
Abstract
American literature has long served as a mirror, reflecting the diverse cultural, social, and political landscapes of the United States. This research investigates the representation of social groups in American literature by employing advanced natural language processing techniques. Specifically, it utilizes contextualized word embedding models to analyze how characters from diverse social identities, particularly in terms of gender, race, and class, are portrayed across a curated corpus of canonical and contemporary American literary texts. The dataset is compiled and preprocessed through tokenization and normalization to prepare the texts for contextual embedding extraction and bias analysis. Bias detection is conducted using a Bidirectional Encoder Representations mutated Weighted Support Vector Machine (BERWSVM) model designed to classify complex social representations. The Contextualized Embedding Association Test (CEAT) isemployed to statistically evaluate the strength of association between social groups and character traits by computing cosine distances between contextual embeddings. Bidirectional Encoder Representations from Transformers (BERT) are used to extract rich semantic representations from the texts, capturing character descriptions, group identity references, and associated traits. The WSVM component classified intersectional group embeddings, enabling the assessment of representational patterns that extend beyond single-identity categorizations. Implemented in Python, the findings show that the BERWSVM approach performs better than multimodal baseline architectures, achieving superior results, with accuracy, F1-score, recall, and precision ranging from 90% to 95%. The findings reveal that the BERWSVM achieved high accuracy in distinguishing characters belonging to intersectional groups, significantly outperforming traditional baseline models. It shows the effectiveness of integrating computational bias detection algorithms with literary interpretation in analyzing social ideologies, representation, diversity, and fairness in narrative structures.
Keywords
Introduction
American literature has been historically considered an essential source of cultural knowledge in the field of social, political, and ideological lives of the United States. 1 Literacy provides both implicit and explicit messages about how society views, marginalizes, and exalts them. 2 Innovative computational applications, like natural language processing (NLP), contextualized embedding systems, and bias analysis algorithms, can systematically decode the patterns of representation and underlying ideological biases of literary collections. 3 The development of NLP has been examined in the literature on a large scale. Models based on contextualized embedding have changed the capability of capturing contextualized meanings in the text by contextual relationships of words, phrases, and sentences. These models form word representations dynamically based on the context of other words, in contrast to the other methods, which produced fixed representations of words. It helps to detect semantics change, undertones, and cultural implications in literary texts. 4 When used in large-scale literary collections, these models can be used to investigate how different social groups were linguistically constructed through the patterns of adjectives, narrative roles or intergroup relations. 5 Trade-offs between fairness and the risk of over-correcting and removing legitimate group differences, and the infeasibility of universal rules of fairness due to varying cultures and contexts. 6
Educational curricula were developed by cultural legacies inherent in literary exposition. The systematic identification of stereotypical portrayals, disproportional representation, or exclusionary tendencies might be achieved by bias detection algorithms. 7 The social group representation was computationally decoded for both academic and socio-cultural significance. The literature was usually perceived for its performative nature in the formation of views and society. 8 Literary works on many levels, such as symbolic, narrative, stylistic, and cultural, it reveal patterns over vast scales but cannot match the imagination of the human or hermetic reading. 9 The bias detection algorithm and contextualized embeddings have significant implications for digital humanities. It enables literacy by being exclusive, rigorous, and socially aware through the strengths of the humanities, for recognizing large-scale pattern recognition in literacy texts. 10 The computational interpretation rectifies the literary representation to measure the theoretical concept of narrative art. The social group representation in contextualized embeddings links the wider theoretical debate on ideology, and discursive configurations. 11 Embeddings were systematically related to specific ethnic groups, poverty, and the risk of stereotypes and discrimination when applied in the route of automated decision-making. 12 Bias detection algorithms can be generalized to detect discriminatory associations within embedding spaces by inspecting word analogy, and computing the causal inference of word embeddings. This task becomes more complicated when dealing with contextualized embeddings because the meaning of a given word changes between sentences. Contextualized embedding identifies the position group in a sentence with varied control that quantifies how it was interpreted to expose the stereotypes. 13 Literature might provide intricate, context-dependent depictions of social groups that were challenging to understand, which could result in incorrect classification.
The objective of this research is to create a revolutionary Bidirectional Encoder Representations mutated Weighted Support Vector Machine (BERWSVM) approach to enhance the underlying patterns of bias, diversity and fairness of contemporary literacy texts. The suggested approach is used to enhance hidden patterns of representations and to classify complex social representations. The key contributions of this research are as follows. • Dataset Collection: A literary social representation dataset was collected from Kaggle. It includes 1800 rows, which describe a literary character along with attributes, gender, race, and class. • Data Pre-Processing: The data was preprocessed by using normalization and tokenization to get the texts ready for bias analysis and contextual embedding extraction. • Optimized Classification Model: The BERWSVM model provides intersectional social groups with an intelligent categorization and bias detection module for literacy text representations. • Real-Time Results: The simulation results evaluate the precision, accuracy, recall, and F1-score for classifying complex social representations in literacy. The degree of correlation between character qualities and social groupings was statistically evaluated using CEAT.
Related works
The relevant literature explores social group representation in American literature, focusing on contextualized word embeddings, integrating NLP-based bias detection models, and dynamically analyzing intersectional identities to uncover patterns of diversity, ideology, and fairness in narrative structures.
Word embeddings were utilized in several tasks related to NLP by Machine learning (ML) models. 14 In a multilingual context, the word embeddings were used to examine the prejudices about immigrants and refugees. According to the findings, stereotypes of immigrants and refugees presented in all languages were strongly resonated. In NLP tasks, the transformer-based contextualized language models were presented. 15 The contextualized-based models often use human-generated text for training to assess the social biases of NLP models. To ensure the impact of gender bias on model performance, a bias consequence was applied to the performance ratings of tasks.
Text classification in information retrieval was a difficult task that required efficient methods, particularly when used on low-resource languages. 16 To examine the model’s effectiveness, its performance was evaluated by using a classification model. Biases in the retrieved data have been demonstrated to amplify the word vector embeddings. The Visualization of Embedding Representations for deBiasing (VERB) was used to assess the ethics and fairness of ML systems in NLP for developing decision-making systems based on word embeddings. 17 The outcome demonstrated how a visual learning tool might assist the NLP in comprehending tasks and reducing word embedding biases.
Word-to-word semantic linkages reveal essential details about the texts. To classify texts, a Convolutional Neural Network (CNN) was trained with semantic connection embeddings. 18 Text categorization incorporated semantic connections in word embedding models. The result showed the comparison of current word-based models and the suggested relationship embedding configurations. The BERT-random forest (RF) model used textual input to extract probabilistic features and contextualized embeddings. 19 The contextualized embedding of words was extracted by using the BERT model by transformer architecture. Evaluation trials demonstrated that the BERT-RF approach has obtained a high accuracy score.
The language models have quickly learned to produce text that was similar to human writing in a variety of tasks and domains. For a long time, spoken language has been used to uphold hegemony and authority in society, particularly through concepts of social identity and appropriate language usage. 20 The outcome showed the discrepancies between human and AI authoring traits, which might influence text assessment to enhance alignment. Fluent text was produced by using BERT-based language models, which effectively modify a variety of NLP applications. 21 The language models pertained to online text corpora that exhibit social bias tendencies and degenerate harmful material. A reinforcement learning-based technique used for reducing toxicity in language models was termed Reinforce-Detoxify. According to the findings, the suggested model performed better than other detoxification techniques toward social identity-generated content.
The objective was to assess the efficiency of pre-trained word embedding models, and investigate an encoding of textual requirements to estimate the analogy. 22 The deep learning (DL) based model was employed to obtain the linear outputs. The experimental outcome demonstrated the potential of using pre-trained incorporation models to predict the word embeddings model. To assess the propagation of unfavorable stereotypes and biased sentences requires the capability to recognize bias in texts by using a contextualized bidirectional dual-transformer (CBDT) system. 23 Context Transformer and Entity Transformer were the two complementary transformer networks combined to enhance the bias detection skills. The outcome demonstrated how well the CBDT models recognize biased phrases.
