
Abstract
This paper aims to establish a predictive model for hydro turbine failures by simulating rare real-world data using a digital twin system. Hydro turbines play a critical role in the renewable energy sector, but their unpredictability in terms of failures results in significant maintenance and operational costs. The traditional fault prediction method based on historical data is difficult to achieve more accurate and generalized modeling, because the data in the real world cannot meet the requirements of the machine learning theory for the same distribution of data and data balance, especially some rare events are difficult to collect in reality. Therefore, in this paper, it is proposed to enhance the robustness of hydro turbine failure prediction by simulating data from some rare situations through a digital twin system. By collecting and simulating rare data from actual hydroelectric turbines, we gain a better understanding of their operational mechanisms and fault patterns. We propose a digital twin system capable of replicating real-world operating conditions in a virtual environment, which serves as the foundation for data-driven fault prediction models. Through deep learning analysis of the simulated data, we can predict the likelihood of hydro turbine failures, thus improving maintenance strategies, reducing costs, and enhancing turbine reliability. Our research offers a promising approach to addressing rare data challenges using digital twin systems and holds broad application potential within the hydropower industry.
Introduction
As the necessity of environmental protection becomes more and more important, energy has also undergone major innovations, and human society has become more and more urgent for renewable and low-carbon energy. 1 Hydropower is a renewable energy source that uses the kinetic energy of water flow to generate electricity. Its renewable, emission-free and long-lasting reliability make it a popular energy source around the world. Hydroelectric power does not rely on the combustion of fuel, so it releases no harmful greenhouse gases or other pollutants and has a smaller impact on the environment. As the primary source of electric power resources,2,3 hydropower is widely used around the world. Globally, hydroelectric power accounts for 15.14% of all electricity consumption. In Iceland, hydroelectric power accounts for as much as 71% of electricity production, and in Norway, this figure reaches 88%. In Bhutan, hydroelectric power even reaches a 100% share. In Canada and Sweden, hydroelectric power represents 61% and 40% of electricity production, respectively. This clearly demonstrates the widespread use and feasibility of hydroelectric power.
As the core equipment of hydroelectric power generation, the healthy operating status of a hydraulic turbine is closely related to power generation and economic effects. Turbine failure may cause immeasurable losses or even catastrophic accidents. 4 Monitoring and observing the operating status of hydraulic turbines, discovering abnormal operation, and repairing and maintaining the turbines are indispensable and even the most important tasks in the hydropower industry. The traditional method often involves a comprehensive assessment of the operating data and historical status of the turbine, which relies heavily on the experience of maintenance personnel. Even so, due to the numerous operating parameters of the turbine, it is often difficult for staff to detect some subtle abnormalities in time.
Time series forecasting (TSF), a fundamental component of time series analysis (TSA), is concerned with predicting future states. Due to its broad array of applications encompassing fields such as healthcare, stock market trends, weather forecasting, fault prediction, and more, time series forecasting has garnered growing interest from both academia and industry.
Time series prediction can be roughly divided into two categories: statistical learning methods and deep learning methods. Statistical learning methods often convert time series signals into frequency domain signals by designing time series signal analysis, such as Fourier transform and wavelet transform, and design a large number of manual features in the time domain and frequency domain respectively based on experience and statistical theory, and then use machine learning models (such as SVM) to perform prediction or classification. In recent years, due to the significant successes of deep learning methods in various domains, there has been extensive research on utilizing neural networks with forward propagation and gradient back propagation to adapt network parameters for time series prediction tasks, yielding promising results. The mainstream deep learning methods for time series prediction are mainly based on convolutional neural networks (CNNs), recurrent neural networks (RNNs), and Transformer, which has achieved great success in the field of natural language. Each of these methods has its own advantages and disadvantages. CNNs use convolution operators to extract local features and stack multiple layers. The network structure achieves the capture of global features, but deeper convolutional layers mean greater computing power and more difficult training. At the same time, CNNs does not capture the feature of event sequence, which happens to be the most important factor in time series prediction. RNNs have the capability to capture temporal sequences, but they suffer from issues such as gradient vanishing and gradient explosion. Additionally, as the data length increases, there is a bottleneck in extracting global temporal information. Subsequent improved network structures like LSTM and GRU have not fully addressed these problems. Transformer exhibits strong capabilities in extracting and integrating global information. However, its core component, self-attention computation, has a high time complexity. Subsequent enhancements such as linear self-attention, sparse self-attention, and local self-attention have to some extent overcome these shortcomings. In addition to the aforementioned points, there is another critical issue. In machine learning and deep learning theory, data-driven learning methods require data to be independently and identically distributed (i.i.d.) and balanced across classes. However, in real-world scenarios, obtaining a large volume of data for rare events such as extreme weather conditions, water pollution, floods, and the like can be challenging. This leads to a situation where these rare events are not adequately represented in the modeling process.
The concept of digital twins (DT) can be traced back to 1991 when David Gelernter first proposed it. It is a mapping from the real world to the virtual world and consists of three main components: objects in the real world, models in the virtual world, and the connections that bring them together. These connections involve the exchange of data, information, and knowledge. All data originate from sensors on physical objects in the real world, and this data is used to create or update the virtual models. Furthermore, digital twinsystems can predict the state of physical objects and transmit information back to the real world, such as weather conditions, water flow, water quality, and more. In the real world, there are also extreme examples, such as the catastrophic floods in China in 1998 and the sustained heatwaves in 2022. These events lack reference data, making it nearly impossible to predict anything in such cases. Fortunately, we can simulate these scenarios within the system, enhancing rare data and improving the model’s fit for these situations. This enhances the overall robustness of the model in different circumstances, resulting in more accurate and reliable outcomes and significantly reducing the occurrence of risks. To achieve this, our center has developed a hydroelectric turbine digital twin system. Through extensive data exchange between the real world and the virtual world using numerous sensors, and with the ability to simulate real-world scenarios, we can provide the system with data representing various external factors for the model to learn from.
This paper introduces an architecture for predicting the health status of hydroelectric turbines, using real-world historical records and simulated data from a digital twin system as inputs. The core modules of this method include attention mechanisms and gate mechanisms. We utilize gate mechanisms, similar to those in Convolutional Neural Networks, to capture and filter basic features. Additionally, we employ masked self-attention to capture semantic features while avoiding information leakage. We collected a substantial amount of data for relatively rare real-world scenarios to validate the effectiveness of our proposed approach. Experimental results demonstrate that the method presented in this paper outperforms traditional time series forecasting models and provides valuable insights for other time series prediction models.
