed images. As shown in Figure 1, in the model learning phase, a machine learning-based model is trained using a substantial dataset to improve the quality of reconstructed images. Multiple global models are trained to cater to different spatial structures and pixel types. This method has advantages over deep learning methods, such as fast processing speed and analyzable learning process. The core learning and application process of a global filter. By using traditional image compression methods to obtain the reconstructed image, a machine learning-based GALFMLM network is established to learn from the original image and the reconstructed image, obtaining parameters that can provide compression quality for the reconstructed image.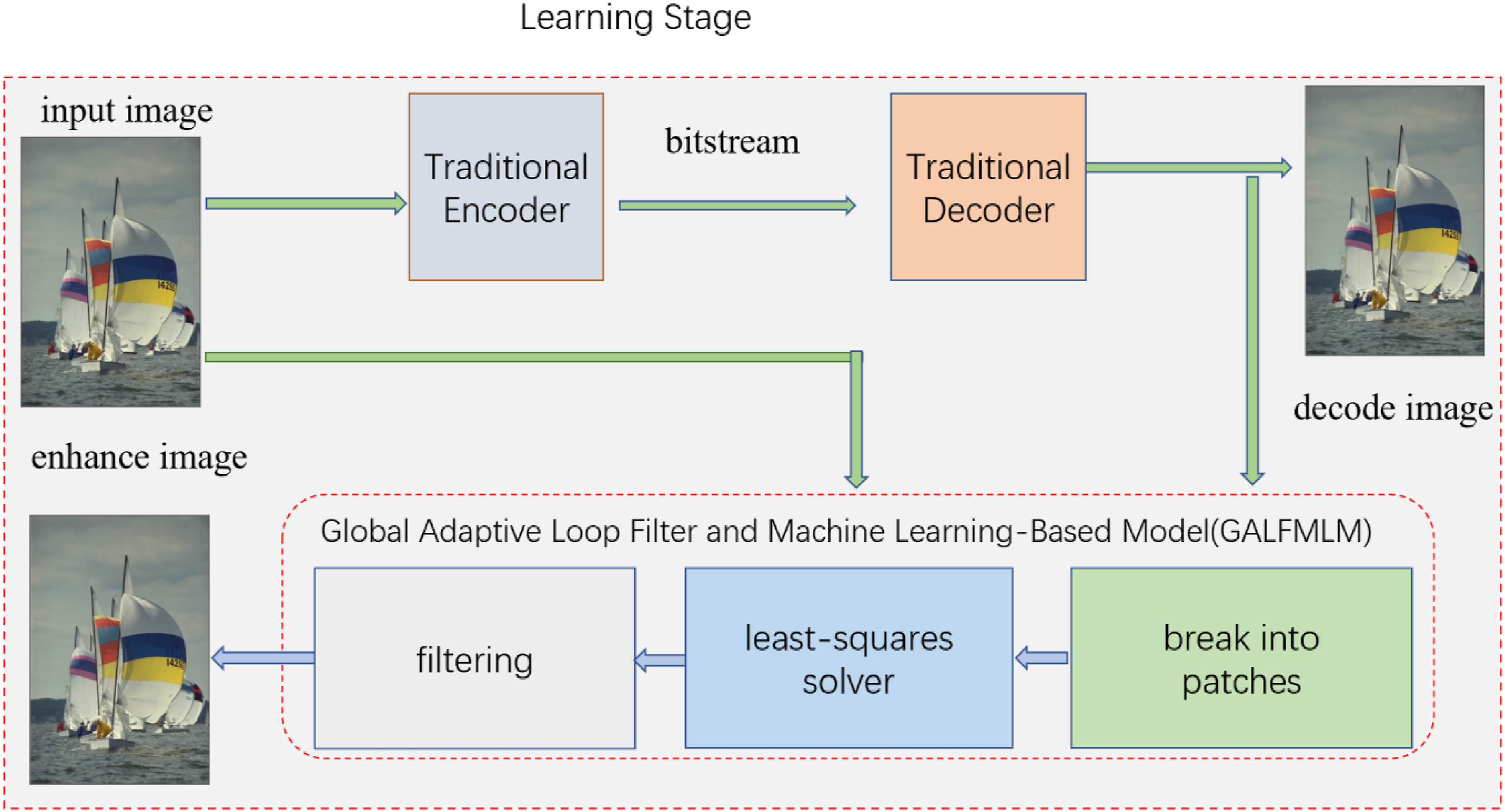
As shown in Figure 2, when multiple image quality enhancement models are trained, during the encoding stage, a rate-distortion approach is used to try all the models for image filtering on the decoded image. The model with the lowest rate-distortion is selected as the best image filtering model. Then, the selected optimal filtering model is applied to filter the decoded image. At the same time, the enablement of filtering and the type of filtering are digitally entropy encoded and included in the bitstream. Based on different global filtering models, the optimal encoding and decoding method is selected. During the actual image de-artifacting process of compression reconstruction, it is determined whether to perform image filtering based on the rate-distortion value.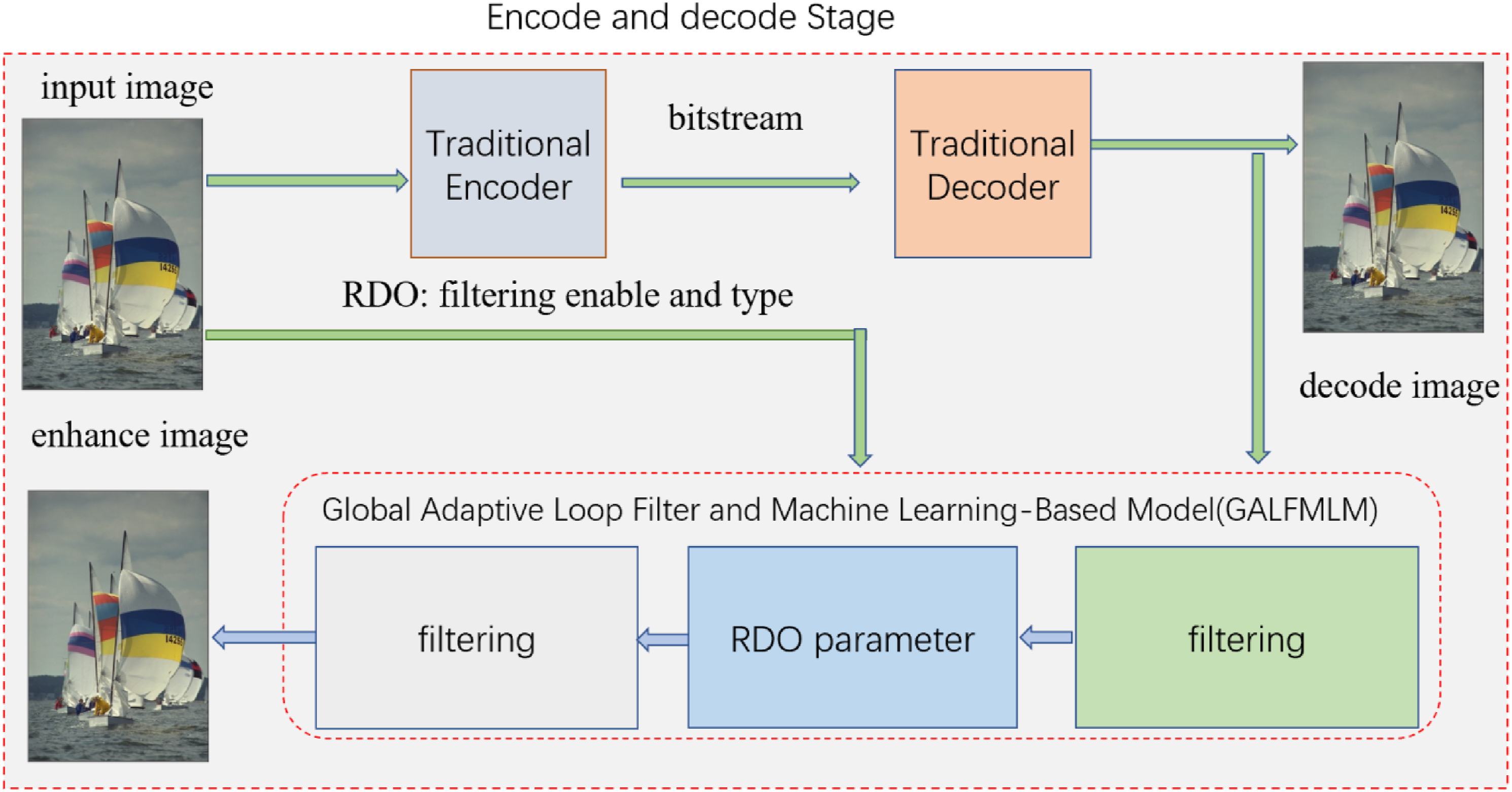
Video coding architecture
