
Abstract
In this article, we examine how generative AI (GenAI) influences cognitive biases in strategic decision-making by focusing on cognitive processing as the underlying mechanism. We argue that GenAI use reshapes how decision-makers construct, compare, and evaluate alternatives, with consequences for anchoring, confirmation, and overconfidence biases. Using a randomized laboratory experiment in which 273 business professionals completed a time-constrained, high-uncertainty market-entry task, we find a curvilinear relationship between GenAI use and biases: intermediate levels of use are associated with stronger cognitive processing and lower biases, whereas both low and high levels yield weaker outcomes. This relationship is conditioned by qualitative engagement, which determines whether GenAI outputs are critically interrogated and compared—sustaining deliberation and reducing bias—or accepted with limited scrutiny, which weakens these effects. Our findings highlight how GenAI reorganizes evaluative processes and shapes bias in strategic judgment.
Introduction
In organizations, strategic decision-making is best understood as a process of constructing and evaluating alternatives, usually under uncertainty, in which representation, search, and the aggregation of judgments are organized to enable forward-looking, value-creating action (Csaszar, 2018; Gavetti et al., 2007; March and Simon, 1958). Judgment breaks down when this evaluative process becomes imbalanced—when attention narrows too quickly, comparison across alternatives is insufficiently sustained, or confidence is not adequately calibrated against competing representations—making biases such as anchoring, confirmation, and overconfidence more likely as fast, coherence-seeking reasoning overrides reflective scrutiny (Evans and Stanovich, 2013; Kahneman et al., 1982; Sibony et al., 2017). Yet greater deliberation does not necessarily improve strategic judgment (Todd and Gigerenzer, 2012). What matters, instead, is how evaluation is organized over time before decision-makers settle on an answer.
Recent behavioral strategy research has increasingly emphasized that bias reflects not only cognitive limits, but how judgment unfolds during evaluation (Cristofaro et al., 2025; Rau and Bromiley, 2025). This perspective aligns with emerging debates on whether AI can perform core elements of strategy, which conceptualize strategic decision-making as structured by representation, search, and the aggregation of judgments (Chatterji et al., 2026; Csaszar et al., 2026). These debates highlight a fundamental tension: while AI can expand representation and search at unprecedented scale, strategy remains rooted in forward-looking judgment, causal reasoning, and the ability to sustain disagreement and deliberation. The implication is that AI matters for strategy not only because it may improve answers, but because it may reorganize the evaluative process through which answers are reached.
The growing use of generative AI (GenAI) in business settings makes this tension more salient. Firms increasingly deploy GenAI in strategically consequential activities such as evaluating market entry opportunities, generating strategic alternatives, assessing competitive positioning, and simulating future scenarios, where outputs inform forward-looking judgments under uncertainty (McKinsey, 2025; Thomson Reuters, 2025). Unlike earlier tools that primarily supported analysis—such as forecasting models or decision support systems that required human interpretation—GenAI generates interpretations, proposes options, and recommends actions, directly shaping how problems are framed and how alternatives are represented and evaluated (Felin and Holweg, 2024; Salvi et al., 2025). Viewed historically, this shift reflects the latest wave of AI in management, in which organizational attention has moved from symbolic AI, expert systems, machine learning, and big-data analytics toward human–AI collaboration and responsible AI (Cristofaro and Giardino, 2025b). This introduces a qualitatively different challenge. While many innovations have altered how information is processed, they typically expanded analytical capacity without directly influencing how evaluation itself unfolds. By contrast, GenAI produces coherent, ready-to-use representations that may substitute for comparative reasoning rather than simply support it. The fluency and internal consistency of these outputs can make particular interpretations appear more complete, potentially reducing the need for further comparison (Chatterji et al., 2026). At the same time, recent evidence suggests that strong performance on general AI benchmarks does not necessarily translate into better strategic judgment under uncertainty (Allen and McDonald, 2026). As a result, it remains unclear whether GenAI expands evaluation by introducing alternative representations or instead narrows it by accelerating convergence around coherent outputs. This ambiguity is particularly consequential in strategic decision-making, where the quality of judgment depends on how alternatives are constructed, compared, and scrutinized over time.
This creates an important tension for strategic decision-making. On one hand, GenAI can broaden search, surface alternatives, and support reflection, thereby sustaining comparative evaluation and reducing biases (Boussioux et al., 2024; Cristofaro et al., 2025). Related experimental evidence in entrepreneurial decision-making shows the same ambivalence: AI can expand opportunity recognition and deepen evaluation, while also reducing novelty and innovation when not integrated with sector-specific knowledge (Cristofaro et al., 2026). On the other hand, it can make some interpretations feel unusually coherent, narrowing comparison and accelerating convergence around a single representation (Doshi et al., 2025; Kellogg et al., 2020; Neshenko and Ryall, 2026). The issue, then, is not whether GenAI affects judgment, but how—specifically, how it reshapes cognitive processing during evaluation. Rather than remaining a mere input, GenAI may become part of the evaluative process itself by influencing how problems are framed, alternatives are constructed and compared, and judgment is brought to closure. This problem speaks directly to a core debate in behavioral strategy: judgment quality depends on how intuition, analysis, and affect are balanced over time (Healey and Hodgkinson, 2017; Hodgkinson and Sadler-Smith, 2018).
We examine this issue in a randomized laboratory experiment involving 273 business professionals engaged in a high-uncertainty, time-constrained market-entry decision. Access to GenAI is randomly assigned, whereas GenAI-use intensity is observed behaviorally through interaction logs. We argue that GenAI-use intensity is associated with changes in cognitive processing, which in turn relate to variation in judgment quality, with the strongest deliberative profile emerging at intermediate levels of use (Cristofaro and Giardino, 2025a; Felin and Holweg, 2024).
To capture these mechanisms, we develop two process measures: the Cognitive Thinking Index (CTI), which captures the extent to which decision-making reflects deliberative, comparative processing, and the Qualitative Engagement Index (QEI), which captures the epistemic quality of interaction with GenAI and conditions how such processing unfolds. We then examine anchoring, confirmation, and overconfidence as outcomes associated with premature closure (Lovallo and Kahneman, 2003; Rau and Bromiley, 2025). Results reveal an inverted U-shaped relationship between GenAI use and cognitive biases, such that anchoring, confirmation bias, and overconfidence are lowest at intermediate levels of use. This pattern reflects variation in cognitive processing: moderate use is associated with stronger deliberative engagement (higher CTI), sustaining comparison and delaying closure, whereas low use provides insufficient support and high use is associated with reduced self-monitoring and earlier convergence around GenAI-supported interpretations. Moreover, these effects are conditioned by qualitative engagement (QEI): higher-quality engagement reinforces comparative processing and bias reduction, whereas lower-quality engagement promotes uncritical reliance, narrowing evaluation and increasing bias.
Consequently, this study advances behavioral strategy by directly engaging the question of whether AI can do strategy (Chatterji et al., 2026; Csaszar et al., 2026). We show that GenAI shapes strategic judgment not only through the information it provides, but by reorganizing the evaluative process itself—how alternatives are represented, compared, and brought to closure. In doing so, we recast GenAI from an input into decision-making to a constitutive element of evaluation. Our findings reveal that cognitive bias does not arise solely from individual limitations, but from how evaluation unfolds: whether decision processes sustain comparative scrutiny and unresolved alternatives, or converge prematurely around a single, coherent interpretation. GenAI can support the former, but it can also accelerate the latter. This leads to a sharper implication for both theory and practice. The question is not whether AI improves strategic decision-making, but whether decision processes are designed so that AI expands evaluation without displacing it. In this sense, GenAI does not replace strategy—it reshapes the conditions under which strategy becomes possible.
Theoretical background and hypotheses development
GenAI, cognitive processing, and strategic decision-making
Strategic decision-making unfolds under conditions of uncertainty, where leaders operate with incomplete, noisy, and open-to-multiple-interpretations information (March and Simon, 1958). Such decisions rarely approximate full rationality. Instead, bounded cognition, affect, and organizational context shape how decision-makers attend to information, prioritize cues, frame problems, and form judgments (Cristofaro et al., 2025; Powell et al., 2011). To cope with complexity and time pressure, executives rely on heuristics that economize cognitive effort by narrowing the cues considered and the comparisons performed (Gavetti et al., 2007). While functional, these simplifications introduce predictable distortions in judgment.
Dual-process theory explains how such judgments unfold by distinguishing intuitive processing (System 1), which is fast and coherence-seeking, from deliberative processing (System 2), which is slower and supports comparison and critical evaluation (Evans and Stanovich, 2013; Kahneman, 2011; Kahneman et al., 1982). Importantly, cognitive processing is not merely a background condition but the mechanism through which judgment quality is shaped: biases such as anchoring, confirmation, and overconfidence emerge when intuitive coherence and selective salience dominate deliberative reassessment, limiting comparison and calibration over time (Tversky and Kahneman, 1974). Accordingly, bias mitigation depends less on individual awareness than on how decision processes structure attention, search, comparison, and calibration (Kahneman et al., 2011; Rau and Bromiley, 2025), shaping how problems are framed, evidence is interpreted, and commitment unfolds (Cristofaro et al., 2022; Sydow et al., 2020).
