
Abstract
Axial piston pumps operate under dynamic conditions in practical applications, leading to cross-domain data distribution discrepancies that pose challenges for their deep-learning based fault diagnosis. While transfer learning has shown promise in mitigating such data distribution discrepancies between different domains, existing single-source transfer learning methods exhibit limited diagnostic accuracy when confronted with substantial domain shift. To address this challenge, this article proposes a novel transfer learning framework that fuses knowledge from multisource subdomains and simulation-driven soft labels. Each source subdomain has an independent domain-specific classifier, and its contribution to the final classification decision is weighted by the distribution discrepancy between source and target data. A computational fluid dynamics model is developed to simulate discharge pressure signals under target operating conditions. These simulated signals are used to compute soft labels through interclass similarity, which enables prior knowledge of target domain to be incorporated during classifier training. Experiments on an axial piston pump at various rotational speeds demonstrate that the proposed model increases the diagnostic accuracy by 28.03% over conventional single-source methods. Furthermore, the integration of simulation-driven soft labels yields an additional 13.59% accuracy gain. As a result, the proposed model achieves a superior average accuracy of 99.02%.
Introduction
Hydraulic transmission systems have a wide range of applications in various industries, including aerospace, automotive, construction machinery, and machine tools. At the core of these systems, axial piston pumps function as the hydraulic “heart,” converting mechanical energy into hydraulic power for delivering pressurized fluid to actuators. However, axial piston pumps are particularly vulnerable to extreme operating conditions, such as high speed, high pressure, and wide temperature ranges. 1 Failures in these pumps can lead to machine breakdown, resulting in substantial economic losses and potential safety risks. Consequently, implementing intelligent operation and maintenance for axial piston pumps is vital to guarantee safe and reliable performance of hydraulic transmission systems. 2
Fault diagnosis is a critical component of intelligent operation and maintenance for mechanical equipment. 3 For axial piston pumps, two primary approaches are employed: physics-based models and data-driven models. The former relies on domain-specific knowledge to establish specific physical models under certain assumptions. However, these models are often constrained by noisy operating environments and complex dynamic systems. Additionally, they cannot be updated in real time using online observed data, which restricts their capability to provide timely maintenance recommendations. In contrast, data-driven models require no complex and sophisticated mathematical models, making them increasingly popular for diagnosing hydraulic pumps. 4
Conventional data-driven fault diagnosis methods typically input hand-crafted features extracted using signal processing technique5,6 into shallow machine learning models—such as extreme learning machine, 7 support vector machine, 8 K-nearest neighbor, 9 and decision tree 10 —for pattern classification or regression. Driven by advances in artificial intelligence and Industrial Internet of Things, deep learning, which automatically extracts deep feature representations directly from raw data, has become a transformative paradigm for data-driven fault diagnosis of rotary machinery.11,12 These supervised methods have demonstrated their effectiveness in the fault diagnosis of axial piston pumps, 2 but they heavily rely on the ideal assumption of abundant labeled data as well as independent and identical distributions for training and testing datasets. Unfortunately, labeled samples are often scarce in practical applications. Furthermore, the distribution discrepancies arising from varying operating conditions or diverse mechanical devices inevitably lead to severe performance degradation and poor generalization in new scenarios, hindering their practical engineering deployment. 13
To overcome these limitations, transfer learning has emerged as a promising solution to enhance model generalization by mitigating distribution discrepancies across different domains.14,15 Two main transfer learning strategies, comprising discrepancy-based and adversarial-based frameworks, have been extensively explored in mechanical fault diagnosis research. 16 The former minimizes the data distribution discrepancy between source and target domains using various metrics, such as maximum mean discrepancy (MMD)17,18 and its variants, including multikernel MMD, 19 joint MMD, 20 and local MMD (LMMD). 21 The adversarial-based transfer learning strategy learns domain-invariant features through adversarial training between a domain discriminator and a feature generator.22,23 The discriminator is responsible for distinguishing between source and target samples, while the generator learns to produce features that deceive the discriminator. Building upon the adversarial paradigm, advanced variant models such as cycle-consistent generative adversarial networks have been developed to address the critical scarcity of labeled fault samples in target scenarios.24,25
Transfer learning has demonstrated significant advances in machinery fault diagnosis in recent years, particularly in areas such as bearings, 26 gearboxes, 27 and hydraulic pumps.28,29 While effective for cross-domain tasks, most existing studies concentrate on single-source domain knowledge transfer to target domain. However, labeled dataset are often collected from diverse sources, and a single-source dataset often provides insufficient knowledge for many real-world applications. Consequently, conventional single-source transfer learning models may exhibit suboptimal diagnostic accuracy in the target domain.
By contrast, multisource domains can offer complementary knowledge from various operating conditions or machines. Mansour et al. 30 demonstrated that the target distribution in multisource domain adaptation can be represented as a weighted combination of source distributions. This implies that a target classifier can be constructed by combining diverse source-specific classifiers with appropriate weights, provided that source-target domain relationships are known, 31 thus supporting multisource transfer learning theoretically. Duan et al. 32 further introduced a multisource domain adaptation approach that integrates base classifiers pretrained on labeled source data to construct a robust target domain classifier. Pioneering work in multisource domain adaptation methods primarily aimed to learn shared domain-invariant features across all domains. However, Zhu et al. 33 found that large distribution shifts between labeled source datasets can impede learning a single domain-invariant representation. They tackled this by mapping each source-target pair into a separate feature space to learn distinct domain-invariant representations.
Recent progress in mechanical fault diagnosis increasingly leverages multisource transfer learning to optimize utilization of heterogeneous diagnostic data. Tian et al. 34 introduced a multisource subdomain adaptation (MSSA) framework for bearing and gearbox fault diagnosis, employing LMMD to align feature distributions between source-target domain pairs and integrating weighted source classifiers into a joint target classifier. Huang et al. 35 presented a multisource transfer learning approach for fault diagnosis of bearings across variable conditions. Their study emphasized the critical role of employing independent domain-specific feature extractors rather than a shared architecture, as negative transfer from low-quality source domains could degrade feature learning in other domains.
To further improve diagnostic performance in complex industrial scenarios, recent research has promoted multisource domain adaptation from diverse methodological perspectives, including advanced transfer architectures,36,37 reliable source-weighting mechanisms,38,39 and adaptability to complex nonasymmetric or open-set transfer tasks.40,41 Despite these remarkable algorithmic advancements, current studies typically focus on pure data-reliant paradigm. Consequently, the frameworks in these studies remain highly vulnerable to statistical distribution shifts of signals, as they completely exclude the underlying physical mechanisms and prior knowledge from the domain alignment process. To date, fusing mechanism-based prior knowledge into multisource transfer learning remains an unaddressed gap in intelligent fault diagnosis.
The literature review reveals that relying solely on single-source domain data is inadequate for addressing data distribution discrepancies, particularly in axial piston pump fault diagnosis under varying operating conditions. Furthermore, even within existing multisource paradigms, the lack of domain-specific physical prior knowledge to guide domain adaptation severely constrains the generalization capability of purely data-driven transfer networks. To overcome these limitations, we propose a novel transfer learning method that integrates MSSA and simulation-driven soft labeling (SL). The main contributions are outlined below:
A multisource transfer learning framework is developed to effectively utilize data from multiple source subdomains, enhancing feature representation and domain adaptability under various operational conditions.
A reliable source-weighting mechanism based on LMMD is introduced to ensure that larger weights are assigned to source subdomains exhibiting smaller distribution discrepancy relative to the target domain.
Through high-fidelity computational fluid dynamics (CFD) simulation of the pump’s discharge pressures, the target-domain physical constraints are directly incorporated into classifier training.
The rest of this article is structured as follows: the second section elaborates on the proposed transfer learning method; the third section introduces experimental validation on a test pump; the fourth section evaluates diagnostic performance; and the final section concludes with future research directions.
Proposed method
Transfer learning framework
Figure 1 illustrates the transfer learning framework architecture, leveraging labeled data from multiple source subdomains and unlabeled data from target domain while integrating target-domain prior knowledge via simulation-driven soft labels. The framework processes discharge pressure signals from multiple operating conditions (source subdomains) and unlabeled target-condition data. A shared feature extractor learns domain-invariant representations, while source-specific classifiers are dynamically weighted according to source-target domain discrepancies. This adaptive weighting strategy ensures that sub-domains with higher similarity to the target domain exert greater influence on the final decision.
