
Abstract
Existing photoelectric detection systems often suffer from inadequate image feature extraction accuracy and suboptimal performance in multimodal information fusion, particularly under complex and dynamic environmental conditions. To address these challenges, this paper presents a novel photoelectric detection framework based on the self-supervised vision model DINOv2 and a cross-modal Transformer architecture with deformable attention. First, DINOv2 is employed to extract rich, global semantic features from visible and infrared images, generating high-fidelity visual representations at a unified scale without reliance on large annotated datasets. Second, a deformable cross-modal attention mechanism within a Transformer-based fusion network is designed to enable adaptive spatial alignment and deep integration of heterogeneous modalities, effectively capturing long-range dependencies and local structural correspondences. Finally, a self-supervised fine-tuning module based on contrastive learning is introduced to enhance feature consistency across modalities and improve the robustness of the fused representation under environmental variations. Experimental results on benchmark multimodal detection tasks demonstrate that the proposed method achieves a target recognition accuracy ranging from 86.4% to 93.2%, with a maximum performance gain of 7.8% over baseline models. Moreover, the cross-modal alignment error is reduced to within 2.7%, indicating superior fusion precision. The proposed framework significantly enhances both detection accuracy and fusion consistency, offering a promising solution for the development of high-performance, robust photoelectric detection systems in real-world scenarios.
Keywords
Introduction
With the widespread application of intelligent sensing technology in security, remote sensing, military and other fields, optoelectronic detection systems have put forward higher requirements for target recognition and tracking accuracy in complex scenes.1,2 In order to improve the environmental adaptability and target recognition accuracy of the system, multimodal information fusion has become a key direction for the development of photoelectric detection systems in recent years.3,4 By complementing the features of multi-source data such as visible light and infrared images and jointly modeling them, the system’s perception robustness and discrimination ability in uncertain environments can be significantly enhanced.5,6 However, current multimodal fusion systems still have technical bottlenecks such as insufficient feature representation capabilities, poor semantic consistency between modalities, and rough fusion strategies, which require systematic optimization from the perspectives of underlying modeling methods and system structure design.7,8 Therefore, building a new photoelectric detection system with high-precision semantic understanding, multimodal alignment and stable output capabilities has important theoretical significance and engineering value for promoting the development of intelligent sensing technology and achieving high-reliability detection in complex scenarios.9,10
Current photoelectric detection systems still face three key challenges in complex environments, which seriously restrict their application performance in high-precision perception and engineering deployment.11,12 Challenge 1: Existing feature extraction methods based on convolutional neural networks are limited by the receptive field and local convolution structure, making it difficult to capture long-range dependencies and global semantic information in images. Especially in low-contrast, partial occlusion, and strong background interference scenes, it is often impossible to extract discriminative deep semantic features, resulting in a significant decrease in recognition accuracy.13,14 Challenge 2: Traditional multimodal fusion is mostly based on static strategies such as feature splicing and weighted averaging, which do not take into account the semantic offset between modalities, the difference in perceptual granularity and redundant interference information, resulting in blurring and distortion of features after fusion and degradation of discrimination ability.15,16 Challenge 3: Due to the heterogeneity of infrared and visible light in spatial structure, imaging mechanism and signal-to-noise characteristics, inaccurate modality alignment can easily lead to semantic mismatch and reduce the expression effectiveness of the fused features.17,18
To solve the above problems, recent studies have attempted to introduce self-supervised visual Transformer models and contrastive learning mechanisms to enhance multimodal perception capabilities.19,20 For example, self-supervised models such as DINO (Distillation with No labels) and MAE (Masked Autoencoders) have demonstrated superior semantic modeling capabilities on large-scale unlabeled images and have the potential to transfer knowledge to heterogeneous modalities such as infrared/visible light.21,22 At the same time, the Transformer fusion mechanism based on the deformable cross-modal attention structure and modality contrast loss have made progress in some visual tasks. However, current methods generally have the following shortcomings: First, multimodal features lack spatial structural uniformity in the encoding stage, making it difficult to directly align semantic distribution; second, most fusion strategies are static splicing or unified attention paths, which makes it difficult to perform structural adaptive adjustments based on local differences in input features. To this end, this paper introduces DINOv2 combined with a cross-modal Transformer mechanism, supplemented by a contrastive learning optimization strategy, to improve the system’s adaptability and recognition accuracy for multi-source information.
This study aims to develop a high-precision, multimodal fusion framework for photoelectric detection systems capable of operating reliably in complex environments. To this end, we employ the self-supervised vision model DINOv2 (Self-Distillation with No Labels v2) to extract rich, global semantic features from visible and infrared imagery, achieving high-quality, label-free visual representations under diverse conditions. A Transformer-based fusion architecture incorporating a cross-modal attention mechanism is specifically designed to enable deep, adaptive alignment and integration of heterogeneous modalities, effectively capturing both spatial and semantic correspondences. Furthermore, a contrastive learning-based self-supervised optimization module is introduced to enhance the consistency of fused features across modalities and improve the robustness of target recognition under environmental variations. Experimental results demonstrate that the proposed method achieves a target recognition accuracy ranging from 86.4% to 93.2% in multimodal detection tasks, with a modal alignment error reduced to within acceptable limits. These outcomes confirm the framework’s effectiveness in addressing key limitations of existing systems—particularly low fusion accuracy and poor robustness—under challenging operational scenarios. The proposed approach provides a solid foundation for the next generation of intelligent, multimodal photoelectric detection systems.
Construction of optoelectronic detection system optimization model
DINOv2 feature extraction based on spectral adaptation
This paper uses DINOv2 as the basic feature encoder and trains infrared images and visible light images separately under unsupervised conditions to obtain semantic embedding representations with unified dimensions and coordinated distribution.
Parameter configuration.
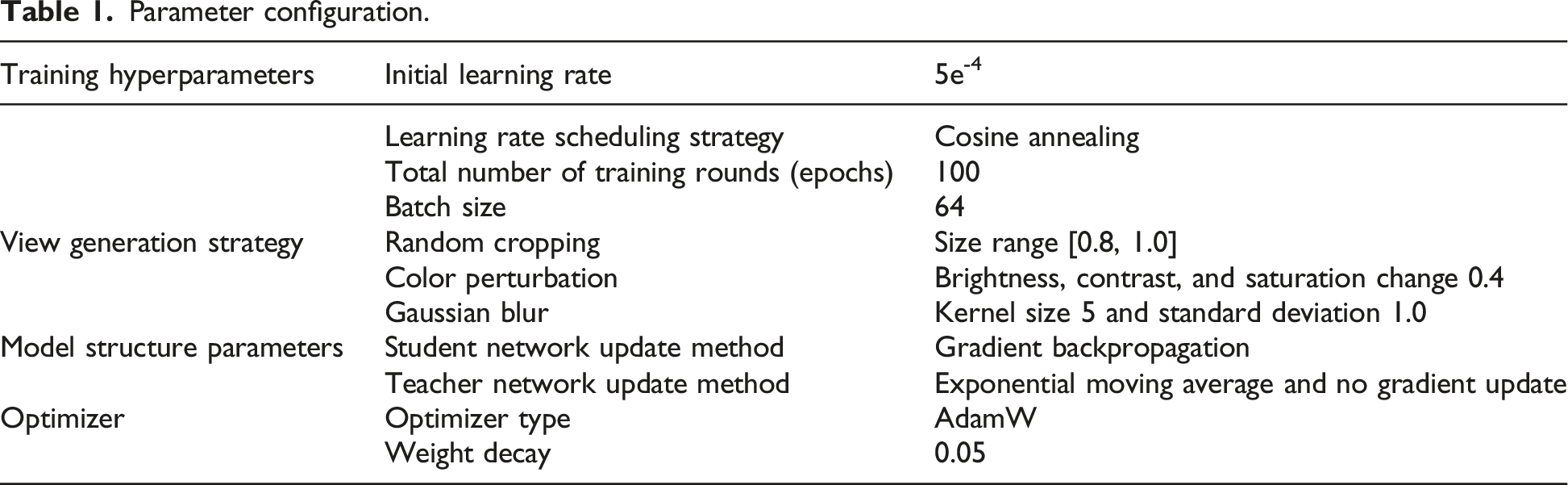
Table 1 covers the key parameter configurations in the DINOv2 training process. The initial learning rate is set to 5e-4, and the Cosine Annealing strategy is used to smoothly decrease. The training is performed for 100 rounds with a batch size of 64 to ensure stable training and moderate efficiency. The view generation strategy enhances input diversity through random cropping, color perturbation, and Gaussian blur, effectively improving the model’s robustness to cross-modal interference such as lighting and texture changes. The student network uses gradient back propagation to update parameters, while the teacher network is updated without gradient through exponential moving average to ensure stability and consistency during training. The optimizer selected AdamW, combined with a weight decay of 0.05, helps prevent overfitting and promotes model generalization. The overall configuration is scientific and reasonable, providing a solid training foundation for the model in multimodal image feature extraction tasks.
