
Abstract
With the rapid growth of video resources on online education platforms, accurately recommending resources that meet learners’ needs has become crucial. This paper proposes a personalized resource recommendation model based on social tags, aiming to address the challenges of cold start and data sparsity, thereby enhancing the prediction accuracy of recommendation platforms. The model generates video tags by analyzing descriptive information, user annotations, and comments associated with videos, and constructs dynamic learner profiles. The similarity between video tags and learner profiles is calculated using Euclidean distance to recommend resources that meet learners’ personalized needs. Experimental results demonstrate that, compared to traditional user-based and item-based collaborative filtering algorithms, our model achieves approximately 15% and 8% improvements in precision and recall. These findings not only enhance learning efficiency but also significantly improve learner engagement and loyalty, showcasing the model’s significant application potential in the educational domain.
Introduction
The development of information technology and the widespread use of the Internet have brought new opportunities and challenges to the field of education. Emerging teaching models, such as online courses and flipped classrooms, have not only transformed traditional teaching methods but also provided new approaches to enhancing educational equity and quality. China Education Modernization 2035 explicitly advocates for developing high-quality education with Chinese characteristics at an advanced global level. It emphasizes leveraging modern information technology to enrich and innovate curriculum formats and to build a lifelong learning system accessible to all. The plan underscores the importance of educational equity, proposing the use of educational informatization to promote the equitable distribution of high-quality educational resources and to improve education quality as a means of advancing fairness in education. However, current online learning resources face several challenges.
First, learning efficiency is low. Many videos are simply recordings of complete classroom sessions, requiring students to manually scroll through playback to locate specific segments of interest, leading to a suboptimal learning experience.
Second, learner engagement is limited. Most MOOC platforms can’t support direct annotation of videos, preventing students from sharing their thoughts or feelings during the browsing process. Instead, learners can only comment on entire videos, which lack specificity and reduces interaction to a mere formality.
Third, learners face resource disorientation. As the volume of learning resources continues to grow, learners often struggle to define their needs, express their requirements clearly, or find data results that align with their personal tastes and preferences. This can leave them feeling overwhelmed and uncertain about where to start.
With the deep integration of emerging technologies such as mobile internet, cloud computing, big data, and learning analytics into education, conditions have been created for the accumulation of educational big data. Every learner’s study process data can now be recorded, collected, and stored anytime and anywhere, forming a rich repository of educational big data. This opens possibilities for personalized services in educational resources. Therefore, constructing recommendation algorithms that combine learner and resource models to provide customized services and improve learning efficiency and quality holds profound research significance.
Related research
Personalized recommendations
Research on personalized recommendations began with the first paper on collaborative filtering published by Resnick et al. in 1994. 1 This study aimed to recommend potential items of interest to users. Such web applications can predict users’ preferences for item selection. However, due to the vast and complex nature of the data, users often struggle to quickly find the most suitable items from an overwhelming amount of information. As a result, personalized recommendations have become a common need for users. Personalized recommendation methods can be broadly categorized into three types:
Content-based recommendation algorithms
Content-based recommendation algorithms primarily face challenges related to semantic analysis and the cold start problems. Huang Ran enhanced the semantic analysis capability of traditional content-based recommendation algorithms by integrating semantic information with the TF-IDF (Term Frequency-Inverse Document Frequency) vector space model for item modeling and similarity calculation, 2 Van Dat N argued that in probabilistic contexts, similarity calculation methods significantly influence the accuracy of content-based recommendations. He proposed a new content-based recommendation method using a Gaussian Mixture Model to improve the accuracy of probabilistic recommendation problems, 3 Huang Linlin utilized content-based recommendation techniques and the k-nearest neighbor algorithm in recommendation systems to identify similarities among traffic conditions. By analyzing historical data of selected similar traffic conditions, she predicted the compatibility of current traffic conditions with various timing schemes, recommending and ranking timing schemes accordingly. 4 Gu Yanshuo collected user information through surveys and applied content-based recommendation algorithms to analyze users’ personal dietary preferences. This approach introduced personalized dish recommendations for online meal ordering, personalized dish push notifications, and feedback functionalities. It effectively addressed challenges such as difficulty in ordering, meal collection, and dining, saving time and effort while meeting the demands of fast-paced lifestyles 5 ;Wang Yuzhe employed a vectorization method based on TF-IDF to transform movie genres and director information into feature vectors. By calculating the similarity between movies using cosine similarity, he measured the correlation between movies. Based on users’ preferences and needs, he improved the priority of relevant movie recommendations through weighted similarity scores, selecting the most suitable recommendation results from a pool of candidate movies. 6
Research on collaborative filtering-based recommendation algorithms. Collaborative filtering-based recommendation algorithms primarily face challenges related to data sparsity and the cold start problem
Du Yanping addressed the issue of data sparsity by considering the impact of common book ratings on similarity calculations. Using the average rating of all books as a threshold, the common rating weights were incorporated into the user similarity calculations. For data filling, the user’s average rating was encoded along with basic attributes such as age and gender. An initial Euclidean distance was computed for hierarchical clustering of users. The Shope-One algorithm was then used to calculate fill values for the top-m similar users, which were weighted and summed to derive the final fill values, thereby improving the data filling method. 7 Chen Hailong tackled the issue of matrix sparsity caused by the randomness of user-annotated tags, proposing a tag-extension collaborative filtering recommendation algorithm. This algorithm calculates tag-based similarity using user-tagging behaviors and evaluates tag similarity from the perspectives of user behavior and tag semantics. The tag similarity was then used to extend each item’s tags, reducing matrix sparsity caused by the association between items and tags. 8 Zhang Yanju addressed problems of missing data and ambiguity in traditional recommendation algorithms by employing an intuitionistic fuzzy rough set to process missing data and calculate intuitionistic fuzzy numbers. A density function was used to initialize clustering centers, and intuitionistic fuzzy C-means clustering was applied to identify the cluster category of the target user. The neighbor set was determined using a feature coefficient instead of the traditional similarity coefficient, and a priority relation ordering method replaced traditional recommendation algorithms to form the recommendation list. 9
Research on hybrid recommendation algorithms
To address the limitations of content-based and collaborative filtering recommendation algorithms, many researchers have turned their attention to hybrid recommendation algorithms. Li Xiangjun proposed a hybrid recommendation algorithm based on user review sentiment and matrix factorization. The algorithm first calculates the sentiment tendency of user reviews using the Long Short-Term Memory (LSTM) algorithm. Then, it incorporates the sentiment values of user ratings to enhance the accuracy of actual user ratings and combines matrix factorization recommendation algorithms to improve recommendation quality. 10 Bing Wu introduced a personalized hybrid recommendation algorithm combining clustering and collaborative filtering. First, it utilizes multidimensional item response theory to integrate learners’ course rating preferences, course attribute preferences, and multidimensional ability data matched with course features. Second, considering the dynamic changes in learners’ preferences and abilities over time, the algorithm incorporates Ebbinghaus’ forgetting curve through memory weighting to improve the accuracy and interpretability of the proposed MOOC recommendation algorithm. 11 Wang Yue applied the Term Frequency-Inverse Document Frequency (TF-IDF) concept to fill sparse matrices. In calculating user similarity, the traditional modified Euclidean distance formula was enhanced by introducing two distinct influence factors to mitigate the impact of user rating discrepancies. Two different time decay functions were also employed to adjust for the influence of time factors on the relationships between users and items as well as between users themselves. 12
A review of the relevant literature reveals that researchers have designed various recommendation algorithms from different perspectives. To address the challenges of cold start and data sparsity, this paper comprehensively considers the attributes of both users and items. When users lack browsing histories, the model uses a cold start strategy to initialize user information as an initial profiles. As more videos are recommended and users generate browsing histories, the model dynamically adjusts to mitigate the cold start impact. Based on videos in the browsing history, the model calculates user profiles and computes the similarity between video profiles and user profiles using Euclidean distance, enabling precise recommendations of videos that interest learners.
