
Abstract
Timely and accurate fault diagnosis of suspension systems is paramount for ensuring the operational safety of rail vehicles. Recent years have witnessed extensive research in this field, primarily categorized into model-based and data-driven methods based on their underlying knowledge sources. Model-based methods rely on precise mathematical models to achieve fault detection and isolation via state or parameter estimation. Data-driven methods leverage historical and real-time data to extract fault features using statistical analysis, traditional machine learning, or deep learning techniques. This article presents a systematic review of these methods, offering a detailed comparison of their advantages and disadvantages, while summarizing current development trends and existing challenges. Finally, several future research directions are proposed, including model-data fusion diagnostic strategies, enhancement of real-time performance and robustness, enhancement of reliability prediction and uncertainty quantification, translation into engineering applications, and intelligent diagnostic techniques under small-sample conditions, aiming to provide references for the further development of suspension system fault diagnosis technology.
Highlights
Representative rail vehicle suspension fault diagnosis works are reviewed.
Methods are categorized into model-based and data-driven approaches.
Advantages, disadvantages of each method are summarized.
Key future research directions are proposed.
Introduction
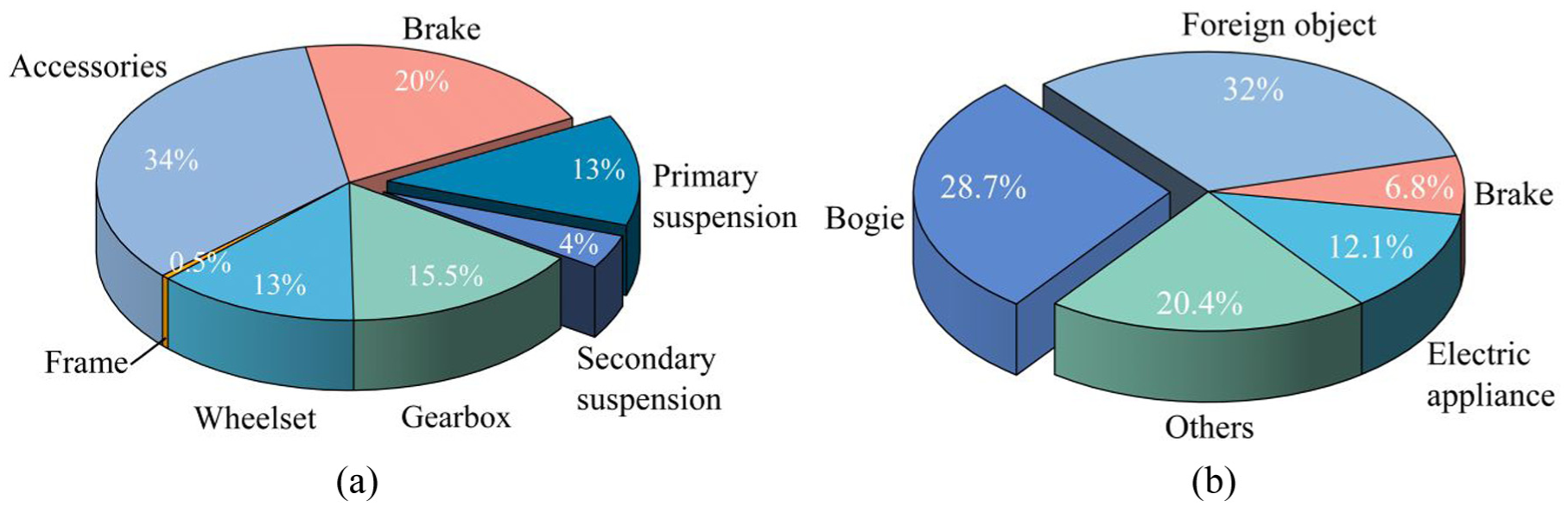
As a core subsystem of the rail vehicle bogie, the suspension system directly affects the running stability and ride comfort of the vehicle, while its health condition is crucial for ensuring operational safety. During long-term operation under complex dynamic loads, internal components (including springs and dampers) are prone to wear and degradation, significantly increasing the risk of failure. Liu et al. 1 performed a statistical analysis on bogie faults in a specific high-speed trainset in China. As shown in Figure 1(a), primary and secondary suspension faults accounted for 32 and 98 cases, respectively, out of 751 total fault records, representing a combined proportion of approximately 17%. Xu 2 conducted a statistical analysis of faults in passenger vehicles at the Changchun Depot of China Railway Shenyang Bureau Group Co., Ltd. The results indicate (Figure 1(b)) that bogie faults averaged 313 incidents per month, accounting for 28.7% of the total fault volume. Although these data reflect only partial operational conditions, they clearly demonstrate the high incidence of suspension system faults in rail vehicles.
Critical suspension components, such as springs and dampers, are subjected to continuous impact and alternating stress during long-term high-speed operation, leading to fatigue, aging, and the gradual degradation of dynamic characteristics. Moreover, the operational environment of rail vehicles is complex and variable. Uncertainties such as track irregularities and external excitations further increase the probability of suspension component fault. Figure 2 illustrates common suspension faults, including air spring deflation, air bag rupture, damper oil leakage, damper mount detachment, and spring breakage.

Extensive research has been conducted globally on railway system fault diagnosis, and several review studies have systematically summarized these efforts. For instance, Li et al. 8 surveyed on-board health monitoring systems, classifying diagnostic methods into model-based and data-driven categories while analyzing their respective merits and limitations. Bernal et al. 9 summarized on-board condition monitoring for freight wagons, covering fault detection for key subsystems (including wheelsets, bearings, suspensions, and brakes). However, these earlier reviews8,9 did not capture recent breakthroughs in emerging technologies like artificial intelligence (AI) and deep learning (DL) for intelligent diagnosis and predictive maintenance. Strano and Terzo 10 focused on model-based condition monitoring of rail vehicle dynamics but did not cover data-driven methods. Xie et al. 11 reviewed diagnostic methods for multiple high-speed train systems but provided limited specific discussion on suspensions. Hossain et al. 12 reviewed AI applications in automotive diagnosis but did not extend the scope to rail vehicles.
To systematically review the research status of rail vehicle suspension fault diagnosis, this article analyzed approximately 120 relevant publications retrieved from the Web of Science and Google Scholar databases (up to October 2025) using keywords such as “rail vehicle suspension,”“train suspension,” and “fault.” Based on the existing classification framework, 8 this article categorizes current diagnostic methods into two primary categories:
(1) Model-based methods: These rely on the physical model of the vehicle system, achieving fault detection and isolation (FDI) by analyzing residuals between model outputs and actual responses. Model-based methods encompass state estimation and parameter estimation. State estimation employs observers to estimate internal states under the premise of known model parameters, diagnosing faults through residual analysis. Parameter estimation identifies system model parameters and monitors whether they deviate from their normal ranges to detect faults.
(2) Data-driven methods: These operate independently of the physical vehicle model. Instead, they utilize historical and real-time operational data to extract implicit information regarding the system’s health status through statistical analysis or machine learning (including DL) techniques, thereby enabling fault pattern recognition and diagnosis.
As indicated in Figure 3, although model-based diagnostic methods were established early (before 2005), their recent development has stagnated. This trend stems primarily from inherent limitations: constructing high-fidelity vehicle dynamic models is complex, and diagnostic performance is easily compromised by strong system nonlinearities or time-varying parameters, resulting in poor adaptability to complex operational environments. Consequently, the research method for rail vehicle suspension fault diagnosis is undergoing a fundamental shift, transitioning from a model-based dominance to a data-driven focus. This trend is driven by three key factors: First, the widespread deployment of sensing technologies and on-board health monitoring systems has enabled the accumulation of massive real-time operational data, providing a robust foundation for training and validating data-driven models. Second, breakthroughs in AI, particularly DL’s capabilities in automatic feature extraction and complex pattern recognition, enable the mining of fault features from high-dimensional, nonlinear data that are often elusive to traditional physical models. This significantly enhances the diagnostic potential for unknown and compound faults. Finally, data-driven methods bypass complex and time-consuming physical modeling processes. They demonstrate superior adaptability and robustness against uncertainties such as time-varying parameters and environmental fluctuations, allowing diagnostic performance to evolve continuously with data accumulation.
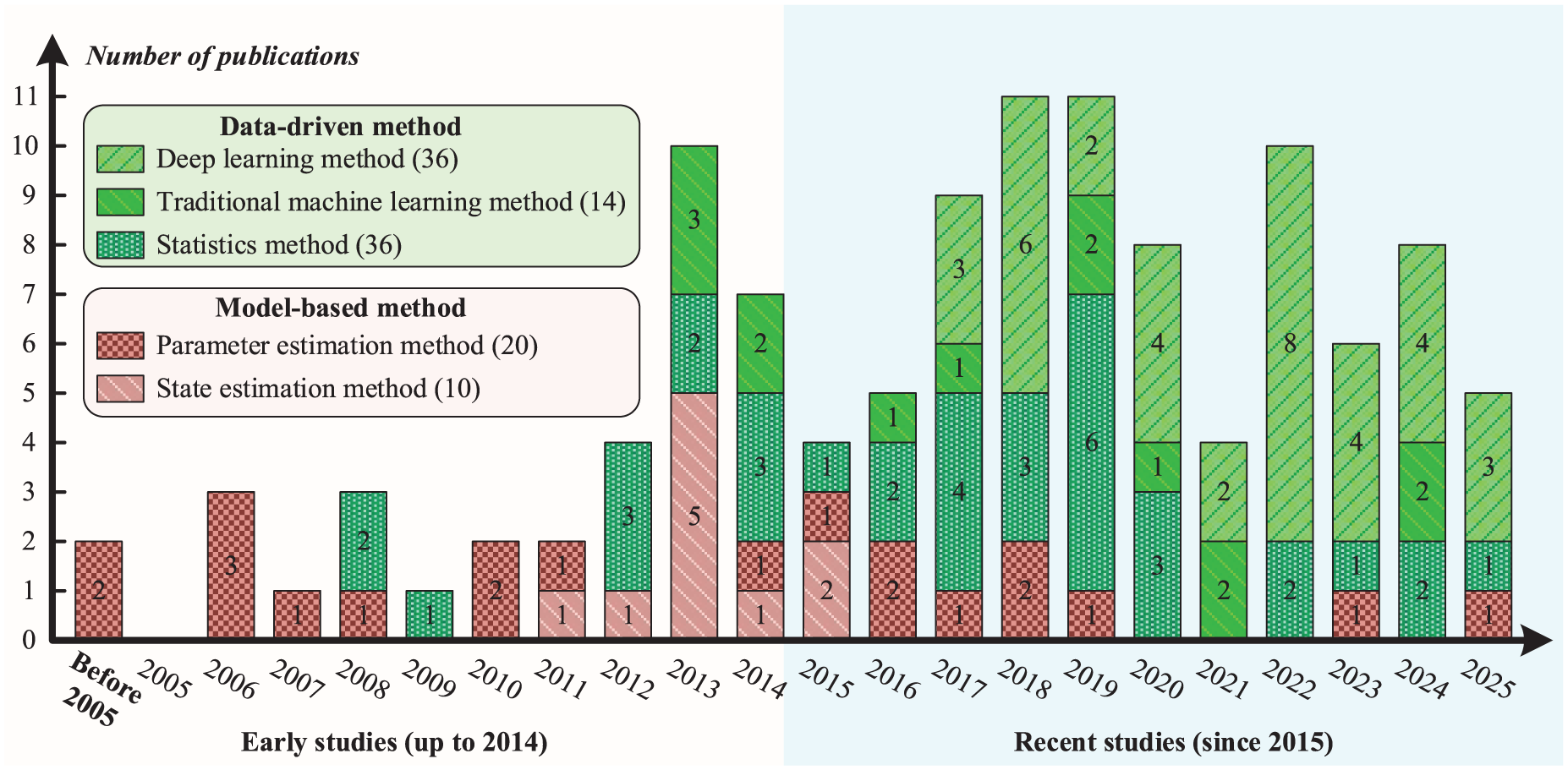
The number of references surveyed in this article.
While prior reviews have documented these fault diagnosis techniques, they are either limited by early publication dates and do not encompass recent breakthroughs in AI, such as DL, or they lack specificity by not thoroughly exploring the research and application within rail vehicle suspension systems. This review focuses on the domain of rail vehicle suspension fault diagnosis and provides a novel conceptual framework that interprets the technological transition as a multistage evolutionary trajectory from physical models to data intelligence. The core objective of this study is to critically analyze the technological essence and evolutionary drivers behind this trajectory, offering new perspectives for the field by revealing the inherent principles of the shift from analytic redundancy to high-dimensional representation learning. Furthermore, this review establishes a systematic cross-paradigm performance evaluation framework under the unified dimensions of five key engineering trade-offs. By deeply reconciling physical mechanistic interpretability with data-driven adaptability, this work aims to provide theoretical support and guidance for the development of next-generation intelligent diagnostic strategies in rail transit.
The remainder of this article is organized as follows: the second section systematically reviews model-based methods; the third section focuses on data-driven methods; the fourth section presents a cross-paradigm performance assessment, analyzes the overall characteristics, development trends, and the evolutionary trajectory from physical models to data intelligence; the fifth section discusses current challenges and outlines future research directions; the sixth section concludes the article.
Model-based method
Model-based fault diagnosis technology has evolved with the introduction of the concept of analytic redundancy. The core advantage of these methods lies in their ability to provide deep insights into the intrinsic dynamic characteristics of vehicle systems and enable real-time FDI. However, their primary limitation stems from a heavy reliance on the accuracy of the mathematical models. Model-based diagnostic methods primarily encompass two categories: state estimation and parameter estimation. It should be noted that these classifications are not mutually exclusive. For instance, the Kalman filter (KF), while typically categorized under state estimation, is also applicable to parameter estimation.
State estimation method
The fundamental principle of the state estimation methods involves constructing a state observer based on the system’s mathematical model to estimate internal states in real time. Residual signals are generated by comparing the observer’s output with actual measurements. In a fault-free state, residuals should remain within a specific statistical range. Upon fault occurrence, changes in system dynamics cause the statistical properties of the residuals to deviate from the normal interval, triggering a fault alarm. This method enables sensitive fault detection and facilitates fault isolation, though its performance relies heavily on model accuracy. Based on specific implementations, state estimation methods are primarily categorized into the classical KF and the extended KF (EKF). The development of these methods is listed in Figure 4, with representative research concentrated between 2011 and 2015.
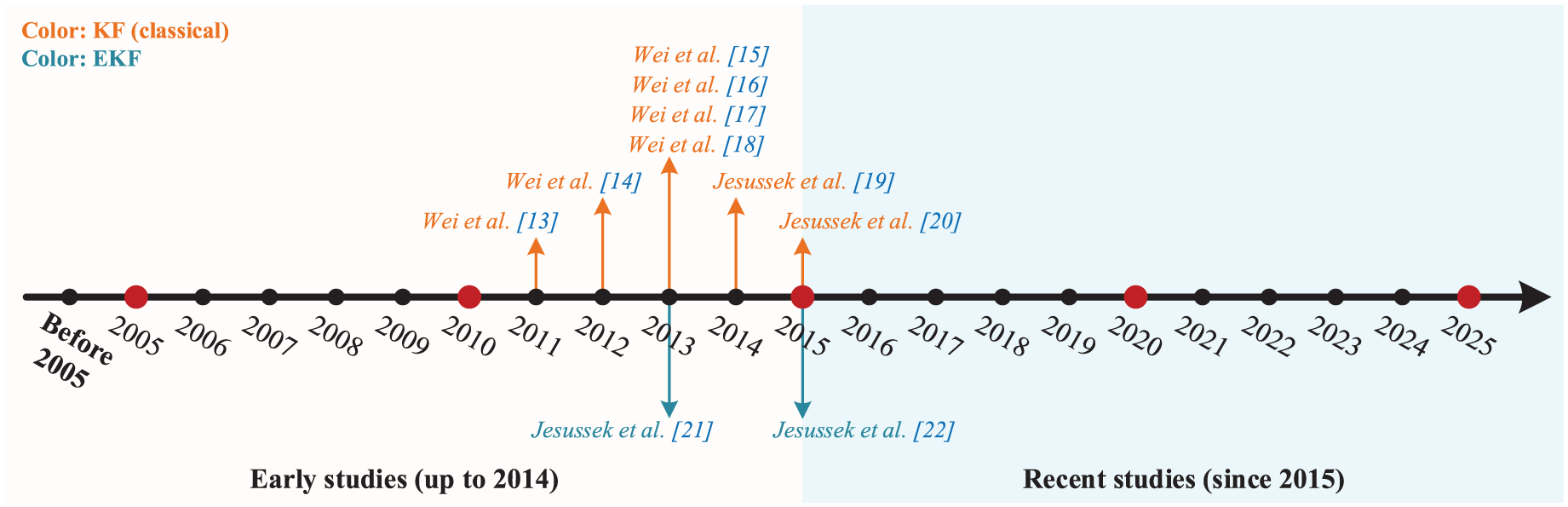
Representative publications on state estimation methods.
Classical KF
The classical KF (see Table 1) is characterized by its computational efficiency and suitability for online fault diagnosis in linear systems. By fusing system model predictions with real-time sensor measurements, this method achieves precise estimation of internal system states and detects faults by monitoring residual deviations from the normal range.
Classical KF algorithm. 8

KF: Kalman filter.
Wei et al. 13 established a light rail vehicle model consisting of two carbodies with two power bogies, one carbody with one trailer bogie. The KF was used to generate residuals, and the generalized likelihood ratio test was employed for analyzing residuals. This approach achieved online detection of secondary vertical damper and secondary spring faults. However, this study did not address the issue of fault isolation. Similar studies can be found in the studies by Wei et al.14,15
To achieve suspension system fault isolation, Wei et al.16–18 further introduced Dempster–Shafer (D-S) evidence theory to fuse information from KF-generated residuals. The core methodology involves first constructing a feature database containing multiple typical fault modes. Subsequently, the Eros similarity measure and norm distance measurement methods were employed to match new fault features against those in the database, generating basic belief assignments. Finally, these assignments were fused via the D-S evidence combination. A case study demonstrated that this framework effectively identifies and isolates faulty suspension components and their degrees of degradation.
Jesussek and Ellermann 19 employed multiple KFs for FDI in a full-scale rail vehicle suspension system. This approach involves establishing a set of KFs comprising a fault-free model and various fault models to perform parallel state estimation. By calculating residuals between the outputs of each KF and actual measurements to generate fault indicators, the method effectively detects single-component faults (including secondary vertical damper, yaw damper, and lateral damper) and distinguishes between multiple simultaneous faults. A similar study can be found in the study by Jesussek and Ellermann. 20
Extended KF
Although the classical KF exhibits robust estimation performance in linear systems, it is inapplicable to nonlinear contexts. The EKF (see Table 2) overcomes this limitation by employing Taylor series expansion to linearize nonlinear functions, effectively extending the estimation capabilities of the classical KF to nonlinear systems.
EKF algorithm. 8

EKF: extended Kalman filter.
Jesussek and Ellermann
21
proposed a fault diagnosis strategy based on a hybrid EKF and a nonlinear residual generator to capture the nonlinear characteristics of the damper. This method enables FDI for nonlinear rail vehicle dampers. Simulation results based on a half-train model demonstrated that, in most scenarios, the method reliably identifies lateral and yaw damper faults with high sensitivity. Jesussek and Ellermann
22
extended the hybrid EKF to a full-train multibody dynamic model, incorporating
Summary
In the context of rail vehicle suspension fault diagnosis, state estimation methods primarily comprise the classical KF and EKF, as summarized in Table 3.
Comparison of various state estimation methods.
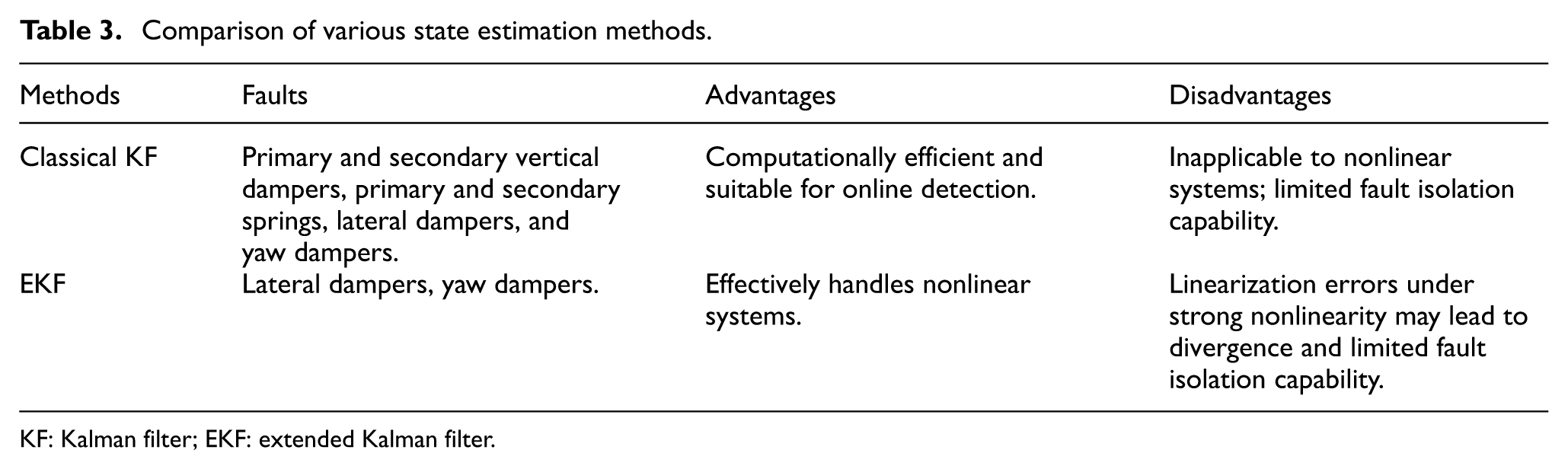
KF: Kalman filter; EKF: extended Kalman filter.
In summary, while the classical KF offers algorithmic simplicity and computational efficiency, its restriction to linear systems severely limits its applicability to nonlinear suspension contexts. Although the EKF addresses this limitation via local linearization, making it a mainstream choice in early research, it suffers from linearization errors and divergence risks under conditions of strong nonlinearity. Moreover, the requirement for complex Jacobian matrix calculations renders its implementation cumbersome.
Parameter estimation method
The fundamental premise of parameter estimation methods is that faults induce variations in suspension process parameters, subsequently altering vehicle model parameters. Consequently, diagnosis is achieved by monitoring these parametric deviations. Common techniques include the Rao–Blackwellized particle filter (RBPF), the recursive least squares (RLS), and the sliding-mode-based (SM-based) methods. Additionally, state estimation algorithms, including the classical KF, EKF, unscented KF (UKF), and cubature KF (CKF), can be employed for joint state-parameter estimation. Compared to state estimation methods, parameter estimation methods are generally more advantageous for fault isolation. The development trajectory of these methods is illustrated in Figure 5. Despite an early inception (with research emerging before 2005), published studies in this area have notably declined over the past decade, specifically since 2015.
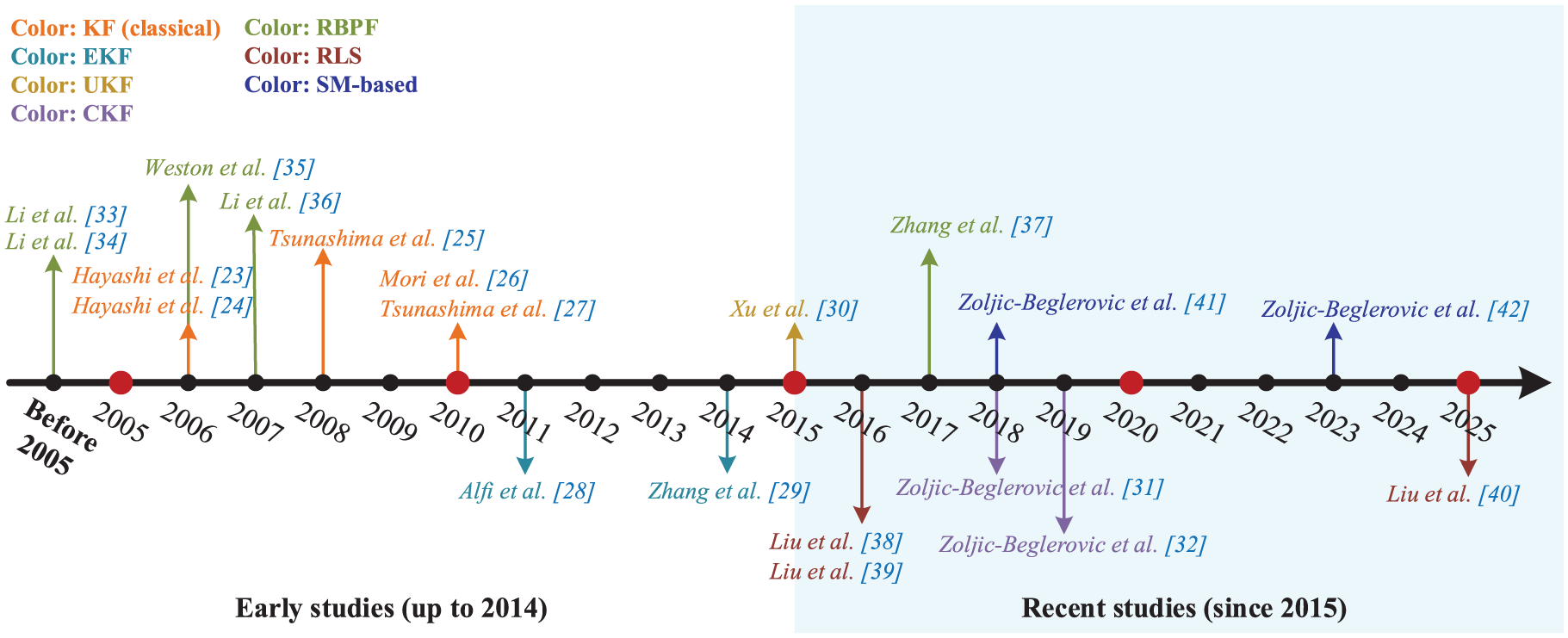
Representative publications on parameter estimation methods.
Classical KF
The classical KF based on the interacting multiple-model framework (IMM-KF) (see Figure 6) is widely applied in parameter estimation. This algorithm operates multiple KFs in parallel (each corresponding to a specific system mode) and fuses their outputs based on model matching probability, thereby achieving precise estimation of system states and parameters.