Social media platforms have made it easier to communicate, share information, and interact with people online. The Bidirectional Gated Recurrent Units and Long Short-Term Memory (BiGRU-LSTM) model was used for enhancing contextual text-based classification. 24 The experimental findings demonstrated that the suggested approach could identify social media-based contextual text classification. Due to the extensive usage of online social media, people might now communicate their ideas, feelings, opinions, and sentiments in the languages of their choice. The BERT model was trained and tuned for multiclass sentiment analysis. 25 The experimental outcome demonstrated how well the suggested method works for sentiment analysis in low-resource languages. Social media communication used linguistic forms that need a sophisticated understanding of tone and context. 26 The Long Short-term Memory with an attention mechanism (LSTM-AM) was a sophisticated NLP technique used to recognize sentiment changes, contextual dependencies, and subtle clues. The experimental outcome demonstrated the complex linguistic subtleties in digital communication.
Current advancements in contextualized embeddings and computational bias detection have greatly enhanced the social representation in literature. Text classification in low-resource languages arises with the problem, which limits the training and generalization of the model. 16 The special linguistic textures and writing mannerisms of these languages usually decrease the quality of native approaches. Biases in the training set endure through word embeddings with unfair characterization. It often struggles to tackle code-switching, informal language, and regional dialects, which were prevalent in low-resource language environments. The performance of the CBDT model largely depends on the quality and variability of training data. Identified a biased language to detect implicit forms of bias that require more context about society and culture. 23 The dual-transformer architecture was inaccurate during real-time scenarios. The CBDT model could be overfit to a particular set of linguistic patterns that cannot be generalized across various domains and languages. The cross-lingual performance was relatively unexplored, which limits its scalability to low-resource languages.
To overcome these issues, the suggested approach, BERWSVM, was used to analyze American literature by intelligently detecting and classifying biased social representations. By leveraging BERT and WSVM, the system improved accuracy in identifying intersectional identities, ensured nuanced interpretation, and supported scalable analysis of diversity, ideology, and fairness across contemporary texts.
Proposed methodology
The previous section reviewed recent studies on social group representation in American literature. The proposed model addresses the research gap by combining contextualized embeddings to accurately detect bias, and classify intersectional identities and patterns across contemporary texts.
A literary social representation dataset was collected from Kaggle. The data was preprocessed by tokenizing and normalizing. The BERWSVM model offers a smart classification and bias detection module to intersectional social groupings for representations of texts in literacy. CEAT is used to statistically assess the degree of relationship between social groupings and character traits. Figure 1 illustrates the overall process of social group representation in American literature. Overall flow of social group representation in American literature.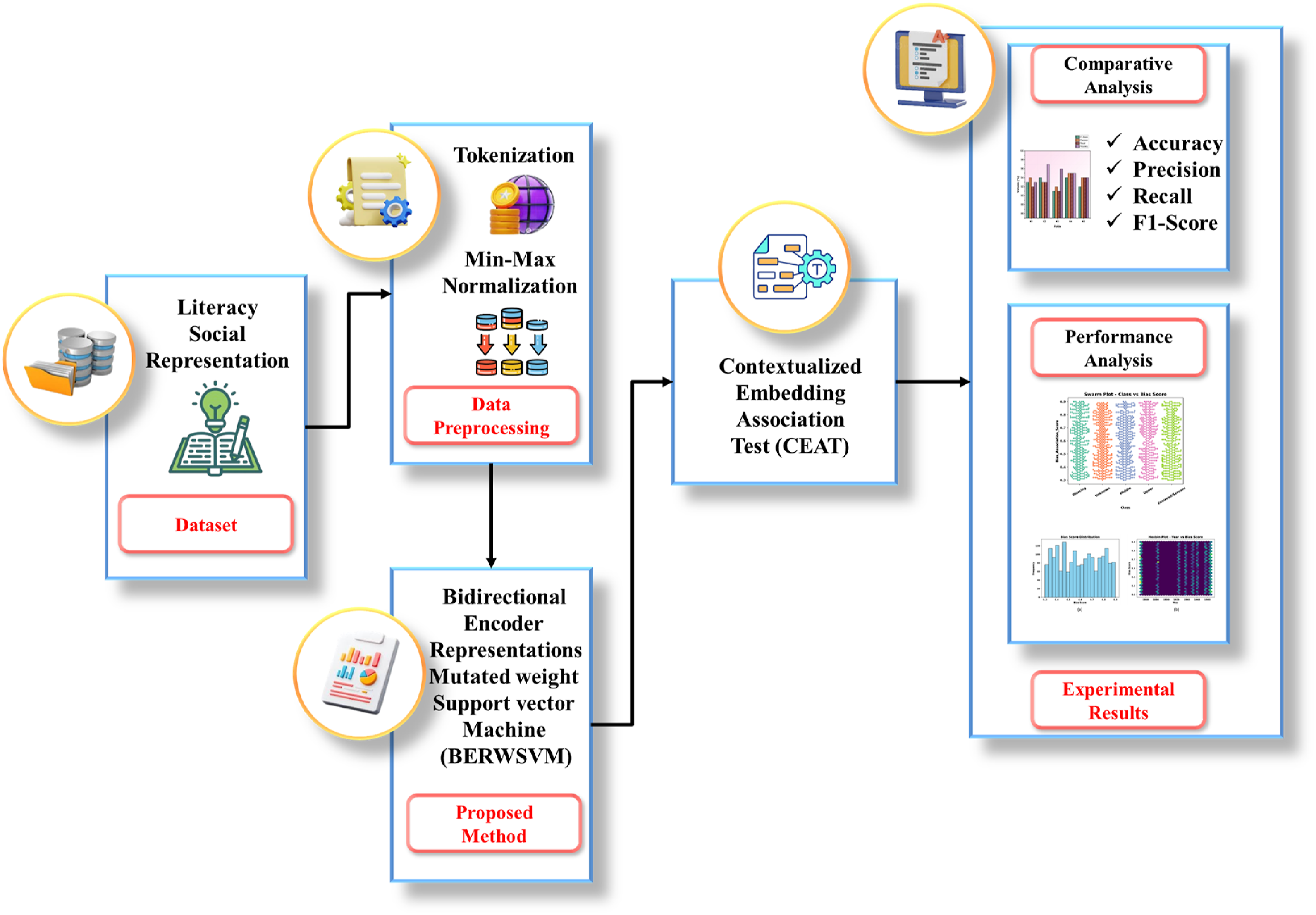
Dataset
A literary social representation dataset was collected from Kaggle. This dataset uses computational techniques to analyze the representation of social groups in American literature. It includes 1800 rows, which describe a literary character along with attributes, gender, race, and class. This dataset contains metadata for each entry, such as the author, genre, year of release, and sometimes the work’s location or historical context. Structured annotations were added to this dataset, which uses textual evidence to categorize social representation. It helps to analyze how different authors approach social commentary through narrative. The distributional and relational insights across bias, time, and classification labels, were depicted in Figure 2. Distributional and relational insights across bias, time, and classification labels. Source: https://www.kaggle.com/datasets/programmer3/literary-social-representation-dataset.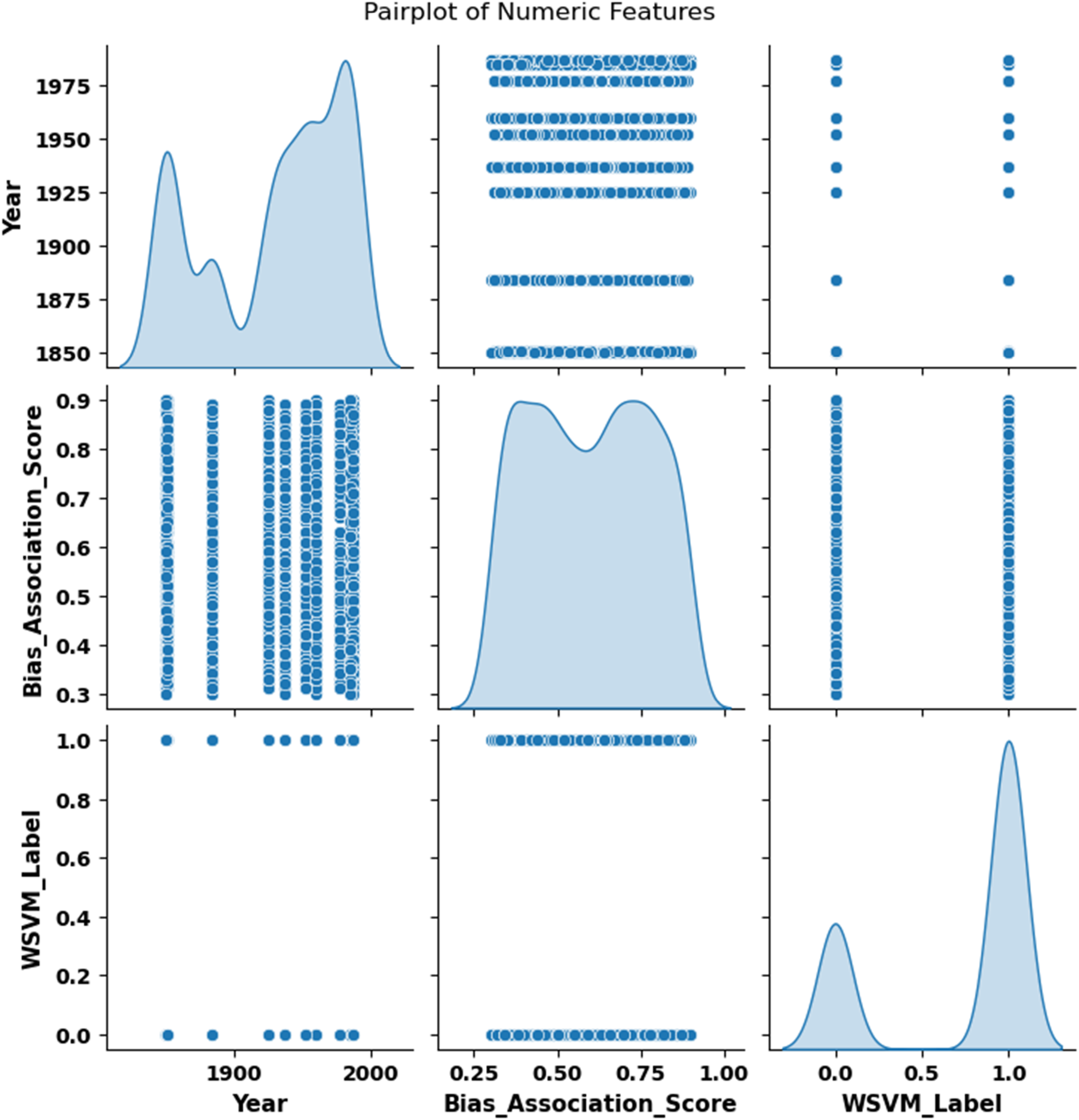
Data pre-processing
The raw data was preprocessed by data processing. Data pre-processing was a crucial stage in data exploration, which converted raw data into a usable format. Data pre-processing includes tokenization and min-max normalization.
