
Abstract
In this research, an attention-based feature fusion network (AFFNet), with a backbone residual network (ResNet101) enhanced with two attention mechanism modules, is proposed for automatic pixel-level detection of concrete crack. In particular, the inclusion of attention mechanism modules, for example, the vertical and horizontal compression attention module (VH-CAM) and the efficient channel attention upsample module (ECAUM), is to enable selective concentration on the crack feature. The VH-CAM generates a feature map integrating pixel-level information in vertical and horizontal directions. The ECAUM applied on each decoder layer combines efficient channel attention (ECA) and feature fusion, which can provide rich contextual information as guidance to help low-level features recover crack localization. The proposed model is evaluated on the test dataset and the results reach 84.49% for mean intersection over union (MIoU). Comparison with other state-of-the-art models proves high efficiency and accuracy of the proposed method.
Introduction
Due to the low tensile strength of concrete, 1 cracks will inevitably appear under the influence of external load and temperature change in concrete structures. The existence of crack accelerates the corrosion of rebar, seriously affecting the load-carrying capacity and durability of the structure. 2 Because cracks are an important indicator to evaluate structural damage and durability, 3 crack detection is of considerable importance in concrete structure maintenance. The traditional crack detection method is through periodical manual inspection and generally involves sending inspectors to measure cracks by the use of bulky equipment. 4 However, the results are susceptible to subjective factors and the process is also time-consuming and labor-intensive. 5 For these reasons, new crack detection approach with high accuracy and efficiency is desirable and such development is of great interest to all stakeholders.
To overcome the drawbacks of these human-based methods, many image-processing-technique (IPT)-based crack detections have been proposed, such as image threshold,6,7 edge detection8,9 and morphological operation.10,11 However, the prediction results rely highly on manually defined parameters and are easily affected by complex environment in real-world situations.
Recently, deep learning (DL) has been proposed and rapidly developed 12 as a result of the reasons mentioned above. Compared with IPTs, DL can automatically extract abundant abstract features from massive surface crack data. 13 Therefore, researchers have adopted DL algorithms to improve the accuracy and efficiency of crack detection.14,15 Due to the outstanding ability to achieve pixel-level prediction of cracks, most recently, semantic segmentation approaches, which can classify each pixel as crack or noncrack, 16 have obtained increasing attention. The semantic segmentation network is usually with encoder-decoder model, which utilizes the encoder backbone derived from the state-of-the-art image classification architecture.17–19 Yang et al. 20 used fully convolutional network (FCN) with a backbone VGG19 to detect concrete crack, where training time was lower than CrackNet 21 on account of the end-to-end structure. Huyan et al. 22 adopted two U-Net with backbone VGGNet and ResNet to perform pavement crack segmentation task from good quality images without noise, which exhibited significant advantages compared to FCN. Li et al. 23 proposed FCN with a backbone DenseNet121 to analyze smartphone images for automatic detection of four damages in the concrete structure. On the other hand, to prevent information loss in down-sampling operation, researchers tend to develop DL models without pooling layers. Zhang et al. 24 proposed a model named CrackNetII, which removed all pooling layer, for automatic pavement crack detection using 3000 asphalt surface images. However, those semantic segmentation approaches have an obvious challenge that they cannot aggregate rich contextual information well. To address it, two well-known models are proposed to aggregate such context. The first is DeepLabv3, 25 which uses atrous spatial pyramid pooling (ASPP) to fuse feature maps at different scales to capture contextual information. The second is PSPNet, 26 which employs pyramid pooling module to aggregate multiscale context. Wang et al. 27 used 2446 concrete and asphalt crack images to train and evaluate five semantic segmentation models, including FCN, GCN, PSPNet, UPerNet and DeepLabv3+, and found that DeepLabv3+ shows the best performance. Ji et al. 28 adopted DeepLabv3+ to do the automatic detection of pavement crack, and crack images collected by UAV were tested to obtain the mean intersection over union (MIoU) of 78.75%. However, the above method can only collect local contextual information, while the global information on the crack image cannot be fully captured.
The attention mechanism, firstly proposed by Bahdanau et al., 29 is a cognitive process to enable selective concentration on nominated features and intentionally disregard unimportant information. The attention mechanism can be applied to semantic segmentation models as global context exploration methods, such as SENet, 30 CBAM, 31 and DANet. 32 In crack detection, there have been attempts to combine the attention mechanism with available networks to improve detection efficiency.33–35 For example, Pan et al. 36 modified the backbone of DANet from ResNet101 to VGG19, namely SCHNet, and added a new attention mechanism named feature pyramid attention to improve crack detection accuracy. The results demonstrated that three attention mechanisms can increase MIoU by 10.88% than the baseline model. The attention maps in SCHNet are obtained by calculating the similarities among all pixels in the feature map. However, these feature maps are obtained by 1 × 1 convolution, which means that each pixel is influenced by only one pixel in the input feature map. This leads to a troublesome situation that one pixel is unable to contain much spatial information, which makes the attention map not optimally designed. In addition, SCHNet has not considered the fusion of low-level features and high-level features, which could help the decoder to generate high-resolution semantic features. Meanwhile, the direct fusion will downgrade the performance of crack segmentation. To solve these problems, this research designs a novel model combining FCN and two attention mechanism modules to aggregate rich contextual information for automatic concrete crack detection.
Upon the crack detection from the image, the evaluation of the crack such as crack area and crack width would be a direct demand, which is able to assist the practitioners for decision-making and further maintenance schedule. Conversion from crack pixel information to physical dimension is required to achieve above objective. Li et al. 37 proposed a crack image binarization architecture called SegNet-DCRF and further calculated the unidirectional crack width and web crack area. Bhowmick et al. 38 proposed U-Net architecture for crack image segmentation and used morphological operations from image processing to quantify the geometrical properties of concrete surface cracks. Built on the accurate identification of crack from image, this research conducts the morphological feature measurement and the crack severity ranking to enable potential application of the proposed algorithm.
In this research, an attention-based feature fusion network (AFFNet) is proposed for crack segmentation under various complex conditions. The use of attention mechanism is to aggregate crack features and suppress irrelevant features to improve segmentation performance. To capture rich contextual information, the vertical and horizontal compression attention module (VH-CAM) is set on the top of the backbone ResNet101, 39 which uses two asymmetric convolutions to enable the single pixel containing more information. Meanwhile, the efficient channel attention upsample module (ECAUM) combines the efficient channel attention (ECA) and feature fusion to restore semantic boundaries by guiding low-level features. In consequence, these two attention mechanism modules can contribute to better feature representations and more precise crack segmentation results. In addition, the semantic segmentation images of crack by AFFNet are used to quantitatively measure the morphological features of cracks by using single-pixel width skeletons.
The content of this paper is organized as follows. Section “Methodology” presents the detailed feature fusion network. Section “Implementation details” is devoted to the implementation details, including process of generating the dataset and training parameters setting. Section “Experimental results” introduces the experimental results and corresponding analysis. Section “Discussion” describes the discussion of different test sets. Section “Conclusion” summarizes the conclusion of this paper.
Methodology
To distinguish crack pixels and non-crack pixels, this research proposes a novel model named AFFNet with a backbone ResNet101 pretrained on ImageNet and the integration of two attention mechanism modules. The backbone network, ResNet, 39 is the first convolutional neural network with a depth of more than 100 layers, which solves the degradation problem that accuracy tends to saturate and then decreases with the depth of the network increasing. It won the ILSVRC and COCO 2015 competition and has been widely used in semantic segmentation. In addition, dilated convolution with a rate of two is employed and the stride is modified from two to one in the last ResNet block to enlarge the output size of ResNet101 from 1/32 to 1/16 of the raw image. In this way, more details of feature maps can be retained. The structure of the proposed AFFNet, which is made up of two attention mechanism modules including VH-CAM and ECAUM, is shown in Figure 1. The quadrangular prisms represent the block of ResNet101 and the arrows represent the operations of the model. The detailed network parameters are listed in Table 1. Notably, ReLU and BN layers, which are used in the ResNet101, are not presented in Table 1. The keep probability of the dropout layer in Figure 1 is 0.9, which can assign the value of 0 to each channel with a probability of 0.1.
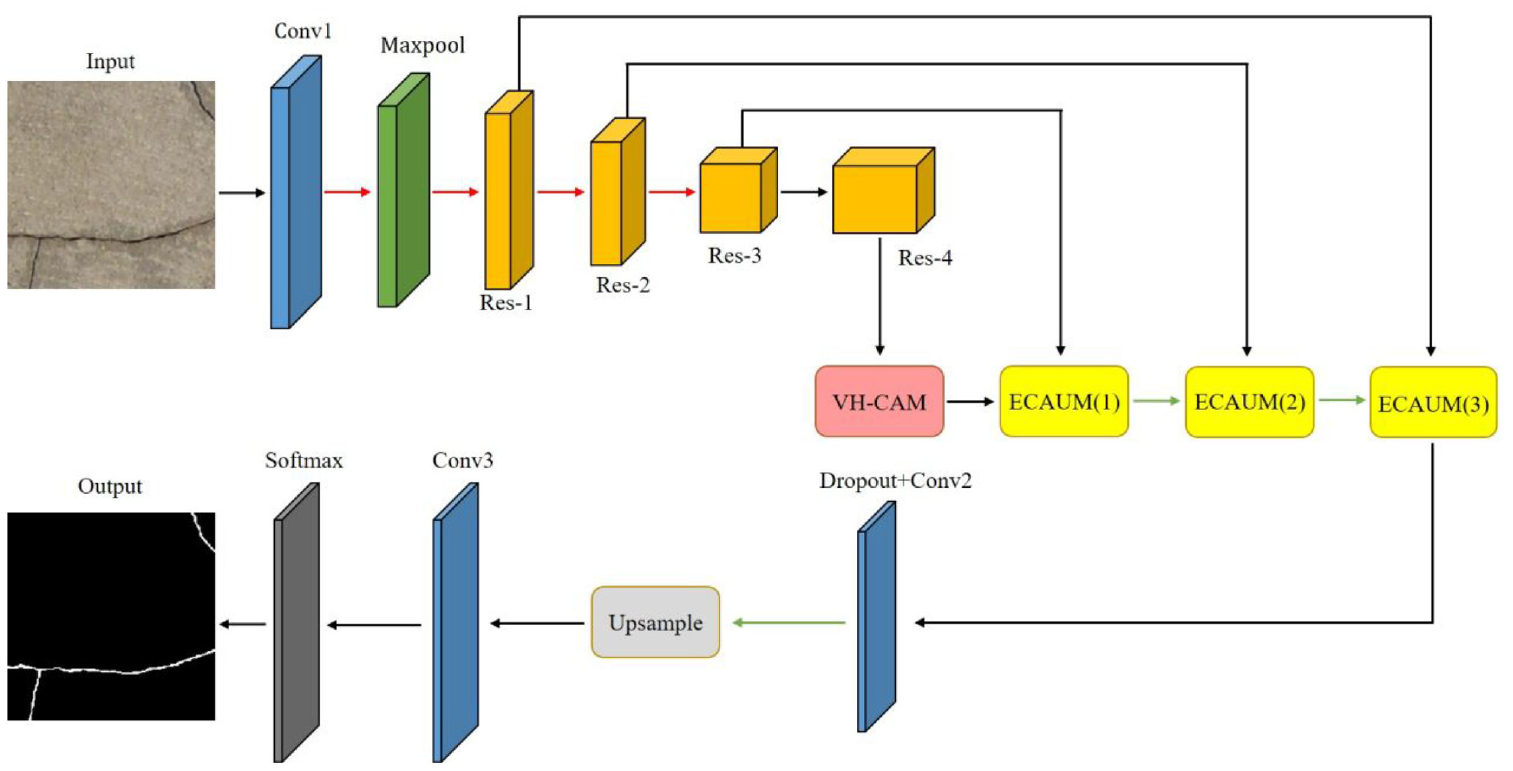
Overall architecture of proposed AFFNet for semantic segmentation. The red and green lines represent down-sampling and up-sampling operations. The proposed model uses ResNet101 as backbone and apply VH-CAM and ECAUM to improve crack segmentation.
The detailed configuration of each layer in AFFNet.
