
Abstract
The complexity of information data makes strengthening information evaluation and screening an important research content. Traditional association analysis algorithms are difficult to perform strong analysis on association rules, and they do not sufficiently grasp data feature information. Therefore, based on the original association classification algorithm, multiple learning of training sets and setting of interest threshold are studied to improve the correlation between category labels and reduce the interference of redundant information. Subsequently, multiple tag feature selection algorithms and frequent pattern trees are introduced to measure data information using tag importance as a metric, improving information processing efficiency, and implementing algorithm processing through local connection and pruning operations. The information evaluation results of the improved algorithm proposed in the study show that the training error of the improved association classification (AC) algorithm is 2.36%, and the maximum training error difference and time consumption range between the improved AC algorithm and other algorithms reach 31.28% and 14.28%, greatly improving the operational efficiency and classification accuracy of the algorithm. Simultaneously improve the average classification error and Recall@K Increased to 10.37% and above 5%, effectively achieving information evaluation accuracy. The information evaluation algorithm can effectively provide practical tools and method reference value for data mining and related management work.
Keywords
Introduction
The development of Internet technology and big data platform makes the data link information that people are exposed to relatively large and complex, and there are significant differences in the content and nature of information. 1 Data mining technology can analyze and filter data that cannot be manually processed, effectively analyzing the potential correlation paradigms contained in different data, presenting more intuitive and convenient visualization results, and improving people’s efficiency in using and analyzing data.2,3 The association rule algorithm, as an important data mining algorithm, can explore potential connections by searching for correlations between data items, and has good applicability in fields such as education and teaching, medical data, and financial investment.4,5 Strengthening the correlation analysis of data can effectively grasp the potential connections between information, thereby providing guidance for decision-making evaluation and the formulation of relevant plans. The current information technology evaluation methods have prominent issues such as excessive reliance on data and difficulty in quantifying indicator levels. Therefore, research is using correlation algorithms for improvement. At the same time, in response to the problem that traditional association algorithms cannot effectively achieve the unity of research object data and types in data analysis, an improved association algorithm based on learning and interest setting, multi-label features, and maximum diversity frequent itemsets is proposed. By grasping the correlation and characteristics of data information, we can improve computational efficiency, reduce unnecessary operational processes, and ensure the level and effectiveness of information system evaluation, providing technical means and improvement ideas for guiding information technology decision-making and improvement work.
Literature review
The associative classification (AC) algorithm includes Apriori algorithm, frequent pattern-growth (FP-G), FreeSpan algorithm, etc. As a kind of data mining, AC algorithm can effectively achieve the classification of classifier construction and attribute relevance. Zhang et al. proposed a hybrid method of Apriori and graph computation to improve the efficiency of association rule mining. This method initially used Apriori to calculate frequent k-itemsets. When k increases and the number of itemset candidates decreases, it switches to the graph calculation method. The experimental results show that the proposed method outperforms Apriori and graph computing methods on all test cases. 6 Ozaydin et al. studied and analyzed the accident data on Türkiye fishing vessels with a total length of 12 m and above in order to study the unreported maritime accidents. A Bayesian network was proposed to summarize the occurrence of fishing vessel accidents, and a predictive Apriori algorithm was used to establish rules for accident occurrence. The results show that the developed hybrid model can be used to analyze unreported occupational accidents on fishing vessels. 7 Sakai et al. proposed an improved Apriori algorithm to handle rule generation in incomplete information systems based on Apriori. The results show that the algorithm can handle SQL datasets and address new research topics, such as estimating the likelihood of missing values. 5 Li et al. proposed an optimized Apriori algorithm to address the issues of poor applicability and low computational efficiency of data mining algorithms in landslide disasters. This algorithm strictly controls the construction of pre- and post-itemsets, stores factors and deformation events by dimension and hierarchy, and achieves parallelization of key calculations. The results show that the algorithm has significant advantages in analyzing massive high-dimensional landslide disaster monitoring data. 8 Abid et al. proposed a solution based on multi-objective genetic algorithm and knowledge notification to address the lack of explanation and the use of random change operators in existing reconstruction tools. This scheme generates association rules through the Apriori algorithm and uses these rules to improve search and seeding mechanisms. The results show that this solution is superior to existing technologies in reducing ineffective refactoring, improving quality, and increasing developer trust. 9 Raj et al. proposed a Spark framework based on the optimization of Apriori algorithm based on Spark framework and used this optimized Apriori algorithm for data mining analysis, and the results showed that the algorithm can reduce the overhead of mashup. 10 Omuya et al. developed a hybrid filtering model based on principal component analysis and information gain for feature selection. The experimental results show that the model can reduce data dimensions, select appropriate feature sets, and shorten training time, with high classification performance and accuracy. 11 Yang et al. proposed a Bayesian network causal structure learning algorithm to address the difficulty of noise processing in massive data. The algorithm incorporates partial rank correlation coefficients into data dimension processing, and the results show that the algorithm has good detection performance and application effectiveness. 12
With the rapid development of information technology and Internet technology, the development and application of artificial intelligence technology has been very mature and has been widely used in various fields. Among them, the information technology evaluation technology is an important embodiment of the application of artificial intelligence technology, which can help the relevant personnel to obtain the deficiencies in the evaluation object, and then make targeted improvements to the evaluation object, so as to improve the efficiency and effectiveness of work. The rapid development of network technology has led to a rapid expansion of information volume. Traditional keywords for searching data are time-consuming and inefficient. Zhang et al. proposed an Association Rule Enhanced Knowledge Graph Attention Network (AR-KGAN) to address the problem of existing knowledge graph embedding methods that only utilize fact triplets and have not thoroughly studied logical rules. This method combines modeling triples and logical rules, using association rules and attention weights to aggregate neighbors. The results showed that AR-KGAN achieved significant improvements on three benchmark datasets. 13 Data mining technology has a good application effect in semantic information. Khan M N et al. used association rule data mining techniques to analyze trajectory level data in order to further investigate the speed selection behavior of drivers under adverse weather conditions. A new method has been proposed to deeply study the speed selection behavior of drivers in adverse weather conditions using promising association rule data mining techniques. The results show that there are significant differences in the speed choices of drivers under different weather conditions. 14 Yu used an improved AprioriTid algorithm to mine and analyze instructional data and proposed an emotion recognition method for intelligent assessment of online instructional quality. 15 Regarding the issue of data denoising, Zheng et al. proposed a fully integrated empirical mode decomposition method based on adaptive noise and applied it to unmanned aerial vehicle measurement data. The results showed that this method can effectively identify real signals and has high denoising performance. 16 Ngo et al. constructed a landslide susceptibility mapping assessment model based on deep learning algorithm, and the test results showed that the performance of the model is superior. 17 Bui Thi et al. proposed a method based on clustering and pattern representation to automatically detect beliefs and reveal unexpected patterns from data. This method can automatically detect beliefs, capture semantic relationships between patterns, and identify potential unexpected patterns using outliers. The experimental evaluation has demonstrated the effectiveness of the method and the correlation between the discovered patterns. 18 When conducting mining and estimation analysis of landslide data, Kusak et al. used association algorithms to analyze factors such as terrain, hydrology, and vegetation of the studied terrain, and combined them with K-means clustering algorithm to achieve regional feature analysis. The results indicate that the K-clustering algorithm has good classification performance for regional analysis, and it greatly improves the accuracy of the algorithm by analyzing the performance between different factors. 19
As can be seen in the above, the current application of AC algorithms is very common, but the performance of traditional AC algorithms is generally deficient and needs to be optimized and improved. At present, information technology assessment based on intelligent algorithms plays an important role in various fields, and information technology assessment based on AC algorithms also has certain research results. However, at present, the efficiency and accuracy of information technology assessment based on AC algorithm are not satisfactory. To address this problem, the study proposes an improved AC algorithm, improves its selection of information features and correlation analysis of association rules, and carries out informatization evaluation of this improved algorithm to analyze its accuracy and capability of information extraction in the context of big data, in order to better achieve its evaluation effectiveness and application accuracy. It provides a reference for the decision of government target policies and a new idea for the improvement of data mining algorithm. The study carries out multiple learning of the training set and the setting of the interest threshold to improve the correlation between the category labels on the original association classification algorithm, and carries out multi-label feature selection algorithm and the introduction of the frequent pattern tree to measure the data information and improve the efficiency of the information processing by using the label importance as the metric. The algorithms proposed in the study are more based on the consideration of the properties of the data information itself and the computational performance, including the correlation threshold, label importance, and data mining and traversal characteristics, and the methodological ideas consider more contents and are data-oriented. This ensures the comprehensive objectivity of the data informatization assessment content on the basis of also different from other algorithms single on the association rule selection or process improvement. The method can meet the data processing needs in the process of practical application, and can better adapt to different types of data, its scalability has a certain guarantee, and the computational volume is small, which is conducive to improving the operational efficiency of the system.