Related work
In recent years, the application of deep learning methods for time series forecasting has gained significant attention from researchers due to their effectiveness in capturing complex temporal patterns. Traditional time series forecasting methods, such as the autoregressive integrated moving average (ARIMA) model, 5 rely on statistical and mathematical analysis, making them theoretically robust. However, they do have certain drawbacks. Firstly, statistical theory is population-based, which means that it tends to overlook intricate details, sometimes leading to suboptimal outcomes. Secondly, these methods are primarily suited for univariate forecasting problems, limiting their applicability in the context of multivariate time series data. With the ever-increasing availability of data, the relevance of these methods may dwindle over time. In contrast, recent advancements in deep learning-based approaches have witnessed remarkable success in the realm of time series analysis.6–13
Early on, recurrent neural networks (RNNs) and their variants were the predominant choices for time series forecasting.14,15 These models retained historical information in hidden states and updated them at each time step to propagate information from the past to the future. Nevertheless, issues like gradient vanishing and exploding and computational inefficiency have significantly constrained the widespread adoption of RNNs.
Convolutional neural networks have traditionally been associated with image processing tasks, but they have shown promise in handling sequential data as well. In time series forecasting, CNNs apply convolutional filters to capture local patterns within the data. Various studies have explored CNN-based approaches, Bryan et al. 6 introduced the use of 1D convolutional neural networks for time series prediction, demonstrating their effectiveness in capturing local dependencies within the data. Yu et al. 16 proposed a spatiotemporal convolutional network for traffic prediction, which combines spatial and temporal information to enhance prediction accuracy. Temporal convolutional networks,9,17 rooted in convolutional architecture, represent another category of time series forecasting methods. Their design, leveraging convolutional operators, excels at capturing local features. However, the trade-offs include limited receptive field size and the escalating computational cost associated with deeper networks.
Following the triumphant performance of Transformers in natural language processing, Transformer-based methods have gradually supplanted RNNs in nearly all sequence modeling tasks. The Transformer’s remarkable capability to capture global features efficiently has garnered high praise from researchers and engineers alike. Lim et al. 18 proposed the Temporal Fusion Transformer (TFT) specifically designed for time series forecasting. TFT combines self-attention with autoregressive components, achieving state-of-the-art performance on various forecasting benchmarks.
