
Abstract
Due to adverse working conditions of rotating machinery in actual engineering, bearing fault data are more difficult to acquire compared to normal data. That said, the real collected bearing vibration data are usually characterized by imbalance. Meanwhile, fault information of the raw collected bearing vibration data is effortlessly drowned out by strong noises, which indicates that it is awkward to efficiently recognize bearing fault states via using traditional fault diagnosis methods under this background. To overcome these problems, this research proposes an individual approach formally intituled as robust multi-scale learning network (RMSLN) with quasi-hyperbolic momentum-based Adam (QHAdam) optimizer for bearing fault diagnosis, which mainly includes convolution-pooling operation, multi-scale branch, and classification layer. Within the proposed method, the channel attention mechanism based on squeezed excitation network is embedded into the multi-scale branch in the form of residual connections, which not only reinforce important information and weaken noise interference, but also capture fault features more comprehensively and enhance the discrimination of fault states with fewer samples. Additionally, in the training process, QHAdam optimizer is introduced to tightly control the loss of RMSLN to enable a faster and smoother convergence. Two groups of experimental bearing data are studied to support the availability of presented approach, and several traditional fault diagnosis methods and representative imbalance fault diagnosis approaches are compared in four evaluation metrics (accuracy, macro-precision, macro-recall, and macro-F1 score) to highlight the advantages of the presented method.
Highlights
1. A robust multi-scale learning network (RMSLN) is proposed.
2. A novel approach formally intituled as RMSLN with QHAdam optimizer is proposed for intelligent fault diagnosis of rolling bearing.
3. The effectiveness of the proposed method is validated by experimental cases.
Introduction
With the advance of high-end intelligent manufacturing technology, it means strict requirements for mechanical equipment security and reliability. Rolling element bearing as a crucial supporting component of mechanical equipment, its health status pertains to the whole mechanical equipment process.1–3 Once the rolling element bearing is defective, it can slow down the progress of equipment work and potentially culminate in a tragic casualty accident. 4 Hence, it is of great scientific and realistic engineering importance to ascertain bearing faults promptly and to avoid continuous deterioration of bearing faults.5–7
In the early days of the popularity of data-driven rolling bearing fault diagnosis methods, scholars, and experts adopted some machine learning algorithms to recognize faults.8,9 Common diagnostic methods of machine learning include random forest (RF), 10 support vector machine (SVM) 11 , and K-nearest neighbor algorithm (KNN). 12 For instance, Xiao et al. 13 used a weighted RF to classify multiple features extracted from multiple domains of the bearing vibration signal. Aiming at the low diagnostic efficiency of traditional RF algorithm and the need for multiple voting, Wang et al. 14 combined Spark with improved RF, which not only banishes recurrent voting prone decision trees, but also enhances diagnosis speed. Ye et al. 15 considered the multiscale permutation entropy (MPE) of raw vibration signal as the feature and input it into SVM to diagnose bearing faults. Chen et al. 16 analyzed raw signals by correlation coefficients and picked some susceptive feature indicators to input into Adboost-SVM for the identification of early bearing defects. By applying this method on experimental data, it was verified that this approach may successfully extract features of feeble defects. Yan et al. 17 used multi-scale envelope dispersion entropy for feature extraction of bearings and used KNN for fault pattern recognition. Although traditional machine learning methods have yielded outstanding success and have provided a solid foundation for the fault diagnosis industry, there still remain some issues. As these methods have a limited feature learning capability, they need to draw on human experience to extract easily distinguishable features. These methods are time-consuming and fail to provide reasonable diagnostic accuracy once confronted with immense sample data and data under complex working conditions.
As an archetypical method of deep learning, convolutional neural network (CNN)18,19 can effectively alleviate the limitations of traditional machine learning methods. CNN and its variants have been widely used in mechanical fault diagnosis20–22 due to their integration of feature extraction and pattern recognition, saving the time of artificial feature selection. For example, Xu et al. 23 presented an online transfer CNN that not only achieves desired diagnostic accuracy, but also cuts the diagnostic time in half. Zhai et al. 24 proposed a CNN with adaptive learning rate for diagnosis of bearing under dynamic conditions. Chen et al. 25 translated vibration signal into a two-dimensional feature map by cyclic spectral coherence, which was fed into CNN with group normalization for fault classification. Li et al. 26 applied CNN and DNN to learn raw vibration signals and time-domain statistical indicators in parallel and fused the features they learned. The experiments show that the parallel combined model has stronger feature extraction capability than the single model. Zhang et al. 27 used 1DCNN to analyze the vibro-acoustic signals to extract rich complementary features, effectively identifying the type of damage in a strong noise environment. To overcome the problem of damaged data being hard to harvest, Ali and Cha 28 proposed a GAN with an attention mechanism to generate synthetic data to accommodate the demand of IDSNet with massive samples. Zhao et al. 29 proposed a new unsupervised network with feature extractor and cluster extractor to solve the troublesome issue of labeling samples, which provides valuable theoretical benefits for realizing unsupervised fault diagnosis of rotating machinery. Li et al. 30 utilized the modified deep belief network to process infrared thermal images in fault states to implement rotor-bearing system fault diagnosis. However, the factual fault signals captured are intricate, often encompassing multiple fault characteristics and distributed over different time scales. Single-scale CNN struggles to take into account global features in the process of learning features, which may result in missing some fault information. Therefore, to fully exploit feature information on different scales, Chen et al. 31 applied multi-scale CNNs to ascertain bearing faults. Zhang et al. 32 adopted deeply separable convolution instead of traditional convolution to make multi-scale networks lighter and save training time. Additionally, to avoid degradation of performance due to overly deep networks, Liu et al. 33 proposed multi-scale residual networks. The relevant experimental analysis showed that, when there are an identical number of faulty samples and normal samples, all of the above methods may deliver favorable diagnostic performance. Nevertheless, in practical engineering applications, due to adverse working conditions of mechanical equipment, the collected bearing fault data is limited and does not meet the requirement having equivalent sample numbers in each category. As a result, some imbalance fault diagnosis approaches have been presented for handling sample imbalance or small sample problems. For instance, Li et al. 34 employed predictive generative denoising autoencoder to generate samples so that the imbalanced dataset comes to an equilibrium state. Pan et al. 35 suggested deep feature generation network that may automatically derive fault features from existing samples and generate plentiful fake fault features. Subsequently, these hybrid fault features are fed into the classifier for conducting model training, which mitigates sample imbalance problem. Besides, considering the data imbalance, Zhao et al. 36 suggested a normalized CNN to determine the health status of rolling bearings. Through experiments and comparative analysis, the suggested approach manages to maintain more outstanding stability in the case of extreme data imbalance. Unfortunately, when collected bearing data are contaminated by heavy noisy environments, recognition accuracy of aforementioned imbalance fault diagnosis approches will face a decline in identifying fault patterns.
Inspired by the above background, to tackle the problem of degradation of recognition accuracy due to sample imbalance and strong noise interference, this paper proposes a robust multi-scale learning network (RMSLN) with quasi-hyperbolic momentum-based Adam (QHAdam) optimizer for bearing fault diagnosis. Firstly, a convolution-pooling operation is employed to process input signals, which allows for fast global feature extraction and dimensionality reduction. Secondly, the multi-scale branch is utilized to learn the previous features in a parallel way and enhance the diversity of features. Additionally, to reinforce important information and weaken useless information, the channel attention mechanism is embedded in multi-scale branch, which can avoid the degradation of model performance. Meanwhile, to weaken the effect of some anomalous feature values and reduce computational memories, global averaging pooling (GAP) is adopted to flatten the features of each branch. Finally, all feature vectors are concatenated and fed into the softmax classifier for obtaining fault recognition result. Note that, in the training process, a new optimization method named QHAdam optimizer is also introduced to strictly control the loss value, which is able to not only accelerate model converge, but also improve recognition accuracy. The essential contributions of this paper are listed below.
(1) A novel model hailed as RMSLN is presented by embedding skillfully the channel attention mechanism to multi-scale branch in the way of residual connection, which can not only strengthen the learning of discriminative features, but also overcome the problem of degradation of model performance existing in traditional learning network.
(2) An RMSLN-based end-to-end data-driven intelligent bearing fault diagnosis framework is presented, which does not require expert knowledge and manual feature extraction.
(3) Two separate sets of experimental data serve for establishing the validity of presented approach. Additionally, the advantages of presented approach within sample imbalance and strong noise environment are highlighted in comparison with some representative methods.
The following is the outline of this paper. The theory of related works (i.e., residual learning and channel attention) is introduced in section “Related works.” The model structure and training process of the proposed RMSLN is presented in section “The proposed method.” Section “The proposed fault diagnosis framework” describes the overall operational processes of the proposed fault diagnosis framework for rolling bearing. In section “Experimental validation,” multi-perspective comparative analysis verifies the feasibility and superiority of the proposed method. Section “Conclusions” mounts the conclusions.
Related works
Residual learning
Residual learning was proposed by He et al. 37 in 2015 to address model learning ability decline due to too many network layers. Figure 1 shows a typical residual module. By adding a constant mapping branch it is ensured that the network does not deteriorate in terms of learning. The expression for residual learning is given below 38

x and
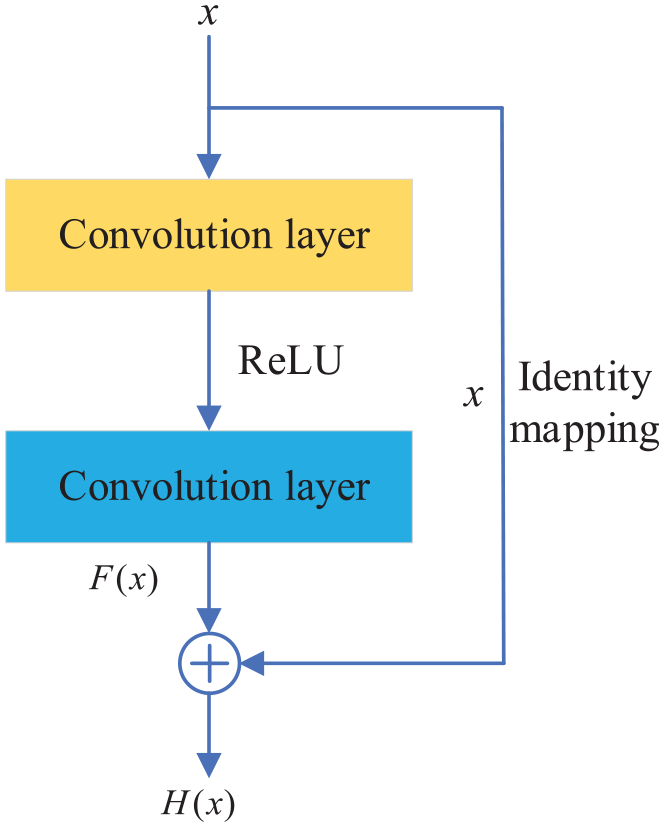
Schematic diagram of the residual module.
Channel attention
Squeeze and excitation network (SENet) was proposed by Hu et al., 39 to solve image classification problems. SENet has been applied in the field of fault diagnosis due to its powerful ability to adaptively reinforce important features.40,41 Concretely speaking, SENet amounts to a channel attention mechanism, which can both allocate a larger weight to channels containing more feature information and attach a smaller weight to channels containing less feature information or have more noisy information through adaptive learning. Figure 2 delineates the diagram of SENet and its specific steps are as follows:
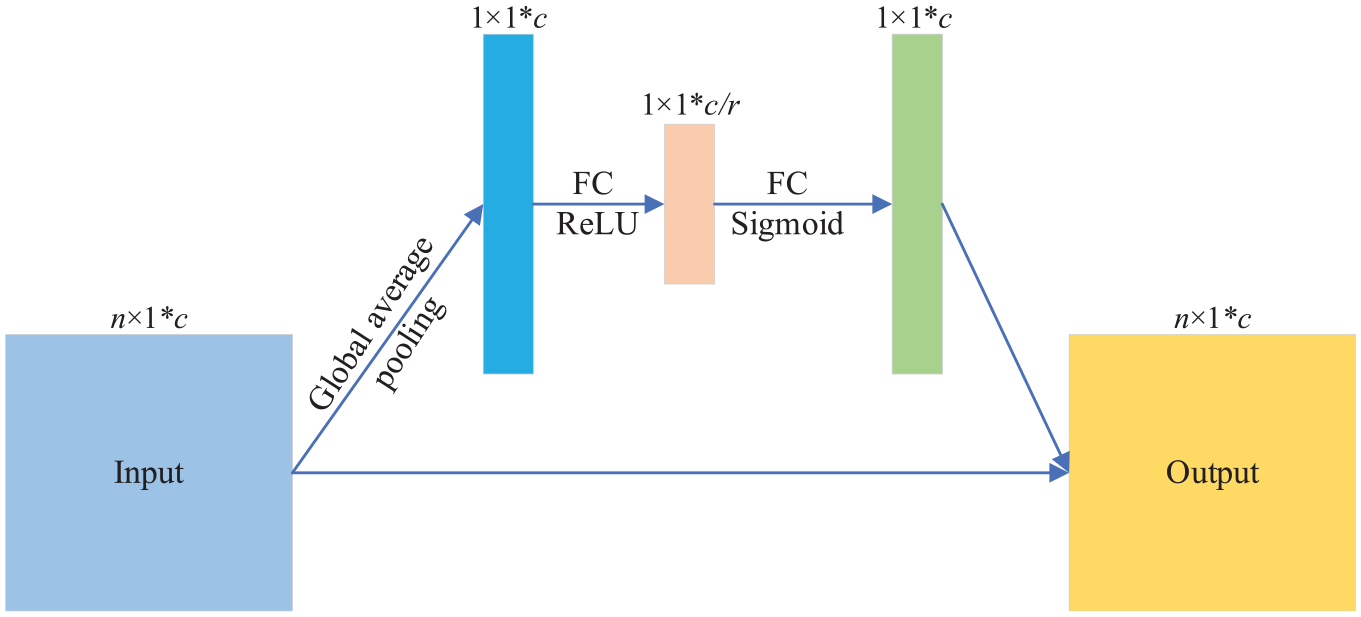
Structure diagram of the SENet module.
Firstly, a global average pooling operation is performed on the feature map
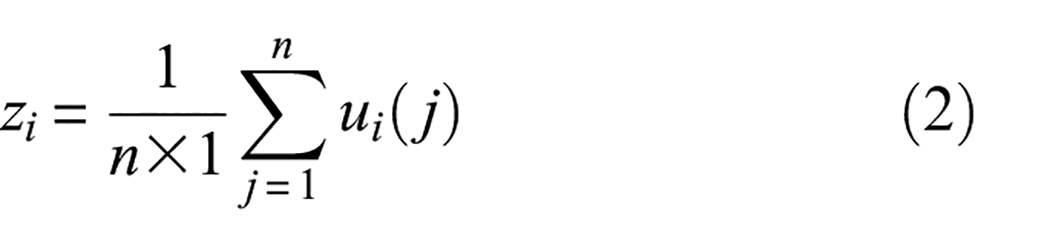
where c represents the number of channels for input features. n represents the number of feature values of each channel.
Next, each channel is assigned a weight value through the fully connected (FC) layer. Specifically, the number of channels is first compressed and then expanded to match the original number of channels.
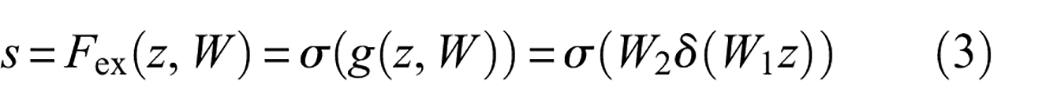
where
Finally, the weights are multiplied with input features to obtain a final output of SENet.
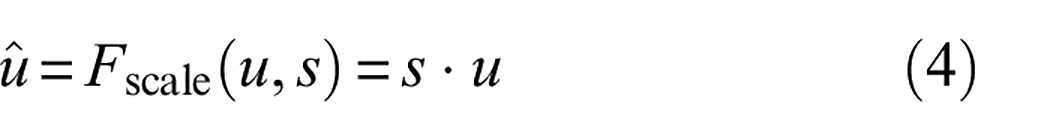
The proposed method
In this section, a new model entitled RMSLN with QHAdam optimizer is presented for bearing fault diagnosis, which is described below with respect to the model structure and training process of the presented RMSLN.
