
Abstract
Federated learning safeguards privacy by training models collaboratively on distributed data and has demonstrated substantial promise in industrial fault diagnosis. Nevertheless, non-identically distributed client data, bespoke local model architectures, and catastrophic forgetting induced by evolving task streams markedly limit diagnostic performance. To address these challenges, a heterogeneous federated contrastive diagnosis framework with knowledge distillation and continual learning (HFCDF-KDCL) is introduced. Initially, each client is tasked with learning a personalized feature extractor from its own labeled private data to capture domain-specific characteristics. Subsequently, unlabeled public data are leveraged in a contrastive learning phase that minimizes the feature distance between identical samples across clients while maximizing inter-sample disparity, thereby yielding domain-invariant and highly discriminative representations compatible with heterogeneous-model structures. Finally, a dual-stream knowledge-distillation strategy is devised: within each task, the local pre-trained and the globally aggregated models act jointly as teachers whose soft targets fuse intra- and cross-domain knowledge, whereas across tasks, earlier-task models serve as distillation teachers to constrain parameter updates and mitigate catastrophic forgetting. Extensive experiments on multiple gear and bearing fault datasets indicate that HFCDF-KDCL achieves superior diagnostic accuracy and robustness relative to the current state-of-the-art federated approaches.
Keywords
Introduction
Gears and bearings are among the most widely used rotating components in aerospace systems, rail transportation, metallurgical manufacturing, and other safety-critical industrial equipment. They are responsible for motion transmission, load support, and power conversion, and their operating condition directly affects the reliability, stability, and service life of the entire mechanical system. 1 Once early faults such as cracks, pitting, wear, or local spalling occur, they may gradually evolve into severe failures, resulting in unexpected shutdowns, economic losses, and even safety accidents. Therefore, timely and accurate fault diagnosis of rotating machinery is of great importance for predictive maintenance, health management, and safe industrial operation. 2
In practical engineering scenarios, vibration signals are widely used for machinery health monitoring because they contain rich dynamic information related to fault initiation and degradation. Traditional fault diagnosis methods usually rely on expert knowledge and signal processing techniques, such as time-domain statistical analysis, frequency-domain analysis, and time–frequency transformation, to extract handcrafted features for fault identification. Although these methods have achieved certain success, their performance strongly depends on expert experience and prior knowledge of specific machines or operating conditions. As a result, they are often subjective, difficult to generalize, and inefficient when facing complex working conditions, variable loads, and large-scale industrial monitoring tasks. 3 Recent advances in deep learning have provided powerful tools for intelligent fault diagnosis. Deep neural networks can automatically learn discriminative high-level representations from raw monitoring signals or transformed signal features, thereby reducing the dependence on manual feature engineering and improving diagnostic accuracy. 4 However, the successful application of deep learning usually requires a large amount of high-quality labeled data. In real industrial environments, fault samples are difficult to collect because faults occur infrequently, destructive experiments are costly, and equipment downtime is unacceptable. Meanwhile, data collected by different factories, devices, or users are often stored locally because of privacy protection, commercial confidentiality, and data security regulations. These factors lead to limited labeled samples, isolated data resources, and severe data distribution differences, which have become major bottlenecks for deploying deep learning-based fault diagnosis methods in real applications. 5
Federated learning (FL) provides a promising privacy-preserving distributed learning paradigm for this problem. In FL, multiple clients collaboratively train a shared diagnostic model without directly exchanging raw monitoring data. Each client performs local model training using its own data and uploads only model parameters or gradients to a central server for aggregation. In this way, FL can alleviate data-sharing barriers while reducing privacy leakage risks, making it suitable for collaborative fault diagnosis across different enterprises, devices, or operating scenarios. 6 Nevertheless, directly applying conventional FL methods to industrial fault diagnosis remains challenging. First, the data collected by different clients are usually non-identically distributed, because machines may operate under different speeds, loads, fault severities, sensor layouts, and environmental disturbances. This non-IID characteristic causes local models to learn biased feature distributions, which weakens the generalization ability of the aggregated global model. Second, different enterprises or equipment vendors may adopt different diagnostic models according to their own computational resources, deployment platforms, and monitoring requirements. Therefore, the assumption that all clients share an identical model architecture is often unrealistic. This model heterogeneity makes standard parameter aggregation-based FL methods unsuitable for many industrial scenarios. Third, industrial diagnostic systems are usually required to operate continuously. As new tasks, fault types, or working conditions appear over time, the model should not only learn new knowledge but also retain previously acquired diagnostic ability. However, conventional FL models may suffer from catastrophic forgetting during continual task evolution, resulting in degraded performance on historical tasks. 7 To address distribution shifts in federated fault diagnosis, some studies have attempted to introduce domain-adaptation or feature-alignment techniques into FL. These methods aim to reduce the discrepancy among client domains and improve cross-client knowledge transfer. However, several critical limitations remain. First, most existing methods are designed under the assumption of homogeneous model architectures and thus cannot effectively support personalized diagnostic models with different structures. Second, existing feature-alignment strategies usually focus on the current task and ignore the retention of historical diagnostic knowledge during continual learning. Third, a unified representation alignment mechanism across heterogeneous clients is still lacking, which restricts the effectiveness of collaborative learning and knowledge transfer under complex industrial conditions.8,9 Therefore, it is necessary to develop a federated fault diagnosis framework that can simultaneously handle data heterogeneity, model heterogeneity, and catastrophic forgetting.
To overcome these issues, a heterogeneous federated contrastive diagnosis framework integrating knowledge distillation and continual learning (HFCDF-KDCL) is proposed. The illustration of a heterogeneous federated diagnosis framework is presented in Figure 1. The framework tackles data heterogeneity, model heterogeneity, and catastrophic forgetting through three key designs. First, each client trains a personalized feature extractor on its labeled data to capture domain-specific diagnostics, achieving local optimality. Unlabeled public data are then employed to build a contrastive feature-alignment strategy that minimizes the distance between identical samples across clients and maximizes inter-sample disparity, producing domain-invariant and discriminative representations compatible with heterogeneous models and enhancing cross-client knowledge transfer. Finally, a dual-path distillation scheme is developed: (1) within a single task, soft labels from the local pretrained model (intra-domain guidance) and the globally aggregated model (cross-domain perspective) are fused to promote multi-source knowledge sharing; and (2) during task evolution, historical-task models serve as teachers with adaptive temperature tuning to constrain current updates, preserving prior knowledge and mitigating catastrophic forgetting. Contributions are summarized as:
An end-to-end heterogeneous federated diagnosis framework is presented that accommodates personalized model architectures while strengthening collaborative training.
A cross-client contrastive learning mechanism aligns features under unlabeled auxiliary data, enhancing representation consistency and discriminability.
A dual-stream knowledge-distillation strategy provides intra-task knowledge complementarity and inter-task knowledge retention, ensuring continual diagnostic capability.
