
Abstract
In complex urban environments, traditional path planning methods have significant shortcomings in terms of safety assurance, multi-objective path optimization, and personalized travel recommendations. To address these issues, this paper proposes a reinforcement learning-based path planning algorithm with a strategy-guided mechanism and further constructs a path optimization model suitable for multi-destination travel scenarios. This method introduces a safety-aware potential field and a composite reward mechanism to guide the agent to achieve a dynamic balance between path length and safety. In the experimental section, a dataset incorporating map and urban public safety information was constructed, and 800 rounds of path learning simulation experiments were conducted. The results show that the convergence time of the proposed algorithm is 32% shorter than that of the greedy strategy-based method and 27% shorter than that of the policy enhancement method. Additionally, the average path length is reduced by over 100 m, and the safety score improves by over 14%. In multi-destination travel tests, when the number of target points was 20, the total path length was reduced by 3.00% compared to the distance matrix method and by 0.15% compared to the genetic algorithm, verifying its scalability and stability in complex scenarios. The research results indicate that this method can provide efficient, safe, and personalized path planning solutions for urban travelers, offering broad application prospects.
Keywords
Introduction
With the development of society and the prosperity of tourism, travel path planning has become an increasingly important research field. When planning their journeys, modern travelers are increasingly demanding the efficiency and convenience of routes, while also focusing more and more on the safety of paths and personalized experiences. This trend reflects the significant changes in travel consumer behavior in today’s society, in which safety and personalization have become important considerations.1,2 However, with the diversification of tourist destinations and the increasing personalization needs of travelers, traditional route planning methods have faced many challenges in dealing with complex routes, ensuring safety, and meeting personalization needs. On the one hand, complex urban road structures and frequent traffic incidents pose challenges to travel efficiency and safety. On the other hand, users’ demand for multi-destination, real-time response, and safety-assured route planning is increasing.3,4 In the context of smart city and intelligent transportation system construction, how to achieve efficient, safe, and personalized travel route planning has become an important issue that needs to be addressed urgently. Furthermore, with the proliferation of smartphones and location-based services, travelers are more inclined to use these technologies to enhance their travel experience. The popularity of smart devices and applications has created unprecedented data resources for trip planning, but it also presents challenges in how to effectively use this data to meet personalized needs.5,6 To this end, the study proposes a Q-learning path intelligent planning algorithm (QL-PIPA) based on policy guidance mechanism (PGM). The research aims to address the challenges of path planning in modern travel, including path diversity, safety, and personalization needs. The objective is to develop an intelligent path planning solution that provides travelers with safe and efficient travel routes and is able to satisfy users’ needs for a personalized travel experience. In light of the fact that travelers may visit multiple destinations, the research further develops multi-objective path intelligent planning (MO-PIP) algorithms with the objective of optimizing travelers’ paths between multiple stops. This study refers to the synchronous motion wobble control proposed for self-reconfiguring mobile robots in reference 7, particle swarm optimization for optimizing a novel proportional-integral differential neural network model in reference 8, and a neural network study on the control of nonlinear dynamic systems in reference 9. Furthermore, this study aims to address the challenges faced by traditional path planning algorithms in terms of dynamic environment adaptation, computational complexity, multi-objective optimization, and personalization and customization requirements.
The innovative aspects of this research are as follows: introducing a safety-aware potential field to guide agents in avoiding high-risk areas, thereby achieving a dynamic balance between path safety and efficiency. Second, a composite reward mechanism combining path length and safety distance was designed to meet personalized travel needs and enhance the robustness of path planning. By integrating pointer networks and reinforcement learning, the MO-PIP model was proposed to effectively address the complexity and scalability challenges of multi-destination path planning. Additionally, the proposed algorithm outperforms traditional Q-learning and reinforcement learning methods in terms of convergence speed, safety, and computational efficiency, demonstrating significant practical application potential.
The main contributions of this study are as follows: First, a QL-PIPA model incorporating PGM is proposed. By introducing a safety-aware latent field, the model achieves a dynamic trade-off between path length and safety, thereby enhancing the algorithm’s adaptability in complex urban environments. Second, a composite reward function system based on safety distance and risk level weighting is constructed, effectively guiding agents to avoid high-risk areas and improving the safety and personalization of path planning results. For multi-destination travel scenarios, the MO-PIP model, which combines pointer networks and reinforcement learning mechanisms, is designed to maintain good convergence performance and path optimization effects even when the number of nodes increases. The methods proposed in this study have strong practical application value.
The overall structure of the study consists of four sections. In the first section, the relevant research results and shortcomings of domestic and foreign trip planning are summarized. In the second section, the study first proposes QL-PIPA based on PGM, and further proposes MO-PIP considering that travelers usually visit multiple destinations. In the third section, the research experiments are compared and analyzed by the proposed model. In the fourth section, the experimental results are summarized, the shortcomings of the study are pointed out, and future research directions are proposed.
Related works
In recent years, the application of deep learning in the field of path planning has received increasing attention. With the advancement of technology, especially in computing power and data processing, deep learning has become a key technology in optimizing urban traffic, autonomous driving, and intelligent tourism planning. 10 Some of the related studies by scientists and academicians are presented below. Zamoum et al. addressed the path planning problem for unmanned aerial vehicles (UAVs) navigating in complex environments by applying deep Q-learning (QL) and Dyna Q-learning methods to UAV path planning and introducing fuzzy logic for enhanced control, thereby optimizing the accuracy, adaptability, and obstacle avoidance capabilities of path planning. 11 Merikhipour et al. addressed the issue that traditional transportation mode recognition models rely on manual features and struggle to capture complex temporal patterns. They proposed a deep learning model that integrates a spatial attention mechanism and combined it with the proximal policy optimization (PPO) algorithm to optimize feature selection, thereby improving the accuracy and robustness of transportation mode recognition. 12 Nikookar et al. addressed the issue of insufficient model reusability in reinforcement learning by proposing a framework based on graph data models and designing a parameterized algorithm that balances efficiency and cumulative rewards, thereby achieving efficient strategy reuse and performance improvements in tasks such as query optimization and robot control. 13 To solve the problem of high network deployment complexity due to resource constraints of UAVs, Xi et al. proposed a lightweight reinforcement learning-based real-time path planning method, the adaptive soft actor-critical algorithm. The generalization capability was enhanced by interacting structured environment models with dynamic information, thus improving the adaptability and planning efficiency of UAVs in complex environments. 14 Shang Y et al. proposed an improved RRT algorithm combining QL and Gaussian distribution of obstacles for path planning of self-driving vehicles. The step size was dynamically adjusted according to the density of obstacle distribution to quickly generate the initial path and reduce the planning time. Ultimately, the paths were optimized by an enhanced bi-directional pruning technique to ensure that the resulting paths were complied with vehicle kinematics and dynamics constraints while ensuring smooth safety. 15 Cai et al. proposed a novel robot path planning method that combines DRL and construction worker motion prediction to enhance the safety and efficiency of human–robot collaboration on construction sites. In addition, the predicted motion of workers was innovatively integrated into the state space and reward function computation. The results showed that this prediction-based path planning method could ensure that the robot successfully reaches the destination along the near shortest path. 16
Zhou Y et al. tuned the exploration rate and learning rate of classical QL in order to improve its convergence speed. The study also designed an improved Dyna-2 algorithm to enhance the generalization ability of the QL algorithm. The effectiveness of this hybrid intelligent algorithm was demonstrated by path planning experiments in two static complex environments. 17 Chen et al. proposed a soft actor-critic method based on deep reinforcement learning (DRL) for dynamic obstacle avoidance path planning of a robotic arm. The method achieved effective avoidance of moving obstacles in the environment and real-time path planning by designing an integrated reward function for dynamic obstacle avoidance and goal approximation. The results revealed that the method could effectively avoid moving obstacles and complete the planning task with a high success rate. 18 Brandonisio et al. created an artificial intelligence agent through deep Q-network and dominant actor critic methods and followed reinforcement learning principles for training. The results showed that the trained agent performed well in expanding the target coverage. 19
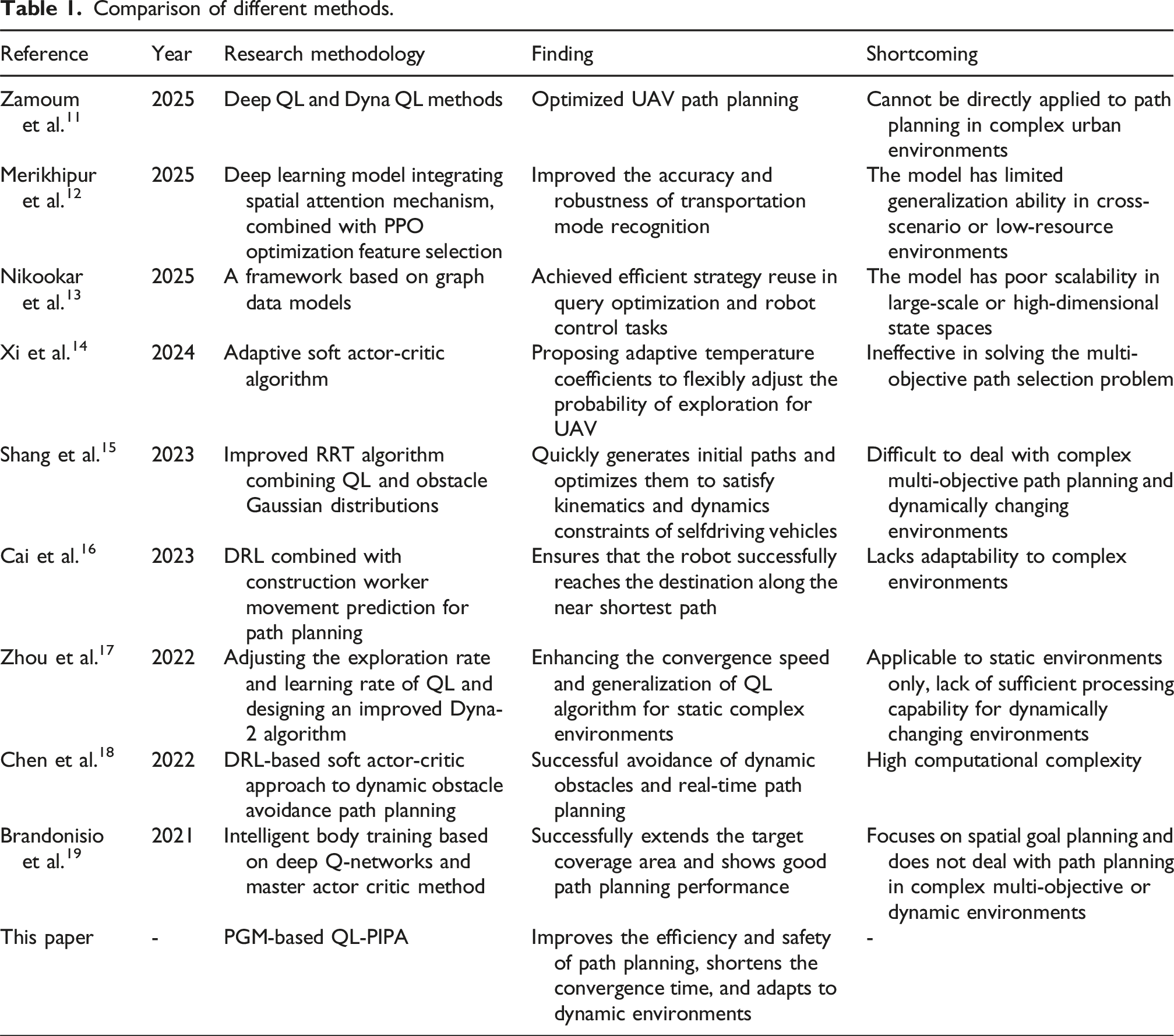
Comparison of different methods.