Learner profiles
The concept of “user persona” was first introduced by Alan Cooper, the father of interaction design. He defined “user persona” as a virtual user, created based on real user data, which serves to represent and characterize the user profiles. With the widespread application of user personas in the business field, more and more scholars have focused on this concept, applying data to the construction of user profiles to make them more scientific, rational, and targeted. A data-driven user profiles refers to a collection of tags that describe the user, generated through the mining and analysis of user behavior data. 13
In the field of education, user profiles aimed at learners are also referred to as learner profiles. With the advancement of educational big data storage and analysis technologies, research on learner profiles has been gaining increasing attention year by year. Lei Qingfeng established dynamic user profiles by collecting and studying multidimensional feature data of users. By mining and analyzing the characteristic information of test items in question banks, he proposed a user-oriented personalized recommendation method for test items. 14 Zhang Xue and colleagues conducted profiles research on online non-native language learners. By analyzing collected learner data, they extracted learning behavior features and applied clustering algorithms to group learners, thereby constructing learner group profiles for different categories. 15 Xiao Jun developed an online learner profiling framework based on the Experience API (XAPI) standard through steps such as data collection, storage, analysis, and personalized recommendation. 16
A review of the relevant literature reveals that researchers have designed various learner profiles from different perspectives, including those for teacher training, teaching evaluation, and online professional development. Most researchers agree that learner profiles can provide supportive services for learning. However, no studies have yet combined video profiles with learner profiles for research purposes.
Video profiles
Video profiles refers to the tags generated for video content to help users better understand and categorize the video. Video tags enable users to quickly find videos of interest and improve the visibility and click-through rate of the videos.
Video tags is a method of adding tags to videos. It can record the annotation time and content of video segments, thereby reducing the time users spend searching for and previewing annotated segments. Currently, there are two main methods of video tags: manual tagging and machine learning-based tagging. (1) Research on Manual Tagging. Manual tagging involves watching videos and annotating features of the video content based on subjective understanding. These annotations are then linked to specific video frame numbers or time axes, facilitating the comprehension of segmented video content.
17
To identify the basic requirements for designing effective time annotation recording technologies, Yudai Tanaka developed a prototype wearable camera video annotation system that allows users to annotate videos during the recording process. Other researchers have studied and developed systems such as a microteaching video annotation system
18
and a teaching skills training and reflection system for pre-service teachers, which enhance the depth of reflection on video cases. (2) Research on Machine Learning-Based Tagging. Machine learning-based tagging involves using manually annotated videos as training samples to build semantic concept models, which are then generalized to automatically annotate other videos. This method can be categorized into supervised learning, semi-supervised learning, and active learning. Jiang Mingyun constructed an ethnic music teaching resource library and used the K-Nearest Neighbor (KNN) algorithm to classify teaching resources within the library. Based on the classification results, the characteristics of teaching resources were described to recommend appropriate resources to corresponding learners.
19
Jia fengLi proposed a personalized mobile video recommendation method based on deep features and social tags to model user preferences.
20
Alex Hoi Hang Chan employed a hybrid tagging approach by first using a machine learning framework to preprocess videos and then applying manual annotations to save annotation time.
20
Currently, there is no shortage of advanced techniques for video representation and description. The key lies in reflecting and organizing the actual associations between videos and users. This approach not only adds deeper value to the interconnections between videos but also facilitates meaningful learning relationships among learners, thereby bringing warmth back to educational communication activities.
This study, grounded in the concept of collective intelligence, introduces social tagging into the representation and organization of case videos. Generative tagging is applied to video segments to form social tags, which are refined through collective wisdom. The TF-IDF method describes video attributes, which can provide relatively comprehensive, accurate, and objective descriptions for video cases. These attributes will change dynamically with real-time comments and annotations. In addition, through explicit and implicit collection of information about learners, the system master’s the current learning needs of learners and analyzes their learning preferences. The learner profiles will be updated dynamically using videos they have browsed. It computes the Euclidean distance for every video profiles and learner profiles to perform a Top-N recommendation, satisfying learners’ personalized needs. The two approaches improve learning performance and enhance user experience.
