
Abstract
This study addresses the limitations of traditional image reconstruction techniques in handling complex textures and fine details, which often result in poor image quality due to detail fidelity bottlenecks. An innovative image reconstruction framework is proposed by combining the global feature extraction capabilities of fully convolutional networks (FCNs) with the detail optimization advantages of the Pix2Pix generative adversarial network. The FCN’s fully convolutional architecture effectively captures the macro-structure of images, providing a solid foundation for reconstruction. The Pix2Pix network then generates preliminary results through adversarial learning, significantly enhancing image realism and texture naturalness. The performance of the proposed FCN-Pix2Pix framework was evaluated using the high-standard DIV2K dataset, which includes a variety of complex scenes. Compared to enhanced deep super-resolution network (EDSR) and super-resolution generative adversarial network (SRGAN), the FCN-Pix2Pix combination outperformed both in detail preservation and structural similarity. Specifically, the FCN-Pix2Pix model improved the peak signal-to-noise ratio (PSNR) by 3.2 and 4.0, and the structural similarity index (SSIM) by 0.03 and 0.06, respectively. The results demonstrate the significant advantages of this approach in maintaining image details and structural integrity. In conclusion, the integration of FCN and Pix2Pix not only addresses the challenges of image reconstruction in complex textured scenes but also significantly enhances image detail richness and texture quality, providing a reliable and efficient solution for high-quality image reconstruction in visual communication design.
Keywords
Introduction
With the rapid development of technology, the application of digital image processing technology is becoming increasingly widespread in multiple industries, especially in visual communication design. The quality of images has become a key factor in measuring the visual impact and user experience of design works.1,2 As a visual carrier of information transmission, visual communication design covers a wide range of fields such as advertising design, graphic design, and user interface design. Its requirements for image clarity and detail fidelity are extremely demanding.3,4 Especially when dealing with complex scenes and images with numerous details, how to accurately display every detail while maintaining the overall coherence of the image has become a major challenge for designers.
Currently, traditional image reconstruction techniques such as bicubic interpolation and Laplacian pyramid method often face problems such as loss of details and blurred edges when processing images with complex textures and multi-level details, making it difficult to meet the high standards of image quality in the field of visual communication design.5,6 These issues are particularly prominent in advertising and user interface design, where even minor declines in image quality can weaken the brand’s display effect or reduce the user interface’s interactive pleasure. To address this technological bottleneck, deep learning techniques, especially deep learning models represented by convolutional neural networks (CNNs), are gradually becoming the forefront of research in the field of image reconstruction. These algorithms have shown great potential in improving image reconstruction accuracy compared to traditional methods by deeply mining image features and constructing fine models. However, even advanced deep learning algorithms face the challenge of balancing maintaining the global structure of the image with fine local details when processing highly detailed images.7,8 Therefore, how to maintain the overall consistency of the image while ensuring the integrity and authenticity of detailed information in the process of image reconstruction has become an urgent technical challenge in the field of visual communication design. Future research needs to further explore more efficient and intelligent image reconstruction strategies, and combine them with the latest deep learning technologies to continuously optimize algorithm architectures, in order to achieve high-quality reconstruction of complex texture and detail rich images, providing more accurate and vivid image representation methods for visual communication design, and promoting technological progress and innovative development in this field.
In order to solve the above problems, this article uses an image reconstruction method that combines fully convolutional network (FCN) and Pix2Pix generative adversarial network (GAN), aiming to improve the overall quality and detail representation of the image. Firstly, this article uses FCN to extract global features from the input image, reconstruct the macroscopic structure of the image, and ensure the global consistency of the image. The initial reconstruction results are then optimized using the Pix2Pix generative adversarial network, focusing on improving the fidelity of details and the naturalness of textures.9,10 The Pix2Pix generator operates in concert with the discriminator through an adversarial learning mechanism to ensure that the generated images are visually more realistic and natural.11,12 To verify the effectiveness of the method in this article, experimental tests are conducted using the DIV2K dataset, which contains multiple complex textures and rich detail scenes. As a comparison, this article selects enhanced deep super-resolution network (EDSR) and super-resolution generative adversarial network (SRGAN) as benchmark algorithms for performance comparison. 13 The experimental outcomes demonstrate that the image reconstruction algorithm combining FCN and Pix2Pix used in this article exhibits significant advantages in several objective evaluation metrics. Regarding peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM), the method in this article, compared to EDSR and SRGAN, improves PSNR by 3.2 and 4.0, respectively, and improves SSIM values by 0.03 and 0.06. 14 This result indicates that the algorithm proposed in this article performs well in processing images with rich details, especially in terms of detail fidelity, and can effectively address image reconstruction problems in complex scenes.
Further analysis reveals that the method proposed in this article not only excels in quantitative evaluation but also holds significant promise for practical applications in visual communication design. Visual communication design focuses on the accurate transmission and natural presentation of image information, and the proposed algorithm enhances the clarity and realism of image details by reinforcing the global structure. This improvement provides designers with powerful tools for visual expression, particularly in advertising creativity, user interface optimization, and other areas. In advertising design, the algorithm helps designers amplify the visual impact of products or brands by creating more refined and compelling images. In user interface design, clearer and more detailed images not only enhance aesthetic appeal but also improve user interaction and overall satisfaction.
The combination of FCN and Pix2Pix for image reconstruction offers an innovative solution for handling images with complex textures and fine details. The experimental results demonstrate its remarkable advantages in detail restoration and overall image quality, especially when applied to high-complexity images. This contribution enriches the theoretical landscape of image generation technology and paves the way for new practical applications in visual communication design, showing vast potential for future use. Moving forward, research can focus on optimizing network architectures to enhance algorithm efficiency and explore its applications in broader fields of visual creativity and interactive design, providing designers with more efficient and intelligent image processing tools and further driving innovation in visual arts.
Related work
In recent years, significant progress has been made in the field of image reconstruction. Many researchers have improved image detail restoration and global consistency by applying deep learning-based techniques. Fessler 15 used compressive sensing method to reconstruct magnetic resonance imaging (MRI) in his research, and introduced multiple key models and optimization algorithms for MRI reconstruction, including FDA (Food and Drug Administration) approved clinical application methods, as well as cutting-edge technologies being explored in the research community using data adaptive regularizers. Hashimoto 16 used an unsupervised PET (positron emission tomography) image reconstruction method that combined a depth image prior framework. By utilizing convolutional neural networks (CNNs), this method demonstrated comparable performance to other traditional methods in PET image reconstruction and had faster computational speed. Jensen 17 conducted quantitative and qualitative evaluations of deep learning image reconstruction algorithms for abdominal enhanced tumor CT (computed tomography) images. His research showed that deep learning image reconstruction algorithms had significant effects in improving the texture, resolution, and overall image quality of clinical images. Wang 18 used an electrical capacitance tomography (ECT) image reconstruction method based on density peak clustering (DPC) and K-means algorithm. Compared with traditional methods, the improved image reconstruction algorithm achieved better reconstruction results while reducing manual intervention. The research of Ben Yedder 19 utilized deep learning (DL) techniques to achieve automatic feature extraction of image information and thus real-time inference. This approach not only significantly reduced image artifacts, but also sped up the reconstruction process, which was particularly suitable for biomedical image reconstruction scenarios. Overall, the application of deep learning has brought more efficient solutions for image reconstruction, especially in the field of medical imaging, gradually becoming an important tool for improving reconstruction results and computational efficiency.