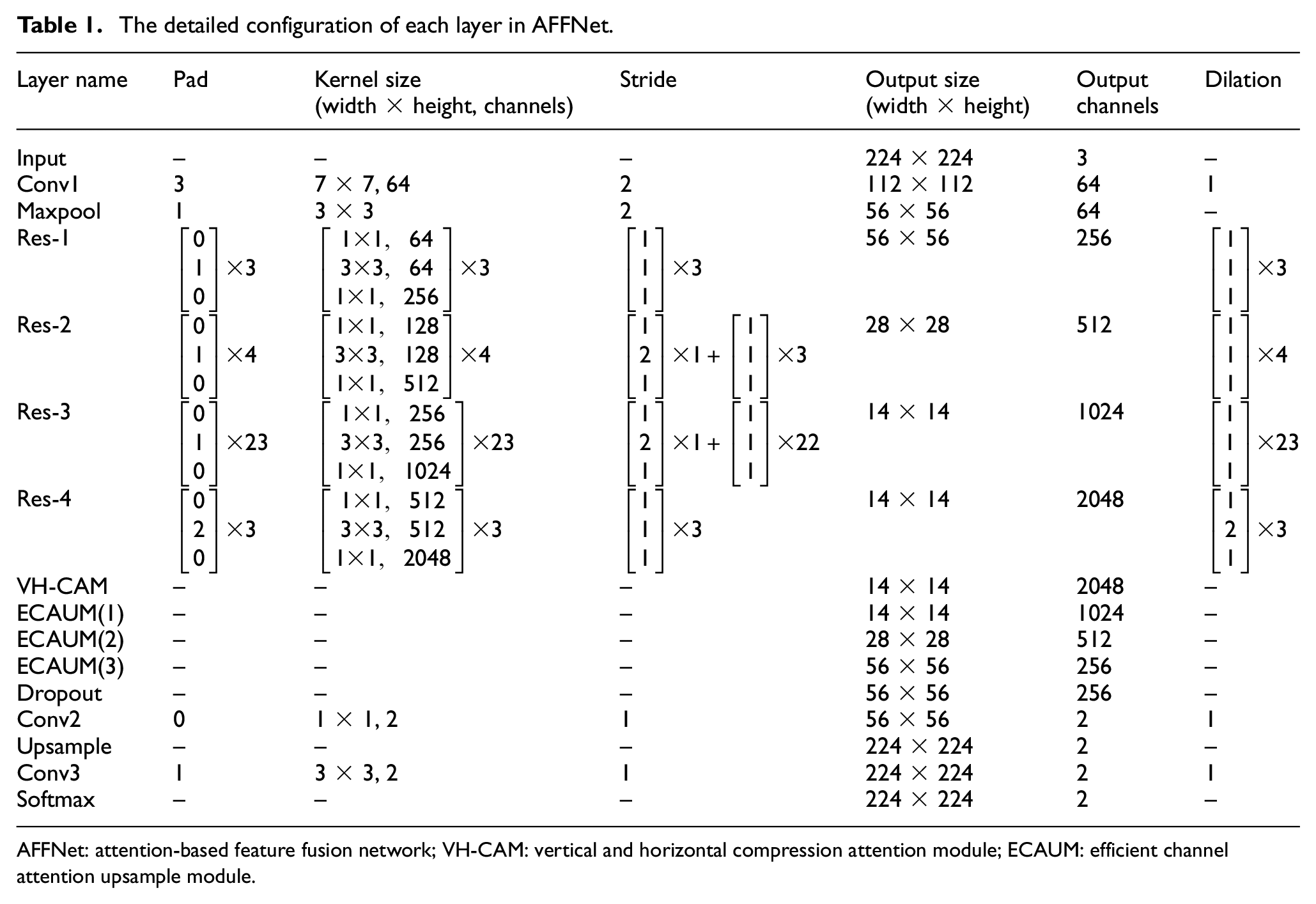
AFFNet: attention-based feature fusion network; VH-CAM: vertical and horizontal compression attention module; ECAUM: efficient channel attention upsample module.
Similar to human attention, the attention mechanism can concentrate on the features that need to be focused on to acquire more details and ignore irrelevant information. 40 The essence of the attention mechanism is to learn weight distribution relevant to feature maps. In recent years, the attention mechanism has been developed rapidly in computer vision in light of its advantages. Here, VH-CAM and ECAUM are chosen with key features and explained in following sections.
Vertical and horizontal compression attention module
It is known that the contextual information is of considerable importance in semantic segmentation due to multiple scales of objects. 41 However, local features from traditional FCN may mislead the classification process at the pixel level. 32 To overcome this issue, the VH-CAM is introduced, 41 which can capture rich contextual information to accomplish the crack segmentation task. Different from the position attention module in DANet, VH-CAM employs two asymmetric convolutions with the kernel size of 1 × W and H × 1 to enable each pixel to contain more information. Then the attention map is obtained through matrix operations, which is more comprehensive than using 1 × 1 convolution. Next, the process to aggregate contextual information between crack and background is introduced.
The exact working principle of VH-CAM is described in Figure 2. The feature map

where
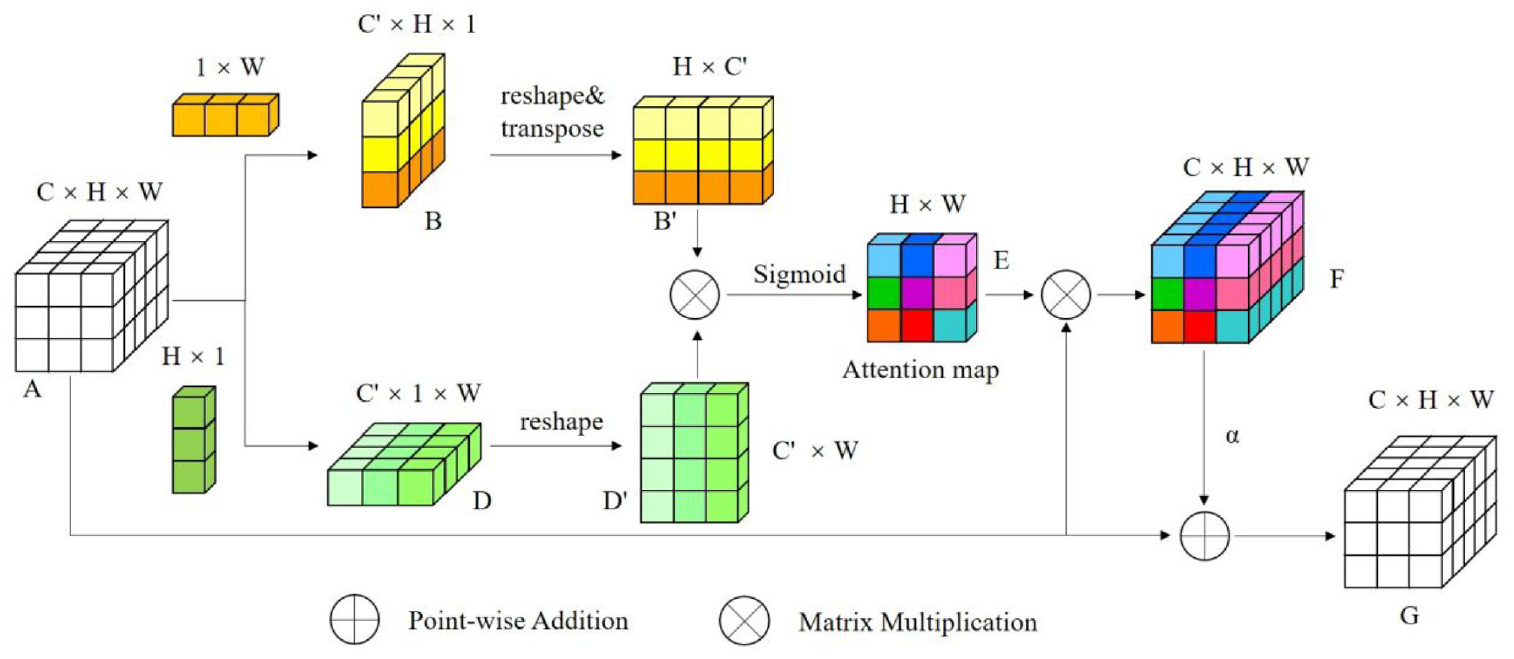
Structure of the proposed vertical and horizontal compression attention module.
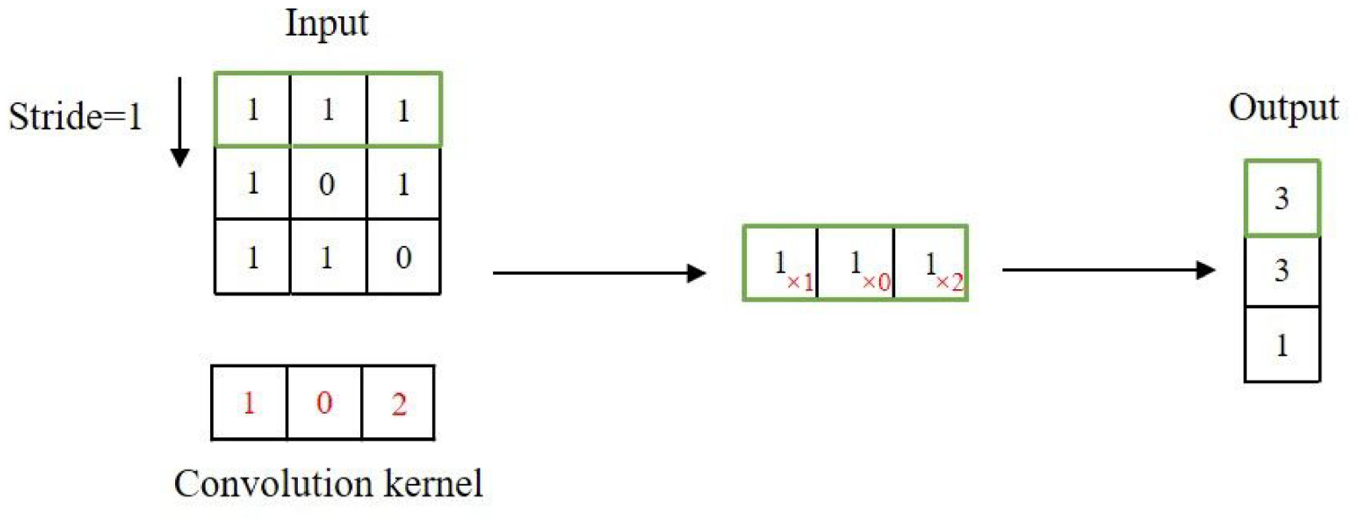
The example of asymmetric convolution (refer to the mathematical process to generate B feature map in Figure 1, the same principle can be used to generate feature map D when the convolutional kernel is a H × 1 vector).
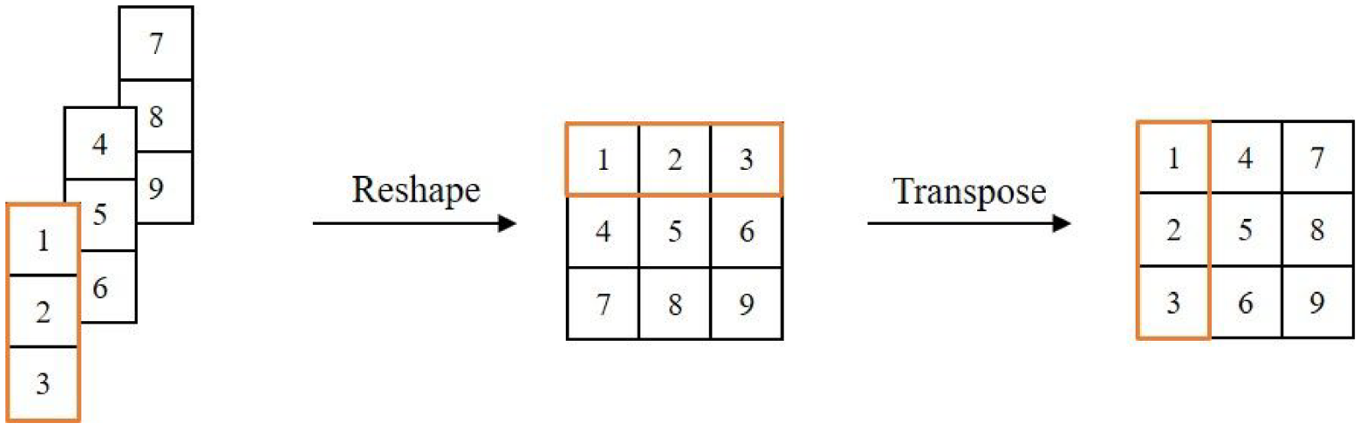
The example of reshape and transpose operations.
Then, a multiplication operation is applied to E and A to generate a new feature map

where
Finally, each element in feature map F is multiplied by the parameter
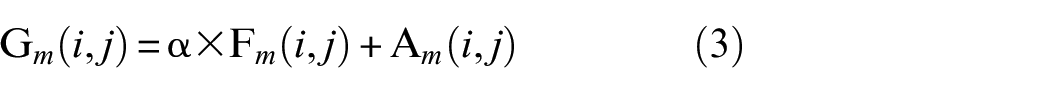
where
Efficient channel attention upsample module
In general, low-level features and high-level features are equally important. 42 To restore the lost details in consecutive down-sampling, many models adopt encoder-decoder structures, such as FCN, 43 U-Net 44 , and SegNet. 45 However, these encoder-decoder structures lack appropriate guidance and may cause misclassification. 41 To overcome this problem, ECAUM combined with the attention mechanism and feature fusion is adopted here. Due to less parameters involved and high performance, the ECA 46 in ECAUM is performed to provide high-level semantic information as guidance to help low-level features select precise resolution details. Moreover, since residual blocks dominate performance of ResNet101, three ECAUM is used to perform the feature fusion with residual block and decoder.
