
Abstract
Support matrix machine (SMM) has emerged as a powerful intelligent classification technique with broad applications in mechanical fault diagnosis. However, SMM and its derivative methods can only complete the recognition of a single-objective task at the same time, making it difficult to balance multitask classification, and easily ignoring information between multiobjectives. Therefore, a multitask failure pattern identification scheme based on multitask soft-margin twin matrix machine (MTSTMM) is proposed. In MTSTMM, a soft-margin is designed to improve the flexibility of handling noisy, and to elevate the model’s out-of-distribution generalization capacity by increasing tolerance for misclassification. Meanwhile, by setting a regularized multitask learning weighting term, matrix singularity during computation and model overfitting during training are avoided, and implicit information between multiple tasks is effectively utilized. In addition, a kernel technique is used to fully utilize the structural information of matrix samples, which effectively solve the problem of slow convergence in traditional matrix classifiers. Through two independent experiments, experimental findings demonstrate that the proposed MTSTMM exhibits stronger multitask classification ability in noisy environments.
Keywords
Introduction
Rolling bearings and gears, as two key components widely used in rotating machinery, play a crucial role in various fields such as industrial production, transportation, and aerospace. However, due to long-term operation in complex environments, such as high-load, high-speed, and variable working conditions, rolling bearings, and gears are prone to failure, which can affect the normal operation of the entire system and even lead to serious economic losses and safety accidents. Therefore, conducting fault diagnosis research on typical components of rotating machinery is of great significance.1–3
Traditional fault diagnosis methods mainly rely on manual experience, using senses such as hearing and touch to determine equipment status, which is not only inefficient but also difficult to guarantee accuracy and reliability. As artificial intelligence technology advances at breakneck speed, data-driven fault diagnosis approaches have increasingly emerged as a focal point of research. Pattern recognition, as an important part of artificial intelligence, includes methods such as artificial neural networks,4–6 random forests,7,8 extreme learning machines,9,10 and support vector machines (SVMs),11–13 providing powerful tools for fault diagnosis. However, the above method requires extracting a limited number of features from the original signal during data sample classification, which may result in the loss of structural information of the original features. Therefore, support matrix machine (SMM) and its improved algorithms based on matrix theory have been proposed.14,15 SMM achieves grouping effects by expanding the spectrum of a conventional elastic network on a matrix, thereby capitalizing on the inherent structural correlations within matrix-form data. To further enhance the performance of SMM, Zheng et al. 16 proposed the sparse SMM (SSMM), which improves the sparsity property of the model by defining new regularization terms. Wu et al. 17 proposed transfer least square SMM, which solves the problem of insufficient label samples through transfer learning. Pan et al. 18 put forward the symplectic hyperdisk matrix machine, which reduces the interference of noise in the original signal on the model through symplectic geometric similarity transform. Li et al. 19 proposed the nonparallel least squares SMM (NPLSSMM), which reduces the computational complexity of the model by using a matrix form squared loss term. However, SMM and its derivative methods are based on modeling a single-task and cannot utilize the intertask correlation information when dealing with multitask classification.
Considering the limited feature data available for single-objective learning methods, multitask learning (MTL) methods can mine shared information between tasks, resulting in good learning outcomes for all tasks. Therefore, relevant scholars have proposed combining SVM with MTL to further improve learning ability and achieve multitask classification. Zhang et al. 20 proposed a multitask support vector with pinball loss, which achieves insensitivity to noise and stability to resampling by maximizing the quantile distance of each task. Mei and Xu 21 proposed the multitask least squares twin support vector machine (MTLS-TWSVM), which improves computational efficiency by using the least squares algorithm to avoid solving quadratic programming problem (QPP). In addition, Liu and Xu 22 proposed a multitask nonparallel support vector machine (MTNPSVM), which introduces a new loss term to avoid matrix inversion operations and reduce computational costs. Although these methods can effectively achieve multitask classification, they lack flexibility in handling noisy samples and insufficient extraction of intertask correlation information.
Considering the importance of implicit and common information in multitask classification processes, as well as the strong interference of strong noise information on hard classification boundaries, a novel fault diagnosis model based on multitask soft-margin twin matrix machine (MTSTMM) is put forward. In MTSTMM, a soft margin is designed to enhance the flexibility of the model in handling noisy, which significantly enhances generalization ability of the model by increasing its tolerance for misclassification. Meanwhile, the problem of matrix singularity in the calculation and the model overfitting phenomenon during the training process are effectively avoided by setting regularized MTL weighting term (RMTLW). In addition, by defining a kernel technique, the iterative algorithm of traditional matrix classifiers is transformed into solving QPPs, improving computational efficiency. This research makes three fundamental contributions:
A soft-margin model is constructed to improve the flexibility of handling noisy, which significantly enhances generalization ability of the model.
A RMTLW is designed to avoid the problems of matrix singularity in the calculation process and model overfitting during training.
MTSTMM is applied to the fault dataset of rotating machinery, and the result shows that MTSTMM has excellent multitask classification performance.
The subsequent sections of this article are organized as follows: with the second section providing background information. In the third section, the proposed method is introduced. In the fourth section, the classification performance of the proposed method is verified through a large number of experiments. In the fifth section, the conclusion is given.
Background
Support matrix machine
SMM is based on the principle of minimizing nuclear norm and uses the sum of singular values of the matrix as the low rank approximation of the matrix. SMM takes matrix sample
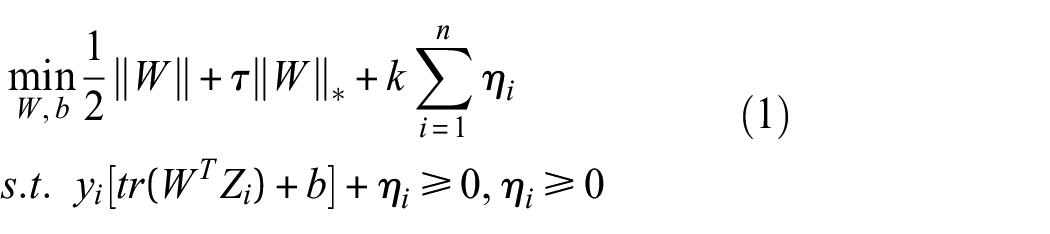
where
By solving the optimization function and obtaining the weight matrix and threshold, a decision function is constructed for unknown samples as shown in Equation (2):

Multitask nonparallel support vector machine
In the tth task,

MTNPSVM assumes that all tasks have common information
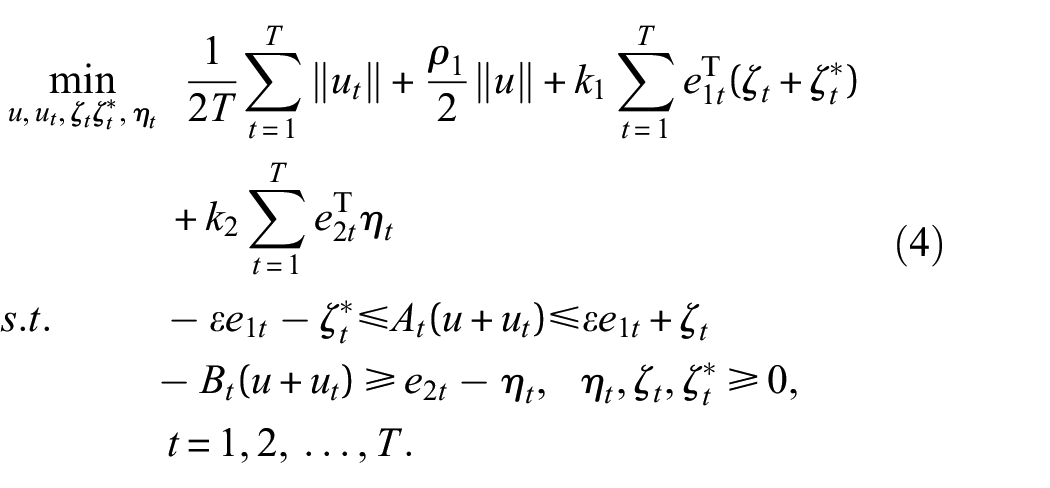
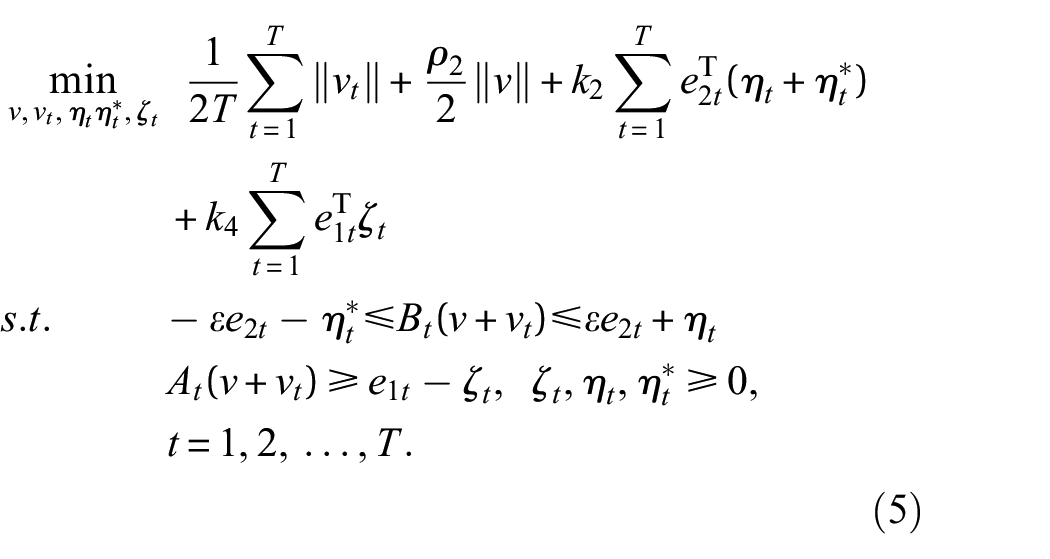
where
By solving the above two QPPs, the weight and threshold of each task can be determined. Finally, the class label of the unknown sample for the tth task is determined by the decision function Equation (6).
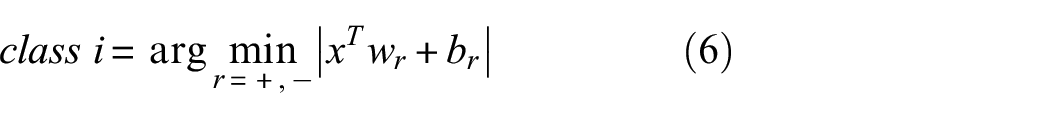
Although SMM capitalizes on the inherent structural correlations within matrix-form data, it is sensitive to noise, and solving it through ADMM algorithm results in longer model training time. MTNPSVM can achieve multitask classification, but it lacks sufficient extraction of implicit information between tasks and flexibility in handling noisy samples. Therefore, a new classification method is proposed that can address the shortcomings of SMM and MTNPSVM, while also having superior classification performance.