Compared to traditional L2 loss, GAN’s adversarial loss enables the generator to learn richer texture information, resulting in images that are visually closer to real images. However, despite the significant advantages of SRGAN in improving image detail representation, the generated images may still exhibit issues such as unnatural textures and insufficient detail processing in some complex scenes.20,21 In addition, methods such as VDSR (very deep super-resolution) and DCSCN (deep CNN with skip connection and network in network) have also made some progress in the field of image reconstruction, especially performing well in super-resolution tasks. These methods mainly improve the quality of image reconstruction by deepening the network depth and increasing the number of network parameters. However, when dealing with images with complex textures and diverse details, the computational overhead and hardware requirements of the network also increase.22,23 However, these methods often neglect the maintenance of global structure while improving the fidelity of image details, resulting in insufficient overall consistency despite improvements in local details.24,25 Therefore, finding a balance between global and local details remains a difficult problem in the field of image reconstruction. To better solve this problem, researchers have begun to try to combine the advantages of multiple network architectures. FCN, through its unique fully convolutional design, can efficiently capture the macroscopic structural information of images, resulting in excellent overall consistency of the generated images.26,27 Meanwhile, FCN replaces traditional fully connected layers with convolutional operations, significantly reducing the number of network parameters and improving its computational efficiency in large-scale image processing tasks. This feature enables FCN to balance global consistency and detail processing when processing images with complex structures, thus better serving image reconstruction tasks.
Pix2Pix, a type of generative adversarial network (GAN) designed specifically for image-to-image translation tasks, has demonstrated strong performance in areas such as image reconstruction and enhancement. By leveraging adversarial learning, Pix2Pix optimizes both the generator and discriminator, resulting in more natural and detailed image generation, particularly in the restoration of complex textures.28,29 It has achieved high-quality image generation in tasks like edge-to-image translation and black-and-white-to-color conversion. The generator refines initial outputs by learning high-frequency details from intricate regions, leading to improved fidelity and overall naturalness.30,31
However, while both fully convolutional networks (FCNs) and Pix2Pix excel in their respective domains, they each have notable limitations. FCN, despite its capability to capture global structural information, often struggles with blurry details in scenes rich in fine textures. On the other hand, while Pix2Pix is effective in detail restoration, it is less adept at capturing global structures. To address these challenges, this article proposes an image reconstruction method that combines FCN’s strengths in global feature extraction with Pix2Pix’s superior detail optimization. This approach aims to overcome the limitations of existing methods by enhancing both global consistency and detail fidelity, ensuring a more comprehensive and accurate image reconstruction.
FCN global feature extraction
Network architecture design
The FCN architecture used in this study includes multiple convolutional layers and pooling layers. Specifically, the architecture consists of 4 convolutional layers and 3 pooling layers. Each convolutional layer is followed by a ReLU activation function to apply nonlinear characteristics. The pooling layer is used to gradually reduce the size of the feature map while preserving key spatial information. Among them, the convolutional layer (with a kernel size of 3 × 3 and a stride of 1) is responsible for feature extraction, while the pooling layer (with a kernel size of 2 × 2 and a stride of 2) gradually reduces the size of the feature map while preserving key spatial information. Due to the absence of fully connected layers, the network is capable of processing input images of any size and generating output images of the same size. This design allows the FCN to effectively capture the global features of the input image and avoids the feature compression problem caused by the fully connected layer.
Feature extraction process and sampling
In the process of feature extraction, the image is first processed through a carefully selected 3 × 3 convolutional layer, which performs excellently in balancing computational complexity and feature capture capability. Subsequently, nonlinear characteristics are applied through the ReLU activation function, enhancing the expressive power of the model. Each convolutional layer is followed by a 2 × 2 max pooling layer, which is used to reduce the size of the feature map and extract global structural information. In order to generate an output image of the same size as the input image, the network uses transpose convolution for upsampling, gradually restoring the spatial resolution of the feature map. This not only preserves global structural information, but also reduces blurring, improving image clarity and details.
Figure 1 shows the steps of feature extraction and restoration in the image processing process of FCN. The horizontal axis represents different stages of the network, including multiple convolutional layers (such as Conv1 and Conv2), bottleneck layers (Bottleneck), and deconvolution layers (Deconv1, Deconv2, etc.) in the decoding stage; the vertical axis represents two key parameters: the blue curve represents the size of the feature map, and the red curve represents the number of filters. After the image is input into the FCN, the spatial resolution of its feature map gradually decreases from the initial 256 × 256. After multiple layers of convolution processing from “Conv1” to “Conv4,” the resolution gradually decreases and eventually reaches 16 × 16 at the bottleneck layer. This process demonstrates that the network extracts higher-level and abstract features by compressing spatial information layer by layer. Feature extraction and restoration process of FCN.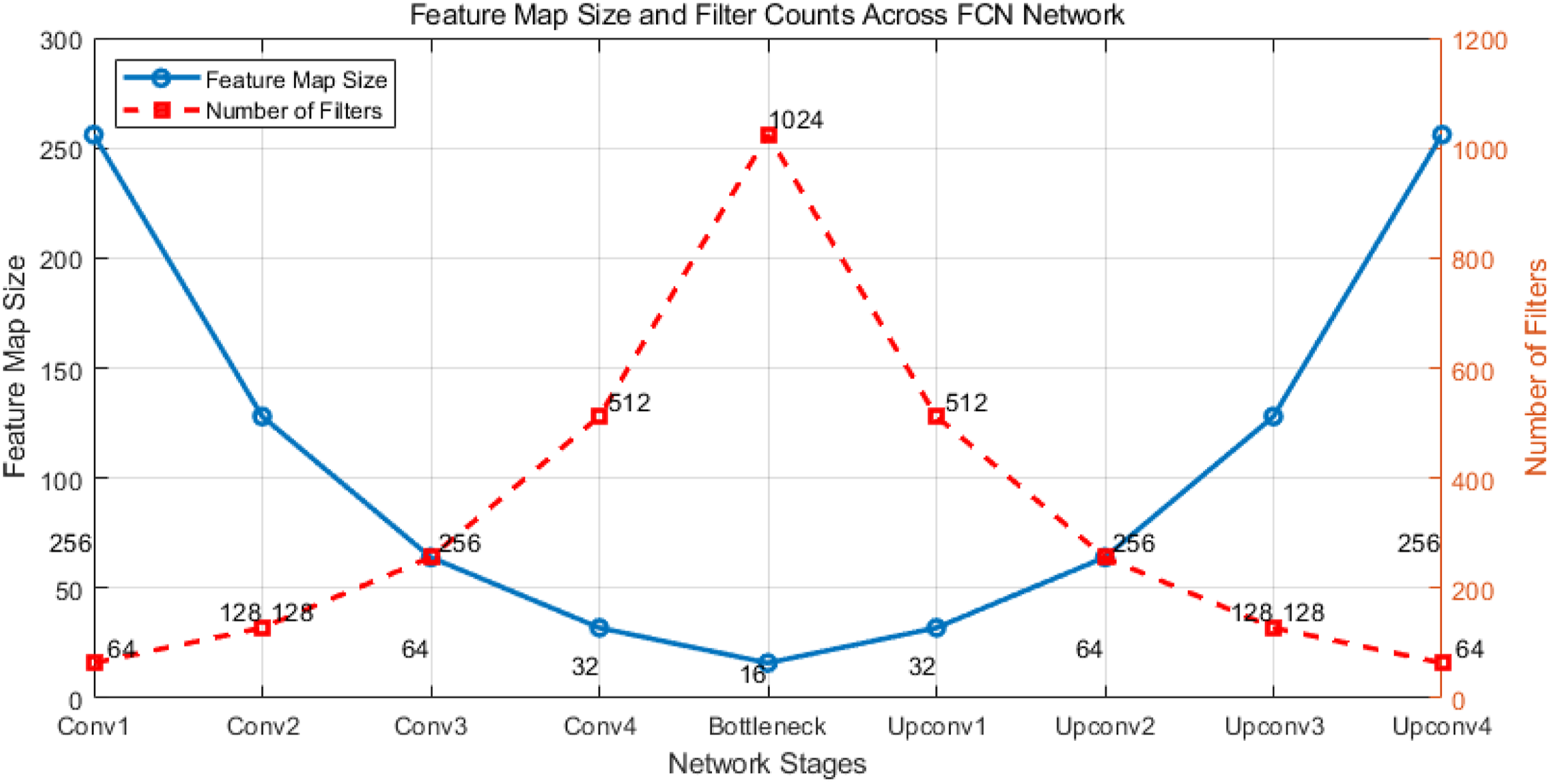
As the depth of the network progresses, the number of filters starting from “Conv1” gradually increases from 64 to 1024 in the bottleneck layer, reflecting the powerful ability of FCN deep structure in capturing multi-dimensional and complex features of images. In the decoding stage, the spatial resolution of the feature map is gradually restored to the original input level of 256 × 256 pixels through fine control of deconvolution operations. At the same time, the number of filters decreases from 1024 to 64 in the output layer. This process cleverly balances upsampling and feature extraction, not only effectively preserving the global structural information of the image, but also achieving precise reconstruction and restoration of detailed information through fine convolution and deconvolution mechanisms, demonstrating the core advantages and key role of FCN in the field of image reconstruction.