Video codecs are essential for compressing and decompressing video data to ensure efficient transmission and storage. The basic architecture involves three main stages: preprocessing, compression, and decompression. In the preprocessing stage, the original video undergoes various treatments to enhance its quality and compression efficiency. This involves filtering techniques such as denoising, smoothing, and enhancement. Degradations compensation, motion estimation, transformation, and quantization are some of the filters used. In the compression stage, a video coding standard is employed to encode and compress the preprocessed video. Standards like H.264 and H.265 make use of local and global correlations in the video sequence for efficient compression. The main steps include prediction, transformation, quantization, and entropy coding. In the decompression stage, the decoder decodes and decompresses the compressed data, reconstructing the original video sequence. The decoder parses and decodes the bitstream according to the encoding method, reconstructing the preprocessed video sequence. Video codecs achieve video signal compression and transmission through preprocessing, compression, and decompression, meeting requirements for high efficiency, low latency, high quality, and flexibility.
Adaptive loop filter (ALF) is a common technique used to remove blocking effects (BLE) caused by video block coding. BLE can lead to edge distortions and discontinuities. ALF filters the coded video to improve visual quality, based on Wiener filter design. ALF needs to classify each coding tree unit (CTU), calculate corresponding Wiener filter coefficients for each category, and use linear interpolation between