
Abstract
To meet the demand for high-precision recognition and real-time processing when using intelligent detection methods in daily concrete bridge crack detection tasks, a high-precision lightweight crack image recognition method based on knowledge distillation is proposed. Through semisupervised learning, the information embedded in unlabeled data is used to train a lightweight network to obtain high-precision crack recognition results. First, by comparing the recognition accuracy of lightweight network under different training strategies, the effectiveness of the knowledge distillation method in improving the accuracy of lightweight network is verified. Second, a label-free knowledge distillation method for engineering detection is proposed. Finally, using MobileNetv3 as the student model, under the self-built three-classification dataset of nearly 700,000 images, the accuracy reached 99.84% through the proposed knowledge distillation method, which is very close to the teacher model ResNeXt101 accuracy (−0.08%), and MobileNetv3 compared with ResNeXt101 its model inference speed increased by more than 13 times. At the same time, the MobileNetv3 model improves the inference speed by more than 13 times and reduces the number of model parameters by more than 35 times compared to the ResNeXt101 model. The research results fully demonstrate that under the premise of having a large amount of unlabeled data, using the proposed knowledge distillation method, the recognition accuracy of the trained lightweight model has a significant advantage over the existing lightweight network training strategies.
Keywords
Highlights
An unlabeled knowledge distillation method for bridge detection is established.
The effectiveness of knowledge distillation method in improving the accuracy of lightweight network is verified.
Experiment and result for constructing a high-precision lightweight bridge crack recognition method.
Introduction
During the long-term use of the bridge, it will inevitably be affected by the load effect, material aging and deterioration, temperature, humidity changes, rainstorm and snowstorm and other natural environments, which will affect the service life of the bridge. It has been shown that as much as 90% of concrete bridges are structurally damaged due to the presence of cracks. 1 Therefore, it is extremely necessary to detect bridge cracks.
At present, manual inspection and bridge inspection vehicle are the main methods of bridge inspection. However, since the inspection process mainly relies on human eye observation and requires multiple people to work, it is difficult to meet the existing demand for bridge crack inspection in terms of both inspection efficiency and accuracy. For this reason, the development of economic, safe, and efficient intelligent crack detection methods has become a current research hotspot in the field of bridge structure inspection. Crack image detection refers to the process of automatically identifying cracks in images, typically through the use of computer vision algorithms and techniques. In recent years, bridge crack image detection methods based on deep learning models have received widespread attention for their ability to autonomously learn the characteristic parameters of crack images.
Zhang et al. 2 verified the feasibility of crack recognition for the first time using a supervised deep convolutional neural network (CNN) and applying a sliding window algorithm. Yu et al.3,4 developed a vision-based crack diagnosis method using deep CNN optimized by enhanced chicken swarm algorithm and constructed a hybrid framework considering noise effect for concrete crack image detection. Cha et al. 5 used an improved CNN model to detect concrete cracks in order to solve the problem of low recognition accuracy under unfavorable environmental conditions, and 98% crack recognition accuracy can be obtained using this network. Qu et al. 6 combined the VGG16 network with the cross-entropy loss function to detect various types of concrete pavement cracks in different environments, and the results of the study showed that the method has a high accuracy and recall rate. Wu et al. 7 improved the GoogLeNet network, and the classification accuracy of crack images can reach 98.5% under the transfer learning method. Wang et al. 8 proposed an end-to-end bridge crack detection model based on Inception convolution and ResNet network, which is capable of extracting the background information at different scales, and effectively improves the accuracy of crack recognition.
Obviously, deep learning networks such as Visual Geometry Group (VGG) network, ResNet series networks, and GoogLeNet network have shown great advantages in the field of crack image recognition. However, these kinds of large network models are more complex and have higher parameter quantities to achieve high-precision recognition results. However, when the amount of network parameters is too large, it will consume a large amount of memory and arithmetic power, which makes it difficult for large deep networks to be deployed on resource-limited devices (e.g., embedded systems or mobile devices), limiting their popularization in practical applications. In order to reduce the arithmetic parameters and improve the detection efficiency, deep learning networks are beginning to develop in the direction of high efficiency and light weight.9,10
In recent years, some lightweight network models have begun to emerge, such as SqueezeNet network, 11 MobileNet series networks, 12 and ShuffleNet series networks. 13 Chen et al. 14 have used the lightweight network model MobileNetv3 15 combined with the convolutional block attention module as the backbone network, and used the Focal Loss method to deal with the problem of data imbalance during the training process, obtaining a relatively good crack recognition performance.
The design of lightweight networks can solve the problems of complex deep neural network models, high number of parameters, and slow operation speed, but due to the reduced number of parameters and structural complexity of their networks, these lightweight networks tend to have lower recognition accuracy compared to their larger counterparts. To address this limitation, current lightweight network training based on knowledge distillation (KD) 16 has gradually become an effective means to improve its training accuracy. Chen et al. 17 constructed a high-performance lightweight network termed multipath convolution feature fusion lightweight network and utilized the concept of KD. The network had a fast crack detection speed and could be used for embedded device. Wang et al. 18 used channelwise KD to normalize the activation mapping between the teacher and student models and provided an effective solution for crack segmentation in realistic scenarios. Sepahvand et al. 16 proposed an adaptive teacher-student learning algorithm with decomposed KD. The student model designed by the ResNet-18 architecture has fewer number of parameters with lower computational complexity as tested by the benchmark dataset. The essence of KD is to use a larger and more accurate teacher model to guide the training of a smaller and more efficient student model, so that the student model can mimic the teacher model’s behavior and obtain higher accuracy. 19
In this article, we propose a concrete bridge crack recognition method based on KD to construct a lightweight crack identification network, and the information embedded in unlabeled data is utilized to train the student model through semisupervised learning to obtain high-precision bridge crack classification results. The feasibility and superiority of the proposed method in bridge crack recognition is verified using a self-constructed dataset of nearly 700,000 bridge crack images.
The remainder of the article is organized as follows: After the introduction section, section “Theoretical background” describes the basic theoretical models used and the rationale for their selection. Section “The proposed method” proposes a novel method for high-precision lightweight concrete bridge crack image recognition. In section “Experimental preparation,” an actual concrete bridge crack dataset is constructed and some specific image enhancement schemes are presented. Section “Analysis of experimental results” analyzes the results of concrete bridge crack identification and verifies the effectiveness of the proposed methodology. Section “Conclusions and future work” is the conclusions summarized.