Methodology
In this research, the QL safe path planning algorithm is first introduced and QL-PIPA incorporating PGM is further developed to improve the convergence speed of the algorithm. Subsequently, considering the needs of multi-destination travels, MO-PIP is proposed with the aim of providing travelers with a safe as well as an efficient multi-destination path planning scheme.
QL-PIPA construction with policy guidance
The main goal of the research is to address the challenges of travel path planning in modern dynamic environments. Specifically, the research aims to develop an intelligent path planning algorithm capable of efficiently navigating through complex urban environments while prioritizing safety and personalization. The study defines 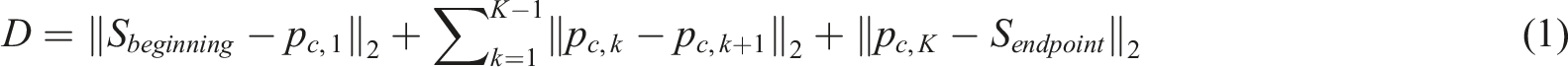
In equation (1), 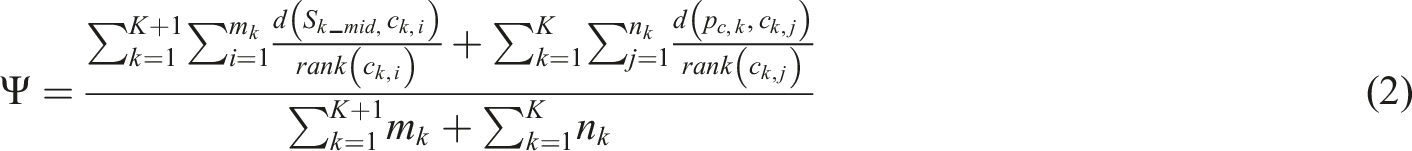
In equation (2), Framework diagram of interaction between agent and environment.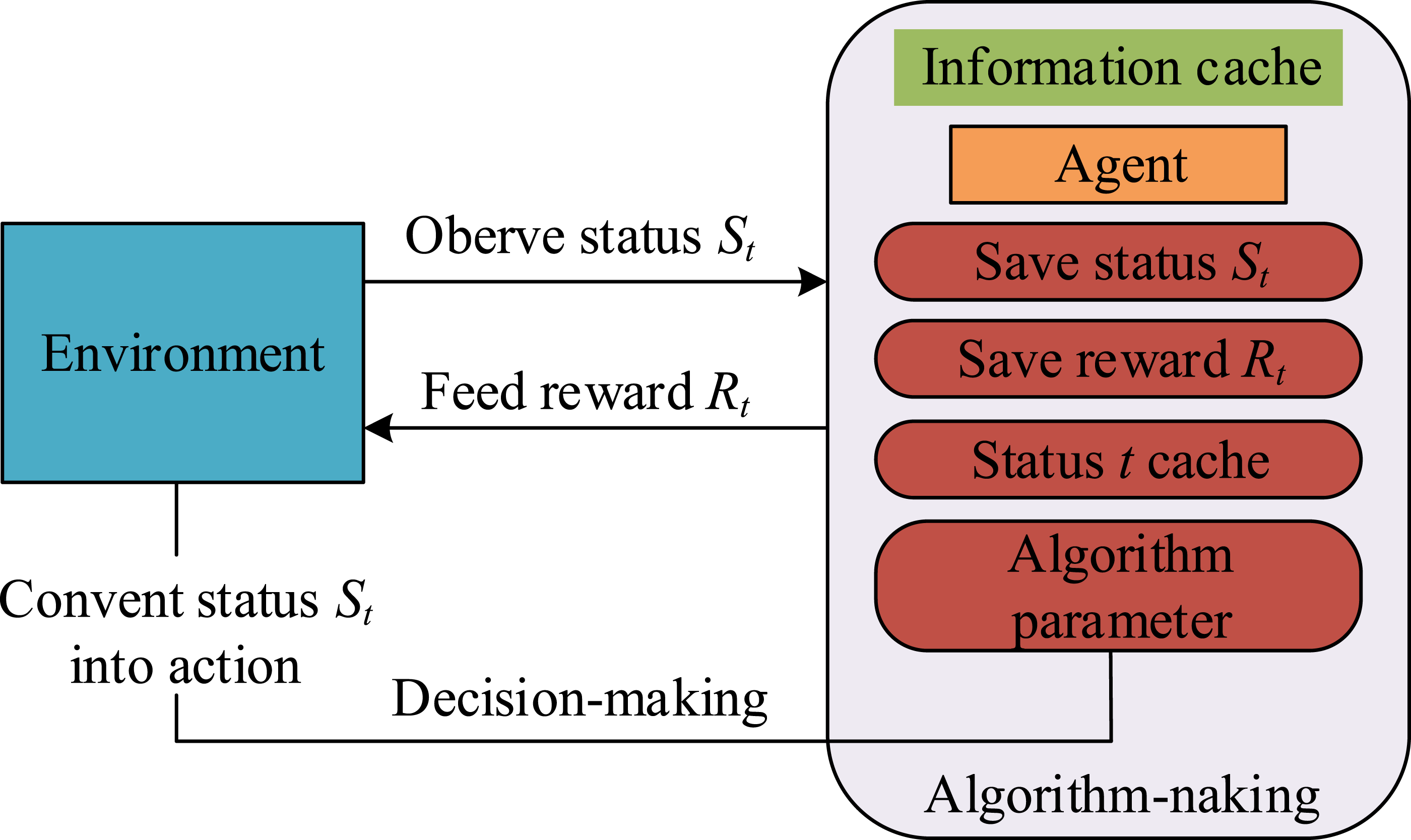
Figure 1 illustrates that the structure includes a simulated robotic intelligence that interacts with the map environment to find the best path with limited information. In this context, QL-PIPA framework.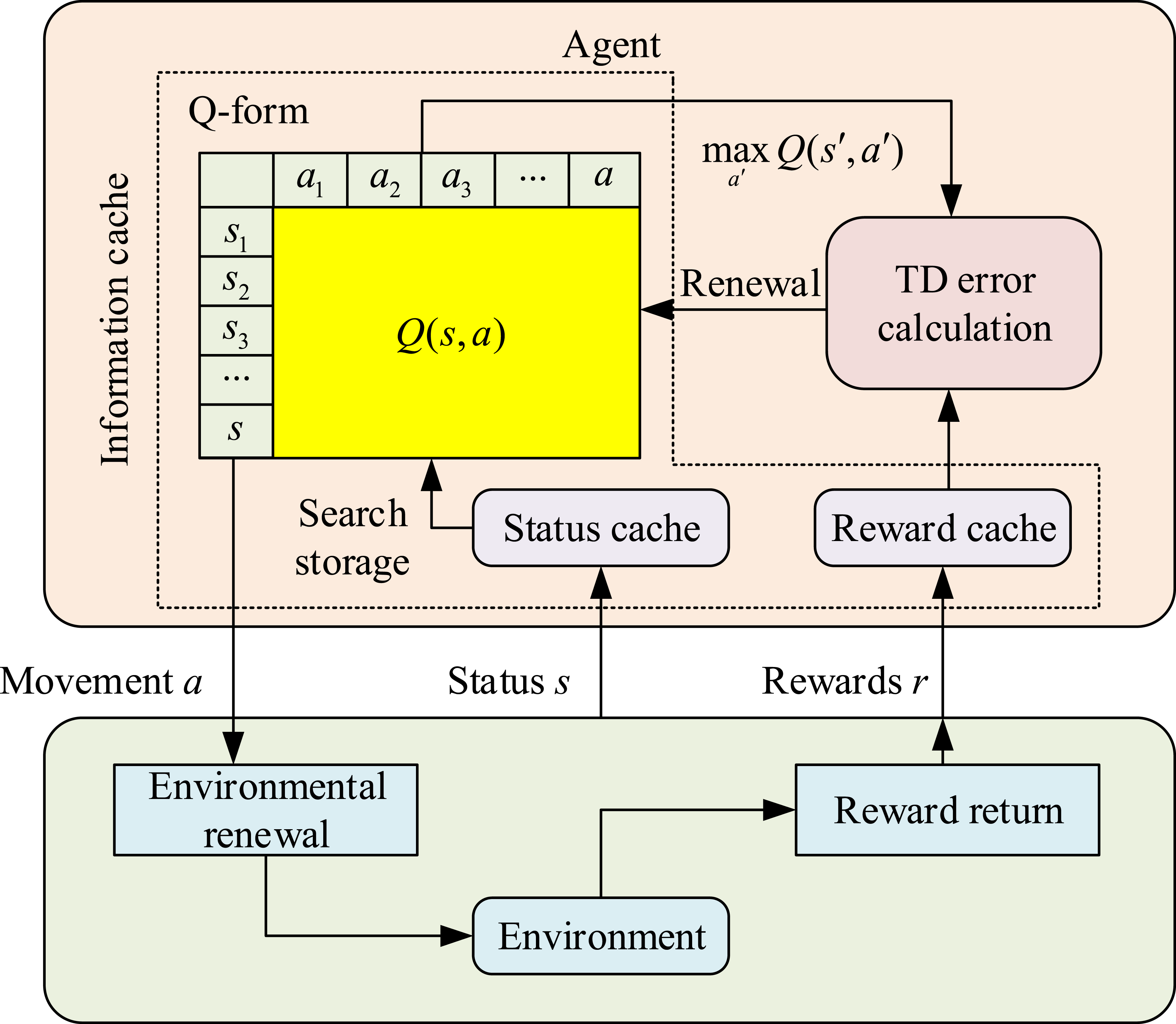
Figure 2 shows the overall framework of the QL-PIPA, which includes the interaction mechanism between the intelligent body and the environment. In this framework, the intelligent body continuously optimizes the path planning strategy by interacting