
Abstract
In order to extract the semantic information from a large number of student comments on the online education platform, this paper investigates and develops a Chinese comment classification model using the Voting and BiLSTM algorithm. The model classified the course reviews from two aspects of sentiment and content. The sentiment aspect was divided into three categories of “Positive,” “Negative,” and “Neutral,” and the content aspect was divided into three categories of “course,” “platform environment,” and “other.” In the collection and processing of data sets, an effective data set that accurately represents the characteristics of the education field is constructed by utilizing comments obtained from the NetEase Cloud course platform. The HuggingFace open source Bert pre-training model is then employed for word vector training. In the model construction, based on the Voting and BiLSTM model classification algorithm, a weighted fusion Bi_Voting strategy is proposed, and the classification principle based on SVM and the resampling enhance module are introduced. The experimental results show that the classification model has significant advantages in terms of accuracy, recall rate, and F1 value. In addition, to obtain more comprehensive information, we also conducted an in-depth analysis of different categories of reviews using hierarchical clustering and TextRank keyword extraction.
Introduction
With the gradual popularization of the online education model in the post-epidemic era, several online course platforms have emerged in the market, including MOOCs, NetEase Cloud courses, and micro-classes, among others. These platforms provide a large number of high-quality courses and are transforming the current educational landscape. We must adapt to the virtual and digital classroom environment.1,2 What will online education bring to the field of education? While enjoying the convenience and speed of “Internet + education,” there is also a flood of massive information on the network. How to evaluate the quality of online courses? How can one grasp the key information of these courses? How to select excellent online courses that offer real interactive teaching? It is a difficult problem in online course management. 3 Currently, numerous online course platforms have incorporated comment sections, and analyzing the sentiment of these comments has consistently been a popular subject in the field of natural language processing. For example, typical sentiment analysis tasks can classify opinions expressed in texts as positive, negative, or neutral. 4 In order to effectively mine and utilize the rich semantic information contained in student reviews on online education platforms, and improve the quality of education services and user experience, this study aims to design and implement an efficient and accurate Chinese review classification model.
To date, methods for text classification have included the use of traditional machine learning techniques and deep neural networks to construct models. Whether it is mechanical learning or deep learning, the text must be transformed into a word vector representation before training the text for classification. In the past, the commonly used method was to train word vectors using word2vec. In order to address the intricate issues in the Chinese context, the conversion of word vectors utilizes a pre-trained Chinese model called “Bert-base-Chinese,” which is an open-source resource provided by HuggingFace. This approach yields superior outcomes compared to word2vec. 5
Due to the exponential growth of online course content, researchers are increasingly interested in data analysis in education, teaching, and learning. This interest has led to the development of analytical models, methods, and techniques. 6 Traditional machine learning methods include support vector machines, logistic regression, random forest, etc., all of which are single classification models. 7 In order to achieve better performance than using a single classification model, ensemble learning is proposed to combine the strengths and weaknesses of multiple classification models. However, with the rapid development of software and hardware technologies, text classification problems are now shifting from traditional machine learning to deep learning. Deep learning models, such as convolutional neural networks, recurrent neural networks, and graph neural networks, 8 are being increasingly used in this field.
In light of the current challenge of classifying Chinese online course reviews, it is worth considering the strengths and weaknesses of traditional machine learning methods that can combine multiple single-classification models through voting. Additionally, deep learning, particularly the common recurrent neural network LSTM, shows promise in text prediction models. LSTM addresses the issue of long-term dependence in traditional RNN by introducing a gate control mechanism. This allows for better processing of sequence data and has yielded positive outcomes in natural language processing.9–11 The voting method is a combined strategy used for classification problems in ensemble learning. In this paper, a voting classifier is used to integrate five individual model classifiers of machine learning, namely Naive Bayes, random forest, decision tree, logistic regression, and k-nearest neighbor. A 5-fold cross-validation with grid search is performed on each individual classifier to enhance the performance of machine learning.12,13 As an extended form of LSTM, bidirectional long short-term neural network can transmit and extract information from both forward and backward input sequences simultaneously. This allows it to capture contextual relations and understand sequence data in a more comprehensive way. In the practice and demonstration of previous researchers, it has been shown to achieve higher accuracy on numerous popular data sets.14–16 According to the analysis above, this paper proposes a classification model based on the Voting and BiLSTM algorithms to further enhance the extraction of comment information and achieve improved classification results. Through the bi-dimensional classification of sentiment orientation (positive, negative, neutral) and content topic (course, platform environment, other), the model can deeply mine the emotional attitude and specific concerns behind the reviews, and provide valuable feedback for educational institutions.