Model structure of RMSLN
Figure 3 depicts the model structure configuration of RMSLN, which is mainly composed of convolution-pooling operation, multi-scale branch, and classification layer. The multi-scale branch is the core part of the proposed RMSLN model. Different from traditional multi-scale networks, in the proposed RMSLN, the channel attention mechanism based on SENet module is dexterously placed at multi-scale branch to highlight the discriminative features and reduce the convolution depth without loss of learning performance. Specifically, enlightened by the idea of residual learning, in multi-scale learning procedure of RMSLN, the learned features of one branch are superimposed with the results of SENet module of the learned features of another branch to boost feature learning of RMSLN. Besides, the alternative to the traditional flattening layer, GAP is employed to flatten learned features of each branch, which provides the effective reduction of model parameters and the attenuation of the impact of abnormal feature values. Finally, the 1D feature vectors obtained from different branches are integrated and input to the classification layer for achieving bearing fault state recognition. The proposed RMSLN model is described in detail as follows:
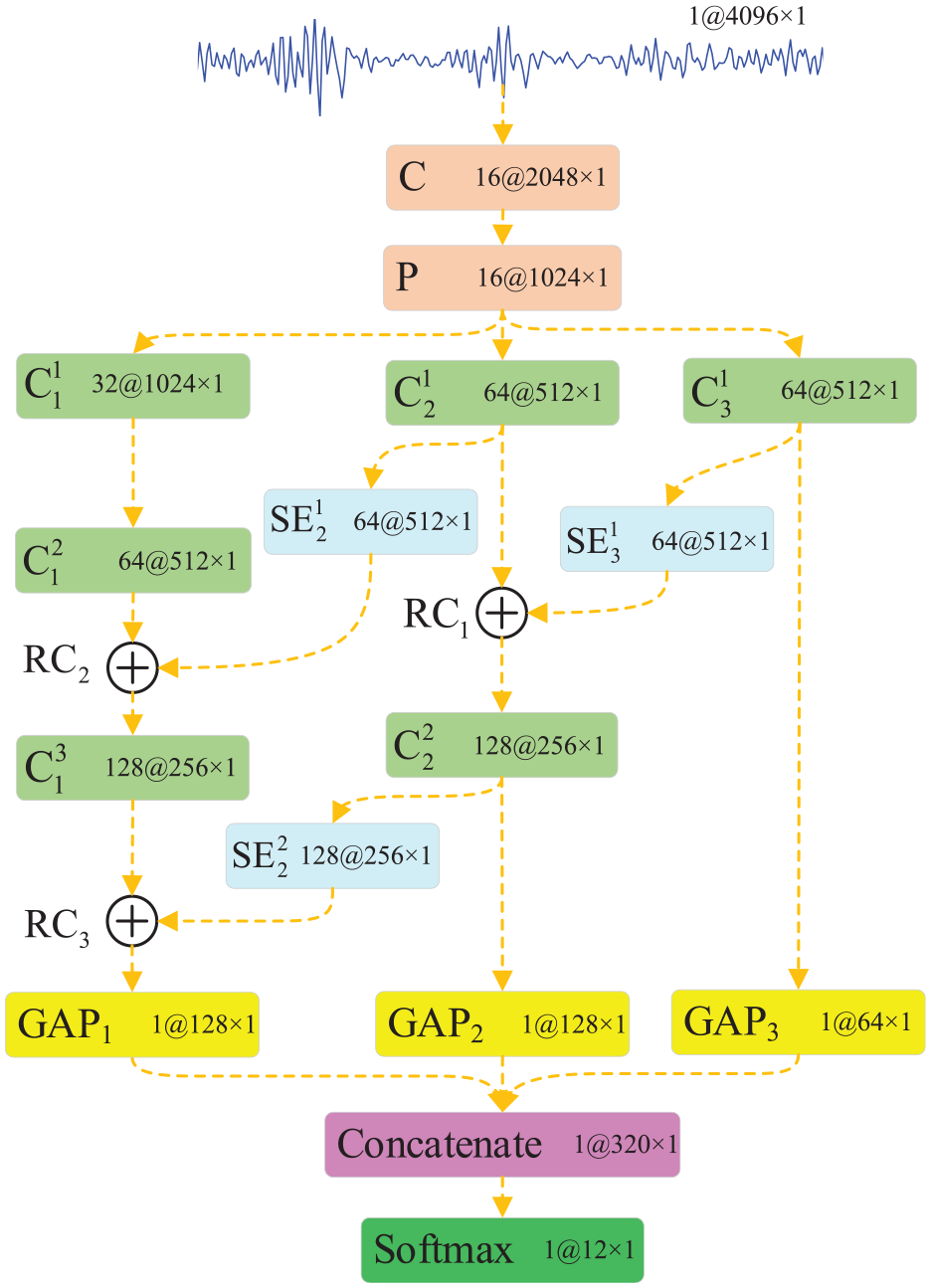
Structure diagram of the proposed RMSLN model.
Firstly, a basic convolution-pooling operation with wide convolutional kernel is employed for initial feature extraction of input signals, which can not only filter out some noise signals, but also reduce the feature dimensionality to decrease the computational burden for subsequent feature learning. The convolution-pooling operation is represented as follows.
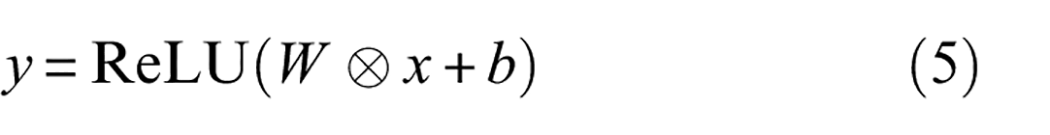

where the pooling operation uses maximum pooling and r×1 denotes the size of the local pooling.
Then, the application of a multi-scale branch after the convolution-pooling operation allows for a more thorough extraction of discriminative features by considering different scales. Each branch performs different depth of convolution activation operation and uses different size convolution kernel. The first branch uses a small convolution kernel for three convolution activation operations. The second branch uses a medium convolution kernel for two convolution activation operations. The third branch uses a large convolution kernel for one convolution activation operation. The mathematical expression for each branch convolution activation operation is as follows:
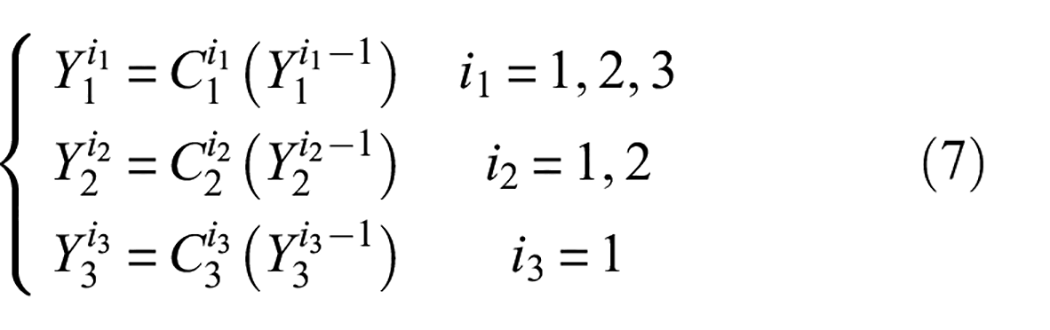
where
To ensure that main features can be learned adequately even with a handful of fault samples, the SENet module is embedded in shallow branches. Meanwhile, the feature maps of shallow branches weighted by the SENet module are superimposed with the feature maps of the deeper branches after convolution activation through residual connectivity. Deeper branches can capture complementary information that might be missed by shallow branches. This enables the network to learn more diverse and discriminative features. Specifically, as shown in Figure 3, SENet module is embedded after
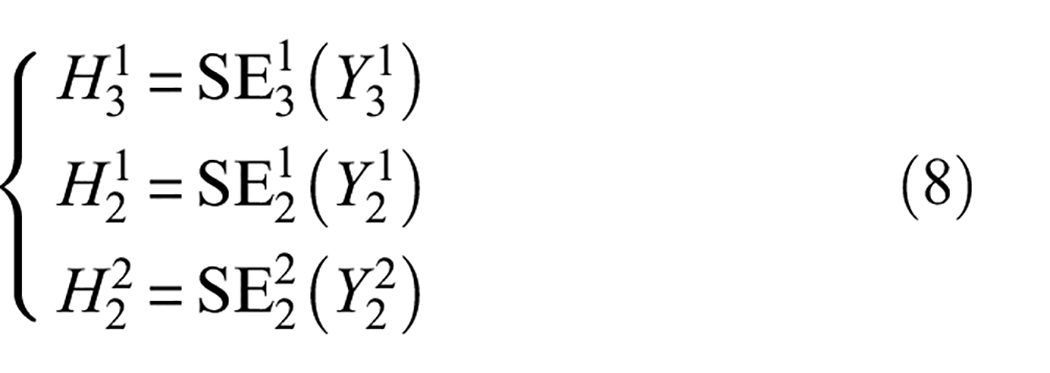
where
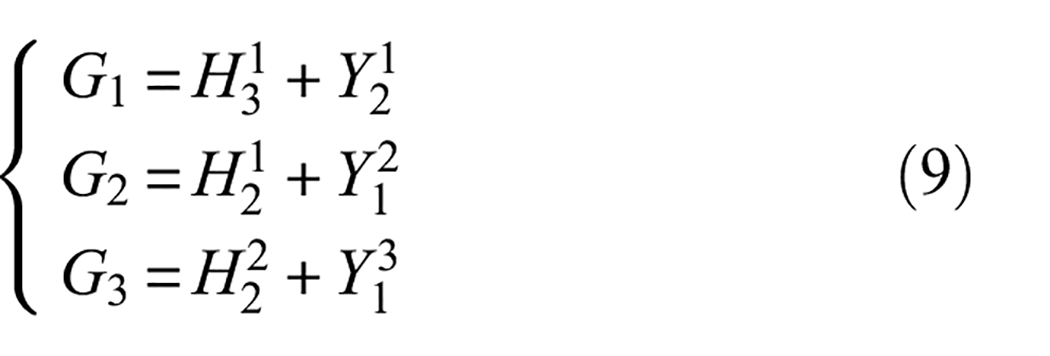
where
Finally, GAP is applied to transform each branch output feature map into a 1D vector, which aims at reducing computational effort effectively and weakening influences of some abnormal feature values. Meanwhile, these feature vectors are stitched together by a feature fusion operation. GAP and feature fusion processes are described as follows:
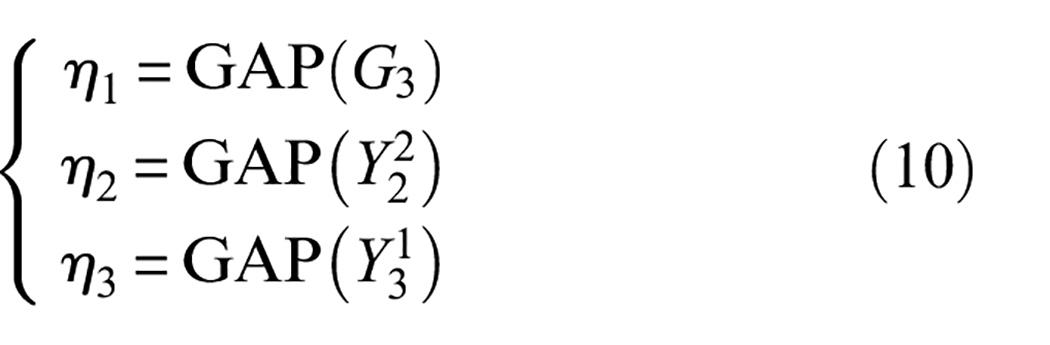
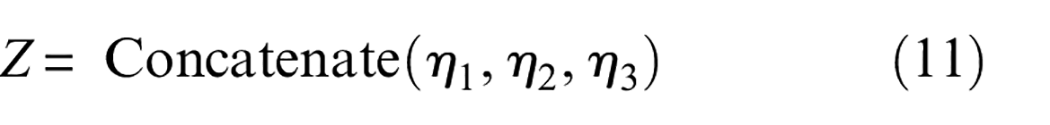
where
The model training process of RMSLN
In the process of training the RMSLN model, the cross-entropy loss function is chosen as the optimization objective of the model. The calculation of the cross-entropy loss function is relatively simple and efficient. Even in the case of imbalance between categories, minimizing the cross-entropy loss function can drive the RMSLN model in the right direction for optimization. The identity of the cross-entropy loss function is presented in the following expression:
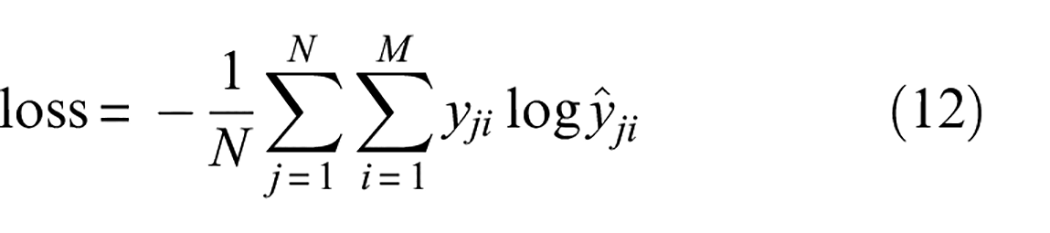
where N denotes the number of samples and M denotes the sample category.

The proposed fault diagnosis framework
The fault diagnosis framework of the proposed method, as depicted in Figure 4, comprises four primary steps. A more detailed description of each step is as follows:
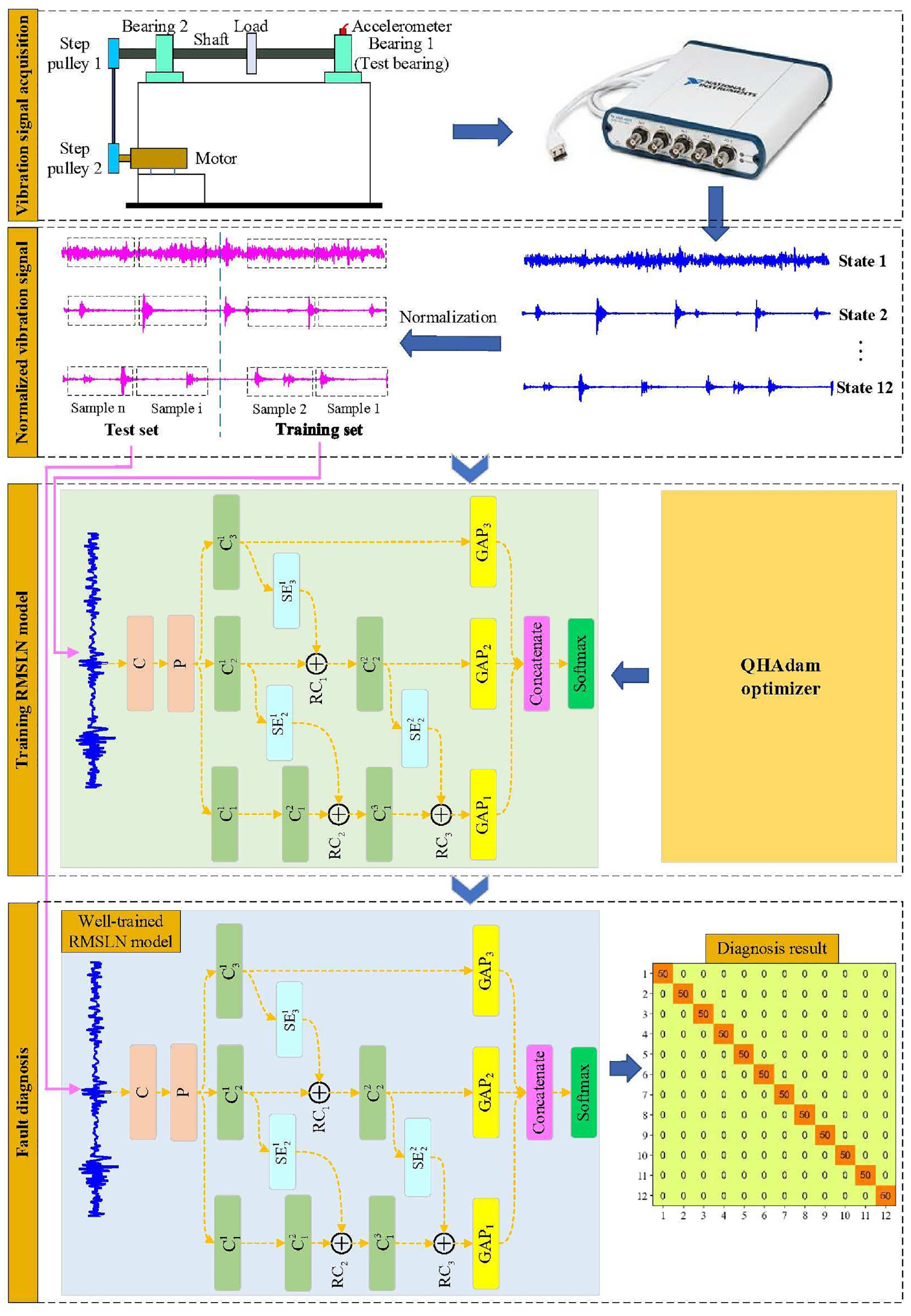
The implementation flow diagram of the proposed fault diagnosis approach.
