
Abstract
The difficulty of collecting fault samples of bearings under stable operation results in imbalanced data and considerably weakened capability of the deep learning-based intelligent fault diagnosis methods. Thus, a novel digital twin (DT)-driven feature enhancement generative adversarial network (DFGAN) was proposed in this study to augment the imbalanced multisensor data and improve diagnostic accuracy. First, a generic DT model with multiple degrees of freedom was developed to obtain simulated vibration data containing fault features. Subsequently, DFGAN was adopted to translate simulated data into measured data and generate synthetic samples with distributions similar to those of the measured samples. Specifically, the DFGAN incorporated an improved squeeze-and-excitation U-Net as the generator and integrated a spectral correlation loss to enhance the quality of synthetic samples. Finally, the imbalanced multisensor data were augmented with the synthetic samples, and bearing fault diagnosis was achieved by a multibranch convolutional neural network. Furthermore, the proposed method was verified to diagnose two rolling bearing datasets. The results reveal that the proposed method effectively augmented imbalanced data and significantly enhanced diagnostic performance.
Introduction
Rotating machinery plays an important role in the fields of energy conversion, power transmission, and automation control. With advancements in industrial development, rotating machinery is evolving toward highly intelligent integration and enhanced reliability. As a critical component of rotating machinery, rolling bearings may fail under extreme operating conditions, resulting in the loss of human life and impacting industrial manufacturing.1,2 Therefore, real-time monitoring and diagnosis of bearing operating conditions is critical for ensuring safe operation and reducing system maintenance costs.
Data-driven deep learning (DL) methods have demonstrated high performance in bearing fault diagnosis in the last decade. Classical models, such as long short-term memory (LSTM), 3 denoising autoencoder, 4 convolutional neural network (CNN), 5 deep belief network, 6 along with their variants,7–9 have achieved high diagnostic accuracy and widespread application. Data-driven methods can still be applicable to challenging diagnostic tasks. Liang et al. 10 integrated Stockwell transform and data augmentation method with a capsule neural network (CapsNet) to diagnostic the compound fault of wind turbine gearboxes. Zhang et al. 11 proposed a novel self-supervised graph neural network, which utilizes negative-sample-free contrastive learning and scale attention mechanism to solve the problems of underutilization of graph features in fault diagnosis. Li et al. 12 proposed a method that converts raw vibration signals into envelope spectra through combined Hilbert and Fourier transforms. They designed architecture combined CNN and CapsNet, which effectively maintains spatial features, achieving superior diagnostic accuracy. Xu et al. 13 used cascadic multireceptive learning network to construct a feature extractor for obtaining rich multilevel features from monitoring signals, which improves the performance of the diagnostic model. Zhong et al. 14 designed a two-branch GCN combined with an improved bidirectional gated recurrent unit to integrate spatial and temporal features of feature samples. The extracted domain-invariant features are utilized to achieve cross-domain fault diagnosis of bearing. Some studies have fused multisensor features to overcome the limitations of single-sensor data and improve fault diagnosis accuracy. For example, Zhang et al. 15 introduced structural attention into multiscale group Mamba network to efficiently extract fault features from multisensor data of rotating machinery for diagnostic tasks. Yan et al. 16 designed a multibranch convolutional neural network (MCNN) and implemented an end-to-end multisensor data fusion mechanism for fault diagnosis of rotating machinery. In addition, Wang et al. 17 extracted and fused features from vibration and sound signals using a CNN, achieving fault diagnosis of rolling bearings. Furthermore, Ma et al. 18 designed a dual-branch CNN with a multiscale attention module to achieve multisensor information fusion and equipment fault diagnosis. Using information entropy to calculate fusion weights, Zhang et al. 19 proposed a dual-level data fusion model for bearing fault diagnosis, incorporating a multimodal image fusion strategy. However, data-driven DL methods require sufficient fault samples to achieve effective fault feature extraction. 20 In applications, it is challenging to collect fault samples during the safe operation of a system, leading to imbalanced data and greatly reducing the capability of most DL-based models. 21
Generative adversarial networks (GANs) can be used to learn the feature distribution of fault data and transform random noise into a distribution similar to that of real data through learning mapping, making them an effective method for imbalanced bearing fault diagnosis.21–23 Liang et al. 24 transformed vibration signals into time–frequency images and augmented an imbalanced dataset using a GAN. Pan et al. 25 incorporated a feature extractor into a conditional GAN to acquire the feature distribution of real data, allowing networks to output rich synthetic fault features by introducing additional sequences. To stabilize the training process, many researchers have employed Wasserstein GANs (WGANs), which utilize the Wasserstein distance as the loss function of the discriminator instead of the Jensen–Shannon divergence. 26 Li et al. 27 introduced a strategy based on an auxiliary classifier GAN, which employs the Wasserstein distance and spectral normalization to optimize the loss function of the discriminator. Su et al. 28 encoded fault samples using a kurtosis perceptron, feeding the encoded features into a WGAN to generate synthetic samples for imbalanced data. Gu et al. 29 incorporated cosine similarity loss into WGAN with gradient penalty (WGAN-GP), improving the stability of synthetic sample generation and the diagnostic accuracy. Guo et al. 30 improved the generator structure of WGAN-GP using convolutional variational autoencoding to improve the effectiveness of output samples. Li et al. 31 introduced domain classifier into WGAN-GP to generate pseudo samples, achieving cross-domain fault diagnosis for imbalanced samples. Although GANs and their variants address the limitations of imbalanced data, their training process is highly unstable. 32 In the absence of fault samples, the synthetic samples generated by GANs are ineffective and provide limited improvement in imbalanced fault diagnosis.
Digital twin (DT) technology is an innovative approach to addressing the aforementioned challenges,33,34 with simulated signals obtained from DT models improving diagnostic accuracy.35,36 In the past year, several transfer learning (TL) frameworks for imbalanced fault diagnosis utilizing DT models have been proposed. Li et al. 37 improved CNN model by employing focus modulation to learn the features of simulated samples generated by the DT model, enhancing the diagnosis performance. To address insufficient fault data, Yan et al. 38 obtained simulated signals generated by a finite-element-based DT model, which trained the TL network with a subdomain adaptive mechanism for imbalanced fault diagnosis. In addition, Zhang et al. 39 developed a high-fidelity DT model for rolling bearings and designed a TL framework with an adversarial strategy to learn fault features in simulated data for diagnosis.
Combining DT technology with GANs provides new opportunities to fully utilize the fault information contained in simulated data, thus improving fault diagnosis performance. 40 Xia et al. 41 constructed a DT model of a gear system to generate simulated vibration signals and fused simulated and measured data using a WGAN. The fused samples improved diagnostic accuracy under imbalanced data conditions. Using a cycle-consistent GAN (CycleGAN), Liu et al. 42 extended simulated bearing fault data for fault diagnosis. Qin et al. 43 improved CycleGAN using LSTM to establish a mapping between measured and simulated signals from the DT model, enabling imbalanced data augmentation.
The combination of GANs and DT is advantageous in that simulated data generated by the DT model contain a large amount of fault information, facilitating stable GAN training. In addition, GANs help bridge the gap between simulated and measured signals, greatly enhancing the auxiliary effect of simulated signals in imbalanced bearing fault diagnosis. However, diverse service conditions make it difficult to construct a generic DT model with high simulation accuracy, and the synthetic data generated by GANs may differ from the measured data, particularly in the frequency domain. These factors limit the effectiveness of DT technology. 44
Therefore, the main problems of existing data augmentation methods that combine DT and GAN are detailed as follows: (1) The traditional DT modeling method ignores the internal force state of the bearing, leading to lower generality and simulation accuracy. (2) Existing GAN models cannot adequately retain the simulated fault information of the DT model when synthesizing samples. (3) The frequency domain distributions of the synthetic samples differ from those of the measured samples in the absence of explicit constraints on their frequency-domain features. To address the above issues, this article introduces a novel method for imbalanced fault diagnosis of rolling bearings. This method combines a generic high-fidelity DT model and a DT-driven feature enhancement generative adversarial network (DFGAN) to generate synthetic samples. Unlike the existing methods, the degrees of freedom (DOFs) of each bearing component are innovatively considered in the DT model to reinforce generalizability and simulation accuracy. Additionally, an improved generator named squeeze-and-excitation U-Net (SEU-Net) is utilized in DFGAN to adaptively select effective simulated fault information from the DT model to be fused into the synthetic samples. Moreover, the loss function of DFGAN is improved to constrain the frequency distribution of the synthetic samples based on the correlation of spectrums. An overview of the proposed method is given in Figure 1. First, a generic high-fidelity DT model with multiple DOFs is developed to simulate the bearing fault state and acquire the simulated dynamic response of the system. Subsequently, a DFGAN is introduced with the purpose of learning the mapping between measured and simulated data and generate synthetic samples of the measured samples. Finally, imbalanced multisensor data are augmented with synthetic samples to improve fault diagnosis accuracy. The main contributions of this study are summarized as follows:
A generic high-fidelity DT model of rolling bearings with multiple DOFs is developed using the lumped parameter method, employing fault and structure parameters as inputs. By considering the translational and rotational DOFs of the rollers, inner race, and outer race, the proposed DT model generates simulated vibration data containing sufficient fault feature information, thereby aiding in the diagnosis of bearing faults.
DFGAN is proposed to bridge the gap between simulated and measured samples and generate synthetic samples with a data distribution similar to that of measured signals. An improved generator called SEU-Net is designed to perform multilayer deep fusion of fault information from the simulated samples. In addition, a spectral correlation loss function (LF) is designed to minimize the discrepancy between the frequency components of synthetic and measured samples.
The synthetic fault samples generated by DFGAN are utilized to augment imbalanced multisensor data. Then, multisensor data fusion is achieved using MCNN, improving bearing imbalanced fault diagnosis accuracy.
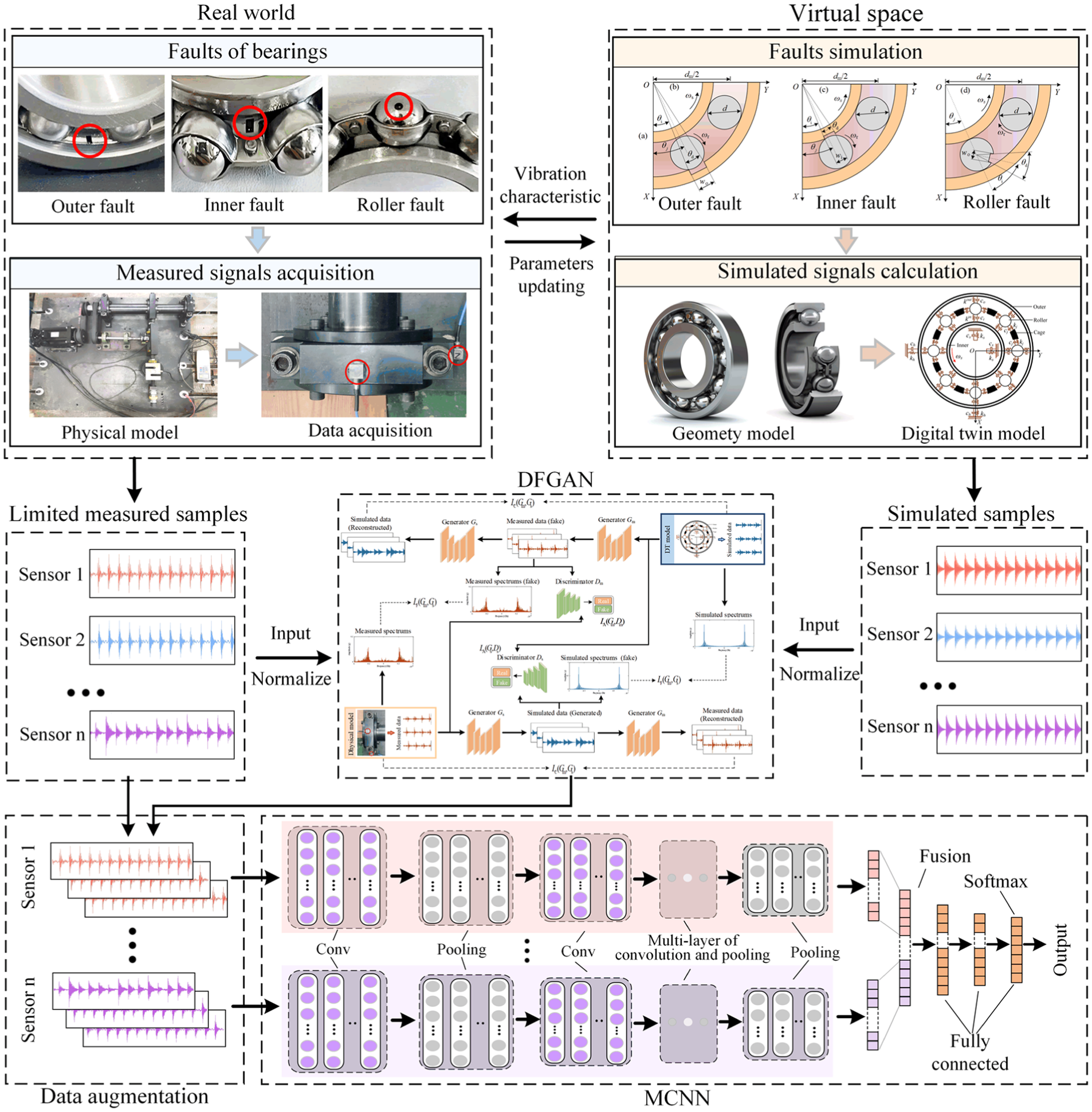
Overview of the proposed framework.
The DT model of bearings
Localized defects on the surface of rolling bearings lead to abnormal contact between the rollers and raceways, thereby exciting excitations of time-varying displacement in the system. Developing a DT model of rolling bearings to simulate localized bearing faults and obtain simulated vibration signals containing fault features is critical for fault diagnosis. The dynamic response of rolling bearings obtained from the DT model should accurately reflect the features of the measured signals of the system in both the time and frequency domains. The information interaction between the DT and physical models is illustrated in Figure 2.
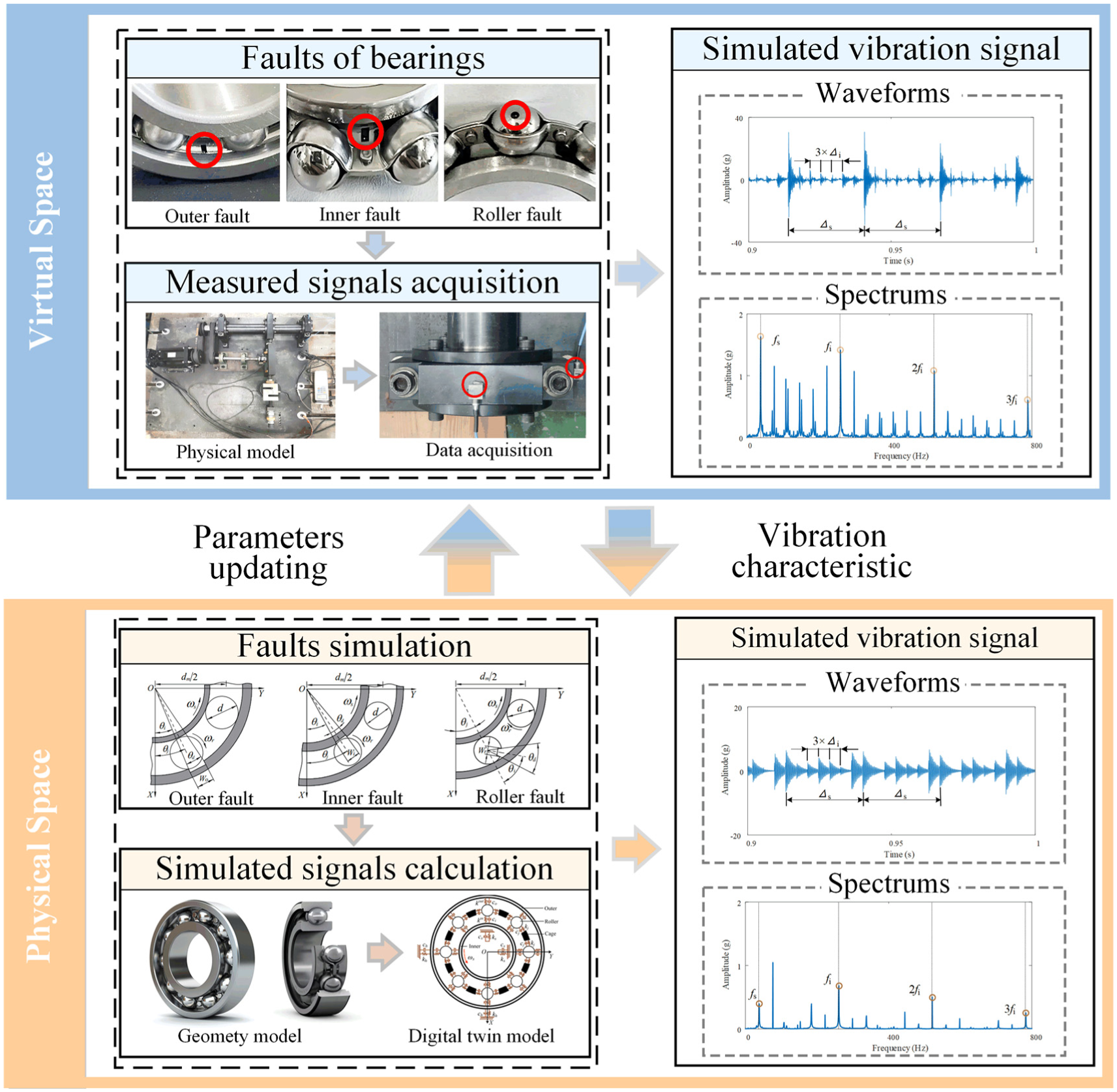
Information interaction between DT model and physical model.