Time series data’s local correlations are often reflected in the continuous variations within specific time intervals. Convolutional filters are adept at capturing these local features effectively. Typically, small-sized convolutional filters are preferred, as larger filters increase computational costs without significantly improving performance. To expand the receptive field, stacking additional convolutional layers is a common approach. However, this results in a deeper network, which can be computationally expensive and challenging to train.
In our study, we harness the strengths of both CNNs and Transformers. Our proposed architecture can be likened to an encoder-decoder framework. The encoder takes real-world historical records as input in a multi-channel format. To accentuate important features and filter out irrelevant information, we employ channel-wise attention CNN. Subsequently, self-attention is employed to capture global semantic representations. The decoder receives input from the simulated data generated by the digital twin system. To prevent information leakage, we incorporate temporal convolutional network (TCN) and masked self-attention. All the intricate details of our method are elaborated in the following sections.
Method
Figure 1 illustrates the architecture of our proposed time series prediction model. The input consists of two parts: real-world historical records and future states simulated from the digital twin system. Inspired by the causal generative model in natural language processing models, different network designs are used for the two parts of input. The historical input part accepts the past records as input and uses standard convolution operators for feature extraction. The simulated input part takes the simulated data as input, in order to prevent information leakage from causing failure of the prediction task, and the convolution operator in this part adopts the TCN convolution structure. A more detailed description of the model structure will be explained in the following sections. A brief view of our proposed architecture. The input of the proposed architecture consists of two parts: the past records in the real world and the simulated data from digital twin system. Channel-wise attention mechanism, gating mechanism, and CNN are used to extract basic features. To capture global semantic representation and avoid information leakage, masked self-attention is applied.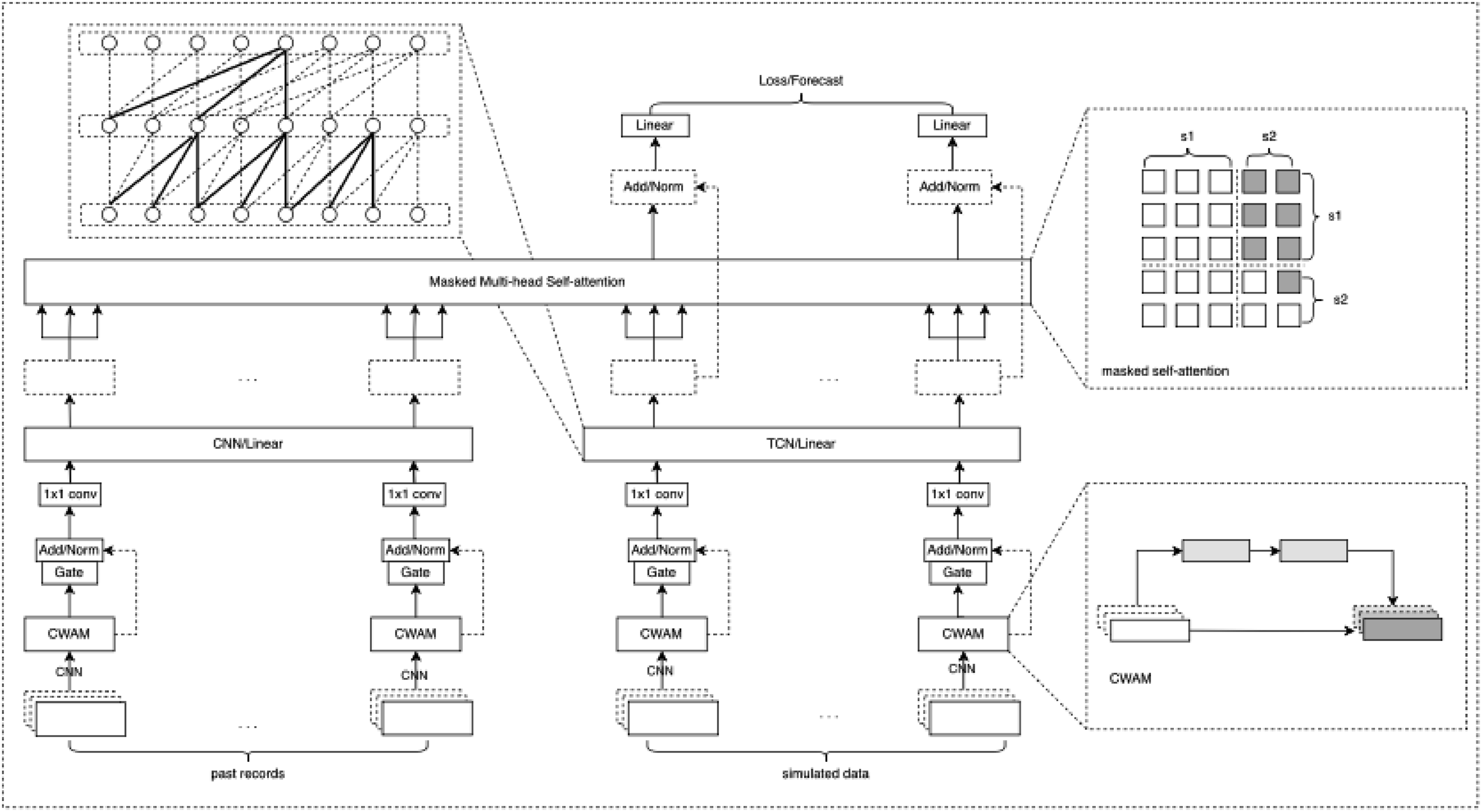
Data preprocessing
The input includes various factors. We call the different factors channels and divide them according to predetermined time units (the default is days). Since the sampling rate of each channel is different when collecting, the length of the input is also different. Therefore, we downsample different channels to approximate lengths and truncate the remaining parts that cannot be calculated accurately. Stack all channels into a 1D multi-channel input

Channel-wise attention mechanism (CWAM)
