
Abstract
Cognitive testing has become routine for well-designed surveys. However, the protocols for cognitive testing vary widely, and observers have been concerned that analysis of the results is not systematic, that results are not replicable, and that the bases for conclusions are not transparent. To address some of those concerns, in this study the cognitive interviews were structured so that interviewers gathered information specifically about whether there was a problem with any of the four standard issues in question answering: comprehension, retrieval, estimation, and providing an answer. From the tape-recorded interviews, the percentage of respondents who had “no problem” with each element of question answering was tabulated for each question. In addition to being systematic and transparent, a strength of the approach is that it documents the positive features of questions, potentially providing evidence for the validity of answers as well as identifying possible question problems.
Introduction
One of the important methodological advances for survey research in recent decades has been the increased use of cognitive interviews to evaluate survey questions. A variety of approaches have been used (Beatty and Willis 2007; Willis et al. 1999). Some research organizations emphasize “think aloud” strategies; others rely more on follow-up probes. Some researchers script much of the follow-up probing; others give interviewers considerable flexibility to design their own probing questions. However, the goal of gathering information about how questions are understood and how answers are formed is a common element across all forms of cognitive testing of survey questions.
An aspect of the process that we think could be strengthened is the way results are analyzed and reported. Most often results of cognitive testing take the form of reporting whether a “problem” was identified and what the nature of the problem was. In a recent critique of cognitive interviewing methods, Miller (2011) singled out the lack of systematic approaches and transparency as major areas in need of attention. This article reports on an attempt to evaluate an approach to improving the transparency and value of cognitive testing by focusing the interviewers’ probing and systematizing some of the analyses of the results.
Like many who study the question–answering process, the framework we used was the one outlined by Tourangeau (1984) that specifies four steps: comprehending what is being asked, retrieving relevant information from memory, estimating or using judgment as needed to put information in the form needed to answer the question, and then providing the answer.
One element of our revised protocol was to have interviewers specifically probe to collect enough information, so that we could evaluate each of Tourangeau’s four elements of the answering process for each question (Tourangeau et al. 2000; Willis 2005). The other innovation was to have independent coders listen to audiotapes of the interviews and for each question record whether they thought each of the four aspects of the question answering process was problematic or problem free. Conrad and Blair (2004, 2009) also used independent coders in at least two of their studies.
In so doing, we thought we could achieve at least four improvements to current less-structured approaches that report cognitive interview results: The process of analysis would be transparent, by which we mean that it is evident to all exactly how issues with questions are identified. The results could be easier to compare across testing sites and questions. The results in this form might more specifically pinpoint the nature of the problems with questions. Reporting results in this form might make a more persuasive case for the validity of questions and answers that are not found to be problematic in any way.
A project to evaluate alternative ways of asking patients questions about how well they were taking their HIV medications gave us an opportunity to try out these new procedures. In this article, we describe the procedures we used and provide examples of the kind of analyses we did with the results.
Method
This article reports on three iterative rounds of cognitive testing of questions designed to measure how well patients with HIV had been taking their medications.
The Samples
Samples came from two clinics that serve patients with HIV: Miriam Hospital in Providence, Rhode Island; and Tufts New England Medical Center in Boston, Massachusetts. To be eligible for the study, patients had to have been on HIV medications and they had to have a detectible viral load. In addition, to permit testing questions with HIV and non-HIV medications, patients had to be on at least one non-HIV medication that they were supposed to take every day. At Tufts, clinic staff members approached patients when they were waiting for their appointments, explained the study, screened them for eligibility, and asked those eligible if they would be interested in helping with a research study by making an appointment to come back to the clinic on another day to be interviewed about their medications. At Miriam, flyers were posted in the exam rooms, and potential participants were also identified through recommendations from treating physicians and medical record review. Participants were paid US$80 dollars for up to two hours of their time. Of the total 250 patients screened, 71 were eligible and 58 completed an interview. Each respondent participated in only one round of testing.
The Questionnaires
The questionnaire design process began by reviewing articles in which HIV medication adherence had been measured and actually collecting 27 different survey instruments that had been used in those studies. Many of those studies are referenced in articles by Simoni et al. (2006) and by Wilson et al. (2009). We decided to only test questions that used a week or a month as a reference period.