with the environment to improve the efficiency and safety of path planning. By updating the state and reward information, the algorithm is able to converge to the optimal path to ensure the safety and efficiency of the path. After an intelligent body performs an action, if the next state of the environment reaches the end of the path, the update of the 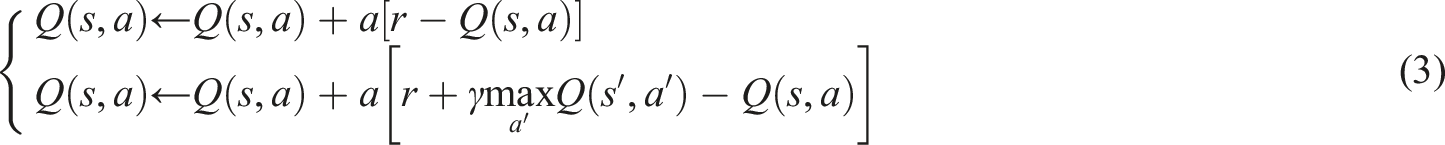
In equation (3), 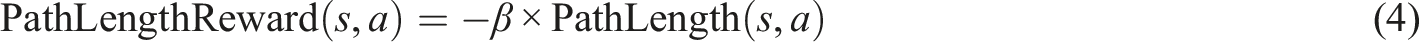
In equation (4), 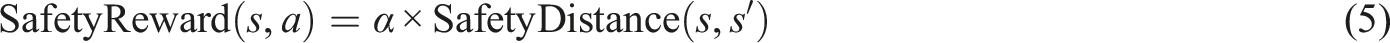
In equation (5), 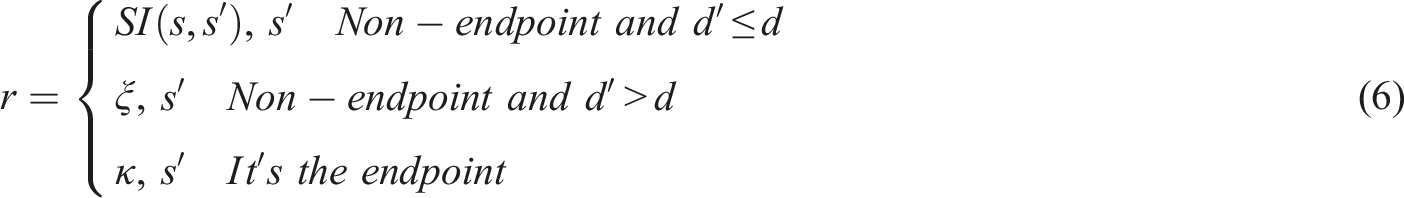
In equation (6), 
In equation (7), 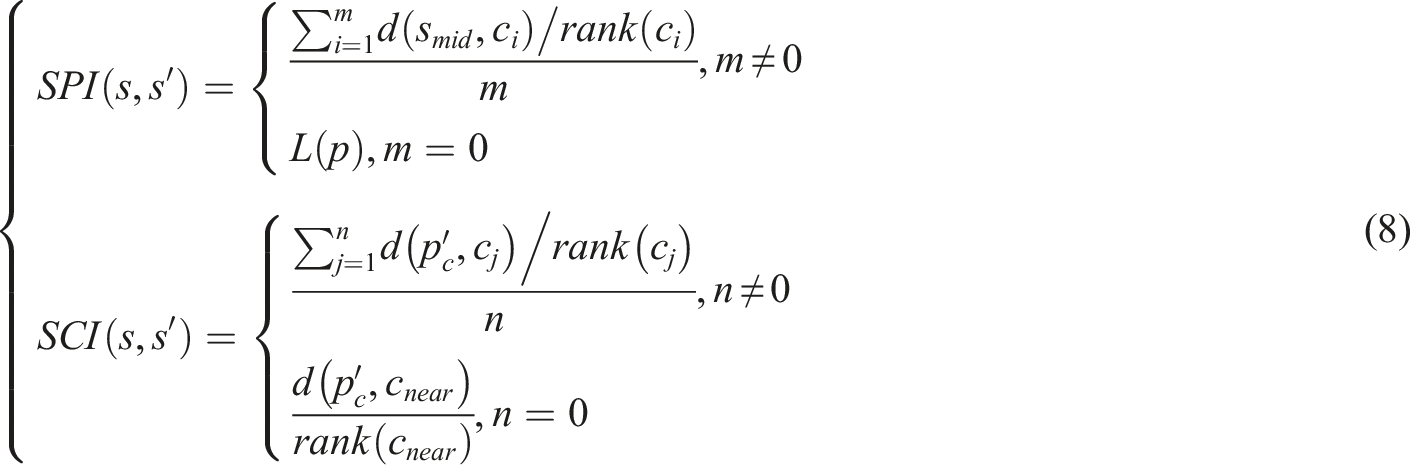
In equation (8), 
In equation (9), 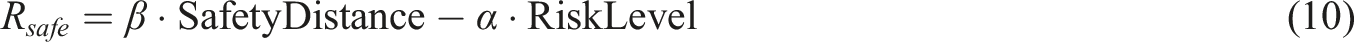
In equation (10), Flowchart of intelligent planning of PGM and QL safe paths.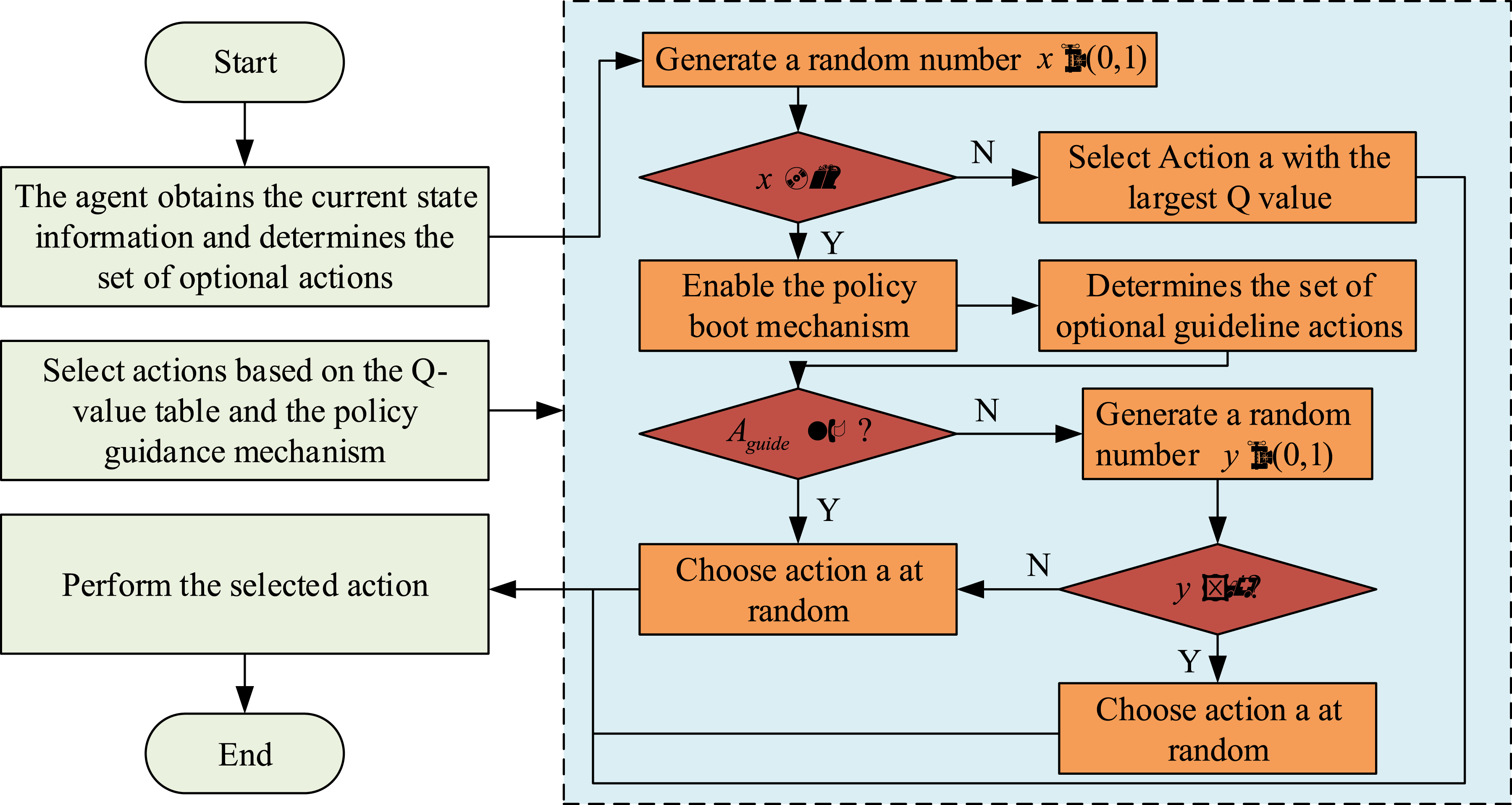
Pseudo-code for QL-PIPA

MOPIP design for multi-destination planning
Since PGM based QL-PIPA for safe paths is for single destination safe path planning problem. In order to satisfy the needs of multiple travel destinations, the research further proposes the MOPIP algorithm. The algorithm models the problem as an optimization task similar to the traveler’s problem and adapts multi-destination planning by combining pointer networks (PNs) and networks of long and short-term memory cells. The multi-destination locations are represented in the form of a two-dimensional sequence of coordinates as shown in equation (11).
