
Abstract
Accurate prediction of the remaining useful life (RUL) of aircraft engines is critical for predictive maintenance and operational reliability. It enables airlines to plan maintenance operations, thereby avoiding unexpected failures and unnecessary unscheduled downtime. Through the use of sensor signals and complex deep learning models, RUL estimation ensures safety, maximizes engine utilization, and saves on maintenance costs. This work addresses the fundamental problem of precisely forecasting the RUL of aircraft engines based on NASA’s Commercial Modular Aero-Propulsion System Simulation (NASA C-MAPSS) dataset, which has modeling difficulties, including truncated RUL labels, operational regime shifts, nonlinear degradation patterns, and sensor redundancy, which makes conventional modeling approaches inadequate. To overcome these obstacles, this paper proposes a novel transformer-based dual-input model (TDIM), which effectively integrates raw sensor sequences and aggregated statistical features through a parallel encoding design. The TDIM is evaluated against the state-of-the-art architectures on the NASA C-MAPSS turbofan engine degradation dataset. Experimental results demonstrate that the TDIM significantly outperforms the existing baselines, achieving an
Introduction
The advent of smart industrial systems has led to the increased usage of new technologies like artificial intelligence (AI), machine learning (ML), and sensor-based monitoring. These technological advancements are essential in transforming conventional maintenance strategies into more proactive and intelligent methods.1,2 Among their most impactful applications is predictive maintenance (PdM), which focuses on anticipating equipment failures before they occur.3,4 According to McKinsey & Company, PdM can save 30%–50% in machine downtime and extend machine life by 20%–40%, resulting in an improvement in productivity and cost reduction. 5 It not only reduces unplanned downtimes and maintenance but also improves operational safety and reliability.6,7 A key activity in PdM is the precise calculation of an asset’s remaining useful life (RUL), which is the time remaining until the system declines below a functioning limit. In safety-critical industries such as aerospace, power generation, and transportation, prediction of RUL is critical to scheduling maintenance and mitigating risk.8,9 According to Deloitte, precise RUL forecasting is important, as sudden equipment breakdowns are the cause of almost 42% of unplanned downtime in industrial environments. 10 Aircraft turbofan engines, being safety-critical and expensive assets, are prime candidates for PdM systems. For instance, engine failures on aircraft have disastrous outcomes; hence, accurate prediction of RUL facilitates proactive action and optimizes asset availability. 11 With the proliferation of high-resolution sensor data from sophisticated machines, there is a mounting need for resilient AI-based models that can learn from time-series signals under diverse operation conditions.12–15
To realize these objectives, modern industrial PdM architectures combine Industrial Internet of Things (IIoT)-enabled devices and industrial sensors using standardized protocols to sense and forward data to a central core engine. The core engine processes raw data, and then, data are sent through a user interface layer that includes modules such as asset managers, alarms, schedulers, and user managers to yield actionable insights and facilitate intuitive decision-making in industrial environments.16–18
However, with the rise of IIoT and the availability of high-frequency, multivariate sensor data from industrial machinery, several challenges have emerged. These industrial subsets are typically high-dimensional, nonstationary, noisy, and exhibits complex temporal dynamics. These characteristics make it difficult to model and extract meaningful patterns using conventional statistical methods. Therefore, in recent years, ML and deep learning (DL) approaches have been widely used to overcome these restrictions. Recurrent neural networks (RNNs) have demonstrated considerable potential in capturing long-range dependencies in time-series data, especially long short-term memory (LSTM) networks and their bidirectional variations (BiLSTM).19,20 More recently, transformer architectures, initially developed for natural language processing, have proved to be superior at sequential modeling tasks by exploiting attention mechanisms in order to access global context.
One prominent benchmark for data-driven prognostics research is the NASA Commercial Modular Aero-Propulsion System Simulation (NASA C-MAPSS) turbofan engine dataset, or rather its FD001 subset, representing simulated turbofan engine degradation paths under controlled operational conditions.21–25 The C-MAPSS dataset is a computer-simulated run-to-failure dataset for aircraft jet engines, commonly used for the progress and validation of RUL prediction models. It provides time-series sensor data for multiple engines under various fault modes and operating conditions and has spurred numerous studies in developing prognostic algorithms.26,27 However, its complex temporal dependencies, high dimensionality, and noise level pose challenges for conventional ML approaches.
To address this, various DL models have been investigated such as RNNs, and especially the LSTM and BiLSTM architectures proved very capable of capturing long-range dependencies. More recently, transformer-based architectures, relying on self-attention mechanisms, reached state-of-the-art performance in terms of modeling sequential dependencies by effectively capturing global context. Another improvement has been achieved by hybrid architectures such as CNN-LSTM-Attention, multistream transformers, and dual-branch temporal encoders through fusing spatial and temporal representations. However, most models usually suffer from heavy cross-attention mechanisms and redundant temporal branches, further increasing the computational cost and the risk of semantic dilution of degradation trends. Despite extensive research into DL architectures for RUL estimation, current approaches suffer from some important limitations: (a) they often regard all sensor data as homogeneous temporal sequences, without considering the complementary nature of dynamic and static degradation information; (b) traditional multistream and attention-based fusion models suffer from redundant temporal encoding, leading to inefficiency and information redundancy; and (c) the heavy fusion mechanisms, including cross-attention and multistage fusion, increase the computational overhead, which restricts deployment in real-time industrial systems.
Hence, there is the need for a compact, computationally efficient, and heterogeneous model capable of decoupling short-term dynamic variations from long-term degradation patterns without sacrificing strong prediction accuracy.22,28 To bridge these gaps, this study introduces a transformer-based dual input model (TDIM) for RUL prediction of turbofan engines where novelty lies in its heterogeneous dual-stream architecture that decouples sensor data into a dynamic temporal stream (transformer encoder) for sequential sensor data and a static statistical stream (feedforward encoder) for aggregated window-level features. The model further employs a lightweight late-fusion mechanism that avoids heavy cross-attention and substantially reduces computational cost, while also integrating noise reduction, RUL clipping, and attention-based feature weighting for achieving robust temporal learning and generalization. The major contributions of this work are as follows:
This article proposes, implements, and rigorously evaluates a novel TDIM for RUL prediction in turbofan engines, which integrates temporal sequence modeling with aggregated statistical features to capture both short-term dynamics and long-term degradation patterns. A dual-stream model architecture is applied, where sequential and statistical inputs are processed in parallel for enhanced RUL estimation accuracy.
It introduces a heterogeneous dual-stream fusion mechanism that explicitly decouples the temporal and statistical streams before fusion, enabling complementary learning between dynamic and static degradation trends a distinction from conventional single-input or twin temporal-branch models.
It validates the effectiveness and practical relevance of the proposed TDIM, experimental results are obtained on the widely used NASA C-MAPSS FD001 dataset, demonstrating superior performance over state-of-the-art baselines in root-mean-square error (RMSE), R-squared (
The outline of the article is as follows. The second section offers an extensive literature review, noting progress in DL methods in PdM. The third section provides the description of the NASA Turbofan Engine Degradation and discusses the proposed model methodology along with the evaluation metrics. The fourth section highlights the experimental design, results and discussion of using DL models on NASA C-MAPSS dataset. And finally, conclusion with major findings and possible future research directions is given in the fifth section.
Related work
Various studies have formulated prognostics of RUL based on data-driven methods that monitor certain degradation of a component through sensor readings and applying such prognostics practically to maintenance planning. Since each component or system has different patterns of degradation, maintenance planning considers RUL prognostics specific to each component and suggests individualized maintenance activities, in this case the engine. For instance, a study 29 presented an alarm-based PdM system for aviation engines with ambiguous RUL prognosis. The system adjusts dynamically to update RUL forecasts and sound warnings under specified thresholds using convolutional neural networks (CNNs) for RUL estimation and integer linear programming for scheduling. The strategy, which has been applied to a fleet of 20 aircraft, limits engine breakdown expenses to 7.4% of overall maintenance expenses. With 13.6 engine breakdowns over 10 years, prices increased by 24.3% when compared to ideal RUL prognostics. The outcomes show the effectiveness of adaptive scheduling in maximizing dependability and minimizing maintenance expenses. Moreover, to estimate RUL in prognostics, the research in the study by Li et al. 30 suggests using a deep convolutional neural network (DCNN) method, which does not require physical deterioration models or expert knowledge. For feature extraction, raw sensor readings are normalized as direct inputs using a temporal window technique. The suggested method is experimentally evaluated using the C-MAPSS dataset for accurate aero-engine prognostics. When compared to conventional ML techniques, the suggested DCNN model performs better in estimating RUL. The findings show how DL may be used to improve system reliability and maintenance scheduling in industrial prognostics and health management (PHM).
A probabilistic RUL prognostic deep reinforcement learning (DRL) approach for predictive airplane maintenance was described in the study by Lee and Mitici, 31 where CNNs and Monte Carlo dropout are used to forecast RUL for uncertainty quantification. By reducing reliance on strict deterioration limits, DRL optimizes maintenance activities. Compared to a mean RUL replacement policy, the technique reduces overall maintenance costs for turbofan aircraft engines by 29.3%. Engine life waste is limited to 12.81 cycles, and 95.6% of unplanned maintenance is avoided. The results demonstrated the effectiveness of DRL in PdM planning that is both cost-effective and adaptive. Likewise, Wang et al. 32 described a Bayesian-optimized multilayer perceptron (MLP) and a random forest (RF) for feature selection in their RUL prediction approach for turbofan engines. While an exponential smoothing technique lowers noise, the RF algorithm captures the most crucial elements determining an engine’s lifespan. Bayesian optimization was used to train this MLP model, which improved prediction accuracy and parameter selection. The method’s capacity to forecast RUL more precisely than other approaches is demonstrated by assessments conducted on the NASA C-MAPSS dataset, which indicate a 6.1% drop in RMSE compared to other methods. This performed noticeably better in intricate multioperational situations than both classical and ML-based approaches.
