
Abstract
Generative processes and generative design approaches are topics of continuing interest and debate within the realms of architectural design and related fields. While they are often held up as giving designers the opportunity (the freedom) to explore far greater numbers of options/alternatives than would otherwise be possible, questions also arise regarding the limitations of such approaches on the design spaces explored, in comparison with more conventional, human-centric design processes. This article addresses the controversy with a specific focus on parametric-associative modelling and genetic programming methods of generative design. These represent two established contenders within the pool of procedural design approaches gaining increasingly wide acceptance in architectural computational research, education and practice. The two methods are compared and contrasted to highlight important differences in freedoms and limitations they afford, with respect to each other and to ‘manual’ design. We conclude that these methods may be combined with an appropriate balance of automation and human intervention to obtain ‘optimal’ design freedom, and we suggest steps towards finding that balance.
Keywords
Introduction – the sources of freedoms in generative design processes and of limitations thereto
Design is a ‘messy’ activity, full of iterative attempts to solve ‘wicked’ ill-defined problems using incomplete knowledge and imperfect methods, 1 and thus full of freedom. This article outlines some issues concerning design freedom raised by applying computational approaches currently used in Architecture, Engineering and Construction (AEC). Conventional ‘manual’ (i.e. non-digital/non-computational) design activities and methods afford great freedom in terms of methods, media, inspirations and other influences, but frequently are considered limited in the complexity of tractable geometrical forms, the speed and accuracy of designs’ development and in the number of design variations. The limited variations result from both the amount of time required to produce them and sometimes also from lack of inventiveness by designers.
Generative digital design methods and tools are used to overcome these limitations and thus afford designers more freedom by harnessing computational power to address issues of speed and accuracy, as well as complexity. This works when improved speed and accuracy can make handling more complex forms and relationships tractable. Computation helps in some cases even to augment inventiveness. This occurs mainly by increasing the number of design variations examinable (or at least producible) and also by increasing the range of variations – not forgetting ‘happy accidents’ whereby unintended results become favoured design decisions. Additional advantages include design repeatability and reusability via encoding (logic capture/storing) which again potentially give freedom for other tasks if they save time.
While the improvements noted are generally accepted as a positive contribution to design activity – mainly by those who use computational technology for design – there seems to be relatively limited critical analysis of the drawbacks which this choice engenders – except by those who reject the computational approach entirely or largely. Herein, we look at these capabilities and limitations more closely, develop a better understanding of the trade-offs involved and suggest where a good balance between human designer and machine design work can be found, recognising it is not a case of ‘either-or’. We also describe an approach which can mitigate some of the limitations. Our contributions, thus, are to give an overview of some key points in order to consolidate knowledge on this issue and to propose specific ways a good balance can be approached so as to improve the state-of-the-art regarding computational design systems.
We examine the issues with reference to ‘mixed-initiative’ systems2,3 that meld the differing but potentially complementary capabilities of humans and computers. Our aim, again, is to seek powerful computational support for design practice with as much freedom and as few limitations as possible.
We will illustrate more specific examples of the points above using the cases of ‘parametric-associative (P-A) modelling’4,5 and ‘genetic programming (GP)’6–9 as representative methods within contemporary research on and practice of generative design. We briefly overview both cases as well as comparisons with conventional ‘manual’ design activity, and we draw from these a collection of example freedoms and limitations, of which some are quite obvious and others perhaps less so. Following this, we look at implications on design activity, viewed through the lens of ‘design space exploration’.10,11 We conclude with a summary, some recommendations regarding maintenance of greater freedom within generative design methods by applying GP to production of both design templates and evaluation schema, learning of user preferences12,13 and indications for planned future work in this direction. For clarity, we use ‘template’ in place of ‘model’ to describe a particular P-A system capable of producing alternative designs by variation of its parameters – however, not by variation of its associations or other logics, which would produce an alternative template, a second-order effect.
Paradigms for generative design – the expansion of design variations with human/machine interventions
To investigate freedoms and limitations in design processes, we focus on two paradigms, both illustrating the issues and representing widespread trends in practice and research on generative design, namely: 1) Parametric-Associative modelling4,5 and 2) Genetic Programming.6–9
As P-A design systems are increasingly used in collaborative design practice, especially for getting rapid feedback while trying design variations, 14 we compare them with generative methods to understand the limits of freedom in generative design systems.
We summarise the main aspects of these paradigms in the following subsections, showing where key issues of freedom versus limitation arise. These generative systems include different levels of control and freedom which we can define formally. The freedoms exist at two different levels: first, defining the generative system itself (which defines what is possible, the global freedoms of the system) and, second, manipulating after the system is set (which defines the specific solution, the local freedoms the system enables). This is important as it determines the level of variability available to the person defining the system and also the range of the subsequent exploration it allows.
System context
The use of these paradigms is neither exclusive nor fixed, as design approaches can utilise many technologies across members of a team, typically based on effectiveness. Industrial examples demonstrate combinations such as manual and parametric 15 and coupling multiple user analysis and parametric methods 16 and also combining parametric and generative techniques. 17 However, although methods are often adopted and exchanged on merit, we observe from experience and also the literature that it is not a simple matter. Due to the complex and sometimes specialist nature of using these systems, a significant degree of ‘lock-in’ and friction arises in practice, for example, the difficulty of collaborative effort to develop parametric models, 18 with computational designers working as ‘lone guns’ on tight deadlines 19 making support of many modes problematic especially at early design stages. Under these circumstances, appropriate choice of system(s) with sufficient capability and flexibility is important to success of design activities. Thus, the focus of this article although mainly on individual systems is relevant also to mixed systems and by analysing these obstacles also helps project new modes of working between them based on analysis of the fundamental hurdles of each.
Parametric-Associative modelling key features
Definitions of P-A modelling – often abbreviated to ‘parametric modelling’ or ‘parametric design’ – vary somewhat, but the major software implementations in architecture (e.g. Generative Components, Grasshopper, Dynamo) are relatively similar. Their important features are as follows:
Discrete units of logic, often geometric, encapsulated in functions, components or nodes.