Model construction
The research model framework in this study, as illustrated in the figure, consists of input and output components (Figures 1 and 2). Research model of the system Learner profiles model.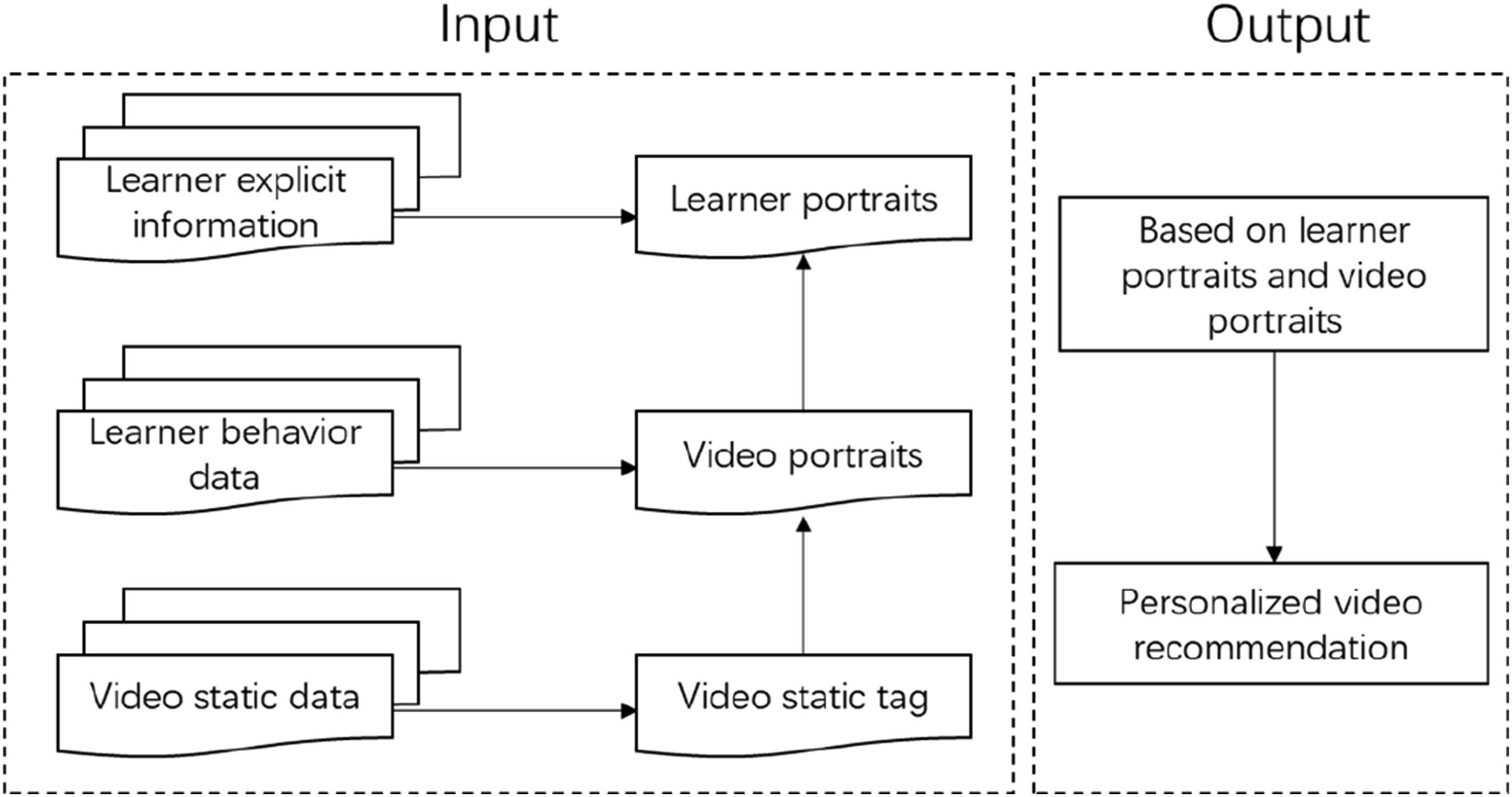
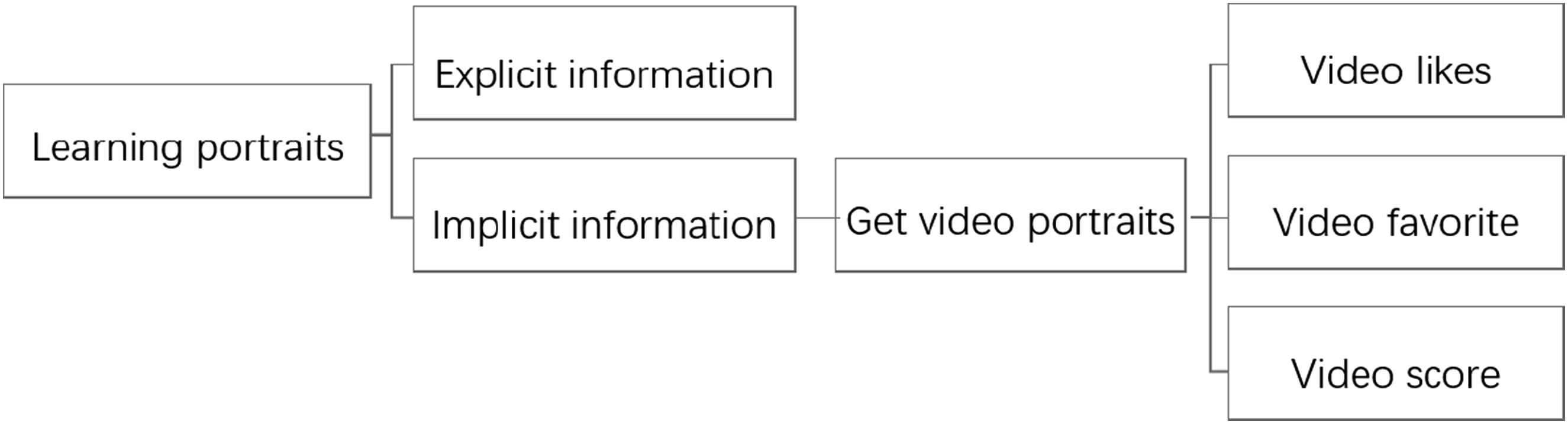
Construction of the learner profiles model
The establishment of the learner profiles is fundamental to achieving personalized resource recommendations. This study utilizes a tagging approach to process learner profiles, enabling a better understanding of learners’ basic information, cognitive abilities, knowledge states, learning styles, and interests and preferences. These insights serve as reference data for recommending videos to learners. Learner profiles are divided into explicit and implicit information. Explicit information is obtained before the start of course learning by having learners fill out basic information forms, complete specialized scales, questionnaires, or tests. This data is analyzed manually to extract some personality traits. Implicit information is gathered during the learning process by mining various interaction data between learners and the platform, resources, peers, and teachers. Examples of such interactions include video browsing, tagging, commenting, liking, favoriting, and rating, which also contribute to the generation of video profiles. For instance, learners’ actions such as liking, favoriting, and rating videos are assigned specific weights by the platform. These weights increase the influence of corresponding tags in learner profiles. During profiles updates, higher weights are assigned in the ranking process, thus increasing the likelihood that similar videos to those interacted with will be recommended to the user.
The specific algorithm is as follows:
Here

Parameter explanations for the learner profiles formula.

