
Abstract
This paper proposes an improved YOLO v8 grape leaf disease identification method MSAM-YOLO based on attention mechanism to address the problem of multiple types and similar small target features in grape leaf disease images. This method introduces a multi-scale convolution attention module (MSAM) in the feature extraction network to enhance the focus on grape leaf disease. By performing convolution operations on features at different scales and using attention mechanism to emphasize the features of the diseased area, the model can better capture the subtle features of the disease. Experimental results show that MSAM-YOLO improves the original model by 4% in grape leaf disease identification task, with higher accuracy and real-time performance. This method provides a new perspective for the detection of plant leaf diseases, contributing to the improvement of the quality and efficiency of agricultural production.
Keywords
Introduction
Agriculture is crucial for the development of a country; however, the diseases and pests of crops, as a major component of biological disasters, severely restrict the sustainable development of agriculture, causing significant economic losses to agricultural production. Direct losses caused by diseases and pests account for 20%–40% of agricultural production losses globally. 1 Furthermore, these diseases and pests not only affect the yield but also the nutritional value of crops, posing a threat to human health. 2 As for grapes, the main diseases affecting grape leaves include powdery mildew, downy mildew, grape leaf spot, and grape yellow spot disease, among which downy mildew alone results in a yield reduction of over 15%. 3 Therefore, it becomes particularly important to manage the health of crops. The symptoms of grape diseases mainly appear on the leaves, and compared to expensive and complex laboratory pathogen identification methods such as pathogen isolation, molecular biology, and immunology, 4 computer vision and deep learning provide an efficient, rapid, and relatively low-cost diagnostic method.
In the process of utilizing computer vision technology to identify diseases in crops, researchers use image segmentation techniques to separate the area of interest from the background, and then extract features such as the size, shape, and color distribution of the diseased areas on the leaves. Finally, machine learning algorithms or deep learning models are used for disease identification. 5
Previous studies have been conducted on the identification of grape leaf diseases, primarily using traditional machine learning methods such as SVM. 6 These methods perform well under specific conditions, but their performance is often limited when dealing with complex or changing environments. As data volumes grow and computing capabilities enhance, deep learning models, especially convolutional neural networks, have gradually become more effective alternatives. 7
A convolutional neural network model was used to analyze leaf images for early identification of grape diseases, outperforming traditional machine learning methods, 8 it utilized an improved CNN model to detect grape diseases, achieving a 96.5% accuracy rate. 9 Although these deep learning methods have achieved good accuracy, they still face challenges such as limited receptive fields, long-range dependencies, and poor noise resistance.
The YOLO series algorithm, introduced by Joseph Redmon and colleagues in 2016, stands as a quintessential example of an object detection algorithm. The main idea is to transform the object detection problem into a regression problem by predicting bounding boxes and class probabilities on the image to detect the objects. Compared to traditional object detection methods, YOLO’s main feature is its high real-time performance. The entire image serves as input, and through one network forward propagation, the positions of all objects in the image, their corresponding categories, and their respective confidence probabilities can be obtained.
In recent years, YOLO has achieved significant advancements and widespread applications in the field of target detection and object recognition. Since its proposal by Joseph Redmon in 2016, it has continuously improved, undergoing major developments such as YOLOv3 (2018), which introduced a multi-scale prediction mechanism by incorporating additional paths into the network to enhance the model’s ability to detect small targets. YOLOv5 adopted the CSPDarkNet53+Focus for the backbone network and SPP + PAN for the neck, while YOLOv7 combined the neck and head layers into the head layer, incorporating an Extended-ELAN efficient long-range attention network. YOLOv8, the latest version, utilizes a lightweight network structure, enabling smoother operation on mobile devices. Additionally, it employs dual-path prediction to better handle objects of different sizes, further enhancing the algorithm’s efficiency.
