
Abstract
Electromechanical impedance (EMI) technology has been widely used in structural health monitoring, yet its potential has been limited by conventional impedance measurement methods. This study proposes a novel axial and bending modal excitation method for EMI measurement, enabling simultaneous capture of dual-modal vibration responses. Based on these dual-modal characteristics, a novel bidirectional multilevel fusion network framework for EMI signal processing was proposed. The innovations of this study include (1) a logarithmic frequency dual attention module was designed, where first-order derivative attention mechanism captures instantaneous signal changes, second-order derivative attention mechanism captures curvature features, and fusion attention combines the advantages of both, improving the training accuracy of difficult-to-fit signals to 92.5%. (2) A bidirectional-attention multistage fusion network was proposed. This network adopts an innovative additive fusion strategy to effectively avoid gradient vanishing, fully utilizes the complementary features of axial and bending vibration modes, achieves deep information fusion and synergistic enhancement, enables the model to comprehensively grasp corrosion characteristics from different dimensions, and improves the training accuracy from 82.04% and 92.5% in single-modal scenarios to 100%. The method also demonstrated excellent noise resistance under various signal-to-noise ratio conditions, maintaining reliable performance in complex monitoring environments. These results confirm that the proposed dual-modal measurement method, combined with the fusion framework, provides an enhanced solution for EMI-based damage detection, offering improved sensitivity and reliability. This work establishes a new paradigm for EMI signal acquisition and processing in structural health monitoring applications.
Keywords
Introduction
Structural health monitoring has become increasingly critical in fields such as energy infrastructure, chemical engineering, and marine engineering, with significant implications for equipment safety and reliability. Previous research indicates that structural damage is one of the main causes of industrial equipment accidents, resulting in severe economic losses annually. 1 Particularly in complex service environments, such as marine and atmospheric conditions, the challenges of damage detection and monitoring become more pronounced. Mahmoodian’s research demonstrates that preventive maintenance strategies incorporating advanced monitoring technologies can reduce life-cycle costs by approximately 25%–35% compared to reactive maintenance, while significantly improving system reliability. 2 Various nondestructive testing technologies have been developed to address these challenges. Vasagar et al. 3 systematically reviewed existing detection methods, comparing electromagnetic and acoustic approaches. While single-modal detection methods such as magnetic flux leakage (MFL), 4 ultrasonic testing, 5 and eddy current testing 6 have shown effectiveness in specific scenarios, they often face limitations in providing comprehensive structural health information. Advanced sensing technologies like fiber Bragg grating (FBG)-based systems 7 and specialized monitoring probes 8 have demonstrated advantages in continuous monitoring, yet the challenge of integrating and processing multimodal sensor data remains significant. Moreover, the widespread implementation of these technologies is often constrained by their high costs, with ultrasonic arrays and distributed fiber-optic systems requiring substantial initial investment and specialized maintenance expertise. This economic consideration has driven the search for more cost-effective monitoring solutions.
EMI as an emerging structural health monitoring method, demonstrates unique advantages in corrosion damage detection. Annamdas et al. 9 explained the basic principles of EMI technology, confirming that the coupling effect between lead zirconate titanate and structures is the key mechanism for corrosion monitoring. Talakokula et al.10,11 pioneered the application of EMI technology in concrete rebar corrosion monitoring, with their research showing significant correlation between admittance characteristics and corrosion levels. EMI technology has been applied in steel structures and wooden structures.12,13 Na and Park 14 experimentally verified the feasibility of EMI technology in detecting metal pipeline wall thickness loss, providing new insights for pipeline corrosion monitoring. Wang et al. 15 proposed and validated a quantitative rod-type corrosion measurement probe based on piezoelectric stack and EMI technology, proving its reliability and accuracy in corrosion monitoring through theoretical modeling and experimental verification. Subsequently, Wang et al. 16 developed a conical corrosion measurement probe based on EMI technology, successfully achieving quantitative monitoring of pipeline corrosion through combined finite element analysis and experimental validation. The reusable piezoelectric sensors developed by Raju et al. 17 showed good performance in corrosion assessment, particularly with their nonbonded configuration showing higher sensitivity to corrosion damage. Liu et al. 18 studied the application of EMI technology in concrete damage diagnosis, demonstrating its effectiveness in structural damage detection and characterization through impedance feature analysis. Zhang et al. 19 achieved breakthroughs in environmental factor compensation, significantly improving corrosion monitoring accuracy. In summary, EMI technology offers advantages of high sensitivity, rapid response, and strong autonomous monitoring capabilities. However, existing research still faces challenges. First, the quantitative relationship between impedance characteristics and corrosion degree needs further investigation. Second, signal processing and feature extraction methods in complex working conditions need further improvement. Addressing these challenges, the development of EMI corrosion monitoring methods with enhanced environmental adaptability and high precision holds substantial theoretical value and significant engineering application potential.
Deep learning technology has made significant progress in EMI signal processing and structural health monitoring. De Oliveira et al. 20 pioneered a novel structural health monitoring method combining PZT sensors with convolutional neural networks, integrating traditional sensing technology with advanced deep learning methods to achieve more accurate damage detection and classification. Chen et al. 21 proposed a quantitative monitoring method for bolt loosening that combines multichannel piezoelectric active sensing and attention mechanism based convolutional neural networks, improving the accuracy of bolt loosening recognition through attention-enhanced deep learning models. Li et al. 22 proposed a method combining EMI technology with convolutional neural networks to address the quantitative assessment of concrete structure damage under different temperature conditions, improving temperature adaptability and accuracy of damage identification. Yan et al. 23 developed an intelligent monitoring system integrating EMI with neural networks for real-time monitoring and evaluation of early hydration and setting processes in cement mortar, achieving intelligent characterization of early cement material properties. Ai et al. 24 developed an automated method based on convolutional neural networks to identify compressive stress and damage states of concrete specimens by learning electromechanical admittance features, achieving intelligent assessment of concrete structure conditions. Ai et al. 25 proposed a one-dimensional convolutional neural network-based EMI deep learning method for concrete structure damage identification, achieving efficient damage feature extraction and recognition through direct processing of raw impedance signals. Yang et al. 26 proposed a novel nondestructive testing method based on EMI for evaluating fiber content in concrete, providing a new solution for rapid, nondestructive assessment of concrete fiber content. Ai et al. 27 proposed a two-dimensional convolutional neural network-based EMI deep learning method, achieving precise quantitative assessment of concrete structure damage by converting impedance signals into two-dimensional feature maps. These research findings demonstrate the enormous potential of deep learning technology in structural health monitoring. The application of this technology to quantitative monitoring of pipeline corrosion has important practical implications. However, most existing methods rely on single-modal analysis and traditional frequency shift techniques, which limit their ability to capture comprehensive structural information and process complex damage features effectively. The integration of multimodal information remains largely unexplored, presenting a significant opportunity for improving monitoring accuracy and reliability.
To address these limitations and advance the field of pipeline corrosion monitoring, there is a pressing need for methods that can effectively process and integrate multimodal EMI signals while leveraging the advantages of deep learning technology. This study proposes a dual-modal EMI monitoring method integrated with a bidirectional multilevel fusion network. Traditional single-modal EMI methods face challenges in achieving comprehensive structural health monitoring, while conventional frequency shift analysis shows limitations in extracting complex damage features. The hardware core of this method involves attaching piezoelectric patches to the surface of metal probes, using EMI harmonic excitation to generate axial vibration mode and bending vibration mode respectively. These dual-modal signals provide complementary information about the structural state, as different vibration modes exhibit varying sensitivities to structural changes. When structural changes occur, they cause shifts in characteristic resonance frequencies of both modes, which can be captured through impedance spectroscopy. Unlike traditional frequency shift linear analysis, this study innovatively employs a bidirectional multilevel fusion network to process the dual-modal impedance spectral data. The fusion process extracts and integrates channel attention and temporal attention from both vibration modes, completing the comprehensive feature extraction through residual connections. This approach enables more robust and sensitive structural health monitoring by leveraging the complementary advantages of different vibration modes.
The remainder of this study is organized as follows: Section “Proposed framework” presents the proposed framework. Section “Logarithmic frequency dual attention module” introduces the logarithmic frequency dual attention signal processing method and novel multimodal fusion network structure. Section “Bidirectional-attention multistage fusion network” describes the design of corrosion probes capable of receiving both vibration modal signals for accelerated corrosion testing. Section “Experimental verification” analyzes and discusses the theoretical and experimental results. Section “Result analysis” concludes the article.
Proposed framework
Drawing inspiration from Alexander et al., 28 this study proposes novel axial and bending modal excitation methods. To address the issue that single-modal EMI signals cannot fully reflect structural characteristics, a dual-modal EMI fusion method that comprehensively captures structural feature information by combining axial and bending signal modalities was proposed in this study. To address the problem of signals spanning multiple orders of magnitude causing lower-order signals to be ignored, a logarithmic frequency dual attention signal processing method was proposed to learn features from signals of different magnitudes. Based on this, a bidirectional multilevel fusion network was designed, which consists of intermediate fusion and final fusion stages to achieve deep feature extraction and fusion of multimodal signals. The designed bidirectional attention fusion module effectively combines two inputs through channel attention and temporal attention, and further deepens feature learning through residual connections. This method successfully fuses signals from different vibration modalities, enhancing the richness and discriminative ability of feature representation, providing technical support for structural health monitoring and fault diagnosis. The proposed method flow was shown in Figure 1. BMFN is a dual-parallel network structure where the bending modal signal first undergoes feature enhancement preprocessing through Logarithmic frequency dual attention module (LFDM), while the axial modal signal directly inputs to the convolutional layer, and finally achieves bidirectional feature fusion of both modal signals through intermediate fusion modules and final fusion modules (BFM modules). This design fully utilizes LFDM’s advantages in processing bending modal signals and achieves effective integration of different modal information through BFM modules.
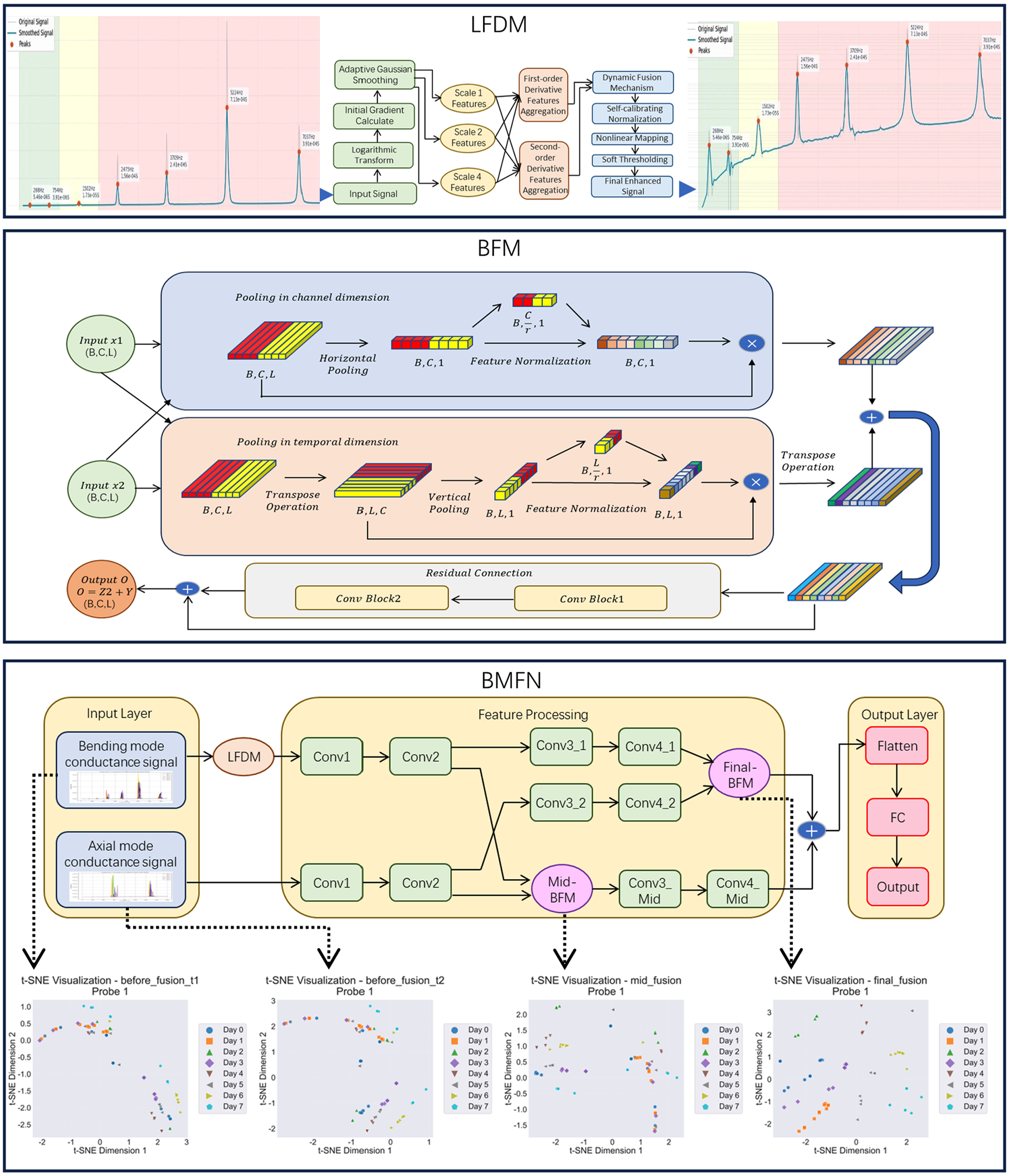
Method flowchart.
Logarithmic frequency dual attention module
This section proposes a logarithmic domain multiorder derivative adaptive signal processing method, which is built upon three core theoretical foundations. First, logarithmic domain signal processing theory provides an effective method for handling large dynamic range signals. Through logarithmic transformation, it compresses signal dynamic range, enhances weak signal features, and makes signal feature distribution more uniform, thereby laying the foundation for subsequent processing. Adaptive smoothing theory is the second theoretical pillar of this algorithm, which overcomes the drawback of traditional fixed-window smoothing methods that easily cause loss of signal details. By dynamically adjusting the smoothing degree according to local gradients, it maintains more details in areas of dramatic signal changes while performing stronger smoothing in gentle areas, achieving optimal balance between signal enhancement and denoising. Finally, multiorder Gaussian derivative theory provides mathematical tools for feature extraction. First-order derivatives capture signal change trends and edge features, while second-order derivatives reflect curvature changes and detect local extrema and inflection points. The combination of these multiorder derivatives enables a more complete characterization of local structural information. The organic integration of these three theoretical foundations combines traditional signal processing theory with modern deep learning methods. This integration maintains algorithmic interpretability while enhancing the ability to process complex signals, thus providing solid theoretical support for subsequent algorithm design.
The design philosophy of LFDM is developed to effectively capture the structural dynamic characteristics in EMI-based monitoring. The logarithmic transformation mechanism is specifically designed to process the wide frequency spectrum (0–7000 Hz) that encompasses both axial and bending vibration modes, ensuring balanced sensitivity across different modal responses. This transformation is particularly effective in handling the multiscale nature of structural dynamics, where both global modes at lower frequencies and local modes at higher frequencies carry crucial information about structural integrity. The adaptive Gaussian smoothing mechanism preserves the dynamic characteristics of the structure by maintaining the sharpness and shape of resonance peaks, which are direct manifestations of the structure’s natural frequencies and damping properties. Through the multiorder derivative features and dual attention fusion mechanism, LFDM achieves comprehensive monitoring by capturing both the shifts in resonance frequencies (reflecting changes in structural stiffness) and variations in peak shapes (indicating alterations in structural damping characteristics), thereby providing detailed insights into the evolution of structural mechanical properties.
This section details the design principles and mathematical derivation of the logarithmic frequency dual attention module, with the flow diagram shown in Figure 2. Through the organic combination of logarithmic transformation, adaptive Gaussian smoothing, multiscale derivative feature extraction, dual attention mechanism, and nonlinear mapping, this module achieves effective enhancement of input signals. The logarithmic frequency multiorder derivative attention mechanism proposed in this study contains several key components, and their mathematical principles and derivation processes are elaborated below.
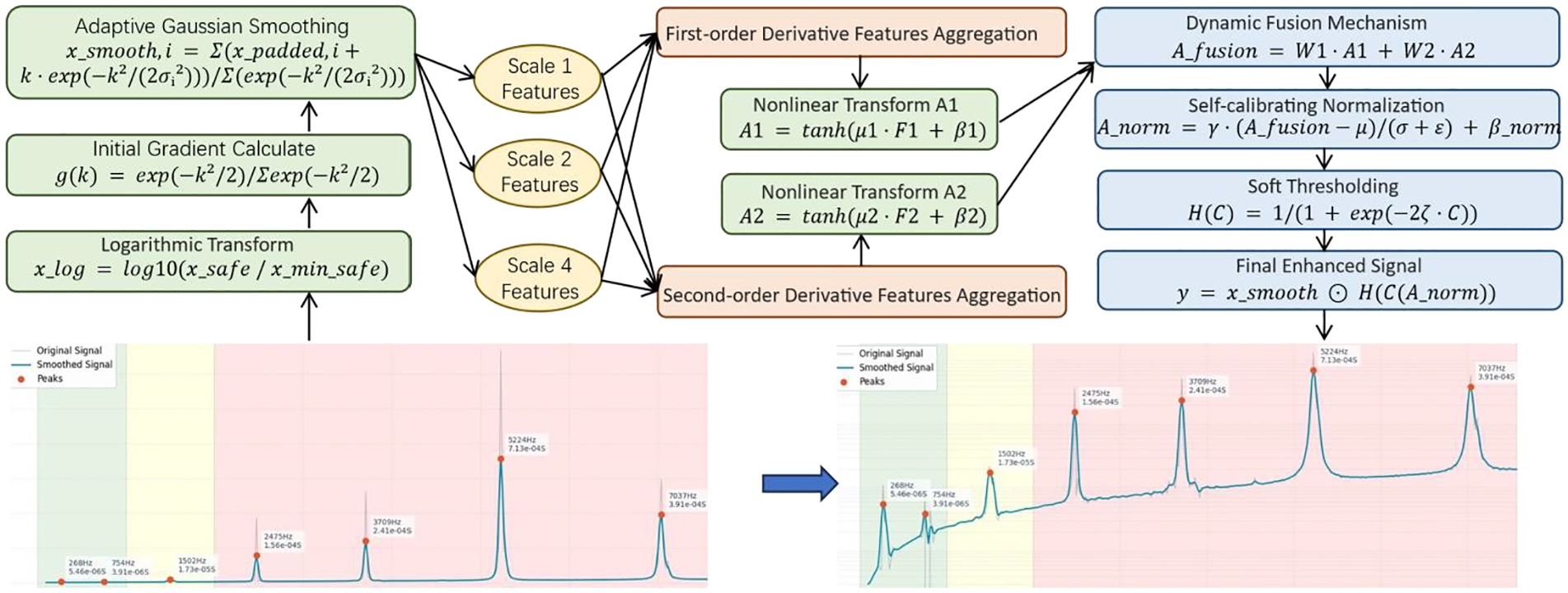
Logarithmic frequency dual attention signal processing method flowchart.
First, to stabilize variance and normalize the input data, the module performs logarithmic transformation on the input signal. Given an input tensor x with shape (B, C, L), where B is the batch size, C is the number of channels, and L is the signal length. The mathematical expression for logarithmic transformation is