The structure of ECAUM is illustrated in Figure 5 and the mathematical evolution of ECA is described in Figure 6. First, the high-level feature map
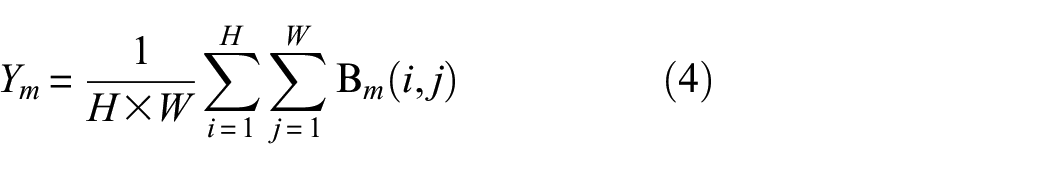
Here,
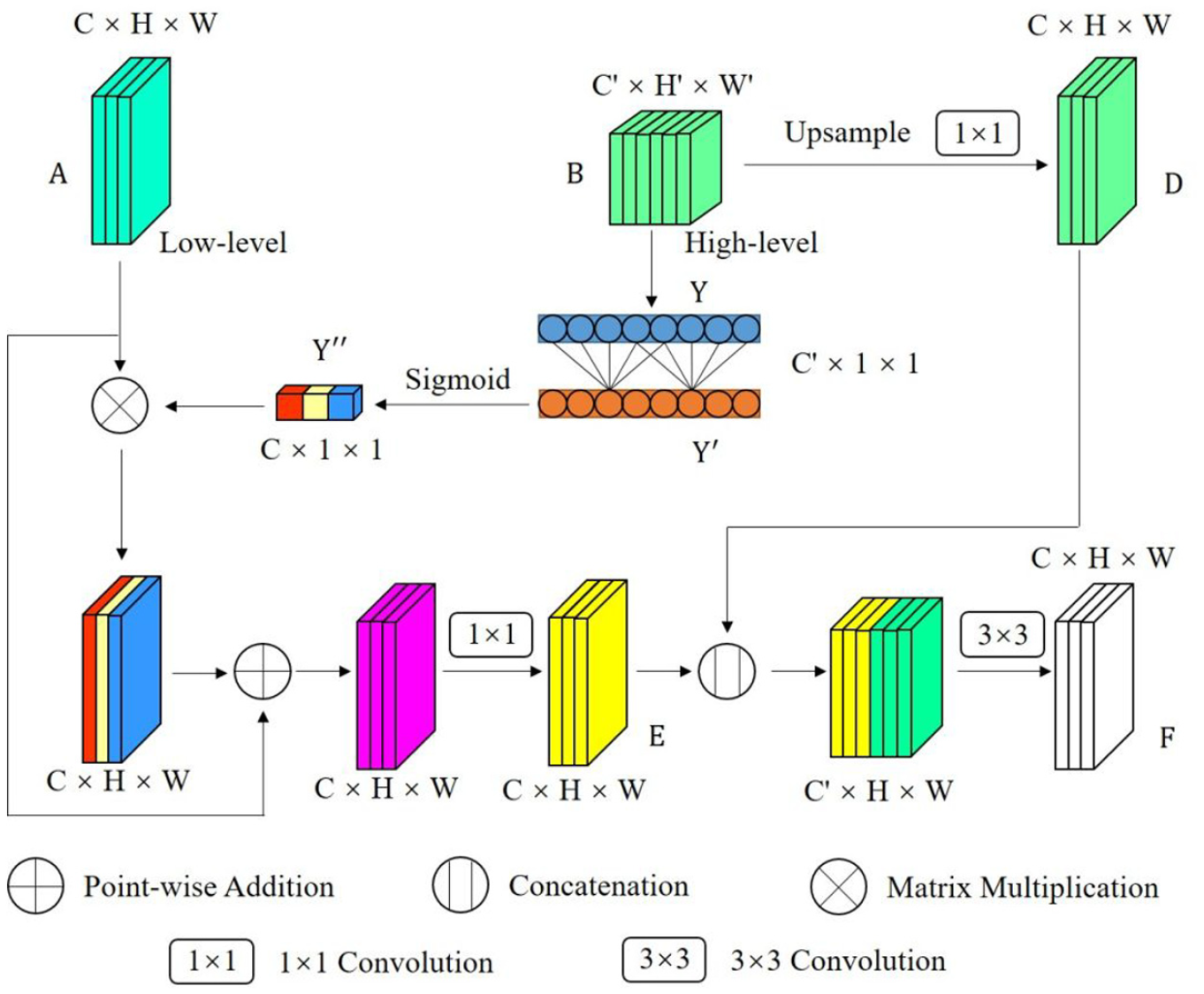
Structure of the proposed efficient channel attention upsample module.
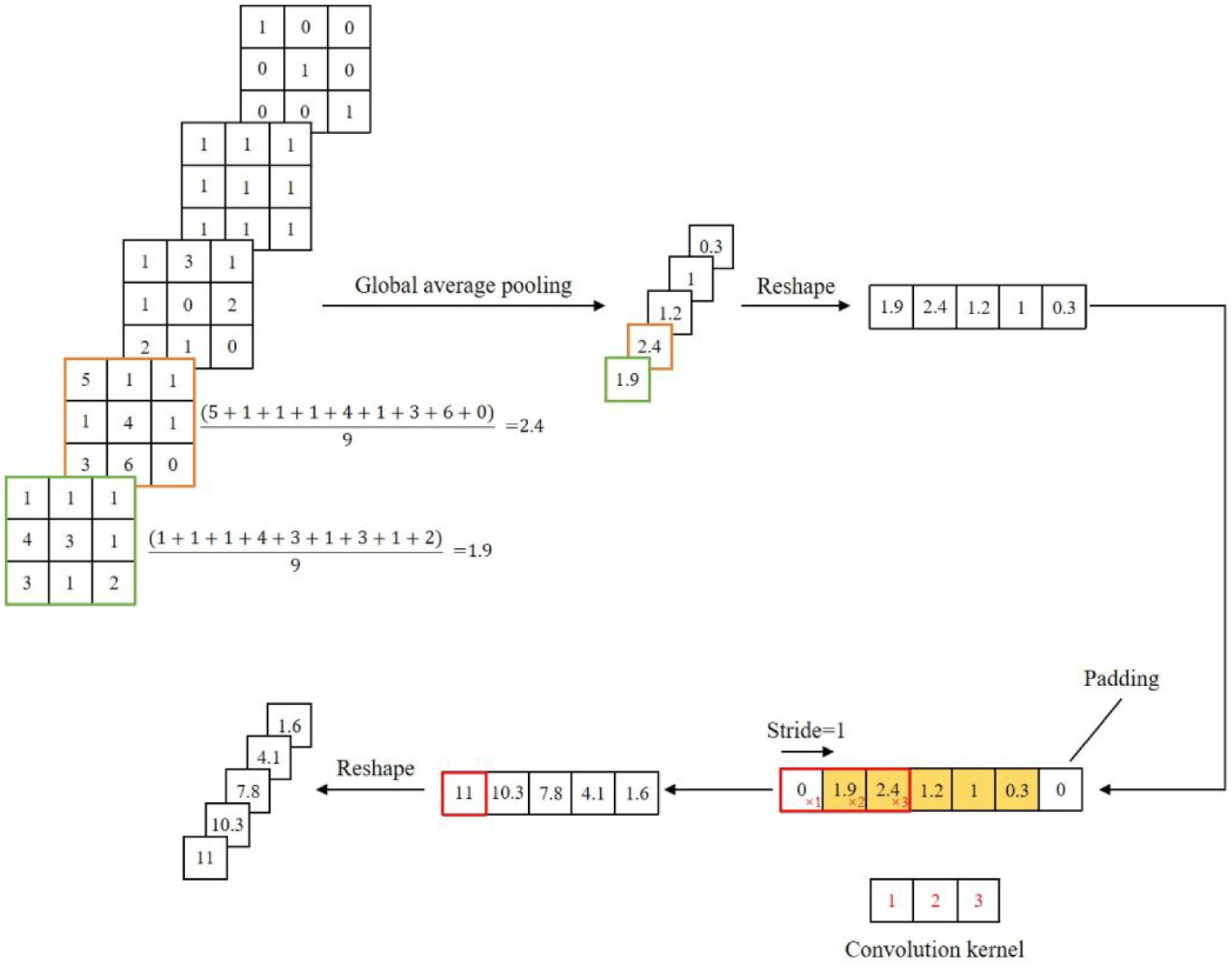
The details of efficient channel attention.
Then, the channel weight vector

where
Then,

where
The fusion of low-level features and high-level features is an effective approach to restore the lost details caused by the consecutive down-sampling. The transposed convolution upsample is utilized as an efficient method to enlarge the high-level feature map
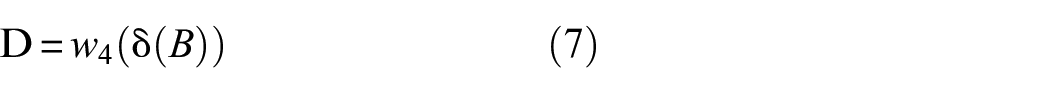
where
Finally, E and D is spliced and a 3 × 3 convolution operation followed by BN and ReLU is adopted to obtain the final output

where
Implementation details
Dataset construction
To verify the effectiveness and robustness of AFFNet, a concrete crack image dataset is constructed for the following experimental validations. To ensure the variability, the images in the dataset contain not only wall cracks, but also pavement and bridge cracks, saved in JPG format. Furthermore, some of the crack images also contain various types of noise that often observed with concrete structures, such as spots, shadows, water stain, handwriting, Gaussian noise, and insufficient lightening.
The dataset contains 1760 crack images, of which 776 crack images are found in paper, 20 524 crack images are collected manually, and 460 crack images are generated using data augmentation techniques. The manually collected images are taken by a 40-megapixel smartphone at different distances without zoom, where the aperture is f/1.8, the ISO is 50, and the original full image resolution is 2736 × 3648 pixels. To decrease the computational cost of the training model, the original images are cropped into sub-images with a size of 224 × 224 pixels. In order to detect crack with more complex environments, we use data augmentation techniques such as rotation and Gaussian noise to increase the complexity of the dataset. The proposed AFFNet generates the crack shape and location through segmenting crack images to obtain important crack features. Therefore, the images obtained by cropping operation are labeled as ground truths using Photoshop software. Then, these ground truths are converted to PNG format with a single channel, where crack pixels and background pixels are labeled as 255 and 0, respectively. In order to assess the generalization ability of the proposed AFFNet, 1760 images in the dataset are randomly divided into three parts that 64% are used for training, 16% are used for validation, and the last 20% are used to test the model. Specifically, eight types of cracks are included in the dataset, containing cracks without noise and cracks with noise. For the former, there are four subgroups: (1) diagonal crack: contains only one crack in diagonal direction; (2) transverse crack: contains only single transverse crack; (3) reticulation crack: contains more than one crack; (4) wide crack that is filled with stones and earth. For the latter, there are also six groups: (1) crack with spalls in the concrete surface; (2) crack with shadow, which contains shadow interfere with crack detection; (3) crack with water stain, which has water stain around crack; (4) crack with handwriting that contains black handwriting similar to crack; (5) crack with Gaussian noise; (6) crack in insufficient lightening.
Model initialization
Model initialization is to determine whether the model converges. 47 When training the AFFNet, transfer learning is adopted to improve the training efficiency and crack segmentation performance of AFFNet instead of training it from scratch. In consequence, the initialization method of all convolutional layers is the same as that of pretrained ResNet101, where weights are initialized with the Kaiming method, 48 and biases are set to 0 and untrained.
Moreover, the AFFNet used the transposed convolution method to enlarge the high-level feature map. Compared to other upsample methods, the transposed convolution method is learnable and can be learned through the network to obtain a better upsample result.
Loss function
The loss function can estimate the discrepancy between the predicted result and the ground truth. 20 The optimal solution of the model needs to minimize the value of loss function by fine-tuning parameters in the training process. Therefore, the selection of an appropriate loss function is indispensable for AFFNet. Since crack segmentation can be regarded as pixel-level classification, cross entropy loss function is applied to the proposed AFFNet on account of its effectiveness and solid theoretical grounding. The formula of the corresponding loss function for each pixel can be represented as:
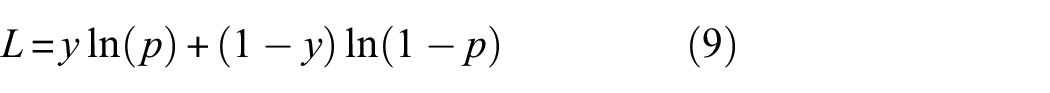
where y and p indicate the ground truth value and predicted value, respectively. And the total loss for each concrete crack image is the mean of all losses for the pixels.