Our research object is multi-variable continuous time series. We believe that there is digital redundancy in multi-variable continuous time series between channels and within channels. Within channels, we have eliminated certain redundancies through down sampling.19–22 As for between channels, we use CWAM to control, and the main goal of CWAM is to enhance the importance of the model to different channels or features while reducing the dependence on irrelevant channels or features to improve the performance and generalization ability of the model. CWAM operator is shown in Figure 2. We use The channel-wise attention module.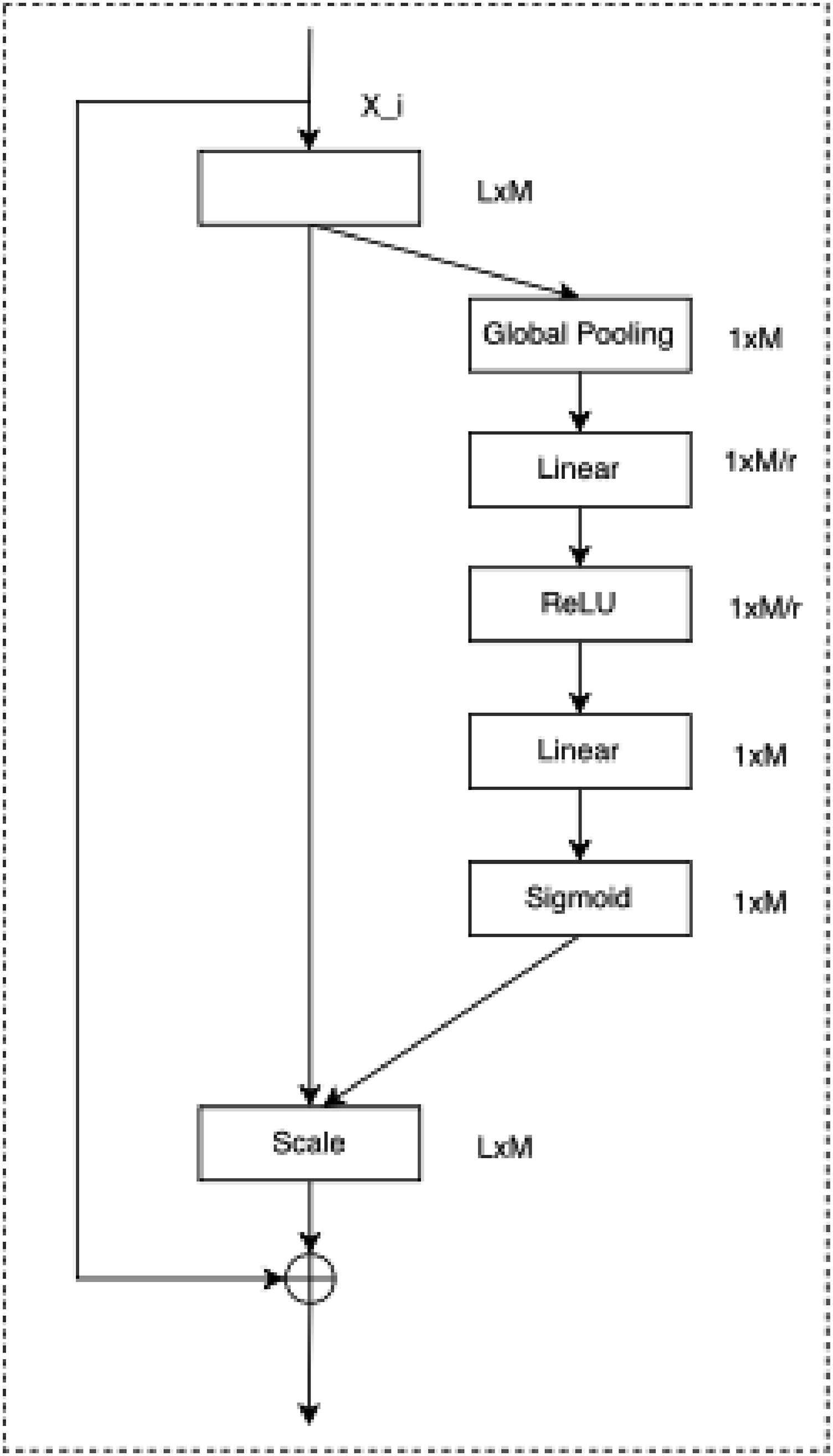



Inspired by transformer architecture, we add a residual connection between the input and scale operation results, and this is used to build a direct channel of the network, thereby making the training of the network more stable. The final output of channel-wise attention module is computed as follows:

Mixture gating mechanism (MGM)
As shown in the previous two sections, we filtered the redundant information between channels and within channels to a certain extent. But the two are separated, and the multi-variable timing input should be treated as a whole. Motivated by this view, an additional MGM is used to once again increase the enhancement and filtering of multi-variable timing information. For time step t hidden state Overview of masked self-attention operation.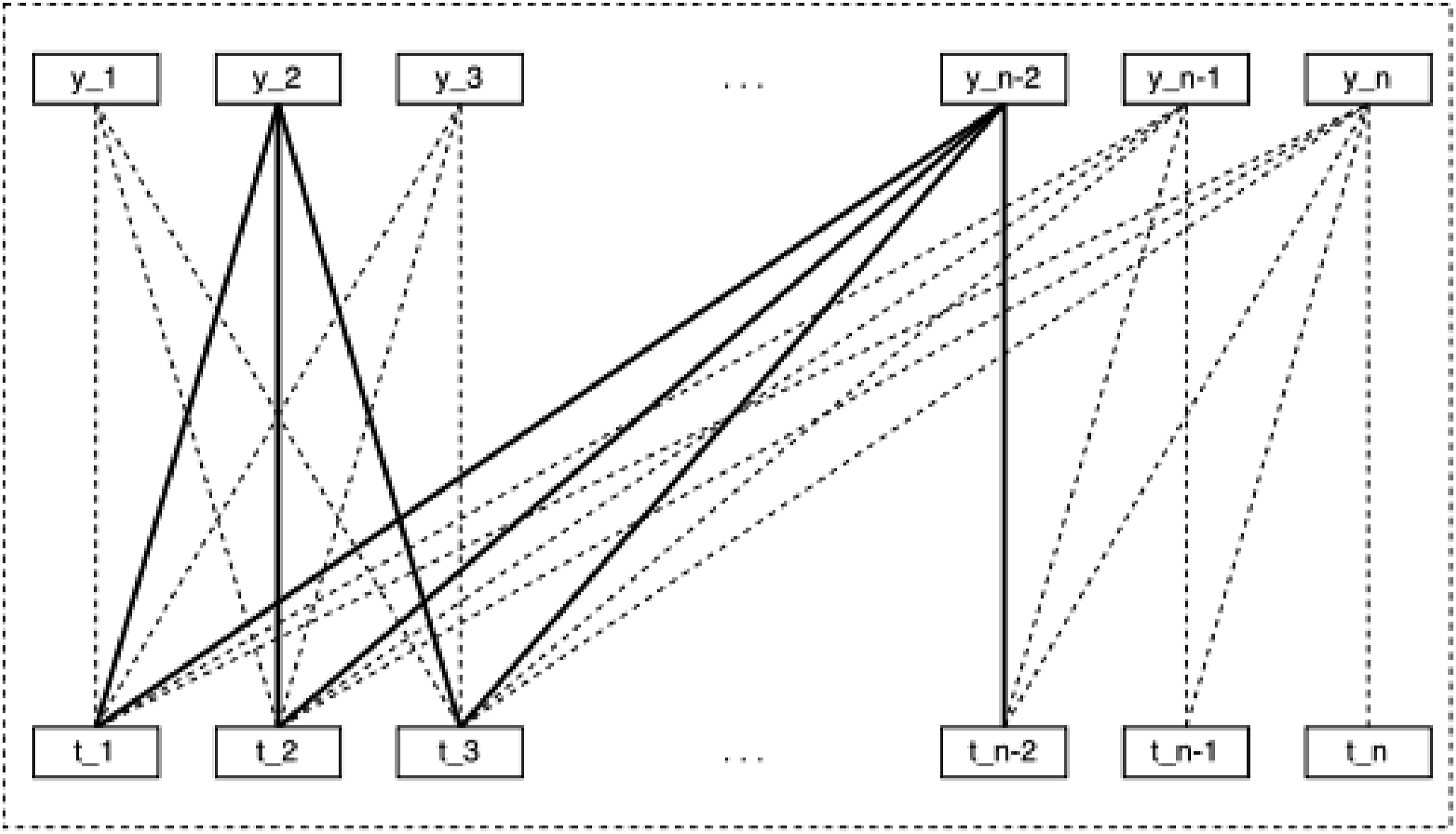

Masked self-attention
Self-attention is the core component of transformer, which was proposed in 23–25. By mapping different tokens to different linear spaces of Q, K, and V through linear transformation, weighted sum of V by different correlations of Q and K as weights. Therefore, it has strong power to extract global information through the interaction of K, Q, and V.
As mentioned in 23, self-attention is calculated by


To improve the learning capacity of self-attention, multi-head self-attention is proposed, employing different heads for different representation subspaces:
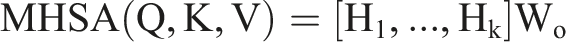

where
As can be seen from the above introduction, self-attention is a bidirectional encoder. This calculation method is not suitable for timing prediction tasks and will cause information leakage, that is, the future information will be introduced into the present, but in the real world, and cannot predict future information in advance, so there is often a big difference between training and inference. Therefore, we mask the attention matrix formed by all Q and K so that no future information is introduced when integrating the information at the current time. Specifically, the above A(*) operator becomes the following way:

Experiments
Datasets
Utilizing the digital twin system we’ve developed in-house—a visual representation of which is depicted in Figure 4—we have the capability to recreate a myriad of extreme scenarios through simulation. These scenarios encompass a range of adverse conditions including elevated temperatures, periods of drought, flooding, typhoons, and instances of water contamination, among others. In concert with each simulated data point, we meticulously acquire contemporaneous environmental, meteorological, and water quality data to ensure comprehensive datasets. The appearance of the digital twin system (a) and (b) are the 3D visualization model of hydro turbine (c) is the plane of running parameters.
Collected data dimensions and data types.