Loss function and optimization
To enhance the global coherence of the generated image, the FCN model adopts a pixel level MSE loss function, considers the fusion of similarity loss functions such as SSIM (structural similarity index) to further improve global coherence, and accurately measure the pixel differences between the generated image and the target image, and drives network optimization to minimize this error, thereby better capturing global features. In addition, the specific role of pixel level MSE loss function in enhancing global coherence is further explored and compared with other loss functions such as perceptual loss. During the optimization process, the Adam optimizer is used, which combines momentum strategy and adaptive learning rate to accelerate training convergence, improve image reconstruction accuracy, and effectively reduce training fluctuations. In addition, the performance data and related experimental results of the Adam optimizer in specific application scenarios are added to more clearly demonstrate its impact on image reconstruction accuracy.
Experiments and results
In the experiment, FCN implements comprehensive feature extraction on the DIV2K dataset. The training cycle begins with the weight update of the discriminator, during which a certain number or proportion of small samples of real and generated images are randomly selected to calculate and optimize the adversarial loss. The initially generated low-resolution global reconstruction image has a coherent structure and distinct macroscopic features, laying a solid foundation for subsequent detail enhancement while ensuring global coordination and consistency in the detail restoration process, reflecting the efficiency and robustness of FCN in image reconstruction tasks.
Figure 2 visually illustrates the block processing flow of the input image. Among them, the original 256 × 256 pixel image is finely divided into multiple 64 × 64 small blocks, which simulates the segmentation processing mechanism of FC for images. Each small block is independently subjected to global feature extraction through FCN, followed by the generation of low-resolution reconstructed images of corresponding sizes (such as 64 × 64). These preliminary reconstructed images, although slightly blurry in the details, successfully preserve the macroscopic structural features of the original images, ensuring a solid foundation for global consistency. Although this stage focuses on grasping the overall structure, it lays a solid foundation for the subsequent refinement of details. Partition processing flow.
FCN, with its fully convolutional architecture design, demonstrates excellent adaptability to diverse sizes and content images. By using deformable convolution and dilated convolution in the network, FCN can process input images of different sizes without changing the network structure. This flexible input-output size processing capability enables FCN to handle practical applications with ease. In addition, by adjusting the depth and convolution kernel size of the network architecture, FCN can further optimize feature extraction performance and flexibly respond to diverse image reconstruction challenges. During this process, FCN not only efficiently captures the global features of the image, but also provides strong macro structural support for subsequent detail enhancement, ensuring the dual optimization of global coherence and detail realism in the final output image.
Adversarial training mechanism
Adversarial and L1 loss functions
The core of adversarial training lies in the design of adversarial loss functions. The generator strives to make the generated image as realistic as possible by minimizing the judgment error of the discriminator; the discriminator maximizes the ability to distinguish between real images and generated images. In implementation, the generator and discriminator update parameters through alternating training, and the generator uses random noise as input to generate generated images that are similar to real images. This design gradually approximates the distribution of real data in the generated image, thereby improving the quality of the generated image. Adversarial losses are represented by Formula (1).
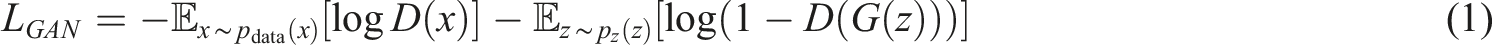
Among them,

Among them,
Training process
When training generative adversarial networks (GANs), this article adopts a refined alternating optimization strategy aimed at balancing the performance improvement of the generator and discriminator. The training cycle begins with the weight update of the discriminator. In this stage, small samples of real and generated images are randomly selected to calculate and optimize adversarial losses. The adaptive learning rate and momentum characteristics of the Adam optimizer are utilized to achieve fast and stable parameter adjustment. Subsequently, the discriminator weights are fixed, and the training process focuses on optimizing the generator. The generator generates higher quality images by comprehensively considering adversarial loss and L1 pixel loss. Adversarial loss enables the generator to learn strategies for generating more realistic images, while L1 pixel loss ensures that the generated image is as close to the target image as possible at the pixel level, thereby improving the accuracy of details. The core essence of GANs training lies in the close interaction and dynamic competition between the generator and discriminator. The generator continuously adjusts its generation strategy based on the latest feedback from the discriminator, striving to generate images that are more difficult to distinguish; the discriminator continues to enhance its discriminative ability to distinguish between increasingly realistic generated images and real images. This continuous adversarial interaction creates a positive feedback loop, driving a dual leap in generated images in terms of detail accuracy and overall aesthetics. To improve training stability, this article incorporates key techniques such as batch normalization and generator skip connections. The former effectively alleviates the gradient problem, while the latter promotes the cross layer flow of information, jointly accelerating the convergence process of the model. In addition, by carefully adjusting the weight ratio of adversarial loss and L1 loss, this article constructs a comprehensive loss function (as shown in Formula (3)), which balances the realism and detail preservation of the image in the optimal way, ensuring high-quality output of the generated image.

Among them,
Pix2Pix local detail optimization
Pix2Pix generator design
The Pix2Pix generator is based on the U-Net structure, a classic encoding decoding network architecture that preserves more detailed information through skip connections, enabling the generator to have higher performance in restoring image details. The encoding part of the generator gradually extracts and compresses the feature information of the image through multiple convolutional and pooling layers. The decoding part gradually restores the spatial resolution of the image through transposed convolutional layers. The skip connections in the U-Net structure directly connect the feature maps of the encoding and decoding layers to preserve more detailed information. This design enables the generator to preserve local features of the input image and generate high-resolution detail images when restoring image details.