The development of RUL prediction models focused on NASA’s C-MAPSS dataset was continued by Isbilen et al., 33 who explored both ML and DL models, improving accuracy through hybrid strategies such as ensemble learning and similarity-based approaches. While ML models showed practical strengths, DL models achieved the highest accuracy. In the study by Peng et al., 11 a turbofan engine RUL prediction model using an improved echo state network with attention integrated for online adaptive RUL estimation and an improved stacked sparse autoencoder for deep feature extraction was developed. This model demonstrated a 75% accuracy improvement over traditional approaches, achieving an RMSE of 10.14 and NASA score of 197. Its design focused on stable predictions, robust feature extraction, and noise reduction. Similarly, Solis et al. 34 proposed a stacked DCNN model for estimating a turbofan engine’s RUL. To extract a low-dimensional feature vector from raw data, the methodology uses a first DCNN. A second DCNN then uses these traits to estimate RUL. Bayesian approaches tested on the NASA C-MAPSS dataset are used to optimize the model. The NASA score was 0.64 and the RMSE was 6.24, both of which were better than conventional methods. The approach proved to be reliable and accurate in RUL prediction, placing third in the 2021 PHM Conference Data Challenge. To address the drawbacks of RNNs, such as gradient explosion and the failure to consider spatial data, Peng et al. 35 introduced a spatiotemporal attention-based method for RUL prediction of turbofan engines. This model recovers the relationships of spatial and temporal features by combining temporal position encoding with a multihead attention mechanism. With RMSE values of 11.07 (FD001), 18.10 (FD002), 10.73 (FD003), and 17.00 (FD004), the suggested solution outperformed current approaches in evaluations conducted on NASA’s C-MAPSS dataset. Its goal was to increase accuracy and stability, especially in multioperational scenarios. As a result, the method improves PdM by using DL to generate a more accurate RUL estimate. New probabilistic evaluation criteria for RUL prediction about turbofan engines are presented in the study by de Pater and Mitici. 29 To forecast RUL distributions, the current study uses a CNN in conjunction with Monte Carlo dropout. The accuracy, sharpness, and reliability are assessed using Continuous Ranked Probability Score (CRPS), weighted CRPS, Coverage, and Reliability Score. RMSE = 12.76 (FD001) and 18.03 (FD004) on the NASA C-MAPSS dataset provide precise and trustworthy RUL estimates. By incorporating uncertainty quantification, the suggested metrics offer a comprehensive evaluation format for probabilistic RUL prognostics and grant improvements over conventional RMSE-based evaluations.
Recently, a comprehensive survey 36 has reviewed CNN, LSTM, and hybrid attention models for RUL in aero-engines, providing an exhaustive overview of up-to-date data-driven approaches to RUL prediction of aero-engines, comparing traditional statistical, ML, and DL models. It highlights the supremacy of hybrid DL models, especially ones combining CNN, LSTM, and attention mechanisms, to address complex degradation patterns. The paper reinforces the importance of proper data pre-processing and the right training protocols to enhance prediction accuracy with widely used datasets like NASA C-MAPSS. Overall, it offers valuable insights toward constructing PdM systems in aerospace engineering. In line with the theme of PdM through DL, this work 36 extends another level by focusing on hyperparameter optimization as a solution to improve CNN-LSTM performance, thereby offering complementary insights to prior research that has been focused on architectural innovation. Building on this, another evaluation 37 explains the design and vital specifications of a new improved multistage LSTM with clustering (ILSTMC) model for the RUL prediction of aircraft engines. By integrating K-means clustering into LSTM, the predictive accuracy of multistage applications will be improved. When combined with NASA’s C-MAPSS dataset, ILSTMC gives a mean reduction of 0.85% RMSE in the final stage, compared to LSTM, and an average reduction of 1.87% per stage. The life-cycle-wise accuracies have improved by an average of 0.59% and 1.84% between the same stages. Results thus exhibit the capability of ILSTMC to reduce prediction errors with improved performance than LSTM, RNN, and Linear Predictions (LP) techniques, acting as a very reliable platform for PdM in civil aviation. While several dual-branch prognostic frameworks have been explored in prior research, such as the Siamese-Attention Augmented Model 38 and the EMD-LSTM Dual-Branch approach, 39 their architectural formulations differ fundamentally from the design adopted in this work. In existing dual-branch methods, two transformed or parallel temporal sequences, such as paired signal streams or Empirical Mode Decomposition (EMD)-derived temporal components, are commonly processed and combined by interaction-heavy fusion mechanisms, including cross-attention or recurrent fusion. In contrast, the TDIM architecture proposed in this paper integrates two heterogeneous information pathways: a transformer-encoded temporal sequence that captures the dynamic evolution of sensors and a nontemporal statistical representation that summarizes long-term degradation within each window. These streams are encoded using different computational blocks tailored to their respective roles and later combined through a lightweight late-fusion module that avoids cross-branch attention. In this way, it reduces computational complexity while preserving complementary information, making TDIM different from prior models with a dual-branch structure, operating solely on temporal inputs. Recent research has also extended toward more advanced multibranch architectures and health indicator driven prognostics which horizontally expanded subnetworks to learn supplementary degradation features from parallel temporal views, enhancing robustness and fault tolerance in RUL prediction for both aero-engines and rotating machinery.40,41 Similarly, comprehensive reviews on Health Indicator (HI)-dependent RUL prediction methodologies42,43 focus on the integration of domain-driven degradation indicators with DL models for improved interpretability and stability across various types of machinery. These works together underscore the increasing importance of hybrid and multibranch frameworks that balance data-driven feature extraction with physically meaningful health trends, an idea very much aligned with the motivation of the proposed TDIM.
In addition to the studies discussed above, various DL based state-of-the-art prognostic models have gone one step further toward improving RUL prediction through significant architectural innovations. Take, for instance, sensor-aware capsule networks that enhance multivariate feature extraction by modeling hierarchical part-whole relationships and improving robustness under sensor noise or failure. 44 On the other hand, multiscale cross-channel attention networks leverage multiresolution temporal embeddings and cross-sensor attention to capture heterogeneous degradation rates across engine subsystems, thus overcoming single-scale temporal model limitations. 45 Complementing these, conformal-prediction-based frameworks introduce uncertainty-aware RUL estimation by generating statistically reliable prediction intervals rather than point estimates and thus improve decision confidence in safety-critical environments. 46 In addition, comprehensive surveys published during the years 2023–2024 reveal emerging trends such as hybrid attention mechanisms, multibranch fusion architectures, and health-indicator-dependent learning, all of which reflect a shift toward models integrating domain knowledge with learned representations. All these recent works together signal the rapid evolution of DL for aero-engine prognostics and further reinforce the need for models with the capability of jointly capturing fast transient sensor behavior and slow, monotonic degradation patterns a goal directly inspiring the design of the proposed TDIM framework.
Although numerous models have demonstrated success on the NASA C-MAPSS dataset, limitations persist in effectively capturing both short- and long-range temporal dependencies, motivating the proposed dual-input framework.
Materials and methods
This section describes the dataset, the suggested DL architectures, and experimental procedures employed for predicting the RUL of turbofan engines. The research uses the publicly available NASA C-MAPSS FD001 dataset, which artificially simulates engine degradation in real operational conditions. This section initially presents information on the application context of the dataset. Second, the methodology with a developed TDIM is proposed. Finally, the performance evaluation strategy is presented, including the metrics, training setup, and benchmarking strategy employed to examine the predictive accuracy and generalizability of the models.
Application and dataset
In the context of PdM, precise RUL estimation of key components like aircraft turbofan engines is vital for reducing unexpected downtime, optimizing maintenance planning, and improving operational safety. The aim of this research is centered on the use of RUL prediction for turbofan engines using the NASA C-MAPSS dataset, a popularly used benchmark in prognostics research. It contains run-to-failure time-series data from several engines, each exposed to different fault modes and conditions. Every engine starts from a healthy state, which gradually deteriorates, with the failure showing up toward the end of the trajectory. Engine ID, time cycles, three operating settings, and 21 sensor measurements that include a portion of degradation are among the 26 features in the collection. There are four data subsets, FD001, FD002, FD003, and FD004, with unique operating and fault conditions, and we have used the FD001 operating condition, as depicted in Table 1. Each of the subsets has one training set, in which measurements are collected up to the engine failure, and one test set. In the test set, sensor recordings are cut off, and the target is to forecast the RUL at that time for each engine. In all instances, every engine undergoes a unique amount of initial wear. Over time, the health of an engine deteriorates as it comes close to failing. The objective is to forecast the number of operational cycles remaining until failure in the test set, that is, the number of operational cycles from the last cycle that the engine will keep running.
FD001 dataset description.

NASA C-MAPSS: NASA’s Commercial Modular Aero-Propulsion System Simulation; RUL: remaining useful life.
For this research, FD001 operating condition of the NASA C-MAPSS dataset was used for RUL estimation, which comprises of training set
The FD001 dataset simulates a fleet of turbofan engines operating under a single operating condition with a consistent failure mode. It contains run-to-failure trajectories of 100 engines, each represented as multivariate time-series data. Each engine instance is monitored across up to 362 cycles, and failure is defined at the final recorded cycle. The data include 21 sensor measurements and 3 operational settings. For pre-processing, sensor noise and irrelevant features were filtered based on correlation and variance analysis, retaining the most informative sensor channels. The RUL target is constructed by assigning a maximum RUL cap (e.g., 125 cycles) and then linearly degrading until the end of life for each engine. This capping reduces target imbalance and enhances model convergence. The dataset is split into a training set (full trajectories) and a test set (partial sequences with provided ground truth RUL values).
Furthermore, the correlation heatmap of the NASA C-MAPSS turbofan engine deterioration dataset is illustrated in Figure 1, which represents the correlations among sensor readings, operating parameters, and engine cycle data. The majority of sensor readings show only modest connections with one another, suggesting that each one adds something special to the failure prediction models. A strong correlation has been found between “Corrected fan speed (rpm)” and “Corrected core speed (rpm),” suggesting that these predictors were redundant. This observation is critical for feature selection since highly correlated variables might cause computation redundancy and decrease model efficiency. The heatmap employs a color gradient, with dark blue denoting high correlations and red for low correlations. The analysis is helpful in the selection of important features and in reducing multicollinearity for better RUL prediction in PdM tasks.
