
Abstract
Fault diagnosis approaches leveraging deep transfer learning typically assume that the fault classes in the source and target domains are identical. However, this assumption is often unrealistic in engineering practice due to operational complexity and uncertainty that result in unknown fault classes. In this paper, a dual-path adversarial and progressive self-training network (DAPSN) is proposed for cross-condition open-set domain adaptation (OSDA) fault diagnosis. A three-stage dual-path adversarial progressive self-training strategy is designed to mitigate negative transfer. Through the integration of a gradient reversal layer and a dual-path adversarial discriminator, DAPSN concurrently filters novel target samples and aligns representations of known classes, thereby enhancing inter-class separability and intra-class cohesion. Its effectiveness is verified under two OSDA scenarios. Comparative experiments demonstrate that the proposed DAPSN sustains high classification accuracy and reliable unknown-class detection across varying domain shifts and different proportions of open-set samples, outperforming existing baselines. The DAPSN method combines dual-path adversarial and progressive self-training mechanisms to achieve precise classification of known faults and effective identification of unknown faults.
Keywords
Introduction
In recent years, with the rapid development of data-driven deep learning techniques and their ability to function without extensive prior domain knowledge while extracting nonlinear patterns, modern neural models have been widely adopted for rolling bearing fault diagnosis,1,2 achieving notable success in practical applications. Representative models include autoencoder, 3 which are suitable for unsupervised dimensionality reduction and signal reconstruction; deep belief networks, 4 which extract hierarchical features through layer-wise pre-training; convolutional neural networks (CNNs), 5 well-suited for capturing local spatial patterns in structured sensor data; long short-term memory networks, 6 capable of leveraging long-range temporal dependencies; and generative adversarial networks (GANs), 7 which generate synthetic samples to augment training data. It is important to emphasize that these models rely on a fundamental premise: training and testing data must originate from the same distribution. 8 When distributional discrepancies arise between training and test datasets, diagnostic performance typically declines substantially.
Beyond these standard models, the landscape of intelligent fault diagnosis has recently evolved to include advanced architectures designed to address limitations in feature hierarchy and global dependency modeling. For instance, recognizing that traditional networks may overlook the spatial hierarchy of features, researchers have introduced Capsule Networks to the field. Notable contributions include the Deep Adversarial Capsule Network 9 and Sensor-aware CapsNet, 10 which leverage dynamic routing mechanisms to preserve part-whole relationships in sensor data. In addition, to capture long-range dependencies and enhance global feature representation, sophisticated frameworks such as WavCapsNet 11 and Exofeature-Aware Transformer 12 have been proposed. These studies highlight a significant progression from traditional deep learning to more complex, hierarchy-aware, and globally attentive frameworks.
Domain adaptation (DA) has therefore become a compelling solution for mechanical fault diagnosis, addressing the distribution shift challenge. However, most existing methods assume that the fault categories present during test are fully covered by those observed during training. This assumption rarely holds in real industrial scenarios, where novel failure modes may emerge during deployment. When unknown fault types appear, traditional DA methods designed for closed-label spaces often suffer from negative transfer, causing pronounced drops in accuracy. To address these issues, domain-adaptation-based fault diagnosis techniques 13 aim to exploit transferable knowledge across domains. Domain-adaptive methods 14 have proven highly effective for reliable fault recognition. Early studies primarily focused on aligning marginal distributions, with typical methods including Maximum Mean Discrepancy (MMD)-based alignment 15 and adversarial learning strategies. 16 For example, Qian et al. 17 proposed a modified discrepancy metric to better align cross-domain representations, while Kuang et al. 18 developed a domain-conditional joint network for dependable bearing fault diagnosis under distribution shift.
To further address real-world challenges, open-set DA (OSDA) approaches were introduced to explicitly identify unknown fault types. However, initial OSDA methods struggled to jointly counter domain shift and detect unknown samples, limiting their practical utility. Busto and Gall 19 first formalized the OSDA scenario using a linear classifier to detect samples outside known categories. Saito et al. 20 later developed a competitive learning framework to separate known and novel faults. Additional OSDA strategies based on extreme value theory, 21 instance-wise weighting, 22 and dual adversarial architectures 23 attempted to address unknown faults, yet many depended heavily on source-domain features and insufficiently exploited discriminative structures in the target domain. Fang et al. 24 provided a theoretical error-bound framework for OSDA, though practical implementation strategies remained limited. Subsequently, Deng et al. 25 proposed a mechanical open-set transfer model that integrates theoretical bounds with adversarial learning, employing entropy regularization and calibrated similarity weights to improve robustness. More recently, Tian et al. 26 generated adaptive similarity weights and introduced a new mechanism for unknown fault identification, enabling accurate separation of seen and unseen categories under open-set conditions. In addition, multiple OSDA methods have emerged in computer vision, such as open-set back-propagation (OSBP), separate to adapt (STA), 27 and calibrate multiple uncertainties (CMU). 28 Inspired by OSBP, Li et al. 29 developed the deep adversarial transfer learning network (DATLN) for online rotating machinery fault detection.
Figure 1 illustrates the primary distinction between closed-set DA (CSDA) and OSDA: CSDA assumes identical fault labels in training and testing, whereas OSDA transfers diagnostic knowledge from a source domain with known faults to a target domain potentially containing novel fault categories. OSDA must therefore establish an adaptive classification boundary to distinguish between known and unknown target-domain faults.
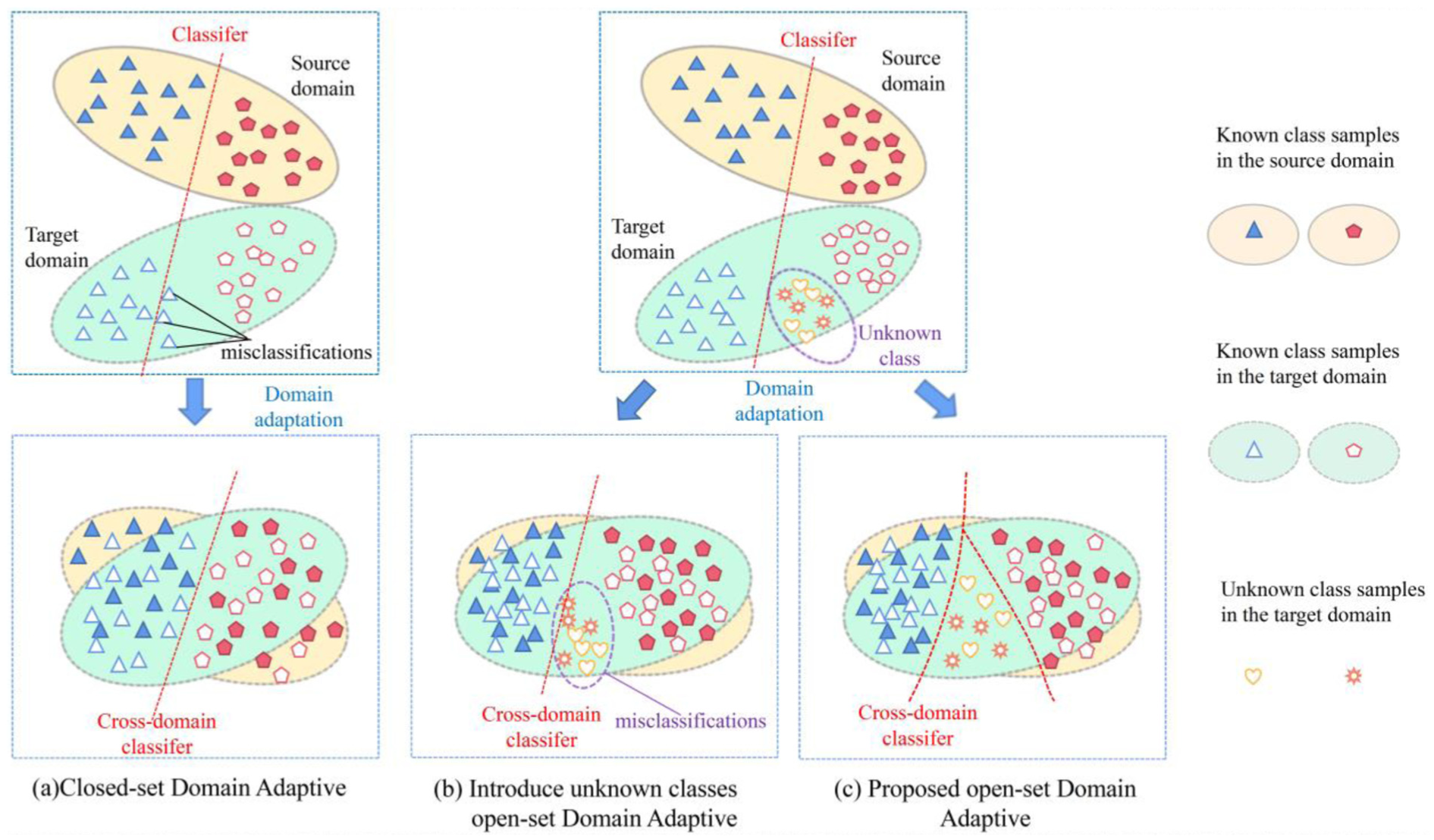
The differences between traditional closed-set and OSDA methods: (a) CSDA method; (b) when new fault categories appear in the target domain, traditional CSDA methods fail to detect them; (c) the proposed method, which effectively aligns known fault categories and possesses the capability to detect unknown fault categories. OSDA: open-set domain adaptation; CSDA: closed-set domain adaptation.
Consequently, successfully tackling the OSDA problem hinges on simultaneously fulfilling two key requirements:
Optimization of inter-class separability: The core objective is to establish a sharp classification boundary capable of reliably distinguishing between samples belonging to known fault types and those representing unknown categories within the target domain. This capability improves the system’s sensitivity to anomalous patterns and enhances generalization across operational conditions under open-set environments, while preserving strong discrimination among distinct fault categories. 30
Enhancement of intra-class compactness: This objective focuses on harmonizing feature representations from the source and target domains for classes shared by both domains. Such alignment encourages samples of the same fault type to concentrate into compact, well-structured clusters across domains, thereby increasing consistency in embedded feature space. 31
Nevertheless, current OSDA approaches continue to encounter two major challenges:
Challenge of decision boundary uncertainty: A principal challenge arises from the lack of prior information regarding the composition of the target domain, especially the proportion of samples belonging to unknown fault types. This uncertainty complicates the establishment of a stable and universal decision threshold. In high-openness settings, strict boundaries (high confidence thresholds) risk missing a considerable number of true unknown samples. Conversely, in low-openness conditions, loose boundaries (low thresholds) may incorrectly label known samples as unknown. This sensitivity results from reliance on fixed-threshold strategies that do not adapt to varying openness. To balance missed detection and false alarms, adaptive thresholding mechanisms responsive to underlying data distributions are essential. 32
Challenge of interactive negative transfer: In cross-domain OSDA, the dual tasks of correctly classifying known classes and reliably identifying unknown classes can interfere due to gradient conflict. When domain shift is pronounced, samples from known and unknown classes may overlap in feature space, leading to ambiguous decision boundaries. Such overlap increases the likelihood that known samples are mistakenly treated as unknown or vice versa. This misalignment disrupts feature matching across domains and distorts the decision boundary learning process, reinforcing a negative feedback loop. The issue is particularly severe in adversarial learning frameworks, where an improperly guided domain discriminator may inadvertently propagate source-domain knowledge to unknown target samples, amplifying confusion and triggering interactive negative transfer.
To address these issues, a novel cross-condition fault diagnosis network is proposed: a dual-path adversarial and progressive self-training network (DAPSN) for OSDA. The method is designed to simultaneously achieve accurate classification of known fault types and effective detection of unknown faults in open-set scenarios. Grounded in a theoretical error bound, the approach jointly optimizes two complementary objectives: an open-set detection loss to separate unknown categories and a domain-invariant learning loss to harmonize feature distributions across environments. Through this dual optimization, the model enhances inter-class separability at the macro scale, ensuring a clear distinction between known and unknown fault types, while strengthening intra-class compactness at the micro-scale across domains.
This architectural design explicitly bridges significant conceptual gaps that limit the efficacy of existing OSDA frameworks. First, methods such as OSBP and STA typically utilize a fixed probability threshold or a dedicated classifier for the unknown class. However, such approaches are often prone to error accumulation when the domain gap is significant. To overcome this limitation, the proposed method adopts a Coarse-to-Fine progressive strategy that employs an initial coarse alignment followed by a fine-grained uncertainty ranking mechanism to progressively isolate unknown samples. Second, in contrast to weighting-based approaches like CMU that rely on single transferability metrics such as entropy to suppress likely unknown samples, the proposed method introduces a dual-path adversarial mechanism. This mechanism simultaneously optimizes domain discrimination to verify domain invariance and class-aware discrimination to verify semantic consistency, thereby constructing a more robust dynamic weighting coefficient. Finally, distinct from methods that address negative transfer through static feature norms such as Fast Inference Neural Network (FINN), the proposed approach explicitly mitigates this issue by integrating dynamic weights into the dual-adversarial loss. This strategy ensures that alignment forces are applied exclusively to high-confidence known samples.
To further minimize negative transfer, a three-stage progressive self-training framework is developed. Initial stage: An adversarial classifier computes domain membership probabilities for shallow features from both the source and target domains. Cross-entropy loss is used to evaluate source-domain classification accuracy, forming an initial feature representation. Second stage: A dynamic classification threshold is adaptively generated to detect unknown faults in the target domain. By iteratively optimizing training risk and open-set risk, inter-class separability is enhanced. Third stage: A dual-path adversarial strategy is employed to learn domain-invariant features from the shared known classes in both source and target domains, increasing within-class compactness and supporting robust generalization under varying openness levels.
The developmental process of the DAPSN is shown in Figure 2. Initial state (Figure 2(a)): In the open-set setting, the source and target domains share known fault types, while the latter contains additional unknown fault categories. Stage two (Figure 2(b)): A preliminary boundary is established to separate known and unknown classes, enabling basic diagnostic capability. A dual-grained decision boundary, involving coarse and fine distinctions, is then constructed to more accurately isolate known and unknown samples in the target domains. Stage three (Figure 2(c)): Continued adversarial alignment gradually draws feature representations of known-class samples from both domains closer in shared space, strengthening intra-class compactness. Converged state (Figure 2(d)): After iterative optimization through unknown separation and attraction mechanisms, unknown target samples are pushed away from the shared space, while known class samples form cohesive clusters with their source-domain counterparts, yielding a clear and well-separated cross-domain feature distribution.
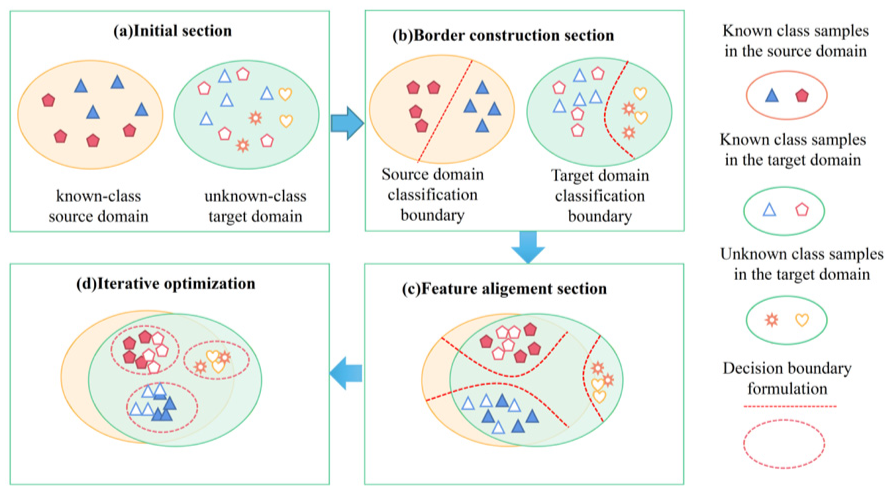
Dynamic evolution of the DAPSN framework: (a) initial section, (b) border construction section, (c) feature alignment section, and (d) iterative optimization. DAPSN:dual-path adversarial and progressive self-training network.
