
Abstract
Human coding remains an important part of the data-generating process for many political scientists. Yet, we lack a systematic understanding of how researchers approach and describe the human coding process. I analyze published articles in major political science journals from 2010 to 2024 that mention human coders (N = 258). While articles largely state some form of intercoder reliability measure, a substantial percentage of articles lack minimally descriptive information on coder qualifications and replicable coding procedures—components that, respectively, are a best practice and are important for ensuring research transparency. The results suggest that some researchers emphasize the product of human coding without fully addressing how human coding is used as a process. I conclude with suggestions for better describing human coders’ work.
Human judgment is a key component of the political science research process. A typical research article includes dozens, if not hundreds, of potentially consequential decisions about how a research question is framed, data collected, analysis performed, and results interpreted. Recently, the discipline has made two related pushes: one toward the establishment and use of best practices in empirical research and a second toward open, replicable, and transparent research (APSA, 2022: 10; Stockemer et al., 2018).
While machine learning and other automated techniques have the potential to standardize and to make transparent some decisions made during the research process (Grimmer et al., 2021), 1 humans are increasingly relied upon to produce the training data and validity checks that undergird machine learning algorithms. Humans are also skilled at determining complexity, providing clean training data or validity checks (Song et al., 2020), and helping researchers understand data-generating processes (Heseltine and Clemm Von Hohenberg, 2024; Lacy et al., 2015; Schedler, 2012; Zamith and Lewis, 2015). How does the discipline approach the use of best practices and transparent research when working with human coders?
Understanding how researchers use and describe human coders is important because of their pervasiveness and use in performing many tasks. I characterize human coders as interpreters—people who are asked to take raw data and to make judgments to transform these data into a standardized form suitable for analysis. So, while a researcher may ask someone to transcribe handwritten meeting minutes into a spreadsheet, that task only involves human coding if the person is instructed to interpret the minutes, say to judge the tone of the minutes using a researcher-provided scale.
Prior work has focused on how human coders are involved in either dataset creation or validity checks. In dataset creation, human coders can be classified as “experts,” typically thought to be especially well qualified and, therefore, given more agency over more complex coding tasks, or are people who perform what I term “basic” analysis. There is not a clear definition on who constitutes an expert, and whether a task requires basic or expert coding is left to researcher interpretation (e.g. Lindstädt et al., 2020; Martínez and Van Ham, 2015). Robust discussion has evaluated how experts assess quantities of interest in well-established political science datasets including Varieties of Democracy (Knutsen et al., 2024; McMann et al., 2022), the American National Election Study (DeBell, 2013), and the Comparative Manifesto Project (Hjorth et al., 2015; Mikhaylov et al., 2012). What constitutes expertise is often left unstated, allowing for heuristics and assumptions to be made about expert qualifications (O’Brien et al., 2022). Yet, even if the identity of experts is known and well described, experts can exhibit systematic biases that increase the need for transparent and replicable coding procedures (Levick and Olavarria-Gambi, 2020, but see Marquardt et al., 2019).
Individuals performing basic analysis are typically characterized as crowd workers or student coders. A stated advantage of using crowd workers is that their selection and the resulting coding procedures are more systematic and transparent compared to expert evaluations or those conducted by student coders (Winter et al., 2020), and they have been used with some resulting success (Benoit et al., 2016; Horn, 2019; Niemann-Lenz et al., 2023). Employing crowd workers also helps to provide training data for or to check the validity of automated methods (e.g. Carlson and Montgomery, 2017; Kaufman, 2024; Ying et al., 2022). Both expert and basic analysis can be conducted on existing observational data or on data that the researcher collects.
Human coding is also used as part of a machine learning process to create training data or as a validity check. Validity checks can involve humans independently coding data or coders can review machine-coded data. In the former case, coders do the same work as for dataset creation, but researchers use the data differently, whereas the process of coders reviewing machine-coded data is distinct. In all cases, typically one or two coders are used, though it is also possible to use many crowd workers (e.g. Kaufman, 2024; Ying et al., 2022).