Definitions of base input data primarily: Geometric definitions from external sources; Parameters, usually with a specific range and number set such as real or integer.
Associations between nodes whereby the output(s) of one or more node(s) can be fed into the input(s) of the subsequent node(s).
Feed forward only, thus no cyclical dependencies (formally a directed acrylic graph).
Duplication results in repeated function calls and repeated output data, often called replication.
System regeneration based on changes to nodes and propagation and re-evaluation downstream of the graph.
An example of P-A template with procedural graph and resulting model geometry is shown in Figure 1 to illustrate the main points above.
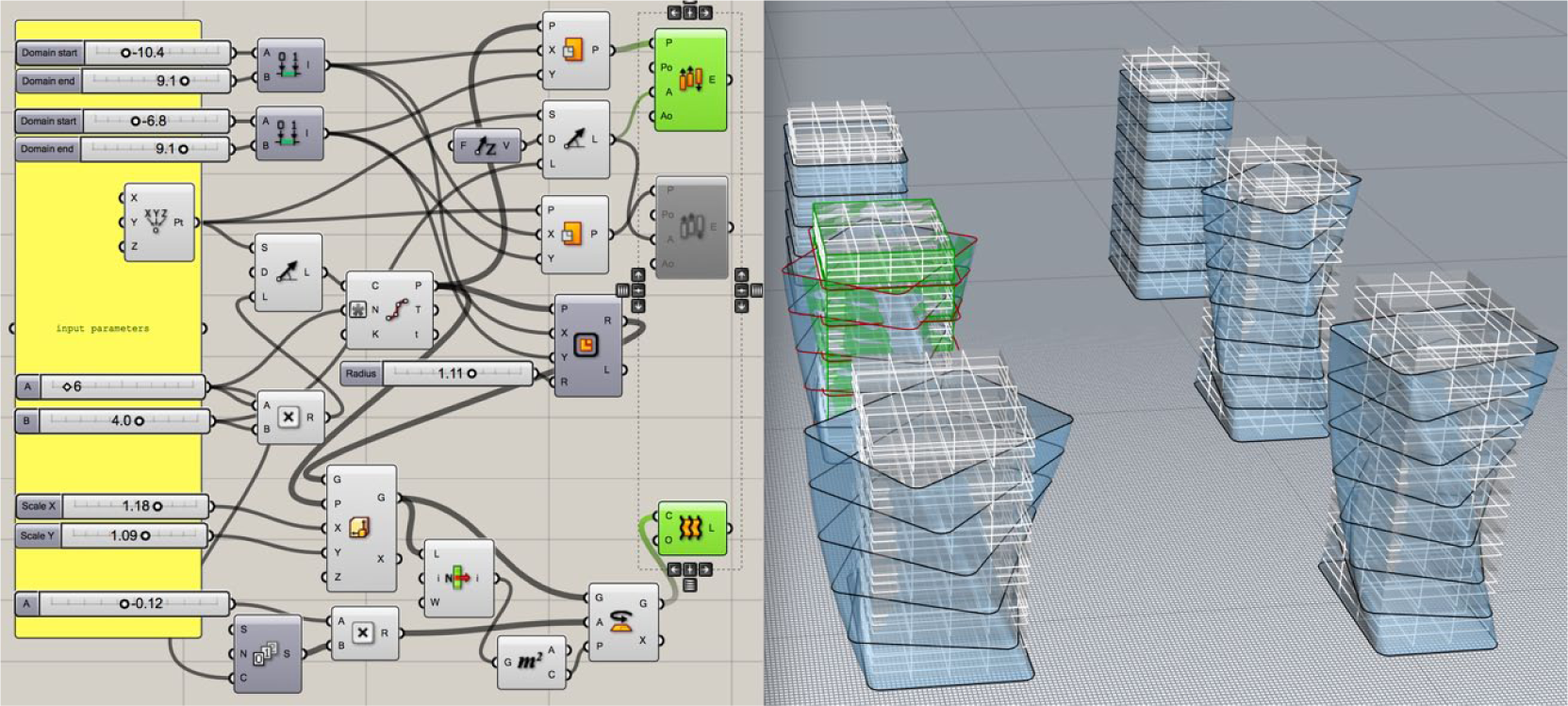
Example P-A template and resulting model, with function as the grey nodes, connected together, input geometry at far left (in yellow) and resulting output models at far right (in green).
While some argue that P-A modelling is not truly generative – due to its internal determinism, first-order logic, and lack of recursion, feedback or emergence – we note that ‘exercising’ (or exploration, see section ‘Summary and further work’) of such a model is normally embedded within a recursive process of evaluation. This process may be implicit or explicit, tacit or deliberate, systematic or aleatory, automated or manual. Even with a designer manipulating a single template by trying different settings for the variable parameters, normally there is some internal mental process guiding the successive choices of settings, with resulting changes examined and ‘accepted’ or ‘rejected’, singly or in combinations, eventually settling on one or a few preferred outcomes. Thus, for our purposes, the use of P-A systems is minimally generative as long as they include some guiding feedback, even if the criteria and methods of evaluation are not specified. (Therefore, neither random ‘generation’ nor systematic, ‘exhaustive’ testing of parameter changes would qualify, although either or both may still be useful.) With algorithmic explorations such as optimisation routines, the feedback process is typically more extensive, methodical and rapid (per design variation). Furthermore, design via a P-A template may also involve (manually) changing components, parameters, links/associations and/or logics of the model, which thus further supports ‘generativity’ by introduction of second-order logic. This holds especially, again, when changes are deliberate and have some degree of goal-orientedness so that intermediate outcomes influence further modifications. (Thus, some freedom is present to increase not only the depth but also the breadth of design exploration, but as noted above, ‘lock-in’ to a particular template or set of very similar templates is common in practice due to various factors.)