Improved design of association classification algorithm in information technology evaluation
Association classification algorithm based on multiple learning and interest degree setting
The information evaluation process, as an important guiding practice for target mining, is mainly through target determination, data preprocessing, data mining and knowledge discovery modules to achieve the analysis of the connection between data information, and the meaning and content of the mining for practice, in order to better achieve the decision support for the objectives of the decision-making department. Figure 1 shows the data mining model for information technology evaluation. Informatization evaluation data mining model.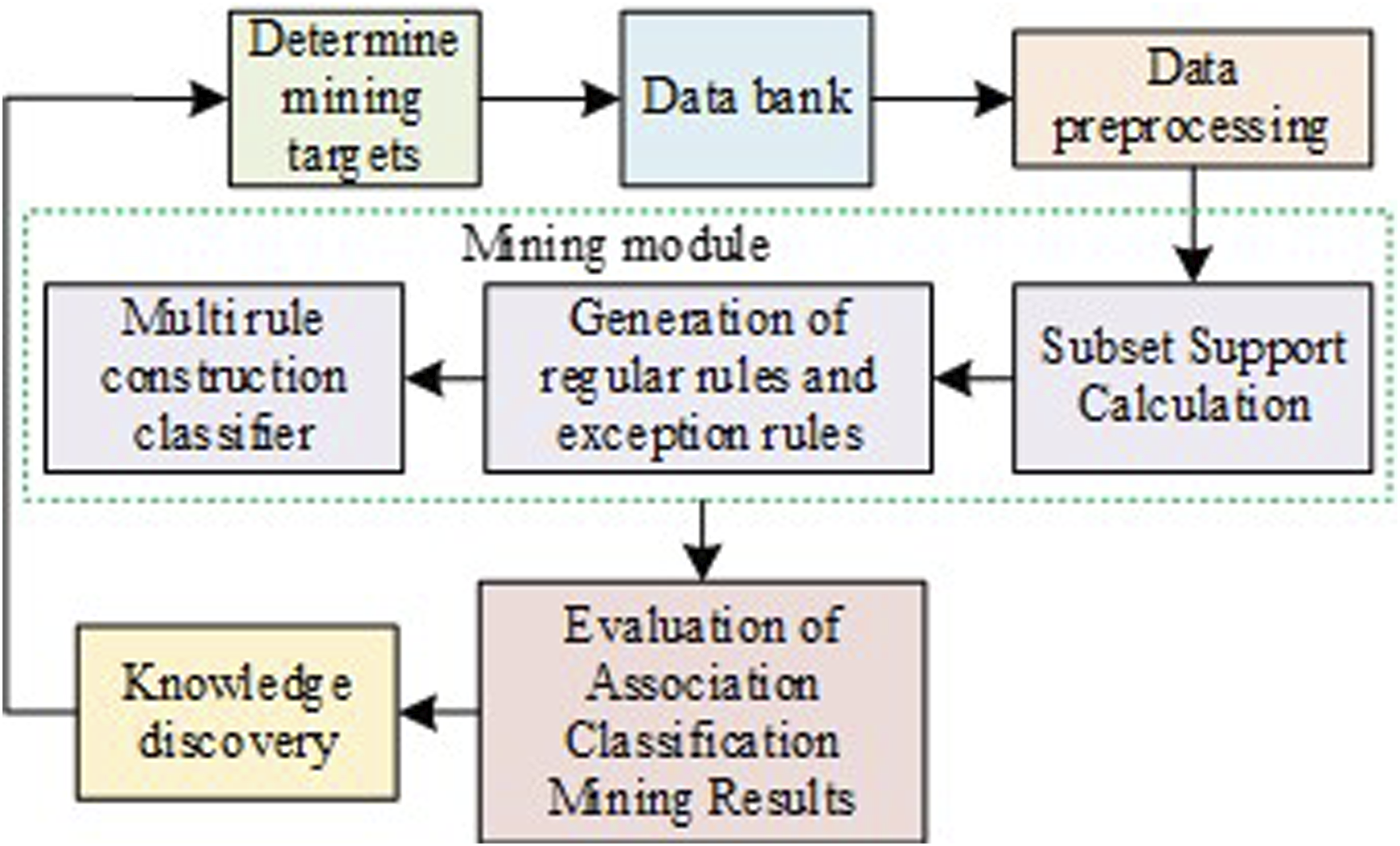
In Figure 1, information technology evaluation mainly includes several important distributions such as target determination, data preprocessing, data mining, and knowledge discovery. The determination of targets is designed based on the characteristics of the dataset and actual needs, while data preprocessing is mainly aimed at ensuring the uniformity of data files, reducing the interference of noisy and incomplete data. The data mining section includes three parts: multi rule classifier construction, rule generation, and subset calculation. As a kind of data mining, associative classification (AC) algorithm can effectively achieve the integration of classifier construction and attribute relevance analysis, and its classification of association rules mining can show high classification accuracy. However, the validity of the rule data generated by AC algorithm is low, and it is difficult to classify the imbalanced data with high quality and difference, and it is difficult to achieve both the overall performance accuracy and small classification effectiveness. However, the actual information data contains more label categories, and its dimensional hierarchy and the number of correlations are large, and the AC algorithm often has difficulty in producing effective classification accuracy and retaining the integrity of data information features when processing such data. Therefore, the study proposes the improved association classification algorithm based on multiple learning and CCS confidence (IAMC) for the training set to address the problem of more redundant rules in the traditional AC algorithm. The IAMC algorithm extracts the training set multiple times and performs rule mining with a new metric association degree. The training dataset and category are set as

In equation (1),

In equation (2),
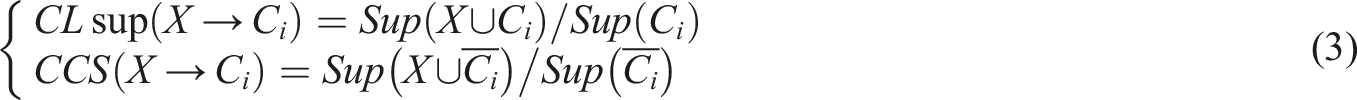
In equation (3),

If the lifting degree is less than 1, it indicates a negative correlation between the itemset and the category. At the same time, in order to avoid the formula not being valid due to the complementary category support degree of 0, it is necessary to design a very small rule strength that fully takes into account the correlation between type categories. The mathematical expression is shown in equation (5).
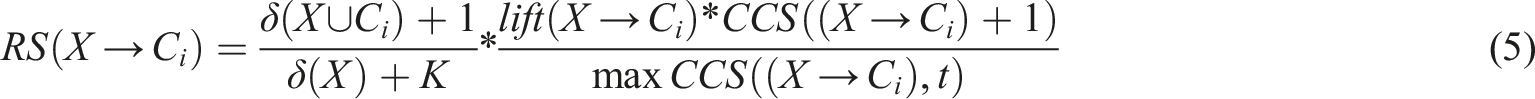
In equation (5),

In equation (6),
Algorithm for evaluating association classification information based on multi-label feature selection algorithm
Also, to ensure the quality of rule extraction, the data prediction with a new rule metric is studied, which can analyze the category relevance and set the confidence rule ranking results. Multi-label feature selection (MLFS) with label importance as the metric, which is mainly done with the help of mutual information between labels, classifies the important and unimportant labels with multiple relevant features and few relevant features to achieve the effect of extracting feature information while avoiding data redundancy. With mutual information as the metric and information gain as the metric, its mathematical expression is shown in equation (7).