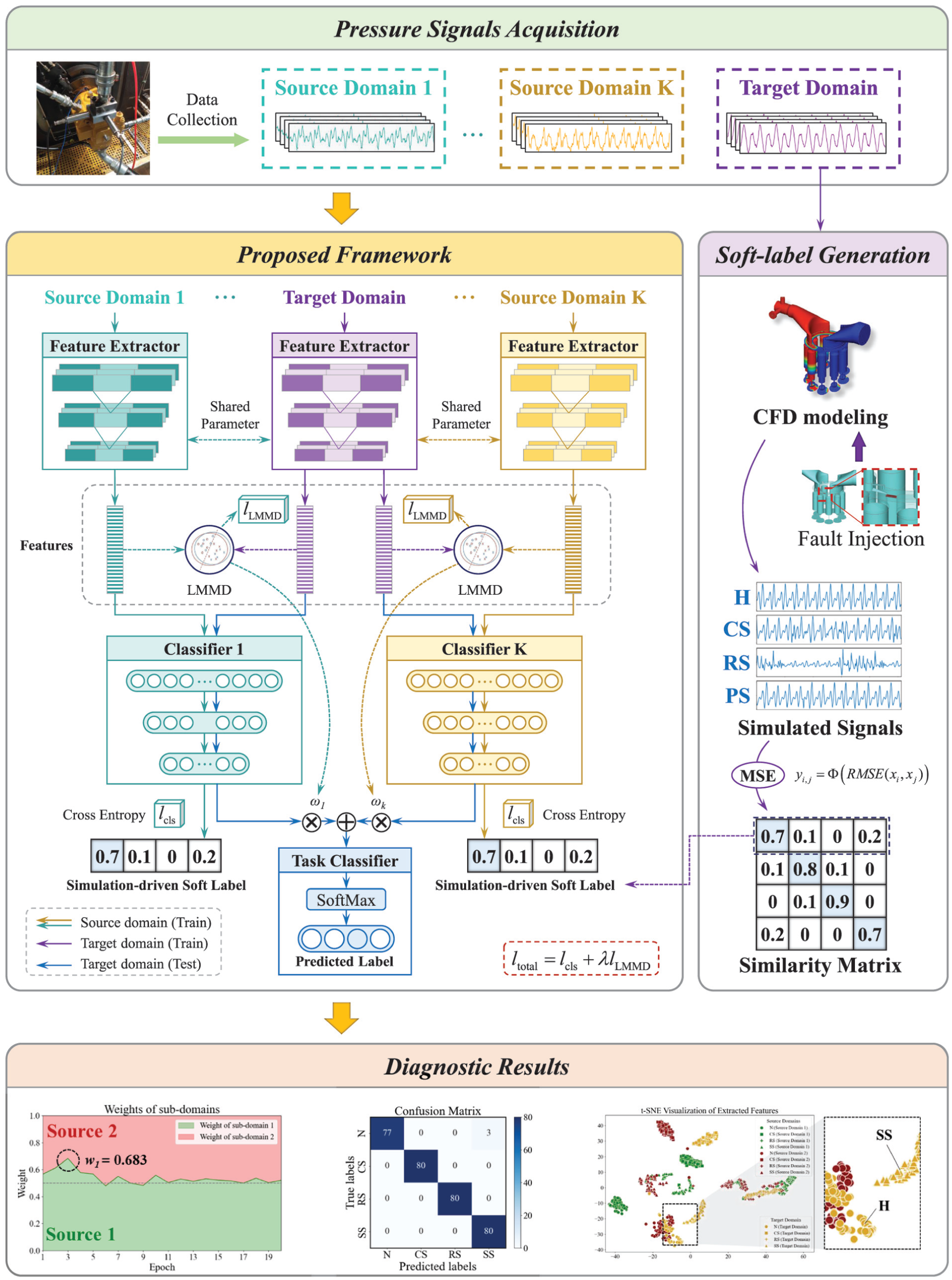
Proposed method architecture.
To reduce the domain gap between source and target conditions, simulation-driven soft labels are constructed to incorporate physics-based prior knowledge. A high-fidelity CFD model of the pump is first built to simulate target-condition discharge pressure signals. By introducing typical faults into the CFD model and calculating the interclass similarity of the simulated signals, probabilistic soft labels are generated to represent the class probability distribution. These physics-informed soft labels replace standard one-hot labels to be integrated into the network’s training process as a sophisticated regularization mechanism. This strategy prevents the model from becoming overconfident on source subdomain features and mitigates potential model overfitting, thereby enhancing the robustness and diagnostic performance of cross-condition transfer learning.
CFD modeling and fault injection
Compared to motor current 42 and vibration 43 signals, discharge pressure signals provide more informative insights into the health status of the axial piston pump and are often readily measurable in hydraulic systems. To generate these critical discharge pressure signals under both normal and faulty conditions, we employ high-fidelity CFD simulations, as illustrated in Figure 2. The fluid domain is derived from the pump’s three-dimensional (3D) model, with particular attention to four critical friction pairs (i.e., slipper/swash plate, piston/slipper, piston/cylinder block, and valve plate/cylinder block) where 10 μm oil films are set to match the simulated leakage rate with that of the test pump. The computational domain and grid generation have been described in our previous work. 44 To account for the significant variations in rotational speed and discharge pressure across different practical applications, various operating conditions are simulated by adjusting the parameters of outlet pressure and angular velocity in the CFD model. To guarantee the simulation accuracy, the developed CFD model has been validated against experimental data in our previous work. 45 In that work, the simulated and experimental pressure signals exhibit strong agreement in periodicity and waveform, with cosine similarity values consistently ranging between 0.85 and 0.92, which successfully verifies the model’s effectiveness.
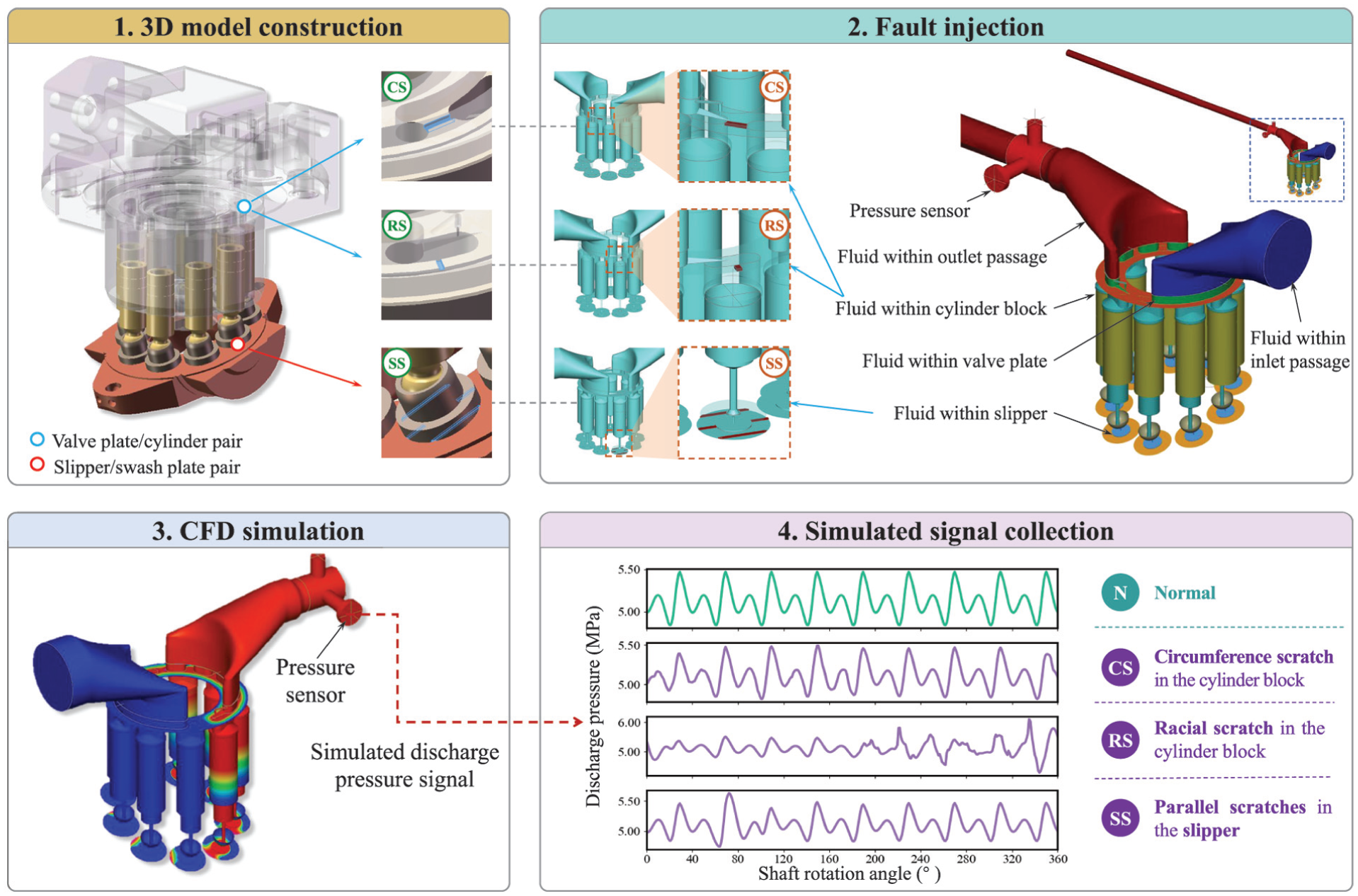
CFD modeling and fault injection for axial piston pumps. 45
Scratches on critical friction pairs are among the most common incipient failure modes in axial piston pumps. In this study, we validate the diagnostic framework by detecting scratches across various friction pairs. Specifically, three types of scratches are investigated: circumferential scratches (CS) and radial scratches (RS) in the cylinder block, as well as parallel scratches (SS) in the slipper. These fault conditions are accurately replicated in our CFD model through precise geometric modifications to the fluid domain, where rectangular grooves are introduced at the respective friction pairs to realistically simulate the characteristic leakage paths caused by scratch damage. The scratch-induced leakage causes distinct waveform variations in the discharge pressure signals, captured by a virtual pressure sensor at the pump outlet. Besides, the initial angular position of the shaft is kept identical across all simulation models to ensure inherent phase synchronization. This comprehensive simulation approach generates a robust dataset of pressure signals under various faulty conditions, establishing a reliable data foundation for fault diagnosis while overcoming the challenges associated with physical fault injection in experimental setups.
Soft label generation
The inherent variability in discharge pressure signals across different operating conditions poses a high risk of overfitting in cross-domain transfer learning for diagnosing axial piston pumps. Recent studies46,47 have demonstrated that soft label training offers an effective solution to this problem, with a careful calibration of soft label values being the key to realizing superior generalization and accuracy. To address the challenge of overfitting, this study introduces a soft label generation strategy based on sample similarity derived from simulation data. By assigning soft labels tailored to the target domain, the proposed strategy effectively mitigates overfitting and improves model generalization. The detailed process for generating these soft labels is illustrated in Figure 3.
