
Abstract
To address the challenges posed by the limited generalization of diagnostic models due to data sparsity in RV reducers, the lack of targeted multimodal fusion strategies, and complex operating conditions, this paper proposes a novel fault diagnosis method based on an enhanced generative adversarial network (GAN) and dual-branch multimodal data fusion. First, an Rotate Vector (RV) reducer fault test bench was established to acquire vibration and current signals. Subsequently, a Wasserstein GAN-residual and attention guidance network, incorporating double-layer residual connections and a multihead self-attention mechanism, was employed for multimodal data augmentation. This approach significantly improves the quality and diversity of generated samples, effectively mitigating data scarcity while ensuring stable training via Wasserstein distance and gradient penalty techniques. The augmented data were then transformed into time-frequency representations using the short-time Fourier transform. Finally, leveraging the global representativeness of vibration signals and the sensitivity of current signals to localized disturbances, an Self-Calibrated Convolution and Vision Transformer Fusion Network for Dual-Modality Classification (SCViT) dual-branch model was developed. This model achieves comprehensive fault diagnosis through multimodal feature fusion. Experimental results demonstrate that the proposed method exhibits superior diagnostic performance under three operating conditions, with diagnostic accuracies of 97.40, 97.83, and 96.54%, respectively. Compared with single-modality diagnosis, the method achieves an average improvement of 3.8 percentage points in diagnostic accuracy. The proposed method maintains high stability and accuracy under loaded conditions and reciprocating motions, providing novel insights for the intelligent maintenance of RV reducers.
Introduction
As a fundamental transmission component in high-precision machinery such as industrial robots and Computer Numerical Control (CNC) machine tools, the Rotate Vector (RV) reducer occupies a pivotal position in intelligent manufacturing owing to its superior transmission efficiency, prolonged service life, and excellent dynamic performance.1–6 Nonetheless, under complex operating conditions, RV reducers subjected to sustained high loads are susceptible to critical failures such as cycloidal gear wear and planetary gear train malfunctions,7–9 thereby compromising equipment safety and production efficiency. With the ongoing advancement of intelligent manufacturing and Industry 4.0, the necessity for efficient and intelligent predictive maintenance and health monitoring technologies for RV reducers has become increasingly imperative.10,11
Data-driven fault diagnosis methods automatically extract fault features through the analysis of extensive operational data, thereby overcoming the inherent limitations of traditional model-based approaches and exhibiting substantial potential in the health monitoring of industrial equipment.12,13 However, in practical industrial applications, fault diagnosis for RV reducers encounters three principal challenges: limited small-sample data resulting in constrained model generalization capabilities, inefficiencies in multisource data fusion, and difficulties in accurately characterizing complex operating conditions. These challenges markedly hinder the effective deployment of intelligent diagnostic technologies.
In practical industrial environments, the acquisition of equipment failure data is both challenging and resource-intensive, rendering the small-sample problem a critical bottleneck that impedes the broad implementation of intelligent diagnostic technologies. Generative adversarial networks (GANs) have attracted considerable interest owing to their powerful data generation capabilities. Nonetheless, existing GAN architectures exhibit limitations related to data quality and training stability. These limitations include challenges in capturing subtle feature variations within fault signals, 14 inadequate compensation for information loss during signal transformation, 15 absence of effective mechanisms to identify and preserve essential feature information, 16 as well as common issues such as training instability and gradient vanishing. Collectively, these challenges substantially restrict the quality and diversity of the generated data. Hu et al. 17 proposed PCASTNet, a physics-constrained adaptive style transfer network, which decouples fault content and machine style via wavelet transform and AdaSN module, and ensures physical consistency of generated samples through band energy constraint, effectively mitigating the drawbacks of traditional GANs. Similarly, Huang et al. 18 proposed a simulation-to-real transformation framework for aeroengine dual-rotor systems, integrating asymmetric Gaussian chirplet model (AGCM)-based feature enhancement and adaptive multiscale style transfer network (AMSTN) to align simulation-real data distributions while preserving fault semantics, achieving excellent small-sample diagnostic performance.
Under variable load and reciprocating operating conditions, RV reducers exhibit fault characteristics characterized by pronounced nonlinearity and time-varying behavior, which pose significant challenges for traditional feature extraction methods in accurately characterizing such complex operating states. Multisource data fusion technology substantially improves fault diagnosis accuracy and reliability by integrating signals acquired from heterogeneous sensors. Nonetheless, current fusion techniques remain constrained when handling multimodal data, manifesting as insufficient refinement in feature engineering and fusion strategies, 19 inadequate consideration of the intrinsic characteristics of multimodal data, 20 and a lack of specialized designs tailored to the distinct properties of different modalities. Xia et al. 21 proposed a multisource data fusion approach based on hierarchical attention mechanisms; however, the limited diversity of fault samples in their study restricts the model’s generalization capability and diagnostic accuracy when confronted with unknown or heterogeneous faults. Peng et al. 22 achieved multidomain feature integration via deep residual networks combined with a fusion embedding layer; yet, their hierarchical fusion strategy did not effectively consolidate features across multiple abstraction levels. Moreover, prevailing deep learning methodologies predominantly utilize single-network architectures, which hampers the simultaneous extraction of both global and local features,23,24 often leading to the omission of critical nonlinear feature information under complex operating conditions. 25 In addition, there remains a paucity of systematic analysis concerning performance variations across different modalities under complex scenarios, resulting in suboptimal adaptability of feature extraction strategies.
Vibration signals, because of their direct interaction with mechanical structures, rich informational content, stability, capability to reflect multiple fault types, and independence from operating conditions, provide a comprehensive representation of the system’s overall macroscopic dynamic response and mechanical integrity.26,27 Accordingly, they serve as an optimal global feature source for fault diagnosis. Conversely, current signals demonstrate heightened sensitivity to transient variations in mechanical load. Localized faults generate periodic torque oscillations transmitted through the drive shaft to the motor, inducing fluctuations in rotational speed and electromagnetic parameters. The modulation depth of amplitude and frequency within the current signal exhibits a linear correlation with the severity of the fault impact. 28 Therefore, current signals more precisely capture the dynamic characteristics associated with localized faults. Based on these complementary attributes, this study employs vibration and current signals as the primary input modalities for multimodal fault diagnosis.
In summary, current research on fault diagnosis of RV reducers continues to face several critical technical challenges: (1) the absence of high-quality data generation methods to address small-sample issues; existing GAN architectures demonstrate limitations in capturing detailed signal features and ensuring stable training; (2) insufficient efficacy of multimodal information fusion strategies, with existing methods inadequately accounting for the intrinsic differences in signal characteristics across modalities when integrating multisource data such as vibration and current signals. Moreover, these fusion strategies lack specificity and fail to effectively consolidate complementary information; (3) constrained feature representation capabilities under complex operating conditions, where existing approaches struggle to concurrently extract both global and local features and lack hierarchical fusion mechanisms.
To address the aforementioned challenges, this paper proposes a fault diagnosis method for RV reducers based on an improved GAN and a dual-branch fusion framework for multimodal data. The key contributions are summarized as follows:
Enhanced GAN architecture: The proposed architecture significantly improves the extraction of detailed features from vibration signals and effectively mitigates the vanishing gradient problem, thereby enhancing training stability and the quality of generated data.
Efficient multimodal data fusion strategy: A dual-branch fault diagnosis model is developed, integrating self-calibrating convolutional (SCConv) neural networks and Vision Transformers (ViTs) to achieve effective fusion of multilevel features.
Feature representation under complex operating conditions: The generated one-dimensional signals are transformed into two-dimensional time-frequency images, preserving both temporal and spectral information. Furthermore, differentiated feature extraction strategies for vibration and current signals are employed to enhance the robustness and accuracy of the diagnostic model under complex scenarios such as variable loads and reciprocating motions.
The remainder of this paper is organized as follows: the second section presents the relevant theoretical foundations; the third section describes the experimental data utilized; the fourth section details the experimental validation; and the final section provides a summary of the conclusions.
Theoretical foundation
Generative adversarial network
GAN, introduced by Goodfellow et al.,
29
constitute a robust deep learning framework for synthetic data generation. The fundamental mechanism of GAN is characterized by a dynamic adversarial learning process involving two neural networks: a generator (G) and a discriminator (D), which engage in a competitive yet collaborative training paradigm. The generator aims to produce samples that closely resemble real data to deceive the discriminator, whereas the discriminator endeavors to accurately differentiate between real and generated samples. Through this adversarial interplay, GAN progressively improves the quality of generated data, ultimately approximating the true data distribution with high fidelity. Specifically, the generator G accepts a random noise vector z as input, mapping it through nonlinear transformations to the target data space to generate a synthetic sample G(z). The discriminator D functions as a binary classifier, tasked with accurately distinguishing real samples x from generated samples G(z). It outputs probability values D(x) or
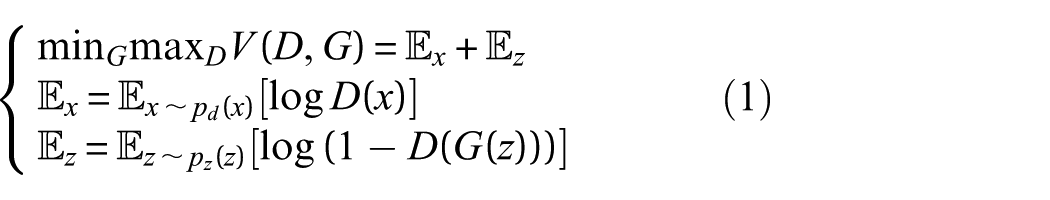
where
During the practical training process, the discriminator and generator are alternately optimized. Through this adversarial learning mechanism, the generator progressively learns to produce samples that are difficult to distinguish from real fault signals, thereby enhancing the model’s capability to understand various fault patterns. In the context of fault diagnosis for RV reducers, GANs can effectively mitigate data imbalance issues and improve the recognition accuracy of rare fault types.
Wasserstein distance and GP
The Wasserstein distance, also referred to as the earth Mover’s distance (EMD), quantifies the minimal “cost” required to transform one probability distribution into another. Employing the Wasserstein distance in lieu of the Jensen–Shannon divergence to assess the distributional discrepancy between real and generated samples has been demonstrated to substantially enhance the training stability of GANs, 30 Mathematically, the Wasserstein distance is defined as:
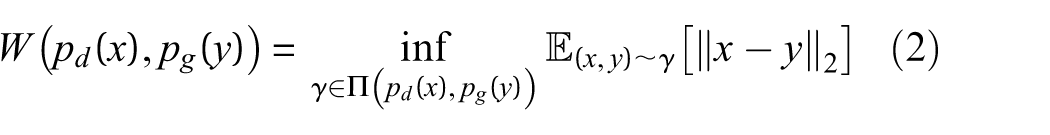
where
Then, the loss function of the Wasserstein GAN (WGAN) can be expressed as:
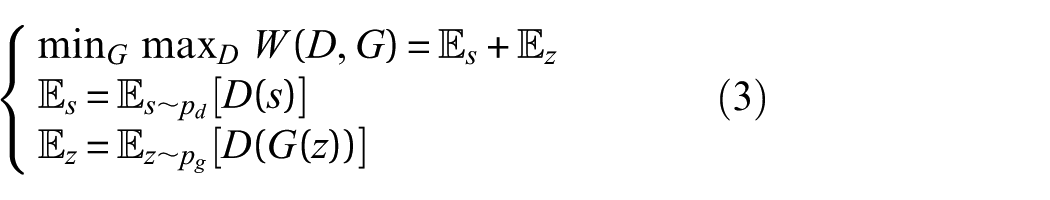
Gradient penalty (GP) is a regularization method explicitly formulated to enforce the discriminator’s gradient norm to remain close to unity. It serves as an alternative to weight clipping, aiming to improve the stability of network training. 31 The objective of GP is to introduce an auxiliary loss term that constrains the gradient norm within a desired range, thereby addressing the limitations associated with weight clipping. The GP loss is formally defined as:
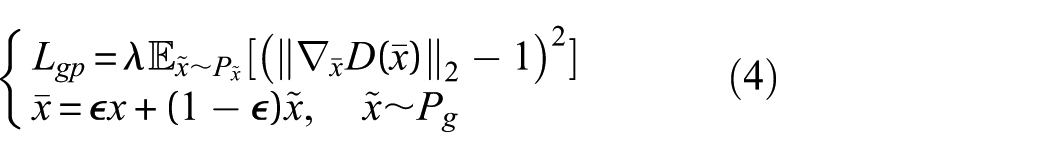
where ∇ represents the gradient,
Convolutional neural network
Convolutional neural network (CNN) has demonstrated outstanding performance in image feature extraction and pattern recognition, attributable to their inherent local receptive fields and translation invariance. In the context of RV reducer fault diagnosis, CNNs are capable of effectively processing time-frequency representations derived from transformed fault signals, thereby capturing the spatial structural characteristics intrinsic to fault features.32,33
A CNN primarily consists of convolutional layers, pooling layers, and fully connected layers. The convolution operation extracts local features by sliding convolutional kernels over the input data, while the parameter-sharing mechanism endows the model with translation invariance, enabling it to recognize positional variations in fault features. The core computation of the convolution operation can be expressed as:
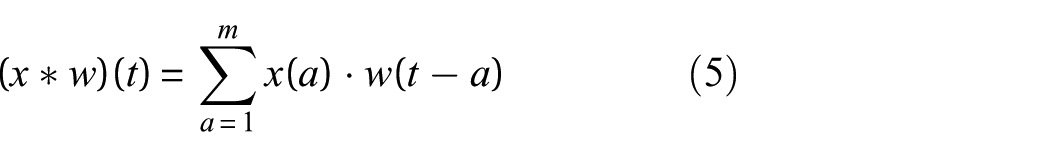
where x represents the input information, w denotes the weight kernel, t represents the bias term, and m represents the size of the weight kernel.