Three iterative rounds of testing were done, each building on what was learned in its predecessor. To maximize the number of questions we could test with each interview, in the first round we asked respondents to answer five questions about one of their HIV medications and a similar number of different questions about one non-HIV medication that they were supposed to take daily. The wording of the questions in each series varied the reference periods and the response tasks, so respondents were not answering exactly the same questions more than once. The seven questions tested in the second round included some variations that had not been included in the first round. The five third-round test questions were those we considered to be the strongest candidates for a final instrument. Interviews lasted about 75 minutes. All tested questions are included in Appendix A.
The Interviewers
Five interviewers worked on this study. Three had 10 or more years of experience in doing cognitive interviewing of various types; 2 of those 3 were also research associates with extensive experience in question design and evaluation. The other two were experienced survey interviewers who had no previous cognitive interviewing experience. They received two days training in how to do cognitive interviewing. All were female.
Data Collection Protocols
When potential respondents returned to the clinic for the interview, a clinic staff member reviewed the purposes and procedures, answered questions, and obtained signed informed consent. The staff member then brought the respondent into a private room where the interviewer conducted the interview. Procedures were approved by the Institutional Review Boards (IRBs) of UMass Boston, Brown University, and the two participating hospitals. Testing took place between September 2011 and March 2012.
The basic protocol was first to have the respondent answer all of the questions in a self-administered form. Then, the interviewer went back over the questions, one by one, and asked the respondent about how he or she had understood the questions and gone about answering them. The cognitive interview instrument consisted of the test questions and a series of suggested probes for each question. For example, “In your own words, what did you think this question was asking?” “Can you walk me through how you decided on your answer?” and “What did you think was meant by XX?” The distinctive part of the interviewers’ protocol was that before completing the discussion of each question, interviewers were instructed to use their own probes as needed to collect enough information to fully evaluate how the respondent had dealt with each of the four cognitive elements: comprehension, retrieval, estimation, and providing an answer. They were to not only probe for problems but also to probe to get enough information about how the respondents had performed the tasks to be able to conclude that they had performed the tasks properly, if that was indeed the case. All the interviews were tape recorded.
After the interviews, interviewers wrote up notes on the questions. At the end of each round, interviewers met with supervisors in person to discuss their observations. A summary of the question-by-question findings was written up in a report after each round of testing.
Coding
The tape recordings of each cognitive interview were coded by two research assistants who were specially trained for the purpose. The first few interviews were coded by both coders, and the results compared, to ensure that they had a consistent understanding of the coding procedures. They then coded the balance of the interviews independently.
For each question, coders recorded whether the respondent’s description of how each task was performed was or was not what was needed to provide a valid answer. Did the respondent understand the question as intended (Comprehension of Question)? Did the respondent have the information needed to answer the question (Retrieval of Needed Information)? Did the respondent properly do any estimating or exercise the judgment necessary to put the information retrieved into the form the answer required (Estimation Process)? Did the respondent give an appropriate answer, given the information available to him or her (Choosing an Answer)?
We initially included the comprehension of the reference period with question comprehension. However, we concluded that attention to the reference period was different from understanding other aspects of the question, so we added a fifth item to code for each question: Did the respondent properly use the reference period when answering the question (Attention to Reference Period)?
Finally, as one might expect, the coders found situations in which they were not sure whether the respondent did or did not perform the task correctly. Therefore, in addition to coding “yes” or “no,” coders could use a “maybe” code.
Analysis
To illustrate the potential value of the resulting data, we addressed five specific hypotheses about question characteristics and validity:
Early in our testing process, it became apparent that the answering process for respondents who were convinced they essentially never missed taking medicines they were supposed to was different from the answering process for those who knew they had missed some doses. Hence, we tabulated answers separately for those two groups of respondents (which we labeled “adherent” and “nonadherent”).
The core of our analysis is to tabulate the coding of the comprehension and answering issues by the characteristics of the questions tested using statistics is a software package (SPSS, Version 18). The tables report the percentage of times the questions of a particular type were asked for which coders were convinced that respondents had no problem with a particular cognitive task. This is essentially the converse of the percentage of time they observed a problem. The “maybe” code was used less than 10% of the time.