Theoretical background
Teacher model—ResNeXt101 network
Compared to the classic models such as AlexNet, VGG, and GoogLeNet, the ResNeXt model 20 allows for the construction of deeper network, solves the problem of gradient vanishing, and improves network performance. At the same time, ResNeXt integrates features from different levels, which can be enriched by the depth of the network to better capture the information in the image. ResNeXt proposes grouped convolution, which simplifies the design of inception by adjusting the number of groups based on the variable cardinality. 21 In this article, we adopt 32 × 16d ResNeXt101 model as the teacher network, where 32 denotes the number of grouped convolutions and 16d denotes the number of channels in each group. The specific network structure is shown in Figure 1.
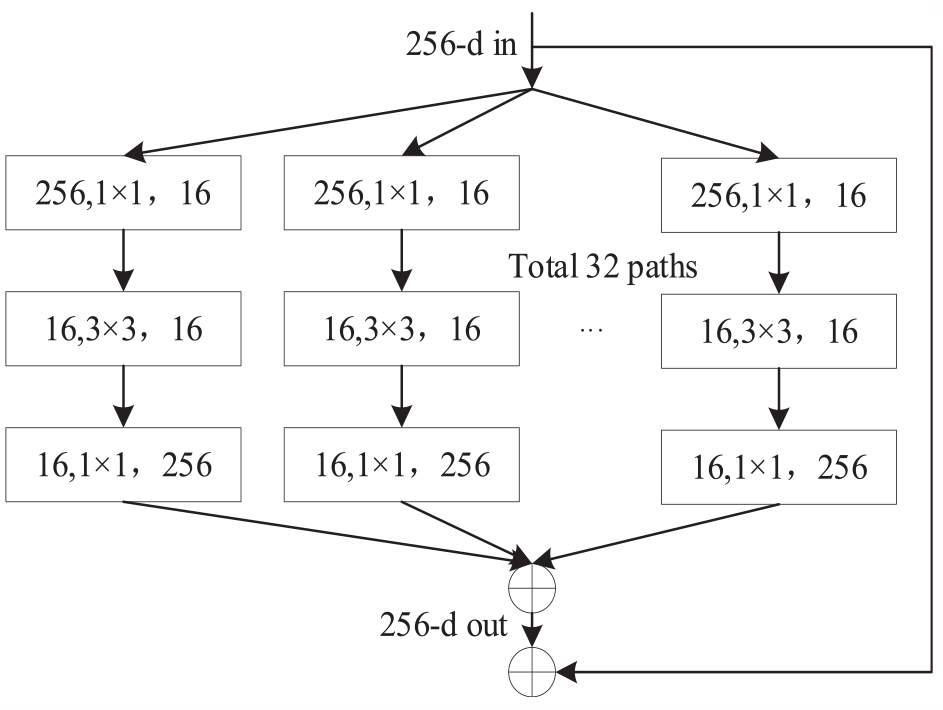
ResNeX101 network structure.
Student model—MobileNetv3 network
MobileNetv3 15 is a lightweight CNN based on deeply separable convolution. It is designed using Neural A rchitecture Search (NAS) search (determining the network structure by means of a neural architecture search algorithm), nonlinear activation function selection (using the smoother and nonlinear Swish activation function), and a dynamic convolution strategy (dynamically selecting different convolution kernels based on the size and location of the input feature maps). In addition, MobileNetv3’s use of adaptive computation units (ACUs)-based strategies also allows it to automatically adjust the amount of computation at runtime to achieve a better balance of accuracy and speed. Its network structure is shown in Figure 2.
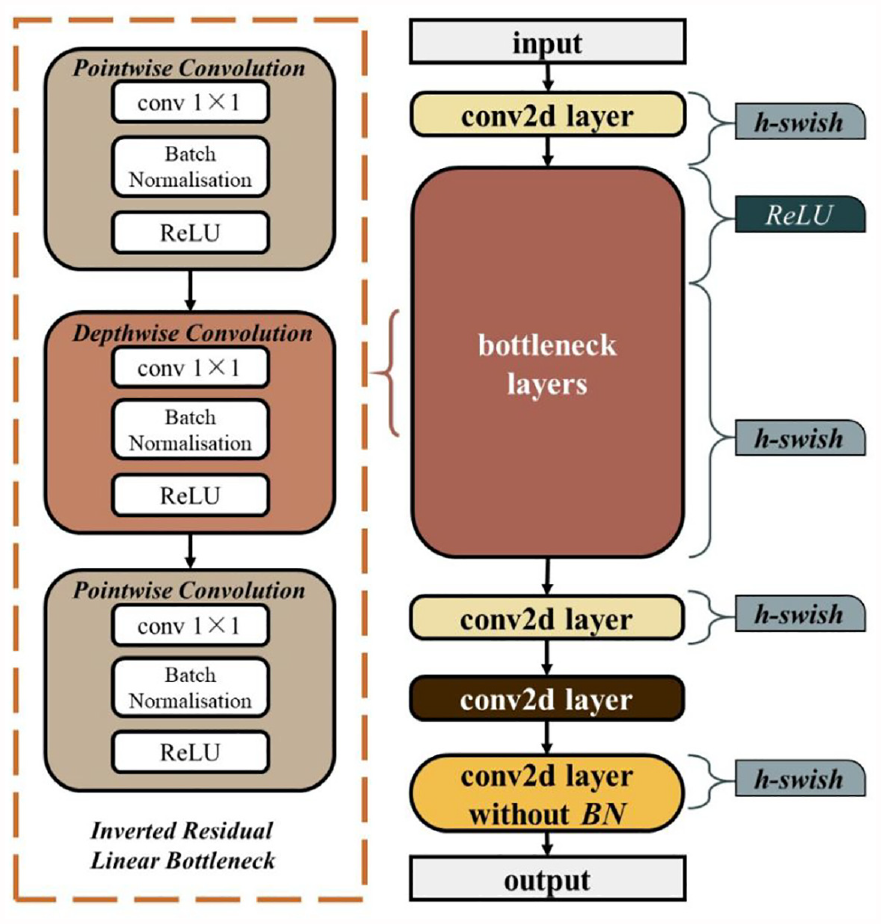
MobileNetv3 network structure. 15
Knowledge distillation
First proposed by Hinton et al., 19 the learning core of KD is for the student network to learn the Softmax layer output probability distribution of the teacher network, as opposed to learning knowledge directly from image labels. In traditional CNNs, the Softmax layer is usually used as a classifier to map the output of the last convolutional layer to the category probability distribution, which is trained by the cross-entropy loss function. The existing mainstream KD methods are progressive learning, 22 simultaneous learning, 23 and soft-label learning. 24
The advantage of soft-label learning over other KD methods is that it can better balance the accuracy and generalization performance of the model. Since soft-labels contain more information, they can improve the accuracy of the model without overfitting the model, which improves the generalization ability of the model. In addition, soft label learning can be used for semisupervised learning, that is, to improve the performance of small models with limited labeled data by combining a large amount of unlabeled data with soft labels of complex models. In this article, we will establish a suitable KD scheme based on soft label learning, the basic principle of which is shown in Figure 3.