The proposed method
Multitask soft-margin twin matrix machine
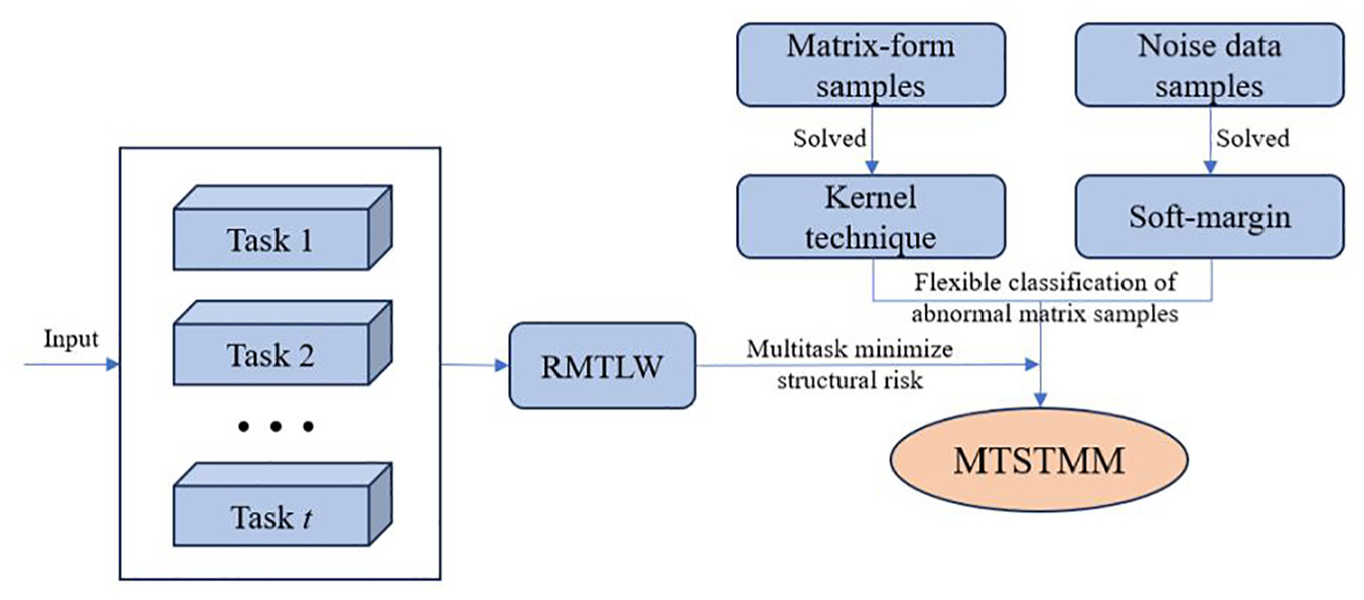
In this section, a multitask matrix classifier is proposed, and its classification principle is shown in Figure 1.
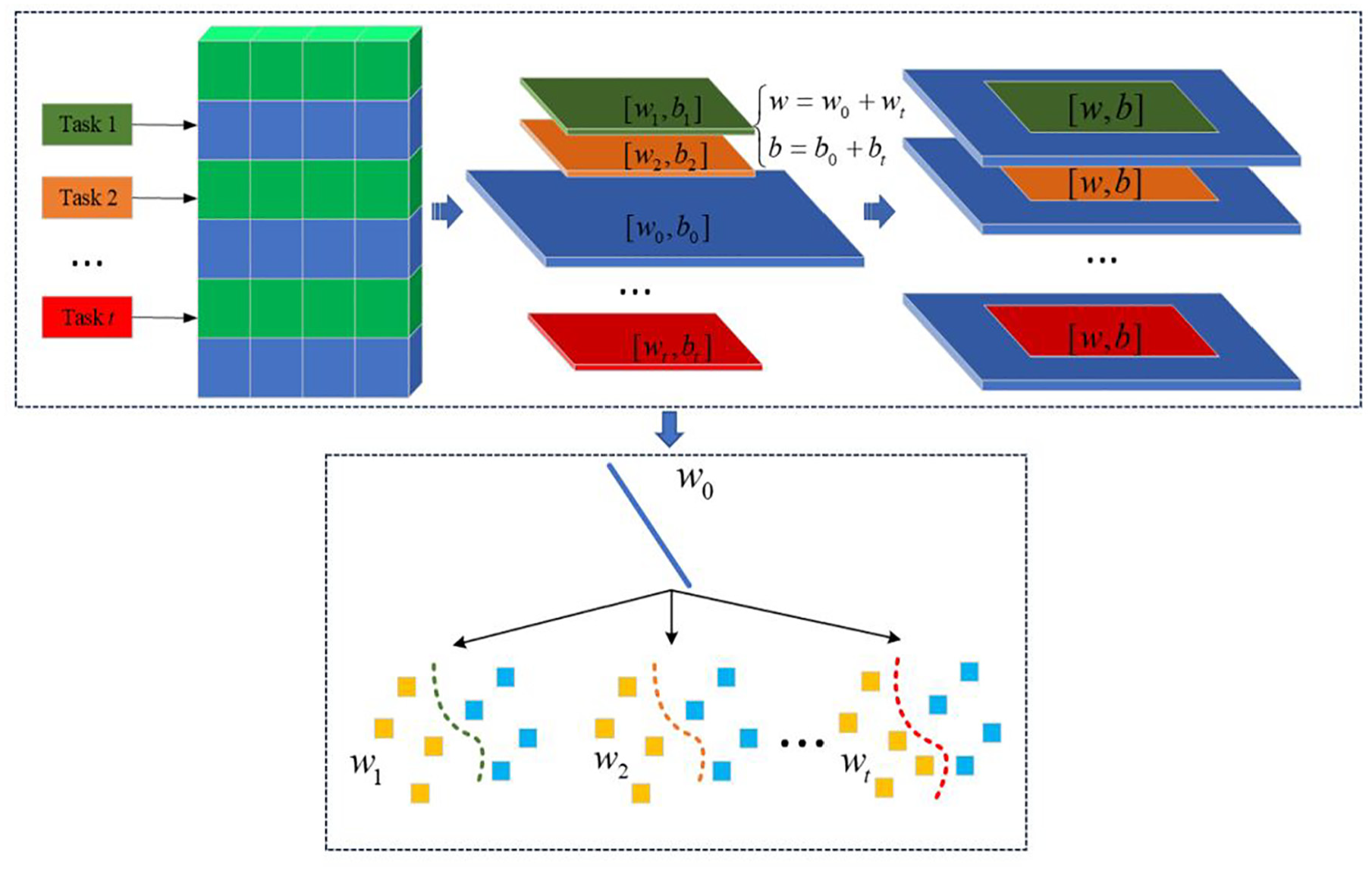
The classification principle of MTSTMM.
Assuming there are T distinct yet interrelated diagnostic tasks. The sample of each task is
Define: Assuming there are two types of matrix sample datasets, namely X and Y.

Thus, Equation (8) is constructed as follows: where
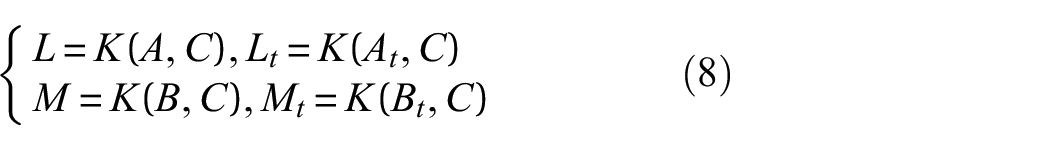
In addition, to make the model insensitive to noise and sparse, a sparse ball constraint term is introduced. Its definition is shown as Equation (9). Under these constraints, the model has more flexible classification performance when dealing with outliers or noise. Besides, MTSTMM elevates the model’s out-of-distribution generalization capacity by increasing the tolerance for misclassification, and the classification model of MTSTMM is shown in Figure 2.
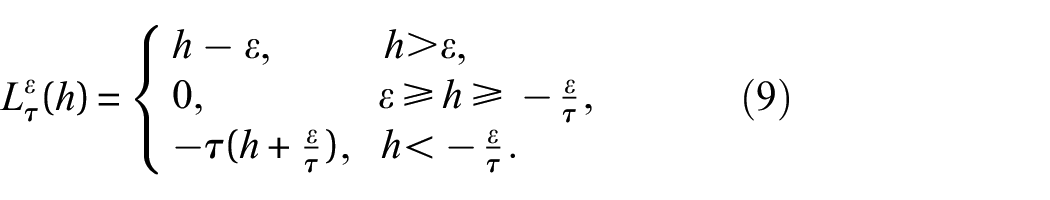
where
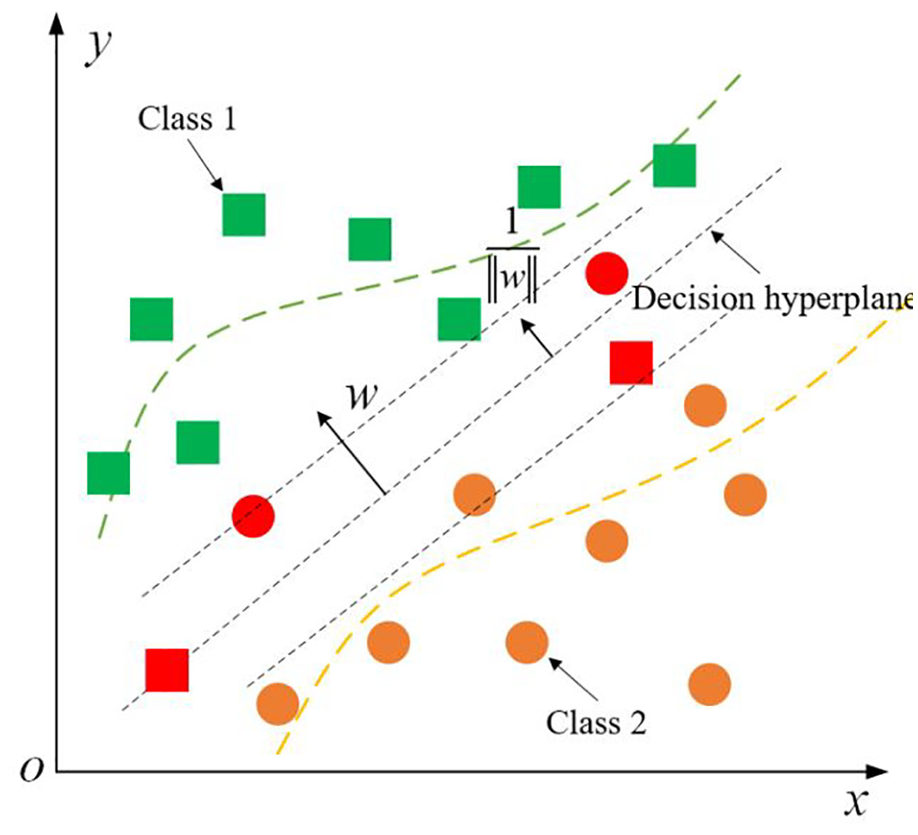
The classification model of MTSTMM.