Tokenization
Tokenization of character traits and social identities.

Min-max normalization
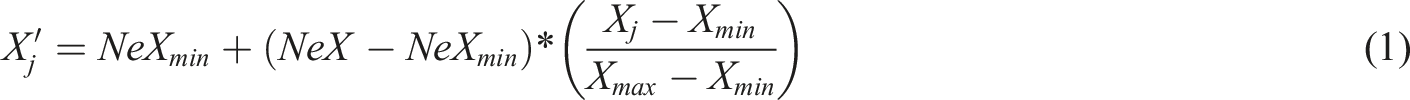
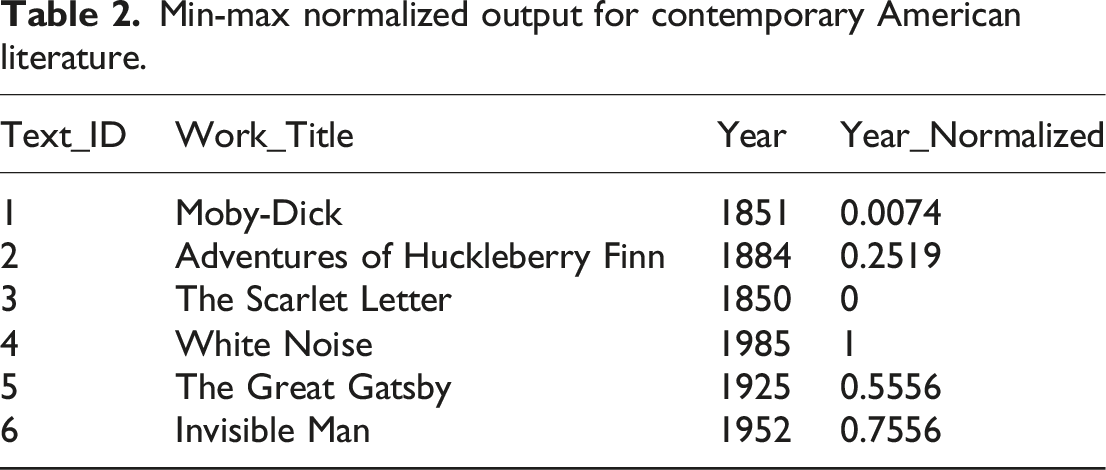
Min-max normalized output for contemporary American literature.
Bidirectional Encoder Representations mutated Weighted Support Vector Machine (BERWSVM)
The integration of BERT and WSVM presents a hybrid approach for classifying complex social representations. BERT model intricacies include bidirectional training, and it was sensitive to the small semantic and syntactic clues in passages, giving a close assessment of characterization, story arcs, and political dissections. BERT model effectively analyzes how marginalized and dominant groups were referred through literary periods beyond the surface level examination methods using keywords. WSVM algorithm was essential for correcting class imbalances and giving sufficient recognition to the minority, which was typically suppressed in literary works. WSVM model gives more priority to low-density data and provides well-balanced performance across data classes to ensure certain classes. This synergy helps to identify the implicit stereotypes, linguistic exclusions and cultural hierarchies coded in literary discourse. The hybrid model BERWSVM improves the accuracy of analysis of a literary work in addition to delivering the digital humanities’ proficient insights of cultural narratives. The integration of BERT contextual embeddings with the ability of WSVM to manage class imbalance leads to finding the invisible structures of prejudice informing cultural memorability to blend ML models with literature. The BERWSVM hybrid model classifies texts but also mediates the power relations, ideological leanings, and representational politics that constitute American literature, providing a reproducible paradigm regarding the complex interplay of language, identity, and social justice via computation. The BERWSVM hybrid model is used to enhance the social group representation by equation (2).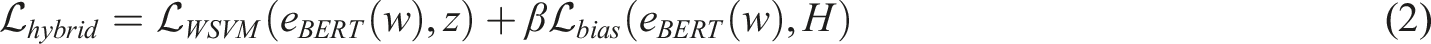
Here,
Bidirectional Encoder Representations from Transformers (BERT)
The BERT model was sensitive to the subtle syntactic and semantic cues in passages and was trained in both directions. It provided a detailed evaluation of political dissections, plot arcs, and characterization. The BERT model analyzes how dominant and marginalized groups were referred to across literary periods. A complete linguistic understanding of the structure and context was produced using the BERT model. The upper layers of BERT can be tuned to handle entity recognition and sentiment analysis. The BERT model fully gathers the contextual information of the text through a bilateral self-attention process. BERT learns language rules from a huge corpus using self-supervised learning in the pre-training phase of the model. BERT applies the pre-trained parameters to the text classification problem for optimizing the model’s performance. By recognizing the connections between textual words, self-attention mechanisms included in every Transformer encoder layer were able to create long-distance dependencies. The sequence of input text was expressed as 
Here,
Weighted Support Vector Machine (WSVM)