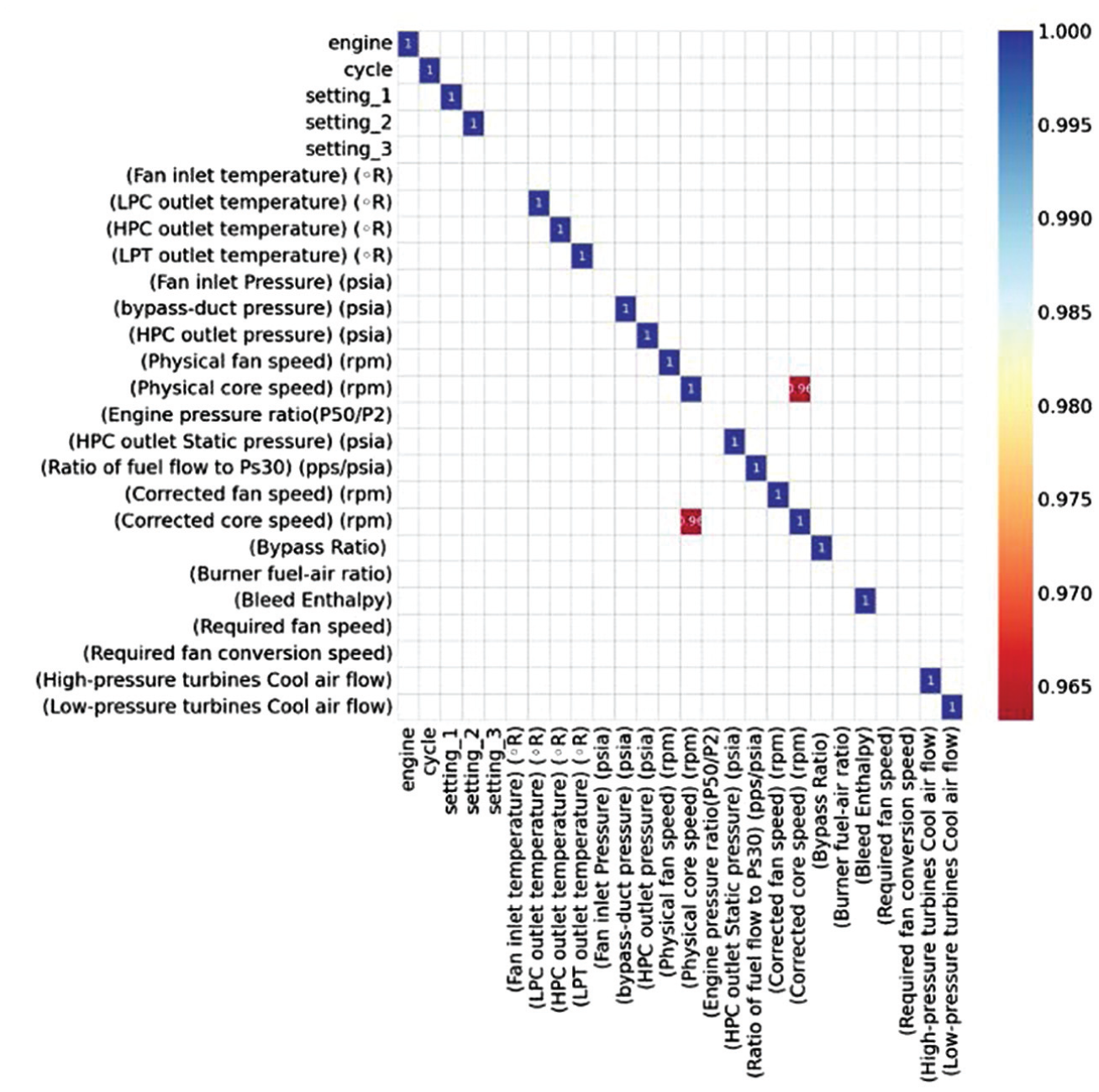
Correlation heatmap of sensor readings and operational parameters from the NASA Turbofan Engine Degradation dataset.
The NASA C-MAPSS sensor readings and operating parameters are summarized in Table 2. It includes descriptive statistics for each parameter, including count, mean, standard deviation, minimum, and quartiles. These features include rotational speeds via rpm for physical fan core speed and corrected speeds, engine and cycle indices, different temperature readings for Fan, Low-Pressure Compressor (LPC), High-Pressure Compressor (HPC), and Low-Pressure Turbine (LPT) outlet temperatures, pressure values for fan inlet, bypass-duct, HPC outlet, and HPC static pressure, and operational efficiency indicators, such as fuel–air ratio, engine pressure ratio, and bypass ratio. Thus, this dataset function accurately detects engine behavior patterns in terms of degradation. Based on this statistical assessment, the next phase involves data pre-processing, where noisy, constant, or less informative signals are filtered, and the data are reshaped for time-series modeling through windowing and RUL labeling.
Statistical summary of sensor readings and operational settings from the NASA Turbofan Engine Degradation dataset.
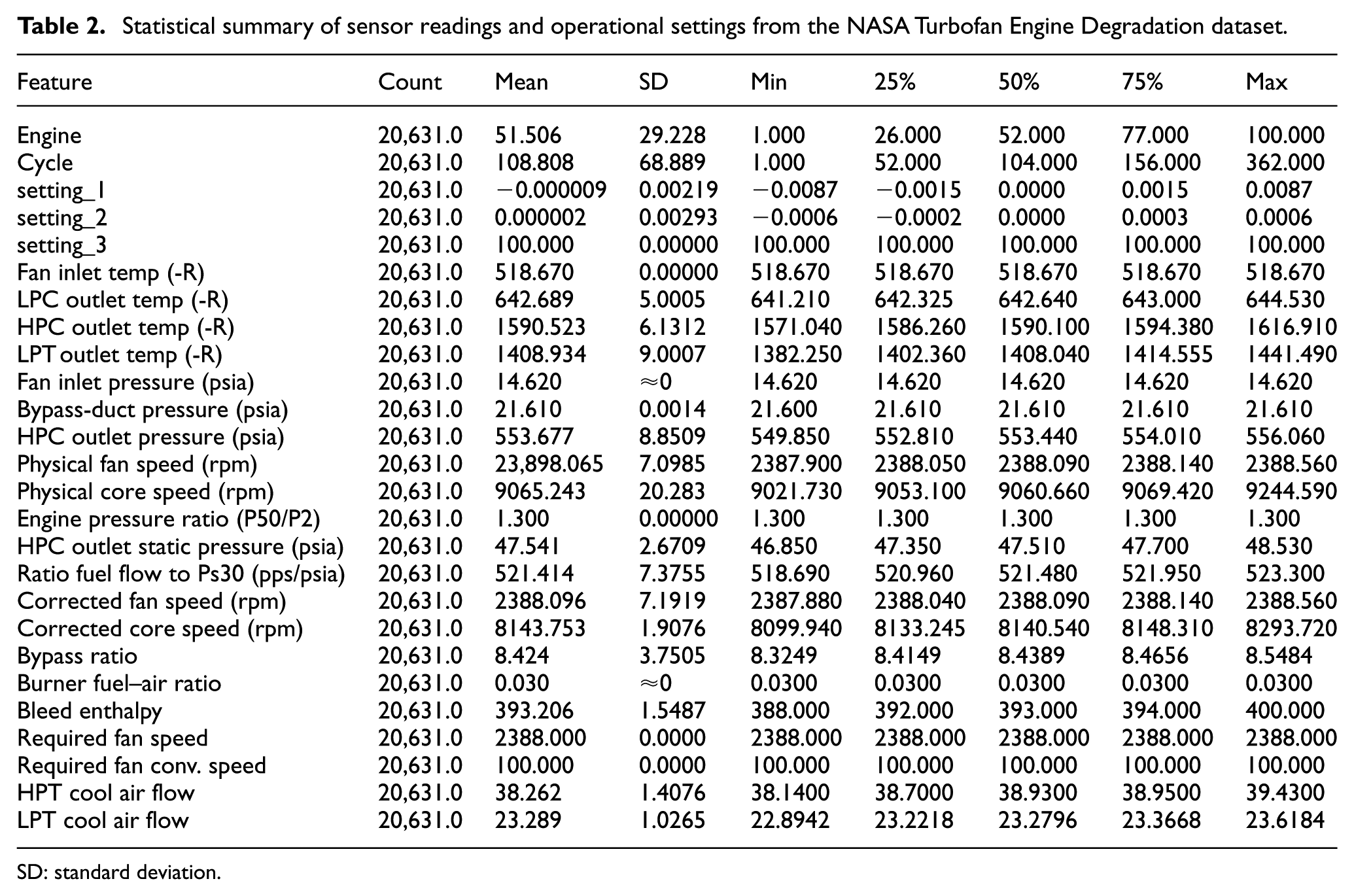
SD: standard deviation.
Method: a TDIM
The FD001 subset of the NASA C-MAPSS dataset is utilized for RUL estimation. For each unit, the RUL is taken to be the maximum cycle of the unit minus the present cycle, clipped up to a maximum value (e.g., 125). Fourteen informative sensor signals that are appropriate are chosen based on statistical criteria like correlation and variance analysis, and for normalization, min–max scaling is utilized. Pre-processing involves imputation of missing values, normalization of sensor readings, and conversion of the time-series data to fixed-length sequences with a sliding window scheme. Each resulting sequence is subsequently labeled with the corresponding RUL value, allowing supervised learning dataset formation. This pre-processing scheme ensures data uniformity, facilitates temporal modeling, and is ready for input into future DL architectures.
Moreover, to enhance the model’s ability to capture both temporal dynamics and overall degradation trends, statistical feature engineering is applied to each time-series window. For any given fixed-size window of size W = 30 cycles, statistical aggregations of mean, standard deviation, minimum, and maximum are calculated over all of the chosen sensor channels. A window length of 30 cycles was selected based on the meaningful changes in sensor trends that, in general, develop over medium-range horizons according to the temporal behavior of the FD001 degradation trajectories. A smaller window size, such as 15–20 cycles, is not sufficient to capture the gradual evolution of degradation, whereas a larger one, such as more than 40 cycles, will introduce redundant information and dilute the model’s sensitivity with respect to localized variations in health. Previous RUL turbofan studies using CNN-LSTM and transformer architectures also report the best performance within the range of 25–35 cycles, further justifying 30 cycles as a balanced selection that captures transient dynamics without unnecessary temporal redundancy.
These composite descriptors are then combined with raw sequence inputs in order to enable dual-feature modeling, where the model learns about temporal changes and global summary trends at the same time. Trend-type features such as slopes are also extracted to measure directional sensor signal changes over time, enhancing the model’s capacity to identify degradation paths. This mixture of trend-based and statistical characteristics enhances the representation of the input and aids in stronger RUL prediction. Dual-input DL architectures, TDIM, are being designed to capture the temporal dynamics as well as the global statistical aspects of sensor data. These models use sequential representations and aggregated information to improve RUL prediction accuracy.38,39 The subsections define this model in detail.
Proposed TDIM. A TDIM is proposed in order to properly exploit both the temporal patterns of sensor signals and their statistical trend of degradations. The complete architecture is described in Figure 2 and its implementation pipeline is as follows:
(a) Input stage: Every engine path from the C-MAPSS dataset is split into sliding windows. Two views are extracted from every window:
• A multivariate time-series sequence: a short segment (30 time steps) of 14 selected sensors, preserving how the signals evolve over time.
• An aggregated feature set: a compact summary of the same window, obtained by calculating statistical descriptors (mean, standard deviation, minimum, maximum) for each sensor, providing 56 features.