where
After logarithmic transformation, the first-order variation characteristics of the signal are captured by calculating the initial gradient. The initial gradient is obtained through convolution with a first-order derivative kernel:

where the first-order derivative kernel
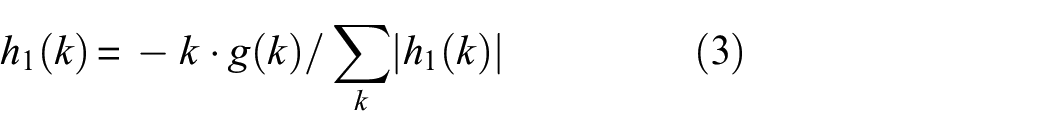
The expression for Gaussian kernel
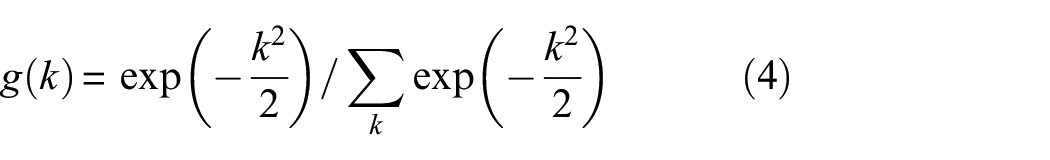
Based on initial gradients, the module implements adaptive Gaussian smoothing. The smoothing intensity is dynamically adjusted through local gradients, preserving more details in areas of dramatic signal changes while applying stronger smoothing in flat regions. The formula for calculating the adaptive standard deviation is

smoothing operation expression is
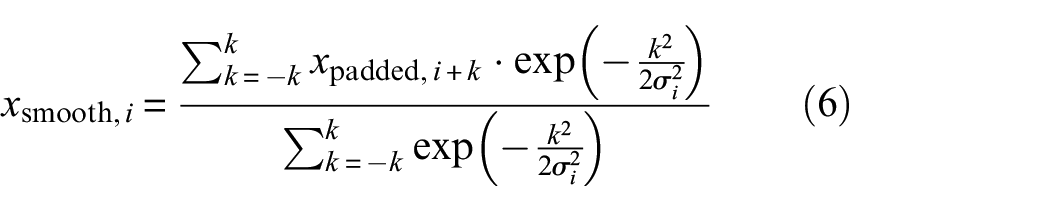
where
To capture features at multiple resolutions, the module extracts first-order and second-order derivative features at different scales. For each scale

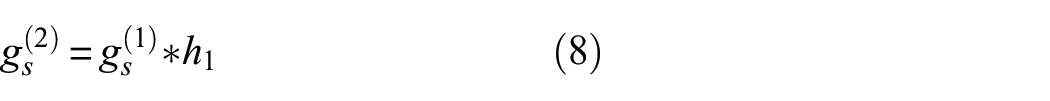
multiscale features are aggregated through learnable weights:

where

where μ, β are learnable parameters.
To effectively fuse dual attention maps, the module employs a dynamic fusion mechanism:


where
The fused attention map undergoes self-calibrating normalization:
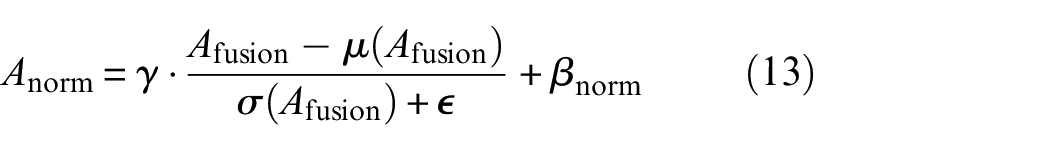
where

Finally, introduce a soft threshold mechanism through a smoothed Heaviside function:

where ζ is a learnable parameter that controls the steepness of the transition. The final enhanced signal is obtained through the following method:

where ⊙ denotes elementwise multiplication operation.
At the implementation level, the logarithmic frequency dual attention module is built based on PyTorch’s nn.Module. All learnable parameters, including
Through the careful design and organic integration of the above components, the logarithmic frequency dual attention module achieves effective enhancement of input signals. This module not only adaptively adjusts processing intensity but also captures signal features at multiple scales, providing a reliable foundation for subsequent signal processing tasks.
Bidirectional-attention multistage fusion network
Network framework
In the field of signal processing, the effective processing and fusion of multichannel signals has consistently been a key area of research. Traditional methods often adopt a single fusion strategy, making it difficult to fully utilize feature information from different levels. To address this issue, this study proposes a new network architecture that enhances model performance through multistage attention feature fusion. The network employs a progressive feature extraction strategy and introduces attention mechanisms at different levels for feature fusion, effectively improving feature utilization efficiency. The proposed network architecture is shown in Figure 3, which extracts features through multilayer convolutional neural networks (CNN) and achieves effective feature fusion using bilateral attention fusion modules (BFM). The following sections will provide a detailed description of each component of the network, along with its mathematical formulation.
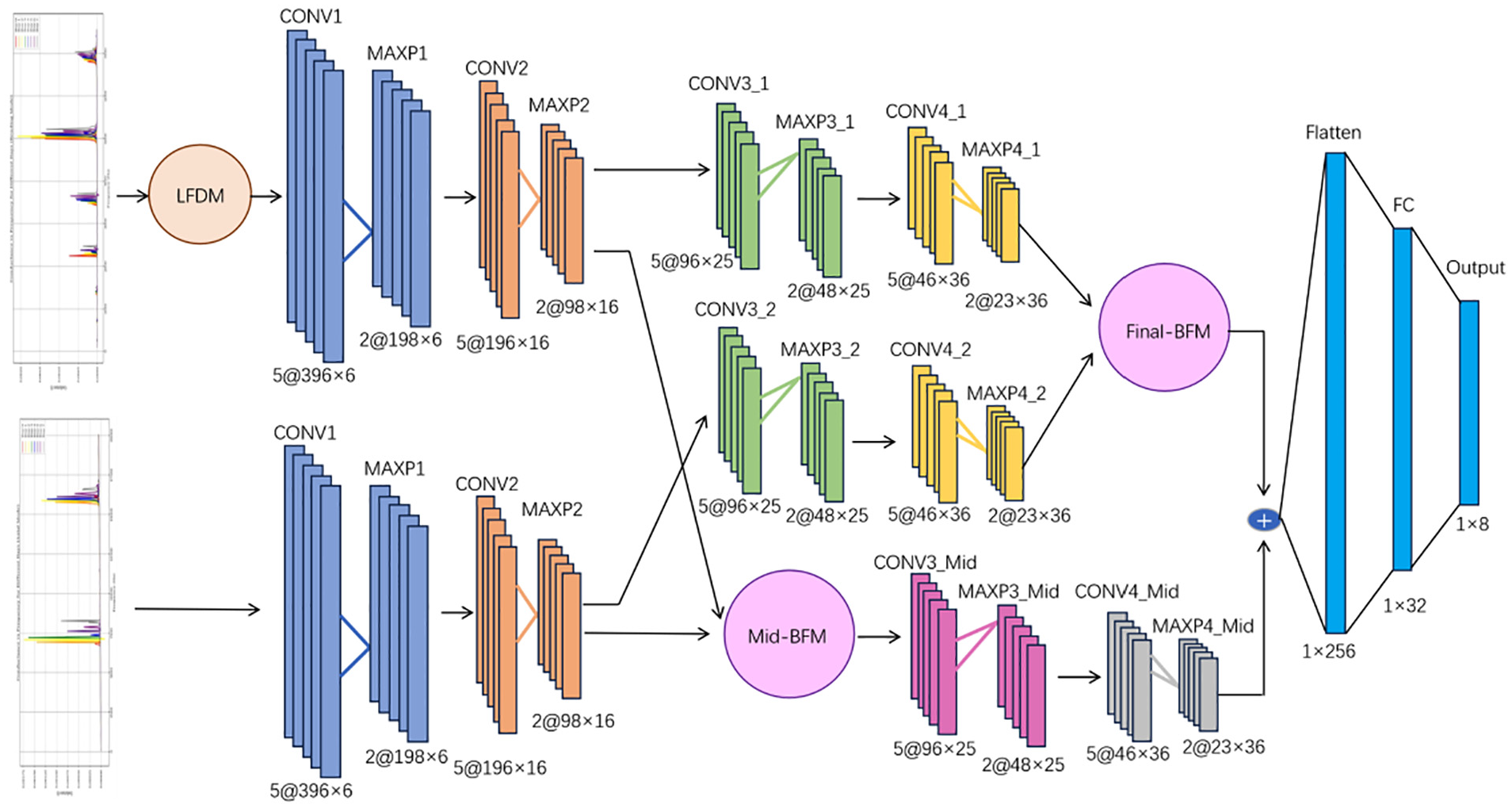
Bidirectional multilevel fusion network structure.
The overall network consists of logarithmic frequency dual attention module, feature extraction layers (including multiple convolution, batch normalization, pooling, and activation function layers), a middle fusion module (Mid-BFM), a final fusion module (Final-BFM), and fully connected layers (FC). The network receives two input signals (
Before the input signal enters the feature extraction layer, it first undergoes preprocessing through the logarithmic frequency dual attention module, which is a logarithmic frequency domain dual attention mechanism, to enhance the expression of important features. Let the input signal be (x), and the output after the attention mechanism is:

Parameters for Conv1d operations:
Continues to perform convolution processing on the features output from the first layer to extract higher-level features:

Here,
The features extracted from the second layer are fused through the intermediate fusion module BFM:

Subsequently, the fused features undergo further processing through convolutional layers:
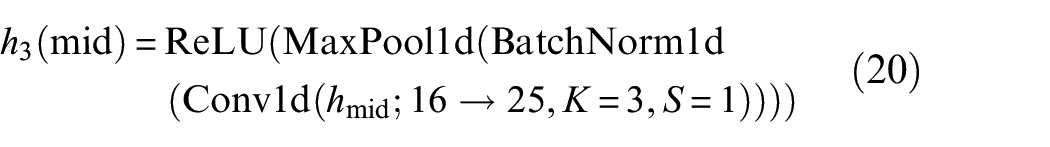
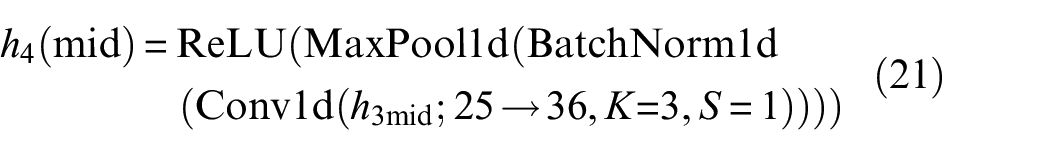
Among them, Conv1d increases the number of channels from 16 to 25, and then to 36.
Outside the middle-layer fusion branch, the original feature branch continues to propagate forward, going through the third and fourth convolutional layers:
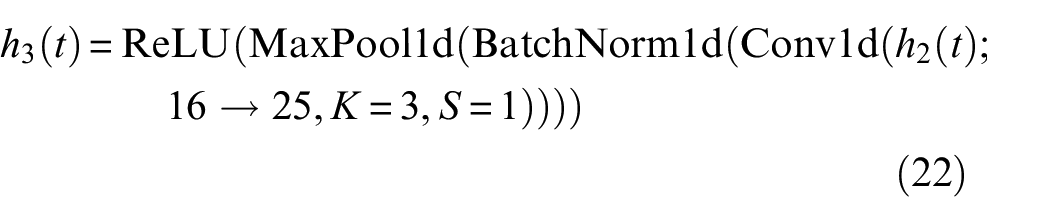
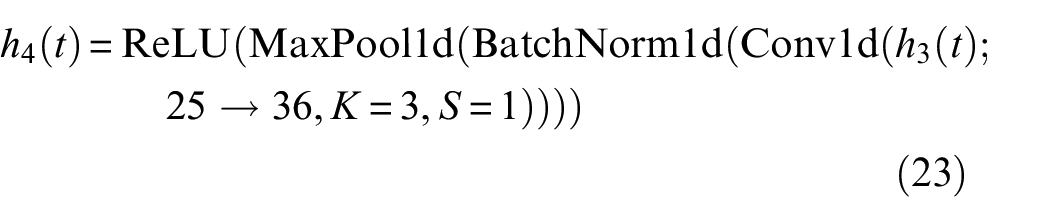
Here, Conv1d increases the number of channels from 25 to 36.
Fuses the fourth layer features of the original branch through the final fusion module BFM:

Next, use the weighted fusion mechanism to combine the features of middle-layer fusion and final fusion:
In summary, the network proposed in this study adopts an innovative two-stage feature fusion strategy. The first stage performs intermediate feature fusion after the second convolutional layer, and the fused features continue through their respective processing branches. The second stage performs final feature fusion after the fourth convolutional layer to obtain more comprehensive feature representation.
First-stage feature fusion: After completing the initial parallel feature extraction, the network implements a novel bidirectional attention fusion mechanism to integrate feature signals from both branches at the intermediate level. This early fusion strategy is designed to timely integrate multisource information and prevent effective features from degrading in deeper networks. The fused features continue through two consecutive convolutional layers, with channels progressively expanding to 25 and 36, forming a mid-level fusion branch. This progressive channel expansion strategy ensures sufficient feature extraction while avoiding excessive computational resource consumption.
Second stage feature fusion: After the first stage fusion strategy, the mid-level fusion branch proceeds in parallel with the continuous extraction of original features. The two original branches continue to be processed through convolutional networks with identical structures, maintaining a channel expansion strategy (16 → 25 → 36) consistent with the mid-level fusion branch. This symmetrical design not only maintains the consistency of feature extraction but also provides a solid foundation for subsequent feature fusion. Each convolutional layer is still equipped with complete Batch Norm, MaxPool, and ReLU components, ensuring effective extraction of deep features. A bidirectional attention fusion mechanism is similarly designed at the network’s end for deep feature fusion.
This network architecture offers several technical advantages: first, the multistage fusion strategy effectively leverages feature information across different scales; second, the adaptive fusion mechanism dynamically adjusts the importance of each fusion stage using learnable parameters; third, the hook mechanism allows for efficient monitoring of key node features, facilitating network analysis and debugging; and finally, the bidirectional symmetric structure ensures balanced processing of input signals.
Bidirectional-attention fusion module
While attention mechanisms have demonstrated remarkable success in various deep learning tasks, limitations still exist when dealing with one-dimensional convolutional neural networks. SE-Net 29 pioneered the channel attention mechanism by explicitly modeling interdependencies between channels: first compressing global spatial information into channel descriptors, then activating these descriptors to recalibrate channel feature responses. However, SE-Net only focuses on channel relationships, ignoring temporal dependencies in one-dimensional sequential data. CBAM 30 expanded the application of attention mechanisms by serially integrating channel and spatial attention modules. Although CBAM achieved impressive performance in two-dimensional image processing tasks, its spatial attention module was designed specifically for 2D feature maps and cannot be directly applied to one-dimensional sequential data without significant modifications. Temporal attention emphasizes the importance of temporal information in sequential data by capturing dependencies along the time dimension, while effective in modeling temporal relationships, it neglects channel correlations that could provide complementary feature representations. Coordinate attention 31 proposed a position-sensitive attention mechanism that preserves precise position information in 2D images and effectively captures channel and spatial dependencies, but its design is specifically optimized for two-dimensional scenarios and cannot be directly applied to one-dimensional sequence data processing.
To address the limitations of existing attention mechanisms in processing one-dimensional sequence data, a BFM is proposed, which can simultaneously model channel and temporal dependencies in one-dimensional convolutional neural networks. Compared to existing methods, BFM has significant advantages: unlike SE-Net which only focuses on single-dimensional attention, unlike CBAM and coordinate attention which require two-dimensional input, and unlike temporal attention which ignores channel relationships. BFM adopts a bidirectional parallel structure to simultaneously capture channel relationships and temporal dependencies, providing more comprehensive feature representation for one-dimensional sequence data.
Based on a thorough understanding of the limitations of existing attention mechanisms, the proposed BFM not only innovatively achieves parallel computation of bidirectional attention, but more importantly introduces a feature fusion mechanism. BFM adopts a modular design as shown in Figure 4. Specifically, BFM contains two key innovations: first, it calculates channel attention and temporal attention separately through a parallel dual-branch structure, avoiding potential information loss from traditional serial structures; second, it employs an additive fusion mechanism to merge enhanced features with original features, effectively enhancing features while preserving original feature information through residual connections.
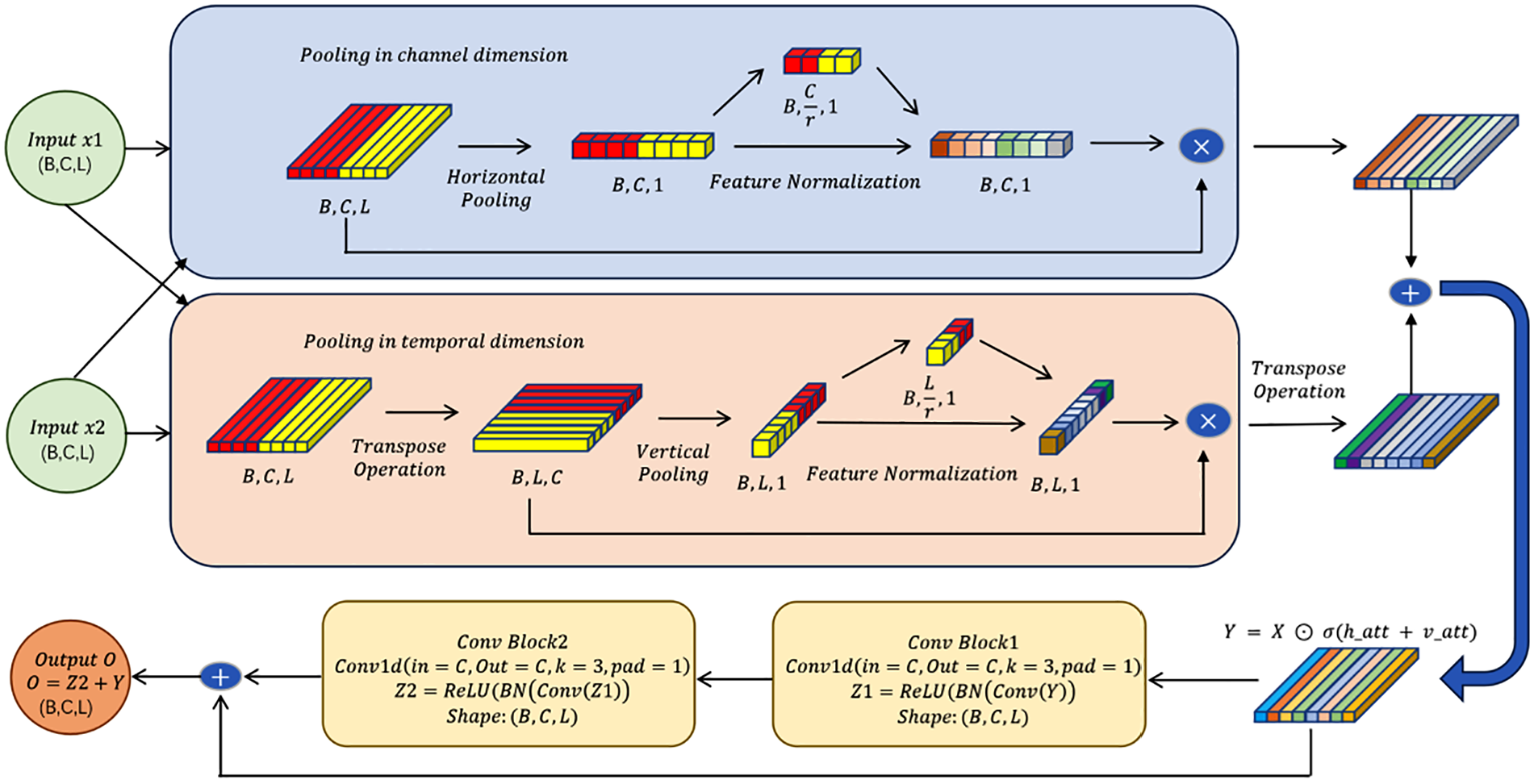
Bidirectional-attention fusion module architecture diagram.
From a mathematical perspective, the dual-branch structure can be viewed as an orthogonal decomposition of the feature space, which decomposes the original feature map
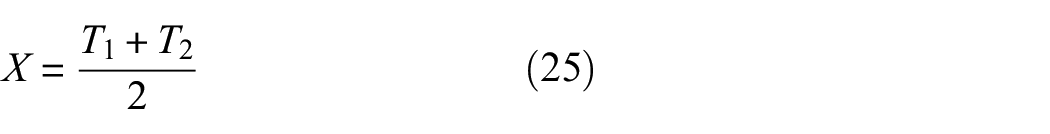
applies global average pooling along the temporal dimension first to capture temporal dependencies:
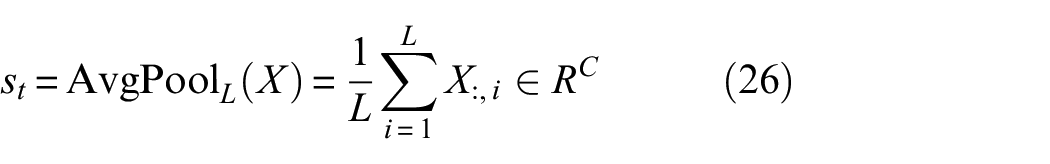
Here,
Then, pass
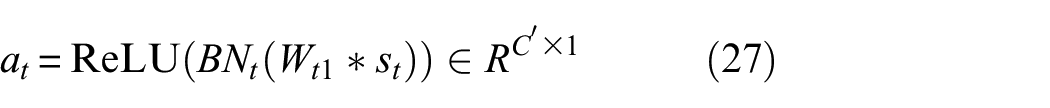

where
Adopts a similar approach in channel-dependent processing, first applying global average pooling along the channel dimension. Since the standard 1D convolution layer in PyTorch does not directly support pooling along the channel dimension, this process is simulated by transposing the dimensions of X:
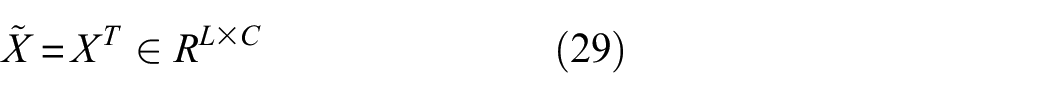
applies global average pooling along the new temporal dimension (original channel dimension):
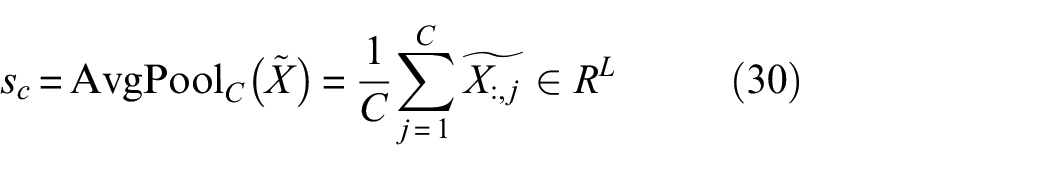
reshapes
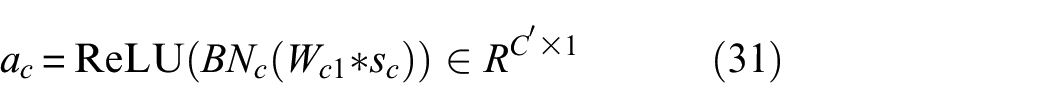

where
Next, the attention map is generated by integrating temporal and channel attention features, followed by the application of the Sigmoid activation function:

where σ represents the element-wise Sigmoid function.
After obtaining the attention map, it is applied to the features. The attention map A is expanded to match the dimensions of the input feature map and is applied to the fused features:

where ⊙ represents elementwise multiplication, and A is broadcast along the temporal dimension to match the shape of
To further enhance the discriminative ability of features, a convolutional refinement process with residual connections is introduced. The feature map Y processed by the attention mechanism first goes through the initial convolution block, applying 1D convolution with a kernel size of 3, followed by batch normalization and ReLU activation:
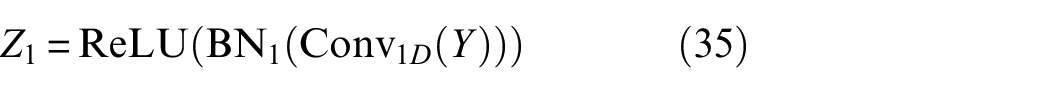
where
Immediately applies the second convolution block in a similar way:
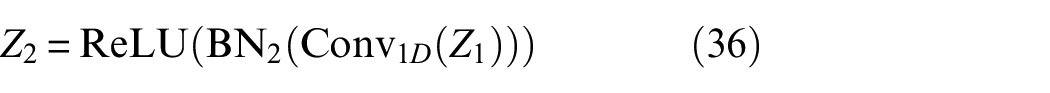
where
Finally, to promote gradient flow and improve training stability, the attention-applied features Y are added to the output of the second convolutional block to form a residual connection:
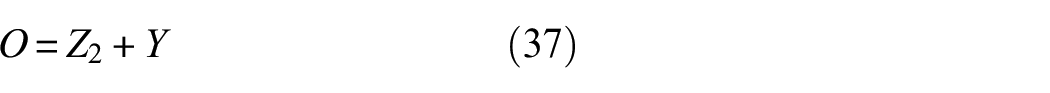
This residual addition helps the network learn identity mapping, making it easier to optimize. In this way, the output O represents the optimized feature map, which effectively combines information from both modalities while emphasizing discriminative features through the coordinate attention mechanism.
In summary, this mechanism receives two input feature sequences (both with dimensions B×C×L, where B is batch size, C is number of channels, and L is sequence length), and processes them in parallel through two paths. In the channel attention branch, average operation is used along the channel dimension for feature aggregation to obtain correlation information between channels; in the temporal attention branch, adaptive average pooling compresses the temporal dimension to unit length, generating compact temporal feature descriptions. The features from these two branches are concatenated and transformed through two stages of convolutional neural networks. The first convolutional layer, coupled with batch normalization and ReLU activation function, performs feature dimensionality reduction, with the temporal branch compressing C channels to C/r and the channel branch compressing 2 feature maps to L/r (where r is the compression ratio). The second convolutional layer remaps the features to their original dimensions and generates attention weight maps through a Sigmoid function. This design based on learnable convolutional layers enables the model to adaptively adjust feature weights in different dimensions, thereby highlighting important temporal patterns and channel features.
Experimental verification
Experimental specimen and instrument setup
Three electrochemical corrosion probes were fabricated in Hubei key laboratory of earthquake early warning, with dimensions shown in Figure 5. The probes are labeled as No. 1, No. 2, and No. 3. These probes were manufactured using high-purity aluminum to ensure material consistency and experimental reliability. Each probe measures 236 mm (length) × 26 mm (width) × 4 mm (thickness), designed to simulate common corrosion environments. An aluminum cubic mass block measuring 29 × 29 × 29 mm was welded to the end of each probe, which not only enhanced the mechanical stability of the probe but also helped simulate stress distribution under actual working conditions. The mass block was made of the same aluminum material as the probe body to avoid electrochemical performance inconsistencies due to material differences.
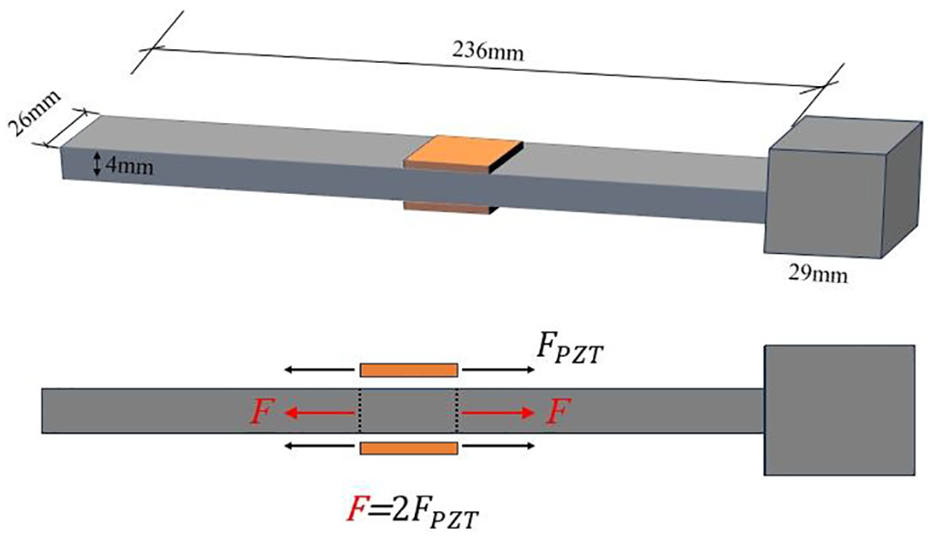
Corrosion probe schematic diagram.
PZT-5H piezoelectric sensors with dimensions of 20 × 20 × 0.5 mm were installed on both the front and back sides at the center of the probe. Highly conductive epoxy resin was applied to the surface of the probe, extending 1 mm beyond the piezoelectric sheet to ensure optimal electrical signal transmission and mechanical coupling. This setup was used to monitor conductance changes during the corrosion process. The sensor was installed at the center of the probe to ensure that the changes in the conductance signal could be accurately captured at different corrosion stages. The conductance measurement system of the experiment mainly consists of an impedance analyzer, a data acquisition system, and a computer, as shown in Figure 6. The impedance analyzer used in the experiment was the WAYNE KERR 6500B, which accurately measured the conductance signal of the probe under varying corrosion conditions. The subsequent processing was completed by a computer equipped with an Intel Core i7 processor (Intel Corporation, Santa Clara, California, USA) and 16 GB of memory.