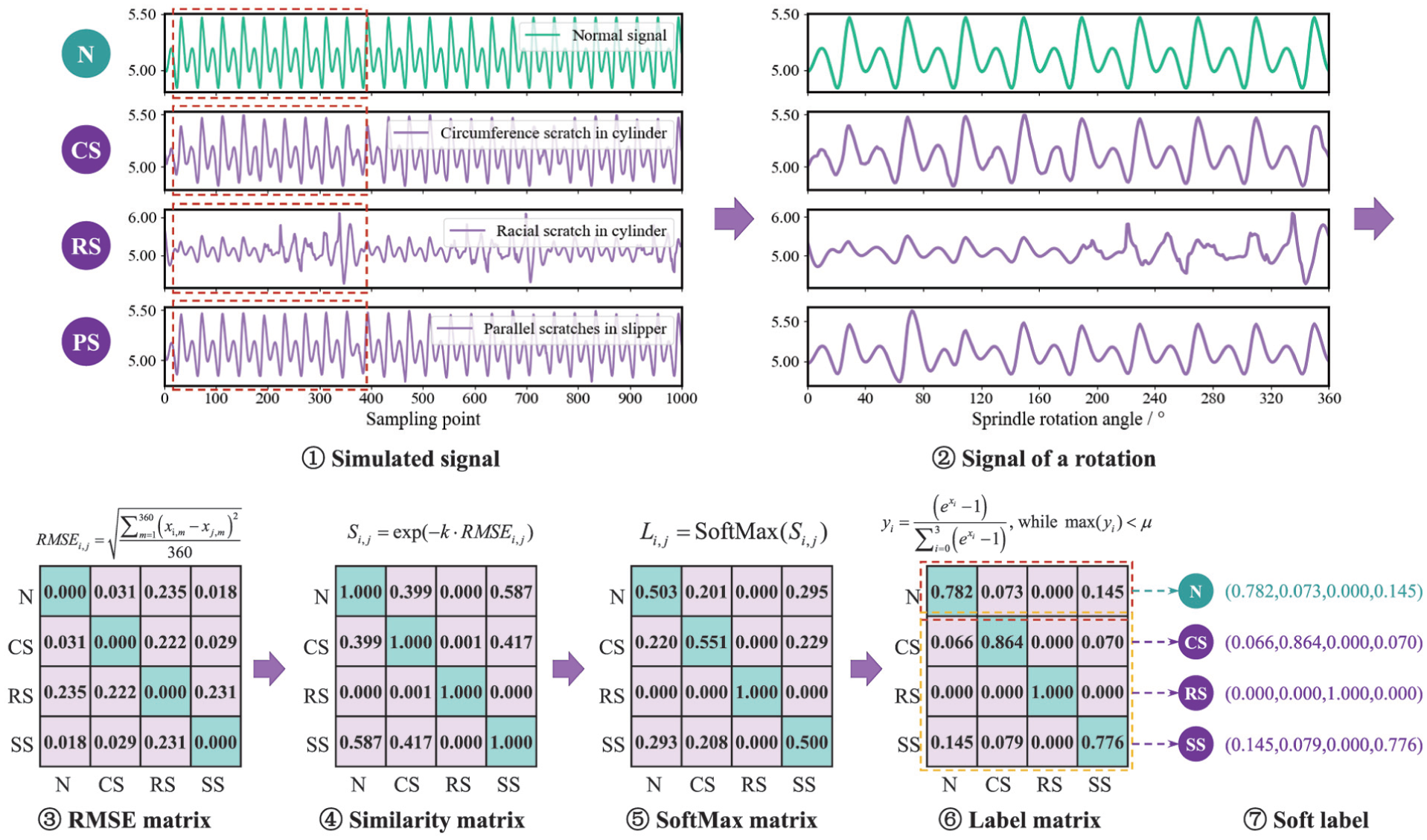
Procedure of soft-label generation.
The sampling interval of the virtual pressure sensor in the CFD model is set to 1°, yielding 360 data points per revolution cycle. As a result, the simulated signals are divided into segments, each containing 360 points. Given that all CFD simulations start at the same phase, signal alignment before similarity evaluation is not required. To quantify the dissimilarity between different signal classes, the root mean square error (RMSE) is selected as the distance metric.
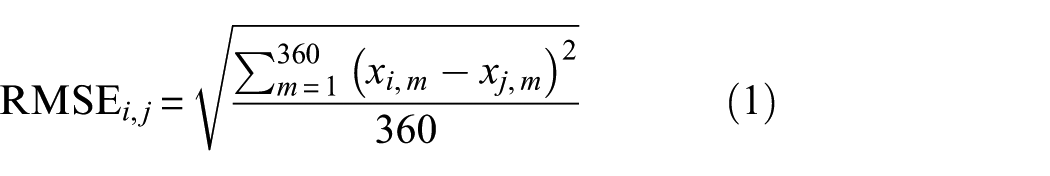
where i and j represent two distinct classes, x i,m and x j,m denote the mth data point in the representative signal series of class i and j, respectively. The RMSE i,j value reflects the geometric distance between two waveforms: higher RMSE values indicate greater waveform deviations, while a RMSE value of 0 signifies identical signals.
To construct the soft labels, the RMSE is mapped to a similarity metric Si,j within the range [0, 1] using an exponential decay function:

where k is a scaling parameter that regulates the sensitivity of the similarity distribution. For this study, k is empirically set to 5. The SoftMax function is then applied to normalize these similarity scores, generating a probability distribution where the sum of all elements equals 1:

As shown in the SoftMax matrix in Figure 3, the diagonal elements, which represent the confidence in the true class, may become insufficiently dominant due to high interclass similarity. This can lead to underfitting or ambiguity in classification. To mitigate this issue, a correction mechanism is introduced to ensure a minimum confidence level for the ground truth class:
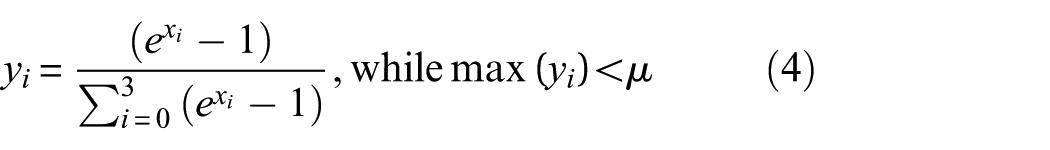
where x i and y i denote the ith probability value in the original and the rectified soft label, respectively. The parameter μ serves as a threshold to enforce the lower bound of the true class probability, which is set to 0.7 in this study.
MSSA network
The proposed MSSA network is designed to achieve robust fault diagnosis under diverse operating conditions by extracting domain-invariant features. As illustrated in Figure 1, the architecture comprises a shared feature extractor F multiple source-specific classifiers
A core strategy in transfer learning involves reducing the distribution discrepancy between source and target domains to facilitate effective knowledge transfer. To quantify this distribution discrepancy, the MMD serves as a widely adopted nonparametric metric, measuring the distance
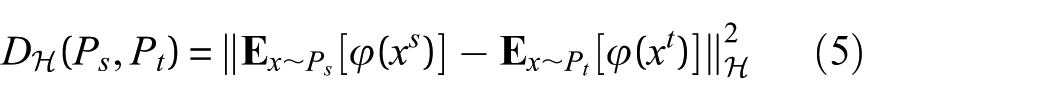
where φ(·) represents the feature mapping function related to the characteristic kernel

Note that the standard MMD only aligns the global distributions, ignoring the local class-conditional structures. For the task of fault diagnosis, aligning relevant subdomains within the same class is critical. Therefore, the LMMD is selected in the MSSA framework to align the distributions of each category independently, as defined below:
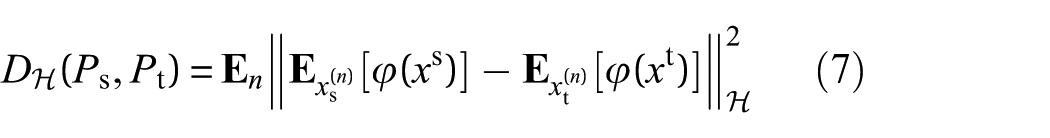
where n indicates the nth category, Ps( n ) and Pt( n ) denote the distributions of class n in the source and target domains, respectively. The LMMD progressively aligns these distributions across domains during training. Its unbiased estimator is given by
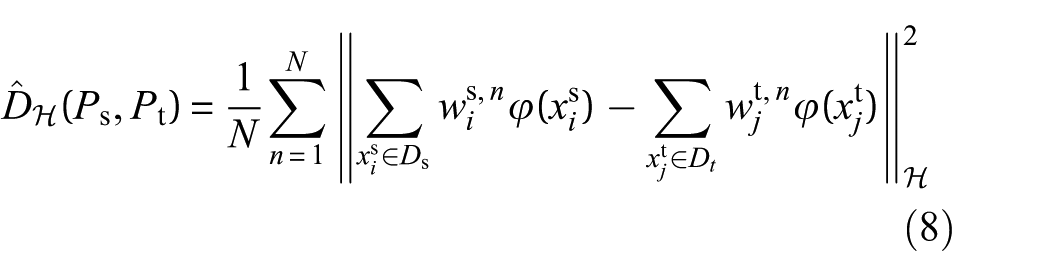
where