The key contributions of this work are summarized as follows:
A dual-path adversarial mechanism is constructed, incorporating two types of adversarial learning that jointly guide the feature extractor to generate representations robust to domain shifts. These representations maintain discriminative capability, enabling a model trained on the source domain to effectively adapt to data from the target domain.
A progressive self-training network is developed, employing a three-stage collaborative strategy. Through a dynamic openness estimation module, it automatically adjusts the decision boundary tightness to accommodate domain shifts under varying openness levels. Meanwhile, a weighted adversarial distribution alignment module promotes feature alignment within the shared label space.
A stepwise channel compression technique, together with hierarchical regularization, is employed to suppress overfitting and enhance generalization capability by uniformly dropping neurons. In addition, a GRL is incorporated after the five designed convolutional layers to cooperate with the dual-path adversarial discriminator by reversing gradients, improving training efficiency, and convergence stability.
The remainder of this manuscript is structured as follows: Section “Theoretical foundations” introduces the theoretical foundations, including the problem formulation and generalization error margin derivation for the OSDA model under an open-set scenario, followed by the section, which details the core architecture of DAPSN. Section “Experimental validation and analysis” presents extensive experimental evaluations to demonstrate the effectiveness of DAPSN. The final section concludes the study and outlines future research directions.
Theoretical foundations
Problem formulation
In open-set problem formulations, it is generally assumed that a source-domain data a target environment data
This study aims to develop a comprehensive diagnostic system for the precise assignment of test samples belonging to known classes to the
Derivation of the upper bound of theoretical error
For the theoretical error upper bound, assuming that the hypothesis space
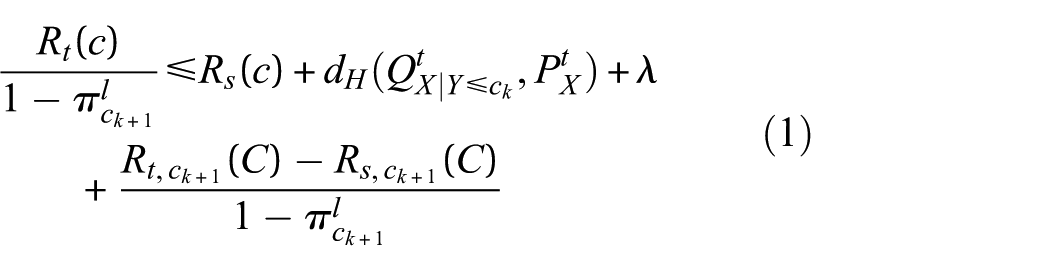
The variable k denotes the shared error.
33
C
k
indicates the number of known classes. While
Source risk items
Differences in distance
Sharing errors λ: When there is an inter-domain shift in the conditional distribution
Risk adjustment for opening μ0: This term describes cross-domain discrepancy in classification performance for unknown classes. The term
For the purpose of acquiring cross-domain consistent representations, the feature distribution differences are minimized via a GAN. The corresponding training objective is expressed as:
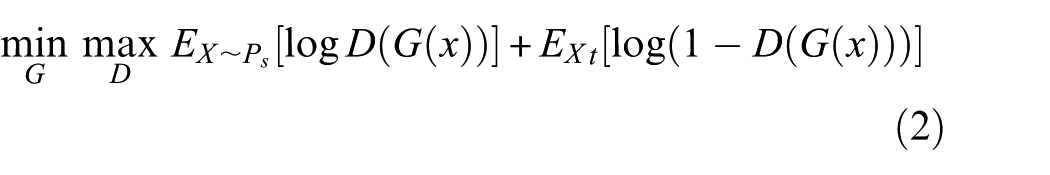
Here, G denotes the feature extraction network, responsible for generating cross-domain consistent representations, while D denotes the domain classifier, which promotes alignment of the feature space by inducing domain confusion and suppressing domain-specific features. For the open-set risk,
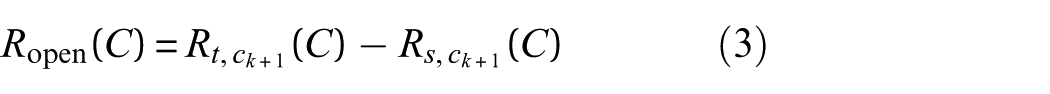
It incorporates a bidirectional regulation mechanism: the positive
Regarding the dual-path adversarial discriminator, component G (the generator) and component D1(the classifier) are trained in a minimax manner to align cross-domain statistical properties. This objective is formulated as:
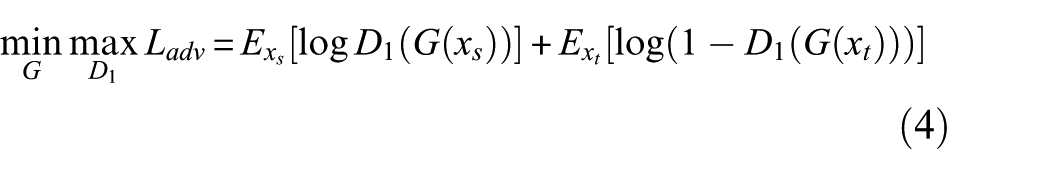
The class perception discriminator D2 calculates the class-conditional similarity of target samples on the source data. Higher outputs imply closer similarity to known source-class distributions. The confidence produced by D2 supports the boundary formation module by dynamically sharpening the decision boundary between known and unknown categories. It is defined as:

The core architecture of DAPSN
DAPSN methodology
The DAPSN framework consists of three primary modules: a feature extraction module, a boundary construction module, and a feature alignment module, as shown in Figure 3. The feature extraction module processes vibration spectra through the generator G to obtain both shallow and deep representations. The boundary construction module estimates the source risk and open-set risk by employing cross-domain consistency evaluation and uncertainty estimation, using confidence metrics and cross-entropy to compute classification losses for both known and unknown instances. In the feature alignment module, a dual-path adversarial discriminator is proposed. Within this setup, component G and domain discriminant D1 undergo minimax competition to obtain domain-transferable representations. Concurrently, the class-aware discriminator D2, which does not participate in adversarial training, evaluates the similarity of each target sample to the source data distribution. This design avoids gradient conflict arising from a single discriminator attempting to jointly optimize alignment and unknown detection. Based on dual-path adversarial loss and confidence scores, known and unknown samples are separated; unknown samples receive lower weights, and additional constraints are applied to low-confidence samples to mitigate negative transfer.
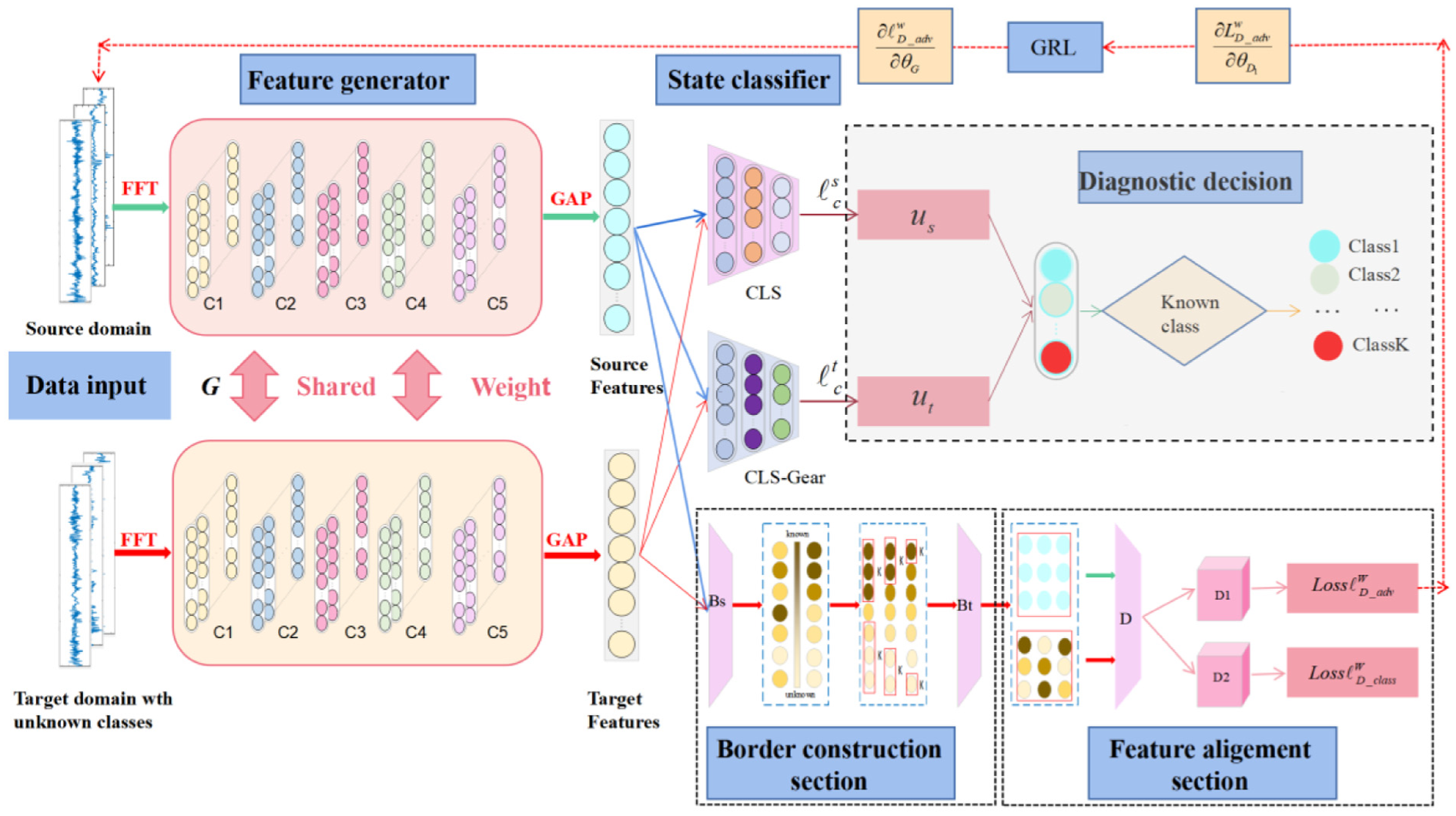
The implementation architecture of the proposed DAPSN network. DAPSN: dual-path adversarial and progressive self-training network.
Feature extraction module
The detailed configuration of the network is shown in Figure 4. A customized two-dimensional CNN (2D-CNN) serves as the central module for automatically extracting shallow and deep representations from both source and target domain data. The model consists of five convolutional layers and one fully connected layer. It processes a three-channel signal and outputs a 1024-dimensional feature vector. The design objective is to progressively extract semantic representations through layered convolution, compressing spatial features into high-level embeddings.
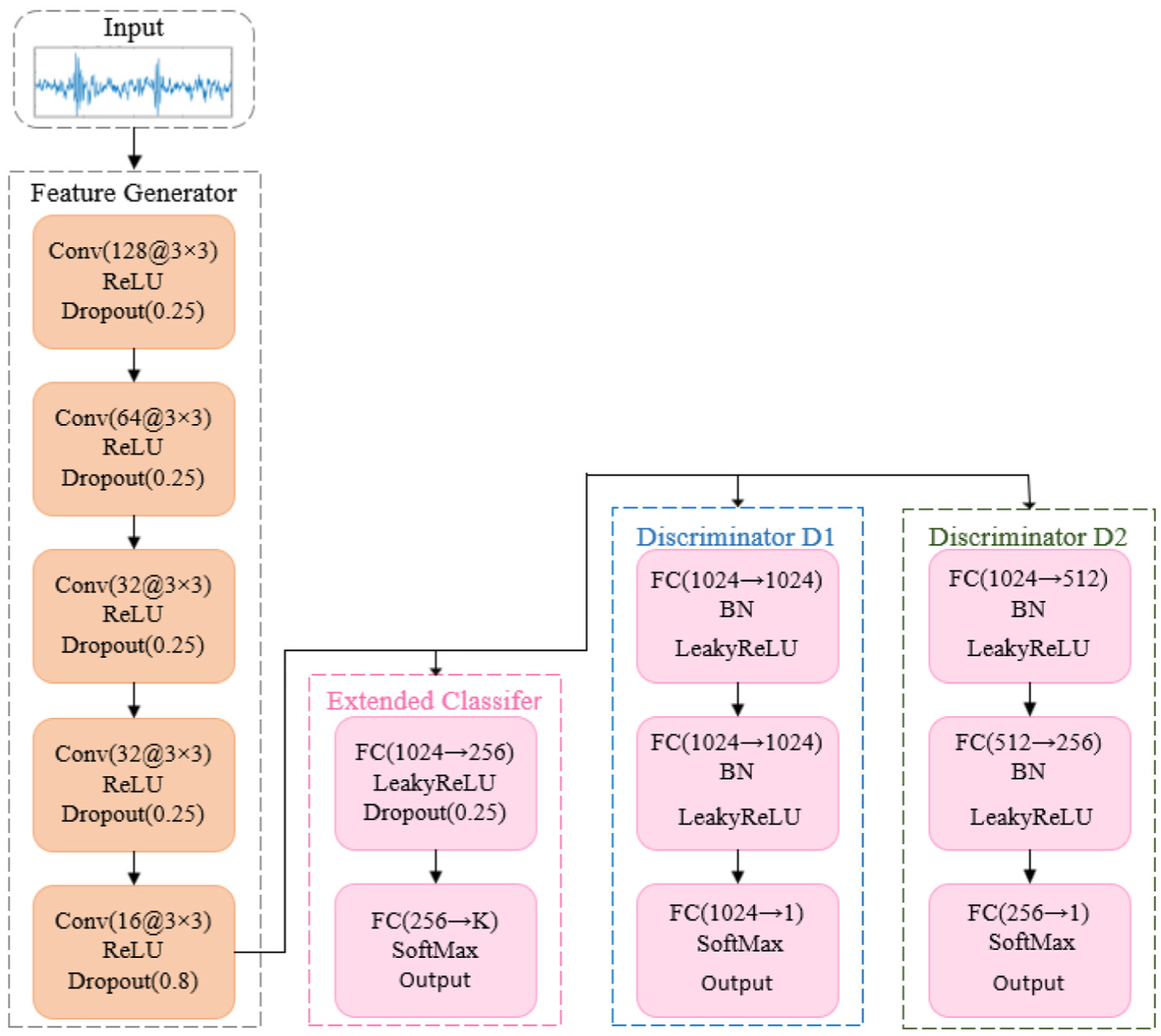
Detailed parameters of network architecture.
The five convolutional layers (conv1–conv5) sequentially extract spatial features while reducing channel dimensions (128 → 64 → 32 → 32 → 16). Conv1 uses 128 (3 × 3) kernels to encode low-level edge features. Conv2–Conv4 progressively reduce dimensions, while Conv5 employs 16 (3 × 3) kernels to obtain high-dimensional semantic features. Each layer uses Rectified Linear Unit (ReLU) activation to enhance nonlinear expression and avoid gradient vanishing. Dropout regularization is applied at layers (p=0.25 for the first four layers and p=0.8 for the final layer). The final layer adopts a high dropout rate to enhance generalization. A fully connected layer compresses features into a 1024-dimensional vector. Finally, a gradient reversal layer (GRL) is integrated to promote domain-invariant representation learning during adversarial training, cooperating with the dual-path adversarial discriminator for end-to-end optimization.