Results
Table 1 compares questions that asked about different reference periods: about one week (or 7 days) versus those about one month (or 30 days). There are two evident differences in the results. The clearest and most striking one is the difference in the degree which respondents said they specifically attended to the reference period in their answers. They were much more likely to do that for the one-week reference periods than for the one-month reference period. However, it is also clear that even for the one-week period, a high percentage of respondents were not careful about using the reference period when answering. Second, while retrieval was clearly much easier for those who thought they were completely adherent about their pill taking than those who were not, there was some evidence (about a 17% difference) of more retrieval problems when the question asked about a month than when it asked about a week.
Percentage Who Had No Problem with Each Cognitive Task by Adherencea and Length of Reference Period.
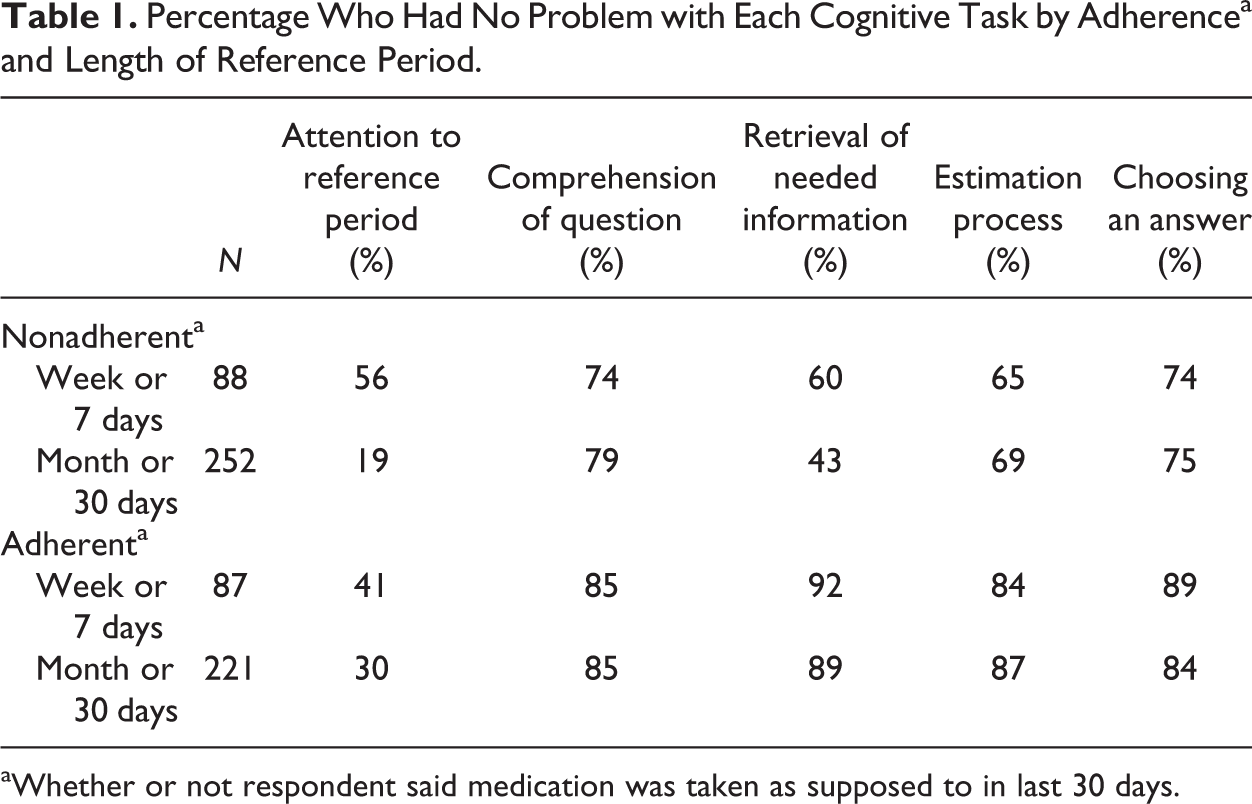
aWhether or not respondent said medication was taken as supposed to in last 30 days.
Table 2 compares questions that used different ways to describe the reference period: “last week” or “month” versus those that asked about the last “7” or “30 days.” The data confirm that the “days” form of the question is more consistently understood as intended than “week” or “month.”