Optimizer
The optimizer is one of the crucial components of DL due to the ability of minimizing the value of loss function and updating model parameters. Due to the fast updating speed and simple setting, the stochastic gradient descent with momentum (SGDM) is employed to train AFFNet. 12 The weight decay, an important parameter in the optimizer, is set to 0.0001. In addition, the batch size is set to eight when training AFFNet. The expression for updating parameters using SGDM is as follows:

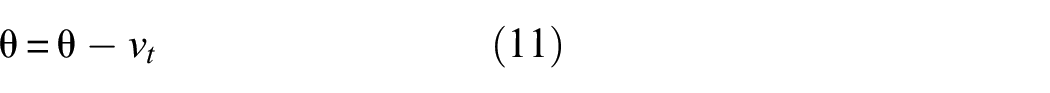
where
The learning rate is used to control the updating speed of the model parameters in the training process. The small learning rate reduces the updating speed, but an over-large leaning rate can result in parameters hovering around the optimal value. Therefore, a learning rate decay method used exponential decay function is adopted in this paper, as follows:
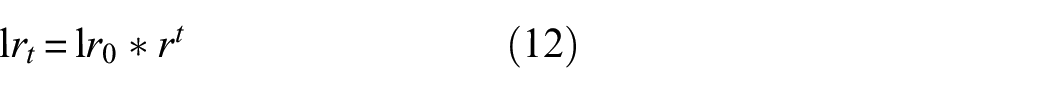
where r = 0.95 is the drop factor, t is the drop period, and it is specified as the learning rate updated each epoch.
Evaluation metrics
The performance of AFFNet in crack detection needs to be evaluated by standard and well-known metrics.
48
Here in this paper, pixel accuracy (PA), mean pixel accuracy (MPA), MIoU, and frequency weighted intersection over union (FWIoU) are used as our metrics.
48
We first introduce all symbols in the formula: for a segmentation task, if the dataset contains k + 1 classes,

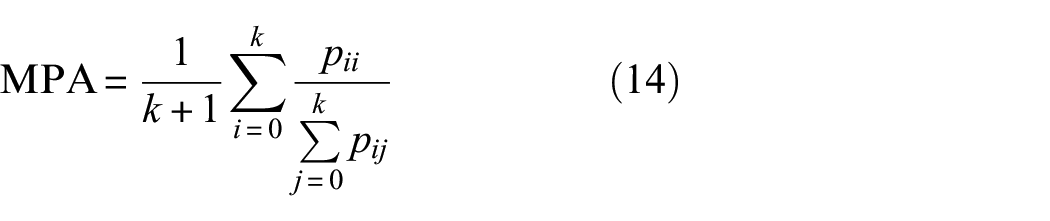
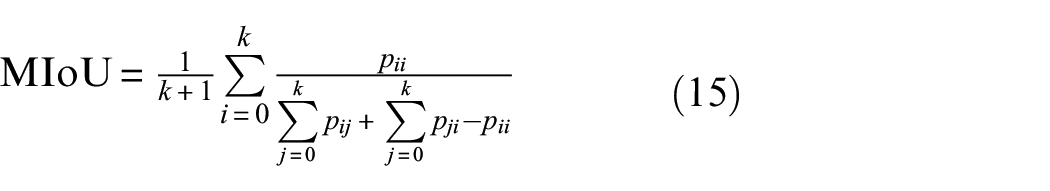
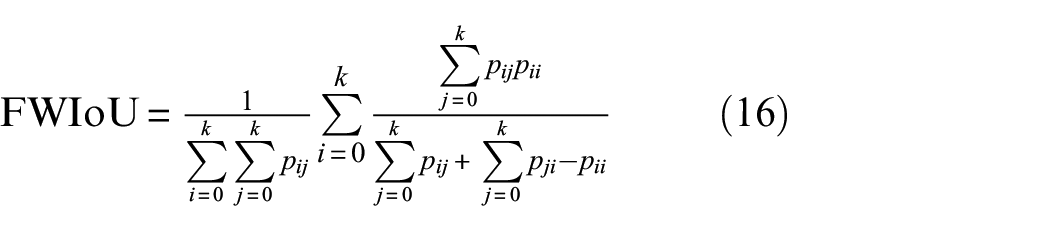
Among all the above metrics, MIoU stands out to evaluate segmentation models because of its representativeness and simplicity.
Experimental results
Analysis of results
Initial learning rate
A number of studies have shown that the initial learning rate significantly affects the convergence of the loss function.
50
It is known that a small learning rate will result in slow convergence, while a large one may hinder convergence. To obtain an appropriate value, three initial learning rates including
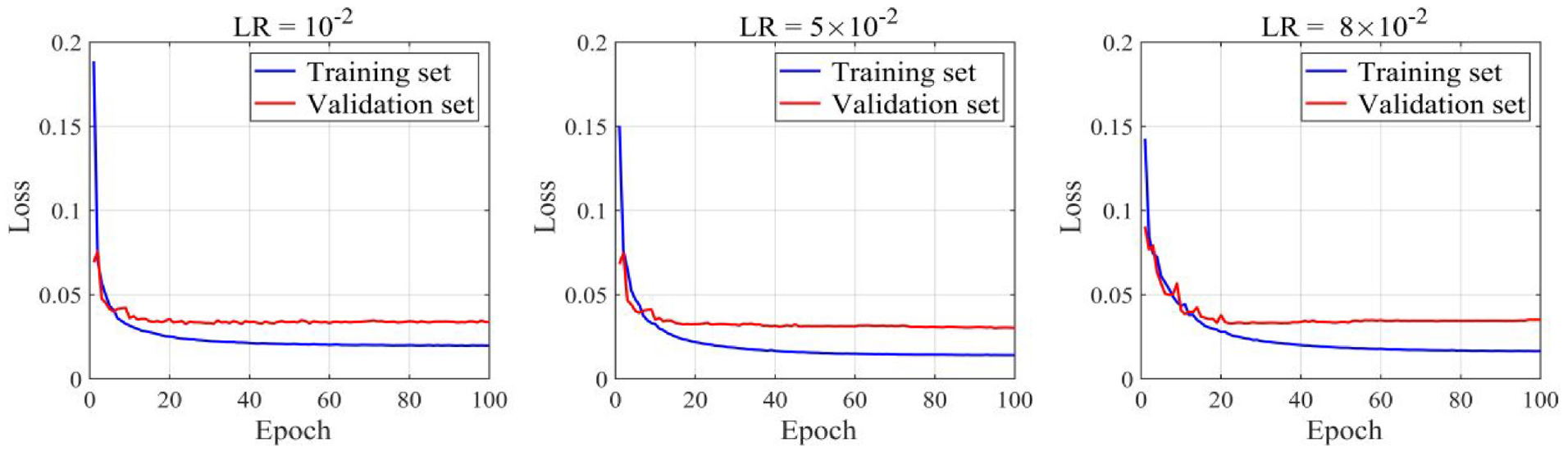
Training and validation loss curves under three initial learning rates during 100 epochs.
However, the loss function curves cannot fully reflect the performance of AFFNet.
51
The metric MIoU is also used to select an appropriate initial learning rate. The MIoU curves are shown in Figure 8. It is observed that the MIoU of the validation set is higher when the initial learning rate is
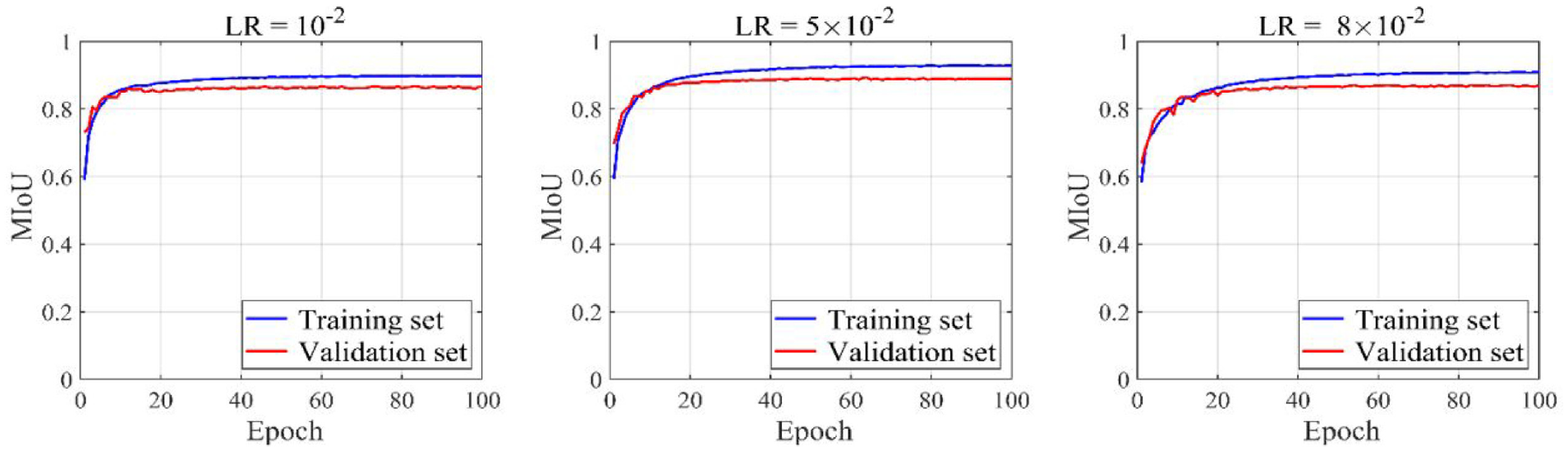
MIoU curves of three initial learning rates on training set and validation set during 100 epochs.
Execution time
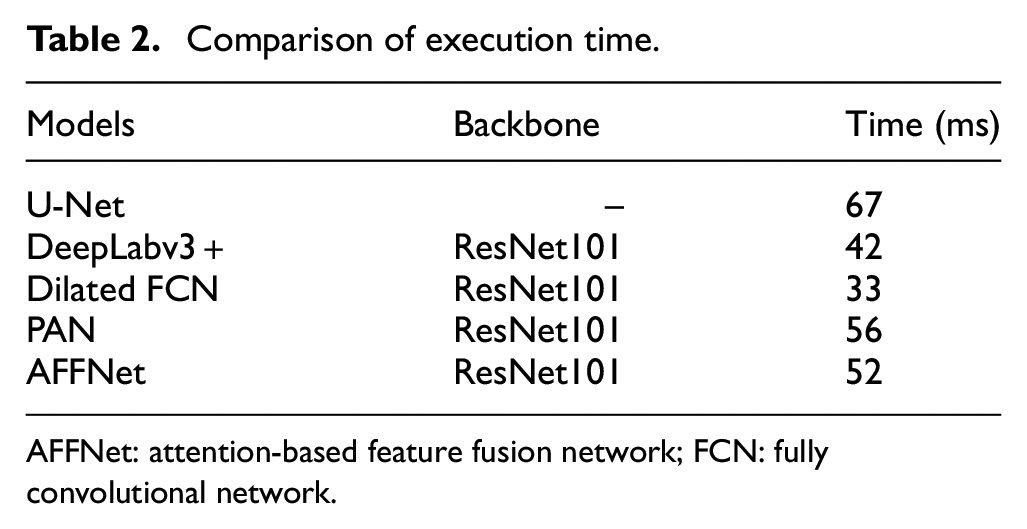
The execution time, which represents training times for each image, is a valuable metric to evaluate the model efficiency. 49 In order to reflect the advantage of execution time, AFFNet is in comparison with four state-of-the-art models, including U-Net, DeepLabv3+, Dilated FCN, and PAN. Due to the multi-scale feature fusion and wide application, U-Net 52 is used as a comparison. To assign the same size of the input image as that of the output image, zero-padding is adopted in the convolutional layer. Due to the advantage of combination with ASPP and encoder-decoder structure, DeepLabv3+ 53 is also chosen. Dilated FCN 43 as the baseline is also used for comparison. To reflect the advantage of two attention mechanisms, PAN 54 with the same structure as AFFNet is also used for comparison. In order to ensure a fair comparison, all these models are trained with the same hyper-parameters and epochs. The runtime is measured on a computer with a high-performance GPU (NVIDIA GeForce RTX 1060, 6 GB) based on the PyTorch-1.7.1 framework. The execution time of AFFNet is competitive with other state-of-the-art models, with results summarized in Table 2. The descending order of execution time can be shown as: U-Net > PAN > AFFNet > DeepLabv3+ > Dilated FCN. In Table 2, U-Net shows the longest execution time (67 ms) due to the use of deconvolutional layers. Although Dilated FCN has the shortest execution time (33 ms) due to the simple decoder structure, its segmentation process compromised its overall performance. In summary, AFFNet has an acceptable execution time (52 ms) and the highest MIoU (see Table 5).