Experimental validation
Case 1: Bearing fault data at different rotating speeds
Description of experimental data
The bearing dataset collected from the Mechanical Engineering Laboratory of Jiangnan University to show the effectiveness of our presented approach.42,43 Figure 5 demonstrates the test stand. The test stand mainly contains a servo motor, a loading device, and a data acquisition module. The Mitsubishi HG-SR352BJ servo motor is given a speed to drive the shaft. 3000 N pressure is applied to the shaft by the Shizuoka RCS2-RA13R loading device. The accelerometer captures faulty vibration signals at three speeds (600, 800, and 1000 rpm) and a normal vibration signal at 800 rpm. Figure 6 illustrates three types of bearing failure. These faults are handled manually using the cutter. The fault widths and fault depths are 0.3 and 0.025 mm. N205 bearings are utilized to capture vibration signals for outer ring fault, rolling element fault, and normal condition. NU205 bearings are utilized to capture vibration signals for inner ring fault. Figure 7 presents the time-domain waveform of 12 types of collected raw bearing vibration signals.
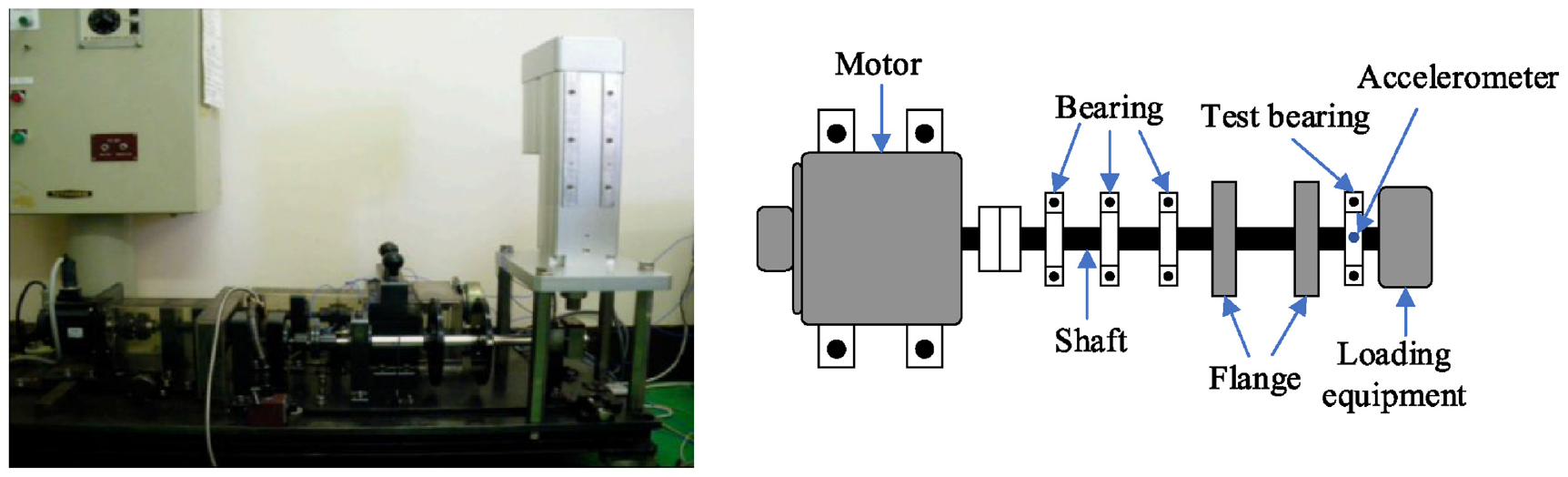
Test bench of Case 1.

Three types of bearing failure: (a) outer ring fault, (b) inner ring fault, and (c) rolling element fault.
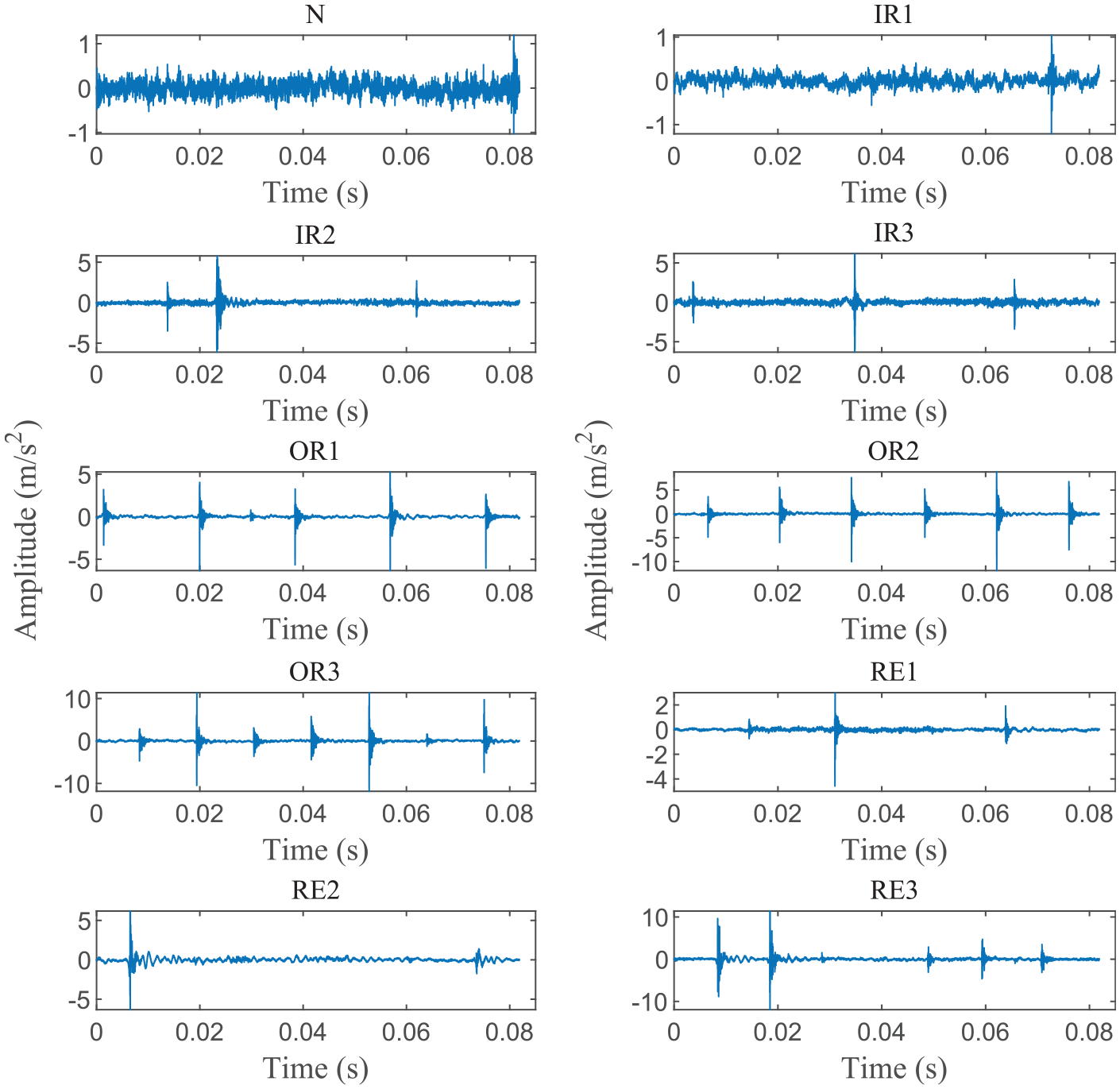
Raw bearing vibration signals of Case 1.
Result and analysis of Case 1
In order to verify the feasibility of the proposed approach to identify fault states at different rotational speeds, the bearing fault data from Case 1 is analyzed following the steps in Figure 4. Firstly, the original data of Case 1 is standardized to avoid large differences in sample data of the same type affecting the convergence speed and stationarity of the proposed RMSLN model. Figure 8 exhibits the normalized vibration signal. Then, each type of normalized data is divided into a group of 4096 points into 150 samples, 100 for training, and 50 for testing. A total of 1500 samples are obtained. Detailed information is depicted in Table 1. The training set is fed into the proposed RMSLN model to train. Parameters of the RMSLN model are defined. The convolution-pooling operation uses a convolutional kernel size of 7*1. In the multi-scale branch, the convolution kernel sizes chosen for the three branches are 3*1, 5*1, and 7*1 respectively. The scaling of the SENet module is set to 4. Deploy the number of neurons in classification layer to 10. In this paper, three branched features are fused and fed directly into the classification layer, and not too many FC layers are used, which can avoid excessive computation and overfitting problems. Configure batch size and number of iterations to 32 and 200. Based on the experience of the literature,
44
the parameters affecting the stability of the QHAdam are set to
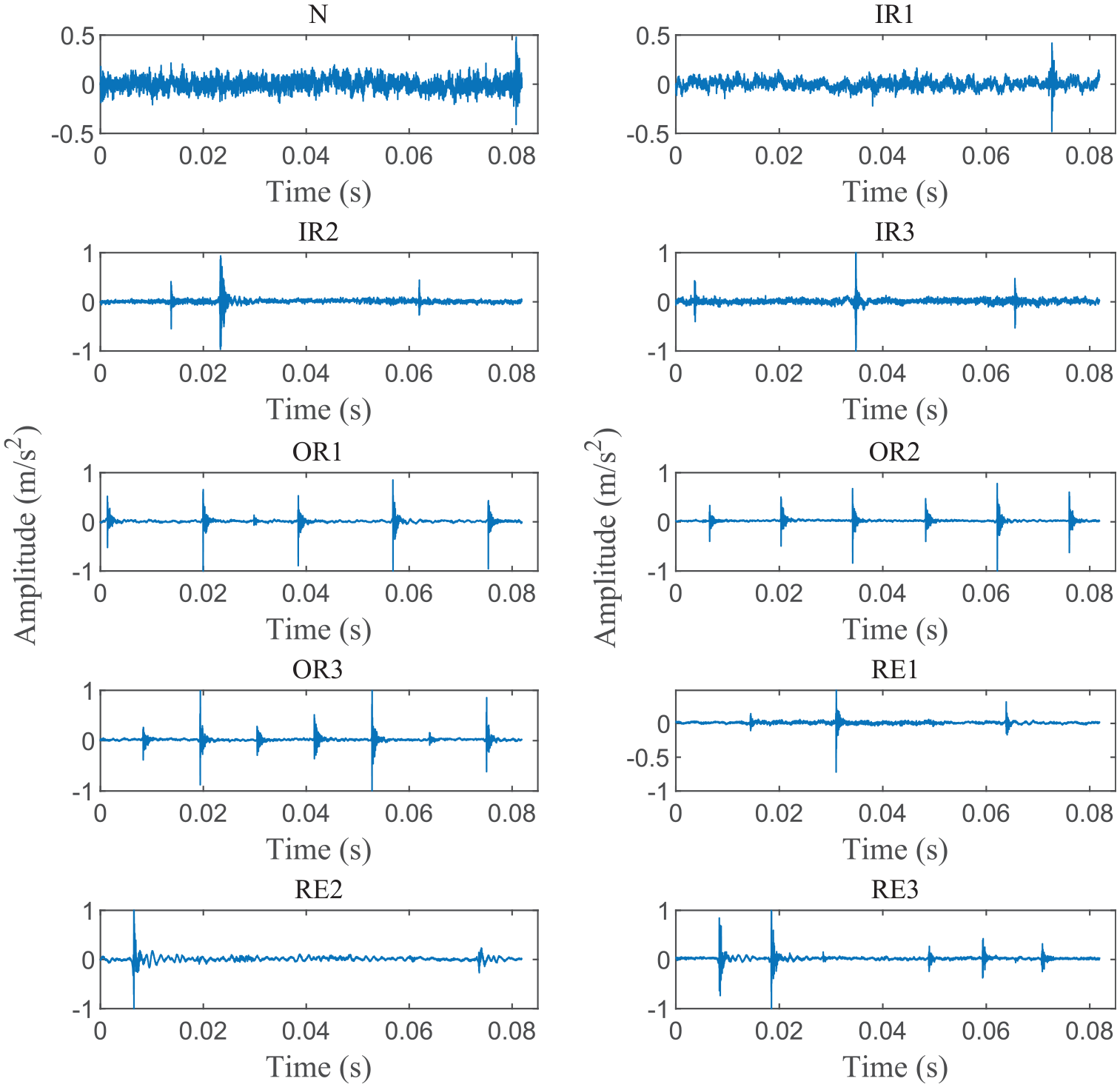
Normalized vibration signals of Case 1.
Sample set description of Case 1.
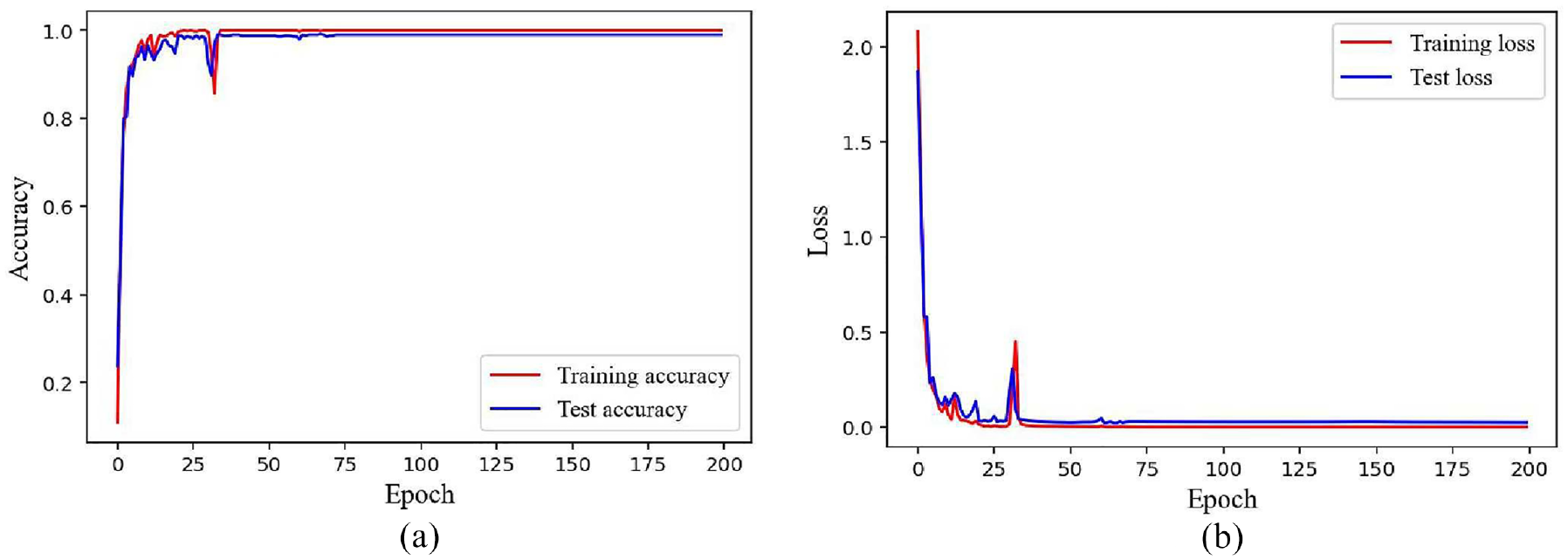
The training result of proposed RMSLN in Case 1: (a) Accuracy convergence curve and (b) loss convergence curve.
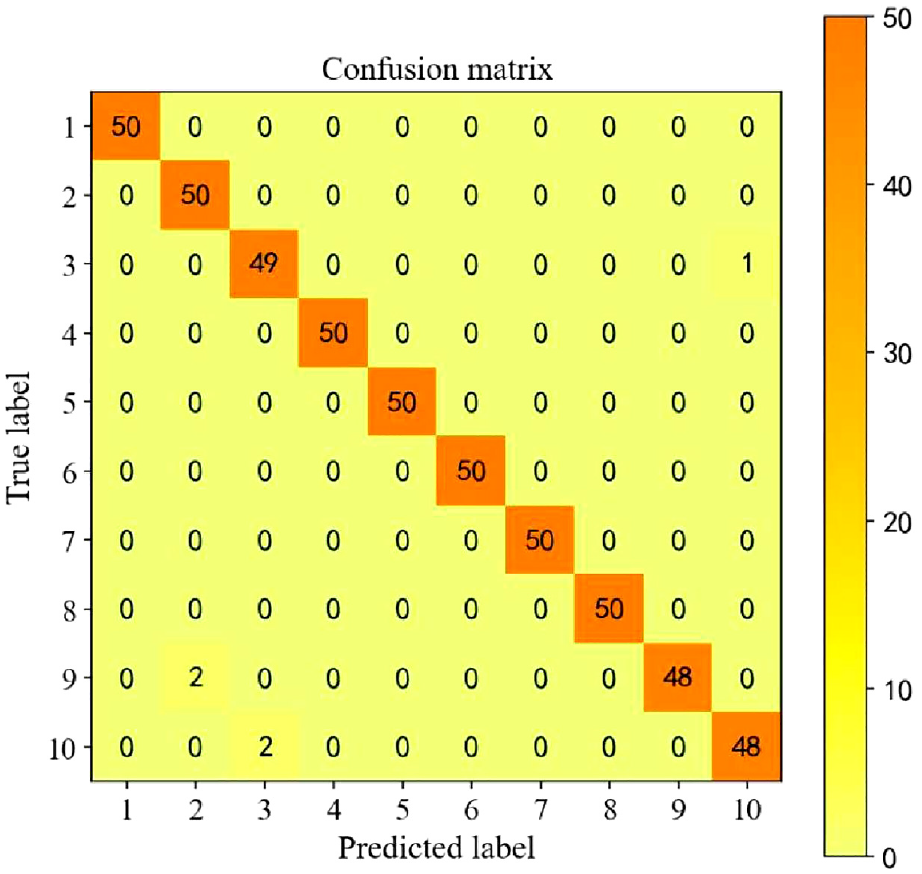
The test result of proposed RMSLN in Case 1.