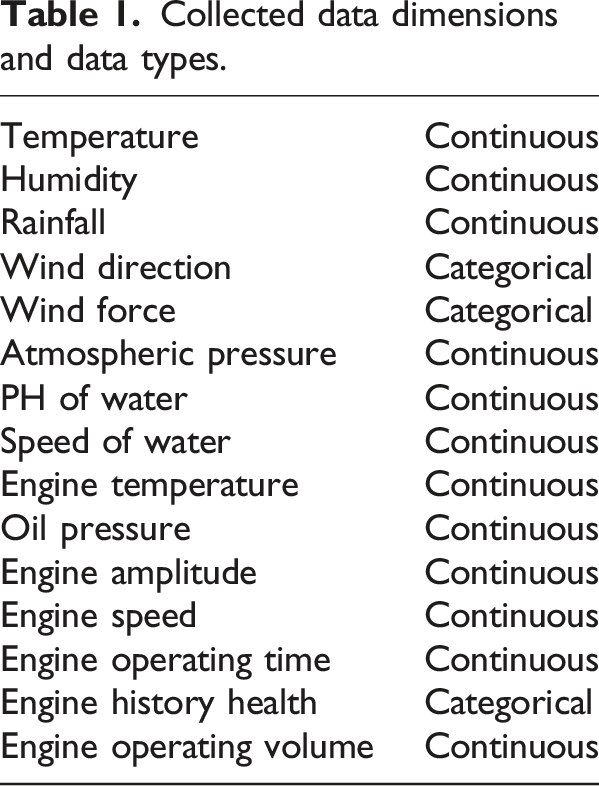
The dataset at our disposal comprises a variety of data types including but not limited to temperature readings, meteorological conditions, and precipitation levels, along with other external environmental factors. These datasets consist of continuous numerical values that vary in magnitude and are represented as floating-point numbers of assorted lengths. We organize this information on a daily basis, designating the preceding day’s data as the target for our forecasts, while utilizing the antecedent data as a historical reference.
Embedded within this collection are several parameters indicative of the hydro turbine’s state, such as the engine’s temperature, oil pressure, and vibrational amplitude. To enhance the realism of our data, we employ state-of-the-art simulators that replicate abnormal operational conditions mirroring real-life scenarios. These simulations are then harmonized with our digital twin system using an array of sensors. Upon the digital twin system’s acquisition of new data, it activates its internal simulation engine to project various future scenarios, generating additional simulated data. This simulated output is subsequently captured via sensors and the data interface of the digital twin system.
The aforementioned process encapsulates an interactive loop where data transmission and collection are carried out in tandem. All assimilated data is temporarily housed within our database, serving as a reservoir for future analytical endeavors. Both historical and simulated datasets are amalgamated to serve as inputs for our model. Our experimentation is anchored in classification, distinguishing between Normal State (NS), Alert State (AS), and Fault State (FS). The proportional distribution of these categories within our collected data is visually represented in Figure 5. To ensure the rigor and reliability of our experimental results, we have implemented 3-fold cross-validation within our methodological framework. The categories distribution of hydro health state forecasting.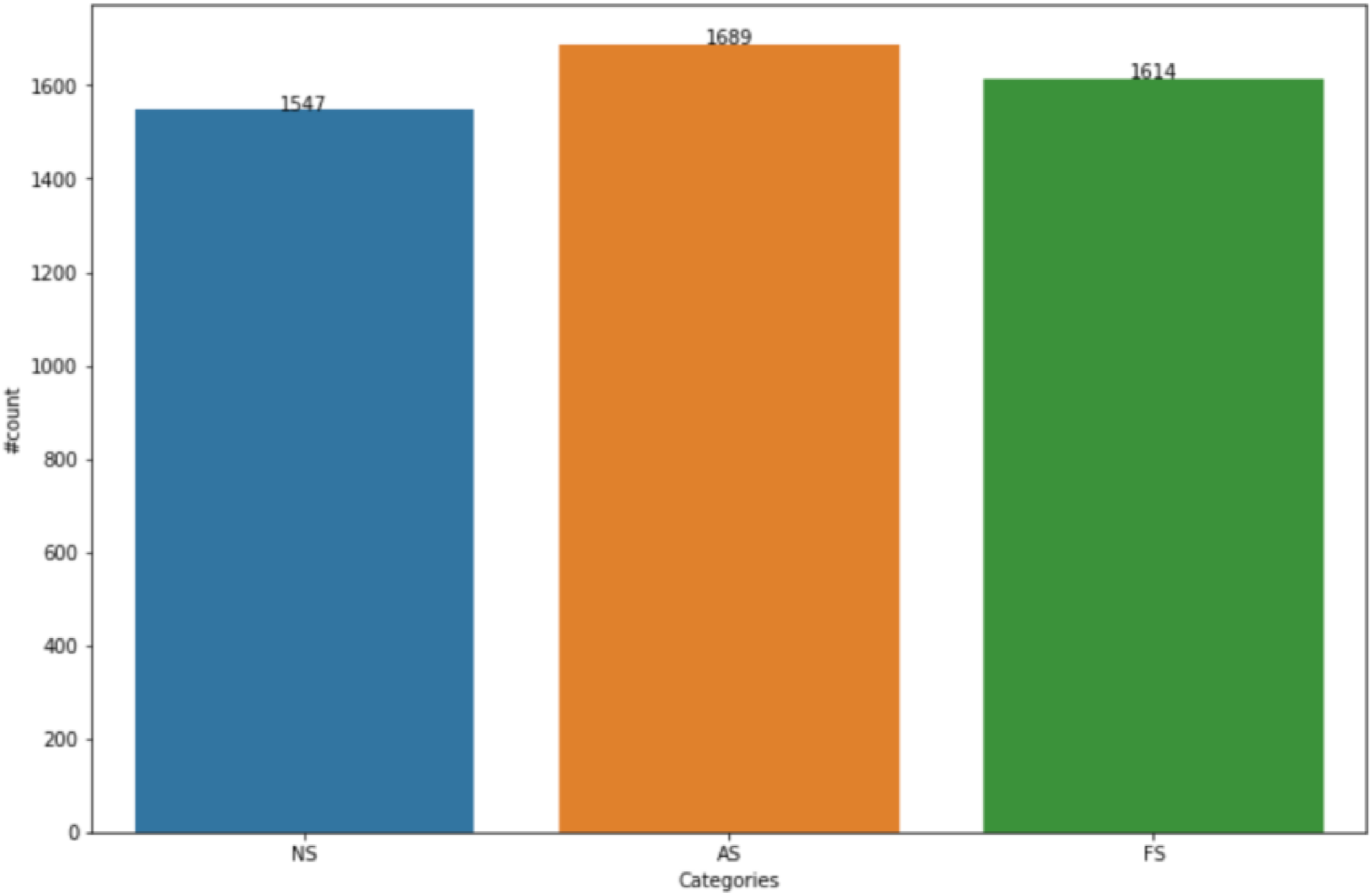
Preprocessing
It can be seen from Table 1 that the collected data includes two types of data: continuous type and discrete type. When these different data types are to be input into the model at the same time, these data types need to be processed uniformly. First, we perform embedding processing on the discrete data, transform it into a vector through linear transformation, and update the parameters along with the model training. For continuous data, due to the difference in sensor sampling rate, the length of each data is different. In order to better handle continuous variables with different sampling rates, we use resampling technology to sample all data to 1 k, and then use the average value of each second as the value at the current time step. The above-mentioned day is used as and the divided data is normalized by min-max normalization to eliminate the influence of data size, and data less than 1 day is truncated and discarded. We also tried Z-score normalization, but the final effect was worse. And align it with the dimension after discrete data embedding through linear transformation. Finally, all the data are spliced according to different channels to form multi-channel data. The channels are then manipulated through a convolutional neural network to satisfy the operational requirements of the model data flow. And through experiments, it is found that too large a dimension and too small an embedding dimension will affect the performance of the model, and the dimension between 512 and 768 has basically no effect on the final performance.