Comparison of execution time.
AFFNet: attention-based feature fusion network; FCN: fully convolutional network.
Visualization of attention module
For VH-CAM, the attention map in Figure 2 is a crucial component, which can intuitively observe the weight distribution after visualizing the attention map. In Figure 9, for two input images, corresponding attention maps are showed in column three. Significantly, red areas indicate high contribution to the feature map while blue areas indicate low contribution. It is observed that some blue areas are in the background that avoids the crack. This proves that VH-CAM can indeed guide the proposed model to focus on the crack, even if not all the red areas are attached to the crack.
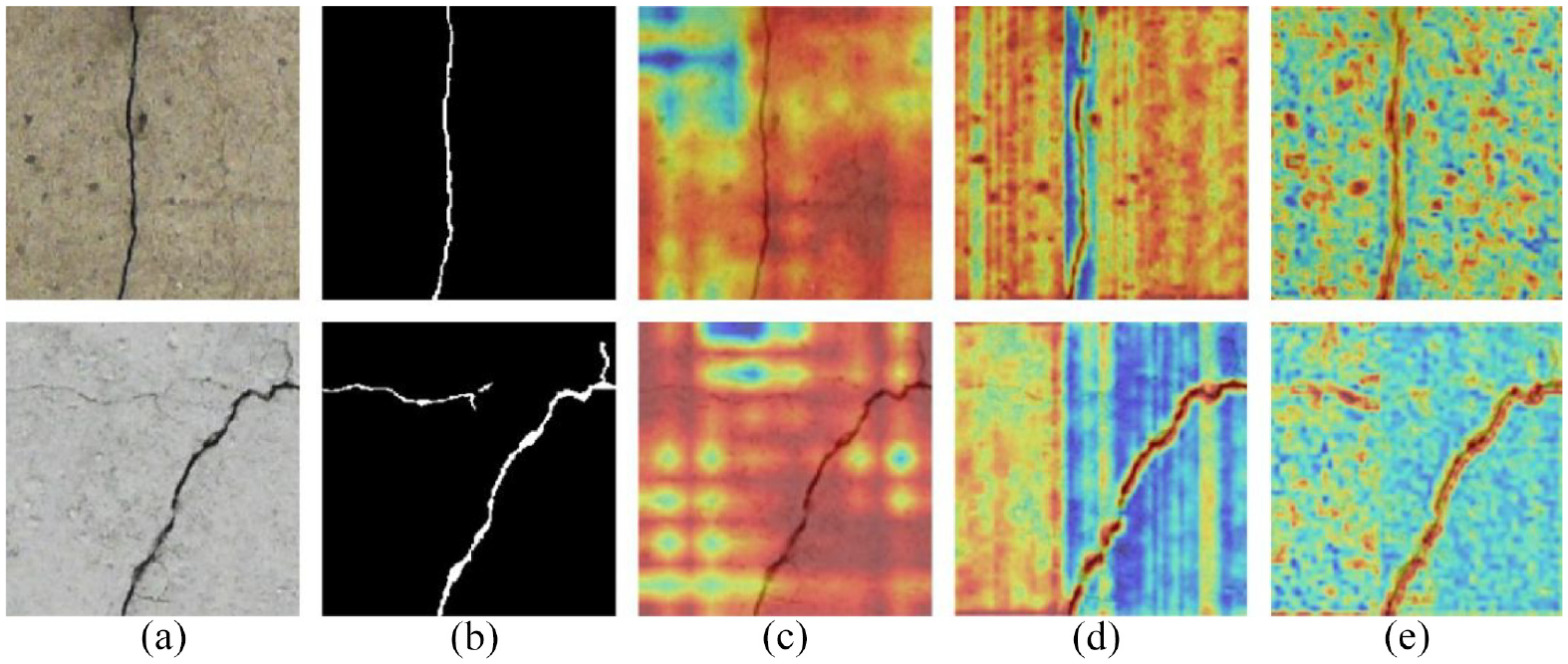
Visualization of feature maps produced by two attention mechanisms: (a) Input, (b) ground truth, (c) the attention map in VH-CAM, (d) visualization results before using ECA, and (e) visualization results after using ECA.
For ECAUM, the ECA is performed on each channel using 1 × 1 convolution. Due to the small size of the feature maps and the large number of channels, it is not feasible to directly visualize the attention map. Here, the Grad-CAM 55 is used as the visualization tool to visualize the feature maps before and after the ECA in the last attention module (i.e., ECAUM(3) in Figure 1). In Figure 9, corresponding feature maps before and after using channel attention are visualized in columns three and five, respectively, to verify whether it highlights crack areas. Before using channel attention, only a few blue areas are in the background, which means that the model considers that cracks and background are equally important. However, after using channel attention, most of red areas in the background become blue. It is obvious that the ECAUM can help to locate crack pixels. In short, these visualization methods demonstrate the importance of two attention mechanisms for improving segmentation performance in crack detection.
Effects of attention mechanisms
From the previous section, it can be seen that the attention mechanism can remarkably improve the segmentation performance by focusing on the important features, that is, crack. In order to further understand the advantage of two attention mechanisms, effects of VH-CAM and ECAUM are visualized in Figure 10, where red boxes denote incorrect segmentation predictions. Here, comparison among four networks are demonstrated, for example, backbone ResNet101, ResNet101 with VH-CAM only, ResNet101 with ECAUM, and ResNet101 with both attention mechanisms. As shown in Figure 10(c), a part of thin cracks is missed if not using any attention mechanisms, especially the cracks at the image boundary. Meanwhile, Figure 10(d) demonstrates that some misclassified crack pixels at the image boundary are now correctly classified after using VH-CAM. However, it is still not a continuous crack and it is divided into multiple disconnected segmentations. Because ECAUM can locate crack pixels better than VH-CAM, more crack pixels are classified correctly and these cracks become more continuous. However, there are still some undetected crack pixels, such as the thin crack at the bottom of the second image in Figure 10(e). By comparison, it is found that the segmentation predictions using both VH-CAM and ECAUM are better than using one of them and cracks become more complete as a result.

Visualization results of different attention mechanisms: (a) input, (b) ground truth, (c) without any attention mechanism, (d) with VH-CAM, (e) with ECAUM and (f) with VH-CAM and ECAUM.
Visualization of feature maps
Visualizing the feature maps of DL models can provide a deep insight on how the proposed models work. Figure 11 takes three concrete crack images as examples to show the visualization results of feature maps. It is observed that the feature maps closer to the input layer such as Res-1 and Res-2 can capture substantial crack features. However, the noise such as handwriting is also captured by AFFNet, which can be shown in Figure 11(a). As the image progresses through the next layers, features become increasingly abstract, which is important for the model to detect crack. With the increase on the size of the feature maps in the decoder, the crack features begin to become more accurate and the noise is filtered out. When the image reaches the output layer, the pixels are classified as crack and background.
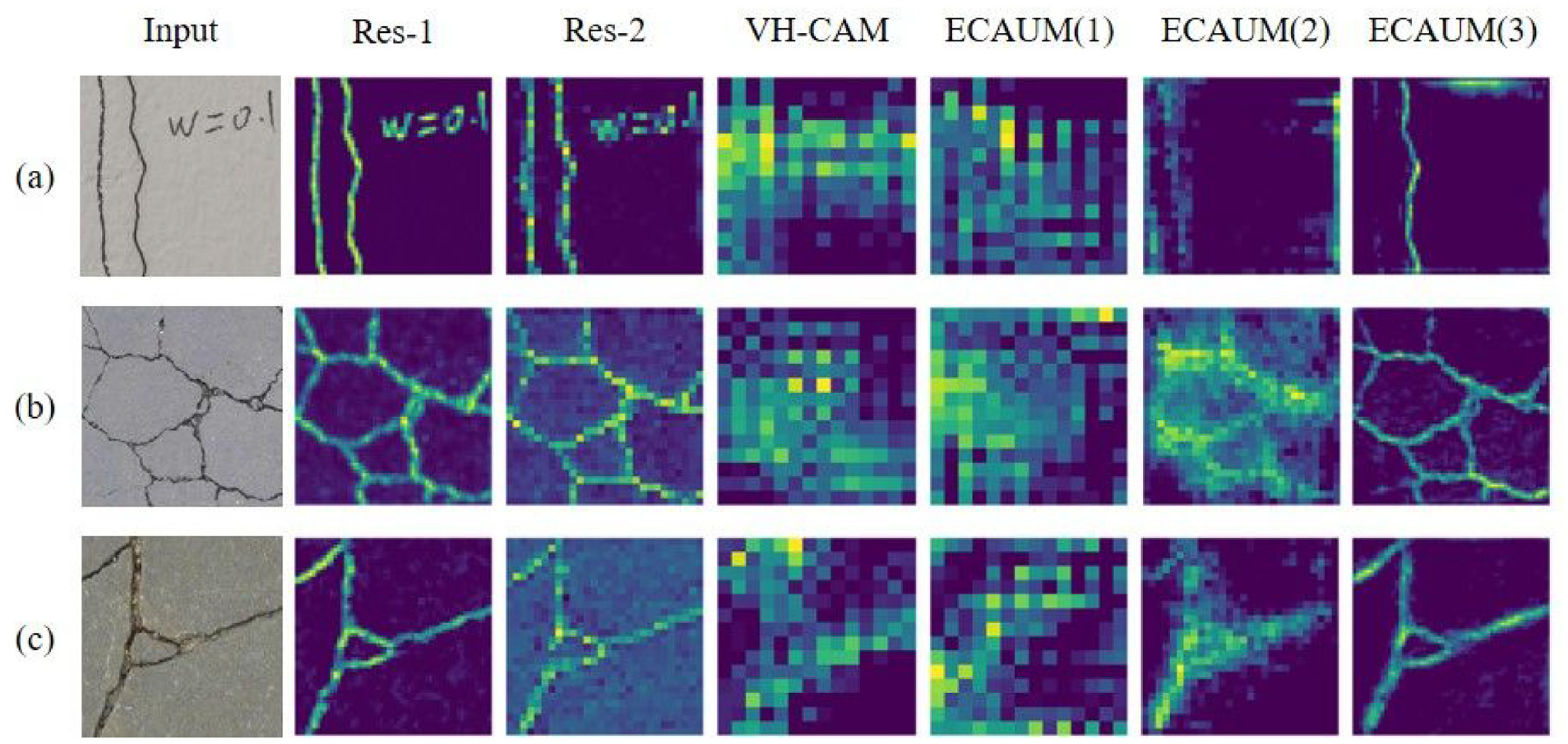
Visualization of feature maps at different modules: (a) image 1, (b) image 2 and (c) image 3.
Comparative study
Ablation study for k in ECAUM
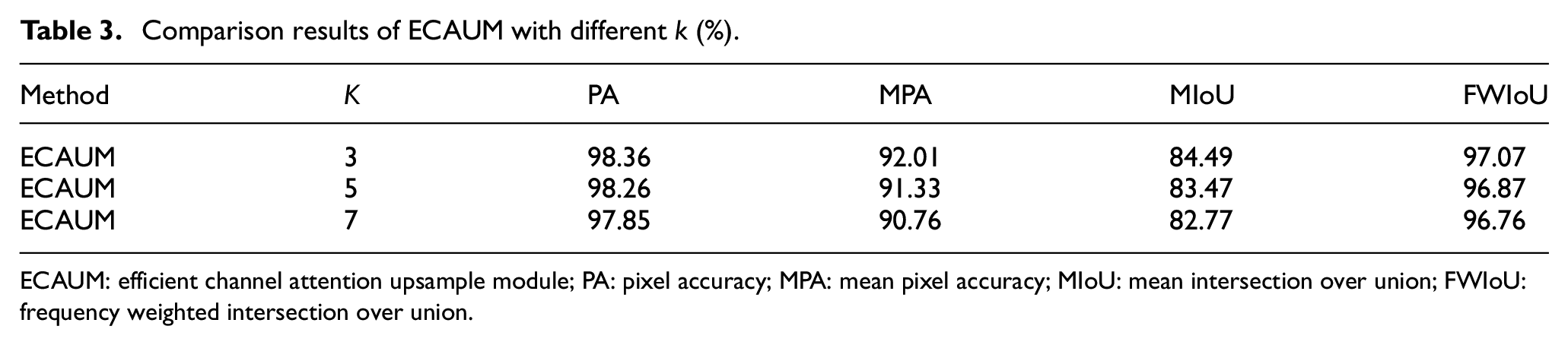
The ECAUM involves a 1D convolutional layer with a crucial parameter, that is, the kernel size k. The kernel size k needs to be determined due to the ability of capturing local cross-channel interaction. 46 Therefore, AFFNet is trained using different values of k, and the comparison results are summarized in Table 3, where k is fixed in all 1D convolutional layers. It can be seen that MIoU shows an increasing trend when the value of k becomes smaller. Since AFFNet has more hidden layers, using smaller k can improve the nonlinear fitting ability of AFFNet. Consequently, the proposed AFFNet has the best result at k = 3.