I examine whether articles that mention human coders follow best practices—containing reliability measures and a description of coder qualifications—and provide replicable procedures. To do so, I collect data from peer-reviewed political science journal articles published between 2010 and 2024 in the American Political Science Review (APSR), American Journal of Political Science (AJPS), the Journal of Politics (JOP), Political Research Quarterly (PRQ), Social Science Quarterly (SSQ), Polity, and PS: Political Science & Politics. I categorize the way that the term “coder” is used. Even among application articles that directly engage in and use human coding, 30% fail to provide reliability measures, 37% contain inadequate coder descriptions, and 41% lack replicable coding procedures. These results suggest a lack of disciplinary norms regarding the use and description of human coders. Consequently, researchers engage in many good faith efforts to describe the use of human coding, and some descriptions can be substantially improved. I conclude by describing some potential strategies and challenges for working with and describing human coders.
Reliability Measures, Coder Qualifications, and Replicability
To sufficiently analyze the use of human coders in political science, I first establish two main areas of interest—best practice use and replicability—and subsequent techniques employed to measure them.
The discipline has long worked to suggest best practices that help to standardize how scholarship is conducted and to improve its overall quality. The best practices by which such standards are developed come from two sources: regulating entities—like journals and professional associations—and disciplinary agreement (Freese and Peterson, 2017). Often, structures develop to make following best practices simpler with the eventual intent of requiring their usage. Consider the example of pre-analysis plans, which were introduced as part of broader data transparency initiatives and have been the subject of much scholarly discussion amid their increasing adoption (see Rubenson, 2021 for a review). Organizations like the Open Science Foundation (OSF) have established repositories for pre-analysis plans, and the Journal of Politics notably began a process of requiring such plans in 2021 before removing this requirement after a change in editors. 2 Ofosu and Posner (2023) establish best practices for the content of such plans and find mixed uptake, perhaps due to some researchers submitting a plan just to claim compliance (McDermott, 2022). Similar discussions on best practices have occurred in the discipline regarding statistical power (Arel-Bundock et al., 2024; Gelman, 2018) and, of course, methodological pluralism (Monroe, 2005), among other topics.
While political science has not widely discussed best practices in the use of human coders, other social science disciplines have established reliability measures and describing coder qualifications as requisite components. Human coding involves some degree of subjective judgment on behalf of the humans involved in the coding process. To assess the impact of these judgments on the coded data, researchers recommend employing intercoder reliability measures (Hayes and Krippendorff, 2007; Lovejoy et al., 2016). Percentage agreement and Krippendorff’s alpha are two common measures of intercoder reliability, though there are others, and some measures are more appropriate for certain kinds of human coding tasks.
Though often excluded (e.g. Ahn et al., 2012; Anani Sarab and Amini Farsani, 2024), researchers should include a description of human coder qualifications. Stating coder qualifications is important because they can help to contextualize lower than expected intercoder reliability and to determine the perspective with which coders worked. Krippendorff (2018: 131) recommends “clear and communicable descriptions of coders’ backgrounds” to facilitate replicability. 3 Using students and research assistants to conduct human coding (Goehring, 2024) reinforces broader questions about power dynamics present in data collection and analysis processes (Deane and Stevano, 2016; Dumenden, 2012). Crowd worker selection can be easily made transparent, but is often not equitably compensated (O’Brochta and Parikh, 2021).
Replicable research refers to the process of providing readers with sufficient information so that they can repeat the data collection and analysis process and arrive at the same results. 4 The discipline has encouraged and often requires statistical code and datasets to be provided as replication data (Key, 2016). Though this practice has become relatively standard over time (Stockemer et al., 2018), there remains discussion on what replicable research looks like and how researchers can best follow replication policies (Alvarez et al., 2018).
Human coding requires interpretation and, therefore aligns more closely with ongoing discussions of replication in qualitative political science (Elman and Kapiszewski, 2014; Golden, 1995). Providing a full description of coder training and coding procedures can ensure replicability and reduce coding inconsistency (e.g. Paritosh, 2012; Pickel et al., 2015; Reiter, 2020). Though we know that comprehensive coder training is critically important to replicability (Budak et al., 2021), there is less of a norm to provide training instructions in articles or appendices, so I adopt the more minimal definition of whether minimally informative coding procedures are stated (Hak and Bernts, 1996).