sampling grids to generate filtered video frames. However, ALF has limitations: it only supports pixel-based filters, the filter coefficients are static at runtime, and its effectiveness in image enhancement is not satisfactory (Figure 3). The traditional video coding architectures are utilized to compress the original image and subsequently obtain the reconstructed image.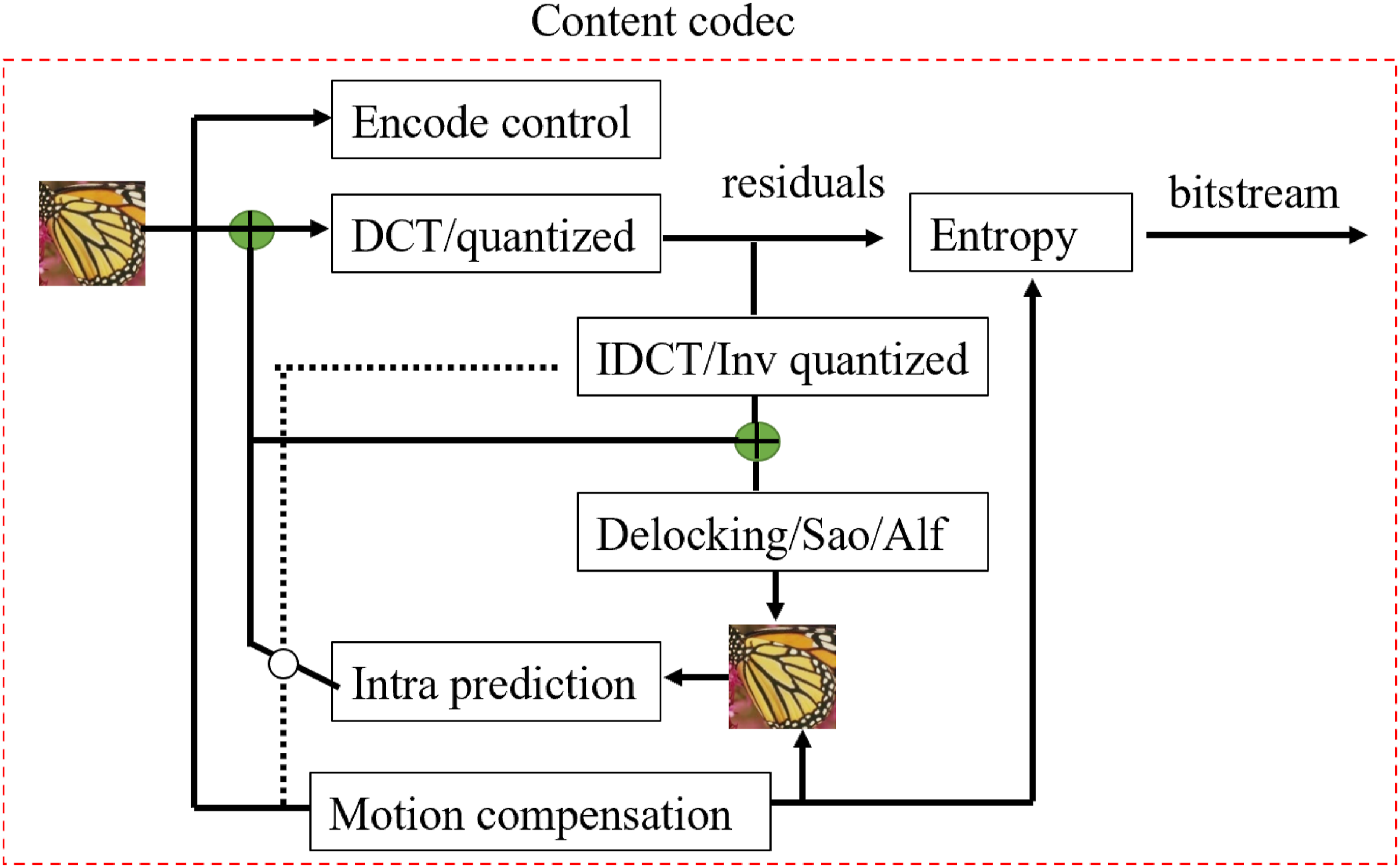
Adaptive loop filter in video compression architecture
ALF aims to minimize the error, which requires a significant amount of computation to obtain the filter coefficients. It divides pixels into different categories using diagonal gradients and texture features in the reconstructed image. ALF process consists of five stages: pixel classification, filter parameter merging, filter switching decision (ALF CU adaptive), filter amplitude decision, and filter parameter entropy coding. The final stage encodes the filter parameters into the bitstream using entropy coding techniques, as shown in Figure 4. The HEVC adaptive loop filter framework is designed to enhance the video compression process by dynamically adjusting the filtering parameters to improve the quality of the reconstructed image.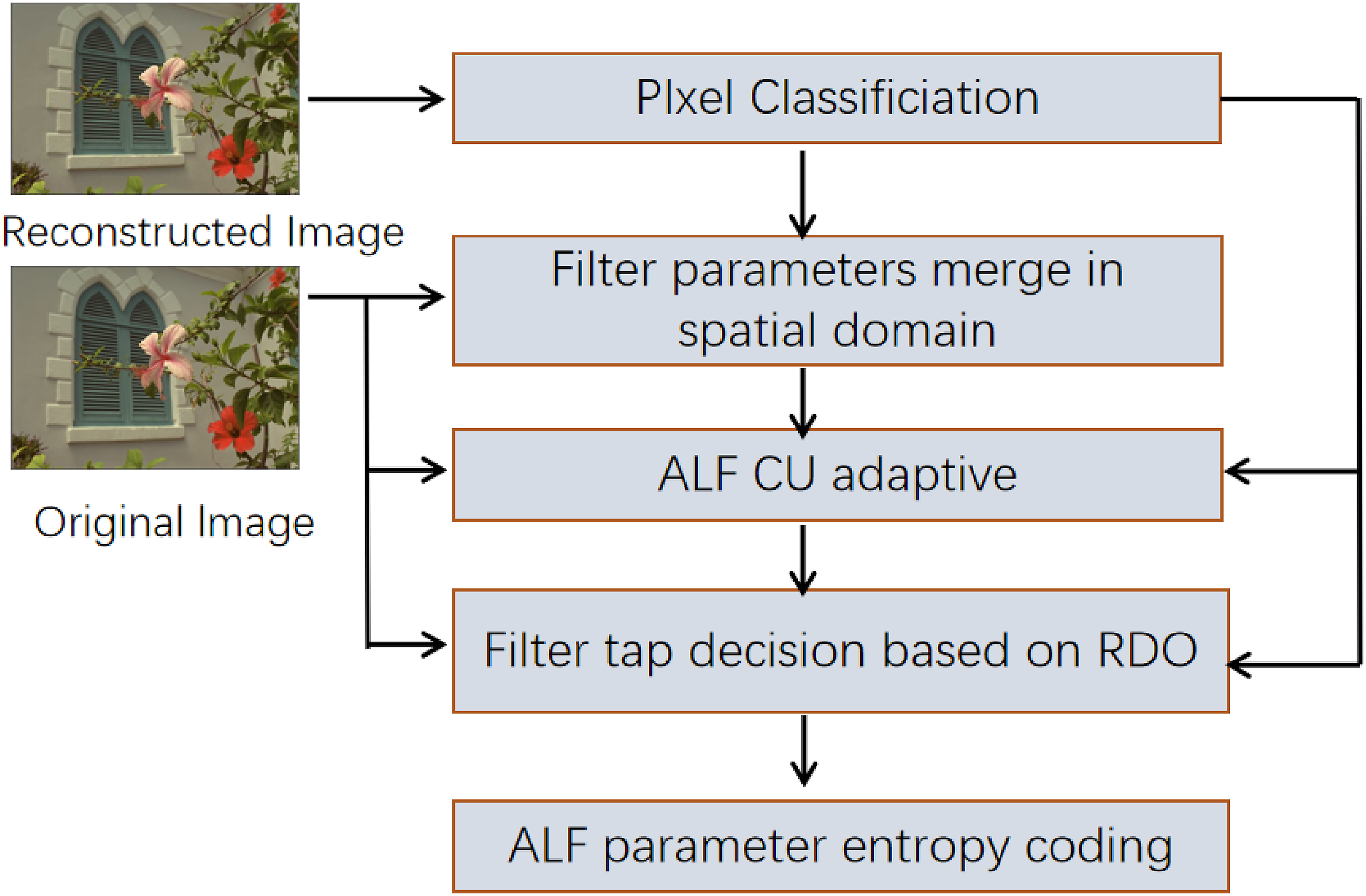
Our proposed global adaptive loop filter and machine learning-based model
Our approach is inspired by RAISR
16
and introduces an efficient global image filtering method that efficiently enhances the image quality of reconstructed images. It achieves good adaptability by applying pre-learned filters to image patches extracted from the input image, which may be blurry and contain artifacts. The approach is known for its