Development of DT model
Ignoring the force states of the internal parts of the bearings, existing DT models rely heavily on the DOF of the inner and outer raceways to solve the simulated fault signals. In this section, thus, a generic high-fidelity DT model is developed to simulate the fault states of a rolling bearing. Different from the existing bearing DT modeling method, the high-fidelity DT model proposed in this article fully considers the motion of each part in the bearing. Except for the inner and outer raceways, the rollers and cage are also analyzed regarding force. Meanwhile, the DOFs of each part are considered in the proposed DT model to improve the simulation accuracy. As shown in Figure 3, the DT model consists of a total of 4 + 3(Nb + 1) DOFs, where Nb represents the number of rollers. In the model, the stiffness of the shaft and housing shell is represented by ks and kh, respectively, while the corresponding damping is represented by cs and ch. The contact stiffness between the rollers and raceways is denoted by kin and kout, with the corresponding damping denoted by ci and co. In addition, the contact stiffness between the roller and cage is represented by k j , with the damping represented by c j . These parameters are described in detail in Liu and Shao. 45
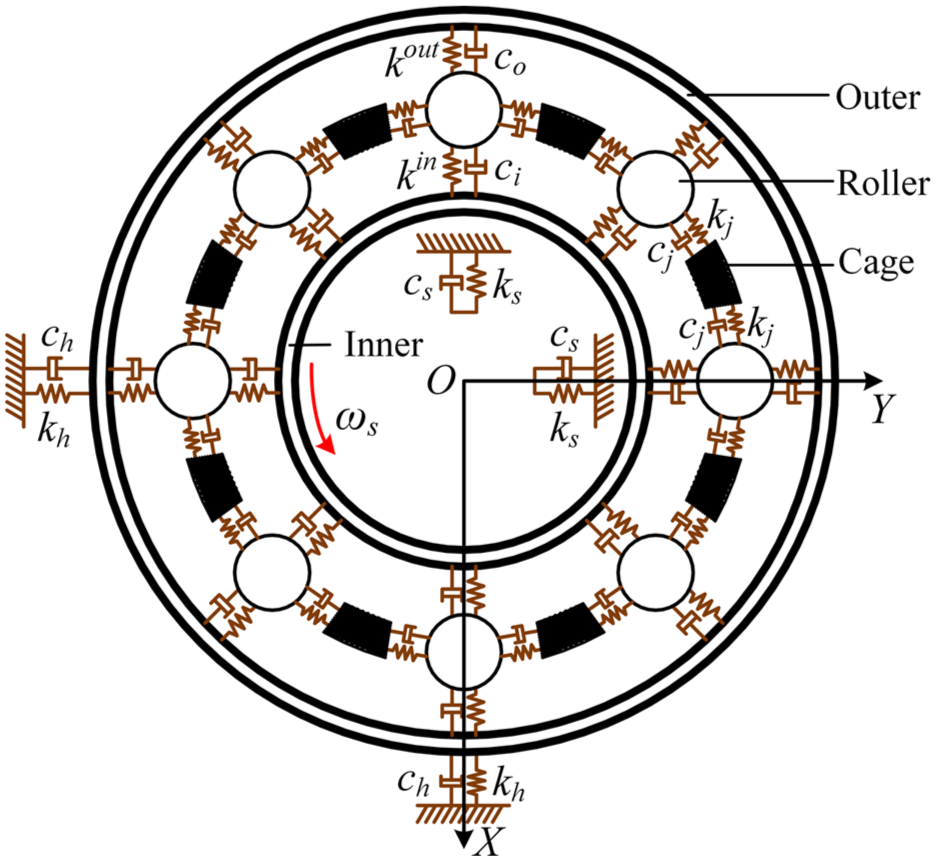
DT model of a rolling bearing.
As illustrated in Figure 4(a), when the bearing is operating stably, there is a complex interaction between its components. Under the action of radial load, the roller experiences contact and friction forces with the inner and outer raceways. The relationship between the rolling bearing load and contact deformation is as follows:
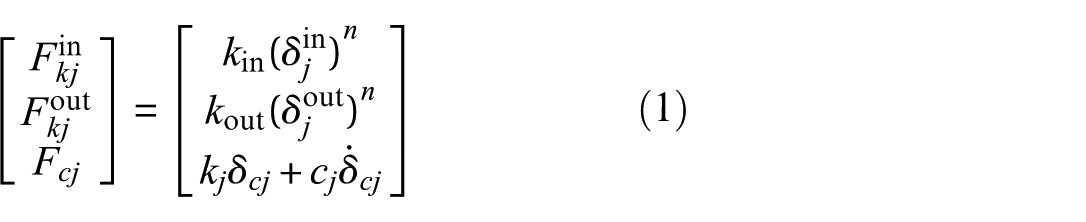
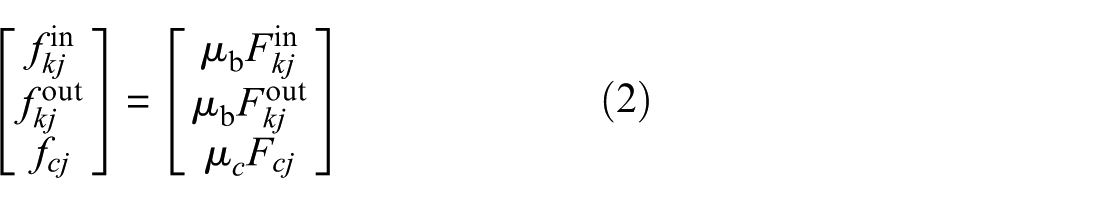
where n = 3/2 for rolling bearings, μb is the coefficient of friction between the roller and raceway, and μc is the coefficient of friction between the roller and cage. The calculation of μb and μc is provided in Gupta.
46
In addition,
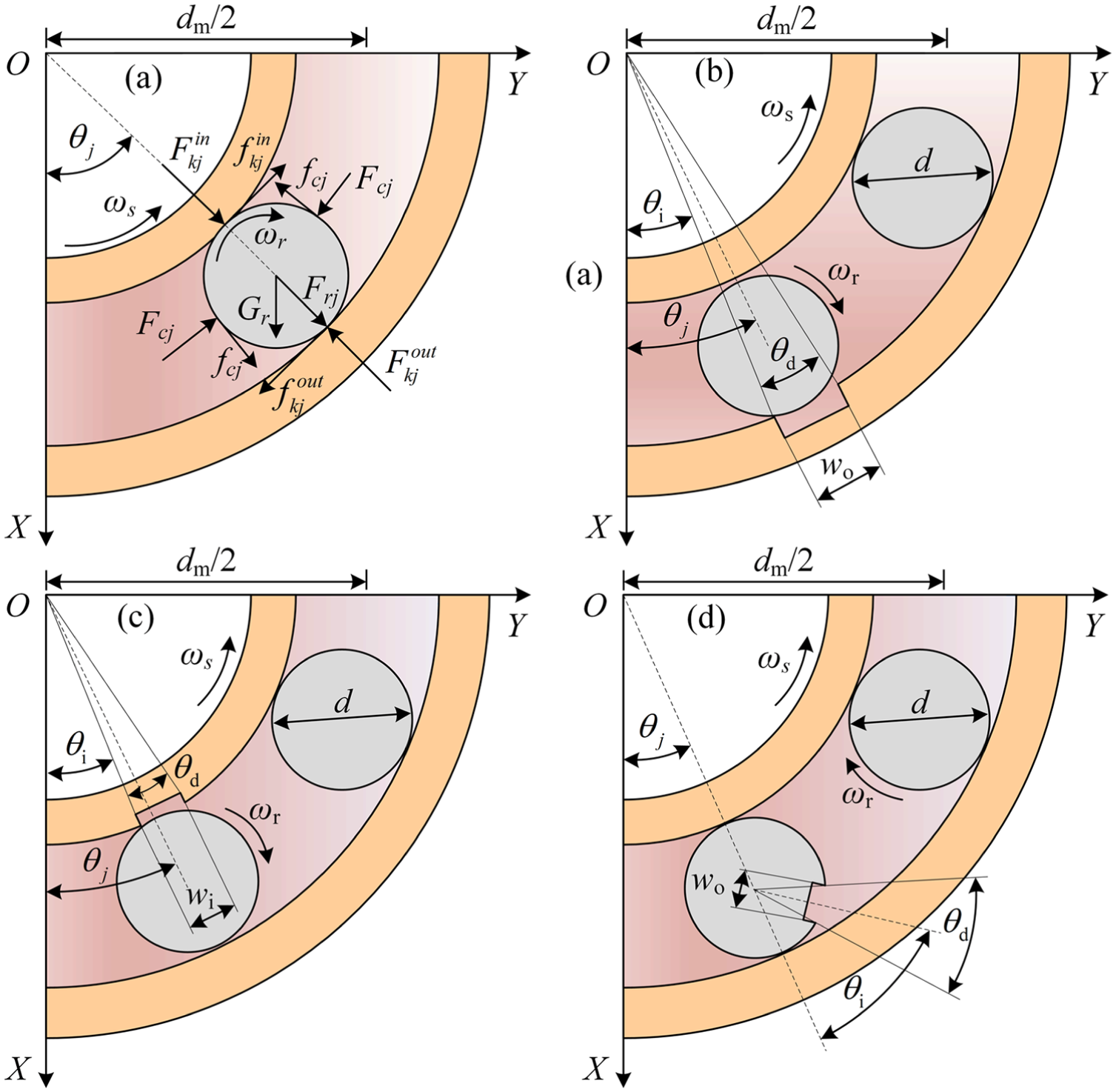
Structure of spalling faults: (a) healthy, (b) outer race faults, (c) inner race faults, and (d) roller faults.
Under a given operating condition, the load brings about a compressive deformation between the rollers and raceways of the bearing. This forms an elliptical contact surface, presenting a typical Hertz contact. The contact state is related to the structure and load of the bearing. At this time, the contact stiffness between the rollers and raceways serves as the Hertz contact stiffness, which can be expressed as follows:
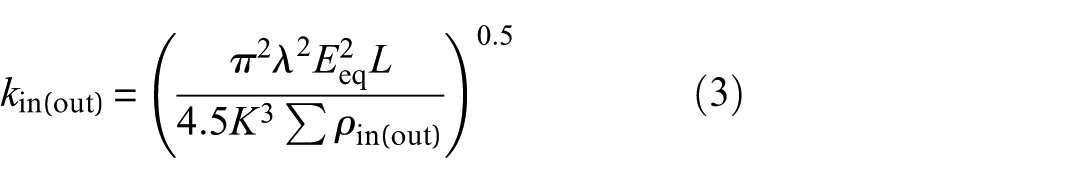
where Eeq is the equivalent Young’s modulus of the material in the two contacting objects, λ is the parameter of the point contact elliptic eccentricity. K and L are elliptic integrals of the first and second kind, respectively.
The damping of bearing is usually set in the range of 0.25 × 10−5–2.5 × 10−5 times the bearing stiffness. 48 Therefore, the damping ci and co in the Hertz contact zone between the rollers and the raceways can be obtained from the following formula:
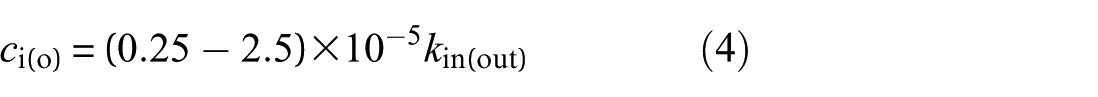
When a bearing has a localized defect, rollers enter and exit the defective region with a fixed period. This defect increases the displacement range of the rollers, causing time-varying displacement of the system. Figure 4(b) to (d) illustrates the localized fault structures of the outer race, inner race, and roller, respectively. The time-varying displacement can be described using a half-sine function, as follows:
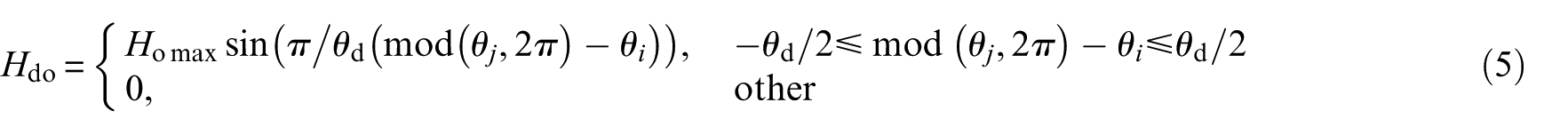
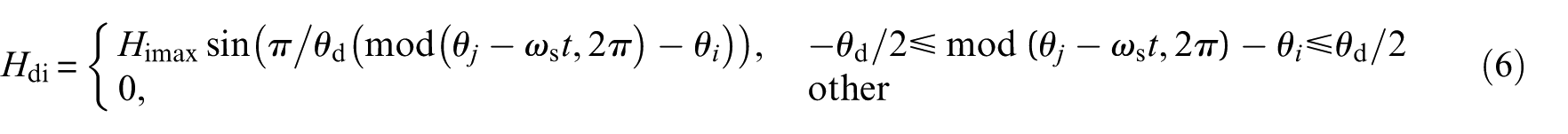
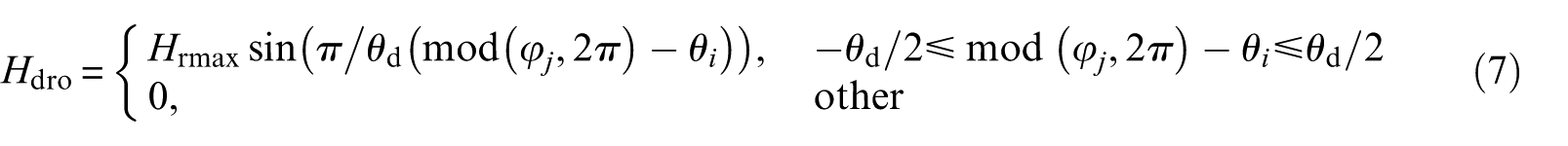
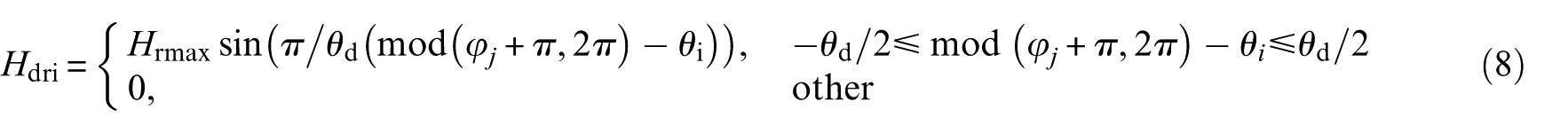
where Homax, Hrmax, and Himax denote the maximum additional displacement caused by spalling faults in the outer race, roller, and inner race, respectively. Initial angular position of the fault is denoted as θ i . θ j denotes the angular position of the j-th roller, and φ j denotes the angular position of the roller spalling fault. These parameters are described in Qin et al. 47
Under the influence of time-varying displacement caused by bearing failure, contact deformations of the rolling element with the raceways and cage is expressed as follows:
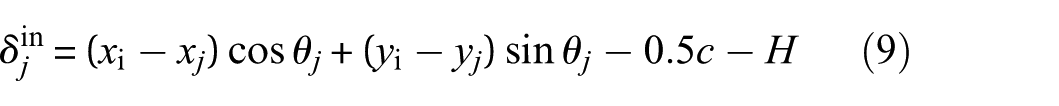
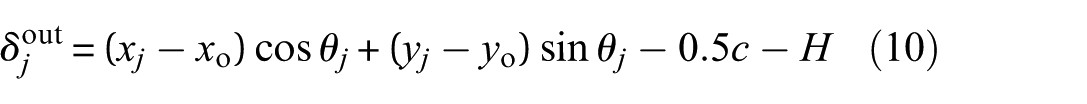
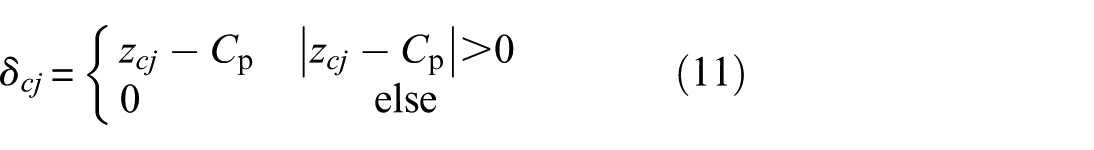
where xo, xi, and x
j
denote the displacements of the outer race, inner race, and the j-th roller along the X-axis, respectively, while yo, yi, and y
j
denote the displacements along the Y-axis. The term z
cj
denotes the relative position between the roller and the center of the cage pocket hole, where
When outer ring defects occur, H = Hdo, while when inner ring defects occur, H = Hdi. When the roller fails, H = Hdro + Hdri. Force analysis is performed, and the kinetic differential equations for the inner and outer races are obtained.