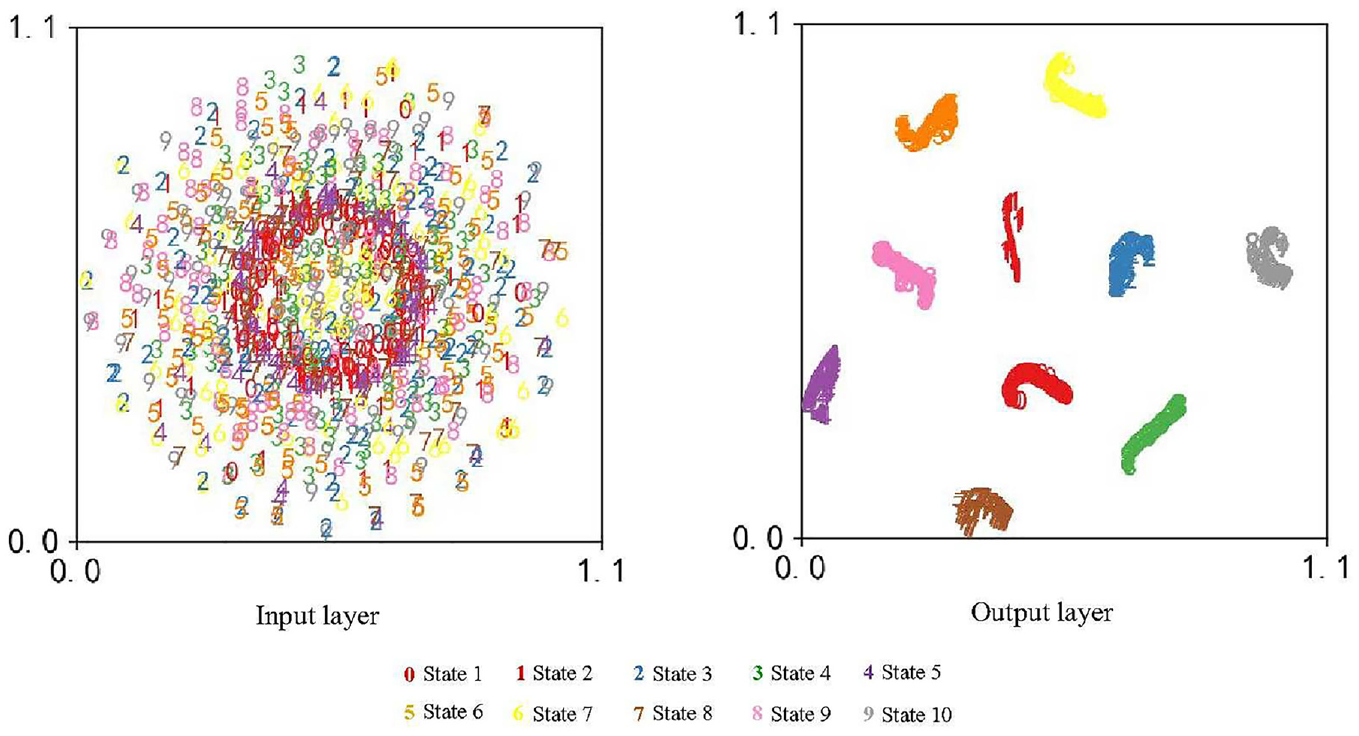
The visualization of proposed RMSLN via t-SNE in Case 1.
Performance under sample imbalance
In practical engineering applications, bearings operate in a damaged condition for very little time, making it challenging to gain valid and abundant fault samples. The vibration data in the normal state is adequate. This situation leads to a sample imbalance problem. Accurate estimation of the number of fault samples usually requires speculation based on the limited available samples and domain knowledge. This research investigates diagnostic effectiveness of RMSLN at different unbalanced proportions (2:1, 5:1, 10:1, and 20:1). The unbalanced proportions here represent the ratio of normal samples to each type of faulty sample. To ensure fairness, the mean of ten results is taken as the final result of each unbalanced proportion. Table 2 summarizes diagnostic results of four unbalanced proportions. As listed in Table 2, average identfication accuracy of the proposed RMSLN is 97.19% in the unbalanced proportion of 2:1. When the unbalanced proportion is increased to 5:1, the presented RMSLN still acquires classification accuracy of 94.54%. This preliminarily verifies the effectiveness of the proposed method in unbalanced fault diagnosis. Nevertheless, when there are only five fault samples in each classification, average accuracy of the presented RMSLN is 81.59%. That said, the average accuracy of RMSLN tends to decrease as the unbalanced proportion increases. From our personal point of view, as the unbalanced proportion increases, the available information containing in fault category with fewer samples is gradually reduced, so it increases the difficulty of unbalanced fault diagnosis. This is considered to be a potential factor for the performance degradation of the proposed methods in the process of increasing the unbalanced proportion, which is also a mutual problem of unbalanced fault diagnosis worth striving to overcome in future work.
Performance results of RMSLN of different unbalanced proportions in Case 1.
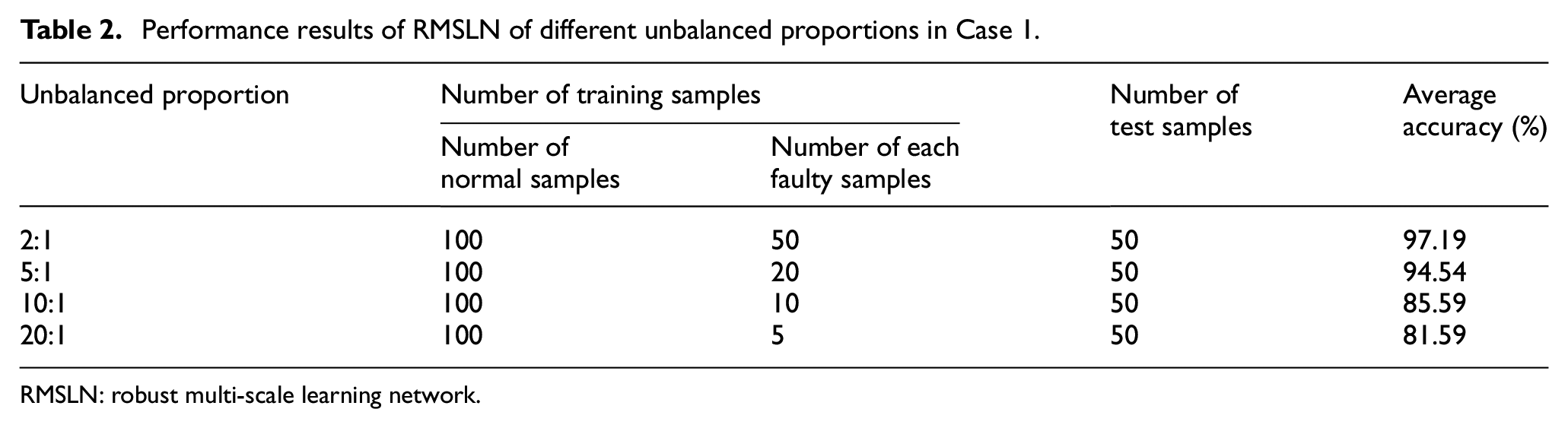
RMSLN: robust multi-scale learning network.
The performance of the suggested RMSLN is evaluated by comparing it with several other mainstream approaches (e.g., CNN, squeeze and excitation networks-based CNN (CNN-SE), multiscale permutation entropy-based support vector machine (MPE-SVM), multi-scale kernel-based residual network (MK-ResCNN)) and imbalance fault diagnosis approaches (e.g., normalized convolutional neural network (NCNN) and enhanced generative adversarial network (EGAN)) in Case 1. Detailed descriptions of these as comparative methods are depicted in Table 3. Figure 12 presents the mean accuracy and standard deviation of different approaches. For balanced samples, RMSLN achieved an outstanding accuracy of over 98%, surpassing all other approaches. As the unbalanced proportion increases, performance results of seven approaches exhibit a downward trend. However, even under such imbalanced conditions, RMSLN consistently outperforms alternative methods in terms of both recognition accuracy and standard deviation. This compellingly highlights the strong advantages and stability of RMSLN.
Detailed structure of comparison methods.

CNN: convolutional neural network; CNN-SE: squeeze and excitation networks-based CNN; MPE-SVM: multiscale permutation entropy-based support vector machine; MK-ResCNN: multi-scale kernel based residual network; NCNN: normalized convolutional neural network; EGAN: enhanced generative adversarial network.
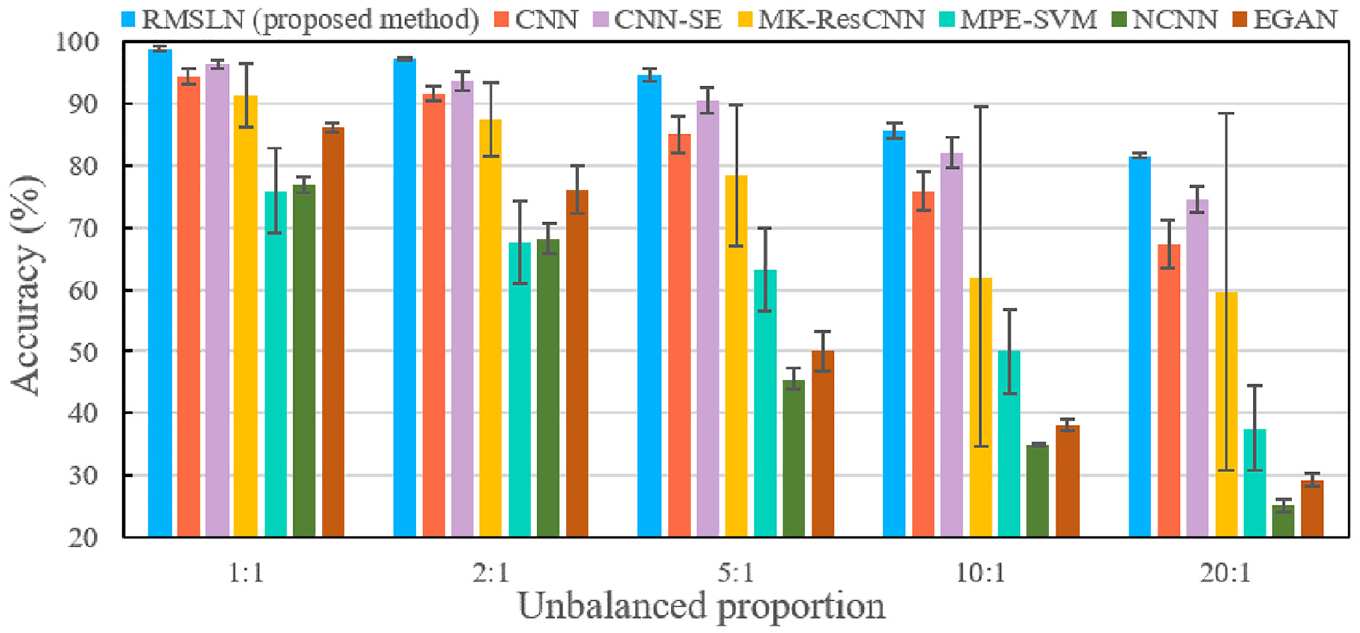
The comparative results of different methods in Case 1.
In order to better evaluate the computational requirements of each model, the total number of operating parameters for seven models is calculated. The total number of parameters for the seven models is calculated in Table 4. The total number of parameters for RMSLN is relatively moderate. Compared with the complex models (MK-ResCNN and EGAN), RMSLN has a great improvement in operational efficiency. Although NCNN and MPE-SVM have a smaller number of parameters compared to RMSLN, the recognition effect under unbalanced scenarios is inferior. Considering the diagnostic performance and computing efficiency together, RMSLN performs the best for fault diagnosis under unbalanced scenarios.
The total number of parameters for seven models in Case 1.
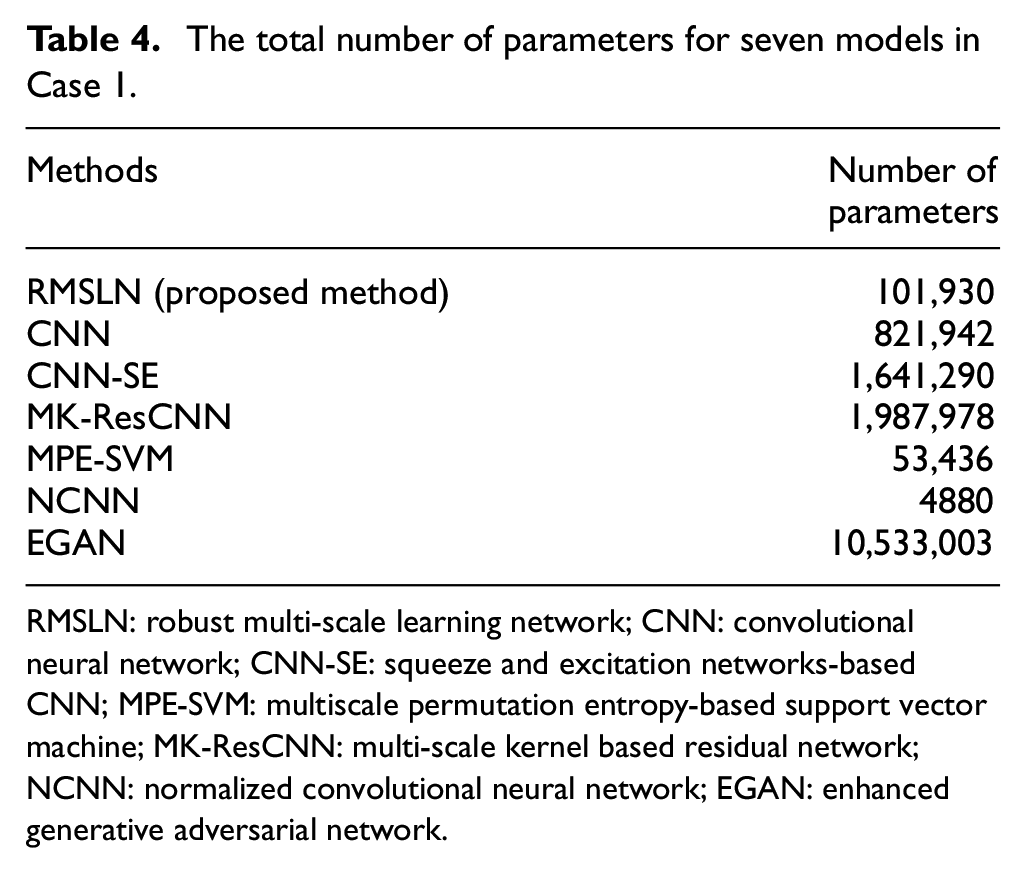
RMSLN: robust multi-scale learning network; CNN: convolutional neural network; CNN-SE: squeeze and excitation networks-based CNN; MPE-SVM: multiscale permutation entropy-based support vector machine; MK-ResCNN: multi-scale kernel based residual network; NCNN: normalized convolutional neural network; EGAN: enhanced generative adversarial network.