When using YOLOv8 for detection on the grape leaf disease dataset, there has been a significant improvement in speed. However, the accuracy is limited due to the following issues: (1) The disease targets on grape leaves are usually small and difficult to detect. (2) Some grape leaf diseases are concentrated in the entire leaf area, requiring inference from global information. Based on the characteristics of the grape leaf disease data mentioned above, in order to achieve higher recognition performance, this paper proposes the MSAM-Yolo improved model, which combines the attention mechanism of feature channels and feature space to improve the recognition accuracy and speed of grape leaf diseases. Experimental results on the Plant Village dataset and self-collected grape leaf disease dataset show that MSAM-Yolo outperforms other models.
Relevant work
YOLOv8 network structure
YOLO v8 network is a major update version on the basis of v5, comprising of Backbone and Head. The Head part combines the original Neck and Head. (1) The Backbone still uses the CSPDarkNet structure. The kernel of the first convolutional layer changes from 6 × 6 to 3 × 3, and all C3 structures are replaced by C2f structures. The number of blocks in C2f changes from 3-6-9-3 to 3-6-6-3. (2) The Neck part also uses a PANet structure similar to YOLOv5, which is efficient and fast. The Backbone goes through an SPPF, then passes through 8x downsample layer and 16x downsample layer as inputs to the PANet structure. After upsampling and channel fusion, the three output branches of PANet are sent to the Head for loss calculation