Comparison results of ECAUM with different k (%).
ECAUM: efficient channel attention upsample module; PA: pixel accuracy; MPA: mean pixel accuracy; MIoU: mean intersection over union; FWIoU: frequency weighted intersection over union.
Ablation study for attention modules
The ablation study is designed to validate the effectiveness of two attention mechanisms. The models with different attention mechanisms and corresponding evaluation metrics are summarized in Table 4. Because crack pixels normally occupy only a small proportion of the total pixels, MPA and MIoU are sensitive to small changes in the amount of crack pixels according to Equations (14) and (15). Therefore, MPA and MIoU are used as main indicators in this research. It can be seen that the baseline FCN without any attention mechanisms obtains the lowest evaluation metrics, returning the MPA and MIoU of 82.96% and 76.26%. After applying the attention mechanism, the MPA and MIoU increase steadily by increasing of the amount of correct detected crack pixels. Compared to the baseline FCN, the MPA and MIoU of the model only adopting VH-CAM can yield a slight improvement of 1.84% and 1.95% to 84.8% and 78.21%. Meanwhile, only adopting ECAUM can achieve a substantial increase on MPA and MIoU with 8.9% and 7.96% to 91.86% and 84.22%. The combination of VH-CAM and ECAUM however can yield a result of 92.01% and 84.49% in MPA and MIoU, which proves that two attention mechanisms work complementary.
Ablation study of two proposed attention mechanism modules on the test set (%).

FCN: fully convolutional network; AFFNet: attention-based feature fusion network; VH-CAM: vertical and horizontal compression attention module; ECAUM: efficient channel attention upsample module; PA: pixel accuracy; MPA: mean pixel accuracy; MIoU: mean intersection over union; FWIoU: frequency weighted intersection over union.
Comparison with other semantic segmentation models
To reflect the excellent performance of AFFNet, four state-of-the-art models trained by the same dataset are compared with the proposed model. The segmentation results of five models are listed in Table 5. It is clear that the proposed AFFNet outperforms other models. Owing to the concentration on crack features by VH-CAM and ECAUM, AFFNet can obtain the most crack pixels than other models. Therefore, AFFNet achieves the highest evaluation metrics and its value of MPA and MIoU reach the highest 92.01% and 84.49%, respectively. The Dilated FCN with simple decoder shows the lowest MPA and MIoU compared to other models with more trainable parameters in the decoder. PAN achieved a slightly higher MPA and MIoU than Dilated FCN, which attributes to the simple combination of feature fusion and the attention mechanism used, namely global attention upsample, incapable of capturing fine crack features (76.79% in MIoU with global attention upsample only). The combination of ASPP and encoder-decoder structure contributes to the good performance of DeepLabv3+ in crack detection. However, two upsample operations cannot restore the lost details efficiently, the performance of DeepLabv3+ is inferior to U-Net and AFFNet. Four deconvolutional layers in U-Net are able to recover the image resolution. However, its MIoU is still lower than AFFNet on account of the direct fusion between low-level features and high-level features. 42 Consequently, the proposed AFFNet has the distinct advantages and achieves the best performance and can capture rich contextual information and guide low-level features to recover the crack localization.
Segmentation results of five models (%).
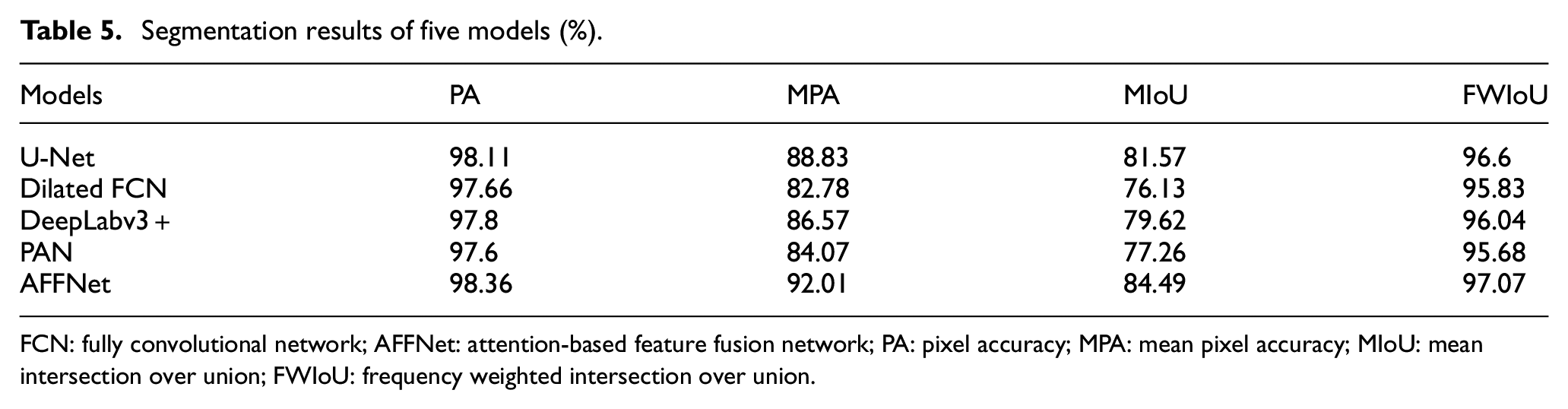
FCN: fully convolutional network; AFFNet: attention-based feature fusion network; PA: pixel accuracy; MPA: mean pixel accuracy; MIoU: mean intersection over union; FWIoU: frequency weighted intersection over union.
On the other hand, in order to understand respective enhancement brought by two designed attention mechanisms, the VH-CAM and ECAUM are incorporated into U-Net and DeepLabv3+ as comparison. The same training set and test set are used to conduct this experiment with two modified models. The result shows that the MIoU of DeepLabv3+ increases by 1.17%, from 79.62% to 80.79%. Due to only one feature fusion operation, the performance of DeepLabv3+ is not much improved. However, four feature fusion operations of U-Net result in a great improvement in its performance with the addition of two attention mechanisms, and its MIoU increases from 81.57% to 83.11%. These results indicate that two attention mechanisms can indeed improve the performance of other models, but the extent of improvement is related to the number of feature fusion operations. Thus, VH-CAM and ECAUM can be plugged into existing semantic segmentation models.
Discussion
Visualization results of multi-type crack image
To verify the effectiveness and robustness of AFFNet, the comparative experiment is conducted using different types of cracks. Figure 12 shows the visual comparison result between AFFNet and other models. From top to bottom, four types of cracks are diagonal cracks, transverse cracks, reticulation cracks, and wide cracks, respectively. From left to right, concrete crack images predicted by different models are input image, ground truth, U-Net, Dilated FCN, DeepLabv3+, PAN, and AFFNet, respectively. It can be seen that when thin cracks or the low contrast between cracks and background appear, Dilated FCN, DeepLabv3+, and PAN are not able to capture part of thin cracks, clearly presented in the reticulation crack case. The performance of U-Net is better than above three models, but a few crack features in reticulation crack image is still missing. Meanwhile, for wide cracks, the edge of the crack predicted by U-Net will appear some scattered pixels that should belong to background pixels but are misclassified as crack pixels. In wide crack case, Dilated FCN produces small holes in the crack area and PAN cannot generate a complete crack due to the influence of background noise. In contrast, AFFNet adopts two attention mechanisms to extract more crack information, which brings great benefits in improving the accuracy of the crack detection. Overall, the segmentation performance of AFFNet is better than other models.
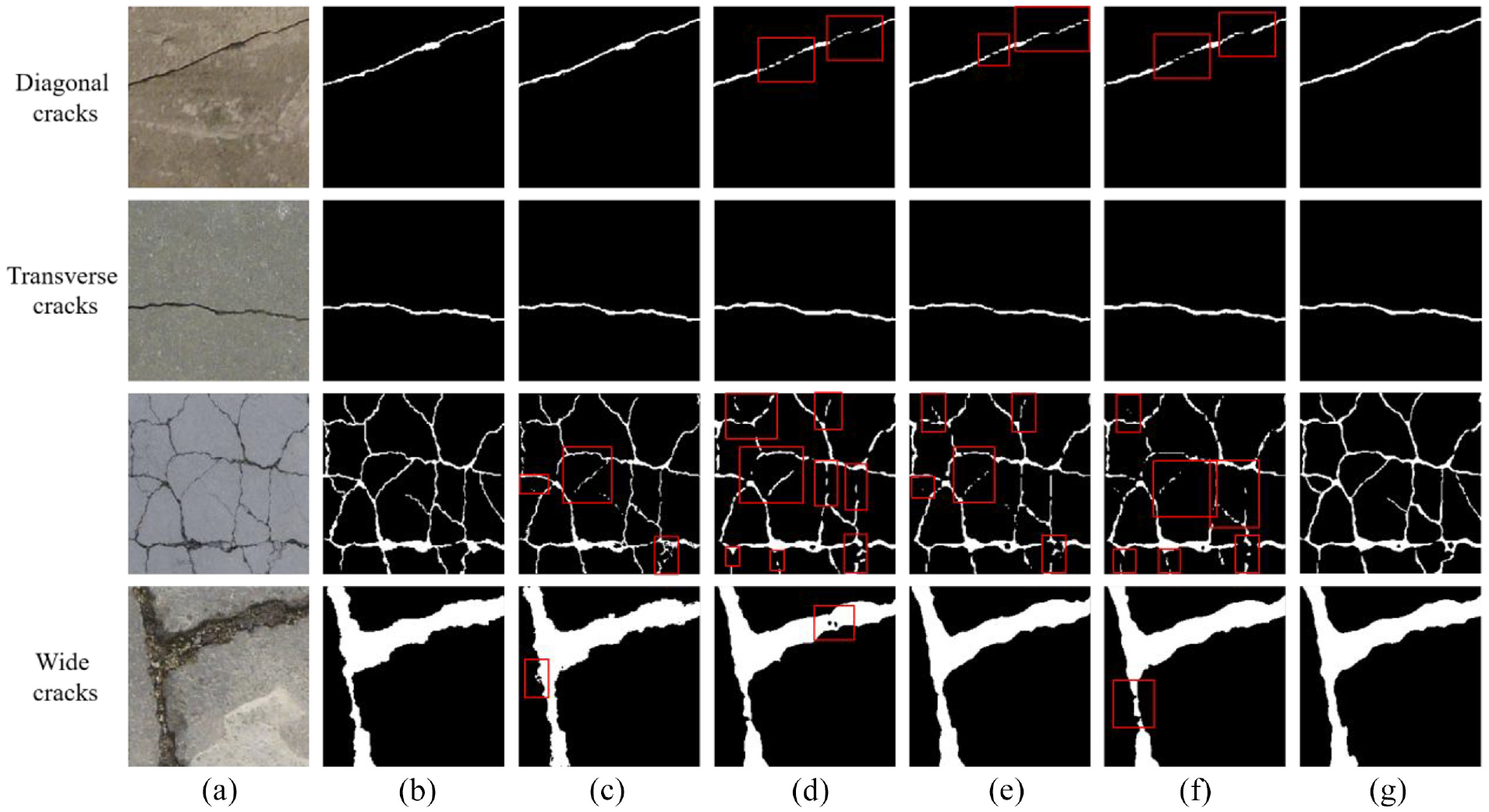
Prediction results of different types of cracks using different models: (a) input, (b) ground truth, (c) U-Net, (d) Dilated FCN, (e) DeepLabv3+, (f) PAN and (g) AFFNet.
Visualization results of concrete cracks under complex conditions
It should be noted that above concrete crack images are relatively clean and contain low-level noise. However, in reality, the cracks are quite versatile and can present with various imagery disturbances. These images will be interfered by spots, shadow, water stain, and handwriting, which increase the difficulty of crack detection. Therefore, another comparative experiment is conducted using cracks under complex conditions. Figure 13 shows the visual comparison result between AFFNet and other models on six types of cracks, such as crack with spots, crack with shadow, crack withwater stain, crack with handwriting, and so on. It can be seen that all the models have plausible abilities to distinguish crack and noise when detecting cracks with spots and shadow. However, the model deficiencies described in the previous section still exist. For example, Dilated FCN, DeepLabv3+, and PAN are unable to detect the thin part of the crack and U-Net misclassifies part of background as cracks at the edge of the wide crack. In addition, U-Net also incorrectly detects background of the shadow edge as crack. For crack with water stain, all other models exhibit false positives due to the low contrast between crack and water stain. These models overlook the width information of cracks, usually with the predicted crack width larger than the ground truth. Meanwhile, part of thin cracks is also ignored by Dilated FCN, DeepLabv3+, and PAN. Considering the crack with handwriting, the discrepancy in crack detection is more distinct. Due to the unified pretrained ResNet101, Dilated FCN, DeepLabv3+, and PAN perfectly distinguish cracks and handwriting. However, U-Net incorrectly recognizes part of handwriting as cracks. Different from other models, the AFFNet based on a pretrained ResNet101 still provides a satisfactory crack segmentation result when detecting concrete cracks under complex conditions.