Building on this perspective, recent research conceptualizes GenAI as an organizational artifact that reshapes cognitive processing by altering representation, search, and evaluation (Boussioux et al., 2024; Chatterji et al., 2026; Csaszar et al., 2026). GenAI can expand the set of alternatives considered, sustain comparison, and support deliberative reasoning. At the same time, its outputs may concentrate attention around dominant representations, introducing path dependence and accelerating convergence (Doshi et al., 2025). Consequently, GenAI-use intensity influences cognitive biases through its effects on cognitive processing: it may either sustain evaluative balance between intuitive and deliberative reasoning or promote premature closure around a single interpretation (Allen and McDonald, 2026).
Anchoring bias and GenAI
Anchoring bias arises when an initial representation—for example, numerical estimates, forecasts, or salient analogies—becomes focal and organizes subsequent judgment. In strategic decisions such as market entry, investment scale, or partnership formation, executives must evaluate risks and returns before outcomes are observable, which shapes how the decision situation is framed (Gavetti et al., 2007).
Dual-process theory clarifies why anchoring emerges and persists in such contexts. In the absence of structured challenges, System 1 tends to dominate strategic judgment by generating internally coherent reference points that simplify complexity and reduce cognitive effort. System 2, which would be required to reassess these reference points, compare alternatives, or test counterfactuals, is weakly activated under time pressure and uncertainty (Kahneman et al., 1982). Hence, the problem is that comparative evaluation may narrow before alternative interpretations are seriously considered. We conceptualize this evaluative dynamic as cognitive processing, reflected in the extent to which decision-makers critically reassess initial anchors, compare competing representations, and adjust judgments through counterfactual reasoning.
GenAI may alter evaluation by adding another representation of the strategic situation (Csaszar, 2025; Raisch and Fomina, 2025). We argue that GenAI-use intensity influences anchoring through its effects on this cognitive processing mechanism. At intermediate observed levels of use, decision-makers’ own judgments and GenAI outputs are more likely to remain jointly present, sustaining comparison, prompting scrutiny of discrepancies, and delaying closure around any single frame, which may reduce anchoring (Boussioux et al., 2024). At very high observed levels of use, however, this effect may weaken as GenAI outputs cease to function as a distinct basis for comparison and instead become the primary frame for evaluating the situation; comparative evaluation then narrows, contestation declines, and anchoring may reappear, not around one’s own initial intuition, but around a GenAI-supplied reference point (Doshi et al., 2025; Kellogg et al., 2020). Moreover, the extent to which GenAI sustains or narrows cognitive processing depends on how decision-makers engage with its outputs: higher-quality engagement encourages interrogation and comparison, whereas lower-quality engagement promotes uncritical reliance, amplifying anchoring tendencies.
Confirmation bias and GenAI
Confirmation bias reflects the tendency to search for, interpret, and integrate information in ways that favor existing beliefs (Nickerson, 1998). Early beliefs about markets, competitors, or strategic feasibility shape which cues receive attention, how evidence is weighted, and which interpretations gain traction during organizational sense-making (Lovallo and Sibony, 2018). From a dual-process perspective, confirmation bias arises when intuitive processing (System 1) dominates evaluation: belief-consistent cues are processed more fluently and appear more compelling than disconfirming information (Kahneman, 2011). Although deliberative processing (System 2) enables the active search for counterevidence and the reassessment of prior beliefs, it is easily disengaged under time pressure and complexity (Kahneman et al., 1982). Consequently, evaluation may narrow around belief-consistent information, limiting the exploration of alternative interpretations and reinforcing initial frames. This evaluative dynamic, that is, cognitive processing, is reflected in the extent to which decision-makers actively seek and engage with disconfirming evidence, compare competing interpretations, and revise prior beliefs.
GenAI may alter this evaluative dynamic by introducing additional representations into the assessment of a strategic situation (Csaszar, 2025; Raisch and Fomina, 2025). We argue that GenAI-use intensity influences confirmation bias through its effects on this cognitive processing mechanism. At intermediate levels of use, decision-makers’ prior beliefs and GenAI outputs are more likely to remain jointly present, sustaining comparison, surfacing counterarguments, and prompting engagement with disconfirming cues, thereby delaying premature closure (Boussioux et al., 2024). At very high levels of use, however, GenAI outputs may become the dominant evaluative frame, reducing contestation, and narrowing comparison. In such cases, confirmation bias may re-emerge—not through reliance on prior beliefs alone, but because evaluation again converges too quickly on a single, GenAI-supported interpretation (Doshi et al., 2025; Kellogg et al., 2020). Moreover, the extent to which GenAI sustains or narrows cognitive processing depends on how decision-makers engage with its outputs: higher-quality engagement promotes interrogation and comparison, whereas lower-quality engagement encourages uncritical reliance, reinforcing belief-consistent evaluation.
Overconfidence and GenAI
Overconfidence reflects a miscalibration between subjective confidence and objective accuracy, including overprecision, exaggerated beliefs in one’s own control, and unwarranted certainty under uncertainty (Moore and Healy, 2008). In strategic decision-making, this bias directs attention away from uncertainty, feedback, and alternative scenarios, thereby reinforcing premature commitment and excessive risk-taking (Lovallo and Kahneman, 2003).
According to dual-process theory, overconfidence arises when decision-makers rely on internal cues such as narrative coherence, subjective plausibility, or prior success, rather than on external validity. System 2, which would require explicit comparison against benchmarks, counterfactuals, or disconfirming evidence, is weakly engaged (Kahneman, 2011). Thus, the problem is that self-evaluation may narrow before those judgments are seriously calibrated against alternative assessments. This evaluative dynamic, that is, cognitive processing, is reflected in the extent to which decision-makers sustain calibration, benchmark their confidence against alternative assessments, and critically reassess the validity of their judgments.
GenAI may alter confidence calibration by introducing additional benchmarks, probabilistic assessments, and comparative analyses into the evaluation of a strategic situation (Csaszar, 2025; Raisch and Fomina, 2025). We argue that GenAI-use intensity influences overconfidence through its effects on this cognitive processing mechanism. At intermediate observed levels of use, decision-makers’ own confidence judgments and GenAI-generated evaluations are more likely to remain jointly present, helping keep calibration active by surfacing discrepancies, prompting scrutiny of certainty, and delaying closure around initially confident judgments, which may reduce overconfidence (Felin and Holweg, 2024). At very high observed levels of use, however, this corrective effect may weaken as GenAI outputs cease to serve as a distinct basis for calibration and instead become a more focal reference in how confidence is assessed; calibration may then narrow, scrutiny may decline, and overconfidence may reappear, not because decision-makers rely only on their own internal certainty, but because confidence again becomes anchored in a single evaluative basis now reinforced by GenAI (Choudhary et al., 2025; Felin and Holweg, 2024). Moreover, the extent to which GenAI sustains or narrows cognitive processing depends on how decision-makers engage with its outputs: higher-quality engagement promotes calibration and comparative scrutiny, whereas lower-quality engagement encourages uncritical reliance, reinforcing overconfidence.
Figure 1 presents the study’s conceptual framework. It proposes that GenAI-use intensity is associated with cognitive biases through changes in cognitive processing. Rather than treating GenAI as uniformly beneficial, the framework emphasizes that its effects depend on how evaluation is organized during use. It also identifies qualitative engagement as a conditioning factor, where higher-quality engagement supports reflective comparison, while lower-quality engagement aligns with more intuitive or uncritical reliance.
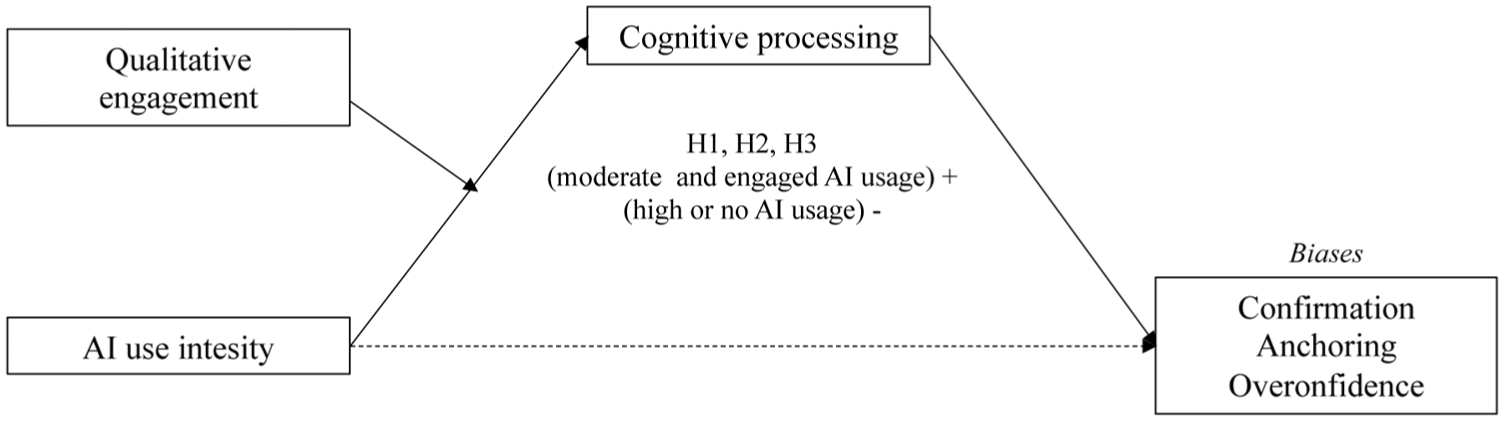
Empirical model.