Research Design
Though there are of course different ways to describe people that perform human coding, I reduce the judgment involved in determining whether an article involves the process of human coding by focusing on articles that identify one or more individuals as a “coder.” This term has a conventionally agreed upon definition in the discipline that implies a formal and systematic process, and researchers who choose to use the term self-identify with that definition. 5
I collected articles mentioning the word “coder” for the period from 2010 to 2024. I chose 2010 as the starting point because this period marked the start of a movement to enhance research transparency and replicability. The Dataverse project for depositing replication data was established in 2007 (King, 2007), and PS ran a 2010 symposium addressing recent discussion in APSA about data collection, storage, and replication (McDermott, 2010). Further, the traditional “top three” political science journals—APSR, AJPS, and JOP—all had functions for authors to provide online-only appendices at this time. The APSR and AJPS specifically required authors to provide full descriptions of data coding procedures. 6 To these journals, I add the other major journals of political science associations in the United States: PRQ, SSQ, PS, and Polity.
I searched each journal on Google Scholar for the term “coder.” Using Google Scholar provides a consistent search process across the journals. After downloading each article, I collected a variety of quantities of interest related to the use of the term “coder” in the article. My focus is on three questions: 1. How is the term “coder” used in the article? 2. For articles that apply human coding, what is being coded? and 3. For articles that apply human coding, what are the coding procedures—do they follow best practices and are they replicable? I proceed by reviewing each question; full procedures are in the Supplemental Information.
How Is “Coder” Used?
I begin by examining the characteristics of articles that discuss coders (N = 258). I categorized each article based on the primary way that they use human coders. In order of increasing focus on human coding, articles categorized as cite existing work cited existing research using human coders and mentioned human coders in their description of that research. Propose human alternative articles also mentioned human coding, but did so as they presented a new approach to coding that did not rely on human coders. Use existing dataset articles described and utilized a previously created human coded dataset in their research. Human coding was part of the machine learning process in both training data and validity check articles, occurring at different points in the training and testing of machine learning algorithms. Finally, application articles applied human coding techniques to code one or more quantities of interest that are then utilized in the article.
Table 1 displays the type of article broken down by subfield. Articles discussing human coding are more common in American and comparative compared to IR or methods. Comparing the subfield breakdown to the 2022 APSR editor’s report of manuscript acceptances, articles employing human coders are 15% more likely to be about American politics, 10% more likely to be about methods, 15% less likely to cover comparative politics, and 5% less likely to cover IR (Tripp and Dion, 2023).
Use of Human Coding Across Subfields.
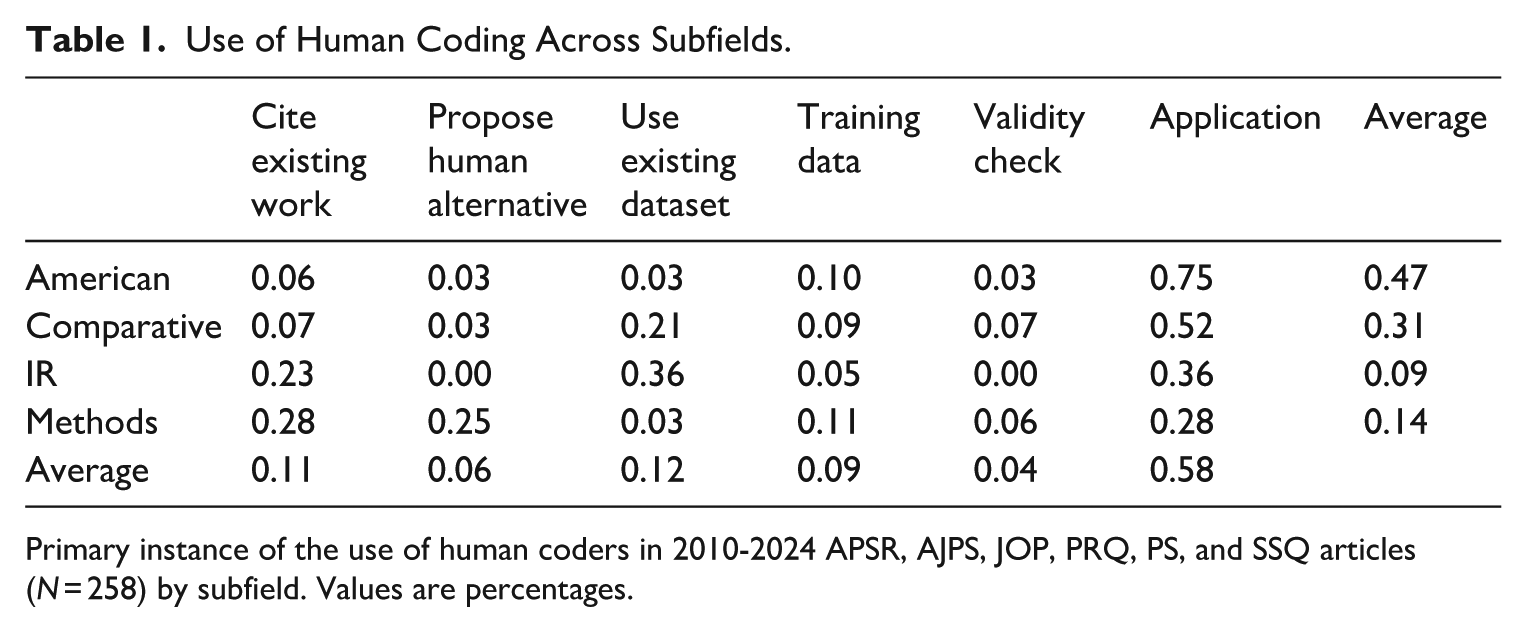
Primary instance of the use of human coders in 2010-2024 APSR, AJPS, JOP, PRQ, PS, and SSQ articles (N = 258) by subfield. Values are percentages.