Implementation details
Our proposed architecture is developed using the deep learning framework PyTorch, specifically version 1.8.0. The entire suite of modules has been cohesively trained within an environment powered by Ubuntu 18.04. This robust setup is underpinned by a fleet of ten Intel Core i7 processors clocking in at 2.70 GHz, complemented by the formidable computational prowess of two NVIDIA GeForce 3090 GPUs, and bolstered by an ample 128 GB of RAM. Parallel computing support is provided through CUDA version 11.0, and the system is driven by Python 3.8.
To ensure a solid foundation for the network’s learning capability, parameters are strategically initialized using the Xavier method, which is renowned for its efficiency in maintaining the scale of gradients. We’ve harnessed the Adam optimizer for our training process, adhering to its default configuration which includes β1 set to 0.9, β2 to 0.999, and a weight decay rate of 0.005, balancing the fine-tuning of our model’s convergence. Starting with a learning rate of 0.01, we employ a cosine decay strategy to progressively refine the learning process throughout the training phases. Our training regimen prescribes a batch size of 128, spread across 200 epochs to thoroughly instill the necessary patterns and features in our model. During the model training, the standard cross-entropy loss function was used.
Additionally, we have calibrated the channel-wise attention mechanism with a reduction ratio, r, of 1.25. This fine-tuning aims to enhance the model’s focus on relevant features across channels, thereby improving the efficacy and precision of the learning outcomes.
Experimental results
Comparison results of methods.
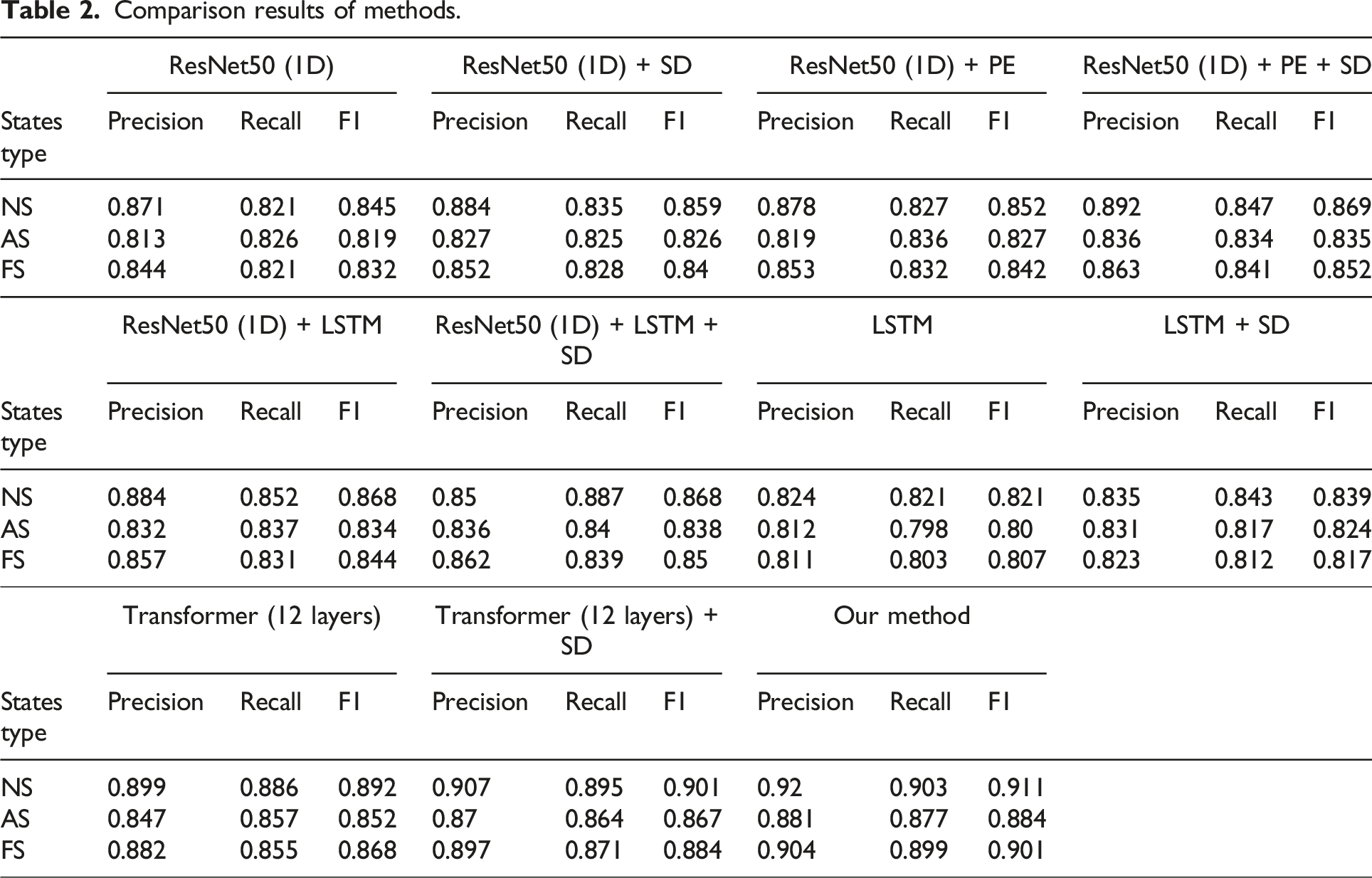