Pooling layers reduce the dimensionality of feature maps to improve computational efficiency while preserving essential features. Common pooling strategies include max pooling and average pooling. Fully connected layers are responsible for integrating high-dimensional features to achieve the final classification. Activation functions introduce nonlinear mappings, enabling the network to learn complex relationships; typical examples include the rectified linear unit (ReLU) and Sigmoid functions. The loss function quantifies the discrepancy between the model’s predictions and the ground truth. In this study, the cross-entropy loss is employed, coupled with the Adam optimizer for parameter optimization, with the objective of minimizing the loss and enhancing model performance.
The hierarchical architecture of CNNs facilitates the automatic extraction of multilevel representations from fault signals. Specifically, shallow layers capture fundamental texture and edge features, whereas deeper layers integrate these low-level features to form more abstract and discriminative representations of fault patterns. This capability of hierarchical feature learning enables CNNs to effectively identify various fault types in RV reducers, including wear and fracture. Nonetheless, CNNs are intrinsically constrained by their limited local receptive fields, which impedes their ability to capture long-range temporal dependencies and cross-cycle correlations within fault signals.
Transformer architecture
The Transformer architecture, owing to its powerful information modeling capabilities, 34 effectively overcomes the inherent limitations of traditional deep learning networks in capturing non-local correlations. This advantage is particularly crucial in the fault diagnosis of RV reducers, as fault features in planetary gear systems often manifest as complex modulated phenomena spanning multiple rotational cycles, which necessitate models with deep global feature correlation modeling capabilities. Specifically, in planetary gear systems, fault characteristics generated by sun-planet gear meshing impacts frequently exhibit modulation effects across several rotational cycles. These interrelated feature patterns, distributed in different regions of the time-frequency map, are difficult for conventional CNNs to fully extract.
To leverage the strengths of the Transformer for image-based time-frequency feature analysis, this paper introduces the ViT architecture, which is an improved version based on the standard Transformer. ViT reconstructs two-dimensional time-frequency images into a sequence of image patches and processes them as sequential data. Through its core self-attention mechanism, ViT dynamically assigns weights between different image patches, thereby overcoming the local perception limitations of CNNs. By transforming image processing into a sequence modeling task, ViT is able to break through the local perception constraints of traditional CNNs. Consequently, ViT effectively captures cross-regional feature coupling within fault signals.
The self-attention mechanism is the core component of the Transformer architecture. It enables the model to dynamically compute the relevance between any two positions in the input sequence, thereby capturing global dependencies.
34
The multihead attention mechanism extends this by running multiple attention heads in parallel, allowing the model to simultaneously focus on information from different representation subspaces and positions. Specifically, given an input sequence
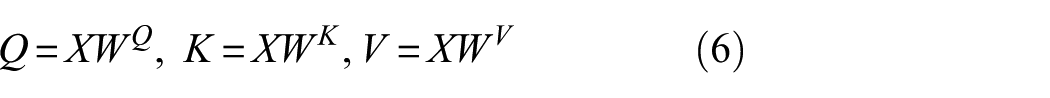
where
The attention score between Query, Key, and Value is computed based on the scaled dot-product attention as follows:
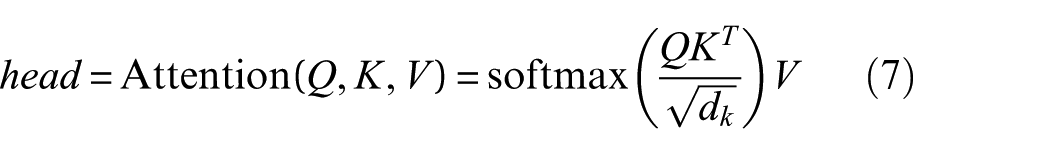
where
The outputs of all attention heads are concatenated and then passed through a final linear projection to produce the multihead attention output. This process can be mathematically expressed as:
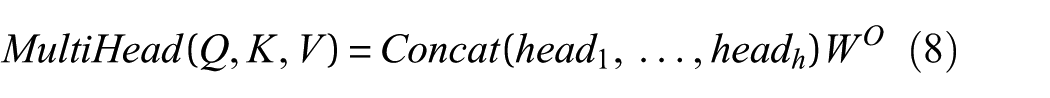
where W O is a learnable weight matrix used for the final linear projection of the multihead attention output.
Fault diagnosis model based on multisource multimodal data fusion for small samples
This section presents a multisource data fusion framework for fault diagnosis specifically designed for RV reducers operating under small-sample conditions. The proposed framework mitigates data scarcity by leveraging an enhanced GAN and utilizes a dual-branch feature extraction network to comprehensively exploit the complementary information inherent in vibration and current signals. This approach enables precise and reliable fault identification.
WGAN-RAG network architecture
Although WGAN and its GP variant (WGAN-GP) have significantly improved the training stability and generative performance of traditional GANs by mitigating issues such as mode collapse and vanishing gradients, they remain challenged when modeling complex time-series signals. These architectures demonstrate limited capability in extracting local features and insufficient awareness of the global signal structure and periodic variations, thereby impeding the generation of high-fidelity synthetic data that accurately captures fault characteristics. To overcome these limitations, this study proposes an enhanced GAN architecture termed WGAN with residual and attention guidance (WGAN-RAG). This architecture systematically augments both the generator and discriminator modules, enhancing model stability and improving output fidelity. The network architecture of WGAN-RAG is depicted in Figure 1.
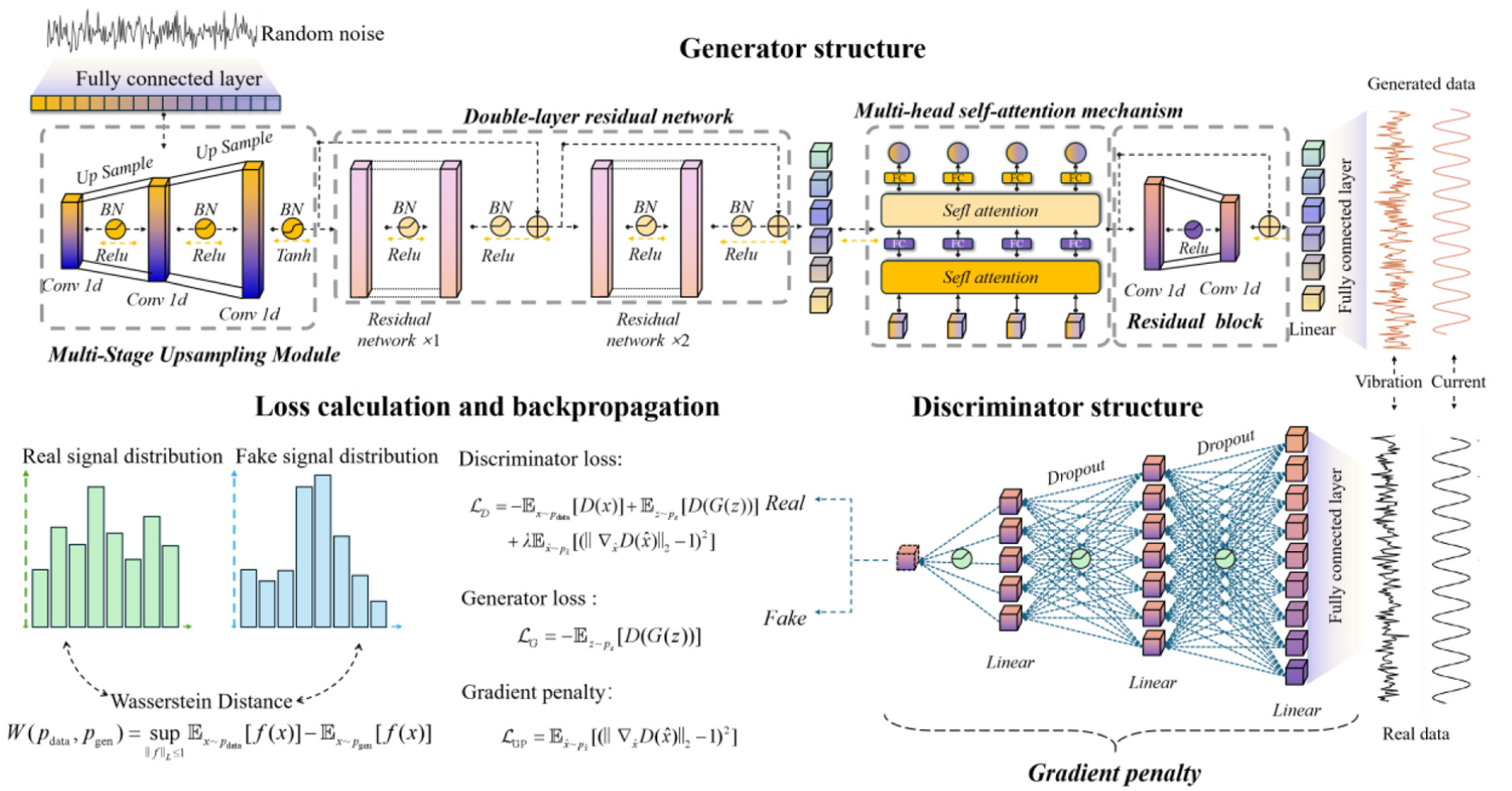
Schematic diagram of the WGAN-RAG architecture. WGAN: Wasserstein generative adversarial network; RAG: residual and attention guidance.
Generator improvements
To address the limitations of WGAN-GP in insufficient local feature extraction and inadequate perception of the overall structural and periodic variations of signals, this paper first optimizes the generator. The generator architecture mainly comprises an initial feature mapping and upsampling layer, a deep residual feature extraction network, a multihead self-attention mechanism, and a final residual block followed by a multichannel output layer:
1) Initial feature mapping and upsampling layer: The input noise vector is initially mapped into a high-dimensional feature space through a fully connected layer. Subsequently, the network employs a combination of two upsampling operations and one-dimensional convolutions to progressively construct and refine temporally structured high-dimensional features. After these two processing steps, an independent one-dimensional convolutional layer is applied, with its output range constrained by a Tanh activation function. These three layers of one-dimensional convolutions and upsampling operations work in close coordination. Their combined configuration and parameter design aim to optimize the initial representation of temporal signals, thereby enhancing the feature learning efficiency of subsequent modules.
2) Deep residual feature extraction network: To further enhance the robust extraction of complex temporal features within deep generator networks and effectively alleviate the vanishing gradient problem commonly encountered in traditional deep network training, this study proposes a deep residual network composed of two sequential residual blocks (denoted as the double-layer residual network module in Figure 1). Each residual block internally integrates batch normalization (BN), ReLU activation functions, and skip connections, ensuring smooth propagation of deep feature information while effectively preserving multilevel temporal characteristics. This architectural design enables the generator to thoroughly mine and learn intricate patterns present in fault signals, while maintaining stable training dynamics.
First, through the first residual block process xinit, obtain the intermediate feature through the first residual block x1:
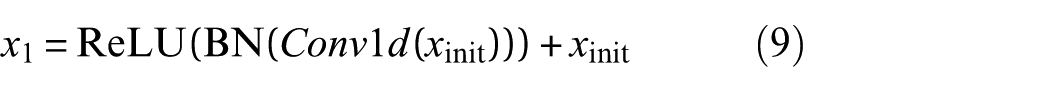
Next, take x1 as the input, through the second residual block, obtain the final output of the residual network
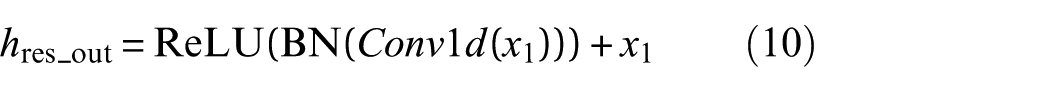
3) Introduction of multihead self-attention mechanism: Due to the limited local receptive fields of convolutional layers, effectively capturing complex dependencies between nonadjacent time steps in long-term sequential signals remains challenging. To address this, the present study incorporates a multihead self-attention mechanism following the extraction of high-level features by the deep residual network. This mechanism allows the model to dynamically compute the relevance between each time step in the generated sequence and all other time steps in the input sequence, thereby directly modeling the contextual dependencies within the data. The final output features are obtained through a weighted combination of the multihead attention outputs and the original features. The output of the multihead attention M is fused with the original features
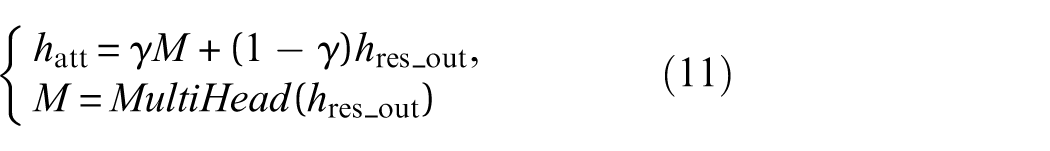
where γ denotes the fusion coefficient between the attention output and the original features.
4) Final residual block and multichannel output layer: To further refine feature representations and ensure output stability, this study incorporates a final residual block subsequent to the multihead self-attention mechanism. This residual block performs the ultimate optimization and reconstruction of attention-enhanced features, thereby augmenting their representational capacity and establishing a robust foundation for the subsequent multichannel output layer.
Discriminator improvements
To augment the generalization ability of the discriminator, this study implements a multilevel Dropout mechanism, thereby establishing a stochastic feature suppression strategy:
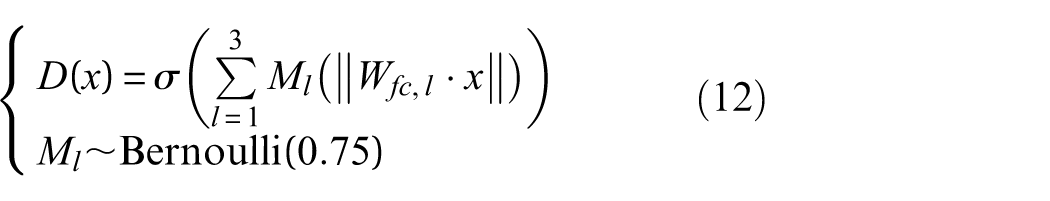
where M l denotes the lth dropout layer, following a Bernoulli distribution, Dropout probability is set to 0.25 in this article, Wfc,l represents the weights of the l th layer of the discriminator. The symbol ⊙ denotes element-wise multiplication.