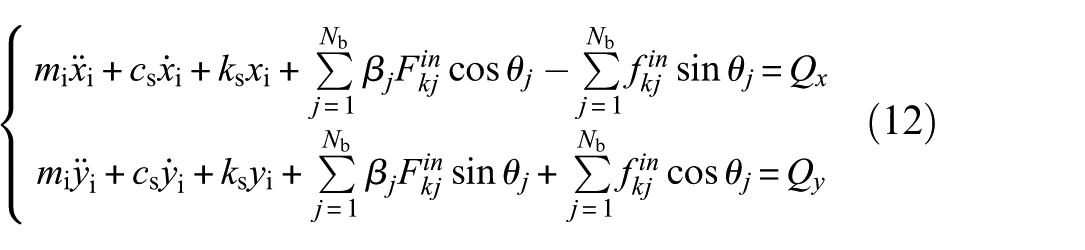
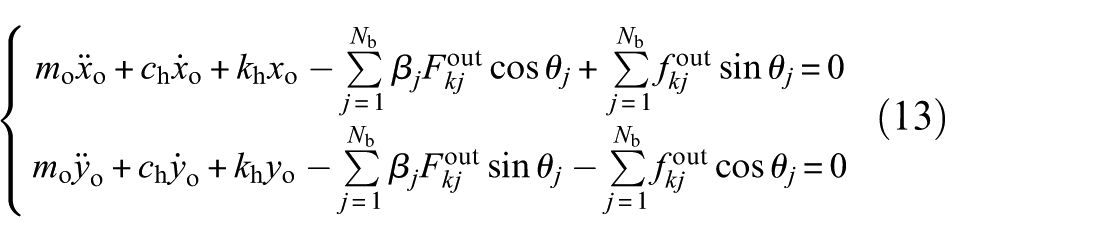
where mi is the total mass of the shaft and inner race, while mo donates the total mass of the housing and outer race. In addition, Q x and Q y denote the loads applied along the X-axis and Y-axis, respectively, while β j represents the Heaviside function. 49
The kinetic differential equations of rollers are as follows:
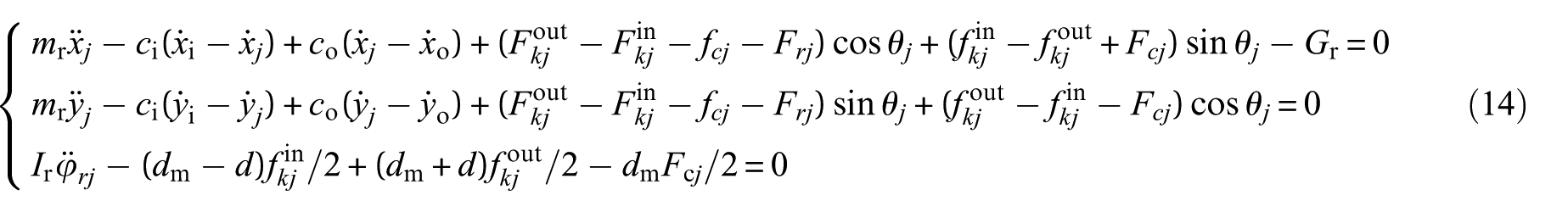
where mr, F
rj
, and
For the cage, the kinetic differential equations are:
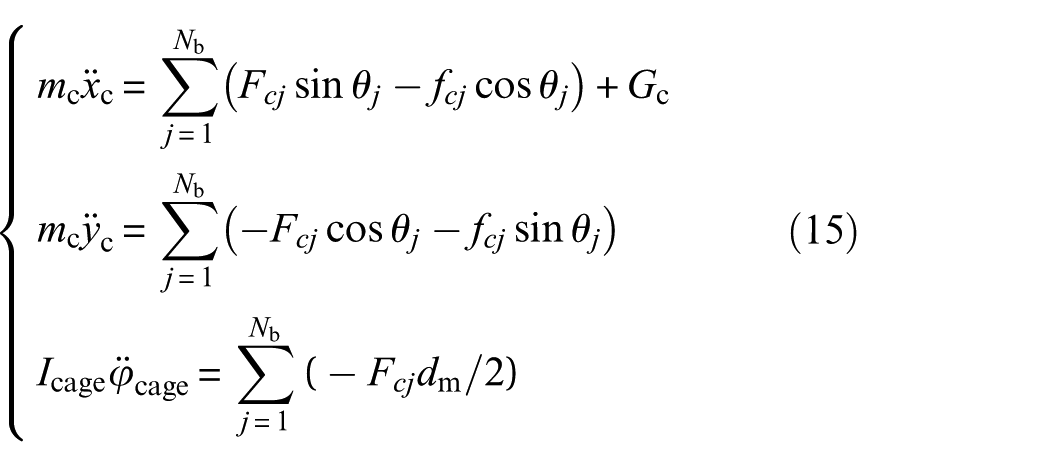
where xc and yc denote the displacement of the cage along the X-axis and Y-axis, respectively. Terms mc, Icage, and
Structural parameters are different in various bearing models. The proposed modeling method requires only structural, failure, and operational parameters as inputs to acquire a high fidelity DT model of the bearing. Specifically, the critical parameters such as contact stiffness kin, kout and damping ci, co can be updated in real time by substituting fault parameters and real-time operating condition parameters into (3)–(8) based on available structural parameters. These parameters are employed in the force analysis of bearings to obtain the contact deformations of the rollers with the raceways and cage. Subsequently, the dynamic model of the bearing can be expressed as (12)–(15).
Verification of simulated signals
Effective DT models of rolling bearings aim to obtain simulated data reflecting the features of measured signals, thereby aiding in health status monitoring. To validate the DT model, the vibration response of NSK 6012 rolling bearings was collected under various fault states and operating conditions. Table 1 presents the detailed parameters of NSK 6012, and simulated vibration signals were obtained by applying the parameters to (12)–(15). Because the measured signal was collected at the shell, the simulated signal of the outer race was selected for comparative analysis.
Parameters of NSK 6012 bearings.

When the outer race fails (wo = 1 mm), the bearing is subjected to a 1194 N load along the X-axis, and the rotational frequency of the inner race is fs = 27.5 Hz. The roller passing frequency of the outer race is fo = 142.75 Hz. The acceleration of the simulated and measured signals along the X-axis is presented in Figure 5(a) and (b), respectively. In the time domain, both the simulated and measured signals exhibit periodic impulses caused by the outer race fault, with an interval of Δo = 0.007 s, which corresponds to fo. As illustrated in Figure 5(b) and (d), in the envelope spectra, the main frequency components of the simulated and measured signals are fo and its harmonic components (2fo, 3fo, …).
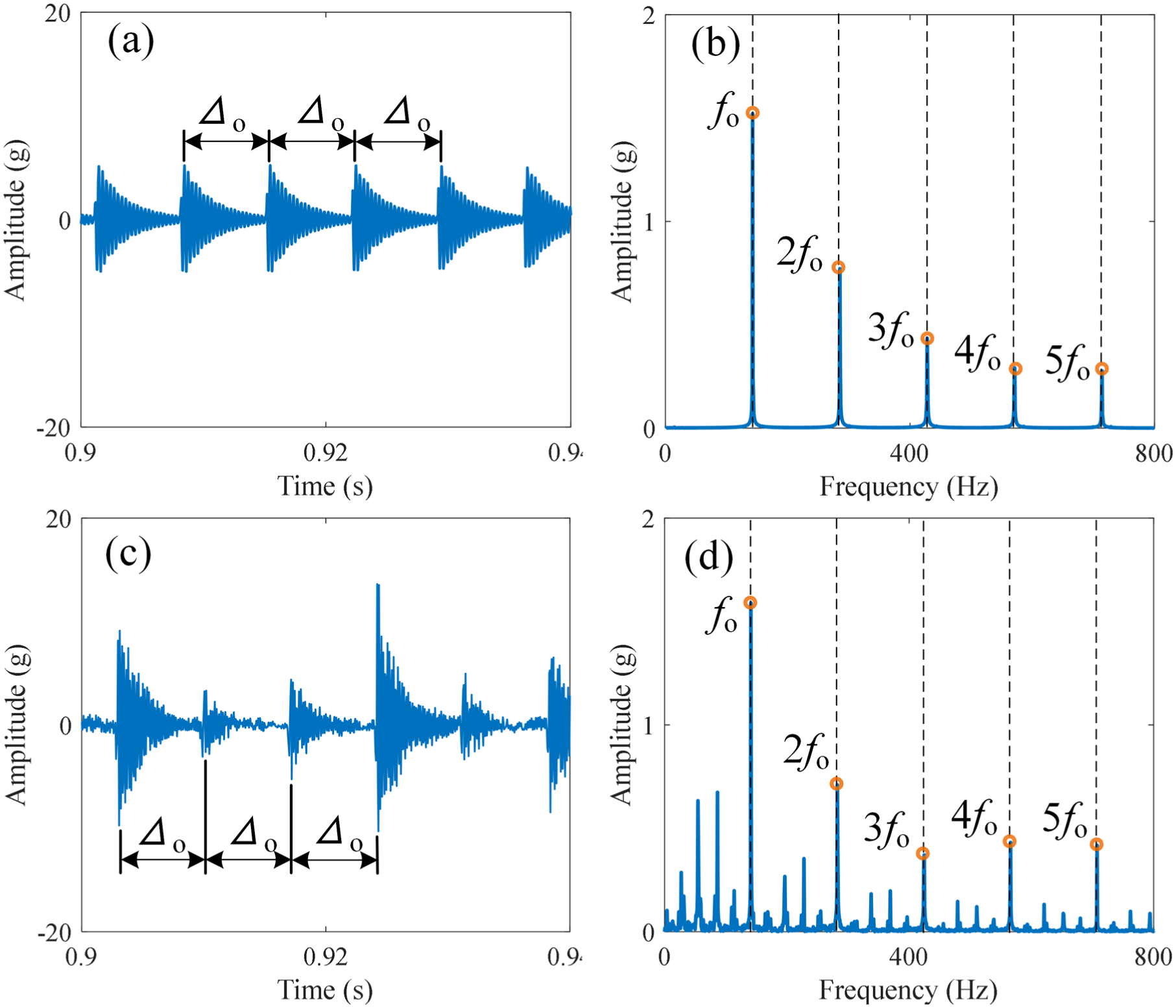
Accelerations with outer race faults along the X-axis. (a, c) Waveforms of simulated and measured data, respectively. (b, d) Envelope spectra of simulated and measured data, respectively.
Similarly, when the inner race fails with a fault size of wi = 1 mm, the load is 856 N along the X-axis, and fs = 38.33 Hz. The acceleration is presented in Figure 6(a) and (b). In the time domain, both the simulated and measured signals exhibit considerable modulation. Periodic impulses, occurring at intervals Δi (0.004 s) and Δs (0.026 s), are induced by the roller passing frequency of the outer race fi (142.75 Hz) and fs, respectively. The envelope spectra, illustrated in Figure 6(b) and (d), illustrate that apart from fs, the main frequency components of both the simulated and measured signals are fi and its harmonic components (2fi, 3fi, …).
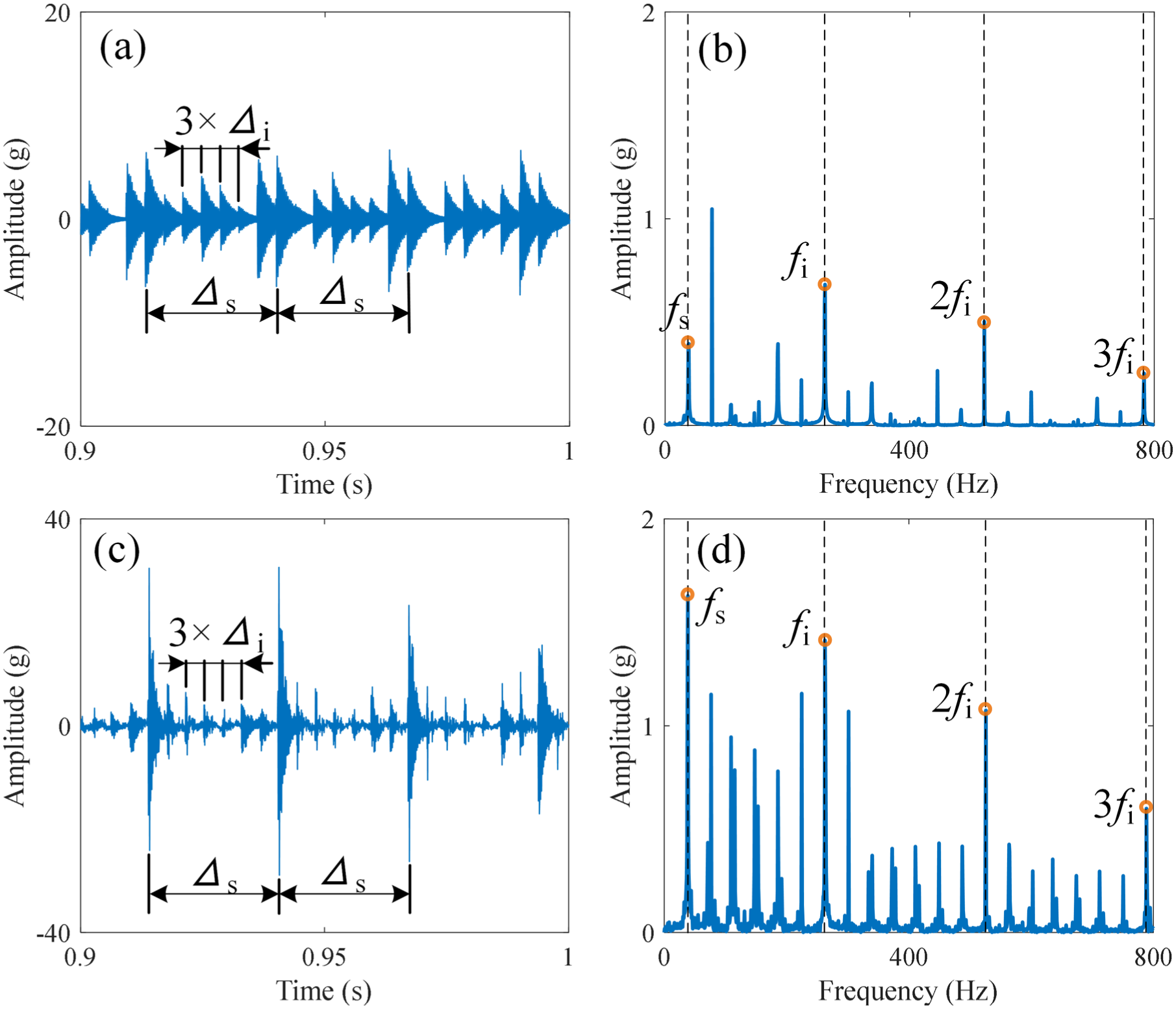
Accelerations with inner race faults along the X-axis. (a, c) Waveforms of simulated and measured data, respectively. (b, d) Envelope spectra of simulated and measured data, respectively.
The results indicate that simulated signals obtained from DT models, which are developed based on the structure and fault parameters of the bearings, effectively reflect the vibration characteristics of the measured signals in the time and frequency domains. This demonstrates the effectiveness of the proposed DT model and its ability to simulate bearing faults under various operating conditions.
Framework for imbalanced fault diagnosis
DFGAN is proposed to learn the mapping between the distributions of simulated and measured data, thereby reducing these discrepancies and enabling mutual conversion between simulated and measured samples. SEU-Nets are utilized as generators to optimize the performance of fault information extraction from simulated data. After training, simulated multisensor data are transformed into synthetic samples with a distribution similar to that of measured samples using the trained SEU-Net.
Principle of DFGAN
DFGAN is employed to transform simulated fault samples into synthetic samples with a data distribution similar to that of measured samples. As illustrated in Figure 7, DFGAN consists of two generators (Gs, Gm) and two discriminators (Ds, Dm). Both generators Gs and Gm utilize SEU-Net as a structural to achieve optimized extraction and deep fusion of fault features from the simulated samples. Both discriminators Ds and Dm utilize an identical Patch-GAN architecture. 31
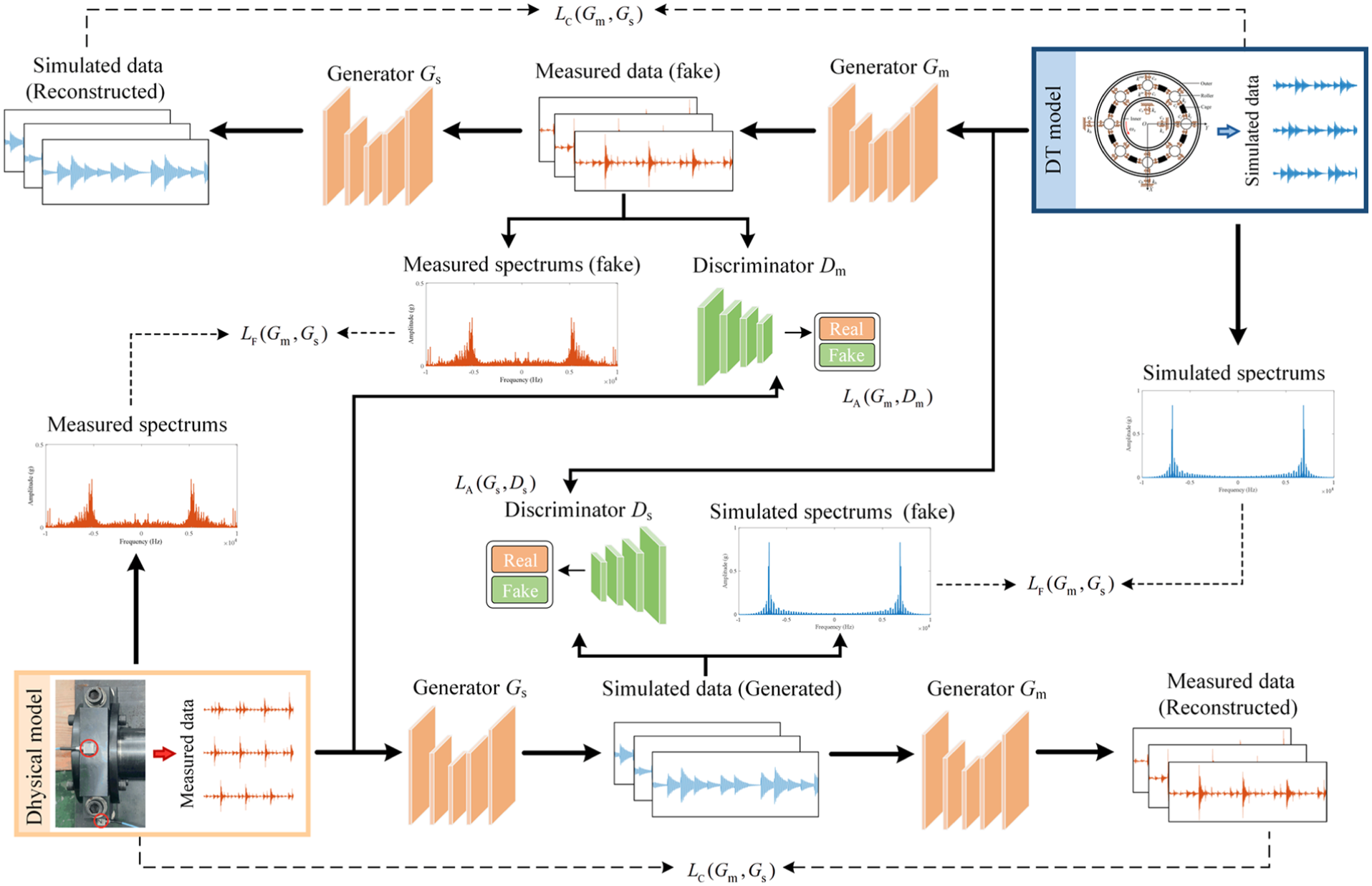
Architecture of DFGAN.