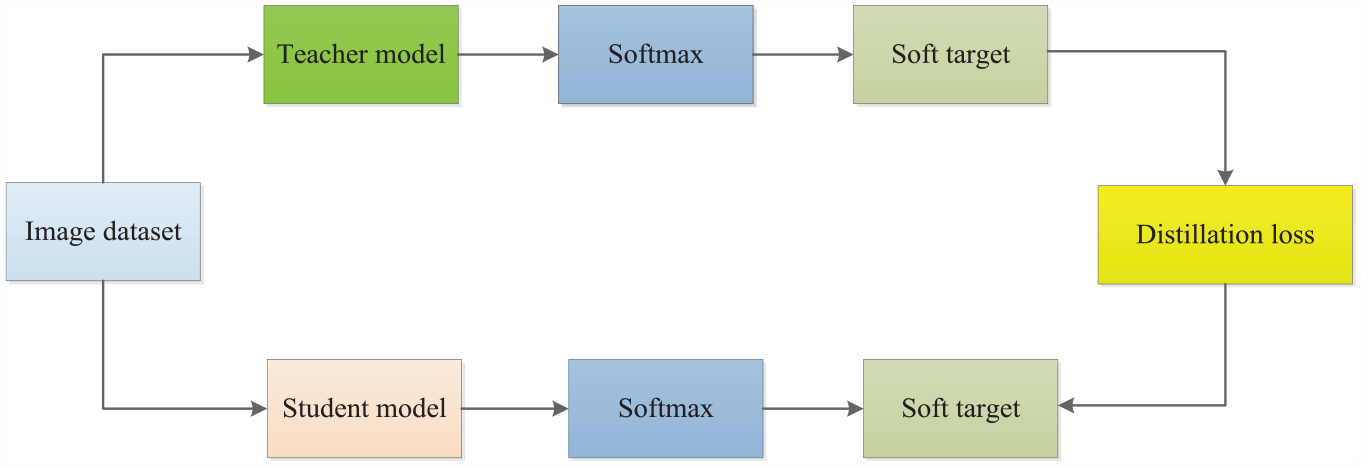
Knowledge distillation principle.
Analysis of the reasons for the selected teacher model and student model
Since in KD, the similarity of the network structure of the teacher network and the student network will affect the learning efficiency and effectiveness of the student network. 25 Therefore, when selecting teacher networks and student networks, it is necessary to ensure that they have a certain structural similarity. At the same time, it is also necessary to retain a certain structural difference to ensure the diversity of KD. For this reason, in this article, the most popular server-side and mobile-side models, the ResNeXt and MobileNet network families, are chosen as the teacher network and student network, respectively.
The two network models, ResNeXt101 and MobileNetV3, were chosen for their similarities in model structure: (1) both networks use Residual Connection, which makes Feature Alignment between the teacher network and the student network easier to achieve. (2) Both networks use Bottleneck Structure to make the feature dimension between the two networks closer, thus reducing the information loss during KD. (3) Both networks use grouped convolution to make the feature distribution between the two networks more similar, thus enhancing the information transfer during KD.
In addition, the SE Attention Mechanism and inverted residual structure used in MobileNetv3 network also make some differences between the two networks. Moreover, the ResNeXt101 network usually has a fixed-size input image due to the use of fully connected layers, whereas two 1 × 1 convolutional layers are used instead of fully connected layers in the MobileNetv3 network structure, which allows the network to support variable-size image inputs in order to better handle different scales of images in the testing phase.
The proposed method
In this article, based on the distillation method in the Cui et al., 26 a bridge crack semisupervised labeling KD (BCSLD) method is proposed to identify concrete bridge cracks with high accuracy in a lightweight network by targeting the cracks’ morphological characteristics. This method overcomes the drawback of general KD methods that require high amount of distillation data. In contrast to other KD methods, BCSLD method can significantly improve the accuracy of the lightweight network model without increasing the computational cost and training time, and its overall flow is shown in Figure 4.