Due to the zero gradient of
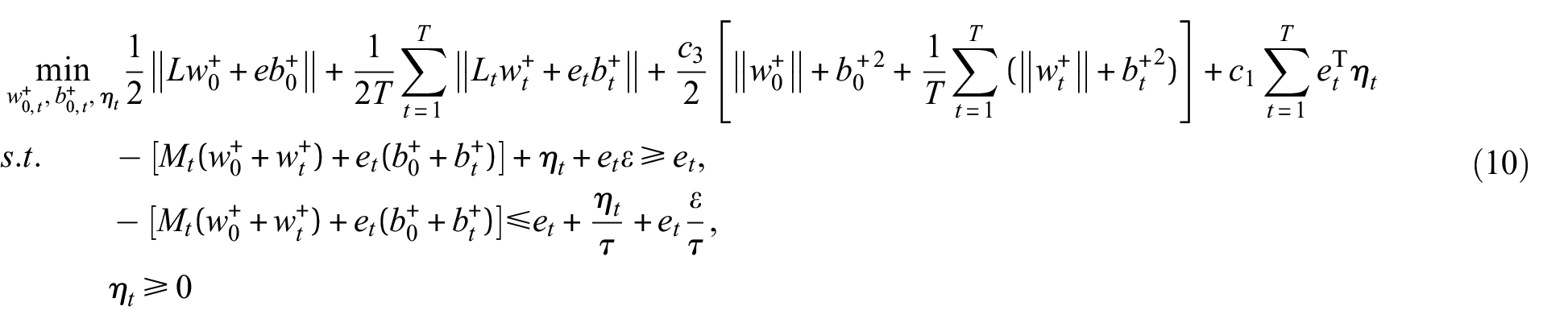
and
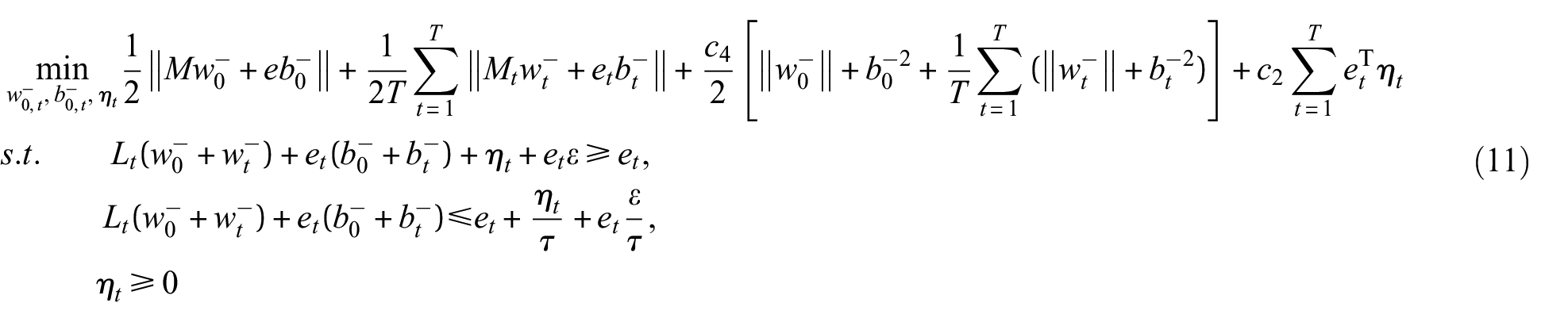
where
Next, solve Equations (10) and (11) separately. First, the Lagrange multiplier method is introduced for Equation (10) and the Lagrange function is constructed as shown in Equation (12).
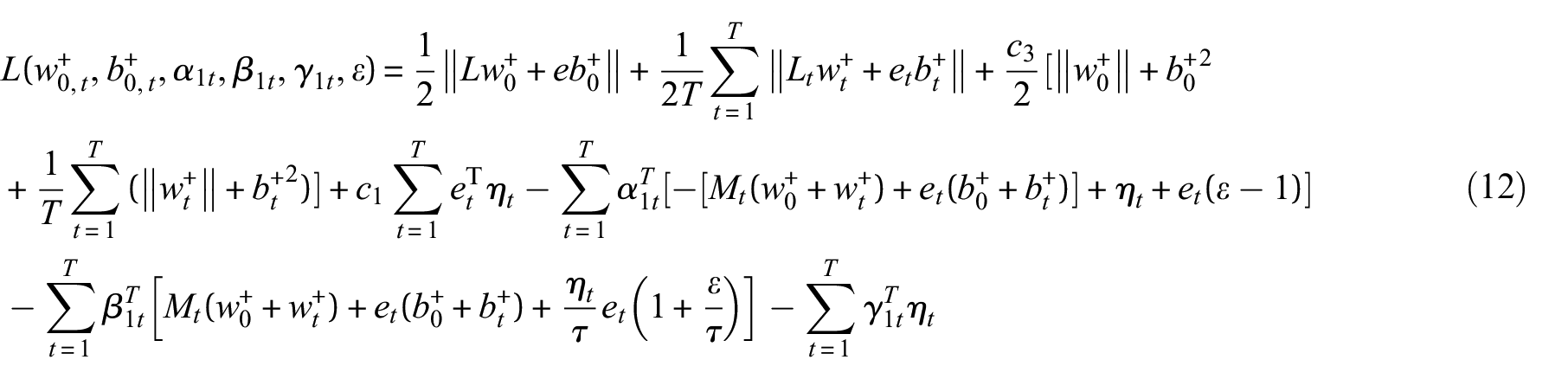
where
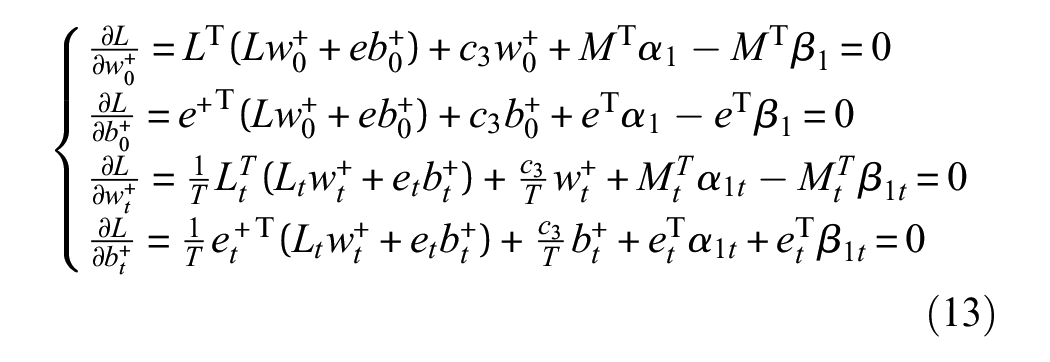
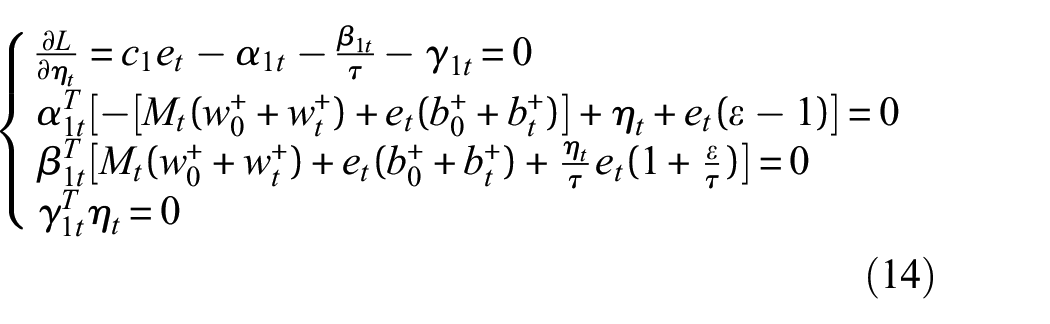
Then, Equation (15) can be obtained from Equation (13):
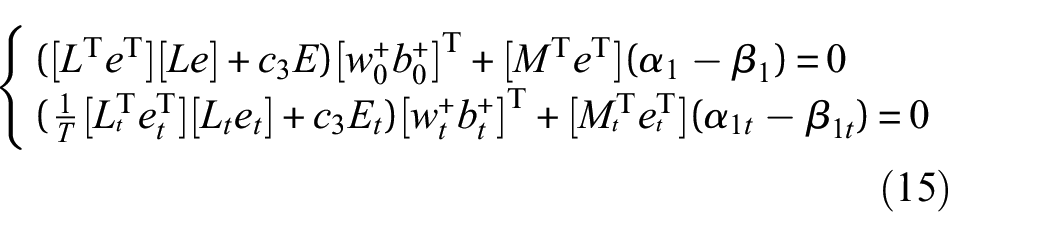
For convenience, the following substitutions are made
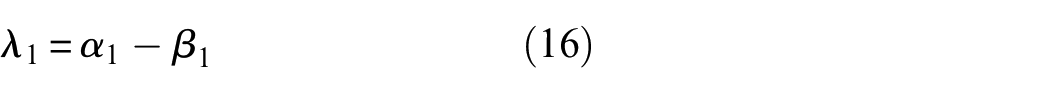
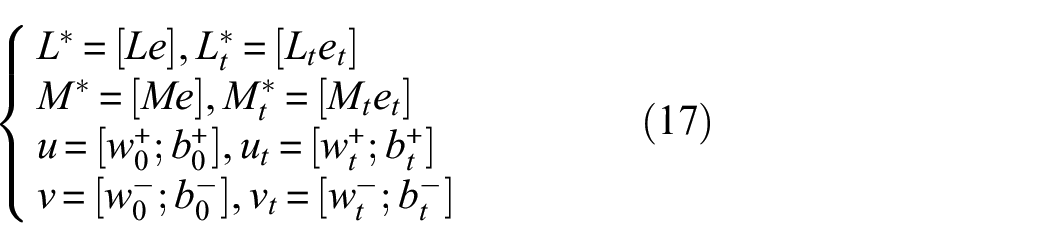
Equation (15) can be rewritten as Equation (18).
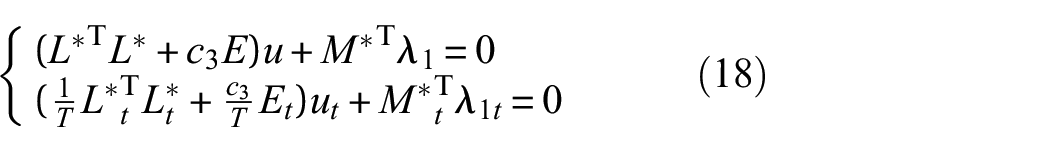
Because of
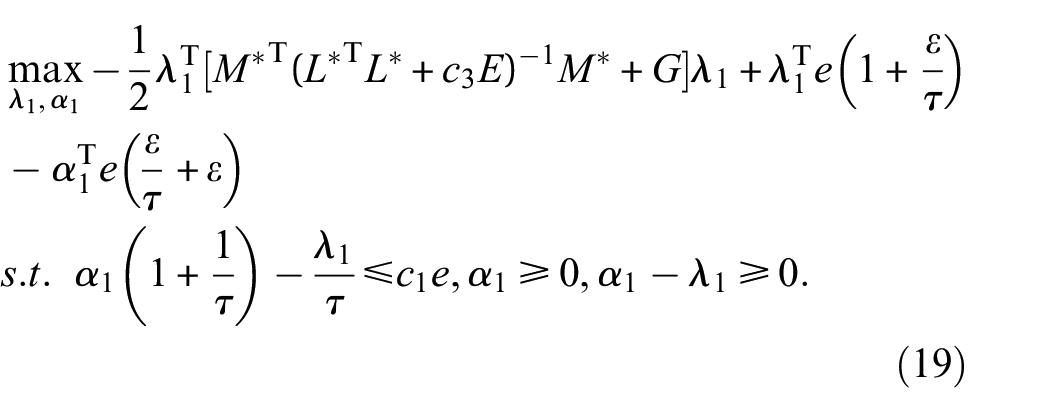
where
Similarly, the dual problem of Equation (11) can be obtained in Equation (20).