The shared feature extractor F processes samples from both domains during training, with the extracted features F(x) serving as inputs for the LMMD-based domain adaptation loss:
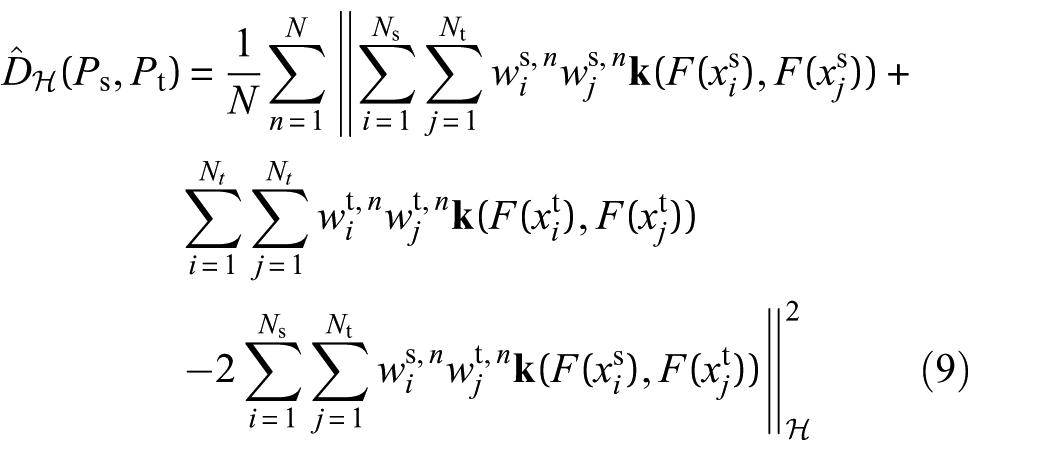
To leverage knowledge from multiple operating conditions, the total domain adaptation loss lLMMD is calculated as the sum of LMMD losses across all K source domains:
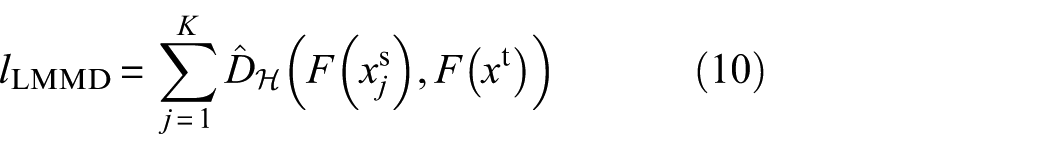
The extracted features are passed to the domain-specific classifier C j . To mitigate overfitting and incorporate the prior knowledge obtained from simulation data, the soft labels generated in “Soft label generation” section are used as the ground truth. We define the classification loss lcls as the cross-entropy between the output of classifier C j and these soft labels:
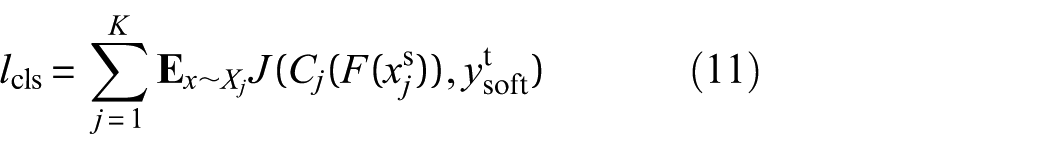
where J(·, ·) denotes the cross-entropy function:

where y
i
and
The total loss ltotal of the MSSA network combines the classification loss lcls and domain adaptation loss lLMMD through weighted summation:

where λ is the trade-off coefficient balancing these two losses. To ensure stable convergence, a dynamic trade-off adaptation strategy 22 is implemented as follows:

where scaling hyperparameter γ is fixed to 10, and p is the training progress linearly changing from 0 to 1. Under this configuration, the trade-off coefficient λ remains close to zero during the early stage of training to avoid divergence, while rapidly increasing to 1 in later epochs to enforce the extraction of domain-invariant features.
During inference, relying solely on a single classifier or simple averaging is suboptimal due to the varying correlation between the target and different source domains. Therefore, we establish an ensemble task classifier by integrating the outputs of source-specific classifiers. Each classifier is dynamically assigned a weight based on the LMMD distance between its corresponding source and target domain features. The weighting mechanism ensures that smaller LMMD distance means higher similarity and thus a larger weight. The weight ω j for the jth classifier is given by
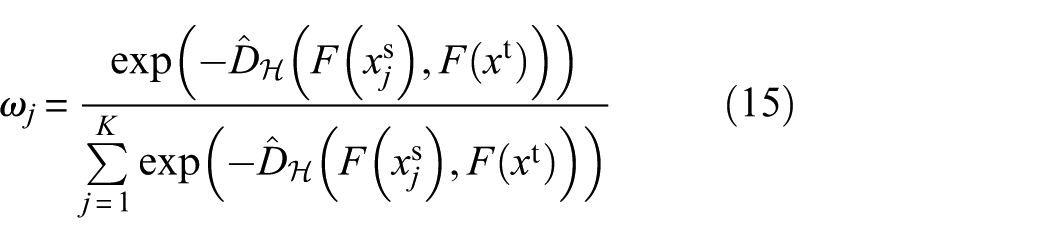
Finally, the output of the task classifier is determined as the weighted sum of the predictions from all specific classifiers, as shown in Equation (16). The final diagnostic result of the task classifier is determined by the class with the maximum probability in the aggregated output.

Experimental setup
The experimental investigation was performed using a swash-plate axial piston pump featuring a 71 mL/rev maximum displacement, as illustrated in Figure 4. The experimental apparatus and its circuit diagram are shown in Figure 5. The test pump powered by an electric motor drew low-pressure fluid from the tank and delivered high-pressure fluid to the hydraulic system. The temperature of the supplied oil was maintained at approximately 50°C. To avoid cavitation effects, a charge pump was employed to elevate the suction pressure at the test pump’s inlet to 1.6 bar. The control unit was responsible for regulating the rotational speed and discharge pressure. A proportional relief valve was used for adjustable load applications, which allowed for variable pressure loads independent of the rotational speed.
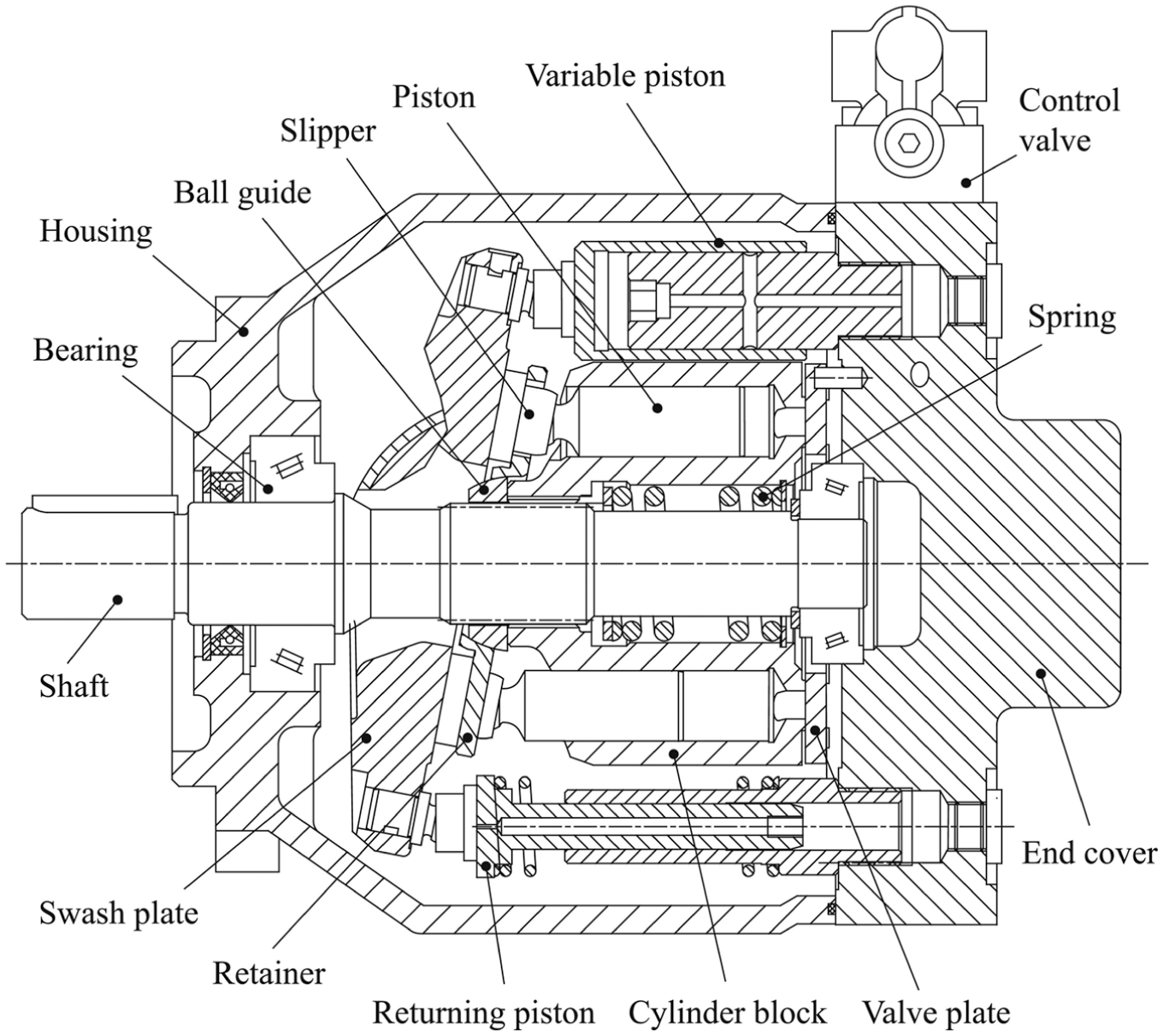
Configuration of the test pump. 48
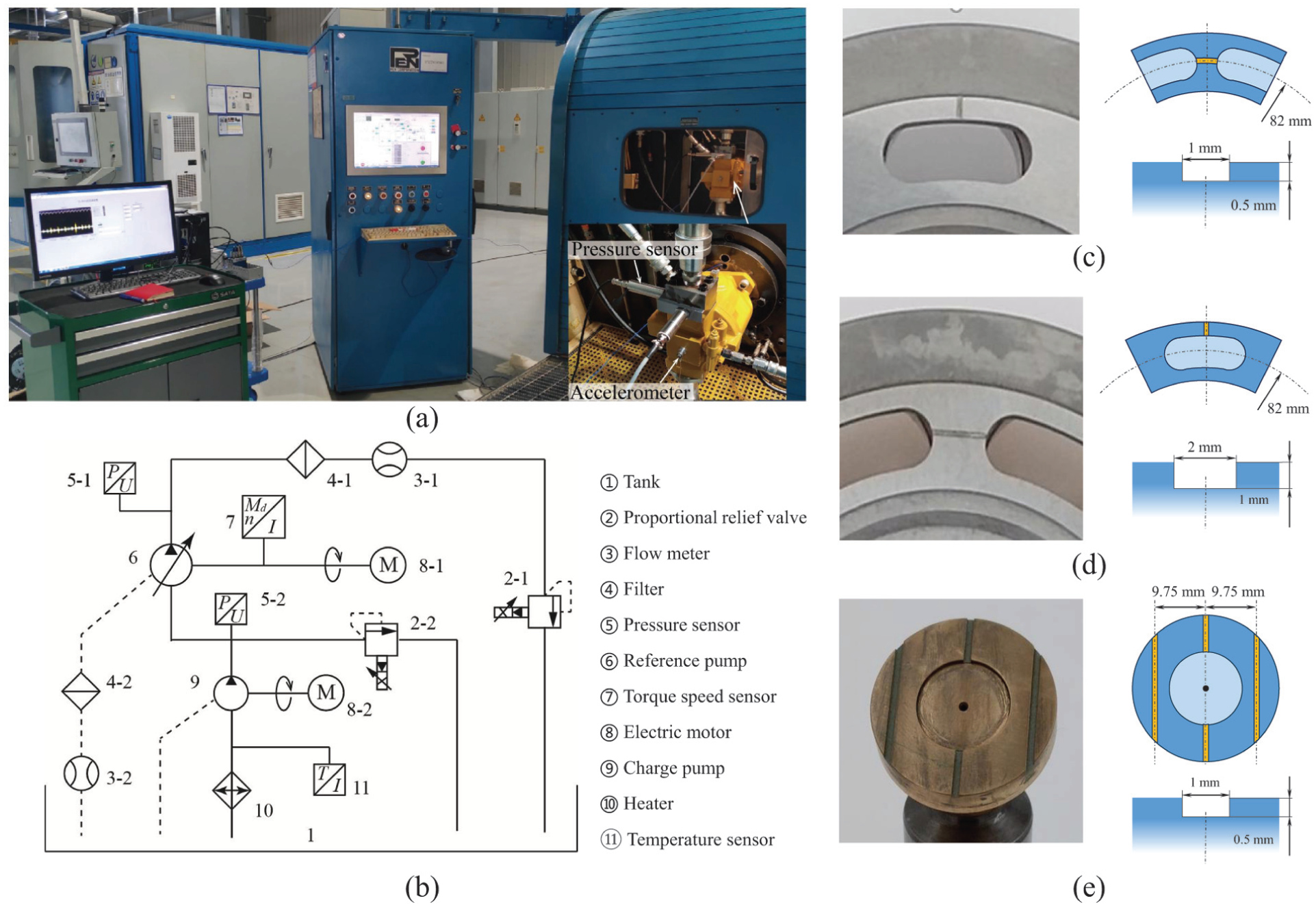