WSVM algorithm makes the framework effective to pick out both explicit and implicit forms of social bias in literature. It shows the disparities in representation with an emphasis on stereotypical groups. WSVM provides better results in classification accuracy when managing the unbalanced polarities of social groups. The WSVM model was a global optimization, and has the complexity that was independent of the feature space dimension. Parametric improvements have been made to the SVM model’s structure to enhance its interpretability through the use of empirical data. The WSVM model planning procedure yields the value function 

Here, 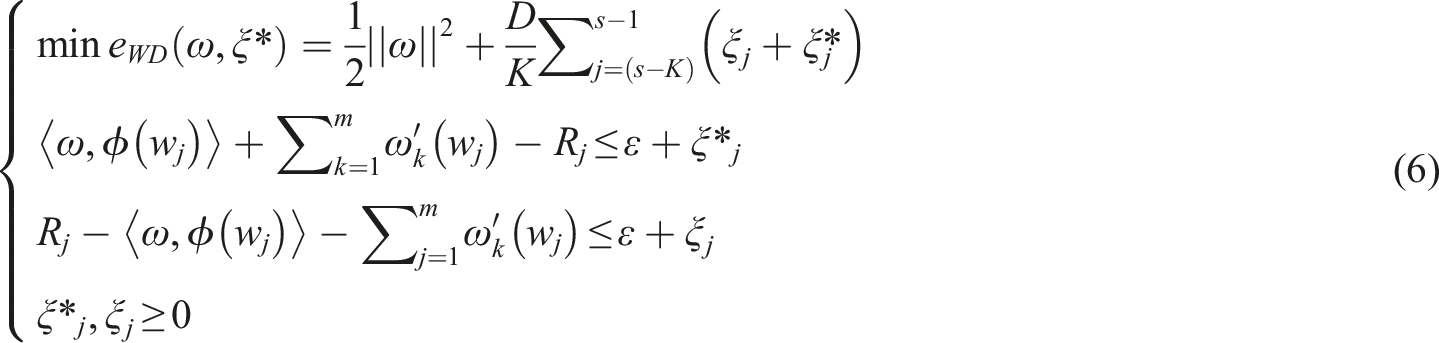
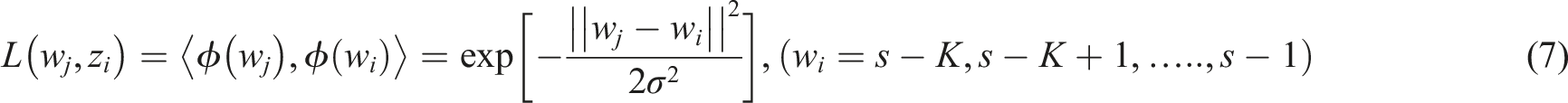
Here, 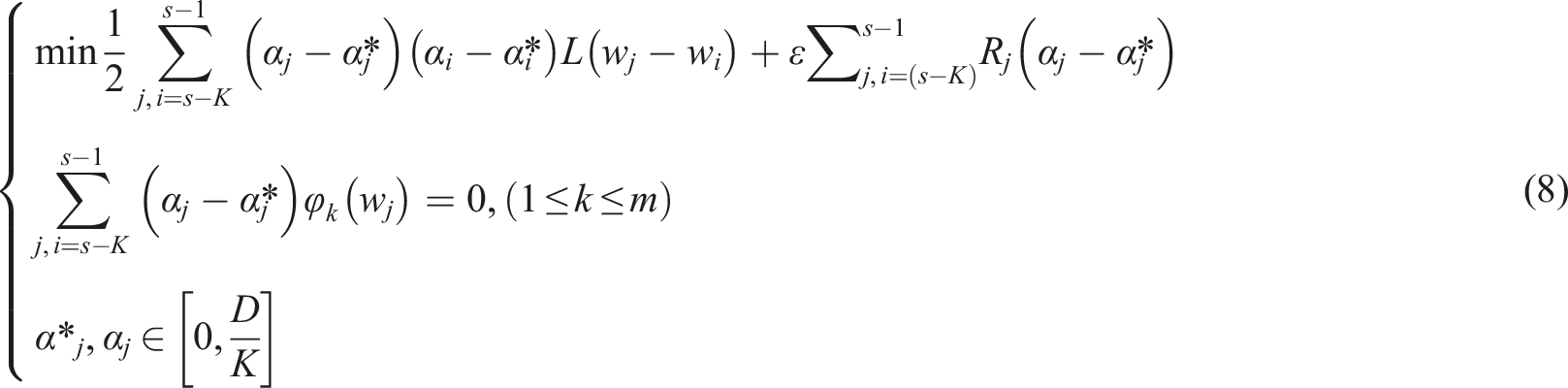
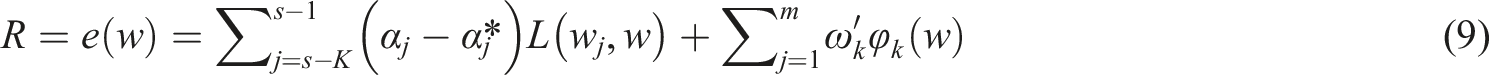

Here, 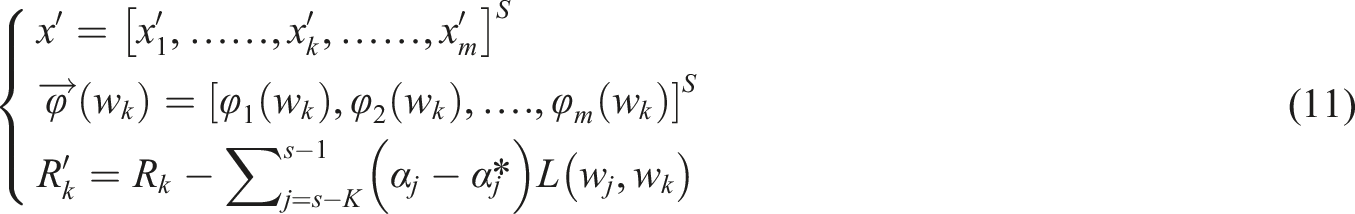
The BERT combined with WSVM for enhancing rich semantic information and categorizing bias or stereotype representations across the genres and historical setup in an efficient manner. The BERWSVM hybrid model is used to comprehend the multilayered and frequently opaque nature of group representation within cultural history in American culture. Algorithm 1 shows the proposed BERWSVM model working procedure.

Contextualized Embedding Association Test (CEAT)
The CEAT was employed to quantify the magnitude of contextualized social biases in word embeddings based on American literary works. CEAT was a generalized extension of a human-like test used in the static word embedding, as the Word Embedding Association Test (WEAT). The contextualized word embedding depends on text context to filter the data with WEAT; it provides the true extent of representational bias. CEAT evaluates the distributions of effect sizes based on the repeated contextual embeddings of a single stimulus word. To quantify the level of association between group identities and traits, the effect size (Cohen’s d) was calculated by CEAT. The strength of the associations between some identities and evaluative descriptors was represented by a positive or negative effect size. In the CEAT test, the BERT was used to derive target and attribute embeddings of words in context in the curated corpus of literary text. Several embeddings were produced through sampling of the distribution of occurrences of characters in various contexts throughout the texts. The resulting distribution of effect sizes was modeled with random-effects models to estimate the level of bias and its overall significance.
Results and discussions
Experimental data indicate that the suggested model, BERWSVM, enhances bias detection performance in American literature. The stability of the model behavior was explained by BERT and WSVM to enhance the precise classification of intersectional identities and nuanced social portrayals. These findings prove that it was effective in improving interpretative accuracy and supporting large-scale analysis of diversity and fairness in literary narratives.
Experimental system
The experimental system was executed using Python 3.10.1 to implement the suggested method. This Python version was selected for its compatibility and improved performance over previous versions. The setup ensures an accurate assessment of contextual embeddings, reliable detection of CEAT, and effective classification of intersectional identities in large-scale American literary corpora.