(b) Model stage (TDIM): The model handles the following two inputs in parallel:
• The sequence of time series is projected into a higher-dimensional space and processed with two stacked transformer encoder layers, each having four-head self-attention. This allows the model to learn relationships between various sensors and time steps. The whole sequence is then reduced to a single representation of 64 dimensions through a temporal pooling operation.
• The statistical characteristics are passed through a small feedforward network that compresses them into a 32-dimensional temporal pooling operation.
• Finally, the two representations are concatenated together to produce a single 96-dimensional feature vector that integrates rich temporal dynamics with overall statistical trends.
(c) Output stage: The model outputs a single scalar value, representing the predicted RUL of the engine at any given cycle window. This balance between capturing both short- and long-term degradation patterns is achieved by the dual-input structure of the model. While the transformer encoder captures rapid temporal variations and transient dependencies among sensor readings, the statistical input branch encodes slowly evolving degradation trends aggregated over each time window. By fusing these complementary features in the late fusion layer, the model learns both fast changing sensor dynamics and gradual health deterioration simultaneously. This ensures a holistic and temporally balanced understanding of the engine’s condition for more stable and accurate RUL prediction.
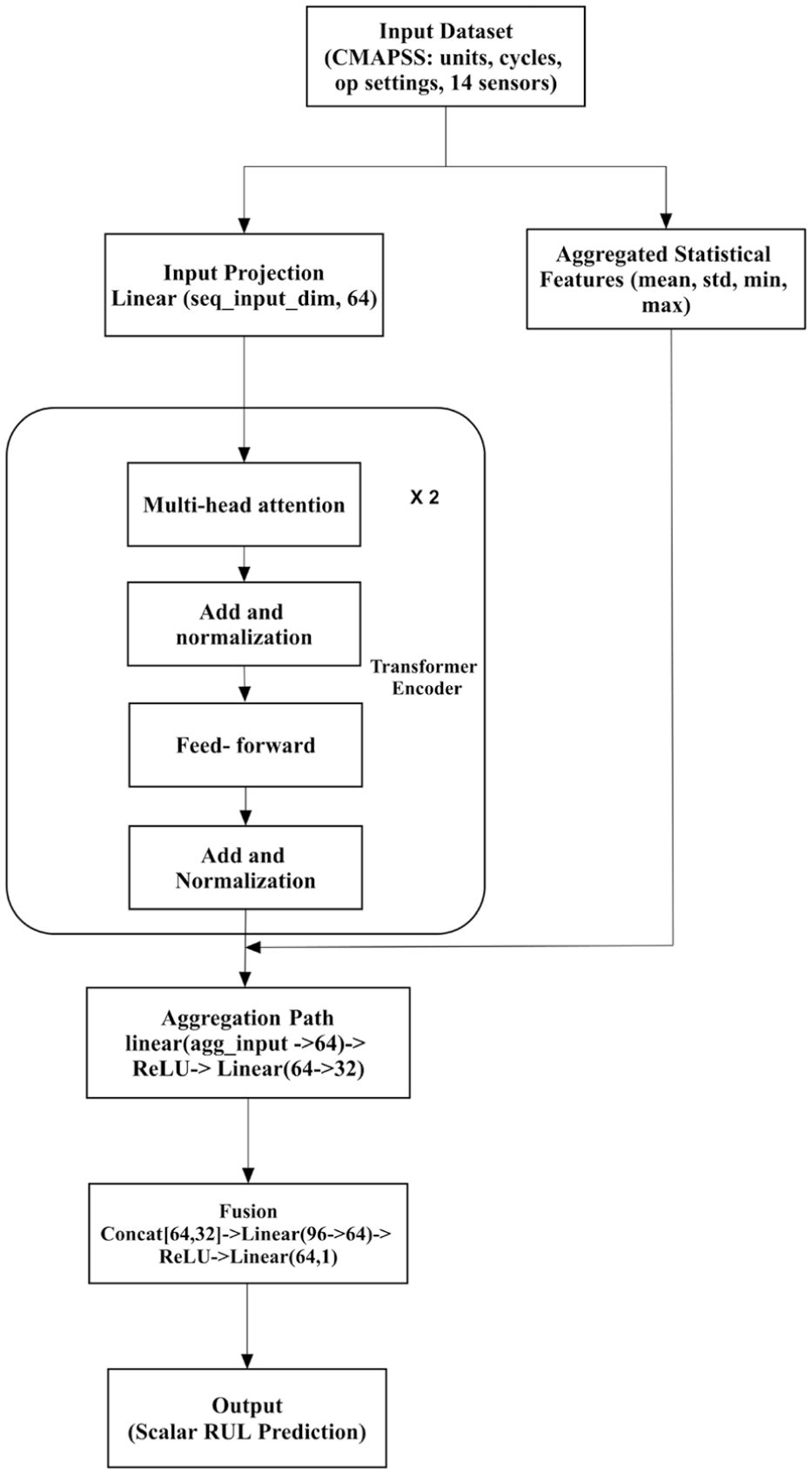
Architecture of the proposed TDIM. TDIM: Transformer-based dual-input model.
The model’s mathematical formulation is expressed in Equations (1)–(6). Given an input sequence
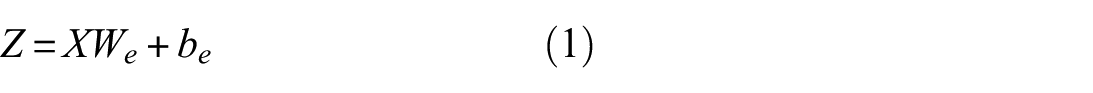
where
After obtaining the projected representation

where
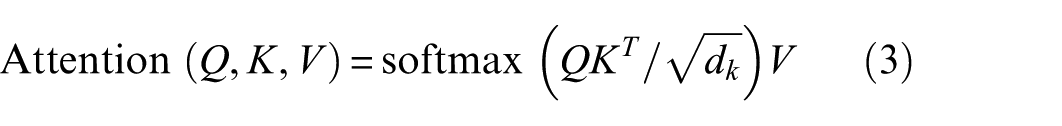
where
Simultaneously, aggregated features

where,
The two vectors are concatenated:
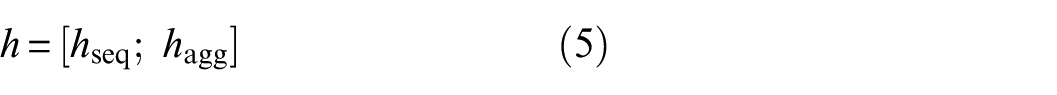
where
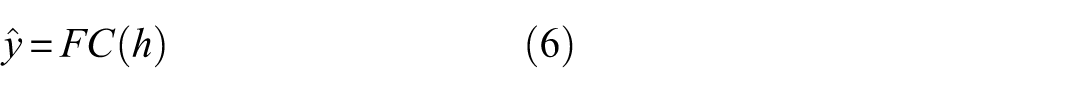
where FC depicts a fully connected (dense) layer for RUL regression
The model, as illustrated in Figure 2, can learn both high-level statistical summaries and raw temporal patterns because of its dual-input approach, which enhances generalization. The encoded features of both branches are concatenated and used as input for a fully connected regression layer to predict the RUL. This architecture allows the model to utilize both the dynamic evolution of sensor measurements and the context information in the statistical summaries, providing strong performance across different degradation conditions.
Hyperparameter settings.Table 3 summarizes the key hyperparameters chosen for the implementation of the proposed DL architectures, which are subsequently used in the algorithmic framework described in the section.
Hyperparameters used for the proposed TDIM.
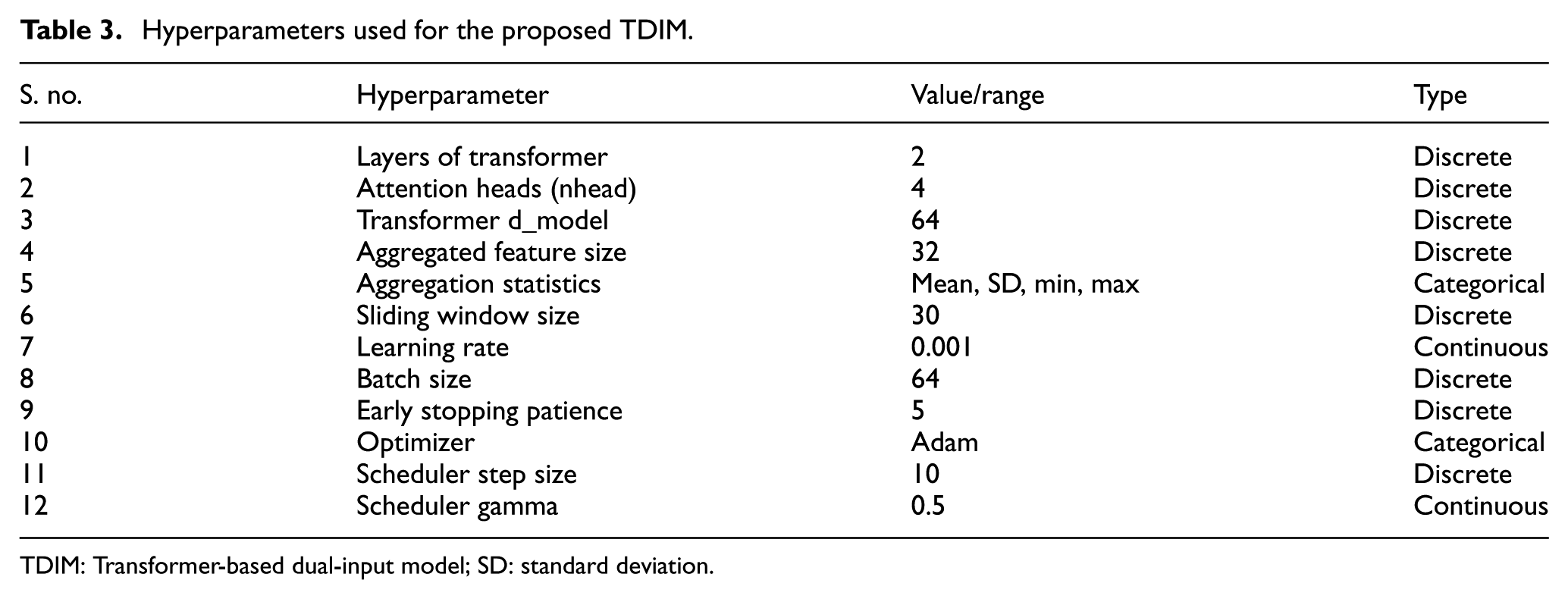
TDIM: Transformer-based dual-input model; SD: standard deviation.