In equation (11), 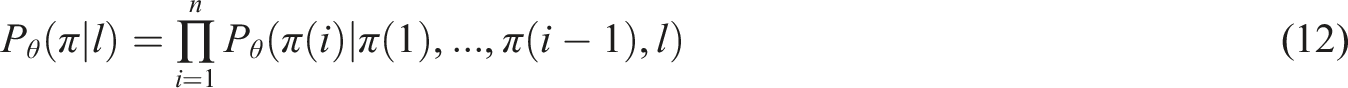
MO-PIP network deals with sequence pairs with strong correlation and uses recurrent neural networks for sequence prediction decision-making. Moreover, combined with bidirectional long and short-term memory and attention mechanism, it specifically solves the prediction problem of output and input correlation. For sequence pair 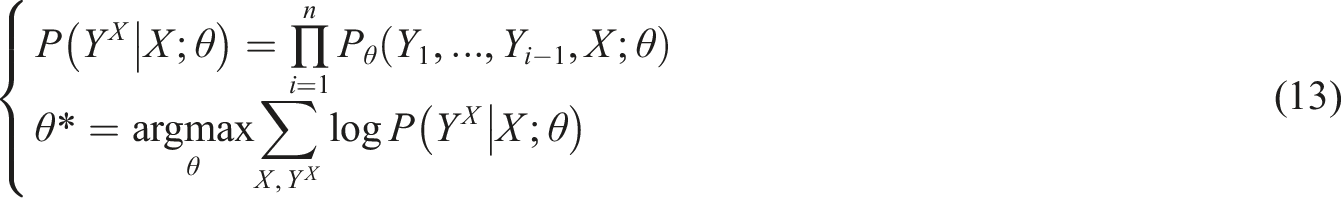
The sequence-to-sequence model employs two long and short-term memory units as encoder and decoder, respectively, as shown in Figure 4. The model reads the elements Encoder and decoder processes for sequence-to-sequence models.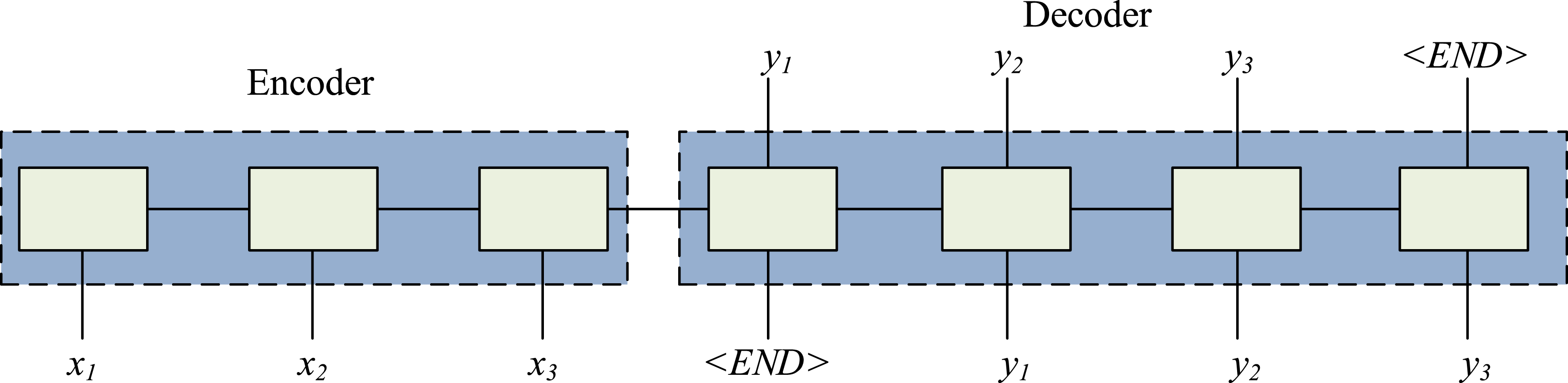
To accommodate the traveler problem, where the output sequence length is the same as the input sequence length, the study proposes an improved sequence model. This model incorporates the attention mechanism as shown in equation (14).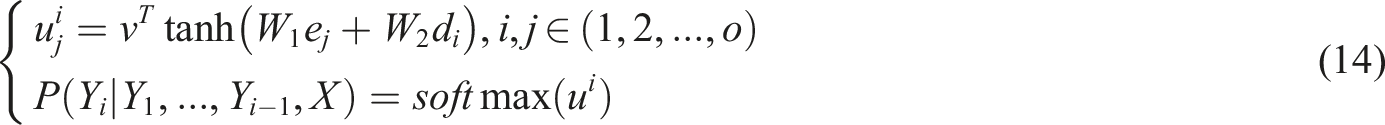
In equation (14), Evaluation network structure diagram.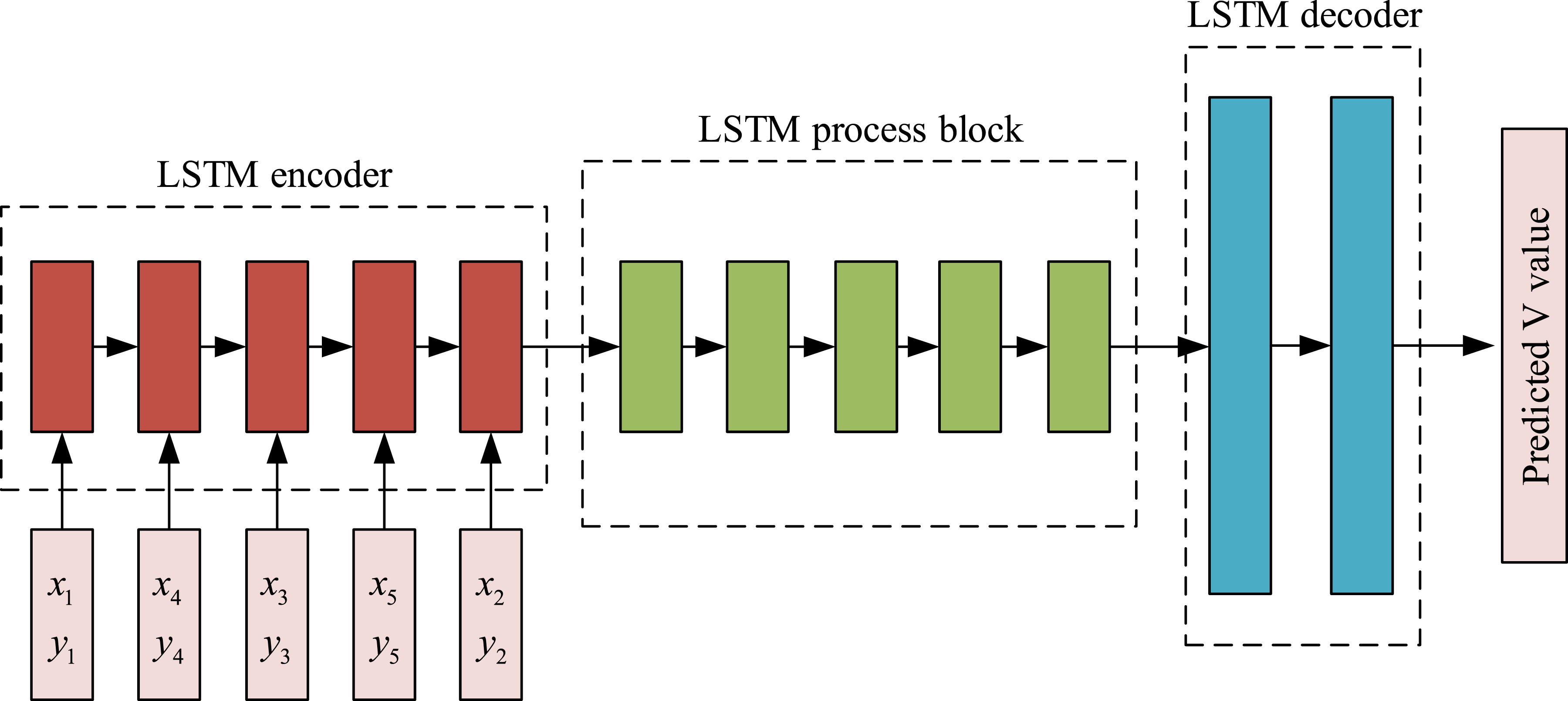
In Figure 5, the encoder of the PN uses the same structure as the long and short-term memory unit to encode a two-dimensional coordinate sequence 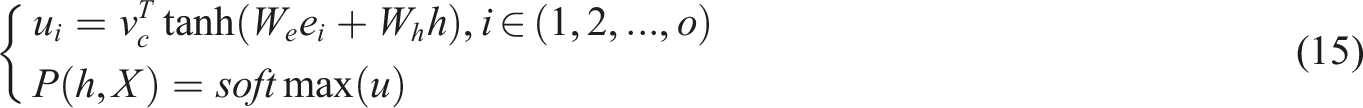
In the final stage of the process, a two-layer fully-connected network is used to perform a dimensionality reduction on the hidden layer state to produce a prediction of the state of the multi-target point sequence Schematic diagram of MOPIP algorithm network training update structure.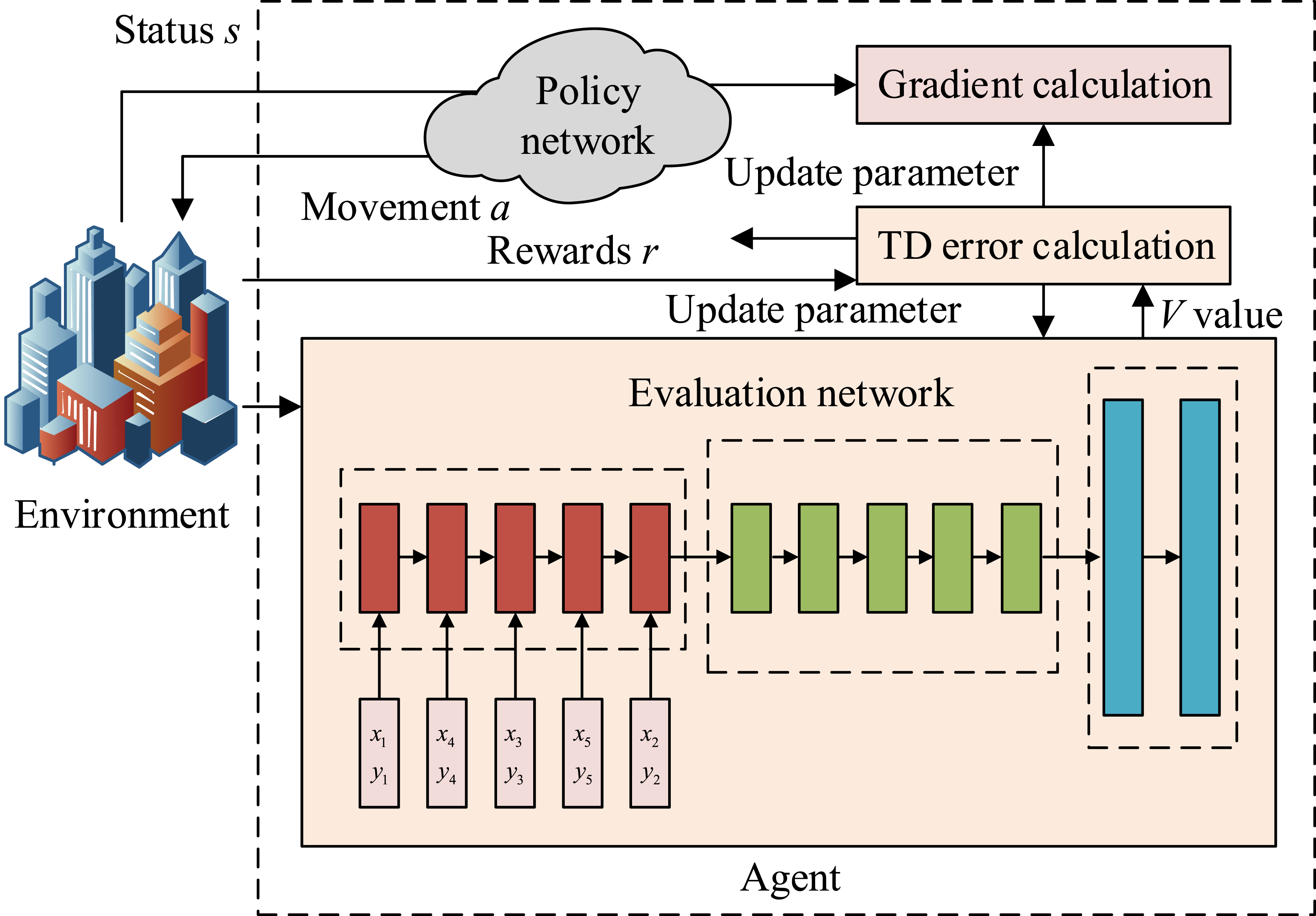
In the MOPIP algorithm, the sequence of multi-target point locations is defined as the state, the sequence of accesses output by the policy network is the action. Moreover, the feedback from the environment on these actions is represented by a reward signal containing total length information, constructed as a Markov decision framework. As it interacts with the environment, the intelligent body continuously acquires information about the current state, feeds it into policy and evaluation networks, predicts actions based on the state and environmental impact, and receives rewards from environmental feedback. The network parameters are updated by calculating the error and gradient. In the specific step of training, the intelligent body uses the initial parameters of the strategy network to interact with the sequence of multi-target points for A times, forming a series of interaction trajectories that record the whole process from the initial sequence to the reward. Among them, the specific equation of the instantaneous reward is shown in equation (16).