Experimental setup of axial piston pumps: (a) test bench and its (b) hydraulic circuit diagram48; (c–e) RS, CS, and SS fault injection into internal components. CS: circumferential scratches; RS: radial scratches; SS; parallel scratches.
An array of sensors was deployed to monitor the test pump’s characteristic parameters. Pressure sensors were located at both the pump’s inlet and outlet lines to measure suction and discharge pressures, respectively. Additionally, flowmeters were positioned at the outlet and drain lines to quantify volumetric delivery flow rate and leakage flow rate. Vibration behavior was captured using a uniaxial accelerometer, magnetically mounted on the pump’s rear end cover. During steady-state operation, all signals were acquired simultaneously via a data acquisition unit. The discharge pressure and vibration data were acquired at 51.2 kHz, while the other parameters were logged at 1 kHz.
The test pump was first operated under normal conditions (N) at three rotational speeds of 500, 1000, and 1500 r/min, and four discharge pressures of 5, 10, 15, and 20 MPa. Once the experiments under N were finished, the test pump was disassembled to introduce specific fault modes, including CS, RS, and SS, by replacing the corresponding internal components. These scratches were fabricated via electrical discharge machining to form a rectangular cross-sectional profile, with their location and dimensional parameters detailed in Figure 5(c) to (e). After reassembly, the faulty pump was tested under identical operating conditions to collect sensor signals. Although artificially machined scratches exhibit a geometric discrepancy compared to real scratches, they induce highly consistent pressure ripple and leakage characteristics, and thus have been widely adopted in previous research. 49
Figure 6 presents a sample measurement of the test pump’s discharge pressure under normal and faulty conditions at 20 MPa and three rotational speeds (500, 1000, and 1500 r/min). Under N, the discharge pressure waveform exhibits a periodic pulsation over one cycle. In contrast, under faulty conditions, this periodic pulsation waveform becomes distorted due to increased internal leakage caused by injected faulty internal components. Additionally, the waveform of the discharge pressure signals varies with different operating conditions, even when the test pump has no faulty components or the same faulty component.
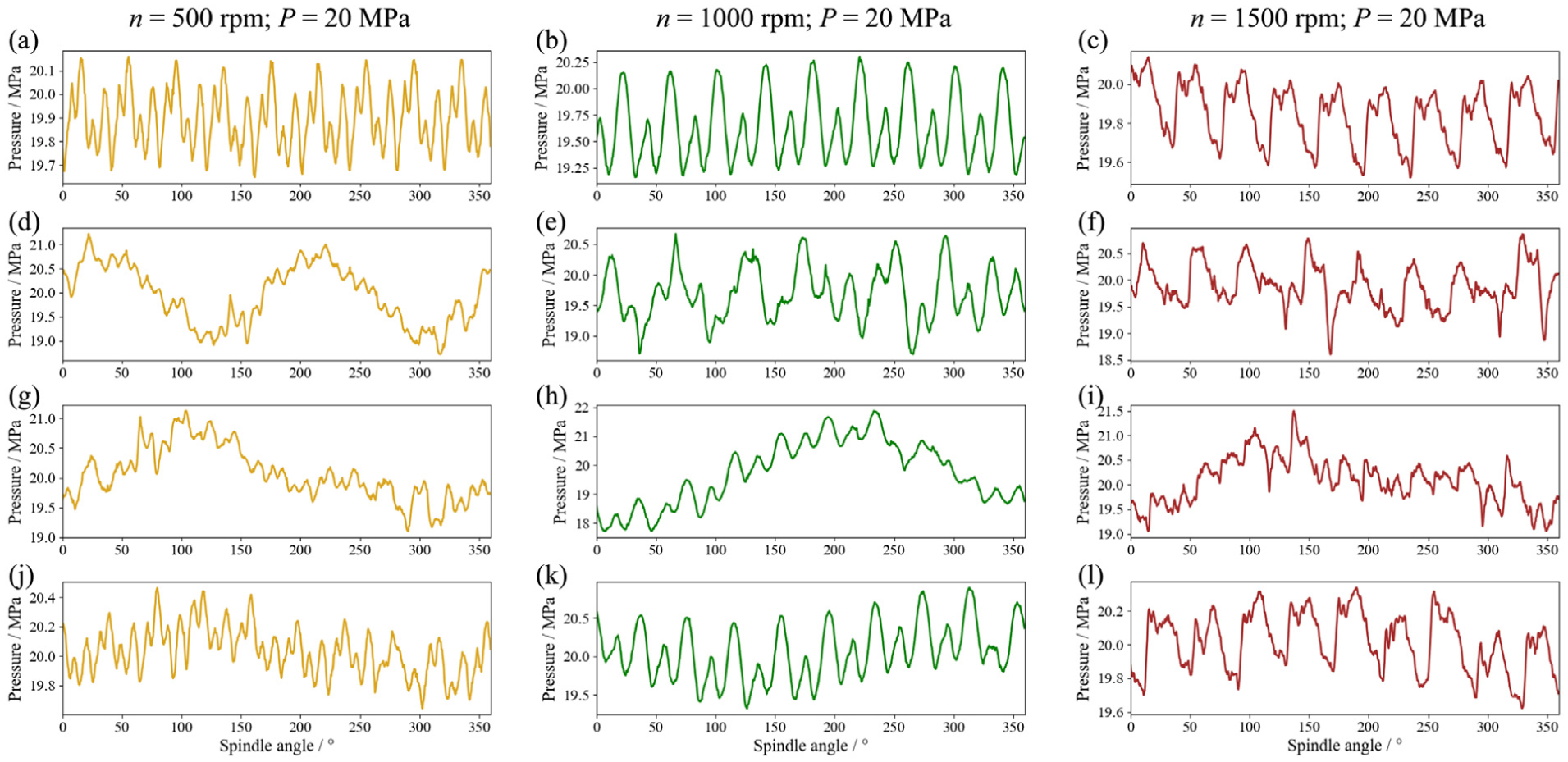
Discharge pressure waveforms of the test pump with different faults: (a–c) N, (d–f) CS, (g–i) RS, and (j–l) SS. N: normal conditions; CS: circumferential scratches; RS: radial scratches; SS; parallel scratches
The variability in operating conditions, particularly changes in rotational speed, induces substantial deviations in discharge pressure signals, significantly complicating the pump’s fault diagnosis. To rigorously validate the proposed diagnostic framework, eight cross-speed transfer learning tasks were systematically designed, as detailed in Table 1. These tasks cover four discharge pressures (5, 10, 15, and 20 MPa) to evaluate the model’s generalization capability. The study employs both interpolation and extrapolation scenarios: in tasks T1–T4, the target domain speed of 1000 r/min lies within the source domain speed range of 500–1500 r/min, while in tasks T5–T8, the target speed of 500 r/min extends beyond the source domain range of 1000–1500 r/min, providing a robust assessment across different operating conditions.