The aforementioned hyperparameters were identified by empirical exploration, informed by previously published RUL studies on the NASA C-MAPSS dataset. Among the configuration tested, a window size of 30 cycles emerged as the best compromise that captured sufficient degradation context without redundant long-term information. Similarly, increasing the embedding dimension or the number of attention heads beyond 64 and 4, respectively, did not provide significant gains but added to computational cost. Also, two layers of transformers provided a sufficient model of temporal dependencies without overfitting. A moderate learning rate of 0.001 with the Adam optimizer and early stopping guaranteed stable convergence. These settings have collectively allowed the validation performance to be consistent over multiple runs, proving that the predictive capability of the model is insensitive to modest variations in hyperparameters. The next section presents the algorithmic framework, describing the key steps and procedures adopted to achieve efficient RUL estimation.
RUL prediction. A pseudocode that encapsulates the suggested RUL prediction framework with TDIM is given in Algorithm 1. It describes major steps such as data pre-processing, feature building, model training, and validation on the C-MAPSS FD001 dataset.

Hence, the proposed algorithm efficiently integrates sequence modeling and feature aggregation to enhance RUL prediction accuracy. The algorithm takes advantage of the self-attention ability of the transformer to model short- and long-term dependencies in sensor measurements. The modular structure enables flexible composition of feature fusion and DL modules. The method shows strong performance on the C-MAPSS FD001 dataset and can be applied to other industrial PdM tasks.
Performance evaluation
To measure the performance of the RUL prediction model, key evaluation metrics used to measure accuracy and generalization ability are as depicted through Equations (7)–(10):
(a) R-squared (

(b) Mean squared error (MSE): It plays an important role on greater errors as it is based on the square. These measurements give a holistic view of model reliability and efficiency in actual real-world PdM scenarios:

(c) RMSE: It is utilized to quantify the difference between predicted and real RUL values, where lower values show a more accurate model. It is also utilized to quantify the difference between predicted and real RUL values, where lower values show a more accurate model:

(d) Accuracy: Accuracy at
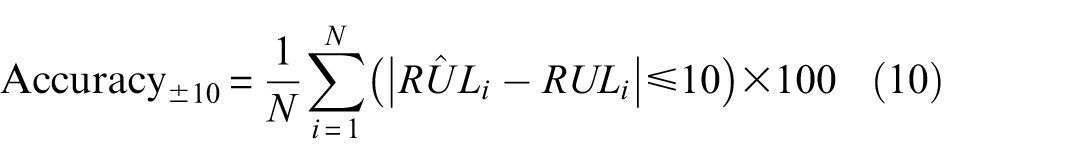
Since the FD001 dataset employs clipped RUL targets (maximum RUL = 125 cycles) to mitigate extreme target imbalance. All the evaluation metrics, including
To train the proposed architectures, fixed hyperparameters were employed from previous experimentation. The sequence length of the input was fixed at 30, with clipping of RUL to 125 to reduce target skewness. Training was done for a maximum of 50 epochs with a batch size of 64. An embedding size of 64 was utilized with two encoder layers and four attention heads for TDIM. The Adam optimizer with a learning rate of 0.001 was used, together with the StepLR scheduler and early stopping. The SmoothL1 loss function was adopted for its robustness to outliers. No hyperparameter tuning was automated; however, the empirically selected values yielded stable training and consistent performance on the C-MAPSS FD001 dataset.
Experimental results
This section depicts the results of multiple experiments undertaken to assess the efficacy of the suggested DL architectures for RUL prediction. The evaluation was conducted utilizing many criteria, including MAE, RMSE,
Experimental design and setup
All experiments were conducted using the FD001 subset of the NASA C-MAPSS dataset. Sensor readings were normalized using min–max scaling, and sequences were windowed using a fixed size of 30 cycles. Model training was executed on Graphical Processing Unit (GPU)-enabled hardware to accelerate computational efficiency. Optimization was performed using the Adam optimizer with an initial learning rate of 0.001. A StepLR scheduler was applied with step_size = 10 and gamma = 0.5 to reduce the learning rate periodically. Early stopping was used to prevent overfitting, with a patience of 15 epochs. The models were trained for a maximum of 100 epochs with a batch size of 64. Table 4 describes all experimental platform specifications, including local system configuration, cloud computing environment, and supporting software libraries used for model development and evaluation.
Experimental platform and software specifications.
The experimental design of this study is structured to systematically examine the performance and generalization capability of the proposed DL architectures for RUL prediction of turbofan engines under realistic and volatile operational situations. The design emphasizes fair, reproducible, and open benchmarking in the following domains:
(a) Application baselines: Standard models from the prior research, including K-nearest neighbors, support vector machines (SVMs), RFs, and a baseline LSTM model, were employed as reference points.47–50 These represent established approaches for RUL prediction and facilitate a performance benchmark against the proposed PdM models.
(b) Methodology baselines: An advanced architecture, namely, the TDIM, was designed and systematically evaluated.19,31,51 These models serve as a consistent point of reference for state-of-the-art DL methods to demonstrate the performance gain achieved.
Following the implementation and training of the suggested DL models, the following section provides and discusses the performance results. The results are presented based on traditional evaluation measures like RMSE, MAE, R2, and cumulative accuracy (within ±10 cycles).
Results and comparative studies
This section presents the experimental results and performance evaluation of the proposed PdM framework for turbofan engines, specifically addressing the problem of RUL estimation under realistic operational conditions. The focus is on analyzing the predictive accuracy, error distribution, and the overall impact of RUL forecasts on maintenance scheduling decisions. Consequently, the study explores DL architectures that not only aim to minimize error but also introduce two additional evaluation metrics: MAE and accuracy within ±10 cycles to comprehensively assess predictive reliability. The proposed dual-input architecture utilized both temporal and statistical features very effectively. Visualization of prediction outcomes further confirmed the excellence of the transformer model. It displayed stable prediction curves very closely following true RUL values under different engine instances, with less fluctuation and smaller lag.
The results underscore the advantage of modern architectures like transformer Dual Input, which not only deliver superior prediction performance but also maintain competitive inference times, thereby making them highly suitable for real-time PdM applications. In order to substantiate the real-time feasibility of the TDIM, inference latency measurements were carried out. The model yielded an average inference time of 1.47 ms per sample (±0.07 ms), which equates to approximately 20,877 samples per second. This level of responsiveness strongly underlines its deployability in real-time use cases where fast, cycle-wise updates of RUL estimates are deemed necessary. These results highlight the model’s suitability for high-frequency maintenance monitoring, especially in IIoT contexts with critical latency constraints. The cumulative accuracy curve in Figure 3 shows that the model performs well in estimating RUL with a greater tolerance. At
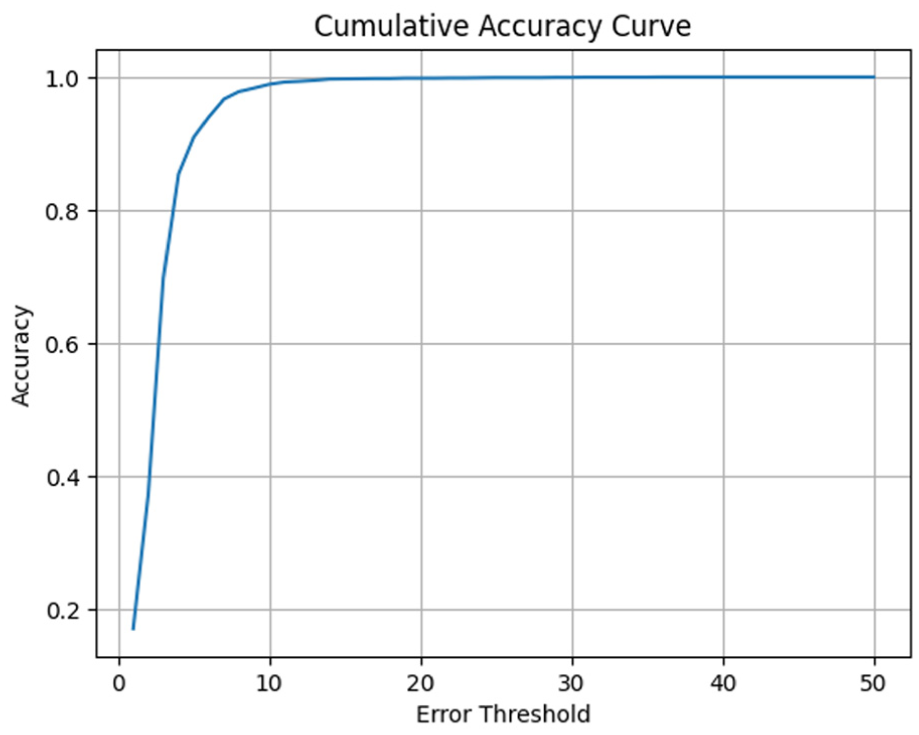
Cumulative accuracy curve for the TDIM showing the proportion of predictions within increasing RUL error thresholds. TDIM: Transformer-based dual-input model; RUL: remaining useful life.
Actual RUL values and model-predicted values are compared in Figure 4. The model performs well since the great majority of predictions are really close to the perfect diagonal. Across the working range, the transformer dual model shows how closely the predictions match the true values. The tight clustering around the red line suggests that the model has adequate predictive performance across the range of RUL values.