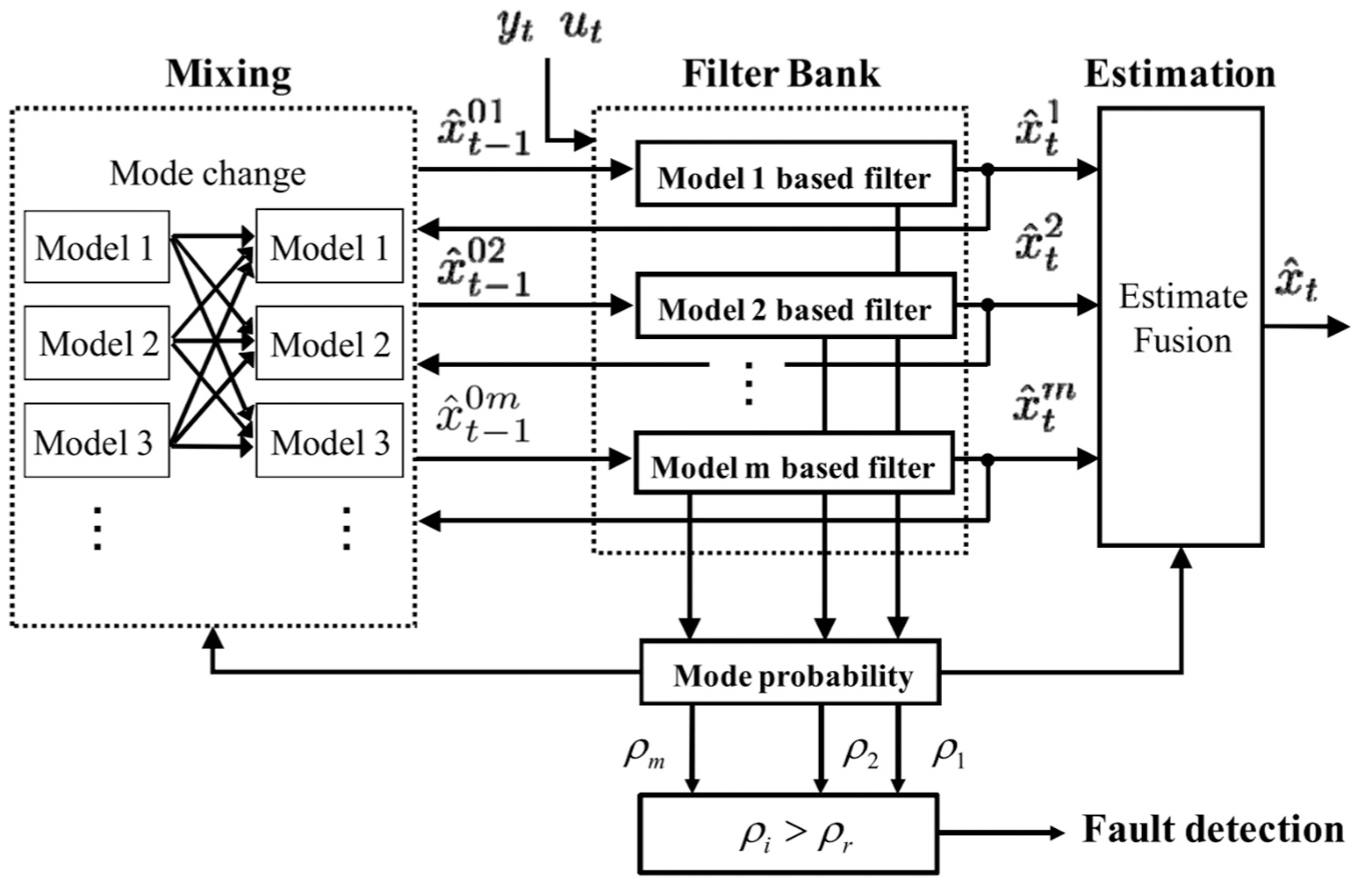
Fault diagnosis framework based on the IMM-KF algorithm in the study by Mori and Tsunashima. 26 IMM-KF: Kalman filter based on the interacting multiple-model framework.
Hayashi et al.23,24 proposed a solution based on the IMM-KF algorithm for the fault diagnosis of rail vehicle suspension systems and sensors. The core mechanism involves operating a bank of KFs in parallel, where each filter corresponds to a specific system mode (including the fault-free state, varying degrees of damper degradation, spring faults, and sensor faults). By updating mode probabilities based on the match between each model and current measurements, the method enables the identification of fault types and severities. Simulation results demonstrated that the method effectively detects performance degradation in secondary lateral dampers, accurately estimates damping coefficients, and successfully distinguishes between suspension and sensor faults. A similar study can be found in the study by Tsunashima et al. 25
Mori and Tsunashima26,27 integrated an updated estimation model into the IMM-KF framework. Simulation results indicate that this method effectively detects varying degrees of faults in secondary lateral dampers. Comparisons with the standard IMM-KF demonstrated that the IMM-KF algorithm equipped with the updated estimation model has superior parameter estimation performance.
Extended KF
When a single EKF simultaneously estimates multiple parameters, divergence or bias issues may arise. To address this, Alfi et al. 28 proposed a three-stage procedure (see Figure 7). First, an EKF independently estimates the equivalent conicity. Then, a bank of parallel EKFs estimates specific suspension parameters, including lateral and yaw damper damping. Finally, a set of KFs identifies the most probable estimation, employing a Bayesian recursive algorithm to analyze residuals for fault isolation. The practical applicability of this condition monitoring system was validated on the ETR 500-Y1 high-speed train.
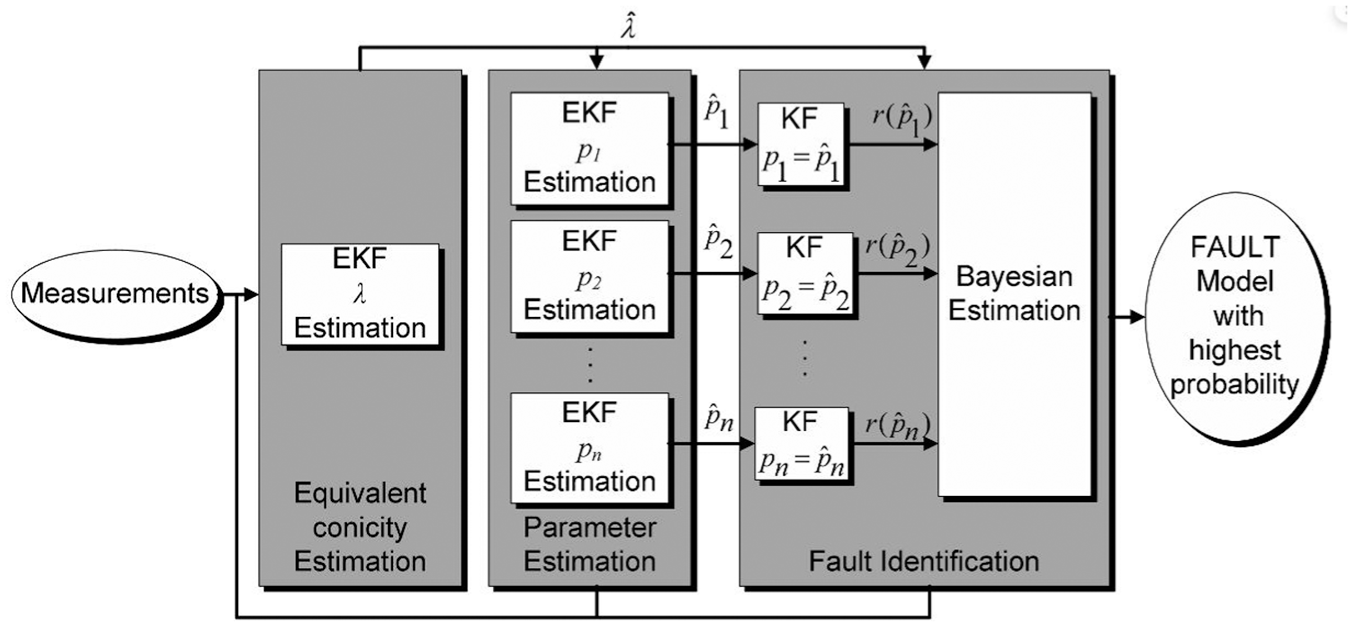
Fault diagnosis scheme based on multiple EKFs in the study by Alfi et al. 28 EKF: extended Kalman filter.
Zhang et al. 29 leveraged the computational efficiency and online implementation potential of the EKF to investigate the normal and faulty modes of the CRH380A vehicle operating at 360 km/h under realistic track irregularities. By estimating the parameters of suspension components for fault diagnosis, the method accurately localizes fault positions and identifies fault types of critical bogie components.
Unscented KF
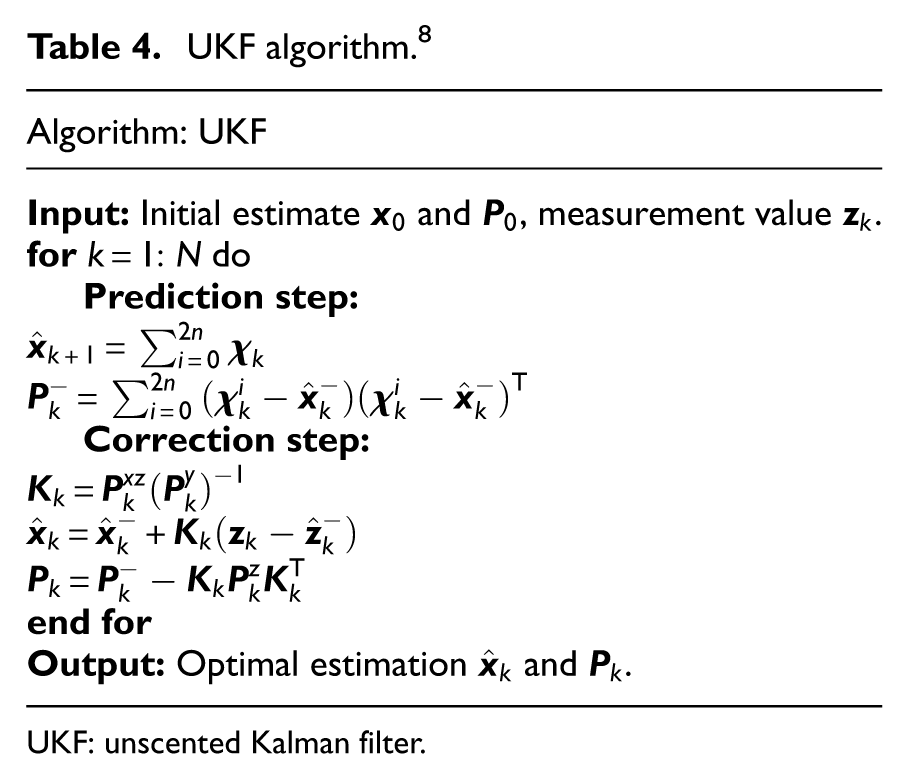
While the EKF offers advantages in handling nonlinear systems, its reliance on first or second-order Taylor series expansions for linearization neglects higher-order terms. This approximation inevitably introduces linearization errors and may even lead to filter divergence. To address the limitations of the standard EKF, various improved variants, such as the UKF (see Table 4), have been developed.
UKF algorithm. 8
UKF: unscented Kalman filter.
Xu et al. 30 applied both the UKF and EKF to secondary suspension parameter estimation, evaluating their performance via simulations using linear and nonlinear models subject to random track irregularities. The results demonstrated the superiority of the UKF. Specifically, under identical initial conditions, the UKF yielded lower relative errors in convergence values compared to the EKF.
Cubature KF
To circumvent the linearization errors and derivative calculation requirements of the EKF, the CKF (see Table 5) has been developed. In most scenarios, the CKF yields higher and more stable estimation accuracy and is particularly suitable for highly nonlinear systems.
CKF algorithm. 31

CKF: cubature Kalman filter.
Zoljic-Beglerovic et al. 31 proposed and validated a CKF-based fault diagnosis method for rail vehicle suspension systems. The performance of the CKF was evaluated by introducing specific faults into the secondary vertical damper, including abrupt (± 50%) and drift-like (+ 25%) changes in the damping coefficient. Simulation results demonstrated that under both fault scenarios, CKF estimates rapidly converge to the true values with deviations of less than 3%. Moreover, a comparison with the discrete EKF highlights the superior parameter estimation performance of the CKF. A similar study can be found in the study by Zoljic-Beglerovic et al. 32
Rao–Blackwellized PF
The PF is a representative nonlinear filtering technique that avoids the need for system model linearization, making it advantageous for handling complex systems. The RBPF is an enhanced variant of the standard PF, which partitions the state vector into linear and nonlinear components. By processing these components using the KF and PF, respectively, the RBPF achieves an effective balance between computational efficiency and estimation accuracy.
Li et al. 33 applied the RBPF method to parameter estimation within rail vehicle dynamic models, specifically targeting suspension damping parameters. Simulation results demonstrated that, compared to the traditional EKF, RBPF estimates converge rapidly and stably to true values, effectively overcoming issues such as estimation bias and divergence often associated with the EKF. A similar study can be found in the study by Li et al. 34 Weston et al. 35 integrated RBPF-based parameter estimation with KF-based state estimation to develop a comprehensive integrated vehicle-track condition monitoring system. Within this framework, the RBPF was used to monitor vehicle component conditions, while the KF was used to rapidly respond to abrupt faults. Li et al. 36 shifted their research focus toward the engineering practicality and robustness of the RBPF method. By evaluating the impact of various sensor configurations on parameter estimation, they validated the feasibility of the method using only bogie and carbody sensors, thereby demonstrating its engineering utility. Validation using field data from a Coradia Class 175 railway vehicle confirmed that the method successfully identifies damper damping coefficients and equivalent conicity from actual dynamic responses.
Building on the RBPF algorithm (see Figure 8), Zhang et al. 37 proposed a repeat-uniform-sampling RBPF strategy to simultaneously address the diagnosis of suspension component parameter degradation and sudden faults. The method’s effectiveness was validated via numerical simulations on a full-vehicle lateral dynamic model. Results demonstrated that this method not only achieves high-precision estimation for up to six suspension parameters but also rapidly identifies abrupt component (including dampers) faults, through the repeat-uniform-sampling strategy.
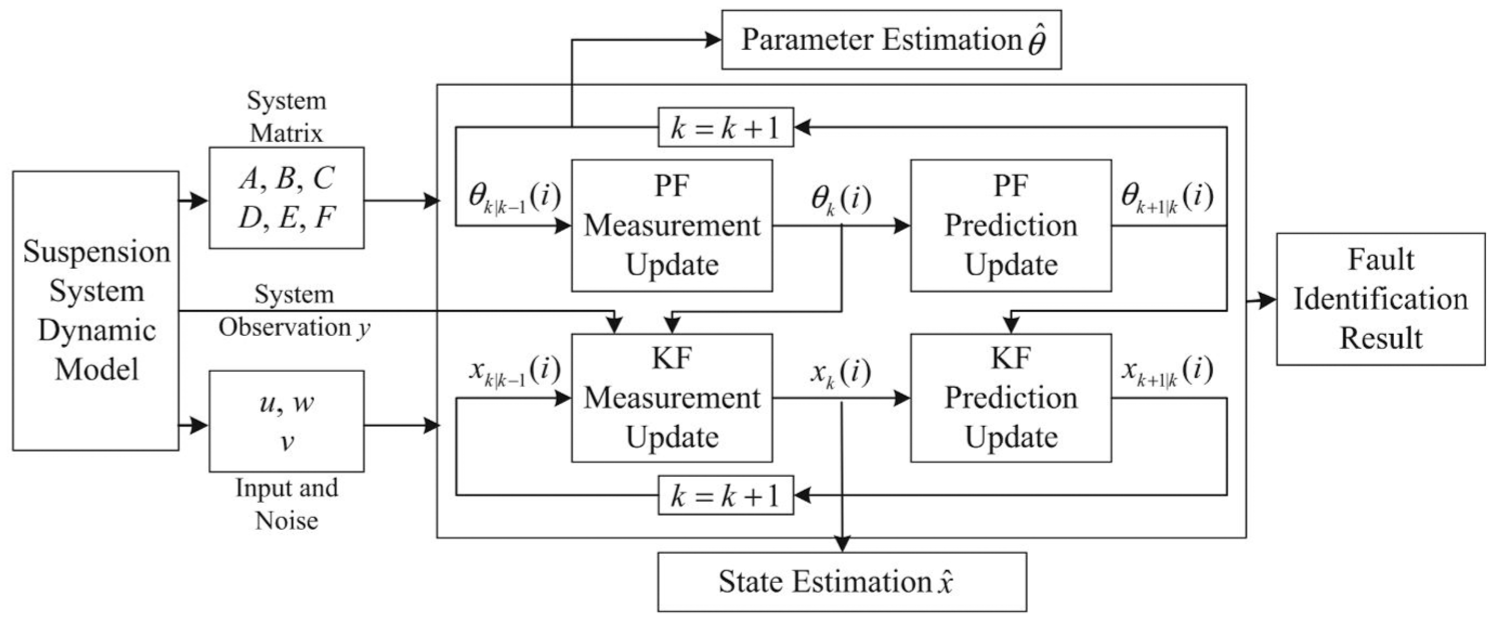
Implementation of RBPF in the study by Zhang et al. 37 RBPF: Rao–Blackwellized particle filter.
RLS method
The RLS possesses the memory property that enables parameter identification from the autocorrelation and cross-correlation of input and output variables in noisy systems, making it suitable for processing highly correlated signals.
Liu et al.38,39 proposed a model-based condition monitoring strategy for rail vehicle suspensions using the RLS algorithm (see Table 6), focusing on fault identification for primary springs and dampers. Validated via numerical simulations and field tests on the E464 locomotive, the results demonstrated the method’s ability to accurately identify suspension component faults and monitor performance degradation.
RLS algorithm. 38

RLS: recursive least squares.
Liu and Bevan 40 expanded the RLS method into an integrated, modular condition monitoring system. Targeting the more structurally complex Co-Co locomotive, this study innovatively designed three independent diagnostic modules, including vertical, lateral, and yaw motions, to achieve synchronous estimation and decoupling of multidimensional suspension parameters. The system’s engineering feasibility for multifault diagnosis and isolation was validated through simulations of various concurrent fault scenarios using the multibody software VAMPIRE.
SM-based method
The SM-based parameter identification method is grounded in SM control theory and nonlinear observer principles. It is suitable for rail vehicle suspension systems, which are engineering systems characterized by nonlinearity, time-varying dynamics, and susceptibility to external disturbances.
Zoljic-Beglerovic et al. 41 proposed an SM-based algorithm for FDI in rail vehicle suspension systems. The method was validated via simulations encompassing various scenarios, including fault-free conditions, abrupt parameter changes, and drift-like parameter changes. The results demonstrated that the algorithm not only identifies suspension parameters with high precision but also exhibits superior convergence speed and robustness compared to the traditional EKF. Zoljic-Beglerovic et al. 42 systematically presented a comprehensive framework for applying SM-based parameter identification to rail vehicle suspension fault diagnosis (see Figure 9). A key innovation of this study lies in applying the SM-based identifier to complex full and half vehicle models, enabling the simultaneous decoupling and identification of primary and secondary suspension parameters. Through a comparative study across four dimensions (including parameterization workload, computational efficiency, estimation accuracy, and convergence speed), the SM-based algorithm was proven to significantly outperform the hybrid EKF.
Framework for rail vehicle suspension system fault diagnosis in the study by Zoljic-Beglerovic et al. 42
Summary
In rail vehicle suspension fault diagnosis, parameter estimation methods include the classical KF, EKF, UKF, CKF, RBPF, RLS, and SM-based methods, as summarized in Table 7.
Comparison of various parameter estimation methods.
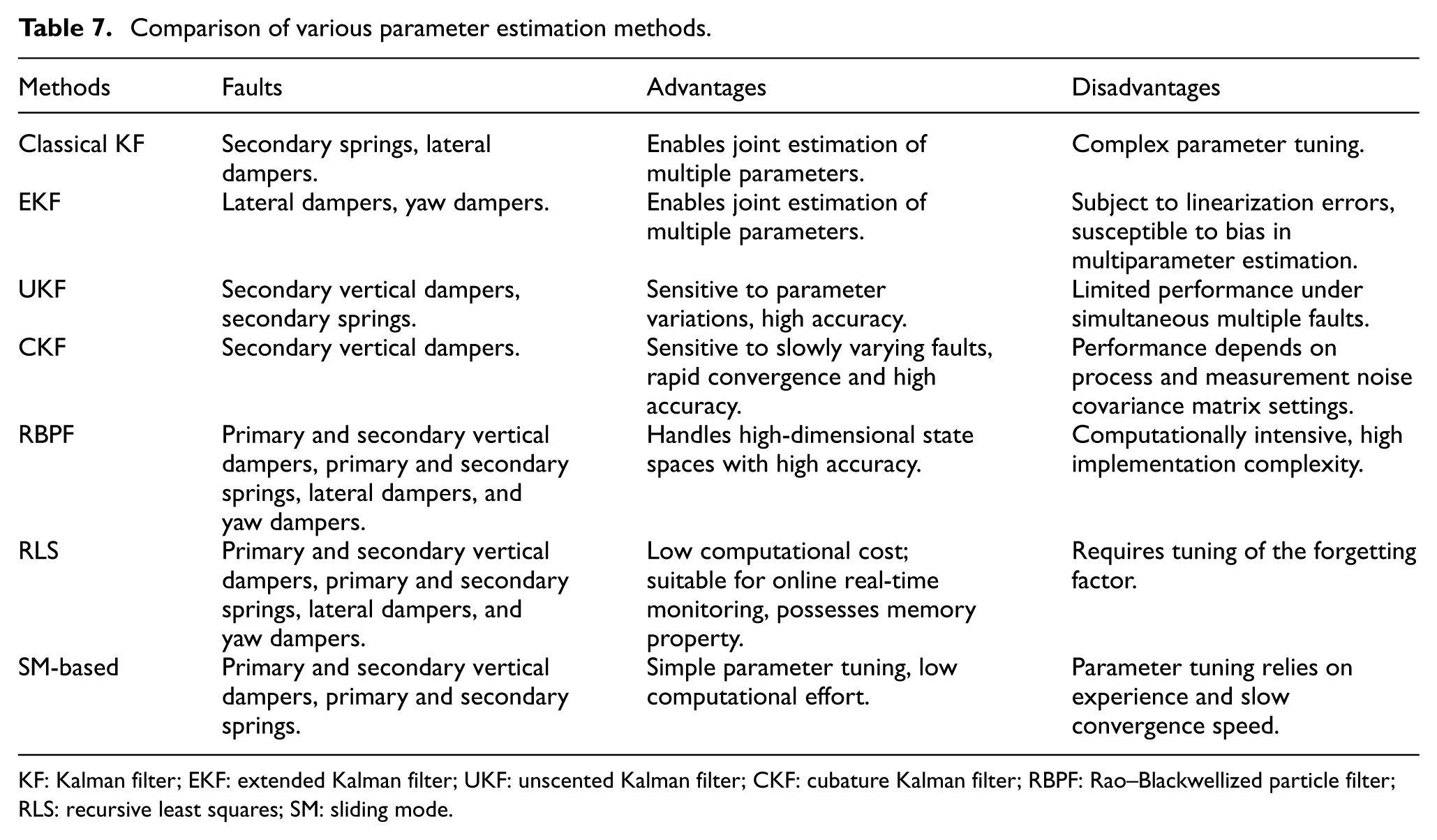
KF: Kalman filter; EKF: extended Kalman filter; UKF: unscented Kalman filter; CKF: cubature Kalman filter; RBPF: Rao–Blackwellized particle filter; RLS: recursive least squares; SM: sliding mode.
In summary, parameter estimation methods facilitate precise fault localization and degradation assessment by monitoring deviations in the physical parameters of the suspension system. Compared to single-state observation, the IMM-KF framework effectively manages mode switching of the train between different operating conditions through parallel processing of multiple models. The UKF and CKF employ the unscented transform and cubature rules to directly capture the nonlinear characteristics of the system and circumvent complex Jacobian matrix calculations, thereby achieving superior stability in parameter identification compared to traditional linearization methods. Although the RBPF exhibits excellent estimation accuracy when dealing with high-dimensional nonlinear state spaces, its performance remains sensitive to the prior settings of system noise characteristics and the total count of particles. The RLS offers excellent real-time performance and low computational demand. However, it is restricted to linear or approximately linear systems and imposes high requirements on model accuracy and data preprocessing. Additionally, parameter identification algorithms based on SM theory offer significant advantages in robustness when facing model uncertainties and external disturbances. The primary focus of these methods is to directly map fault mechanisms through variations in physical parameters. However, their effectiveness is typically limited by the accuracy of the physical models and the quality of data preprocessing.
Modeling principles and engineering evaluation of model-based methods
Correlation between modeling assumptions and failure modes
The technical logic of state estimation methods is founded upon the modeling assumption of analytic redundancy, which posits that the physical parameters of the system are precisely known and constant before the occurrence of a fault. Under this premise, the algorithm captures abnormal information within the system by monitoring abrupt changes in the observation residuals. This characteristic provides state estimation methods with a distinct advantage in identifying abrupt faults,14,15 such as the sensitive detection of air bag ruptures, air spring deflations, or steel spring breakages that induce instantaneous step changes in system dynamic characteristics. However, the limitation of this assumption resides in its high sensitivity to model plant mismatch, as nonfault perturbations triggered by track irregularities or severe fluctuations in the operating environment are frequently misidentified as system state anomalies.
The modeling premise of parameter estimation methods is that faults manifest as drifts in physical parameters. Such methods30,36 achieve diagnosis by tracking the evolution trajectories of key parameters such as system stiffness or damping coefficients in real time. This modeling logic aligns more closely with the evolutionary patterns of long-term performance degradation in suspension systems. For instance, it can effectively evaluate damping reduction caused by damper oil leakage or stiffness attenuation triggered by the long-term service of suspension springs.31,41 However, the identifiability of parameters depends heavily on the intensity of external excitations. Under operating conditions with low excitations, the algorithms may fail or produce severe fluctuations due to insufficient input signal excitation. Additionally, when multiple physical parameters undergo coupled degradation simultaneously, a single algorithm often struggles to accurately isolate specific fault sources.
Evaluation metrics and engineering trade-off analysis
To systematically evaluate the practical utility of various model-based methods in engineering applications, five key performance indicators consisting of complexity, accuracy, detection delay, false alarm rate (FAR), and computational cost are introduced (see Table 8) to perform a comparative analysis of the model-based algorithms within a unified dimension.
Comparison of various model-based methods based on unified evaluation metrics.
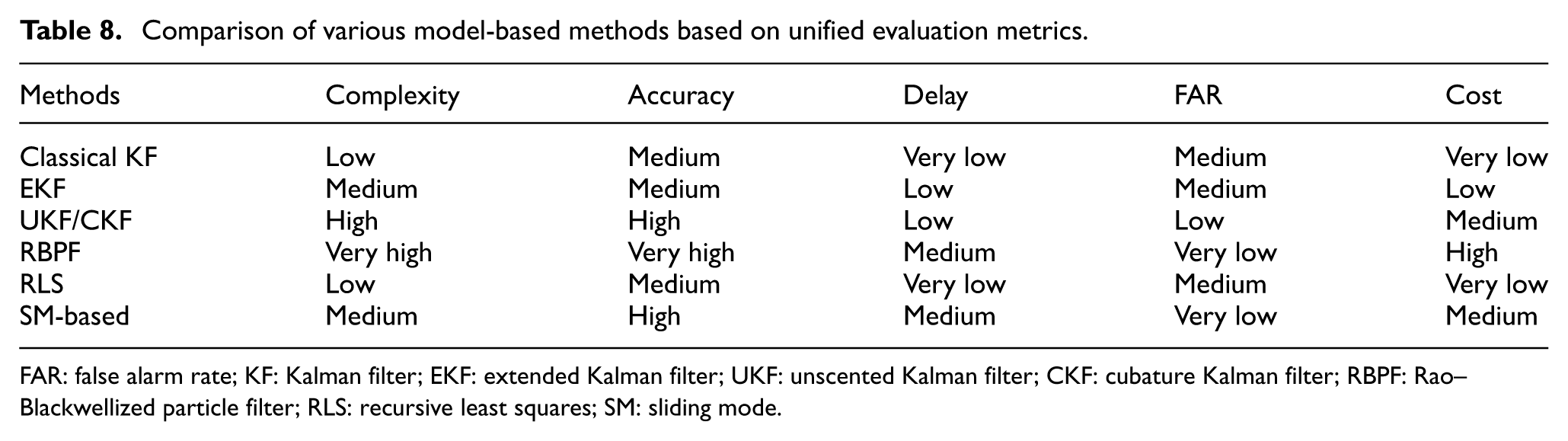
FAR: false alarm rate; KF: Kalman filter; EKF: extended Kalman filter; UKF: unscented Kalman filter; CKF: cubature Kalman filter; RBPF: Rao–Blackwellized particle filter; RLS: recursive least squares; SM: sliding mode.
Analysis demonstrates that model-based methods exhibit significant trade-off relationships among these metrics. In state estimation methods, the classical KF and EKF possess extremely low computational costs and minimal delays, which make them highly suitable for the online real-time monitoring of linear or weakly nonlinear systems. However, when confronted with complex track excitations or strong nonlinear conditions, the estimation bias resulting from linearization errors significantly increases the risk of false alarms. Within the category of parameter estimation methods, UKF, CKF, and RBPF significantly enhance diagnostic accuracy through nonlinear filtering techniques. Nevertheless, this improvement in accuracy often comes at the expense of computational efficiency. For example, the computational cost of RBPF is typically several times higher than that of EKF due to its intensive particle sampling requirements, which limit its real-time application in large-scale sensor networks. In contrast, the RLS method provides an acceptable balance between accuracy and delay while maintaining low computational overhead due to its recursive storage characteristics, making it one of the mainstream engineering choices for balancing real-time performance and accuracy.