Methods
Experimental design
This study employs a between-groups randomized experiment to examine how access to GenAI shapes strategic cognition and cognitive bias in a complex decision-making task, while variation in GenAI-use intensity is analyzed as an emergent behavioral measure within the GenAI-enabled condition (Di Stefano and Gutierrez, 2019; Ehrig and Schmidt, 2021). A total of 273 participants took part in the main study (Section “Participants and procedure”), preregistered in As Predicted (9wx4ef; Research Box 5355). Participation was voluntary and uncompensated. After consent and baseline items, participants were automatically assigned through the embedded questionnaire platform to one of two conditions using a prespecified unequal allocation ratio:
No-AI condition (control). Participants completed the strategic scenario using only the provided materials (see Supplementary Material SM1).
GenAI-enabled condition. Participants had access to ChatGPT through a controlled interface and could consult it during the task.
GenAI access (No-AI vs GenAI-enabled) is the only fully randomized factor. Because reliance on GenAI was discretionary, GenAI-use intensity was not manipulated but recorded continuously as the total number of prompts, including follow-ups and regeneration requests. This design enables causal inference regarding GenAI access, while variation in use intensity remains observational.
All participants completed the same market-entry decision under uncertainty within a fixed time limit, ensuring comparable time-on-task. In the GenAI-enabled condition, prompting was unrestricted but external tools were blocked, and all interactions were logged. Participants followed a think-aloud protocol, with verbalizations recorded and transcribed. These data underpin the process measures used in the analyses, including the CTI and the QEI (Supplemental Appendices A and B).
The main study builds on two prior investigations. Study 1 (251 business professionals), preregistered on As Predicted (ID: w6a8rf) and documented in an online repository (ResearchBox project 4923), was used to refine the scenario and develop beta versions of the CTI and QEI. A subsequent pilot study (66 professionals) assessed feasibility and measurement reliability, testing the preregistered procedures for the main study.
The study reported here constitutes the first fully powered, confirmatory test of the hypotheses. Only data from the main study are used for inferential analyses. Participants provided informed consent, and all interaction logs were de-identified at the time of capture.
Participants and procedure
Participants were recruited through professional networks, executive education programs, and targeted social media outreach aimed at individuals with experience in business development, strategy, or related managerial roles. A total of 291 professionals initially enrolled. After excluding incomplete responses, technical failures, and protocol violations (e.g. misuse of the GenAI interface), the final sample comprised 273 participants who completed the full procedure.
Consistent with the analytical focus, participants were unevenly allocated across conditions to ensure sufficient power both for comparing GenAI-enabled and no-AI decision-making and for analyzing continuous GenAI-use intensity. Specifically, 100 participants were assigned to the No-AI condition and 173 to the GenAI-enabled condition. Power considerations reflected the study’s dual goals: detecting the main effect of GenAI access and examining linear and nonlinear relationships between GenAI-use intensity and cognitive outcomes. Assuming small-to-medium effects (α = .05, power = .80; Cohen, 1988), prior benchmarks indicate that samples exceeding 200 participants are sufficient. The final sample, combined with a larger GenAI-enabled group, provides adequate power for the planned analyses.
Condition assignment was executed automatically through the embedded questionnaire platform after consent and baseline items, using a prespecified unequal allocation ratio. To ensure realism, participants assumed the role of senior executives at a mid-sized European technology firm (“TechCo”) considering expansion into Germany, a context chosen for its strategic ambiguity and economic relevance (Csaszar, 2018; Gavetti et al., 2007). Full materials are provided in SM2.
Before the task, participants completed a questionnaire assessing background knowledge and potential sources of bias, including perceptions of the German business environment and prior exposure to relevant technologies. Responses were used to screen for domain expertise and construct control variables. Participants had 90 min to complete the task and provide a recommendation with written justification, ensuring comparable time-on-task. In the GenAI-enabled condition, participants interacted with ChatGPT (5.2 Standard Thinking) through a controlled interface, with all interactions logged.
During the task, participants followed a think-aloud protocol, with verbalizations recorded and transcribed. After completion, participants filled out a short post-task questionnaire assessing task difficulty, attentiveness, and perceived usefulness and trust in GenAI.
Measurements
This section describes the measures used to capture key outcomes, process variables, and GenAI-related behavioral indicators.
GenAI-use
To capture behavioral reliance on GenAI, we operationalize GenAI-use intensity as prompt count. For each participant in the GenAI-enabled condition, we counted the total number of user-initiated prompts recorded in the interaction log, including initial queries, follow-ups, and regeneration requests. This count serves as a continuous measure of GenAI consultation during the decision process and is treated as a continuous predictor rather than a categorical treatment. References to lower, intermediate, or higher levels of use denote descriptive regions of the distribution, not experimental groups. This approach follows research using digitally logged behavioral traces to capture real-time activity (Simsek et al., 2019).
CTI
Cognitive processing was assessed using a think-aloud protocol (Wolcott and Lobczowski, 2021). Verbalizations produced during the decision task were transcribed and coded using dual-process theory (Evans and Stanovich, 2013). The revised CTI captures three categories of utterances: (1) intuitive, (2) deliberative, and (3) meta-cognitive. Utterances were segmented and coded by three trained researchers using a structured manual, and CTI is computed as a preregistered weighted composite reflecting increasing cognitive effort across processing modes (Supplemental Appendix A). CTI captures the internal structure and evolution of cognitive processing over time, that is, how participants generate, compare, and revise judgments as the decision unfolds. It reflects the balance between intuitive, deliberative, and meta-cognitive reasoning and is used as a continuous process indicator of how thinking develops during the task.
QEI
To capture how participants engaged with GenAI beyond usage frequency, we employ the QEI, a multi-facet, transcript-based measure of the epistemic quality of human–AI interaction. QEI builds on sociocultural and constructivist views of knowledge co-construction (Lave and Wenger, 1991), as well as research in human–computer interaction (HCI) and computer-supported collaborative learning (CSCL) emphasizing inquiry, reflection, and integration of external inputs (Chi, 2009; Stahl, 2017). In the main study, QEI is operationalized as a continuous index composed of five facets: query depth, reflective integration, conversation complexity, iteration quality, and counter-argumentation (Supplemental Appendix B). QEI captures the quality of participants’ interaction with GenAI during the task, specifically how they formulate queries, iterate on outputs, and engage with alternative representations. Unlike CTI, it does not assess internal cognitive processing, but the interactional and epistemic practices through which external inputs are incorporated into the decision process. It is therefore treated as a behavioral indicator of engagement that conditions how GenAI use translates into cognitive processing.
Anchoring bias: Anchoring was measured as the extent to which participants’ final probability estimates remained tied to an initial numerical anchor (“80% success rate for entry into Germany”). After reading the scenario, participants provided a final success estimate (0%—100%). Anchoring bias was operationalized using the Anchoring Bias Score (ABS)
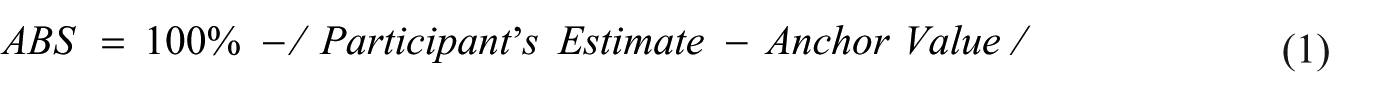
Higher ABS values indicate stronger anchoring. Participants in the No-AI condition relied solely on case materials, whereas those in the GenAI-enabled condition could consult ChatGPT. ABS is treated as a continuous outcome and modeled as a function of GenAI-use intensity (prompt count, including zeros for No-AI participants) using linear and quadratic terms.
To account for the potential direct influence of GenAI outputs, we conducted exposure-aware robustness checks. For each transcript, we coded an Anchor-Echo flag indicating whether ChatGPT repeated the 80% anchor. Models were re-estimated controlling for this flag and excluding flagged sessions. Results remain unchanged, suggesting anchoring effects are not driven by GenAI repetition (see SM2).
Confirmation bias: Following Frost et al. (2015), confirmation bias was measured as the tendency to favor information supporting one’s emerging position. In the No-AI condition, participants selected relevant cues from a predefined list classified as supporting (SC) or opposing (OC) market entry. In the GenAI condition, cues were generated dynamically via ChatGPT interactions; extracted statements were coded relative to each participant’s final stance. The Confirmation Bias Score (CB) was computed as

where TC is the total cues. CB ranges from −1 (only opposing) to +1 (only supporting), with higher values indicating stronger confirmation bias. CB is treated as a continuous outcome and related to GenAI-use intensity and process measures (CTI, QEI). To address potential imbalance in GenAI-generated evidence, we coded a cue-balance indicator (ratio of supporting vs opposing arguments in model outputs). Results remain robust when controlling for this measure and excluding sessions with skewed outputs (SM2).