Construction of video profiling models
Video profiling serves as the foundation for building learner profiles. Firstly, uploaded videos are categorized, and descriptive information is added to form static video tags, which remain relatively fixed. Secondly, based on the concept of collective intelligence, video annotation allows targeted tagging of video segments and the sharing of personal insights. The platform stores learners’ annotations, including the annotator, annotation content, start and end times of the annotation, and other information. Combined with complete video comments, this creates dynamic video tags. Subsequently, tags undergo processing using a Chinese word segmentation tool (JIEBA) to perform word segmentation and remove stop words, with certain weights assigned to the tags. For calculating static tags, as the title and description information rarely produce duplicate tags, TF-IDF is computed directly. For dynamic tags, the real word frequency of each tag is first calculated. Based on the real word frequency, the TF-IDF of dynamic tags is then calculated. Both types of tags are normalized, and weighted values are ranked. The top-N ranked tags are used as the video profiles, as shown in Figure 3. Video profiling model.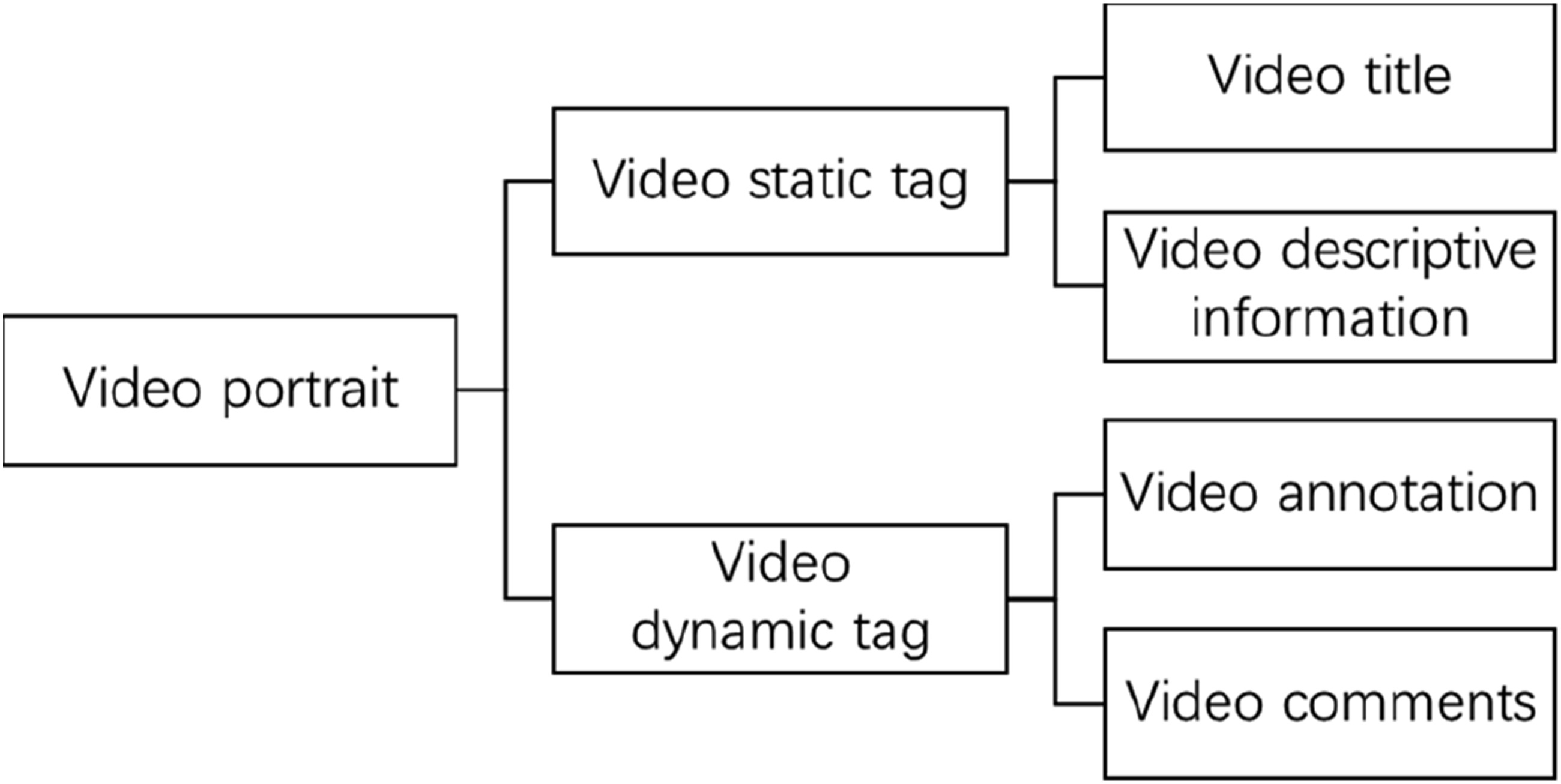
The specific algorithm is as follows:
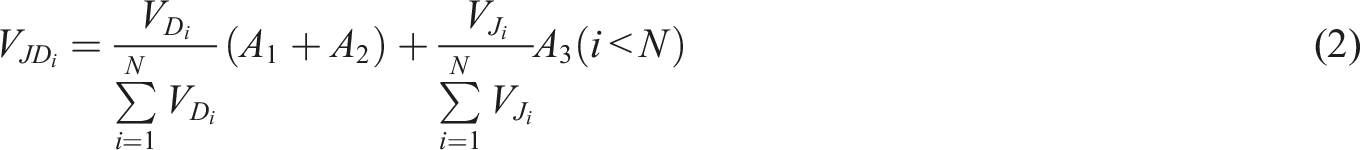
Explanation of parameters in the video profiling formula.

Construction of a personalized recommendation model based on learner and video profiles
The core principle of the recommendation algorithm based on user profiles is to annotate videos, mimicking the learning behavior of intelligent beings. It continuously defines videos and users. When the user profiles closely aligns with the video profiles, the video can be output to the user as a solution set. For example, if Learner A recently watched a video on improving instructional design skills, the video profiles would include thematic keywords like “instructional design,” “skills,” and “improvement.” These keywords update the user profiles, and upon re-entering the platform, videos related to Learner profiles will be recommended.
The main process of the personalized recommendation model algorithm is as follows: 1. Extract the feature profiles of videos and learners. 2. Convert profiles into feature vectors. 3. Traverse and calculate the similarity between video feature profiles and learner feature profiles, recommending videos with high similarity to the learner profiles.
Algorithm Flow Analysis. Given that users generally provide limited explicit information and substantial implicit information, it is necessary to assign weights to explicit and implicit information to ensure explicit information is not overshadowed. Using the Euclidean distance algorithm, the algorithm traverses video profiles, calculates the minimum and maximum Euclidean distance, performs normalization, and assigns weighted values. The results are then ranked, and the top-N videos are recommended.
The algorithm is as follows: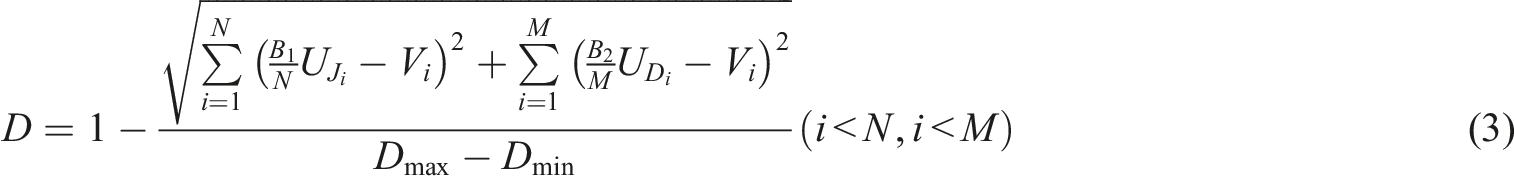
Explanation of parameters in the personalized recommendation formula.