Data-driven method
Data-driven methods operate independently of precise systems’ mathematical models. They are predicated on the acquisition of historical data from diverse sources and types, using data mining techniques to extract latent effective information. This enables the characterization of both normal and fault modes, thereby facilitating fault detection and diagnosis. A primary advantage of these methods is the avoidance of complex mathematical modeling, rendering them particularly effective for nonlinear systems or those with undefined physical mechanisms. However, their performance relies heavily on the massive, high-quality historical datasets. Moreover, these models often function as “black boxes” with limited interpretability. Based on the underlying data analysis techniques, data-driven methods are categorized into (1) statistical methods, (2) traditional machine learning (TML) methods, and (3) DL methods.
Statistical method
Statistical methods achieve fault diagnosis by performing statistical analysis on system signals to extract features indicative of state changes. Typically characterized by low computational complexity, these methods are well suited for online monitoring. The development trajectory of these methods is illustrated in Figure 10. Research activity is primarily concentrated between 2010 and 2020, with a noticeable decline in relevant publications over the past 5 years.
Representative publications on statistical methods.
Correlation method
The diagnostic principle of correlation methods is that suspension faults disrupt structural symmetry, inducing changes in the dynamic interactions between carbody and bogie motion modes. These variations manifest as specific pattern alterations within signal cross-correlation functions.
Mei and Ding 43 leveraged the structural symmetry of the bogie to achieve fault diagnosis by analyzing the dynamic coupling induced by suspension imbalance. Specifically, this method requires no precise system model, relying solely on basic parameters such as vehicle speed and distance between suspensions. It identifies performance degradation in suspension components (e.g., dampers) by calculating cross-correlation functions between the acceleration signals of the front and rear suspensions (or bounce and pitch accelerations) and monitoring feature variations at specific time shifts. A similar study can be found in the study by Guo et al. 44 Also Ding et al. 45 considered a full bogie model comprising three degrees of freedom (DOF), including bounce, pitch, and roll, to analyze the pairwise dynamic interactions among these motions. The introduction of cross-correlation coefficients enhanced the method’s robustness against variations in vehicle speed and track irregularities.
Mei and Ding 46 proposed a fault detection scheme based on cross-correlation coefficients and augmented by a low-pass filter. This method maintains high sensitivity while mitigating the impact of increased bogie mode resonance caused by reduced damping associated with damper faults. Simulations using a nine-DOF vehicle model further validated the effectiveness of this method for suspension FDI. Kojima and Sugahara 47 proposed a fault detection method for rail vehicle vertical dampers based on vibration phase difference. The principle of the method is that within a symmetric fault-free system, the phase difference between the bounce and pitch motions of the bogie or cabody remains at ± 90 °. However, damper faults disrupt this system symmetry, inducing abnormal phase differences. The effectiveness of this method for detecting faults in both primary and secondary dampers was validated through test rig experiments and on-track field tests. Similar studies can be found in the studies by Dumitriu.48–50
Distinct from methods relying on the correlation analysis of on-board acceleration data, Teng and Wei 51 proposed a track-side signal detection method for diagnosing urban rail vehicle suspension faults. This method employs a rigid-flexible coupled wheel-rail contact model and track-side accelerometers to capture vertical vibration signals during train passage. The signals are analyzed using continuous wavelet packet analysis and short-time Fourier transform (STFT), followed by decomposition via local mean decomposition. Fault severity is then quantified by calculating the correlation coefficients between faulty and healthy signal components. Overcoming the limitations of traditional on-board monitoring, this noncontact method offers advantages such as ease of deployment and compatibility with existing lines, demonstrating robust performance in detecting and assessing the severity of spring and damper faults.
The aforementioned studies demonstrate the application of correlation-based diagnostic methods in passenger train suspensions. These techniques are equally applicable to freight wagons. Li et al. 52 used only two tri-axial accelerometers to analyze the cross-correlation between acceleration signals at the front-left and rear-right carbody positions. By constructing a specific fault index, the detection of ± 25% stiffness variation in bolster springs was achieved (see Figure 11). A similar study can be found in the study by Li et al. 53 Alfi et al. 54 employed the cross-correlation of bogie bounce, pitch, and roll vibrations to detect faults in Y25 freight wagon bogies (see Figure 12). Validated through numerical experiments, the results demonstrated that under full load conditions, the method effectively identified abnormal variations in suspension stiffness and friction characteristics, excelling particularly in spring fault detection. However, the diagnostic capability deteriorated significantly under tare load conditions, highlighting the significant influence of load status on freight wagon suspension fault detectability.
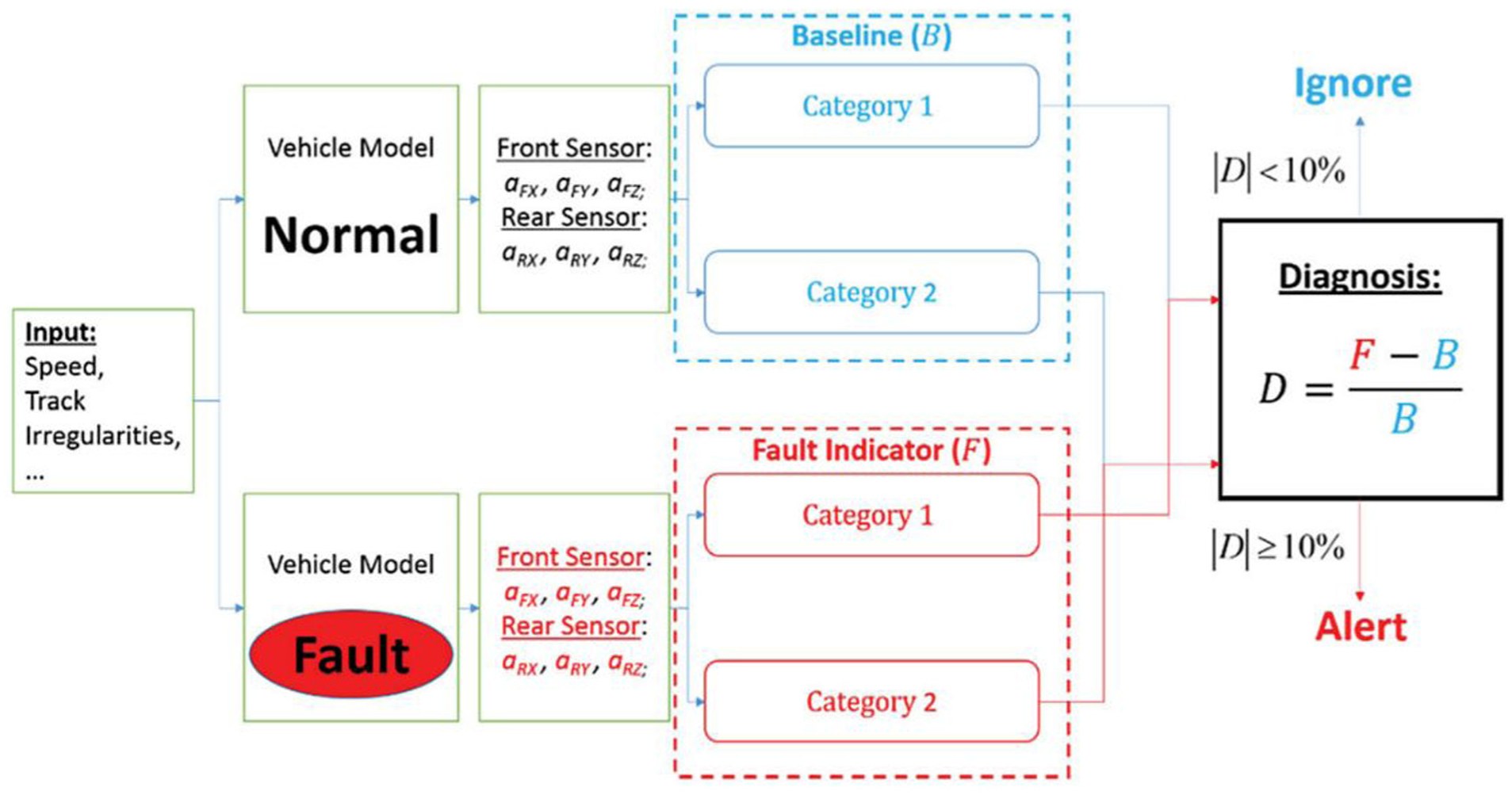
Fault detection framework based on carbody vibration correlation in the study by Li et al. 52
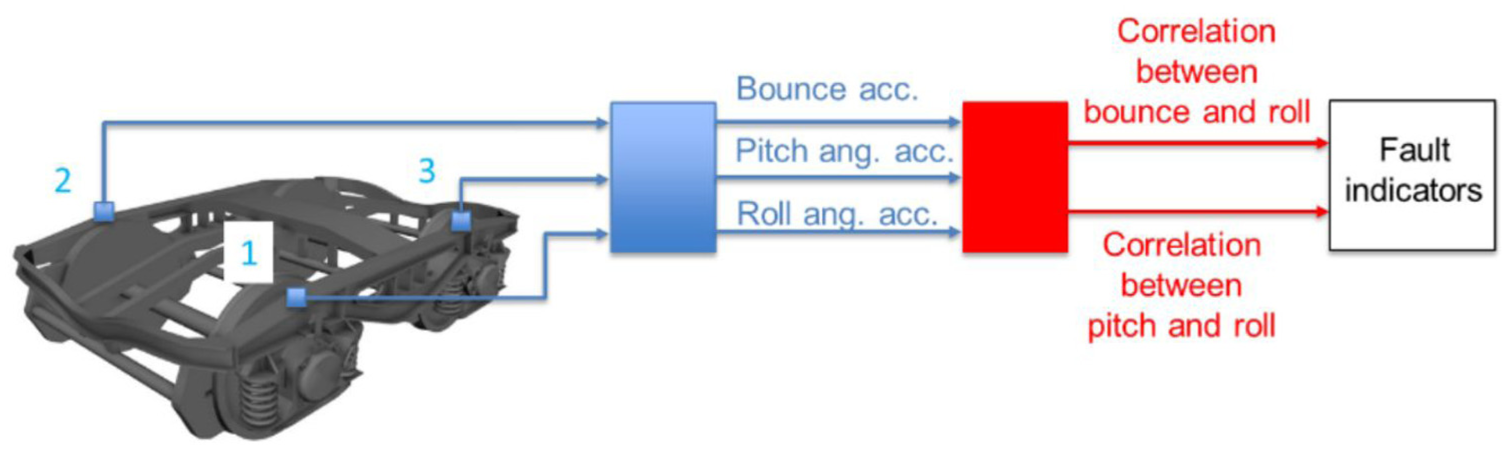
Fault detection framework based on bogie vibration correlation in the study by Alfi et al. 54
The studies above amply demonstrate that suspension faults can be effectively diagnosed by analyzing system dynamic interactions manifested in inertial sensor signals. Following this rationale, the system asymmetry induced by suspension faults also influences acoustic characteristics. Sorribes-Palmer et al. 55 proposed a suspension fault diagnosis method using on-board acoustic sensors. By analyzing variations in acoustic emissions resulting from changes in structural mode coupling induced by suspension component faults, this method circumvents the placement constraints associated with inertial sensors. Experimental validation on a test ring confirmed the method’s superior classification performance for both complete fault and partial degradation of primary and secondary dampers.
Statistical characteristics method
The fundamental premise of statistical characteristics methods is that the operational status of equipment (normal or faulty) is manifested in generated signals such as vibration and acoustics, where state changes induce shifts in statistical characteristics. Consequently, extracting and analyzing these features enables both fault identification and severity assessment.
Melnik and Kostrzewski 3 evaluated the feasibility and limitations of acceleration-based statistical characteristics suspension fault monitoring (sensor placement shown in Figure 13) through field tests on passenger and freight vehicles. Results indicated that although parameters such as the root mean square (RMS), interquartile range (IQR), and crest factor reflect suspension state changes to a certain degree, their diagnostic effectiveness is sensitive to track excitation, measurement direction, and fault type, and damper fault detection is particularly challenging. Finally, the study proposed a potential diagnostic method based on geometric distances within a multidimensional space. A similar study can be found in the study by Chudzikiewicz et al. 56
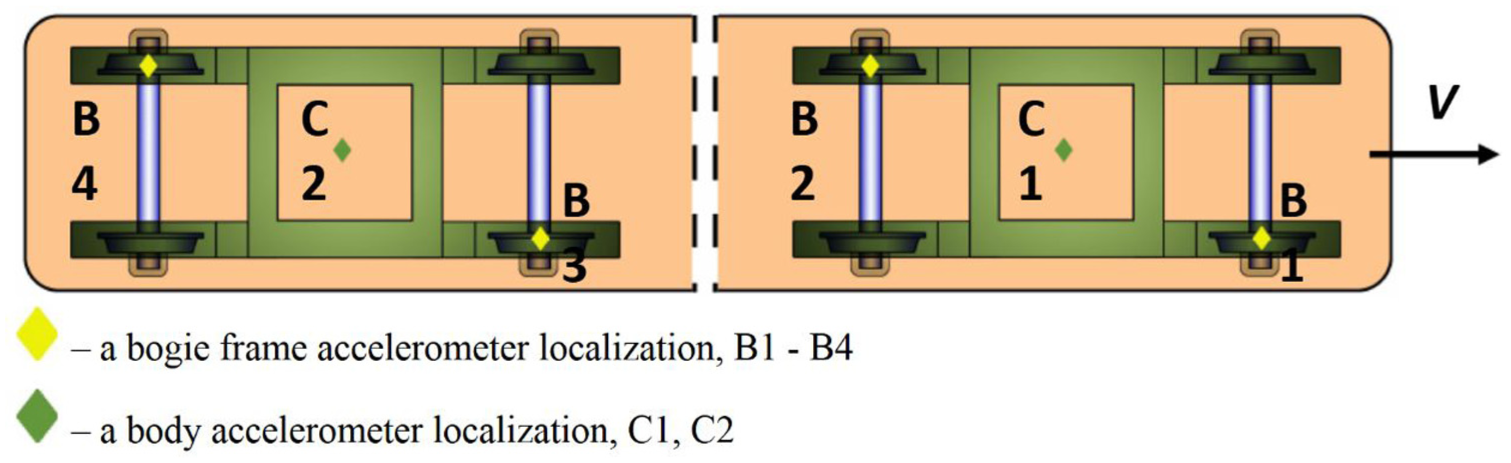
Accelerometer placement in the study by Melnik and Kostrzewski. 3
Melnik and Sowiński 57 departed from simple threshold comparisons of standard statistical characteristics, instead employing a method that calculates the distance between current and normal states within a multidimensional space to achieve effective fault identification. Guided by the criterion of maximizing the spatial distance between normal and faulty states, the study screened specific parameter combinations sensitive to suspension faults (including signal energy, IQR, zero-peak, and peak-peak), thereby enabling the effective identification of reduced stiffness and damping faults. Hu 58 developed a dynamic model of the CRH380B high-speed train to investigate the impact of three specific suspension faults (including primary vertical damper, air spring, and yaw damper) on vehicle dynamic responses. A fault detection and localization method based on frequency-domain filtering and RMS analysis was proposed. By explicitly identifying sensitive signals and characteristic frequency bands for each fault type and vehicle model, this method achieved precise diagnostic localization.
Oosterhof and Peters 59 proposed a suspension fault diagnosis method based on dynamic wheel load difference. By leveraging the Gotcha measurement system to monitor load disparities between left and right wheels during operation, a dynamic suspension imbalance index framework was designed to differentiate between primary and secondary suspension faults. Kraemer et al. 4 investigated the impact of leaf spring faults on the vibration response of freight wagons, validating a diagnostic method based on vibration energy distribution and symmetry principles. Spring faults in the suspension system induce a loss of vibration energy in measurement signals and shifts in high-vibration modes. By employing symmetrically arranged sensors on the carbody and using RMS ratios as fault indicators, the method effectively translates suspension stiffness variations into observable feature deviations. Dumitriu 60 proposed a primary damper fault detection method based on bogie vertical vibration, using only four accelerometers mounted on the frame and axle boxes (see Figure 14). By developing a vehicle-track system model and integrating field measurements with numerical simulations, the study characterized the RMS acceleration distribution of the bogie under both normal and faulty primary damper conditions. The results indicated that damper faults cause a significant increase in RMS acceleration at the frame, whereas changes at the axle box are not obvious.
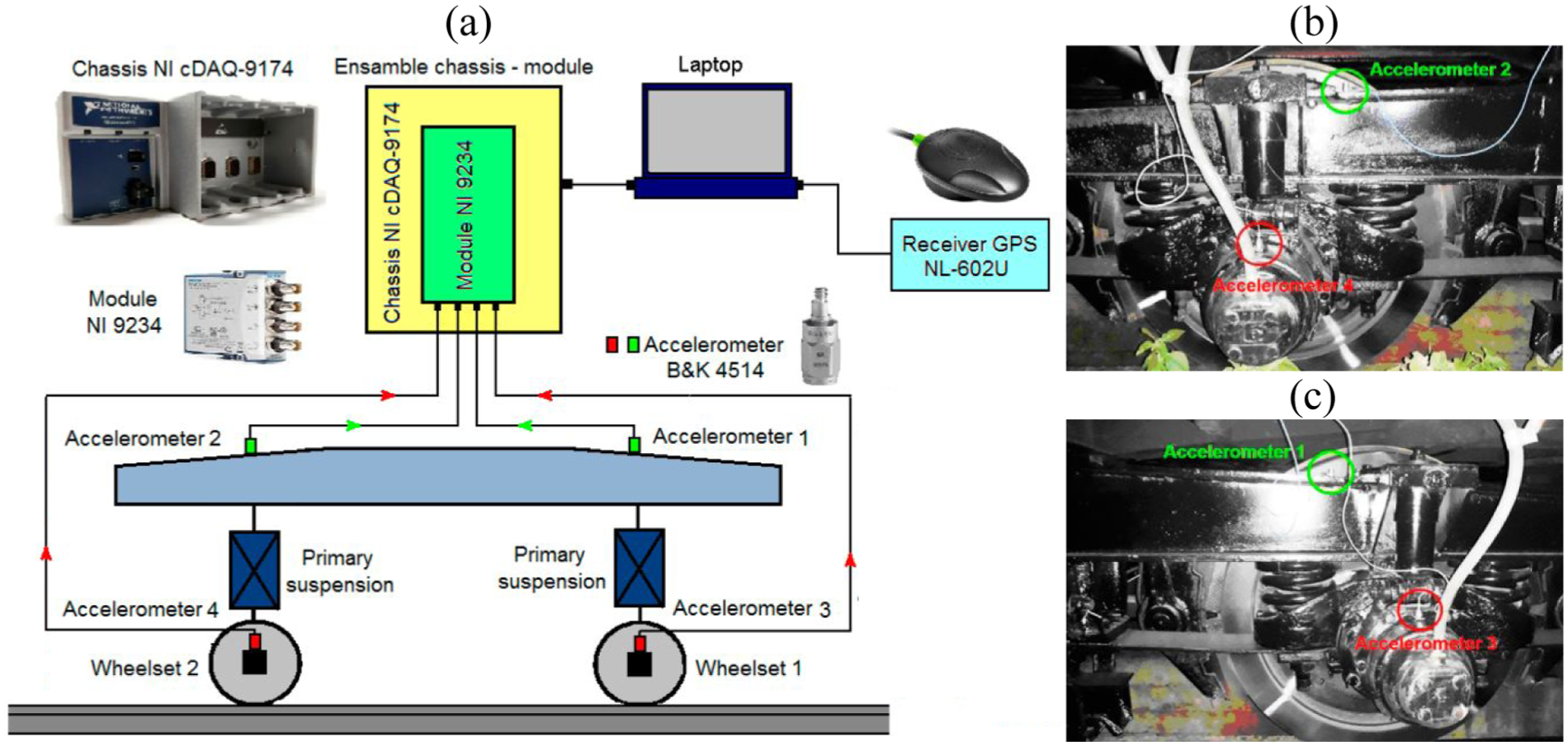
(a) Bogie vibration acceleration acquisition system; (b and c) accelerometer mounting positions in the study by Dumitriu. 60
Multivariate statistical method
Multivariate statistical methods do not require precise system models and are capable of processing high-dimensional data to detect abnormal states. However, the lack of diagnostic “labels” often limits their effectiveness in fault isolation. Common techniques include principal component analysis (PCA) (Table 9), partial least squares (PLS) (Table 10), independent component analysis, and canonical variate analysis (CVA). 61
PCA algorithm. 63

PCA: principal component analysis; SPE: squared prediction error.
PLS algorithm. 63

PLS: partial least squares; SPE: squared prediction error.
Wei et al. 62 estimated a dynamic model of a rail vehicle suspension system to perform fault detection using two multivariate statistical methods, including PCA and CVA, relying solely on accelerometer data. Simulation results indicated that while both methods demonstrated high detection performance for large magnitude faults in springs and dampers, they failed to detect minor faults.
Wei et al. 64 applied dynamic PCA (DPCA) and consensus PCA (CPCA) to suspension fault detection. A comparative analysis of the results revealed that CPCA was capable of detecting minor faults that elude DPCA, while also demonstrating a faster fault response speed. Wei et al. 65 applied an extended PLS method, which is multiblock PLS (MBPLS), to rail vehicle suspension fault detection. Simulation results demonstrated that MBPLS was capable of detecting minor faults in suspension springs and dampers, exhibiting detection performance superior to that of DPCA. A similar study can be found in the study by Zhang. 66
Building on DPCA, Wei Guo 67 employed a distributed DPCA approach to diagnose faults in primary springs and secondary dampers. By partitioning the suspension system into multiple subsystems and establishing separate DPCA models for each, the method leverages the distributed relation of the subsystems to achieve fault detection and preliminary isolation. Wei et al. 68 proposed an FDI method integrating PLS with D-S evidence theory. PLS was employed for rapid fault detection, demonstrating excellent performance in identifying moderate and severe faults. Moreover, D-S evidence theory was used to fuse the frequency-domain features of fault data with the standard feature database to successfully isolate both fault locations and severity levels. Wang et al. 69 introduced a multilinear PCA (MPCA) framework for extracting features of minor faults by using tensor data. Comparisons with classical PCA and its extension, DPCA, demonstrated MPCA’s superior performance in the detection and isolation of minor faults. Fang et al. 70 proposed a real-time monitoring method for high-speed train suspension systems based on probability-relevant PCA (PRPCA). This method exhibited high sensitivity to incipient suspension faults and outperforms traditional PCA in fault detection performance.
Subspace method
Subspace identification methods operate independently of a priori system models, avoiding parameterization and nonlinear optimization issues. They enable the direct extraction of system dynamics from input and output data.
Liu et al. 71 proposed a condition monitoring scheme for rail vehicle suspension systems based on the average correlation signals-based stochastic subspace identification (ACS-SSI) algorithm. The diagnostic logic relies on the premise that suspension faults directly induce variations in global modal parameters. Thus, identifying deviations in these parameters enables effective fault diagnosis. Validated via a SIMPACK dynamic model simulating normal conditions, spring faults, and damper faults, the results demonstrated that ACS-SSI accurately identifies modal frequencies and mode shapes, indicating potential for online condition monitoring. Liu et al. 72 validated the practical applicability of the ACS-SSI algorithm for operational modal analysis and condition monitoring of rail vehicle suspensions through experimental studies on a Y25 bogie. Liu et al. 73 further proposed an online modal identification scheme using correlation subset-based SSI (CoS-SSI) for suspension condition monitoring. Validation results on a 1/5th scale roller rig (see Figure 15) demonstrated that CoS-SSI not only accurately identifies all critical suspension modes but also outperforms both covariance-based SSI (Cov-SSI) and ACS-SSI. Jung et al. 74 combined SSI with an eigenfrequency density estimator to construct a suspension monitoring system capable of automatically distinguishing between healthy and faulty states. Validated through simulations involving a progressive reduction in primary spring stiffness (from 5 to 70%), the method demonstrated low classification error rates even under conditions of minor stiffness loss.
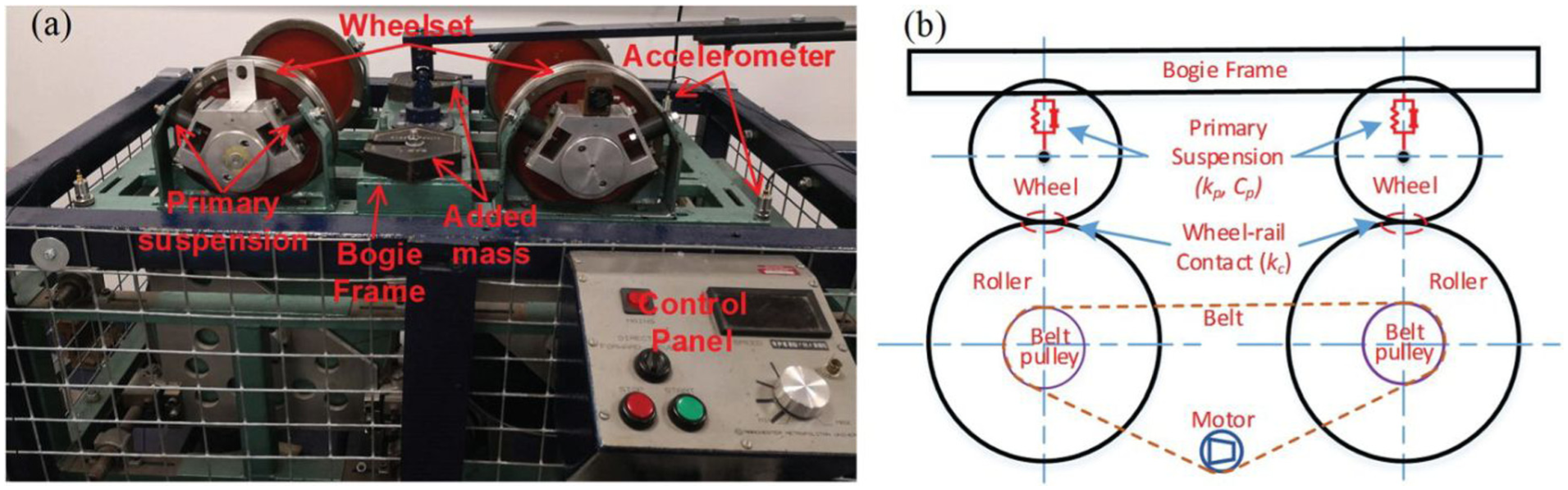
(a) The 1/5th scaled roller rig and (b) side view schematic of the roller rig in the study by Liu et al. 73
Addressing the challenge of detecting incipient faults in high-speed train suspension springs and dampers, Wu et al. 75 proposed a data-driven total measurable fault information residual (ToMFIR) detection method. By fusing output and controller residuals and using subspace techniques to extract fault features from historical data, the ToMFIR method achieves sensitive detection of slowly varying faults without reliance on precise system models. Simulation results demonstrated its effectiveness in identifying a 15% gradual reduction in spring and damper coefficients, exhibiting both high detection speed and accuracy. Addressing the challenges of FDI in nonlinear high-speed train suspension systems, Wu et al. 76 proposed a framework incorporating the Takagi–Sugeno fuzzy dynamical model, building upon the ToMFIR method. Simulation results demonstrated that this scheme was effective not only in detecting slowly varying faults but also in identifying incipient faults with intermittent characteristics. A similar study can be found in the study by Wu et al. 77 Vlachospyros et al. 78 proposed a data-driven method using multiinput single-output transmittance within a multiple-model framework for the early detection and localization of rail vehicle suspension faults under varying operating conditions. This method employs the multiple-model structure to capture and compensate for uncertainties induced by load variations, while using PCA to reduce the dimensionality of the model parameter space for enhanced robustness (see Figure 16). Simulations and field tests on the Athens Metro demonstrated that, using only six sensors and limited training data, the method successfully detects incipient faults and achieves a precise component localization rate of 95.8%.
(a) Sensor placement and faulty components (red) and (b) schematic of the fault detection method in the study by Vlachospyros et al. 78
Summary
Statistical methods offer various solutions based on signal and data analysis for rail vehicle suspension fault diagnosis. The characteristics of these methods are summarized in Table 11.
Comparison of various statistical methods.