In summary, the module configuration of the improved GAN WGAN-RAG is presented in Table 1. The parameter settings of the convolutional modules (Conv_blocks), upsampling module (Up_sample), residual network (Res_blocks), and multihead self-attention mechanism (MHSA) are designed to maximize the model’s capability to capture complex dynamic features of time-series signals. By meticulously designing the number of layers, convolutional kernel sizes, attention head counts, and residual connection schemes for each component, the model capacity between the generator and discriminator is balanced, thereby ensuring the stability of adversarial training and the quality of the generated samples.
WGAN-RAG architecture configuration.
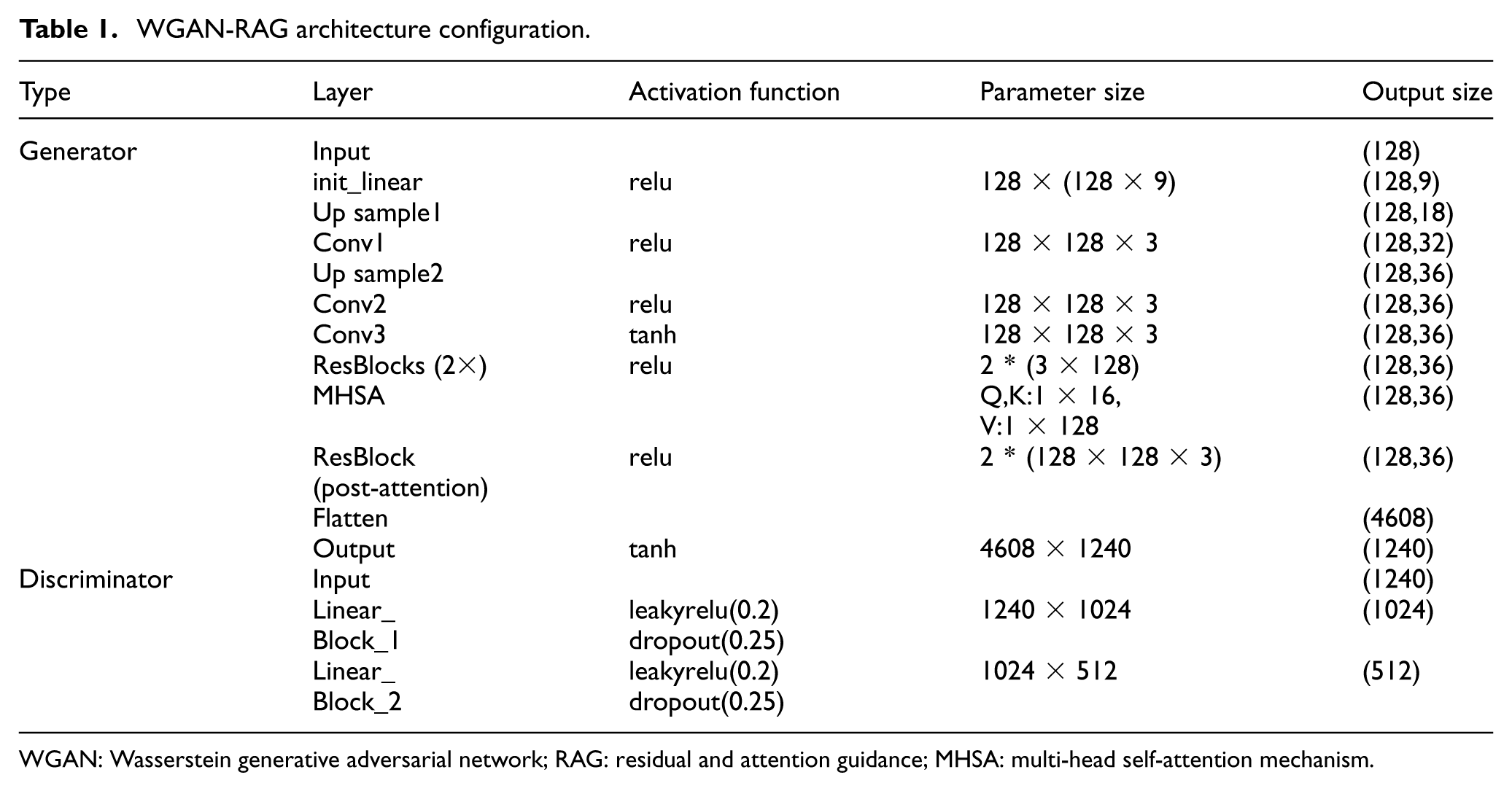
WGAN: Wasserstein generative adversarial network; RAG: residual and attention guidance; MHSA: multi-head self-attention mechanism.
The core architecture of WGAN-RAG, which integrates dual-layer residual connections and multihead self-attention mechanisms, features strong modular compatibility. Regardless of variations in dataset modal types or levels of sample imbalance, the model retains its core residual-attention backbone. Only targeted adjustments to specific components are needed instead of a full architectural redesign. The residual-attention mechanism and Wasserstein distance-based training framework of WGAN-RAG are generalizable to other rotating machinery. Through transfer learning-based fine-tuning of the feature mapping layer, the model can adapt to the fault feature distributions of different target mechanical systems. The multihead self-attention module maintains its effectiveness in modeling long-range dependencies of periodic fault-related signals, while relevant layers can be adjusted appropriately to match the signal characteristics of the target system, ensuring stable generative performance.
SCViT dual-branch fusion diagnostic model
In the presence of gear faults such as cracks or wear, the vibration signals of RV reducers exhibit distinct periodic impact and modulation phenomena. These effects extend over multiple meshing cycles, resulting in continuous variations in the signal’s energy and frequency components over prolonged time scales. Such variations characterize the comprehensive health condition of the mechanical system, herein referred to as the “overall time-frequency correlation characteristics.” Complementarily, current signals demonstrate high sensitivity to transient mechanical load fluctuations. Localized defects (e.g., root cracks) induce periodic oscillations in the load torque, which, through electromechanical coupling, generate amplitude and frequency modulations in the stator currents. These modulations manifest as characteristic sidebands within the frequency spectrum. These “local dynamic perturbations” convey critical diagnostic information essential for the accurate identification of early-stage or minor faults.
In summary, to address the intrinsic differences between vibration and current signals in terms of frequency distribution and time-domain characteristics, this study proposes the Self-Calibrated Convolution and Vision Transformer Fusion Network for Dual-Modality Classification (SCViT) dual-branch fusion diagnostic model (a self-calibrated convolution and ViT fusion network for dual-modality classification). The model incorporates dedicated feature extraction pathways tailored to each signal modality: (1) the SCConv-based vibration branch is designed to effectively capture comprehensive dynamic patterns spanning multiple fault feature cycles within vibration signals; (2) the ViT-based current branch utilizes its self-attention mechanism to precisely identify localized spectral line variations and periodic modulation patterns induced by fault-related modulations in current signals. This targeted architectural design enables the dual-branch network to more thoroughly exploit the complementary information inherent in both modalities, thereby enhancing diagnostic accuracy.
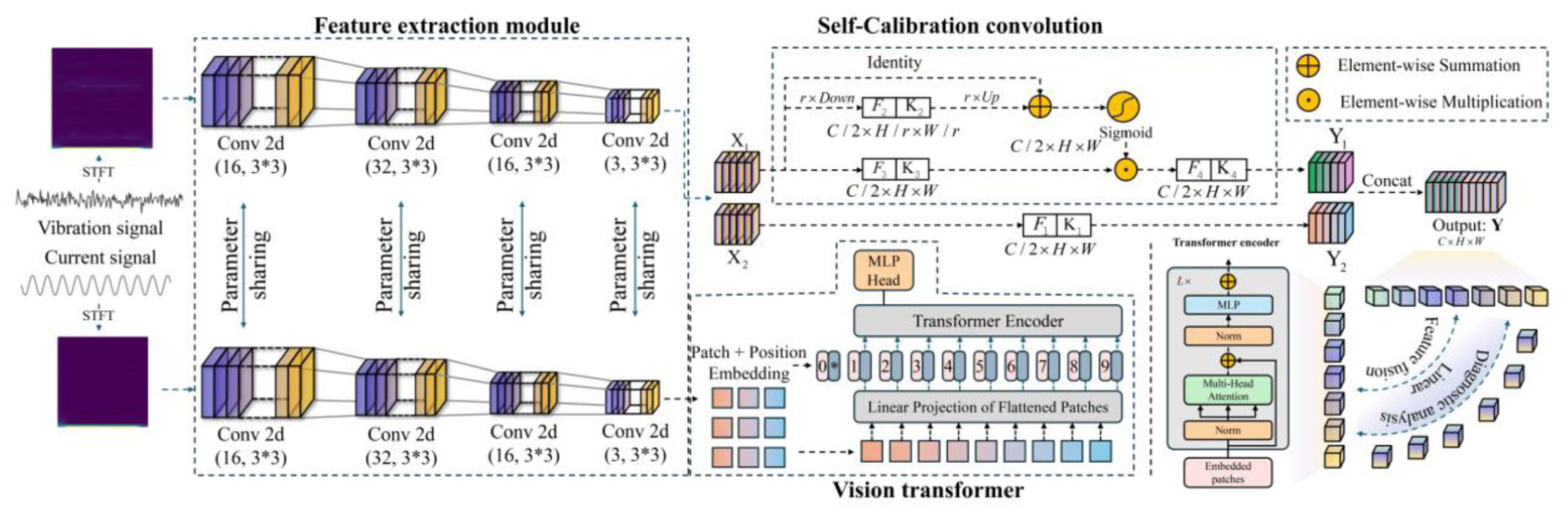
The dual-branch diagnostic framework is depicted in Figure 2. It comprises an SCConv-based vibration feature extraction branch and a ViT-based current feature extraction branch, collectively facilitating the comprehensive utilization of complementary information from multi-source heterogeneous data.
Structure of the dual-branch diagnostic model.
Time-frequency transformation of multisource signals
To fully preserve the temporal characteristics of the signals and facilitate subsequent deep learning model processing, this study employs the short-time Fourier transform (STFT) to convert one-dimensional signals into two-dimensional time-frequency representations. 35 STFT is a widely used method for time-frequency analysis. The fundamental computational formula of STFT is expressed as follows:
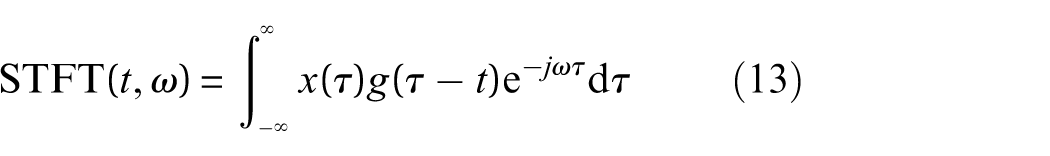
where
It is noteworthy that the length of the window function directly affects the resolution trade-off between the time and frequency domains. Therefore, to achieve precise analysis tailored to specific signal characteristics, careful selection of the window length is imperative. The parameter values adopted in this study are summarized in Table 7.
Self-calibrated convolution
Traditional CNNs, because of their inherent locality in feature extraction, struggle to effectively capture the global time-frequency characteristics of vibration spectrograms for RV reducer fault diagnosis. To address the limitations of local feature enhancement in vibration signals, this study introduces SCConv as a core feature extraction module. SCConv establishes local feature associations between spatial regions of the input spectrogram, 36 thereby enabling the extraction of comprehensive time-frequency features from vibration signals and enhancing the overall discriminative capability.
As illustrated in the architecture of the self-calibrated convolution module in Figure 3, the module employs a dual-path design for feature extraction. Specifically, the input feature map
1) Multiscale spatial transformation
RV reducer fault diagnosis architecture.
Initially, the self-calibrated convolution module downsamples the input
This multiscale spatial transformation is essential for capturing the overall time-frequency correlation patterns within vibration signals. For example, in distributed faults such as multi-tooth surface wear on sun gears, where the effects extend across multiple meshing cycles, SCConv can effectively integrate these cross-temporal and cross-frequency patterns by expanding the receptive field.
2) Adaptive feature calibration
Adaptive feature calibration constitutes the core component of the self-calibrated convolution. It performs local weighting on multiscale temporal features extracted from X1. The calibrated feature Y1 is computed as follows:
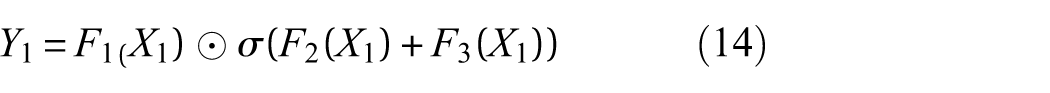
where ⊙ denotes element-wise multiplication, and σ represents the Sigmoid activation function.
Adaptive feature calibration utilizes the global temporal features extracted from path 1 as a reference, while path 2 preserves the original multiscale features for adaptive weighting and correction. This mechanism enables the model to emphasize fault-related characteristics within vibration signals.
3) Dual-path fusion
The final output is obtained by concatenating the output Y1 from path 1 and the output Y2 from path 2, as expressed by:

Given that gear faults in RV reducers (such as root cracks and tooth surface wear) induce periodic impacts, resonances, and modulations in vibration signals exhibiting holistic correlation characteristics across cycles and frequencies, the SCConv module effectively captures and integrates these dispersed yet interrelated time-frequency correlation patterns distributed across different regions of the time-frequency map via its self-calibration mechanism. This approach compensates for the inherent limitations of traditional CNNs’ localized receptive fields, thereby providing more comprehensive vibration feature representations for diagnosing distributed faults such as multitooth surface wear.