fast execution time and ability to generate high-quality images. The filters are acquired by learning from reconstructed image patches and their corresponding high-resolution ground truth pixels. The basic structure is illustrated in Figure 5. Blocks of size 11 × 11 are extracted from the reconstructed image, and hash values are computed on the central 9 × 9 block. The output target high-resolution image pixels are estimated by convolving the reconstructed image blocks using the pre-trained filters. Our proposed design for image compression. By comparing the original high-definition image with the reconstructed image, the filtering parameters are obtained through contrastive learning.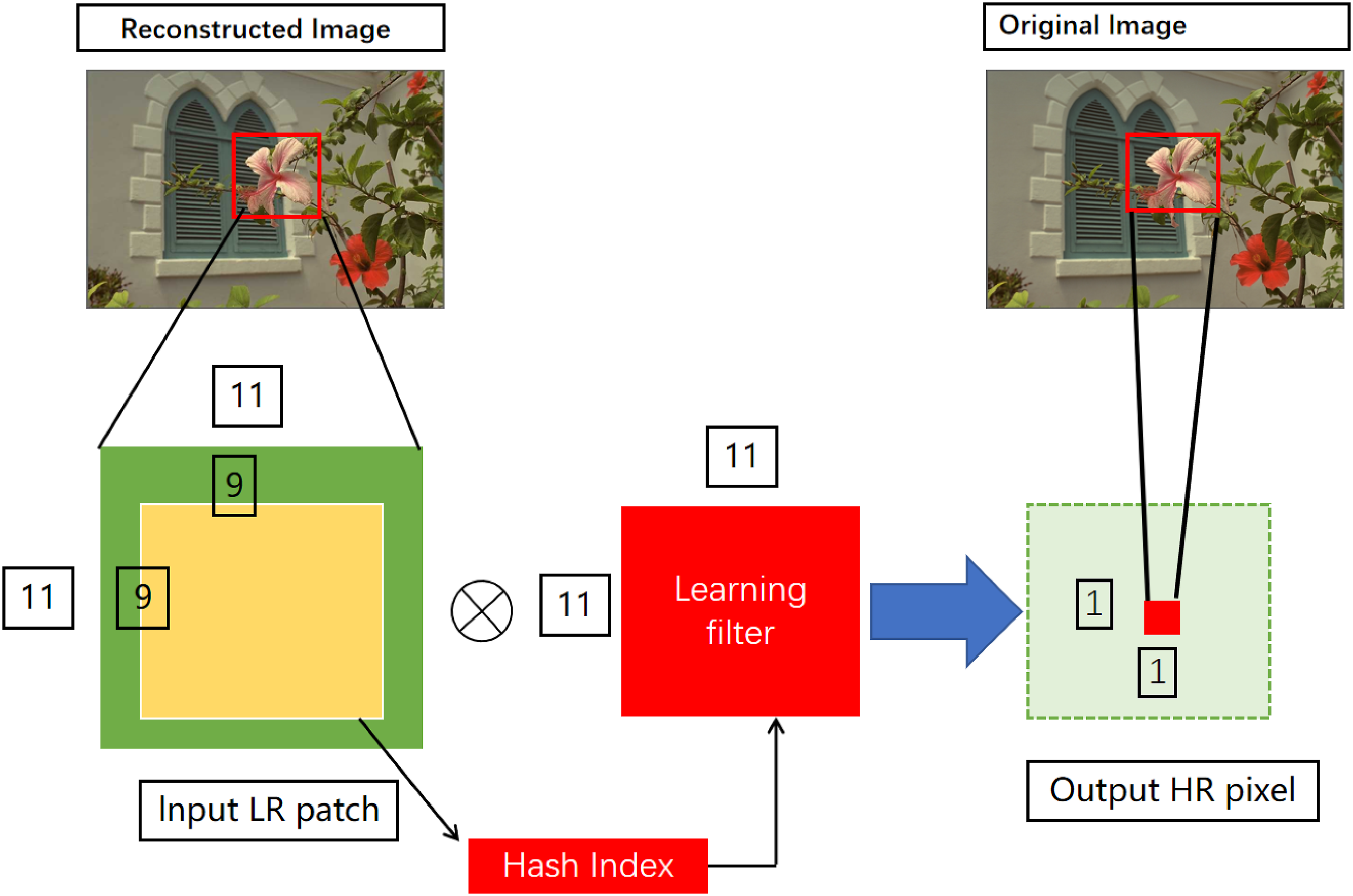
Gradient statistical classification adaptive filtering method based on data training
ALF improves the image quality by estimating Wiener filters at the encoder, which minimize the mean square error (MSE) between the original and reconstructed samples.
17
Initially, each pixel is categorized into one of L classes
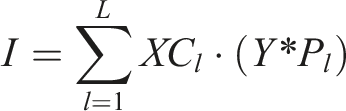
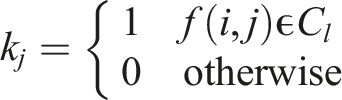
Our proposed approach introduces new feature-based classifiers to replace the existing classifier used in GALF. Each pixel location (i, j) is classified into one of multiple classes
This paper presents a method to achieve image content adaptivity by dividing pixels into classifiers and constructing filters based on gradient statistics. We use gradient angle, strength, and coherence as hash table keys. The goal is to improve the performance of image processing algorithms by adapting to the unique characteristics of different image regions.