Design of classification model for course reviews
Data acquisition and preprocessing
Data ingestion
At present, there is a lack of standardized Chinese online course review datasets in China. In order to better understand the characteristics of text in the field of education, this paper utilizes a crawler tool to gather a dataset from the online practical skills learning platform “NetEase Cloud Classroom.” We searched for the keyword “office software” and successfully collected 16 online courses related to it after filtering the dataset. These courses cover PPT design, Word application, and advanced Excel mastery, among others. They include “High PPT Design Secrets: Popular Experience Version,” “Word Lessons for New Professionals,” and “30 Postures for Advanced Excel Mastery,” among others. In total, there are 18,068 text comments.
Data preprocessing
Manual category labeling
Indicates the situation.

Chinese word segmentation and stop words
Word segmentation is a crucial step for Chinese text. We utilize the jieba word segmentation tool to segment the manually labeled online course review data. Additionally, we customize a splitting dictionary specifically designed for office courses in order to enhance the effectiveness of the segmentation process. When processing Chinese word segmentation on review data, we have observed that a significant number of them contain non-Chinese characters, such as punctuation marks, special characters, emoticons, and numbers. In order to prevent these characters from affecting the identification of text content tags, we utilize the Chinese stop words list (which includes 1,208 stop words) published by the Chinese Natural Language Processing Open Platform of the Institute of Computing Science, Chinese Academy of Sciences, to eliminate stop words. To process the data segmentation of emotion tags, a custom stop word list is used. This is done to account for the possibility that these characters may include network hot words or other factors that could impact the accuracy of emotion tag discrimination.
Model construction based on voting and BiLSTM algorithm
The model proposed in this paper is applied to Chinese text classification, and its algorithm flow chart (Figure 1) is mainly composed of three parts. Feature engineering involves several steps, including the transformation of Bert word vectors, normalization, and LDA dimensionality reduction. After that, the classification model is trained. Finally, the training set data is processed by the application module. Flowchart of the algorithm.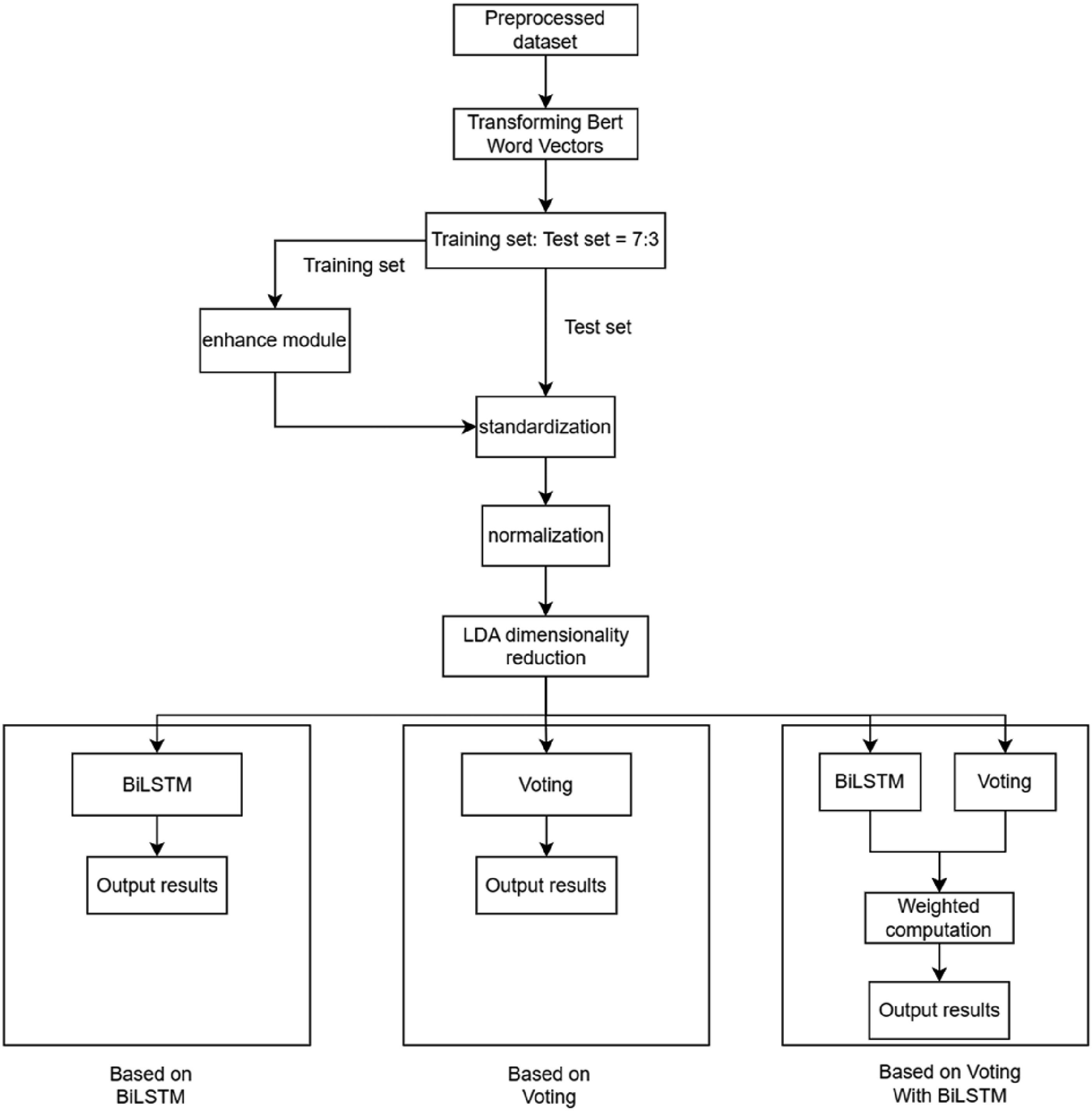
Feature engineering
A. By utilizing the “BERT-base-Chinese” pre-trained Chinese model, which is an open-source model provided by HuggingFace, we can convert the text into Bert word vectors. Compared to the traditional word2vec transformation word vectors, this approach allows for a more accurate representation of the global context of each word. As a result, richer semantic and contextual information can be obtained, which is conducive to solving complex problems in the Chinese context.