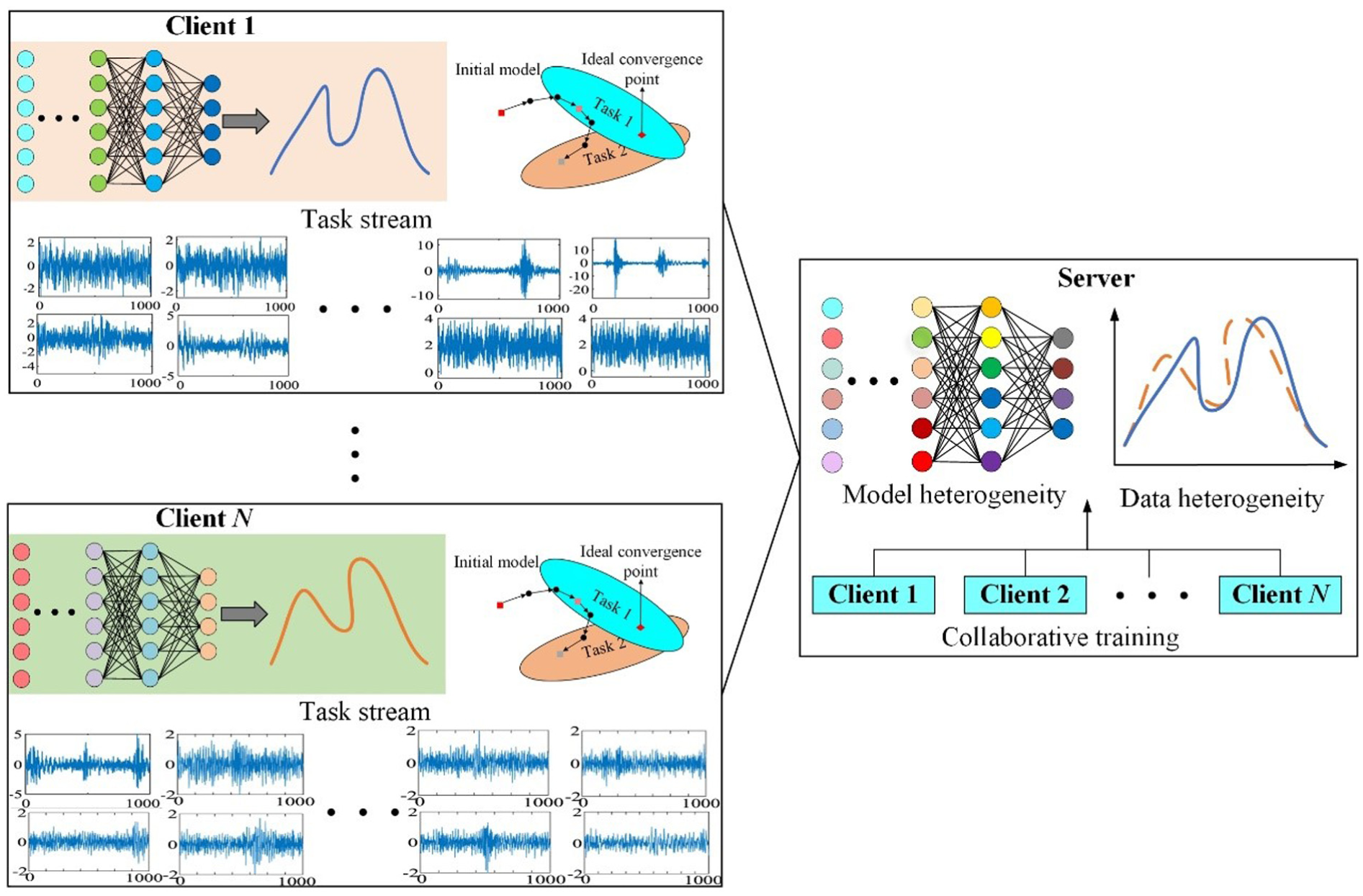
The illustration of a heterogeneous federated diagnosis framework.
Related works
FL has attracted considerable attention in industrial fault diagnosis because it preserves data privacy.10,11 Yu et al. employed structurally identical convolutional auto-encoders at each client, and an adaptive weighting scheme was devised to aggregate local parameters efficiently. 12 Zhang et al. proposed an FL-based mechanical-fault diagnostic approach that maintained privacy while enhancing accuracy through self-supervised pre-training. 13 A dual-channel classifier was incorporated by Mehta et al. into an FL framework, enabling reliable diagnosis of coupled component faults. 14 Zhang et al. adopted convolutional neural networks as local models and combined several training strategies, thereby mitigating performance degradation under non-IID conditions. 15 Lu et al. integrated multiple privacy-enhancing techniques into FL and designed a gradient-based supervision mechanism to address sample imbalance in fault datasets. 16 Given the pronounced inter-client distribution shifts observed in practice, FL has increasingly been combined with domain-adaptation techniques.
Zhao et al. defined a privacy space to align client distributions and fine-tuned the global model with high-confidence target samples, improving diagnostic performance. 17 Li et al. suppressed decision boundaries via pseudo-class generation and introduced prediction alignment and consensus to facilitate cross-domain knowledge transfer. 18 Chen et al. devised an aggregation strategy that incorporated maximum mean discrepancy, jointly achieving distribution alignment and global optimization; superior results were reported on several datasets. 19 Qian et al. surveyed privacy protection, communication efficiency, and distribution alignment in federated transfer learning for fault diagnosis. 20 A federated domain-generalization method with a shared reference domain was proposed by Li et al.; pairwise alignment and local–global synchronization endowed the model with robust generalization to unseen domains while preserving privacy. 21 Although federated domain-adaptation methods have advanced fault diagnosis under data heterogeneity, two critical gaps remain. Model-structure heterogeneity has seldom been addressed, limiting collaborative learning, and catastrophic forgetting across sequential tasks lacks systematic mitigation. A unified framework that simultaneously tackles data heterogeneity, model heterogeneity, and task continuity is therefore needed to enhance the practical and engineering value of federated intelligent fault diagnosis.22,23
Methodology
The fault diagnosis process of HFCDF-KDCL consists of two primary stages. In the first stage, each client independently trains a local model using its private data to fully capture domain-specific feature patterns and fault information. In the second stage, knowledge transfer across clients is achieved through a federated framework. To effectively align feature representations from heterogeneous clients while preserving discriminability, a contrastive learning-based feature-alignment strategy is constructed. This strategy minimizes the feature distance between identical samples extracted by different client models and maximizes the separation between features of different classes, thereby producing domain-invariant yet highly discriminative representations. In addition, a dual-stream knowledge-distillation mechanism is proposed. This mechanism performs knowledge transfer based on both iteratively updated models and pretrained models, facilitating intra-domain knowledge retention and enhancing cross-domain generalization. To mitigate catastrophic forgetting in multi-task learning, a regularization constraint is introduced during model updates to prevent the erosion of prior knowledge, thereby ensuring that the model retains memory of and remains adaptable to previous tasks while learning new ones. In summary, HFCDF-KDCL enables privacy-preserving collaborative modeling and continual learning across multiple domains and tasks. The overall framework is illustrated in Figure 2.