To compute the direction, strength, and coherence, we analyze the local neighborhood of each pixel with a size of
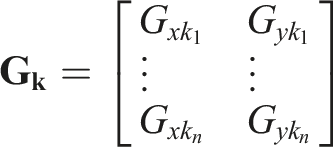
Global pixel filters learning
The filter h is obtained through learning from a dataset of images, which includes compressed reconstructed images

In this context, the filter h is represented as a vector of size d 2 × 1. The matrix
Due to the variations in image characteristics among different images, a single set of filter parameters may lead to algorithmic inefficiency. Therefore, in order to ensure compatibility and reliability of the algorithm, the image pixels are classified into different categories.
To achieve adaptivity to the image content, we adopt a clustering approach, dividing the image patches into clusters. For each cluster, we construct an appropriate filter using an efficient hashing technique based on angle, strength, and coherence, similar to the approach used in RAISR. This enables adaptive filtering while maintaining the low complexity of linear filtering.
In Figure 6, we observe the training of global filters and their application to enhance the quality of decoded frames. The global filter set consists of 216 filters, with angle, strength, and coherence values set at 24, 3, and 3, respectively. To determine the relevant filters for each patch in the initial interpolated image, we compute the hash table key using the equation angle9 + strength3 + coherence. This key allows for efficient identification of the appropriate filters for each patch. Global filters learning stage.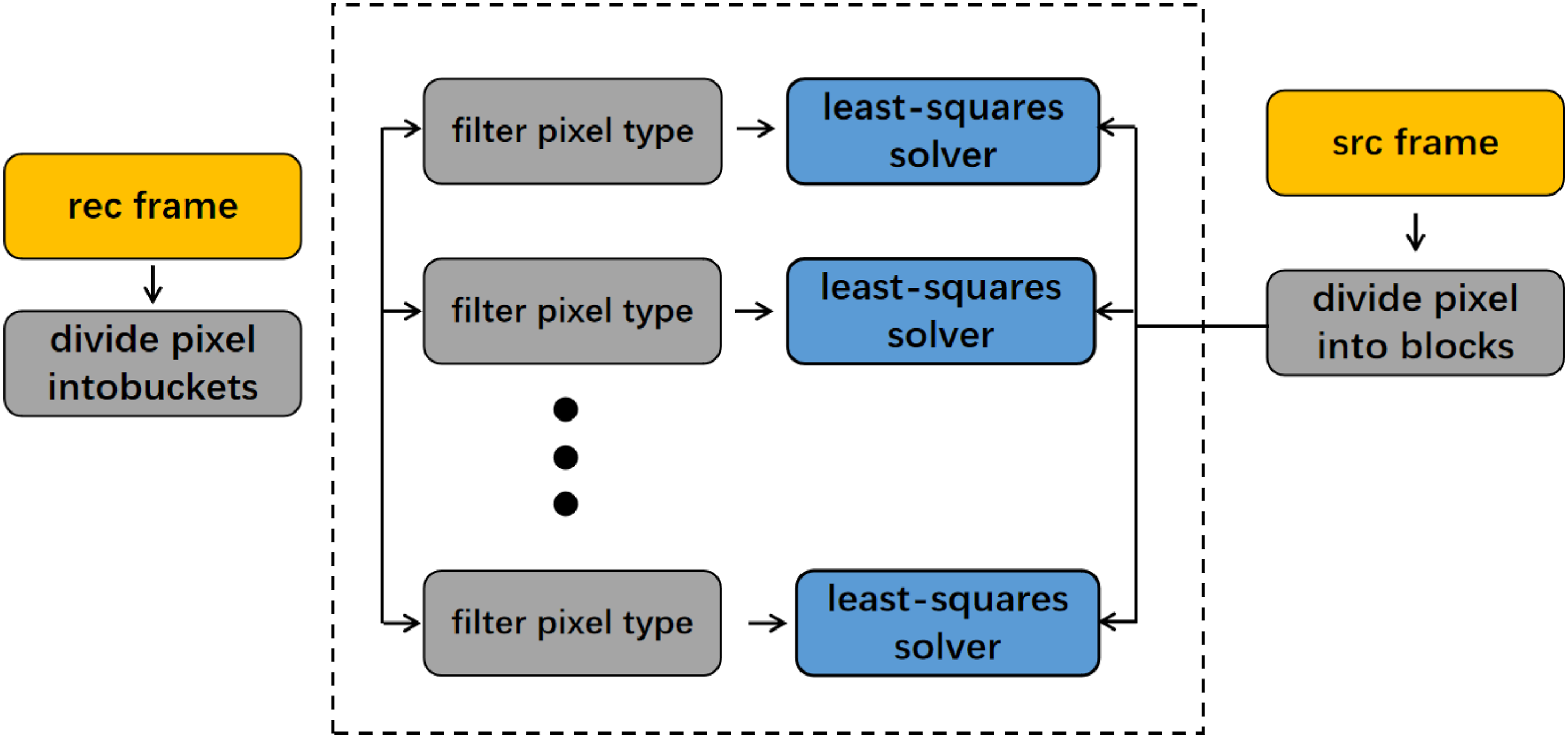
By training, a set of parameters that effectively enhance the quality of reconstructed images is obtained. Then, based on these parameters, the optimal settings for image filtering are chosen to achieve improved image quality. This is illustrated in Figure 7, which depicts the image reconstruction filtering stage. Reconstruction filter stage.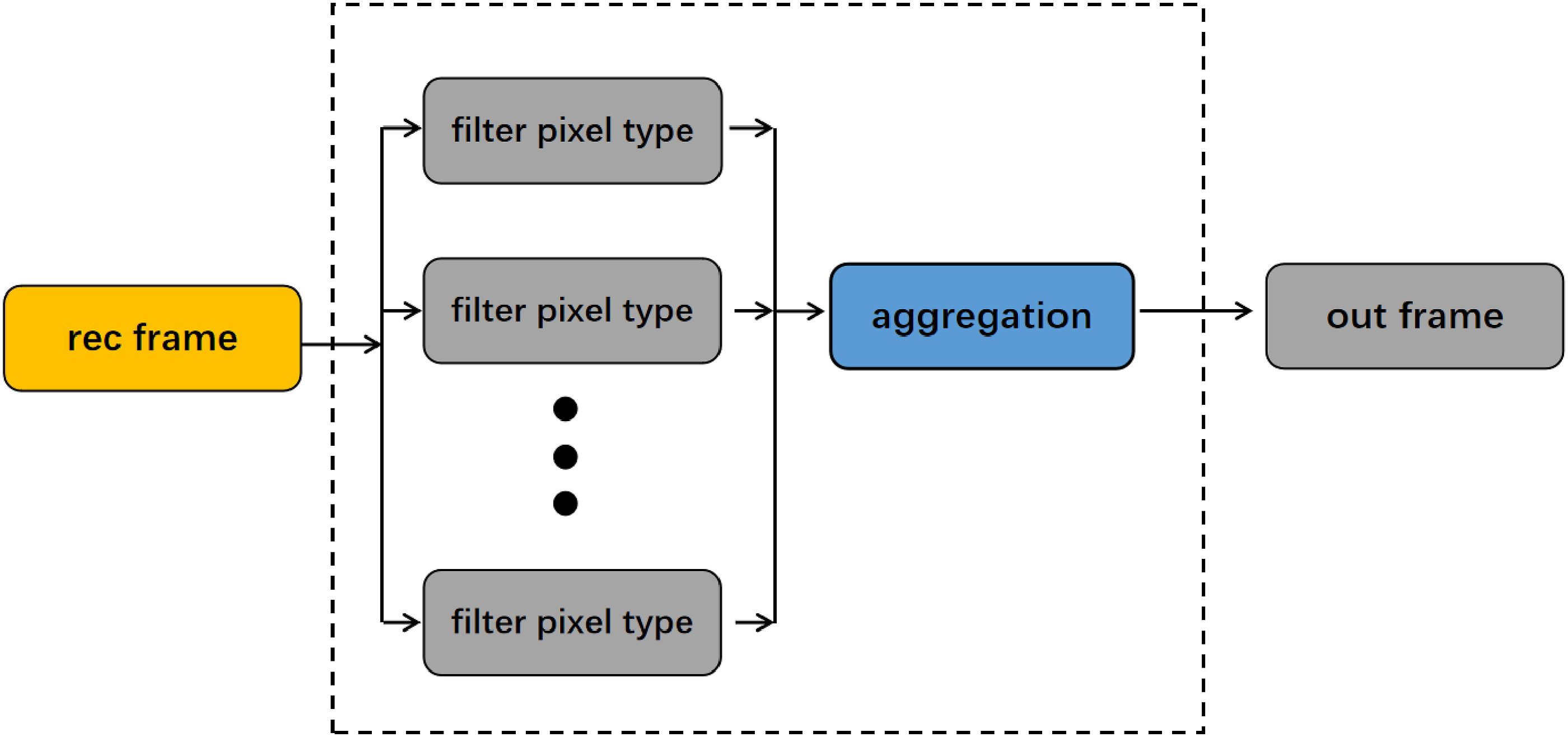
Results and discussion experiments
In this study, we introduce the GALFMLM, which integrates machine learning techniques for image filtering enhancement. We comprehensively evaluate its performance by juxtaposing it with existing methods. We delve into its proposed performance and provide a thorough comparison with alternative approaches. To validate our approach, we contrast it with the JPEG image compression algorithm in terms of practical performance enhancement. For comprehensive comparison, we employ both rate-distortion (R-D) analysis and subjective quality assessment. Furthermore, we conduct an ablation study on the GALFMLM to further validate and optimize its performance. To enrich the content of this paper, we conduct numerous experiments and analyses to establish the feasibility and efficacy of the model.