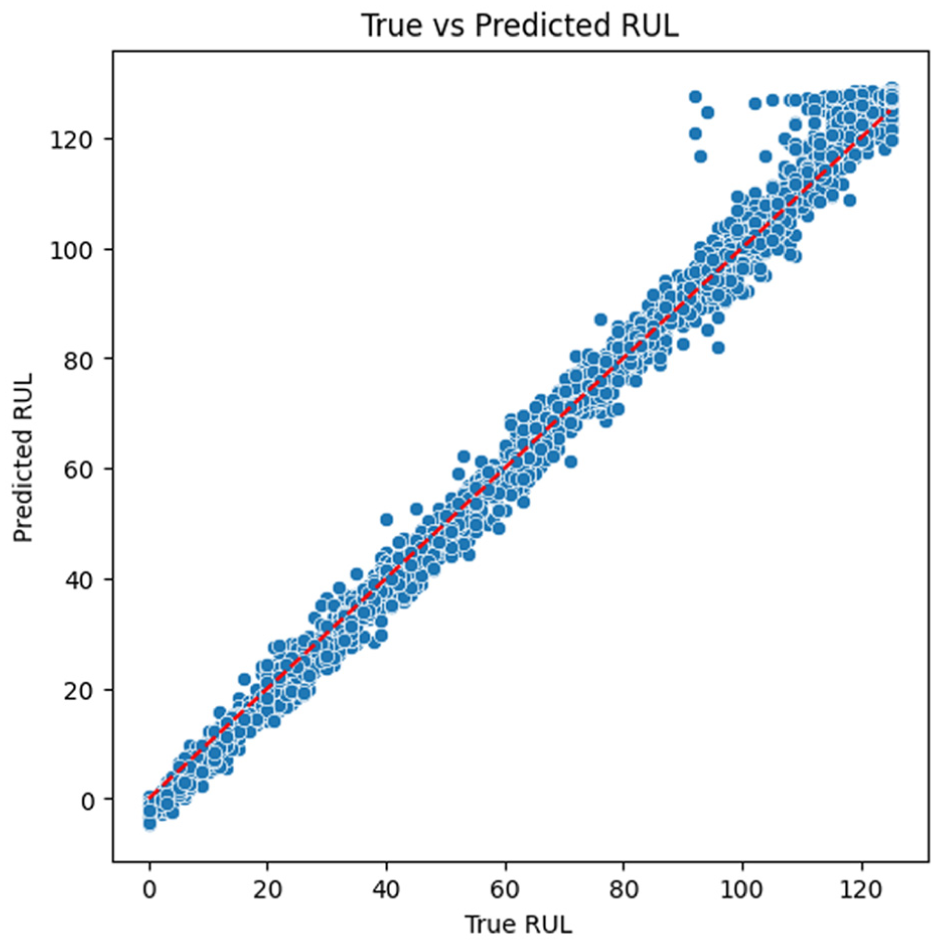
Scatter plot of true versus predicted RUL using TDIM with the red line indicating perfect predictions. TDIM: Transformer-based dual-input model; RUL: remaining useful life.
The distribution of absolute errors in RUL estimations based on the TDIM is seen in the error boxplot in Figure 5. The transformer dual model boxplot shows the distribution of prediction errors. The box represents the interquartile range (IQR), the horizontal line inside is the median error, and the circles represent outliers. Most errors are low, though some larger outliers exist (
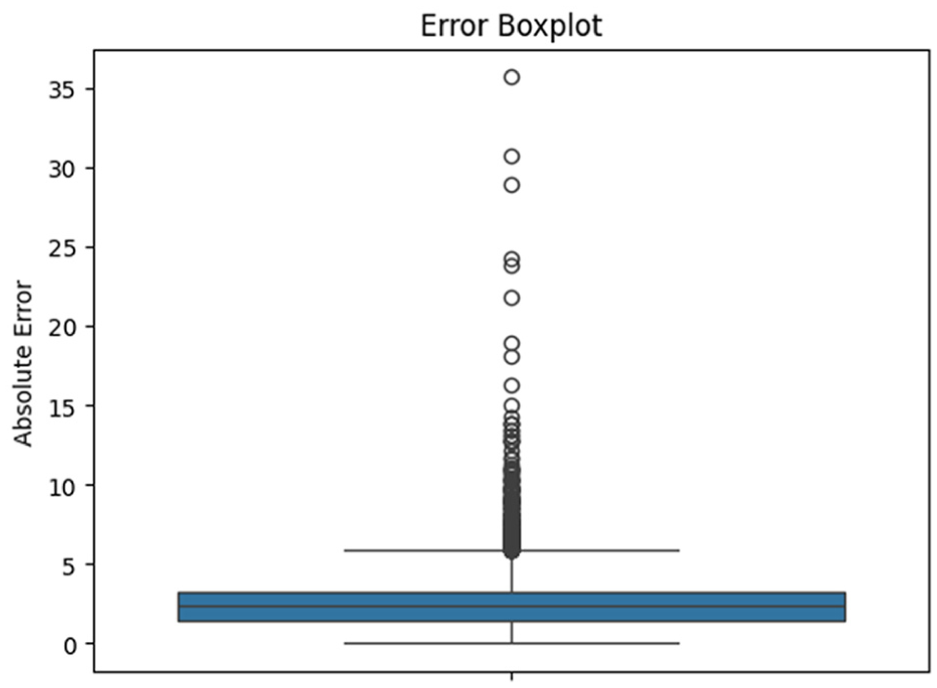
Boxplot of absolute prediction errors for TDIM on RUL estimation. TDIM: Transformer-based dual-input model; RUL: remaining useful life.
Overall, a compact box and short whiskers suggest low variance and robust predictions. The running total of prediction errors for the TDIM is displayed in the cumulative error plot in Figure 6. In the transformer dual model, it represents the IQR, the horizontal line inside is the median error, and the circles represent outliers. The distribution of absolute errors in TDIM is shown by this histogram in Figure 7. The TDIM shows the frequency distribution of prediction errors. Most errors lie between 0 and 10, with a peak around 3, indicating the model often predicts quite close to the true RUL. There is a long right tail, which shows a few larger errors, suggesting the presence of some outliers or challenging samples.
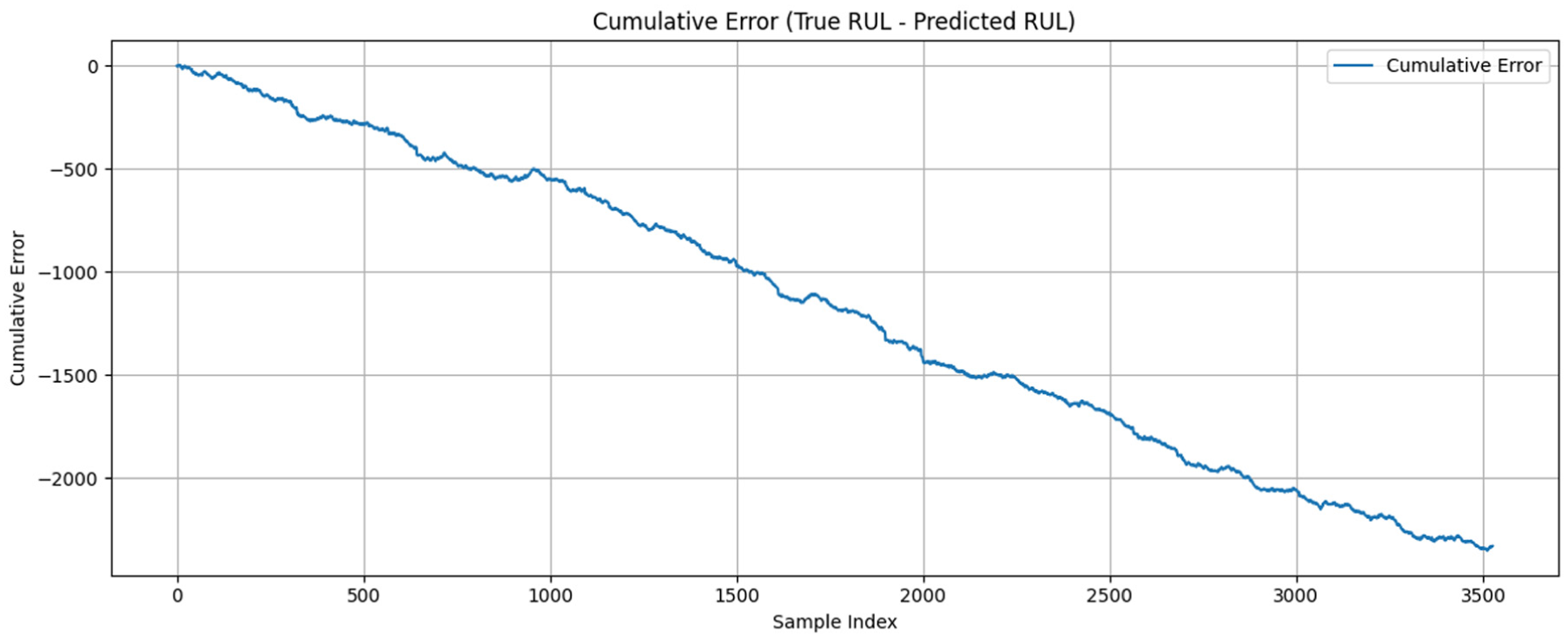
Cumulative error curve of TDIM showing deviation between true and predicted RUL values. TDIM: Transformer-based dual-input model; RUL: remaining useful life.
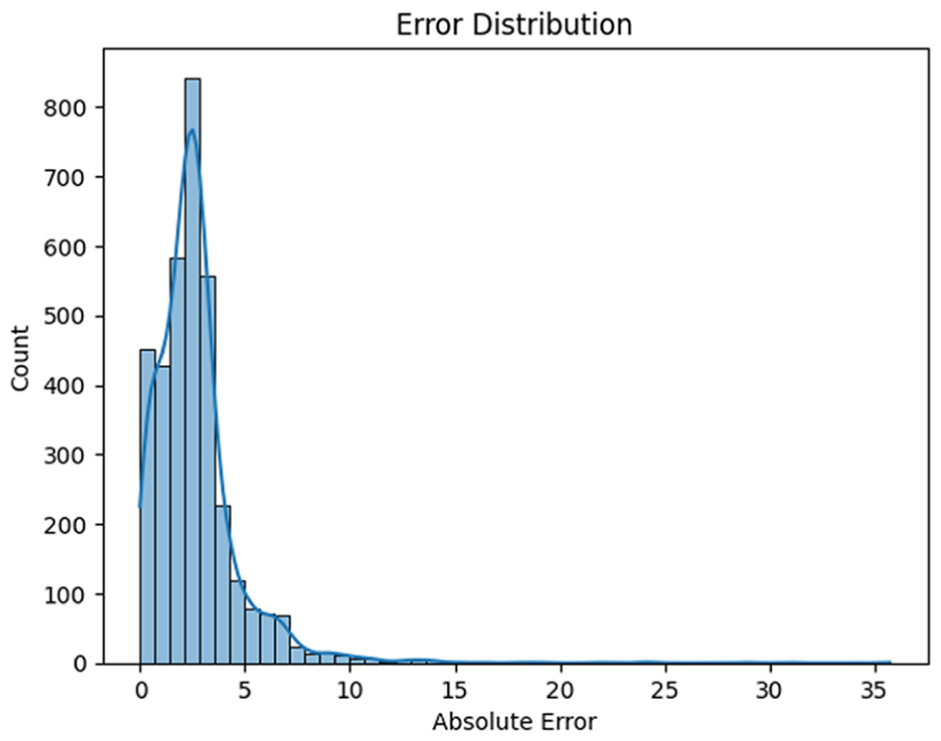
Absolute error distribution of TDIM predictions for RUL. TDIM: Transformer-based dual-input model; RUL: remaining useful life.