Experimental specimen and instrument setup.
During the measurement of conductance signals, specific circuit connection methods were employed to collect signals from both axial and bending vibration modes. The specific connection methods are shown in Figure 7. For the axial vibration mode, lead 1 of both piezoelectric sensors (PZT-A and PZT-B) are connected to terminal 1 of the impedance analyzer, while both lead 2 are connected to terminal 2. For the bending vibration mode, as shown in Figure 7(b), the connections are reversed: lead 1 of PZT-A and lead 2 of PZT-B are connected to terminal 1, while lead 1 of PZT-B and lead 2 of PZT-A are connected to terminal 2. This bidirectional connection method effectively measures conductance signals in both axial and bending modes, ensuring the accuracy and reliability of signal acquisition.
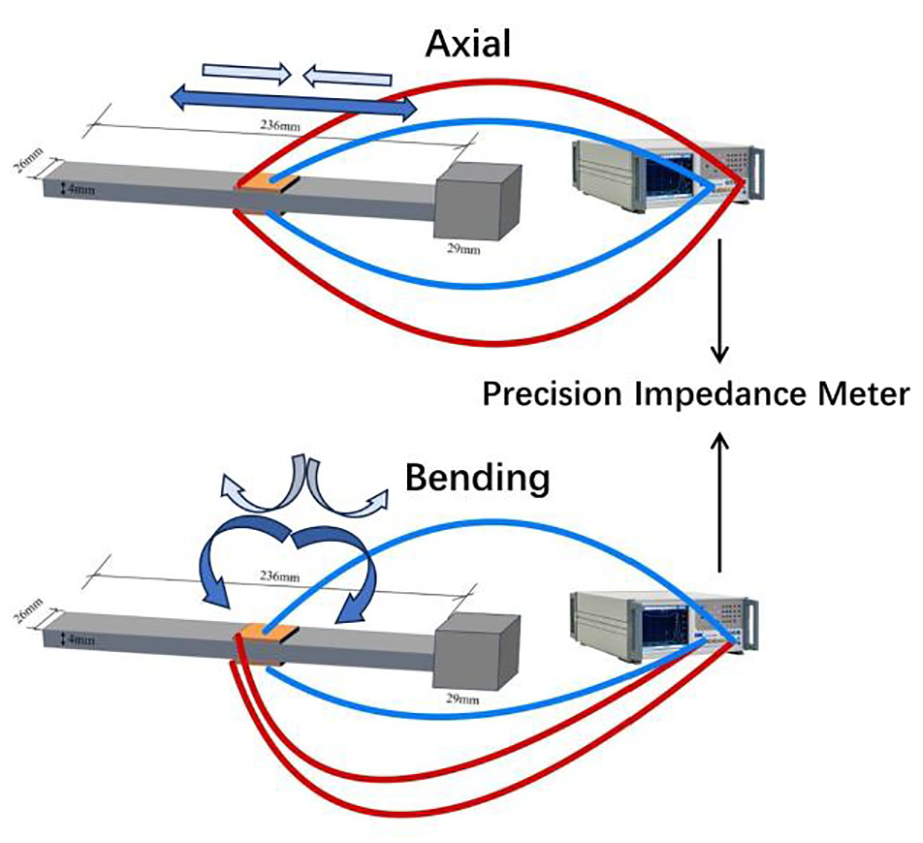
(a) Axial mode: similar leads are connected together and (b) Bending mode: leads are interchanged before connection.
Experimental procedure
The objective of this study is to evaluate the performance of aluminum probes No. 1, No. 2, and No. 3 through accelerated corrosion tests conducted in real-world corrosive environments. To ensure experimental reproducibility and data accuracy, the experimental environment was strictly controlled at a constant temperature of 26°C and 60% relative humidity, with an air conditioning system maintaining stable indoor temperature. The corrosive medium used was 3.5% sodium chloride (NaCl) solution to simulate corrosive conditions in marine environments. During the experimental preparation phase, all probes were subjected to a surface cleaning procedure. Ethanol was employed to remove contaminants and oxide layers from the surfaces. Additionally, special attention was given to securing the welding points of the aluminum cubic mass blocks to prevent mechanical loosening throughout the subsequent corrosion process. After sensor installation, careful inspection of connections was required to avoid signal loss during data acquisition. According to different connection methods for axial and bending modes, the impedance analyzer was connected to the sensors, ensuring good contact at all connection terminals. To guarantee measurement accuracy, all instruments and equipment underwent strict calibration before the experiment. The impedance analyzer was zero-calibrated before each experiment, and the data acquisition system was verified using standard signal sources.
The design of the accelerated corrosion test apparatus is illustrated in Figure 8. In this setup, the aluminum probe functions as the anode and is connected to the positive terminal of the DC power supply. The copper plate serves as the cathode and is connected to the negative terminal of the power supply. To ensure uniform corrosion process, the third section of the probe is immersed in 3.5% NaCl solution along with the copper plate. During the accelerated corrosion process, a constant current of 620 mA is applied to accelerate the corrosion rate of the aluminum probe. This current setting was specifically chosen to achieve a controlled corrosion rate of 5 g mass loss per day, which serves as our basic classification unit for corrosion progression (Day 0 corresponding to 0 g mass loss, Day 1 to 5 g, Day 2 to 10 g, and so forth). According to Faraday’s law, the relationship between mass loss Δm and applied current I, time t, charge number of aluminum ions z, and Faraday’s constant F is

where M is the atomic mass of aluminum (27 g/mol), z is the charge number of aluminum ions (z = 3), and F is the Faraday constant (96,485 C/mol). The expected daily mass loss is approximately 5 g. The entire test process lasted for 8 days, and the experiment was conducted under constant room temperature conditions to ensure consistency and reproducibility of the experimental environment.