Boundary construction module
In the boundary construction module, unlabeled unknown samples are separated from the target domain. First, the k-means algorithm generates pseudo-labels for target samples. Feature centroids for both domains are computed, followed by establishing cross-domain category correspondences via bidirectional matching. Matching reliability is computed for both source-to-target and target-to-source directions, ensuring selection of high-quality alignment pairs and avoiding bias from one-way matching.
To estimate openness more accurately, hierarchical adversarial training is applied. A coarse-grained discriminator B s aligns shallow features and learns global domain-invariant characteristics. A fine-grained discriminator B t focuses on deep features, incorporating high-confidence and uncertain target samples for class-level semantic alignment.
Finally, entropy-weighted uncertainty sampling is conducted. Samples are filtered using normalized prediction entropy (p1-entropy) from the target domain. High-confidence samples participate in feature alignment, while low-confidence samples receive an “unknown class” constraint to prevent misalignment. A higher entropy value indicates greater uncertainty. The calibrated similarity
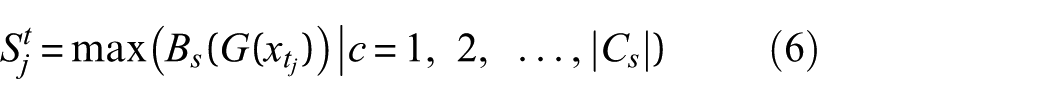
where
This approach yields reliable outputs for target-domain instances belonging to known classes, since their underlying representations are consistent with the source domain. By contrast, for instances from previously unseen categories, their distinctive structural characteristics are absent in the source distribution, resulting in weaker discrimination ability and biased affinity estimates. To address this issue, a self-supervised uncertainty calibration technique based on entropy analysis is introduced. The entropy term
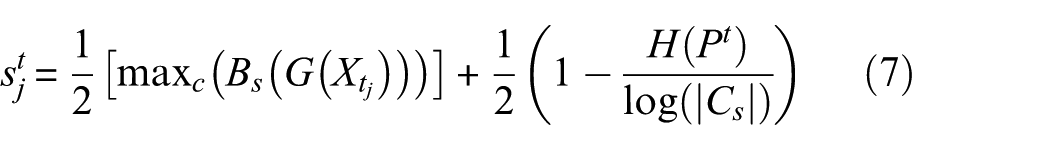
A multi-objective loss integrates classification, adversarial, and uncertainty constraints to improve generalization in the target domain. The complete objective function is written as:
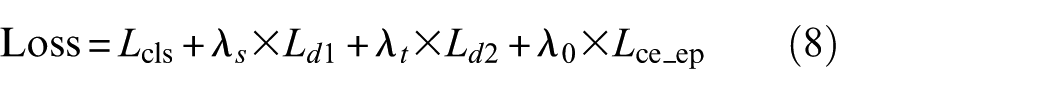
where Lcls represents the classification loss,
Feature alignment module
Feature alignment aims to draw known fault samples in the target domain closer to their source-domain counterparts to ensure consistent representations across domains. This prevents performance degradation caused by the incorrect pairing of labeled source samples with unlabeled target samples. A dual-channel adversarial discriminator is used for coordinated optimization. A dynamic weight A is embedded in the dual-path adversarial loss, where low-confidence samples receive reduced weights to minimize noise interference. Based on the output probability of the target discriminator B
t
, the weight for each target sample

A value of
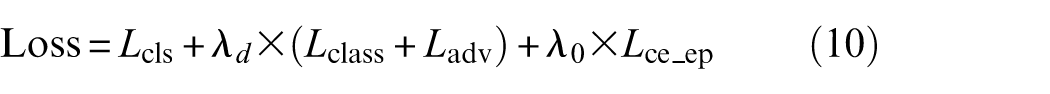
where Lcls denotes the classification error,
The online training process
The DAPSN employs a three-stage progressive self-training strategy. Initially, all model parameters and loss weights
Step 1. Align adversarial distribution
In the first stage, the feature generator G and classifier C are jointly optimized to maximize classification accuracy for source-domain fault states under supervised learning using cross-entropy loss. This stage establishes a discriminative mapping from raw signals to fault labels, forming the basis for later stages.
Step 2. Boundary construction phase
In this stage, a dedicated original-data B
s
and intended-data discriminator B
t
are trained to form coarse-to-fine boundaries that distinguish known from unknown fault types. Let
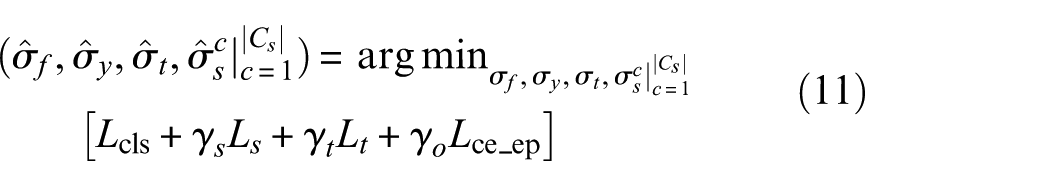
Step 3. Feature alignment phase
In the final stage, a minimax optimization adjusts parameters of the feature generator G and discriminator D to align source and target distributions. Only samples from known target classes are attracted to their corresponding source classes, excluding unknown samples. Let
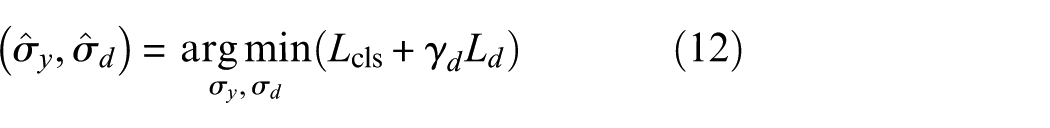
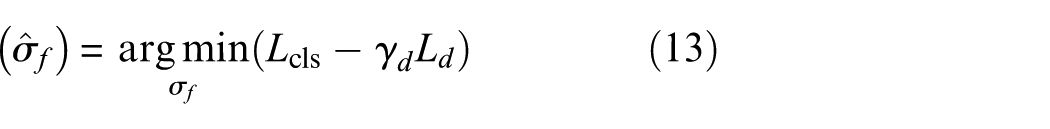
Table 1 summarizes the DAPSN workflow. Through its progressive self-training mechanism, the model effectively tightens the theoretical error bound for OSDA and suppresses negative transfer from unknown categories. Beginning with adversarial initialization of the feature space, iterative boundary refinement and feature alignment push unknown target samples away from the shared space, while clustering known samples tightly with source-domain instances. As a result, a more precise boundary for unknown data is achieved.
The detailed algorithm flow of the proposed DAPSN.

DAPSN: dual-path adversarial and progressive self-training network.
Experimental validation and analysis
Data set description
Paderborn University (PU) bearing dataset
The employed dataset originates from the rolling bearing dataset of the University of Paderborn and includes samples from bearings exhibiting both artificially induced faults and naturally evolving operational faults. Vibration signals were acquired from the bearing housings using piezoelectric accelerometers at a sampling frequency of 64 kHz. By adjusting the rotational speed of the drive system, modifying radial loads on the bearings, and applying torque to the transmission system, data under multiple operating conditions were collected. Eight bearings were selected for accelerated life testing to obtain representative real-world degradation data. The operating conditions of the dataset are summarized in Table 2.
PU bearing dataset specification.
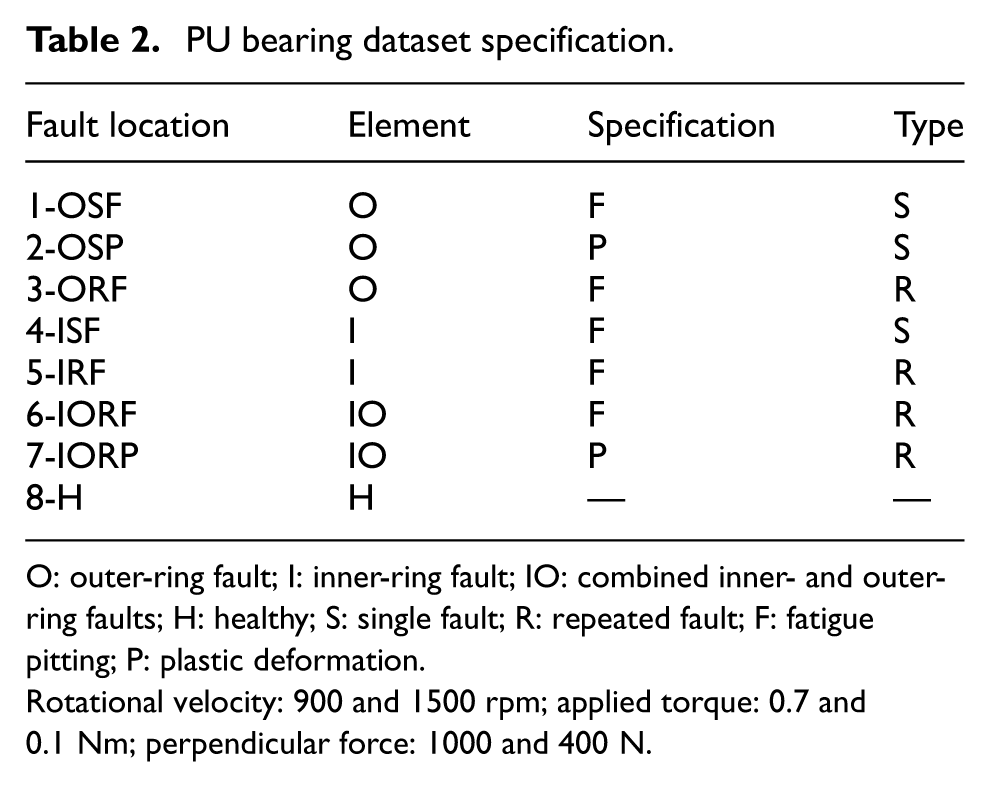
O: outer-ring fault; I: inner-ring fault; IO: combined inner- and outer-ring faults; H: healthy; S: single fault; R: repeated fault; F: fatigue pitting; P: plastic deformation.
Rotational velocity: 900 and 1500 rpm; applied torque: 0.7 and 0.1 Nm; perpendicular force: 1000 and 400 N.
PHM09 gearbox dataset
The second dataset is obtained from the planetary gearbox dataset of the PHM09 Data Challenge and contains three drive shafts, four gears, and six bearings. The experiments investigate multiple failure modes across two gear types (straight and helical). Vibration signals were recorded from two accelerometer channels and one tachometer channel to obtain rotational speed. All signals were continuously sampled at 66.67 kHz for 4 s. This dataset covers six operational states of planetary gearboxes, detailed in Table 3.
PHM09 gearbox dataset standard.

Rotational frequency: 30/35/40/45/50 Hz; loading: low/high. Source condition: applied torque 0.1 Nm, radial load 1000 N. Target condition: applied torque 0.7 Nm, radial load 400 N.
Data preprocessing and implementation details
To enable the 2D-CNN to effectively capture discriminative features from one-dimensional time-series data, a data preprocessing method was designed. The raw vibration signals collected from the experimental test rig were first subjected to a data augmentation strategy based on an overlapping sliding window technique. The length of each sample window was set to 6000 data points to ensure sufficient frequency resolution. To maximize the number of training samples, the sliding step was set to 25 data points, resulting in an overlap ratio of approximately 99.6%. Subsequently, the Fast Fourier Transform was applied to each time-domain segment to obtain the frequency spectrum. To eliminate the interference of low-frequency trends and high-frequency noise irrelevant to mechanical fault characteristics, the amplitude spectrum was truncated to retain the frequency index range from 128 to 1024.
Regarding the specific setup for the open-set transfer tasks, the source and target domains were constructed to simulate asymmetric label spaces. The source domain contains samples from a subset of known fault categories, while the target domain includes both the shared known categories and additional unknown fault types that were not present during training. For the unsupervised clustering module essential to the proposed progressive self-training strategy, the k-means algorithm was employed. The initialization was performed using the k-means strategy to ensure stable convergence, and the maximum number of iterations was fixed at 300.
A heuristic search mechanism was implemented to address the challenge of estimating the unknown number of clusters in the target domain. Since the exact number of fault types in the target domain is initially undetermined, the algorithm iteratively varies the hypothesis of the target cluster number from c to
Comparison method and experimental details
Hyperparameter configuration and experimental framework: all hyperparameters for the comparison models were selected based on prior research and experimental needs to ensure competitive performance. PyTorch served as the training platform, and computation was accelerated using NVIDIA 4070 Ti GPUs.
Experimental design: two state-of-the-art OSDA approaches were integrated for performance benchmarking. To ensure fairness, all comparison methods use the same backbone network.
OSBP (Open-Set Back Propagation) adapts the classifier and feature extractor jointly to learn a discriminative boundary capable of identifying unseen categories.
DATLN addresses industrial open-set knowledge transfer by combining adversarial classification with category-aligned representation learning while identifying unknown samples.
Importance Weighted (IW)-OSDA introduces instance-level weighting and anomaly detection within an adversarial structure to assign affinity-based weights to target samples relative to known source categories.
CMU computes a composite transferability metric using entropy, prediction certainty, and prediction stability to detect out-of-distribution samples.
FINN learns domain-invariant features via cross-layer distribution matching and semi-supervised label refinement, minimizing multi-layer maximum mean discrepancy.
STA adopts a dual-stage framework: separation of unknown target samples followed by adaptation on shared categories.
DAPSN (proposed): Adam optimizer with weight decay is used. The initial learning rate is set to 5 × 10−4, with rapid initial convergence followed by gradual decay to ensure training stability. The batch size is fixed at 40.
Open-domain adaptive tasks and evaluation indicators
Domain-adaptive tasks
Ten OSDA tasks are constructed using the bearing and gearbox datasets. Tables 4 and 5 configurations progressively increase openness, representing higher proportions of unknown categories.
Open-set domain adaptive tasks for PU bearing dataset.
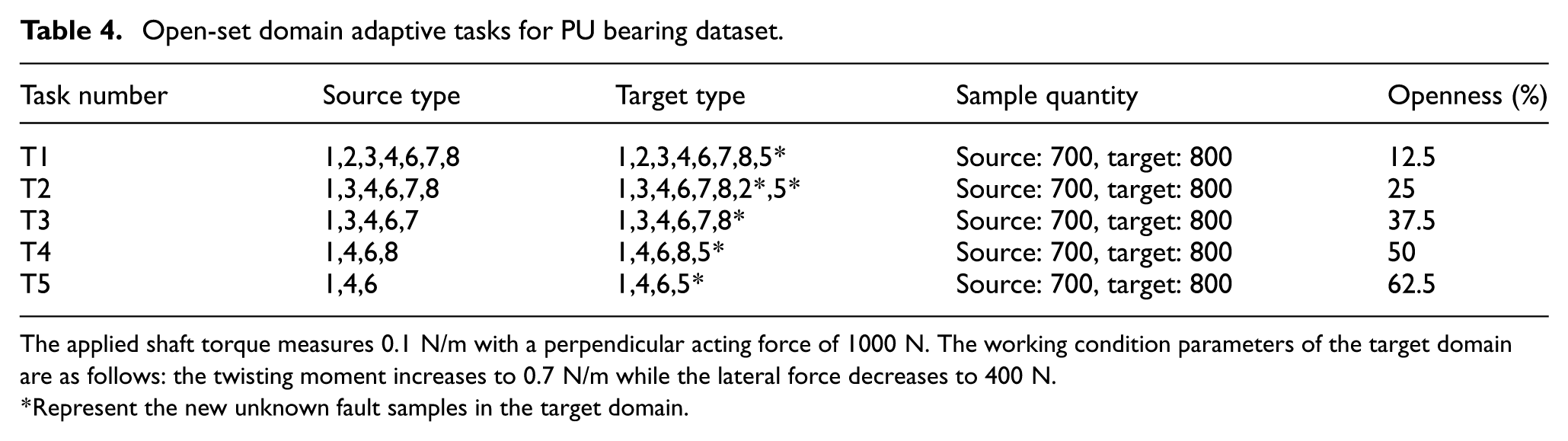
The applied shaft torque measures 0.1 N/m with a perpendicular acting force of 1000 N. The working condition parameters of the target domain are as follows: the twisting moment increases to 0.7 N/m while the lateral force decreases to 400 N.