In equation (16), the reward received by an intelligent body in state 
The evaluation network uses the mean square value of the temporal difference error as a loss measure and uses gradient adjustment techniques, i.e., rise and fall methods, to optimize its network parameters as shown in equation (18).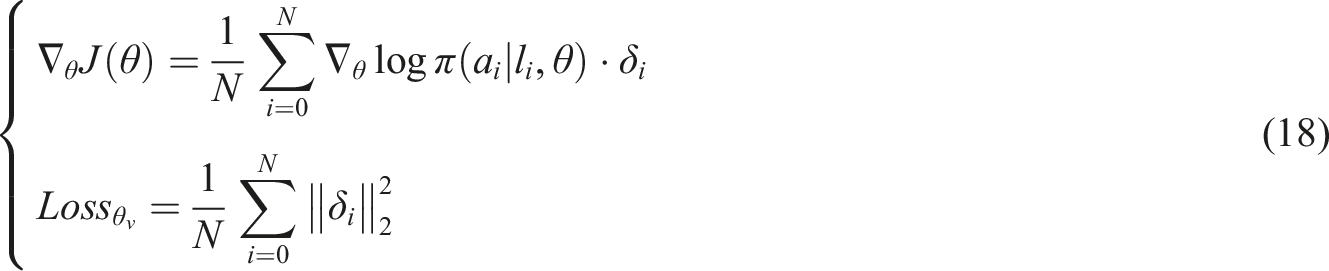
Experiments and results
A travel path planning dataset containing maps and city safety information is first constructed. Then, based on these data, a safe path intelligent planning algorithm for PGM is evaluated to verify its efficacy in ensuring traveler safety. Finally, the study focuses on the results of multi-objective safe path intelligent planning and its analysis.
QL-PIPA performance analysis
The study develops a route planning dataset employing OpenStreetMap maps and Chicago municipal public safety data. The safety risk data encompassed crime and traffic accident records from 2021 to 2023. The data are temporally segmented into two categories: daytime and nighttime. They are then normalized to score different risk types using a uniform metric. The main objective of the dataset is to evaluate the effectiveness of the proposed QL-PIPA for path planning in complex urban environments, especially its balance between safety and efficiency. The detailed information is shown in Figure 7. City map network latitude and longitude data. (a) A city with a high concentration of illegal activities (b) Targeting pedestrians and vehicles passing through areas with high levels of illegal activity.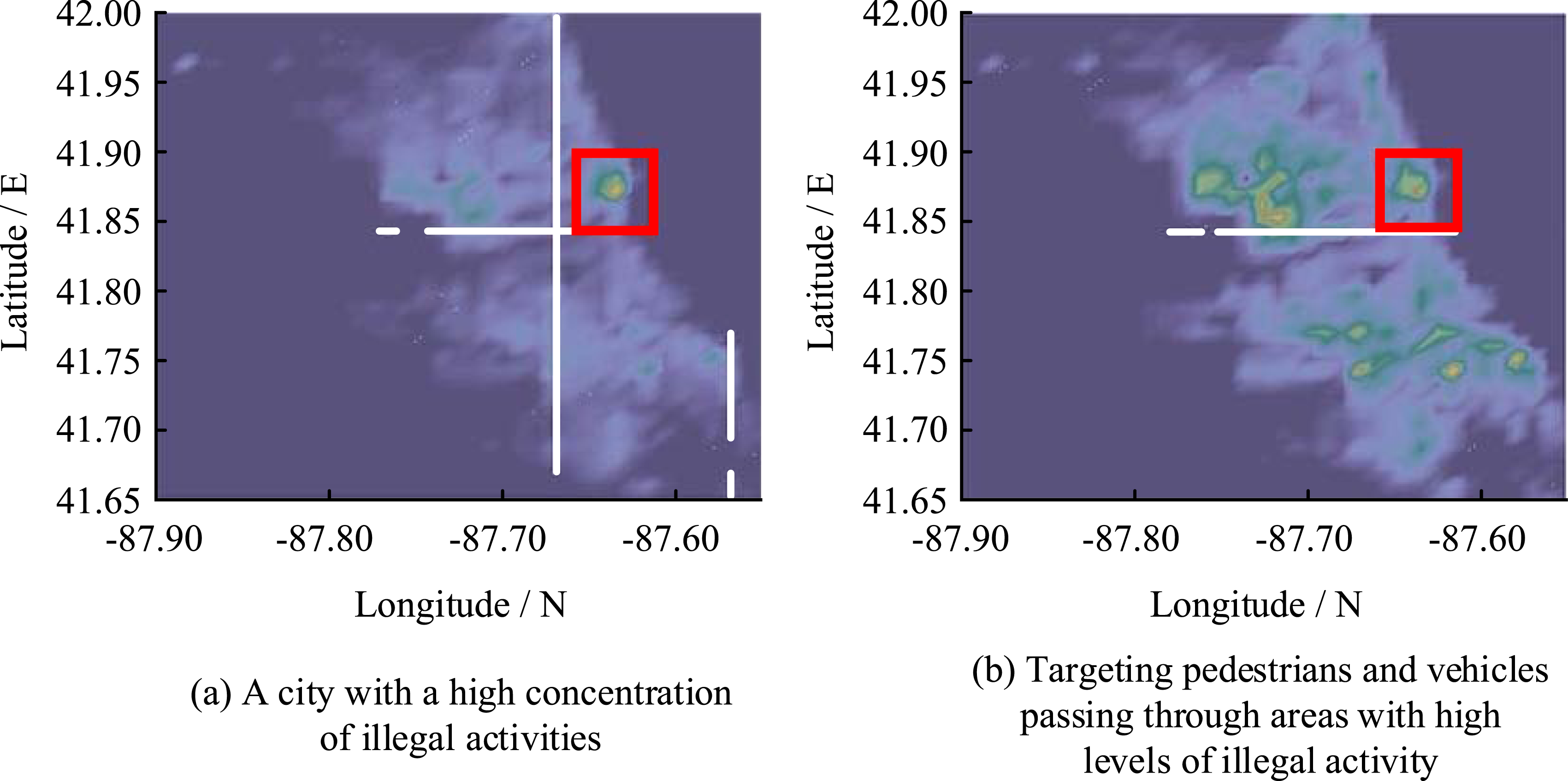
Figure 7(a) shows the area of intensive offenses, while Figure 7(b) shows the area of intensive offenses targeting pedestrians and vehicles passing through the area, which can be seen from these two sub-maps approximately between latitude 41.877° and 41.887°, and longitude −87.635° and −87.625°. Safety risk data are collected and integrated into the path planning algorithms. These data included information on crime-intensive areas, particularly those targeting pedestrians and vehicles. The study area is known for its frequent criminal activities and has multiple security concerns, which is essential to assess the effectiveness of the proposed path planning algorithm in ensuring traveler safety. Meanwhile, the study defines the safe area based on the distance of each node on the path from the surrounding dangerous area. The level of the dangerous area is assessed by historical data and crime frequency. The safe distance of each path node is defined as the shortest distance between the node and the nearest dangerous area, and a larger safe distance means a safer path. During path planning, the algorithm prioritizes paths with larger safe distances to ensure the safety of travelers.
Before using the data for the path planning algorithm, certain pre-processing steps are required, including data cleaning, data integration, feature engineering, normalization, and data segmentation. The multiple feasible routes in this region provide a suitable test scenario for the study’s proposed PGM-based intelligent planning algorithm for safe routes to evaluate its effectiveness in ensuring travelers’ safety. To improve the stability and generalization ability of the model, the study conducted feature screening before modeling. The initial feature set is constructed based on domain knowledge, and redundant or invalid features are eliminated by correlation analysis and variance filtering method. 27 On this basis, the importance of each variable is ranked using the replacement feature importance method under the XGBoost framework, and the more influential features are retained as final inputs.