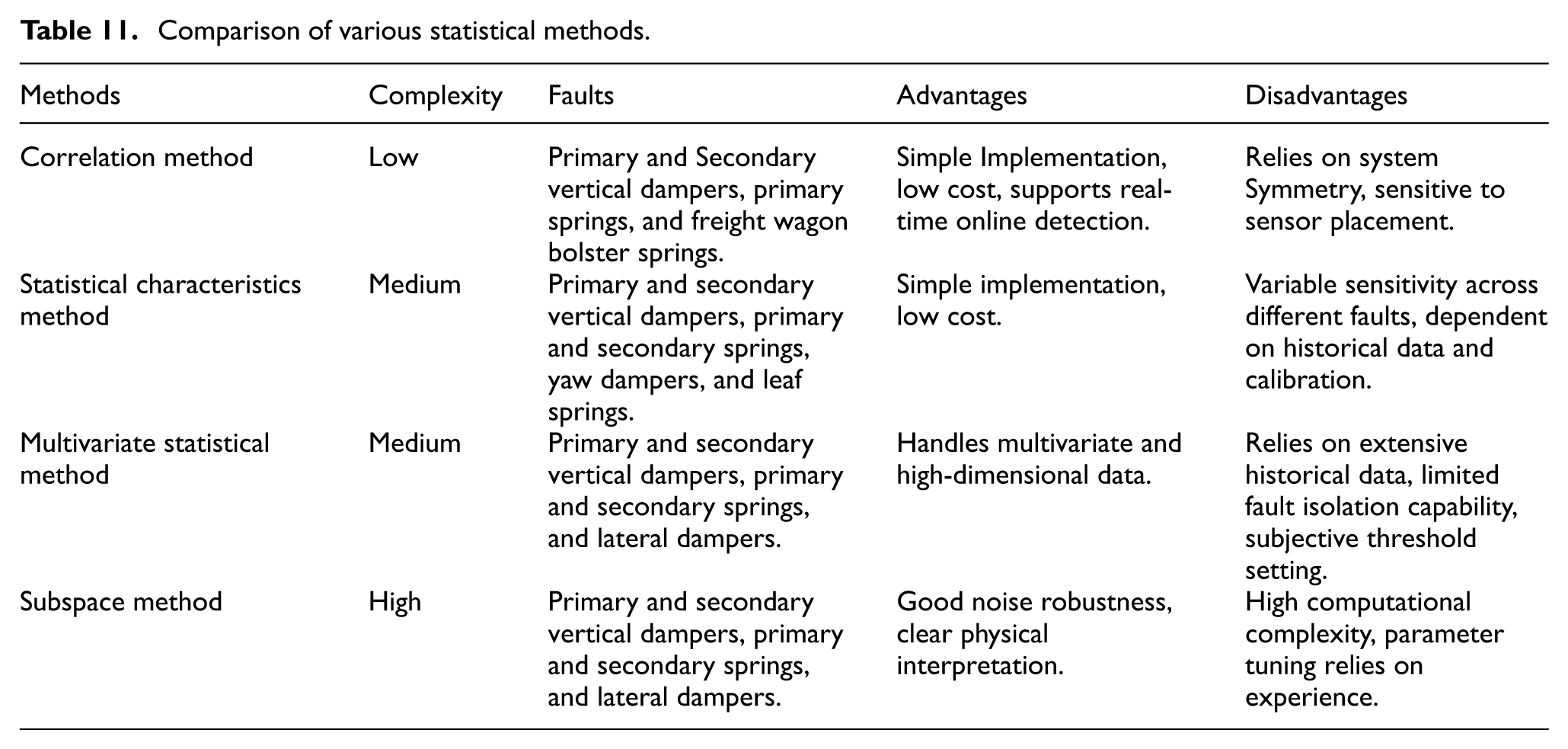
In summary, correlation methods offer excellent real-time performance and simplicity. However, they heavily rely on structural symmetry and exhibit limited capability in isolating concurrent faults. Statistical characteristics methods provide richer fault information than correlation methods and function without system models, yet their offline computation processes are often cumbersome. Multivariate statistical methods effectively handle high-dimensional multivariate data but involve complex implementation, depend on extensive, high-quality historical data for model construction, and exhibit weak fault isolation capabilities. While computationally intensive, subspace methods demonstrate strong adaptability to nonstationary and nonlinear systems, providing a reliable physical basis for fault localization.
TML method
Based on the reviewed literature, TML methods for suspension fault diagnosis are primarily categorized into three types according to their core principles and task objectives: K-nearest neighbor (KNN), support vector machine (SVM), and support vector regression (SVR). It should be noted that these methods are not mutually exclusive in practice; they frequently involve hybridization or appear as improved variants. The development trajectory of these methods is illustrated in Figure 17, with research activity concentrated in the post-2010 period.
Representative publications on TML methods. TML: traditional machine learning.
K-nearest neighbor
The KNN algorithm is an intuitive, nonparametric supervised learning technique applicable to both classification and regression tasks. Its core principle involves identifying the KNNs in the training set that are most similar to a new data point and predicting its class via majority voting or weighted aggregation of the neighbors’ labels (see Figure 18).
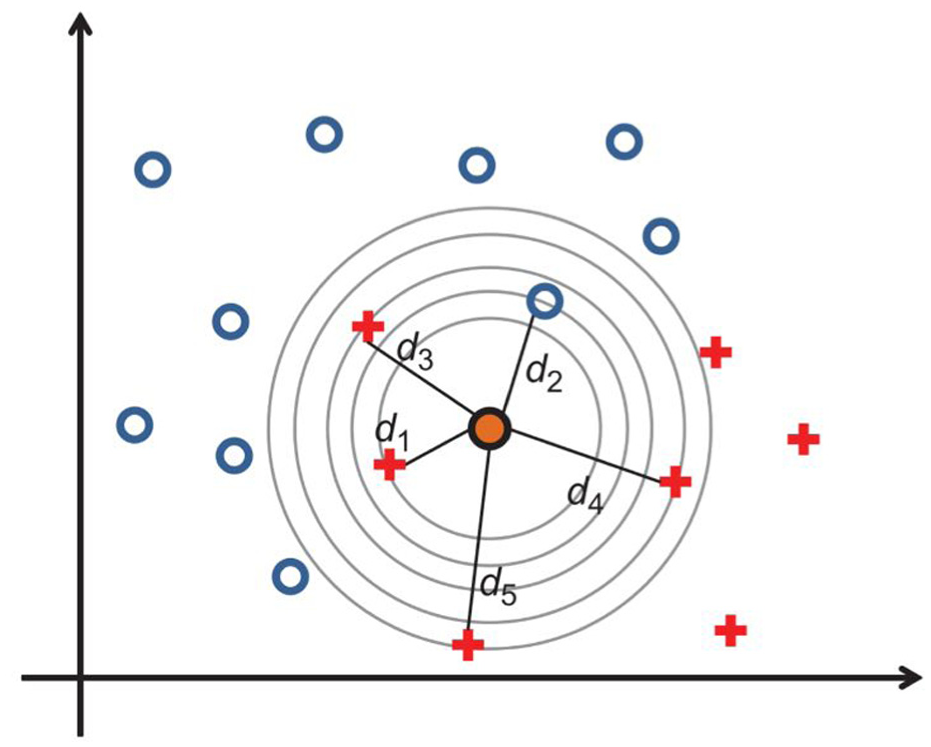
Exemplification of the KNN classification method in the study by Gasparetto et al
79
: the filled circle is the sample to be classified, whereas the void circles and crosses are the training samples representative of two different fault categories. In the example, it is assumed
Gasparetto et al. 79 employed the random decrement technique and Prony analysis to extract bogie stability parameters (including frequency, damping ratio, and amplitude ratio) from lateral frame acceleration. The KNN algorithm was used to classify wheel wear conditions and yaw damper fault states. Validated through the construction of a fault database and field tests on the ETR500 Y1 train, the results indicated that the method effectively distinguishes between new and worn wheel profiles and assesses the status of yaw dampers.
Support vector machine
The SVM is a robust supervised learning model renowned for its superior generalization capabilities, particularly in small-sample learning scenarios. Its primary objective is to construct an optimal separating hyperplane that maximizes the margin between data points of distinct classes, thereby facilitating efficient data classification (see Figure 19).
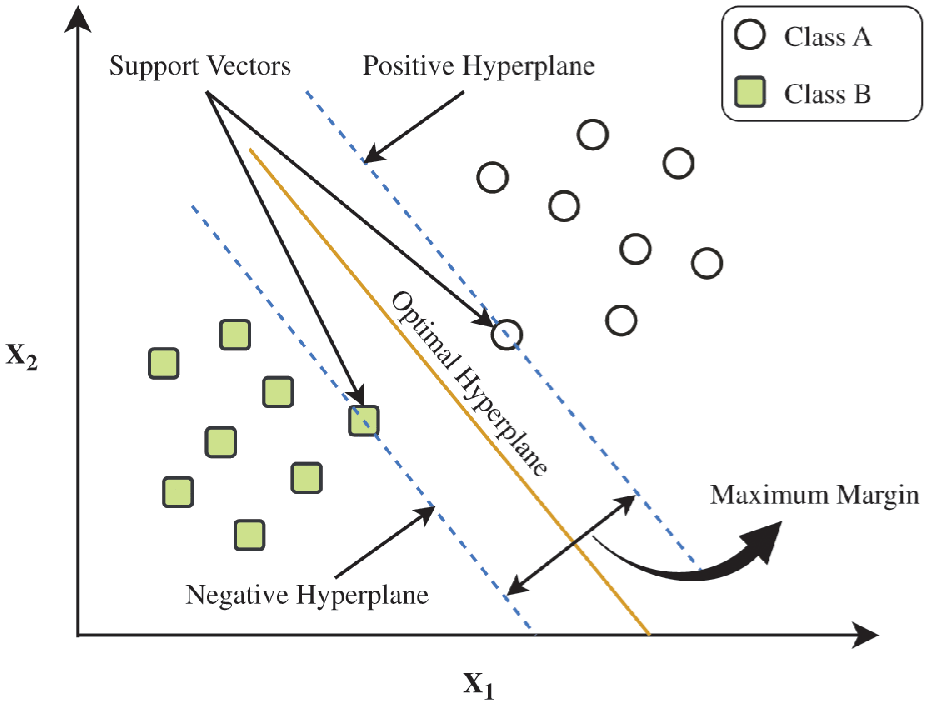
Schematic diagram of SVM for two data features, where
Qin et al. 80 proposed a fault diagnosis method for high-speed train bogies based on wavelet entropy features and SVM. By acquiring bogie vibration signals, the study extracted six wavelet entropy features (such as energy entropy and time entropy) to construct a high-dimensional feature space, using SVM for the effective detection and classification of suspension component faults. Simulation experiments demonstrated that the method performed effectively in distinguishing among the healthy state, air spring faults, yaw damper faults, and lateral damper faults.
Wei et al.81,82 investigated fault isolation in rail vehicle lateral suspension systems, proposing a framework based on multisensor feature fusion combined with D-S evidence theory, Fisher discrimination analysis (FDA), and SVM. By constructing a 17-DOF dynamic model and designing a low-cost accelerometer network, the study extracted seven time and frequency domain fault features and compared the performance of these three classification methods. Simulation results indicated that D-S evidence theory outperformed both FDA and SVM in terms of fault component isolation accuracy and faulty-type prediction accuracy, while exhibiting robust performance against fault magnitude changes. A similar study can be found in the study by Wei et al. 83 In 2016, addressing the high DOF and strong correlations among monitoring data points in high-speed trains, Wu et al. 84 proposed a fault feature extraction method based on multivariate multiscale sample entropy (MMSE). The study employed multivariate empirical mode decomposition to perform synchronous joint analysis of multichannel vibration signals under various operating conditions, thereby extracting common modes across data channels. The MMSE of the signals served as the fault feature, with an SVM used for fault state classification. Experimental results demonstrated that the classification recognition rate exceeds 90% across various speeds. Karlsson et al. 85 generated a dataset encompassing diverse operating conditions and damper fault states via multibody dynamics simulation to evaluate the performance of various machine learning classifiers (including the 1-nearest neighbor classifier, linear SVM, Naïve Bayes, linear discriminant analysis, and Decision Trees) in suspension fault diagnosis. The study found that the 1-nearest-neighbor and linear SVM classifiers exhibited superior performance in damper fault classification, characterized by high accuracy, low false negative rate, and low misconfused damper rate. A similar study can be found in the study by Ye et al. 86
Girstmair et al. 87 compared the performance of standard simple criteria against statistical models for yaw damper fault diagnosis. Through multiscenario testing under actual operational conditions, the study demonstrated the significant advantages of statistical methods, such as SVM, in terms of sensitivity and robustness. Notably, statistical models exhibited superior adaptability and fault detection capabilities when confronting complex operational environments (such as various equivalent conicities and speeds). Girstmair and Moshammer 88 integrated physical simulation, signal processing, SVM, and Bayesian inference to construct an efficient and reliable fault diagnosis framework for rail vehicle suspension systems (see Figure 20). Using a two-stage architecture comprising offline learning and online deployment, the method effectively detected and isolated faults in critical components such as dampers and springs, exhibiting superior performance even in noisy environments. Currently, this algorithm has been deployed on a Siemens commuter train.
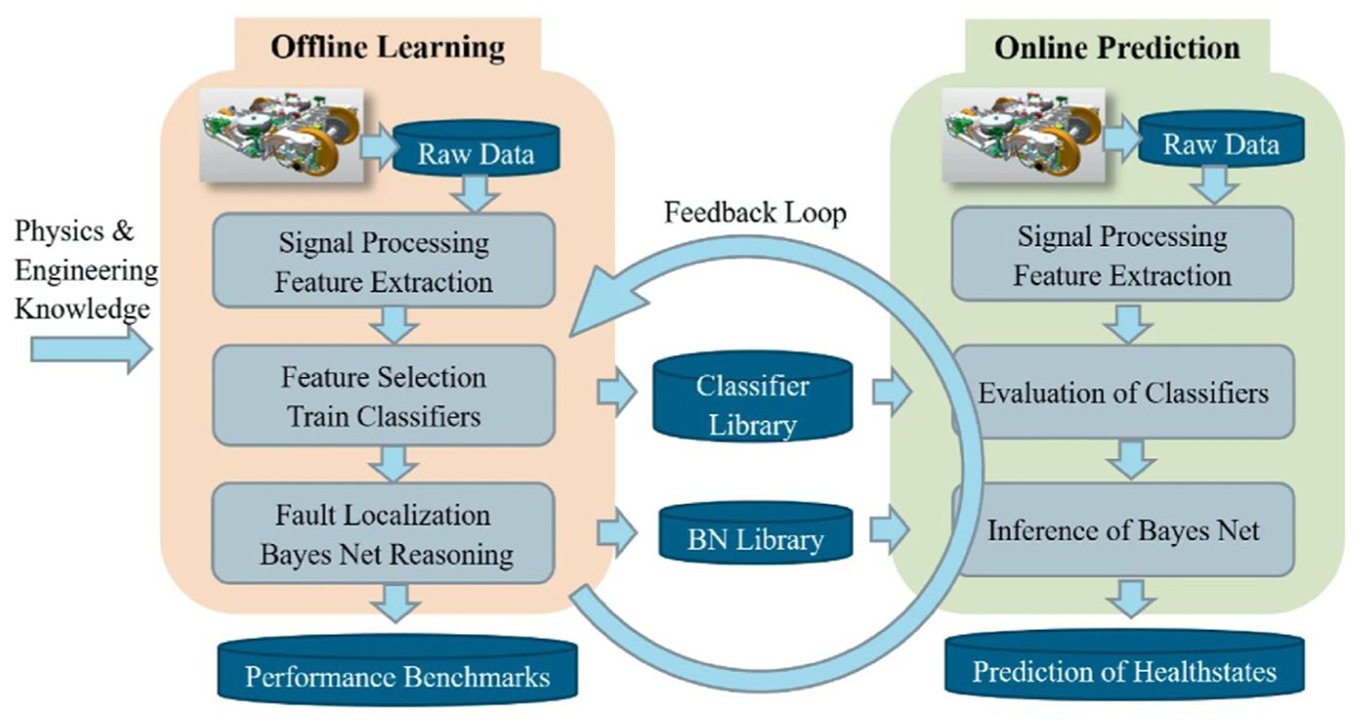
Fault diagnosis framework for rail vehicle suspension systems in the study by Girstmair and Moshammer. 88
Liu et al. 89 proposed a machine learning approach integrating PCA and SVM for rail vehicle suspension fault diagnosis. Wavelet energy entropy extracted from axle box vibration signals served as the fault feature, with PCA employed to reduce feature dimensionality. Multiple SVM classifiers were used to diagnose seven operating conditions, including damper faults. Experimental validation on a 1/5th scaled roller rig demonstrated an overall diagnostic accuracy of 90%. However, the identification accuracy for minor damper faults was relatively low. Feng et al. 90 proposed an incipient fault diagnosis method for suspension systems based on PRPCA and SVM. This method employed a Wasserstein distance-based nonlinear PRPCA for fault detection and data preprocessing. Then, SVM is used for fault identification, with diagnostic performance evaluated using the F1-Measure index. Comparative study against traditional PCA and SVM methods confirmed the superiority of this method in detecting and identifying incipient faults in dampers and springs.
Support vector regression
The SVR is the regression extension of SVM, which maps low-dimensional nonlinear problems into a high-dimensional space. By determining the optimal hyperplane that maximizes the margin relative to the training data, it effectively solves linear regression problems. This margin maximization strategy enhances the algorithm’s robustness and generalization capabilities, rendering SVR particularly suitable for fitting small-sample data compared to other machine learning methods.
Addressing the prediction of performance degradation in urban rail vehicle suspension systems, Wang et al. 91 proposed a predictive model combining least squares SVR (LSSVR) with the particle swarm optimization (PSO) algorithm. By constructing a fault sample set via a simulation platform and comparing prediction performance under varying input features, the results demonstrated that this model outperforms the traditional LSSVR model in both prediction accuracy and computational efficiency. Hong et al. 92 proposed a fault diagnosis framework for monitoring the status of high-speed rail vehicle suspension systems via train vibration measurements (see Figure 21). Based on multioutput SVR (MSVR), the on-board measured vibration signal was used to monitor suspension stiffness and damping coefficients in real time. Comparative study against multivariate Gaussian process regression and multivariate least squares linear regression demonstrated the significant accuracy advantage of MSVR.
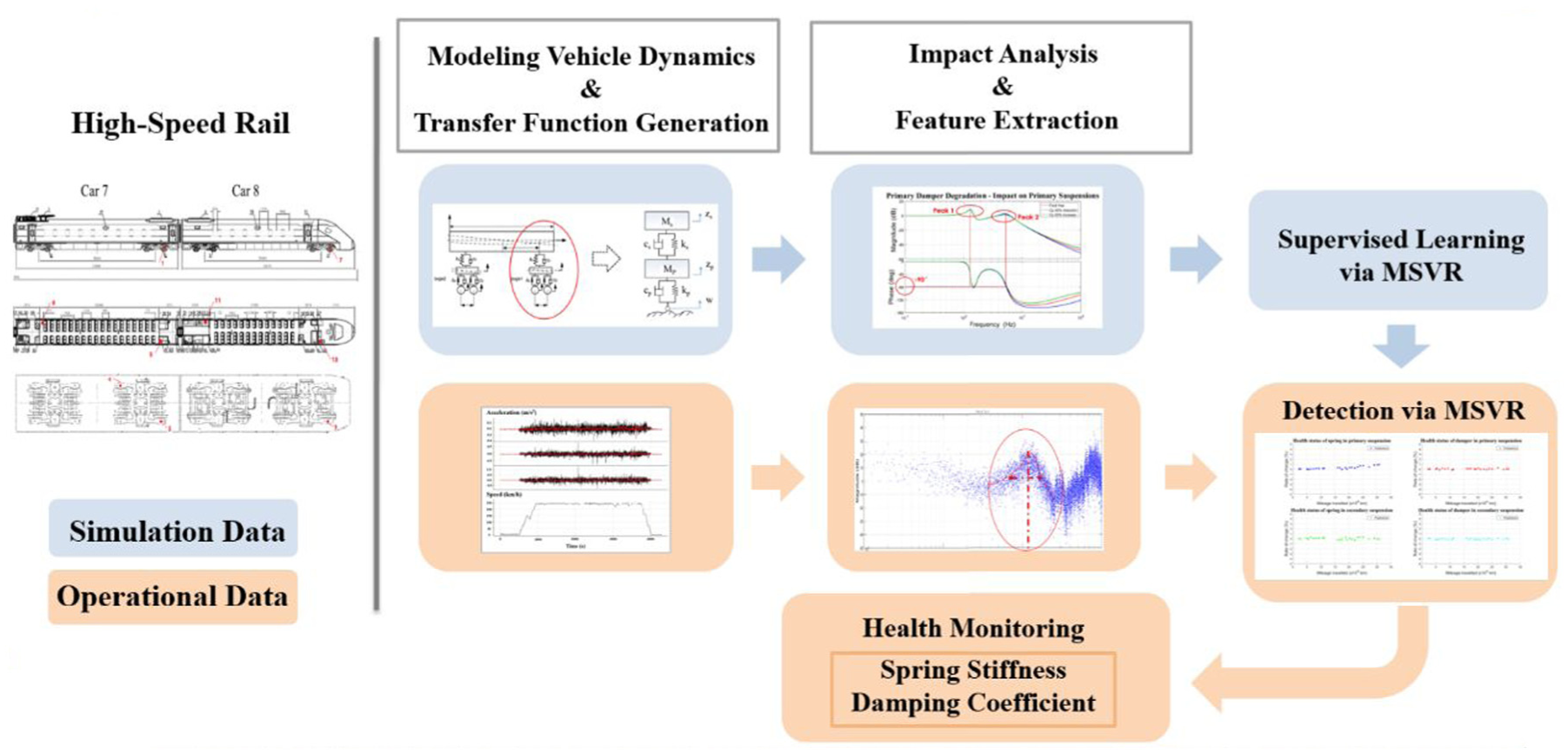
Integral framework for suspension system health monitoring in the study by Hong et al. 92
Summary
In the context of rail vehicle suspension fault diagnosis, TML methods primarily include KNN, SVM, and SVR, as summarized in Table 12.
Comparison of various TML methods.

TML: traditional machine learning; KNN: K-nearest neighbor; SVM: support vector machine; SVR: support vector regression.
In summary, KNN offers a simple implementation without complex training, effectively handling small-sample classification tasks. However, it suffers from low prediction efficiency and sensitivity to data quality. SVM exhibits robust classification capabilities and superior generalization in small-sample, high-dimensional feature spaces, making it highly suitable for multifault pattern recognition. Nevertheless, its performance is heavily contingent upon the selection of kernel functions and parameters. SVR enables the direct output of degradation parameters with explicit physical significance (such as stiffness and damping), thereby achieving fine-grained monitoring and trend prediction of suspension status, though it entails high model complexity and significant training and tuning costs.
DL method
As a cutting-edge branch of machine learning, DL leverages neural network models characterized by multilayer nonlinear transformations to automatically learn hierarchical feature representations directly from raw data, thereby circumventing the complex manual feature engineering associated with traditional methods. In the domain of fault diagnosis, DL has emerged as a critical tool for processing high-dimensional, nonlinear data, owing to its robust capabilities in feature learning and pattern recognition. Based on variations in network architecture and application scenarios, this section reviews the specific applications of multilayer perceptron (MLP), autoencoder, long short-term memory (LSTM) networks, convolutional neural network (CNN), and graph neural network (GNN) in suspension system fault diagnosis. The development trajectory of these methods is illustrated in Figure 22. Despite a relatively late inception, research in this area has exhibited rapid growth since 2015, establishing itself as a research hotspot.
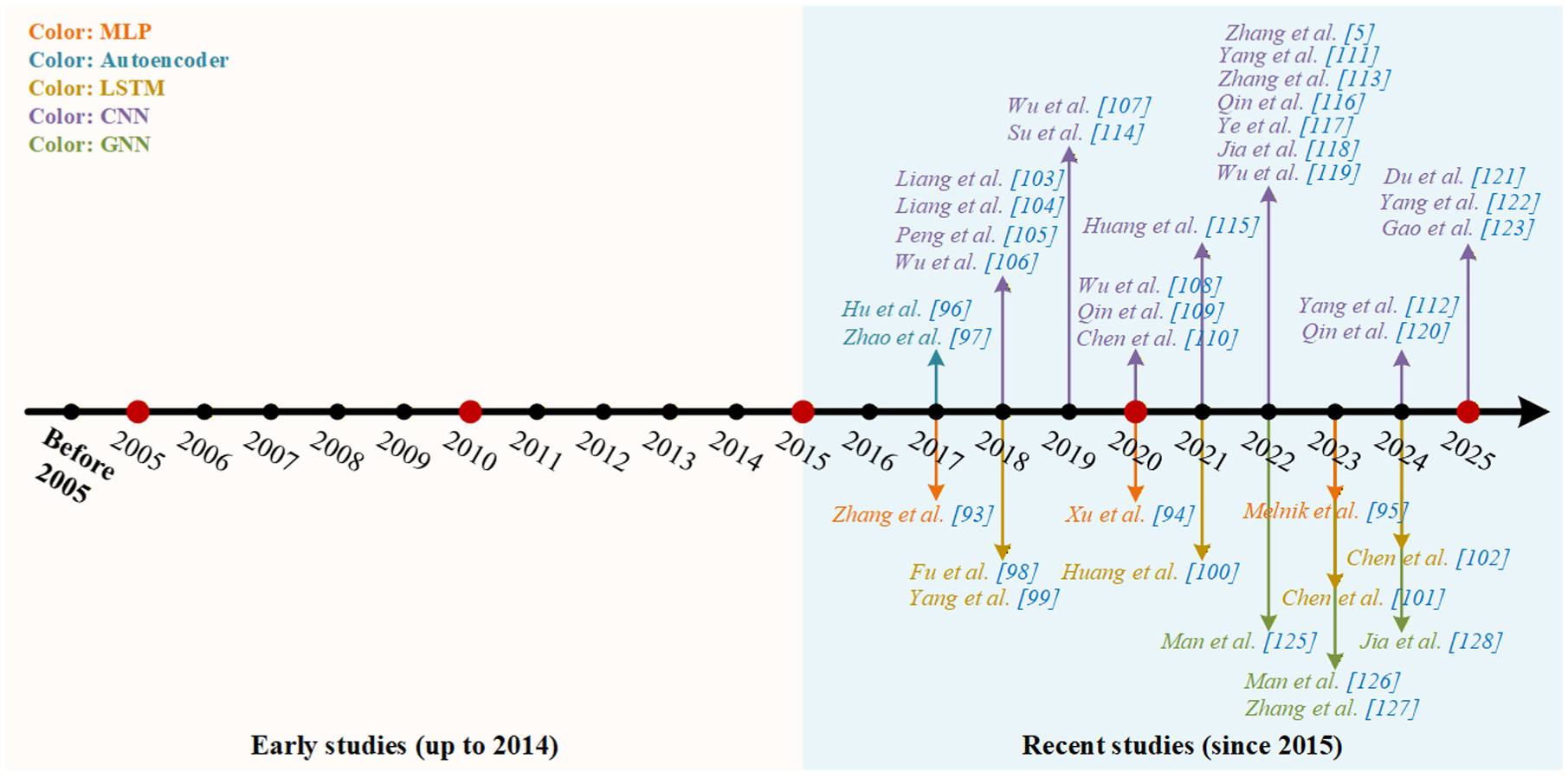
Representative publications on DL methods. DL: deep learning.
Multilayer perceptron
The MLP is a type of feedforward artificial neural network (ANN) typically employed in supervised learning tasks. It is composed of multiple layers of interconnected neurons that sequentially transform input data to generate the final output. Figure 23 illustrates the fundamental structure of the MLP, comprising an input layer, one or more hidden layers, and an output layer.