Transfer learning tasks.

To maintain data consistency across varying operating conditions, each raw discharge pressure signal is segmented into samples representing one complete pump revolution. Due to the variation in the number of sampling points per revolution with rotational speed, an instantaneous speed-guided linear interpolation method is applied to standardize the length of each sample to 720 points, thereby eliminating speed-induced domain discrepancies across different working conditions. This configuration yields a precise angular resolution of 0.5° per point to effectively preserve transient fault features. For each transfer learning task, the model is trained on 324 samples from each source and target domain, reserving 20% of these samples as a validation set to monitor the training progress. An additional 324 independent target domain samples serve as a test set to rigorously evaluate the diagnostic performance.
The proposed diagnostic network runs in PyTorch and is trained on a workstation equipped with a CPU featuring Intel® Core™ i9-14900HX and a GPU featuring NVIDIA GeForce RTX 4060. Hyperparameters have been optimized to ensure the model performance. Specifically, the input signals are normalized to the range [–1, 1] to accelerate convergence. Model training was conducted over 20 epochs with a batch size of 16, using the SGD optimizer (momentum = 0.9, weight decay = 0.0005). The initial learning rate of 0.002 was dynamically adjusted via a StepLR scheduler, reducing the learning rate by a factor of 0.2 every 10 epochs.
Results and discussion
To enhance domain adaptation, the proposed method incorporates prior knowledge of faulty signals in the target domain through simulation-driven soft labels. For each transfer learning task, these soft labels are generated from simulated signals under the target domain’s specific operating conditions (as detailed in Section “Soft label generation”). The resulting soft label values for each task are presented in Figure 7, where higher values indicate a greater probability of the corresponding category.
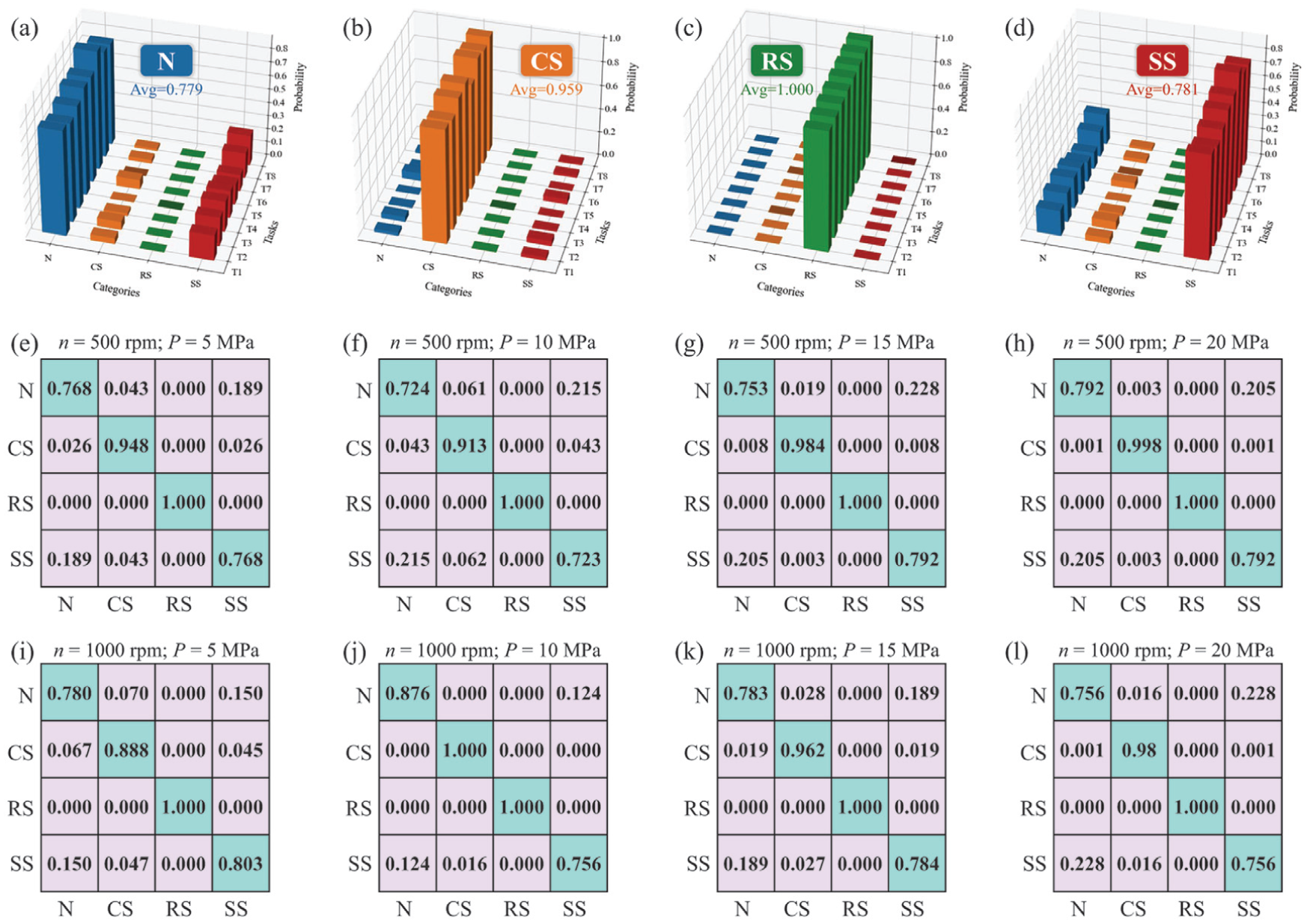
(a–d) Soft labels of each fault category; (e–l) soft label matrices under different working conditions.
As illustrated in Figure 7, the generated soft labels consistently yield peak values for their respective true categories, confirming their discriminative capability. For the N samples in Figure 7(a), the soft label values associated with the SS category remain substantially greater than zero, reflecting significant inter-class similarity between N and SS categories. A similar phenomenon is evident in Figure 7(d), where the true SS samples show relatively high soft label values for the N category. This observation aligns with the discharge pressure signal characteristics shown in Figure 6, where the waveform distortions caused by SS faults are relatively subtle and the waveform of SS samples looks like the N samples. By leveraging these soft labels, a fuzzy classification strategy is introduced between N and SS samples, which minimizes misclassification arising from sharp decision boundaries and better reflects their inherent physical similarities. In contrast, the soft labels for CS and RS samples remain close to a standard one-hot representation due to their distinct waveform characteristics. This distinction facilitates clearer fault identification and enhances the model’s generalization across diverse operating conditions.
To evaluate the diagnostic performance of the proposed method, we conducted an ablation study comparing five distinct model configurations across transfer learning tasks T1–T8. This systematic evaluation was designed to isolate and quantify the individual contributions of two key components: (1) multisource information fusion and (2) the simulation-driven SL strategy.
(a) Source I only/Source II only: These two baseline configurations represent conventional single-source domain adaptation approaches, where the model is trained exclusively on either source I or II along with the unlabeled target domain. The source-target domain discrepancy is minimized via LMMD to align their local feature distributions during training.
(b) DAN: This configuration combines data from both source I and source II into a single merged source domain, treating them as a homogeneous dataset. The model follows the classical domain adaptation network (DAN) but utilizes LMMD for distribution alignment to maintain metric consistency, thereby neglecting the distinct weights of individual domains.
(c) MSSA: This configuration adopts the MSSA framework described in Section “MSSA network”, but uses standard one-hot encoding for the classification loss.
(d) MSSA + SL: This is the complete proposed framework in this work, which integrates simulation-driven SL to effectively leverage prior knowledge from the target domain.
To ensure a fair and conclusive comparison, all models are trained for 20 epochs with a batch size of 16 using the same SGD optimizer and dynamic trade-off strategy as the proposed method. The learning rate is specified as 0.005 for the Source I only, Source II only, and DAN methods, and 0.002 for both MSSA and MSSA + SL to guarantee convergence. Furthermore, all comparison methods share an identical feature extractor structure and use the same neural network topology for their classifiers, with the number of classifiers dynamically matching that of source domains.
Figure 8 and Table 2 compare the diagnostic accuracies across the transfer learning tasks T1–T8 between the five models. The proposed method achieves the highest average accuracy of 99.02% while consistently outperforming other competing models in all tasks except T8. In contrast, the transfer learning models relying solely on source I or II exhibit significantly limited diagnostic performance, with accuracies rarely surpassing 75%. While the DAN achieves high diagnostic accuracy in specific tasks (e.g., 100% in T2) by leveraging data from diverse operating conditions, its generalization capability remains unstable compared to the MSSA and MSSA + SL methods. Notably, the diagnostic accuracy of the DAN in T6 drops below that of the “Source I only” setting, suggesting that incorporating additional source domains with large distribution discrepancies introduces interference rather than improvement.