The situation can be seen to fit Schon and Wiggins’ 20 ‘see-move-see’ account of reflective design, where the ‘see’ stages correspond to evaluations of the ‘move’ stages’ results. Importantly, however, the moves are neither random nor deterministic, nor are they tightly bounded in a human/manual design process, whereas in a procedural one, they typically are clearly bounded, even if the exploration process is stochastically directed.
Genetic Programming key features
Turning now to GP, we will see how some (but not all) of the limitations mentioned can be overcome or circumvented. While this is a broad subject, a few specific features qualify GP:
Target system to evolve (typically a programming language or mathematical schema);
Higher level abstraction of the language into a simple but generic form;
Ability to encode the abstraction into a single string or definition;
Methods to combine and partially modify these definition strings while still being valid with respect to the system;
Formulation of target behaviour for the system as method to quantitatively measure definitions;
Typically, the use of Genetic Algorithm (GA) to evolve the system by stochastically trialling automatically generated functions;
Stopping criteria after which best performing definition is returned.
An example for GP appears in Figure 2, illustrating how components (in this case, arithmetic operators and numerical operands) can be reconfigured to produce a new template. To expand the analogy, if the fixed numeric values in Figure 2 were variables instead, we would have a system somewhat approximating the behaviour of a P-A template. One method developed for the automatic generation of valid parametric models purely generatively within the Grasshopper modelling environment 21 was used to successfully generate useable options in design practice. 22
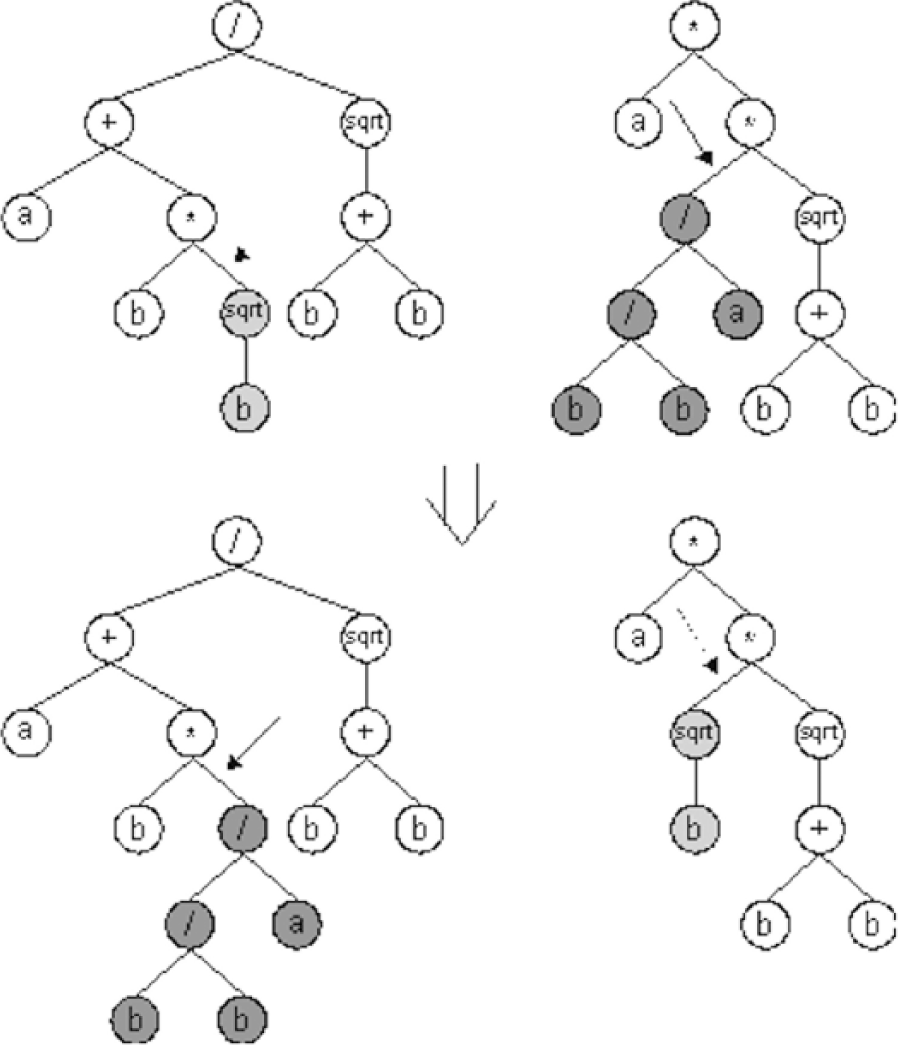
Example of Genetic Programming on a function definition. Two functions (above) represented as trees are ‘bred’ to generate new alternate functions (below) after. 7
Computational design freedoms and limitations
The above reveals various issues of freedom versus limitations. Most obviously, perhaps, the definition of which quantities (or other, non-numeric qualities) to make variable and of what types and ranges of values they may take on are key decisions. For a creator of P-A templates, these are both freedoms and limitations, while for a user who can only change the values (but not their ranges or types), the freedom is more limited. When defining the associations and other logics operating within the template – for example, the flow and filtering of data through the procedural setup – the creator of the template again has both freedoms and limitations to contend with, while the basic case of just using different parameters or ‘sliders’ has far fewer freedoms. Consequently, in these situations, the number of potential variations explorable increases, but the range of their variation decreases in comparison with a non-procedural design approach.