Comparison of evaluation metrics
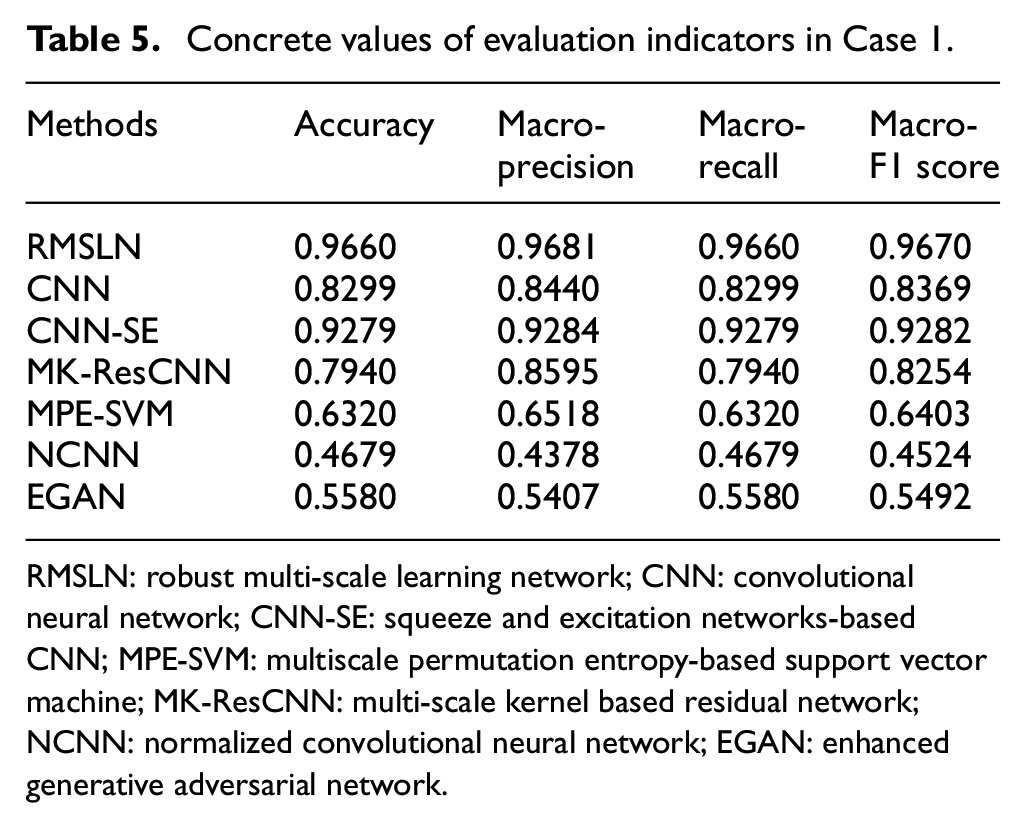
Four evaluation indicators (accuracy, macro-precision, macro-recall, and macro-F1 score) are used to judge the quality of the seven approaches at an imbalance ratio of 5:1. The design of the four evaluation indicators is shown in Equations (13) to (16). Macro-precision and macro-recall represent the average precision and average recall across all categories. Accuracy measures the overall recognition accuracy, while macro-F1 score represents the harmonic mean. The quantitative results of these evaluation indicators are displayed in Table 5. Notably, RMSLN consistently outshines other approaches across all indicators. This clearly demonstrates that RMSLN holds a superior advantage and delivers excellent diagnostic results.
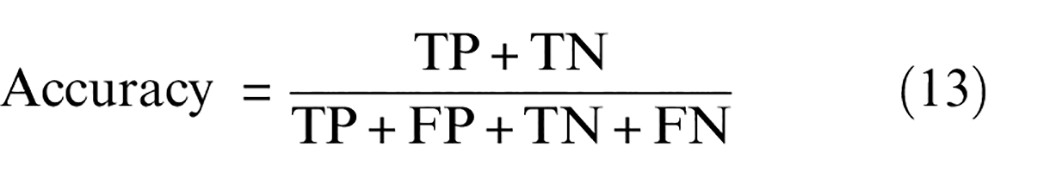

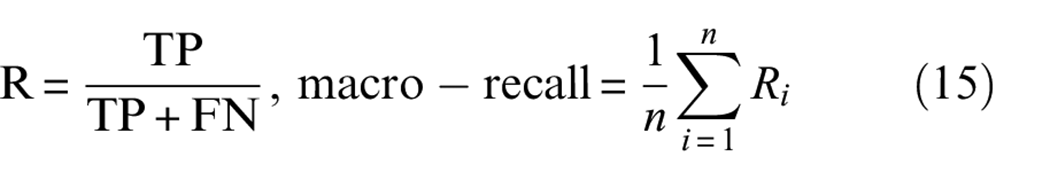

Concrete values of evaluation indicators in Case 1.
RMSLN: robust multi-scale learning network; CNN: convolutional neural network; CNN-SE: squeeze and excitation networks-based CNN; MPE-SVM: multiscale permutation entropy-based support vector machine; MK-ResCNN: multi-scale kernel based residual network; NCNN: normalized convolutional neural network; EGAN: enhanced generative adversarial network.
Comparative analysis of robustness
To examine the robustness of RMSLN, seven approaches are used to analyze noisy data. According to Equation (17), the background noises are added to data with sample proportion of 1:1 to imitate the signals collected at different noise levels. Figure 13 illustrates recognition results of seven methods with different signal-to-noise ratios (SNRs). Seen from Figure 13, MPE-SVM is the least effective in identifying the noisy data, while other six approaches accomplish an acceptable classification accuracy at larger SNR. However, our proposed approach consistently receives the highest classification accuracy across all SNR levels. Experiments confirm that compared with other methods, RMSLN offers tremendous merit in extracting discriminative features from noisy bearing vibration data. That said, our proposed approach has better noise resistance robustness.
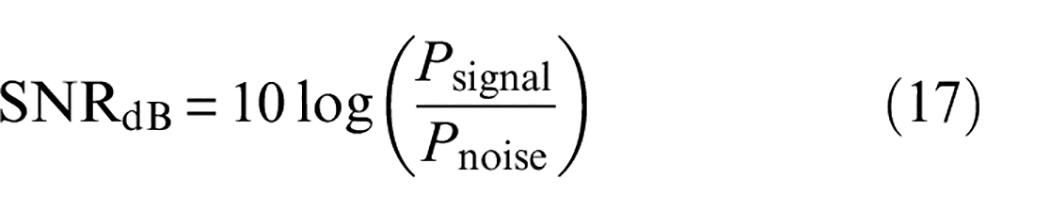
where
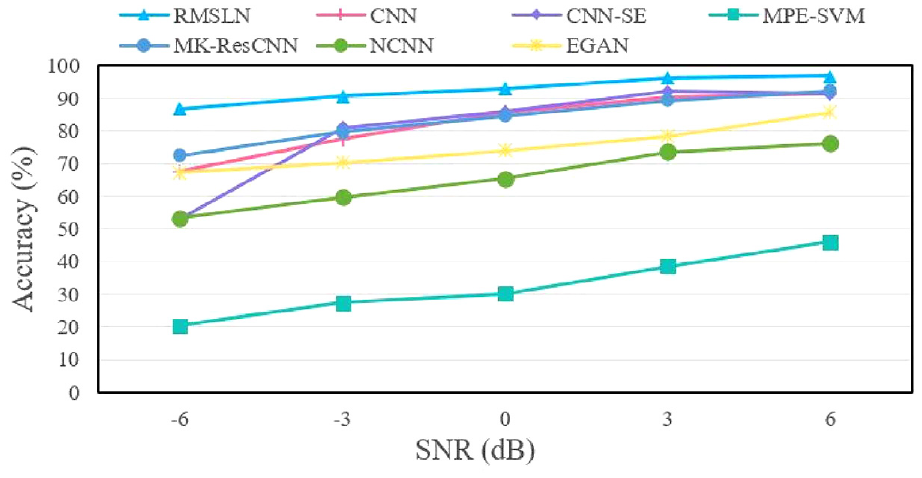
Recognition results with different SNR in Case 1.
In reality, the collected bearing vibration data may have both sample imbalance and noise disturbance together. To illustrate the superiority of RMSLN for fault diagnosis under unbalanced scenarios and noise disturbances, the seven methods mentioned above are utilized to analyze the unbalanced data with different SNR values. Due to the limitation of space, this section concentrates on analyzing the 2:1 and 5:1 data with SNR values of −6, −3, 0, 3, and 6 dB. Figure 14 demonstrates comparison results of seven methods under sample imbalance and noise disturbance. In the case of sample imbalance, the performance of all methods decreases as the SNR values decrease, but the accuracy of RMSLN is still significantly higher than that of CNN, CNN-SE, MPE-SVM, MK-ResCNN, NCNN, and EGAN. This proves that RMSLN is advantageous over the mentioned comparison methods under imbalanced scenarios and noise interference.
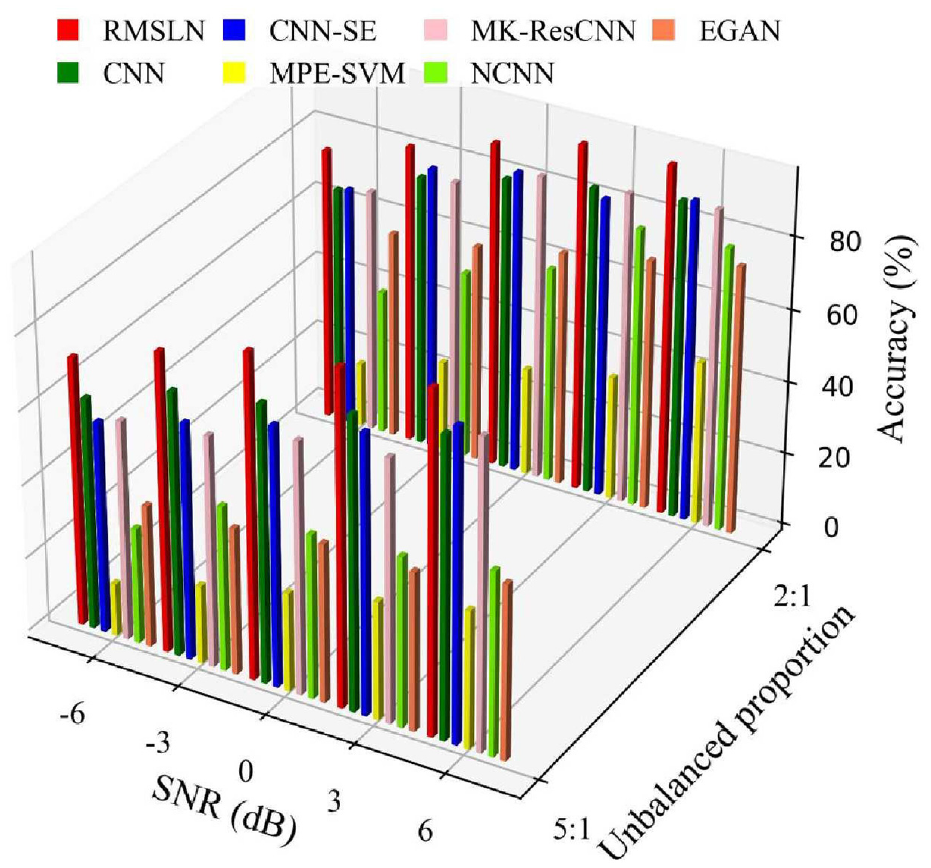
Comparison results under sample imbalance and noise disturbance in Case 1.
Performance comparison of RMSLN with different number of branches
To explore the effect of the number of branches on RMSLN performance, RMSLN with different numbers of branches is used to analyze data with an unbalanced proportion of 5:1. RMSLN-II denotes RMSLN with two branches and RMSLN-IV denotes RMSLN with four branches. RMSLN-III, namely the proposed method, contains three branches. Table 6 presents the performance comparison of RMSLN with different branch numbers. Although the total number of parameters of RMSLN-II is small, the recognition accuracy is unable to meet the fault diagnosis requirements, which is mainly attributable to the fact that there are fewer branches and the learned fault information is deficient. The recognition accuracy of RMSLN-III is higher than that of RMSLN-II and RMSLN-IV. In addition, the number of RMSLN-IV model parameters is huge, more than two times that of the RMSLN-III model, which requires consuming more computer memory. Therefore, considering the accuracy and computational memory consumption, RMSLN with three branches is selected in Case 1.
Performance comparison of the proposed RMSLN model with different branches in Case 1.
RMSLN: robust multi-scale learning network.
Performance comparison of different optimizers
To illustrate that the QHAdam optimizer has better results in RMSLN: In Case 1, stochastic gradient descent (SGD), Adaptive moment estimation (Adam), Root mean square propagation (RMSprop) and QHAdam are respectively adopted to update RMSLN parameters, and the effects of different optimizers are reflected through the loss value and accuracy. All optimizers have a learning rate of 0.001. Data with an unbalanced proportion of 5:1 is chosen as the subject of this analysis. Results of RMSLN with different optimizers are portrayed in Figure 15. In terms of accuracy, QHAdam allows RMSLN to have a high recognition accuracy compared to other optimizers. In terms of loss, QHAdam not only converges quickly and smoothly, but also has relatively small loss values. This illustrates the superiority of using QHAdam in the proposed model.
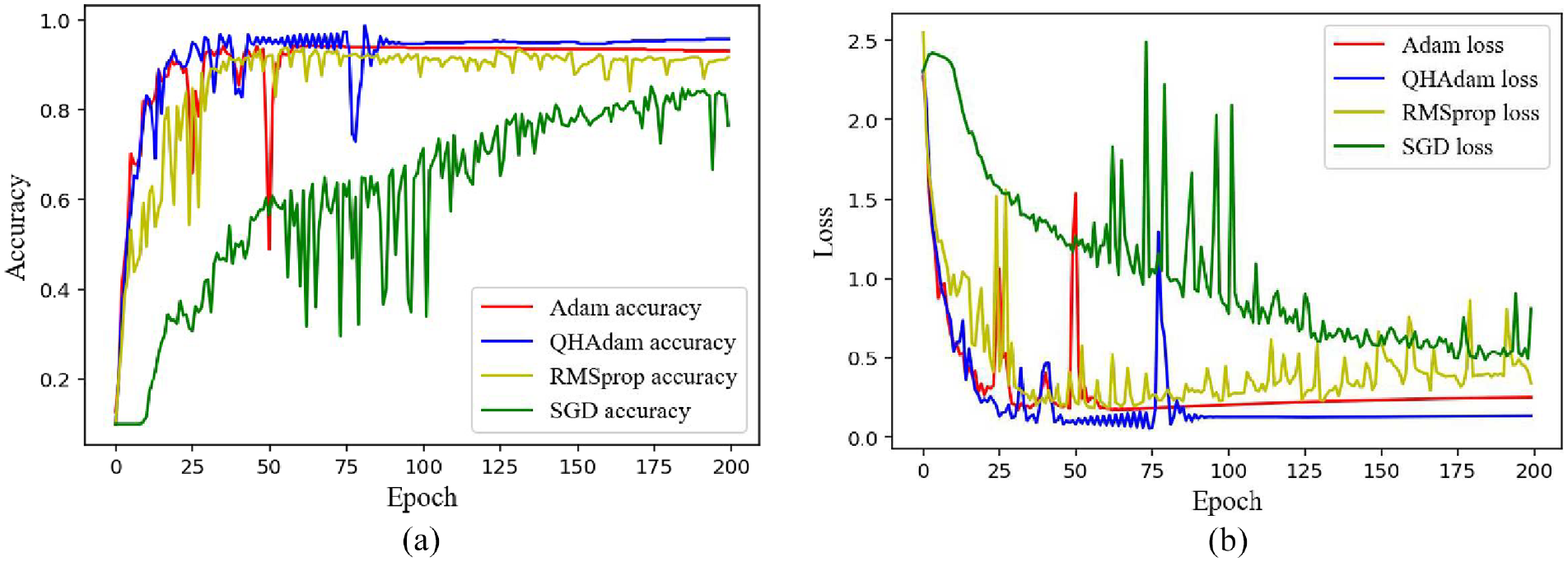
Contrast results of different optimizers in Case 1: (a) Accuracy convergence curve and (b) loss convergence curve.
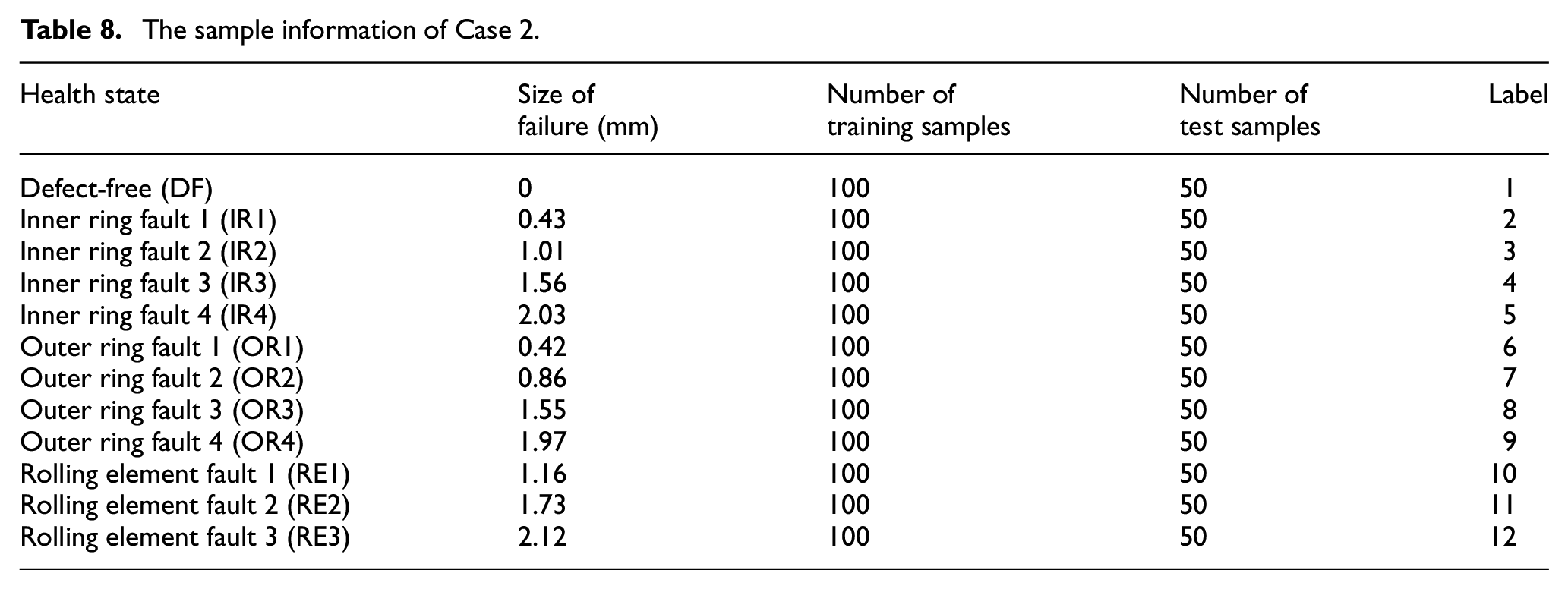
Case 2: Bearing fault data of different damage sizes
Description of experimental data
Bearing vibration data of Case 2 are from the laboratories of the Saint-Langevin Institute of Engineering and Technology.49,50 Figure 16 shows the experimental system of Case 2. The measured bearing (NBC: NU205E) parameter arrangements are detailed in Table 7. During the experiments, the motor provides a constant speed of 2050 rpm to the shaft and the loading device imparts 200 N load in the vertical direction. The data acquisition system acquires a series of fault vibration signals and a defect-free vibration signal under 70 kHz sampling frequency. The fault signals consist of four inner ring fault vibration signals with different damage levels, four outer ring fault vibration signals with different damage levels, and three rolling element fault vibration signals with different damage levels. Raw vibration signals are demonstrated in Figure 17.