Overconfidence bias: Overconfidence was conceptualized as miscalibrated confidence in one’s strategic decision-making ability. Participants rated their confidence twice, on an 11-point scale (1 = “not at all confident,” 10 = “extremely confident”): (1) before working on the scenario (“In general, how confident are you in your ability to make effective strategic decisions in your current professional role?”) and (2) after submitting their final recommendation. The Overconfidence Change Score (OCS) captures within-person change
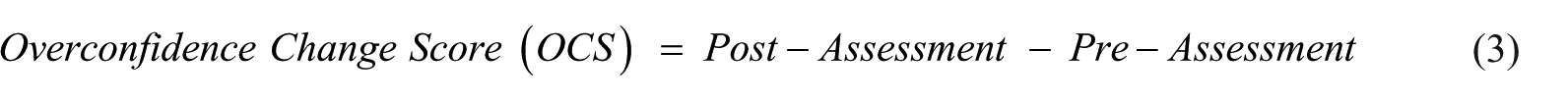
Positive values indicate increased confidence. To contextualize self-ratings, we also elicited an external Decision Competence Anchor (DCA). Ten industry professionals with experience in strategic decision-making rated “the level of confidence that would be appropriate for a typical business developer completing a similar strategic decision under comparable conditions” on the same 1–10 scale. The DCA is the average of these expert ratings
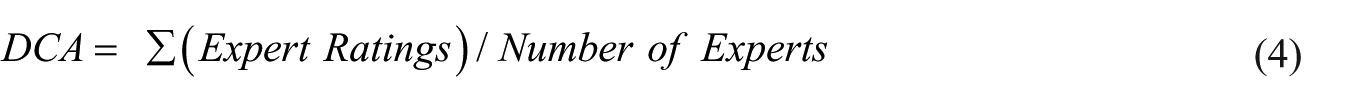
Overconfidence is thus examined in two complementary ways: as change in confidence (OCS) and as post-task miscalibration relative to DCA (i.e. how far participants’ post-task confidence exceeds or falls below the expert-based benchmark). Both indicators are modeled as continuous outcomes and related to GenAI-use intensity and process measures. This dual operationalization allows distinguishing benign confidence gains from systematic overestimation of one’s strategic competence.
Measurement development and validation
Measures were adapted from established literature (e.g. Frost et al., 2015; Moore and Healy, 2008) and tailored to the GenAI context. Newly specified indices (ABS, CB, OCS, DCA) were subjected to descriptive checks and sensitivity analyses (e.g. alternative thresholds, exclusion of biased GenAI outputs). Validation details for process measures (CTI, QEI) are provided in Supplemental Appendices A and B, with additional robustness checks reported in SM2.
Group parity verification and control variables
We assessed group comparability and potential confounds through balance checks and individual-difference controls. As described in Section “Participants and procedure,” condition assignment was executed automatically through the questionnaire platform using an unequal allocation ratio, supporting internal validity alongside the diagnostics reported below.
To account for baseline cognitive differences, participants completed the Cognitive Reflection Test (CRT; Frederick, 2005), capturing tendencies toward reflective versus intuitive reasoning (Pennycook et al., 2016). Familiarity with GenAI was measured using a 12-item AI literacy scale (Wang et al., 2023; α = .83; M = 3.91, SD = 0.69), and professional experience (years in strategic roles) was recorded. These variables were included as covariates in robustness analyses.
The No-AI condition serves as the baseline category. Because GenAI-use intensity is operationalized as prompt count, we tested whether QEI simply reflects interaction volume. Results show that QEI is only weakly related to prompt count and session length, and remains distinct when modeled jointly, supporting its interpretation as engagement quality.
Balance checks indicate no significant differences across conditions in demographics, experience, CRT, or AI literacy (all p > .10; see SM4). All models include these controls, with bootstrapped confidence intervals to ensure robustness. Together, these checks support internal validity and the interpretation of CTI and QEI as behavioral mechanisms rather than artifacts of assignment or usage intensity.
Results
Descriptive statistics
The final sample comprised 273 business professionals with experience in strategy, business development, or related managerial roles, drawn from executive education programs, professional networks, and targeted outreach. Of these, 100 participants completed the task without GenAI support, while 173 had access to GenAI and exercised discretionary use during the decision task.
Participants averaged 38.4 years of age (SD = 4.1) and 10.2 years of professional experience (SD = 3.1). Most reported involvement in strategic decision-making (81%), international business exposure (84%), and participation in European or cross-border projects (86%). Gender distribution was balanced (53% male), and no significant demographic differences emerged between GenAI-enabled and No-AI subsamples.
Within the GenAI-enabled group, GenAI-use intensity varied substantially, supporting its treatment as a continuous behavioral variable. The number of prompts ranged from 1 to 29 (M = 11.8, SD = 6.7). GenAI-use intensity was only weakly correlated with session length (r = .18, p = .07) and uncorrelated with prompt verbosity, indicating that interaction frequency does not trivially proxy for engagement depth.
Participants completed measures of anchoring bias, confirmation bias, overconfidence, the CTI, and the QEI. Table 1 reports descriptive statistics and zero-order correlations.
Descriptive statistics and correlation matrix for study variables.
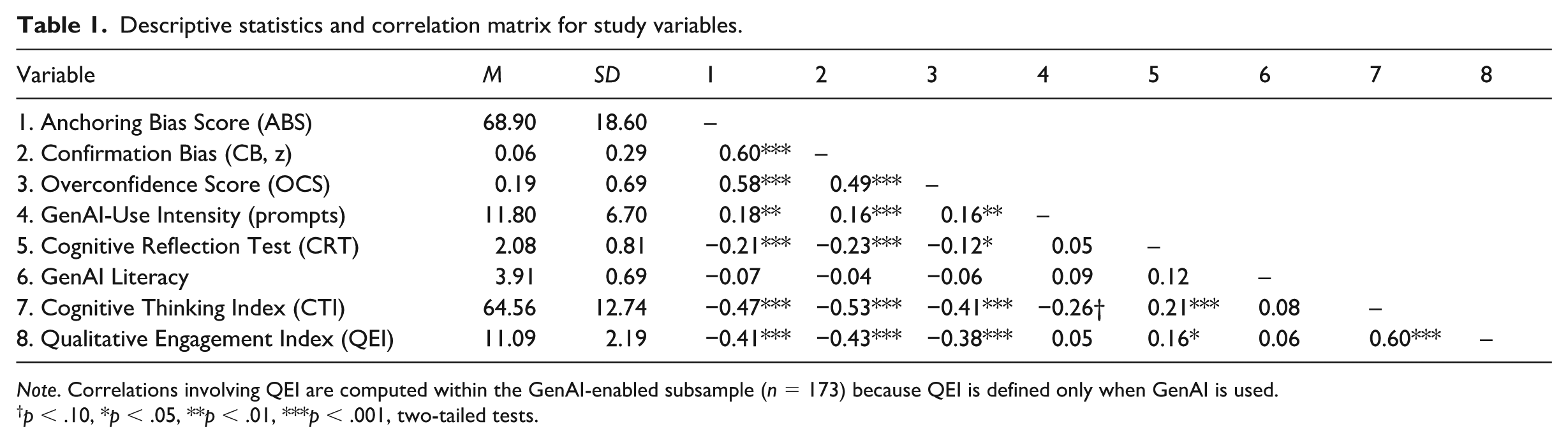
Note. Correlations involving QEI are computed within the GenAI-enabled subsample (n = 173) because QEI is defined only when GenAI is used.
p < .10, *p < .05, **p < .01, ***p < .001, two-tailed tests.
ABSs averaged 68.9 (SD = 18.6). Confirmation bias scores (CB) averaged 0.06 (SD = 0.29), and overconfidence (OCS) averaged 0.19 (SD = 0.69). The three biases were moderately to strongly intercorrelated: anchoring correlated with confirmation bias (r = .60, p < .001) and overconfidence (r = .58, p < .001), and confirmation bias correlated with overconfidence (r = .49, p < .001), indicating clustering of cognitive biases in strategic judgment.
CTI showed substantial dispersion (M = 64.3, SD = 13.7, range = 39–101). CTI correlated negatively with anchoring (r = −.47), confirmation bias (r = −.53), and overconfidence (r = −.41; all ps < .001). Decomposition revealed that deliberative and meta-cognitive utterances primarily drove these associations, whereas intuitive utterances were positively related to all three biases (rs = .31–.38). CTI was only modestly correlated with CRT scores (r = .21, p < .01).
CTI varied systematically with GenAI-use intensity (Figure 2), following an inverted-U pattern: CTI increased across the lower-to-intermediate observed range of GenAI-use intensity and declined thereafter. This pattern was stronger among participants with high QEI, while low-QEI participants showed a flatter relationship. Deliberative and meta-cognitive processing were highest in the intermediate observed region of the GenAI-use distribution.