Performance assessment of the suggested method
The heatmap facilitates the identification of feature correlations, which could guide feature development and selection models. The heatmap of pairwise correlation into feature redundancy and complementarity was illustrated in Figure 3. It provides a color-coded visual representation of correlations among three variables, such as year, bias association score, and WSVM label. The heatmap correlation was used to understand the strong relationships. This visualization helps to evaluate the feature selection or analyze model behavior, particularly if predictive modeling makes use of these factors. Heatmap correlation of feature interdependence in bias classification.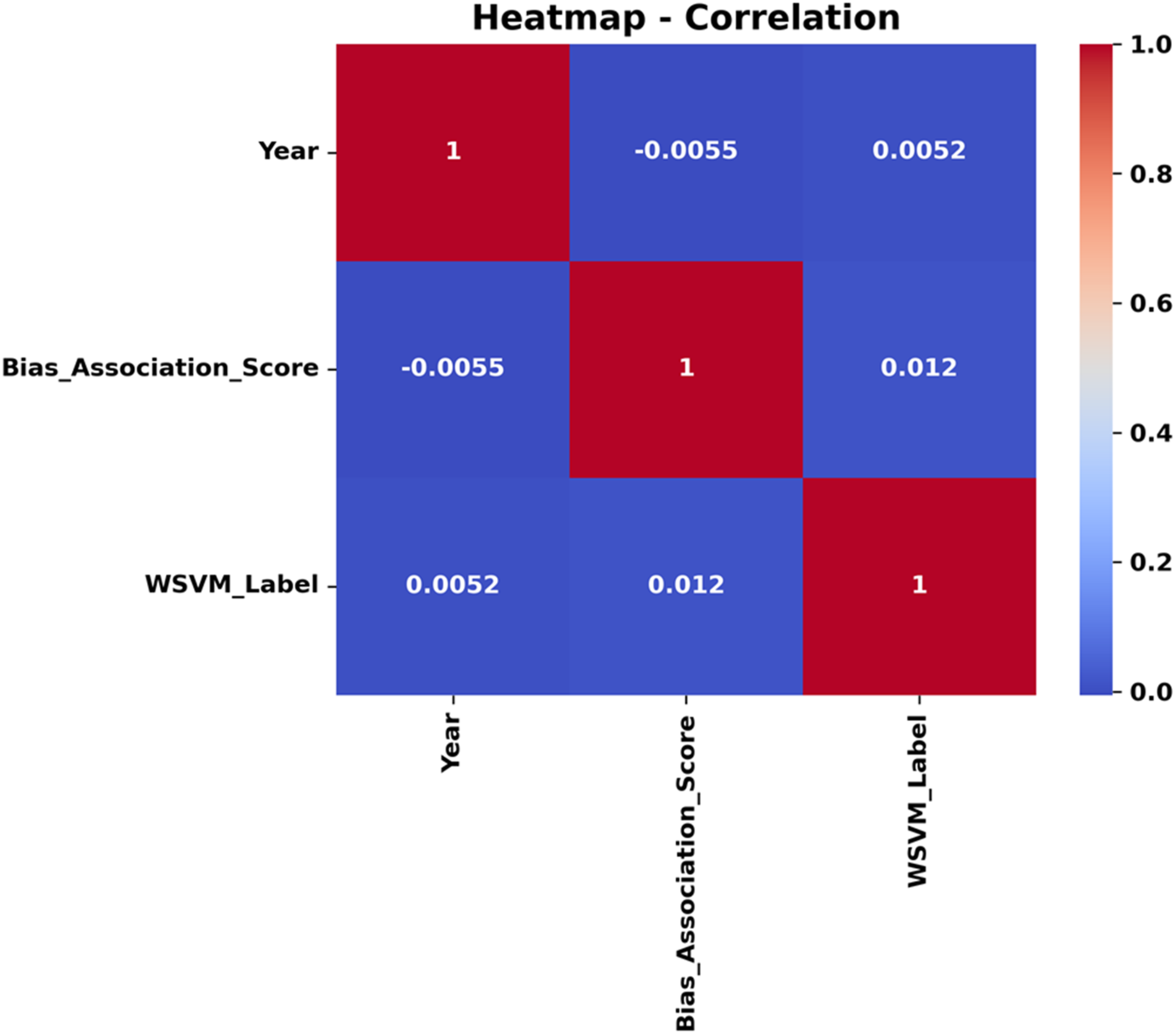
The gender distribution reveals a gender identity within a given population, segmented into four categories such as Unknown (26.8%), Male (25.3%), Non-binary (24.4%), and Female (23.5%). It helps to quickly assess the relative size of each category. Figure 4(a) visualization emphasizes how crucial demographic reporting is to acknowledge and validate the non-binary identities. The race distribution offers a visually engaging breakdown of racial composition within a given population. It includes Asian (18.1%), Unknown (18.2%), White (15.2%), Mixed (15.6%), Indigenous (15.7%), and Black (17.3%), as depicted in Figure 4(b). The donut style highlights the relative sizes of each segment without overpowering the audience. This visualization helps to evaluate the modeling, sample equity, and policy decisions that depend on demographic balance. (a) Gender distribution and (b) race distribution.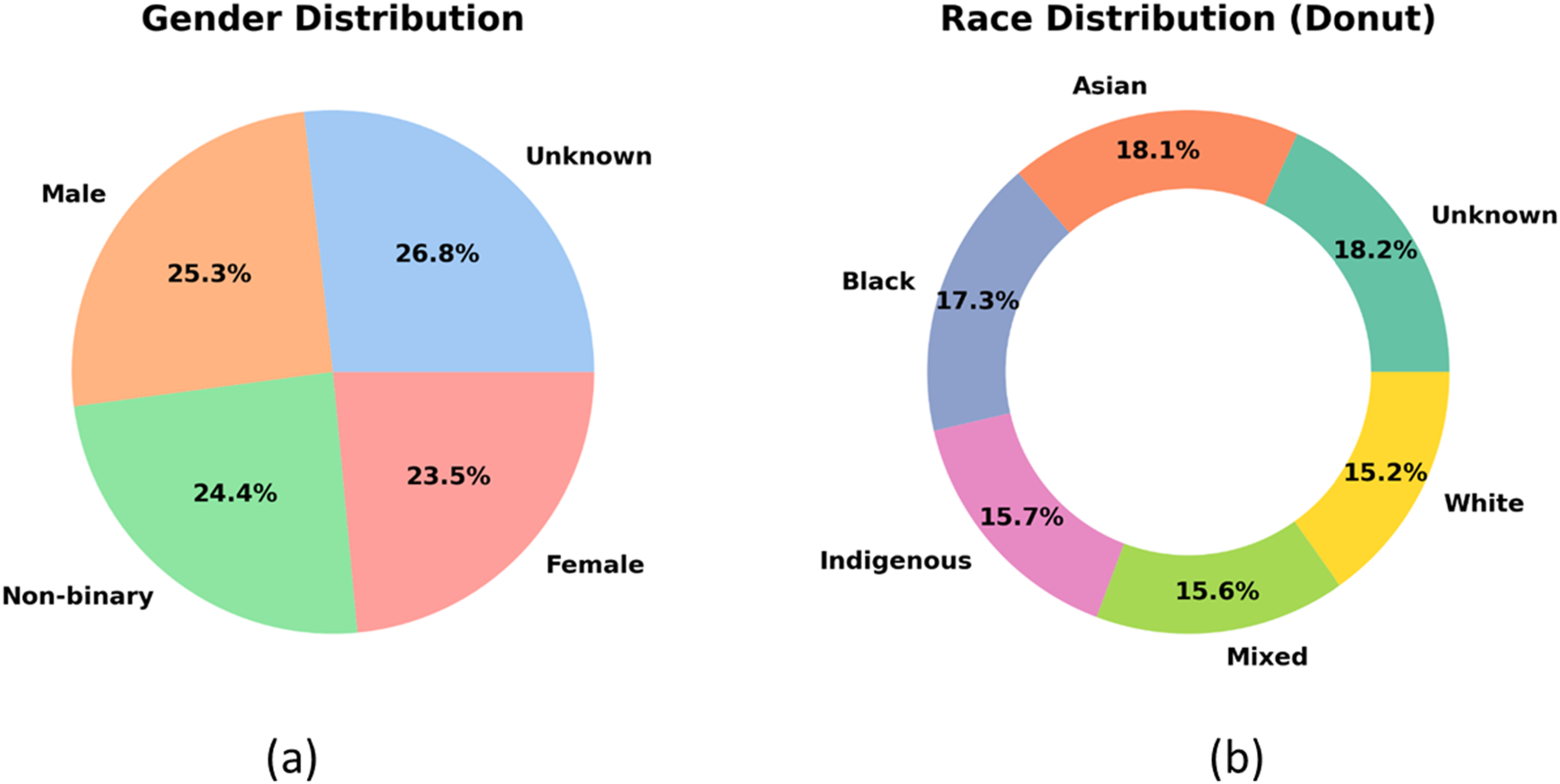