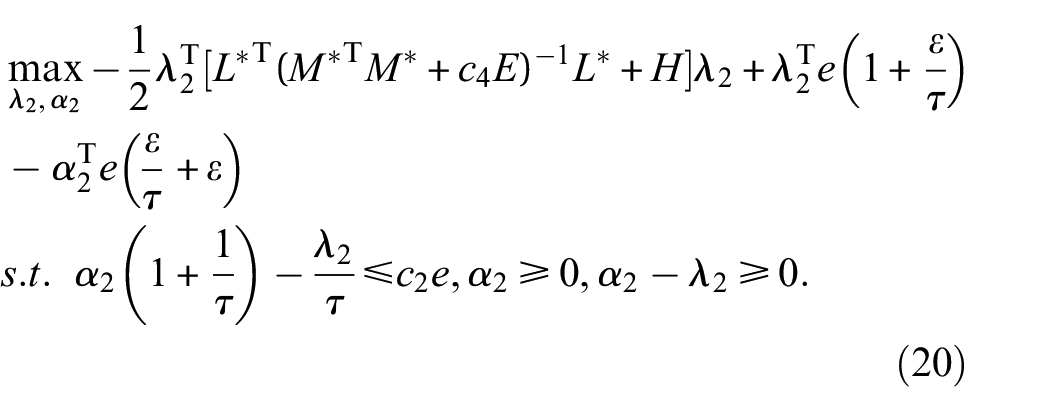
where
Finally, the optimal solution of the optimization function is determined by solving two QPPs. For the tth task, the predicted label of the unknown sample is determined by Equation (21).
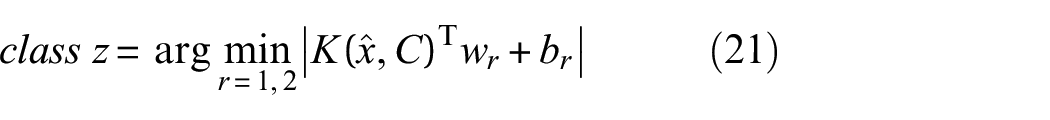
Noise insensitivity analysis
To demonstrate the robustness of the proposed method to noise, further analysis is conducted on the limiting terms. The subgradient of Equation (9) can be calculated as shown in Equation (22):
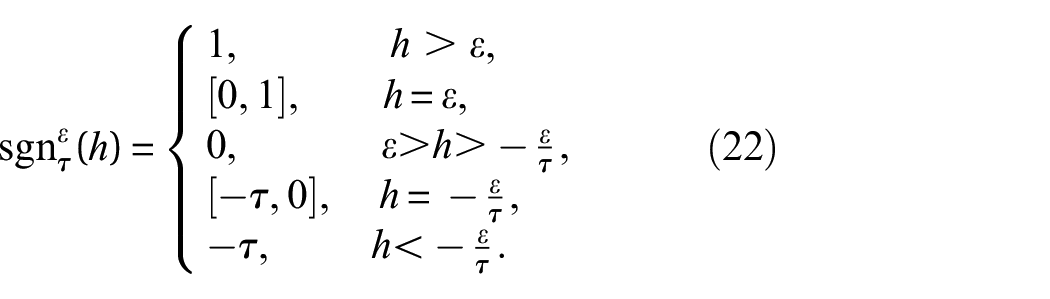
Obviously, Equation (10) has an optimal solution; therefore, for the tth task, Equation (23) can be rewritten as follows:
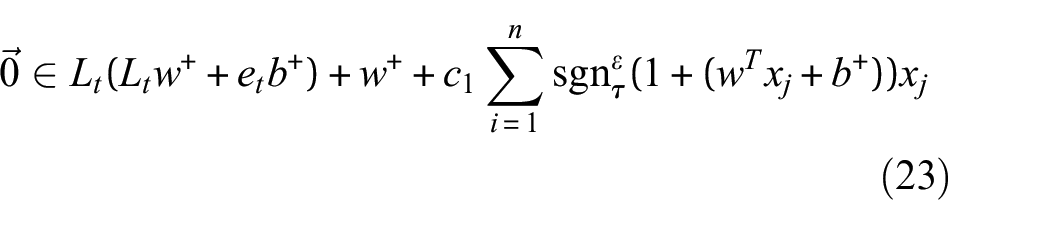
where
Next, the index set can be divided into five sets as follows:
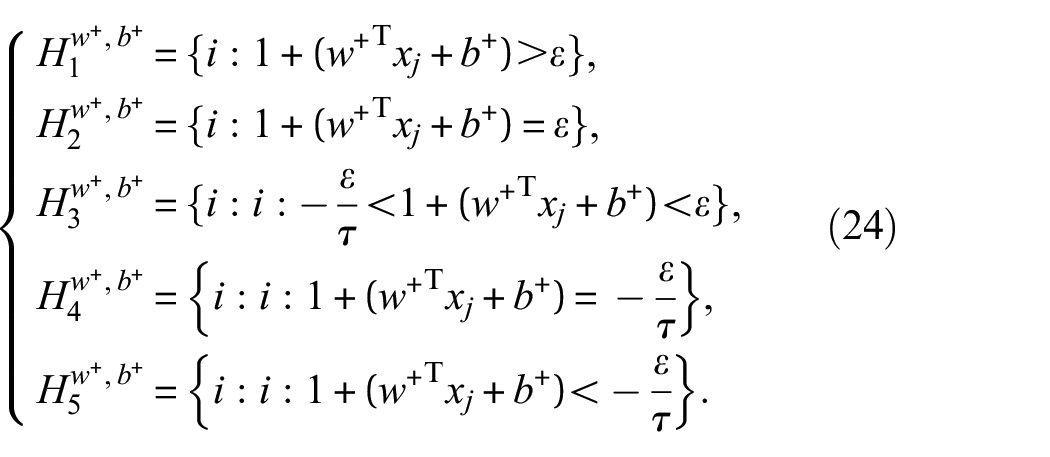
From Equation (22), it can be seen that the subgradient in set
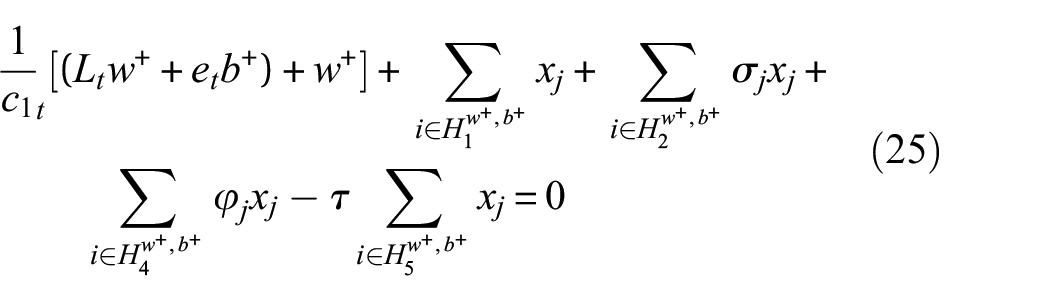
If the value of
Experimental analysis
To verify the effectiveness of MTSTMM method, experiments are conducted using the rolling bearing and gear datasets from Shandong University of Science and Technology (SDUST) and the datasets from Anhui University of Technology (AHUT). In addition, to evaluate the superiority of MTSTMM, several assessment criteria are introduced to estimate its classification precision, namely accuracy (Acc), kappa (Kap), sensitivity (Sens), specification (Spec), area under curve (AUC), and G-mean (G-m). To display the diagnostic performance of MTSTMM more clearly, Figure 3 shows the modeling flowchart of MTSTMM, and compare it with multitask classification methods such as Multi-task twin bounded support vector machine (MT-TBSVM), 23 MTNPSVM, MTLS-TWSVM, as well as single task classification methods such as SSMM, NPLSSMM, and dual path convolution with attention mechanism-Bidirectional Gated Recurrent Unit (DCA-BiGRU). 24
The modeling flowchart of MTSTMM.
Due to the fact that both the proposed method and the single-task algorithm classifiers (excluding DCA-BiGRU) are matrix classifiers, it is necessary to construct matrix datasets, and the process of signal acquisition is easily affected by noise. To diminish the detrimental effect of noise on the classification outcomes, the symplectic geometry similarity transform (SGST) 18 is introduced to preprocess the initial signal. The fault diagnosis flowchart based on MTSTMM is shown in Figure 4.