To provide a more vivid and discernible contrast between the varied methodologies, we have rendered the experimental outcomes in Figure 6. Inspection of this visual aid reveals that our method exhibits a considerable enhancement in performance compared to the other surveyed techniques. The incorporation of additional simulated data has been instrumental in augmenting the predictive accuracy. The issue of temporal constraints arises from the inherent inability of conventional CNNs to integrate positional data, which is pivotal for time-sensitive analysis. While prior research has suggested that CNNs can implicitly gain some positional awareness via padding operations, this mechanism is substantially limited, especially in the context of long-term time series evaluation. When juxtaposing the performance of “ResNet50 (1D) + PE + SD” with “ResNet50 (1D) + LSTM + SD,” it becomes apparent that the disparities between LSTM and CNN augmented with PE are not pronounced, indicating that CNNs with positional encoding can rival the capabilities of RNNs. Nevertheless, LSTMs are observed to fall short in the domain of extensive temporal modeling, struggling to aptly capture long-range dependencies. Visualization of comparison results.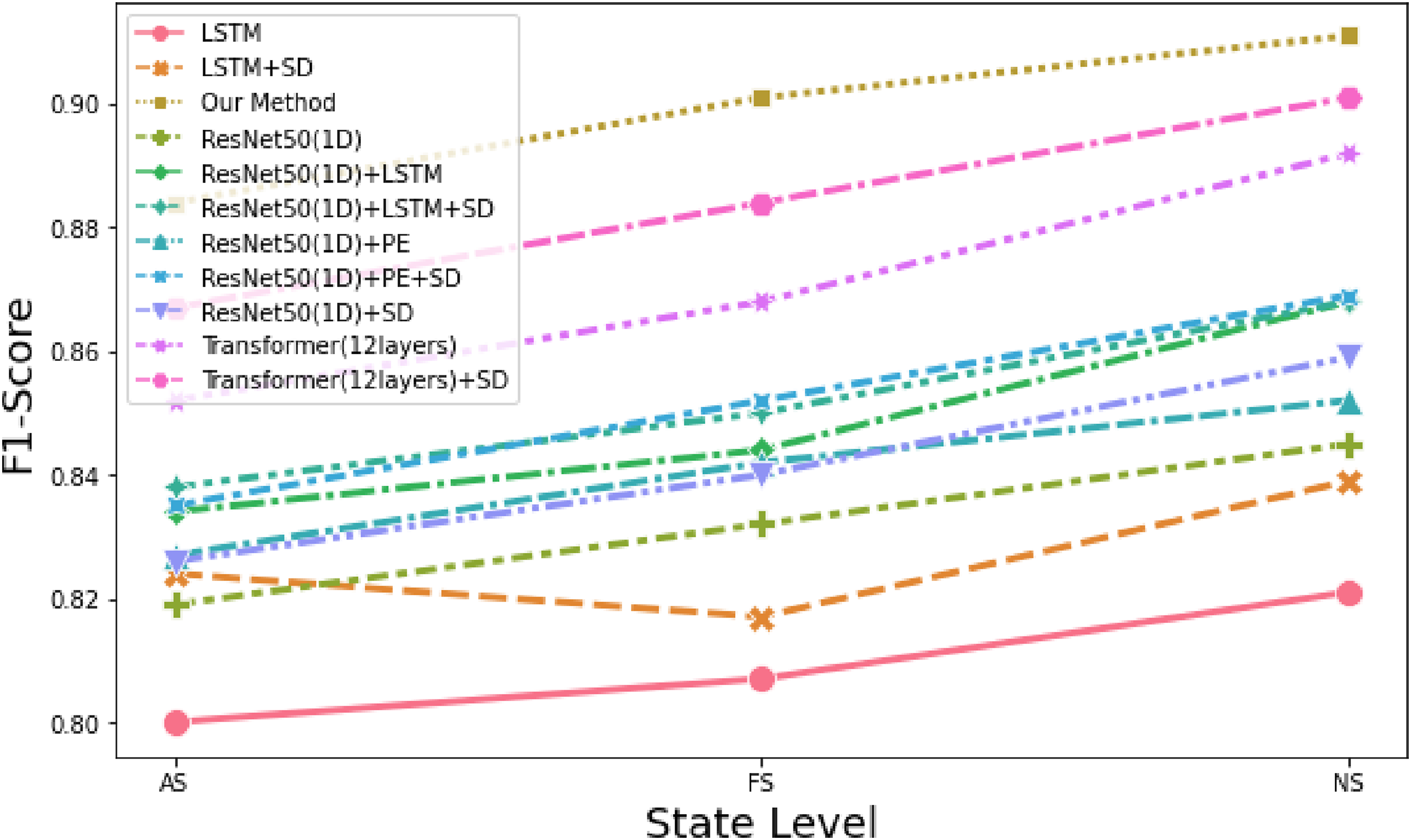
On the other hand, Transformers excel in long-term dependency modeling and are adept at discerning global relationships. Their shortfall, however, lies in the attenuation of local feature significance, such as form, relative magnitude, and similar attributes. In contrast, our proposed methodology amalgamates the strengths of both worlds: utilizing CNNs for the extraction of local features and employing Transformers for global contextual interpretation. Furthermore, the simulation of additional data factors via a digital twin system proves to be immensely beneficial in projecting the health state of hydro turbines. This dual-faceted approach ensures a comprehensive capture of both micro and macro-level dynamics, leading to a significant stride in predictive maintenance technologies.