To evaluate the effectiveness of the policy-guided QL-based algorithm proposed in this research for intelligent planning of travel paths, 800 simulation experiments are executed. These experiments are based on city maps and safety hazard data, defining the start and goal points as [41.880°, −87.633°], [41.886°, −87.630°], respectively. The experimental environment is CPU Intel Core i7-9700K, GPU: NVIDIA RTX 3080, RAM: 32 GB DDR4. Each journey of the intelligent body from the starting point to the end point is regarded as a learning cycle. In the experiments, the algorithm is compared with EGS and strategy enhancement methods. The learning rate Three strategies converge efficiency and effectiveness in path planning. (a) Cumulative reward (b) Path total length (c) Learning steps (d) Learning time.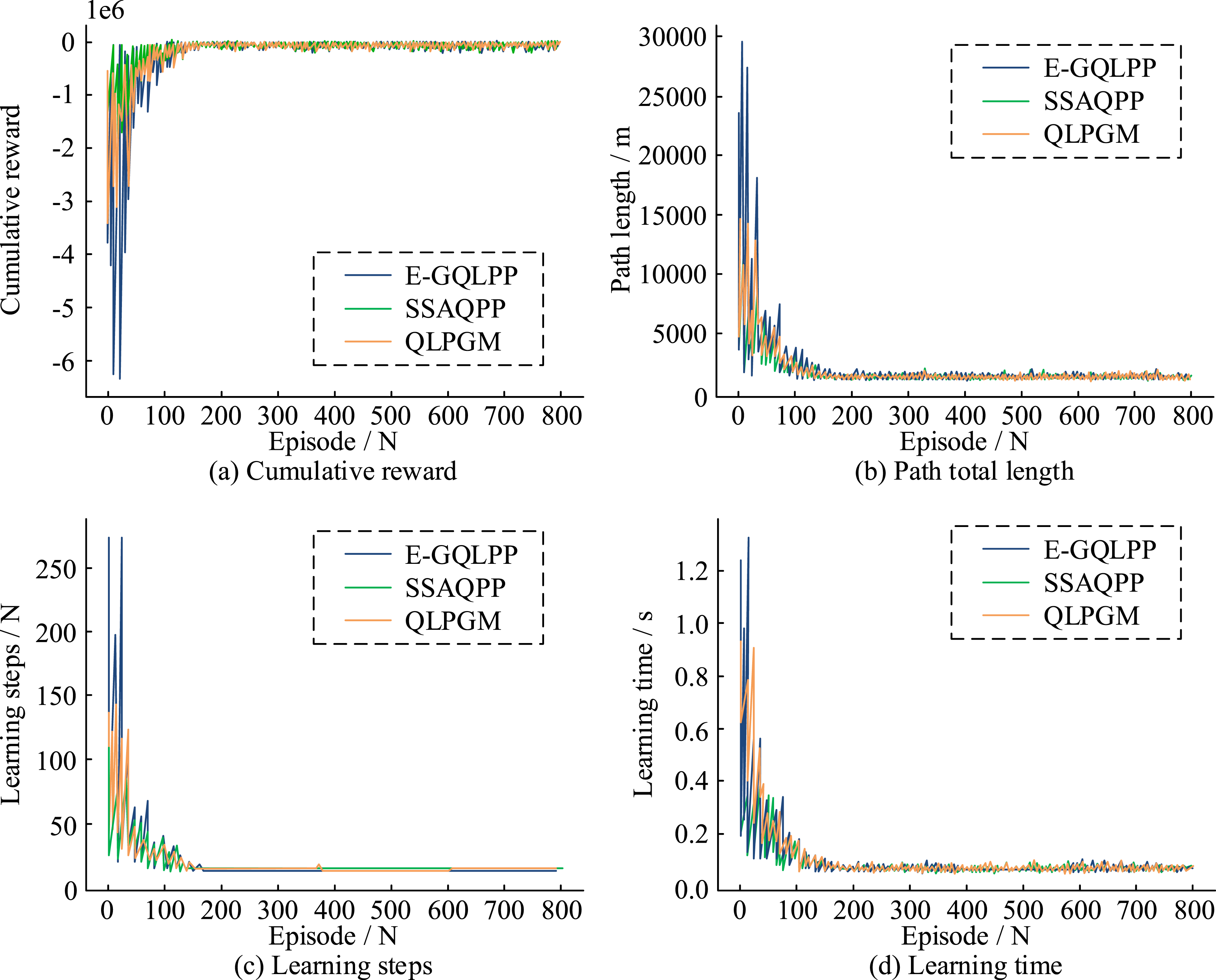
As illustrated in Figure 8(a), the convergence trend of the cumulative reward comparison demonstrates that the method stabilizes after an initial 160 iterations. Comparing the total path length in Figure 8(b), E-GQLPP requires the longest path. The superiority of QLPGM can be further illustrated by combining Figure 8(c) learning steps and (d) time consumption. The proposed algorithm of this study effectively reduces the initial fluctuation, accelerates the discovery of the optimal policy, and reduces the time consumption of each iteration. Therefore, the research-proposed method demonstrates significant advantages in terms of efficiency and performance. Convergence is a key metric for evaluating the performance of optimization algorithms. It is shown that the QL-PIPA reduces the convergence time by 32% and 27% compared to the E-GQLPP and SSAQPP respectively. The convergence trend of the method can be observed by monitoring the cumulative reward of the method after each iteration. The experimental results display that the method significantly improves its performance by exploring unknown environments and trial-and-error learning in the first 80 iterations and stabilizes after 160 iterations. Figure 9 further compares the convergence time of three strategy method. Convergence time of three strategy methods.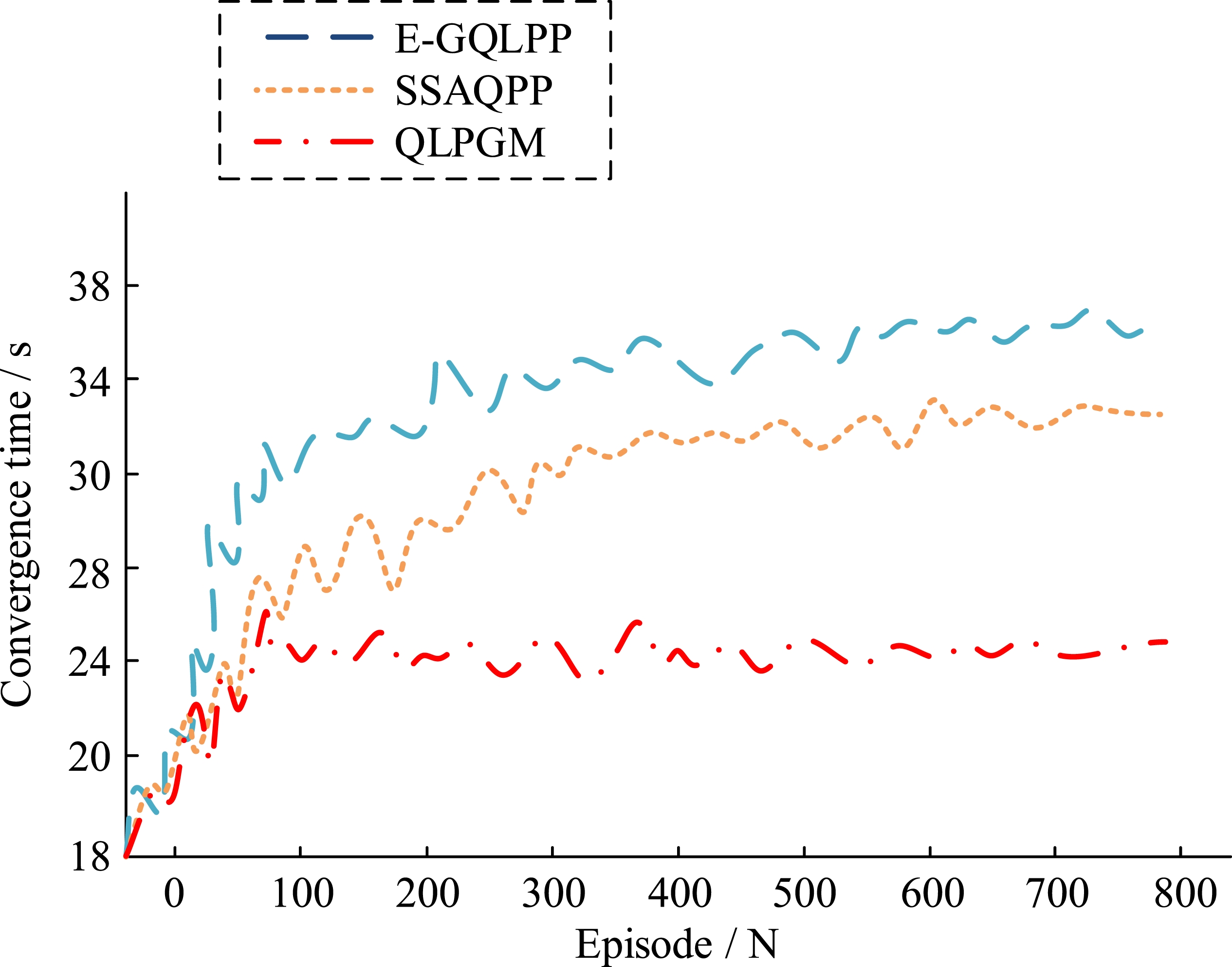
Verification results of ablation experiments.