Percentage Who Had No Problem with Each Cognitive Task by Adherencea and Wording of Reference Period.
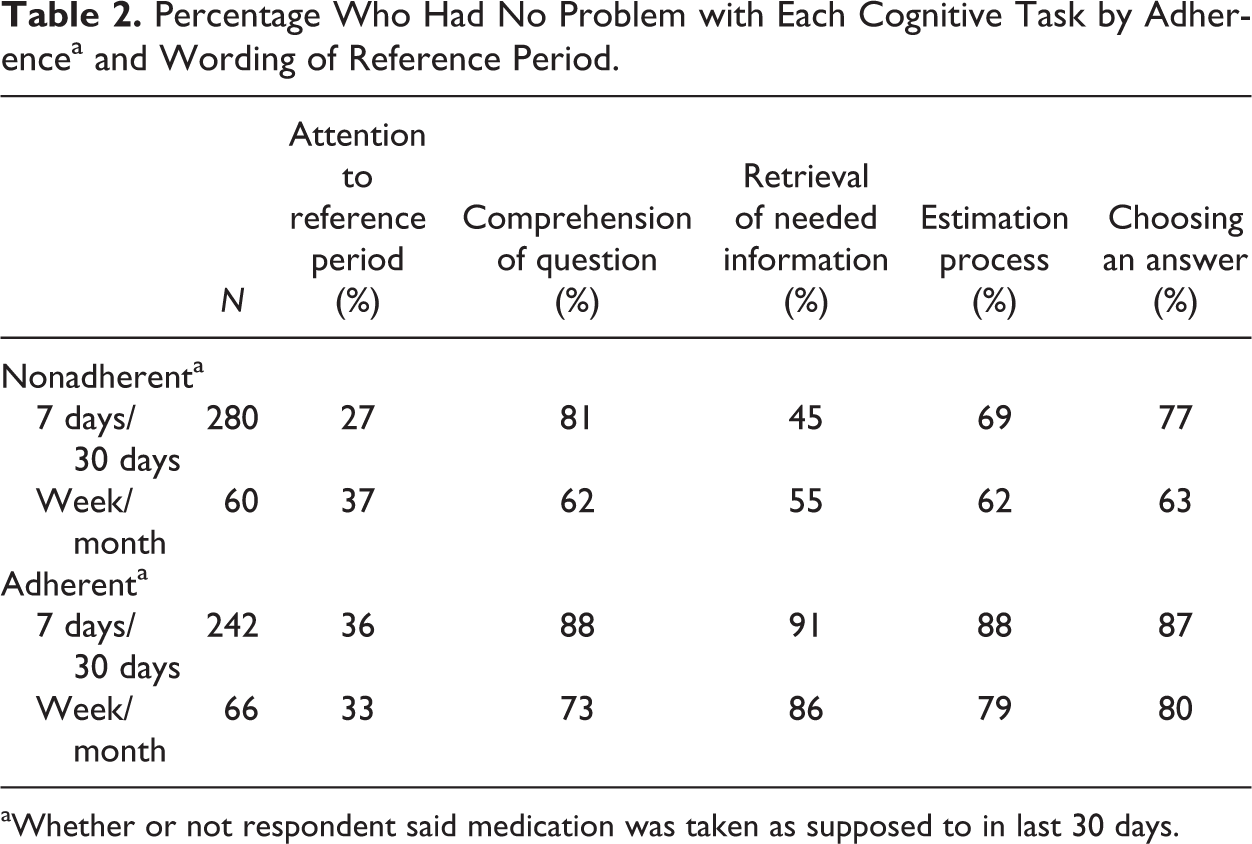
aWhether or not respondent said medication was taken as supposed to in last 30 days.
The data in both Tables 1 and 2 clearly show that, as one would expect, for all these reference periods, those who do not think they always took their medicines (the nonadherents) more often have a problem with retrieval.
Table 3 compares questions answered in the form of adjectival scales with those answered in specific number form. For those who were nonadherent (but not for those who believed they took their medicines virtually perfectly), retrieval of the information needed to answer the questions was more problematic when answers were in number form than when they were in the form of adjectival scales. That finding is almost certainly due to the fact that respondents had to retrieve much more specific and detailed information to answer in numerical than in adjectival terms. For example, to be able to confidently answer that one did a “very good” job of taking the prescribed medicines last month requires less information than to say “3 doses were missed.” For all other aspects of the questions, there were no obvious differences.