Training and testing
During the experimental process, we utilized different open-source datasets for our training and testing sets to adequately verify the effectiveness of our proposed methodology. Specifically, the paper employed the BSDS500 database 18 as our model’s training set. This entailed using the disjoint training set consisting of 200 images for both training and testing purposes, while the validation set containing 100 images was solely employed for validation. In practice, we trained our model using the 200 images from the training set.
For testing purposes, we employed the Kodak dataset 19 along with Set14. 20 The Kodak dataset primarily comprises 24 images with a size of 768 × 512 pixels. The Set14 dataset is another commonly used dataset for super-resolution reconstruction. It consists of 14 testing images with a size of 512 × 512 pixels. These images encompass various scenes and objects, allowing for testing the algorithm’s robustness and generalization capabilities.
Implementation details
The proposed method utilizes the following parameter settings: In our method, we adopt an 11 × 11 patch size for the filter, which aligns with the original RAISR approach. For the computation of hash key parameters, the hash table index size is set to 9 × 9, centered around the patch. Additionally, the λ threshold value is set to 1.08 × σ × 10^-2 for both steps in our proposed method. This threshold value helps determine the significance of coefficients and enhances the overall performance of the method. All experiments in this paper were conducted on a 2.60 GHz Intel Xeon(R) Gold 6132 CPU processor with 64 GB memory, using Python. Additionally, two NVIDIA Tesla T4 GPUs were available, although they were not utilized for comparison purposes. Quality assessment in this paper was performed using PSNR and SSIM measurements.
Performance comparison
To assess the rate-distortion performance, we observed rate-distortion (R-D) points and plotted R-D curves. Specifically, the rate was measured using bits per pixel (bpp). We conducted evaluations of the compressed reconstructed images using two methods: subjective evaluation and objective evaluation. Subjective evaluation is influenced by various factors and primarily relies on human visual perception to evaluate the quality of the compressed reconstructed images. In this study, we employed PSNR as an objective evaluation metric to investigate the performance of compressed image reconstruction. To visually demonstrate the superiority of our proposed model, we calculated the PSNR values of the compression reconstruction images generated using our method and compared them with those obtained from other methods.