Accelerated corrosion test device diagram:
During the experiment, impedance spectroscopy measurements of each probe were conducted at regular times daily, and mass loss data were recorded. The specific procedure was at the same time each day, the current supply was stopped, and an impedance analyzer was used to record the conductance characteristics of the probes in their current corrosion state, obtaining conductance data in two modalities. Meanwhile, a precision balance was used to measure the mass loss of each probe, ensuring data accuracy through multiple measurements and calibrations. All daily impedance spectra and mass loss data were recorded and saved, forming a systematic time series database. During the data processing and analysis phase, the collected impedance spectra and mass loss data were transferred to a computer for analyzing the trends of impedance spectra over corrosion time, exploring the relationship between conductance characteristics and corrosion degree, providing a basis for multimodal fusion analysis. During the experiment, regular checks of connection circuits and sensor status were necessary to promptly identify and eliminate potential faults, ensuring smooth experimental progress.
Through the optimized experimental process above, rich corrosion data could be obtained in a relatively short time, verifying the performance of aluminum probes in actual corrosive environments. This not only provided a solid data foundation for subsequent corrosion behavior analysis but also offered practical support for the application of multimodal fusion technology in corrosion monitoring.
Frequency response characteristics analysis and frequency domain selection
The analysis of the first two resonance peaks in the axial mode is shown in Figure 9, where the main resonance frequencies of Day 0 are marked in the figure. Through detailed analysis of the conductance-frequency curve, two significant resonance characteristics can be observed. The first resonance peak appears at approximately 7500 Hz, which is the most significant resonance response region, with a maximum conductance value of about 0.00175 Siemens (S). This resonance peak exhibits very sharp characteristics, indicating highly concentrated energy at this frequency point, particularly prominent on the second and third days of the experiment. Notably, the amplitude of this resonance peak shows certain variation trends as experimental days progress, which may be related to the degree of material corrosion. The second resonance peak is located in the high-frequency region at approximately 16,000 Hz, and although its amplitude is relatively smaller, about 0.0013 Siemens, it still shows clear resonance characteristics. This high-frequency resonance peak demonstrates good consistency across different test dates, with clearly distinguishable peak shapes, indicating that the structural response at this frequency has good reproducibility and stability. In the frequency range between the two resonance peaks, the conductance curve appears relatively smooth, maintaining at a relatively low level, indicating no significant resonance phenomena occur in these frequency ranges.
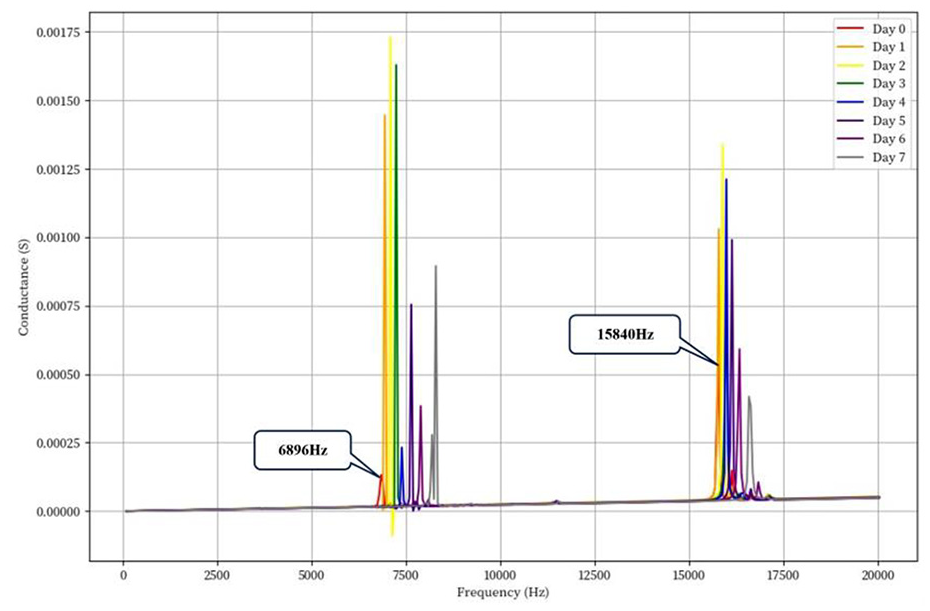
Axial mode conductance curve.
The analysis of the first seven resonance peaks in the bending mode is shown in Figure 10, where the main resonance frequencies of Day 0 are marked in the figure. The first resonance peak appears at approximately 300 Hz, representing the fundamental bending vibration mode of the structure. Its amplitude is relatively small and shows good stability across all test samples. The second resonance peak is located at approximately 700Hz, corresponding to the second-order bending vibration of the structure, with concentrated energy distribution but still lower amplitude than the peaks in the high-frequency region. The third resonance peak at approximately 1500 Hz exhibits moderate resonance response, with a narrow and clear peak shape and good response consistency across test dates. The fourth resonance peak is located at approximately 2500 Hz, showing strong resonance characteristics with peak amplitude significantly higher than the low-frequency band and stable performance across different test dates. The fifth resonance peak appears in the high-frequency band at approximately 3800 Hz, serving as a significant characteristic peak with concentrated energy and distinct peak values, showing moderate response intensity. The sixth resonance peak is located at approximately 5000 Hz, representing the strongest resonance response area with maximum peak amplitude and good reproducibility across test dates. Finally, the seventh resonance peak appears in the highest frequency band at approximately 6500–7000 Hz, maintaining stability despite relatively low energy, with clearly distinguishable peak values reflecting the structure’s response characteristics under high-frequency excitation.
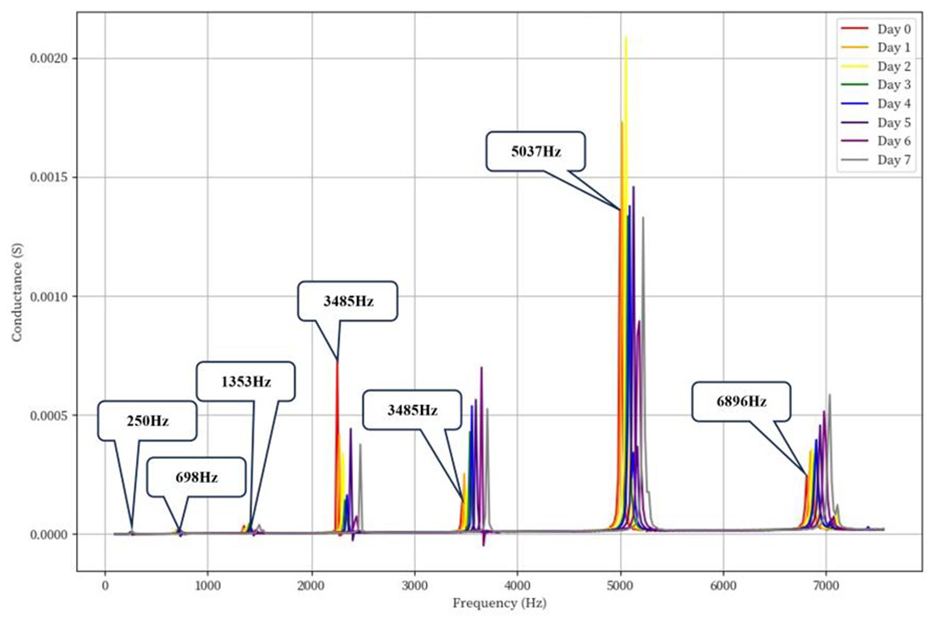
Bending mode conductance curve.
Through analysis of experimental data, the optimal acquisition parameters and frequency ranges were determined. For the axial mode, a frequency range of 100 Hz to 20 kHz was selected, containing two main resonance peaks with significant signal characteristics and good data repeatability, collecting 400 data points for each condition. For the bending mode, a frequency range of 100 Hz to 7.5 kHz was selected, covering seven characteristic resonance peaks, providing rich frequency response information, with 400 data points collected for each condition as well. During the experiment, the conductance signals of both axial and bending modes were collected independently to facilitate subsequent multimodal fusion analysis.
Result analysis
Logarithmic frequency dual attention module result analysis
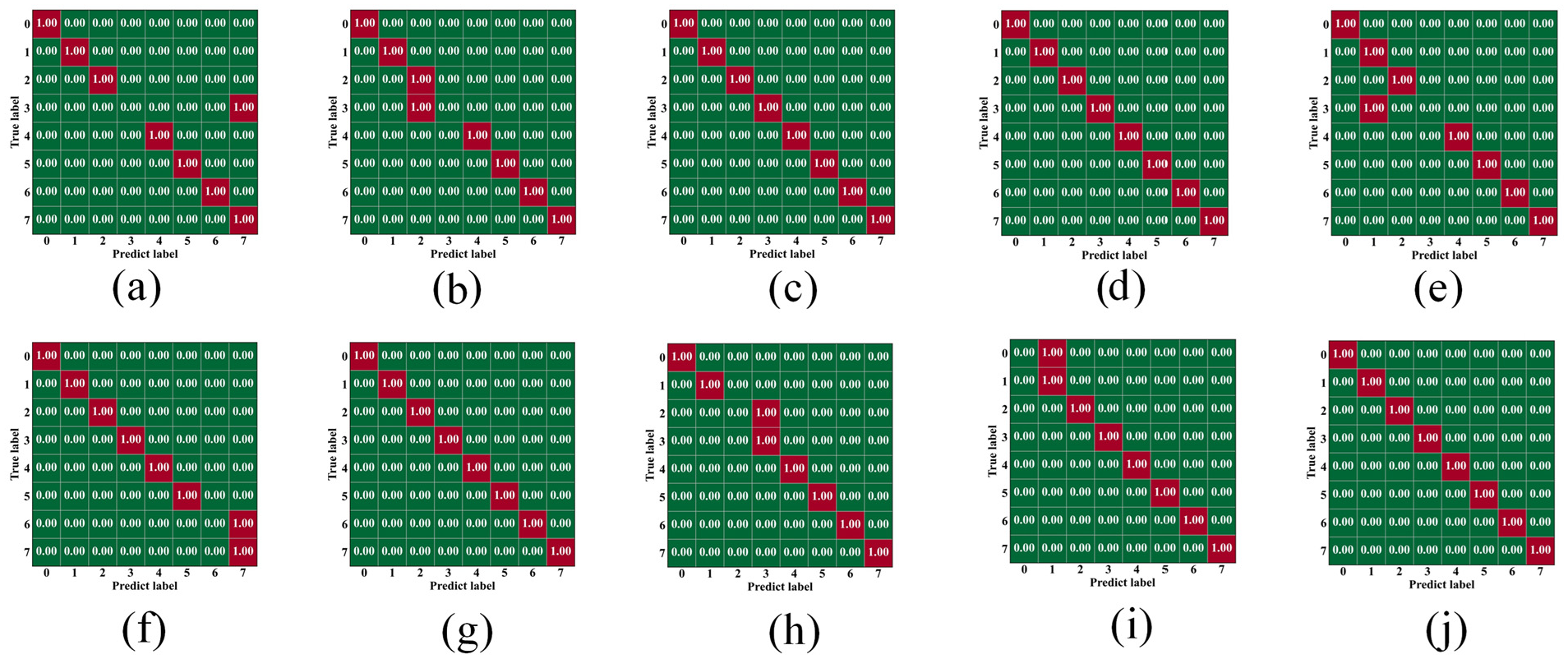
This study validates the effectiveness of the proposed model through systematic experimental design and comprehensive data analysis. The experiments were conducted under the PyTorch framework, with the network accepting input data of dimension (batch_size, 1, 400). Through layer-by-layer feature extraction, the intermediate feature dimensions were 6, 16, 25, and 36 successively, ultimately outputting prediction results for eight categories. The dataset was randomly divided into training and test sets at an 80:20 ratio. During training, SGD optimizer with momentum was used for parameter optimization, with a learning rate of 0.0015, momentum factor of 0.9, and CrossEntropyLoss as the loss function. Training was conducted for five epochs, with a batch size of 16 for training and four for testing to balance computational efficiency and model performance. To monitor the training process, the system recorded changes in loss values and accuracy during both training and testing, presenting them through visualization. To verify the performance and stability of the proposed model, this study conducted 10 independent training experiments on the axial vibration mode recognition model, with results shown in Figure 11. The model achieved accuracies of 82.5%, 96.63%, 92.38%, 88.88%, 66.63%, 81.88%, 79.13%, 66.88%, 83.00%, and 82.5% across the 10 training runs, with an average accuracy of 82.04%. The highest accuracy was 96.63%, the lowest was 66.63%, with a standard deviation of 9.47%. The experimental data shows that six experiments achieved accuracy above 80%, with three reaching over 90%, indicating that the model maintains good recognition performance in most cases and has the potential to achieve excellent performance.
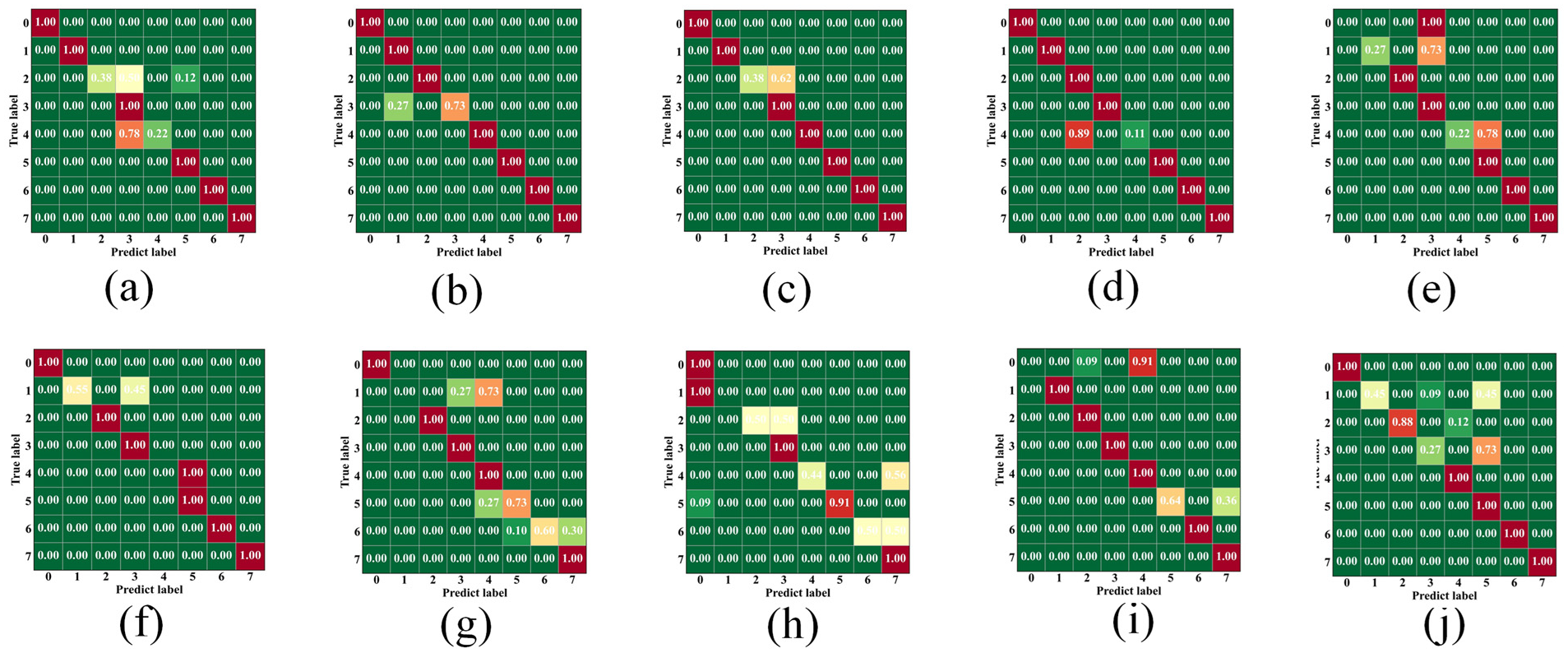
Axial mode training confusion matrix: (a)-(j) Confusion matrices for ten independent training runs.
From the perspective of model stability, there are five experimental results in the 80%–85% accuracy range, representing the model’s stability performance interval. Although the standard deviation of accuracy at 9.47% indicates some fluctuation in model performance, considering the randomness in deep learning model training (such as weight initialization, data shuffling, and other factors), this level of fluctuation is acceptable. Notably, the model maintains accuracy above 66% across multiple experiments, with a 30% occurrence rate of accuracy above 90%, further confirming the model’s good reliability and excellent performance potential.
In conclusion, the experimental results demonstrate that the proposed axial vibration mode recognition model has good application potential. Despite some performance fluctuations, its overall performance is stable and reliable. Through further optimization and improvement, the model’s recognition accuracy and stability are expected to improve significantly, providing more solid technical support for practical applications. However, when training for bending vibration modes using the same experimental setup and training process, as shown in Figure 12, the model failed to effectively fit the data, experiencing collapse during training and failing to converge to an ideal state. This indicates that the original model has significant limitations in processing bending vibration mode signal characteristics and struggles to capture key time–frequency features.
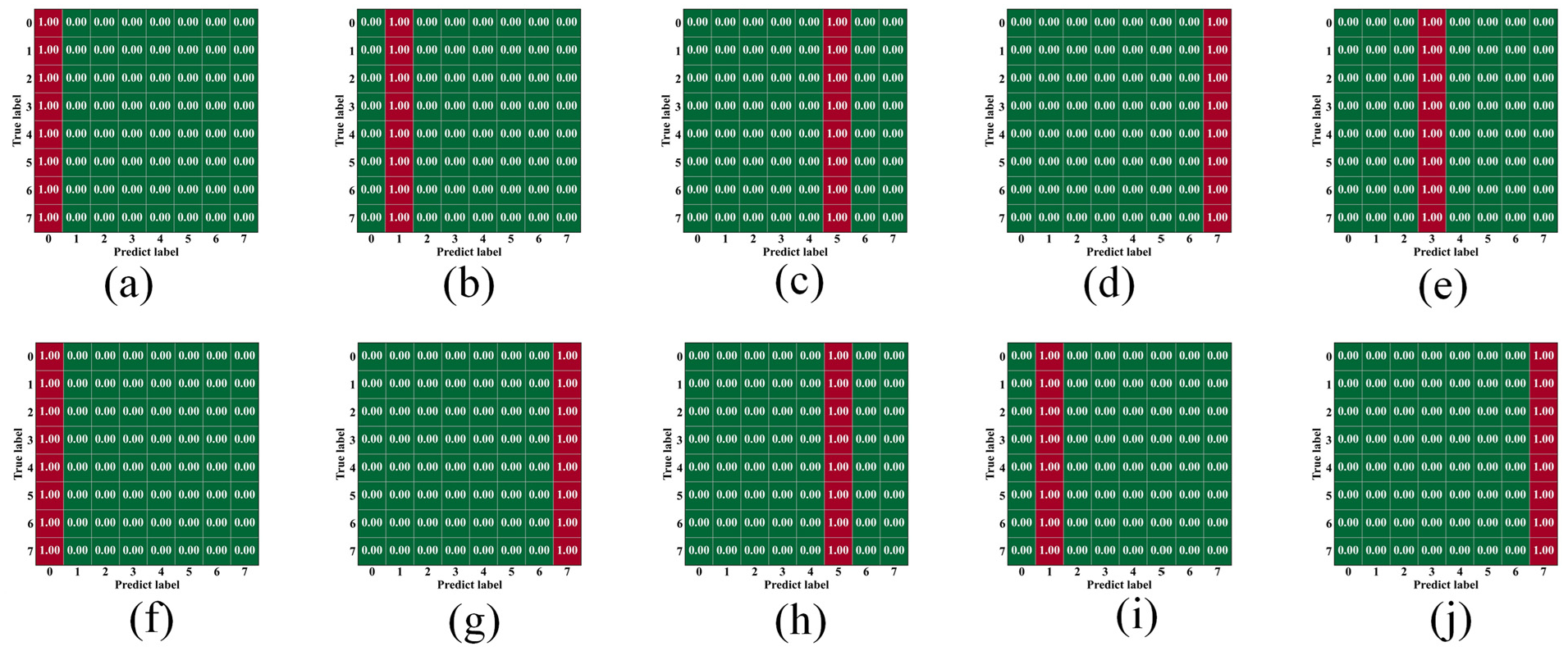
Bending mode training confusion matrix: (a)-(j) Confusion matrices for ten independent training runs.