In terms of model architecture, DINOv2 uses Vision Transformer (ViT) as the encoding backbone, divides the input image into a patch sequence of fixed size, obtains embedding through linear projection, and then inputs the Transformer backbone for global modeling. This structure models the semantic dependencies between arbitrary regions in an image through a multi-head self-attention mechanism, effectively making up for the weakness of the CNN (Convolutional Neural Network) structure in long-distance modeling. The features extracted by this mechanism retain the boundary information, structural semantics and multi-scale context of the target, which is conducive to information alignment and matching in subsequent modal fusion, as shown in Figure 1. DINOv2 model architecture.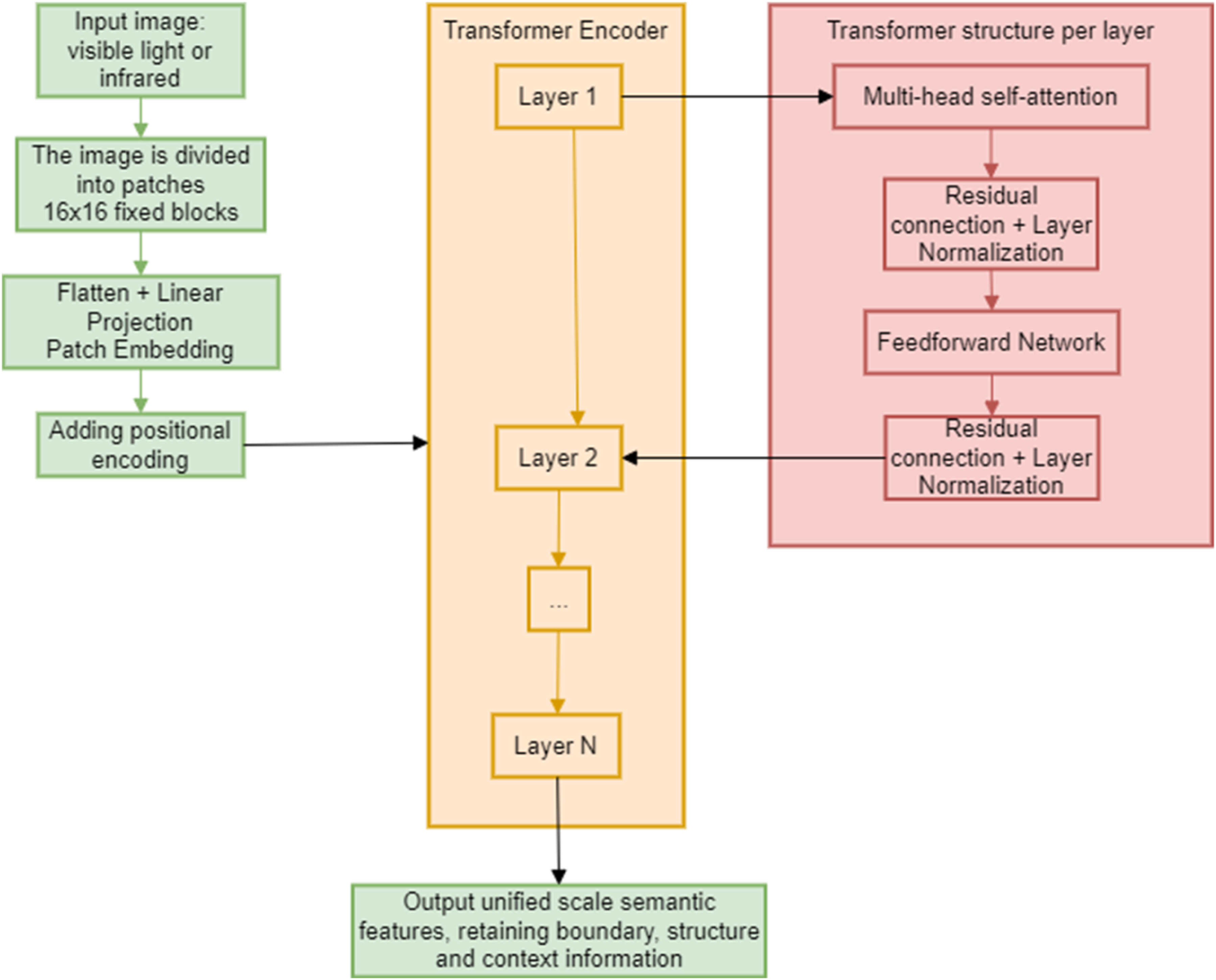
Figure 1 shows the image encoding process based on Vision Transformer in DINOv2. The input includes visible light or infrared images, which serve as the original data source of the system. The input image is divided into multiple non-overlapping image blocks of fixed size (6 × 16 pixels), and the two-dimensional image is converted into a series of one-dimensional Patch sequences for easy processing by Transformer. Each patch is flattened into a one-dimensional vector and mapped to a unified high-dimensional feature space through a linear transformation layer to generate an embedded representation of the patch. The Transformer model captures the spatial position information between patches and adds the corresponding position information encoding to each patch embedding vector to make up for the defect that the Transformer structure itself does not have position information.
During the training process, in order to ensure that the infrared and visible light images have a good alignment basis in the feature space, this paper introduces an additional inter-modal structural consistency constraint term in addition to the regularized objective function of DINOv2. Specifically, the structure-preserving loss is used to constrain the cosine similarity of the features extracted from images of different modalities but the same scene, so that they are close in the embedding space, thereby alleviating the semantic shift problem caused by the difference in modal distribution. The loss is defined as follows:
In addition, DINOv2 itself has the ability to cluster features, that is, the model aggregates the features of semantically consistent areas through self-supervision, effectively improving the semantic consistency under unlabeled conditions. Combined with multimodal input, the infrared image and the visible light image are trained to activate the attention maps of the same area in the Transformer backbone, thereby aligning the structural information and providing high-semantic correlation features for downstream modal fusion.