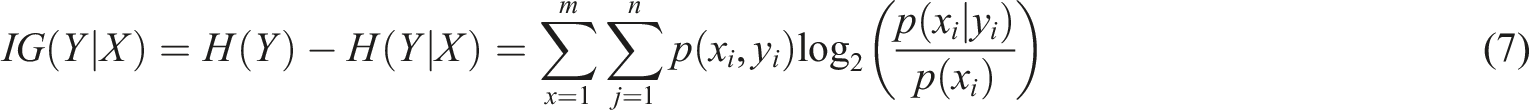
In equation (7),

In equation (8),

In equation (9), FP*-tree.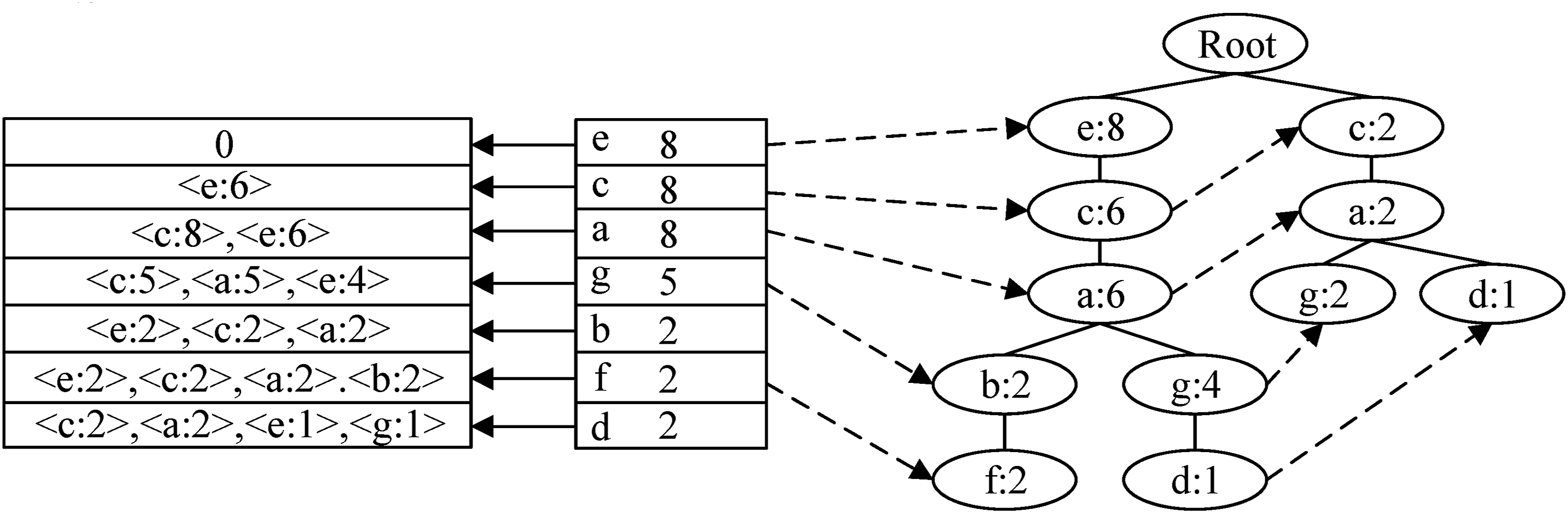
Figure 2 shows the creation process of transaction data at a minimum support threshold of 2. In the figure, FP*-tree mainly adds a corresponding inverted table for each item in the header table. The inverted table for item e in the header table is empty because item e is the most supported item in the dataset, so it is the first element of FP*-tree’s header table. When the inverted table of item a is {(c, 8), (e, 6)}, it indicates that item c and item a appear simultaneously in eight and six transaction datasets. But FP*-tree does not record the appearance of another item in the inverted table of two items at the same time, but only records the appearance of the other item in one item, for example, recording a binary (c, 8) in the inverted table of item a. The FP*-tree algorithm needs to go through two stages in its operation: data preparation and data insertion. Its main purpose in the data preparation stage is to scan the dataset and remove the items that do not meet the minimum support threshold, and then sort them in descending order according to their frequency size. The filtered sorting results are then inserted into the FP*-tree algorithm, and the items in the inserted records are processed sequentially, and the tree structure, chain table and inverted table in this algorithm are updated. Figure 3 shows the flow diagram of the insertion process. Flow chart for inserting transaction records into FP*-tree.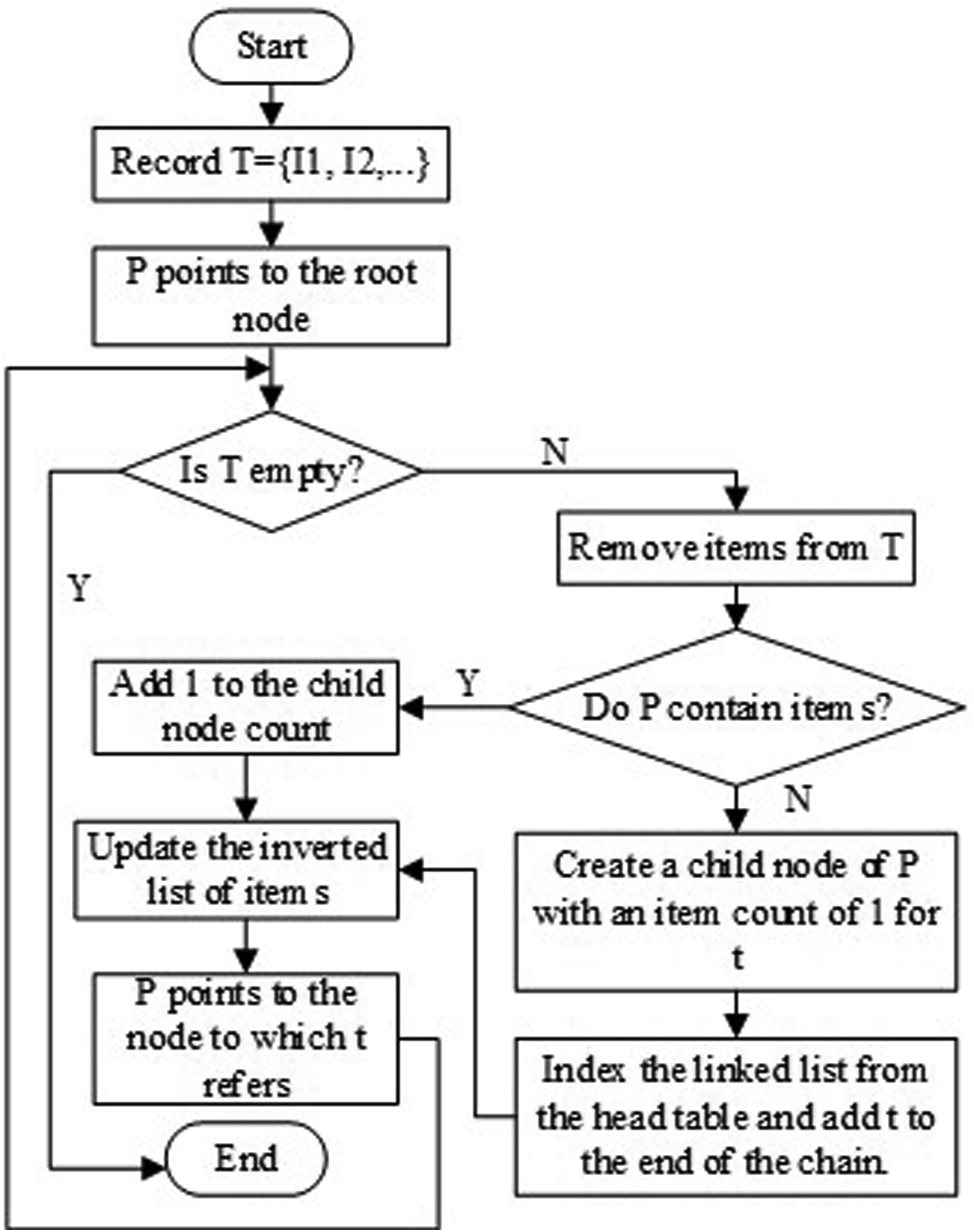
In Figure 3, when a transaction record is inserted into FP*-tree, the transaction records that have been filtered and sorted during the data preparation stage will be inserted into FP*-tree according to the sorting order. The algorithm will record the node created (or updated) last time and determine whether the node created (or updated) last time has a child node of the current item. If it exists, simply increase the count of the child node by 1 and update the inverted table of the current inserted item. Otherwise, create a child node for the current node and update the linked list of that item in the header table. Insert the newly created node into the end of the linked list, update the inverted table of the current inserted item, and record the nodes created (or updated) when inserting the current item in sequence until all items in the transaction record are processed, thus ending the process. The algorithm can detect the upper bound of the mined maximal frequent itemsets and the unmined maximal frequent itemsets in the mining process, and when the upper bound of the diversity of the two maximal frequent itemsets is larger, then the repeated mining of the maximal frequent itemsets can be avoided and the operation efficiency can be improved. At the same time, an algorithm based on boundary detection for the maximum diversity frequent itemset is proposed, which calculates the upper bound of the diversity of the maximum frequent itemset during the data mining process and compares it with the maximum frequent itemset. When the required maximum itemset is reached, the algorithm exits early to avoid unnecessary mining processes. The flowchart of this algorithm is shown in Figure 4. Algorithm flow chart.