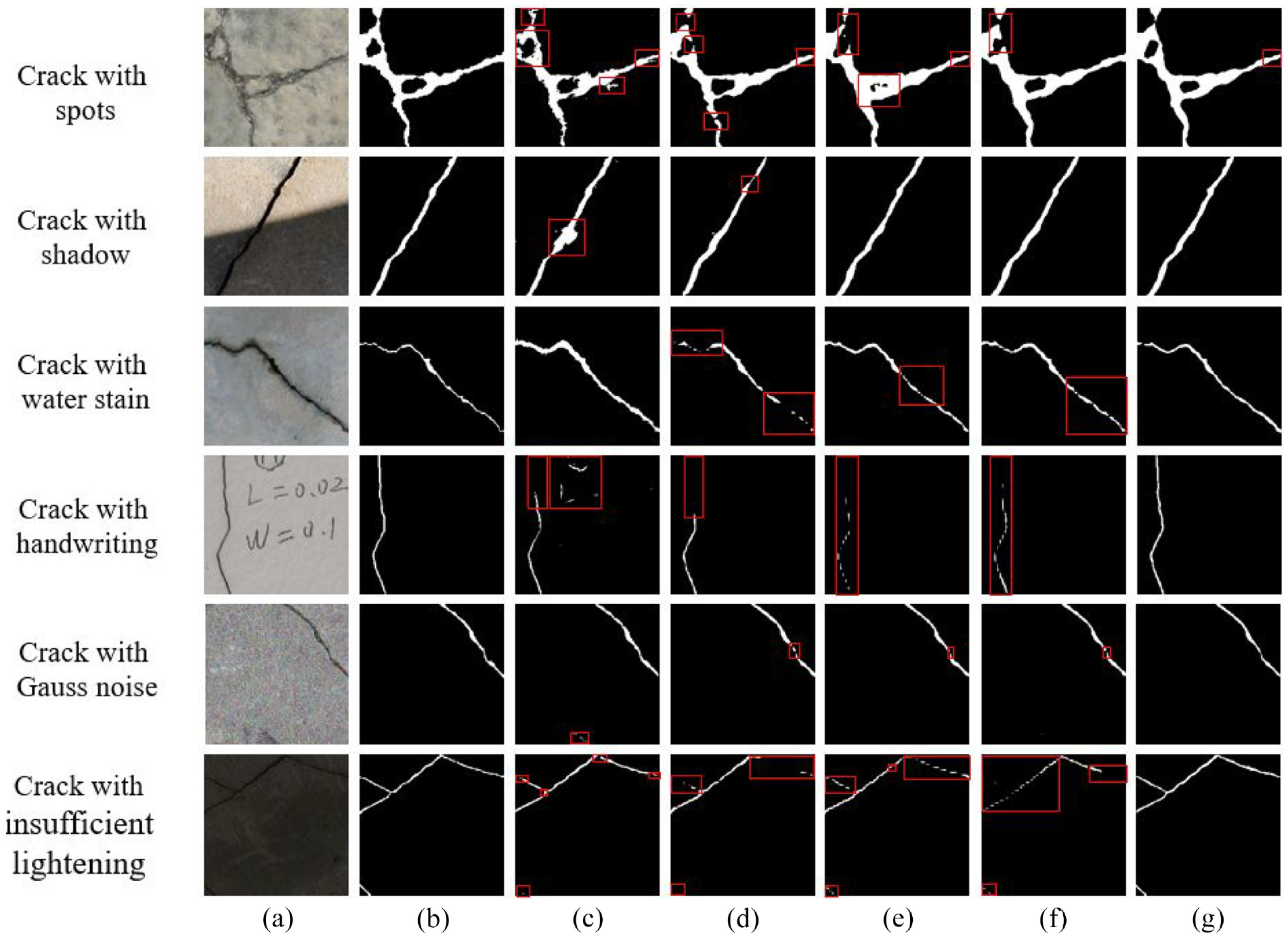
Prediction results of cracks under complex conditions using different models: (a) input, (b) ground truth, (c) U-Net,(d) Dilated FCN, (e) DeepLabv3+, (f) PAN and (g) AFFNet.
Quantification of crack images
Crack identification by AFFNet in the test set are employed for the quantification of three morphological features at a pixel level: crack area, crack length, and crack mean width. The crack area is obtained by calculating the number of crack pixels. The acquisition of crack length is relatively complex. The crack needs to be skeletonized into the thin lines with a single-pixel width and then the crack length can be obtained by calculating the number of pixels in thin lines. In this paper, the approach in the research 56 is used to perform the skeletonizing crack task. The crack mean width is the ratio between the crack area and the crack length.
The quantification differences between predicted results and ground truth are illustrated in Figure 14. As shown in Figure 14(a), the accuracy of the crack area is not competent yet, with scattered points diverted above the diagnostic line, indicating that there are background pixels in crack images misclassified as crack pixels. Meanwhile, some crack pixels are ignored by AFFNet when the crack area is more than 6000 pixels. It is obvious that AFFNet is susceptible to underestimating the crack area for large cracks. With respect to crack length, it is observed that most plotted points are near the diagnostic line, which means that AFFNet performs well in identifying crack length. The crack mean width is influenced by two other indicators. Statistically, the predicted area and mean width are greater than the ground truth in 69.6% and 72.3% of the cases, while 74.23% of the predicted length is lower. This means that the proposed model tends to enlarge the crack width and decrease the crack length. The possible reason of enlargement on crack width is that AFFNet is prone to generating coarse segmentation when thin cracks appear because of up-sampling. The reason of the underestimation on crack length is that thin cracks especially reticulation cracks are missed by AFFNet.
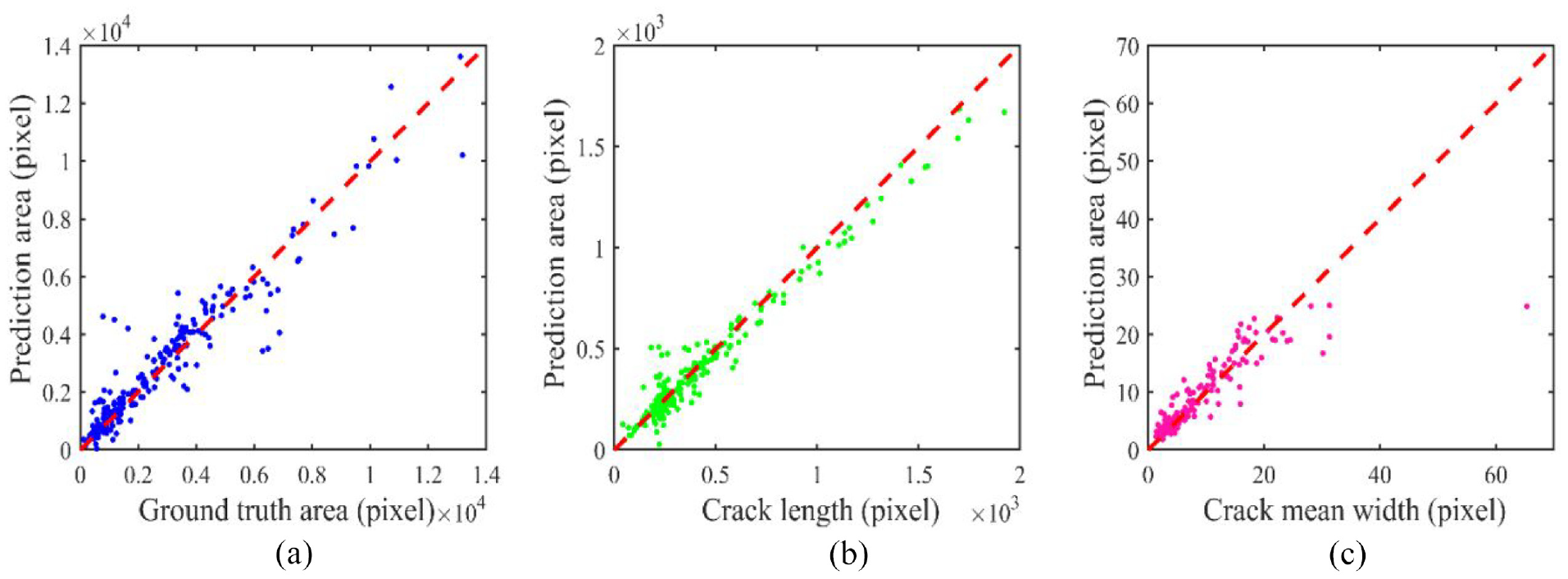
Quantification of concrete crack images at a pixel level: (a) crack area, (b) crack length and (c) crack mean width.
In order to further evaluate the effectiveness of the proposed algorithm and to obtain the geometric information of the actual concrete cracks, a new crack dataset called AFF-D (AFFNet datasets) was collected. The crack image acquisition process is shown in Figure 15, the concrete crack datasets were obtained by IPHONE camera and the distance from camera to the concrete surface was set at 30 cm by using laser rangefinder. Then, a crack width meter was used to measure the actual size of concrete crack. After performing the above operation, more than 1700 concrete crack images with a resolution of

The crack image acquisition process.
Built on the proposed AFFNet algorithm, the crack morphological features such as crack area, crack length, and crack mean width can be calculated for the AFF-D dataset. As mentioned above, the crack can be skeletonized into the thin lines with a single-pixel width and then the crack geometric information can be obtained by calculating the number of pixels in thin lines. Then, the actual crack area, length, and mean width could be obtained by multiplying the area and length represented by each pixel using the camera calibration parameter k.
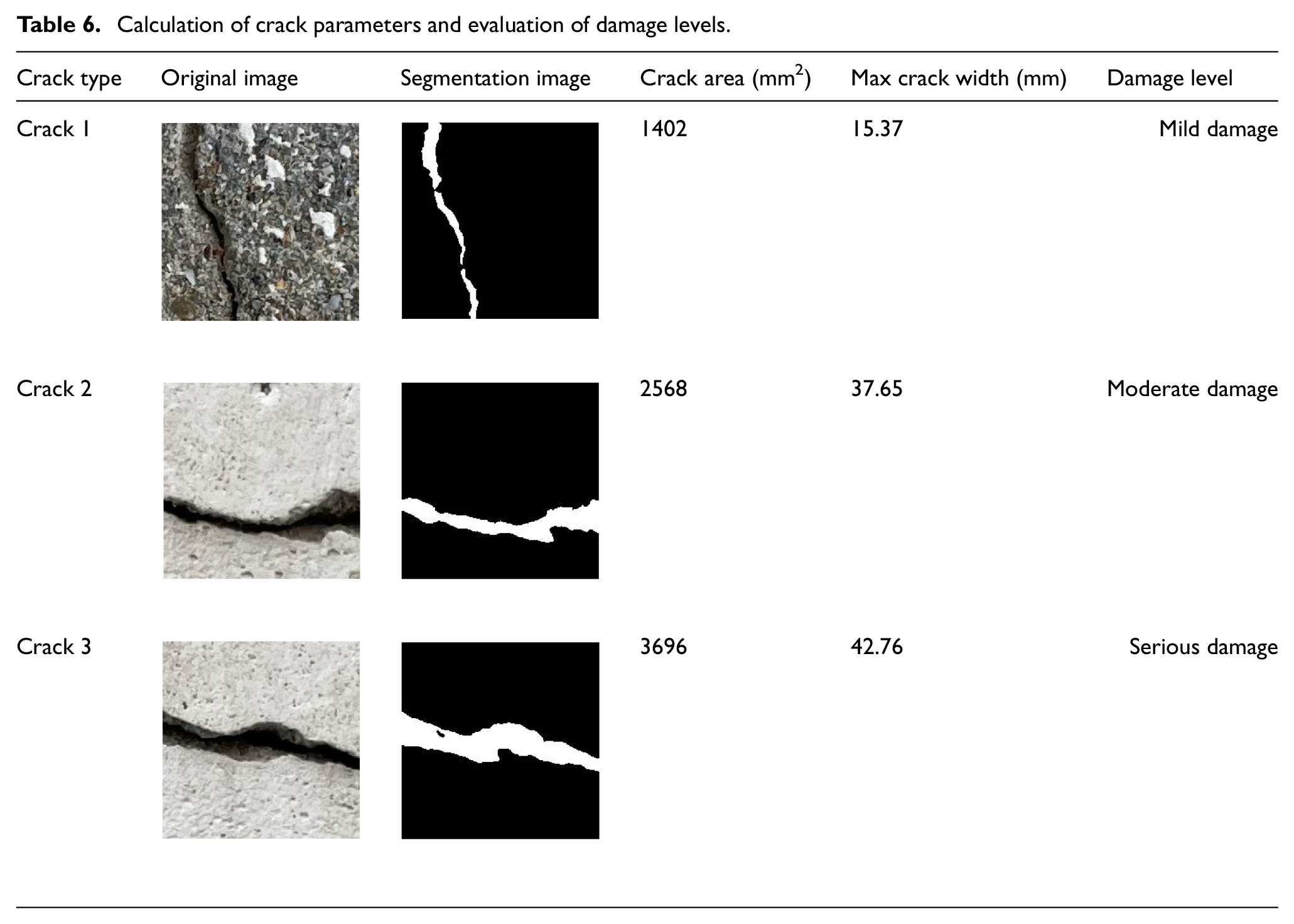
In Table 6, the geometric information of the actual concrete cracks was calculated, and the damage level of the crack was evaluated based on the actual crack area, which were valuable indicators for inspectors to evaluate and monitor the structural health quantitatively.