Represent the new unknown fault samples in the target domain.
Open-set domain adaptive tasks for PHM09 gearbox dataset.
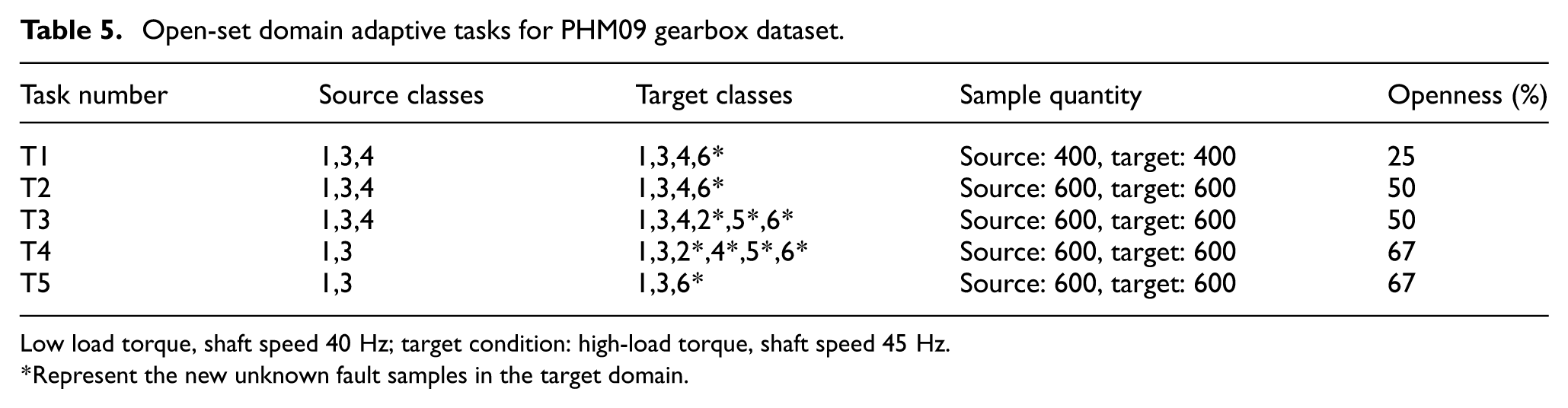
Low load torque, shaft speed 40 Hz; target condition: high-load torque, shaft speed 45 Hz.
Represent the new unknown fault samples in the target domain.
Gearbox OSDA task design: Five tasks were constructed according to the gearbox dataset with the aim of quantitatively comparing models’ adaptability to unknown fault categories through progressively increasing inter-domain openness gaps.
Evaluation indicator
In OSDA research, the design of performance indicators is essential for accurately assessing algorithmic effectiveness. Based on prior studies,36,37 two core evaluation metrics are adopted. Definitions are as follows:
M k : Quantity of target-domain samples from known categories correctly classified, reflecting the model’s capability to recognize known patterns;
M u : Quantity of target-domain samples correctly identified as “unknown,” reflecting the ability to reject unseen categories;
N k : Total number of known-category samples in the target domain;
N u : Total number of unknown-category samples in the target domain.
The class accuracy rate evaluates the model’s precision in classifying known samples within the target domain, quantifying its ability to preserve and apply domain knowledge. A higher

The overall accuracy evaluates performance across both known and unknown classes in the target domain, measuring the ability to align known categories and identify unseen categories. It reflects comprehensive model performance in open-set conditions. The formula is:
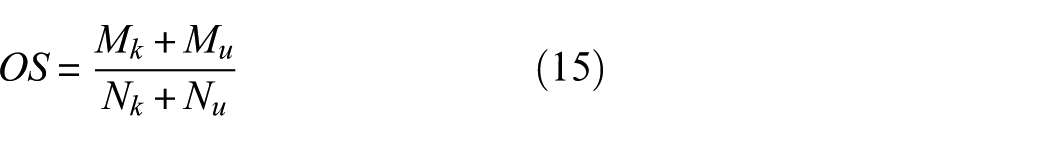
Together,
Experimental assessment and analysis
Evaluation of diagnostic performance on the PU bearing dataset
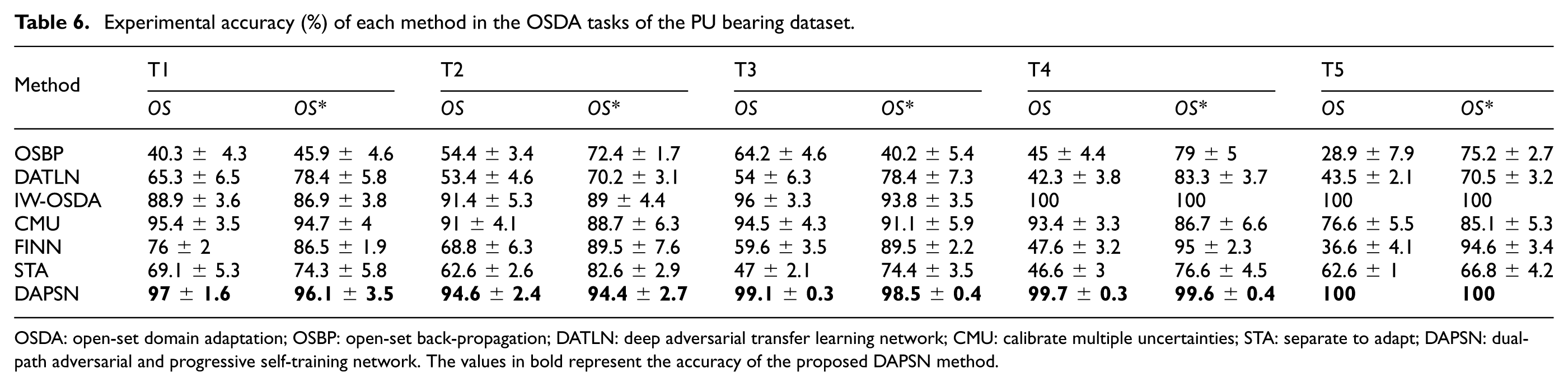
The diagnostic results on the PU Bearing dataset are shown in Table 6, presenting OS and
Experimental accuracy (%) of each method in the OSDA tasks of the PU bearing dataset.
OSDA: open-set domain adaptation; OSBP: open-set back-propagation; DATLN: deep adversarial transfer learning network; CMU: calibrate multiple uncertainties; STA: separate to adapt; DAPSN: dual-path adversarial and progressive self-training network. The values in bold represent the accuracy of the proposed DAPSN method.
Average OS and comparison model of DAPSN under the bearing dataset. DAPSN: dual-path adversarial and progressive self-training network.
The proposed DAPSN exhibits consistent superiority across all tasks. When evaluating only known-category accuracy (
Yet, when newly emerging and unrecognized fault instances are incorporated into the target data, the model’s overall performance declines sharply due to misclassification of these instances, reducing the combined accuracy to 36.6%. The OSBP and DATLN models exhibit similar behavior: while they achieve satisfactory recognition performance for known-class samples in the absence of unknown interference, their accuracy decreases markedly once unknown samples are introduced. This demonstrates that unknown fault samples can induce negative transfer, thereby impairing model performance.
Figure 6 further compares the classification performance of different models under varying openness levels in bearing task T5. In complex mechanical systems, novel and previously unrecorded faults frequently occur—conditions represented by high openness levels where known categories are limited and unknown categories predominate. Under openness as high as 70%, the proposed method achieves substantially superior performance on an industrial dataset, clearly outperforming existing approaches in such challenging environments. Traditional DA methods experience significant performance degradation in the presence of unseen anomaly types. Their main limitation lies in employing global domain alignment without accounting for unlabeled category instances in the target distribution. This non-discriminative alignment unintentionally forces unknown faults to align with known classes, blurring decision boundaries and leading to misclassification, ultimately diminishing generalization capability.
Recognition outcomes yielded by different benchmark approaches for OSDA scenario T5 using the PU bearing data: (a) the comparison methods and (b) the proposed DAPSN. OSDA: open-set domain adaptation; DAPSN: dual-path adversarial and progressive self-training network.
These issues substantially constrain the robustness of FINN and DATLN in OSDA scenarios, with their degradation becoming more evident as openness increases. Experimental results indicate that the proposed approach attains significantly improved clustering precision compared with conventional methods. Moreover, the observed performance variance remains consistently low across diverse task configurations, suggesting stable convergence behavior across multiple experimental trials.
Analysis of the diagnostic accuracy of the PHM gearbox dataset
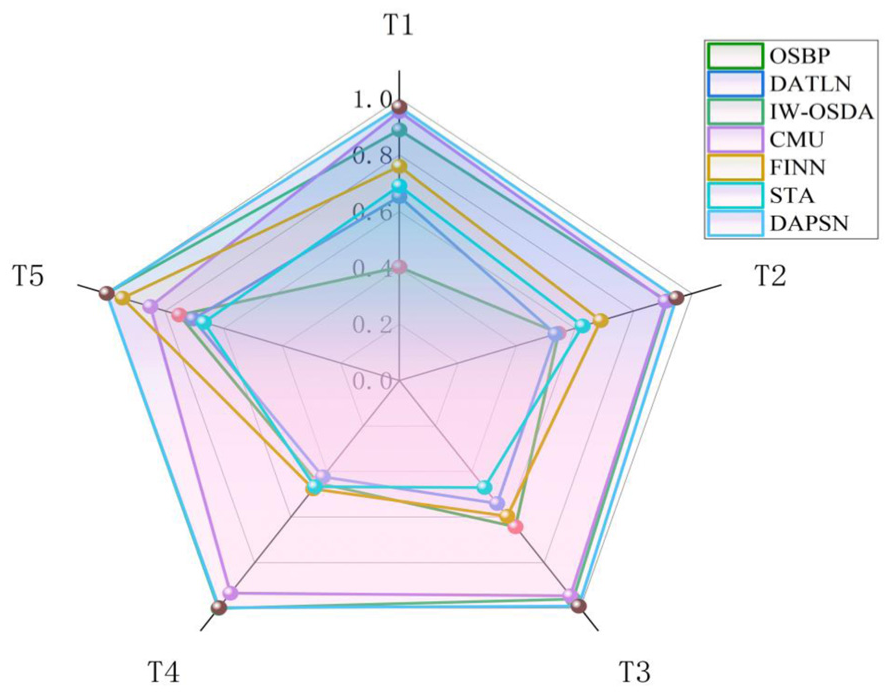
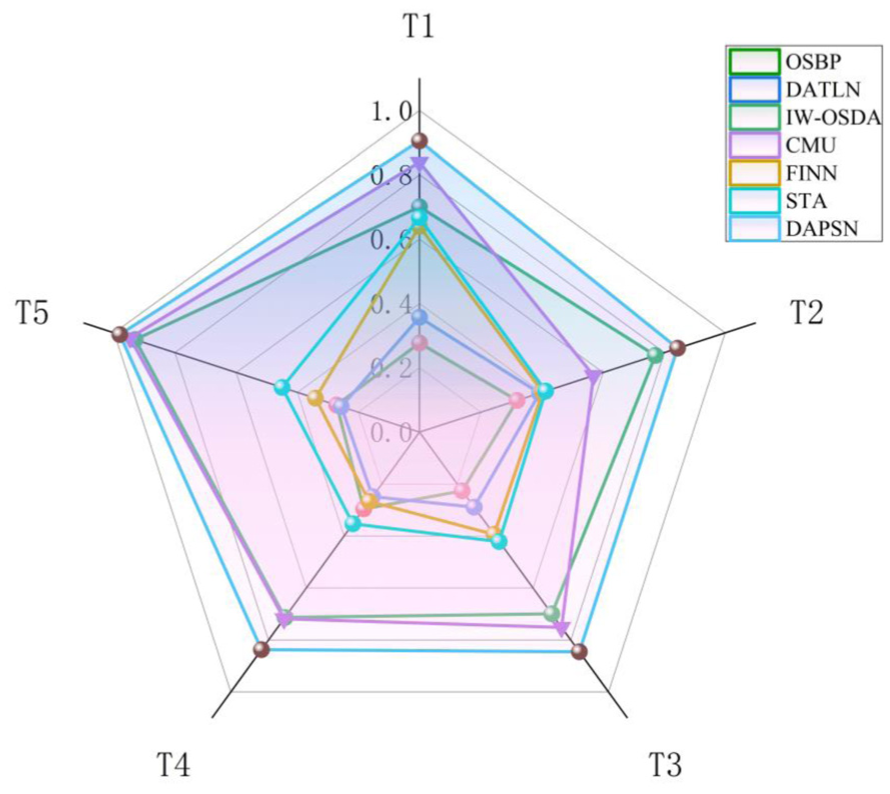
Table 7 summarizes the recognition results for the PHM09 gearbox dataset, including the combined accuracy metric OS computed over the entire evaluation set and the class-specific accuracy
Each method’s experimental accuracy (%) in the OSDA tasks of the PHM09 gearbox dataset.
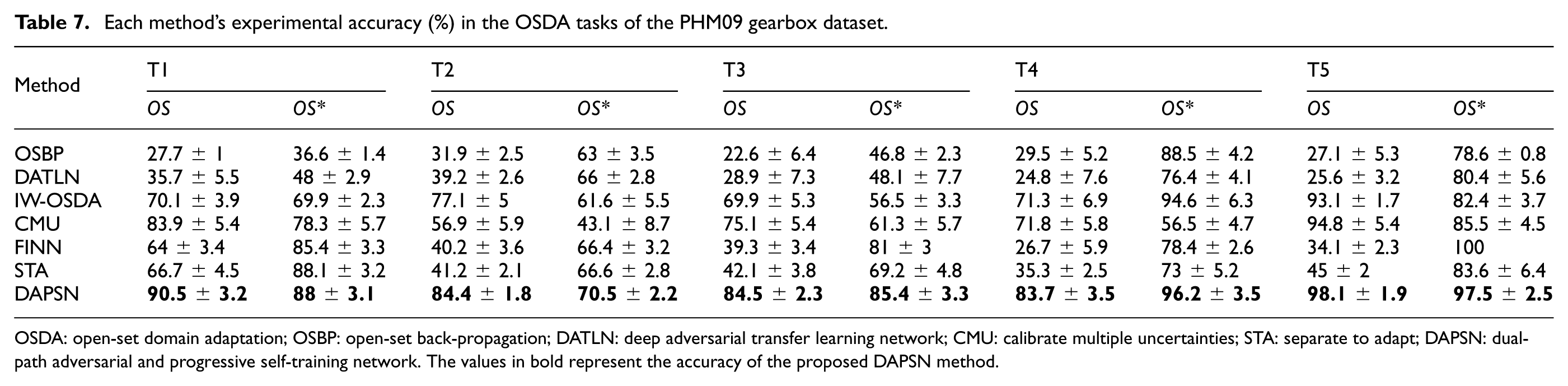
OSDA: open-set domain adaptation; OSBP: open-set back-propagation; DATLN: deep adversarial transfer learning network; CMU: calibrate multiple uncertainties; STA: separate to adapt; DAPSN: dual-path adversarial and progressive self-training network. The values in bold represent the accuracy of the proposed DAPSN method.