To address this issue, logarithmic frequency dual attention module was introduced based on the original model. Figure 13 demonstrates the effectiveness of the proposed method in frequency response analysis. To comprehensively showcase the processing capability of the algorithm, both linear scale and logarithmic scale analysis results are presented. From the figure, it can be observed that the adaptive smoothing process (blue line) effectively preserves the main frequency characteristics of the original signal (gray line) while significantly suppressing noise effects. Particularly, under the logarithmic scale, the processing effects on low-amplitude signals can be observed more clearly.
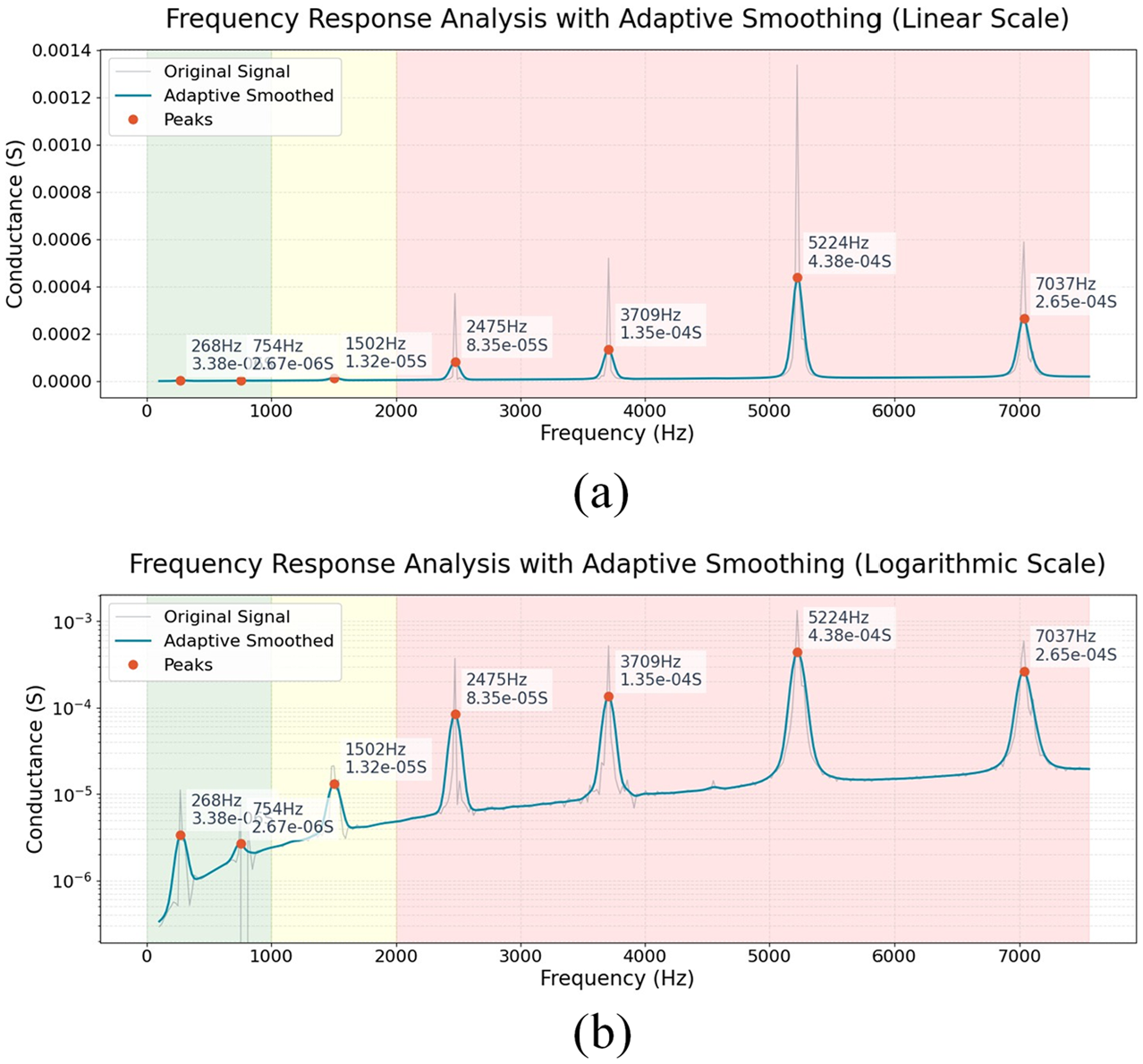
(a) Conductance curve in linear scale and (b) conductance curve in logarithmic scale.
Through analysis, it can be found that this method successfully identified and preserved seven main characteristic frequencies: 268, 754, 1502, 2475, 3709, 5224, and 7037 Hz. The amplitudes of these frequency components span multiple orders of magnitude, ranging from 10−6 to 10−3. In the linear scale spectrum shown in Figure 13(a), the processing effect of high-amplitude frequency components (such as the peak at 5224 Hz) can be intuitively observed, but low-amplitude frequency components are ignored. In contrast, in the logarithmic scale spectrum shown in Figure 13(b), not only is the high-amplitude information preserved, but the low-amplitude frequency components (such as peaks at 268 and 754 Hz) are also clearly displayed, achieving comprehensive visualization of both high- and low-amplitude frequency components.
The adaptive smoothing algorithm demonstrates excellent performance in frequency selectivity, not only significantly improving the signal-to-noise ratio while maintaining peak amplitudes but also effectively preserving the integrity of high-frequency components. For example, for the frequency component at 3709 Hz, the algorithm maintains the peak amplitude (1.35e-04S) while making the frequency response curve smoother and clearer. Similarly, for the high-frequency component at 7037 Hz (2.65e-04S), the algorithm also shows good processing capability. Notably, in the low-frequency band (0–1000 Hz) processing, the algorithm exhibits outstanding noise suppression ability. The logarithmic scale plot clearly shows that the algorithm successfully suppresses the surrounding background noise while preserving 2 weak signals at 268 Hz (3.38e-06S) and 754 Hz (2.67e-06S), an effect that is difficult to achieve with traditional linear smoothing methods.
By comparing the frequency response curves before and after processing, it is found that the peak position of the main frequency component remains unchanged, proving the phase retention characteristics of the algorithm; the frequency response between peaks is smoother, indicating that the background noise is effectively suppressed; signals of different amplitude levels are properly processed, reflecting the adaptive characteristics of the algorithm. These results fully demonstrate the effectiveness of the proposed adaptive smoothing algorithm in frequency domain processing, especially in achieving the key goal of noise suppression while maintaining signal characteristics. The addition of this module significantly improves the performance of the model, with an average accuracy of 92.5%. As shown in Figure 14, the introduction of logarithmic frequency dual attention module not only solves the problem that the original model cannot effectively fit the data but also significantly improves the model’s ability to recognize complex signals by integrating the adaptive attention mechanism of the first-order and second-order derivatives.
Logarithmic frequency dual attention module confusion matrix: (a)-(j) Confusion matrices for ten independent training runs.
Furthermore, to more intuitively demonstrate the role of the LFDM, a visualization analysis of the model’s attention weights was conducted. In Figure 15(a) is a logarithmic scale spectrum. The attention weight distribution based on first-order derivatives mainly captures the rate of change characteristics of signals as shown in Figure 15(b), presenting sharp peaks in the spectrum. The strongest attention response appears near 2500 Hz with a weight of 1.0, and the secondary peak is at 4000 Hz (weight approximately 0.9). However, these attention weights are unevenly distributed along the frequency axis, particularly in the low-frequency band (0–1000 Hz), where the weights are lower, limiting feature extraction capability. The attention weight distribution based on second-order derivatives reflects the curvature change characteristics of signals as shown in Figure 15(c), with attention weights showing discrete peaks in the spectrum. The strongest response is also near 2500 Hz, but the overall weight distribution lacks continuity, and the feature extraction capability in the high-frequency band is also limited.
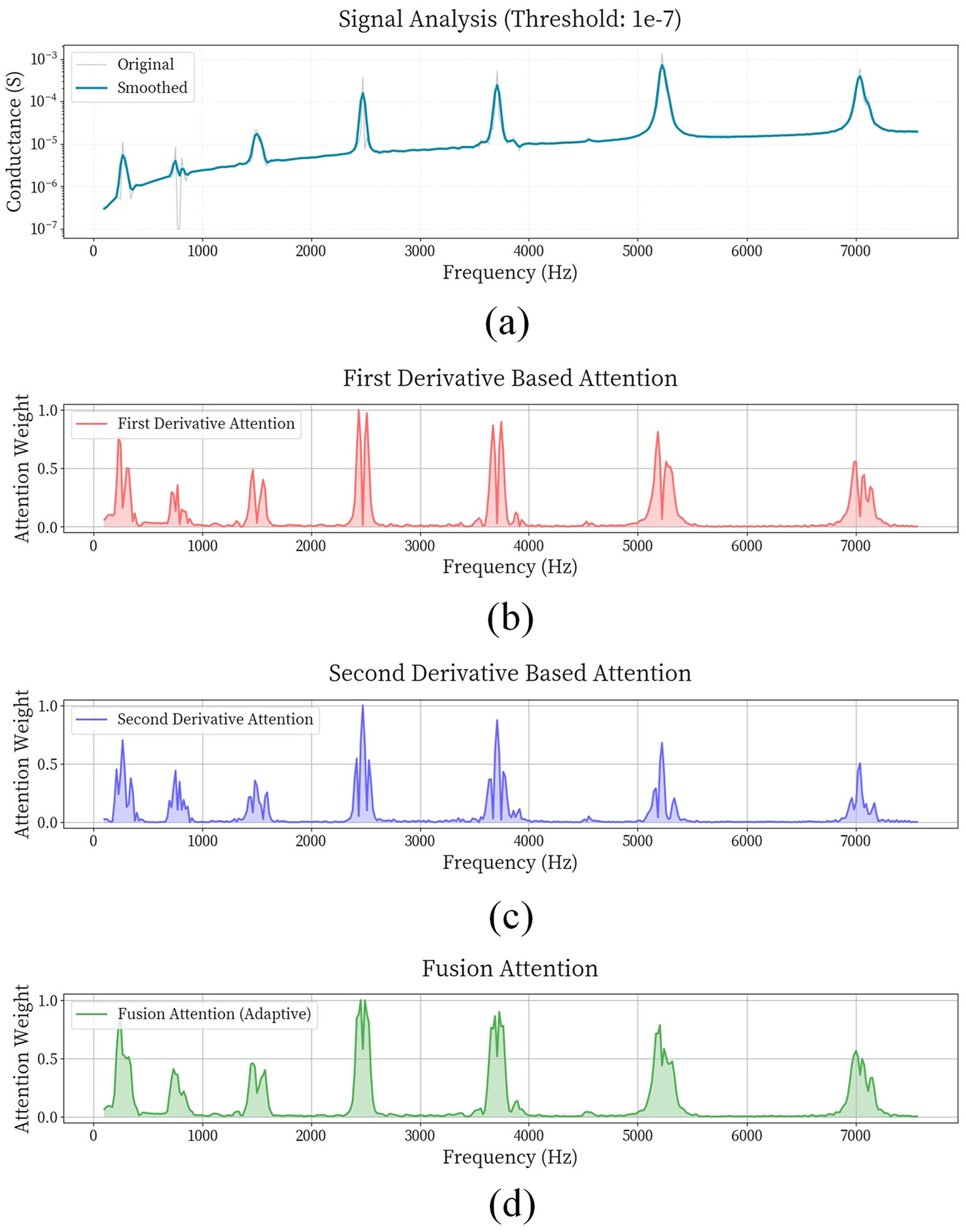
Frequency dual attention weight visualization analysis diagram: (a) Signal Ananlysis, (b) First Derivative Based Attention, (c) Second Derivative Based Attention, and (d) Fusion Attion.
In contrast, the adaptive fusion attention shown in Figure 15(d) combines the advantages of first-order and second-order derivatives in its weight distribution, presenting a smooth and balanced distribution. The strongest peak appears at 2500 Hz (weight 1.0), with a significant secondary peak at 4000 Hz (weight approximately 0.9). In both low- and high-frequency bands, the attention weights maintain stable responses with more steady curve trends. This smooth attention curve enables the model to extract signal features evenly across the entire frequency range, avoiding the limitation of focusing only on specific frequencies and enhancing robustness to complex signals. By effectively integrating the advantageous features of first-order and second-order derivatives, the fusion attention mechanism achieves comprehensive capture of multidimensional signal features. This mechanism not only optimizes the distribution of attention weights and improves the model’s adaptability to complex signal features but also significantly enhances the reliability of feature extraction and overall model performance by maintaining stable response characteristics across different frequency intervals.
Deep learning network result analysis
This study proposes a fusion network-based method that performs deep fusion of probe conductance signals in electrochemical corrosion experiments to achieve high-precision corrosion state diagnosis. The fusion network proposed in the methodology is used for deep learning by combining conductance signals from axial vibration modes and bending vibration modes. As shown in Figure 16, the fusion network achieved 100% accuracy in all ten training sessions for the classification task, significantly outperforming single-signal processing methods, fully demonstrating the excellent performance and broad application prospects of multimodal fusion in conductance signal processing.
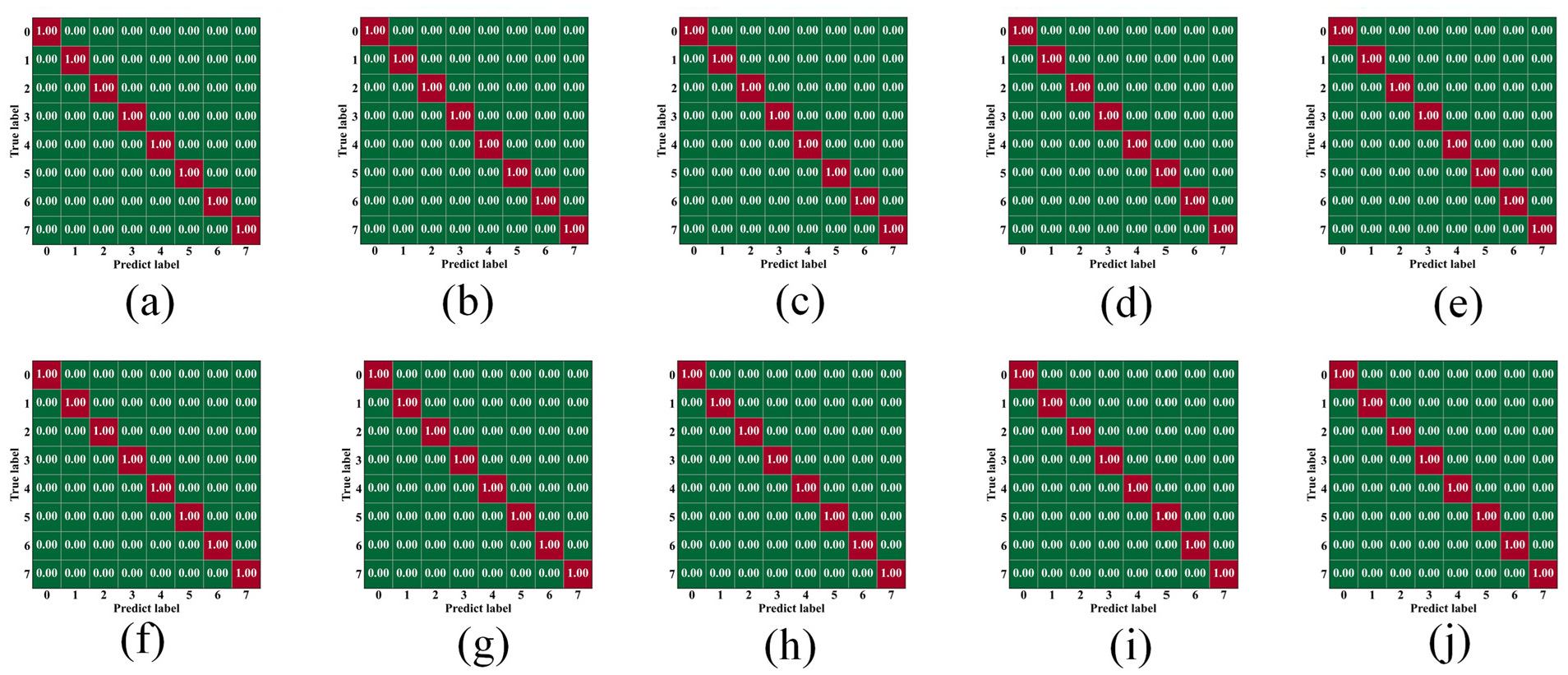
Confusion matrix after modal fusion training: (a)-(j) Confusion matrices for ten independent training runs.
In the design of the fusion network, deep integration of conductance signal features from two modalities is achieved through multilevel feature extraction and effective information fusion. Additionally, the residual connections and batch normalization modules introduced in the network architecture not only deepen the network’s hierarchical structure but also effectively alleviate the vanishing gradient problem in deep network training, ensuring training stability and efficiency. Batch normalization performs standardization processing in each network layer, reducing internal covariate shift, significantly accelerating model convergence speed, while enhancing the model’s generalization capability.
To further investigate the advantages of multilevel fusion networks and bidirectional attention fusion modules, this study installed t-SNE hooks at the pre-fusion, intermediate fusion layers, and final fusion layers, enabling effective monitoring of key node features. The following detailed analysis of t-SNE diagrams from three probe groups at different stages (as shown in Figure 17) thoroughly discusses the results of three control experiments conducted under the same method and experimental conditions, aiming to evaluate the robustness and adaptability of this method.
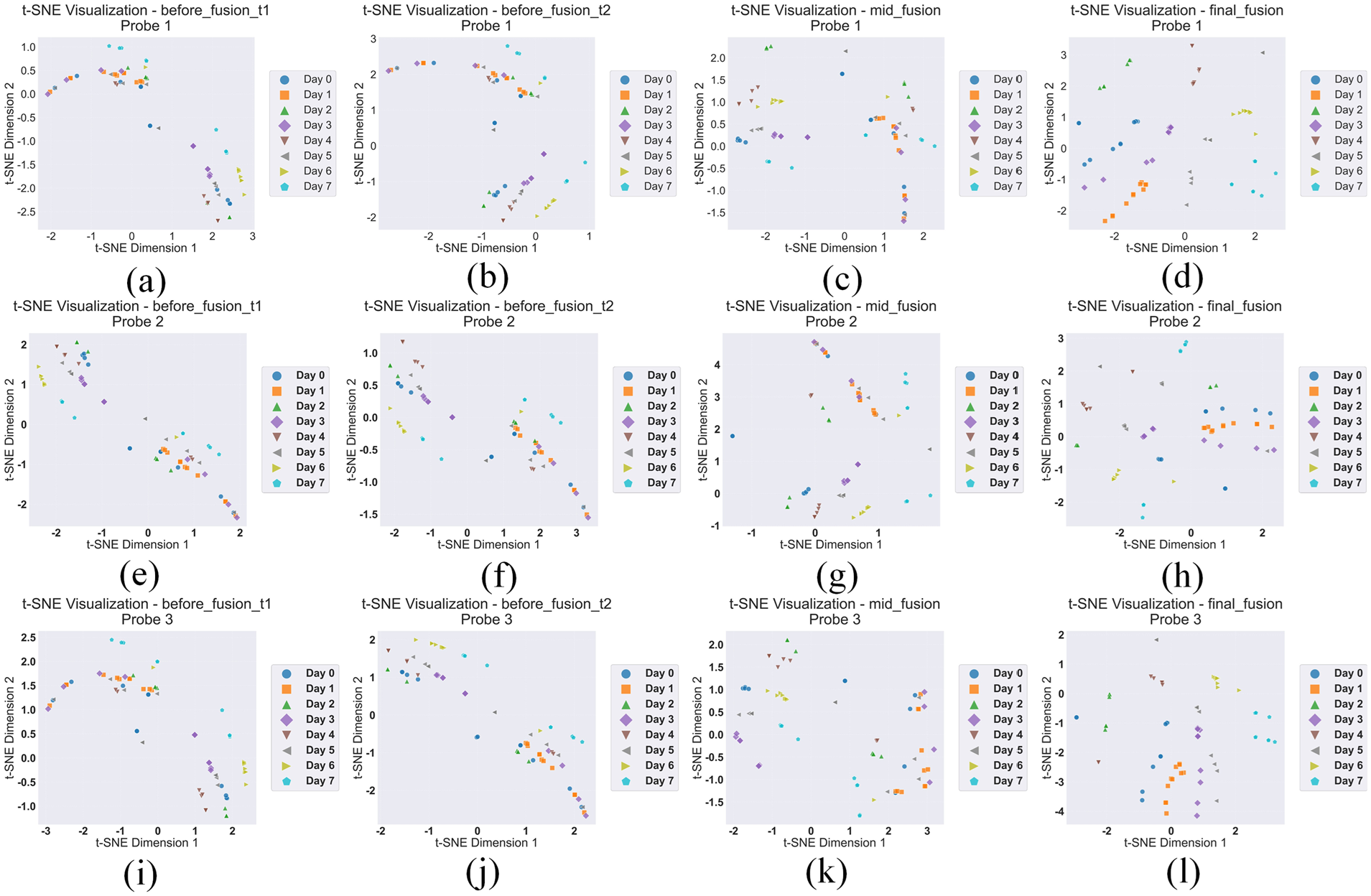
t-SNE visualization of feature distributions at different fusion stages: (a)-(d) Probe 1 features at before_fusion_t1, before_fusion_t2, mid_fusion, and final_fusion stages, and (e)-(h) Probe 2 features at corresponding stages. (i)-(l) Probe 3 features at corresponding stages.
Before_fusion_t1 as shown in Figure 17(a) and Before_fusion_t2 as shown in Figure 17(b) display different feature distribution patterns. t1 shows a distinct layered structure from top to bottom, with an overall loose distribution and unclear boundaries between classes. t2 exhibits a diagonal distribution pattern, showing stronger polarization characteristics compared to t1. In the middle fusion layer (mid_fusion) as shown in Figure 17(c), the data show a dispersed but regular distribution pattern, with Day 0 and Day 5 data points relatively concentrated, Day 2 and Day 6 data points mainly distributed in the upper region, and the remaining data points, although scattered, maintain relatively independent distribution areas. In contrast, the final fusion layer (final_fusion) demonstrates clearer temporal evolution characteristics, with data points generally showing a distribution trend from left to right and bottom to top.