DFGAN is trained using a limited number of measured and simulated fault samples. Specifically, the first GAN consists of Gm and Dm, which facilitate the conversion of simulated samples xs in the source domain S into the measured samples xm in the target domain T. The generator Gm is utilized to learn fault features from the simulated samples xs and generate synthetic samples Gm(xs) of the measured signals xm. Multiple feature fusion blocks in Gm extract and deeply fuse the fault features in xs. Subsequently, feature weights are automatically obtained, and effective fault features are passed to Gm(xs). As a result, the synthetic samples Gm(xs) exhibit a data distribution similar to that of measured samples xt in domain T, which can realize feature enhancement of measured samples xm. The discriminator Dm differentiates the synthetic samples Gm(xs) from the measured samples xm, which opposes the training objective of Gm. Finally, the generator Gd attempts to map Gm(xs) back to the domain S to ensure that Gm(xs) retains the effective fault information in xs. Similarly, the alternating training of Gs and Ds in the second GAN achieves the conversion of measured samples xm into simulated samples xs.
SEU-Nets for generators
Within DFGAN, SEU-Nets serve as generators, consisting of a down-sampling block, an up-sampling block, and feature fusion blocks. The structure and parameters of SEU-Net are illustrated in Figure 8(a). The down-sampling block reduces feature dimensions through three serially connected down-sampling layers. The up-sampling block restores feature dimensions using transposed convolutions, aiming to reconstruct features and generate synthetic samples. In addition, instance normalization (IN), dropout (DP), and rectified linear unit (ReLU) are utilized to enhance feature extraction and generalization ability of the network. Different from the existing generator structures, multiple feature fusion blocks are adopted in SEU-Net to realize the multilayer deep fusion of the feature maps from simulated signal xs, as demonstrated in Figure 9. Feature fusion layers copy and concatenate down-sampled feature maps with their corresponding inputs in the up-sampling block in a multilayer based on the channel dimensions. With the purpose of fully retaining the fault information contained in the simulated signal xs in synthetic samples, squeeze-and-excitation blocks are introduced as the attention module to prioritize critical features and compute channel-specific weights, allowing for multilayer deep feature fusion. 50 Specifically, global average pooling is utilized to process the input concatenated feature maps by compressing the spatial information of each channel into a scalar. Afterward, nonlinear dependencies between channels are learned by two fully connected (FC) operations to obtain channel weights. Finally, the channel weights are applied to the original feature map to weight critical feature channels and suppress irrelevant channels. This allows more effective fault information in the input samples to be retained in the fake samples, thus improving the accuracy of sample reconstruction, and preserving detailed features.
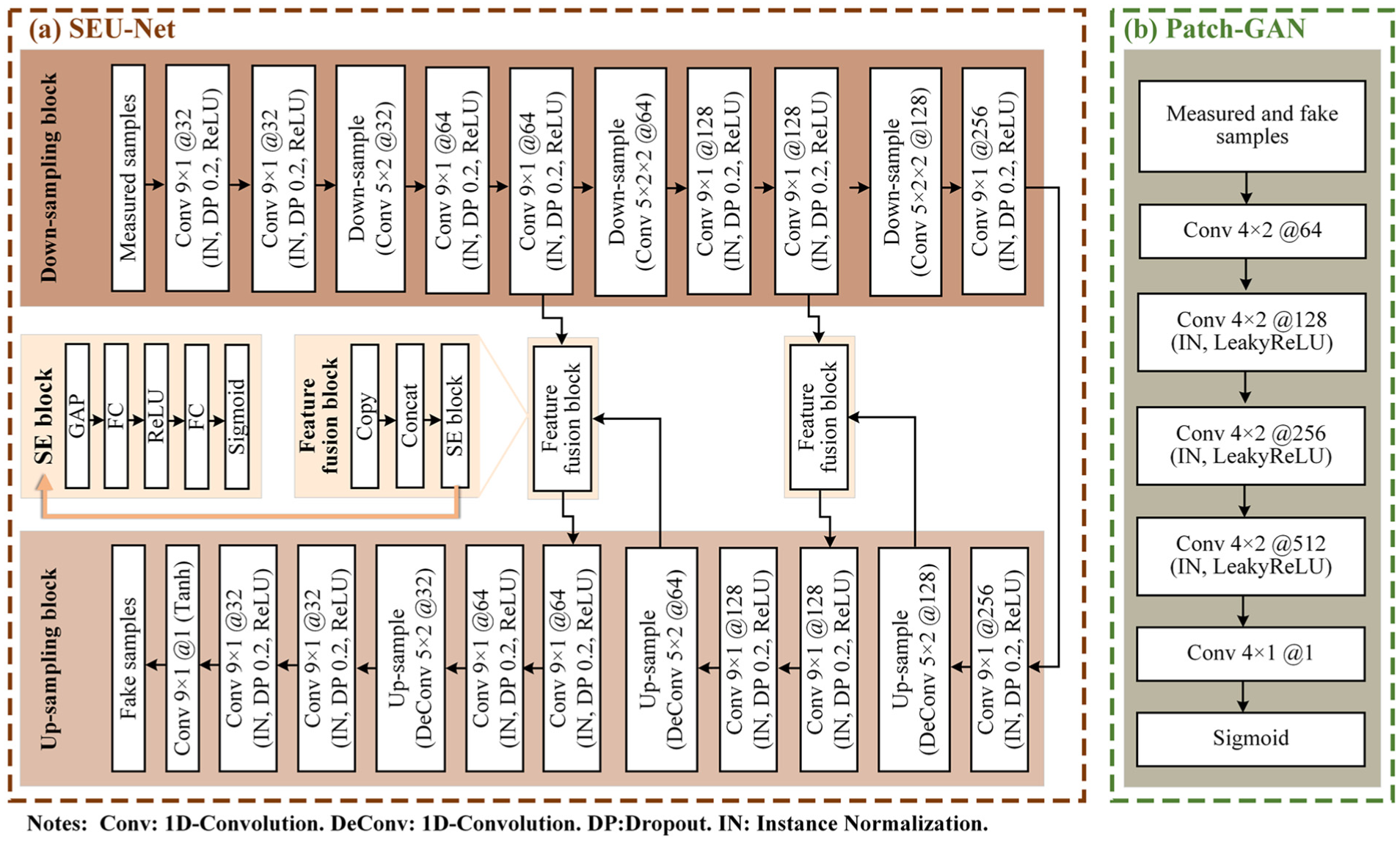
(a) Structure and parameters of the SEU-Net generator. (b) Structure and parameters of the Path-GAN discriminator.
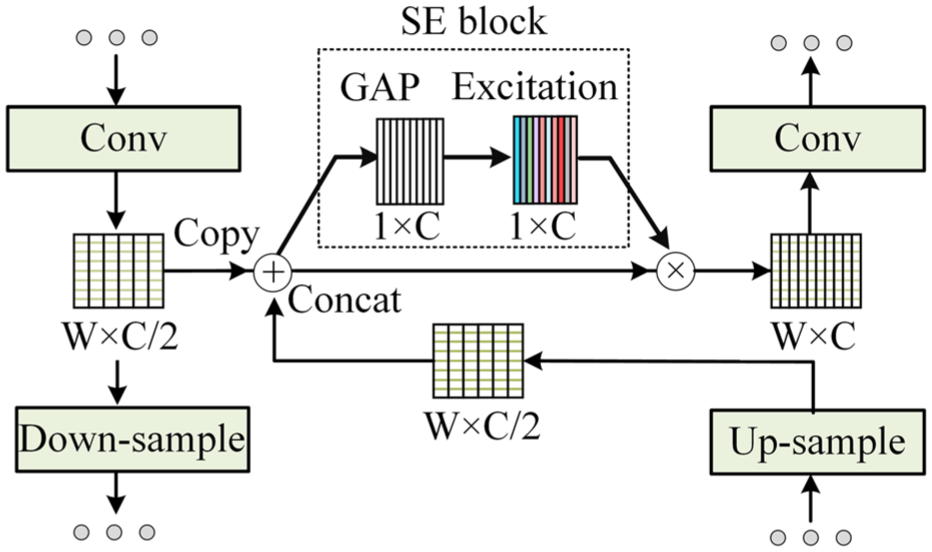
Diagram of the feature fusion block.
Patch-GAN for discriminators
Patch-GAN can better focus on the local features of input samples than traditional GAN discriminators. Therefore, Patch-GANs are used as discriminators. Figure 8(b) presents the structure and parameters of the discriminators, which serve to discriminate between synthetic samples. The elements in the output matrix are converted to values between 0 and 1 by the sigmoid activation function. These values represent the probability that different regions of the input data correspond to real samples.
The loss function with spectral correlation loss of the DFGAN
Frequency-domain analysis reveals the intensity of the signal over different frequency components, which are not directly captured by time-domain analysis. However, loss functions are generally designed in existing data generation methods based only on the time series data of samples, resulting in the lack of explicit constraints on frequency-domain features. Moreover, there may still exist large discrepancies between synthetic and measured samples in the frequency domain. Thus, a loss function called spectral correlation loss (LF) is designed following the Pearson’s correlation of the spectra to curtail these discrepancies. Pearson’s correlation is a crucial indicator for evaluating the similarity between two sets of data. The closer the Pearson’s correlation coefficient between samples is to 1, the higher the consistency of the data distribution. Unlike existing methods, LF utilizes the correlation coefficient to constrain the spectral data distribution of the synthetic samples, so as to achieve the alignment of the frequency distributions of the synthetic and measured samples. The Pearson’s correlation coefficient can be calculated as follows:
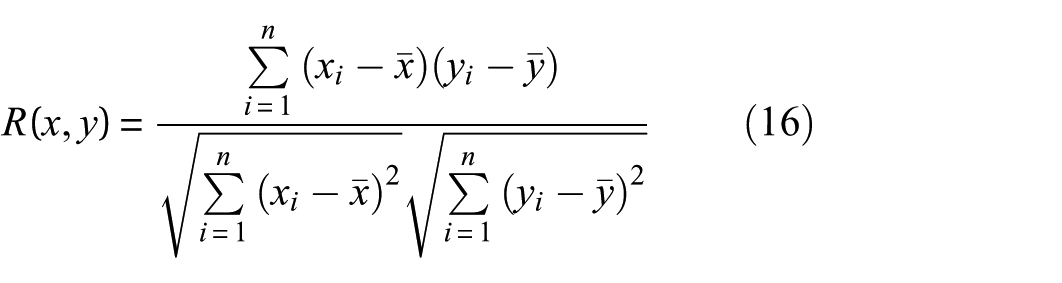
where x and y denote two samples containing the same number of points.
DFGAN is designed to learn the bidirectional mapping relationship between simulated samples xs and measured samples xm, realizing the interconversion of samples in domain T and sample in domain S. Therefore, the composition of spectral correlation loss LF should be considered in two parts: (1) the linear correlation between the spectrums of Gm(xs) and measured sample xm; (2) the linear correlation between the spectrums of Gs(xm) and simulated sample xs. LF needs to constrain both the domain S to T and the domain T to S conversion process simultaneously. Considering the correlation coefficients between the spectra of the synthetic samples generated by Gm and Gs and the spectra of the measured samples, the spectral correlation loss of DFGAN is obtained as follows:
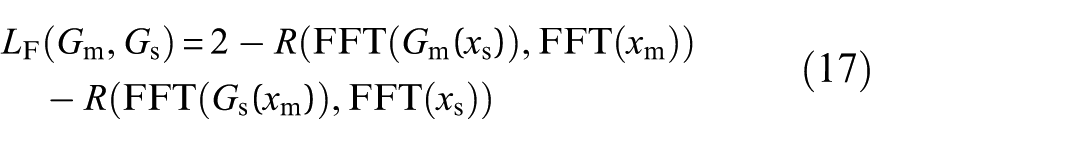
where FFT(·) denotes the complex representation of data in the frequency domain.
The adversarial losses LA(Gm, Gd) and LA(Gs, Gs) are utilized to ensure that the generated synthetic samples match the data distribution in T:
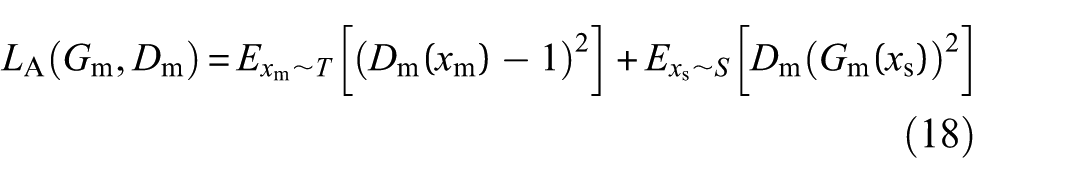
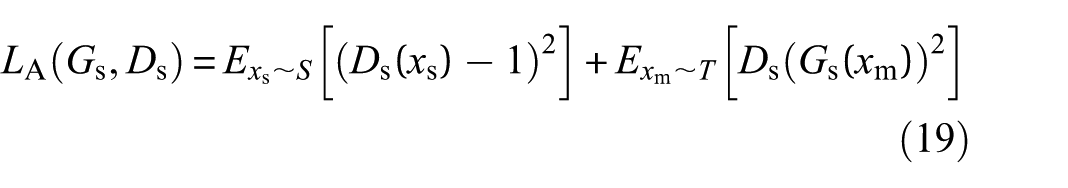
where
The cycle-consistency loss LC(Gm, Gd) is introduced to constrain the training of generators Gm and Gd:
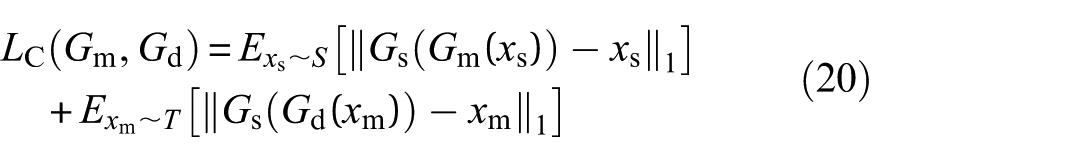
To allow the generators to extract and retain fault features from input samples, identity-mapping loss is introduced, which helps to reduce the migration of irrelevant features:
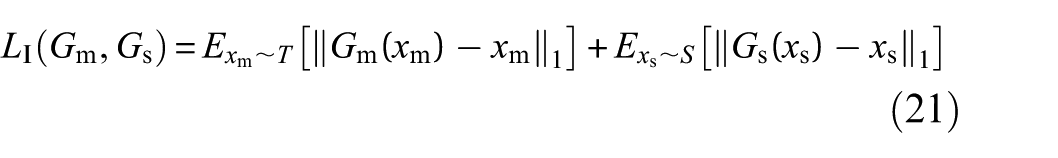
In summary, the objective function of DFGAN during training can be expressed as follows:
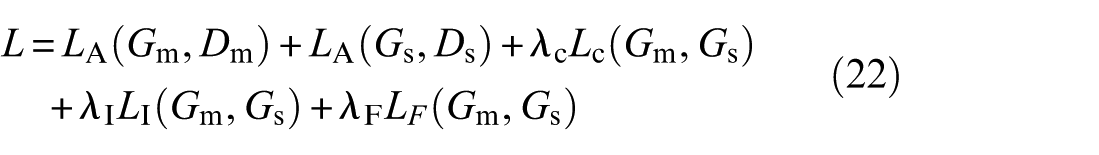
where λC, λI, and λF represent the trade-off parameters of LC, LI, and LF, respectively.
MCNN for fault diagnosis
To effectively utilize fault information from multisensor data and enhance the accuracy of bearing diagnosis, MCNN is proposed as the classifier for feature extraction and fusion of multisensor data. The parameters and structure of MCNN are presented in Figure 1 and Table 2. The architecture incorporates multibranch CNNs, with the number of branches corresponding to the number of sensors. In feature extraction, batch normalization (BN), and ReLU operations are performed sequentially following each convolution to optimize the feature extraction of MCNN.
Structure of each branch of MCNN.
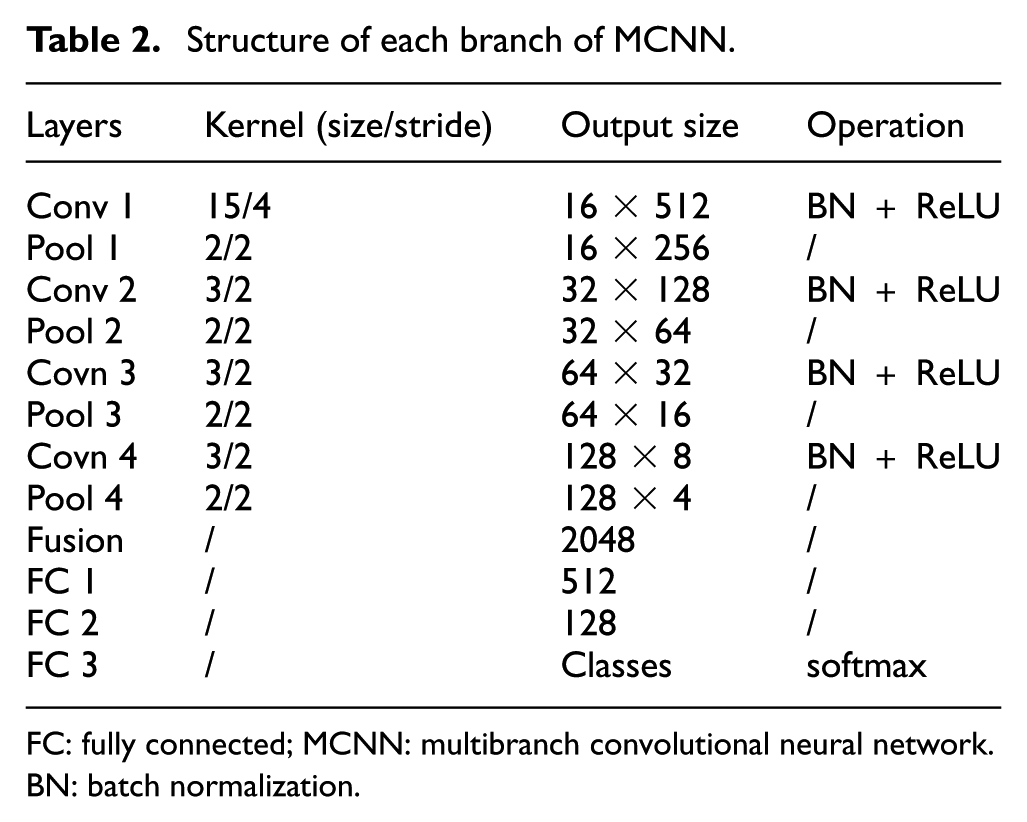
FC: fully connected; MCNN: multibranch convolutional neural network. BN: batch normalization.
Multisensor data are fed into individual branch CNNs to extract the corresponding fused features. Subsequently, three FC layers with softmax are utilized to achieve fault diagnosis based on the fused features. Cross-entropy loss is employed to evaluate diagnostic performance.