Finally, each input image is mapped into a semantic embedding vector of uniform dimension (768 dimensions) as the input basis of the multimodal Transformer module. In order to further improve the semantic density and robustness of features extracted from images of different modalities, this paper performs feature normalization after pre-training, and maps all modal features into a unified fusion space through a linear projection layer, thereby constructing a feature base representation with high fusibility and cross-modal consistency.
Deformable cross-modal transformer fusion
In order to achieve high-precision feature fusion and alignment between infrared and visible light modalities, this paper designs and implements a multi-layer Transformer fusion structure based on a deformable cross-modal attention mechanism to complete deep interaction modeling and semantic alignment between modalities. In this module, the infrared image features
Second, a two-stream cross-attention Transformer structure is constructed, where each layer consists of two independent deformable cross-modal attention modules and a shared Feedforward module. The deformable cross-modal attention module uses visible light as the query and infrared as the key and value to achieve information interaction between modalities. The specific expression is: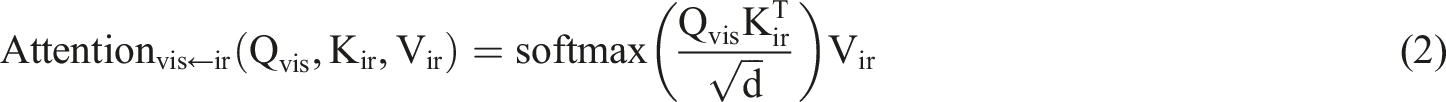
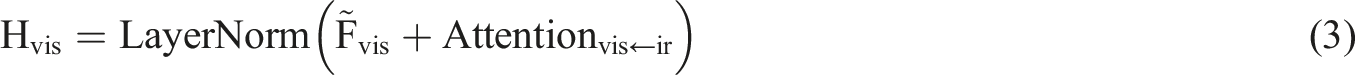
This structure switches the modality direction in the next layer (i.e., infrared is used as the query) to ensure bidirectional semantic alignment. After stacking 

In addition, in order to improve the accuracy of local area alignment, this paper embeds a local fine-grained matching module in each layer of Transformer. This module takes each patch as the center, constructs the corresponding neighborhood matching graph using the cosine similarity between modalities, and performs local weighted fusion operations on the features in the matching area. The graph matching strategy is used to adaptively align the misaligned regions between modalities at the patch level to optimize the consistent representation of the final features.
During the training process, the modal balance loss function is introduced to constrain the distribution difference of the two modal contributions in the fusion feature, which is defined as:
This loss is used to guide the network to automatically balance the information proportion of different modalities in the fusion process, prevent a specific modality from dominating the attention mechanism for a long time, and improve the expression integrity of multimodal features. Finally, the fusion structure output
Noise-aware contrastive learning optimization
In order to further improve the robustness and consistency of cross-modal fusion features, this paper introduces a self-supervised modality consistency contrastive learning optimization module based on DINOv2 feature extraction and deformable cross-modal attention fusion structure. By constructing positive and negative sample pairs and defining a consistency contrast loss function, the fused features are guided to maintain the convergence of inter-modal representations in the semantic space, thereby alleviating the semantic shift and fusion ambiguity problems between heterogeneous modalities.
In the feature construction stage, the visible light image and infrared image obtained in the same scene are assumed to be 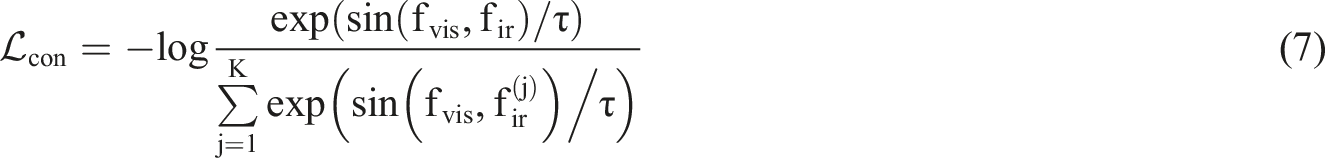
In order to ensure the consistency of local areas instead of relying solely on global feature matching, this paper further divides the fused feature 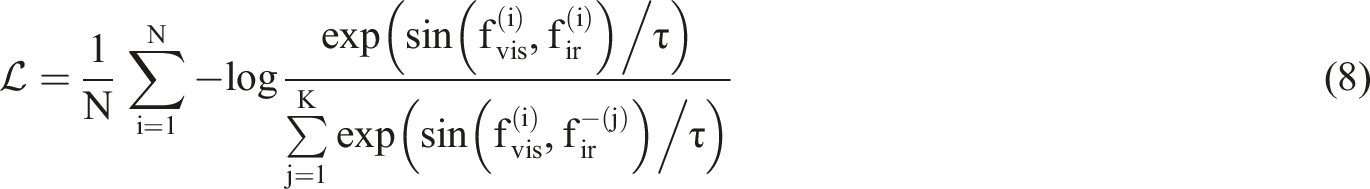
This loss term strengthens the consistency of semantic responses of local regions in different modalities, effectively improving the detail alignment accuracy and target distinction ability after modal fusion.
In the actual training process, in order to improve the stability of feature contrast learning, the momentum encoder mechanism is used to build a contrast sample library. That is, a replica network with slow parameter updates is constructed for the DINOv2 feature encoder, and its parameter 
At the same time, the contrast feature normalization process is introduced. Each feature vector is first normalized by LayerNorm and then L2 normalized to map it to the unit sphere to enhance the separability of different modal features in the angular space and improve the distinguishing ability of cosine similarity:
In addition, in order to reduce the impact of pseudo-negative samples, this paper introduces the Hard Negative Mining strategy, which dynamically updates the negative sample selection set based on the feature similarity generated in the initial training stage, retaining only sample pairs whose similarity with positive samples is lower than a certain threshold to enter the loss calculation, excluding modality mismatch samples and improving the purity of contrastive learning.
Finally, the total loss is composed of a weighted combination of the global contrast loss 
Implementation of software-hardware collaborative system
In order to achieve accurate perception, deep fusion and efficient recognition of multimodal images in complex scenes, this paper deeply integrates the DINOv2 feature extraction module, the cross-modal Transformer fusion structure and the modality consistency comparison learning optimization module to build an end-to-end integrated photoelectric detection system framework.23,24 The system is based on the main process structure of “input-perception-fusion-discrimination.” Through modular deployment and unified training strategies, it solves the problems of information fragmentation, unstable fusion and weak feature representation in traditional systems.
Computing resource allocation.