Platform construction
Development tools
The platform developed in this study uses Vue 2 and D Player for the frontend and is built on the Java Spring Boot 2 framework for the backend. The database is MySQL 5.7, and the platform incorporates a Python Turtle compilation environment for internal deployment. Video files on the platform are transcoded using FFmpeg.
Basic platform modules
This platform applies advanced recommendation technology to online learning, as shown in Figure 4. The platform is designed with three main modules: the Annotation and Retrieval Module, the Daily Recommendation Module, and the Personal Center Module. The Annotation and Retrieval Module is used to search for video segments; learners can input keywords, and the platform will search for synonymous video annotations, allowing learners to quickly locate specific video segments by clicking on the annotations. The Daily Recommendation Module provides personalized learning paths for learners. When registering on the platform, learners are required to fill out their basic information, based on which the platform recommends video resources. During video playback, learners can annotate, rate, and like video segments. The platform automatically records learners’ behavior and dynamically adjusts the recommendation strategy accordingly. The Personal Center Module mainly records learners’ learning behaviors, enabling them to review and consolidate their learning. The platform has been patented. Basic platform modules.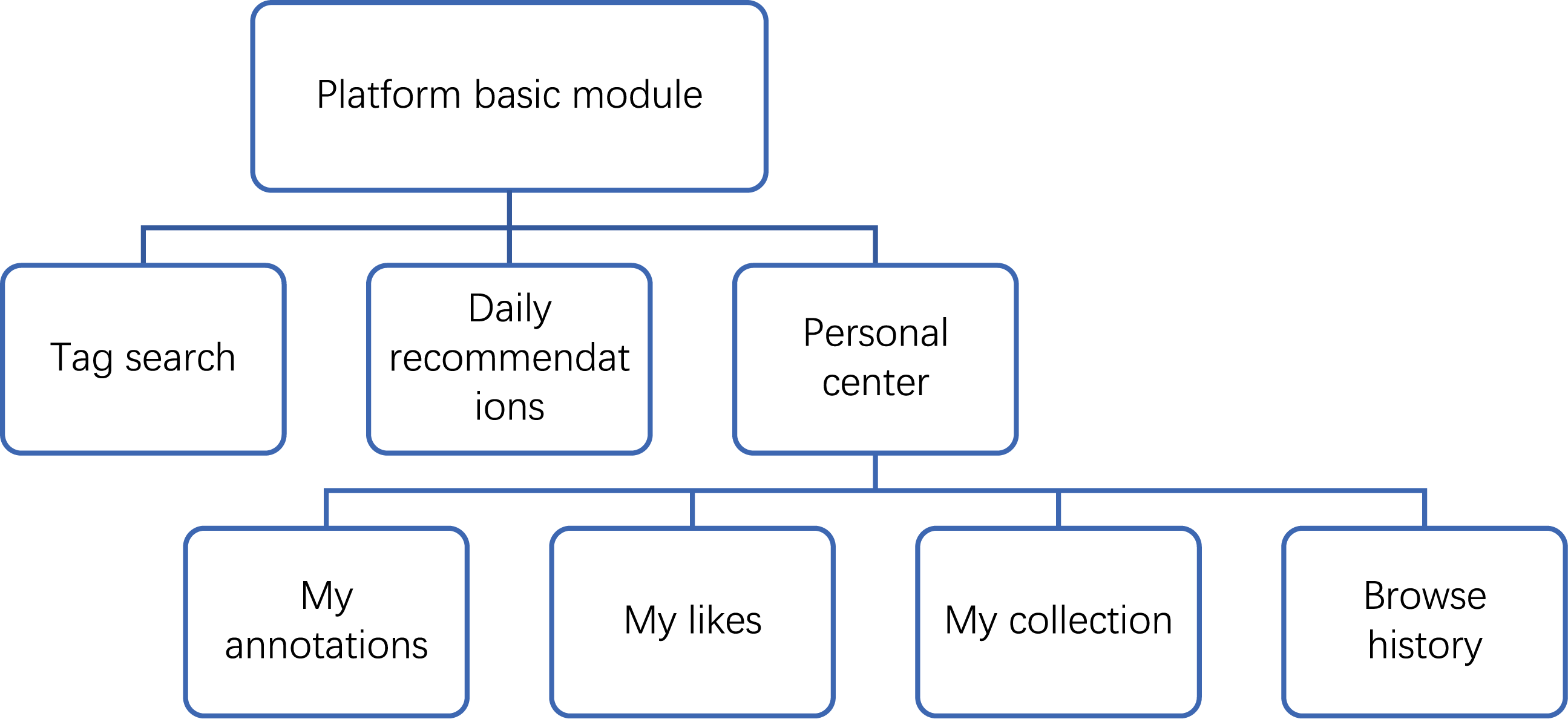
Experimental methods
Experimental design
The study openly recruited university students as experimental participants. Since the platform is still in the exploratory research phase, a small-sample experiment was chosen. Ultimately, 100 students participated in the course and completed the learning tasks over a 1-month experiment. Regarding gender distribution, the sample consisted of 55 female and 45 male students, maintaining a good gender balance. All participants voluntarily joined the study and signed informed consent forms.
The platform selected “How to Improve Pre-Service Teachers’ Introduction Skills” as the research topic. This theme was chosen because practical knowledge is often tacit and cannot be fully conveyed through theoretical classroom learning alone. It requires the integration of theory and practice through video case studies to foster students’ teaching reflection, making it well-suited for experimental research. The platform uploaded 25 video case studies from previous students and 25 from exemplary teachers, all of which were accessible exclusively within the campus network for study purposes.
After the experiment, learner 001 was randomly selected as an example. Data on their video annotations, likes, and interactions were exported from the platform. Video recommendation values were collected through breakpoint debugging to analyze the outcomes.
Generating learner profiles
User explicit and implicit tag weights were set at 50% each. Learner 001 annotated 6 videos, with a total of 43 annotations.