Application articles are the most popular or tied for the most popular uses for human coders across subfields. Comparative and IR rely increasingly more on existing datasets that involve human coding. IR also features several articles about human coders that provide citations to existing work. Logically, methods articles are the most likely to propose alternative approaches to using human coders and to use human coders to produce training data.
What Is Being Coded?
For the remainder of the analysis, I focus on articles using human coding for an application, training data, or a validity check. These articles all directly involve the article authors performing human coding, whereas articles that cite existing work, propose a human coding alternative, or use an existing dataset reference, but do not directly conduct human coding.
Human coding can be applied to different kinds of research questions. I categorized the unit of analysis in each article to describe the type of material humans were coding. Humans were most often used to code government documents like presidential speeches or legislative bills (24%). News content (18%), survey responses (14%), and campaign materials like advertisements (10%) were also common. Social media posts (10%), correspondence (usually e-mails in audit studies, 8%), and a residual category (17%) completed the categorization.
How Does Coding Take Place?
Reliability
Reliability describes whether an article performed any intercoder reliability calculations with 1 indicating that calculations were performed and 0 indicating that no calculations were mentioned in the article. 7
Reliability calculations were common in application articles (70%) and validity checks (55%). 8 These percentages are lower than in allied disciplines like communication studies where reliability calculations are almost universal (Lovejoy et al., 2016).
Most articles reported that their coding was highly reliable. However, there were exceptions including a correlation coefficient of 0.22 (AJPS.33), intercoder agreement of 70% (AJPS.18), and Krippendorff’s alpha of 0.41 (JOP.14), among others. Some of these values fall below recommended levels for reliability (Krippendorff, 2018: 356). Variation in intercoder reliability underscores the fact that human coding best practices require authors to provide additional information about coders and their coding procedures.
Qualifications
Qualifications takes a value of 1 if coders were described at all and 0 if they were referred to as “human coders” with no additional information provided. Some qualifications were described in 63% of application articles, 79% of training data articles, and 64% of validity check articles.
If Qualifications was 1, I categorized how the coders were described. Students (41.6%) included coders described as undergraduate or graduate students or research assistants. Crowd sourced workers commonly referred to individuals hired on Amazon Mechanical Turk, but also Crowd Flower and its successors (11.9%). In some cases, the author completed the coding (16.2%). Some coders were referred to as “experts” without additional details (2.2%). Finally, some coders were identified as qualified based on very short descriptions—usually one or two words (3.8%). More than one coder type could be employed in each article, and 13.0% of articles did so.
Coder qualifications may be inadequate even in cases where Qualifications is 1. For example, the short descriptions used included “native Vietnamese speakers” (APSR.13) and “two people familiar with Chinese politics” (APSR.48). While useful, there are tens of millions of native Vietnamese speakers, and it is unclear what “familiarity” with Chinese politics means. About half of the articles using crowd workers provided any description of how the crowd workers were selected.