The discrepancy highlights the unequal distribution of prejudice among racial groups. The radial shape facilitates the easy comparison and makes it clear which categories were disproportionately impacted. To assess bias and fairness in algorithmic decision-making, the radar chart was an effective diagnostic tool. The symmetry and contrast make the chart visually striking and instructive, making it perfect for bias audits. The bias levels of six racial categories, like Indian, Black, Asian, White, Unknown, and Mixed, were depicted in Figure 5. Bias distribution across racial categories evaluation.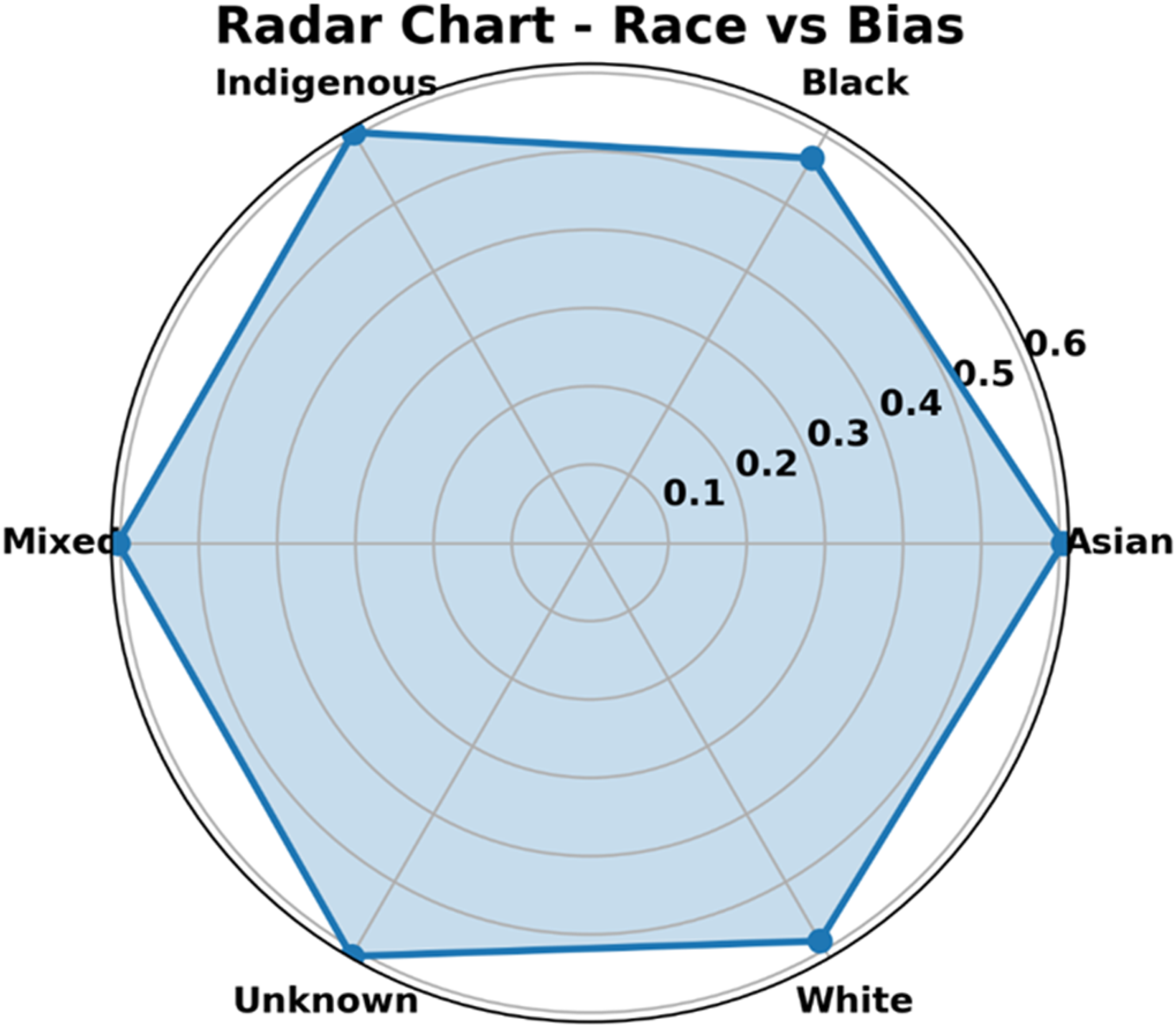
The bias score clustering reveals class-based disparities for five distinct classes, such as working, unknown, middle, upper, and enslaved. Where Bias score clustering reveals class-based disparities.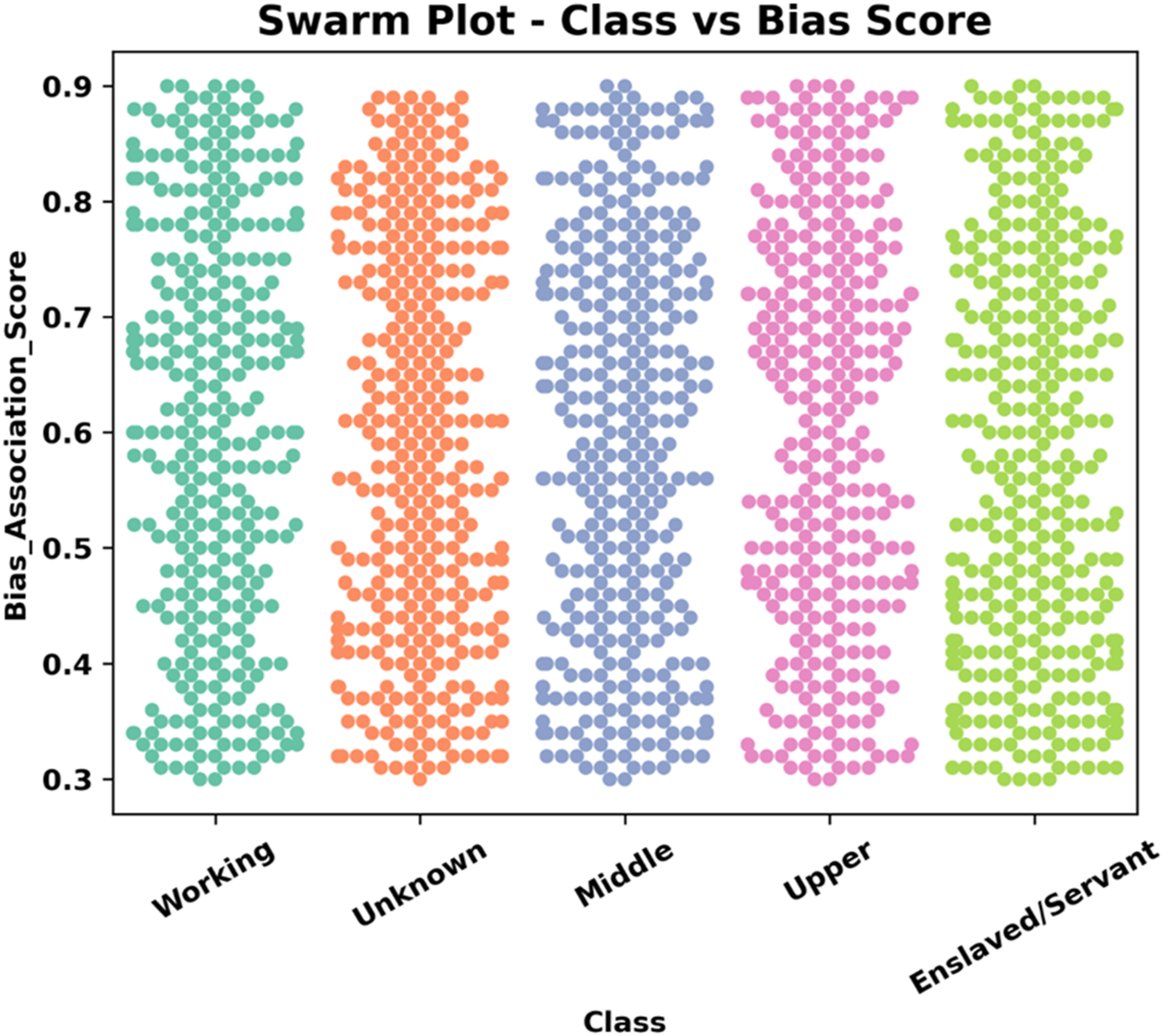
The bias score distribution provides a comprehension of how frequently different bias scores appear, as illustrated in Figure 7(a). Where (a) Bias score distribution and (b) Bias score variability across historical timeframes.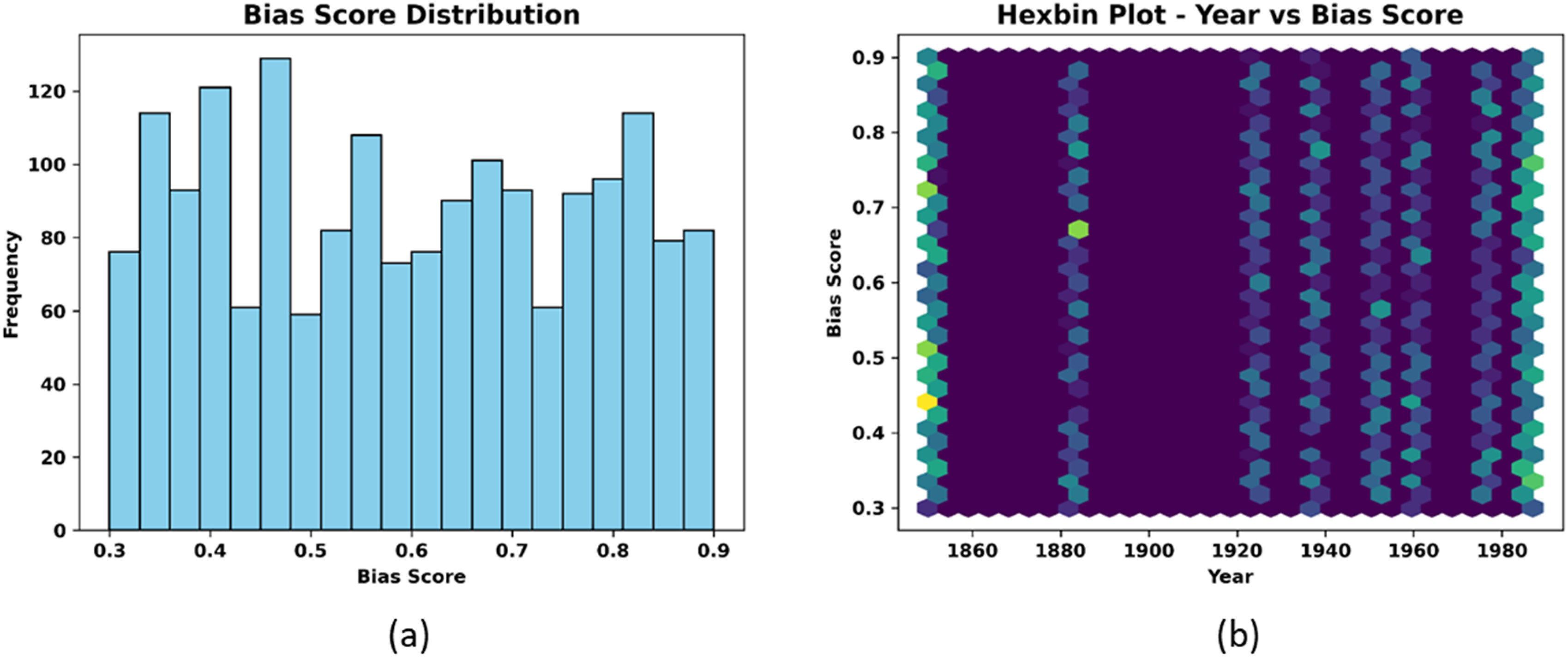
Metrics for evaluating the effectiveness of the suggested model
Cross-validation was a standard technique for evaluating the performance of the BERWSVM model. A 5-fold cross-validation process was performed, and the given dataset was split into five equal portions. It was employed to reduce issues like underfitting and overfitting to gain a sense of how the model would generalize on an independent dataset. This strategy helps to estimate the performance of the model for analyzing the social group representations in American literature. • Accuracy: Measures the total accuracy of