Final_fusion demonstrates superior feature representation capabilities and data distribution characteristics compared to mid_fusion. From Figure 17(d), it can be observed that the data points exhibit a more regular radial distribution pattern in two-dimensional space, with data points from Day 2, Day 4, Day 6, and Day 7 (green, brown, yellow, cyan) arranged in an orderly manner, while data points from Day 0, Day 1, Day 3, and Day 5 (blue, orange, purple, gray) extend toward the lower left corner, forming a clear temporal evolution trajectory. Compared to mid_fusion, final_fusion not only maintains good interclass separation but also achieves more compact intraclass aggregation, with data points from each day being more concentrated and having clearer boundaries. Particularly in the transition areas, final_fusion shows more natural gradient characteristics, maintaining continuity between adjacent time points while effectively reflecting the feature differences between different periods. This multistage fusion strategy successfully integrates feature information from different levels, accurately capturing the dynamic evolution characteristics of the corrosion process while maintaining data separability.
The t-SNE plots of probe two and probe three reflect characteristics consistent with the previous probes, further validating the advantages of multilevel fusion strategy in feature representation. During the analysis of corrosion monitoring data, we observed a gradual enhancement in feature expression capability: from the distinct distribution characteristics of two independent modalities before fusion (modality 1 showing diagonal distribution, modality 2 showing layered structure), to the more organized structure displayed in the middle fusion layer (mid_fusion), and finally to the clear clustering structure formed in the final fusion layer (final_fusion). The entire process clearly demonstrates the progressive evolution of feature optimization, with the model’s ability to capture temporal features significantly improving as fusion levels deepen, particularly excelling in early-stage feature extraction. This hierarchical feature fusion strategy not only achieved a transformation from “chaos” to “order” while preserving the complementarity of original modalities but also accomplished optimal feature combination; through t-SNE visualization results, we can observe the gradual improvement in feature expression capability, ultimately forming high intraclass cohesion and interclass separation. This multilevel processing approach not only provides important experimental evidence for understanding the evolutionary characteristics of deep learning models in feature learning processes but also offers strong support for improving corrosion monitoring system performance, confirming the superiority of this strategy in handling complex temporal data.
To quantify the effects of multilevel fusion strategies, we introduced multiple evaluation metrics for comprehensive assessment of model performance. Dimension utilization refers to the proportion of effectively utilized feature dimensions to total feature dimensions, where higher dimension utilization indicates more features are fully utilized, enhancing the model’s expressiveness and accuracy. Category overlap ratio measures the degree of sample overlap between different categories, where higher category overlap indicates lower distinction between categories, potentially leading to increased classifier misidentification. Feature discrimination indicates the ability of features to distinguish between different categories, where higher feature discrimination means features can more effectively differentiate categories, improving classification performance. Category separation describes the degree of separation between different categories in feature space, where good category separation indicates large interclass distances without interference, contributing to improved classification accuracy. Clustering effect evaluates the ability of clustering algorithms to group similar samples together, where good clustering effect means samples within classes are tightly grouped while showing clear differences between classes. Finally, overall performance comprehensively measures the model or method’s performance across various metrics, including accuracy, stability, and robustness, reflecting the model’s comprehensive capabilities.
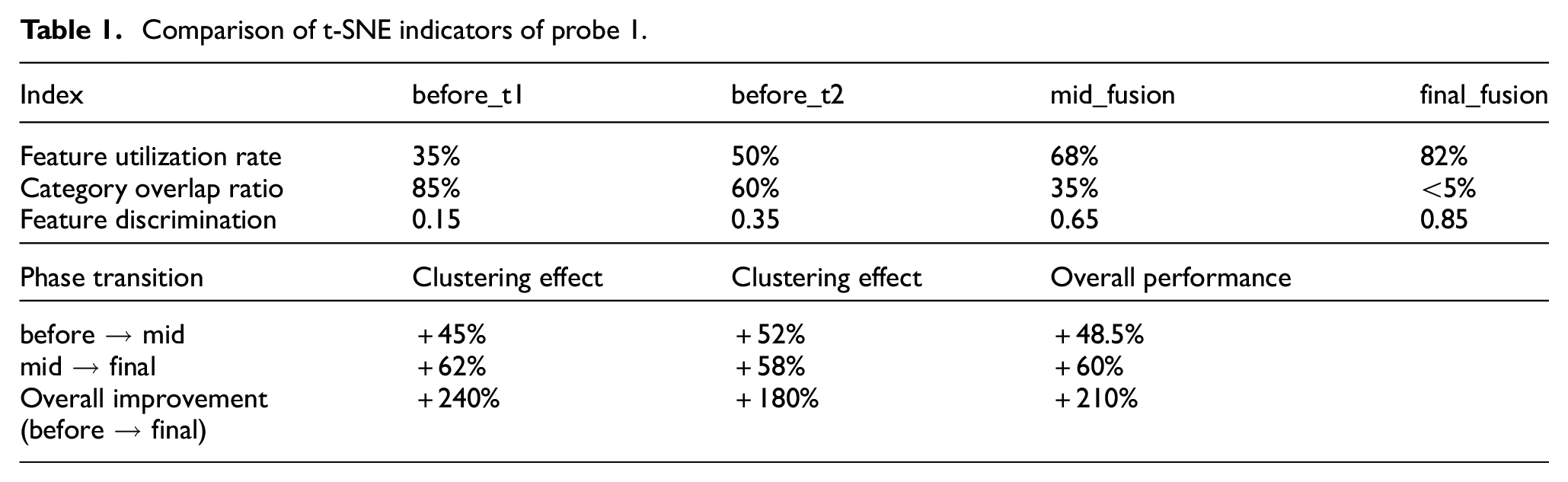
The t-SNE results of probe No. 1 are shown in Table 1. The initial phase (before_t1) data shows a dimensional utilization rate of 35%, a category overlap ratio of up to 85%, and a feature discrimination of only 0.15, indicating significant deficiencies in feature extraction and category discrimination in the unprocessed method. As the experiment progressed through multiple processing stages, the dimensional utilization rate in the final fusion stage increased to 82%, the category overlap ratio decreased to less than 5%, and the feature discrimination improved to 0.85, demonstrating the method’s efficiency in optimizing initial data. Overall, from the initial stage to the final fusion stage, category separation improved by 240%, clustering effect improved by 180%, and overall performance improved by 210%, fully proving the robustness and effectiveness of this method.
Comparison of t-SNE indicators of probe 1.
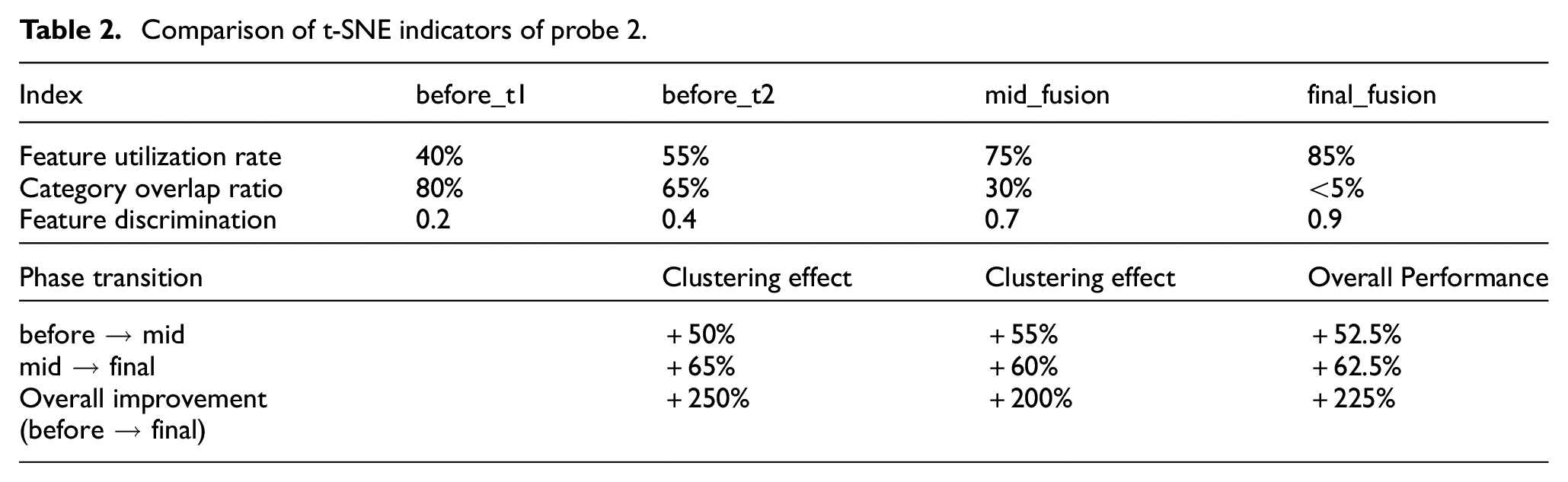
The t-SNE metrics of probe No. 2 are shown in Table 2. The initial phase (before_t1) data shows a dimensional utilization rate of 40%, a category overlap ratio of up to 80%, and a feature discrimination of only 0.2, indicating significant deficiencies in feature extraction and category discrimination in the unprocessed method. As the experiment progressed, the final fusion phase showed an increase in dimensional utilization to 85%, a decrease in category overlap to less than 5%, and an improvement in feature discrimination to 0.9, demonstrating the method’s effectiveness in optimizing initial data. Overall, from the initial phase to the final fusion phase, category separation improved by 250%, clustering effectiveness increased by 200%, and overall performance improved by 225%, further validating the significant role of this method in enhancing system performance and accuracy.
Comparison of t-SNE indicators of probe 2.
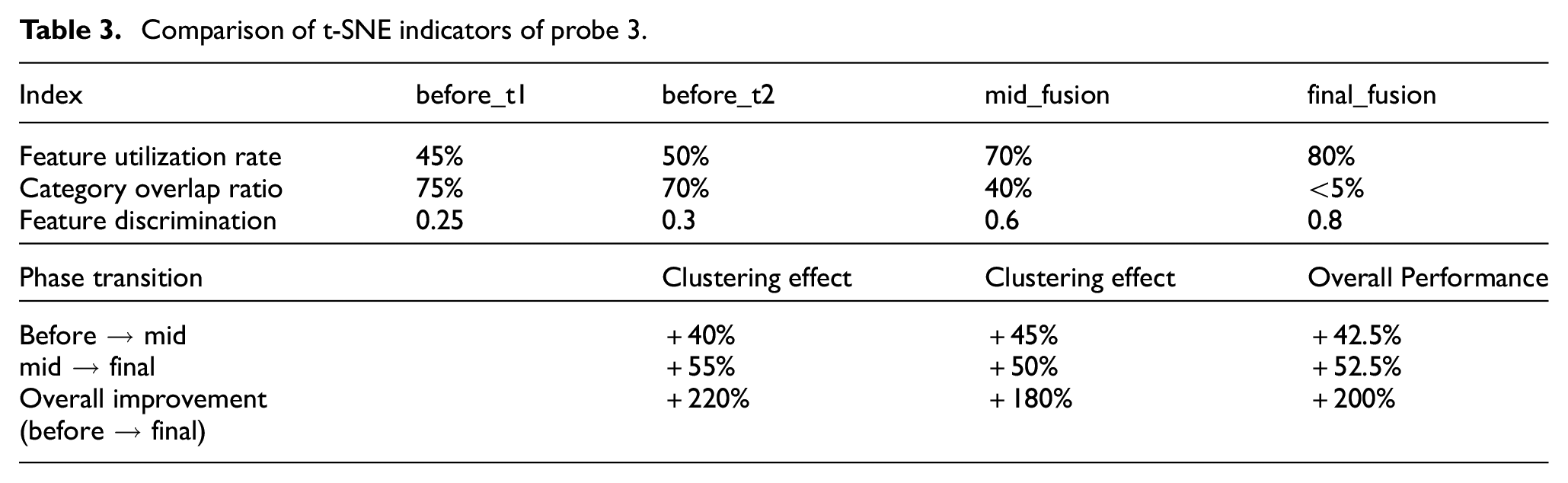
The t-SNE metrics of probe 3 are shown in Table 3. In the initial phase (before_t1), the data shows a dimensional utilization rate of 45%, a category overlap ratio of 75%, and a feature discrimination of only 0.25, indicating significant deficiencies in feature extraction and category discrimination in the unprocessed method. During the intermediate fusion stage (mid_fusion), the dimensional utilization rate increased to 70%, the category overlap ratio decreased to 40%, and the feature discrimination improved to 0.6, demonstrating the crucial role of multistage fusion in optimizing features and reducing category overlap. In the final fusion stage (final_fusion), the dimensional utilization rate further increased to 80%, the category overlap ratio decreased to less than 5%, and the feature discrimination improved to 0.8, proving the significant importance of multistage fusion for continuous system performance improvement. Overall, from the initial stage to the final fusion stage, category separation improved by 220%, clustering effect improved by 180%, and overall performance improved by 200%, demonstrating the effectiveness of multistage fusion in improving system efficiency and accuracy.
Comparison of t-SNE indicators of probe 3.
The results of three sets of control experiments show that despite minor fluctuations between different experiments, the overall trends and key indicators remain highly consistent, demonstrating the stability and reliability of the proposed method across multiple independent experiments. The steady improvement in dimensional utilization, effective reduction in category overlap ratio, and continuous enhancement in feature discrimination all indicate that this method has significant effects in enhancing data feature representation and category discrimination capabilities. However, the category overlap ratio remains relatively high, indicating that in complex datasets, the method still has room for improvement in completely eliminating intercategory overlap, requiring further optimization in the future to enhance overall performance.
Comparative test results analysis