When the learner registered, the platform recorded that they were interested in third-grade primary school language arts content, resulting in explicit user tags such as “third grade,” “primary school,” and “language arts.” By collecting the learner’s implicit tags and obtaining their features along with the corresponding TF-IDF values, a word cloud was generated based on formula (1), as shown in Figure 5. Word cloud of learner 001’s learning profiles.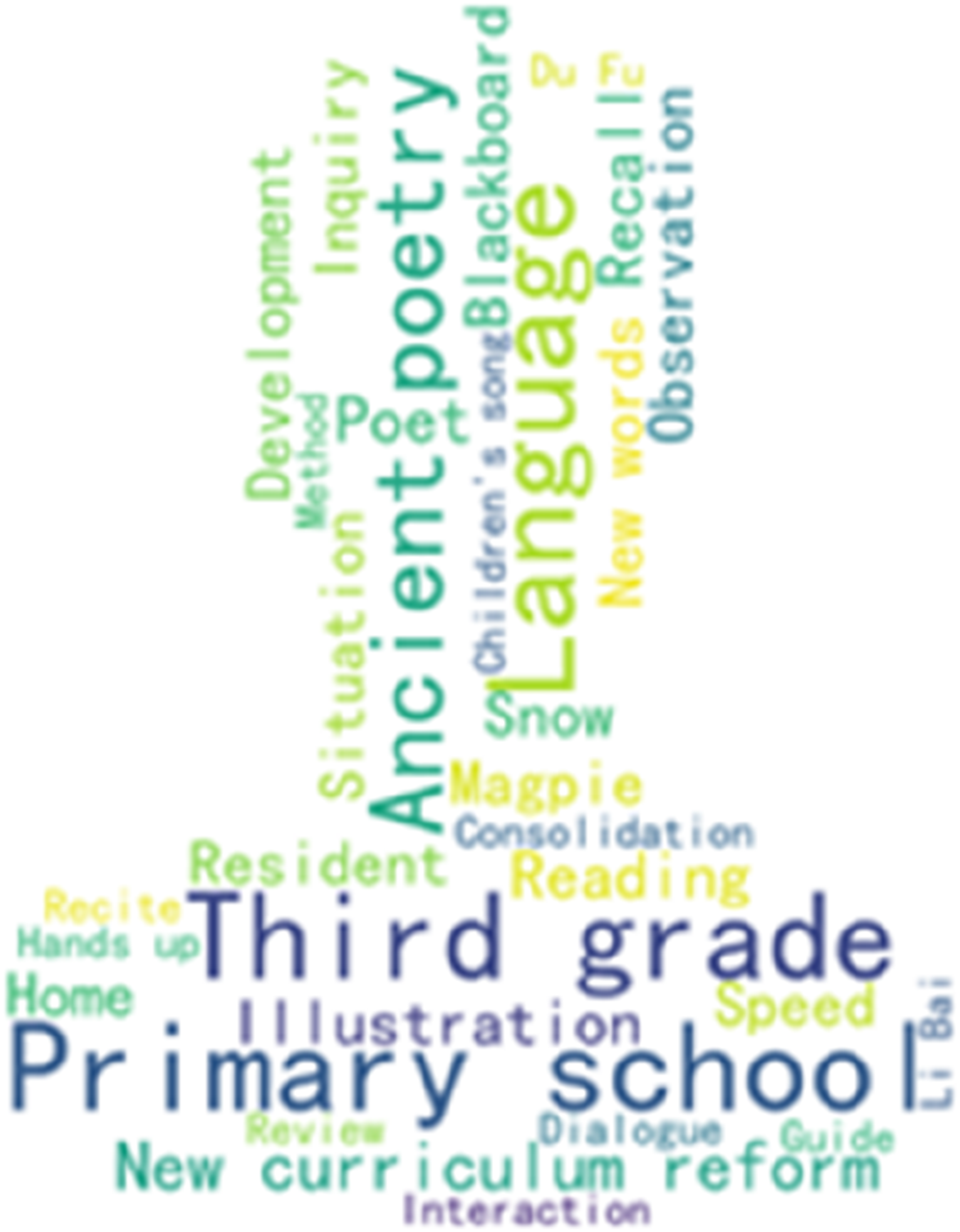
Generating video profiles
The platform analyzes the collected video titles, descriptions, annotations, and comments to form key video features, including static and dynamic tags. To highlight the distinctive features of the videos, emotional words are filtered out during the calculation of TF-IDF. Emotional words are often associated with subjective sentiments, which can interfere with the objectivity required in certain topic modeling tasks. Filtering out these words ensures that extracted keywords are more focused on the text’s theme, reducing noise in text analysis and making the keywords more representative. The steps for constructing the emotional word lexicon are as follows:
Collect text data, including video descriptive information, annotations, and comments.
Preprocess the text data by removing stop words, punctuation marks, and other irrelevant elements.
Filtered word lexicon.

By filtering out 120 emotional words, video tags is generated. Static and dynamic video tags weights are set at 50% each. Within the dynamic tags, annotations account for 30% and comments account for 20%. The actual word frequency is calculated, and the static and dynamic tags are normalized to extract video features and their corresponding TF-IDF values. Taking “Watching Mount Tianmen” as an example, a visualized video profiles word cloud is generated based on formula (2), as shown in Figure 6. Word cloud of the video profiles for “Watching Mount Tianmen.”
Personalized video recommendations
Video recommendation values.
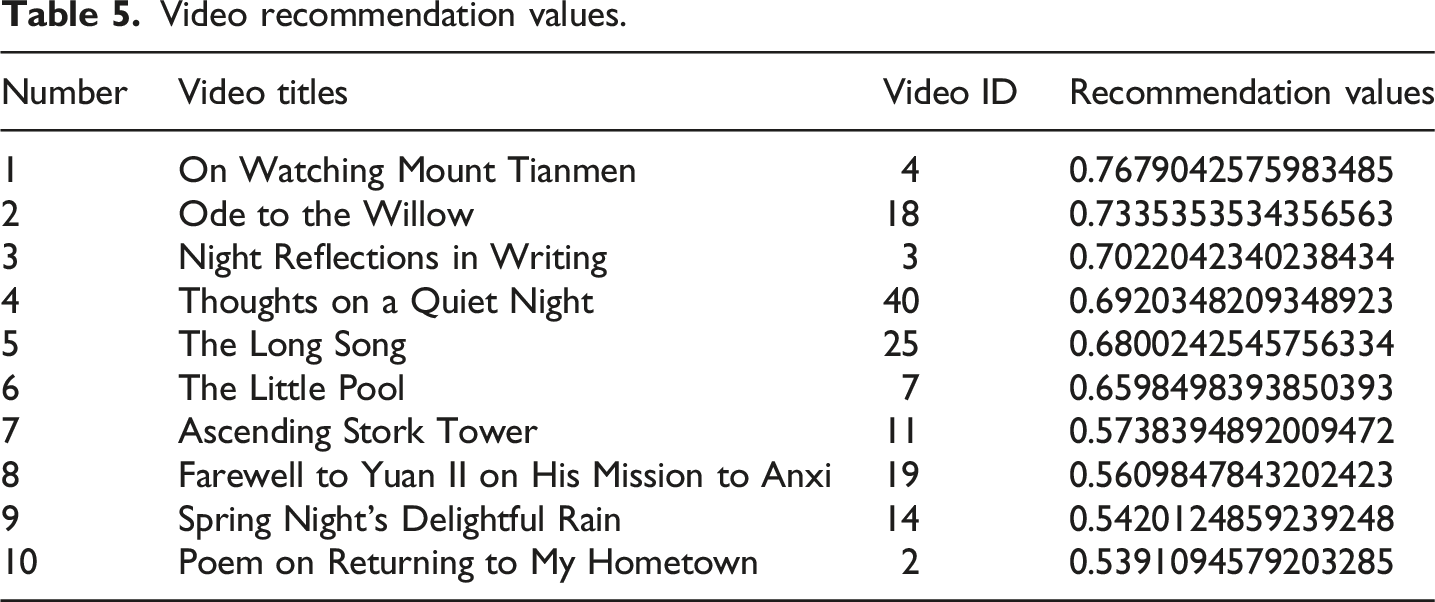
Experimental results and analysis
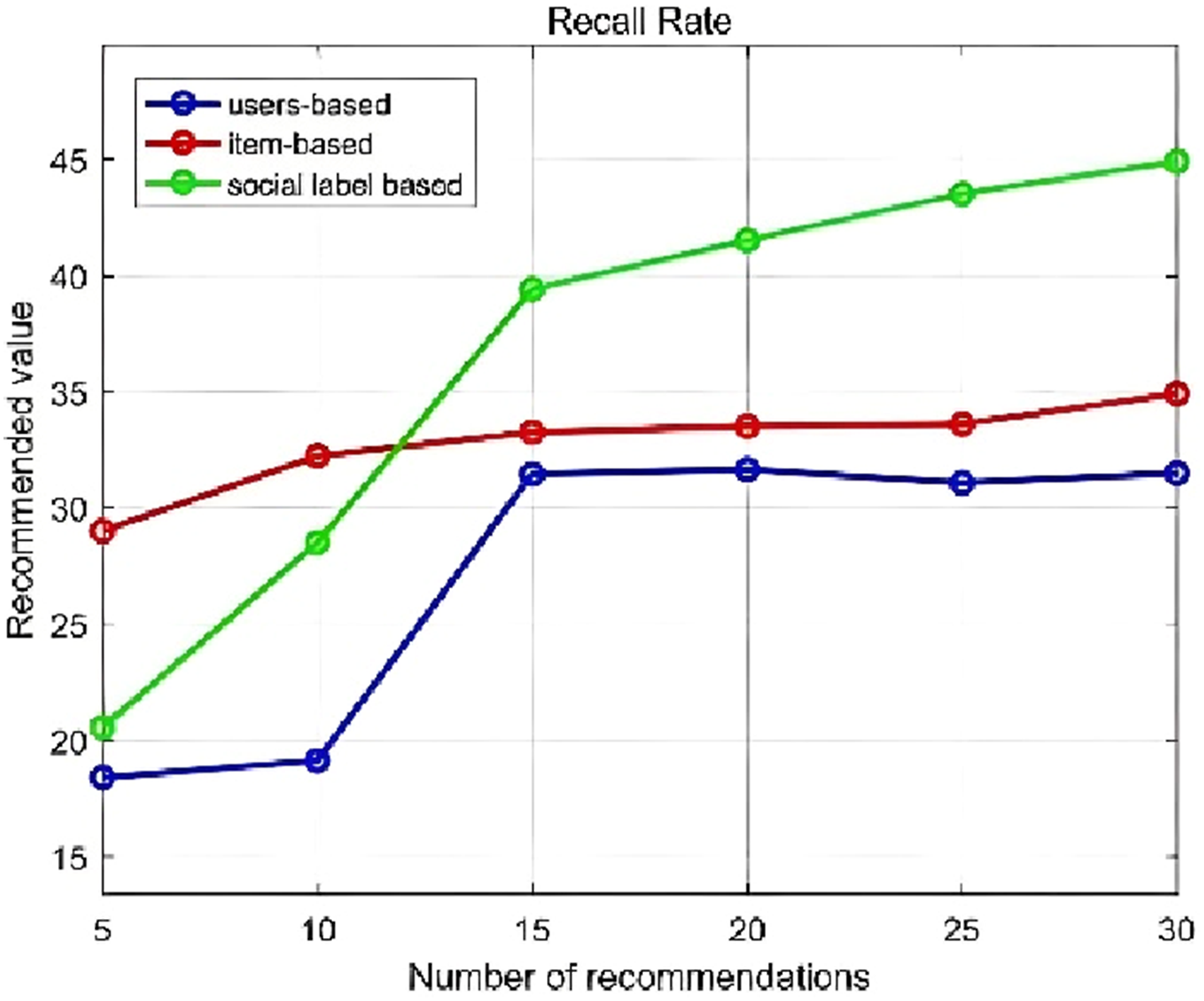
To demonstrate that the proposed method in this experiment provides better recommendation quality, a comparative experiment was conducted using the proposed social tag-based recommendation algorithm, user-based collaborative filtering, and item-based collaborative filtering algorithms. The precision and recall rates of the three methods were calculated for recommendation lengths of 5, 10, 15, 20, 25, and 30. The results are shown in Figures 7 and 8. Accuracy (%). Recall (%).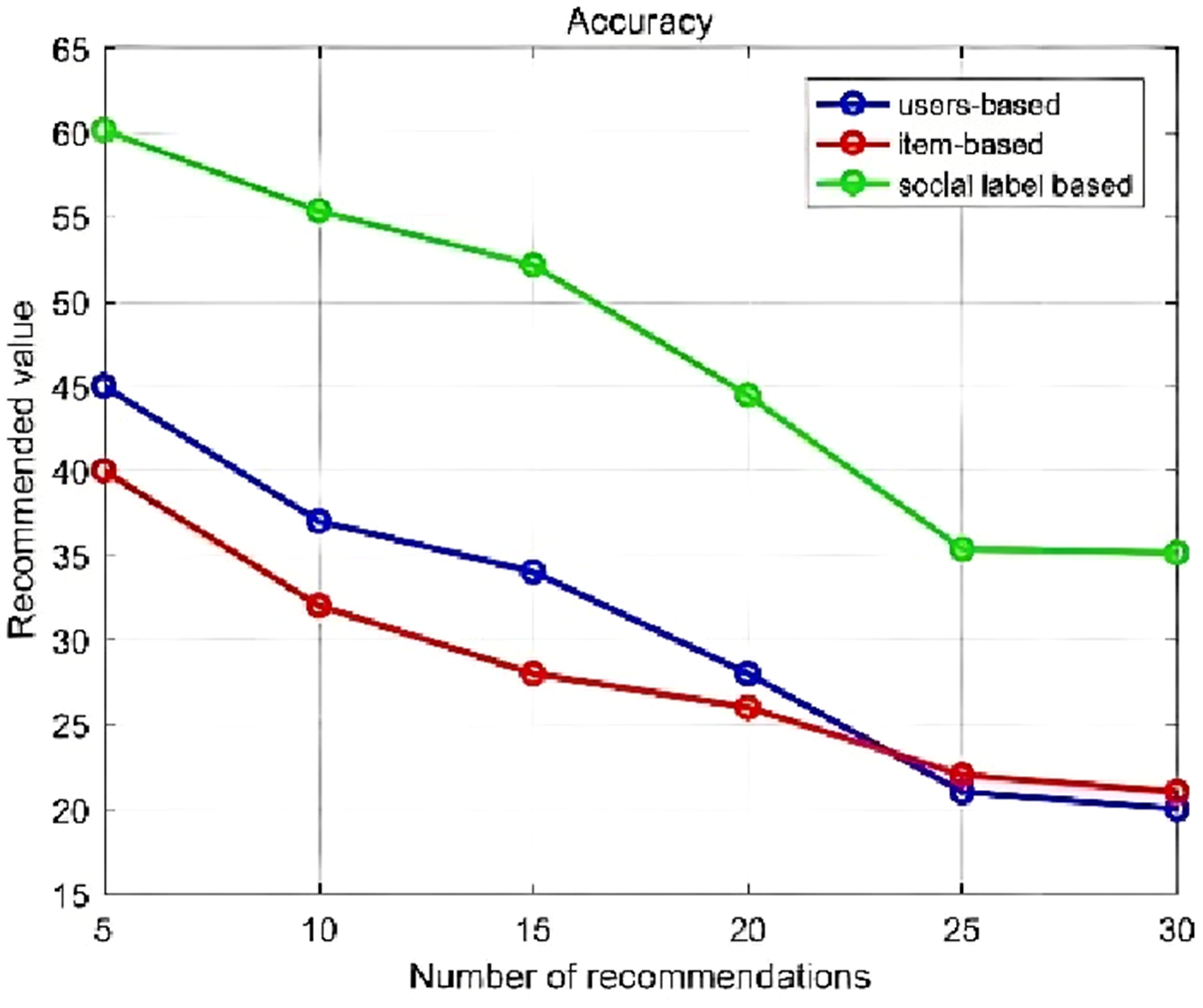
Based on the observations from Figure 7, it is evident that the social tagging-based video resource recommendation algorithm demonstrates higher accuracy compared to user-based and item-based recommendation algorithms when a specified number of recommended videos is set. When the recommendation length reaches 25 or more, the accuracy gradually stabilizes, with the average performance of the social tagging-based recommendation surpassing the others by approximately 15%.