Figure 3 provides a detailed depiction of the U-Net architecture adopted by the Pix2Pix generator, specifically designed for image reconstruction tasks. The input image undergoes a progressive convolutional transformation through the encoder, from Conv1 to Conv4, where each layer deepens the abstraction level of features, accompanied by an increase in the number of filters and a gradual reduction in spatial resolution. During this process, a fixed 4 × 4 filter works in conjunction with a 2-step filter to effectively compress the spatial information of the image, ultimately converging at the core bottleneck layer, which serves as the feature refinement hub in the U-Net structure. U-Net network architecture for image reconstruction.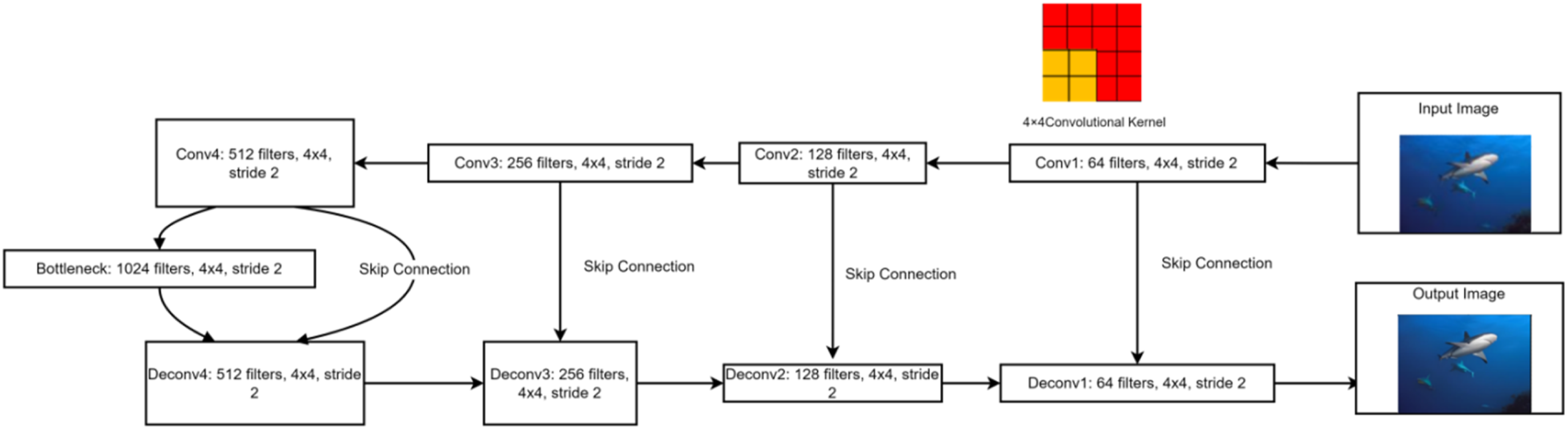
In the decoding stage, the deconvolution sequence consisting of Deconv1 to Deconv4 gradually reverses this process, restoring the spatial dimension of the image to its original state. Of particular note is the unique skip connection mechanism of U-Net, which directly connects the features of each layer of the encoder to the corresponding level of the decoder. This not only accelerates the recovery of spatial resolution, but also preserves rich detail information during the reconstruction process, ensuring the consistency of the global structure of the image and the accurate restoration of local details. The clever design of this architecture enables Pix2Pix generator to demonstrate extraordinary capabilities in dealing with complex textures and high-density detail scenes, effectively avoiding the common problems of detail loss and global information blurring in traditional methods.
Detail optimization of feature maps
The generator pays special attention to complex textures and detail areas during the process of detail optimization. To enhance the naturalness of details, the generator uses batch normalization and leaky ReLU activation functions after each convolution and transposed convolution layer. The generator also preserves the feature map information of the encoding and decoding layers through a skip connection mechanism, so as to preserve more local features when restoring image details. When processing high-frequency textures and small details, the generator gradually extracts and integrates local features through layer by layer convolution operations, and gradually restores details during upsampling, making the final generated image more realistic and natural. Batch normalization improves the stability and speed of training by standardizing each small batch of data. The process of batch normalization involves standardizing the input of each layer and subsequently applying scaling and translation:


Training process
During the training process, Pix2Pix is trained using the DIV2K dataset to handle images with various complex textures and rich details. Training is divided into multiple stages, with each stage adjusting the network parameters of the generator and discriminator. In the initial stage, the generator focuses on generating rough details, and gradually optimizes the accuracy of details as training progresses; the discriminator improves its ability to distinguish between real images and generated images. After training, quantitative evaluation is conducted by calculating the PSNR and SSIM metrics of the generated images to verify the fidelity of details and overall quality of the images.
The double Y-axis bar chart in Figure 4 analyzes the changes in PSNR (peak signal-to-noise ratio) and SSIM (structural similarity index) during the training process. The horizontal axis represents the training iteration period (1 to 10), and the left Y-axis shows that the PSNR gradually increases from the initial 20 dB to about 43 dB, indicating a significant improvement in image quality in terms of detail presentation and noise suppression. The Y-axis on the right reflects the SSIM value, which is initially 0.52 and reaches 0.92 at the 10th iteration, indicating an enhancement in the structural similarity between the generated image and the reference image. The synchronous increase of PSNR and SSIM indicates that the model gradually optimizes the details and overall structure of the input image. By training the generator and discriminator, Pix2Pix generative adversarial network effectively improves the details of FCN generated images, especially in complex texture areas, thereby enhancing the realism and naturalness of the images, and providing a high-quality image reconstruction solution for visual communication design. Changes in PSNR and SSIM.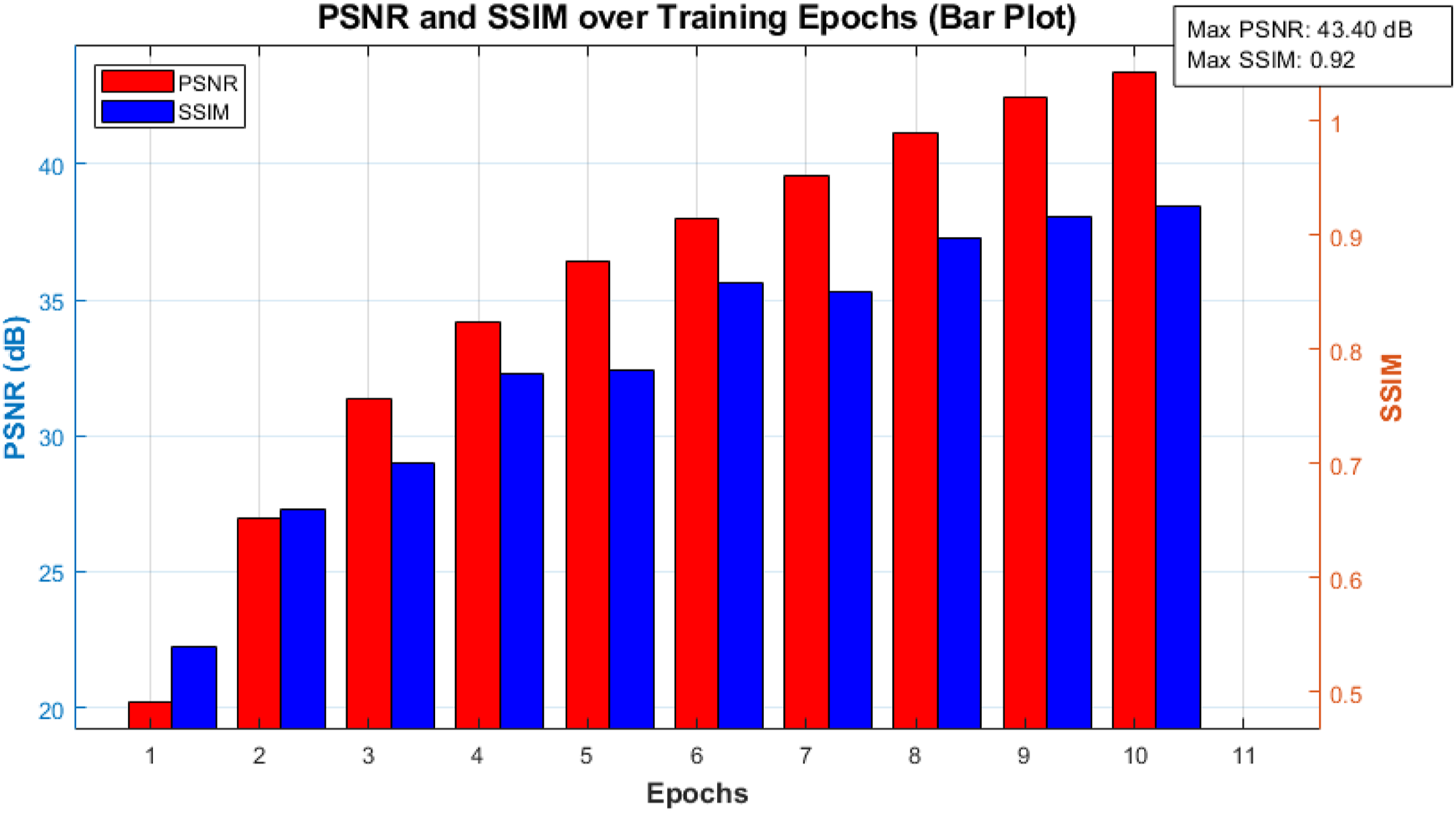
Training using DIV2K dataset
Dataset preparation and image preprocessing
The DIV2K dataset consists of 2000 high-resolution images, covering a variety of complex textures and scenes with rich details. For the purpose of conducting experiments, the dataset is divided into a training set, a validation set, and a test set, with the training set containing 1800 images and the validation and test sets each containing 100 images. To improve the generalization ability of the model and the diversity of the dataset, data augmentation processing is performed on the images in the training set, including random cropping, horizontal flipping, and color jitter. Random cropping helps the model learn image features of different scales and positions by randomly selecting regions of different positions and sizes from the original image as training samples. Horizontal flipping increases the diversity of samples through mirror transformation, making the model robust to the left and right directions of the image. Color jitter simulates image changes under different lighting and shooting conditions by adjusting parameters such as brightness, contrast, and saturation of the image, thereby improving the model’s adaptability to color changes. Before training, all images undergo unified preprocessing. The specific steps include adjusting the image to a uniform size of 256 × 256 pixels. The selection of this size is mainly based on the needs of model training and considerations of computing resources. It is a moderate size that can ensure image quality and effectively reduce computational burden. In addition, the images are standardized by reducing pixel values to within the range of [0, 1] to ensure data stability during model training.