B. Standardization and normalization in the classification training of the dataset can improve the convergence speed of the model, reduce the influence of outliers, and prevent numerical overflow, thereby achieving better classification performance. The data is normalized using min-max normalization, which maps it into a new interval range of [0, 1]. This allows for the comparison and weighting of different features. Normalization calculation formula (1):
C. LDA dimension reduction can simplify high-dimensional data into two or three dimensions, facilitating data visualization and enhancing the understanding and explanation of trends within the data. LDA can improve the accuracy of the model by selecting the most significant features to remove redundant ones. It can also enhance the classification accuracy by projecting the data onto the most distinguishable dimensions. It makes it easier for the model to distinguish between different classes.
17
The scatter plot of the data set after LDA dimensionality reduction is shown in Figure 2. Scatter plot of data set features after LDA dimensionality reduction.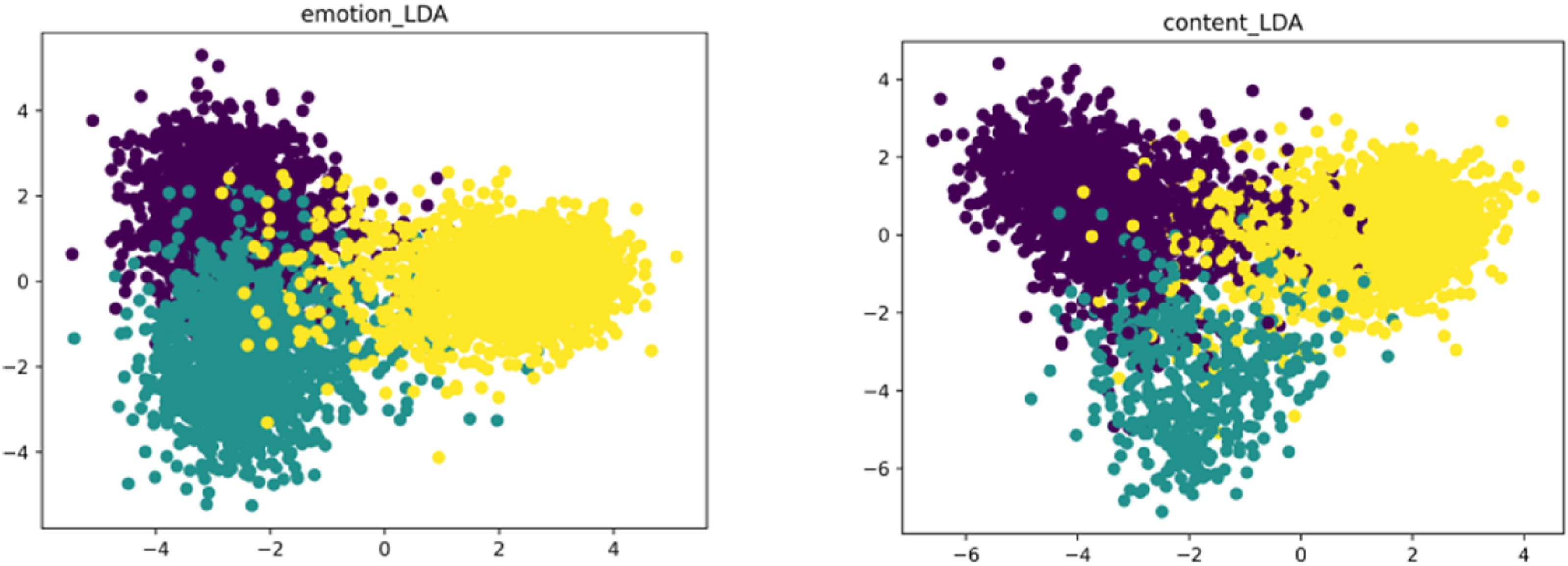
Classification model training
Voting is an ensemble strategy that combines the prediction results of multiple basic classifiers. In this paper, the soft voting output type is used to integrate five machine learning single model classifiers: Bayes, random forest, decision tree, logistic regression, and k-nearest neighbor. At the same time, grid search is used for five-fold cross-validation for each individual classifier. This approach allows for a more accurate evaluation of the model’s performance and enhances its stability, generalization, and robustness.