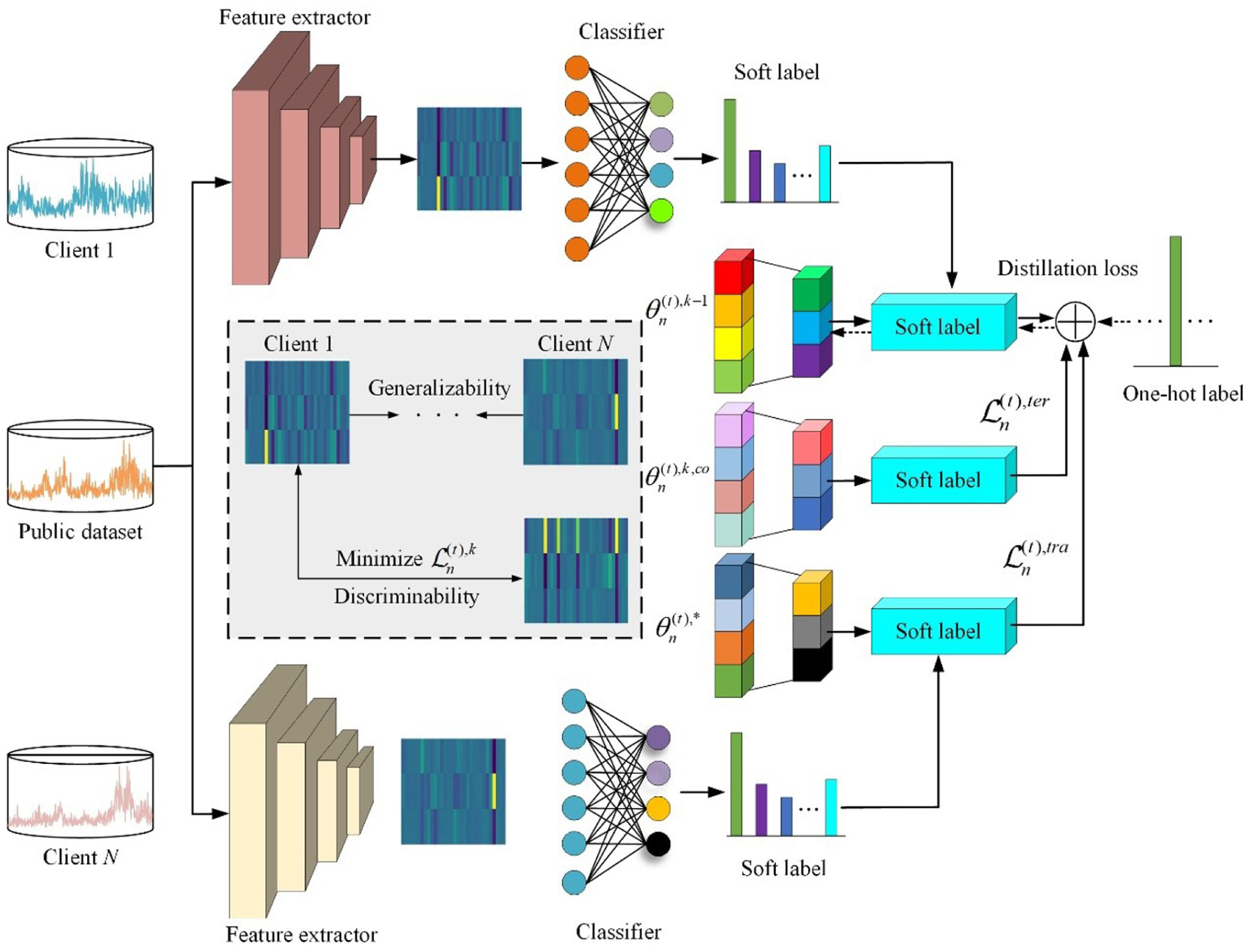
Working principle diagram of HFCDF-KDCL.
Problem formulation
In practical industrial fault diagnosis scenarios, directly collecting all raw data into a central server is usually impractical due to privacy protection, data security, commercial confidentiality, and communication cost. Therefore, traditional centralized learning methods are difficult to apply in real distributed industrial environments. Meanwhile, independently training a local model for each client may suffer from limited fault samples and insufficient generalization ability, especially for rare fault categories. FL provides a feasible solution by enabling multiple clients to collaboratively train diagnostic models without sharing raw monitoring data. In this paradigm, each client performs local training using its own private data, while only model knowledge, such as parameters, features, logits, or soft labels, is exchanged for global knowledge aggregation.
A standard FL configuration is assumed, comprising N local clients and a central server. The local dataset of the nth client is denoted as
To enhance generalization, an unlabeled public dataset
Pseudo-code of HFCDF-KDCL.

Contrastive feature-alignment strategy
The proposed study addresses cross-domain fault diagnosis under model heterogeneity, a setting in which conventional domain-adaptation techniques and global-model aggregation are inapplicable. Existing heterogeneous-FL methods usually collapse the extracted representations into one-dimensional vectors for mutual learning, a simplification that discards fine-grained semantics and severely limits alignment accuracy. To overcome this limitation, contrastive learning is introduced to align the high-dimensional features produced by each client’s extractor, thereby tackling data heterogeneity more precisely.
24
Privacy constraints preclude raw-data exchange; consequently, an unlabeled public dataset
For the nth client, a local model
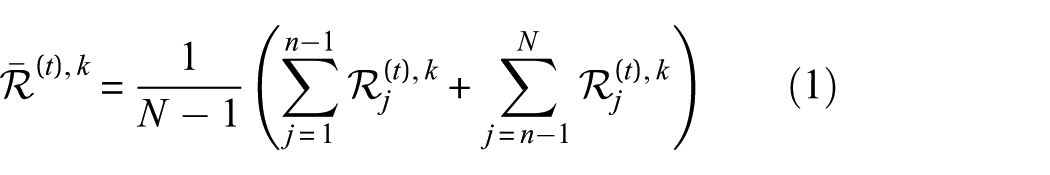
The distance between client n and the remainder is then
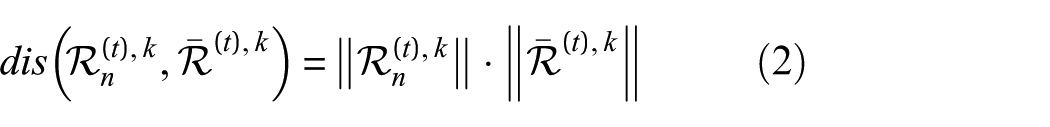
where
Following the anchor–positive–negative paradigm, positive pairs are defined as representations of the same public sample produced by different clients, whereas negative pairs correspond to representations of different samples. The collaborative contrastive loss is formulated as:
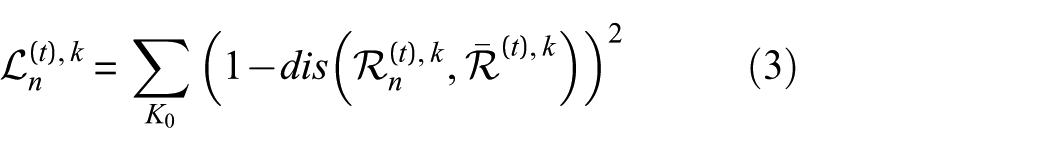
The loss function aims to minimize the distance. Through contrastive learning, the features of the same sample output will be concentrated in the same semantic subspace, which is convenient for subsequent knowledge distillation and task generalization and realizes federated collaborative training.
Federated multi-domain continual learning
Within the FL framework, the acquisition of well-generalized representations during local training is hindered by the non-identically distributed datasets held by individual clients. To ensure that local models remain robust and generalizable across multiple domains, knowledge from other clients must be effectively integrated while local-domain expertise is preserved. However, because of privacy-preserving mechanisms, raw data and model parameters are prohibited from being shared among clients during training, resulting in each round being isolated and confined to local optimization. Such isolated training is prone to inducing overfitting and therefore severely limits cross-domain transfer. In addition, catastrophic forgetting is encountered in continual-learning scenarios involving task streams, and long-term adaptability and stability in dynamic multi-task environments are markedly reduced.
To address these challenges, a knowledge-distillation mechanism is introduced, and a dual-stream distillation strategy is proposed with two concurrent objectives: (i) domain-specific knowledge inheritance, whereby the current local model is guided to learn from its historical counterpart so that accumulated knowledge is retained; and (ii) cross-domain knowledge transfer, whereby guidance from a global teacher is provided so that representations from other clients are absorbed without revealing private data, thereby enhancing cross-domain performance. Moreover, to alleviate catastrophic forgetting, a memory-enhanced distillation scheme is further proposed; by constructing a historical-model replay module and a distillation-guided loss, the model is encouraged to retain prior knowledge while adapting to new tasks, thereby achieving a dynamic balance of knowledge update. The theoretical formulation of the dual-stream knowledge-distillation strategy is detailed below.