Vison transformer
This study adopts the ViT as the feature extraction module to address localized modulated disturbances present in current signals caused by faults. ViT partitions the time-frequency map into nonoverlapping local patches and encodes them into feature vectors, thereby capturing modulation components within specific temporal windows and frequency bands. By incorporating positional encoding, ViT preserves spatiotemporal information, enabling precise localization of modulation effects. Its self-attention mechanism dynamically establishes cross-region correlations, effectively constructing a fault feature representation network. 37
ViT initially segments the input time-frequency map into fixed-size, nonoverlapping image patches, which are subsequently flattened and projected linearly into embedding vectors to preliminarily capture local features within each patch. To retain spatiotemporal positional information, a class token is prepended to the embedding sequence, accompanied by learnable positional encodings, forming the input sequence to the Transformer encoder. This sequence is then processed by a Transformer encoder composed of L identical stacked Encoder layers. Each Encoder layer integrates an MHSA module and a multilayer perceptron module, employing layer normalization and residual connections to stabilize training. At this stage, theself-attention mechanism dynamically establishes cross-region dependencies, directly capturing relationships among image patches. Finally, the corresponding feature vector
where
Dual-branch diagnostic network for vibration and current feature fusion
In summary, this study proposes the SCViT diagnostic model architecture, which integrates two distinct processing branches to comprehensively exploit the complementary information inherent in vibration and current signals:
1) Vibration signal branch (CNN-SCConv): Vibration signals represent the energy dissipation within mechanical systems, with their broadband energy distribution reflecting the overall dynamic performance of the reducer. This branch employs a parameter-sharing CNN to extract preliminary features, which are subsequently enhanced by an SCConv module. This design effectively consolidates global information from the time-frequency representation and integrates cross-dimensional features, enabling precise characterization of complex cross-cycle patterns within the vibration signals.
2) Current signal branch (CNN-ViT): Current signals are more sensitive to transient mechanical load variations; for example, step changes in meshing stiffness caused by sun gear cracks manifest as abrupt spikes in the current time-domain signal. This branch similarly utilizes a parameter-sharing CNN for initial feature extraction and incorporates a ViT architecture. Leveraging multihead attention mechanisms, the ViT focuses on localized regions within the time-frequency map while effectively modeling long-range dependencies among these regions, thereby facilitating comprehensive analysis of dynamic disturbance features in current signals.
Features extracted from both branches undergo adaptive pooling and are concatenated along the same dimension before being input to a fully connected layer for classification across seven fault categories (including the normal state) under various operating conditions. This architectural design complements the full-time-domain modulation patterns of vibration signals with the localized abrupt features of current signals, thereby substantially enhancing diagnostic accuracy. The principal structural parameters of the model are summarized in Table 2.
Selected parameters of the model.
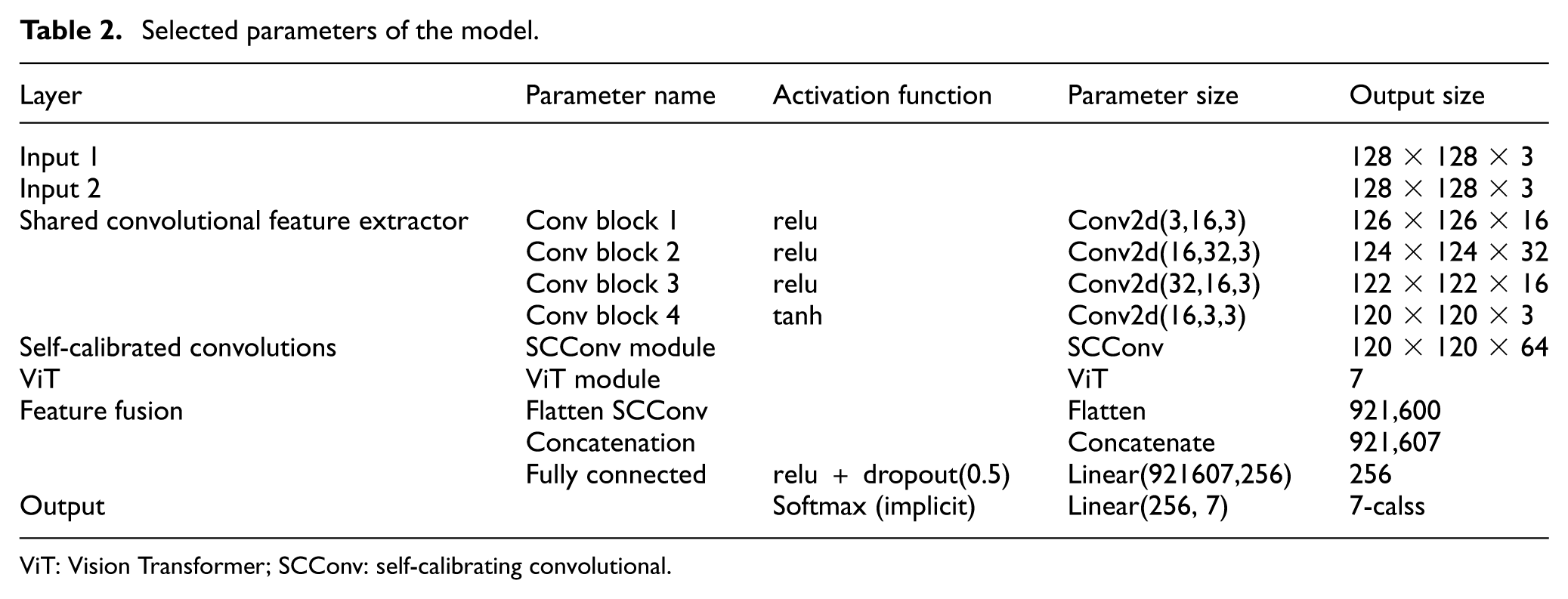
ViT: Vision Transformer; SCConv: self-calibrating convolutional.
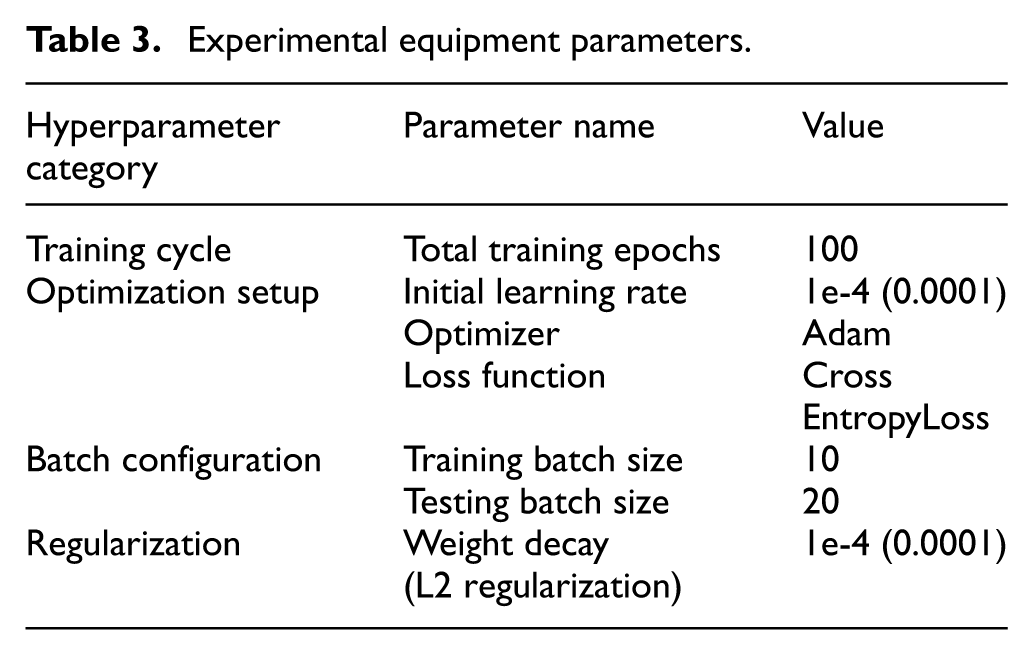
To ensure methodological rigor and clarify the impact of training settings on performance, key training hyperparameters and configuration details of the SCViTNet are summarized in Table 3. This study sets the total number of training epochs to 100, which is determined based on the actual convergence of model training: real-time monitoring of the training process shows that the model stabilizes in terms of training loss and test accuracy around the 40th epoch. Extending the training epochs to 100, on the one hand, ensures complete model convergence to fully learn the time-frequency features and fusion rules of bimodal signals, avoiding insufficient feature learning and gradient updates caused by too few epochs, this would fail to capture the global time-frequency correlation features of vibration signals and the local dynamic perturbation features of current signals, thereby leading to low fault classification accuracy. On the other hand, the 100-epoch training cycle involves no redundant computation and thus does not cause unnecessary consumption of computing resources. For multi-fault classification, CrossEntropyLoss is adopted, which accurately measures the discrepancy between predicted probability distributions and true fault labels. As the optimal choice for multifault classification tasks, it effectively drives the model to learn discriminative bimodal fusion features.
Experimental equipment parameters.
Proposed model algorithm flow
The overall fault diagnosis procedure of the proposed method is depicted in Figure 3, with the detailed steps as follows:
Step 1: Synchronously acquire periodic vibration signals and periodic current signals from the RV reducer under various fault types and operating conditions, thereby constructing a raw fault dataset comprising vibration and current signals across multiple operating scenarios.
Step 2: Construct an original small-sample imbalanced dataset (refer to Table 6), train the WGAN-RAG model on the imbalanced raw dataset, then use the trained model to generate augmented data.
Step 3: Generate augmented one-dimensional data to expand the imbalanced small-sample dataset, followed by conversion into time-frequency representations via STFT.
Step 4: Develop the SCViTNet dual-branch network for model training, integrating a vibration feature extraction branch composed of a parameter-sharing CNN and SCConv, as well as a current feature extraction branch combining a parameter-sharing CNN with a ViT. Partition the two-dimensional time-frequency image fault dataset of vibration and current signals from the RV reducer under different operating conditions into training and testing subsets, using the training subset for model training.
Step 5: Independently processed features from the SCConv and ViT branches are merged. The merged features undergo adaptive average pooling for dimensionality reduction, followed by concatenation along the same dimension to ensure data consistency. Finally, the features are linearly transformed into the output space to generate the final diagnostic results.
The aforementioned theoretical advancements collectively address the principal challenges in RV reducer fault diagnosis: (1) to mitigate the weak generalization capability of diagnostic models caused by sparse small-sample data in RV reducers, the WGAN-RAG network alleviates data scarcity and improves the quality of generated samples under small-sample conditions; (2) to overcome the lack of targeted multimodal information fusion, the SCViT dual-branch architecture (SCConv and ViT) differentially extracts holistic spatiotemporal correlation features from vibration signals and localized dynamic perturbations from current signals, thereby enhancing the specificity of multimodal fusion strategies; (3) to tackle the difficulty of feature representation under complex operating conditions, the SCViT dual-branch network, through its differentiated feature extraction and deep fusion mechanism, effectively captures and integrates fault features across varying load, reciprocating, and other complex conditions, thereby enhancing the model’s feature representation capability and diagnostic robustness under dynamic operating environments.
Experimental validation and analysis
Experimental setup and data acquisition
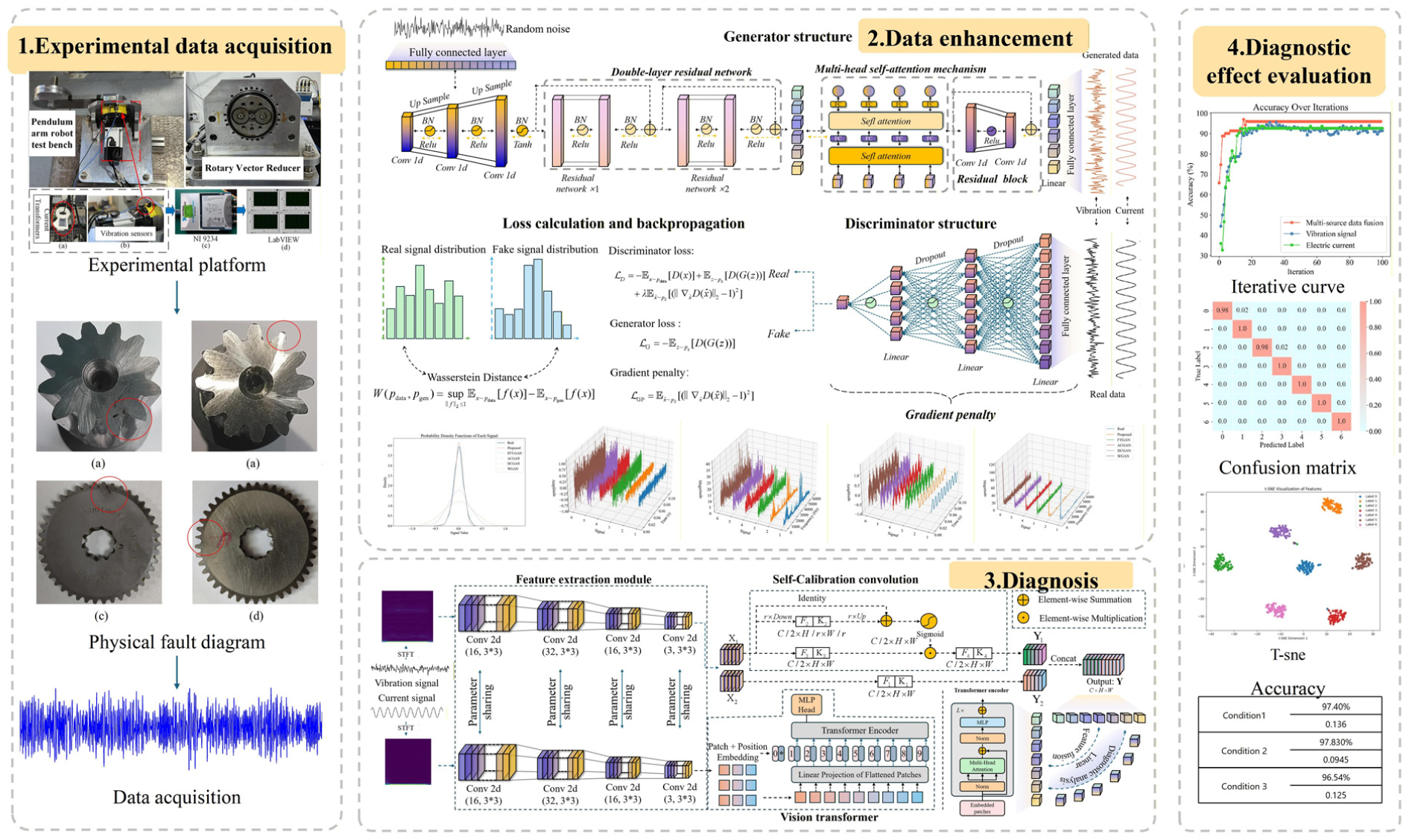
To demonstrate the effectiveness of the proposed method, a dedicated RV reducer test rig was established, as illustrated in Figure 4. The test rig comprises four principal components: a drive system, an RV reducer, a sensing unit, and a data acquisition system. During the experimental procedures, a servo drive controlled a permanent magnet synchronous motor, which served as the power source to actuate the RV reducer via reciprocating oscillation tests. The signal acquisition subsystem incorporated current sensors and tri-axial vibration accelerometers, synchronously capturing multichannel signals through an National Instruments (NI) data acquisition card interfaced with the LabVIEW platform. The key equipment specifications and detailed operational parameters are summarized in Table 4.