With the limitations relating to the model creator, we are referring both to direct constraints in the model placed by the creator, of course, and also to limitations placed upon the model creator regarding the many and various rules governing model creation – including the very need to define direct constraints on variable values. That is, no procedural system yet allows variables to be undefined and take on (or adapt to) simply whatever value may occur, regardless of type, range and so on. To compare this to programming paradigms, P-A modelling is akin to a ‘typed’ system where inputs and outputs are defined, and any input that is not expected will not compute, as compared to untyped languages, which are designed to parse data rather than bring up a syntax error, even if this may result in unexpected behaviour. Indeed, such rules are a practically unquestioned necessity in procedural design approaches. Yet, they represent a considerable reduction in freedom in comparison with conventional ‘manual’ design approaches, where ambiguity and multivalence are frequent and often positive features supporting creativity and innovation. This is not (yet) to say the rules result uniformly in less freedom – that is, the net effect is less freedom in design. For in some cases, the greater number of alternatives they enable designers to produce and examine may offset these other limitations. However, it is important to bear the trade-offs in mind, and the trade-offs appropriate for design refinement may not be for initial conceptualisation. 23
While the points on freedoms and limitations above refer particularly to P-A modelling and genetic programming, they apply in some respects more broadly to procedural design approaches (e.g. cellular automata, L-systems, shape grammars) in general. In all cases, they have specific implications as described in the next section.
Implications for design space exploration and transformation
Design space exploration10,11 provides a compelling – if not altogether definitive – conceptual model for describing and analysing design activity. To review briefly, the basic premise is that all designs can be represented as points within a highly multi-dimensional space. The dimensions normally correspond to physical attributes (including locations, dimensions, materials, etc.) of tangible designed artefacts, and possibly organisational, operational and other attributes as well, of designs both tangible and intangible (e.g. of services, control systems). The process of design in this account consists largely in ‘moving’ among points within the space of possibilities. Accessibility of points depends on factors such as capabilities of the human designer’s knowledge and imagination or limitations of a procedural system’s algorithms or other methods (e.g. codified/‘cookbook’ design). However, another very significant aspect is the very definition and redefinition of the design space itself. This consists largely in problem-setting and problem-seeking, determining the criteria for judging designs, thus influencing what can or cannot be considered as valid designs. Changes in these elements constitute transformation of the design space, as design requirements and goals may and often do shift except in very highly constrained cases (such as classroom problems).
In a nutshell, human designers, especially skilled and experienced ones, often have much greater ability – that is freedom – to transform design spaces than computational procedures do, but much less ability to explore by examining specific instances (i.e. designs or partial designs) within those spaces. For these reasons, it seems to remain the case, as observed also by others, 23 that first-order procedural design approaches are better suited to later-stage refinements of designs (as in optimisations) – when the main parameters, constraints and other key conditions have already been chosen – than to early-stage conceptual or ‘ideational’ design activities, which normally demand greater fluidity, flexibility and even ambiguity. A partial exception is for a few cases such as using exploratory optimisations 24 to rapidly get a feeling for the ‘landscape’ of variations produceable with a given P-A template, using only indicative objective functions. However, changing the P-A templates remains a human operation, as does definition and eventual alteration of problems and objectives.
From the point of view of ‘mixed-intiative’ human–computer interaction, the conclusion could be that the early stages and re-emerging episodes of conceptual/ideational design activity would be best served by a relatively heavier emphasis on the human, while computational input to the process is gradually increased as the scope for variation is reduced, and the need for detailed production and evaluation comes to the fore. This is of course no great news and tends to happen as a matter of course in design practice (if not necessarily in academia); however, both in practice and research, interesting questions remain regarding just where the boundaries (more likely transition zones) lie and how to push those boundaries when more computational work is desired, but limitations resulting must be minimised. Also, there is the question of how the work is divided: ‘mixed-initiative’ per Allen 2 basically refers to a collaborative mode where work can be done (especially inputs provided, objects acted upon) either by the human or by the machine; meanwhile, a cooperative mode is also conceivable – and perhaps preferable in many cases – where tasks are allocated either to the human or to the machine.
Our proposition is that by combining P-A modelling with the generative methods of genetic programming, we can contribute significantly to these boundary pushing efforts by the following:
Generating large numbers of P-A templates (in more or less goal-directed ways) to explore relatively limited design spaces using various optimisation algorithms and/or other variational strategies (as already described above regarding conventional, first-order procedural design space exploration);
Generating (potentially large numbers of) alternative objective functions against which to evaluate the performance qualities and other desiderata upon whose basis particular design templates or designs would be chosen for detailed examination, development and perhaps realisation.
Furthermore, we propose maintaining a strong role for the human designer. This could be achieved by designing such a Parametric-Associative and Genetic Programming (P-AGP) system to both allow and require interaction. Figure 3 summarises points in a design process where machine intervention is possible and where human interaction is possible or even necessary. The decisions about which to promote, as well as where and when, may be conditioned by speed, precision, pattern- or change-detection capacity, interpretive ability and so on. These points can be seen in a more detailed view of the design-analysis integration cycle, as in Figure 4.
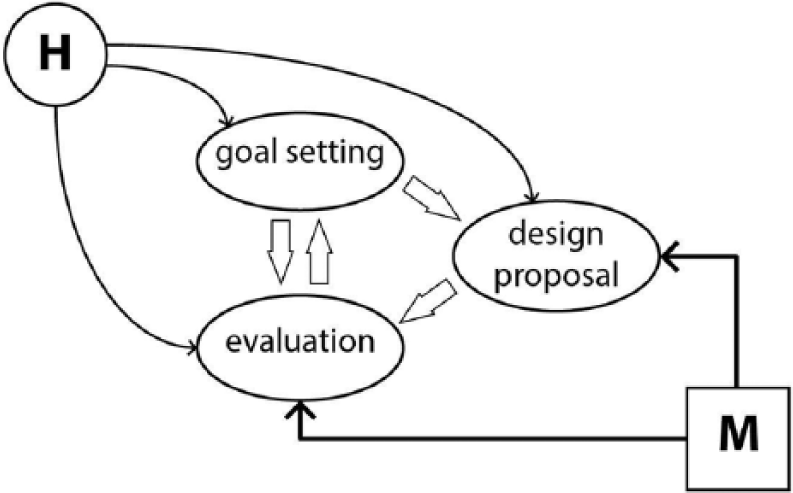
Diagram of design process components where human and machine actions are appropriate.