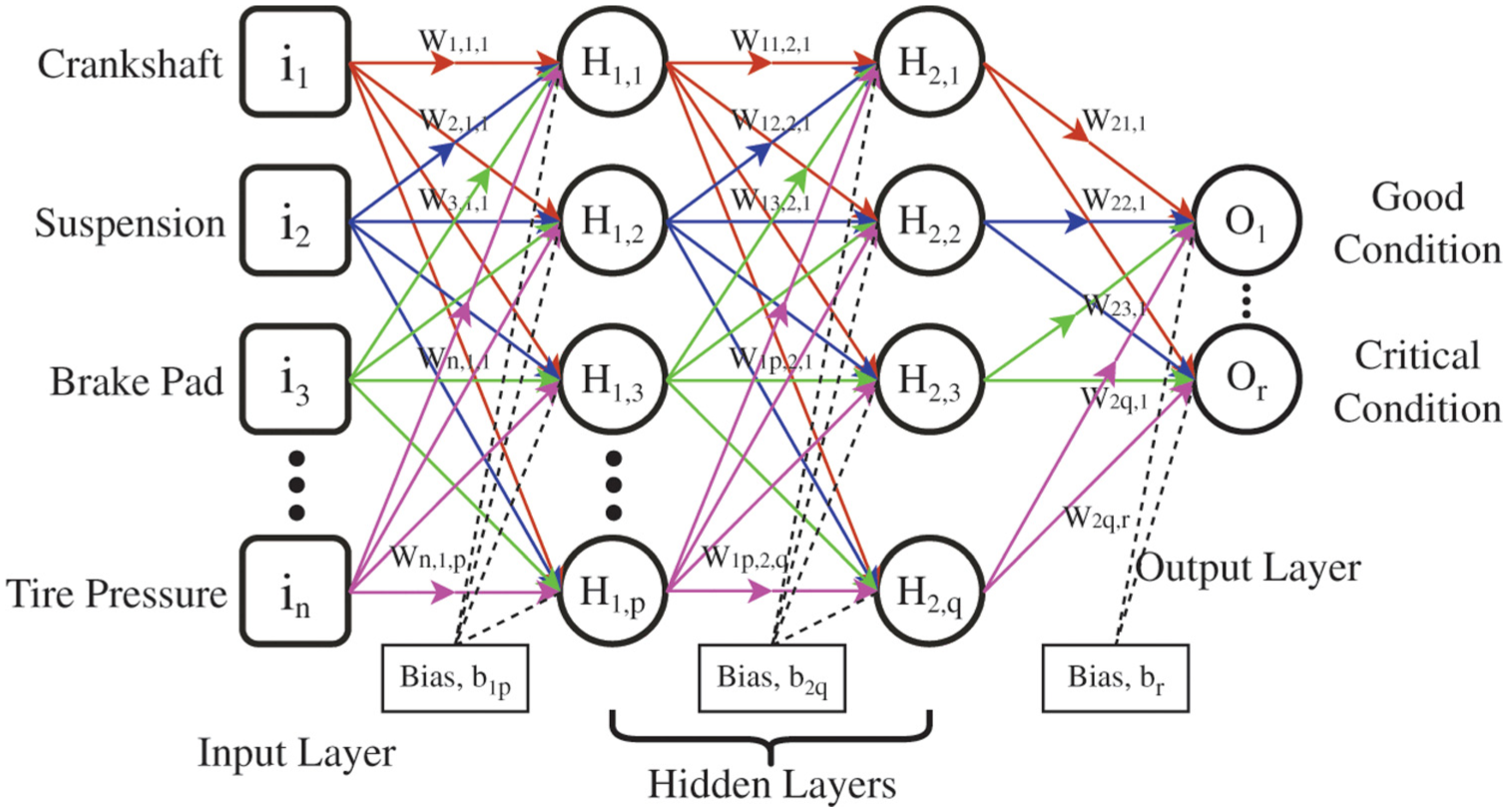
MLP with two hidden layers. 12 MLP: multilayer perceptron.
Zhang et al. 93 proposed a power spectral density (PSD) distance feature extraction method and developed a hybrid algorithm by integrating fuzzy possibilistic C-means clustering with a back propagation (BP) neural network to isolate faults across different suspension components. Simulation results demonstrated that the PSD distance feature extraction method improved sample quality, while the hybrid algorithm exhibited superior stability and accuracy in fault isolation compared to the standalone BP neural network. Xu and Yao 94 used a genetic algorithm to optimize the BP neural network for rail vehicle suspension fault diagnosis. By extracting multidimensional fault features from a vertical vehicle dynamic model and employing the genetic algorithm for optimization, the method significantly enhanced diagnostic accuracy and stability. Experimental results demonstrated that the proposed method performed excellently in the multistate recognition of spring faults, outperforming the unimproved BP neural network. Melnik et al. 95 employed an ANN to analyze the PSD of vertical and lateral acceleration signals from 36 measurement points distributed across the carbody, frame, and axle box. While the method achieved the detection of varying degrees of damper faults under complex vibration coupling and variable operating conditions, the maximum accuracy was below 63%.
Autoencoder
Autoencoders represent a class of self-supervised neural networks that play a pivotal role in unsupervised learning and dimensionality reduction tasks. As illustrated in Figure 24, the autoencoder architecture comprises an encoder, which compresses high-dimensional input data into a compact latent representation, and a decoder, tasked with reconstructing the original input from this compressed form. These networks are optimized to minimize reconstruction error, typically quantified by loss functions such as mean squared error or binary cross-entropy with parameters adjusted via the BP algorithm. In the context of fault diagnosis, autoencoders excel in dimensionality reduction, signal denoising, and efficient data compression, proving particularly effective for anomaly detection in complex, multivariate time-series sensor data.
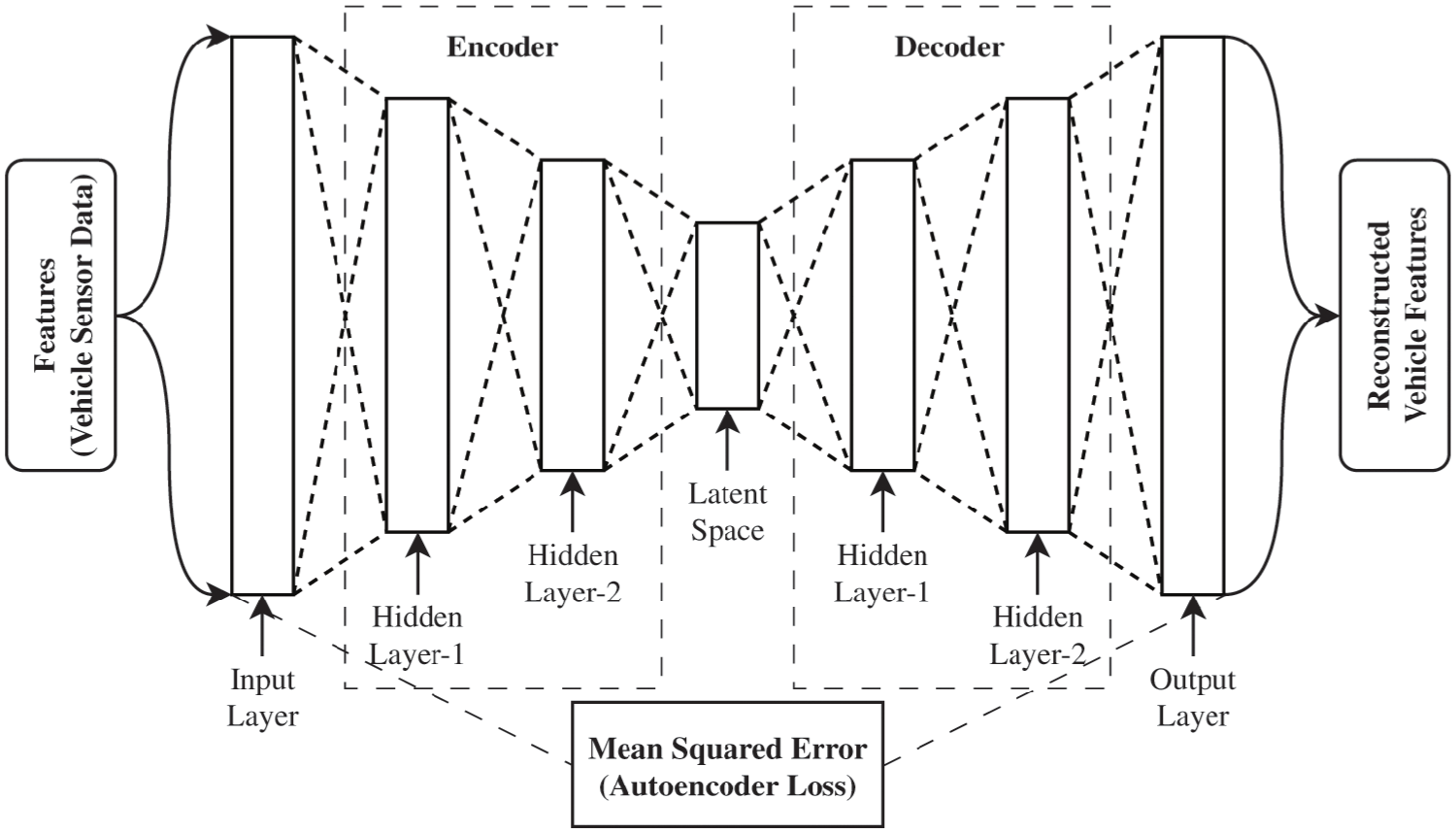
Structure of autoencoder. 12
Hu et al. 96 proposed a deep neural network (DNN)-based fault diagnosis method for high-speed train suspension systems. By constructing a deep architecture comprising autoencoders, the method enabled adaptive feature extraction from vibration signals, eliminating the reliance on traditional signal processing experience. Experimental results demonstrated that the method exhibited superior diagnostic accuracy and stability across various fault types, operating speeds, and small-sample conditions, significantly outperforming BP neural networks and their variants. Zhao et al. 97 applied a DNN method based on the stacked denoising autoencoder (DAE) to suspension fault diagnosis (see Figure 25). Initial validation on a standard bearing fault dataset demonstrated that its diagnostic accuracy and stability significantly outperformed traditional neural networks, such as the firefly ANN and PSO neural network. The study used a multibody dynamic model to acquire vibration data representing the healthy state and seven single and compound fault conditions, extracting 16-dimensional time and frequency domain features. Experimental results indicated that the diagnostic model achieved an average accuracy of 98.3, with a standard deviation as low as 0.71, while demonstrating a significant advantage in training convergence speed.
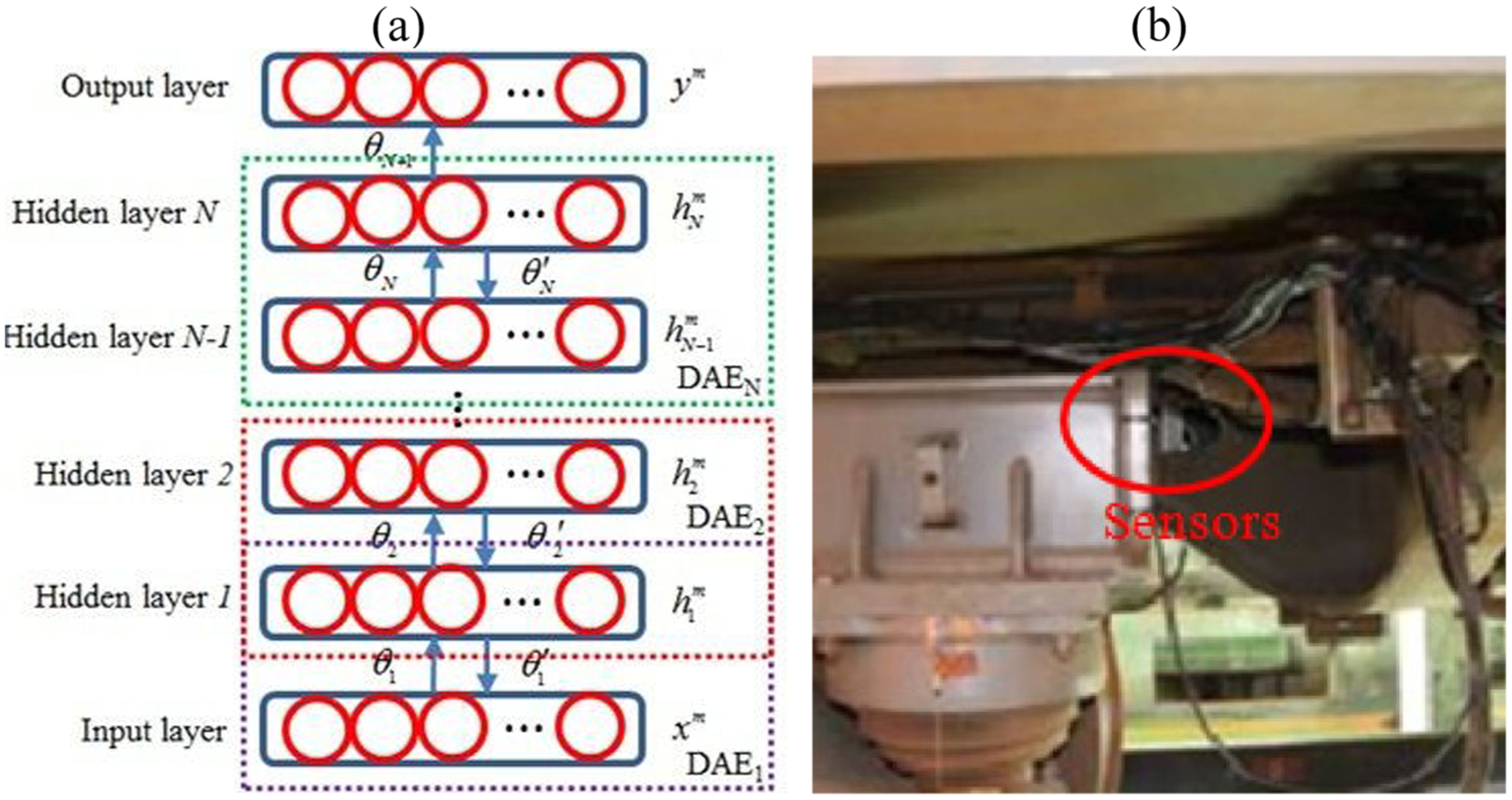
(a) Architecture of the autoencoder-based DNN and (b) actual sensor mounting positions in the study by Zhao et al. 97 DNN: deep neural network.
LSTM network
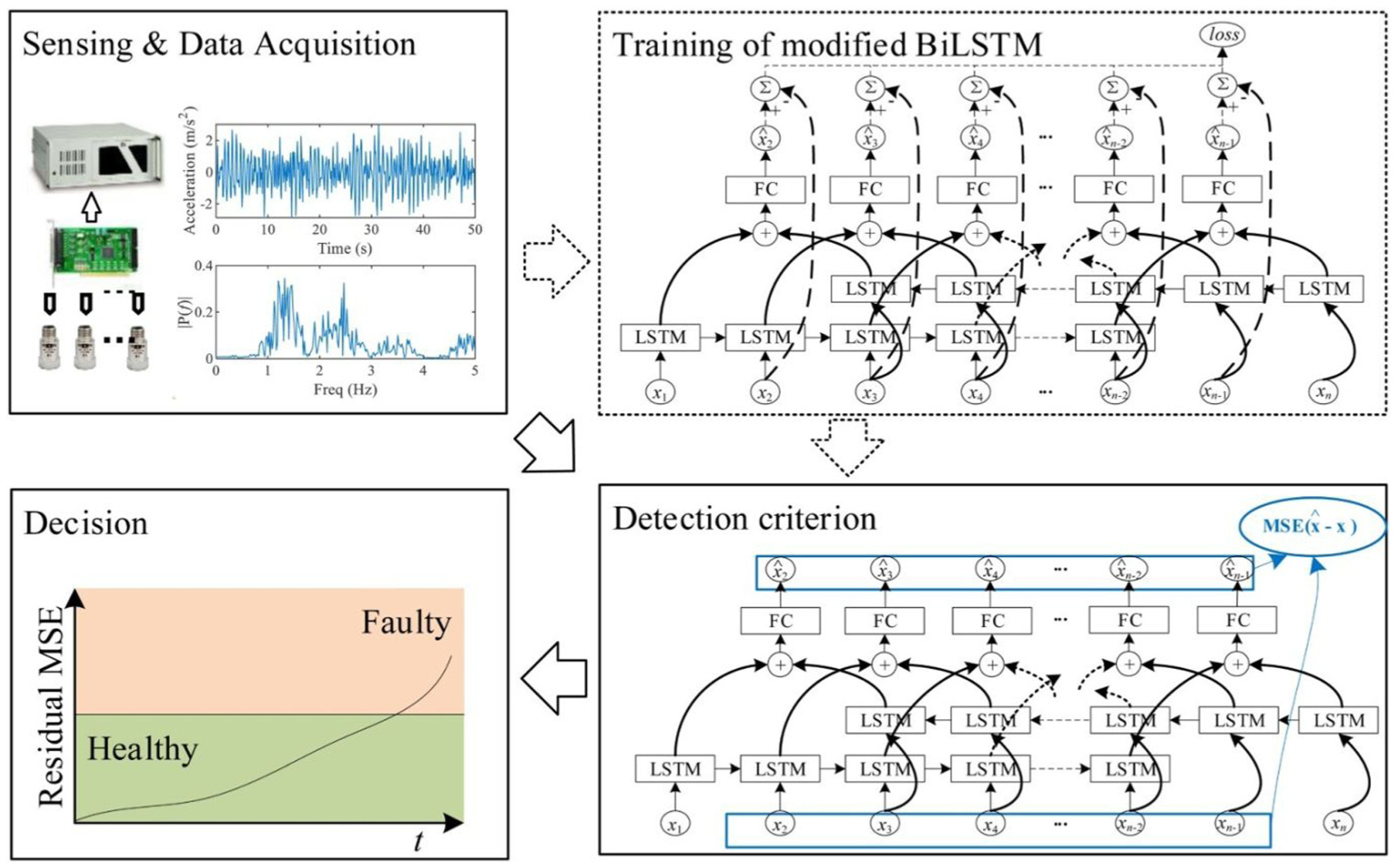
The LSTM network is a specialized variant of the recurrent neural network (RNN), designed to process sequential data characterized by long-term dependencies, such as speech, text, and time-series data. While traditional RNNs propagate hidden states to generate sequential outputs, they often suffer from vanishing or exploding gradient problems when processing extended sequences, which hinder the learning of long-term dependencies. The LSTM architecture alleviates this issue by incorporating “memory cells” that regulate the retention or forgetting of information through a selective gating mechanism. The structure of the LSTM network is illustrated in Figure 26.
The algorithm flow based on the LSTM network in the study by Chen et al. 100 LSTM: long short-term memory.
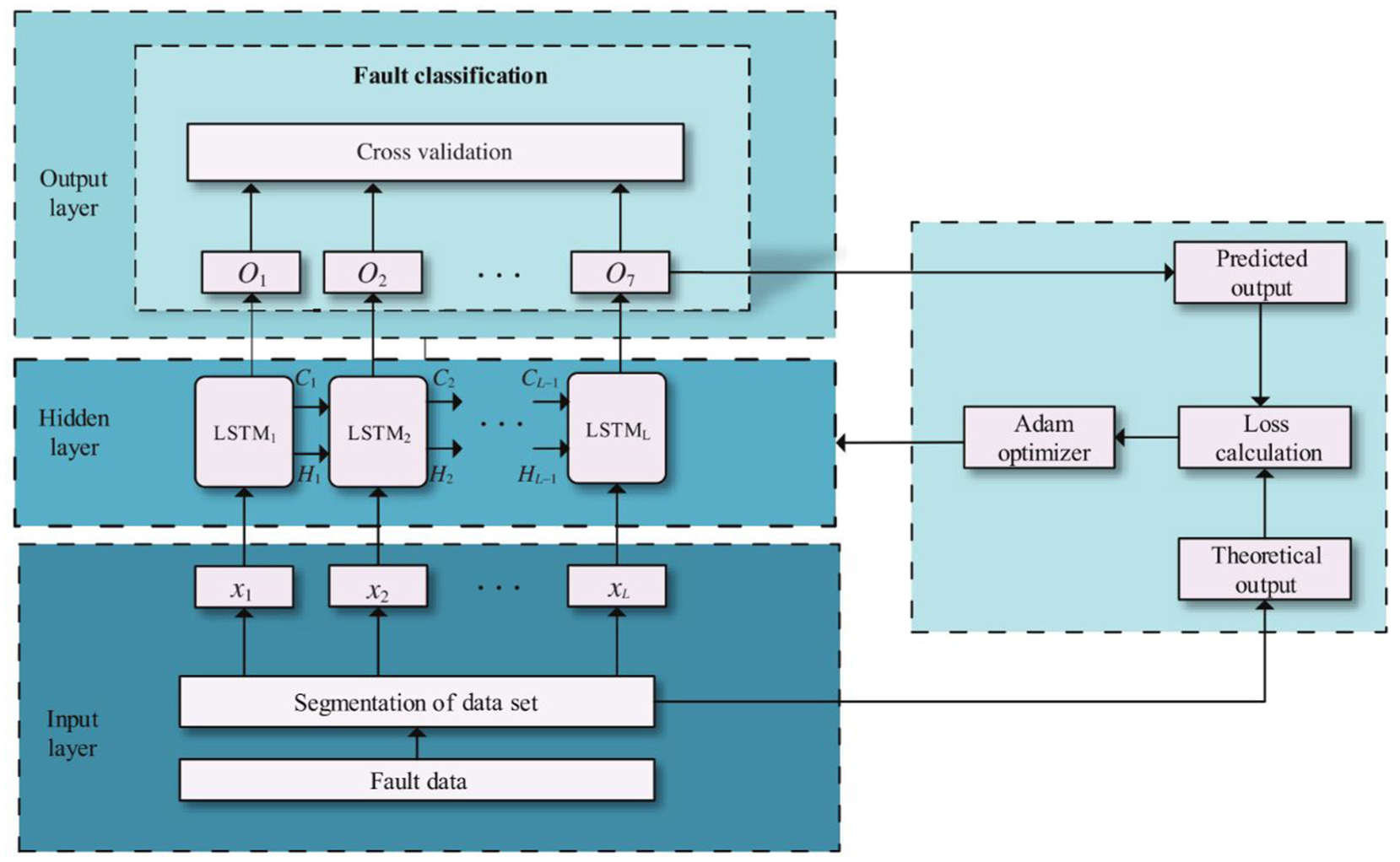
Fu et al. 98 developed a bogie model of the CRH-380A train using the SIMPACK simulation platform. Vibration signals from 58 channels were acquired, encompassing the healthy state and various typical faults (such as single and compound faults involving air springs, lateral dampers, and yaw dampers). The study demonstrated that the LSTM network can learn the spatiotemporal correlations of fault features within vibration signals without requiring data preprocessing or a priori knowledge, thereby validating the effectiveness of LSTM in bogie fault diagnosis. Similar studies can be found in the studies by Yang et al. 99 and Huang et al. 100 Chen et al. 101 proposed a modified bidirectional LSTM (BiLSTM) neural network architecture (see Figure 27) to address the limitation of the existing BiLSTM fault detection method, which requires condition monitoring data from fault states to determine additional noise levels. In this method, the specific output data point was excluded from the input when predicting this specific output data point. Validated using simulation data generated from a vehicle-track coupled dynamics model, the results demonstrated that the method exhibited superior fault detection accuracy and robustness across various fault types and severities compared to linear autoregression, LSTM, and BiLSTM-DAE models.
Fault detection framework based on the modified BiLSTM network in the study by Chen et al. 101 BiLSTM: bidirectional long short-term memory.
Chen et al. 102 further proposed a deep LSTM-based fault detection method for rail vehicle suspension systems. By employing the goodness-of-fit criterion as the fault detection index instead of the traditional LSTM residual mean square value, the method enhanced the sensitivity and accuracy of fault identification. Experiments using simulation data demonstrated that this method outperforms both the vanilla LSTM model and the linear autoregression model in detecting varying degrees of spring faults.
Convolutional neural network
A typical CNN consists of multiple layers, each playing a specific role in the network’s ability to learn and extract features from input images. The architecture of the CNN is illustrated in Figure 28.
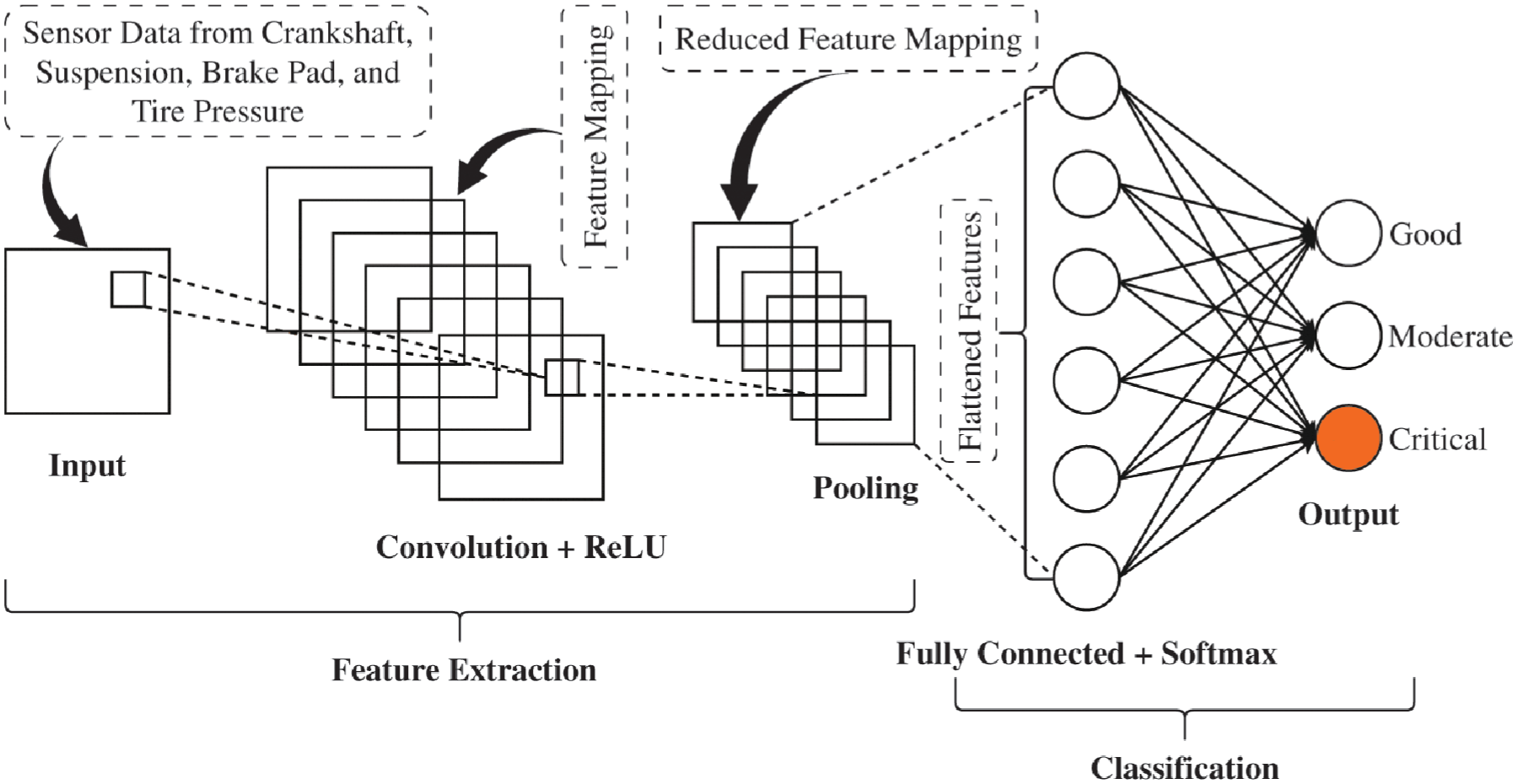
Basic structure of the CNN. 12 CNN: convolutional neural network.
Liang et al. 103 combined CNN and RNN architectures to propose a convolutional RNN (CRNN) for diagnosing single and compound faults in rail vehicle suspension systems. This method leverages the strengths of both the one-dimensional CNN (1D CNN) and the simple recurrent unit (SRU). Features were first extracted from bogie vibration signals via multiple convolutional layers and subsequently passed to stacked SRU recurrent layers to capture hidden features with time-series correlations. Finally, these features were fed into the fully connected layer to calculate classification probabilities. Experimental results indicated that the CRNN outperforms both 1D CNN and LSTM models in terms of detection accuracy and training speed. A similar study can be found in the study by Liang et al. 104 Peng and Jin 105 proposed a fault detection method based on deep semisupervised feature extraction, validating it on rail vehicle suspension systems. This method first transforms multisensor vibration signals into time–frequency spectrograms using STFT, subsequently employs a convolutional autoencoder (CAE) for unsupervised pretraining on a dataset containing unlabeled faulty data, and finally fine-tunes a CNN using labeled healthy data to extract high-level features. Experimental results demonstrated that the method effectively detected vertical spring and damper faults even when using only labeled data from the normal state. Addressing the challenge of multichannel fault diagnosis in high-speed train suspension systems, Wu and Jin 106 proposed a modular fault diagnosis method based on depthwise convolution. The core philosophy involves a structural design that separates feature extraction from channel fusion, thereby preventing the premature fusion of multichannel signals often encountered in traditional convolutions. Experimental results indicated that this method enhanced suspension fault diagnosis accuracy and demonstrated superior robustness under noisy and variable operating conditions.