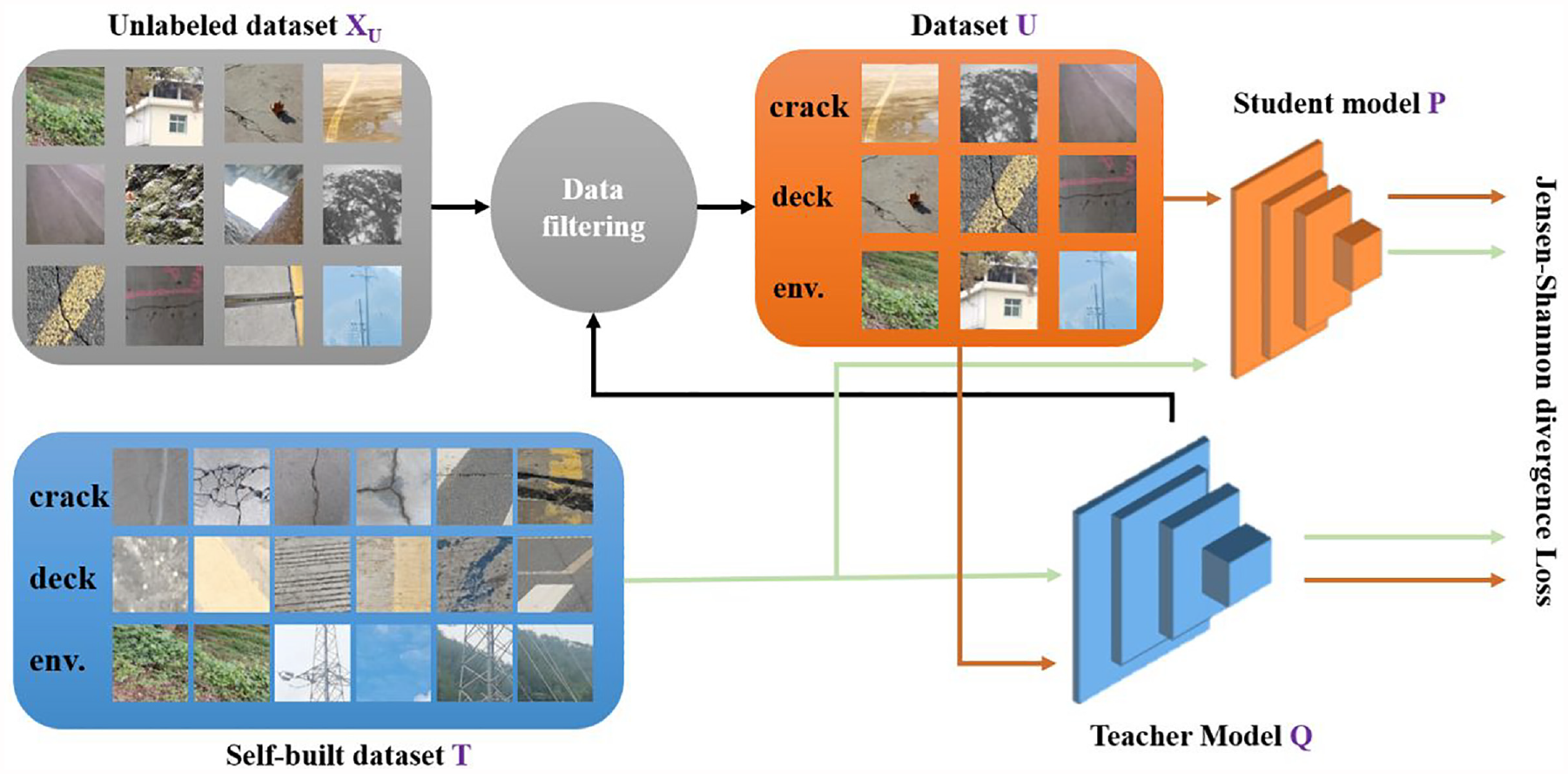
Concrete bridge crack identification process based on knowledge distillation.
Step 1: training of teacher model
Based on the self-constructed bridge crack dataset
Step 2: data filtering
In this step, the unlabeled dataset
The main work of data filtering in this article is to select those categories that are correctly predicted by the teacher model with high confidence based on the probability or confidence of the teacher model’s prediction for each category as a part of the training set for the student model
Data filtering is specifically expressed as follows:
We assume that the teacher model
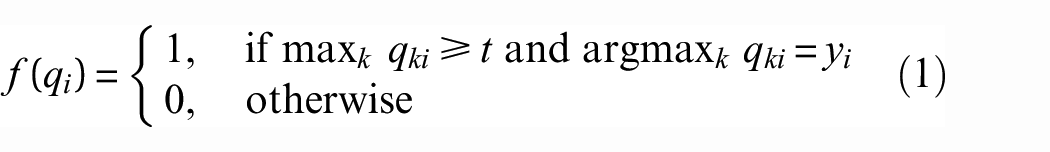
where
Step 3: combination of student model P and teacher model Q
The student model
The method proposed in this article assumes that the generalization error of the teacher model is small, so it can be used to guide the student model without considering the real labels (datasets
Step 4: calculation of the KD loss function
Jensen–Shannon (JS) divergence is calculated using the soft labels of the teacher model and the student model and its value is used as a loss function for distillation model training.
Unlike other KD schemes, the BCSLD method proposed in this article only enforces the constraint that the student model
JS divergence is a metric used to measure the distance between two probability distributions. In KD task, its generally used as a loss function to measure the difference between two probability distributions. JS divergence is based on the Kullback–Leibler (KL) divergence in information theory to measure the distance between two probability distributions, which is calculated as
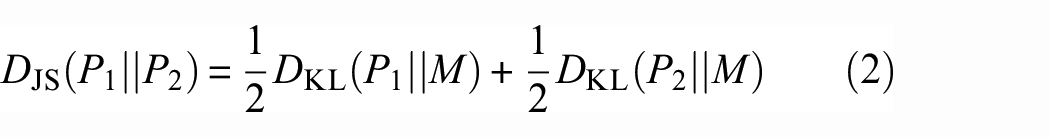
where P1 and P2 denote the two given probability distributions, M denotes the mean distribution of P1 and P2,
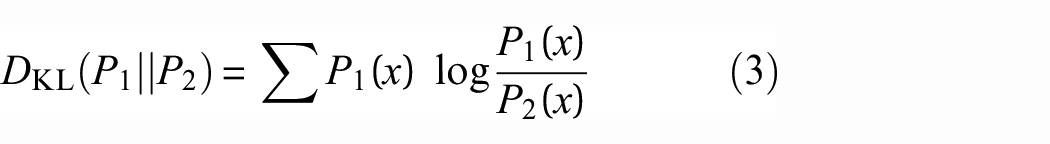
The value domain of JS divergence is between [0, 1], which is 0 when the two probability distributions are exactly the same, and 1 when the two probability distributions are exactly different. When used as a loss for the KD task, its value can be expressed as
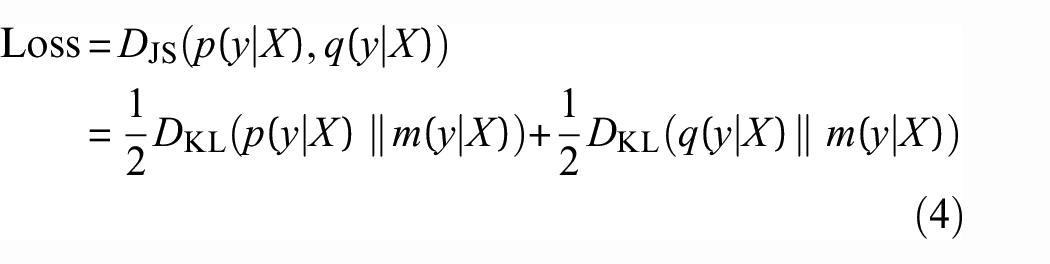
where
By minimizing the loss value of
Experimental preparation
Concrete bridge crack dataset construction
On the basis of the existing public concrete bridge dataset, this paper constructs a three-classification dataset by itself by combining the bridge inspection images, UAV images, and images taken by hand-held devices acquired in the actual project. Among them, the disease images of 761 bridge decks and bridge bottoms acquired through bridge inspection vehicles in Shanghang County, Longyan City, accounted for the main proportion, as shown in Figure 5.