Percentage Who Had No Problem with Each Cognitive Task by Adherencea and Response Type.
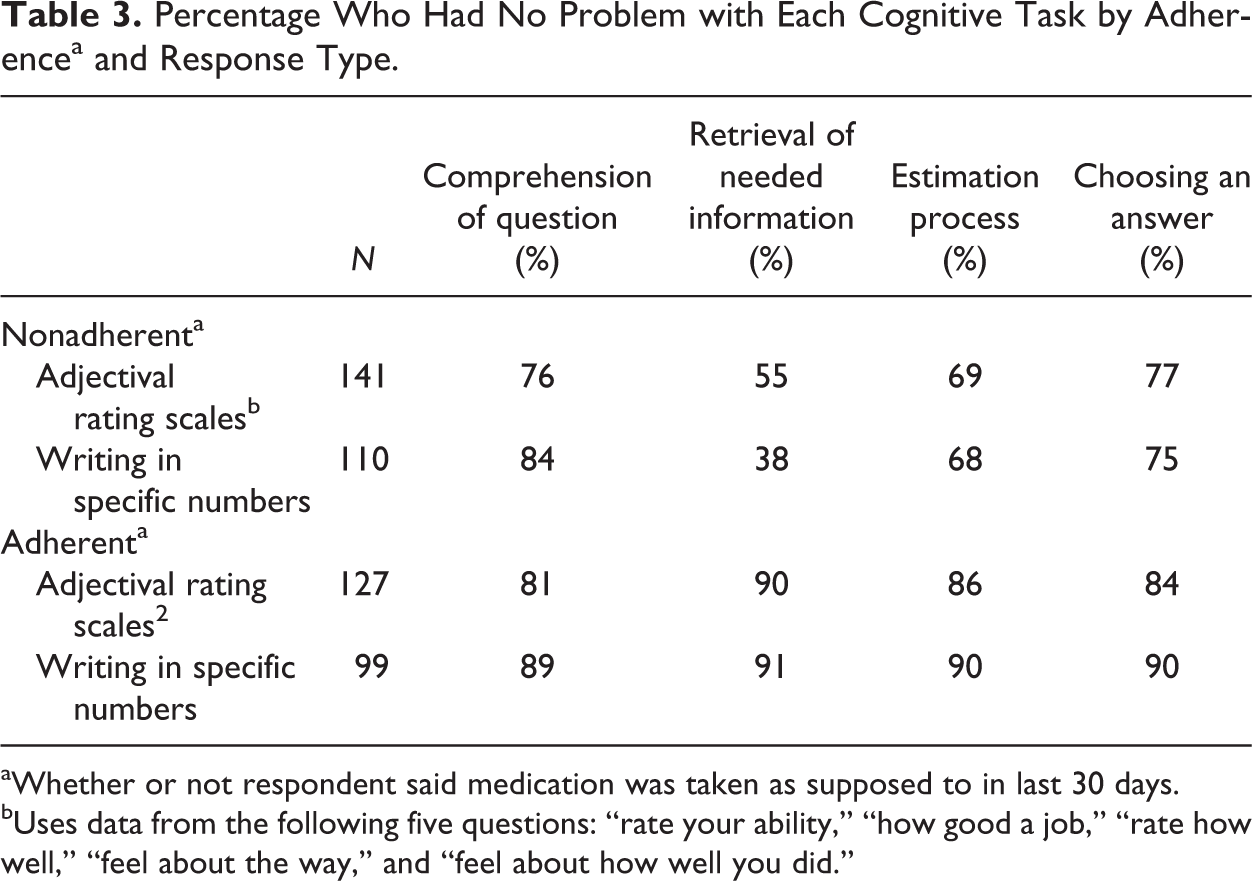
aWhether or not respondent said medication was taken as supposed to in last 30 days.
bUses data from the following five questions: “rate your ability,” “how good a job,” “rate how well,” “feel about the way,” and “feel about how well you did.”