or result computation. PANet is a bidirectional path network. Compared with FPN, PANet introduces a bottom-up path, making it easier for low-level information to be transmitted to the top. (3) Unlike the Coupled Head of v5, the Head part of YOLOv8 uses a Decoupled Head, which was used in v6, separating the regression branch and the prediction branch. The DFL strategy is used for the regression branch, transforming the coordinates into a distribution.
The YOLOv8’s loss function directly uses the TaskAlignedAssigner to identify positive samples by leveraging weighted scores across classification and regression tasks. This computation encompasses distinct branches for classification and regression: employing BCE Loss for classification, while utilizing Distribution Focal Loss and CIoU Loss for regression. The integration of these three losses, each weighted appropriately, underpins the algorithm’s efficacy.
Attention mechanism
The attention mechanism is a core feature of human intelligence, allowing us to focus our attention on the most important tasks or information at hand while ignoring less significant stimuli. In the research of deep learning, various attention models have been developed by simulating the principles of human attention mechanism, demonstrating outstanding performance in areas such as image recognition.
10
The attention mechanism can be further divided into channel attention mechanism (CAM) and spatial attention mechanism (SAM). CAM calculates the importance of each channel to weight the feature maps, enabling the model to focus on the most important features. SAM performs self-attention calculation on each position of the feature map to obtain an attention weight matrix, which is then multiplied with the original feature map to obtain the weighted feature map. CBAM is an attention integrator that combines CAM and SAM,
11
as shown in Figure 1. Overview of CBAM.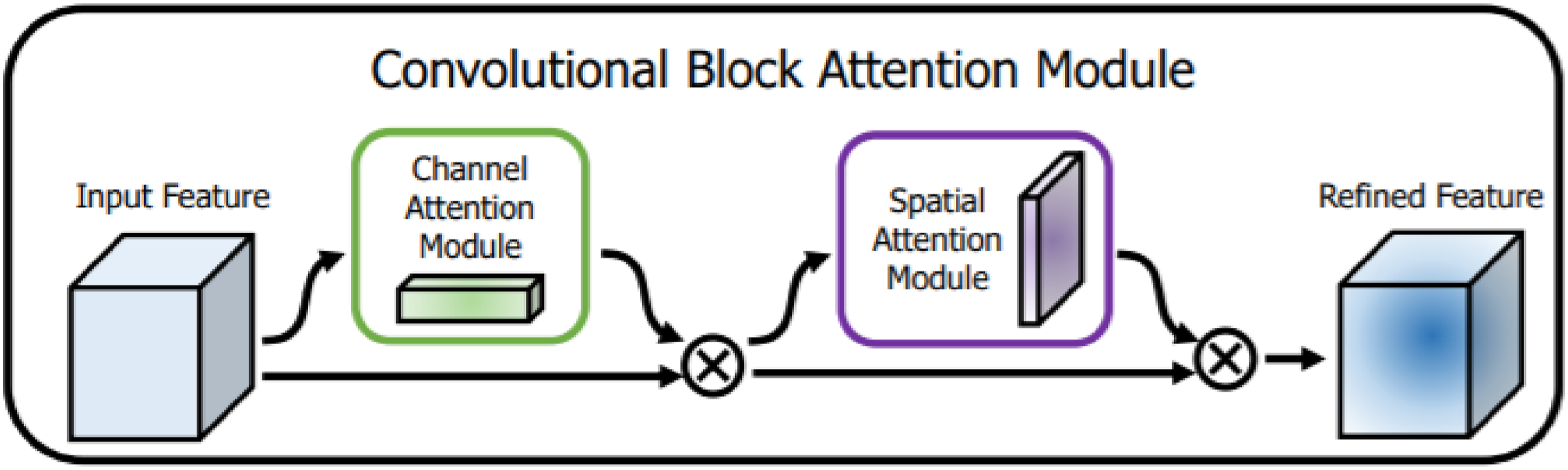
CBAM separately conducted channel and spatial attention, not only saving parameters and computational resources, but also ensuring that it can be integrated as a plug-and-play module into existing network structures.
On public datasets, these additional attention mechanisms can effectively improve network performance. However, in experiments on the grape leaf disease dataset, due to the variations of grape leaf diseases in different growth stages and different disease types, the ideal effect was not achieved. Therefore, this paper proposes an optimized method for CBAM called MSAM, which replaces the original channel attention mechanism with multi-scale convolution attention. This method constructs a grape leaf disease recognition network.12–18
Grape leaf disease detection
In order to improve the identification rate of grape leaf diseases on Plant Village, this paper proposes a network architecture MSAM-YOLO based on YOLO v8 as shown in Figure 2 for grape leaf disease detection. Network architecture of MSAM-YOLO.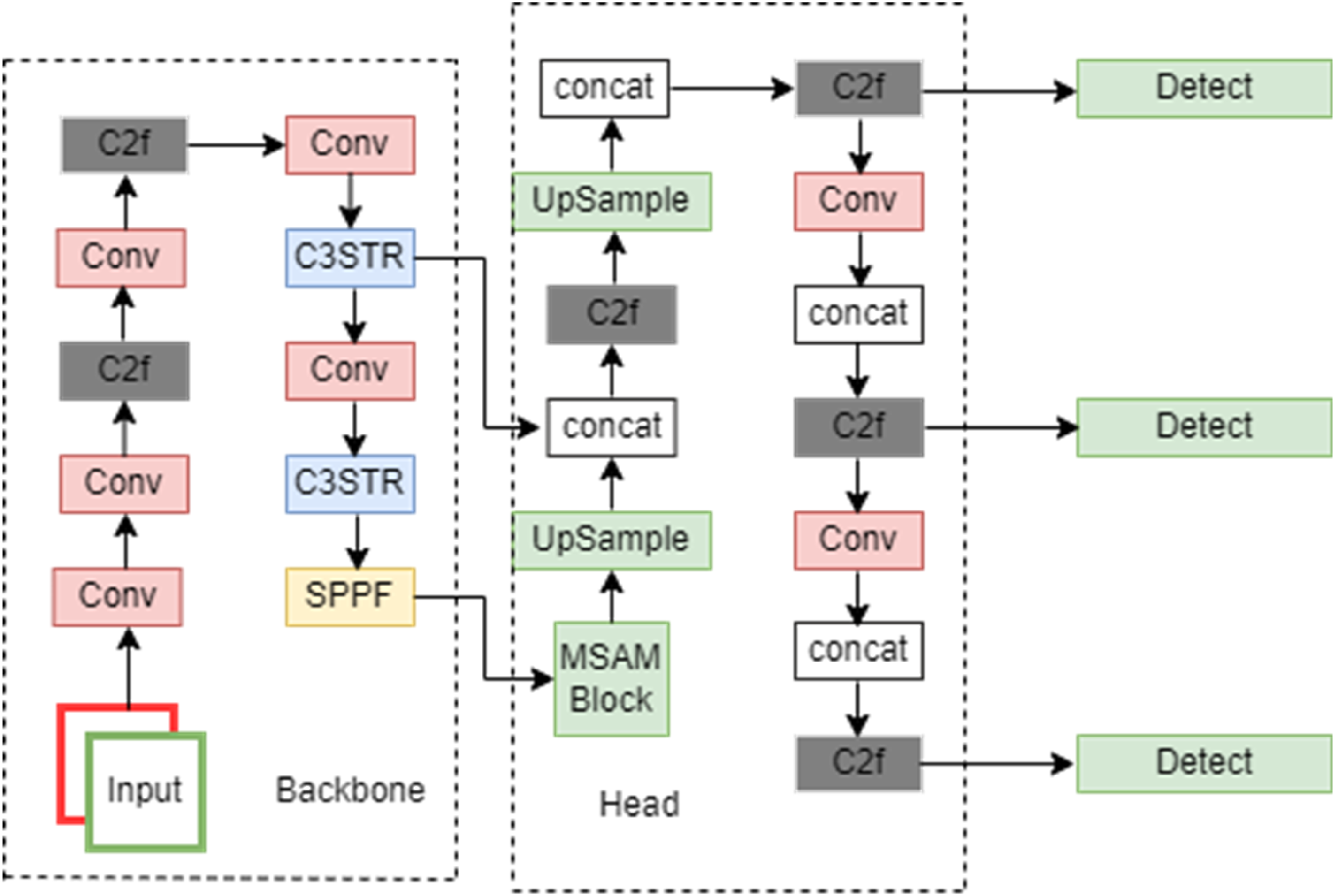
Network architecture of MSAM-YOLO
As shown in Figure 2, In the Backbone section, we adopt the idea of YOLOv8’s Cross Stage Partial Networks (CSP), which is responsible for extracting features from the input image, reducing the number of model parameters and computational cost without sacrificing performance, thus helping to improve the model’s operational speed.