(a) Dual-stream knowledge distillation: A task stream

where

Based on these logits, the cross-domain knowledge-distillation loss is defined below:
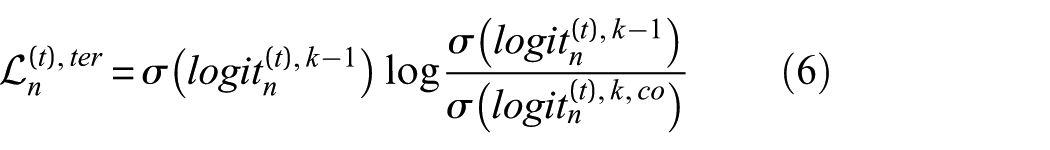
where
To this end, the client retains the pretrained parameters

The intra-domain distillation loss is formulated as:
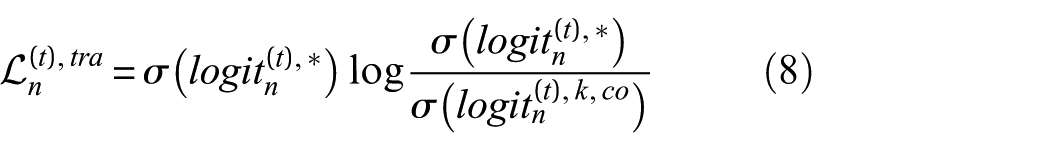
This loss encourages the current model to inherit the stable knowledge embedded in the pretrained model, effectively mitigating the fluctuations caused by frequent updates and thus enhancing training stability. Finally, by combining supervised learning with the dual-stream distillation strategy, the total local loss is designed as:
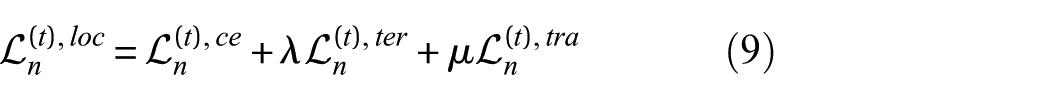
where
(b) Memory-augmented knowledge distillation: In realistic diagnostic scenarios, tasks typically arrive as a stream, and each client collects a new local dataset
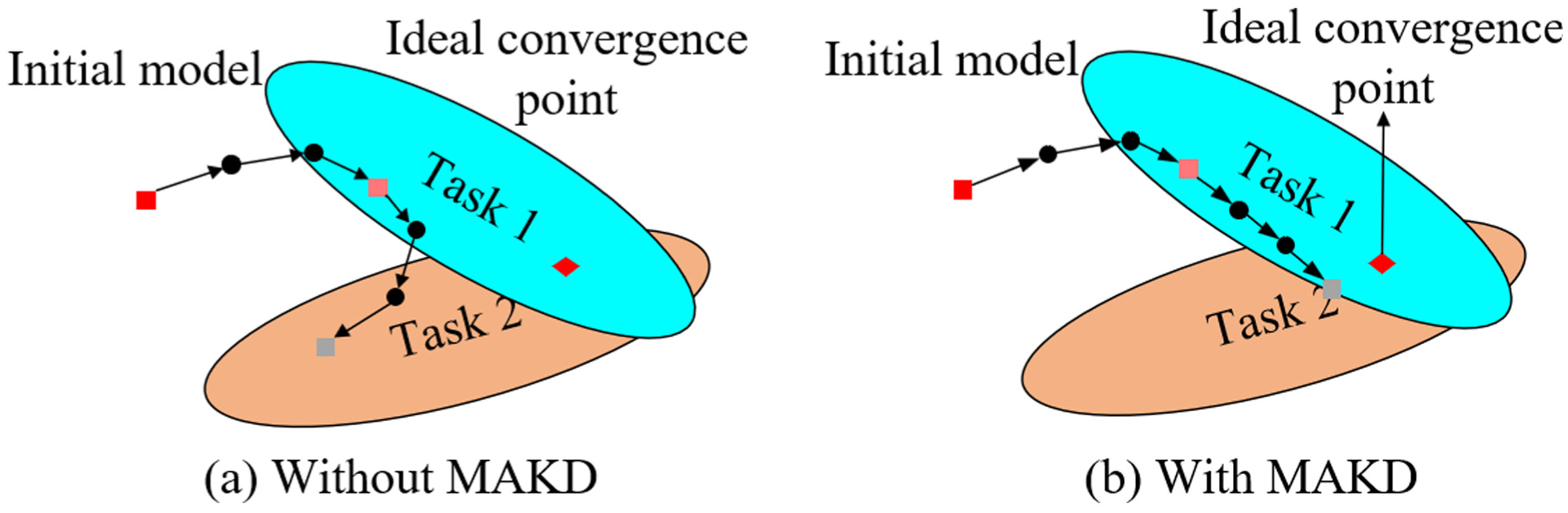
Comparison of model performance with and without MAKD.
After the task stream

To ensure that the current model maintains “memory” of prior tasks while learning the new one, these historical logits serve as the teacher to distill the current collaborative output
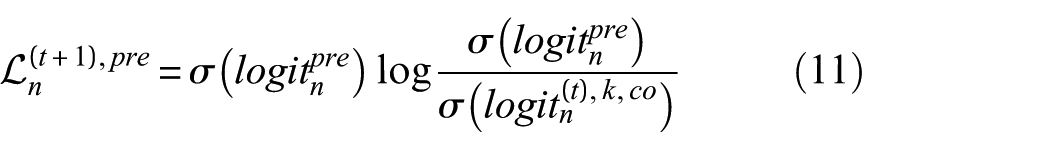
By combining Eq. (9) with Eq. (11), the total loss for client
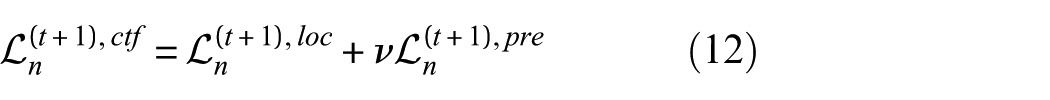
where
Experimental validation
Dataset description
Four datasets were utilized in this study, comprising three rotating machinery datasets and one unlabeled public dataset. Detailed descriptions of each dataset are provided below.
The first dataset was collected by our research group using a sliding bearing fault simulation testbed, designed and manufactured in collaboration with Jiangsu Lianyiyou Technology Co., Ltd. The testbed, illustrated in Figure 4, consists of a T-slot cast-iron working platform, a three-phase variable-frequency motor, a speed/torque sensor, a sliding bearing–rotor system, a coupling, a torque loading device, and a system control cabinet data acquisition was performed using an HD9200 multi-channel data-acquisition card and HD-YD-232 vibration acceleration sensors, both produced by Wuxi Houde Automation Instrument Co., Ltd. The sampling frequency was set to 102,400 Hz. Five operational conditions were defined: normal operation, rotor unbalance, rotor misalignment, rotor–stator rub, and rotor crack fault. By configuring different rotational speeds and torque levels, four subsets of operational data were obtained. Each subset contains 1,000 samples, with a sample length of 1024 data points. The specific operating parameters are as follows: WB1, 1500 rpm, 0 N·m, WB2, 2000 rpm, 2 N·m, WB3, 2500 rpm, 0 N·m, and WB4, 3000 rpm, 2 N·m.

Sliding bearing fault simulation testbed.
The second dataset was acquired on a gear-fault simulation testbed constructed by the research team; the equipment was designed and manufactured by Jiangsu Lianyiyou Technology Co., Ltd., as shown in Figure 5. The system is composed of a motor, a dynamic-torque sensor, a ZLS160-5-S-T planetary gearbox, a magnetic-particle brake, and ancillary modules, thereby providing a complete gear-fault simulation environment. The data-acquisition setup was identical to that used for dataset 1, and a sampling rate of 25,600 Hz was adopted. Five operating states were defined: normal, pitting, cracking, tooth breakage, and missing tooth. Four condition subsets with markedly different distributions were created by adjusting the rotational speed; each subset comprised 1000 samples of 1024 points. The specific operating speeds were set to WG1, 1000 rpm, WG2, 1500 rpm, WG3, 2000 rpm, and WG4, 2500 rpm.

Gear-fault simulation testbed.
The third validation dataset was obtained from a public gear-fault set released by Shandong University of Science and Technology. 25 The experimental platform comprises a motor, rotor, bearing housings, couplings, a gearbox, and a brake, and signals were sampled at 12,800 Hz. Seven operating states are included: normal, planetary-gear fracture, planetary-gear pitting, planetary-gear wear, sun-gear fracture, sun-gear pitting, and sun-gear wear. Four condition subsets were created by adjusting the rotational speed; each subset contains 1400 samples, with a sample length of 1024 points. The specific operating speeds were BG1, 1000 rpm, BG2, 1500 rpm, BG3, 1800 rpm, and BG4, 2000 rpm.