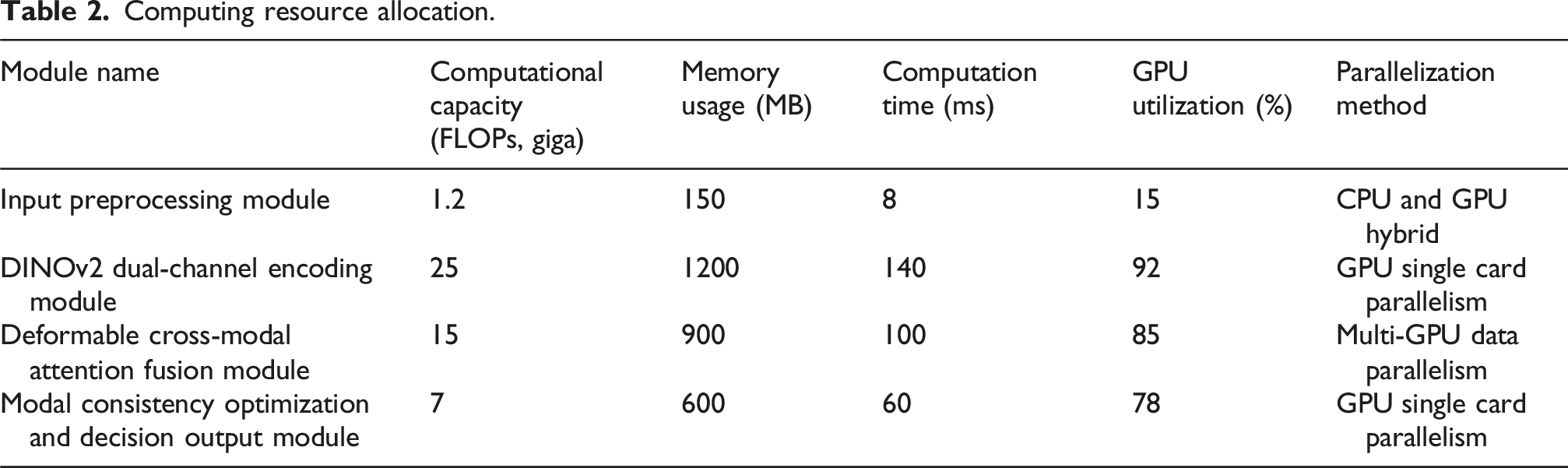
Table 2 shows the distribution of data processing and computing resources of each core module in the photoelectric detection system. The input preprocessing module has a low computational workload, small memory requirements and computational time. It is mainly responsible for data format conversion and preliminary screening, and adopts a hybrid computing method of CPU (Central Processing Unit) and GPU to ensure high efficiency. The DINOv2 dual-channel encoding module, as the backbone of feature extraction, has the largest amount of computation, the most intensive memory usage, the longest running time, and a GPU utilization rate of 92%, indicating that this module is the computational bottleneck of the system and that efficient processing can be achieved by using a single GPU card in parallel. The cross-modal Transformer fusion module is at a medium level in terms of computation and memory consumption, and uses multi-GPU data parallelism to further accelerate the deep interaction and alignment process. The modality consistency optimization and decision output module has relatively low computational resource requirements, but still maintains a high GPU utilization rate, and is responsible for feature consistency reinforcement and final judgment.
In the input stage, the system receives visible light image
After the fusion feature output, it enters the modality consistency contrast learning module. The module uses the constructed contrast loss function to constrain the consistency of the fusion features of
In order to realize the photoelectric detection output at the system task level, this paper introduces a task head based on Transformer Decoder at the end of the fusion module.27,28 The task head contains two sub-modules: one is the classification branch based on Class Token, which outputs the target category confidence; the other is the spatial prediction branch based on position encoding, which generates the center coordinates and bounding box parameters of the target. The multi-task joint loss 
Figure 2 shows the change in learning rate and the decrease in training loss during model training. The left vertical axis is the learning rate. The Cosine Annealing strategy is used to make the learning rate gradually decrease smoothly from the initial value along the cosine curve, which helps the stable convergence of training. The vertical axis on the right is the training loss, and the reverse axis shows that the loss gradually decreases from about 1 to about 0.05, reflecting that the error of the model parameters gradually decreases after multiple rounds of iterative optimization, and the training effect continues to improve. With the reasonable scheduling of the learning rate, the model training process is smooth and effective, and finally reaches a lower loss level, which verifies the effectiveness of the training strategy and the convergence of the model. Training evaluation.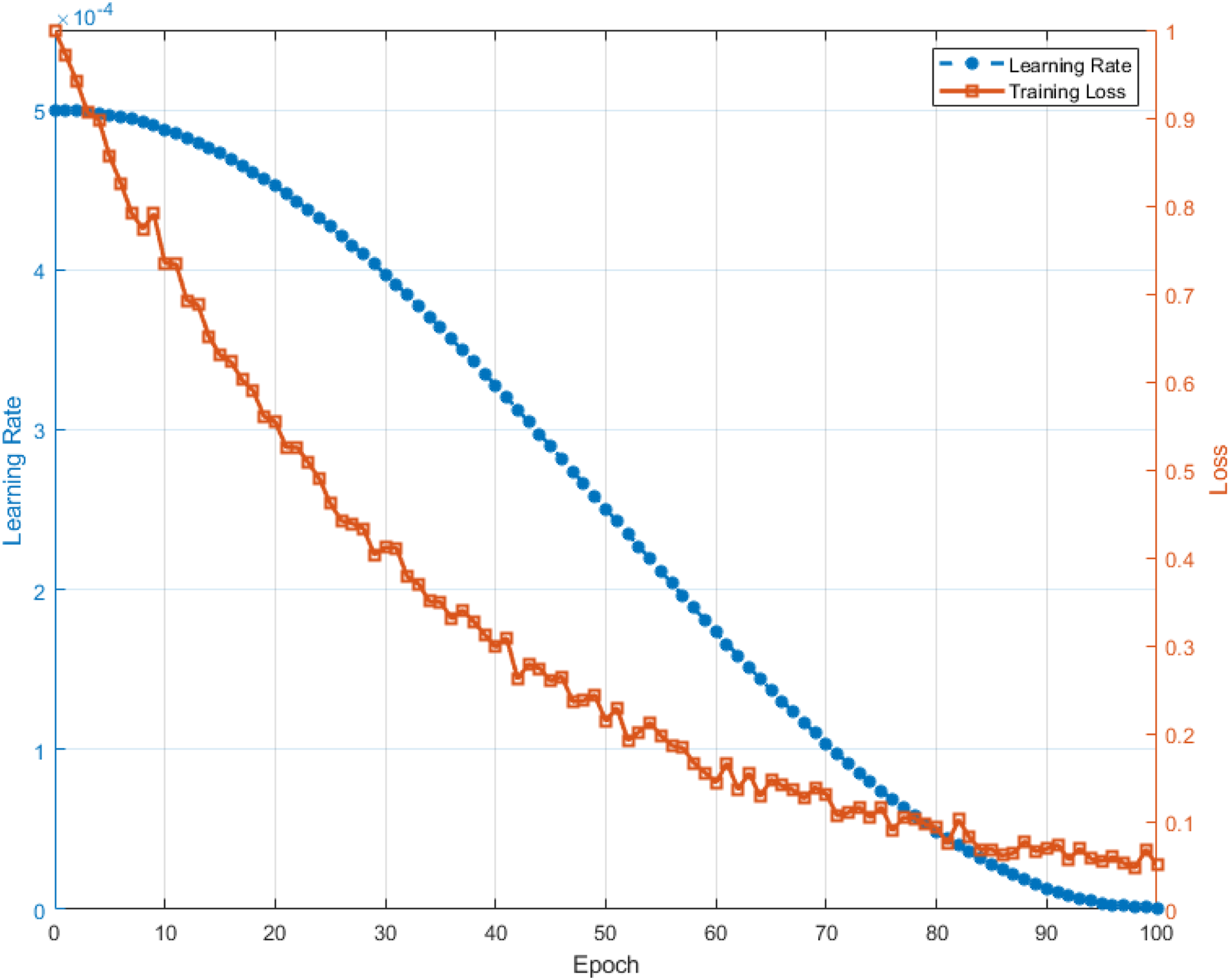
Evaluation
Accuracy of multimodal target recognition
This paper constructs a multimodal image dataset that contains visible light images and infrared images, covering five typical environmental scenes: sunny, cloudy, rainy, foggy, and night. The image sizes are aligned and the pixel values are normalized. The training set and test set are constructed separately to ensure balanced distribution of scenes and annotate target categories as supervisory signals for the classification task. The comparison methods are set as: Method 1: Traditional CNN baseline model, Method 2: ResNet50 (ImageNet pre-training + fine-tune), Method 3: DINOv2 (self-supervised pre-trained Vision Transformer), Method 4: DINOv2 + Deformable Cross-modal Attention Transformer (this method). The evaluation indicator is the multimodal object recognition accuracy. The definition is the number of samples correctly classified by the model in each scene/the total number of test samples. The evaluation method is to independently evaluate the target recognition accuracy in the test sets of five scenes under each method. All methods keep the same data partitioning and experimental parameters to ensure fair comparison. Each group of experiments is repeated 3 times and the average value is taken as the final result.