Experiment and analysis
The code for the proposed method is implemented using the PyTorch 2.1 developed by Facebook AI Research (FAIR) and written in Python 3.8 developed by Python Software Foundaton (PSF). To minimize the influence of random factors, all experiments were repeated 10 times, and the model performance was evaluated based on the average diagnostic accuracy.
Training details
The hyperparameters of DFGAN and MCNN were set by parameter fine-tuning to fully utilize the performance of the proposed method. Concerning both DFGAN and MCNN, the Adam optimizer was selected as the adaptive optimization algorithm to update model parameters and accelerate network convergence. The learning rate lr should be dynamically updated to match the gradient descent process of the loss function. In DFGAN, the lr of generators Gm and Gs and discriminators Dm and Ds, where the lr decreased from 0.0005 to 0.0001, were updated by the cosine-annealing algorithm to avoid local minima and find the global optimum. Additionally, the weight parameter λF of the LF was set at 1 to constrain the frequency distribution of the synthetic samples. The training iterations of DFGAN were set at 4000 to ensure the stable generation of synthetic samples. In MCNN, to determine the optimal solution for classification task, the initial lr of MCNN was set to 0.0002 and reduced by 80% every 20 iterations. The training iterations were set to 120 with a batch size of 128 to avoid overfitting of the diagnostic model.
Methods for comparison
To evaluate the performance of DFGAN for imbalanced fault diagnosis of rolling bearings, five methods were selected for comparison. The diagnostic models for all comparison methods are the same as for DFGAN.
MCNN 16 : Without sample augmentation, raw imbalanced data is fed into the diagnostic model, and multisensor data features are extracted by a multibranch CNN, used as a baseline.
DCGAN 51 : It serves as a data generation model. A deep CNN is used as a generator for synthesizing fault samples.
LSGAN 52 : It serves as a data generation model. Least squares loss is employed to optimize model training.
WGAN-GP 31 : It serves as a data augmentation method. WGAN-GP uses the Wasserstein distance as a loss function. The Lipschitz constraint is forced to be satisfied by the gradient penalty to increase the stability of model training.
CycleGAN 53 : CycleGAN is used to learn the mapping between simulated samples from the DT model and measured samples and synthesize fault samples, so as to synthesize fault samples. It is an effective sample augmentation method.
Case1: Case Western Reserve University (CWRU) dataset
Description and processing of dataset
The structure of the test bench corresponding to the CWRU dataset is presented in Figure 10. Accelerometers were placed on the fan end (FE) and drive end (DE) of the motor housing. An SKF 6203 rolling bearing was employed to support the FE, with its parameters presented in Table 3. To simulate the health conditions of the FE, faults were introduced separately on the roller, outer race, and inner race of the 6203 bearings, with three fault sizes: 0.007, 0.014, and 0.021 in. Therefore, including the normal state, the 6203 bearing had a total of 10 health conditions. Under the 3-hp operating condition, faults on the outer race were located at the 3 o’clock position. This study employed vibration data from the FE and DE sensors for processing and analysis to simulate imbalanced multisensor data.

The test bench of Case Western Reserve University (CWRU) dataset.
Parameters of SKF 6203 bearings.

Using the fault parameters as inputs, the DT model of the 6203 rolling bearing with multiple DOFs was developed using (12)–(15). The simulated and measured data were processed using a sliding window technique for both the DE and FD sensors. 5 For each health condition, the vibration data were divided into 400 measured samples, each containing 2048 consecutive points. However, fault samples are generally difficult to obtain in applications, and the difference in the number of samples affects the reliability of the diagnostic model. Therefore, it is necessary to investigate the performance of DFGAN for data synthesis under extreme imbalanced data. In this section, only two measured samples from the DE and FD sensors were randomly selected to perform DFGAN training under each fault condition. Meanwhile, 300 samples under normal conditions were used as the majority class to simulate the data distribution in industrial scenarios. In this way, the ratio of each fault condition to the normal condition sample (imbalance ratio) reaches 1:150, forming extremely imbalanced data. Then, the imbalanced data were augmented with synthetic samples obtained from DFGAN. Consequently, the number of samples in each fault class was equal to that of the normal class. The augmented data were utilized to implement bearing fault diagnosis. Therefore, the training set included 300 samples (298 synthetic and 2 measured) from each sensor (excluding the normal state). The testing set for each health condition consisted of 100 real samples from each of the DE and FD sensors. The dataset is presented in Table 4.
The datasets for DE and FE sensors.
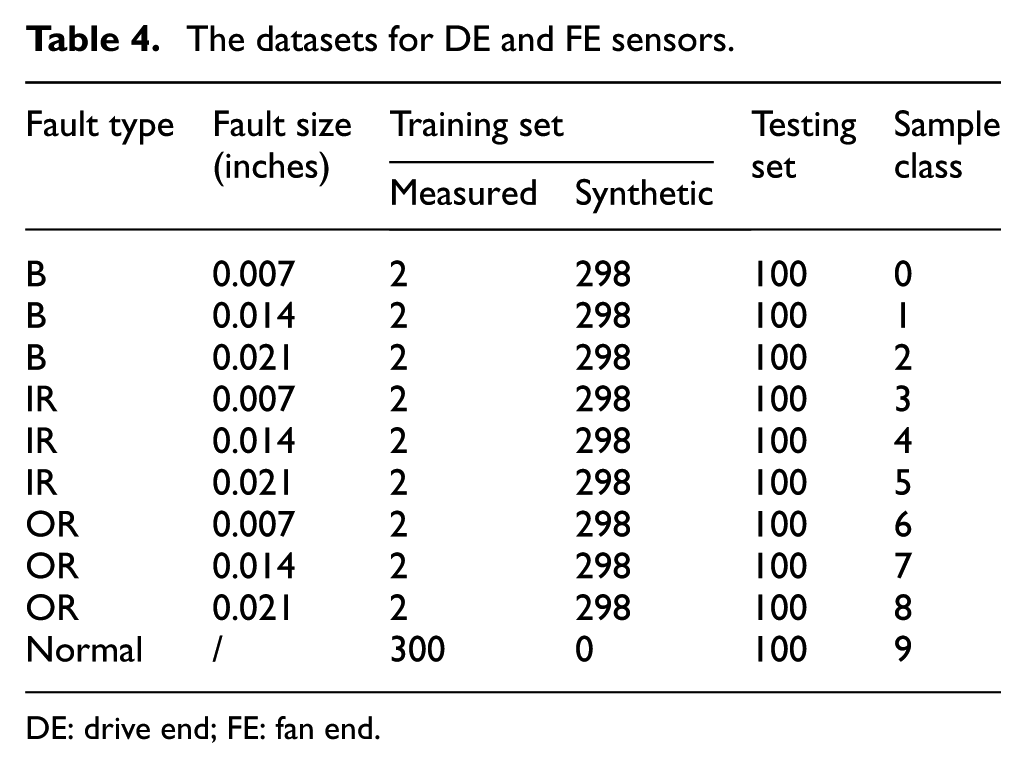
DE: drive end; FE: fan end.
Evaluation of synthetic samples
The data from the FE sensor are selected for analysis in this section to validate the synthetic samples obtained with DFGAN in each fault class on the CWRU dataset. As observed from Figure 11, the waveforms and spectrums of the synthetic samples were compared with those of the measured samples. Bearing faults induced periodic impulses in the waveforms. The synthetic and measured samples in each fault class demonstrated similar time-domain waveforms with the same intervals of impulses. In other words, the synthetic samples can accurately reflect the fault features of the measured samples in the time domain. In the frequency domain, the Pearson’s correlation coefficients Corr between the spectrums of the synthetic and the measured samples in each fault class reached more than 0.7, implying that the synthetic samples accurately reconstructed the frequency components of the measured samples. This also verified the validity of the LF on the CWRU dataset.
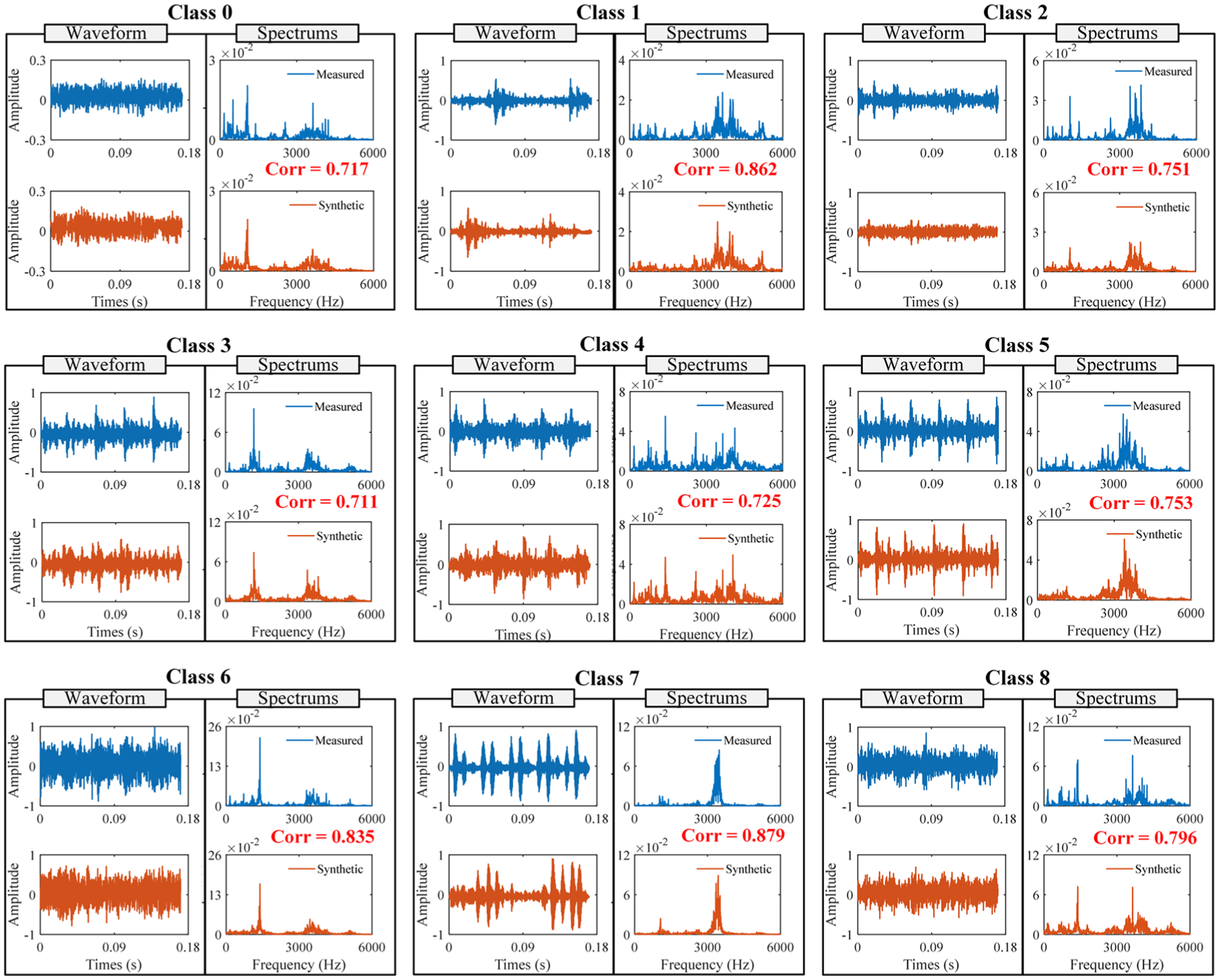
Waveforms and spectrums of the synthetic and measured samples corresponding to the FE sensor.
The quality of the synthesized samples is quantitatively analyzed. Maximum mean discrepancy (MMD) determines whether samples originate from the same data distribution by calculating their mean difference in a high-dimensional space. 30 A lower MMD value indicates a higher-quality synthetic sample. Using data from the FE sensor as an example, the MMD values of the synthetic samples obtained from different methods are displayed in Table 5. In most health conditions, the MMD value between the synthetic samples obtained from DFGAN and the measured samples is the lowest, indicating that the synthetic samples are of higher quality.
The MMD values of the synthetic samples corresponding to the FE Sensor.
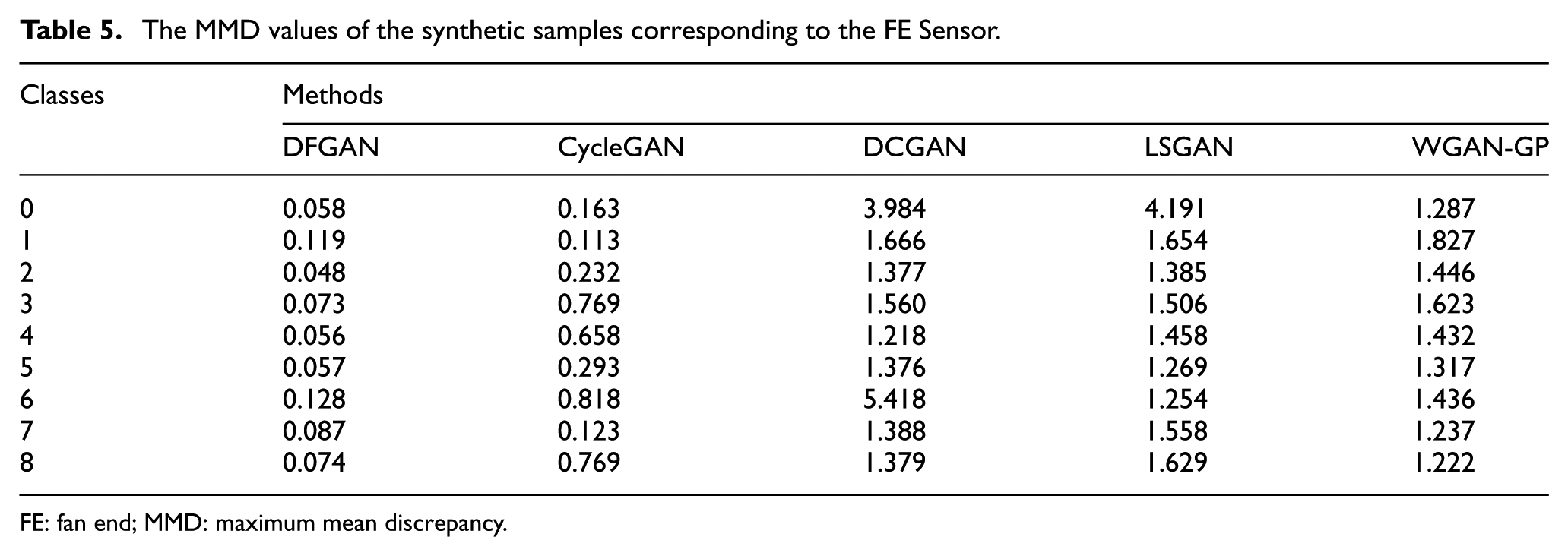
FE: fan end; MMD: maximum mean discrepancy.
Experimental results and discussion
The performance of the different methods was evaluated using the test samples, with the diagnostic results displayed in Figure 12 and Table 6. With a limited number of measured fault samples, MCNN achieved an average diagnostic accuracy of only 63.24%. Through DTs, DFGAN achieved a diagnostic accuracy of 99.96%, an improvement of 36.72% over MCNN. This reflects that simulated fault information from DT models helps improve the imbalanced fault diagnostic performance of bearings. In addition, WGAN-GP, LSGAN, DCGAN, and CycleGAN all enhanced the imbalanced multisensor data, exhibiting better performance than MCNN, with an average diagnostic accuracy of 82.66%, 89.65%, 90.70%, and 95.88%, respectively. Compared with the comparison methods, the DFGAN achieved the highest average diagnostic accuracy on the CWRU dataset, outperforming WGAN-GP, LSGAN, DCGAN, and CycleGAN by 17.30%, 10.31%, 9.26%, and 4.08%, respectively. The diagnostic results demonstrate the superiority of DFGAN. The standard deviation (SD) of the accuracy over 10 trials demonstrates the stability of the model. With a SD value of just 0.001, the proposed method exhibits superior stability than comparison methods. As suggested in Table 6, statistical analysis was performed on the diagnostic results. The 95% confidence intervals (CI) of different methods were calculated to verify the robustness of the proposed method. The 95% CI for DFGAN is [99.87, 100], which is the narrowest and does not overlap with those of the comparison methods. Hence, the performance improvements achieved by DFGAN are statistically significant with excellent robustness.
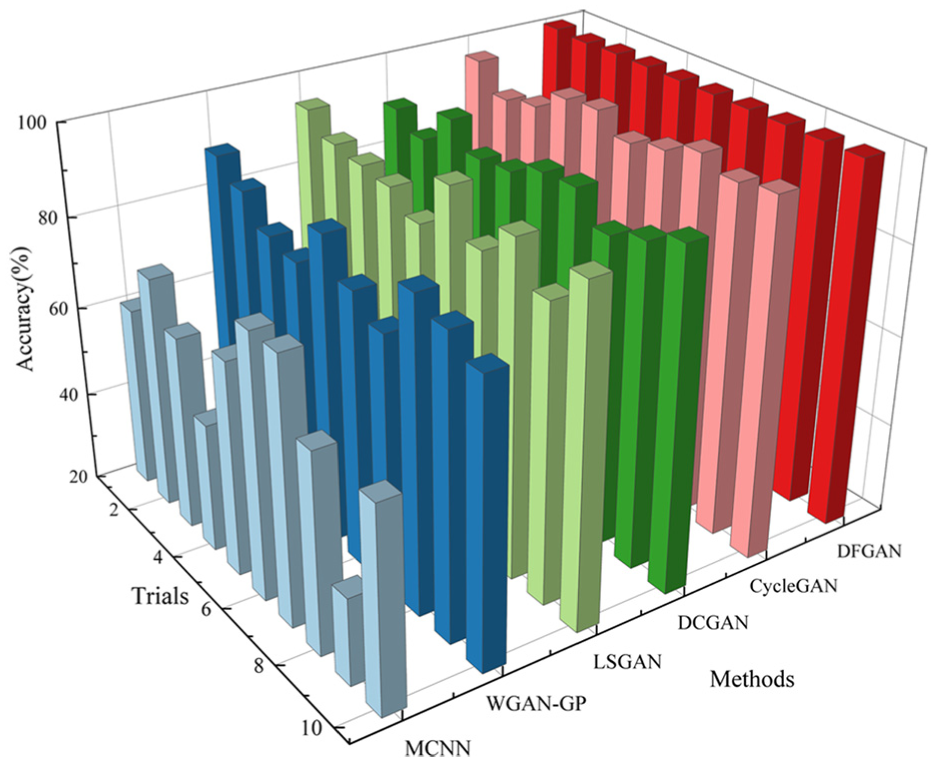
Diagnosis results for CWRU dataset.