Average OS and comparison model of DAPSN under the gearbox dataset. DAPSN: dual-path adversarial and progressive self-training network.
Figure 8 further compares the classification performance of various models under different openness levels for gearbox task T5.
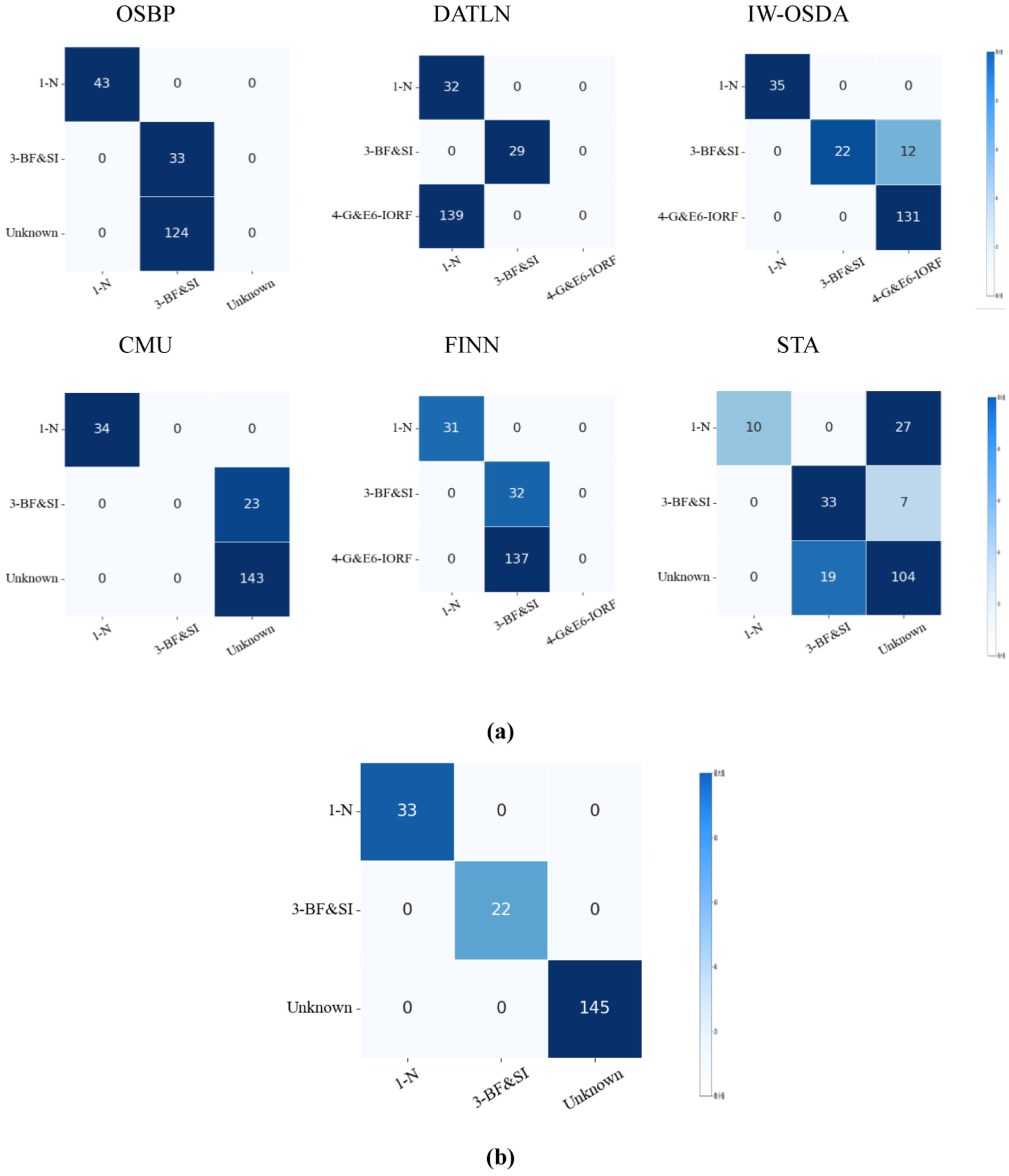
Classification results of various comparative methods on the OSDA task T5 for the PHM09 gearbox dataset: (a) the comparison methods and (b) the proposed DAPSN. OSDA: open-set domain adaptation; DAPSN: dual-path adversarial and progressive self-training network.
Feature visualization
Visualization results of each comparison method and the proposed method
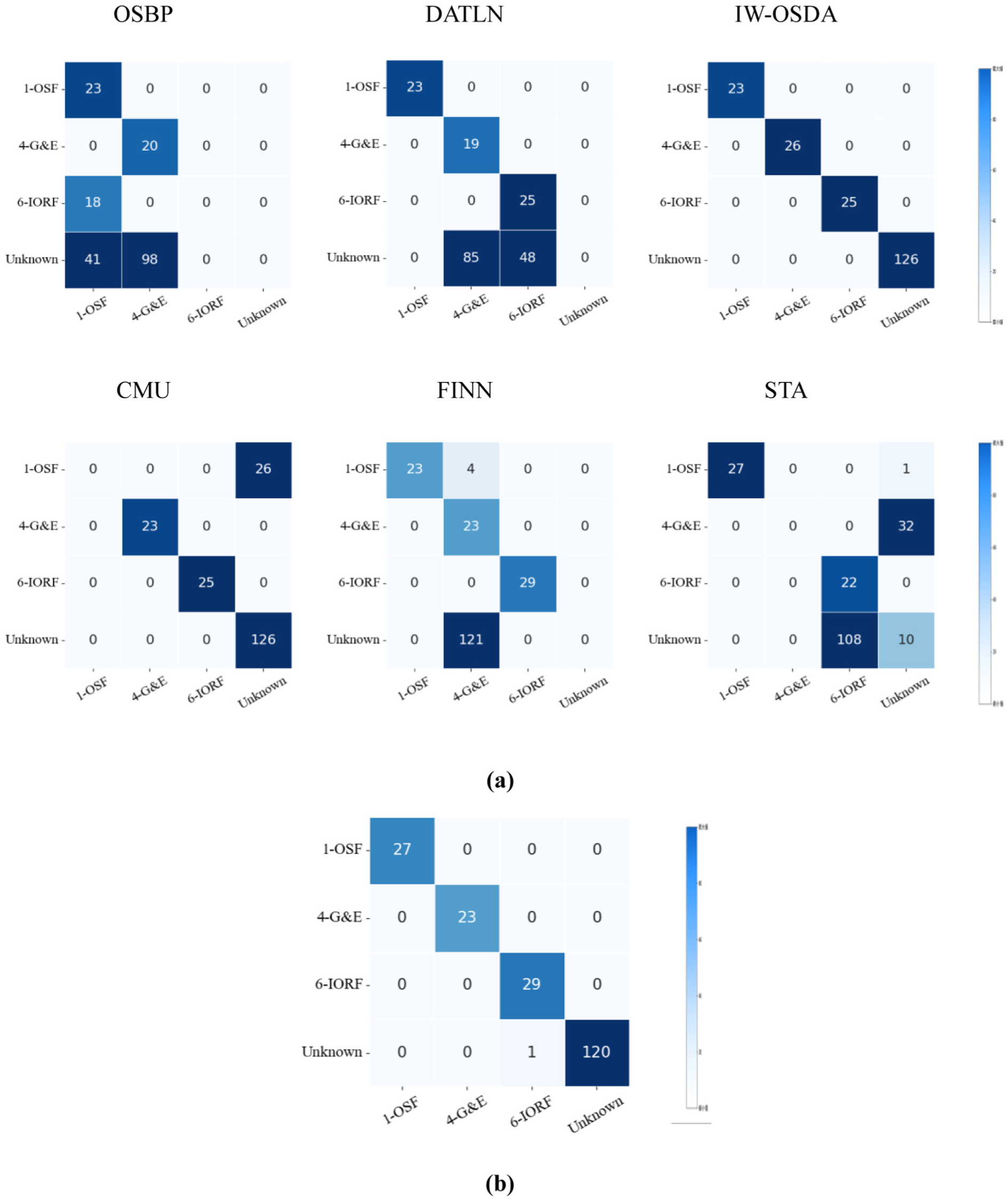
Dimensionality reduction via t-distributed Stochastic Neighbor Embedding (t-SNE) 38 was employed to visualize high-dimensional representations learned by each model, as illustrated in Figure 9. For OSBP and FINN, known and unknown target samples are heavily intermixed in the feature space, indicating limited capability to distinguish unseen faults, which undermines diagnostic robustness. While STA and CMU use weighting strategies to identify anomalies, the feature plots reveal their limitations.
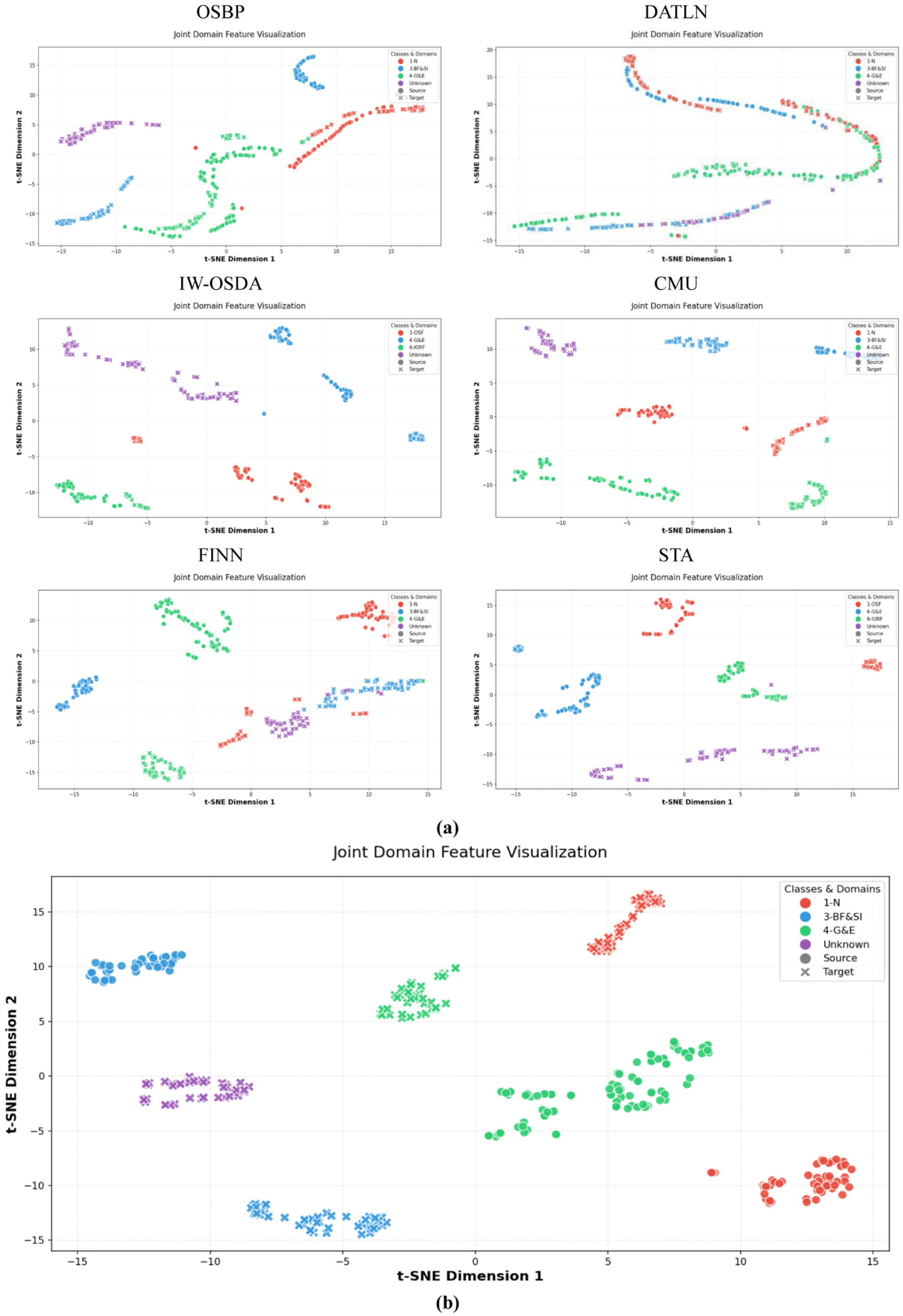
Visualization results on task T1 of the PHM09 dataset: (a) comparison methods and (b) DAPSN. DAPSN: dual-path adversarial and progressive self-training network.
Specifically, STA applies a two-level discriminator and treats all outliers as a single cluster, ignoring internal structure within abnormal samples. This misclassifies outliers that resemble known classes, reducing performance. CMU assigns weights through combined statistical cues such as confidence, entropy, and consistency, yet struggles when outliers closely resemble known samples—an expected condition in open environments. Since CMU relies on surface-level statistical differences without deeper semantic modeling, its robustness is constrained.
By contrast, the proposed method forms a clear boundary separating unknown instances from all source samples while clustering known instances into cohesive and well-separated groups across domains. These visualizations confirm its capability to learn discriminative, domain-invariant features for known faults while effectively minimizing interference from unknown categories.
Visualization of data processed through each convolutional layer
To visually demonstrate the performance of the proposed feature extraction module and the progressive domain alignment process, a layer-wise feature visualization analysis on the PU bearing dataset under the cross-condition OSDA scenario (task T5) was conducted. Specifically, t-SNE was employed to visualize the feature distributions extracted from various layers (ranging from conv1 to the Fully Connected Layer (FC) layer) of the module. As illustrated in Figure 10, the source and target domains are initially well-separated in the shallow layers, indicating a significant domain shift. However, as the data propagate through the deeper layers of the proposed model, the domain discrepancy is gradually mitigated. In the final layers, samples from the same category across different domains cluster compactly, while the unknown fault samples are distinctively isolated.