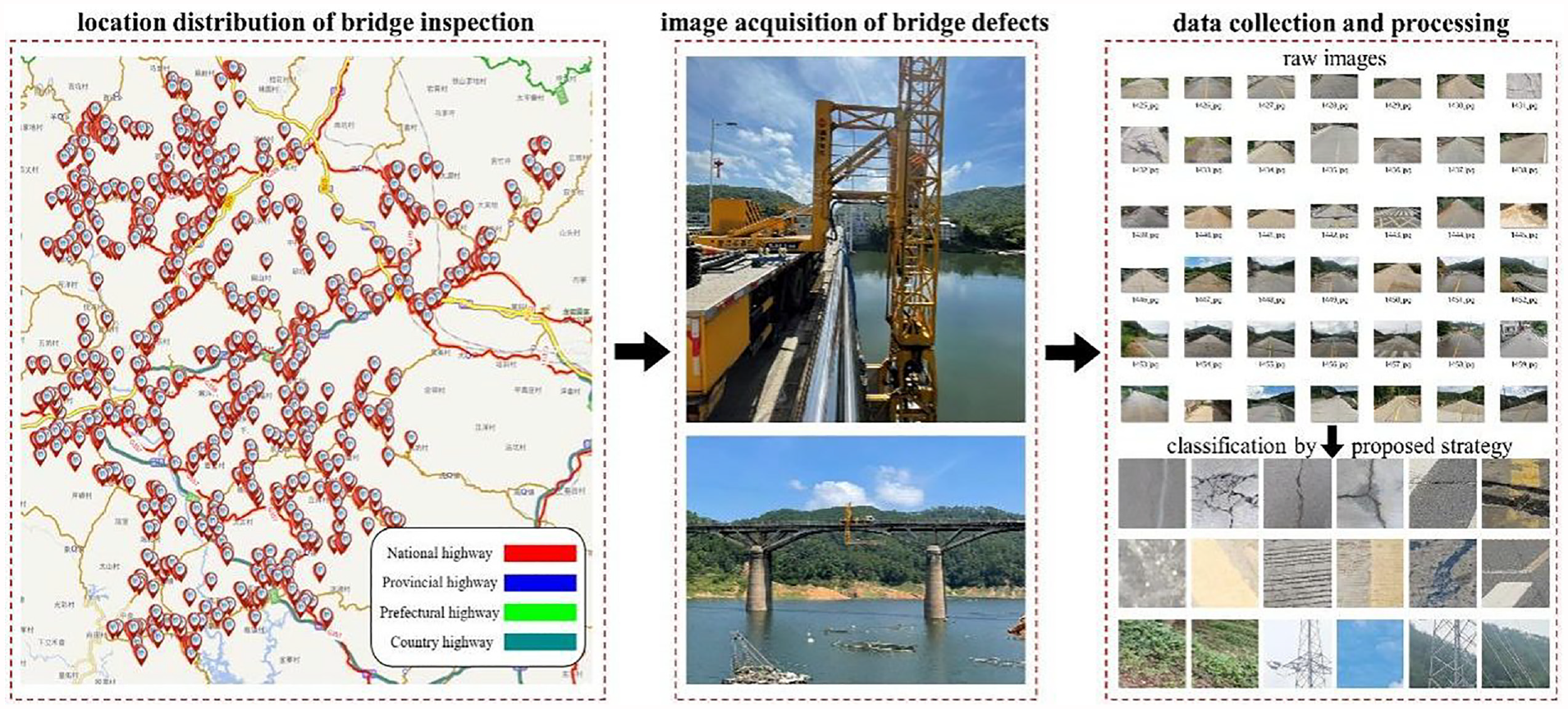
The flowchart of data processing on bridge detection images.
The images are cropped in batches of 256 × 256 pixels as recognition size and categorized under the labels “crack,”“bridge deck,”“environment,” and stored in “jpg” format. The percentage of data in each category and the amount of labeled and unlabeled data are shown in Figure 6.

Percentage of samples in each category in the concrete bridge crack dataset.
Among the total number of 685036 images after cropping, the total number of self-labeled images is 322645, of which the number ratios of “environment,”“bridge deck,” and cracks are 198116:67925:56604 in that order, and the remaining unlabeled 362391 images will be used as the training data for the subsequent semisupervised learning of classification network based on KD scheme.
Data preprocessing
In order to improve the generalization ability and robustness of the model, a specific image enhancement strategy is used in this article (Table 1). Image transformation enhancement is performed on each batch of images loaded before each training.
Image enhancement scheme for concrete bridge crack dataset.

Experimental environment
In this article, dual GPUs (2 × 2080Ti) are used for model training, performance evaluation, and experimental comparison tasks, and Compute Unified Device Architecture (CUDA) and CUDA Deep Neural Network (CUDNN) libraries are used to accelerate the speed of GPU parallel computation of multiple image data. The computational processing unit CPU is i9-9820X. Software is developed and programmed in Windows environment using Python language, and Anaconda is used for package management and virtual environment configuration. Pytorch is used for the deep learning framework. The specific hardware and software configurations are shown in Figure 7.

Software and hardware configuration.
Model evaluation metrics
For evaluating the proposed model, four types of evaluation metrics are used: accuracy, Precision, recall and F1-score (F1). These metrics are defined as follows:



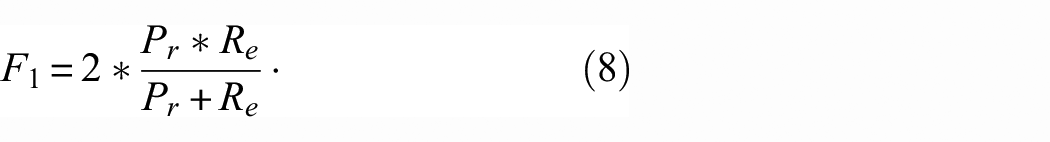
where TP, TN, FP, and FN are the numbers of True Positive, True Negative, False Positive, and False Negative samples, respectively.