The true and expected RUL differences for 200 samples are displayed in the residual plot for TDIM in Figure 8. Residuals show unbiased forecasts with no discernible trend or heteroscedasticity, oscillating around zero. Based on the TDIM, the plots of the actual and predicted RUL for 200 samples are shown in Figure 9. Figure 9 depicts the actual and predicted RUL for 200 samples using the TDIM. The predicted curve largely follows the actual trend of the true RUL through most of the engine trajectories, hence reflecting a strong predictive capability. Within the early operational cycles where degradation patterns are minimal or not observable, the model predicts high RUL values that are close to the capped maximum at approximately 125 cycles, which agrees with the expected healthy state of the engines. As degradation wears on, the model gradually reduces its predictions, tracking the actual decline in RUL with little lag. Minor deviations, such as regions in which the predicted RUL remains flat while the true RUL decreases, represent transient phases before evidence of sufficient degradation becomes available. This behavior in general confirms the robustness of TDIM to handle both early and late life cycle phases effectively, distinguishing healthy and degraded states along the operational timeline of the engines.
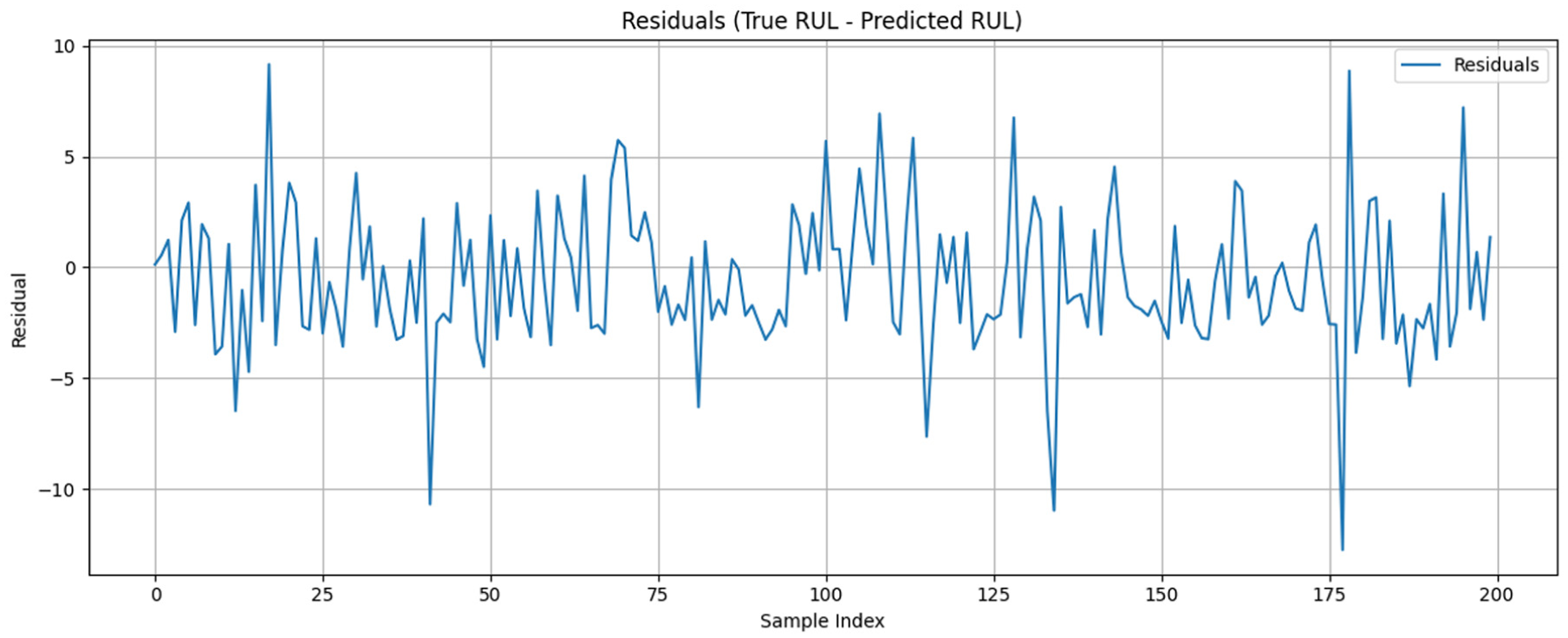
Residual plot showing the difference between actual and predicted RUL using TDIM. TDIM: Transformer-based dual-input model; RUL: remaining useful life.
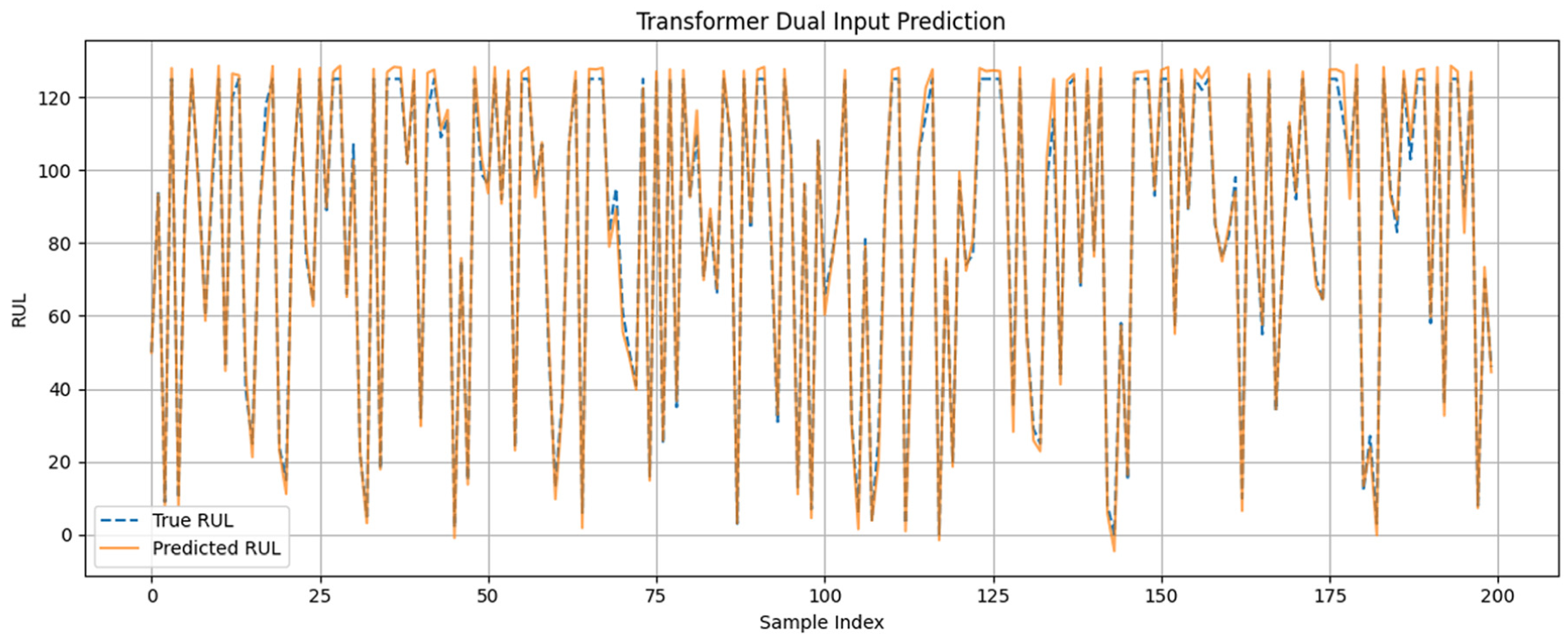
True versus predicted RUL using TDIM. TDIM: Transformer-based dual-input model; RUL: remaining useful life.
In order to validate the effectiveness of the proposed model, its performance was benchmarked against multiple established baseline methods reported in the literature, as summarized in Table 5. These baselines include LSTM, XGBoost, Support Vector Regression (SVR), RF, MLP, gated recurrent unit (GRU), and hybrid models such as autoregressive integrated moving average SVMs (ARIMA-SVMs). DL models, particularly CNN-LSTM and DNN-RNN, provide higher accuracy, with RMSEs below 15 in certain circumstances. The TDIM significantly outperforms all baselines with an RMSE of 3.45 and
State-of-the-art comparative analysis of DL techniques for RUL prediction.
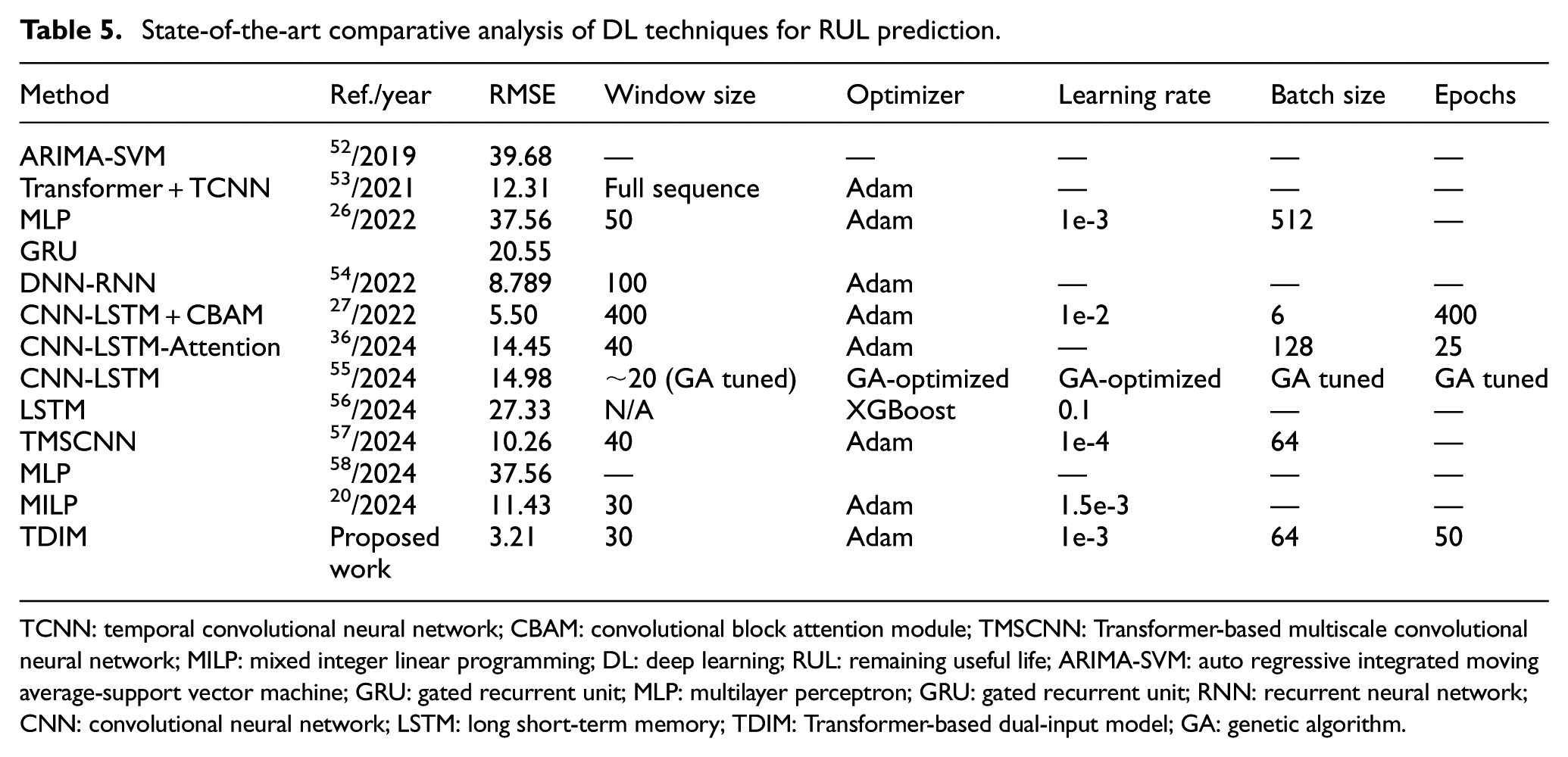
TCNN: temporal convolutional neural network; CBAM: convolutional block attention module; TMSCNN: Transformer-based multiscale convolutional neural network; MILP: mixed integer linear programming; DL: deep learning; RUL: remaining useful life; ARIMA-SVM: auto regressive integrated moving average-support vector machine; GRU: gated recurrent unit; MLP: multilayer perceptron; GRU: gated recurrent unit; RNN: recurrent neural network; CNN: convolutional neural network; LSTM: long short-term memory; TDIM: Transformer-based dual-input model; GA: genetic algorithm.