The unlabeled public dataset was drawn from the classic rolling-bearing repository of Case Western Reserve University and was sampled at 12000 Hz. Two subsets were extracted according to fault type—CWRU5 (five classes) and CWRU7 (seven classes); each class comprises 200 samples of 1024 points.
Experimental setup
To rigorously evaluate the diagnostic capability of the proposed approach, the following baselines were adopted for comparison. MSWTKD—a multi-source cross-domain diagnosis method that ignores privacy constraints and directly aggregates all available data to transfer knowledge from source to target domains. 26 FedMD—a heterogeneous federated framework that combines transfer learning with knowledge distillation. 27 FedDF—an ensemble-distillation aggregation scheme that trains a central classifier on the pseudo-labels predicted by client models over unlabeled data, enabling efficient collaboration among heterogeneous clients. 28 RHFL—a heterogeneous-FL framework that improves recognition across multiple source distributions via model alignment, a noise-robust loss, and a confidence reweighting strategy. 29 RCFL—a heterogeneous-FL algorithm that employs a weighted aggregation scheme to address label heterogeneity and leverages cross-label overlap information to enhance performance. 30
Appropriate hyperparameter selection critically affects diagnostic accuracy; the values for HFCDF-KDCL were determined empirically through extensive testing. The hyperparameters
Model-parameter settings.

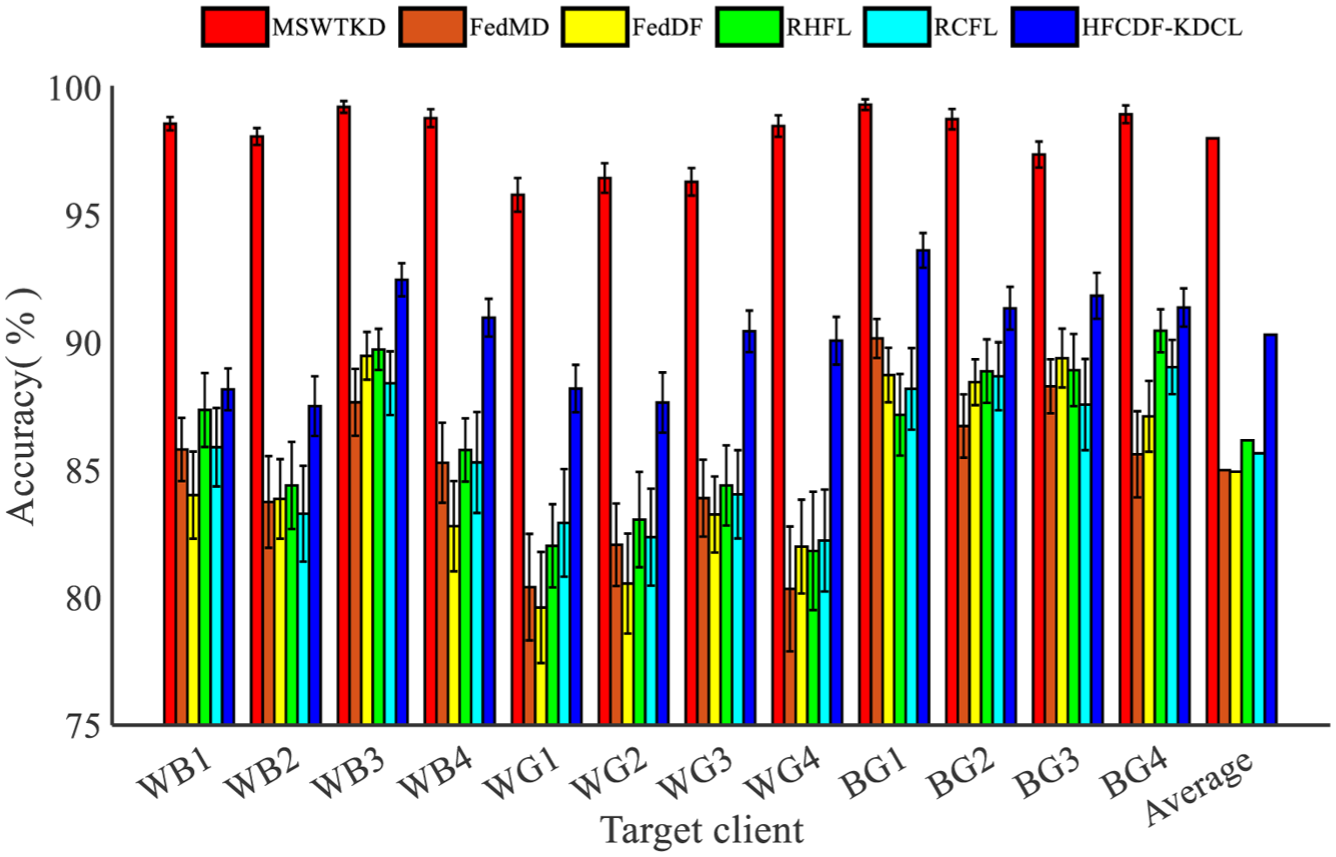
It should be noted that WB1 designates the target client, whereas WB2, WB3, and WB4 act as source clients; the same convention applies to all other groups. According to the results in Table 2, HFCDF-KDCL exceeded every existing FL method on each target client, attaining a mean accuracy of 90.30 %—an improvement of 5.30, 5.36, 4.13, and 4.64 percentage points over FedMD (85.00 %), FedDF (84.94 %), RHFL (86.17 %), and RCFL (85.66 %), respectively. For the bearing tasks WB1–WB4, accuracies of 88.17 %, 87.51 %, 92.46 %, and 90.97 % were obtained, surpassing all FL baselines by 2–6 pp. These gains demonstrate that contrastive feature-alignment and dual-stream distillation effectively counteract the performance loss caused by data and architectural heterogeneity while maintaining high robustness and validating the strong generalization of the domain-invariant representations. Within the gear-diagnosis tasks WG1–WG4, accuracies ranged from 88.20% to 90.44%, outperforming the best competing method, RHFL by roughly 6 pp on average, further confirming the sensitivity and discriminative power of the proposed framework. On the public Shandong University gear dataset (BG1–BG4), HFCDF-KDCL likewise delivered stable scores between 91.34% and 93.61 %, clearly outstripping all federated counterparts; these results indicate that the distillation-and-alignment mechanism, assisted by unlabeled public data, yields superior performance in multi-source heterogeneous environments. By contrast, the centralized baseline MSWTKD achieved the highest accuracies in every task (>95 %) and an overall mean of 98.01 %—showing that training on all source- and target-domain data produces excellent performance, though at the expense of industrial privacy requirements. Collectively, HFCDF-KDCL overcomes the simultaneous challenges of non-IID data and model heterogeneity while preserving privacy, thereby offering superior practicality and robustness and providing a solid foundation for engineering deployment of heterogeneous federated continual learning.
The diagnosis results of all methods.