The head section utilizes the multi-scale feature fusion of the image, while YOLOv8 uses decoupled heads, separating the classification head and the measurement head. The improvements in this paper are focused on the Head section.
MSAM
MSAM is a multi-scale convolutional attention module that uses the multi-scale convolutional attention (MSCA) to replace the original CBMA’s CAM, enabling channel attention to have multi-scale capabilities.
As shown in the left of Figure 3, MSCA consists of three parts, including a deep convolutional layer for aggregating local information, a multi-branch deep stripe convolutional layer for capturing multi-scale contextual information, and a 1 × 1 convolutional layer for establishing relationships between different channels. Depicts the structure and explanation of MSCA.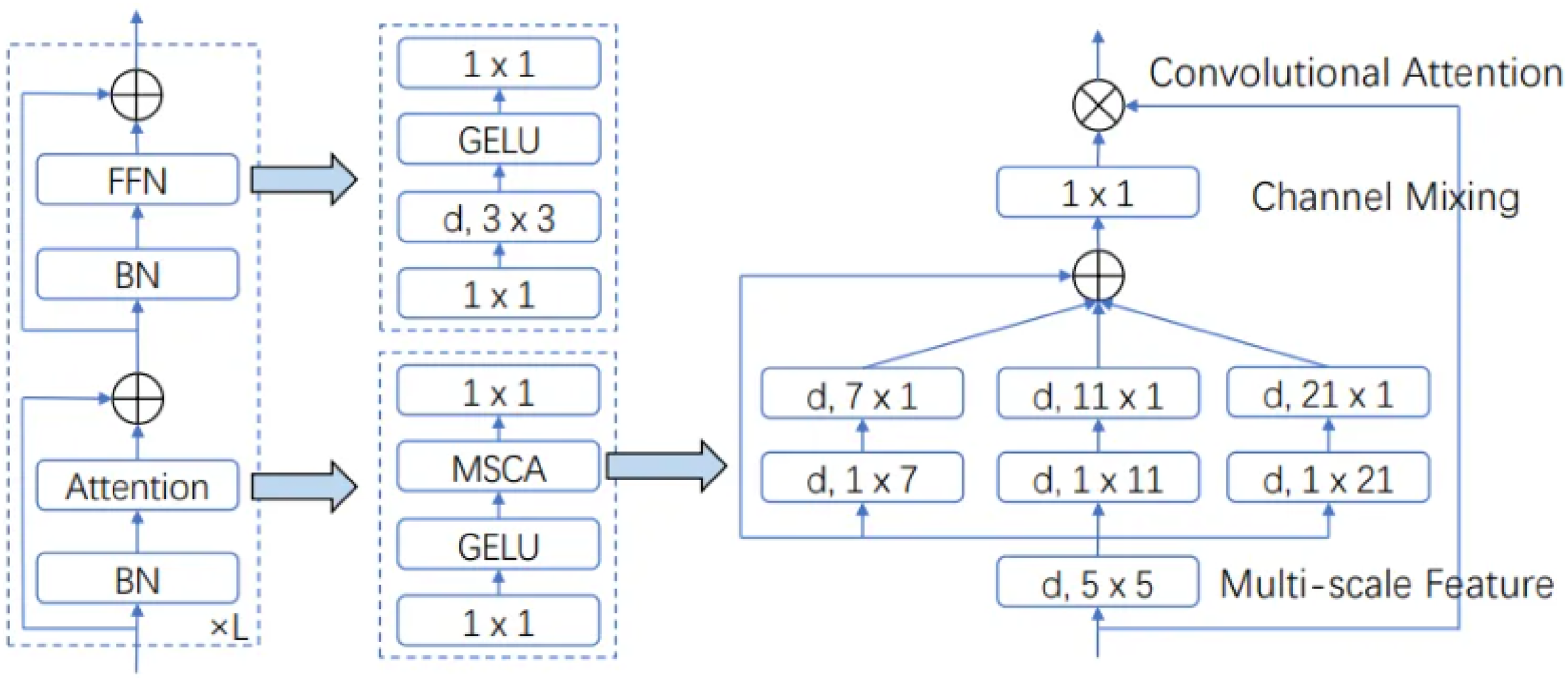
In mathematics, MSCA can be represented as:
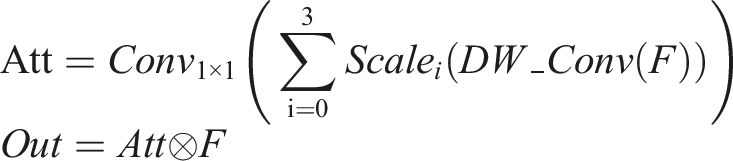
The variables Att and Out represent the attention map and the output, F denotes the input features,
By integrating convolutional operations at different scales, we can simultaneously capture both the local details and the overall structure of grape leaf diseases, effectively extracting and utilizing the characteristic information of grape leaf diseases, thereby improving the accuracy of disease identification. Through experiments, we can conclude that the model with MSAM added can better identify grape leaf diseases.