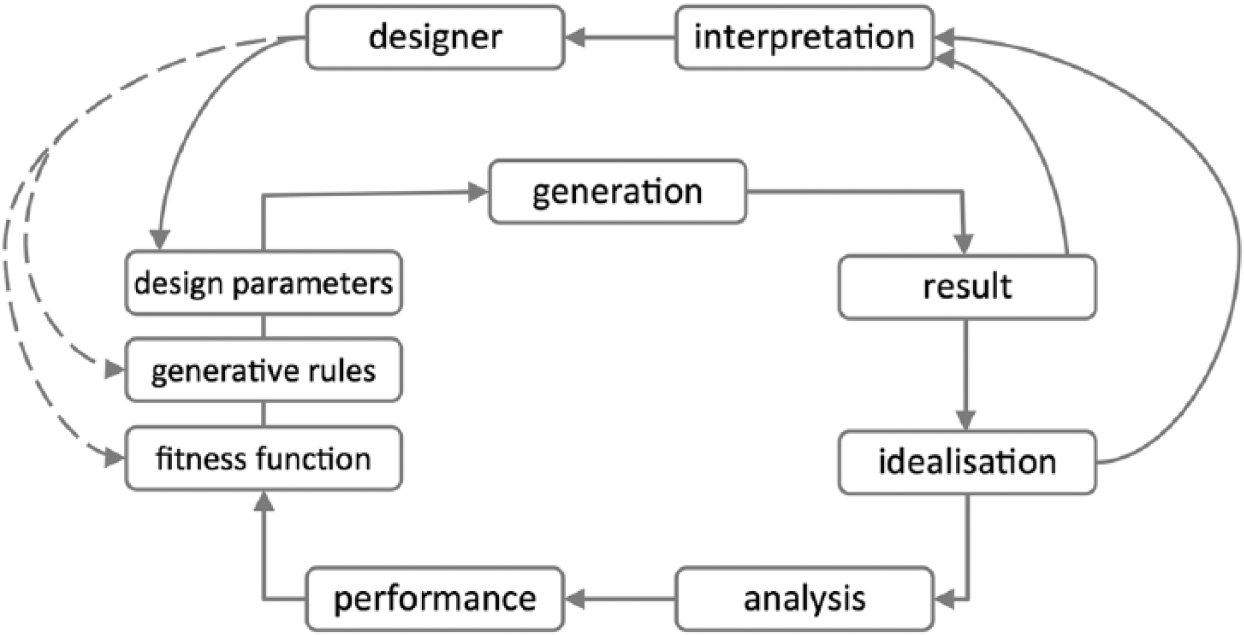
Design generation evaluation loop showing typical design input region of parametric variables, generative rules and evaluation logic, driven by feedback from the generated result.
Although it requires abstracting from the messy design situations found in practice – in order to focus on process features of particular interest – we can summarise the contrast between ‘manual’, P-A and GP approaches with Figure 5 which illustrates first a generic human design process represented with some points representing differing designs – possibly with examination of some alternatives only slightly varying from one another – and the indication of a ‘design space’ which is not really clearly defined or delimited: the designer’s interests may shift, and knowledge (and rationality) can be expanded. Next, a P-A approach is illustrated where the design space is more firmly defined (e.g. as a ‘problem’ with one or more ‘solutions’) and with tightly bounded fields within which a given P-A template can explore many (but not very dissimilar) variations so that a larger design space requires multiple P-A templates (human-produced or GP-generated) for coverage, and the region of design space explorable is still bounded by the given problem statement/objective function. Finally, a more open approach allows for revision of the problem/objective(s) as well (thus transforming the design space), as mentioned above and described in more detail below.
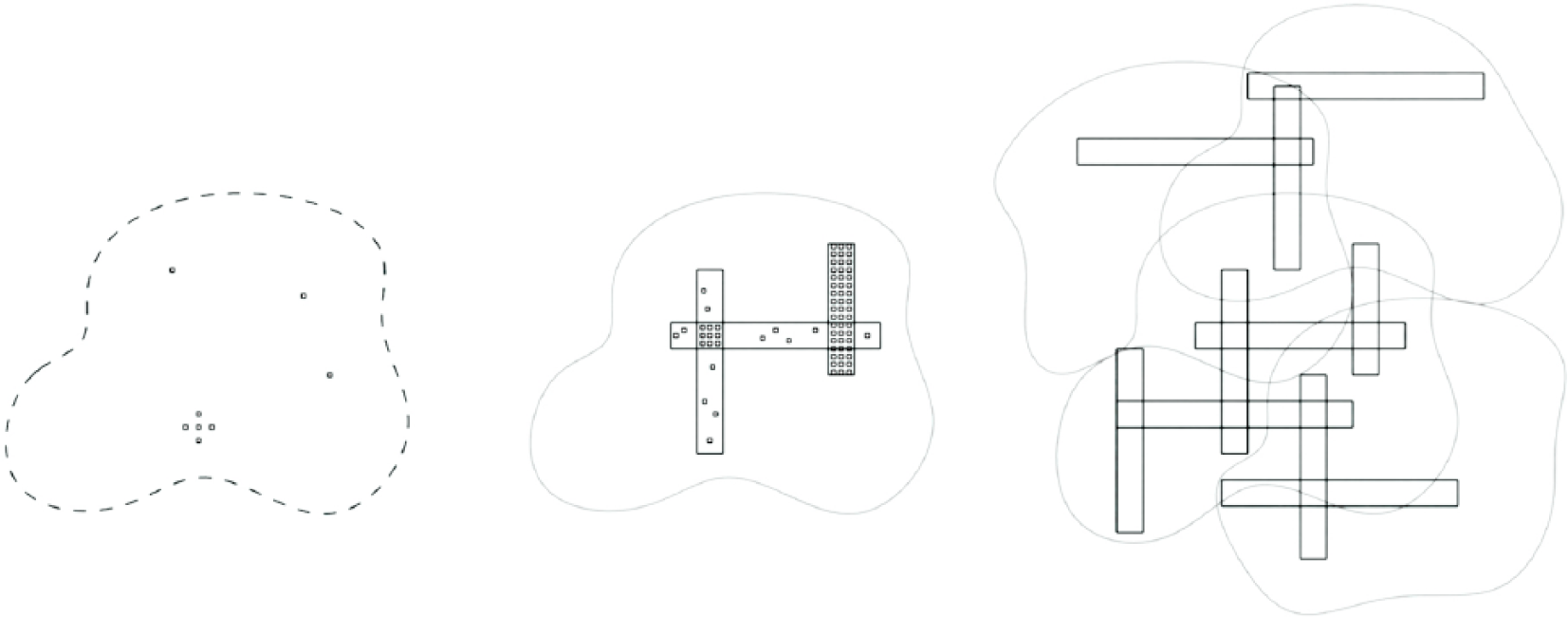
Schematic of three abstracted approaches to design space exploration – left: human/manual/conventional; middle: parametric-associative, with fixed problem statement/objective function; right: genetic programming augmented approach with revisions of problem and generation of alternative parametric-associative templates. (Note that design variation points within templates are omitted for clarity in right-hand sub-figure.)