Experimental platform: (a) current transformers, (b) vibration sensors, (c) NI 9234 data acquisition card, and (d) LabVIEW interface.
Experimental equipment parameters.

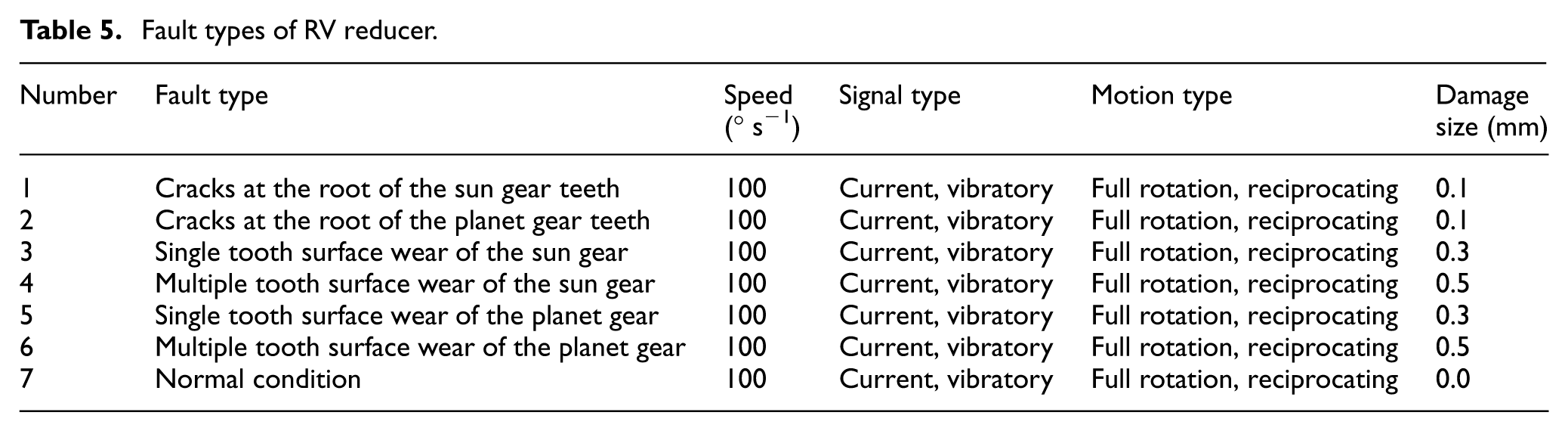
The experimental platform employs electrical discharge machining to fabricate artificial defects on the sun and planet gears, encompassing three damage sizes (0.1, 0.3, and 0.5 mm) and two failure categories: crack-type and wear-type failures. This setup results in six representative failure modes: cracks at the root of the sun gear teeth, cracks at the root of the planet gear teeth, single tooth surface wear of the sun gear, multiple tooth surface wear of the sun gear, single tooth surface wear of the planet gear, and multiple tooth surface wear of the planet gear. Together with the normal condition, these constitute seven operational states of the RV reducer, as summarized in Table 5. Figure 5 presents physical samples corresponding to each failure mode: Figure 5(a) illustrates cracks at the root of the sun gear teeth, Figure 5(b) depicts cracks at the root of the planet gear teeth, Figure 5(c) shows single tooth surface wear of the sun gear, Figure 5(d) demonstrates multiple tooth surface wear of the sun gear, Figure 5(e) displays single tooth surface wear of the planet gear, and Figure 5(f) exhibits multiple tooth surface wear of the planet gear. The reducer was tested under three operational conditions: condition 1 involved continuous unidirectional rotation of the output shaft through a complete cycle without additional load; condition 2 consisted of reciprocal oscillation of the output shaft at 90° intervals with an 8 kg external load; condition 3 entailed reciprocal oscillation of the output shaft at 90° intervals without load. The rotational speed was maintained at 100° s−1 for all three conditions. Figure 6 depicts the time-domain periodic waveforms of vibration and current signals acquired from the sun gear exhibiting single tooth surface wear.
Fault types of RV reducer.

Gear fault images: (a) cracks at the root of the sun gear teeth, (b) cracks at the root of the planet gear teeth, (c) single tooth surface wear of the sun gear, (d) multiple tooth surface wear of the sun gear, (e) single tooth surface wear of the planet gear, and (f) multiple tooth surface wear of the planet gear.
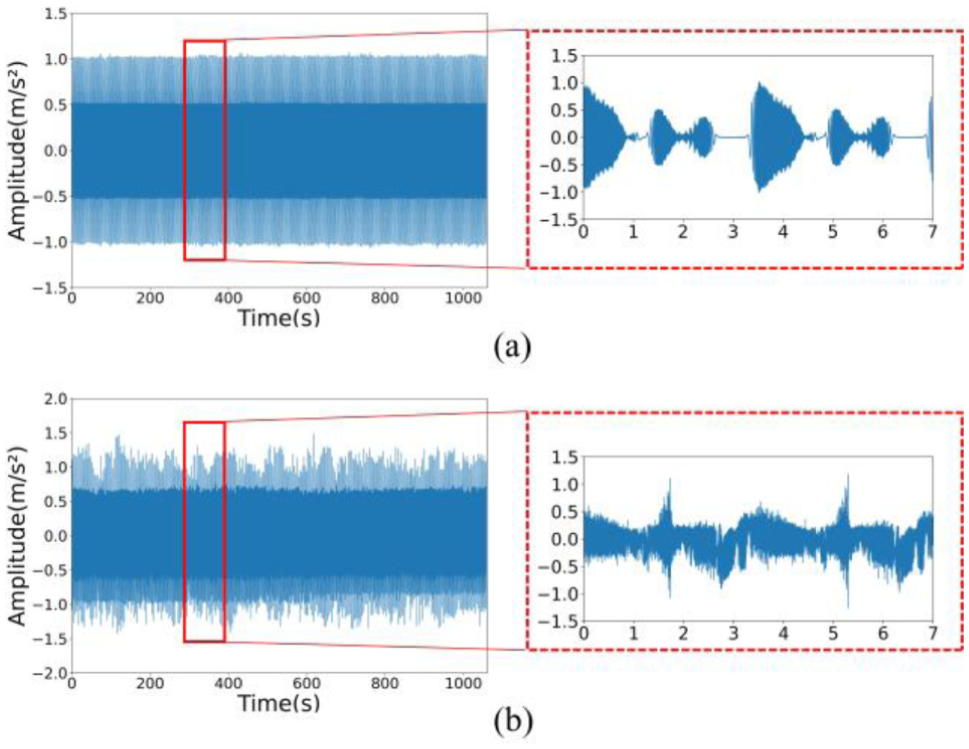
Sun gear single tooth surface fault of RV reducer: (a) current signal and (b) vibration signal.
Diagnostic results and analysis
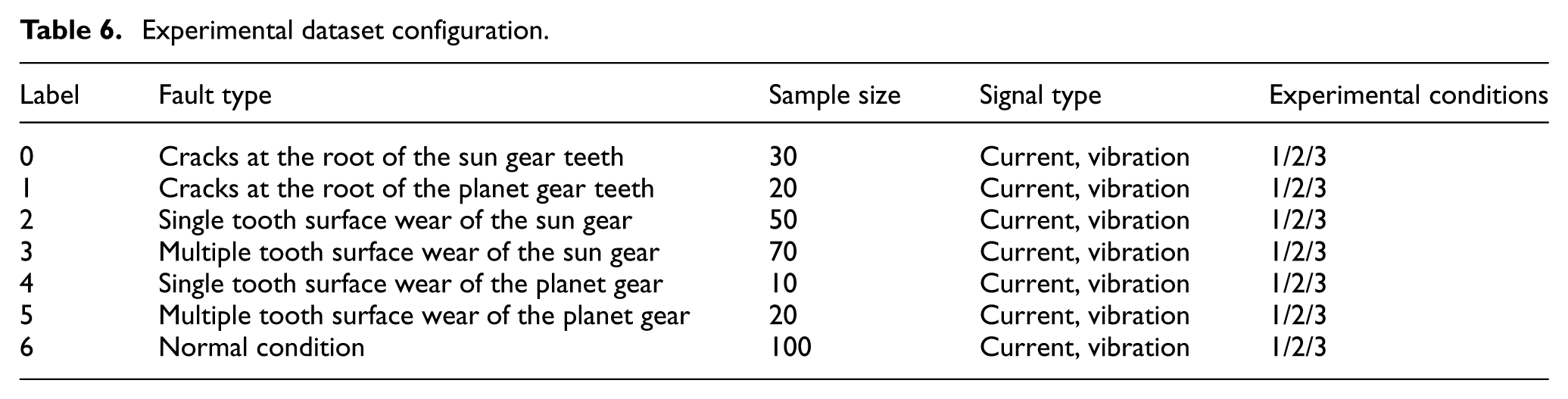
Experimental data were acquired and subsequently processed on a Windows 11 platform equipped with a GeForce RTX 3050 GPU and 12 GB of RAM. The raw signals were segmented into segments of 1240 samples each to form a small-sample, imbalanced dataset. The detailed configuration of the experimental dataset is provided in Table 6.
Experimental dataset configuration.
The proposed small-sample multisource data fusion method initially inputs the raw samples into the pre-trained WGAN-RAG model for data augmentation, thereby expanding the total sample size to 700, with 100 samples allocated per fault category. The augmented one-dimensional signals are then transformed into two-dimensional time-frequency images (Figure 7) via STFT, whose parameter settings are specified in Table 7. Finally, these images are fed into the SCViT dual-branch feature fusion diagnostic network for fault identification.
STFT maps of generated images: (a) vibration signal and (b) current signal. STFT: short-time Fourier transform.
STFT parameter settings.

STFT: short-time Fourier transform.
Evaluation of generated data quality
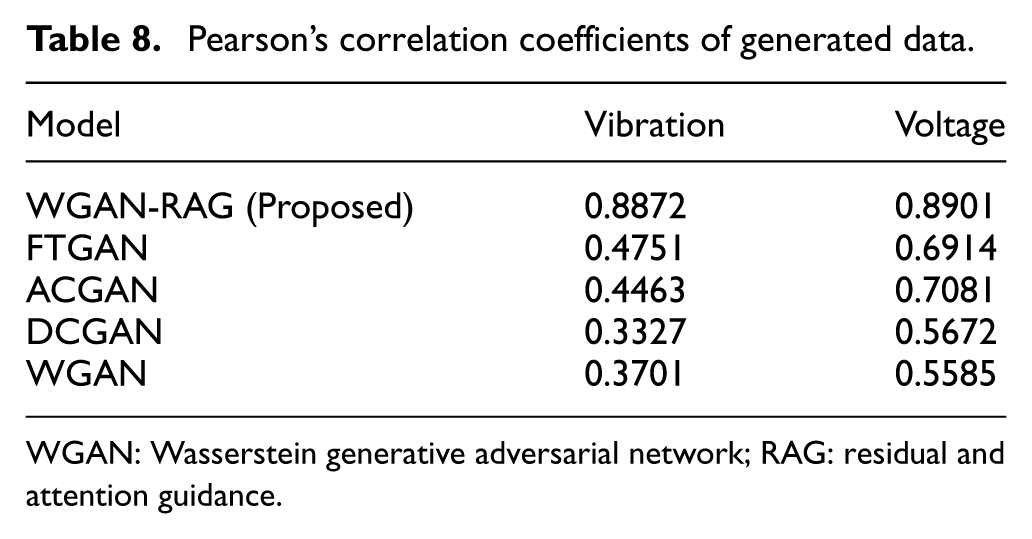
To evaluate the data generation quality of the improved GAN network, this study conducted a comparative analysis involving four classical GAN models: A Novel GAN-Based Data Augmentation Method Coupled Time–Frequency Domain (FTGAN), 38 Auxiliary Classifier Generative Adversarial Network (ACGAN), 39 Deep Convolutional Generative Adversarial Networks (DCGAN), 40 and WGAN. 30 Figure 8 presents the comparison of the generated time-domain signals from each model. It is observed that, for both current and vibration signals, the data generated by the proposed model exhibit a high degree of similarity in pattern to the real data, whereas the data generated by the other models contain varying levels of noise interference, particularly in the cases of DCGAN and WGAN. To further validate the effectiveness of the proposed model, signal similarity was analyzed using probability density function (PDF) curves. Figure 9 presents a comparison of PDF curves between the original data and those generated by various models for cracks at the root of the sun gear teeth (damage size 0.1 mm). The results indicate that the probability distribution of the data generated by the proposed WGAN-RAG model is most similar to the real data, with Pearson’s correlation coefficients reaching 0.8872 for vibration signals and 0.8901 for current signals, which are significantly higher than those of the comparative models (Table 8). The results demonstrate that WGAN-RAG maintains high generation fidelity across all fault categories in the RV reducer dataset, including those categories with relatively small original sample sizes. This indicates the model’s robustness to imbalanced and small-sample distributions, laying a foundation for its application to other mechanical systems with similar data characteristics.