Diagnosis accuracy for CWRU dataset.
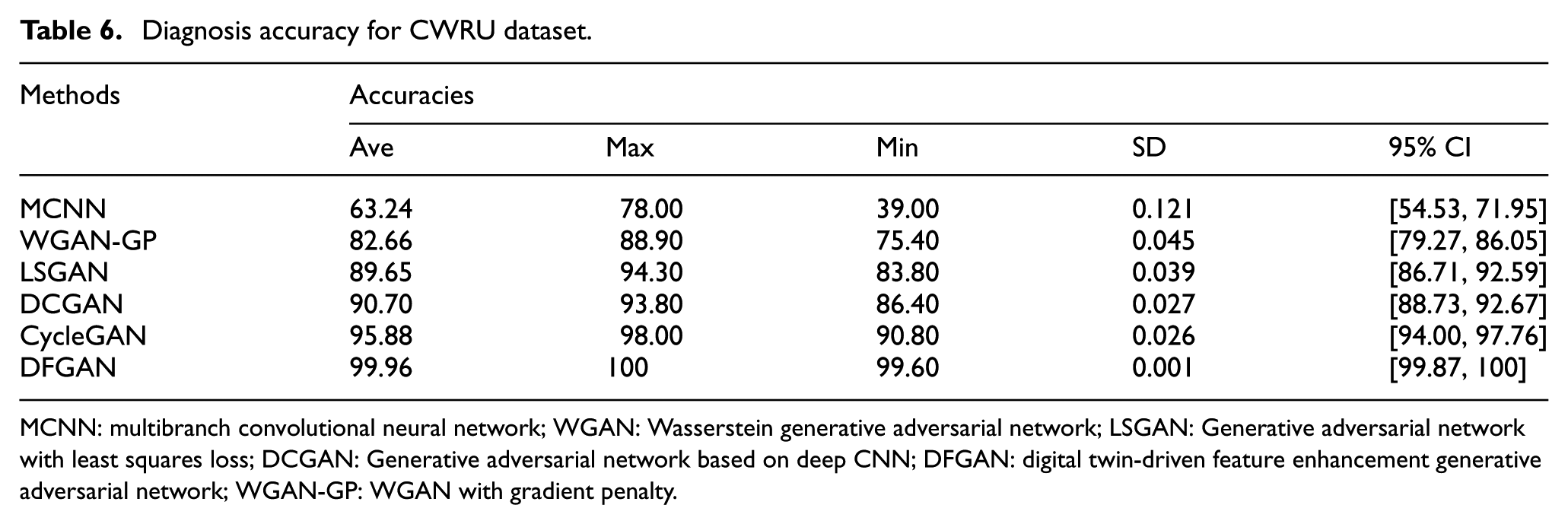
MCNN: multibranch convolutional neural network; WGAN: Wasserstein generative adversarial network; LSGAN: Generative adversarial network with least squares loss; DCGAN: Generative adversarial network based on deep CNN; DFGAN: digital twin-driven feature enhancement generative adversarial network; WGAN-GP: WGAN with gradient penalty.
The diagnostic results were visualized for further analysis, with the confusion matrices of the different methods displayed in Figure 13. Due to insufficient fault samples, MCNN achieved a diagnostic accuracy of over 80% only for classes 1, 2, 3, and 9. Given the low quality of the generated samples, the diagnostic accuracy of WGAN-GP for classes 2, 3, and 5 was only 69%, 70%, and 73%, respectively. As displayed in Figure 13(c) and (d), LSGAN and DCGAN achieved diagnostic accuracy of 48% and 70% for class 3, and the corresponding values for class 5 were 70% and 63%, respectively. In other words, neither LSGAN nor DCGAN can accurately identify samples from classes 3 and 5. In addition, CycleGAN identified 20% of class 0 samples as class 2. As illustrated in Figure 13(f), the highest diagnostic accuracy was achieved by DFGAN for all health conditions, further demonstrating the superiority of the proposed method.
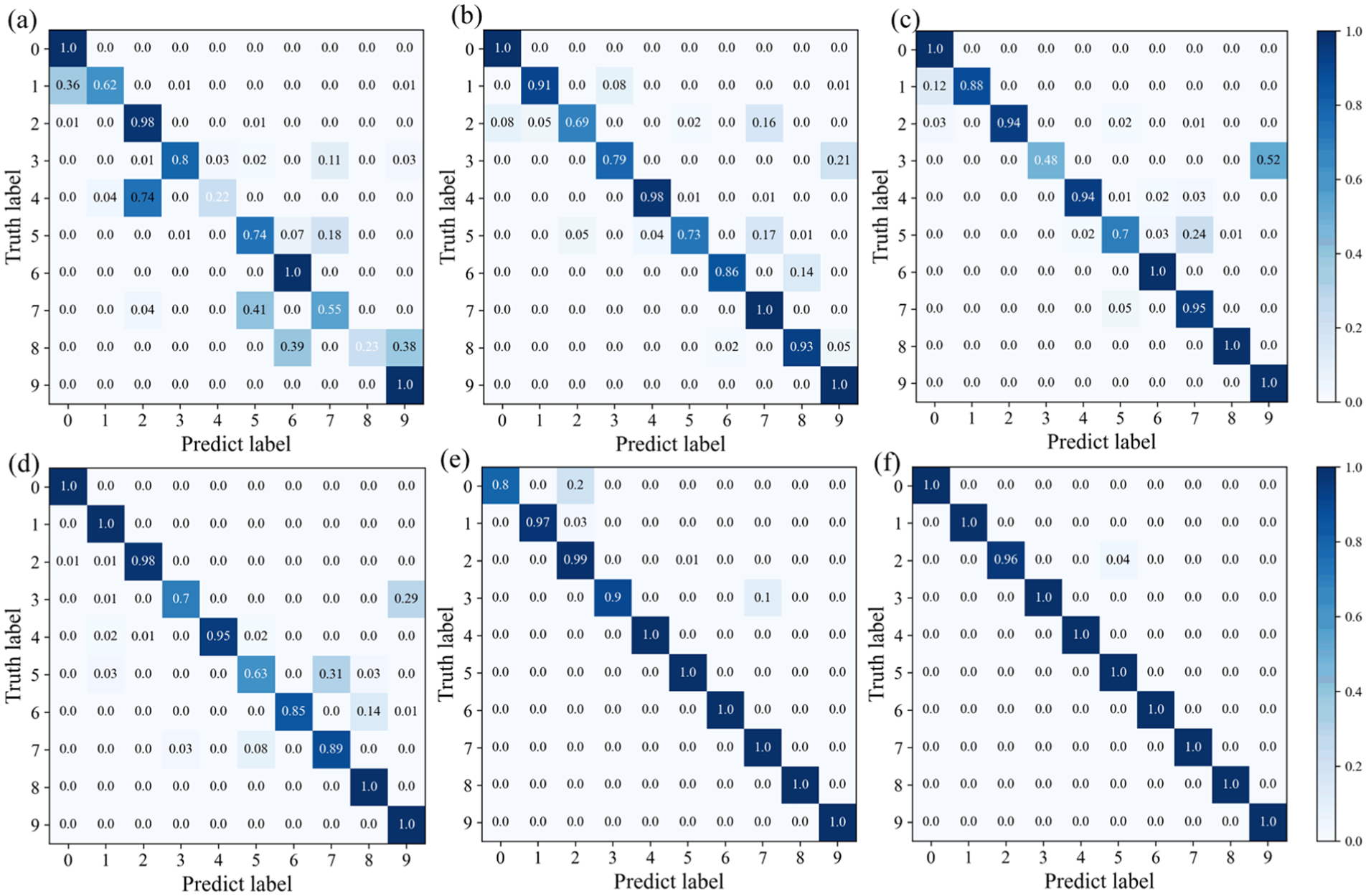
Confusion matrices for CWRU dataset: (a) MCNN, (b) WGAN-GP, (c) LSGAN, (d) DCGAN, (e) CycleGAN, and (f) DFGAN.
Analysis of synthetic samples with different number
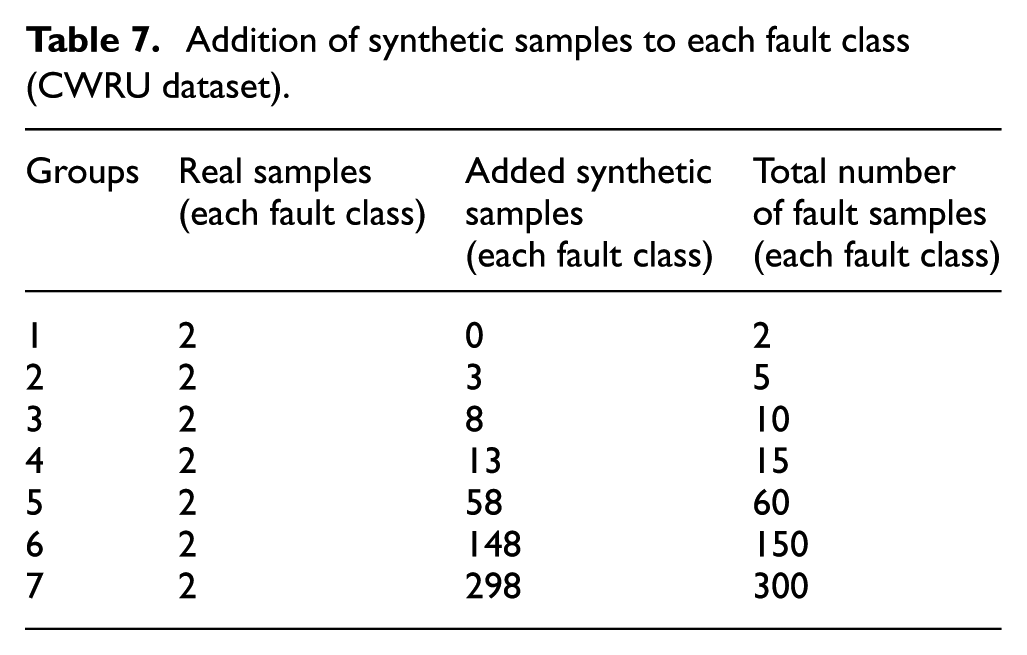
Sufficient samples in each health condition are essential for the diagnostic model to extract fault features and achieve reliable diagnostic results. In fault diagnosis, the difference in the number of normal and fault samples may introduce bias to the diagnostic model. As revealed in Table 7, the effect of the number of fault samples on the diagnostic performance was investigated by adding different numbers of synthetic fault samples to each fault class (Class 0–Class 9), which gradually restores the imbalanced data to the balanced state. The experimental setup is the same as in Section “Experimental results and discussion.” The diagnostic results are exhibited in Figure 14.
Addition of synthetic samples to each fault class (CWRU dataset).
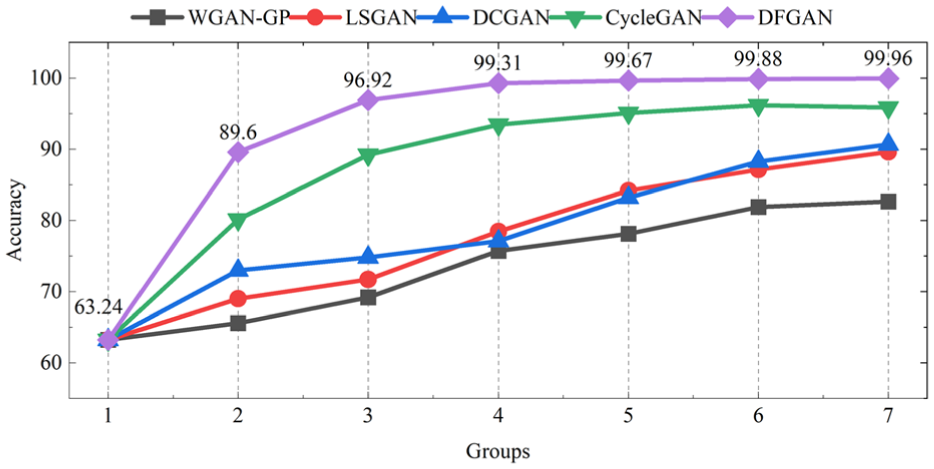
Diagnostic results with different numbers of synthetic samples added to each fault class (CWRU dataset).
Table 7 and Figure 14 reflect that the diagnostic accuracy corresponding to all methods increases as the number of synthetic samples increases. After 3, 8, 13, 58, 148, and 297 synthetic samples were added for each fault class, the proposed method achieved 89.60%, 96.92%, 99.31%, 99.67%, 99.6%, and 99.96% diagnostic accuracy, respectively. After the total number of fault samples for each fault class reached 15, the performance of the proposed method tended to stabilize, with diagnostic accuracies all over 99%. Compared to the comparison methods, the proposed method reached the highest diagnostic accuracy under the addition of different synthetic samples, demonstrating the superiority of the proposed method.
Case2: Self-built (AHU) dataset
Description and processing of dataset
The effectiveness of the proposed method is also verified by the dataset obtained from the self-built test bench (AHU dataset). The structure and parameters of test bench are displayed in Figure 15 and Table 1. To simulate different health conditions, faults were introduced separately on the inner and outer races. In addition, a multifault was simulated by introducing faults on the roller and inner race simultaneously. Vibration signals were acquired via accelerometers mounted in the horizontal and vertical directions of the test bearings, with a sampling frequency of 20 kHz.

Structure of the test bench for NSK 6012 bearing.
As in Case 1, the dataset was split using the sliding window method, with each sample containing 2048 consecutive data points. Two measured samples from the vertical accelerometer (VA) and horizontal accelerometer (HA) were randomly selected to train DFGAN to generate synthetic samples. Therefore, as illustrated in Table 8 for each health condition, the training set consisted of 298 synthetic samples and 2 measured samples per sensor, except for the normal state.
Datasets for VA and HA accelerometers.
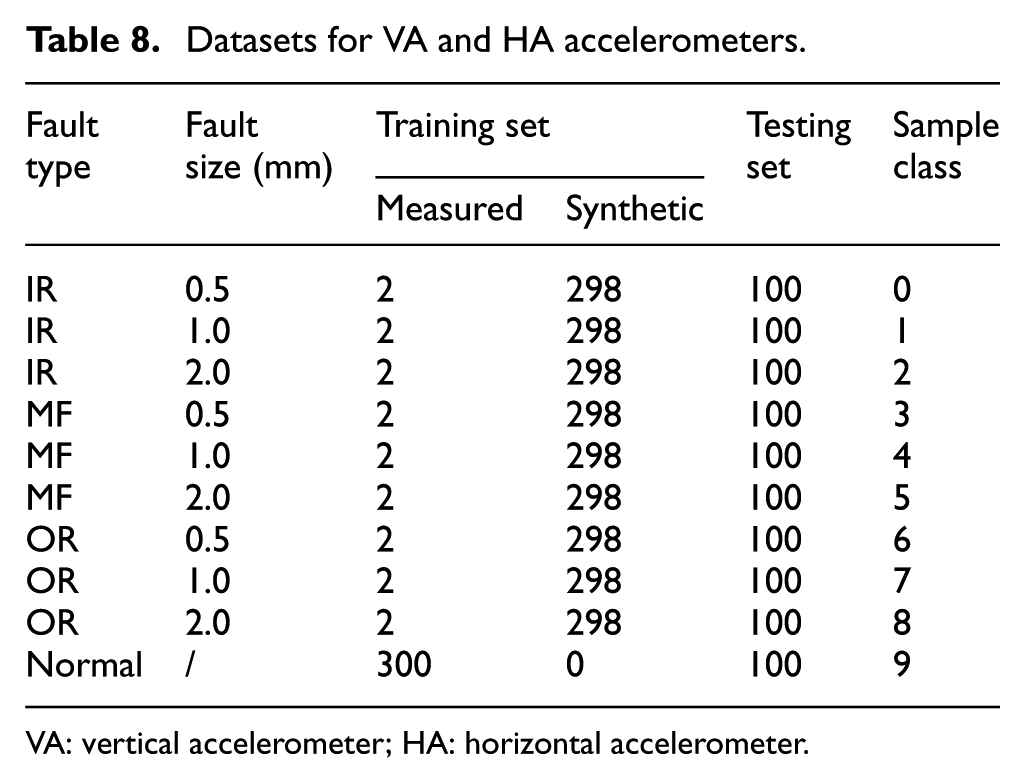
VA: vertical accelerometer; HA: horizontal accelerometer.
Evaluation of synthetic samples
In this section, the quality of the synthetic samples is assessed by analyzing the data from the VA accelerometer on the AHU dataset. As observed from Figure 16, the waveforms and spectrums of the synthetic samples were compared with those of the measured samples. In the time domain, bearing faults induced obvious periodic impulses in the waveforms. It can be obviously that both the synthetic and the measured samples have similar time-domain waveforms and the same intervals of impulses in each fault class, which indicates that the synthetic samples can accurately reflect the time-domain fault features of the measured samples. In the frequency domain, the Pearson’s correlation coefficients Corr between the spectrums of the synthetic and the measured samples in each fault class reach more than 0.7, which indicates that the synthetic samples accurately reconstruct the frequency components of the measured samples, and proves the validity of the LF on the AHU dataset.