Wu et al. 107 analyzed the similarity among vibration signals using three synchronization measures (including instantaneous phase synchrony, amplitude envelope synchrony, and composite synchrony). By employing hierarchical clustering for intelligent channel grouping and incorporating a group convolution mechanism into the CNN, the method achieved the centralized processing of signals with similar patterns alongside differentiated feature extraction (see Figure 29). Experimental results demonstrated that this synchrony group convolutions method outperforms both normal convolutions and normal group convolutions in suspension fault classification tasks, exhibiting not only higher accuracy but also superior training stability and faster convergence.
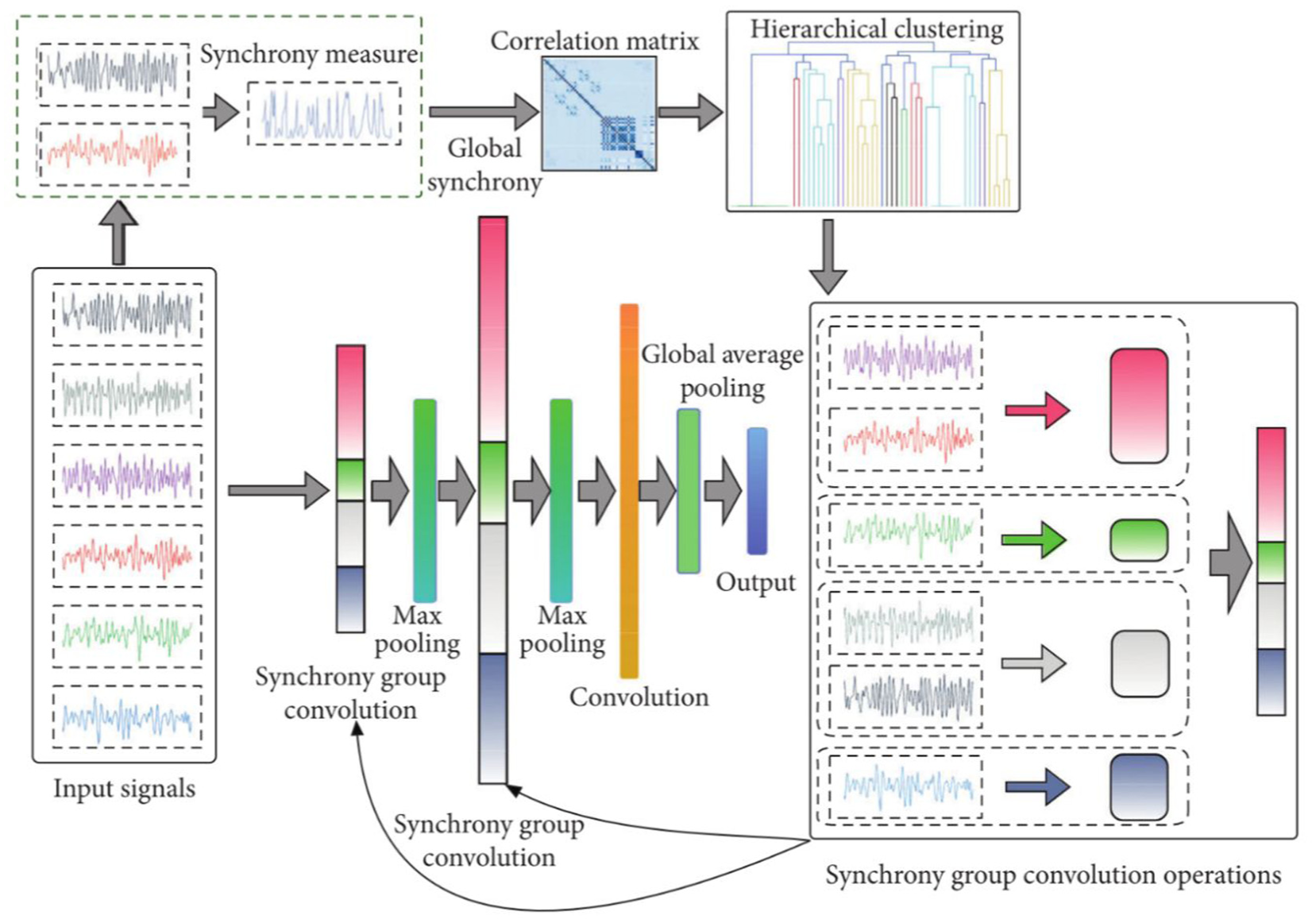
The framework based on synchrony group convolutions for fault diagnosis of the high-speed train in the study by Wu et al. 107
Wu et al. 108 introduced a Bayesian DL framework for the fault diagnosis of high-speed train suspension systems. By interpreting Dropout as an approximation of Bayesian inference, a CNN model capable of quantifying prediction uncertainty was developed. This method not only accurately identifies known suspension fault types but also effectively detects unknown and concurrent faults, demonstrating strong generalization capabilities. Qin et al. 109 and Chen et al., 110 respectively, investigated the applications of multiple CRNN and capsule network (CapsNet) (see Figure 30) in high-speed train suspension fault diagnosis. The former employed two parallel CRNN frameworks to achieve the synchronous diagnosis of fault types and performance degradation states. Conversely, the latter leveraged the vector output characteristics of capsules to achieve high-precision recognition of seven operating conditions, encompassing both single and compound faults, demonstrating superior performance, particularly in compound fault diagnosis.
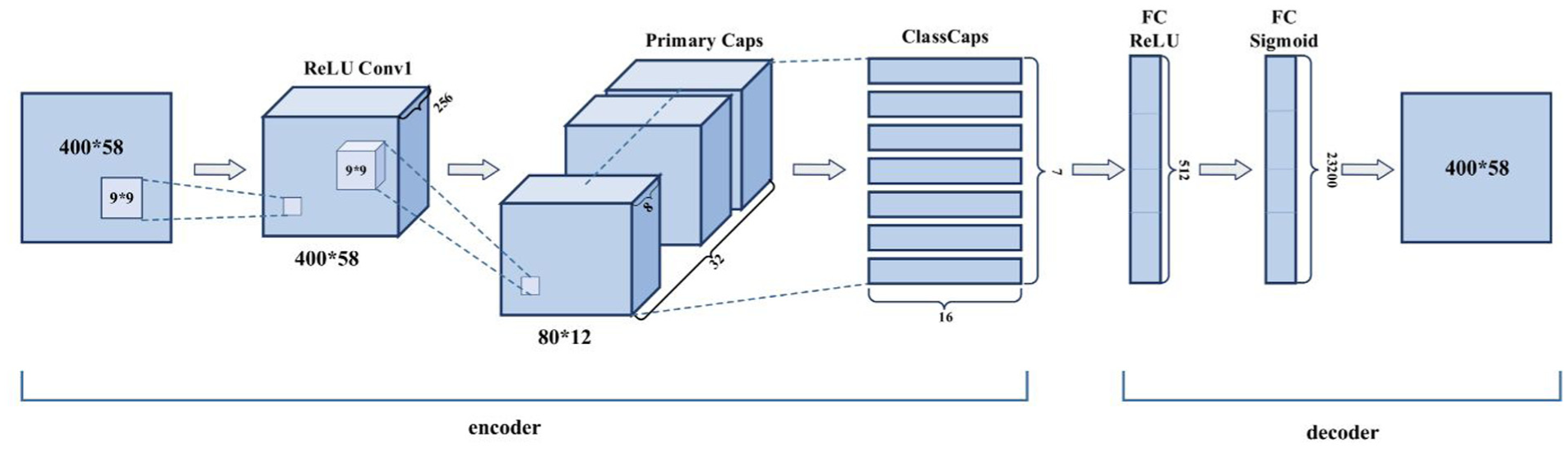
The CapsNet architecture in the study by Chen et al. 110 CapsNet: capsule network.
Addressing the challenge of sample scarcity in high-speed train suspension fault diagnosis, Yang et al. 111 proposed a few-shot diagnosis method combining model-agnostic meta-learning with the two-dimensional (2D) CNN. A sample reconstruction technique was employed to transform 1D suspension vibration signals into 2D feature matrices, thereby enhancing fault feature representation. This enabled the 2D CNN to achieve a diagnostic accuracy exceeding 90% even under small-sample conditions. Experimental results demonstrated that the method performed exceptionally well across various speed conditions, significantly outperforming traditional methods such as 1D CNN, gated recurrent units (GRUs), and CapsNet. A similar study can be found in the study by Yang et al. 112 Zhang et al.5,113 proposed two 1D CNN-based models for suspension fault diagnosis: the Fractional Brownian motion network and the Dense-Squeeze (DenseNet) network. The former integrated fractional Brownian motion into the 1D CNN architecture, endowing the model with the capability to perceive unknown faults and enabling the distinction between known and unknown suspension faults. The latter incorporated DenseNet and a feature channel weighting mechanism to enhance diagnostic precision, maintaining high accuracy under multi-speed conditions. Further studies on 1D CNNs can be found in studies.114–117 Jia et al. 118 proposed a clustered blueprint separable CNN aimed at achieving lightweight and high-precision fault diagnosis for suspension systems. First, multisource sensor signals were clustered based on channel similarity. Then, a multibranch blueprint separable convolution structure was employed for lightweight feature extraction. This method exhibited high diagnostic accuracy while significantly reducing model complexity and training costs. Wu et al. 119 proposed a digital twin-based fault diagnosis framework for high-speed train suspension systems (see Figure 31). By constructing a seven-dimensional bogie digital twin system, the framework achieved deep fusion and real-time data interaction between physical and virtual models. An analytical-driven model was used for preliminary signal processing and feature extraction, while employing a multilayer CNN for deep feature learning and fault classification from vibration signals. This diagnostic mechanism, characterized by virtual-real linkage and model-data fusion, significantly enhanced the identification accuracy and real-time performance of suspension component faults.
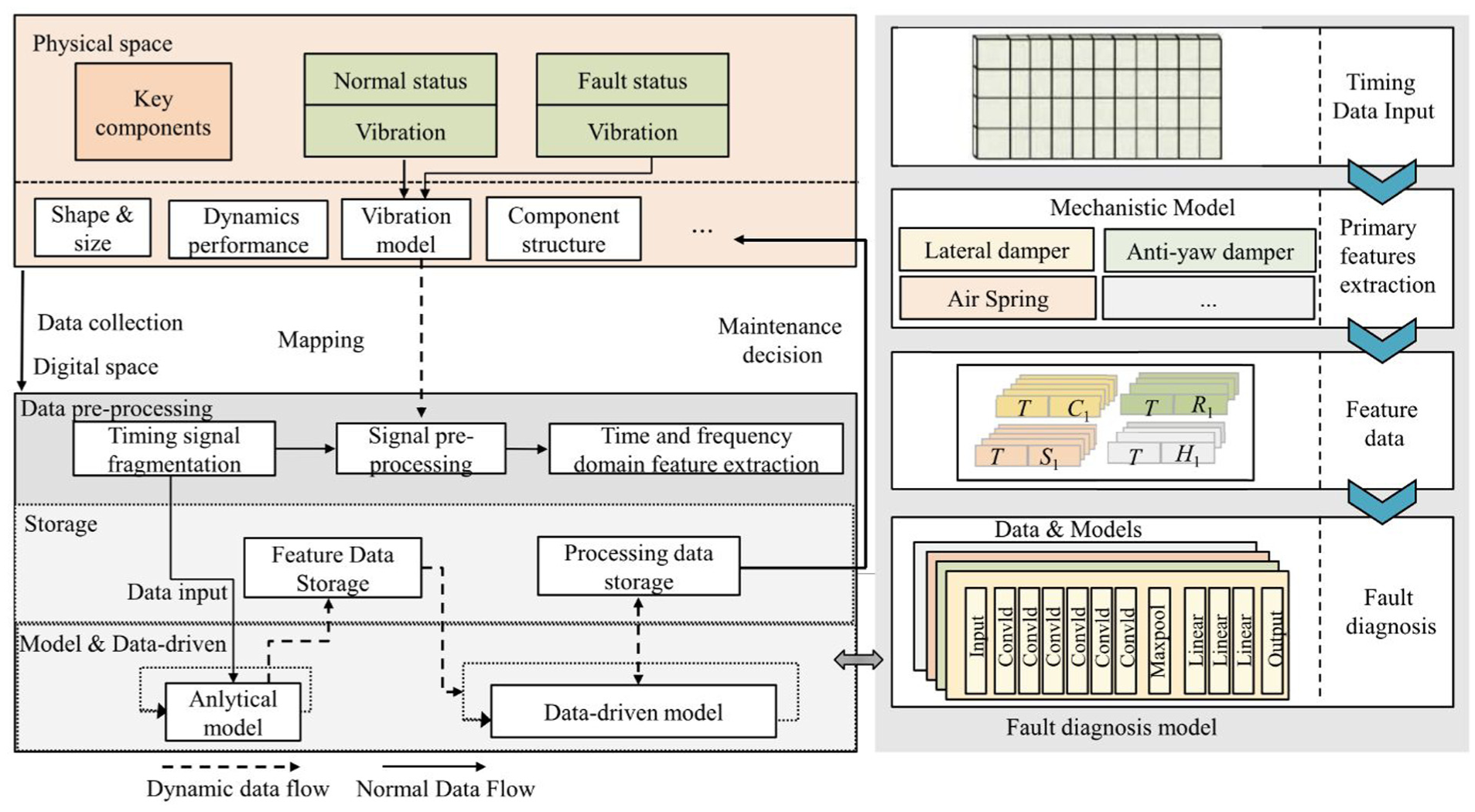
Digital twin-based bogie fault diagnosis framework in the study by Wu et al. 119
Qin et al. 120 focused on identifying unknown suspension fault types. By employing a residual network as the feature extractor and using a diffusion model to generate features for unknown faults, the method achieved the diagnosis of both known and unknown suspension faults. Addressing the challenges of data imbalance and privacy protection in high-speed train suspension fault diagnosis, Du et al. 121 proposed a multirank federated distillation framework (see Figure 32). By employing priority-ranked interclient knowledge distillation, decoupled distillation loss design, adaptive multitask weight adjustment, and a personalized model transfer mechanism, the framework significantly enhanced the diagnostic performance of small-sample clients while safeguarding data security. Experimental results demonstrated that the proposed method outperformed existing federated learning methods across multiple railway datasets, exhibiting strong generalization capabilities and practicality.
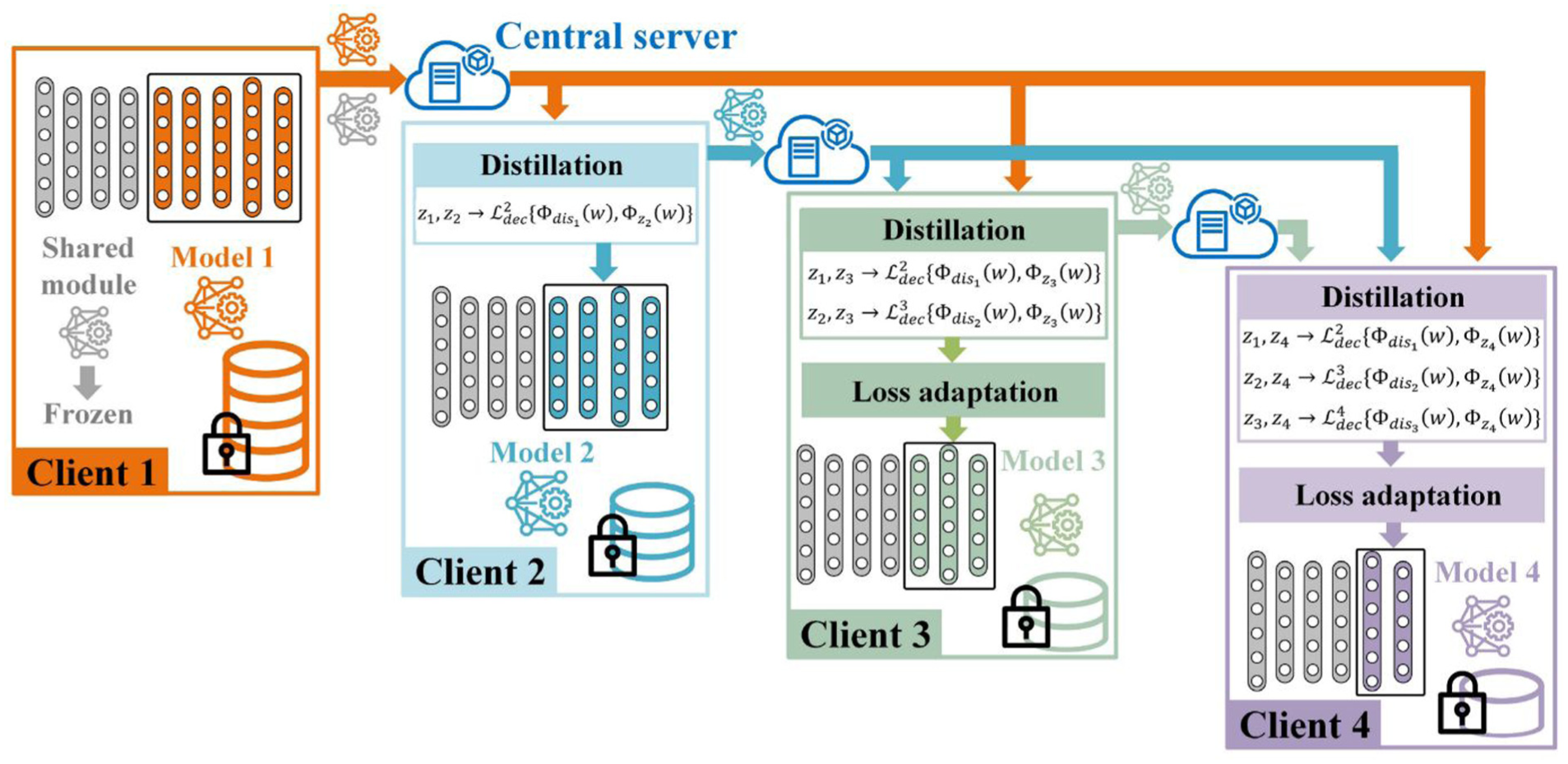
Basic process of the multirank federated distillation framework in the study by Du et al. 121
Addressing the challenge of fault diagnosis for high-speed train suspension systems under variable speed conditions, Yang et al. 122 proposed a dynamic transfer loss weight-deep subdomain adaptation network (DTLW-DSAN). This method optimized the single-sensor layout using wavelet packet energy and the coefficient of variation, thereby reducing system complexity. Using a single accelerometer and unsupervised training, DTLW-DSAN automatically updated transfer loss weights. Experiments on simulation and public datasets demonstrated that DTLW-DSAN achieved high diagnostic accuracy and stability under variable speed conditions, outperforming other existing mainstream methods. Gao et al. 123 integrated the superior time–frequency localization properties of the Morlet wavelet (MW) into the CNN pooling design, facilitating a transition in feature selection from the spatial to the frequency domain. Building on this, a multiscale CNN incorporating MW pooling (MW-CNN) was developed. Multiscale feature extraction and residual learning were combined to establish a deep architecture for high-speed train bogie fault diagnosis. Experiments on a CRH380A simulation dataset demonstrated that MW-CNN achieved a diagnostic accuracy of 99.94% and maintains robust diagnostic performance across varying noise levels and operating conditions.
Graph neural network
The fundamental principle of GNN-based fault diagnosis (see Figure 33) lies in abstracting physical systems (e.g., mechanical equipment) into graph structures, where nodes represent components or sensors and edges denote their connections or correlations. By leveraging the message-passing mechanism, each node aggregates information from its neighbors, thereby capturing fault propagation paths and global impacts within the system to ultimately achieve high-precision classification and localization. Compared to DNNs, GNNs are particularly adept at processing data characterized by complex spatiotemporal dependencies. 124
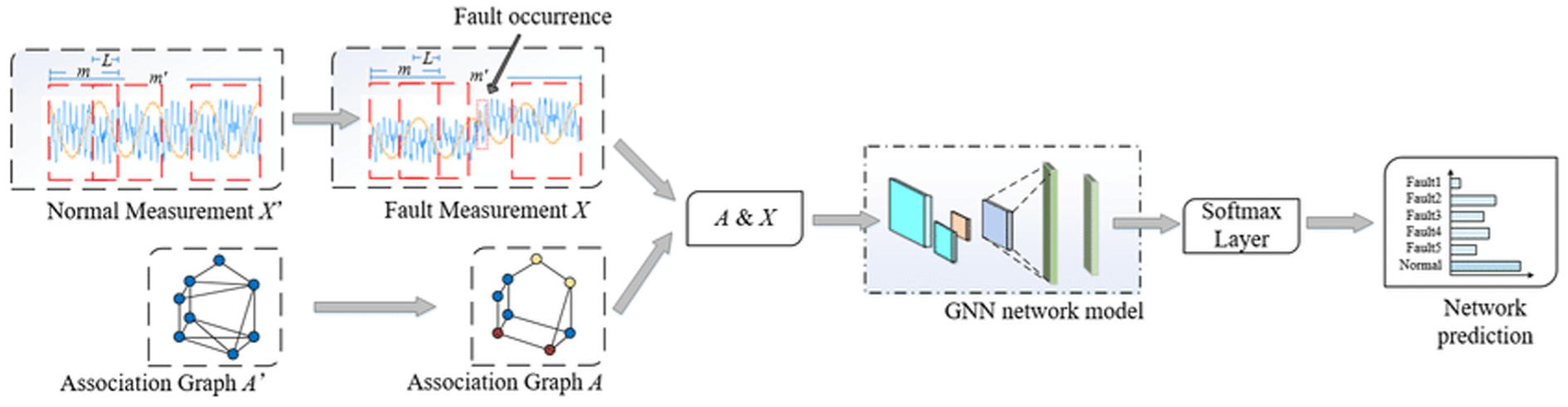
GNN-based fault diagnosis framework. 124 GNN: graph neural network.
Man et al. 125 proposed a novel suspension fault diagnosis scheme based on the graph convolutional network (GCN) (see Figure 34), GRU, and the attention mechanism. First, the bogie data network was established; then, temporal and spatial features were extracted and fused using the GCG unit. Moreover, an attention mechanism was incorporated to enhance the capture of critical fault information, with final fault classification performed via GCN. Experimental validation demonstrated that the model achieved high diagnostic accuracy for seven types of bogie faults using actual operational data, while exhibiting strong robustness on small-scale datasets. Man et al. 126 further designed a deep network architecture integrating the graph attention network (GAT) with the residual-squeeze network (RS-Net). By employing RS-Net as the framework and using GAT for spatial information fusion and feature extraction, the model achieved the identification of six types of bogie faults.
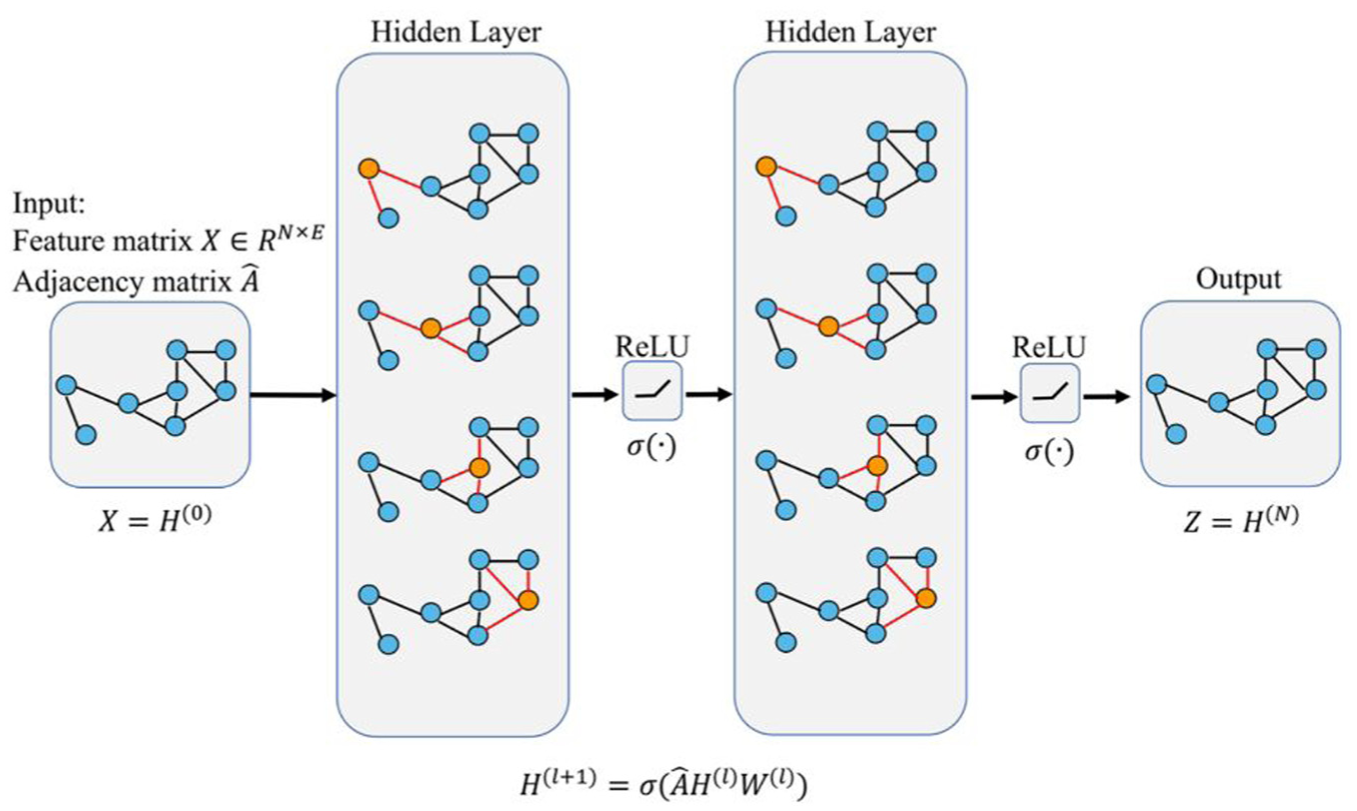
GCN structure. 124 GCN: graph convolutional network.
Leveraging deep transfer learning and GNN, Zhang et al. 127 proposed a suspension fault diagnosis method based on a multisensor graph transfer network. A multisensor GNN (MSGNN) was constructed to extract features from vibration signals collected at three distinct train locations, and the graph-based fusion layer was used to achieve effective multisource information fusion. Experimental results on both simulated and measured data demonstrated that the MSGNN outperforms traditional data-driven methods in detecting spring and damper faults. Jia et al. 128 integrated GNN with federated learning to construct a fault diagnosis and localization system for high-speed train suspension systems in multisensor environments (see Figure 35). The multisensor network was first mapped into a graph with identical node and edge features, which was then optimized via graph spectral filtering and node-level attention mechanisms. Then, graph-level topology adaptive technology and a postclassifier were employed to localize faulty suspension components within a single railway. Finally, personalized models were tailored for each railway through railway-specific optimization. Experimental results demonstrate that this method achieved high accuracy in both fault component localization and status identification.