Using the Grad-CAM tool to visualize the effect of feature extraction before entering the UpSample layer. This article uses black rot disease as an example, as shown in Figure 4. Before introducing MSAM, the YOLOv8 network extracted features from the samples relatively randomly, with insufficient focus on the feature points of the leaf disease area. After introducing MSAM, during the forward propagation process, the important feature channels gradually occupy a larger proportion, allowing the network to learn the parts that need special attention, enabling the improved MSAM-YOLO model to more efficiently extract difficult-to-distinguish feature information from the images. Comparison of Grad-CAM results. (a) The causal organism of leaft blight, (b) Grad-CAM image of YOLOv8, and (c) Grad-CAM image of MSAM-YOLOv8.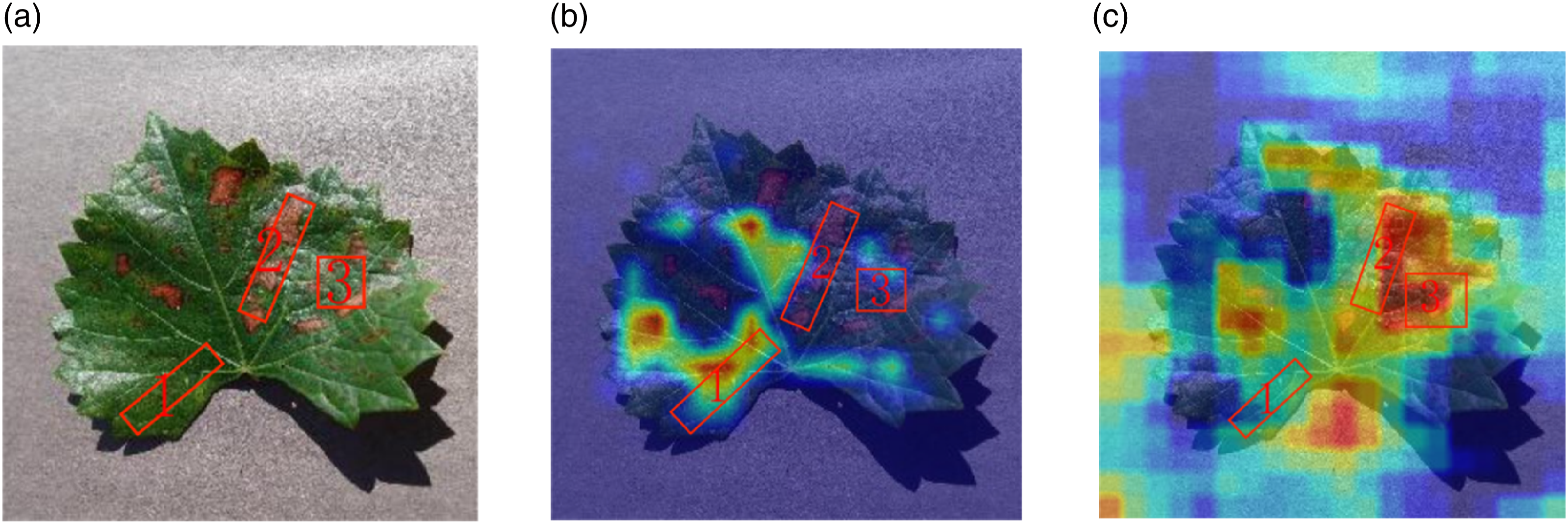
From Figure 4, it can be observed that there are recognition errors such as 1 and failures to recognize like 2 and 3 before incorporating the MSAM module. So with MSAM module its pays more attention to the details of the disease area on grape leaves, which helps the model in identifying grape leaf diseases.
Experimental results and analysis
Dataset and preprocessing
This article uses the Windows 11 Professional operating system, Python 3.8, and the PyTorch 2.1 deep learning framework. It employs an Intel(R) Xeon(R) CPU E5-26800v2, NVIDIA GeForce GTX 1080, and CUDA 12.3 framework.
The dataset includes data collected from PlantVillage and other networks, this paper acquired four common diseases original images (black_root, black_measles, blight and healthy).
The training set consists of 7279 images, the validation set has 1479 images, and the test set comprises 485 images, all with a resolution of 640×640. Also use the labeling tool to annotate images in YOLO format.
Identification result
The improved MSAM-YOLOv8 model was used for the identification of grape leaf diseases, and the results are shown in Figure 5. It can be seen from the figure that MSAM-YOLOv8 is capable of accurate localization and identification of grape leaf diseases. Comparison of identification results before and after improvement. (a) Identification result of YOLOv8. (b) Identification result of MSAM-YOLOv8.
Comparison of different models
Comparison of evaluation metrics for different models.