Analysis of experimental results
To enhance the accuracy and precision of our testing methodology, we utilized distinct image datasets for the training and testing phases. Specifically, the BSD500 dataset was employed for training purposes, while the Kodak dataset and Set14 dataset were used as separate testing sets to evaluate the performance of our approach.
Rate-distortion performance
During the training process, we used the BSD500 dataset for training purposes. The original images from this dataset were compressed and then reconstructed using JPEG with a quantization parameter (QP) set to 50. These reconstructed images were utilized as input for the training set. The original high-resolution images from the BSD500 dataset served as the ground truth for comparison and evaluation. By training the machine learning model on this data, we obtained the parameters necessary for image filtering.
During testing, the Kodak dataset was employed. The JPEG image compression was performed with various QP values: 5, 10, 20, 30, 40, 50, 60, 70, 80, and 90. This yielded corresponding reconstructed images. Subsequently, the trained model was applied to enhance the reconstructed images using image filtering techniques, as shown in the figure. To assess the performance of our approach across various compression configurations, we performed JPEG image compression with various quantization parameter (QP) values. Specifically, we used QP values of 5, 10, 20, 30, 40, 50, 60, 70, 80, and 90 to compress the images from the test dataset. This process generated a series of reconstructed images corresponding to each QP value. We applied our trained model to enhance the reconstructed images using image filtering techniques. The enhancement process is illustrated in the figure mentioned in the paper. During the testing phase, we employed the Kodak dataset to evaluate the R-D performance curve. As shown in Figure 8, our proposed machine learning approach resulted in a significant enhancement in the quality of the reconstructed images. Additionally, based on the quantization distribution, when the QP values were set at 40, 50, 60, and 70, the quality improvement was more pronounced compared to other quantization parameters. Our proposed PSNR improved over JPEG codec R-D performance averaged on Kodak dataset.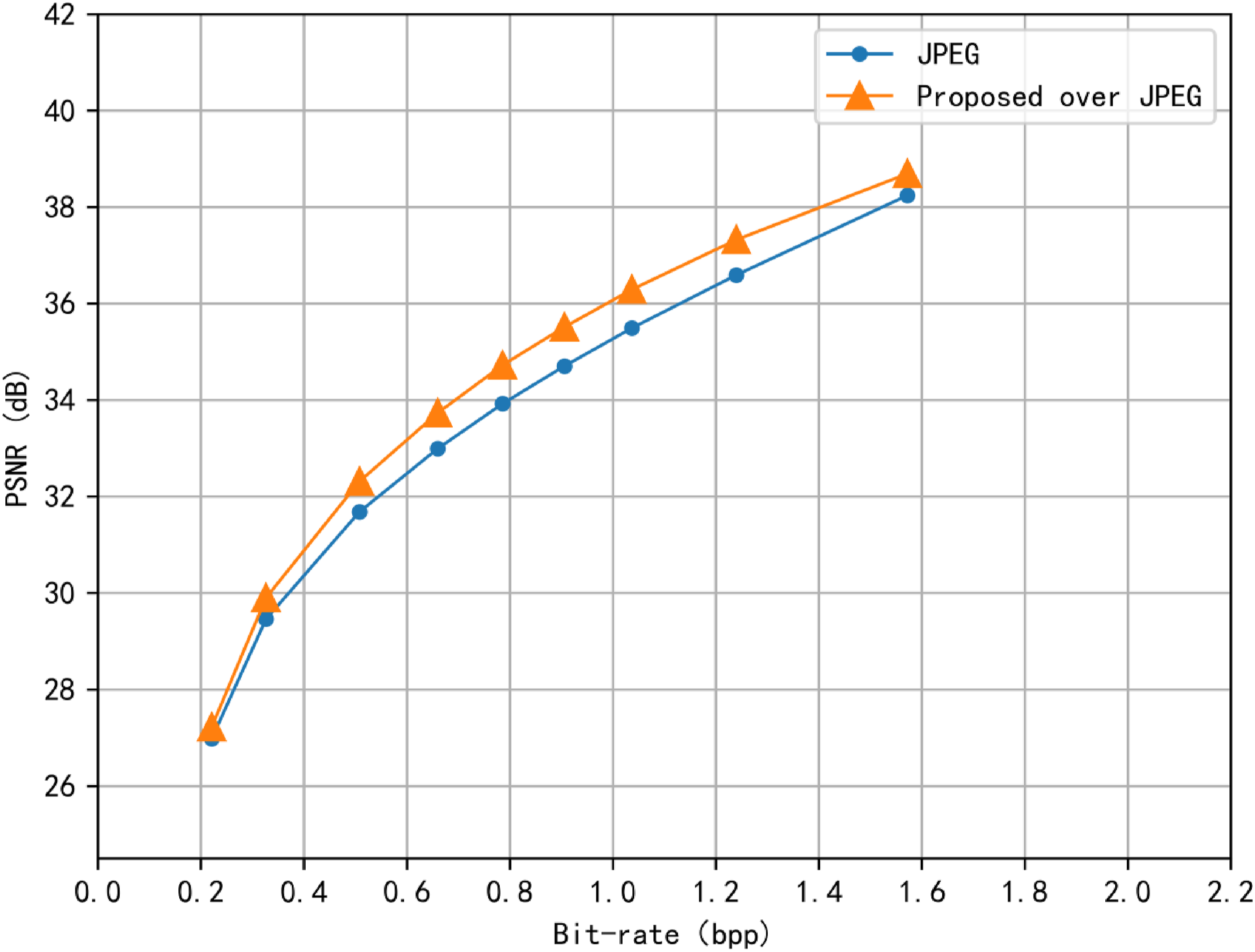
During the testing phase, we utilized the Kodak dataset to test R-D performance curve on Set14 dataset. The performance improvement is illustrated in Figure 9. Our proposed PSNR improved over JPEG codec R-D performance averaged on Set14 dataset.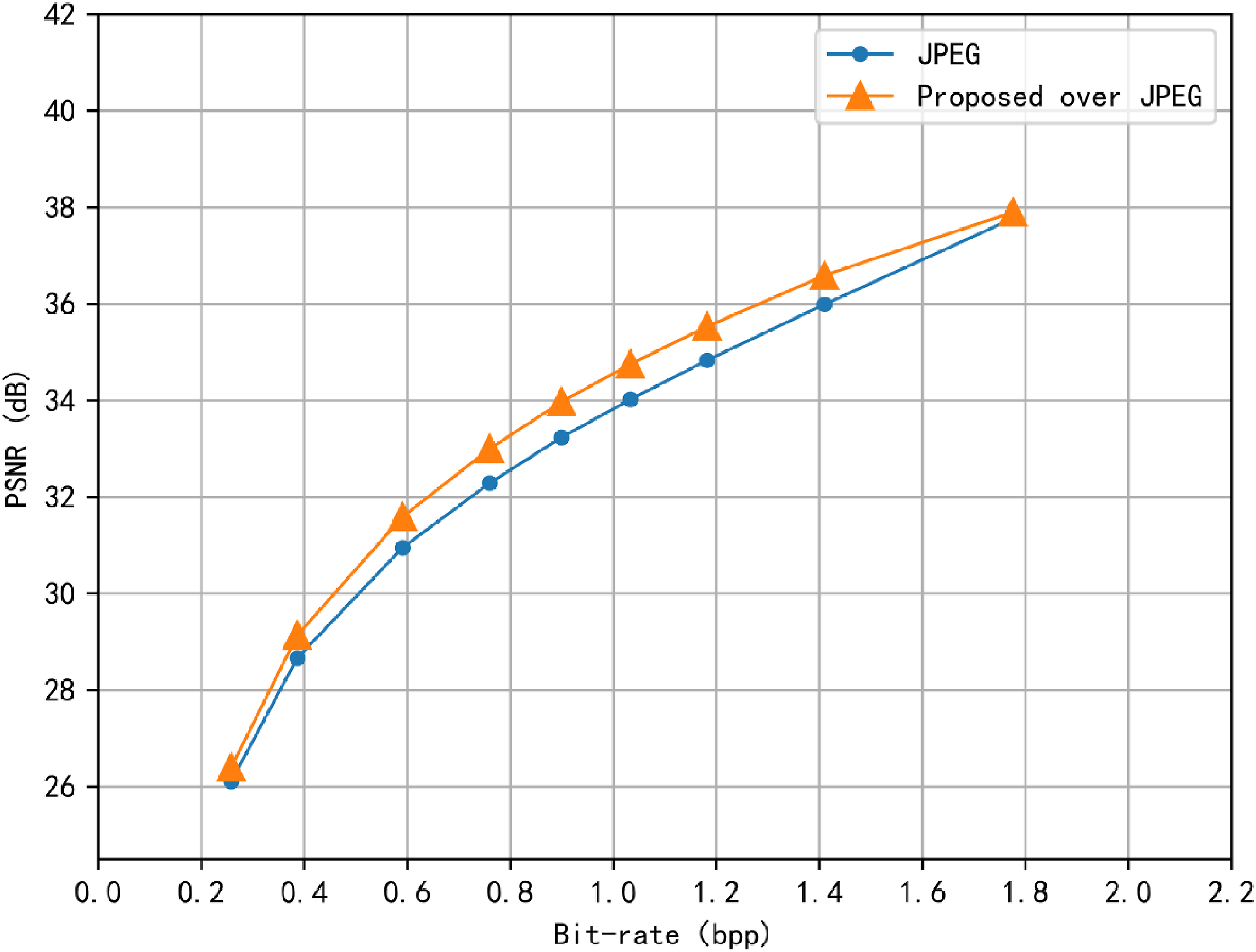
This paper adopts a traditional machine learning approach that learns global image filter groups, which effectively addresses the issues of artifact removal and distortion in the image reconstruction process. Through experimental results, our proposed model demonstrates the ability to significantly improve the quality of reconstructed images and enhance compression efficiency. Compared to deep learning-based methods, our model exhibits faster image filtering speed and better compression capabilities.