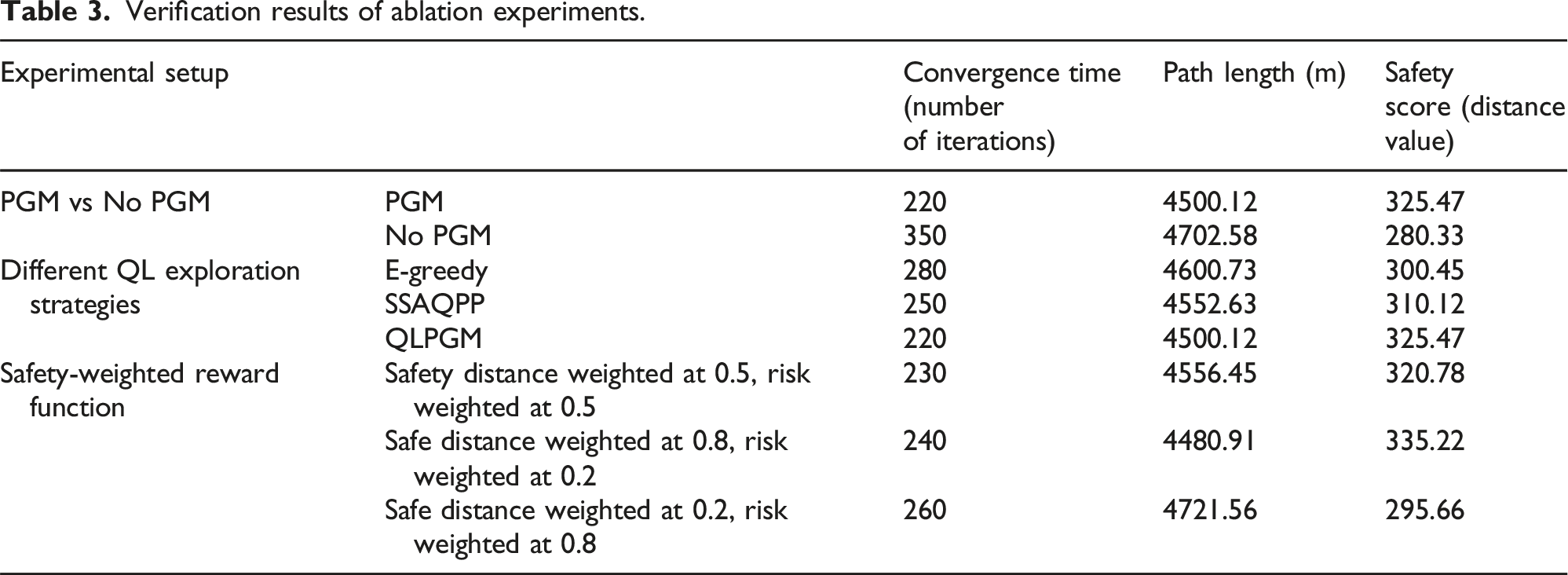
In Table 3, the method with PGM reduces the convergence time by 37% and improves the security score by 14.4% compared to the algorithm without PGM. This indicates that PGM significantly improves the efficiency and safety of path planning. Compared with the EGS and SSAQPP, the PGM-based QL method performs better in terms of both convergence time and path length, and has the highest security score. It indicates that the bootstrapping mechanism of PGM can effectively reduce unnecessary random exploration and optimize path selection. In addition, the study verified the impact of different safety distances and risk weights. It can be seen that when the weight of the safety distance is greater, the method tends to choose a safer path, but the path length increases. On the other hand, increasing the weight of risk results in a shorter path, but the safety score decreases. This indicates that the reward function has good adjustability and adaptability, and parameters can be adjusted according to different urban environments.
Safe path planning evaluation
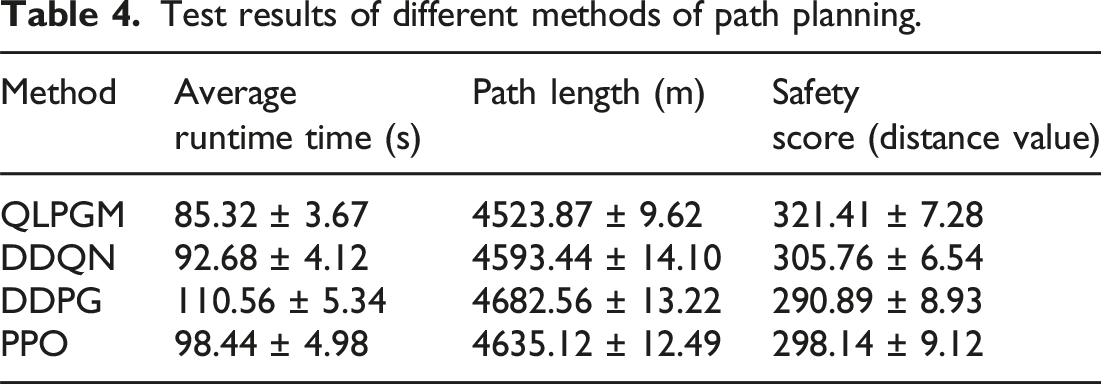
Test results of different methods of path planning.
Data related to starting and destination points.

Next, the intelligent planning of the paths is evaluated in terms of length and safety, based on the overall length of the paths and the average of the safety distances, as shown in Figure 10. Path one in Figure 10(a), Path two in Figure 10(b), and Path three in Figure 10(c) present the effect of the planning done by the three algorithms for the paths listed in Figure 10, respectively. The average length and safe distance of the planning algorithm for paths one to three. (a) Path one (2) Path two (3) Path three.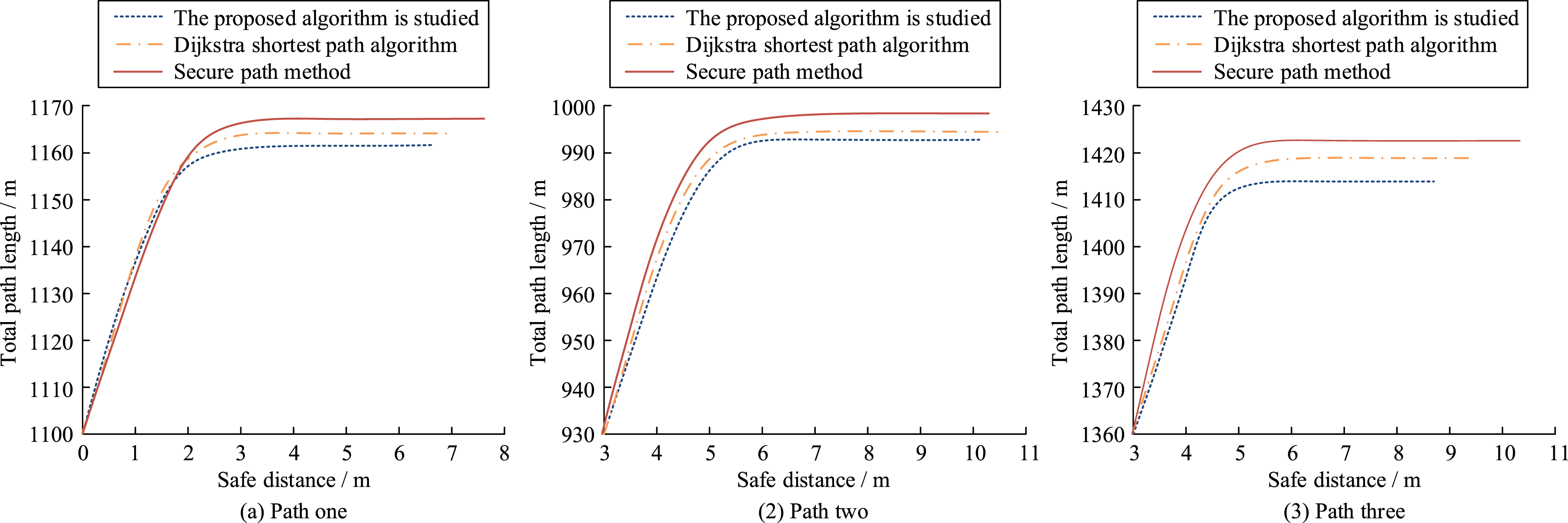
As can be observed from paths one through three of these three subgraphs, the proposed algorithm substantially improves the safe distance averages by 0.39%, 0.63%, and 0.55%, respectively, while keeping the path lengths similar to the shortest paths. Whereas, the safe distance averages are improved by 8.01%, 11.96%, and 16.50%, respectively. In contrast, the traditional shortest path algorithm mainly optimizes the path length and fails to effectively avoid the safety hazards. Compared to the safe path approach, the studied algorithm shows a slight increase in path length, but a more significant improvement in the average safe distance. Although the safe path approach takes safety into account, it may lead to ignoring some of the high-risk paths in short path planning. Therefore, the studied algorithm demonstrates better safety and efficiency in travel path planning.
Multi-destination planning evaluation
The research experiments first set the number of target points to 5 and 10, and the initial learning rate is 0.001. When the number of target points is 20, the initial learning rate is adjusted to 0.0001, and the number of interactions is 10,000. Next, the Euclidean distances are used to calculate the distance between the target points and to compare the path planning effects of distance matrix mapping (DMM), genetic algorithm (GA), PN, and MOPIP algorithms for path planning results, as shown in Figure 11. Different algorithm path length comparison.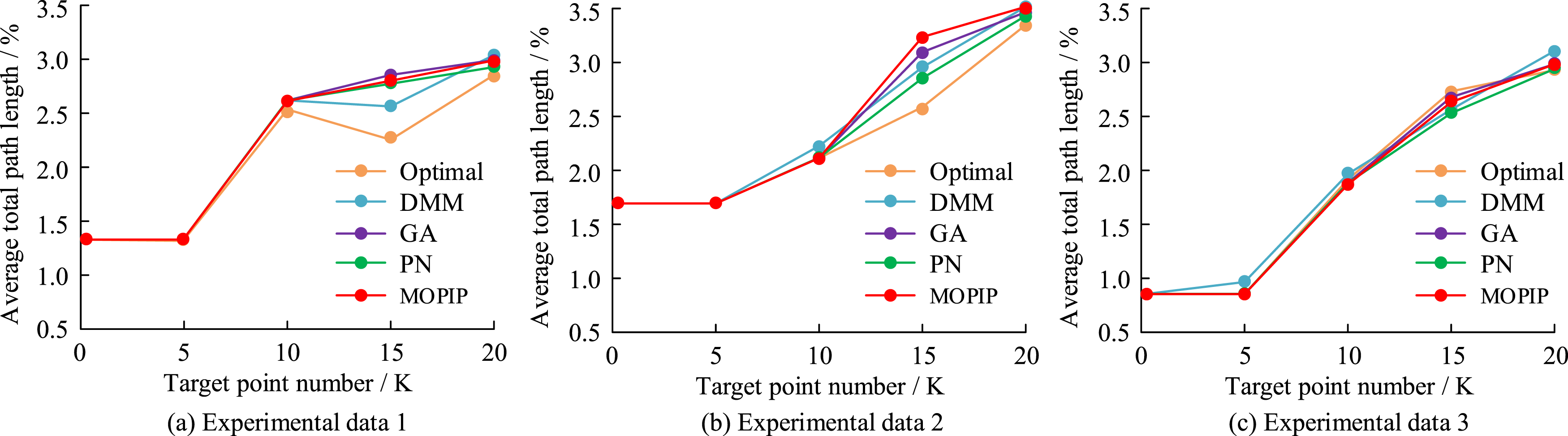
Comparison of the results of intelligent planning algorithm for multi-target point security path.