Ablation studies
A systematic ablation study was designed to analyze the contribution of individual architectural components. Several configurations were created by selectively removing or modifying critical blocks, including the statistical fusion mechanism, and dual-input structure. In order to assess the efficiency of each component in the proposed TDIM, a systematic ablation study was performed. A number of model versions were built by selectively eliminating or altering key architectural elements, such as the statistical combination mechanism and the dual-input architecture.
Model m2 (Transformer Only): It eliminates the aggregated statistical input stream and uses raw sensor sequences only. While this model produced fairly robust performance, it always lagged behind compared to the full TDIM (m1), indicating the supplementary contribution of statistical features to long-range temporal modeling.
Model m3 (Hybrid Transformer + BiLSTM): It replaces the transformers attention-based encoder with a BiLSTM subnetwork. The hybrid architecture yielded impaired performance, reflecting architectural incompatibility and redundancy between sequential and attention modules.
Model m1 (TDIM): It uses both raw sensor sequences and aggregated features with a dual-input attention mechanism, performed the best on all metrics.
These results confirm that the TDIM suggested that the dual-input and fusion structure is essential for improving prediction accuracy and model stability. To provide fair, repeatable, and impartial evaluation across all model configurations, all experiments were conducted using consistent hyperparameters, data partitions, learning rate schedules, and early termination conditions. As seen by ongoing increases in RMSE,
Results of ablation study showing the impact of different architectural variants on RUL prediction performance using NASA FD001 dataset.
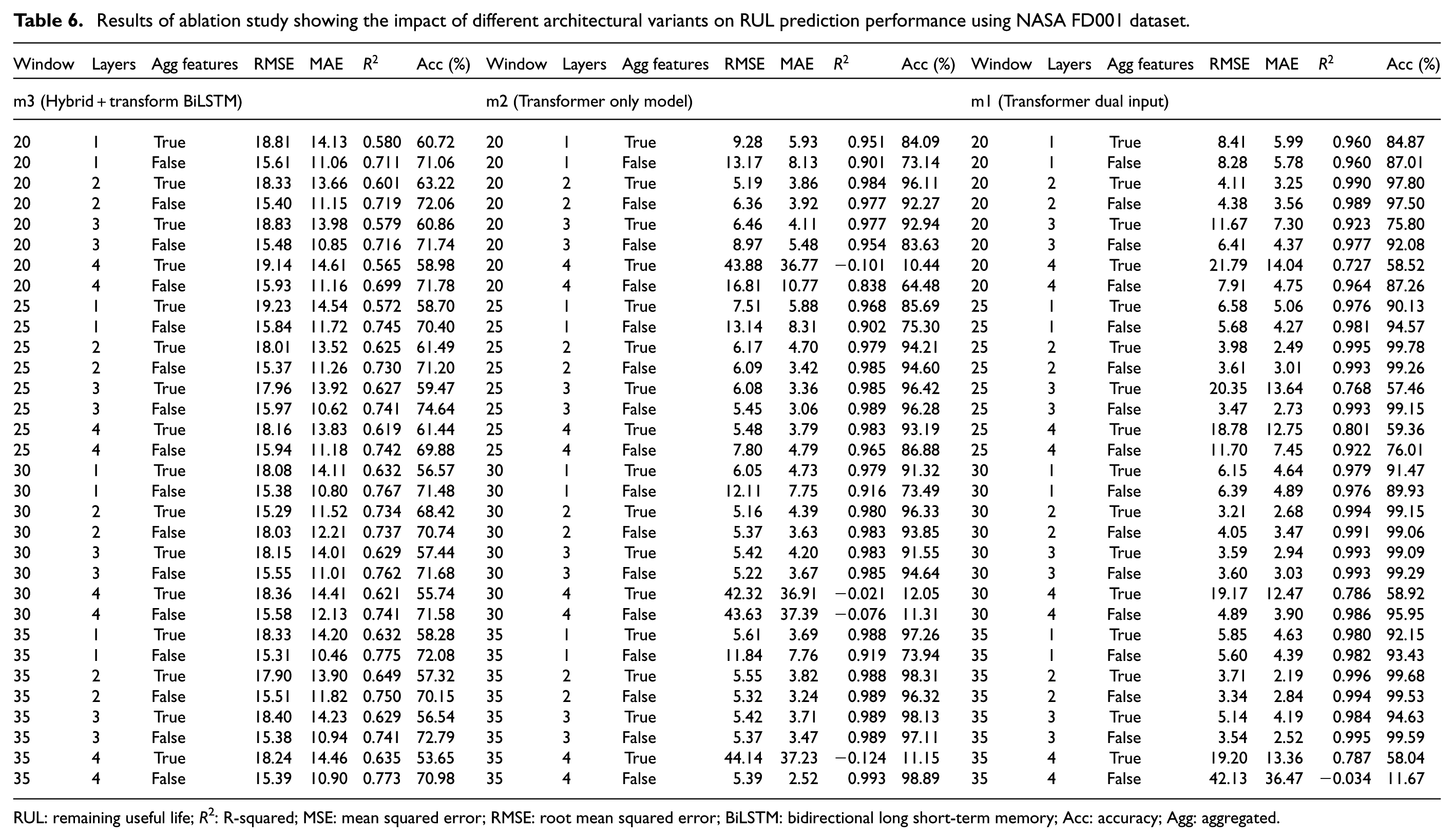
RUL: remaining useful life; R2: R-squared; MSE: mean squared error; RMSE: root mean squared error; BiLSTM: bidirectional long short-term memory; Acc: accuracy; Agg: aggregated.
According to the ablation results, the suggested model m1 performs the best. It performs better than other versions by effectively fusing dual-input fusion with global attention. With observable performance reductions seen when attention, fusion, or transformer modules are eliminated or modified, the study emphasizes the vital significance of every architectural element. Beyond numerical improvements, the attention heads in the TDIM also provide insight into the physical process of degradation. Examination of the learned attention weights shows that sensors such as high-pressure compressor outlet temperature (T48), corrected core speed (Nc), and fuel flow ratio (Wf) consistently attract higher attention in later life cycles, reflecting known degradation-sensitive parameters in turbofan engines. In contrast, early-cycle attention is dominated by sensors reflecting stable operating conditions such as fan speed (Nf) or LPC inlet pressure (P2). Such a progressive attention shift from healthy state indicators to degradation sensitive variables implies that the model learns meaningful physical relationships rather than purely statistical patterns, hence improving the interpretability and engineering trustworthiness of the TDIM framework.
Conclusion
This study presents an advanced DL architecture, TDIM, for RUL prediction using the NASA C-MAPSS FD001 dataset. An advanced DL architecture for RUL prediction on the NASA C-MAPSS FD001 dataset is proposed and tested: a TDIM. The motivation behind this work lies in addressing the need for accurate, real-time RUL predictions to reduce unexpected equipment failures and maintenance costs. The outcomes show that DL, especially attention-based transformer models, has tremendous potential in PdM tasks. By facilitating early failure detection and accurate RUL estimations, such models play a crucial role in operational efficiency, cost reduction, and safety in industrial settings. Our experimental findings highlight that the TDIM significantly outperforms the baseline models. These results validate the potential of transformer-based approaches for developing robust, real-time PdM solutions in industrial environments. The proposed model, the TDIM architecture, shows promise in enabling condition-based maintenance strategies that are more proactive, cost-effective, and capable of improving overall operational reliability.
While the models show promising results in the C-MAPSS dataset, the direction of further research can be toward generalizability and practical applicability. In this research, a controlled benchmark represented by the FD001 subset was considered, given the least complicating operating condition and a single fault mode to validate the efficiency of the proposed TDIM architecture. This popular subset is chosen in most RUL prediction works because baseline performances are established before generalizing them to more complicated subsets. Future work will involve extending analysis to the remaining C-MAPSS subsets (FD002-FD004), which contain multiple operating and fault conditions, to further validate model robustness and adaptability. Testing the models on real-world industrial data with sensor noise, missing values, and variability over real operations, which is not captured in the simulation data from C-MAPSS, is also necessary. Further advances in prediction accuracy and stability may be obtained by ensemble learning or hybrid models that combine strengths of the BiLSTM and transformer architectures. Also, extensions to the framework can be developed for multisensor fusion, transfer learning for domain adaptation, and online learning for continual model updates that enhance real-world applicability. Integration with Explainable Artificial Intelligence (XAI) techniques will improve the interpretability and trust in these models, while edge or fog deployment can enable real-time, scalable PdM. The TDIM framework thus advances the quest for reliable, interpretable, and intelligent PdM systems and has strong potential in IIoT applications.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.