BiLSTM is a variation of the traditional one-way LSTM. It addresses the limitation of only transmitting information forward from the past state by considering both the forward and backward context information of the input sequence. This allows it to capture richer context and dependency relationships. BiLSTM has demonstrated significant advantages in previous research on Chinese reviews.
By leveraging the strengths of ensemble learning and sequence modeling through voting and BiLSTM, respectively, this study emphasizes the potential for further enhancing prediction performance and model robustness. The classification effect of both models on this task is similar, thus an average weighted method is adopted in this paper to combine their prediction results. This weighted fusion approach effectively harnesses the advantages of different algorithms while mitigating individual shortcomings, resulting in more accurate and reliable predictions. The proposed fusion method is termed Bi_Voting.
Enhance module
Since SVM itself seeks the hyperplane that minimizes the distance between all samples and maintains the maximum margin in the classification process,
18
the data screening is achieved by adjusting the distance d+. This is illustrated in Figure 3, where the margin represents the minimum distance from the hyperplane, and the fuzzy region represents the selected data set region. Region of ambiguity.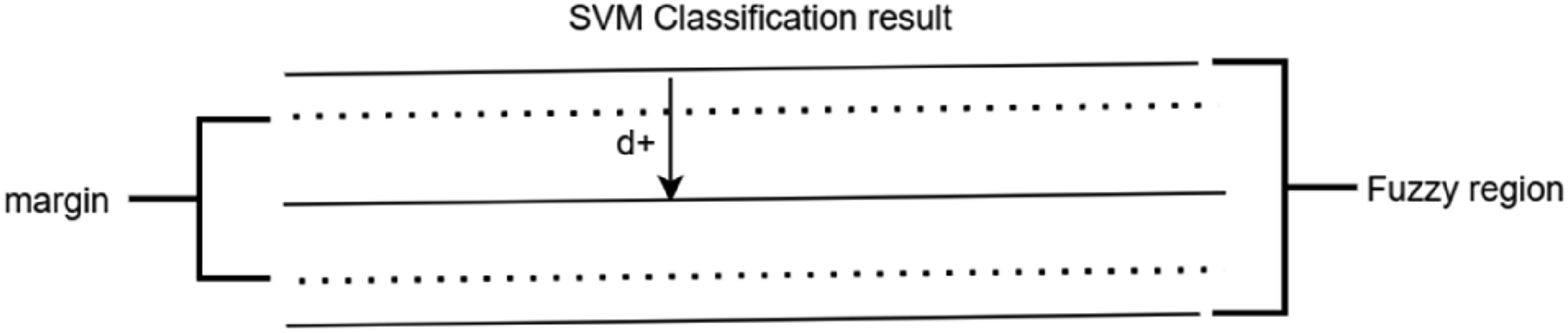