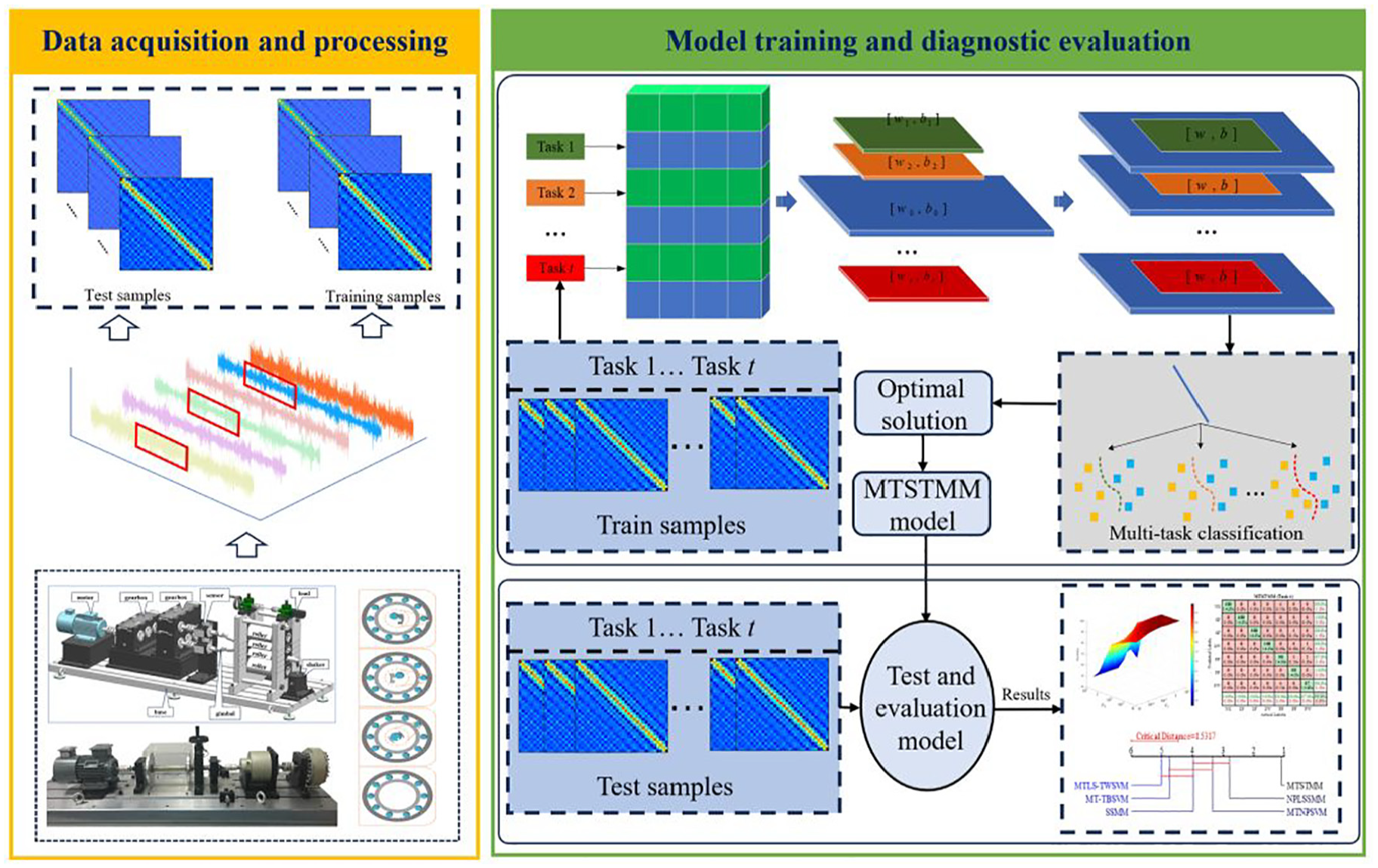
Fault diagnosis flowchart based on MTSTMM.
Experiment 1
To verify the classification performance of MTSTMM, multitask datasets is constructed using the rolling bearing gear dataset of SDUST, with specific parameters shown in Tables 1 and 2. The experimental components of this dataset are 6205 bearings and planetary gearboxes (including sun gears and planetary gears), with a sampling time of 40 s. The experimental platform is shown in Figure 5. Two hundred samples are constructed for each fault category, of which the training set is composed of 100 samples, and the testing set is composed of an equal number.
Gear dataset for task 1.

Bearing dataset for task 2.
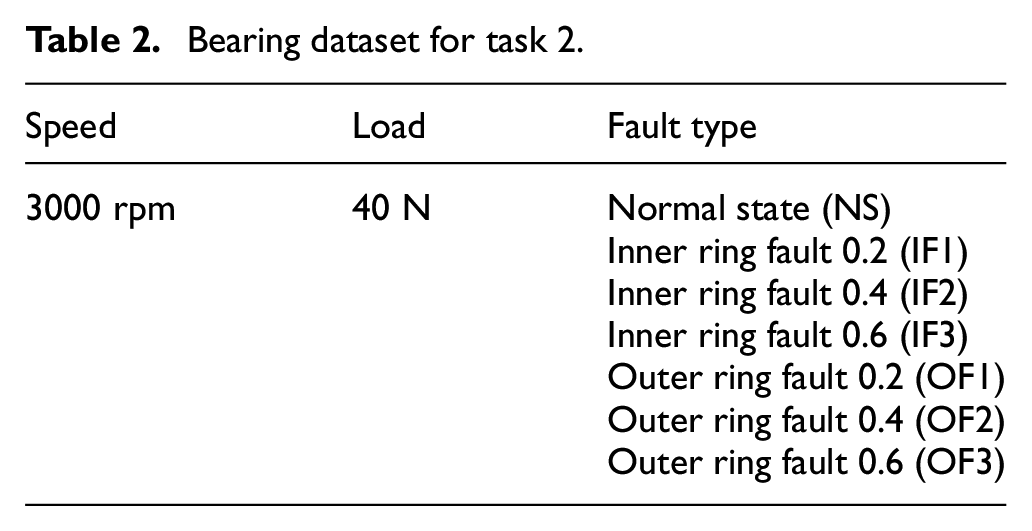

SDUST test bench. SDUST: Shandong University of Science and Technology.
The parameters
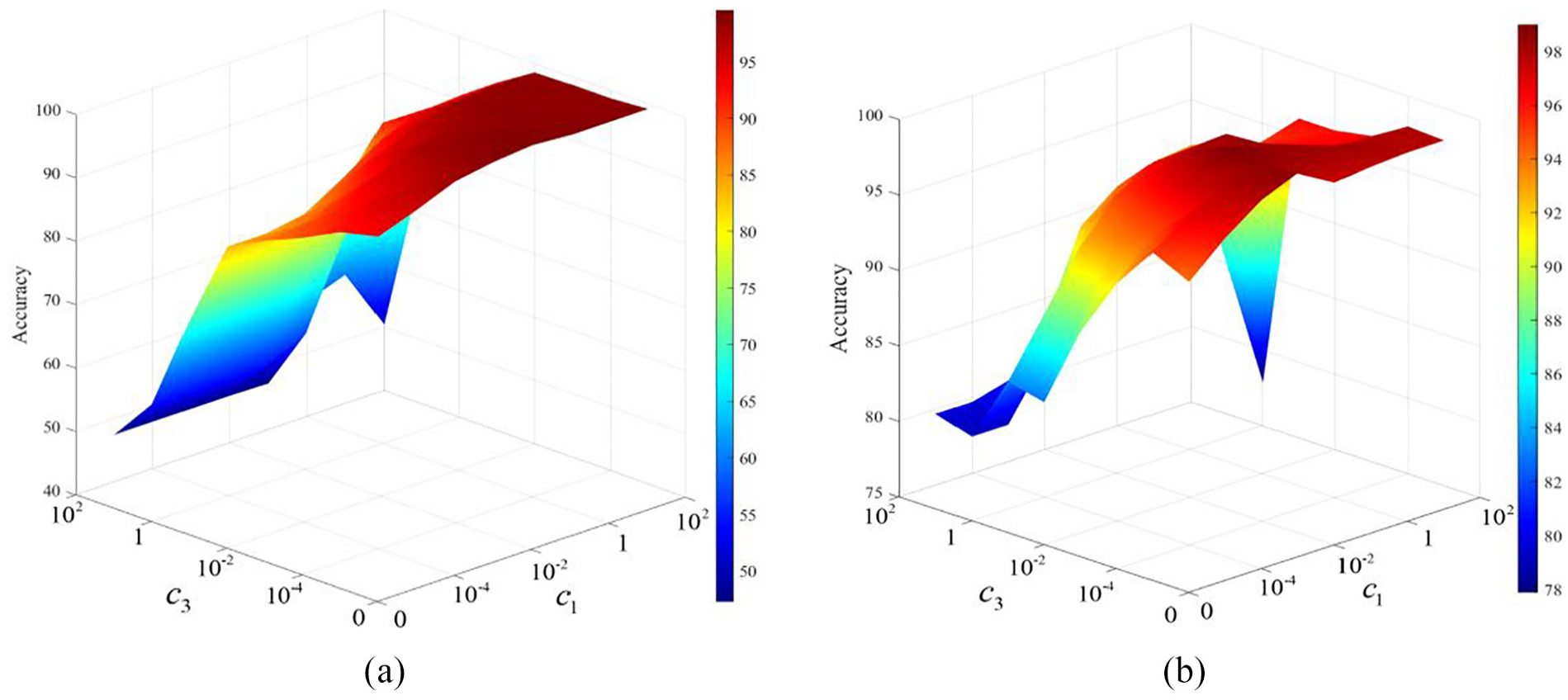
Parameter optimization results. (a) The results of the gear dataset. (b) The results of the rolling bearing dataset.
Similarly, the optimal parameters for the comparison methods are set as shown in Table 3. Among them, DCA-BiGRU uses hyperparameter grid search to determine the optimal parameters. Then, the datasets of tasks 1 and 2 are input into various methods, and the confusion matrix of classification results are shown in Figure 7. First, compared to multitasking methods, the proposed method achieved the accuracy of over 98% in both tasks, indicating its extremely excellent classification performance. From Figure 7, Only seven samples are misclassified in task 1, and only eight samples are misclassified in task 2. Although MT-TBSVM and MTNPSVM achieve the accuracy of over 97% in task 2, it has a large number of misclassifications in task 1. MTLS-TWSVM performed well in task 1, but the result is significantly lower in task 2. From the experimental results, when performing multitask classification, there will always be a situation where the classification result of a certain task is poor. The reason is that these methods are all vector classifiers, which lead to the destruction of the structural information of the data when processing matrix samples. Therefore, the classification performance of the proposed method is superior to MT-TBSVM, MTNPSVM, and MTLS-TWSVM.
Parameter setting.
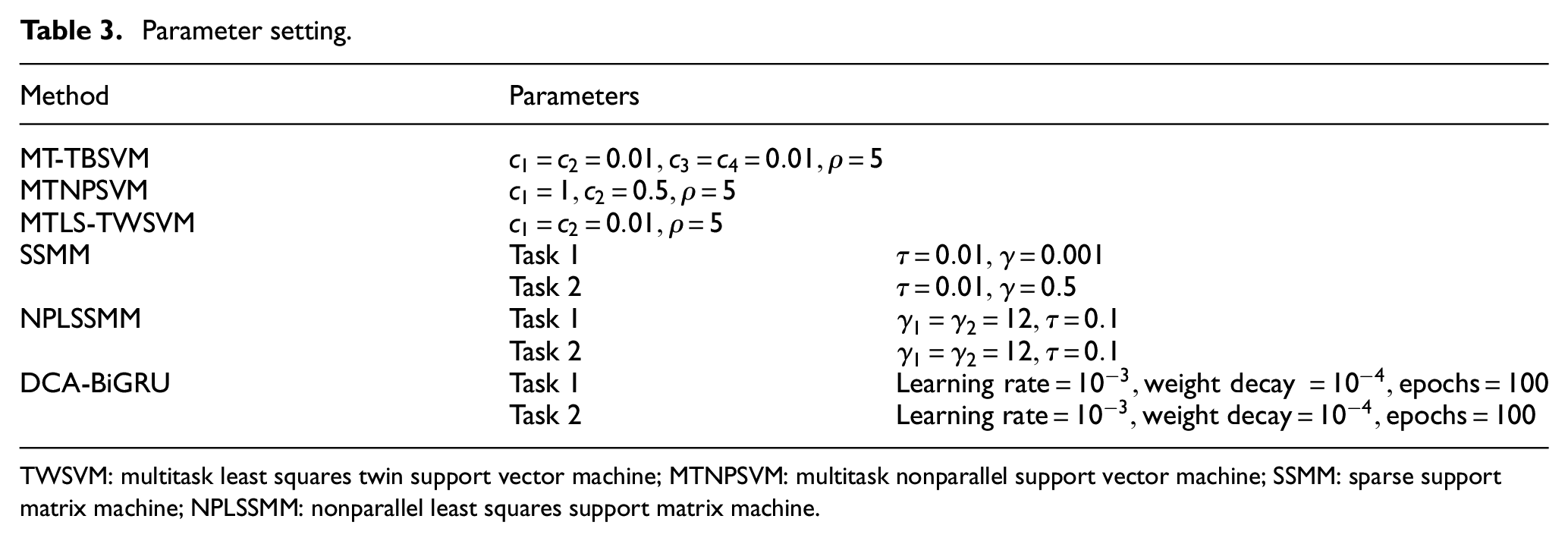
TWSVM: multitask least squares twin support vector machine; MTNPSVM: multitask nonparallel support vector machine; SSMM: sparse support matrix machine; NPLSSMM: nonparallel least squares support matrix machine.