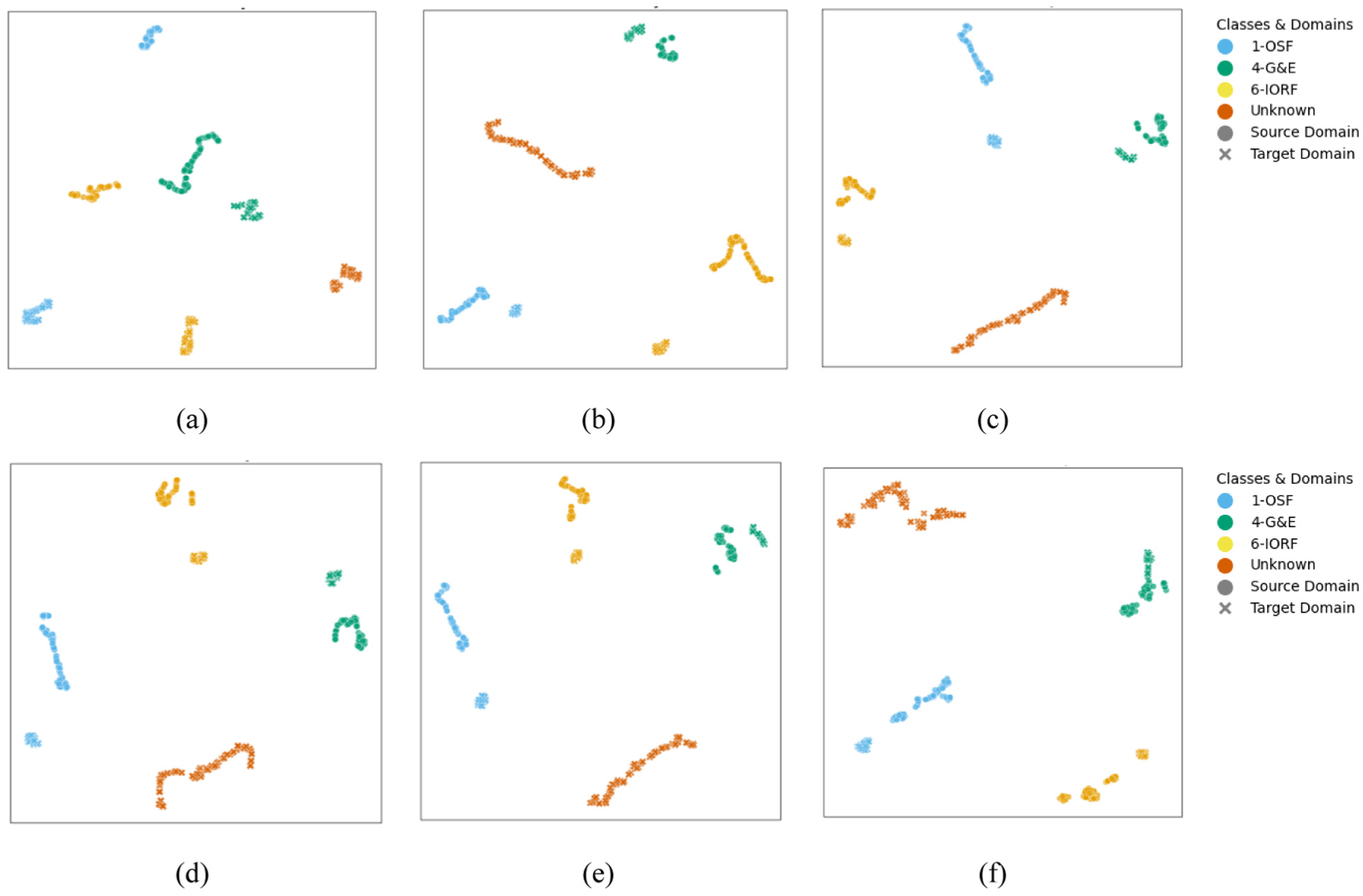
Visualization of data processed through each convolutional layer: (a) the visualization results of layer conv1, (b) the visualization results of layer conv2, (c) the visualization results of layer conv3, (d) the visualization results of layer conv4, (e) the visualization results of layer conv5, and (f) the visualization results of FC.
Ablation experiment
Complexity analysis
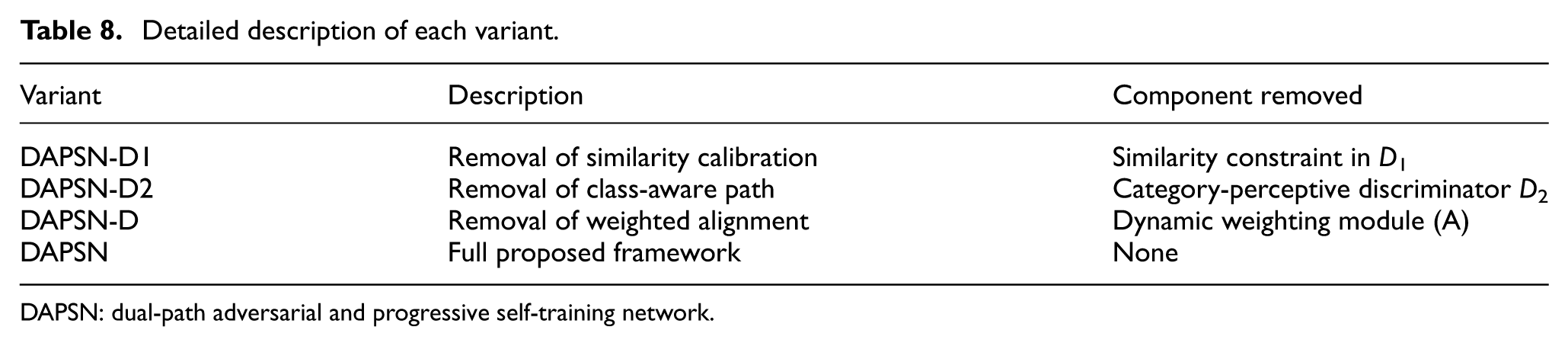
Ablation experiments were conducted using three modified DAPSN variants to evaluate the contributions of the similarity-based discriminator D1, the category-perceptive discriminator D2, and the weighted adversarial alignment module. The variants include DAPSN without similarity calibration in D1, DAPSN without the adaptive class-aware discriminator D2, and DAPSN without the weighted alignment module. To provide a clearer definition of each model variant, Table 8 details the specific modules retained or removed for each variant.
Detailed description of each variant.
DAPSN: dual-path adversarial and progressive self-training network.
Similarity weight dynamics were examined on OSDA task T3 of the PU bearing dataset and OSDA task T3 of the PHM09 gearbox dataset. Cosine similarity 39 was used to calculate the L2-norm of similarity weights across training iterations. The horizontal axis represents update iterations, and the vertical axis denotes the corresponding L2-norm values.
Figure 11 illustrates the experimental results on the PU and PHM09 dataset. In the PU T3 experiment (40 iterations), the complete DAPSN assigns maximum weight (1.0) to class 0 (single-point outer raceway fault) while suppressing unknown samples, converging within 15 iterations and achieving rapid stability. In the PHM09 T3 experiment (100 iterations), DAPSN again stabilizes in about 15 iterations, maintaining a high weight of 0.95 without overfitting, reducing training energy by about 60% compared to the variants. Variant (f) shows declining weight for class 0, indicating diagnostic degradation, while variant (h) exhibits weight instability, posing risks for real-time deployment.
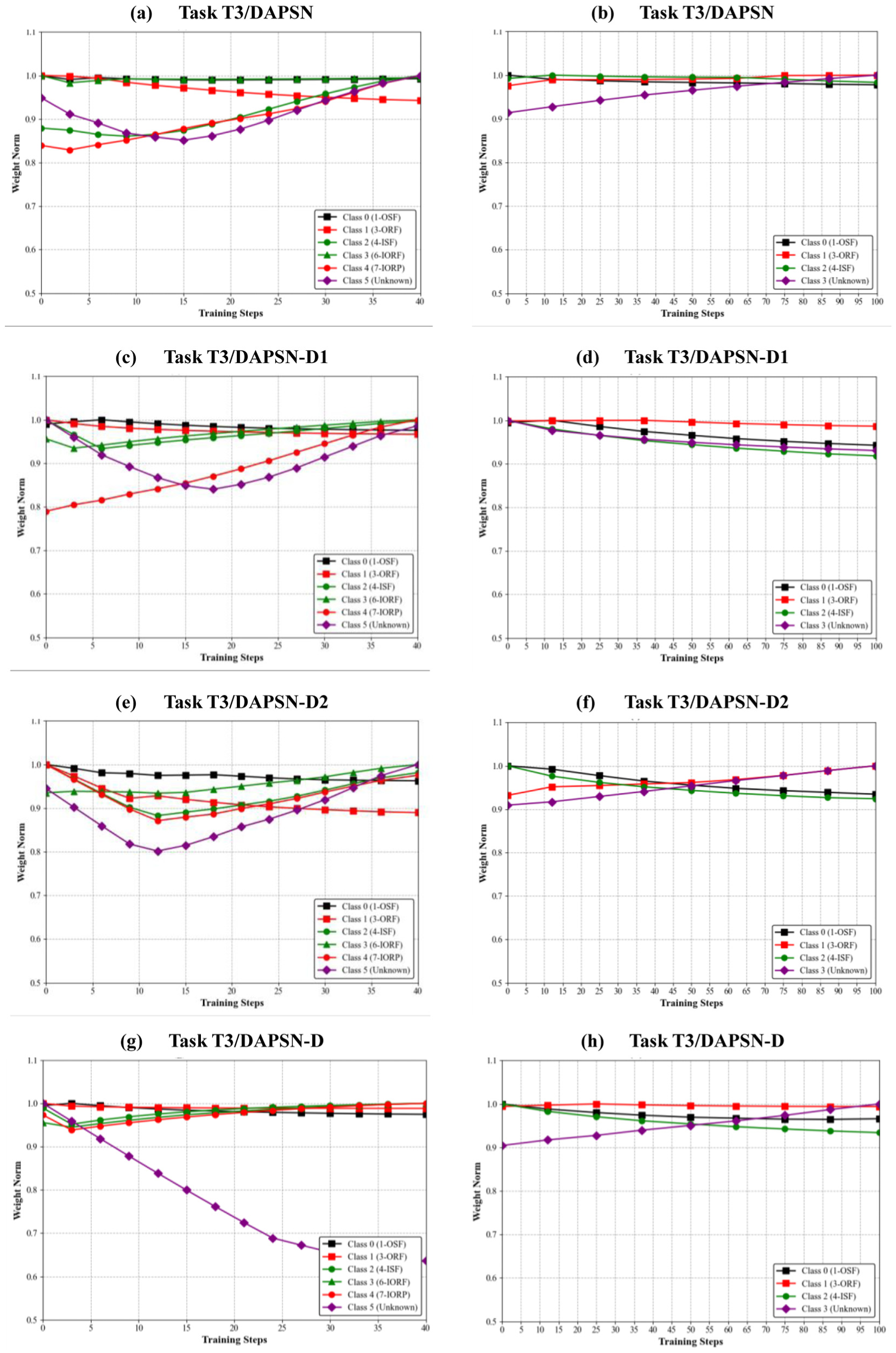
Similarity weight curve of the comparison methods with task T3 on PU and PHM09: (a) task T3/DAPSN, (b) task T3/DAPSN, (c) task T3/DAPSN-D1, (d) task T3/DAPSN-D1, (e) task T3/DAPSN-D2, (f) task T3/DAPSN-D2, (g) task T3/DAPSN-D, and (h) task T3/DAPSN-D. DAPSN: dual-path adversarial and progressive self-training network.
Confusion matrices for similarity weights on PU and PHM09 are shown in Figures 12 and 13, respectively. The complete model consistently provides cleaner separation between known and unknown classes. Across all experiments, removing any individual DAPSN component reduces effectiveness, demonstrating that each module is essential for optimal performance.
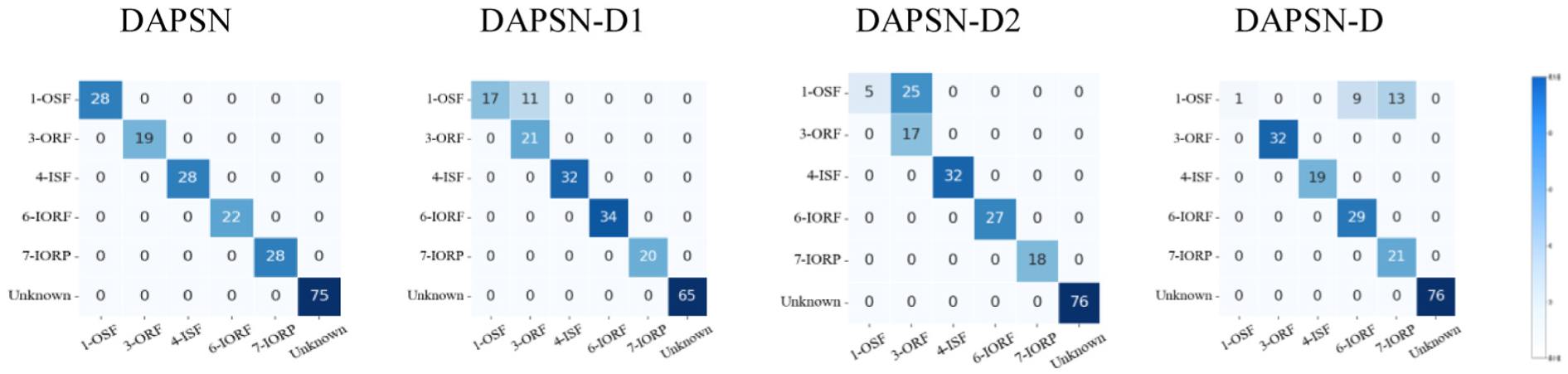
Similarity weight confusion matrix of each comparison method with task T3 on PU.
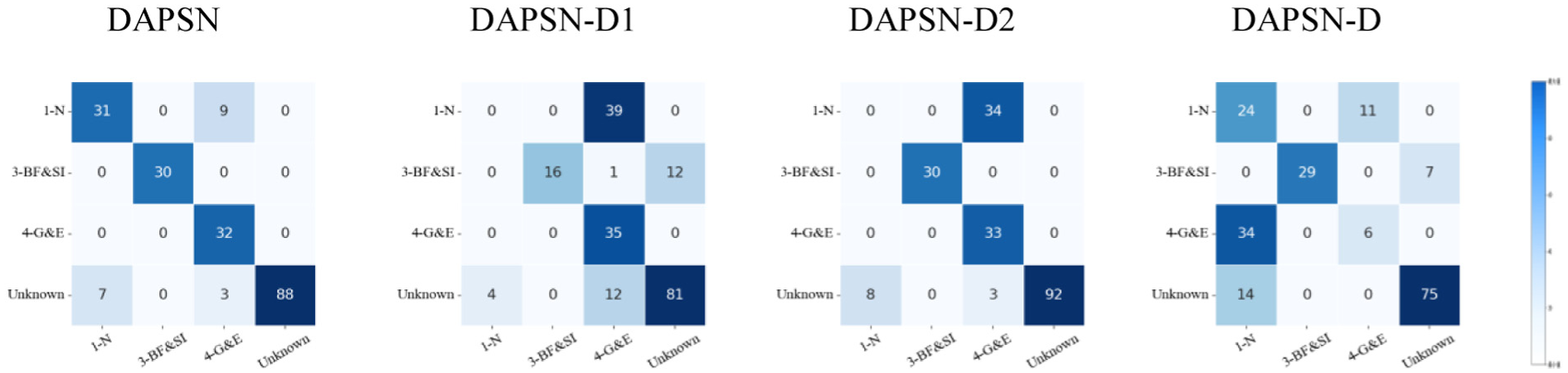
Similarity weight confusion matrix of each comparison method with task T3 on PHM09.
Computational efficiency analysis
Table 9 reports the average computational time for model optimization and inference across benchmark methods in the OSDA scenario T5 (PU bearing dataset) and scenario T1 (PHM09 gearbox dataset). The results demonstrate that, while maintaining rapid training speeds and achieving the fastest training time on the PHM09 dataset, the proposed DAPSN also exhibits high testing efficiency (fastest on PHM09 and second only to OSBP on PU). DAPSN therefore provides clear advantages in training efficiency, requiring reduced execution time while enhancing the capability to detect unknown fault classes.
Computation time (s) of each comparison method and the proposed DAPSN.