Figure 3 shows the target recognition accuracy of different multimodal fusion methods in various typical environmental scenarios. The horizontal axis in the figure represents five common photoelectric detection scenarios (sunny, cloudy, rainy, foggy, and night). Regardless of the scenario, DINOv2 + Transformer always has the highest recognition accuracy, stabilizing in the range of 86.4% to 93.2%, demonstrating superior cross-modal modeling capabilities and robustness. As the complexity of the environment increases (such as foggy days and nighttime), the accuracy of all methods decreases, indicating that this method is more stable under complex conditions. The accuracy of traditional CNN methods is generally low, only 68.3% at night, and performs poorly for weak texture and low-contrast targets. ResNet50 is slightly higher than CNN in all scenarios. DINOv2 shows good semantic modeling capabilities. DINOv2 + Transformer comprehensively utilizes global semantic features and cross-modal alignment strategies to achieve optimal results in all scenarios. DINOv2 + Transformer has the smallest accuracy fluctuation range (maximum 93.2%, minimum 86.4%, and fluctuation of only 6.8%), which reflects its ability to maintain high recognition performance in various complex environments. In contrast, the recognition accuracy of the CNN method fluctuates by about 10%, and its stability is poor. Multimodal target recognition accuracy.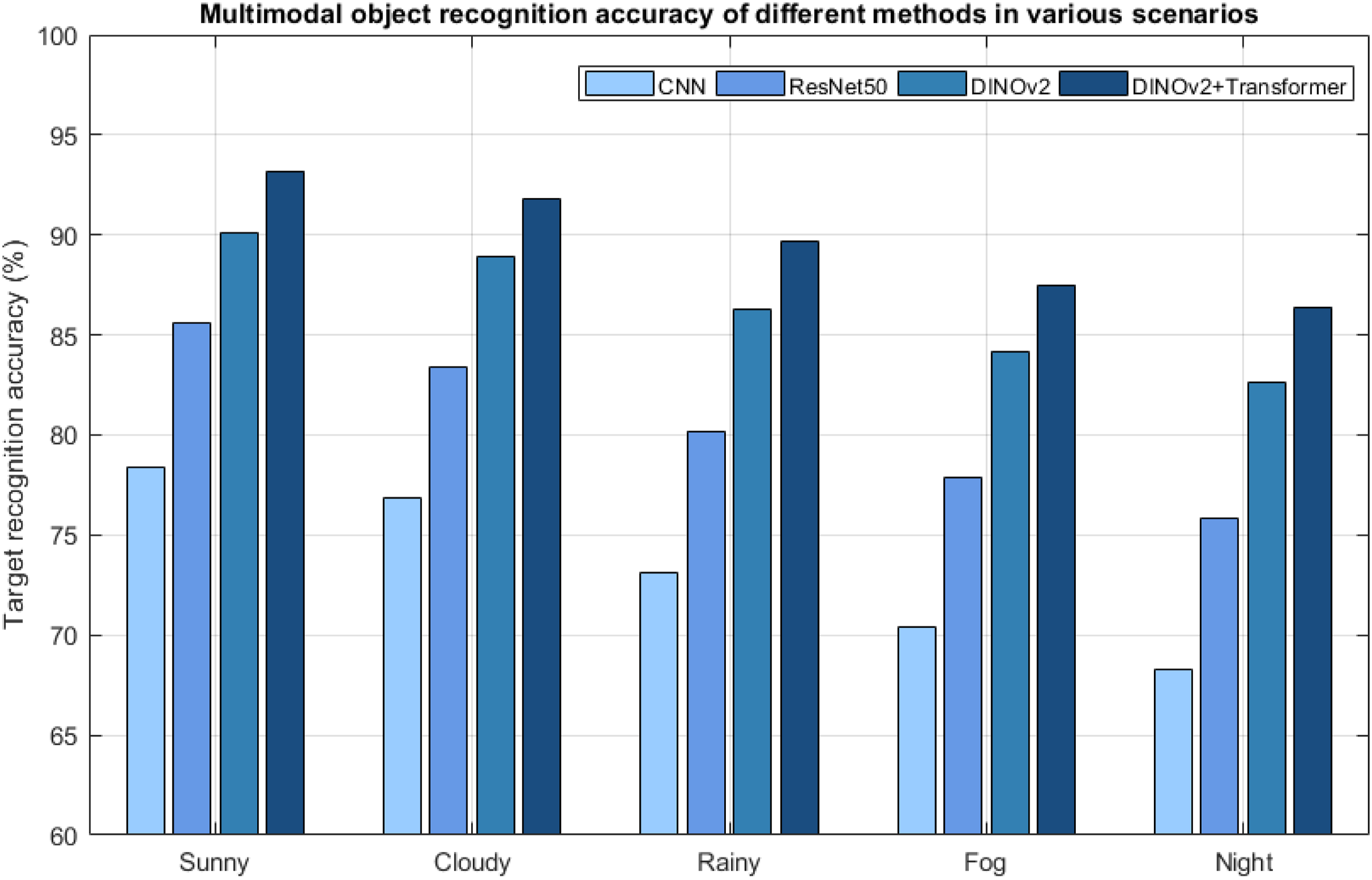
Average modal alignment error
This paper collects multimodal data including visible light and infrared image pairing, covering five typical environmental scenes: sunny, cloudy, rainy, foggy, and night. Four methods are used to process the data: traditional CNN model, ResNet50 model, DINOv2 self-supervised visual Transformer, and the DINOv2 and deformable cross-modal attention Transformer fusion architecture proposed in this paper. For each method, model training or feature learning is completed on the training set. For each pair of multimodal images in the test set, the fused feature representation is extracted. The spatial or semantic distance difference between different modal features is calculated to obtain the modal alignment error. The errors of all test samples in each scene are averaged to obtain the average modal alignment error of the method in that scene.