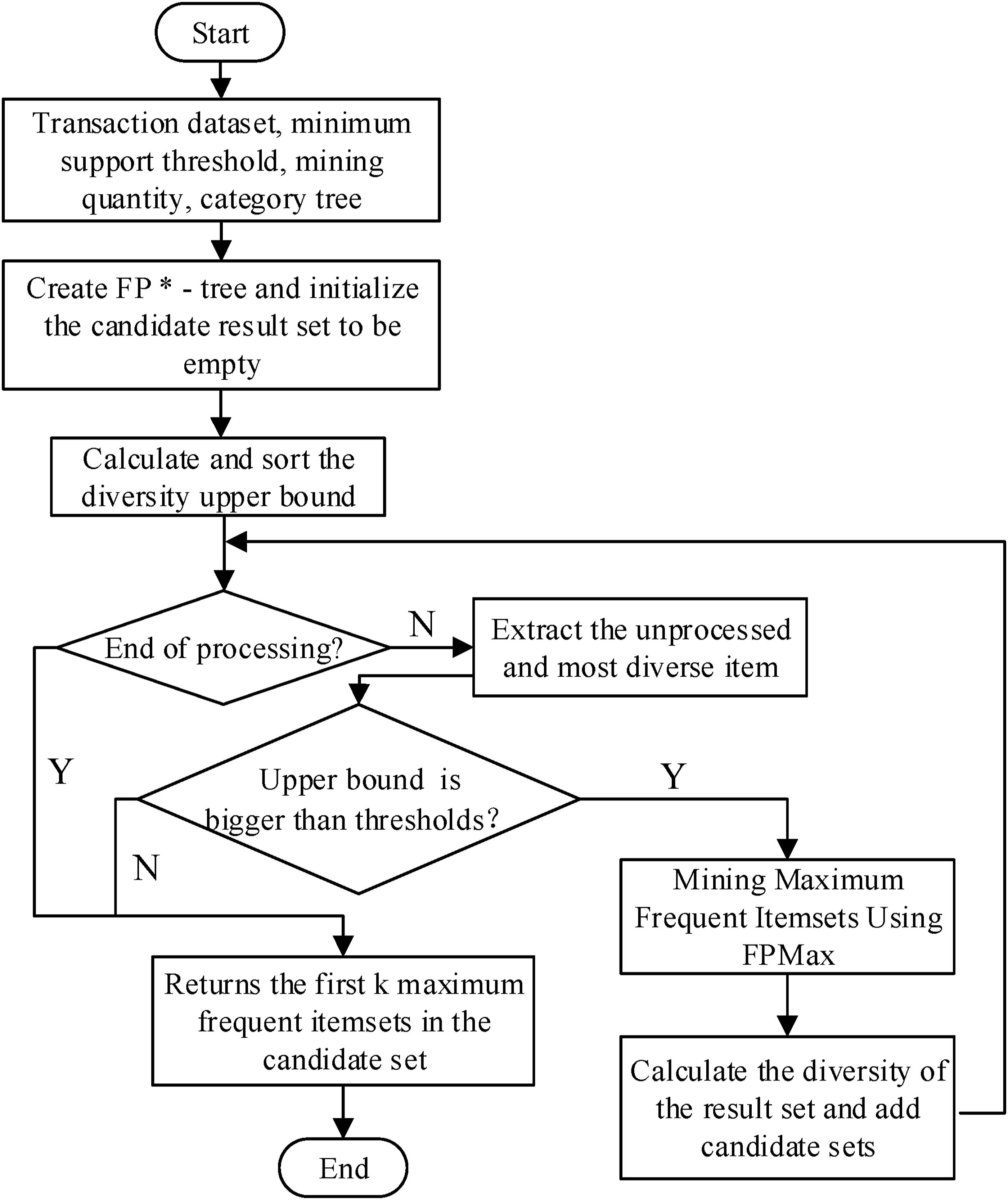
In Figure 4, the algorithm detects and compares the diversity upper bound of the maximum frequent itemset candidate set currently mined and unmined when mining each item in the FP*-tree header table. When the upper bound of the mined candidate set is maximum, the algorithm can be terminated. On the contrary, it is necessary to recalculate the diversity of the maximum frequent itemset based on the header table. This method can effectively avoid unnecessary mining processes. Subsequently, the design of the improved association classification algorithm is studied with the help of parallelized platform, that is, the transactional dataset is distributed to multiple sub-nodes and Resilient Distributed Datasets (RDDs) transformation to implement the scheme design to find frequent itemsets with local join and pruning operations to reduce the memory burden of global lookup. The specific flow is shown in Figure 5. Parallelization process.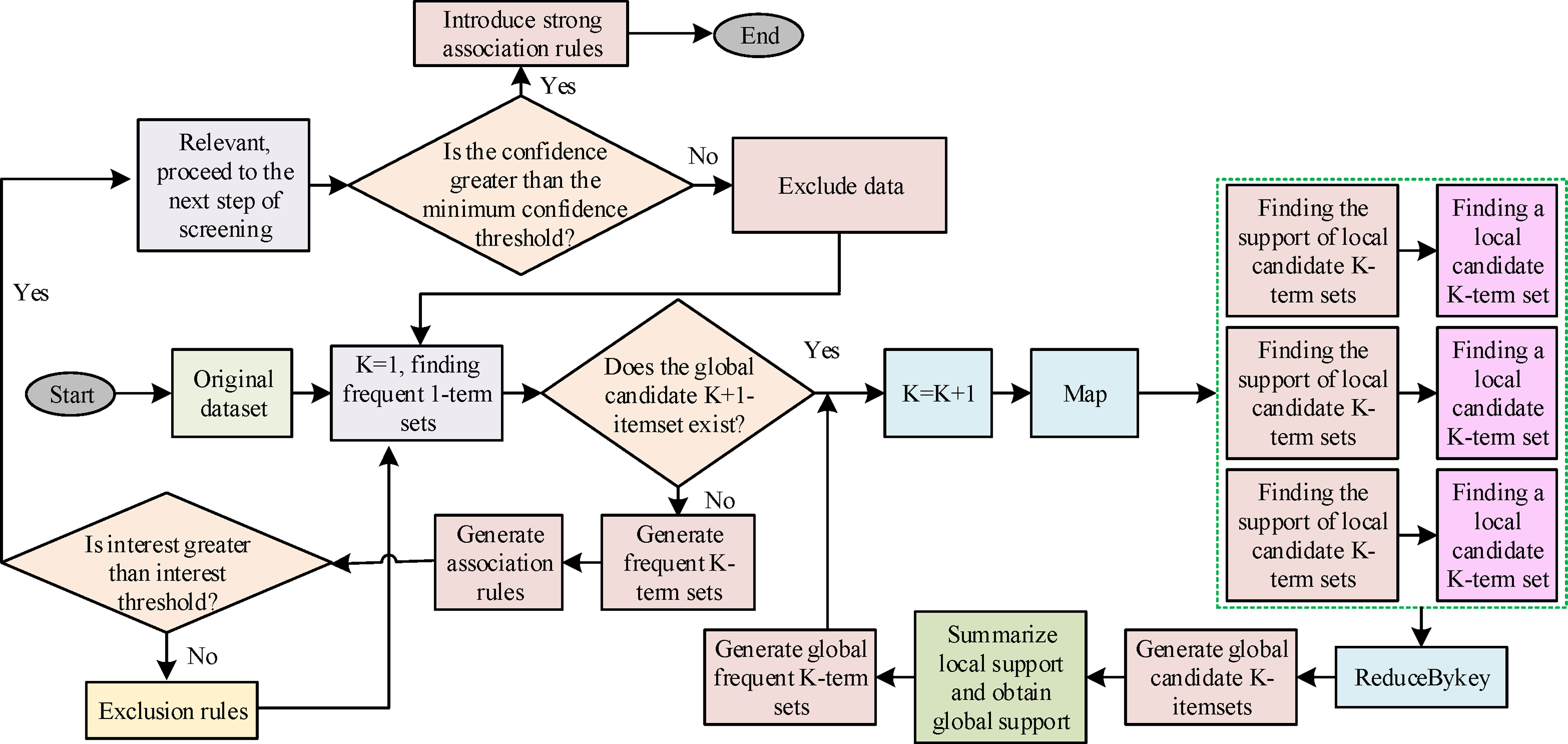
In Figure 5, the improved algorithm obtains relevant data in a distributed file and generates a dataset RDD. Then, the number of items is counted to perform frequent itemset calculations, and the dataset is cached using map and cache operations. In the process of frequent itemset iteration, operator data is filtered using the frequent itemsets on the working node to generate a local candidate set, and its global support is counted until all association rules are extracted. Subsequently, rule filtering is performed using interest threshold and confidence threshold, and association rules with confidence greater than the minimum confidence threshold are considered strong association rules.
Improving the effectiveness of association classification algorithm in information technology assessment
Performance testing of improved association classification algorithms
The study selects part of the dataset of the “China-EU Information Society Project” as the experimental data, and the data source is obtained by sampling the results of the questionnaire and processing, and the value is filled into the missing position of the attribute, and the null value of the noun attribute is replaced by the value with the highest frequency it exhibits for the constant. The data covering more information data are processed in a hierarchical manner, and the replacement of the original data is realized with high-level concepts, such as regional household registration information. All