Finally, the bulk of authors who identified their coders utilized student coders and identified them by status (undergraduate or graduate) or job (research assistant). On occasion, student coders were given a description including the location of the coders (e.g. Argentina, AJPS.18; Brazil, PRQ.25; three universities, AJPS.36) or specified qualifications (e.g. political science students, AJPS.21 or SSQ.3; French speaking, AJPS.47; Spanish speaking, SSQ.16; members of a specific course, PS.15). One article stated that, “intelligent students . . . interested in learning about research” were recruited as coders (AJPS.56).
Replicable Procedures
Procedures takes a value of 1 if the article contained at least
A trained teacher with experience in coding tasks and I independently coded procedures for the APSR, AJPS, and JOP articles to determine if they contained a minimal level of detail. The teacher taught secondary school and is now a full-time freelance translator and specialist in data entry. I have worked with this collaborator on several coding projects during the past four years, including several months of work designing and implementing coding procedures to code caste identities. Percentage agreement between coders was 0.93 and Krippendorff’s alpha was 0.86. 9 SI.1 contains details on how coders were selected, coder training, and specific coding procedures. When there were discrepancies between coders, I included those cases as replicable.
Looking across all journals in the sample, 73% of validity check articles, 65% of application articles, and 65% of training dataset articles provided adequate procedures. A typical article with adequate procedures provided a lengthy description of how the coding procedure was implemented, often including part of the procedure in the main text and additional discussion in an appendix. Examples of articles with inadequate procedures include, “we had the slant of each article assessed” (APSR.17) and “In irregular cases, human coders assist in the creation of the hypothetical bill versions” (JOP.60). Neither of these articles enable someone seeking to understand or to replicate the coding procedure to successfully do so. Sometimes, the mechanics of the coding process were featured, while the content of the coding performed was less well described as is this description where coders were “trained and provided with a codebook. . .codebook is available upon request” (PRQ.6).
Characteristics of Application Articles
Application articles represent the most well-established use case for human coders. In application articles, human coders are primarily responsible for a part of original data collection or processing, and the resulting dataset is introduced in the article. 30% of application articles failed to provide reliability measures, 37% contained inadequate coder descriptions, and 41% lacked replicable coding procedures.
I correlate whether application articles (N = 150) provide reliability measures, coder qualifications, and coding procedures with descriptive characteristics of the articles including log number of authors, publication year, journal, funding, non-U.S. authors, subfield, and whether coding processes are described in an appendix.