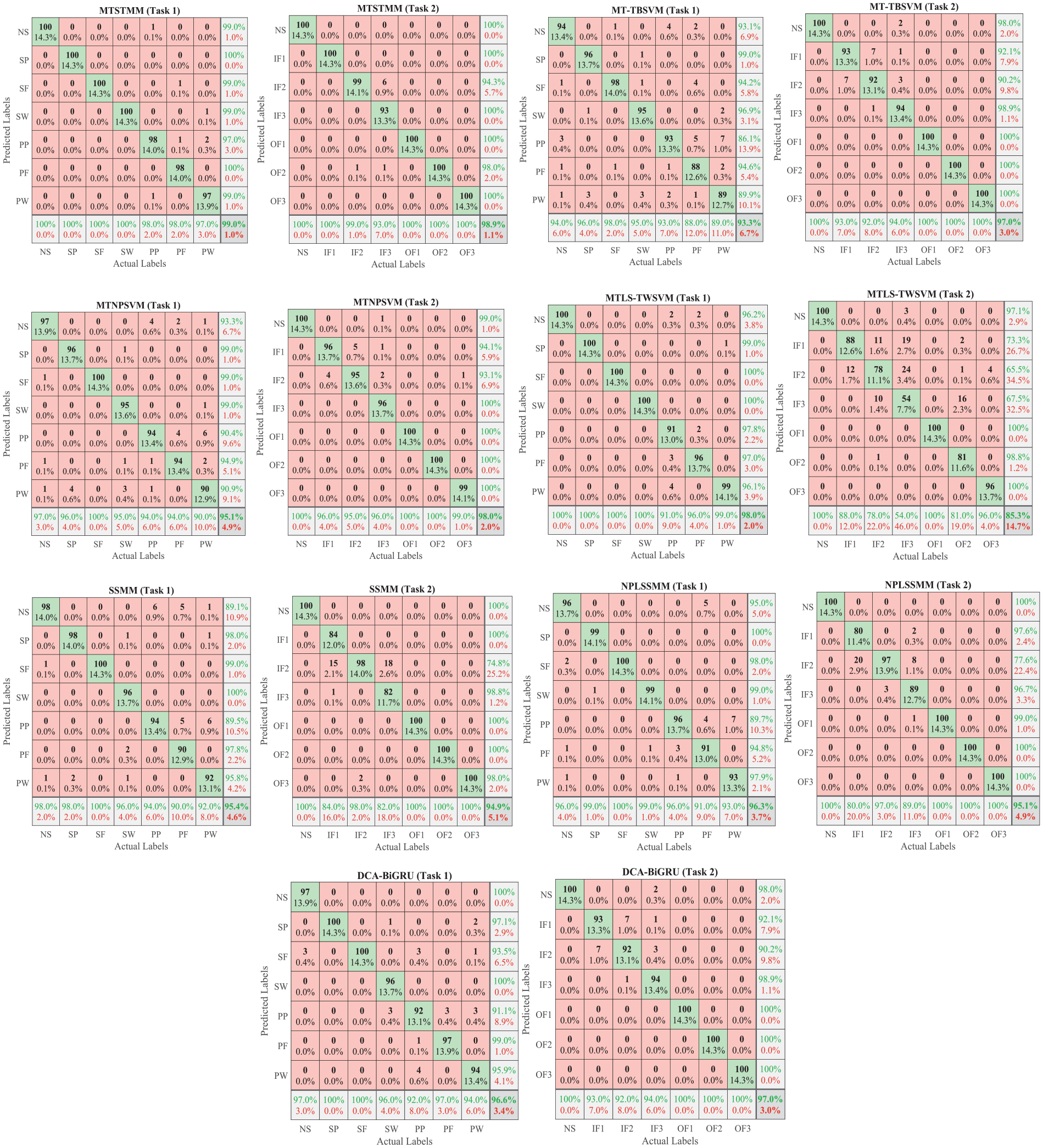
Classification confusion matrix of six methods.
Next, compared with single-task classification methods, SSMM and NPLSSMM are both matrix classifiers that can protect the internal information of raw data. The classification accuracies of SSMM are 95.43 and 94.86%, respectively, while the classification accuracies of NPLSSMM are 96.29 and 95.14%, respectively. It appears that the classification performance of NPLSSMM is superior to SSMM. The reason is that SSMM constructs a pair of parallel hyperplanes, which limit its classification performance. NPLSSMM improves its classification efficiency by addressing two smaller QPPs. However, due to the fact that SSMM and NPLSSMM are both based on single-task learning, the information they utilize is limited. DCA-BiGRU, as a deep learning method, can use dual path convolution with attention mechanism (DCA) to extract fusion features of vibration signals, but it can only be based on single-task feature information fusion.
In addition, Table 4 provides the total time for different methods to classify the two tasks, and the training time of MTSTMM is relatively short. Owing to the fact that MT-TBSVM, MTNPSVM, and MTLS-TWSVM process vector data with smaller dimensions, their classification time is shorter. NPLSSMM and SSMM both require iterative computation, resulting in longer training times. Although MTSTMM processes matrix samples, it avoids iterative algorithms through kernel techniques, thereby reducing training time. DCA-BiGRU requires multiple training sessions to achieve stable classification accuracy, so the training time is relatively long.
Training time of six models.
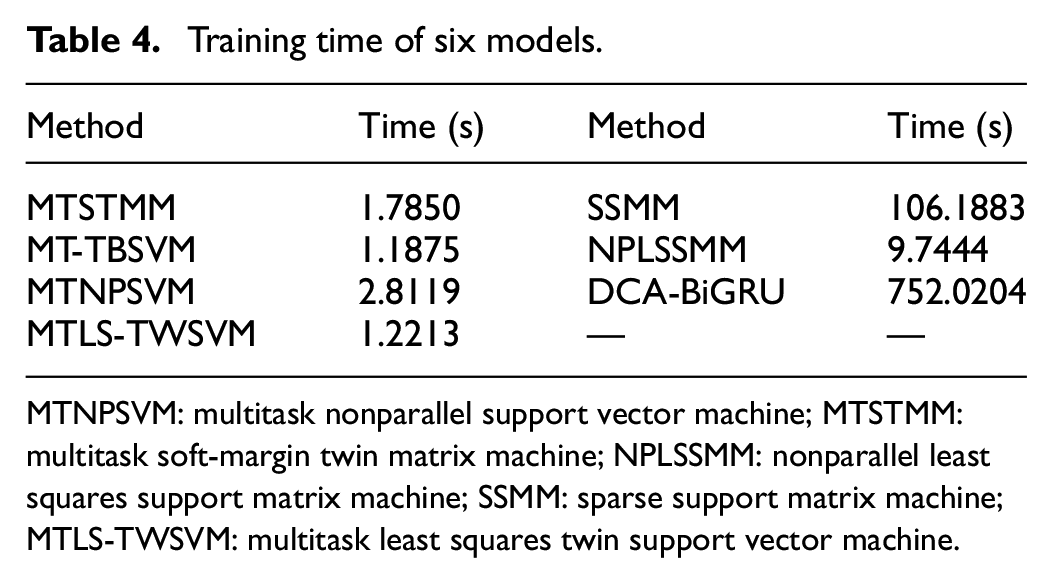
MTNPSVM: multitask nonparallel support vector machine; MTSTMM: multitask soft-margin twin matrix machine; NPLSSMM: nonparallel least squares support matrix machine; SSMM: sparse support matrix machine; MTLS-TWSVM: multitask least squares twin support vector machine.
MT-TBSVM is essentially an extension of TSVM, with a computational complexity of
To further testify the performance of the MTSTMM method, the datasets of tasks 1 and 2 are randomly shuffled. The dataset partitioning scheme is reconfigured to ensure rigorous validation, with redefining samples applied to both training and testing subsets, repeating the experiment five times, and the results are shown in Tables 5 and 6. It can be seen that MTSTMM has the highest evaluation metrics in both tasks 1 and 2, proving that the classification precision of MTSTMM is brilliant. The reason is that the designed kernel technique can fully utilize the internal information of matrix samples and can mine the correlation information between tasks in MTL algorithms. Although MT-TBSVM, MTNPSVM, and MTLS-TWSVM are also MTL algorithms, they all vectorize matrix samples, resulting in the loss of structural information in the samples. SSMM and NPLSSMM are both based on single-task learning algorithms, which cannot utilize the common information between tasks, thus limiting their classification performance. DCA-BiGRU requires more computing resources during the training process, which may to some extent limit its classification performance. In addition, the standard deviation of the proposed algorithms is almost always the smallest, verifying its more stable classification performance.
The results for task 1.
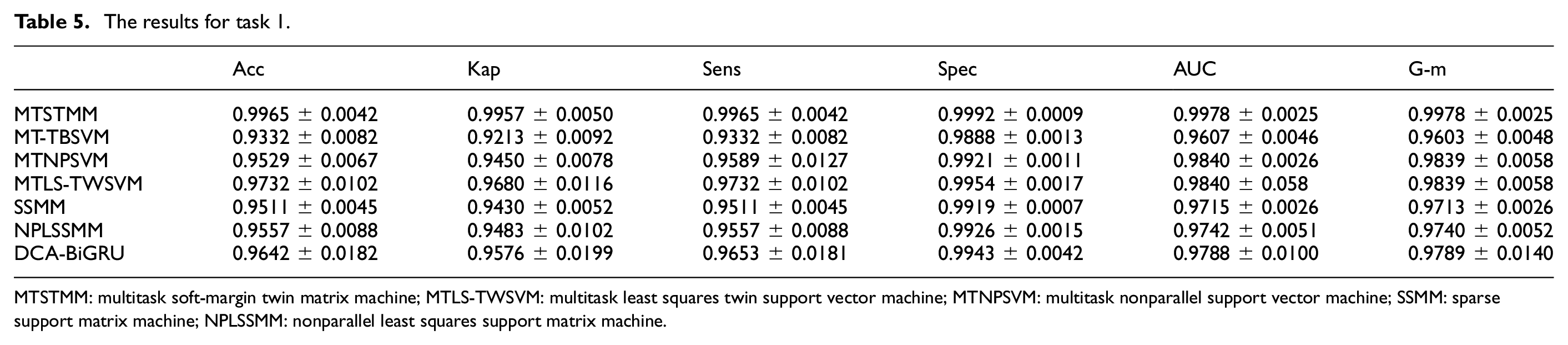
MTSTMM: multitask soft-margin twin matrix machine; MTLS-TWSVM: multitask least squares twin support vector machine; MTNPSVM: multitask nonparallel support vector machine; SSMM: sparse support matrix machine; NPLSSMM: nonparallel least squares support matrix machine.