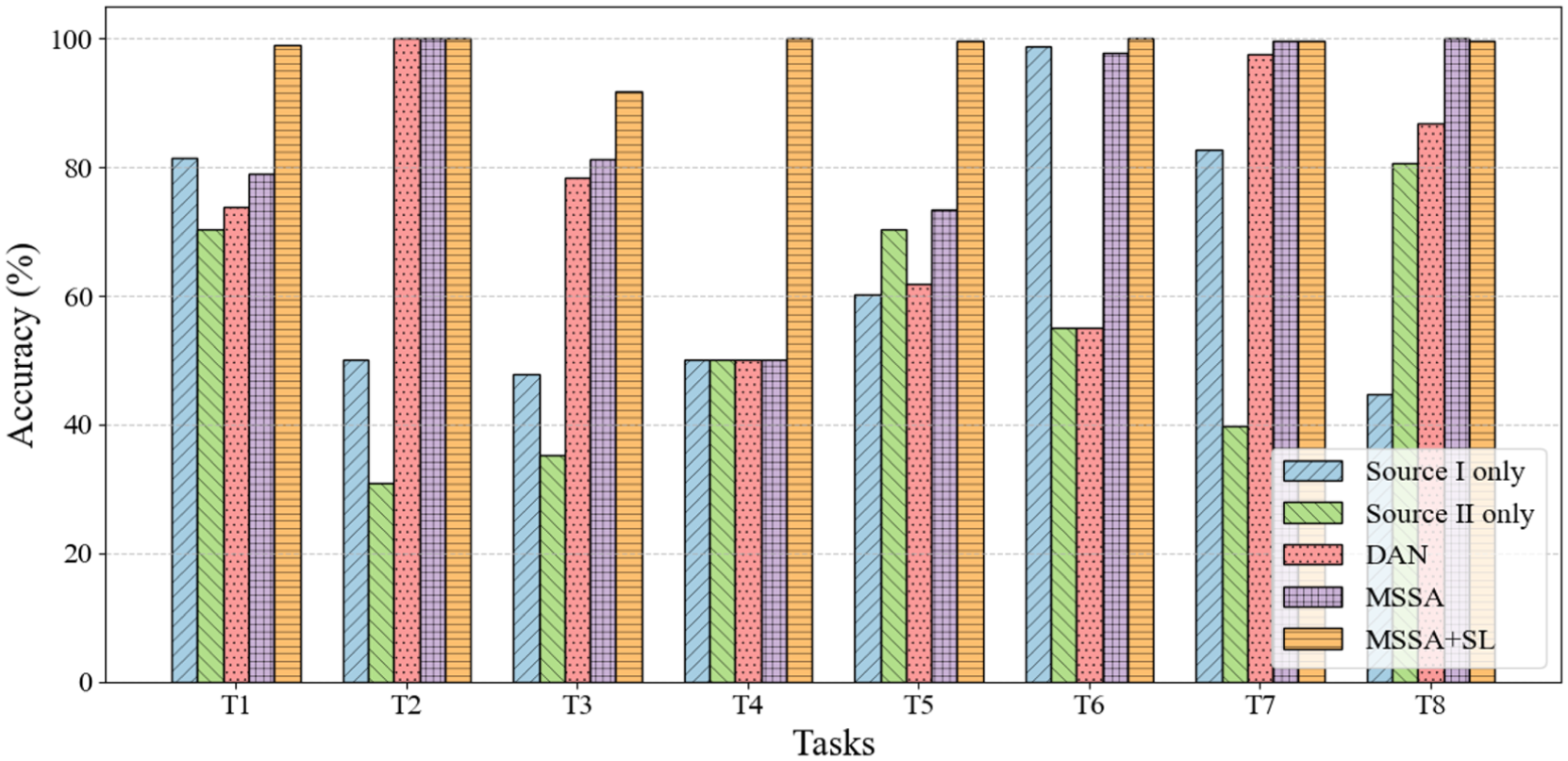
Comparison results of diagnostic accuracy between different methods.
Comparative diagnostic accuracy across transfer learning tasks.
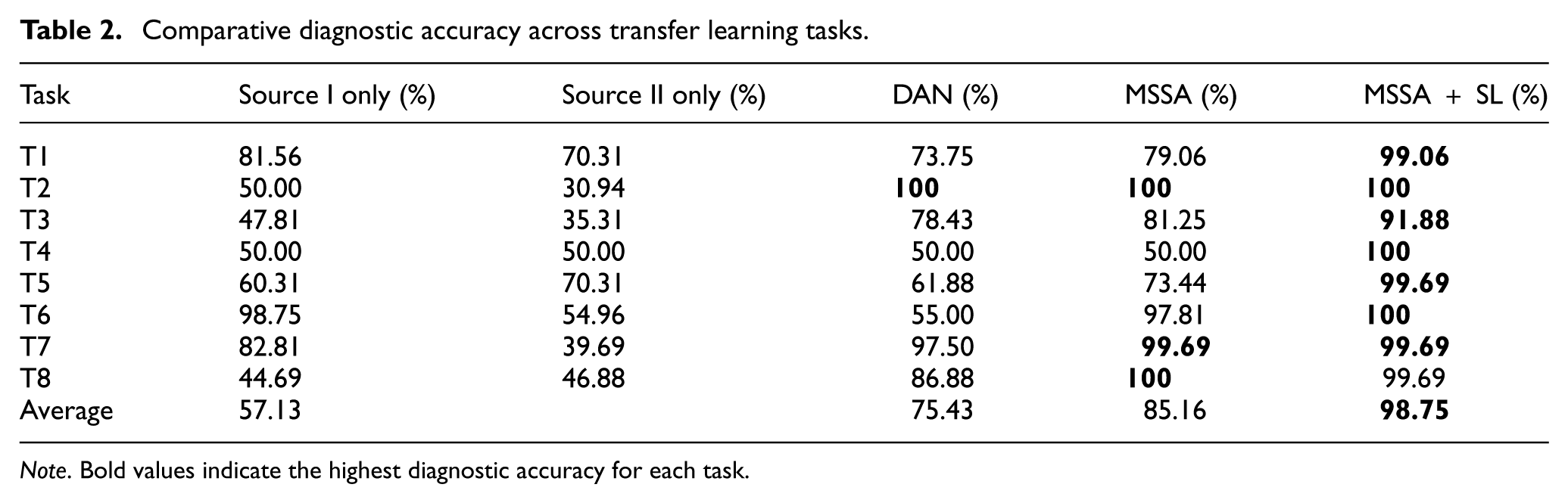
Note. Bold values indicate the highest diagnostic accuracy for each task.
The conventional MSSA demonstrates a notable improvement over the DAN, achieving nearly 100% diagnostic accuracy in T2 and T6–T8, owing to its dynamic weighting mechanism, which prioritizes relevant source domains while suppressing noise from dissimilar ones. Nonetheless, the proposed method still surpasses the conventional MSSA in challenging tasks such as T1 and T3–T6, where distinguishing between similar fault categories demands higher discriminative capability.
In general, transfer learning leveraging multisource data consistently outperforms single-source approaches. Specifically, compared to their single-source baselines, DAN, MSSA, and MSSA + SL achieve average accuracy improvements of 18.30%, 28.03%, and 41.62%, respectively. Despite using the same source domain data, these methods exhibit significant performance differences. For instance, while the DAN model fails to distinguish between CS and RS samples in T8 (Figure 9(a)), the MSSA-based methods achieve accurate diagnosis (Figure 9(d) and (g))—likely due to their more refined domain alignment strategies.
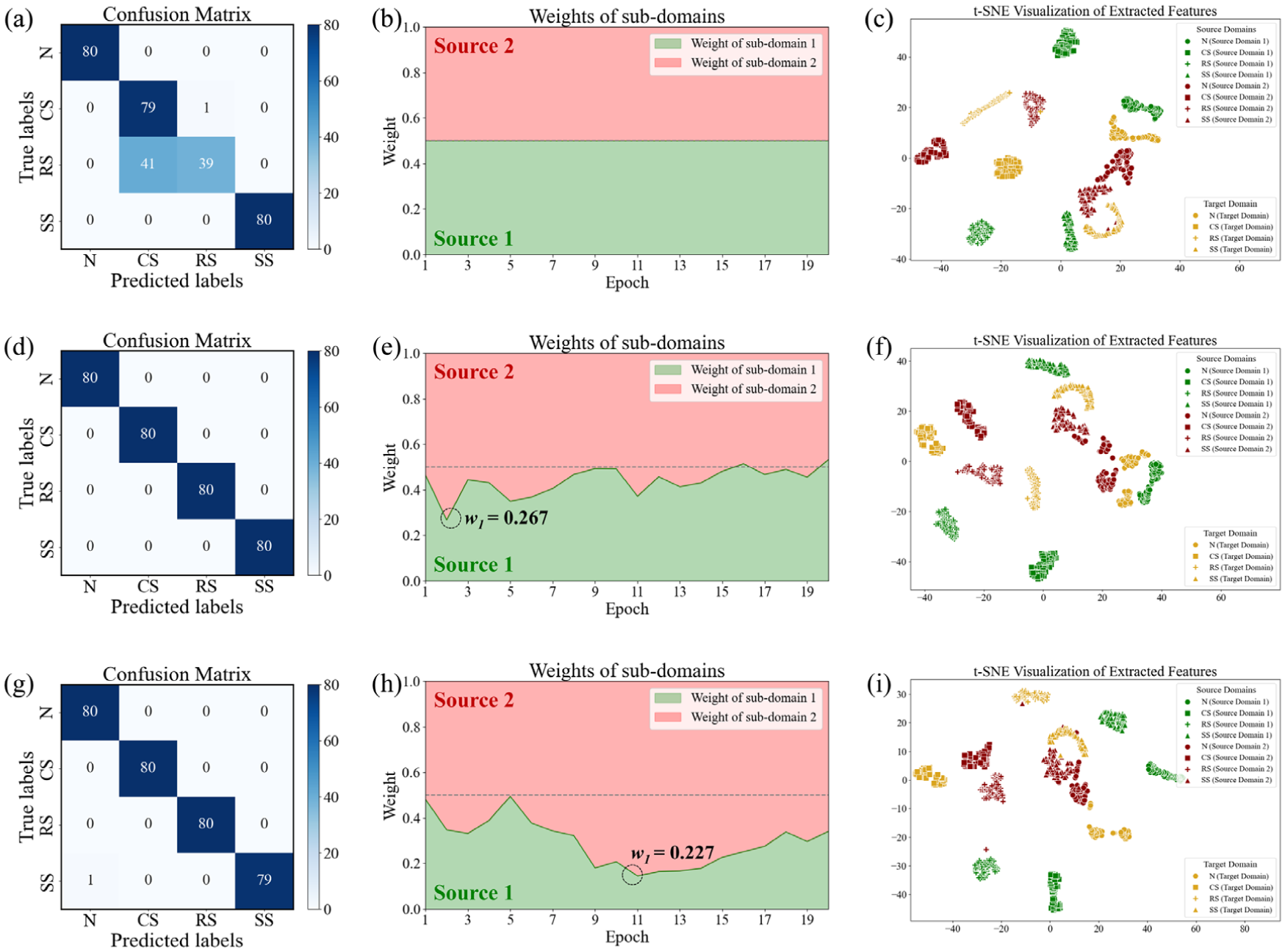
Effects of sub-domain weights on the diagnostic performance in T8: (a–c) confusion matrix, sub-domain weights, and t-SNE visualization of DAN; (d–f) confusion matrix, sub-domain weights, and t-SNE visualization of MSSA; (g–i) confusion matrix, sub-domain weights, and t-SNE visualization of MSSA + SL. DAN: domain adaptation network; MSSA; multi-source subdomain adaptation; SL; soft labeling.