the correct classification of character representations. It shows that the model classifies the various social groups in literacy. • Precision: Indicates the percentage of how many predicted group classifications occurred. It shows how the model captures the truthful depictions of gender, race, and classes and time reduces misclassifications. • Recall: Measures the model performance in recognizing the real cases of social group representations. This will ensure that the group depictions are less often noticeable. • F1-Score: Indicates a combination of precision and recall in an overall measure by harmonic mean. It underscores the validity and justice of the model for identifying a variety of social identities in literacy. Figure 8 and Table 3 illustrate the cross-validation scores of K folds for BERWSVM model evaluation. Evaluation of BERWSVM models, cross-validation scores of K folds, precision, accuracy, recall, and F1-score. Performance metrics across K folds for BERWSVM model evaluation.
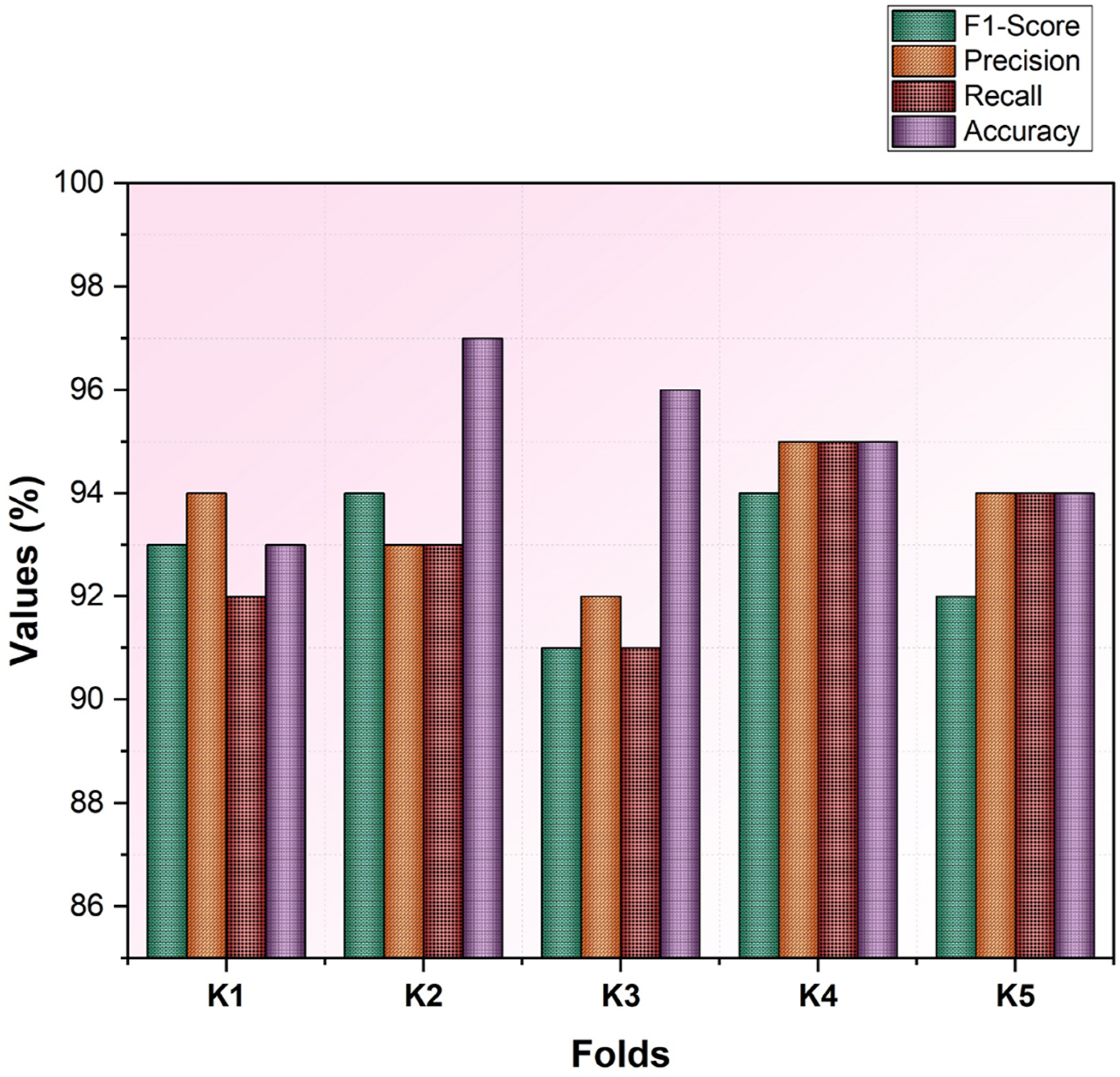
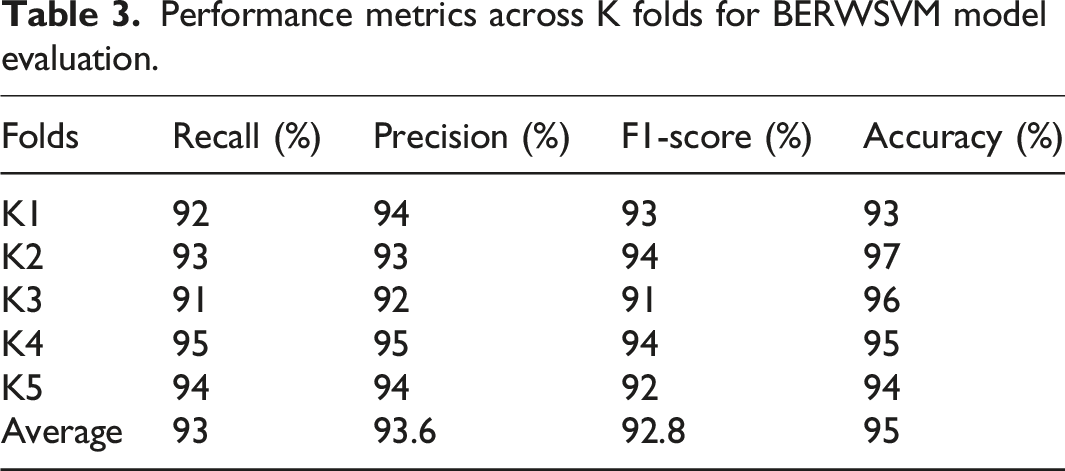
The BERWSVM approach was proposed to analyze social group representations in American literature. The system demonstrates 95% accuracy, reflecting its strong capability to generate consistent and reliable predictions in classification. The model demonstrates high reliability in detecting portrayals of social identities, with a precision of 93.6% along with a recall rate of 93%. The F1-score reaching 92.8% strengthens evidence on capturing nuanced and intersectional patterns of representation, thereby providing a robust foundation for recognizing diversity, fairness, and ideological structures among literary narratives.