Model training
FCN and Pix2Pix models are trained using the DIV2K dataset. The DIV2K dataset consists of 2000 high-resolution images, of which 1800 are used for training, 100 for validation, and another 100 for testing. Firstly, FCN is trained to extract global features. Using multiple iterations, images are randomly selected for forward and backward propagation in each round, and cross-entropy loss is used to optimize global structural consistency. Next, the Pix2Pix model is trained with alternating optimization of the generator and discriminator. The generator improves image authenticity through adversarial loss and ensures pixel level similarity through L1 loss. Using the Adam optimizer and validated through experiments, the learning rate is ultimately set to 0.0002 to achieve the optimal balance between training speed and stability. These steps enable Pix2Pix to generate higher quality images.
In the training process of Pix2Pix model, the horizontal axis in Figure 5 represents the epochs of training; the left vertical axis represents the adversarial loss and L1 loss of the generator, and the right vertical axis represents the adversarial loss of the discriminator. The adversarial loss of the generator gradually decreases from 1.28 to 0.1, and the L1 loss decreases from 0.8 to 0.05, indicating that the generator is gradually improving in generating high-resolution and detail rich images. The adversarial loss of the discriminator decreases from 0.98 to 0.09, reflecting the increasing ability of the discriminator to distinguish between generated images and real images. Throughout the entire training process, the generator and discriminator optimize through adversarial interaction, resulting in a significant improvement in the quality of the generated images. The trend of data changes reflects the increasingly stable performance of the model in complex texture and detail rich scenes, ensuring the high fidelity of generated images in terms of global consistency and local details. Pix2Pix model training process.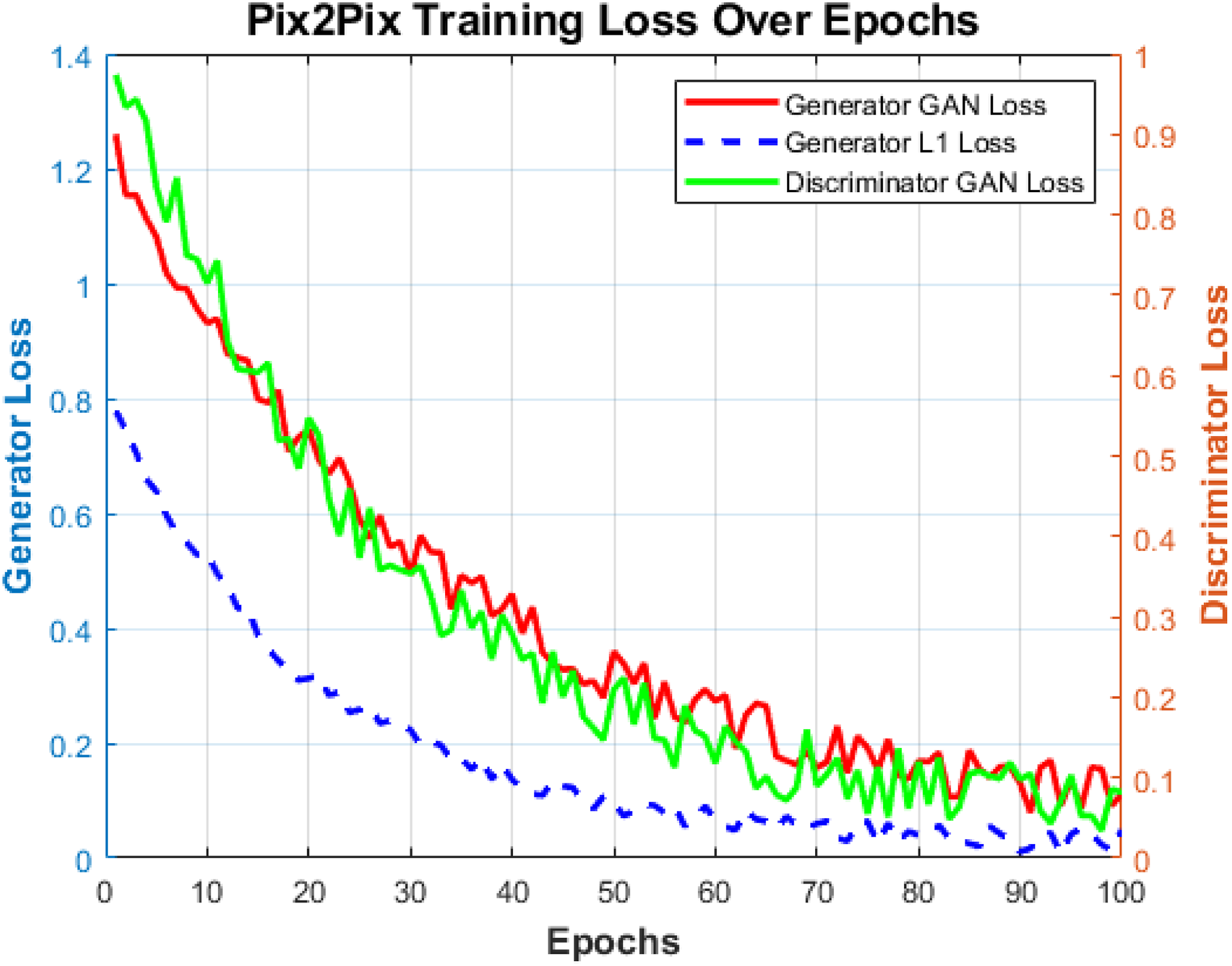
Verification and adjustment
During the training phase, this article implements a regular validation mechanism, using an independent validation set to monitor model performance to prevent overfitting. The validation frequency is once every 5 iterations, and validation metrics include PSNR and SSIM to evaluate the quality of generated images, including detail fidelity, global structural consistency, and other aspects. Through regular validation, problems during the model training process can be identified and adjusted in a timely manner. By using quantitative indicators such as PSNR and SSIM, the quality dimensions of the generated images are deeply analyzed, and the parameters and structure of the model are gradually adjusted based on the feedback from these indicators. Based on this, the training parameters and model architecture are flexibly adjusted, striving to achieve the optimal balance between detail fidelity and global coherence. After the training cycle is completed, the model’s generalization ability is tested using a wide coverage of diverse textures and fine detail images in the test set. The re-application of indicators such as PSNR and SSIM to detect the quality of generated images confirms the significant advantages of the fusion FCN and Pix2Pix GAN strategy in complex image processing compared to traditional methods, especially in preserving details and maintaining the unity of global structure.