As seen in Figure 8, with the increase in recommendation length, the recall rate of the social tagging-based video resource recommendation algorithm also surpasses those of the user-based and item-based recommendation algorithms. When the recommendation length is 15, the recall rate of the social tagging-based algorithm exceeds that of the other two algorithms, with an average improvement of approximately 8%.
In summary, the social tagging-based video resource recommendation algorithm not only addresses the challenges of cold start and data sparsity but also provides higher recommendation quality, offering better services to users.
Experimental conclusions
Quickly accessing video clips to enhance learners’ efficiency
The video resources are recorded specifically to address issues encountered in classroom teaching, focusing on the learning of specific knowledge points. When learners face challenges during offline training, traditional platforms typically offer on-demand access to complete videos, requiring learners to watch from start to finish to find answers to their questions. In contrast, this platform enables learners to quickly retrieve specific video clips through video annotations. For example, if learners are uncertain about how to design a chalkboard layout or are unfamiliar with chalkboard norms, they can search for keywords like “chalkboard design” or “chalkboard norms” within the “chalkboard drawing” skill section to locate relevant video clips for reference. This targeted learning approach can effectively resolve issues and significantly improve learners’ efficiency, as illustrated in Figure 9. Video annotation list.
Adding video annotations during the learning process to enhance platform experience
Traditional platforms do not allow learners to share reflections made during the learning process. After watching a video, learners can only leave summary notes in the comment section, but such observational comments often lack effectiveness and do not indicate whether the learner has mastered the knowledge point. In contrast, on this platform, learners can annotate video resources at any time, share their insights, and have them preserved for other users to view and explore. For instance, while watching a video, a learner may recognize that a particular knowledge point effectively activates prior knowledge and facilitates the acquisition of advanced knowledge. They can then annotate the video, input their perspective, and share it with others. When learners see their annotations shared or liked by others, it fosters a sense of presence and further motivates their interest in learning, as illustrated in Figure 10. Adding case annotations during the viewing process.
Precisely recommending video resources to enhance platform engagement