Design option production with P-A template generation
Production of new or modified templates primarily involves placement and/or removal as well as linking and/or delinking of ‘components’. The components typically describe geometric primitives and/or more complex geometric entities and/or functions performed upon these, while the links (aka associations, constraints) typically specify control via data flow, defining the logic(s) operative in the template’s production of specific design instances for given inputs (parameter values). Any or all of these elements are modifiable by a human and also – much more quickly albeit somewhat less reliably – by an algorithm based on principles of genetic programming (e.g. Cartesian Genetic Programming26,27).
Examples of such template production are given in Harding et al., 21 where massive numbers of varied building massing models were obtained from topologically varied P-A ‘graph schema’. In this work, one process described envisions how a collection of templates is produced from a starting condition (‘seed’), with subsequent additions of new components chosen to be the lexicon of the grammar.
Of course, other more manual methods of template production are also possible, such as the use of design patterns 28 or modular programming. 18 Furthermore, even within the genetic programming method described above, additional degrees of freedom could be introduced, such as the following:
Alteration of the ranges over which variable parameters may change;
Converting previously fixed values (numeric or otherwise) to variables;
Recomposition of component outputs (so that subsequent, dependent parameters accept multiple inputs, resulting in graphs which not only branch but can also converge).
Altogether then, options for generating alternative design templates are many and open, although hurdles do exist such as ensuring (before generation) or testing (after generation) the validity and meaningfulness of their results. When such template-production processes are coupled with (meta-)criterion evaluations – template simplicity, efficiency and so on – even more degrees of freedom can be introduced via the specific designs of the evaluations and specific (but potentially variable) values of the parameters controlling/governing them. Examples would be using the ‘heating regime’ of a simulated annealing algorithm or the mutation rate of a GA to optimise template complexity/simplicity. Of course as with templates themselves, neither a very large nor very small number of meta-parameters are likely to be best: rather, a ‘just right’ quantity would be preferable.
Evaluation: objective function generation and preference learning
The freedom to search a design space is primarily of value if the final outcome of the built form improves. Effective selection of design options depends on evaluating them. The scale and speed of evaluation essentially limit freedom, as even if a large design space can be defined and explored by a design system, if not evaluated any given design variant cannot be appreciated and thus chosen. Human evaluation is primarily limited by the effort to correctly analyse the design. This has been considerably helped by computational tools which provide geometric and engineering feedback 14 such as material volume, structural performance, insolation characteristics and a host of others. While this saves much effort, it is only of some help when evaluating a very large space of options.
To counter these issues, the concept and practice of automated optimising are increasingly used, whereby functional requirements are more formally defined and used to evaluate the variants within a design space computationally to find the best performing options. Even assuming correct results, this raises its own problems with respect to design freedom, as a single objective optimum is by definition only a single value. And even in the case of multi-objective optimisation, which returns a Pareto front and thus a range of options representing the trade-off between different previously determined performance variables, this does not represent the level of freedom typically encountered in manual design, where various design requirements can not only be adjusted in their importance relative to each other but are also being adapted based on feedback from the design evaluation itself.
One promising approach has been proposed and developed by both Von Buelow 29 and Mueller and Ochsendorf 30 using an ‘Interactive Evolutionary Framework’ whereby the fitness criteria for a GA are influenced or determined by user input. However, here we are still constrained to influencing only the input/slider values and cannot change the internal second-order logic of the design template.
Objective function generation
Assuming all the desiderata relevant for selecting a given design template or design instance – whether produced ‘manually’ or computationally – can be encapsulated into ‘objective’ (or ‘fitness’) functions which can be evaluated sufficiently to guide decision-making, we can consider ways of constructing such objective functions and producing alternative objective functions as one (if not the only) way of transforming design space and so increasing design freedom. A typical function, F(m), would be a linear combination of terms as in equation (1) – each term typically reflecting the result of some kind of performance evaluation, such as structural stiffness, daylighting autonomy, project cost and time to build, and so on – with weights assigned to modify the relative importance of each term:
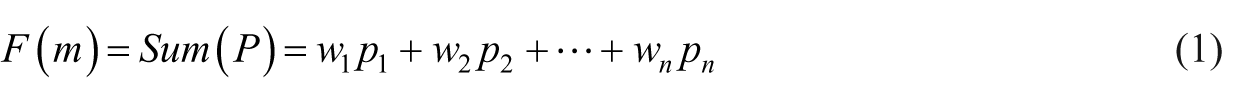
Individual performance evaluations (p1, p2, etc.) may be simple or complex, and although they are quantitative by necessity in this formulation, conceivably the qualitative assessments of some aspects are mappable to appropriate numeric scales or ‘scores’ (e.g. expert assessments and/or crowd-sourced votes on aspects not evaluable by simulation or calculation). Of course, the effort to calculate or otherwise evaluate some individual performance components may be substantial – for example, for simulations requiring hours or days to run – but this is primarily an infra-issue dependent upon computational power available and precision desired.