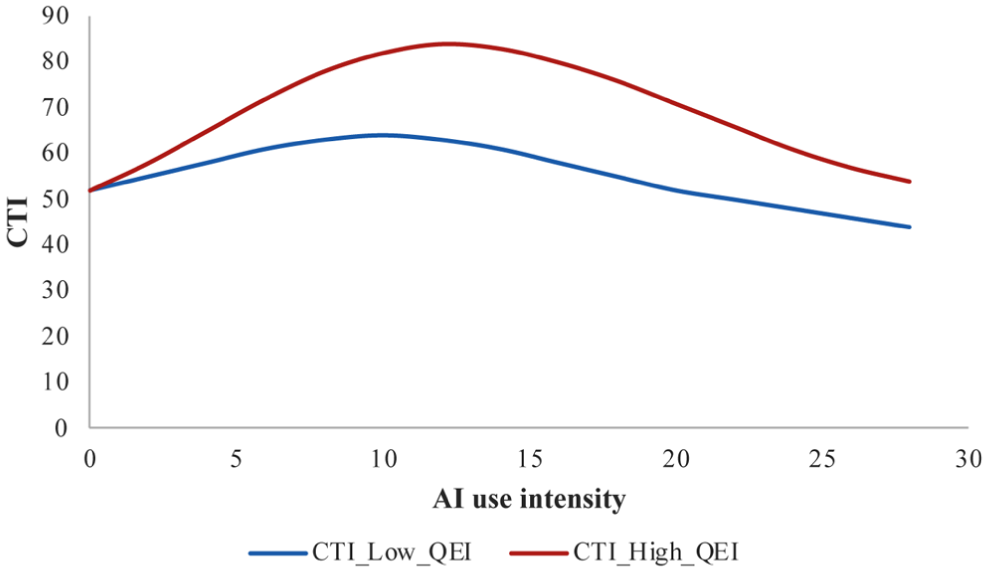
Cognitive Thinking Index (CTI) as a function of AI-use intensity, moderated by qualitative engagement (QEI).
Among GenAI-enabled participants, QEI scores ranged from 6 to 15 (M = 11.2, SD = 2.3), indicating substantial heterogeneity in the epistemic quality of human–AI interaction. Based on established QEI cutoffs, 28% of participants exhibited high engagement quality (QEI ⩾ 13), 47% intermediate engagement quality (QEI = 10–12), and 25% low engagement quality (QEI ⩽ 9). Importantly, QEI was uncorrelated with GenAI-use intensity (r = .08, ns), reinforcing that engagement quality and usage frequency represent distinct dimensions of GenAI adoption.
QEI correlated strongly with CTI (r = .63, p < .001), particularly with the meta-cognitive component (r = .57, p < .001). This pattern is consistent with a close empirical association between engagement quality and the coded process indicators captured by CTI. Higher QEI was also associated with lower anchoring (r = −.41, p < .001), lower confirmation bias (r = −.38, p < .001), and lower overconfidence (r = −.32, p < .001). While empirically related, QEI and CTI capture distinct dimensions: interactional engagement with GenAI versus internal cognitive processing.
Neither CRT performance (M = 2.08, SD = 0.81) nor AI literacy (M = 3.91, SD = 0.69) showed significant direct correlations with anchoring, confirmation bias, or overconfidence (all |r|s < .12, ns), suggesting that general cognitive reflection skills and self-reported familiarity with GenAI are insufficient to explain variation in bias expression. Instead, the observed correlations are more consistent with variation in situated cognitive processing and interaction quality than with general cognitive reflection or self-reported GenAI familiarity.
Importantly, the three core constructs –GenAI-use intensity, QEI, and CTI—exhibited a differentiated correlational structure. GenAI-use intensity was weakly correlated with CTI (r = .26, p = .06) and uncorrelated with QEI (r = .05, ns). By contrast, QEI and CTI were strongly correlated (r = .63, p < .001). Taken together, these patterns suggest that interaction frequency, engagement quality, and cognitive processing are empirically distinguishable and motivate the moderated and nonlinear analyses reported below.
Curvilinear association between GenAI-use intensity and cognitive processing
Building on the descriptive patterns reported in Section “Descriptive statistics,” we next formally tested whether GenAI-use intensity exhibits a nonlinear relationship with cognitive processing, as captured by the CTI. We estimated regression models including both linear and quadratic terms for GenAI-use intensity, treating intensity as a continuous behavioral variable and retaining participants in the No-AI condition as zero-intensity observations. Zero values correspond to the absence of GenAI access and are included to preserve comparability across conditions. Table 2 reports the regression results; full results for CTI components are reported in SM2.
Curvilinear association between GenAI-use intensity and cognitive processing (CTI).
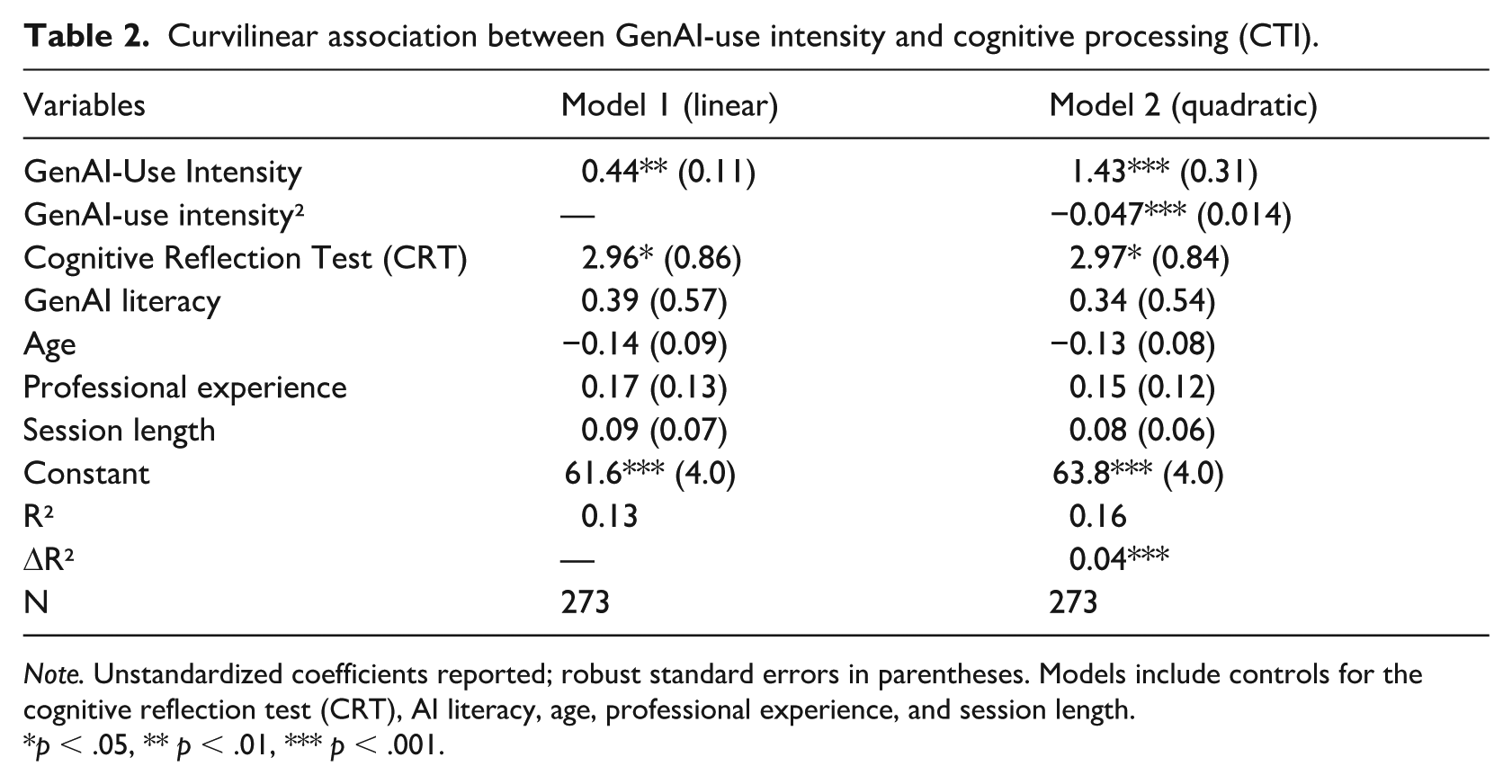
Note. Unstandardized coefficients reported; robust standard errors in parentheses. Models include controls for the cognitive reflection test (CRT), AI literacy, age, professional experience, and session length.
p < .05, ** p < .01, *** p < .001.
Results indicate a statistically significant inverted-U association between GenAI-use intensity and CTI. The linear term for GenAI-use intensity was positive and significant (standardized β = .88, p < .001), whereas the quadratic term was negative and significant (standardized β = −.61, p < .001). This pattern indicates that CTI peaks in the intermediate observed region of the GenAI-use intensity distribution.