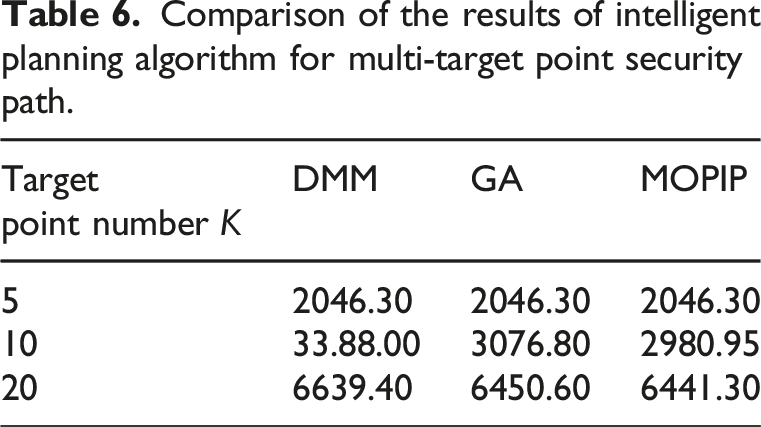
In Table 6, the MOPIP algorithm, the DMM method, and the GA show good performance in the scenario with 5 target points. However, as the number of target points increases, the superiority of the MOPIP algorithm becomes more obvious. In the case of 10 target points, the total length of safe paths planned by the MOPIP algorithm is reduced by 11.98% and 3.09% compared to the DMM method and GA, respectively. When the number of target points increases to 20, this advantage is still significant and the total path length is reduced by 3.00% and 0.15% compared to the DMM method and GA, respectively. This indicates that the MOPIP algorithm has a significant efficiency advantage when dealing with more complex multi-objective point path planning tasks. It is also shown that the MO-PIP algorithm can effectively handle more complex multi-objective point path planning tasks with good stability.
Computational complexity analysis
Finally, the study further analyzes the computational complexity of the QL-PIPA and the MO-PIP algorithm in the proposed framework, as well as a comparison of the complexity of both with other algorithms. Figure 12 depicts the details. Comparison of computational complexity of different algorithms. (a) Comparison of time complexity (b) Comparison of space complexity.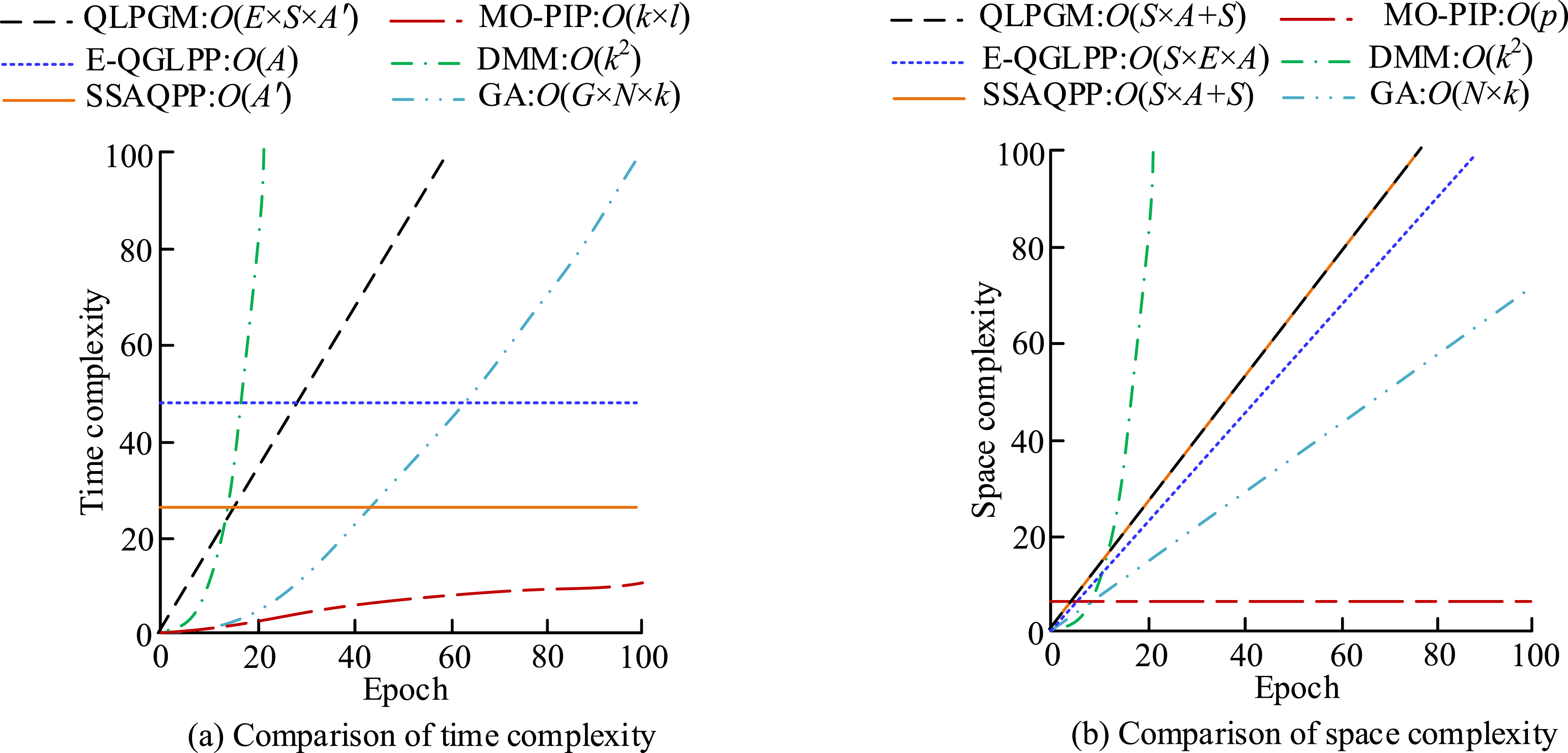
Figure 12(a) and (b) show the comparison of time and space complexity of different algorithms. Among them, E denotes the number of learning iterations, S denotes the size of the state space, A denotes the size of the action space, and A′ denotes the average number of actions in each state after the introduction of PGM. k denotes the number of target points, l denotes the number of layers of the network, and p denotes the number of parameters of the network. The g denotes the total number of iterations required by the GA, and N denotes the population size. In Figure 12, the QLPGM algorithm is significantly reduced in time complexity after the introduction of PGM. The QLPGM algorithm needs to store additional policy guidance information, so it requires more storage space than the E-QGLPP algorithm. Combining the QLPGM and MOPIP algorithms, it can be concluded that the total time complexity of the proposed framework under study is O(E × S × A′ +k × l) and the total space complexity is O(S × A + S + p).
Discussion
To address the limitations of traditional path planning algorithms in complex urban environments, the study proposed the QL-PIPA based on PGM and extended it to the multi-objective planning scenario with MO-PIP. The experimental results showed that, compared with E-GQLPP and SSAQPP, the proposed method improved the convergence speed by 32% and 27%, respectively, and exhibited strong stability after 160 iterations. This improvement was due to the PGM. It effectively balanced exploration and exploitation by introducing safety-conscious potential fields and reward function design. The study showed that PGM could avoid unnecessary exploration of the agent and converge to optimal policies quickly. 33 This indicated that the introduction of the PGM strategy in the study had certain advantages.
In terms of safety, QL-PIPA outperformed Dijkstra’s shortest path and traditional safe path algorithms. Although the increase in path length is minimal, the average safety distance was significantly improved, confirming the algorithm’s advantage in navigating high-risk urban areas. In multi-goal scenarios, the MO-PIP algorithm showed significant performance gains as the number of goal points increases. When the number of destinations reached 20, MO-PIP reduces the total path length by 3.00% compared to DMM and by 0.15% compared to GA. This demonstrated its scalability and suitability for complex routing problems. Compared to baseline methods such as DDQN, DDPG, and PPO, the proposed method achieved better average runtime, shorter paths, and higher safety scores. In addition, ablation experiments confirmed the critical contribution of PGM and safety-weighted reward functions to overall performance.
In addition, the path planning algorithm proposed in this paper has good practical applicability. In the context of smart city construction, this algorithm can be integrated into navigation applications, urban emergency evacuation systems, and public transportation scheduling platforms to provide travelers with safe and efficient path recommendations. In the logistics and delivery sector, the MO-PIP model can address path optimization challenges in multi-destination delivery tasks, enhancing delivery efficiency and reducing operational risks. In autonomous driving scenarios, the strategy-guided mechanism helps vehicles avoid high-risk areas in complex road networks, ensuring driving safety. Therefore, the methodology proposed in this study demonstrates feasibility and scalability for deployment in real-world urban mobility and traffic control systems.
Nevertheless, there are limitations to this approach. Although the proposed method performs well in static or semi-dynamic environments, its adaptability to rapidly changing environments, such as real-time traffic updates and weather disturbances, has not been fully tested. Future research could further introduce time-sensitive risk weighting mechanisms to enhance the model’s adaptability in dynamic safety environments. A similar modelling approach has been applied in references 1 Zhu et al.'s research on time-aware path planning. In addition, uncertainty quantification (UQ) mechanisms can also be introduced, following the approach proposed by Barzegar et al. to achieve efficient UQ without changing the network structure. 34 The incorporation of such mechanisms is expected to improve the stability and reliability of the model in high-risk areas or data-sparse scenarios.
Conclusions
This study proposed a policy-guided QL-PIPA and its MO-PIP to address the safety, efficiency, and scalability requirements of modern travel path planning. Through a series of experiments in realistic urban scenarios: QL-PIPA reduced convergence time by up to 32% compared to baseline QL strategies. The algorithm significantly improved path safety, increasing the average safety distance by over 10% while maintaining competitive path lengths. The MO-PIP model demonstrated strong scalability, with improved performance in multi-destination route planning as the number of destinations increased. Compared to DDQN, DDPG, and PPO, the proposed algorithm achieved better runtime and higher safety scores, validating its effectiveness. These results indicated that the proposed framework could provide travelers with safer and more efficient routes, especially in complex urban environments. It also laid the foundation for future use in applications such as autonomous driving, logistics routing, and smart tourism.
Future research will integrate dynamic environmental data such as traffic conditions and weather changes to improve the real-time adaptability of the algorithms, explore lightweight model variants suitable for deployment on mobile or edge devices. Moreover, it combines PGM with DRL techniques to deal with higher dimensional state-action spaces and more complex decision scenarios. In addition, input perturbation analysis and feature attribution methods are introduced to clarify the degree of influence of different features on model output, optimize feature weights and model structure, and improve model interpretability.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by: Special ideological and political project of scientific research projects in Colleges and universities of the autonomous region in 2021, Research on the teaching method of integrating the red tour into the ideological and political course of Tourism Specialty in Higher Vocational Colleges, (NO. NJSZZX2174).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.