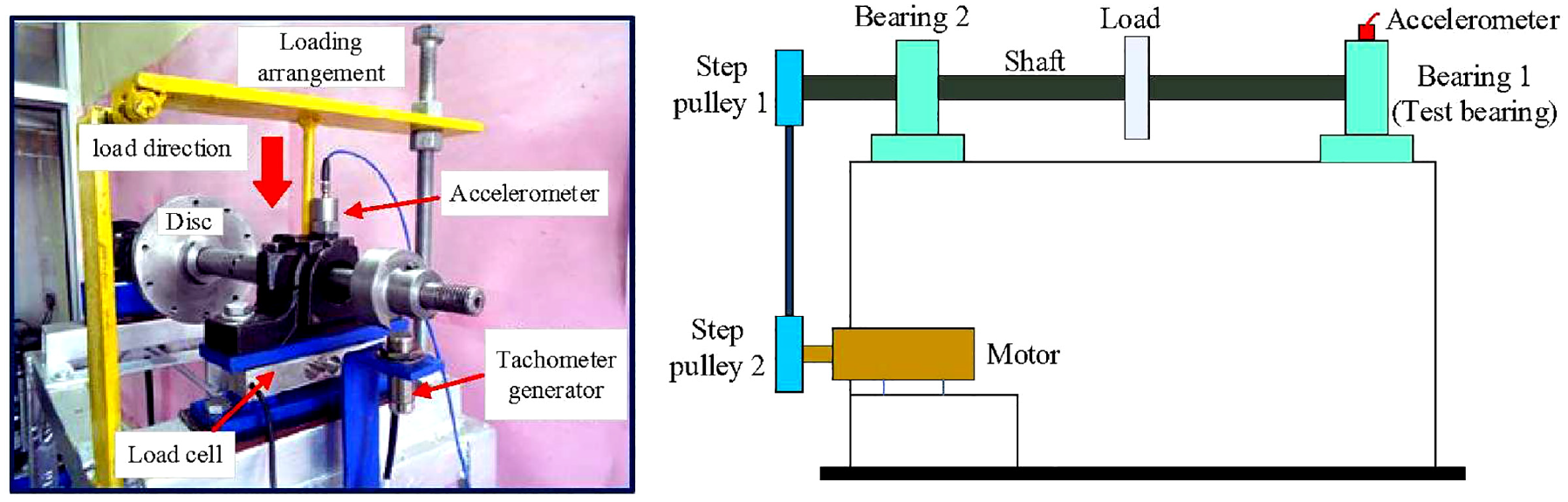
Experimental system of Case 2.
Particulars of trial bearings in Case 2.

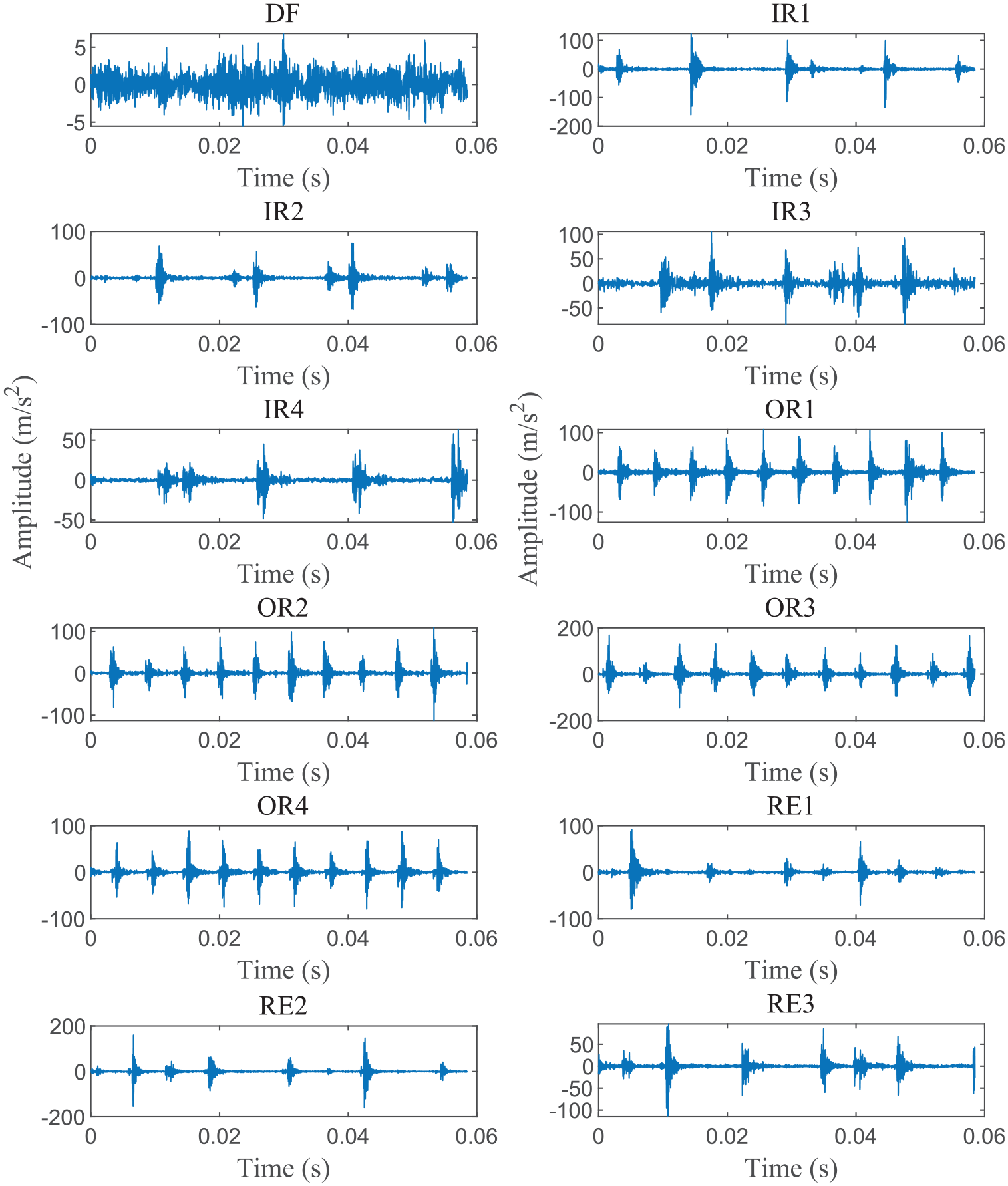
Raw vibration signals in Case 2.
Result and analysis of Case 2
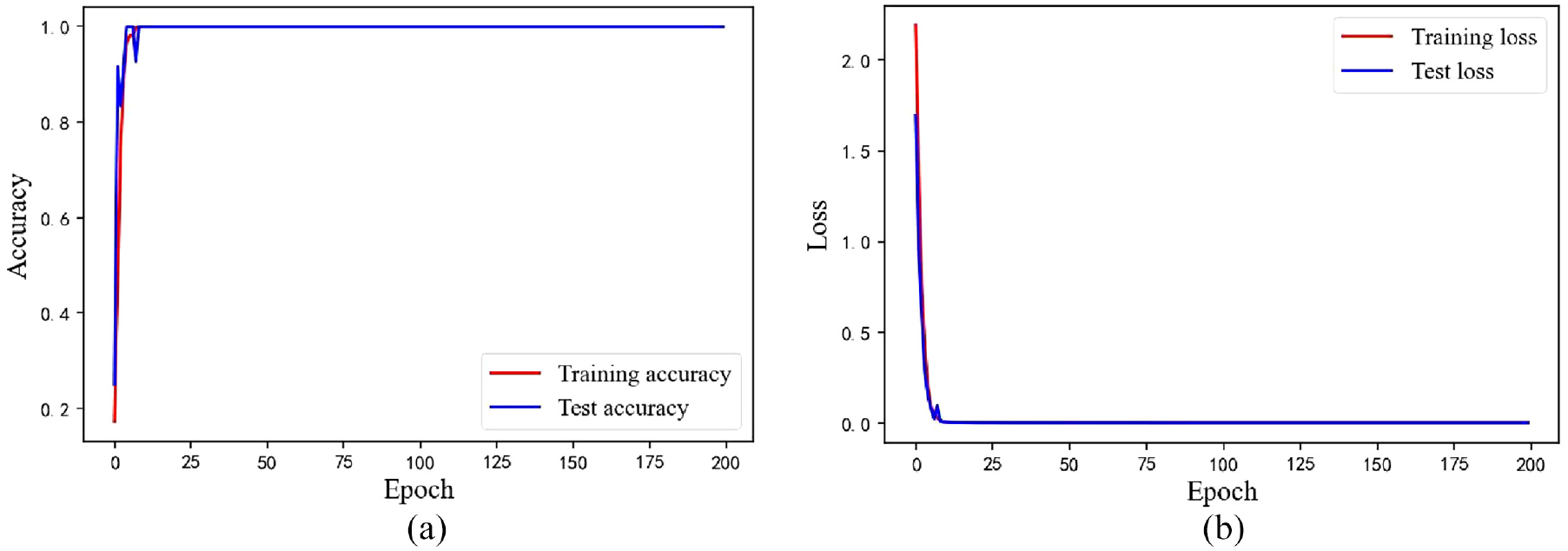
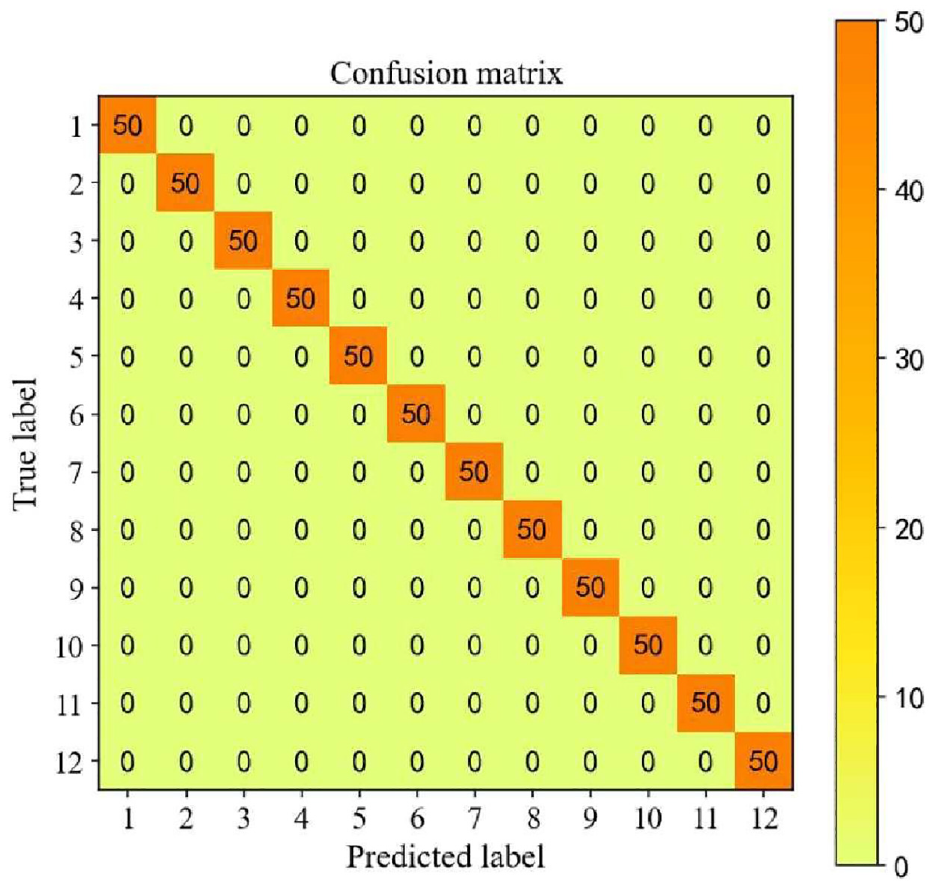
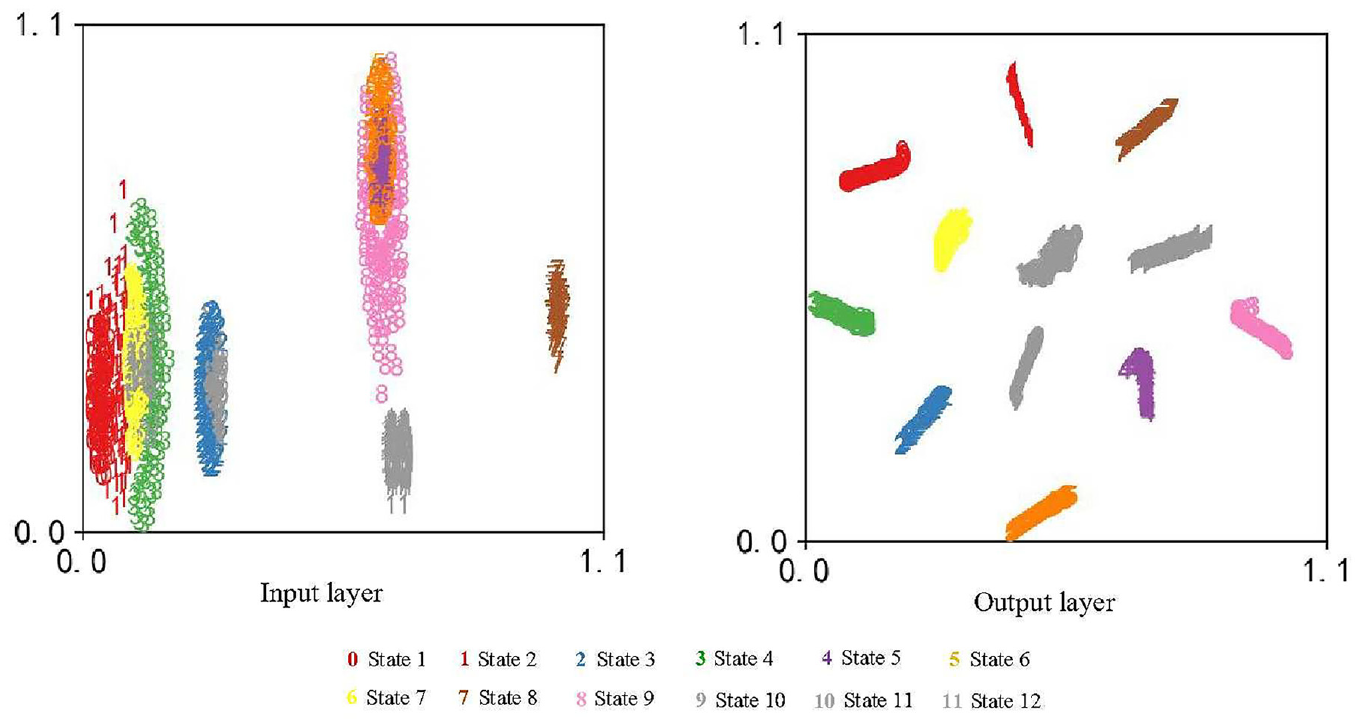
The data from Case 2 is assessed utilizing the methodology depicted in Figure 4 to confirm the feasibility of the suggested method for identifying different bearing fault levels. Firstly, the raw data collected in Case 2 is normalized, which is described in Figure 18. Next, samples are selected in the same way as in Case 1. The sample information is provided in Table 8. Then, the training samples are fed into RMSLN to train. In Case 2, neurons of the classification layer are adjusted to 12, and the learning rate of QHAdam is changed to 0.001. The remaining parameters of RMSLN and QHAdam are the same as in Case 1. Finally, test samples are fed into the well-trained RMSLN for diagnosis. Figure 19 displays the training results of RMSLN. It may be discovered that the RMSLN model converges very quickly, and after about 15 iterations the loss values and accuracy rates reach satisfactory results. Figure 20 exhibits the confusion matrix of test samples. Obviously, the accuracy of test samples reached an impressive 100%, and the predicted and true values are exactly the same. Figure 21 presents the feature distribution after the adoption of t-SNE technology. Although the input signal has a certain degree of differentiation after dimension reduction by t-SNE technology, there are overlaps between different categories. However, after the proposed model extracts the features, it is evident that the same categories are clustered together and the categories are widely spaced.