data are discrete, and the overall good dataset includes sex(S), nation(N), region(R), education(E), income(In), job(J), internet(I), and Other—data to be classified(O). The datasets can be classified into three levels according to their level of informatization. The processed dataset is divided into test and training sets according to the ratio of 1:4, and the cross-validation and mean values are taken as the experimental results. The experimental environment parameters were first set up, that is, the hardware environment was Inter(R) Core(TM) i5-3470 CPU @ 3.20 GHz, processed on a platform with Windows 10, 16 GB of memory, 32-bit, x64 operating processor, IE 6.0 browser, and C++ programming language.
The dataset selected in the experiment is the UCI Machine Learning Dataset Library (UCI ML Repository). The UCI ML Repository is a public dataset library that provides many commonly used machine learning datasets for research and experimentation. The UCI ML Repository contains datasets from multiple fields, such as classification, regression, clustering, etc. This dataset library is maintained and managed by the Department of Computer Science at the University of California, Irvine. These datasets have been processed and organized to meet the needs of the field of machine learning, making them easy to use and analyze. The dataset of UCI ML Repository typically contains multiple features and labels for training and testing the performance of machine learning models. By using these datasets, researchers can perform algorithm comparisons, evaluate model performance, perform feature selection, and establish predictive models. The UCI ML Repository can help researchers and developers conduct experiments and validations, driving progress in the field of machine learning. The monk dataset is a manually generated dataset used to simulate classification tasks. It contains multiple features and labels, such as numerical, discrete, and categorical features, and is often used to train and test the effectiveness of classification algorithms. The spect dataset is extracted from real medical image data and used for classification tasks of lung tomography images, such as identifying diseases, and is mainly provided in the form of images. At the same time, the monk dataset contains relatively small sample sizes, so the extraction of details and other information is more accurate and prominent when conducting classification result testing. The performance of the improved association analysis algorithm proposed in the study is then analyzed and compared with AC, IAMC, MLFS, and FP-tree algorithms, and the results of the application of training and testing errors are shown in Figure 6. Comparison of error results during testing and training. (a) Test process, (b) training process.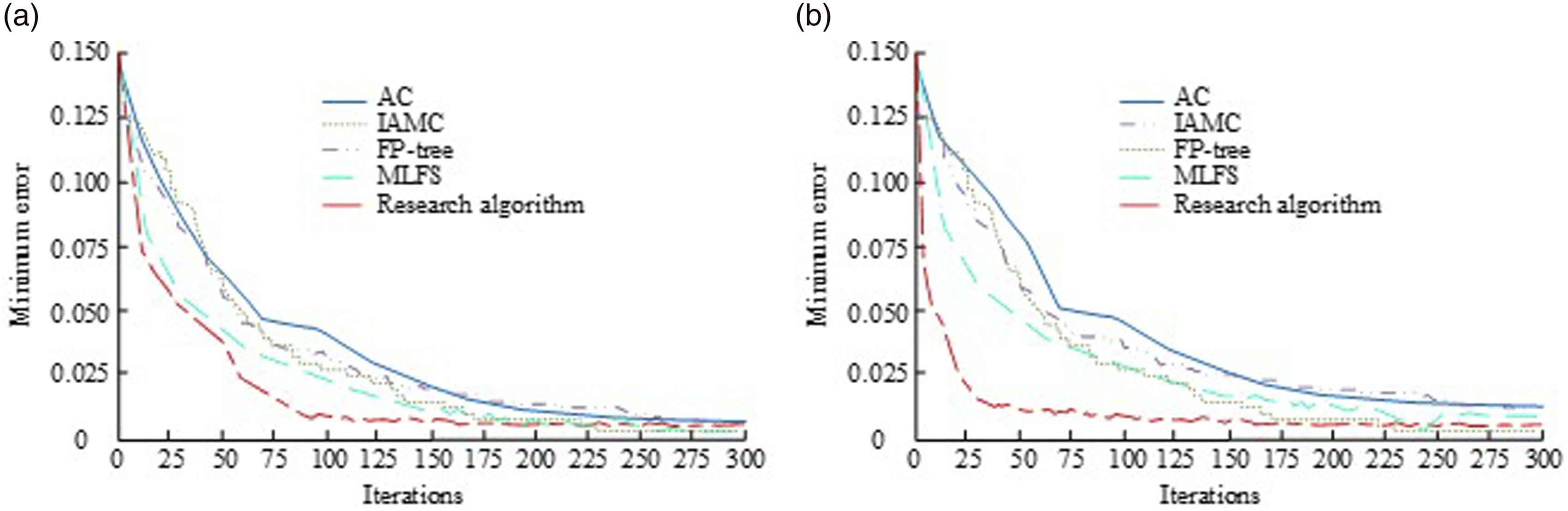
Data classification error and time consumption results of different algorithms.