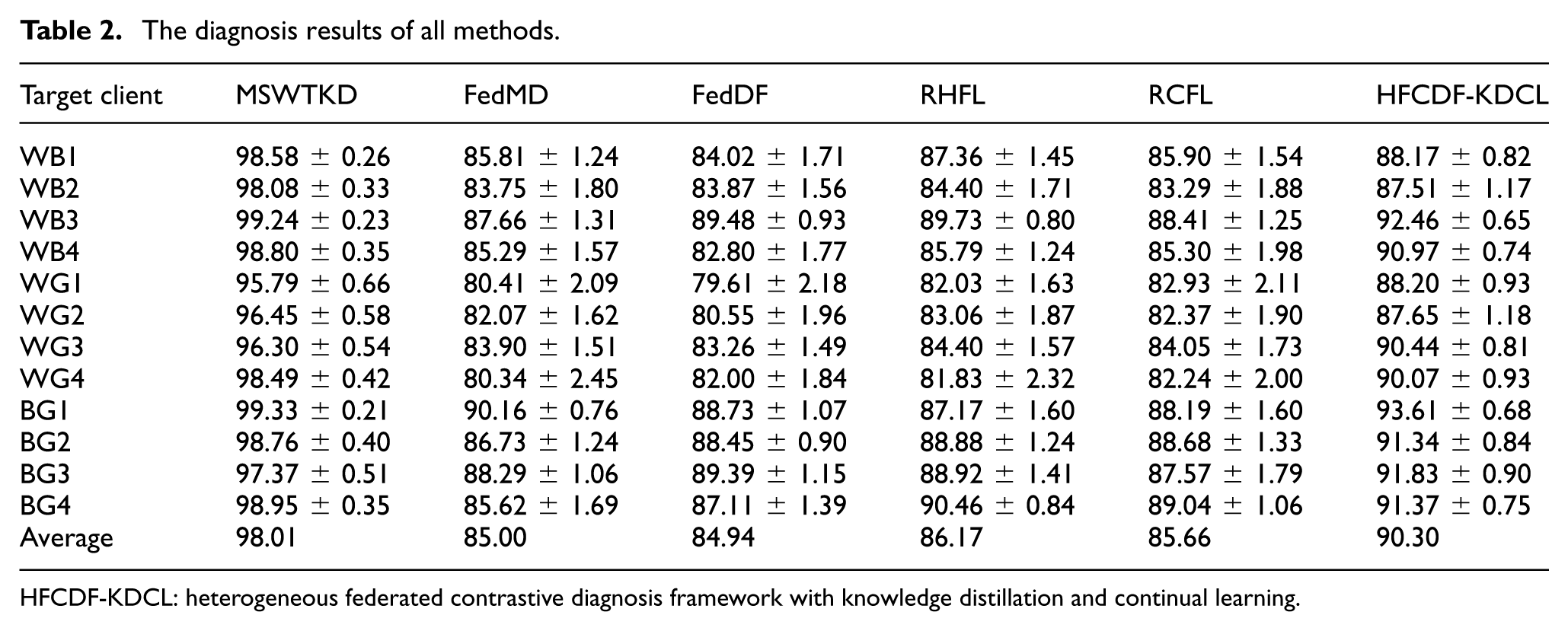
HFCDF-KDCL: heterogeneous federated contrastive diagnosis framework with knowledge distillation and continual learning.
The diagnostic results demonstrate that HFCDF-KDCL outperforms all compared FL methods on most target clients. The average accuracy reaches 90.30%, which is higher than that of FedMD, FedDF, RHFL, and RCFL. These improvements indicate that the proposed framework can better handle non-IID data and heterogeneous-model structures. Compared with FedMD and FedDF, HFCDF-KDCL benefits from feature-level alignment and dual-path distillation rather than relying only on output-level ensemble distillation. Compared with RHFL and RCFL, the proposed method further introduces intra-domain knowledge preservation and cross-task historical distillation, which improve stability under heterogeneous and continual-learning scenarios. However, the centralized MSWTKD method still achieves higher accuracy than HFCDF-KDCL. This is because centralized training can directly access all source and target data, allowing the model to learn complete sample-level distributions and more accurate global decision boundaries. In contrast, HFCDF-KDCL is constrained by privacy-preserving FL, where private raw data cannot be shared. Knowledge transfer is performed indirectly through feature-alignment and soft-label distillation, which inevitably causes information loss. In addition, heterogeneous client architectures make parameter-level aggregation impossible and increase the difficulty of representation alignment. Therefore, the gap between HFCDF-KDCL and centralized training reflects the trade-off between diagnostic performance and privacy preservation. Although HFCDF-KDCL does not surpass centralized multi-source training, it achieves competitive performance under stricter and more realistic industrial constraints, including data privacy, model heterogeneity, and distributed deployment (Figure 6).
Bar chart of diagnostic accuracy achieved by all methods. (a) MSWTKD, (b) FedMD, (c) FedDF, (d) RHFL, (e) RCFL, (f) HFCDF-KDCL.
In Figure 7, confusion matrixes for the five operating conditions of target client WG1 (normal, pitting, cracking, tooth breakage, and missing tooth) are plotted for six methods to facilitate direct visual comparison. The diagonal entries of the centralized MSWTKD matrix are nearly saturated (normal 179, pitting 184, cracking 193, tooth breakage 200, missing tooth 200), with only minor misclassifications—normal samples occasionally being labeled as pitting or missing tooth, and a few pitting samples mislabelled as normal—thus exhibiting the highest precision. Among the FL methods, FedMD and FedDF produced the most severe confusions between pitting and missing-tooth classes: FedMD misclassified 41 pitting and 35 missing-tooth samples as normal, whereas FedDF mislabelled 44 pitting and 34 missing-tooth samples as normal. Although RHFL improved the recognition of cracking and tooth breakage, 29 cracking samples were confused with tooth breakage, and 25 missing-tooth samples with normal. RCFL separated normal and pitting reasonably well (normal 173, pitting 152) but still misclassified 43 missing-tooth samples as normal and 27 as pitting. By contrast, HFCDF-KDCL restored correct identification for the majority of cracking and tooth-breakage cases (cracking 167, tooth breakage 192), reduced normal–pitting confusion to its minimum (only 14 normal as pitting and 28 pitting as normal), and distinguished missing-tooth samples most precisely (only 21 mislabelled as pitting and 15 as tooth breakage). Overall, HFCDF-KDCL markedly compressed off-diagonal errors—especially in the easily confused pitting and missing-tooth categories—thereby confirming the combined advantages of contrastive multi-domain alignment and dual-stream fusion of intra- and cross-domain knowledge.
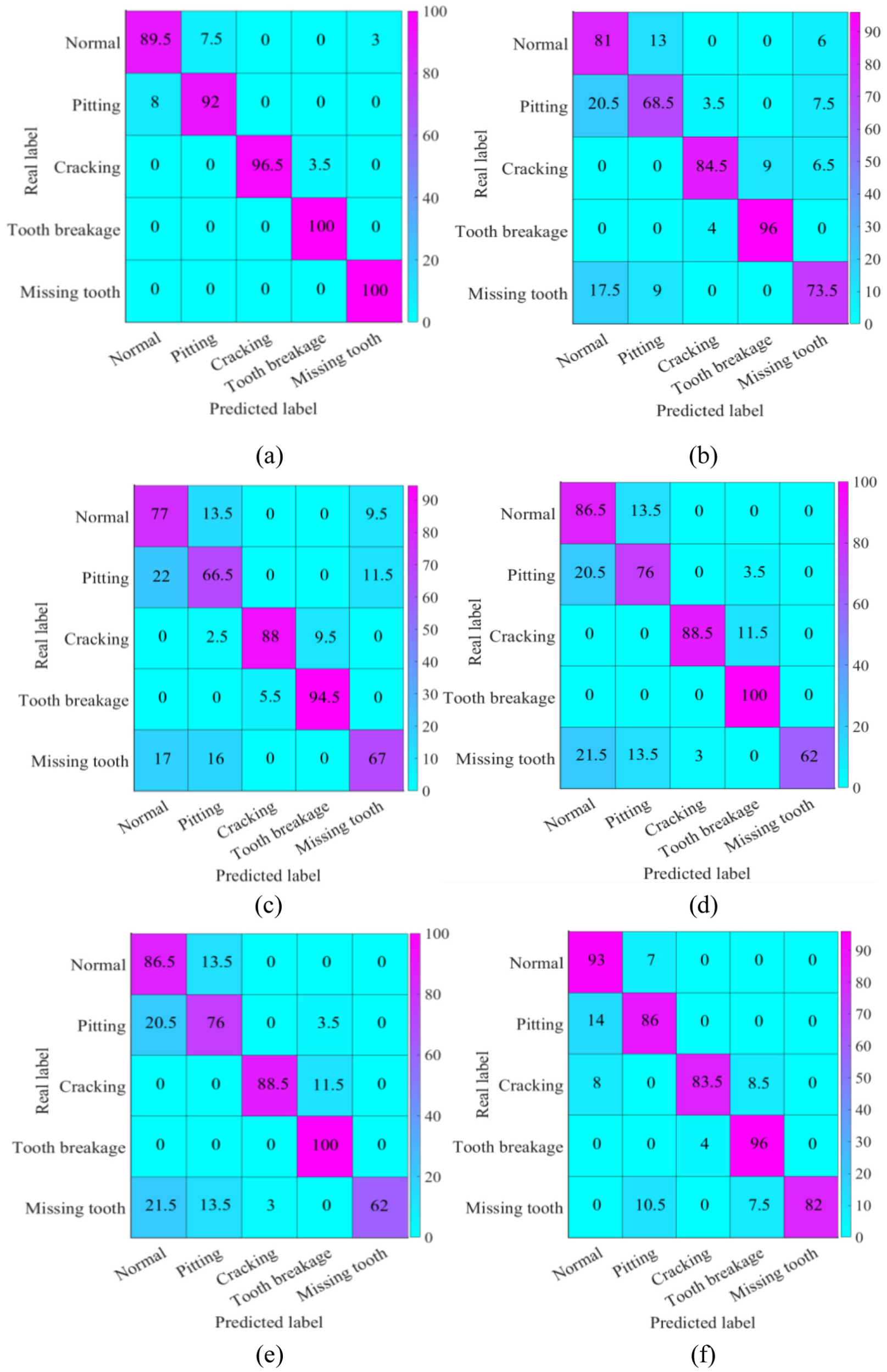
The confusion matrixes of all methods on the target client WB1.