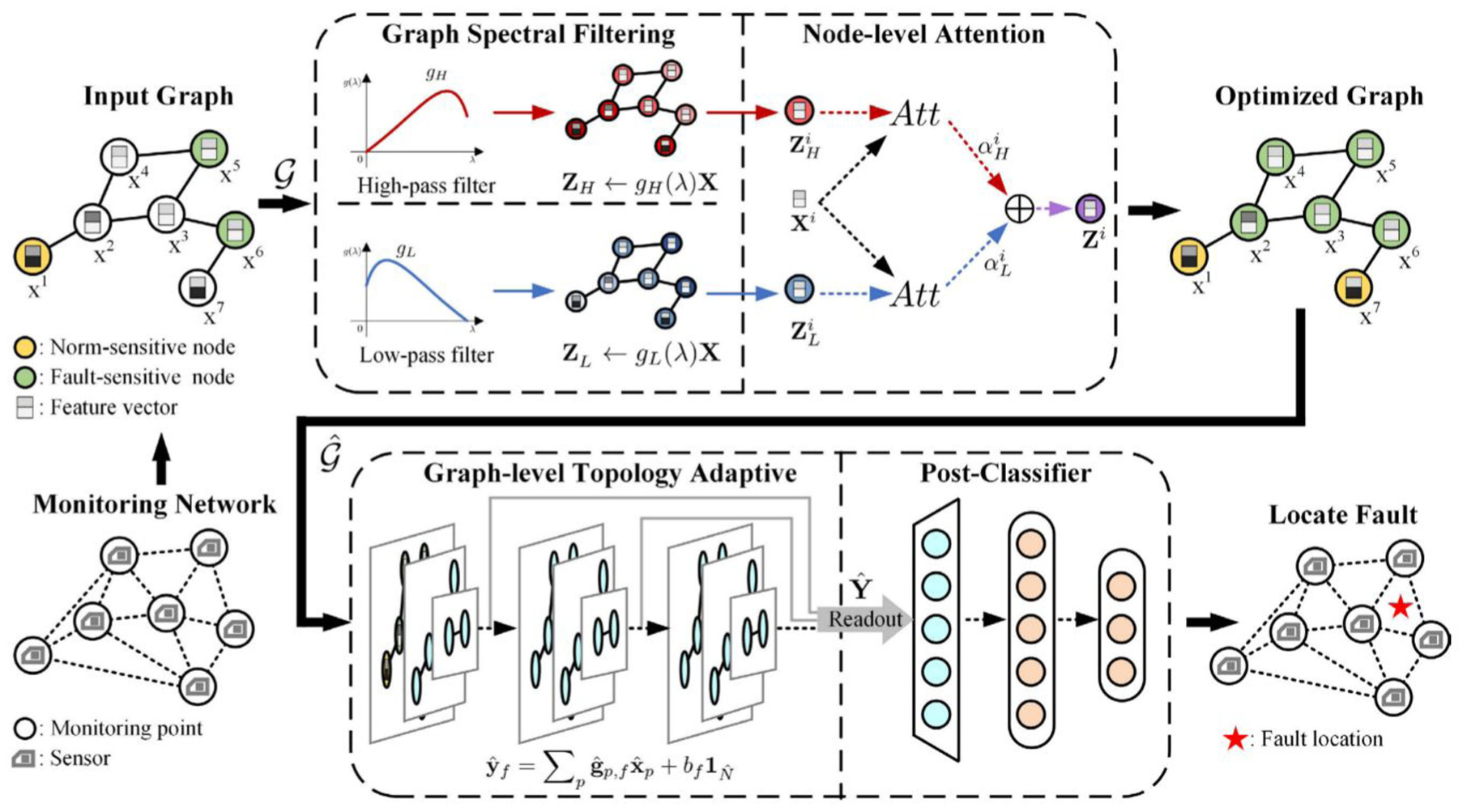
Fault diagnosis and localization system for high-speed train suspension system in the study by Jia et al. 128
Beyond the aforementioned modeling approaches focusing on spatial topological structures between sensors, recent research has introduced the time–frequency fully connected GNN, 129 which offers a complementary perspective for capturing deep features in the vibration signals of rail vehicle suspension systems. This approach transforms multisource sensor signals into time–frequency representations and employs localized time–frequency patches as nodes to construct a fully connected graph, thereby overcoming the constraints of physical topology in traditional GNN and achieving profound feature coupling across spatiotemporal dimensions. Since vibration signals from suspension systems exhibit significant nonstationarity and time–variance, the model accurately captures transient time–frequency fluctuations triggered by subtle faults, which substantially improves the feature representation depth and robustness of diagnostic models in complex dynamic environments.
Summary
In rail vehicle suspension fault diagnosis, DL methods encompass MLP, autoencoder, LSTM network, CNN, and GNN, as summarized in Table 13.
Comparison of various DL methods.
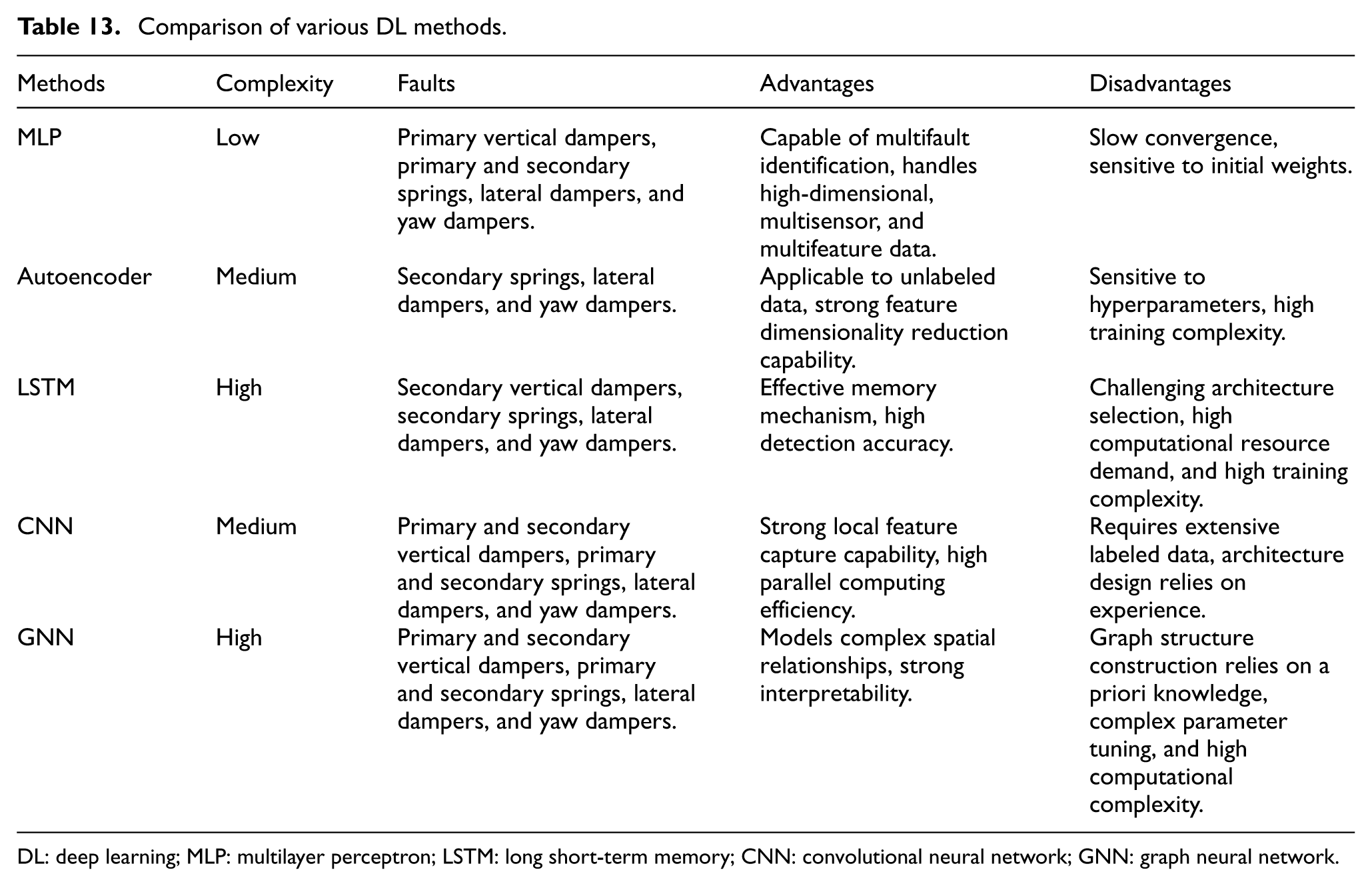
DL: deep learning; MLP: multilayer perceptron; LSTM: long short-term memory; CNN: convolutional neural network; GNN: graph neural network.
In summary, while the MLP offers structural simplicity and rapid training, its performance relies heavily on the quality of manual feature extraction, making it difficult to capture complex nonlinear patterns within vibration signals. Autoencoder facilitates unsupervised feature dimensionality reduction and anomaly detection with robustness to noisy data. However, its performance is constrained by its encoding capacity. LSTM network excels in processing time-series vibration signals, effectively capturing long-term fault dependencies and achieving high diagnostic accuracy. Nevertheless, it suffers from complex model structures, time-consuming training processes, and sensitivity to hyperparameters. CNN automatically extracts effective local spatial features from raw signals, reducing reliance on feature engineering, though its architectural design remains experience-dependent. Finally, GNN explicitly models the physical correlations among suspension sensors, providing a novel perspective for fault propagation analysis. However, it faces challenges regarding graph structure construction, high model complexity, and substantial computational costs.
Intelligence principles and engineering evaluation of data-driven methods
Correlation between modeling assumptions and failure modes
The core logic of data-driven methods is founded on the principle that the health status of the suspension system is implicitly contained within vast operational data.
The statistical method is established upon the assumption of signal symmetry or statistical distribution consistency, providing the advantage of bypassing complex modeling processes to identify faults directly through signal cross-correlation or statistical components. However, these methods often fail in rail applications where intense background noise and stochastic vibrations from wheel–rail interactions mask subtle suspension defects. The TML methods typically assume that fault features are linearly separable in low-dimensional or kernel-transformed high-dimensional spaces. The primary advantage of these methods lies in their capability to use small sample sets. However, their reliance on manual feature engineering restricts the capture of the complex and time-varying dynamic characteristics inherent in vehicle systems. When encountering environmental uncertainties such as poor track quality, the predefined feature sets fail to effectively represent system variations, resulting in a decline in algorithmic robustness. The DL methods assume the automatic learning of hierarchical feature representations through multilayer nonlinear transformations, demonstrating significant advantages in mining implicit fault features from high-dimensional and nonlinear data. However, their heavy reliance on large-scale labeled datasets makes them struggle with practical deployment, as samples for low-probability but high-stakes suspension faults are scarce.
Evaluation metrics and engineering trade-off analysis
To systematically evaluate the practical utility of various data-driven methods in engineering applications, five key performance indicators consisting of complexity, accuracy, detection delay, FAR, and computational cost are introduced (see Table 14) to perform a comparative analysis of the data-driven algorithms within a unified dimension.
Comparison of various data-driven methods based on unified evaluation metrics.
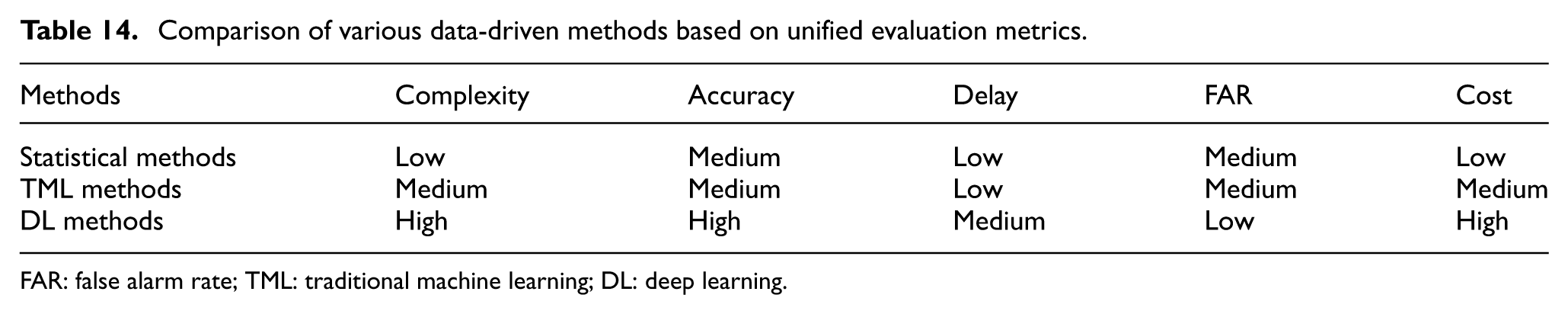
FAR: false alarm rate; TML: traditional machine learning; DL: deep learning.
Analysis demonstrates that data-driven methods exhibit significant trade-off relationships among these performance metrics. Statistical methods perform excellently in terms of computational cost and detection delay because their relatively streamlined algorithmic logic makes them highly suitable for real-time deployment in computationally constrained on-board embedded environments. The TML methods demonstrate strong robustness in small sample scenarios; these methods offer a balance between diagnostic accuracy and resource consumption. While the DL methods possess absolute advantages in diagnostic accuracy and FAR suppression, the extremely high model complexity and dependence on high-performance computing resources represent barriers to large-scale engineering deployment. Furthermore, the substantial data demand and lengthy offline training processes associated with the DL methods significantly increase the initial development and subsequent maintenance costs of the system.
Comparative analysis and synergistic evolution of diagnostic paradigms
Current fault diagnosis methods for rail vehicle suspension systems are primarily categorized into two technological paradigms: model-based and data-driven methods. This section analyzes the research landscape from a national perspective and systematically compares the general characteristics and development trends of these two methods.
Research progress in different countries
The number of published articles on suspension system fault diagnosis by different countries is illustrated in Figure 36 and Table 15. From a global perspective, significant disparities exist in the research activity and focus areas of various nations within this field.
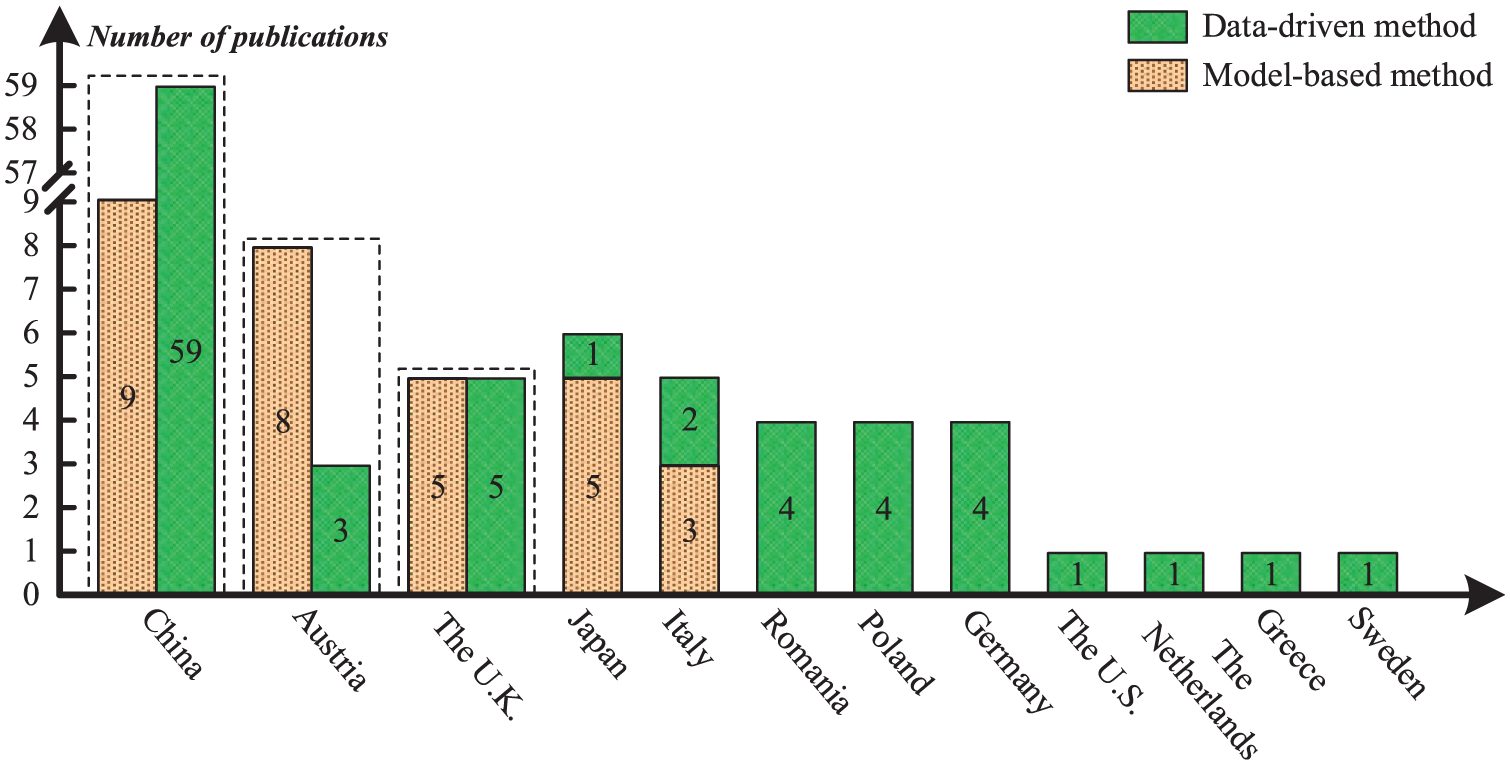
Publications from different countries surveyed in this paper.
Publications by country for subcategories of the two main methods.
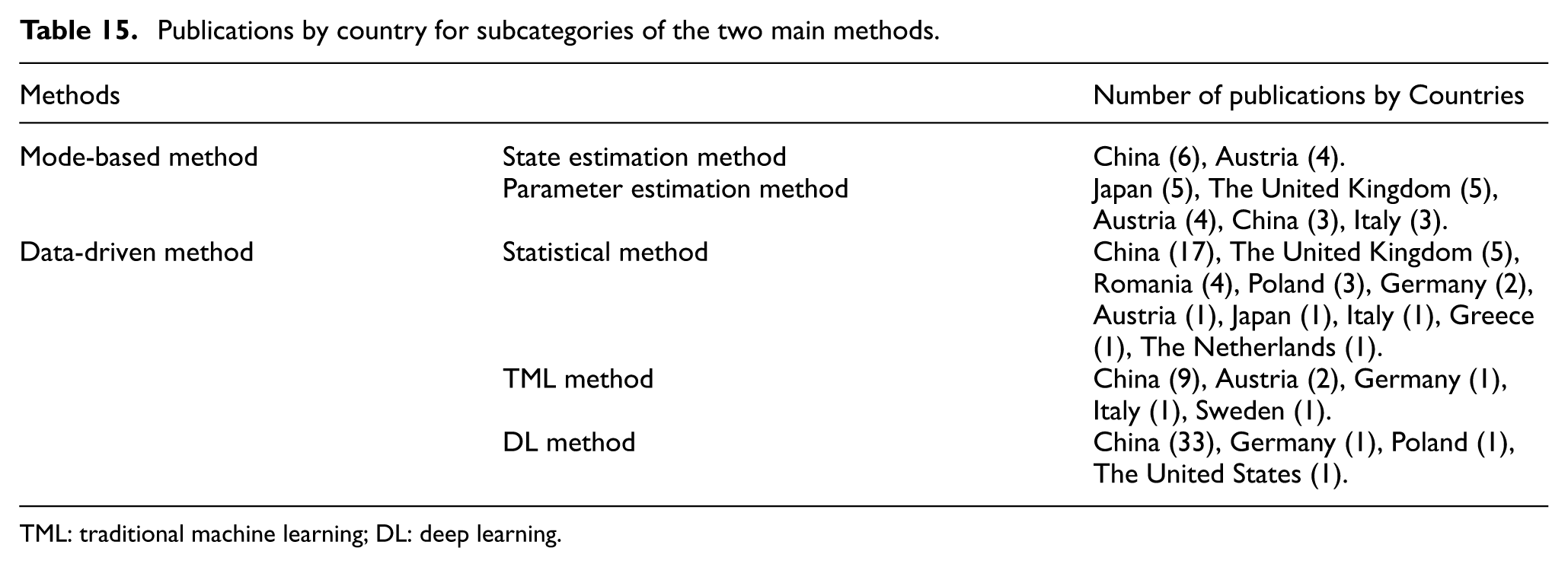
TML: traditional machine learning; DL: deep learning.
Chinese research institutions rank among the global leaders in the number of published academic papers in the field of suspension system fault diagnosis. This prominence stems from the rapid advancement of Chinese railway technology and the vast application scenarios provided by large-scale network construction, supported by a growing pool of research talent and refined scientific innovation incentive mechanisms. In terms of technological approaches, early research activity was concentrated on model-based methods, influenced by their initial technical maturity. However, coinciding with the explosive growth of AI in recent years, data-driven methods have emerged as a research hotspot for domestic scholars. This is attributed to their capability to efficiently process the massive real-time data generated by the high-speed rail network and effectively extract system state features under complex operational environments, resulting in a significant surge in related publications.
In the Asian region, Japan demonstrates the most profound research engagement in rail vehicle suspension fault diagnosis, second only to China. In Europe, nations such as Austria, the United Kingdom, and Italy have a long-standing commitment to this domain, evidenced by a substantial body of published academic literature that reflects Europe’s continuous investment in railway technology development.
Cross-paradigm performance assessment and synthesis
This section aims to move beyond a merely descriptive account of individual algorithms by providing a cross-paradigm synthesis of model-based and data-driven methods for rail vehicle suspension fault diagnosis. The analysis is conducted across multiple key perspectives, including technical essence, evolutionary drivers, and multidimensional performance comparison.
Technical essence and evolutionary drivers
Model-based and data-driven methods represent two fundamentally distinct diagnostic logics, and their evolutionary drivers differ significantly.
Model-based methods: The technical essence lies in leveraging analytical redundancy as a surrogate for hardware redundancy, with an evolutionary trajectory reflecting a transition from linear simplification toward addressing strong nonlinearity and system uncertainty. Tracing its application history in rail vehicle suspension fault diagnosis, these methods emerged around 2005 (see Figures 4 and 5), during which early research frequently employed RBPF for parameter identification alongside classical KF for state estimation in linear systems. With escalating requirements for the nonlinear modeling of rail vehicles, the EKF was introduced to the field around 2010 to manage local nonlinearities through Taylor series expansions. Post-2015, advanced variants such as the UKF and CKF were adopted to mitigate linearization errors and enhance filtering stability in high-dimensional spaces. In recent years, SM-based methods and RLS methods have received increasing attention to promote onboard online detection, primarily due to their low computational cost and simple parameter tuning. This evolutionary process reveals an intrinsic technological pattern whereby model-based algorithms continuously adapt to the strong nonlinear dynamic characteristics and complex environmental uncertainties of rail vehicle suspension through the iterative refinement of mathematical architectures to compensate for the limitations of physical modeling, thereby achieving precise perception and identification of fault states in complex suspension dynamical systems.
Data-driven methods: The technical essence lies in uncovering latent mapping patterns within massive multisource datasets to circumvent the complexities of physical modeling, with an evolutionary trajectory reflecting a transition from manual feature engineering toward automated and high-dimensional representation learning. Tracing its application history in rail vehicle suspension fault diagnosis, these methods gained momentum around 2010 (see Figures 10, 17, and 22), when initial research focused primarily on traditional multivariate statistical methods (e.g., PCA and CVA) as well as TML (e.g., SVM). Since 2015, the field has experienced a significant shift toward DL architectures (e.g., CNN), which effectively automate the feature extraction process and enable the construction of end-to-end diagnostic pipelines. Post-2020, the demand for modeling complex spatial-temporal correlations and addressing data scarcity has prompted researchers to adopt GNN for multi-sensor topological modeling. This evolutionary process reveals an intrinsic technological pattern where data-driven algorithms continuously evolve from shallow statistical inference toward deep hierarchical perception. By leveraging advanced sensing technologies, these methods effectively bridge the gap between high-dimensional raw data and precise fault identification in complex rail vehicle systems.
From physical models to data intelligence: The evolutionary trajectory from model-based methods to data intelligence reveals a fundamental shift in the management of uncertainty within complex systems. Initially, the model-based methods prioritized the rigor of physical logic. However, with the escalation of train speeds and system complexity, traditional simplified linear models struggled to capture nonlinear and nonstationary dynamic behaviors. As sensor technology advanced, the focus of research transitioned toward data-driven methods. Although data-driven approaches provided robust tools for feature representation, they introduced novel challenges concerning decision transparency and physical consistency. The contemporary shift toward data intelligence represents a fusion stage that effectively reconciles the disparity between theoretical abstraction and empirical data through the profound integration of mechanistic laws and DL architectures. This evolution is not a mere replacement of technologies but rather a synergistic advancement intended to achieve an optimal equilibrium between interpretability and adaptability in railway operations.
Cross-paradigm performance comparison
To provide a more intuitive illustration of the inherent trade-offs, Table 16 provides a comprehensive comparative analysis of model-based and data-driven methods within the specific context of rail vehicle suspension fault diagnosis.
Cross-paradigm performance for suspension fault diagnosis.
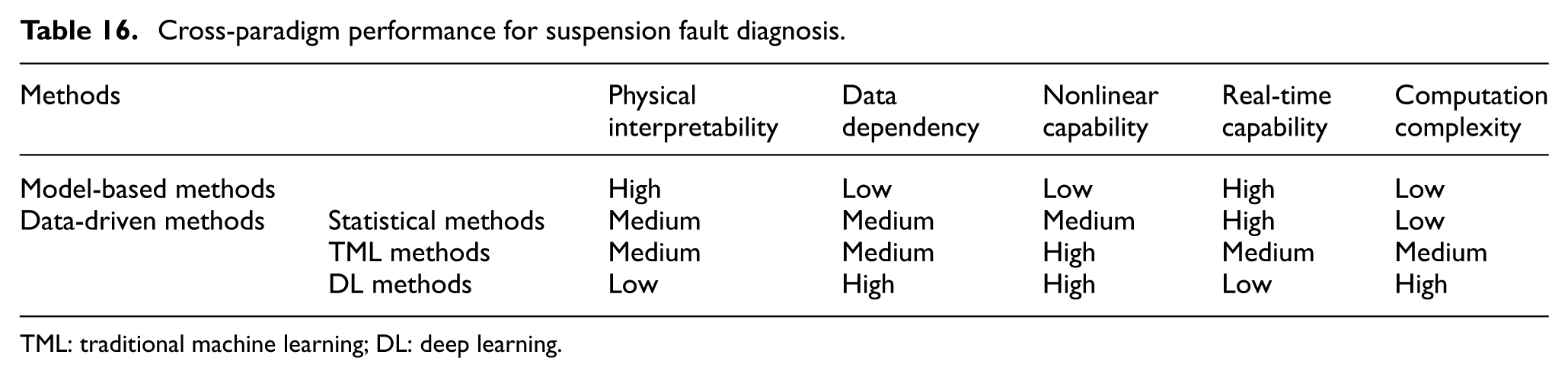
TML: traditional machine learning; DL: deep learning.
General characteristics and development trends of the two paradigms
Model-based and data-driven methods offer two distinct yet complementary technical paradigms for suspension system fault diagnosis. Their general characteristics and development trends are summarized as follows.
General characteristics and development trends of model-based methods
The core advantage of model-based methods lies in their strong theoretical foundation and inherent interpretability, as the diagnosis is rooted in the system’s physical mechanism model. This enables deep insight into system dynamic behavior and targeted analysis of specific faults. However, constructing high-fidelity mathematical models is typically a complex and high-cost process, and diagnostic performance is susceptible to degradation when the system exhibits strong nonlinearities or time-varying parameters. Future research should focus on developing simplified high-precision models that preserve mechanistic integrity while adapting to practical operational constraints to balance computational efficiency and diagnostic accuracy. Meanwhile, the active exploration of deep fusion approaches with data-driven methods, which use mechanistic knowledge to guide data learning and achieve complementary advantages, has emerged as a prevailing research trend. Furthermore, enhancing the online adaptive updating and parameter identification capabilities of models to track the progressive performance degradation of suspension components in real time constitutes another critical evolutionary direction.
General characteristics and development trends of data-driven methods
Data-driven methods facilitate fault diagnosis by extracting features directly from operational data, bypassing complex physical modeling. While they excel at handling nonlinear systems and discovering new fault modes, these methods remain constrained by their dependency on large-scale labeled datasets and the black-box nature of DL. This lack of interpretability limits their adoption in rail transit. Adhering to the technical evolution of DL is essential for constructing a comprehensive intelligent maintenance framework and overcoming the deficiencies of data-driven methods. An analysis of the recent trends in DL is presented below, including self-supervised learning, 130 foundation models, 131 physics-informed learning, 132 and structured representation learning133–136:
(1) Self-supervised learning provides a novel approach for mitigating the scarcity of labeled data in rail vehicle suspension systems by designing pretext tasks to extract intrinsic structural features directly from massive, unlabeled raw vibration signals. Using the time–frequency dual-domain contrast and fusion strategy 130 as an example, this method uses dual-domain encoders to learn temporal and spectral evolutionary characteristics under complex nonlinear operating conditions during pretraining, which enables the capture of critical feature signals without the need for manual annotation. Subsequently, the model is fine-tuned using a limited number of labeled samples to achieve the precise identification of fault patterns. This approach can resolve the imbalance between voluminous unlabeled data and scarce labeled samples encountered during the long-term service of rail vehicles.