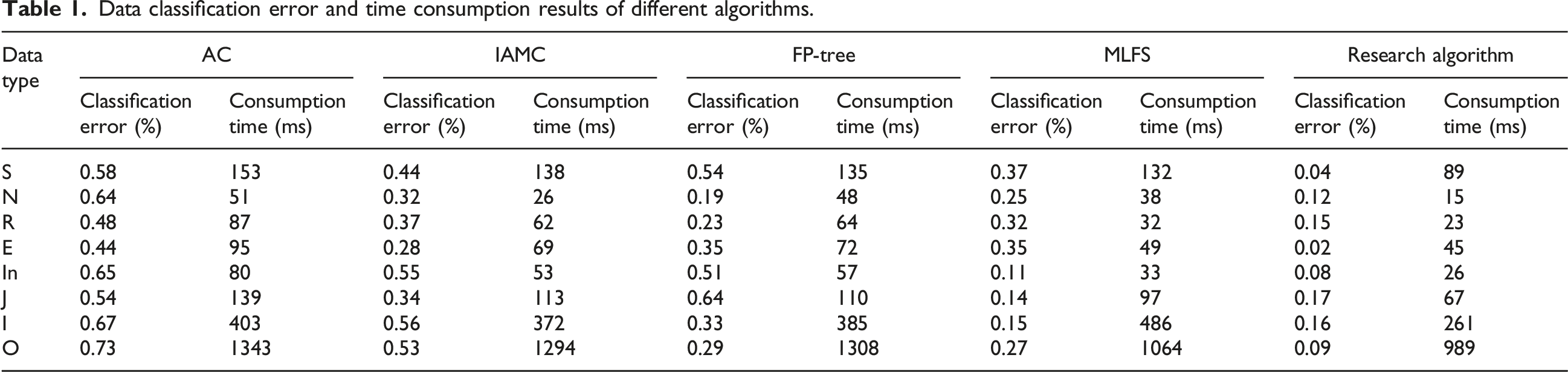
The results in Table 1 show that different classification algorithms exhibit poor differences in classification performance, specifically, in terms of time consumption, the AC algorithm and the FP-tree algorithm consume time with maximum values of 1343 ms and 1308 ms, and minimum values of 51 ms and 48 ms. The IAMC algorithm and the MLFS algorithm consume relatively less time for data classification, and the maximum consumption time is 1294 ms and 1064 ms, where the maximum time difference between MLFS algorithm and AC algorithm and FP-tree algorithm has a magnitude of more than 13%. The time consumption of the proposed algorithm is less than that of the other compared algorithms for all eight data types, and the difference in maximum time consumption between the AC algorithm, FP-tree algorithm, IAMC algorithm, and MLFS algorithm reaches 14.28%, 13.27%, 11.64%, and 10.75%, which indicates that it has a higher sample processing speed when performing data runs. Processing speed is higher, which is attributed to its threshold design of association rules during the run that effectively reduces the processing of redundant information data. From the data classification results, the accuracy classification of the AC algorithm exceeds 40% error results for all eight data types, and the maximum classification error reaches 73% for other data types. The data classification errors of the FP-tree algorithm exceed 15%, with a minimum classification error of 19% and a large variation in the overall classification results. The classification errors of the MLFS algorithm are between 15% and 40%, and its classification performance is better than the AC algorithm, FP-tree algorithm, and IAMC algorithm but is still lower than the algorithm proposed in the study. The algorithm proposed in the study showed better classification results under eight data types and all of them were below 20% overall, with an average classification error of 10.37% and less data fluctuation, showing better performance.
Analysis of information evaluation application of improved algorithms
The algorithm was then analyzed for resource logging response efficiency in performing information evaluation, and the results are shown in Figure 7. Resource login response efficiency of the algorithm in information evaluation.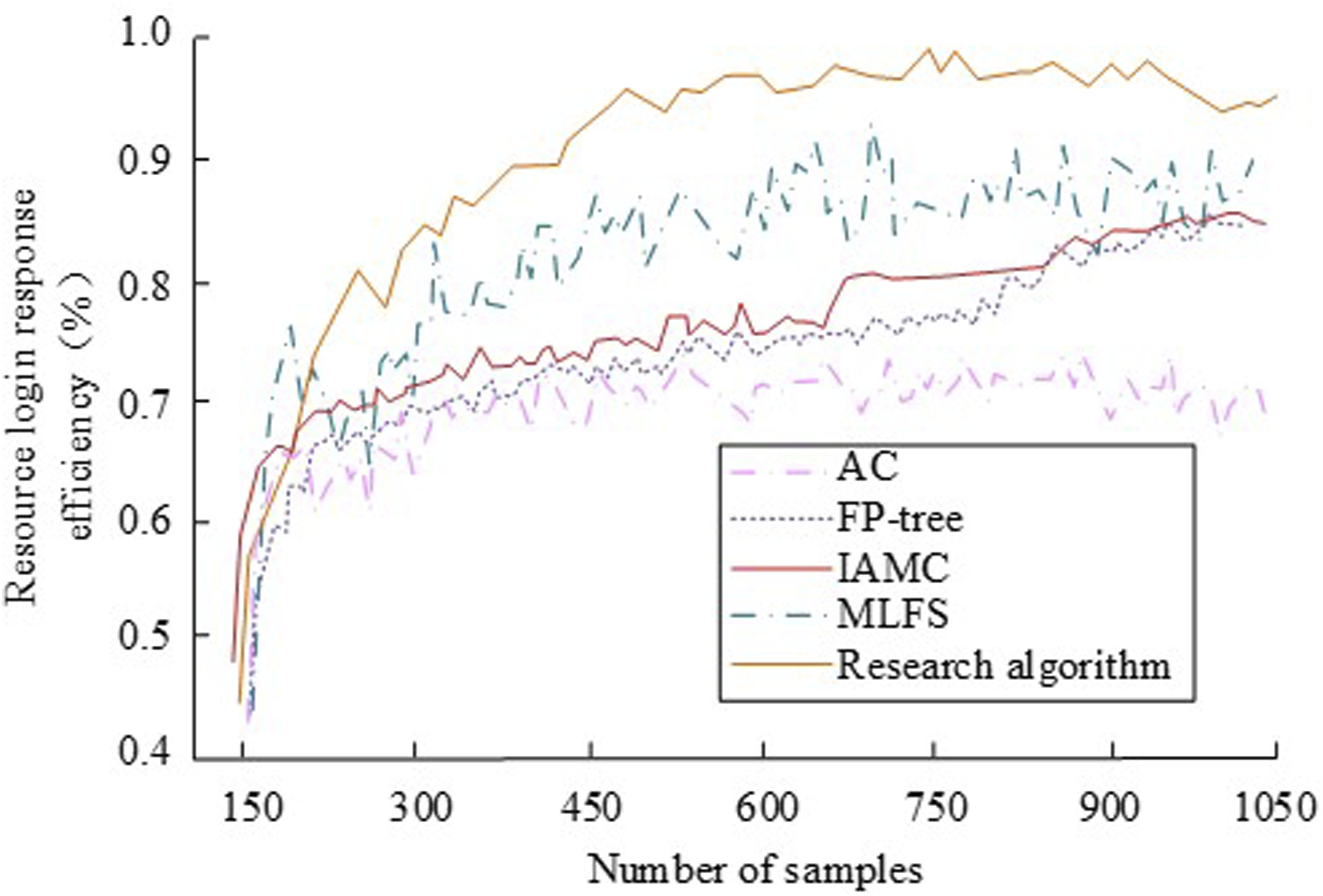
The results in Figure 7 show that there are differences in the fluctuations of the resource login response change curves exhibited by different algorithms at different sample sizes. The response efficiency of the AC algorithm, FP-tree algorithm, and IAMC algorithm is less than 85% overall, and their fluctuating nodes are more. The response efficiency of the MLFS algorithm is better, and its maximum improvement efficiency reaches 91.05% at the sample size of 700, but its overall fluctuation is within 2%, and its performance is slightly worse than that of the proposed algorithm. The response curve of the proposed algorithm has a larger slope and more obvious improvement under the small sample size, and the average response efficiency under the large sample size basically remains above 94%, with the maximum value reaching 97.23%. The above results indicate that the improved correlation classification algorithm proposed in the study has better stability and its performance efficiency in the system test responses is better.