Finally, to illustrate the feature-representation differences among algorithms on client WG1, t-SNE was applied to project the high-dimensional features extracted by four methods on the target client WG1 (with WG2 as the source client) into two dimensions; the clustering outcomes are shown in Figure 8. The centralized baseline MSWTKD yielded five tightly clustered and clearly separated groups, each corresponding to a fault type, indicating near-perfect feature compactness. By contrast, the point clouds produced by FedMD exhibited extensive overlap—particularly between normal ↔ pitting and cracking ↔ tooth breakage—revealing that pure distillation or ensemble schemes struggle to retain discriminability in heterogeneous environments. RCFL improved separation for the normal and missing-tooth classes through weighted aggregation, yet remained insufficiently robust for intermediate fault types. In comparison, HFCDF-KDCL generated feature clouds that formed independent, uniformly distributed clusters with sharp inter-cluster boundaries and minimal overlap, validating that the synergy of contrastive, domain-invariant alignment and dual-stream distillation markedly enhances discriminative power and generalization under multi-source heterogeneity.
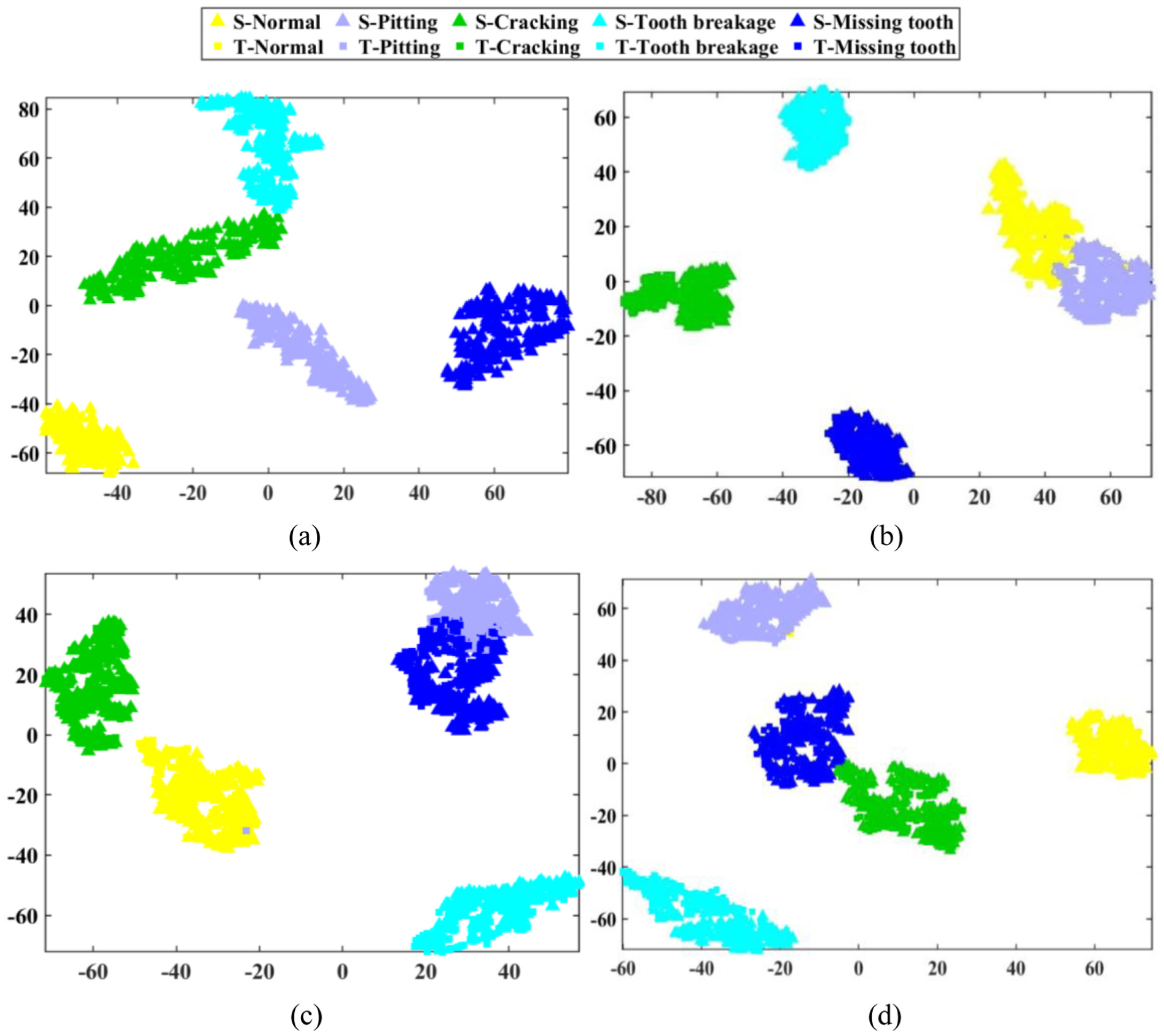
Comparison of feature visualization results. (a) MSWTKD, (b) FedMD, (c) RCFL (d) HFCDF-KDCL
Evaluation of anti-forgetting capability
Mitigating catastrophic forgetting in multi-task scenarios constitutes a key contribution of the proposed framework. Five methods—FedMD, FedDF, RHFL, RCFL, and HFCDF-KDCL—were compared. The model trained on the target client WB1 served as the initial model for WG1 fine-tuning; after each fine-tuning round, the global model was saved to assess performance on both the new and the historical tasks, as illustrated in Figure 9.