For three-classification data, this paper utilizes a one-to-many approach to construct the hyperplane. As a result, each data point will have three distances to the hyperplane, with both positive and negative directions. Therefore, the absolute value of the calculated distance should be taken, and the minimum distance of each data point should be determined. The threshold, denoted as d+, should be determined based on the distribution map of the minimum distances. The minimum distance distribution diagram of the data set in this paper is shown in Figure 4, where the dotted line in the figure labels the mode of the distance set, so the threshold d+ takes the intermediate integer unit 0.2. Minimum distance distribution.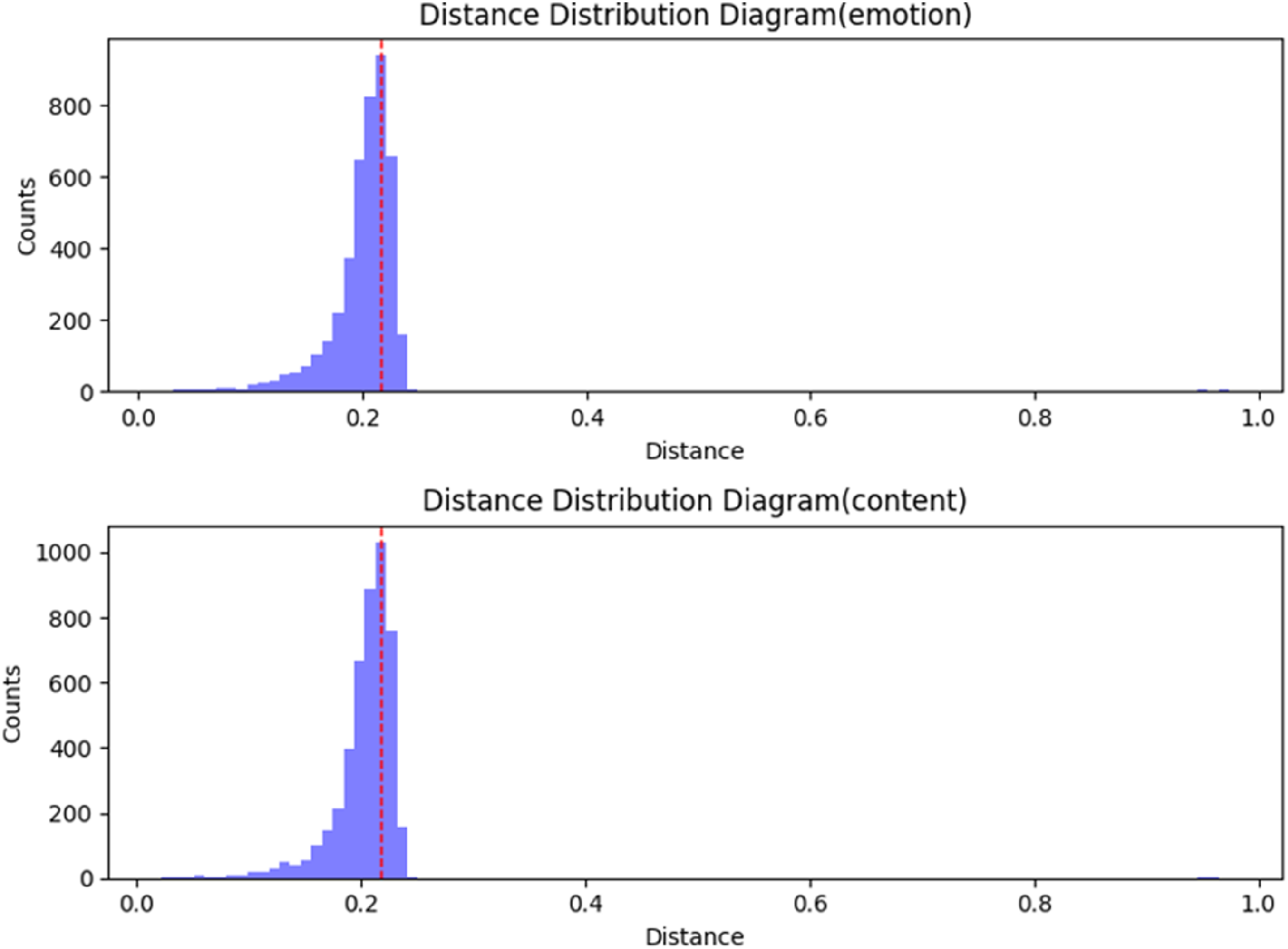
According to the above introduction, the data in the fuzzy region of the training set are screened using the SVM model. The filtered data are then upsampled and amplified to create a new training set along with the original training set. Considering the data balance, the amplification factor (n) is calculated by dividing the total number of training sets by the number of screening data and then subtracting 1. The data set in this paper is calculated with n = 2, and the formula is as follows formula (2):
We will refer to this process as the enhance module, and the flow is illustrated in Figure 5. Enhance module.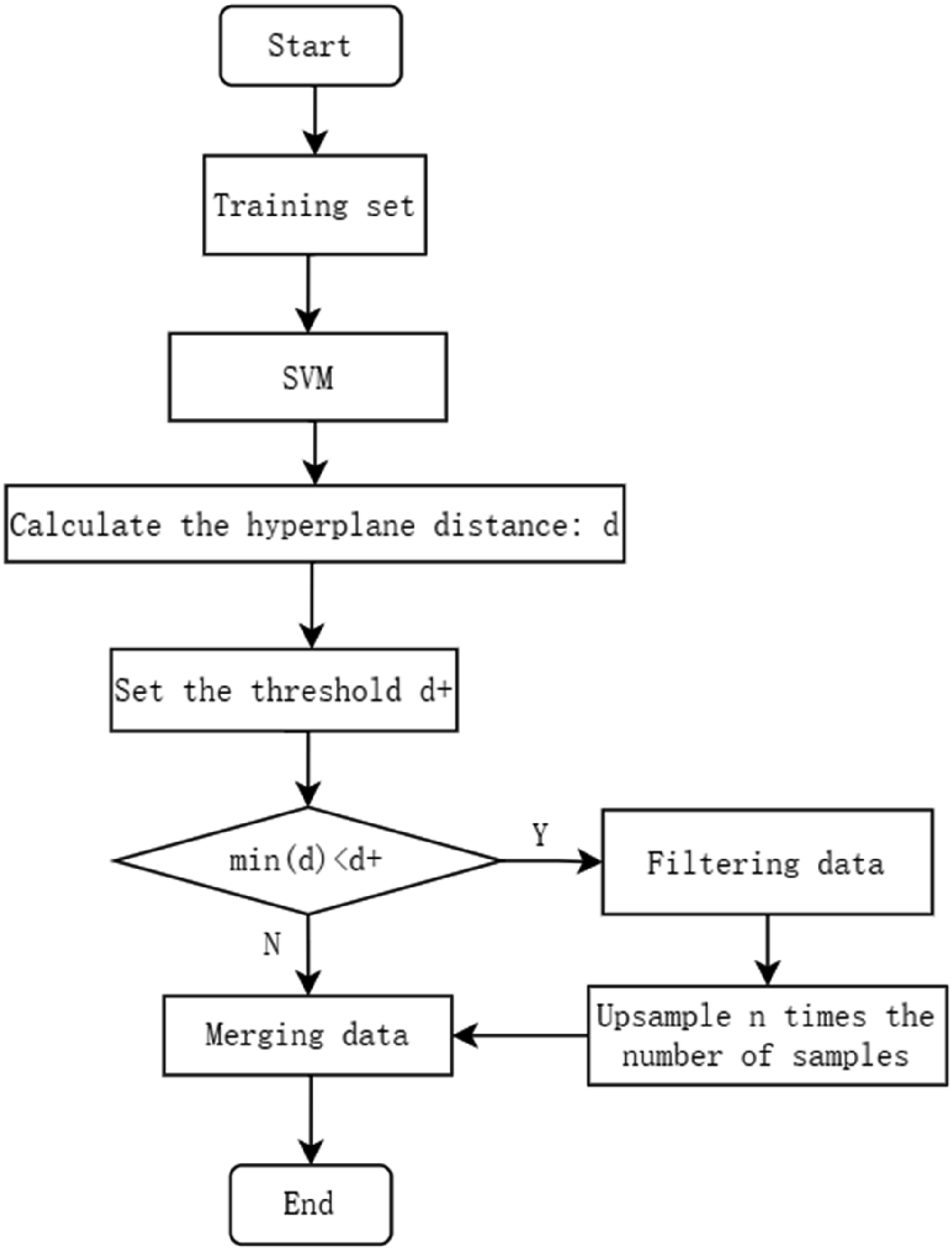
Evaluation and analysis of model classification algorithms
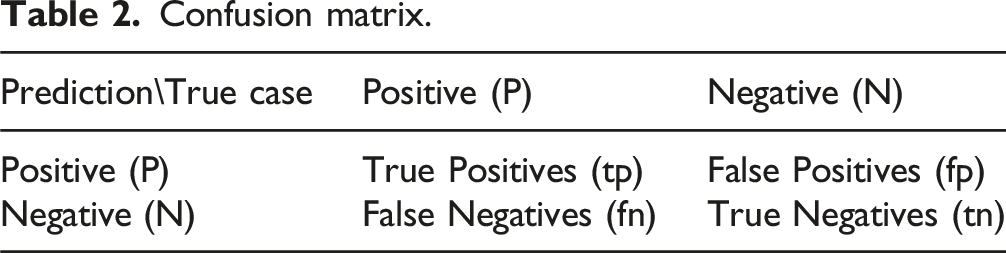
Performance evaluation indicators
Confusion matrix.