Calculation of crack parameters and evaluation of damage levels.
Evaluation of AFFNet using other dataset
To further verify the effectiveness of AFFNet, a robustness analysis is performed. Here two new datasets, for example, DeepCrack 57 and SDNET2018 datasets, are used for crack detection with five selected models. The images in two datasets contain a variety of noise, which is different from our built dataset. For example, obstructions in DeepCrack include surface roughness and mark. Meanwhile, obstructions in SDNET2018 include holes and low lightening. It should be noted that these two datasets are not utilized to train AFFNet prior to the test, with the aim to examine the model robustness. The crack images in datasets need to be resized to 224 × 224 pixels due to the requirement of asymmetric convolution in VH-CAM.
Table 7 lists the performance of five models tested by the DeepCrack dataset containing 527 crack images. Compared with other models, AFFNet achieves the highest MIoU of 82.28%, with a distinct margin of at least 4.34% than other models. As shown in Figure 16, four characteristic crack images are selected to display the prediction results. From left to right, the types of cracks are reticulation crack, crack with white line, crack with joint, and crack with handwriting. It can be seen that AFFNet can effectively detect cracks, including the cracks with rough background.
Segmentation results of five models on DeepCrack dataset (%).
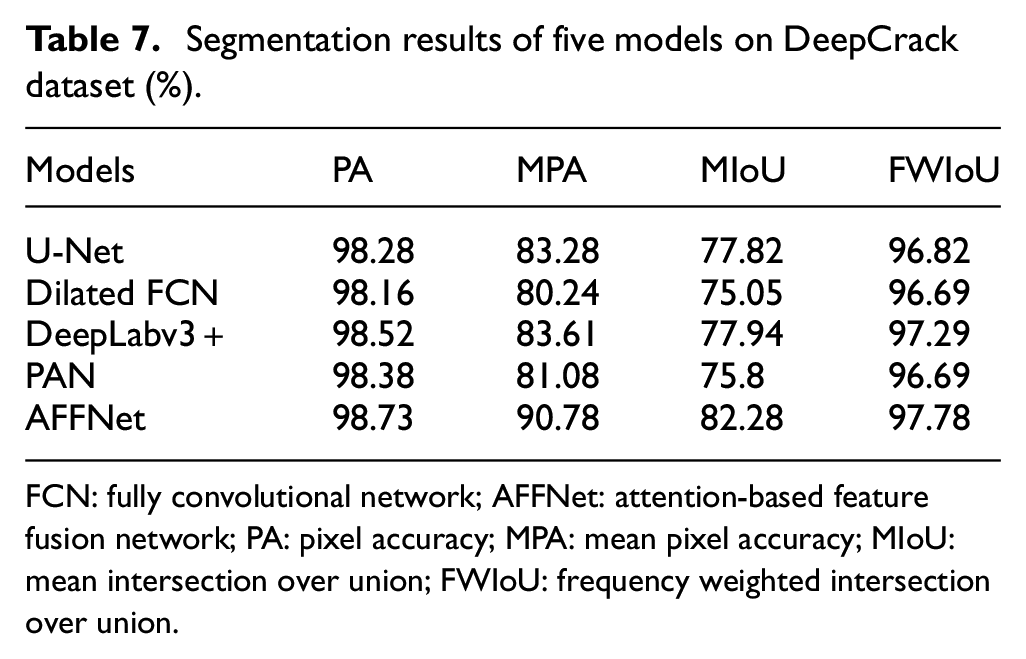
FCN: fully convolutional network; AFFNet: attention-based featurefusion network; PA: pixel accuracy; MPA: mean pixel accuracy; MIoU: mean intersection over union; FWIoU: frequency weighted intersection over union.
Prediction results in the DeepCrack dataset using AFFNet: (a) reticulation crack, (b) crack with white line, (c) crack with joint, and (d) crack with handwriting.
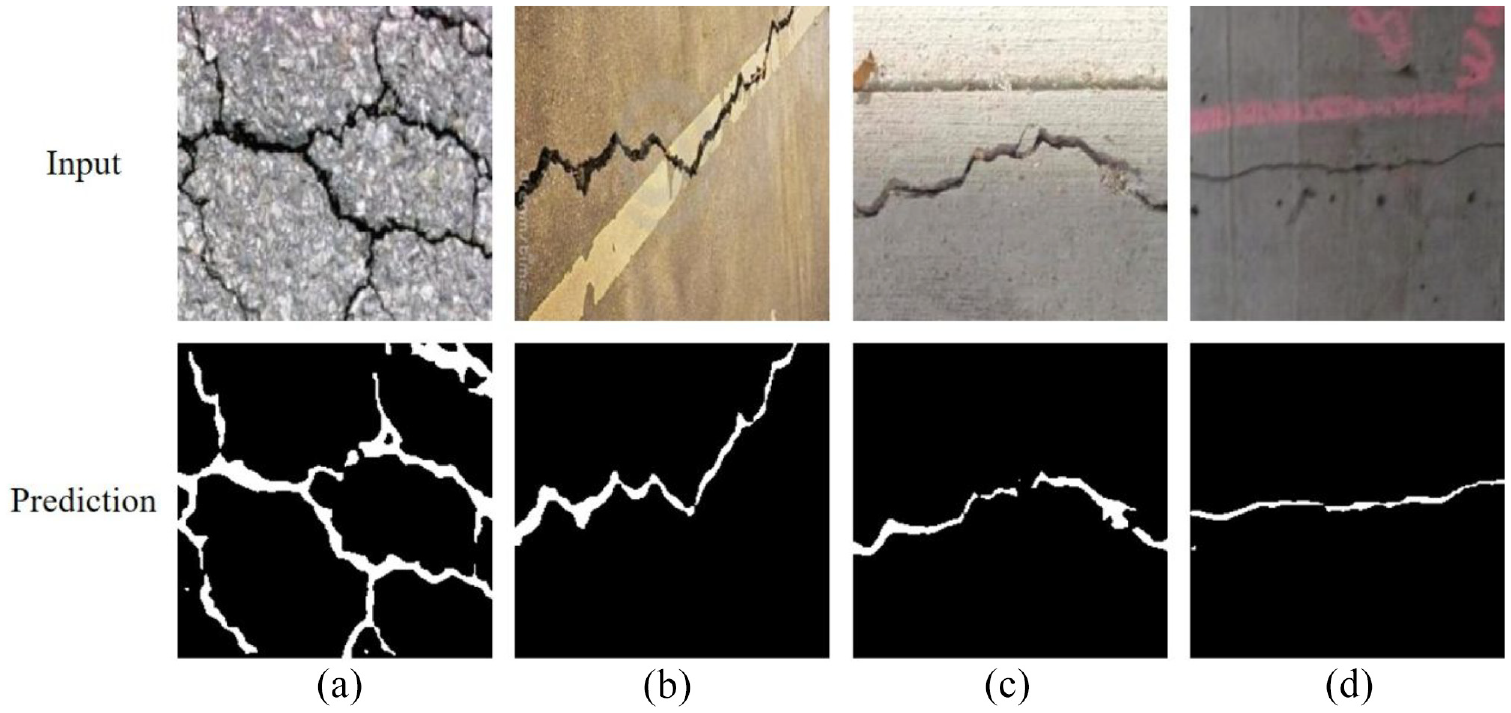
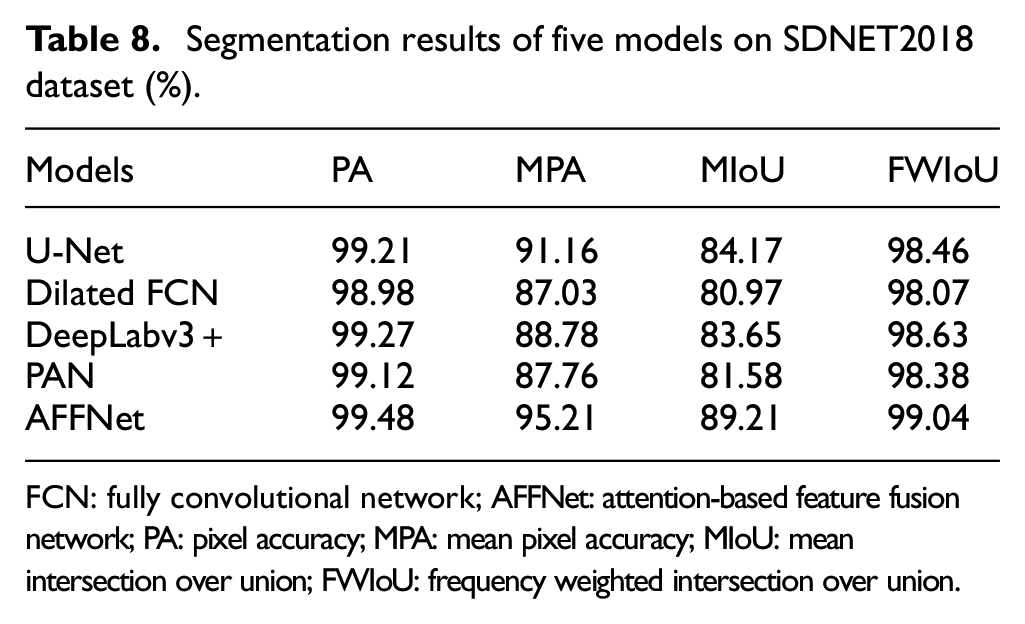
Besides the DeepCrack dataset, the SDNET2018 dataset is also used to test the effectiveness of AFFNet. A total of 50 randomly selected crack images are resized to 224 × 224 pixels with RGB channels and then manually labeled as test images. Table 8 lists the performance of five models tested by the SDNET2018 dataset, which has shown that AFFNet achieves the highest MIoU of 89.21%. Figure 17 illustrates four typical concrete crack images in the SDNET2018 dataset, including transverse crack, crack with low lightening and crack with holes. The prediction results have shown that AFFNet has strong robustness regardless the conditions the crack attached.
Segmentation results of five models on SDNET2018 dataset (%).
FCN: fully convolutional network; AFFNet: attention-based feature fusion network; PA: pixel accuracy; MPA: mean pixel accuracy; MIoU: mean intersection over union; FWIoU: frequency weighted intersection over union.

Prediction results in the SDNET2018 dataset using AFFNet: (a) transverse crack, (b) crack with low lightening, (c) crack with big holes, and (d) crack with tiny holes.
Conclusion
In order to cope with complex conditions around the concrete structure, this paper implements a novel DL-based framework, namely AFFNet, for automatic concrete crack detection at the pixel level. In particular, the proposed AFFNet consists of ResNet101 as backbone and two attention mechanism modules, including the VH-CAM and the ECAUM. Specifically, the VH-CAM uses two convolution layers of kernel size 1 × W and H × 1 to make each pixel obtain more information and then generate the attention map through the matrix multiplication to capture rich contextual information. The ECAUM provides rich contextual information to guide low-level features.
The effectiveness and robustness of AFFNet are verified by a concrete crack dataset after a serious of experiments. The experimental results show that two attention mechanisms can contribute a better performance in crack segmentation. The proposed model achieves the highest MIoU of 84.49% in comparison with other existing models, including U-Net, Dilated FCN, DeepLabv3+, and PAN. In addition, a robustness analysis is also conducted using DeepCrack and SDNET2018 datasets. The prediction results show that the proposed model can also maintain an accurate segmentation performance in detecting cracks with untrained dataset.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Youth fund project of Jiangsu Natural Science Foundation (No. BK20180708) and Science and Education Integration Innovation Pilot Program from Qilu University of Technology (Shandong Academy of Sciences)–International Collaboration Project (2022GH006).