Based on the test results, this article deepens the optimization strategy, focusing on the dual improvement of detail restoration and global structure maintenance. Through meticulous parameter tuning and network structure optimization, the model performance is continuously improved. At the same time, data augmentation methods such as random rotation and brightness adjustment are added to address the issues exposed during testing, in order to enhance the model’s generalization ability.
Figure 6 shows the performance of the model in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) under different combinations of learning rates and batch sizes, and the results are visualized through a heatmap. The heatmap on the left shows that when the batch size is 32, the PSNR increases from 31 to 31.5 at a learning rate of 0.0005, indicating that larger batch sizes can improve model performance. The heatmap on the right shows that when the learning rate is 0.0005 and the batch size is 32, the SSIM reaches 0.905, demonstrating the best structural consistency. These heatmaps visually demonstrate the impact of parameter configuration on model performance, emphasizing the importance of adjusting the learning rate and batch size reasonably for image reconstruction results. Model performance under different combinations of learning rates and batch sizes.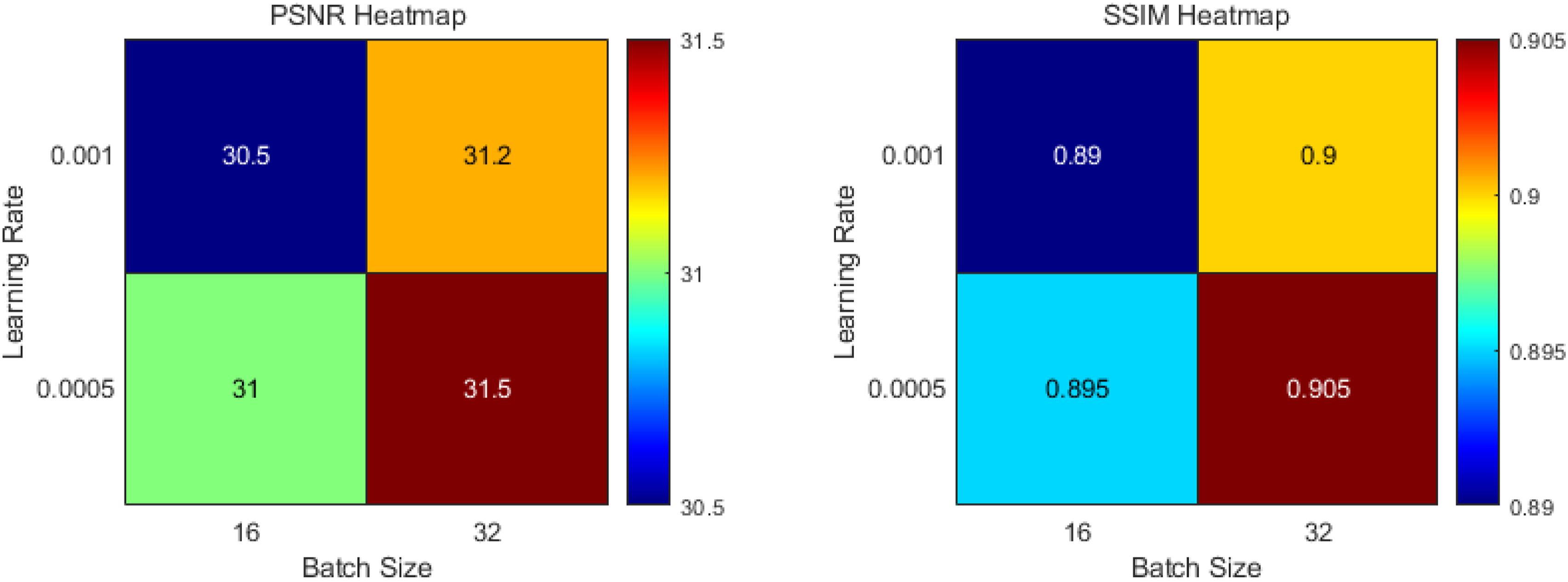
Performance evaluation of image reconstruction
Display of model effects for detail optimization
After further processing these global images using a detail optimization model, the generated high-resolution images (simulated through image sharpening operations) significantly improve the fidelity of details. The detailed areas such as edges and leopard fur texture are effectively restored, and the processed image is more coherent, as shown in Figure 7. The comparison of two reconstructed images shows the complete process from global feature extraction to detail optimization, and the FCN fully convolutional network has a strong ability to extract global features. This processing method that combines global and local details makes the generated image visually more realistic and natural. High-resolution image obtained by model processing.
PSNR
PSNR is a commonly used indicator to measure the quality of image reconstruction, used to evaluate the differences between the reconstructed image and the original image. The higher the PSNR value, the closer the reconstructed image is to the original image. This article quantifies the overall quality of different algorithms in generating images by calculating the PSNR of the reconstructed images. Specifically, the PSNR calculation formula is:

Figure 8 shows the PSNR performance of different image reconstruction algorithms on various scenes and datasets, including the performance of FCN, Pix2Pix, and EDSR algorithms on the validation and test sets. For each algorithm, this article evaluates it in three scene categories: landscape, portrait, and building. PSNR performance of different image reconstruction algorithms on various scenes and datasets.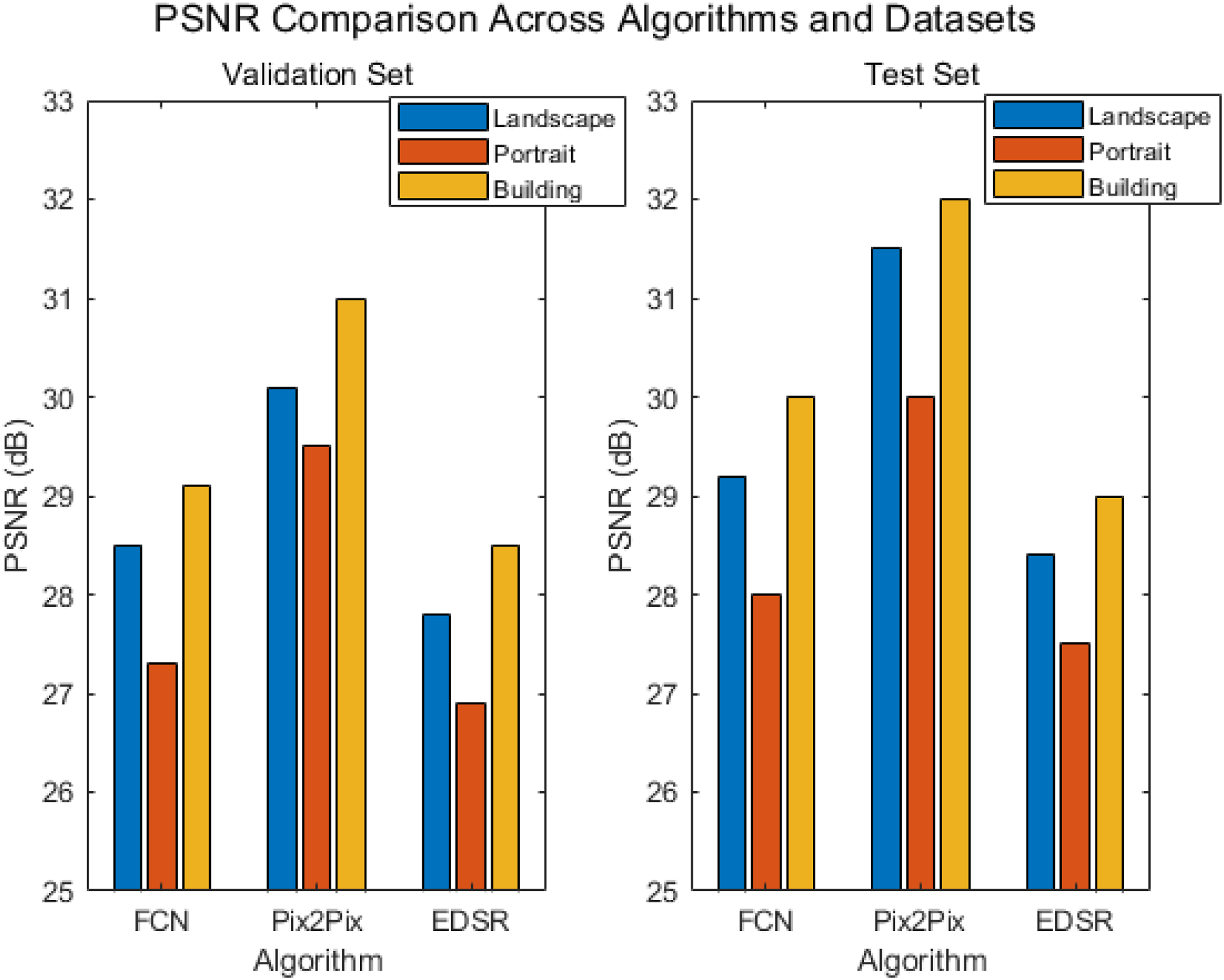
From the data results, it can be seen that the Pix2Pix algorithm has significantly higher PSNR (peak signal-to-noise ratio) than FCN and EDSR in various scenes and datasets. Especially on the test set, its PSNR reaches 31.5 dB in landscape scenes, 30.0 dB in portrait scenes, and 32.0 dB in building scenes, fully demonstrating its advantages in image detail restoration and overall quality. In contrast, the PSNR value of FCN is slightly lower, with landscape scenes at 29.2 dB, portraits at 28.0 dB, and building scenes at 30.0 dB. This indicates that although FCN has good performance in global consistency, it is not as good as Pix2Pix in detail restoration. Compared to Pix2Pix, EDSR performs even worse, with PSNRs of 28.4 dB, 27.5 dB, and 29.0 dB in landscape, portrait, and building scenes, respectively, indicating that its performance is inferior to Pix2Pix in processing complex texture and detail rich images.