The accuracy is calculated as formula (3):
The precision is calculated as formula (4):
The recall is calculated as formula (5):
The F1 is calculated as formula (6):
Empirical results
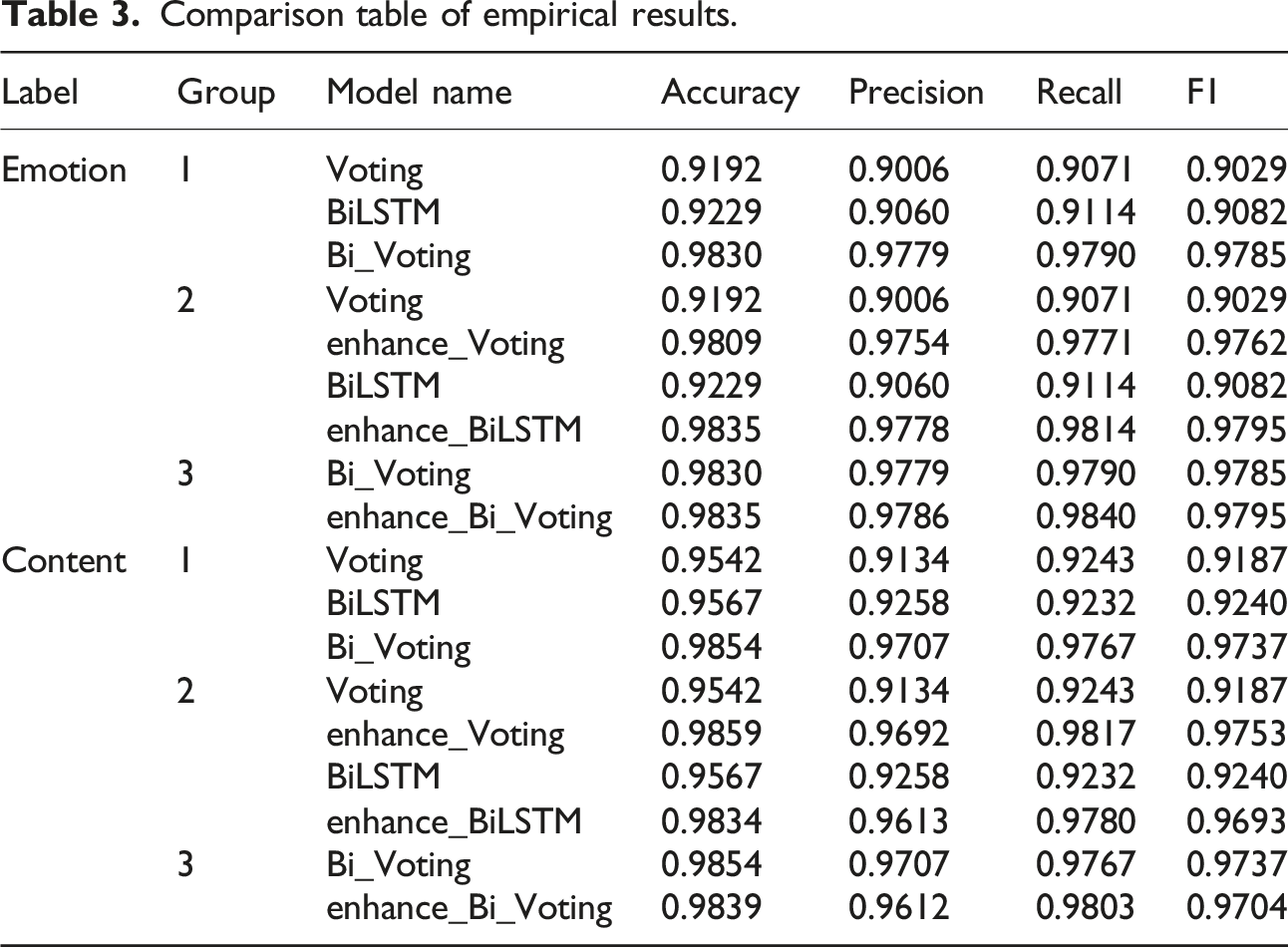
Comparison table of empirical results.