To further investigate the training dynamics, the variations of domain weights are evaluated. As shown in Figure 9(b), (e), and (h), the MSSA and MSSA + SL models assign higher weights to source II during training. According to the optimization objective of the MSSA framework, a smaller LMMD loss inherently triggers a larger domain weight. Therefore, this dynamic weight allocation indicates that source II shares a higher distribution similarity with the target domain in the latent space. By intensifying the contribution of the more relevant source sub-domain, the model focuses on domain-invariant features while suppressing potential negative transfer from irrelevant features. Compared to the feature distribution of the DAN model in Figure 9(c), the t-distributed stochastic neighbor embedding (t-SNE) visualizations in Figure 9(f) and (i) demonstrate that the target domain features generated by the MSSA-based methods are clustered closer to source II and farther from source I. This observation confirms that the weighting mechanism successfully promotes alignment between target domain features and the most relevant source domain features in the latent space, which leads to a more compact intraclass clustering and higher classification accuracy in the final diagnostic results.
Distinguishing between N and SS samples remains a significant challenge in cross-condition diagnosis due to the similarity of their pressure waveforms. As shown in the confusion matrices for task T1 in Figure 10(a) and (c), both DAN and MSSA models demonstrate limited diagnostic accuracy, with frequent misclassification between these two categories. The t-SNE visualizations in Figure 10(b) and (d) reveal that while N and SS samples from the source domains (red and green markers) are well-separated, their counterparts in the target domain (yellow markers) exhibit substantial overlap. This indicates that these two models suffer from overfitting and fail to generalize the subtle interclass differences to the target domain. A likely explanation is that the rigid one-hot labels may encourage the model to learn trivial features that minimize classification loss on the source domains, rather than robust cross-domain representations.
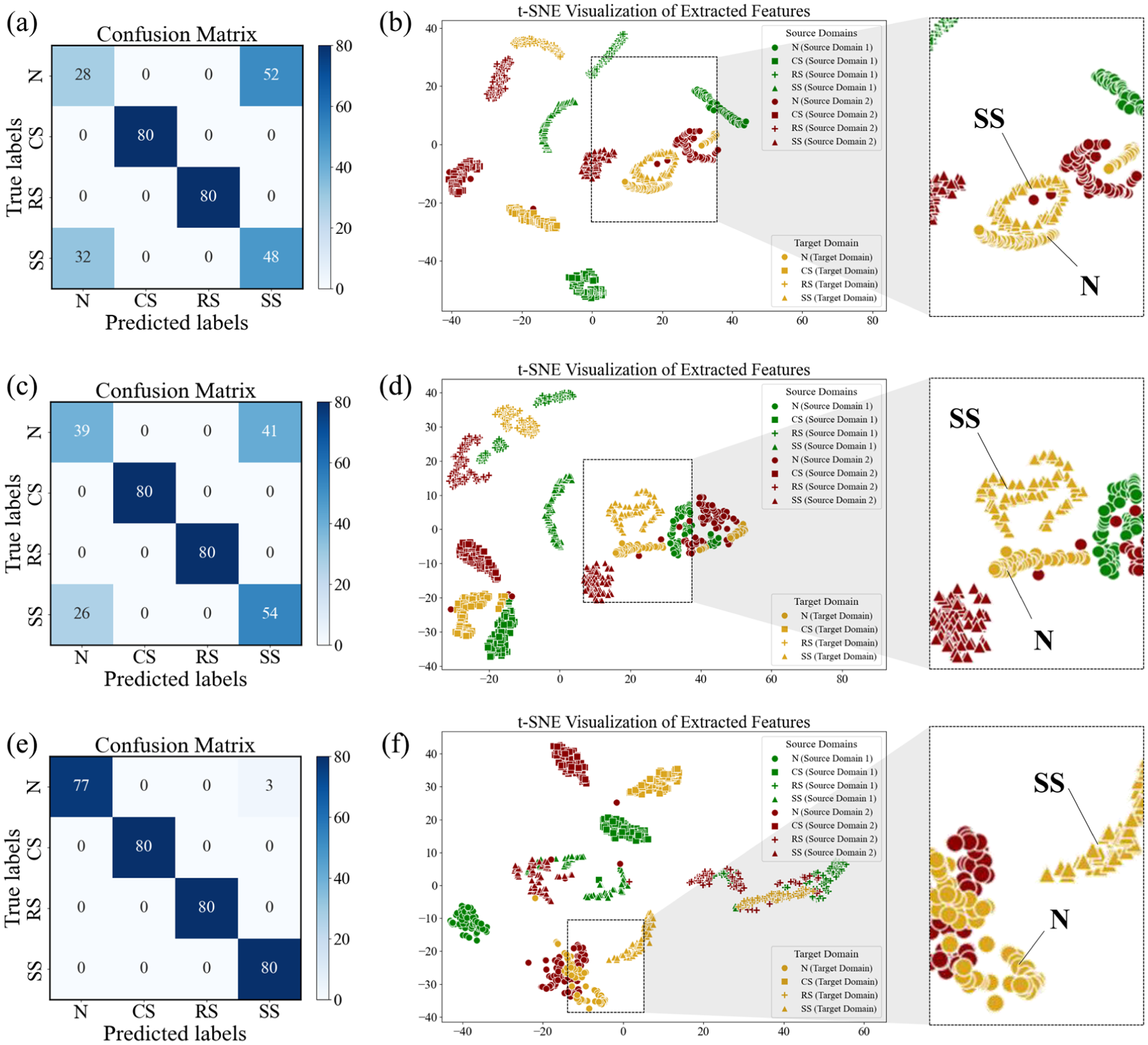
Diagnostic performance in T1: (a–b) confusion matrix and t-SNE visualization of DAN; (c–d) confusion matrix and t-SNE visualization of MSSA; (e–f) confusion matrix and t-SNE visualization of MSSA + SL. DAN: domain adaptation network; MSSA; multisource subdomain adaptation; SL; soft labeling.
To address this limitation, simulation-driven soft labels are introduced to mitigate overfitting. By assigning nonzero probabilities to the visually similar categories, the model learns a softer decision boundary with enhanced tolerance to classification errors. The confusion matrix in Figure 10(e) reveals a substantial enhancement in diagnostic performance, particularly evident in the improved classification accuracy between the N and SS categories. Furthermore, the t-SNE visualization in Figure 10(f) highlights that feature representations of several N-class samples (red circles) now overlap with SS-class clusters (red triangles)—a result of the intentionally softened class boundaries during training. This strategy enhances feature robustness and generalization, ultimately enabling the MSSA + SL method to achieve clearer separation between N and SS samples in the target domain, resulting in a notable improvement in classification accuracy.
Conclusion
The diagnostic performance of axial piston pumps is challenged by operating condition variations that induce distortions in discharge pressure signals, which severely limit the generalization of conventional data-driven approaches. To address these challenges in cross-condition fault diagnosis, we propose a novel MSSA framework integrated with simulation-driven soft labels. The experimental results across eight cross-speed transfer learning tasks demonstrate that leveraging data from diverse working conditions is crucial for enhancing diagnostic performance. Compared to single-source baselines, the multisource approaches yield a substantial accuracy improvement of at least 18.30%. Specifically, the dynamic weighting mechanism within the MSSA-based method effectively prioritizes knowledge from the most relevant source domains, increasing diagnostic accuracy by 9.73%. Furthermore, ablation study verifies the necessity of simulation-driven soft labels derived from a high-fidelity CFD model. By incorporating target-domain prior knowledge into classifier training, the MSSA + SL method can learn more robust features, achieving a superior average accuracy of 99.02%.
While the proposed MSSA + SL framework demonstrates excellent performance for cross-condition fault diagnosis in axial piston pumps, two limitations need to be addressed in future work. First, the high-fidelity CFD simulation for generating soft labels is computationally time-consuming, which could be effectively accelerated by training surrogate models for data generation. Second, as a domain adaptation method, the MSSA framework still requires unlabeled target-domain data for training. Therefore, multisource domain generalization methods will be investigated to achieve reliable zero-shot fault diagnosis under unknown operating conditions.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (no. 52475064) and the Special Fund for Science and Technology Innovation Teams of Shanxi Province (no. 202304051001033).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.