SSIM
The algorithm’s performance in detail fidelity and visual quality is verified by calculating the SSIM value between the images generated by FCN and Pix2Pix and the original image. The SSIM value takes into account factors such as brightness, contrast, and structure of the image, which collectively determine the visual quality of the image. A higher SSIM value means that the generated image is closer to the original image in terms of brightness, contrast, and structure, thereby exhibiting better detail fidelity and visual quality.
Figure 9 compares the SSIM performance of FCN, Pix2Pix, and their fusion models in image generation. The analysis shows that the images generated by FCN alone do not perform as well as Pix2Pix on SSIM, while the fusion model significantly outperforms both, especially in terms of detail preservation and restoration. Specifically, in Image 1, the FCN score is 0.82; Pix2Pix improves to 0.88; the fusion model reaches 0.91, bringing gains of 0.09 and 0.03, respectively, highlighting the promoting effect of fusion strategy on image quality. Similarly, Images 2 and 3 also witness the average improvement of the fusion model on SSIM, which are 0.07 and 0.08 compared to FCN, and 0.02 and 0.03 compared to Pix2Pix, respectively. On average, the fusion model improves by 0.078 compared to FCN and 0.028 compared to Pix2Pix, effectively integrating the strengths of both, enhancing the structural similarity and overall visual quality of the images. Comparison of structural similarity among different image types.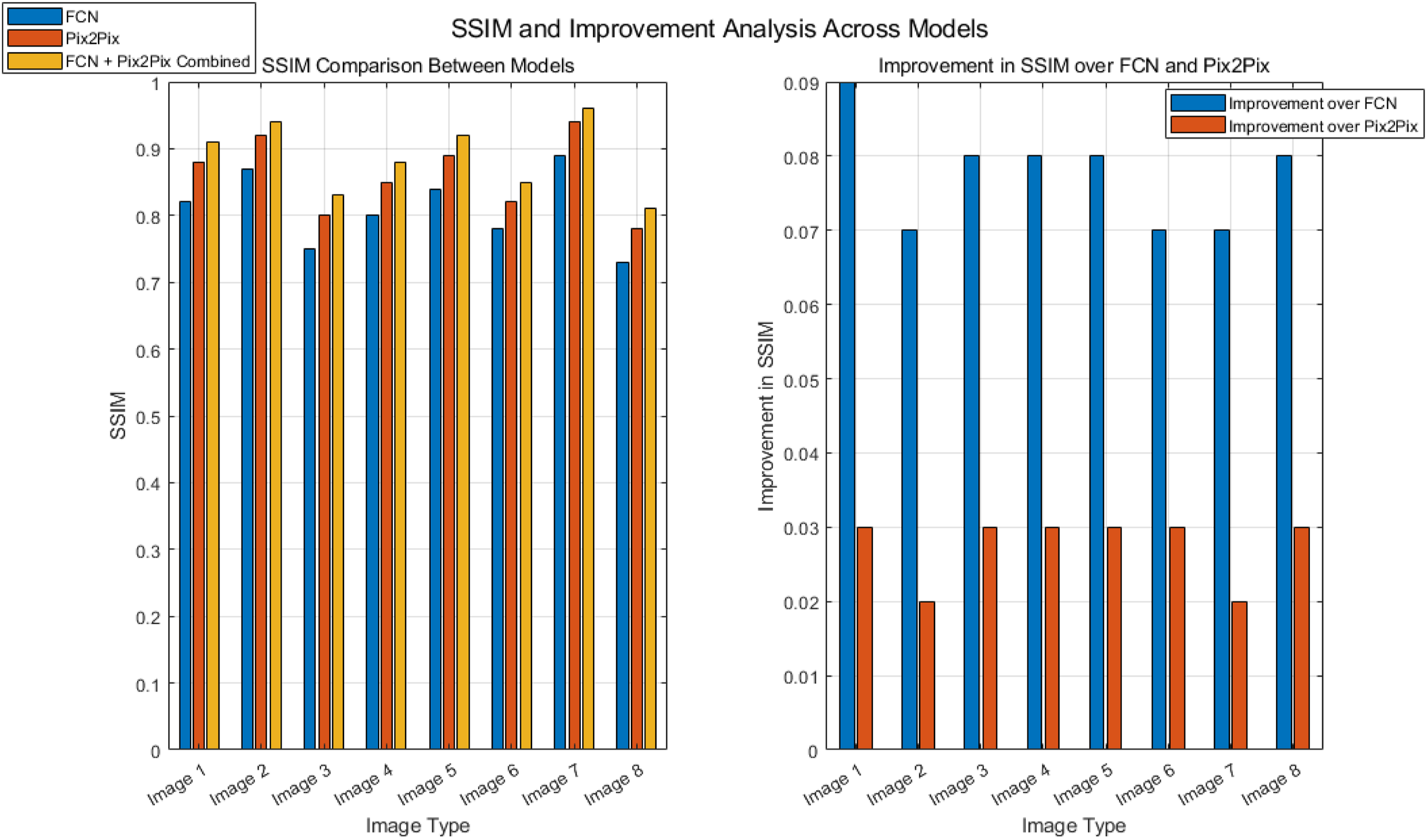
Comparative experiments with existing methods
To verify the effectiveness of the method used in this article, a performance comparison is made with the current advanced image reconstruction algorithms EDSR and SRGAN. The experimental results demonstrate improvements in both PSNR and SSIM metrics, particularly in complex texture and detail rich scenes.