Table 4 compares questions asking for answers in percentage versus specific number form. There seems to be a difference in the rates of comprehension for both adherent and nonadherent respondents: Requests for numbers were consistently better understood than requests for percentages. Respondents also have much more trouble with the computations required to come up with the answers and with providing the correct answer when they report percentages than when they are just asked to give a specific number.
Percentage Who Had No Problem with Each Cognitive Task by Adherencea and Use of Percentages or Specific Numbers.
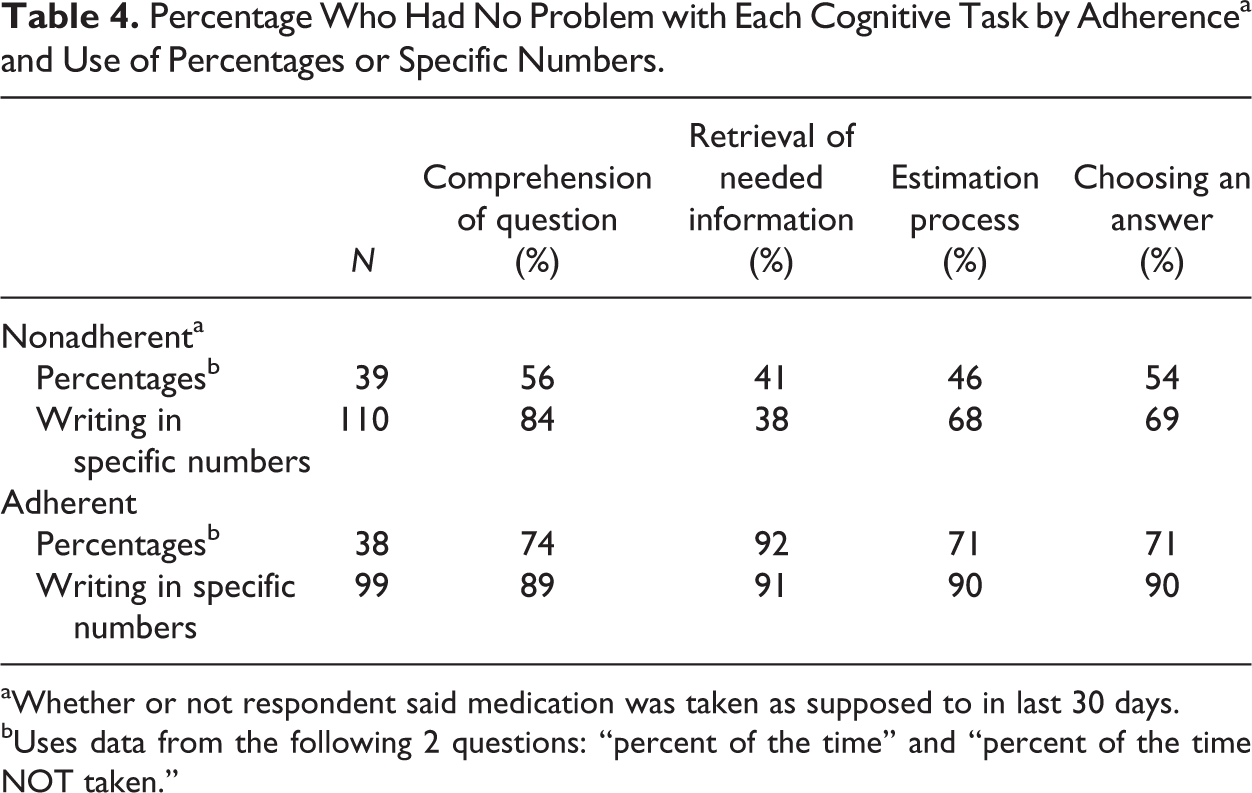
aWhether or not respondent said medication was taken as supposed to in last 30 days.
bUses data from the following 2 questions: “percent of the time” and “percent of the time NOT taken.”
We had thought that respondents would have more trouble with retrieval and with estimation for questions that asked about days or doses “taken” rather than days or doses “missed.” We thought counting missed days, since that is a smaller number for most respondents, would be the natural, easy way to retrieve an answer. The coding does not support that hypothesis (data in Appendix B). Nonadherent respondents were more often coded as having trouble with retrieval with the “missed” form of the question than with the “take” form; there was no difference in the estimation task. However, we should note that there were only 20 nonadherent respondents who were asked questions in the “take” form, so this result may not be reliable.