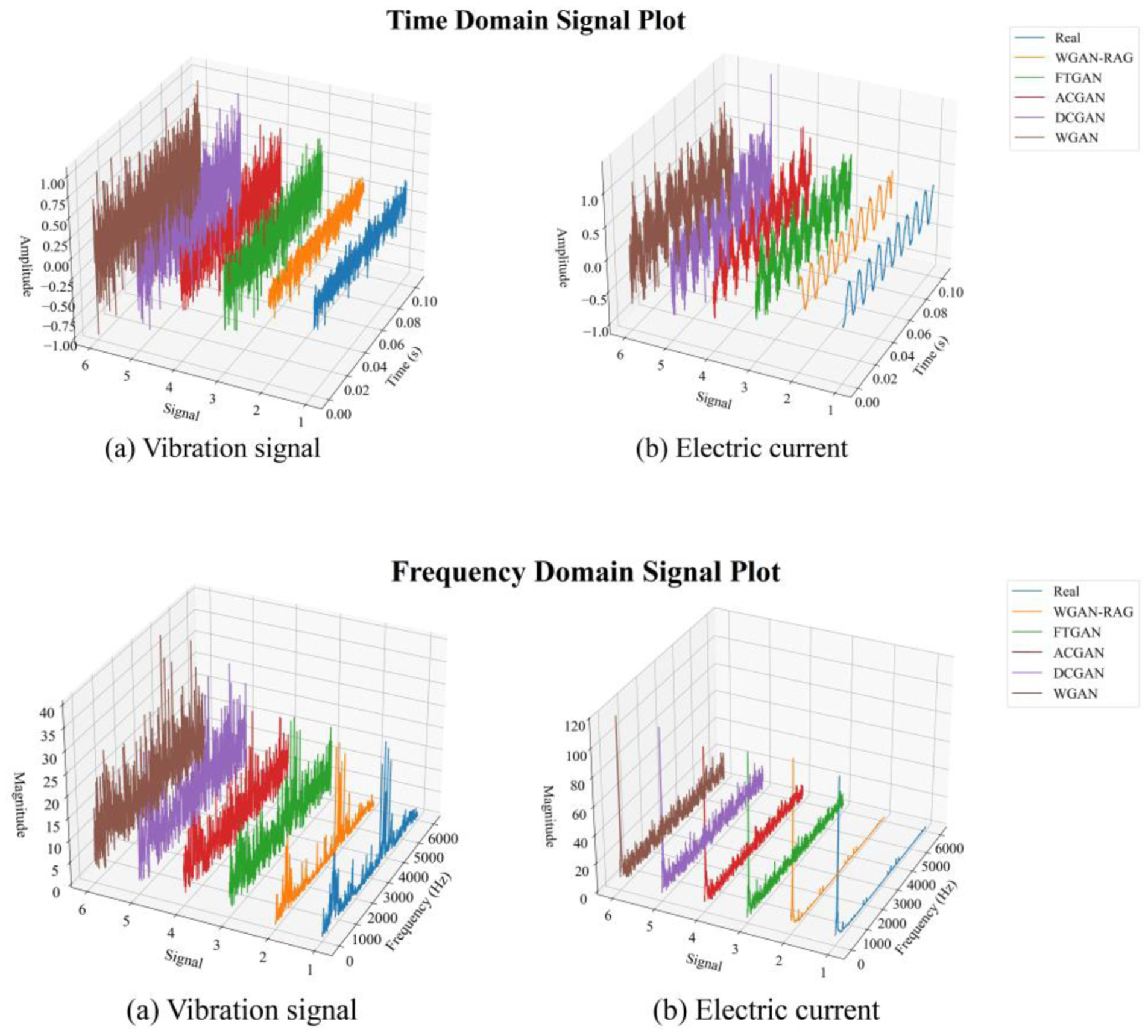
Time- and frequency-domain comparison of signals generated by different models. Top row: time-domain plots of (a) vibration signal and (b) electric current. Bottom row: frequency-domain plots of (a) vibration signal and (b) electric current.
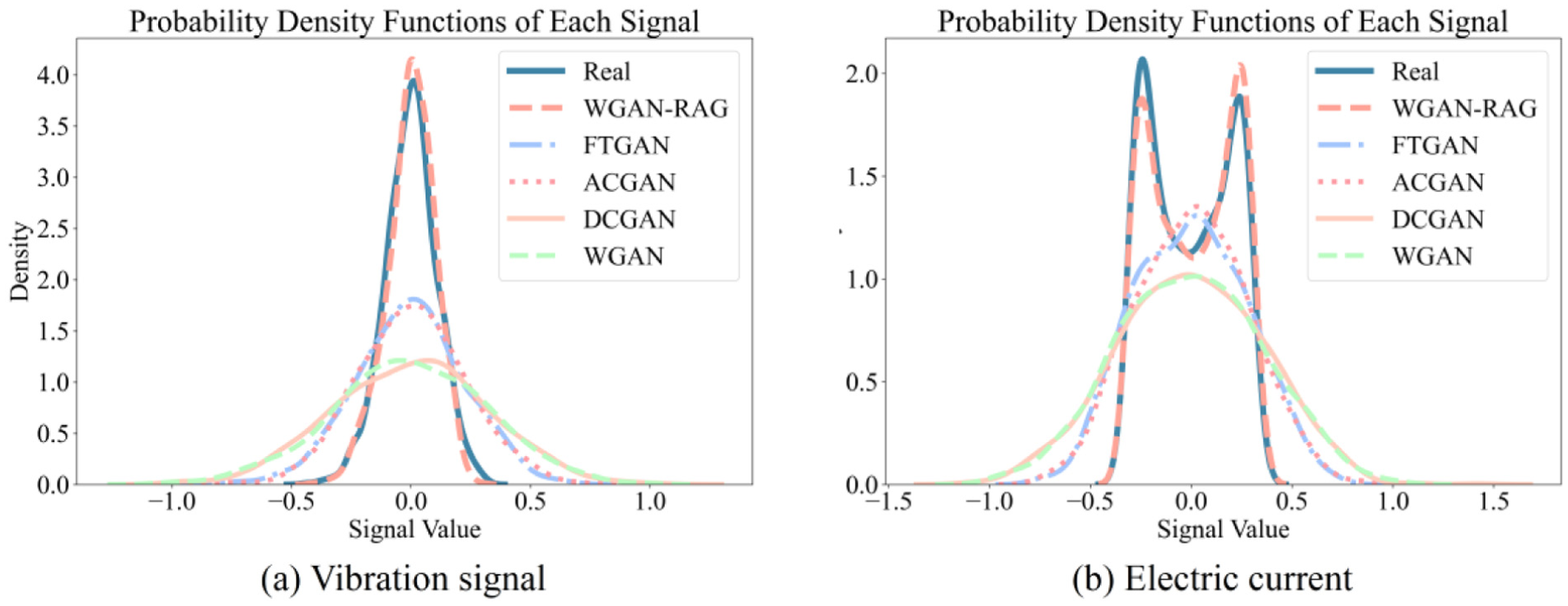
Probability density curves of generated data by various models for label 0: cracks at the root of the sun gear teeth: (a) vibration signal and (b) current signal.
Pearson’s correlation coefficients of generated data.
WGAN: Wasserstein generative adversarial network; RAG: residual and attention guidance.
The proposed GAN-based network was utilized to perform data augmentation on the original small-sample dataset, expanding each fault sample to 100 instances. The dataset was divided into 75% for training and 25% for testing. The dual-branch model for vibration and current signals was trained using the training set, and its performance was evaluated on the testing set.
Validation of diagnostic performance for dual-branch architecture
To verify the rationality of the dual-branch architecture design, five comparative experiments were conducted under condition 1. Independent diagnostics were performed on the CNN-SCConv, CNN-ViT, CNN, and ViT branches, and their results were compared with those of the dual-branch fusion diagnostic model. Figure 10 illustrates the diagnostic accuracy curves for each architecture. The results demonstrate that the proposed dual-branch diagnostic model achieves the highest accuracy of 97.40% with the most stable diagnostic curve. The next best performances were observed in the CNN-ViT branch incorporating the ViT and the CNN-SCConv branch integrating the SCConv module, with accuracies of 93.94 and 90.91%, respectively. Models employing the CNN or ViT branches solely exhibited accuracies well below 90% and showed greater fluctuations.
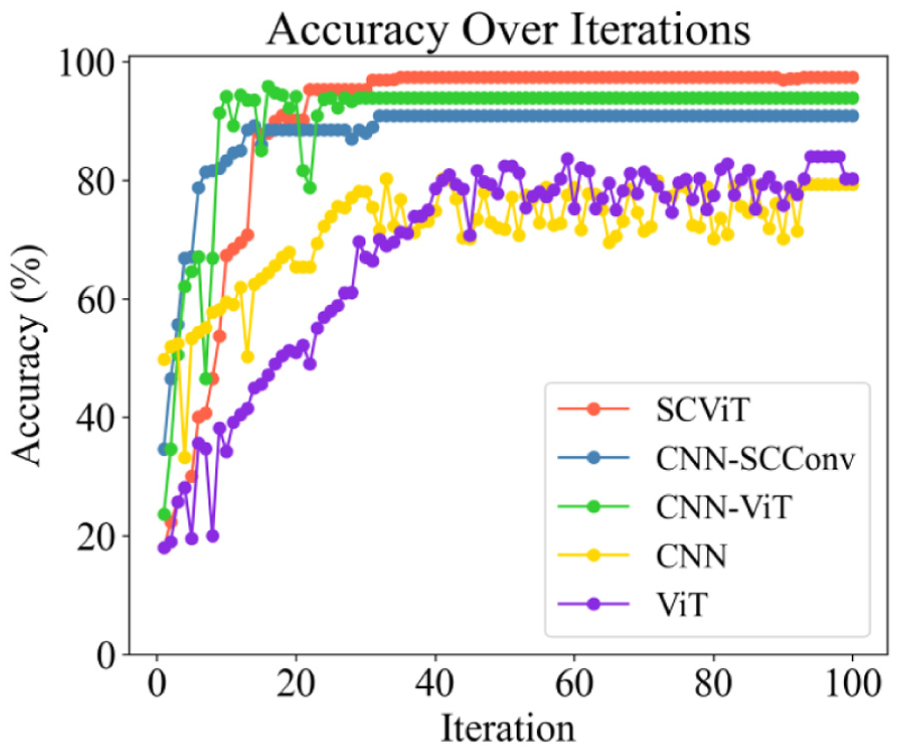
Comparative diagnostic accuracy curves of single-branch and dual-branch architectures under condition 1.
Analysis of the advantages of multisource data fusion
To compare the advantages of multisource data fusion versus single-modality diagnosis, ablation experiments were conducted in this study. Figure 11 presents the diagnostic accuracy curves of single-modality and multimodality fusion under three working conditions:
1) Condition 1 (full rotation, unidirectional forward rotation, no load): the vibration single-modality accuracy reached 94.57%, the current single-modality accuracy stabilized at 91.56%, while the dual-modality fusion accuracy rapidly stabilized at 97.40%;
2) Conditions 2 (partial rotation, reciprocating, with load) and 3 (partial rotation, reciprocating, no load): conditions 2 (non-full rotation reciprocating load) and 3 (non-full rotation reciprocating no-load): the vibration single-modality curves exhibited oscillations, whereas the dual-modality fusion diagnostic accuracies stabilized at 97.83 and 96.54%, respectively.
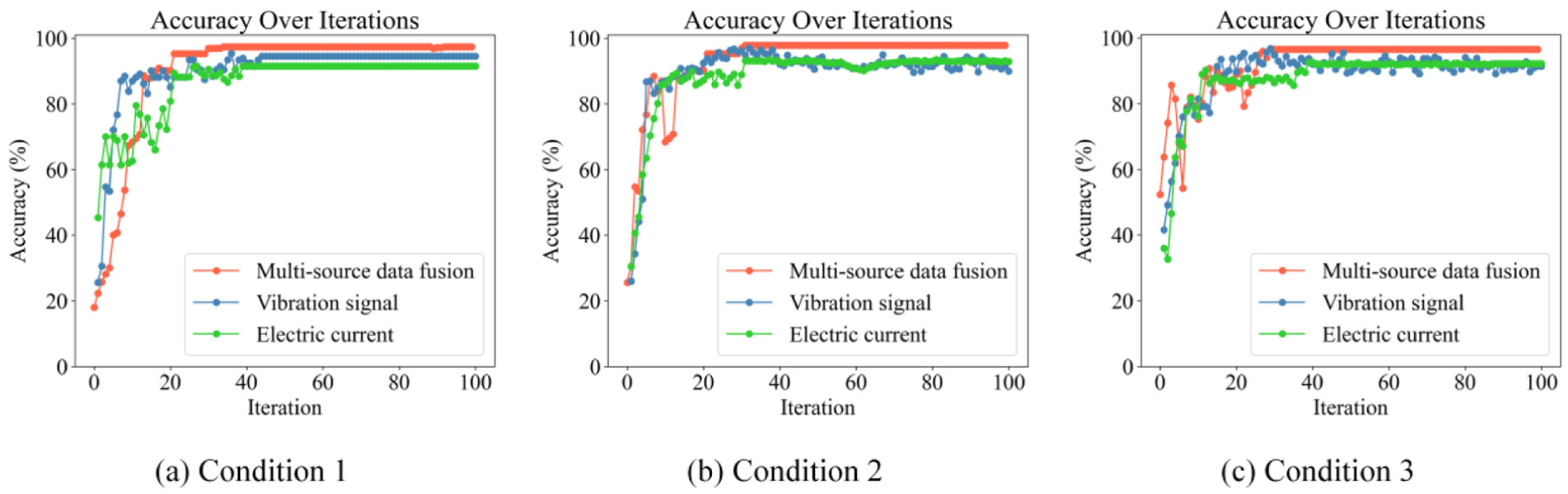
Diagnostic results under different working conditions: (a) condition 1, (b) condition 2 and (c) condition 3.
Notably, the current single-modality showed convergence delay characteristics across all conditions, whereas the vibration-current fusion diagnostic model achieved the highest accuracy, faster convergence speed, and stronger stability under all conditions.