Figure 4 shows the modal alignment error performance of different algorithm methods in five typical environmental scenarios. The horizontal axis is the four algorithm methods, namely CNN, ResNet50, DINOv2 and the DINOv2 + Transformer fusion structure proposed in this paper. The vertical axis is the five photoelectric detection scenarios of sunny, cloudy, rainy, foggy and night. The method in this paper (DINOv2 + Transformer) achieves the lowest modal alignment error in all scenarios, with the best fusion effect, and the modal alignment error is reduced to no more than 2.7%. In contrast, the traditional CNN and ResNet50 methods generally have higher errors and darker colors, showing poor cross-modal alignment capabilities. When DINOv2 is used alone, the error is reduced, but it is still not as stable and significantly improved as after fusion with Transformer. The errors of all methods increase with the complexity of the scene (such as foggy days and nighttime), reflecting that complex environments pose higher challenges to modal alignment. The proposed method still maintains a low error in such complex scenes, indicating that its fusion strategy has strong robustness and adaptability. Modal alignment error.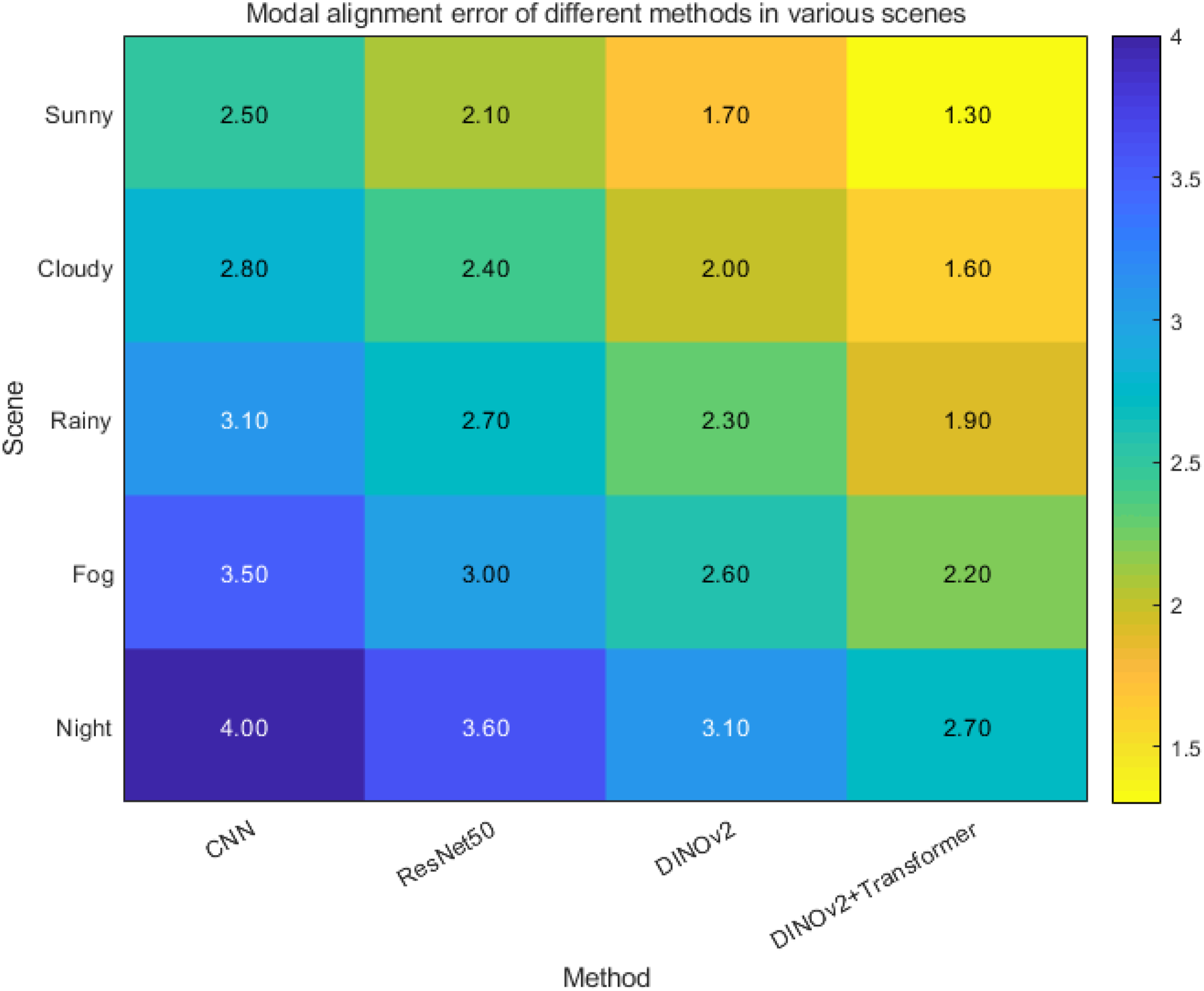
Feature consistency
This paper collects and preprocesses multimodal photoelectric detection data, including visible light and infrared images, to ensure data alignment and complete annotation. The DINOv2 model is used to perform self-supervised training on visible light and infrared images to extract high-semantic feature representations of unified dimensions. The extracted multimodal features are input into a multi-layer deformable cross-modal attention Transformer to achieve cross-modal deep interaction encoding and spatial semantic alignment to generate fused features. Positive and negative sample pairs are constructed, with positive samples being homologous image pairs and negative samples being heterologous image pairs. Based on the designed contrast loss function, the fusion features are self-supervised and trained to strengthen the consistency of features between modalities. The distance distribution of positive and negative sample pairs in the feature space after contrastive learning is calculated as the basis for feature consistency evaluation. The kernel density estimation method is used to draw the probability density curve of the feature distance between positive and negative samples, which intuitively reflects the distribution difference between positive and negative samples. The feature consistency score is calculated based on the distance distribution, and the score values of different methods are compared to evaluate the modal consistency optimization effect of each method.