The results for task 2.
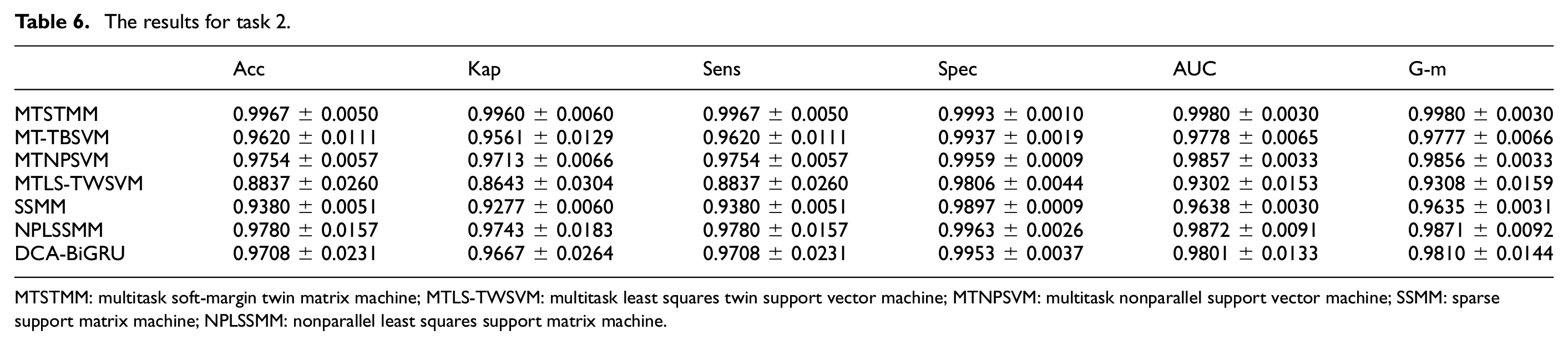
MTSTMM: multitask soft-margin twin matrix machine; MTLS-TWSVM: multitask least squares twin support vector machine; MTNPSVM: multitask nonparallel support vector machine; SSMM: sparse support matrix machine; NPLSSMM: nonparallel least squares support matrix machine.
To systematically evaluate the noise robustness of the proposed methodology, 5 dB of noise is added to both datasets mentioned above. Then, the experiments are repeated with samples containing noise, and the results are shown in Figure 8.

Results for faulty datasets containing noise. (a) Results for task 1. (b) Results for task 2.
Comparing the classification accuracy with and without noise, the recognition rates of MTSTMM, MT-TBSVM, MTNPSVM, MTLS-TWSVM, SSMM, NPLSSMM, and DCA-BiGRU are reduced by 1.43, 6.00, 5.57, 3.71, 2.43, 3.58, and 3.28% in tasks 1, and 2.43, 1.57, 2.14, 1.29, 2.57, 1.00, and 3.55% in task 2, respectively. Although the classification accuracy of the comparative methods decreases slightly in task 2, it significantly decreases in task 1. The proposed method demonstrates robust classification ability in both tasks 1 and 2, as the introduction of sparse pinball constraint term can improve the sparsity property and robustness to noise of the model. From Figure 7, the proposed method has the highest evaluation metrics in both datasets, indicating its superior performance. The reason behind this is that MTSTMM has superior flexibility in handling noisy samples by establishing a soft-margin model, which is lacking in comparison methods. MT-TBSVM, MTNPSVM, and MTLS-TWSVM always have poor classification results in one of these two tasks. The reason is that MT-TBSVM and MTLS-TWSVM introduce hinge loss, which is sensitive to noise, thus limiting their classification performance. MTNPSVM constructs two nonparallel hyperplanes, which cannot strengthen the model’s resilience against noise. SSMM improves its sparsity by designing low rank loss, but lacks robustness. NPLSSMM essentially belongs to a semihard margin model by constructing two hyperplanes, which result in the inability to flexibly handle noisy data. Although DCA-BiGRU has certain noise resistance performance, it assumes that all sample weights are equal when modeling and does not explicitly distinguish between noise and normal data.
Experiment 2
To further validate the multitask diagnostic capability of MTSTMM, experimental verification is executed to use data from the AHUT test bench, as shown in Figure 9. In the experiment, the load is set to 2 kN, and the motor speed is set to 1200 rpm. The multitask datasets are constructed using vibration signals from four states of rolling bearings and gears. In task 1, the rolling bearing fault states include inner ring ball failure, inner and outer ring ball failure (OBF), inner and outer ring ball failure, and OBF. In task 2, the gear fault states include pitting, peeling, tooth breakage, and cracks. Each fault state is divided into 1024 sampling points to obtain 200 matrix samples, with the samples in the training and testing sets consistent with experiment 1.
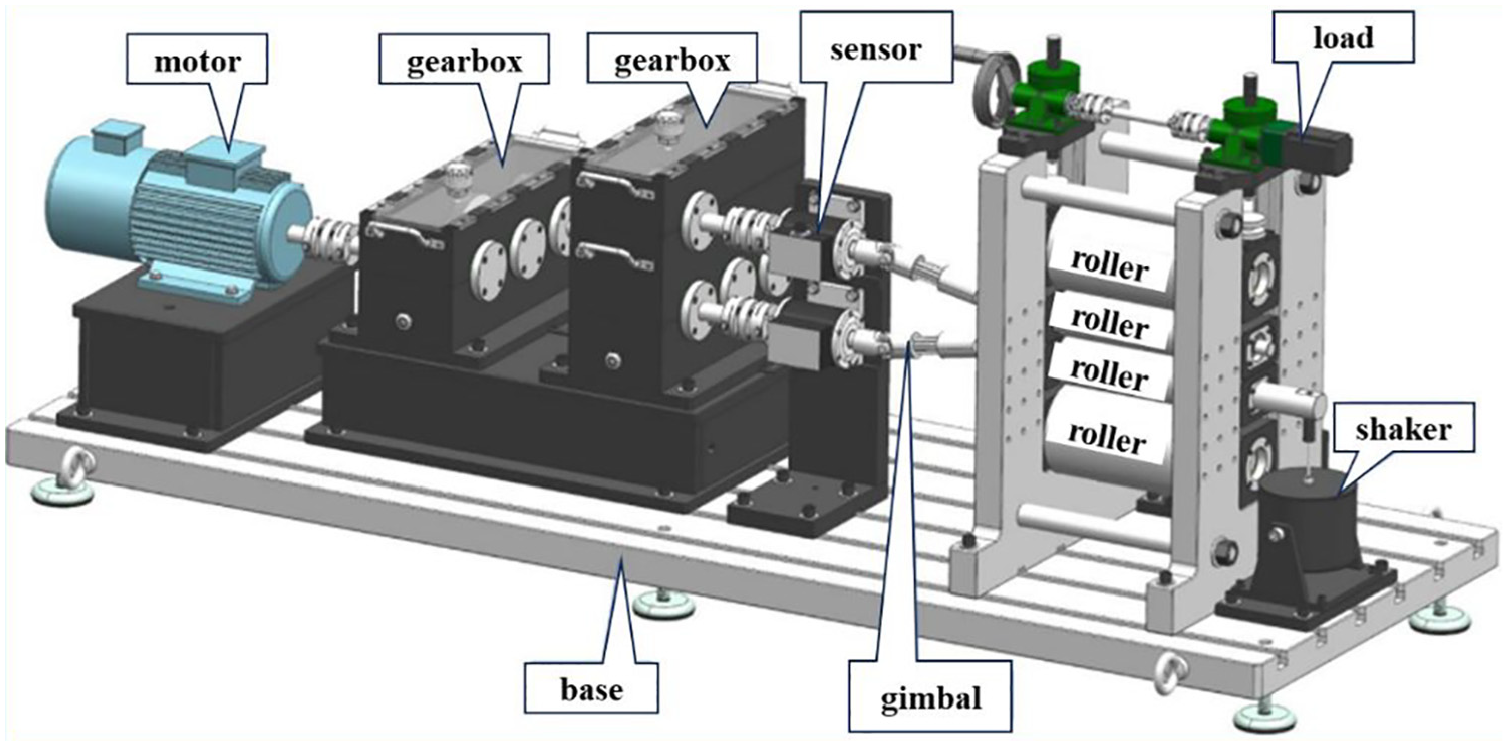
AHUT test bench.
After adding 5 dB noise to the above two datasets, six methods are tested and trained, and the results of each method are shown in Figure 10. From Figure 10, the proposed method achieves classification accuracy of over 94% in both tasks under noisy conditions, indicating that MTSTMM has stable multitask diagnostic performance. The accuracy of MTLS-TWSVM reached 95% in task 1, but the result is lower in task 2. The reason is that MTSTMM constructs soft-margin model to diminish the model’s responsiveness to noise and preserve sparsity, while MT-TBSVM, MTLS-TWSVM, and MTNPSVM are all sensitive to noise points, resulting in inferior classification performance compared to the proposed method. In addition, the setting of RMTLW term avoids overfitting during model training, thereby significantly improving the diagnostic efficiency of the proposed method. SSMM has improved its classification performance to some extent by relying on its sparsity, but lacks robustness to noise. NPLSSMM improves its computational efficiency by designing matrix squared loss, but it does not reduce the sensitivity to noise. Due to the high complexity and strong fitting ability of the DCA-BiGRU model, it is easy to mistake the noise in the training data for effective features for learning, resulting in a slightly decrease in the classification performance.