The results in Figure 8 show that the error rates of the correlation rules of different algorithms under the equivalent eigenvalue interval are different from those under the traditional decision classification. The classification error rates of the four algorithms, AC algorithm, FP-tree algorithm, IAMC algorithm and MLFS algorithm, are 3.23%, 2.15%, 2.06%, 1.37%, and 0.21%, respectively. It shows that the classification algorithms proposed in the study have good application performance and their error control situation is good, and their basic stability of this algorithm is good, less subject to fluctuation and produce large distance change situation, and the stability posture is good. To further analyze the information evaluation performance of the algorithm, the study selected the standard data UCI ML Repository in monk-1, monk-2, spect, and the integrated dataset of the study for experimental analysis, which has seven attribute values in the dataset in UCI ML Repository, and the results are as follows. Statistics of association rule classification error rates for different algorithms in equal precision intervals.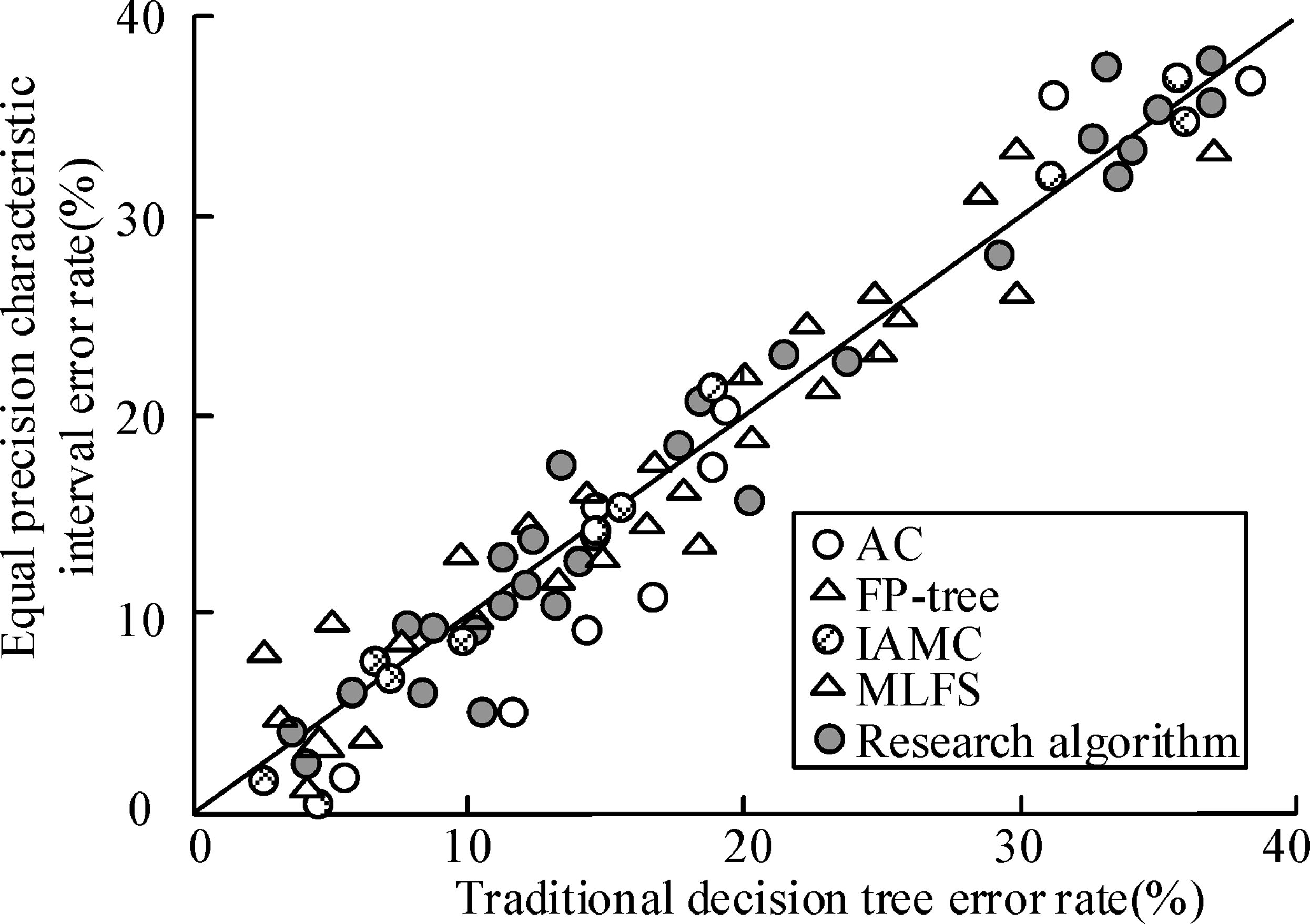
Figure 9 shows that there are significant differences in information evaluation between different algorithms in the monk-1 and monk-2 datasets, reflecting some differences in data accuracy. The sample data properties of the monk-1 and monk-2 datasets are consistent, with the monk-2 dataset having finer data classification. Recall@K Indicator refers to the average value of correctly identified samples in the identification of all samples, which can be used to measure the accuracy effect. Specifically, in the monk-1 dataset, the research proposes an improved AC algorithm that performs well under different data ratios Recall@K The value is higher, and its maximum value can approach 0.48, which is much higher than the 0.33 of AC algorithm and IAMC algorithm under the same conditions, the 0.43 of FP-tree algorithm, and the 0.446 of MLFS algorithm. In the monk-2 dataset, the algorithm proposed in the study also showed a good trend of accuracy growth, with an average of Recall@K. There is a maximum accuracy difference of over 25% between the value and other algorithms. The reason for the above results is that traditional AC algorithms may not be precise enough in feature extraction and rule localization of data, especially in high-dimensional data and noisy backgrounds, ignoring the dependency relationships between data attributes and the internal structure of the data. Although the IAMC algorithm has undergone multiple rounds of training on the dataset, if it does not effectively filter features and adjust rules, it may lead to overfitting and resource waste in the model, which in turn affects classification accuracy. FP-tree and MLFS algorithms can mine and analyze data, but the evaluation of individual special information and the selection of important information are still difficult to meet the characteristics of data association. When the proportion of data increases, it means that the amount of data to be processed increases significantly, and the disadvantages of the above comparison algorithms will also be more prominent. The algorithm proposed in the study can combine the advantages of interest threshold screening and multi-label feature selection, effectively associate strong rule algorithms, and better grasp the inherent characteristics of the data, thus demonstrating good evaluation accuracy. Spect dataset and the results of the ensemble proposed by the study are shown in Figure 10. Different algorithms on different datasets Recall@K Evaluation results. (a) monk-1, (b) monk-2. Recall@K results of four datasets in the Top-K recommendation task. (a) Spect, (b) research collection.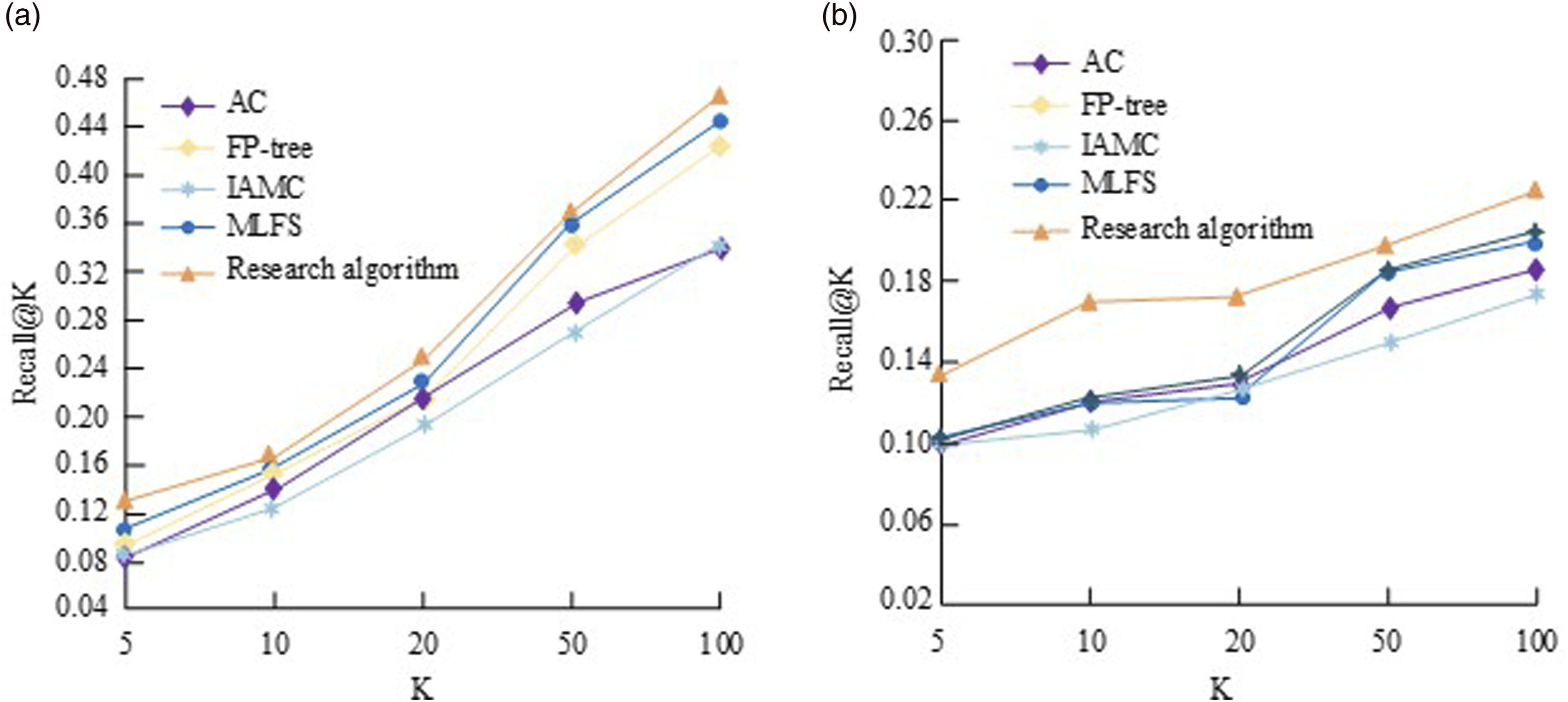