This study comparatively analyzes three common basic fusion network methods—Early Fusion, Late Fusion, and Average Fusion, and compares their performance with the proposed BMFN network. To comprehensively evaluate the robustness and adaptability of each method, these methods were tested under different signal-to-noise ratio (SNR) conditions with simultaneous noise addition to axial vibration mode and bending vibration mode, as shown in Figure 18. These basic fusion methods each have their characteristics: Early fusion integrates data from different sources at the feature level, which can fully utilize the complementary information of multisource data to enhance the model’s expressiveness, but may face issues of feature alignment and dimensional inconsistency. Late fusion integrates data from different sources at the decision level, where modal data are processed through independent models before weighted averaging or voting fusion, offering advantages in flexibility and modular design, but may fail to fully capture potential intermodal correlations. Average fusion, as a simple late fusion strategy, obtains final predictions by averaging the output results of independent models, and while simple to implement with low computational cost, it performs poorly when handling cases with significant performance differences between models, as it cannot adaptively allocate weights to different models, limiting overall performance.
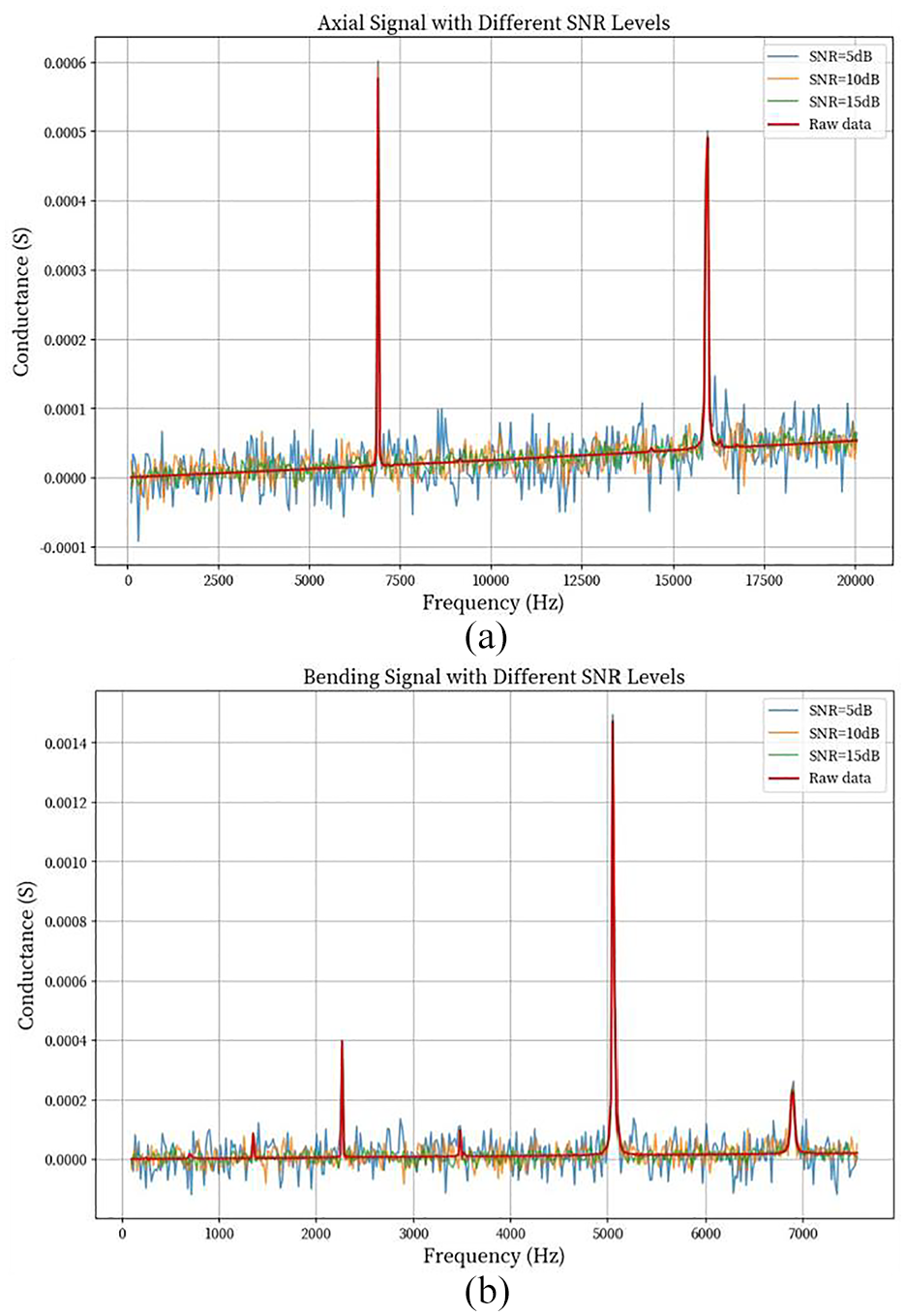
(a) Axial mode conductance curves at different SNR and (b) bending mode conductance curves at different SNR.
The experimental results are shown in Figure 19. Under all signal-to-noise ratio conditions, the BMFN network achieves higher accuracy than other fusion methods, particularly in low SNR (5 dB) conditions, where the BMFN network’s accuracy is approximately 10 percentage points higher than late fusion, demonstrating stronger robustness and adaptability in environments with significant noise interference. As SNR increases, the accuracy of various fusion methods generally improves, indicating that signal quality enhancement has a significant positive impact on model performance. Under high SNR (15 dB) conditions, early fusion, late fusion, and BMFN network all achieve 100% accuracy, showing that these methods can achieve perfect classification under favorable signal conditions. Specifically, early fusion performs excellently under high SNR conditions but relatively weakly under low SNR, possibly due to noise accumulation at the feature level affecting the model’s discriminative ability; late fusion outperforms early fusion and average fusion under all SNR conditions, particularly under medium SNR (10 dB) conditions, where its accuracy approaches that of the BMFN network, demonstrating good balance; average fusion, as the simplest fusion strategy, performs the weakest under all conditions, mainly because it cannot effectively integrate the advantages of different models, limiting overall performance.
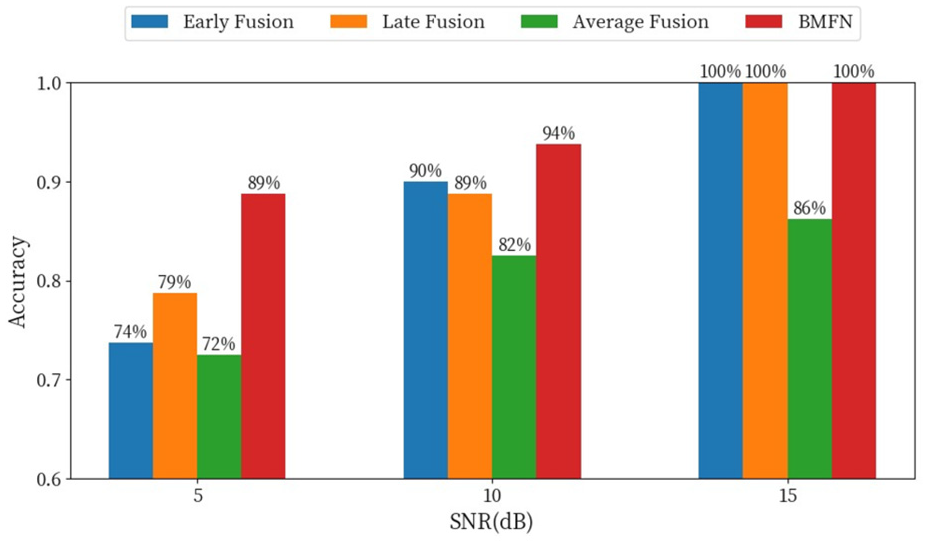
Performance of different fusion methods under noisy conditions.
The experimental results further demonstrate that the fused features exhibit enhanced robustness, maintaining high classification performance even in the presence of noise interference. This is primarily attributed to multimodal fusion’s ability to integrate redundant information from different time periods, effectively counteracting noise effects in individual signals and improving the overall system’s stability and reliability.
Discussion and conclusion
In response to the insufficient multimodal information fusion in current conductance signal processing and corrosion state diagnosis, which makes it difficult to comprehensively and accurately assess equipment corrosion conditions, this study proposes a corrosion monitoring method based on multimodal fusion neural network. The main contributions include
A new multimodal fusion framework of the resonance characteristics of the two modes was proposed, which organically combines the signal characteristics of the axial mode and the bending mode. The axial mode is outstanding in the clarity of the double-peak characteristics, and the bending mode provides richer modal information. The frequency responses of the two complement each other, providing a reliable basis for the comprehensive evaluation of material properties. The experimental results show that within their respective characteristic frequency ranges, both modes exhibit excellent signal stability and data repeatability, laying a solid foundation for subsequent damage monitoring and life assessment.
The logarithmic frequency dual attention module was proposed, which innovatively introduces first-order derivative attention and second-order derivative attention to enhance the feature extraction capability. First-order derivative attention emphasizes the instantaneous change of the signal and is suitable for capturing rapidly changing features; second-order derivative attention focuses on the curvature change of the signal and is suitable for capturing complex dynamic features. Fusion attention combines the advantages of the two derivative attentions, achieves more comprehensive and flexible feature extraction, improves the accuracy and stability of the model, and verifies its effectiveness in enhancing feature expression.
The bidirectional-attention multistage fusion network was constructed, and an advanced fusion strategy was adopted to effectively integrate multisource information at the feature level and decision level. The performance advantages of the network were verified through a comprehensive analysis of three sets of experimental results. First, the method has good repeatability, and the trends of the three sets of experimental results are consistent; second, the classification effect gradually improves as the experiment progresses, especially in probe C, reaching the best level; finally, t-SNE visualization analysis intuitively demonstrates the effectiveness of the method in feature extraction and category distinction. In particular, under low signal-to-noise ratio (SNR) conditions, the classification performance is significantly improved, which proves the effectiveness of the method in dealing with noise interference and complex signal environments.
The bidirectional-attention fusion module was proposed, which innovatively combines temporal and channel attention and adopts an additive fusion strategy to effectively capture complex spatiotemporal dependencies. The attention weights generated by the two branches are applied to the original features through additive fusion, which not only captures long-term dependencies but also provides richer feature representations while maintaining numerical stability. Compared with the traditional multiplicative attention mechanism, additive fusion can better avoid the gradient vanishing problem and improve the training stability of the model. Ablation experiments further prove the effectiveness of each key component, among which the additive fusion strategy and dual-input feature design contribute the most to performance improvement.
In summary, the corrosion quantitative monitoring method proposed in this study, based on dual-modal EMI and a bidirectional multilevel fusion network, offers significant improvements in the accuracy and robustness of conductance signal processing and corrosion state diagnosis. This approach provides an effective solution for monitoring equipment corrosion in complex industrial environments.
Although this study has achieved some meaningful results, it also has some shortcomings. Future work will focus on extending the application scope of the proposed fusion network. We plan to expand our testing environments beyond the standard 3.5% NaCl solution to include various corrosive media such as acidic and high-temperature environments, which will help validate LFDM’s adaptability across different corrosion scenarios. Additionally, extended monitoring experiments over several months to years in real-world environments will be conducted to thoroughly evaluate the method’s long-term durability and reliability. To enhance model interpretability, we will incorporate explainable AI techniques such as SHAP values and LIME to analyze the contribution of different frequency components, particularly the resonance peaks, to the network’s decisions. This analysis will provide valuable insights into why certain frequencies play more dominant roles in damage classification. Furthermore, comprehensive comparisons with advanced deep learning architectures, such as transformer-based models (which excel at capturing long-range dependencies in frequency sequences) and graph neural networks (which could potentially model the intrinsic relationships between different resonance modes), will be conducted to provide a more thorough evaluation of LFDM’s performance. To ensure practical applicability, we will evaluate the model’s real-time performance on embedded devices commonly used in industrial monitoring systems, including latency testing and necessary optimizations for efficient deployment. Specifically, classical EMI damage detection experiments with artificial defects, such as cracks and holes of different damage levels on metal plates, will be conducted to further validate the network’s performance and generalization capability. These controlled experiments will help establish the broader applicability of our fusion approach in various structural health monitoring scenarios beyond corrosion detection.
Footnotes
Author contributions
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported in this study was partially supported by Hubei Provincial Natural Science Foundation of China (2023AFB859), the Postgraduate Research & Practice Innovation Program of Jiangsu Province (No. SJCX24_0085), the SEU Innovation Capability Enhancement Plan for Doctoral Students (No. CXJH_SEU 24096).