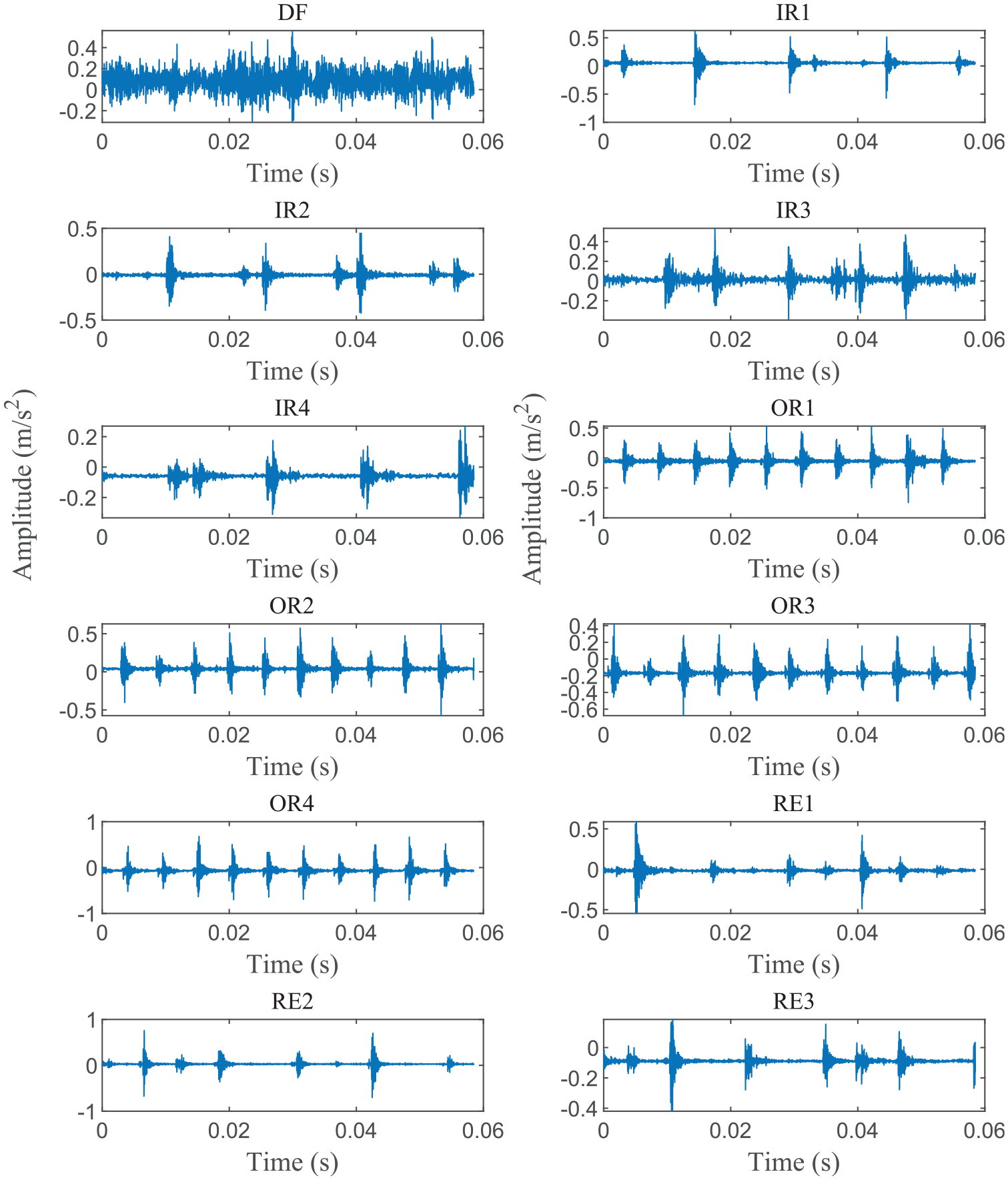
Normalized vibration signals in Case 2.
The sample information of Case 2.
The training results of RMSLN in Case 2: (a) Accuracy convergence curve and (b) loss convergence curve.
The confusion matrix of test samples in Case 2.
t-SNE of proposed RMSLN in Case 2.
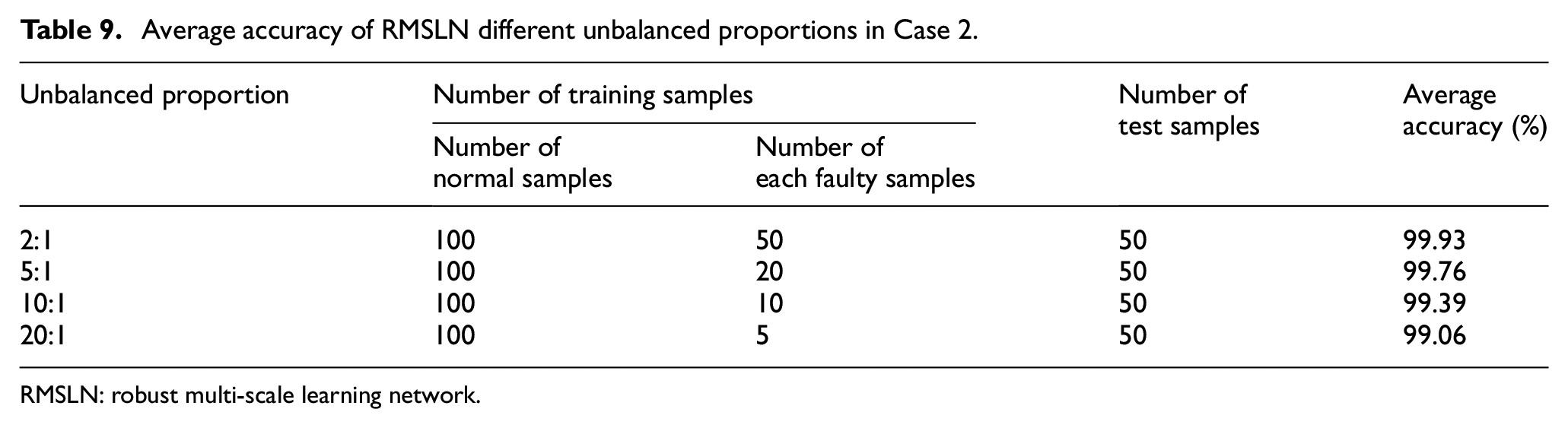
Performantce under sample imbalance
This paper investigates the diagnostic effect of RMSLN under unbalanced samples. The performance at different unbalanced proportions is outlined in Table 9. An interesting observation from Table 7 is that the recognition accuracy does not decrease noticeably, even when the amount of fault samples drops considerably. Surprisingly, the accuracy is consistently above 99% even when the unbalanced proportion reaches 20:1. This demonstrates that RMSLN is still adept to learn useful features adequately and has a high recognition accuracy despite the sample imbalance. However, it needs to be mentioned that, as the imbalance ratio increases, compared to Case 1, the diagnostic accuracy of RMSLN dropped slower in Case 2. From our personal perspective, the reasons for this phenomenon may be divided into the following two aspects. On the one hand, in Case 2, bearing vibration data under all faults are collected at constant speed of 2050 rpm, but bearing vibration data under same faults are obtained based on different fault sizes. Take the outer ring fault as an example, the outer ring fault signal with four fault sizes (i.e., 0.42, 0.86, 1.55, and 1.97 mm) are collected at the same speed. That said, Case 2 is equivalent to a bearing fault identification problem under constant speed conditions. Generally speaking, with the increase of fault sizes, faut feature information of the collected bearing vibration data will be more obvious, especially for serious faults. This means that there is a comparatively large differentiation between feature information under the same bearing fault data in Case 2. Therefore, RMSLN can effectively adapt to bearing health status recognition with different fault sizes under constant speed conditions, even for a large imbalance proportion. On the other hand, in Case 1, bearing vibration data under same faults are obtained based on same fault size, but they are collected at different rotating speed. Similarly, take the outer ring fault as an example, the outer ring fault signal with three rotating speeds (i.e., 600, 800, and 1000 rmp) are collected at the same fault size (i.e., 0.3 mm width and 0.025 mm depth). That said, Case 1 is equivalent to a bearing fault identification problem under variable speed conditions. Theoretically speaking, compared with the constant speed condition, the features of bearing vibration signal under variable speed conditions are more complex, and the collected bearing vibration signal will exhibit strong non-stationary characteristics of frequency-modulation and amplitude-modulation, which increases the difficulty of fault identification. Therefore, compared with Case 2, when RMSLN is adopted to handle fault identification problems under variable speed conditions, its diagnostic performance may be decreased, especially for a large imbalance proportion. That said, RMSLN in Case 1 has less stability in identifying different imbalanced data than in Case 2. Considering these facts, in our future work, RMSLN will be further improved to promote the stability of its recognition results by moderately increasing the number of samples, making it can be better suited for fault diagnosis problems under strong imbalance proportion at variable speed conditions.
Average accuracy of RMSLN different unbalanced proportions in Case 2.
RMSLN: robust multi-scale learning network.
To clarify the superiority of the proposed RMSLN, a comparative investigation is conducted utilizing data from Case 2. RMSLN is compared with several mainstream diagnostic models, and results are reflected in Figure 22. Two single-scale networks (i.e., CNN and CNN-SE) cannot correctly identify fault states with a large proportion of unbalanced samples. In contrast, RMSLN exhibits exceptional performance, especially at an unbalanced proportion of 20:1, which is at least 5% superior to other approaches. The comparative investigation provides noteworthy proof that the presented RMSLN may overcome challenges posed by sample imbalance and obtain superior diagnostic accuracy.
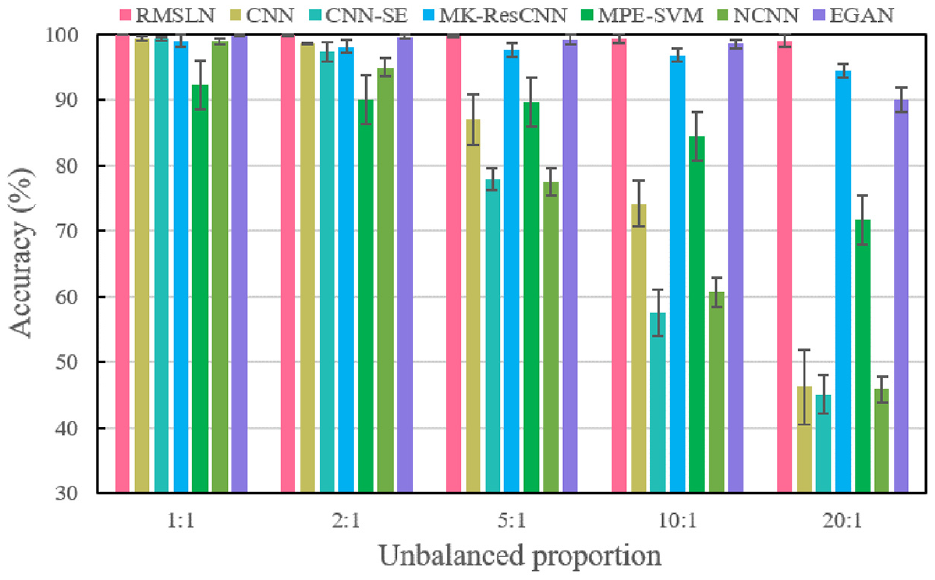
The comparison results of different diagnostic models in Case 2.
In addition, the complexity and operational efficiency of models is compared by taking the total number of parameters as the benchmark. The total number of parameters of seven methods is listed in Table 10. The total number of parameters of RMSLN is not large, and is reduced by about 100 times compared to EGAN. The two models with the smallest number of parameters, NCNN and MPE-SVM, cannot effectively perform the fault diagnosis task under unbalanced scenarios. With the premise that the fault diagnosis task under unbalanced scenarios is completed with high accuracy, RMSLN has less complexity and higher operational efficiency.
The total number of parameters for seven models in Case 2.
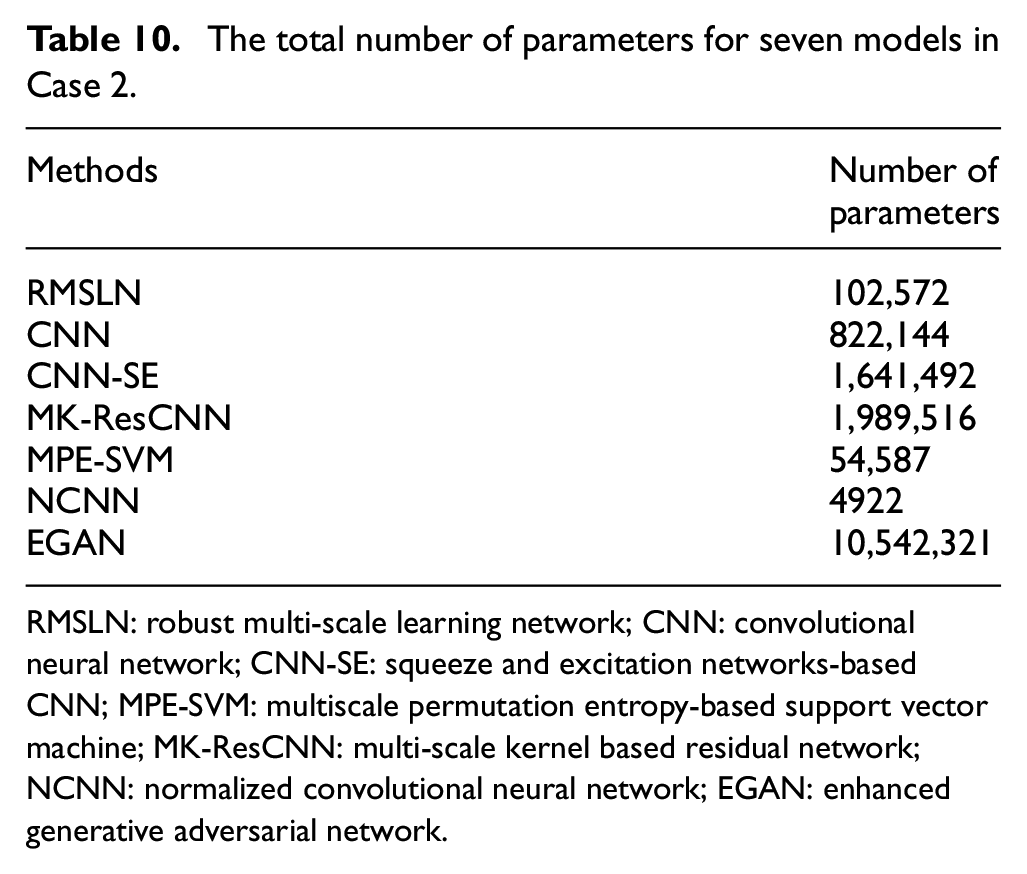
RMSLN: robust multi-scale learning network; CNN: convolutional neural network; CNN-SE: squeeze and excitation networks-based CNN; MPE-SVM: multiscale permutation entropy-based support vector machine; MK-ResCNN: multi-scale kernel based residual network; NCNN: normalized convolutional neural network; EGAN: enhanced generative adversarial network.
Comparison of evaluation metrics
Like Case 1, four metrics are utilized to investigate the identification performance of seven models in Case 2. Table 11 lists the calculation results of evaluation indicators for the seven models. RMSLN achieves one for all four evaluation metrics, which is approximately 0.25 higher than the poorer-performing NCNN model. Although EGAN manifests acceptable fault identification ability with values above 0.99 for all the metrics, it is still slightly lower than RMSLN. The proposed RMSLN thus proves to be extremely competent in fault identification compared to other models.
Concrete values of evaluation metrics in Case 2.