CEAT evaluation
CEAT-based bias scores of social group representations.
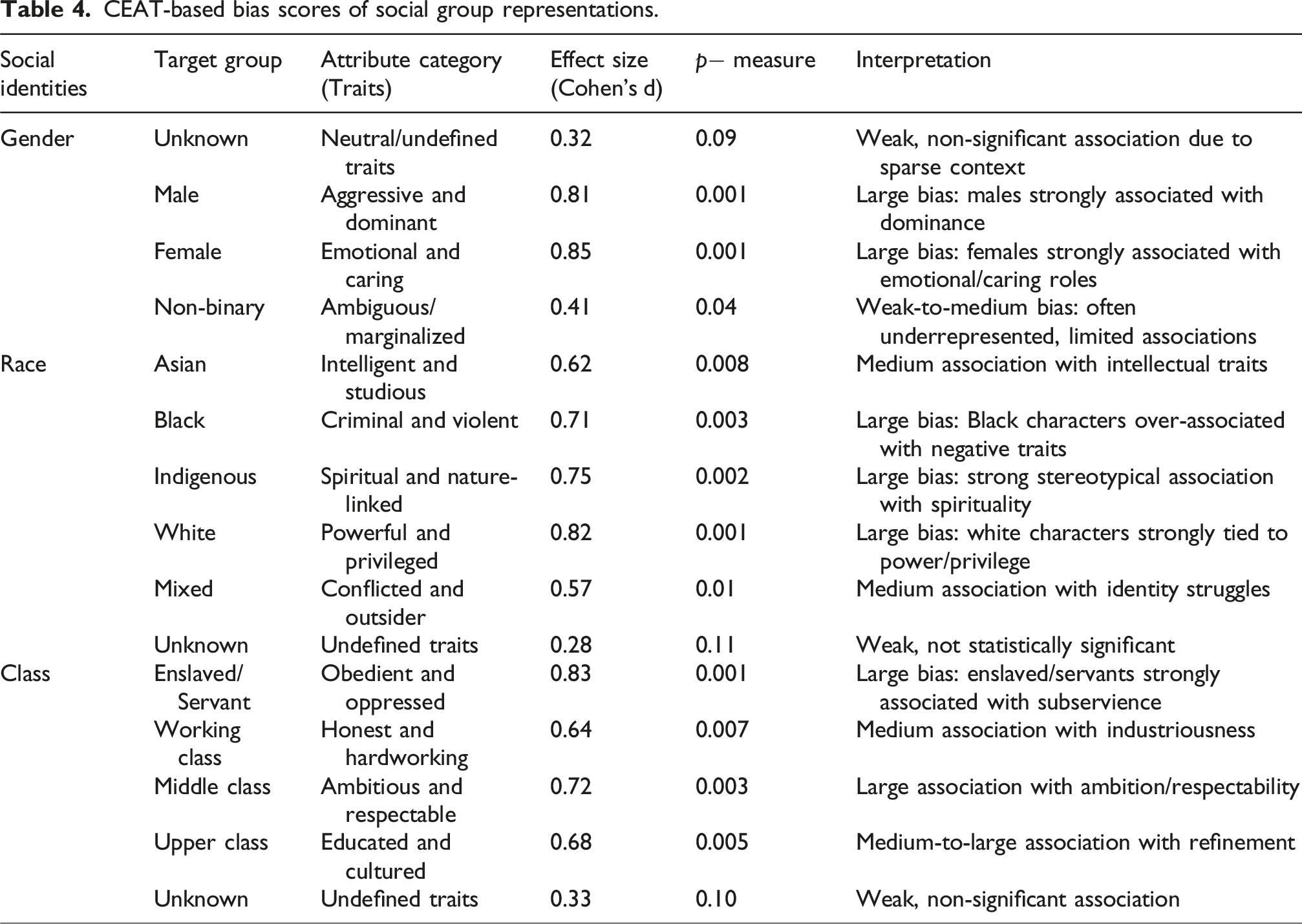
The CEAT findings that assess the bias levels with respect to gender, racial, and class identities in American literature were presented. In gender identities, the unknown gender has
Discussion
The bias detection algorithm and contextualized embeddings endure the significant implications for digital humanities. It enables literacy by being exclusive, rigorous, and socially aware by of the strengths of the humanities for recognizing large-scale pattern recognition in literacy texts. The BERT-RF model uses pre-trained contextualized embeddings, which might not represent all required nuances under consideration as the training corpus. 19 BERT was capable to of encapsulating word context in an effective manner; the RF model does not constitute syntactic or semantic dependencies. Moreover, interpretability was high, since using BERT embeddings and ensembles makes it more difficult to comprehend which features were less important. The model relies heavily on hyperparameter tuning, and can be unreliable with rare words or out-of-vocabulary terms. A CNN with semantic connectivity embeddings effectively picks the local tendencies inside fixed-size and it does not constitute for long-distance associations among words in a text. 18 In semantic connections, it might not capture the full sense of the complex contextual or syntactic meanings, and thus it weakens the understanding of the models. The CNN model was less adaptable to variable-length texts, resulting in a significant amount of information loss. The model was being sensitive to the quality of pre-trained embeddings in any domain specified vocabulary. It fails to investigate robustness, and transferability on text, which might be pertinent to actual applications in real life.
To overcome these limitations, the suggested BERWSVM model enhances representational analysis through contextualized embedding interpretation and intersectional classification mechanisms. The BERT module reads semantic connections in the description of the characters, whereas the WSVM makes different social identities complex and precise between groups. This combined approach quantifies associations between traits and social groups in a rigorous manner. Overall, the BERWSVM approach provides a robust, efficient, and scalable solution for analyzing diversity, fairness, and social ideologies in American literature.
Conclusion
The social group representation computationally constitutes both academic and socio-cultural significance. The literacy of text was usually perceived as a factor in the formation of views on society. American literature has acted as a mirror, reflecting the country’s many political, social, and cultural environments. The dataset was collected from Kaggle. The dataset was compiled and preprocessed through tokenization and normalization to prepare the texts for contextual embedding extraction and bias analysis. For literacy text representations, the BERWSVM model offers an intelligent classification and bias detection module for social groupings. CEAT was employed to statistically evaluate the strength of association between social groups. Extensive experiments demonstrated that the proposed BERWSVM model outperforms baseline architectures, achieving superior results in terms of accuracy (95%), F1-score (92.8%), recall (93.6%), and precision (93%) to classify complex social representations. The male and female show the largest effect sizes with highly significant p-measures, indicating strong, measurable biases in dominance with emotional/caring traits. These findings highlight the effectiveness of integrating computational bias detection algorithms with literary interpretation in analyzing social ideologies, representation, diversity, and fairness in narrative structures.
Limitations and future scope
Large-scale text frequently has social prejudices that are reflected in pre-trained language models. This might affect how accurately subtle or historical biases in literature were detected. Future studies should encompass a wider variety of literary genres, historical periods, and cultural contexts that might yield a deeper comprehension of social representation. Integrating multimodal analysis for text and historical context might improve the identification of bias detection. Developing adaptive algorithms for linguistic shifts throughout time and cultural quirks for bias detection’s accuracy.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The raw/derived data supporting the findings of this study are available from the corresponding author at request.