We have delved into the convergence velocity of our model throughout its training phase, with the findings illustrated in Figure 7. An examination of the outcomes from the Transformer model with 12 layers versus the same model supplemented with simulated data (Transformer (12 layers) + SD) reveals that incorporating simulated data expedites the training convergence significantly. The training loss curve.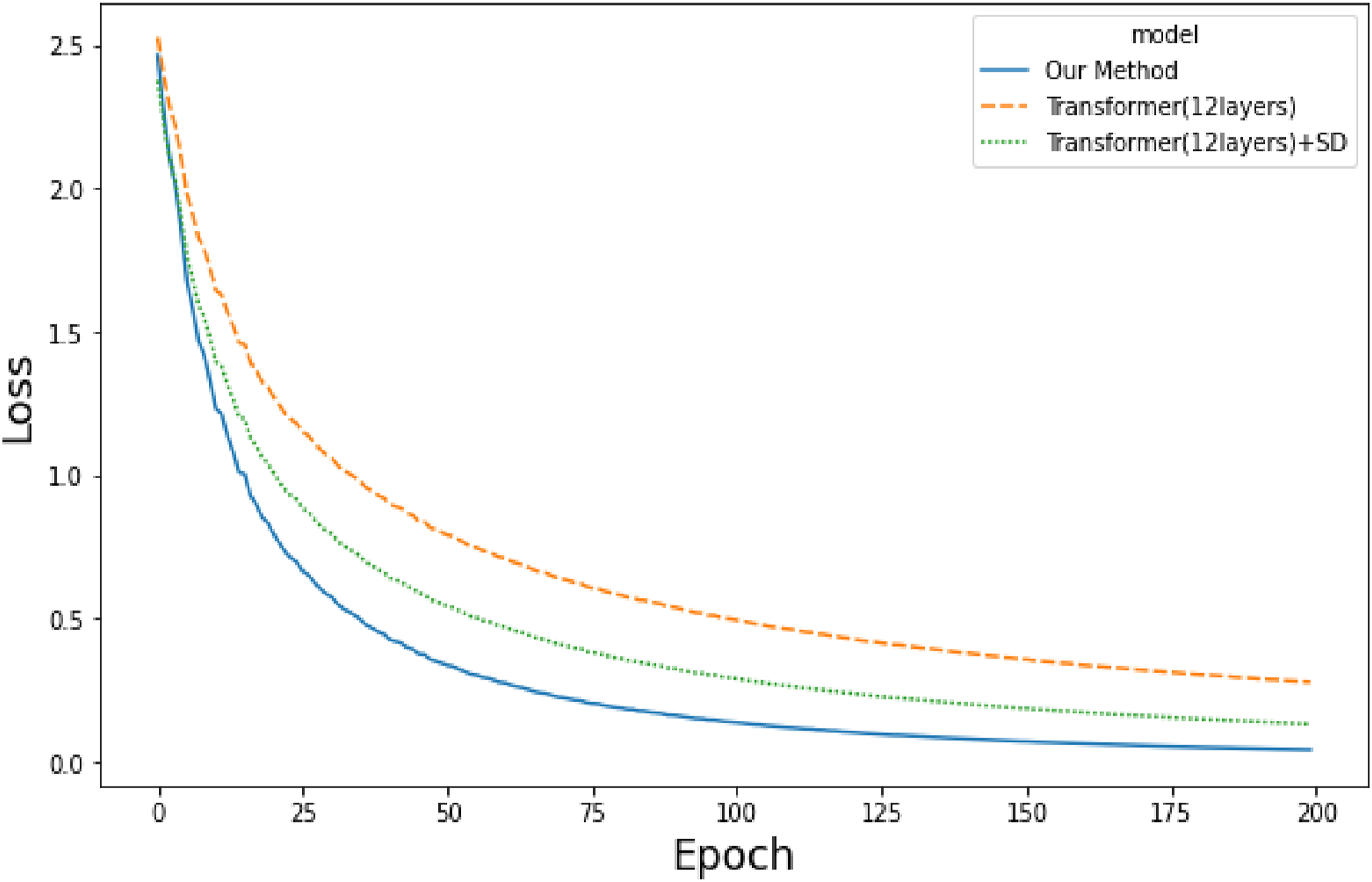
Thanks to the inductive biases inherent in CNNs, our method achieves a superior level of convergence precision. This assertion is substantiated by the comparative data illustrating the superior performance of our methods over a Transformer with 12 layers.
Our experimentation underscores the limitations of conventional CNNs and RNNs in the realm of time series prediction, particularly due to their deficiencies in extracting global features and managing long-range dependencies. In contrast, Transformers demonstrate a robust capability to address these issues effectively.
Beyond the experimental details mentioned above, we would like to elaborate on an additional point. In our experiments, we tried to implement some data augmentation strategies, such as adding random noise, mirroring data within segments, and mixing and recombining data between segments. However, these did not lead to improved results. We speculate that this might be due to the strong temporal requirements of the data, coupled with the sensitivity of the sampling rate signals to noise.
Furthermore, forecasts based solely on historical data regarding the condition of hydro turbines are inherently constrained. The digital twin system, however, provides a formidable ally, simulating not only the hydro turbine’s state but also incorporating external variables such as environmental conditions, water quality, and weather patterns. The integration of this diverse spectrum of simulated data facilitates a more comprehensive and accurate forecasting performance.
Conclusion
We advocate for a holistic approach to time series forecasting, one that transcends the confines of historical data analysis and incorporates prospective factors as well. Specifically, in projecting the health state of hydro turbines, it is imperative to factor in future variables such as environmental conditions, water quality, and meteorological patterns alongside historical turbine status data in the modeling process.
To serve this comprehensive forecasting model, we have constructed a sophisticated digital twin system at our research center. This advanced system is engineered to simulate pertinent data that inform our forecasts. Concurrently, we have introduced an innovative architecture that synergizes the historical operational data of the hydro turbines with the forward-looking simulations generated by the digital twin system.
The empirical data we have amassed unequivocally demonstrates that our approach significantly outstrips conventional forecasting methods. Notably, it achieves this with a swifter and more reliable convergence trajectory. Our aspiration is that this pioneering method will serve as a catalyst for innovation among scholars and practitioners in allied disciplines.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.