(2) Foundation models, represented by a large language model, 131 are leading a shift in fault diagnosis toward multimodal semantic reasoning. This method can employ modal alignment technology to facilitate cross-modal mapping between complex sensor signals from suspension systems and external information such as fault descriptions, operating conditions, and maintenance logs within knowledge bases. To address the challenge of highly aliased vibration signal features in suspension systems, the approach introduces fuzzy semantic embedding while leveraging the logical reasoning capabilities of large models to overcome the limitations of DL, including low transparency. This method enables the diagnostic system to evolve from a simple classifier into an explainable intelligent assistant capable of synthesizing specific operating conditions to generate diagnostic reports and maintenance recommendations.
(3) The core mechanism of physics-informed learning lies in the construction of specialized loss functions during the training process to penalize nonphysical solutions that violate fundamental physical laws. By leveraging automatic differentiation, neural networks are constrained to strictly adhere to the underlying governing dynamics. 132 This approach integrates physical prior knowledge, such as the multibody dynamics equations of rail vehicle suspension systems, directly into DL architectures. Consequently, it effectively addresses the issues of physical distortion and weak generalization prevalent in purely data-driven methods. By bridging the gap between mechanistic principles and real-world operational data, this method provides a diagnostic methodology characterized by physical consistency and deterministic reliability.
(4) In the transition of DL from automated feature extraction toward interpretable structured representation, the CapsNet provides a new trajectory for the reliable monitoring of rail vehicle suspension systems through its vector representation mechanism. Specifically, the deep adversarial CapsNet 133 aligns multidomain distributions via adversarial training, which enhances the model’s cross-condition generalization robustness under varying train operating speeds and loads. The sensor-aware CapsNet 134 uses attention mechanisms to achieve weighted fusion and reliability assessment of multisource information from the suspension system, thereby increasing the confidence levels of diagnostic results. The wavelet CapsNet 135 integrates the physical characteristics of wavelet transforms with the structured representation of capsules to provide a physically meaningful and interpretable basis for the decoupling of composite faults and the identification of weak signatures in suspension systems.
Discussion and outlook
Despite remarkable strides in the theoretical research and application exploration of rail vehicle suspension fault diagnosis technologies, there remain prominent problems that hinder their full-scale engineering adoption and performance optimization. These challenges span from the intrinsic limitations of diagnostic methodologies to the practical barriers in translating lab-based research into real-world rail operations. Below are an in-depth analysis of the key challenges and a forward-looking outlook on future research priorities.
Key challenges in current research and application
(1) Insufficient synergy between model-based and data-driven paradigms: Model-based and data-driven methods each have irreplaceable strengths but also inherent shortcomings that are difficult to overcome in isolation. Model-based methods possess a solid physical foundation and robust interpretability, but they exhibit suboptimal performance when addressing the strong nonlinear characteristics of suspension systems. For instance, EKF methods are highly susceptible to linearization errors or even filter divergence when estimating nonlinear damper parameters because they rely on Taylor series expansions for linearization. 30 In practical engineering, uncertainties, including varying vehicle loads and track irregularities, render the construction of high-fidelity physical models prohibitively complex and costly, while these models also struggle to adapt in real-time to the gradual performance degradation of suspension components. Data-driven methods, exemplified by DL, have demonstrated exceptional precision in complex pattern recognition.103,107 Nevertheless, these algorithms are frequently characterized as black boxes due to the lack of physical interpretability in their decision-making logic, which raises significant deployment concerns within the safety-critical rail transportation sector. Moreover, data-driven methods rely heavily on annotated datasets, yet acquiring labeled fault samples remains a formidable challenge in actual rail operations. Currently, a limited number of studies have attempted to bridge these paradigmatic divides. For instance, the digital twin-based framework (see Figure 31) 119 establishes a bridge for real-time interaction between physical and digital spaces. This system uses a mechanistic model for preliminary signal processing and feature extraction alongside multilayer CNNs for deep feature learning, thereby achieving an integration of mechanistic analysis and data-driven techniques. However, the majority of existing research merely employs physical models to generate training data 122 or uses data-driven algorithms to optimize model parameters, which means that genuine deep-level fusion mechanisms remain critically scarce.
(2) Low sensitivity and slow response to incipient and abrupt faults: Incipient faults (e.g., gradual degradation of spring stiffness or damper damping) are characterized by weak and noise-masked features. Although the ToMFIR method 75 has been demonstrated to detect a 15% attenuation in stiffness or damping coefficients, the minor fault features of the suspension system are frequently obscured by noise interference, such as track irregularities, which lead to low detection rates for existing diagnostic methods during the incipient stages of fault. For instance, the multivariate statistical methods, including PCA and CVA, are susceptible to detection faults when addressing minor suspension faults. 62 Abrupt faults (e.g., sudden air spring rupture or damper mount detachment) evolve rapidly and require real-time detection and early warning to avoid safety risks. Although the SM-based algorithm41,42 demonstrates exceptionally high detection sensitivity and estimation accuracy when abrupt faults occur to fulfill the requirements of real-time on-board early warning, their primary disadvantage is a relatively slow convergence speed reaching only approximately 60% of that achieved by KF. This limitation indicates that the SM-based method exhibits a delayed response when detecting abrupt faults. Similarly, while the RBPF strategy 37 facilitates the simultaneous identification of abrupt faults and parameter degradation, the massive consumption of computational resources caused by high particle counts significantly undermines the real-time early warning capability during high-speed train operations. Current diagnostic techniques often cannot balance sensitivity and timeliness: methods optimized for incipient fault detection lack the precision to identify weak fault signals, while real-time monitoring methods tend to have high computational latency. This leads to either missed detection of early faults or delayed response to abrupt faults, posing significant threats to rail vehicle operational safety.
(3) Difficulties in translating theoretical research to engineering practice: Most diagnostic algorithms are validated only in simulated environments (e.g., multibody dynamics models or lab test rigs),106–109,111,112,120 with few being successfully deployed in actual rail operations. Currently, the key obstacle in translating theoretical research into engineering practice lies in the absence of a quantitative correlation between fault features, failure severity, and operational safety: there are no clear, industry-recognized fault thresholds or maintenance criteria tailored to different vehicle types, track conditions, and operational loads. Despite this, a few successful industrial deployments have been realized: Siemens deployed a two-stage fault diagnosis system (see Figure 20) for bogie suspensions, integrating machine learning and Bayesian network inference, on Siemens commuter trains to monitor the condition of the suspension systems. 88 During five months of operation, the system identified a high fault probability (80–90%) for the yaw damper. Subsequent disassembly confirmed that the cause was loosened valve screws on the piston. These internal faults are undetectable through conventional visual inspections and not captured by EN 14363 instability criteria (see Figure 37). This instance underscores the practical engineering value of data-driven diagnostics in preventing faults and reducing maintenance expenditures.
(4) Gap between macrolevel operational indicators and microlevel health status: The representative criteria currently applied to rail vehicle fault evaluation are summarized in Table 17. As synthesized in Table 17, the fault evaluation frameworks widely adopted in the current railway industry are primarily grounded in threshold-based criteria for dynamic responses, focusing on ensuring that the vehicle operates within established safety and comfort boundaries. However, a critical gap exists between these macrolevel operational indicators and the microlevel health status of suspension components. Specifically, current standards can identify that a safety limit has been breached, but they struggle to quantify the specific degree of physical degradation that led to the anomaly. This approach limits the ability of maintenance personnel to implement proactive interventions before a minor fault escalates into a safety risk, as demonstrated in the study by Girstmair and Moshammer, 88 the EN 14363 instability criteria fail to detect subtle anomalies such as loosened valve screws on the piston in the yaw damper, whereby the fault remains below the threshold of conventional stability metrics.
(5) Systemic vulnerabilities regarding dataset bias, label quality, and domain shift in data-driven methods: DL, as the mainstream data-driven method, relies on large-scale, high-quality labeled datasets to optimize high-dimensional nonlinear features. However, in practical rail operations, systemic vulnerabilities regarding data quality significantly hinder the generalization and deployment of these models. 1) Small sample constraints and label scarcity: In real rail operations, collecting labeled fault data is extremely difficult due to safety constraints and the low incidence of suspension faults; small-sample, weakly labeled, or even unlabeled data scenarios are common. The diagnostic accuracy of the conventional data-driven methods suffers a substantial decrease when the volume of available data diminishes. 121 2) Dataset bias and label ambiguity: Most diagnostic models are trained on simulation data or specific line records, which often fail to encapsulate the stochastic track irregularities and complex environmental excitations of diverse operational networks. Furthermore, the issue of label quality is frequently overlooked; sensor noise or overlapping fault signatures can lead to ambiguous labels, causing the model to learn noise rather than the underlying physics of the fault. 3) Domain shift and generalization failure: Rail vehicles operate under highly dynamic conditions, including varying speeds, load levels, and diverse track geometries. These variations cause a distribution shift in the vibration signals. Conventional DL methods often fail in these scenarios because the features learned under one operating condition may not generalize to another. The lack of a critical treatment of this domain shift can lead to false negatives. To mitigate these systemic vulnerabilities, recent research has pivoted toward advanced methods such as small sample learning and transfer learning. These strategies focus on enhancing model robustness and cross-domain adaptation without requiring extensive labeled datasets for every new operational scenario. The current small sample learning and transfer learning methods applied to rail vehicle suspension fault diagnosis are summarized in Table 18.
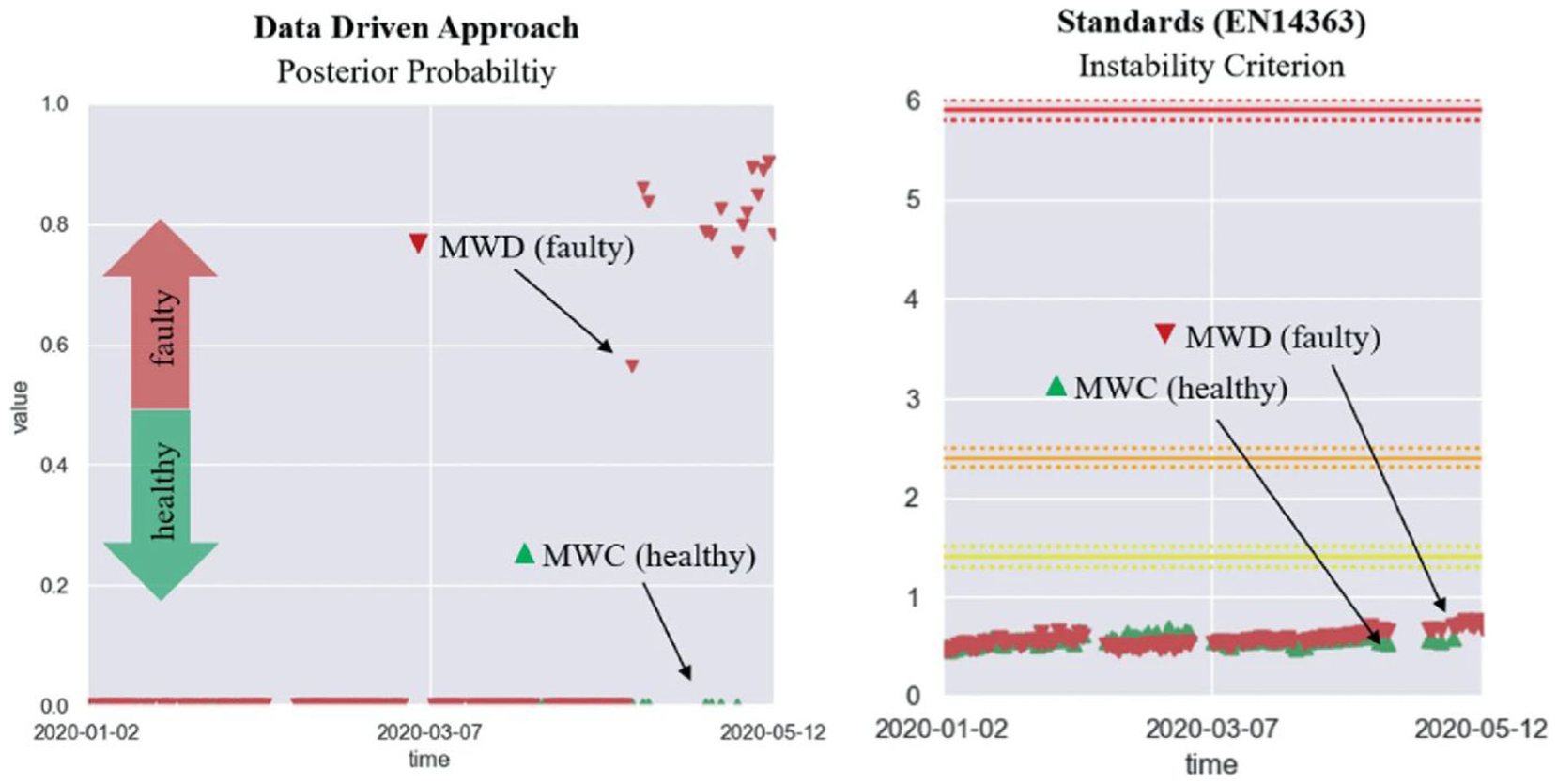
Performance comparison of two fault detection methods deployed on Siemens commuter train in the study by Girstmair and Moshammer. 88
The current criteria applied to rail vehicle fault evaluation and maintenance.
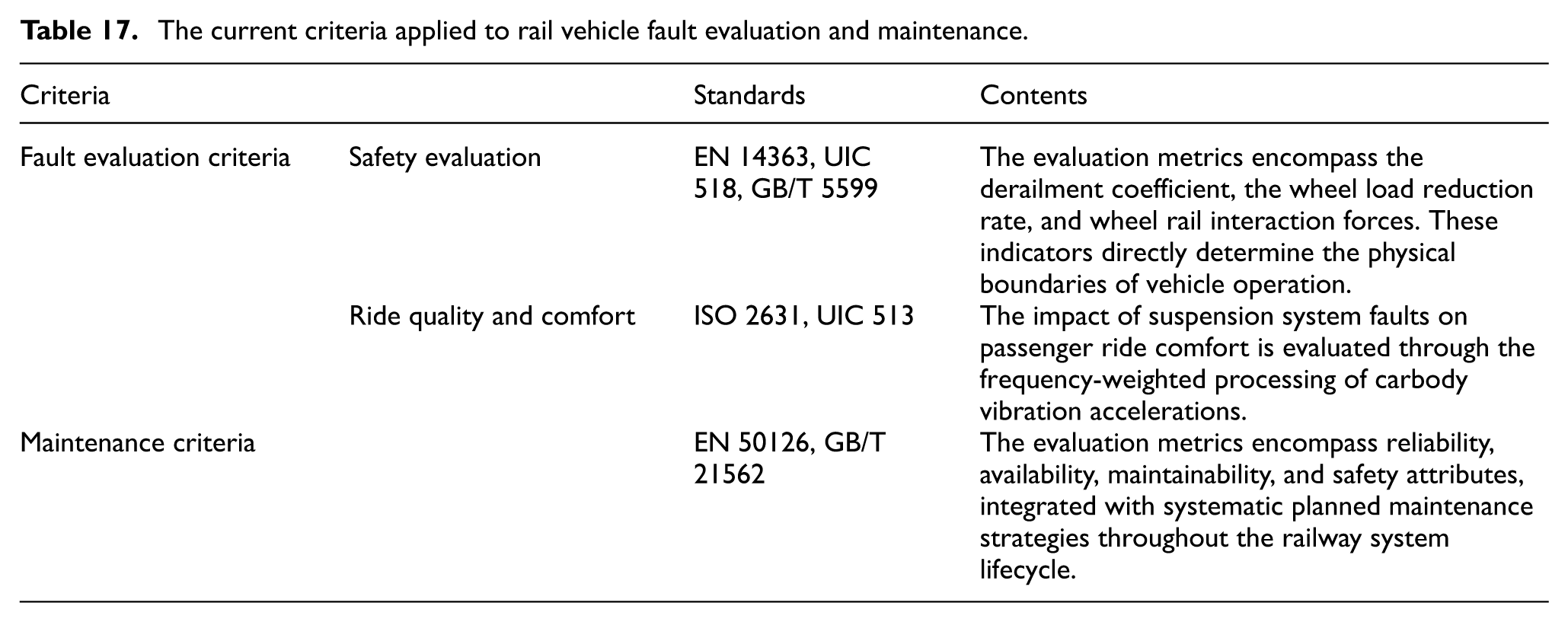
Structured comparison of small sample and transfer learning solutions.
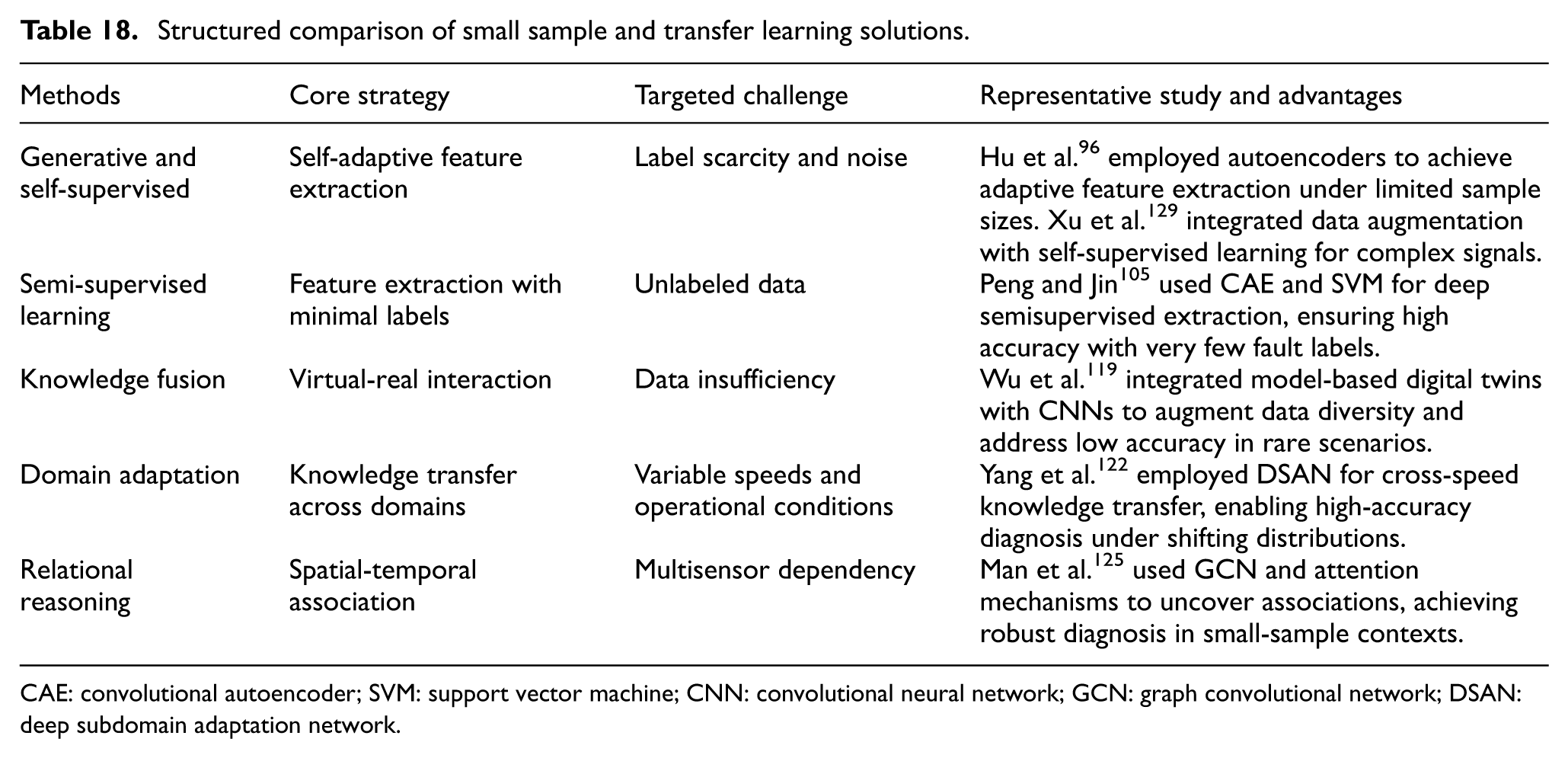
CAE: convolutional autoencoder; SVM: support vector machine; CNN: convolutional neural network; GCN: graph convolutional network; DSAN: deep subdomain adaptation network.
Future research directions
(1) Deep fusion of model-based and data-driven diagnostic strategies: Future research should prioritize the structural and functional integration of mechanistic principles within data-driven architectures to transcend the limitations of superficial model and data combinations. Instead of merely using physical models for data augmentation or parameter estimation, research efforts must be directed toward embedding differential equations and physical constraints directly into the loss functions or internal topologies of neural networks, a concept exemplified by the framework of physics-informed neural networks. 132 This paradigm shift ensures that the learning process is strictly governed by the underlying dynamics of suspension systems, thereby guaranteeing physical consistency and enhancing the extrapolation capability of models in extreme or unseen operating scenarios. By establishing a symbiotic relationship where physical knowledge constrains the feature extraction and decision-making layers, such as through the virtual–real interaction mechanisms found in digital twin frameworks, 119 diagnostic systems can achieve a superior balance between the rigorous interpretability of mechanistic models and the robust representation power of DL.
(2) High-sensitivity and real-time fault detection algorithms: Future research should prioritize the advancement of signal processing and computational architectures to achieve superior detection sensitivity and minimal processing latency. This objective necessitates the development of adaptive time–frequency analysis techniques, such as variational mode decomposition and multiscale entropy analysis, to effectively decouple subtle incipient fault signatures from high-intensity operational noise. To facilitate practical onboard deployment, the optimization of lightweight DL models through techniques such as model pruning or knowledge distillation is required to ensure the instantaneous identification of abrupt faults while significantly reducing computational overhead. Furthermore, the integration of prognostic algorithms with real-time detection frameworks is essential to forecast fault evolution trends based on identified incipient anomalies. This transition from reactive detection to proactive trend estimation provides a critical foundation for predictive maintenance strategies by leveraging health indicators to estimate the remaining useful life (RUL) of suspension components. 137 Such a comprehensive framework can substantially reduce unplanned downtime and enhance the overall reliability of rail vehicle suspension systems during long-term service.
(3) Enhancing reliability prediction and uncertainty quantification: The safety-critical nature of rail vehicle suspension systems necessitates that predictive models provide not only precise point estimates but also the capability to quantify predictive uncertainty. Traditional DL models are prone to introducing risks into practical engineering decision-making if they lack metrics for assessing the confidence of outcomes when subjected to sensor noise or operational fluctuations. Consequently, uncertainty quantification has emerged as a pivotal research direction for enhancing the transparency and reliability of diagnostic and prognostic systems. Among various methods, reliable RUL estimation inspired by conformal prediction demonstrates significant advantages. Unlike traditional heuristic uncertainty estimation approaches, the conformal prediction framework generates prediction intervals with rigorous statistical validity for underlying algorithms under minimal assumptions.138,139 By applying this technique to the predictive maintenance of key suspension components, models can yield confidence intervals that encompass the true lifespan while providing mathematically rigorous reliability guarantees for the results. Such uncertainty aware prediction mechanisms are essential for establishing trust in AI decision-making within rail operation environments, effectively mitigating risks associated with predictive biases.
(4) Establishment of engineering-oriented fault evaluation and maintenance criteria: To bridge this gap between macrolevel operational indicators and the microlevel health status of suspension components and accelerate the industrial application of fault diagnosis technologies, future research should shift its primary focus from solitary algorithm development toward the construction of systematic engineering evaluation standards. Specifically, large-scale field tests should be conducted to quantify the impact of varying fault severities on vehicle dynamic responses and operational safety, which will facilitate the establishment of a quantitative mapping system between fault features and safety risk indicators. Building upon this, tiered fault severity standards and differentiated maintenance strategies tailored to diverse vehicle types, including high-speed train sets, subways, and heavy haul freight, should be developed to achieve an optimal balance between safety redundancy requirements and life cycle maintenance costs. Furthermore, promoting the standardization and certification of diagnostic algorithms is essential for transitioning from traditional preventive maintenance to advanced condition-based maintenance.
(5) Advanced AI techniques for small-sample and weakly labeled scenarios: Future research should be dedicated to establishing multidimensional and data-efficient diagnostic methods that systematically diminish the reliance of diagnostic models on high-quality fault labels through the extensive application of small-sample learning, self-supervised/unsupervised learning, and transfer learning. Specifically, transfer learning should be used to facilitate the effective migration of knowledge from simulated environments or data-rich rail lines to data-scarce scenarios. Furthermore, the integration of federated learning frameworks121,128 is essential to enable cross-platform collaborative model training while safeguarding the data privacy of individual operators, thereby simultaneously addressing the dual challenges of data silos and sample scarcity. In addition, diagnostic systems should evolve toward architectures featuring online adaptive and incremental learning capabilities to allow for continuous optimization based on real-time operational data, ensuring sustained and robust diagnostic performance under real-world small-sample conditions.
Conclusions
Rail vehicle suspension systems, as core components affecting operational safety and comfort, have attracted extensive attention in fault diagnosis research. This article comprehensively reviews the two major technical paradigms of model-based and data-driven fault diagnosis methods, and summarizes their core principles, application effects, and development trends through in-depth analysis and comparison, leading to the following key conclusions:
In terms of model-based methods, which have a relatively mature development foundation, they are mainly divided into state estimation and parameter estimation. State estimation methods represented by the classical KF and EKF have the advantages of high computational efficiency and suitability for online diagnosis. However, the classical KF is limited to linear systems, while the EKF is prone to linearization errors under strong nonlinear conditions. Parameter estimation methods, including RBPF, RLS, and SM-based methods, are more advantageous in fault isolation. For example, the CKF has high accuracy in diagnosing slowly varying faults, and the RLS method is suitable for real-time online monitoring due to its low computational cost. Nevertheless, model-based methods generally have strict requirements on the accuracy of mathematical models, resulting in insufficient adaptability when facing complex and variable operational environments such as track irregularities and time-varying system parameters.
Data-driven methods have become the current research focus with the advancement of AI technology. Statistical methods, characterized by simple implementation and low cost, apply to online monitoring but are sensitive to sensor placement and system symmetry. TML methods such as SVM show excellent generalization ability in small-sample scenarios, but their performance is highly dependent on manual feature extraction. DL methods, including CNN, LSTM, and GNN, realize automatic extraction of high-dimensional nonlinear features from raw data, significantly improving diagnostic accuracy. Especially in handling compound faults and unknown faults, they demonstrate unique advantages. However, data-driven methods are plagued by problems such as excessive reliance on high-quality labeled data, poor interpretability of black-box models, and high computational resource consumption, which restrict their large-scale engineering application.
Looking ahead, the development of rail vehicle suspension fault diagnosis technology will focus on breaking through existing problems and realizing the organic integration of precision, intelligence, and practicality. The key research directions include five aspects: first, promoting the deep fusion of model-based and data-driven methods to achieve complementary advantages in physical interpretability and environmental adaptability; second, developing high-sensitivity and real-time fault detection algorithms to effectively identify incipient and abrupt faults; third, enhancing reliability prediction and uncertainty quantification to provide statistically valid confidence intervals for diagnostic results, thereby establishing trust in AI decision-making within safety sensitive environments; fourth, establishing engineering-oriented fault evaluation criteria and maintenance strategies to bridge the gap between theoretical research and practical application; fifth, exploring advanced AI technologies such as few-shot learning and federated learning to solve the problem of insufficient labeled data in practical scenarios. Through the cross-integration of multiple disciplines and technologies, suspension fault diagnosis technology will provide more reliable technical support for the safe, efficient, and economical operation of rail transportation in the future.
Footnotes
Author contributions
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China (grant nos U2468227, 52388102, and U2268211), the Natural Science Foundation of Sichuan Province (grant nos 2026NSFSC0288 and 2025ZNSFSC0398), and the Science and Technology Research and Development Program Topics of China State Railway Group Co., Ltd (grant no. N2024J038).
Data availability Statement
Data will be made available on request.