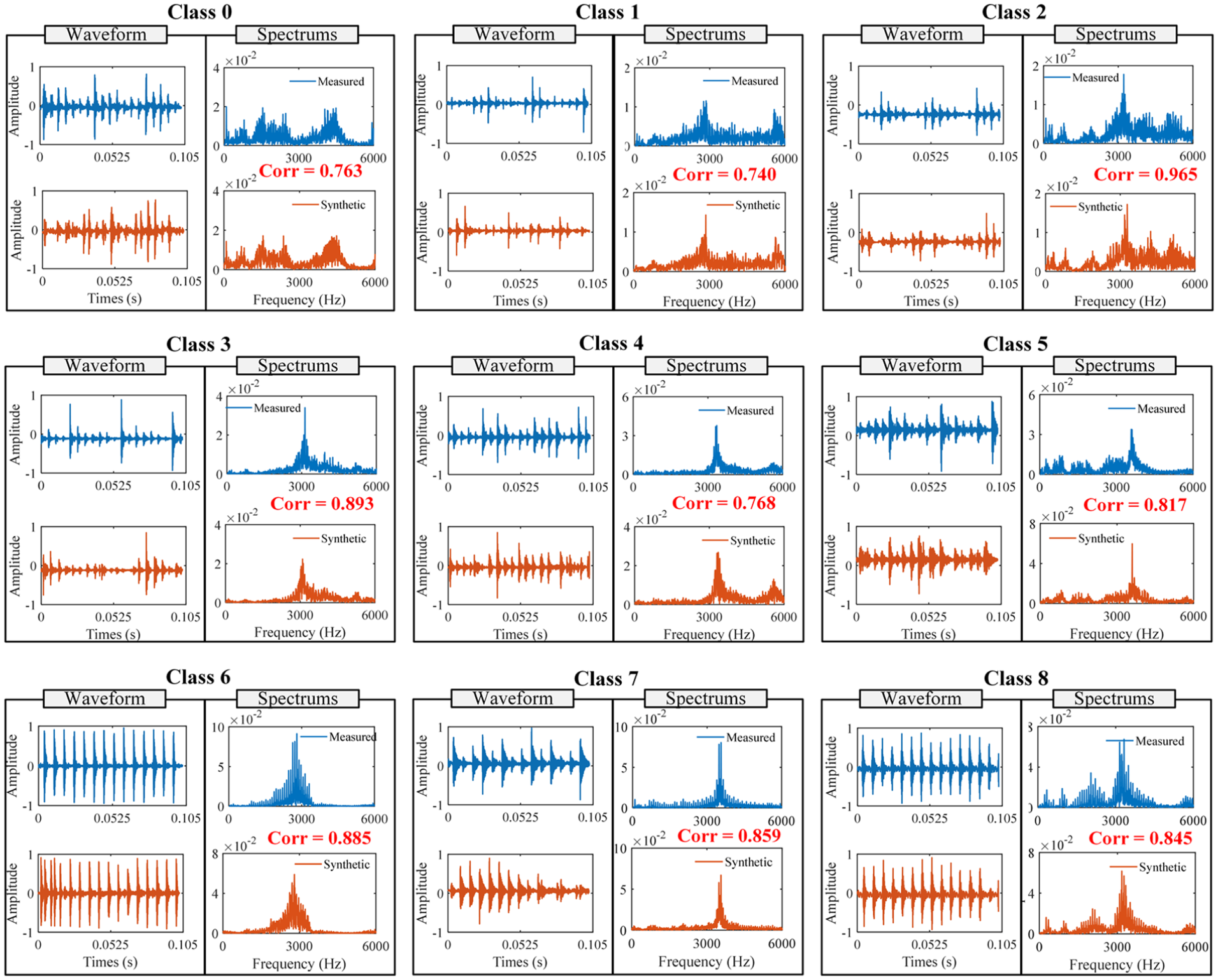
Waveforms and spectrums of synthetic and measured samples corresponding to VA accelerometers.
To assess the quality of the synthetic samples, data from the VA sensor were employed to generate synthetic samples by WGAN-GP, LSGAN, DCGAN, CycleGAN, and DFGAN. The MMD values between the synthetic and real samples are presented in Table 9. The synthetic samples generated by DFGAN exhibited the lowest MMD values for all fault conditions, indicating that their data distribution was closest to that of the measured samples.
MMD values of synthetic samples corresponding to VA accelerometers.
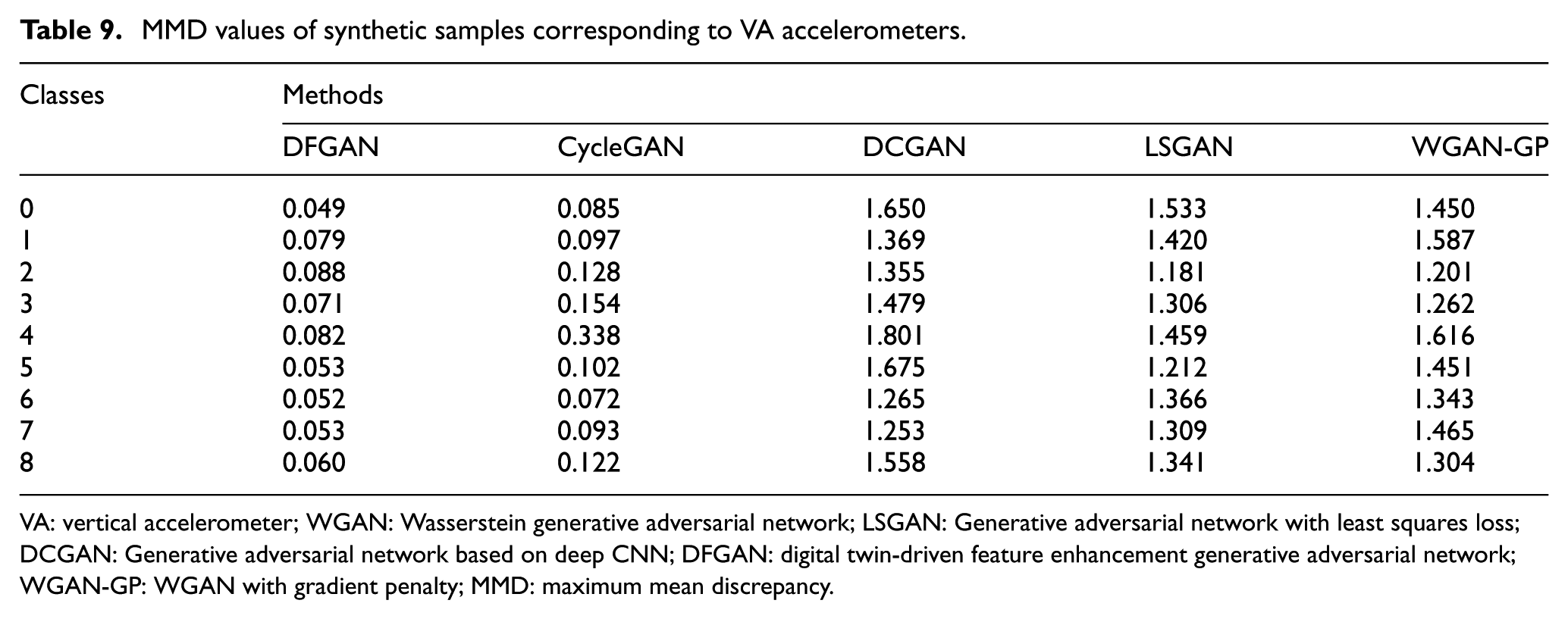
VA: vertical accelerometer; WGAN: Wasserstein generative adversarial network; LSGAN: Generative adversarial network with least squares loss; DCGAN: Generative adversarial network based on deep CNN; DFGAN: digital twin-driven feature enhancement generative adversarial network; WGAN-GP: WGAN with gradient penalty; MMD: maximum mean discrepancy.
Experimental results and discussion
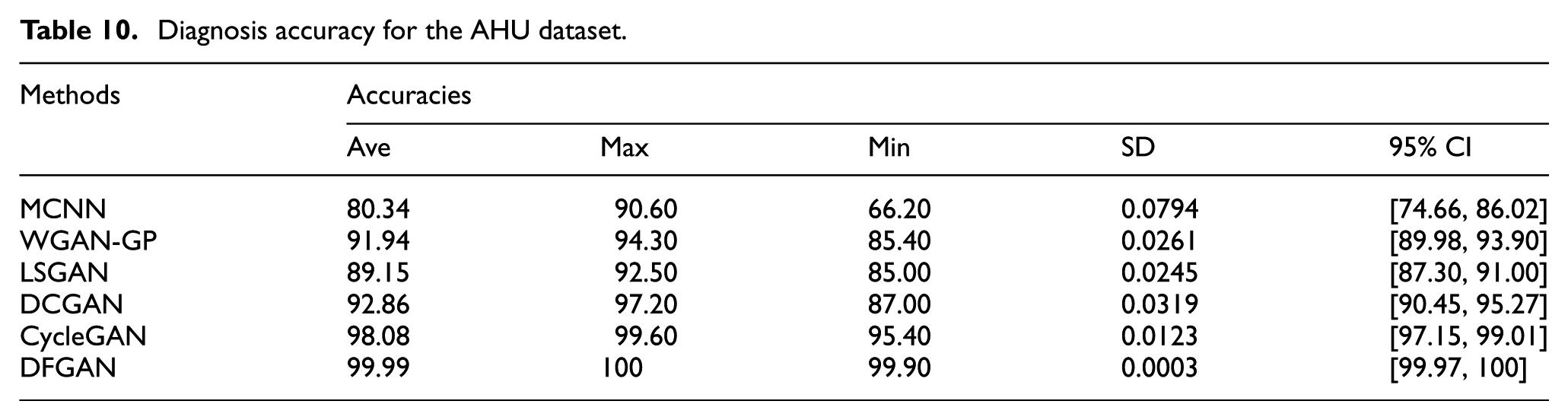
Using the imbalanced data from the VA and HA sensors, the diagnosis results obtained are displayed in Figure 17 and Table 10. MCNN, WGAN-GP, LSGAN, DCGAN, and CycleGAN achieved average accuracies of 80.34%, 91.94%, 89.15%, 92.86%, and 98.08%, respectively, all of which are lower than the average accuracy (99.99%) of DFGAN, demonstrating the superiority of the latter. With the assistance of DT, the diagnostic accuracy of DFGAN was improved by 36.72% on the AHU dataset compared to MCNN. This suggests that the fault information embedded in DT models based on real physical mechanisms can effectively enhance the performance of diagnostic models. In addition, after 10 trials, the SD of the experimental accuracies of MCNN, WGAN-GP, LSGAN, DCGAN, CycleGAN, and DFGAN was 0.0794, 0.0261, 0.0245, 0.0319, 0.0123, and 0.0003, respectively, indicating that DFGAN exhibited more stable diagnostic performance. The 95% CI for the diagnostic results of DFGAN on the AHU dataset is [99.97, 100], which is the narrowest and does not overlap with those of the comparison methods. In other words, the performance of DFGAN has excellent robustness.
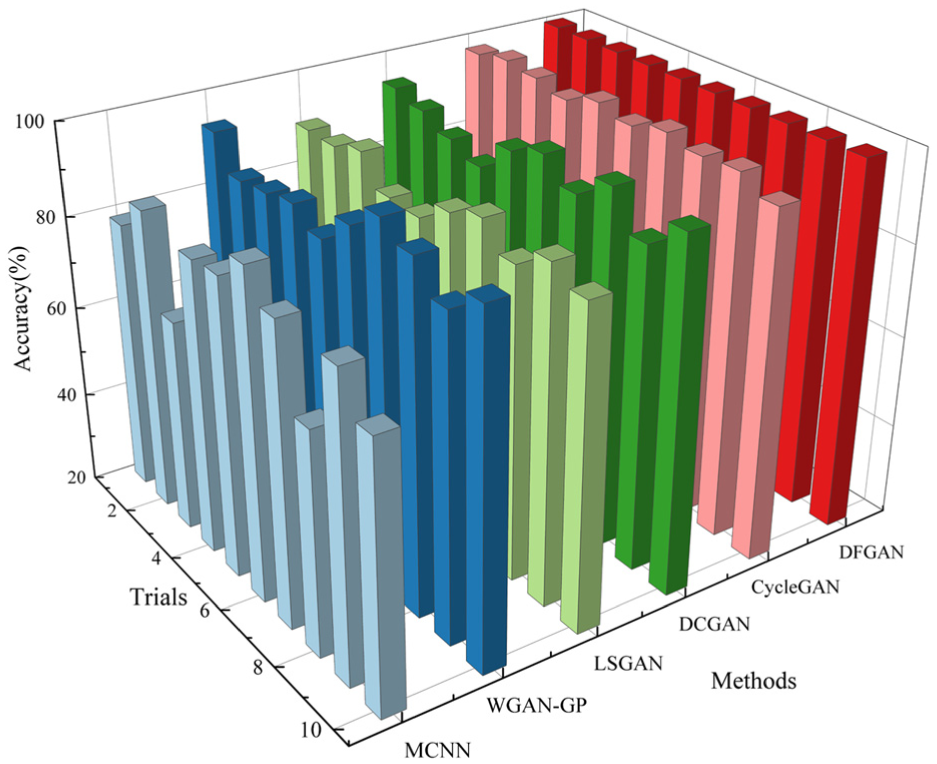
Diagnosis results for AHU dataset.
Diagnosis accuracy for the AHU dataset.
As Figure 18(a) shows, the diagnostic accuracy for class 0 was only 27%, while that for class 7 was as low as 17%, the performance of MCNN was much lower than that of the other methods. As illustrated in Figures. 18(b) to (e), the diagnostic performance of WGAN-GP, LSGAN, DCGAN, and CycleGAN was directly affected by the poor quality of the synthetic samples that they generated. WGAN-GP has low diagnostic accuracy for test samples from class 1 and class 4, only 64% and 63%, respectively. LSGAN and DCGAN achieved diagnostic accuracy of 35% and 73% for class 0, and the corresponding values for class 8 were 66% and 78%, respectively. This implies that neither LSGAN nor DCGAN can accurately identify samples from classes 3 and 5. CycleGAN also struggled to accurately distinguish test samples from class 4 (78%). In contrast, Figure 18(f) demonstrates that DFGAN achieved the highest diagnostic accuracy across all fault conditions, demonstrating its superior generalization performance.
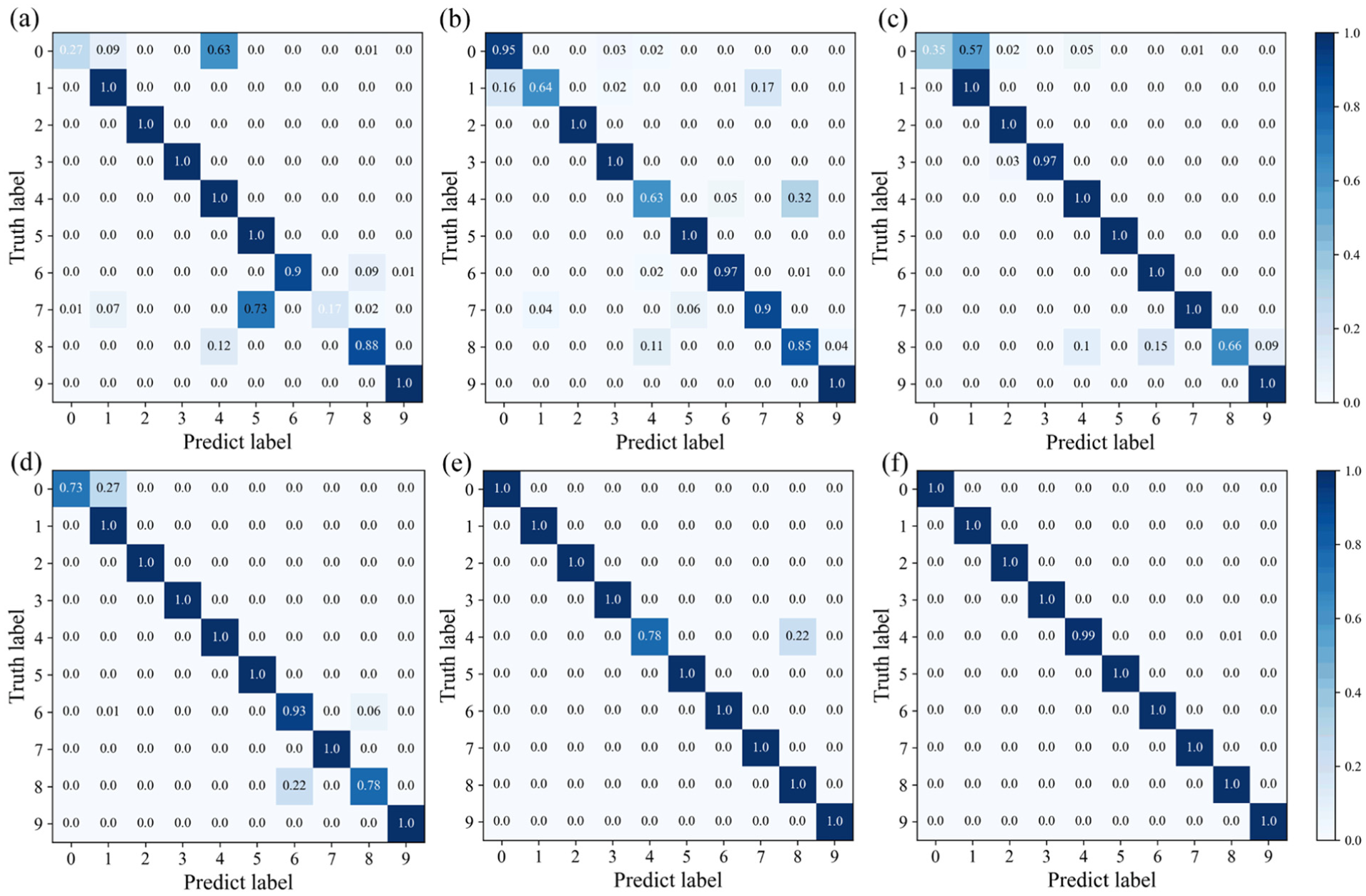
Confusion matrices for AHU dataset: (a) MCNN, (b) WGAN-GP, (c) LSGAN, (d) DCGAN, (e) CycleGAN, and (f) DFGAN.
Analysis of synthetic samples with different number
The insufficient samples of a minority class (Class 0–Class 9) are augmented through synthetic samples obtained by different methods, respectively, to investigate the effect of the number of samples on the classifier performance. The imbalanced data are gradually restored to the equilibrium state. As presented in Table 11, the number of synthetic samples added to each fault class is 3, 8, 13, 58, 148, and 298, respectively, and the classifier performance is tested by the augmented data with the same experimental setup as in Section “Experimental results and discussion.”