For a systematic evaluation of classification reliability, global performance analysis was conducted using confusion matrices (Figure 12). It should be noted that the confusion matrix is derived from data under condition 1, serving as a typical case to visualize classification results. The diagonal elements of the confusion matrices represent the classification accuracy of each fault type. The diagonal values of the multisource data fusion approach are close to 1.0, indicating minimal misclassification; in contrast, the number of misclassifications significantly increased with the single-modality approach.
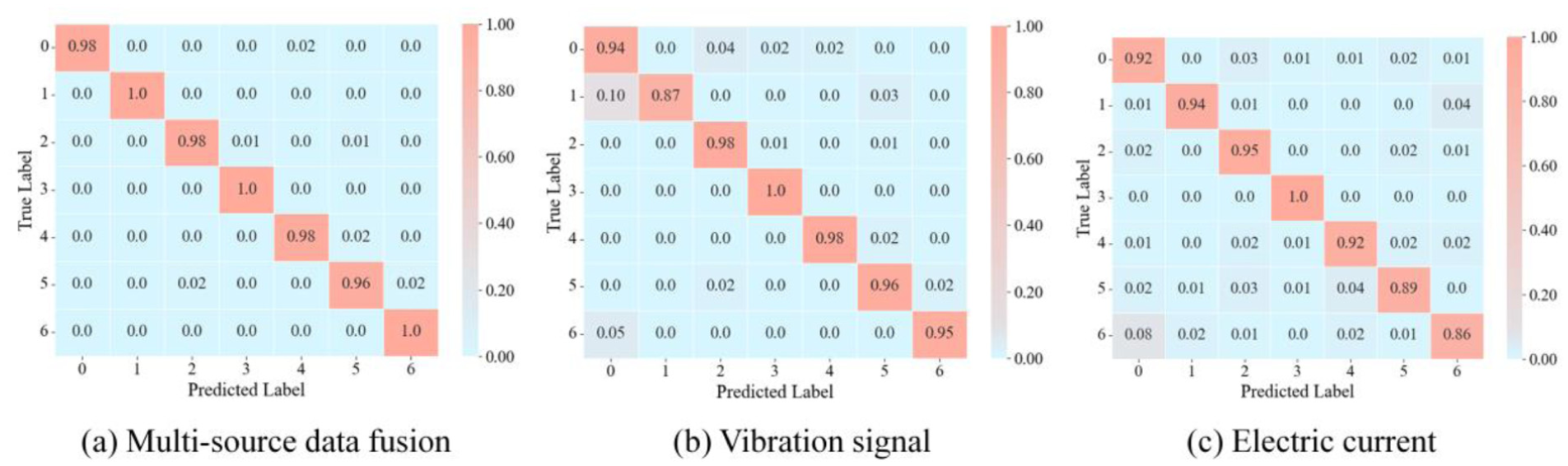
Confusion matrices for each diagnostic method: (a) multisource data fusion, (b) vibration signal and (c) electric current.
To gain deeper insight into the diagnostic performance of the model, t-distributed stochastic neighbor embedding (t-SNE) was employed for dimensionality reduction and visualization of features (Figure 13). Consistent with the confusion matrix, the t-SNE visualization is also based on condition 1 data. The results show that the fault feature clusters derived from multisource data fusion have clear boundaries and high separability, whereas the features from single-modality data exhibit significant overlap, leading to reduced diagnostic accuracy.
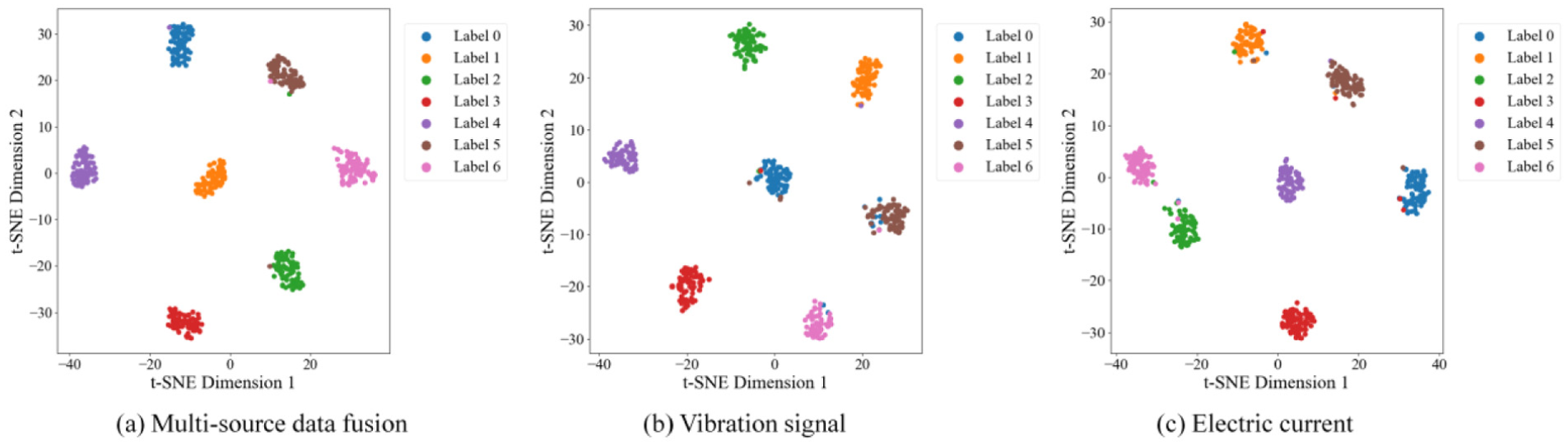
t-SNE visualization of fault diagnosis for multisource data fusion and single-source data: (a) multi-source data fusion, (b) vibration signal and (c) electric current. t-SNE: t-distributed stochastic neighbor embedding.
To further quantify the discriminative ability of the model, receiver operating characteristic (ROC) curves and the corresponding area under the curve (AUC) values were utilized for performance evaluation (Figure 14). Similar to the confusion matrix and t-SNE visualization, the ROC curves are generated based on condition 1 data. ROC curves are superior for performance assessment as they comprehensively reflect the trade-off between true positive rate (TPR) and false positive rate (FPR) across all classification thresholds, rather than relying on a single threshold, thus providing a more robust and holistic evaluation of the model’s discriminative power. As shown in Figure 14, the macro-average ROC curve of multisource fusion (Figure 14(a)) is closest to the top-left corner (ideal classifier performance), while those of single-modality methods (vibration and electric current, Figure 14(b) and (c)) deviate noticeably. In addition, the per-class curves of multi-source fusion cluster tightly near the top, indicating stable and strong discriminative power across all faults. In contrast, single-modality curves are more dispersed, with some deviating further, confirming the superiority of multi-source fusion.
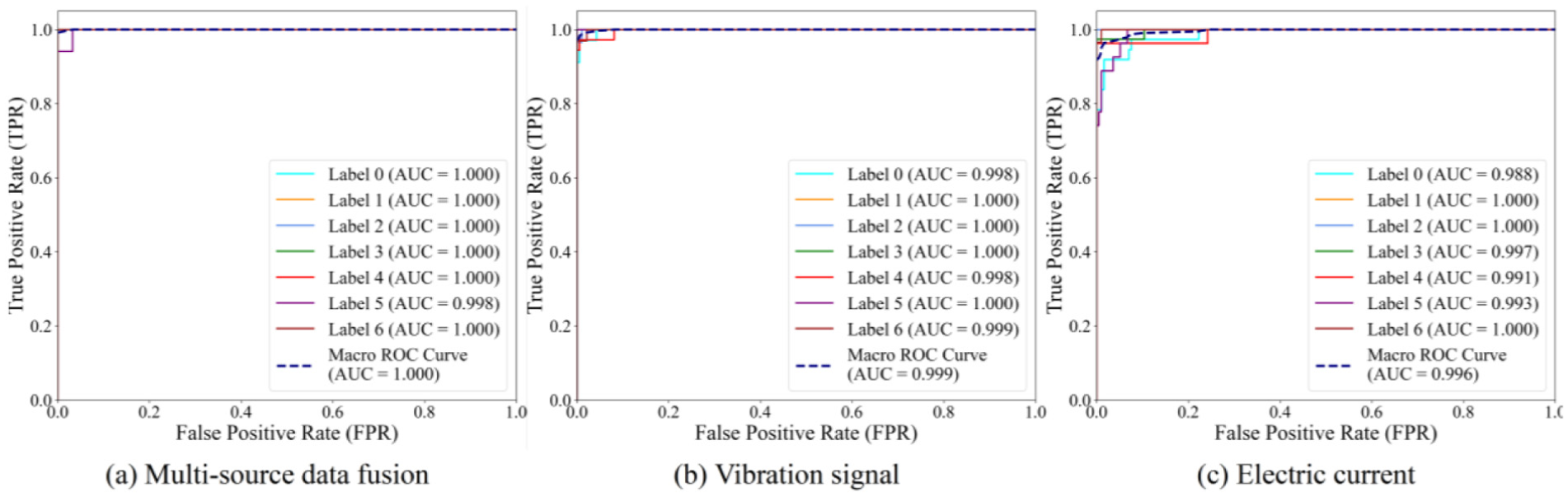
ROC curves of multisource data fusion versus single-source data for fault diagnosis: (a) multisource data fusion, (b) vibration signal and (c) electric current. ROC: receiver operating characteristic.
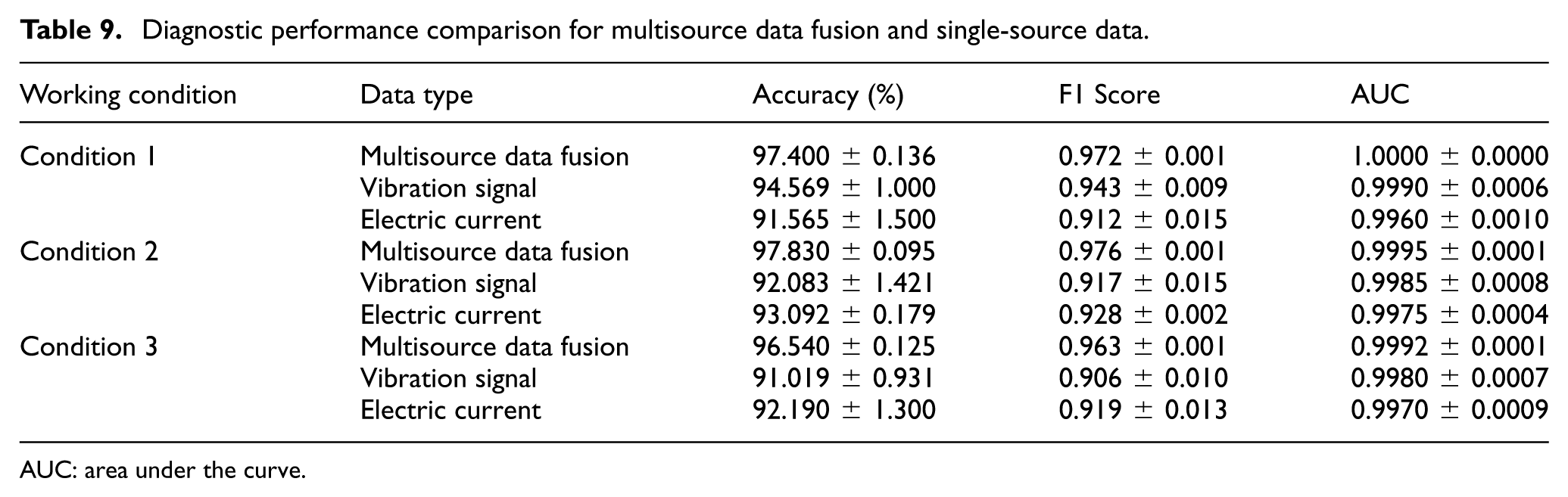
For a comprehensive and quantitative comparison of diagnostic performance across all three working conditions, Table 9 (diagnostic performance comparison for multisource data fusion and single-source data) summarizes the Accuracy, F1 Score, and AUC values of multisource fusion, vibration single-modality, and electric current single-modality under each condition. The F1 Score, as a harmonic mean of precision and recall, effectively balances the two metrics and is particularly suitable for evaluating classification performance in fault diagnosis tasks with potential class imbalance. The table provides complete statistical results, including standard deviations, which compensate for the lack of visualization results for conditions 2 and 3. It is worth noting that visualizations for conditions 2 and 3 are omitted to avoid redundant content, as their variation trends are consistent with condition 1. Multisource fusion consistently outperforms single-modality methods in terms of accuracy, stability, and discriminative ability. The statistical results in Table 9 fully validate the generality and effectiveness of the proposed multisource fusion strategy across different working conditions.
Diagnostic performance comparison for multisource data fusion and single-source data.
AUC: area under the curve.
Comprehensive performance comparison across models
To validate the advantages of the proposed method, comparative tests were conducted between the proposed model and classical models, including entropy-weighted complementary ensemble empirical mode decomposition and support vector machine (EWCEEMD-SVM), Multi-Scale Convolutional Neural Network (MSCNN), and Transformer, under three working conditions. Detailed comparison results are presented in Table 10 and Figure 15:
Condition 1 (full rotation, unidirectional forward rotation, no load): The model proposed in this paper outperforms all comparison methods with an accuracy of 97.4%, which is 3.1 percentage points higher than the traditional spectrum analysis model EWCEEMD-SVM. At the same time, the predicted standard deviation is 78.1% lower than that of the Transformer with the highest accuracy, except for SCViTNet proposed in this paper;
Condition 2 (partial rotation, reciprocating, with load): facing the coupled interference of 8 kg dynamic load and local angular displacement, the proposed model attained an accuracy of 97.83%, with a standard deviation of 0.095, representing a 59.2% reduction compared to Multi-Scale Convolutional Neural Network-Long Short-Term Memory (MCNN-LSTM’s) 0.247;
Condition 3 (partial rotation, reciprocating, no load): the proposed method maintained the highest diagnostic accuracy of 96.54%, and its prediction stability (standard deviation 0.105) improved by 90.6% compared to Subdomain Adaptation Transfer Learning Network (SATLN).
Diagnostic accuracy of different models under various working conditions.