Analysis of experimental results
Comparison of MobileNetv3 performance under different training strategies
In order to verify the advantages of the lightweight network model MobileNetv3 and the proposed KD method, this section compares the dataset training performance of multiple strategies under 20 epochs, respectively. The number of training samples for each category taken in this experiment is cracks:bridge deck:environment = 20000:20000:20000. Under the KD method, the MobileNetv3 network is guided to learn with 100,000 unlabeled data in the ResNeXt101 network trained by 60,000 labeled data.
According to the existing experience,15,20,25 during the training process, the hyperparameters of MobileNetv3 and ResNeXt101 networks include batch size (bs), initial learning rate (lr), momentum (mt), weight decay factor (wdf), and L2 regularization factor (L2r). The specific settings of hyperparameters are shown in Table 2. The learning decay strategies of MobileNetv3 and ResNeXt101 networks adopt multistep decay and cosine annealing decay, respectively.
Hyperparameter setting of MobileNetv3 and ResNeXt101 networks.

In this article, there are five training strategies set up for comparison, which are (1) MobileNetv3 + KD (with image enhancement and transfer learning already included); (2) MobileNetv3 + Image enhancement (with transfer learning already included); (3) Mobile Netv3+ Transfer learning; (4) MobileNetv3 + Training from scratch; and (5) ResNet18 + Training from scratch. The concrete bridge crack recognition accuracy under different training strategies are shown in Figure 8.
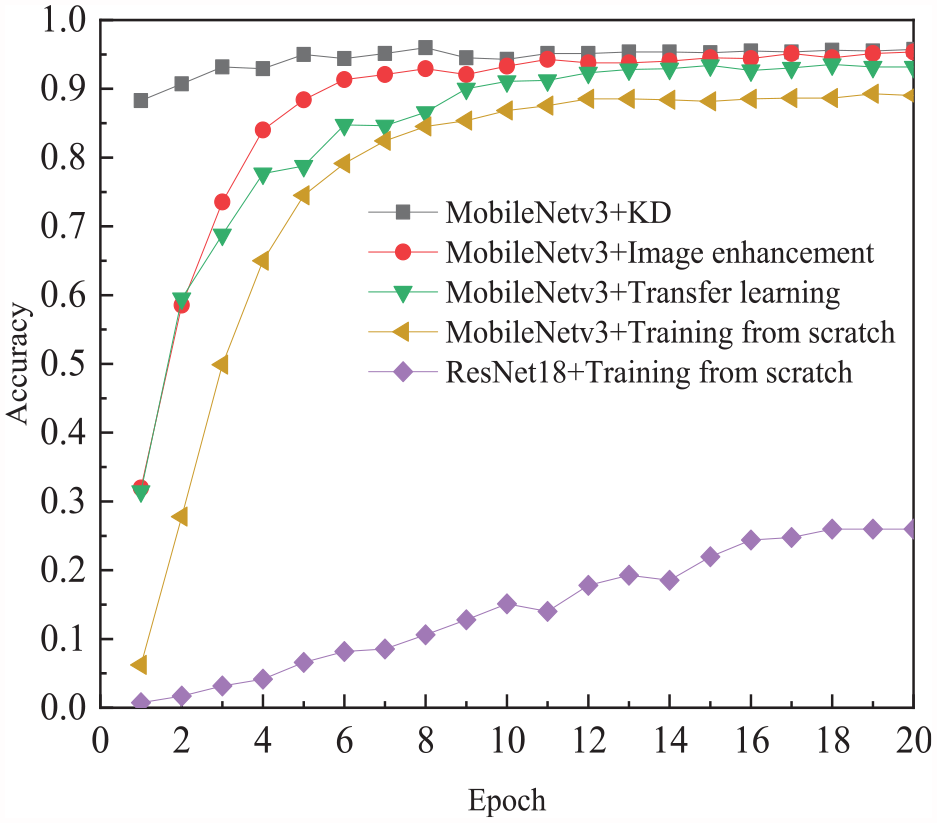
Comparison of concrete bridge crack recognition accuracy under different training strategies.
As can be seen in Figure 8, the recognition accuracy of the “ResNet18+Training from scratch” strategy can only reach 25.98% after 20 epochs, which is the worst recognition performance. The recognition accuracy of the four strategies, “MobileNetv3+Training from scratch,”“MobileNetv3+Transfer learning,”“MobileNetv3+Image enhancement,” and “Mobile Netv3+KD,” are 27.8%, 59.51%, 58.54%, and 90.73%, respectively, after the completion of training at the first epoch. The KD method has a huge accuracy improvement (+32.19%) based on the image enhancement method, which shows that the KD scheme has a significant advantage in accelerating the model training. In the subsequent six epochs, the recognition accuracy of the KD scheme is slowly improved, and the other methods are accelerated; then the recognition accuracy of the four methods gradually stabilizes. In the 20th epoch, the recognition accuracy of each method is 89.02%, 93.17%, 94.39%, 95.37%, 95.73%, which is 7.1%, 2.95%, 0.75%, 0.39%, respectively, different from the recognition accuracy of the teacher’s network ResNeXt101 of 96.12%. This shows that the KD scheme can indeed effectively improve the recognition accuracy of the lightweight network MobileNetv3 without increasing the labeled data.
In order to further verify the feasibility of the proposed method, a validation set is established to test the performance of the above five strategies. The number of samples in the validation set is: cracks:bridge deck:environment = 5000:5000:5000. The corresponding accuracy of concrete bridge crack identification is shown in Figure 9, and the statistical results of various evaluation indexes are shown in Table 3.