Improving the digital literacy and information processing capabilities of all learners can help narrow the “digital divide” to some extent. However, human capacity for filtering and processing information, as well as time and energy, are inherently limited. In the face of overwhelming information, it is essential to leverage artificial intelligence technologies and personalized recommendation platforms to deliver learning resources that meet learners’ needs in real time, achieving personalized education services. This experiment highlights video representation and organization techniques that reflect the actual association between videos and individuals. Compared to collaborative filtering techniques based on users or items, the recommendation results are more human-centered and precise.
Conclusion
To address the cold start and data sparsity issues in existing content-based and collaborative filtering recommendation algorithms, the study proposed a social tagging-based video resource recommendation algorithm. Through the video annotation process, learners with diverse backgrounds and social experiences can engage in indirect idea exchange. The collective and collaborative tagging process reflects the social construction of knowledge, providing a more comprehensive, accurate, and objective description of video resources, thereby enabling personalized recommendations. At the same time, we introduced the user feedback mechanism, designed a satisfaction questionnaire and pushed it through the online education platform to collect users’ scores and opinions on the recommended video. Based on these feedback, we adjusted the video weight and optimized the video tags generation mechanism to more accurately reflect user interests and improve the accuracy and relevance of recommendations. However, the study has certain limitations, such as a small-sample size and a relatively homogeneous distribution of learners’ ages and professional backgrounds. These factors may lead to less than adequate statistical power and lessen generalizability and reliability, which may impact the findings’ broader validity in educational applications. These points will be analyzed and discussed in the future research. Future research will further explore and improve these limitations to better use video tagging to support learners’ online learning.
Statements and declarations
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The paper is the research results of the 2022 Ministry of Education Humanities and Social Sciences Research Planning Fund Project “Research on Video Label Based Learner Model and Teaching Skill Case Push Mechanism” (No. 22YJC880009). The Zhejiang Higher Education Association’s “Research on Artificial Intelligence Empowered Education and Teaching Applications” special project “Research on the Path of Digital Empowered Teaching Mode Transformation Based on Knowledge Graph” (No. KT2024442). Topics of “Teacher Professional Development Project” and “School Enterprise Cooperation Project” for domestic visiting scholars and visiting engineers in Zhejiang Province “research on Undergraduate Curriculum Reform in Vocational Education under the Background of ‘Golden Course’” (No. FX2024102).