Visual comparison
In Figure 10, we provide visual representations of the reconstructions and close-ups obtained via the JPEG compression method and our proposed approach. The comparison focuses on examining the bit rate around 0.76 bits per pixel (bpp). Visual inspection reveals that our proposed method effectively improves the subjective quality by producing images with enhanced sharpness in textures and reduced noise when compared to the results obtained from JPEG compression. Enhanced Qualitative Visualization: Our proposal significantly improves subjective image quality, with each image marked with its PSNR and corresponding BPP values.
Conclusions
In this paper, we propose a machine learning-based image compression method that achieves high-quality results. Our approach surpasses the performance of the original JPEG compression on Kodak dataset and Set14. The GALFMLM method learns global image filters using machine learning and effectively restores high-definition images. By leveraging JPEG decoded image features, our method employs a unique approach to learn and apply global filters using an efficient hashing mechanism, resulting in enhanced reconstructed images. This innovative method holds promise for improving image quality in various applications, and further refinements and investigations are recommended for future exploration.
Statements and declarations
Footnotes
Conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge Foundation for 2022 Basic and Applied Basic Research Project of Guangzhou Basic Research Plan (research on video compression algorithm based on dual neural network, Grant: 202201011753), Research and Practice on AI-based Classroom Teaching Evaluation Reform (Grant: 2023GXJK736), Guangdong Polytechnic of Science and Technology College-level Project: Deep Learning-Based Classroom Teaching Quality Evaluation System (Grant: XJPY202302), Research and Practice on Classroom Teaching Evaluation Reform Based on Virtual and Reality Integrated Education in the Metaverse (Grant: JG202216), Computer Vision Application Innovation Team (Grant: 2022KCXTD047), Guangdong Intelligent Vocational Education Engineering Technology Research Center (Grant: 2021A118), Special projects in Key Fields of Colleges and Universities in Guangdong Province, China (Research on intelligent security inspection technology of X-ray fluoroscopy articles based on AI image recognition Grant: 2021ZDZX3040), Special projects in Key Fields of Colleges and Universities in Guangdong Province (new generation electronic information Grant: 2022ZDZX1053), and Key field Project of General Colleges and Universities of Guangdong Provincial Department of Education (Grant: 2021ZDZX3029).