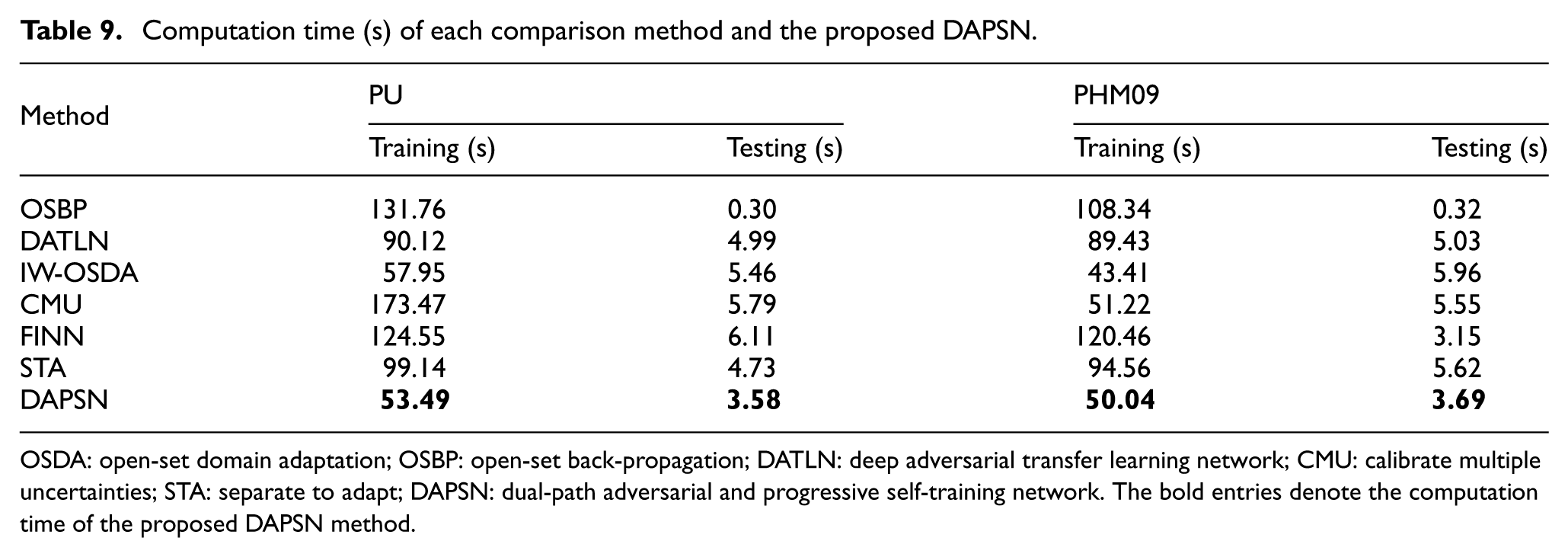
OSDA: open-set domain adaptation; OSBP: open-set back-propagation; DATLN: deep adversarial transfer learning network; CMU: calibrate multiple uncertainties; STA: separate to adapt; DAPSN: dual-path adversarial and progressive self-training network. The bold entries denote the computation time of the proposed DAPSN method.
Additional validation on the CWRU dataset
To further validate the robustness and generalization performance of the proposed DAPSN method in open-set scenarios, additional experiments were conducted on the Case Western Reserve University (CWRU) bearing dataset. Specifically, five cross-condition OSDA tasks were designed. The performance of the proposed DAPSN is comprehensively evaluated from three perspectives: accuracy comparison, confusion matrix visualization, and t-SNE visualization.
Dataset description and OSDA task construction
The Case Western Reserve University dataset contains vibration signals collected from the drive end of a motor housing at a sampling frequency of 12 kHz. In this study, data under different motor loads, including 1, 2, and 3 HP, are utilized to represent distinct domains. Each domain consists of four health conditions: normal, ball fault, inner race fault, and outer race fault. The operating conditions of the dataset are summarized in Table 10. To construct the OSDA tasks, specific categories are designated as known and others as unknown in the target domain. Five cross-condition tasks are established to test the capability of the model to align known categories while successfully identifying the unknown fault type. The specific construction of adaptive tasks for open set domains is shown in Table 11.
CWRU bearing dataset specification.
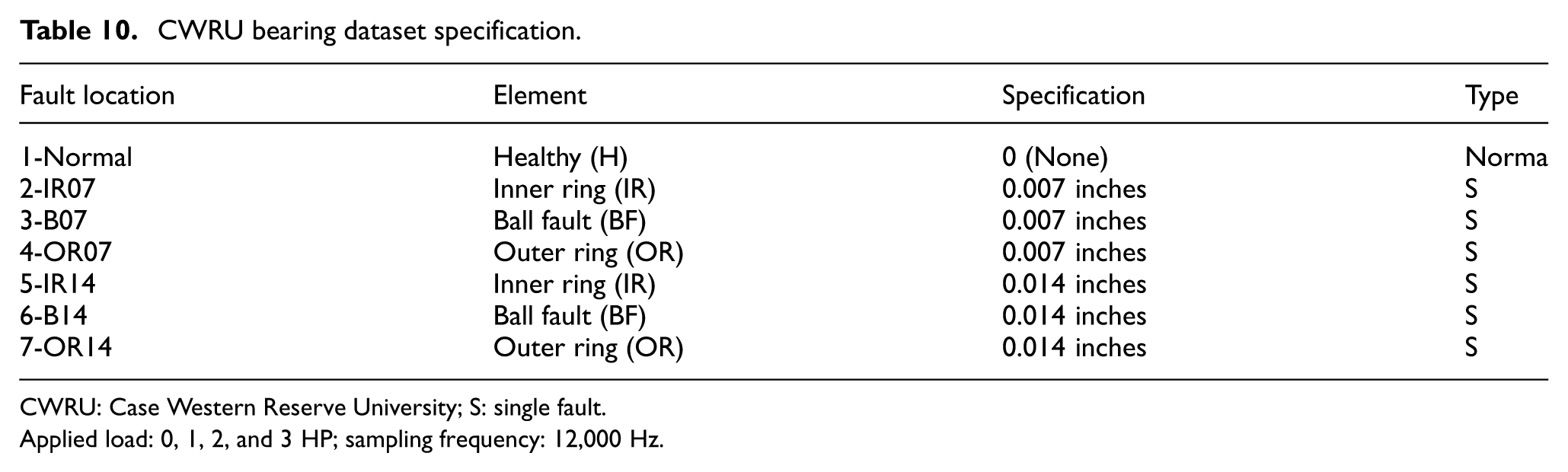
CWRU: Case Western Reserve University; S: single fault.
Applied load: 0, 1, 2, and 3 HP; sampling frequency: 12,000 Hz.
Open-set domain adaptive tasks for the CWRU bearing dataset.
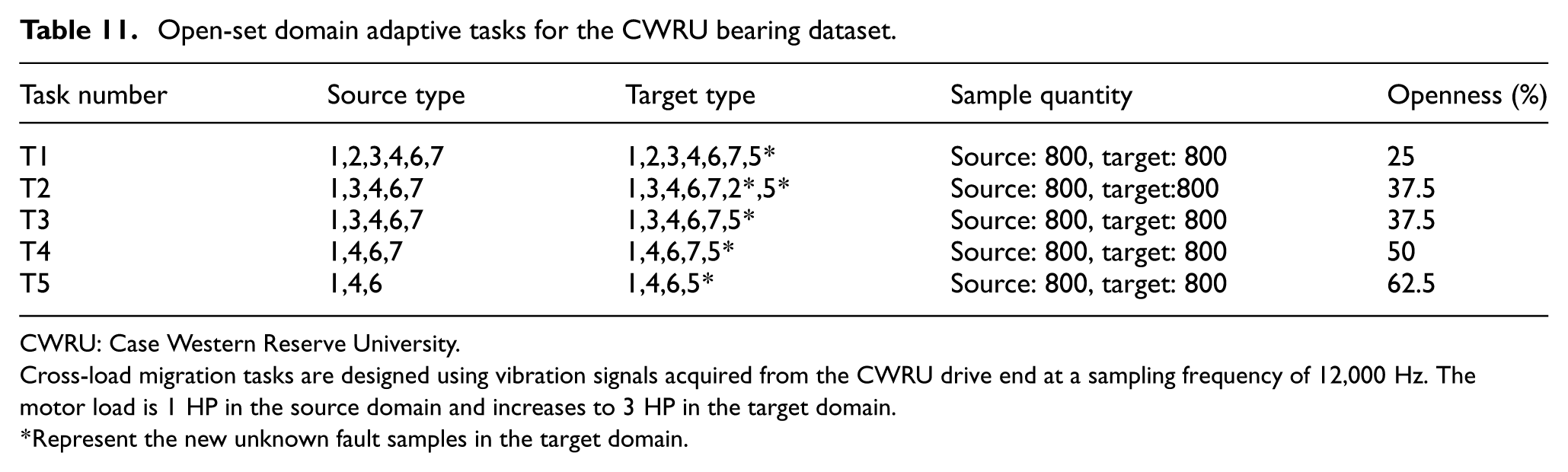
CWRU: Case Western Reserve University.
Cross-load migration tasks are designed using vibration signals acquired from the CWRU drive end at a sampling frequency of 12,000 Hz. The motor load is 1 HP in the source domain and increases to 3 HP in the target domain.
Represent the new unknown fault samples in the target domain.
Accuracy results and confusion matrix analysis
Table 12 presents a comprehensive evaluation of the accuracy for various methods across different OSDA tasks using the CWRU bearing dataset. The evaluation metrics consist of the overall accuracy designated as OS for global classification performance in the target domain and the accuracy for known classes referred to as
Accuracy (%) of each method in the OSDA tasks of the CWRU bearing dataset.
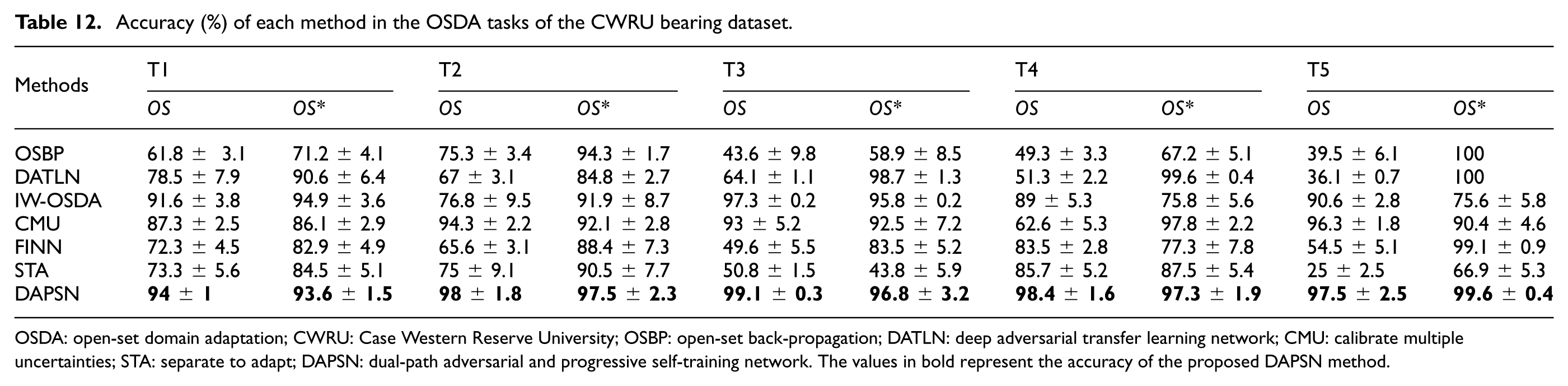
OSDA: open-set domain adaptation; CWRU: Case Western Reserve University; OSBP: open-set back-propagation; DATLN: deep adversarial transfer learning network; CMU: calibrate multiple uncertainties; STA: separate to adapt; DAPSN: dual-path adversarial and progressive self-training network. The values in bold represent the accuracy of the proposed DAPSN method.
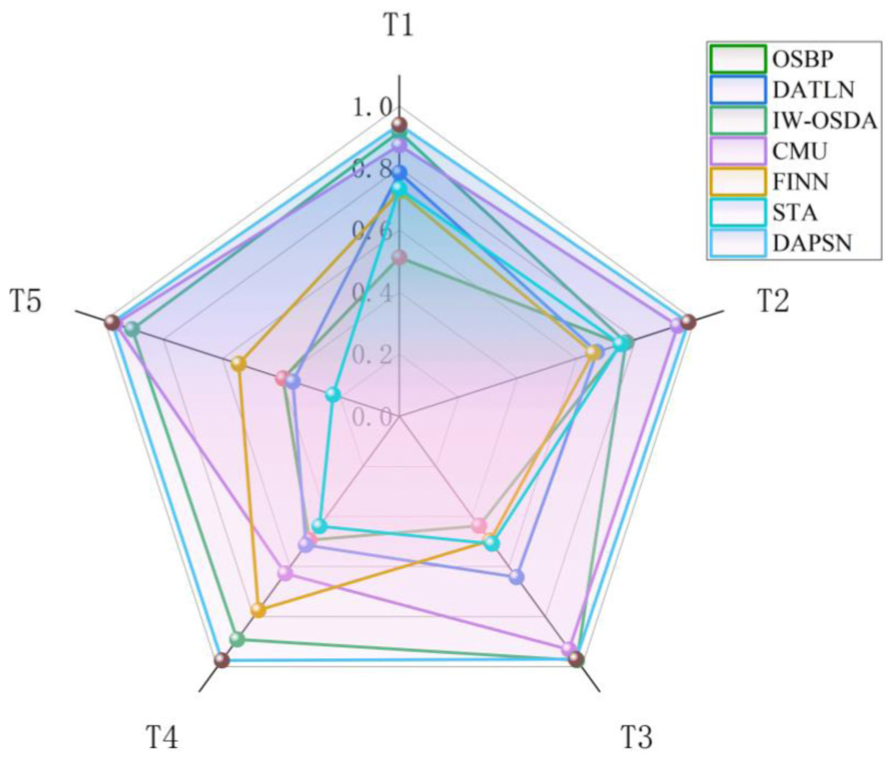
Average OS of DAPSN and the comparison model under the CWRU bearing dataset. DAPSN: dual-path adversarial and progressive self-training network; CWRU: Case Western Reserve University.

The confusion matrix visualization of OSDA tasks under the CWRU bearing dataset. OSDA: open-set domain adaptation; CWRU: Case Western Reserve University.
Feature visualization via t-SNE
To intuitively evaluate the feature extraction and domain alignment capabilities, a visualization analysis of the classification results produced by the proposed DAPSN method on the CWRU dataset is conducted using t-SNE. As shown in Figure 16, the features of the target domain are well-clustered. The known categories from the source and target domains are tightly aligned in the feature space, indicating effective domain-invariant feature learning. Simultaneously, the unknown samples form a distinct cluster separated from the known categories. The visualization results demonstrate that the proposed method achieves both the alignment of known categories and the effective rejection of unknown samples in OSDA environments.