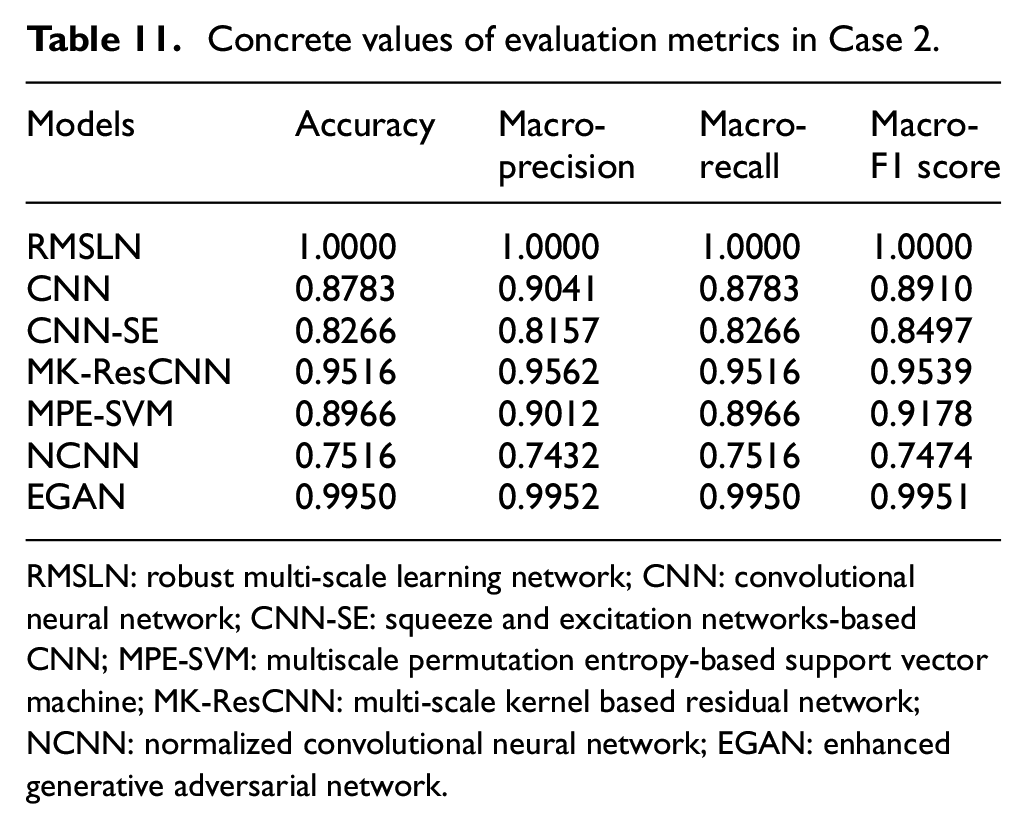
RMSLN: robust multi-scale learning network; CNN: convolutional neural network; CNN-SE: squeeze and excitation networks-based CNN; MPE-SVM: multiscale permutation entropy-based support vector machine; MK-ResCNN: multi-scale kernel based residual network; NCNN: normalized convolutional neural network; EGAN: enhanced generative adversarial network.
Comparative analysis of robustness
To evaluate the superiority of RMSLN in a noisy environment, seven approaches are implemented to comparatively analyze experimental data containing different noise disturbances. Figure 23 exhibits the comparison results of seven approaches with different SNRs. As viewed in Figure 23, MPE-SVM is not suitable for diagnosing fault data in a strong noisy environment. Under extremely noisy disturbances (SNR = −12 dB), the properties of CNN, CNN-SE, MK-ResCNN, NCNN, and EGAN degrade dramatically, while RMSLN still maintains over 95% accuracy. This compelling evidence underscores the immense potential and practical utility of RMSLN, particularly in scenarios where noise interference is prevalent.
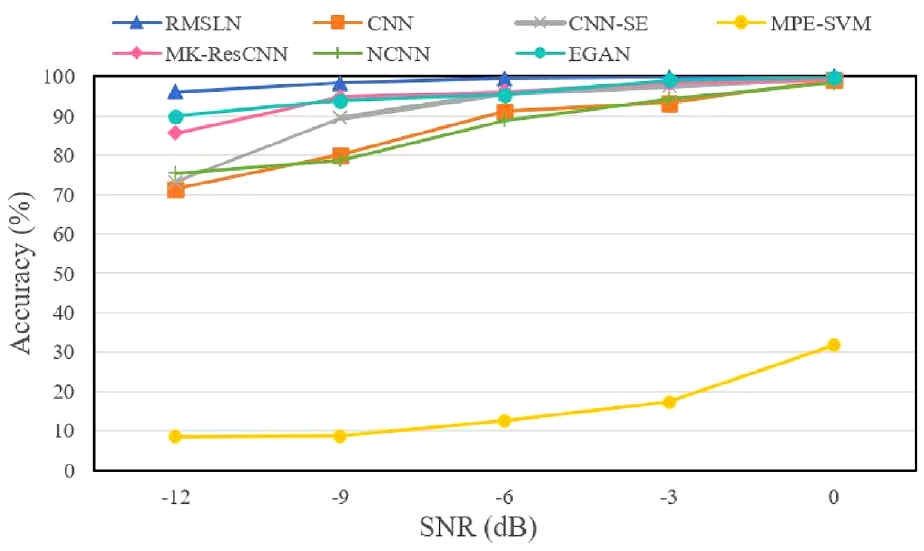
Recognition results with different SNR in Case 2.
To survey the fault diagnosis properties of each method under imbalanced scenarios and noise interference, the above methods are used to analyze data with unbalanced proportions of 2:1 and 5:1, which have noise disturbances of different intensities at the same time. Comparison results of seven methods under sample imbalance and noise disturbance are demonstrated in Figure 24. As the unbalanced proportion increases and the SNR value decreases, the diagnosis performance of RMSLN does not degrade significantly, which maintains an accuracy of over 95% even in scenarios with an unbalanced proportion of 5:1 and SNR value of −12 dB. However, the diagnostic accuracy of the other six methods showed a sharp decrease. The above analysis evidences that RMSLN can successfully address the existing challenges of sample imbalance and strong noise interference in fault diagnosis.
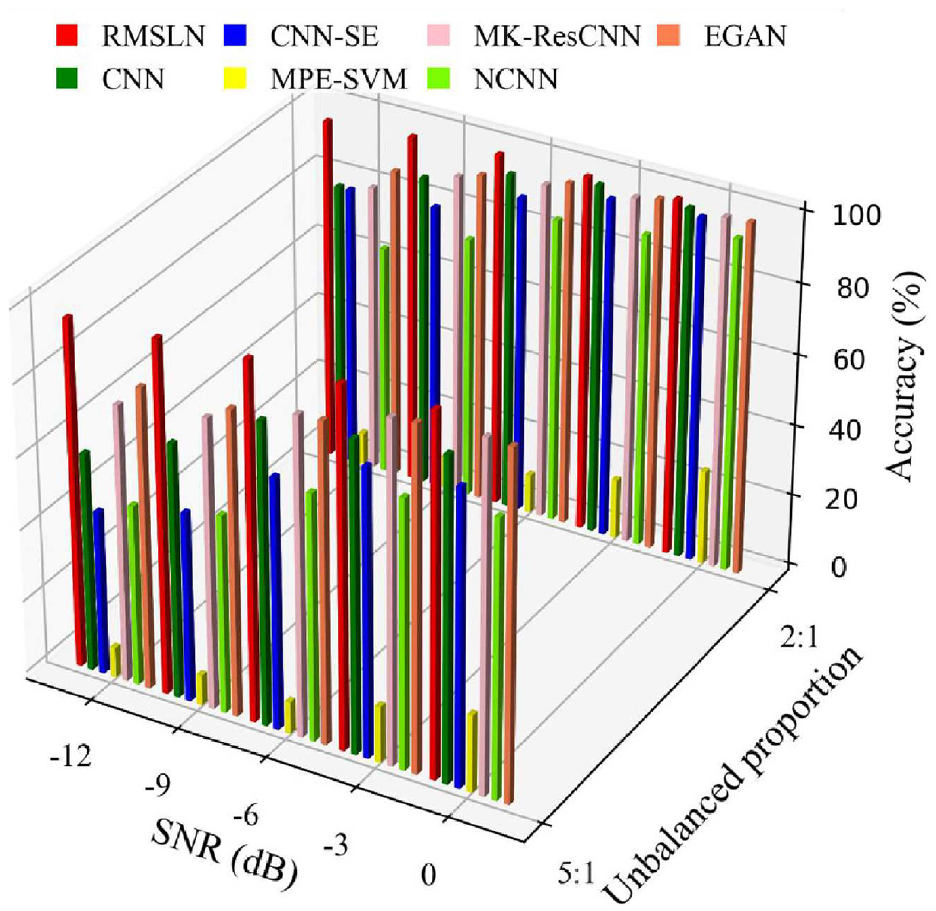
Comparison results under sample imbalance and noise disturbance in Case 2.
Performance comparison of RMSLN with different number of branches
To investigate the effect of branch numbers in the RMSLN model on the fault diagnosis performance, experiments are conducted using the RMSLN model containing different numbers of branches for the 5:1 data. Table 12 lists recognition accuracy and the total number of parameters of the RMSLN model containing different numbers of branches. As indicated in Table 12, the number of branches has less influence on the diagnostic results, and the diagnostic accuracy of all three RMSLNs is higher than 99%. Among them, RMSLN-III has the highest recognition accuracy and a moderate number of parameters. RMSLN-IV not only increases the parameter computation, but also has lower diagnostic accuracy than RMSLN-III, which is mainly because the increased number of branches makes the learned information too redundant and instead reduces the sensitivity of the features.
Performance comparison of the proposed RMSLN model with different branches in Case 2.
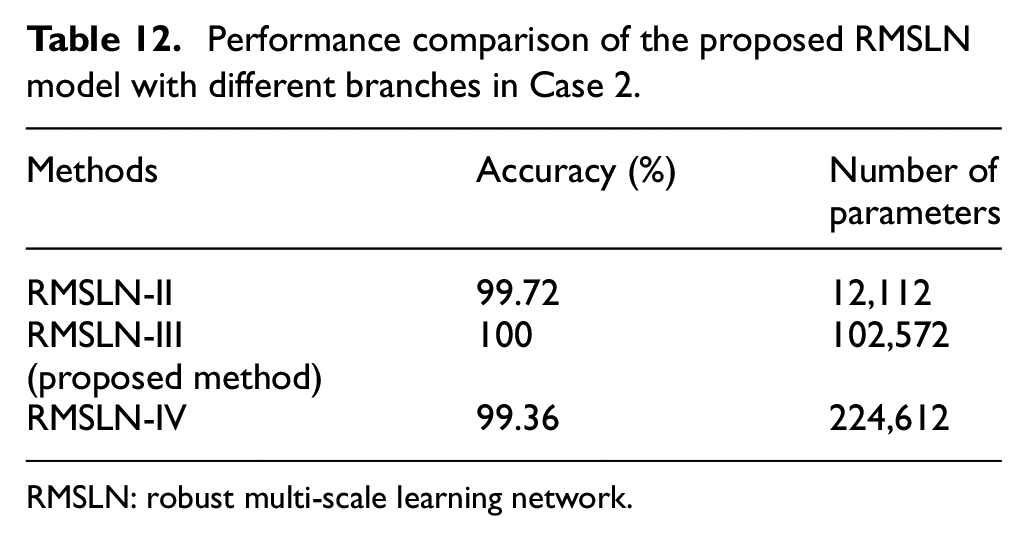
RMSLN: robust multi-scale learning network.
Performance comparison of different optimizers
To illustrate the superiority of the QHAdam optimizer, QHAdam, and other optimization algorithms (SGD, Adam, and RMSprop) are used to optimize RMSLN model for the data with unbalanced proportion of 5:1. The learning rate of SGD, Adam, and RMSprop is set the same as that of QHAdam, which is 0.001. Figure 25 illustrates the comparative results of the different optimization algorithms. After 200 iterations, the SGD curve still did not converge. QHAdam has a smaller advantage relative to Adam and RMSprop on accuracy. Considering the velocity and stability of convergence, QHAdam may effortlessly minimize the loss curve with fewer iterations. This further underlines that the use of the QHAdam optimization algorithm can facilitate fast and stable convergence of the proposed model.
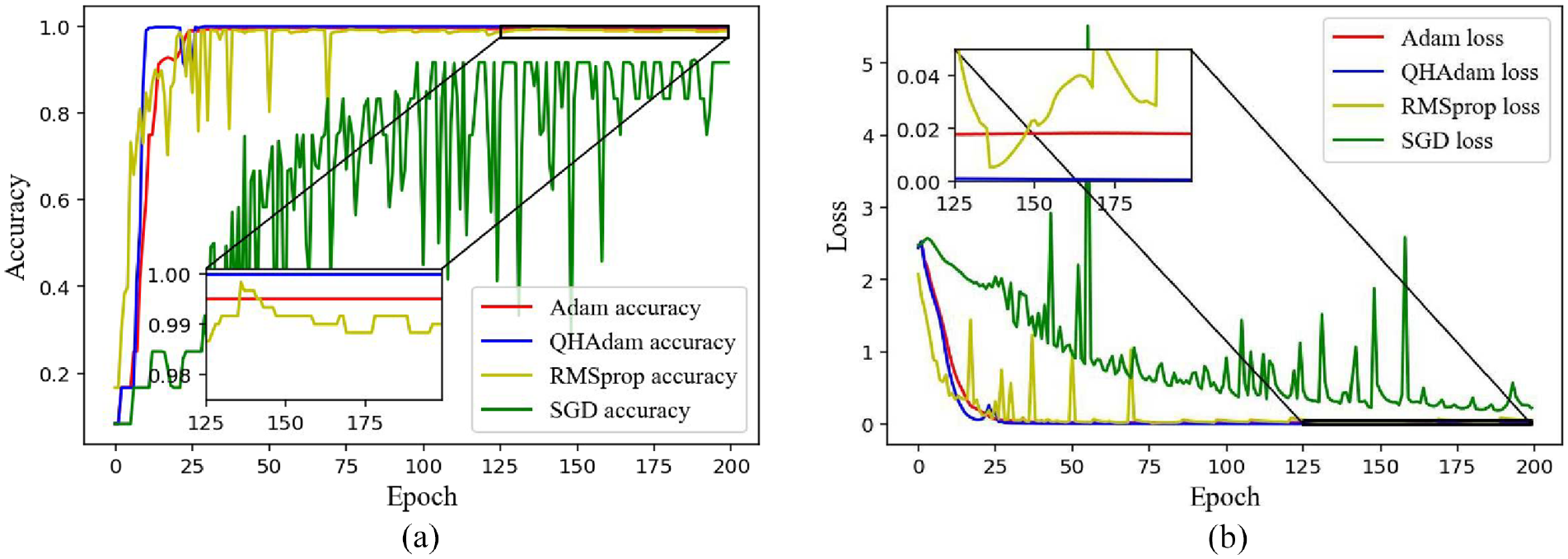
Contrast results of different optimizers in Case 2: (a) Accuracy convergence curve and (b) loss convergence curve.
Discussions
The feasibility and superiority of the proposed RMSLN under sample imbalance scenarios and noisy environments are verified by experiments with two different data sets and multiple comparative analyses. The SENet module is introduced in the RMSLN, which not only weakens the interference of noise but also enhances the attention to the fault classes with minor samples. Additionally, by constructing residual connections between adjacent branches, RMSLN can reduce feature loss during delivery and facilitate the features of minority samples better delivered to the softmax layer. Consequently, based on these factors, the proposed RMSLN can be considered as an alternative for addressing fault diagnosis problems under sample unbalance in real-life applications. However, RMSLN also has some areas for improvement. First, it can be found from Case 1 that the RMSLN is not sufficiently stable for fault diagnosis of strong imbalance data at variable rotational speeds. Migration technology will be introduced subsequently to enhance the applicability and stability of RMSLN for fault diagnosis under strong unbalance conditions at variable speeds. Second, the training parameters of RMSLN need to be further optimized and shrunk to raise the diagnostic efficiency and better meet the demand of diagnosing bearing faults in real time.
It is mentioned that the vibration signals used in this work are all from single sensor. However, in some sophisticated operating situations, multiple sensors are required to collect bearing failure data from multiple locations. Hence, we will consider fusion of multiple sensors or fusion of multiple data sources (e.g., vibration and acoustic) in subsequent studies. In addition, in some specific environments, the collected fault data may not have accurate markers or have fewer markers. Therefore, in future research, we will introduce clustering means and graph networks to study unbalance fault diagnosis without labels and unbalance fault diagnosis with fewer labels.
Conclusions
This study presents a new method based on RMSLN with QHAdam optimizer for intelligent fault diagnosis of rolling bearings. Furthermore, the QHAdam optimizer is employed to adjust the loss values of the presented RMSLN model, which can help the model converge quickly and steadily on the premise of obtaining a high diagnostic accuracy. The main contributions of this study are summarized as follows:
(1) A novel model named RMSLN with theoretical ideas of channel attention and residual learning, which can both implement multi-branch integrated learning and augment the feature learning power of traditional multi-scale network model.
(2) A new optimization method abbreviated as QHAdam optimizer is introduced to optimize the training process of RMSLN model, which can accelerate network convergence under the guarantee of satisfactory accuracy.
(3) An end-to-end data-driven intelligent fault diagnosis framework based on RMSLN with QHAdam is proposed for bearing fault diagnosis, which gets rid of the dependence of expert experience in artificial feature extraction.
(4) The presented approach is applied to two different experimental data to authenticate its workability under sample imbalance. The superiority of the presented method is highlighted through comparative analysis from multiple perspectives. It is further demonstrated that the presented method can effectively learn important fault information and achieve a satisfactory identification accuracy, even for the scenario of a large unbalanced proportion and strong noise.
Footnotes
Acknowledgements
The authors want to express their gratitude to the editor and the uncharted specialists for their important proposals. Also, the authors want to express their gratitude to Jiangnan University and Saint-Langevin Institute of Engineering and Technology for supplying laboratory data.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (No. 52005265) and Natural Science Fund for Colleges and Universities in Jiangsu Province (No. 20KJB460002), and the Postgraduate Research & Practice Innovation Program of Jiangsu Province (Grant No. KYCX23_1131).