Empirical analysis
From the comparison of empirical results in Table 3, it can be seen that when only adding the enhancement module to the BiLSTM algorithm or the Voting algorithm, the evaluation index is significantly higher than that without adding the enhancement module. Additionally, the weighted fusion of the two models can also significantly improve the evaluation index of the model classification algorithm. Considering accuracy, precision, recall and F1 score, our experimental results show that the fusion algorithm based on “BiLSTM-Voting” improves each index by 6.01%, 7.19%, 6.76%, and 7.03%, respectively, compared with BiLSTM algorithm only. Compared with the Voting algorithm, they are 6.38%, 7.73%, 7.19%, and 7.56 higher, respectively. However, the weighted fusion of the two models, achieved by incorporating the enhance module, improves the evaluation index for the emotion category. However, it has little effect on the evaluation index for the content category. From the evaluation indicators of each model, there is no significant difference between the BiLSTM algorithm and the Voting algorithm alone. After the weighted fusion of the results from the two models, each evaluation indicator shows significant improvement. However, the addition of the enhance module leads to varying effects on different types of classification.
Category analysis based on hierarchical clustering and TextRank keyword extraction
Based on the aforementioned experimental findings, the enhance_Bi_Voting model has been chosen for sentiment analysis, while the enhance_Voting model is selected for content classification. Unlabeled data from a specific course is processed using these trained three-classification models, yielding initial results in emotion and content categorization. Subsequently, clustering and keyword extraction are performed to clearly identify primary comments and underlying causes within each category, effectively capturing key information. Taking the “Learn Excel Video Tutorial from Wang Peifeng” course as an example, 6,786 unlabeled pieces of data undergo category analysis based on emotional labeling within the classification model.
Hierarchical clustering
Clustering result table (part).

TextRank extracts keywords
The TextRank algorithm is an efficient graph-based sorting algorithm that is primarily used for keyword extraction and automatic document summarization.
19
The algorithm utilizes the semantic relationship between words in the text. By extracting and calculating co-occurrence information, it can automatically extract keywords, key phrases, and key sentences from the text. Using this method, not only can the core information of the text be extracted quickly and accurately, but the automatic text summarization method can also greatly enhance the readability and comprehension of the text. Still taking the “Positive” class data under the label “emotion” as an example, the comment data of this category is concatenated into a large paragraph separated by commas. The keywords are then extracted using the TextRank algorithm, and the word cloud map is generated by counting the frequency of these keywords. This process is illustrated in Figure 6. Word cloud of emotion (Positive).
Conclusion
At the current stage, deep learning has become the dominant technology for processing text analysis tasks. Pre-trained language models can significantly enhance the performance of the model in text analysis. In the field of education, curriculum reviews serve as a crucial avenue for students to provide feedback and also serve as a fundamental basis for teachers to enhance teaching quality and schools to optimize their curricula. By leveraging the combination of Voting and BiLSTM, we are able not only to accurately discern the sentiment orientation (positive, negative or neutral) in reviews but also to thoroughly analyze review content and categorize it into specific topics or categories. This study presents a course review classification model that combines Voting and BiLSTM. This approach leverages the strengths of both models to enhance the model’s ability to express text data. Additionally, SVM is used to filter out ambiguous data for upsampling enhancement, resulting in excellent experimental results. The experimental results show that our proposed improved scheme is superior to the single classification algorithm in terms of accuracy, recall rate and F1 value, and shows high efficiency when dealing with large-scale text data. At the same time, we also introduce the hierarchical clustering algorithm and the TextRank algorithm for category analysis to gain a better understanding of the structure and key information within text data.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the 2020 Philosophy and Social Science Research Project of Education Department of Hubei Province: A Semantic analysis model of course review for online course evaluation and application (Project Number: 20Y190), by Teaching Research Project of Hubei University of Education (X2019011), and by Hubei Provincial Collaborative Innovation Center for Basic Education Information Technology Services NO. OFHUE202308.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.