Discussion
Boeije and Willis (2013), in their review of the state of cognitive testing of survey questions, concluded: “Analysis may be the most serious ‘black box’ in cognitive interview reports as investigators rarely describe how they moved from data collection to the production of results” (p. 93). We think the approach described here helps address that problem.
There are two innovations in the protocol reported here. First, asking interviewers to probe each question until they thought that they could evaluate each element of the question-answering process is a strategy we have not seen in the research literature. It is more typical (and perhaps more efficient) to focus probing on preidentified targets or issues that clearly emerge as potential problems in the course of the interviews (Willis 2005). Thus, one source of variability is eliminated by imposing consistency on which issues interviewers target. Second, while there are examples of researchers coding the types of problems identified in cognitive interviewing, and many of them use coding schemes that are derived to some degree from the Tourangeau framing of the answering process (e.g., Conrad and Blair 2004, 2009; DeMaio and Landreth 2004; Presser and Blair 1994), we do not know of any studies that used independent coders to code whether or not each of the four elements of question answering was problematic. This potentially reduces the inconsistency about which issues are reported on and what criteria are used to produce results.
This is a case study. We do not have results with the same questions and a different protocol that would provide a comparison. However, we have seen many reports of cognitive interviewing where, as Boeije and Willis (2013) note, the path from interviewing to the results goes through a black box. In addition, we think the approach is distinctive in collecting and reporting data on aspects of the questions that are working well and in identifying aspects of questions that are potentially problematic. Also, by forcing the interviewers and coders to address all four issues for each question, the approach may detect unforeseen issues.
We did not do formal statistical testing of our results for this article. Calculating the probabilities of differences observed was not our goal. Most cognitive testing projects do not have large enough samples and make too many comparisons for probability calculations to be meaningful. The samples are invariably convenience samples, so statistical generalization implied by testing is not really appropriate. Moreover, we are not trying to transform an essentially qualitative process into a quantitative analysis. Coders still have to decide if the respondent performed a task correctly, and researchers still have to decide when a “problem” occurs often enough that a question must be changed. The purpose of producing results such as those we report is to present the data on which judgments will be made in a systematic, transparent, and easy to describe way.
We framed our analysis around five hypotheses as one way of illustrating that the results are meaningful. Differences tended to appear where we would expect them and not where we did not. However, the purpose of this project was not to test those hypotheses per se, but to provide examples of how these data could be used. Combining results across questions would obviously not be the usual way to analyze cognitive testing results.
There are, of course, some drawbacks to this approach for routine cognitive testing. It takes extra time and resources to have coders code the cognitive interviews as we propose. Whether those extra resources will be a problem obviously will depend on the project. In addition, we should note that knowing how to fix the problems identified is one of the most important goals of cognitive testing. While the systematic coding results identify issues that may need to be addressed, the details about the nature of the problems and how to fix them come from the qualitative debriefing of interviewers and coders. Also, we used the Tourangeau model of question answering, which focuses only on cognitive issues. There are other aspects of questions that can affect validity, such as their social or interpersonal effects, that we do not address. For example, in the case of reporting medication adherence, there are clear pressures on patients to overreport adherence. In fact, we tried to address that issue in our question design, but the data reported in this article were not helpful in that respect. Further, we did not eliminate judgment from the analysis of results. We did not do enough check coding to calculate the reliability of coder judgments. However, this approach makes it quite feasible to ensure that the coding of problems is reliable and replicable, albeit still involving judgment.
In conclusion, other writers have criticized cognitive interviewing for not being systematic enough and for not producing results that were transparent and reliable. We think this approach goes a long way toward addressing those concerns. In addition, we particularly value the fact that the results provide evidence of the validity of answers as well as evidence about question problems. We are not proposing that this systematic analysis should replace other forms of evaluating how respondents answer questions. However, we do think the approach we used may provide a model for one way to strengthen cognitive testing procedures.
Footnotes
Appendix A
Appendix B
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Institute of Mental Health at the National Institutes of Health (Grant No. RO1 MH 092238). Dr. Wilson was also supported by a K24 grant, (2K24MH092242).