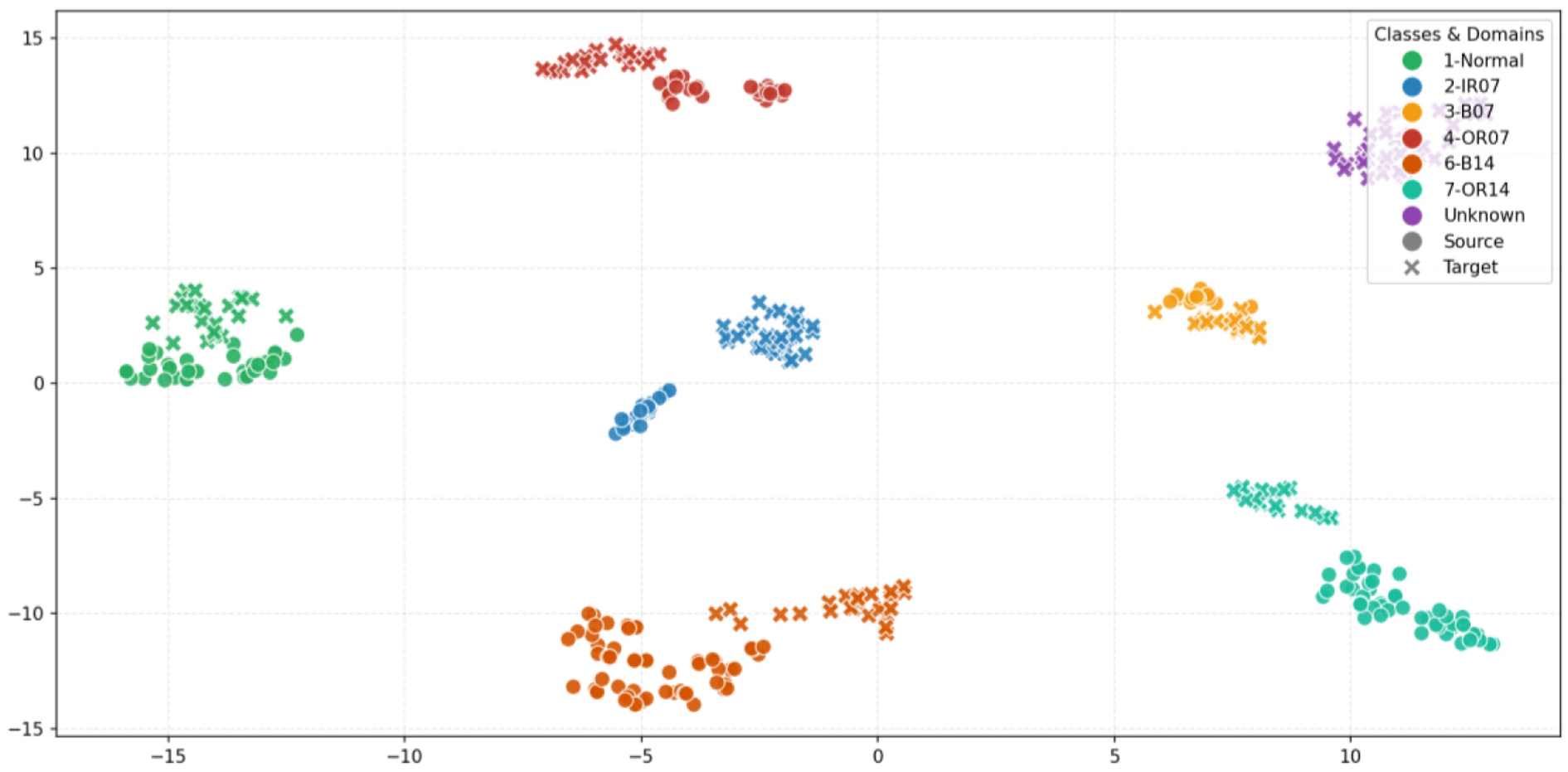
The t-SNE visualization results of the proposed method on the OSDA task T1 under the CWRU dataset. OSDA: open-set domain adaptation; CWRU: Case Western Reserve University.
Hyperparameter sensitivity analysis
To investigate the impact of key hyperparameters on the proposed model’s performance and verify the rationality of the selected values, a series of sensitivity analysis experiments was conducted. Specifically, it focused on two critical sets of hyperparameters: the Dropout regularization rate and the weight coefficients in the objective function. The experiments were conducted on the PU bearing dataset under task T1 to ensure representativeness.
Impact of dropout regularization rate
In the proposed model, a differential dropout strategy is adopted. Specifically, a lower dropout rate (p=0.25) is applied to the first four layers to preserve low-level structural information, while a higher dropout rate (p=0.8) is employed in the final layer to enforce the extraction of robust high-level semantic features and enhance the model’s generalization capability. To verify the rationality of this configuration, a sensitivity analysis experiment was conducted on the PU bearing dataset under the cross-condition OSDA task T1. The experimental results are illustrated in Figure 17. To mitigate the impact of randomness, the average accuracy calculated from five independent trials was utilized as the performance evaluation metric.
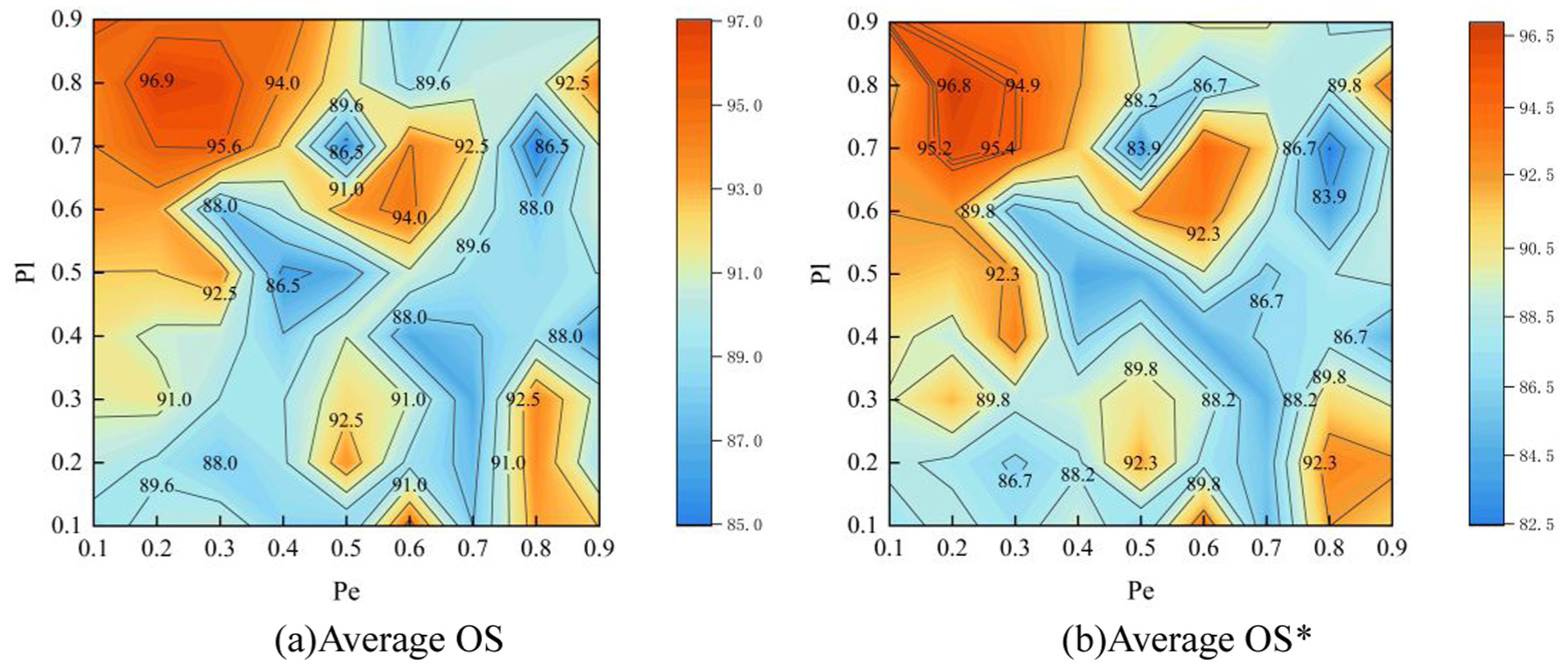
Impact of regularization hyperparameters on accuracy: (a) contour map of overall accuracy of target domain (average OS) and (b) contour map of known class accuracy (average OS*).
The contour maps in Figure 17 demonstrate the diagnostic accuracy variations across different combinations of the early layer dropout rate P e and the final layer dropout rate P l . The results indicate that the highest accuracy levels are consistently concentrated in the upper left region of the plots. This pattern reveals that the model achieves superior performance when P e is maintained at a low value while P l is set to a relatively high value. Specifically, the peak diagnostic accuracy is reached when P e ranges from 0.2 to 0.3, and P l ranges from 0.7 to 0.9. These observations confirm that a smaller dropout rate in the initial layers is essential for retaining the fundamental characteristics of the vibration signals. Simultaneously, applying a more intensive dropout in the terminal layer provides stronger regularization, which helps the model focus on robust high-level features and improves its ability to generalize across different domains. By contrast, the diagnostic accuracy shows a significant decline in the regions where P e is high, or P l is low, as visualized by the blue areas in the maps. Consequently, the configuration of P e equal to 0.25 and P l equal to 0.8 is identified as the optimal balance for the proposed fault diagnosis framework.
Impact of loss function weights
The total loss function involves trade-off parameters that balance the source classifier loss
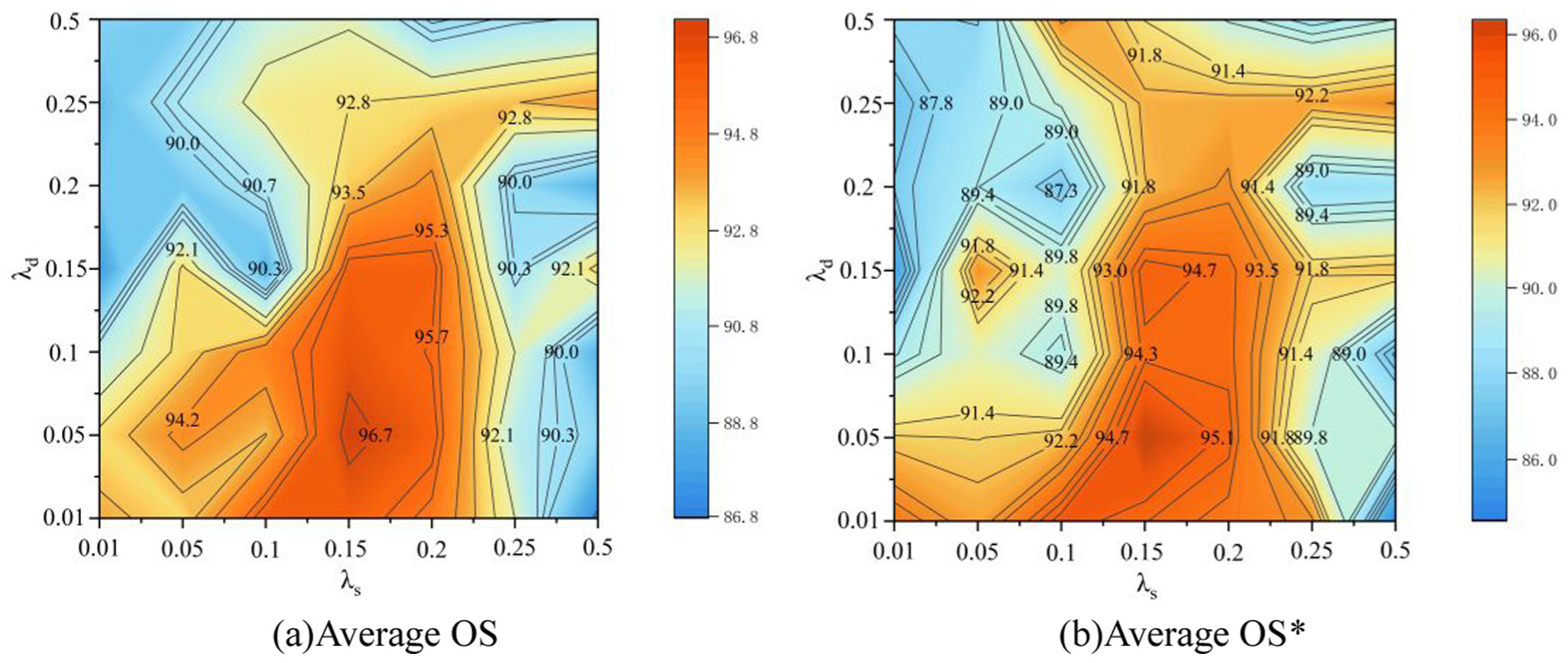
Impact of loss function weight hyperparameters on accuracy: (a) contour map of overall accuracy of target domain (average OS) and (b) contour map of known class accuracy (OS*).
Specifically, the weight of the open set separation loss, denoted as λ0,was initially fixed at 0.1 to serve as an empirical baseline for the sensitivity analysis of other parameters. This configuration is primarily motivated by the need to maintain gradient stability during the early stages of the adversarial training process. Since the separation loss relies on the identification of unknown samples via predicted uncertainty, which inherently functions as a form of pseudo-labeling, assigning a relatively small weight, such as 0.1, prevents the potential noise from uncertain target samples from dominating the total gradient. Consequently, this ensures that the feature extractor first learns stable and discriminative representations from the labeled source domain. Furthermore, setting auxiliary loss weights to the magnitude of 0.1 is a standard empirical practice in recent OSDA studies for machinery fault diagnosis.40–42 This allows the model to capture the characteristics of unknown classes without interfering with the categorical boundaries of known classes. Based on this fixed value, the other tradeoff parameters were then systematically varied to identify their optimal ranges for maximizing cross-domain generalization performance.
Figure 18 provides a comprehensive evaluation of the diagnostic performance variations under different combinations of the hyperparameters λ s and λ d . Figure 18(a) illustrates the contour map regarding the overall accuracy in the target domain, where the color transition from blue to red represents an increase in classification performance. It is observed that the model maintains a relatively high overall accuracy when λ s is within the interval of 0.1 to 0.2, and λ d resides between 0.01 and 0.15. The peak accuracy of 96.7% is achieved at the coordinate where λ s equals 0.15 and λ d equals 0.05. This observation indicates that a moderate weight for the domain alignment loss and the class separation loss tends to facilitate the extraction of domain-invariant features while preserving the distinct boundaries between different fault categories.
The sensitivity of the known class accuracy is depicted in Figure 18(b), which exhibits a distribution pattern highly consistent with that of the overall accuracy. This similarity suggests that the optimization of the tradeoff parameters does not disproportionately favor unknown sample detection at the cost of known class recognition. However, the performance appears to diminish as λ s or λ d increases beyond 0.25. Such a decline might be attributed to the excessive influence of the auxiliary losses, which potentially distort the underlying distribution of the source features and complicate the convergence of the primary classifier. Conversely, when these weights are set to extremely small values such as 0.01, the lack of sufficient regularization often leads to poor DA results, as evidenced by the blue regions on the left and top edges of the contour maps. Therefore, selecting values such as 0.15 for λ s and 0.05 for λ d . provides a stable and effective configuration for the proposed machinery fault diagnosis framework.
Conclusions
A novel cross-condition OSDA fault diagnosis method based on dual-path adversarial learning and progressive self-training, termed DAPSN, has been presented. To mitigate negative transfer, DAPSN adopts a three-stage framework integrating a GRL and a dual-path adversarial discriminator to simultaneously filter unknown target samples and align representations of known classes, enhancing class discrimination and within-class compactness. Evaluated under two OSDA settings, DAPSN consistently surpasses baseline approaches in both classification accuracy and unknown-class detection across diverse domain shifts and openness ratios. On the PU bearing dataset (task T3), DAPSN exceeds the second-best method (CMU) by 3.1% in the average OS metric; on the PHM09 gearbox dataset (task T5), it outperforms IW-OSDA by 5%. Although certain comparison methods achieve isolated advantages under specific scenarios, DAPSN demonstrates superior stability and generalization across tasks.
It should be pointed out that this study is currently limited to single-channel vibration data and relies on a heuristic strategy for openness estimation. To address these issues, future work will focus on three key directions: first, extending the framework to multi-sensor fusion scenarios to exploit complementary multi-modal information; second, developing continual OSDA methodologies to handle time-varying environments without catastrophic forgetting; and third, integrating physics-based models into the deep architecture to further enhance interpretability and generalization under complex industrial conditions.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was financially supported by the National Natural Science Foundation of China (Nos 52575632 and 52405124) and the Suzhou Science and Technology Plan (Basic Research) Project (no. SJC2023002).