The estimated turning point of the fitted curve occurred at approximately 14–15 GenAI interactions, corresponding to the intermediate observed region of the continuous GenAI-use distribution shown in Figure 2. Model fit statistics further confirmed the relevance of the nonlinear specification: the quadratic model explained significantly more variance in CTI than a linear-only model (ΔR² = .04, FΔ(1, 266) = 11.4, p < .001).
To probe the cognitive meaning of this curvilinear effect, we decomposed CTI into its constituent components. Follow-up analyses revealed that the inverted-U pattern was driven primarily by deliberative (D) and meta-cognitive (M) utterances. Deliberative utterances increased across the lower-to-intermediate observed range of GenAI-use intensity (β = .65, p < .001) but declined at very high observed levels (β² = −.43, p < .01). Meta-cognitive utterances showed a similar pattern (β = .69, p < .001; β² = −.46, p < .001). By contrast, intuitive utterances (I) displayed a monotonic increase with GenAI-use intensity (β = –.10, ns).
These findings indicate that the association between GenAI-use intensity and CTI is nonlinear rather than uniformly positive. CTI is highest in the intermediate observed region of the continuous intensity distribution and lower at both the low and very high observed ends. This pattern is concentrated in the deliberative and meta-cognitive components of CTI. These curvilinear estimates remained robust after controlling for age, professional experience, CRT performance, AI literacy, and session length.
CTI as a mediating process indicator between GenAI-use intensity and cognitive biases
Having established a nonlinear association between GenAI-use intensity and CTI, we next examined whether CTI statistically accounts for part of the association between GenAI-use intensity and anchoring, confirmation bias, and overconfidence, and whether this indirect pattern depends on the quality of engagement with GenAI (QEI). Table 3 summarizes the moderated mediation results across all three bias outcomes.
Moderated mediation of GenAI-use intensity and cognitive biases via CTI.
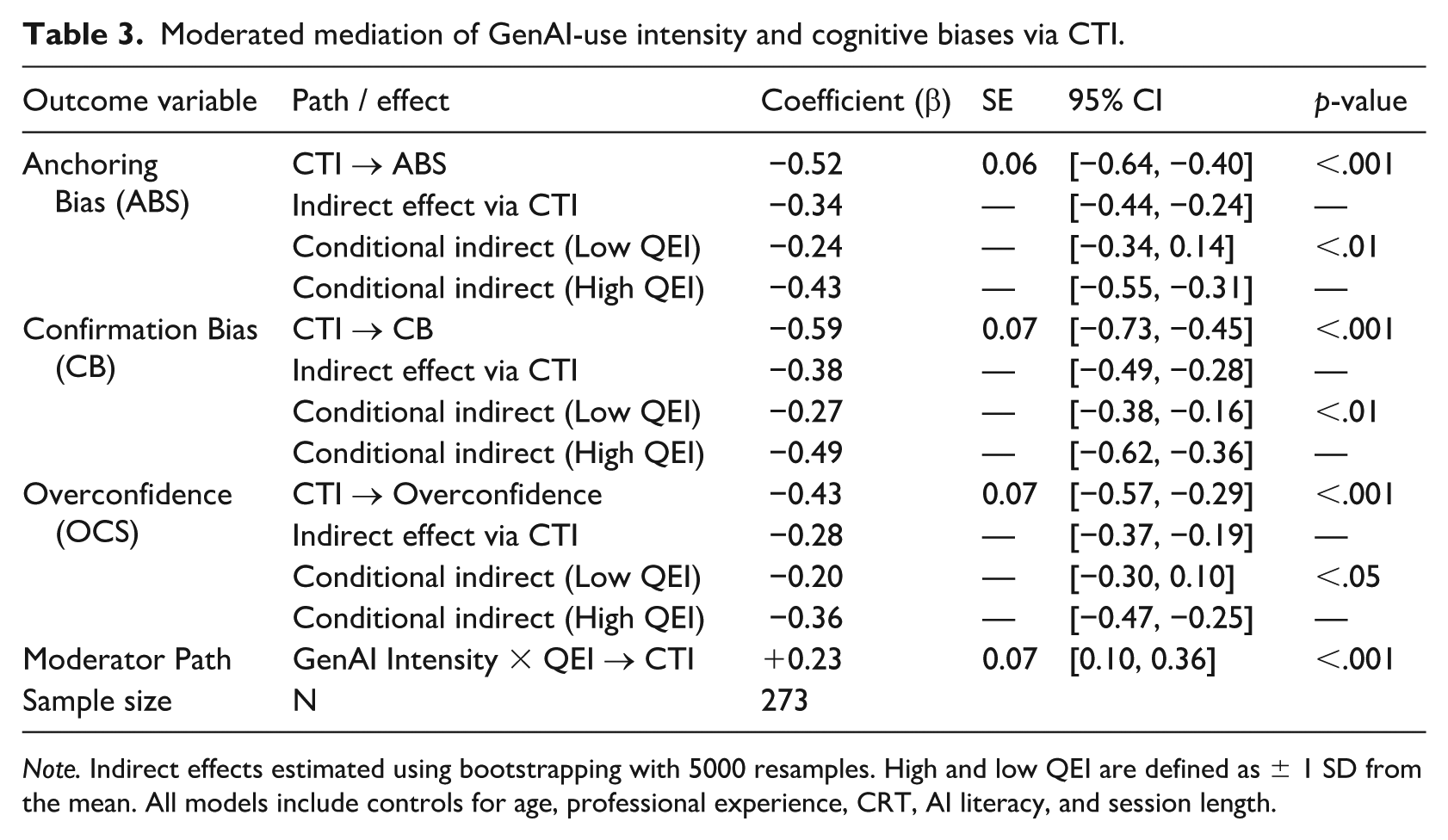
Note. Indirect effects estimated using bootstrapping with 5000 resamples. High and low QEI are defined as ± 1 SD from the mean. All models include controls for age, professional experience, CRT, AI literacy, and session length.
We first estimated mediation models in which GenAI-use intensity (linear and quadratic terms) predicted each bias outcome indirectly through CTI. CTI was negatively associated with all three bias outcomes. Higher CTI scores were associated with lower anchoring (β = −.52, p < .001), lower confirmation bias (β = −.59, p < .001), and lower overconfidence (β = −.43, p < .001), controlling for GenAI-use intensity and covariates.
Results further indicated that CTI partially mediated the relationship between GenAI-use intensity and each bias outcome. Bootstrapped indirect effects were statistically significant for anchoring (indirect effect = −.34, 95% CI [−.44, −.24]), confirmation bias (indirect effect = −.38, 95% CI [−.49, −.28]), and overconfidence (indirect effect = −.28, 95% CI [−.37, −.19]). Importantly, direct effects of GenAI-use intensity on biases remained significant in most models, indicating partial rather than full mediation. This pattern is consistent with indirect associations through CTI as well as additional pathways not captured by the present process measure.
We next tested whether the indirect association through CTI varies with participants’ engagement with GenAI, as captured by QEI. Specifically, we estimated moderated mediation models in which QEI moderates the relationship between GenAI-use intensity and CTI.
Results revealed a consistent pattern across all three biases. The interaction between GenAI-use intensity and QEI was positive and significant in predicting CTI (β = .23, p < .001), indicating that GenAI-use is associated with higher cognitive processing primarily when engagement quality is high. Among participants with high QEI (one SD above the mean), GenAI-use intensity was positively associated with CTI over the lower-to-intermediate observed range of use, whereas among low-QEI participants, this association was weaker.
Conditional indirect effects confirmed this pattern. For high-QEI participants, the indirect effect of GenAI-use intensity on bias reduction via CTI was significant for anchoring (indirect effect = −.43, 95% CI [−.55, −.35]), confirmation bias (−.49, 95% CI [−.62, −.36]), and overconfidence (−.36, 95% CI [−.47, −.25]). By contrast, for low-QEI participants, indirect effects were substantially attenuated (anchoring –.24, confirmation bias –.27, overconfidence –.20). These findings indicate that lower bias scores were observed primarily when GenAI-use intensity co-occurred with higher-quality engagement and higher CTI.
In sum, these results are consistent with an indirect association between GenAI-use intensity and the three bias outcomes through CTI, and with variation in that indirect pattern by engagement quality. The indirect effects were concentrated among participants with higher QEI and were weaker among those with lower QEI.
Robustness analyses and process diagnostics
To assess the robustness of the findings and rule out alternative explanations, we conducted supplementary analyses addressing potential concerns related to GenAI output artifacts, interaction quantity, and alternative operationalizations of cognitive processing. Across all specifications, the core results reported in Sections “Curvilinear association between GenAI-use intensity and cognitive processing” and “CTI as a mediating process indicator between GenAI-use intensity and cognitive biases” remained substantively unchanged (see SM3: Tables S13–S16; Figures S1–S3).
In addition to the composite CTI measure, we examined two complementary process diagnostics derived from CTI. The Deliberation Balance Index (DBI), computed as (D−I)/(D + I), captures the relative predominance of deliberative over intuitive reasoning. The Meta-Cognitive Ratio (MCR), computed as M/(I + D + M), reflects the extent of reflective monitoring and self-regulation. Both indices were tested as alternative mediators in otherwise identical moderated mediation models. Results were consistent with those obtained using CTI, indicating that the findings are not driven by a specific operationalization of cognitive processing.