Again, one key feature of human design activity is modification of goals during exploration. Thus, weights of performance terms may change, a trade-off opportunity reflected in the concept of the Pareto frontier – or (hyper)surface – in multi-disciplinary/multi-objective optimisations (aka ‘many objective’). The question arises of whether it is more sensible for the change to be directed by a human designer, by a computational/procedural system (algorithm) or by some hybrid of these. (Note that in the extremum, we can imagine a process where only one design is produced, but many alternative objective functions are proposed/generated with the aim of making the given design ‘score’ as highly as possible.) While this is a nearly absurd case more akin to salesmanship than design – and not incidentally plays a significant role in post-rationalisation of designs – it does serve to emphasise the importance of how quality is judged, and experience shows time and again that project goals rarely remain fixed.
We can also consider cases where not only weights but also components of performance change, for example, for some particular set of evaluations at some particular period in a design space exploration, energy use, operating expenses and public health impacts may not be considered as appropriate to guiding the design (path). Yet later in the same project, one or more of these terms may become included. It might be argued that this is merely a case of setting their weights to zero when excluding them and some other value otherwise, but this assumes a comprehensive list of relevant performance components is conceivable, feasible and desirable – none of which is immediately obviously true. Instead, it seems more likely true that in a valid, relevant design process – particularly an innovative, ground-breaking one – desiderata not possible to anticipate will become apparent during the process, a significant factor in the potential for emergence in design processes. As Cedric Price 31 put it, ‘Architecture should have little to do with problem solving – rather it should create desirable conditions and opportunities hitherto thought impossible’. Here, again the question arises of human, machine or mixed initiatives for introducing such terms/components/aspects for inclusion in evaluation of design templates and/or instances. For example, should emergent design and performance features be recognised and evaluated interactively, procedurally or how? (Is an algorithm even capable of recognising emergent performance aspects?)
Finally, we can consider the possibility of changing the basic structure of the objective function to alternatives from a linear combination. For example, some criteria may become relevant conditionally, as when some other criterion reaches some threshold value. Or some terms may be multiplicative rather than additive. Other more complex logics are also conceivable, such as decision trees, 32 which might more faithfully mirror the kinds of sensemaking and evaluation processes found in everyday design activity and thus provide the degrees of freedom it affords.
Considering this more concretely, the fitness function represented as a tree (Figure 6) could itself be evolved to suit the preferences of the user(s) of the system. While this may seem unnecessary for the more well-defined functional requirements of a design (such as the minimisation of weight and maximisation of structural strength), desirable aesthetic qualities typically emerge during the design process. For example, when creating a tower, the proportion of the height to base width may be viewed as pivotal to the iconic quality of the building. This property can be captured using a GP type definition, whereby the measurements (leaf nodes of the evaluation tree) relate to defined outputs within the parametric definition.
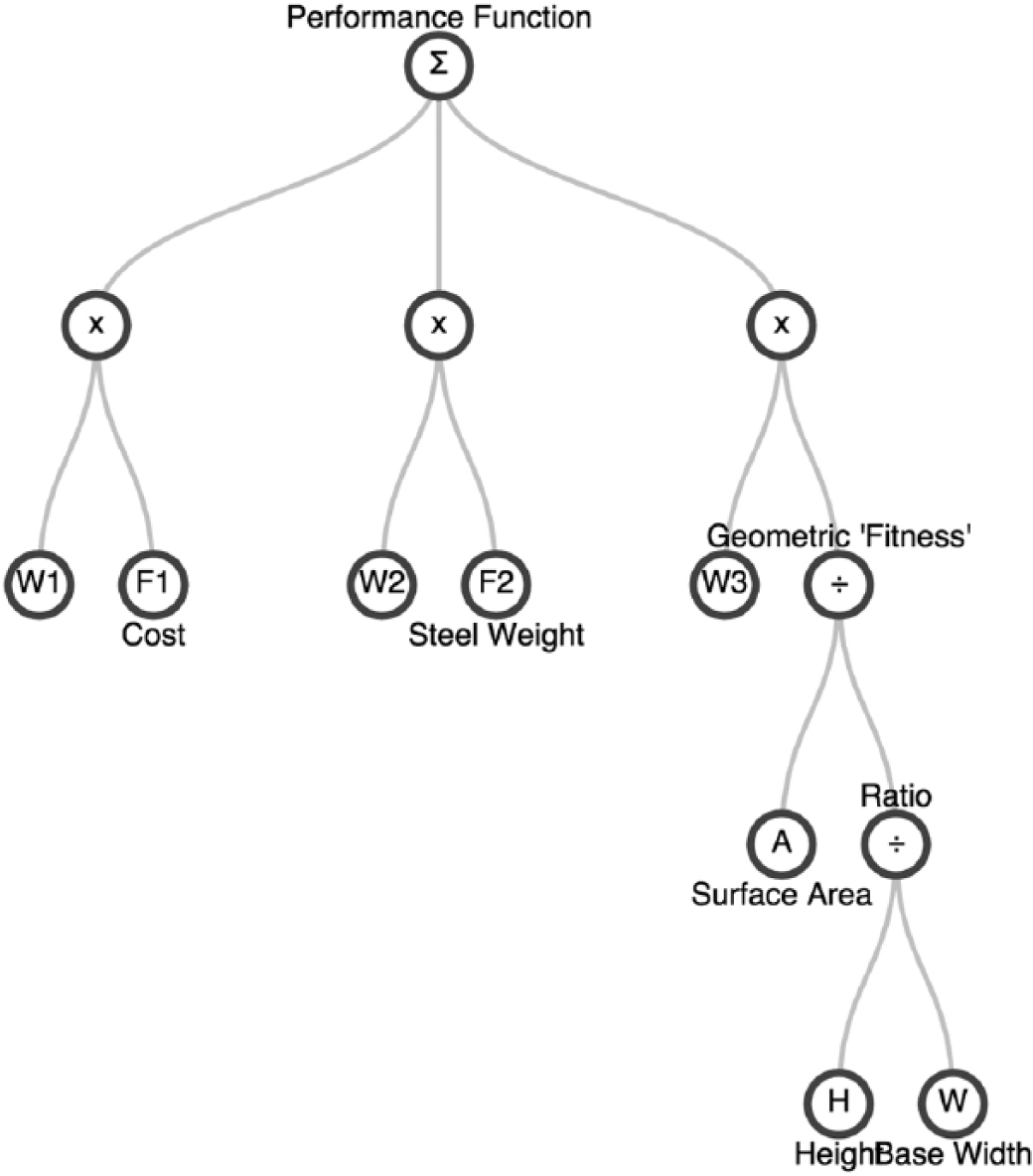
An explicitly defined objective function for evaluation of design alternatives, represented as a tree suitable for genetic programming operations.