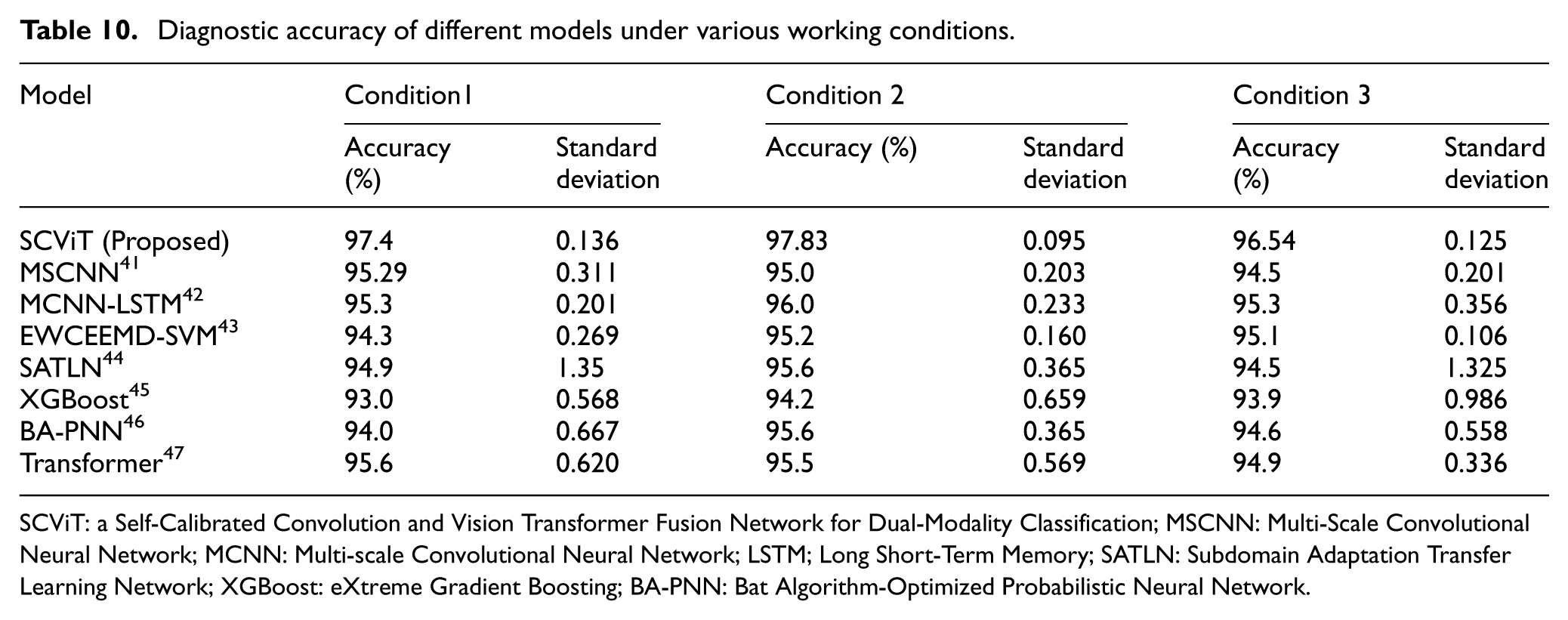
SCViT: a Self-Calibrated Convolution and Vision Transformer Fusion Network for Dual-Modality Classification; MSCNN: Multi-Scale Convolutional Neural Network; MCNN: Multi-scale Convolutional Neural Network; LSTM; Long Short-Term Memory; SATLN: Subdomain Adaptation Transfer Learning Network; XGBoost: eXtreme Gradient Boosting; BA-PNN: Bat Algorithm-Optimized Probabilistic Neural Network.
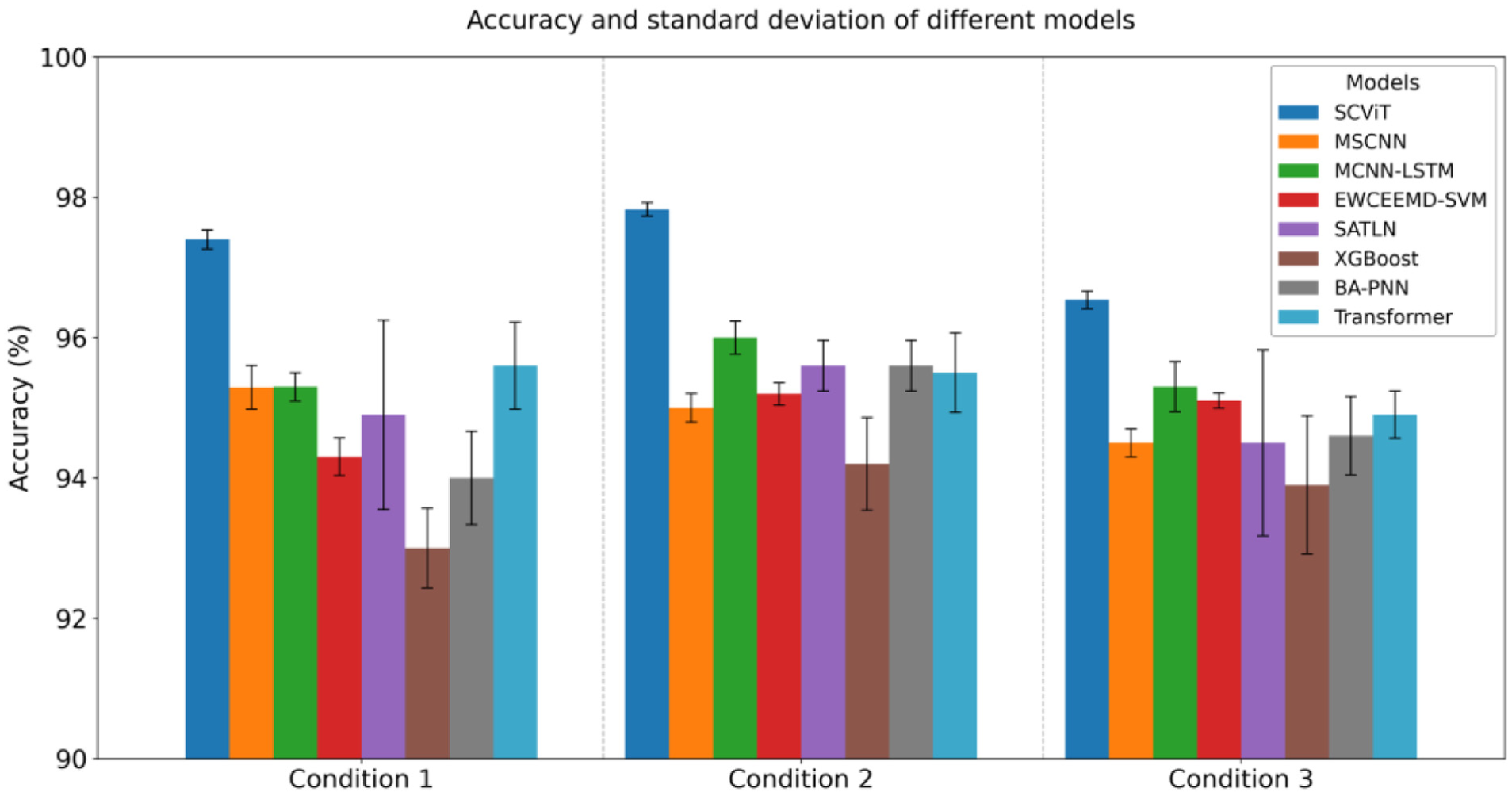
Diagnostic results of different models under various working conditions.
Across the three working conditions, the standard deviation of the proposed model was controlled within the range of 0.095–0.136, representing a reduction of 49.4–90.6% compared to representative models. These results demonstrate the superior performance of the proposed method under multidimensional variable coupling scenarios, including full and non-full rotations, as well as loaded and unloaded states.
Stability evaluation of small-sample augmentation
To evaluate the contribution of the GAN-based augmentation strategy for small-sample enhancement, this study compares the comprehensive diagnostic performance of different models under multiple augmentation ratios of 5:1, 10:1, 20:1, 50:1, and 100:1 using radar charts (Figure 16). The results indicate that the proposed model maintains high accuracy across all augmentation ratios; in contrast, other models, such as MSCNN and MCNN-LSTM, perform acceptably at low augmentation ratios (5:1), but their performance significantly deteriorates as the augmentation ratio increases to 50:1 or 100:1, due to the insufficient quality of generated samples.
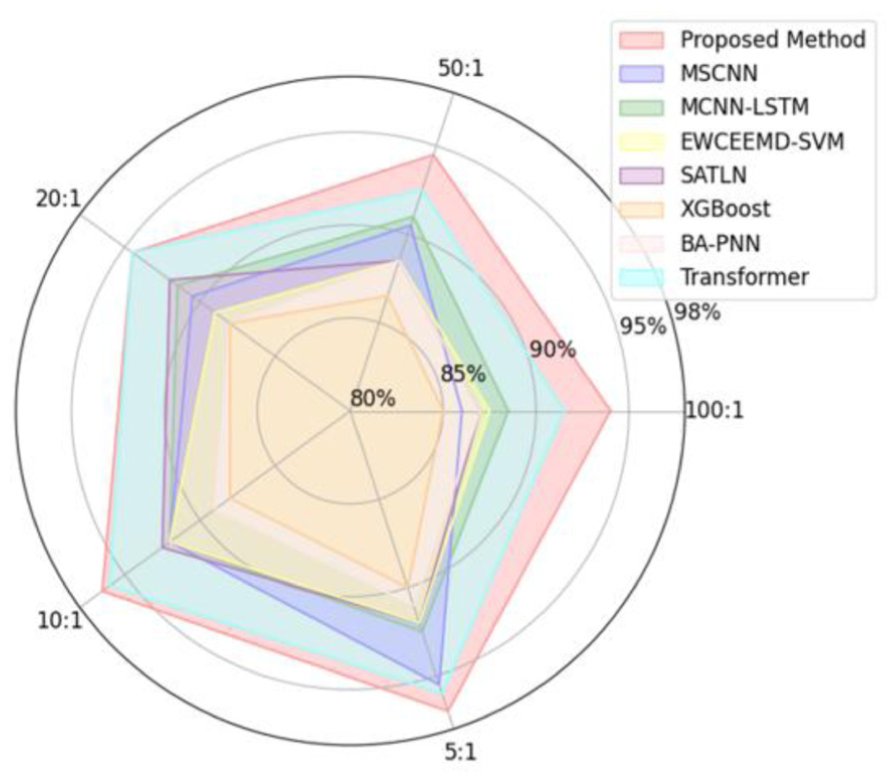
Performance comparison of models under imbalanced sample ratios.
The experiments demonstrate that the improved GAN proposed in this paper, by dynamically balancing the generation ratio, effectively alleviates model bias caused by data scarcity and maintains stable performance under high augmentation ratio scenarios, showing strong adaptability to small-sample conditions.
Conclusion
To address key challenges in small-sample fault diagnosis of RV reducers, such as data scarcity and insufficient generation quality, inadequate multi-modal information fusion strategies, and limited feature representation capability under complex working conditions, this study proposes a collaborative diagnostic framework, SCViT, integrating a WGAN-RAG network with cross-modal feature fusion. The following innovations have led to significant improvements in diagnostic performance:
WGAN-RAG architecture for small-sample data augmentation: This approach improves the generation quality of small-sample fault data and effectively mitigates data distribution skewness. The probability distributions of generated data closely approximate those of real data, with Pearson correlation coefficients reaching 0.8872 (vibration) and 0.8901 (current), respectively.
SCViT dual-branch fusion diagnostic network fully leveraging modal characteristics: Based on vibration and current signals, a dual-path feature extraction mechanism is constructed, integrating parameter-shared CNN, self-calibrated convolution, and ViT. The differentiated feature extraction strategy effectively overcomes the modality limitations of single-source signals, significantly improving fusion diagnostic accuracy. Under load conditions, the diagnostic stability standard deviation is reduced to 1/3 of that of single-modality methods.
Validation under multidimensional working conditions: Experiments demonstrate that the proposed method maintains stable diagnostic accuracy within the range of 96.54–97.83% across complex scenarios, including complete cycle motion, reciprocating motion, and load. Compared to state-of-the-art deep learning frameworks, the standard deviation is reduced by 49.4–90.6%, validating the strong adaptability of the method to complex mechanical motions.
Stability under high-ratio sample augmentation: Systematic comparisons under augmentation ratios from 5:1 to 100:1 verify that the framework maintains stable performance in high-ratio data expansion scenarios, confirming its strong adaptability to small-sample conditions.
Experimental results indicate that the proposed approach effectively addresses critical challenges in small-sample fault diagnosis of RV reducers, exhibiting superior engineering applicability under various working conditions and providing a novel technical solution for intelligent operation and maintenance of rotating machinery.
Despite the aforementioned advancements and promising results, this study still has certain limitations that warrant further attention. Specifically, under conditions of imbalanced original data distributions, the proposed framework tends to yield comparatively higher misclassification rates for fault categories with limited initial samples than for those with sufficient data. To address these limitations and enhance the practical applicability of the framework, future work will focus on the following directions. First, to improve the diagnostic performance for rare faults in imbalanced data scenarios, we plan to integrate advanced few-shot learning techniques with the existing WGAN-RAG framework. In particular, the incorporation of meta-learning mechanisms is envisaged to empower the model to rapidly adapt to novel fault diagnosis tasks with limited labeled samples, thereby improving its generalization capability across imbalanced distributions. Second, considering the stringent requirements for real-time processing and computational efficiency in industrial applications, subsequent research will also concentrate on model lightweight design and inference acceleration to facilitate efficient deployment of the framework in industrial environments.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the following projects: (1) National Natural Science Foundation of China, “Research on Industrial Robot Joint Health Condition Assessment and Evolution Mechanism Based on Current Information and Modal Analysis” (project no. 52165065) and (2) Yunnan Provincial Department of Science and Technology General Program, “Research on Industrial Robot Health Assessment and Damage Mechanism Based on Multi-source Sensors and Multi-deep Learning Model Fusion” (project no. 02401AT070346).