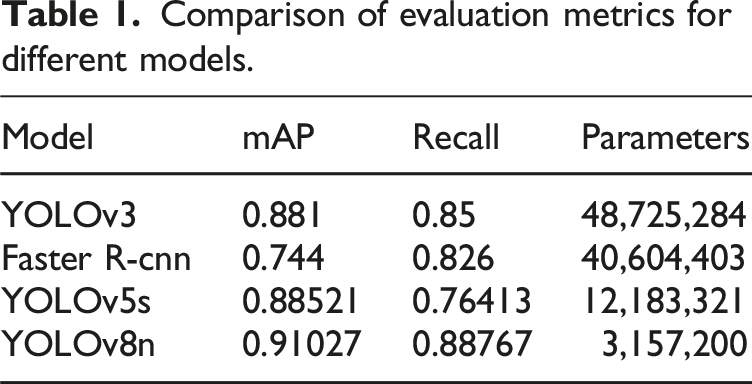
Firstly, in the realm of average accuracy and recall, YOLOv8 demonstrates exceptional performance, particularly in scenarios demanding precise recognition of grape leaf diseases. Its performance is truly noteworthy in these cases.
Secondly, a noteworthy aspect is that YOLOv8 boasts a substantial reduction in the number of parameters compared to its counterparts. This reduced parameter count translates to a lighter model, making it ideal for deployment on mobile devices or in resource-constrained environments. Given that grape leaf disease identification often necessitates on-site operations, a lightweight model such as YOLOv8 not only enhances real-time recognition but also minimizes hardware requirements, thereby facilitating wider adoption and application of the technology.
Ablation experiment
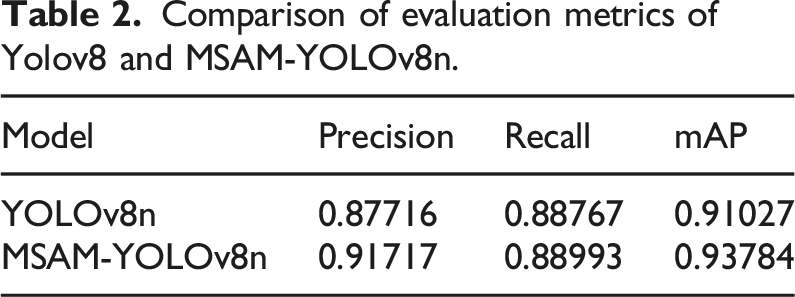
Comparison of evaluation metrics of Yolov8 and MSAM-YOLOv8n.
The F1_curve, P_curve, PR_curve, and R-curve of each model are shown in Figure 6. The F1_curve, P_curve, PR_curve, and R-curve of each model.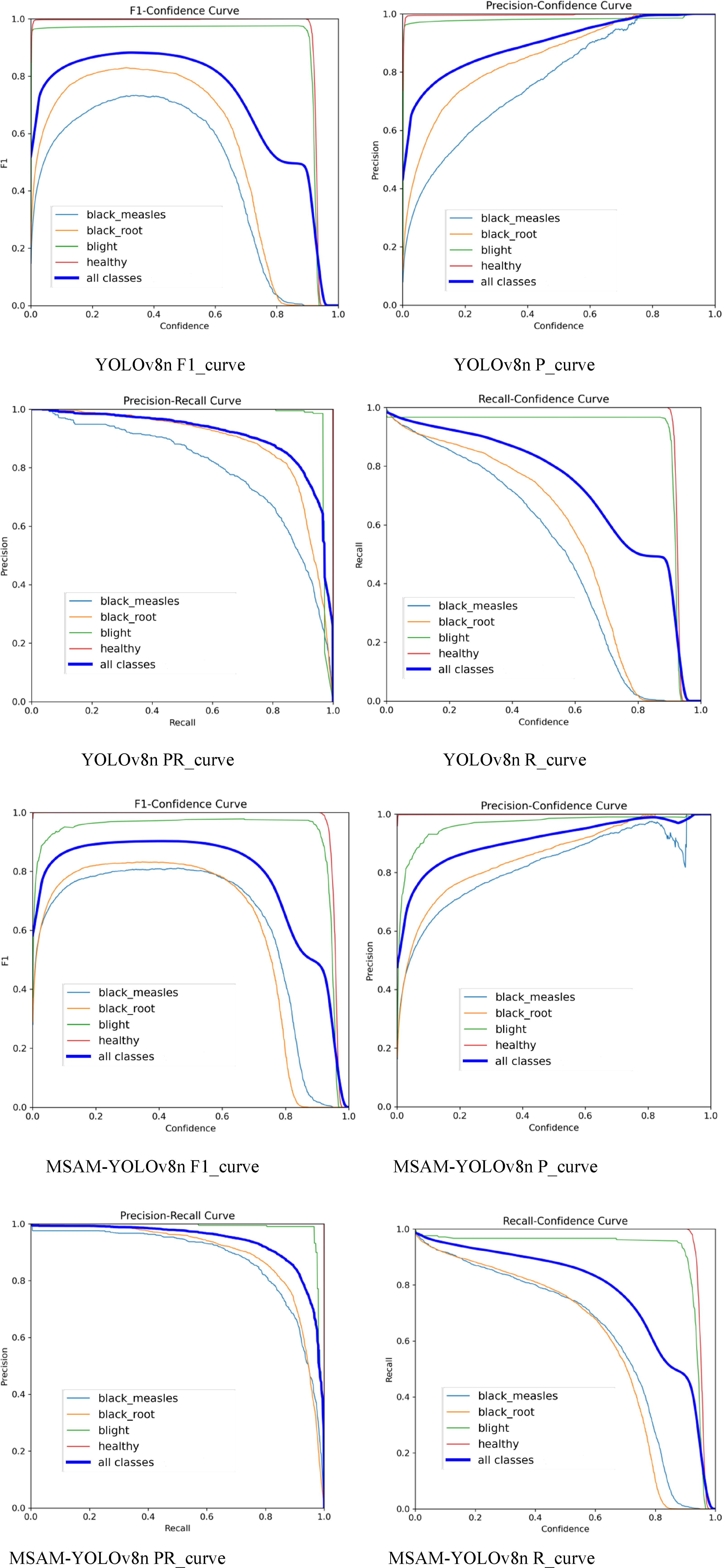
From the F1_curve and P_curve of the two models in the Figure 6, it can be seen that the new model performs better. The PR_curve of the new model is closer to the top right corner at all thresholds, which means it has higher precision at all levels of recall. Also, the R_curve of the new model rises faster than the old model at all thresholds, indicating that the new model can achieve higher recall rates over a wider range of thresholds.
Conclusions
The MSAM-YOLOv8 model proposed in this paper introduces the multi-scale convolutional attention module (MSAM) into the feature extraction network. By focusing more on the diseased parts, it helps to improve the detection rate of grape leaf diseases. The MSAM, by performing convolution operations at different scales and using attention mechanisms to emphasize the features of the diseased area, enables the model to capture subtle features of diseases more effectively. This design, which focuses on the diseased parts, is significant in the task of detecting grape leaf diseases.
Furthermore, the introduction of the MSAM module not only improves the detection rate of grape leaf diseases but also has a certain universality. It can be applied to disease detection tasks in other types of plant leaves. This makes the MSAM-YOLOv8 model a powerful tool in the field of plant leaf disease detection, helping to improve the quality and efficiency of agricultural production.
Despite the excellent performance of the MSAM-YOLOv8 model in grape leaf disease detection tasks, there may be some challenges, such as the model’s high computational complexity, which prevents effective deployment on end devices with limited computing resources. In future research, we may explore how to optimize the structure and parameters of the model to reduce computational complexity and improve the model’s real-time performance and practicality.
Statements and declarations
Footnotes
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by the Zhejiang Provincial Colleges and Universities Domestic Visiting Scholars “Teacher Professional Development Program” Projects, FX2023114.