As a result, the fitness function, including the hard to formally define constituents of it, could evolve along with the design. This is a natural occurrence in manual design and has been to some extent explored in computational contexts where explicit articulation of design objectives is possible. 33 Where this is not, other approaches to interactive evolution – such as those in evolutionary art34–36 – may provide the desired degrees of freedom.
Objective definition by preference learning
Where design objectives cannot be explicitly specified (e.g. by a mathematical function, as above), it may still be possible to offer computational support to evaluation via implicit learning of design(er) preferences,12,13,37 as expressed, for example, by their ‘voting’ on, grading or otherwise expressing interest in particular generated design variations, which then act as guides for further generation.
The previously mentioned interactive evolutionary frameworks 29 exemplify how human preference may be more abstractly accounted for by representing it as a high-level heuristic expressed by responding to proposed values. However, this representation of preference is not persistent (learnt by this approach) as it relies on reinforcement by the user at each generation, although the evolved generations represent a ‘preference-space’ which becomes more accurate over time (assuming similar preferences are expressed at each appraisal).
Alternatives able to learn preferences directly are Neural-Networks or Classifiers, whereby complex inputs (such as geometry) can be interpreted and reduced to more simple outputs (in this case, preference metrics). If taught with sufficient reinforcement, learning these might at least partially reproduce user preferences or requirements. While the algorithm captures preferences, it is worth pointing out that this is not explicit as the fitness functions mentioned above, but an implicit or ‘black-box’ type of learning which even if highly accurate would still not be definable, much as the intricacies of human preferences are not possible to formally define.
Thus, genetic programming can potentially increase the scope (especially breadth, but also depth) of design space exploration by generating both P-A templates and objective functions. Nevertheless, significant human intervention/input remains necessary and desirable in such a process, for example, to avoid overproduction of invalid (meaningless) alternatives and to account for preferences which cannot be captured within an objective function. Regardless, then, of how exactly the variations in designs, design templates or evaluation schema are produced – whether proposed by humans, generated by algorithms or something of both – these different sources of variation all need to be preserved in order to claim we have achieved freedom in design, and it seems that for the foreseeable future, digital tools alone will be insufficient for this. But genetic programming and preference learning do offer promising directions in which to augment our digitally enhanced human design capabilities.
Summary and further work
We have reviewed issues questioning the freedom afforded by procedural digital design approaches, specifically in P-A modelling and genetic programming. By comparing these to each other and conventional ‘manual’ design, we have seen implications of generative and other procedural approaches for design activity, illustrated by design space exploration and transformation. Consequently, we have concluded that despite the great potentials offered by parametric approaches for the examination in exquisite detail of large and even vast regions of design space(s), their specific limitations – inherent properties of the systems themselves – such as variable ranges, value types, element associations and logics typically result in very real constraints upon fluidity, flexibility and ambiguity (i.e. polyvalence) in design. These constraints thus tend to limit the main applicability of generative approaches to design refinement and arguably make them less well suited to concept generation. However, the understanding of the origins, nature and extent of these limitations potentially provides continued opportunities to reduce, if not entirely overcome them.
For example, applicability of procedural design approaches could be extended by (1) genetic programming to produce additional P-A templates, (2) operating on the design process’ evaluation schema with genetic programming and preference learning and furthermore (3) enabling human interaction in the procedural operations via deliberate intervention. One strategy for this latter is creating ‘mixed-initiative’ systems2,3 which allow, encourage and even require human intervention for (1) setting goals and revising these as and when appropriate, (2) maintaining diversity in generative operations and (3) supporting sensemaking and intuition which can help the procedural system continue to produce meaningful results.
In producing the next generation of GP-based systems for generating P-A templates and evaluation schema with mixed-initiative inputs, we see needs and opportunities for further work on points given below.
Addressing ‘atomicity’: level of de-/re-composition of components in templates
The operation of a genetic programming process on a P-A modelling template raises interesting questions about the level of detail upon which the recombination could and should act, similarly to text composition by reuse of entire paragraphs, sentences, phrases or just words, letters and marks. As for text so for code: the larger the ‘chunks’ in a modular approach, the more functionality is preserved within modules, but the less potential for variation is afforded, and possibly more difficulty is found in interfacing ‘chunks’ due to more inputs and outputs requiring correct matching to produce syntactic and semantic order. Thus, further work should experiment with different degrees of decomposition.
Learning designer preferences to guide objective function evolution
While a GP approach could clearly produce vast quantities of syntactically correct, weighted objective functions, some way is needed of (meta-)evaluating whether the evaluations themselves are meaningful. One direction for this would be towards learning designer-user’s preferences for objectives and the design variations resulting from them, predisposing production to instances with higher likelihood of acceptance. The system may then have a relationship more akin to a design assistant in conversation with the human designer, rather than being merely a tool. Maintaining sufficient diversity within this ‘vetted’ set would remain a challenge for additional investigation.
The paths foreseeable in this exploration of ways to increase freedom in computational design support are many and promising, and as this line of research is still near its inception, we invite interested readers to contact us for discussion and possible collaboration.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) wish to thank the SUTD-MIT International Design Centre (IDC) for funding to support this work.