The results shown in Figure 1 from linear models indicate few correlates to features in the coding process (see SI.2 for logistic regression models). Comparative politics articles were less likely to include reliability measures, while articles with an appendix were more likely to do so. Articles that were written in the APSR or PS compared to the AJPS were more likely to describe coder qualifications. Articles that include an appendix with more detail about the coding process and that are newer were more likely to have replicable procedures.
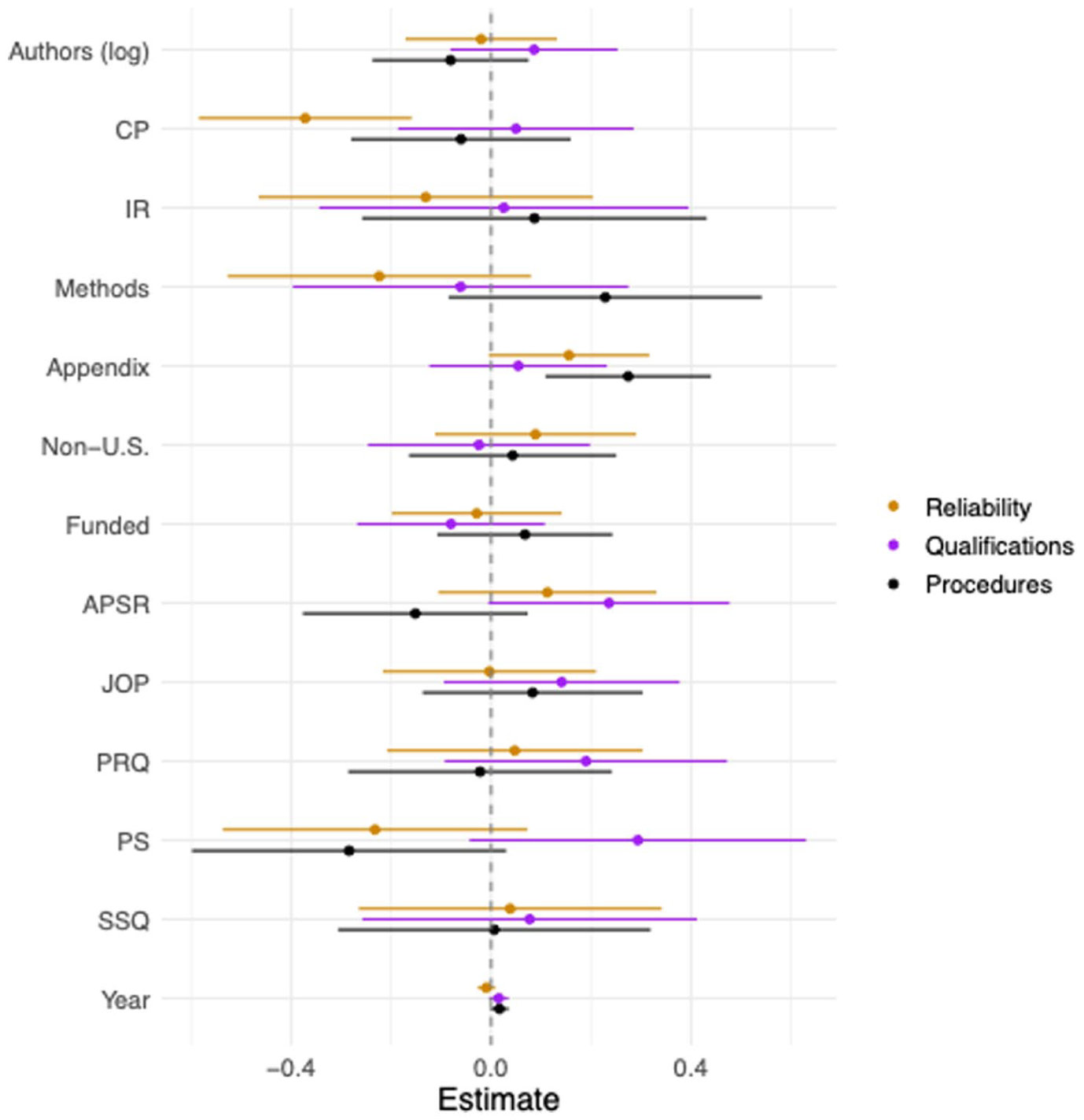
Predicting Presence of Reliability, Qualifications, and Procedures.
Beyond the Minimum
We might be interested in articles that go beyond meeting just one of the three criteria. Among application articles, 29% met all three criteria, 40% met two, 25% met one, and 6% met zero. Articles published more recently were more likely to meet more criteria. On average, application articles published between 2020 and 2024 met 2.12 standards compared to 1.70 standards for application articles published between 2010 and 2014 (t-value = 2.66, p-value = 0.01). Focusing on replicable procedures, I counted the number of words in descriptions of procedures. This is, at best, a crude measure of procedural detail as procedures often include tables and figures where words are more difficult to count. Still, application articles with replicable procedures spent 321 words on average describing them compared to 80 words for application articles without replicable procedures.
Recall that the definition of replicable procedures is generous—any article with the potential for procedures to be replicated is counted as having replicable procedures. It is challenging to further differentiate between articles that meet that minimum standard and articles that substantially exceed it because there are no disciplinary standards on what constitutes replicable procedures. I subset to just application articles marked as having replicable procedures. Here, the application articles that met additional standards beyond having replicable procedures do not have statistically significantly longer procedures compared to the application articles that only met the replicable procedures standard (303 versus 433 words, t-value = 0.58, p-value = 0.57). While the length of coding procedures is important in determining whether they are replicable, length was not associated with compliance with other minimum standards.
So which articles go beyond the minimum? Among those with replicable procedures, 44 of 89 (49%) met all three standards. AJPS.51 is the application article meeting all three standards with the shortest replicable procedures. These procedures state, “Responses to the open-ended FMCs were coded as correct or incorrect by two independent coders.” The article is about factual manipulation checks. Some manipulation check questions eschewed multiple-choice options for an open text box. Human coders then matched the open-ended responses to the list of multiple-choice topics. A detailed 47-page appendix provides information on a variety of different uses of human coding and coding procedures across the several studies presented in the article. There is some inherent subjectivity in matching open-ended responses to a list of topics. Could the authors have provided a table listing common open-ended responses and their associated topic or, better yet, the complete correspondence listing each response and the categorized topic? Yes, but then again, the combination of this description and the replication files are likely enough to replicate the study and this coding procedure with good accuracy.