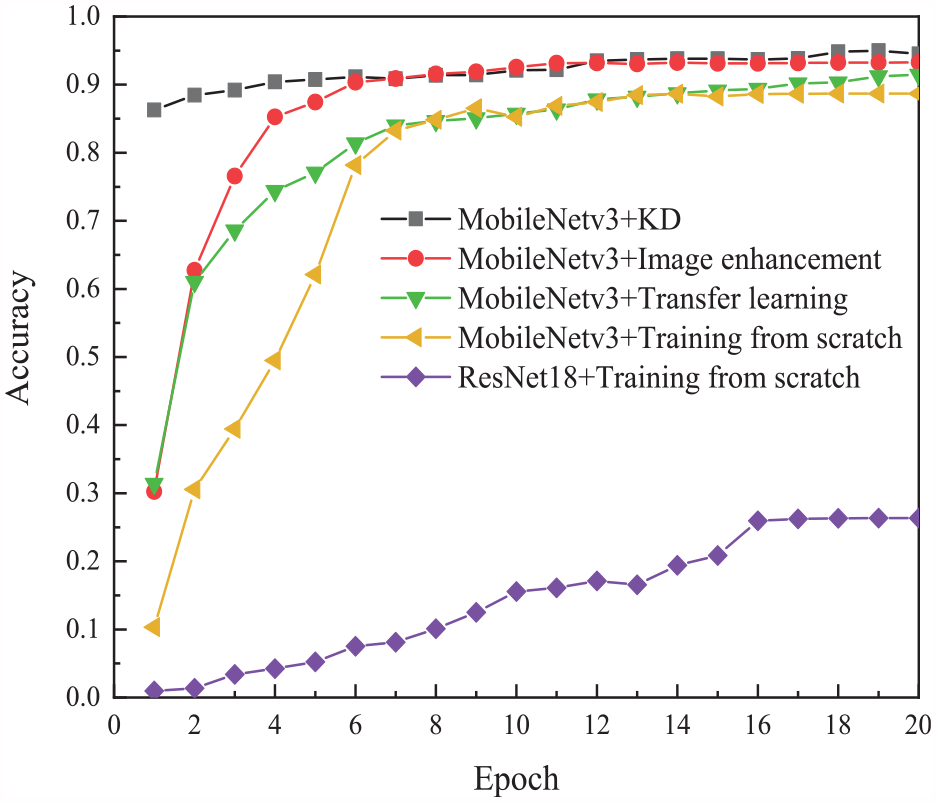
Comparison of bridge crack recognition accuracy on the validation set.
Statistical results of evaluation indexes for five strategies.
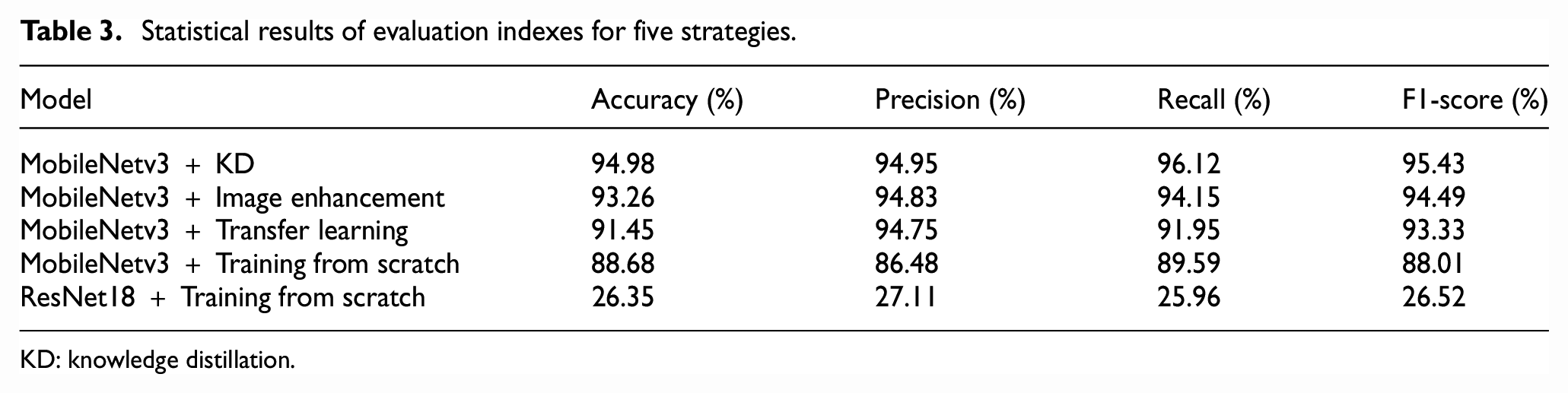
KD: knowledge distillation.
From Figure 9 and Table 3, it can be seen that the “MobileNetv3+KD” strategy on the validation set has the best performance in all the four evaluation indexes, and the performance of the other four strategies is consistent with the performance in the training set. This fully validates the effectiveness of the proposed KD method.
Analysis of bridge crack identification results
In order to explore the change of the gap in recognition accuracy between the lightweight model and the teacher network model under a larger unlabeled dataset, in this article, we use the 322645 self-labeled images in the constructed categorical dataset as the self-constructed dataset T and the unlabeled 362391 images as the unlabeled dataset
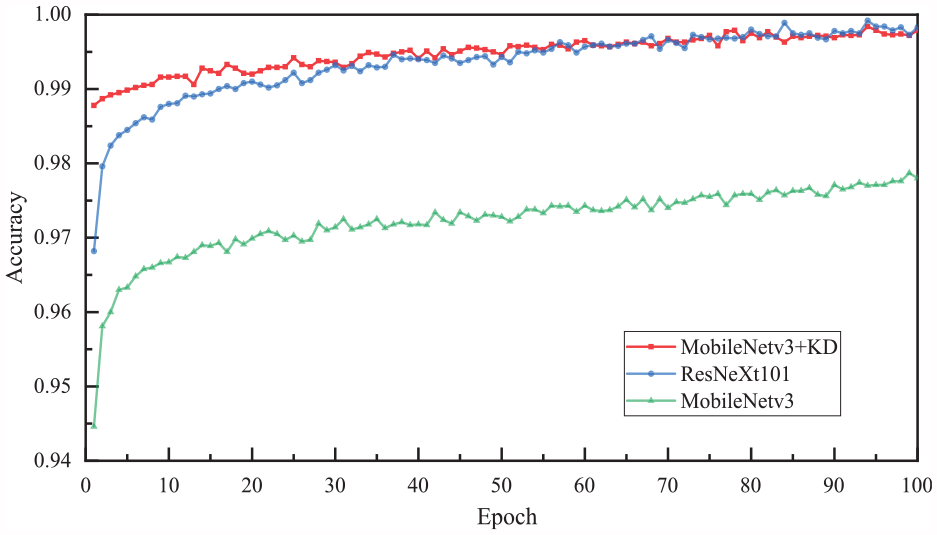
The images are divided according to the ratio of training set: validation set = 0.8:0.2, and then the network is trained and tested. The network hyperparameters are set as in section “Comparison of Mobile Netv3 performance under different training strategies,” and the total number of training rounds is 100 epochs. The crack recognition accuracy of the three methods MobileNetv3, ResNeXt101, and “MobileNetv3+KD” on a large validation set are given in Figure 10. The statistical results of the various evaluation indexes are shown in Table 4.