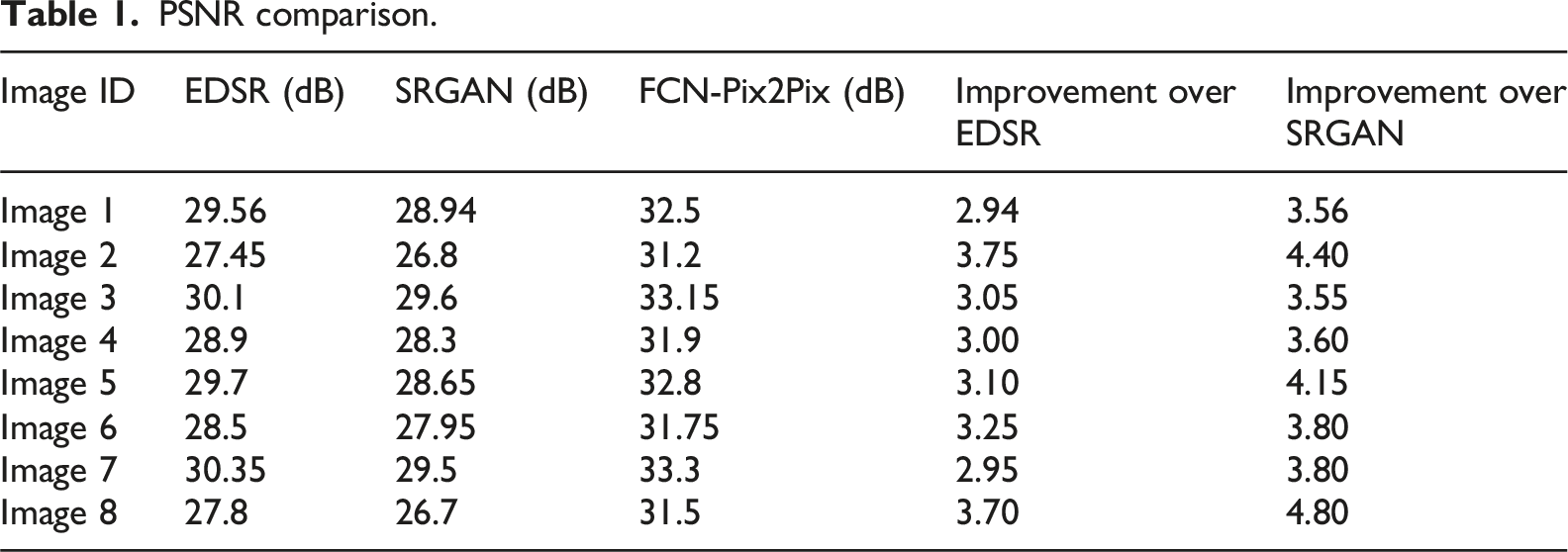
PSNR comparison.
SSIM comparison.
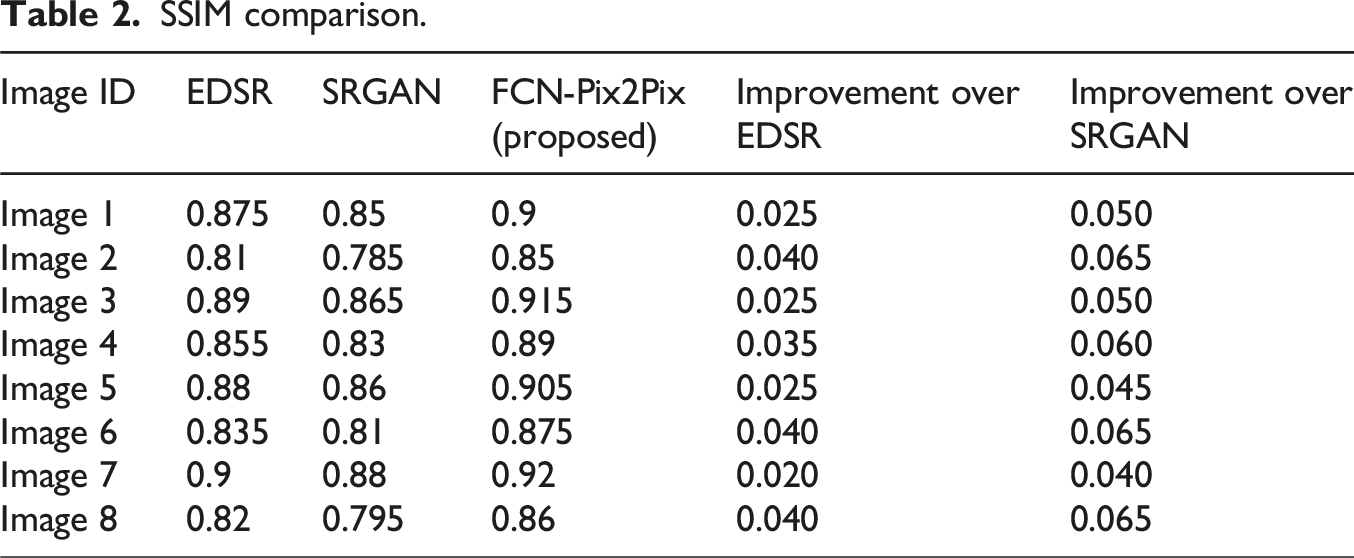
The SSIM in Table 2 measures the similarity of image structures, and FCN-Pix2Pix is also superior to other methods. In Image 7, the SSIM of FCN-Pix2Pix is 0.920, significantly higher than EDSR’s 0.900 and SRGAN’s 0.880. On average, the PSNR of FCN-Pix2Pix is 3.2 and 4.0 higher than EDSR and SRGAN, respectively, and the SSIM is improved by 0.03 and 0.06, indicating that the algorithm has significant advantages in image reconstruction quality, especially in scenes with rich details.
Conclusions
This article used an image reconstruction algorithm that combined FCN and Pix2Pix, and applied it to image reconstruction tasks in visual communication design. By using FCN for global feature extraction, preliminary image reconstruction results were generated, and Pix2Pix was used to optimize the details of these results, significantly improving the fidelity of image details and overall quality. The experimental results showed that the algorithm combining FCN and Pix2Pix significantly improved PSNR and SSIM metrics when dealing with complex textures and richly detailed scenes, outperforming traditional EDSR and SRGAN algorithms. Although the methods used perform well in terms of detail fidelity and image quality, there are still certain limitations. The reconstruction effect of extremely low-resolution images may not be as good as that of high-resolution images. Future research can further optimize algorithms to improve their applicability and robustness in a wider range of scenes, while exploring more data augmentation and model improvement strategies to enhance the model’s generalization ability and performance.
Future research in this area could explore several directions to further enhance the performance and applicability of the image reconstruction algorithm combining FCN and Pix2Pix. One key focus could be improving the algorithm’s robustness, particularly in handling extremely low-resolution images. While the current method shows significant improvement in high-resolution contexts, its performance on low-resolution images could be less effective. Research can be directed toward optimizing the feature extraction and detail enhancement processes specifically for low-resolution inputs, possibly through the integration of multi-scale or hybrid models that can handle varying levels of image quality.
Another avenue for future work involves expanding the algorithm’s generalization ability across a broader range of complex scenes. While the current approach excels in specific texture-rich scenarios, extending its applicability to diverse real-world conditions with varying textures, lighting, and backgrounds remains a challenge. Future studies could focus on refining data augmentation techniques, such as introducing diverse synthetic datasets or using domain adaptation strategies, to ensure the model can generalize effectively across different environments and image types.
Moreover, further research could explore improvements in the overall model architecture. While FCN and Pix2Pix have complementary strengths, other advanced architectures such as attention mechanisms, transformer models, or even hybrid deep learning models could be integrated to enhance both the global structure preservation and fine detail restoration. Additionally, leveraging unsupervised or semi-supervised learning techniques could provide more flexibility in model training, allowing for better performance with less labeled data. Finally, the practical applications of this research could be expanded by investigating how the enhanced image reconstruction algorithm can be used in real-time or resource-constrained environments. For instance, exploring ways to reduce computational complexity without sacrificing image quality would be beneficial for applications in mobile devices or interactive design tools where real-time processing is crucial. Future research should focus on optimizing the algorithm for low-resolution images, broadening its applicability to diverse scenes, refining the model architecture, and ensuring its efficiency for practical, real-time use cases. These advancements will help push the boundaries of image reconstruction and establish more reliable, versatile tools for visual communication design.
Statements and declarations
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.