The left figure of Figure 5 reflects the feature distance distribution of positive sample pairs and negative sample pairs. The blue solid line represents the feature distance of homologous image pairs, which is concentrated and small, indicating that after optimization, the feature representation of the same target in different modalities is highly consistent. The red dotted line represents the feature distance of heterogeneous image pairs, which is relatively scattered and large, indicating that the features of different targets or modalities are obviously different. The obvious separation of the two distributions verifies that the designed contrastive learning loss effectively improves the feature consistency between modalities. The figure on the right shows the feature consistency scores of various methods. This method achieved the highest score of 0.94, which is significantly better than the traditional CNN and ResNet50 baseline models, indicating that the framework combining DINOv2 with multimodal fusion and contrastive learning optimization has stronger capabilities in feature consistency modeling. Feature consistency.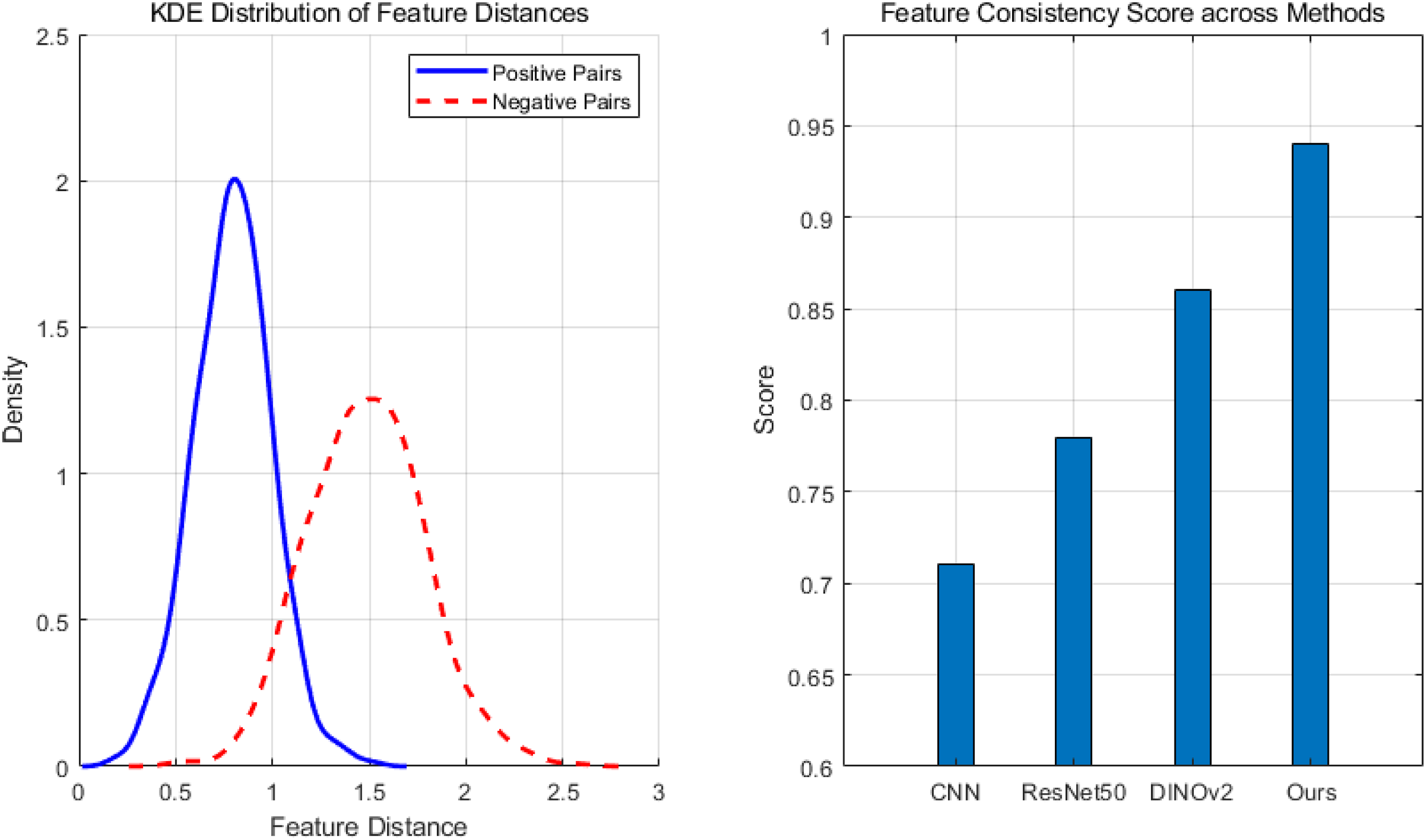
Robustness evaluation
This paper designs three types of diverse input change scenarios, including light intensity, weather conditions, and noise levels. Each type of scenario is subdivided into multiple levels to simulate the diverse conditions in actual complex environments. This paper collects multimodal photoelectric image datasets covering the above-mentioned levels of environment, ensures sample balance and performs necessary preprocessing, including image normalization and alignment. The trained photoelectric detection system based on DINOv2 and cross-modal Transformer fusion is independently operated in each environmental scenario, and the system performs feature extraction, fusion and target recognition on the input image. The tests in each scenario are repeated multiple times, and the consistency of the system’s output results in multiple tests is statistically analyzed to calculate the system output stability rate, that is, the proportion of system output that does not fluctuate significantly in the same scenario.
The model stability index (System Stability Rate) indicates the consistency and robustness of the output results of the photoelectric detection system under a given environment or changes in input conditions. The specific calculation method is: the number of times the system output results remain unchanged or fluctuate very little within the preset tolerance range in multiple repeated tests/total number of tests.
Figure 6 shows the stability of the photoelectric detection system under three different environmental change conditions: light intensity, weather conditions, and noise level. From the lighting condition sub-figure, it can see that the system has the highest stability rate (about 0.90) in medium lighting (medium), and the stability decreases in extreme lighting environments (very low and extreme), indicating that lighting changes have a certain impact on the robustness of the system, but overall it maintains a high stability. The weather condition sub-figure shows that the system stability rate is relatively high (over 0.89) in clear and cloudy environments. As the weather deteriorates (such as rain, fog, and storms), the stability rate gradually decreases, indicating that the system’s adaptability to severe weather has weakened. The noise level sub-figure reflects the system’s response to different noise intensities. The stability rate gradually decreases from the highest point of 0.95 in the noise-free environment to 0.75 in the extreme noise environment, indicating that noise interference has a significant impact on system performance, but the system still maintains good stability in a wider noise range. Robustness evaluation.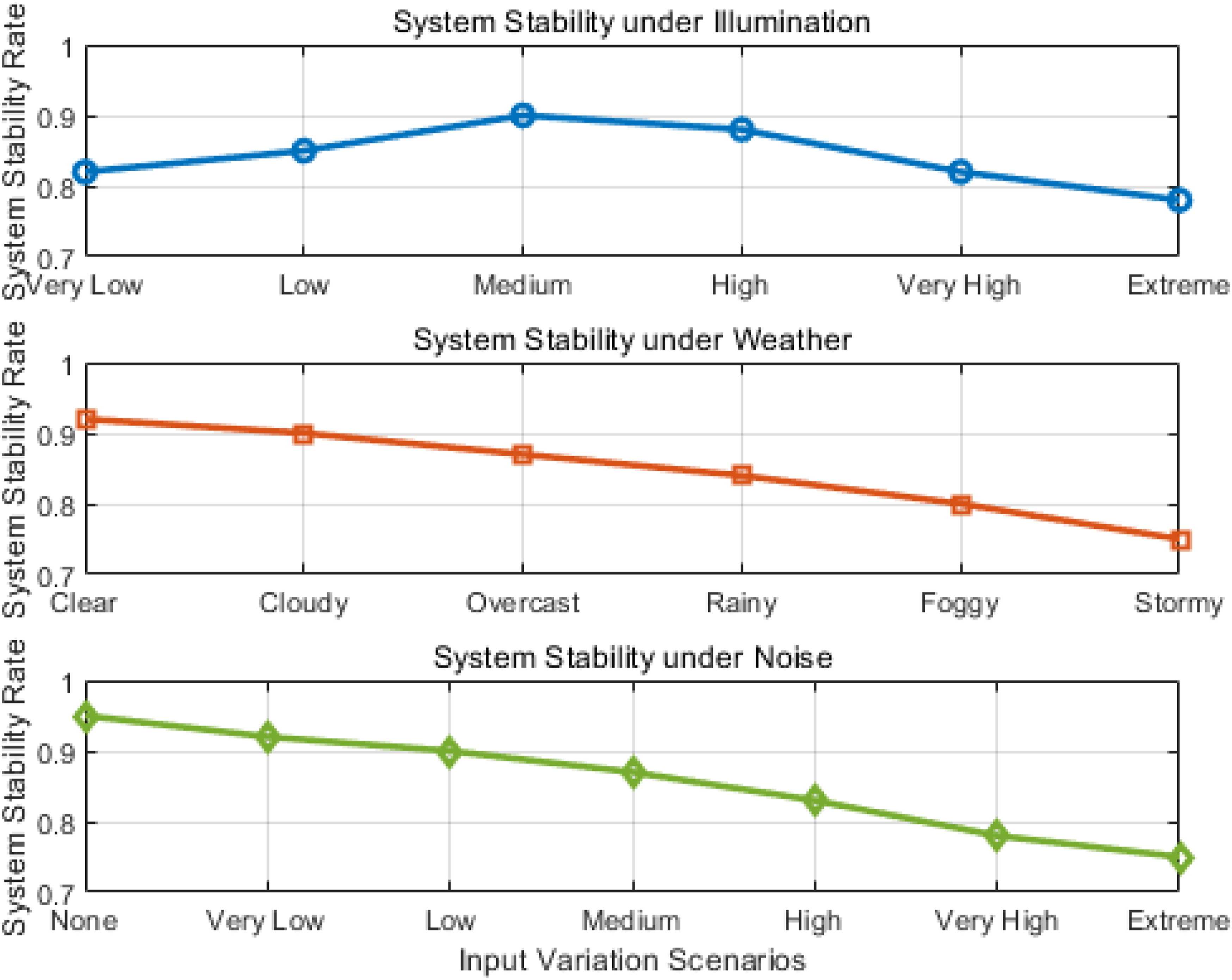
Inference latency
This paper collects multimodal photoelectric detection data sets, including visible light and infrared images, to ensure data diversity and representativeness, and deploys four target recognition models (CNN, ResNet50, DINOv2, and DINOv2 + Transformer) on the NVIDIA Jetson AGX Orin platform to ensure consistency in hardware configuration and system status. This paper performs multiple inferences on each model on a fixed test set, records the time delay from image input to result output each time, collects all inference delay data, and calculates the distribution of inference delay of each model, including median, quartiles, and outliers.