Comparison of the crack recognition accuracy of three models on the large validation set.
Statistical results of evaluation indexes for three models.
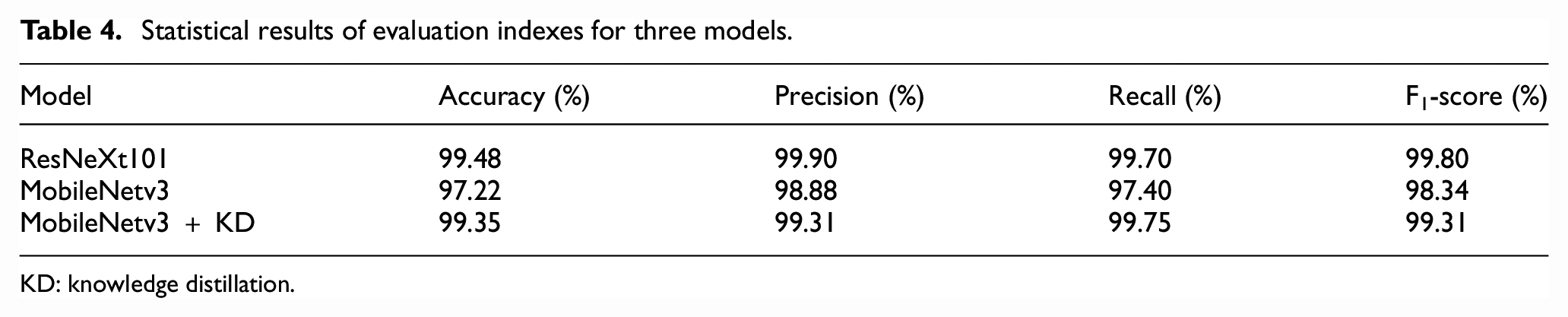
KD: knowledge distillation.
From Figure 10 and Table 4, it can be seen that (1) the average recognition accuracy of MobileNetv3, ResNeXt101, and “MobileNetv3+KD” on the validation set are 97.22%, 99.48%, and 99.35%, respectively, and the highest recognition accuracy are 97.87%, 99.92%, and 99.84%, respectively. Meanwhile, the overall accuracy of the model also maintains a slow growth trend after 100 epochs. It can be seen that the larger the dataset is, the more stable the training process is, and the higher the model accuracy is. (2) The “MobileNetv3+KD” model and ResNeXt101 model are very close to each other in terms of precision, recall, F1-score and other indicators. It fully indicates that the performance of MobileNetv3 model has been effectively improved after KD.
In addition, it can also be seen from Figure 10 that the difference in recognition accuracy between the student model and the teacher model is steadily decreasing due to the increase in the unlabeled dataset. “MobileNetv3+KD” model compares to the teacher network ResNeXt101, and the average and maximum accuracy are reduced by only 0.13% and 0.08%, respectively, but the number of model parameters decreases by more than 35 times (193M:5.48M), and the model inference speed increases by more than 13 times (113.02 ms/pic:8.38 ms/pic). Compared with MobileNetv3 before its own distillation, the recognition accuracy increases by 2.13% and 1.97% respectively. This shows the great potential of KD to improve the accuracy of lightweight models. Meanwhile, since the proposed method does not need to use the true value labels of the images, it can arbitrarily expand the size of the dataset, and in the future, we will consider combining with the Generative Adversarial Network (GAN) technology to further improve the accuracy of the model.
Conclusions and future work
(1) In this article, we propose a semisupervised labeling KD framework, BCSLD, to construct a high-precision lightweight student model MobileNetv3. The proposed method is validated by self-built large labeled dataset and unlabeled dataset, and achieves a high accuracy of 99.84% for crack recognition, which reaches an accuracy close to that of the teacher network ResNeXt101 (−0.08%), but the number of parameters is reduced by more than 35 times compared to the ResNeXt101 model.
(2) Due to the extremely fast inference speed (8.38 ms/pic) brought by MobileNetv3’s own lightweight structure and the high recognition accuracy harvested through the KD method, it exceeds the recognition accuracy requirement of 9.35% in the “Automated Highway Pavement Technical Condition Inspection Regulation,” and achieves the engineering usability.
(3) The “MobileNetv3+KD” model constructed in this article requires far fewer parameters and computational resources than traditional deep learning models, and thus the model has the potential to enable crack detection systems to be deployed on a wide range of mobile devices to improve the cost of bridge safety inspection and assessment.
(4) In addition to effectively improving the performance of the lightweight student network, the proposed method in this article also has the important advantage that it does not need to annotate all the datasets, but only needs to annotate part of the datasets, and then train with a large amount of unlabeled data, which can effectively reduce the time cost of data annotation. However, the method proposed in this article also has some limitations, when the amount of unlabeled data is small, the performance improvement effect of the proposed method on the student network may not be obvious.
Future research work should be devoted to exploring the deployment scheme based on edge computing to achieve the real-time analysis and processing of crack image data near the network edge.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article is supported by the Natural Science Foundation of Fujian Province (No. 2023J01062), Xiamen Construction Technology Project (No. XJK2023-1-13), Science and Technology Research and Development Project of Fujian Provincial Housing and Construction Department (No. 2022-K-168), Guiding Project of Fujian Science and Technology Program (No. 2022Y0046), Leizhi Innovation Foundation (No. 202201), Fujian Provincial Natural Resources Science and Technology Innovation Project (No. KY-070000-04-2022-009).
Data availability
Data will be made available on request.