Discussion and Conclusion
The discipline lacks a consensus on how to discuss human coding. Without such a consensus, many researchers approach human coding with good intentions and describe what they feel is relevant. Readers can understand some coding processes as a result. However, standardization of the ways in which the human coding process is described can lead to a rush toward meeting only minimal requirements.
Researchers should include a good faith description of coding processes with an eye toward transparency and openness—a conversation ongoing in other disciplines (Aguinis and Solarino, 2019). Describing coders as such with no additional details and stating that coders coded a concept, again with no additional details, are not a good faith description of coding processes, yet such approaches are common in political science.
This article reveals patterns about how human coding is discussed and how human coders are used. Toward the former, there are few reliable predictors of whether discussions about human coding will meet minimum standards. One predictor is the presence of an appendix describing the coding process. That having an appendix is correlated with increased discussion of reliability measures and replicable procedures suggests that articles using human coding may require more space to adequately discuss how the coding occurred. While the Internet has made it easier for journals to offer online-only appendices without increasing journal formatting costs, many journals are now offering short article formats with more restricted word counts. Should information about human coding be mostly or fully relegated to an appendix, must the contents of that appendix be clearly identified in the manuscript text, and what is the appropriate amount of information contained in the manuscript itself?
Identifying a coder as a “coder,” “research assistant,” or “research assistant with four years studying this topic” is a difference of up to seven words. That discussions of coder qualifications are more common in particular journals suggests that journals may have reputations or norms to encourage more or less description of these kinds of research design decisions.
Authors and journal editors can move the conversation on describing human coders forward by naming the lack of consensus on how to do so as a problem. Before journals make a decision about potential standards for manuscripts using human coders, the discipline should hold discussions on different ways to describe human coding and develop a variety of models for doing so. In this way, the process of describing human coding can follow the lengthy, but fruitful process of discussing standards for pre-analysis plans. Though still the subject of extensive discussion, the discipline has largely acknowledged that pre-analysis plans are appropriate in many circumstances. Organizations have developed to engage a variety of stakeholders in the process of setting policies on the kinds of information required to produce such plans. This strategy can be replicated for standards discussing the use of human coders. By doing so, more voices and perspectives can be heard and disciplinary norms formed before any potential journal mandates follow. Recent work on human coding exemplars Edgell et al. (2025) may be a start to this process, and it should proceed with both a reality of the current state of human coding and aspirations for developing best practices.
As the conversation of describing the use of human coders progresses, it will inevitably prompt questions about how human coders are used. This article finds that human coders are used for a variety of coding tasks across subfields. Coders are typically undergraduate or graduate students. Thresholds for reliability are up to researcher interpretation. Each of these findings deserves additional exploration and understanding. Human coding is foundational to the production of political science data, and the systems, people, and practices we use to perform human coding tasks are worthy of additional attention.
This article reviews how human coding is used and described in several general interest journals in political science. For consistency, I selected journals based in the United States and sponsored by political science associations. Future work would do well to extend this work to other general interest journals headquartered by non-U.S. associations and to subfield journals. There is often much to learn from both of these groups about good research practice.
Since the discipline appears to lack consensus on how to describe the human coding process, I set what I regard as minimum standards: whether a coder is identified, if reliability calculations are mentioned, and if there is some amount of detail in the coding procedure. Once the discipline makes additional progress on establishing disciplinary norms and best practices regarding the use and description of human coders, it will be worthwhile to revisit these and additional data to identify the proportion of articles meeting these new and likely more substantial standards.
Supplemental Material
sj-docx-1-psw-10.1177_14789299251395515 – Supplemental material for How Human Coding Is Used and Described
Supplemental material, sj-docx-1-psw-10.1177_14789299251395515 for How Human Coding Is Used and Described by William O’Brochta in Political Studies Review
Footnotes
Acknowledgements
I thank Nivedita Mehta and Sunita Parikh for assistance and comments.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Texas Lutheran University.
Supplemental material
Additional Supplementary Information may be found with the online version of this article.
SI.1: Variables and Procedures Table SI.1.1: Alternative Identifiers to “Coders” SI.2: Models Table S1: Linear Regression Models Table S2: Logistic Regression Models SI.3: List of Articles
Notes
Author biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.