Figure 7 shows the performance distribution of the four methods in terms of inference latency. The DINOv2 + Transformer method has the lowest median inference latency of about 35 milliseconds, which is significantly better than the other three methods, indicating that its overall inference speed is the fastest. The traditional CNN model has the highest inference latency, while ResNet50 is slightly better. DINOv2 uses a self-supervised visual Transformer structure to significantly improve efficiency. This paper combines the DINOv2 model with the Transformer structure to achieve the lowest inference latency, meeting the strict real-time requirements of the photoelectric detection system. Delay distribution.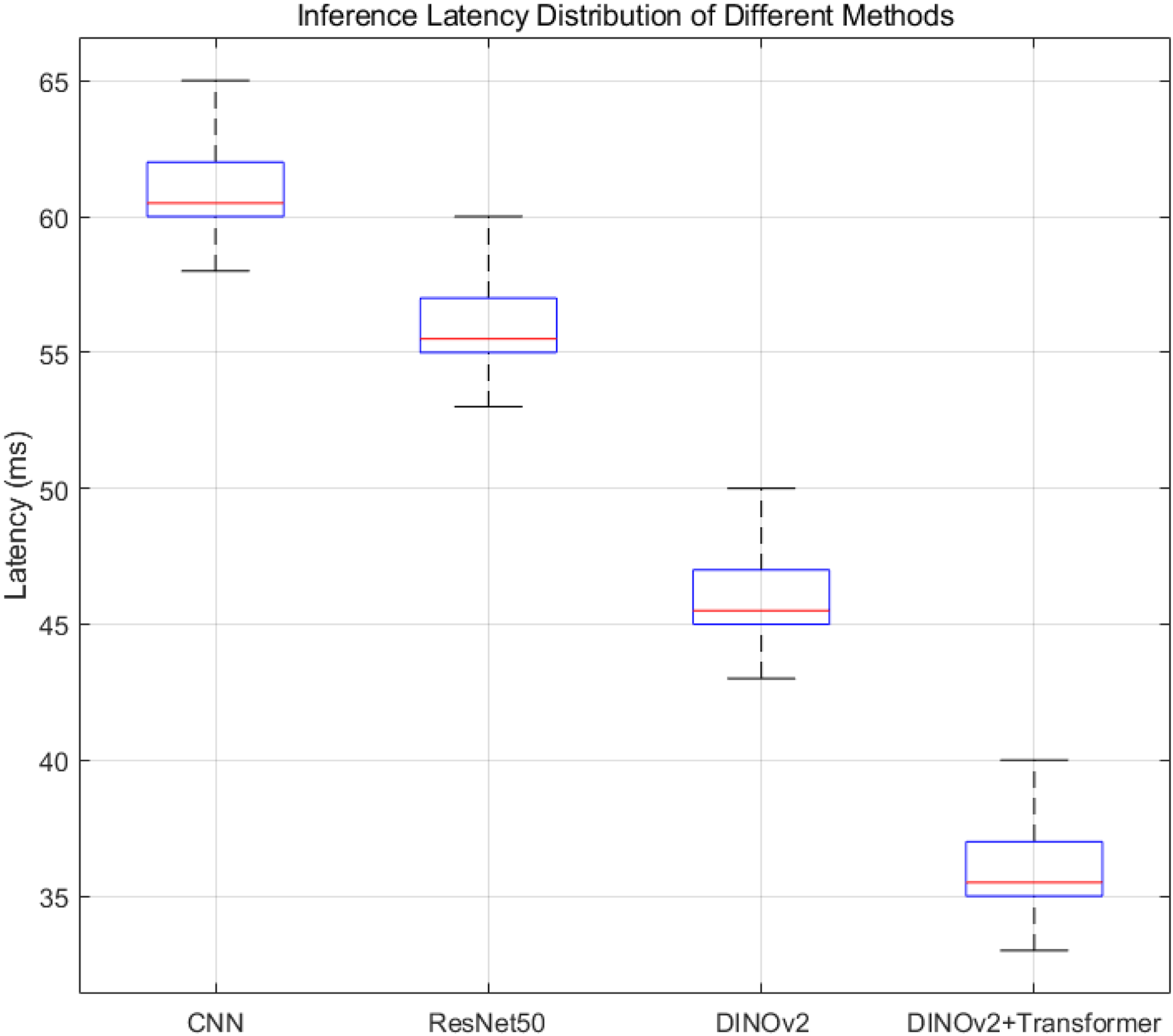
Conclusion
This paper addresses the critical challenges of limited perception accuracy and unstable multimodal fusion in photoelectric detection systems operating under complex environmental conditions. To overcome these limitations, we propose an end-to-end optimization framework that integrates DINOv2-based self-supervised semantic feature extraction with a cross-modal Transformer fusion architecture. Specifically, DINOv2 is employed to extract high-level semantic features from visible and infrared modalities at a unified spatial scale, enabling robust representation learning without reliance on extensive labeled data. A multi-layer deformable cross-modal attention mechanism is then introduced to achieve fine-grained spatial alignment and deep semantic fusion across modalities. Furthermore, a modality consistency-aware contrastive learning strategy is incorporated to enhance the coherence and robustness of the fused feature space. The integrated framework effectively constructs a high-precision, high-stability multimodal photoelectric detection system. Experimental results demonstrate that the proposed method outperforms state-of-the-art approaches in both multimodal recognition accuracy and cross-modal alignment error. Nevertheless, limitations remain in real-time processing efficiency and generalization to large-scale, diverse datasets. Future work will focus on developing lightweight network architectures and adaptive modality selection mechanisms to improve computational efficiency and scalability, thereby enhancing the system’s practicality for deployment in real-world, resource-constrained scenarios.
Footnotes
Author contributions
All authors contributed to the study conception and design. Material preparation and data analysis were performed by Hong Xiao, Kexuan Wang, and Han Deng. The first draft of the manuscript was written by Hong Xiao、Zijian Gao, and Shangbing Huang. All authors read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The authors confirm that the data supporting the findings of this study are available within the article.