To address the possibility that GenAI outputs mechanically influenced bias scores, we excluded sessions in which (a) the model explicitly repeated or paraphrased the numerical anchor (“anchor-echo”) or (b) generated strongly imbalanced supporting versus opposing cues (“cue imbalance”). After excluding 39 sessions (remaining N = 234), all models were re-estimated. Results remained stable: the inverted-U relationship between GenAI-use intensity and CTI persisted (β_linear = .38, p < .001; β_quadratic = −.32, p < .001), and CTI continued to mediate the relationship between GenAI use and all three bias outcomes. Conditional indirect effects for high-QEI participants remained significant for anchoring (−.14, 95% CI [−.21, −.08]), confirmation bias (−.16, 95% CI [−.24, −.10]), and overconfidence (−.15, 95% CI [−.23, −.09]). These findings suggest that results are not driven by mechanical properties of GenAI outputs but by variation in how participants engaged with them.
Finally, to disentangle interaction quality from quantity, we re-estimated all models controlling for session length and lexical repetition (verbatim reuse of GenAI outputs). Session length showed only a marginal association with CTI (β = .11, p = .08), while lexical repetition was positively associated with intuitive utterances (β = .19, p < .05) and negatively with meta-cognitive markers (β = −.21, p < .01). Neither variable altered the magnitude or significance of the main effects.
Across all robustness checks, the substantive conclusions remain unchanged, reinforcing the interpretation of the results as driven by cognitive processing and engagement quality rather than artifacts of GenAI output or interaction volume.
Discussion and implications
General discussion
This study examines how GenAI use is associated with strategic judgment under uncertainty, showing that its effects are neither linear nor uniformly debiasing. The results point to a process-based explanation: GenAI reshapes cognitive processing by altering how decision-makers represent problems, search for and compare alternatives, and determine when to stop evaluating (Csaszar et al., 2026; Gavetti et al., 2007; March and Simon, 1958). Rather than simply adding information, GenAI changes the structure of evaluation itself.
Across anchoring, confirmation, and overconfidence biases, a consistent curvilinear pattern emerges. Bias is lowest at intermediate levels of GenAI use and higher at both low and very high levels. This pattern is best understood as a shift in dominant modes of cognitive processing rather than as a function of information quantity. At low levels of use, decision-makers rely primarily on internally generated representations, which limits comparison and increases susceptibility to bias (Kahneman, 2011; Tversky and Kahneman, 1974). At intermediate levels, GenAI introduces additional representations that coexist with initial intuitions, sustaining discrepancy and keeping evaluation open. This coexistence supports comparison, counterfactual reasoning, and calibration—core elements of deliberative processing (Evans and Stanovich, 2013)—which are reflected in higher cognitive processing and lower biases.
At very high levels of use, however, this dynamic reverses. As interaction intensifies, GenAI outputs increasingly become the dominant frame through which the problem is interpreted. Because these outputs are fluent and internally consistent, they reduce the perceived need for further evaluation, narrowing cognitive processing (Kahneman et al., 1982; Ocasio, 1997). In this regime, GenAI no longer expands the evaluative space but compresses it, leading to renewed anchoring, confirmation, and overconfidence. This interpretation resonates with recent concerns that AI may compress strategic deliberation into singular, authoritative-seeming recommendations, weakening the disagreement and scrutiny on which strategy depends (Chatterji et al., 2026). It is also consistent with intuitions that AI systems can struggle under strategic uncertainty and may exhibit systematic biases, such as favoring short-term exploitation over long-term positioning (Allen and McDonald, 2026).
Crucially, GenAI-use intensity alone does not determine these outcomes. The findings show that qualitative engagement conditions how GenAI use translates into cognitive processing. While this latter reflects how decision-makers think (i.e. the balance between intuitive, deliberative, and meta-cognitive reasoning), qualitative engagement reflects how decision-makers deal with GenAI outputs (i.e. whether outputs are interrogated, revised, and compared or accepted as given). Higher qualitative engagement sustains cognitive processing by maintaining multiple representations and prompting critical evaluation, consistent with research emphasizing reflective engagement and knowledge co-construction (Chi, 2009; Stahl, 2017). Lower qualitative engagement, by contrast, leads to uncritical reliance, allowing GenAI outputs to function as default answers and narrowing evaluation.
This distinction explains why similar levels of GenAI use can produce different outcomes. GenAI does not directly determine how decisions are made; instead, it provides inputs whose impact depends on how they are incorporated into the evaluative process. When engagement is high, GenAI acts as a source of variation that expands the space of possible interpretations; when engagement is lower, this expansionary effect is dampened, and GenAI more readily functions as a focal point. This dual role aligns with emerging views of human–AI complementarity, where AI can either more strongly or more weakly augment human judgment depending on how it is used (Boussioux et al., 2024; Felin and Holweg, 2024).
More broadly, these findings point to a set of epistemic trade-offs introduced by GenAI use in strategic decision-making. While GenAI can expand representation and accelerate analysis, it may simultaneously reduce the need for continued scrutiny, creating a trade-off between speed and evaluative depth. Similarly, the coherence and fluency of GenAI outputs can enhance interpretability, but at the cost of contestability, as alternative interpretations may receive less attention once a plausible narrative is established. Evidence from emotionally salient human–AI communication similarly shows that AI-generated content is not evaluated only by linguistic quality; attribution, perceived intentionality, and source identity shape whether fluent outputs are treated as authentic or hollow (Dorigoni and Giardino, 2025). Finally, GenAI enables cognitive offloading by structuring information and generating options, but this may also lead to cognitive disengagement if decision-makers reduce active interrogation of outputs. These trade-offs suggest that the central risk of GenAI is not only biased output, but the potential concentration of epistemic authority in a single, coherent representation, which can narrow evaluation prematurely.
Therefore, these findings extend bounded rationality (March and Simon, 1958) by showing that cognitive limits in GenAI-supported decisions are shaped not only by individual constraints but also by the structure of human–AI interaction. AI can relax constraints on representation, search, and aggregation, but it can also reintroduce new constraints by shaping attention and compressing evaluation (Csaszar et al., 2026). Strategy, therefore, remains grounded in problem formulation, comparison, and judgment under uncertainty—processes that are transformed, but not replaced, by AI (Chatterji et al., 2026).
Implications for theory
This study contributes to behavioral strategy, dual-process cognition, and human–AI research by clarifying how GenAI use is associated with strategic judgment under uncertainty. Rather than treating GenAI as a tool that directly improves accuracy or reduces bias, we show that it reshapes the process through which judgment unfolds. In doing so, we offer three core theoretical contributions.
First, we intervene in the emerging debate on whether AI can perform strategic reasoning. Recent work suggests that GenAI can enhance strategic tasks by expanding representation, search, and aggregation, raising the possibility that strategy itself may become increasingly automatable (Chatterji et al., 2026; Csaszar, 2025; Csaszar et al., 2024, 2026). At the same time, other accounts emphasize that strategy fundamentally relies on problem framing, judgment under uncertainty, and the maintenance of competing interpretations—elements that may not be reducible to computational optimization (Chatterji et al., 2026; Csaszar et al., 2026). Our findings refine this debate by showing that GenAI does not simply substitute for strategic reasoning, but reshapes how evaluation proceeds. Specifically, GenAI influences when and how decision-makers converge on an interpretation. Intermediate use sustains multiple representations and delays closure, whereas very high use promotes early convergence around GenAI-supported frames. The implication is that AI does not “do strategy” in a standalone sense; rather, it reorganizes the evaluative process through which strategy is constructed. Strategy remains contingent on maintaining comparison and unresolved alternatives—conditions that GenAI can either support or undermine.
Second, we extend dual-process theory by specifying how GenAI alters the conditions under which deliberation is sustained. Dual-process theory explains bias as the result of imbalances between intuitive and deliberative processing (Evans and Stanovich, 2013; Kahneman, 2011; Kahneman et al., 1982), with behavioral strategy highlighting how intuitive judgments override scrutiny (Lovallo and Kahneman, 2003; Sibony et al., 2017). We show that GenAI can shift these dynamics by modifying the cues that signal whether further evaluation is needed. Intermediate use introduces discrepancy between internal judgments and external outputs, sustaining deliberation, whereas very high use generates fluent, coherent outputs that reduce the perceived need for continued evaluation. This identifies a key mechanism: deliberation is not only effortful but situationally cued, and GenAI can either sustain or suppress those cues. This insight complements recent work highlighting both the promise and risks of AI in strategic reasoning (Chatterji et al., 2026) and aligns with evidence that AI performance may deteriorate under strategic uncertainty (Allen and McDonald, 2026).