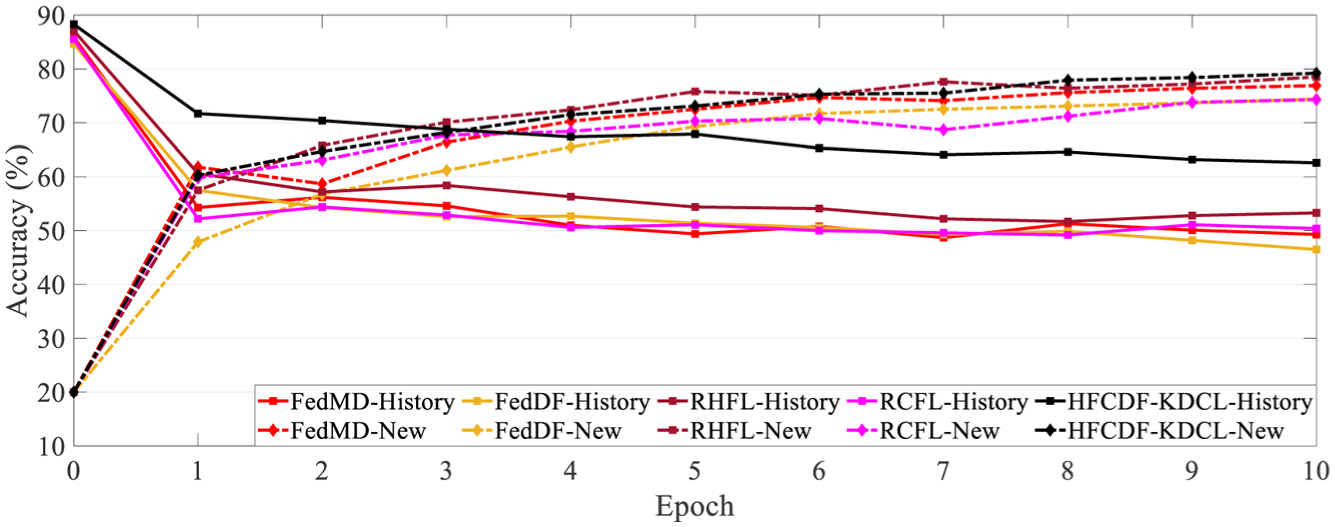
Comparison of cross-task performance.
During multi-task fine-tuning, FedMD, FedDF, RHFL, and RCFL all suffered pronounced catastrophic forgetting. For example, the accuracy of FedMD on the former task (WB1) plummeted from 85.9% to 49.3% by round 10; FedDF and RCFL fell to 46.5% and 50.4%, respectively, while RHFL, despite noise-robust enhancements, declined to 53.3%. In stark contrast, HFCDF-KDCL demonstrated exceptional resilience: the previous-task accuracy decreased only from 88.3% to 62.6%, with a markedly smoother trajectory, confirming that the continual-learning strategy effectively retained prior knowledge. All methods exhibited rising accuracy on the new task (WG1); nevertheless, HFCDF-KDCL achieved both the fastest convergence and the highest final accuracy (79.2%), indicating its ability to accommodate new tasks while safeguarding historical knowledge. At a deeper level, the dual-stream distillation scheme in HFCDF-KDCL provided intra-task knowledge complementarity and inter-task knowledge preservation, thereby balancing parameters across the task stream, improving new-task performance, and substantially reducing forgetting—a critical prerequisite for long-term, online industrial diagnosis.
Ablation study
To evaluate the contribution of each key component, ablation experiments were conducted by removing one module at a time. The following variants were constructed: w/o FA: HFCDF-KDCL without cross-client feature alignment. w/o CD: HFCDF-KDCL without cross-domain distillation. w/o ID: HFCDF-KDCL without intra-domain distillation. w/o TD: HFCDF-KDCL without cross-task historical distillation. Full model: The complete HFCDF-KDCL. Three representative tasks, namely WB1, WG1, and BG1, were selected for evaluation. The ablation study results are presented in Table 3.
The ablation study results.
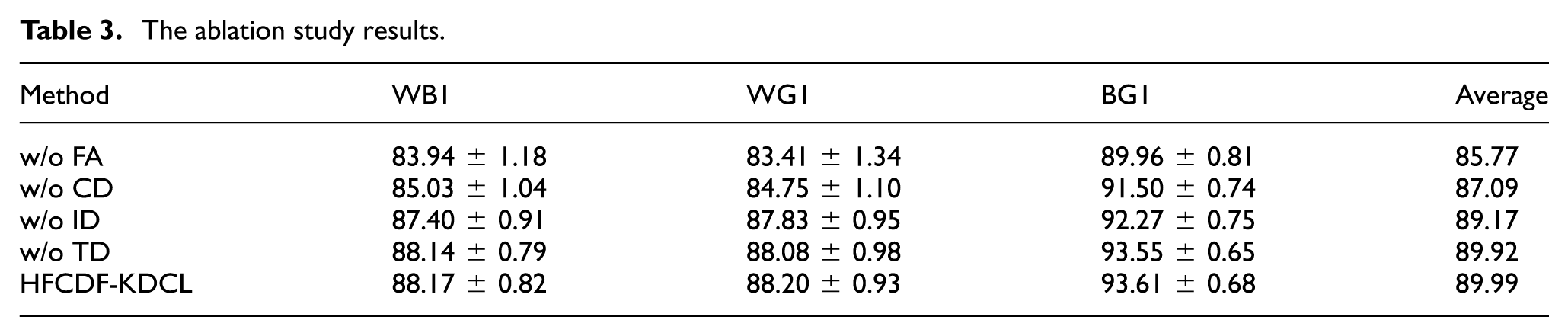
As shown in Table 3, removing any key component leads to different degrees of performance degradation, indicating that the proposed modules contribute to the final diagnostic performance from different perspectives. Among all variants, removing the cross-client feature-alignment module causes the most obvious decline, with the average accuracy decreasing from 89.99% to 85.77%. This result demonstrates that public-data-driven feature alignment plays an important role in reducing representation discrepancies among heterogeneous client models. Without this module, different clients fail to establish consistent representations of the shared public data, weakening cross-client knowledge transfer and inter-class separability. When the cross-domain distillation module is removed, the average accuracy decreases to 87.09%. This indicates that complementary knowledge from other clients is beneficial for improving generalization under non-IID data distributions. Without cross-domain distillation, each client tends to rely more heavily on its own local data, which may lead to domain-biased representations and reduced target-client performance. Removing the intra-domain distillation module also results in a performance decrease, with the average accuracy dropping to 89.17%. This suggests that intra-domain distillation helps preserve stable local diagnostic knowledge during federated updates. By using the local pretrained model as a teacher, the client model can avoid excessive deviation from domain-specific fault characteristics, thereby improving training stability under heterogeneous FL. Compared with the other variants, removing cross-task historical distillation causes only a slight decrease in the current-task diagnostic accuracy, from 89.99% to 89.92%. This is reasonable because cross-task distillation is mainly designed to alleviate catastrophic forgetting during continual task evolution, rather than to directly improve single-task classification accuracy. Therefore, its contribution is more clearly reflected in the anti-forgetting experiment rather than in the current-task ablation results. The cross-task evaluation in Section 4.6 further verifies that historical-knowledge distillation is essential for retaining previous-task performance when new diagnostic tasks arrive.
Overall, the ablation results confirm the effectiveness of the main modules in HFCDF-KDCL. Feature alignment and cross-domain distillation mainly improve cross-client knowledge transfer and generalization; intra-domain distillation enhances local knowledge preservation and training stability; and cross-task distillation supports continual diagnostic capability by mitigating forgetting across sequential tasks.
Conclusion
To address data heterogeneity, architectural disparity, and stringent privacy constraints in industrial fault diagnosis, a heterogeneous federated framework—HFCDF-KDCL—was presented. By deeply integrating contrastive learning, dual-stream knowledge distillation, and continual learning, unified modeling and knowledge transfer across multiple tasks and domains were achieved. Experiments on diverse bearing and gear datasets demonstrated an average diagnostic accuracy of 90.30%, significantly surpassing mainstream FL baselines. The dual-stream distillation strategy effectively alleviated catastrophic forgetting, balancing memory of previous tasks with adaptation to new ones. t-SNE visualizations confirmed superior class separation, and confusion-matrix analyses underscored notable gains on previously confounding fault types. Despite these advances, a performance gap relative to centralized learning persists.
Furthermore, the present study focused on cross-domain collaboration among homogeneous devices and did not yet encompass more complex scenarios such as cross-device or heterogeneous-sensor environments. Future work will explore more efficient distillation-and-alignment mechanisms and extend the framework to cross-device, multi-modal applications to further enhance generalization and engineering applicability.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the National Natural Science Foundation of China (No. 12102345) and the Guangdong Basic and Applied Basic Research Foundation (No. 2023A1515010764).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Data will be made available on request.