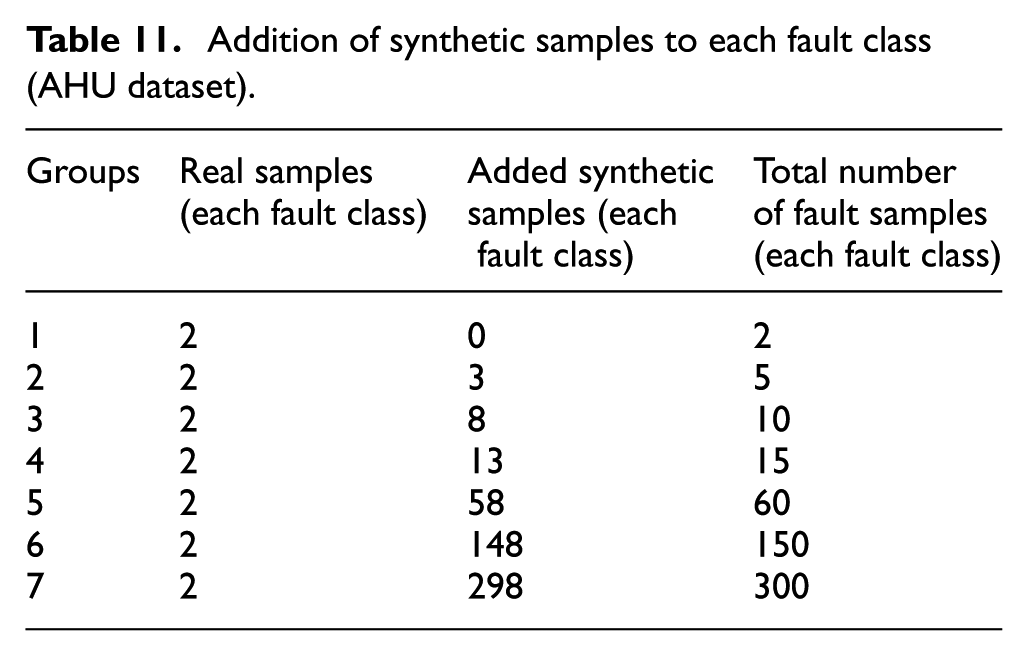
Addition of synthetic samples to each fault class (AHU dataset).
The diagnostic results obtained by adding different numbers of synthetic samples are illustrated in Figure 19. Similar to the diagnostic results obtained on the CWRU dataset, the diagnostic accuracy corresponding to all the methods on the AHU dataset is improved as the number of synthetic samples increases. Compared to the comparison method, the diagnostic accuracies achieved by the proposed method with different numbers of synthetic samples are 95.96%, 96.70%, 99.41%, 99.85%, 99.98%, and 99.99%, respectively, which are all better than the corresponding values of the comparison method. After the total number of fault samples for each fault class reaches 15, the performance of the proposed method tends to stabilize, with diagnostic accuracies all over 99%. To sum up, even a small number of synthetic samples obtained with DFGAN can achieve good diagnostic accuracy, which proves the superiority of DFGAN.
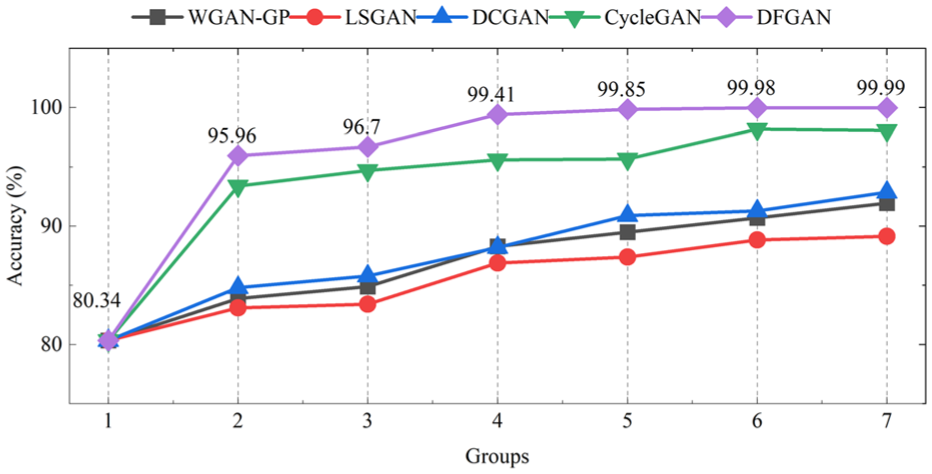
Diagnosis accuracy with different number of added fault samples in each fault class (AHU dataset).
Summary of diagnostic results on Case 1 and Case 2
The CWRU dataset and AHU dataset contain 10 types of fault data of SKF 6203 and NSK 6012 bearings, respectively, to verify the generalization ability of the DFGAN. Different from the CWRU dataset, the AHU dataset obtained the compound fault data of rollers and inner raceway through a self-built test bench. Compared to comparison methods, DFGAN achieved the lowest MMD between synthetic and measured samples across all fault classes on both datasets, demonstrating the effectiveness of synthetic samples generated by DFGAN. Using synthetic samples to augment imbalanced data, DFGAN exhibited superior performance on both the CWRU and AHU datasets. Moreover, it achieved diagnostic accuracies of 99.96% and 99.99%, respectively, significantly outperforming existing comparison methods. Additionally, the increase in the number of added synthetic samples contributes to the improved diagnostic performance. Diagnostic results indicate that the performance of DFGAN stabilizes on both datasets once the total number of samples for each fault class reaches 15.
Parameter analysis
The above results specify that DFGAN achieve the best diagnostic results on both CWRU and AHU datasets compared with the comparison method. However, the training parameters of DFGAN may affect its ability to synthesize fault sample generation. In this section, the merits of the proposed method are further verified from two perspectives: hyperparameter tuning and the number of measured fault samples for training.
Hyperparameter tuning
Analysis of learning rate lr
The learning rate (lr) is a critical hyperparameter that directly influences the final performance of DFGAN. While the models with large learning rates may skip the optimal solution, too small learning rates may not allow the model to converge quickly. With the purpose of determining the optimal learning rate of DFGAN, Adam is selected for model parameter optimization algorithms, and the cosine annealing algorithm is employed to update the lr. Meanwhile, the initial lr of DFGAN is set in the range of 5e−6 to 5e−3 to obtain synthetic samples and augment the dataset. The diagnostic results of the two datasets at different learning rates are illustrated in Figure 20(a).
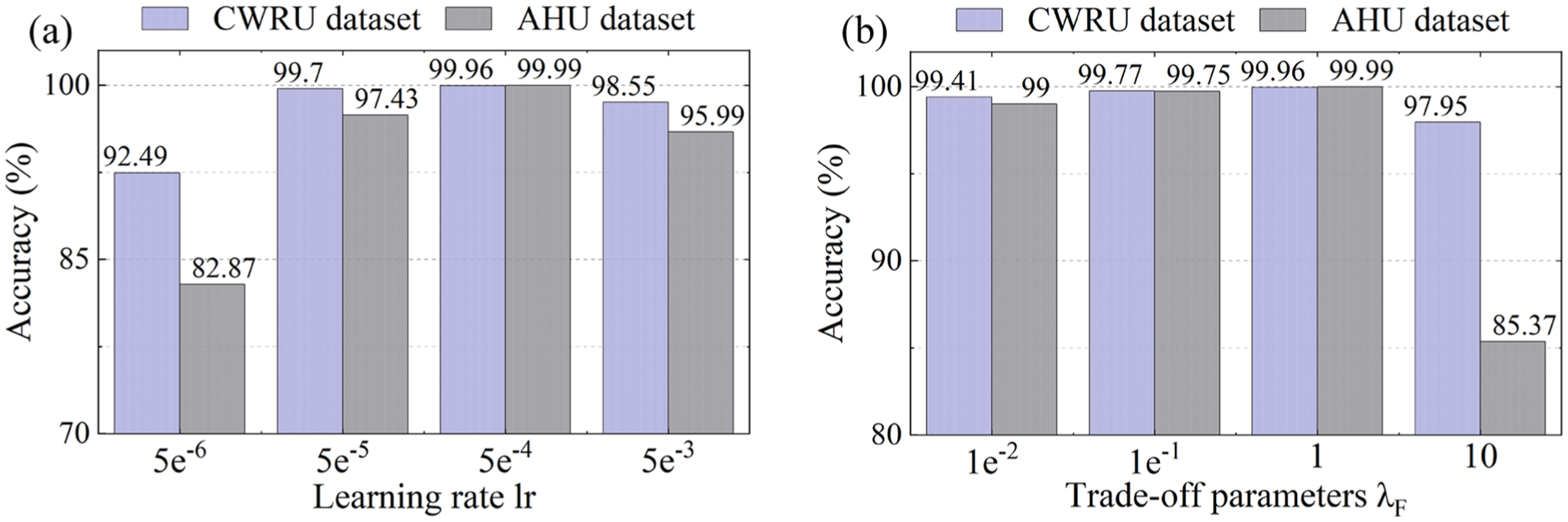
The diagnostic accuracy obtained by DFGAN of CWRU and AHU datasets with different hyperparameters: (a) learning rate lr, (b) trade-off parameter λF.
Figure 20(a) suggests that the imbalanced fault diagnosis accuracies on both CWRU and AHU datasets first increase and then decrease with the continuous increase in lr. Thus, both too large and too small learning rates can bring about a decrease in fault diagnosis accuracy. The effect of the learning rate lr on the diagnostic results of the AHU dataset is significantly larger than that of the CWRU dataset. When lr is equal to 5e–5, the proposed method achieves the highest diagnostic accuracy on both the CWRU and AHU datasets; therefore, it is reasonable to set the value of the learning rate lr to 5e−5.
Analysis of trade-off parameter λF
The spectral correlation loss LF is adopted to achieve the alignment of the synthetic and measured sample distributions in the frequency domain. The trade-off parameter λF of the LF impacts the DFGAN training. Therefore, the trade-off parameter λF is set to increase sequentially to find the optimal λF. In this section, the λF is set in the range of 1e−2 to 10 to obtain the synthetic samples and augment the dataset. The diagnostic results of the two datasets under different values of trade-off parameter λF are depicted in Figure 20(b).
As observed from Figure 20(b), the fault diagnosis accuracies on both the CWRU and AHU datasets first increase and then decrease as the λF continues to increase. When λF is equal to 1, the proposed method achieves the highest diagnostic accuracy on both CWRU and AHU datasets.
Number of measured fault samples for training
DFGAN can be applied to obtain synthetic fault samples and augment insufficient fault data. The augmented data can be adopted to adequately train the diagnostic model. All the above diagnostic results are obtained with DFGAN trained by two measured samples in each fault class (an imbalance ratio of 1:150). However, the number of measured fault samples also affects the performance of DFGAN. DFGAN is trained with 1, 2, and 4 measured fault samples in each fault class, which corresponds to imbalance ratios of 1:300, 1:150, and 1:75, respectively, to verify the robustness of the proposed method in extreme imbalance scenarios. The accuracies achieved by the diagnostic model on the two datasets with different numbers of real fault samples are detailed in Table 12.
Diagnostic accuracy with different numbers of measured fault samples.
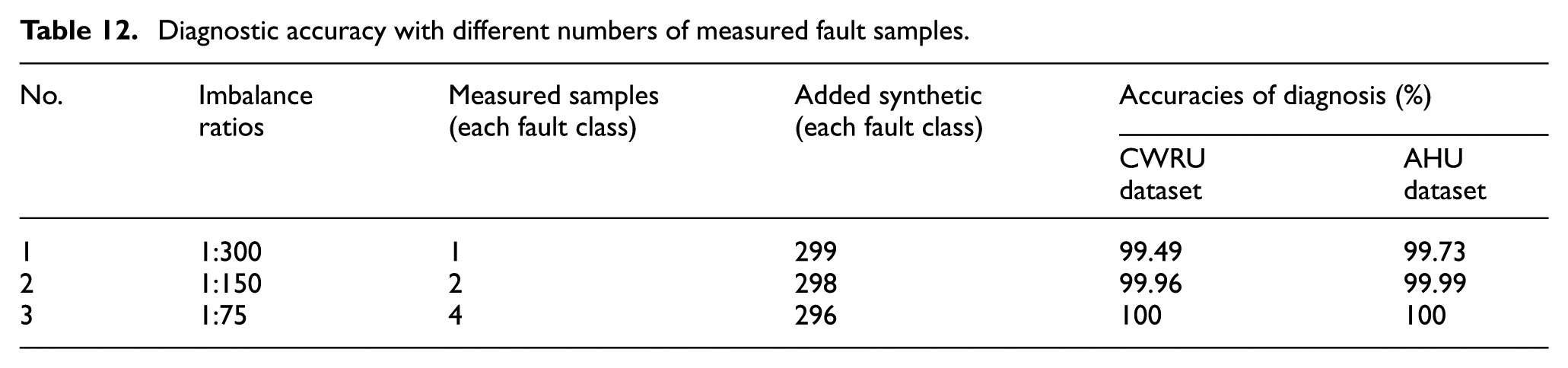
Table 1 reflects that, regarding the CWRU dataset, training DFGAN with 1, 2, and 4 measured samples in each fault state achieved diagnostic accuracies of 99.49%, 99.96%, and 100%, respectively, and the corresponding values for the AHU dataset were 99.73%, 99.99%, and 100%. The diagnostic accuracies of both CWRU and AHU datasets exceed 99% for different numbers of measured samples, verifying that the proposed DFGAN still maintains excellent performance in extreme imbalance scenarios. Furthermore, the diagnostic accuracies on both datasets surpass 99.9% when the number of measured samples for training the DFGAN exceeds 2, indicating the stable performance of the proposed method.
Ablation studies
DFGAN is multioptimized by the DT model, spectral correlation loss LF, MCNN, and SEU-Net to obtain synthetic samples for use in augmenting the imbalanced data. In this section, four sets of imbalance fault diagnosis experiments are designed for ablation studies to demonstrate the necessity of the model design and evaluate the contribution of each part, so as to improve the model performance:
DFGAN without SEU-Net [M1]: ResNet 54 is used instead of SEU-Net as the structure of the DFGAN generator to investigate the impact of SEU-Net with multiple feature fusion layers on the model performance.
DFGAN without LF [M2]: Spectral correlation loss LF is removed from the loss function of DFGAN, and the alignment of the distribution of synthetic fault samples with measured fault samples in the frequency domain is ignored.
DFGAN without MCNN [M3]: A traditional CNN is employed to construct the classifier only through the data from a single sensor. Concerning the CWRU dataset, the data from FE sensors are selected for analysis. Regarding the AHU dataset, the data from the VA accelerometers dataset are selected for analysis.
DFGAN [M4]: In a control experiment, all parts are used to optimize DFGAN.
The setup of each experiment is the same as in Sections “Case1: CRUW dataset” and “Case2: Self-built dataset (AHU dataset), and only two measured samples are adopted to train the DFGAN for each fault class. All experiments are repeated 10 trials to minimize the error. The corresponding diagnostic results on the CWRU and AHU datasets are summarized in Table 13.
Diagnostic results of ablation studies.

Effectiveness of SEU-Net
In this section, the effectiveness of SEU-Net on the diagnostic model is investigated. The DFGAN without SEU-Net is compared with the DFGAN to evaluate the contribution of SEU-Net. The fault diagnosis results are summarized in Table 13. Compared with DFGAN without SEU-Net, the DFGAN achieves higher average accuracies, with 1.66% and 1.03% enhancements on the CWRU and AHU datasets, respectively. This enhancement is attributed to the effective extraction and deep fusion of fault information in the simulated samples by SEU-Net. Moreover, the simulated fault information is fully retained in the synthetic samples.
Contribution of spectral correlation loss LF
DFGAN without LF is compared with DFGAN to assess the contribution of the LF, with the fault diagnosis results listed in Table 13. Specifically, the diagnosis accuracy of DFGAN on the CWRU and AHU datasets is improved by 1.18% and 1.05%, respectively, with the assistance of LF. This is because the DFGAN training dynamics are guided by LF, which improves the alignment of the synthetic samples with the measured samples in the frequency-domain distribution.
Effects of MCNN
In this section, the effect of the MCMM part is evaluated by comparing the DFGAN with the DFGAN without MCNN. The fault diagnosis results are summarized in Table 13, suggesting that DFGAN achieves a higher average accuracy compared to DFGAN without MCNN, with an enhancement of 0.59% and 0.42% on the CWRU and AHU datasets, respectively. This enhancement stems from the effective multisensor feature information extracted by branch CNNs in MCNN. The effective utilization of multisensor data improves the performance of learning fault feature representation.
Conclusion
To enhance the diagnostic accuracy of rolling bearings under imbalanced data, a DT-driven fault diagnosis method is proposed in this article. To generate simulated signals that obtain the dynamic response features of the system, a generic high-fidelity DT model with multiple DOFs is established using the lumped parameter method, employing fault and structure parameters as inputs. DFGAN is introduced to transform simulated fault samples from the DT model into synthetic samples with a data distribution similar to that of measured samples. The DFGAN generator is reconstructed with feature fusion layers, which extract and deeply fuses fault features from simulated samples. A spectral correlation loss based on the Pearson’s correlation of the spectra is designed, which reduces the discrepancy between synthetic and measured samples in the frequency domain. Subsequently, synthetic samples of the measured fault signals are employed to augment the imbalanced multisensor data, achieving imbalanced fault diagnosis of bearings.
The results of the quantitative analysis of the synthetic samples reveal that the proposed DFGAN obtained the lowest value of MMD between the synthetic and the measured samples compared to the existing advanced methods. Thus, the synthetic samples obtained by the proposed method exhibited superior quality compared to those obtained by existing advanced methods. Given two measured samples in each fault class, the proposed method achieved 99.96% and 99.99% diagnostic accuracies on the datasets of CWRU and AHU, respectively. The experimental results verified the superiority of the proposed method, which can significantly improve diagnostic accuracy and provide superior performance in imbalanced fault diagnosis for bearing systems. Furthermore, the results of ablation studies unveil that all parts of DFGAN can improve the diagnostic performance under imbalanced multisensor data, specifying the effectiveness of the model design. However, the simulation accuracy of vibration signals must be improved. In addition, the performance of GAN-based sample generation methods is low when the number of samples is insufficient, resulting in large discrepancies between generated synthetic samples and measured samples. Addressing these challenges will be a key focus in future research.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Anhui Province Science and Technology Tackling Key Problems Project (No. 202423i08050021), Anhui Province Key Research and Development Plan (No. 202304a05020058), Anhui Province Natural Science Foundation excellent youth project (No. 2408085Y029), National Natural Science Foundation of China (No. 52575087).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.