Third, we contribute methodologically to theory by introducing and validating process-sensitive measures that disentangle AI use, cognitive processing, and engagement quality. Prior research typically relies on coarse proxies such as AI adoption or self-reported use (Krakowski et al., 2023; Raisch and Fomina, 2025), limiting insight into how AI shapes decision processes. By contrast, we develop and jointly deploy three complementary constructs: GenAI-use intensity (interaction volume), the CTI, which captures the internal structure of reasoning, and the QEI, which captures the epistemic quality of human–AI interaction. This architecture enables separation of how much AI is used from how it is used and from how decision-makers think. Theoretically, this distinction is critical: it shows that AI effects operate through cognitive processing (CTI) and are conditioned by engagement (QEI), rather than being driven solely by exposure. More broadly, it opens a process-level perspective on human–AI cognition, enabling theorizing about the microfoundations of AI-supported strategy.
Implications for practice
This study suggests that GenAI should not be treated as a neutral analytical aid in strategic decision-making. Instead, its use actively shapes how problems are framed, how alternatives are compared, and when decisions reach closure. The central practical implication is that the value of GenAI depends less on access or frequency of use than on whether decision processes are structured to preserve comparison and delay premature convergence.
At the individual level, the findings indicate that GenAI is most effective when used to challenge rather than confirm initial judgments. A practical implication is to separate decision-making into two stages: (1) independent judgment formation and (2) GenAI-assisted evaluation. Decision-makers should first articulate their own assumptions and preferred option, and only then use GenAI to generate counterarguments, downside scenarios, and alternative framings. Concretely, prompts should be designed to elicit disagreement (e.g. “What would make this strategy fail?” or “What assumptions am I overlooking?”) rather than validation. In addition, confidence ratings should be explicitly revisited after interacting with GenAI to prevent unwarranted increases in certainty (Lovallo and Kahneman, 2003). Without such structured use, the fluency and coherence of GenAI outputs can lead to uncritical acceptance and early closure (Felin and Holweg, 2024).
At the group level, GenAI introduces a new coordination risk: it can become a shared focal point that accelerates consensus before alternatives are fully explored. To counter this, teams should institutionalize forced comparison. For example, before making a decision, teams can be required to present at least two competing interpretations—one human-generated and one GenAI-supported—and explicitly discuss differences. Assigning roles such as a “GenAI challenger” (tasked with critiquing AI outputs) or requiring parallel analyses using different prompts can help preserve epistemic diversity. The goal is not to slow decisions indiscriminately, but to ensure that convergence occurs after meaningful comparison rather than before it (Kellogg et al., 2020; Sibony et al., 2017).
At the organizational level, the findings imply that GenAI should be embedded selectively within decision processes rather than used continuously. Specifically, GenAI appears most valuable in early-stage activities—such as option generation, scenario exploration, and stress testing—where expanding the set of alternatives is critical (Boussioux et al., 2024; Csaszar and Steinberger, 2022). Its role should be more constrained in later stages, where excessive reliance can accelerate closure around a single representation. Organizations can operationalize this by defining “entry points” for GenAI in decision routines (e.g. mandatory use during exploration phases, optional or restricted use during final evaluation) and by requiring documentation of how GenAI outputs were challenged before adoption.
More broadly, these findings suggest that effective GenAI use requires process design, not just user training. Individual skill, team practices, and organizational rules must jointly ensure that GenAI expands evaluation without displacing it. The key managerial task is therefore not to increase AI use, but to structure it in ways that sustain comparison, disagreement, and reflective judgment under uncertainty (March and Simon, 1958; Ocasio, 1997; Sibony et al., 2017).
Limitations and future research
This study advances a process account of GenAI-supported strategic judgment by suggesting that GenAI use is associated with cognitive biases that shape when evaluation ends and commitment begins. Several limitations delineate the scope of this contribution and point toward an agenda for future research.
First, evaluation stopping is inferred rather than directly manipulated. Our theorizing centers on the idea that intermediate observed levels of GenAI use sustain evaluative comparison, whereas very high observed levels accelerate cognitive closure by signaling resolution. In the present design, this dynamic is captured indirectly through cognitive-process measures rather than through explicit manipulation of stopping rules. Future research should therefore treat evaluation termination as a first-order construct by manipulating cues that signal sufficiency, such as output convergence, confidence statements, or summary recommendations, while holding informational content constant. Varying epistemic framing, such as GenAI as a challenger rather than a validator, would further clarify how GenAI interacts with attention and control (Kellogg et al., 2020; Ocasio, 1997; Sydow et al., 2020).
Second, the focus on cognition-centered biases limits generalizability. Anchoring, confirmation, and overconfidence biases are prototypical distortions rooted in premature stabilization of representations, but they capture only one class of strategic biases. Future research should examine whether the same stopping-rule logic applies to more socially embedded distortions such as escalation of commitment, self-serving interpretations, or identity-based persistence. The strong intercorrelations among the three biases also suggest a higher-order vulnerability related to evaluative rigidity. Modeling a latent construct capturing early stabilization could clarify whether GenAI is associated with isolated biases or with a broader pattern of evaluative rigidity (Rau and Bromiley, 2025).
Third, authority, time, and collectivity remain underexplored. The present study abstracts from authority relations, political exposure, and collective sense-making, all of which are central to real strategic decisions (Cristofaro et al., 2025). Future research should extend the model to group and committee settings in which GenAI serves as a shared reference point. Designs could vary whether GenAI outputs are shared or private, introduced early or late, or framed as advisory rather than authoritative. Longitudinal studies could further examine whether repeated exposure shifts the threshold at which GenAI signals resolution as model fluency and persuasive power increase (Doshi et al., 2025).
Fourth, our findings arise in a context where GenAI use is discretionary and salient. As GenAI becomes more embedded, agentic, and routine, the discrepancy between human intuitions and algorithmic outputs may diminish, shifting the point at which AI signals sufficiency. Our framework, therefore, predicts that the range in which GenAI sustains deliberation narrows as outputs become familiar and taken for granted.
Finally, although QEI and CTI are grounded in dual-process theory, they should be interpreted as researcher-coded process indicators rather than as direct observations of underlying cognition. This limitation resonates with work questioning strict System 1–System 2 separability and advancing more dialectical models of judgment (Sadler-Smith, 2016). Moreover, decision quality is assessed through bias attenuation rather than downstream outcomes. From an ecological rationality perspective (Gigerenzer and Todd, 2000), lower bias prevalence does not necessarily imply superior strategic performance. Future research should therefore link GenAI-induced cognitive shifts to decision accuracy, implementation quality, and firm performance using performance-based tasks or longitudinal designs.
Conclusion
This study challenges the assumption that GenAI straightforwardly improves strategic decision-making. Instead, it shows that GenAI reshapes how judgment happens. The findings reveal a fundamental tension: GenAI can both expand and compress evaluation. When used in ways that sustain comparison, deliberation, and meta-cognitive monitoring, it is associated with lower bias. When its outputs become dominant and unchallenged, it is associated with renewed bias—even in the presence of abundant analytical support. The core contribution is therefore not that GenAI is beneficial or harmful, but that its effects depend on how it reorganizes cognitive processing. Strategic judgment does not improve simply because more information or computation is available. It improves when decision processes preserve evaluative tension—the coexistence of competing interpretations long enough to prevent premature closure. GenAI can sustain this tension, but it can also eliminate it. More broadly, the study reframes the role of GenAI in strategy. The central question is no longer whether AI can support or even perform strategic tasks, but whether organizations can design decision processes in which AI expands reasoning without displacing it. As GenAI becomes embedded in managerial work, the critical capability may not be using AI more, but using it in ways that keep judgment open, contested, and reflexive under uncertainty.
Supplemental Material
sj-docx-1-soq-10.1177_14761270261457350 – Supplemental material for Generative AI and cognitive biases in strategic decision-making
Supplemental material, sj-docx-1-soq-10.1177_14761270261457350 for Generative AI and cognitive biases in strategic decision-making by Matteo Cristofaro, Pier Luigi Giardino and Mie-Sophia Augier in Strategic Organization
Supplemental Material
sj-docx-2-soq-10.1177_14761270261457350 – Supplemental material for Generative AI and cognitive biases in strategic decision-making
Supplemental material, sj-docx-2-soq-10.1177_14761270261457350 for Generative AI and cognitive biases in strategic decision-making by Matteo Cristofaro, Pier Luigi Giardino and Mie-Sophia Augier in Strategic Organization
Supplemental Material
sj-docx-3-soq-10.1177_14761270261457350 – Supplemental material for Generative AI and cognitive biases in strategic decision-making
Supplemental material, sj-docx-3-soq-10.1177_14761270261457350 for Generative AI and cognitive biases in strategic decision-making by Matteo Cristofaro, Pier Luigi Giardino and Mie-Sophia Augier in Strategic Organization
Footnotes
Ethical considerations
Ethical review was not formally required for this study because, at the institution where the research was conducted, no dedicated ethics committee or institutional review board was available for the evaluation of non-medical, minimal-risk behavioral research. Nevertheless, the study was conducted in accordance with accepted ethical standards and the principles of the Declaration of Helsinki.
Informed consent
All participants were informed about the purpose of the research, the voluntary nature of participation, their right to withdraw at any time, and the confidential treatment of their responses. Written informed consent was obtained from all participants before participation.
Consent to participate
Informed consent to participate in the study was obtained in written form from all participants prior to data collection.
Author contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request. The datasets are not publicly available due to privacy considerations and the substantial resources required for data collection.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.