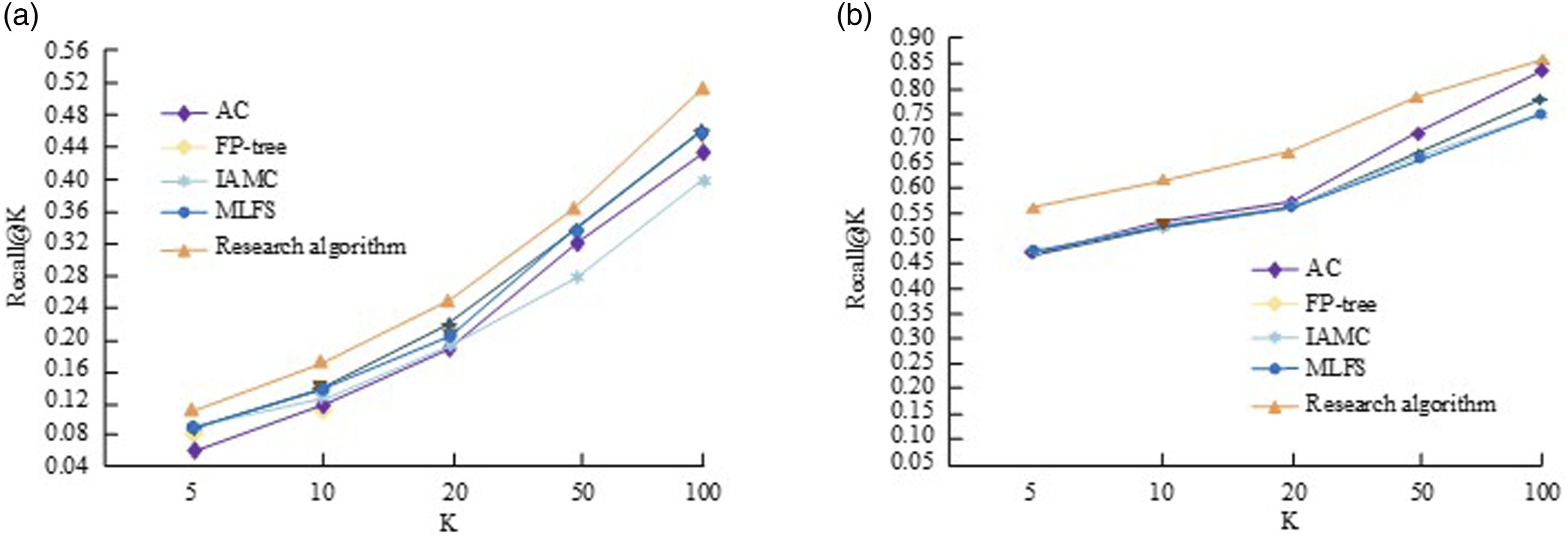
The results of combining Figure 9 and Figure 10 indicate that the improved association classification algorithm proposed in the study performs better in different datasets, with less overall interference fluctuation and good stability. It can identify and evaluate information under different data types, effectively providing new reference value for decision-making information formulation.
Conclusion
The study improves the association classification algorithm and analyzes the results based on the characteristics of information technology evaluation data and the results of association rule data. The results show that the improved association analysis algorithm proposed by the study has smaller error values in the error comparison results with AC, IAMC, MLFS, and FP-tree algorithms. The average test error results of the tests are from largest to smallest: AC algorithm > IAMC algorithm > FP-tree algorithm > MLFS algorithm > research proposed algorithm, and the training errors are from smallest to large: research proposed algorithm (2.36%) > MLFS algorithm (5.64%) > IAMC algorithm (13.26%) > FP-tree algorithm (15.21%) > AC algorithm (33.64%). Meanwhile the maximum values of time consumption of AC algorithm, FP-tree algorithm, IAMC algorithm and MLFS algorithm are 1343 ms, 1308 ms, 1294 ms, and 1064 ms, while the studied improved AC algorithm has the least time consumption with the difference magnitude of 14.28%, 13.27%, 11.64%, and 10.75%, which reduces the processing of redundant information. Meanwhile, the average classification error of the improved AC algorithm is 10.37%, and the average response efficiency basically remains above 94%, with the maximum value reaching 97.23%, which is better than other algorithms, with better error control and average Recall@K improvement values all above 5%. The improved AC algorithm can better pass the set threshold rules for multidimensional classification, and its information processing is optimized for better application. Although the algorithm proposed in the study has shown good application effects, there are still certain shortcomings. In response to the explosive growth of data volume at present, the proposed classification algorithm based on learning and interest setting needs to consider how to improve the efficiency of rule data storage without increasing the algorithm’s spatiotemporal complexity. At the same time, the mining and analysis of rule examples should also pay attention to the uneven distribution of categories in multi-label data. Optimizing the creation and batch updating of FP*-tree, strengthening the preprocessing and machine learning capabilities of the dataset, and building a comprehensive information evaluation data mining platform are the key research areas and directions for future research.
Statements and declarations
Footnotes
Conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by 2021 Henan Provincial Philosophy and Social Sciences Planning Project: Researches on Design of Personal Information Protection Mechanism in Digital Economy Era (2021BZH004).