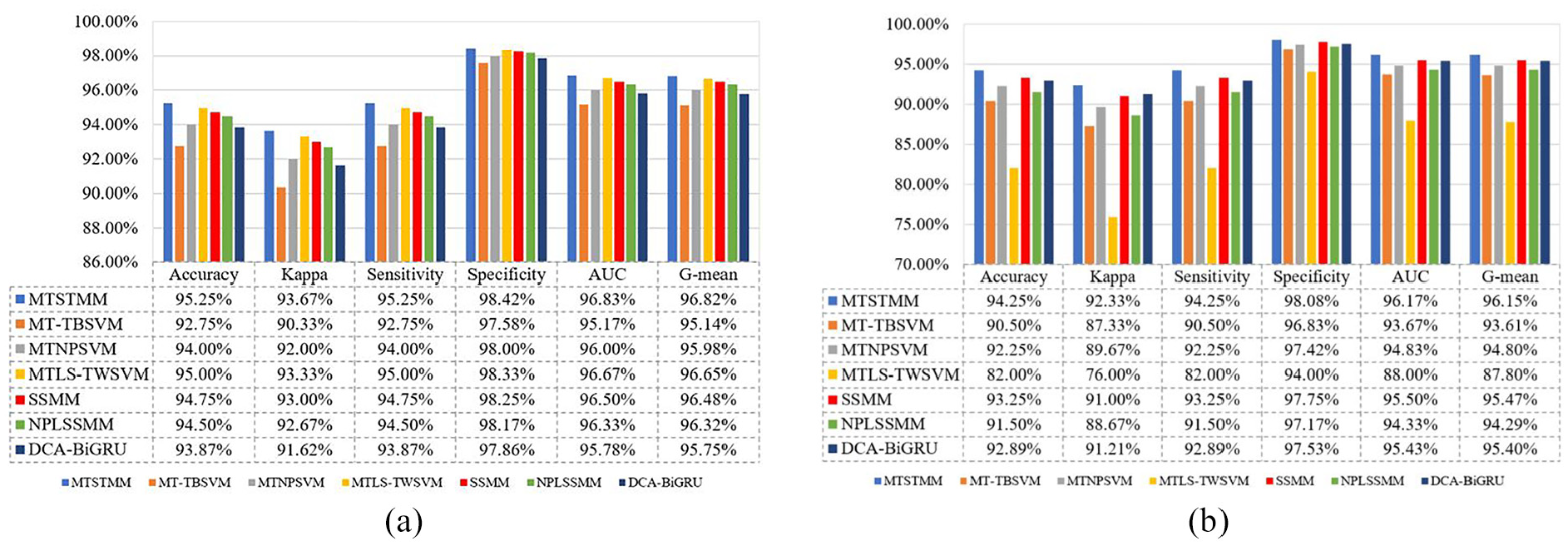
Experimental results of AHUT dataset under noise. (a) The result of task 1. (b) The result of task 2.
To avoid randomness, the above two datasets are validated five times, and the accuracy results of each experiment are shown in Figure 11 and Table 7. From Figure 11, the first group of experiments had slightly inferior results compared to SSMM in task 1, but in the other four groups of experiments, the classification results are the best. In task 2, the results of each experiment are superior to other methods. The average accuracy of the methods proposed in both tasks is the highest from Table 7, indicating their effectiveness in multitask fault diagnosis. Meanwhile, its standard deviation of classification accuracy in the two datasets is the smallest, indicating that it has more stable diagnostic performance. The reason behind this is that the soft-margin set by MTSTMM gives the model greater flexibility in handling noisy data. Moreover, the setting of RMTLW is based on minimizing structural risk, which can significantly enhance the computational accuracy of the model, and MTSTMM can more fully explore the structural information of multitarget samples through kernel techniques, achieving a certain degree of information enhancement.
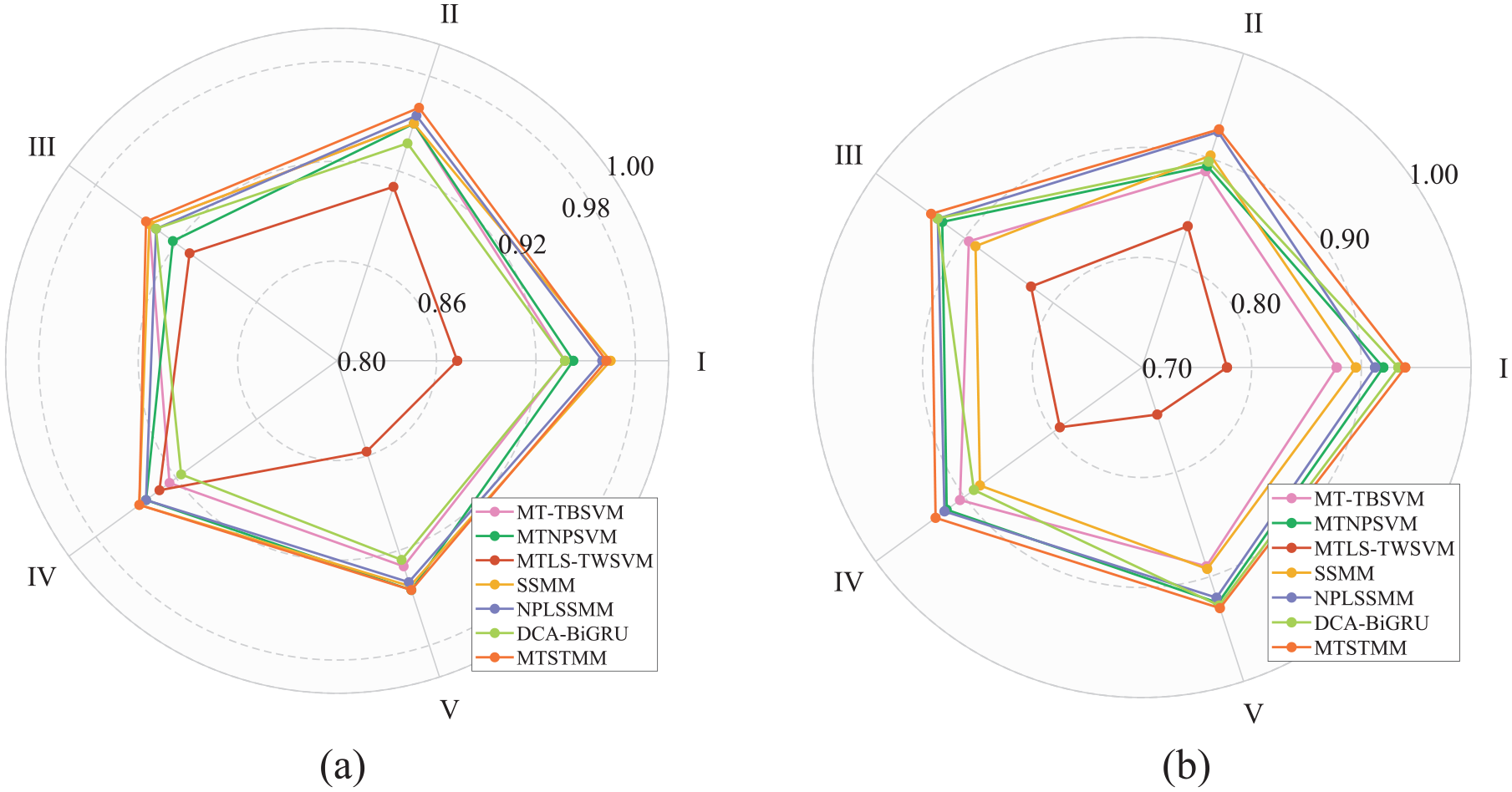
Five verification results. (a) Five verification results for task 1. (b) Five verification results for task 2.
Average accuracy and standard deviation.

MTSTMM: multitask soft-margin twin matrix machine; MTLS-TWSVM: multitask least squares twin support vector machine; MTNPSVM: multitask nonparallel support vector machine; SSMM: sparse support matrix machine; NPLSSMM: nonparallel least squares support matrix machine.
Statistical analysis
To further evaluate the differences between the MTSTMM method and other methods, Friedman test and Nemenyi test25,26 are used for analysis, and the calculation formulas for Friedman test and Nemenyi test are given by Equations (26) and (27), respectively.
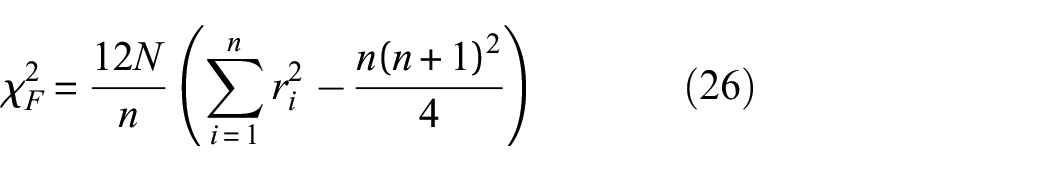
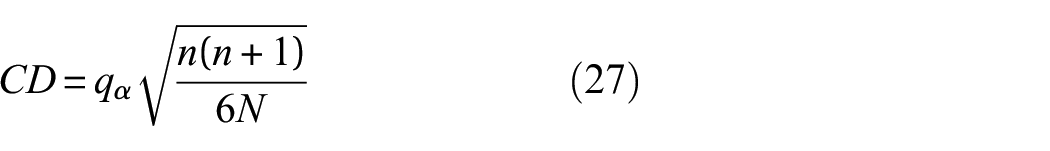
where N is the number of experiments, n is the number of methods,
The five validation results from experiments 1 and 2 are sorted, and the average rank of each method is determined as shown in Table 8. When the degrees of freedom are
The average rank of six methods.

MTSTMM: multitask soft-margin twin matrix machine; MTLS-TWSVM: multitask least squares twin support vector machine; MTNPSVM: multitask nonparallel support vector machine; SSMM: sparse support matrix machine; NPLSSMM: nonparallel least squares support matrix machine.
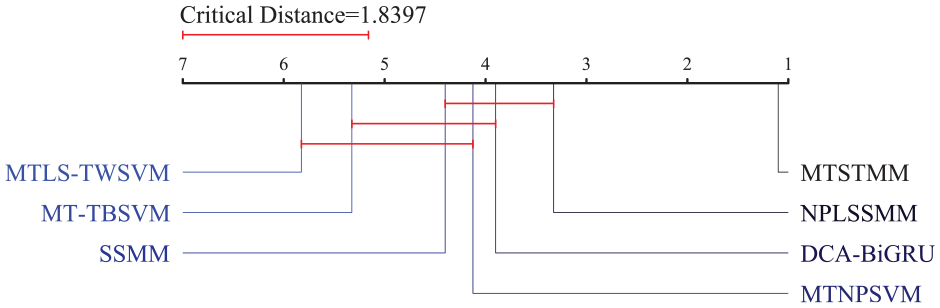
Nemenyi test CD encoding diagram.
Conclusion
This article proposes a multitask mechanical fault diagnosis method based on MTSTMM and applies it to multiple experiments for verification. MTSTMM improves its flexibility in handling noisy samples by constructing a soft-margin model, resulting in superior classification performance compared to the aforementioned comparison methods. Besides, by defining RMLTW, the problems of matrix singularity in computation and model overfitting during training can be avoided, which effectively improves the classification precision of the algorithm. Moreover, implicit information between multiple tasks is effectively utilized by MTSTMM, which SSMM and NPLSSMM do not possess. In addition, the design of kernel techniques enables MTSTMM to solve only two QPPs instead of iterative calculations, improving its computational efficiency, which makes the model faster in training than SSMM and NPLSSMM. Thus, compared to MT-TBSVM, MTNPSVM, MTLS-TWSVM, SSMM, NPLSSMM, and DCA-BiGRU methods, MTSTMM has more superior multitask diagnostic performance.
MTSTMM demonstrates superior diagnostic performance in both datasets, but faced challenges in deploying in real-world industrial environments such as small sample sizes, weak correlation feature multitasking data, and so on. Therefore, further optimizing the model to improve the practicality of the proposed method is one of the future works.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Anhui Provincial Natural Science Foundation (no. 2408085ME113) and the Outstanding Youth Fund of Universities in Anhui Province (no. 2022AH020032).